
text
stringlengths 23
371k
| source
stringlengths 32
152
|
|---|---|
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# UPerNet
## Overview
The UPerNet model was proposed in [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221)
by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun. UPerNet is a general framework to effectively segment
a wide range of concepts from images, leveraging any vision backbone like [ConvNeXt](convnext) or [Swin](swin).
The abstract from the paper is the following:
*Humans recognize the visual world at multiple levels: we effortlessly categorize scenes and detect objects inside, while also identifying the textures and surfaces of the objects along with their different compositional parts. In this paper, we study a new task called Unified Perceptual Parsing, which requires the machine vision systems to recognize as many visual concepts as possible from a given image. A multi-task framework called UPerNet and a training strategy are developed to learn from heterogeneous image annotations. We benchmark our framework on Unified Perceptual Parsing and show that it is able to effectively segment a wide range of concepts from images. The trained networks are further applied to discover visual knowledge in natural scenes.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/upernet_architecture.jpg"
alt="drawing" width="600"/>
<small> UPerNet framework. Taken from the <a href="https://arxiv.org/abs/1807.10221">original paper</a>. </small>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code is based on OpenMMLab's mmsegmentation [here](https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/uper_head.py).
## Usage examples
UPerNet is a general framework for semantic segmentation. It can be used with any vision backbone, like so:
```py
from transformers import SwinConfig, UperNetConfig, UperNetForSemanticSegmentation
backbone_config = SwinConfig(out_features=["stage1", "stage2", "stage3", "stage4"])
config = UperNetConfig(backbone_config=backbone_config)
model = UperNetForSemanticSegmentation(config)
```
To use another vision backbone, like [ConvNeXt](convnext), simply instantiate the model with the appropriate backbone:
```py
from transformers import ConvNextConfig, UperNetConfig, UperNetForSemanticSegmentation
backbone_config = ConvNextConfig(out_features=["stage1", "stage2", "stage3", "stage4"])
config = UperNetConfig(backbone_config=backbone_config)
model = UperNetForSemanticSegmentation(config)
```
Note that this will randomly initialize all the weights of the model.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with UPerNet.
- Demo notebooks for UPerNet can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/UPerNet).
- [`UperNetForSemanticSegmentation`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/semantic-segmentation) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/semantic_segmentation.ipynb).
- See also: [Semantic segmentation task guide](../tasks/semantic_segmentation)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## UperNetConfig
[[autodoc]] UperNetConfig
## UperNetForSemanticSegmentation
[[autodoc]] UperNetForSemanticSegmentation
- forward
|
huggingface/transformers/blob/main/docs/source/en/model_doc/upernet.md
|
Tensorflow API
[[autodoc]] safetensors.tensorflow.load_file
[[autodoc]] safetensors.tensorflow.load
[[autodoc]] safetensors.tensorflow.save_file
[[autodoc]] safetensors.tensorflow.save
|
huggingface/safetensors/blob/main/docs/source/api/tensorflow.mdx
|
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# PoolFormer
## Overview
The PoolFormer model was proposed in [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Sea AI Labs. Instead of designing complicated token mixer to achieve SOTA performance, the target of this work is to demonstrate the competence of transformer models largely stem from the general architecture MetaFormer.
The abstract from the paper is the following:
*Transformers have shown great potential in computer vision tasks. A common belief is their attention-based token mixer module contributes most to their competence. However, recent works show the attention-based module in transformers can be replaced by spatial MLPs and the resulted models still perform quite well. Based on this observation, we hypothesize that the general architecture of the transformers, instead of the specific token mixer module, is more essential to the model's performance. To verify this, we deliberately replace the attention module in transformers with an embarrassingly simple spatial pooling operator to conduct only the most basic token mixing. Surprisingly, we observe that the derived model, termed as PoolFormer, achieves competitive performance on multiple computer vision tasks. For example, on ImageNet-1K, PoolFormer achieves 82.1% top-1 accuracy, surpassing well-tuned vision transformer/MLP-like baselines DeiT-B/ResMLP-B24 by 0.3%/1.1% accuracy with 35%/52% fewer parameters and 48%/60% fewer MACs. The effectiveness of PoolFormer verifies our hypothesis and urges us to initiate the concept of "MetaFormer", a general architecture abstracted from transformers without specifying the token mixer. Based on the extensive experiments, we argue that MetaFormer is the key player in achieving superior results for recent transformer and MLP-like models on vision tasks. This work calls for more future research dedicated to improving MetaFormer instead of focusing on the token mixer modules. Additionally, our proposed PoolFormer could serve as a starting baseline for future MetaFormer architecture design.*
The figure below illustrates the architecture of PoolFormer. Taken from the [original paper](https://arxiv.org/abs/2111.11418).
<img width="600" src="https://user-images.githubusercontent.com/15921929/142746124-1ab7635d-2536-4a0e-ad43-b4fe2c5a525d.png"/>
This model was contributed by [heytanay](https://huggingface.co/heytanay). The original code can be found [here](https://github.com/sail-sg/poolformer).
## Usage tips
- PoolFormer has a hierarchical architecture, where instead of Attention, a simple Average Pooling layer is present. All checkpoints of the model can be found on the [hub](https://huggingface.co/models?other=poolformer).
- One can use [`PoolFormerImageProcessor`] to prepare images for the model.
- As most models, PoolFormer comes in different sizes, the details of which can be found in the table below.
| **Model variant** | **Depths** | **Hidden sizes** | **Params (M)** | **ImageNet-1k Top 1** |
| :---------------: | ------------- | ------------------- | :------------: | :-------------------: |
| s12 | [2, 2, 6, 2] | [64, 128, 320, 512] | 12 | 77.2 |
| s24 | [4, 4, 12, 4] | [64, 128, 320, 512] | 21 | 80.3 |
| s36 | [6, 6, 18, 6] | [64, 128, 320, 512] | 31 | 81.4 |
| m36 | [6, 6, 18, 6] | [96, 192, 384, 768] | 56 | 82.1 |
| m48 | [8, 8, 24, 8] | [96, 192, 384, 768] | 73 | 82.5 |
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with PoolFormer.
<PipelineTag pipeline="image-classification"/>
- [`PoolFormerForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## PoolFormerConfig
[[autodoc]] PoolFormerConfig
## PoolFormerFeatureExtractor
[[autodoc]] PoolFormerFeatureExtractor
- __call__
## PoolFormerImageProcessor
[[autodoc]] PoolFormerImageProcessor
- preprocess
## PoolFormerModel
[[autodoc]] PoolFormerModel
- forward
## PoolFormerForImageClassification
[[autodoc]] PoolFormerForImageClassification
- forward
|
huggingface/transformers/blob/main/docs/source/en/model_doc/poolformer.md
|
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# TensorBoard logger
TensorBoard is a visualization toolkit for machine learning experimentation. TensorBoard allows tracking and visualizing
metrics such as loss and accuracy, visualizing the model graph, viewing histograms, displaying images and much more.
TensorBoard is well integrated with the Hugging Face Hub. The Hub automatically detects TensorBoard traces (such as
`tfevents`) when pushed to the Hub which starts an instance to visualize them. To get more information about TensorBoard
integration on the Hub, check out [this guide](https://huggingface.co/docs/hub/tensorboard).
To benefit from this integration, `huggingface_hub` provides a custom logger to push logs to the Hub. It works as a
drop-in replacement for [SummaryWriter](https://tensorboardx.readthedocs.io/en/latest/tensorboard.html) with no extra
code needed. Traces are still saved locally and a background job push them to the Hub at regular interval.
## HFSummaryWriter
[[autodoc]] HFSummaryWriter
|
huggingface/huggingface_hub/blob/main/docs/source/en/package_reference/tensorboard.md
|
div align="center">
<h1><code>create-wasm-app</code></h1>
<strong>An <code>npm init</code> template for kick starting a project that uses NPM packages containing Rust-generated WebAssembly and bundles them with Webpack.</strong>
<p>
<a href="https://travis-ci.org/rustwasm/create-wasm-app"><img src="https://img.shields.io/travis/rustwasm/create-wasm-app.svg?style=flat-square" alt="Build Status" /></a>
</p>
<h3>
<a href="#usage">Usage</a>
<span> | </span>
<a href="https://discordapp.com/channels/442252698964721669/443151097398296587">Chat</a>
</h3>
<sub>Built with 🦀🕸 by <a href="https://rustwasm.github.io/">The Rust and WebAssembly Working Group</a></sub>
</div>
## About
This template is designed for depending on NPM packages that contain
Rust-generated WebAssembly and using them to create a Website.
* Want to create an NPM package with Rust and WebAssembly? [Check out
`wasm-pack-template`.](https://github.com/rustwasm/wasm-pack-template)
* Want to make a monorepo-style Website without publishing to NPM? Check out
[`rust-webpack-template`](https://github.com/rustwasm/rust-webpack-template)
and/or
[`rust-parcel-template`](https://github.com/rustwasm/rust-parcel-template).
## 🚴 Usage
```
npm init wasm-app
```
## 🔋 Batteries Included
- `.gitignore`: ignores `node_modules`
- `LICENSE-APACHE` and `LICENSE-MIT`: most Rust projects are licensed this way, so these are included for you
- `README.md`: the file you are reading now!
- `index.html`: a bare bones html document that includes the webpack bundle
- `index.js`: example js file with a comment showing how to import and use a wasm pkg
- `package.json` and `package-lock.json`:
- pulls in devDependencies for using webpack:
- [`webpack`](https://www.npmjs.com/package/webpack)
- [`webpack-cli`](https://www.npmjs.com/package/webpack-cli)
- [`webpack-dev-server`](https://www.npmjs.com/package/webpack-dev-server)
- defines a `start` script to run `webpack-dev-server`
- `webpack.config.js`: configuration file for bundling your js with webpack
## License
Licensed under either of
* Apache License, Version 2.0, ([LICENSE-APACHE](LICENSE-APACHE) or http://www.apache.org/licenses/LICENSE-2.0)
* MIT license ([LICENSE-MIT](LICENSE-MIT) or http://opensource.org/licenses/MIT)
at your option.
### Contribution
Unless you explicitly state otherwise, any contribution intentionally
submitted for inclusion in the work by you, as defined in the Apache-2.0
license, shall be dual licensed as above, without any additional terms or
conditions.
|
huggingface/tokenizers/blob/main/tokenizers/examples/unstable_wasm/www/README.md
|
Gradio Demo: audio_component
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
gr.Audio()
