Дообучение SpeechT5
Теперь, когда вы знакомы с задачей преобразования текста в речь и внутренним устройством модели SpeechT5, которая была предварительно обучена на англоязычных данных, давайте посмотрим, как мы можем дообучить ее для другого языка.
House-keeping
Если вы хотите воспроизвести этот пример, убедитесь, что у вас есть графический процессор. В блокноте это можно проверить с помощью следующей команды:
nvidia-smi
В нашем примере мы будем использовать около 40 часов обучающих данных. Если вы хотите повторить этот процесс, используя бесплатный тарифный план Google Colab, необходимо уменьшить объем обучающих данных примерно до 10-15 часов и сократить количество шагов обучения.
Вам также понадобятся некоторые дополнительные зависимости:
pip install transformers datasets soundfile speechbrain accelerate
Наконец, не забудьте войти в свою учетную запись Hugging Face, чтобы загрузить свою модель и поделиться ею с сообществом:
from huggingface_hub import notebook_login
notebook_login()Набор данных
В данном примере мы возьмем подмножество голландского (nl) языка из датасета VoxPopuli.
VoxPopuli - это обширный многоязычный речевой корпус, состоящий из данных,
полученных из записей мероприятий Европейского парламента 2009-2020 гг. Он содержит маркированные данные аудио-транскрипций для 15 европейских языков.
Хотя мы будем использовать подмножество голландского языка, вы можете выбрать другое подмножество.
Это набор данных автоматического распознавания речи (ASR), поэтому, как уже говорилось, он не является наиболее подходящим вариантом для обучения TTS-моделей. Однако для данного упражнения этого будет вполне достаточно.
Давайте загрузим данные:
from datasets import load_dataset, Audio
dataset = load_dataset("facebook/voxpopuli", "nl", split="train")
len(dataset)Output:
20968
20968 примеров должно быть достаточно для дообучения. Для SpeechT5 требуется, чтобы частота дискретизации аудиоданных составляла 16 кГц, поэтому убедимся, что примеры в наборе данных соответствуют этому требованию:
dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))Препроцессинг данных
Начнем с определения используемой контрольной точки модели и загрузки соответствующего процессора, содержащего как токенизатор, так и экстрактор признаков, которые понадобятся нам для подготовки данных к обучению:
from transformers import SpeechT5Processor
checkpoint = "microsoft/speecht5_tts"
processor = SpeechT5Processor.from_pretrained(checkpoint)Очистка текста для токенизации SpeechT5
Во-первых, для подготовки текста нам понадобится часть процессора - токенизатор, поэтому возьмем его:
tokenizer = processor.tokenizer
Рассмотрим пример:
dataset[0]Output:
{'audio_id': '20100210-0900-PLENARY-3-nl_20100210-09:06:43_4',
'language': 9,
'audio': {'path': '/root/.cache/huggingface/datasets/downloads/extracted/02ec6a19d5b97c03e1379250378454dbf3fa2972943504a91c7da5045aa26a89/train_part_0/20100210-0900-PLENARY-3-nl_20100210-09:06:43_4.wav',
'array': array([ 4.27246094e-04, 1.31225586e-03, 1.03759766e-03, ...,
-9.15527344e-05, 7.62939453e-04, -2.44140625e-04]),
'sampling_rate': 16000},
'raw_text': 'Dat kan naar mijn gevoel alleen met een brede meerderheid die wij samen zoeken.',
'normalized_text': 'dat kan naar mijn gevoel alleen met een brede meerderheid die wij samen zoeken.',
'gender': 'female',
'speaker_id': '1122',
'is_gold_transcript': True,
'accent': 'None'}Можно заметить, что примеры из датасета содержат признаки raw_text и normalized_text. При выборе признака
в качестве входного текста важно знать, что в токенизаторе SpeechT5 нет токенов для чисел. В normalized_text
числа записываются в виде текста. Таким образом, он лучше подходит, и в качестве входного текста следует использовать normalized_text.
Поскольку SpeechT5 обучалась на английском языке, она может не распознать некоторые символы в голландском наборе данных. Если
оставить все как есть, то эти символы будут преобразованы в токены <unk>. Однако в голландском языке некоторые символы, например à, используются
для выделения слогов. Чтобы сохранить смысл текста, можно заменить этот символ на обычное a.
