Transformers documentation
Wav2Vec2
Wav2Vec2
Overview
The Wav2Vec2 model was proposed in wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
The abstract from the paper is the following:
We show for the first time that learning powerful representations from speech audio alone followed by fine-tuning on transcribed speech can outperform the best semi-supervised methods while being conceptually simpler. wav2vec 2.0 masks the speech input in the latent space and solves a contrastive task defined over a quantization of the latent representations which are jointly learned. Experiments using all labeled data of Librispeech achieve 1.8/3.3 WER on the clean/other test sets. When lowering the amount of labeled data to one hour, wav2vec 2.0 outperforms the previous state of the art on the 100 hour subset while using 100 times less labeled data. Using just ten minutes of labeled data and pre-training on 53k hours of unlabeled data still achieves 4.8/8.2 WER. This demonstrates the feasibility of speech recognition with limited amounts of labeled data.
This model was contributed by patrickvonplaten.
Note: Meta (FAIR) released a new version of Wav2Vec2-BERT 2.0 - it’s pretrained on 4.5M hours of audio. We especially recommend using it for fine-tuning tasks, e.g. as per this guide.
Usage tips
- Wav2Vec2 is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
- Wav2Vec2 model was trained using connectionist temporal classification (CTC) so the model output has to be decoded using Wav2Vec2CTCTokenizer.
Using Flash Attention 2
Flash Attention 2 is an faster, optimized version of the model.
Installation
First, check whether your hardware is compatible with Flash Attention 2. The latest list of compatible hardware can be found in the official documentation. If your hardware is not compatible with Flash Attention 2, you can still benefit from attention kernel optimisations through Better Transformer support covered above.
Next, install the latest version of Flash Attention 2:
pip install -U flash-attn --no-build-isolation
Usage
To load a model using Flash Attention 2, we can pass the argument attn_implementation="flash_attention_2" to .from_pretrained. We’ll also load the model in half-precision (e.g. torch.float16), since it results in almost no degradation to audio quality but significantly lower memory usage and faster inference:
>>> from transformers import Wav2Vec2Model
model = Wav2Vec2Model.from_pretrained("facebook/wav2vec2-large-960h-lv60-self", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to(device)
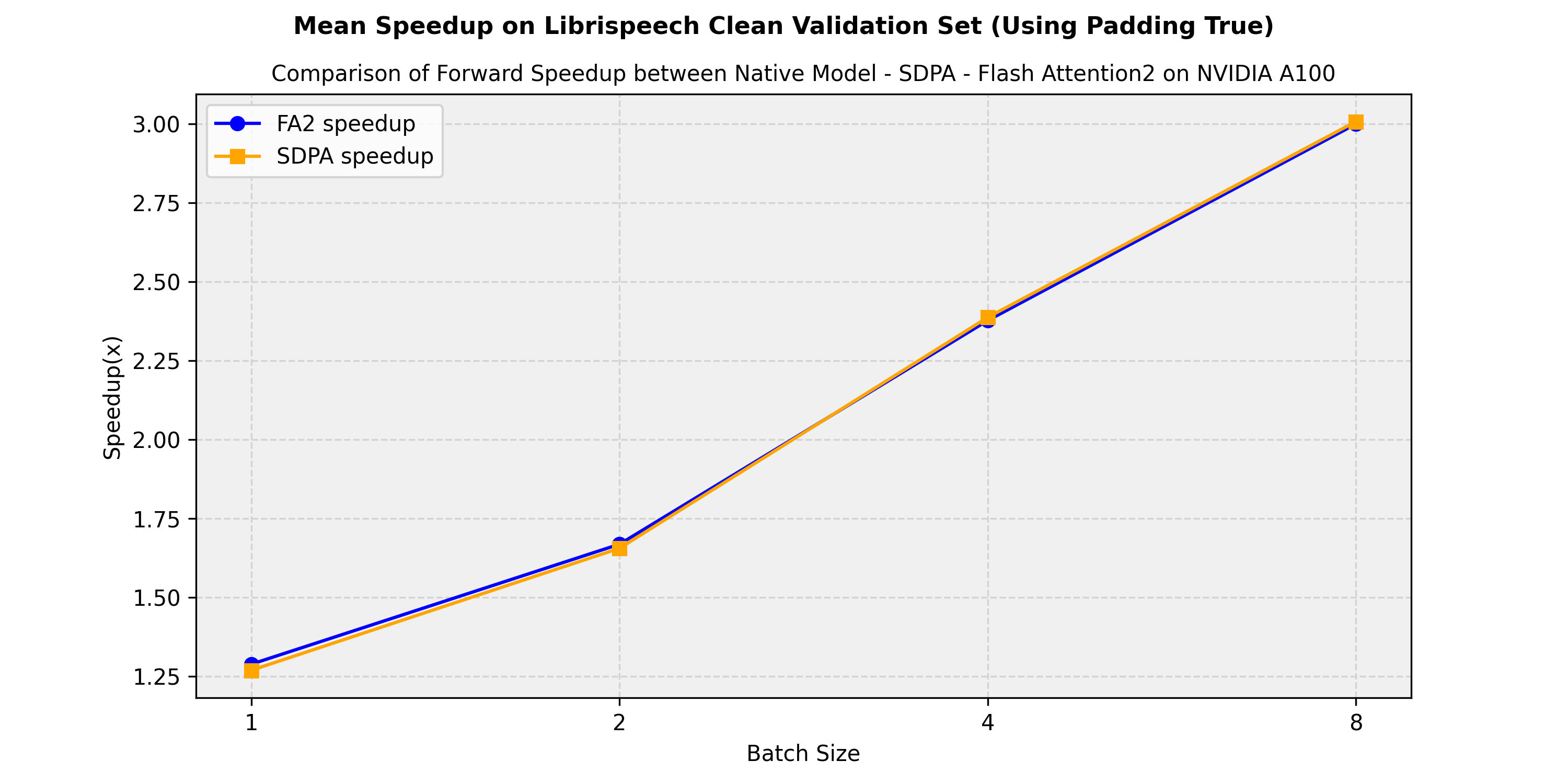
...Expected speedups
Below is an expected speedup diagram comparing the pure inference time between the native implementation in transformers of the facebook/wav2vec2-large-960h-lv60-self model and the flash-attention-2 and sdpa (scale-dot-product-attention) versions. . We show the average speedup obtained on the librispeech_asr clean validation split:
Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Wav2Vec2. If you’re interested in submitting a resource to be included here, please feel free to open a Pull Request and we’ll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
- A notebook on how to leverage a pretrained Wav2Vec2 model for emotion classification. 🌎
- Wav2Vec2ForCTC is supported by this example script and notebook.
- Audio classification task guide
- A blog post on boosting Wav2Vec2 with n-grams in 🤗 Transformers.
- A blog post on how to finetune Wav2Vec2 for English ASR with 🤗 Transformers.
- A blog post on finetuning XLS-R for Multi-Lingual ASR with 🤗 Transformers.
- A notebook on how to create YouTube captions from any video by transcribing audio with Wav2Vec2. 🌎
- Wav2Vec2ForCTC is supported by a notebook on how to finetune a speech recognition model in English, and how to finetune a speech recognition model in any language.
- Automatic speech recognition task guide
🚀 Deploy
- A blog post on how to deploy Wav2Vec2 for Automatic Speech Recognition with Hugging Face’s Transformers & Amazon SageMaker.
Wav2Vec2Config
class transformers.Wav2Vec2Config
< source >( vocab_size = 32 hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 intermediate_size = 3072 hidden_act = 'gelu' hidden_dropout = 0.1 activation_dropout = 0.1 attention_dropout = 0.1 feat_proj_dropout = 0.0 feat_quantizer_dropout = 0.0 final_dropout = 0.1 layerdrop = 0.1 initializer_range = 0.02 layer_norm_eps = 1e-05 feat_extract_norm = 'group' feat_extract_activation = 'gelu' conv_dim = (512, 512, 512, 512, 512, 512, 512) conv_stride = (5, 2, 2, 2, 2, 2, 2) conv_kernel = (10, 3, 3, 3, 3, 2, 2) conv_bias = False num_conv_pos_embeddings = 128 num_conv_pos_embedding_groups = 16 do_stable_layer_norm = False apply_spec_augment = True mask_time_prob = 0.05 mask_time_length = 10 mask_time_min_masks = 2 mask_feature_prob = 0.0 mask_feature_length = 10 mask_feature_min_masks = 0 num_codevectors_per_group = 320 num_codevector_groups = 2 contrastive_logits_temperature = 0.1 num_negatives = 100 codevector_dim = 256 proj_codevector_dim = 256 diversity_loss_weight = 0.1 ctc_loss_reduction = 'sum' ctc_zero_infinity = False use_weighted_layer_sum = False classifier_proj_size = 256 tdnn_dim = (512, 512, 512, 512, 1500) tdnn_kernel = (5, 3, 3, 1, 1) tdnn_dilation = (1, 2, 3, 1, 1) xvector_output_dim = 512 pad_token_id = 0 bos_token_id = 1 eos_token_id = 2 add_adapter = False adapter_kernel_size = 3 adapter_stride = 2 num_adapter_layers = 3 output_hidden_size = None adapter_attn_dim = None **kwargs )
Parameters
- vocab_size (
int, optional, defaults to 32) — Vocabulary size of the Wav2Vec2 model. Defines the number of different tokens that can be represented by theinputs_idspassed when calling Wav2Vec2Model or TFWav2Vec2Model. Vocabulary size of the model. Defines the different tokens that can be represented by the inputs_ids passed to the forward method of Wav2Vec2Model. - hidden_size (
int, optional, defaults to 768) — Dimensionality of the encoder layers and the pooler layer. - num_hidden_layers (
int, optional, defaults to 12) — Number of hidden layers in the Transformer encoder. - num_attention_heads (
int, optional, defaults to 12) — Number of attention heads for each attention layer in the Transformer encoder. - intermediate_size (
int, optional, defaults to 3072) — Dimensionality of the “intermediate” (i.e., feed-forward) layer in the Transformer encoder. - hidden_act (
strorfunction, optional, defaults to"gelu") — The non-linear activation function (function or string) in the encoder and pooler. If string,"gelu","relu","selu"and"gelu_new"are supported. - hidden_dropout (
float, optional, defaults to 0.1) — The dropout probability for all fully connected layers in the embeddings, encoder, and pooler. - activation_dropout (
float, optional, defaults to 0.1) — The dropout ratio for activations inside the fully connected layer. - attention_dropout (
float, optional, defaults to 0.1) — The dropout ratio for the attention probabilities. - final_dropout (
float, optional, defaults to 0.1) — The dropout probability for the final projection layer of Wav2Vec2ForCTC. - layerdrop (
float, optional, defaults to 0.1) — The LayerDrop probability. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556) for more details. - initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - layer_norm_eps (
float, optional, defaults to 1e-12) — The epsilon used by the layer normalization layers. - feat_extract_norm (
str, optional, defaults to"group") — The norm to be applied to 1D convolutional layers in feature encoder. One of"group"for group normalization of only the first 1D convolutional layer or"layer"for layer normalization of all 1D convolutional layers. - feat_proj_dropout (
float, optional, defaults to 0.0) — The dropout probability for output of the feature encoder. - feat_extract_activation (
str,optional, defaults to“gelu”) -- The non-linear activation function (function or string) in the 1D convolutional layers of the feature extractor. If string,“gelu”,“relu”,“selu”and“gelu_new”` are supported. - feat_quantizer_dropout (
float, optional, defaults to 0.0) — The dropout probability for quantized feature encoder states. - conv_dim (
Tuple[int]orList[int], optional, defaults to(512, 512, 512, 512, 512, 512, 512)) — A tuple of integers defining the number of input and output channels of each 1D convolutional layer in the feature encoder. The length of conv_dim defines the number of 1D convolutional layers. - conv_stride (
Tuple[int]orList[int], optional, defaults to(5, 2, 2, 2, 2, 2, 2)) — A tuple of integers defining the stride of each 1D convolutional layer in the feature encoder. The length of conv_stride defines the number of convolutional layers and has to match the length of conv_dim. - conv_kernel (
Tuple[int]orList[int], optional, defaults to(10, 3, 3, 3, 3, 3, 3)) — A tuple of integers defining the kernel size of each 1D convolutional layer in the feature encoder. The length of conv_kernel defines the number of convolutional layers and has to match the length of conv_dim. - conv_bias (
bool, optional, defaults toFalse) — Whether the 1D convolutional layers have a bias. - num_conv_pos_embeddings (
int, optional, defaults to 128) — Number of convolutional positional embeddings. Defines the kernel size of 1D convolutional positional embeddings layer. - num_conv_pos_embedding_groups (
int, optional, defaults to 16) — Number of groups of 1D convolutional positional embeddings layer. - do_stable_layer_norm (
bool, optional, defaults toFalse) — Whether to apply stable layer norm architecture of the Transformer encoder.do_stable_layer_norm is Truecorresponds to applying layer norm before the attention layer, whereasdo_stable_layer_norm is Falsecorresponds to applying layer norm after the attention layer. - apply_spec_augment (
bool, optional, defaults toTrue) — Whether to apply SpecAugment data augmentation to the outputs of the feature encoder. For reference see SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition. - mask_time_prob (
float, optional, defaults to 0.05) — Percentage (between 0 and 1) of all feature vectors along the time axis which will be masked. The masking procecure generates ”mask_time_problen(time_axis)/mask_time_length” independent masks over the axis. If reasoning from the propability of each feature vector to be chosen as the start of the vector span to be masked, mask_time_prob should be `prob_vector_startmask_time_length. Note that overlap may decrease the actual percentage of masked vectors. This is only relevant ifapply_spec_augment is True`. - mask_time_length (
int, optional, defaults to 10) — Length of vector span along the time axis. - mask_time_min_masks (
int, optional, defaults to 2), — The minimum number of masks of lengthmask_feature_lengthgenerated along the time axis, each time step, irrespectively ofmask_feature_prob. Only relevant if ”mask_time_prob*len(time_axis)/mask_time_length < mask_time_min_masks” - mask_feature_prob (
float, optional, defaults to 0.0) — Percentage (between 0 and 1) of all feature vectors along the feature axis which will be masked. The masking procecure generates ”mask_feature_problen(feature_axis)/mask_time_length” independent masks over the axis. If reasoning from the propability of each feature vector to be chosen as the start of the vector span to be masked, mask_feature_prob should be `prob_vector_startmask_feature_length. Note that overlap may decrease the actual percentage of masked vectors. This is only relevant ifapply_spec_augment is True`. - mask_feature_length (
