Bitsandbytes documentation
Introduction: 8-bit optimizers
Introduction: 8-bit optimizers
With 8-bit optimizers, larger models can be finetuned with the same GPU memory compared to standard 32-bit optimizer training. 8-bit optimizers are a drop-in replacement for regular optimizers, with the following properties:
- Faster (e.g. 4x faster than regular Adam)
- 75% less memory, same performance
- No hyperparameter tuning needed
8-bit optimizers are mostly useful to finetune large models that did not fit into memory before. They also make it easier to pretrain larger models and have great synergy with sharded data parallelism. 8-bit Adam, for example, is already used across multiple teams in Facebook. This optimizer saves a ton of memory at no accuracy hit.
Generally, our 8-bit optimizers have three components:
- block-wise quantization isolates outliers and distributes the error more equally over all bits,
- dynamic quantization quantizes both small and large values with high precision,
- a stable embedding layer improves stability during optimization for models with word embeddings.
With these components, performing an optimizer update with 8-bit states is straightforward and for GPUs, this makes 8-bit optimizers way faster than regular 32-bit optimizers. Further details below
We feature 8-bit Adagrad, Adam, AdamW, LAMB, LARS, Lion, RMSprop and SGD (momentum).
Caveats
8-bit optimizers reduce the memory footprint and accelerate optimization on a wide range of tasks. However, since 8-bit optimizers reduce only the memory footprint proportional to the number of parameters, models that use large amounts of activation memory, such as convolutional networks, have few benefits from using 8-bit optimizers. Thus, 8-bit optimizers are most beneficial for training or finetuning models with many parameters on highly memory-constrained GPUs.
Usage
It only requires a two-line code change to get started.
import bitsandbytes as bnb
- adam = torch.optim.Adam(...)
+ adam = bnb.optim.Adam8bit(...)
# recommended for NLP models
- before: torch.nn.Embedding(...)
+ bnb.nn.StableEmbedding(...)The arguments passed are the same as standard Adam. For NLP models we recommend to also use the StableEmbedding layers which improves results and helps with stable 8-bit optimization.
Note that by default all parameter tensors with less than 4096 elements are kept at 32-bit even if you initialize those parameters with 8-bit optimizers. This is done since such small tensors do not save much memory and often contain highly variable parameters (biases) or parameters that require high precision (batch norm, layer norm). You can change this behavior like so:
# For parameter tensors with less than 16384 values are optimized in 32-bit
# it is recommended to use multiplies of 4096:
adam = bnb.optim.Adam8bit(model.parameters(), min_8bit_size=16384)Some more examples of how you can replace your old optimizer with the 8-bit optimizer:
import bitsandbytes as bnb
- adam = torch.optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.995)) # comment out old optimizer
+ adam = bnb.optim.Adam8bit(model.parameters(), lr=0.001, betas=(0.9, 0.995)) # add bnb optimizer
# use 32-bit Adam with 5th percentile clipping
+ adam = bnb.optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.995), optim_bits=32, percentile_clipping=5)
- adam = torch.optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.995)) # comment out old optimizerOverview of supported 8-bit optimizers
Currently, bitsandbytes supports the following optimizers:
Adagrad,Adagrad8bit,Adagrad32bitAdam,Adam8bit,Adam32bit,PagedAdam,PagedAdam8bit,PagedAdam32bitAdamW,AdamW8bit,AdamW32bit,PagedAdamW,PagedAdamW8bit,PagedAdamW32bitLAMB,LAMB8bit,LAMB32bitLARS,LARS8bit,LARS32bit,PytorchLARSLion,Lion8bit,Lion32bit,PagedLion,PagedLion8bit,PagedLion32bitRMSprop,RMSprop8bit,RMSprop32bitSGD,SGD8bit,SGD32bit
Additionally, for cases in which you want to optimize some unstable parameters with 32-bit Adam and others with 8-bit Adam, you can use the GlobalOptimManager, as explained in greater detail below.