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/audio_component/run.ipynb
|
Gradio Demo: musical_instrument_identification
### This demo identifies musical instruments from an audio file. It uses Gradio's Audio and Label components.
```
!pip install -q gradio torch==1.12.0 torchvision==0.13.0 torchaudio==0.12.0 librosa==0.9.2 gdown
```
```
# Downloading files from the demo repo
import os
!wget -q https://github.com/gradio-app/gradio/raw/main/demo/musical_instrument_identification/data_setups.py
```
```
import gradio as gr
import torch
import torchaudio
from timeit import default_timer as timer
from data_setups import audio_preprocess, resample
import gdown
url = 'https://drive.google.com/uc?id=1X5CR18u0I-ZOi_8P0cNptCe5JGk9Ro0C'
output = 'piano.wav'
gdown.download(url, output, quiet=False)
url = 'https://drive.google.com/uc?id=1W-8HwmGR5SiyDbUcGAZYYDKdCIst07__'
output= 'torch_efficientnet_fold2_CNN.pth'
gdown.download(url, output, quiet=False)
device = "cuda" if torch.cuda.is_available() else "cpu"
SAMPLE_RATE = 44100
AUDIO_LEN = 2.90
model = torch.load("torch_efficientnet_fold2_CNN.pth", map_location=torch.device('cpu'))
LABELS = [
"Cello", "Clarinet", "Flute", "Acoustic Guitar", "Electric Guitar", "Organ", "Piano", "Saxophone", "Trumpet", "Violin", "Voice"
]
example_list = [
["piano.wav"]
]
def predict(audio_path):
start_time = timer()
wavform, sample_rate = torchaudio.load(audio_path)
wav = resample(wavform, sample_rate, SAMPLE_RATE)
if len(wav) > int(AUDIO_LEN * SAMPLE_RATE):
wav = wav[:int(AUDIO_LEN * SAMPLE_RATE)]
else:
print(f"input length {len(wav)} too small!, need over {int(AUDIO_LEN * SAMPLE_RATE)}")
return
img = audio_preprocess(wav, SAMPLE_RATE).unsqueeze(0)
model.eval()
with torch.inference_mode():
pred_probs = torch.softmax(model(img), dim=1)
pred_labels_and_probs = {LABELS[i]: float(pred_probs[0][i]) for i in range(len(LABELS))}
pred_time = round(timer() - start_time, 5)
return pred_labels_and_probs, pred_time
demo = gr.Interface(fn=predict,
inputs=gr.Audio(type="filepath"),
outputs=[gr.Label(num_top_classes=11, label="Predictions"),
gr.Number(label="Prediction time (s)")],
examples=example_list,
cache_examples=False
)
demo.launch(debug=False)
```
|
gradio-app/gradio/blob/main/demo/musical_instrument_identification/run.ipynb
|
``python
import os
import torch
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, default_data_collator, get_linear_schedule_with_warmup
from peft import get_peft_model, PromptTuningConfig, TaskType, PromptTuningInit
from torch.utils.data import DataLoader
from tqdm import tqdm
from datasets import load_dataset
os.environ["TOKENIZERS_PARALLELISM"] = "false"
device = "cuda"
model_name_or_path = "t5-large"
tokenizer_name_or_path = "t5-large"
checkpoint_name = "financial_sentiment_analysis_prompt_tuning_v1.pt"
text_column = "sentence"
label_column = "text_label"
max_length = 128
lr = 1
num_epochs = 5
batch_size = 8
```
```python
# creating model
peft_config = PromptTuningConfig(
task_type=TaskType.SEQ_2_SEQ_LM,
prompt_tuning_init=PromptTuningInit.TEXT,
num_virtual_tokens=20,
prompt_tuning_init_text="What is the sentiment of this article?\n",
inference_mode=False,
tokenizer_name_or_path=model_name_or_path,
)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
model
```
```python
# loading dataset
dataset = load_dataset("financial_phrasebank", "sentences_allagree")
dataset = dataset["train"].train_test_split(test_size=0.1)
dataset["validation"] = dataset["test"]
del dataset["test"]
classes = dataset["train"].features["label"].names
dataset = dataset.map(
lambda x: {"text_label": [classes[label] for label in x["label"]]},
batched=True,
num_proc=1,
)
dataset["train"][0]
```
```python
# data preprocessing
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
target_max_length = max([len(tokenizer(class_label)["input_ids"]) for class_label in classes])
def preprocess_function(examples):
inputs = examples[text_column]
targets = examples[label_column]
model_inputs = tokenizer(inputs, max_length=max_length, padding="max_length", truncation=True, return_tensors="pt")
labels = tokenizer(
targets, max_length=target_max_length, padding="max_length", truncation=True, return_tensors="pt"
)
labels = labels["input_ids"]
labels[labels == tokenizer.pad_token_id] = -100
model_inputs["labels"] = labels
return model_inputs
processed_datasets = dataset.map(
preprocess_function,
batched=True,
num_proc=1,
remove_columns=dataset["train"].column_names,
load_from_cache_file=False,
desc="Running tokenizer on dataset",
)
train_dataset = processed_datasets["train"]
eval_dataset = processed_datasets["validation"]
train_dataloader = DataLoader(
train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True
)
eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
```
```python
# optimizer and lr scheduler
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=(len(train_dataloader) * num_epochs),
)
```
```python
# training and evaluation
model = model.to(device)
for epoch in range(num_epochs):
model.train()
total_loss = 0
for step, batch in enumerate(tqdm(train_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
total_loss += loss.detach().float()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
eval_loss = 0
eval_preds = []
for step, batch in enumerate(tqdm(eval_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
eval_loss += loss.detach().float()
eval_preds.extend(
tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True)
)
eval_epoch_loss = eval_loss / len(eval_dataloader)
eval_ppl = torch.exp(eval_epoch_loss)
train_epoch_loss = total_loss / len(train_dataloader)
train_ppl = torch.exp(train_epoch_loss)
print(f"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")
```
```python
# print accuracy
correct = 0
total = 0
for pred, true in zip(eval_preds, dataset["validation"]["text_label"]):
if pred.strip() == true.strip():
correct += 1
total += 1
accuracy = correct / total * 100
print(f"{accuracy=} % on the evaluation dataset")
print(f"{eval_preds[:10]=}")
print(f"{dataset['validation']['text_label'][:10]=}")
```
```python
# saving model
peft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"
model.save_pretrained(peft_model_id)
```
```python
ckpt = f"{peft_model_id}/adapter_model.bin"
!du -h $ckpt
```
```python
from peft import PeftModel, PeftConfig
peft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)
model = PeftModel.from_pretrained(model, peft_model_id)
```
```python
model.eval()
i = 107
input_ids = tokenizer(dataset["validation"][text_column][i], return_tensors="pt").input_ids
print(dataset["validation"][text_column][i])
print(input_ids)
with torch.no_grad():
outputs = model.generate(input_ids=input_ids, max_new_tokens=10)
print(outputs)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
```
|
huggingface/peft/blob/main/examples/conditional_generation/peft_prompt_tuning_seq2seq.ipynb
|
--
title: Brier Score
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
The Brier score is a measure of the error between two probability distributions.
---
# Metric Card for Brier Score
## Metric Description
Brier score is a type of evaluation metric for classification tasks, where you predict outcomes such as win/lose, spam/ham, click/no-click etc.
`BrierScore = 1/N * sum( (p_i - o_i)^2 )`
Where `p_i` is the prediction probability of occurrence of the event, and the term `o_i` is equal to 1 if the event occurred and 0 if not. Which means: the lower the value of this score, the better the prediction.
## How to Use
At minimum, this metric requires predictions and references as inputs.
```python
>>> brier_score = evaluate.load("brier_score")
>>> predictions = np.array([0, 0, 1, 1])
>>> references = np.array([0.1, 0.9, 0.8, 0.3])
>>> results = brier_score.compute(predictions=predictions, references=references)
```
### Inputs
Mandatory inputs:
- `predictions`: numeric array-like of shape (`n_samples,`) or (`n_samples`, `n_outputs`), representing the estimated target values.
- `references`: numeric array-like of shape (`n_samples,`) or (`n_samples`, `n_outputs`), representing the ground truth (correct) target values.
Optional arguments:
- `sample_weight`: numeric array-like of shape (`n_samples,`) representing sample weights. The default is `None`.
- `pos_label`: the label of the positive class. The default is `1`.
### Output Values
This metric returns a dictionary with the following keys:
- `brier_score (float)`: the computed Brier score.
Output Example(s):
```python
{'brier_score': 0.5}
```
#### Values from Popular Papers
### Examples
```python
>>> brier_score = evaluate.load("brier_score")
>>> predictions = np.array([0, 0, 1, 1])
>>> references = np.array([0.1, 0.9, 0.8, 0.3])
>>> results = brier_score.compute(predictions=predictions, references=references)
>>> print(results)
{'brier_score': 0.3375}
```
Example with `y_true` contains string, an error will be raised and `pos_label` should be explicitly specified.
```python
>>> brier_score_metric = evaluate.load("brier_score")
>>> predictions = np.array(["spam", "ham", "ham", "spam"])
>>> references = np.array([0.1, 0.9, 0.8, 0.3])
>>> results = brier_score.compute(predictions, references, pos_label="ham")
>>> print(results)
{'brier_score': 0.0374}
```
## Limitations and Bias
The [brier_score](https://huggingface.co/metrics/brier_score) is appropriate for binary and categorical outcomes that can be structured as true or false, but it is inappropriate for ordinal variables which can take on three or more values.
## Citation(s)
```bibtex
@article{scikit-learn,
title={Scikit-learn: Machine Learning in {P}ython},
author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V.
and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P.
and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and
Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.},
journal={Journal of Machine Learning Research},
volume={12},
pages={2825--2830},
year={2011}
}
@Article{brier1950verification,
title={Verification of forecasts expressed in terms of probability},
author={Brier, Glenn W and others},
journal={Monthly weather review},
volume={78},
number={1},
pages={1--3},
year={1950}
}
```
## Further References
- [Brier Score - Wikipedia](https://en.wikipedia.org/wiki/Brier_score)
|
huggingface/evaluate/blob/main/metrics/brier_score/README.md
|
Gradio Demo: change_vs_input
```
!pip install -q gradio
```
```
# Downloading files from the demo repo
import os
os.mkdir('files')
!wget -q -O files/cantina.wav https://github.com/gradio-app/gradio/raw/main/demo/change_vs_input/files/cantina.wav
!wget -q -O files/lion.jpg https://github.com/gradio-app/gradio/raw/main/demo/change_vs_input/files/lion.jpg
!wget -q -O files/world.mp4 https://github.com/gradio-app/gradio/raw/main/demo/change_vs_input/files/world.mp4
```
```
import os
import gradio as gr
with gr.Blocks() as demo:
set_button = gr.Button("Set Values")
with gr.Row():
with gr.Column(min_width=200):
gr.Markdown("# Enter Here")
text = gr.Textbox()
num = gr.Number()
slider = gr.Slider()
checkbox = gr.Checkbox()
checkbox_group = gr.CheckboxGroup(["a", "b", "c"])
radio = gr.Radio(["a", "b", "c"])
dropdown = gr.Dropdown(["a", "b", "c"])
colorpicker = gr.ColorPicker()
code = gr.Code()
dataframe = gr.Dataframe()
image = gr.Image(elem_id="image-original")
audio = gr.Audio(elem_id="audio-original")
video = gr.Video(elem_id="video-original")
with gr.Column(min_width=200):
gr.Markdown("# ON:INPUT/UPLOAD")
text_in = gr.Textbox()
num_in = gr.Number()
slider_in = gr.Slider()
checkbox_in = gr.Checkbox()
checkbox_group_in = gr.CheckboxGroup(["a", "b", "c"])
radio_in = gr.Radio(["a", "b", "c"])
dropdown_in = gr.Dropdown(["a", "b", "c"])
colorpicker_in = gr.ColorPicker()
code_in = gr.Code()
dataframe_in = gr.Dataframe()
image_up = gr.Image(elem_id="image-upload")
audio_up = gr.Audio(elem_id="audio-upload")
video_up = gr.Video(elem_id="video-upload")
with gr.Column(min_width=200):
gr.Markdown("# ON:CHANGE")
text_ch = gr.Textbox()
num_ch = gr.Number()
slider_ch = gr.Slider()
checkbox_ch = gr.Checkbox()
checkbox_group_ch = gr.CheckboxGroup(["a", "b", "c"])
radio_ch = gr.Radio(["a", "b", "c"])
dropdown_ch = gr.Dropdown(["a", "b", "c"])
colorpicker_ch = gr.ColorPicker()
code_ch = gr.Code()
dataframe_ch = gr.Dataframe()
image_ch = gr.Image(elem_id="image-change")
audio_ch = gr.Audio(elem_id="audio-change")
video_ch = gr.Video(elem_id="video-change")
with gr.Column(min_width=200):
gr.Markdown("# ON:CHANGE x2")
text_ch2 = gr.Textbox()
num_ch2 = gr.Number()
slider_ch2 = gr.Slider()
checkbox_ch2 = gr.Checkbox()
checkbox_group_ch2 = gr.CheckboxGroup(["a", "b", "c"])
radio_ch2 = gr.Radio(["a", "b", "c"])
dropdown_ch2 = gr.Dropdown(["a", "b", "c"])
colorpicker_ch2 = gr.ColorPicker()
code_ch2 = gr.Code()
dataframe_ch2 = gr.Dataframe()
image_ch2 = gr.Image(elem_id="image-change-2")
audio_ch2 = gr.Audio(elem_id="audio-change-2")
video_ch2 = gr.Video(elem_id="video-change-2")
counter = gr.Number(label="Change counter")
lion = os.path.join(os.path.abspath(''), "files/lion.jpg")
cantina = os.path.join(os.path.abspath(''), "files/cantina.wav")
world = os.path.join(os.path.abspath(''), "files/world.mp4")
set_button.click(
lambda: ["asdf", 555, 12, True, ["a", "c"], "b", "b", "#FF0000", "import gradio as gr", [["a", "b", "c", "d"], ["1", "2", "3", "4"]], lion, cantina, world],
None,
[text, num, slider, checkbox, checkbox_group, radio, dropdown, colorpicker, code, dataframe, image, audio, video])
text.input(lambda x:x, text, text_in)
num.input(lambda x:x, num, num_in)
slider.input(lambda x:x, slider, slider_in)
checkbox.input(lambda x:x, checkbox, checkbox_in)
checkbox_group.input(lambda x:x, checkbox_group, checkbox_group_in)
radio.input(lambda x:x, radio, radio_in)
dropdown.input(lambda x:x, dropdown, dropdown_in)
colorpicker.input(lambda x:x, colorpicker, colorpicker_in)
code.input(lambda x:x, code, code_in)
dataframe.input(lambda x:x, dataframe, dataframe_in)
image.upload(lambda x:x, image, image_up)
audio.upload(lambda x:x, audio, audio_up)
video.upload(lambda x:x, video, video_up)
text.change(lambda x,y:(x,y+1), [text, counter], [text_ch, counter])
num.change(lambda x,y:(x, y+1), [num, counter], [num_ch, counter])
slider.change(lambda x,y:(x, y+1), [slider, counter], [slider_ch, counter])
checkbox.change(lambda x,y:(x, y+1), [checkbox, counter], [checkbox_ch, counter])
checkbox_group.change(lambda x,y:(x, y+1), [checkbox_group, counter], [checkbox_group_ch, counter])
radio.change(lambda x,y:(x, y+1), [radio, counter], [radio_ch, counter])
dropdown.change(lambda x,y:(x, y+1), [dropdown, counter], [dropdown_ch, counter])
colorpicker.change(lambda x,y:(x, y+1), [colorpicker, counter], [colorpicker_ch, counter])
code.change(lambda x,y:(x, y+1), [code, counter], [code_ch, counter])
dataframe.change(lambda x,y:(x, y+1), [dataframe, counter], [dataframe_ch, counter])
image.change(lambda x,y:(x, y+1), [image, counter], [image_ch, counter])
audio.change(lambda x,y:(x, y+1), [audio, counter], [audio_ch, counter])
video.change(lambda x,y:(x, y+1), [video, counter], [video_ch, counter])
text_ch.change(lambda x:x, text_ch, text_ch2)
num_ch.change(lambda x:x, num_ch, num_ch2)
slider_ch.change(lambda x:x, slider_ch, slider_ch2)
checkbox_ch.change(lambda x:x, checkbox_ch, checkbox_ch2)
checkbox_group_ch.change(lambda x:x, checkbox_group_ch, checkbox_group_ch2)
radio_ch.change(lambda x:x, radio_ch, radio_ch2)
dropdown_ch.change(lambda x:x, dropdown_ch, dropdown_ch2)
colorpicker_ch.change(lambda x:x, colorpicker_ch, colorpicker_ch2)
code_ch.change(lambda x:x, code_ch, code_ch2)
dataframe_ch.change(lambda x:x, dataframe_ch, dataframe_ch2)
image_ch.change(lambda x:x, image_ch, image_ch2)
audio_ch.change(lambda x:x, audio_ch, audio_ch2)
video_ch.change(lambda x:x, video_ch, video_ch2)
if __name__ == "__main__":
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/change_vs_input/run.ipynb
|
hy are fast tokenizers called fast? In this video we will see exactly how much faster the so-called fast tokenizers are compared to their slow counterparts. For this benchmark, we will use the GLUE MNLI dataset, which contains 432 thousands pairs of texts. We will see how long it takes for the fast and slow versions of a BERT tokenizer to process them all. We define our fast and slow tokenizer using the AutoTokenizer API. The fast tokenizer is the default (when available), so we pass along use_fast=False to define the slow one. In a notebook, we can time the execution of a cell with the time magic command, like this. Processing the whole dataset is four times faster with a fast tokenizer. That's quicker indeed, but not very impressive however. That's because we passed along the texts to the tokenizer one at a time. This is a common mistake to do with fast tokenizers, which are backed by Rust and thus able to parallelize the tokenization of multiple texts. Passing them only one text at a time is like sending a cargo ship between two continents with just one container, it's very inefficient. To unleash the full speed of our fast tokenizers, we need to send them batches of texts, which we can do with the batched=True argument of the map method. Now those results are impressive! The fast tokenizer takes 12 seconds to process a dataset that takes 4 minutes to the slow tokenizer. Summarizing the results in this table, you can see why we have called those tokenizers fast. And this is only for tokenizing texts. If you ever need to train a new tokenizer, they do this very quickly too!
