Deploy Meta Llama 3.1 405B with TGI DLC on Vertex AI
Meta Llama 3.1 is the latest open LLM from Meta, a follow up iteration of Llama 3, released in July 2024. Meta Llama 3.1 comes in three sizes: 8B for efficient deployment and development on consumer-size GPU, 70B for large-scale AI native applications, and 405B for synthetic data, LLM as a Judge or distillation; among other use cases. Amongst Meta Llama 3.1 new features, the ones to highlight are: a large context length of 128K tokens (vs original 8K), multilingual capabilities, tool usage capabilities, and a more permissive license.
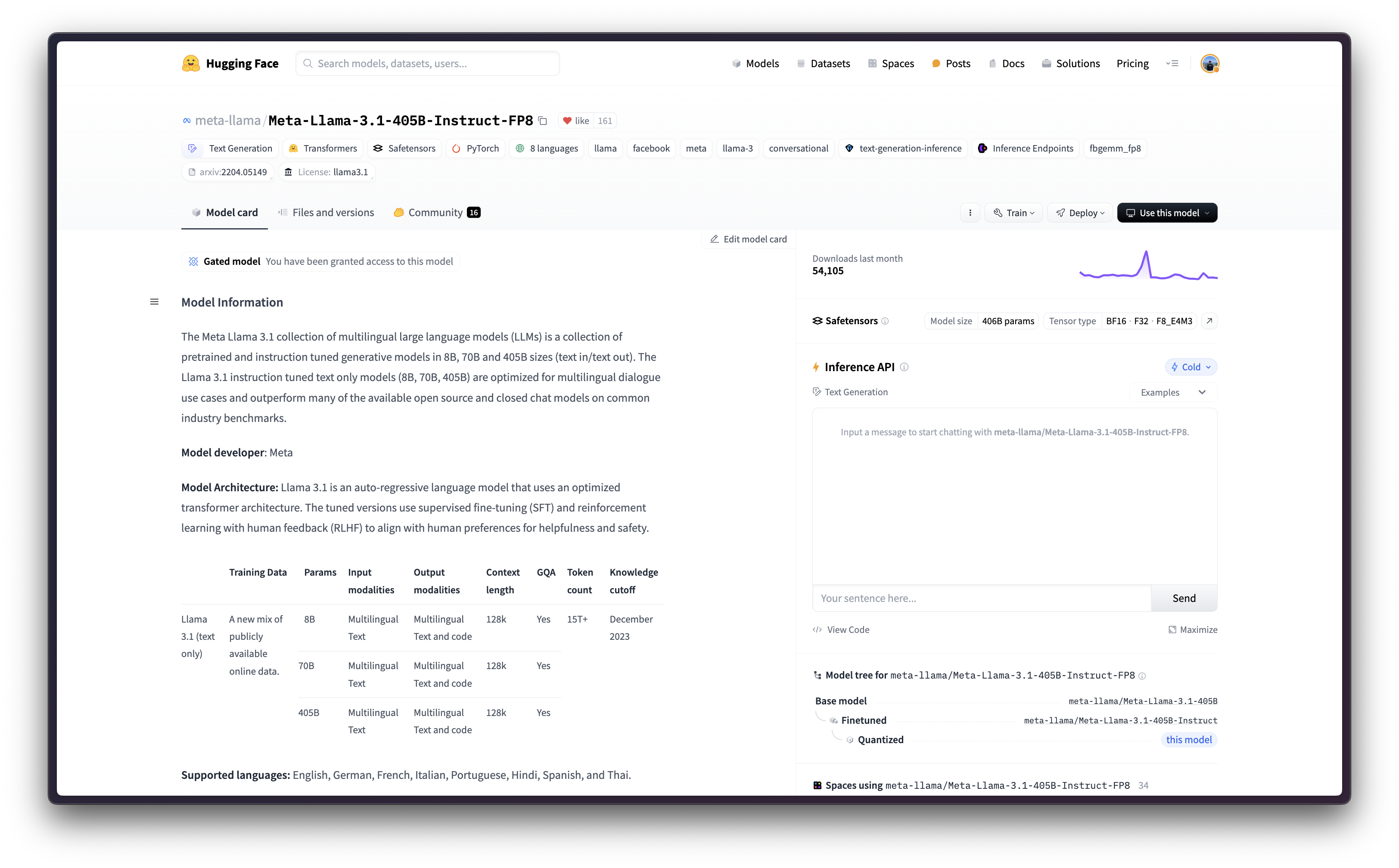
This example showcases how to deploy meta-llama/Meta-Llama-3.1-405B-Instruct-FP8 on Vertex AI with an A3 accelerator-optimized instance with 8 NVIDIA H100s via the Hugging Face purpose-built Deep Learning Container (DLC) for Text Generation Inference (TGI) on Google Cloud.
