Audio Course documentation
Раздел 3. Архитектуры трансформеров для аудио
Раздел 3. Архитектуры трансформеров для аудио
В этом курсе мы рассмотрим, прежде всего, трансформерные модели и их применение для решения задач аудио. Хотя вам не обязательно знать внутренние детали этих моделей, полезно понимать основные концепции, обеспечивающие их работу, поэтому здесь мы приведем краткую справку. Для более глубокого погружения в трансформеры ознакомьтесь с нашим [курсом по NLP] (https://huggingface.co/course/chapter1/1).
Как работает трансформер?
Оригинальная модель трансформера предназначалась для перевода письменного текста с одного языка на другой. Ее архитектура выглядела следующим образом:

Слева находится энкодер, а “справа находится декодер.
Энкодер получает входной сигнал, в данном случае последовательность текстовых токенов, и строит его представление (признаки). Эта часть модели обучается для получения понимания из входных данных.
Декодер использует представление кодера (признаки) вместе с другими входными данными (ранее предсказанными токенами) для генерации целевой последовательности. Эта часть модели обучается генерировать выходные данные. В оригинальном дизайне выходная последовательность состояла из текстовых лексем.
Существуют также модели на основе трансформеров, использующие только энкодерную часть (хорошо подходят для задач, требующих понимания входных данных, например, для классификации) или только декодерную часть (хорошо подходят для задач, например, для генерации текста). Примером модели, использующей только энкодер, является BERT, а примером модели, использующей только декодер, является GPT2.
Ключевой особенностью трансформерных моделей является то, что при их построении используются специальные слои, называемые слоями внимания (attention layers). Эти слои указывают модели на необходимость уделять особое внимание определенным элементам входной последовательности и игнорировать другие при вычислении представлений признаков.
Использование трансформеров для аудио
Аудио модели, которые мы рассмотрим в этом курсе, обычно имеют стандартную архитектуру трансформера, как показано выше, но с небольшими изменениями на входе или выходе, позволяющими использовать аудио данные вместо текста. Поскольку все эти модели по своей сути являются трансформерами, большая часть их архитектуры будет общей, а основные различия заключаются в способах их обучения и использования.
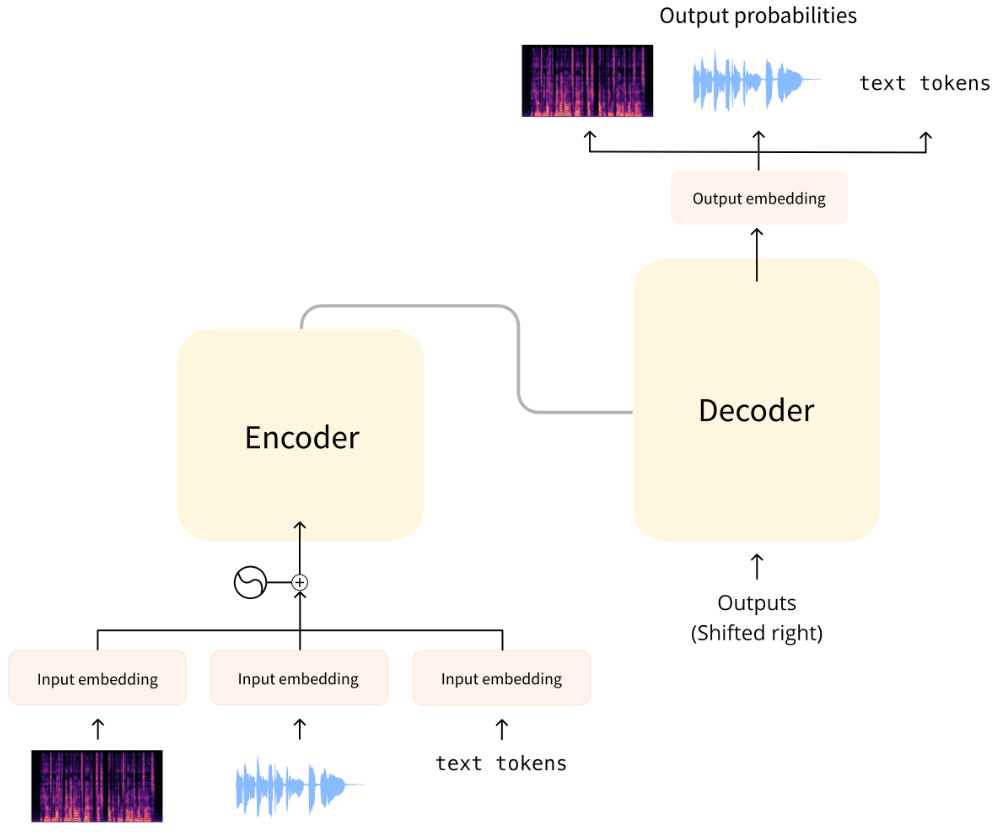
Для задач, связанных с аудио, входные и/или выходные последовательности могут быть не текстовыми, а звуковыми:
Автоматическое распознавание речи (Automatic speech recognition - ASR): На входе - речь, на выходе - текст.