|
huggingface/course/blob/main/subtitles/en/raw/chapter6/03a_why-fast-tokenizers.md
|
--
title: "Introduction to 3D Gaussian Splatting"
thumbnail: /blog/assets/124_ml-for-games/thumbnail-gaussian-splatting.png
authors:
- user: dylanebert
---
# Introduction to 3D Gaussian Splatting
3D Gaussian Splatting is a rasterization technique described in [3D Gaussian Splatting for Real-Time Radiance Field Rendering](https://huggingface.co/papers/2308.04079) that allows real-time rendering of photorealistic scenes learned from small samples of images. This article will break down how it works and what it means for the future of graphics.
## What is 3D Gaussian Splatting?
3D Gaussian Splatting is, at its core, a rasterization technique. That means:
1. Have data describing the scene.
2. Draw the data on the screen.
This is analogous to triangle rasterization in computer graphics, which is used to draw many triangles on the screen.

However, instead of triangles, it's gaussians. Here's a single rasterized gaussian, with a border drawn for clarity.

It's described by the following parameters:
- **Position**: where it's located (XYZ)
- **Covariance**: how it's stretched/scaled (3x3 matrix)
- **Color**: what color it is (RGB)
- **Alpha**: how transparent it is (α)
In practice, multiple gaussians are drawn at once.
That's three gaussians. Now what about 7 million gaussians?

Here's what it looks like with each gaussian rasterized fully opaque:

That's a very brief overview of what 3D Gaussian Splatting is. Next, let's walk through the full procedure described in the paper.
## How it works
### 1. Structure from Motion
The first step is to use the Structure from Motion (SfM) method to estimate a point cloud from a set of images. This is a method for estimating a 3D point cloud from a set of 2D images. This can be done with the [COLMAP](https://colmap.github.io/) library.

### 2. Convert to Gaussians
Next, each point is converted to a gaussian. This is already sufficient for rasterization. However, only position and color can be inferred from the SfM data. To learn a representation that yields high quality results, we need to train it.
### 3. Training
The training procedure uses Stochastic Gradient Descent, similar to a neural network, but without the layers. The training steps are:
1. Rasterize the gaussians to an image using differentiable gaussian rasterization (more on that later)
2. Calculate the loss based on the difference between the rasterized image and ground truth image
3. Adjust the gaussian parameters according to the loss
4. Apply automated densification and pruning
Steps 1-3 are conceptually pretty straightforward. Step 4 involves the following:
- If the gradient is large for a given gaussian (i.e. it's too wrong), split/clone it
- If the gaussian is small, clone it
- If the gaussian is large, split it
- If the alpha of a gaussian gets too low, remove it
This procedure helps the gaussians better fit fine-grained details, while pruning unnecessary gaussians.
### 4. Differentiable Gaussian Rasterization
As mentioned earlier, 3D Gaussian Splatting is a *rasterization* approach, which draws the data to the screen. However, some important elements are also that it's:
1. Fast
2. Differentiable
The original implementation of the rasterizer can be found [here](https://github.com/graphdeco-inria/diff-gaussian-rasterization). The rasterization involves:
1. Project each gaussian into 2D from the camera perspective.
2. Sort the gaussians by depth.
3. For each pixel, iterate over each gaussian front-to-back, blending them together.
Additional optimizations are described in [the paper](https://huggingface.co/papers/2308.04079).
It's also essential that the rasterizer is differentiable, so that it can be trained with stochastic gradient descent. However, this is only relevant for training - the trained gaussians can also be rendered with a non-differentiable approach.
## Who cares?
Why has there been so much attention on 3D Gaussian Splatting? The obvious answer is that the results speak for themselves - it's high-quality scenes in real-time. However, there may be more to story.
There are many unknowns as to what else can be done with Gaussian Splatting. Can they be animated? The upcoming paper [Dynamic 3D Gaussians: tracking by Persistent Dynamic View Synthesis](https://arxiv.org/pdf/2308.09713) suggests that they can. There are many other unknowns as well. Can they do reflections? Can they be modeled without training on reference images?
Finally, there is growing research interest in [Embodied AI](https://ieeexplore.ieee.org/iel7/7433297/9741092/09687596.pdf). This is an area of AI research where state-of-the-art performance is still orders of magnitude below human performance, with much of the challenge being in representing 3D space. Given that 3D Gaussian Splatting yields a very dense representation of 3D space, what might the implications be for Embodied AI research?
These questions call attention to the method. It remains to be seen what the actual impact will be.
## The future of graphics
So what does this mean for the future of graphics? Well, let's break it up into pros/cons:
**Pros**
1. High-quality, photorealistic scenes
2. Fast, real-time rasterization
3. Relatively fast to train
**Cons**
1. High VRAM usage (4GB to view, 12GB to train)
2. Large disk size (1GB+ for a scene)
3. Incompatible with existing rendering pipelines
3. Static (for now)
So far, the original CUDA implementation has not been adapted to production rendering pipelines, like Vulkan, DirectX, WebGPU, etc, so it's yet to be seen what the impact will be.
There have already been the following adaptations:
1. [Remote viewer](https://huggingface.co/spaces/dylanebert/gaussian-viewer)
2. [WebGPU viewer](https://github.com/cvlab-epfl/gaussian-splatting-web)
3. [WebGL viewer](https://huggingface.co/spaces/cakewalk/splat)
4. [Unity viewer](https://github.com/aras-p/UnityGaussianSplatting)
5. [Optimized WebGL viewer](https://gsplat.tech/)
These rely either on remote streaming (1) or a traditional quad-based rasterization approach (2-5). While a quad-based approach is compatible with decades of graphics technologies, it may result in lower quality/performance. However, [viewer #5](https://gsplat.tech/) demonstrates that optimization tricks can result in high quality/performance, despite a quad-based approach.
So will we see 3D Gaussian Splatting fully reimplemented in a production environment? The answer is *probably yes*. The primary bottleneck is sorting millions of gaussians, which is done efficiently in the original implementation using [CUB device radix sort](https://nvlabs.github.io/cub/structcub_1_1_device_radix_sort.html), a highly optimized sort only available in CUDA. However, with enough effort, it's certainly possible to achieve this level of performance in other rendering pipelines.
If you have any questions or would like to get involved, join the [Hugging Face Discord](https://hf.co/join/discord)!
|
huggingface/blog/blob/main/gaussian-splatting.md
|
Gated datasets
To give more control over how datasets are used, the Hub allows datasets authors to enable **access requests** for their datasets. Users must agree to share their contact information (username and email address) with the datasets authors to access the datasets files when enabled. Datasets authors can configure this request with additional fields. A dataset with access requests enabled is called a **gated dataset**. Access requests are always granted to individual users rather than to entire organizations. A common use case of gated datasets is to provide access to early research datasets before the wider release.
## Manage gated datasets as a dataset author
<a id="manual-approval"></a> <!-- backward compatible anchor -->
<a id="notifications-settings"></a> <!-- backward compatible anchor -->
To enable access requests, go to the dataset settings page. By default, the dataset is not gated. Click on **Enable Access request** in the top-right corner.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-gated-disabled.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-gated-disabled-dark.png"/>
</div>
By default, access to the dataset is automatically granted to the user when requesting it. This is referred to as **automatic approval**. In this mode, any user can access your dataset once they've shared their personal information with you.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-gated-enabled.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-gated-enabled-dark.png"/>
</div>
If you want to manually approve which users can access your dataset, you must set it to **manual approval**. When this is the case, you will notice more options:
- **Add access** allows you to search for a user and grant them access even if they did not request it.
- **Notification frequency** lets you configure when to get notified if new users request access. It can be set to once a day or real-time. By default, an email is sent to your primary email address. You can set a different email address in the **Notifications email** field. For datasets hosted under an organization, emails are sent to the first 5 admins of the organization.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-gated-manual-approval.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-gated-manual-approval-dark.png"/>
</div>
### Review access requests
Once access requests are enabled, you have full control of who can access your dataset or not, whether the approval mode is manual or automatic. You can review and manage requests either from the UI or via the API.
### From the UI
You can review who has access to your gated dataset from its settings page by clicking on the **Review access requests** button. This will open a modal with 3 lists of users:
- **pending**: the list of users waiting for approval to access your dataset. This list is empty unless you've selected **manual approval**. You can either **Accept** or **Reject** the demand. If the demand is rejected, the user cannot access your dataset and cannot request access again.
- **accepted**: the complete list of users with access to your dataset. You can choose to **Reject** access at any time for any user, whether the approval mode is manual or automatic. You can also **Cancel** the approval, which will move the user to the *pending* list.
