PEFT documentation
LoRA for semantic similarity tasks
LoRA for semantic similarity tasks
Low-Rank Adaptation (LoRA) is a reparametrization method that aims to reduce the number of trainable parameters with low-rank representations. The weight matrix is broken down into low-rank matrices that are trained and updated. All the pretrained model parameters remain frozen. After training, the low-rank matrices are added back to the original weights. This makes it more efficient to store and train a LoRA model because there are significantly fewer parameters.
💡 Read LoRA: Low-Rank Adaptation of Large Language Models to learn more about LoRA.
In this guide, we’ll be using a LoRA script to fine-tune a intfloat/e5-large-v2 model on the smangrul/amazon_esci dataset for semantic similarity tasks. Feel free to explore the script to learn how things work in greater detail!
Setup
Start by installing 🤗 PEFT from source, and then navigate to the directory containing the training scripts for fine-tuning DreamBooth with LoRA:
cd peft/examples/feature_extractionInstall all the necessary required libraries with:
pip install -r requirements.txt
Next, import all the necessary libraries:
- 🤗 Transformers for loading the
intfloat/e5-large-v2model and tokenizer - 🤗 Accelerate for the training loop
- 🤗 Datasets for loading and preparing the
smangrul/amazon_escidataset for training and inference - 🤗 Evaluate for evaluating the model’s performance
- 🤗 PEFT for setting up the LoRA configuration and creating the PEFT model
- 🤗 huggingface_hub for uploading the trained model to HF hub
- hnswlib for creating the search index and doing fast approximate nearest neighbor search
It is assumed that PyTorch with CUDA support is already installed.
Train
Launch the training script with accelerate launch and pass your hyperparameters along with the --use_peft argument to enable LoRA.
This guide uses the following LoraConfig:
peft_config = LoraConfig(
r=8,
lora_alpha=16,
bias="none",
task_type=TaskType.FEATURE_EXTRACTION,
target_modules=["key", "query", "value"],
)Here’s what a full set of script arguments may look like when running in Colab on a V100 GPU with standard RAM:
accelerate launch \
--mixed_precision="fp16" \
peft_lora_embedding_semantic_search.py \
--dataset_name="smangrul/amazon_esci" \
--max_length=70 --model_name_or_path="intfloat/e5-large-v2" \
--per_device_train_batch_size=64 \
--per_device_eval_batch_size=128 \
--learning_rate=5e-4 \
--weight_decay=0.0 \
--num_train_epochs 3 \
--gradient_accumulation_steps=1 \
--output_dir="results/peft_lora_e5_ecommerce_semantic_search_colab" \
--seed=42 \
--push_to_hub \
--hub_model_id="smangrul/peft_lora_e5_ecommerce_semantic_search_colab" \
--with_tracking \
--report_to="wandb" \
--use_peft \
--checkpointing_steps "epoch"Dataset for semantic similarity
The dataset we’ll be using is a small subset of the esci-data dataset (it can be found on Hub at smangrul/amazon_esci).
Each sample contains a tuple of (query, product_title, relevance_label) where relevance_label is 1 if the product matches the intent of the query, otherwise it is 0.
Our task is to build an embedding model that can retrieve semantically similar products given a product query.
This is usually the first stage in building a product search engine to retrieve all the potentially relevant products of a given query.
Typically, this involves using Bi-Encoder models to cross-join the query and millions of products which could blow up quickly.
Instead, you can use a Transformer model to retrieve the top K nearest similar products for a given query by
embedding the query and products in the same latent embedding space.
The millions of products are embedded offline to create a search index.
At run time, only the query is embedded by the model, and products are retrieved from the search index with a
fast approximate nearest neighbor search library such as FAISS or HNSWlib.
The next stage involves reranking the retrieved list of products to return the most relevant ones; this stage can utilize cross-encoder based models as the cross-join between the query and a limited set of retrieved products. The diagram below from awesome-semantic-search outlines a rough semantic search pipeline:
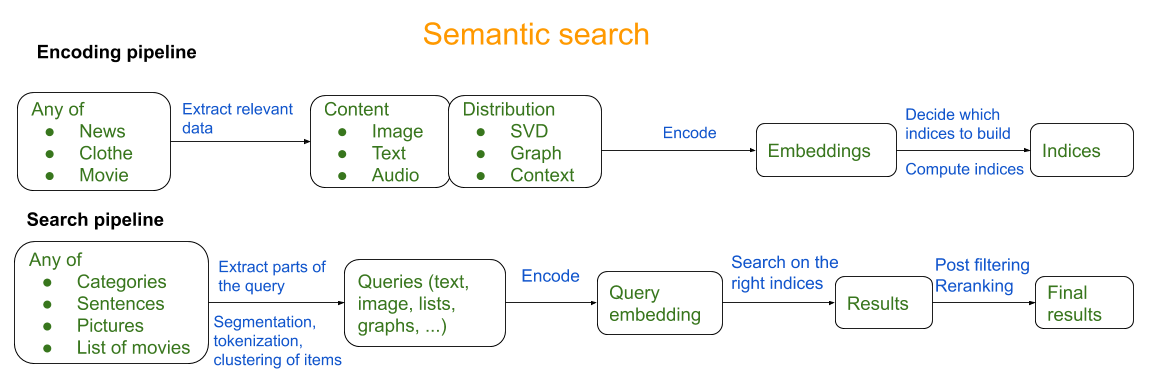
For this task guide, we will explore the first stage of training an embedding model to predict semantically similar products given a product query.
