DreamBooth
DreamBooth is a method to personalize text-to-image models like Stable Diffusion given just a few (3-5) images of a subject. It allows the model to generate contextualized images of the subject in different scenes, poses, and views.

Data Preparation
The data format for DreamBooth training is simple. All you need is images of a concept (e.g. a person) and a concept token.
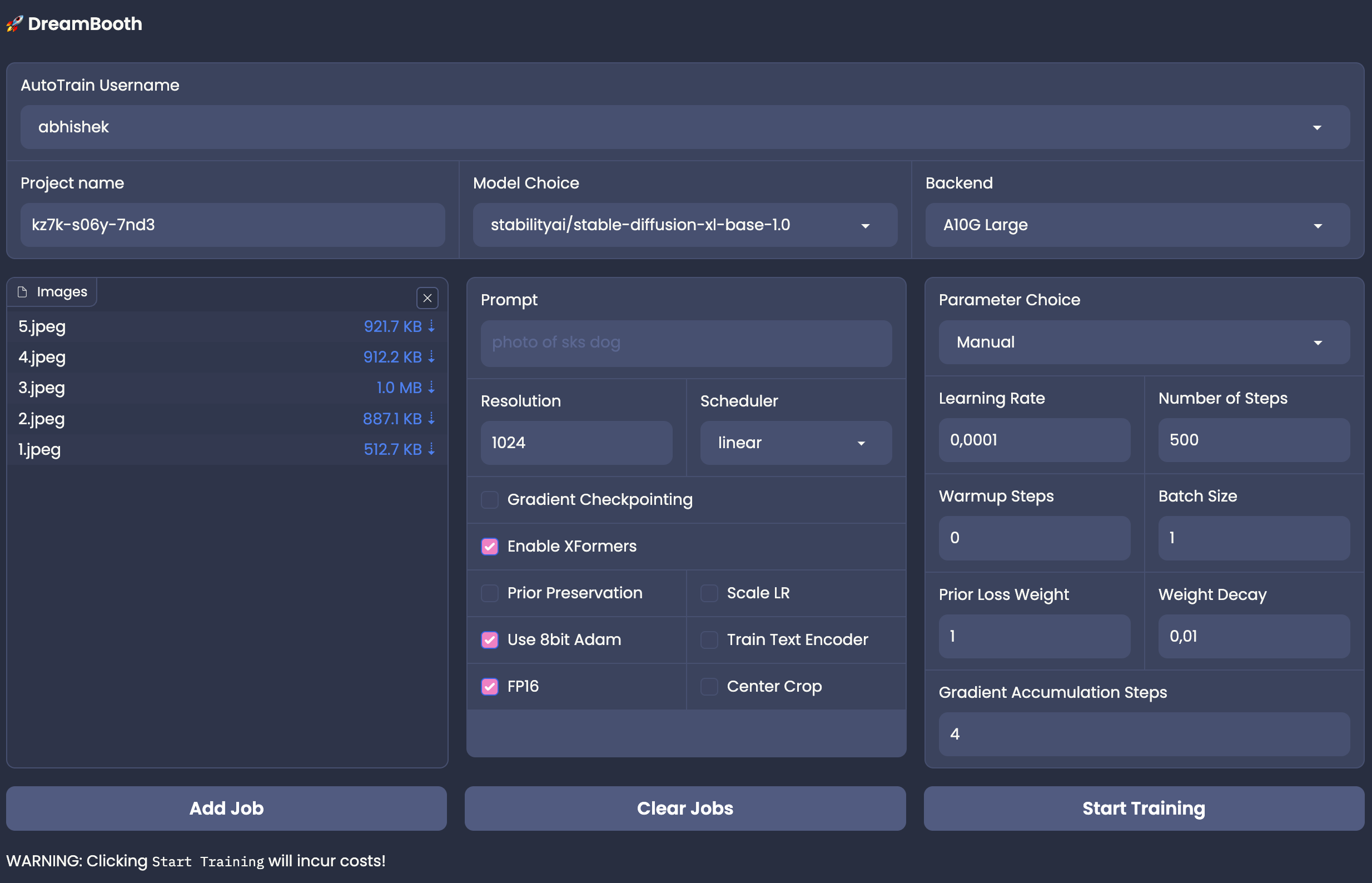
To train a dreambooth model, please select an appropriate model from the hub. You can also let AutoTrain decide the best model for you! When choosing a model from the hub, please make sure you select the correct image size compatible with the model.
Same as other tasks, you also have an option to select the parameters manually or automatically using AutoTrain.
For each concept that you want to train, you must have a concept token and concept images. Concept token is nothing but a word that is not available in the dictionary.