
update README with training details
Browse files- README.md +28 -4
- validation_wer.png +0 -0
README.md
CHANGED
|
@@ -25,13 +25,16 @@ model-index:
|
|
| 25 |
- name: Test WER
|
| 26 |
type: wer
|
| 27 |
value: 26.55
|
|
|
|
|
|
|
|
|
|
| 28 |
---
|
| 29 |
|
| 30 |
# Wav2Vec2-Large-XLSR-53-Arabic
|
| 31 |
|
| 32 |
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53)
|
| 33 |
-
on Arabic using the [Common Voice](https://huggingface.co/datasets/common_voice)
|
| 34 |
-
and
|
| 35 |
When using this model, make sure that your speech input is sampled at 16kHz.
|
| 36 |
|
| 37 |
## Usage
|
|
@@ -174,5 +177,26 @@ print(f"WER: {metrics['wer']:.2%}")
|
|
| 174 |
|
| 175 |
## Training
|
| 176 |
|
| 177 |
-
|
| 178 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 25 |
- name: Test WER
|
| 26 |
type: wer
|
| 27 |
value: 26.55
|
| 28 |
+
- name: Validation WER
|
| 29 |
+
type: wer
|
| 30 |
+
value: 23.39
|
| 31 |
---
|
| 32 |
|
| 33 |
# Wav2Vec2-Large-XLSR-53-Arabic
|
| 34 |
|
| 35 |
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53)
|
| 36 |
+
on Arabic using the `train` splits of [Common Voice](https://huggingface.co/datasets/common_voice)
|
| 37 |
+
and [Arabic Speech Corpus](https://huggingface.co/datasets/arabic_speech_corpus).
|
| 38 |
When using this model, make sure that your speech input is sampled at 16kHz.
|
| 39 |
|
| 40 |
## Usage
|
|
|
|
| 177 |
|
| 178 |
## Training
|
| 179 |
|
| 180 |
+
For more details, see [Fine-Tuning with Arabic Speech Corpus](https://github.com/huggingface/transformers/tree/1c06240e1b3477728129bb58e7b6c7734bb5074e/examples/research_projects/wav2vec2#fine-tuning-with-arabic-speech-corpus).
|
| 181 |
+
|
| 182 |
+
This model represents Arabic in a format called [Buckwalter transliteration](https://en.wikipedia.org/wiki/Buckwalter_transliteration).
|
| 183 |
+
The Buckwalter format only includes ASCII characters, some of which are non-alpha (e.g., `">"` maps to `"أ"`).
|
| 184 |
+
The [lang-trans](https://github.com/kariminf/lang-trans) package is used to convert (transliterate) Arabic abjad.
|
| 185 |
+
|
| 186 |
+
[This script](https://github.com/huggingface/transformers/blob/1c06240e1b3477728129bb58e7b6c7734bb5074e/examples/research_projects/wav2vec2/finetune_large_xlsr_53_arabic_speech_corpus.sh)
|
| 187 |
+
was used to first fine-tune [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53)
|
| 188 |
+
on the `train` split of the [Arabic Speech Corpus](https://huggingface.co/datasets/arabic_speech_corpus) dataset;
|
| 189 |
+
the `validation` split was used for model selection; the resulting model at this point is saved as [elgeish/wav2vec2-large-xlsr-53-levantine-arabic](https://huggingface.co/elgeish/wav2vec2-large-xlsr-53-levantine-arabic).