int, optional, defaults to 10) — Length of vector span along the feature axis. - mask_feature_min_masks (
int, optional, defaults to 0), — The minimum number of masks of lengthmask_feature_lengthgenerated along the feature axis, each time step, irrespectively ofmask_feature_prob. Only relevant if ”mask_feature_prob*len(feature_axis)/mask_feature_length < mask_feature_min_masks” - num_codevectors_per_group (
int, optional, defaults to 320) — Number of entries in each quantization codebook (group). - num_codevector_groups (
int, optional, defaults to 2) — Number of codevector groups for product codevector quantization. - contrastive_logits_temperature (
float, optional, defaults to 0.1) — The temperature kappa in the contrastive loss. - feat_quantizer_dropout (
float, optional, defaults to 0.0) — The dropout probability for the output of the feature encoder that’s used by the quantizer. - num_negatives (
int, optional, defaults to 100) — Number of negative samples for the contrastive loss. - codevector_dim (
int, optional, defaults to 256) — Dimensionality of the quantized feature vectors. - proj_codevector_dim (
int, optional, defaults to 256) — Dimensionality of the final projection of both the quantized and the transformer features. - diversity_loss_weight (
int, optional, defaults to 0.1) — The weight of the codebook diversity loss component. - ctc_loss_reduction (
str, optional, defaults to"sum") — Specifies the reduction to apply to the output oftorch.nn.CTCLoss. Only relevant when training an instance of Wav2Vec2ForCTC. - ctc_zero_infinity (
bool, optional, defaults toFalse) — Whether to zero infinite losses and the associated gradients oftorch.nn.CTCLoss. Infinite losses mainly occur when the inputs are too short to be aligned to the targets. Only relevant when training an instance of Wav2Vec2ForCTC. - use_weighted_layer_sum (
bool, optional, defaults toFalse) — Whether to use a weighted average of layer outputs with learned weights. Only relevant when using an instance of Wav2Vec2ForSequenceClassification. - classifier_proj_size (
int, optional, defaults to 256) — Dimensionality of the projection before token mean-pooling for classification. - tdnn_dim (
Tuple[int]orList[int], optional, defaults to(512, 512, 512, 512, 1500)) — A tuple of integers defining the number of output channels of each 1D convolutional layer in the TDNN module of the XVector model. The length of tdnn_dim defines the number of TDNN layers. - tdnn_kernel (
Tuple[int]orList[int], optional, defaults to(5, 3, 3, 1, 1)) — A tuple of integers defining the kernel size of each 1D convolutional layer in the TDNN module of the XVector model. The length of tdnn_kernel has to match the length of tdnn_dim. - tdnn_dilation (
Tuple[int]orList[int], optional, defaults to(1, 2, 3, 1, 1)) — A tuple of integers defining the dilation factor of each 1D convolutional layer in TDNN module of the XVector model. The length of tdnn_dilation has to match the length of tdnn_dim. - xvector_output_dim (
int, optional, defaults to 512) — Dimensionality of the XVector embedding vectors. - add_adapter (
bool, optional, defaults toFalse) — Whether a convolutional network should be stacked on top of the Wav2Vec2 Encoder. Can be very useful for warm-starting Wav2Vec2 for SpeechEncoderDecoder models. - adapter_kernel_size (
int, optional, defaults to 3) — Kernel size of the convolutional layers in the adapter network. Only relevant ifadd_adapter is True. - adapter_stride (
int, optional, defaults to 2) — Stride of the convolutional layers in the adapter network. Only relevant ifadd_adapter is True. - num_adapter_layers (
int, optional, defaults to 3) — Number of convolutional layers that should be used in the adapter network. Only relevant ifadd_adapter is True. - adapter_attn_dim (
int, optional) — Dimension of the attention adapter weights to be used in each attention block. An example of a model using attention adapters is facebook/mms-1b-all. - output_hidden_size (
int, optional) — Dimensionality of the encoder output layer. If not defined, this defaults to hidden-size. Only relevant ifadd_adapter is True.
This is the configuration class to store the configuration of a Wav2Vec2Model. It is used to instantiate an Wav2Vec2 model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the Wav2Vec2 facebook/wav2vec2-base-960h architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import Wav2Vec2Config, Wav2Vec2Model
>>> # Initializing a Wav2Vec2 facebook/wav2vec2-base-960h style configuration
>>> configuration = Wav2Vec2Config()
>>> # Initializing a model (with random weights) from the facebook/wav2vec2-base-960h style configuration
>>> model = Wav2Vec2Model(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configWav2Vec2CTCTokenizer
class transformers.Wav2Vec2CTCTokenizer
< source >( vocab_file bos_token = '<s>' eos_token = '</s>' unk_token = '<unk>' pad_token = '<pad>' word_delimiter_token = '|' replace_word_delimiter_char = ' ' do_lower_case = False target_lang = None **kwargs )
Parameters
- vocab_file (
str) — File containing the vocabulary. - bos_token (
str, optional, defaults to"<s>") — The beginning of sentence token. - eos_token (
str, optional, defaults to"</s>") — The end of sentence token. - unk_token (
str, optional, defaults to"<unk>") — The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this token instead. - pad_token (
str, optional, defaults to"<pad>") — The token used for padding, for example when batching sequences of different lengths. - word_delimiter_token (
str, optional, defaults to"|") — The token used for defining the end of a word. - do_lower_case (
bool, optional, defaults toFalse) — Whether or not to accept lowercase input and lowercase the output when decoding. - target_lang (
str, optional) — A target language the tokenizer should set by default.target_langhas to be defined for multi-lingual, nested vocabulary such as facebook/mms-1b-all.**kwargs — Additional keyword arguments passed along to PreTrainedTokenizer
Constructs a Wav2Vec2CTC tokenizer.
This tokenizer inherits from PreTrainedTokenizer which contains some of the main methods. Users should refer to the superclass for more information regarding such methods.
__call__
< source >( text: Union = None text_pair: Union = None text_target: Union = None text_pair_target: Union = None add_special_tokens: bool = True padding: Union = False truncation: Union = None max_length: Optional = None stride: int = 0 is_split_into_words: bool = False pad_to_multiple_of: Optional = None padding_side: Optional = None return_tensors: Union = None return_token_type_ids: Optional = None return_attention_mask: Optional = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True **kwargs ) → BatchEncoding
Parameters
- text (
str,List[str],List[List[str]], optional) — The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must setis_split_into_words=True(to lift the ambiguity with a batch of sequences). - text_pair (
str,List[str],List[List[str]], optional) — The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must setis_split_into_words=True(to lift the ambiguity with a batch of sequences). - text_target (
str,List[str],List[List[str]], optional) — The sequence or batch of sequences to be encoded as target texts. Each sequence can be a string or a list of strings (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must setis_split_into_words=True(to lift the ambiguity with a batch of sequences). - text_pair_target (
str,List[str],List[List[str]], optional) — The sequence or batch of sequences to be encoded as target texts. Each sequence can be a string or a list of strings (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must setis_split_into_words=True(to lift the ambiguity with a batch of sequences). - add_special_tokens (
bool, optional, defaults toTrue) — Whether or not to add special tokens when encoding the sequences. This will use the underlyingPretrainedTokenizerBase.build_inputs_with_special_tokensfunction, which defines which tokens are automatically added to the input ids. This is usefull if you want to addbosoreostokens automatically. - padding (
bool,stror PaddingStrategy, optional, defaults toFalse) — Activates and controls padding. Accepts the following values:Trueor'longest': Pad to the longest sequence in the batch (or no padding if only a single sequence if provided).'max_length': Pad to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided.Falseor'do_not_pad'(default): No padding (i.e., can output a batch with sequences of different lengths).
- truncation (
bool,stror TruncationStrategy, optional, defaults toFalse) — Activates and controls truncation. Accepts the following values:Trueor'longest_first': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will truncate token by token, removing a token from the longest sequence in the pair if a pair of sequences (or a batch of pairs) is provided.'only_first': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the first sequence of a pair if a pair of sequences (or a batch of pairs) is provided.'only_second': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the second sequence of a pair if a pair of sequences (or a batch of pairs) is provided.Falseor'do_not_truncate'(default): No truncation (i.e., can output batch with sequence lengths greater than the model maximum admissible input size).
- max_length (
int, optional) — Controls the maximum length to use by one of the truncation/padding parameters.If left unset or set to
None, this will use the predefined model maximum length if a maximum length is required by one of the truncation/padding parameters. If the model has no specific maximum input length (like XLNet) truncation/padding to a maximum length will be deactivated. - stride (
int, optional, defaults to 0) — If set to a number along withmax_length, the overflowing tokens returned whenreturn_overflowing_tokens=Truewill contain some tokens from the end of the truncated sequence returned to provide some overlap between truncated and overflowing sequences. The value of this argument defines the number of overlapping tokens. - is_split_into_words (
bool, optional, defaults toFalse) — Whether or not the input is already pre-tokenized (e.g., split into words). If set toTrue, the tokenizer assumes the input is already split into words (for instance, by splitting it on whitespace) which it will tokenize. This is useful for NER or token classification. - pad_to_multiple_of (
int, optional) — If set will pad the sequence to a multiple of the provided value. Requirespaddingto be activated. This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability>= 7.5(Volta). - padding_side (
str, optional) — The side on which the model should have padding applied. Should be selected between [‘right’, ‘left’]. Default value is picked from the class attribute of the same name. - return_tensors (
stror TensorType, optional) — If set, will return tensors instead of list of python integers. Acceptable values are:'tf': Return TensorFlowtf.constantobjects.'pt': Return PyTorchtorch.Tensorobjects.'np': Return Numpynp.ndarrayobjects.
