Transformers documentation
Swin2SR
Swin2SR
개요
Swin2SR 모델은 Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte가 제안한 논문 Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration에서 소개되었습니다. Swin2SR은 SwinIR 모델을 개선하고자 Swin Transformer v2 레이어를 도입함으로써, 훈련 불안정성, 사전 훈련과 미세 조정 간의 해상도 차이, 그리고 데이터 의존성 문제를 완화시킵니다.
논문의 초록은 다음과 같습니다:
압축은 스트리밍 서비스, 가상 현실, 비디오 게임과 같은 대역폭이 제한된 시스템을 통해 이미지와 영상을 효율적으로 전송하고 저장하는 데 중요한 역할을 합니다. 하지만 압축은 필연적으로 원본 정보의 손실과 아티팩트를 초래하며, 이는 시각적 품질을 심각하게 저하시킬 수 있습니다. 이러한 이유로, 압축된 이미지의 품질 향상은 활발한 연구 주제가 되고 있습니다. 현재 대부분의 최첨단 이미지 복원 방법은 합성곱 신경망을 기반으로 하지만, SwinIR과 같은 트랜스포머 기반 방법들도 이 작업에서 인상적인 성능을 보여주고 있습니다. 이번 논문에서는 Swin Transformer V2를 사용해 SwinIR을 개선하여 이미지 초해상도 작업, 특히 압축된 입력 시나리오에서 성능을 향상시키고자 합니다. 이 방법을 통해 트랜스포머 비전 모델을 훈련할 때 발생하는 주요 문제들, 예를 들어 훈련 불안정성, 사전 훈련과 미세 조정 간 해상도 차이, 그리고 데이터 의존성을 해결할 수 있습니다. 우리는 JPEG 압축 아티팩트 제거, 이미지 초해상도(클래식 및 경량), 그리고 압축된 이미지 초해상도라는 세 가지 대표적인 작업에서 실험을 수행했습니다. 실험 결과, 우리의 방법인 Swin2SR은 SwinIR의 훈련 수렴성과 성능을 향상시킬 수 있으며, “AIM 2022 Challenge on Super-Resolution of Compressed Image and Video”에서 상위 5위 솔루션으로 선정되었습니다.
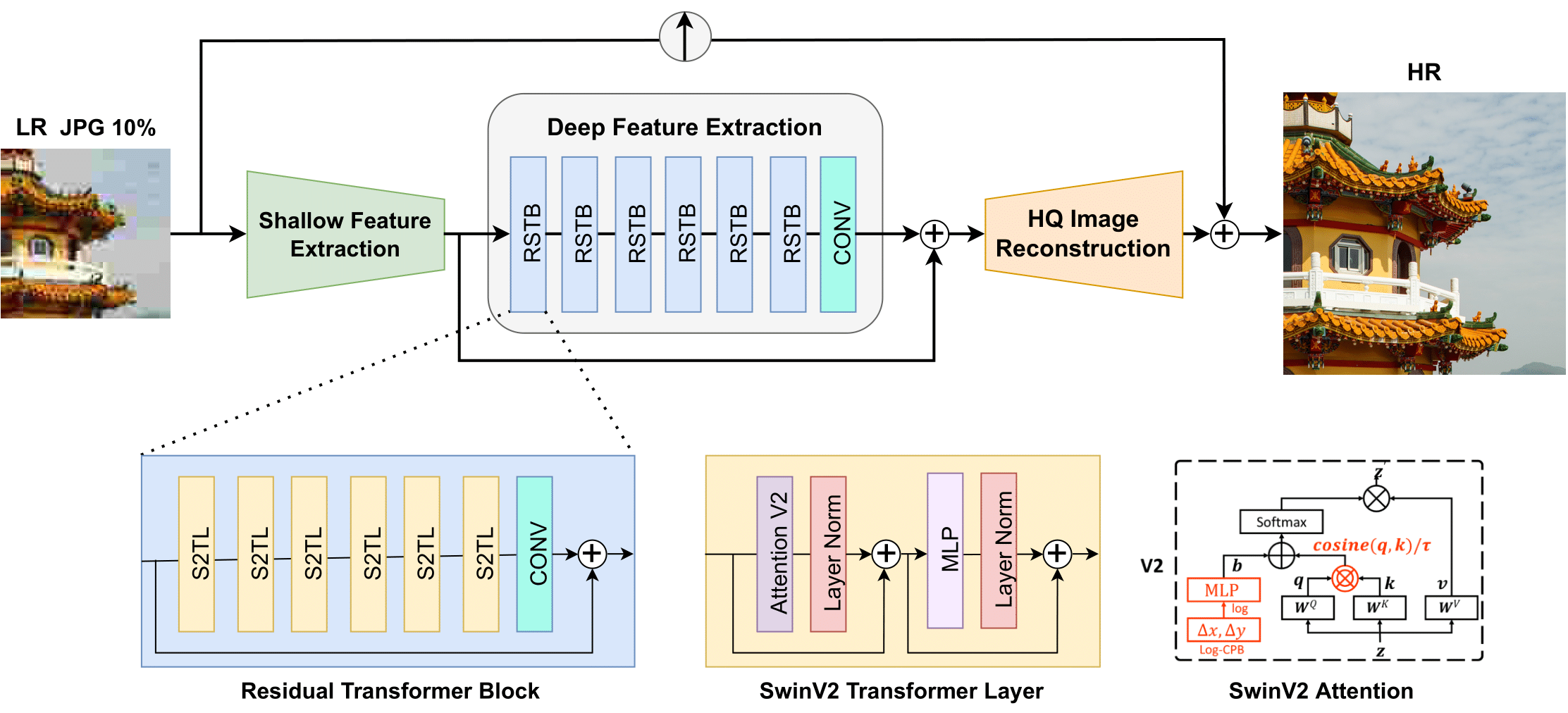 Swin2SR 아키텍처. 원본 논문에서 발췌.
Swin2SR 아키텍처. 원본 논문에서 발췌. 이 모델은 nielsr가 기여하였습니다. 원본 코드는 여기에서 확인할 수 있습니다.
리소스
Swin2SR demo notebook은 여기에서 확인할 수 있습니다.
SwinSR을 활용한 image super-resolution demo space는 여기에서 확인할 수 있습니다.
Swin2SRImageProcessor
class transformers.Swin2SRImageProcessor
< source >( do_rescale: bool = True rescale_factor: typing.Union[int, float] = 0.00392156862745098 do_pad: bool = True pad_size: int = 8 **kwargs )
Parameters
- do_rescale (
bool, optional, defaults toTrue) — Whether to rescale the image by the specified scalerescale_factor. Can be overridden by thedo_rescaleparameter in thepreprocessmethod. - rescale_factor (
