Transformers documentation
LeViT
LeViT
Overview
The LeViT model was proposed in LeViT: Introducing Convolutions to Vision Transformers by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze. LeViT improves the Vision Transformer (ViT) in performance and efficiency by a few architectural differences such as activation maps with decreasing resolutions in Transformers and the introduction of an attention bias to integrate positional information.
The abstract from the paper is the following:
We design a family of image classification architectures that optimize the trade-off between accuracy and efficiency in a high-speed regime. Our work exploits recent findings in attention-based architectures, which are competitive on highly parallel processing hardware. We revisit principles from the extensive literature on convolutional neural networks to apply them to transformers, in particular activation maps with decreasing resolutions. We also introduce the attention bias, a new way to integrate positional information in vision transformers. As a result, we propose LeVIT: a hybrid neural network for fast inference image classification. We consider different measures of efficiency on different hardware platforms, so as to best reflect a wide range of application scenarios. Our extensive experiments empirically validate our technical choices and show they are suitable to most architectures. Overall, LeViT significantly outperforms existing convnets and vision transformers with respect to the speed/accuracy tradeoff. For example, at 80% ImageNet top-1 accuracy, LeViT is 5 times faster than EfficientNet on CPU.
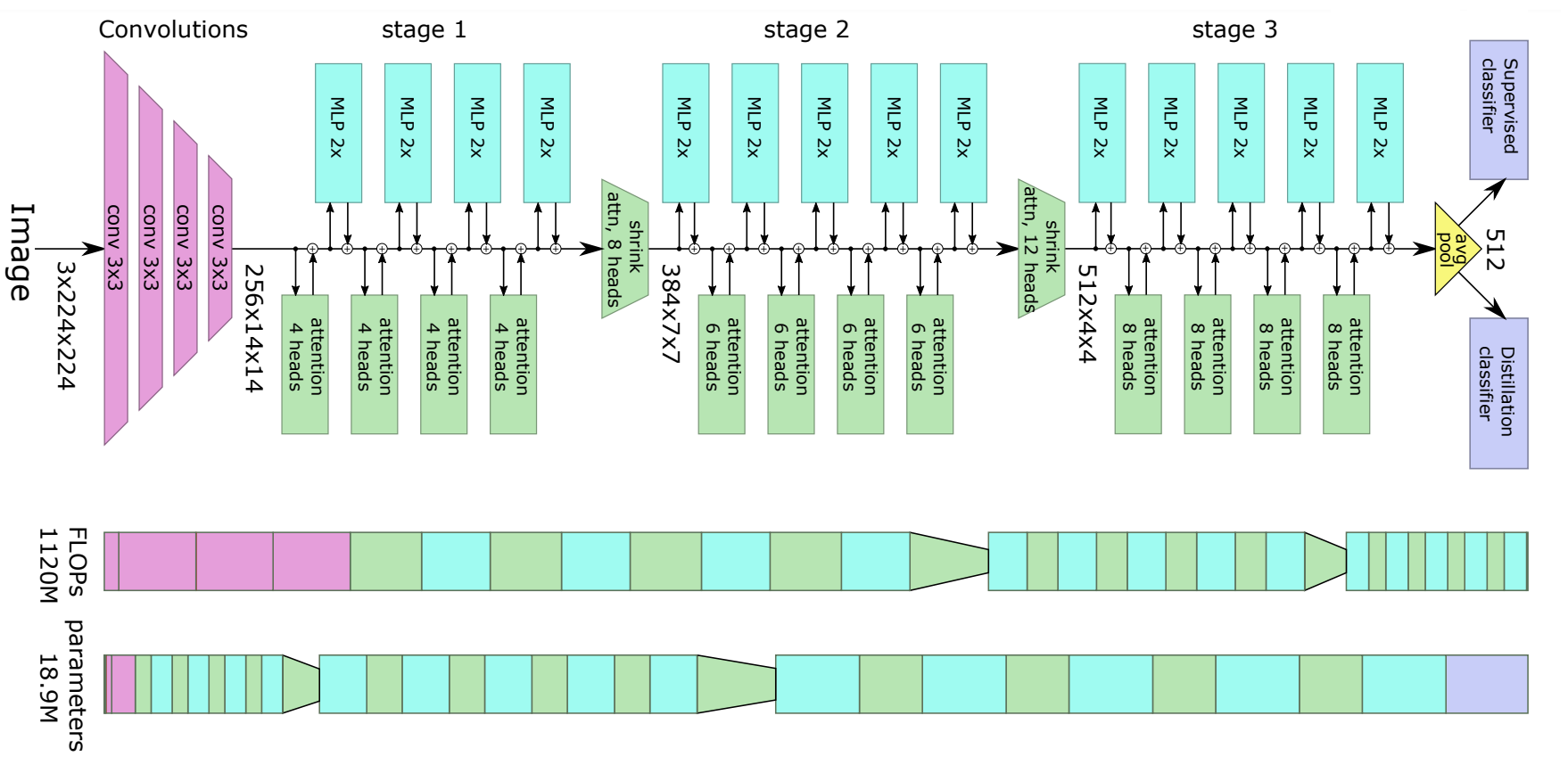 LeViT Architecture. Taken from the original paper.
