Transformers documentation
MarkupLM
MarkupLM
Overview
The MarkupLM model was proposed in MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei. MarkupLM is BERT, but applied to HTML pages instead of raw text documents. The model incorporates additional embedding layers to improve performance, similar to LayoutLM.
The model can be used for tasks like question answering on web pages or information extraction from web pages. It obtains state-of-the-art results on 2 important benchmarks:
- WebSRC, a dataset for Web-Based Structual Reading Comprehension (a bit like SQuAD but for web pages)
- SWDE, a dataset for information extraction from web pages (basically named-entity recogntion on web pages)
The abstract from the paper is the following:
Multimodal pre-training with text, layout, and image has made significant progress for Visually-rich Document Understanding (VrDU), especially the fixed-layout documents such as scanned document images. While, there are still a large number of digital documents where the layout information is not fixed and needs to be interactively and dynamically rendered for visualization, making existing layout-based pre-training approaches not easy to apply. In this paper, we propose MarkupLM for document understanding tasks with markup languages as the backbone such as HTML/XML-based documents, where text and markup information is jointly pre-trained. Experiment results show that the pre-trained MarkupLM significantly outperforms the existing strong baseline models on several document understanding tasks. The pre-trained model and code will be publicly available.
Tips:
- In addition to
input_ids, forward() expects 2 additional inputs, namelyxpath_tags_seqandxpath_subs_seq. These are the XPATH tags and subscripts respectively for each token in the input sequence. - One can use MarkupLMProcessor to prepare all data for the model. Refer to the usage guide for more info.
- Demo notebooks can be found here.
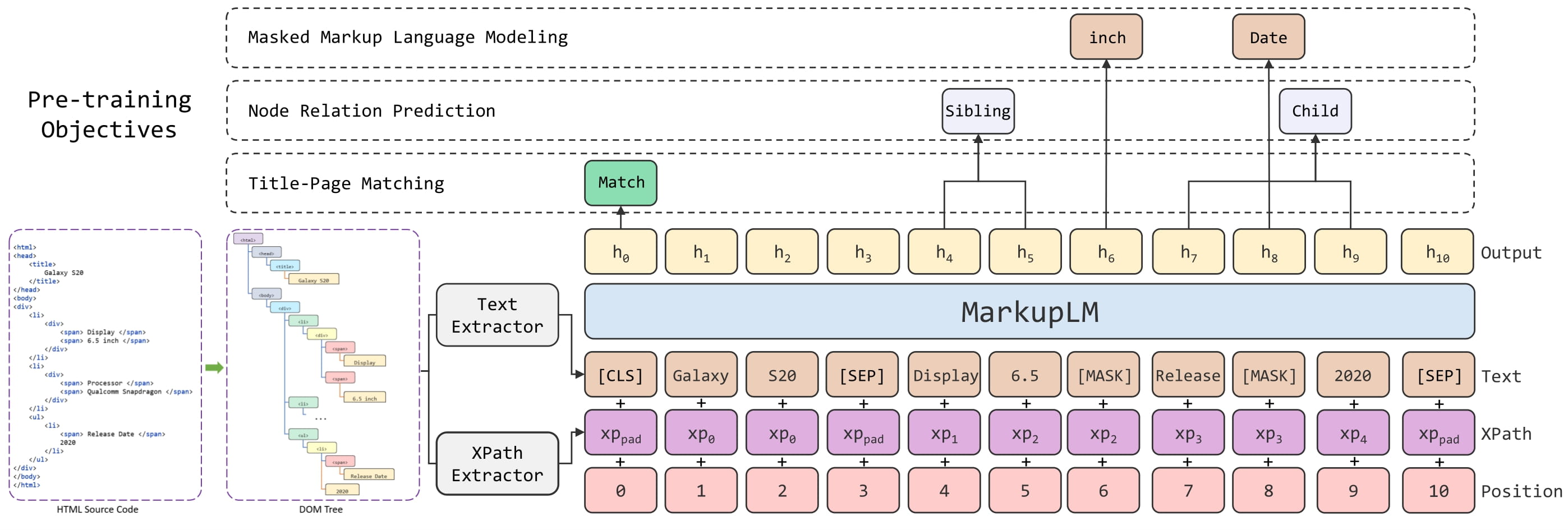 MarkupLM architecture. Taken from the original paper.
MarkupLM architecture. Taken from the original paper.
This model was contributed by nielsr. The original code can be found here.
Usage: MarkupLMProcessor
The easiest way to prepare data for the model is to use MarkupLMProcessor, which internally combines a feature extractor
(MarkupLMFeatureExtractor) and a tokenizer (MarkupLMTokenizer or MarkupLMTokenizerFast). The feature extractor is
used to extract all nodes and xpaths from the HTML strings, which are then provided to the tokenizer, which turns them into the
token-level inputs of the model (input_ids etc.). Note that you can still use the feature extractor and tokenizer separately,
if you only want to handle one of the two tasks.
from transformers import MarkupLMFeatureExtractor, MarkupLMTokenizerFast, MarkupLMProcessor
feature_extractor = MarkupLMFeatureExtractor()
tokenizer = MarkupLMTokenizerFast.from_pretrained("microsoft/markuplm-base")
processor = MarkupLMProcessor(feature_extractor, tokenizer)In short, one can provide HTML strings (and possibly additional data) to MarkupLMProcessor,
and it will create the inputs expected by the model. Internally, the processor first uses
MarkupLMFeatureExtractor to get a list of nodes and corresponding xpaths. The nodes and
xpaths are then provided to MarkupLMTokenizer or MarkupLMTokenizerFast, which converts them
to token-level input_ids, attention_mask, token_type_ids, xpath_subs_seq, xpath_tags_seq.
Optionally, one can provide node labels to the processor, which are turned into token-level labels.
MarkupLMFeatureExtractor uses Beautiful Soup, a Python library for pulling data out of HTML and XML files, under the hood. Note that you can still use your own parsing solution of choice, and provide the nodes and xpaths yourself to MarkupLMTokenizer or MarkupLMTokenizerFast.