Чтобы выявить неподдерживаемые токены, извлечем все уникальные символы из датасета с помощью SpeechT5Tokenizer, который
работает с символами как с токенами. Для этого напишем функцию отображения extract_all_chars, которая объединяет
транскрипции из всех примеров в одну строку и преобразует ее в набор символов. [NL]
Обязательно задайте batched=True и batch_size=-1 в dataset.map(), чтобы все транскрипции были доступны сразу для
функции отображения.
def extract_all_chars(batch):
all_text = " ".join(batch["normalized_text"])
vocab = list(set(all_text))
return {"vocab": [vocab], "all_text": [all_text]}
vocabs = dataset.map(
extract_all_chars,
batched=True,
batch_size=-1,
keep_in_memory=True,
remove_columns=dataset.column_names,
)
dataset_vocab = set(vocabs["vocab"][0])
tokenizer_vocab = {k for k, _ in tokenizer.get_vocab().items()}Теперь у вас есть два набора символов: один со словарем из датасета, другой - со словарем из токенизатора. Для выявления неподдерживаемых символов в наборе данных можно взять разность между этими двумя наборами. Полученный набор будет содержать символы, которые есть в наборе данных, но отсутствуют в токенизаторе.
dataset_vocab - tokenizer_vocab
Output:
{' ', 'à', 'ç', 'è', 'ë', 'í', 'ï', 'ö', 'ü'}Для работы с неподдерживаемыми символами, выявленными на предыдущем этапе, можно определить функцию, которая сопоставляет эти символы с допустимыми токенами.
Заметим, что пробелы уже заменены на ▁ в токенизаторе и не нуждаются в отдельной обработке.
replacements = [
("à", "a"),
("ç", "c"),
("è", "e"),
("ë", "e"),
("í", "i"),
("ï", "i"),
("ö", "o"),
("ü", "u"),
]
def cleanup_text(inputs):
for src, dst in replacements:
inputs["normalized_text"] = inputs["normalized_text"].replace(src, dst)
return inputs
dataset = dataset.map(cleanup_text)Теперь, когда мы разобрались со специальными символами в тексте, пришло время переключить внимание на аудио данные.
Дикторы