LeViT Architecture. Taken from the original paper.
Tips:
- Compared to ViT, LeViT models use an additional distillation head to effectively learn from a teacher (which, in the LeViT paper, is a ResNet like-model). The distillation head is learned through backpropagation under supervision of a ResNet like-model. They also draw inspiration from convolution neural networks to use activation maps with decreasing resolutions to increase the efficiency.
- There are 2 ways to fine-tune distilled models, either (1) in a classic way, by only placing a prediction head on top of the final hidden state and not using the distillation head, or (2) by placing both a prediction head and distillation head on top of the final hidden state. In that case, the prediction head is trained using regular cross-entropy between the prediction of the head and the ground-truth label, while the distillation prediction head is trained using hard distillation (cross-entropy between the prediction of the distillation head and the label predicted by the teacher). At inference time, one takes the average prediction between both heads as final prediction. (2) is also called “fine-tuning with distillation”, because one relies on a teacher that has already been fine-tuned on the downstream dataset. In terms of models, (1) corresponds to LevitForImageClassification and (2) corresponds to LevitForImageClassificationWithTeacher.
- All released checkpoints were pre-trained and fine-tuned on ImageNet-1k (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes). only. No external data was used. This is in contrast with the original ViT model, which used external data like the JFT-300M dataset/Imagenet-21k for pre-training.
- The authors of LeViT released 5 trained LeViT models, which you can directly plug into LevitModel or LevitForImageClassification. Techniques like data augmentation, optimization, and regularization were used in order to simulate training on a much larger dataset (while only using ImageNet-1k for pre-training). The 5 variants available are (all trained on images of size 224x224): facebook/levit-128S, facebook/levit-128, facebook/levit-192, facebook/levit-256 and facebook/levit-384. Note that one should use LevitFeatureExtractor in order to prepare images for the model.
- LevitForImageClassificationWithTeacher currently supports only inference and not training or fine-tuning.
- You can check out demo notebooks regarding inference as well as fine-tuning on custom data here (you can just replace ViTFeatureExtractor by LevitFeatureExtractor and ViTForImageClassification by LevitForImageClassification or LevitForImageClassificationWithTeacher).
This model was contributed by anugunj. The original code can be found here.
