Audio Course documentation
Unité 3 : Architectures de transformers pour l’audio
Unité 3 : Architectures de transformers pour l’audio
Dans ce cours, nous examinons principalement les transformers et comment ils peuvent être appliqués aux tâches audio. Bien que vous n’ayez pas besoin de connaître les détails internes de ces modèles, il est utile de comprendre les principaux concepts qui les font fonctionner. Nous faisons donc ici un rappel rapide. Pour une plongée profonde dans les transformers, consultez notre cours de NLP.
Comment fonctionne un transformer ?
Le transformer original a été conçu pour traduire du texte écrit d’une langue à une autre. Son architecture ressemble à ceci :

À gauche se trouve l’encodeur et à droite le décodeur.
- L’encodeur reçoit une entrée, dans ce cas une séquence de tokens de texte, et construit une représentation de celle-ci (ses caractéristiques). Cette partie du modèle est entraînée pour acquérir une compréhension à partir de l’entrée.
- Le décodeur utilise la représentation de l’encodeur (les caractéristiques) ainsi que d’autres entrées (les tokens prédits précédemment) pour générer une séquence cible. Cette partie du modèle est entraînée pour générer des extrants. Dans la conception originale, la séquence de sortie se composait de tokens de texte. Il existe également des modèles basés sur des transformers n’utilisant que la partie encodeur (bon pour les tâches qui nécessitent une compréhension de l’entrée, comme la classification), ou uniquement la partie décodeur (bon pour les tâches telles que la génération de texte). Un exemple de modèle d’encodeur seul est BERT ; un exemple de modèle de décodeur seul est GPT2. Une caractéristique clé des transformers est qu’ils sont construits avec des couches spéciales appelées couches d’attention. Ces couches indiquent au modèle d’accorder une attention particulière à certains éléments de la séquence d’entrée et d’en ignorer d’autres lors du calcul des représentations d’entités.
Utilisation de transformers pour l’audio
Les modèles audio que nous aborderons dans ce cours ont généralement un transformer standard comme indiqué ci-dessus, mais avec une légère modification du côté de l’entrée ou de la sortie pour gérer des données audio au lieu de texte. Puisque tous ces modèles sont des transformers dans l’âme, ils ont pour la plupart une architecture commune et les principales différences sont dans la façon dont ils sont entraînés et utilisés.
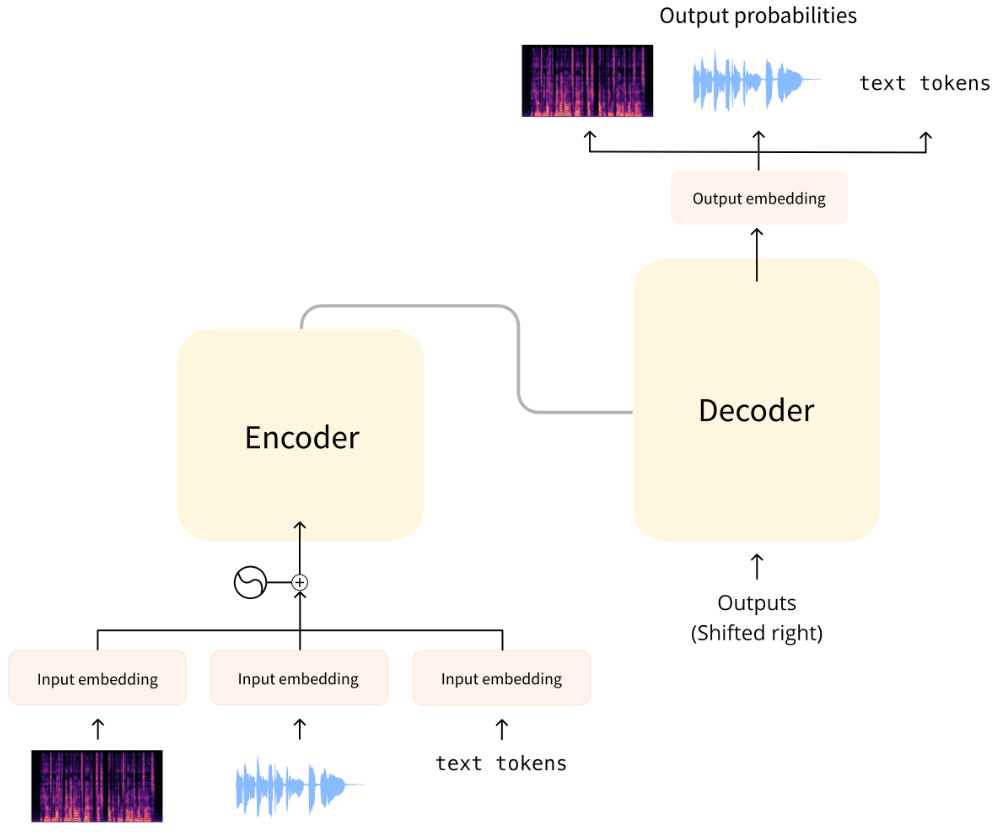
Pour les tâches audio, les séquences d’entrée et/ou de sortie sont de l’audio au lieu de texte :
- Reconnaissance automatique de la parole (ASR pour Automatic speech recognition) : l’entrée est la parole, la sortie est du texte.
