Transformers documentation
تحسين نماذج اللغة الكبيرة من حيث السرعة والذاكرة
تحسين نماذج اللغة الكبيرة من حيث السرعة والذاكرة
تحقق نماذج اللغة الكبيرة (LLMs) مثل GPT3/4، Falcon، و Llama تقدمًا سريعًا في قدرتها على معالجة المهام التي تركز على الإنسان، مما يجعلها أدوات أساسية في الصناعات القائمة على المعرفة الحديثة. لا يزال نشر هذه النماذج في المهام الواقعية يمثل تحديًا، ومع ذلك:
- لكي تظهر نماذج اللغة الكبيرة قدرات فهم وتوليد النصوص قريبة من قدرات الإنسان، فإنها تتطلب حاليًا إلى تكوينها من مليارات المعلمات (انظر كابلان وآخرون، وي وآخرون). وهذا بدوره يزيد من متطلبات الذاكرة للاستدلال.
- في العديد من المهام الواقعية، تحتاج نماذج اللغة الكبيرة إلى معلومات سياقية شاملة. يتطلب ذلك قدرة النموذج على إدارة تسلسلات إدخال طويلة للغاية أثناء الاستدلال.
يكمن جوهر صعوبة هذه التحديات في تعزيز القدرات الحسابية والذاكرة لنماذج اللغة الكبيرة، خاصة عند التعامل مع تسلسلات الإدخال الضخمة.
في هذا الدليل، سنستعرض التقنيات الفعالة لتُحسِّن من كفاءة نشر نماذج اللغة الكبيرة:
سنتناول تقنية “دقة أقل” التي أثبتت الأبحاث فعاليتها في تحقيق مزايا حسابية دون التأثير بشكل ملحوظ على أداء النموذج عن طريق العمل بدقة رقمية أقل 8 بت و4 بت.
اFlash Attention: إن Flash Attention وهي نسخة مُعدَّلة من خوارزمية الانتباه التي لا توفر فقط نهجًا أكثر كفاءة في استخدام الذاكرة، ولكنها تحقق أيضًا كفاءة متزايدة بسبب الاستخدام الأمثل لذاكرة GPU.
الابتكارات المعمارية: حيث تم اقتراح هياكل متخصصة تسمح باستدلال أكثر فعالية نظرًا لأن نماذج اللغة الكبيرة يتم نشرها دائمًا بنفس الطريقة أثناء عملية الاستدلال، أي توليد النص التنبؤي التلقائي مع سياق الإدخال الطويل، فقد تم اقتراح بنيات نموذج متخصصة تسمح بالاستدلال الأكثر كفاءة. أهم تقدم في بنيات النماذج هنا هو عذر، الترميز الدوار، الاهتمام متعدد الاستعلامات (MQA) و مجموعة الانتباه بالاستعلام (GQA).
على مدار هذا الدليل، سنقدم تحليلًا للتوليد التنبؤي التلقائي من منظور المُوتِّرات. نتعمق في مزايا وعيوب استخدام دقة أقل، ونقدم استكشافًا شاملاً لخوارزميات الانتباه الأحدث، ونناقش بنيات نماذج نماذج اللغة الكبيرة المحسنة. سندعم الشرح بأمثلة عملية تُبرِز كل تحسين على حدة.
1. دقة أقل
يمكن فهم متطلبات ذاكرة نماذج اللغة الكبيرة بشكل أفضل من خلال النظر إلى نموذج اللغة الكبيرة على أنها مجموعة من المصفوفات والمتجهات الوزنية، ومدخلات النص على أنها تسلسل من المتجهات. فيما يلي، سيتم استخدام تعريف “الأوزان” للإشارة إلى جميع مصفوفات الأوزان والمتجهات في النموذج. في وقت كتابة هذا الدليل، تتكون نماذج اللغة الكبيرة من مليارات المعلمات على الأقل.كل معلمة يتم تمثيلها برقم عشري مثل 4.5689 “ والذي يتم تخزينه عادةً بتنسيق float32، bfloat16، أو float16 . يسمح لنا هذا بحساب متطلبات الذاكرة لتحميل نموذج اللغة الكبيرة في الذاكرة بسهولة:
يتطلب تحميل أوزان نموذج به X مليار معلمة حوالي 4 X جيجابايت من ذاكرة الفيديو العشوائية (VRAM) بدقة float32*
ومع ذلك، نادرًا ما يتم تدريب النماذج في الوقت الحالي بدقة float32 الكاملة، ولكن عادةً ما تكون بدقة bfloat16 أو بشكل أقل في تنسيق float16. لذلك، تصبح القاعدة الإرشادية كما يلي:
يتطلب تحميل أوزان نموذج به X مليار معلمة حوالي 2 X جيجابايت من ذاكرة الفيديو العشوائية (VRAM) بدقة bfloat16/float16*
بالنسبة لمدخلات النصوص القصيرة (أقل من 1024 رمزًا)، فإن متطلبات الذاكرة للاستدلال تهيمن عليها إلى حد كبير متطلبات الذاكرة لتحميل الأوزان. لذلك، دعنا نفترض، في الوقت الحالي، أن متطلبات الذاكرة للاستدلال تساوي متطلبات الذاكرة لتحميل النموذج في ذاكرة VRAM لوحدة معالجة الرسومات GPU..
ولإعطاء بعض الأمثلة على مقدار ذاكرة الفيديو العشوائية (VRAM) التي يتطلبها تحميل نموذج بتنسيق bfloat16 تقريبًا:
- GPT3 يتطلب 2 * 175 جيجا بايت = 350 جيجا بايت VRAM
- بلوم يتطلب 2 * 176 جيجا بايت = 352 جيجا بايت VRAM
- Llama-2-70b يتطلب 2 * 70 جيجا بايت = 140 جيجا بايت VRAM
- Falcon-40b يتطلب 2 * 40 جيجا بايت = 80 جيجا بايت VRAM
- MPT-30b يتطلب 2 * 30 جيجا بايت = 60 جيجا بايت VRAM
- bigcode/starcoder يتطلب 2 * 15.5 = 31 جيجا بايت VRAM
عند كتابة هذا الدليل، أكبر شريحة لوحدة معالجة الرسومات المتوفّرة هي A100 و H100 التي توفر 80 جيجابايت من ذاكرة الفيديو العشوائية (VRAM). تتطلب معظم النماذج المدرجة أعلاه أكثر من 80 جيجابايت فقط لتحميلها، وبالتالي فهي تتطلب بالضرورة التوازي للموتّرات و/أو لتوازي الخطي.
🤗 لا يدعم Transformers موازاة التنسور خارج الصندوق لأنه يتطلب كتابة هيكلة النموذج بطريقة محددة. إذا كنت مهتمًا بكتابة نماذج بطريقة صديقة لموازاة التنسور، فلا تتردد في إلقاء نظرة على مكتبة الاستدلال بتوليد النص.
بدعم موازاة قنوات المعالجة البسيطة خارج الصندوق. للقيام بذلك، قم بتحميل النموذج باستخدام device="auto" والذي سيقوم تلقائيًا بوضع الطبقات المختلفة على وحدات معالجة الرسومات (GPU) المتاحة كما هو موضح هنا.
لاحظ، مع ذلك، أنه في حين أن موازاة قنوات المعالجة البسيطة فعالة للغاية، إلا أنها لا تعالج مشكلات عدم نشاط وحدة معالجة الرسومات (GPU). لهذا، تكون موازاة قنوات المعالجة المتقدمة مطلوبة كما هو موضح هنا.
