

init
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .DS_Store +0 -0
- .idea/.gitignore +3 -0
- .idea/inspectionProfiles/Project_Default.xml +29 -0
- .idea/inspectionProfiles/profiles_settings.xml +6 -0
- .idea/materials.mhg-ged.iml +12 -0
- .idea/modules.xml +8 -0
- .idea/vcs.xml +6 -0
- README.md +78 -3
- __init__.py +5 -0
- __pycache__/__init__.cpython-310.pyc +0 -0
- __pycache__/load.cpython-310.pyc +0 -0
- graph_grammar/.DS_Store +0 -0
- graph_grammar/__init__.py +19 -0
- graph_grammar/__pycache__/__init__.cpython-310.pyc +0 -0
- graph_grammar/__pycache__/hypergraph.cpython-310.pyc +0 -0
- graph_grammar/algo/__init__.py +20 -0
- graph_grammar/algo/__pycache__/__init__.cpython-310.pyc +0 -0
- graph_grammar/algo/__pycache__/tree_decomposition.cpython-310.pyc +0 -0
- graph_grammar/algo/tree_decomposition.py +821 -0
- graph_grammar/graph_grammar/__init__.py +20 -0
- graph_grammar/graph_grammar/__pycache__/__init__.cpython-310.pyc +0 -0
- graph_grammar/graph_grammar/__pycache__/base.cpython-310.pyc +0 -0
- graph_grammar/graph_grammar/__pycache__/corpus.cpython-310.pyc +0 -0
- graph_grammar/graph_grammar/__pycache__/hrg.cpython-310.pyc +0 -0
- graph_grammar/graph_grammar/__pycache__/symbols.cpython-310.pyc +0 -0
- graph_grammar/graph_grammar/__pycache__/utils.cpython-310.pyc +0 -0
- graph_grammar/graph_grammar/base.py +30 -0
- graph_grammar/graph_grammar/corpus.py +152 -0
- graph_grammar/graph_grammar/hrg.py +1065 -0
- graph_grammar/graph_grammar/symbols.py +180 -0
- graph_grammar/graph_grammar/utils.py +130 -0
- graph_grammar/hypergraph.py +544 -0
- graph_grammar/io/__init__.py +20 -0
- graph_grammar/io/__pycache__/__init__.cpython-310.pyc +0 -0
- graph_grammar/io/__pycache__/smi.cpython-310.pyc +0 -0
- graph_grammar/io/smi.py +559 -0
- graph_grammar/nn/__init__.py +11 -0
- graph_grammar/nn/__pycache__/__init__.cpython-310.pyc +0 -0
- graph_grammar/nn/__pycache__/decoder.cpython-310.pyc +0 -0
- graph_grammar/nn/__pycache__/encoder.cpython-310.pyc +0 -0
- graph_grammar/nn/dataset.py +121 -0
- graph_grammar/nn/decoder.py +158 -0
- graph_grammar/nn/encoder.py +199 -0
- graph_grammar/nn/graph.py +313 -0
- images/mhg_example.png +0 -0
- images/mhg_example1.png +0 -0
- images/mhg_example2.png +0 -0
- load.py +83 -0
- mhg_gnn.egg-info/PKG-INFO +102 -0
- mhg_gnn.egg-info/SOURCES.txt +46 -0
.DS_Store
ADDED
|
Binary file (10.2 kB). View file
|
|
|
.idea/.gitignore
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Default ignored files
|
| 2 |
+
/shelf/
|
| 3 |
+
/workspace.xml
|
.idea/inspectionProfiles/Project_Default.xml
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<component name="InspectionProjectProfileManager">
|
| 2 |
+
<profile version="1.0">
|
| 3 |
+
<option name="myName" value="Project Default" />
|
| 4 |
+
<inspection_tool class="PyPackageRequirementsInspection" enabled="true" level="WARNING" enabled_by_default="true">
|
| 5 |
+
<option name="ignoredPackages">
|
| 6 |
+
<value>
|
| 7 |
+
<list size="16">
|
| 8 |
+
<item index="0" class="java.lang.String" itemvalue="accelerate" />
|
| 9 |
+
<item index="1" class="java.lang.String" itemvalue="matplotlib" />
|
| 10 |
+
<item index="2" class="java.lang.String" itemvalue="torch-geometric" />
|
| 11 |
+
<item index="3" class="java.lang.String" itemvalue="torchinfo" />
|
| 12 |
+
<item index="4" class="java.lang.String" itemvalue="caikit" />
|
| 13 |
+
<item index="5" class="java.lang.String" itemvalue="pytorch-fast-transformers" />
|
| 14 |
+
<item index="6" class="java.lang.String" itemvalue="e3nn" />
|
| 15 |
+
<item index="7" class="java.lang.String" itemvalue="rdkit" />
|
| 16 |
+
<item index="8" class="java.lang.String" itemvalue="PyImpetus" />
|
| 17 |
+
<item index="9" class="java.lang.String" itemvalue="torch-scatter" />
|
| 18 |
+
<item index="10" class="java.lang.String" itemvalue="torch-nl" />
|
| 19 |
+
<item index="11" class="java.lang.String" itemvalue="torch-sparse" />
|
| 20 |
+
<item index="12" class="java.lang.String" itemvalue="mordred" />
|
| 21 |
+
<item index="13" class="java.lang.String" itemvalue="xgboost" />
|
| 22 |
+
<item index="14" class="java.lang.String" itemvalue="mamba-ssm" />
|
| 23 |
+
<item index="15" class="java.lang.String" itemvalue="evaluate" />
|
| 24 |
+
</list>
|
| 25 |
+
</value>
|
| 26 |
+
</option>
|
| 27 |
+
</inspection_tool>
|
| 28 |
+
</profile>
|
| 29 |
+
</component>
|
.idea/inspectionProfiles/profiles_settings.xml
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<component name="InspectionProjectProfileManager">
|
| 2 |
+
<settings>
|
| 3 |
+
<option name="USE_PROJECT_PROFILE" value="false" />
|
| 4 |
+
<version value="1.0" />
|
| 5 |
+
</settings>
|
| 6 |
+
</component>
|
.idea/materials.mhg-ged.iml
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<?xml version="1.0" encoding="UTF-8"?>
|
| 2 |
+
<module type="PYTHON_MODULE" version="4">
|
| 3 |
+
<component name="NewModuleRootManager">
|
| 4 |
+
<content url="file://$MODULE_DIR$" />
|
| 5 |
+
<orderEntry type="inheritedJdk" />
|
| 6 |
+
<orderEntry type="sourceFolder" forTests="false" />
|
| 7 |
+
</component>
|
| 8 |
+
<component name="PyDocumentationSettings">
|
| 9 |
+
<option name="format" value="NUMPY" />
|
| 10 |
+
<option name="myDocStringFormat" value="NumPy" />
|
| 11 |
+
</component>
|
| 12 |
+
</module>
|
.idea/modules.xml
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<?xml version="1.0" encoding="UTF-8"?>
|
| 2 |
+
<project version="4">
|
| 3 |
+
<component name="ProjectModuleManager">
|
| 4 |
+
<modules>
|
| 5 |
+
<module fileurl="file://$PROJECT_DIR$/.idea/materials.mhg-ged.iml" filepath="$PROJECT_DIR$/.idea/materials.mhg-ged.iml" />
|
| 6 |
+
</modules>
|
| 7 |
+
</component>
|
| 8 |
+
</project>
|
.idea/vcs.xml
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<?xml version="1.0" encoding="UTF-8"?>
|
| 2 |
+
<project version="4">
|
| 3 |
+
<component name="VcsDirectoryMappings">
|
| 4 |
+
<mapping directory="" vcs="Git" />
|
| 5 |
+
</component>
|
| 6 |
+
</project>
|
README.md
CHANGED
|
@@ -1,3 +1,78 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: apache-2.0
|
| 3 |
-
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
---
|
| 4 |
+
# mhg-gnn
|
| 5 |
+
|
| 6 |
+
This repository provides PyTorch source code assosiated with our publication, "MHG-GNN: Combination of Molecular Hypergraph Grammar with Graph Neural Network"
|
| 7 |
+
|
| 8 |
+
**Paper:** [Arxiv Link](https://arxiv.org/pdf/2309.16374)
|
| 9 |
+
|
| 10 |
+

|
| 11 |
+
|
| 12 |
+
## Introduction
|
| 13 |
+
|
| 14 |
+
We present MHG-GNN, an autoencoder architecture
|
| 15 |
+
that has an encoder based on GNN and a decoder based on a sequential model with MHG.
|
| 16 |
+
Since the encoder is a GNN variant, MHG-GNN can accept any molecule as input, and
|
| 17 |
+
demonstrate high predictive performance on molecular graph data.
|
| 18 |
+
In addition, the decoder inherits the theoretical guarantee of MHG on always generating a structurally valid molecule as output.
|
| 19 |
+
|
| 20 |
+
## Table of Contents
|
| 21 |
+
|
| 22 |
+
1. [Getting Started](#getting-started)
|
| 23 |
+
1. [Pretrained Models and Training Logs](#pretrained-models-and-training-logs)
|
| 24 |
+
2. [Installation](#installation)
|
| 25 |
+
2. [Feature Extraction](#feature-extraction)
|
| 26 |
+
|
| 27 |
+
## Getting Started
|
| 28 |
+
|
| 29 |
+
**This code and environment have been tested on Intel E5-2667 CPUs at 3.30GHz and NVIDIA A100 Tensor Core GPUs.**
|
| 30 |
+
|
| 31 |
+
### Pretrained Models and Training Logs
|
| 32 |
+
|
| 33 |
+
We provide checkpoints of the MHG-GNN model pre-trained on a dataset of ~1.34M molecules curated from PubChem. (later) For model weights: [HuggingFace Link]()
|
| 34 |
+
|
| 35 |
+
Add the MHG-GNN `pre-trained weights.pt` to the `models/` directory according to your needs.
|
| 36 |
+
|
| 37 |
+
### Installation
|
| 38 |
+
|
| 39 |
+
We recommend to create a virtual environment. For example:
|
| 40 |
+
|
| 41 |
+
```
|
| 42 |
+
python3 -m venv .venv
|
| 43 |
+
. .venv/bin/activate
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
Type the following command once the virtual environment is activated:
|
| 47 |
+
|
| 48 |
+
```
|
| 49 |
+
git clone git@github.ibm.com:CMD-TRL/mhg-gnn.git
|
| 50 |
+
cd ./mhg-gnn
|
| 51 |
+
pip install .
|
| 52 |
+
```
|
| 53 |
+
|
| 54 |
+
## Feature Extraction
|
| 55 |
+
|
| 56 |
+
The example notebook [mhg-gnn_encoder_decoder_example.ipynb](notebooks/mhg-gnn_encoder_decoder_example.ipynb) contains code to load checkpoint files and use the pre-trained model for encoder and decoder tasks.
|
| 57 |
+
|
| 58 |
+
To load mhg-gnn, you can simply use:
|
| 59 |
+
|
| 60 |
+
```python
|
| 61 |
+
import torch
|
| 62 |
+
import load
|
| 63 |
+
|
| 64 |
+
model = load.load()
|
| 65 |
+
```
|
| 66 |
+
|
| 67 |
+
To encode SMILES into embeddings, you can use:
|
| 68 |
+
|
| 69 |
+
```python
|
| 70 |
+
with torch.no_grad():
|
| 71 |
+
repr = model.encode(["CCO", "O=C=O", "OC(=O)c1ccccc1C(=O)O"])
|
| 72 |
+
```
|
| 73 |
+
|
| 74 |
+
For decoder, you can use the function, so you can return from embeddings to SMILES strings:
|
| 75 |
+
|
| 76 |
+
```python
|
| 77 |
+
orig = model.decode(repr)
|
| 78 |
+
```
|
__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding:utf-8 -*-
|
| 2 |
+
# Rhizome
|
| 3 |
+
# Version beta 0.0, August 2023
|
| 4 |
+
# Property of IBM Research, Accelerated Discovery
|
| 5 |
+
#
|
__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (214 Bytes). View file
|
|
|
__pycache__/load.cpython-310.pyc
ADDED
|
Binary file (3.04 kB). View file
|
|
|
graph_grammar/.DS_Store
ADDED
|
Binary file (8.2 kB). View file
|
|
|
graph_grammar/__init__.py
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# -*- coding: utf-8 -*-
|
| 3 |
+
# Rhizome
|
| 4 |
+
# Version beta 0.0, August 2023
|
| 5 |
+
# Property of IBM Research, Accelerated Discovery
|
| 6 |
+
#
|
| 7 |
+
"""
|
| 8 |
+
PLEASE NOTE THIS IMPLEMENTATION INCLUDES THE ORIGINAL SOURCE CODE (AND SOME ADAPTATIONS)
|
| 9 |
+
OF THE MHG IMPLEMENTATION OF HIROSHI KAJINO AT IBM TRL ALREADY PUBLICLY AVAILABLE.
|
| 10 |
+
THIS MIGHT INFLUENCE THE DECISION OF THE FINAL LICENSE SO CAREFUL CHECK NEEDS BE DONE.
|
| 11 |
+
"""
|
| 12 |
+
|
| 13 |
+
""" Title """
|
| 14 |
+
|
| 15 |
+
__author__ = "Hiroshi Kajino <KAJINO@jp.ibm.com>"
|
| 16 |
+
__copyright__ = "(c) Copyright IBM Corp. 2018"
|
| 17 |
+
__version__ = "0.1"
|
| 18 |
+
__date__ = "Jan 1 2018"
|
| 19 |
+
|
graph_grammar/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (666 Bytes). View file
|
|
|
graph_grammar/__pycache__/hypergraph.cpython-310.pyc
ADDED
|
Binary file (15.3 kB). View file
|
|
|
graph_grammar/algo/__init__.py
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# -*- coding:utf-8 -*-
|
| 3 |
+
# Rhizome
|
| 4 |
+
# Version beta 0.0, August 2023
|
| 5 |
+
# Property of IBM Research, Accelerated Discovery
|
| 6 |
+
#
|
| 7 |
+
|
| 8 |
+
"""
|
| 9 |
+
PLEASE NOTE THIS IMPLEMENTATION INCLUDES THE ORIGINAL SOURCE CODE (AND SOME ADAPTATIONS)
|
| 10 |
+
OF THE MHG IMPLEMENTATION OF HIROSHI KAJINO AT IBM TRL ALREADY PUBLICLY AVAILABLE.
|
| 11 |
+
THIS MIGHT INFLUENCE THE DECISION OF THE FINAL LICENSE SO CAREFUL CHECK NEEDS BE DONE.
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
""" Title """
|
| 15 |
+
|
| 16 |
+
__author__ = "Hiroshi Kajino <KAJINO@jp.ibm.com>"
|
| 17 |
+
__copyright__ = "(c) Copyright IBM Corp. 2018"
|
| 18 |
+
__version__ = "0.1"
|
| 19 |
+
__date__ = "Jan 1 2018"
|
| 20 |
+
|
graph_grammar/algo/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (659 Bytes). View file
|
|
|
graph_grammar/algo/__pycache__/tree_decomposition.cpython-310.pyc
ADDED
|
Binary file (19.5 kB). View file
|
|
|
graph_grammar/algo/tree_decomposition.py
ADDED
|
@@ -0,0 +1,821 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# -*- coding: utf-8 -*-
|
| 3 |
+
# Rhizome
|
| 4 |
+
# Version beta 0.0, August 2023
|
| 5 |
+
# Property of IBM Research, Accelerated Discovery
|
| 6 |
+
#
|
| 7 |
+
|
| 8 |
+
"""
|
| 9 |
+
PLEASE NOTE THIS IMPLEMENTATION INCLUDES THE ORIGINAL SOURCE CODE (AND SOME ADAPTATIONS)
|
| 10 |
+
OF THE MHG IMPLEMENTATION OF HIROSHI KAJINO AT IBM TRL ALREADY PUBLICLY AVAILABLE.
|
| 11 |
+
THIS MIGHT INFLUENCE THE DECISION OF THE FINAL LICENSE SO CAREFUL CHECK NEEDS BE DONE.
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
""" Title """
|
| 15 |
+
|
| 16 |
+
__author__ = "Hiroshi Kajino <KAJINO@jp.ibm.com>"
|
| 17 |
+
__copyright__ = "(c) Copyright IBM Corp. 2017"
|
| 18 |
+
__version__ = "0.1"
|
| 19 |
+
__date__ = "Dec 11 2017"
|
| 20 |
+
|
| 21 |
+
from copy import deepcopy
|
| 22 |
+
from itertools import combinations
|
| 23 |
+
from ..hypergraph import Hypergraph
|
| 24 |
+
import networkx as nx
|
| 25 |
+
import numpy as np
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class CliqueTree(nx.Graph):
|
| 29 |
+
''' clique tree object
|
| 30 |
+
|
| 31 |
+
Attributes
|
| 32 |
+
----------
|
| 33 |
+
hg : Hypergraph
|
| 34 |
+
This hypergraph will be decomposed.
|
| 35 |
+
root_hg : Hypergraph
|
| 36 |
+
Hypergraph on the root node.
|
| 37 |
+
ident_node_dict : dict
|
| 38 |
+
ident_node_dict[key_node] gives a list of nodes that are identical (i.e., the adjacent hyperedges are common)
|
| 39 |
+
'''
|
| 40 |
+
def __init__(self, hg=None, **kwargs):
|
| 41 |
+
self.hg = deepcopy(hg)
|
| 42 |
+
if self.hg is not None:
|
| 43 |
+
self.ident_node_dict = self.hg.get_identical_node_dict()
|
| 44 |
+
else:
|
| 45 |
+
self.ident_node_dict = {}
|
| 46 |
+
super().__init__(**kwargs)
|
| 47 |
+
|
| 48 |
+
@property
|
| 49 |
+
def root_hg(self):
|
| 50 |
+
''' return the hypergraph on the root node
|
| 51 |
+
'''
|
| 52 |
+
return self.nodes[0]['subhg']
|
| 53 |
+
|
| 54 |
+
@root_hg.setter
|
| 55 |
+
def root_hg(self, hypergraph):
|
| 56 |
+
''' set the hypergraph on the root node
|
| 57 |
+
'''
|
| 58 |
+
self.nodes[0]['subhg'] = hypergraph
|
| 59 |
+
|
| 60 |
+
def insert_subhg(self, subhypergraph: Hypergraph) -> None:
|
| 61 |
+
''' insert a subhypergraph, which is extracted from a root hypergraph, into the tree.
|
| 62 |
+
|
| 63 |
+
Parameters
|
| 64 |
+
----------
|
| 65 |
+
subhg : Hypergraph
|
| 66 |
+
'''
|
| 67 |
+
num_nodes = self.number_of_nodes()
|
| 68 |
+
self.add_node(num_nodes, subhg=subhypergraph)
|
| 69 |
+
self.add_edge(num_nodes, 0)
|
| 70 |
+
adj_nodes = deepcopy(list(self.adj[0].keys()))
|
| 71 |
+
for each_node in adj_nodes:
|
| 72 |
+
if len(self.nodes[each_node]["subhg"].nodes.intersection(
|
| 73 |
+
self.nodes[num_nodes]["subhg"].nodes)\
|
| 74 |
+
- self.root_hg.nodes) != 0 and each_node != num_nodes:
|
| 75 |
+
self.remove_edge(0, each_node)
|
| 76 |
+
self.add_edge(each_node, num_nodes)
|
| 77 |
+
|
| 78 |
+
def to_irredundant(self) -> None:
|
| 79 |
+
''' convert the clique tree to be irredundant
|
| 80 |
+
'''
|
| 81 |
+
for each_node in self.hg.nodes:
|
| 82 |
+
subtree = self.subgraph([
|
| 83 |
+
each_tree_node for each_tree_node in self.nodes()\
|
| 84 |
+
if each_node in self.nodes[each_tree_node]["subhg"].nodes]).copy()
|
| 85 |
+
leaf_node_list = [x for x in subtree.nodes() if subtree.degree(x)==1]
|
| 86 |
+
redundant_leaf_node_list = []
|
| 87 |
+
for each_leaf_node in leaf_node_list:
|
| 88 |
+
if len(self.nodes[each_leaf_node]["subhg"].adj_edges(each_node)) == 0:
|
| 89 |
+
redundant_leaf_node_list.append(each_leaf_node)
|
| 90 |
+
for each_red_leaf_node in redundant_leaf_node_list:
|
| 91 |
+
current_node = each_red_leaf_node
|
| 92 |
+
while subtree.degree(current_node) == 1 \
|
| 93 |
+
and len(subtree.nodes[current_node]["subhg"].adj_edges(each_node)) == 0:
|
| 94 |
+
self.nodes[current_node]["subhg"].remove_node(each_node)
|
| 95 |
+
remove_node = current_node
|
| 96 |
+
current_node = list(dict(subtree[remove_node]).keys())[0]
|
| 97 |
+
subtree.remove_node(remove_node)
|
| 98 |
+
|
| 99 |
+
fixed_node_set = deepcopy(self.nodes)
|
| 100 |
+
for each_node in fixed_node_set:
|
| 101 |
+
if self.nodes[each_node]["subhg"].num_edges == 0:
|
| 102 |
+
if len(self[each_node]) == 1:
|
| 103 |
+
self.remove_node(each_node)
|
| 104 |
+
elif len(self[each_node]) == 2:
|
| 105 |
+
self.add_edge(*self[each_node])
|
| 106 |
+
self.remove_node(each_node)
|
| 107 |
+
else:
|
| 108 |
+
pass
|
| 109 |
+
else:
|
| 110 |
+
pass
|
| 111 |
+
|
| 112 |
+
redundant = True
|
| 113 |
+
while redundant:
|
| 114 |
+
redundant = False
|
| 115 |
+
fixed_edge_set = deepcopy(self.edges)
|
| 116 |
+
remove_node_set = set()
|
| 117 |
+
for node_1, node_2 in fixed_edge_set:
|
| 118 |
+
if node_1 in remove_node_set or node_2 in remove_node_set:
|
| 119 |
+
pass
|
| 120 |
+
else:
|
| 121 |
+
if self.nodes[node_1]['subhg'].is_subhg(self.nodes[node_2]['subhg']):
|
| 122 |
+
redundant = True
|
| 123 |
+
adj_node_list = set(self.adj[node_1]) - {node_2}
|
| 124 |
+
self.remove_node(node_1)
|
| 125 |
+
remove_node_set.add(node_1)
|
| 126 |
+
for each_node in adj_node_list:
|
| 127 |
+
self.add_edge(node_2, each_node)
|
| 128 |
+
|
| 129 |
+
elif self.nodes[node_2]['subhg'].is_subhg(self.nodes[node_1]['subhg']):
|
| 130 |
+
redundant = True
|
| 131 |
+
adj_node_list = set(self.adj[node_2]) - {node_1}
|
| 132 |
+
self.remove_node(node_2)
|
| 133 |
+
remove_node_set.add(node_2)
|
| 134 |
+
for each_node in adj_node_list:
|
| 135 |
+
self.add_edge(node_1, each_node)
|
| 136 |
+
|
| 137 |
+
def node_update(self, key_node: str, subhg) -> None:
|
| 138 |
+
""" given a pair of a hypergraph, H, and its subhypergraph, sH, return a hypergraph H\sH.
|
| 139 |
+
|
| 140 |
+
Parameters
|
| 141 |
+
----------
|
| 142 |
+
key_node : str
|
| 143 |
+
key node that must be removed.
|
| 144 |
+
subhg : Hypegraph
|
| 145 |
+
"""
|
| 146 |
+
for each_edge in subhg.edges:
|
| 147 |
+
self.root_hg.remove_edge(each_edge)
|
| 148 |
+
self.root_hg.remove_nodes(self.ident_node_dict[key_node])
|
| 149 |
+
|
| 150 |
+
adj_node_list = list(subhg.nodes)
|
| 151 |
+
for each_node in subhg.nodes:
|
| 152 |
+
if each_node not in self.ident_node_dict[key_node]:
|
| 153 |
+
if set(self.root_hg.adj_edges(each_node)).issubset(subhg.edges):
|
| 154 |
+
self.root_hg.remove_node(each_node)
|
| 155 |
+
adj_node_list.remove(each_node)
|
| 156 |
+
else:
|
| 157 |
+
adj_node_list.remove(each_node)
|
| 158 |
+
|
| 159 |
+
for each_node_1, each_node_2 in combinations(adj_node_list, 2):
|
| 160 |
+
if not self.root_hg.is_adj(each_node_1, each_node_2):
|
| 161 |
+
self.root_hg.add_edge(set([each_node_1, each_node_2]), attr_dict=dict(tmp=True))
|
| 162 |
+
|
| 163 |
+
subhg.remove_edges_with_attr({'tmp' : True})
|
| 164 |
+
self.insert_subhg(subhg)
|
| 165 |
+
|
| 166 |
+
def update(self, subhg, remove_nodes=False):
|
| 167 |
+
""" given a pair of a hypergraph, H, and its subhypergraph, sH, return a hypergraph H\sH.
|
| 168 |
+
|
| 169 |
+
Parameters
|
| 170 |
+
----------
|
| 171 |
+
subhg : Hypegraph
|
| 172 |
+
"""
|
| 173 |
+
for each_edge in subhg.edges:
|
| 174 |
+
self.root_hg.remove_edge(each_edge)
|
| 175 |
+
if remove_nodes:
|
| 176 |
+
remove_edge_list = []
|
| 177 |
+
for each_edge in self.root_hg.edges:
|
| 178 |
+
if set(self.root_hg.nodes_in_edge(each_edge)).issubset(subhg.nodes)\
|
| 179 |
+
and self.root_hg.edge_attr(each_edge).get('tmp', False):
|
| 180 |
+
remove_edge_list.append(each_edge)
|
| 181 |
+
self.root_hg.remove_edges(remove_edge_list)
|
| 182 |
+
|
| 183 |
+
adj_node_list = list(subhg.nodes)
|
| 184 |
+
for each_node in subhg.nodes:
|
| 185 |
+
if self.root_hg.degree(each_node) == 0:
|
| 186 |
+
self.root_hg.remove_node(each_node)
|
| 187 |
+
adj_node_list.remove(each_node)
|
| 188 |
+
|
| 189 |
+
if len(adj_node_list) != 1 and not remove_nodes:
|
| 190 |
+
self.root_hg.add_edge(set(adj_node_list), attr_dict=dict(tmp=True))
|
| 191 |
+
'''
|
| 192 |
+
else:
|
| 193 |
+
for each_node_1, each_node_2 in combinations(adj_node_list, 2):
|
| 194 |
+
if not self.root_hg.is_adj(each_node_1, each_node_2):
|
| 195 |
+
self.root_hg.add_edge(
|
| 196 |
+
[each_node_1, each_node_2], attr_dict=dict(tmp=True))
|
| 197 |
+
'''
|
| 198 |
+
subhg.remove_edges_with_attr({'tmp':True})
|
| 199 |
+
self.insert_subhg(subhg)
|
| 200 |
+
|
| 201 |
+
|
| 202 |
+
def _get_min_deg_node(hg, ident_node_dict: dict, mode='mol'):
|
| 203 |
+
if mode == 'standard':
|
| 204 |
+
degree_dict = hg.degrees()
|
| 205 |
+
min_deg_node = min(degree_dict, key=degree_dict.get)
|
| 206 |
+
min_deg_subhg = hg.adj_subhg(min_deg_node, ident_node_dict)
|
| 207 |
+
return min_deg_node, min_deg_subhg
|
| 208 |
+
elif mode == 'mol':
|
| 209 |
+
degree_dict = hg.degrees()
|
| 210 |
+
min_deg = min(degree_dict.values())
|
| 211 |
+
min_deg_node_list = [each_node for each_node in hg.nodes if degree_dict[each_node]==min_deg]
|
| 212 |
+
min_deg_subhg_list = [hg.adj_subhg(each_min_deg_node, ident_node_dict)
|
| 213 |
+
for each_min_deg_node in min_deg_node_list]
|
| 214 |
+
best_score = np.inf
|
| 215 |
+
best_idx = -1
|
| 216 |
+
for each_idx in range(len(min_deg_subhg_list)):
|
| 217 |
+
if min_deg_subhg_list[each_idx].num_nodes < best_score:
|
| 218 |
+
best_idx = each_idx
|
| 219 |
+
return min_deg_node_list[each_idx], min_deg_subhg_list[each_idx]
|
| 220 |
+
else:
|
| 221 |
+
raise ValueError
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
def tree_decomposition(hg, irredundant=True):
|
| 225 |
+
""" compute a tree decomposition of the input hypergraph
|
| 226 |
+
|
| 227 |
+
Parameters
|
| 228 |
+
----------
|
| 229 |
+
hg : Hypergraph
|
| 230 |
+
hypergraph to be decomposed
|
| 231 |
+
irredundant : bool
|
| 232 |
+
if True, irredundant tree decomposition will be computed.
|
| 233 |
+
|
| 234 |
+
Returns
|
| 235 |
+
-------
|
| 236 |
+
clique_tree : nx.Graph
|
| 237 |
+
each node contains a subhypergraph of `hg`
|
| 238 |
+
"""
|
| 239 |
+
org_hg = hg.copy()
|
| 240 |
+
ident_node_dict = hg.get_identical_node_dict()
|
| 241 |
+
clique_tree = CliqueTree(org_hg)
|
| 242 |
+
clique_tree.add_node(0, subhg=org_hg)
|
| 243 |
+
while True:
|
| 244 |
+
degree_dict = org_hg.degrees()
|
| 245 |
+
min_deg_node = min(degree_dict, key=degree_dict.get)
|
| 246 |
+
min_deg_subhg = org_hg.adj_subhg(min_deg_node, ident_node_dict)
|
| 247 |
+
if org_hg.nodes == min_deg_subhg.nodes:
|
| 248 |
+
break
|
| 249 |
+
|
| 250 |
+
# org_hg and min_deg_subhg are divided
|
| 251 |
+
clique_tree.node_update(min_deg_node, min_deg_subhg)
|
| 252 |
+
|
| 253 |
+
clique_tree.root_hg.remove_edges_with_attr({'tmp' : True})
|
| 254 |
+
|
| 255 |
+
if irredundant:
|
| 256 |
+
clique_tree.to_irredundant()
|
| 257 |
+
return clique_tree
|
| 258 |
+
|
| 259 |
+
|
| 260 |
+
def tree_decomposition_with_hrg(hg, hrg, irredundant=True, return_root=False):
|
| 261 |
+
''' compute a tree decomposition given a hyperedge replacement grammar.
|
| 262 |
+
the resultant clique tree should induce a less compact HRG.
|
| 263 |
+
|
| 264 |
+
Parameters
|
| 265 |
+
----------
|
| 266 |
+
hg : Hypergraph
|
| 267 |
+
hypergraph to be decomposed
|
| 268 |
+
hrg : HyperedgeReplacementGrammar
|
| 269 |
+
current HRG
|
| 270 |
+
irredundant : bool
|
| 271 |
+
if True, irredundant tree decomposition will be computed.
|
| 272 |
+
|
| 273 |
+
Returns
|
| 274 |
+
-------
|
| 275 |
+
clique_tree : nx.Graph
|
| 276 |
+
each node contains a subhypergraph of `hg`
|
| 277 |
+
'''
|
| 278 |
+
org_hg = hg.copy()
|
| 279 |
+
ident_node_dict = hg.get_identical_node_dict()
|
| 280 |
+
clique_tree = CliqueTree(org_hg)
|
| 281 |
+
clique_tree.add_node(0, subhg=org_hg)
|
| 282 |
+
root_node = 0
|
| 283 |
+
|
| 284 |
+
# construct a clique tree using HRG
|
| 285 |
+
success_any = True
|
| 286 |
+
while success_any:
|
| 287 |
+
success_any = False
|
| 288 |
+
for each_prod_rule in hrg.prod_rule_list:
|
| 289 |
+
org_hg, success, subhg = each_prod_rule.revert(org_hg, True)
|
| 290 |
+
if success:
|
| 291 |
+
if each_prod_rule.is_start_rule: root_node = clique_tree.number_of_nodes()
|
| 292 |
+
success_any = True
|
| 293 |
+
subhg.remove_edges_with_attr({'terminal' : False})
|
| 294 |
+
clique_tree.root_hg = org_hg
|
| 295 |
+
clique_tree.insert_subhg(subhg)
|
| 296 |
+
|
| 297 |
+
clique_tree.root_hg = org_hg
|
| 298 |
+
|
| 299 |
+
for each_edge in deepcopy(org_hg.edges):
|
| 300 |
+
if not org_hg.edge_attr(each_edge)['terminal']:
|
| 301 |
+
node_list = org_hg.nodes_in_edge(each_edge)
|
| 302 |
+
org_hg.remove_edge(each_edge)
|
| 303 |
+
|
| 304 |
+
for each_node_1, each_node_2 in combinations(node_list, 2):
|
| 305 |
+
if not org_hg.is_adj(each_node_1, each_node_2):
|
| 306 |
+
org_hg.add_edge([each_node_1, each_node_2], attr_dict=dict(tmp=True))
|
| 307 |
+
|
| 308 |
+
# construct a clique tree using the existing algorithm
|
| 309 |
+
degree_dict = org_hg.degrees()
|
| 310 |
+
if degree_dict:
|
| 311 |
+
while True:
|
| 312 |
+
min_deg_node, min_deg_subhg = _get_min_deg_node(org_hg, ident_node_dict)
|
| 313 |
+
if org_hg.nodes == min_deg_subhg.nodes: break
|
| 314 |
+
|
| 315 |
+
# org_hg and min_deg_subhg are divided
|
| 316 |
+
clique_tree.node_update(min_deg_node, min_deg_subhg)
|
| 317 |
+
|
| 318 |
+
clique_tree.root_hg.remove_edges_with_attr({'tmp' : True})
|
| 319 |
+
if irredundant:
|
| 320 |
+
clique_tree.to_irredundant()
|
| 321 |
+
|
| 322 |
+
if return_root:
|
| 323 |
+
if root_node == 0 and 0 not in clique_tree.nodes:
|
| 324 |
+
root_node = clique_tree.number_of_nodes()
|
| 325 |
+
while root_node not in clique_tree.nodes:
|
| 326 |
+
root_node -= 1
|
| 327 |
+
elif root_node not in clique_tree.nodes:
|
| 328 |
+
while root_node not in clique_tree.nodes:
|
| 329 |
+
root_node -= 1
|
| 330 |
+
else:
|
| 331 |
+
pass
|
| 332 |
+
return clique_tree, root_node
|
| 333 |
+
else:
|
| 334 |
+
return clique_tree
|
| 335 |
+
|
| 336 |
+
|
| 337 |
+
def tree_decomposition_from_leaf(hg, irredundant=True):
|
| 338 |
+
""" compute a tree decomposition of the input hypergraph
|
| 339 |
+
|
| 340 |
+
Parameters
|
| 341 |
+
----------
|
| 342 |
+
hg : Hypergraph
|
| 343 |
+
hypergraph to be decomposed
|
| 344 |
+
irredundant : bool
|
| 345 |
+
if True, irredundant tree decomposition will be computed.
