Audio Course documentation
অডিও ডাটা প্রক্রিয়াকরণ
অডিও ডাটা প্রক্রিয়াকরণ
🤗 ডেটাসেটের সাথে একটি ডেটাসেট লোড করা মজার অর্ধেক। আপনি যদি এটি একটি মডেল train করার জন্য বা inference চালানোর জন্য ব্যবহার করার পরিকল্পনা করেন, আপনাকে প্রথমে ডেটা প্রাক-প্রক্রিয়া করতে হবে। সাধারণভাবে, এটি নিম্নলিখিত পদক্ষেপগুলিকে অন্তর্ভুক্ত করবে:
- অডিও ডেটা resample করা
- ডেটাসেট ফিল্টার করা
- মডেলের প্রত্যাশিত ইনপুটে অডিও ডেটা রূপান্তর করা
অডিও ডাটা কে Resample করা
load_dataset ফাংশনটি যেই sampling rate এর সাথে অডিও উদাহরণগুলি upload করা হয়েছিল সেই sampling rate এ সেই অডিও উদাহরণগুলিকে ডাউনলোড করে। এটি সর্বদা
আপনি যে মডেলকে train করার পরিকল্পনা করছেন বা inference জন্য ব্যবহার করছেন তার দ্বারা প্রত্যাশিত sampling rate এর সমান নাও হতে পারে । যদি এর মধ্যে অমিল থাকে
তাহলে আপনাকে অডিও তাকে resample করতে হবে ।
উপলব্ধ প্রাক-প্রশিক্ষিত মডেলগুলির বেশিরভাগই ১৬ kHz এর নমুনা হারে অডিও ডেটাসেটে পূর্বপ্রশিক্ষিত হয়েছে। যখন আমরা MINDS-14 ডেটাসেট অন্বেষণ করেছি, আপনি হয়তো লক্ষ্য করেছেন যে এটি ৮ kHz এ sample করা হয়েছে, যার মানে আমাদের resample করতে হবে।
এটি করতে, 🤗 ডেটাসেটের cast_column পদ্ধতি ব্যবহার করুন। এই অপারেশন জায়গায় অডিও পরিবর্তন করে না, বরং সংকেত
ডেটাসেটগুলি লোড করার সময় ফ্লাইতে অডিও উদাহরণগুলি পুনরায় নমুনা করতে। নিম্নলিখিত কোড স্যাম্পলিং সেট করবে
১৬ kHz পর্যন্ত হার:
from datasets import Audio
minds = minds.cast_column("audio", Audio(sampling_rate=16_000))MINDS-14 ডেটাসেটে প্রথম অডিও উদাহরণটি পুনরায় লোড করুন এবং এটি পছন্দসই sampling rate-এ পুনরায় নমুনা করা হয়েছে কিনা তা পরীক্ষা করুন:
minds[0]আউটপুট:
{
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"audio": {
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"array": array(
[
2.0634243e-05,
1.9437837e-04,
2.2419340e-04,
...,
9.3852862e-04,
1.1302452e-03,
7.1531429e-04,
],
dtype=float32,
),
"sampling_rate": 16000,
},
"transcription": "I would like to pay my electricity bill using my card can you please assist",
"intent_class": 13,
}আপনি লক্ষ্য করতে পারেন যে অ্যারের মানগুলিও এখন ভিন্ন। এর কারণ হল আমরা এখন এর জন্য amplitude মানগুলির দ্বিগুণ সংখ্যা পেয়েছি প্রতিটি যে আমরা আগে ছিল.
