Datasets:

Commit
•
b0aa839
1
Parent(s):
f9a1893
Update README.md
Browse files
README.md
CHANGED
|
@@ -30,7 +30,8 @@ pretty_name: Stanford Natural Language Inference
|
|
| 30 |
- **Total amount of disk used:** 54 MB
|
| 31 |
### Dataset Summary
|
| 32 |
|
| 33 |
-
|
|
|
|
| 34 |
|
| 35 |
|
| 36 |
|
|
|
|
| 30 |
- **Total amount of disk used:** 54 MB
|
| 31 |
### Dataset Summary
|
| 32 |
|
| 33 |
+
|
| 34 |
+
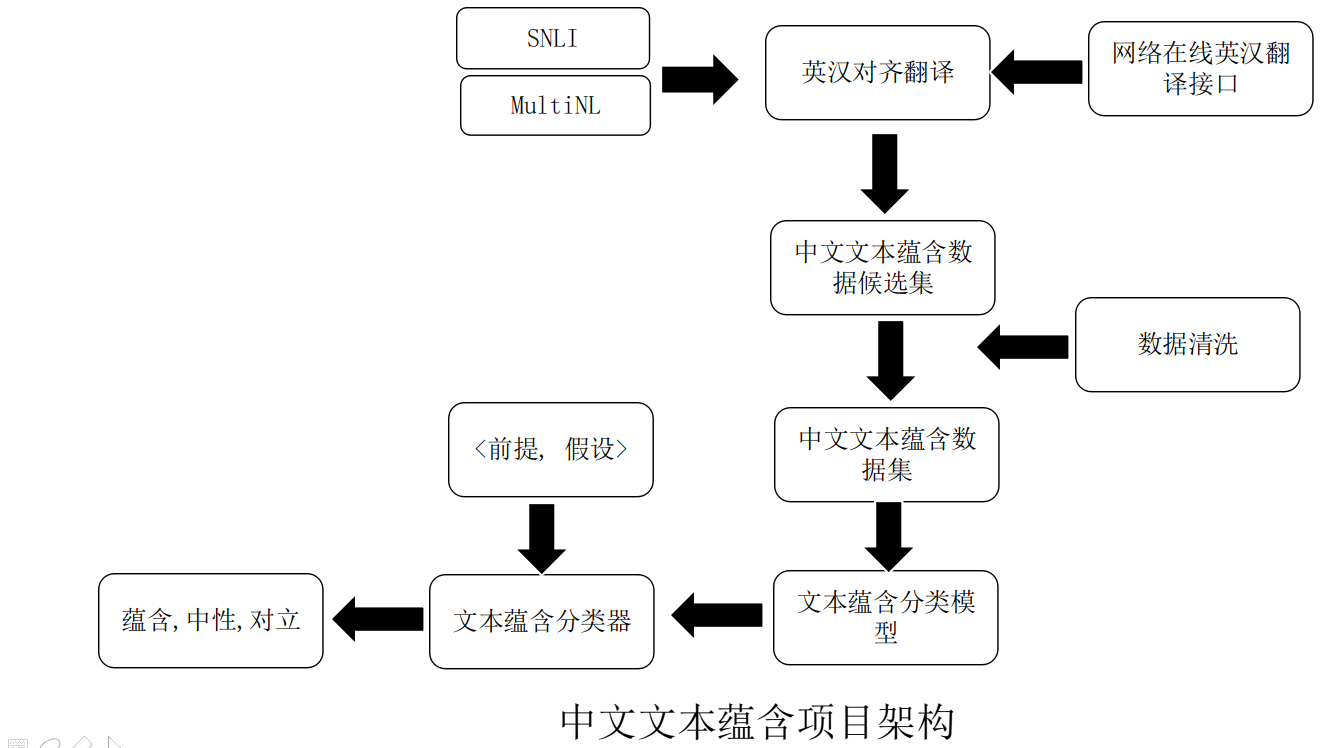
中文SNLI和MultiNLI数据集,翻译自英文[SNLI](https://huggingface.co/datasets/snli)和[MultiNLI](https://huggingface.co/datasets/multi_nli)
|
| 35 |
|
| 36 |

|
| 37 |
|