Supervised Fine-tuning Trainer
Supervised fine-tuning (or SFT for short) is a crucial step in RLHF. In TRL we provide an easy-to-use API to create your SFT models and train them with few lines of code on your dataset.
Check out a complete flexible example inside examples/scripts folder.
Quickstart
If you have a dataset hosted on the 🤗 Hub, you can easily fine-tune your SFT model using SFTTrainer from TRL. Let us assume your dataset is imdb, the text you want to predict is inside the text field of the dataset, and you want to fine-tune the facebook/opt-350m model.
The following code-snippet takes care of all the data pre-processing and training for you:
from datasets import load_dataset
from trl import SFTTrainer
dataset = load_dataset("imdb", split="train")
trainer = SFTTrainer(
"facebook/opt-350m",
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=512,
)
trainer.train()Make sure to pass a correct value for max_seq_length as the default value will be set to min(tokenizer.model_max_length, 1024).
You can also construct a model outside of the trainer and pass it as follows:
from transformers import AutoModelForCausalLM
from datasets import load_dataset
from trl import SFTTrainer
dataset = load_dataset("imdb", split="train")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
trainer = SFTTrainer(
model,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=512,
)
trainer.train()The above snippets will use the default training arguments from the transformers.TrainingArguments class. If you want to modify that, make sure to create your own TrainingArguments object and pass it to the SFTTrainer constructor as it is done on the supervised_finetuning.py script on the stack-llama example.
Advanced usage
Train on completions only
You can use the DataCollatorForCompletionOnlyLM to train your model on the generated prompts only. Note that this works only in the case when packing=False.
To instantiate that collator for instruction data, pass a response template and the tokenizer. Here is an example of how it would work to fine-tune opt-350m on completions only on the CodeAlpaca dataset:
from transformers import AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset
from trl import SFTTrainer, DataCollatorForCompletionOnlyLM
dataset = load_dataset("lucasmccabe-lmi/CodeAlpaca-20k", split="train")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
def formatting_prompts_func(example):
output_texts = []
for i in range(len(example['instruction'])):
text = f"### Question: {example['instruction'][i]}\n ### Answer: {example['output'][i]}"
output_texts.append(text)
return output_texts
response_template = " ### Answer:"
collator = DataCollatorForCompletionOnlyLM(response_template, tokenizer=tokenizer)
trainer = SFTTrainer(
model,
train_dataset=dataset,
formatting_func=formatting_prompts_func,
data_collator=collator,
)
trainer.train() To instantiate that collator for assistant style conversation data, pass a response template, an instruction template and the tokenizer. Here is an example of how it would work to fine-tune opt-350m on assistant completions only on the Open Assistant Guanaco dataset:
from transformers import AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset
from trl import SFTTrainer, DataCollatorForCompletionOnlyLM
dataset = load_dataset("timdettmers/openassistant-guanaco", split="train")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
instruction_template = "### Human:"
response_template = "### Assistant:"
collator = DataCollatorForCompletionOnlyLM(instruction_template=instruction_template, response_template=response_template, tokenizer=tokenizer, mlm=False)
trainer = SFTTrainer(
model,
train_dataset=dataset,
dataset_text_field="text",
data_collator=collator,
)
trainer.train() Using token_ids directly for response_template
Some tokenizers like Llama 2 (meta-llama/Llama-2-XXb-hf) tokenize sequences differently depending whether they have context or not. For example:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
def print_tokens_with_ids(txt):
tokens = tokenizer.tokenize(txt, add_special_tokens=False)
token_ids = tokenizer.encode(txt, add_special_tokens=False)
print(list(zip(tokens, token_ids)))
prompt = """### User: Hello\n\n### Assistant: Hi, how can I help you?"""
print_tokens_with_ids(prompt) # [..., ('▁Hello', 15043), ('<0x0A>', 13), ('<0x0A>', 13), ('##', 2277), ('#', 29937), ('▁Ass', 4007), ('istant', 22137), (':', 29901), ...]
