Datasets:

Unnamed: 0
int64 1
89.2k
| case_id
int64 6
1.91k
| duration_seconds
int64 1
4.47k
| last_screen
stringclasses 15
values | device
stringclasses 3
values | ethn_hispanic
int64 0
1
| ethn_white
int64 0
1
| ethn_afr_american
int64 0
1
| ethn_asian
int64 0
1
| ethn_sth_else
int64 0
1
| ethn_prefer_not
int64 0
1
| age
float64 18
93
⌀ | education
float64 1
6
⌀ | english_fl
float64 1
2
⌀ | twitter_use
float64 1
6
⌀ | socmedia_use
float64 1
6
⌀ | prolific_hours
float64 0
900
⌀ | task_fun
int64 0
1
| task_interesting
int64 0
1
| task_boring
int64 0
1
| task_repetitive
int64 0
1
| task_important
int64 0
1
| task_depressing
int64 0
1
| task_offensive
int64 0
1
| repeat_tweet_coding
float64 1
3
⌀ | repeat_hs_coding
float64 1
3
⌀ | target_online_harassment
float64 1
2
⌀ | target_other_harassment
float64 1
2
⌀ | party_affiliation
float64 1
3
⌀ | societal_relevance_hs
float64 1
3
⌀ | annotator_id
int64 5
1.91k
| condition
stringclasses 5
values | tweet_batch
stringclasses 50
values | hate_speech
bool 2
classes | offensive_language
bool 2
classes | tweet_id
int64 1
3.05k
| orig_label_hs
float64 0
3
⌀ | orig_label_ol
float64 0
3
⌀ | orig_label_ne
float64 0
3
⌀ | tweet_hashed
stringlengths 5
277
⌀ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
1 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R1 | false | true | 1 | 0 | 2 | 1 | @###### bro that hoe live |
2 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R2 | false | true | 2 | 0 | 2 | 1 | Stop using the word "redskin(s)". |
3 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R3 | false | true | 3 | 0 | 3 | 0 | Now when I put this pussy on Vivian she bet not be playing 😂😭😏 |
4 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R4 | false | true | 4 | 0 | 3 | 0 | RT @###### Call her 1st thing in da AM.... Let her know dat pussy on yo mind.... |
5 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R5 | true | true | 5 | 2 | 1 | 0 | I just want to punch you in the throat when you get my order wrong stupid bitch at sonic |
6 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R6 | true | true | 6 | 2 | 1 | 0 | @###### @###### fight me you fucking obese niglet |
7 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R7 | false | true | 7 | 0 | 2 | 1 | Really. 3 hours to find paper work is retarded. Tarrant County Courts suck. #wasteoftime |
8 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R8 | false | true | 8 | 0 | 2 | 1 | ' You Deserve x August Alsina 󾮞󾮞 Im dedicating that to all my old side hoes 󾌴󾌴󾌴󾌴󾌺󾌺󾌺󾌺󾌺󾮟 . |
9 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R9 | false | false | 9 | 0 | 1 | 2 | @###### @###### trash |
10 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R10 | true | false | 10 | 3 | 0 | 0 | @###### I hate that nigger. |
11 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R11 | false | false | 11 | 0 | 0 | 3 | Panda Express is so trash but I wanted Chinese and didn't feel like gettin out the car |
12 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R12 | false | false | 12 | 1 | 2 | 0 | RT @###### Perfect vision....Me, my niggs, mas hoes, mas clicquot, mas dom p, mas moet, "my type of party" blasting out a Cali condo |
13 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R13 | false | false | 13 | 0 | 1 | 2 | LMFAOOOOO BYE “@###### American sports trash. Soccer and Hockey the best sports.” |
14 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R14 | false | true | 14 | 1 | 2 | 0 | @###### dude was a bitch nigga and took off running |
15 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R15 | false | true | 15 | 0 | 3 | 0 | @###### brooooo I miss you bitch |
16 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R16 | false | false | 16 | 0 | 0 | 3 | Tattoos are about expression not meaning. One mans trash is another mans treasure 💡💰 |
17 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R17 | false | false | 17 | 3 | 0 | 0 | RT @###### Well, Maryland is just a bunch of hateful rednecks, anyway. |
18 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R18 | false | true | 18 | 1 | 2 | 0 | @###### @###### haha you playin nigga I fuck bitches make money and smoke that straight og kush |
19 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R19 | true | false | 19 | 3 | 0 | 0 | @###### whats your youtube channel then faggot |
20 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R20 | false | false | 20 | 0 | 0 | 3 | Ayyyyy I'm sipping on a free slurpee and seeing The Front Bottoms tonight. I'm a happy clam. |
