

language: de
license: mit
thumbnail: >-
https://static.tildacdn.com/tild6438-3730-4164-b266-613634323466/german_bert.png
tags:
- exbert

German BERT

Table of Contents
- Model Details
- Uses
- Risks, Limitations and Biases
- Training
- Evaluation
- Environmental Impact
- Model Card Contact
- How to Get Started With the Model
Model Details
- Model Description: German BERT allows the developers working with text data in German to be more efficient with their natural language processing (NLP) tasks.
- Developed by:
- Model Type: Fill-Mask
- Language(s): German
- License: MIT
- Parent Model: See the BERT base cased model for more information about the BERT base model.
- Resources for more information:
- Update October 2020: Research Paper
- Website: German BERT
- GitRepo: FARM
- Git Repo: Haystack
Uses
Direct Use
This model can be used for masked language modelling.
Risks, Limitations and Biases
CONTENT WARNING: Readers should be aware this section contains content that is disturbing, offensive, and can propagate historical and current stereotypes.
Significant research has explored bias and fairness issues with language models (see, e.g., Sheng et al. (2021) and Bender et al. (2021)).
Training
Training Data
Training data: Wiki, OpenLegalData, News (~ 12GB)
As training data we used the latest German Wikipedia dump (6GB of raw txt files), the OpenLegalData dump (2.4 GB) and news articles (3.6 GB).
The data dumps were cleaned with tailored scripts and segmented sentences with spacy v2.1. To create tensorflow records the model developers used the recommended sentencepiece library for creating the word piece vocabulary and tensorflow scripts to convert the text to data usable by BERT.
Update April 3rd, 2020: the model developers updated the vocabulary file on deepset's s3 to conform with the default tokenization of punctuation tokens.
For details see the related FARM issue. If you want to use the old vocab we have also uploaded a "deepset/bert-base-german-cased-oldvocab" model.
Training Procedure
- We trained using Google's Tensorflow code on a single cloud TPU v2 with standard settings.
- We trained 810k steps with a batch size of 1024 for sequence length 128 and 30k steps with sequence length 512. Training took about 9 days.
See https://deepset.ai/german-bert for more details
Hyperparameters
batch_size = 1024
n_steps = 810_000
max_seq_len = 128 (and 512 later)
learning_rate = 1e-4
lr_schedule = LinearWarmup
num_warmup_steps = 10_000
Evaluation
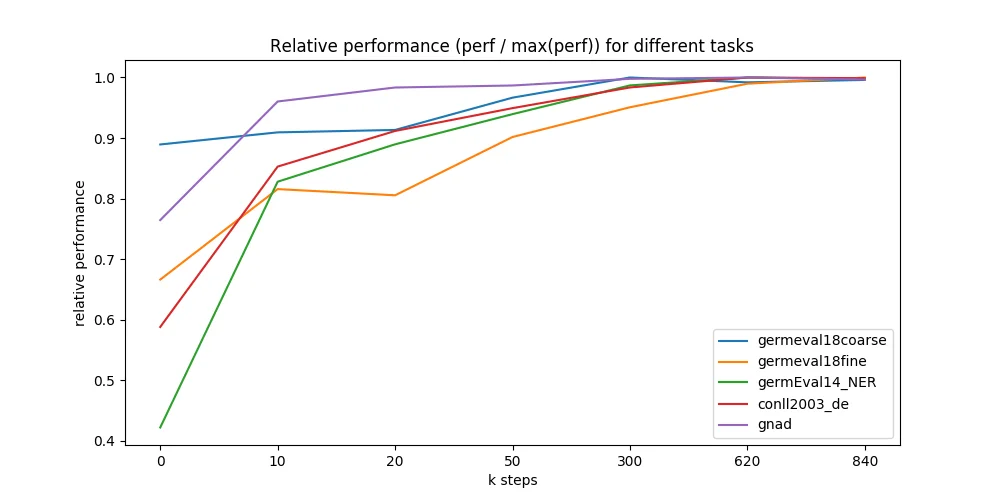
- Eval data: Conll03 (NER), GermEval14 (NER), GermEval18 (Classification), GNAD (Classification)
Performance
During training we monitored the loss and evaluated different model checkpoints on the following German datasets:
- germEval18Fine: Macro f1 score for multiclass sentiment classification
- germEval18coarse: Macro f1 score for binary sentiment classification
- germEval14: Seq f1 score for NER (file names deuutf.*)
- CONLL03: Seq f1 score for NER
- 10kGNAD: Accuracy for document classification
Even without thorough hyperparameter tuning, we observed quite stable learning especially for our German model. Multiple restarts with different seeds produced quite similar results.

We further evaluated different points during the 9 days of pre-training and were astonished how fast the model converges to the maximally reachable performance. We ran all 5 downstream tasks on 7 different model checkpoints - taken at 0 up to 840k training steps (x-axis in figure below). Most checkpoints are taken from early training where we expected most performance changes. Surprisingly, even a randomly initialized BERT can be trained only on labeled downstream datasets and reach good performance (blue line, GermEval 2018 Coarse task, 795 kB trainset size).
Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019). We present the hardware type based on the associated paper.
Hardware Type: Tensorflow code on a single cloud TPU v2
Hours used: 216 (9 days)
Cloud Provider: GCP
Compute Region: [More information needed]
Carbon Emitted: [More information needed]
Model Card Contact
Click to expand
![]()
We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
How to Get Started With the Model
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("bert-base-german-cased")
model = AutoModelForMaskedLM.from_pretrained("bert-base-german-cased")