Transformers documentation
Jamba
Jamba
Overview
Jamba is a state-of-the-art, hybrid SSM-Transformer LLM. It is the first production-scale Mamba implementation, which opens up interesting research and application opportunities. While this initial experimentation shows encouraging gains, we expect these to be further enhanced with future optimizations and explorations.
For full details of this model please read the release blog post.
Model Details
Jamba is a pretrained, mixture-of-experts (MoE) generative text model, with 12B active parameters and an overall of 52B parameters across all experts. It supports a 256K context length, and can fit up to 140K tokens on a single 80GB GPU.
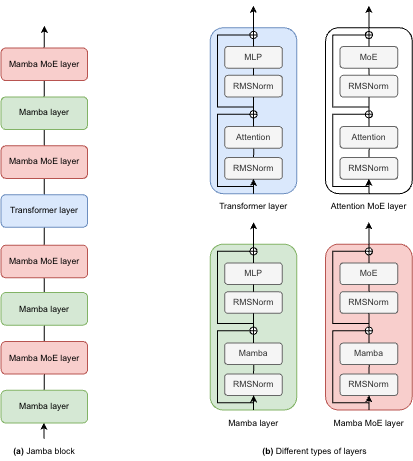
As depicted in the diagram below, Jamba’s architecture features a blocks-and-layers approach that allows Jamba to successfully integrate Transformer and Mamba architectures altogether. Each Jamba block contains either an attention or a Mamba layer, followed by a multi-layer perceptron (MLP), producing an overall ratio of one Transformer layer out of every eight total layers.
Usage
Presequities
Jamba requires you use transformers version 4.39.0 or higher:
pip install transformers>=4.39.0
In order to run optimized Mamba implementations, you first need to install mamba-ssm and causal-conv1d:
pip install mamba-ssm causal-conv1d>=1.2.0
You also have to have the model on a CUDA device.
You can run the model not using the optimized Mamba kernels, but it is not recommended as it will result in significantly lower latencies. In order to do that, you’ll need to specify use_mamba_kernels=False when loading the model.
Run the model
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("ai21labs/Jamba-v0.1")
tokenizer = AutoTokenizer.from_pretrained("ai21labs/Jamba-v0.1")
input_ids = tokenizer("In the recent Super Bowl LVIII,", return_tensors='pt').to(model.device)["input_ids"]
outputs = model.generate(input_ids, max_new_tokens=216)
print(tokenizer.batch_decode(outputs))
# ["<|startoftext|>In the recent Super Bowl LVIII, the Kansas City Chiefs emerged victorious, defeating the San Francisco 49ers in a thrilling overtime showdown. The game was a nail-biter, with both teams showcasing their skills and determination.\n\nThe Chiefs, led by their star quarterback Patrick Mahomes, displayed their offensive prowess, while the 49ers, led by their strong defense, put up a tough fight. The game went into overtime, with the Chiefs ultimately securing the win with a touchdown.\n\nThe victory marked the Chiefs' second Super Bowl win in four years, solidifying their status as one of the top teams in the NFL. The game was a testament to the skill and talent of both teams, and a thrilling end to the NFL season.\n\nThe Super Bowl is not just about the game itself, but also about the halftime show and the commercials. This year's halftime show featured a star-studded lineup, including Usher, Alicia Keys, and Lil Jon. The show was a spectacle of music and dance, with the performers delivering an energetic and entertaining performance.\n"]Loading the model in half precision
The published checkpoint is saved in BF16. In order to load it into RAM in BF16/FP16, you need to specify torch_dtype:
from transformers import AutoModelForCausalLM
import torch
model = AutoModelForCausalLM.from_pretrained("ai21labs/Jamba-v0.1", torch_dtype=torch.bfloat16)
# you can also use torch_dtype=torch.float16When using half precision, you can enable the FlashAttention2 implementation of the Attention blocks. In order to use it, you also need the model on a CUDA device. Since in this precision the model is to big to fit on a single 80GB GPU, you’ll also need to parallelize it using accelerate:
from transformers import AutoModelForCausalLM
import torch
model = AutoModelForCausalLM.from_pretrained("ai21labs/Jamba-v0.1",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
device_map="auto")Load the model in 8-bit
Using 8-bit precision, it is possible to fit up to 140K sequence lengths on a single 80GB GPU. You can easily quantize the model to 8-bit using bitsandbytes. In order to not degrade model quality, we recommend to exclude the Mamba blocks from the quantization:
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_8bit=True, llm_int8_skip_modules=["mamba"])
model = AutoModelForCausalLM.from_pretrained(
"ai21labs/Jamba-v0.1", torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2", quantization_config=quantization_config
)JambaConfig
class transformers.JambaConfig
< source >( vocab_size = 65536 tie_word_embeddings = False hidden_size = 4096 intermediate_size = 14336 num_hidden_layers = 32 num_attention_heads = 32 num_key_value_heads = 8 hidden_act = 'silu' initializer_range = 0.02 rms_norm_eps = 1e-06 use_cache = True num_logits_to_keep = 1 output_router_logits = False router_aux_loss_coef = 0.001 pad_token_id = 0 bos_token_id = 1 eos_token_id = 2 sliding_window = None max_position_embeddings = 262144 attention_dropout = 0.0 num_experts_per_tok = 2 num_experts = 16 expert_layer_period = 2 expert_layer_offset = 1 attn_layer_period = 8 attn_layer_offset = 4 use_mamba_kernels = True mamba_d_state = 16 mamba_d_conv = 4 mamba_expand = 2 mamba_dt_rank = 'auto' mamba_conv_bias = True mamba_proj_bias = False **kwargs )
Parameters
- vocab_size (
int, optional, defaults to 65536) — Vocabulary size of the Jamba model. Defines the number of different tokens that can be represented by theinputs_idspassed when calling JambaModel - tie_word_embeddings (
