Audio Course documentation
오디오 데이터셋 전처리하기
오디오 데이터셋 전처리하기
🤗 Datasets을 이용하여 데이터셋을 불러오는건 재미의 반에 불과합니다. 모델을 학습시키거나 추론(inference)을 실행하기 위해선 먼저 데이터를 전처리해야할 것입니다. 일반적으로 이는 다음의 단계를 거칩니다:
- 오디오 데이터 리샘플링
- 데이터셋 필터링
- 오디오 데이터를 모델의 입력에 맞게 변환
오디오 데이터 리샘플링하기
load_dataset 함수는 오디오 데이터를 게시된(published) 샘플링 속도에 맞춰 다운로드합니다. 이 샘플링 속도는 여러분이 계획한 학습 혹은 추론을 위한 샘플링 속도가 아닐 수 있습니다. 이렇게 샘플링 속도간 불일치가 있다면, 모델이 기대하는 샘플링 속도에 맞춰 리샘플링을 할 수 있습니다.
대부분의 사전 학습된 모델들은 16 kHz의 샘플링 속도를 가진 오디오 데이터셋에 대하여 사전학습이 이뤄져있습니다. 여러분이 MINDS-14 데이터셋을 살펴보신다면 8 kHz로 샘플링된것을 알 수 있을겁니다. 업샘플링이 필요하다는 뜻이죠.
이를 위해, 🤗 Datasets의 cast_column 메소드를 써봅시다. 이 연산은 오디오를 in-place로 변경하는 것이 아니라 오디오 데이터들이 불러와질때 즉석에서 리샘플링되도록 데이터셋에 신호를 보냅니다. 다음의 코드는 샘플링 속도를 16 kHz로 설정합니다:
from datasets import Audio
minds = minds.cast_column("audio", Audio(sampling_rate=16_000))MINDS-14 데이터셋의 첫번째 오디오 예제를 다시 불러와 원하는 sampling_rate으로 리샘플링 되었는지 확인해 보겠습니다:
minds[0]Output:
{
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"audio": {
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"array": array(
[
2.0634243e-05,
1.9437837e-04,
2.2419340e-04,
...,
9.3852862e-04,
1.1302452e-03,
7.1531429e-04,
],
dtype=float32,
),
"sampling_rate": 16000,
},
"transcription": "I would like to pay my electricity bill using my card can you please assist",
"intent_class": 13,
}여러분은 아마 배열의 값들 역시 달라졌음을 눈치채셨을 겁니다. 이는 기존에 비해 진폭값들의 갯수가 전부 두배로 늘어났기 때문입니다.
데이터셋 필터링하기
여러분은 데이터를 어떤 기준에 맞춰 필터링해야할 때도 있을겁니다. 흔한 경우로는 오디오 데이터를 특정 길이에 맞춰 제한하는 경우가 있을 수 있습니다. 예를 들어, 모델 학습시 out-of-memory 에러를 피하기 위해 20초 보다 긴 모든 데이터를 필터링하길 원할 수도 있습니다.
🤗 Datasets의 filter 메소드에 필터링 로직을 짠 함수를 집어넣어 쓴다면 이를 수행할 수 있습니다. 한번 어떤 데이터를 쓸지 또는 버릴지를 알려주는 함수를 작성해 이를 써봅시다. 함수 is_audio_length_in_range는 만약 샘플이 20초보다 짧다면 True를 그렇지 않다면 False를 반환합니다.
MAX_DURATION_IN_SECONDS = 20.0
def is_audio_length_in_range(input_length):
return input_length < MAX_DURATION_IN_SECONDS필터링 함수는 데이터셋의 컬럼에 적용될 수 있지만 이 데이터셋엔 오디오 트랙 길이가 없습니다. 그러나 우린 새로 이런 컬럼을 만들 수 있으니 새로 만든 후 이 컬럼의 값에 필터를 적용하고 최종적으로는 다시 지워봅시다.
# use librosa to get example's duration from the audio file
new_column = [librosa.get_duration(filename=x) for x in minds["path"]]
minds = minds.add_column("duration", new_column)
# use 🤗 Datasets' `filter` method to apply the filtering function
minds = minds.filter(is_audio_length_in_range, input_columns=["duration"])
# remove the temporary helper column
minds = minds.remove_columns(["duration"])
mindsOutput:
Dataset({features: ["path", "audio", "transcription", "intent_class"], num_rows: 624})데이터셋의 숫자가 654개에서 624개로 감소한것을 확인하실 수 있습니다.
