


Model Download | Evaluation Results | Model Architecture | API Platform | License | Citation
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
1. Introduction
Last week, the release and buzz around DeepSeek-V2 have ignited widespread interest in MLA (Multi-head Latent Attention)! Many in the community suggested open-sourcing a smaller MoE model for in-depth research. And now DeepSeek-V2-Lite comes out:
- 16B total params, 2.4B active params, scratch training with 5.7T tokens
- Outperforms 7B dense and 16B MoE on many English & Chinese benchmarks
- Deployable on single 40G GPU, fine-tunable on 8x80G GPUs
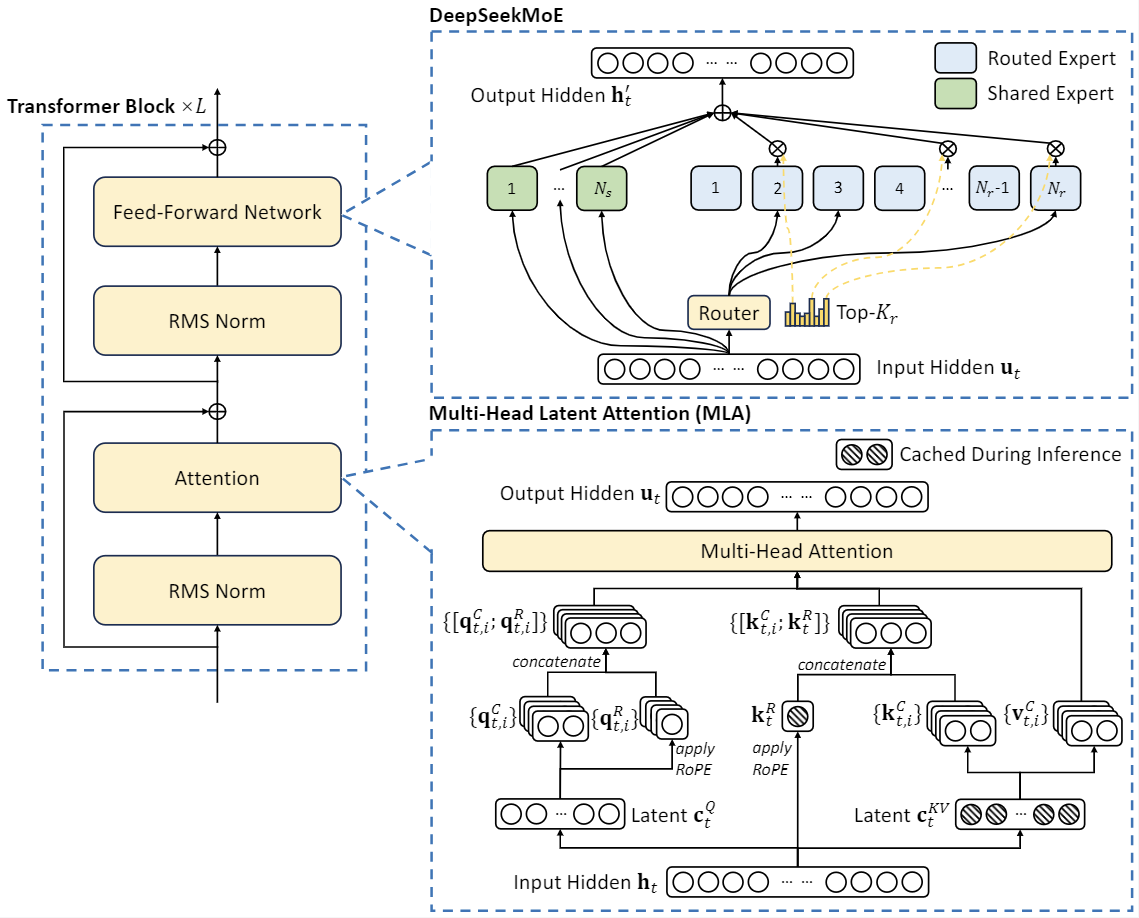
DeepSeek-V2, a strong Mixture-of-Experts (MoE) language model characterized by economical training and efficient inference. DeepSeek-V2 adopts innovative architectures including Multi-head Latent Attention (MLA) and DeepSeekMoE. MLA guarantees efficient inference through significantly compressing the Key-Value (KV) cache into a latent vector, while DeepSeekMoE enables training strong models at an economical cost through sparse computation.
2. News
- 2024.05.16: We released the DeepSeek-V2-Lite.
- 2024.05.06: We released the DeepSeek-V2.
3. Model Downloads
With DeepSeek-V2, we are open-sourcing base and chat models across two sizes:
| Model | #Total Params | #Activated Params | Context Length | Download |
|---|---|---|---|---|
| DeepSeek-V2-Lite | 16B | 2.4B | 32k | 🤗 HuggingFace |
| DeepSeek-V2-Lite-Chat (SFT) | 16B | 2.4B | 32k | 🤗 HuggingFace |
| DeepSeek-V2 | 236B | 21B | 128k | 🤗 HuggingFace |
| DeepSeek-V2-Chat (RL) | 236B | 21B | 128k | 🤗 HuggingFace |
Due to the constraints of HuggingFace, the open-source code currently experiences slower performance than our internal codebase when running on GPUs with Huggingface. To facilitate the efficient execution of our model, we offer a dedicated vllm solution that optimizes performance for running our model effectively.
