Transformers documentation
Quantize 🤗 Transformers models
Quantize 🤗 Transformers models
AWQ integration
AWQ method has been introduced in the AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration paper. With AWQ you can run models in 4-bit precision, while preserving its original quality (i.e. no performance degradation) with a superior throughput that other quantization methods presented below - reaching similar throughput as pure float16 inference.
We now support inference with any AWQ model, meaning anyone can load and use AWQ weights that are pushed on the Hub or saved locally. Note that using AWQ requires to have access to a NVIDIA GPU. CPU inference is not supported yet.
Quantizing a model
We advise users to look at different existing tools in the ecosystem to quantize their models with AWQ algorithm, such as:
llm-awqfrom MIT Han Labautoawqfromcasper-hansen- Intel neural compressor from Intel - through
optimum-intel
Many other tools might exist in the ecosystem, please feel free to open a PR to add them to the list.
Currently the integration with 🤗 Transformers is only available for models that have been quantized using autoawq library and llm-awq. Most of the models quantized with auto-awq can be found under TheBloke namespace of 🤗 Hub, and to quantize models with llm-awq please refer to the convert_to_hf.py script in the examples folder of llm-awq.
Load a quantized model
You can load a quantized model from the Hub using the from_pretrained method. Make sure that the pushed weights are quantized, by checking that the attribute quantization_config is present in the model’s configuration file (configuration.json). You can confirm that the model is quantized in the AWQ format by checking the field quantization_config.quant_method which should be set to "awq". Note that loading the model will set other weights in float16 by default for performance reasons. If you want to change that behavior, you can pass torch_dtype argument to torch.float32 or torch.bfloat16. You can find in the sections below some example snippets and notebook.
Example usage
First, you need to install autoawq library
pip install autoawq
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "TheBloke/zephyr-7B-alpha-AWQ"
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="cuda:0")In case you first load your model on CPU, make sure to move it to your GPU device before using
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "TheBloke/zephyr-7B-alpha-AWQ"
model = AutoModelForCausalLM.from_pretrained(model_id).to("cuda:0")Combining AWQ and Flash Attention