Find the API docs here (still under construction).
Overview of expected gains
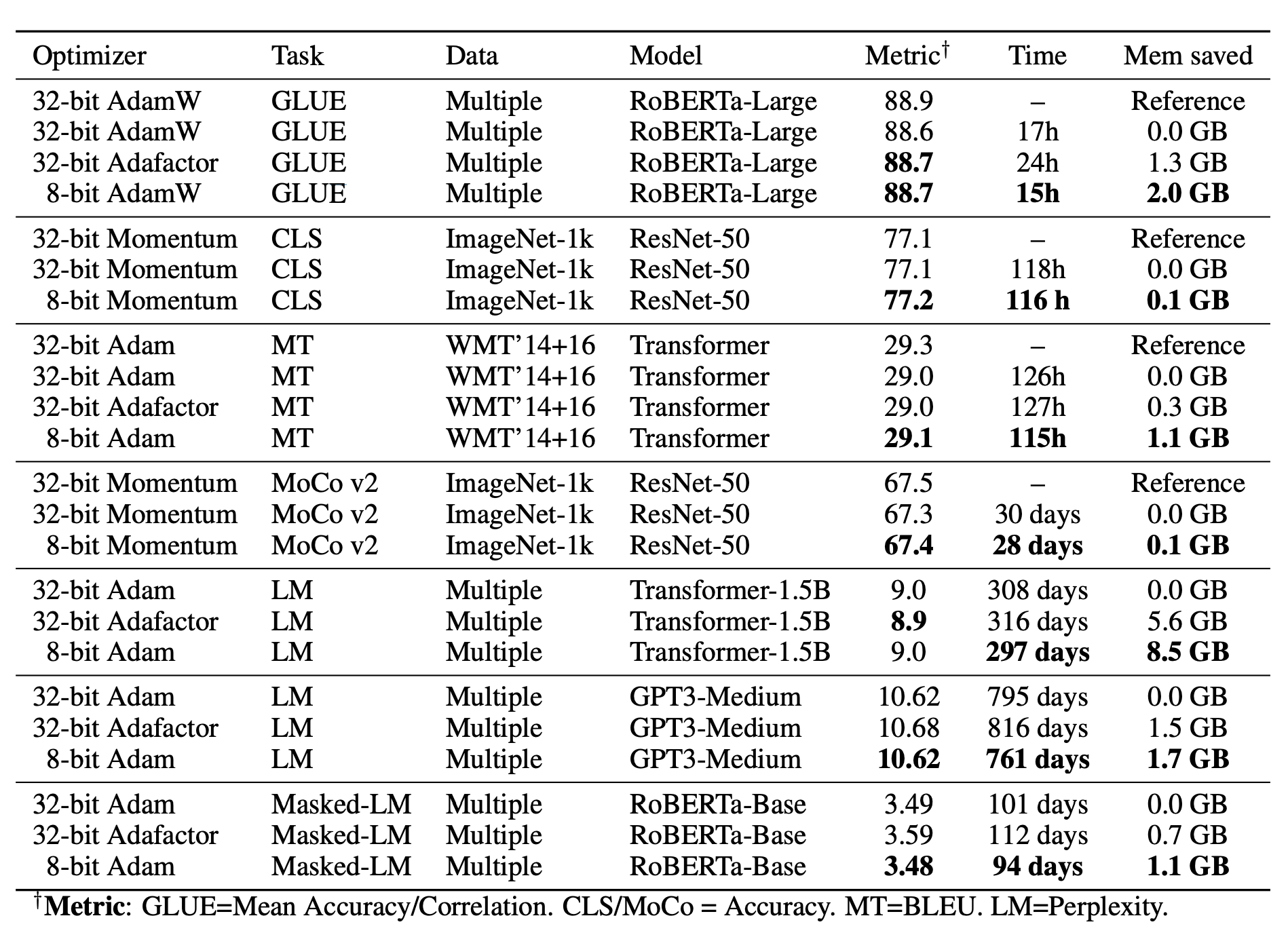
See here an overview of the biggest models that can be trained based on optimizer usage:

Research Background
Stateful optimizers maintain gradient statistics over time, e.g. the exponentially smoothed sum (SGD with momentum) or squared sum (Adam) of past gradient values. This state can be used to accelerate optimization compared to plain stochastic gradient descent but uses memory that might otherwise be allocated to model parameters, thereby limiting the maximum size of models trained in practice. bitsandbytes optimizers use 8-bit statistics, while maintaining the performance levels of using 32-bit optimizer states.
