Transformers documentation
ZoeDepth
ZoeDepth
Overview
The ZoeDepth model was proposed in ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth by Shariq Farooq Bhat, Reiner Birkl, Diana Wofk, Peter Wonka, Matthias Müller. ZoeDepth extends the DPT framework for metric (also called absolute) depth estimation. ZoeDepth is pre-trained on 12 datasets using relative depth and fine-tuned on two domains (NYU and KITTI) using metric depth. A lightweight head is used with a novel bin adjustment design called metric bins module for each domain. During inference, each input image is automatically routed to the appropriate head using a latent classifier.
The abstract from the paper is the following:
This paper tackles the problem of depth estimation from a single image. Existing work either focuses on generalization performance disregarding metric scale, i.e. relative depth estimation, or state-of-the-art results on specific datasets, i.e. metric depth estimation. We propose the first approach that combines both worlds, leading to a model with excellent generalization performance while maintaining metric scale. Our flagship model, ZoeD-M12-NK, is pre-trained on 12 datasets using relative depth and fine-tuned on two datasets using metric depth. We use a lightweight head with a novel bin adjustment design called metric bins module for each domain. During inference, each input image is automatically routed to the appropriate head using a latent classifier. Our framework admits multiple configurations depending on the datasets used for relative depth pre-training and metric fine-tuning. Without pre-training, we can already significantly improve the state of the art (SOTA) on the NYU Depth v2 indoor dataset. Pre-training on twelve datasets and fine-tuning on the NYU Depth v2 indoor dataset, we can further improve SOTA for a total of 21% in terms of relative absolute error (REL). Finally, ZoeD-M12-NK is the first model that can jointly train on multiple datasets (NYU Depth v2 and KITTI) without a significant drop in performance and achieve unprecedented zero-shot generalization performance to eight unseen datasets from both indoor and outdoor domains.
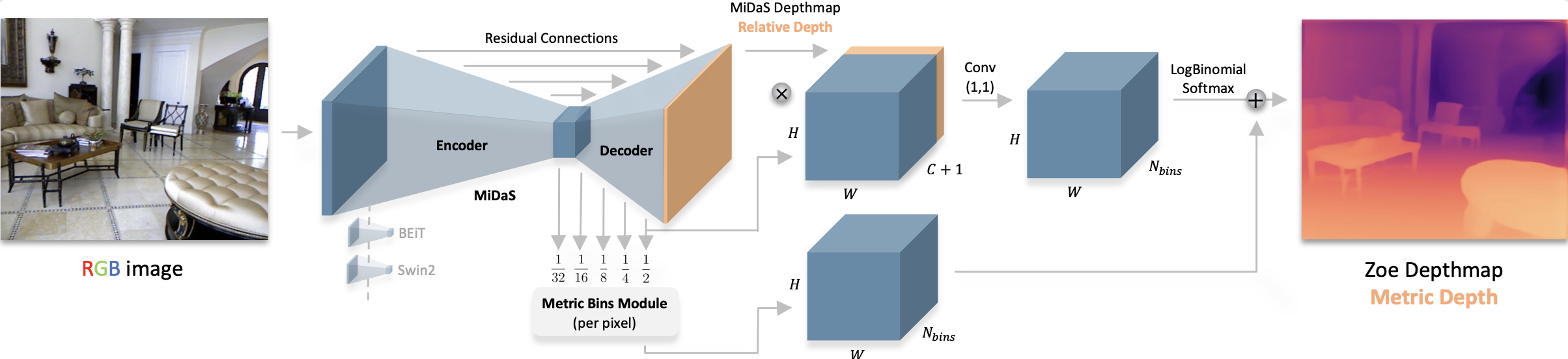 ZoeDepth architecture. Taken from the original paper.
ZoeDepth architecture. Taken from the original paper. This model was contributed by nielsr. The original code can be found here.
Usage tips
- ZoeDepth is an absolute (also called metric) depth estimation model, unlike DPT which is a relative depth estimation model. This means that ZoeDepth is able to estimate depth in metric units like meters.