- **rejected**: the list of users you've manually rejected. Those users cannot access your datasets. If they go to your dataset repository, they will see a message *Your request to access this repo has been rejected by the repo's authors*.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-gated-enabled-pending-users.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-gated-enabled-pending-users-dark.png"/>
</div>
#### Via the API
You can automate the approval of access requests by using the API. You must pass a `token` with `write` access to the gated repository. To generate a token, go to [your user settings](https://huggingface.co/settings/tokens).
| Method | URI | Description | Headers | Payload
| ------ | --- | ----------- | ------- | ------- |
| `GET` | `/api/datasets/{repo_id}/user-access-request/pending` | Retrieve the list of pending requests. | `{"authorization": "Bearer $token"}` | |
| `GET` | `/api/datasets/{repo_id}/user-access-request/accepted` | Retrieve the list of accepted requests. | `{"authorization": "Bearer $token"}` | |
| `GET` | `/api/datasets/{repo_id}/user-access-request/rejected` | Retrieve the list of rejected requests. | `{"authorization": "Bearer $token"}` | |
| `POST` | `/api/datasets/{repo_id}/user-access-request/handle` | Change the status of a given access request to `status`. | `{"authorization": "Bearer $token"}` | `{"status": "accepted"/"rejected"/"pending", "user": "username"}` |
| `POST` | `/api/datasets/{repo_id}/user-access-request/grant` | Allow a specific user to access your repo. | `{"authorization": "Bearer $token"}` | `{"user": "username"} ` |
The base URL for the HTTP endpoints above is `https://huggingface.co`.
Those endpoints are not officially supported in `huggingface_hub` or `huggingface.js` yet but [this code snippet](https://github.com/huggingface/huggingface_hub/issues/1535#issuecomment-1614693412) (in Python) might help you getting started.
### Download access report
You can download a report of all access requests for a gated datasets with the **download user access report** button. Click on it to download a json file with a list of users. For each entry, you have:
- **user**: the user id. Example: *julien-c*.
- **fullname**: name of the user on the Hub. Example: *Julien Chaumond*.
- **status**: status of the request. Either `"pending"`, `"accepted"` or `"rejected"`.
- **email**: email of the user.
- **time**: datetime when the user initially made the request.
<a id="modifying-the-prompt"></a> <!-- backward compatible anchor -->
### Customize requested information
By default, users landing on your gated dataset will be asked to share their contact information (email and username) by clicking the **Agree and send request to access repo** button.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-gated-user-side.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-gated-user-side-dark.png"/>
</div>
If you want to collect more user information, you can configure additional fields. This information will be accessible from the **Settings** tab. To do so, add an `extra_gated_fields` property to your [dataset card metadata](./datasets-cards#dataset-card-metadata) containing a list of key/value pairs. The *key* is the name of the field and *value* its type. A field can be either `text` (free text area) or `checkbox`. Finally, you can also personalize the message displayed to the user with the `extra_gated_prompt` extra field.
Here is an example of customized request form where the user is asked to provide their company name and country and acknowledge that the dataset is for non-commercial use only.
```yaml
---
extra_gated_prompt: "You agree to not use the dataset to conduct experiments that cause harm to human subjects."
extra_gated_fields:
Company: text
Country: text
I agree to use this dataset for non-commercial use ONLY: checkbox
---
```
In some cases, you might also want to modify the text in the gate heading and the text in the button. For those use cases, you can modify `extra_gated_heading` and `extra_gated_button_content` like this:
```yaml
---
extra_gated_heading: "Acknowledge license to accept the repository"
extra_gated_button_content: "Acknowledge license"
---
```
## Access gated datasets as a user
As a user, if you want to use a gated dataset, you will need to request access to it. This means that you must be logged in to a Hugging Face user account.
Requesting access can only be done from your browser. Go to the dataset on the Hub and you will be prompted to share your information:
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-gated-user-side.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-gated-user-side-dark.png"/>
</div>
By clicking on **Agree**, you agree to share your username and email address with the dataset authors. In some cases, additional fields might be requested. To help the dataset authors decide whether to grant you access, try to fill out the form as completely as possible.
Once the access request is sent, there are two possibilities. If the approval mechanism is automatic, you immediately get access to the dataset files. Otherwise, the requests have to be approved manually by the authors, which can take more time.
<Tip warning={true}>
The dataset authors have complete control over dataset access. In particular, they can decide at any time to block your access to the dataset without prior notice, regardless of approval mechanism or if your request has already been approved.
</Tip>
### Download files
To download files from a gated dataset you'll need to be authenticated. In the browser, this is automatic as long as you are logged in with your account. If you are using a script, you will need to provide a [user token](./security-tokens). In the Hugging Face Python ecosystem (`transformers`, `diffusers`, `datasets`, etc.), you can login your machine using the [`huggingface_hub`](https://huggingface.co/docs/huggingface_hub/index) library and running in your terminal:
```bash
huggingface-cli login
```
Alternatively, you can programmatically login using `login()` in a notebook or a script:
```python
>>> from huggingface_hub import login
>>> login()
```
You can also provide the `token` parameter to most loading methods in the libraries (`from_pretrained`, `hf_hub_download`, `load_dataset`, etc.), directly from your scripts.
For more details about how to login, check out the [login guide](https://huggingface.co/docs/huggingface_hub/quick-start#login).
|
huggingface/hub-docs/blob/main/docs/hub/datasets-gated.md
|
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Environment variables
`huggingface_hub` can be configured using environment variables.
If you are unfamiliar with environment variable, here are generic articles about them
[on macOS and Linux](https://linuxize.com/post/how-to-set-and-list-environment-variables-in-linux/)
and on [Windows](https://phoenixnap.com/kb/windows-set-environment-variable).
This page will guide you through all environment variables specific to `huggingface_hub`
and their meaning.
## Generic
### HF_INFERENCE_ENDPOINT
To configure the inference api base url. You might want to set this variable if your organization
is pointing at an API Gateway rather than directly at the inference api.
Defaults to `"https://api-inference.huggingface.com"`.
### HF_HOME
To configure where `huggingface_hub` will locally store data. In particular, your token
and the cache will be stored in this folder.
Defaults to `"~/.cache/huggingface"` unless [XDG_CACHE_HOME](#xdgcachehome) is set.
### HF_HUB_CACHE
To configure where repositories from the Hub will be cached locally (models, datasets and
spaces).
Defaults to `"$HF_HOME/hub"` (e.g. `"~/.cache/huggingface/hub"` by default).
### HF_ASSETS_CACHE
To configure where [assets](../guides/manage-cache#caching-assets) created by downstream libraries
will be cached locally. Those assets can be preprocessed data, files downloaded from GitHub,
logs,...
Defaults to `"$HF_HOME/assets"` (e.g. `"~/.cache/huggingface/assets"` by default).
### HF_TOKEN
To configure the User Access Token to authenticate to the Hub. If set, this value will
overwrite the token stored on the machine (in `"$HF_HOME/token"`).
For more details about authentication, check out [this section](../quick-start#authentication).
### HF_HUB_VERBOSITY
Set the verbosity level of the `huggingface_hub`'s logger. Must be one of
`{"debug", "info", "warning", "error", "critical"}`.
Defaults to `"warning"`.
For more details, see [logging reference](../package_reference/utilities#huggingface_hub.utils.logging.get_verbosity).
### HF_HUB_LOCAL_DIR_AUTO_SYMLINK_THRESHOLD
Integer value to define under which size a file is considered as "small". When downloading files to a local directory,
small files will be duplicated to ease user experience while bigger files are symlinked to save disk usage.
For more details, see the [download guide](../guides/download#download-files-to-local-folder).
### HF_HUB_ETAG_TIMEOUT
Integer value to define the number of seconds to wait for server response when fetching the latest metadata from a repo before downloading a file. If the request times out, `huggingface_hub` will default to the locally cached files. Setting a lower value speeds up the workflow for machines with a slow connection that have already cached files. A higher value guarantees the metadata call to succeed in more cases. Default to 10s.
### HF_HUB_DOWNLOAD_TIMEOUT
Integer value to define the number of seconds to wait for server response when downloading a file. If the request times out, a TimeoutError is raised. Setting a higher value is beneficial on machine with a slow connection. A smaller value makes the process fail quicker in case of complete network outage. Default to 10s.
## Boolean values
The following environment variables expect a boolean value. The variable will be considered
as `True` if its value is one of `{"1", "ON", "YES", "TRUE"}` (case-insensitive). Any other value
(or undefined) will be considered as `False`.
### HF_HUB_OFFLINE
If set, no HTTP calls will me made to the Hugging Face Hub. If you try to download files, only the cached files will be accessed. If no cache file is detected, an error is raised This is useful in case your network is slow and you don't care about having the latest version of a file.
If `HF_HUB_OFFLINE=1` is set as environment variable and you call any method of [`HfApi`], an [`~huggingface_hub.utils.OfflineModeIsEnabled`] exception will be raised.
**Note:** even if the latest version of a file is cached, calling `hf_hub_download` still triggers a HTTP request to check that a new version is not available. Setting `HF_HUB_OFFLINE=1` will skip this call which speeds up your loading time.
### HF_HUB_DISABLE_IMPLICIT_TOKEN
Authentication is not mandatory for every requests to the Hub. For instance, requesting
details about `"gpt2"` model does not require to be authenticated. However, if a user is
[logged in](../package_reference/login), the default behavior will be to always send the token
in order to ease user experience (never get a HTTP 401 Unauthorized) when accessing private or gated repositories. For privacy, you can
disable this behavior by setting `HF_HUB_DISABLE_IMPLICIT_TOKEN=1`. In this case,
the token will be sent only for "write-access" calls (example: create a commit).
**Note:** disabling implicit sending of token can have weird side effects. For example,
if you want to list all models on the Hub, your private models will not be listed. You
would need to explicitly pass `token=True` argument in your script.
### HF_HUB_DISABLE_PROGRESS_BARS
For time consuming tasks, `huggingface_hub` displays a progress bar by default (using tqdm).
You can disable all the progress bars at once by setting `HF_HUB_DISABLE_PROGRESS_BARS=1`.
### HF_HUB_DISABLE_SYMLINKS_WARNING
If you are on a Windows machine, it is recommended to enable the developer mode or to run
`huggingface_hub` in admin mode. If not, `huggingface_hub` will not be able to create
symlinks in your cache system. You will be able to execute any script but your user experience
will be degraded as some huge files might end-up duplicated on your hard-drive. A warning
message is triggered to warn you about this behavior. Set `HF_HUB_DISABLE_SYMLINKS_WARNING=1`,
to disable this warning.
For more details, see [cache limitations](../guides/manage-cache#limitations).
### HF_HUB_DISABLE_EXPERIMENTAL_WARNING
Some features of `huggingface_hub` are experimental. This means you can use them but we do not guarantee they will be
maintained in the future. In particular, we might update the API or behavior of such features without any deprecation
cycle. A warning message is triggered when using an experimental feature to warn you about it. If you're comfortable debugging any potential issues using an experimental feature, you can set `HF_HUB_DISABLE_EXPERIMENTAL_WARNING=1` to disable the warning.
If you are using an experimental feature, please let us know! Your feedback can help us design and improve it.
### HF_HUB_DISABLE_TELEMETRY
By default, some data is collected by HF libraries (`transformers`, `datasets`, `gradio`,..) to monitor usage, debug issues and help prioritize features.
Each library defines its own policy (i.e. which usage to monitor) but the core implementation happens in `huggingface_hub` (see [`send_telemetry`]).
You can set `HF_HUB_DISABLE_TELEMETRY=1` as environment variable to globally disable telemetry.
### HF_HUB_ENABLE_HF_TRANSFER
Set to `True` for faster uploads and downloads from the Hub using `hf_transfer`.
By default, `huggingface_hub` uses the Python-based `requests.get` and `requests.post` functions. Although these are reliable and versatile, they may not be the most efficient choice for machines with high bandwidth. [`hf_transfer`](https://github.com/huggingface/hf_transfer) is a Rust-based package developed to maximize the bandwidth used by dividing large files into smaller parts and transferring them simultaneously using multiple threads. This approach can potentially double the transfer speed. To use `hf_transfer`, you need to install it separately [from PyPI](https://pypi.org/project/hf-transfer/) and set `HF_HUB_ENABLE_HF_TRANSFER=1` as an environment variable.
Please note that using `hf_transfer` comes with certain limitations. Since it is not purely Python-based, debugging errors may be challenging. Additionally, `hf_transfer` lacks several user-friendly features such as resumable downloads and proxies. These omissions are intentional to maintain the simplicity and speed of the Rust logic. Consequently, `hf_transfer` is not enabled by default in `huggingface_hub`.
## Deprecated environment variables
In order to standardize all environment variables within the Hugging Face ecosystem, some variables have been marked as deprecated. Although they remain functional, they no longer take precedence over their replacements. The following table outlines the deprecated variables and their corresponding alternatives:
| Deprecated Variable | Replacement |
| --- | --- |
| `HUGGINGFACE_HUB_CACHE` | `HF_HUB_CACHE` |
| `HUGGINGFACE_ASSETS_CACHE` | `HF_ASSETS_CACHE` |
| `HUGGING_FACE_HUB_TOKEN` | `HF_TOKEN` |
| `HUGGINGFACE_HUB_VERBOSITY` | `HF_HUB_VERBOSITY` |
## From external tools
Some environment variables are not specific to `huggingface_hub` but are still taken into account when they are set.
