Transformers documentation
LiLT
LiLT
Overview
The LiLT model was proposed in LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding by Jiapeng Wang, Lianwen Jin, Kai Ding. LiLT allows to combine any pre-trained RoBERTa text encoder with a lightweight Layout Transformer, to enable LayoutLM-like document understanding for many languages.
The abstract from the paper is the following:
Structured document understanding has attracted considerable attention and made significant progress recently, owing to its crucial role in intelligent document processing. However, most existing related models can only deal with the document data of specific language(s) (typically English) included in the pre-training collection, which is extremely limited. To address this issue, we propose a simple yet effective Language-independent Layout Transformer (LiLT) for structured document understanding. LiLT can be pre-trained on the structured documents of a single language and then directly fine-tuned on other languages with the corresponding off-the-shelf monolingual/multilingual pre-trained textual models. Experimental results on eight languages have shown that LiLT can achieve competitive or even superior performance on diverse widely-used downstream benchmarks, which enables language-independent benefit from the pre-training of document layout structure.
Tips:
- To combine the Language-Independent Layout Transformer with a new RoBERTa checkpoint from the hub, refer to this guide.
The script will result in
config.jsonandpytorch_model.binfiles being stored locally. After doing this, one can do the following (assuming you’re logged in with your HuggingFace account):
from transformers import LiltModel
model = LiltModel.from_pretrained("path_to_your_files")
model.push_to_hub("name_of_repo_on_the_hub")- When preparing data for the model, make sure to use the token vocabulary that corresponds to the RoBERTa checkpoint you combined with the Layout Transformer.
- As lilt-roberta-en-base uses the same vocabulary as LayoutLMv3, one can use LayoutLMv3TokenizerFast to prepare data for the model. The same is true for lilt-roberta-en-base: one can use LayoutXLMTokenizerFast for that model.
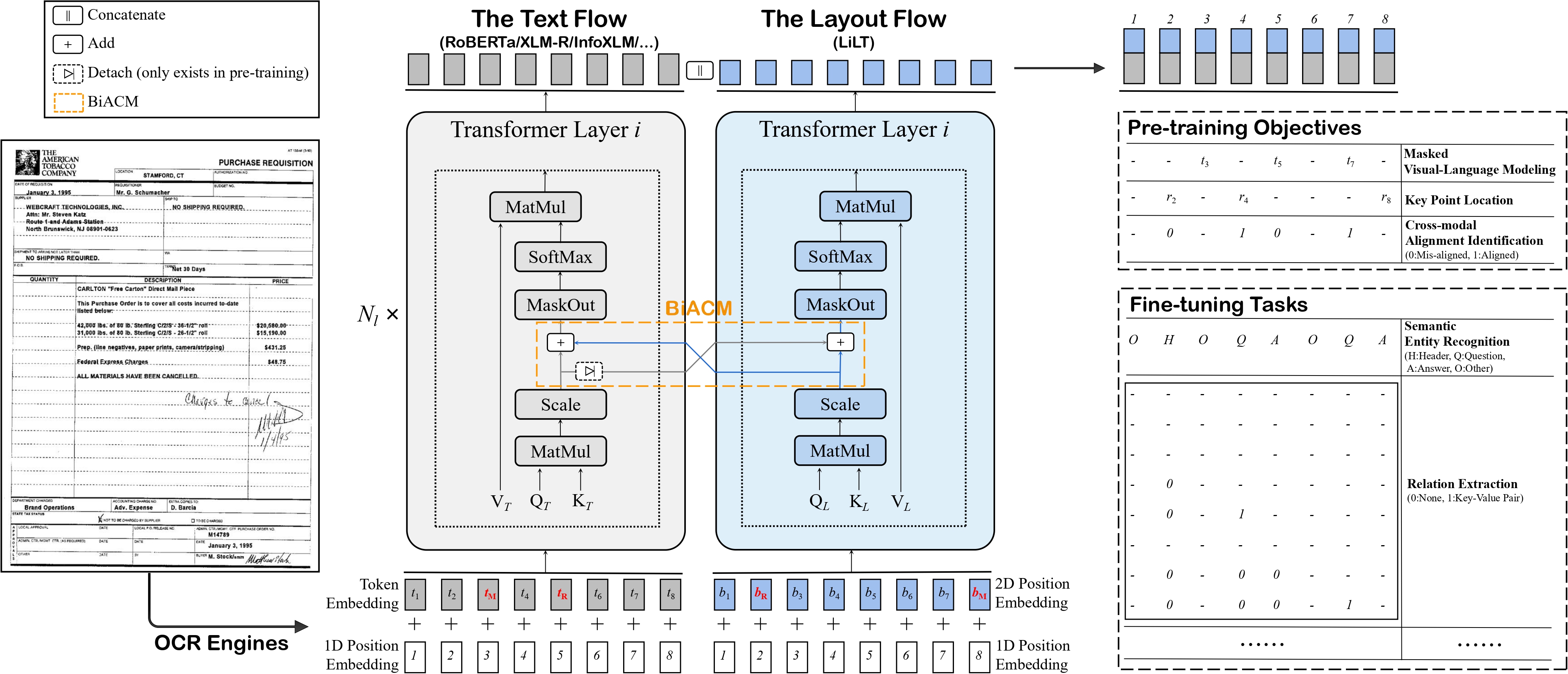 LiLT architecture. Taken from the original paper.