LevitConfig
class transformers.LevitConfig
< source >( image_size = 224 num_channels = 3 kernel_size = 3 stride = 2 padding = 1 patch_size = 16 hidden_sizes = [128, 256, 384] num_attention_heads = [4, 8, 12] depths = [4, 4, 4] key_dim = [16, 16, 16] drop_path_rate = 0 mlp_ratio = [2, 2, 2] attention_ratio = [2, 2, 2] initializer_range = 0.02 **kwargs )
Parameters
-
image_size (
int, optional, defaults to 224) — The size of the input image. -
num_channels (
int, optional, defaults to 3) — Number of channels in the input image. -
kernel_size (
int, optional, defaults to 3) — The kernel size for the initial convolution layers of patch embedding. -
stride (
int, optional, defaults to 2) — The stride size for the initial convolution layers of patch embedding. -
padding (
int, optional, defaults to 1) — The padding size for the initial convolution layers of patch embedding. -
patch_size (
int, optional, defaults to 16) — The patch size for embeddings. -
hidden_sizes (
List[int], optional, defaults to[128, 256, 384]) — Dimension of each of the encoder blocks. -
num_attention_heads (
List[int], optional, defaults to[4, 8, 12]) — Number of attention heads for each attention layer in each block of the Transformer encoder. -
depths (
List[int], optional, defaults to[4, 4, 4]) — The number of layers in each encoder block. -
key_dim (
List[int], optional, defaults to[16, 16, 16]) — The size of key in each of the encoder blocks. -
drop_path_rate (
int, optional, defaults to 0) — The dropout probability for stochastic depths, used in the blocks of the Transformer encoder. -
mlp_ratios (
List[int], optional, defaults to[2, 2, 2]) — Ratio of the size of the hidden layer compared to the size of the input layer of the Mix FFNs in the encoder blocks. -
attention_ratios (
List[int], optional, defaults to[2, 2, 2]) — Ratio of the size of the output dimension compared to input dimension of attention layers. -
initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
This is the configuration class to store the configuration of a LevitModel. It is used to instantiate a LeViT model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the LeViT facebook/levit-base-192 architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import LevitModel, LevitConfig
>>> # Initializing a LeViT levit-base-192 style configuration
>>> configuration = LevitConfig()
>>> # Initializing a model from the levit-base-192 style configuration
>>> model = LevitModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configLevitFeatureExtractor
class transformers.LevitFeatureExtractor
< source >( do_resize = True size = 224 resample = <Resampling.BICUBIC: 3> do_center_crop = True do_normalize = True image_mean = [0.485, 0.456, 0.406] image_std = [0.229, 0.224, 0.225] **kwargs )
Parameters
-
do_resize (
bool, optional, defaults toTrue) — Whether to resize the shortest edge of the input to int(256/224 *size). -
size (
intorTuple(int), optional, defaults to 224) — Resize the input to the given size. If a tuple is provided, it should be (width, height). If only an integer is provided, then shorter side of input will be resized to ‘size’. -
resample (
int, optional, defaults toPIL.Image.BICUBIC) — An optional resampling filter. This can be one ofPIL.Image.NEAREST,PIL.Image.BOX,PIL.Image.BILINEAR,PIL.Image.HAMMING,PIL.Image.BICUBICorPIL.Image.LANCZOS. Only has an effect ifdo_resizeis set toTrue. -
do_center_crop (
bool, optional, defaults toTrue) — Whether or not to center crop the input tosize. -
do_normalize (
bool, optional, defaults toTrue) — Whether or not to normalize the input with mean and standard deviation. -
image_mean (
List[int], defaults to[0.229, 0.224, 0.225]) — The sequence of means for each channel, to be used when normalizing images. -
image_std (
List[int], defaults to[0.485, 0.456, 0.406]) — The sequence of standard deviations for each channel, to be used when normalizing images.
Constructs a LeViT feature extractor.
This feature extractor inherits from FeatureExtractionMixin which contains most of the main methods. Users should refer to this superclass for more information regarding those methods.
__call__
< source >( images: typing.Union[PIL.Image.Image, numpy.ndarray, ForwardRef('torch.Tensor'), typing.List[PIL.Image.Image], typing.List[numpy.ndarray], typing.List[ForwardRef('torch.Tensor')]] return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None **kwargs ) → BatchFeature
Parameters
-
images (
PIL.Image.Image,np.ndarray,torch.Tensor,List[PIL.Image.Image],List[np.ndarray],List[torch.Tensor]) — The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a number of channels, H and W are image height and width. -
return_tensors (
stror TensorType, optional, defaults to'np') — If set, will return tensors of a particular framework. Acceptable values are:'tf': Return TensorFlowtf.constantobjects.'pt': Return PyTorchtorch.Tensorobjects.'np': Return NumPynp.ndarrayobjects.'jax': Return JAXjnp.ndarrayobjects.
Returns
A BatchFeature with the following fields:
- pixel_values — Pixel values to be fed to a model, of shape (batch_size, num_channels, height, width).
Main method to prepare for the model one or several image(s).
NumPy arrays and PyTorch tensors are converted to PIL images when resizing, so the most efficient is to pass PIL images.
