Audio Course documentation
Архитектуры CTC
Архитектуры CTC
CTC (Connectionist Temporal Classification) или Коннекционистская Временная Классификация это техника, используемая в моделях трансформеров состоящих только из энкодера, для задачи автоматического распознавания речи (ASR). Примерами таких моделей являются Wav2Vec2, HuBERT и M-CTC-T.
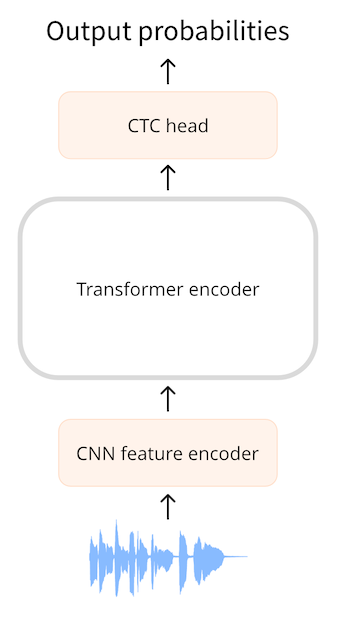
Трансформеры состоящие только из энкодера, являются самыми простыми, поскольку в них используется только часть модели, состоящая из энкодера. Энкодер считывает входную последовательность (форму волны звука) и преобразует ее в последовательность скрытых состояний, которые также известны как выходные эмбеддинги.
В модели CTC мы применяем дополнительное линейное отображение на последовательность скрытых состояний для получения предсказаний метки класса. Метками классов являются символы алфавита (a, b, c, …). Таким образом, мы можем предсказать любое слово на целевом языке с небольшой классификационной головой, поскольку словарный запас должен состоять всего из 26 символов плюс несколько специальных токенов.
Пока это очень похоже на то, что мы делаем в NLP с помощью такой модели, как BERT: модель трансформер состоящая только из энкодера отображает наши текстовые токены в последовательность скрытых состояний энкодера, а затем мы применяем линейное отображение для получения одного предсказания метки класса для каждого скрытого состояния.
Вот в чем загвоздка: в речи мы не знаем соответствия между входными аудио сигналами и текстовыми выходами. Мы знаем, что порядок произнесения речи совпадает с порядком транскрибирования текста (так называемое монотонное выравнивание), но мы не знаем, как символы в транскрипции соотносятся с аудиозаписью. В этом случае на помощь приходит алгоритм CTC.
Дружище, где мое выравнивание?
Автоматическое распознавание речи, или ASR, подразумевает прием аудиосигнала на вход и выдачу текста на выход. У нас есть несколько вариантов того, как предсказать текст:
- как отдельные символы
- как фонемы
- как токены слова
Модель ASR обучается на наборе данных, состоящем из пар (аудио, текст), где текст представляет собой транскрипцию аудиофайла, выполненную человеком. Как правило, набор данных не содержит никакой временной информации, указывающей, какое слово или слог встречается в аудиофайле. Поскольку в процессе обучения мы не можем полагаться на информацию о времени, мы не имеем представления о том, как должны быть выровнены входные и выходные последовательности.
Предположим, что на вход нам подается односекундный аудиофайл. В Wav2Vec2 модели сначала понижают дискретизацию (downsampling) входного аудиосигнала с помощью кодера признаков CNN до более короткой последовательности скрытых состояний, где на каждые 20 миллисекунд аудиосигнала приходится один вектор скрытых состояний. Для одной секунды звука мы передаем на энкодер трансформера последовательность из 50 скрытых состояний. (Звуковые сегменты, извлеченные из входной последовательности, частично перекрываются, поэтому, хотя один вектор скрытых состояний выдается каждые 20 мс, каждое скрытое состояние фактически представляет собой 25 мс звука).
Энкодер трансформера предсказывает одно представление признака для каждого из этих скрытых состояний, то есть мы получаем последовательность из 50 выходов трансформера. Каждый из этих выходов имеет размерность 768. Таким образом, выходная последовательность энкодера трансформера в данном
примере имеет форму (768, 50). Поскольку каждый из этих прогнозов охватывает 25 мс времени, что меньше длительности фонемы, имеет смысл прогнозировать отдельные фонемы или символы, но не целые слова. CTC лучше всего работает с небольшим словарным запасом, поэтому мы будем предсказывать символы.

Для предсказания текста мы сопоставляем каждый из 768-мерных выходов энкодера с метками символов с помощью линейного слоя (” голова CTC”). Затем модель предсказывает тензор (50, 32), содержащий логиты, где 32 - количество токенов в словаре. Поскольку мы делаем по одному прогнозу для
каждого из признаков в последовательности, в итоге получается 50 прогнозов символов для каждой секунды звука.
Однако если мы просто прогнозируем один символ каждые 20 мс, то наша выходная последовательность может выглядеть примерно так:
BRIIONSAWWSOMEETHINGCLOSETOPANICONHHISOPPONENT'SSFAACEWHENTHEMANNFINALLLYRREECOGGNNIIZEDHHISSERRRRORR ...