bool, optional, defaults toFalse) — Whether the model’s input and output word embeddings should be tied. Note that this is only relevant if the model has a output word embedding layer. - hidden_size (
int, optional, defaults to 4096) — Dimension of the hidden representations. - intermediate_size (
int, optional, defaults to 14336) — Dimension of the MLP representations. - num_hidden_layers (
int, optional, defaults to 32) — Number of hidden layers in the Transformer encoder. - num_attention_heads (
int, optional, defaults to 32) — Number of attention heads for each attention layer in the Transformer encoder. - num_key_value_heads (
int, optional, defaults to 8) — This is the number of key_value heads that should be used to implement Grouped Query Attention. Ifnum_key_value_heads=num_attention_heads, the model will use Multi Head Attention (MHA), ifnum_key_value_heads=1the model will use Multi Query Attention (MQA) otherwise GQA is used. When converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed by meanpooling all the original heads within that group. For more details checkout this paper. If it is not specified, will default to8. - hidden_act (
strorfunction, optional, defaults to"silu") — The non-linear activation function (function or string) in the decoder. - initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - rms_norm_eps (
float, optional, defaults to 1e-06) — The epsilon used by the rms normalization layers. - use_cache (
bool, optional, defaults toTrue) — Whether or not the model should return the last key/values attentions (not used by all models). Only relevant ifconfig.is_decoder=True. - num_logits_to_keep (
intorNone, optional, defaults to 1) — Number of prompt logits to calculate during generation. IfNone, all logits will be calculated. If an integer value, only lastnum_logits_to_keeplogits will be calculated. Default is 1 because only the logits of the last prompt token are needed for generation. For long sequences, the logits for the entire sequence may use a lot of memory so, settingnum_logits_to_keep=1will reduce memory footprint significantly. - output_router_logits (
bool, optional, defaults toFalse) — Whether or not the router logits should be returned by the model. Enabling this will also allow the model to output the auxiliary loss. See here for more details - router_aux_loss_coef (
float, optional, defaults to 0.001) — The aux loss factor for the total loss. - pad_token_id (
int, optional, defaults to 0) — The id of the padding token. - bos_token_id (
int, optional, defaults to 1) — The id of the “beginning-of-sequence” token. - eos_token_id (
int, optional, defaults to 2) — The id of the “end-of-sequence” token. - sliding_window (
int, optional) — Sliding window attention window size. If not specified, will default toNone. - max_position_embeddings (
int, optional, defaults to 262144) — This value doesn’t have any real effect. The maximum sequence length that this model is intended to be used with. It can be used with longer sequences, but performance may degrade. - attention_dropout (
float, optional, defaults to 0.0) — The dropout ratio for the attention probabilities. - num_experts_per_tok (
int, optional, defaults to 2) — The number of experts to root per-token, can be also interpreted as thetop-prouting parameter - num_experts (
int, optional, defaults to 16) — Number of experts per Sparse MLP layer. - expert_layer_period (
int, optional, defaults to 2) — Once in this many layers, we will have an expert layer - expert_layer_offset (
int, optional, defaults to 1) — The first layer index that contains an expert mlp layer - attn_layer_period (
int, optional, defaults to 8) — Once in this many layers, we will have a vanilla attention layer - attn_layer_offset (
int, optional, defaults to 4) — The first layer index that contains a vanilla attention mlp layer - use_mamba_kernels (
bool, optional, defaults toTrue) — Flag indicating whether or not to use the fast mamba kernels. These are available only ifmamba-ssmandcausal-conv1dare installed, and the mamba modules are running on a CUDA device. Raises ValueError ifTrueand kernels are not available - mamba_d_state (
int, optional, defaults to 16) — The dimension the mamba state space latents - mamba_d_conv (
int, optional, defaults to 4) — The size of the mamba convolution kernel - mamba_expand (
int, optional, defaults to 2) — Expanding factor (relative to hidden_size) used to determine the mamba intermediate size - mamba_dt_rank (
Union[int,str], optional, defaults to"auto") — Rank of the the mamba discretization projection matrix."auto"means that it will default tomath.ceil(self.hidden_size / 16) - mamba_conv_bias (
bool, optional, defaults toTrue) — Flag indicating whether or not to use bias in the convolution layer of the mamba mixer block. - mamba_proj_bias (
bool, optional, defaults toFalse) — Flag indicating whether or not to use bias in the input and output projections ([“in_proj”, “out_proj”]) of the mamba mixer block
This is the configuration class to store the configuration of a JambaModel. It is used to instantiate a Jamba model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the Jamba-v0.1 model.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
JambaModel
class transformers.JambaModel
< source >( config: JambaConfig )
Parameters