Setup / Configuration
First, you need to install gcloud in your local machine, which is the command-line tool for Google Cloud, following the instructions at Cloud SDK Documentation - Install the gcloud CLI.
Then, you also need to install the google-cloud-aiplatform Python SDK, required to programmatically create the Vertex AI model, register it, acreate the endpoint, and deploy it on Vertex AI.
!pip install --upgrade --quiet google-cloud-aiplatform
Optionally, to ease the usage of the commands within this tutorial, you need to set the following environment variables for GCP:
%env PROJECT_ID=your-project-id
%env LOCATION=your-location
%env CONTAINER_URI=us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-generation-inference-cu124.2-3.ubuntu2204.py311Then you need to login into your GCP account and set the project ID to the one you want to use to register and deploy the models on Vertex AI.
!gcloud auth login
!gcloud auth application-default login # For local development
!gcloud config set project $PROJECT_IDOnce you are logged in, you need to enable the necessary service APIs in GCP, such as the Vertex AI API, the Compute Engine API, and Google Container Registry related APIs.
!gcloud services enable aiplatform.googleapis.com !gcloud services enable compute.googleapis.com !gcloud services enable container.googleapis.com !gcloud services enable containerregistry.googleapis.com !gcloud services enable containerfilesystem.googleapis.com
Once everything is set up, you can already initialize the Vertex AI session via the google-cloud-aiplatform Python SDK as follows:
import os
from google.cloud import aiplatform
aiplatform.init(
project=os.getenv("PROJECT_ID"),
location=os.getenv("LOCATION"),