### DO_NOT_TRACK
Boolean value. Equivalent to `HF_HUB_DISABLE_TELEMETRY`. When set to true, telemetry is globally disabled in the Hugging Face Python ecosystem (`transformers`, `diffusers`, `gradio`, etc.). See https://consoledonottrack.com/ for more details.
### NO_COLOR
Boolean value. When set, `huggingface-cli` tool will not print any ANSI color.
See [no-color.org](https://no-color.org/).
### XDG_CACHE_HOME
Used only when `HF_HOME` is not set!
This is the default way to configure where [user-specific non-essential (cached) data should be written](https://wiki.archlinux.org/title/XDG_Base_Directory)
on linux machines.
If `HF_HOME` is not set, the default home will be `"$XDG_CACHE_HOME/huggingface"` instead
of `"~/.cache/huggingface"`.
|
huggingface/huggingface_hub/blob/main/docs/source/en/package_reference/environment_variables.md
|
--
title: "Train your ControlNet with diffusers"
thumbnail: /blog/assets/136_train-your-controlnet/thumbnail.png
authors:
- user: multimodalart
- user: pcuenq
---
# Train your ControlNet with diffusers 🧨
## Introduction
[ControlNet](https://huggingface.co/blog/controlnet) is a neural network structure that allows fine-grained control of diffusion models by adding extra conditions. The technique debuted with the paper [Adding Conditional Control to Text-to-Image Diffusion Models](https://huggingface.co/papers/2302.05543), and quickly took over the open-source diffusion community author's release of 8 different conditions to control Stable Diffusion v1-5, including pose estimations, depth maps, canny edges, sketches, [and more](https://huggingface.co/lllyasviel).

In this blog post we will go over each step in detail on how we trained the [_Uncanny_ Faces model](#) - a model on face poses based on 3D synthetic faces (the uncanny faces was an unintended consequence actually, stay tuned to see how it came through).
## Getting started with training your ControlNet for Stable Diffusion
Training your own ControlNet requires 3 steps:
1. **Planning your condition**: ControlNet is flexible enough to tame Stable Diffusion towards many tasks. The pre-trained models showcase a wide-range of conditions, and the community has built others, such as conditioning on [pixelated color palettes](https://huggingface.co/thibaud/controlnet-sd21-color-diffusers).
2. **Building your dataset**: Once a condition is decided, it is time to build your dataset. For that, you can either construct a dataset from scratch, or use a sub-set of an existing dataset. You need three columns on your dataset to train the model: a ground truth `image`, a `conditioning_image` and a `prompt`.
3. **Training the model**: Once your dataset is ready, it is time to train the model. This is the easiest part thanks to the [diffusers training script](https://github.com/huggingface/diffusers/tree/main/examples/controlnet). You'll need a GPU with at least 8GB of VRAM.
## 1. Planning your condition
To plan your condition, it is useful to think of two questions:
1. What kind of conditioning do I want to use?
2. Is there an already existing model that can convert 'regular' images into my condition?
For our example, we thought about using a facial landmarks conditioning. Our reasoning was: 1. the general landmarks conditioned ControlNet works well. 2. Facial landmarks are a widespread enough technique, and there are multiple models that calculate facial landmarks on regular pictures 3. Could be fun to tame Stable Diffusion to follow a certain facial landmark or imitate your own facial expression.

## 2. Building your dataset
Okay! So we decided to do a facial landmarks Stable Diffusion conditioning. So, to prepare the dataset we need:
- The ground truth `image`: in this case, images of faces
- The `conditioning_image`: in this case, images where the facial landmarks are visualised
- The `caption`: a caption that describes the images being used
For this project, we decided to go with the `FaceSynthetics` dataset by Microsoft: it is a dataset that contains 100K synthetic faces. Other face research datasets with real faces such as `Celeb-A HQ`, `FFHQ` - but we decided to go with synthetic faces for this project.

The `FaceSynthetics` dataset sounded like a great start: it contains ground truth images of faces, and facial landmarks annotated in the iBUG 68-facial landmarks format, and a segmented image of the face.

Perfect. Right? Unfortunately, not really. Remember the second question in the "planning your condition" step - that we should have models that convert regular images to the conditioning? Turns out there was is no known model that can turn faces into the annotated landmark format of this dataset.

So we decided to follow another path:
- Use the ground truths `image` of faces of the `FaceSynthetics` datase
- Use a known model that can convert any image of a face into the 68-facial landmarks format of iBUG (in our case we used the SOTA model [SPIGA](https://github.com/andresprados/SPIGA))
- Use custom code that converts the facial landmarks into a nice illustrated mask to be used as the `conditioning_image`
- Save that as a [Hugging Face Dataset](https://huggingface.co/docs/datasets/indexx)
[Here you can find](https://huggingface.co/datasets/pcuenq/face_synthetics_spiga) the code used to convert the ground truth images from the `FaceSynthetics` dataset into the illustrated mask and save it as a Hugging Face Dataset.
Now, with the ground truth `image` and the `conditioning_image` on the dataset, we are missing one step: a caption for each image. This step is highly recommended, but you can experiment with empty prompts and report back on your results. As we did not have captions for the `FaceSynthetics` dataset, we ran it through a [BLIP captioning](https://huggingface.co/docs/transformers/model_doc/blip). You can check the code used for captioning all images [here](https://huggingface.co/datasets/multimodalart/facesyntheticsspigacaptioned)
With that, we arrived to our final dataset! The [Face Synthetics SPIGA with captions](https://huggingface.co/datasets/multimodalart/facesyntheticsspigacaptioned) contains a ground truth image, segmentation and a caption for the 100K images of the `FaceSynthetics` dataset. We are ready to train the model!

## 3. Training the model
With our [dataset ready](https://huggingface.co/datasets/multimodalart/facesyntheticsspigacaptioned), it is time to train the model! Even though this was supposed to be the hardest part of the process, with the [diffusers training script](https://github.com/huggingface/diffusers/tree/main/examples/controlnet), it turned out to be the easiest. We used a single A100 rented for US$1.10/h on [LambdaLabs](https://lambdalabs.com).
### Our training experience
We trained the model for 3 epochs (this means that the batch of 100K images were shown to the model 3 times) and a batch size of 4 (each step shows 4 images to the model). This turned out to be excessive and overfit (so it forgot concepts that diverge a bit of a real face, so for example "shrek" or "a cat" in the prompt would not make a shrek or a cat but rather a person, and also started to ignore styles).
With just 1 epoch (so after the model "saw" 100K images), it already converged to following the poses and not overfit. So it worked, but... as we used the face synthetics dataset, the model ended up learning uncanny 3D-looking faces, instead of realistic faces. This makes sense given that we used a synthetic face dataset as opposed to real ones, and can be used for fun/memetic purposes. Here is the [uncannyfaces_25K](https://huggingface.co/multimodalart/uncannyfaces_25K) model.
<iframe src="https://wandb.ai/apolinario/controlnet/reports/ControlNet-Uncanny-Faces-Training--VmlldzozODcxNDY0" style="border:none;height:512px;width:100%"></iframe>
In this interactive table you can play with the dial below to go over how many training steps the model went through and how it affects the training process. At around 15K steps, it already started learning the poses. And it matured around 25K steps. Here
### How did we do the training
All we had to do was, install the dependencies:
```shell
pip install git+https://github.com/huggingface/diffusers.git transformers accelerate xformers==0.0.16 wandb
huggingface-cli login
wandb login
```
And then run the [train_controlnet.py](https://github.com/huggingface/diffusers/blob/main/examples/controlnet/train_controlnet.py) code
```shell
!accelerate launch train_controlnet.py \
--pretrained_model_name_or_path="stabilityai/stable-diffusion-2-1-base" \
--output_dir="model_out" \
--dataset_name=multimodalart/facesyntheticsspigacaptioned \
--conditioning_image_column=spiga_seg \
--image_column=image \
--caption_column=image_caption \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./face_landmarks1.jpeg" "./face_landmarks2.jpeg" "./face_landmarks3.jpeg" \
--validation_prompt "High-quality close-up dslr photo of man wearing a hat with trees in the background" "Girl smiling, professional dslr photograph, dark background, studio lights, high quality" "Portrait of a clown face, oil on canvas, bittersweet expression" \
--train_batch_size=4 \
--num_train_epochs=3 \
--tracker_project_name="controlnet" \
--enable_xformers_memory_efficient_attention \
--checkpointing_steps=5000 \
--validation_steps=5000 \
--report_to wandb \
--push_to_hub
```
Let's break down some of the settings, and also let's go over some optimisation tips for going as low as 8GB of VRAM for training.
- `pretrained_model_name_or_path`: The Stable Diffusion base model you would like to use (we chose v2-1 here as it can render faces better)
- `output_dir`: The directory you would like your model to be saved
- `dataset_name`: The dataset that will be used for training. In our case [Face Synthetics SPIGA with captions](https://huggingface.co/datasets/multimodalart/facesyntheticsspigacaptioned)
- `conditioning_image_column`: The name of the column in your dataset that contains the conditioning image (in our case `spiga_seg`)
- `image_column`: The name of the colunn in your dataset that contains the ground truth image (in our case `image`)
- `caption_column`: The name of the column in your dataset that contains the caption of tha image (in our case `image_caption`)
- `resolution`: The resolution of both the conditioning and ground truth images (in our case `512x512`)
- `learning_rate`: The learing rate. We found out that `1e-5` worked well for these examples, but you may experiment with different values ranging between `1e-4` and `2e-6`, for example.
- `validation_image`: This is for you to take a sneak peak during training! The validation images will be ran for every amount of `validation_steps` so you can see how your training is going. Insert here a local path to an arbitrary number of conditioning images
- `validation_prompt`: A prompt to be ran togehter with your validation image. Can be anything that can test if your model is training well
- `train_batch_size`: This is the size of the training batch to fit the GPU. We can afford `4` due to having an A100, but if you have a GPU with lower VRAM we recommend bringing this value down to `1`.
- `num_train_epochs`: Each epoch corresponds to how many times the images in the training set will be "seen" by the model. We experimented with 3 epochs, but turns out the best results required just a bit more than 1 epoch, with 3 epochs our model overfit.
- `checkpointing_steps`: Save an intermediary checkpoint every `x` steps (in our case `5000`). Every 5000 steps, an intermediary checkpoint was saved.
- `validation_steps`: Every `x` steps the `validaton_prompt` and the `validation_image` are ran.
- `report_to`: where to report your training to. Here we used Weights and Biases, which gave us [this nice report]().
But reducing the `train_batch_size` from `4` to `1` may not be enough for the training to fit a small GPU, here are some additional parameters to add for each GPU VRAM size:
- `push_to_hub`: a parameter to push the final trained model to the Hugging Face Hub.
### Fitting on a 16GB VRAM GPU
```shell
pip install bitsandbytes
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--use_8bit_adam
```
The combination of a batch size of 1 with 4 gradient accumulation steps is equivalent to using the original batch size of 4 we used in our example. In addition, we enabled gradient checkpointing and 8-bit Adam for additional memory savings.
### Fitting on a 12GB VRAM GPU
```shell
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--use_8bit_adam
--set_grads_to_none
```
### Fitting on a 8GB VRAM GPU
Please follow [our guide here](https://github.com/huggingface/diffusers/tree/main/examples/controlnet#training-on-an-8-gb-gpu)
## 4. Conclusion!
This experience of training a ControlNet was a lot of fun. We succesfully trained a model that can follow real face poses - however it learned to make uncanny 3D faces instead of real 3D faces because this was the dataset it was trained on, which has its own charm and flare.
Try out our [Hugging Face Space](https://huggingface.co/spaces/pcuenq/uncanny-faces):
<iframe
src="https://pcuenq-uncanny-faces.hf.space"
frameborder="0"
width="100%"
height="1150"
style="border:0"
></iframe>
As for next steps for us - in order to create realistically looking faces, while still not using a real face dataset, one idea is running the entire `FaceSynthetics` dataset through Stable Diffusion Image2Imaage, converting the 3D-looking faces into realistically looking ones, and then trainign another ControlNet.
And stay tuned, as we will have a ControlNet Training event soon! Follow Hugging Face on [Twitter](https://twitter.com/huggingface) or join our [Discord]( http://hf.co/join/discord) to stay up to date on that.
|
huggingface/blog/blob/main/train-your-controlnet.md
|
!---
Copyright 2021 The Google Flax Team Authors and HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Token classification examples
Fine-tuning the library models for token classification task such as Named Entity Recognition (NER), Parts-of-speech tagging (POS) or phrase extraction (CHUNKS). The main script run_flax_ner.py leverages the 🤗 Datasets library. You can easily customize it to your needs if you need extra processing on your datasets.