To overcome the resulting computational, quantization and stability challenges, 8-bit optimizers have three components:
- Block-wise quantization divides input tensors into smaller blocks that are independently quantized, therein isolating outliers and distributing the error more equally over all bits. Each block is processed in parallel across cores, yielding faster optimization and high precision quantization.
- Dynamic quantization, which quantizes both small and large values with high precision and
- a stable embedding layer improves stability during optimization for models with word embeddings.
With these components, performing an optimizer update with 8-bit states is straightforward. We dequantize the 8-bit optimizer states to 32-bit, perform the update and then quantize the states back to 8-bit for storage.
We do this 8-bit to 32-bit conversion element-by-element in registers, which means no slow copies to GPU memory or additional temporary memory are needed to perform quantization and dequantization. For GPUs, this makes 8-bit optimizers much faster than regular 32-bit optimizers.
For more details, please refer to the paper 8-bit Optimizers via Block-wise Quantization.
Stable Embedding Layer
The Stable Embedding Layer enhances the standard word embedding layer for improved training stability in NLP tasks. It addresses the challenge of non-uniform input distributions and mitigates extreme gradient variations, ensuring smoother training processes.
Features:
- Initialization: Utilizes Xavier uniform initialization to maintain consistent variance, reducing the likelihood of large gradients.
- Normalization: Incorporates layer normalization before adding positional embeddings, aiding in output stability.
- Optimizer States: Employs 32-bit optimizer states exclusively for this layer to enhance stability, while the rest of the model may use standard 16-bit precision.
Benefits:
- Designed to support more aggressive quantization strategies without compromising training stability.
- Helps in achieving stable training outcomes, particularly important for models dealing with diverse and complex language data.
Paged optimizers
Paged optimizers are build on top of the unified memory feature of CUDA. This feature is not supported by PyTorch and we added it to bitsandbytes.
It works like regular CPU paging, which means that it only becomes active if one runs out of GPU memory. Only then will the memory be transferred, page-by-page, from GPU to CPU. The memory is mapped, meaning that pages are preallocated on the CPU, but they are not updated automatically. They are only updated if the memory is accessed, or a swapping operation is launched.
The unified memory feature is less efficient than regular asynchronous memory transfers. This means, one usually will not be able to get full PCIe memory bandwidth utilization. If one does a manual prefetch, transfer speeds can be high but still about half or worse than the full PCIe memory bandwidth (tested on 16x lanes PCIe 3.0).
This all means performance depends highly on the particular use-case. If one evicts, say, 1 GB of memory per forward-backward-optimizer loop: One can expect about 50% of the PCIe bandwidth as time in the best case. So 1 GB for PCIe 3.0 with 16x lanes, which runs at 16 GB/s, is 1/(16*0.5) = 1/8 = 125ms overhead per optimizer step. Other overhead can be estimated for the particular use-case given a PCIe interface, lanes, and the memory that is evicted in each iteration.
Compared to CPU offloading, this has the advantage that there is zero overhead if all the memory fits into the device and only some overhead if some of memory needs to be evicted. For offloading, one would usually offload fixed parts of the model and need to off and onload all this memory with each iteration through the model (sometimes twice for both forward and backward pass).
Find more details in this discussion.
GlobalOptimManager : How to override config hyperparameters for particular weights/parameters
If you want to optimize some unstable parameters with 32-bit Adam and others with 8-bit Adam, you can use the GlobalOptimManager. With this, we can also configure specific hyperparameters for particular layers, such as embedding layers. To do that, we need two things:
- Register the parameter while they are still on the CPU.