You can combine AWQ quantization with Flash Attention to get a model that is both quantized and faster. Simply load the model using from_pretrained and pass use_flash_attention_2=True argument.
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("TheBloke/zephyr-7B-alpha-AWQ", use_flash_attention_2=True, device_map="cuda:0")Benchmarks
We performed some speed, throughput and latency benchmarks using optimum-benchmark library.
Note at that time of writing this documentation section, the available quantization methods were: awq, gptq and bitsandbytes.
The benchmark was run on a NVIDIA-A100 instance and the model used was TheBloke/Mistral-7B-v0.1-AWQ for the AWQ model, TheBloke/Mistral-7B-v0.1-GPTQ for the GPTQ model. We also benchmarked it against bitsandbytes quantization methods and native float16 model. Some results are shown below:
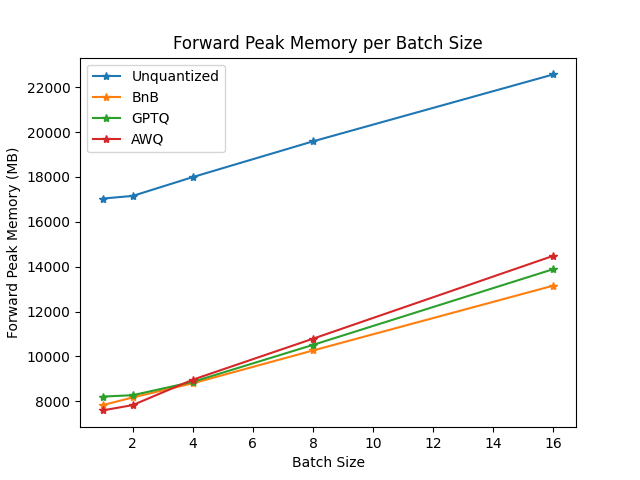
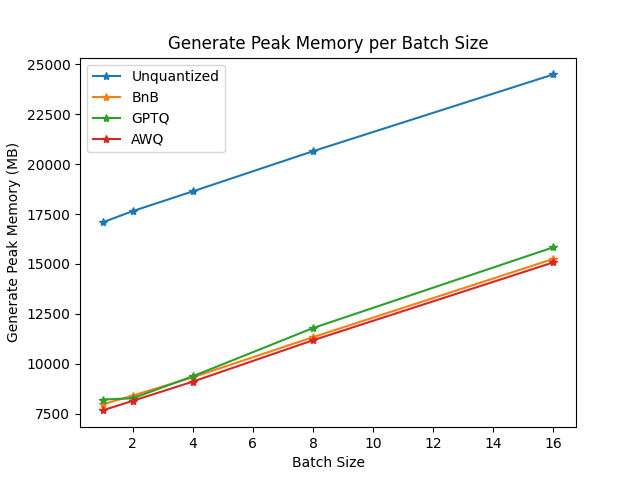
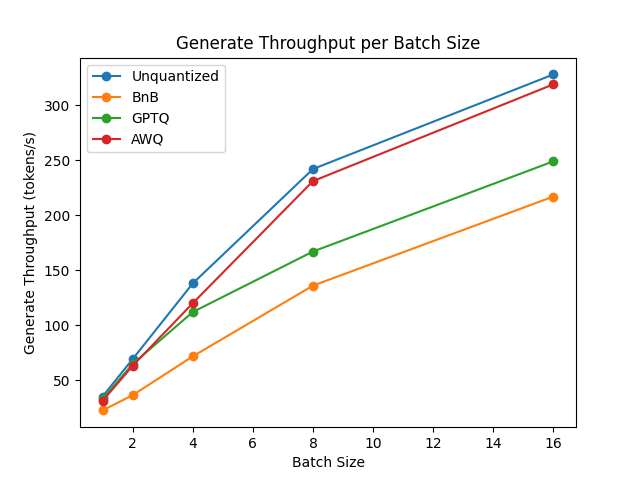
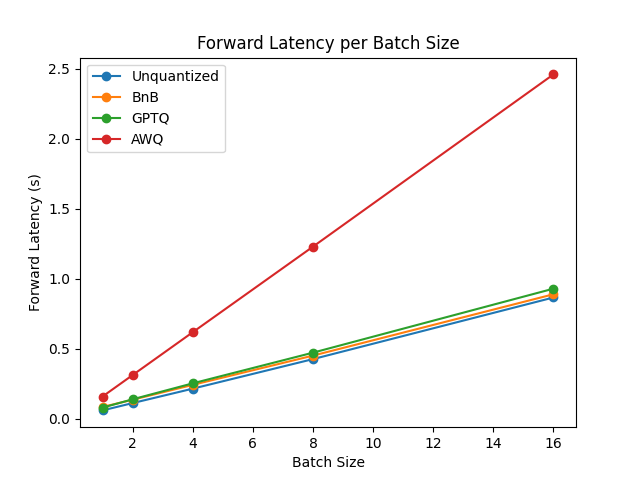
You can find the full results together with packages versions in this link.
From the results it appears that AWQ quantization method is the fastest quantization method for inference, text generation and among the lowest peak memory for text generation. However, AWQ seems to have the largest forward latency per batch size.
Google colab demo
Check out how to use this integration throughout this Google Colab demo!
AwqConfig
class transformers.AwqConfig
< source >( bits: int = 4 group_size: int = 128 zero_point: bool = True version: AWQLinearVersion = <AWQLinearVersion.GEMM: 'gemm'> backend: AwqBackendPackingMethod = <AwqBackendPackingMethod.AUTOAWQ: 'autoawq'> **kwargs )
Parameters
- bits (
int, optional, defaults to 4) — The number of bits to quantize to. - group_size (
int, optional, defaults to 128) — The group size to use for quantization. Recommended value is 128 and -1 uses per-column quantization. - zero_point (
bool, optional, defaults toTrue) — Whether to use zero point quantization. - version (
AWQLinearVersion, optional, defaults toAWQLinearVersion.GEMM) — The version of the quantization algorithm to use. GEMM is better for big batch_size (e.g. >= 8) otherwise, GEMV is better (e.g. < 8 ) - backend (
AwqBackendPackingMethod, optional, defaults toAwqBackendPackingMethod.AUTOAWQ) — The quantization backend. Some models might be quantized usingllm-awqbackend. This is useful for users that quantize their own models usingllm-awqlibrary.
This is a wrapper class about all possible attributes and features that you can play with a model that has been
loaded using auto-awq library awq quantization relying on auto_awq backend.
