Datasets:

annotations_creators:
- shibing624
language_creators:
- liuhuanyong
language:
- zh
license: cc-by-4.0
multilinguality:
- monolingual
size_categories:
- 100K<n<20M
source_datasets:
- https://github.com/liuhuanyong/ChineseTextualInference/
task_categories:
- text-classification
task_ids:
- natural-language-inference
- semantic-similarity-scoring
- text-scoring
paperswithcode_id: snli
pretty_name: Stanford Natural Language Inference
Dataset Card for SNLI_zh
Dataset Description
- Repository: Chinese NLI dataset
- Dataset: train data from ChineseTextualInference
- Size of downloaded dataset files: 54 MB
- Total amount of disk used: 54 MB
Dataset Summary
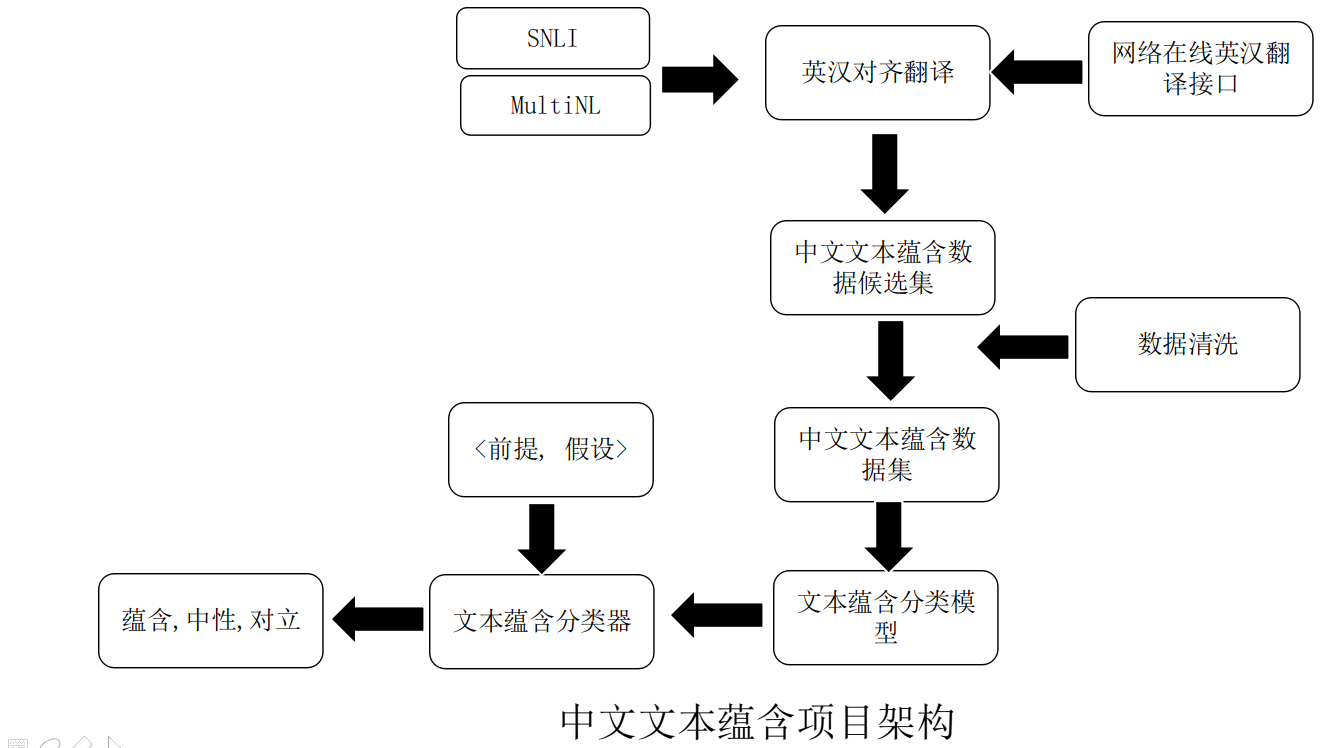
中文SNLI和MultiNLI数据集,翻译自英文SNLI和MultiNLI
Supported Tasks and Leaderboards
Supported Tasks: 支持中文文本匹配任务,文本相似度计算等相关任务。
中文匹配任务的结果目前在顶会paper上出现较少,我罗列一个我自己训练的结果:
Leaderboard: NLI_zh leaderboard
Languages
数据集均是简体中文文本。
Dataset Structure
Data Instances
An example of 'train' looks as follows.