|
| 346 |
+
|
| 347 |
+
Returns
|
| 348 |
+
-------
|
| 349 |
+
clique_tree : nx.Graph
|
| 350 |
+
each node contains a subhypergraph of `hg`
|
| 351 |
+
"""
|
| 352 |
+
def apply_normal_decomposition(clique_tree):
|
| 353 |
+
degree_dict = clique_tree.root_hg.degrees()
|
| 354 |
+
min_deg_node = min(degree_dict, key=degree_dict.get)
|
| 355 |
+
min_deg_subhg = clique_tree.root_hg.adj_subhg(min_deg_node, clique_tree.ident_node_dict)
|
| 356 |
+
if clique_tree.root_hg.nodes == min_deg_subhg.nodes:
|
| 357 |
+
return clique_tree, False
|
| 358 |
+
clique_tree.node_update(min_deg_node, min_deg_subhg)
|
| 359 |
+
return clique_tree, True
|
| 360 |
+
|
| 361 |
+
def apply_min_edge_deg_decomposition(clique_tree):
|
| 362 |
+
edge_degree_dict = clique_tree.root_hg.edge_degrees()
|
| 363 |
+
non_tmp_edge_list = [each_edge for each_edge in clique_tree.root_hg.edges \
|
| 364 |
+
if not clique_tree.root_hg.edge_attr(each_edge).get('tmp')]
|
| 365 |
+
if not non_tmp_edge_list:
|
| 366 |
+
return clique_tree, False
|
| 367 |
+
min_deg_edge = None
|
| 368 |
+
min_deg = np.inf
|
| 369 |
+
for each_edge in non_tmp_edge_list:
|
| 370 |
+
if min_deg > edge_degree_dict[each_edge]:
|
| 371 |
+
min_deg_edge = each_edge
|
| 372 |
+
min_deg = edge_degree_dict[each_edge]
|
| 373 |
+
node_list = clique_tree.root_hg.nodes_in_edge(min_deg_edge)
|
| 374 |
+
min_deg_subhg = clique_tree.root_hg.get_subhg(
|
| 375 |
+
node_list, [min_deg_edge], clique_tree.ident_node_dict)
|
| 376 |
+
if clique_tree.root_hg.nodes == min_deg_subhg.nodes:
|
| 377 |
+
return clique_tree, False
|
| 378 |
+
clique_tree.update(min_deg_subhg)
|
| 379 |
+
return clique_tree, True
|
| 380 |
+
|
| 381 |
+
org_hg = hg.copy()
|
| 382 |
+
clique_tree = CliqueTree(org_hg)
|
| 383 |
+
clique_tree.add_node(0, subhg=org_hg)
|
| 384 |
+
|
| 385 |
+
success = True
|
| 386 |
+
while success:
|
| 387 |
+
clique_tree, success = apply_min_edge_deg_decomposition(clique_tree)
|
| 388 |
+
if not success:
|
| 389 |
+
clique_tree, success = apply_normal_decomposition(clique_tree)
|
| 390 |
+
|
| 391 |
+
clique_tree.root_hg.remove_edges_with_attr({'tmp' : True})
|
| 392 |
+
if irredundant:
|
| 393 |
+
clique_tree.to_irredundant()
|
| 394 |
+
return clique_tree
|
| 395 |
+
|
| 396 |
+
def topological_tree_decomposition(
|
| 397 |
+
hg, irredundant=True, rip_labels=True, shrink_cycle=False, contract_cycles=False):
|
| 398 |
+
''' compute a tree decomposition of the input hypergraph
|
| 399 |
+
|
| 400 |
+
Parameters
|
| 401 |
+
----------
|
| 402 |
+
hg : Hypergraph
|
| 403 |
+
hypergraph to be decomposed
|
| 404 |
+
irredundant : bool
|
| 405 |
+
if True, irredundant tree decomposition will be computed.
|
| 406 |
+
|
| 407 |
+
Returns
|
| 408 |
+
-------
|
| 409 |
+
clique_tree : CliqueTree
|
| 410 |
+
each node contains a subhypergraph of `hg`
|
| 411 |
+
'''
|
| 412 |
+
def _contract_tree(clique_tree):
|
| 413 |
+
''' contract a single leaf
|
| 414 |
+
|
| 415 |
+
Parameters
|
| 416 |
+
----------
|
| 417 |
+
clique_tree : CliqueTree
|
| 418 |
+
|
| 419 |
+
Returns
|
| 420 |
+
-------
|
| 421 |
+
CliqueTree, bool
|
| 422 |
+
bool represents whether this operation succeeds or not.
|
| 423 |
+
'''
|
| 424 |
+
edge_degree_dict = clique_tree.root_hg.edge_degrees()
|
| 425 |
+
leaf_edge_list = [each_edge for each_edge in clique_tree.root_hg.edges \
|
| 426 |
+
if (not clique_tree.root_hg.edge_attr(each_edge).get('tmp'))\
|
| 427 |
+
and edge_degree_dict[each_edge] == 1]
|
| 428 |
+
if not leaf_edge_list:
|
| 429 |
+
return clique_tree, False
|
| 430 |
+
min_deg_edge = leaf_edge_list[0]
|
| 431 |
+
node_list = clique_tree.root_hg.nodes_in_edge(min_deg_edge)
|
| 432 |
+
min_deg_subhg = clique_tree.root_hg.get_subhg(
|
| 433 |
+
node_list, [min_deg_edge], clique_tree.ident_node_dict)
|
| 434 |
+
if clique_tree.root_hg.nodes == min_deg_subhg.nodes:
|
| 435 |
+
return clique_tree, False
|
| 436 |
+
clique_tree.update(min_deg_subhg)
|
| 437 |
+
return clique_tree, True
|
| 438 |
+
|
| 439 |
+
def _rip_labels_from_cycles(clique_tree, org_hg):
|
| 440 |
+
''' rip hyperedge-labels off
|
| 441 |
+
|
| 442 |
+
Parameters
|
| 443 |
+
----------
|
| 444 |
+
clique_tree : CliqueTree
|
| 445 |
+
org_hg : Hypergraph
|
| 446 |
+
|
| 447 |
+
Returns
|
| 448 |
+
-------
|
| 449 |
+
CliqueTree, bool
|
| 450 |
+
bool represents whether this operation succeeds or not.
|
| 451 |
+
'''
|
| 452 |
+
ident_node_dict = clique_tree.ident_node_dict #hg.get_identical_node_dict()
|
| 453 |
+
for each_edge in clique_tree.root_hg.edges:
|
| 454 |
+
if each_edge in org_hg.edges:
|
| 455 |
+
if org_hg.in_cycle(each_edge):
|
| 456 |
+
node_list = clique_tree.root_hg.nodes_in_edge(each_edge)
|
| 457 |
+
subhg = clique_tree.root_hg.get_subhg(
|
| 458 |
+
node_list, [each_edge], ident_node_dict)
|
| 459 |
+
if clique_tree.root_hg.nodes == subhg.nodes:
|
| 460 |
+
return clique_tree, False
|
| 461 |
+
clique_tree.update(subhg)
|
| 462 |
+
'''
|
| 463 |
+
in_cycle_dict = {each_node: org_hg.node_attr(each_node)['is_in_ring'] for each_node in node_list}
|
| 464 |
+
if not all(in_cycle_dict.values()):
|
| 465 |
+
node_not_in_cycle = [each_node for each_node in in_cycle_dict.keys() if not in_cycle_dict[each_node]][0]
|
| 466 |
+
node_list = [node_not_in_cycle]
|
| 467 |
+
node_list.extend(clique_tree.root_hg.adj_nodes(node_not_in_cycle))
|
| 468 |
+
edge_list = clique_tree.root_hg.adj_edges(node_not_in_cycle)
|
| 469 |
+
import pdb; pdb.set_trace()
|
| 470 |
+
subhg = clique_tree.root_hg.get_subhg(
|
| 471 |
+
node_list, edge_list, ident_node_dict)
|
| 472 |
+
|
| 473 |
+
clique_tree.update(subhg)
|
| 474 |
+
'''
|
| 475 |
+
return clique_tree, True
|
| 476 |
+
return clique_tree, False
|
| 477 |
+
|
| 478 |
+
def _shrink_cycle(clique_tree):
|
| 479 |
+
''' shrink a cycle
|
| 480 |
+
|
| 481 |
+
Parameters
|
| 482 |
+
----------
|
| 483 |
+
clique_tree : CliqueTree
|
| 484 |
+
|
| 485 |
+
Returns
|
| 486 |
+
-------
|
| 487 |
+
CliqueTree, bool
|
| 488 |
+
bool represents whether this operation succeeds or not.
|
| 489 |
+
'''
|
| 490 |
+
def filter_subhg(subhg, hg, key_node):
|
| 491 |
+
num_nodes_cycle = 0
|
| 492 |
+
nodes_in_cycle_list = []
|
| 493 |
+
for each_node in subhg.nodes:
|
| 494 |
+
if hg.in_cycle(each_node):
|
| 495 |
+
num_nodes_cycle += 1
|
| 496 |
+
if each_node != key_node:
|
| 497 |
+
nodes_in_cycle_list.append(each_node)
|
| 498 |
+
if num_nodes_cycle > 3:
|
| 499 |
+
break
|
| 500 |
+
if num_nodes_cycle != 3:
|
| 501 |
+
return False
|
| 502 |
+
else:
|
| 503 |
+
for each_edge in hg.edges:
|
| 504 |
+
if set(nodes_in_cycle_list).issubset(hg.nodes_in_edge(each_edge)):
|
| 505 |
+
return False
|
| 506 |
+
return True
|
| 507 |
+
|
| 508 |
+
#ident_node_dict = hg.get_identical_node_dict()
|
| 509 |
+
ident_node_dict = clique_tree.ident_node_dict
|
| 510 |
+
for each_node in clique_tree.root_hg.nodes:
|
| 511 |
+
if clique_tree.root_hg.in_cycle(each_node)\
|
| 512 |
+
and filter_subhg(clique_tree.root_hg.adj_subhg(each_node, ident_node_dict),
|
| 513 |
+
clique_tree.root_hg,
|
| 514 |
+
each_node):
|
| 515 |
+
target_node = each_node
|
| 516 |
+
target_subhg = clique_tree.root_hg.adj_subhg(target_node, ident_node_dict)
|
| 517 |
+
if clique_tree.root_hg.nodes == target_subhg.nodes:
|
| 518 |
+
return clique_tree, False
|
| 519 |
+
clique_tree.update(target_subhg)
|
| 520 |
+
return clique_tree, True
|
| 521 |
+
return clique_tree, False
|
| 522 |
+
|
| 523 |
+
def _contract_cycles(clique_tree):
|
| 524 |
+
'''
|
| 525 |
+
remove a subhypergraph that looks like a cycle on a leaf.
|
| 526 |
+
|
| 527 |
+
Parameters
|
| 528 |
+
----------
|
| 529 |
+
clique_tree : CliqueTree
|
| 530 |
+
|
| 531 |
+
Returns
|
| 532 |
+
-------
|
| 533 |
+
CliqueTree, bool
|
| 534 |
+
bool represents whether this operation succeeds or not.
|
| 535 |
+
'''
|
| 536 |
+
def _divide_hg(hg):
|
| 537 |
+
''' divide a hypergraph into subhypergraphs such that
|
| 538 |
+
each subhypergraph is connected to each other in a tree-like way.
|
| 539 |
+
|
| 540 |
+
Parameters
|
| 541 |
+
----------
|
| 542 |
+
hg : Hypergraph
|
| 543 |
+
|
| 544 |
+
Returns
|
| 545 |
+
-------
|
| 546 |
+
list of Hypergraphs
|
| 547 |
+
each element corresponds to a subhypergraph of `hg`
|
| 548 |
+
'''
|
| 549 |
+
for each_node in hg.nodes:
|
| 550 |
+
if hg.is_dividable(each_node):
|
| 551 |
+
adj_edges_dict = {each_edge: hg.in_cycle(each_edge) for each_edge in hg.adj_edges(each_node)}
|
| 552 |
+
'''
|
| 553 |
+
if any(adj_edges_dict.values()):
|
| 554 |
+
import pdb; pdb.set_trace()
|
| 555 |
+
edge_in_cycle = [each_key for each_key, each_val in adj_edges_dict.items() if each_val][0]
|
| 556 |
+
subhg1, subhg2, subhg3 = hg.divide(each_node, edge_in_cycle)
|
| 557 |
+
return _divide_hg(subhg1) + _divide_hg(subhg2) + _divide_hg(subhg3)
|
| 558 |
+
else:
|
| 559 |
+
'''
|
| 560 |
+
subhg1, subhg2 = hg.divide(each_node)
|
| 561 |
+
return _divide_hg(subhg1) + _divide_hg(subhg2)
|
| 562 |
+
return [hg]
|
| 563 |
+
|
| 564 |
+
def _is_leaf(hg, divided_subhg) -> bool:
|
| 565 |
+
''' judge whether subhg is a leaf-like in the original hypergraph
|
| 566 |
+
|
| 567 |
+
Parameters
|
| 568 |
+
----------
|
| 569 |
+
hg : Hypergraph
|
| 570 |
+
divided_subhg : Hypergraph
|
| 571 |
+
`divided_subhg` is a subhypergraph of `hg`
|
| 572 |
+
|
| 573 |
+
Returns
|
| 574 |
+
-------
|
| 575 |
+
bool
|
| 576 |
+
'''
|
| 577 |
+
'''
|
| 578 |
+
adj_edges_set = set([])
|
| 579 |
+
for each_node in divided_subhg.nodes:
|
| 580 |
+
adj_edges_set.update(set(hg.adj_edges(each_node)))
|
| 581 |
+
|
| 582 |
+
|
| 583 |
+
_hg = deepcopy(hg)
|
| 584 |
+
_hg.remove_subhg(divided_subhg)
|
| 585 |
+
if nx.is_connected(_hg.hg) != (len(adj_edges_set - divided_subhg.edges) == 1):
|
| 586 |
+
import pdb; pdb.set_trace()
|
| 587 |
+
return len(adj_edges_set - divided_subhg.edges) == 1
|
| 588 |
+
'''
|
| 589 |
+
_hg = deepcopy(hg)
|
| 590 |
+
_hg.remove_subhg(divided_subhg)
|
| 591 |
+
return nx.is_connected(_hg.hg)
|
| 592 |
+
|
| 593 |
+
subhg_list = _divide_hg(clique_tree.root_hg)
|
| 594 |
+
if len(subhg_list) == 1:
|
| 595 |
+
return clique_tree, False
|
| 596 |
+
else:
|
| 597 |
+
while len(subhg_list) > 1:
|
| 598 |
+
max_leaf_subhg = None
|
| 599 |
+
for each_subhg in subhg_list:
|
| 600 |
+
if _is_leaf(clique_tree.root_hg, each_subhg):
|
| 601 |
+
if max_leaf_subhg is None:
|
| 602 |
+
max_leaf_subhg = each_subhg
|
| 603 |
+
elif max_leaf_subhg.num_nodes < each_subhg.num_nodes:
|
| 604 |
+
max_leaf_subhg = each_subhg
|
| 605 |
+
clique_tree.update(max_leaf_subhg)
|
| 606 |
+
subhg_list.remove(max_leaf_subhg)
|
| 607 |
+
return clique_tree, True
|
| 608 |
+
|
| 609 |
+
org_hg = hg.copy()
|
| 610 |
+
clique_tree = CliqueTree(org_hg)
|
| 611 |
+
clique_tree.add_node(0, subhg=org_hg)
|
| 612 |
+
|
| 613 |
+
success = True
|
| 614 |
+
while success:
|
| 615 |
+
'''
|
| 616 |
+
clique_tree, success = _rip_labels_from_cycles(clique_tree, hg)
|
| 617 |
+
if not success:
|
| 618 |
+
clique_tree, success = _contract_cycles(clique_tree)
|
| 619 |
+
'''
|
| 620 |
+
clique_tree, success = _contract_tree(clique_tree)
|
| 621 |
+
if not success:
|
| 622 |
+
if rip_labels:
|
| 623 |
+
clique_tree, success = _rip_labels_from_cycles(clique_tree, hg)
|
| 624 |
+
if not success:
|
| 625 |
+
if shrink_cycle:
|
| 626 |
+
clique_tree, success = _shrink_cycle(clique_tree)
|
| 627 |
+
if not success:
|
| 628 |
+
if contract_cycles:
|
| 629 |
+
clique_tree, success = _contract_cycles(clique_tree)
|
| 630 |
+
clique_tree.root_hg.remove_edges_with_attr({'tmp' : True})
|
| 631 |
+
if irredundant:
|
| 632 |
+
clique_tree.to_irredundant()
|
| 633 |
+
return clique_tree
|
| 634 |
+
|
| 635 |
+
def molecular_tree_decomposition(hg, irredundant=True):
|
| 636 |
+
""" compute a tree decomposition of the input molecular hypergraph
|
| 637 |
+
|
| 638 |
+
Parameters
|
| 639 |
+
----------
|
| 640 |
+
hg : Hypergraph
|
| 641 |
+
molecular hypergraph to be decomposed
|
| 642 |
+
irredundant : bool
|
| 643 |
+
if True, irredundant tree decomposition will be computed.
|
| 644 |
+
|
| 645 |
+
Returns
|
| 646 |
+
-------
|
| 647 |
+
clique_tree : CliqueTree
|
| 648 |
+
each node contains a subhypergraph of `hg`
|
| 649 |
+
"""
|
| 650 |
+
def _divide_hg(hg):
|
| 651 |
+
''' divide a hypergraph into subhypergraphs such that
|
| 652 |
+
each subhypergraph is connected to each other in a tree-like way.
|
| 653 |
+
|
| 654 |
+
Parameters
|
| 655 |
+
----------
|
| 656 |
+
hg : Hypergraph
|
| 657 |
+
|
| 658 |
+
Returns
|
| 659 |
+
-------
|
| 660 |
+
list of Hypergraphs
|
| 661 |
+
each element corresponds to a subhypergraph of `hg`
|
| 662 |
+
'''
|
| 663 |
+
is_ring = False
|
| 664 |
+
for each_node in hg.nodes:
|
| 665 |
+
if hg.node_attr(each_node)['is_in_ring']:
|
| 666 |
+
is_ring = True
|
| 667 |
+
if not hg.node_attr(each_node)['is_in_ring'] \
|
| 668 |
+
and hg.degree(each_node) == 2:
|
| 669 |
+
subhg1, subhg2 = hg.divide(each_node)
|
| 670 |
+
return _divide_hg(subhg1) + _divide_hg(subhg2)
|
| 671 |
+
|
| 672 |
+
if is_ring:
|
| 673 |
+
subhg_list = []
|
| 674 |
+
remove_edge_list = []
|
| 675 |
+
remove_node_list = []
|
| 676 |
+
for each_edge in hg.edges:
|
| 677 |
+
node_list = hg.nodes_in_edge(each_edge)
|
| 678 |
+
subhg = hg.get_subhg(node_list, [each_edge], hg.get_identical_node_dict())
|
| 679 |
+
subhg_list.append(subhg)
|
| 680 |
+
remove_edge_list.append(each_edge)
|
| 681 |
+
for each_node in node_list:
|
| 682 |
+
if not hg.node_attr(each_node)['is_in_ring']:
|
| 683 |
+
remove_node_list.append(each_node)
|
| 684 |
+
hg.remove_edges(remove_edge_list)
|
| 685 |
+
hg.remove_nodes(remove_node_list, False)
|
| 686 |
+
return subhg_list + [hg]
|
| 687 |
+
else:
|
| 688 |
+
return [hg]
|
| 689 |
+
|
| 690 |
+
org_hg = hg.copy()
|
| 691 |
+
clique_tree = CliqueTree(org_hg)
|
| 692 |
+
clique_tree.add_node(0, subhg=org_hg)
|
| 693 |
+
|
| 694 |
+
subhg_list = _divide_hg(deepcopy(clique_tree.root_hg))
|
| 695 |
+
#_subhg_list = deepcopy(subhg_list)
|
| 696 |
+
if len(subhg_list) == 1:
|
| 697 |
+
pass
|
| 698 |
+
else:
|
| 699 |
+
while len(subhg_list) > 1:
|
| 700 |
+
max_leaf_subhg = None
|
| 701 |
+
for each_subhg in subhg_list:
|
| 702 |
+
if _is_leaf(clique_tree.root_hg, each_subhg) and not _is_ring(each_subhg):
|
| 703 |
+
if max_leaf_subhg is None:
|
| 704 |
+
max_leaf_subhg = each_subhg
|
| 705 |
+
elif max_leaf_subhg.num_nodes < each_subhg.num_nodes:
|
| 706 |
+
max_leaf_subhg = each_subhg
|
| 707 |
+
|
| 708 |
+
if max_leaf_subhg is None:
|
| 709 |
+
for each_subhg in subhg_list:
|
| 710 |
+
if _is_ring_label(clique_tree.root_hg, each_subhg):
|
| 711 |
+
if max_leaf_subhg is None:
|
| 712 |
+
max_leaf_subhg = each_subhg
|
| 713 |
+
elif max_leaf_subhg.num_nodes < each_subhg.num_nodes:
|
| 714 |
+
max_leaf_subhg = each_subhg
|
| 715 |
+
if max_leaf_subhg is not None:
|
| 716 |
+
clique_tree.update(max_leaf_subhg)
|
| 717 |
+
subhg_list.remove(max_leaf_subhg)
|
| 718 |
+
else:
|
| 719 |
+
for each_subhg in subhg_list:
|
| 720 |
+
if _is_leaf(clique_tree.root_hg, each_subhg):
|
| 721 |
+
if max_leaf_subhg is None:
|
| 722 |
+
max_leaf_subhg = each_subhg
|
| 723 |
+
elif max_leaf_subhg.num_nodes < each_subhg.num_nodes:
|
| 724 |
+
max_leaf_subhg = each_subhg
|
| 725 |
+
if max_leaf_subhg is not None:
|
| 726 |
+
clique_tree.update(max_leaf_subhg, True)
|
| 727 |
+
subhg_list.remove(max_leaf_subhg)
|
| 728 |
+
else:
|
| 729 |
+
break
|
| 730 |
+
if len(subhg_list) > 1:
|
| 731 |
+
'''
|
| 732 |
+
for each_idx, each_subhg in enumerate(subhg_list):
|
| 733 |
+
each_subhg.draw(f'{each_idx}', True)
|
| 734 |
+
clique_tree.root_hg.draw('root', True)
|
| 735 |
+
import pickle
|
| 736 |
+
with open('buggy_hg.pkl', 'wb') as f:
|
| 737 |
+
pickle.dump(hg, f)
|
| 738 |
+
return clique_tree, subhg_list, _subhg_list
|
| 739 |
+
'''
|
| 740 |
+
raise RuntimeError('bug in tree decomposition algorithm')
|
| 741 |
+
clique_tree.root_hg.remove_edges_with_attr({'tmp' : True})
|
| 742 |
+
|
| 743 |
+
'''
|
| 744 |
+
for each_tree_node in clique_tree.adj[0]:
|
| 745 |
+
subhg = clique_tree.nodes[each_tree_node]['subhg']
|
| 746 |
+
for each_edge in subhg.edges:
|
| 747 |
+
if set(subhg.nodes_in_edge(each_edge)).issubset(clique_tree.root_hg.nodes):
|
| 748 |
+
clique_tree.root_hg.add_edge(set(subhg.nodes_in_edge(each_edge)), attr_dict=dict(tmp=True))
|
| 749 |
+
'''
|
| 750 |
+
if irredundant:
|
| 751 |
+
clique_tree.to_irredundant()
|
| 752 |
+
return clique_tree #, _subhg_list
|
| 753 |
+
|
| 754 |
+
def _is_leaf(hg, subhg) -> bool:
|
| 755 |
+
''' judge whether subhg is a leaf-like in the original hypergraph
|
| 756 |
+
|
| 757 |
+
Parameters
|
| 758 |
+
----------
|
| 759 |
+
hg : Hypergraph
|
| 760 |
+
subhg : Hypergraph
|
| 761 |
+
`subhg` is a subhypergraph of `hg`
|
| 762 |
+
|
| 763 |
+
Returns
|
| 764 |
+
-------
|
| 765 |
+
bool
|
| 766 |
+
'''
|
| 767 |
+
if len(subhg.edges) == 0:
|
| 768 |
+
adj_edge_set = set([])
|
| 769 |
+
subhg_edge_set = set([])
|
| 770 |
+
for each_edge in hg.edges:
|
| 771 |
+
if set(hg.nodes_in_edge(each_edge)).issubset(subhg.nodes) and hg.edge_attr(each_edge).get('tmp', False):
|
| 772 |
+
subhg_edge_set.add(each_edge)
|
| 773 |
+
for each_node in subhg.nodes:
|
| 774 |
+
adj_edge_set.update(set(hg.adj_edges(each_node)))
|
| 775 |
+
if subhg_edge_set.issubset(adj_edge_set) and len(adj_edge_set.difference(subhg_edge_set)) == 1:
|
| 776 |
+
return True
|
| 777 |
+
else:
|
| 778 |
+
return False
|
| 779 |
+
elif len(subhg.edges) == 1:
|
| 780 |
+
adj_edge_set = set([])
|
| 781 |
+
subhg_edge_set = subhg.edges
|
| 782 |
+
for each_node in subhg.nodes:
|
| 783 |
+
for each_adj_edge in hg.adj_edges(each_node):
|
| 784 |
+
adj_edge_set.add(each_adj_edge)
|
| 785 |
+
if subhg_edge_set.issubset(adj_edge_set) and len(adj_edge_set.difference(subhg_edge_set)) == 1:
|
| 786 |
+
return True
|
| 787 |
+
else:
|
| 788 |
+
return False
|
| 789 |
+
else:
|
| 790 |
+
raise ValueError('subhg should be nodes only or one-edge hypergraph.')
|
| 791 |
+
|
| 792 |
+
def _is_ring_label(hg, subhg):
|
| 793 |
+
if len(subhg.edges) != 1:
|
| 794 |
+
return False
|
| 795 |
+
edge_name = list(subhg.edges)[0]
|
| 796 |
+
#assert edge_name in hg.edges, f'{edge_name}'
|
| 797 |
+
is_in_ring = False
|
| 798 |
+
for each_node in subhg.nodes:
|
| 799 |
+
if subhg.node_attr(each_node)['is_in_ring']:
|
| 800 |
+
is_in_ring = True
|
| 801 |
+
else:
|
| 802 |
+
adj_edge_list = list(hg.adj_edges(each_node))
|
| 803 |
+
adj_edge_list.remove(edge_name)
|
| 804 |
+
if len(adj_edge_list) == 1:
|
| 805 |
+
if not hg.edge_attr(adj_edge_list[0]).get('tmp', False):
|
| 806 |
+
return False
|
| 807 |
+
elif len(adj_edge_list) == 0:
|
| 808 |
+
pass
|
| 809 |
+
else:
|
| 810 |
+
raise ValueError
|
| 811 |
+
if is_in_ring:
|
| 812 |
+
return True
|
| 813 |
+
else:
|
| 814 |
+
return False
|
| 815 |
+
|
| 816 |
+
def _is_ring(hg):
|
| 817 |
+
for each_node in hg.nodes:
|
| 818 |
+
if not hg.node_attr(each_node)['is_in_ring']:
|
| 819 |
+
return False
|
| 820 |
+
return True
|
| 821 |
+
|
graph_grammar/graph_grammar/__init__.py
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# -*- coding: utf-8 -*-
|
| 3 |
+
# Rhizome
|
| 4 |
+
# Version beta 0.0, August 2023
|
| 5 |
+
# Property of IBM Research, Accelerated Discovery
|
| 6 |
+
#
|
| 7 |
+
|
| 8 |
+
"""
|
| 9 |
+
PLEASE NOTE THIS IMPLEMENTATION INCLUDES THE ORIGINAL SOURCE CODE (AND SOME ADAPTATIONS)
|
| 10 |
+
OF THE MHG IMPLEMENTATION OF HIROSHI KAJINO AT IBM TRL ALREADY PUBLICLY AVAILABLE.
|
| 11 |
+
THIS MIGHT INFLUENCE THE DECISION OF THE FINAL LICENSE SO CAREFUL CHECK NEEDS BE DONE.
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
""" Title """
|
| 15 |
+
|
| 16 |
+
__author__ = "Hiroshi Kajino <KAJINO@jp.ibm.com>"
|
| 17 |
+
__copyright__ = "(c) Copyright IBM Corp. 2018"
|
| 18 |
+
__version__ = "0.1"
|
| 19 |
+
__date__ = "Jan 1 2018"
|
| 20 |
+
|
graph_grammar/graph_grammar/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (680 Bytes). View file
|
|
|
graph_grammar/graph_grammar/__pycache__/base.cpython-310.pyc
ADDED
|
Binary file (1.17 kB). View file
|
|
|
graph_grammar/graph_grammar/__pycache__/corpus.cpython-310.pyc
ADDED
|
Binary file (4.71 kB). View file
|
|
|
graph_grammar/graph_grammar/__pycache__/hrg.cpython-310.pyc
ADDED
|
Binary file (29.1 kB). View file
|
|
|
graph_grammar/graph_grammar/__pycache__/symbols.cpython-310.pyc
ADDED
|
Binary file (5.38 kB). View file
|
|
|
graph_grammar/graph_grammar/__pycache__/utils.cpython-310.pyc
ADDED
|
Binary file (3.63 kB). View file
|
|
|
graph_grammar/graph_grammar/base.py
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# -*- coding: utf-8 -*-
|
| 3 |
+
# Rhizome
|
| 4 |
+
# Version beta 0.0, August 2023
|
| 5 |
+
# Property of IBM Research, Accelerated Discovery
|
| 6 |
+
#
|
| 7 |
+
|
| 8 |
+
"""
|
| 9 |
+
PLEASE NOTE THIS IMPLEMENTATION INCLUDES THE ORIGINAL SOURCE CODE (AND SOME ADAPTATIONS)
|
| 10 |
+
OF THE MHG IMPLEMENTATION OF HIROSHI KAJINO AT IBM TRL ALREADY PUBLICLY AVAILABLE.
|
| 11 |
+
THIS MIGHT INFLUENCE THE DECISION OF THE FINAL LICENSE SO CAREFUL CHECK NEEDS BE DONE.
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
""" Title """
|
| 15 |
+
|
| 16 |
+
__author__ = "Hiroshi Kajino <KAJINO@jp.ibm.com>"
|
| 17 |
+
__copyright__ = "(c) Copyright IBM Corp. 2017"
|
| 18 |
+
__version__ = "0.1"
|
| 19 |
+
__date__ = "Dec 11 2017"
|
| 20 |
+
|
| 21 |
+
from abc import ABCMeta, abstractmethod
|
| 22 |
+
|
| 23 |
+
class GraphGrammarBase(metaclass=ABCMeta):
|
| 24 |
+
@abstractmethod
|
| 25 |
+
def learn(self):
|
| 26 |
+
pass
|
| 27 |
+
|
| 28 |
+
@abstractmethod
|
| 29 |
+
def sample(self):
|
| 30 |
+
pass
|
graph_grammar/graph_grammar/corpus.py
ADDED
|
@@ -0,0 +1,152 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# -*- coding: utf-8 -*-
|
| 3 |
+
# Rhizome
|
| 4 |
+
# Version beta 0.0, August 2023
|
| 5 |
+
# Property of IBM Research, Accelerated Discovery
|
| 6 |
+
#
|
| 7 |
+
|
| 8 |
+
"""
|
| 9 |
+
PLEASE NOTE THIS IMPLEMENTATION INCLUDES THE ORIGINAL SOURCE CODE (AND SOME ADAPTATIONS)
|
| 10 |
+
OF THE MHG IMPLEMENTATION OF HIROSHI KAJINO AT IBM TRL ALREADY PUBLICLY AVAILABLE.
|
| 11 |
+
THIS MIGHT INFLUENCE THE DECISION OF THE FINAL LICENSE SO CAREFUL CHECK NEEDS BE DONE.
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
""" Title """
|
| 15 |
+
|
| 16 |
+
__author__ = "Hiroshi Kajino <KAJINO@jp.ibm.com>"
|
| 17 |
+
__copyright__ = "(c) Copyright IBM Corp. 2018"
|
| 18 |
+
__version__ = "0.1"
|
| 19 |
+
__date__ = "Jun 4 2018"
|
| 20 |
+
|
| 21 |
+
from collections import Counter
|
| 22 |
+
from functools import partial
|
| 23 |
+
from .utils import _easy_node_match, _edge_match, _node_match, common_node_list, _node_match_prod_rule
|
| 24 |
+
from networkx.algorithms.isomorphism import GraphMatcher
|
| 25 |
+
import os
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class CliqueTreeCorpus(object):
|
| 29 |
+
|
| 30 |
+
''' clique tree corpus
|
| 31 |
+
|
| 32 |
+
Attributes
|
| 33 |
+
----------
|
| 34 |
+
clique_tree_list : list of CliqueTree
|
| 35 |
+
subhg_list : list of Hypergraph
|
| 36 |
+
'''
|
| 37 |
+
|
| 38 |
+
def __init__(self):
|
| 39 |
+
self.clique_tree_list = []
|
| 40 |
+
self.subhg_list = []
|
| 41 |
+
|
| 42 |
+
@property
|
| 43 |
+
def size(self):
|
| 44 |
+
return len(self.subhg_list)
|
| 45 |
+
|
| 46 |
+
def add_clique_tree(self, clique_tree):
|
| 47 |
+
for each_node in clique_tree.nodes:
|
| 48 |
+
subhg = clique_tree.nodes[each_node]['subhg']
|
| 49 |
+
subhg_idx = self.add_subhg(subhg)
|
| 50 |
+
clique_tree.nodes[each_node]['subhg_idx'] = subhg_idx
|
| 51 |
+
self.clique_tree_list.append(clique_tree)
|
| 52 |
+
|
| 53 |
+
def add_to_subhg_list(self, clique_tree, root_node):
|
| 54 |
+
parent_node_dict = {}
|
| 55 |
+
current_node = None
|
| 56 |
+
parent_node_dict[root_node] = None
|
| 57 |
+
stack = [root_node]
|
| 58 |
+
while stack:
|
| 59 |
+
current_node = stack.pop()
|
| 60 |
+
current_subhg = clique_tree.nodes[current_node]['subhg']
|
| 61 |
+
for each_child in clique_tree.adj[current_node]:
|
| 62 |
+
if each_child != parent_node_dict[current_node]:
|
| 63 |
+
stack.append(each_child)
|
| 64 |
+
parent_node_dict[each_child] = current_node
|
| 65 |
+
if parent_node_dict[current_node] is not None:
|
| 66 |
+
parent_subhg = clique_tree.nodes[parent_node_dict[current_node]]['subhg']
|
| 67 |
+
common, _ = common_node_list(parent_subhg, current_subhg)
|
| 68 |
+
parent_subhg.add_edge(set(common), attr_dict={'tmp': True})
|
| 69 |
+
|
| 70 |
+
parent_node_dict = {}
|
| 71 |
+
current_node = None
|
| 72 |
+
parent_node_dict[root_node] = None
|
| 73 |
+
stack = [root_node]
|
| 74 |
+
while stack:
|
| 75 |
+
current_node = stack.pop()
|
| 76 |
+
current_subhg = clique_tree.nodes[current_node]['subhg']
|
| 77 |
+
for each_child in clique_tree.adj[current_node]:
|
| 78 |
+
if each_child != parent_node_dict[current_node]:
|
| 79 |
+
stack.append(each_child)
|
| 80 |
+
parent_node_dict[each_child] = current_node
|
| 81 |
+
if parent_node_dict[current_node] is not None:
|
| 82 |
+
parent_subhg = clique_tree.nodes[parent_node_dict[current_node]]['subhg']
|
| 83 |
+
common, _ = common_node_list(parent_subhg, current_subhg)
|
| 84 |
+
for each_idx, each_node in enumerate(common):
|
| 85 |
+
current_subhg.set_node_attr(each_node, {'ext_id': each_idx})
|
| 86 |
+
|
| 87 |
+
subhg_idx, is_new = self.add_subhg(current_subhg)
|
| 88 |
+
clique_tree.nodes[current_node]['subhg_idx'] = subhg_idx
|
| 89 |
+
return clique_tree
|
| 90 |
+
|
| 91 |
+
def add_subhg(self, subhg):
|
| 92 |
+
if len(self.subhg_list) == 0:
|
| 93 |
+
node_dict = {}
|
| 94 |
+
for each_node in subhg.nodes:
|
| 95 |
+
node_dict[each_node] = subhg.node_attr(each_node)['symbol'].__hash__()
|
| 96 |
+
node_list = []
|
| 97 |
+
for each_key, _ in sorted(node_dict.items(), key=lambda x:x[1]):
|
| 98 |
+
node_list.append(each_key)
|
| 99 |
+
for each_idx, each_node in enumerate(node_list):
|
| 100 |
+
subhg.node_attr(each_node)['order4hrg'] = each_idx
|
| 101 |
+
self.subhg_list.append(subhg)
|
| 102 |
+
return 0, True
|
| 103 |
+
else:
|
| 104 |
+
match = False
|
| 105 |
+
subhg_bond_symbol_counter \
|
| 106 |
+
= Counter([subhg.node_attr(each_node)['symbol'] \
|
| 107 |
+
for each_node in subhg.nodes])
|
| 108 |
+
subhg_atom_symbol_counter \
|
| 109 |
+
= Counter([subhg.edge_attr(each_edge).get('symbol', None) \
|
| 110 |
+
for each_edge in subhg.edges])
|
| 111 |
+
for each_idx, each_subhg in enumerate(self.subhg_list):
|
| 112 |
+
each_bond_symbol_counter \
|
| 113 |
+
= Counter([each_subhg.node_attr(each_node)['symbol'] \
|
| 114 |
+
for each_node in each_subhg.nodes])
|
| 115 |
+
each_atom_symbol_counter \
|
| 116 |
+
= Counter([each_subhg.edge_attr(each_edge).get('symbol', None) \
|
| 117 |
+
for each_edge in each_subhg.edges])
|
| 118 |
+
if not match \
|
| 119 |
+
and (subhg.num_nodes == each_subhg.num_nodes
|
| 120 |
+
and subhg.num_edges == each_subhg.num_edges
|
| 121 |
+
and subhg_bond_symbol_counter == each_bond_symbol_counter
|
| 122 |
+
and subhg_atom_symbol_counter == each_atom_symbol_counter):
|
| 123 |
+
gm = GraphMatcher(each_subhg.hg,
|
| 124 |
+
subhg.hg,
|
| 125 |
+
node_match=_easy_node_match,
|
| 126 |
+
edge_match=_edge_match)
|
| 127 |
+
try:
|
| 128 |
+
isomap = next(gm.isomorphisms_iter())
|
| 129 |
+
match = True
|
| 130 |
+
for each_node in each_subhg.nodes:
|
| 131 |
+
subhg.node_attr(isomap[each_node])['order4hrg'] \
|
| 132 |
+
= each_subhg.node_attr(each_node)['order4hrg']
|
| 133 |
+
if 'ext_id' in each_subhg.node_attr(each_node):
|
| 134 |
+
subhg.node_attr(isomap[each_node])['ext_id'] \
|
| 135 |
+
= each_subhg.node_attr(each_node)['ext_id']
|
| 136 |
+
return each_idx, False
|
| 137 |
+
except StopIteration:
|
| 138 |
+
match = False
|
| 139 |
+
if not match:
|
| 140 |
+
node_dict = {}
|
| 141 |
+
for each_node in subhg.nodes:
|
| 142 |
+
node_dict[each_node] = subhg.node_attr(each_node)['symbol'].__hash__()
|
| 143 |
+
node_list = []
|
| 144 |
+
for each_key, _ in sorted(node_dict.items(), key=lambda x:x[1]):
|
| 145 |
+
node_list.append(each_key)
|
| 146 |
+
for each_idx, each_node in enumerate(node_list):
|
| 147 |
+
subhg.node_attr(each_node)['order4hrg'] = each_idx
|
| 148 |
+
|
| 149 |
+
#for each_idx, each_node in enumerate(subhg.nodes):
|
| 150 |
+
# subhg.node_attr(each_node)['order4hrg'] = each_idx
|
| 151 |
+
self.subhg_list.append(subhg)
|
| 152 |
+
return len(self.subhg_list) - 1, True
|
graph_grammar/graph_grammar/hrg.py
ADDED
|
@@ -0,0 +1,1065 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# -*- coding: utf-8 -*-
|
| 3 |
+
# Rhizome
|
| 4 |
+
# Version beta 0.0, August 2023
|
| 5 |
+
# Property of IBM Research, Accelerated Discovery
|
| 6 |
+
#
|
| 7 |
+
|
| 8 |
+
"""
|
| 9 |
+
PLEASE NOTE THIS IMPLEMENTATION INCLUDES THE ORIGINAL SOURCE CODE (AND SOME ADAPTATIONS)
|
| 10 |
+
OF THE MHG IMPLEMENTATION OF HIROSHI KAJINO AT IBM TRL ALREADY PUBLICLY AVAILABLE.
|
| 11 |
+
THIS MIGHT INFLUENCE THE DECISION OF THE FINAL LICENSE SO CAREFUL CHECK NEEDS BE DONE.
