Audio Course documentation
CTC 아키텍처
CTC 아키텍처
연결주의 시간 분류(CTC, Connectionist Temporal Classification)는 자동 음성 인식을 위한 인코더 전용 트랜스포머 모델에 사용되는 기법입니다. 이러한 모델의 예로는 Wav2Vec2, HuBERT 및 M-CTC-T가 있습니다.
인코더 전용 트랜스포머는 모델의 인코더 부분만 사용하기 때문에 가장 간단한 종류의 트랜스포머입니다. 인코더는 입력 시퀀스(오디오 파형)를 읽고 이를 출력 임베딩이라고도 하는 은닉 상태 시퀀스로 매핑합니다.
CTC 모델을 사용하면 은닉 상태 시퀀스에 추가 선형 매핑을 적용하여 클래스 레이블 예측을 얻습니다. 클래스 레이블은 알파벳 문자(a, b, c, …)입니다. 이렇게 하면 어휘가 26자와 몇 개의 특수 토큰으로만 존재하면 되기 때문에 작은 분류 헤드로 대상 언어의 모든 단어를 예측할 수 있습니다.
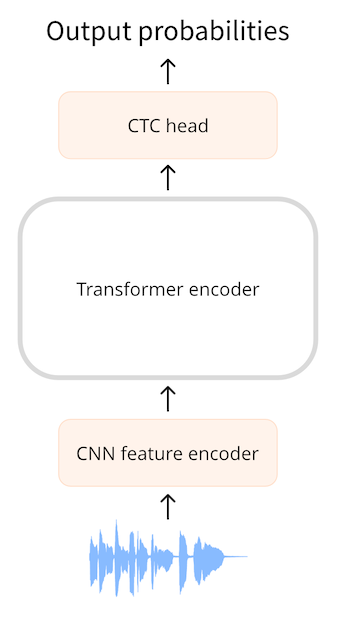
지금까지는 NLP에서 BERT와 같은 모델을 사용하는 것과 매우 유사합니다. 인코더 전용 트랜스포머 모델이 텍스트 토큰을 인코더 숨겨진 상태 시퀀스에 매핑한 다음 선형 매핑을 적용하여 각 숨겨진 상태에 대해 하나의 클래스 레이블 예측을 얻습니다.
음성에서는 오디오 입력과 텍스트 출력의 ‘정렬(alignment)‘을 알 수 없다는 점이 문제입니다. 음성이 말하는 순서와 텍스트를 필사(transcribe)하는 순서가 같다는 것은 알지만(소위 단조로운 정렬의 경우), 필사하는 텍스트의 문자가 오디오와 어떻게 일치하는지는 알 수 없습니다. 바로 이 부분에서 CTC 알고리즘이 등장합니다.
정렬을 어떻게 확인하지?
자동 음성 인식(ASR)은 오디오를 입력으로 받아 텍스트를 출력으로 생성합니다. 텍스트를 예측하는 방법에는 몇 가지 선택지가 있습니다:
- 개별 문자로 인식
- 음소(phonemes)로 인식
- 단어 토큰으로 인식
자동 음성 인식 모델은 (오디오, 텍스트) 쌍으로 구성된 데이터 셋에 대해 학습되며, 텍스트는 오디오 파일의 사람이 만든 필사본입니다. 일반적으로 데이터 셋에는 오디오 파일에서 어떤 단어나 음절이 어디에 나오는지 알려주는 타이밍 정보가 포함되지 않습니다. 훈련 중에 타이밍 정보에 의존할 수 없기 때문에 입력과 출력 순서를 어떻게 정렬해야 하는지 알 수 없습니다.
입력이 1초짜리 오디오 파일이라고 가정해 봅시다. Wav2Vec2 모델에서는 먼저 CNN 피처 인코더를 사용하여 오디오 입력을 더 짧은 은닉 상태 시퀀스로 다운샘플링하는데, 여기에는 오디오 20밀리초당 하나의 은닉 상태 벡터가 있습니다. 오디오 1초에 대해 50개의 은닉 상태 시퀀스를 트랜스포머 인코더로 전달합니다. (입력 시퀀스에서 추출된 오디오 세그먼트는 부분적으로 겹치므로 20밀리초마다 하나의 은닉 상태 벡터가 출력되지만 각 은닉 상태는 실제로 25밀리초의 오디오를 나타냅니다.)