|
| 190 |
+
|
| 191 |
+
Training was then resumed using the `train` split of the [Common Voice](https://huggingface.co/datasets/common_voice) dataset;
|
| 192 |
+
similarly, the `validation` split was used for model selection;
|
| 193 |
+
training was stopped to meet the deadline of [Fine-Tune-XLSR Week](https://github.com/huggingface/transformers/blob/700229f8a4003c4f71f29275e0874b5ba58cd39d/examples/research_projects/wav2vec2/FINE_TUNE_XLSR_WAV2VEC2.md):
|
| 194 |
+
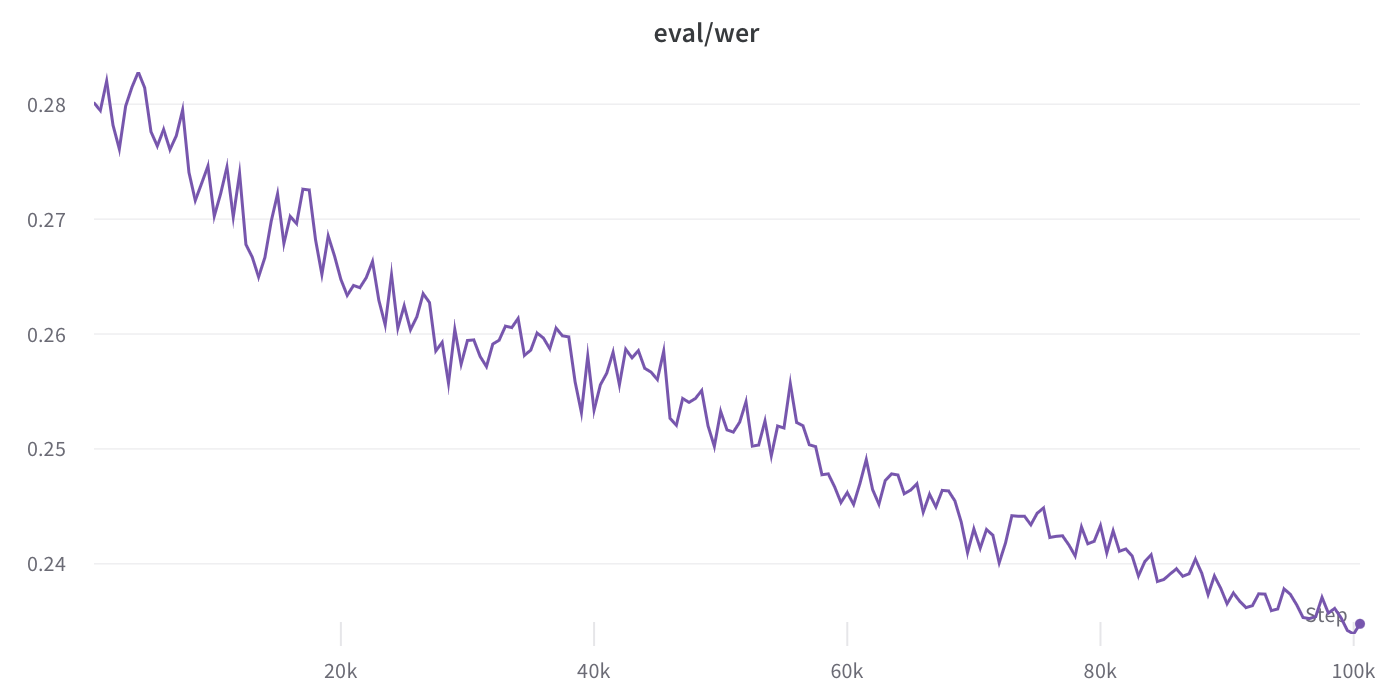
this model is the checkpoint at 100k steps and a validation WER of **23.39%**.
|
| 195 |
+
|
| 196 |
+
<img src="validation_wer.png" alt="Validation WER" width="50%" />
|
| 197 |
+
|
| 198 |
+
It's worth noting that validation WER is trending down, indicating the potential of further training (resuming the decaying learning rate at 7e-6).
|
| 199 |
+
|
| 200 |
+
## Future Work
|
| 201 |
+
One area to explore is using `attention_mask` in model input, which is recommended [here](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2).
|
| 202 |
+
Also, exploring data augmentation using datasets used to train models listed [here](https://paperswithcode.com/sota/speech-recognition-on-common-voice-arabic).
|
validation_wer.png
ADDED
|