- Synthèse vocale (TTS pour Text-to-speech) : l’entrée est du texte, la sortie est de la parole.
- Classification audio : l’entrée est de l’audio, la sortie est une probabilité de classe (une pour chaque élément de la séquence ou une probabilité de classe unique pour la séquence entière).
- Conversion vocale ou amélioration de la parole : l’entrée et la sortie sont de l’audio.
Il existe différentes façons de gérer l’audio afin qu’il puisse être utilisé via un transformer. La principale considération est de savoir s’il faut utiliser l’audio dans sa forme brute (comme une forme d’onde) ou le traiter comme un spectrogramme à la place.
Entrées du modèle
L’entrée d’un modèle audio peut être du texte ou du son. L’objectif est de convertir cette entrée en un enchâssement pouvant être traité par le transformer.
Entrée textuelle
Un modèle de synthèse vocale prend du texte comme entrée. Cela fonctionne comme le transformer d’origine en NLP : le texte d’entrée est d’abord tokenisé, ce qui donne une séquence de tokens de texte. Cette séquence est envoyée via une couche d’enchâssement d’entrée pour convertir les tokens en vecteurs de 512 dimensions. Ces enchâssements sont ensuite transmis dans l’encodeur du transformer.
Entrée sous forme de forme d’onde
Un modèle de reconnaissance de la parole automatique prend l’audio comme entrée. Pour pouvoir utiliser un transformer pour l’ASR, nous devons d’abord convertir l’audio en une séquence d’enchâssements d’une manière ou d’une autre. Des modèles tels que Wav2Vec2 et HuBERT utilisent la forme d’onde audio directement comme entrée du modèle. Comme vous l’avez vu dans [le chapitre sur les données audio (../chapter1/introduction), une forme d’onde est une séquence unidimensionnelle de nombres à virgule flottante, où chaque nombre représente l’amplitude échantillonnée à un moment donné. Cette forme d’onde brute est d’abord normalisée à la moyenne nulle et à la variance unitaire, ce qui permet de normaliser les échantillons audio sur différents volumes (amplitudes).
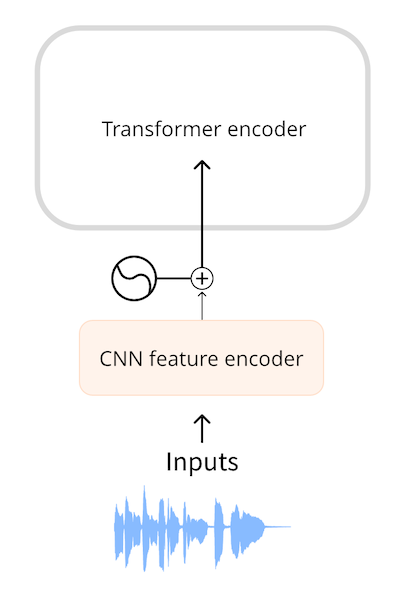
Après la normalisation, la séquence d’échantillons audio est transformée en un enchâssement à l’aide d’un petit réseau neuronal convolutionnel, connu sous le nom d’encodeur de caractéristiques. Chacune des couches convolutives de ce réseau traite la séquence d’entrée, sous-échantillonnant l’audio pour réduire la longueur de la séquence, jusqu’à ce que la couche convolutive finale produise un vecteur à 512 dimensions avec l’enchâssement pour chaque 25 ms d’audio. Une fois que la séquence d’entrée a été transformée en une séquence de tels enchâssements, le transformer traitera les données comme d’habitude.
Entrée sous forme de spectrogramme
Un inconvénient de l’utilisation de la forme d’onde brute comme entrée est qu’elles ont tendance à avoir de longues longueurs de séquence. Par exemple, trente secondes d’audio à une fréquence d’échantillonnage de 16 kHz donnent une entrée de longueur 30 * 16000 = 480000. Des longueurs de séquence plus longues nécessitent plus de calculs dans le transformer et donc une utilisation plus élevée de la mémoire.
Pour cette raison, les formes d’onde audio brutes ne sont généralement pas la forme la plus efficace de représenter une entrée audio. En utilisant un spectrogramme, nous obtenons la même quantité d’informations, mais sous une forme plus comprimée.