- return_token_type_ids (
bool, optional) — Whether to return token type IDs. If left to the default, will return the token type IDs according to the specific tokenizer’s default, defined by thereturn_outputsattribute. - return_attention_mask (
bool, optional) — Whether to return the attention mask. If left to the default, will return the attention mask according to the specific tokenizer’s default, defined by thereturn_outputsattribute. - return_overflowing_tokens (
bool, optional, defaults toFalse) — Whether or not to return overflowing token sequences. If a pair of sequences of input ids (or a batch of pairs) is provided withtruncation_strategy = longest_firstorTrue, an error is raised instead of returning overflowing tokens. - return_special_tokens_mask (
bool, optional, defaults toFalse) — Whether or not to return special tokens mask information. - return_offsets_mapping (
bool, optional, defaults toFalse) — Whether or not to return(char_start, char_end)for each token.This is only available on fast tokenizers inheriting from PreTrainedTokenizerFast, if using Python’s tokenizer, this method will raise
NotImplementedError. - return_length (
bool, optional, defaults toFalse) — Whether or not to return the lengths of the encoded inputs. - verbose (
bool, optional, defaults toTrue) — Whether or not to print more information and warnings. **kwargs — passed to theself.tokenize()method
Returns
A BatchEncoding with the following fields:
-
input_ids — List of token ids to be fed to a model.
-
token_type_ids — List of token type ids to be fed to a model (when
return_token_type_ids=Trueor if “token_type_ids” is inself.model_input_names). -
attention_mask — List of indices specifying which tokens should be attended to by the model (when
return_attention_mask=Trueor if “attention_mask” is inself.model_input_names). -
overflowing_tokens — List of overflowing tokens sequences (when a
max_lengthis specified andreturn_overflowing_tokens=True). -
num_truncated_tokens — Number of tokens truncated (when a
max_lengthis specified andreturn_overflowing_tokens=True). -
special_tokens_mask — List of 0s and 1s, with 1 specifying added special tokens and 0 specifying regular sequence tokens (when
add_special_tokens=Trueandreturn_special_tokens_mask=True). -
length — The length of the inputs (when
return_length=True)
Main method to tokenize and prepare for the model one or several sequence(s) or one or several pair(s) of sequences.
decode
< source >( token_ids: Union skip_special_tokens: bool = False clean_up_tokenization_spaces: bool = None output_char_offsets: bool = False output_word_offsets: bool = False **kwargs ) → str or Wav2Vec2CTCTokenizerOutput
Parameters
- token_ids (
Union[int, List[int], np.ndarray, torch.Tensor, tf.Tensor]) — List of tokenized input ids. Can be obtained using the__call__method. - skip_special_tokens (
bool, optional, defaults toFalse) — Whether or not to remove special tokens in the decoding. - clean_up_tokenization_spaces (
bool, optional) — Whether or not to clean up the tokenization spaces. - output_char_offsets (
bool, optional, defaults toFalse) — Whether or not to output character offsets. Character offsets can be used in combination with the sampling rate and model downsampling rate to compute the time-stamps of transcribed characters.Please take a look at the example below to better understand how to make use of
output_char_offsets. - output_word_offsets (
bool, optional, defaults toFalse) — Whether or not to output word offsets. Word offsets can be used in combination with the sampling rate and model downsampling rate to compute the time-stamps of transcribed words.Please take a look at the example below to better understand how to make use of
output_word_offsets. - kwargs (additional keyword arguments, optional) — Will be passed to the underlying model specific decode method.
Returns
str or Wav2Vec2CTCTokenizerOutput
The list of decoded
sentences. Will be a Wav2Vec2CTCTokenizerOutput when
output_char_offsets == True or output_word_offsets == True.
Converts a sequence of ids in a string, using the tokenizer and vocabulary with options to remove special tokens and clean up tokenization spaces.
Similar to doing self.convert_tokens_to_string(self.convert_ids_to_tokens(token_ids)).
Example:
>>> # Let's see how to retrieve time steps for a model
>>> from transformers import AutoTokenizer, AutoFeatureExtractor, AutoModelForCTC
>>> from datasets import load_dataset
>>> import datasets
>>> import torch
>>> # import model, feature extractor, tokenizer
>>> model = AutoModelForCTC.from_pretrained("facebook/wav2vec2-base-960h")
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/wav2vec2-base-960h")
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base-960h")
>>> # load first sample of English common_voice
>>> dataset = load_dataset("mozilla-foundation/common_voice_11_0", "en", split="train", streaming=True, trust_remote_code=True)
>>> dataset = dataset.cast_column("audio", datasets.Audio(sampling_rate=16_000))
>>> dataset_iter = iter(dataset)
>>> sample = next(dataset_iter)
>>> # forward sample through model to get greedily predicted transcription ids
>>> input_values = feature_extractor(sample["audio"]["array"], return_tensors="pt").input_values
>>> logits = model(input_values).logits[0]
>>> pred_ids = torch.argmax(logits, axis=-1)
>>> # retrieve word stamps (analogous commands for `output_char_offsets`)
>>> outputs = tokenizer.decode(pred_ids, output_word_offsets=True)
>>> # compute `time_offset` in seconds as product of downsampling ratio and sampling_rate
>>> time_offset = model.config.inputs_to_logits_ratio / feature_extractor.sampling_rate
>>> word_offsets = [
... {
... "word": d["word"],
... "start_time": round(d["start_offset"] * time_offset, 2),
... "end_time": round(d["end_offset"] * time_offset, 2),
... }
... for d in outputs.word_offsets
... ]
>>> # compare word offsets with audio `en_train_0/common_voice_en_19121553.mp3` online on the dataset viewer:
>>> # https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0/viewer/en
>>> word_offsets[:3]
[{'word': 'THE', 'start_time': 0.7, 'end_time': 0.78}, {'word': 'TRICK', 'start_time': 0.88, 'end_time': 1.08}, {'word': 'APPEARS', 'start_time': 1.2, 'end_time': 1.64}]batch_decode
< source >( sequences: Union skip_special_tokens: bool = False clean_up_tokenization_spaces: bool = None output_char_offsets: bool = False output_word_offsets: bool = False **kwargs ) → List[str] or Wav2Vec2CTCTokenizerOutput
Parameters
- sequences (
Union[List[int], List[List[int]], np.ndarray, torch.Tensor, tf.Tensor]) — List of tokenized input ids. Can be obtained using the__call__method. - skip_special_tokens (
bool, optional, defaults toFalse) — Whether or not to remove special tokens in the decoding. - clean_up_tokenization_spaces (
bool, optional) — Whether or not to clean up the tokenization spaces. - output_char_offsets (
bool, optional, defaults toFalse) — Whether or not to output character offsets. Character offsets can be used in combination with the sampling rate and model downsampling rate to compute the time-stamps of transcribed characters.Please take a look at the Example of decode() to better understand how to make use of
output_char_offsets. batch_decode() works the same way with batched output. - output_word_offsets (
bool, optional, defaults toFalse) — Whether or not to output word offsets. Word offsets can be used in combination with the sampling rate and model downsampling rate to compute the time-stamps of transcribed words.Please take a look at the Example of decode() to better understand how to make use of
output_word_offsets. batch_decode() works the same way with batched output. - kwargs (additional keyword arguments, optional) — Will be passed to the underlying model specific decode method.
Returns
List[str] or Wav2Vec2CTCTokenizerOutput
The list of decoded
sentences. Will be a Wav2Vec2CTCTokenizerOutput when
output_char_offsets == True or output_word_offsets == True.
Convert a list of lists of token ids into a list of strings by calling decode.
Set the target language of a nested multi-lingual dictionary
Wav2Vec2FeatureExtractor
class transformers.Wav2Vec2FeatureExtractor
< source >( feature_size = 1 sampling_rate = 16000 padding_value = 0.0 return_attention_mask = False do_normalize = True **kwargs )
Parameters
- feature_size (
int, optional, defaults to 1) — The feature dimension of the extracted features. - sampling_rate (
int, optional, defaults to 16000) — The sampling rate at which the audio files should be digitalized expressed in hertz (Hz). - padding_value (
float, optional, defaults to 0.0) — The value that is used to fill the padding values. - do_normalize (
bool, optional, defaults toTrue) — Whether or not to zero-mean unit-variance normalize the input. Normalizing can help to significantly improve the performance for some models, e.g., wav2vec2-lv60. - return_attention_mask (
bool, optional, defaults toFalse) — Whether or not call() should returnattention_mask.Wav2Vec2 models that have set
config.feat_extract_norm == "group", such as wav2vec2-base, have not been trained usingattention_mask. For such models,input_valuesshould simply be padded with 0 and noattention_maskshould be passed.For Wav2Vec2 models that have set
config.feat_extract_norm == "layer", such as wav2vec2-lv60,attention_maskshould be passed for batched inference.
Constructs a Wav2Vec2 feature extractor.
This feature extractor inherits from SequenceFeatureExtractor which contains most of the main methods. Users should refer to this superclass for more information regarding those methods.
__call__
< source >( raw_speech: Union padding: Union = False max_length: Optional = None truncation: bool = False pad_to_multiple_of: Optional = None return_attention_mask: Optional = None return_tensors: Union = None sampling_rate: Optional = None **kwargs )
Parameters
- raw_speech (
np.ndarray,List[float],List[np.ndarray],List[List[float]]) — The sequence or batch of sequences to be padded. Each sequence can be a numpy array, a list of float values, a list of numpy arrays or a list of list of float values. Must be mono channel audio, not stereo, i.e. single float per timestep. - padding (
bool,stror PaddingStrategy, optional, defaults toFalse) — Select a strategy to pad the returned sequences (according to the model’s padding side and padding index) among:Trueor'longest': Pad to the longest sequence in the batch (or no padding if only a single sequence if provided).'max_length': Pad to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided.Falseor'do_not_pad'(default): No padding (i.e., can output a batch with sequences of different lengths).
- max_length (
int, optional) — Maximum length of the returned list and optionally padding length (see above). - truncation (
bool) — Activates truncation to cut input sequences longer than max_length to max_length. - pad_to_multiple_of (
int, optional) — If set will pad the sequence to a multiple of the provided value.This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability
>= 7.5(Volta), or on TPUs which benefit from having sequence lengths be a multiple of 128. - return_attention_mask (
bool, optional) — Whether to return the attention mask. If left to the default, will return the attention mask according to the specific feature_extractor’s default.Wav2Vec2 models that have set
config.feat_extract_norm == "group", such as wav2vec2-base, have not been trained usingattention_mask. For such models,input_valuesshould simply be padded with 0 and noattention_maskshould be passed.For Wav2Vec2 models that have set
config.feat_extract_norm == "layer", such as wav2vec2-lv60,attention_maskshould be passed for batched inference. - return_tensors (
stror TensorType, optional) — If set, will return tensors instead of list of python integers. Acceptable values are:'tf': Return TensorFlowtf.constantobjects.'pt': Return PyTorchtorch.Tensorobjects.'np': Return Numpynp.ndarrayobjects.
- sampling_rate (
int, optional) — The sampling rate at which theraw_speechinput was sampled. It is strongly recommended to passsampling_rateat the forward call to prevent silent errors. - padding_value (
float, optional, defaults to 0.0) —
Main method to featurize and prepare for the model one or several sequence(s).
Wav2Vec2Processor
class transformers.Wav2Vec2Processor
< source >( feature_extractor tokenizer )
Parameters
- feature_extractor (
Wav2Vec2FeatureExtractor) — An instance of Wav2Vec2FeatureExtractor. The feature extractor is a required input. - tokenizer (PreTrainedTokenizer) — An instance of PreTrainedTokenizer. The tokenizer is a required input.
Constructs a Wav2Vec2 processor which wraps a Wav2Vec2 feature extractor and a Wav2Vec2 CTC tokenizer into a single processor.
Wav2Vec2Processor offers all the functionalities of Wav2Vec2FeatureExtractor and PreTrainedTokenizer. See the docstring of call() and decode() for more information.
__call__
< source >( audio: Union = None text: Union = None images = None videos = None **kwargs: Unpack )
When used in normal mode, this method forwards all its arguments to Wav2Vec2FeatureExtractor’s
call() and returns its output. If used in the context
as_target_processor() this method forwards all its arguments to PreTrainedTokenizer’s
call(). Please refer to the docstring of the above two methods for more information.
