Ses verilerine giriş
Ses dalgası doğası gereği sürekli bir sinyaldir, yani belirli bir zamanda sonsuz sayıda sinyal değeri içerir. Bu durum sonlu dizileri bekleyen dijital cihazlar için sorun yaratır. Bu tip veriler dijital cihazlar tarafından işlenmeden, depolanmadan ve iletilmeden önce önce sürekli ses dalgasının bir dizi ayrık değere dönüştürülmesi gerekmektedir. Buna dijital temsil de denir.
Herhangi bir ses verisetine baktığınızda, ses örneklerini içeren dijital dosyalar bulacaksınız. Bu örneklerin arasında metin anlamı ya da müzik parçaları bulabilir, .wav (Dalgaformu Ses Dosyası), .flac (Ücretsiz Kayıpsız Ses Kodlayıcı) ve .mp3 (MPEG-1 Ses Katmanı 3) gibi farklı dosya formatlarıyla karşılaşabilirsiniz. Bu formatlar temelde ses sinyalinin dijital temsilini nasıl sıkıştırdıklarına göre farklılıklar gösterirler.
Şimdi bir sürekli sinyalden bu temsile nasıl ulaştığımıza bir göz atalım. Analog sinyal önce bir mikrofon tarafından yakalanır ve ses dalgalarını elektriksel bir sinyale dönüştürür. Elektriksel sinyal, örnekleme yoluyla dijital temsil elde etmek için bir Analog-Dijital Dönüştürücü tarafından sayısallaştırılır.
Örnekleme ve örnekleme oranı
Örnekleme, sürekli bir sinyalin değerini sabit zaman aralıklarında ölçme işlemidir. Örnekleme yapılmış dalga formu, sabit aralıklarla ayrık sinyal değerlerini içerdiği için ayrık bir şekildedir.
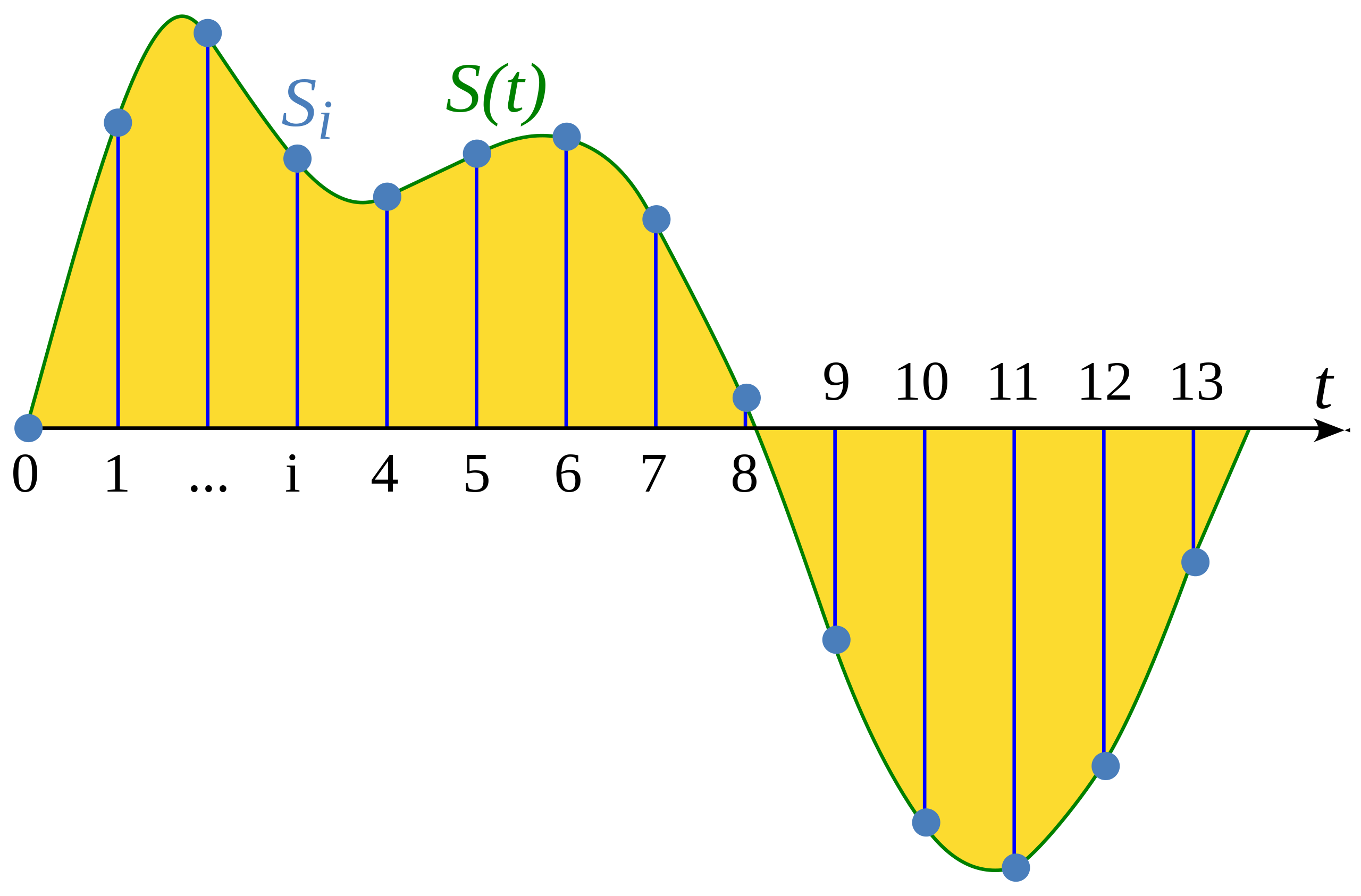
Wikipedia makalesinden örnek: Örneklem (sinyal işleme)
Örnekleme hızı (aynı zamanda örnekleme frekansı olarak da adlandırılır), bir saniyede alınan örnek sayısıdır ve hertz (Hz) cinsinden ölçülür. Bir referans noktası vermek gerekirse, CD kalitesindeki sesin örnekleme hızı 44.100 Hz’dir, yani saniyede 44.100 örnek alınır. Karşılaştırma yapmak için, yüksek çözünürlüklü sesin örnekleme hızı 192.000 Hz veya 192 kHz’dir. Konuşma modellerini eğitirken yaygın olarak kullanılan bir örnekleme hızı ise 16.000 Hz veya 16 kHz’dir.