Набор данных VoxPopuli включает речь нескольких дикторов, но сколько дикторов представлено в наборе? Чтобы определить это, мы можем подсчитать количество уникальных дикторов и количество примеров, которые каждый диктор вносит в набор данных. Учитывая, что всего в наборе данных 20 968 примеров, эта информация позволит нам лучше понять распределение дикторов и примеров в данных.
from collections import defaultdict
speaker_counts = defaultdict(int)
for speaker_id in dataset["speaker_id"]:
speaker_counts[speaker_id] += 1Построив гистограмму, можно получить представление о том, сколько данных имеется для каждого диктора.
import matplotlib.pyplot as plt
plt.figure()
plt.hist(speaker_counts.values(), bins=20)
plt.ylabel("Speakers")
plt.xlabel("Examples")
plt.show()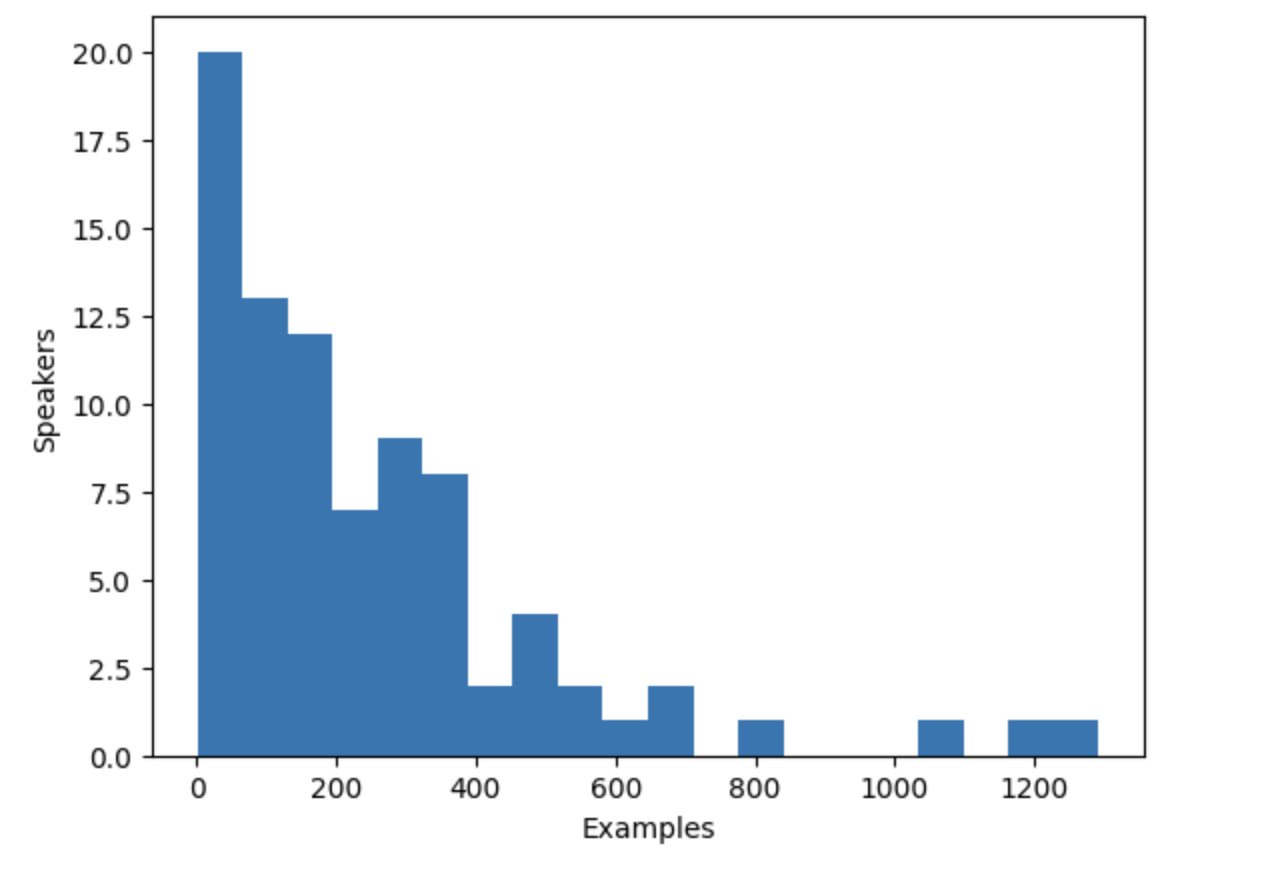
Гистограмма показывает, что примерно треть дикторов в наборе данных имеет менее 100 примеров, в то время как около десяти дикторов имеют более 500 примеров. Чтобы повысить эффективность обучения и сбалансировать набор данных, мы можем ограничить данные дикторами, имеющими от 100 до 400 примеров.
def select_speaker(speaker_id):
return 100 <= speaker_counts[speaker_id] <= 400
dataset = dataset.filter(select_speaker, input_columns=["speaker_id"])Проверим, сколько осталось дикторов:
len(set(dataset["speaker_id"]))Output:
42
Посмотрим, сколько осталось примеров:
len(dataset)Output:
9973В результате вы получаете чуть менее 10 000 примеров из примерно 40 уникальных дикторов, что должно быть вполне достаточно.
Отметим, что некоторые дикторы с небольшим количеством примеров могут иметь больше аудиофайлов, если примеры длинные. Однако определение общего объема аудиозаписей для каждого диктора требует сканирования всего датасета, что является трудоемким процессом, включающим загрузку и декодирование каждого аудиофайла. Поэтому в данном случае мы решили пропустить этот этап.
Эмбеддинги диктора
Для того чтобы модель TTS могла различать несколько дикторов, необходимо создать эмбеддинги диктора для каждого примера. Эмбеддинги дикторов - это дополнительный вход для модели, который фиксирует характеристики голоса конкретного диктора. Для создания эмбеддингов диктора используется предварительно обученная модель spkrec-xvect-voxceleb от SpeechBrain.
