Audio Course documentation
3단원. 오디오를 위한 트랜스포머 아키텍처
3단원. 오디오를 위한 트랜스포머 아키텍처
이 강좌에서는 주로 트랜스포머 모델과 이를 오디오 작업에 적용하는 방법을 살펴봅니다. 모델의 내부의 세부 내용을 알 필요는 없지만 모델이 동작하는 주요 개념을 이해하는 것이 중요하기 때문에 간단히 복습하겠습니다. 트랜스포머에 대해 자세히 살펴보고 싶으시다면 NLP 과정을 참조하세요.
트렌스포머의 작동 원리
원래 트랜스포머 모델은 텍스트를 한 언어에서 다른 언어로 번역하도록 설계되었습니다. 구조는 다음과 같습니다.:

왼쪽에는 인코더(encoder)가 있고 오른쪽에는 디코더(decoder)가 있습니다.
인코더는 입력(이 경우 텍스트 토큰 시퀀스)을 수신하고 그 표현(특징)을 구축합니다. 모델의 이 부분은 입력을 통해 이해력을 습득하도록 학습됩니다.
디코더는 인코더의 표현(특징)을 다른 입력(이전에 예측된 토큰)과 함께 사용하여 목표 시퀀스를 생성합니다. 모델의 이 부분은 출력을 생성하도록 훈련됩니다. 원래 설계에서 출력 시퀀스는 텍스트 토큰으로 구성되었습니다.
인코더 부분만 사용하는 트랜스포머 기반 모델(분류와 같이 입력에 대한 이해가 필요한 작업에 적합) 또는 디코더 부분만 사용하는 모델(텍스트 생성과 같은 작업에 적합)도 있습니다. 인코더 전용 모델의 예로는 BERT가 있고, 디코더 전용 모델의 예로는 GPT2가 있습니다.
트랜스포머 모델의 핵심 특징은 어텐션(attention) 레이어라는 특수 레이어로 구축된다는 점입니다. 이 레이어는 특징 표현을 계산할 때 입력 시퀀스의 특정 요소에 특별히 주의를 기울이고 다른 요소는 무시하도록 모델에 지시합니다.
오디오에 트랜스포머 사용하기
이 강좌에서 다룰 오디오 모델은 일반적으로 위와 같은 표준 트랜스포머 아키텍처를 사용하지만, 텍스트 대신 오디오 데이터를 사용할 수 있도록 입력 또는 출력 측에서 약간의 수정이 이루어집니다. 이러한 모든 모델은 기본적으로 트랜스포머이므로 대부분의 아키텍처가 공통적이며 주요 차이점은 학습 및 사용 방식에 있습니다.
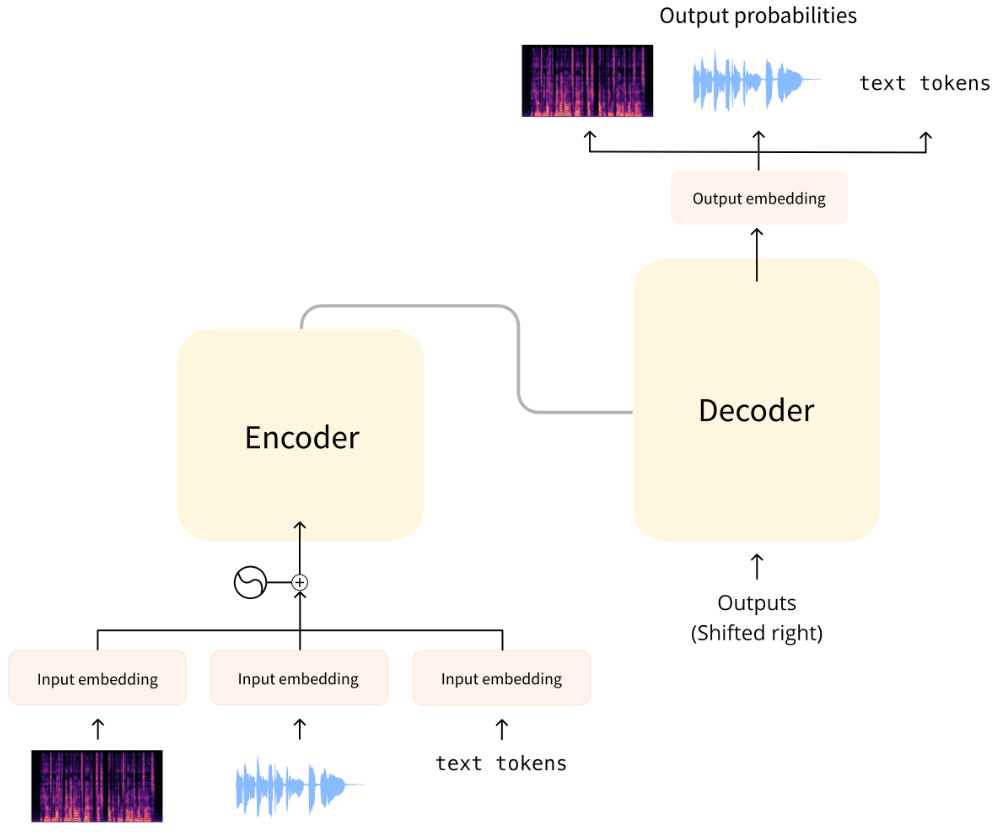
오디오 작업의 경우 입력과 출력 전체 혹은 각각의 시퀀스가 텍스트가 아닌 오디오일 수 있습니다:
자동 음성 인식(ASR, Automatic Speech Recognition): 입력은 음성, 출력은 텍스트입니다.
