Architectures avec CTC
CTC ou classification temporelle connexionniste est une technique utilisée avec les transformers encodeur pour la reconnaissance automatique de la parole. Des exemples de tels modèles sont Wav2Vec2, HuBERT et M-CTC-T. Un transformer encodeur est le type de transformer le plus simple car il utilise uniquement la partie encodeur du modèle. L’encodeur lit la séquence d’entrée (la forme d’onde audio) et l’associe dans une séquence d’états cachés, également appelée enchâssement de sortie. Avec un modèle avec CTC, nous appliquons un association linéaire supplémentaire sur la séquence des états cachés pour obtenir des prédictions d’étiquettes de classe. Les étiquettes de classe sont les caractères de l’alphabet (a, b, c, …). De cette façon, nous sommes en mesure de prédire n’importe quel mot dans la langue cible avec une petite tête de classification, car le vocabulaire ne contient que 26 caractères plus quelques tokens spéciaux.
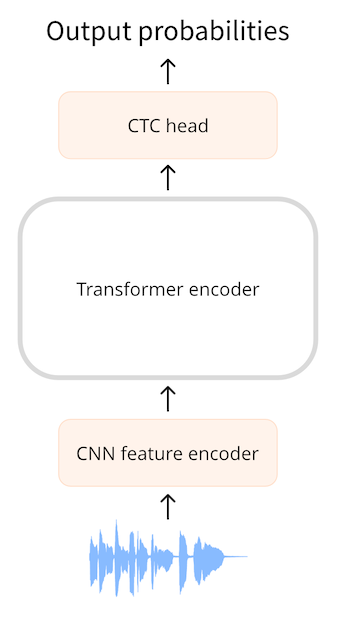
Jusqu’à présent, cela est très similaire à ce que nous faisons en NLP avec un modèle tel que BERT : un transformer encodeur associe nos tokens de texte dans une séquence d’états cachés de l’encodeur, puis nous appliquons une association linéaire pour obtenir une prédiction d’étiquette de classe pour chaque état caché. Voici le hic : dans la parole, nous ne connaissons pas l’alignement des entrées audio et des sorties de texte. Nous savons que l’ordre dans lequel le discours est prononcé est le même que l’ordre dans lequel le texte est transcrit (l’alignement est dit monotone), mais nous ne savons pas comment les caractères de la transcription s’alignent sur l’audio. C’est là qu’intervient l’algorithme CTC.
Où est mon alignement?
L’ASR consiste à prendre l’audio en entrée et à produire du texte en sortie. Nous avons quelques choix pour prédire le texte:
- comme caractères
- comme phonèmes
- comme mots
Un modèle d’ASR est entraîné sur un ensemble de données composé de paires (audio, texte) où le texte est une transcription humaine du fichier audio. En règle générale, le jeu de données n’inclut aucune information de synchronisation indiquant quel mot ou syllabe apparaît où dans le fichier audio. Comme nous ne pouvons pas compter sur les informations de synchronisation pendant l’entraînement, nous n’avons aucune idée de la façon dont les séquences d’entrée et de sortie doivent être alignées.
Supposons que notre entrée soit un fichier audio d’une seconde. Dans Wav2Vec2, le modèle sous-échantillonne l’entrée audio à l’aide de l’encodeur ConvNet pour une séquence plus courte d’états cachés, où il y a un vecteur d’état caché pour chaque 20 millisecondes d’audio. Pour une seconde d’audio, nous transmettons ensuite une séquence de 50 états cachés à l’encodeur du transformer. Les segments audio extraits de la séquence d’entrée se chevauchent partiellement, de sorte que même si un vecteur à état caché est émis toutes les 20 ms, chaque état caché représente en fait 25 ms d’audio.
L’encodeur du transformer prédit une représentation des caractéristiques pour chacun de ces états cachés, ce qui signifie que nous recevons du transformer une séquence de 50 sorties. Chacune de ces sorties a une dimensionnalité de 768. Dans cet exemple, la séquence de sortie de l’encodeur du transformer a donc la forme (768, 50). Comme chacune de ces prédictions couvre 25 ms de temps, ce qui est plus court que la durée d’un phonème, il est logique de prédire des phonèmes ou des caractères individuels, mais pas des mots entiers. La CTC fonctionne mieux avec un petit vocabulaire, nous allons donc prédire les caractères.

Pour faire des prédictions de texte, nous associons chacune des sorties d’encodeur à 768 dimensions à nos étiquettes de caractères à l’aide d’une couche linéaire (la « tête CTC »). Le modèle prédit alors un tenseur (50, 32) contenant les logits, où 32 est le nombre de tokens dans le vocabulaire. Puisque nous faisons une prédiction pour chacune des caractéristiques de la séquence, nous nous retrouvons avec un total de prédictions de 50 caractères pour chaque seconde d’audio.
Cependant, si nous prédisons simplement un caractère toutes les 20 ms, notre séquence de sortie pourrait ressembler à ceci:
BRIIONSAWWSOMEETHINGCLOSETOPANICONHHISOPPONENT'SSFAACEWHENTHEMANNFINALLLYRREECOGGNNIIZEDHHISSERRRRORR ...