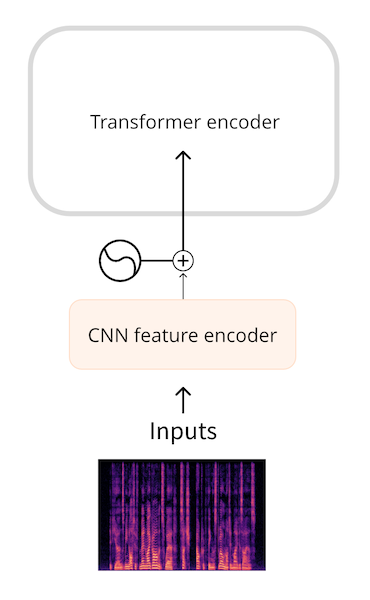
Des modèles tels que Whisper convertissent d’abord la forme d’onde en un spectrogramme log-mel. Whisper divise toujours l’audio en segments de 30 secondes, et le spectrogramme log-mel pour chaque segment a la forme (80, 3000) où 80 est le nombre de bacs mel et 3000 est la longueur de la séquence. En convertissant en spectrogramme log-mel, nous avons réduit la quantité de données d’entrée, mais plus important encore, il s’agit d’une séquence beaucoup plus courte que la forme d’onde brute. Le spectrogramme log-mel est ensuite traité par un petit réseau convolutif en une séquence d’enchâssements, allant ensuite dans le transformer comme d’habitude.
Dans les deux cas, l’entrée de la forme d’onde et du spectrogramme, il y a un petit réseau devant le transformer convertissant l’entrée en enchâssement, puis le transformerprend le relais pour faire son travail.
Sorties du modèle
L’architecture du transformer génère une séquence de vecteurs à états cachés, également appelés enchâssement de sortie. Notre objectif est de transformer ces vecteurs en sortie textuelle ou audio.
Sortie textuelle
L’objectif d’un modèle d’ASR est de prédire une séquence de tokens de texte. Cela se fait en ajoutant une tête de modélisation du langage (généralement une seule couche linéaire) suivie d’une softmax au-dessus de la sortie du transformer. On alors prédit les probabilités sur les tokens de texte dans le vocabulaire.
Sortie sous forme de spectrogramme
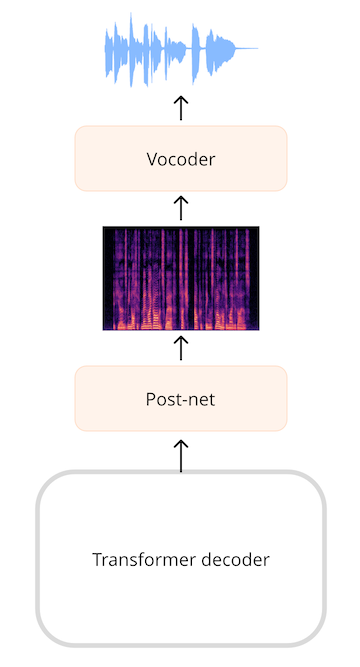
Pour les modèles qui génèrent de l’audio, tels qu’un modèle de synthèse vocale, nous devons ajouter des couches pouvant produire une séquence audio. Il est très courant de générer un spectrogramme, puis d’utiliser un réseau neuronal supplémentaire, connu sous le nom de vocodeur, pour transformer ce spectrogramme en une forme d’onde. Par exemple dans le modèle SpeechT5 la sortie du transformer est une séquence de vecteurs à 768 éléments. Une couche linéaire projette cette séquence dans un spectrogramme log-mel. Un post-réseau, composé de couches linéaires et convolutives supplémentaires, affine le spectrogramme en réduisant le bruit. Le vocodeur crée alors la forme d’onde audio finale.
Sortie sous forme de forme d’onde
Il est également possible pour les modèles de produire directement une forme d’onde au lieu d’un spectrogramme comme étape intermédiaire, mais nous n’avons actuellement aucun modèle dans 🤗 Transformers qui le fait.
Conclusion
En résumé: la plupart des transformers audio se ressemblent plus que différents. Ils sont tous construits sur la même architecture et les mêmes couches d’attention, bien que certains modèles n’utilisent que la partie encodeur du transformer tandis que d’autres utilisent à la fois l’encodeur et le décodeur. Vous avez également vu comment obtenir des données audio dans et hors des transformers. Pour effectuer les différentes tâches audio d’ASR, TTS, etc., nous pouvons simplement échanger les couches qui prétraitent les entrées en enchâssements, et échanger les couches qui post-traitent les enchâssements prédites en sorties, tandis que le backbone du transformer reste le même. Examinons dans les suite différentes façons dont ces modèles peuvent être entraînés à effectuer une reconnaissance vocale automatique.
< > Update on GitHub