response_template = "### Assistant:"
print_tokens_with_ids(response_template) # [('▁###', 835), ('▁Ass', 4007), ('istant', 22137), (':', 29901)]In this case, and due to lack of context in response_template, the same string (”### Assistant:”) is tokenized differently:
- Text (with context):
[2277, 29937, 4007, 22137, 29901] response_template(without context):[835, 4007, 22137, 29901]
This will lead to an error when the DataCollatorForCompletionOnlyLM does not find the response_template in the dataset example text:
RuntimeError: Could not find response key [835, 4007, 22137, 29901] in token IDs tensor([ 1, 835, ...]) To solve this, you can tokenize the response_template with the same context than in the dataset, truncate it as needed and pass the token_ids directly to the response_template argument of the DataCollatorForCompletionOnlyLM class. For example:
response_template_with_context = "\n### Assistant:" # We added context here: "\n". This is enough for this tokenizer
response_template_ids = tokenizer.encode(response_template_with_context, add_special_tokens=False)[2:] # Now we have it like in the dataset texts: `[2277, 29937, 4007, 22137, 29901]`
data_collator = DataCollatorForCompletionOnlyLM(response_template_ids, tokenizer=tokenizer)Format your input prompts
For instruction fine-tuning, it is quite common to have two columns inside the dataset: one for the prompt & the other for the response. This allows people to format examples like Stanford-Alpaca did as follows:
Below is an instruction ...
### Instruction
{prompt}
### Response:
{completion}Let us assume your dataset has two fields, question and answer. Therefore you can just run:
...
def formatting_prompts_func(example):
output_texts = []
for i in range(len(example['question'])):
text = f"### Question: {example['question'][i]}\n ### Answer: {example['answer'][i]}"
output_texts.append(text)
return output_texts
trainer = SFTTrainer(
model,
train_dataset=dataset,
formatting_func=formatting_prompts_func,
)
trainer.train()To preperly format your input make sure to process all the examples by looping over them and returning a list of processed text. Check out a full example on how to use SFTTrainer on alpaca dataset here
Packing dataset ( ConstantLengthDataset )
SFTTrainer supports example packing, where multiple short examples are packed in the same input sequence to increase training efficiency. This is done with the ConstantLengthDataset utility class that returns constant length chunks of tokens from a stream of examples. To enable the usage of this dataset class, simply pass packing=True to the SFTTrainer constructor.
...
trainer = SFTTrainer(
"facebook/opt-350m",
train_dataset=dataset,
dataset_text_field="text",
packing=True
)
trainer.train()Note that if you use a packed dataset and if you pass max_steps in the training arguments you will probably train your models for more than few epochs, depending on the way you have configured the packed dataset and the training protocol. Double check that you know and understand what you are doing.
Customize your prompts using packed dataset
If your dataset has several fields that you want to combine, for example if the dataset has question and answer fields and you want to combine them, you can pass a formatting function to the trainer that will take care of that. For example:
def formatting_func(example):
text = f"### Question: {example['question']}\n ### Answer: {example['answer']}"
return text
trainer = SFTTrainer(
"facebook/opt-350m",
train_dataset=dataset,
packing=True,
formatting_func=formatting_func
)
trainer.train()You can also customize the ConstantLengthDataset much more by directly passing the arguments to the SFTTrainer constructor. Please refer to that class’ signature for more information.
Control over the pretrained model
You can directly pass the kwargs of the from_pretrained() method to the SFTTrainer. For example, if you want to load a model in a different precision, analogous to
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.bfloat16)
```python
...
trainer = SFTTrainer(
"facebook/opt-350m",
train_dataset=dataset,
dataset_text_field="text",
)
trainer.train()Note that all keyword arguments of from_pretrained() are supported.
Training adapters
We also support a tight integration with 🤗 PEFT library so that any user can conveniently train adapters and share them on the Hub instead of training the entire model
from datasets import load_dataset
from trl import SFTTrainer
from peft import LoraConfig
dataset = load_dataset("imdb", split="train")
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
trainer = SFTTrainer(
"EleutherAI/gpt-neo-125m",
train_dataset=dataset,
dataset_text_field="text",
peft_config=peft_config
)
trainer.train()Note that in case of training adapters, we manually add a saving callback to automatically save the adapters only:
class PeftSavingCallback(TrainerCallback):
def on_save(self, args, state, control, **kwargs):
checkpoint_path = os.path.join(args.output_dir, f"checkpoint-{state.global_step}")
kwargs["model"].save_pretrained(checkpoint_path)
if "pytorch_model.bin" in os.listdir(checkpoint_path):
os.remove(os.path.join(checkpoint_path, "pytorch_model.bin"))If you want to add more callbacks, make sure to add this one as well to properly save the adapters only during training.