21 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R21 | false | true | 21 | 0 | 2 | 1 | You ever randomly woke up and ya bitch standing over you, just staring. |
22 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R22 | false | false | 22 | 0 | 1 | 2 | RT @###### First day of spring break: ate half a pan of brownies & watched 6 episodes of Parks and Rec with @###### & @###### |
23 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R23 | true | false | 23 | 0 | 1 | 2 | yea so about @###### 's new friend.. all my friends kno they're only allowed one cute darkie friend n that's me! lol |
24 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R24 | true | false | 24 | 1 | 0 | 2 | I think I found a normal roommate again! Praise be to Jesus! These current ones are about to get their throats slit in their sleep! |
25 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R25 | true | false | 25 | 2 | 1 | 0 | @###### shut up you stupid bitch |
26 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R26 | false | true | 26 | 3 | 0 | 0 | @###### I don't hate that he blew up from 3005 like a hipster but I hate the faggots who say they love his music based off his worst + |
27 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R27 | false | false | 27 | 0 | 1 | 2 | RT @###### Joey Badass said "Traded in my Nikes for a new mic, I guess it's safe to say he sold his soles for a new life" |
28 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R28 | true | false | 28 | 3 | 0 | 0 | RT @###### Fuck the Islamic State!! We will kill those cunts🇬🇧 |
29 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R29 | false | true | 29 | 0 | 3 | 0 | @###### lol bitch yo display name |
30 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R30 | false | false | 30 | 0 | 1 | 2 | They took it there bro you know I'm civil. RT @###### @###### wait a minute! Lol. Don't get ghetto V! |
31 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R31 | false | true | 31 | 2 | 1 | 0 | I need to chat with @###### . Where dat nicca at? Lol |
32 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R32 | false | true | 32 | 1 | 2 | 0 | I hate that when I have assigned seats they sit me by the most annoying bitches in the whole class. |
33 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R33 | true | false | 33 | 1 | 2 | 0 | @###### #Sequester Den the fat colored girl chased me down day street while she swingin da table wit one arm... I wants my pay!!! |
34 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R34 | false | false | 34 | 0 | 1 | 2 | Other Jihadi news #ISIS executed #Kuwait preacher Redha Lari coz he was..“too extreme” & hampered reconciliation with Nusra with his fatwas |
35 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R35 | true | false | 35 | 2 | 0 | 1 | @###### @###### @###### @###### Ahmed and retard mikey for special Olympic boxing |
36 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R36 | true | false | 36 | 2 | 1 | 0 | RT @###### @###### you're a fucking queer |
37 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R37 | false | true | 37 | 0 | 3 | 0 | RT @###### I love me some down ass bitches. |
38 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R38 | false | false | 38 | 0 | 0 | 3 | RT @###### A bird doesn't sing because it has an answer, it sings because it has a song.MAYA ANGELOU
#poetry #writing |
39 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R39 | true | false | 39 | 1 | 0 | 2 | Bengals kicker trash. |
40 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R40 | false | false | 40 | 0 | 0 | 3 | RT @###### Yo BCU band made UCF band look like trash |
41 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R41 | false | true | 41 | 0 | 2 | 1 | @###### @###### 😂bitch you always hatin lmao |
42 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R42 | false | false | 42 | 0 | 0 | 3 | Giants secondary lookin like trash |
43 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R43 | false | false | 43 | 0 | 1 | 2 | @###### @###### khan has been facing nothing but trash since his L to Garcia |
44 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R44 | true | true | 44 | 0 | 3 | 0 | Screaming money over hoes nigga you ain't fuck shit |
45 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R45 | false | true | 45 | 0 | 3 | 0 | RT @###### Don't be 32 on here and saying "all my friends and everyone I know has a baby".