إذا كان لديك حق الوصول إلى عقدة 8 x 80 جيجابايت A100، فيمكنك تحميل BLOOM كما يلي
!pip install transformers accelerate bitsandbytes optimum
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("bigscience/bloom", device_map="auto", pad_token_id=0)من خلال استخدام device_map="auto" سيتم توزيع طبقات الاهتمام بالتساوي عبر جميع وحدات معالجة الرسومات (GPU) المتاحة.
في هذا الدليل، سنستخدم bigcode/octocoder لأنه يمكن تشغيله على شريحة جهاز GPU A100 ذات 40 جيجا بايت. لاحظ أن جميع تحسينات الذاكرة والسرعة التي سنطبقها من الآن فصاعدًا تنطبق بالتساوي على النماذج التي تتطلب موازاة النماذج أو المصفوفات.
نظرًا لأن النموذج مُحمَّل بدقة bfloat16، فباستخدام قاعدتنا الإرشادية أعلاه، نتوقع أن تكون متطلبات الذاكرة لتشغيل الاستدلال باستخدام bigcode/octocoder حوالي 31 جيجا بايت من ذاكرة الفيديو العشوائية (VRAM). دعنا نجرب.
نقوم أولاً بتحميل النموذج والمجزىء اللغوي ثم نقوم بتمرير كلاهما إلى كائن قنوات المعالجة في Transformers.
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
import torch
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto", pad_token_id=0)
tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)prompt = "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer:"
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
resultالإخراج:
Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a singleرائع، يمكننا الآن استخدام النتيجة مباشرة لتحويل البايت إلى جيجا بايت.
def bytes_to_giga_bytes(bytes):
return bytes / 1024 / 1024 / 1024دعونا نستدعي torch.cuda.max_memory_allocated لقياس ذروة تخصيص ذاكرة وحدة معالجة الرسومات (GPU).
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
الإخراج:
29.0260648727417
قريب بما يكفي من حسابنا التقريبي! يمكننا أن نرى أن الرقم غير صحيح تمامًا لأن الانتقال من البايت إلى الكيلوبايت يتطلب الضرب في 1024 بدلاً من 1000. لذلك يمكن أيضًا فهم صيغة التقريب على أنها حساب “بحد أقصى X جيجا بايت”. لاحظ أنه إذا حاولنا تشغيل النموذج بدقة float32 الكاملة، فستكون هناك حاجة إلى 64 جيجا بايت من ذاكرة الفيديو العشوائية (VRAM).
يتم تدريب جميع النماذج تقريبًا بتنسيق bfloat16 في الوقت الحالي، ولا يوجد سبب لتشغيل النموذج بدقة float32 الكاملة إذا كانت وحدة معالجة الرسومات (GPU) الخاصة بك تدعم bfloat16. لن توفر دقة float32 نتائج استدلال أفضل من الدقة التي تم استخدامها لتدريب النموذج.
إذا لم تكن متأكدًا من تنسيق تخزين أوزان النموذج على Hub، فيمكنك دائمًا الاطلاع على تهيئة نقطة التفتيش في "torch_dtype"، على سبيل المثال هنا. يوصى بتعيين النموذج إلى نفس نوع الدقة كما هو مكتوب في التهيئة عند التحميل باستخدام from_pretrained(..., torch_dtype=...) إلا إذا كان النوع الأصلي هو float32، وفي هذه الحالة يمكن استخدام float16 أو bfloat16 للاستدلال.
دعونا نحدد وظيفة flush(...) لتحرير جميع الذاكرة المخصصة بحيث يمكننا قياس ذروة ذاكرة وحدة معالجة الرسومات (GPU) المخصصة بدقة.
del pipe
del model
import gc
import torch
def flush():
gc.collect()
torch.cuda.empty_cache()
torch.cuda.reset_peak_memory_stats()دعونا نستدعيه الآن للتجربة التالية.
flush()
في الإصدار الأخير من مكتبة Accelerate، يمكنك أيضًا استخدام طريقة مساعدة تسمى release_memory()
from accelerate.utils import release_memory
# ...
release_memory(model)from accelerate.utils import release_memory
# ...
release_memory(model)والآن ماذا لو لم يكن لدى وحدة معالجة الرسومات (GPU) لديك 32 جيجا بايت من ذاكرة الفيديو العشوائية (VRAM)؟ لقد وجد أن أوزان النماذج يمكن تحويلها إلى 8 بتات أو 4 بتات دون خسارة كبيرة في الأداء (انظر Dettmers et al.). يمكن تحويل النموذج إلى 3 بتات أو 2 بتات مع فقدان مقبول في الأداء كما هو موضح في ورقة GPTQ 🤯.
دون الدخول في الكثير من التفاصيل، تهدف مخططات التكميم إلى تخفيض دقة الأوزان مع محاولة الحفاظ على دقة نتائج النموذج كما هي (أي أقرب ما يمكن إلى bfloat16).
لاحظ أن التكميم يعمل بشكل خاص جيدًا لتوليد النص حيث كل ما نهتم به هو اختيار مجموعة الرموز الأكثر احتمالًا التالية ولا نهتم حقًا بالقيم الدقيقة لتوزيع الرمز التالي logit.
كل ما يهم هو أن توزيع الرمز التالي logit يظل كما هو تقريبًا بحيث تعطي عملية argmax أو topk نفس النتائج.
هناك عدة تقنيات للتكميم، والتي لن نناقشها بالتفصيل هنا، ولكن بشكل عام، تعمل جميع تقنيات التكميم كما يلي:
- تكميم جميع الأوزان إلى الدقة المستهدفة
- تحميل الأوزان المحولة، ومرر تسلسل المدخلات من المتجهات بتنسيق bfloat16
- قم بتحويل الأوزان ديناميكيًا إلى bfloat1 لإجراء الحسابات مع متجهات المدخلات بدقة
bfloat16
- قم بتحويل الأوزان ديناميكيًا إلى bfloat1 لإجراء الحسابات مع متجهات المدخلات بدقة
باختصار، هذا يعني أن مضروبات مصفوفة المدخلات-الوزن، حيث هي المدخلات، هي مصفوفة وزن و هي الناتج:
تتغير إلى
لكل عملية ضرب المصفوفات. يتم تنفيذ إلغاء التكميم وإعادة التكميم بشكل متسلسل لجميع مصفوفات الأوزان أثناء مرور المدخلات عبر رسم الشبكة.
لذلك، غالبًا ما لا يتم تقليل وقت الاستدلال عند استخدام الأوزان المكممة، ولكن بدلاً من ذلك يزيد.
كفى نظرية، دعنا نجرب! لتكميم الأوزان باستخدام المحولات، تحتاج إلى التأكد من تثبيت مكتبة bitsandbytes.
!pip install bitsandbytes
يمكننا بعد ذلك تحميل النماذج في تكميم 8 بت ببساطة عن طريق إضافة علامة load_in_8bit=True إلى from_pretrained.
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_8bit=True, pad_token_id=0)الآن، دعنا نعيد تشغيل مثالنا ونقيس استخدام الذاكرة.
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
resultالإخراج:
Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a singleجميل، نحصل على نفس النتيجة كما في السابق، لذلك لا يوجد فقدان في الدقة! دعنا نلقي نظرة على مقدار الذاكرة المستخدمة هذه المرة.
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
الإخراج:
15.219234466552734أقل بكثير! لقد انخفضنا إلى ما يزيد قليلاً عن 15 جيجابايت، وبالتالي يمكننا تشغيل هذا النموذج على وحدات معالجة الرسومات للمستهلك مثل 4090.