When used in normal mode, this method forwards all its arguments to Wav2Vec2FeatureExtractor’s
pad() and returns its output. If used in the context
as_target_processor() this method forwards all its arguments to PreTrainedTokenizer’s
pad(). Please refer to the docstring of the above two methods for more information.
save_pretrained
< source >( save_directory push_to_hub: bool = False **kwargs )
Parameters
- save_directory (
stroros.PathLike) — Directory where the feature extractor JSON file and the tokenizer files will be saved (directory will be created if it does not exist). - push_to_hub (
bool, optional, defaults toFalse) — Whether or not to push your model to the Hugging Face model hub after saving it. You can specify the repository you want to push to withrepo_id(will default to the name ofsave_directoryin your namespace). - kwargs (
Dict[str, Any], optional) — Additional key word arguments passed along to the push_to_hub() method.
Saves the attributes of this processor (feature extractor, tokenizer…) in the specified directory so that it can be reloaded using the from_pretrained() method.
This class method is simply calling save_pretrained() and save_pretrained(). Please refer to the docstrings of the methods above for more information.
This method forwards all its arguments to PreTrainedTokenizer’s batch_decode(). Please refer to the docstring of this method for more information.
This method forwards all its arguments to PreTrainedTokenizer’s decode(). Please refer to the docstring of this method for more information.
Wav2Vec2ProcessorWithLM
class transformers.Wav2Vec2ProcessorWithLM
< source >( feature_extractor: FeatureExtractionMixin tokenizer: PreTrainedTokenizerBase decoder: BeamSearchDecoderCTC )
Parameters
- feature_extractor (Wav2Vec2FeatureExtractor or SeamlessM4TFeatureExtractor) — An instance of Wav2Vec2FeatureExtractor or SeamlessM4TFeatureExtractor. The feature extractor is a required input.
- tokenizer (Wav2Vec2CTCTokenizer) — An instance of Wav2Vec2CTCTokenizer. The tokenizer is a required input.
- decoder (
pyctcdecode.BeamSearchDecoderCTC) — An instance ofpyctcdecode.BeamSearchDecoderCTC. The decoder is a required input.
Constructs a Wav2Vec2 processor which wraps a Wav2Vec2 feature extractor, a Wav2Vec2 CTC tokenizer and a decoder with language model support into a single processor for language model boosted speech recognition decoding.
When used in normal mode, this method forwards all its arguments to the feature extractor’s
__call__() and returns its output. If used in the context
as_target_processor() this method forwards all its arguments to
Wav2Vec2CTCTokenizer’s call(). Please refer to the docstring of the above two
methods for more information.
When used in normal mode, this method forwards all its arguments to the feature extractor’s
~FeatureExtractionMixin.pad and returns its output. If used in the context
as_target_processor() this method forwards all its arguments to
Wav2Vec2CTCTokenizer’s pad(). Please refer to the docstring of the above two methods
for more information.
from_pretrained
< source >( pretrained_model_name_or_path **kwargs )
Parameters
- pretrained_model_name_or_path (
stroros.PathLike) — This can be either:- a string, the model id of a pretrained feature_extractor hosted inside a model repo on huggingface.co.
- a path to a directory containing a feature extractor file saved using the
save_pretrained() method, e.g.,
./my_model_directory/. - a path or url to a saved feature extractor JSON file, e.g.,
./my_model_directory/preprocessor_config.json. **kwargs — Additional keyword arguments passed along to both SequenceFeatureExtractor and PreTrainedTokenizer
Instantiate a Wav2Vec2ProcessorWithLM from a pretrained Wav2Vec2 processor.
This class method is simply calling the feature extractor’s
from_pretrained(), Wav2Vec2CTCTokenizer’s
from_pretrained(), and
pyctcdecode.BeamSearchDecoderCTC.load_from_hf_hub.
Please refer to the docstrings of the methods above for more information.
batch_decode
< source >( logits: ndarray pool: Optional = None num_processes: Optional = None beam_width: Optional = None beam_prune_logp: Optional = None token_min_logp: Optional = None hotwords: Optional = None hotword_weight: Optional = None alpha: Optional = None beta: Optional = None unk_score_offset: Optional = None lm_score_boundary: Optional = None output_word_offsets: bool = False n_best: int = 1 )
Parameters
- logits (
np.ndarray) — The logits output vector of the model representing the log probabilities for each token. - pool (
multiprocessing.Pool, optional) — An optional user-managed pool. If not set, one will be automatically created and closed. The pool should be instantiated afterWav2Vec2ProcessorWithLM. Otherwise, the LM won’t be available to the pool’s sub-processes.Currently, only pools created with a ‘fork’ context can be used. If a ‘spawn’ pool is passed, it will be ignored and sequential decoding will be used instead.
- num_processes (
int, optional) — Ifpoolis not set, number of processes on which the function should be parallelized over. Defaults to the number of available CPUs. - beam_width (
int, optional) — Maximum number of beams at each step in decoding. Defaults to pyctcdecode’s DEFAULT_BEAM_WIDTH. - beam_prune_logp (
int, optional) — Beams that are much worse than best beam will be pruned Defaults to pyctcdecode’s DEFAULT_PRUNE_LOGP. - token_min_logp (
int, optional) — Tokens below this logp are skipped unless they are argmax of frame Defaults to pyctcdecode’s DEFAULT_MIN_TOKEN_LOGP. - hotwords (
List[str], optional) — List of words with extra importance, can be OOV for LM - hotword_weight (
int, optional) — Weight factor for hotword importance Defaults to pyctcdecode’s DEFAULT_HOTWORD_WEIGHT. - alpha (
float, optional) — Weight for language model during shallow fusion - beta (
float, optional) — Weight for length score adjustment of during scoring - unk_score_offset (
float, optional) — Amount of log score offset for unknown tokens - lm_score_boundary (
bool, optional) — Whether to have kenlm respect boundaries when scoring - output_word_offsets (
bool, optional, defaults toFalse) — Whether or not to output word offsets. Word offsets can be used in combination with the sampling rate and model downsampling rate to compute the time-stamps of transcribed words. - n_best (
int, optional, defaults to1) — Number of best hypotheses to return. Ifn_bestis greater than 1, the returnedtextwill be a list of lists of strings,logit_scorewill be a list of lists of floats, andlm_scorewill be a list of lists of floats, where the length of the outer list will correspond to the batch size and the length of the inner list will correspond to the number of returned hypotheses . The value should be >= 1.Please take a look at the Example of decode() to better understand how to make use of
output_word_offsets. batch_decode() works the same way with batched output.
Batch decode output logits to audio transcription with language model support.
This function makes use of Python’s multiprocessing. Currently, multiprocessing is available only on Unix systems (see this issue).
If you are decoding multiple batches, consider creating a Pool and passing it to batch_decode. Otherwise,
batch_decode will be very slow since it will create a fresh Pool for each call. See usage example below.
Example: See Decoding multiple audios.
decode
< source >( logits: ndarray beam_width: Optional = None beam_prune_logp: Optional = None token_min_logp: Optional = None hotwords: Optional = None hotword_weight: Optional = None alpha: Optional = None beta: Optional = None unk_score_offset: Optional = None lm_score_boundary: Optional = None output_word_offsets: bool = False n_best: int = 1 )
Parameters
- logits (
np.ndarray) — The logits output vector of the model representing the log probabilities for each token. - beam_width (
int, optional) — Maximum number of beams at each step in decoding. Defaults to pyctcdecode’s DEFAULT_BEAM_WIDTH. - beam_prune_logp (
int, optional) — A threshold to prune beams with log-probs less than best_beam_logp + beam_prune_logp. The value should be <= 0. Defaults to pyctcdecode’s DEFAULT_PRUNE_LOGP. - token_min_logp (
int, optional) — Tokens with log-probs below token_min_logp are skipped unless they are have the maximum log-prob for an utterance. Defaults to pyctcdecode’s DEFAULT_MIN_TOKEN_LOGP. - hotwords (
List[str], optional) — List of words with extra importance which can be missing from the LM’s vocabulary, e.g. [“huggingface”] - hotword_weight (
int, optional) — Weight multiplier that boosts hotword scores. Defaults to pyctcdecode’s DEFAULT_HOTWORD_WEIGHT. - alpha (
float, optional) — Weight for language model during shallow fusion - beta (
float, optional) — Weight for length score adjustment of during scoring - unk_score_offset (
float, optional) — Amount of log score offset for unknown tokens - lm_score_boundary (
bool, optional) — Whether to have kenlm respect boundaries when scoring - output_word_offsets (
bool, optional, defaults toFalse) — Whether or not to output word offsets. Word offsets can be used in combination with the sampling rate and model downsampling rate to compute the time-stamps of transcribed words. - n_best (
int, optional, defaults to1) — Number of best hypotheses to return. Ifn_bestis greater than 1, the returnedtextwill be a list of strings,logit_scorewill be a list of floats, andlm_scorewill be a list of floats, where the length of these lists will correspond to the number of returned hypotheses. The value should be >= 1.Please take a look at the example below to better understand how to make use of
output_word_offsets.
Decode output logits to audio transcription with language model support.
Example:
>>> # Let's see how to retrieve time steps for a model
>>> from transformers import AutoTokenizer, AutoProcessor, AutoModelForCTC
>>> from datasets import load_dataset
>>> import datasets
>>> import torch
>>> # import model, feature extractor, tokenizer
>>> model = AutoModelForCTC.from_pretrained("patrickvonplaten/wav2vec2-base-100h-with-lm")
>>> processor = AutoProcessor.from_pretrained("patrickvonplaten/wav2vec2-base-100h-with-lm")
>>> # load first sample of English common_voice
>>> dataset = load_dataset("mozilla-foundation/common_voice_11_0", "en", split="train", streaming=True, trust_remote_code=True)
>>> dataset = dataset.cast_column("audio", datasets.Audio(sampling_rate=16_000))
>>> dataset_iter = iter(dataset)
>>> sample = next(dataset_iter)
>>> # forward sample through model to get greedily predicted transcription ids
>>> input_values = processor(sample["audio"]["array"], return_tensors="pt").input_values
>>> with torch.no_grad():
... logits = model(input_values).logits[0].cpu().numpy()
>>> # retrieve word stamps (analogous commands for `output_char_offsets`)
>>> outputs = processor.decode(logits, output_word_offsets=True)
>>> # compute `time_offset` in seconds as product of downsampling ratio and sampling_rate
>>> time_offset = model.config.inputs_to_logits_ratio / processor.feature_extractor.sampling_rate
>>> word_offsets = [
... {
... "word": d["word"],
... "start_time": round(d["start_offset"] * time_offset, 2),
... "end_time": round(d["end_offset"] * time_offset, 2),
... }
... for d in outputs.word_offsets
... ]
>>> # compare word offsets with audio `en_train_0/common_voice_en_19121553.mp3` online on the dataset viewer:
>>> # https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0/viewer/en
>>> word_offsets[:4]
[{'word': 'THE', 'start_time': 0.68, 'end_time': 0.78}, {'word': 'TRACK', 'start_time': 0.88, 'end_time': 1.1}, {'word': 'APPEARS', 'start_time': 1.18, 'end_time': 1.66}, {'word': 'ON', 'start_time': 1.86, 'end_time': 1.92}]Decoding multiple audios
If you are planning to decode multiple batches of audios, you should consider using batch_decode() and passing an instantiated multiprocessing.Pool.
Otherwise, batch_decode() performance will be slower than calling decode() for each audio individually, as it internally instantiates a new Pool for every call. See the example below:
>>> # Let's see how to use a user-managed pool for batch decoding multiple audios
>>> from multiprocessing import get_context
>>> from transformers import AutoTokenizer, AutoProcessor, AutoModelForCTC
>>> from datasets import load_dataset
>>> import datasets
>>> import torch
>>> # import model, feature extractor, tokenizer
>>> model = AutoModelForCTC.from_pretrained("patrickvonplaten/wav2vec2-base-100h-with-lm").to("cuda")
>>> processor = AutoProcessor.from_pretrained("patrickvonplaten/wav2vec2-base-100h-with-lm")
>>> # load example dataset
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> dataset = dataset.cast_column("audio", datasets.Audio(sampling_rate=16_000))
>>> def map_to_array(batch):
... batch["speech"] = batch["audio"]["array"]
... return batch
>>> # prepare speech data for batch inference
>>> dataset = dataset.map(map_to_array, remove_columns=["audio"])
>>> def map_to_pred(batch, pool):
... inputs = processor(batch["speech"], sampling_rate=16_000, padding=True, return_tensors="pt")
... inputs = {k: v.to("cuda") for k, v in inputs.items()}
... with torch.no_grad():
... logits = model(**inputs).logits
... transcription = processor.batch_decode(logits.cpu().numpy(), pool).text
... batch["transcription"] = transcription
... return batch
>>> # note: pool should be instantiated *after* `Wav2Vec2ProcessorWithLM`.