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
""" Title """
|
| 15 |
+
|
| 16 |
+
__author__ = "Hiroshi Kajino <KAJINO@jp.ibm.com>"
|
| 17 |
+
__copyright__ = "(c) Copyright IBM Corp. 2017"
|
| 18 |
+
__version__ = "0.1"
|
| 19 |
+
__date__ = "Dec 11 2017"
|
| 20 |
+
|
| 21 |
+
from .corpus import CliqueTreeCorpus
|
| 22 |
+
from .base import GraphGrammarBase
|
| 23 |
+
from .symbols import TSymbol, NTSymbol, BondSymbol
|
| 24 |
+
from .utils import _node_match, _node_match_prod_rule, _edge_match, masked_softmax, common_node_list
|
| 25 |
+
from ..hypergraph import Hypergraph
|
| 26 |
+
from collections import Counter
|
| 27 |
+
from copy import deepcopy
|
| 28 |
+
from ..algo.tree_decomposition import (
|
| 29 |
+
tree_decomposition,
|
| 30 |
+
tree_decomposition_with_hrg,
|
| 31 |
+
tree_decomposition_from_leaf,
|
| 32 |
+
topological_tree_decomposition,
|
| 33 |
+
molecular_tree_decomposition)
|
| 34 |
+
from functools import partial
|
| 35 |
+
from networkx.algorithms.isomorphism import GraphMatcher
|
| 36 |
+
from typing import List, Dict, Tuple
|
| 37 |
+
import networkx as nx
|
| 38 |
+
import numpy as np
|
| 39 |
+
import torch
|
| 40 |
+
import os
|
| 41 |
+
import random
|
| 42 |
+
|
| 43 |
+
DEBUG = False
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
class ProductionRule(object):
|
| 47 |
+
""" A class of a production rule
|
| 48 |
+
|
| 49 |
+
Attributes
|
| 50 |
+
----------
|
| 51 |
+
lhs : Hypergraph or None
|
| 52 |
+
the left hand side of the production rule.
|
| 53 |
+
if None, the rule is a starting rule.
|
| 54 |
+
rhs : Hypergraph
|
| 55 |
+
the right hand side of the production rule.
|
| 56 |
+
"""
|
| 57 |
+
def __init__(self, lhs, rhs):
|
| 58 |
+
self.lhs = lhs
|
| 59 |
+
self.rhs = rhs
|
| 60 |
+
|
| 61 |
+
@property
|
| 62 |
+
def is_start_rule(self) -> bool:
|
| 63 |
+
return self.lhs.num_nodes == 0
|
| 64 |
+
|
| 65 |
+
@property
|
| 66 |
+
def ext_node(self) -> Dict[int, str]:
|
| 67 |
+
""" return a dict of external nodes
|
| 68 |
+
"""
|
| 69 |
+
if self.is_start_rule:
|
| 70 |
+
return {}
|
| 71 |
+
else:
|
| 72 |
+
ext_node_dict = {}
|
| 73 |
+
for each_node in self.lhs.nodes:
|
| 74 |
+
ext_node_dict[self.lhs.node_attr(each_node)["ext_id"]] = each_node
|
| 75 |
+
return ext_node_dict
|
| 76 |
+
|
| 77 |
+
@property
|
| 78 |
+
def lhs_nt_symbol(self) -> NTSymbol:
|
| 79 |
+
if self.is_start_rule:
|
| 80 |
+
return NTSymbol(degree=0, is_aromatic=False, bond_symbol_list=[])
|
| 81 |
+
else:
|
| 82 |
+
return self.lhs.edge_attr(list(self.lhs.edges)[0])['symbol']
|
| 83 |
+
|
| 84 |
+
def rhs_adj_mat(self, node_edge_list):
|
| 85 |
+
''' return the adjacency matrix of rhs of the production rule
|
| 86 |
+
'''
|
| 87 |
+
return nx.adjacency_matrix(self.rhs.hg, node_edge_list)
|
| 88 |
+
|
| 89 |
+
def draw(self, file_path=None):
|
| 90 |
+
return self.rhs.draw(file_path)
|
| 91 |
+
|
| 92 |
+
def is_same(self, prod_rule, ignore_order=False):
|
| 93 |
+
""" judge whether this production rule is
|
| 94 |
+
the same as the input one, `prod_rule`
|
| 95 |
+
|
| 96 |
+
Parameters
|
| 97 |
+
----------
|
| 98 |
+
prod_rule : ProductionRule
|
| 99 |
+
production rule to be compared
|
| 100 |
+
|
| 101 |
+
Returns
|
| 102 |
+
-------
|
| 103 |
+
is_same : bool
|
| 104 |
+
isomap : dict
|
| 105 |
+
isomorphism of nodes and hyperedges.
|
| 106 |
+
ex) {'bond_42': 'bond_37', 'bond_2': 'bond_1',
|
| 107 |
+
'e36': 'e11', 'e16': 'e12', 'e25': 'e18',
|
| 108 |
+
'bond_40': 'bond_38', 'e26': 'e21', 'bond_41': 'bond_39'}.
|
| 109 |
+
key comes from `prod_rule`, value comes from `self`.
|
| 110 |
+
"""
|
| 111 |
+
if self.is_start_rule:
|
| 112 |
+
if not prod_rule.is_start_rule:
|
| 113 |
+
return False, {}
|
| 114 |
+
else:
|
| 115 |
+
if prod_rule.is_start_rule:
|
| 116 |
+
return False, {}
|
| 117 |
+
else:
|
| 118 |
+
if prod_rule.lhs.num_nodes != self.lhs.num_nodes:
|
| 119 |
+
return False, {}
|
| 120 |
+
|
| 121 |
+
if prod_rule.rhs.num_nodes != self.rhs.num_nodes:
|
| 122 |
+
return False, {}
|
| 123 |
+
if prod_rule.rhs.num_edges != self.rhs.num_edges:
|
| 124 |
+
return False, {}
|
| 125 |
+
|
| 126 |
+
subhg_bond_symbol_counter \
|
| 127 |
+
= Counter([prod_rule.rhs.node_attr(each_node)['symbol'] \
|
| 128 |
+
for each_node in prod_rule.rhs.nodes])
|
| 129 |
+
each_bond_symbol_counter \
|
| 130 |
+
= Counter([self.rhs.node_attr(each_node)['symbol'] \
|
| 131 |
+
for each_node in self.rhs.nodes])
|
| 132 |
+
if subhg_bond_symbol_counter != each_bond_symbol_counter:
|
| 133 |
+
return False, {}
|
| 134 |
+
|
| 135 |
+
subhg_atom_symbol_counter \
|
| 136 |
+
= Counter([prod_rule.rhs.edge_attr(each_edge)['symbol'] \
|
| 137 |
+
for each_edge in prod_rule.rhs.edges])
|
| 138 |
+
each_atom_symbol_counter \
|
| 139 |
+
= Counter([self.rhs.edge_attr(each_edge)['symbol'] \
|
| 140 |
+
for each_edge in self.rhs.edges])
|
| 141 |
+
if subhg_atom_symbol_counter != each_atom_symbol_counter:
|
| 142 |
+
return False, {}
|
| 143 |
+
|
| 144 |
+
gm = GraphMatcher(prod_rule.rhs.hg,
|
| 145 |
+
self.rhs.hg,
|
| 146 |
+
partial(_node_match_prod_rule,
|
| 147 |
+
ignore_order=ignore_order),
|
| 148 |
+
partial(_edge_match,
|
| 149 |
+
ignore_order=ignore_order))
|
| 150 |
+
try:
|
| 151 |
+
return True, next(gm.isomorphisms_iter())
|
| 152 |
+
except StopIteration:
|
| 153 |
+
return False, {}
|
| 154 |
+
|
| 155 |
+
def applied_to(self,
|
| 156 |
+
hg: Hypergraph,
|
| 157 |
+
edge: str) -> Tuple[Hypergraph, List[str]]:
|
| 158 |
+
""" augment `hg` by replacing `edge` with `self.rhs`.
|
| 159 |
+
|
| 160 |
+
Parameters
|
| 161 |
+
----------
|
| 162 |
+
hg : Hypergraph
|
| 163 |
+
edge : str
|
| 164 |
+
`edge` must belong to `hg`
|
| 165 |
+
|
| 166 |
+
Returns
|
| 167 |
+
-------
|
| 168 |
+
hg : Hypergraph
|
| 169 |
+
resultant hypergraph
|
| 170 |
+
nt_edge_list : list
|
| 171 |
+
list of non-terminal edges
|
| 172 |
+
"""
|
| 173 |
+
nt_edge_dict = {}
|
| 174 |
+
if self.is_start_rule:
|
| 175 |
+
if (edge is not None) or (hg is not None):
|
| 176 |
+
ValueError("edge and hg must be None for this prod rule.")
|
| 177 |
+
hg = Hypergraph()
|
| 178 |
+
node_map_rhs = {} # node id in rhs -> node id in hg, where rhs is augmented.
|
| 179 |
+
for num_idx, each_node in enumerate(self.rhs.nodes):
|
| 180 |
+
hg.add_node(f"bond_{num_idx}",
|
| 181 |
+
#attr_dict=deepcopy(self.rhs.node_attr(each_node)))
|
| 182 |
+
attr_dict=self.rhs.node_attr(each_node))
|
| 183 |
+
node_map_rhs[each_node] = f"bond_{num_idx}"
|
| 184 |
+
for each_edge in self.rhs.edges:
|
| 185 |
+
node_list = []
|
| 186 |
+
for each_node in self.rhs.nodes_in_edge(each_edge):
|
| 187 |
+
node_list.append(node_map_rhs[each_node])
|
| 188 |
+
if isinstance(self.rhs.nodes_in_edge(each_edge), set):
|
| 189 |
+
node_list = set(node_list)
|
| 190 |
+
edge_id = hg.add_edge(
|
| 191 |
+
node_list,
|
| 192 |
+
#attr_dict=deepcopy(self.rhs.edge_attr(each_edge)))
|
| 193 |
+
attr_dict=self.rhs.edge_attr(each_edge))
|
| 194 |
+
if "nt_idx" in hg.edge_attr(edge_id):
|
| 195 |
+
nt_edge_dict[hg.edge_attr(edge_id)["nt_idx"]] = edge_id
|
| 196 |
+
nt_edge_list = [nt_edge_dict[key] for key in range(len(nt_edge_dict))]
|
| 197 |
+
return hg, nt_edge_list
|
| 198 |
+
else:
|
| 199 |
+
if edge not in hg.edges:
|
| 200 |
+
raise ValueError("the input hyperedge does not exist.")
|
| 201 |
+
if hg.edge_attr(edge)["terminal"]:
|
| 202 |
+
raise ValueError("the input hyperedge is terminal.")
|
| 203 |
+
if hg.edge_attr(edge)['symbol'] != self.lhs_nt_symbol:
|
| 204 |
+
print(hg.edge_attr(edge)['symbol'], self.lhs_nt_symbol)
|
| 205 |
+
raise ValueError("the input hyperedge and lhs have inconsistent number of nodes.")
|
| 206 |
+
if DEBUG:
|
| 207 |
+
for node_idx, each_node in enumerate(hg.nodes_in_edge(edge)):
|
| 208 |
+
other_node = self.lhs.nodes_in_edge(list(self.lhs.edges)[0])[node_idx]
|
| 209 |
+
attr = deepcopy(self.lhs.node_attr(other_node))
|
| 210 |
+
attr.pop('ext_id')
|
| 211 |
+
if hg.node_attr(each_node) != attr:
|
| 212 |
+
raise ValueError('node attributes are inconsistent.')
|
| 213 |
+
|
| 214 |
+
# order of nodes that belong to the non-terminal edge in hg
|
| 215 |
+
nt_order_dict = {} # hg_node -> order ("bond_17" : 1)
|
| 216 |
+
nt_order_dict_inv = {} # order -> hg_node
|
| 217 |
+
for each_idx, each_node in enumerate(hg.nodes_in_edge(edge)):
|
| 218 |
+
nt_order_dict[each_node] = each_idx
|
| 219 |
+
nt_order_dict_inv[each_idx] = each_node
|
| 220 |
+
|
| 221 |
+
# construct a node_map_rhs: rhs -> new hg
|
| 222 |
+
node_map_rhs = {} # node id in rhs -> node id in hg, where rhs is augmented.
|
| 223 |
+
node_idx = hg.num_nodes
|
| 224 |
+
for each_node in self.rhs.nodes:
|
| 225 |
+
if "ext_id" in self.rhs.node_attr(each_node):
|
| 226 |
+
node_map_rhs[each_node] \
|
| 227 |
+
= nt_order_dict_inv[
|
| 228 |
+
self.rhs.node_attr(each_node)["ext_id"]]
|
| 229 |
+
else:
|
| 230 |
+
node_map_rhs[each_node] = f"bond_{node_idx}"
|
| 231 |
+
node_idx += 1
|
| 232 |
+
|
| 233 |
+
# delete non-terminal
|
| 234 |
+
hg.remove_edge(edge)
|
| 235 |
+
|
| 236 |
+
# add nodes to hg
|
| 237 |
+
for each_node in self.rhs.nodes:
|
| 238 |
+
hg.add_node(node_map_rhs[each_node],
|
| 239 |
+
attr_dict=self.rhs.node_attr(each_node))
|
| 240 |
+
|
| 241 |
+
# add hyperedges to hg
|
| 242 |
+
for each_edge in self.rhs.edges:
|
| 243 |
+
node_list_hg = []
|
| 244 |
+
for each_node in self.rhs.nodes_in_edge(each_edge):
|
| 245 |
+
node_list_hg.append(node_map_rhs[each_node])
|
| 246 |
+
edge_id = hg.add_edge(
|
| 247 |
+
node_list_hg,
|
| 248 |
+
attr_dict=self.rhs.edge_attr(each_edge))#deepcopy(self.rhs.edge_attr(each_edge)))
|
| 249 |
+
if "nt_idx" in hg.edge_attr(edge_id):
|
| 250 |
+
nt_edge_dict[hg.edge_attr(edge_id)["nt_idx"]] = edge_id
|
| 251 |
+
nt_edge_list = [nt_edge_dict[key] for key in range(len(nt_edge_dict))]
|
| 252 |
+
return hg, nt_edge_list
|
| 253 |
+
|
| 254 |
+
def revert(self, hg: Hypergraph, return_subhg=False):
|
| 255 |
+
''' revert applying this production rule.
|
| 256 |
+
i.e., if there exists a subhypergraph that matches the r.h.s. of this production rule,
|
| 257 |
+
this method replaces the subhypergraph with a non-terminal hyperedge.
|
| 258 |
+
|
| 259 |
+
Parameters
|
| 260 |
+
----------
|
| 261 |
+
hg : Hypergraph
|
| 262 |
+
hypergraph to be reverted
|
| 263 |
+
return_subhg : bool
|
| 264 |
+
if True, the removed subhypergraph will be returned.
|
| 265 |
+
|
| 266 |
+
Returns
|
| 267 |
+
-------
|
| 268 |
+
hg : Hypergraph
|
| 269 |
+
the resultant hypergraph. if it cannot be reverted, the original one is returned without any replacement.
|
| 270 |
+
success : bool
|
| 271 |
+
this indicates whether reverting is successed or not.
|
| 272 |
+
'''
|
| 273 |
+
gm = GraphMatcher(hg.hg, self.rhs.hg, node_match=_node_match_prod_rule,
|
| 274 |
+
edge_match=_edge_match)
|
| 275 |
+
try:
|
| 276 |
+
# in case when the matched subhg is connected to the other part via external nodes and more.
|
| 277 |
+
not_iso = True
|
| 278 |
+
while not_iso:
|
| 279 |
+
isomap = next(gm.subgraph_isomorphisms_iter())
|
| 280 |
+
adj_node_set = set([]) # reachable nodes from the internal nodes
|
| 281 |
+
subhg_node_set = set(isomap.keys()) # nodes in subhg
|
| 282 |
+
for each_node in subhg_node_set:
|
| 283 |
+
adj_node_set.add(each_node)
|
| 284 |
+
if isomap[each_node] not in self.ext_node.values():
|
| 285 |
+
adj_node_set.update(hg.hg.adj[each_node])
|
| 286 |
+
if adj_node_set == subhg_node_set:
|
| 287 |
+
not_iso = False
|
| 288 |
+
else:
|
| 289 |
+
if return_subhg:
|
| 290 |
+
return hg, False, Hypergraph()
|
| 291 |
+
else:
|
| 292 |
+
return hg, False
|
| 293 |
+
inv_isomap = {v: k for k, v in isomap.items()}
|
| 294 |
+
'''
|
| 295 |
+
isomap = {'e35': 'e8', 'bond_13': 'bond_18', 'bond_14': 'bond_19',
|
| 296 |
+
'bond_15': 'bond_17', 'e29': 'e23', 'bond_12': 'bond_20'}
|
| 297 |
+
where keys come from `hg` and values come from `self.rhs`
|
| 298 |
+
'''
|
| 299 |
+
except StopIteration:
|
| 300 |
+
if return_subhg:
|
| 301 |
+
return hg, False, Hypergraph()
|
| 302 |
+
else:
|
| 303 |
+
return hg, False
|
| 304 |
+
|
| 305 |
+
if return_subhg:
|
| 306 |
+
subhg = Hypergraph()
|
| 307 |
+
for each_node in hg.nodes:
|
| 308 |
+
if each_node in isomap:
|
| 309 |
+
subhg.add_node(each_node, attr_dict=hg.node_attr(each_node))
|
| 310 |
+
for each_edge in hg.edges:
|
| 311 |
+
if each_edge in isomap:
|
| 312 |
+
subhg.add_edge(hg.nodes_in_edge(each_edge),
|
| 313 |
+
attr_dict=hg.edge_attr(each_edge),
|
| 314 |
+
edge_name=each_edge)
|
| 315 |
+
subhg.edge_idx = hg.edge_idx
|
| 316 |
+
|
| 317 |
+
# remove subhg except for the externael nodes
|
| 318 |
+
for each_key, each_val in isomap.items():
|
| 319 |
+
if each_key.startswith('e'):
|
| 320 |
+
hg.remove_edge(each_key)
|
| 321 |
+
for each_key, each_val in isomap.items():
|
| 322 |
+
if each_key.startswith('bond_'):
|
| 323 |
+
if each_val not in self.ext_node.values():
|
| 324 |
+
hg.remove_node(each_key)
|
| 325 |
+
|
| 326 |
+
# add non-terminal hyperedge
|
| 327 |
+
nt_node_list = []
|
| 328 |
+
for each_ext_id in self.ext_node.keys():
|
| 329 |
+
nt_node_list.append(inv_isomap[self.ext_node[each_ext_id]])
|
| 330 |
+
|
| 331 |
+
hg.add_edge(nt_node_list,
|
| 332 |
+
attr_dict=dict(
|
| 333 |
+
terminal=False,
|
| 334 |
+
symbol=self.lhs_nt_symbol))
|
| 335 |
+
if return_subhg:
|
| 336 |
+
return hg, True, subhg
|
| 337 |
+
else:
|
| 338 |
+
return hg, True
|
| 339 |
+
|
| 340 |
+
|
| 341 |
+
class ProductionRuleCorpus(object):
|
| 342 |
+
|
| 343 |
+
'''
|
| 344 |
+
A corpus of production rules.
|
| 345 |
+
This class maintains
|
| 346 |
+
(i) list of unique production rules,
|
| 347 |
+
(ii) list of unique edge symbols (both terminal and non-terminal), and
|
| 348 |
+
(iii) list of unique node symbols.
|
| 349 |
+
|
| 350 |
+
Attributes
|
| 351 |
+
----------
|
| 352 |
+
prod_rule_list : list
|
| 353 |
+
list of unique production rules
|
| 354 |
+
edge_symbol_list : list
|
| 355 |
+
list of unique symbols (including both terminal and non-terminal)
|
| 356 |
+
node_symbol_list : list
|
| 357 |
+
list of node symbols
|
| 358 |
+
nt_symbol_list : list
|
| 359 |
+
list of unique lhs symbols
|
| 360 |
+
ext_id_list : list
|
| 361 |
+
list of ext_ids
|
| 362 |
+
lhs_in_prod_rule : array
|
| 363 |
+
a matrix of lhs vs prod_rule (= lhs_in_prod_rule)
|
| 364 |
+
'''
|
| 365 |
+
|
| 366 |
+
def __init__(self):
|
| 367 |
+
self.prod_rule_list = []
|
| 368 |
+
self.edge_symbol_list = []
|
| 369 |
+
self.edge_symbol_dict = {}
|
| 370 |
+
self.node_symbol_list = []
|
| 371 |
+
self.node_symbol_dict = {}
|
| 372 |
+
self.nt_symbol_list = []
|
| 373 |
+
self.ext_id_list = []
|
| 374 |
+
self._lhs_in_prod_rule = None
|
| 375 |
+
self.lhs_in_prod_rule_row_list = []
|
| 376 |
+
self.lhs_in_prod_rule_col_list = []
|
| 377 |
+
|
| 378 |
+
@property
|
| 379 |
+
def lhs_in_prod_rule(self):
|
| 380 |
+
if self._lhs_in_prod_rule is None:
|
| 381 |
+
self._lhs_in_prod_rule = torch.sparse.FloatTensor(
|
| 382 |
+
torch.LongTensor(list(zip(self.lhs_in_prod_rule_row_list, self.lhs_in_prod_rule_col_list))).t(),
|
| 383 |
+
torch.FloatTensor([1.0]*len(self.lhs_in_prod_rule_col_list)),
|
| 384 |
+
torch.Size([len(self.nt_symbol_list), len(self.prod_rule_list)])
|
| 385 |
+
).to_dense()
|
| 386 |
+
return self._lhs_in_prod_rule
|
| 387 |
+
|
| 388 |
+
@property
|
| 389 |
+
def num_prod_rule(self):
|
| 390 |
+
''' return the number of production rules
|
| 391 |
+
|
| 392 |
+
Returns
|
| 393 |
+
-------
|
| 394 |
+
int : the number of unique production rules
|
| 395 |
+
'''
|
| 396 |
+
return len(self.prod_rule_list)
|
| 397 |
+
|
| 398 |
+
@property
|
| 399 |
+
def start_rule_list(self):
|
| 400 |
+
''' return a list of start rules
|
| 401 |
+
|
| 402 |
+
Returns
|
| 403 |
+
-------
|
| 404 |
+
list : list of start rules
|
| 405 |
+
'''
|
| 406 |
+
start_rule_list = []
|
| 407 |
+
for each_prod_rule in self.prod_rule_list:
|
| 408 |
+
if each_prod_rule.is_start_rule:
|
| 409 |
+
start_rule_list.append(each_prod_rule)
|
| 410 |
+
return start_rule_list
|
| 411 |
+
|
| 412 |
+
@property
|
| 413 |
+
def num_edge_symbol(self):
|
| 414 |
+
return len(self.edge_symbol_list)
|
| 415 |
+
|
| 416 |
+
@property
|
| 417 |
+
def num_node_symbol(self):
|
| 418 |
+
return len(self.node_symbol_list)
|
| 419 |
+
|
| 420 |
+
@property
|
| 421 |
+
def num_ext_id(self):
|
| 422 |
+
return len(self.ext_id_list)
|
| 423 |
+
|
| 424 |
+
def construct_feature_vectors(self):
|
| 425 |
+
''' this method constructs feature vectors for the production rules collected so far.
|
| 426 |
+
currently, NTSymbol and TSymbol are treated in the same manner.
|
| 427 |
+
'''
|
| 428 |
+
feature_id_dict = {}
|
| 429 |
+
feature_id_dict['TSymbol'] = 0
|
| 430 |
+
feature_id_dict['NTSymbol'] = 1
|
| 431 |
+
feature_id_dict['BondSymbol'] = 2
|
| 432 |
+
for each_edge_symbol in self.edge_symbol_list:
|
| 433 |
+
for each_attr in each_edge_symbol.__dict__.keys():
|
| 434 |
+
each_val = each_edge_symbol.__dict__[each_attr]
|
| 435 |
+
if isinstance(each_val, list):
|
| 436 |
+
each_val = tuple(each_val)
|
| 437 |
+
if (each_attr, each_val) not in feature_id_dict:
|
| 438 |
+
feature_id_dict[(each_attr, each_val)] = len(feature_id_dict)
|
| 439 |
+
|
| 440 |
+
for each_node_symbol in self.node_symbol_list:
|
| 441 |
+
for each_attr in each_node_symbol.__dict__.keys():
|
| 442 |
+
each_val = each_node_symbol.__dict__[each_attr]
|
| 443 |
+
if isinstance(each_val, list):
|
| 444 |
+
each_val = tuple(each_val)
|
| 445 |
+
if (each_attr, each_val) not in feature_id_dict:
|
| 446 |
+
feature_id_dict[(each_attr, each_val)] = len(feature_id_dict)
|
| 447 |
+
for each_ext_id in self.ext_id_list:
|
| 448 |
+
feature_id_dict[('ext_id', each_ext_id)] = len(feature_id_dict)
|
| 449 |
+
dim = len(feature_id_dict)
|
| 450 |
+
|
| 451 |
+
feature_dict = {}
|
| 452 |
+
for each_edge_symbol in self.edge_symbol_list:
|
| 453 |
+
idx_list = []
|
| 454 |
+
idx_list.append(feature_id_dict[each_edge_symbol.__class__.__name__])
|
| 455 |
+
for each_attr in each_edge_symbol.__dict__.keys():
|
| 456 |
+
each_val = each_edge_symbol.__dict__[each_attr]
|
| 457 |
+
if isinstance(each_val, list):
|
| 458 |
+
each_val = tuple(each_val)
|
| 459 |
+
idx_list.append(feature_id_dict[(each_attr, each_val)])
|
| 460 |
+
feature = torch.sparse.LongTensor(
|
| 461 |
+
torch.LongTensor([idx_list]),
|
| 462 |
+
torch.ones(len(idx_list)),
|
| 463 |
+
torch.Size([len(feature_id_dict)])
|
| 464 |
+
)
|
| 465 |
+
feature_dict[each_edge_symbol] = feature
|
| 466 |
+
|
| 467 |
+
for each_node_symbol in self.node_symbol_list:
|
| 468 |
+
idx_list = []
|
| 469 |
+
idx_list.append(feature_id_dict[each_node_symbol.__class__.__name__])
|
| 470 |
+
for each_attr in each_node_symbol.__dict__.keys():
|
| 471 |
+
each_val = each_node_symbol.__dict__[each_attr]
|
| 472 |
+
if isinstance(each_val, list):
|
| 473 |
+
each_val = tuple(each_val)
|
| 474 |
+
idx_list.append(feature_id_dict[(each_attr, each_val)])
|
| 475 |
+
feature = torch.sparse.LongTensor(
|
| 476 |
+
torch.LongTensor([idx_list]),
|
| 477 |
+
torch.ones(len(idx_list)),
|
| 478 |
+
torch.Size([len(feature_id_dict)])
|
| 479 |
+
)
|
| 480 |
+
feature_dict[each_node_symbol] = feature
|
| 481 |
+
for each_ext_id in self.ext_id_list:
|
| 482 |
+
idx_list = [feature_id_dict[('ext_id', each_ext_id)]]
|
| 483 |
+
feature_dict[('ext_id', each_ext_id)] \
|
| 484 |
+
= torch.sparse.LongTensor(
|
| 485 |
+
torch.LongTensor([idx_list]),
|
| 486 |
+
torch.ones(len(idx_list)),
|
| 487 |
+
torch.Size([len(feature_id_dict)])
|
| 488 |
+
)
|
| 489 |
+
return feature_dict, dim
|
| 490 |
+
|
| 491 |
+
def edge_symbol_idx(self, symbol):
|
| 492 |
+
return self.edge_symbol_dict[symbol]
|
| 493 |
+
|
| 494 |
+
def node_symbol_idx(self, symbol):
|
| 495 |
+
return self.node_symbol_dict[symbol]
|
| 496 |
+
|
| 497 |
+
def append(self, prod_rule: ProductionRule) -> Tuple[int, ProductionRule]:
|
| 498 |
+
""" return whether the input production rule is new or not, and its production rule id.
|
| 499 |
+
Production rules are regarded as the same if
|
| 500 |
+
i) there exists a one-to-one mapping of nodes and edges, and
|
| 501 |
+
ii) all the attributes associated with nodes and hyperedges are the same.
|
| 502 |
+
|
| 503 |
+
Parameters
|
| 504 |
+
----------
|
| 505 |
+
prod_rule : ProductionRule
|
| 506 |
+
|
| 507 |
+
Returns
|
| 508 |
+
-------
|
| 509 |
+
prod_rule_id : int
|
| 510 |
+
production rule index. if new, a new index will be assigned.
|
| 511 |
+
prod_rule : ProductionRule
|
| 512 |
+
"""
|
| 513 |
+
num_lhs = len(self.nt_symbol_list)
|
| 514 |
+
for each_idx, each_prod_rule in enumerate(self.prod_rule_list):
|
| 515 |
+
is_same, isomap = prod_rule.is_same(each_prod_rule)
|
| 516 |
+
if is_same:
|
| 517 |
+
# we do not care about edge and node names, but care about the order of non-terminal edges.
|
| 518 |
+
for key, val in isomap.items(): # key : edges & nodes in each_prod_rule.rhs , val : those in prod_rule.rhs
|
| 519 |
+
if key.startswith("bond_"):
|
| 520 |
+
continue
|
| 521 |
+
|
| 522 |
+
# rewrite `nt_idx` in `prod_rule` for further processing
|
| 523 |
+
if "nt_idx" in prod_rule.rhs.edge_attr(val).keys():
|
| 524 |
+
if "nt_idx" not in each_prod_rule.rhs.edge_attr(key).keys():
|
| 525 |
+
raise ValueError
|
| 526 |
+
prod_rule.rhs.set_edge_attr(
|
| 527 |
+
val,
|
| 528 |
+
{'nt_idx': each_prod_rule.rhs.edge_attr(key)["nt_idx"]})
|
| 529 |
+
return each_idx, prod_rule
|
| 530 |
+
self.prod_rule_list.append(prod_rule)
|
| 531 |
+
self._update_edge_symbol_list(prod_rule)
|
| 532 |
+
self._update_node_symbol_list(prod_rule)
|
| 533 |
+
self._update_ext_id_list(prod_rule)
|
| 534 |
+
|
| 535 |
+
lhs_idx = self.nt_symbol_list.index(prod_rule.lhs_nt_symbol)
|
| 536 |
+
self.lhs_in_prod_rule_row_list.append(lhs_idx)
|
| 537 |
+
self.lhs_in_prod_rule_col_list.append(len(self.prod_rule_list)-1)
|
| 538 |
+
self._lhs_in_prod_rule = None
|
| 539 |
+
return len(self.prod_rule_list)-1, prod_rule
|
| 540 |
+
|
| 541 |
+
def get_prod_rule(self, prod_rule_idx: int) -> ProductionRule:
|
| 542 |
+
return self.prod_rule_list[prod_rule_idx]
|
| 543 |
+
|
| 544 |
+
def sample(self, unmasked_logit_array, nt_symbol, deterministic=False):
|
| 545 |
+
''' sample a production rule whose lhs is `nt_symbol`, followihng `unmasked_logit_array`.