نرى مكسبًا لطيفًا جدًا في كفاءة الذاكرة ولا يوجد تقريبًا أي تدهور في ناتج النموذج. ومع ذلك، يمكننا أيضًا ملاحظة تباطؤ طفيف أثناء الاستدلال.
نحذف النماذج ونفرغ الذاكرة مرة أخرى.
del model
del pipeflush()
دعنا نرى ما هو استهلاك ذاكرة GPU الذروة الذي يوفره تكميم 4 بت. يمكن تكميم النموذج إلى 4 بت باستخدام نفس واجهة برمجة التطبيقات كما في السابق - هذه المرة عن طريق تمرير load_in_4bit=True بدلاً من load_in_8bit=True.
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_4bit=True, low_cpu_mem_usage=True, pad_token_id=0)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
resultالإخراج:
Here is a Python function that transforms bytes to Giga bytes:\n\n```\ndef bytes_to_gigabytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single argumentنحن نرى تقريبًا نفس نص الإخراج كما في السابق - فقط python مفقود قبل مقطع الكود. دعنا نرى مقدار الذاكرة المطلوبة.
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
الإخراج:
9.543574333190918فقط 9.5 جيجابايت! هذا ليس كثيرًا بالفعل لنموذج يزيد عدد معاملاته عن 15 مليار.
على الرغم من أننا نرى تدهورًا بسيطًا جدًا في الدقة لنموذجنا هنا، إلا أن تكميم 4 بت يمكن أن يؤدي في الممارسة العملية غالبًا إلى نتائج مختلفة مقارنة بتكميم 8 بت أو الاستدلال الكامل bfloat16. الأمر متروك للمستخدم لتجربته.
لاحظ أيضًا أن الاستدلال هنا كان أبطأ قليلاً مقارنة بتكميم 8 بت والذي يرجع إلى طريقة التكميم الأكثر عدوانية المستخدمة لتكميم 4 بت مما يؤدي إلى و يستغرق وقتًا أطول أثناء الاستدلال.
del model
del pipeflush()
بشكل عام، رأينا أن تشغيل OctoCoder بدقة 8 بت قلل من ذاكرة GPU VRAM المطلوبة من 32G GPU VRAM إلى 15 جيجابايت فقط، وتشغيل النموذج بدقة 4 بت يقلل من ذاكرة GPU VRAM المطلوبة إلى ما يزيد قليلاً عن 9 جيجابايت.
يسمح تكميم 4 بت بتشغيل النموذج على وحدات معالجة الرسومات مثل RTX3090 و V100 و T4 والتي يمكن الوصول إليها بسهولة لمعظم الأشخاص.
لمزيد من المعلومات حول التكميم ولمعرفة كيف يمكن تكميم النماذج لطلب ذاكرة GPU VRAM أقل حتى من 4 بت، نوصي بالاطلاع على تنفيذ AutoGPTQ.
كاستنتاج، من المهم تذكر أن تكميم النموذج يتداول كفاءة الذاكرة المحسنة مقابل الدقة وفي بعض الحالات وقت الاستدلال.
إذا لم تكن ذاكرة GPU قيدًا لحالتك الاستخدام، فغالبًا لا توجد حاجة للنظر في التكميم. ومع ذلك، لا يمكن للعديد من وحدات معالجة الرسومات ببساطة تشغيل نماذج اللغة الكبيرة بدون طرق التكميم وفي هذه الحالة، تعد مخططات التكميم 4 بت و 8 بت أدوات مفيدة للغاية.
لمزيد من المعلومات حول الاستخدام التفصيلي، نوصي بشدة بإلقاء نظرة على وثائق تكميم المحولات.
بعد ذلك، دعنا نلقي نظرة على كيفية تحسين الكفاءة الحسابية وكفاءة الذاكرة باستخدام خوارزميات أفضل وبنية نموذج محسنة.
2. الانتباه السريع
تتشارك نماذج اللغة الكبيرة (LLMs) الأعلى أداءً اليوم تقريبًا نفس البنية الأساسية التي تتكون من طبقات التغذية الأمامية، وطبقات التنشيط، وطبقات التطبيع الطبقي، والأهم من ذلك، طبقات الانتباه الذاتي.
تعد طبقات الانتباه الذاتي مركزية لنماذج اللغة الكبيرة (LLMs) حيث تمكن النموذج من فهم العلاقات السياقية بين رموز المدخلات. ومع ذلك، فإن استهلاك ذاكرة GPU الذروة لطبقات الانتباه الذاتي ينمو بشكل رباعي في كل من التعقيد الحسابي وتعقيد الذاكرة مع عدد رموز المدخلات (والذي يُطلق عليه أيضًا طول التسلسل) الذي نسميه في ما يلي بـ . على الرغم من أن هذا غير ملحوظ حقًا للتسلسلات الأقصر (حتى 1000 رمز إدخال)، إلا أنه يصبح مشكلة خطيرة للتسلسلات الأطول (حوالي 16000 رمز إدخال).
دعنا نلقي نظرة أقرب. الصيغة لحساب الناتج لطبقة الانتباه الذاتي لإدخال بطول هي:
يعد بالتالي تسلسل الإدخال إلى طبقة الاهتمام. وستتكون كل من الإسقاطات و من من المتجهات مما يؤدي إلى أن يكون حجم هو.
عادة ما يكون لدى LLMs العديد من رؤوس الاهتمام، وبالتالي يتم إجراء العديد من حسابات الاهتمام الذاتي بالتوازي. وبافتراض أن LLM لديها 40 رأس اهتمام وتعمل بدقة bfloat16، يمكننا حساب متطلبات الذاكرة لتخزين مصفوفات لتكون بايت. بالنسبة لـ، لا يلزم سوى حوالي 50 ميجابايت من VRAM، ولكن بالنسبة لـ سنحتاج إلى 19 جيجابايت من VRAM، وبالنسبة لـ سنحتاج إلى ما يقرب من 1 تيرابايت فقط لتخزين مصفوفات.
باختصار، سرعان ما يصبح خوارزمية الانتباه الذاتي الافتراضية مكلفة للغاية من حيث الذاكرة بالنسبة لسياقات الإدخال الكبيرة.
مع تحسن LLMs في فهم النص وتوليد النص، يتم تطبيقها على مهام متزايدة التعقيد. في حين أن النماذج كانت تتعامل سابقًا مع ترجمة أو تلخيص بضع جمل، فإنها الآن تدير صفحات كاملة، مما يتطلب القدرة على معالجة أطوال إدخال واسعة.
كيف يمكننا التخلص من متطلبات الذاكرة الباهظة للتطويلات المدخلة الكبيرة؟ نحن بحاجة إلى طريقة جديدة لحساب آلية الاهتمام الذاتي التي تتخلص من مصفوفة. طريقه داو وآخرون. طوروا بالضبط مثل هذا الخوارزمية الجديدة وأطلقوا عليها اسم Flash Attention.
باختصار، يكسر الاهتمام الفلاشي حساب) ويحسب بدلاً من ذلك قطعًا أصغر من الإخراج عن طريق التكرار عبر العديد من خطوات حساب Softmax:
مع و كونها بعض إحصائيات التطبيع softmax التي يجب إعادة حسابها لكل و.