트랜스포머 인코더는 이러한 숨겨진 상태 각각에 대해 하나의 특징 표현을 예측하므로 트랜스포머로부터 50개의 출력 시퀀스를 수신합니다. 이러한 각 출력의 차원은 768입니다. 따라서 이 예제에서 트랜스포머 인코더의 출력 시퀀스는 (768, 50) 모양을 갖습니다. 이러한 각 예측은 음소 지속 시간보다 짧은 25ms의 시간을 포함하므로 전체 단어가 아닌 개별 음소 또는 문자를 예측하는 것이 합리적입니다. CTC는 작은 어휘에서 가장 잘 작동하므로 문자를 예측해 보겠습니다.

텍스트 예측을 위해 768차원 인코더 출력 각각을 선형 레이어(“CTC 헤드”)를 사용하여 문자 레이블에 매핑합니다. 그런 다음 모델은 로그를 포함하는 (50, 32) 텐서(여기서 32는 어휘의 토큰 수)를 예측합니다. 시퀀스의 각 특징에 대해 하나의 예측을 수행하므로 오디오의 각 초에 대해 총 50개의 문자를 예측하게 됩니다.
그러나 단순히 20ms마다 한 문자를 예측한다면 출력 시퀀스는 다음과 같이 보일 수 있습니다:
BRIIONSAWWSOMEETHINGCLOSETOPANICONHHISOPPONENT'SSFAACEWHENTHEMANNFINALLLYRREECOGGNNIIZEDHHISSERRRRORR ...
자세히 보면 영어와 다소 비슷하지만 많은 문자가 중복되어 있습니다. 이는 모델이 입력 시퀀스의 오디오 20밀리초마다 어떤 것을 출력해야 하기 때문이며, 한 문자가 20밀리초보다 긴 기간에 걸쳐 분산되어 있으면 출력에 여러 번 나타나게 됩니다. 특히 훈련 중에는 대본의 타이밍을 알 수 없기 때문에 이를 피할 방법이 없습니다. CTC는 이러한 중복을 필터링하는 방법입니다.
(실제로 예측된 시퀀스에는 모델이 소리가 무엇을 나타내는지 잘 모를 때나 문자 사이의 빈 공간을 위한 많은 패딩 토큰도 포함되어 있습니다. 명확성을 위해 예제에서 이러한 패딩 토큰을 제거했습니다. 오디오 세그먼트가 부분적으로 겹치는 것도 출력에서 문자가 중복되는 또 다른 이유입니다.)
CTC 알고리즘
CTC 알고리즘의 핵심은 흔히 공백 토큰이라고 불리는 특수 토큰을 사용하는 것입니다. 이것은 모델이 예측하는 또 다른 토큰이며 어휘의 일부입니다. 이 예시에서 빈 토큰은 _로 표시됩니다. 이 특수 토큰은 문자 그룹 간의 엄격한 경계 역할을 합니다.
CTC 모델의 전체 출력은 다음과 같을 수 있습니다:
B_R_II_O_N_||_S_AWW_|||||_S_OMEE_TH_ING_||_C_L_O_S_E||TO|_P_A_N_I_C_||_ON||HHI_S||_OP_P_O_N_EN_T_'SS||_F_AA_C_E||_W_H_EN||THE||M_A_NN_||||_F_I_N_AL_LL_Y||||_RREE_C_O_GG_NN_II_Z_ED|||HHISS|||_ER_RRR_ORR||||
토큰 |는 단어 구분 문자입니다. 이 예에서는 공백 대신 |를 사용하여 단어 나누기 위치를 더 쉽게 파악할 수 있도록 했지만 동일한 용도로 사용됩니다.