음성 합성(TTS): 입력은 텍스트, 출력은 음성입니다.
오디오 분류(audio classification): 입력은 오디오이고 출력은 클래스 확률(시퀀스의 각 요소에 대해 하나씩 또는 전체 시퀀스에 대해 단일 클래스 확률)입니다.
음성 변환(voice conversion) 또는 음성 향상(speech enhancement): 입력과 출력 모두 오디오입니다.
트랜스포머와 함께 사용할 수 있도록 오디오를 처리하는 방법에는 몇 가지가 있습니다. 주요 고려 사항은 오디오를 원시 형태(파형)로 사용할지, 아니면 스펙트로그램으로 처리할지 여부입니다.
모델 입력
오디오 모델에 대한 입력은 텍스트 또는 사운드일 수 있습니다. 목표는 이 입력을 트랜스포머 아키텍처에서 처리할 수 있는 임베딩 벡터로 변환하는 것입니다.
텍스트 입력
텍스트 음성 변환 모델은 텍스트를 입력으로 받습니다. 이는 원래의 트랜스포머나 다른 NLP(Natural Language Processing) 모델과 똑같이 작동합니다: 입력 텍스트는 먼저 토큰화되어 일련의 텍스트 토큰을 제공합니다. 이 시퀀스는 입력 임베딩 레이어를 통해 전송되어 토큰을 512차원 벡터로 변환합니다. 그런 다음 이러한 임베딩 벡터는 트랜스포머 인코더로 전달됩니다.
파형 입력
자동 음성 인식 모델은 오디오를 입력으로 받습니다. ASR에 트랜스포머를 사용하려면 먼저 오디오를 어떤 식으로든 임베딩 벡터 시퀀스로 변환해야 합니다.
Wav2Vec2 및 HuBERT와 같은 모델은 오디오 파형을 모델에 대한 입력으로 직접 사용합니다. 오디오 데이터 소개에서 살펴보았듯이 파형은 부동 소수점 숫자의 1차원 시퀀스이며, 각 숫자는 주어진 시간에 샘플링된 진폭을 나타냅니다. 이 원시 파형은 먼저 평균과 단위 분산이 0으로 정규화되어 다양한 음량(진폭)의 오디오 샘플을 표준화하는 데 도움이 됩니다.
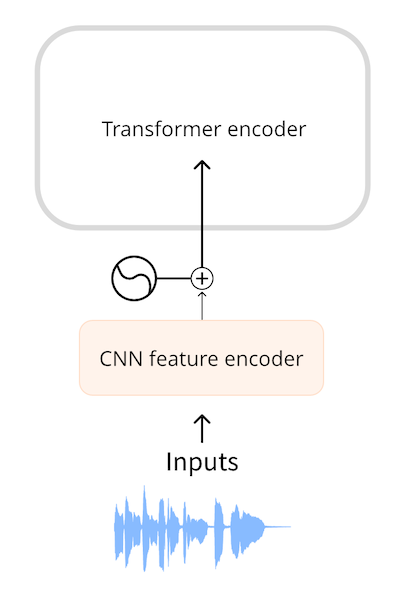
정규화 후 오디오 샘플 시퀀스는 특징 인코더(feature encoder)로 알려진 작은 컨볼루션 신경망을 사용하여 임베딩으로 변환됩니다. 이 네트워크의 각 컨볼루션 레이어는 입력 시퀀스를 처리하고 오디오를 서브샘플링하여 시퀀스 길이를 줄인 다음 최종 컨볼루션 레이어가 오디오 25ms마다 임베딩이 포함된 512차원 벡터를 출력할 때까지 처리합니다. 입력 시퀀스가 이러한 임베딩 시퀀스로 변환되면 트랜스포머는 평소와 같이 데이터를 처리합니다.
스펙트로그램 입력
원시 파형을 입력으로 사용할 때의 한 가지 단점은 시퀀스 길이가 길어지는 경향이 있다는 것입니다. 예를 들어 샘플링 속도가 16kHz인 30초 분량의 오디오는 ‘30 * 16000 = 480000’ 길이의 입력이 됩니다. 시퀀스 길이가 길수록 트랜스포머 모델에서 더 많은 계산이 필요하므로 메모리 사용량이 증가합니다.
이 때문에 원시 오디오 파형은 일반적으로 오디오 입력을 표현하는 가장 효율적인 형태가 아닙니다. 스펙트로그램을 사용하면 동일한 양의 정보를 더 압축된 형태로 얻을 수 있습니다.
