Hub Python Library documentation
Search the Hub
Search the Hub
In this tutorial, you will learn how to search models, datasets and spaces on the Hub using huggingface_hub.
How to list repositories ?
huggingface_hub library includes an HTTP client HfApi to interact with the Hub.
Among other things, it can list models, datasets and spaces stored on the Hub:
>>> from huggingface_hub import HfApi
>>> api = HfApi()
>>> models = api.list_models()The output of list_models() is an iterator over the models stored on the Hub.
Similarly, you can use list_datasets() to list datasets and list_spaces() to list Spaces.
How to filter repositories ?
Listing repositories is great but now you might want to filter your search. The list helpers have several attributes like:
filterauthorsearch- …
Two of these parameters are intuitive (author and search), but what about that filter?
filter takes as input a ModelFilter object (or DatasetFilter). You can instantiate
it by specifying which models you want to filter.
Let’s see an example to get all models on the Hub that does image classification, have been trained on the imagenet dataset and that runs with PyTorch. That can be done with a single ModelFilter. Attributes are combined as “logical AND”.
models = hf_api.list_models(
filter=ModelFilter(
task="image-classification",
library="pytorch",
trained_dataset="imagenet"
)
)While filtering, you can also sort the models and take only the top results. For example, the following example fetches the top 5 most downloaded datasets on the Hub:
>>> list_datasets(sort="downloads", direction=-1, limit=5)
[DatasetInfo: {
id: glue
downloads: 897789
(...)How to explore filter options ?
Now you know how to filter your list of models/datasets/spaces. The problem you might have is that you don’t know exactly what you are looking for. No worries! We also provide some helpers that allows you to discover what arguments can be passed in your query.
ModelSearchArguments and DatasetSearchArguments are nested namespace objects that
have every single option available on the Hub and that will return what should be passed
to filter. The best of all is: it has tab completion 🎊 .
>>> from huggingface_hub import ModelSearchArguments, DatasetSearchArguments
>>> model_args = ModelSearchArguments()
>>> dataset_args = DatasetSearchArguments()Before continuing, please we aware that ModelSearchArguments and DatasetSearchArguments are legacy helpers meant for exploratory purposes only. Their initialization require listing all models and datasets on the Hub which makes them increasingly slower as the number of repos on the Hub increases. For some production-ready code, consider passing raw strings when making a filtered search on the Hub.
Now, let’s check what is available in model_args by checking it’s output, you will find:
>>> model_args
Available Attributes or Keys:
* author
* dataset
* language
* library
* license
* model_name
* pipeline_tagIt has a variety of attributes or keys available to you. This is because it is both an object
and a dictionary, so you can either do model_args["author"] or model_args.author.
The first criteria is getting all PyTorch models. This would be found under the library attribute, so let’s see if it is there:
>>> model_args.library
Available Attributes or Keys:
* AdapterTransformers
* Asteroid
* ESPnet
* Fairseq
* Flair
* JAX
* Joblib
* Keras
* ONNX
* PyTorch
* Rust
* Scikit_learn
* SentenceTransformers
* Stable_Baselines3 (Key only)
* Stanza
* TFLite
* TensorBoard
* TensorFlow
* TensorFlowTTS
* Timm
* Transformers
* allenNLP
* fastText