The easiest to perform inference with ZoeDepth is by leveraging the pipeline API:
>>> from transformers import pipeline
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> pipe = pipeline(task="depth-estimation", model="Intel/zoedepth-nyu-kitti")
>>> result = pipe(image)
>>> depth = result["depth"]Alternatively, one can also perform inference using the classes:
>>> from transformers import AutoImageProcessor, ZoeDepthForDepthEstimation
>>> import torch
>>> import numpy as np
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("Intel/zoedepth-nyu-kitti")
>>> model = ZoeDepthForDepthEstimation.from_pretrained("Intel/zoedepth-nyu-kitti")
>>> # prepare image for the model
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(pixel_values)
>>> # interpolate to original size and visualize the prediction
>>> ## ZoeDepth dynamically pads the input image. Thus we pass the original image size as argument
>>> ## to `post_process_depth_estimation` to remove the padding and resize to original dimensions.
>>> post_processed_output = image_processor.post_process_depth_estimation(
... outputs,
... source_sizes=[(image.height, image.width)],
... )
>>> predicted_depth = post_processed_output[0]["predicted_depth"]
>>> depth = (predicted_depth - predicted_depth.min()) / (predicted_depth.max() - predicted_depth.min())
>>> depth = depth.detach().cpu().numpy() * 255
>>> depth = Image.fromarray(depth.astype("uint8"))In the original implementation ZoeDepth model performs inference on both the original and flipped images and averages out the results. The post_process_depth_estimation function can handle this for us by passing the flipped outputs to the optional outputs_flipped argument:
>>> with torch.no_grad():
... outputs = model(pixel_values)
... outputs_flipped = model(pixel_values=torch.flip(inputs.pixel_values, dims=[3]))
>>> post_processed_output = image_processor.post_process_depth_estimation(
... outputs,
... source_sizes=[(image.height, image.width)],
... outputs_flipped=outputs_flipped,
... )
Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ZoeDepth.
- A demo notebook regarding inference with ZoeDepth models can be found here. 🌎
ZoeDepthConfig
class transformers.ZoeDepthConfig
< source >( backbone_config = None backbone = None use_pretrained_backbone = False backbone_kwargs = None hidden_act = 'gelu' initializer_range = 0.02 batch_norm_eps = 1e-05 readout_type = 'project' reassemble_factors = [4, 2, 1, 0.5] neck_hidden_sizes = [96, 192, 384, 768] fusion_hidden_size = 256 head_in_index = -1 use_batch_norm_in_fusion_residual = False use_bias_in_fusion_residual = None num_relative_features = 32 add_projection = False bottleneck_features = 256 num_attractors = [16, 8, 4, 1] bin_embedding_dim = 128 attractor_alpha = 1000 attractor_gamma = 2 attractor_kind = 'mean' min_temp = 0.0212 max_temp = 50.0 bin_centers_type = 'softplus' bin_configurations = [{'n_bins': 64, 'min_depth': 0.001, 'max_depth': 10.0}] num_patch_transformer_layers = None patch_transformer_hidden_size = None patch_transformer_intermediate_size = None patch_transformer_num_attention_heads = None **kwargs )
Parameters
- backbone_config (
Union[Dict[str, Any], PretrainedConfig], optional, defaults toBeitConfig()) — The configuration of the backbone model. - backbone (
str, optional) — Name of backbone to use whenbackbone_configisNone. Ifuse_pretrained_backboneisTrue, this will load the corresponding pretrained weights from the timm or transformers library. Ifuse_pretrained_backboneisFalse, this loads the backbone’s config and uses that to initialize the backbone with random weights. - use_pretrained_backbone (
bool, optional, defaults toFalse) — Whether to use pretrained weights for the backbone. - backbone_kwargs (
dict, optional) — Keyword arguments to be passed to AutoBackbone when loading from a checkpoint e.g.{'out_indices': (0, 1, 2, 3)}. Cannot be specified ifbackbone_configis set. - hidden_act (
strorfunction, optional, defaults to"gelu") — The non-linear activation function (function or string) in the encoder and pooler. If string,"gelu","relu","selu"and"gelu_new"are supported. - initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - batch_norm_eps (
float, optional, defaults to 1e-05) — The epsilon used by the batch normalization layers. - readout_type (
str, optional, defaults to"project") — The readout type to use when processing the readout token (CLS token) of the intermediate hidden states of the ViT backbone. Can be one of ["ignore","add","project"].- “ignore” simply ignores the CLS token.