)Quotas on Google Cloud
To serve meta-llama/Meta-Llama-3.1-405B-Instruct-FP8 you need an instance with at least 400GiB of GPU VRAM that supports the FP8 data-type, and the A3 accelerator-optimized machines on Google Cloud are the machines you would need to use.
Even if the A3 accelerator-optimized machines with 8 x NVIDIA H100 80GB GPUs are available within Google Cloud, you will still need to request a custom quota increase in Google Cloud, as those need a specific approval. Note that the A3 accelerator-optimized machines are only available in some zones, so make sure to check the availability of both A3 High or even A3 Mega per zone at Compute Engine - GPU regions and zones.
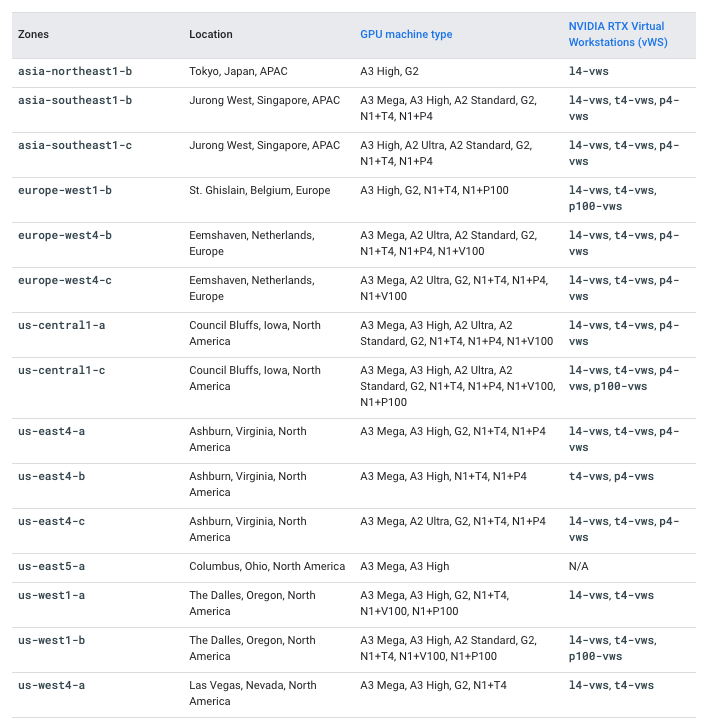
In this case, to request a quota increase to use the machine with 8 NVIDIA H100s you will need to increase the following quotas:
Service: Vertex AI APIandName: Custom model serving Nvidia H100 80GB GPUs per regionset to 8Service: Vertex AI APIandName: Custom model serving A3 CPUs per regionset to 208
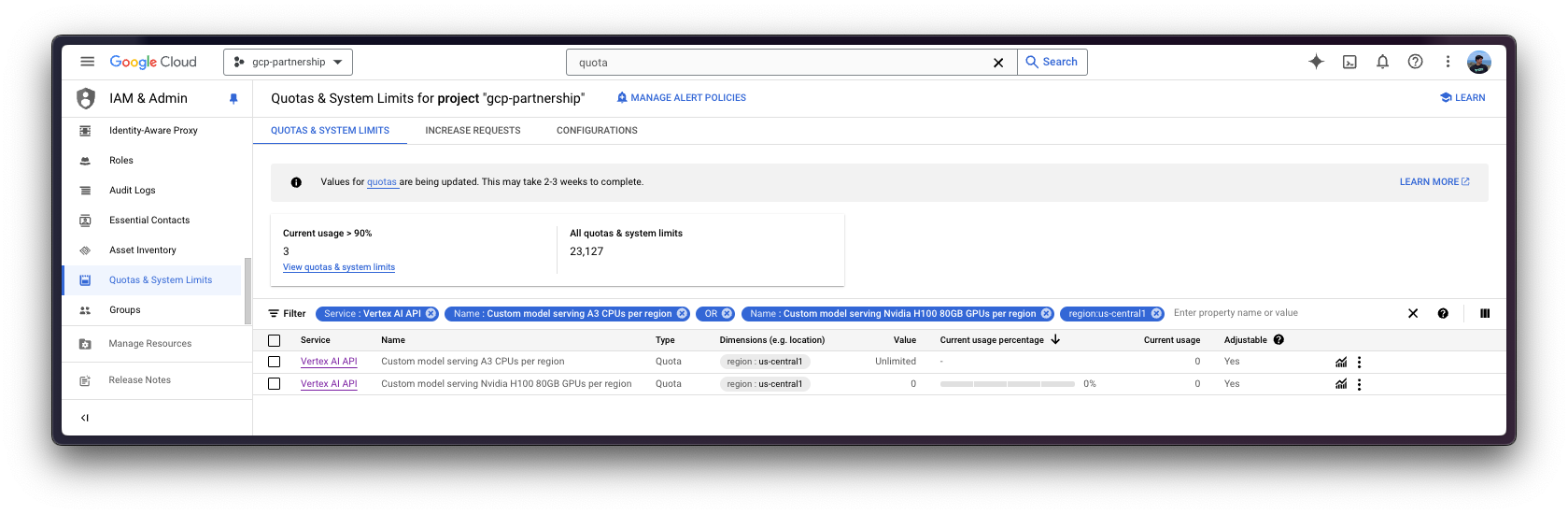
Read more on how to request a quota increase at Google Cloud Documentation - View and manage quotas.
Register model on Vertex AI
Since meta-llama/Meta-Llama-3.1-405B-Instruct-FP8 is a gated model, you need to login into your Hugging Face Hub account, accept the gating requirements, and then generate an access token either with fine-grained read access to the gated model only (recommended), or read-access to your account.
Read more about access tokens for the Hugging Face Hub.
To authenticate, you can either use the huggingface_hub Python SDK as shown below (recommended), or just set the environment variable HF_TOKEN instead.