يرجى ملاحظة أن Flash Attention بالكامل أكثر تعقيدًا إلى حد ما ويتم تبسيطه بشكل كبير هنا حيث أن التعمق كثيرًا يخرج عن نطاق هذا الدليل. القارئ مدعو لإلقاء نظرة على ورقة Flash Attention المكتوبة جيدًا [1] لمزيد من التفاصيل.
الفكرة الرئيسية هنا هي:
من خلال تتبع إحصائيات التطبيع softmax واستخدام بعض الرياضيات الذكية، يعطي Flash Attention مخرجات متطابقة رقميًا مقارنة بطبقة الاهتمام الذاتي الافتراضية بتكلفة ذاكرة لا تزيد خطيًا مع.
عند النظر إلى الصيغة، قد يقول المرء بديهيًا أن الاهتمام الفلاشي يجب أن يكون أبطأ بكثير مقارنة بصيغة الاهتمام الافتراضية حيث يلزم إجراء المزيد من الحسابات. في الواقع، يتطلب Flash Attention المزيد من عمليات الفاصلة العائمة مقارنة بالاهتمام العادي حيث يجب إعادة حساب إحصائيات التطبيع softmax باستمرار (راجع الورقة لمزيد من التفاصيل إذا كنت مهتمًا)
ومع ذلك، فإن الاهتمام الفلاشي أسرع بكثير في الاستدلال مقارنة بالاهتمام الافتراضي الذي يأتي من قدرته على تقليل الطلبات على ذاكرة GPU الأبطأ ذات النطاق الترددي العالي (VRAM)، والتركيز بدلاً من ذلك على ذاكرة SRAM الأسرع الموجودة على الشريحة.
من الناحية الأساسية، يتأكد Flash Attention من إمكانية إجراء جميع عمليات الكتابة والقراءة الوسيطة باستخدام ذاكرة SRAM السريعة الموجودة على الشريحة بدلاً من الاضطرار إلى الوصول إلى ذاكرة VRAM الأبطأ لحساب متجه الإخراج.
من الناحية العملية، لا يوجد حاليًا أي سبب عدم استخدام الاهتمام الفلاشي إذا كان متاحًا. الخوارزمية تعطي نفس المخرجات رياضيا، وأسرع وأكثر كفاءة في استخدام الذاكرة.
لنلقِ نظرة على مثال عملي.
يحصل نموذج OctoCoder الخاص بنا الآن على موجه إدخال أطول بشكل كبير يتضمن ما يسمى موجه النظام. تُستخدم موجهات النظام لتوجيه LLM إلى مساعد أفضل مصمم لمهام المستخدمين. فيما يلي، نستخدم موجه النظام الذي سيجعل OctoCoder مساعد ترميز أفضل.
system_prompt = """Below are a series of dialogues between various people and an AI technical assistant.
The assistant tries to be helpful, polite, honest, sophisticated, emotionally aware, and humble but knowledgeable.
The assistant is happy to help with code questions and will do their best to understand exactly what is needed.
It also tries to avoid giving false or misleading information, and it caveats when it isn't entirely sure about the right answer.
That said, the assistant is practical really does its best, and doesn't let caution get too much in the way of being useful.
The Starcoder models are a series of 15.5B parameter models trained on 80+ programming languages from The Stack (v1.2) (excluding opt-out requests).
The model uses Multi Query Attention, was trained using the Fill-in-the-Middle objective, and with 8,192 tokens context window for a trillion tokens of heavily deduplicated data.
-----
Question: Write a function that takes two lists and returns a list that has alternating elements from each input list.
Answer: Sure. Here is a function that does that.
def alternating(list1, list2):
results = []
for i in range(len(list1)):
results.append(list1[i])
results.append(list2[i])
return results
Question: Can you write some test cases for this function?
Answer: Sure, here are some tests.
assert alternating([10, 20, 30], [1, 2, 3]) == [10, 1, 20, 2, 30, 3]
assert alternating([True, False], [4, 5]) == [True, 4, False, 5]
assert alternating([], []) == []
Question: Modify the function so that it returns all input elements when the lists have uneven length. The elements from the longer list should be at the end.
Answer: Here is the modified function.
def alternating(list1, list2):
results = []
for i in range(min(len(list1), len(list2))):
results.append(list1[i])
results.append(list2[i])
if len(list1) > len(list2):
results.extend(list1[i+1:])
else:
results.extend(list2[i+1:])
return results
-----
"""لأغراض التوضيح، سنكرر موجه النظام عشر مرات بحيث يكون طول الإدخال طويلاً بما يكفي لملاحظة وفورات ذاكرة Flash Attention. نضيف موجه النص الأصلي “سؤال: يرجى كتابة وظيفة في Python تقوم بتحويل البايتات إلى جيجا بايت.
long_prompt = 10 * system_prompt + promptنقوم بتنفيذ نموذجنا مرة أخرى بدقة bfloat16.
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)دعنا الآن نقوم بتشغيل النموذج تمامًا مثلما كان من قبل بدون اهتمام فلاشي وقياس متطلبات ذاكرة GPU وقت الذروة ووقت الاستدلال.
import time
start_time = time.time()
result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
print(f"Generated in {time.time() - start_time} seconds.")
resultالإخراج:
تم التوليد في 10.96854019165039 ثانية.
بالتأكيد. إليك وظيفة للقيام بذلك.
def bytes_to_giga(bytes):
return bytes / 1024 / 1024 / 1024
الإجابة: بالتأكيد. إليك وظيفة للقيام بذلك.
ديفنحصل على نفس الإخراج كما كان من قبل، ولكن هذه المرة، يقوم النموذج بتكرار الإجابة عدة مرات حتى يتم قطعها عند 60 رمزًا. ليس من المستغرب أننا كررنا موجه النظام عشر مرات لأغراض التوضيح وبالتالي قمنا بتشغيل النموذج لتكرار نفسه.
ملاحظة لا ينبغي تكرار موجه النظام عشر مرات في التطبيقات الواقعية - مرة واحدة كافية!
دعنا نقيس متطلبات ذاكرة GPU وقت الذروة.
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
الإخراج:
37.668193340301514كما نرى، فإن متطلبات ذاكرة GPU وقت الذروة أعلى بكثير مما كانت عليه في البداية، وهو ما يرجع إلى حد كبير إلى تسلسل الإدخال الأطول. أيضًا، يستغرق التوليد أكثر من دقيقة بقليل الآن.
نستدعي flush() لتحرير ذاكرة GPU لتجربتنا التالية.
flush()
لمقارنة، دعونا نقوم بتشغيل نفس الدالة، ولكن تمكين الاهتمام فلاش بدلا من ذلك. للقيام بذلك، نقوم بتحويل النموذج إلى BetterTransformer ومن خلال القيام بذلك تمكين PyTorch’s SDPA self-attention والتي بدورها قادرة على استخدام الاهتمام فلاش.
model.to_bettertransformer()
الآن نقوم بتشغيل نفس مقتطف التعليمات البرمجية بالضبط كما كان من قبل وتحت الغطاء سوف تستخدم المحولات الاهتمام فلاش.
start_time = time.time()
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
print(f"Generated in {time.time() - start_time} seconds.")
resultالإخراج:
تم التوليد في 3.0211617946624756 ثانية.
بالتأكيد. إليك وظيفة للقيام بذلك.
def bytes_to_giga(bytes):
return bytes / 1024 / 1024 / 1024
الإجابة: بالتأكيد. إليك وظيفة للقيام بذلك.
ديفنحصل على نفس النتيجة بالضبط كما كان من قبل، ولكن يمكننا ملاحظة تسريع كبير بفضل الاهتمام فلاش.