Örnekleme hızı seçimi sinyalden yakalanabilen en yüksek frekansı belirler. Bu aynı zamanda Nyquist sınırı olarak bilinir ve tam olarak örnekleme hızının yarısıdır. İnsan konuşmasındaki işitilebilir frekanslar 8 kHz’nin altındadır, bu nedenle konuşmayı 16 kHz’de örneklemek yeterlidir. Daha yüksek bir örnekleme hızı kullanmak daha fazla bilgiyi yakalamaz ve sadece bu tür dosyaların işlenmesinin hesap maliyetini artırır. Öte yandan, çok düşük bir örnekleme hızında sesi örneklemek bilgi kaybına neden olur. 8 kHz’de örneklenen konuşma, bu hızda yüksek frekansları yakalayamadığı için donuk bir ses çıkaracaktır.
Herhangi bir ses görevi üzerinde çalışırken, veri kümesindeki tüm ses örneklerinin aynı örnekleme hızına sahip olduğundan emin olmak önemlidir. Öneğitimli bir modeli özelleştirmek için özel ses veriseti kullanmayı planlıyorsanız, modelin önceden eğitildiği verilerin örnekleme hızı ve verilerinizin örnekleme hızı aynı olmalıdır. Örnekleme hızı, ardışık ses örnekleri arasındaki zaman aralığını belirler ve ses verilerinin zamansal çözünürlüğünü etkiler. Örneğin, 16.000 Hz örnekleme hızında 5 saniyelik bir ses, 80.000 değerin bir dizisi olarak temsil edilir, aynı 5 saniyelik ses 8.000 Hz örnekleme hızında ise 40.000 değerin bir dizisi olarak temsil edilir. Ses görevlerini çözen transformer modelleri, örnekleri diziler olarak ele alır. Bu modeller ses verisinin temsilini öğrenen dikkat mekanizmalarına dayanır. Örnekleme hızları farklı olan ses örnekleri için diziler farklı olduğu için, modellerin örnekleme hızları arasında genelleme yapması zor olacaktır. Yeniden örnekleme ses örneklerinin örnekleme hızlarını eşleştirmek için kullanılan bir işlemdir ve ses verilerini ön işleme işleminin bir parçasıdır.