!pip install --upgrade --quiet huggingface_hub
from huggingface_hub import interpreter_login
interpreter_login()Then you can already “upload” the model i.e. register the model on Vertex AI. It is not an upload per se, since the model will be automatically downloaded from the Hugging Face Hub in the Hugging Face DLC for TGI on startup via the MODEL_ID environment variable, so what is uploaded is only the configuration, not the model weights.
Before going into the code, let’s quickly review the arguments provided to the upload method:
display_nameis the name that will be shown in the Vertex AI Model Registry.serving_container_image_uriis the location of the Hugging Face DLC for TGI that will be used for serving the model.serving_container_environment_variablesare the environment variables that will be used during the container runtime, so these are aligned with the environment variables defined by TGI via thetext-generation-launcher, which exposes some environment variables such as the following:MODEL_IDthe model ID on the Hugging Face Hub.NUM_SHARDthe number of shards to use i.e. the number of GPUs to use, in this case set to 8 as a node with 8 NVIDIA H100s will be used.HUGGING_FACE_HUB_TOKENis the Hugging Face Hub token, required asmeta-llama/Meta-Llama-3.1-405B-Instruct-FP8is a gated model.HF_HUB_ENABLE_HF_TRANSFERto enable a faster download speed via thehf_transferlibrary.
For more information on the supported arguments, check aiplatform.Model.upload Python reference.
Starting from TGI 2.3 DLC i.e. us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-generation-inference-cu124.2-3.ubuntu2204.py311, and onwards, you can set the environment variable value MESSAGES_API_ENABLED="true" to deploy the Messages API on Vertex AI, otherwise, the Generate API will be deployed instead.
from huggingface_hub import get_token
model = aiplatform.Model.upload(
display_name="meta-llama--Meta-Llama-3.1-405B-Instruct-FP8",
serving_container_image_uri="",
serving_container_environment_variables={
"MODEL_ID": "meta-llama/Meta-Llama-3.1-405B-Instruct-FP8",
"HUGGING_FACE_HUB_TOKEN": get_token(),
"HF_HUB_ENABLE_HF_TRANSFER": "1",
"NUM_SHARD": "8",
},
)
model.wait()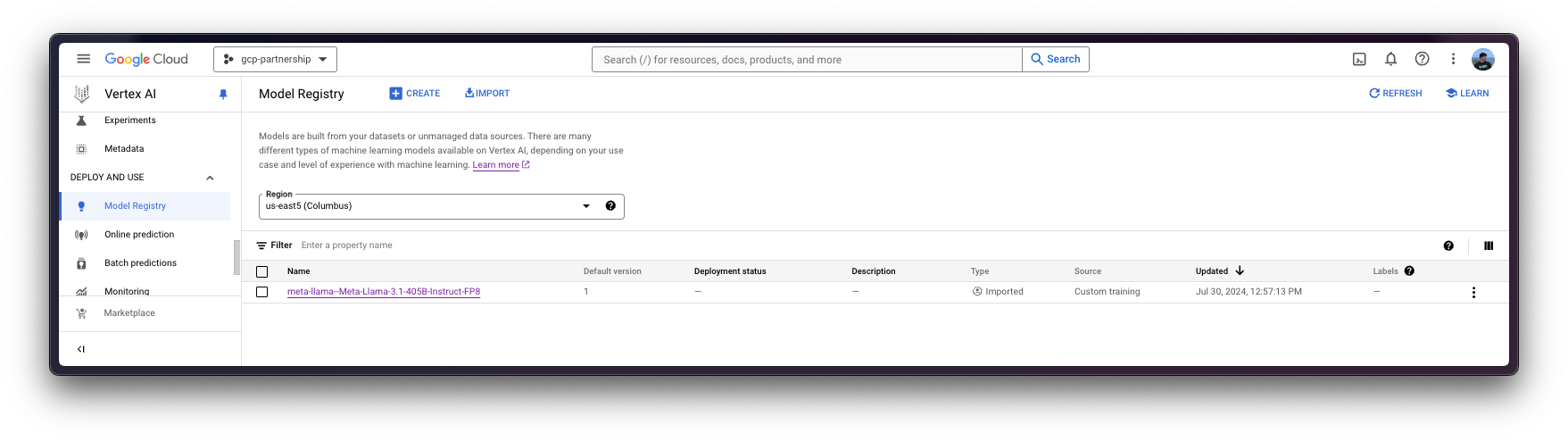
Deploy model on Vertex AI
Once Meta Llama 3.1 405B is registered on Vertex AI Model Registry, you can already deploy it on a Vertex AI Endpoint with the Hugging Face DLC for TGI.