It will either run on a datasets hosted on our hub or with your own text files for training and validation, you might just need to add some tweaks in the data preprocessing.
The following example fine-tunes BERT on CoNLL-2003:
```bash
python run_flax_ner.py \
--model_name_or_path bert-base-cased \
--dataset_name conll2003 \
--max_seq_length 128 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--per_device_train_batch_size 4 \
--output_dir ./bert-ner-conll2003 \
--eval_steps 300 \
--push_to_hub
```
Using the command above, the script will train for 3 epochs and run eval after each epoch.
Metrics and hyperparameters are stored in Tensorflow event files in `--output_dir`.
You can see the results by running `tensorboard` in that directory:
```bash
$ tensorboard --logdir .
```
or directly on the hub under *Training metrics*.
sample Metrics - [tfhub.dev](https://tensorboard.dev/experiment/u52qsBIpQSKEEXEJd2LVYA)
|
huggingface/transformers/blob/main/examples/flax/token-classification/README.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# LyCORIS
[LyCORIS](https://hf.co/papers/2309.14859) (Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion) are LoRA-like matrix decomposition adapters that modify the cross-attention layer of the UNet. The [LoHa](loha) and [LoKr](lokr) methods inherit from the `Lycoris` classes here.
## LycorisConfig
[[autodoc]] tuners.lycoris_utils.LycorisConfig
## LycorisLayer
[[autodoc]] tuners.lycoris_utils.LycorisLayer
## LycorisTuner
[[autodoc]] tuners.lycoris_utils.LycorisTuner
|
huggingface/peft/blob/main/docs/source/package_reference/adapter_utils.md
|
Part 2 completed![[part-2-completed]]
<CourseFloatingBanner
chapter={8}
classNames="absolute z-10 right-0 top-0"
/>
Congratulations, you've made it through the second part of the course! We're actively working on the third one, so subscribe to our [newsletter](https://huggingface.curated.co/) to make sure you don't miss its release.
You should now be able to tackle a range of NLP tasks, and fine-tune or pretrain a model on them. Don't forget to share your results with the community on the [Model Hub](https://huggingface.co/models).
We can't wait to see what you will build with the knowledge that you've gained!
|
huggingface/course/blob/main/chapters/en/chapter8/6.mdx
|
@gradio/chatbot
## 0.5.5
### Patch Changes
- Updated dependencies [[`846d52d`](https://github.com/gradio-app/gradio/commit/846d52d1c92d429077382ce494eea27fd062d9f6), [`828fb9e`](https://github.com/gradio-app/gradio/commit/828fb9e6ce15b6ea08318675a2361117596a1b5d), [`f3abde8`](https://github.com/gradio-app/gradio/commit/f3abde80884d96ad69b825020c46486d9dd5cac5), [`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144)]:
- @gradio/markdown@0.6.0
- @gradio/client@0.9.3
- @gradio/statustracker@0.4.3
- @gradio/atoms@0.4.1
- @gradio/upload@0.5.6
## 0.5.4
### Patch Changes
- Updated dependencies [[`245d58e`](https://github.com/gradio-app/gradio/commit/245d58eff788e8d44a59d37a2d9b26d0f08a62b4)]:
- @gradio/client@0.9.2
- @gradio/upload@0.5.5
## 0.5.3
### Patch Changes
- Updated dependencies [[`5d51fbc`](https://github.com/gradio-app/gradio/commit/5d51fbce7826da840a2fd4940feb5d9ad6f1bc5a), [`34f9431`](https://github.com/gradio-app/gradio/commit/34f943101bf7dd6b8a8974a6131c1ed7c4a0dac0)]:
- @gradio/upload@0.5.4
- @gradio/client@0.9.1
## 0.5.2
### Features
- [#6399](https://github.com/gradio-app/gradio/pull/6399) [`053bec9`](https://github.com/gradio-app/gradio/commit/053bec98be1127e083414024e02cf0bebb0b5142) - Improve CSS token documentation in Storybook. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.5.1
### Fixes
- [#6574](https://github.com/gradio-app/gradio/pull/6574) [`2b625ad`](https://github.com/gradio-app/gradio/commit/2b625ad9403c3449b34a8a3da68ae48c4347c2db) - Ensure Chatbot messages are properly aligned when `rtl` is true. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6572](https://github.com/gradio-app/gradio/pull/6572) [`206af31`](https://github.com/gradio-app/gradio/commit/206af31d7c1a31013364a44e9b40cf8df304ba50) - Improve like/dislike functionality. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.5.0
### Features
- [#6537](https://github.com/gradio-app/gradio/pull/6537) [`6d3fecfa4`](https://github.com/gradio-app/gradio/commit/6d3fecfa42dde1c70a60c397434c88db77289be6) - chore(deps): update all non-major dependencies. Thanks [@renovate](https://github.com/apps/renovate)!
## 0.4.8
### Features
- [#6296](https://github.com/gradio-app/gradio/pull/6296) [`46f13f496`](https://github.com/gradio-app/gradio/commit/46f13f4968c8177e318c9d75f2eed1ed55c2c042) - chore(deps): update all non-major dependencies. Thanks [@renovate](https://github.com/apps/renovate)!
## 0.4.7
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/atoms@0.3.0
- @gradio/icons@0.3.0
- @gradio/statustracker@0.4.0
- @gradio/upload@0.5.0
- @gradio/markdown@0.3.3
## 0.4.6
### Patch Changes
- Updated dependencies [[`2f805a7dd`](https://github.com/gradio-app/gradio/commit/2f805a7dd3d2b64b098f659dadd5d01258290521), [`f816136a0`](https://github.com/gradio-app/gradio/commit/f816136a039fa6011be9c4fb14f573e4050a681a)]:
- @gradio/upload@0.4.2
- @gradio/atoms@0.2.2
- @gradio/icons@0.2.1
- @gradio/markdown@0.3.2
- @gradio/statustracker@0.3.2
## 0.4.5
### Fixes
- [#6386](https://github.com/gradio-app/gradio/pull/6386) [`e76a9e8fc`](https://github.com/gradio-app/gradio/commit/e76a9e8fcbbfc393298de2aa539f2b152c0d6400) - Fix Chatbot Pending Message Issues. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
## 0.4.4
### Patch Changes
- Updated dependencies [[`854b482f5`](https://github.com/gradio-app/gradio/commit/854b482f598e0dc47673846631643c079576da9c), [`f1409f95e`](https://github.com/gradio-app/gradio/commit/f1409f95ed39c5565bed6a601e41f94e30196a57)]:
- @gradio/upload@0.4.0
- @gradio/client@0.8.0
## 0.4.3
### Fixes
- [#6316](https://github.com/gradio-app/gradio/pull/6316) [`4b1011bab`](https://github.com/gradio-app/gradio/commit/4b1011bab03c0b6a09329e0beb9c1b17b2189878) - Maintain text selection in `Chatbot` button elements. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.4.2
### Patch Changes
- Updated dependencies [[`aaa55ce85`](https://github.com/gradio-app/gradio/commit/aaa55ce85e12f95aba9299445e9c5e59824da18e)]:
- @gradio/upload@0.3.2
## 0.4.1
### Patch Changes
- Updated dependencies [[`2ba14b284`](https://github.com/gradio-app/gradio/commit/2ba14b284f908aa13859f4337167a157075a68eb)]:
- @gradio/client@0.7.1
- @gradio/upload@0.3.1
## 0.4.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - fix circular dependency with client + upload. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Clean root url. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Fix selectable prop in the backend. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Image v4. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
## 0.4.0-beta.9
### Features
- [#6143](https://github.com/gradio-app/gradio/pull/6143) [`e4f7b4b40`](https://github.com/gradio-app/gradio/commit/e4f7b4b409323b01aa01b39e15ce6139e29aa073) - fix circular dependency with client + upload. Thanks [@pngwn](https://github.com/pngwn)!
- [#6136](https://github.com/gradio-app/gradio/pull/6136) [`667802a6c`](https://github.com/gradio-app/gradio/commit/667802a6cdbfb2ce454a3be5a78e0990b194548a) - JS Component Documentation. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6094](https://github.com/gradio-app/gradio/pull/6094) [`c476bd5a5`](https://github.com/gradio-app/gradio/commit/c476bd5a5b70836163b9c69bf4bfe068b17fbe13) - Image v4. Thanks [@pngwn](https://github.com/pngwn)!
- [#6135](https://github.com/gradio-app/gradio/pull/6135) [`bce37ac74`](https://github.com/gradio-app/gradio/commit/bce37ac744496537e71546d2bb889bf248dcf5d3) - Fix selectable prop in the backend. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.4.0-beta.8
### Features
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
### Fixes
- [#6046](https://github.com/gradio-app/gradio/pull/6046) [`dbb7de5e0`](https://github.com/gradio-app/gradio/commit/dbb7de5e02c53fee05889d696d764d212cb96c74) - fix tests. Thanks [@pngwn](https://github.com/pngwn)!
## 0.4.0-beta.7
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.5.3
### Fixes
- [#5827](https://github.com/gradio-app/gradio/pull/5827) [`48e09ee88`](https://github.com/gradio-app/gradio/commit/48e09ee88799efa38a5cc9b1b61e462f72ec6093) - Quick fix: Chatbot change event. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
## 0.5.2
### Patch Changes
- Updated dependencies [[`e4a307ed6`](https://github.com/gradio-app/gradio/commit/e4a307ed6cde3bbdf4ff2f17655739addeec941e)]:
- @gradio/theme@0.2.0
- @gradio/utils@0.1.2
- @gradio/atoms@0.1.4
- @gradio/markdown@0.3.1
- @gradio/statustracker@0.2.2
- @gradio/upload@0.3.2
## 0.5.1
### Fixes
- [#5775](https://github.com/gradio-app/gradio/pull/5775) [`e2874bc3c`](https://github.com/gradio-app/gradio/commit/e2874bc3cb1397574f77dbd7f0408ed4e6792970) - fix pending chatbot message styling and ensure messages with value `None` don't render. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.5.0
### Features
- [#5699](https://github.com/gradio-app/gradio/pull/5699) [`8f0fed857`](https://github.com/gradio-app/gradio/commit/8f0fed857d156830626eb48b469d54d211a582d2) - Improve chatbot accessibility and UX. Thanks [@hannahblair](https://github.com/hannahblair)!
### Fixes
- [#5755](https://github.com/gradio-app/gradio/pull/5755) [`e842a561a`](https://github.com/gradio-app/gradio/commit/e842a561af4394f8109291ee5725bcf74743e816) - Fix new line issue in chatbot. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
## 0.4.1
### Patch Changes
- Updated dependencies [[`ee8eec1e5`](https://github.com/gradio-app/gradio/commit/ee8eec1e5e544a0127e0aa68c2522a7085b8ada5)]:
- @gradio/markdown@0.2.2
## 0.4.0
### Features
- [#5671](https://github.com/gradio-app/gradio/pull/5671) [`6a36c3b78`](https://github.com/gradio-app/gradio/commit/6a36c3b786700600d3826ce1e0629cc5308ddd47) - chore(deps): update dependency @types/prismjs to v1.26.1. Thanks [@renovate](https://github.com/apps/renovate)!
- [#5554](https://github.com/gradio-app/gradio/pull/5554) [`75ddeb390`](https://github.com/gradio-app/gradio/commit/75ddeb390d665d4484667390a97442081b49a423) - Accessibility Improvements. Thanks [@hannahblair](https://github.com/hannahblair)!
### Fixes
- [#5604](https://github.com/gradio-app/gradio/pull/5604) [`faad01f8e`](https://github.com/gradio-app/gradio/commit/faad01f8e10ef6d18249b1a4587477c59b74adb2) - Add `render_markdown` parameter to chatbot. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#5593](https://github.com/gradio-app/gradio/pull/5593) [`88d43bd12`](https://github.com/gradio-app/gradio/commit/88d43bd124792d216da445adef932a2b02f5f416) - Fixes avatar image in chatbot being squashed. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
## 0.3.2
### Fixes
- [#5470](https://github.com/gradio-app/gradio/pull/5470) [`a4e010a9`](https://github.com/gradio-app/gradio/commit/a4e010a96f1d8a52b3ac645e03fe472b9c3cbbb1) - Fix share button position. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
## 0.3.1
### Patch Changes
- Updated dependencies [[`afac0006`](https://github.com/gradio-app/gradio/commit/afac0006337ce2840cf497cd65691f2f60ee5912)]:
- @gradio/markdown@0.2.0
- @gradio/statustracker@0.2.0
- @gradio/theme@0.1.0
- @gradio/utils@0.1.1
- @gradio/atoms@0.1.2
- @gradio/upload@0.2.1
## 0.3.0
### Highlights
#### Like/Dislike Button for Chatbot ([#5391](https://github.com/gradio-app/gradio/pull/5391) [`abf1c57d`](https://github.com/gradio-app/gradio/commit/abf1c57d7d85de0df233ee3b38aeb38b638477db))
Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
### Features
- [#5334](https://github.com/gradio-app/gradio/pull/5334) [`c5bf9138`](https://github.com/gradio-app/gradio/commit/c5bf91385a632dc9f612499ee01166ac6ae509a9) - Add chat bubble width param. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
### Fixes
- [#5304](https://github.com/gradio-app/gradio/pull/5304) [`05892302`](https://github.com/gradio-app/gradio/commit/05892302fb8fe2557d57834970a2b65aea97355b) - Adds kwarg to disable html sanitization in `gr.Chatbot()`. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#5366](https://github.com/gradio-app/gradio/pull/5366) [`0cc7e2dc`](https://github.com/gradio-app/gradio/commit/0cc7e2dcf60e216e0a30e2f85a9879ce3cb2a1bd) - Hide avatar when message none. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
## 0.2.2
### Fixes
- [#5319](https://github.com/gradio-app/gradio/pull/5319) [`3341148c`](https://github.com/gradio-app/gradio/commit/3341148c109b5458cc88435d27eb154210efc472) - Fix: wrap avatar-image in a div to clip its shape. Thanks [@Keldos-Li](https://github.com/Keldos-Li)!