Genlik ve bit derinliği
Örnekleme oranı size örneklerin ne sıklıkta alındığını söyler. Peki, her bir örnekteki değerler tam olarak nedir?
Ses, insanlar tarafından duyulabilir frekansta hava basıncındaki değişikliklerle oluşur. Bir sesin genliği, herhangi bir anki ses basınç seviyesini tanımlar ve decibel (dB) cinsinden ölçülür. Genliği sesin yüksekliği olarak algılarız. Örnek vermek gerekirse, normal bir konuşma sesi 60 dB’nin altındadır ve bir rock konseri insan işitme sınırlarını zorlayacak şekilde yaklaşık olarak 125 dB’de olabilir.
Dijital seste, her ses örneği bir zaman noktasında ses dalgasının genliğini kaydeder. Örneğin bit derinliği, bu genlik değerinin ne kadar hassasiyetle tanımlanabileceğini belirler. Yüksek bit derinliği, dijital temsilin orijinal sürekli ses dalgasına ne kadar doğru bir şekilde yaklaştığına işaret eder.
En yaygın ses bit derinlikleri 16 bit ve 24 bittir. İkisi de ikili bir terimdir, genlik değerinin sürekli olarak ayrıksallaştırıldığında kaç farklı adıma ayrıksallaştırılabileceğini temsil eder. Bu ayrıksallaştırma 16-bit ses için 65,536 adım, 24-bit ses için 16,777,216 adımdır. Çünkü ayrıksallaştırma, sürekli değeri ayrıksallaştırılmış bir değere yuvarlama işlemi içerdiğinden, örnekleme işlemi gürültü ekler. Bit derinliği ne kadar yüksekse, bu ayrıksallaştırma gürültüsü o kadar küçüktür. Pratikte, 16-bit sesin ayrıksalaştırma gürültüsü zaten işitilemeyecek kadar küçüktür, ve daha yüksek bit derinliklerini kullanmanıza gerek kalmaz.
32-bit sese de rastlayabilirsiniz. 32-bit ses örnekleri gerçel olarak saklar, oysa 16-bit ve 24-bit ses tamsayı örnekleri kullanır. 32-bit gerçel sayı hassasiyeti 24 bit olarak kabul edilir, bu da ona 24-bit sesle aynı bit derinliğini verir. Gerçel sayılı ses örneklerinin [-1.0, 1.0] aralığı içinde bulunması beklenir. Makine öğrenme modelleri doğal olarak gerçel sayılarla çalıştığından, ses önce gerçel sayı formatına dönüştürülmelidir. Bunun nasıl yapılacağını Önişleme bölümünde göreceğiz.
Sürekli ses sinyalleri gibi, dijital sesin genliği genellikle desibel (dB) cinsinden ifade edilir. İnsan işitmesi logaritmik olduğundan dolayı - kulaklarımız seslerdeki küçük dalgalanmalara yüksek seslerden daha hassastır - bir sesin yüksekliği, genliklerin de logaritmik olan desibel cinsinden ifade edilmesiyle daha kolay yorumlanır. Gerçek dünya sesi için desibel ölçeği 0 dB’den başlar, bu da insanların duyabileceği en sessiz sesi temsil eder ve daha yüksek sesler daha büyük değerlere sahiptir. Ancak dijital ses sinyalleri için 0 dB en yüksek genlikken, diğer tüm genlikler negatiftir. Hızlı bir kural olarak: her -6 dB, genliğin yarı yarıya azalması anlamına gelir ve genellikle -60 dB’nin altındaki her şey, sesi gerçekten yüksek bir ses seviyesine çıkarmazsanız işitilemez.
Dalga biçimi olarak ses
Seslerin zaman içindeki örnek değerlerinin ve değişimlerinin dalga formu olarak görselleştirildiğini görmüş olabilirsiniz. Bu aynı zamanda sesin zaman alanı temsili olarak da bilinir.
