অডিও ডাটার সাথে পরিচয়
প্রকৃতপক্ষে, একটি শব্দ তরঙ্গ একটি অবিচ্ছিন্ন সংকেত(continious signal), যার অর্থ এটি একটি নির্দিষ্ট সময়ে অসীম সংখ্যক সংকেত মান ধারণ করে। এটি ডিজিটাল ডিভাইসগুলির জন্য সমস্যা তৈরি করে যাদের সীমিত সংরক্ষণাগার আছে। তাই এই অবিচ্ছিন্ন সংকেতকে (continious signal) বিযুক্ত মানগুলির একটি সিরিজে(discrete values) রূপান্তর করতে হবে যাতে এটি ডিজিটাল ডিভাইস দ্বারা প্রক্রিয়াকরণ, সংরক্ষণ এবং প্রেরণ করা যায়।
আপনি যদি কোনও অডিও ডেটাসেট দেখেন, আপনি টেক্সট বর্ণনা বা সঙ্গীতের মতো শব্দের উদ্ধৃতি সহ ডিজিটাল ফাইলগুলি খুঁজে পাবেন।
আপনি বিভিন্ন ফাইল ফরম্যাটের সম্মুখীন হতে পারেন যেমন .wav (ওয়েভফর্ম অডিও ফাইল), .flac (ফ্রি লসলেস অডিও কোডেক)
এবং .mp3 (MPEG-1 অডিও লেয়ার 3)। এই ফর্ম্যাটগুলির মধ্যে মূল পার্থক্য হলো তারা কিভাবে অডিও সিগন্যালের ডিজিটাল উপস্থাপনাকে সংকুচিত করে তার মধ্যে।
চলুন এক নজরে দেখে নেওয়া যাক কিভাবে আমরা একটি ক্রমাগত সংকেত(continious signal) থেকে বিযুক্ত মানগুলির একটি সিরিজে(discrete values) রূপান্তর করবো। অ্যানালগ সংকেত কে প্রথমে একটি মাইক্রোফোন দ্বারা ক্যাপচার করা হয়, তারপর ক্যাপচার করা শব্দ তরঙ্গকে বৈদ্যুতিক সংকেতে রূপান্তরিত করা হয়। বৈদ্যুতিক সংকেত কে তারপর Analog-to-Digital Converter এর দ্বারা Sampling প্রক্রিয়ার মাদ্ধমে ডিজিটাইজ করা। এইভাবে আমরা একটি অ্যানালগ সংকেত থেকে বিযুক্ত মানগুলির সিরিজ অথবা discrete values পেয়ে থাকি।
Sampling এবং sampling rate
কোনো এক continious signal এর একক নির্দিষ্ট সময়ের মান বের করার প্রক্রিয়া কে Sampling বলে। যথাক্রমে sampled waveform, discrete হয়, কারণ discrete waveform টির অভিন্ন বিরতিতে একটি সীমিত সংখ্যক সংকেত মান রয়েছে।
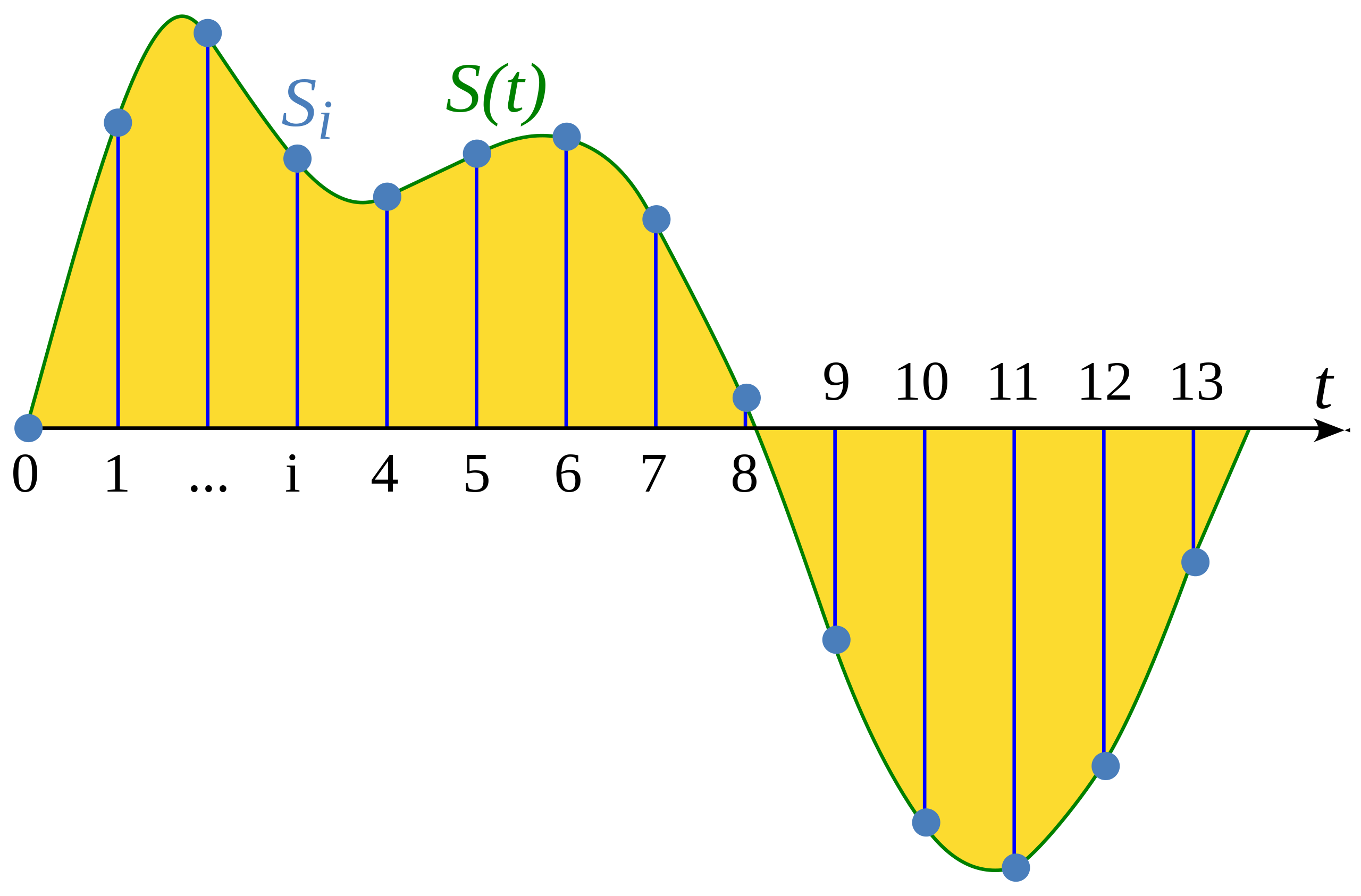
উইকিপিডিয়া নিবন্ধ থেকে দৃষ্টান্ত: Sampling (signal processing)
Sampling Rate (এটিকে Sampling Frequency ও বলা হয়) হল কোনো continious signal কে discrete করার সময় এক সেকেন্ডে নেওয়া নমুনার সংখ্যা এবং এটি পরিমাপ করা হয় hertz (hz)। উদাহরণ স্বরূপ, সিডি-গুণমানের অডিওর Sampling Rate হলো ৪৪,১০০ Hz, যার অর্থ প্রতি সেকেন্ডে ৪৪,১০০ বার নমুনা নেওয়া হয়েছে। তুলনা করার জন্য, উচ্চ-রেজোলিউশন অডিওর একটি Sampling Rate হলো ১৯২,০০০ Hz বা ১৯২kHz। একটি সাধারণ প্রশিক্ষণ বক্তৃতা মডেলগুলিতে ব্যবহৃত Sampling Rate হল ১৬,০০০ Hz বা ১৬ kHz।