## 0.2.1
### Patch Changes
- Updated dependencies [[`31996c99`](https://github.com/gradio-app/gradio/commit/31996c991d6bfca8cef975eb8e3c9f61a7aced19)]:
- @gradio/markdown@0.1.1
## 0.2.0
### Highlights
#### Improve startup performance and markdown support ([#5279](https://github.com/gradio-app/gradio/pull/5279) [`fe057300`](https://github.com/gradio-app/gradio/commit/fe057300f0672c62dab9d9b4501054ac5d45a4ec))
##### Improved markdown support
We now have better support for markdown in `gr.Markdown` and `gr.Dataframe`. Including syntax highlighting and Github Flavoured Markdown. We also have more consistent markdown behaviour and styling.
##### Various performance improvements
These improvements will be particularly beneficial to large applications.
- Rather than attaching events manually, they are now delegated, leading to a significant performance improvement and addressing a performance regression introduced in a recent version of Gradio. App startup for large applications is now around twice as fast.
- Optimised the mounting of individual components, leading to a modest performance improvement during startup (~30%).
- Corrected an issue that was causing markdown to re-render infinitely.
- Ensured that the `gr.3DModel` does re-render prematurely.
Thanks [@pngwn](https://github.com/pngwn)!
### Features
- [#5215](https://github.com/gradio-app/gradio/pull/5215) [`fbdad78a`](https://github.com/gradio-app/gradio/commit/fbdad78af4c47454cbb570f88cc14bf4479bbceb) - Lazy load interactive or static variants of a component individually, rather than loading both variants regardless. This change will improve performance for many applications. Thanks [@pngwn](https://github.com/pngwn)!
- [#5112](https://github.com/gradio-app/gradio/pull/5112) [`1cefee7f`](https://github.com/gradio-app/gradio/commit/1cefee7fc05175aca23ba04b3a3fda7b97f49bf0) - chore(deps): update dependency marked to v7. Thanks [@renovate](https://github.com/apps/renovate)!
- [#5258](https://github.com/gradio-app/gradio/pull/5258) [`92282cea`](https://github.com/gradio-app/gradio/commit/92282cea6afdf7e9930ece1046d8a63be34b3cea) - Chatbot Avatar Images. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
### Fixes
- [#5242](https://github.com/gradio-app/gradio/pull/5242) [`2b397791`](https://github.com/gradio-app/gradio/commit/2b397791fe2059e4beb72937ff0436f2d4d28b4b) - Fix message text overflow onto copy button in `gr.Chatbot`. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#5285](https://github.com/gradio-app/gradio/pull/5285) [`cdfd4217`](https://github.com/gradio-app/gradio/commit/cdfd42174a9c777eaee9c1209bf8e90d8c7791f2) - Tweaks to `icon` parameter in `gr.Button()`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5122](https://github.com/gradio-app/gradio/pull/5122) [`3b805346`](https://github.com/gradio-app/gradio/commit/3b8053469aca6c7a86a6731e641e4400fc34d7d3) - Allows code block in chatbot to scroll horizontally. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
## 0.1.0
### Features
- [#5125](https://github.com/gradio-app/gradio/pull/5125) [`80be7a1c`](https://github.com/gradio-app/gradio/commit/80be7a1ca44c0adef1668367b2cf36b65e52e576) - chatbot conversation nodes can contain a copy button. Thanks [@fazpu](https://github.com/fazpu)!
- [#5137](https://github.com/gradio-app/gradio/pull/5137) [`22aa5eba`](https://github.com/gradio-app/gradio/commit/22aa5eba3fee3f14473e4b0fac29cf72fe31ef04) - Use font size `--text-md` for `<code>` in Chatbot messages. Thanks [@jaywonchung](https://github.com/jaywonchung)!
## 0.0.2
### Patch Changes
- Updated dependencies [[`41c83070`](https://github.com/gradio-app/gradio/commit/41c83070b01632084e7d29123048a96c1e261407)]:
- @gradio/theme@0.0.2
- @gradio/utils@0.0.2
- @gradio/atoms@0.0.2
- @gradio/upload@0.0.2
|
gradio-app/gradio/blob/main/js/chatbot/CHANGELOG.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Transformer2D
A Transformer model for image-like data from [CompVis](https://huggingface.co/CompVis) that is based on the [Vision Transformer](https://huggingface.co/papers/2010.11929) introduced by Dosovitskiy et al. The [`Transformer2DModel`] accepts discrete (classes of vector embeddings) or continuous (actual embeddings) inputs.
When the input is **continuous**:
1. Project the input and reshape it to `(batch_size, sequence_length, feature_dimension)`.
2. Apply the Transformer blocks in the standard way.
3. Reshape to image.
When the input is **discrete**:
<Tip>
It is assumed one of the input classes is the masked latent pixel. The predicted classes of the unnoised image don't contain a prediction for the masked pixel because the unnoised image cannot be masked.
</Tip>
1. Convert input (classes of latent pixels) to embeddings and apply positional embeddings.
2. Apply the Transformer blocks in the standard way.
3. Predict classes of unnoised image.
## Transformer2DModel
[[autodoc]] Transformer2DModel
## Transformer2DModelOutput
[[autodoc]] models.transformer_2d.Transformer2DModelOutput
|
huggingface/diffusers/blob/main/docs/source/en/api/models/transformer2d.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Fully Sharded Data Parallel
[Fully Sharded Data Parallel (FSDP)](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/) is a data parallel method that shards a model's parameters, gradients and optimizer states across the number of available GPUs (also called workers or *rank*). Unlike [DistributedDataParallel (DDP)](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html), FSDP reduces memory-usage because a model is replicated on each GPU. This improves GPU memory-efficiency and allows you to train much larger models on fewer GPUs. FSDP is integrated with the Accelerate, a library for easily managing training in distributed environments, which means it is available for use from the [`Trainer`] class.
Before you start, make sure Accelerate is installed and at least PyTorch 2.1.0 or newer.
```bash
pip install accelerate
```
## FSDP configuration
To start, run the [`accelerate config`](https://huggingface.co/docs/accelerate/package_reference/cli#accelerate-config) command to create a configuration file for your training environment. Accelerate uses this configuration file to automatically setup the correct training environment based on your selected training options in `accelerate config`.
```bash
accelerate config
```
When you run `accelerate config`, you'll be prompted with a series of options to configure your training environment. This section covers some of the most important FSDP options. To learn more about the other available FSDP options, take a look at the [fsdp_config](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments.fsdp_config) parameters.
### Sharding strategy
FSDP offers a number of sharding strategies to select from:
* `FULL_SHARD` - shards model parameters, gradients and optimizer states across workers; select `1` for this option
* `SHARD_GRAD_OP`- shard gradients and optimizer states across workers; select `2` for this option
* `NO_SHARD` - don't shard anything (this is equivalent to DDP); select `3` for this option
* `HYBRID_SHARD` - shard model parameters, gradients and optimizer states within each worker where each worker also has a full copy; select `4` for this option
* `HYBRID_SHARD_ZERO2` - shard gradients and optimizer states within each worker where each worker also has a full copy; select `5` for this option
This is enabled by the `fsdp_sharding_strategy` flag.
### CPU offload
You could also offload parameters and gradients when they are not in use to the CPU to save even more GPU memory and help you fit large models where even FSDP may not be sufficient. This is enabled by setting `fsdp_offload_params: true` when running `accelerate config`.
### Wrapping policy
FSDP is applied by wrapping each layer in the network. The wrapping is usually applied in a nested way where the full weights are discarded after each forward pass to save memory for use in the next layer. The *auto wrapping* policy is the simplest way to implement this and you don't need to change any code. You should select `fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP` to wrap a Transformer layer and `fsdp_transformer_layer_cls_to_wrap` to specify which layer to wrap (for example `BertLayer`).
Otherwise, you can choose a size-based wrapping policy where FSDP is applied to a layer if it exceeds a certain number of parameters. This is enabled by setting `fsdp_wrap_policy: SIZE_BASED_WRAP` and `min_num_param` to the desired size threshold.
### Checkpointing
Intermediate checkpoints should be saved with `fsdp_state_dict_type: SHARDED_STATE_DICT` because saving the full state dict with CPU offloading on rank 0 takes a lot of time and often results in `NCCL Timeout` errors due to indefinite hanging during broadcasting. You can resume training with the sharded state dicts with the [`~accelerate.Accelerator.load_state`]` method.
```py
# directory containing checkpoints
accelerator.load_state("ckpt")
```
However, when training ends, you want to save the full state dict because sharded state dict is only compatible with FSDP.
```py
if trainer.is_fsdp_enabled:
trainer.accelerator.state.fsdp_plugin.set_state_dict_type("FULL_STATE_DICT")
trainer.save_model(script_args.output_dir)
```
### TPU
[PyTorch XLA](https://pytorch.org/xla/release/2.1/index.html) supports FSDP training for TPUs and it can be enabled by modifying the FSDP configuration file generated by `accelerate config`. In addition to the sharding strategies and wrapping options specified above, you can add the parameters shown below to the file.
```yaml
xla: True # must be set to True to enable PyTorch/XLA
xla_fsdp_settings: # XLA-specific FSDP parameters
xla_fsdp_grad_ckpt: True # use gradient checkpointing
```
The [`xla_fsdp_settings`](https://github.com/pytorch/xla/blob/2e6e183e0724818f137c8135b34ef273dea33318/torch_xla/distributed/fsdp/xla_fully_sharded_data_parallel.py#L128) allow you to configure additional XLA-specific parameters for FSDP.
## Launch training
An example FSDP configuration file may look like:
```yaml
compute_environment: LOCAL_MACHINE
debug: false
distributed_type: FSDP
downcast_bf16: 'no'
fsdp_config:
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_backward_prefetch_policy: BACKWARD_PRE
fsdp_cpu_ram_efficient_loading: true
fsdp_forward_prefetch: false
fsdp_offload_params: true
fsdp_sharding_strategy: 1
fsdp_state_dict_type: SHARDED_STATE_DICT
fsdp_sync_module_states: true
fsdp_transformer_layer_cls_to_wrap: BertLayer
fsdp_use_orig_params: true
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
To launch training, run the [`accelerate launch`](https://huggingface.co/docs/accelerate/package_reference/cli#accelerate-launch) command and it'll automatically use the configuration file you previously created with `accelerate config`.
```bash
accelerate launch my-trainer-script.py
```
```bash
accelerate launch --fsdp="full shard" --fsdp_config="path/to/fsdp_config/ my-trainer-script.py
```
## Next steps
FSDP can be a powerful tool for training really large models and you have access to more than one GPU or TPU. By sharding the model parameters, optimizer and gradient states, and even offloading them to the CPU when they're inactive, FSDP can reduce the high cost of large-scale training. If you're interested in learning more, the following may be helpful:
* Follow along with the more in-depth Accelerate guide for [FSDP](https://huggingface.co/docs/accelerate/usage_guides/fsdp).
* Read the [Introducing PyTorch Fully Sharded Data Parallel (FSDP) API](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/) blog post.