Training script deep dive
We finetune e5-large-v2 which tops the MTEB benchmark using PEFT-LoRA.
AutoModelForSentenceEmbedding returns the query and product embeddings, and the mean_pooling function pools them across the sequence dimension and normalizes them:
class AutoModelForSentenceEmbedding(nn.Module):
def __init__(self, model_name, tokenizer, normalize=True):
super(AutoModelForSentenceEmbedding, self).__init__()
self.model = AutoModel.from_pretrained(model_name)
self.normalize = normalize
self.tokenizer = tokenizer
def forward(self, **kwargs):
model_output = self.model(**kwargs)
embeddings = self.mean_pooling(model_output, kwargs["attention_mask"])
if self.normalize:
embeddings = torch.nn.functional.normalize(embeddings, p=2, dim=1)
return embeddings
def mean_pooling(self, model_output, attention_mask):
token_embeddings = model_output[0] # First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
def __getattr__(self, name: str):
"""Forward missing attributes to the wrapped module."""
try:
return super().__getattr__(name) # defer to nn.Module's logic
except AttributeError:
return getattr(self.model, name)
def get_cosine_embeddings(query_embs, product_embs):
return torch.sum(query_embs * product_embs, axis=1)
def get_loss(cosine_score, labels):
return torch.mean(torch.square(labels * (1 - cosine_score) + torch.clamp((1 - labels) * cosine_score, min=0.0)))The get_cosine_embeddings function computes the cosine similarity and the get_loss function computes the loss. The loss enables the model to learn that a cosine score of 1 for query and product pairs is relevant, and a cosine score of 0 or below is irrelevant.
Define the PeftConfig with your LoRA hyperparameters, and create a PeftModel. We use 🤗 Accelerate for handling all device management, mixed precision training, gradient accumulation, WandB tracking, and saving/loading utilities.
Results
The table below compares the training time, the batch size that could be fit in Colab, and the best ROC-AUC scores between a PEFT model and a fully fine-tuned model:
| Training Type | Training time per epoch (Hrs) | Batch Size that fits | ROC-AUC score (higher is better) |
|---|---|---|---|
| Pre-Trained e5-large-v2 | - | - | 0.68 |
| PEFT | 1.73 | 64 | 0.787 |
| Full Fine-Tuning | 2.33 | 32 | 0.7969 |
The PEFT-LoRA model trains 1.35X faster and can fit 2X batch size compared to the fully fine-tuned model, and the performance of PEFT-LoRA is comparable to the fully fine-tuned model with a relative drop of -1.24% in ROC-AUC. This gap can probably be closed with bigger models as mentioned in The Power of Scale for Parameter-Efficient Prompt Tuning .
Inference
Let’s go! Now we have the model, we need to create a search index of all the products in our catalog.
Please refer to peft_lora_embedding_semantic_similarity_inference.ipynb for the complete inference code.