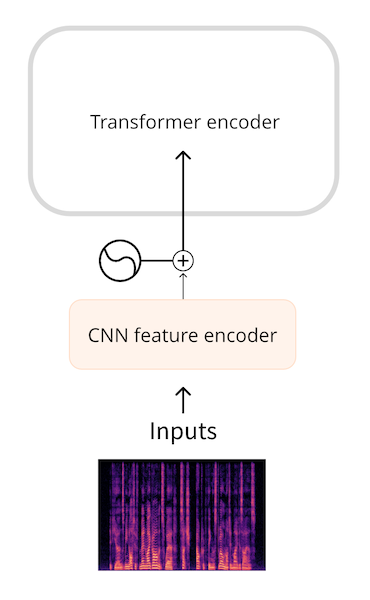
Whisper와 같은 모델은 먼저 파형을 로그 멜 스펙트로그램으로 변환합니다. Whisper는 항상 오디오를 30초 세그먼트로 분할하며, 각 세그먼트의 로그 멜 스펙트로그램은 80, 3000의 형태를 갖습니다. 여기서 80은 멜 빈의 수이고 3000은 시퀀스 길이입니다. 로그 멜 스펙트로그램으로 변환함으로써 입력 데이터의 양을 줄였지만, 더 중요한 것은 원시 파형보다 훨씬 짧은 시퀀스라는 점입니다. 그런 다음 로그 멜 스펙트로그램은 작은 CNN에 의해 임베딩 시퀀스로 처리되어 평소와 같이 트랜스포머로 들어갑니다.
파형과 스펙트로그램 입력 두 경우 모두, 트랜스포머 앞에 작은 네트워크가 있어 입력을 임베딩으로 변환한 다음 트랜스포머가 작업을 수행합니다.
모델 출력
트랜스포머 아키텍처는 출력 임베딩이라고도 하는 은닉 상태 벡터의 시퀀스를 출력합니다. 우리의 목표는 이러한 벡터를 텍스트 또는 오디오 출력으로 변환하는 것입니다.
텍스트 출력
자동 음성 인식 모델의 목표는 텍스트 토큰의 시퀀스를 예측하는 것입니다. 이는 언어 모델링 헤드(일반적으로 단일 선형 레이어)를 추가한 다음 트랜스포머의 출력 위에 소프트맥스를 추가하여 수행됩니다. 이렇게 하면 어휘의 텍스트 토큰에 대한 확률을 예측할 수 있습니다
스펙트로그램 출력
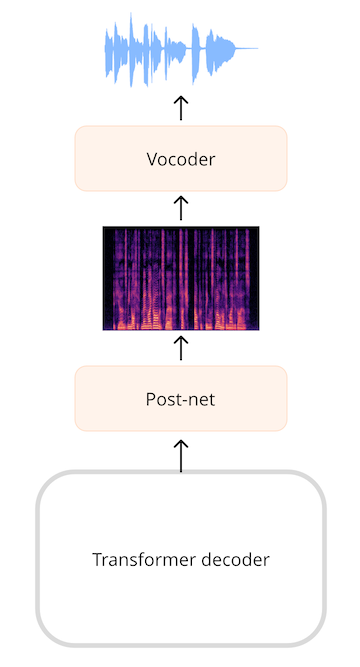
텍스트 음성 변환(TTS) 모델과 같이 오디오를 생성하는 모델의 경우 오디오 시퀀스를 생성할 수 있는 레이어를 추가해야 합니다. 스펙트로그램을 생성한 다음 보코더(vocoder)라고 하는 추가 신경망을 사용하여 이 스펙트로그램을 파형으로 변환하는 것이 매우 일반적입니다.
예를 들어 SpeechT5 TTS 모델에서 트랜스포머 네트워크의 출력은 768개 요소 벡터의 시퀀스입니다. 선형 레이어는 이 시퀀스를 로그 멜 스펙트로그램으로 투영합니다. 추가 선형 및 컨볼루션 레이어로 구성된 이른바 포스트넷(post-net)은 노이즈를 줄여 스펙트로그램을 개선합니다. 그런 다음 보코더가 최종 오디오 파형을 생성합니다.
파형 출력
모델이 중간 단계로 스펙트로그램 대신 파형을 직접 출력하는 것도 가능하지만, 현재 🤗 트랜스포머에는 이 기능을 지원하는 모델이 없습니다.
결론
요약: 대부분의 오디오 트랜스포머 모델은 다른 점보다는 비슷한 점이 더 많은데, 일부 모델은 트랜스포머의 인코더 부분만 사용하고 다른 모델은 인코더와 디코더를 모두 사용하지만 모두 동일한 트랜스포머 아키텍처와 어텐션 레이어를 기반으로 구축됩니다.
또한 트랜스포머 모델에 오디오 데이터를 가져오고 내보내는 방법도 살펴봤습니다. ASR, TTS 등의 다양한 오디오 작업을 수행하려면 입력을 임베딩으로 전처리하는 레이어를 교체하고, 예측된 임베딩을 출력으로 후처리하는 레이어를 교체하면 되며, 트랜스포머 백본(backbone)은 그대로 유지하면 됩니다.
다음으로, 이러한 모델을 자동 음성 인식으로 학습시킬 수 있는 몇 가지 방법을 살펴보겠습니다.
< > Update on GitHub