Transformers documentation
NLLB
NLLB
Updated tokenizer behavior
DISCLAIMER: The default behaviour for the tokenizer was fixed and thus changed in April 2023.
The previous version adds [self.eos_token_id, self.cur_lang_code] at the end of the token sequence for both target and source tokenization. This is wrong as the NLLB paper mentions (page 48, 6.1.1. Model Architecture) :
Note that we prefix the source sequence with the source language, as opposed to the target language as previously done in several works (Arivazhagan et al., 2019; Johnson et al., 2017). This is primarily because we prioritize optimizing zero-shot performance of our model on any pair of 200 languages at a minor cost to supervised performance.
Previous behaviour:
>>> from transformers import NllbTokenizer
>>> tokenizer = NllbTokenizer.from_pretrained("facebook/nllb-200-distilled-600M")
>>> tokenizer("How was your day?").input_ids
[13374, 1398, 4260, 4039, 248130, 2, 256047]
>>> # 2: '</s>'
>>> # 256047 : 'eng_Latn'New behaviour
>>> from transformers import NllbTokenizer
>>> tokenizer = NllbTokenizer.from_pretrained("facebook/nllb-200-distilled-600M")
>>> tokenizer("How was your day?").input_ids
[256047, 13374, 1398, 4260, 4039, 248130, 2]Enabling the old behaviour can be done as follows:
>>> from transformers import NllbTokenizer
>>> tokenizer = NllbTokenizer.from_pretrained("facebook/nllb-200-distilled-600M", legacy_behaviour=True)For more details, feel free to check the linked PR and Issue.
Overview
The NLLB model was presented in No Language Left Behind: Scaling Human-Centered Machine Translation by Marta R. Costa-jussà, James Cross, Onur Çelebi, Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula, Loic Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, John Hoffman, Semarley Jarrett, Kaushik Ram Sadagopan, Dirk Rowe, Shannon Spruit, Chau Tran, Pierre Andrews, Necip Fazil Ayan, Shruti Bhosale, Sergey Edunov, Angela Fan, Cynthia Gao, Vedanuj Goswami, Francisco Guzmán, Philipp Koehn, Alexandre Mourachko, Christophe Ropers, Safiyyah Saleem, Holger Schwenk, and Jeff Wang.
The abstract of the paper is the following:
Driven by the goal of eradicating language barriers on a global scale, machine translation has solidified itself as a key focus of artificial intelligence research today. However, such efforts have coalesced around a small subset of languages, leaving behind the vast majority of mostly low-resource languages. What does it take to break the 200 language barrier while ensuring safe, high quality results, all while keeping ethical considerations in mind? In No Language Left Behind, we took on this challenge by first contextualizing the need for low-resource language translation support through exploratory interviews with native speakers. Then, we created datasets and models aimed at narrowing the performance gap between low and high-resource languages. More specifically, we developed a conditional compute model based on Sparsely Gated Mixture of Experts that is trained on data obtained with novel and effective data mining techniques tailored for low-resource languages. We propose multiple architectural and training improvements to counteract overfitting while training on thousands of tasks. Critically, we evaluated the performance of over 40,000 different translation directions using a human-translated benchmark, Flores-200, and combined human evaluation with a novel toxicity benchmark covering all languages in Flores-200 to assess translation safety. Our model achieves an improvement of 44% BLEU relative to the previous state-of-the-art, laying important groundwork towards realizing a universal translation system.
This implementation contains the dense models available on release.
The sparse model NLLB-MoE (Mixture of Expert) is now available! More details here
This model was contributed by Lysandre. The authors’ code can be found here.
Generating with NLLB
While generating the target text set the forced_bos_token_id to the target language id. The following
example shows how to translate English to French using the facebook/nllb-200-distilled-600M model.
Note that we’re using the BCP-47 code for French fra_Latn. See here
for the list of all BCP-47 in the Flores 200 dataset.