- Override the config with the new desired hyperparameters (anytime, anywhere).
For global overrides in many different places in your code you can do:
import torch
import bitsandbytes as bnb
mng = bnb.optim.GlobalOptimManager.get_instance()
model = MyModel()
mng.register_parameters(model.parameters()) # 1. register parameters while still on CPU
model = model.cuda()
# use 8-bit optimizer states for all parameters
adam = bnb.optim.Adam(model.parameters(), lr=0.001, optim_bits=8)
# 2a. override: the parameter model.fc1.weight now uses 32-bit Adam
mng.override_config(model.fc1.weight, 'optim_bits', 32)
# 2b. override: the two special layers use
# sparse optimization + different learning rate + different Adam betas
mng.override_config([model.special.weight, model.also_special.weight],
key_value_dict ={'is_sparse': True, 'lr': 1e-5, 'betas'=(0.9, 0.98)})Possible options for the config override are: betas, eps, weight_decay, lr, optim_bits, min_8bit_size, percentile_clipping, block_wise, max_unorm.
For overrides for particular layers, we recommend overriding locally in each module. You can do this by passing the module, the parameter, and its attribute name to the GlobalOptimManager:
class MyModule(torch.nn.Module):
def __init__(d_in, d_out):
super(MyModule, self).__init__()
self.linear = torch.nn.Linear(d_in, d_out)
# optimization will happen in 32-bit and
# learning rate will be set to 0.0001 independent of the main learning rate
config = {'optim_bits': 32, 'lr' : 0.0001}
GlobalOptimManager.get_instance().register_module_override(self, 'weight', config)
API Docs
… under construction …
Here we’ll provide further auto-generated API docs soon. Please feel free to contribute doc-strings for the respective optimizers, as bitsandbytes is a community effort.
StableEmbedding
class bitsandbytes.nn.StableEmbedding
< source >( num_embeddings: int embedding_dim: int padding_idx: Optional = None max_norm: Optional = None norm_type: float = 2.0 scale_grad_by_freq: bool = False sparse: bool = False _weight: Optional = None device = None dtype = None )
Custom embedding layer designed to improve stability during training for NLP tasks by using 32-bit optimizer states. It is designed to reduce gradient variations that can result from quantization. This embedding layer is initialized with Xavier uniform initialization followed by layer normalization.
Example:
# Initialize StableEmbedding layer with vocabulary size 1000, embedding dimension 300
embedding_layer = StableEmbedding(num_embeddings=1000, embedding_dim=300)
# Reset embedding parameters
embedding_layer.reset_parameters()
# Perform a forward pass with input tensor
input_tensor = torch.tensor([1, 2, 3])
output_embedding = embedding_layer(input_tensor)Methods: reset_parameters(): Reset embedding parameters using Xavier uniform initialization. forward(input: Tensor) -> Tensor: Forward pass through the stable embedding layer.
__init__
< source >( num_embeddings: int embedding_dim: int padding_idx: Optional = None max_norm: Optional = None norm_type: float = 2.0 scale_grad_by_freq: bool = False sparse: bool = False _weight: Optional = None device = None dtype = None )
Parameters
- num_embeddings (
int) — The number of unique embeddings (vocabulary size). - embedding_dim (
int) — The dimensionality of the embedding. - padding_idx (
Optional[int]) — Pads the output with zeros at the given index. - max_norm (
Optional[float]) — Renormalizes embeddings to have a maximum L2 norm. - norm_type (
float, defaults to2.0) — The p-norm to compute for themax_normoption. - scale_grad_by_freq (
bool, defaults toFalse) — Scale gradient by frequency during backpropagation. - sparse (
bool, defaults toFalse) — Computes dense gradients. Set toTrueto compute sparse gradients instead. - _weight (
Optional[Tensor]) — Pretrained embeddings.