- “add” passes the information from the CLS token to all other tokens by adding the representations.
- “project” passes information to the other tokens by concatenating the readout to all other tokens before projecting the representation to the original feature dimension D using a linear layer followed by a GELU non-linearity.
- reassemble_factors (
List[int], optional, defaults to[4, 2, 1, 0.5]) — The up/downsampling factors of the reassemble layers. - neck_hidden_sizes (
List[str], optional, defaults to[96, 192, 384, 768]) — The hidden sizes to project to for the feature maps of the backbone. - fusion_hidden_size (
int, optional, defaults to 256) — The number of channels before fusion. - head_in_index (
int, optional, defaults to -1) — The index of the features to use in the heads. - use_batch_norm_in_fusion_residual (
bool, optional, defaults toFalse) — Whether to use batch normalization in the pre-activate residual units of the fusion blocks. - use_bias_in_fusion_residual (
bool, optional, defaults toTrue) — Whether to use bias in the pre-activate residual units of the fusion blocks. - num_relative_features (
int, optional, defaults to 32) — The number of features to use in the relative depth estimation head. - add_projection (
bool, optional, defaults toFalse) — Whether to add a projection layer before the depth estimation head. - bottleneck_features (
int, optional, defaults to 256) — The number of features in the bottleneck layer. - num_attractors (
List[int], *optional*, defaults to[16, 8, 4, 1]`) — The number of attractors to use in each stage. - bin_embedding_dim (
int, optional, defaults to 128) — The dimension of the bin embeddings. - attractor_alpha (
int, optional, defaults to 1000) — The alpha value to use in the attractor. - attractor_gamma (
int, optional, defaults to 2) — The gamma value to use in the attractor. - attractor_kind (
str, optional, defaults to"mean") — The kind of attractor to use. Can be one of ["mean","sum"]. - min_temp (
float, optional, defaults to 0.0212) — The minimum temperature value to consider. - max_temp (
float, optional, defaults to 50.0) — The maximum temperature value to consider. - bin_centers_type (
str, optional, defaults to"softplus") — Activation type used for bin centers. Can be “normed” or “softplus”. For “normed” bin centers, linear normalization trick is applied. This results in bounded bin centers. For “softplus”, softplus activation is used and thus are unbounded. - bin_configurations (
List[dict], optional, defaults to[{'n_bins' -- 64, 'min_depth': 0.001, 'max_depth': 10.0}]): Configuration for each of the bin heads. Each configuration should consist of the following keys:- name (
str): The name of the bin head - only required in case of multiple bin configurations. n_bins(int): The number of bins to use.min_depth(float): The minimum depth value to consider.max_depth(float): The maximum depth value to consider. In case only a single configuration is passed, the model will use a single head with the specified configuration. In case multiple configurations are passed, the model will use multiple heads with the specified configurations.
- name (
- num_patch_transformer_layers (
int, optional) — The number of transformer layers to use in the patch transformer. Only used in case of multiple bin configurations. - patch_transformer_hidden_size (
int, optional) — The hidden size to use in the patch transformer. Only used in case of multiple bin configurations. - patch_transformer_intermediate_size (
int, optional) — The intermediate size to use in the patch transformer. Only used in case of multiple bin configurations. - patch_transformer_num_attention_heads (
int, optional) — The number of attention heads to use in the patch transformer. Only used in case of multiple bin configurations.