In total, there are 5 use cases that are supported by the processor. Below, we list them all. Note that each of these use cases work for both batched and non-batched inputs (we illustrate them for non-batched inputs).
Use case 1: web page classification (training, inference) + token classification (inference), parse_html = True
This is the simplest case, in which the processor will use the feature extractor to get all nodes and xpaths from the HTML.
>>> from transformers import MarkupLMProcessor
>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
>>> html_string = """
... <!DOCTYPE html>
... <html>
... <head>
... <title>Hello world</title>
... </head>
... <body>
... <h1>Welcome</h1>
... <p>Here is my website.</p>
... </body>
... </html>"""
>>> # note that you can also add provide all tokenizer parameters here such as padding, truncation
>>> encoding = processor(html_string, return_tensors="pt")
>>> print(encoding.keys())
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])Use case 2: web page classification (training, inference) + token classification (inference), parse_html=False
In case one already has obtained all nodes and xpaths, one doesn’t need the feature extractor. In that case, one should
provide the nodes and corresponding xpaths themselves to the processor, and make sure to set parse_html to False.
>>> from transformers import MarkupLMProcessor
>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
>>> processor.parse_html = False
>>> nodes = ["hello", "world", "how", "are"]
>>> xpaths = ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span", "html/body", "html/body/div"]
>>> encoding = processor(nodes=nodes, xpaths=xpaths, return_tensors="pt")
>>> print(encoding.keys())
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])Use case 3: token classification (training), parse_html=False
For token classification tasks (such as SWDE), one can also provide the
corresponding node labels in order to train a model. The processor will then convert these into token-level labels.
By default, it will only label the first wordpiece of a word, and label the remaining wordpieces with -100, which is the
ignore_index of PyTorch’s CrossEntropyLoss. In case you want all wordpieces of a word to be labeled, you can
initialize the tokenizer with only_label_first_subword set to False.
>>> from transformers import MarkupLMProcessor
>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
>>> processor.parse_html = False
>>> nodes = ["hello", "world", "how", "are"]
>>> xpaths = ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span", "html/body", "html/body/div"]
>>> node_labels = [1, 2, 2, 1]
>>> encoding = processor(nodes=nodes, xpaths=xpaths, node_labels=node_labels, return_tensors="pt")
>>> print(encoding.keys())
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq', 'labels'])Use case 4: web page question answering (inference), parse_html=True
For question answering tasks on web pages, you can provide a question to the processor. By default, the processor will use the feature extractor to get all nodes and xpaths, and create [CLS] question tokens [SEP] word tokens [SEP].
>>> from transformers import MarkupLMProcessor
>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
>>> html_string = """
... <!DOCTYPE html>
... <html>
... <head>
... <title>Hello world</title>
... </head>
... <body>
... <h1>Welcome</h1>
... <p>My name is Niels.</p>
... </body>
... </html>"""
>>> question = "What's his name?"
>>> encoding = processor(html_string, questions=question, return_tensors="pt")
>>> print(encoding.keys())
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])Use case 5: web page question answering (inference), parse_html=False
For question answering tasks (such as WebSRC), you can provide a question to the processor. If you have extracted
all nodes and xpaths yourself, you can provide them directly to the processor. Make sure to set parse_html to False.
>>> from transformers import MarkupLMProcessor
>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
>>> processor.parse_html = False
>>> nodes = ["hello", "world", "how", "are"]
>>> xpaths = ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span", "html/body", "html/body/div"]
>>> question = "What's his name?"
>>> encoding = processor(nodes=nodes, xpaths=xpaths, questions=question, return_tensors="pt")
>>> print(encoding.keys())
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])MarkupLMConfig
class transformers.MarkupLMConfig
< source >( vocab_size = 30522 hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 intermediate_size = 3072 hidden_act = 'gelu' hidden_dropout_prob = 0.1 attention_probs_dropout_prob = 0.1 max_position_embeddings = 512 type_vocab_size = 2 initializer_range = 0.02 layer_norm_eps = 1e-12 pad_token_id = 0 bos_token_id = 0 eos_token_id = 2 gradient_checkpointing = False max_xpath_tag_unit_embeddings = 256 max_xpath_subs_unit_embeddings = 1024 tag_pad_id = 216 subs_pad_id = 1001 xpath_unit_hidden_size = 32 max_depth = 50 position_embedding_type = 'absolute' use_cache = True classifier_dropout = None **kwargs )
Parameters
-
vocab_size (
int, optional, defaults to 30522) — Vocabulary size of the MarkupLM model. Defines the different tokens that can be represented by the inputs_ids passed to the forward method of MarkupLMModel. -
hidden_size (
int, optional, defaults to 768) — Dimensionality of the encoder layers and the pooler layer. -
num_hidden_layers (
int, optional, defaults to 12) — Number of hidden layers in the Transformer encoder. -
num_attention_heads (
int, optional, defaults to 12) — Number of attention heads for each attention layer in the Transformer encoder. -
intermediate_size (
int, optional, defaults to 3072) — Dimensionality of the “intermediate” (i.e., feed-forward) layer in the Transformer encoder. -
hidden_act (
strorfunction, optional, defaults to"gelu") — The non-linear activation function (function or string) in the encoder and pooler. If string,"gelu","relu","silu"and"gelu_new"are supported. -
hidden_dropout_prob (
float, optional, defaults to 0.1) — The dropout probability for all fully connected layers in the embeddings, encoder, and pooler. -
attention_probs_dropout_prob (
float, optional, defaults to 0.1) — The dropout ratio for the attention probabilities. -
max_position_embeddings (
int, optional, defaults to 512) — The maximum sequence length that this model might ever be used with. Typically set this to something large just in case (e.g., 512 or 1024 or 2048). -
type_vocab_size (
int, optional, defaults to 2) — The vocabulary size of thetoken_type_idspassed into MarkupLMModel. -
initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. -
layer_norm_eps (
float, optional, defaults to 1e-12) — The epsilon used by the layer normalization layers. -
gradient_checkpointing (
bool, optional, defaults toFalse) — If True, use gradient checkpointing to save memory at the expense of slower backward pass. -
max_tree_id_unit_embeddings (
int, optional, defaults to 1024) — The maximum value that the tree id unit embedding might ever use. Typically set this to something large just in case (e.g., 1024). -
max_xpath_tag_unit_embeddings (
int, optional, defaults to 256) — The maximum value that the xpath tag unit embedding might ever use. Typically set this to something large just in case (e.g., 256). -
max_xpath_subs_unit_embeddings (
int, optional, defaults to 1024) — The maximum value that the xpath subscript unit embedding might ever use. Typically set this to something large just in case (e.g., 1024). -
tag_pad_id (
int, optional, defaults to 216) — The id of the padding token in the xpath tags. -
subs_pad_id (
int, optional, defaults to 1001) — The id of the padding token in the xpath subscripts. -
xpath_tag_unit_hidden_size (
int, optional, defaults to 32) — The hidden size of each tree id unit. One complete tree index will have (50*xpath_tag_unit_hidden_size)-dim. -
max_depth (
int, optional, defaults to 50) — The maximum depth in xpath.