Создадим функцию create_speaker_embedding(), которая принимает входную волновую форму звука и выдает 512-элементный вектор,
содержащий соответствующие эмбеддинги диктора.
import os
import torch
from speechbrain.pretrained import EncoderClassifier
spk_model_name = "speechbrain/spkrec-xvect-voxceleb"
device = "cuda" if torch.cuda.is_available() else "cpu"
speaker_model = EncoderClassifier.from_hparams(
source=spk_model_name,
run_opts={"device": device},
savedir=os.path.join("/tmp", spk_model_name),
)
def create_speaker_embedding(waveform):
with torch.no_grad():
speaker_embeddings = speaker_model.encode_batch(torch.tensor(waveform))
speaker_embeddings = torch.nn.functional.normalize(speaker_embeddings, dim=2)
speaker_embeddings = speaker_embeddings.squeeze().cpu().numpy()
return speaker_embeddingsВажно отметить, что модель speechbrain/spkrec-xvect-voxceleb была обучена на английской речи из датасета VoxCeleb,
в то время как учебные примеры в данном руководстве представлены на голландском языке. Хотя мы считаем, что данная модель все равно будет генерировать разумные эмбеддинги диктора
для нашего голландского датасета, это предположение может быть справедливо не во всех случаях.
Для получения оптимальных результатов необходимо сначала обучить модель X-вектора на целевой речи. Это позволит модели лучше улавливать уникальные речевые особенности, присущие голландскому языку. Если вы хотите обучить свою собственную X-векторную модель, то в качестве примера можно использовать этот скрипт.
Обработка датасета
Наконец, обработаем данные в тот формат, который ожидает модель. Создадим функцию prepare_dataset, которая принимает
один пример и использует объект SpeechT5Processor для токенизации входного текста и загрузки целевого аудио в лог-мел спектрограмму.
Она также должна добавлять эмбеддинги диктора в качестве дополнительного входного сигнала.
def prepare_dataset(example):
audio = example["audio"]
example = processor(
text=example["normalized_text"],
audio_target=audio["array"],
sampling_rate=audio["sampling_rate"],
return_attention_mask=False,
)
# strip off the batch dimension
example["labels"] = example["labels"][0]
# use SpeechBrain to obtain x-vector
example["speaker_embeddings"] = create_speaker_embedding(audio["array"])
return exampleПроверить правильность обработки можно на одном из примеров:
processed_example = prepare_dataset(dataset[0])
list(processed_example.keys())Output:
['input_ids', 'labels', 'stop_labels', 'speaker_embeddings']Эмбеддинги диктора должны представлять собой 512-элементный вектор:
processed_example["speaker_embeddings"].shapeOutput:
(512,)Метки должны представлять собой лог-мел спектрограмму с 80 мел бинами.
import matplotlib.pyplot as plt
plt.figure()
plt.imshow(processed_example["labels"].T)
plt.show()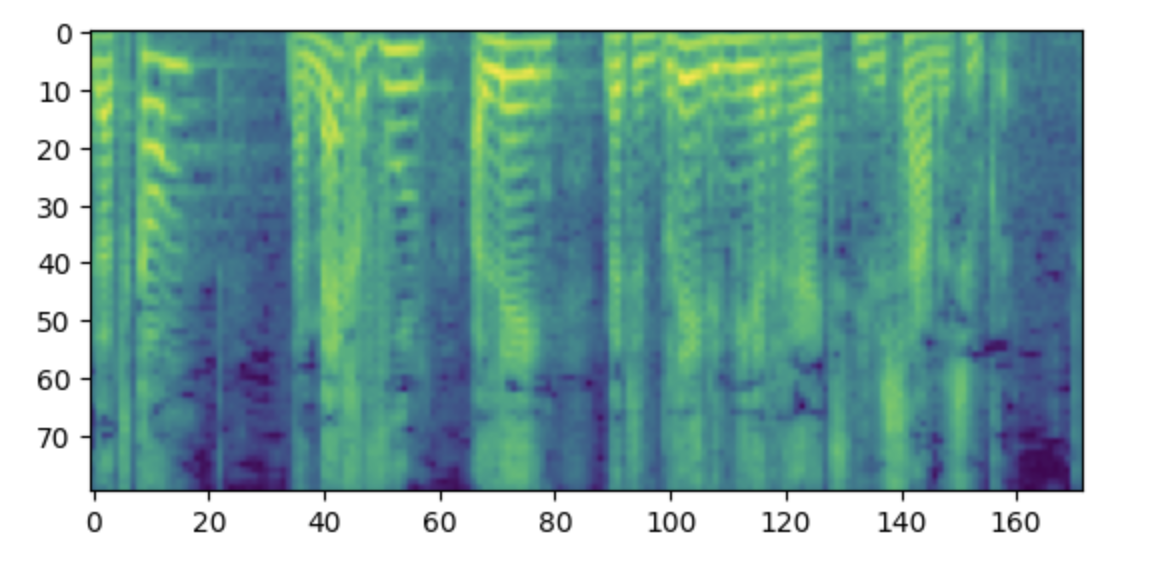
Примечание: Если данная спектрограмма кажется вам непонятной, то это может быть связано с тем, что вы привыкли располагать низкие частоты внизу, а высокие - вверху графика. Однако при построении спектрограмм в виде изображения с помощью библиотеки matplotlib ось y переворачивается, и спектрограммы выглядят перевернутыми.
