Hub Python Library documentation
Inference Endpoints
Inference Endpoints
Inference Endpoints provides a secure production solution to easily deploy any transformers, sentence-transformers, and diffusers models on a dedicated and autoscaling infrastructure managed by Hugging Face. An Inference Endpoint is built from a model from the Hub.
In this guide, we will learn how to programmatically manage Inference Endpoints with huggingface_hub. For more information about the Inference Endpoints product itself, check out its official documentation.
This guide assumes huggingface_hub is correctly installed and that your machine is logged in. Check out the Quick Start guide if that’s not the case yet. The minimal version supporting Inference Endpoints API is v0.19.0.
Create an Inference Endpoint
The first step is to create an Inference Endpoint using create_inference_endpoint():
>>> from huggingface_hub import create_inference_endpoint
>>> endpoint = create_inference_endpoint(
... "my-endpoint-name",
... repository="gpt2",
... framework="pytorch",
... task="text-generation",
... accelerator="cpu",
... vendor="aws",
... region="us-east-1",
... type="protected",
... instance_size="x2",
... instance_type="intel-icl"
... )In this example, we created a protected Inference Endpoint named "my-endpoint-name", to serve gpt2 for text-generation. A protected Inference Endpoint means your token is required to access the API. We also need to provide additional information to configure the hardware requirements, such as vendor, region, accelerator, instance type, and size. You can check out the list of available resources here. Alternatively, you can create an Inference Endpoint manually using the Web interface for convenience. Refer to this guide for details on advanced settings and their usage.
The value returned by create_inference_endpoint() is an InferenceEndpoint object:
>>> endpoint
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='pending', url=None)It’s a dataclass that holds information about the endpoint. You can access important attributes such as name, repository, status, task, created_at, updated_at, etc. If you need it, you can also access the raw response from the server with endpoint.raw.
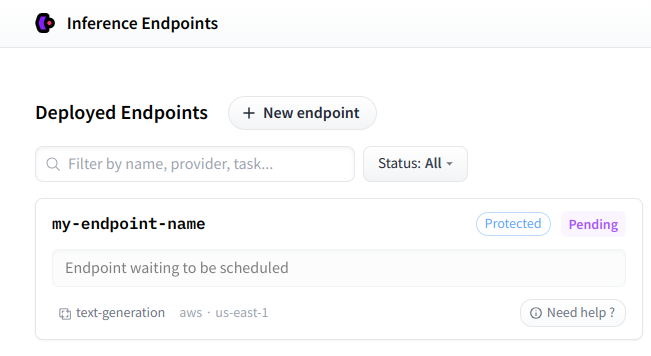
Once your Inference Endpoint is created, you can find it on your personal dashboard.
Using a custom image
By default the Inference Endpoint is built from a docker image provided by Hugging Face. However, it is possible to specify any docker image using the custom_image parameter. A common use case is to run LLMs using the text-generation-inference framework. This can be done like this:
# Start an Inference Endpoint running Zephyr-7b-beta on TGI
>>> from huggingface_hub import create_inference_endpoint
>>> endpoint = create_inference_endpoint(
... "aws-zephyr-7b-beta-0486",
... repository="HuggingFaceH4/zephyr-7b-beta",
... framework="pytorch",
... task="text-generation",
... accelerator="gpu",
... vendor="aws",
... region="us-east-1",
... type="protected",
... instance_size="x1",
... instance_type="nvidia-a10g",
... custom_image={
... "health_route": "/health",
... "env": {
... "MAX_BATCH_PREFILL_TOKENS": "2048",
... "MAX_INPUT_LENGTH": "1024",
... "MAX_TOTAL_TOKENS": "1512",
... "MODEL_ID": "/repository"
... },
... "url": "ghcr.io/huggingface/text-generation-inference:1.1.0",
... },
... )The value to pass as custom_image is a dictionary containing a url to the docker container and configuration to run it. For more details about it, checkout the Swagger documentation.
Get or list existing Inference Endpoints
In some cases, you might need to manage Inference Endpoints you created previously. If you know the name, you can fetch it using get_inference_endpoint(), which returns an InferenceEndpoint object. Alternatively, you can use list_inference_endpoints() to retrieve a list of all Inference Endpoints. Both methods accept an optional namespace parameter. You can set the namespace to any organization you are a part of. Otherwise, it defaults to your username.
>>> from huggingface_hub import get_inference_endpoint, list_inference_endpoints
# Get one
>>> get_inference_endpoint("my-endpoint-name")
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='pending', url=None)
# List all endpoints from an organization
>>> list_inference_endpoints(namespace="huggingface")
[InferenceEndpoint(name='aws-starchat-beta', namespace='huggingface', repository='HuggingFaceH4/starchat-beta', status='paused', url=None), ...]
# List all endpoints from all organizations the user belongs to
>>> list_inference_endpoints(namespace="*")
[InferenceEndpoint(name='aws-starchat-beta', namespace='huggingface', repository='HuggingFaceH4/starchat-beta', status='paused', url=None), ...]Check deployment status
In the rest of this guide, we will assume that we have a InferenceEndpoint object called endpoint. You might have noticed that the endpoint has a status attribute of type InferenceEndpointStatus. When the Inference Endpoint is deployed and accessible, the status should be "running" and the url attribute is set:
>>> endpoint
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='running', url='https://jpj7k2q4j805b727.us-east-1.aws.endpoints.huggingface.cloud')Before reaching a "running" state, the Inference Endpoint typically goes through an "initializing" or "pending" phase. You can fetch the new state of the endpoint by running fetch(). Like every other method from InferenceEndpoint that makes a request to the server, the internal attributes of endpoint are mutated in place:
>>> endpoint.fetch()
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='pending', url=None)Instead of fetching the Inference Endpoint status while waiting for it to run, you can directly call wait(). This helper takes as input a timeout and a fetch_every parameter (in seconds) and will block the thread until the Inference Endpoint is deployed. Default values are respectively None (no timeout) and 5 seconds.