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/nllb-200-distilled-600M")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-200-distilled-600M")
>>> article = "UN Chief says there is no military solution in Syria"
>>> inputs = tokenizer(article, return_tensors="pt")
>>> translated_tokens = model.generate(
... **inputs, forced_bos_token_id=tokenizer.lang_code_to_id["fra_Latn"], max_length=30
... )
>>> tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
Le chef de l'ONU dit qu'il n'y a pas de solution militaire en SyrieGenerating from any other language than English
English (eng_Latn) is set as the default language from which to translate. In order to specify that you’d like to translate from a different language,
you should specify the BCP-47 code in the src_lang keyword argument of the tokenizer initialization.
See example below for a translation from romanian to german:
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained(
... "facebook/nllb-200-distilled-600M", token=True, src_lang="ron_Latn"
... )
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-200-distilled-600M", token=True)
>>> article = "Şeful ONU spune că nu există o soluţie militară în Siria"
>>> inputs = tokenizer(article, return_tensors="pt")
>>> translated_tokens = model.generate(
... **inputs, forced_bos_token_id=tokenizer.lang_code_to_id["deu_Latn"], max_length=30
... )
>>> tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
UN-Chef sagt, es gibt keine militärische Lösung in SyrienResources
NllbTokenizer
class transformers.NllbTokenizer
< source >( vocab_file bos_token = '<s>' eos_token = '</s>' sep_token = '</s>' cls_token = '<s>' unk_token = '<unk>' pad_token = '<pad>' mask_token = '<mask>' tokenizer_file = None src_lang = None tgt_lang = None sp_model_kwargs: Optional = None additional_special_tokens = None legacy_behaviour = False **kwargs )
Parameters
- vocab_file (
str) — Path to the vocabulary file. - bos_token (
str, optional, defaults to"<s>") — The beginning of sequence token that was used during pretraining. Can be used a sequence classifier token.When building a sequence using special tokens, this is not the token that is used for the beginning of sequence. The token used is the
cls_token. - eos_token (
str, optional, defaults to"</s>") — The end of sequence token.When building a sequence using special tokens, this is not the token that is used for the end of sequence. The token used is the
sep_token. - sep_token (
str, optional, defaults to"</s>") — The separator token, which is used when building a sequence from multiple sequences, e.g. two sequences for sequence classification or for a text and a question for question answering. It is also used as the last token of a sequence built with special tokens. - cls_token (
str, optional, defaults to"<s>") — The classifier token which is used when doing sequence classification (classification of the whole sequence instead of per-token classification). It is the first token of the sequence when built with special tokens. - unk_token (
str, optional, defaults to"<unk>") — The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this token instead. - pad_token (
str, optional, defaults to"<pad>") — The token used for padding, for example when batching sequences of different lengths. - mask_token (
str, optional, defaults to"<mask>") — The token used for masking values. This is the token used when training this model with masked language modeling. This is the token which the model will try to predict. - tokenizer_file (
str, optional) — The path to a tokenizer file to use instead of the vocab file. - src_lang (
str, optional) — The language to use as source language for translation. - tgt_lang (
str, optional) — The language to use as target language for translation. - sp_model_kwargs (
Dict[str, str]) — Additional keyword arguments to pass to the model initialization.
Construct an NLLB tokenizer.
Adapted from RobertaTokenizer and XLNetTokenizer. Based on SentencePiece.
The tokenization method is <tokens> <eos> <language code> for source language documents, and `<language code>
Examples:
>>> from transformers import NllbTokenizer
>>> tokenizer = NllbTokenizer.from_pretrained(
... "facebook/nllb-200-distilled-600M", src_lang="eng_Latn", tgt_lang="fra_Latn"
... )
>>> example_english_phrase = " UN Chief Says There Is No Military Solution in Syria"
>>> expected_translation_french = "Le chef de l'ONU affirme qu'il n'y a pas de solution militaire en Syrie."