오디오 데이터 전처리하기
오디오 데이터셋을 준비할 때 가장 어려운점 중 하나는 모델 학습에 맞는 형식을 갖추는 것입니다. 여러분이 앞서 보셧듯, 원시 오디오 데이터는 샘플값들의 배열로 제공됩니다. 그러나, 사전 학습된 모델같은 경우(이를 추론을 위해 쓰든 파인튜닝을 위해 쓰든) 이런 원시 데이터를 입력 feature에 맞춰야합니다. 이런 입력 feature의 요구사항은 모델마다 다를 수 있습니다. 이는 모델의 구조와 어떤 데이터로 사전학습이 이뤄졌는지에 달려있습니다. 좋은 소식은 🤗 Transformers는 지원하는 모든 모델에 대해 원시 데이터를 모델이 원하는 입력 feature로 바꿔주는 feature extractor 클래스를 제공한다는 것입니다.
이 feature extractor는 그럼 원시 데이터로 무엇을 하는 걸까요? 일반적인 feature extraction 변환을 이해하기 위해 Whisper의 feature extractor를 살펴보겠습니다. Whisper는 자동 음성 인식(ASR)을 위해 사전 학습된 모델로 2022년 9월에 OpenAI의 Alec Radford와 공동 연구자들이 발표했습니다.
첫번째로, Whisper의 feature extractor는 모든 데이터가 30초의 길이를 갖도록 덧붙이거나(pad) 자릅니다(truncate). 30초 보다 짧은 데이터는 시퀀스의 끝에 0을 붙여 길이를 늘립니다(오디오 신호에서 0은 신호 없음 혹은 무음과 같습니다). 30초 보다 긴 데이터는 30초가 되도록 자릅니다. 배치의 모든 요소가 input space의 최대 길이에 맞춰 덧붙여지거나 잘렸으므로 별도의 attention mask는 필요 없습니다. 이런 점에서 Whisper는 특별한데, 대부분의 다른 오디오 모델들은 self-attention 메커니즘에서 어느 부분을 무시해야하는지를 알려주기 위해 시퀀스의 어디가 덧붙여졌는지 알려주는 attention mask가 필요하기 때문입니다. Whisper는 attention mask 없이 작동하도록 훈련되어 음성 신호에서 직접 입력의 어느 부분을 무시해야 하는지를 추론합니다.
Whisper feature extractor가 수행하는 두번째 작업은 덧붙여진 오디오 배열들을 로그-멜 스펙트로그램으로 바꾸는 것입니다. 아시다시피, 이 스펙트로그램은 신호의 주파수가 시간에 따라 어떻게 변하는지를 멜 스케일에 맞춰 데시벨(로그 부분)로 측정하여 주파수와 진폭이 사람의 청각 시스템을 더 잘 표현하도록 합니다.
이 모든 변환은 몇 줄의 코드로 여러분의 원시 데이터에 적용될 수 있습니다. 사전 학습된 Whisper의 체크포인트에서 feature extractor를 불러와 오디오 데이터에 사용할 준비를 해봅시다:
from transformers import WhisperFeatureExtractor
feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-small")다음으로, feature_extractor를 통해 각각의 오디오 데이터를 전처리할 함수를 작성할 수 있습니다.
def prepare_dataset(example):
audio = example["audio"]
features = feature_extractor(
audio["array"], sampling_rate=audio["sampling_rate"], padding=True
)
return features🤗 Datasets의 map 메소드를 이용하여 모든 학습 데이터에 적용시킬 수 있습니다:
minds = minds.map(prepare_dataset)
mindsOutput:
Dataset(
{
features: ["path", "audio", "transcription", "intent_class", "input_features"],
num_rows: 624,
}
)이렇게 간단히, 로그-멜 스펙트로그램을 데이터셋의 input_features에 저장할 수 있습니다.