The deploy method will link the previously created endpoint resource with the model that contains the configuration of the serving container, and then, it will deploy the model on Vertex AI in the specified instance.
Before going into the code, let’s quickly review the arguments provided to the deploy method:
endpointis the endpoint to deploy the model to, which is optional, and by default will be set to the model display name with the_endpointsuffix.machine_type,accelerator_typeandaccelerator_countare arguments that define which instance to use, and additionally, the accelerator to use and the number of accelerators, respectively. Themachine_typeand theaccelerator_typeare tied together, so you will need to select an instance that supports the accelerator that you are using and vice-versa. More information about the different instances at Compute Engine Documentation - GPU machine types, and about theaccelerator_typenaming at Vertex AI Documentation - MachineSpec.
For more information on the supported arguments you can check aiplatform.Model.deploy Python reference.
As mentioned before, since Meta Llama 3.1 405B in FP8 takes ~400 GiB of disk space, that means you need at least 400 GiB of GPU VRAM to load the model, and the GPUs within the node need to support the FP8 data type. In this case, an A3 instance with 8 x NVIDIA H100 80GB with a total of ~640 GiB of VRAM will be used to load the model while also leaving some free VRAM for the KV Cache and the CUDA Graphs.
deployed_model = model.deploy(
endpoint=aiplatform.Endpoint.create(display_name="Meta-Llama-3.1-405B-FP8-Endpoint"),
machine_type="a3-highgpu-8g",
accelerator_type="NVIDIA_H100_80GB",
accelerator_count=8,
enable_access_logging=True,
)meta-llama/Meta-Llama-3.1-405B-Instruct-FP8 deployment on Vertex AI will take ~30 minutes to deploy, as it needs to allocate the resources on Google Cloud, and then download the weights from the Hugging Face Hub (~10 minutes) and load those for inference in TGI (~3 minutes).
Online predictions on Vertex AI
Finally, you can run the online predictions on Vertex AI using the predict method, which will send the requests to the running endpoint in the /predict route specified within the container following Vertex AI I/O payload formatting.
As /generate is the endpoint that is being exposed through TGI on Vertex AI, you will need to format the messages with the chat template before sending the request to Vertex AI, so you will need to install 🤗transformers to use the apply_chat_template method from the PreTrainedTokenizerFast.
%%bash pip install --upgrade --quiet transformers
And then apply the chat template to a conversation using the tokenizer as follows:
import os
from huggingface_hub import get_token
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(
"meta-llama/Meta-Llama-3.1-405B-Instruct-FP8",
token=get_token(),
)
messages = [
{"role": "system", "content": "You are an assistant that responds as a pirate."},
{"role": "user", "content": "What's the Theory of Relativity?"},
]
inputs = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
# <|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nYou are an assistant that responds as a pirate.<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nWhat's the Theory of Relativity?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nWhich is what you will be sending within the payload to the deployed Vertex AI Endpoint, as well as the generation parameters as in Consuming Text Generation Inference (TGI) -> Generate.
Via Python
Within the same session
If you are willing to run the online prediction within the current session, you can send requests programmatically via the aiplatform.Endpoint (returned by the aiplatform.Model.deploy method) as in the following snippet:
output = deployed_model.predict(
instances=[
{
"inputs": "<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nYou are an assistant that responds as a pirate.<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nWhat's the Theory of Relativity?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n",
"parameters": {
"max_new_tokens": 128,
"do_sample": True,
"top_p": 0.95,
"temperature": 1.0,
},
},
]
)
print(output.predictions[0])Producing the following output:
Prediction(predictions=["Yer want ta know about them fancy science things, eh? Alright then, matey, settle yerself down with a pint o' grog and listen close. I be tellin' ye about the Theory o' Relativity, as proposed by that swashbucklin' genius, Albert Einstein.\n\nNow, ye see, Einstein said that time and space be connected like the sea and the wind. Ye can't have one without the other, savvy? And he proposed that how ye see time and space depends on how fast ye be movin' and where ye be standin'. That be called relativity, me"], deployed_model_id='***', metadata=None, model_version_id='1', model_resource_name='projects/***/locations/us-central1/models/***', explanations=None)From a different session
If the Vertex AI Endpoint was deployed in a different session and you want to use it but don’t have access to the deployed_model variable returned by the aiplatform.Model.deploy method as in the previous section; you can also run the following snippet to instantiate the deployed aiplatform.Endpoint via its resource name as projects/{PROJECT_ID}/locations/{LOCATION}/endpoints/{ENDPOINT_ID}.