* fastai
* pyannote_audio
* spaCy
* speechbrainIt is! The PyTorch name is there, so you’ll need to use model_args.library.PyTorch:
>>> model_args.library.PyTorch
'pytorch'Below is an animation repeating the process for finding both the Text Classification and glue requirements:
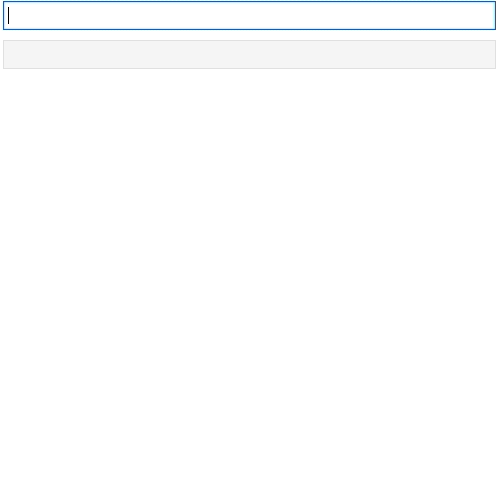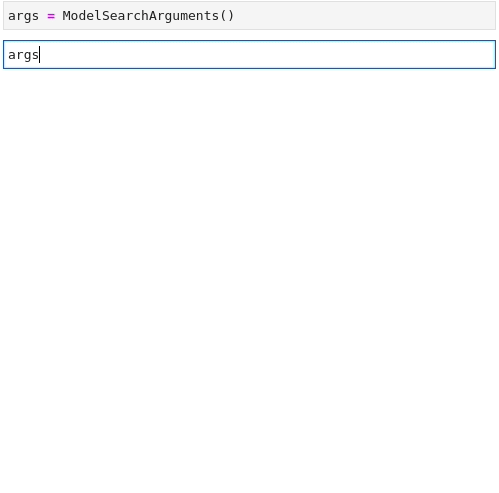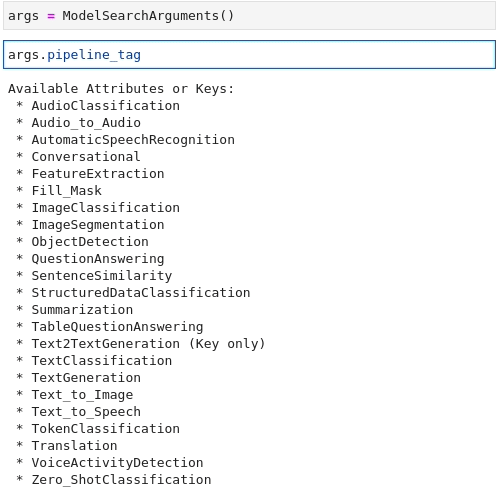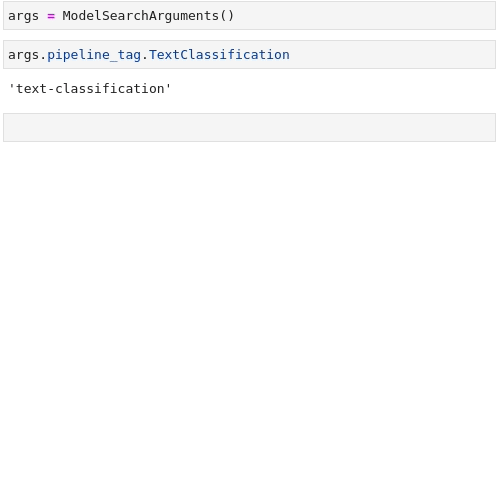
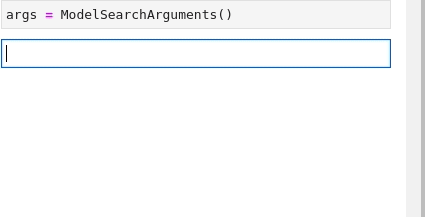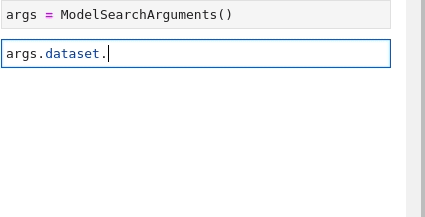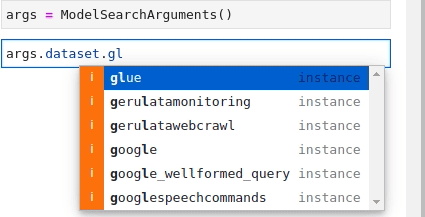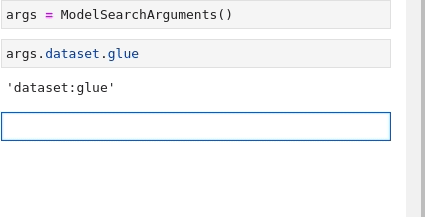
Now that all the pieces are there, the last step is to combine them all for something the API can use through the ModelFilter and DatasetFilter classes (i.e. strings).
>>> from huggingface_hub import ModelFilter, DatasetFilter
>>> filt = ModelFilter(
... task=model_args.pipeline_tag.TextClassification,
... trained_dataset=dataset_args.dataset_name.glue,
... library=model_args.library.PyTorch
... )
>>> api.list_models(filter=filt)[0]
ModelInfo: {
modelId: Jiva/xlm-roberta-large-it-mnli
sha: c6e64469ec4aa17fedbd1b2522256f90a90b5b86
lastModified: 2021-12-10T14:56:38.000Z
tags: ['pytorch', 'xlm-roberta', 'text-classification', 'it', 'dataset:multi_nli', 'dataset:glue', 'arxiv:1911.02116', 'transformers', 'tensorflow', 'license:mit', 'zero-shot-classification']
pipeline_tag: zero-shot-classification
siblings: [ModelFile(rfilename='.gitattributes'), ModelFile(rfilename='README.md'), ModelFile(rfilename='config.json'), ModelFile(rfilename='pytorch_model.bin'), ModelFile(rfilename='sentencepiece.bpe.model'), ModelFile(rfilename='special_tokens_map.json'), ModelFile(rfilename='tokenizer.json'), ModelFile(rfilename='tokenizer_config.json')]
config: None
id: Jiva/xlm-roberta-large-it-mnli
private: False
downloads: 11061
library_name: transformers
likes: 1
}As you can see, it found the models that fit all the criteria. You can even take it further
by passing in an array for each of the parameters from before. For example, let’s take a look
for the same configuration, but also include TensorFlow in the filter:
>>> filt = ModelFilter(
... task=model_args.pipeline_tag.TextClassification,
... library=[model_args.library.PyTorch, model_args.library.TensorFlow]
... )
>>> api.list_models(filter=filt)[0]
ModelInfo: {
modelId: distilbert-base-uncased-finetuned-sst-2-english
sha: ada5cc01a40ea664f0a490d0b5f88c97ab460470
lastModified: 2022-03-22T19:47:08.000Z
tags: ['pytorch', 'tf', 'rust', 'distilbert', 'text-classification', 'en', 'dataset:sst-2', 'transformers', 'license:apache-2.0', 'infinity_compatible']
pipeline_tag: text-classification
siblings: [ModelFile(rfilename='.gitattributes'), ModelFile(rfilename='README.md'), ModelFile(rfilename='config.json'), ModelFile(rfilename='map.jpeg'), ModelFile(rfilename='pytorch_model.bin'), ModelFile(rfilename='rust_model.ot'), ModelFile(rfilename='tf_model.h5'), ModelFile(rfilename='tokenizer_config.json'), ModelFile(rfilename='vocab.txt')]
config: None
id: distilbert-base-uncased-finetuned-sst-2-english
private: False
downloads: 3917525
library_name: transformers
likes: 49
}This query is strictly equivalent to:
>>> filt = ModelFilter(
... task="text-classification",
... library=["pytorch", "tensorflow"],
... )Here, the ModelSearchArguments has been a helper to explore the options available on the Hub. However, it is not a requirement to make a search. Another way to do that is to visit the models and datasets pages in your browser, search for some parameters and look at the values in the URL.