Safety checker that arguments are correct
AutoGPTQ Integration
🤗 Transformers has integrated optimum API to perform GPTQ quantization on language models. You can load and quantize your model in 8, 4, 3 or even 2 bits without a big drop of performance and faster inference speed! This is supported by most GPU hardwares.
To learn more about the quantization model, check out:
Requirements
You need to have the following requirements installed to run the code below:
Install latest
AutoGPTQlibrarypip install auto-gptqInstall latest
optimumfrom sourcepip install git+https://github.com/huggingface/optimum.gitInstall latest
transformersfrom sourcepip install git+https://github.com/huggingface/transformers.gitInstall latest
acceleratelibrarypip install --upgrade accelerate
Note that GPTQ integration supports for now only text models and you may encounter unexpected behaviour for vision, speech or multi-modal models.
Load and quantize a model
GPTQ is a quantization method that requires weights calibration before using the quantized models. If you want to quantize transformers model from scratch, it might take some time before producing the quantized model (~5 min on a Google colab for facebook/opt-350m model).
Hence, there are two different scenarios where you want to use GPTQ-quantized models. The first use case would be to load models that has been already quantized by other users that are available on the Hub, the second use case would be to quantize your model from scratch and save it or push it on the Hub so that other users can also use it.
GPTQ Configuration
In order to load and quantize a model, you need to create a GPTQConfig. You need to pass the number of bits, a dataset in order to calibrate the quantization and the tokenizer of the model in order prepare the dataset.
model_id = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(model_id)
gptq_config = GPTQConfig(bits=4, dataset = "c4", tokenizer=tokenizer)Note that you can pass your own dataset as a list of string. However, it is highly recommended to use the dataset from the GPTQ paper.
dataset = ["auto-gptq is an easy-to-use model quantization library with user-friendly apis, based on GPTQ algorithm."]
quantization = GPTQConfig(bits=4, dataset = dataset, tokenizer=tokenizer)Quantization
You can quantize a model by using from_pretrained and setting the quantization_config.
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=gptq_config)
Note that you will need a GPU to quantize a model. We will put the model in the cpu and move the modules back and forth to the gpu in order to quantize them.
If you want to maximize your gpus usage while using cpu offload, you can set device_map = "auto".
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", quantization_config=gptq_config)Note that disk offload is not supported. Furthermore, if you are out of memory because of the dataset, you may have to pass max_memory in from_pretained. Checkout this guide to learn more about device_map and max_memory.
Push quantized model to 🤗 Hub
You can push the quantized model like any 🤗 model to Hub with push_to_hub. The quantization config will be saved and pushed along the model.
quantized_model.push_to_hub("opt-125m-gptq")
tokenizer.push_to_hub("opt-125m-gptq")If you want to save your quantized model on your local machine, you can also do it with save_pretrained:
quantized_model.save_pretrained("opt-125m-gptq")
tokenizer.save_pretrained("opt-125m-gptq")Note that if you have quantized your model with a device_map, make sure to move the entire model to one of your gpus or the cpu before saving it.
quantized_model.to("cpu")
quantized_model.save_pretrained("opt-125m-gptq")Load a quantized model from the 🤗 Hub
You can load a quantized model from the Hub by using from_pretrained.
Make sure that the pushed weights are quantized, by checking that the attribute quantization_config is present in the model configuration object.
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq")If you want to load a model faster and without allocating more memory than needed, the device_map argument also works with quantized model. Make sure that you have accelerate library installed.
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto")Exllama kernels for faster inference
For 4-bit model, you can use the exllama kernels in order to a faster inference speed. It is activated by default. You can change that behavior by passing use_exllama in GPTQConfig. This will overwrite the quantization config stored in the config. Note that you will only be able to overwrite the attributes related to the kernels. Furthermore, you need to have the entire model on gpus if you want to use exllama kernels. Also, you can perform CPU inference using Auto-GPTQ for Auto-GPTQ version > 0.4.2 by passing device_map = “cpu”. For CPU inference, you have to pass use_exllama = False in the GPTQConfig.
import torch
gptq_config = GPTQConfig(bits=4)
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto", quantization_config=gptq_config)With the release of the exllamav2 kernels, you can get faster inference speed compared to the exllama kernels. You just need to pass exllama_config={"version": 2} in GPTQConfig:
import torch
gptq_config = GPTQConfig(bits=4, exllama_config={"version":2})
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto", quantization_config = gptq_config)Note that only 4-bit models are supported for now. Furthermore, it is recommended to deactivate the exllama kernels if you are finetuning a quantized model with peft.