Sampling Rate এর মান প্রাথমিকভাবে সিগন্যাল থেকে ক্যাপচার করা সর্বোচ্চ ফ্রিকোয়েন্সি নির্ধারণ করে। এটা Nyquist সীমা হিসাবে পরিচিত এবং এটি Sampling Rate এর ঠিক অর্ধেক হয়। মানুষের বক্তৃতার শ্রবণযোগ্য ফ্রিকোয়েন্সি ৮ kHz এর নিচে এবং তাই ১৬ kHz এ নমুনা বক্তৃতা যথেষ্ট। একটি উচ্চ Sampling Rate ব্যবহার করলে আরো তথ্য ক্যাপচার করা হবে না কিন্তু শুধুমাত্র ফাইল প্রক্রিয়াকরণের গণনামূলক খরচ বৃদ্ধি হবে। অন্যদিকে, Sampling Rate খুব কম হলে তথ্য এর ক্ষতি হবে। ৮ kHz-এ ক্যাপচার করা মানুষের বক্তৃতা শ্রবণযোগ্য হবে না কারণ তাতে higher frequency ক্যাপচার হবে না ।
যেকোনো অডিও টাস্কে কাজ করার সময় আপনার ডেটাসেটের সমস্ত অডিওর Sampling Rate একই আছে কি না তা নিশ্চিত করা গুরুত্বপূর্ণ। আপনি যদি একটি pre-trained মডেলকে fine-tune করার জন্য কাস্টম অডিও ডেটা ব্যবহার করার পরিকল্পনা করেন, তাহলে আপনার ডেটার Sampling Rate, অবশ্যই model টিকে pre-train করার সময় ব্যবহার করা Sampling Rate এর সাথে মিলতে হবে। Sampling Rate ধারাবাহিকের মধ্যে সময়ের ব্যবধান নির্ধারণ করে অডিও নমুনা, যা অডিও ডেটার অস্থায়ী রেজোলিউশনকে প্রভাবিত করে। উদাহরণ স্বরূপ: একটি 5-সেকেন্ডের অডিওর ১৬,০০০ Hz Sampling Rate থাকা মানে তার মধ্যে ৮০,০০০ খানা আলাদা আলাদা মান আছে, কিন্তু যদি সেই একই অডিওর Sampling রাতে যদি ৮,০০০ Hz হতো তাহলে তাতে মোট ৪০,০০০ খানা আলাদা আলাদা মান থাকতো। Transformer মডেল যেগুলি অডিও টাস্কগুলি সমাধান করে সেগুলি অডিও মানে শুধু সংখ্যা বোঝে তাই সঠিক সংখ্যার পরিমান খুবই গুরুত্বপূর্ণ ৷ যেহেতু আলাদা আলাদা অডিও ফাইল এর আলাদা আলাদা Sampling Rate আছে তাই সব ফাইলস গুলোকে একই Sampling Rate এ আন্তে হবে। এই প্রক্রিয়াকে Resampling বলে। আমরা এর ব্যাপারে আরো জানতে পারবো প্রিপ্রসেসিং অধ্যায় এ।
Amplitude এবং bit depth
Sampling Rate আপনাকে বলে যে এর সেকেন্ডে কত ঘন ঘন নমুনা নেওয়া হয়, কিন্তু প্রতিটি নমুনার মানগুলি ঠিক কিরকম?