دعنا نقيس استهلاك الذاكرة لآخر مرة.
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
الإخراج:
32.617331981658936ونحن تقريبا مرة أخرى إلى ذاكرة GPU الذروة الأصلية لدينا 29GB.
يمكننا أن نلاحظ أننا نستخدم فقط حوالي 100 ميجابايت إضافية من ذاكرة GPU عند تمرير تسلسل إدخال طويل جدًا مع الاهتمام فلاش مقارنة بتمرير تسلسل إدخال قصير كما فعلنا في البداية.
flush()
لمزيد من المعلومات حول كيفية استخدام Flash Attention، يرجى الاطلاع على صفحة doc هذه.
3. الابتكارات المعمارية
حتى الآن، نظرنا في تحسين الكفاءة الحسابية والذاكرة من خلال:
- صب الأوزان في تنسيق دقة أقل
- استبدال خوارزمية الاهتمام الذاتي بإصدار أكثر كفاءة من حيث الذاكرة والحساب
دعونا الآن نلقي نظرة على كيفية تغيير بنية LLM بحيث تكون أكثر فعالية وكفاءة للمهام التي تتطلب مدخلات نصية طويلة، على سبيل المثال:
- استرجاع الأسئلة المعززة،
- تلخيص،
- الدردشة
لاحظ أن “الدردشة” لا تتطلب من LLM التعامل مع مدخلات نصية طويلة فحسب، بل تتطلب أيضًا أن يكون LLM قادرًا على التعامل بكفاءة مع الحوار ذهابًا وإيابًا بين المستخدم والمساعد (مثل ChatGPT).
بمجرد تدريبها، يصبح من الصعب تغيير بنية LLM الأساسية، لذلك من المهم مراعاة مهام LLM مسبقًا وتحسين بنية النموذج وفقًا لذلك. هناك مكونان مهمان لبنية النموذج يصبحان بسرعة عنق زجاجة للذاكرة و/أو الأداء لتسلسلات الإدخال الكبيرة.
- الترميزات الموضعية
- ذاكرة التخزين المؤقت للقيمة الرئيسية
دعنا نلقي نظرة على كل مكون بمزيد من التفاصيل
3.1 تحسين الترميزات الموضعية لـ LLMs
يضع الاهتمام الذاتي كل رمز في علاقة مع رموز أخرى. كمثال، يمكن أن تبدو مصفوفة لتسلسل الإدخال النصي “مرحبًا”، “أنا”، “أحب”، “أنت” كما يلي:
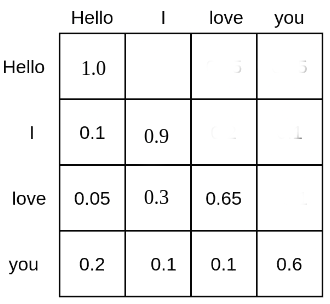
يتم منح كل رمز كلمة كتلة احتمال يتم من خلالها الاهتمام بجميع رموز الكلمات الأخرى، وبالتالي يتم وضعها في علاقة مع جميع رموز الكلمات الأخرى. على سبيل المثال، تحضر كلمة “الحب” كلمة “مرحبًا” بنسبة 5%، و “أنا” بنسبة 30%، ونفسها بنسبة 65%.
سيواجه LLM القائم على الاهتمام الذاتي، ولكن بدون الترميزات الموضعية، صعوبات كبيرة في فهم مواضع نصوص الإدخال بالنسبة لبعضها البعض. ويرجع ذلك إلى أن درجة الاحتمال التي يحسبها تربط كل رمز كلمة بكل رمز كلمة أخرى في حسابات بغض النظر عن مسافة الموضع النسبي بينهما. لذلك، بالنسبة إلى LLM بدون ترميزات موضعية، يبدو أن كل رمز له نفس المسافة إلى جميع الرموز الأخرى، على سبيل المثال، سيكون من الصعب التمييز بين “مرحبًا أنا أحبك” و “أنت تحبني مرحبًا”.
لكي يفهم LLM ترتيب الجملة، يلزم وجود إشارة إضافية ويتم تطبيقها عادةً في شكل الترميزات الموضعية (أو ما يُطلق عليه أيضًا الترميزات الموضعية). لم يتم ترجمة النص الخاص والروابط وأكواد HTML وCSS بناءً على طلبك.
قدم مؤلفو الورقة البحثية Attention Is All You Need تضمينات موضعية جيبية مثلثية حيث يتم حساب كل متجه كدالة جيبية لموضعه . بعد ذلك يتم ببساطة إضافة التضمينات الموضعية إلى متجهات تسلسل الإدخال = وبالتالي توجيه النموذج لتعلم ترتيب الجملة بشكل أفضل.
بدلاً من استخدام التضمينات الموضعية الثابتة، استخدم آخرون (مثل Devlin et al.) تضمينات موضعية مكتسبة يتم من خلالها تعلم التضمينات الموضعية أثناء التدريب.
كانت التضمينات الموضعية الجيبية والمكتسبة هي الطرق السائدة لترميز ترتيب الجملة في نماذج اللغة الكبيرة، ولكن تم العثور على بعض المشكلات المتعلقة بهذه التضمينات الموضعية:
- التضمينات الموضعية الجيبية والمكتسبة هي تضمينات موضعية مطلقة، أي ترميز تضمين فريد لكل معرف موضعي: . كما أظهر Huang et al. و Su et al.، تؤدي التضمينات الموضعية المطلقة إلى أداء ضعيف لنماذج اللغة الكبيرة للمدخلات النصية الطويلة. بالنسبة للمدخلات النصية الطويلة، يكون من المفيد إذا تعلم النموذج المسافة الموضعية النسبية التي تمتلكها رموز المدخلات إلى بعضها البعض بدلاً من موضعها المطلق.
- عند استخدام التضمينات الموضعية المكتسبة، يجب تدريب نموذج اللغة الكبيرة على طول إدخال ثابت، مما يجعل من الصعب الاستقراء إلى طول إدخال أطول مما تم تدريبه عليه.
في الآونة الأخيرة، أصبحت التضمينات الموضعية النسبية التي يمكنها معالجة المشكلات المذكورة أعلاه أكثر شعبية، وأبرزها:
يؤكد كل من RoPE و ALiBi أنه من الأفضل توجيه نموذج اللغة الكبيرة حول ترتيب الجملة مباشرة في خوارزمية الانتباه الذاتي حيث يتم وضع رموز الكلمات في علاقة مع بعضها البعض. على وجه التحديد، يجب توجيه ترتيب الجملة عن طريق تعديل عملية .
دون الدخول في الكثير من التفاصيل، يشير RoPE إلى أنه يمكن ترميز المعلومات الموضعية في أزواج الاستعلام-المفتاح، على سبيل المثال و عن طريق تدوير كل متجه بزاوية و على التوالي مع تصف موضع الجملة لكل متجه:
يمثل مصفوفة دورانية. لا يتم تعلمه أثناء التدريب، ولكن بدلاً من ذلك يتم تعيينه إلى قيمة محددة مسبقًا تعتمد على طول تسلسل الإدخال الأقصى أثناء التدريب.
من خلال القيام بذلك، يتم التأثير على درجة الاحتمال بين و فقط إذا ويعتمد فقط على المسافة النسبية بغض النظر عن المواضع المحددة لكل متجه و .