LiLT architecture. Taken from the original paper.
This model was contributed by nielsr. The original code can be found here.
Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LiLT.
- Demo notebooks for LiLT can be found here.
Documentation resources
If you’re interested in submitting a resource to be included here, please feel free to open a Pull Request and we’ll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
LiltConfig
class transformers.LiltConfig
< source >( vocab_size = 30522 hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 intermediate_size = 3072 hidden_act = 'gelu' hidden_dropout_prob = 0.1 attention_probs_dropout_prob = 0.1 max_position_embeddings = 512 type_vocab_size = 2 initializer_range = 0.02 layer_norm_eps = 1e-12 pad_token_id = 0 position_embedding_type = 'absolute' classifier_dropout = None channel_shrink_ratio = 4 max_2d_position_embeddings = 1024 **kwargs )
Parameters
-
vocab_size (
int, optional, defaults to 30522) — Vocabulary size of the LiLT model. Defines the number of different tokens that can be represented by theinputs_idspassed when calling LiltModel. -
hidden_size (
int, optional, defaults to 768) — Dimensionality of the encoder layers and the pooler layer. Should be a multiple of 24. -
num_hidden_layers (
int, optional, defaults to 12) — Number of hidden layers in the Transformer encoder. -
num_attention_heads (
int, optional, defaults to 12) — Number of attention heads for each attention layer in the Transformer encoder. -
intermediate_size (
int, optional, defaults to 3072) — Dimensionality of the “intermediate” (often named feed-forward) layer in the Transformer encoder. -
hidden_act (
strorCallable, optional, defaults to"gelu") — The non-linear activation function (function or string) in the encoder and pooler. If string,"gelu","relu","silu"and"gelu_new"are supported. -
hidden_dropout_prob (
float, optional, defaults to 0.1) — The dropout probability for all fully connected layers in the embeddings, encoder, and pooler. -
attention_probs_dropout_prob (
float, optional, defaults to 0.1) — The dropout ratio for the attention probabilities. -
max_position_embeddings (
int, optional, defaults to 512) — The maximum sequence length that this model might ever be used with. Typically set this to something large just in case (e.g., 512 or 1024 or 2048). -
type_vocab_size (
int, optional, defaults to 2) — The vocabulary size of thetoken_type_idspassed when calling LiltModel. -
initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. -
layer_norm_eps (
float, optional, defaults to 1e-12) — The epsilon used by the layer normalization layers. -
position_embedding_type (
str, optional, defaults to"absolute") — Type of position embedding. Choose one of"absolute","relative_key","relative_key_query". For positional embeddings use"absolute". For more information on"relative_key", please refer to Self-Attention with Relative Position Representations (Shaw et al.). For more information on"relative_key_query", please refer to Method 4 in Improve Transformer Models with Better Relative Position Embeddings (Huang et al.). -
classifier_dropout (
float, optional) — The dropout ratio for the classification head. -
channel_shrink_ratio (
int, optional, defaults to 4) — The shrink ratio compared to thehidden_sizefor the channel dimension of the layout embeddings. -
max_2d_position_embeddings (
int, optional, defaults to 1024) — The maximum value that the 2D position embedding might ever be used with. Typically set this to something large just in case (e.g., 1024).