মানুষের কাছে শ্রবণযোগ্য ফ্রিকোয়েন্সিতে বাতাসের চাপের পরিবর্তনের মাধ্যমে শব্দ তৈরি হয়। একটি শব্দের amplitude বর্ণনা করে যে কোনো তাৎক্ষণিক শব্দ চাপের মাত্রা এবং ডেসিবেল (dB) এ পরিমাপ করা হয়। আপনাকে একটি উদাহরণ দিতে, একটি সাধারণ কথা বলার ভয়েস ৬০ dB এর নিচে এবং একটি রক কনসার্ট প্রায় ১২৫ dB হতে পারে।
ডিজিটাল অডিওতে, প্রতিটি অডিও নমুনা একটি সময়ে অডিও তরঙ্গের amplitude রেকর্ড করে। এর bit depth নমুনা নির্ধারণ করে কত নির্ভুলতার সাথে এই প্রশস্ততার মান বর্ণনা করা যেতে পারে। bit depth যত বেশি, তত বেশি বিশ্বস্তভাবে ডিজিটাল উপস্থাপনা মূল অবিচ্ছিন্ন শব্দ তরঙ্গকে আনুমানিক করে।
সবচেয়ে সাধারণ অডিও bit depth হল ১৬-বিট এবং ২৪-বিট। ১৬-বিট অডিওর জন্য ৬৫,৫৩৬ টি বাইনারি bits, ২৪-বিট অডিওর জন্য ১৬,৭৭৭,২১৬ টি বাইনারি bits লাগে। যেহেতু quantizing প্রক্তিয়াটি একটি continious signal এর মানগুলোর শেষ এর সংখ্যাকে বাদ দেয় তাই এই প্রক্রিয়া সিগন্যাল এর সাথে নয়েজ যুক্ত করে। বিট গভীরতা যত বেশি হবে, এই নয়েজ শব্দ তত কম হবে। সাধারণত, ১৬-বিট অডিওর কোয়ান্টাইজেশন নয়েজ ইতিমধ্যেই যথেষ্ট ছোট যা অশ্রাব্য হতে পারে এবং উচ্চতর বিট গভীরতা ব্যবহার করা সাধারণত জরুরী নয়।
আপনি ৩২-বিট অডিওর ব্যাপারে শুনে থাকতে পারেন। এটি ফ্লোটিং-পয়েন্ট মান হিসাবে নমুনাগুলি সংরক্ষণ করে, যেখানে ১৬-বিট এবং ২৪-বিট অডিও পূর্ণসংখ্যা নমুনা ব্যবহার করে। একটি ৩২-বিট ফ্লোটিং-পয়েন্ট মানের নির্ভুলতা হল ২৪ বিট, এটিকে ২৪-বিট অডিওর সমান bit depth দেয়। ফ্লোটিং-পয়েন্ট অডিও নমুনাগুলি [-১.0, ১.0] সীমার মধ্যে থাকে এবং models গুলো স্বাভাবিকভাবেই ফ্লোটিং-পয়েন্ট ডেটার উপর কাজ করে, অডিও যদি ফ্লোটিং-পয়েন্ট এ না হয়ে থাকে তাহলে অডিওকে প্রথমে ফ্লোটিং-পয়েন্ট ফরম্যাটে রূপান্তর করতে হব। এর ব্যাপারে আমরা প্রিপ্রসেসিং বিভাগে দেখবো।
অবিচ্ছিন্ন অডিও সংকেতের মতোই, ডিজিটাল অডিওর প্রশস্ততা সাধারণত ডেসিবেলে (dB) প্রকাশ করা হয়। মানুষের শ্রবণশক্তি লগারিদমিক প্রকৃতির - আমাদের কান উচ্চস্বরের চেয়ে শান্ত শব্দে ছোট ওঠানামার প্রতি বেশি সংবেদনশীল । একটি শব্দের amplitudes ব্যাখ্যা করা সহজ যদি প্রশস্ততা ডেসিবেলে হয়, যা লগারিদমিকও হয়। রিয়েল-ওয়ার্ল্ড অডিওর জন্য ডেসিবেল স্কেল ০ dB থেকে শুরু হয়, যা মানুষের শোনা সম্ভব সবচেয়ে শান্ত শব্দের প্রতিনিধিত্ব করে এবং উচ্চতর শব্দের dB মান আরো বাড়ে । যাইহোক, ডিজিটাল অডিও সিগন্যালের জন্য, 0 dB হল সবচেয়ে জোরে সম্ভাব্য প্রশস্ততা । একটি দ্রুত নিয়ম হিসাবে: প্রতি -৬ dB হল প্রশস্ততার অর্ধেক, এবং -৬০ dB এর নীচের কিছু আপনি সত্যিই ভলিউম আপ না করলে শুনতে পারবেন না।