Bu tür görselleştirmeler, sinyalin zamanlaması, ses olayları, sinyalin genel ses yüksekliği ve seste mevcut olan herhangi bir düzensizlik veya gürültüleri gibi sinyalin belli özelliklerini tanımlamada kullanılır
Bir ses sinyalinin dalga biçimini çizmek için ‘librosa’ adlı bir Python kütüphanesini kullanabiliriz:
pip install librosa
Kütüphaneyle birlikte gelen “trumpet” adlı ses örneğini ele alalım:
import librosa
array, sampling_rate = librosa.load(librosa.ex("trumpet"))Bu örnek, ses zaman serisi (burada buna ‘dizi’ diyoruz) ve örnekleme hızından (‘sampling_rate’) oluşan bir demet olarak yüklenir.
Librosa’nın waveshow() fonksiyonunu kullanarak bu sesin dalga formuna bir göz atalım:
import matplotlib.pyplot as plt
import librosa.display
plt.figure().set_figwidth(12)
librosa.display.waveshow(array, sr=sampling_rate)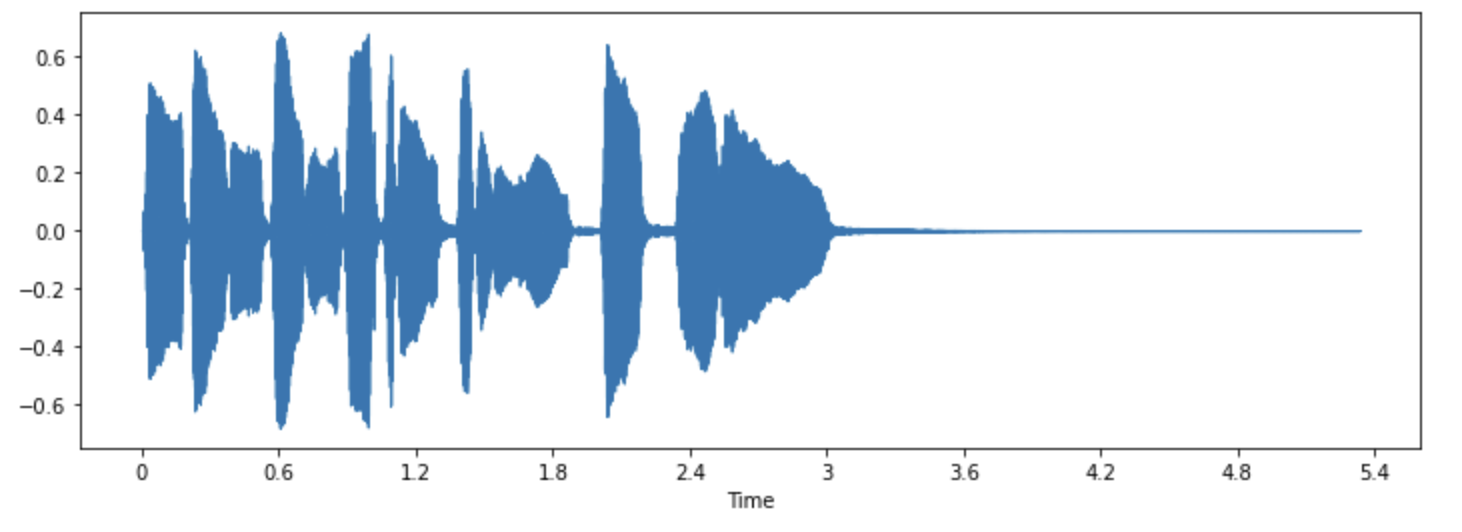
Bu, sinyalin genliğini y ekseni üzerinde ve zamanı x ekseni boyunca çizer. Başka bir deyişle, her bir nokta, örnekleme sırasında alınan tek bir örnek değerine karşılık gelir. Ayrıca, librosa sesi genliği [-1.0, 1.0] arasında gerçel sayılı değerler olarak döndürür.
Görselleştirme, ses verilerini dinlerken üzerinde çalıştığınız verileri anlamak için kullanışlı bir araçtır. Sinyalin şeklini görebilir, örüntüleri gözlemleyebilir, gürültü veya bozulma belirlemeyi öğrenebilirsiniz. Veriyi normalizasyon, yeniden örnekleme veya filtreleme gibi bazı yöntemlerle önişlediyseniz, önişleme adımlarının doğru bir şekilde uygulandığını görselden doğrulayabilirsiniz. Bir modeli eğittikten sonra (örneğin, ses sınıflandırma görevinde) hata oluşan örnekleri görselleştirebilir ve sorunu gidermek için kullanabilirsiniz.