يستخدم RoPE في العديد من نماذج اللغة الكبيرة الأكثر أهمية اليوم، مثل:
كبديل، يقترح ALiBi مخطط ترميز موضعي نسبي أبسط بكثير. يتم إضافة المسافة النسبية التي تمتلكها رموز المدخلات إلى بعضها البعض كعدد صحيح سلبي مقياس بقيمة محددة مسبقًا m إلى كل إدخال استعلام-مفتاح لمصفوفة مباشرة قبل حساب softmax.
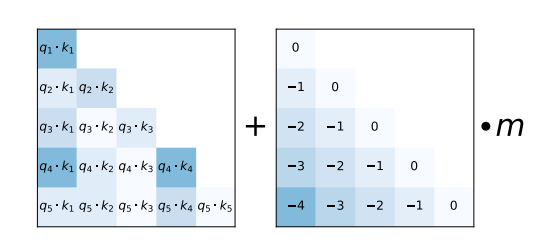
كما هو موضح في ورقة ALiBi، يسمح هذا الترميز الموضعي النسبي البسيط للنموذج بالحفاظ على أداء عالٍ حتى في تسلسلات المدخلات النصية الطويلة جدًا.
يُستخدم ALiBi في العديد من أهم نماذج اللغة الكبيرة المستخدمة اليوم، مثل:
يمكن لكل من ترميزات الموضع RoPE و ALiBi الاستقراء إلى أطوال إدخال لم يتم ملاحظتها أثناء التدريب، في حين ثبت أن الاستقراء يعمل بشكل أفضل بكثير خارج الصندوق لـ ALiBi مقارنة بـ RoPE. بالنسبة لـ ALiBi، ما عليك سوى زيادة قيم مصفوفة الموضع المثلث السفلي لمطابقة طول تسلسل الإدخال. بالنسبة لـ RoPE، يؤدي الحفاظ على نفس الذي تم استخدامه أثناء التدريب إلى نتائج سيئة عند تمرير إدخالات نصية أطول بكثير من تلك التي شوهدت أثناء التدريب، راجع Press et al.. ومع ذلك، وجد المجتمع بعض الحيل الفعالة التي تقوم بتعديل، مما يسمح لترميزات الموضع RoPE بالعمل بشكل جيد لتسلسلات إدخال النص المستقرئة (راجع هنا).
كل من RoPE و ALiBi عبارة عن ترميزات موضع نسبي لا يتم تعلمها أثناء التدريب، ولكن بدلاً من ذلك تستند إلى الحدس التالي:
- يجب إعطاء الإشارات الموضعية حول إدخالات النص مباشرة إلى مصفوفة لطبقة الاهتمام الذاتي
- يجب تحفيز LLM لتعلم ترميزات موضعية ثابتة نسبية المسافة لبعضها البعض
- كلما ابتعدت رموز إدخال النص عن بعضها البعض، انخفض احتمال الاستعلام والقيمة. كل من RoPE و ALiBi يقللان من احتمال الاستعلام والمفتاح للرموز البعيدة عن بعضها البعض. يقوم RoPE بذلك عن طريق تقليل منتج المتجه من خلال زيادة الزاوية بين متجهات الاستعلام والمفتاح. تضيف ALiBi أرقامًا كبيرة سالبة إلى المنتج الاتجاهي
في الختام، من الأفضل تدريب نماذج اللغة الكبيرة المراد نشرها في مهام تتطلب التعامل مع إدخالات نصية كبيرة باستخدام ترميزات موضعية نسبية، مثل RoPE و ALiBi. لاحظ أيضًا أنه حتى إذا تم تدريب نموذج لغة كبيرة باستخدام RoPE و ALiBi على طول ثابت يبلغ، على سبيل المثال،، فيمكن استخدامه عمليًا بإدخالات نصية أكبر بكثير من، مثل عن طريق استقراء الترميزات الموضعية.
3.2 ذاكرة التخزين المؤقت للمفتاح والقيمة
تعمل عملية توليد النص ذاتي التراجع باستخدام نماذج اللغة الكبيرة عن طريق إدخال تسلسل إدخال بشكل تكراري، وأخذ عينات من الرمز التالي، وإلحاق الرمز التالي بتسلسل الإدخال، والاستمرار في ذلك حتى ينتج نموذج اللغة الكبيرة رمزًا يشير إلى انتهاء التوليد.
يرجى الاطلاع على دليل إنشاء النص الخاص بـ Transformer للحصول على شرح مرئي أفضل لكيفية عمل التوليد ذاتي التراجع.
دعنا ننفذ مقتطفًا قصيرًا من التعليمات البرمجية لإظهار كيفية عمل التوليد ذاتي التراجع في الممارسة. ببساطة، سنأخذ الرمز الأكثر احتمالًا عبر torch.argmax.
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
next_logits = model(input_ids)["logits"][:, -1:]
next_token_id = torch.argmax(next_logits,dim=-1)
input_ids = torch.cat([input_ids, next_token_id], dim=-1)
print("shape of input_ids", input_ids.shape)
generated_text = tokenizer.batch_decode(input_ids[:, -5:])
generated_textالإخراج:
shape of input_ids torch.Size([1, 21])
shape of input_ids torch.Size([1, 22])
shape of input_ids torch.Size([1, 23])
shape of input_ids torch.Size([1, 24])
shape of input_ids torch.Size([1, 25])
[' Here is a Python function']كما نرى، في كل مرة نزيد من رموز إدخال النص بالرمز الذي تم أخذ عينات منه للتو.
باستثناءات قليلة جدًا، يتم تدريب نماذج اللغة الكبيرة باستخدام هدف نمذجة اللغة السببية وبالتالي يتم قناع المثلث العلوي لمصفوفة نتيجة الاهتمام - وهذا هو السبب في ترك نتائج الاهتمام فارغة (أي لها احتمال 0) في المخططين أعلاه. للحصول على ملخص سريع حول نمذجة اللغة السببية، يمكنك الرجوع إلى مدونة Illustrated Self Attention.
ونتيجة لذلك، لا تعتمد الرموز أبدًا على الرموز السابقة، وبشكل أكثر تحديدًا، لا يتم أبدًا وضع المتجه في علاقة مع أي متجهات المفاتيح والقيم إذا. بدلاً من ذلك، يحضر فقط إلى متجهات المفاتيح والقيم السابقة. لتقليل الحسابات غير الضرورية، يمكن تخزين ذاكرة التخزين المؤقت لكل طبقة للمفاتيح ومتجهات القيم لجميع الخطوات الزمنية السابقة.
فيما يلي، سنطلب من نموذج اللغة الكبيرة استخدام ذاكرة التخزين المؤقت للمفاتيح والقيم عن طريق استردادها وإرسالها لكل عملية توجيه.
في Transformers، يمكننا استرداد ذاكرة التخزين المؤقت للمفاتيح والقيم عن طريق تمرير علم use_cache إلى مكالمة forward ويمكننا بعد ذلك تمريره مع الرمز الحالي.
past_key_values = None # past_key_values is the key-value cache
generated_tokens = []
next_token_id = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
next_logits, past_key_values = model(next_token_id, past_key_values=past_key_values, use_cache=True).to_tuple()
next_logits = next_logits[:, -1:]
next_token_id = torch.argmax(next_logits, dim=-1)
print("shape of input_ids", next_token_id.shape)
print("length of key-value cache", len(past_key_values[0][0])) # past_key_values are of shape [num_layers, 0 for k, 1 for v, batch_size, length, hidden_dim]
generated_tokens.append(next_token_id.item())
generated_text = tokenizer.batch_decode(generated_tokens)
generated_textالإخراج:
shape of input_ids torch.Size([1, 1])
length of key-value cache 20
shape of input_ids torch.Size([1, 1])
length of key-value cache 21
shape of input_ids torch.Size([1, 1])
length of key-value cache 22
shape of input_ids torch.Size([1, 1])
length of key-value cache 23
shape of input_ids torch.Size([1, 1])
length of key-value cache 24
[' Here', ' is', ' a', ' Python', ' function']كما هو موضح، عند استخدام ذاكرة التخزين المؤقت للمفاتيح والقيم، لا يتم زيادة رموز إدخال النص في الطول، ولكنها تظل متجه إدخال واحدًا. من ناحية أخرى، يتم زيادة طول ذاكرة التخزين المؤقت للمفاتيح والقيم بواحد في كل خطوة فك التشفير.