Well bitch. Life. |
46 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R46 | false | false | 46 | 0 | 0 | 3 | We over here struggling with college and work and ice jj fish making money for being trash lol. What has this world come to. |
47 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R47 | true | false | 47 | 0 | 1 | 2 | @###### pay your taxes teabaggers |
48 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R48 | false | true | 48 | 0 | 1 | 2 | Weekend is here. What an amazing week this has been. Let's use this extended weekend to celebrate our successes my fellow queer folk. |
49 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R49 | true | false | 49 | 1 | 2 | 0 | Only white trash watch hockey. |
50 | 14 | 796 | THANKS | Desktop | 1 | 0 | 0 | 0 | 0 | 0 | 23 | 3 | 1 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 2 | 2 | 2 | 13 | A | R50 | true | false | 50 | 3 | 0 | 0 | If you kill all cops and cracker babies, what next?????? Black states, white states, and Latino states? Isn't that moving backwards? |
51 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R1 | true | true | 601 | 2 | 1 | 0 | fucking CHRIST i hate tutors and TAs. you literally get paid to teach retards to stop picking their nose. GET THE FUCK OUTTA MY FACE |
52 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R2 | false | false | 602 | 1 | 2 | 0 | For instance...Nikki said BET you won't fight her. I said bet? She said bet. Whipped a quick u-turn, whooped that ass, and went to jail 😂 |
53 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R3 | false | true | 603 | 1 | 2 | 0 | NEWS FLASH: Obama won the election and increase their numbers in congress. Stop with the bullshit already and compromise bitches! |
54 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R4 | false | false | 604 | 0 | 2 | 1 | @###### @###### yall trash but @###### cold |
55 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R5 | false | true | 605 | 0 | 2 | 1 | I'm not the type of guy to bitch about how hot it is but it's about to be 11 and I'm still sweating |
56 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R6 | true | false | 606 | 1 | 0 | 2 | Have you noticed all the ghetto people naming their kids after cars? Mercedes… Lexus… Repossessed. |
57 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R7 | false | true | 607 | 1 | 2 | 0 | RT @###### Def a whiny bitch RT @###### “@###### A girl who cries is a girl who cares.” Or a whiny bitch |
58 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R8 | false | true | 608 | 1 | 2 | 0 | I hate when those little white kids try and act black. Like bitch YOU ARE WHITE |
59 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R9 | false | false | 609 | 2 | 0 | 1 | @###### Y’all whitey gots to PAY fo da preparations |
60 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R10 | false | false | 610 | 0 | 1 | 2 | Well Jay I guess if you wanna keep your house from burning down...the bird is the word yeah!!!! #jaymohrsports @###### |
61 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R11 | false | false | 611 | 0 | 1 | 2 | RT @###### I hate stereotypes. Preconceived notions that black men are athletes or criminals.. Black women are ghetto and confined to t… |
62 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R12 | false | false | 612 | 0 | 1 | 2 | @###### @###### @###### ha booner has that twitter @###### ha |
63 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R13 | false | true | 613 | 0 | 3 | 0 | RT @###### Just barrass Meez ctfu um zoned out wit my fro out while um hitin hoes from da back #comebacktoreality |
64 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R14 | false | true | 614 | 0 | 3 | 0 | RT @###### @###### "you don't want to play cs:go you're a bitch!" "no I won't play fucking league of legends that game is shit I… |
65 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R15 | false | true | 615 | 0 | 2 | 1 | RT @###### Every time a Black woman says "oh bitch", I smile. |
66 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R16 | false | true | 616 | 0 | 2 | 1 | “@###### that new 1d song diana is well written well done boyzzzzzz” bow down bitch |