Frekans spektrumu
Ses verilerini görselleştirmenin başka bir yolu da frekans alanı olarak da bilinen bir ses sinyalinin frekans spektrumunu çizmektir. Spektrum, ayrık Fourier dönüşümü veya DFT kullanılarak hesaplanır. Spektrum, sinyali oluşturan her bir frekansı ve ne kadar güçlü olduğunu tarif eder.
Numpy’nin rfft() fonksiyonunu kullanarak DFT’yi alarak aynı trompet sesi için frekans spektrumunu çizelim.
Tüm sesin spektrumunu çizmek mümkünse de, bunun yerine küçük bir bölgeye bakmak daha kullanışlıdır. Aşağıda,
ilk 4096 örneğin DFT’sini alalım, bu aşağı yukarı çalınan ilk notanın uzunluğuna eşit olacak.
import numpy as np
dft_input = array[:4096]
# DFT hesaplama
window = np.hanning(len(dft_input))
windowed_input = dft_input * window
dft = np.fft.rfft(windowed_input)
# genlik spektrumunu desibel cinsinden elde edin
amplitude = np.abs(dft)
amplitude_db = librosa.amplitude_to_db(amplitude, ref=np.max)
# frekans aralıklarını alın
frequency = librosa.fft_frequencies(sr=sampling_rate, n_fft=len(dft_input))
plt.figure().set_figwidth(12)
plt.plot(frequency, amplitude_db)
plt.xlabel("Frequency (Hz)")
plt.ylabel("Amplitude (dB)")
plt.xscale("log")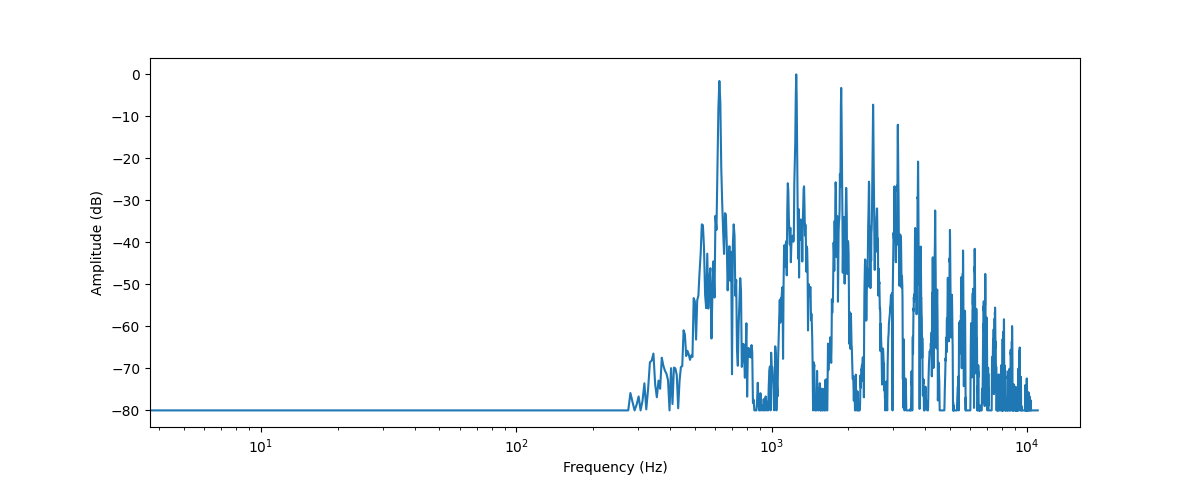
Bu, bu ses bölümünde mevcut olan çeşitli frekans bileşenlerinin gücünü gösterir. Frekans değerleri açık x ekseni genellikle logaritmik ölçekte çizilir, genlikleri ise y ekseni üzerindedir.
Çizdiğimiz frekans spektrumu birkaç tepe noktası gösteriyor. Bu tepeler notanın harmoniklerine karşılık gelir. yüksek harmonikler daha sessiz olacak şekilde çalınır. İlk zirve 620 Hz civarında olduğundan, bu bir E♭ notasının frekans spektrumudur.