This is the configuration class to store the configuration of a ZoeDepthForDepthEstimation. It is used to instantiate an ZoeDepth model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the ZoeDepth Intel/zoedepth-nyu architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import ZoeDepthConfig, ZoeDepthForDepthEstimation
>>> # Initializing a ZoeDepth zoedepth-large style configuration
>>> configuration = ZoeDepthConfig()
>>> # Initializing a model from the zoedepth-large style configuration
>>> model = ZoeDepthForDepthEstimation(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configZoeDepthImageProcessor
class transformers.ZoeDepthImageProcessor
< source >( do_pad: bool = True do_rescale: bool = True rescale_factor: Union = 0.00392156862745098 do_normalize: bool = True image_mean: Union = None image_std: Union = None do_resize: bool = True size: Dict = None resample: Resampling = <Resampling.BILINEAR: 2> keep_aspect_ratio: bool = True ensure_multiple_of: int = 32 **kwargs )
Parameters
- do_pad (
bool, optional, defaults toTrue) — Whether to apply pad the input. - do_rescale (
bool, optional, defaults toTrue) — Whether to rescale the image by the specified scalerescale_factor. Can be overidden bydo_rescaleinpreprocess. - rescale_factor (
intorfloat, optional, defaults to1/255) — Scale factor to use if rescaling the image. Can be overidden byrescale_factorinpreprocess. - do_normalize (
bool, optional, defaults toTrue) — Whether to normalize the image. Can be overridden by thedo_normalizeparameter in thepreprocessmethod. - image_mean (
floatorList[float], optional, defaults toIMAGENET_STANDARD_MEAN) — Mean to use if normalizing the image. This is a float or list of floats the length of the number of channels in the image. Can be overridden by theimage_meanparameter in thepreprocessmethod. - image_std (
floatorList[float], optional, defaults toIMAGENET_STANDARD_STD) — Standard deviation to use if normalizing the image. This is a float or list of floats the length of the number of channels in the image. Can be overridden by theimage_stdparameter in thepreprocessmethod. - do_resize (
bool, optional, defaults toTrue) — Whether to resize the image’s (height, width) dimensions. Can be overidden bydo_resizeinpreprocess. - size (
Dict[str, int]optional, defaults to{"height" -- 384, "width": 512}): Size of the image after resizing. Size of the image after resizing. Ifkeep_aspect_ratioisTrue, the image is resized by choosing the smaller of the height and width scaling factors and using it for both dimensions. Ifensure_multiple_ofis also set, the image is further resized to a size that is a multiple of this value. Can be overidden bysizeinpreprocess. - resample (
PILImageResampling, optional, defaults toResampling.BILINEAR) — Defines the resampling filter to use if resizing the image. Can be overidden byresampleinpreprocess. - keep_aspect_ratio (
bool, optional, defaults toTrue) — IfTrue, the image is resized by choosing the smaller of the height and width scaling factors and using it for both dimensions. This ensures that the image is scaled down as little as possible while still fitting within the desired output size. In caseensure_multiple_ofis also set, the image is further resized to a size that is a multiple of this value by flooring the height and width to the nearest multiple of this value. Can be overidden bykeep_aspect_ratioinpreprocess. - ensure_multiple_of (
int, optional, defaults to 32) — Ifdo_resizeisTrue, the image is resized to a size that is a multiple of this value. Works by flooring the height and width to the nearest multiple of this value.Works both with and without
keep_aspect_ratiobeing set toTrue. Can be overidden byensure_multiple_ofinpreprocess.
Constructs a ZoeDepth image processor.