67 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R17 | false | true | 617 | 0 | 3 | 0 | Nippin these Clarke Motel bitches...they get free pizza EVERY DAY and don't tip shit. Also never give us any business. Game is over. |
68 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R18 | false | true | 618 | 1 | 2 | 0 | RT @###### Behind every REAL bitch, there's a bitch ass nigga that did her wrong but made her strong. |
69 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R19 | true | true | 619 | 0 | 3 | 0 | You know how hard it is to find a good woman? But yo hoe ass being ungrateful and cheating on your good woman cuz what? Faggot shit. |
70 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R20 | false | false | 620 | 0 | 1 | 2 | RT @###### “@###### Mo Claiborne is so trash”I can't say it enough fam 😒 |
71 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R21 | false | false | 621 | 1 | 0 | 2 | RT @###### Cue the liberal left's Uncle Tom attacks against Tim Scott in 4...3...2... #tcot #teaparty #GOP |
72 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R22 | true | false | 622 | 0 | 1 | 2 | @###### poor coon.......snow stopped here,now if the wind would it might be nice out,well for winter |
73 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R23 | false | false | 623 | 0 | 1 | 2 | Alexa's phone gave us colors and Julia got yellow I'm dying #racistaf |
74 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R24 | false | true | 624 | 1 | 2 | 0 | Yes yes yes that's all you gone hear never met a hoe yet that a tell me no |
75 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R25 | false | false | 625 | 1 | 0 | 2 | If you enjoy hunting for sport, then you're trash. If you hunt for food, you deserve to starve. |
76 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R26 | true | false | 626 | 1 | 0 | 2 | Oh it's coon bike week in Charlotte ok makes sense now |
77 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R27 | true | true | 627 | 1 | 2 | 0 | ON. SIGHT!! RT @###### Bitch I bet not see you in the streets @###### trash ass nigga |
78 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R28 | false | false | 628 | 1 | 0 | 2 | @###### oh state, just enjoy your trailer trash and your sub par sports. |
79 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R29 | false | false | 629 | 0 | 1 | 2 | 30 mins for @###### n @###### to pick out a trash can @ meijer....now do u guys understand why I took 3 shots before this trip |
80 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R30 | true | false | 630 | 3 | 0 | 0 | @###### pats owner is a kike. |
81 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R31 | true | true | 631 | 3 | 0 | 0 | @###### so your a "nigger" fighter huh |
82 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R32 | false | false | 632 | 0 | 1 | 2 | The Pirates have made the playoffs and the Yankees are out...hell has frozen over |
83 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R33 | true | false | 633 | 0 | 2 | 1 | “@###### yeah it's really far and it's alright if you like living by a whole lot of hicks haha |
84 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R34 | false | true | 634 | 1 | 2 | 0 | Want to cry cause of the girls at La fitness ... Imma bitch |
85 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R35 | false | false | 635 | 0 | 3 | 0 | her "friends" said I was shallow, conceited and controlling. I grabbed her wrist and said "never talk to those fat jealous bitches again!" |
86 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R36 | true | true | 636 | 0 | 2 | 1 | "😂😂😂😂😂😂😂😂😂😂😂@###### Teanna Trump probably cleaner than most of these twitter hoes but........." |
87 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R37 | false | false | 637 | 1 | 0 | 2 | Fitzpatrick is trash bruh |
88 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R38 | false | true | 638 | 0 | 2 | 1 | RT @###### These hoes ain't got nothin' on ya 🎶 |
89 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R39 | false | true | 639 | 1 | 2 | 0 | One thing i always tell my lor cousins big cousins my bitches && niggah u always gonna be good regardless |
90 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R40 | false | true | 640 | 1 | 2 | 0 | @###### @###### @###### @###### you ain't 6 feet under its not over pussy |