|
| 546 |
+
|
| 547 |
+
Parameters
|
| 548 |
+
----------
|
| 549 |
+
unmasked_logit_array : array-like, length `num_prod_rule`
|
| 550 |
+
nt_symbol : NTSymbol
|
| 551 |
+
'''
|
| 552 |
+
if not isinstance(unmasked_logit_array, np.ndarray):
|
| 553 |
+
unmasked_logit_array = unmasked_logit_array.numpy().astype(np.float64)
|
| 554 |
+
if deterministic:
|
| 555 |
+
prob = masked_softmax(unmasked_logit_array,
|
| 556 |
+
self.lhs_in_prod_rule[self.nt_symbol_list.index(nt_symbol)].numpy().astype(np.float64))
|
| 557 |
+
return self.prod_rule_list[np.argmax(prob)]
|
| 558 |
+
else:
|
| 559 |
+
return np.random.choice(
|
| 560 |
+
self.prod_rule_list, 1,
|
| 561 |
+
p=masked_softmax(unmasked_logit_array,
|
| 562 |
+
self.lhs_in_prod_rule[self.nt_symbol_list.index(nt_symbol)].numpy().astype(np.float64)))[0]
|
| 563 |
+
|
| 564 |
+
def masked_logprob(self, unmasked_logit_array, nt_symbol):
|
| 565 |
+
if not isinstance(unmasked_logit_array, np.ndarray):
|
| 566 |
+
unmasked_logit_array = unmasked_logit_array.numpy().astype(np.float64)
|
| 567 |
+
prob = masked_softmax(unmasked_logit_array,
|
| 568 |
+
self.lhs_in_prod_rule[self.nt_symbol_list.index(nt_symbol)].numpy().astype(np.float64))
|
| 569 |
+
return np.log(prob)
|
| 570 |
+
|
| 571 |
+
def _update_edge_symbol_list(self, prod_rule: ProductionRule):
|
| 572 |
+
''' update edge symbol list
|
| 573 |
+
|
| 574 |
+
Parameters
|
| 575 |
+
----------
|
| 576 |
+
prod_rule : ProductionRule
|
| 577 |
+
'''
|
| 578 |
+
if prod_rule.lhs_nt_symbol not in self.nt_symbol_list:
|
| 579 |
+
self.nt_symbol_list.append(prod_rule.lhs_nt_symbol)
|
| 580 |
+
|
| 581 |
+
for each_edge in prod_rule.rhs.edges:
|
| 582 |
+
if prod_rule.rhs.edge_attr(each_edge)['symbol'] not in self.edge_symbol_dict:
|
| 583 |
+
edge_symbol_idx = len(self.edge_symbol_list)
|
| 584 |
+
self.edge_symbol_list.append(prod_rule.rhs.edge_attr(each_edge)['symbol'])
|
| 585 |
+
self.edge_symbol_dict[prod_rule.rhs.edge_attr(each_edge)['symbol']] = edge_symbol_idx
|
| 586 |
+
else:
|
| 587 |
+
edge_symbol_idx = self.edge_symbol_dict[prod_rule.rhs.edge_attr(each_edge)['symbol']]
|
| 588 |
+
prod_rule.rhs.edge_attr(each_edge)['symbol_idx'] = edge_symbol_idx
|
| 589 |
+
pass
|
| 590 |
+
|
| 591 |
+
def _update_node_symbol_list(self, prod_rule: ProductionRule):
|
| 592 |
+
''' update node symbol list
|
| 593 |
+
|
| 594 |
+
Parameters
|
| 595 |
+
----------
|
| 596 |
+
prod_rule : ProductionRule
|
| 597 |
+
'''
|
| 598 |
+
for each_node in prod_rule.rhs.nodes:
|
| 599 |
+
if prod_rule.rhs.node_attr(each_node)['symbol'] not in self.node_symbol_dict:
|
| 600 |
+
node_symbol_idx = len(self.node_symbol_list)
|
| 601 |
+
self.node_symbol_list.append(prod_rule.rhs.node_attr(each_node)['symbol'])
|
| 602 |
+
self.node_symbol_dict[prod_rule.rhs.node_attr(each_node)['symbol']] = node_symbol_idx
|
| 603 |
+
else:
|
| 604 |
+
node_symbol_idx = self.node_symbol_dict[prod_rule.rhs.node_attr(each_node)['symbol']]
|
| 605 |
+
prod_rule.rhs.node_attr(each_node)['symbol_idx'] = node_symbol_idx
|
| 606 |
+
|
| 607 |
+
def _update_ext_id_list(self, prod_rule: ProductionRule):
|
| 608 |
+
for each_node in prod_rule.rhs.nodes:
|
| 609 |
+
if 'ext_id' in prod_rule.rhs.node_attr(each_node):
|
| 610 |
+
if prod_rule.rhs.node_attr(each_node)['ext_id'] not in self.ext_id_list:
|
| 611 |
+
self.ext_id_list.append(prod_rule.rhs.node_attr(each_node)['ext_id'])
|
| 612 |
+
|
| 613 |
+
|
| 614 |
+
class HyperedgeReplacementGrammar(GraphGrammarBase):
|
| 615 |
+
"""
|
| 616 |
+
Learn a hyperedge replacement grammar from a set of hypergraphs.
|
| 617 |
+
|
| 618 |
+
Attributes
|
| 619 |
+
----------
|
| 620 |
+
prod_rule_list : list of ProductionRule
|
| 621 |
+
production rules learned from the input hypergraphs
|
| 622 |
+
"""
|
| 623 |
+
def __init__(self,
|
| 624 |
+
tree_decomposition=molecular_tree_decomposition,
|
| 625 |
+
ignore_order=False, **kwargs):
|
| 626 |
+
from functools import partial
|
| 627 |
+
self.prod_rule_corpus = ProductionRuleCorpus()
|
| 628 |
+
self.clique_tree_corpus = CliqueTreeCorpus()
|
| 629 |
+
self.ignore_order = ignore_order
|
| 630 |
+
self.tree_decomposition = partial(tree_decomposition, **kwargs)
|
| 631 |
+
|
| 632 |
+
@property
|
| 633 |
+
def num_prod_rule(self):
|
| 634 |
+
''' return the number of production rules
|
| 635 |
+
|
| 636 |
+
Returns
|
| 637 |
+
-------
|
| 638 |
+
int : the number of unique production rules
|
| 639 |
+
'''
|
| 640 |
+
return self.prod_rule_corpus.num_prod_rule
|
| 641 |
+
|
| 642 |
+
@property
|
| 643 |
+
def start_rule_list(self):
|
| 644 |
+
''' return a list of start rules
|
| 645 |
+
|
| 646 |
+
Returns
|
| 647 |
+
-------
|
| 648 |
+
list : list of start rules
|
| 649 |
+
'''
|
| 650 |
+
return self.prod_rule_corpus.start_rule_list
|
| 651 |
+
|
| 652 |
+
@property
|
| 653 |
+
def prod_rule_list(self):
|
| 654 |
+
return self.prod_rule_corpus.prod_rule_list
|
| 655 |
+
|
| 656 |
+
def learn(self, hg_list, logger=print, max_mol=np.inf, print_freq=500):
|
| 657 |
+
""" learn from a list of hypergraphs
|
| 658 |
+
|
| 659 |
+
Parameters
|
| 660 |
+
----------
|
| 661 |
+
hg_list : list of Hypergraph
|
| 662 |
+
|
| 663 |
+
Returns
|
| 664 |
+
-------
|
| 665 |
+
prod_rule_seq_list : list of integers
|
| 666 |
+
each element corresponds to a sequence of production rules to generate each hypergraph.
|
| 667 |
+
"""
|
| 668 |
+
prod_rule_seq_list = []
|
| 669 |
+
idx = 0
|
| 670 |
+
for each_idx, each_hg in enumerate(hg_list):
|
| 671 |
+
clique_tree = self.tree_decomposition(each_hg)
|
| 672 |
+
|
| 673 |
+
# get a pair of myself and children
|
| 674 |
+
root_node = _find_root(clique_tree)
|
| 675 |
+
clique_tree = self.clique_tree_corpus.add_to_subhg_list(clique_tree, root_node)
|
| 676 |
+
prod_rule_seq = []
|
| 677 |
+
stack = []
|
| 678 |
+
|
| 679 |
+
children = sorted(list(clique_tree[root_node].keys()))
|
| 680 |
+
|
| 681 |
+
# extract a temporary production rule
|
| 682 |
+
prod_rule = extract_prod_rule(
|
| 683 |
+
None,
|
| 684 |
+
clique_tree.nodes[root_node]["subhg"],
|
| 685 |
+
[clique_tree.nodes[each_child]["subhg"]
|
| 686 |
+
for each_child in children],
|
| 687 |
+
clique_tree.nodes[root_node].get('subhg_idx', None))
|
| 688 |
+
|
| 689 |
+
# update the production rule list
|
| 690 |
+
prod_rule_id, prod_rule = self.update_prod_rule_list(prod_rule)
|
| 691 |
+
children = reorder_children(root_node,
|
| 692 |
+
children,
|
| 693 |
+
prod_rule,
|
| 694 |
+
clique_tree)
|
| 695 |
+
stack.extend([(root_node, each_child) for each_child in children[::-1]])
|
| 696 |
+
prod_rule_seq.append(prod_rule_id)
|
| 697 |
+
|
| 698 |
+
while len(stack) != 0:
|
| 699 |
+
# get a triple of parent, myself, and children
|
| 700 |
+
parent, myself = stack.pop()
|
| 701 |
+
children = sorted(list(dict(clique_tree[myself]).keys()))
|
| 702 |
+
children.remove(parent)
|
| 703 |
+
|
| 704 |
+
# extract a temp prod rule
|
| 705 |
+
prod_rule = extract_prod_rule(
|
| 706 |
+
clique_tree.nodes[parent]["subhg"],
|
| 707 |
+
clique_tree.nodes[myself]["subhg"],
|
| 708 |
+
[clique_tree.nodes[each_child]["subhg"]
|
| 709 |
+
for each_child in children],
|
| 710 |
+
clique_tree.nodes[myself].get('subhg_idx', None))
|
| 711 |
+
|
| 712 |
+
# update the prod rule list
|
| 713 |
+
prod_rule_id, prod_rule = self.update_prod_rule_list(prod_rule)
|
| 714 |
+
children = reorder_children(myself,
|
| 715 |
+
children,
|
| 716 |
+
prod_rule,
|
| 717 |
+
clique_tree)
|
| 718 |
+
stack.extend([(myself, each_child)
|
| 719 |
+
for each_child in children[::-1]])
|
| 720 |
+
prod_rule_seq.append(prod_rule_id)
|
| 721 |
+
prod_rule_seq_list.append(prod_rule_seq)
|
| 722 |
+
if (each_idx+1) % print_freq == 0:
|
| 723 |
+
msg = f'#(molecules processed)={each_idx+1}\t'\
|
| 724 |
+
f'#(production rules)={self.prod_rule_corpus.num_prod_rule}\t#(subhg in corpus)={self.clique_tree_corpus.size}'
|
| 725 |
+
logger(msg)
|
| 726 |
+
if each_idx > max_mol:
|
| 727 |
+
break
|
| 728 |
+
|
| 729 |
+
print(f'corpus_size = {self.clique_tree_corpus.size}')
|
| 730 |
+
return prod_rule_seq_list
|
| 731 |
+
|
| 732 |
+
def sample(self, z, deterministic=False):
|
| 733 |
+
""" sample a new hypergraph from HRG.
|
| 734 |
+
|
| 735 |
+
Parameters
|
| 736 |
+
----------
|
| 737 |
+
z : array-like, shape (len, num_prod_rule)
|
| 738 |
+
logit
|
| 739 |
+
deterministic : bool
|
| 740 |
+
if True, deterministic sampling
|
| 741 |
+
|
| 742 |
+
Returns
|
| 743 |
+
-------
|
| 744 |
+
Hypergraph
|
| 745 |
+
"""
|
| 746 |
+
seq_idx = 0
|
| 747 |
+
stack = []
|
| 748 |
+
z = z[:, :-1]
|
| 749 |
+
init_prod_rule = self.prod_rule_corpus.sample(z[0], NTSymbol(degree=0,
|
| 750 |
+
is_aromatic=False,
|
| 751 |
+
bond_symbol_list=[]),
|
| 752 |
+
deterministic=deterministic)
|
| 753 |
+
hg, nt_edge_list = init_prod_rule.applied_to(None, None)
|
| 754 |
+
stack = deepcopy(nt_edge_list[::-1])
|
| 755 |
+
while len(stack) != 0 and seq_idx < z.shape[0]-1:
|
| 756 |
+
seq_idx += 1
|
| 757 |
+
nt_edge = stack.pop()
|
| 758 |
+
nt_symbol = hg.edge_attr(nt_edge)['symbol']
|
| 759 |
+
prod_rule = self.prod_rule_corpus.sample(z[seq_idx], nt_symbol, deterministic=deterministic)
|
| 760 |
+
hg, nt_edge_list = prod_rule.applied_to(hg, nt_edge)
|
| 761 |
+
stack.extend(nt_edge_list[::-1])
|
| 762 |
+
if len(stack) != 0:
|
| 763 |
+
raise RuntimeError(f'{len(stack)} non-terminals are left.')
|
| 764 |
+
return hg
|
| 765 |
+
|
| 766 |
+
def construct(self, prod_rule_seq):
|
| 767 |
+
""" construct a hypergraph following `prod_rule_seq`
|
| 768 |
+
|
| 769 |
+
Parameters
|
| 770 |
+
----------
|
| 771 |
+
prod_rule_seq : list of integers
|
| 772 |
+
a sequence of production rules.
|
| 773 |
+
|
| 774 |
+
Returns
|
| 775 |
+
-------
|
| 776 |
+
UndirectedHypergraph
|
| 777 |
+
"""
|
| 778 |
+
seq_idx = 0
|
| 779 |
+
init_prod_rule = self.prod_rule_corpus.get_prod_rule(prod_rule_seq[seq_idx])
|
| 780 |
+
hg, nt_edge_list = init_prod_rule.applied_to(None, None)
|
| 781 |
+
stack = deepcopy(nt_edge_list[::-1])
|
| 782 |
+
while len(stack) != 0:
|
| 783 |
+
seq_idx += 1
|
| 784 |
+
nt_edge = stack.pop()
|
| 785 |
+
hg, nt_edge_list = self.prod_rule_corpus.get_prod_rule(prod_rule_seq[seq_idx]).applied_to(hg, nt_edge)
|
| 786 |
+
stack.extend(nt_edge_list[::-1])
|
| 787 |
+
return hg
|
| 788 |
+
|
| 789 |
+
def update_prod_rule_list(self, prod_rule):
|
| 790 |
+
""" return whether the input production rule is new or not, and its production rule id.
|
| 791 |
+
Production rules are regarded as the same if
|
| 792 |
+
i) there exists a one-to-one mapping of nodes and edges, and
|
| 793 |
+
ii) all the attributes associated with nodes and hyperedges are the same.
|
| 794 |
+
|
| 795 |
+
Parameters
|
| 796 |
+
----------
|
| 797 |
+
prod_rule : ProductionRule
|
| 798 |
+
|
| 799 |
+
Returns
|
| 800 |
+
-------
|
| 801 |
+
is_new : bool
|
| 802 |
+
if True, this production rule is new
|
| 803 |
+
prod_rule_id : int
|
| 804 |
+
production rule index. if new, a new index will be assigned.
|
| 805 |
+
"""
|
| 806 |
+
return self.prod_rule_corpus.append(prod_rule)
|
| 807 |
+
|
| 808 |
+
|
| 809 |
+
class IncrementalHyperedgeReplacementGrammar(HyperedgeReplacementGrammar):
|
| 810 |
+
'''
|
| 811 |
+
This class learns HRG incrementally leveraging the previously obtained production rules.
|
| 812 |
+
'''
|
| 813 |
+
def __init__(self, tree_decomposition=tree_decomposition_with_hrg, ignore_order=False):
|
| 814 |
+
self.prod_rule_list = []
|
| 815 |
+
self.tree_decomposition = tree_decomposition
|
| 816 |
+
self.ignore_order = ignore_order
|
| 817 |
+
|
| 818 |
+
def learn(self, hg_list):
|
| 819 |
+
""" learn from a list of hypergraphs
|
| 820 |
+
|
| 821 |
+
Parameters
|
| 822 |
+
----------
|
| 823 |
+
hg_list : list of UndirectedHypergraph
|
| 824 |
+
|
| 825 |
+
Returns
|
| 826 |
+
-------
|
| 827 |
+
prod_rule_seq_list : list of integers
|
| 828 |
+
each element corresponds to a sequence of production rules to generate each hypergraph.
|
| 829 |
+
"""
|
| 830 |
+
prod_rule_seq_list = []
|
| 831 |
+
for each_hg in hg_list:
|
| 832 |
+
clique_tree, root_node = tree_decomposition_with_hrg(each_hg, self, return_root=True)
|
| 833 |
+
|
| 834 |
+
prod_rule_seq = []
|
| 835 |
+
stack = []
|
| 836 |
+
|
| 837 |
+
# get a pair of myself and children
|
| 838 |
+
children = sorted(list(clique_tree[root_node].keys()))
|
| 839 |
+
|
| 840 |
+
# extract a temporary production rule
|
| 841 |
+
prod_rule = extract_prod_rule(None, clique_tree.nodes[root_node]["subhg"],
|
| 842 |
+
[clique_tree.nodes[each_child]["subhg"] for each_child in children])
|
| 843 |
+
|
| 844 |
+
# update the production rule list
|
| 845 |
+
prod_rule_id, prod_rule = self.update_prod_rule_list(prod_rule)
|
| 846 |
+
children = reorder_children(root_node, children, prod_rule, clique_tree)
|
| 847 |
+
stack.extend([(root_node, each_child) for each_child in children[::-1]])
|
| 848 |
+
prod_rule_seq.append(prod_rule_id)
|
| 849 |
+
|
| 850 |
+
while len(stack) != 0:
|
| 851 |
+
# get a triple of parent, myself, and children
|
| 852 |
+
parent, myself = stack.pop()
|
| 853 |
+
children = sorted(list(dict(clique_tree[myself]).keys()))
|
| 854 |
+
children.remove(parent)
|
| 855 |
+
|
| 856 |
+
# extract a temp prod rule
|
| 857 |
+
prod_rule = extract_prod_rule(
|
| 858 |
+
clique_tree.nodes[parent]["subhg"], clique_tree.nodes[myself]["subhg"],
|
| 859 |
+
[clique_tree.nodes[each_child]["subhg"] for each_child in children])
|
| 860 |
+
|
| 861 |
+
# update the prod rule list
|
| 862 |
+
prod_rule_id, prod_rule = self.update_prod_rule_list(prod_rule)
|
| 863 |
+
children = reorder_children(myself, children, prod_rule, clique_tree)
|
| 864 |
+
stack.extend([(myself, each_child) for each_child in children[::-1]])
|
| 865 |
+
prod_rule_seq.append(prod_rule_id)
|
| 866 |
+
prod_rule_seq_list.append(prod_rule_seq)
|
| 867 |
+
self._compute_stats()
|
| 868 |
+
return prod_rule_seq_list
|
| 869 |
+
|
| 870 |
+
|
| 871 |
+
def reorder_children(myself, children, prod_rule, clique_tree):
|
| 872 |
+
""" reorder children so that they match the order in `prod_rule`.
|
| 873 |
+
|
| 874 |
+
Parameters
|
| 875 |
+
----------
|
| 876 |
+
myself : int
|
| 877 |
+
children : list of int
|
| 878 |
+
prod_rule : ProductionRule
|
| 879 |
+
clique_tree : nx.Graph
|
| 880 |
+
|
| 881 |
+
Returns
|
| 882 |
+
-------
|
| 883 |
+
new_children : list of str
|
| 884 |
+
reordered children
|
| 885 |
+
"""
|
| 886 |
+
perm = {} # key : `nt_idx`, val : child
|
| 887 |
+
for each_edge in prod_rule.rhs.edges:
|
| 888 |
+
if "nt_idx" in prod_rule.rhs.edge_attr(each_edge).keys():
|
| 889 |
+
for each_child in children:
|
| 890 |
+
common_node_set = set(
|
| 891 |
+
common_node_list(clique_tree.nodes[myself]["subhg"],
|
| 892 |
+
clique_tree.nodes[each_child]["subhg"])[0])
|
| 893 |
+
if set(prod_rule.rhs.nodes_in_edge(each_edge)) == common_node_set:
|
| 894 |
+
assert prod_rule.rhs.edge_attr(each_edge)["nt_idx"] not in perm
|
| 895 |
+
perm[prod_rule.rhs.edge_attr(each_edge)["nt_idx"]] = each_child
|
| 896 |
+
new_children = []
|
| 897 |
+
assert len(perm) == len(children)
|
| 898 |
+
for i in range(len(perm)):
|
| 899 |
+
new_children.append(perm[i])
|
| 900 |
+
return new_children
|
| 901 |
+
|
| 902 |
+
|
| 903 |
+
def extract_prod_rule(parent_hg, myself_hg, children_hg_list, subhg_idx=None):
|
| 904 |
+
""" extract a production rule from a triple of `parent_hg`, `myself_hg`, and `children_hg_list`.
|
| 905 |
+
|
| 906 |
+
Parameters
|
| 907 |
+
----------
|
| 908 |
+
parent_hg : Hypergraph
|
| 909 |
+
myself_hg : Hypergraph
|
| 910 |
+
children_hg_list : list of Hypergraph
|
| 911 |
+
|
| 912 |
+
Returns
|
| 913 |
+
-------
|
| 914 |
+
ProductionRule, consisting of
|
| 915 |
+
lhs : Hypergraph or None
|
| 916 |
+
rhs : Hypergraph
|
| 917 |
+
"""
|
| 918 |
+
def _add_ext_node(hg, ext_nodes):
|
| 919 |
+
""" mark nodes to be external (ordered ids are assigned)
|
| 920 |
+
|
| 921 |
+
Parameters
|
| 922 |
+
----------
|
| 923 |
+
hg : UndirectedHypergraph
|
| 924 |
+
ext_nodes : list of str
|
| 925 |
+
list of external nodes
|
| 926 |
+
|
| 927 |
+
Returns
|
| 928 |
+
-------
|
| 929 |
+
hg : Hypergraph
|
| 930 |
+
nodes in `ext_nodes` are marked to be external
|
| 931 |
+
"""
|
| 932 |
+
ext_id = 0
|
| 933 |
+
ext_id_exists = []
|
| 934 |
+
for each_node in ext_nodes:
|
| 935 |
+
ext_id_exists.append('ext_id' in hg.node_attr(each_node))
|
| 936 |
+
if ext_id_exists and any(ext_id_exists) != all(ext_id_exists):
|
| 937 |
+
raise ValueError
|
| 938 |
+
if not all(ext_id_exists):
|
| 939 |
+
for each_node in ext_nodes:
|
| 940 |
+
hg.node_attr(each_node)['ext_id'] = ext_id
|
| 941 |
+
ext_id += 1
|
| 942 |
+
return hg
|
| 943 |
+
|
| 944 |
+
def _check_aromatic(hg, node_list):
|
| 945 |
+
is_aromatic = False
|
| 946 |
+
node_aromatic_list = []
|
| 947 |
+
for each_node in node_list:
|
| 948 |
+
if hg.node_attr(each_node)['symbol'].is_aromatic:
|
| 949 |
+
is_aromatic = True
|
| 950 |
+
node_aromatic_list.append(True)
|
| 951 |
+
else:
|
| 952 |
+
node_aromatic_list.append(False)
|
| 953 |
+
return is_aromatic, node_aromatic_list
|
| 954 |
+
|
| 955 |
+
def _check_ring(hg):
|
| 956 |
+
for each_edge in hg.edges:
|
| 957 |
+
if not ('tmp' in hg.edge_attr(each_edge) or (not hg.edge_attr(each_edge)['terminal'])):
|
| 958 |
+
return False
|
| 959 |
+
return True
|
| 960 |
+
|
| 961 |
+
if parent_hg is None:
|
| 962 |
+
lhs = Hypergraph()
|
| 963 |
+
node_list = []
|
| 964 |
+
else:
|
| 965 |
+
lhs = Hypergraph()
|
| 966 |
+
node_list, edge_exists = common_node_list(parent_hg, myself_hg)
|
| 967 |
+
for each_node in node_list:
|
| 968 |
+
lhs.add_node(each_node,
|
| 969 |
+
deepcopy(myself_hg.node_attr(each_node)))
|
| 970 |
+
is_aromatic, _ = _check_aromatic(parent_hg, node_list)
|
| 971 |
+
for_ring = _check_ring(myself_hg)
|
| 972 |
+
bond_symbol_list = []
|
| 973 |
+
for each_node in node_list:
|
| 974 |
+
bond_symbol_list.append(parent_hg.node_attr(each_node)['symbol'])
|
| 975 |
+
lhs.add_edge(
|
| 976 |
+
node_list,
|
| 977 |
+
attr_dict=dict(
|
| 978 |
+
terminal=False,
|
| 979 |
+
edge_exists=edge_exists,
|
| 980 |
+
symbol=NTSymbol(
|
| 981 |
+
degree=len(node_list),
|
| 982 |
+
is_aromatic=is_aromatic,
|
| 983 |
+
bond_symbol_list=bond_symbol_list,
|
| 984 |
+
for_ring=for_ring)))
|
| 985 |
+
try:
|
| 986 |
+
lhs = _add_ext_node(lhs, node_list)
|
| 987 |
+
except ValueError:
|
| 988 |
+
import pdb; pdb.set_trace()
|
| 989 |
+
|
| 990 |
+
rhs = remove_tmp_edge(deepcopy(myself_hg))
|
| 991 |
+
#rhs = remove_ext_node(rhs)
|
| 992 |
+
#rhs = remove_nt_edge(rhs)
|
| 993 |
+
try:
|
| 994 |
+
rhs = _add_ext_node(rhs, node_list)
|
| 995 |
+
except ValueError:
|
| 996 |
+
import pdb; pdb.set_trace()
|
| 997 |
+
|
| 998 |
+
nt_idx = 0
|
| 999 |
+
if children_hg_list is not None:
|
| 1000 |
+
for each_child_hg in children_hg_list:
|
| 1001 |
+
node_list, edge_exists = common_node_list(myself_hg, each_child_hg)
|
| 1002 |
+
is_aromatic, _ = _check_aromatic(myself_hg, node_list)
|
| 1003 |
+
for_ring = _check_ring(each_child_hg)
|
| 1004 |
+
bond_symbol_list = []
|
| 1005 |
+
for each_node in node_list:
|
| 1006 |
+
bond_symbol_list.append(myself_hg.node_attr(each_node)['symbol'])
|
| 1007 |
+
rhs.add_edge(
|
| 1008 |
+
node_list,
|
| 1009 |
+
attr_dict=dict(
|
| 1010 |
+
terminal=False,
|
| 1011 |
+
nt_idx=nt_idx,
|
| 1012 |
+
edge_exists=edge_exists,
|
| 1013 |
+
symbol=NTSymbol(degree=len(node_list),
|
| 1014 |
+
is_aromatic=is_aromatic,
|
| 1015 |
+
bond_symbol_list=bond_symbol_list,
|
| 1016 |
+
for_ring=for_ring)))
|
| 1017 |
+
nt_idx += 1
|
| 1018 |
+
prod_rule = ProductionRule(lhs, rhs)
|
| 1019 |
+
prod_rule.subhg_idx = subhg_idx
|
| 1020 |
+
if DEBUG:
|
| 1021 |
+
if sorted(list(prod_rule.ext_node.keys())) \
|
| 1022 |
+
!= list(np.arange(len(prod_rule.ext_node))):
|
| 1023 |
+
raise RuntimeError('ext_id is not continuous')
|
| 1024 |
+
return prod_rule
|
| 1025 |
+
|
| 1026 |
+
|
| 1027 |
+
def _find_root(clique_tree):
|
| 1028 |
+
max_node = None
|
| 1029 |
+
num_nodes_max = -np.inf
|
| 1030 |
+
for each_node in clique_tree.nodes:
|
| 1031 |
+
if clique_tree.nodes[each_node]['subhg'].num_nodes > num_nodes_max:
|
| 1032 |
+
max_node = each_node
|
| 1033 |
+
num_nodes_max = clique_tree.nodes[each_node]['subhg'].num_nodes
|
| 1034 |
+
'''
|
| 1035 |
+
children = sorted(list(clique_tree[each_node].keys()))
|
| 1036 |
+
prod_rule = extract_prod_rule(None,
|
| 1037 |
+
clique_tree.nodes[each_node]["subhg"],
|
| 1038 |
+
[clique_tree.nodes[each_child]["subhg"]
|
| 1039 |
+
for each_child in children])
|
| 1040 |
+
for each_start_rule in start_rule_list:
|
| 1041 |
+
if prod_rule.is_same(each_start_rule):
|
| 1042 |
+
return each_node
|
| 1043 |
+
'''
|
| 1044 |
+
return max_node
|
| 1045 |
+
|
| 1046 |
+
def remove_ext_node(hg):
|
| 1047 |
+
for each_node in hg.nodes:
|
| 1048 |
+
hg.node_attr(each_node).pop('ext_id', None)
|
| 1049 |
+
return hg
|
| 1050 |
+
|
| 1051 |
+
def remove_nt_edge(hg):
|
| 1052 |
+
remove_edge_list = []
|
| 1053 |
+
for each_edge in hg.edges:
|
| 1054 |
+
if not hg.edge_attr(each_edge)['terminal']:
|
| 1055 |
+
remove_edge_list.append(each_edge)
|
| 1056 |
+
hg.remove_edges(remove_edge_list)
|
| 1057 |
+
return hg
|
| 1058 |
+
|
| 1059 |
+
def remove_tmp_edge(hg):
|
| 1060 |
+
remove_edge_list = []
|
| 1061 |
+
for each_edge in hg.edges:
|
| 1062 |
+
if hg.edge_attr(each_edge).get('tmp', False):
|
| 1063 |
+
remove_edge_list.append(each_edge)
|
| 1064 |
+
hg.remove_edges(remove_edge_list)
|
| 1065 |
+
return hg
|
graph_grammar/graph_grammar/symbols.py
ADDED
|
@@ -0,0 +1,180 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# -*- coding: utf-8 -*-
|
| 3 |
+
# Rhizome
|
| 4 |
+
# Version beta 0.0, August 2023
|
| 5 |
+
# Property of IBM Research, Accelerated Discovery
|
| 6 |
+
#
|
| 7 |
+
|
| 8 |
+
"""
|
| 9 |
+
PLEASE NOTE THIS IMPLEMENTATION INCLUDES THE ORIGINAL SOURCE CODE (AND SOME ADAPTATIONS)
|
| 10 |
+
OF THE MHG IMPLEMENTATION OF HIROSHI KAJINO AT IBM TRL ALREADY PUBLICLY AVAILABLE.
|
| 11 |
+
THIS MIGHT INFLUENCE THE DECISION OF THE FINAL LICENSE SO CAREFUL CHECK NEEDS BE DONE.
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
""" Title """
|
| 16 |
+
|
| 17 |
+
__author__ = "Hiroshi Kajino <KAJINO@jp.ibm.com>"
|
| 18 |
+
__copyright__ = "(c) Copyright IBM Corp. 2018"
|
| 19 |
+
__version__ = "0.1"
|
| 20 |
+
__date__ = "Jan 1 2018"
|
| 21 |
+
|
| 22 |
+
from typing import List
|
| 23 |
+
|
| 24 |
+
class TSymbol(object):
|
| 25 |
+
|
| 26 |
+
''' terminal symbol
|
| 27 |
+
|
| 28 |
+
Attributes
|
| 29 |
+
----------
|
| 30 |
+
degree : int
|
| 31 |
+
the number of nodes in a hyperedge
|
| 32 |
+
is_aromatic : bool
|
| 33 |
+
whether or not the hyperedge is in an aromatic ring
|
| 34 |
+
symbol : str
|
| 35 |
+
atomic symbol
|
| 36 |
+
num_explicit_Hs : int
|
| 37 |
+
the number of hydrogens associated to this hyperedge
|
| 38 |
+
formal_charge : int
|
| 39 |
+
charge
|
| 40 |
+
chirality : int
|
| 41 |
+
chirality
|
| 42 |
+
'''
|
| 43 |
+
|
| 44 |
+
def __init__(self, degree, is_aromatic,
|
| 45 |
+
symbol, num_explicit_Hs, formal_charge, chirality):
|
| 46 |
+
self.degree = degree
|
| 47 |
+
self.is_aromatic = is_aromatic
|
| 48 |
+
self.symbol = symbol
|
| 49 |
+
self.num_explicit_Hs = num_explicit_Hs
|
| 50 |
+
self.formal_charge = formal_charge
|
| 51 |
+
self.chirality = chirality
|
| 52 |
+
|
| 53 |
+
@property
|
| 54 |
+
def terminal(self):
|
| 55 |
+
return True
|
| 56 |
+
|
| 57 |
+
def __eq__(self, other):
|
| 58 |
+
if not isinstance(other, TSymbol):
|
| 59 |
+
return False
|
| 60 |
+
if self.degree != other.degree:
|
| 61 |
+
return False
|
| 62 |
+
if self.is_aromatic != other.is_aromatic:
|
| 63 |
+
return False
|
| 64 |
+
if self.symbol != other.symbol:
|
| 65 |
+
return False
|
| 66 |
+
if self.num_explicit_Hs != other.num_explicit_Hs:
|
| 67 |
+
return False
|
| 68 |
+
if self.formal_charge != other.formal_charge:
|
| 69 |
+
return False
|
| 70 |
+
if self.chirality != other.chirality:
|
| 71 |
+
return False
|
| 72 |
+
return True
|
| 73 |
+
|
| 74 |
+
def __hash__(self):
|
| 75 |
+
return self.__str__().__hash__()
|
| 76 |
+
|
| 77 |
+
def __str__(self):
|
| 78 |
+
return f'degree={self.degree}, is_aromatic={self.is_aromatic}, '\
|
| 79 |
+
f'symbol={self.symbol}, '\
|
| 80 |
+
f'num_explicit_Hs={self.num_explicit_Hs}, '\
|
| 81 |
+
f'formal_charge={self.formal_charge}, chirality={self.chirality}'
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
class NTSymbol(object):
|
| 85 |
+
|
| 86 |
+
''' non-terminal symbol
|
| 87 |
+
|
| 88 |
+
Attributes
|
| 89 |
+
----------
|
| 90 |
+
degree : int
|
| 91 |
+
degree of the hyperedge
|
| 92 |
+
is_aromatic : bool
|
| 93 |
+
if True, at least one of the associated bonds must be aromatic.
|
| 94 |
+
node_aromatic_list : list of bool
|
| 95 |
+
indicate whether each of the nodes is aromatic or not.
|
| 96 |
+
bond_type_list : list of int
|
| 97 |
+
bond type of each node"
|
| 98 |
+
'''
|
| 99 |
+
|
| 100 |
+
def __init__(self, degree: int, is_aromatic: bool,
|
| 101 |
+
bond_symbol_list: list,
|
| 102 |
+
for_ring=False):
|
| 103 |
+
self.degree = degree
|
| 104 |
+
self.is_aromatic = is_aromatic
|
| 105 |
+
self.for_ring = for_ring
|
| 106 |
+
self.bond_symbol_list = bond_symbol_list
|
| 107 |
+
|
| 108 |
+
@property
|
| 109 |
+
def terminal(self) -> bool:
|
| 110 |
+
return False
|
| 111 |
+
|
| 112 |
+
@property
|
| 113 |
+
def symbol(self):
|
| 114 |
+
return f'NT{self.degree}'
|
| 115 |
+
|
| 116 |
+
def __eq__(self, other) -> bool:
|
| 117 |
+
if not isinstance(other, NTSymbol):
|
| 118 |
+
return False
|
| 119 |
+
|
| 120 |
+
if self.degree != other.degree:
|
| 121 |
+
return False
|
| 122 |
+
if self.is_aromatic != other.is_aromatic:
|
| 123 |
+
return False
|
| 124 |
+
if self.for_ring != other.for_ring:
|
| 125 |
+
return False
|
| 126 |
+
if len(self.bond_symbol_list) != len(other.bond_symbol_list):
|
| 127 |
+
return False
|
| 128 |
+
for each_idx in range(len(self.bond_symbol_list)):
|
| 129 |
+
if self.bond_symbol_list[each_idx] != other.bond_symbol_list[each_idx]:
|
| 130 |
+
return False
|
| 131 |
+
return True
|
| 132 |
+
|
| 133 |
+
def __hash__(self):
|
| 134 |
+
return self.__str__().__hash__()
|
| 135 |
+
|
| 136 |
+
def __str__(self) -> str:
|
| 137 |
+
return f'degree={self.degree}, is_aromatic={self.is_aromatic}, '\
|
| 138 |
+
f'bond_symbol_list={[str(each_symbol) for each_symbol in self.bond_symbol_list]}'\
|
| 139 |
+
f'for_ring={self.for_ring}'
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
class BondSymbol(object):
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
''' Bond symbol
|
| 146 |
+
|
| 147 |
+
Attributes
|
| 148 |
+
----------
|
| 149 |
+
is_aromatic : bool
|
| 150 |
+
if True, at least one of the associated bonds must be aromatic.
|
| 151 |
+
bond_type : int
|
| 152 |
+
bond type of each node"
|
| 153 |
+
'''
|
| 154 |
+
|
| 155 |
+
def __init__(self, is_aromatic: bool,
|
| 156 |
+
bond_type: int,
|
| 157 |
+
stereo: int):
|
| 158 |
+
self.is_aromatic = is_aromatic
|
| 159 |
+
self.bond_type = bond_type
|
| 160 |
+
self.stereo = stereo
|
| 161 |
+
|
| 162 |
+
def __eq__(self, other) -> bool:
|
| 163 |
+
if not isinstance(other, BondSymbol):
|
| 164 |
+
return False
|
| 165 |
+
|
| 166 |
+
if self.is_aromatic != other.is_aromatic:
|
| 167 |
+
return False
|
| 168 |
+
if self.bond_type != other.bond_type:
|
| 169 |
+
return False
|
| 170 |
+
if self.stereo != other.stereo:
|
| 171 |
+
return False
|
| 172 |
+
return True
|
| 173 |
+
|
| 174 |
+
def __hash__(self):
|
| 175 |
+
return self.__str__().__hash__()
|
| 176 |
+
|
| 177 |
+
def __str__(self) -> str:
|
| 178 |
+
return f'is_aromatic={self.is_aromatic}, '\
|
| 179 |
+
f'bond_type={self.bond_type}, '\
|
| 180 |
+
f'stereo={self.stereo}, '
|
graph_grammar/graph_grammar/utils.py
ADDED
|
@@ -0,0 +1,130 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# -*- coding: utf-8 -*-
|
| 3 |
+
# Rhizome
|
| 4 |
+
# Version beta 0.0, August 2023
|
| 5 |
+
# Property of IBM Research, Accelerated Discovery
|
| 6 |
+
#
|
| 7 |
+
|
| 8 |
+
"""
|
| 9 |
+
PLEASE NOTE THIS IMPLEMENTATION INCLUDES THE ORIGINAL SOURCE CODE (AND SOME ADAPTATIONS)
|
| 10 |
+
OF THE MHG IMPLEMENTATION OF HIROSHI KAJINO AT IBM TRL ALREADY PUBLICLY AVAILABLE.
|
| 11 |
+
THIS MIGHT INFLUENCE THE DECISION OF THE FINAL LICENSE SO CAREFUL CHECK NEEDS BE DONE.