This is the configuration class to store the configuration of a MarkupLMModel. It is used to instantiate a MarkupLM model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the MarkupLM microsoft/markuplm-base architecture.
Configuration objects inherit from BertConfig and can be used to control the model outputs. Read the documentation from BertConfig for more information.
Examples:
>>> from transformers import MarkupLMModel, MarkupLMConfig
>>> # Initializing a MarkupLM microsoft/markuplm-base style configuration
>>> configuration = MarkupLMConfig()
>>> # Initializing a model from the microsoft/markuplm-base style configuration
>>> model = MarkupLMModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configMarkupLMFeatureExtractor
Constructs a MarkupLM feature extractor. This can be used to get a list of nodes and corresponding xpaths from HTML strings.
This feature extractor inherits from PreTrainedFeatureExtractor() which contains most
of the main methods. Users should refer to this superclass for more information regarding those methods.
__call__
< source >( html_strings ) → BatchFeature
Parameters
-
html_strings (
str,List[str]) — The HTML string or batch of HTML strings from which to extract nodes and corresponding xpaths.
Returns
A BatchFeature with the following fields:
- nodes — Nodes.
- xpaths — Corresponding xpaths.
Main method to prepare for the model one or several HTML strings.
Examples:
>>> from transformers import MarkupLMFeatureExtractor
>>> page_name_1 = "page1.html"
>>> page_name_2 = "page2.html"
>>> page_name_3 = "page3.html"
>>> with open(page_name_1) as f:
... single_html_string = f.read()
>>> feature_extractor = MarkupLMFeatureExtractor()
>>> # single example
>>> encoding = feature_extractor(single_html_string)
>>> print(encoding.keys())
>>> # dict_keys(['nodes', 'xpaths'])
>>> # batched example
>>> multi_html_strings = []
>>> with open(page_name_2) as f:
... multi_html_strings.append(f.read())
>>> with open(page_name_3) as f:
... multi_html_strings.append(f.read())
>>> encoding = feature_extractor(multi_html_strings)
>>> print(encoding.keys())
>>> # dict_keys(['nodes', 'xpaths'])MarkupLMTokenizer
class transformers.MarkupLMTokenizer
< source >( vocab_file merges_file tags_dict errors = 'replace' bos_token = '<s>' eos_token = '</s>' sep_token = '</s>' cls_token = '<s>' unk_token = '<unk>' pad_token = '<pad>' mask_token = '<mask>' add_prefix_space = False max_depth = 50 max_width = 1000 pad_width = 1001 pad_token_label = -100 only_label_first_subword = True **kwargs )
Parameters
-
vocab_file (
str) — Path to the vocabulary file. -
merges_file (
str) — Path to the merges file. -
errors (
str, optional, defaults to"replace") — Paradigm to follow when decoding bytes to UTF-8. See bytes.decode for more information. -
bos_token (
str, optional, defaults to"<s>") — The beginning of sequence token that was used during pretraining. Can be used a sequence classifier token.When building a sequence using special tokens, this is not the token that is used for the beginning of sequence. The token used is the
cls_token. -
eos_token (
str, optional, defaults to"</s>") — The end of sequence token.When building a sequence using special tokens, this is not the token that is used for the end of sequence. The token used is the
sep_token. -
sep_token (
str, optional, defaults to"</s>") — The separator token, which is used when building a sequence from multiple sequences, e.g. two sequences for sequence classification or for a text and a question for question answering. It is also used as the last token of a sequence built with special tokens. -
cls_token (
str, optional, defaults to"<s>") — The classifier token which is used when doing sequence classification (classification of the whole sequence instead of per-token classification). It is the first token of the sequence when built with special tokens. -
unk_token (
str, optional, defaults to"<unk>") — The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this token instead. -
pad_token (
str, optional, defaults to"<pad>") — The token used for padding, for example when batching sequences of different lengths. -
mask_token (
str, optional, defaults to"<mask>") — The token used for masking values. This is the token used when training this model with masked language modeling. This is the token which the model will try to predict. -
add_prefix_space (
bool, optional, defaults toFalse) — Whether or not to add an initial space to the input. This allows to treat the leading word just as any other word. (RoBERTa tokenizer detect beginning of words by the preceding space).
Construct a MarkupLM tokenizer. Based on byte-level Byte-Pair-Encoding (BPE). MarkupLMTokenizer can be used to
turn HTML strings into to token-level input_ids, attention_mask, token_type_ids, xpath_tags_seq and
xpath_tags_seq. This tokenizer inherits from PreTrainedTokenizer which contains most of the main methods.
Users should refer to this superclass for more information regarding those methods.
build_inputs_with_special_tokens
< source >(
token_ids_0: typing.List[int]
token_ids_1: typing.Optional[typing.List[int]] = None
)
→
List[int]
Parameters
-
token_ids_0 (
List[int]) — List of IDs to which the special tokens will be added. -
token_ids_1 (
List[int], optional) — Optional second list of IDs for sequence pairs.