Синтез речи (Text To Speech - TTS): На входе - текст, на выходе - речь.
Классификация аудио: На входе - аудио, на выходе - вероятность класса - по одному для каждого элемента в последовательности или единая вероятность класса для всей последовательности.
Преобразование голоса или улучшение речи: И на входе, и на выходе - аудио.
Существует несколько различных способов обработки аудио, чтобы его можно было использовать с трансформером. Основное внимание уделяется тому, использовать ли звук в исходном виде - как форму волны - или вместо этого обработать его как спектрограмму.
Входы модели
Входными данными для аудио модели могут быть как текстом, так и звуком. Задача состоит в том, чтобы преобразовать эти входные данные в вектор эмбединга, который может быть обработан архитектурой трансформера.
Текстовый ввод
Модель преобразования текста в речь принимает текст на вход. Она работает так же, как и оригинальный трансформер или любая другая модель NLP: Входной текст сначала подвергается токенизации, в результате чего получается последовательность текстовых токенов. Эта последовательность проходит через слой эмбединга, который преобразует токены в 512-мерные векторы. Затем эти векторы эмбеддинга передаются в энкодер трансформера.
Входной сигнал в форме волны
Модель автоматического распознавания речи принимает на вход аудиосигнал. Для того чтобы использовать трансформер для ASR, необходимо сначала каким-то образом преобразовать звук в последовательность векторов эмбеддинга.
Такие модели, как Wav2Vec2 и HuBERT, используют непосредственно форму волны звукового сигнала в качестве входного сигнала для модели. Как вы уже видели в главе, посвященной аудиоданным, форма волны представляет собой одномерную последовательность чисел с плавающей точкой, где каждое число представляет собой амплитуду дискретизации в данный момент времени. Эта необработанная форма волны сначала нормализуется до нулевого среднего и единичной дисперсии, что позволяет стандартизировать аудио образцы разной громкости (амплитуды).
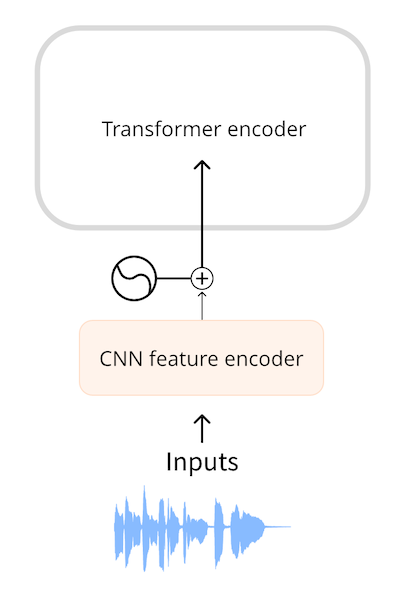
После нормализации последовательность аудио образцов они превращается в эмбединг с помощью небольшой сверточной нейронной сети, называемой энкодером признаков (feature encoder). Каждый из сверточных слоев этой сети обрабатывает входную последовательность, субсэмплируя звук для уменьшения длины последовательности, пока последний сверточный слой не выдает 512-мерный вектор с эмбдингами для каждых 25 мс звука. После преобразования входной последовательности в последовательность таких эмбеддингов трансформер обрабатывает данные обычным образом.
Ввод спектрограмм
Недостатком использования в качестве входных данных необработанной формы волны является то, что они, как правило, имеют большую длину последовательности. Например, тридцать секунд звука с частотой дискретизации 16 кГц дают входной
сигнал длиной 30 * 16000 = 480000. Большая длина последовательности требует большего количества вычислений в модели трансформера, а значит, и большего объема памяти.
В связи с этим необработанные формы звуковых сигналов, как правило, не являются наиболее эффективной формой представления входного аудиосигнала. Используя спектрограмму, мы получаем тот же объем информации, но в более сжатом виде.