This is the configuration class to store the configuration of a LiltModel. It is used to instantiate a LiLT model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the LiLT SCUT-DLVCLab/lilt-roberta-en-base architecture. Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Examples:
>>> from transformers import LiltConfig, LiltModel
>>> # Initializing a LiLT SCUT-DLVCLab/lilt-roberta-en-base style configuration
>>> configuration = LiltConfig()
>>> # Randomly initializing a model from the SCUT-DLVCLab/lilt-roberta-en-base style configuration
>>> model = LiltModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configLiltModel
class transformers.LiltModel
< source >( config add_pooling_layer = True )
Parameters
- config (LiltConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare LiLT Model transformer outputting raw hidden-states without any specific head on top. This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >(
input_ids: typing.Optional[torch.Tensor] = None
bbox: typing.Optional[torch.Tensor] = None
attention_mask: typing.Optional[torch.Tensor] = None
token_type_ids: typing.Optional[torch.Tensor] = None
position_ids: typing.Optional[torch.Tensor] = None
head_mask: typing.Optional[torch.Tensor] = None
inputs_embeds: typing.Optional[torch.Tensor] = None
output_attentions: typing.Optional[bool] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.modeling_outputs.BaseModelOutputWithPooling or tuple(torch.FloatTensor)
Parameters
-
input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
-
bbox (
torch.LongTensorof shape(batch_size, sequence_length, 4), optional) — Bounding boxes of each input sequence tokens. Selected in the range[0, config.max_2d_position_embeddings-1]. Each bounding box should be a normalized version in (x0, y0, x1, y1) format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1, y1) represents the position of the lower right corner. See Overview for normalization. -
attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
-
token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
-
position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. -
head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
-
inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. -
output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. -
output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. -
return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.modeling_outputs.BaseModelOutputWithPooling or tuple(torch.FloatTensor)
A transformers.modeling_outputs.BaseModelOutputWithPooling or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (LiltConfig) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. -
pooler_output (
torch.FloatTensorof shape(batch_size, hidden_size)) — Last layer hidden-state of the first token of the sequence (classification token) after further processing through the layers used for the auxiliary pretraining task. E.g. for BERT-family of models, this returns the classification token after processing through a linear layer and a tanh activation function. The linear layer weights are trained from the next sentence prediction (classification) objective during pretraining. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The LiltModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoTokenizer, AutoModel
>>> from datasets import load_dataset
>>> tokenizer = AutoTokenizer.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
>>> model = AutoModel.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
>>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train")
>>> example = dataset[0]
>>> words = example["tokens"]
>>> boxes = example["bboxes"]
>>> encoding = tokenizer(words, boxes=boxes, return_tensors="pt")
>>> outputs = model(**encoding)
>>> last_hidden_states = outputs.last_hidden_stateLiltForSequenceClassification
class transformers.LiltForSequenceClassification
< source >( config )
Parameters
- config (LiltConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
LiLT Model transformer with a sequence classification/regression head on top (a linear layer on top of the pooled output) e.g. for GLUE tasks.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >(
input_ids: typing.Optional[torch.LongTensor] = None
bbox: typing.Optional[torch.Tensor] = None
attention_mask: typing.Optional[torch.FloatTensor] = None
token_type_ids: typing.Optional[torch.LongTensor] = None
position_ids: typing.Optional[torch.LongTensor] = None
head_mask: typing.Optional[torch.FloatTensor] = None
inputs_embeds: typing.Optional[torch.FloatTensor] = None
labels: typing.Optional[torch.LongTensor] = None
output_attentions: typing.Optional[bool] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)
Parameters
-
input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
-
bbox (
torch.LongTensorof shape(batch_size, sequence_length, 4), optional) — Bounding boxes of each input sequence tokens. Selected in the range[0, config.max_2d_position_embeddings-1]. Each bounding box should be a normalized version in (x0, y0, x1, y1) format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1, y1) represents the position of the lower right corner. See Overview for normalization. -
attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
-
token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
-
position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. -
head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
-
inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. -
output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. -
output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. -
return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. -
labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the sequence classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy).
Returns
transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.SequenceClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (LiltConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. -
logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The LiltForSequenceClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> from datasets import load_dataset
>>> tokenizer = AutoTokenizer.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
>>> model = AutoModelForSequenceClassification.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
>>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train")
>>> example = dataset[0]
>>> words = example["tokens"]
>>> boxes = example["bboxes"]
>>> encoding = tokenizer(words, boxes=boxes, return_tensors="pt")
>>> outputs = model(**encoding)
>>> predicted_class_idx = outputs.logits.argmax(-1).item()
>>> predicted_class = model.config.id2label[predicted_class_idx]LiltForTokenClassification
class transformers.LiltForTokenClassification
< source >( config )
Parameters
- config (LiltConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Lilt Model with a token classification head on top (a linear layer on top of the hidden-states output) e.g. for Named-Entity-Recognition (NER) tasks.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >(
input_ids: typing.Optional[torch.LongTensor] = None
bbox: typing.Optional[torch.LongTensor] = None
attention_mask: typing.Optional[torch.FloatTensor] = None
token_type_ids: typing.Optional[torch.LongTensor] = None
position_ids: typing.Optional[torch.LongTensor] = None
head_mask: typing.Optional[torch.FloatTensor] = None
inputs_embeds: typing.Optional[torch.FloatTensor] = None
labels: typing.Optional[torch.LongTensor] = None
output_attentions: typing.Optional[bool] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.modeling_outputs.TokenClassifierOutput or tuple(torch.FloatTensor)
Parameters
-
input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
-
bbox (
torch.LongTensorof shape(batch_size, sequence_length, 4), optional) — Bounding boxes of each input sequence tokens. Selected in the range[0, config.max_2d_position_embeddings-1]. Each bounding box should be a normalized version in (x0, y0, x1, y1) format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1, y1) represents the position of the lower right corner. See Overview for normalization. -
attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
-
token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
-
position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. -
head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
-
inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. -
output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. -
output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. -
return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. -
labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Labels for computing the token classification loss. Indices should be in[0, ..., config.num_labels - 1].