- config (JambaConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights. config — JambaConfig
The bare Jamba Model outputting raw hidden-states without any specific head on top. This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
Transformer decoder consisting of config.num_hidden_layers layers. Each layer is a JambaDecoderLayer
forward
< source >( input_ids: LongTensor = None attention_mask: Optional = None position_ids: Optional = None past_key_values: Optional = None inputs_embeds: Optional = None use_cache: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None output_router_logits: Optional = None return_dict: Optional = None cache_position: Optional = None )
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
If
past_key_valuesis used, optionally only the lastinput_idshave to be input (seepast_key_values).If you want to change padding behavior, you should read
modeling_opt._prepare_decoder_attention_maskand modify to your needs. See diagram 1 in the paper for more information on the default strategy.- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
HybridMambaAttentionDynamicCache, optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — A HybridMambaAttentionDynamicCache object containing pre-computed hidden-states (keys and values in the self-attention blocks and convolution and ssm states in the mamba blocks) that can be used (seepast_key_valuesinput) to speed up sequential decoding. Key and value cache tensors have shape(batch_size, num_heads, seq_len, head_dim). Convolution and ssm states tensors have shape(batch_size, d_inner, d_conv)and(batch_size, d_inner, d_state)respectively. See theHybridMambaAttentionDynamicCacheclass for more details.If
past_key_valuesare used, the user can optionally input only the lastinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of allinput_idsof shape(batch_size, sequence_length). - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - output_router_logits (
bool, optional) — Whether or not to return the logits of all the routers. They are useful for computing the router loss, and should not be returned during inference. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - cache_position (
torch.LongTensorof shape(sequence_length), optional) — Indices depicting the position of the input sequence tokens in the sequence. Contrarily toposition_ids, this tensor is not affected by padding. It is used to update the cache in the correct position and to infer the complete sequence length.
The JambaModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
JambaForCausalLM
forward
< source >( input_ids: LongTensor = None attention_mask: Optional = None position_ids: Optional = None past_key_values: Optional = None inputs_embeds: Optional = None labels: Optional = None use_cache: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None output_router_logits: Optional = None return_dict: Optional = None cache_position: Optional = None num_logits_to_keep: Optional = None ) → transformers.modeling_outputs.MoeCausalLMOutputWithPast or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
If
past_key_valuesis used, optionally only the lastinput_idshave to be input (seepast_key_values).If you want to change padding behavior, you should read
modeling_opt._prepare_decoder_attention_maskand modify to your needs. See diagram 1 in the paper for more information on the default strategy.- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
HybridMambaAttentionDynamicCache, optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — A HybridMambaAttentionDynamicCache object containing pre-computed hidden-states (keys and values in the self-attention blocks and convolution and ssm states in the mamba blocks) that can be used (seepast_key_valuesinput) to speed up sequential decoding. Key and value cache tensors have shape(batch_size, num_heads, seq_len, head_dim). Convolution and ssm states tensors have shape(batch_size, d_inner, d_conv)and(batch_size, d_inner, d_state)respectively. See theHybridMambaAttentionDynamicCacheclass for more details.If
past_key_valuesare used, the user can optionally input only the lastinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of allinput_idsof shape(batch_size, sequence_length). - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - output_router_logits (
bool, optional) — Whether or not to return the logits of all the routers. They are useful for computing the router loss, and should not be returned during inference. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - cache_position (
torch.LongTensorof shape(sequence_length), optional) — Indices depicting the position of the input sequence tokens in the sequence. Contrarily toposition_ids, this tensor is not affected by padding. It is used to update the cache in the correct position and to infer the complete sequence length.Args — labels (
torch.LongTensorof shape(batch_size, sequence_length), optional): Labels for computing the masked language modeling loss. Indices should either be in[0, ..., config.vocab_size]or -100 (seeinput_idsdocstring). Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels in[0, ..., config.vocab_size].num_logits_to_keep (
intorNone, optional): Calculate logits for the lastnum_logits_to_keeptokens. IfNone, calculate logits for allinput_ids. Only last token logits are needed for generation, and calculating them only for that token can save memory, which becomes pretty significant for long sequences.