Returns
List[int]
List of input IDs with the appropriate special tokens.
Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and adding special tokens. A RoBERTa sequence has the following format:
- single sequence:
<s> X </s> - pair of sequences:
<s> A </s></s> B </s>
get_special_tokens_mask
< source >(
token_ids_0: typing.List[int]
token_ids_1: typing.Optional[typing.List[int]] = None
already_has_special_tokens: bool = False
)
→
List[int]
Parameters
- Retrieve sequence ids from a token list that has no special tokens added. This method is called when adding —
-
special tokens using the tokenizer
prepare_for_modelmethod. — token_ids_0 (List[int]): List of IDs. token_ids_1 (List[int], optional): Optional second list of IDs for sequence pairs. already_has_special_tokens (bool, optional, defaults toFalse): Whether or not the token list is already formatted with special tokens for the model.
Returns
List[int]
A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
create_token_type_ids_from_sequences
< source >(
token_ids_0: typing.List[int]
token_ids_1: typing.Optional[typing.List[int]] = None
)
→
List[int]
Create a mask from the two sequences passed to be used in a sequence-pair classification task. RoBERTa does not make use of token type ids, therefore a list of zeros is returned.
MarkupLMTokenizerFast
class transformers.MarkupLMTokenizerFast
< source >( vocab_file merges_file tags_dict tokenizer_file = None errors = 'replace' bos_token = '<s>' eos_token = '</s>' sep_token = '</s>' cls_token = '<s>' unk_token = '<unk>' pad_token = '<pad>' mask_token = '<mask>' add_prefix_space = False max_depth = 50 max_width = 1000 pad_width = 1001 pad_token_label = -100 only_label_first_subword = True trim_offsets = False **kwargs )
Parameters
-
vocab_file (
str) — Path to the vocabulary file. -
merges_file (
str) — Path to the merges file. -
errors (
str, optional, defaults to"replace") — Paradigm to follow when decoding bytes to UTF-8. See bytes.decode for more information. -
bos_token (
str, optional, defaults to"<s>") — The beginning of sequence token that was used during pretraining. Can be used a sequence classifier token.When building a sequence using special tokens, this is not the token that is used for the beginning of sequence. The token used is the
cls_token. -
eos_token (
str, optional, defaults to"</s>") — The end of sequence token.When building a sequence using special tokens, this is not the token that is used for the end of sequence. The token used is the
sep_token. -
sep_token (
str, optional, defaults to"</s>") — The separator token, which is used when building a sequence from multiple sequences, e.g. two sequences for sequence classification or for a text and a question for question answering. It is also used as the last token of a sequence built with special tokens. -
cls_token (
str, optional, defaults to"<s>") — The classifier token which is used when doing sequence classification (classification of the whole sequence instead of per-token classification). It is the first token of the sequence when built with special tokens. -
unk_token (
str, optional, defaults to"<unk>") — The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this token instead. -
pad_token (
str, optional, defaults to"<pad>") — The token used for padding, for example when batching sequences of different lengths. -
mask_token (
str, optional, defaults to"<mask>") — The token used for masking values. This is the token used when training this model with masked language modeling. This is the token which the model will try to predict. -
add_prefix_space (
bool, optional, defaults toFalse) — Whether or not to add an initial space to the input. This allows to treat the leading word just as any other word. (RoBERTa tokenizer detect beginning of words by the preceding space).
Construct a MarkupLM tokenizer. Based on byte-level Byte-Pair-Encoding (BPE).
MarkupLMTokenizerFast can be used to turn HTML strings into to token-level input_ids, attention_mask,
token_type_ids, xpath_tags_seq and xpath_tags_seq. This tokenizer inherits from PreTrainedTokenizer which
contains most of the main methods.
Users should refer to this superclass for more information regarding those methods.
batch_encode_plus
< source >( batch_text_or_text_pairs: typing.Union[typing.List[str], typing.List[typing.Tuple[str, str]], typing.List[typing.List[str]]] is_pair: bool = None xpaths: typing.Optional[typing.List[typing.List[typing.List[int]]]] = None node_labels: typing.Union[typing.List[int], typing.List[typing.List[int]], NoneType] = None add_special_tokens: bool = True padding: typing.Union[bool, str, transformers.utils.generic.PaddingStrategy] = False truncation: typing.Union[bool, str, transformers.tokenization_utils_base.TruncationStrategy] = None max_length: typing.Optional[int] = None stride: int = 0 pad_to_multiple_of: typing.Optional[int] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None return_token_type_ids: typing.Optional[bool] = None return_attention_mask: typing.Optional[bool] = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True **kwargs )
add_special_tokens (bool, optional, defaults to True):
Whether or not to encode the sequences with the special tokens relative to their model.
padding (bool, str or PaddingStrategy, optional, defaults to False):
Activates and controls padding. Accepts the following values:
Trueor'longest': Pad to the longest sequence in the batch (or no padding if only a single sequence if provided).'max_length': Pad to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided.Falseor'do_not_pad'(default): No padding (i.e., can output a batch with sequences of different lengths). truncation (bool,stror TruncationStrategy, optional, defaults toFalse): Activates and controls truncation. Accepts the following values:Trueor'longest_first': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will truncate token by token, removing a token from the longest sequence in the pair if a pair of sequences (or a batch of pairs) is provided.'only_first': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the first sequence of a pair if a pair of sequences (or a batch of pairs) is provided.'only_second': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the second sequence of a pair if a pair of sequences (or a batch of pairs) is provided.Falseor'do_not_truncate'(default): No truncation (i.e., can output batch with sequence lengths greater than the model maximum admissible input size). max_length (int, optional): Controls the maximum length to use by one of the truncation/padding parameters.
