Hub Python Library documentation
Access the Inference API
Access the Inference API
The Inference API provides fast inference for your hosted models. The Inference API can be accessed via usual HTTP requests with your favorite programming language, but the huggingface_hub library has a client wrapper to access the Inference API programmatically. This guide will show you how to make calls to the Inference API with the huggingface_hub library.
If you want to make the HTTP calls directly, please refer to Accelerated Inference API Documentation or to the sample snippets visible on every supported model page.
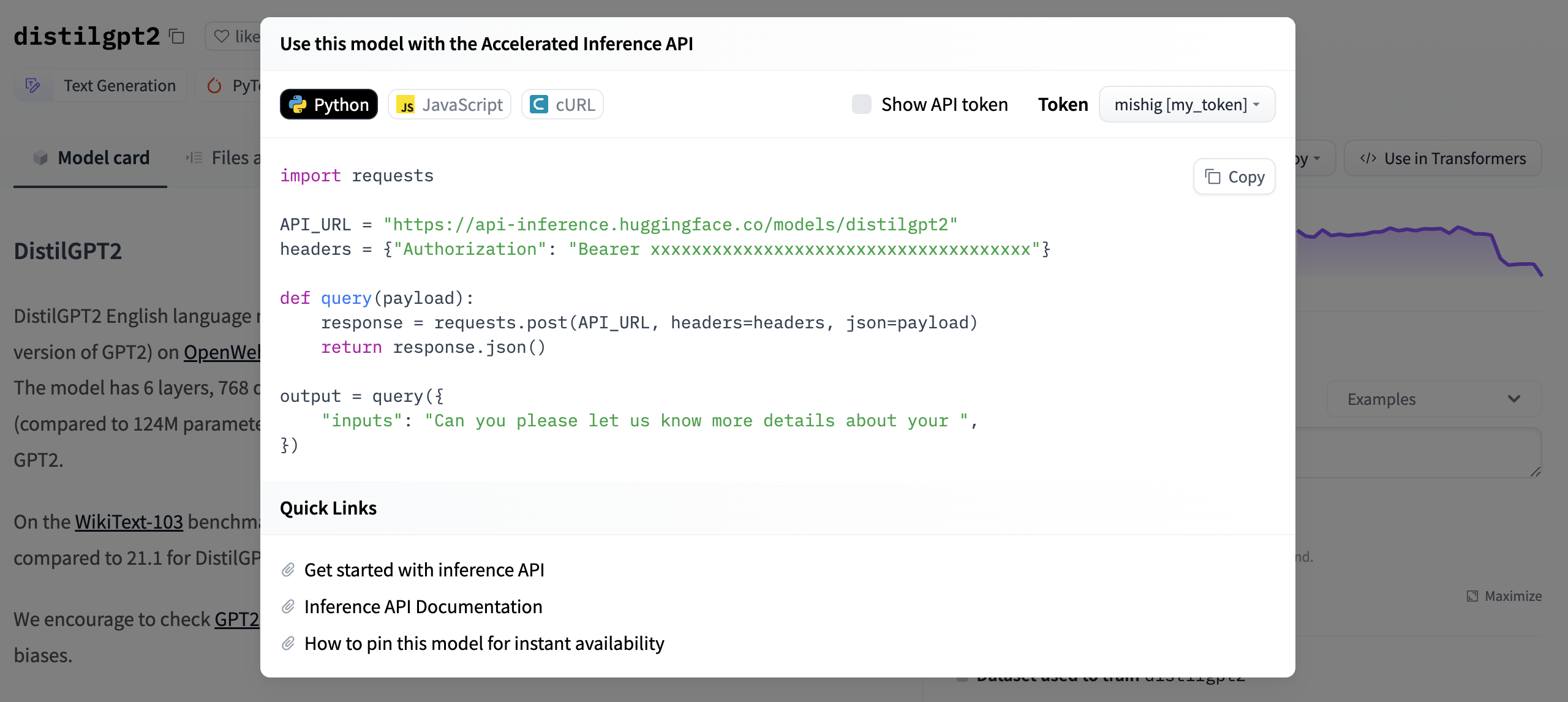
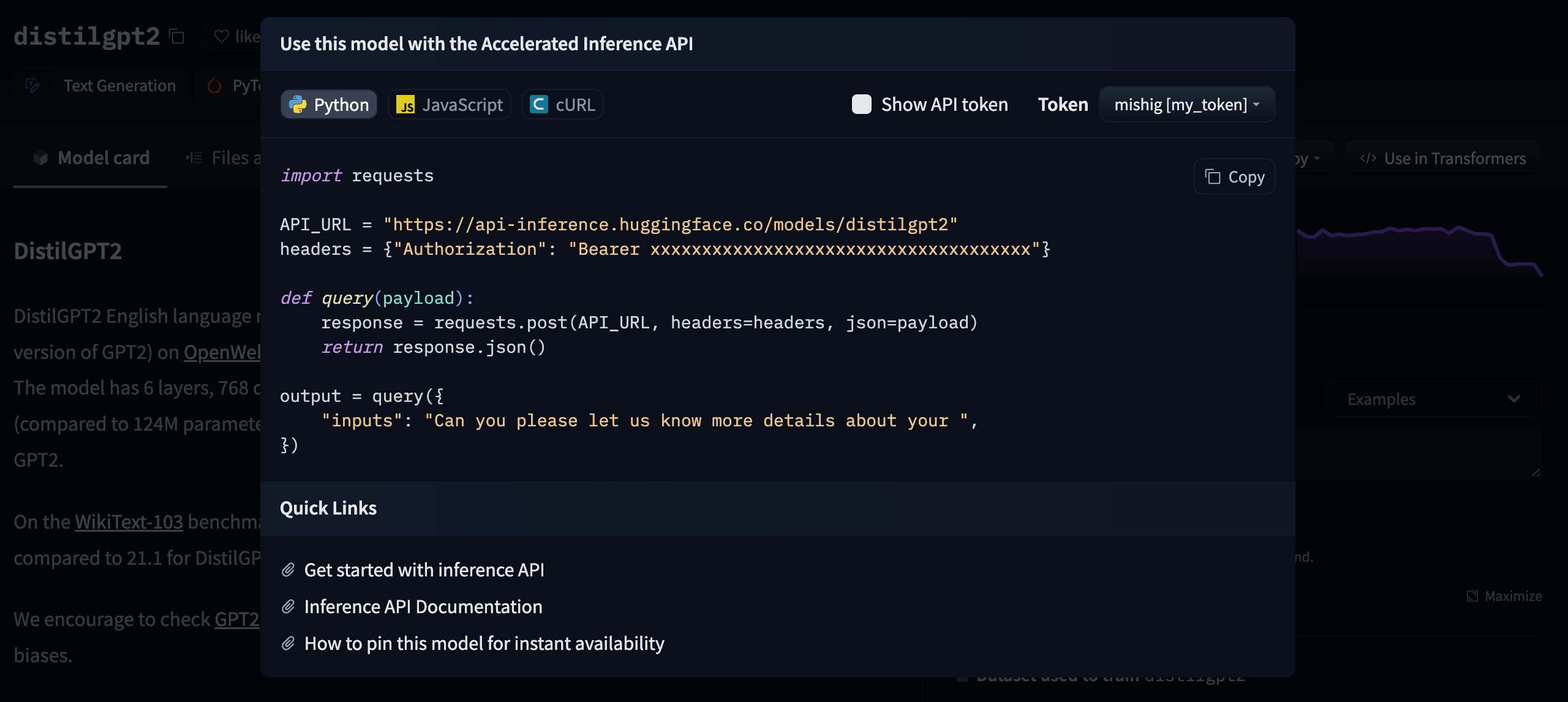
Begin by creating an instance of the InferenceApi with the model repository ID of the model you want to use. You can find your API_TOKEN under Settings from your Hugging Face account. The API_TOKEN will allow you to send requests to the Inference API.
>>> from huggingface_hub.inference_api import InferenceApi
>>> inference = InferenceApi(repo_id="bert-base-uncased", token=API_TOKEN)The metadata in the model card and configuration files (see here for more details) determines the pipeline type. For example, when using the bert-base-uncased model, the Inference API can automatically infer that this model should be used for a fill-mask task.
>>> from huggingface_hub.inference_api import InferenceApi
>>> inference = InferenceApi(repo_id="bert-base-uncased", token=API_TOKEN)
>>> inference(inputs="The goal of life is [MASK].")