DFT’nin çıktısı, gerçel ve sanal bileşenlerden oluşan karmaşık sayıların bir dizisidir. np.abs(dft) ile büyüklük, spektrogramdan genlik bilgisini elde eder. Gerçek ve sanal bileşenler arasındaki açı, faz spektrumunu sağlar, ancak bu genellikle makine öğrenme uygulamalarında atlanır veya kullanılmaz.
Genlik değerlerini desibel ölçeğine dönüştürmek için librosa.amplitude_to_db() kullandınız, böylece spektrumdaki daha ince ayrıntıları görmeyi kolaylaştırdınız. Bazen insanlar genlik yerine enerjiyi ölçen güç spektrumunu kullanır;
bu basitçe genlik değerlerinin karesi olan bir spektrumdur.
Bir ses sinyalinin frekans spektrumu, dalga formuyla aynı bilgiyi içerir. Bunlar aynı veriye (burada trompet sesinden ilk 4096 örnek) bakmanın iki farklı yoludur. Dalga formunun genliğe karşı zaman içinde çizdiği yerde, spektrum her bir frekansın genliğini sabit bir noktada görselleştirir.
Spektrogram
Bir ses sinyalindeki frekansların değişimini nasıl görselleştirebiliriz? Trompet birkaç nota çalıyor ve hepsinde farklı frekanslar var. Sorun, spektrumun yalnızca belirli bir andaki frekansların donmuş anlık görüntüsünü göstermesidir. Çözüm, her biri yalnızca küçük bir zaman dilimini kapsayan birden fazla DFT almak ve elde edilen spektrumları bir araya toplayıp spektrograma dönüştürmektir.
Spektrogram, zaman içinde değişen bir ses sinyalinin frekans içeriğini çizer. Zamanı, frekansı ve genliği tek bir grafikte görmenizi sağlar Bu hesaplamayı gerçekleştiren algoritma STFT veya Kısa Zamanlı Fourier Dönüşümüdür.
Spektrogram, kullanabileceğiniz en bilgilendirici ses araçlarından biridir. Örneğin bir müzik kaydıyla çalışırken, çeşitli enstrümanları ve vokal parçalarını ve bunların genel sese nasıl katkıda bulunduğunu görebilirsiniz. Konuşma verisinde ise her sesli harf belirli frekanslarla karakterize edildiğinden farklı sesli harfleri görebilirsiniz.
Librosa’nın “stft()” ve “specshow()” işlevlerini kullanarak aynı trompet sesi için bir spektrogram çizelim:
import numpy as np
D = librosa.stft(array)
S_db = librosa.amplitude_to_db(np.abs(D), ref=np.max)
plt.figure().set_figwidth(12)
librosa.display.specshow(S_db, x_axis="time", y_axis="hz")
plt.colorbar()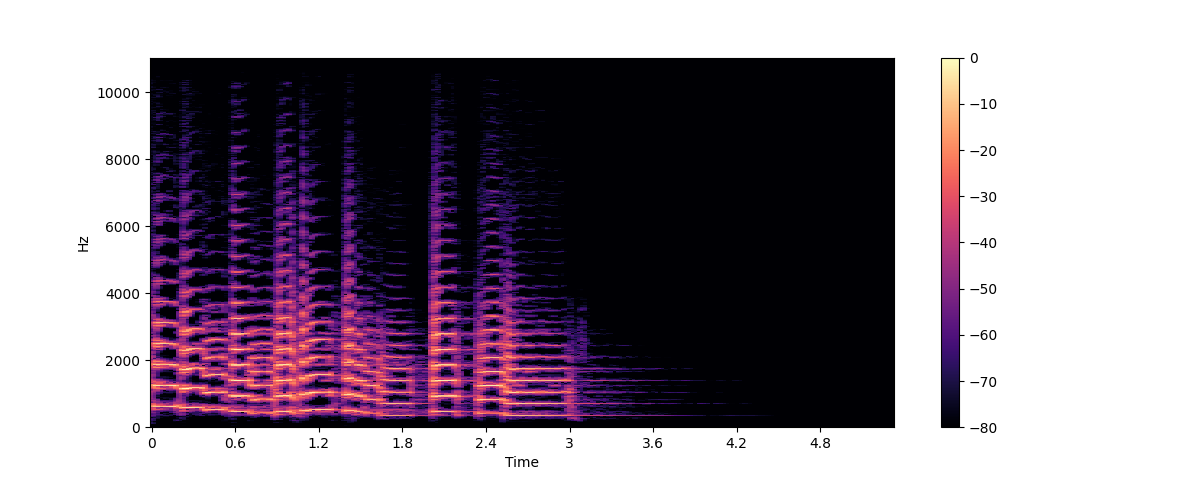
Bu çizimde, x ekseni dalga biçimi görselleştirmesinde olduğu gibi zamanı temsil eder, ancak y ekseni Hz cinsinden frekansı temsil eder. Rengin yoğunluğu, zamanın her noktasında frekans bileşeninin desibel (dB) cinsinden ölçülen genliğini veya gücünü verir.