Теперь необходимо применить функцию препроцессинга ко всему набору данных. Это займет от 5 до 10 минут.
dataset = dataset.map(prepare_dataset, remove_columns=dataset.column_names)Появится предупреждение о том, что длина некоторых примеров в датасете превышает максимальную длину входных данных, которую может обработать модель (600 лексем). Удалите эти примеры из датасета. Здесь мы идем еще дальше и для того, чтобы увеличить размер батча, удаляем все, что превышает 200 токенов.
def is_not_too_long(input_ids):
input_length = len(input_ids)
return input_length < 200
dataset = dataset.filter(is_not_too_long, input_columns=["input_ids"])
len(dataset)Output:
8259Затем создадим базовое разделение на тренировочную и тестовую части:
dataset = dataset.train_test_split(test_size=0.1)Коллатор данных
Для того чтобы объединить несколько примеров в батч, необходимо определить пользовательский коллатор данных. Этот коллатор будет дополнять более короткие последовательности токенами,
гарантируя, что все примеры будут иметь одинаковую длину. Для меток спектрограммы дополняемая части заменяются на специальное значение -100.
Это специальное значение указывает модели игнорировать эту часть спектрограммы при расчете потерь спектрограммы.
from dataclasses import dataclass
from typing import Any, Dict, List, Union
@dataclass
class TTSDataCollatorWithPadding:
processor: Any
def __call__(
self, features: List[Dict[str, Union[List[int], torch.Tensor]]]
) -> Dict[str, torch.Tensor]:
input_ids = [{"input_ids": feature["input_ids"]} for feature in features]
label_features = [{"input_values": feature["labels"]} for feature in features]
speaker_features = [feature["speaker_embeddings"] for feature in features]
# collate the inputs and targets into a batch
batch = processor.pad(
input_ids=input_ids, labels=label_features, return_tensors="pt"
)
# replace padding with -100 to ignore loss correctly
batch["labels"] = batch["labels"].masked_fill(
batch.decoder_attention_mask.unsqueeze(-1).ne(1), -100
)
# not used during fine-tuning
del batch["decoder_attention_mask"]
# round down target lengths to multiple of reduction factor
if model.config.reduction_factor > 1:
target_lengths = torch.tensor(
[len(feature["input_values"]) for feature in label_features]
)
target_lengths = target_lengths.new(
[
length - length % model.config.reduction_factor
for length in target_lengths
]
)
max_length = max(target_lengths)
batch["labels"] = batch["labels"][:, :max_length]
# also add in the speaker embeddings
batch["speaker_embeddings"] = torch.tensor(speaker_features)
return batchВ SpeechT5 входная информация для декодера уменьшается в 2 раза. Другими словами, отбрасывается каждый второй временной шаг из целевой последовательности.Затем декодер предсказывает последовательность, которая в два раза длиннее. Поскольку исходная длина целевой последовательности [NL] может быть нечетной, коллатор данных обязательно округляет максимальную длину батча до значения [NL], кратного 2.