একটি তরঙ্গরূপ হিসাবে অডিও
আপনি অডিও কে একটি তরঙ্গরূপ হিসাবে কল্পনা করা চিত্রগুলো দেখেছেন, যা সময়ের সাথে নমুনা মানগুলিকে প্লট করে এবং পরিবর্তনগুলিকে চিত্রিত করে শব্দের amplitude। এটি শব্দের time domain উপস্থাপনা হিসাবেও পরিচিত।
এই ধরনের ভিজ্যুয়ালাইজেশন অডিও সিগন্যালের নির্দিষ্ট বৈশিষ্ট্য যেমন কোনো ঘটনার সময় চিহ্নিত করার জন্য, সিগন্যালের সামগ্রিক উচ্চতা এবং অডিওতে উপস্থিত কোনো অনিয়ম বা শব্দ কে চিহ্নিত করে ।
একটি অডিও সিগন্যালের জন্য তরঙ্গরূপ প্লট করার জন্য, আমরা একটি python লাইব্রেরি ব্যবহার করতে পারি যার নাম ‘librosa’:
pip install librosa
আসুন লাইব্রেরির সাথে আসা “trumpet” নামক একটি উদাহরণ নেওয়া যাক:
import librosa
array, sampling_rate = librosa.load(librosa.ex("trumpet"))উদাহরণটিতে অডিওটি, টাইম সিরিজের একটি tuple হিসাবে লোড করা হয়েছে (এখানে আমরা এটিকে array বলি), এবং Sampling Rate (sampling_rate)।
চলুন librosa র waveshow() ফাংশন ব্যবহার করে এই শব্দের তরঙ্গরূপটি একবার দেখে নেওয়া যাক:
import matplotlib.pyplot as plt
import librosa.display
plt.figure().set_figwidth(12)
librosa.display.waveshow(array, sr=sampling_rate)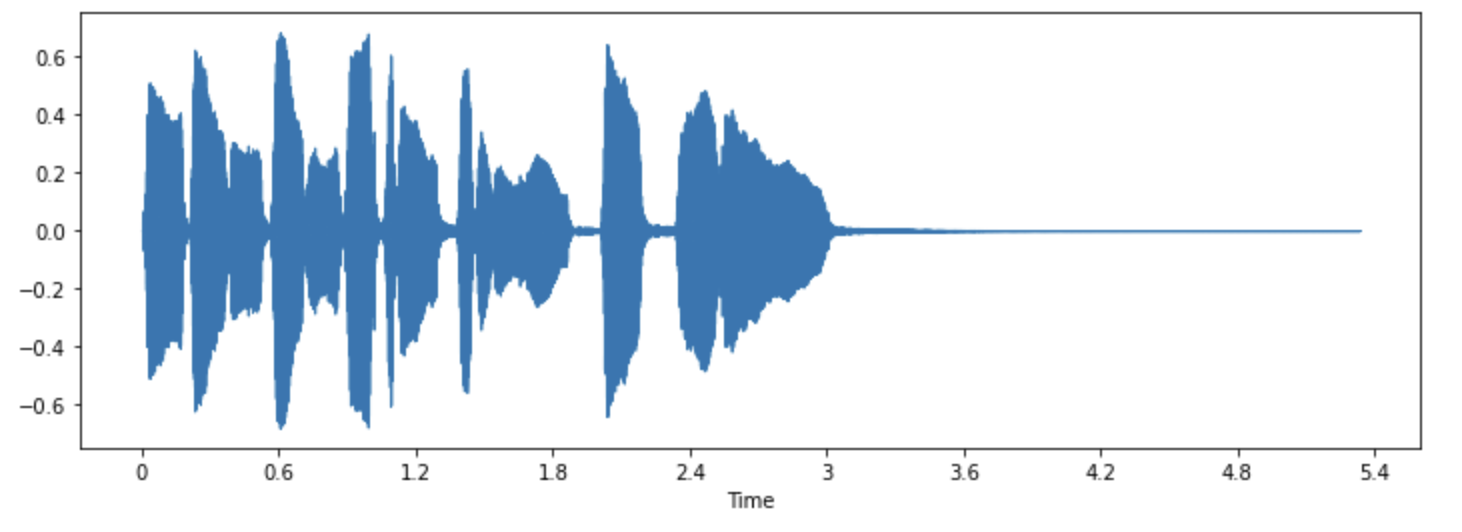
এটি y-অক্ষে সংকেতের amplitude এবং x-অক্ষ বরাবর সময় প্লট করে। অন্য কথায়, প্রতিটি পয়েন্ট নির্দেশ করে একটি একক নমুনা মান যা এই শব্দের নমুনা নেওয়ার সময় নেওয়া হয়েছিল। এছাড়াও মনে রাখবেন যে librosa ফ্লোটিং-পয়েন্ট মানগুলোকে অডিও হিসাবে প্রদান করে, এবং প্রশস্ততার মানগুলি প্রকৃতপক্ষে [-১.০, ১.০] পরিসরের মধ্যে রয়েছে৷
আপনি যে ডেটা নিয়ে কাজ করছেন তা বোঝার জন্য এটিকে শোনার পাশাপাশি অডিওটি ভিজ্যুয়ালাইজ করা একটি দরকারী টুল হতে পারে। আপনি সংকেতের আকার দেখতে পারেন, নিদর্শনগুলি পর্যবেক্ষণ করতে পারেন, শব্দ বা বিকৃতি দেখতে পারেন। আপনি যদি কিছু ডেটা প্রক্রিয়া করেন যেমন normalization, resampling অথবা filtering তাহলে আপনি প্লটটি দেখে নিশ্চিত হতে পারেন যে প্রক্রিয়াকরণের পদক্ষেপগুলি ঠিক প্রয়োগ করা হয়েছে। একটি মডেল এর training এর পরে, যদি কোনো সমস্যা আসে তাহলে আপনি debug করার সময় এই প্লটস গুলোর সাহায্য নিতে পারবেন।
