Transformers documentation
Depth Anything
Depth Anything
Overview
The Depth Anything model was proposed in Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data by Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao. Depth Anything is based on the DPT architecture, trained on ~62 million images, obtaining state-of-the-art results for both relative and absolute depth estimation.
Depth Anything V2 was released in June 2024. It uses the same architecture as Depth Anything and therefore it is compatible with all code examples and existing workflows. However, it leverages synthetic data and a larger capacity teacher model to achieve much finer and robust depth predictions.
The abstract from the paper is the following:
This work presents Depth Anything, a highly practical solution for robust monocular depth estimation. Without pursuing novel technical modules, we aim to build a simple yet powerful foundation model dealing with any images under any circumstances. To this end, we scale up the dataset by designing a data engine to collect and automatically annotate large-scale unlabeled data (~62M), which significantly enlarges the data coverage and thus is able to reduce the generalization error. We investigate two simple yet effective strategies that make data scaling-up promising. First, a more challenging optimization target is created by leveraging data augmentation tools. It compels the model to actively seek extra visual knowledge and acquire robust representations. Second, an auxiliary supervision is developed to enforce the model to inherit rich semantic priors from pre-trained encoders. We evaluate its zero-shot capabilities extensively, including six public datasets and randomly captured photos. It demonstrates impressive generalization ability. Further, through fine-tuning it with metric depth information from NYUv2 and KITTI, new SOTAs are set. Our better depth model also results in a better depth-conditioned ControlNet.
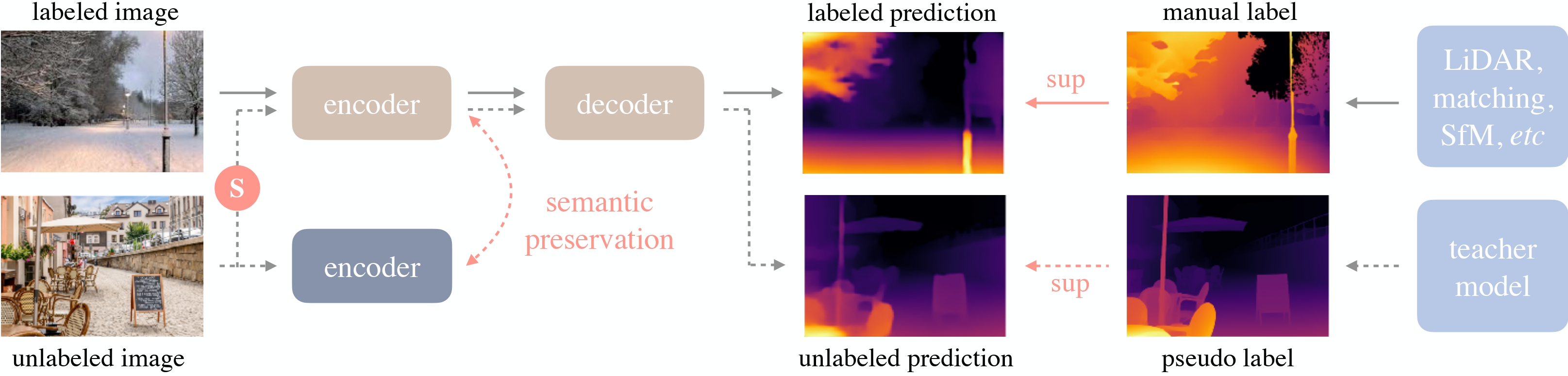 Depth Anything overview. Taken from the original paper.
Depth Anything overview. Taken from the original paper. This model was contributed by nielsr. The original code can be found here.
Usage example
There are 2 main ways to use Depth Anything: either using the pipeline API, which abstracts away all the complexity for you, or by using the DepthAnythingForDepthEstimation class yourself.
Pipeline API
The pipeline allows to use the model in a few lines of code:
>>> from transformers import pipeline
>>> from PIL import Image
>>> import requests
>>> # load pipe
>>> pipe = pipeline(task="depth-estimation", model="LiheYoung/depth-anything-small-hf")
>>> # load image
>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> # inference
>>> depth = pipe(image)["depth"]Using the model yourself
If you want to do the pre- and postprocessing yourself, here’s how to do that:
>>> from transformers import AutoImageProcessor, AutoModelForDepthEstimation
>>> import torch
>>> import numpy as np
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("LiheYoung/depth-anything-small-hf")
>>> model = AutoModelForDepthEstimation.from_pretrained("LiheYoung/depth-anything-small-hf")
>>> # prepare image for the model
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> # interpolate to original size and visualize the prediction
>>> post_processed_output = image_processor.post_process_depth_estimation(
... outputs,
... target_sizes=[(image.height, image.width)],
... )
>>> predicted_depth = post_processed_output[0]["predicted_depth"]
>>> depth = (predicted_depth - predicted_depth.min()) / (predicted_depth.max() - predicted_depth.min())
>>> depth = depth.detach().cpu().numpy() * 255
>>> depth = Image.fromarray(depth.astype("uint8"))Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Depth Anything.