Spektrogram, genellikle birkaç milisaniye süren ses sinyalinin kısa segmentlerini alıp, her segmentin frekans spektrumunu elde etmek için ayrık Fourier dönüşümünü hesaplayarak oluşturulur. Elde edilen spektrumlar daha sonra zaman ekseni üzerine üst üste konur ve spektrogramu oluşturmak için bir araya getirilir. Bu görüntüde her dikey dilim, üstten görüldüğünde tek bir frekans spektrumuna karşılık gelir. Varsayılan olarak, librosa.stft() ses sinyalini 2048 örneklik segmentlere böler, bu da frekans çözünürlüğü ve zaman çözünürlüğü arasında iyi bir denge sağlar.
Spektrogram ve dalga formu, aynı verinin farklı görünümleridir, bu nedenle spektrogramu orijinal dalga formuna döndürmek mümkündür, ancak bunun için genlik bilgisi dışında faz bilgisine de ihtiyaç vardır. Eğer spektrogram bir makine öğrenme modeli tarafından üretildiyse, genellikle yalnızca genlikleri çıkarır. Bu durumda, Griffin-Lim gibi klasik bir faz yeniden yapılandırma algoritması veya bir vokoder olarak adlandırılan bir sinir ağı kullanarak spektrogramdan bir dalga formunu yeniden oluşturabilirsiniz.
Spektrogramlar yalnızca görselleştirme için kullanılmaz. Birçok makine öğrenimi modeli, girdi olarak spektrogramları alır, dalga formlarına dönüştürür ve çıktı olarak spektrogramlar üretir.
Artık spektrogramın ne olduğunu ve nasıl yapıldığını bildiğimize göre, konuşma işlemede yaygın olarak kullanılan bir çeşidine bakalım: mel spektrogramı.
Mel spektrogramı
Mel spektrogramı, konuşma işleme ve makine öğrenimi görevlerinde yaygın olarak kullanılan spektrogramın bir çeşididir. Bir ses sinyalinin zaman içindeki frekans içeriğini ancak farklı bir frekans ekseninde göstermesi bakımından spektrograma benzer.
Standart bir spektrogramda frekans ekseni doğrusaldır ve hertz (Hz) cinsinden ölçülür. Ancak insanın işitme sistemi düşük frekanslardaki değişikliklere yüksek frekanslardan daha duyarlıdır ve bu duyarlılık frekans arttıkça logaritmik olarak azalır. Mel ölçeği, insan kulağının doğrusal olmayan frekans tepkisine yaklaşan algısal bir ölçektir.
Bir mel spektrogramı oluşturmak için ses verisini kısa parçalara ayırıp frekans spektrumları elde edilir. Bunun için STFT kullanılır. Ek olarak, frekansları mel ölçeği dönüştürmek için, her spektrum mel filtre bankası olarak adlandırılan bir dizi filtre aracılığıyla gönderilir.