4. Evaluation Results
Base Model
Standard Benchmark
| Benchmark | Domain | DeepSeek 7B (Dense) | DeepSeekMoE 16B | DeepSeek-V2-Lite (MoE-16B) |
|---|---|---|---|---|
| Architecture | - | MHA+Dense | MHA+MoE | MLA+MoE |
| MMLU | English | 48.2 | 45.0 | 58.3 |
| BBH | English | 39.5 | 38.9 | 44.1 |
| C-Eval | Chinese | 45.0 | 40.6 | 60.3 |
| CMMLU | Chinese | 47.2 | 42.5 | 64.3 |
| HumanEval | Code | 26.2 | 26.8 | 29.9 |
| MBPP | Code | 39.0 | 39.2 | 43.2 |
| GSM8K | Math | 17.4 | 18.8 | 41.1 |
| Math | Math | 3.3 | 4.3 | 17.1 |
Chat Model
Standard Benchmark
| Benchmark | Domain | DeepSeek 7B Chat (SFT) | DeepSeekMoE 16B Chat (SFT) | DeepSeek-V2-Lite 16B Chat (SFT) |
|---|---|---|---|---|
| MMLU | English | 49.7 | 47.2 | 55.7 |
| BBH | English | 43.1 | 42.2 | 48.1 |
| C-Eval | Chinese | 44.7 | 40.0 | 60.1 |
| CMMLU | Chinese | 51.2 | 49.3 | 62.5 |
| HumanEval | Code | 45.1 | 45.7 | 57.3 |
| MBPP | Code | 39.0 | 46.2 | 45.8 |
| GSM8K | Math | 62.6 | 62.2 | 72.0 |
| Math | Math | 14.7 | 15.2 | 27.9 |
5. Model Architecture
DeepSeek-V2 adopts innovative architectures to guarantee economical training and efficient inference:
- For attention, we design MLA (Multi-head Latent Attention), which utilizes low-rank key-value union compression to eliminate the bottleneck of inference-time key-value cache, thus supporting efficient inference.
- For Feed-Forward Networks (FFNs), we adopt DeepSeekMoE architecture, a high-performance MoE architecture that enables training stronger models at lower costs.
6. How to run locally
To utilize DeepSeek-V2-Lite in BF16 format for inference, 40GB*1 GPU is required.
Inference with Huggingface's Transformers
You can directly employ Huggingface's Transformers for model inference.
Text Completion
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/DeepSeek-V2-Lite"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
text = "An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
Chat Completion
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/DeepSeek-V2-Lite-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
messages = [
{"role": "user", "content": "Write a piece of quicksort code in C++"}
]
input_tensor = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(input_tensor.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0][input_tensor.shape[1]:], skip_special_tokens=True)
print(result)
The complete chat template can be found within tokenizer_config.json located in the huggingface model repository.
An example of chat template is as belows:
<|begin▁of▁sentence|>User: {user_message_1}
Assistant: {assistant_message_1}<|end▁of▁sentence|>User: {user_message_2}
Assistant:
You can also add an optional system message:
<|begin▁of▁sentence|>{system_message}
User: {user_message_1}
Assistant: {assistant_message_1}<|end▁of▁sentence|>User: {user_message_2}
Assistant:
Inference with vLLM (recommended)
To utilize vLLM for model inference, please merge this Pull Request into your vLLM codebase: https://github.com/vllm-project/vllm/pull/4650.
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
max_model_len, tp_size = 8192, 1
model_name = "deepseek-ai/DeepSeek-V2-Lite-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_name)
llm = LLM(model=model_name, tensor_parallel_size=tp_size, max_model_len=max_model_len, trust_remote_code=True, enforce_eager=True)
sampling_params = SamplingParams(temperature=0.3, max_tokens=256, stop_token_ids=[tokenizer.eos_token_id])
messages_list = [
[{"role": "user", "content": "Who are you?"}],
[{"role": "user", "content": "Translate the following content into Chinese directly: DeepSeek-V2 adopts innovative architectures to guarantee economical training and efficient inference."}],
[{"role": "user", "content": "Write a piece of quicksort code in C++."}],
]
prompt_token_ids = [tokenizer.apply_chat_template(messages, add_generation_prompt=True) for messages in messages_list]
outputs = llm.generate(prompt_token_ids=prompt_token_ids, sampling_params=sampling_params)
generated_text = [output.outputs[0].text for output in outputs]
print(generated_text)
LangChain Support
Since our API is compatible with OpenAI, you can easily use it in langchain. Here is an example:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model='deepseek-chat',
openai_api_key=<your-deepseek-api-key>,
openai_api_base='https://api.deepseek.com/v1',
temperature=0.85,
max_tokens=8000)
7. License
This code repository is licensed under the MIT License. The use of DeepSeek-V2 Base/Chat models is subject to the Model License. DeepSeek-V2 series (including Base and Chat) supports commercial use.
8. Citation
@misc{deepseekv2,
title={DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model},
author={DeepSeek-AI},
year={2024},
eprint={2405.04434},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
9. Contact
If you have any questions, please raise an issue or contact us at service@deepseek.com.