You can find the benchmark of these kernels here
Fine-tune a quantized model
With the official support of adapters in the Hugging Face ecosystem, you can fine-tune models that have been quantized with GPTQ.
Please have a look at peft library for more details.
Example demo
Check out the Google Colab notebook to learn how to quantize your model with GPTQ and how finetune the quantized model with peft.
GPTQConfig
class transformers.GPTQConfig
< source >( bits: int tokenizer: typing.Any = None dataset: typing.Union[typing.List[str], str, NoneType] = None group_size: int = 128 damp_percent: float = 0.1 desc_act: bool = False sym: bool = True true_sequential: bool = True use_cuda_fp16: bool = False model_seqlen: typing.Optional[int] = None block_name_to_quantize: typing.Optional[str] = None module_name_preceding_first_block: typing.Optional[typing.List[str]] = None batch_size: int = 1 pad_token_id: typing.Optional[int] = None use_exllama: typing.Optional[bool] = None max_input_length: typing.Optional[int] = None exllama_config: typing.Union[typing.Dict[str, typing.Any], NoneType] = None cache_block_outputs: bool = True **kwargs )
Parameters
- bits (
int) — The number of bits to quantize to, supported numbers are (2, 3, 4, 8). - tokenizer (
strorPreTrainedTokenizerBase, optional) — The tokenizer used to process the dataset. You can pass either:- A custom tokenizer object.
- A string, the model id of a predefined tokenizer hosted inside a model repo on huggingface.co.
Valid model ids can be located at the root-level, like
bert-base-uncased, or namespaced under a user or organization name, likedbmdz/bert-base-german-cased. - A path to a directory containing vocabulary files required by the tokenizer, for instance saved
using the save_pretrained() method, e.g.,
./my_model_directory/.
- dataset (
Union[List[str]], optional) — The dataset used for quantization. You can provide your own dataset in a list of string or just use the original datasets used in GPTQ paper [‘wikitext2’,‘c4’,‘c4-new’,‘ptb’,‘ptb-new’] - group_size (
int, optional, defaults to 128) — The group size to use for quantization. Recommended value is 128 and -1 uses per-column quantization. - damp_percent (
float, optional, defaults to 0.1) — The percent of the average Hessian diagonal to use for dampening. Recommended value is 0.1. - desc_act (
bool, optional, defaults toFalse) — Whether to quantize columns in order of decreasing activation size. Setting it to False can significantly speed up inference but the perplexity may become slightly worse. Also known as act-order. - sym (
bool, optional, defaults toTrue) — Whether to use symetric quantization. - true_sequential (
bool, optional, defaults toTrue) — Whether to perform sequential quantization even within a single Transformer block. Instead of quantizing the entire block at once, we perform layer-wise quantization. As a result, each layer undergoes quantization using inputs that have passed through the previously quantized layers. - use_cuda_fp16 (
bool, optional, defaults toFalse) — Whether or not to use optimized cuda kernel for fp16 model. Need to have model in fp16. - model_seqlen (
int, optional) — The maximum sequence length that the model can take. - block_name_to_quantize (
str, optional) — The transformers block name to quantize. - module_name_preceding_first_block (
List[str], optional) — The layers that are preceding the first Transformer block. - batch_size (
int, optional, defaults to 1) — The batch size used when processing the dataset - pad_token_id (
int, optional) — The pad token id. Needed to prepare the dataset whenbatch_size> 1. - use_exllama (
bool, optional) — Whether to use exllama backend. Defaults toTrueif unset. Only works withbits= 4. - max_input_length (
int, optional) — The maximum input length. This is needed to initialize a buffer that depends on the maximum expected input length. It is specific to the exllama backend with act-order. - exllama_config (
Dict[str, Any], optional) — The exllama config. You can specify the version of the exllama kernel through theversionkey. Defaults to{"version": 1}if unset. - cache_block_outputs (
bool, optional, defaults toTrue) — Whether to cache block outputs to reuse as inputs for the succeeding block.
This is a wrapper class about all possible attributes and features that you can play with a model that has been
loaded using optimum api for gptq quantization relying on auto_gptq backend.
Get compatible class with optimum gptq config dict
Safety checker that arguments are correct
Get compatible dict for optimum gptq config
bitsandbytes Integration
🤗 Transformers is closely integrated with most used modules on bitsandbytes. You can load your model in 8-bit precision with few lines of code.