91 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R41 | true | true | 641 | 1 | 2 | 0 | y'all remember that tall ass dyke named Jay??? Lmfaooo |
92 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R42 | false | false | 642 | 0 | 0 | 3 | just found out @###### has an #Australian president! #hoosiers are my team #hoosierstate #indiana #iu #iubb #big10 20-2 tonight! |
93 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R43 | false | true | 643 | 0 | 2 | 1 | @###### i love seing new ones cause i save them and then youse them bitches lmfao |
94 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R44 | true | false | 644 | 0 | 0 | 3 | Thank you Charlie @###### @###### @###### @###### @###### @###### |
95 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R45 | false | true | 645 | 0 | 3 | 0 | RT @###### “@###### “@###### okay now I'm going to Krispy Kreme for real”fat bitch”@###### this nigga trying … |
96 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R46 | true | true | 646 | 2 | 1 | 0 | RT @###### 4) Only pussy niggas who suck dick cry about someone being in their mentions, tweet the person then cry again about the… |
97 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R47 | true | true | 647 | 3 | 0 | 0 | @###### @###### @###### Shit your ass and shabbat your moms pussy u Jew bastard. Ur times coming. Heil Hitler! |
98 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R48 | true | false | 648 | 0 | 0 | 3 | somebody take these Oreos away from me before I eat the whole pack |
99 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R49 | false | true | 649 | 1 | 0 | 2 | @###### ...honestly. That's where I'm the most retarded and is why stuck as artist hoping for a fair "dealer/manager" situation.... |
100 | 16 | 1,300 | THANKS | Desktop | 0 | 1 | 0 | 0 | 0 | 0 | 82 | 3 | 1 | 6 | 2 | 10 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 3 | 3 | 2 | 2 | 2 | 3 | 15 | A | R50 | false | false | 650 | 0 | 0 | 3 | I can't watch Charlie St. Cloud because I cry like a little baby. Every. Single. Time. 😭😭😭😭 |
Tweet Annotation Sensitivity Experiment 2: Annotations in Five Experimental Conditions
Attention: This repository contains cases that might be offensive or upsetting. We do not support the views expressed in these hateful posts.
Description
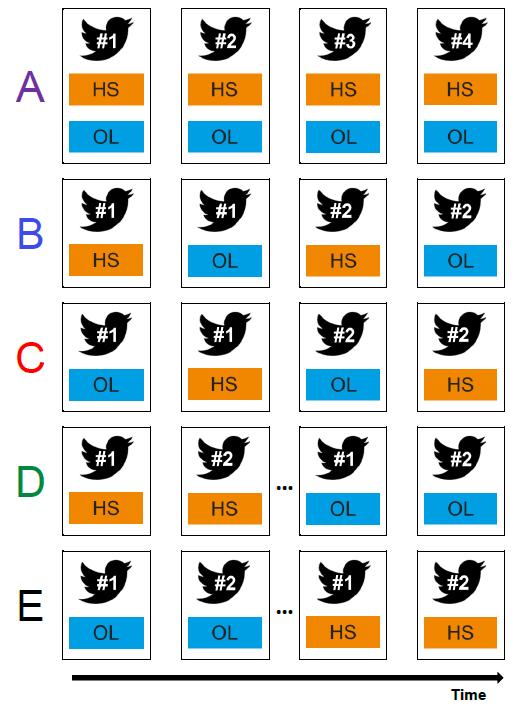
The dataset contains tweet data annotations of hate speech (HS) and offensive language (OL) in five experimental conditions. The tweet data was sampled from the corpus created by Davidson et al. (2017). We selected 3,000 Tweets for our annotation. We developed five experimental conditions that varied the annotation task structure, as shown in the following figure. All tweets were annotated in each condition.
Condition A presented the tweet and three options on a single screen: hate speech, offensive language, or neither. Annotators could select one or both of hate speech, offensive language, or indicate that neither applied.
Conditions B and C split the annotation of a single tweet across two screens.
- For Condition B, the first screen prompted the annotator to indicate whether the tweet contained hate speech. On the following screen, they were shown the tweet again and asked whether it contained offensive language.
- Condition C was similar to Condition B, but flipped the order of hate speech and offensive language for each tweet.
In Conditions D and E, the two tasks are treated independently with annotators being asked to first annotate all tweets for one task, followed by annotating all tweets again for the second task.
- Annotators assigned Condition D were first asked to annotate hate speech for all their assigned tweets, and then asked to annotate offensive language for the same set of tweets.
- Condition E worked the same way, but started with the offensive language annotation task followed by the hate speech annotation task.
We recruited US-based annotators from the crowdsourcing platform Prolific during November and December 2022. Each annotator annotated up to 50 tweets. The dataset also contains demographic information about the annotators. Annotators received a fixed hourly wage in excess of the US federal minimum wage after completing the task.