...
callbacks = [YourCustomCallback(), PeftSavingCallback()]
trainer = SFTTrainer(
"EleutherAI/gpt-neo-125m",
train_dataset=dataset,
dataset_text_field="text",
peft_config=peft_config,
callbacks=callbacks
)
trainer.train()You can also continue training your PeftModel. For that, first load a PeftModel outside SFTTrainer and pass it directly to the trainer without the peft_config argument being passed.
Training adapters with base 8 bit models
For that you need to first load your 8bit model outside the Trainer and pass a PeftConfig to the trainer. For example:
...
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
model = AutoModelForCausalLM.from_pretrained(
"EleutherAI/gpt-neo-125m",
load_in_8bit=True,
device_map="auto",
)
trainer = SFTTrainer(
model,
train_dataset=dataset,
dataset_text_field="text",
peft_config=peft_config,
)
trainer.train()Using Flash Attention and Flash Attention 2
You can benefit from Flash Attention 1 & 2 using SFTTrainer out of the box with minimal changes of code. First, to make sure you have all the latest features from transformers, install transformers from source
pip install -U git+https://github.com/huggingface/transformers.git
Note that Flash Attention only works on GPU now and under half-precision regime (when using adapters, base model loaded in half-precision) Note also both features are perfectly compatible with other tools such as quantization.
Using Flash-Attention 1
For Flash Attention 1 you can use the BetterTransformer API and force-dispatch the API to use Flash Attention kernel. First, install the latest optimum package:
pip install -U optimum
Once you have loaded your model, wrap the trainer.train() call under the with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False): context manager:
...
+ with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
trainer.train()Note that you cannot train your model using Flash Attention 1 on an arbitrary dataset as torch.scaled_dot_product_attention does not support training with padding tokens if you use Flash Attention kernels. Therefore you can only use that feature with packing=True. If your dataset contains padding tokens, consider switching to Flash Attention 2 integration.
Below are some numbers you can get in terms of speedup and memory efficiency, using Flash Attention 1, on a single NVIDIA-T4 16GB.
| use_flash_attn_1 | model_name | max_seq_len | batch_size | time per training step |
|---|---|---|---|---|
| x | facebook/opt-350m | 2048 | 8 | ~59.1s |
| facebook/opt-350m | 2048 | 8 | OOM | |
| x | facebook/opt-350m | 2048 | 4 | ~30.3s |
| facebook/opt-350m | 2048 | 4 | ~148.9s |
Using Flash Attention-2
To use Flash Attention 2, first install the latest flash-attn package:
pip install -U flash-attn
And add use_flash_attention_2=True when calling from_pretrained:
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
use_flash_attention_2=True
)If you don’t use quantization, make sure your model is loaded in half-precision and dispatch your model on a supported GPU device. After loading your model, you can either train it as it is, or attach adapters and train adapters on it in case your model is quantized.
In contrary to Flash Attention 1, the integration makes it possible to train your model on an arbitrary dataset that also includes padding tokens.
Enhance model’s performances using NEFTune
NEFTune is a technique to boost the performance of chat models and was introduced by the paper “NEFTune: Noisy Embeddings Improve Instruction Finetuning” from Jain et al. it consists of adding noise to the embedding vectors during training. According to the abstract of the paper:
Standard finetuning of LLaMA-2-7B using Alpaca achieves 29.79% on AlpacaEval, which rises to 64.69% using noisy embeddings. NEFTune also improves over strong baselines on modern instruction datasets. Models trained with Evol-Instruct see a 10% improvement, with ShareGPT an 8% improvement, and with OpenPlatypus an 8% improvement. Even powerful models further refined with RLHF such as LLaMA-2-Chat benefit from additional training with NEFTune.
