

license: apache-2.0
JetMoE
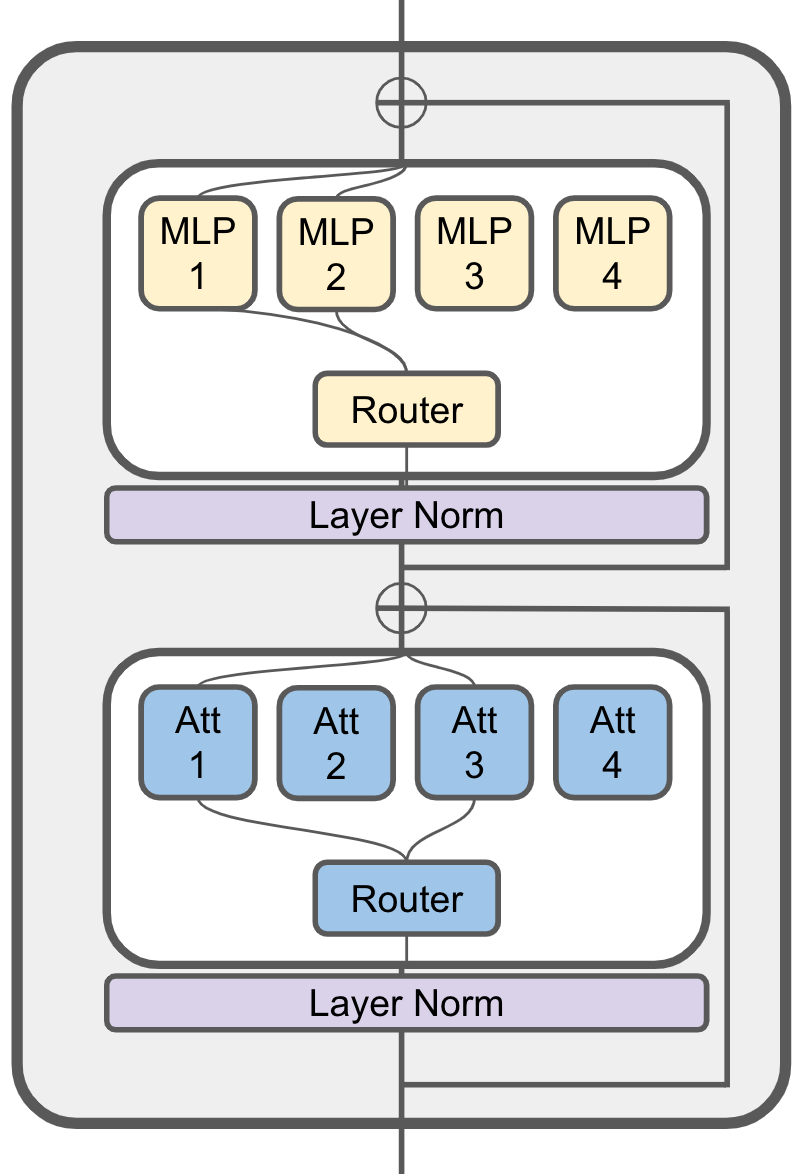
JetMoE-8B is an 8B Mixture-of-Experts (MoE) language model developed by Yikang Shen and MyShell. The goal of JetMoE is to provide a LLaMA2-level performance and efficient language model with a very limited budget. To achieve this goal, JetMoE uses a sparsely activated architecture inspired by the ModuleFormer. Each JetMoE block consists of two MoE layers: Mixture of Attention Heads and Mixture of MLP Experts. Given the input tokens, it activates a subset of its experts to process them. Thus, JetMoE-8B has 8B parameters in total, but only 2B are activated for each input token. This sparse activation schema enables JetMoE achieve much better training throughput compared to similar size dense models. The model is trained with 1.25T tokens from publicly available datasets on 96 H100s within 13 days. Given the current market price of H100 GPU hours, training the model only costs around 0.1 million dollars. To our surprise, JetMoE-8B performs even better than LLaMA2-7B, LLaMA-13B, and DeepseekMoE-16B despite the lower training cost and computation. Compared to a model with similar training and inference computation, JetMoE-8B achieves significantly better performance compared to Gemma-2B.
Evaluation Results
| Model | Activate Params | Training Tokens | ARC-challenge | Hellaswag | MMLU | TruthfulQA | WinoGrande | GSM8k | Open LLM Leaderboard Average | MBPP | HumanEval |
|---|---|---|---|---|---|---|---|---|---|---|---|
| acc | acc | acc | acc | acc | acc | acc | Pass@1 | Pass@1 | |||
| LLaMA2-7B | 7B | 2T | 53.1 | 78.6 | 46.9 | 38.8 | 74 | 14.5 | 51.0 | 20.8 | 12.8 |
| LLaMA-13B | 13B | 1T | 56.2 | 80.9 | 47.7 | 39.5 | 76.2 | 7.6 | 51.4 | 22.0 | 15.8 |
| DeepseekMoE-16B | 2.8B | 2T | 53.2 | 79.8 | 46.3 | 36.1 | 73.7 | 17.3 | 51.1 | 34.0 | 25.0 |
| Gemma-2B | 2B | 2T | 48.4 | 71.8 | 41.8 | 33.1 | 66.3 | 16.9 | 46.4 | 28.0 | 24.4 |
| JetMoE-8B | 2.2B | 1.25T | 48.7 | 80.5 | 49.2 | 41.7 | 70.2 | 27.8 | 53.0 | 34.2 | 14.6 |
Model Usage
To load the models, you need install this package:
pip install -e .
Then you can load the model with the following code:
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoConfig, AutoModelForSequenceClassification
from jetmoe import JetMoEForCausalLM, JetMoEConfig, JetMoEForSequenceClassification
AutoConfig.register("jetmoe", JetMoEConfig)
AutoModelForCausalLM.register(JetMoEConfig, JetMoEForCausalLM)
AutoModelForSequenceClassification.register(JetMoEConfig, JetMoEForSequenceClassification)
tokenizer = AutoTokenizer.from_pretrained('JetMoE/JetMoE-8B')
model = AutoModelForCausalLM.from_pretrained('JetMoE/JetMoE-8B')
The MoE code is based on the ScatterMoE. The code is still under active development, we are happy to receive any feedback or suggestions.
Model Details
JetMoE-8B has 24 blocks. Each block has two MoE layers: Mixture of Attention heads (MoA) and Mixture of MLP Experts (MoE). Each MoA and MoE layer has 8 expert, and 2 experts are activated for each input token. It has 8 billion parameters in total and 2.2B active parameters. JetMoE-8B is trained on 1.25T tokens from publicly available datasets, with a learning rate of 5.0 x 10-4 and a global batch-size of 4M tokens.
Input Models input text only.
Output Models generate text only.
Training Data
JetMoE models are pretrained on 1.25T tokens of data from publicly available sources.
Authors
This project is currently contributed by the following authors:
- Yikang Shen
- Zhen Guo
- Tianle Cai
- Zengyi Qin
Technical Report
For more details, please refer to the JetMoE Technical Report (Coming Soon).
JetMoE Model Index
| Model | Index |
|---|---|
| JetMoE-8B | Link |
Ethical Considerations and Limitations
JetMoE is a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, JetMoE’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of JetMoE, developers should perform safety testing and tuning tailored to their specific applications of the model.