data_collator = TTSDataCollatorWithPadding(processor=processor)
Обучение модели
Загрузите предварительно обученную модель из той же контрольной точки, которая использовалась для загрузки процессора:
from transformers import SpeechT5ForTextToSpeech
model = SpeechT5ForTextToSpeech.from_pretrained(checkpoint)Опция use_cache=True несовместима с использованием градиентных контрольных точек. Отключите ее для обучения и снова включите кэш для генерации,
чтобы ускорить инференс:
from functools import partial
# отключить кэш во время обучения, так как он несовместим с градиентными контрольными точками
model.config.use_cache = False
# заданим язык и задачу для генерации и снова включим кэш
model.generate = partial(model.generate, use_cache=True)Определим аргументы обучения. Здесь мы не вычисляем никаких оценочных метрик в процессе обучения, мы поговорим об оценке позже в этой главе. Вместо этого мы будем рассматривать только потери:
from transformers import Seq2SeqTrainingArguments
training_args = Seq2SeqTrainingArguments(
output_dir="speecht5_finetuned_voxpopuli_nl", # change to a repo name of your choice
per_device_train_batch_size=4,
gradient_accumulation_steps=8,
learning_rate=1e-5,
warmup_steps=500,
max_steps=4000,
gradient_checkpointing=True,
fp16=True,
evaluation_strategy="steps",
per_device_eval_batch_size=2,
save_steps=1000,
eval_steps=1000,
logging_steps=25,
report_to=["tensorboard"],
load_best_model_at_end=True,
greater_is_better=False,
label_names=["labels"],
push_to_hub=True,
)Инстанцируем объект Trainer и передаем ему модель, набор данных и коллатор данных.
from transformers import Seq2SeqTrainer
trainer = Seq2SeqTrainer(
args=training_args,
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
data_collator=data_collator,
tokenizer=processor,
)И с этим мы готовы приступить к обучению! Обучение займет несколько часов. В зависимости от используемого GPU
возможно, что при начале обучения возникнет ошибка CUDA “out-of-memory”. В этом случае можно уменьшить
размер per_device_train_batch_size постепенно в 2 раза и увеличить gradient_accumulation_steps в 2 раза, чтобы компенсировать это.
trainer.train()
Push the final model to the 🤗 Hub:
trainer.push_to_hub()
Инференс
После того как модель дообучена, ее можно использовать для инференса! Загрузите модель из 🤗 Hub (убедитесь, что в следующем фрагменте кода используется имя вашей учетной записи):
model = SpeechT5ForTextToSpeech.from_pretrained(
"YOUR_ACCOUNT/speecht5_finetuned_voxpopuli_nl"
)Выберем пример, здесь мы возьмем пример из тестового набора данных. Получаем эмбеддинги диктора.
example = dataset["test"][304]
speaker_embeddings = torch.tensor(example["speaker_embeddings"]).unsqueeze(0)Определим некоторый входной текст и токенизируем его.
text = "hallo allemaal, ik praat nederlands. groetjes aan iedereen!"Выполним препроцессинг входного текста:
inputs = processor(text=text, return_tensors="pt")Инстанцируем вокодер и сгенерируем речь:
from transformers import SpeechT5HifiGan
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")
speech = model.generate_speech(inputs["input_ids"], speaker_embeddings, vocoder=vocoder)Готовы послушать результат?
from IPython.display import Audio
Audio(speech.numpy(), rate=16000)Получение удовлетворительных результатов с помощью этой модели на новом языке может оказаться непростой задачей. Качество эмбеддингов диктора может быть существенным фактором. Поскольку SpeechT5 была предварительно обучена на английских x-векторах, она показывает наилучшие результаты при использовании эмбеддингов английских дикторов. Если синтезированная речь звучит плохо, попробуйте использовать другие эмбеддинги диктора.
Увеличение продолжительности обучения, вероятно, также повысит качество результатов. Несмотря на это, речь явно голландская, а не английская, и в ней
передаются особенности голоса говорящего (сравните с оригинальным аудио в примере).
Еще один момент, с которым можно поэкспериментировать, - это настройка модели. Например, попробуйте использовать config.reduction_factor = 1, чтобы
посмотреть, улучшит ли это результаты.
В следующем разделе мы расскажем о том, как мы оцениваем модели преобразования текста в речь.
< > Update on GitHub