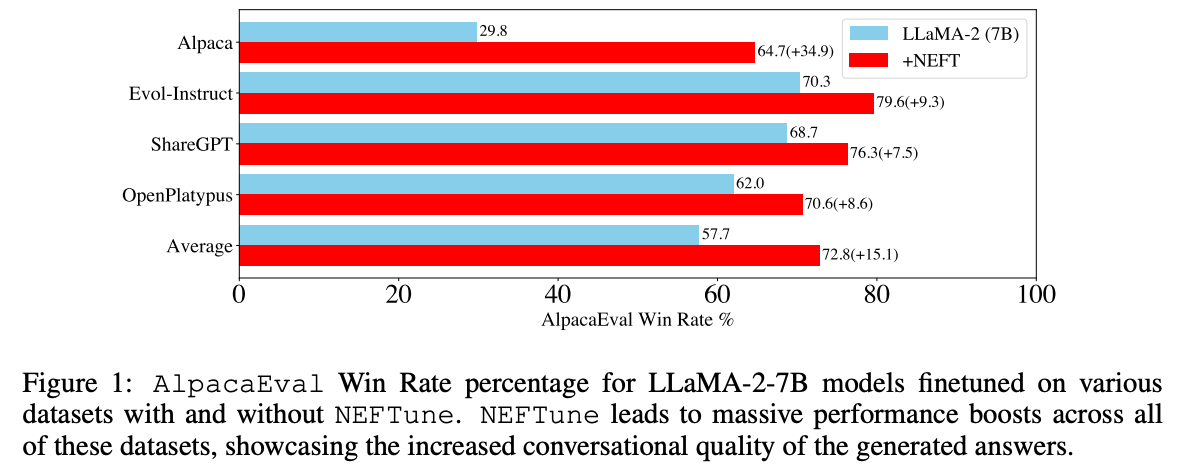
To use it in SFTTrainer simply pass neftune_noise_alpha when creating your SFTTrainer instance. Note that to avoid any surprising behaviour, NEFTune is disabled after training to retrieve back the original behaviour of the embedding layer.
from datasets import load_dataset
from trl import SFTTrainer
dataset = load_dataset("imdb", split="train")
trainer = SFTTrainer(
"facebook/opt-350m",
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=512,
neftune_noise_alpha=5,
)
trainer.train()We have tested NEFTune by training mistralai/Mistral-7B-v0.1 on the OpenAssistant dataset and validated that using NEFTune led to a performance boost of ~25% on MT Bench.
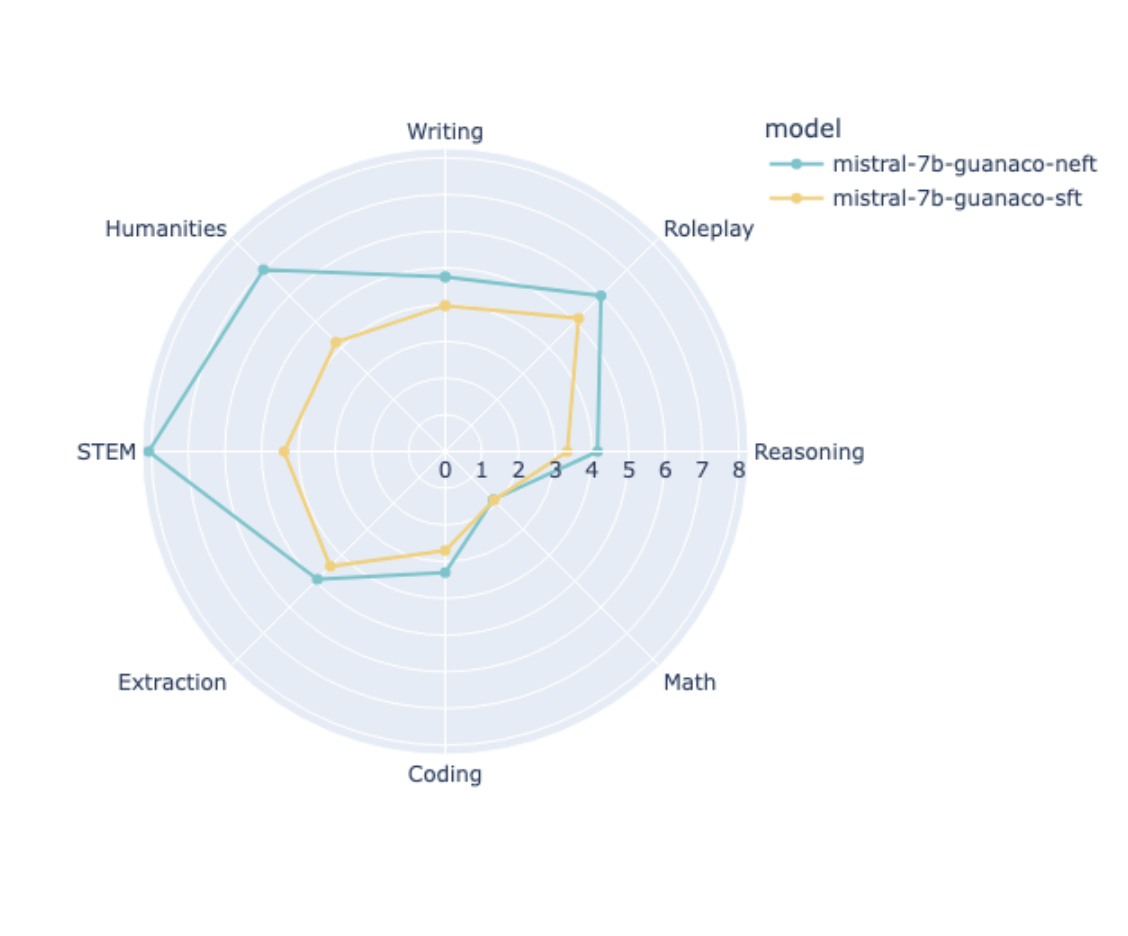
Note however, that the amount of performance gain is dataset dependent and in particular, applying NEFTune on synthetic datasets like UltraChat typically produces smaller gains.