This is supported by most of the GPU hardwares since the 0.37.0 release of bitsandbytes.
Learn more about the quantization method in the LLM.int8() paper, or the blogpost about the collaboration.
Since its 0.39.0 release, you can load any model that supports device_map using 4-bit quantization, leveraging FP4 data type.
If you want to quantize your own pytorch model, check out this documentation from 🤗 Accelerate library.
Here are the things you can do using bitsandbytes integration
General usage
You can quantize a model by using the load_in_8bit or load_in_4bit argument when calling the from_pretrained() method as long as your model supports loading with 🤗 Accelerate and contains torch.nn.Linear layers. This should work for any modality as well.
from transformers import AutoModelForCausalLM
model_8bit = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_8bit=True)
model_4bit = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_4bit=True)By default all other modules (e.g. torch.nn.LayerNorm) will be converted in torch.float16, but if you want to change their dtype you can overwrite the torch_dtype argument:
>>> import torch
>>> from transformers import AutoModelForCausalLM
>>> model_8bit = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_8bit=True, torch_dtype=torch.float32)
>>> model_8bit.model.decoder.layers[-1].final_layer_norm.weight.dtype
torch.float32FP4 quantization
Requirements
Make sure that you have installed the requirements below before running any of the code snippets below.
Latest
bitsandbyteslibrarypip install bitsandbytes>=0.39.0Install latest
acceleratepip install --upgrade accelerateInstall latest
transformerspip install --upgrade transformers
Tips and best practices
Advanced usage: Refer to this Google Colab notebook for advanced usage of 4-bit quantization with all the possible options.
Faster inference with
batch_size=1: Since the0.40.0release of bitsandbytes, forbatch_size=1you can benefit from fast inference. Check out these release notes and make sure to have a version that is greater than0.40.0to benefit from this feature out of the box.Training: According to QLoRA paper, for training 4-bit base models (e.g. using LoRA adapters) one should use
bnb_4bit_quant_type='nf4'.Inference: For inference,
bnb_4bit_quant_typedoes not have a huge impact on the performance. However for consistency with the model’s weights, make sure you use the samebnb_4bit_compute_dtypeandtorch_dtypearguments.
Load a large model in 4bit
By using load_in_4bit=True when calling the .from_pretrained method, you can divide your memory use by 4 (roughly).
# pip install transformers accelerate bitsandbytes
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "bigscience/bloom-1b7"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", load_in_4bit=True)Note that once a model has been loaded in 4-bit it is currently not possible to push the quantized weights on the Hub. Note also that you cannot train 4-bit weights as this is not supported yet. However you can use 4-bit models to train extra parameters, this will be covered in the next section.
Load a large model in 8bit
You can load a model by roughly halving the memory requirements by using load_in_8bit=True argument when calling .from_pretrained method
# pip install transformers accelerate bitsandbytes
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "bigscience/bloom-1b7"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", load_in_8bit=True)Then, use your model as you would usually use a PreTrainedModel.
You can check the memory footprint of your model with get_memory_footprint method.
print(model.get_memory_footprint())With this integration we were able to load large models on smaller devices and run them without any issue.
Note that once a model has been loaded in 8-bit it is currently not possible to push the quantized weights on the Hub except if you use the latest transformers and bitsandbytes. Note also that you cannot train 8-bit weights as this is not supported yet. However you can use 8-bit models to train extra parameters, this will be covered in the next section.
Note also that device_map is optional but setting device_map = 'auto' is prefered for inference as it will dispatch efficiently the model on the available ressources.
Advanced use cases
Here we will cover some advanced use cases you can perform with FP4 quantization
Change the compute dtype
The compute dtype is used to change the dtype that will be used during computation. For example, hidden states could be in float32 but computation can be set to bf16 for speedups. By default, the compute dtype is set to float32.
import torch
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.bfloat16)Using NF4 (Normal Float 4) data type
You can also use the NF4 data type, which is a new 4bit datatype adapted for weights that have been initialized using a normal distribution. For that run:
from transformers import BitsAndBytesConfig
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
)
model_nf4 = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=nf4_config)Use nested quantization for more memory efficient inference
We also advise users to use the nested quantization technique. This saves more memory at no additional performance - from our empirical observations, this enables fine-tuning llama-13b model on an NVIDIA-T4 16GB with a sequence length of 1024, batch size of 1 and gradient accumulation steps of 4.
from transformers import BitsAndBytesConfig
double_quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
)
model_double_quant = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=double_quant_config)Push quantized models on the 🤗 Hub
You can push a quantized model on the Hub by naively using push_to_hub method. This will first push the quantization configuration file, then push the quantized model weights.