- Monocular depth estimation task guide
- A notebook showcasing inference with DepthAnythingForDepthEstimation can be found here. 🌎
If you’re interested in submitting a resource to be included here, please feel free to open a Pull Request and we’ll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
DepthAnythingConfig
class transformers.DepthAnythingConfig
< source >( backbone_config = None backbone = None use_pretrained_backbone = False use_timm_backbone = False backbone_kwargs = None patch_size = 14 initializer_range = 0.02 reassemble_hidden_size = 384 reassemble_factors = [4, 2, 1, 0.5] neck_hidden_sizes = [48, 96, 192, 384] fusion_hidden_size = 64 head_in_index = -1 head_hidden_size = 32 depth_estimation_type = 'relative' max_depth = None **kwargs )
Parameters
- backbone_config (
Union[Dict[str, Any], PretrainedConfig], optional) — The configuration of the backbone model. Only used in caseis_hybridisTrueor in case you want to leverage the AutoBackbone API. - backbone (
str, optional) — Name of backbone to use whenbackbone_configisNone. Ifuse_pretrained_backboneisTrue, this will load the corresponding pretrained weights from the timm or transformers library. Ifuse_pretrained_backboneisFalse, this loads the backbone’s config and uses that to initialize the backbone with random weights. - use_pretrained_backbone (
bool, optional, defaults toFalse) — Whether to use pretrained weights for the backbone. - use_timm_backbone (
bool, optional, defaults toFalse) — Whether or not to use thetimmlibrary for the backbone. If set toFalse, will use the AutoBackbone API. - backbone_kwargs (
dict, optional) — Keyword arguments to be passed to AutoBackbone when loading from a checkpoint e.g.{'out_indices': (0, 1, 2, 3)}. Cannot be specified ifbackbone_configis set. - patch_size (
int, optional, defaults to 14) — The size of the patches to extract from the backbone features. - initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - reassemble_hidden_size (
int, optional, defaults to 384) — The number of input channels of the reassemble layers. - reassemble_factors (
List[int], optional, defaults to[4, 2, 1, 0.5]) — The up/downsampling factors of the reassemble layers. - neck_hidden_sizes (
List[str], optional, defaults to[48, 96, 192, 384]) — The hidden sizes to project to for the feature maps of the backbone. - fusion_hidden_size (
int, optional, defaults to 64) — The number of channels before fusion. - head_in_index (
int, optional, defaults to -1) — The index of the features to use in the depth estimation head. - head_hidden_size (
int, optional, defaults to 32) — The number of output channels in the second convolution of the depth estimation head. - depth_estimation_type (
str, optional, defaults to"relative") — The type of depth estimation to use. Can be one of["relative", "metric"]. - max_depth (
float, optional) — The maximum depth to use for the “metric” depth estimation head. 20 should be used for indoor models and 80 for outdoor models. For “relative” depth estimation, this value is ignored.
This is the configuration class to store the configuration of a DepthAnythingModel. It is used to instantiate a DepthAnything
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
defaults will yield a similar configuration to that of the DepthAnything
LiheYoung/depth-anything-small-hf architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import DepthAnythingConfig, DepthAnythingForDepthEstimation
>>> # Initializing a DepthAnything small style configuration
>>> configuration = DepthAnythingConfig()
>>> # Initializing a model from the DepthAnything small style configuration
>>> model = DepthAnythingForDepthEstimation(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configSerializes this instance to a Python dictionary. Override the default to_dict(). Returns:
Dict[str, any]: Dictionary of all the attributes that make up this configuration instance,
DepthAnythingForDepthEstimation
class transformers.DepthAnythingForDepthEstimation
< source >( config )
Parameters
- config (DepthAnythingConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Depth Anything Model with a depth estimation head on top (consisting of 3 convolutional layers) e.g. for KITTI, NYUv2.
This model is a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( pixel_values: FloatTensor labels: typing.Optional[torch.LongTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.DepthEstimatorOutput or tuple(torch.FloatTensor)
Parameters
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using AutoImageProcessor. See DPTImageProcessor.call() for details. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size, height, width), optional) — Ground truth depth estimation maps for computing the loss.
Returns
transformers.modeling_outputs.DepthEstimatorOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.DepthEstimatorOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (DepthAnythingConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. -
predicted_depth (
torch.FloatTensorof shape(batch_size, height, width)) — Predicted depth for each pixel. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, num_channels, height, width).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, patch_size, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The DepthAnythingForDepthEstimation forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoImageProcessor, AutoModelForDepthEstimation
>>> import torch
>>> import numpy as np
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("LiheYoung/depth-anything-small-hf")
>>> model = AutoModelForDepthEstimation.from_pretrained("LiheYoung/depth-anything-small-hf")
>>> # prepare image for the model
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> # interpolate to original size
>>> post_processed_output = image_processor.post_process_depth_estimation(
... outputs,
... target_sizes=[(image.height, image.width)],
... )
>>> # visualize the prediction
>>> predicted_depth = post_processed_output[0]["predicted_depth"]
>>> depth = predicted_depth * 255 / predicted_depth.max()
>>> depth = depth.detach().cpu().numpy()
>>> depth = Image.fromarray(depth.astype("uint8"))