- Get a list of ids to products which we can call
ids_to_products_dict:
{0: 'RamPro 10" All Purpose Utility Air Tires/Wheels with a 5/8" Diameter Hole with Double Sealed Bearings (Pack of 2)',
1: 'MaxAuto 2-Pack 13x5.00-6 2PLY Turf Mower Tractor Tire with Yellow Rim, (3" Centered Hub, 3/4" Bushings )',
2: 'NEIKO 20601A 14.5 inch Steel Tire Spoon Lever Iron Tool Kit | Professional Tire Changing Tool for Motorcycle, Dirt Bike, Lawn Mower | 3 pcs Tire Spoons | 3 Rim Protector | Valve Tool | 6 Valve Cores',
3: '2PK 13x5.00-6 13x5.00x6 13x5x6 13x5-6 2PLY Turf Mower Tractor Tire with Gray Rim',
4: '(Set of 2) 15x6.00-6 Husqvarna/Poulan Tire Wheel Assy .75" Bearing',
5: 'MaxAuto 2 Pcs 16x6.50-8 Lawn Mower Tire for Garden Tractors Ridings, 4PR, Tubeless',
6: 'Dr.Roc Tire Spoon Lever Dirt Bike Lawn Mower Motorcycle Tire Changing Tools with Durable Bag 3 Tire Irons 2 Rim Protectors 1 Valve Stems Set TR412 TR413',
7: 'MARASTAR 21446-2PK 15x6.00-6" Front Tire Assembly Replacement-Craftsman Mower, Pack of 2',
8: '15x6.00-6" Front Tire Assembly Replacement for 100 and 300 Series John Deere Riding Mowers - 2 pack',
9: 'Honda HRR Wheel Kit (2 Front 44710-VL0-L02ZB, 2 Back 42710-VE2-M02ZE)',
10: 'Honda 42710-VE2-M02ZE (Replaces 42710-VE2-M01ZE) Lawn Mower Rear Wheel Set of 2' ...- Use the trained smangrul/peft_lora_e5_ecommerce_semantic_search_colab model to get the product embeddings:
# base model
model = AutoModelForSentenceEmbedding(model_name_or_path, tokenizer)
# peft config and wrapping
model = PeftModel.from_pretrained(model, peft_model_id)
device = "cuda"
model.to(device)
model.eval()
model = model.merge_and_unload()
import numpy as np
num_products= len(dataset)
d = 1024
product_embeddings_array = np.zeros((num_products, d))
for step, batch in enumerate(tqdm(dataloader)):
with torch.no_grad():
with torch.amp.autocast(dtype=torch.bfloat16, device_type="cuda"):
product_embs = model(**{k:v.to(device) for k, v in batch.items()}).detach().float().cpu()
start_index = step*batch_size
end_index = start_index+batch_size if (start_index+batch_size) < num_products else num_products
product_embeddings_array[start_index:end_index] = product_embs
del product_embs, batch- Create a search index using HNSWlib:
def construct_search_index(dim, num_elements, data):
# Declaring index
search_index = hnswlib.Index(space = 'ip', dim = dim) # possible options are l2, cosine or ip
# Initializing index - the maximum number of elements should be known beforehand
search_index.init_index(max_elements = num_elements, ef_construction = 200, M = 100)
# Element insertion (can be called several times):
ids = np.arange(num_elements)
search_index.add_items(data, ids)
return search_index
product_search_index = construct_search_index(d, num_products, product_embeddings_array)- Get the query embeddings and nearest neighbors:
def get_query_embeddings(query, model, tokenizer, device):
inputs = tokenizer(query, padding="max_length", max_length=70, truncation=True, return_tensors="pt")
model.eval()
with torch.no_grad():
query_embs = model(**{k:v.to(device) for k, v in inputs.items()}).detach().cpu()
return query_embs[0]
def get_nearest_neighbours(k, search_index, query_embeddings, ids_to_products_dict, threshold=0.7):
# Controlling the recall by setting ef:
search_index.set_ef(100) # ef should always be > k
# Query dataset, k - number of the closest elements (returns 2 numpy arrays)
labels, distances = search_index.knn_query(query_embeddings, k = k)
return [(ids_to_products_dict[label], (1-distance)) for label, distance in zip(labels[0], distances[0]) if (1-distance)>=threshold]- Let’s test it out with the query
deep learning books:
query = "deep learning books"
k = 10
query_embeddings = get_query_embeddings(query, model, tokenizer, device)
search_results = get_nearest_neighbours(k, product_search_index, query_embeddings, ids_to_products_dict, threshold=0.7)
print(f"{query=}")
for product, cosine_sim_score in search_results:
print(f"cosine_sim_score={round(cosine_sim_score,2)} {product=}")Output:
query='deep learning books'
cosine_sim_score=0.95 product='Deep Learning (The MIT Press Essential Knowledge series)'
cosine_sim_score=0.93 product='Practical Deep Learning: A Python-Based Introduction'
cosine_sim_score=0.9 product='Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems'
cosine_sim_score=0.9 product='Machine Learning: A Hands-On, Project-Based Introduction to Machine Learning for Absolute Beginners: Mastering Engineering ML Systems using Scikit-Learn and TensorFlow'
cosine_sim_score=0.9 product='Mastering Machine Learning on AWS: Advanced machine learning in Python using SageMaker, Apache Spark, and TensorFlow'
cosine_sim_score=0.9 product='The Hundred-Page Machine Learning Book'
cosine_sim_score=0.89 product='Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems'
cosine_sim_score=0.89 product='Machine Learning: A Journey from Beginner to Advanced Including Deep Learning, Scikit-learn and Tensorflow'
cosine_sim_score=0.88 product='Mastering Machine Learning with scikit-learn'
cosine_sim_score=0.88 product='Mastering Machine Learning with scikit-learn - Second Edition: Apply effective learning algorithms to real-world problems using scikit-learn'Books on deep learning and machine learning are retrieved even though machine learning wasn’t included in the query. This means the model has learned that these books are semantically relevant to the query based on the purchase behavior of customers on Amazon.
The next steps would ideally involve using ONNX/TensorRT to optimize the model and using a Triton server to host it. Check out 🤗 Optimum for related optimizations for efficient serving!