Make sure to use bitsandbytes>0.37.2 (at this time of writing, we tested it on bitsandbytes==0.38.0.post1) to be able to use this feature.
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("bigscience/bloom-560m", device_map="auto", load_in_8bit=True)
tokenizer = AutoTokenizer.from_pretrained("bigscience/bloom-560m")
model.push_to_hub("bloom-560m-8bit")Pushing 8bit models on the Hub is strongely encouraged for large models. This will allow the community to benefit from the memory footprint reduction and loading for example large models on a Google Colab.
Load a quantized model from the 🤗 Hub
You can load a quantized model from the Hub by using from_pretrained method. Make sure that the pushed weights are quantized, by checking that the attribute quantization_config is present in the model configuration object.
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("{your_username}/bloom-560m-8bit", device_map="auto")Note that in this case, you don’t need to specify the arguments load_in_8bit=True, but you need to make sure that bitsandbytes and accelerate are installed.
Note also that device_map is optional but setting device_map = 'auto' is prefered for inference as it will dispatch efficiently the model on the available ressources.
Advanced use cases
This section is intended to advanced users, that want to explore what it is possible to do beyond loading and running 8-bit models.
Offload between cpu and gpu
One of the advanced use case of this is being able to load a model and dispatch the weights between CPU and GPU. Note that the weights that will be dispatched on CPU will not be converted in 8-bit, thus kept in float32. This feature is intended for users that want to fit a very large model and dispatch the model between GPU and CPU.
First, load a BitsAndBytesConfig from transformers and set the attribute llm_int8_enable_fp32_cpu_offload to True:
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(llm_int8_enable_fp32_cpu_offload=True)Let’s say you want to load bigscience/bloom-1b7 model, and you have just enough GPU RAM to fit the entire model except the lm_head. Therefore write a custom device_map as follows:
device_map = {
"transformer.word_embeddings": 0,
"transformer.word_embeddings_layernorm": 0,
"lm_head": "cpu",
"transformer.h": 0,
"transformer.ln_f": 0,
}And load your model as follows:
model_8bit = AutoModelForCausalLM.from_pretrained(
"bigscience/bloom-1b7",
device_map=device_map,
quantization_config=quantization_config,
)And that’s it! Enjoy your model!
Play with llm_int8_threshold
You can play with the llm_int8_threshold argument to change the threshold of the outliers. An “outlier” is a hidden state value that is greater than a certain threshold.
This corresponds to the outlier threshold for outlier detection as described in LLM.int8() paper. Any hidden states value that is above this threshold will be considered an outlier and the operation on those values will be done in fp16. Values are usually normally distributed, that is, most values are in the range [-3.5, 3.5], but there are some exceptional systematic outliers that are very differently distributed for large models. These outliers are often in the interval [-60, -6] or [6, 60]. Int8 quantization works well for values of magnitude ~5, but beyond that, there is a significant performance penalty. A good default threshold is 6, but a lower threshold might be needed for more unstable models (small models, fine-tuning).
This argument can impact the inference speed of the model. We suggest to play with this parameter to find which one is the best for your use case.
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
model_id = "bigscience/bloom-1b7"
quantization_config = BitsAndBytesConfig(
llm_int8_threshold=10,
)
model_8bit = AutoModelForCausalLM.from_pretrained(
model_id,
device_map=device_map,
quantization_config=quantization_config,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)Skip the conversion of some modules
Some models has several modules that needs to be not converted in 8-bit to ensure stability. For example Jukebox model has several lm_head modules that should be skipped. Play with llm_int8_skip_modules
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
model_id = "bigscience/bloom-1b7"
quantization_config = BitsAndBytesConfig(
llm_int8_skip_modules=["lm_head"],
)
model_8bit = AutoModelForCausalLM.from_pretrained(
model_id,
device_map=device_map,
quantization_config=quantization_config,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)Fine-tune a model that has been loaded in 8-bit
With the official support of adapters in the Hugging Face ecosystem, you can fine-tune models that have been loaded in 8-bit.