ফ্রিকোয়েন্সি বর্ণালী
অডিও ডেটা কল্পনা করার আরেকটি উপায় হল একটি অডিও সিগন্যালের ফ্রিকোয়েন্সি বর্ণালী প্লট করা, যা frequency domain নামেও পরিচিত। Discrete Fourier transform or DFT ব্যবহার করে এই বর্ণালী গণনা করা হয়। এটি পৃথক ফ্রিকোয়েন্সি গুলোকে বর্ণনা করে যারা একসাথে সংকেত তৈরি করে এবং তারা কতটা শক্তিশালী।
আসুন numpy এর rfft() ফাংশন ব্যবহার করে DFT নিয়ে একই ট্রাম্পেট শব্দের জন্য ফ্রিকোয়েন্সি বর্ণালী প্লট করি। যদিও এটা
পুরো শব্দের বর্ণালী প্লট করা সম্ভব, এর পরিবর্তে একটি ছোট অঞ্চলের দিকে তাকানো আরও কার্যকর। এখানে আমরা প্রথম ৪০৯৬ টি নমুনার উপরে DFT প্রয়োগ করবো যাতে মোটামুটিভাবে প্রথম নোটের দৈর্ঘ্য প্লে হচ্ছে:
import numpy as np
dft_input = array[:4096]
# calculate the DFT
window = np.hanning(len(dft_input))
windowed_input = dft_input * window
dft = np.fft.rfft(windowed_input)
# get the amplitude spectrum in decibels
amplitude = np.abs(dft)
amplitude_db = librosa.amplitude_to_db(amplitude, ref=np.max)
# get the frequency bins
frequency = librosa.fft_frequencies(sr=sampling_rate, n_fft=len(dft_input))
plt.figure().set_figwidth(12)
plt.plot(frequency, amplitude_db)
plt.xlabel("Frequency (Hz)")
plt.ylabel("Amplitude (dB)")
plt.xscale("log")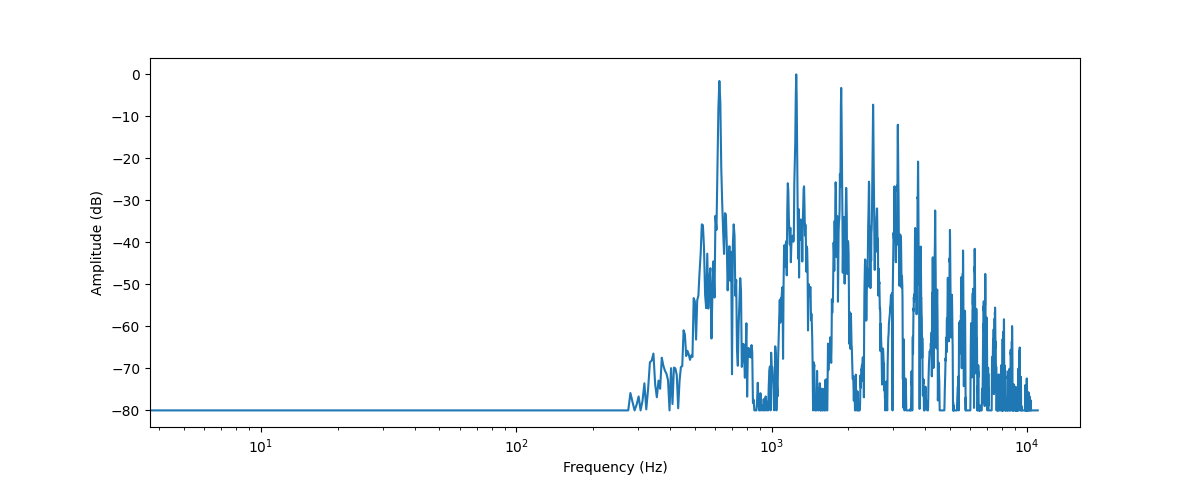
এটি এই অডিও সেগমেন্টে উপস্থিত বিভিন্ন ফ্রিকোয়েন্সি উপাদানগুলির শক্তি প্লট করে৷ ফ্রিকোয়েন্সি মান গুলি x-অক্ষ তে আছে এবং তাদের amplitude, y-অক্ষে থাকে। সাধারণত x-অক্ষকে লগারিদমিক স্কেলে প্লট করা হয়।
আমরা যে ফ্রিকোয়েন্সি বর্ণালী প্লট করেছি তা বেশ কয়েকটি শিখর দেখায়। এই শিখরগুলি যেই নোট প্লে করা হচ্ছে তার হারমোনিক্সের সাথে মিলে যায় যেখানে উচ্চ হারমোনিক্সগুলো শান্ত। যেহেতু প্রথম শিখরটি প্রায় ৬২০ Hz, এটি একটি E♭ নোটের ফ্রিকোয়েন্সি বর্ণালী।
DFT এর আউটপুট হল জটিল সংখ্যার একটি অ্যারে, যা বাস্তব এবং কাল্পনিক উপাদান দিয়ে গঠিত।
np.abs(dft) এর মাদ্ধমে আমরা amplitude তথ্য বের করি। বাস্তব এবং কাল্পনিক উপাদান এর মধ্যে কোণকে ফেজ বর্ণালী বলে, কিন্তু এটি মেশিন লার্নিং অ্যাপ্লিকেশনে নেওয়া হয় না।