preprocess
< source >( images: Union do_pad: bool = None do_rescale: bool = None rescale_factor: float = None do_normalize: bool = None image_mean: Union = None image_std: Union = None do_resize: bool = None size: int = None keep_aspect_ratio: bool = None ensure_multiple_of: int = None resample: Resampling = None return_tensors: Union = None data_format: ChannelDimension = <ChannelDimension.FIRST: 'channels_first'> input_data_format: Union = None )
Parameters
- images (
ImageInput) — Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If passing in images with pixel values between 0 and 1, setdo_rescale=False. - do_pad (
bool, optional, defaults toself.do_pad) — Whether to pad the input image. - do_rescale (
bool, optional, defaults toself.do_rescale) — Whether to rescale the image values between [0 - 1]. - rescale_factor (
float, optional, defaults toself.rescale_factor) — Rescale factor to rescale the image by ifdo_rescaleis set toTrue. - do_normalize (
bool, optional, defaults toself.do_normalize) — Whether to normalize the image. - image_mean (
floatorList[float], optional, defaults toself.image_mean) — Image mean. - image_std (
floatorList[float], optional, defaults toself.image_std) — Image standard deviation. - do_resize (
bool, optional, defaults toself.do_resize) — Whether to resize the image. - size (
Dict[str, int], optional, defaults toself.size) — Size of the image after resizing. Ifkeep_aspect_ratioisTrue, he image is resized by choosing the smaller of the height and width scaling factors and using it for both dimensions. Ifensure_multiple_ofis also set, the image is further resized to a size that is a multiple of this value. - keep_aspect_ratio (
bool, optional, defaults toself.keep_aspect_ratio) — IfTrueanddo_resize=True, the image is resized by choosing the smaller of the height and width scaling factors and using it for both dimensions. This ensures that the image is scaled down as little as possible while still fitting within the desired output size. In caseensure_multiple_ofis also set, the image is further resized to a size that is a multiple of this value by flooring the height and width to the nearest multiple of this value. - ensure_multiple_of (
int, optional, defaults toself.ensure_multiple_of) — Ifdo_resizeisTrue, the image is resized to a size that is a multiple of this value. Works by flooring the height and width to the nearest multiple of this value.Works both with and without
keep_aspect_ratiobeing set toTrue. Can be overidden byensure_multiple_ofinpreprocess. - resample (
int, optional, defaults toself.resample) — Resampling filter to use if resizing the image. This can be one of the enumPILImageResampling, Only has an effect ifdo_resizeis set toTrue. - return_tensors (
strorTensorType, optional) — The type of tensors to return. Can be one of:- Unset: Return a list of
np.ndarray. TensorType.TENSORFLOWor'tf': Return a batch of typetf.Tensor.TensorType.PYTORCHor'pt': Return a batch of typetorch.Tensor.TensorType.NUMPYor'np': Return a batch of typenp.ndarray.TensorType.JAXor'jax': Return a batch of typejax.numpy.ndarray.
- Unset: Return a list of
- data_format (
ChannelDimensionorstr, optional, defaults toChannelDimension.FIRST) — The channel dimension format for the output image. Can be one of:ChannelDimension.FIRST: image in (num_channels, height, width) format.ChannelDimension.LAST: image in (height, width, num_channels) format.
- input_data_format (
ChannelDimensionorstr, optional) — The channel dimension format for the input image. If unset, the channel dimension format is inferred from the input image. Can be one of:"channels_first"orChannelDimension.FIRST: image in (num_channels, height, width) format."channels_last"orChannelDimension.LAST: image in (height, width, num_channels) format."none"orChannelDimension.NONE: image in (height, width) format.
Preprocess an image or batch of images.
ZoeDepthForDepthEstimation
class transformers.ZoeDepthForDepthEstimation
< source >( config )
Parameters
- config (ViTConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
ZoeDepth model with one or multiple metric depth estimation head(s) on top.
This model is a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( pixel_values: FloatTensor labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.modeling_outputs.DepthEstimatorOutput or tuple(torch.FloatTensor)
Parameters
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using AutoImageProcessor. See DPTImageProcessor.call() for details. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size, height, width), optional) — Ground truth depth estimation maps for computing the loss.
Returns
transformers.modeling_outputs.DepthEstimatorOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.DepthEstimatorOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (ZoeDepthConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. -
predicted_depth (
torch.FloatTensorof shape(batch_size, height, width)) — Predicted depth for each pixel. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, num_channels, height, width).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, patch_size, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The ZoeDepthForDepthEstimation forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoImageProcessor, ZoeDepthForDepthEstimation
>>> import torch
>>> import numpy as np
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("Intel/zoedepth-nyu-kitti")
>>> model = ZoeDepthForDepthEstimation.from_pretrained("Intel/zoedepth-nyu-kitti")
>>> # prepare image for the model
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> # interpolate to original size
>>> post_processed_output = image_processor.post_process_depth_estimation(
... outputs,
... source_sizes=[(image.height, image.width)],
... )
>>> # visualize the prediction
>>> predicted_depth = post_processed_output[0]["predicted_depth"]
>>> depth = predicted_depth * 255 / predicted_depth.max()
>>> depth = depth.detach().cpu().numpy()
>>> depth = Image.fromarray(depth.astype("uint8"))