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
""" Title """
|
| 15 |
+
|
| 16 |
+
__author__ = "Hiroshi Kajino <KAJINO@jp.ibm.com>"
|
| 17 |
+
__copyright__ = "(c) Copyright IBM Corp. 2018"
|
| 18 |
+
__version__ = "0.1"
|
| 19 |
+
__date__ = "Jun 4 2018"
|
| 20 |
+
|
| 21 |
+
from ..hypergraph import Hypergraph
|
| 22 |
+
from copy import deepcopy
|
| 23 |
+
from typing import List
|
| 24 |
+
import numpy as np
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def common_node_list(hg1: Hypergraph, hg2: Hypergraph) -> List[str]:
|
| 28 |
+
""" return a list of common nodes
|
| 29 |
+
|
| 30 |
+
Parameters
|
| 31 |
+
----------
|
| 32 |
+
hg1, hg2 : Hypergraph
|
| 33 |
+
|
| 34 |
+
Returns
|
| 35 |
+
-------
|
| 36 |
+
list of str
|
| 37 |
+
list of common nodes
|
| 38 |
+
"""
|
| 39 |
+
if hg1 is None or hg2 is None:
|
| 40 |
+
return [], False
|
| 41 |
+
else:
|
| 42 |
+
node_set = hg1.nodes.intersection(hg2.nodes)
|
| 43 |
+
node_dict = {}
|
| 44 |
+
if 'order4hrg' in hg1.node_attr(list(hg1.nodes)[0]):
|
| 45 |
+
for each_node in node_set:
|
| 46 |
+
node_dict[each_node] = hg1.node_attr(each_node)['order4hrg']
|
| 47 |
+
else:
|
| 48 |
+
for each_node in node_set:
|
| 49 |
+
node_dict[each_node] = hg1.node_attr(each_node)['symbol'].__hash__()
|
| 50 |
+
node_list = []
|
| 51 |
+
for each_key, _ in sorted(node_dict.items(), key=lambda x:x[1]):
|
| 52 |
+
node_list.append(each_key)
|
| 53 |
+
edge_name = hg1.has_edge(node_list, ignore_order=True)
|
| 54 |
+
if edge_name:
|
| 55 |
+
if not hg1.edge_attr(edge_name).get('terminal', True):
|
| 56 |
+
node_list = hg1.nodes_in_edge(edge_name)
|
| 57 |
+
return node_list, True
|
| 58 |
+
else:
|
| 59 |
+
return node_list, False
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def _node_match(node1, node2):
|
| 63 |
+
# if the nodes are hyperedges, `atom_attr` determines the match
|
| 64 |
+
if node1['bipartite'] == 'edge' and node2['bipartite'] == 'edge':
|
| 65 |
+
return node1["attr_dict"]['symbol'] == node2["attr_dict"]['symbol']
|
| 66 |
+
elif node1['bipartite'] == 'node' and node2['bipartite'] == 'node':
|
| 67 |
+
# bond_symbol
|
| 68 |
+
return node1['attr_dict']['symbol'] == node2['attr_dict']['symbol']
|
| 69 |
+
else:
|
| 70 |
+
return False
|
| 71 |
+
|
| 72 |
+
def _easy_node_match(node1, node2):
|
| 73 |
+
# if the nodes are hyperedges, `atom_attr` determines the match
|
| 74 |
+
if node1['bipartite'] == 'edge' and node2['bipartite'] == 'edge':
|
| 75 |
+
return node1["attr_dict"].get('symbol', None) == node2["attr_dict"].get('symbol', None)
|
| 76 |
+
elif node1['bipartite'] == 'node' and node2['bipartite'] == 'node':
|
| 77 |
+
# bond_symbol
|
| 78 |
+
return node1['attr_dict'].get('ext_id', -1) == node2['attr_dict'].get('ext_id', -1)\
|
| 79 |
+
and node1['attr_dict']['symbol'] == node2['attr_dict']['symbol']
|
| 80 |
+
else:
|
| 81 |
+
return False
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
def _node_match_prod_rule(node1, node2, ignore_order=False):
|
| 85 |
+
# if the nodes are hyperedges, `atom_attr` determines the match
|
| 86 |
+
if node1['bipartite'] == 'edge' and node2['bipartite'] == 'edge':
|
| 87 |
+
return node1["attr_dict"]['symbol'] == node2["attr_dict"]['symbol']
|
| 88 |
+
elif node1['bipartite'] == 'node' and node2['bipartite'] == 'node':
|
| 89 |
+
# ext_id, order4hrg, bond_symbol
|
| 90 |
+
if ignore_order:
|
| 91 |
+
return node1['attr_dict']['symbol'] == node2['attr_dict']['symbol']
|
| 92 |
+
else:
|
| 93 |
+
return node1['attr_dict']['symbol'] == node2['attr_dict']['symbol']\
|
| 94 |
+
and node1['attr_dict'].get('ext_id', -1) == node2['attr_dict'].get('ext_id', -1)
|
| 95 |
+
else:
|
| 96 |
+
return False
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def _edge_match(edge1, edge2, ignore_order=False):
|
| 100 |
+
#return True
|
| 101 |
+
if ignore_order:
|
| 102 |
+
return True
|
| 103 |
+
else:
|
| 104 |
+
return edge1["order"] == edge2["order"]
|
| 105 |
+
|
| 106 |
+
def masked_softmax(logit, mask):
|
| 107 |
+
''' compute a probability distribution from logit
|
| 108 |
+
|
| 109 |
+
Parameters
|
| 110 |
+
----------
|
| 111 |
+
logit : array-like, length D
|
| 112 |
+
each element indicates how each dimension is likely to be chosen
|
| 113 |
+
(the larger, the more likely)
|
| 114 |
+
mask : array-like, length D
|
| 115 |
+
each element is either 0 or 1.
|
| 116 |
+
if 0, the dimension is ignored
|
| 117 |
+
when computing the probability distribution.
|
| 118 |
+
|
| 119 |
+
Returns
|
| 120 |
+
-------
|
| 121 |
+
prob_dist : array, length D
|
| 122 |
+
probability distribution computed from logit.
|
| 123 |
+
if `mask[d] = 0`, `prob_dist[d] = 0`.
|
| 124 |
+
'''
|
| 125 |
+
if logit.shape != mask.shape:
|
| 126 |
+
raise ValueError('logit and mask must have the same shape')
|
| 127 |
+
c = np.max(logit)
|
| 128 |
+
exp_logit = np.exp(logit - c) * mask
|
| 129 |
+
sum_exp_logit = exp_logit @ mask
|
| 130 |
+
return exp_logit / sum_exp_logit
|
graph_grammar/hypergraph.py
ADDED
|
@@ -0,0 +1,544 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# -*- coding: utf-8 -*-
|
| 3 |
+
# Rhizome
|
| 4 |
+
# Version beta 0.0, August 2023
|
| 5 |
+
# Property of IBM Research, Accelerated Discovery
|
| 6 |
+
#
|
| 7 |
+
|
| 8 |
+
"""
|
| 9 |
+
PLEASE NOTE THIS IMPLEMENTATION INCLUDES THE ORIGINAL SOURCE CODE (AND SOME ADAPTATIONS)
|
| 10 |
+
OF THE MHG IMPLEMENTATION OF HIROSHI KAJINO AT IBM TRL ALREADY PUBLICLY AVAILABLE.
|
| 11 |
+
THIS MIGHT INFLUENCE THE DECISION OF THE FINAL LICENSE SO CAREFUL CHECK NEEDS BE DONE.
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
""" Title """
|
| 15 |
+
|
| 16 |
+
__author__ = "Hiroshi Kajino <KAJINO@jp.ibm.com>"
|
| 17 |
+
__copyright__ = "(c) Copyright IBM Corp. 2018"
|
| 18 |
+
__version__ = "0.1"
|
| 19 |
+
__date__ = "Jan 31 2018"
|
| 20 |
+
|
| 21 |
+
from copy import deepcopy
|
| 22 |
+
from typing import List, Dict, Tuple
|
| 23 |
+
import networkx as nx
|
| 24 |
+
import numpy as np
|
| 25 |
+
import os
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class Hypergraph(object):
|
| 29 |
+
'''
|
| 30 |
+
A class of a hypergraph.
|
| 31 |
+
Each hyperedge can be ordered. For the ordered case,
|
| 32 |
+
edges adjacent to the hyperedge node are labeled by their orders.
|
| 33 |
+
|
| 34 |
+
Attributes
|
| 35 |
+
----------
|
| 36 |
+
hg : nx.Graph
|
| 37 |
+
a bipartite graph representation of a hypergraph
|
| 38 |
+
edge_idx : int
|
| 39 |
+
total number of hyperedges that exist so far
|
| 40 |
+
'''
|
| 41 |
+
def __init__(self):
|
| 42 |
+
self.hg = nx.Graph()
|
| 43 |
+
self.edge_idx = 0
|
| 44 |
+
self.nodes = set([])
|
| 45 |
+
self.num_nodes = 0
|
| 46 |
+
self.edges = set([])
|
| 47 |
+
self.num_edges = 0
|
| 48 |
+
self.nodes_in_edge_dict = {}
|
| 49 |
+
|
| 50 |
+
def add_node(self, node: str, attr_dict=None):
|
| 51 |
+
''' add a node to hypergraph
|
| 52 |
+
|
| 53 |
+
Parameters
|
| 54 |
+
----------
|
| 55 |
+
node : str
|
| 56 |
+
node name
|
| 57 |
+
attr_dict : dict
|
| 58 |
+
dictionary of node attributes
|
| 59 |
+
'''
|
| 60 |
+
self.hg.add_node(node, bipartite='node', attr_dict=attr_dict)
|
| 61 |
+
if node not in self.nodes:
|
| 62 |
+
self.num_nodes += 1
|
| 63 |
+
self.nodes.add(node)
|
| 64 |
+
|
| 65 |
+
def add_edge(self, node_list: List[str], attr_dict=None, edge_name=None):
|
| 66 |
+
''' add an edge consisting of nodes `node_list`
|
| 67 |
+
|
| 68 |
+
Parameters
|
| 69 |
+
----------
|
| 70 |
+
node_list : list
|
| 71 |
+
ordered list of nodes that consist the edge
|
| 72 |
+
attr_dict : dict
|
| 73 |
+
dictionary of edge attributes
|
| 74 |
+
'''
|
| 75 |
+
if edge_name is None:
|
| 76 |
+
edge = 'e{}'.format(self.edge_idx)
|
| 77 |
+
else:
|
| 78 |
+
assert edge_name not in self.edges
|
| 79 |
+
edge = edge_name
|
| 80 |
+
self.hg.add_node(edge, bipartite='edge', attr_dict=attr_dict)
|
| 81 |
+
if edge not in self.edges:
|
| 82 |
+
self.num_edges += 1
|
| 83 |
+
self.edges.add(edge)
|
| 84 |
+
self.nodes_in_edge_dict[edge] = node_list
|
| 85 |
+
if type(node_list) == list:
|
| 86 |
+
for node_idx, each_node in enumerate(node_list):
|
| 87 |
+
self.hg.add_edge(edge, each_node, order=node_idx)
|
| 88 |
+
if each_node not in self.nodes:
|
| 89 |
+
self.num_nodes += 1
|
| 90 |
+
self.nodes.add(each_node)
|
| 91 |
+
|
| 92 |
+
elif type(node_list) == set:
|
| 93 |
+
for each_node in node_list:
|
| 94 |
+
self.hg.add_edge(edge, each_node, order=-1)
|
| 95 |
+
if each_node not in self.nodes:
|
| 96 |
+
self.num_nodes += 1
|
| 97 |
+
self.nodes.add(each_node)
|
| 98 |
+
else:
|
| 99 |
+
raise ValueError
|
| 100 |
+
self.edge_idx += 1
|
| 101 |
+
return edge
|
| 102 |
+
|
| 103 |
+
def remove_node(self, node: str, remove_connected_edges=True):
|
| 104 |
+
''' remove a node
|
| 105 |
+
|
| 106 |
+
Parameters
|
| 107 |
+
----------
|
| 108 |
+
node : str
|
| 109 |
+
node name
|
| 110 |
+
remove_connected_edges : bool
|
| 111 |
+
if True, remove edges that are adjacent to the node
|
| 112 |
+
'''
|
| 113 |
+
if remove_connected_edges:
|
| 114 |
+
connected_edges = deepcopy(self.adj_edges(node))
|
| 115 |
+
for each_edge in connected_edges:
|
| 116 |
+
self.remove_edge(each_edge)
|
| 117 |
+
self.hg.remove_node(node)
|
| 118 |
+
self.num_nodes -= 1
|
| 119 |
+
self.nodes.remove(node)
|
| 120 |
+
|
| 121 |
+
def remove_nodes(self, node_iter, remove_connected_edges=True):
|
| 122 |
+
''' remove a set of nodes
|
| 123 |
+
|
| 124 |
+
Parameters
|
| 125 |
+
----------
|
| 126 |
+
node_iter : iterator of strings
|
| 127 |
+
nodes to be removed
|
| 128 |
+
remove_connected_edges : bool
|
| 129 |
+
if True, remove edges that are adjacent to the node
|
| 130 |
+
'''
|
| 131 |
+
for each_node in node_iter:
|
| 132 |
+
self.remove_node(each_node, remove_connected_edges)
|
| 133 |
+
|
| 134 |
+
def remove_edge(self, edge: str):
|
| 135 |
+
''' remove an edge
|
| 136 |
+
|
| 137 |
+
Parameters
|
| 138 |
+
----------
|
| 139 |
+
edge : str
|
| 140 |
+
edge to be removed
|
| 141 |
+
'''
|
| 142 |
+
self.hg.remove_node(edge)
|
| 143 |
+
self.edges.remove(edge)
|
| 144 |
+
self.num_edges -= 1
|
| 145 |
+
self.nodes_in_edge_dict.pop(edge)
|
| 146 |
+
|
| 147 |
+
def remove_edges(self, edge_iter):
|
| 148 |
+
''' remove a set of edges
|
| 149 |
+
|
| 150 |
+
Parameters
|
| 151 |
+
----------
|
| 152 |
+
edge_iter : iterator of strings
|
| 153 |
+
edges to be removed
|
| 154 |
+
'''
|
| 155 |
+
for each_edge in edge_iter:
|
| 156 |
+
self.remove_edge(each_edge)
|
| 157 |
+
|
| 158 |
+
def remove_edges_with_attr(self, edge_attr_dict):
|
| 159 |
+
remove_edge_list = []
|
| 160 |
+
for each_edge in self.edges:
|
| 161 |
+
satisfy = True
|
| 162 |
+
for each_key, each_val in edge_attr_dict.items():
|
| 163 |
+
if not satisfy:
|
| 164 |
+
break
|
| 165 |
+
try:
|
| 166 |
+
if self.edge_attr(each_edge)[each_key] != each_val:
|
| 167 |
+
satisfy = False
|
| 168 |
+
except KeyError:
|
| 169 |
+
satisfy = False
|
| 170 |
+
if satisfy:
|
| 171 |
+
remove_edge_list.append(each_edge)
|
| 172 |
+
self.remove_edges(remove_edge_list)
|
| 173 |
+
|
| 174 |
+
def remove_subhg(self, subhg):
|
| 175 |
+
''' remove subhypergraph.
|
| 176 |
+
all of the hyperedges are removed.
|
| 177 |
+
each node of subhg is removed if its degree becomes 0 after removing hyperedges.
|
| 178 |
+
|
| 179 |
+
Parameters
|
| 180 |
+
----------
|
| 181 |
+
subhg : Hypergraph
|
| 182 |
+
'''
|
| 183 |
+
for each_edge in subhg.edges:
|
| 184 |
+
self.remove_edge(each_edge)
|
| 185 |
+
for each_node in subhg.nodes:
|
| 186 |
+
if self.degree(each_node) == 0:
|
| 187 |
+
self.remove_node(each_node)
|
| 188 |
+
|
| 189 |
+
def nodes_in_edge(self, edge):
|
| 190 |
+
''' return an ordered list of nodes in a given edge.
|
| 191 |
+
|
| 192 |
+
Parameters
|
| 193 |
+
----------
|
| 194 |
+
edge : str
|
| 195 |
+
edge whose nodes are returned
|
| 196 |
+
|
| 197 |
+
Returns
|
| 198 |
+
-------
|
| 199 |
+
list or set
|
| 200 |
+
ordered list or set of nodes that belong to the edge
|
| 201 |
+
'''
|
| 202 |
+
if edge.startswith('e'):
|
| 203 |
+
return self.nodes_in_edge_dict[edge]
|
| 204 |
+
else:
|
| 205 |
+
adj_node_list = self.hg.adj[edge]
|
| 206 |
+
adj_node_order_list = []
|
| 207 |
+
adj_node_name_list = []
|
| 208 |
+
for each_node in adj_node_list:
|
| 209 |
+
adj_node_order_list.append(adj_node_list[each_node]['order'])
|
| 210 |
+
adj_node_name_list.append(each_node)
|
| 211 |
+
if adj_node_order_list == [-1] * len(adj_node_order_list):
|
| 212 |
+
return set(adj_node_name_list)
|
| 213 |
+
else:
|
| 214 |
+
return [adj_node_name_list[each_idx] for each_idx
|
| 215 |
+
in np.argsort(adj_node_order_list)]
|
| 216 |
+
|
| 217 |
+
def adj_edges(self, node):
|
| 218 |
+
''' return a dict of adjacent hyperedges
|
| 219 |
+
|
| 220 |
+
Parameters
|
| 221 |
+
----------
|
| 222 |
+
node : str
|
| 223 |
+
|
| 224 |
+
Returns
|
| 225 |
+
-------
|
| 226 |
+
set
|
| 227 |
+
set of edges that are adjacent to `node`
|
| 228 |
+
'''
|
| 229 |
+
return self.hg.adj[node]
|
| 230 |
+
|
| 231 |
+
def adj_nodes(self, node):
|
| 232 |
+
''' return a set of adjacent nodes
|
| 233 |
+
|
| 234 |
+
Parameters
|
| 235 |
+
----------
|
| 236 |
+
node : str
|
| 237 |
+
|
| 238 |
+
Returns
|
| 239 |
+
-------
|
| 240 |
+
set
|
| 241 |
+
set of nodes that are adjacent to `node`
|
| 242 |
+
'''
|
| 243 |
+
node_set = set([])
|
| 244 |
+
for each_adj_edge in self.adj_edges(node):
|
| 245 |
+
node_set.update(set(self.nodes_in_edge(each_adj_edge)))
|
| 246 |
+
node_set.discard(node)
|
| 247 |
+
return node_set
|
| 248 |
+
|
| 249 |
+
def has_edge(self, node_list, ignore_order=False):
|
| 250 |
+
for each_edge in self.edges:
|
| 251 |
+
if ignore_order:
|
| 252 |
+
if set(self.nodes_in_edge(each_edge)) == set(node_list):
|
| 253 |
+
return each_edge
|
| 254 |
+
else:
|
| 255 |
+
if self.nodes_in_edge(each_edge) == node_list:
|
| 256 |
+
return each_edge
|
| 257 |
+
return False
|
| 258 |
+
|
| 259 |
+
def degree(self, node):
|
| 260 |
+
return len(self.hg.adj[node])
|
| 261 |
+
|
| 262 |
+
def degrees(self):
|
| 263 |
+
return {each_node: self.degree(each_node) for each_node in self.nodes}
|
| 264 |
+
|
| 265 |
+
def edge_degree(self, edge):
|
| 266 |
+
return len(self.nodes_in_edge(edge))
|
| 267 |
+
|
| 268 |
+
def edge_degrees(self):
|
| 269 |
+
return {each_edge: self.edge_degree(each_edge) for each_edge in self.edges}
|
| 270 |
+
|
| 271 |
+
def is_adj(self, node1, node2):
|
| 272 |
+
return node1 in self.adj_nodes(node2)
|
| 273 |
+
|
| 274 |
+
def adj_subhg(self, node, ident_node_dict=None):
|
| 275 |
+
""" return a subhypergraph consisting of a set of nodes and hyperedges adjacent to `node`.
|
| 276 |
+
if an adjacent node has a self-loop hyperedge, it will be also added to the subhypergraph.
|
| 277 |
+
|
| 278 |
+
Parameters
|
| 279 |
+
----------
|
| 280 |
+
node : str
|
| 281 |
+
ident_node_dict : dict
|
| 282 |
+
dict containing identical nodes. see `get_identical_node_dict` for more details
|
| 283 |
+
|
| 284 |
+
Returns
|
| 285 |
+
-------
|
| 286 |
+
subhg : Hypergraph
|
| 287 |
+
"""
|
| 288 |
+
if ident_node_dict is None:
|
| 289 |
+
ident_node_dict = self.get_identical_node_dict()
|
| 290 |
+
adj_node_set = set(ident_node_dict[node])
|
| 291 |
+
adj_edge_set = set([])
|
| 292 |
+
for each_node in ident_node_dict[node]:
|
| 293 |
+
adj_edge_set.update(set(self.adj_edges(each_node)))
|
| 294 |
+
fixed_adj_edge_set = deepcopy(adj_edge_set)
|
| 295 |
+
for each_edge in fixed_adj_edge_set:
|
| 296 |
+
other_nodes = self.nodes_in_edge(each_edge)
|
| 297 |
+
adj_node_set.update(other_nodes)
|
| 298 |
+
|
| 299 |
+
# if the adjacent node has self-loop edge, it will be appended to adj_edge_list.
|
| 300 |
+
for each_node in other_nodes:
|
| 301 |
+
for other_edge in set(self.adj_edges(each_node)) - set([each_edge]):
|
| 302 |
+
if len(set(self.nodes_in_edge(other_edge)) \
|
| 303 |
+
- set(self.nodes_in_edge(each_edge))) == 0:
|
| 304 |
+
adj_edge_set.update(set([other_edge]))
|
| 305 |
+
subhg = Hypergraph()
|
| 306 |
+
for each_node in adj_node_set:
|
| 307 |
+
subhg.add_node(each_node, attr_dict=self.node_attr(each_node))
|
| 308 |
+
for each_edge in adj_edge_set:
|
| 309 |
+
subhg.add_edge(self.nodes_in_edge(each_edge),
|
| 310 |
+
attr_dict=self.edge_attr(each_edge),
|
| 311 |
+
edge_name=each_edge)
|
| 312 |
+
subhg.edge_idx = self.edge_idx
|
| 313 |
+
return subhg
|
| 314 |
+
|
| 315 |
+
def get_subhg(self, node_list, edge_list, ident_node_dict=None):
|
| 316 |
+
""" return a subhypergraph consisting of a set of nodes and hyperedges adjacent to `node`.
|
| 317 |
+
if an adjacent node has a self-loop hyperedge, it will be also added to the subhypergraph.
|
| 318 |
+
|
| 319 |
+
Parameters
|
| 320 |
+
----------
|
| 321 |
+
node : str
|
| 322 |
+
ident_node_dict : dict
|
| 323 |
+
dict containing identical nodes. see `get_identical_node_dict` for more details
|
| 324 |
+
|
| 325 |
+
Returns
|
| 326 |
+
-------
|
| 327 |
+
subhg : Hypergraph
|
| 328 |
+
"""
|
| 329 |
+
if ident_node_dict is None:
|
| 330 |
+
ident_node_dict = self.get_identical_node_dict()
|
| 331 |
+
adj_node_set = set([])
|
| 332 |
+
for each_node in node_list:
|
| 333 |
+
adj_node_set.update(set(ident_node_dict[each_node]))
|
| 334 |
+
adj_edge_set = set(edge_list)
|
| 335 |
+
|
| 336 |
+
subhg = Hypergraph()
|
| 337 |
+
for each_node in adj_node_set:
|
| 338 |
+
subhg.add_node(each_node,
|
| 339 |
+
attr_dict=deepcopy(self.node_attr(each_node)))
|
| 340 |
+
for each_edge in adj_edge_set:
|
| 341 |
+
subhg.add_edge(self.nodes_in_edge(each_edge),
|
| 342 |
+
attr_dict=deepcopy(self.edge_attr(each_edge)),
|
| 343 |
+
edge_name=each_edge)
|
| 344 |
+
subhg.edge_idx = self.edge_idx
|
| 345 |
+
return subhg
|
| 346 |
+
|
| 347 |
+
def copy(self):
|
| 348 |
+
''' return a copy of the object
|
| 349 |
+
|
| 350 |
+
Returns
|
| 351 |
+
-------
|
| 352 |
+
Hypergraph
|
| 353 |
+
'''
|
| 354 |
+
return deepcopy(self)
|
| 355 |
+
|
| 356 |
+
def node_attr(self, node):
|
| 357 |
+
return self.hg.nodes[node]['attr_dict']
|
| 358 |
+
|
| 359 |
+
def edge_attr(self, edge):
|
| 360 |
+
return self.hg.nodes[edge]['attr_dict']
|
| 361 |
+
|
| 362 |
+
def set_node_attr(self, node, attr_dict):
|
| 363 |
+
for each_key, each_val in attr_dict.items():
|
| 364 |
+
self.hg.nodes[node]['attr_dict'][each_key] = each_val
|
| 365 |
+
|
| 366 |
+
def set_edge_attr(self, edge, attr_dict):
|
| 367 |
+
for each_key, each_val in attr_dict.items():
|
| 368 |
+
self.hg.nodes[edge]['attr_dict'][each_key] = each_val
|
| 369 |
+
|
| 370 |
+
def get_identical_node_dict(self):
|
| 371 |
+
''' get identical nodes
|
| 372 |
+
nodes are identical if they share the same set of adjacent edges.
|
| 373 |
+
|
| 374 |
+
Returns
|
| 375 |
+
-------
|
| 376 |
+
ident_node_dict : dict
|
| 377 |
+
ident_node_dict[node] returns a list of nodes that are identical to `node`.
|
| 378 |
+
'''
|
| 379 |
+
ident_node_dict = {}
|
| 380 |
+
for each_node in self.nodes:
|
| 381 |
+
ident_node_list = []
|
| 382 |
+
for each_other_node in self.nodes:
|
| 383 |
+
if each_other_node == each_node:
|
| 384 |
+
ident_node_list.append(each_other_node)
|
| 385 |
+
elif self.adj_edges(each_node) == self.adj_edges(each_other_node) \
|
| 386 |
+
and len(self.adj_edges(each_node)) != 0:
|
| 387 |
+
ident_node_list.append(each_other_node)
|
| 388 |
+
ident_node_dict[each_node] = ident_node_list
|
| 389 |
+
return ident_node_dict
|
| 390 |
+
'''
|
| 391 |
+
ident_node_dict = {}
|
| 392 |
+
for each_node in self.nodes:
|
| 393 |
+
ident_node_dict[each_node] = [each_node]
|
| 394 |
+
return ident_node_dict
|
| 395 |
+
'''
|
| 396 |
+
|
| 397 |
+
def get_leaf_edge(self):
|
| 398 |
+
''' get an edge that is incident only to one edge
|
| 399 |
+
|
| 400 |
+
Returns
|
| 401 |
+
-------
|
| 402 |
+
if exists, return a leaf edge. otherwise, return None.
|
| 403 |
+
'''
|
| 404 |
+
for each_edge in self.edges:
|
| 405 |
+
if len(self.adj_nodes(each_edge)) == 1:
|
| 406 |
+
if 'tmp' not in self.edge_attr(each_edge):
|
| 407 |
+
return each_edge
|
| 408 |
+
return None
|
| 409 |
+
|
| 410 |
+
def get_nontmp_edge(self):
|
| 411 |
+
for each_edge in self.edges:
|
| 412 |
+
if 'tmp' not in self.edge_attr(each_edge):
|
| 413 |
+
return each_edge
|
| 414 |
+
return None
|
| 415 |
+
|
| 416 |
+
def is_subhg(self, hg):
|
| 417 |
+
''' return whether this hypergraph is a subhypergraph of `hg`
|
| 418 |
+
|
| 419 |
+
Returns
|
| 420 |
+
-------
|
| 421 |
+
True if self \in hg,
|
| 422 |
+
False otherwise.
|
| 423 |
+
'''
|
| 424 |
+
for each_node in self.nodes:
|
| 425 |
+
if each_node not in hg.nodes:
|
| 426 |
+
return False
|
| 427 |
+
for each_edge in self.edges:
|
| 428 |
+
if each_edge not in hg.edges:
|
| 429 |
+
return False
|
| 430 |
+
return True
|
| 431 |
+
|
| 432 |
+
def in_cycle(self, node, visited=None, parent='', root_node='') -> bool:
|
| 433 |
+
''' if `node` is in a cycle, then return True. otherwise, False.
|
| 434 |
+
|
| 435 |
+
Parameters
|
| 436 |
+
----------
|
| 437 |
+
node : str
|
| 438 |
+
node in a hypergraph
|
| 439 |
+
visited : list
|
| 440 |
+
list of visited nodes, used for recursion
|
| 441 |
+
parent : str
|
| 442 |
+
parent node, used to eliminate a cycle consisting of two nodes and one edge.
|
| 443 |
+
|
| 444 |
+
Returns
|
| 445 |
+
-------
|
| 446 |
+
bool
|
| 447 |
+
'''
|
| 448 |
+
if visited is None:
|
| 449 |
+
visited = []
|
| 450 |
+
if parent == '':
|
| 451 |
+
visited = []
|
| 452 |
+
if root_node == '':
|
| 453 |
+
root_node = node
|
| 454 |
+
visited.append(node)
|
| 455 |
+
for each_adj_node in self.adj_nodes(node):
|
| 456 |
+
if each_adj_node not in visited:
|
| 457 |
+
if self.in_cycle(each_adj_node, visited, node, root_node):
|
| 458 |
+
return True
|
| 459 |
+
elif each_adj_node != parent and each_adj_node == root_node:
|
| 460 |
+
return True
|
| 461 |
+
return False
|
| 462 |
+
|
| 463 |
+
|
| 464 |
+
def draw(self, file_path=None, with_node=False, with_edge_name=False):
|
| 465 |
+
''' draw hypergraph
|
| 466 |
+
'''
|
| 467 |
+
import graphviz
|
| 468 |
+
G = graphviz.Graph(format='png')
|
| 469 |
+
for each_node in self.nodes:
|
| 470 |
+
if 'ext_id' in self.node_attr(each_node):
|
| 471 |
+
G.node(each_node, label='',
|
| 472 |
+
shape='circle', width='0.1', height='0.1', style='filled',
|
| 473 |
+
fillcolor='black')
|
| 474 |
+
else:
|
| 475 |
+
if with_node:
|
| 476 |
+
G.node(each_node, label='',
|
| 477 |
+
shape='circle', width='0.1', height='0.1', style='filled',
|
| 478 |
+
fillcolor='gray')
|
| 479 |
+
edge_list = []
|
| 480 |
+
for each_edge in self.edges:
|
| 481 |
+
if self.edge_attr(each_edge).get('terminal', False):
|
| 482 |
+
G.node(each_edge,
|
| 483 |
+
label=self.edge_attr(each_edge)['symbol'].symbol if not with_edge_name \
|
| 484 |
+
else self.edge_attr(each_edge)['symbol'].symbol + ', ' + each_edge,
|
| 485 |
+
fontcolor='black', shape='square')
|
| 486 |
+
elif self.edge_attr(each_edge).get('tmp', False):
|
| 487 |
+
G.node(each_edge, label='tmp' if not with_edge_name else 'tmp, ' + each_edge,
|
| 488 |
+
fontcolor='black', shape='square')
|
| 489 |
+
else:
|
| 490 |
+
G.node(each_edge,
|
| 491 |
+
label=self.edge_attr(each_edge)['symbol'].symbol if not with_edge_name \
|
| 492 |
+
else self.edge_attr(each_edge)['symbol'].symbol + ', ' + each_edge,
|
| 493 |
+
fontcolor='black', shape='square', style='filled')
|
| 494 |
+
if with_node:
|
| 495 |
+
for each_node in self.nodes_in_edge(each_edge):
|
| 496 |
+
G.edge(each_edge, each_node)
|
| 497 |
+
else:
|
| 498 |
+
for each_node in self.nodes_in_edge(each_edge):
|
| 499 |
+
if 'ext_id' in self.node_attr(each_node)\
|
| 500 |
+
and set([each_node, each_edge]) not in edge_list:
|
| 501 |
+
G.edge(each_edge, each_node)
|
| 502 |
+
edge_list.append(set([each_node, each_edge]))
|
| 503 |
+
for each_other_edge in self.adj_nodes(each_edge):
|
| 504 |
+
if set([each_edge, each_other_edge]) not in edge_list:
|
| 505 |
+
num_bond = 0
|
| 506 |
+
common_node_set = set(self.nodes_in_edge(each_edge))\
|
| 507 |
+
.intersection(set(self.nodes_in_edge(each_other_edge)))
|
| 508 |
+
for each_node in common_node_set:
|
| 509 |
+
if self.node_attr(each_node)['symbol'].bond_type in [1, 2, 3]:
|
| 510 |
+
num_bond += self.node_attr(each_node)['symbol'].bond_type
|
| 511 |
+
elif self.node_attr(each_node)['symbol'].bond_type in [12]:
|
| 512 |
+
num_bond += 1
|
| 513 |
+
else:
|
| 514 |
+
raise NotImplementedError('unsupported bond type')
|
| 515 |
+
for _ in range(num_bond):
|
| 516 |
+
G.edge(each_edge, each_other_edge)
|
| 517 |
+
edge_list.append(set([each_edge, each_other_edge]))
|
| 518 |
+
if file_path is not None:
|
| 519 |
+
G.render(file_path, cleanup=True)
|
| 520 |
+
#os.remove(file_path)
|
| 521 |
+
return G
|
| 522 |
+
|
| 523 |
+
def is_dividable(self, node):
|
| 524 |
+
_hg = deepcopy(self.hg)
|
| 525 |
+
_hg.remove_node(node)
|
| 526 |
+
return (not nx.is_connected(_hg))
|
| 527 |
+
|
| 528 |
+
def divide(self, node):
|
| 529 |
+
subhg_list = []
|
| 530 |
+
|
| 531 |
+
hg_wo_node = deepcopy(self)
|
| 532 |
+
hg_wo_node.remove_node(node, remove_connected_edges=False)
|
| 533 |
+
connected_components = nx.connected_components(hg_wo_node.hg)
|
| 534 |
+
for each_component in connected_components:
|
| 535 |
+
node_list = [node]
|
| 536 |
+
edge_list = []
|
| 537 |
+
node_list.extend([each_node for each_node in each_component
|
| 538 |
+
if each_node.startswith('bond_')])
|
| 539 |
+
edge_list.extend([each_edge for each_edge in each_component
|
| 540 |
+
if each_edge.startswith('e')])
|
| 541 |
+
subhg_list.append(self.get_subhg(node_list, edge_list))
|
| 542 |
+
#subhg_list[-1].set_node_attr(node, {'divided': True})
|
| 543 |
+
return subhg_list
|
| 544 |
+
|
graph_grammar/io/__init__.py
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# -*- coding: utf-8 -*-
|
| 3 |
+
# Rhizome
|
| 4 |
+
# Version beta 0.0, August 2023
|
| 5 |
+
# Property of IBM Research, Accelerated Discovery
|
| 6 |
+
#
|
| 7 |
+
|
| 8 |
+
"""
|
| 9 |
+
PLEASE NOTE THIS IMPLEMENTATION INCLUDES THE ORIGINAL SOURCE CODE (AND SOME ADAPTATIONS)
|
| 10 |
+
OF THE MHG IMPLEMENTATION OF HIROSHI KAJINO AT IBM TRL ALREADY PUBLICLY AVAILABLE.
|
| 11 |
+
THIS MIGHT INFLUENCE THE DECISION OF THE FINAL LICENSE SO CAREFUL CHECK NEEDS BE DONE.