intorfloat, optional, defaults to1/255) — Scale factor to use if rescaling the image. Can be overridden by therescale_factorparameter in thepreprocessmethod.
Constructs a Swin2SR image processor.
preprocess
< source >( images: typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), list['PIL.Image.Image'], list[numpy.ndarray], list['torch.Tensor']] do_rescale: typing.Optional[bool] = None rescale_factor: typing.Optional[float] = None do_pad: typing.Optional[bool] = None pad_size: typing.Optional[int] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None data_format: typing.Union[str, transformers.image_utils.ChannelDimension] = <ChannelDimension.FIRST: 'channels_first'> input_data_format: typing.Union[str, transformers.image_utils.ChannelDimension, NoneType] = None )
Parameters
- images (
ImageInput) — Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If passing in images with pixel values between 0 and 1, setdo_rescale=False. - do_rescale (
bool, optional, defaults toself.do_rescale) — Whether to rescale the image values between [0 - 1]. - rescale_factor (
float, optional, defaults toself.rescale_factor) — Rescale factor to rescale the image by ifdo_rescaleis set toTrue. - do_pad (
bool, optional, defaults toTrue) — Whether to pad the image to make the height and width divisible bywindow_size. - pad_size (
int, optional, defaults to 32) — The size of the sliding window for the local attention. - return_tensors (
strorTensorType, optional) — The type of tensors to return. Can be one of:- Unset: Return a list of
np.ndarray. TensorType.TENSORFLOWor'tf': Return a batch of typ, input_data_format=input_data_formatetf.Tensor.TensorType.PYTORCHor'pt': Return a batch of typetorch.Tensor.TensorType.NUMPYor'np': Return a batch of typenp.ndarray.TensorType.JAXor'jax': Return a batch of typejax.numpy.ndarray.