Returns
transformers.modeling_outputs.MoeCausalLMOutputWithPast or tuple(torch.FloatTensor)
A transformers.modeling_outputs.MoeCausalLMOutputWithPast or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (JambaConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Language modeling loss (for next-token prediction). -
logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). -
aux_loss (
torch.FloatTensor, optional, returned whenlabelsis provided) — aux_loss for the sparse modules. -
router_logits (
tuple(torch.FloatTensor), optional, returned whenoutput_router_probs=Trueandconfig.add_router_probs=Trueis passed or whenconfig.output_router_probs=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, sequence_length, num_experts).Raw router logtis (post-softmax) that are computed by MoE routers, these terms are used to compute the auxiliary loss for Mixture of Experts models.
-
past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head))Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The JambaForCausalLM forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoTokenizer, JambaForCausalLM
>>> model = JambaForCausalLM.from_pretrained("ai21labs/Jamba-v0.1")
>>> tokenizer = AutoTokenizer.from_pretrained("ai21labs/Jamba-v0.1")
>>> prompt = "Hey, are you conscious? Can you talk to me?"
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> # Generate
>>> generate_ids = model.generate(inputs.input_ids, max_length=30)
>>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
"Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."JambaForSequenceClassification
class transformers.JambaForSequenceClassification
< source >( config )
Parameters
- config (JambaConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The Jamba Model with a sequence classification head on top (linear layer).
JambaForSequenceClassification uses the last token in order to do the classification, as other causal models (e.g. GPT-2) do.
Since it does classification on the last token, it requires to know the position of the last token. If a
pad_token_id is defined in the configuration, it finds the last token that is not a padding token in each row. If
no pad_token_id is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
padding tokens when inputs_embeds are passed instead of input_ids, it does the same (take the last value in
each row of the batch).
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: LongTensor = None attention_mask: Optional = None position_ids: Optional = None past_key_values: Union = None inputs_embeds: Optional = None labels: Optional = None use_cache: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None )
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
If
past_key_valuesis used, optionally only the lastinput_idshave to be input (seepast_key_values).If you want to change padding behavior, you should read
modeling_opt._prepare_decoder_attention_maskand modify to your needs. See diagram 1 in the paper for more information on the default strategy.- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
HybridMambaAttentionDynamicCache, optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — A HybridMambaAttentionDynamicCache object containing pre-computed hidden-states (keys and values in the self-attention blocks and convolution and ssm states in the mamba blocks) that can be used (seepast_key_valuesinput) to speed up sequential decoding. Key and value cache tensors have shape(batch_size, num_heads, seq_len, head_dim). Convolution and ssm states tensors have shape(batch_size, d_inner, d_conv)and(batch_size, d_inner, d_state)respectively. See theHybridMambaAttentionDynamicCacheclass for more details.If
past_key_valuesare used, the user can optionally input only the lastinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of allinput_idsof shape(batch_size, sequence_length). - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - output_router_logits (
bool, optional) — Whether or not to return the logits of all the routers. They are useful for computing the router loss, and should not be returned during inference. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - cache_position (
torch.LongTensorof shape(sequence_length), optional) — Indices depicting the position of the input sequence tokens in the sequence. Contrarily toposition_ids, this tensor is not affected by padding. It is used to update the cache in the correct position and to infer the complete sequence length. - labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the sequence classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy).
The JambaForSequenceClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.