Если присмотреться, то она несколько похожа на английский язык, но многие символы продублированы. Это связано с тем, что модель должна выводить нечто на каждые 20 мс звука во входной последовательности, и если символ распределен на период более 20 мс, то он будет появляться на выходе несколько раз. Избежать этого невозможно, тем более что мы не знаем, каково время транскрипции в процессе обучения. CTC - это способ отфильтровать подобные дубликаты.
(В реальности предсказанная последовательность также содержит большое количество токен-заполнителей для случаев, когда модель не совсем уверена в том, что представляет собой звук, или для пустого пространства между символами. Для наглядности мы удалили эти токены из примера. Частичное перекрытие звуковых сегментов - еще одна причина дублирования символов на выходе).
Алгоритм CTC.
Ключом к алгоритму CTC является использование специального токена, часто называемого пустым токеном (blank token). Это просто еще один токен, который модель будет предсказывать, и он является частью словаря. В данном примере пустой токен показан как _. Этот специальный токен служит
жесткой границей между группами символов.
Полный вывод модели CTC может выглядеть следующим образом:
B_R_II_O_N_||_S_AWW_|||||_S_OMEE_TH_ING_||_C_L_O_S_E||TO|_P_A_N_I_C_||_ON||HHI_S||_OP_P_O_N_EN_T_'SS||_F_AA_C_E||_W_H_EN||THE||M_A_NN_||||_F_I_N_AL_LL_Y||||_RREE_C_O_GG_NN_II_Z_ED|||HHISS|||_ER_RRR_ORR||||
Токен | является символом-разделителем слов. В примере мы используем | вместо пробела, чтобы было легче определить места разрыва слов, но это служит той же цели.
Пустой символ CTC позволяет отфильтровать дублирующиеся символы. Для примера рассмотрим последнее слово из спрогнозированной последовательности, _ER_RRR_ORR. Без пустого токена CTC слово выглядело следующим образом:
ERRRRORR
Если бы мы просто удалили дублирующиеся символы, то получилось бы EROR. Это явно не правильное написание. Но с помощью пустого токена CTC мы можем удалить дубликаты в каждой группе, так что:
_ER_RRR_ORR
становится:
_ER_R_OR
и теперь удаляем пустой токен _, чтобы получить окончательное слово:
ERROR
Если применить эту логику ко всему тексту, включая |, и заменить уцелевшие символы | на пробелы, то конечный результат CTC-декодирования будет следующим:
BRION SAW SOMETHING CLOSE TO PANIC ON HIS OPPONENT'S FACE WHEN THE MAN FINALLY RECOGNIZED HIS ERROR
Напомним, что модель предсказывает один токен (символ) на каждые 20 мс (частично перекрывающихся) аудиоданных из входной формы сигнала. Это порождает большое количество дубликатов. Благодаря пустому токену CTC мы можем легко удалить эти дубликаты, не нарушая правильности написания слов. Это очень простой и удобный способ решения проблемы выравнивания выходного текста по входному звуку.
Добавить CTC в модель трансформера энкодера очень просто: выходная последовательность с энкодера поступает на линейный слой, который проецирует акустические признаки на словарь. Модель обучается с помощью специальной функции потерь CTC.
Недостатком CTC является то, что он может выдавать слова, которые звучат правильно, но не написаны правильно. Ведь голова CTC учитывает только отдельные символы, а не целые слова. Одним из способов повышения качества транскрипции звука является использование внешней языковой модели. Эта языковая модель, по сути, выполняет функцию проверки орфографии на выходе CTC.
В чем разница между Wav2Vec2, HuBERT, M-CTC-T, …?
Все модели трансформеры основанные на архитектуре CTC имеют очень схожую архитектуру: в них используется энкодер трансформера (но не декодер) с головой CTC на верху. С точки зрения архитектуры они скорее похожи, чем отличаются.
Разница между Wav2Vec2 и M-CTC-T заключается в том, что первый работает с необработанными формами звуковых сигналов, а второй использует в качестве входных данных мэл спектрограммы. Модели также были обучены для разных целей. Например, M-CTC-T обучен распознаванию многоязычной речи и поэтому имеет относительно большую голову CTC, включающую помимо других алфавитов еще и китайские иероглифы.
Wav2Vec2 и HuBERT используют совершенно одинаковую архитектуру, но обучаются совершенно по-разному. Wav2Vec2 предварительно обучена по аналогии с маскированным языковым моделированим BERT, прогнозирующим речевые единицы для маскированных частей аудио. HuBERT использует идею BERT и учится предсказывать “дискретные единицы речи”, которые являются аналогом токенов в текстовом предложении, так что речь может обрабатываться с помощью известных методов NLP.
Следует отметить, что приведенные здесь модели не являются единственными моделями CTC на основе трансформеров. Существует множество других, но теперь вы знаете, что все они работают примерно одинаково.
< > Update on GitHub