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
""" Title """
|
| 15 |
+
|
| 16 |
+
__author__ = "Hiroshi Kajino <KAJINO@jp.ibm.com>"
|
| 17 |
+
__copyright__ = "(c) Copyright IBM Corp. 2018"
|
| 18 |
+
__version__ = "0.1"
|
| 19 |
+
__date__ = "Jan 1 2018"
|
| 20 |
+
|
graph_grammar/io/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (669 Bytes). View file
|
|
|
graph_grammar/io/__pycache__/smi.cpython-310.pyc
ADDED
|
Binary file (12.9 kB). View file
|
|
|
graph_grammar/io/smi.py
ADDED
|
@@ -0,0 +1,559 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# -*- coding: utf-8 -*-
|
| 3 |
+
# Rhizome
|
| 4 |
+
# Version beta 0.0, August 2023
|
| 5 |
+
# Property of IBM Research, Accelerated Discovery
|
| 6 |
+
#
|
| 7 |
+
|
| 8 |
+
"""
|
| 9 |
+
PLEASE NOTE THIS IMPLEMENTATION INCLUDES THE ORIGINAL SOURCE CODE (AND SOME ADAPTATIONS)
|
| 10 |
+
OF THE MHG IMPLEMENTATION OF HIROSHI KAJINO AT IBM TRL ALREADY PUBLICLY AVAILABLE.
|
| 11 |
+
THIS MIGHT INFLUENCE THE DECISION OF THE FINAL LICENSE SO CAREFUL CHECK NEEDS BE DONE.
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
""" Title """
|
| 15 |
+
|
| 16 |
+
__author__ = "Hiroshi Kajino <KAJINO@jp.ibm.com>"
|
| 17 |
+
__copyright__ = "(c) Copyright IBM Corp. 2018"
|
| 18 |
+
__version__ = "0.1"
|
| 19 |
+
__date__ = "Jan 12 2018"
|
| 20 |
+
|
| 21 |
+
from copy import deepcopy
|
| 22 |
+
from rdkit import Chem
|
| 23 |
+
from rdkit import RDLogger
|
| 24 |
+
import networkx as nx
|
| 25 |
+
import numpy as np
|
| 26 |
+
from ..hypergraph import Hypergraph
|
| 27 |
+
from ..graph_grammar.symbols import TSymbol, BondSymbol
|
| 28 |
+
|
| 29 |
+
# supress warnings
|
| 30 |
+
lg = RDLogger.logger()
|
| 31 |
+
lg.setLevel(RDLogger.CRITICAL)
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
class HGGen(object):
|
| 35 |
+
"""
|
| 36 |
+
load .smi file and yield a hypergraph.
|
| 37 |
+
|
| 38 |
+
Attributes
|
| 39 |
+
----------
|
| 40 |
+
path_to_file : str
|
| 41 |
+
path to .smi file
|
| 42 |
+
kekulize : bool
|
| 43 |
+
kekulize or not
|
| 44 |
+
add_Hs : bool
|
| 45 |
+
add implicit hydrogens to the molecule or not.
|
| 46 |
+
all_single : bool
|
| 47 |
+
if True, all multiple bonds are summarized into a single bond with some attributes
|
| 48 |
+
|
| 49 |
+
Yields
|
| 50 |
+
------
|
| 51 |
+
Hypergraph
|
| 52 |
+
"""
|
| 53 |
+
def __init__(self, path_to_file, kekulize=True, add_Hs=False, all_single=True):
|
| 54 |
+
self.num_line = 1
|
| 55 |
+
self.mol_gen = Chem.SmilesMolSupplier(path_to_file, titleLine=False)
|
| 56 |
+
self.kekulize = kekulize
|
| 57 |
+
self.add_Hs = add_Hs
|
| 58 |
+
self.all_single = all_single
|
| 59 |
+
|
| 60 |
+
def __iter__(self):
|
| 61 |
+
return self
|
| 62 |
+
|
| 63 |
+
def __next__(self):
|
| 64 |
+
'''
|
| 65 |
+
each_mol = None
|
| 66 |
+
while each_mol is None:
|
| 67 |
+
each_mol = next(self.mol_gen)
|
| 68 |
+
'''
|
| 69 |
+
# not ignoring parse errors
|
| 70 |
+
each_mol = next(self.mol_gen)
|
| 71 |
+
if each_mol is None:
|
| 72 |
+
raise ValueError(f'incorrect smiles in line {self.num_line}')
|
| 73 |
+
else:
|
| 74 |
+
self.num_line += 1
|
| 75 |
+
return mol_to_hg(each_mol, self.kekulize, self.add_Hs)
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def mol_to_bipartite(mol, kekulize):
|
| 79 |
+
"""
|
| 80 |
+
get a bipartite representation of a molecule.
|
| 81 |
+
|
| 82 |
+
Parameters
|
| 83 |
+
----------
|
| 84 |
+
mol : rdkit.Chem.rdchem.Mol
|
| 85 |
+
molecule object
|
| 86 |
+
|
| 87 |
+
Returns
|
| 88 |
+
-------
|
| 89 |
+
nx.Graph
|
| 90 |
+
a bipartite graph representing which bond is connected to which atoms.
|
| 91 |
+
"""
|
| 92 |
+
try:
|
| 93 |
+
mol = standardize_stereo(mol)
|
| 94 |
+
except KeyError:
|
| 95 |
+
print(Chem.MolToSmiles(mol))
|
| 96 |
+
raise KeyError
|
| 97 |
+
|
| 98 |
+
if kekulize:
|
| 99 |
+
Chem.Kekulize(mol)
|
| 100 |
+
|
| 101 |
+
bipartite_g = nx.Graph()
|
| 102 |
+
for each_atom in mol.GetAtoms():
|
| 103 |
+
bipartite_g.add_node(f"atom_{each_atom.GetIdx()}",
|
| 104 |
+
atom_attr=atom_attr(each_atom, kekulize))
|
| 105 |
+
|
| 106 |
+
for each_bond in mol.GetBonds():
|
| 107 |
+
bond_idx = each_bond.GetIdx()
|
| 108 |
+
bipartite_g.add_node(
|
| 109 |
+
f"bond_{bond_idx}",
|
| 110 |
+
bond_attr=bond_attr(each_bond, kekulize))
|
| 111 |
+
bipartite_g.add_edge(
|
| 112 |
+
f"atom_{each_bond.GetBeginAtomIdx()}",
|
| 113 |
+
f"bond_{bond_idx}")
|
| 114 |
+
bipartite_g.add_edge(
|
| 115 |
+
f"atom_{each_bond.GetEndAtomIdx()}",
|
| 116 |
+
f"bond_{bond_idx}")
|
| 117 |
+
return bipartite_g
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
def mol_to_hg(mol, kekulize, add_Hs):
|
| 121 |
+
"""
|
| 122 |
+
get a bipartite representation of a molecule.
|
| 123 |
+
|
| 124 |
+
Parameters
|
| 125 |
+
----------
|
| 126 |
+
mol : rdkit.Chem.rdchem.Mol
|
| 127 |
+
molecule object
|
| 128 |
+
kekulize : bool
|
| 129 |
+
kekulize or not
|
| 130 |
+
add_Hs : bool
|
| 131 |
+
add implicit hydrogens to the molecule or not.
|
| 132 |
+
|
| 133 |
+
Returns
|
| 134 |
+
-------
|
| 135 |
+
Hypergraph
|
| 136 |
+
"""
|
| 137 |
+
if add_Hs:
|
| 138 |
+
mol = Chem.AddHs(mol)
|
| 139 |
+
|
| 140 |
+
if kekulize:
|
| 141 |
+
Chem.Kekulize(mol)
|
| 142 |
+
|
| 143 |
+
bipartite_g = mol_to_bipartite(mol, kekulize)
|
| 144 |
+
hg = Hypergraph()
|
| 145 |
+
for each_atom in [each_node for each_node in bipartite_g.nodes()
|
| 146 |
+
if each_node.startswith('atom_')]:
|
| 147 |
+
node_set = set([])
|
| 148 |
+
for each_bond in bipartite_g.adj[each_atom]:
|
| 149 |
+
hg.add_node(each_bond,
|
| 150 |
+
attr_dict=bipartite_g.nodes[each_bond]['bond_attr'])
|
| 151 |
+
node_set.add(each_bond)
|
| 152 |
+
hg.add_edge(node_set,
|
| 153 |
+
attr_dict=bipartite_g.nodes[each_atom]['atom_attr'])
|
| 154 |
+
return hg
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
def hg_to_mol(hg, verbose=False):
|
| 158 |
+
""" convert a hypergraph into Mol object
|
| 159 |
+
|
| 160 |
+
Parameters
|
| 161 |
+
----------
|
| 162 |
+
hg : Hypergraph
|
| 163 |
+
|
| 164 |
+
Returns
|
| 165 |
+
-------
|
| 166 |
+
mol : Chem.RWMol
|
| 167 |
+
"""
|
| 168 |
+
mol = Chem.RWMol()
|
| 169 |
+
atom_dict = {}
|
| 170 |
+
bond_set = set([])
|
| 171 |
+
for each_edge in hg.edges:
|
| 172 |
+
atom = Chem.Atom(hg.edge_attr(each_edge)['symbol'].symbol)
|
| 173 |
+
atom.SetNumExplicitHs(hg.edge_attr(each_edge)['symbol'].num_explicit_Hs)
|
| 174 |
+
atom.SetFormalCharge(hg.edge_attr(each_edge)['symbol'].formal_charge)
|
| 175 |
+
atom.SetChiralTag(
|
| 176 |
+
Chem.rdchem.ChiralType.values[
|
| 177 |
+
hg.edge_attr(each_edge)['symbol'].chirality])
|
| 178 |
+
atom_idx = mol.AddAtom(atom)
|
| 179 |
+
atom_dict[each_edge] = atom_idx
|
| 180 |
+
|
| 181 |
+
for each_node in hg.nodes:
|
| 182 |
+
edge_1, edge_2 = hg.adj_edges(each_node)
|
| 183 |
+
if edge_1+edge_2 not in bond_set:
|
| 184 |
+
if hg.node_attr(each_node)['symbol'].bond_type <= 3:
|
| 185 |
+
num_bond = hg.node_attr(each_node)['symbol'].bond_type
|
| 186 |
+
elif hg.node_attr(each_node)['symbol'].bond_type == 12:
|
| 187 |
+
num_bond = 1
|
| 188 |
+
else:
|
| 189 |
+
raise ValueError(f'too many bonds; {hg.node_attr(each_node)["bond_symbol"].bond_type}')
|
| 190 |
+
_ = mol.AddBond(atom_dict[edge_1],
|
| 191 |
+
atom_dict[edge_2],
|
| 192 |
+
order=Chem.rdchem.BondType.values[num_bond])
|
| 193 |
+
bond_idx = mol.GetBondBetweenAtoms(atom_dict[edge_1], atom_dict[edge_2]).GetIdx()
|
| 194 |
+
|
| 195 |
+
# stereo
|
| 196 |
+
mol.GetBondWithIdx(bond_idx).SetStereo(
|
| 197 |
+
Chem.rdchem.BondStereo.values[hg.node_attr(each_node)['symbol'].stereo])
|
| 198 |
+
bond_set.update([edge_1+edge_2])
|
| 199 |
+
bond_set.update([edge_2+edge_1])
|
| 200 |
+
mol.UpdatePropertyCache()
|
| 201 |
+
mol = mol.GetMol()
|
| 202 |
+
not_stereo_mol = deepcopy(mol)
|
| 203 |
+
if Chem.MolFromSmiles(Chem.MolToSmiles(not_stereo_mol)) is None:
|
| 204 |
+
raise RuntimeError('no valid molecule was obtained.')
|
| 205 |
+
try:
|
| 206 |
+
mol = set_stereo(mol)
|
| 207 |
+
is_stereo = True
|
| 208 |
+
except:
|
| 209 |
+
import traceback
|
| 210 |
+
traceback.print_exc()
|
| 211 |
+
is_stereo = False
|
| 212 |
+
mol_tmp = deepcopy(mol)
|
| 213 |
+
Chem.SetAromaticity(mol_tmp)
|
| 214 |
+
if Chem.MolFromSmiles(Chem.MolToSmiles(mol_tmp)) is not None:
|
| 215 |
+
mol = mol_tmp
|
| 216 |
+
else:
|
| 217 |
+
if Chem.MolFromSmiles(Chem.MolToSmiles(mol)) is None:
|
| 218 |
+
mol = not_stereo_mol
|
| 219 |
+
mol.UpdatePropertyCache()
|
| 220 |
+
Chem.GetSymmSSSR(mol)
|
| 221 |
+
mol = Chem.MolFromSmiles(Chem.MolToSmiles(mol))
|
| 222 |
+
if verbose:
|
| 223 |
+
return mol, is_stereo
|
| 224 |
+
else:
|
| 225 |
+
return mol
|
| 226 |
+
|
| 227 |
+
def hgs_to_mols(hg_list, ignore_error=False):
|
| 228 |
+
if ignore_error:
|
| 229 |
+
mol_list = []
|
| 230 |
+
for each_hg in hg_list:
|
| 231 |
+
try:
|
| 232 |
+
mol = hg_to_mol(each_hg)
|
| 233 |
+
except:
|
| 234 |
+
mol = None
|
| 235 |
+
mol_list.append(mol)
|
| 236 |
+
else:
|
| 237 |
+
mol_list = [hg_to_mol(each_hg) for each_hg in hg_list]
|
| 238 |
+
return mol_list
|
| 239 |
+
|
| 240 |
+
def hgs_to_smiles(hg_list, ignore_error=False):
|
| 241 |
+
mol_list = hgs_to_mols(hg_list, ignore_error)
|
| 242 |
+
smiles_list = []
|
| 243 |
+
for each_mol in mol_list:
|
| 244 |
+
try:
|
| 245 |
+
smiles_list.append(
|
| 246 |
+
Chem.MolToSmiles(
|
| 247 |
+
Chem.MolFromSmiles(
|
| 248 |
+
Chem.MolToSmiles(
|
| 249 |
+
each_mol))))
|
| 250 |
+
except:
|
| 251 |
+
smiles_list.append(None)
|
| 252 |
+
return smiles_list
|
| 253 |
+
|
| 254 |
+
def atom_attr(atom, kekulize):
|
| 255 |
+
"""
|
| 256 |
+
get atom's attributes
|
| 257 |
+
|
| 258 |
+
Parameters
|
| 259 |
+
----------
|
| 260 |
+
atom : rdkit.Chem.rdchem.Atom
|
| 261 |
+
kekulize : bool
|
| 262 |
+
kekulize or not
|
| 263 |
+
|
| 264 |
+
Returns
|
| 265 |
+
-------
|
| 266 |
+
atom_attr : dict
|
| 267 |
+
"is_aromatic" : bool
|
| 268 |
+
the atom is aromatic or not.
|
| 269 |
+
"smarts" : str
|
| 270 |
+
SMARTS representation of the atom.
|
| 271 |
+
"""
|
| 272 |
+
if kekulize:
|
| 273 |
+
return {'terminal': True,
|
| 274 |
+
'is_in_ring': atom.IsInRing(),
|
| 275 |
+
'symbol': TSymbol(degree=0,
|
| 276 |
+
#degree=atom.GetTotalDegree(),
|
| 277 |
+
is_aromatic=False,
|
| 278 |
+
symbol=atom.GetSymbol(),
|
| 279 |
+
num_explicit_Hs=atom.GetNumExplicitHs(),
|
| 280 |
+
formal_charge=atom.GetFormalCharge(),
|
| 281 |
+
chirality=atom.GetChiralTag().real
|
| 282 |
+
)}
|
| 283 |
+
else:
|
| 284 |
+
return {'terminal': True,
|
| 285 |
+
'is_in_ring': atom.IsInRing(),
|
| 286 |
+
'symbol': TSymbol(degree=0,
|
| 287 |
+
#degree=atom.GetTotalDegree(),
|
| 288 |
+
is_aromatic=atom.GetIsAromatic(),
|
| 289 |
+
symbol=atom.GetSymbol(),
|
| 290 |
+
num_explicit_Hs=atom.GetNumExplicitHs(),
|
| 291 |
+
formal_charge=atom.GetFormalCharge(),
|
| 292 |
+
chirality=atom.GetChiralTag().real
|
| 293 |
+
)}
|
| 294 |
+
|
| 295 |
+
def bond_attr(bond, kekulize):
|
| 296 |
+
"""
|
| 297 |
+
get atom's attributes
|
| 298 |
+
|
| 299 |
+
Parameters
|
| 300 |
+
----------
|
| 301 |
+
bond : rdkit.Chem.rdchem.Bond
|
| 302 |
+
kekulize : bool
|
| 303 |
+
kekulize or not
|
| 304 |
+
|
| 305 |
+
Returns
|
| 306 |
+
-------
|
| 307 |
+
bond_attr : dict
|
| 308 |
+
"bond_type" : int
|
| 309 |
+
{0: rdkit.Chem.rdchem.BondType.UNSPECIFIED,
|
| 310 |
+
1: rdkit.Chem.rdchem.BondType.SINGLE,
|
| 311 |
+
2: rdkit.Chem.rdchem.BondType.DOUBLE,
|
| 312 |
+
3: rdkit.Chem.rdchem.BondType.TRIPLE,
|
| 313 |
+
4: rdkit.Chem.rdchem.BondType.QUADRUPLE,
|
| 314 |
+
5: rdkit.Chem.rdchem.BondType.QUINTUPLE,
|
| 315 |
+
6: rdkit.Chem.rdchem.BondType.HEXTUPLE,
|
| 316 |
+
7: rdkit.Chem.rdchem.BondType.ONEANDAHALF,
|
| 317 |
+
8: rdkit.Chem.rdchem.BondType.TWOANDAHALF,
|
| 318 |
+
9: rdkit.Chem.rdchem.BondType.THREEANDAHALF,
|
| 319 |
+
10: rdkit.Chem.rdchem.BondType.FOURANDAHALF,
|
| 320 |
+
11: rdkit.Chem.rdchem.BondType.FIVEANDAHALF,
|
| 321 |
+
12: rdkit.Chem.rdchem.BondType.AROMATIC,
|
| 322 |
+
13: rdkit.Chem.rdchem.BondType.IONIC,
|
| 323 |
+
14: rdkit.Chem.rdchem.BondType.HYDROGEN,
|
| 324 |
+
15: rdkit.Chem.rdchem.BondType.THREECENTER,
|
| 325 |
+
16: rdkit.Chem.rdchem.BondType.DATIVEONE,
|
| 326 |
+
17: rdkit.Chem.rdchem.BondType.DATIVE,
|
| 327 |
+
18: rdkit.Chem.rdchem.BondType.DATIVEL,
|
| 328 |
+
19: rdkit.Chem.rdchem.BondType.DATIVER,
|
| 329 |
+
20: rdkit.Chem.rdchem.BondType.OTHER,
|
| 330 |
+
21: rdkit.Chem.rdchem.BondType.ZERO}
|
| 331 |
+
"""
|
| 332 |
+
if kekulize:
|
| 333 |
+
is_aromatic = False
|
| 334 |
+
if bond.GetBondType().real == 12:
|
| 335 |
+
bond_type = 1
|
| 336 |
+
else:
|
| 337 |
+
bond_type = bond.GetBondType().real
|
| 338 |
+
else:
|
| 339 |
+
is_aromatic = bond.GetIsAromatic()
|
| 340 |
+
bond_type = bond.GetBondType().real
|
| 341 |
+
return {'symbol': BondSymbol(is_aromatic=is_aromatic,
|
| 342 |
+
bond_type=bond_type,
|
| 343 |
+
stereo=int(bond.GetStereo())),
|
| 344 |
+
'is_in_ring': bond.IsInRing()}
|
| 345 |
+
|
| 346 |
+
|
| 347 |
+
def standardize_stereo(mol):
|
| 348 |
+
'''
|
| 349 |
+
0: rdkit.Chem.rdchem.BondDir.NONE,
|
| 350 |
+
1: rdkit.Chem.rdchem.BondDir.BEGINWEDGE,
|
| 351 |
+
2: rdkit.Chem.rdchem.BondDir.BEGINDASH,
|
| 352 |
+
3: rdkit.Chem.rdchem.BondDir.ENDDOWNRIGHT,
|
| 353 |
+
4: rdkit.Chem.rdchem.BondDir.ENDUPRIGHT,
|
| 354 |
+
|
| 355 |
+
'''
|
| 356 |
+
# mol = Chem.AddHs(mol) # this removes CIPRank !!!
|
| 357 |
+
for each_bond in mol.GetBonds():
|
| 358 |
+
if int(each_bond.GetStereo()) in [2, 3]: #2=Z (same side), 3=E
|
| 359 |
+
begin_stereo_atom_idx = each_bond.GetBeginAtomIdx()
|
| 360 |
+
end_stereo_atom_idx = each_bond.GetEndAtomIdx()
|
| 361 |
+
atom_idx_1 = each_bond.GetStereoAtoms()[0]
|
| 362 |
+
atom_idx_2 = each_bond.GetStereoAtoms()[1]
|
| 363 |
+
if mol.GetBondBetweenAtoms(atom_idx_1, begin_stereo_atom_idx):
|
| 364 |
+
begin_atom_idx = atom_idx_1
|
| 365 |
+
end_atom_idx = atom_idx_2
|
| 366 |
+
else:
|
| 367 |
+
begin_atom_idx = atom_idx_2
|
| 368 |
+
end_atom_idx = atom_idx_1
|
| 369 |
+
|
| 370 |
+
begin_another_atom_idx = None
|
| 371 |
+
assert len(mol.GetAtomWithIdx(begin_stereo_atom_idx).GetNeighbors()) <= 3
|
| 372 |
+
for each_neighbor in mol.GetAtomWithIdx(begin_stereo_atom_idx).GetNeighbors():
|
| 373 |
+
each_neighbor_idx = each_neighbor.GetIdx()
|
| 374 |
+
if each_neighbor_idx not in [end_stereo_atom_idx, begin_atom_idx]:
|
| 375 |
+
begin_another_atom_idx = each_neighbor_idx
|
| 376 |
+
|
| 377 |
+
end_another_atom_idx = None
|
| 378 |
+
assert len(mol.GetAtomWithIdx(end_stereo_atom_idx).GetNeighbors()) <= 3
|
| 379 |
+
for each_neighbor in mol.GetAtomWithIdx(end_stereo_atom_idx).GetNeighbors():
|
| 380 |
+
each_neighbor_idx = each_neighbor.GetIdx()
|
| 381 |
+
if each_neighbor_idx not in [begin_stereo_atom_idx, end_atom_idx]:
|
| 382 |
+
end_another_atom_idx = each_neighbor_idx
|
| 383 |
+
|
| 384 |
+
'''
|
| 385 |
+
relationship between begin_atom_idx and end_atom_idx is encoded in GetStereo
|
| 386 |
+
'''
|
| 387 |
+
begin_atom_rank = int(mol.GetAtomWithIdx(begin_atom_idx).GetProp('_CIPRank'))
|
| 388 |
+
end_atom_rank = int(mol.GetAtomWithIdx(end_atom_idx).GetProp('_CIPRank'))
|
| 389 |
+
try:
|
| 390 |
+
begin_another_atom_rank = int(mol.GetAtomWithIdx(begin_another_atom_idx).GetProp('_CIPRank'))
|
| 391 |
+
except:
|
| 392 |
+
begin_another_atom_rank = np.inf
|
| 393 |
+
try:
|
| 394 |
+
end_another_atom_rank = int(mol.GetAtomWithIdx(end_another_atom_idx).GetProp('_CIPRank'))
|
| 395 |
+
except:
|
| 396 |
+
end_another_atom_rank = np.inf
|
| 397 |
+
if begin_atom_rank < begin_another_atom_rank\
|
| 398 |
+
and end_atom_rank < end_another_atom_rank:
|
| 399 |
+
pass
|
| 400 |
+
elif begin_atom_rank < begin_another_atom_rank\
|
| 401 |
+
and end_atom_rank > end_another_atom_rank:
|
| 402 |
+
# (begin_atom_idx +) end_another_atom_idx should be in StereoAtoms
|
| 403 |
+
if each_bond.GetStereo() == 2:
|
| 404 |
+
# set stereo
|
| 405 |
+
each_bond.SetStereo(Chem.rdchem.BondStereo.values[3])
|
| 406 |
+
# set bond dir
|
| 407 |
+
mol = safe_set_bond_dir(mol, begin_atom_idx, begin_stereo_atom_idx, 3)
|
| 408 |
+
mol = safe_set_bond_dir(mol, begin_another_atom_idx, begin_stereo_atom_idx, 0)
|
| 409 |
+
mol = safe_set_bond_dir(mol, end_atom_idx, end_stereo_atom_idx, 0)
|
| 410 |
+
mol = safe_set_bond_dir(mol, end_another_atom_idx, end_stereo_atom_idx, 3)
|
| 411 |
+
elif each_bond.GetStereo() == 3:
|
| 412 |
+
# set stereo
|
| 413 |
+
each_bond.SetStereo(Chem.rdchem.BondStereo.values[2])
|
| 414 |
+
# set bond dir
|
| 415 |
+
mol = safe_set_bond_dir(mol, begin_atom_idx, begin_stereo_atom_idx, 3)
|
| 416 |
+
mol = safe_set_bond_dir(mol, begin_another_atom_idx, begin_stereo_atom_idx, 0)
|
| 417 |
+
mol = safe_set_bond_dir(mol, end_atom_idx, end_stereo_atom_idx, 0)
|
| 418 |
+
mol = safe_set_bond_dir(mol, end_another_atom_idx, end_stereo_atom_idx, 4)
|
| 419 |
+
else:
|
| 420 |
+
raise ValueError
|
| 421 |
+
each_bond.SetStereoAtoms(begin_atom_idx, end_another_atom_idx)
|
| 422 |
+
elif begin_atom_rank > begin_another_atom_rank\
|
| 423 |
+
and end_atom_rank < end_another_atom_rank:
|
| 424 |
+
# (end_atom_idx +) begin_another_atom_idx should be in StereoAtoms
|
| 425 |
+
if each_bond.GetStereo() == 2:
|
| 426 |
+
# set stereo
|
| 427 |
+
each_bond.SetStereo(Chem.rdchem.BondStereo.values[3])
|
| 428 |
+
# set bond dir
|
| 429 |
+
mol = safe_set_bond_dir(mol, begin_atom_idx, begin_stereo_atom_idx, 0)
|
| 430 |
+
mol = safe_set_bond_dir(mol, begin_another_atom_idx, begin_stereo_atom_idx, 4)
|
| 431 |
+
mol = safe_set_bond_dir(mol, end_atom_idx, end_stereo_atom_idx, 4)
|
| 432 |
+
mol = safe_set_bond_dir(mol, end_another_atom_idx, end_stereo_atom_idx, 0)
|
| 433 |
+
elif each_bond.GetStereo() == 3:
|
| 434 |
+
# set stereo
|
| 435 |
+
each_bond.SetStereo(Chem.rdchem.BondStereo.values[2])
|
| 436 |
+
# set bond dir
|
| 437 |
+
mol = safe_set_bond_dir(mol, begin_atom_idx, begin_stereo_atom_idx, 0)
|
| 438 |
+
mol = safe_set_bond_dir(mol, begin_another_atom_idx, begin_stereo_atom_idx, 4)
|
| 439 |
+
mol = safe_set_bond_dir(mol, end_atom_idx, end_stereo_atom_idx, 3)
|
| 440 |
+
mol = safe_set_bond_dir(mol, end_another_atom_idx, end_stereo_atom_idx, 0)
|
| 441 |
+
else:
|
| 442 |
+
raise ValueError
|
| 443 |
+
each_bond.SetStereoAtoms(begin_another_atom_idx, end_atom_idx)
|
| 444 |
+
elif begin_atom_rank > begin_another_atom_rank\
|
| 445 |
+
and end_atom_rank > end_another_atom_rank:
|
| 446 |
+
# begin_another_atom_idx + end_another_atom_idx should be in StereoAtoms
|
| 447 |
+
if each_bond.GetStereo() == 2:
|
| 448 |
+
# set bond dir
|
| 449 |
+
mol = safe_set_bond_dir(mol, begin_atom_idx, begin_stereo_atom_idx, 0)
|
| 450 |
+
mol = safe_set_bond_dir(mol, begin_another_atom_idx, begin_stereo_atom_idx, 4)
|
| 451 |
+
mol = safe_set_bond_dir(mol, end_atom_idx, end_stereo_atom_idx, 0)
|
| 452 |
+
mol = safe_set_bond_dir(mol, end_another_atom_idx, end_stereo_atom_idx, 3)
|
| 453 |
+
elif each_bond.GetStereo() == 3:
|
| 454 |
+
# set bond dir
|
| 455 |
+
mol = safe_set_bond_dir(mol, begin_atom_idx, begin_stereo_atom_idx, 0)
|
| 456 |
+
mol = safe_set_bond_dir(mol, begin_another_atom_idx, begin_stereo_atom_idx, 4)
|
| 457 |
+
mol = safe_set_bond_dir(mol, end_atom_idx, end_stereo_atom_idx, 0)
|
| 458 |
+
mol = safe_set_bond_dir(mol, end_another_atom_idx, end_stereo_atom_idx, 4)
|
| 459 |
+
else:
|
| 460 |
+
raise ValueError
|
| 461 |
+
each_bond.SetStereoAtoms(begin_another_atom_idx, end_another_atom_idx)
|
| 462 |
+
else:
|
| 463 |
+
raise RuntimeError
|
| 464 |
+
return mol
|
| 465 |
+
|
| 466 |
+
|
| 467 |
+
def set_stereo(mol):
|
| 468 |
+
'''
|
| 469 |
+
0: rdkit.Chem.rdchem.BondDir.NONE,
|
| 470 |
+
1: rdkit.Chem.rdchem.BondDir.BEGINWEDGE,
|
| 471 |
+
2: rdkit.Chem.rdchem.BondDir.BEGINDASH,
|
| 472 |
+
3: rdkit.Chem.rdchem.BondDir.ENDDOWNRIGHT,
|
| 473 |
+
4: rdkit.Chem.rdchem.BondDir.ENDUPRIGHT,
|
| 474 |
+
'''
|
| 475 |
+
_mol = Chem.MolFromSmiles(Chem.MolToSmiles(mol))
|
| 476 |
+
Chem.Kekulize(_mol, True)
|
| 477 |
+
substruct_match = mol.GetSubstructMatch(_mol)
|
| 478 |
+
if not substruct_match:
|
| 479 |
+
''' mol and _mol are kekulized.
|
| 480 |
+
sometimes, the order of '=' and '-' changes, which causes mol and _mol not matched.
|
| 481 |
+
'''
|
| 482 |
+
Chem.SetAromaticity(mol)
|
| 483 |
+
Chem.SetAromaticity(_mol)
|
| 484 |
+
substruct_match = mol.GetSubstructMatch(_mol)
|
| 485 |
+
try:
|
| 486 |
+
atom_match = {substruct_match[_mol_atom_idx]: _mol_atom_idx for _mol_atom_idx in range(_mol.GetNumAtoms())} # mol to _mol
|
| 487 |
+
except:
|
| 488 |
+
raise ValueError('two molecules obtained from the same data do not match.')