>>> # otherwise, the LM won't be available to the pool's sub-processes
>>> # select number of processes and batch_size based on number of CPU cores available and on dataset size
>>> with get_context("fork").Pool(processes=2) as pool:
... result = dataset.map(
... map_to_pred, batched=True, batch_size=2, fn_kwargs={"pool": pool}, remove_columns=["speech"]
... )
>>> result["transcription"][:2]
['MISTER QUILTER IS THE APOSTLE OF THE MIDDLE CLASSES AND WE ARE GLAD TO WELCOME HIS GOSPEL', "NOR IS MISTER COULTER'S MANNER LESS INTERESTING THAN HIS MATTER"]Wav2Vec2 specific outputs
class transformers.models.wav2vec2_with_lm.processing_wav2vec2_with_lm.Wav2Vec2DecoderWithLMOutput
< source >( text: Union logit_score: Union = None lm_score: Union = None word_offsets: Union = None )
Parameters
- text (list of
strorstr) — Decoded logits in text from. Usually the speech transcription. - logit_score (list of
floatorfloat) — Total logit score of the beams associated with produced text. - lm_score (list of
float) — Fused lm_score of the beams associated with produced text. - word_offsets (list of
List[Dict[str, Union[int, str]]]orList[Dict[str, Union[int, str]]]) — Offsets of the decoded words. In combination with sampling rate and model downsampling rate word offsets can be used to compute time stamps for each word.
Output type of Wav2Vec2DecoderWithLM, with transcription.
class transformers.modeling_outputs.Wav2Vec2BaseModelOutput
< source >( last_hidden_state: FloatTensor = None extract_features: FloatTensor = None hidden_states: Optional = None attentions: Optional = None )
Parameters
- last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. - extract_features (
torch.FloatTensorof shape(batch_size, sequence_length, conv_dim[-1])) — Sequence of extracted feature vectors of the last convolutional layer of the model. - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
- attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
Base class for models that have been trained with the Wav2Vec2 loss objective.
class transformers.models.wav2vec2.modeling_wav2vec2.Wav2Vec2ForPreTrainingOutput
< source >( loss: Optional = None projected_states: FloatTensor = None projected_quantized_states: FloatTensor = None codevector_perplexity: FloatTensor = None hidden_states: Optional = None attentions: Optional = None contrastive_loss: Optional = None diversity_loss: Optional = None )
Parameters
- loss (optional, returned when
sample_negative_indicesare passed,torch.FloatTensorof shape(1,)) — Total loss as the sum of the contrastive loss (L_m) and the diversity loss (L_d) as stated in the official paper . (classification) loss. - projected_states (
torch.FloatTensorof shape(batch_size, sequence_length, config.proj_codevector_dim)) — Hidden-states of the model projected to config.proj_codevector_dim that can be used to predict the masked projected quantized states. - projected_quantized_states (
torch.FloatTensorof shape(batch_size, sequence_length, config.proj_codevector_dim)) — Quantized extracted feature vectors projected to config.proj_codevector_dim representing the positive target vectors for contrastive loss. - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
- attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
- contrastive_loss (optional, returned when
sample_negative_indicesare passed,torch.FloatTensorof shape(1,)) — The contrastive loss (L_m) as stated in the official paper . - diversity_loss (optional, returned when
sample_negative_indicesare passed,torch.FloatTensorof shape(1,)) — The diversity loss (L_d) as stated in the official paper .
Output type of Wav2Vec2ForPreTraining, with potential hidden states and attentions.
class transformers.models.wav2vec2.modeling_flax_wav2vec2.FlaxWav2Vec2BaseModelOutput
< source >( last_hidden_state: Array = None extract_features: Array = None hidden_states: Optional = None attentions: Optional = None )
Parameters
- last_hidden_state (
jnp.ndarrayof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. - extract_features (
jnp.ndarrayof shape(batch_size, sequence_length, last_conv_dim)) — Sequence of extracted feature vectors of the last convolutional layer of the model withlast_conv_dimbeing the dimension of the last convolutional layer. - hidden_states (
tuple(jnp.ndarray), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple ofjnp.ndarray(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
- attentions (
tuple(jnp.ndarray), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple ofjnp.ndarray(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
Output type of FlaxWav2Vec2BaseModelOutput, with potential hidden states and attentions.
“Returns a new object replacing the specified fields with new values.
class transformers.models.wav2vec2.modeling_flax_wav2vec2.FlaxWav2Vec2ForPreTrainingOutput
< source >( projected_states: Array = None projected_quantized_states: Array = None codevector_perplexity: Array = None hidden_states: Optional = None attentions: Optional = None )
Parameters
- loss (optional, returned when model is in train mode,
jnp.ndarrayof shape(1,)) — Total loss as the sum of the contrastive loss (L_m) and the diversity loss (L_d) as stated in the official paper . (classification) loss. - projected_states (
jnp.ndarrayof shape(batch_size, sequence_length, config.proj_codevector_dim)) — Hidden-states of the model projected to config.proj_codevector_dim that can be used to predict the masked projected quantized states. - projected_quantized_states (
jnp.ndarrayof shape(batch_size, sequence_length, config.proj_codevector_dim)) — Quantized extracted feature vectors projected to config.proj_codevector_dim representing the positive target vectors for contrastive loss. - hidden_states (
tuple(jnp.ndarray), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple ofjnp.ndarray(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
- attentions (
tuple(jnp.ndarray), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple ofjnp.ndarray(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
Output type of FlaxWav2Vec2ForPreTrainingOutput, with potential hidden states and attentions.
“Returns a new object replacing the specified fields with new values.
Wav2Vec2Model
class transformers.Wav2Vec2Model
< source >( config: Wav2Vec2Config )
Parameters
- config (Wav2Vec2Config) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare Wav2Vec2 Model transformer outputting raw hidden-states without any specific head on top. Wav2Vec2 was proposed in wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving etc.).
This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_values: Optional attention_mask: Optional = None mask_time_indices: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.modeling_outputs.Wav2Vec2BaseModelOutput or tuple(torch.FloatTensor)
Parameters
- input_values (
torch.FloatTensorof shape(batch_size, sequence_length)) — Float values of input raw speech waveform. Values can be obtained by loading a.flacor.wavaudio file into an array of typeList[float]or anumpy.ndarray, e.g. via the soundfile library (pip install soundfile). To prepare the array intoinput_values, the AutoProcessor should be used for padding and conversion into a tensor of typetorch.FloatTensor. See Wav2Vec2Processor.call() for details. - attention_mask (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing convolution and attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
attention_maskshould only be passed if the corresponding processor hasconfig.return_attention_mask == True. For all models whose processor hasconfig.return_attention_mask == False, such as wav2vec2-base,attention_maskshould not be passed to avoid degraded performance when doing batched inference. For such modelsinput_valuesshould simply be padded with 0 and passed withoutattention_mask. Be aware that these models also yield slightly different results depending on whetherinput_valuesis padded or not. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.modeling_outputs.Wav2Vec2BaseModelOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.Wav2Vec2BaseModelOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (Wav2Vec2Config) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. -
extract_features (
torch.FloatTensorof shape(batch_size, sequence_length, conv_dim[-1])) — Sequence of extracted feature vectors of the last convolutional layer of the model. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The Wav2Vec2Model forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoProcessor, Wav2Vec2Model
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation", trust_remote_code=True)
>>> dataset = dataset.sort("id")
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
>>> model = Wav2Vec2Model.from_pretrained("facebook/wav2vec2-base-960h")
>>> # audio file is decoded on the fly
>>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 292, 768]Wav2Vec2ForCTC
class transformers.Wav2Vec2ForCTC
< source >( config target_lang: Optional = None )
Parameters
- config (Wav2Vec2Config) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
- target_lang (
str, optional) — Language id of adapter weights. Adapter weights are stored in the format adapter..safetensors or adapter. .bin. Only relevant when using an instance of Wav2Vec2ForCTC with adapters. Uses ‘eng’ by default.
Wav2Vec2 Model with a language modeling head on top for Connectionist Temporal Classification (CTC).
Wav2Vec2 was proposed in wav2vec 2.0: A Framework for Self-Supervised Learning of Speech
Representations by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael
Auli.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving etc.).
This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_values: Optional attention_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None labels: Optional = None ) → transformers.modeling_outputs.CausalLMOutput or tuple(torch.FloatTensor)
Parameters
- input_values (
torch.FloatTensorof shape(batch_size, sequence_length)) — Float values of input raw speech waveform. Values can be obtained by loading a.flacor.wavaudio file into an array of typeList[float]or anumpy.ndarray, e.g. via the soundfile library (pip install soundfile). To prepare the array intoinput_values, the AutoProcessor should be used for padding and conversion into a tensor of typetorch.FloatTensor. See Wav2Vec2Processor.call() for details. - attention_mask (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing convolution and attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
attention_maskshould only be passed if the corresponding processor hasconfig.return_attention_mask == True. For all models whose processor hasconfig.return_attention_mask == False, such as wav2vec2-base,attention_maskshould not be passed to avoid degraded performance when doing batched inference. For such modelsinput_valuesshould simply be padded with 0 and passed withoutattention_mask. Be aware that these models also yield slightly different results depending on whetherinput_valuesis padded or not. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size, target_length), optional) — Labels for connectionist temporal classification. Note thattarget_lengthhas to be smaller or equal to the sequence length of the output logits. Indices are selected in[-100, 0, ..., config.vocab_size - 1]. All labels set to-100are ignored (masked), the loss is only computed for labels in[0, ..., config.vocab_size - 1].
Returns
transformers.modeling_outputs.CausalLMOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.CausalLMOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (Wav2Vec2Config) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Language modeling loss (for next-token prediction). -
logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The Wav2Vec2ForCTC forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoProcessor, Wav2Vec2ForCTC
>>> from datasets import load_dataset
>>> import torch
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation", trust_remote_code=True)
>>> dataset = dataset.sort("id")
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
>>> model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-960h")
>>> # audio file is decoded on the fly
>>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_ids = torch.argmax(logits, dim=-1)
>>> # transcribe speech
>>> transcription = processor.batch_decode(predicted_ids)
>>> transcription[0]
'MISTER QUILTER IS THE APOSTLE OF THE MIDDLE CLASSES AND WE ARE GLAD TO WELCOME HIS GOSPEL'
>>> inputs["labels"] = processor(text=dataset[0]["text"], return_tensors="pt").input_ids
>>> # compute loss
>>> loss = model(**inputs).loss
>>> round(loss.item(), 2)
53.48load_adapter
< source >( target_lang: str force_load = True **kwargs )
Parameters
- target_lang (
str) — Has to be a language id of an existing adapter weight. Adapter weights are stored in the format adapter..safetensors or adapter. .bin - force_load (
bool, defaults toTrue) — Whether the weights shall be loaded even iftarget_langmatchesself.target_lang. - cache_dir (
Union[str, os.PathLike], optional) — Path to a directory in which a downloaded pretrained model configuration should be cached if the standard cache should not be used. - force_download (
bool, optional, defaults toFalse) — Whether or not to force the (re-)download of the model weights and configuration files, overriding the cached versions if they exist. resume_download — Deprecated and ignored. All downloads are now resumed by default when possible. Will be removed in v5 of Transformers. - proxies (
Dict[str, str], optional) — A dictionary of proxy servers to use by protocol or endpoint, e.g.,{'http': 'foo.bar:3128', 'http://hostname': 'foo.bar:4012'}. The proxies are used on each request. - local_files_only(
bool, optional, defaults toFalse) — Whether or not to only look at local files (i.e., do not try to download the model). - token (
strorbool, optional) — The token to use as HTTP bearer authorization for remote files. IfTrue, or not specified, will use the token generated when runninghuggingface-cli login(stored in~/.huggingface). - revision (
str, optional, defaults to"main") — The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a git-based system for storing models and other artifacts on huggingface.co, sorevisioncan be any identifier allowed by git.To test a pull request you made on the Hub, you can pass
revision="refs/pr/<pr_number>". - mirror (
str, optional) — Mirror source to accelerate downloads in China. If you are from China and have an accessibility problem, you can set this option to resolve it. Note that we do not guarantee the timeliness or safety. Please refer to the mirror site for more information.