ডেটাসেট ফিল্টার করা
কিছু মানদণ্ডের উপর ভিত্তি করে ডেটা ফিল্টার করা যেতে পারে। সাধারণ ক্ষেত্রে একটি অডিওর সময়কাল সীমিত। উদাহরণস্বরূপ, একটি মডেল training এর সময় আমরা ২০ সেকেন্ডস এর বেশি যেকোন উদাহরণ ফিল্টার আউট করতে চাই আউট অফ মেমরির ত্রুটিগুলি রোধ করতে।
আমরা 🤗 ডেটাসেটের filter পদ্ধতি ব্যবহার করে এবং ফিল্টারিং লজিক সহ একটি ফাংশন পাস করে এটি করতে পারি। একটি ফাংশন লিখে শুরু করা যাক যা
নির্দেশ করে কোন উদাহরণ রাখতে হবে এবং কোনটি বাতিল করতে হবে। এই ফাংশন, is_audio_length_in_range, একটি নমুনা ২০ সেকেন্ডের চেয়ে ছোট হলে
True এবং ২০ সেকেন্ডের এর বেশি হলে False প্রদান করে।
MAX_DURATION_IN_SECONDS = 20.0
def is_audio_length_in_range(input_length):
return input_length < MAX_DURATION_IN_SECONDSফিল্টারিং ফাংশনটি ডেটাসেটের কলামে প্রয়োগ করা যেতে পারে তবে আমাদের কাছে এতে অডিও ট্র্যাকের সময়কাল সহ একটি কলাম নেই ডেটাসেট যাইহোক, আমরা একটি তৈরি করতে পারি, সেই কলামের মানগুলির উপর ভিত্তি করে ফিল্টার করতে পারি এবং তারপরে এটি সরিয়ে ফেলতে পারি।
# use librosa to get example's duration from the audio file
new_column = [librosa.get_duration(filename=x) for x in minds["path"]]
minds = minds.add_column("duration", new_column)
# use 🤗 Datasets' `filter` method to apply the filtering function
minds = minds.filter(is_audio_length_in_range, input_columns=["duration"])
# remove the temporary helper column
minds = minds.remove_columns(["duration"])
mindsআউটপুট:
Dataset({features: ["path", "audio", "transcription", "intent_class"], num_rows: 624})আমরা যাচাই করতে পারি যে ডেটাসেট ৬৫৪ টি উদাহরণ থেকে ৬২৪ এ ফিল্টার করা হয়েছে।
অডিও ডেটা প্রাক-প্রসেসিং
অডিও ডেটাসেটগুলির সাথে কাজ করার সবচেয়ে চ্যালেঞ্জিং দিকগুলির মধ্যে একটি হল মডেলের জন্য সঠিক বিন্যাসে ডেটা প্রস্তুত করা।আপনি যেমন দেখেছেন, কাঁচা অডিও ডেটা নমুনা মানগুলির একটি অ্যারে হিসাবে আসে। যাইহোক, pre-trained মডেলগুলি ইনপুট ফিচারস আশা করে। এই ইনপুট ফিচারস মডেল থেকে মডেল এ আলাদা হয়। ভাল খবর হল, প্রতিটি সমর্থিত অডিও মডেলের জন্য, 🤗 transformers একটি ফীচার এক্সট্র্যাক্টর ক্লাস অফার করে যা কাঁচা অডিও ডেটা থেকে মডেলের আশা করা ইনপুট ফিচারস এ রূপান্তর করতে পারে।