If left unset or set to None, this will use the predefined model maximum length if a maximum length
is required by one of the truncation/padding parameters. If the model has no specific maximum input
length (like XLNet) truncation/padding to a maximum length will be deactivated.
stride (int, optional, defaults to 0):
If set to a number along with max_length, the overflowing tokens returned when
return_overflowing_tokens=True will contain some tokens from the end of the truncated sequence
returned to provide some overlap between truncated and overflowing sequences. The value of this
argument defines the number of overlapping tokens.
is_split_into_words (bool, optional, defaults to False):
Whether or not the input is already pre-tokenized (e.g., split into words). If set to True, the
tokenizer assumes the input is already split into words (for instance, by splitting it on whitespace)
which it will tokenize. This is useful for NER or token classification.
pad_to_multiple_of (int, optional):
If set will pad the sequence to a multiple of the provided value. This is especially useful to enable
the use of Tensor Cores on NVIDIA hardware with compute capability >= 7.5 (Volta).
return_tensors (str or TensorType, optional):
If set, will return tensors instead of list of python integers. Acceptable values are:
'tf': Return TensorFlowtf.constantobjects.'pt': Return PyTorchtorch.Tensorobjects.'np': Return Numpynp.ndarrayobjects.
add_special_tokens (bool, optional, defaults to True):
Whether or not to encode the sequences with the special tokens relative to their model.
padding (bool, str or PaddingStrategy, optional, defaults to False):
Activates and controls padding. Accepts the following values:
Trueor'longest': Pad to the longest sequence in the batch (or no padding if only a single sequence if provided).'max_length': Pad to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided.Falseor'do_not_pad'(default): No padding (i.e., can output a batch with sequences of different lengths). truncation (bool,stror TruncationStrategy, optional, defaults toFalse): Activates and controls truncation. Accepts the following values:Trueor'longest_first': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will truncate token by token, removing a token from the longest sequence in the pair if a pair of sequences (or a batch of pairs) is provided.'only_first': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the first sequence of a pair if a pair of sequences (or a batch of pairs) is provided.'only_second': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the second sequence of a pair if a pair of sequences (or a batch of pairs) is provided.Falseor'do_not_truncate'(default): No truncation (i.e., can output batch with sequence lengths greater than the model maximum admissible input size). max_length (int, optional): Controls the maximum length to use by one of the truncation/padding parameters. If left unset or set toNone, this will use the predefined model maximum length if a maximum length is required by one of the truncation/padding parameters. If the model has no specific maximum input length (like XLNet) truncation/padding to a maximum length will be deactivated. stride (int, optional, defaults to 0): If set to a number along withmax_length, the overflowing tokens returned whenreturn_overflowing_tokens=Truewill contain some tokens from the end of the truncated sequence returned to provide some overlap between truncated and overflowing sequences. The value of this argument defines the number of overlapping tokens. pad_to_multiple_of (int, optional): If set will pad the sequence to a multiple of the provided value. This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >= 7.5 (Volta). return_tensors (stror TensorType, optional): If set, will return tensors instead of list of python integers. Acceptable values are:'tf': Return TensorFlowtf.constantobjects.'pt': Return PyTorchtorch.Tensorobjects.'np': Return Numpynp.ndarrayobjects.
build_inputs_with_special_tokens
< source >(
token_ids_0: typing.List[int]
token_ids_1: typing.Optional[typing.List[int]] = None
)
→
List[int]
Parameters
-
token_ids_0 (
List[int]) — List of IDs to which the special tokens will be added. -
token_ids_1 (
List[int], optional) — Optional second list of IDs for sequence pairs.
Returns
List[int]
List of input IDs with the appropriate special tokens.
Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and adding special tokens. A RoBERTa sequence has the following format:
- single sequence:
<s> X </s> - pair of sequences:
<s> A </s></s> B </s>
create_token_type_ids_from_sequences
< source >(
token_ids_0: typing.List[int]
token_ids_1: typing.Optional[typing.List[int]] = None
)
→
List[int]
Create a mask from the two sequences passed to be used in a sequence-pair classification task. RoBERTa does not make use of token type ids, therefore a list of zeros is returned.
encode_plus
< source >( text: typing.Union[str, typing.List[str]] text_pair: typing.Optional[typing.List[str]] = None xpaths: typing.Optional[typing.List[typing.List[int]]] = None node_labels: typing.Optional[typing.List[int]] = None add_special_tokens: bool = True padding: typing.Union[bool, str, transformers.utils.generic.PaddingStrategy] = False truncation: typing.Union[bool, str, transformers.tokenization_utils_base.TruncationStrategy] = None max_length: typing.Optional[int] = None stride: int = 0 pad_to_multiple_of: typing.Optional[int] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None return_token_type_ids: typing.Optional[bool] = None return_attention_mask: typing.Optional[bool] = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True **kwargs )
Parameters
-
text (
str,List[str],List[List[str]]) — The first sequence to be encoded. This can be a string, a list of strings or a list of list of strings. -
text_pair (
List[str]orList[int], optional) — Optional second sequence to be encoded. This can be a list of strings (words of a single example) or a list of list of strings (words of a batch of examples). -
add_special_tokens (
bool, optional, defaults toTrue) — Whether or not to encode the sequences with the special tokens relative to their model. -
padding (
bool,stror PaddingStrategy, optional, defaults toFalse) — Activates and controls padding. Accepts the following values:Trueor'longest': Pad to the longest sequence in the batch (or no padding if only a single sequence if provided).'max_length': Pad to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided.Falseor'do_not_pad'(default): No padding (i.e., can output a batch with sequences of different lengths).
-
truncation (
bool,stror TruncationStrategy, optional, defaults toFalse) — Activates and controls truncation. Accepts the following values:Trueor'longest_first': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will truncate token by token, removing a token from the longest sequence in the pair if a pair of sequences (or a batch of pairs) is provided.'only_first': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the first sequence of a pair if a pair of sequences (or a batch of pairs) is provided.'only_second': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the second sequence of a pair if a pair of sequences (or a batch of pairs) is provided.Falseor'do_not_truncate'(default): No truncation (i.e., can output batch with sequence lengths greater than the model maximum admissible input size).