Load a language adapter model from a pre-trained adapter model.
Activate the special “offline-mode” to use this method in a firewalled environment.
Examples:
>>> from transformers import Wav2Vec2ForCTC, AutoProcessor
>>> ckpt = "facebook/mms-1b-all"
>>> processor = AutoProcessor.from_pretrained(ckpt)
>>> model = Wav2Vec2ForCTC.from_pretrained(ckpt, target_lang="eng")
>>> # set specific language
>>> processor.tokenizer.set_target_lang("spa")
>>> model.load_adapter("spa")Wav2Vec2ForSequenceClassification
class transformers.Wav2Vec2ForSequenceClassification
< source >( config )
Parameters
- config (Wav2Vec2Config) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Wav2Vec2 Model with a sequence classification head on top (a linear layer over the pooled output) for tasks like SUPERB Keyword Spotting.
Wav2Vec2 was proposed in wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving etc.).
This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_values: Optional attention_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None labels: Optional = None ) → transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)
Parameters
- input_values (
torch.FloatTensorof shape(batch_size, sequence_length)) — Float values of input raw speech waveform. Values can be obtained by loading a.flacor.wavaudio file into an array of typeList[float]or anumpy.ndarray, e.g. via the soundfile library (pip install soundfile). To prepare the array intoinput_values, the AutoProcessor should be used for padding and conversion into a tensor of typetorch.FloatTensor. See Wav2Vec2Processor.call() for details. - attention_mask (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing convolution and attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
attention_maskshould only be passed if the corresponding processor hasconfig.return_attention_mask == True. For all models whose processor hasconfig.return_attention_mask == False, such as wav2vec2-base,attention_maskshould not be passed to avoid degraded performance when doing batched inference. For such modelsinput_valuesshould simply be padded with 0 and passed withoutattention_mask. Be aware that these models also yield slightly different results depending on whetherinput_valuesis padded or not. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the sequence classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy).
Returns
transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.SequenceClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (Wav2Vec2Config) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. -
logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The Wav2Vec2ForSequenceClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoFeatureExtractor, Wav2Vec2ForSequenceClassification
>>> from datasets import load_dataset
>>> import torch
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation", trust_remote_code=True)
>>> dataset = dataset.sort("id")
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("superb/wav2vec2-base-superb-ks")
>>> model = Wav2Vec2ForSequenceClassification.from_pretrained("superb/wav2vec2-base-superb-ks")
>>> # audio file is decoded on the fly
>>> inputs = feature_extractor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_ids = torch.argmax(logits, dim=-1).item()
>>> predicted_label = model.config.id2label[predicted_class_ids]
>>> predicted_label
'_unknown_'
>>> # compute loss - target_label is e.g. "down"
>>> target_label = model.config.id2label[0]
>>> inputs["labels"] = torch.tensor([model.config.label2id[target_label]])
>>> loss = model(**inputs).loss
>>> round(loss.item(), 2)
6.54Wav2Vec2ForAudioFrameClassification
class transformers.Wav2Vec2ForAudioFrameClassification
< source >( config )
Parameters
- config (Wav2Vec2Config) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Wav2Vec2 Model with a frame classification head on top for tasks like Speaker Diarization.
Wav2Vec2 was proposed in wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving etc.).
This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_values: Optional attention_mask: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.modeling_outputs.TokenClassifierOutput or tuple(torch.FloatTensor)
Parameters
- input_values (
torch.FloatTensorof shape(batch_size, sequence_length)) — Float values of input raw speech waveform. Values can be obtained by loading a.flacor.wavaudio file into an array of typeList[float]or anumpy.ndarray, e.g. via the soundfile library (pip install soundfile). To prepare the array intoinput_values, the AutoProcessor should be used for padding and conversion into a tensor of typetorch.FloatTensor. See Wav2Vec2Processor.call() for details. - attention_mask (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing convolution and attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
attention_maskshould only be passed if the corresponding processor hasconfig.return_attention_mask == True. For all models whose processor hasconfig.return_attention_mask == False, such as wav2vec2-base,attention_maskshould not be passed to avoid degraded performance when doing batched inference. For such modelsinput_valuesshould simply be padded with 0 and passed withoutattention_mask. Be aware that these models also yield slightly different results depending on whetherinput_valuesis padded or not. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the sequence classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy).
Returns
transformers.modeling_outputs.TokenClassifierOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.TokenClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (Wav2Vec2Config) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification loss. -
logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.num_labels)) — Classification scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The Wav2Vec2ForAudioFrameClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoFeatureExtractor, Wav2Vec2ForAudioFrameClassification
>>> from datasets import load_dataset
>>> import torch
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation", trust_remote_code=True)
>>> dataset = dataset.sort("id")
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("anton-l/wav2vec2-base-superb-sd")
>>> model = Wav2Vec2ForAudioFrameClassification.from_pretrained("anton-l/wav2vec2-base-superb-sd")
>>> # audio file is decoded on the fly
>>> inputs = feature_extractor(dataset[0]["audio"]["array"], return_tensors="pt", sampling_rate=sampling_rate)
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> probabilities = torch.sigmoid(logits[0])
>>> # labels is a one-hot array of shape (num_frames, num_speakers)
>>> labels = (probabilities > 0.5).long()
>>> labels[0].tolist()
[0, 0]Wav2Vec2ForXVector
class transformers.Wav2Vec2ForXVector
< source >( config )
Parameters
- config (Wav2Vec2Config) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Wav2Vec2 Model with an XVector feature extraction head on top for tasks like Speaker Verification.
Wav2Vec2 was proposed in wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving etc.).
This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_values: Optional attention_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None labels: Optional = None ) → transformers.modeling_outputs.XVectorOutput or tuple(torch.FloatTensor)
Parameters
- input_values (
torch.FloatTensorof shape(batch_size, sequence_length)) — Float values of input raw speech waveform. Values can be obtained by loading a.flacor.wavaudio file into an array of typeList[float]or anumpy.ndarray, e.g. via the soundfile library (pip install soundfile). To prepare the array intoinput_values, the AutoProcessor should be used for padding and conversion into a tensor of typetorch.FloatTensor. See Wav2Vec2Processor.call() for details. - attention_mask (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing convolution and attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
attention_maskshould only be passed if the corresponding processor hasconfig.return_attention_mask == True. For all models whose processor hasconfig.return_attention_mask == False, such as wav2vec2-base,attention_maskshould not be passed to avoid degraded performance when doing batched inference. For such modelsinput_valuesshould simply be padded with 0 and passed withoutattention_mask. Be aware that these models also yield slightly different results depending on whetherinput_valuesis padded or not. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the sequence classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy).
Returns
transformers.modeling_outputs.XVectorOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.XVectorOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (Wav2Vec2Config) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification loss. -
logits (
torch.FloatTensorof shape(batch_size, config.xvector_output_dim)) — Classification hidden states before AMSoftmax. -
embeddings (
torch.FloatTensorof shape(batch_size, config.xvector_output_dim)) — Utterance embeddings used for vector similarity-based retrieval. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The Wav2Vec2ForXVector forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoFeatureExtractor, Wav2Vec2ForXVector
>>> from datasets import load_dataset
>>> import torch
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation", trust_remote_code=True)
>>> dataset = dataset.sort("id")
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("anton-l/wav2vec2-base-superb-sv")
>>> model = Wav2Vec2ForXVector.from_pretrained("anton-l/wav2vec2-base-superb-sv")
>>> # audio file is decoded on the fly
>>> inputs = feature_extractor(
... [d["array"] for d in dataset[:2]["audio"]], sampling_rate=sampling_rate, return_tensors="pt", padding=True
... )
>>> with torch.no_grad():
... embeddings = model(**inputs).embeddings
>>> embeddings = torch.nn.functional.normalize(embeddings, dim=-1).cpu()
>>> # the resulting embeddings can be used for cosine similarity-based retrieval
>>> cosine_sim = torch.nn.CosineSimilarity(dim=-1)
>>> similarity = cosine_sim(embeddings[0], embeddings[1])
>>> threshold = 0.7 # the optimal threshold is dataset-dependent
>>> if similarity < threshold:
... print("Speakers are not the same!")
>>> round(similarity.item(), 2)
0.98Wav2Vec2ForPreTraining
class transformers.Wav2Vec2ForPreTraining
< source >( config: Wav2Vec2Config )
Parameters
- config (Wav2Vec2Config) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Wav2Vec2 Model with a quantizer and VQ head on top.
Wav2Vec2 was proposed in wav2vec 2.0: A Framework for Self-Supervised Learning of Speech
Representations by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael
Auli.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving etc.).
This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_values: Optional attention_mask: Optional = None mask_time_indices: Optional = None sampled_negative_indices: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.models.wav2vec2.modeling_wav2vec2.Wav2Vec2ForPreTrainingOutput or tuple(torch.FloatTensor)
Parameters
- input_values (
torch.FloatTensorof shape(batch_size, sequence_length)) — Float values of input raw speech waveform. Values can be obtained by loading a.flacor.wavaudio file into an array of typeList[float]or anumpy.ndarray, e.g. via the soundfile library (pip install soundfile). To prepare the array intoinput_values, the AutoProcessor should be used for padding and conversion into a tensor of typetorch.FloatTensor. See Wav2Vec2Processor.call() for details. - attention_mask (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing convolution and attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
attention_maskshould only be passed if the corresponding processor hasconfig.return_attention_mask == True. For all models whose processor hasconfig.return_attention_mask == False, such as wav2vec2-base,attention_maskshould not be passed to avoid degraded performance when doing batched inference. For such modelsinput_valuesshould simply be padded with 0 and passed withoutattention_mask. Be aware that these models also yield slightly different results depending on whetherinput_valuesis padded or not. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - mask_time_indices (
torch.BoolTensorof shape(batch_size, sequence_length), optional) — Indices to mask extracted features for contrastive loss. When in training mode, model learns to predict masked extracted features in config.proj_codevector_dim space. - sampled_negative_indices (
torch.BoolTensorof shape(batch_size, sequence_length, num_negatives), optional) — Indices indicating which quantized target vectors are used as negative sampled vectors in contrastive loss. Required input for pre-training.
Returns
transformers.models.wav2vec2.modeling_wav2vec2.Wav2Vec2ForPreTrainingOutput or tuple(torch.FloatTensor)
A transformers.models.wav2vec2.modeling_wav2vec2.Wav2Vec2ForPreTrainingOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (Wav2Vec2Config) and inputs.
-
loss (optional, returned when
sample_negative_indicesare passed,torch.FloatTensorof shape(1,)) — Total loss as the sum of the contrastive loss (L_m) and the diversity loss (L_d) as stated in the official paper . (classification) loss. -
projected_states (
torch.FloatTensorof shape(batch_size, sequence_length, config.proj_codevector_dim)) — Hidden-states of the model projected to config.proj_codevector_dim that can be used to predict the masked projected quantized states. -
projected_quantized_states (
torch.FloatTensorof shape(batch_size, sequence_length, config.proj_codevector_dim)) — Quantized extracted feature vectors projected to config.proj_codevector_dim representing the positive target vectors for contrastive loss. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
-
contrastive_loss (optional, returned when
sample_negative_indicesare passed,torch.FloatTensorof shape(1,)) — The contrastive loss (L_m) as stated in the official paper . -
diversity_loss (optional, returned when
sample_negative_indicesare passed,torch.FloatTensorof shape(1,)) — The diversity loss (L_d) as stated in the official paper .