|
| 489 |
+
|
| 490 |
+
for each_bond in mol.GetBonds():
|
| 491 |
+
begin_atom_idx = each_bond.GetBeginAtomIdx()
|
| 492 |
+
end_atom_idx = each_bond.GetEndAtomIdx()
|
| 493 |
+
_bond = _mol.GetBondBetweenAtoms(atom_match[begin_atom_idx], atom_match[end_atom_idx])
|
| 494 |
+
_bond.SetStereo(each_bond.GetStereo())
|
| 495 |
+
|
| 496 |
+
mol = _mol
|
| 497 |
+
for each_bond in mol.GetBonds():
|
| 498 |
+
if int(each_bond.GetStereo()) in [2, 3]: #2=Z (same side), 3=E
|
| 499 |
+
begin_stereo_atom_idx = each_bond.GetBeginAtomIdx()
|
| 500 |
+
end_stereo_atom_idx = each_bond.GetEndAtomIdx()
|
| 501 |
+
begin_atom_idx_set = set([each_neighbor.GetIdx()
|
| 502 |
+
for each_neighbor
|
| 503 |
+
in mol.GetAtomWithIdx(begin_stereo_atom_idx).GetNeighbors()
|
| 504 |
+
if each_neighbor.GetIdx() != end_stereo_atom_idx])
|
| 505 |
+
end_atom_idx_set = set([each_neighbor.GetIdx()
|
| 506 |
+
for each_neighbor
|
| 507 |
+
in mol.GetAtomWithIdx(end_stereo_atom_idx).GetNeighbors()
|
| 508 |
+
if each_neighbor.GetIdx() != begin_stereo_atom_idx])
|
| 509 |
+
if not begin_atom_idx_set:
|
| 510 |
+
each_bond.SetStereo(Chem.rdchem.BondStereo(0))
|
| 511 |
+
continue
|
| 512 |
+
if not end_atom_idx_set:
|
| 513 |
+
each_bond.SetStereo(Chem.rdchem.BondStereo(0))
|
| 514 |
+
continue
|
| 515 |
+
if len(begin_atom_idx_set) == 1:
|
| 516 |
+
begin_atom_idx = begin_atom_idx_set.pop()
|
| 517 |
+
begin_another_atom_idx = None
|
| 518 |
+
if len(end_atom_idx_set) == 1:
|
| 519 |
+
end_atom_idx = end_atom_idx_set.pop()
|
| 520 |
+
end_another_atom_idx = None
|
| 521 |
+
if len(begin_atom_idx_set) == 2:
|
| 522 |
+
atom_idx_1 = begin_atom_idx_set.pop()
|
| 523 |
+
atom_idx_2 = begin_atom_idx_set.pop()
|
| 524 |
+
if int(mol.GetAtomWithIdx(atom_idx_1).GetProp('_CIPRank')) < int(mol.GetAtomWithIdx(atom_idx_2).GetProp('_CIPRank')):
|
| 525 |
+
begin_atom_idx = atom_idx_1
|
| 526 |
+
begin_another_atom_idx = atom_idx_2
|
| 527 |
+
else:
|
| 528 |
+
begin_atom_idx = atom_idx_2
|
| 529 |
+
begin_another_atom_idx = atom_idx_1
|
| 530 |
+
if len(end_atom_idx_set) == 2:
|
| 531 |
+
atom_idx_1 = end_atom_idx_set.pop()
|
| 532 |
+
atom_idx_2 = end_atom_idx_set.pop()
|
| 533 |
+
if int(mol.GetAtomWithIdx(atom_idx_1).GetProp('_CIPRank')) < int(mol.GetAtomWithIdx(atom_idx_2).GetProp('_CIPRank')):
|
| 534 |
+
end_atom_idx = atom_idx_1
|
| 535 |
+
end_another_atom_idx = atom_idx_2
|
| 536 |
+
else:
|
| 537 |
+
end_atom_idx = atom_idx_2
|
| 538 |
+
end_another_atom_idx = atom_idx_1
|
| 539 |
+
|
| 540 |
+
if each_bond.GetStereo() == 2: # same side
|
| 541 |
+
mol = safe_set_bond_dir(mol, begin_atom_idx, begin_stereo_atom_idx, 3)
|
| 542 |
+
mol = safe_set_bond_dir(mol, end_atom_idx, end_stereo_atom_idx, 4)
|
| 543 |
+
each_bond.SetStereoAtoms(begin_atom_idx, end_atom_idx)
|
| 544 |
+
elif each_bond.GetStereo() == 3: # opposite side
|
| 545 |
+
mol = safe_set_bond_dir(mol, begin_atom_idx, begin_stereo_atom_idx, 3)
|
| 546 |
+
mol = safe_set_bond_dir(mol, end_atom_idx, end_stereo_atom_idx, 3)
|
| 547 |
+
each_bond.SetStereoAtoms(begin_atom_idx, end_atom_idx)
|
| 548 |
+
else:
|
| 549 |
+
raise ValueError
|
| 550 |
+
return mol
|
| 551 |
+
|
| 552 |
+
|
| 553 |
+
def safe_set_bond_dir(mol, atom_idx_1, atom_idx_2, bond_dir_val):
|
| 554 |
+
if atom_idx_1 is None or atom_idx_2 is None:
|
| 555 |
+
return mol
|
| 556 |
+
else:
|
| 557 |
+
mol.GetBondBetweenAtoms(atom_idx_1, atom_idx_2).SetBondDir(Chem.rdchem.BondDir.values[bond_dir_val])
|
| 558 |
+
return mol
|
| 559 |
+
|
graph_grammar/nn/__init__.py
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding:utf-8 -*-
|
| 2 |
+
# Rhizome
|
| 3 |
+
# Version beta 0.0, August 2023
|
| 4 |
+
# Property of IBM Research, Accelerated Discovery
|
| 5 |
+
#
|
| 6 |
+
|
| 7 |
+
"""
|
| 8 |
+
PLEASE NOTE THIS IMPLEMENTATION INCLUDES THE ORIGINAL SOURCE CODE (AND SOME ADAPTATIONS)
|
| 9 |
+
OF THE MHG IMPLEMENTATION OF HIROSHI KAJINO AT IBM TRL ALREADY PUBLICLY AVAILABLE.
|
| 10 |
+
THIS MIGHT INFLUENCE THE DECISION OF THE FINAL LICENSE SO CAREFUL CHECK NEEDS BE DONE.
|
| 11 |
+
"""
|
graph_grammar/nn/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (508 Bytes). View file
|
|
|
graph_grammar/nn/__pycache__/decoder.cpython-310.pyc
ADDED
|
Binary file (3.98 kB). View file
|
|
|
graph_grammar/nn/__pycache__/encoder.cpython-310.pyc
ADDED
|
Binary file (5.38 kB). View file
|
|
|
graph_grammar/nn/dataset.py
ADDED
|
@@ -0,0 +1,121 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# -*- coding: utf-8 -*-
|
| 3 |
+
# Rhizome
|
| 4 |
+
# Version beta 0.0, August 2023
|
| 5 |
+
# Property of IBM Research, Accelerated Discovery
|
| 6 |
+
#
|
| 7 |
+
|
| 8 |
+
"""
|
| 9 |
+
PLEASE NOTE THIS IMPLEMENTATION INCLUDES THE ORIGINAL SOURCE CODE (AND SOME ADAPTATIONS)
|
| 10 |
+
OF THE MHG IMPLEMENTATION OF HIROSHI KAJINO AT IBM TRL ALREADY PUBLICLY AVAILABLE.
|
| 11 |
+
THIS MIGHT INFLUENCE THE DECISION OF THE FINAL LICENSE SO CAREFUL CHECK NEEDS BE DONE.
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
""" Title """
|
| 15 |
+
|
| 16 |
+
__author__ = "Hiroshi Kajino <KAJINO@jp.ibm.com>"
|
| 17 |
+
__copyright__ = "(c) Copyright IBM Corp. 2018"
|
| 18 |
+
__version__ = "0.1"
|
| 19 |
+
__date__ = "Apr 18 2018"
|
| 20 |
+
|
| 21 |
+
from torch.utils.data import Dataset, DataLoader
|
| 22 |
+
import torch
|
| 23 |
+
import numpy as np
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def left_padding(sentence_list, max_len, pad_idx=-1, inverse=False):
|
| 27 |
+
''' pad left
|
| 28 |
+
|
| 29 |
+
Parameters
|
| 30 |
+
----------
|
| 31 |
+
sentence_list : list of sequences of integers
|
| 32 |
+
max_len : int
|
| 33 |
+
maximum length of sentences.
|
| 34 |
+
if a sentence is shorter than `max_len`, its left part is padded.
|
| 35 |
+
pad_idx : int
|
| 36 |
+
integer for padding
|
| 37 |
+
inverse : bool
|
| 38 |
+
if True, the sequence is inversed.
|
| 39 |
+
|
| 40 |
+
Returns
|
| 41 |
+
-------
|
| 42 |
+
List of torch.LongTensor
|
| 43 |
+
each sentence is left-padded.
|
| 44 |
+
'''
|
| 45 |
+
max_in_list = max([len(each_sen) for each_sen in sentence_list])
|
| 46 |
+
|
| 47 |
+
if max_in_list > max_len:
|
| 48 |
+
raise ValueError('`max_len` should be larger than the maximum length of input sequences, {}.'.format(max_in_list))
|
| 49 |
+
|
| 50 |
+
if inverse:
|
| 51 |
+
return [torch.LongTensor([pad_idx] * (max_len - len(each_sen)) + each_sen[::-1]) for each_sen in sentence_list]
|
| 52 |
+
else:
|
| 53 |
+
return [torch.LongTensor([pad_idx] * (max_len - len(each_sen)) + each_sen) for each_sen in sentence_list]
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def right_padding(sentence_list, max_len, pad_idx=-1):
|
| 57 |
+
''' pad right
|
| 58 |
+
|
| 59 |
+
Parameters
|
| 60 |
+
----------
|
| 61 |
+
sentence_list : list of sequences of integers
|
| 62 |
+
max_len : int
|
| 63 |
+
maximum length of sentences.
|
| 64 |
+
if a sentence is shorter than `max_len`, its right part is padded.
|
| 65 |
+
pad_idx : int
|
| 66 |
+
integer for padding
|
| 67 |
+
|
| 68 |
+
Returns
|
| 69 |
+
-------
|
| 70 |
+
List of torch.LongTensor
|
| 71 |
+
each sentence is right-padded.
|
| 72 |
+
'''
|
| 73 |
+
max_in_list = max([len(each_sen) for each_sen in sentence_list])
|
| 74 |
+
if max_in_list > max_len:
|
| 75 |
+
raise ValueError('`max_len` should be larger than the maximum length of input sequences, {}.'.format(max_in_list))
|
| 76 |
+
|
| 77 |
+
return [torch.LongTensor(each_sen + [pad_idx] * (max_len - len(each_sen))) for each_sen in sentence_list]
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
class HRGDataset(Dataset):
|
| 81 |
+
|
| 82 |
+
'''
|
| 83 |
+
A class of HRG data
|
| 84 |
+
'''
|
| 85 |
+
|
| 86 |
+
def __init__(self, hrg, prod_rule_seq_list, max_len, target_val_list=None, inversed_input=False):
|
| 87 |
+
self.hrg = hrg
|
| 88 |
+
self.left_prod_rule_seq_list = left_padding(prod_rule_seq_list,
|
| 89 |
+
max_len,
|
| 90 |
+
inverse=inversed_input)
|
| 91 |
+
|
| 92 |
+
self.right_prod_rule_seq_list = right_padding(prod_rule_seq_list, max_len)
|
| 93 |
+
self.inserved_input = inversed_input
|
| 94 |
+
self.target_val_list = target_val_list
|
| 95 |
+
if target_val_list is not None:
|
| 96 |
+
if len(prod_rule_seq_list) != len(target_val_list):
|
| 97 |
+
raise ValueError(f'prod_rule_seq_list and target_val_list have inconsistent lengths: {len(prod_rule_seq_list)}, {len(target_val_list)}')
|
| 98 |
+
|
| 99 |
+
def __len__(self):
|
| 100 |
+
return len(self.left_prod_rule_seq_list)
|
| 101 |
+
|
| 102 |
+
def __getitem__(self, idx):
|
| 103 |
+
if self.target_val_list is not None:
|
| 104 |
+
return self.left_prod_rule_seq_list[idx], self.right_prod_rule_seq_list[idx], np.float32(self.target_val_list[idx])
|
| 105 |
+
else:
|
| 106 |
+
return self.left_prod_rule_seq_list[idx], self.right_prod_rule_seq_list[idx]
|
| 107 |
+
|
| 108 |
+
@property
|
| 109 |
+
def vocab_size(self):
|
| 110 |
+
return self.hrg.num_prod_rule
|
| 111 |
+
|
| 112 |
+
def batch_padding(each_batch, batch_size, padding_idx):
|
| 113 |
+
num_pad = batch_size - len(each_batch[0])
|
| 114 |
+
if num_pad:
|
| 115 |
+
each_batch[0] = torch.cat([each_batch[0],
|
| 116 |
+
padding_idx * torch.ones((batch_size - len(each_batch[0]),
|
| 117 |
+
len(each_batch[0][0])), dtype=torch.int64)], dim=0)
|
| 118 |
+
each_batch[1] = torch.cat([each_batch[1],
|
| 119 |
+
padding_idx * torch.ones((batch_size - len(each_batch[1]),
|
| 120 |
+
len(each_batch[1][0])), dtype=torch.int64)], dim=0)
|
| 121 |
+
return each_batch, num_pad
|
graph_grammar/nn/decoder.py
ADDED
|
@@ -0,0 +1,158 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# -*- coding: utf-8 -*-
|
| 3 |
+
# Rhizome
|
| 4 |
+
# Version beta 0.0, August 2023
|
| 5 |
+
# Property of IBM Research, Accelerated Discovery
|
| 6 |
+
#
|
| 7 |
+
|
| 8 |
+
"""
|
| 9 |
+
PLEASE NOTE THIS IMPLEMENTATION INCLUDES THE ORIGINAL SOURCE CODE (AND SOME ADAPTATIONS)
|
| 10 |
+
OF THE MHG IMPLEMENTATION OF HIROSHI KAJINO AT IBM TRL ALREADY PUBLICLY AVAILABLE.
|
| 11 |
+
THIS MIGHT INFLUENCE THE DECISION OF THE FINAL LICENSE SO CAREFUL CHECK NEEDS BE DONE.
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
""" Title """
|
| 15 |
+
|
| 16 |
+
__author__ = "Hiroshi Kajino <KAJINO@jp.ibm.com>"
|
| 17 |
+
__copyright__ = "(c) Copyright IBM Corp. 2018"
|
| 18 |
+
__version__ = "0.1"
|
| 19 |
+
__date__ = "Aug 9 2018"
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
import abc
|
| 23 |
+
import numpy as np
|
| 24 |
+
import torch
|
| 25 |
+
from torch import nn
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class DecoderBase(nn.Module):
|
| 29 |
+
|
| 30 |
+
def __init__(self):
|
| 31 |
+
super().__init__()
|
| 32 |
+
self.hidden_dict = {}
|
| 33 |
+
|
| 34 |
+
@abc.abstractmethod
|
| 35 |
+
def forward_one_step(self, tgt_emb_in):
|
| 36 |
+
''' one-step forward model
|
| 37 |
+
|
| 38 |
+
Parameters
|
| 39 |
+
----------
|
| 40 |
+
tgt_emb_in : Tensor, shape (batch_size, input_dim)
|
| 41 |
+
|
| 42 |
+
Returns
|
| 43 |
+
-------
|
| 44 |
+
Tensor, shape (batch_size, hidden_dim)
|
| 45 |
+
'''
|
| 46 |
+
tgt_emb_out = None
|
| 47 |
+
return tgt_emb_out
|
| 48 |
+
|
| 49 |
+
@abc.abstractmethod
|
| 50 |
+
def init_hidden(self):
|
| 51 |
+
''' initialize the hidden states
|
| 52 |
+
'''
|
| 53 |
+
pass
|
| 54 |
+
|
| 55 |
+
@abc.abstractmethod
|
| 56 |
+
def feed_hidden(self, hidden_dict_0):
|
| 57 |
+
for each_hidden in self.hidden_dict.keys():
|
| 58 |
+
self.hidden_dict[each_hidden][0] = hidden_dict_0[each_hidden]
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
class GRUDecoder(DecoderBase):
|
| 62 |
+
|
| 63 |
+
def __init__(self, input_dim: int, hidden_dim: int, num_layers: int,
|
| 64 |
+
dropout: float, batch_size: int, use_gpu: bool,
|
| 65 |
+
no_dropout=False):
|
| 66 |
+
super().__init__()
|
| 67 |
+
self.input_dim = input_dim
|
| 68 |
+
self.hidden_dim = hidden_dim
|
| 69 |
+
self.num_layers = num_layers
|
| 70 |
+
self.dropout = dropout
|
| 71 |
+
self.batch_size = batch_size
|
| 72 |
+
self.use_gpu = use_gpu
|
| 73 |
+
self.model = nn.GRU(input_size=self.input_dim,
|
| 74 |
+
hidden_size=self.hidden_dim,
|
| 75 |
+
num_layers=self.num_layers,
|
| 76 |
+
batch_first=True,
|
| 77 |
+
bidirectional=False,
|
| 78 |
+
dropout=self.dropout if not no_dropout else 0
|
| 79 |
+
)
|
| 80 |
+
if self.use_gpu:
|
| 81 |
+
self.model.cuda()
|
| 82 |
+
self.init_hidden()
|
| 83 |
+
|
| 84 |
+
def init_hidden(self):
|
| 85 |
+
self.hidden_dict['h'] = torch.zeros((self.num_layers,
|
| 86 |
+
self.batch_size,
|
| 87 |
+
self.hidden_dim),
|
| 88 |
+
requires_grad=False)
|
| 89 |
+
if self.use_gpu:
|
| 90 |
+
self.hidden_dict['h'] = self.hidden_dict['h'].cuda()
|
| 91 |
+
|
| 92 |
+
def forward_one_step(self, tgt_emb_in):
|
| 93 |
+
''' one-step forward model
|
| 94 |
+
|
| 95 |
+
Parameters
|
| 96 |
+
----------
|
| 97 |
+
tgt_emb_in : Tensor, shape (batch_size, input_dim)
|
| 98 |
+
|
| 99 |
+
Returns
|
| 100 |
+
-------
|
| 101 |
+
Tensor, shape (batch_size, hidden_dim)
|
| 102 |
+
'''
|
| 103 |
+
tgt_emb_out, self.hidden_dict['h'] \
|
| 104 |
+
= self.model(tgt_emb_in.view(self.batch_size, 1, -1),
|
| 105 |
+
self.hidden_dict['h'])
|
| 106 |
+
return tgt_emb_out
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
class LSTMDecoder(DecoderBase):
|
| 110 |
+
|
| 111 |
+
def __init__(self, input_dim: int, hidden_dim: int, num_layers: int,
|
| 112 |
+
dropout: float, batch_size: int, use_gpu: bool,
|
| 113 |
+
no_dropout=False):
|
| 114 |
+
super().__init__()
|
| 115 |
+
self.input_dim = input_dim
|
| 116 |
+
self.hidden_dim = hidden_dim
|
| 117 |
+
self.num_layers = num_layers
|
| 118 |
+
self.dropout = dropout
|
| 119 |
+
self.batch_size = batch_size
|
| 120 |
+
self.use_gpu = use_gpu
|
| 121 |
+
self.model = nn.LSTM(input_size=self.input_dim,
|
| 122 |
+
hidden_size=self.hidden_dim,
|
| 123 |
+
num_layers=self.num_layers,
|
| 124 |
+
batch_first=True,
|
| 125 |
+
bidirectional=False,
|
| 126 |
+
dropout=self.dropout if not no_dropout else 0)
|
| 127 |
+
if self.use_gpu:
|
| 128 |
+
self.model.cuda()
|
| 129 |
+
self.init_hidden()
|
| 130 |
+
|
| 131 |
+
def init_hidden(self):
|
| 132 |
+
self.hidden_dict['h'] = torch.zeros((self.num_layers,
|
| 133 |
+
self.batch_size,
|
| 134 |
+
self.hidden_dim),
|
| 135 |
+
requires_grad=False)
|
| 136 |
+
self.hidden_dict['c'] = torch.zeros((self.num_layers,
|
| 137 |
+
self.batch_size,
|
| 138 |
+
self.hidden_dim),
|
| 139 |
+
requires_grad=False)
|
| 140 |
+
if self.use_gpu:
|
| 141 |
+
for each_hidden in self.hidden_dict.keys():
|
| 142 |
+
self.hidden_dict[each_hidden] = self.hidden_dict[each_hidden].cuda()
|
| 143 |
+
|
| 144 |
+
def forward_one_step(self, tgt_emb_in):
|
| 145 |
+
''' one-step forward model
|
| 146 |
+
|
| 147 |
+
Parameters
|
| 148 |
+
----------
|
| 149 |
+
tgt_emb_in : Tensor, shape (batch_size, input_dim)
|
| 150 |
+
|
| 151 |
+
Returns
|
| 152 |
+
-------
|
| 153 |
+
Tensor, shape (batch_size, hidden_dim)
|
| 154 |
+
'''
|
| 155 |
+
tgt_hidden_out, self.hidden_dict['h'], self.hidden_dict['c'] \
|
| 156 |
+
= self.model(tgt_emb_in.view(self.batch_size, 1, -1),
|
| 157 |
+
self.hidden_dict['h'], self.hidden_dict['c'])
|
| 158 |
+
return tgt_hidden_out
|
graph_grammar/nn/encoder.py
ADDED
|
@@ -0,0 +1,199 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# -*- coding: utf-8 -*-
|
| 3 |
+
# Rhizome
|
| 4 |
+
# Version beta 0.0, August 2023
|
| 5 |
+
# Property of IBM Research, Accelerated Discovery
|
| 6 |
+
#
|
| 7 |
+
|
| 8 |
+
"""
|
| 9 |
+
PLEASE NOTE THIS IMPLEMENTATION INCLUDES THE ORIGINAL SOURCE CODE (AND SOME ADAPTATIONS)
|
| 10 |
+
OF THE MHG IMPLEMENTATION OF HIROSHI KAJINO AT IBM TRL ALREADY PUBLICLY AVAILABLE.
|
| 11 |
+
THIS MIGHT INFLUENCE THE DECISION OF THE FINAL LICENSE SO CAREFUL CHECK NEEDS BE DONE.
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
""" Title """
|
| 15 |
+
|
| 16 |
+
__author__ = "Hiroshi Kajino <KAJINO@jp.ibm.com>"
|
| 17 |
+
__copyright__ = "(c) Copyright IBM Corp. 2018"
|
| 18 |
+
__version__ = "0.1"
|
| 19 |
+
__date__ = "Aug 9 2018"
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
import abc
|
| 23 |
+
import numpy as np
|
| 24 |
+
import torch
|
| 25 |
+
import torch.nn.functional as F
|
| 26 |
+
from torch import nn
|
| 27 |
+
from typing import List
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
class EncoderBase(nn.Module):
|
| 31 |
+
|
| 32 |
+
def __init__(self):
|
| 33 |
+
super().__init__()
|
| 34 |
+
|
| 35 |
+
@abc.abstractmethod
|
| 36 |
+
def forward(self, in_seq):
|
| 37 |
+
''' forward model
|
| 38 |
+
|
| 39 |
+
Parameters
|
| 40 |
+
----------
|
| 41 |
+
in_seq_emb : Variable, shape (batch_size, max_len, input_dim)
|
| 42 |
+
|
| 43 |
+
Returns
|
| 44 |
+
-------
|
| 45 |
+
hidden_seq_emb : Tensor, shape (batch_size, max_len, 1 + bidirectional, hidden_dim)
|
| 46 |
+
'''
|
| 47 |
+
pass
|
| 48 |
+
|
| 49 |
+
@abc.abstractmethod
|
| 50 |
+
def init_hidden(self):
|
| 51 |
+
''' initialize the hidden states
|
| 52 |
+
'''
|
| 53 |
+
pass
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
class GRUEncoder(EncoderBase):
|
| 57 |
+
|
| 58 |
+
def __init__(self, input_dim: int, hidden_dim: int, num_layers: int,
|
| 59 |
+
bidirectional: bool, dropout: float, batch_size: int, use_gpu: bool,
|
| 60 |
+
no_dropout=False):
|
| 61 |
+
super().__init__()
|
| 62 |
+
self.input_dim = input_dim
|
| 63 |
+
self.hidden_dim = hidden_dim
|
| 64 |
+
self.num_layers = num_layers
|
| 65 |
+
self.bidirectional = bidirectional
|
| 66 |
+
self.dropout = dropout
|
| 67 |
+
self.batch_size = batch_size
|
| 68 |
+
self.use_gpu = use_gpu
|
| 69 |
+
self.model = nn.GRU(input_size=self.input_dim,
|
| 70 |
+
hidden_size=self.hidden_dim,
|
| 71 |
+
num_layers=self.num_layers,
|
| 72 |
+
batch_first=True,
|
| 73 |
+
bidirectional=self.bidirectional,
|
| 74 |
+
dropout=self.dropout if not no_dropout else 0)
|
| 75 |
+
if self.use_gpu:
|
| 76 |
+
self.model.cuda()
|
| 77 |
+
self.init_hidden()
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
def init_hidden(self):
|
| 81 |
+
self.h0 = torch.zeros(((self.bidirectional + 1) * self.num_layers,
|
| 82 |
+
self.batch_size,
|
| 83 |
+
self.hidden_dim),
|
| 84 |
+
requires_grad=False)
|
| 85 |
+
if self.use_gpu:
|
| 86 |
+
self.h0 = self.h0.cuda()
|
| 87 |
+
|
| 88 |
+
def forward(self, in_seq_emb):
|
| 89 |
+
''' forward model
|
| 90 |
+
|
| 91 |
+
Parameters
|
| 92 |
+
----------
|
| 93 |
+
in_seq_emb : Tensor, shape (batch_size, max_len, input_dim)
|
| 94 |
+
|
| 95 |
+
Returns
|
| 96 |
+
-------
|
| 97 |
+
hidden_seq_emb : Tensor, shape (batch_size, max_len, 1 + bidirectional, hidden_dim)
|
| 98 |
+
'''
|
| 99 |
+
max_len = in_seq_emb.size(1)
|
| 100 |
+
hidden_seq_emb, self.h0 = self.model(
|
| 101 |
+
in_seq_emb, self.h0)
|
| 102 |
+
hidden_seq_emb = hidden_seq_emb.view(self.batch_size,
|
| 103 |
+
max_len,
|
| 104 |
+
1 + self.bidirectional,
|
| 105 |
+
self.hidden_dim)
|
| 106 |
+
return hidden_seq_emb
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
class LSTMEncoder(EncoderBase):
|
| 110 |
+
|
| 111 |
+
def __init__(self, input_dim: int, hidden_dim: int, num_layers: int,
|
| 112 |
+
bidirectional: bool, dropout: float, batch_size: int, use_gpu: bool,
|
| 113 |
+
no_dropout=False):
|
| 114 |
+
super().__init__()
|
| 115 |
+
self.input_dim = input_dim
|
| 116 |
+
self.hidden_dim = hidden_dim
|
| 117 |
+
self.num_layers = num_layers
|
| 118 |
+
self.bidirectional = bidirectional
|
| 119 |
+
self.dropout = dropout
|
| 120 |
+
self.batch_size = batch_size
|
| 121 |
+
self.use_gpu = use_gpu
|
| 122 |
+
self.model = nn.LSTM(input_size=self.input_dim,
|
| 123 |
+
hidden_size=self.hidden_dim,
|
| 124 |
+
num_layers=self.num_layers,
|
| 125 |
+
batch_first=True,
|
| 126 |
+
bidirectional=self.bidirectional,
|
| 127 |
+
dropout=self.dropout if not no_dropout else 0)
|
| 128 |
+
if self.use_gpu:
|
| 129 |
+
self.model.cuda()
|
| 130 |
+
self.init_hidden()
|
| 131 |
+
|
| 132 |
+
def init_hidden(self):
|
| 133 |
+
self.h0 = torch.zeros(((self.bidirectional + 1) * self.num_layers,
|
| 134 |
+
self.batch_size,
|
| 135 |
+
self.hidden_dim),
|
| 136 |
+
requires_grad=False)
|
| 137 |
+
self.c0 = torch.zeros(((self.bidirectional + 1) * self.num_layers,
|
| 138 |
+
self.batch_size,
|
| 139 |
+
self.hidden_dim),
|
| 140 |
+
requires_grad=False)
|
| 141 |
+
if self.use_gpu:
|
| 142 |
+
self.h0 = self.h0.cuda()
|
| 143 |
+
self.c0 = self.c0.cuda()
|
| 144 |
+
|
| 145 |
+
def forward(self, in_seq_emb):
|
| 146 |
+
''' forward model
|
| 147 |
+
|
| 148 |
+
Parameters
|
| 149 |
+
----------
|
| 150 |
+
in_seq_emb : Tensor, shape (batch_size, max_len, input_dim)
|
| 151 |
+
|
| 152 |
+
Returns
|
| 153 |
+
-------
|
| 154 |
+
hidden_seq_emb : Tensor, shape (batch_size, max_len, 1 + bidirectional, hidden_dim)
|
| 155 |
+
'''
|
| 156 |
+
max_len = in_seq_emb.size(1)
|
| 157 |
+
hidden_seq_emb, (self.h0, self.c0) = self.model(
|
| 158 |
+
in_seq_emb, (self.h0, self.c0))
|
| 159 |
+
hidden_seq_emb = hidden_seq_emb.view(self.batch_size,
|
| 160 |
+
max_len,
|
| 161 |
+
1 + self.bidirectional,
|
| 162 |
+
self.hidden_dim)
|
| 163 |
+
return hidden_seq_emb
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
class FullConnectedEncoder(EncoderBase):
|
| 167 |
+
|
| 168 |
+
def __init__(self, input_dim: int, hidden_dim: int, max_len: int, hidden_dim_list: List[int],
|
| 169 |
+
batch_size: int, use_gpu: bool):
|
| 170 |
+
super().__init__()
|
| 171 |
+
self.input_dim = input_dim
|
| 172 |
+
self.hidden_dim = hidden_dim
|
| 173 |
+
self.max_len = max_len
|
| 174 |
+
self.hidden_dim_list = hidden_dim_list
|
| 175 |
+
self.use_gpu = use_gpu
|
| 176 |
+
in_out_dim_list = [input_dim * max_len] + list(hidden_dim_list) + [hidden_dim]
|
| 177 |
+
self.linear_list = nn.ModuleList(
|
| 178 |
+
[nn.Linear(in_out_dim_list[each_idx], in_out_dim_list[each_idx + 1])\
|
| 179 |
+
for each_idx in range(len(in_out_dim_list) - 1)])
|
| 180 |
+
|
| 181 |
+
def forward(self, in_seq_emb):
|
| 182 |
+
''' forward model
|
| 183 |
+
|
| 184 |
+
Parameters
|
| 185 |
+
----------
|
| 186 |
+
in_seq_emb : Tensor, shape (batch_size, max_len, input_dim)
|
| 187 |
+
|
| 188 |
+
Returns
|
| 189 |
+
-------
|
| 190 |
+
hidden_seq_emb : Tensor, shape (batch_size, max_len, 1 + bidirectional, hidden_dim)
|
| 191 |
+
'''
|
| 192 |
+
batch_size = in_seq_emb.size(0)
|
| 193 |
+
x = in_seq_emb.view(batch_size, -1)
|
| 194 |
+
for each_linear in self.linear_list:
|
| 195 |
+
x = F.relu(each_linear(x))
|
| 196 |
+
return x.view(batch_size, 1, -1)
|
| 197 |
+
|
| 198 |
+
def init_hidden(self):
|
| 199 |
+
pass
|
graph_grammar/nn/graph.py
ADDED
|
@@ -0,0 +1,313 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# -*- coding: utf-8 -*-
|
| 3 |
+
# Rhizome
|
| 4 |
+
# Version beta 0.0, August 2023
|
| 5 |
+
# Property of IBM Research, Accelerated Discovery
|
| 6 |
+
#
|
| 7 |
+
|
| 8 |
+
"""
|
| 9 |
+
PLEASE NOTE THIS IMPLEMENTATION INCLUDES THE ORIGINAL SOURCE CODE (AND SOME ADAPTATIONS)
|
| 10 |
+
OF THE MHG IMPLEMENTATION OF HIROSHI KAJINO AT IBM TRL ALREADY PUBLICLY AVAILABLE.
|
| 11 |
+
THIS MIGHT INFLUENCE THE DECISION OF THE FINAL LICENSE SO CAREFUL CHECK NEEDS BE DONE.