-
max_length (
int, optional) — Controls the maximum length to use by one of the truncation/padding parameters.If left unset or set to
None, this will use the predefined model maximum length if a maximum length is required by one of the truncation/padding parameters. If the model has no specific maximum input length (like XLNet) truncation/padding to a maximum length will be deactivated. -
stride (
int, optional, defaults to 0) — If set to a number along withmax_length, the overflowing tokens returned whenreturn_overflowing_tokens=Truewill contain some tokens from the end of the truncated sequence returned to provide some overlap between truncated and overflowing sequences. The value of this argument defines the number of overlapping tokens. -
is_split_into_words (
bool, optional, defaults toFalse) — Whether or not the input is already pre-tokenized (e.g., split into words). If set toTrue, the tokenizer assumes the input is already split into words (for instance, by splitting it on whitespace) which it will tokenize. This is useful for NER or token classification. -
pad_to_multiple_of (
int, optional) — If set will pad the sequence to a multiple of the provided value. This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >= 7.5 (Volta). -
return_tensors (
stror TensorType, optional) — If set, will return tensors instead of list of python integers. Acceptable values are:'tf': Return TensorFlowtf.constantobjects.'pt': Return PyTorchtorch.Tensorobjects.'np': Return Numpynp.ndarrayobjects.
-
add_special_tokens (
bool, optional, defaults toTrue) — Whether or not to encode the sequences with the special tokens relative to their model. -
padding (
bool,stror PaddingStrategy, optional, defaults toFalse) — Activates and controls padding. Accepts the following values:Trueor'longest': Pad to the longest sequence in the batch (or no padding if only a single sequence if provided).'max_length': Pad to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided.Falseor'do_not_pad'(default): No padding (i.e., can output a batch with sequences of different lengths).
-
truncation (
bool,stror TruncationStrategy, optional, defaults toFalse) — Activates and controls truncation. Accepts the following values:Trueor'longest_first': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will truncate token by token, removing a token from the longest sequence in the pair if a pair of sequences (or a batch of pairs) is provided.'only_first': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the first sequence of a pair if a pair of sequences (or a batch of pairs) is provided.'only_second': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the second sequence of a pair if a pair of sequences (or a batch of pairs) is provided.Falseor'do_not_truncate'(default): No truncation (i.e., can output batch with sequence lengths greater than the model maximum admissible input size).
-
max_length (
int, optional) — Controls the maximum length to use by one of the truncation/padding parameters. If left unset or set toNone, this will use the predefined model maximum length if a maximum length is required by one of the truncation/padding parameters. If the model has no specific maximum input length (like XLNet) truncation/padding to a maximum length will be deactivated. -
stride (
int, optional, defaults to 0) — If set to a number along withmax_length, the overflowing tokens returned whenreturn_overflowing_tokens=Truewill contain some tokens from the end of the truncated sequence returned to provide some overlap between truncated and overflowing sequences. The value of this argument defines the number of overlapping tokens. -
pad_to_multiple_of (
int, optional) — If set will pad the sequence to a multiple of the provided value. This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >= 7.5 (Volta). -
return_tensors (
stror TensorType, optional) — If set, will return tensors instead of list of python integers. Acceptable values are:'tf': Return TensorFlowtf.constantobjects.'pt': Return PyTorchtorch.Tensorobjects.'np': Return Numpynp.ndarrayobjects.
Tokenize and prepare for the model a sequence or a pair of sequences. .. warning:: This method is deprecated,
__call__ should be used instead.
Given the xpath expression of one particular node (like “/html/body/div/li[1]/div/span[2]”), return a list of tag IDs and corresponding subscripts, taking into account max depth.
MarkupLMProcessor
class transformers.MarkupLMProcessor
< source >( *args **kwargs )
Parameters
-
feature_extractor (
MarkupLMFeatureExtractor) — An instance of MarkupLMFeatureExtractor. The feature extractor is a required input. -
tokenizer (
MarkupLMTokenizerorMarkupLMTokenizerFast) — An instance of MarkupLMTokenizer or MarkupLMTokenizerFast. The tokenizer is a required input. -
parse_html (
bool, optional, defaults toTrue) — Whether or not to useMarkupLMFeatureExtractorto parse HTML strings into nodes and corresponding xpaths.
Constructs a MarkupLM processor which combines a MarkupLM feature extractor and a MarkupLM tokenizer into a single processor.
MarkupLMProcessor offers all the functionalities you need to prepare data for the model.
It first uses MarkupLMFeatureExtractor to extract nodes and corresponding xpaths from one or more HTML strings.
Next, these are provided to MarkupLMTokenizer or MarkupLMTokenizerFast, which turns them into token-level
input_ids, attention_mask, token_type_ids, xpath_tags_seq and xpath_subs_seq.
__call__
< source >( html_strings = None nodes = None xpaths = None node_labels = None questions = None add_special_tokens: bool = True padding: typing.Union[bool, str, transformers.utils.generic.PaddingStrategy] = False truncation: typing.Union[bool, str, transformers.tokenization_utils_base.TruncationStrategy] = None max_length: typing.Optional[int] = None stride: int = 0 pad_to_multiple_of: typing.Optional[int] = None return_token_type_ids: typing.Optional[bool] = None return_attention_mask: typing.Optional[bool] = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None **kwargs )
This method first forwards the html_strings argument to call(). Next, it
passes the nodes and xpaths along with the additional arguments to __call__() and
returns the output.
Optionally, one can also provide a text argument which is passed along as first sequence.
Please refer to the docstring of the above two methods for more information.