Returns
transformers.modeling_outputs.TokenClassifierOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.TokenClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (LiltConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification loss. -
logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.num_labels)) — Classification scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The LiltForTokenClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoTokenizer, AutoModelForTokenClassification
>>> from datasets import load_dataset
>>> tokenizer = AutoTokenizer.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
>>> model = AutoModelForTokenClassification.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
>>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train")
>>> example = dataset[0]
>>> words = example["tokens"]
>>> boxes = example["bboxes"]
>>> encoding = tokenizer(words, boxes=boxes, return_tensors="pt")
>>> outputs = model(**encoding)
>>> predicted_class_indices = outputs.logits.argmax(-1)LiltForQuestionAnswering
class transformers.LiltForQuestionAnswering
< source >( config )
Parameters
- config (LiltConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Lilt Model with a span classification head on top for extractive question-answering tasks like SQuAD (a linear
layers on top of the hidden-states output to compute span start logits and span end logits).
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >(
input_ids: typing.Optional[torch.LongTensor] = None
bbox: typing.Optional[torch.LongTensor] = None
attention_mask: typing.Optional[torch.FloatTensor] = None
token_type_ids: typing.Optional[torch.LongTensor] = None
position_ids: typing.Optional[torch.LongTensor] = None
head_mask: typing.Optional[torch.FloatTensor] = None
inputs_embeds: typing.Optional[torch.FloatTensor] = None
start_positions: typing.Optional[torch.LongTensor] = None
end_positions: typing.Optional[torch.LongTensor] = None
output_attentions: typing.Optional[bool] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.modeling_outputs.QuestionAnsweringModelOutput or tuple(torch.FloatTensor)
Parameters
-
input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
-
bbox (
torch.LongTensorof shape(batch_size, sequence_length, 4), optional) — Bounding boxes of each input sequence tokens. Selected in the range[0, config.max_2d_position_embeddings-1]. Each bounding box should be a normalized version in (x0, y0, x1, y1) format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1, y1) represents the position of the lower right corner. See Overview for normalization. -
attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
-
token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
-
position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. -
head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
-
inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. -
output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. -
output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. -
return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. -
start_positions (
torch.LongTensorof shape(batch_size,), optional) — Labels for position (index) of the start of the labelled span for computing the token classification loss. Positions are clamped to the length of the sequence (sequence_length). Position outside of the sequence are not taken into account for computing the loss. -
end_positions (
torch.LongTensorof shape(batch_size,), optional) — Labels for position (index) of the end of the labelled span for computing the token classification loss. Positions are clamped to the length of the sequence (sequence_length). Position outside of the sequence are not taken into account for computing the loss.
Returns
transformers.modeling_outputs.QuestionAnsweringModelOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.QuestionAnsweringModelOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (LiltConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Total span extraction loss is the sum of a Cross-Entropy for the start and end positions. -
start_logits (
torch.FloatTensorof shape(batch_size, sequence_length)) — Span-start scores (before SoftMax). -
end_logits (
torch.FloatTensorof shape(batch_size, sequence_length)) — Span-end scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The LiltForQuestionAnswering forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoTokenizer, AutoModelForQuestionAnswering
>>> from datasets import load_dataset
>>> tokenizer = AutoTokenizer.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
>>> model = AutoModelForQuestionAnswering.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
>>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train")
>>> example = dataset[0]
>>> words = example["tokens"]
>>> boxes = example["bboxes"]
>>> encoding = tokenizer(words, boxes=boxes, return_tensors="pt")
>>> outputs = model(**encoding)
>>> answer_start_index = outputs.start_logits.argmax()
>>> answer_end_index = outputs.end_logits.argmax()
>>> predict_answer_tokens = encoding.input_ids[0, answer_start_index : answer_end_index + 1]
>>> predicted_answer = tokenizer.decode(predict_answer_tokens)