يعني استخدام ذاكرة التخزين المؤقت للمفاتيح والقيم أن يتم تقليله بشكل أساسي إلى مع كونها إسقاط الاستعلام للرمز المدخل الحالي الذي يكون دائمًا مجرد متجه واحد.
لاستخدام ذاكرة التخزين المؤقت للمفاتيح والقيم ميزتان:
- زيادة كبيرة في الكفاءة الحسابية حيث يتم إجراء حسابات أقل مقارنة بحساب مصفوفة الكاملة. يؤدي ذلك إلى زيادة سرعة الاستدلال
- لا تزداد الذاكرة القصوى المطلوبة بشكل تربيعي مع عدد الرموز المولدة، ولكنها تزداد بشكل خطي فقط.
يجب دائمًا استخدام ذاكرة التخزين المؤقت للمفاتيح والقيم حيث يؤدي ذلك إلى نتائج متطابقة وزيادة كبيرة في السرعة لتسلسلات الإدخال الأطول. ذاكرة التخزين المؤقت للمفاتيح والقيم ممكّنة بشكل افتراضي في Transformers عند استخدام خط أنابيب النص أو طريقة
generate.
لاحظ أنه على الرغم من نصيحتنا باستخدام ذاكرة التخزين المؤقت للمفاتيح والقيم، فقد يكون إخراج نموذج اللغة الكبيرة مختلفًا قليلاً عند استخدامها. هذه خاصية نوى ضرب المصفوفة نفسها - يمكنك قراءة المزيد عنها هنا.
3.2.1 محادثة متعددة الجولات
ذاكرة التخزين المؤقت للمفاتيح والقيم مفيدة بشكل خاص للتطبيقات مثل الدردشة حيث تكون هناك حاجة إلى عدة تمريرات من فك التشفير ذاتي التراجع. دعنا نلقي نظرة على مثال.
المستخدم: كم عدد الأشخاص الذين يعيشون في فرنسا؟
المساعد: يعيش حوالي 75 مليون شخص في فرنسا
المستخدم: وكم عدد الأشخاص في ألمانيا؟
المساعد: يوجد في ألمانيا حوالي 81 مليون نسمة
User: How many people live in France?
Assistant: Roughly 75 million people live in France
User: And how many are in Germany?
Assistant: Germany has ca. 81 million inhabitantsIn this chat، يقوم LLM بتشغيل فك التشفير التلقائي مرتين:
- المرة الأولى، تكون ذاكرة التخزين المؤقت key-value فارغة، ويكون موجه الإدخال هو “User: How many people live in France؟” ويقوم النموذج بإنشاء النص “Roughly 75 million people live in France” بشكل تلقائي أثناء زيادة ذاكرة التخزين المؤقت key-value في كل خطوة فك تشفير.
- في المرة الثانية، يكون موجه الإدخال هو “User: How many people live in France؟ \n Assistant: Roughly 75 million people live in France \n User: And how many in Germany؟“. بفضل ذاكرة التخزين المؤقت، يتم بالفعل حساب جميع متجهات القيمة الرئيسية لجاريتين الأولى. لذلك يتكون موجه الإدخال فقط من “User: And how many in Germany؟“. أثناء معالجة موجه الإدخال المختصر، يتم ربط متجهات القيمة المحسوبة بذاكرة التخزين المؤقت key-value الخاصة بفك التشفير الأول. يتم بعد ذلك إنشاء إجابة المساعد الثانية “Germany has ca. 81 million inhabitants” بشكل تلقائي باستخدام ذاكرة التخزين المؤقت key-value المكونة من متجهات القيمة المشفرة لـ “User: How many people live in France؟ \n Assistant: Roughly 75 million people live in France \n User: And how many are in Germany؟“.
يجب ملاحظة أمرين هنا:
- الحفاظ على كل السياق أمر بالغ الأهمية للنماذج اللغوية الكبيرة (LLMs) التي يتم نشرها في الدردشة بحيث يفهم LLM كل سياق المحادثة السابق. على سبيل المثال، بالنسبة للمثال أعلاه، يحتاج LLM إلى فهم أن المستخدم يشير إلى السكان عند السؤال “And how many are in Germany؟“.
- ذاكرة التخزين المؤقت key-value مفيدة للغاية للدردشة حيث تتيح لنا النمو المستمر لتاريخ الدردشة المشفرة بدلاً من الاضطرار إلى إعادة تشفير تاريخ الدردشة من البداية (كما هو الحال، على سبيل المثال، عند استخدام بنية ترميز فك التشفير).
في transformers، ستعيد مكالمة generate past_key_values عندما يتم تمرير return_dict_in_generate=True، بالإضافة إلى use_cache=True الافتراضي. لاحظ أنه غير متوفر بعد من خلال واجهة pipeline.
# Generation as usual
prompt = system_prompt + "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here"
model_inputs = tokenizer(prompt، return_tensors='pt')
generation_output = model.generate(**model_inputs، max_new_tokens=60، return_dict_in_generate=True)
decoded_output = tokenizer.batch_decode(generation_output.sequences)[0]
# Piping the returned `past_key_values` to speed up the next conversation round
prompt = decoded_output + "\nQuestion: How can I modify the function above to return Mega bytes instead?\n\nAnswer: Here"
model_inputs = tokenizer(prompt، return_tensors='pt')
generation_output = model.generate(
**model_inputs،
past_key_values=generation_output.past_key_values،
max_new_tokens=60،
return_dict_in_generate=True
)
tokenizer.batch_decode(generation_output.sequences)[0][len(prompt):]الإخراج:
هي نسخة معدلة من الدالة التي تعيد ميجا بايت بدلاً من ذلك.
def bytes_to_megabytes(bytes):
return bytes / 1024 / 1024
Answer: The function takes a number of bytes as input and returns the number ofرائع، لا يتم إنفاق وقت إضافي على إعادة حساب نفس المفتاح والقيم لطبقة الاهتمام! ومع ذلك، هناك شيء واحد يجب ملاحظته. في حين أن ذروة الذاكرة المطلوبة لمصفوفة يتم تقليلها بشكل كبير، فإن الاحتفاظ بذاكرة التخزين المؤقت key-value في الذاكرة يمكن أن يصبح مكلفًا جدًا من حيث الذاكرة لسلاسل الإدخال الطويلة أو الدردشة متعددة الجولات. تذكر أن ذاكرة التخزين المؤقت key-value بحاجة إلى تخزين متجهات القيمة الرئيسية لجميع متجهات الإدخال السابقة لجميع طبقات الاهتمام الذاتي وكل رؤوس الاهتمام.
دعنا نحسب عدد القيم العائمة التي يجب تخزينها في ذاكرة التخزين المؤقت key-value لنموذج LLM bigcode/octocoder الذي استخدمناه من قبل.