The Wav2Vec2ForPreTraining forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> import torch
>>> from transformers import AutoFeatureExtractor, Wav2Vec2ForPreTraining
>>> from transformers.models.wav2vec2.modeling_wav2vec2 import _compute_mask_indices, _sample_negative_indices
>>> from datasets import load_dataset
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base")
>>> model = Wav2Vec2ForPreTraining.from_pretrained("facebook/wav2vec2-base")
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> input_values = feature_extractor(ds[0]["audio"]["array"], return_tensors="pt").input_values # Batch size 1
>>> # compute masked indices
>>> batch_size, raw_sequence_length = input_values.shape
>>> sequence_length = model._get_feat_extract_output_lengths(raw_sequence_length).item()
>>> mask_time_indices = _compute_mask_indices(
... shape=(batch_size, sequence_length), mask_prob=0.2, mask_length=2
... )
>>> sampled_negative_indices = _sample_negative_indices(
... features_shape=(batch_size, sequence_length),
... num_negatives=model.config.num_negatives,
... mask_time_indices=mask_time_indices,
... )
>>> mask_time_indices = torch.tensor(data=mask_time_indices, device=input_values.device, dtype=torch.long)
>>> sampled_negative_indices = torch.tensor(
... data=sampled_negative_indices, device=input_values.device, dtype=torch.long
... )
>>> with torch.no_grad():
... outputs = model(input_values, mask_time_indices=mask_time_indices)
>>> # compute cosine similarity between predicted (=projected_states) and target (=projected_quantized_states)
>>> cosine_sim = torch.cosine_similarity(outputs.projected_states, outputs.projected_quantized_states, dim=-1)
>>> # show that cosine similarity is much higher than random
>>> cosine_sim[mask_time_indices.to(torch.bool)].mean() > 0.5
tensor(True)
>>> # for contrastive loss training model should be put into train mode
>>> model = model.train()
>>> loss = model(
... input_values, mask_time_indices=mask_time_indices, sampled_negative_indices=sampled_negative_indices
... ).lossTFWav2Vec2Model
class transformers.TFWav2Vec2Model
< source >( config: Wav2Vec2Config *inputs **kwargs )
Parameters
- config (Wav2Vec2Config) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare TFWav2Vec2 Model transformer outputing raw hidden-states without any specific head on top.
This model inherits from TFPreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a keras.Model subclass. Use it as a regular TF 2.0 Keras Model and refer to the TF 2.0 documentation for all matter related to general usage and behavior.
TensorFlow models and layers in transformers accept two formats as input:
- having all inputs as keyword arguments (like PyTorch models), or
- having all inputs as a list, tuple or dict in the first positional argument.
The reason the second format is supported is that Keras methods prefer this format when passing inputs to models
and layers. Because of this support, when using methods like model.fit() things should “just work” for you - just
pass your inputs and labels in any format that model.fit() supports! If, however, you want to use the second
format outside of Keras methods like fit() and predict(), such as when creating your own layers or models with
the Keras Functional API, there are three possibilities you can use to gather all the input Tensors in the first
positional argument:
- a single Tensor with
input_valuesonly and nothing else:model(input_values) - a list of varying length with one or several input Tensors IN THE ORDER given in the docstring:
model([input_values, attention_mask])ormodel([input_values, attention_mask, token_type_ids]) - a dictionary with one or several input Tensors associated to the input names given in the docstring:
model({"input_values": input_values, "token_type_ids": token_type_ids})
Note that when creating models and layers with subclassing then you don’t need to worry about any of this, as you can just pass inputs like you would to any other Python function!
call
< source >( input_values: tf.Tensor attention_mask: tf.Tensor | None = None token_type_ids: tf.Tensor | None = None position_ids: tf.Tensor | None = None head_mask: tf.Tensor | None = None inputs_embeds: tf.Tensor | None = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None training: bool = False ) → transformers.modeling_tf_outputs.TFBaseModelOutput or tuple(tf.Tensor)
Parameters
- input_values (
np.ndarray,tf.Tensor,List[tf.Tensor]Dict[str, tf.Tensor]orDict[str, np.ndarray]and each example must have the shape({0})) — Indices of input sequence tokens in the vocabulary.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.call() and PreTrainedTokenizer.encode() for details.
- attention_mask (
np.ndarrayortf.Tensorof shape({0}), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
np.ndarrayortf.Tensorof shape({0}), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
np.ndarrayortf.Tensorof shape({0}), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
np.ndarrayortf.Tensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- inputs_embeds (
np.ndarrayortf.Tensorof shape({0}, hidden_size), optional) — Optionally, instead of passinginput_valuesyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_valuesindices into associated vectors than the model’s internal embedding lookup matrix. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the config will be used instead. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the config will be used instead. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. This argument can be used in eager mode, in graph mode the value will always be set to True. - training (
bool, optional, defaults to `False“) — Whether or not to use the model in training mode (some modules like dropout modules have different behaviors between training and evaluation).
Returns
transformers.modeling_tf_outputs.TFBaseModelOutput or tuple(tf.Tensor)
A transformers.modeling_tf_outputs.TFBaseModelOutput or a tuple of tf.Tensor (if
return_dict=False is passed or when config.return_dict=False) comprising various elements depending on the
configuration (Wav2Vec2Config) and inputs.
-
last_hidden_state (
tf.Tensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. -
hidden_states (
tuple(tf.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftf.Tensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
-
attentions (
tuple(tf.Tensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftf.Tensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The TFWav2Vec2Model forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoProcessor, TFWav2Vec2Model
>>> from datasets import load_dataset
>>> import soundfile as sf
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
>>> model = TFWav2Vec2Model.from_pretrained("facebook/wav2vec2-base-960h")
>>> def map_to_array(batch):
... speech, _ = sf.read(batch["file"])
... batch["speech"] = speech
... return batch
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> ds = ds.map(map_to_array)
>>> input_values = processor(ds["speech"][0], return_tensors="tf").input_values # Batch size 1
>>> hidden_states = model(input_values).last_hidden_stateTFWav2Vec2ForSequenceClassification
call
< source >( input_values: tf.Tensor attention_mask: tf.Tensor | None = None output_attentions: bool | None = None output_hidden_states: bool | None = None return_dict: bool | None = None labels: tf.Tensor | None = None training: bool = False )
TFWav2Vec2ForCTC
class transformers.TFWav2Vec2ForCTC
< source >( config: Wav2Vec2Config *inputs **kwargs )
Parameters
- config (Wav2Vec2Config) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
TFWav2Vec2 Model with a language modeling head on top for Connectionist Temporal Classification (CTC).
This model inherits from TFPreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a keras.Model subclass. Use it as a regular TF 2.0 Keras Model and refer to the TF 2.0 documentation for all matter related to general usage and behavior.
TensorFlow models and layers in transformers accept two formats as input:
- having all inputs as keyword arguments (like PyTorch models), or
- having all inputs as a list, tuple or dict in the first positional argument.
The reason the second format is supported is that Keras methods prefer this format when passing inputs to models
and layers. Because of this support, when using methods like model.fit() things should “just work” for you - just
pass your inputs and labels in any format that model.fit() supports! If, however, you want to use the second
format outside of Keras methods like fit() and predict(), such as when creating your own layers or models with
the Keras Functional API, there are three possibilities you can use to gather all the input Tensors in the first
positional argument:
- a single Tensor with
input_valuesonly and nothing else:model(input_values) - a list of varying length with one or several input Tensors IN THE ORDER given in the docstring:
model([input_values, attention_mask])ormodel([input_values, attention_mask, token_type_ids]) - a dictionary with one or several input Tensors associated to the input names given in the docstring:
model({"input_values": input_values, "token_type_ids": token_type_ids})
Note that when creating models and layers with subclassing then you don’t need to worry about any of this, as you can just pass inputs like you would to any other Python function!
call
< source >( input_values: tf.Tensor attention_mask: tf.Tensor | None = None token_type_ids: tf.Tensor | None = None position_ids: tf.Tensor | None = None head_mask: tf.Tensor | None = None inputs_embeds: tf.Tensor | None = None output_attentions: Optional[bool] = None labels: tf.Tensor | None = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None training: Optional[bool] = False ) → transformers.modeling_tf_outputs.TFCausalLMOutput or tuple(tf.Tensor)
Parameters
- input_values (
np.ndarray,tf.Tensor,List[tf.Tensor]Dict[str, tf.Tensor]orDict[str, np.ndarray]and each example must have the shape({0})) — Indices of input sequence tokens in the vocabulary.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.call() and PreTrainedTokenizer.encode() for details.
- attention_mask (
np.ndarrayortf.Tensorof shape({0}), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
np.ndarrayortf.Tensorof shape({0}), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
np.ndarrayortf.Tensorof shape({0}), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
np.ndarrayortf.Tensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- inputs_embeds (
np.ndarrayortf.Tensorof shape({0}, hidden_size), optional) — Optionally, instead of passinginput_valuesyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_valuesindices into associated vectors than the model’s internal embedding lookup matrix. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the config will be used instead. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the config will be used instead. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. This argument can be used in eager mode, in graph mode the value will always be set to True. - training (
bool, optional, defaults to `False“) — Whether or not to use the model in training mode (some modules like dropout modules have different behaviors between training and evaluation). - labels (
tf.Tensorornp.ndarrayof shape(batch_size, sequence_length), optional) — Labels for computing the masked language modeling loss. Indices should be in[-100, 0, ..., config.vocab_size](seeinput_valuesdocstring) Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels in[0, ..., config.vocab_size]
Returns
transformers.modeling_tf_outputs.TFCausalLMOutput or tuple(tf.Tensor)
A transformers.modeling_tf_outputs.TFCausalLMOutput or a tuple of tf.Tensor (if
return_dict=False is passed or when config.return_dict=False) comprising various elements depending on the
configuration (Wav2Vec2Config) and inputs.
-
loss (
tf.Tensorof shape(n,), optional, where n is the number of non-masked labels, returned whenlabelsis provided) — Language modeling loss (for next-token prediction). -
logits (
tf.Tensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). -
hidden_states (
tuple(tf.Tensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftf.Tensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
-
attentions (
tuple(tf.Tensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftf.Tensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The TFWav2Vec2ForCTC forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> import tensorflow as tf
>>> from transformers import AutoProcessor, TFWav2Vec2ForCTC
>>> from datasets import load_dataset
>>> import soundfile as sf
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
>>> model = TFWav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-960h")
>>> def map_to_array(batch):
... speech, _ = sf.read(batch["file"])
... batch["speech"] = speech
... return batch
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> ds = ds.map(map_to_array)
>>> input_values = processor(ds["speech"][0], return_tensors="tf").input_values # Batch size 1
>>> logits = model(input_values).logits
>>> predicted_ids = tf.argmax(logits, axis=-1)
>>> transcription = processor.decode(predicted_ids[0])
>>> # compute loss
>>> target_transcription = "A MAN SAID TO THE UNIVERSE SIR I EXIST"
>>> # Pass transcription as `text` to encode labels
>>> labels = processor(text=transcription, return_tensors="tf").input_ids
>>> loss = model(input_values, labels=labels).lossFlaxWav2Vec2Model
class transformers.FlaxWav2Vec2Model
< source >( config: Wav2Vec2Config input_shape: Tuple = (1, 1024) seed: int = 0 dtype: dtype = <class 'jax.numpy.float32'> _do_init: bool = True **kwargs )
Parameters
- config (Wav2Vec2Config) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
- dtype (
jax.numpy.dtype, optional, defaults tojax.numpy.float32) — The data type of the computation. Can be one ofjax.numpy.float32,jax.numpy.float16(on GPUs) andjax.numpy.bfloat16(on TPUs).This can be used to enable mixed-precision training or half-precision inference on GPUs or TPUs. If specified all the computation will be performed with the given
dtype.Note that this only specifies the dtype of the computation and does not influence the dtype of model parameters.
If you wish to change the dtype of the model parameters, see to_fp16() and to_bf16().
The bare Wav2Vec2 Model transformer outputting raw hidden-states without any specific head on top. Wav2Vec2 was proposed in wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
This model inherits from FlaxPreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a Flax Linen flax.nn.Module subclass. Use it as a regular Flax Module and refer to the Flax documentation for all matter related to general usage and behavior.
