|
--- |
|
language: |
|
- en |
|
- fr |
|
thumbnail: "https://www.warpy.io/_next/static/media/tgshell_icon.4fa45b6d.svg" |
|
tags: |
|
- text-generation |
|
- t5 |
|
license: "apache-2.0" |
|
datasets: |
|
- wikitext |
|
- bookcorpus |
|
metrics: |
|
- perplexity |
|
- bleu |
|
base_model: "t5" |
|
--- |
|
|
|
# tgs-model |
|
|
|
# Terminal Generative Shell (tgs) Model |
|
|
|
## TGS Model implements NL2Bash: Natural Language Interface to Linux Bash |
|
|
|
|
|
|
|
## Citation |
|
|
|
If you use this software, please cite it as follows: |
|
|
|
```bibtex |
|
@inproceedings{LinWZE2018:NL2Bash, |
|
author = {Xi Victoria Lin and Chenglong Wang and Luke Zettlemoyer and Michael D. Ernst}, |
|
title = {NL2Bash: A Corpus and Semantic Parser for Natural Language Interface to the Linux Operating System}, |
|
booktitle = {Proceedings of the Eleventh International Conference on Language Resources and Evaluation {LREC} 2018, Miyazaki (Japan), 7-12 May, 2018.}, |
|
year = {2018} |
|
} |
|
``` |
|
|
|
## Description |
|
|
|
This project is based on the NL2Bash dataset, constructed from the GitHub repository [nl2bash](https://github.com/TellinaTool/nl2bash). The objective is to create a semantic parser that translates natural language commands into executable Bash commands using deep learning techniques. |
|
|
|
## Installation |
|
|
|
### Prerequisites |
|
|
|
- Python 3.6+ |
|
- PyTorch |
|
- Transformers library |
|
- PyTorch Lightning |
|
- Scikit-learn |
|
- Sentencepiece |
|
|
|
### Setup |
|
|
|
Clone the repository and install the required packages: |
|
|
|
```bash |
|
git clone https://github.com/your-repo/nl2bash.git |
|
cd nl2bash |
|
pip install -r requirements.txt |
|
``` |
|
|
|
## Usage |
|
|
|
1. **Import Libraries** |
|
Import all the necessary libraries including PyTorch, Transformers, and PyTorch Lightning. |
|
|
|
2. **Load Data** |
|
Load the NL2Bash dataset JSON file and inspect its structure. |
|
|
|
3. **Preprocess Data** |
|
Convert the data into a suitable format for training, including tokenization. |
|
|
|
4. **Model Initialization** |
|
Initialize the T5 model and tokenizer, and set up the necessary configurations. |
|
|
|
5. **Training** |
|
Train the model using PyTorch Lightning with specified callbacks and checkpointing. |
|
|
|
6. **Validation and Testing** |
|
Validate and test the model on the NL2Bash dataset. |
|
|
|
7. **Model Inference** |
|
Use the trained model to translate natural language commands to Bash commands. |
|
|
|
## Example |
|
|
|
Here's a quick example to get you started: |
|
|
|
```python |
|
from your_module import NL2BashModel, generate_answer |
|
model = NL2BashModel.load_from_checkpoint('path_to_checkpoint') |
|
tokenizer = YourTokenizer.from_pretrained('path_to_tokenizer') |
|
question = "Prints process tree of a current process with id numbers and parent processes." |
|
answer = generate_answer(question, model, tokenizer) |
|
print(answer) |
|
``` |
|
|
|
## Training Analysis |
|
|
|
The T5 model was fine-tuned for the NL2Bash task. The training process showed the following characteristics: |
|
|
|
 |
|
|
|
- Training Loss: Demonstrated a consistent decrease over time, indicating effective learning and adaptation to the training data. |
|
- Validation Loss: Also decreased, suggesting good generalization to unseen data. |
|
- Stability: The training process was stable, without significant fluctuations in loss values. |
|
- Overfitting: No evidence of overfitting was observed, as both training and validation losses decreased concurrently. |
|
|
|
This analysis provides confidence in the model's ability to learn and generalize from the NL2Bash dataset effectively. |
|
|
|
### Bias Analysis |
|
|
|
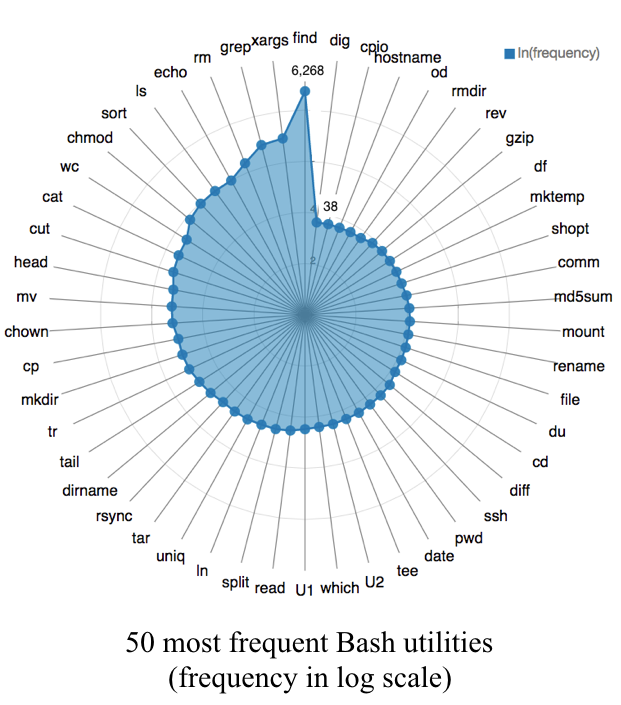
tgs_model `v0.1.0` has a bias towards the NL2Bash dataset. The nl2bashdataset has a huge amount of `find` command on top of the others. |
|
|
|
 |
|
|
|
For the `v0.2.0` model, we will be treating the NL2Bash dataset as a biased dataset. We will be using the [NL2Bash-2](https://github.com/TellinaTool/nl2bash-2) dataset. The dataset is a more balanced dataset with more commands. |
|
|
|
## Contributing |
|
|
|
Contributions to improve NL2Bash are welcome. Please read `CONTRIBUTING.md` for guidelines on how to contribute. |
|
|
|
## License |
|
|
|
This project is licensed under the MIT License - see the `LICENSE` file for details. |
|
|