>>> inputs = tokenizer(example_english_phrase, text_target=expected_translation_french, return_tensors="pt")build_inputs_with_special_tokens
< source >( token_ids_0: List token_ids_1: Optional = None ) → List[int]
Parameters
- token_ids_0 (
List[int]) — List of IDs to which the special tokens will be added. - token_ids_1 (
List[int], optional) — Optional second list of IDs for sequence pairs.
Returns
List[int]
List of input IDs with the appropriate special tokens.
Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and
adding special tokens. An NLLB sequence has the following format, where X represents the sequence:
input_ids(for encoder)X [eos, src_lang_code]decoder_input_ids: (for decoder)X [eos, tgt_lang_code]
BOS is never used. Pairs of sequences are not the expected use case, but they will be handled without a separator.
NllbTokenizerFast
class transformers.NllbTokenizerFast
< source >( vocab_file = None tokenizer_file = None bos_token = '<s>' eos_token = '</s>' sep_token = '</s>' cls_token = '<s>' unk_token = '<unk>' pad_token = '<pad>' mask_token = '<mask>' src_lang = None tgt_lang = None additional_special_tokens = None legacy_behaviour = False **kwargs )
Parameters
- vocab_file (
str) — Path to the vocabulary file. - bos_token (
str, optional, defaults to"<s>") — The beginning of sequence token that was used during pretraining. Can be used a sequence classifier token.When building a sequence using special tokens, this is not the token that is used for the beginning of sequence. The token used is the
cls_token. - eos_token (
str, optional, defaults to"</s>") — The end of sequence token.When building a sequence using special tokens, this is not the token that is used for the end of sequence. The token used is the
sep_token. - sep_token (
str, optional, defaults to"</s>") — The separator token, which is used when building a sequence from multiple sequences, e.g. two sequences for sequence classification or for a text and a question for question answering. It is also used as the last token of a sequence built with special tokens. - cls_token (
str, optional, defaults to"<s>") — The classifier token which is used when doing sequence classification (classification of the whole sequence instead of per-token classification). It is the first token of the sequence when built with special tokens. - unk_token (
str, optional, defaults to"<unk>") — The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this token instead. - pad_token (
str, optional, defaults to"<pad>") — The token used for padding, for example when batching sequences of different lengths. - mask_token (
str, optional, defaults to"<mask>") — The token used for masking values. This is the token used when training this model with masked language modeling. This is the token which the model will try to predict. - tokenizer_file (
str, optional) — The path to a tokenizer file to use instead of the vocab file. - src_lang (
str, optional) — The language to use as source language for translation. - tgt_lang (
str, optional) — The language to use as target language for translation.
Construct a “fast” NLLB tokenizer (backed by HuggingFace’s tokenizers library). Based on BPE.
This tokenizer inherits from PreTrainedTokenizerFast which contains most of the main methods. Users should refer to this superclass for more information regarding those methods.
The tokenization method is <tokens> <eos> <language code> for source language documents, and `<language code>
Examples:
>>> from transformers import NllbTokenizerFast
>>> tokenizer = NllbTokenizerFast.from_pretrained(
... "facebook/nllb-200-distilled-600M", src_lang="eng_Latn", tgt_lang="fra_Latn"
... )
>>> example_english_phrase = " UN Chief Says There Is No Military Solution in Syria"
>>> expected_translation_french = "Le chef de l'ONU affirme qu'il n'y a pas de solution militaire en Syrie."
>>> inputs = tokenizer(example_english_phrase, text_target=expected_translation_french, return_tensors="pt")build_inputs_with_special_tokens
< source >( token_ids_0: List token_ids_1: Optional = None ) → List[int]
Parameters
- token_ids_0 (
List[int]) — List of IDs to which the special tokens will be added. - token_ids_1 (
List[int], optional) — Optional second list of IDs for sequence pairs.
Returns
List[int]
list of input IDs with the appropriate special tokens.
Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and adding special tokens. The special tokens depend on calling set_lang.
An NLLB sequence has the following format, where X represents the sequence:
input_ids(for encoder)X [eos, src_lang_code]decoder_input_ids: (for decoder)X [eos, tgt_lang_code]
BOS is never used. Pairs of sequences are not the expected use case, but they will be handled without a separator.
create_token_type_ids_from_sequences
< source >( token_ids_0: List token_ids_1: Optional = None ) → List[int]
Create a mask from the two sequences passed to be used in a sequence-pair classification task. nllb does not make use of token type ids, therefore a list of zeros is returned.
Reset the special tokens to the source lang setting.
- In legacy mode: No prefix and suffix=[eos, src_lang_code].
- In default mode: Prefix=[src_lang_code], suffix = [eos]
Reset the special tokens to the target lang setting.
- In legacy mode: No prefix and suffix=[eos, tgt_lang_code].
- In default mode: Prefix=[tgt_lang_code], suffix = [eos]
Using Flash Attention 2
Flash Attention 2 is a faster, optimized version of the attention scores computation which relies on cuda kernels.
Installation
First, check whether your hardware is compatible with Flash Attention 2. The latest list of compatible hardware can be found in the official documentation.
Next, install the latest version of Flash Attention 2:
pip install -U flash-attn --no-build-isolation
Usage
To load a model using Flash Attention 2, we can pass the argument attn_implementation="flash_attention_2" to .from_pretrained. You can use either torch.float16 or torch.bfloat16 precision.
>>> import torch
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-200-distilled-600M", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to("cuda").eval()
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/nllb-200-distilled-600M")
>>> article = "Şeful ONU spune că nu există o soluţie militară în Siria"
>>> inputs = tokenizer(article, return_tensors="pt").to("cuda")
>>> translated_tokens = model.generate(
... **inputs, forced_bos_token_id=tokenizer.lang_code_to_id["deu_Latn"], max_length=30
... )
>>> tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
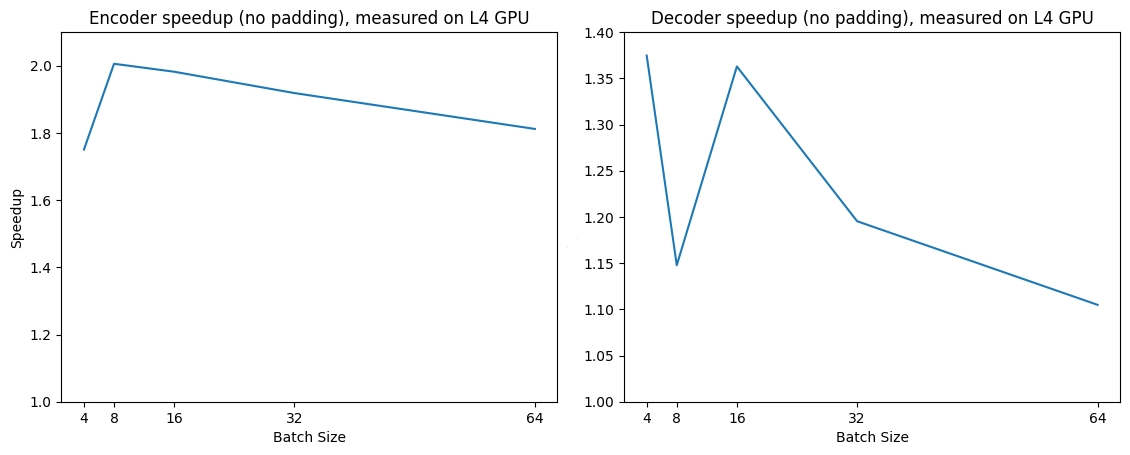
"UN-Chef sagt, es gibt keine militärische Lösung in Syrien"Expected speedups
Below is an expected speedup diagram that compares pure inference time between the native implementation and the Flash Attention 2.