# Pending endpoint
>>> endpoint
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='pending', url=None)
# Wait 10s => raises a InferenceEndpointTimeoutError
>>> endpoint.wait(timeout=10)
raise InferenceEndpointTimeoutError("Timeout while waiting for Inference Endpoint to be deployed.")
huggingface_hub._inference_endpoints.InferenceEndpointTimeoutError: Timeout while waiting for Inference Endpoint to be deployed.
# Wait more
>>> endpoint.wait()
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='running', url='https://jpj7k2q4j805b727.us-east-1.aws.endpoints.huggingface.cloud')If timeout is set and the Inference Endpoint takes too much time to load, a InferenceEndpointTimeoutError timeout error is raised.
Run inference
Once your Inference Endpoint is up and running, you can finally run inference on it!
InferenceEndpoint has two properties client and async_client returning respectively an InferenceClient and an AsyncInferenceClient objects.
# Run text_generation task:
>>> endpoint.client.text_generation("I am")
' not a fan of the idea of a "big-budget" movie. I think it\'s a'
# Or in an asyncio context:
>>> await endpoint.async_client.text_generation("I am")If the Inference Endpoint is not running, an InferenceEndpointError exception is raised:
>>> endpoint.client
huggingface_hub._inference_endpoints.InferenceEndpointError: Cannot create a client for this Inference Endpoint as it is not yet deployed. Please wait for the Inference Endpoint to be deployed using `endpoint.wait()` and try again.For more details about how to use the InferenceClient, check out the Inference guide.
Manage lifecycle
Now that we saw how to create an Inference Endpoint and run inference on it, let’s see how to manage its lifecycle.
In this section, we will see methods like pause(), resume(), scale_to_zero(), update() and delete(). All of those methods are aliases added to InferenceEndpoint for convenience. If you prefer, you can also use the generic methods defined in HfApi: pause_inference_endpoint(), resume_inference_endpoint(), scale_to_zero_inference_endpoint(), update_inference_endpoint(), and delete_inference_endpoint().
Pause or scale to zero
To reduce costs when your Inference Endpoint is not in use, you can choose to either pause it using pause() or scale it to zero using scale_to_zero().
An Inference Endpoint that is paused or scaled to zero doesn’t cost anything. The difference between those two is that a paused endpoint needs to be explicitly resumed using resume(). On the contrary, a scaled to zero endpoint will automatically start if an inference call is made to it, with an additional cold start delay. An Inference Endpoint can also be configured to scale to zero automatically after a certain period of inactivity.
# Pause and resume endpoint
>>> endpoint.pause()
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='paused', url=None)
>>> endpoint.resume()
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='pending', url=None)
>>> endpoint.wait().client.text_generation(...)
...
# Scale to zero
>>> endpoint.scale_to_zero()
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='scaledToZero', url='https://jpj7k2q4j805b727.us-east-1.aws.endpoints.huggingface.cloud')
# Endpoint is not 'running' but still has a URL and will restart on first call.Update model or hardware requirements
In some cases, you might also want to update your Inference Endpoint without creating a new one. You can either update the hosted model or the hardware requirements to run the model. You can do this using update():
# Change target model
>>> endpoint.update(repository="gpt2-large")
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2-large', status='pending', url=None)
# Update number of replicas
>>> endpoint.update(min_replica=2, max_replica=6)
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2-large', status='pending', url=None)
# Update to larger instance
>>> endpoint.update(accelerator="cpu", instance_size="x4", instance_type="intel-icl")
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2-large', status='pending', url=None)Delete the endpoint
Finally if you won’t use the Inference Endpoint anymore, you can simply call ~InferenceEndpoint.delete().
This is a non-revertible action that will completely remove the endpoint, including its configuration, logs and usage metrics. You cannot restore a deleted Inference Endpoint.
An end-to-end example
A typical use case of Inference Endpoints is to process a batch of jobs at once to limit the infrastructure costs. You can automate this process using what we saw in this guide:
>>> import asyncio
>>> from huggingface_hub import create_inference_endpoint
# Start endpoint + wait until initialized
>>> endpoint = create_inference_endpoint(name="batch-endpoint",...).wait()
# Run inference
>>> client = endpoint.client
>>> results = [client.text_generation(...) for job in jobs]
# Or with asyncio
>>> async_client = endpoint.async_client
>>> results = asyncio.gather(*[async_client.text_generation(...) for job in jobs])
# Pause endpoint
>>> endpoint.pause()Or if your Inference Endpoint already exists and is paused:
>>> import asyncio
>>> from huggingface_hub import get_inference_endpoint
# Get endpoint + wait until initialized
>>> endpoint = get_inference_endpoint("batch-endpoint").resume().wait()
# Run inference
>>> async_client = endpoint.async_client
>>> results = asyncio.gather(*[async_client.text_generation(...) for job in jobs])
# Pause endpoint
>>> endpoint.pause()