MarkupLMModel
class transformers.MarkupLMModel
< source >( config add_pooling_layer = True )
Parameters
- config (MarkupLMConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare MarkupLM Model transformer outputting raw hidden-states without any specific head on top. This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >(
input_ids = None
xpath_tags_seq = None
xpath_subs_seq = None
attention_mask = None
token_type_ids = None
position_ids = None
head_mask = None
inputs_embeds = None
output_attentions = None
output_hidden_states = None
return_dict = None
)
→
transformers.modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions or tuple(torch.FloatTensor)
Parameters
-
input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.Indices can be obtained using MarkupLMTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
-
xpath_tags_seq (
torch.LongTensorof shape(batch_size, sequence_length, config.max_depth), optional) — Tag IDs for each token in the input sequence, padded up to config.max_depth. -
xpath_subs_seq (
torch.LongTensorof shape(batch_size, sequence_length, config.max_depth), optional) — Subscript IDs for each token in the input sequence, padded up to config.max_depth. -
attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:1for tokens that are NOT MASKED,0for MASKED tokens. -
token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:0corresponds to a sentence A token,1corresponds to a sentence B token -
position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. -
head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:1indicates the head is not masked,0indicates the head is masked. -
inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convert input_ids indices into associated vectors than the model’s internal embedding lookup matrix. -
output_attentions (
bool, optional) — If set toTrue, the attentions tensors of all attention layers are returned. Seeattentionsunder returned tensors for more detail. -
output_hidden_states (
bool, optional) — If set toTrue, the hidden states of all layers are returned. Seehidden_statesunder returned tensors for more detail. -
return_dict (
bool, optional) — If set toTrue, the model will return a ModelOutput instead of a plain tuple.
Returns
transformers.modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions or tuple(torch.FloatTensor)
A transformers.modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (MarkupLMConfig) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. -
pooler_output (
torch.FloatTensorof shape(batch_size, hidden_size)) — Last layer hidden-state of the first token of the sequence (classification token) after further processing through the layers used for the auxiliary pretraining task. E.g. for BERT-family of models, this returns the classification token after processing through a linear layer and a tanh activation function. The linear layer weights are trained from the next sentence prediction (classification) objective during pretraining. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
-
cross_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueandconfig.add_cross_attention=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights of the decoder’s cross-attention layer, after the attention softmax, used to compute the weighted average in the cross-attention heads.
-
past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)) and optionally ifconfig.is_encoder_decoder=True2 additional tensors of shape(batch_size, num_heads, encoder_sequence_length, embed_size_per_head).Contains pre-computed hidden-states (key and values in the self-attention blocks and optionally if
config.is_encoder_decoder=Truein the cross-attention blocks) that can be used (seepast_key_valuesinput) to speed up sequential decoding.
The MarkupLMModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import MarkupLMProcessor, MarkupLMModel
>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
>>> model = MarkupLMModel.from_pretrained("microsoft/markuplm-base")
>>> html_string = "<html> <head> <title>Page Title</title> </head> </html>"
>>> encoding = processor(html_string, return_tensors="pt")
>>> outputs = model(**encoding)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 4, 768]MarkupLMForSequenceClassification
class transformers.MarkupLMForSequenceClassification
< source >( config )
Parameters
- config (MarkupLMConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
MarkupLM Model transformer with a sequence classification/regression head on top (a linear layer on top of the pooled output) e.g. for GLUE tasks.
This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >(
input_ids: typing.Optional[torch.Tensor] = None
xpath_tags_seq: typing.Optional[torch.Tensor] = None
xpath_subs_seq: typing.Optional[torch.Tensor] = None
attention_mask: typing.Optional[torch.Tensor] = None
token_type_ids: typing.Optional[torch.Tensor] = None
position_ids: typing.Optional[torch.Tensor] = None
head_mask: typing.Optional[torch.Tensor] = None
inputs_embeds: typing.Optional[torch.Tensor] = None
labels: typing.Optional[torch.Tensor] = None
output_attentions: typing.Optional[bool] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)
Parameters
-
input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.Indices can be obtained using MarkupLMTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
-
xpath_tags_seq (
torch.LongTensorof shape(batch_size, sequence_length, config.max_depth), optional) — Tag IDs for each token in the input sequence, padded up to config.max_depth. -
xpath_subs_seq (
torch.LongTensorof shape(batch_size, sequence_length, config.max_depth), optional) — Subscript IDs for each token in the input sequence, padded up to config.max_depth. -
attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:1for tokens that are NOT MASKED,0for MASKED tokens. -
token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:0corresponds to a sentence A token,1corresponds to a sentence B token -
position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. -
head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:1indicates the head is not masked,0indicates the head is masked. -
inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convert input_ids indices into associated vectors than the model’s internal embedding lookup matrix. -
output_attentions (
bool, optional) — If set toTrue, the attentions tensors of all attention layers are returned. Seeattentionsunder returned tensors for more detail. -
output_hidden_states (
bool, optional) — If set toTrue, the hidden states of all layers are returned. Seehidden_statesunder returned tensors for more detail. -
return_dict (
bool, optional) — If set toTrue, the model will return a ModelOutput instead of a plain tuple. -
labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the sequence classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy).
Returns
transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.SequenceClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (MarkupLMConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. -
logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The MarkupLMForSequenceClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoProcessor, AutoModelForSequenceClassification
>>> import torch
>>> processor = AutoProcessor.from_pretrained("microsoft/markuplm-base")
>>> model = AutoModelForSequenceClassification.from_pretrained("microsoft/markuplm-base", num_labels=7)
>>> html_string = "<html> <head> <title>Page Title</title> </head> </html>"
>>> encoding = processor(html_string, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**encoding)
>>> loss = outputs.loss
>>> logits = outputs.logitsMarkupLMForTokenClassification
class transformers.MarkupLMForTokenClassification
< source >( config )
Parameters
- config (MarkupLMConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
MarkupLM Model with a token_classification head on top.
