|
--- |
|
language: de |
|
datasets: |
|
- deepset/germanquad |
|
license: mit |
|
thumbnail: https://thumb.tildacdn.com/tild3433-3637-4830-a533-353833613061/-/resize/720x/-/format/webp/germanquad.jpg |
|
tags: |
|
- exbert |
|
--- |
|
|
|
 |
|
|
|
## Overview |
|
**Language model:** gelectra-base-germanquad |
|
**Language:** German |
|
**Training data:** GermanQuAD train set (~ 12MB) |
|
**Eval data:** GermanQuAD test set (~ 5MB) |
|
**Infrastructure**: 1x V100 GPU |
|
**Published**: Apr 21st, 2021 |
|
|
|
## Details |
|
- We trained a German question answering model with a gelectra-base model as its basis. |
|
- The dataset is GermanQuAD, a new, German language dataset, which we hand-annotated and published [online](https://deepset.ai/germanquad). |
|
- The training dataset is one-way annotated and contains 11518 questions and 11518 answers, while the test dataset is three-way annotated so that there are 2204 questions and with 2204·3−76 = 6536answers, because we removed 76 wrong answers. |
|
|
|
See https://deepset.ai/germanquad for more details and dataset download in SQuAD format. |
|
|
|
## Hyperparameters |
|
``` |
|
batch_size = 24 |
|
n_epochs = 2 |
|
max_seq_len = 384 |
|
learning_rate = 3e-5 |
|
lr_schedule = LinearWarmup |
|
embeds_dropout_prob = 0.1 |
|
``` |
|
## Performance |
|
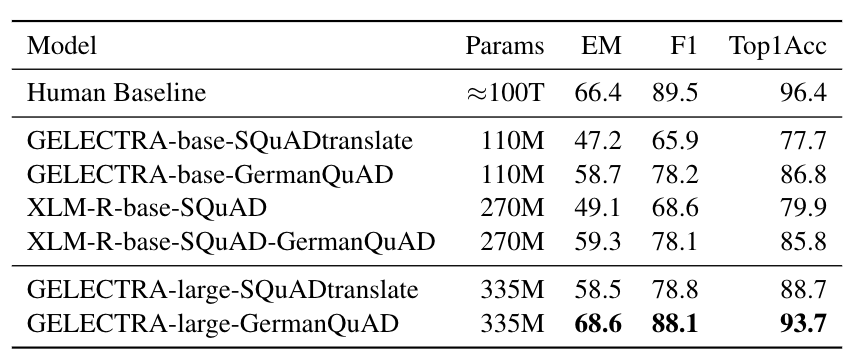
We evaluated the extractive question answering performance on our GermanQuAD test set. |
|
Model types and training data are included in the model name. |
|
For finetuning XLM-Roberta, we use the English SQuAD v2.0 dataset. |
|
The GELECTRA models are warm started on the German translation of SQuAD v1.1 and finetuned on [GermanQuAD](https://deepset.ai/germanquad). |
|
The human baseline was computed for the 3-way test set by taking one answer as prediction and the other two as ground truth. |
|
 |
|
|
|
## Authors |
|
**Timo Möller:** timo.moeller@deepset.ai |
|
**Julian Risch:** julian.risch@deepset.ai |
|
**Malte Pietsch:** malte.pietsch@deepset.ai |
|
|
|
## About us |
|
<div class="grid lg:grid-cols-2 gap-x-4 gap-y-3"> |
|
<div class="w-full h-40 object-cover mb-2 rounded-lg flex items-center justify-center"> |
|
<img alt="" src="https://raw.githubusercontent.com/deepset-ai/.github/main/deepset-logo-colored.png" class="w-40"/> |
|
</div> |
|
<div class="w-full h-40 object-cover mb-2 rounded-lg flex items-center justify-center"> |
|
<img alt="" src="https://raw.githubusercontent.com/deepset-ai/.github/main/haystack-logo-colored.png" class="w-40"/> |
|
</div> |
|
</div> |
|
|
|
[deepset](http://deepset.ai/) is the company behind the open-source NLP framework [Haystack](https://haystack.deepset.ai/) which is designed to help you build production ready NLP systems that use: Question answering, summarization, ranking etc. |
|
|
|
|
|
Some of our other work: |
|
- [Distilled roberta-base-squad2 (aka "tinyroberta-squad2")]([https://huggingface.co/deepset/tinyroberta-squad2) |
|
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert) |
|
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad) |
|
|
|
## Get in touch and join the Haystack community |
|
|
|
<p>For more info on Haystack, visit our <strong><a href="https://github.com/deepset-ai/haystack">GitHub</a></strong> repo and <strong><a href="https://docs.haystack.deepset.ai">Documentation</a></strong>. |
|
|
|
We also have a <strong><a class="h-7" href="https://haystack.deepset.ai/community">Discord community open to everyone!</a></strong></p> |
|
|
|
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Discord](https://haystack.deepset.ai/community) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai) |
|
|
|
By the way: [we're hiring!](http://www.deepset.ai/jobs) |
|
|