আপনি amplitude মানগুলিকে ডেসিবেল স্কেলে রূপান্তর করতে librosa.amplitude_to_db() ব্যবহার করতে পারেন, এটি বর্ণালী মধ্যে সূক্ষ্ম বিবরণ টিকে দেখতে সহজ করে তোলে। কখনও কখনও লোকেরা power বর্ণালী ব্যবহার করে, যা amplitude এর পরিবর্তে শক্তি পরিমাপ করে;
যা কেবলমাত্র amplitude এর মান এর বর্গাকার।
একটি অডিও সিগন্যালের ফ্রিকোয়েন্সি বর্ণালীতে তার তরঙ্গরূপের মতো একই তথ্য থাকে - তারা কেবল দুটি ভিন্ন উপায়, একই ডেটাকে দেখার। যেখানে তরঙ্গরূপ amplitude প্লট করে সময়ের সাথে সাথে অডিও সিগন্যালের এবং বর্ণালী নির্দিষ্ট সময়ে পৃথক ফ্রিকোয়েন্সির amplitude কল্পনা করে।
spectrogram
আমরা যদি দেখতে চাই কিভাবে একটি অডিও সিগন্যালের ফ্রিকোয়েন্সি পরিবর্তন হয়? ট্রাম্পেট বেশ কয়েকটি নোট বাজায় এবং তাদের বিভিন্ন ফ্রিকোয়েন্সি আছে, সমস্যা হল যে স্পেকট্রাম শুধুমাত্র একটি সময়ে প্রদত্ত তাত্ক্ষণিক ফ্রিকোয়েন্সিগুলির প্লট দেখায়। সমাধানটি হল একাধিক DFT নেওয়া, প্রতিটিতে সমগ্র সময়ের কেবলমাত্র একটি ছোট স্লাইস কে ব্যবহার করা এবং তার পরে সব স্পেকট্রাকে একসাথে জুড়ে দেওয়া। এটাকে spectrogram বলে।
একটি spectrogram একটি অডিও সিগন্যালের ফ্রিকোয়েন্সি বিষয়বস্তু প্লট করে কারণ এটি সময়ের সাথে পরিবর্তিত হয়। এটি আপনাকে একই প্লটে সময়, ফ্রিকোয়েন্সি এবং তার সাথে amplitude প্রদর্শন করে। যে অ্যালগরিদমটি এই গণনাটি সম্পাদন করে তা হল STFT বা Short Time Fourier Transform।
চলুন লিব্রোসার stft() এবং specshow() ফাংশন ব্যবহার করে একই ট্রাম্পেট শব্দের জন্য একটি বর্ণালী প্লট করি:
import numpy as np
D = librosa.stft(array)
S_db = librosa.amplitude_to_db(np.abs(D), ref=np.max)
plt.figure().set_figwidth(12)
librosa.display.specshow(S_db, x_axis="time", y_axis="hz")
plt.colorbar()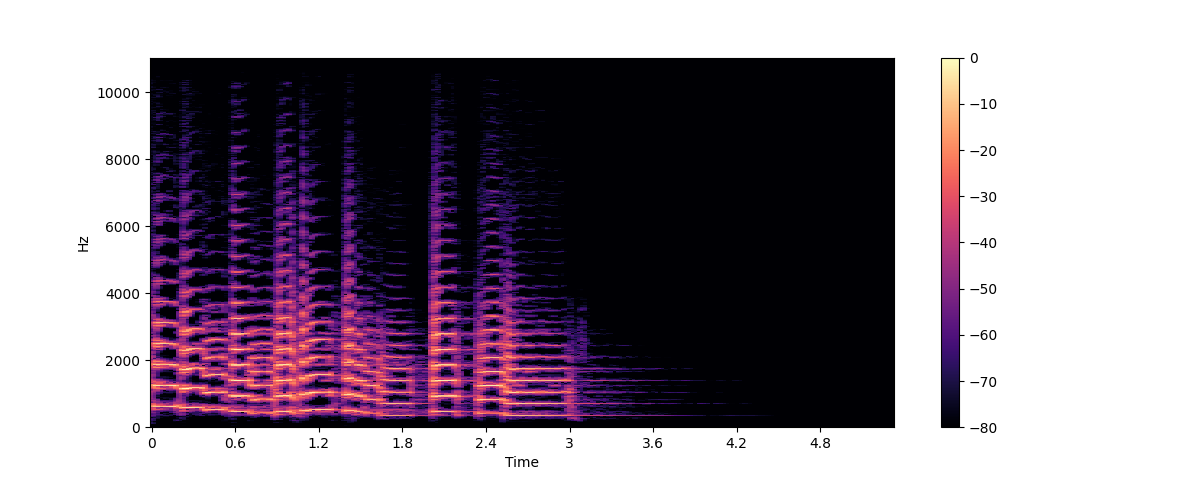
এই প্লটে, x-অক্ষ সময়কে উপস্থাপন করে কিন্তু এখন y-অক্ষ Hz-এ ফ্রিকোয়েন্সি উপস্থাপন করে। রঙের তীব্রতা ডেসিবেলে (dB) পরিমাপ করা সময়ে প্রতিটি বিন্দুতে ফ্রিকোয়েন্সি উপাদানটির amplitude বা শক্তি দেয়।
spectrogram টি অডিও সিগন্যালের ছোট অংশ গ্রহণ করে, যা সাধারণত কয়েক মিলিসেকেন্ড স্থায়ী হয় এবং তার উপর DFT গণনা করে তৈরি করা হয় ফ্রিকোয়েন্সি বর্ণালী।
তারপর বর্ণালীগুলিকে সময় অক্ষের উপর স্ট্যাক করা হয় এবং spectrogram তৈরি করা হয়। এই চিত্রের প্রতিটি উল্লম্ব স্লাইস একটি একক ফ্রিকোয়েন্সি বর্ণালীকে বোঝাই।