This model is a PyTorch torch.nn.Module sub-class. Use
it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
forward
< source >(
input_ids: typing.Optional[torch.Tensor] = None
xpath_tags_seq: typing.Optional[torch.Tensor] = None
xpath_subs_seq: typing.Optional[torch.Tensor] = None
attention_mask: typing.Optional[torch.Tensor] = None
token_type_ids: typing.Optional[torch.Tensor] = None
position_ids: typing.Optional[torch.Tensor] = None
head_mask: typing.Optional[torch.Tensor] = None
inputs_embeds: typing.Optional[torch.Tensor] = None
labels: typing.Optional[torch.Tensor] = None
output_attentions: typing.Optional[bool] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.modeling_outputs.MaskedLMOutput or tuple(torch.FloatTensor)
Parameters
-
input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.Indices can be obtained using MarkupLMTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
-
xpath_tags_seq (
torch.LongTensorof shape(batch_size, sequence_length, config.max_depth), optional) — Tag IDs for each token in the input sequence, padded up to config.max_depth. -
xpath_subs_seq (
torch.LongTensorof shape(batch_size, sequence_length, config.max_depth), optional) — Subscript IDs for each token in the input sequence, padded up to config.max_depth. -
attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:1for tokens that are NOT MASKED,0for MASKED tokens. -
token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:0corresponds to a sentence A token,1corresponds to a sentence B token -
position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. -
head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:1indicates the head is not masked,0indicates the head is masked. -
inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convert input_ids indices into associated vectors than the model’s internal embedding lookup matrix. -
output_attentions (
bool, optional) — If set toTrue, the attentions tensors of all attention layers are returned. Seeattentionsunder returned tensors for more detail. -
output_hidden_states (
bool, optional) — If set toTrue, the hidden states of all layers are returned. Seehidden_statesunder returned tensors for more detail. -
return_dict (
bool, optional) — If set toTrue, the model will return a ModelOutput instead of a plain tuple. -
labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Labels for computing the token classification loss. Indices should be in[0, ..., config.num_labels - 1].
Returns
transformers.modeling_outputs.MaskedLMOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.MaskedLMOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (MarkupLMConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Masked language modeling (MLM) loss. -
logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The MarkupLMForTokenClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoProcessor, AutoModelForTokenClassification
>>> import torch
>>> processor = AutoProcessor.from_pretrained("microsoft/markuplm-base")
>>> processor.parse_html = False
>>> model = AutoModelForTokenClassification.from_pretrained("microsoft/markuplm-base", num_labels=7)
>>> nodes = ["hello", "world"]
>>> xpaths = ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span"]
>>> node_labels = [1, 2]
>>> encoding = processor(nodes=nodes, xpaths=xpaths, node_labels=node_labels, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**encoding)
>>> loss = outputs.loss
>>> logits = outputs.logitsMarkupLMForQuestionAnswering
class transformers.MarkupLMForQuestionAnswering
< source >( config )
Parameters
- config (MarkupLMConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
MarkupLM Model with a span classification head on top for extractive question-answering tasks like SQuAD (a linear
layers on top of the hidden-states output to compute span start logits and span end logits).
This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >(
input_ids: typing.Optional[torch.Tensor] = None
xpath_tags_seq: typing.Optional[torch.Tensor] = None
xpath_subs_seq: typing.Optional[torch.Tensor] = None
attention_mask: typing.Optional[torch.Tensor] = None
token_type_ids: typing.Optional[torch.Tensor] = None
position_ids: typing.Optional[torch.Tensor] = None
head_mask: typing.Optional[torch.Tensor] = None
inputs_embeds: typing.Optional[torch.Tensor] = None
start_positions: typing.Optional[torch.Tensor] = None
end_positions: typing.Optional[torch.Tensor] = None
output_attentions: typing.Optional[bool] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.modeling_outputs.QuestionAnsweringModelOutput or tuple(torch.FloatTensor)
Parameters
-
input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.Indices can be obtained using MarkupLMTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
-
xpath_tags_seq (
torch.LongTensorof shape(batch_size, sequence_length, config.max_depth), optional) — Tag IDs for each token in the input sequence, padded up to config.max_depth. -
xpath_subs_seq (
torch.LongTensorof shape(batch_size, sequence_length, config.max_depth), optional) — Subscript IDs for each token in the input sequence, padded up to config.max_depth. -
attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:1for tokens that are NOT MASKED,0for MASKED tokens. -
token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:0corresponds to a sentence A token,1corresponds to a sentence B token -
position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. -
head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:1indicates the head is not masked,0indicates the head is masked. -
inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convert input_ids indices into associated vectors than the model’s internal embedding lookup matrix. -
output_attentions (
bool, optional) — If set toTrue, the attentions tensors of all attention layers are returned. Seeattentionsunder returned tensors for more detail. -
output_hidden_states (
bool, optional) — If set toTrue, the hidden states of all layers are returned. Seehidden_statesunder returned tensors for more detail. -
return_dict (
bool, optional) — If set toTrue, the model will return a ModelOutput instead of a plain tuple. -
start_positions (
torch.LongTensorof shape(batch_size,), optional) — Labels for position (index) of the start of the labelled span for computing the token classification loss. Positions are clamped to the length of the sequence (sequence_length). Position outside of the sequence are not taken into account for computing the loss. -
end_positions (
torch.LongTensorof shape(batch_size,), optional) — Labels for position (index) of the end of the labelled span for computing the token classification loss. Positions are clamped to the length of the sequence (sequence_length). Position outside of the sequence are not taken into account for computing the loss.
Returns
transformers.modeling_outputs.QuestionAnsweringModelOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.QuestionAnsweringModelOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (MarkupLMConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Total span extraction loss is the sum of a Cross-Entropy for the start and end positions. -
start_logits (
torch.FloatTensorof shape(batch_size, sequence_length)) — Span-start scores (before SoftMax). -
end_logits (
torch.FloatTensorof shape(batch_size, sequence_length)) — Span-end scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The MarkupLMForQuestionAnswering forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import MarkupLMProcessor, MarkupLMForQuestionAnswering
>>> import torch
>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base-finetuned-websrc")
>>> model = MarkupLMForQuestionAnswering.from_pretrained("microsoft/markuplm-base-finetuned-websrc")
>>> html_string = "<html> <head> <title>My name is Niels</title> </head> </html>"
>>> question = "What's his name?"
>>> encoding = processor(html_string, questions=question, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**encoding)
>>> answer_start_index = outputs.start_logits.argmax()
>>> answer_end_index = outputs.end_logits.argmax()
>>> predict_answer_tokens = encoding.input_ids[0, answer_start_index : answer_end_index + 1]
>>> processor.decode(predict_answer_tokens).strip()
'Niels'