[{'sequence': 'the goal of life is life.', 'score': 0.10933292657136917, 'token': 2166, 'token_str': 'life'}]Each task requires a different type of input. A question-answering task expects a dictionary with the question and context keys as the input:
>>> inference = InferenceApi(repo_id="deepset/roberta-base-squad2", token=API_TOKEN)
>>> inputs = {"question":"Where is Hugging Face headquarters?", "context":"Hugging Face is based in Brooklyn, New York. There is also an office in Paris, France."}
>>> inference(inputs)
{'score': 0.94622403383255, 'start': 25, 'end': 43, 'answer': 'Brooklyn, New York'}Some tasks may require additional parameters (see here for a detailed list of all parameters for each task). As an example, for zero-shot-classification tasks, the model needs candidate labels that can be supplied to params:
>>> inference = InferenceApi(repo_id="typeform/distilbert-base-uncased-mnli", token=API_TOKEN)
>>> inputs = "Hi, I recently bought a device from your company but it is not working as advertised and I would like to get reimbursed!"
>>> params = {"candidate_labels":["refund", "legal", "faq"]}
>>> inference(inputs, params)
{'sequence': 'Hi, I recently bought a device from your company but it is not working as advertised and I would like to get reimbursed!', 'labels': ['refund', 'faq', 'legal'], 'scores': [0.9378499388694763, 0.04914155602455139, 0.013008488342165947]}Some models may support multiple tasks. The sentence-transformers models can complete both sentence-similarity and feature-extraction tasks. Specify which task you want to perform with the task parameter:
>>> inference = InferenceApi(repo_id="paraphrase-xlm-r-multilingual-v1",
... task="feature-extraction",
... token=API_TOKEN,
... )