Finally, this model supports inherent JAX features such as:
__call__
< source >( input_values attention_mask = None mask_time_indices = None params: dict = None dropout_rng: PRNGKey = None train: bool = False output_attentions: Optional = None output_hidden_states: Optional = None freeze_feature_encoder: bool = False return_dict: Optional = None ) → transformers.models.wav2vec2.modeling_flax_wav2vec2.FlaxWav2Vec2BaseModelOutput or tuple(torch.FloatTensor)
Parameters
- input_values (
jnp.ndarrayof shape(batch_size, sequence_length)) — Float values of input raw speech waveform. Values can be obtained by loading a.flacor.wavaudio file into an array of typeList[float]or anumpy.ndarray, e.g. via the soundfile library (pip install soundfile). To prepare the array intoinput_values, the AutoProcessor should be used for padding and conversion into a tensor of typejnp.ndarray. See Wav2Vec2Processor.call() for details. - attention_mask (
jnp.ndarrayof shape(batch_size, sequence_length), optional) — Mask to avoid performing convolution and attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
What are attention masks? .. warning::
attention_maskshould only be passed if the corresponding processor hasconfig.return_attention_mask == True. For all models whose processor hasconfig.return_attention_mask == False, such as wav2vec2-base,attention_maskshould not be passed to avoid degraded performance when doing batched inference. For such modelsinput_valuesshould simply be padded with 0 and passed withoutattention_mask. Be aware that these models also yield slightly different results depending on whetherinput_valuesis padded or not. - mask_time_indices (
jnp.ndarrayof shape(batch_size, sequence_length), optional) — Indices to mask extracted features for contrastive loss. When in training mode, model learns to predict masked extracted features in config.proj_codevector_dim space. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.models.wav2vec2.modeling_flax_wav2vec2.FlaxWav2Vec2BaseModelOutput or tuple(torch.FloatTensor)
A transformers.models.wav2vec2.modeling_flax_wav2vec2.FlaxWav2Vec2BaseModelOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (<class 'transformers.models.wav2vec2.configuration_wav2vec2.Wav2Vec2Config'>) and inputs.
-
last_hidden_state (
jnp.ndarrayof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. -
extract_features (
jnp.ndarrayof shape(batch_size, sequence_length, last_conv_dim)) — Sequence of extracted feature vectors of the last convolutional layer of the model withlast_conv_dimbeing the dimension of the last convolutional layer. -
hidden_states (
tuple(jnp.ndarray), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple ofjnp.ndarray(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
-
attentions (
tuple(jnp.ndarray), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple ofjnp.ndarray(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The FlaxWav2Vec2PreTrainedModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoProcessor, FlaxWav2Vec2Model
>>> from datasets import load_dataset
>>> import soundfile as sf
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-large-lv60")
>>> model = FlaxWav2Vec2Model.from_pretrained("facebook/wav2vec2-large-lv60")
>>> def map_to_array(batch):
... speech, _ = sf.read(batch["file"])
... batch["speech"] = speech
... return batch
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> ds = ds.map(map_to_array)
>>> input_values = processor(
... ds["speech"][0], sampling_rate=16_000, return_tensors="np"
... ).input_values # Batch size 1
>>> hidden_states = model(input_values).last_hidden_stateFlaxWav2Vec2ForCTC
class transformers.FlaxWav2Vec2ForCTC
< source >( config: Wav2Vec2Config input_shape: Tuple = (1, 1024) seed: int = 0 dtype: dtype = <class 'jax.numpy.float32'> _do_init: bool = True **kwargs )
Parameters
- config (Wav2Vec2Config) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
- dtype (
jax.numpy.dtype, optional, defaults tojax.numpy.float32) — The data type of the computation. Can be one ofjax.numpy.float32,jax.numpy.float16(on GPUs) andjax.numpy.bfloat16(on TPUs).This can be used to enable mixed-precision training or half-precision inference on GPUs or TPUs. If specified all the computation will be performed with the given
dtype.Note that this only specifies the dtype of the computation and does not influence the dtype of model parameters.
If you wish to change the dtype of the model parameters, see to_fp16() and to_bf16().
Wav2Vec2 Model with a language modeling head on top for Connectionist Temporal Classification (CTC).
Wav2Vec2 was proposed in wav2vec 2.0: A Framework for Self-Supervised Learning of Speech
Representations by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael
Auli.
This model inherits from FlaxPreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a Flax Linen flax.nn.Module subclass. Use it as a regular Flax Module and refer to the Flax documentation for all matter related to general usage and behavior.
Finally, this model supports inherent JAX features such as:
__call__
< source >( input_values attention_mask = None mask_time_indices = None params: dict = None dropout_rng: PRNGKey = None train: bool = False output_attentions: Optional = None output_hidden_states: Optional = None freeze_feature_encoder: bool = False return_dict: Optional = None ) → transformers.modeling_flax_outputs.FlaxMaskedLMOutput or tuple(torch.FloatTensor)
Parameters
- input_values (
jnp.ndarrayof shape(batch_size, sequence_length)) — Float values of input raw speech waveform. Values can be obtained by loading a.flacor.wavaudio file into an array of typeList[float]or anumpy.ndarray, e.g. via the soundfile library (pip install soundfile). To prepare the array intoinput_values, the AutoProcessor should be used for padding and conversion into a tensor of typejnp.ndarray. See Wav2Vec2Processor.call() for details. - attention_mask (
jnp.ndarrayof shape(batch_size, sequence_length), optional) — Mask to avoid performing convolution and attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
What are attention masks? .. warning::
attention_maskshould only be passed if the corresponding processor hasconfig.return_attention_mask == True. For all models whose processor hasconfig.return_attention_mask == False, such as wav2vec2-base,attention_maskshould not be passed to avoid degraded performance when doing batched inference. For such modelsinput_valuesshould simply be padded with 0 and passed withoutattention_mask. Be aware that these models also yield slightly different results depending on whetherinput_valuesis padded or not. - mask_time_indices (
jnp.ndarrayof shape(batch_size, sequence_length), optional) — Indices to mask extracted features for contrastive loss. When in training mode, model learns to predict masked extracted features in config.proj_codevector_dim space. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.modeling_flax_outputs.FlaxMaskedLMOutput or tuple(torch.FloatTensor)
A transformers.modeling_flax_outputs.FlaxMaskedLMOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (<class 'transformers.models.wav2vec2.configuration_wav2vec2.Wav2Vec2Config'>) and inputs.
-
logits (
jnp.ndarrayof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). -
hidden_states (
tuple(jnp.ndarray), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple ofjnp.ndarray(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
-
attentions (
tuple(jnp.ndarray), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple ofjnp.ndarray(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The FlaxWav2Vec2PreTrainedModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> import jax.numpy as jnp
>>> from transformers import AutoProcessor, FlaxWav2Vec2ForCTC
>>> from datasets import load_dataset
>>> import soundfile as sf
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-large-960h-lv60")
>>> model = FlaxWav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-large-960h-lv60")
>>> def map_to_array(batch):
... speech, _ = sf.read(batch["file"])
... batch["speech"] = speech
... return batch
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> ds = ds.map(map_to_array)
>>> input_values = processor(
... ds["speech"][0], sampling_rate=16_000, return_tensors="np"
... ).input_values # Batch size 1
>>> logits = model(input_values).logits
>>> predicted_ids = jnp.argmax(logits, axis=-1)
>>> transcription = processor.decode(predicted_ids[0])
>>> # should give: "A MAN SAID TO THE UNIVERSE SIR I EXIST"FlaxWav2Vec2ForPreTraining
class transformers.FlaxWav2Vec2ForPreTraining
< source >( config: Wav2Vec2Config input_shape: Tuple = (1, 1024) seed: int = 0 dtype: dtype = <class 'jax.numpy.float32'> _do_init: bool = True **kwargs )
Parameters
- config (Wav2Vec2Config) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
- dtype (
jax.numpy.dtype, optional, defaults tojax.numpy.float32) — The data type of the computation. Can be one ofjax.numpy.float32,jax.numpy.float16(on GPUs) andjax.numpy.bfloat16(on TPUs).This can be used to enable mixed-precision training or half-precision inference on GPUs or TPUs. If specified all the computation will be performed with the given
dtype.Note that this only specifies the dtype of the computation and does not influence the dtype of model parameters.
If you wish to change the dtype of the model parameters, see to_fp16() and to_bf16().
Wav2Vec2 Model with a quantizer and VQ head on top.
Wav2Vec2 was proposed in wav2vec 2.0: A Framework for Self-Supervised Learning of Speech
Representations by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael
Auli.
This model inherits from FlaxPreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a Flax Linen flax.nn.Module subclass. Use it as a regular Flax Module and refer to the Flax documentation for all matter related to general usage and behavior.
Finally, this model supports inherent JAX features such as:
__call__
< source >( input_values attention_mask = None mask_time_indices = None gumbel_temperature: int = 1 params: dict = None dropout_rng: PRNGKey = None gumbel_rng: PRNGKey = None train: bool = False output_attentions: Optional = None output_hidden_states: Optional = None freeze_feature_encoder: bool = False return_dict: Optional = None ) → transformers.models.wav2vec2.modeling_flax_wav2vec2.FlaxWav2Vec2ForPreTrainingOutput or tuple(torch.FloatTensor)
Parameters
- input_values (
jnp.ndarrayof shape(batch_size, sequence_length)) — Float values of input raw speech waveform. Values can be obtained by loading a.flacor.wavaudio file into an array of typeList[float]or anumpy.ndarray, e.g. via the soundfile library (pip install soundfile). To prepare the array intoinput_values, the AutoProcessor should be used for padding and conversion into a tensor of typejnp.ndarray. See Wav2Vec2Processor.call() for details. - attention_mask (
jnp.ndarrayof shape(batch_size, sequence_length), optional) — Mask to avoid performing convolution and attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
What are attention masks? .. warning::
attention_maskshould only be passed if the corresponding processor hasconfig.return_attention_mask == True. For all models whose processor hasconfig.return_attention_mask == False, such as wav2vec2-base,attention_maskshould not be passed to avoid degraded performance when doing batched inference. For such modelsinput_valuesshould simply be padded with 0 and passed withoutattention_mask. Be aware that these models also yield slightly different results depending on whetherinput_valuesis padded or not. - mask_time_indices (
jnp.ndarrayof shape(batch_size, sequence_length), optional) — Indices to mask extracted features for contrastive loss. When in training mode, model learns to predict masked extracted features in config.proj_codevector_dim space. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.models.wav2vec2.modeling_flax_wav2vec2.FlaxWav2Vec2ForPreTrainingOutput or tuple(torch.FloatTensor)
A transformers.models.wav2vec2.modeling_flax_wav2vec2.FlaxWav2Vec2ForPreTrainingOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (<class 'transformers.models.wav2vec2.configuration_wav2vec2.Wav2Vec2Config'>) and inputs.
-
loss (optional, returned when model is in train mode,
jnp.ndarrayof shape(1,)) — Total loss as the sum of the contrastive loss (L_m) and the diversity loss (L_d) as stated in the official paper . (classification) loss. -
projected_states (
jnp.ndarrayof shape(batch_size, sequence_length, config.proj_codevector_dim)) — Hidden-states of the model projected to config.proj_codevector_dim that can be used to predict the masked projected quantized states. -
projected_quantized_states (
jnp.ndarrayof shape(batch_size, sequence_length, config.proj_codevector_dim)) — Quantized extracted feature vectors projected to config.proj_codevector_dim representing the positive target vectors for contrastive loss. -
hidden_states (
tuple(jnp.ndarray), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple ofjnp.ndarray(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
-
attentions (
tuple(jnp.ndarray), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple ofjnp.ndarray(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The FlaxWav2Vec2ForPreTraining forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> import optax
>>> import numpy as np
>>> import jax.numpy as jnp
>>> from transformers import AutoFeatureExtractor, FlaxWav2Vec2ForPreTraining
>>> from transformers.models.wav2vec2.modeling_flax_wav2vec2 import _compute_mask_indices
>>> from datasets import load_dataset
>>> import soundfile as sf
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-large-lv60")
>>> model = FlaxWav2Vec2ForPreTraining.from_pretrained("facebook/wav2vec2-large-lv60")
>>> def map_to_array(batch):
... speech, _ = sf.read(batch["file"])
... batch["speech"] = speech
... return batch
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> ds = ds.map(map_to_array)
>>> input_values = feature_extractor(ds["speech"][0], return_tensors="np").input_values # Batch size 1
>>> # compute masked indices
>>> batch_size, raw_sequence_length = input_values.shape
>>> sequence_length = model._get_feat_extract_output_lengths(raw_sequence_length)
>>> mask_time_indices = _compute_mask_indices((batch_size, sequence_length), mask_prob=0.2, mask_length=2)
>>> outputs = model(input_values, mask_time_indices=mask_time_indices)
>>> # compute cosine similarity between predicted (=projected_states) and target (=projected_quantized_states)
>>> cosine_sim = optax.cosine_similarity(outputs.projected_states, outputs.projected_quantized_states)
>>> # show that cosine similarity is much higher than random
>>> assert np.asarray(cosine_sim)[mask_time_indices].mean() > 0.5