librosa.stft() অডিও সংকেতকে ২০৪৮ নমুনার অংশে বিভক্ত করে, যা ফ্রিকোয়েন্সি রেজোলিউশন এবং সময় রেজোলিউশনের মধ্যে একটি ভালো ট্রেড-অফ দেয়।
যেহেতু spectrogram এবং তরঙ্গরূপ একই ডেটার ভিন্ন ভিন্ন দৃষ্টিভঙ্গি, তাই spectrogram থেকে তরঙ্গরূপ এ ফিরিয়ে আনা সম্ভব, তার জন্যে inverse STFT ব্যবহার করতে হবে। যাইহোক, এর জন্য amplitude ছাড়াও ফেজ তথ্য প্রয়োজন। যদি spectrogram একটি মেশিন লার্নিং মডেল দ্বারা তৈরি করা হয়, তবে এটি সাধারণত শুধুমাত্র amplitude আউটপুট করে। সেই ক্ষেত্রে, আমরা একটি ফেজ পুনর্গঠন অ্যালগরিদম ব্যবহার করতে পারি যেমন ক্লাসিক Griffin-Lim অ্যালগরিদম, বা একটি নিউরাল নেটওয়ার্ক ব্যবহার করতে পারি যেটাকে একটি vocoder বলা হয়।
spectrogram গুলি কেবল ভিজ্যুয়ালাইজেশনের জন্য ব্যবহৃত হয় না। অনেক মেশিন লার্নিং মডেল spectrogram কে ইনপুট হিসাবে গ্রহণ করবে এবং আউটপুট হিসাবে spectrogram তৈরি করে।
এখন যেহেতু আমরা জানি একটি spectrogram কী এবং এটি কীভাবে তৈরি করা হয়, আসুন এটির একটি রূপ দেখে নেওয়া যাক যা বক্তৃতা প্রক্রিয়াকরণের জন্য ব্যাপকভাবে ব্যবহৃত হয়: mel spectrogram।
mel spectrogram
একটি mel spectrogram হল spectrogram এর একটি বৈচিত্র যা সাধারণত বক্তৃতা প্রক্রিয়াকরণ এর কাজে ব্যবহৃত হয়। এটি একটি spectrogram এর মতো যে এটি সময়ের সাথে একটি অডিও সিগন্যালের ফ্রিকোয়েন্সি বিষয়বস্তু দেখায়, তবে একটির ফ্রিকোয়েন্সি অক্ষে ভিন্ন।
একটি স্ট্যান্ডার্ড spectrogram এ, ফ্রিকোয়েন্সি অক্ষ রৈখিক এবং হার্টজ (Hz) এ পরিমাপ করা হয়। তবে মানুষের শ্রবণতন্ত্র উচ্চ ফ্রিকোয়েন্সির তুলনায় নিম্ন ফ্রিকোয়েন্সি পরিবর্তনের জন্য বেশি সংবেদনশীল, এবং এই সংবেদনশীলতা ফ্রিকোয়েন্সি বৃদ্ধির সাথে সাথে লগারিদমিকভাবে হ্রাস পায। মেল স্কেল একটি অনুধাবনযোগ্য স্কেল যা মানুষের কানের অ-রৈখিক ফ্রিকোয়েন্সি প্রতিক্রিয়াকে অনুমান করে।
একটি মেল spectrogram তৈরি করতে, STFT ঠিক আগের মতোই ব্যবহার করা হয়, একটি অডিওটিকে ছোট অংশে বিভক্ত করে ফ্রিকোয়েন্সি বর্ণালীগুলিকে তৈরী করা হয়। উপরন্তু, প্রতিটি বর্ণালীকে একটি ফিল্টারের সেটের মধ্যে দিয়ে পাঠানো হয়, যা মেল ফিল্টারব্যাঙ্ক হিসেবে পরিচিত, যা ফ্রিকোয়েন্সিগুলিকে মেল স্কেলে রূপান্তর করুন।
