|
--- |
|
annotations_creators: |
|
- expert-generated |
|
language: |
|
- en |
|
language_creators: |
|
- crowdsourced |
|
license: [] |
|
multilinguality: |
|
- monolingual |
|
pretty_name: Conversation-Entailment |
|
size_categories: |
|
- n<1K |
|
source_datasets: |
|
- original |
|
tags: |
|
- conversational |
|
- entailment |
|
task_categories: |
|
- conversational |
|
- text-classification |
|
task_ids: [] |
|
--- |
|
# Conversation-Entailment |
|
|
|
Official dataset for [Towards Conversation Entailment: An Empirical Investigation](https://sled.eecs.umich.edu/publication/dblp-confemnlp-zhang-c-10/). *Chen Zhang, Joyce Chai*. EMNLP, 2010 |
|
|
|
 |
|
|
|
## Overview |
|
|
|
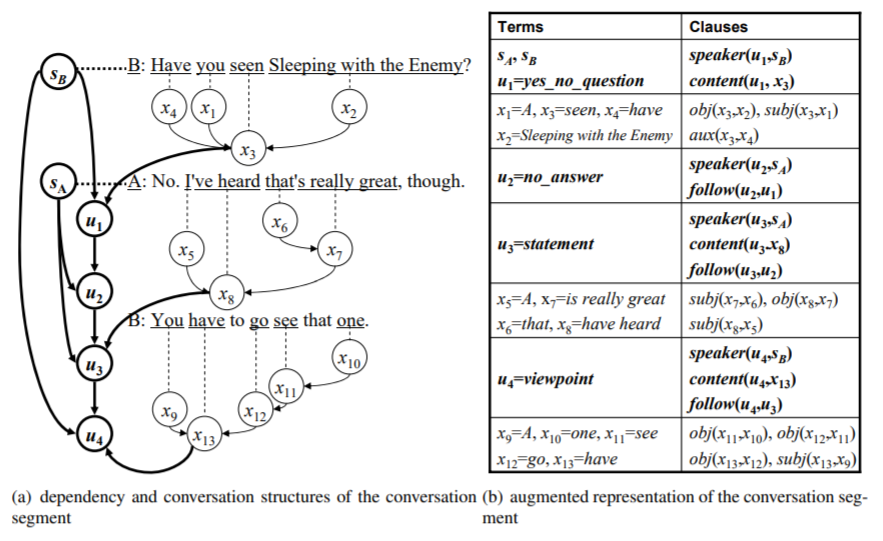
Textual entailment has mainly focused on inference from written text in monologue. Recent years also observed an increasing amount of conversational data such as conversation scripts of meetings, call center records, court proceedings, as well as online chatting. Although conversation is a form of language, it is different from monologue text with several unique characteristics. The key distinctive features include turn-taking between participants, grounding between participants, different linguistic phenomena of utterances, and conversation implicatures. Traditional approaches dealing with textual entailment were not designed to handle these unique conversation behaviors and thus to support automated entailment from conversation scripts. This project intends to address this limitation. |
|
|
|
### Download |
|
```python |
|
from datasets import load_dataset |
|
|
|
dataset = load_dataset("sled-umich/Conversation-Entailment") |
|
``` |
|
* [HuggingFace-Dataset](https://huggingface.co/datasets/sled-umich/Conversation-Entailment) |
|
* [DropBox](https://www.dropbox.com/s/z5vchgzvzxv75es/conversation_entailment.tar?dl=0) |
|
|
|
### Data Sample |
|
```json |
|
{ |
|
"dialog": { |
|
"turn": [ |
|
{ |
|
"num": "2", |
|
"speaker": "B", |
|
"text": "Hi, um, okay what, now, uh, what particularly, particularly what kind of music do you like?" |
|
}, |
|
{ |
|
"num": "3", |
|
"speaker": "A", |
|
"text": "Well, I mostly listen to popular music. I, uh, listen to it all the time in, in my car, so, I, I tend to be one of those people who switches stations a lot because I don't like commercials. But," |
|
}, |
|
{ |
|
"num": "4", |
|
"speaker": "B", |
|
"text": "Yeah." |
|
}, |
|
{ |
|
"num": "5", |
|
"speaker": "A", |
|
"text": "uh, I find myself listening to popular music, and, uh, quite honestly, I, I have some little children and I, unfortunately, found myself listening to a lot of nursery rhyme music here lately, but that's not by my choice." |
|
} |
|
], |
|
"source": "SW2020" |
|
}, |
|
"h": "SpeakerA likes popular music", |
|
"id": "15", |
|
"entailment": "1", |
|
"type": "belief" |
|
} |
|
``` |
|
|
|
|
|
### Cite |
|
|
|
[Towards Conversation Entailment: An Empirical Investigation](https://sled.eecs.umich.edu/publication/dblp-confemnlp-zhang-c-10/). *Chen Zhang, Joyce Chai*. EMNLP, 2010. [[Paper]](https://aclanthology.org/D10-1074/) |
|
|
|
```tex |
|
@inproceedings{zhang-chai-2010-towards, |
|
title = "Towards Conversation Entailment: An Empirical Investigation", |
|
author = "Zhang, Chen and |
|
Chai, Joyce", |
|
booktitle = "Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing", |
|
month = oct, |
|
year = "2010", |
|
address = "Cambridge, MA", |
|
publisher = "Association for Computational Linguistics", |
|
url = "https://aclanthology.org/D10-1074", |
|
pages = "756--766", |
|
} |
|
``` |