You will need to either retrieve the resource name i.e. the projects/{PROJECT_ID}/locations/{LOCATION}/endpoints/{ENDPOINT_ID} URL yourself via the Google Cloud Console, or just replace the ENDPOINT_ID below that can either be found via the previously instantiated endpoint as endpoint.id or via the Google Cloud Console under the Online predictions where the endpoint is listed.
import os
from google.cloud import aiplatform
aiplatform.init(project=os.getenv("PROJECT_ID"), location=os.getenv("LOCATION"))
endpoint_display_name = "Meta-Llama-3.1-405B-FP8-Endpoint" # TODO: change to your endpoint display name
# Iterates over all the Vertex AI Endpoints within the current project and keeps the first match (if any), otherwise set to None
ENDPOINT_ID = next(
(endpoint.name for endpoint in aiplatform.Endpoint.list() if endpoint.display_name == endpoint_display_name), None
)
assert ENDPOINT_ID, (
"`ENDPOINT_ID` is not set, please make sure that the `endpoint_display_name` is correct at "
f"https://console.cloud.google.com/vertex-ai/online-prediction/endpoints?project={os.getenv('PROJECT_ID')}"
)
endpoint = aiplatform.Endpoint(
f"projects/{os.getenv('PROJECT_ID')}/locations/{os.getenv('LOCATION')}/endpoints/{ENDPOINT_ID}"
)
output = endpoint.predict(
instances=[
{
"inputs": "<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nYou are an assistant that responds as a pirate.<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nWhat's the Theory of Relativity?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n",
"parameters": {
"max_new_tokens": 128,
"do_sample": True,
"top_p": 0.95,
"temperature": 0.7,
},
},
],
)
print(output.predictions[0])Producing the following output:
Prediction(predictions=["Yer lookin' fer a treasure trove o' knowledge about them fancy physics, eh? Alright then, matey, settle yerself down with a pint o' grog and listen close, as I spin ye the yarn o' Einstein's Theory o' Relativity.\n\nIt be a tale o' two parts, me hearty: Special Relativity and General Relativity. Now, I know what ye be thinkin': what in blazes be the difference? Well, matey, let me break it down fer ye.\n\nSpecial Relativity be the idea that time and space be connected like the sea and the sky."], deployed_model_id='***', metadata=None, model_version_id='1', model_resource_name='projects/***/locations/us-central1/models/***', explanations=None)Via the Vertex AI Online Prediction UI
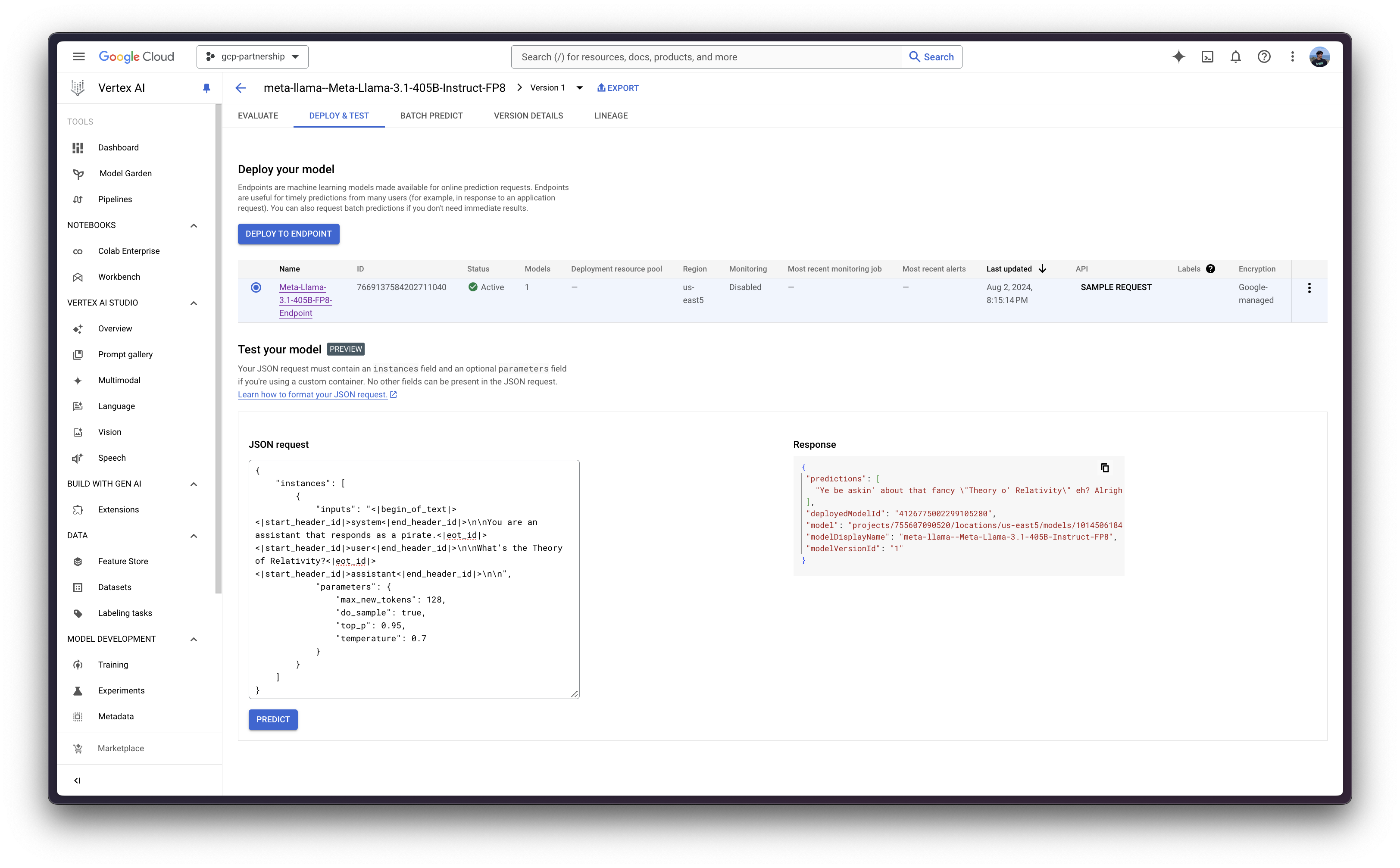
Alternatively, for testing purposes you can also use the Vertex AI Online Prediction UI, that provides a field that expects the JSON payload formatted according to the Vertex AI specification (as in the examples above) being:
{
"instances": [
{
"inputs": "<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nYou are an assistant that responds as a pirate.<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nWhat's the Theory of Relativity?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n",
"parameters": {
"max_new_tokens": 128,
"do_sample": true,
"top_p": 0.95,
"temperature": 0.7
}
}
]
}
Resource clean-up
Finally, you can release the resources that you’ve created as follows, to avoid unnecessary costs:
deployed_model.undeploy_allto undeploy the model from all the endpoints.deployed_model.deleteto delete the endpoint/s where the model was deployed gracefully, after theundeploy_allmethod.model.deleteto delete the model from the registry.
deployed_model.undeploy_all() deployed_model.delete() model.delete()
Alternatively, you can also remove those from the Google Cloud Console following the steps:
- Go to Vertex AI in Google Cloud
- Go to Deploy and use -> Online prediction
- Click on the endpoint and then on the deployed model/s to “Undeploy model from endpoint”
- Then go back to the endpoint list and remove the endpoint
- Finally, go to Deploy and use -> Model Registry, and remove the model
📍 Find the complete example on GitHub here!