তাহলে একটি ফীচার এক্সট্রাক্টর, কাঁচা অডিও ডেটা দিয়ে কী করে? আসুন ফীচার এক্সট্রাক্টর কিছু সাধারণ ফীচার নিষ্কাশন রূপান্তর বুঝতে Whisper এর দিকে একবার নজর দেওয়া যাক। whisper হলো একটি পরে-trained মডেল যা automatic speech recognition (ASR) এর জন্যে 2022 সালের সেপ্টেম্বরে Alec Radford et al দ্বারা প্রকাশিত OpenAI থেকে।
প্রথমত, whisper ফিচার এক্সট্র্যাক্টর প্যাড/ছেঁটে অডিও উদাহরণের একটি ব্যাচ তৈরী করে যাতে সব উদাহরণের ইনপুট দৈর্ঘ্য 30 সেকেন্ড হয়। এর চেয়ে ছোট উদাহরণগুলিকে 30 এর শেষে শূন্য যুক্ত করে প্যাড করা হয় ক্রম (একটি অডিও সিগন্যালে শূন্য কোন সংকেত বা নীরবতার সাথে সঙ্গতিপূর্ণ নয়)। ৩০ এর চেয়ে দীর্ঘ উদাহরণগুলিকে ৩০ এ ছেঁটে ফেলা হয়েছে৷ যেহেতু ব্যাচের সমস্ত উপাদান ইনপুট স্পেসে সর্বাধিক দৈর্ঘ্যে প্যাডেড/ছেঁটে আছে, তাই attention mask এর প্রয়োজন নেই। অন্যান্য অডিও মডেলের জন্য একটি attention mask প্রয়োজন যা নির্দেশ করে যেখানে অডিওগুলি প্যাড করা হয়েছে এবং self-attention mechanism এ সেগুলো উপেক্ষা করে হয়।
whisper ফিচার এক্সট্রাক্টর যে দ্বিতীয় অপারেশনটি করে তা হল প্যাডেড অডিও অ্যারেগুলিকে log-mel spectrogram এ রূপান্তর করা। আপনার মনে আছে, এই spectrogram গুলি বর্ণনা করে যে কীভাবে একটি সংকেতের ফ্রিকোয়েন্সি সময়ের সাথে পরিবর্তিত হয়, এবং ফ্রিকোয়েন্সি এবং amplitude গুলোকে মানুষের শ্রবণশক্তির আরও প্রতিনিধি করে তুলতে mel স্কেলে প্রকাশ করা হয় এবং পরে তাকে ডেসিবেলে পরিমাপ করা হয়।
এই সমস্ত রূপান্তরগুলি কোডের কয়েকটি লাইনের সাথে আপনার কাঁচা অডিও ডেটাতে প্রয়োগ করা যেতে পারে। চলুন whisper ফীচার এক্সট্রাক্টর কে চেক্পইণ্ট থেকে লোড করা যাক:
from transformers import WhisperFeatureExtractor
feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-small")এর পরে, আপনি একটি ফাংশন লিখতে পারেন একটি একক অডিও উদাহরণকে প্রি-প্রসেস করার জন্য এটিকে feature_extractor এর মাধ্যমে পাস করে।
def prepare_dataset(example):
audio = example["audio"]
features = feature_extractor(
audio["array"], sampling_rate=audio["sampling_rate"], padding=True