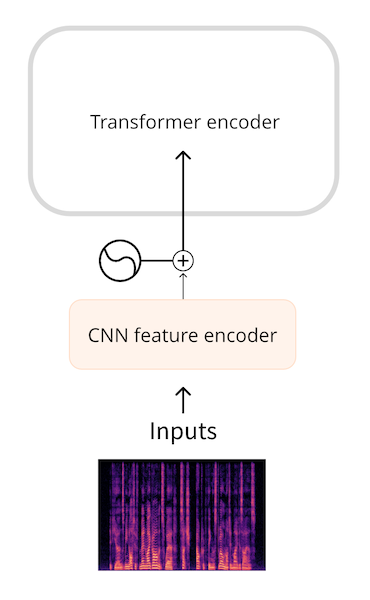
Модели типа Whisper сначала преобразуют форму волны в лог-мел спектрограмму. Whisper всегда разбивает звук на 30-секундные сегменты, и лог-мел спектрограмма для каждого сегмента имеет форму (80, 3000), где 80 - количество
столбцов mel, а 3000 - длина последовательности. Преобразовав в лог-мел спектрограмму, мы уменьшили объем входных данных, но, что более важно, эта последовательность гораздо короче, чем исходная форма сигнала. Затем лог-мел
спектрограмма обрабатывается небольшой CNN в последовательность эмбдингов, которая, как обычно, поступает в трансформер.
В обоих случаях, как при вводе формы волны, так и спектрограммы, перед трансформером имеется небольшая сеть, которая преобразует входной сигнал в эмбеддинги, после чего трансформер начинает выполнять свою работу.
Выходы модели
Архитектура трансформера выдает на выходе последовательность векторов скрытых состояний (hidden-state vectors), также известных как эмбеддинги на выходе. Наша цель - преобразовать эти векторы в текст или аудиоданные.
Вывод текста
Цель модели автоматического распознавания речи - предсказать последовательность текстовых токенов. Для этого на выход трансформера добавляется голова языковой модели - как правило, один линейный слой - с последующим softmax. Таким образом, прогнозируются вероятности для текстовых токенов в словаре.
Вывод спектрограммы
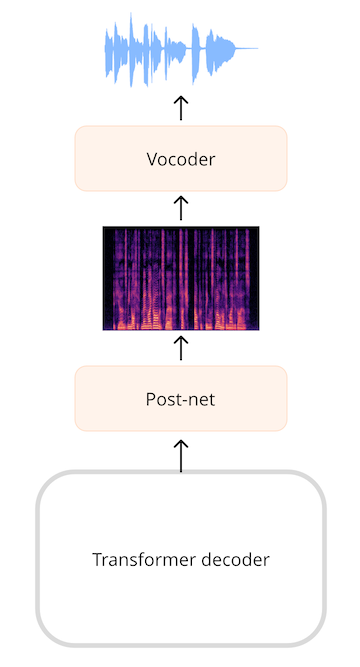
Для моделей, генерирующих звук, таких как модель преобразования текста в речь (TTS), необходимо добавить слои, которые могут генерировать звуковую последовательность. Очень часто генерируется спектрограмма, а затем используется дополнительная нейронная сеть, известная как вокодер, для преобразования этой спектрограммы в форму волны.
Например, в модели TTS SpeechT5 выходной сигнал трансформера представляет собой последовательность 768-элементных векторов. Линейный слой проецирует эту последовательность в лог-мел спектрограмму. Так называемая пост-сеть, состоящая из дополнительных линейных и сверточных слоев, уточняет спектрограмму за счет уменьшения шума. Затем вокодер формирует конечную форму звукового сигнала.
Вывод формы волны
Также существует возможность для моделей напрямую выводить форму волны вместо спектрограммы в качестве промежуточного шага, но в настоящее время в 🤗 Transformers нет ни одной модели, которая бы это делала.
Заключение
Подведем итоги: большинство моделей аудио трансформеров скорее похожи друг на друга, чем отличаются - все они построены на одной и той же архитектуре трансформера и слоях внимания, хотя в некоторых моделях используется только энкодерная часть трансформера, а в других - и энкодер, и декодер.
Вы также увидели, как вводить и выводить аудиоданные из трансформерных моделей. Для выполнения различных аудиозадач ASR, TTS и т.д. мы можем просто менять местами слои, которые предварительно обрабатывают входные данные в эмбеддинги, и менять местами слои, которые после обработки предсказанных эмбеддингов превращаются в выходные данные, при этом основа трансформера остается неизменной.
Далее мы рассмотрим несколько различных способов обучения этих моделей для автоматического распознавания речи.
< > Update on GitHub