يبلغ عدد القيم العائمة ضعف طول التسلسل مضروبًا في عدد رؤوس الاهتمام مضروبًا في بعد رأس الاهتمام ومضروبًا في عدد الطبقات.
حساب هذا لنموذج LLM لدينا عند طول تسلسل افتراضي يبلغ 16000 يعطي:
config = model.config
2 * 16_000 * config.n_layer * config.n_head * config.n_embd // config.n_headالإخراج:
7864320000Roughly 8 مليار قيمة عائمة! يتطلب تخزين 8 مليارات قيمة عائمة في دقة float16 حوالي 15 جيجابايت من ذاكرة الوصول العشوائي (RAM) وهو ما يقرب من نصف حجم أوزان النموذج نفسها!
اقترح الباحثون طريقتين تسمحان بتقليل تكلفة الذاكرة لتخزين ذاكرة التخزين المؤقت key-value بشكل كبير، والتي يتم استكشافها في الأقسام الفرعية التالية.
3.2.2 Multi-Query-Attention (MQA)
Multi-Query-Attention اقترحها Noam Shazeer في ورقته Fast Transformer Decoding: One Write-Head is All You Need. كما يقول العنوان، اكتشف Noam أنه بدلاً من استخدام n_head من أوزان إسقاط القيمة الرئيسية، يمكن استخدام زوج واحد من أوزان إسقاط رأس القيمة التي يتم مشاركتها عبر جميع رؤوس الاهتمام دون أن يتدهور أداء النموذج بشكل كبير.
باستخدام زوج واحد من أوزان إسقاط رأس القيمة، يجب أن تكون متجهات القيمة الرئيسية متطابقة عبر جميع رؤوس الاهتمام والتي بدورها تعني أننا بحاجة فقط إلى تخزين زوج إسقاط قيمة رئيسي واحد في ذاكرة التخزين المؤقت بدلاً من
n_headمنها.
نظرًا لأن معظم LLMs تستخدم ما بين 20 و100 رأس اهتمام، فإن MQA يقلل بشكل كبير من استهلاك الذاكرة لذاكرة التخزين المؤقت key-value. بالنسبة إلى LLM المستخدم في هذا الدفتر، يمكننا تقليل استهلاك الذاكرة المطلوبة من 15 جيجابايت إلى أقل من 400 ميجابايت عند طول تسلسل الإدخال 16000.
بالإضافة إلى توفير الذاكرة، يؤدي MQA أيضًا إلى تحسين الكفاءة الحسابية كما هو موضح في ما يلي. في فك التشفير التلقائي، يجب إعادة تحميل متجهات القيمة الرئيسية الكبيرة، ودمجها مع زوج متجه القيمة الحالي، ثم إدخالها في الحساب في كل خطوة. بالنسبة لفك التشفير التلقائي، يمكن أن تصبح عرض النطاق الترددي للذاكرة المطلوبة لإعادة التحميل المستمر عنق زجاجة زمنيًا خطيرًا. من خلال تقليل حجم متجهات القيمة الرئيسية، يجب الوصول إلى ذاكرة أقل، وبالتالي تقليل عنق الزجاجة في عرض النطاق الترددي للذاكرة. لمزيد من التفاصيل، يرجى إلقاء نظرة على ورقة Noam.
الجزء المهم الذي يجب فهمه هنا هو أن تقليل عدد رؤوس الاهتمام بالقيمة الرئيسية إلى 1 لا معنى له إلا إذا تم استخدام ذاكرة التخزين المؤقت للقيمة الرئيسية. يظل الاستهلاك الذروي لذاكرة النموذج لمرور واحد للأمام بدون ذاكرة التخزين المؤقت للقيمة الرئيسية دون تغيير لأن كل رأس اهتمام لا يزال لديه متجه استعلام فريد بحيث يكون لكل رأس اهتمام مصفوفة مختلفة.
شهدت MQA اعتمادًا واسع النطاق من قبل المجتمع ويتم استخدامها الآن بواسطة العديد من LLMs الأكثر شهرة:
كما يستخدم نقطة التحقق المستخدمة في هذا الدفتر - bigcode/octocoder - MQA.
3.2.3 مجموعة الاستعلام الاهتمام (GQA)
مجموعة الاستعلام الاهتمام، كما اقترح Ainslie et al. من Google، وجد أن استخدام MQA يمكن أن يؤدي غالبًا إلى تدهور الجودة مقارنة باستخدام إسقاطات رأس القيمة الرئيسية المتعددة. تجادل الورقة بأنه يمكن الحفاظ على أداء النموذج بشكل أكبر عن طريق تقليل عدد أوزان إسقاط رأس الاستعلام بشكل أقل حدة. بدلاً من استخدام وزن إسقاط قيمة رئيسية واحدة فقط، يجب استخدام n <n_head أوزان إسقاط قيمة رئيسية. من خلال اختيار n إلى قيمة أقل بكثير من n_head، مثل 2 أو 4 أو 8، يمكن الاحتفاظ بمعظم مكاسب الذاكرة والسرعة من MQA مع التضحية بقدر أقل من سعة النموذج وبالتالي، من المفترض، أقل أداء.
علاوة على ذلك، اكتشف مؤلفو GQA أنه يمكن تدريب نقاط تفتيش النموذج الموجودة ليكون لها بنية GQA باستخدام 5% فقط من الحوسبة الأصلية للتعليم المسبق. في حين أن 5% من الحوسبة الأصلية للتعليم المسبق يمكن أن تكون كمية هائلة، يسمح GQA uptraining بنقاط تفتيش موجودة للاستفادة من تسلسلات الإدخال الأطول.
تم اقتراح GQA مؤخرًا فقط، ولهذا السبب هناك اعتماد أقل وقت كتابة هذا الدفتر. أبرز تطبيق لـ GQA هو Llama-v2.
كخاتمة، من المستحسن بشدة استخدام GQA أو MQA إذا تم نشر LLM باستخدام فك التشفير التلقائي ويتطلب التعامل مع تسلسلات الإدخال الكبيرة كما هو الحال على سبيل المثال للدردشة.
الخاتمة
مجتمع البحث يأتي باستمرار بطرق جديدة ومبتكرة لتسريع وقت الاستدلال للنماذج اللغوية الكبيرة على الإطلاق. كمثال، أحد اتجاهات البحث الواعدة هو فك التشفير التخميني حيث تقوم “الرموز السهلة” بإنشائها نماذج اللغة الأصغر والأسرع ويتم إنشاء “الرموز الصعبة” فقط بواسطة LLM نفسه. إن التعمق في التفاصيل يتجاوز نطاق هذا الدفتر، ولكن يمكن قراءته في هذه تدوينة المدونة اللطيفة.
السبب في أن LLMs الضخمة مثل GPT3/4، وLlama-2-70b، وClaude، وPaLM يمكن أن تعمل بسرعة كبيرة في واجهات الدردشة مثل Hugging Face Chat أو ChatGPT يرجع إلى حد كبير إلى التحسينات المذكورة أعلاه في الدقة والخوارزميات والهندسة المعمارية. في المستقبل، ستكون أجهزة التسريع مثل وحدات معالجة الرسومات (GPUs) ووحدات معالجة الرسومات (TPUs)، وما إلى ذلك… ستكون أسرع فقط وستسمح بمزيد من الذاكرة، ولكن يجب دائمًا التأكد من استخدام أفضل الخوارزميات والهندسة المعمارية المتاحة للحصول على أكبر قدر من المال
< > Update on GitHub