CTC 공백 문자를 사용하면 중복 문자를 필터링할 수 있습니다. 예를 들어 예측된 시퀀스의 마지막 단어인 _ER_RRR_ORR을 살펴봅시다. CTC 공백 토큰이 없으면 이 단어는 다음과 같이 보입니다:
ERRRRORR
단순히 중복된 문자를 제거하면 EROR이 됩니다. 이는 분명 올바른 철자가 아닙니다. 하지만 CTC 빈 토큰을 사용하면 각 그룹에서 중복을 제거할 수 있습니다. 따라서:
_ER_RRR_ORR
는 아래와 같이 변경됩니다.:
_ER_R_OR
이제 _ 빈 토큰을 제거하여 최종 단어를 얻습니다:
ERROR
이 논리를 |를 포함한 전체 텍스트에 적용하고 남은 | 문자를 공백으로 바꾸면 최종 CTC 디코딩된 출력은 다음과 같습니다:
BRION SAW SOMETHING CLOSE TO PANIC ON HIS OPPONENT'S FACE WHEN THE MAN FINALLY RECOGNIZED HIS ERROR
요약하자면, 모델은 입력 파형에서 (부분적으로 겹치는) 오디오의 20ms마다 하나의 토큰(문자)을 예측합니다. 이로 인해 많은 중복이 발생합니다. CTC 빈 토큰 덕분에 단어의 올바른 철자를 파괴하지 않고도 이러한 중복을 쉽게 제거할 수 있습니다. 이는 출력 텍스트를 입력 오디오와 정렬하는 문제를 해결하는 매우 간단하고 편리한 방법입니다.
인코더의 출력 시퀀스가 어휘에 음향 특징을 투영하는 선형 레이어로 이동하기 때문에 트랜스포머 인코더 모델에 CTC를 추가하는 것은 간단합니다.모델은 특수한 CTC 손실로 훈련됩니다.
CTC의 한 가지 단점은 ‘소리’는 정확하지만 ‘철자’는 정확하지 않은 단어를 출력할 수 있다는 점입니다.결국 CTC 헤드는 완전한 단어가 아닌 개별 문자만 고려하기 때문입니다. 오디오 트랜스크립션의 품질을 개선하는 한 가지 방법은 외부 언어 모델을 사용하는 것입니다. 이 언어 모델은 기본적으로 CTC 출력 위에 맞춤법 검사기 역할을 합니다.
Wav2Vec2, HuBERT, M-CTC-T, …의 차이점은 무엇인가요?
모든 트랜스포머 기반 CTC 모델은 매우 유사한 아키텍처를 가지고 있습니다. 트랜스포머 인코더(디코더는 아님)를 사용하며 그 위에 CTC 헤드가 있습니다. 아키텍처 측면에서 보면 다른 점보다는 비슷한 점이 더 많습니다.
Wav2Vec2와 M-CTC-T의 한 가지 차이점은 전자는 원시 오디오 파형에서 작동하는 반면 후자는 멜 스펙트로그램을 입력으로 사용한다는 점입니다. 또한 두 모델은 서로 다른 목적으로 훈련되었습니다. 예를 들어, M-CTC-T는 다국어 음성 인식을 위해 훈련되었기 때문에 다른 알파벳 외에 한자를 포함하는 비교적 큰 CTC 헤드를 가지고 있습니다.
Wav2Vec2와 HuBERT는 완전히 동일한 아키텍처를 사용하지만 매우 다른 방식으로 학습됩니다. Wav2Vec2는 오디오의 마스크된 부분에 대한 음성 단위를 예측하여 BERT의 마스크된 언어 모델링과 같이 사전 학습됩니다. HuBERT는 BERT에서 한 걸음 더 나아가 텍스트 문장의 토큰과 유사한 ‘개별 음성 단위’를 예측하는 방법을 학습하여 기존 NLP 기술을 사용하여 음성을 처리할 수 있도록 합니다.
여기서 강조 표시된 모델만 트랜스포머 기반 CTC 모델이 아니라는 점을 분명히 말씀드립니다. 다른 모델도 많이 있지만 모두 비슷한 방식으로 작동한다는 것을 배웠습니다.
< > Update on GitHub