This enables fine-tuning large models such as flan-t5-large or facebook/opt-6.7b in a single google Colab. Please have a look at peft library for more details.
Note that you don’t need to pass device_map when loading the model for training. It will automatically load your model on your GPU. You can also set the device map to a specific device if needed (e.g. cuda:0, 0, torch.device('cuda:0')). Please note that device_map=auto should be used for inference only.
BitsAndBytesConfig
class transformers.BitsAndBytesConfig
< source >( load_in_8bit = False load_in_4bit = False llm_int8_threshold = 6.0 llm_int8_skip_modules = None llm_int8_enable_fp32_cpu_offload = False llm_int8_has_fp16_weight = False bnb_4bit_compute_dtype = None bnb_4bit_quant_type = 'fp4' bnb_4bit_use_double_quant = False **kwargs )
Parameters
- load_in_8bit (
bool, optional, defaults toFalse) — This flag is used to enable 8-bit quantization with LLM.int8(). - load_in_4bit (
bool, optional, defaults toFalse) — This flag is used to enable 4-bit quantization by replacing the Linear layers with FP4/NF4 layers frombitsandbytes. - llm_int8_threshold (
float, optional, defaults to 6.0) — This corresponds to the outlier threshold for outlier detection as described inLLM.int8() : 8-bit Matrix Multiplication for Transformers at Scalepaper: https://arxiv.org/abs/2208.07339 Any hidden states value that is above this threshold will be considered an outlier and the operation on those values will be done in fp16. Values are usually normally distributed, that is, most values are in the range [-3.5, 3.5], but there are some exceptional systematic outliers that are very differently distributed for large models. These outliers are often in the interval [-60, -6] or [6, 60]. Int8 quantization works well for values of magnitude ~5, but beyond that, there is a significant performance penalty. A good default threshold is 6, but a lower threshold might be needed for more unstable models (small models, fine-tuning). - llm_int8_skip_modules (
List[str], optional) — An explicit list of the modules that we do not want to convert in 8-bit. This is useful for models such as Jukebox that has several heads in different places and not necessarily at the last position. For example forCausalLMmodels, the lastlm_headis kept in its originaldtype. - llm_int8_enable_fp32_cpu_offload (
bool, optional, defaults toFalse) — This flag is used for advanced use cases and users that are aware of this feature. If you want to split your model in different parts and run some parts in int8 on GPU and some parts in fp32 on CPU, you can use this flag. This is useful for offloading large models such asgoogle/flan-t5-xxl. Note that the int8 operations will not be run on CPU. - llm_int8_has_fp16_weight (
bool, optional, defaults toFalse) — This flag runs LLM.int8() with 16-bit main weights. This is useful for fine-tuning as the weights do not have to be converted back and forth for the backward pass. - bnb_4bit_compute_dtype (
torch.dtypeor str, optional, defaults totorch.float32) — This sets the computational type which might be different than the input time. For example, inputs might be fp32, but computation can be set to bf16 for speedups. - bnb_4bit_quant_type (
str, optional, defaults to"fp4") — This sets the quantization data type in the bnb.nn.Linear4Bit layers. Options are FP4 and NF4 data types which are specified byfp4ornf4. - bnb_4bit_use_double_quant (
bool, optional, defaults toFalse) — This flag is used for nested quantization where the quantization constants from the first quantization are quantized again. - kwargs (
Dict[str, Any], optional) — Additional parameters from which to initialize the configuration object.
This is a wrapper class about all possible attributes and features that you can play with a model that has been
loaded using bitsandbytes.
This replaces load_in_8bit or load_in_4bittherefore both options are mutually exclusive.
Currently only supports LLM.int8(), FP4, and NF4 quantization. If more methods are added to bitsandbytes,
then more arguments will be added to this class.
Returns True if the model is quantizable, False otherwise.
Safety checker that arguments are correct - also replaces some NoneType arguments with their default values.
This method returns the quantization method used for the model. If the model is not quantizable, it returns
None.
to_diff_dict
< source >( ) → Dict[str, Any]
Returns
Dict[str, Any]
Dictionary of all the attributes that make up this configuration instance,
Removes all attributes from config which correspond to the default config attributes for better readability and serializes to a Python dictionary.
Quantization with 🤗 optimum
Please have a look at Optimum documentation to learn more about quantization methods that are supported by optimum and see if these are applicable for your use case.