Best practices
Pay attention to the following best practices when training a model with that trainer:
- SFTTrainer always pads by default the sequences to the
max_seq_lengthargument of the SFTTrainer. If none is passed, the trainer will retrieve that value from the tokenizer. Some tokenizers do not provide default value, so there is a check to retrieve the minimum between 2048 and that value. Make sure to check it before training. - For training adapters in 8bit, you might need to tweak the arguments of the
prepare_model_for_kbit_trainingmethod from PEFT, hence we advise users to useprepare_in_int8_kwargsfield, or create thePeftModeloutside the SFTTrainer and pass it. - For a more memory-efficient training using adapters, you can load the base model in 8bit, for that simply add
load_in_8bitargument when creating the SFTTrainer, or create a base model in 8bit outside the trainer and pass it. - If you create a model outside the trainer, make sure to not pass to the trainer any additional keyword arguments that are relative to
from_pretrained()method.
SFTTrainer
class trl.SFTTrainer
< source >( model: typing.Union[transformers.modeling_utils.PreTrainedModel, torch.nn.modules.module.Module, str] = None args: TrainingArguments = None data_collator: typing.Optional[DataCollator] = None train_dataset: typing.Optional[datasets.arrow_dataset.Dataset] = None eval_dataset: typing.Union[datasets.arrow_dataset.Dataset, typing.Dict[str, datasets.arrow_dataset.Dataset], NoneType] = None tokenizer: typing.Optional[transformers.tokenization_utils_base.PreTrainedTokenizerBase] = None model_init: typing.Union[typing.Callable[[], transformers.modeling_utils.PreTrainedModel], NoneType] = None compute_metrics: typing.Union[typing.Callable[[transformers.trainer_utils.EvalPrediction], typing.Dict], NoneType] = None callbacks: typing.Optional[typing.List[transformers.trainer_callback.TrainerCallback]] = None optimizers: typing.Tuple[torch.optim.optimizer.Optimizer, torch.optim.lr_scheduler.LambdaLR] = (None, None) preprocess_logits_for_metrics: typing.Union[typing.Callable[[torch.Tensor, torch.Tensor], torch.Tensor], NoneType] = None peft_config: typing.Optional[ForwardRef('PeftConfig')] = None dataset_text_field: typing.Optional[str] = None packing: typing.Optional[bool] = False formatting_func: typing.Optional[typing.Callable] = None max_seq_length: typing.Optional[int] = None infinite: typing.Optional[bool] = False num_of_sequences: typing.Optional[int] = 1024 chars_per_token: typing.Optional[float] = 3.6 dataset_num_proc: typing.Optional[int] = None dataset_batch_size: int = 1000 neftune_noise_alpha: typing.Optional[float] = None model_init_kwargs: typing.Optional[typing.Dict] = None )
Parameters
- model (Union[
transformers.PreTrainedModel,nn.Module,str]) — The model to train, can be aPreTrainedModel, atorch.nn.Moduleor a string with the model name to load from cache or download. The model can be also converted to aPeftModelif aPeftConfigobject is passed to thepeft_configargument. - args (Optionaltransformers.TrainingArguments) —
The arguments to tweak for training. Please refer to the official documentation of
transformers.TrainingArgumentsfor more information. - data_collator (Optional
transformers.DataCollator) — The data collator to use for training. - train_dataset (Optional
datasets.Dataset) — The dataset to use for training. We recommend users to usetrl.trainer.ConstantLengthDatasetto create their dataset. - eval_dataset (Optional[Union[
datasets.Dataset, Dict[str,datasets.Dataset]]]) — The dataset to use for evaluation. We recommend users to usetrl.trainer.ConstantLengthDatasetto create their dataset. - tokenizer (Optionaltransformers.PreTrainedTokenizer) — The tokenizer to use for training. If not specified, the tokenizer associated to the model will be used.