LevitModel
class transformers.LevitModel
< source >( config )
Parameters
- config (LevitConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare Levit model outputting raw features without any specific head on top. This model is a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >(
pixel_values: FloatTensor = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.modeling_outputs.BaseModelOutputWithPoolingAndNoAttention or tuple(torch.FloatTensor)
Parameters
-
pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using AutoFeatureExtractor. SeeAutoFeatureExtractor.__call__()for details. -
output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. -
return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.modeling_outputs.BaseModelOutputWithPoolingAndNoAttention or tuple(torch.FloatTensor)
A transformers.modeling_outputs.BaseModelOutputWithPoolingAndNoAttention or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (LevitConfig) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Sequence of hidden-states at the output of the last layer of the model. -
pooler_output (
torch.FloatTensorof shape(batch_size, hidden_size)) — Last layer hidden-state after a pooling operation on the spatial dimensions. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, num_channels, height, width).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
The LevitModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import LevitFeatureExtractor, LevitModel
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> feature_extractor = LevitFeatureExtractor.from_pretrained("facebook/levit-128S")
>>> model = LevitModel.from_pretrained("facebook/levit-128S")
>>> inputs = feature_extractor(image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 16, 384]LevitForImageClassification
class transformers.LevitForImageClassification
< source >( config )
Parameters
- config (LevitConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Levit Model with an image classification head on top (a linear layer on top of the pooled features), e.g. for ImageNet.
This model is a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >(
pixel_values: FloatTensor = None
labels: typing.Optional[torch.LongTensor] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.modeling_outputs.ImageClassifierOutputWithNoAttention or tuple(torch.FloatTensor)
Parameters
-
pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using AutoFeatureExtractor. SeeAutoFeatureExtractor.__call__()for details. -
output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. -
return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. -
labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the image classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy).
Returns
transformers.modeling_outputs.ImageClassifierOutputWithNoAttention or tuple(torch.FloatTensor)
A transformers.modeling_outputs.ImageClassifierOutputWithNoAttention or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (LevitConfig) and inputs.
- loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. - logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each stage) of shape(batch_size, num_channels, height, width). Hidden-states (also called feature maps) of the model at the output of each stage.
The LevitForImageClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import LevitFeatureExtractor, LevitForImageClassification
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> feature_extractor = LevitFeatureExtractor.from_pretrained("facebook/levit-128S")
>>> model = LevitForImageClassification.from_pretrained("facebook/levit-128S")
>>> inputs = feature_extractor(image, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_label = logits.argmax(-1).item()
>>> print(model.config.id2label[predicted_label])
tabby, tabby catLevitForImageClassificationWithTeacher
class transformers.LevitForImageClassificationWithTeacher
< source >( config )
Parameters
- config (LevitConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
LeViT Model transformer with image classification heads on top (a linear layer on top of the final hidden state and a linear layer on top of the final hidden state of the distillation token) e.g. for ImageNet. .. warning:: This model supports inference-only. Fine-tuning with distillation (i.e. with a teacher) is not yet supported.
This model is a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >(
pixel_values: FloatTensor = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.models.levit.modeling_levit.LevitForImageClassificationWithTeacherOutput or tuple(torch.FloatTensor)
Parameters
-
pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using AutoFeatureExtractor. SeeAutoFeatureExtractor.__call__()for details. -
output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. -
return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.models.levit.modeling_levit.LevitForImageClassificationWithTeacherOutput or tuple(torch.FloatTensor)
A transformers.models.levit.modeling_levit.LevitForImageClassificationWithTeacherOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (LevitConfig) and inputs.
- logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Prediction scores as the average of thecls_logitsanddistillation_logits. - cls_logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Prediction scores of the classification head (i.e. the linear layer on top of the final hidden state of the class token). - distillation_logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Prediction scores of the distillation head (i.e. the linear layer on top of the final hidden state of the distillation token). - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the model at the output of each layer plus the initial embedding outputs.
The LevitForImageClassificationWithTeacher forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import LevitFeatureExtractor, LevitForImageClassificationWithTeacher
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> feature_extractor = LevitFeatureExtractor.from_pretrained("facebook/levit-128S")
>>> model = LevitForImageClassificationWithTeacher.from_pretrained("facebook/levit-128S")
>>> inputs = feature_extractor(image, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_label = logits.argmax(-1).item()
>>> print(model.config.id2label[predicted_label])
tabby, tabby cat