Tüm bu adımları bizim için gerçekleştiren librosa’nın melspectrogram() fonksiyonunu kullanarak bir mel spektrogramını nasıl çizebileceğimizi görelim:
S = librosa.feature.melspectrogram(y=array, sr=sampling_rate, n_mels=128, fmax=8000)
S_dB = librosa.power_to_db(S, ref=np.max)
plt.figure().set_figwidth(12)
librosa.display.specshow(S_dB, x_axis="time", y_axis="mel", sr=sampling_rate, fmax=8000)
plt.colorbar()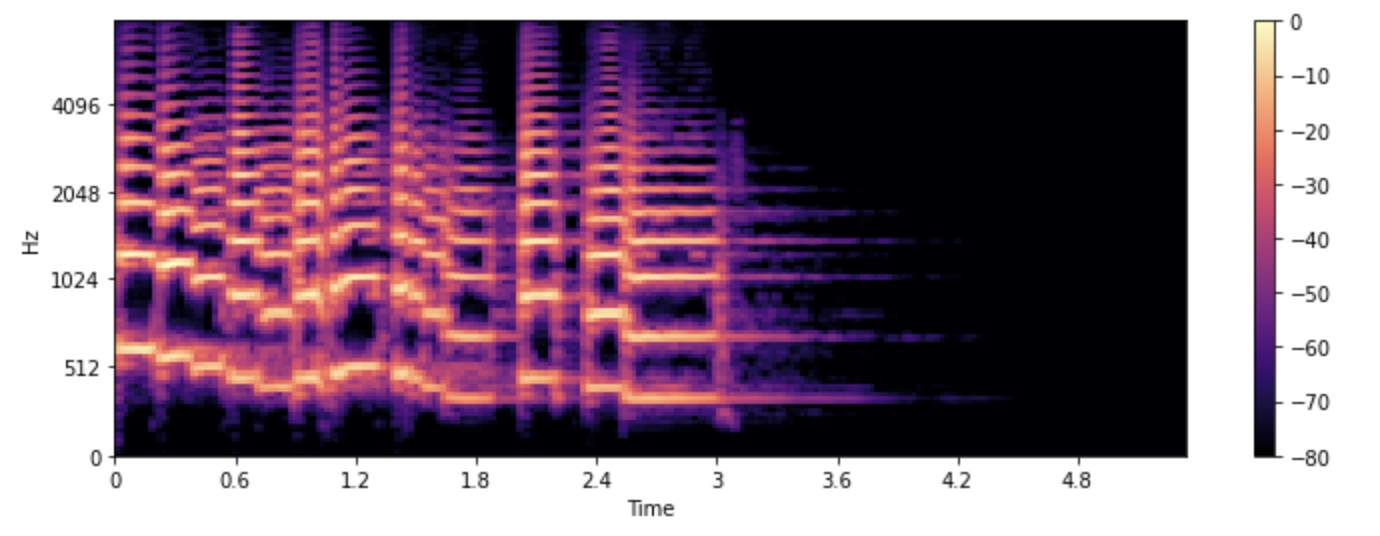
Yukarıdaki örnekte, n_mels, oluşturulacak mel bantlarının sayısını ifade eder. Mel bantları, spektrumu insan işitmesinin farklı frekanslara nasıl tepki verdiğini taklit etmek için seçilen bir dizi filtre kullanarak algısal olarak anlamlı bileşenlere bölen frekans aralıklarını tanımlar. n_mels için yaygın değerler 40 veya 80’dir. fmax, önem verdiğimiz en yüksek frekansı (Hz cinsinden) belirtir.
Düzenli bir spektrogramda olduğu gibi, mel frekans bileşenlerinin gücünü desibel cinsinden ifade etmek yaygın bir uygulamadır. Bu genellikle bir *log-mel spektrogramu olarak adlandırılır, çünkü desibellere dönüştürme işlemi logaritmik bir işlem içerir. Yukarıdaki örnek, librosa.feature.melspectrogram() olarak librosa.power_to_db() kullanarak güç spektrogramı oluşturur.
Bir mel spektrogramı oluşturmak, sinyali filtrelemeyi içerdiği için kayıplı bir işlemdir. Bir mel spektrogramını bir dalga formuna dönüştürmek, bir düzenli spektrogram için bunu yapmaktan daha zordur, çünkü daha önce kaybedilen frekansları tahmin etmeyi gerektirir. Bu nedenle, mel spektrogramından bir dalga formu üretmek için HiFiGAN vokoder gibi makine öğrenme modellerine ihtiyaç vardır.
Standart bir spektrogramla karşılaştırıldığında, bir mel spektrogramı ses sinyalinin daha anlamlı özelliklerini yakalayabilir. Bu, mel spektrogramını, konuşma tanıma, konuşmacıyı tanımlama ve müzik türü sınıflandırması gibi görevlerde onu popüler bir seçim haline getiriyor.
Artık ses verisi örneklerini nasıl görselleştireceğinizi bildiğinize göre, en sevdiğiniz seslerin nasıl göründüğünü görmeye çalışın. :)
< > Update on GitHub