- Unset: Return a list of
- data_format (
ChannelDimensionorstr, optional, defaults toChannelDimension.FIRST) — The channel dimension format for the output image. Can be one of:"channels_first"orChannelDimension.FIRST: image in (num_channels, height, width) format."channels_last"orChannelDimension.LAST: image in (height, width, num_channels) format.- Unset: Use the channel dimension format of the input image.
- input_data_format (
ChannelDimensionorstr, optional) — The channel dimension format for the input image. If unset, the channel dimension format is inferred from the input image. Can be one of:"channels_first"orChannelDimension.FIRST: image in (num_channels, height, width) format."channels_last"orChannelDimension.LAST: image in (height, width, num_channels) format."none"orChannelDimension.NONE: image in (height, width) format.
Preprocess an image or batch of images.
Swin2SRConfig
class transformers.Swin2SRConfig
< source >( image_size = 64 patch_size = 1 num_channels = 3 num_channels_out = None embed_dim = 180 depths = [6, 6, 6, 6, 6, 6] num_heads = [6, 6, 6, 6, 6, 6] window_size = 8 mlp_ratio = 2.0 qkv_bias = True hidden_dropout_prob = 0.0 attention_probs_dropout_prob = 0.0 drop_path_rate = 0.1 hidden_act = 'gelu' use_absolute_embeddings = False initializer_range = 0.02 layer_norm_eps = 1e-05 upscale = 2 img_range = 1.0 resi_connection = '1conv' upsampler = 'pixelshuffle' **kwargs )
Parameters
- image_size (
int, optional, defaults to 64) — The size (resolution) of each image. - patch_size (
int, optional, defaults to 1) — The size (resolution) of each patch. - num_channels (
int, optional, defaults to 3) — The number of input channels. - num_channels_out (
int, optional, defaults tonum_channels) — The number of output channels. If not set, it will be set tonum_channels. - embed_dim (
int, optional, defaults to 180) — Dimensionality of patch embedding. - depths (
list(int), optional, defaults to[6, 6, 6, 6, 6, 6]) — Depth of each layer in the Transformer encoder. - num_heads (
list(int), optional, defaults to[6, 6, 6, 6, 6, 6]) — Number of attention heads in each layer of the Transformer encoder. - window_size (
int, optional, defaults to 8) — Size of windows. - mlp_ratio (
float, optional, defaults to 2.0) — Ratio of MLP hidden dimensionality to embedding dimensionality. - qkv_bias (
bool, optional, defaults toTrue) — Whether or not a learnable bias should be added to the queries, keys and values. - hidden_dropout_prob (
float, optional, defaults to 0.0) — The dropout probability for all fully connected layers in the embeddings and encoder. - attention_probs_dropout_prob (
float, optional, defaults to 0.0) — The dropout ratio for the attention probabilities. - drop_path_rate (
float, optional, defaults to 0.1) — Stochastic depth rate. - hidden_act (
strorfunction, optional, defaults to"gelu") — The non-linear activation function (function or string) in the encoder. If string,"gelu","relu","selu"and"gelu_new"are supported. - use_absolute_embeddings (
bool, optional, defaults toFalse) — Whether or not to add absolute position embeddings to the patch embeddings. - initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - layer_norm_eps (
float, optional, defaults to 1e-05) — The epsilon used by the layer normalization layers. - upscale (
int, optional, defaults to 2) — The upscale factor for the image. 2/3/4/8 for image super resolution, 1 for denoising and compress artifact reduction - img_range (
float, optional, defaults to 1.0) — The range of the values of the input image. - resi_connection (
str, optional, defaults to"1conv") — The convolutional block to use before the residual connection in each stage. - upsampler (
str, optional, defaults to"pixelshuffle") — The reconstruction reconstruction module. Can be ‘pixelshuffle’/‘pixelshuffledirect’/‘nearest+conv’/None.