sentence1 sentence2 gold_label
是的,我想一个洞穴也会有这样的问题 我认为洞穴可能会有更严重的问题。 neutral
几周前我带他和一个朋友去看幼儿园警察 我还没看过幼儿园警察,但他看了。 contradiction
航空旅行的扩张开始了大众旅游的时代,希腊和爱琴海群岛成为北欧人逃离潮湿凉爽的夏天的令人兴奋的目的地。 航空旅行的扩大开始了许多旅游业的发展。 entailment
Data Fields
The data fields are the same among all splits.
sentence1: astringfeature.sentence2: astringfeature.label: a classification label, with possible values including entailment(0), neutral(1), contradiction(2). 注意:此数据集0表示相似,2表示不相似。
Data Splits
after remove None and len(text) < 1 data:
$ wc -l ChineseTextualInference-train.txt
419402 total
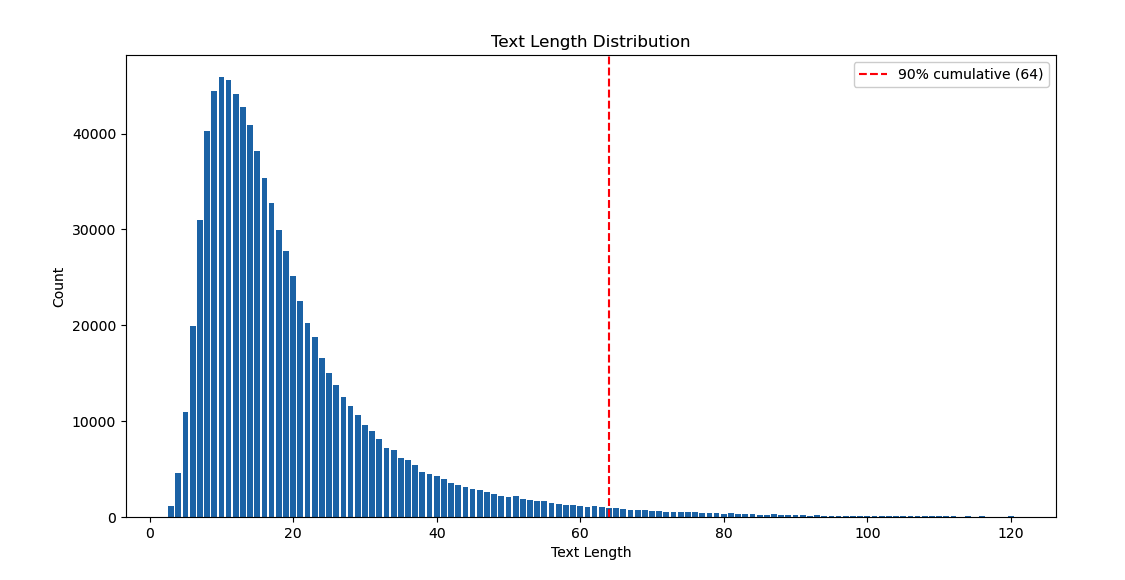
Data Length
Dataset Creation
Curation Rationale
作为中文SNLI(natural langauge inference)数据集,这里把这个数据集上传到huggingface的datasets,方便大家使用。
Source Data
Initial Data Collection and Normalization
Who are the source language producers?
数据集的版权归原作者所有,使用各数据集时请尊重原数据集的版权。
@inproceedings{snli:emnlp2015, Author = {Bowman, Samuel R. and Angeli, Gabor and Potts, Christopher, and Manning, Christopher D.}, Booktitle = {Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP)}, Publisher = {Association for Computational Linguistics}, Title = {A large annotated corpus for learning natural language inference}, Year = {2015} }
Annotations
Annotation process
Who are the annotators?
原作者。
Personal and Sensitive Information
Considerations for Using the Data
Social Impact of Dataset
This dataset was developed as a benchmark for evaluating representational systems for text, especially including those induced by representation learning methods, in the task of predicting truth conditions in a given context.
Systems that are successful at such a task may be more successful in modeling semantic representations.
Discussion of Biases
Other Known Limitations
Additional Information
Dataset Curators
- liuhuanyong翻译成中文
- shibing624 上传到huggingface的datasets
Licensing Information
用于学术研究。
Contributions
shibing624 add this dataset.