Si vous regardez de plus près, cela ressemble un peu à de l’anglais, mais beaucoup de caractères ont été dupliqués. C’est parce que le modèle doit sortir quelque chose pour chaque 20 ms d’audio dans la séquence d’entrée, et si un caractère est étalé sur une période supérieure à 20 ms, il apparaîtra plusieurs fois dans la sortie. Il n’y a aucun moyen d’éviter cela, d’autant plus que nous ne savons pas quel est l’horodatage de la transcription pendant l’entraînement. La CTC est un moyen de filtrer ces doublons. En réalité, la séquence prédite contient également beaucoup de tokens de remplissage lorsque le modèle n’est pas tout à fait sûr de ce que le son représente, ou pour l’espace vide entre les caractères. Nous avons supprimé ces tokens de remplissage de l’exemple pour plus de clarté. Le chevauchement partiel entre les segments audio est une autre raison pour laquelle les caractères sont dupliqués dans la sortie.)
L’algorithme CTC
La clé de l’algorithme CTC est l’utilisation d’un token spécial, souvent appelé token blanc. C’est juste un autre token que le modèle prédira et cela fait partie du vocabulaire. Dans cet exemple, le token blanc est affiché sous la forme _. Ce token spécial sert de délimitation entre les groupes de caractères.
Le résultat complet du modèle CTC pourrait ressembler à ce qui suit :
B_R_II_O_N_||_S_AWW_|||||_S_OMEE_TH_ING_||_C_L_O_S_E||TO|_P_A_N_I_C_||_ON||HHI_S||_OP_P_O_N_EN_T_'SS||_F_AA_C_E||_W_H_EN||THE||M_A_NN_||||_F_I_N_AL_LL_Y||||_RREE_C_O_GG_NN_II_Z_ED|||HHISS|||_ER_RRR_ORR||||
Le token | est le caractère séparateur de mots. Dans l’exemple, nous utilisons | au lieu d’un espace, ce qui permet de repérer plus facilement où se trouvent les sauts de mots, mais cela sert le même but.
Le caractère blanc de la CTC permet de filtrer les caractères en double. Par exemple, regardons le dernier mot de la séquence prédite, « _ER_RRR_ORR ». Sans le token blanc, le mot ressemblait à ceci:
ERRRRORR
Si nous supprimions simplement les caractères en double, cela deviendrait « EROR ». Ce n’est pas l’orthographe correcte. Mais avec le token blanc d ela CTC, nous pouvons supprimer les doublons dans chaque groupe, de sorte que:
_ER_RRR_ORR
devient:
_ER_R_OR
Et maintenant, nous supprimons le jeton blanc _ pour avoir le mot final :
ERROR
Si nous appliquons cette logique à l’ensemble du texte, y compris |, et remplaçons les caractères | survivants par des espaces, la sortie finale décodée par CTC est la suivante :
BRION SAW SOMETHING CLOSE TO PANIC ON HIS OPPONENT'S FACE WHEN THE MAN FINALLY RECOGNIZED HIS ERROR
Pour récapituler, le modèle prédit un token (caractère) pour chaque 20 ms d’audio (partiellement chevauchant) à partir de la forme d’onde d’entrée. Cela donne beaucoup de doublons. Grâce au token blanc de la CTC, nous pouvons facilement supprimer ces doublons sans détruire la bonne l’orthographe des mots. C’est un moyen très simple et pratique de résoudre le problème de l’alignement du texte de sortie avec l’audio d’entrée.
L’ajout de la CTC à un transformer encodeur est facile : la séquence de sortie de l’encodeur va dans une couche linéaire qui projette les caractéristiques acoustiques dans le vocabulaire. Le modèle est entraîné avec une perte de CTC spéciale. Un inconvénient de la CTC est qu’elle peut produire des mots qui sonnent corrects mais ne sont pas orthographiés correctement. Après tout, la tête de la CTC ne prend en compte que les caractères individuels, pas les mots complets. Une façon d’améliorer la qualité des transcriptions audio est d’utiliser un modèle de langage externe. Ce modèle de langage agit essentiellement comme un correcteur orthographique au-dessus de la sortie de la CTC.
Quelle est la différence entre Wav2Vec2, HuBERT, M-CTC-T, etc. ?
Tous les modèles de transformer avec CTC ont une architecture très similaire. Ils utilisent l’encodeur du transformer (mais pas le décodeur) avec une tête CTC sur le dessus. Du point de vue de l’architecture, ils se ressemblent plus que ne sont différents. Une différence entre Wav2Vec2 et M-CTC-T est que le premier fonctionne sur des formes d’onde audio brutes tandis que le second utilise des spectrogrammes mel comme entrée. Les modèles ont également été entraînés à des fins différentes. M-CTC-T, par exemple, est entraîné à la reconnaissance vocale multilingue et possède donc une tête CTC relativement grande qui comprend des caractères chinois en plus d’autres alphabets. Wav2Vec2 & HuBERT utilisent exactement la même architecture mais sont entraînés de manière très différente. Wav2Vec2 est pré-entraîné comme la modélisation du langage masqué de BERT, en prédisant les unités vocales pour les parties masquées de l’audio. HuBERT pousse l’inspiration de BERT un peu plus loin et apprend à prédire les « unités de parole discrètes », qui sont analogues aux tokens dans une phrase de texte, de sorte que la parole peut être traitée en utilisant des techniques de NLP établies. Pour clarifier, les modèles mis en évidence ici ne sont pas les seuls modèles de transformer avec CTC. Il y en a beaucoup d’autres, mais maintenant vous savez qu’ils fonctionnent tous de la même manière.
< > Update on GitHub