This is the configuration class to store the configuration of a Swin2SRModel. It is used to instantiate a Swin Transformer v2 model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the Swin Transformer v2 caidas/swin2sr-classicalsr-x2-64 architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import Swin2SRConfig, Swin2SRModel
>>> # Initializing a Swin2SR caidas/swin2sr-classicalsr-x2-64 style configuration
>>> configuration = Swin2SRConfig()
>>> # Initializing a model (with random weights) from the caidas/swin2sr-classicalsr-x2-64 style configuration
>>> model = Swin2SRModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configSwin2SRModel
class transformers.Swin2SRModel
< source >( config )
Parameters
- config (Swin2SRModel) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare Swin2Sr Model outputting raw hidden-states without any specific head on top.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( pixel_values: FloatTensor head_mask: typing.Optional[torch.FloatTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.BaseModelOutput or tuple(torch.FloatTensor)
Parameters
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, image_size, image_size)) — The tensors corresponding to the input images. Pixel values can be obtained using{image_processor_class}. See{image_processor_class}.__call__for details ({processor_class}uses{image_processor_class}for processing images). - head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.modeling_outputs.BaseModelOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.BaseModelOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (Swin2SRConfig) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The Swin2SRModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Swin2SRForImageSuperResolution
class transformers.Swin2SRForImageSuperResolution
< source >( config )
Parameters
- config (Swin2SRForImageSuperResolution) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Swin2SR Model transformer with an upsampler head on top for image super resolution and restoration.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( pixel_values: typing.Optional[torch.FloatTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.ImageSuperResolutionOutput or tuple(torch.FloatTensor)
Parameters
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, image_size, image_size), optional) — The tensors corresponding to the input images. Pixel values can be obtained using{image_processor_class}. See{image_processor_class}.__call__for details ({processor_class}uses{image_processor_class}for processing images). - head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Labels for computing the masked language modeling loss. Indices should either be in[0, ..., config.vocab_size]or -100 (seeinput_idsdocstring). Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels in[0, ..., config.vocab_size]. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.modeling_outputs.ImageSuperResolutionOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.ImageSuperResolutionOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (Swin2SRConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Reconstruction loss. -
reconstruction (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Reconstructed images, possibly upscaled. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each stage) of shape(batch_size, sequence_length, hidden_size). Hidden-states (also called feature maps) of the model at the output of each stage. -
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, patch_size, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The Swin2SRForImageSuperResolution forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> import torch
>>> import numpy as np
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoImageProcessor, Swin2SRForImageSuperResolution
>>> processor = AutoImageProcessor.from_pretrained("caidas/swin2SR-classical-sr-x2-64")
>>> model = Swin2SRForImageSuperResolution.from_pretrained("caidas/swin2SR-classical-sr-x2-64")
>>> url = "https://huggingface.co/spaces/jjourney1125/swin2sr/resolve/main/samples/butterfly.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> # prepare image for the model
>>> inputs = processor(image, return_tensors="pt")
>>> # forward pass
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> output = outputs.reconstruction.data.squeeze().float().cpu().clamp_(0, 1).numpy()
>>> output = np.moveaxis(output, source=0, destination=-1)
>>> output = (output * 255.0).round().astype(np.uint8) # float32 to uint8
>>> # you can visualize `output` with `Image.fromarray`