- model_init (
Callable[[], transformers.PreTrainedModel]) — The model initializer to use for training. If None is specified, the default model initializer will be used. - compute_metrics (
Callable[[transformers.EvalPrediction], Dict], optional defaults tocompute_accuracy) — The metrics to use for evaluation. If no metrics are specified, the default metric (compute_accuracy) will be used. - callbacks (
List[transformers.TrainerCallback]) — The callbacks to use for training. - optimizers (
Tuple[torch.optim.Optimizer, torch.optim.lr_scheduler.LambdaLR]) — The optimizer and scheduler to use for training. - preprocess_logits_for_metrics (
Callable[[torch.Tensor, torch.Tensor], torch.Tensor]) — The function to use to preprocess the logits before computing the metrics. - peft_config (
Optional[PeftConfig]) — The PeftConfig object to use to initialize the PeftModel. - dataset_text_field (
Optional[str]) — The name of the text field of the dataset, in case this is passed by a user, the trainer will automatically create aConstantLengthDatasetbased on thedataset_text_fieldargument. - formatting_func (
Optional[Callable]) — The formatting function to be used for creating theConstantLengthDataset. - max_seq_length (
Optional[int]) — The maximum sequence length to use for theConstantLengthDatasetand for automaticallty creating the Dataset. Defaults to512. - infinite (
Optional[bool]) — Whether to use an infinite dataset or not. Defaults toFalse. - num_of_sequences (
Optional[int]) — The number of sequences to use for theConstantLengthDataset. Defaults to1024. - chars_per_token (
Optional[float]) — The number of characters per token to use for theConstantLengthDataset. Defaults to3.6. You can check how this is computed in the stack-llama example: https://github.com/huggingface/trl/blob/08f550674c553c36c51d1027613c29f14f3676a5/examples/stack_llama/scripts/supervised_finetuning.py#L53. - packing (
Optional[bool]) — Used only in casedataset_text_fieldis passed. This argument is used by theConstantLengthDatasetto pack the sequences of the dataset. - dataset_num_proc (
Optional[int]) — The number of workers to use to tokenize the data. Only used whenpacking=False. Defaults to None. - dataset_batch_size (
int) — The number of examples to tokenize per batch. If batch_size <= 0 or batch_size == None, tokenize the full dataset as a single batch. Defaults to 1000. - neftune_noise_alpha (
Optional[float]) — If notNone, this will activate NEFTune noise embeddings. This has been proven to drastically improve model performances for instrcution fine-tuning. Check out the original paper here: https://arxiv.org/abs/2310.05914 and the original code here: https://github.com/neelsjain/NEFTune model_init_kwargs — (Optional[Dict], optional): Dict of Optional kwargs to pass when instantiating the model from a string
Class definition of the Supervised Finetuning Trainer (SFT Trainer).
This class is a wrapper around the transformers.Trainer class and inherits all of its attributes and methods.
The trainer takes care of properly initializing the PeftModel in case a user passes a PeftConfig object.
ConstantLengthDataset
class trl.trainer.ConstantLengthDataset
< source >( *args **kwds )
Parameters
- tokenizer (
transformers.PreTrainedTokenizer) — The processor used for processing the data. - dataset (
dataset.Dataset) — Dataset with text files. - dataset_text_field (
str, optional) — Name of the field in the dataset that contains the text. Used only ifformatting_funcisNone. - formatting_func (
Callable, optional) — Function that formats the text before tokenization. Usually it is recommended to have follows a certain pattern such as `”### Question: {question}
Iterable dataset that returns constant length chunks of tokens from stream of text files. The dataset also formats the text before tokenization with a specific format that is provided by the user.
Answer: {answer}
”infinite (bool, *optional*, defaults to False): If True the iterator is reset after dataset reaches end else stops. seq_length (int, *optional*, defaults to 1024): Length of token sequences to return. num_of_sequences (int, *optional*, defaults to 1024): Number of token sequences to keep in buffer. chars_per_token (int, *optional*, defaults to 3.6): Number of characters per token used to estimate number of tokens in text buffer. eos_token_id (int, *optional*, defaults to 0`):
Id of the end of sequence token if the passed tokenizer does not have an EOS token.
shuffle (‘bool’, optional, defaults to True)
Shuffle the examples before they are returned