আসুন দেখি কিভাবে আমরা librosa এর melspectrogram() ফাংশন ব্যবহার করে একটি mel spectrogram প্লট করতে পারি, যা আমাদের জন্য এই সমস্ত পদক্ষেপগুলি সম্পাদন করে:
S = librosa.feature.melspectrogram(y=array, sr=sampling_rate, n_mels=128, fmax=8000)
S_dB = librosa.power_to_db(S, ref=np.max)
plt.figure().set_figwidth(12)
librosa.display.specshow(S_dB, x_axis="time", y_axis="mel", sr=sampling_rate, fmax=8000)
plt.colorbar()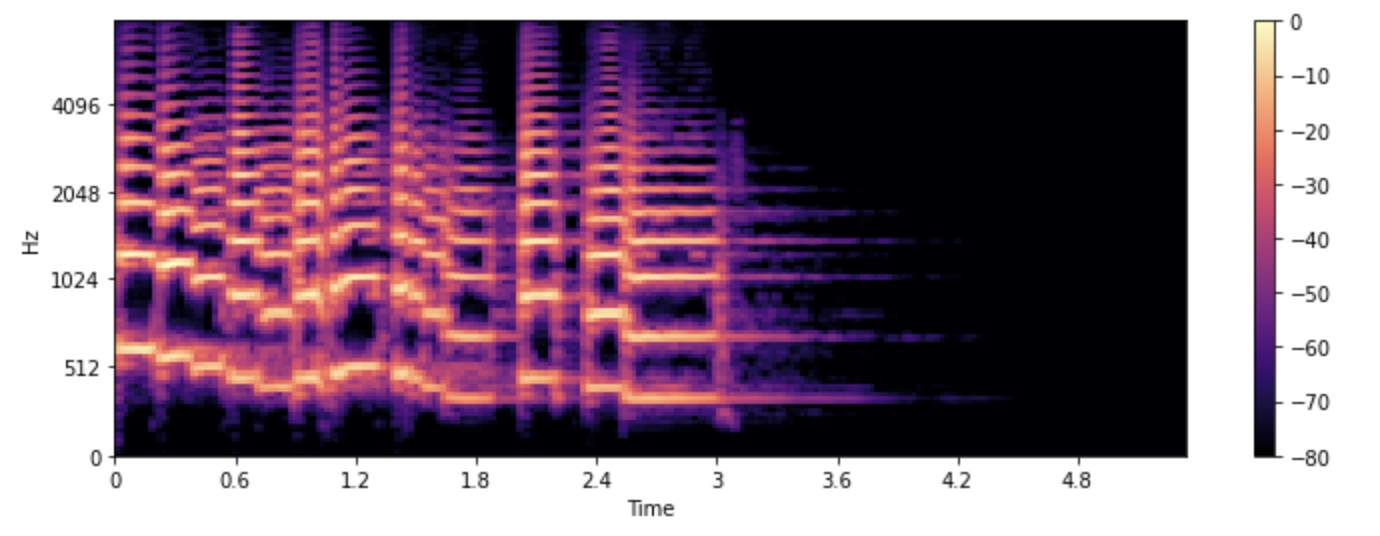
উপরের উদাহরণে, n_mels হল মেল ব্যান্ডের সংখ্যা। মেল ব্যান্ডগুলি হলো ফ্রিকোয়েন্সির একটি সেট যেটি ফিল্টারের এর সাহায্যে বর্ণালীকে অর্থপূর্ণ উপাদানে ভাগ করে
যেখানে ফিল্টার গুলোকে এমনভাবে বেছে নেওয়া হয় যার আকৃতি এবং ব্যবধান মানুষের কান যেভাবে বিভিন্ন ফ্রিকোয়েন্সিতে সাড়া দেয় তা অনুকরণ করতে পারে।
n_mels-এর সাধারণ মান হল ৪০ বা ৮০৷ fmax সর্বোচ্চ ফ্রিকোয়েন্সি নির্দেশ করে (Hz-এ) আমরা যে বিষয়ে চিন্তা করি।
নিয়মিত spectrogram এর মতোই, মেল ফ্রিকোয়েন্সির উপাদানগুলির শক্তি প্রকাশ করার সাধারণ অভ্যাস ডেসিবেলে, এটিকে সাধারণত log-mel spectrogram বলা হয়,
কারণ ডেসিবেলে রূপান্তর করার জন্যে লগারিদমিক অপারেশন প্রয়োগ করতে হয়। উপরের উদাহরণটি librosa.power_to_db() ব্যবহার করে librosa.feature.melspectrogram()
একটি power spectrogram তৈরি করে।
একটি mel spectrogram তৈরি করা একটি ক্ষতিকর অপারেশন কারণ এতে সিগন্যাল ফিল্টার করা জড়িত। একটি mel spectrogram কে নিয়মিত তরঙ্গরূপ এ রূপান্তর করা খুবই কঠিন, এমনকি সাহারণ spectrogram কে নিয়মিত তরঙ্গরূপ এ রূপান্তর করা এর চেয়ে সহজ, কারণ এর জন্য যেই ফ্রিকোয়েন্সিগুলিকে ফেলে দেওয়া হয়েছিল সেগুলোকে অনুমান করা প্রয়োজন। এই কারণেই একটি mel spectrogram থেকে একটি তরঙ্গরূপ তৈরি করতে মেশিন লার্নিং মডেল যেমন HiFiGAN vocoder প্রয়োজন।
একটি স্ট্যান্ডার্ড spectrogram এর তুলনায়, একটি mel spectrogram অডিও সিগন্যালের আরও অর্থপূর্ণ বৈশিষ্ট্যগুলি ক্যাপচার করতে পারে তাই এটি speech recognition, speaker identification, এবং music genre classification এর মতো কাজগুলিতে একটি জনপ্রিয় প্রক্রিয়া করে তোলে।
এখন যেহেতু আপনি অডিও ডেটা উদাহরণগুলি কীভাবে কল্পনা করতে হয় তা জানেন, এগিয়ে যান এবং আপনার প্রিয় শব্দগুলি কেমন তা দেখতে চেষ্টা করুন :)
< > Update on GitHub