Codebook
| Column Name | Description | Type |
|---|---|---|
| case_id | case ID | integer |
| duration_seconds | duration of connection to task in seconds | integer |
| last_screen | last question answered | factor |
| device | device type | factor |
| ethn_hispanic | Hispanic race/ethnicity | binary |
| ethn_white | White race/ethnicity | binary |
| ethn_afr_american | African-American race/ethnicity | binary |
| ethn_asian | Asian race/ethnicity | binary |
| ethn_sth_else | race/ethnicity something else | binary |
| ethn_prefer_not | race/ethnicity prefer not to say | binary |
| age | age | integer |
| education | education attainment 1: Less than high school 2: High school 3: Some college 4: College graduate 5: Master's degree or professional degree (law, medicine, MPH, etc.) 6: Doctoral degree (PhD, DPH, EdD, etc.) |
factor |
| english_fl | English as first language | binary |
| twitter_use | Twitter use frequency 1: Most days 2: Most weeks, but not every day 3: A few times a month 4: A few times a year 5: Less often 6: Never |
factor |
| socmedia_use | social media use frequency 1: Most days 2: Most weeks, but not every day 3: A few times a month 4: A few times a year 5: Less often 6: Never |
factor |
| prolific_hours | workload on the platform prolific in hours in the last month | integer |
| task_fun | task perception: fun | binary |
| task_interesting | task perception: interesting | binary |
| task_boring | task perception: boring | binary |
| task_repetitive | task perception: repetitive | binary |
| task_important | task perception: important | binary |
| task_depressing | task perception: depressing | binary |
| task_offensive | task perception: offensive | binary |
| repeat_tweet_coding | likelihood for another tweet task 1: Not at all likely 2: Somewhat likely 3: Very likely |
factor |
| repeat_hs_coding | likelihood for another hate speech task 1: Not at all likely 2: Somewhat likely 3: Very likely |
factor |
| target_online_harassment | targeted by hateful online behavior | binary |
| target_other_harassment | targeted by other hateful behavior | binary |
| party_affiliation | party identification 1: Republican 2: Democrat 3: Independent |
factor |
| societal_relevance_hs | relevance perception of hate speech 1: Not at all likely 2: Somewhat likely 3: Very likely |
factor |
| annotator_id | annotator ID | integer |
| condition | experimental conditions (A-E) | factor |
| tweet_batch | tweet ID in batch | factor |
| hate_speech | hate speech annotation | logical |
| offensive_language | offensive language annotation | logical |
| tweet_id | tweet ID | integer |
| orig_label_hs | number of persons who annotated the tweet as hate speech in the original dataset from Davidson et al. (2017) | integer |
| orig_label_ol | number of persons who annotated the tweet as offensive language in the original dataset from Davidson et al. (2017) | integer |
| orig_label_ne | number of persons who annotated the tweet as neither in the original dataset from Davidson et al. (2017) | integer |
| tweet_hashed | tweet with usernames hashed | character |
Citation
If you find the dataset useful, please cite:
@inproceedings{kern-etal-2023-annotation,
title = "Annotation Sensitivity: Training Data Collection Methods Affect Model Performance",
author = "Kern, Christoph and
Eckman, Stephanie and
Beck, Jacob and
Chew, Rob and
Ma, Bolei and
Kreuter, Frauke",
editor = "Bouamor, Houda and
Pino, Juan and
Bali, Kalika",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2023",
month = dec,
year = "2023",
address = "Singapore",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.findings-emnlp.992",
pages = "14874--14886",
}
@inproceedings{beck-etal-2024-order,
title = "Order Effects in Annotation Tasks: Further Evidence of Annotation Sensitivity",
author = "Beck, Jacob and
Eckman, Stephanie and
Ma, Bolei and
Chew, Rob and
Kreuter, Frauke",
editor = {V{\'a}zquez, Ra{\'u}l and
Celikkanat, Hande and
Ulmer, Dennis and
Tiedemann, J{\"o}rg and
Swayamdipta, Swabha and
Aziz, Wilker and
Plank, Barbara and
Baan, Joris and
de Marneffe, Marie-Catherine},
booktitle = "Proceedings of the 1st Workshop on Uncertainty-Aware NLP (UncertaiNLP 2024)",
month = mar,
year = "2024",
address = "St Julians, Malta",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.uncertainlp-1.8",
pages = "81--86",
}
- Downloads last month
- 73