Dataset viewer documentation
Analyze a dataset on the Hub
Analyze a dataset on the Hub
In the Quickstart, you were introduced to various endpoints for interacting with datasets on the Hub. One of the most useful ones is the /parquet endpoint, which allows you to get a dataset stored on the Hub and analyze it. This is a great way to explore the dataset, and get a better understanding of it’s contents.
To demonstrate, this guide will show you an end-to-end example of how to retrieve a dataset from the Hub and do some basic data analysis with the Pandas library.
Get a dataset
The Hub is home to more than 200,000 datasets across a wide variety of tasks, sizes, and languages. For this example, you’ll use the codeparrot/codecomplex dataset, but feel free to explore and find another dataset that interests you! The dataset contains Java code from programming competitions, and the time complexity of the code is labeled by a group of algorithm experts.
Let’s say you’re interested in the average length of the submitted code as it relates to the time complexity. Here’s how you can get started.
Use the /parquet endpoint to convert the dataset to a Parquet file and return the URL to it:
import requests
API_URL = "https://datasets-server.huggingface.co/parquet?dataset=codeparrot/codecomplex"
def query():
response = requests.get(API_URL)
return response.json()
data = query(){"parquet_files":
[
{"dataset": "codeparrot/codecomplex", "config": "default", "split": "train", "url": "https://huggingface.co/datasets/codeparrot/codecomplex/resolve/refs%2Fconvert%2Fparquet/default/train/0000.parquet", "filename": "0000.parquet", "size": 4115908}
],
"pending": [], "failed": [], "partial": false
}Read dataset with Pandas
With the URL, you can read the Parquet file into a Pandas DataFrame:
import pandas as pd
url = "https://huggingface.co/datasets/codeparrot/codecomplex/resolve/refs%2Fconvert%2Fparquet/default/train/0000.parquet"
df = pd.read_parquet(url)
df.head(5)| src | complexity | problem | from |
|---|---|---|---|
| import java.io.*;\nimport java.math.BigInteger… | quadratic | 1179_B. Tolik and His Uncle | CODEFORCES |
| import java.util.Scanner;\n \npublic class pil… | linear | 1197_B. Pillars | CODEFORCES |
| import java.io.BufferedReader;\nimport java.io… | linear | 1059_C. Sequence Transformation | CODEFORCES |
| import java.util.;\n\nimport java.io.;\npubl… | linear | 1011_A. Stages | CODEFORCES |
| import java.io.OutputStream;\nimport java.io.I… | linear | 1190_C. Tokitsukaze and Duel | CODEFORCES |
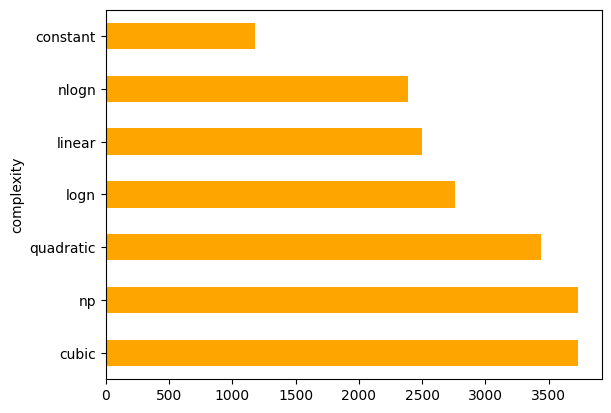
Calculate mean code length by time complexity
Pandas is a powerful library for data analysis; group the dataset by time complexity, apply a function to calculate the average length of the code snippet, and plot the results:
df.groupby('complexity')['src'].apply(lambda x: x.str.len().mean()).sort_values(ascending=False).plot.barh(color="orange")