)
return featuresআমরা 🤗 ডেটাসেটের map পদ্ধতি ব্যবহার করে আমাদের সমস্ত প্রশিক্ষণ উদাহরণগুলিতে ডেটা প্রস্তুতির ফাংশন প্রয়োগ করতে পারি:
minds = minds.map(prepare_dataset)
mindsআউটপুট:
Dataset(
{
features: ["path", "audio", "transcription", "intent_class", "input_features"],
num_rows: 624,
}
)যতটা সহজ, আমাদের কাছে এখন ডেটাসেটে input_features হিসেবে log-mel spectrogram আছে।
আসুন এটিকে ‘minds’ ডেটাসেটের একটি উদাহরণের জন্য কল্পনা করি:
import numpy as np
example = minds[0]
input_features = example["input_features"]
plt.figure().set_figwidth(12)
librosa.display.specshow(
np.asarray(input_features[0]),
x_axis="time",
y_axis="mel",
sr=feature_extractor.sampling_rate,
hop_length=feature_extractor.hop_length,
)
plt.colorbar()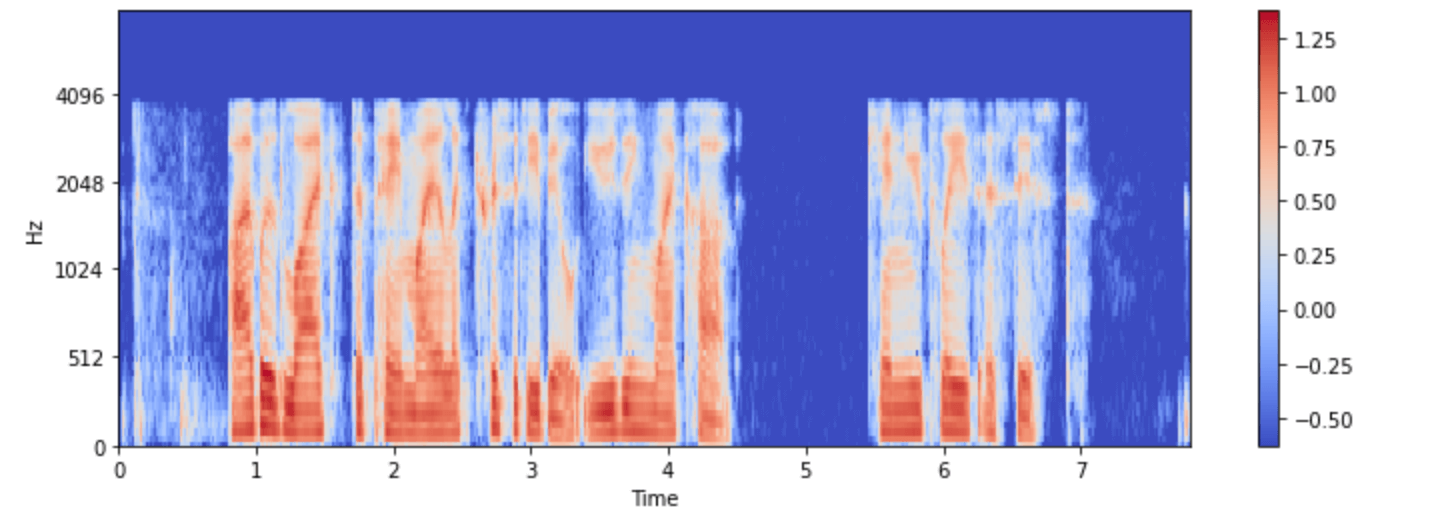
এখন আপনি প্রি-প্রসেসিংয়ের পরে whisper মডেলের অডিও ইনপুটটি কেমন দেখায় তা দেখতে পারেন।
মডেলের বৈশিষ্ট্য এক্সট্র্যাক্টর ক্লাসটি মডেলটি প্রত্যাশা করে এমন ফর্ম্যাটে কাঁচা অডিও ডেটা রূপান্তর করার যত্ন নেয়। যাহোক, অডিও জড়িত অনেক কাজ মাল্টিমোডাল, যেমন কন্ঠ সনান্তকরণ. এই ধরনের ক্ষেত্রে 🤗 ট্রান্সফরমারগুলিও মডেল-নির্দিষ্ট অফার করে টেক্সট ইনপুট প্রক্রিয়া করার জন্য tokenizers. টোকেনাইজারগুলিতে গভীরভাবে ডুব দেওয়ার জন্য, অনুগ্রহ করে আমাদের NLP কোর্স দেখুন।
আপনি Whisper এবং অন্যান্য মাল্টিমডাল মডেলের জন্য আলাদাভাবে বৈশিষ্ট্য এক্সট্র্যাক্টর এবং টোকেনাইজার লোড করতে পারেন, অথবা আপনি প্রসেসর ক্লাস এর মাদ্ধমে উভয় লোড করতে পারেন।
জিনিসগুলিকে আরও সহজ করতে, একটি মডেলের ফিচার এক্সট্র্যাক্টর এবং প্রসেসর লোড করতে AutoProcessor ব্যবহার করুন
চেকপয়েন্ট, এই মত:
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("openai/whisper-small")এখানে আমরা মৌলিক তথ্য প্রস্তুতির ধাপগুলি চিত্রিত করেছি। অবশ্যই, কাস্টম ডেটা আরও জটিল প্রিপ্রসেসিংয়ের প্রয়োজন হতে পারে।
এই ক্ষেত্রে, আপনি যেকোন ধরণের কাস্টম ডেটা ট্রান্সফরমেশন করার জন্য prepare_dataset ফাংশনটি প্রসারিত করতে পারেন। 🤗 আপনি যদি এটি একটি পাইথন
ফাংশন হিসাবে লিখতে পারেন, তাহলে আপনি এটি আপনার ডেটাসেটে প্রয়োগ করতে পারেন!