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
""" Title """
|
| 15 |
+
|
| 16 |
+
__author__ = "Hiroshi Kajino <KAJINO@jp.ibm.com>"
|
| 17 |
+
__copyright__ = "(c) Copyright IBM Corp. 2018"
|
| 18 |
+
__version__ = "0.1"
|
| 19 |
+
__date__ = "Jan 1 2018"
|
| 20 |
+
|
| 21 |
+
import numpy as np
|
| 22 |
+
import torch
|
| 23 |
+
import torch.nn.functional as F
|
| 24 |
+
from graph_grammar.graph_grammar.hrg import ProductionRuleCorpus
|
| 25 |
+
from torch import nn
|
| 26 |
+
from torch.autograd import Variable
|
| 27 |
+
|
| 28 |
+
class MolecularProdRuleEmbedding(nn.Module):
|
| 29 |
+
|
| 30 |
+
''' molecular fingerprint layer
|
| 31 |
+
'''
|
| 32 |
+
|
| 33 |
+
def __init__(self, prod_rule_corpus, layer2layer_activation, layer2out_activation,
|
| 34 |
+
out_dim=32, element_embed_dim=32,
|
| 35 |
+
num_layers=3, padding_idx=None, use_gpu=False):
|
| 36 |
+
super().__init__()
|
| 37 |
+
if padding_idx is not None:
|
| 38 |
+
assert padding_idx == -1, 'padding_idx must be -1.'
|
| 39 |
+
self.prod_rule_corpus = prod_rule_corpus
|
| 40 |
+
self.layer2layer_activation = layer2layer_activation
|
| 41 |
+
self.layer2out_activation = layer2out_activation
|
| 42 |
+
self.out_dim = out_dim
|
| 43 |
+
self.element_embed_dim = element_embed_dim
|
| 44 |
+
self.num_layers = num_layers
|
| 45 |
+
self.padding_idx = padding_idx
|
| 46 |
+
self.use_gpu = use_gpu
|
| 47 |
+
|
| 48 |
+
self.layer2layer_list = []
|
| 49 |
+
self.layer2out_list = []
|
| 50 |
+
|
| 51 |
+
if self.use_gpu:
|
| 52 |
+
self.atom_embed = torch.randn(self.prod_rule_corpus.num_edge_symbol,
|
| 53 |
+
self.element_embed_dim, requires_grad=True).cuda()
|
| 54 |
+
self.bond_embed = torch.randn(self.prod_rule_corpus.num_node_symbol,
|
| 55 |
+
self.element_embed_dim, requires_grad=True).cuda()
|
| 56 |
+
self.ext_id_embed = torch.randn(self.prod_rule_corpus.num_ext_id,
|
| 57 |
+
self.element_embed_dim, requires_grad=True).cuda()
|
| 58 |
+
for _ in range(num_layers):
|
| 59 |
+
self.layer2layer_list.append(nn.Linear(self.element_embed_dim, self.element_embed_dim).cuda())
|
| 60 |
+
self.layer2out_list.append(nn.Linear(self.element_embed_dim, self.out_dim).cuda())
|
| 61 |
+
else:
|
| 62 |
+
self.atom_embed = torch.randn(self.prod_rule_corpus.num_edge_symbol,
|
| 63 |
+
self.element_embed_dim, requires_grad=True)
|
| 64 |
+
self.bond_embed = torch.randn(self.prod_rule_corpus.num_node_symbol,
|
| 65 |
+
self.element_embed_dim, requires_grad=True)
|
| 66 |
+
self.ext_id_embed = torch.randn(self.prod_rule_corpus.num_ext_id,
|
| 67 |
+
self.element_embed_dim, requires_grad=True)
|
| 68 |
+
for _ in range(num_layers):
|
| 69 |
+
self.layer2layer_list.append(nn.Linear(self.element_embed_dim, self.element_embed_dim))
|
| 70 |
+
self.layer2out_list.append(nn.Linear(self.element_embed_dim, self.out_dim))
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def forward(self, prod_rule_idx_seq):
|
| 74 |
+
''' forward model for mini-batch
|
| 75 |
+
|
| 76 |
+
Parameters
|
| 77 |
+
----------
|
| 78 |
+
prod_rule_idx_seq : (batch_size, length)
|
| 79 |
+
|
| 80 |
+
Returns
|
| 81 |
+
-------
|
| 82 |
+
Variable, shape (batch_size, length, out_dim)
|
| 83 |
+
'''
|
| 84 |
+
batch_size, length = prod_rule_idx_seq.shape
|
| 85 |
+
if self.use_gpu:
|
| 86 |
+
out = Variable(torch.zeros((batch_size, length, self.out_dim))).cuda()
|
| 87 |
+
else:
|
| 88 |
+
out = Variable(torch.zeros((batch_size, length, self.out_dim)))
|
| 89 |
+
for each_batch_idx in range(batch_size):
|
| 90 |
+
for each_idx in range(length):
|
| 91 |
+
if int(prod_rule_idx_seq[each_batch_idx, each_idx]) == len(self.prod_rule_corpus.prod_rule_list):
|
| 92 |
+
continue
|
| 93 |
+
else:
|
| 94 |
+
each_prod_rule = self.prod_rule_corpus.prod_rule_list[int(prod_rule_idx_seq[each_batch_idx, each_idx])]
|
| 95 |
+
layer_wise_embed_dict = {each_edge: self.atom_embed[
|
| 96 |
+
each_prod_rule.rhs.edge_attr(each_edge)['symbol_idx']]
|
| 97 |
+
for each_edge in each_prod_rule.rhs.edges}
|
| 98 |
+
layer_wise_embed_dict.update({each_node: self.bond_embed[
|
| 99 |
+
each_prod_rule.rhs.node_attr(each_node)['symbol_idx']]
|
| 100 |
+
for each_node in each_prod_rule.rhs.nodes})
|
| 101 |
+
for each_node in each_prod_rule.rhs.nodes:
|
| 102 |
+
if 'ext_id' in each_prod_rule.rhs.node_attr(each_node):
|
| 103 |
+
layer_wise_embed_dict[each_node] \
|
| 104 |
+
= layer_wise_embed_dict[each_node] \
|
| 105 |
+
+ self.ext_id_embed[each_prod_rule.rhs.node_attr(each_node)['ext_id']]
|
| 106 |
+
|
| 107 |
+
for each_layer in range(self.num_layers):
|
| 108 |
+
next_layer_embed_dict = {}
|
| 109 |
+
for each_edge in each_prod_rule.rhs.edges:
|
| 110 |
+
v = layer_wise_embed_dict[each_edge]
|
| 111 |
+
for each_node in each_prod_rule.rhs.nodes_in_edge(each_edge):
|
| 112 |
+
v = v + layer_wise_embed_dict[each_node]
|
| 113 |
+
next_layer_embed_dict[each_edge] = self.layer2layer_activation(self.layer2layer_list[each_layer](v))
|
| 114 |
+
out[each_batch_idx, each_idx, :] \
|
| 115 |
+
= out[each_batch_idx, each_idx, :] + self.layer2out_activation(self.layer2out_list[each_layer](v))
|
| 116 |
+
for each_node in each_prod_rule.rhs.nodes:
|
| 117 |
+
v = layer_wise_embed_dict[each_node]
|
| 118 |
+
for each_edge in each_prod_rule.rhs.adj_edges(each_node):
|
| 119 |
+
v = v + layer_wise_embed_dict[each_edge]
|
| 120 |
+
next_layer_embed_dict[each_node] = self.layer2layer_activation(self.layer2layer_list[each_layer](v))
|
| 121 |
+
out[each_batch_idx, each_idx, :]\
|
| 122 |
+
= out[each_batch_idx, each_idx, :] + self.layer2out_activation(self.layer2out_list[each_layer](v))
|
| 123 |
+
layer_wise_embed_dict = next_layer_embed_dict
|
| 124 |
+
|
| 125 |
+
return out
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
class MolecularProdRuleEmbeddingLastLayer(nn.Module):
|
| 129 |
+
|
| 130 |
+
''' molecular fingerprint layer
|
| 131 |
+
'''
|
| 132 |
+
|
| 133 |
+
def __init__(self, prod_rule_corpus, layer2layer_activation, layer2out_activation,
|
| 134 |
+
out_dim=32, element_embed_dim=32,
|
| 135 |
+
num_layers=3, padding_idx=None, use_gpu=False):
|
| 136 |
+
super().__init__()
|
| 137 |
+
if padding_idx is not None:
|
| 138 |
+
assert padding_idx == -1, 'padding_idx must be -1.'
|
| 139 |
+
self.prod_rule_corpus = prod_rule_corpus
|
| 140 |
+
self.layer2layer_activation = layer2layer_activation
|
| 141 |
+
self.layer2out_activation = layer2out_activation
|
| 142 |
+
self.out_dim = out_dim
|
| 143 |
+
self.element_embed_dim = element_embed_dim
|
| 144 |
+
self.num_layers = num_layers
|
| 145 |
+
self.padding_idx = padding_idx
|
| 146 |
+
self.use_gpu = use_gpu
|
| 147 |
+
|
| 148 |
+
self.layer2layer_list = []
|
| 149 |
+
self.layer2out_list = []
|
| 150 |
+
|
| 151 |
+
if self.use_gpu:
|
| 152 |
+
self.atom_embed = nn.Embedding(self.prod_rule_corpus.num_edge_symbol, self.element_embed_dim).cuda()
|
| 153 |
+
self.bond_embed = nn.Embedding(self.prod_rule_corpus.num_node_symbol, self.element_embed_dim).cuda()
|
| 154 |
+
for _ in range(num_layers+1):
|
| 155 |
+
self.layer2layer_list.append(nn.Linear(self.element_embed_dim, self.element_embed_dim).cuda())
|
| 156 |
+
self.layer2out_list.append(nn.Linear(self.element_embed_dim, self.out_dim).cuda())
|
| 157 |
+
else:
|
| 158 |
+
self.atom_embed = nn.Embedding(self.prod_rule_corpus.num_edge_symbol, self.element_embed_dim)
|
| 159 |
+
self.bond_embed = nn.Embedding(self.prod_rule_corpus.num_node_symbol, self.element_embed_dim)
|
| 160 |
+
for _ in range(num_layers+1):
|
| 161 |
+
self.layer2layer_list.append(nn.Linear(self.element_embed_dim, self.element_embed_dim))
|
| 162 |
+
self.layer2out_list.append(nn.Linear(self.element_embed_dim, self.out_dim))
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
def forward(self, prod_rule_idx_seq):
|
| 166 |
+
''' forward model for mini-batch
|
| 167 |
+
|
| 168 |
+
Parameters
|
| 169 |
+
----------
|
| 170 |
+
prod_rule_idx_seq : (batch_size, length)
|
| 171 |
+
|
| 172 |
+
Returns
|
| 173 |
+
-------
|
| 174 |
+
Variable, shape (batch_size, length, out_dim)
|
| 175 |
+
'''
|
| 176 |
+
batch_size, length = prod_rule_idx_seq.shape
|
| 177 |
+
if self.use_gpu:
|
| 178 |
+
out = Variable(torch.zeros((batch_size, length, self.out_dim))).cuda()
|
| 179 |
+
else:
|
| 180 |
+
out = Variable(torch.zeros((batch_size, length, self.out_dim)))
|
| 181 |
+
for each_batch_idx in range(batch_size):
|
| 182 |
+
for each_idx in range(length):
|
| 183 |
+
if int(prod_rule_idx_seq[each_batch_idx, each_idx]) == len(self.prod_rule_corpus.prod_rule_list):
|
| 184 |
+
continue
|
| 185 |
+
else:
|
| 186 |
+
each_prod_rule = self.prod_rule_corpus.prod_rule_list[int(prod_rule_idx_seq[each_batch_idx, each_idx])]
|
| 187 |
+
|
| 188 |
+
if self.use_gpu:
|
| 189 |
+
layer_wise_embed_dict = {each_edge: self.atom_embed(
|
| 190 |
+
Variable(torch.LongTensor(
|
| 191 |
+
[each_prod_rule.rhs.edge_attr(each_edge)['symbol_idx']]
|
| 192 |
+
), requires_grad=False).cuda())
|
| 193 |
+
for each_edge in each_prod_rule.rhs.edges}
|
| 194 |
+
layer_wise_embed_dict.update({each_node: self.bond_embed(
|
| 195 |
+
Variable(
|
| 196 |
+
torch.LongTensor([
|
| 197 |
+
each_prod_rule.rhs.node_attr(each_node)['symbol_idx']]),
|
| 198 |
+
requires_grad=False).cuda()
|
| 199 |
+
) for each_node in each_prod_rule.rhs.nodes})
|
| 200 |
+
else:
|
| 201 |
+
layer_wise_embed_dict = {each_edge: self.atom_embed(
|
| 202 |
+
Variable(torch.LongTensor(
|
| 203 |
+
[each_prod_rule.rhs.edge_attr(each_edge)['symbol_idx']]
|
| 204 |
+
), requires_grad=False))
|
| 205 |
+
for each_edge in each_prod_rule.rhs.edges}
|
| 206 |
+
layer_wise_embed_dict.update({each_node: self.bond_embed(
|
| 207 |
+
Variable(
|
| 208 |
+
torch.LongTensor([
|
| 209 |
+
each_prod_rule.rhs.node_attr(each_node)['symbol_idx']]),
|
| 210 |
+
requires_grad=False)
|
| 211 |
+
) for each_node in each_prod_rule.rhs.nodes})
|
| 212 |
+
|
| 213 |
+
for each_layer in range(self.num_layers):
|
| 214 |
+
next_layer_embed_dict = {}
|
| 215 |
+
for each_edge in each_prod_rule.rhs.edges:
|
| 216 |
+
v = layer_wise_embed_dict[each_edge]
|
| 217 |
+
for each_node in each_prod_rule.rhs.nodes_in_edge(each_edge):
|
| 218 |
+
v += layer_wise_embed_dict[each_node]
|
| 219 |
+
next_layer_embed_dict[each_edge] = self.layer2layer_activation(self.layer2layer_list[each_layer](v))
|
| 220 |
+
for each_node in each_prod_rule.rhs.nodes:
|
| 221 |
+
v = layer_wise_embed_dict[each_node]
|
| 222 |
+
for each_edge in each_prod_rule.rhs.adj_edges(each_node):
|
| 223 |
+
v += layer_wise_embed_dict[each_edge]
|
| 224 |
+
next_layer_embed_dict[each_node] = self.layer2layer_activation(self.layer2layer_list[each_layer](v))
|
| 225 |
+
layer_wise_embed_dict = next_layer_embed_dict
|
| 226 |
+
for each_edge in each_prod_rule.rhs.edges:
|
| 227 |
+
out[each_batch_idx, each_idx, :] = self.layer2out_activation(self.layer2out_list[self.num_layers](v))
|
| 228 |
+
for each_edge in each_prod_rule.rhs.edges:
|
| 229 |
+
out[each_batch_idx, each_idx, :] = self.layer2out_activation(self.layer2out_list[self.num_layers](v))
|
| 230 |
+
|
| 231 |
+
return out
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
class MolecularProdRuleEmbeddingUsingFeatures(nn.Module):
|
| 235 |
+
|
| 236 |
+
''' molecular fingerprint layer
|
| 237 |
+
'''
|
| 238 |
+
|
| 239 |
+
def __init__(self, prod_rule_corpus, layer2layer_activation, layer2out_activation,
|
| 240 |
+
out_dim=32, num_layers=3, padding_idx=None, use_gpu=False):
|
| 241 |
+
super().__init__()
|
| 242 |
+
if padding_idx is not None:
|
| 243 |
+
assert padding_idx == -1, 'padding_idx must be -1.'
|
| 244 |
+
self.feature_dict, self.feature_dim = prod_rule_corpus.construct_feature_vectors()
|
| 245 |
+
self.prod_rule_corpus = prod_rule_corpus
|
| 246 |
+
self.layer2layer_activation = layer2layer_activation
|
| 247 |
+
self.layer2out_activation = layer2out_activation
|
| 248 |
+
self.out_dim = out_dim
|
| 249 |
+
self.num_layers = num_layers
|
| 250 |
+
self.padding_idx = padding_idx
|
| 251 |
+
self.use_gpu = use_gpu
|
| 252 |
+
|
| 253 |
+
self.layer2layer_list = []
|
| 254 |
+
self.layer2out_list = []
|
| 255 |
+
|
| 256 |
+
if self.use_gpu:
|
| 257 |
+
for each_key in self.feature_dict:
|
| 258 |
+
self.feature_dict[each_key] = self.feature_dict[each_key].to_dense().cuda()
|
| 259 |
+
for _ in range(num_layers):
|
| 260 |
+
self.layer2layer_list.append(nn.Linear(self.feature_dim, self.feature_dim).cuda())
|
| 261 |
+
self.layer2out_list.append(nn.Linear(self.feature_dim, self.out_dim).cuda())
|
| 262 |
+
else:
|
| 263 |
+
for _ in range(num_layers):
|
| 264 |
+
self.layer2layer_list.append(nn.Linear(self.feature_dim, self.feature_dim))
|
| 265 |
+
self.layer2out_list.append(nn.Linear(self.feature_dim, self.out_dim))
|
| 266 |
+
|
| 267 |
+
|
| 268 |
+
def forward(self, prod_rule_idx_seq):
|
| 269 |
+
''' forward model for mini-batch
|
| 270 |
+
|
| 271 |
+
Parameters
|
| 272 |
+
----------
|
| 273 |
+
prod_rule_idx_seq : (batch_size, length)
|
| 274 |
+
|
| 275 |
+
Returns
|
| 276 |
+
-------
|
| 277 |
+
Variable, shape (batch_size, length, out_dim)
|
| 278 |
+
'''
|
| 279 |
+
batch_size, length = prod_rule_idx_seq.shape
|
| 280 |
+
if self.use_gpu:
|
| 281 |
+
out = Variable(torch.zeros((batch_size, length, self.out_dim))).cuda()
|
| 282 |
+
else:
|
| 283 |
+
out = Variable(torch.zeros((batch_size, length, self.out_dim)))
|
| 284 |
+
for each_batch_idx in range(batch_size):
|
| 285 |
+
for each_idx in range(length):
|
| 286 |
+
if int(prod_rule_idx_seq[each_batch_idx, each_idx]) == len(self.prod_rule_corpus.prod_rule_list):
|
| 287 |
+
continue
|
| 288 |
+
else:
|
| 289 |
+
each_prod_rule = self.prod_rule_corpus.prod_rule_list[int(prod_rule_idx_seq[each_batch_idx, each_idx])]
|
| 290 |
+
edge_list = sorted(list(each_prod_rule.rhs.edges))
|
| 291 |
+
node_list = sorted(list(each_prod_rule.rhs.nodes))
|
| 292 |
+
adj_mat = torch.FloatTensor(each_prod_rule.rhs_adj_mat(edge_list + node_list).todense() + np.identity(len(edge_list)+len(node_list)))
|
| 293 |
+
if self.use_gpu:
|
| 294 |
+
adj_mat = adj_mat.cuda()
|
| 295 |
+
layer_wise_embed = [
|
| 296 |
+
self.feature_dict[each_prod_rule.rhs.edge_attr(each_edge)['symbol']]
|
| 297 |
+
for each_edge in edge_list]\
|
| 298 |
+
+ [self.feature_dict[each_prod_rule.rhs.node_attr(each_node)['symbol']]
|
| 299 |
+
for each_node in node_list]
|
| 300 |
+
for each_node in each_prod_rule.ext_node.values():
|
| 301 |
+
layer_wise_embed[each_prod_rule.rhs.num_edges + node_list.index(each_node)] \
|
| 302 |
+
= layer_wise_embed[each_prod_rule.rhs.num_edges + node_list.index(each_node)] \
|
| 303 |
+
+ self.feature_dict[('ext_id', each_prod_rule.rhs.node_attr(each_node)['ext_id'])]
|
| 304 |
+
layer_wise_embed = torch.stack(layer_wise_embed)
|
| 305 |
+
|
| 306 |
+
for each_layer in range(self.num_layers):
|
| 307 |
+
message = adj_mat @ layer_wise_embed
|
| 308 |
+
next_layer_embed = self.layer2layer_activation(self.layer2layer_list[each_layer](message))
|
| 309 |
+
out[each_batch_idx, each_idx, :] \
|
| 310 |
+
= out[each_batch_idx, each_idx, :] \
|
| 311 |
+
+ self.layer2out_activation(self.layer2out_list[each_layer](message)).sum(dim=0)
|
| 312 |
+
layer_wise_embed = next_layer_embed
|
| 313 |
+
return out
|
images/mhg_example.png
ADDED

|
images/mhg_example1.png
ADDED
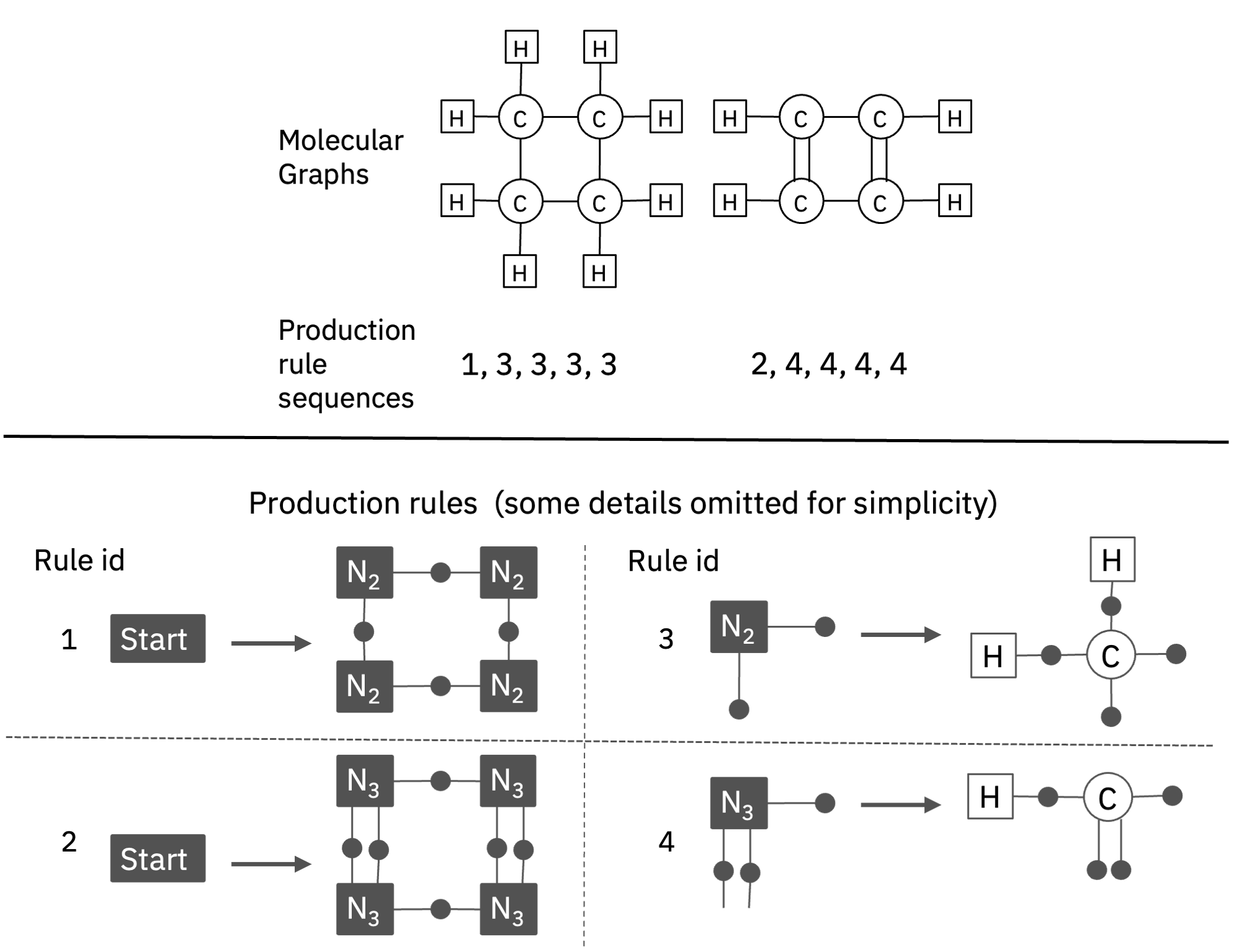
|
images/mhg_example2.png
ADDED
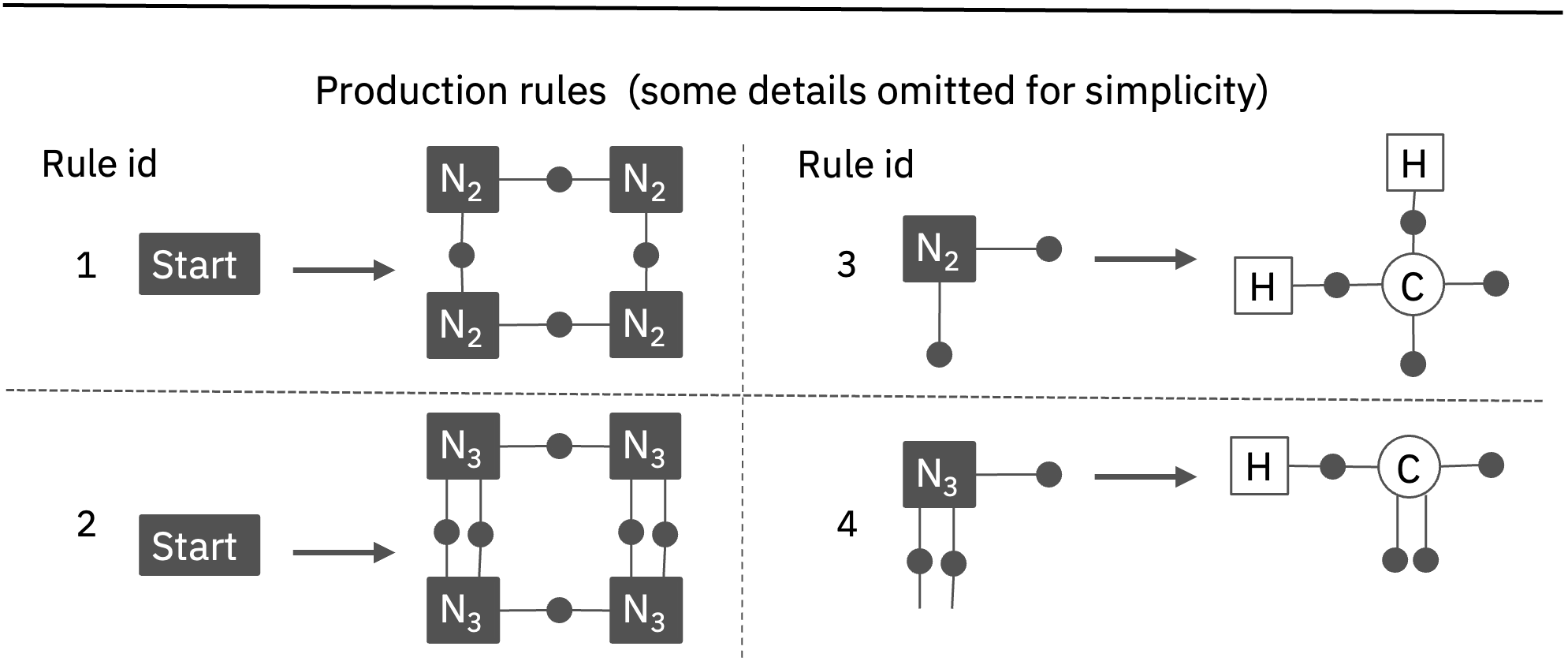
|
load.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding:utf-8 -*-
|
| 2 |
+
# Rhizome
|
| 3 |
+
# Version beta 0.0, August 2023
|
| 4 |
+
# Property of IBM Research, Accelerated Discovery
|
| 5 |
+
#
|
| 6 |
+
|
| 7 |
+
import os
|
| 8 |
+
import pickle
|
| 9 |
+
import sys
|
| 10 |
+
|
| 11 |
+
from rdkit import Chem
|
| 12 |
+
import torch
|
| 13 |
+
from torch_geometric.utils.smiles import from_smiles
|
| 14 |
+
|
| 15 |
+
from typing import Any, Dict, List, Optional, Union
|
| 16 |
+
from typing_extensions import Self
|
| 17 |
+
|
| 18 |
+
from .graph_grammar.io.smi import hg_to_mol
|
| 19 |
+
from .models.mhgvae import GrammarGINVAE
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
class PretrainedModelWrapper:
|
| 23 |
+
model: GrammarGINVAE
|
| 24 |
+
|
| 25 |
+
def __init__(self, model_dict: Dict[str, Any]) -> None:
|
| 26 |
+
json_params = model_dict['gnn_params']
|
| 27 |
+
encoder_params = json_params['encoder_params']
|
| 28 |
+
encoder_params['node_feature_size'] = model_dict['num_features']
|
| 29 |
+
encoder_params['edge_feature_size'] = model_dict['num_edge_features']
|
| 30 |
+
self.model = GrammarGINVAE(model_dict['hrg'], rank=-1, encoder_params=encoder_params,
|
| 31 |
+
decoder_params=json_params['decoder_params'],
|
| 32 |
+
prod_rule_embed_params=json_params["prod_rule_embed_params"],
|
| 33 |
+
batch_size=512, max_len=model_dict['max_length'])
|
| 34 |
+
self.model.load_state_dict(model_dict['model_state_dict'])
|
| 35 |
+
|
| 36 |
+
self.model.eval()
|
| 37 |
+
|
| 38 |
+
def to(self, device: Union[str, int, torch.device]) -> Self:
|
| 39 |
+
dev_type = type(device)
|
| 40 |
+
if dev_type != torch.device:
|
| 41 |
+
if dev_type == str or torch.cuda.is_available():
|
| 42 |
+
device = torch.device(device)
|
| 43 |
+
else:
|
| 44 |
+
device = torch.device("mps", device)
|
| 45 |
+
|
| 46 |
+
self.model = self.model.to(device)
|
| 47 |
+
return self
|
| 48 |
+
|
| 49 |
+
def encode(self, data: List[str]) -> List[torch.tensor]:
|
| 50 |
+
# Need to encode them into a graph nn
|
| 51 |
+
output = []
|
| 52 |
+
for d in data:
|
| 53 |
+
params = next(self.model.parameters())
|
| 54 |
+
g = from_smiles(d)
|
| 55 |
+
if (g.cpu() and params != 'cpu') or (not g.cpu() and params == 'cpu'):
|
| 56 |
+
g.to(params.device)
|
| 57 |
+
ltvec = self.model.graph_embed(g.x, g.edge_index, g.edge_attr, g.batch)
|
| 58 |
+
output.append(ltvec[0])
|
| 59 |
+
return output
|
| 60 |
+
|
| 61 |
+
def decode(self, data: List[torch.tensor]) -> List[str]:
|
| 62 |
+
output = []
|
| 63 |
+
for d in data:
|
| 64 |
+
mu, logvar = self.model.get_mean_var(d.unsqueeze(0))
|
| 65 |
+
z = self.model.reparameterize(mu, logvar)
|
| 66 |
+
flags, _, hgs = self.model.decode(z)
|
| 67 |
+
if flags[0]:
|
| 68 |
+
reconstructed_mol, _ = hg_to_mol(hgs[0], True)
|
| 69 |
+
output.append(Chem.MolToSmiles(reconstructed_mol))
|
| 70 |
+
else:
|
| 71 |
+
output.append(None)
|
| 72 |
+
return output
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def load(model_name: str = "models/mhg_model/pickles/mhggnn_pretrained_model_0724_2023.pickle") -> Optional[
|
| 76 |
+
PretrainedModelWrapper]:
|
| 77 |
+
for p in sys.path:
|
| 78 |
+
file = p + "/" + model_name
|
| 79 |
+
if os.path.isfile(file):
|
| 80 |
+
with open(file, "rb") as f:
|
| 81 |
+
model_dict = pickle.load(f)
|
| 82 |
+
return PretrainedModelWrapper(model_dict)
|
| 83 |
+
return None
|
mhg_gnn.egg-info/PKG-INFO
ADDED
|
@@ -0,0 +1,102 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Metadata-Version: 2.1
|
| 2 |
+
Name: mhg-gnn
|
| 3 |
+
Version: 0.0
|
| 4 |
+
Summary: Package for mhg-gnn
|
| 5 |
+
Author: team
|
| 6 |
+
License: TBD
|
| 7 |
+
Classifier: Programming Language :: Python :: 3
|
| 8 |
+
Classifier: Programming Language :: Python :: 3.9
|
| 9 |
+
Description-Content-Type: text/markdown
|
| 10 |
+
Requires-Dist: networkx>=2.8
|
| 11 |
+
Requires-Dist: numpy<2.0.0,>=1.23.5
|
| 12 |
+
Requires-Dist: pandas>=1.5.3
|
| 13 |
+
Requires-Dist: rdkit-pypi<2023.9.6,>=2022.9.4
|
| 14 |
+
Requires-Dist: torch>=2.0.0
|
| 15 |
+
Requires-Dist: torchinfo>=1.8.0
|
| 16 |
+
Requires-Dist: torch-geometric>=2.3.1
|
| 17 |
+
|
| 18 |
+
# mhg-gnn
|
| 19 |
+
|
| 20 |
+
This repository provides PyTorch source code assosiated with our publication, "MHG-GNN: Combination of Molecular Hypergraph Grammar with Graph Neural Network"
|
| 21 |
+
|
| 22 |
+
**Paper:** [Arxiv Link](https://arxiv.org/pdf/2309.16374)
|
| 23 |
+
|
| 24 |
+
For more information contact: SEIJITKD@jp.ibm.com
|
| 25 |
+
|
| 26 |
+

|
| 27 |
+
|
| 28 |
+
## Introduction
|
| 29 |
+
|
| 30 |
+
We present MHG-GNN, an autoencoder architecture
|
| 31 |
+
that has an encoder based on GNN and a decoder based on a sequential model with MHG.
|
| 32 |
+
Since the encoder is a GNN variant, MHG-GNN can accept any molecule as input, and
|
| 33 |
+
demonstrate high predictive performance on molecular graph data.
|
| 34 |
+
In addition, the decoder inherits the theoretical guarantee of MHG on always generating a structurally valid molecule as output.
|
| 35 |
+
|
| 36 |
+
## Table of Contents
|
| 37 |
+
|
| 38 |
+
1. [Getting Started](#getting-started)
|
| 39 |
+
1. [Pretrained Models and Training Logs](#pretrained-models-and-training-logs)
|
| 40 |
+
2. [Replicating Conda Environment](#replicating-conda-environment)
|
| 41 |
+
2. [Feature Extraction](#feature-extraction)
|
| 42 |
+
|
| 43 |
+
## Getting Started
|
| 44 |
+
|
| 45 |
+
**This code and environment have been tested on Intel E5-2667 CPUs at 3.30GHz and NVIDIA A100 Tensor Core GPUs.**
|
| 46 |
+
|
| 47 |
+
### Pretrained Models and Training Logs
|
| 48 |
+
|
| 49 |
+
We provide checkpoints of the MHG-GNN model pre-trained on a dataset of ~1.34M molecules curated from PubChem. (later) For model weights: [HuggingFace Link]()
|
| 50 |
+
|
| 51 |
+
Add the MHG-GNN `pre-trained weights.pt` to the `models/` directory according to your needs.
|
| 52 |
+
|
| 53 |
+
### Replacicating Conda Environment
|
| 54 |
+
|
| 55 |
+
Follow these steps to replicate our Conda environment and install the necessary libraries:
|
| 56 |
+
|
| 57 |
+
```
|
| 58 |
+
conda create --name mhg-gnn-env python=3.8.18
|
| 59 |
+
conda activate mhg-gnn-env
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
#### Install Packages with Conda
|
| 63 |
+
|
| 64 |
+
```
|
| 65 |
+
conda install -c conda-forge networkx=2.8
|
| 66 |
+
conda install numpy=1.23.5
|
| 67 |
+
# conda install -c conda-forge rdkit=2022.9.4
|
| 68 |
+
conda install pytorch=2.0.0 torchvision torchaudio -c pytorch
|
| 69 |
+
conda install -c conda-forge torchinfo=1.8.0
|
| 70 |
+
conda install pyg -c pyg
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
#### Install Packages with pip
|
| 74 |
+
```
|
| 75 |
+
pip install rdkit torch-nl==0.3 torch-scatter torch-sparse
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
## Feature Extraction
|
| 79 |
+
|
| 80 |
+
The example notebook [mhg-gnn_encoder_decoder_example.ipynb](notebooks/mhg-gnn_encoder_decoder_example.ipynb) contains code to load checkpoint files and use the pre-trained model for encoder and decoder tasks.
|
| 81 |
+
|
| 82 |
+
To load mhg-gnn, you can simply use:
|
| 83 |
+
|
| 84 |
+
```python
|
| 85 |
+
import torch
|
| 86 |
+
import load
|
| 87 |
+
|
| 88 |
+
model = load.load()
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
To encode SMILES into embeddings, you can use:
|
| 92 |
+
|
| 93 |
+
```python
|
| 94 |
+
with torch.no_grad():
|
| 95 |
+
repr = model.encode(["CCO", "O=C=O", "OC(=O)c1ccccc1C(=O)O"])
|
| 96 |
+
```
|
| 97 |
+
|
| 98 |
+
For decoder, you can use the function, so you can return from embeddings to SMILES strings:
|
| 99 |
+
|
| 100 |
+
```python
|
| 101 |
+
orig = model.decode(repr)
|
| 102 |
+
```
|
mhg_gnn.egg-info/SOURCES.txt
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
README.md
|
| 2 |
+
setup.cfg
|
| 3 |
+
setup.py
|
| 4 |
+
./graph_grammar/__init__.py
|
| 5 |
+
./graph_grammar/hypergraph.py
|
| 6 |
+
./graph_grammar/algo/__init__.py
|
| 7 |
+
./graph_grammar/algo/tree_decomposition.py
|
| 8 |
+
./graph_grammar/graph_grammar/__init__.py
|
| 9 |
+
./graph_grammar/graph_grammar/base.py
|
| 10 |
+
./graph_grammar/graph_grammar/corpus.py
|
| 11 |
+
./graph_grammar/graph_grammar/hrg.py
|
| 12 |
+
./graph_grammar/graph_grammar/symbols.py
|
| 13 |
+
./graph_grammar/graph_grammar/utils.py
|
| 14 |
+
./graph_grammar/io/__init__.py
|
| 15 |
+
./graph_grammar/io/smi.py
|
| 16 |
+
./graph_grammar/nn/__init__.py
|
| 17 |
+
./graph_grammar/nn/dataset.py
|
| 18 |
+
./graph_grammar/nn/decoder.py
|
| 19 |
+
./graph_grammar/nn/encoder.py
|
| 20 |
+
./graph_grammar/nn/graph.py
|
| 21 |
+
./models/__init__.py
|
| 22 |
+
./models/mhgvae.py
|
| 23 |
+
graph_grammar/__init__.py
|
| 24 |
+
graph_grammar/hypergraph.py
|
| 25 |
+
graph_grammar/algo/__init__.py
|
| 26 |
+
graph_grammar/algo/tree_decomposition.py
|
| 27 |
+
graph_grammar/graph_grammar/__init__.py
|
| 28 |
+
graph_grammar/graph_grammar/base.py
|
| 29 |
+
graph_grammar/graph_grammar/corpus.py
|
| 30 |
+
graph_grammar/graph_grammar/hrg.py
|
| 31 |
+
graph_grammar/graph_grammar/symbols.py
|
| 32 |
+
graph_grammar/graph_grammar/utils.py
|
| 33 |
+
graph_grammar/io/__init__.py
|
| 34 |
+
graph_grammar/io/smi.py
|
| 35 |
+
graph_grammar/nn/__init__.py
|
| 36 |
+
graph_grammar/nn/dataset.py
|
| 37 |
+
graph_grammar/nn/decoder.py
|
| 38 |
+
graph_grammar/nn/encoder.py
|
| 39 |
+
graph_grammar/nn/graph.py
|
| 40 |
+
mhg_gnn.egg-info/PKG-INFO
|
| 41 |
+
mhg_gnn.egg-info/SOURCES.txt
|
| 42 |
+
mhg_gnn.egg-info/dependency_links.txt
|
| 43 |
+
mhg_gnn.egg-info/requires.txt
|
| 44 |
+
mhg_gnn.egg-info/top_level.txt
|
| 45 |
+
models/__init__.py
|
| 46 |
+
models/mhgvae.py
|