minds 데이터셋 중 하나를 시각화해봅시다:
import numpy as np
example = minds[0]
input_features = example["input_features"]
plt.figure().set_figwidth(12)
librosa.display.specshow(
np.asarray(input_features[0]),
x_axis="time",
y_axis="mel",
sr=feature_extractor.sampling_rate,
hop_length=feature_extractor.hop_length,
)
plt.colorbar()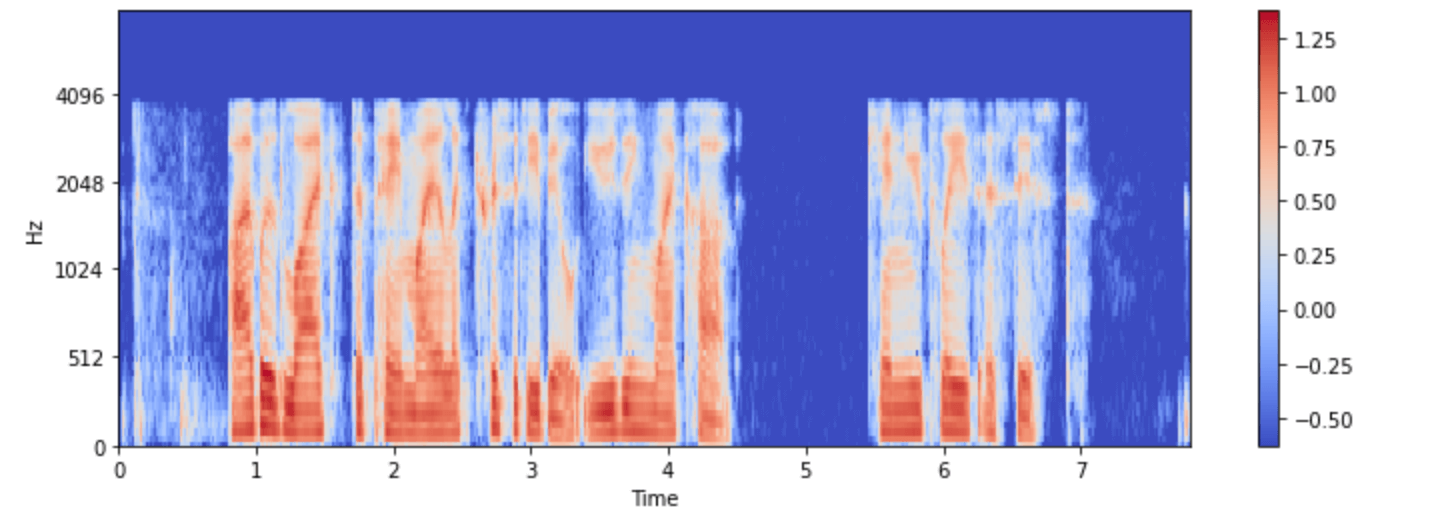
이제 전처리 후 Whisper 모델에 대한 오디오 입력이 어떻게 보이는지 확인하실 수 있습니다.
모델의 feature extractor 클래스는 원시 데이터를 모델이 원하는 포맷으로 변경하는 작업을 처리합니다. 그러나, 대개의 오디오 작업은(예를 들어, 음성 인식) multimodal입니다. 이런 경우 🤗 Transformers는 텍스트 입력을 처리하기 위해 모델별 토크나이저(tokenizer)를 제공합니다. 토크나이저에 대해 더 자세히 알고 싶으시다면 NLP 코스를 참고하세요.
Whisper와 다른 multimodal 모델에 대해 각각의 feature extractor와 토크나이저를 별도로 불러오거나, 이른바 processor를 통해 한번에 불러올 수도 있습니다. 더 간단히 다음의 코드처럼 AutoProcessor로 체크포인트에서 모델의 feature extractor와 processor를 불러올 수도 있습니다:
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("openai/whisper-small")여기에서는 기본적인 데이터 준비 단계를 설명했습니다. 물론 커스텀 데이터는 더 복잡한 전처리가 필요할 수도 있습니다.
이 경우, 여러분은 어떤 종류의 커스텀 데이터도 변환이 가능하도록 prepare_dataset 함수를 확장할 수 있습니다. 🤗 Datasets과 함께라면, 여러분은 파이썬 함수로 작성 할 수만 있다면 여러분의 데이터에 이를 적용시킬 수 있을겁니다!