* Read the [Scaling PyTorch models on Cloud TPUs with FSDP](https://pytorch.org/blog/scaling-pytorch-models-on-cloud-tpus-with-fsdp/) blog post.
|
huggingface/transformers/blob/main/docs/source/en/fsdp.md
|
@gradio/button
## 0.2.13
### Patch Changes
- Updated dependencies [[`828fb9e`](https://github.com/gradio-app/gradio/commit/828fb9e6ce15b6ea08318675a2361117596a1b5d), [`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144)]:
- @gradio/client@0.9.3
- @gradio/upload@0.5.6
## 0.2.12
### Patch Changes
- Updated dependencies [[`245d58e`](https://github.com/gradio-app/gradio/commit/245d58eff788e8d44a59d37a2d9b26d0f08a62b4)]:
- @gradio/client@0.9.2
- @gradio/upload@0.5.5
## 0.2.11
### Patch Changes
- Updated dependencies [[`5d51fbc`](https://github.com/gradio-app/gradio/commit/5d51fbce7826da840a2fd4940feb5d9ad6f1bc5a), [`34f9431`](https://github.com/gradio-app/gradio/commit/34f943101bf7dd6b8a8974a6131c1ed7c4a0dac0)]:
- @gradio/upload@0.5.4
- @gradio/client@0.9.1
## 0.2.10
### Patch Changes
- Updated dependencies [[`6a9151d`](https://github.com/gradio-app/gradio/commit/6a9151d5c9432c724098da7d88a539aaaf5ffe88), [`d76bcaa`](https://github.com/gradio-app/gradio/commit/d76bcaaaf0734aaf49a680f94ea9d4d22a602e70), [`67ddd40`](https://github.com/gradio-app/gradio/commit/67ddd40b4b70d3a37cb1637c33620f8d197dbee0)]:
- @gradio/upload@0.5.3
- @gradio/client@0.9.0
## 0.2.9
### Patch Changes
- Updated dependencies []:
- @gradio/upload@0.5.2
## 0.2.8
### Patch Changes
- Updated dependencies [[`71f1a1f99`](https://github.com/gradio-app/gradio/commit/71f1a1f9931489d465c2c1302a5c8d768a3cd23a)]:
- @gradio/client@0.8.2
- @gradio/upload@0.5.1
## 0.2.7
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/upload@0.5.0
## 0.2.6
### Patch Changes
- Updated dependencies [[`2f805a7dd`](https://github.com/gradio-app/gradio/commit/2f805a7dd3d2b64b098f659dadd5d01258290521)]:
- @gradio/upload@0.4.2
## 0.2.5
### Patch Changes
- Updated dependencies [[`324867f63`](https://github.com/gradio-app/gradio/commit/324867f63c920113d89a565892aa596cf8b1e486)]:
- @gradio/client@0.8.1
- @gradio/upload@0.4.1
## 0.2.4
### Patch Changes
- Updated dependencies [[`854b482f5`](https://github.com/gradio-app/gradio/commit/854b482f598e0dc47673846631643c079576da9c), [`f1409f95e`](https://github.com/gradio-app/gradio/commit/f1409f95ed39c5565bed6a601e41f94e30196a57)]:
- @gradio/upload@0.4.0
- @gradio/client@0.8.0
## 0.2.3
### Patch Changes
- Updated dependencies [[`bca6c2c80`](https://github.com/gradio-app/gradio/commit/bca6c2c80f7e5062427019de45c282238388af95), [`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780)]:
- @gradio/client@0.7.2
- @gradio/upload@0.3.3
## 0.2.2
### Patch Changes
- Updated dependencies [[`aaa55ce85`](https://github.com/gradio-app/gradio/commit/aaa55ce85e12f95aba9299445e9c5e59824da18e)]:
- @gradio/upload@0.3.2
## 0.2.1
### Patch Changes
- Updated dependencies [[`2ba14b284`](https://github.com/gradio-app/gradio/commit/2ba14b284f908aa13859f4337167a157075a68eb)]:
- @gradio/client@0.7.1
- @gradio/upload@0.3.1
## 0.2.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - fix circular dependency with client + upload. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Clean root url. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
## 0.2.0-beta.7
### Features
- [#6143](https://github.com/gradio-app/gradio/pull/6143) [`e4f7b4b40`](https://github.com/gradio-app/gradio/commit/e4f7b4b409323b01aa01b39e15ce6139e29aa073) - fix circular dependency with client + upload. Thanks [@pngwn](https://github.com/pngwn)!
- [#6136](https://github.com/gradio-app/gradio/pull/6136) [`667802a6c`](https://github.com/gradio-app/gradio/commit/667802a6cdbfb2ce454a3be5a78e0990b194548a) - JS Component Documentation. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6149](https://github.com/gradio-app/gradio/pull/6149) [`90318b1dd`](https://github.com/gradio-app/gradio/commit/90318b1dd118ae08a695a50e7c556226234ab6dc) - swap `mode` on the frontned to `interactive` to match the backend. Thanks [@pngwn](https://github.com/pngwn)!
## 0.2.0-beta.6
### Fixes
- [#6046](https://github.com/gradio-app/gradio/pull/6046) [`dbb7de5e0`](https://github.com/gradio-app/gradio/commit/dbb7de5e02c53fee05889d696d764d212cb96c74) - fix tests. Thanks [@pngwn](https://github.com/pngwn)!
## 0.2.0-beta.5
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.2.3
### Patch Changes
- Updated dependencies []:
- @gradio/upload@0.3.3
## 0.2.2
### Patch Changes
- Updated dependencies []:
- @gradio/utils@0.1.2
- @gradio/upload@0.3.2
## 0.2.1
### Patch Changes
- Updated dependencies []:
- @gradio/upload@0.3.1
## 0.2.0
### Features
- [#5554](https://github.com/gradio-app/gradio/pull/5554) [`75ddeb390`](https://github.com/gradio-app/gradio/commit/75ddeb390d665d4484667390a97442081b49a423) - Accessibility Improvements. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.1.3
### Patch Changes
- Updated dependencies []:
- @gradio/utils@0.1.1
- @gradio/upload@0.2.1
## 0.1.2
### Patch Changes
- Updated dependencies [[`abf1c57d`](https://github.com/gradio-app/gradio/commit/abf1c57d7d85de0df233ee3b38aeb38b638477db), [`79d8f9d8`](https://github.com/gradio-app/gradio/commit/79d8f9d891901683c5a1b7486efb44eab2478c96)]:
- @gradio/utils@0.1.0
- @gradio/upload@0.2.0
## 0.1.1
### Highlights
#### Improve startup performance and markdown support ([#5279](https://github.com/gradio-app/gradio/pull/5279) [`fe057300`](https://github.com/gradio-app/gradio/commit/fe057300f0672c62dab9d9b4501054ac5d45a4ec))
##### Improved markdown support
We now have better support for markdown in `gr.Markdown` and `gr.Dataframe`. Including syntax highlighting and Github Flavoured Markdown. We also have more consistent markdown behaviour and styling.
##### Various performance improvements
These improvements will be particularly beneficial to large applications.
- Rather than attaching events manually, they are now delegated, leading to a significant performance improvement and addressing a performance regression introduced in a recent version of Gradio. App startup for large applications is now around twice as fast.
- Optimised the mounting of individual components, leading to a modest performance improvement during startup (~30%).
- Corrected an issue that was causing markdown to re-render infinitely.
- Ensured that the `gr.3DModel` does re-render prematurely.
Thanks [@pngwn](https://github.com/pngwn)!
### Fixes
- [#5285](https://github.com/gradio-app/gradio/pull/5285) [`cdfd4217`](https://github.com/gradio-app/gradio/commit/cdfd42174a9c777eaee9c1209bf8e90d8c7791f2) - Tweaks to `icon` parameter in `gr.Button()`. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.1.0
### Features
- [#5080](https://github.com/gradio-app/gradio/pull/5080) [`37caa2e0`](https://github.com/gradio-app/gradio/commit/37caa2e0fe95d6cab8beb174580fb557904f137f) - Add icon and link params to `gr.Button`. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.0.2
### Patch Changes
- Updated dependencies []:
- @gradio/utils@0.0.2
|
gradio-app/gradio/blob/main/js/button/CHANGELOG.md
|
Gradio Demo: dataframe_colorful
```
!pip install -q gradio
```
```
import pandas as pd
import gradio as gr
df = pd.DataFrame({"A" : [14, 4, 5, 4, 1],
"B" : [5, 2, 54, 3, 2],
"C" : [20, 20, 7, 3, 8],
"D" : [14, 3, 6, 2, 6],
"E" : [23, 45, 64, 32, 23]})
t = df.style.highlight_max(color = 'lightgreen', axis = 0)
with gr.Blocks() as demo:
gr.Dataframe(t)
if __name__ == "__main__":
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/dataframe_colorful/run.ipynb
|
How to Style the Gradio Dataframe
Tags: DATAFRAME, STYLE, COLOR
## Introduction
Data visualization is a crucial aspect of data analysis and machine learning. The Gradio `DataFrame` component is a popular way to display tabular data (particularly data in the form of a `pandas` `DataFrame` object) within a web application.
This post will explore the recent enhancements in Gradio that allow users to integrate the styling options of pandas, e.g. adding colors to the DataFrame component, or setting the display precision of numbers.
Let's dive in!
**Prerequisites**: We'll be using the `gradio.Blocks` class in our examples.
You can [read the Guide to Blocks first](https://gradio.app/quickstart/#blocks-more-flexibility-and-control) if you are not already familiar with it. Also please make sure you are using the **latest version** version of Gradio: `pip install --upgrade gradio`.
## Overview
The Gradio `DataFrame` component now supports values of the type `Styler` from the `pandas` class. This allows us to reuse the rich existing API and documentation of the `Styler` class instead of inventing a new style format on our own. Here's a complete example of how it looks:
```python
import pandas as pd
import gradio as gr
# Creating a sample dataframe
df = pd.DataFrame({
"A" : [14, 4, 5, 4, 1],
"B" : [5, 2, 54, 3, 2],
"C" : [20, 20, 7, 3, 8],
"D" : [14, 3, 6, 2, 6],
"E" : [23, 45, 64, 32, 23]
})
# Applying style to highlight the maximum value in each row
styler = df.style.highlight_max(color = 'lightgreen', axis = 0)
# Displaying the styled dataframe in Gradio
with gr.Blocks() as demo:
gr.DataFrame(styler)
demo.launch()
```
The Styler class can be used to apply conditional formatting and styling to dataframes, making them more visually appealing and interpretable. You can highlight certain values, apply gradients, or even use custom CSS to style the DataFrame. The Styler object is applied to a DataFrame and it returns a new object with the relevant styling properties, which can then be previewed directly, or rendered dynamically in a Gradio interface.
To read more about the Styler object, read the official `pandas` documentation at: https://pandas.pydata.org/docs/user_guide/style.html
Below, we'll explore a few examples:
## Highlighting Cells
Ok, so let's revisit the previous example. We start by creating a `pd.DataFrame` object and then highlight the highest value in each row with a light green color:
```python
import pandas as pd
# Creating a sample dataframe
df = pd.DataFrame({
"A" : [14, 4, 5, 4, 1],
"B" : [5, 2, 54, 3, 2],
"C" : [20, 20, 7, 3, 8],
"D" : [14, 3, 6, 2, 6],
"E" : [23, 45, 64, 32, 23]
})
# Applying style to highlight the maximum value in each row
styler = df.style.highlight_max(color = 'lightgreen', axis = 0)
```
Now, we simply pass this object into the Gradio `DataFrame` and we can visualize our colorful table of data in 4 lines of python:
```python
import gradio as gr
with gr.Blocks() as demo:
gr.Dataframe(styler)
demo.launch()
```
Here's how it looks:

## Font Colors
Apart from highlighting cells, you might want to color specific text within the cells. Here's how you can change text colors for certain columns:
```python
import pandas as pd
import gradio as gr
# Creating a sample dataframe
df = pd.DataFrame({
"A" : [14, 4, 5, 4, 1],
"B" : [5, 2, 54, 3, 2],
"C" : [20, 20, 7, 3, 8],
"D" : [14, 3, 6, 2, 6],
"E" : [23, 45, 64, 32, 23]
})
# Function to apply text color
def highlight_cols(x):
df = x.copy()
df.loc[:, :] = 'color: purple'
df[['B', 'C', 'E']] = 'color: green'
return df
# Applying the style function
s = df.style.apply(highlight_cols, axis = None)
# Displaying the styled dataframe in Gradio
with gr.Blocks() as demo:
gr.DataFrame(s)
demo.launch()
```
In this script, we define a custom function highlight_cols that changes the text color to purple for all cells, but overrides this for columns B, C, and E with green. Here's how it looks:
## Display Precision
Sometimes, the data you are dealing with might have long floating numbers, and you may want to display only a fixed number of decimals for simplicity. The pandas Styler object allows you to format the precision of numbers displayed. Here's how you can do this:
```python
import pandas as pd
import gradio as gr
# Creating a sample dataframe with floating numbers
df = pd.DataFrame({
"A" : [14.12345, 4.23456, 5.34567, 4.45678, 1.56789],
"B" : [5.67891, 2.78912, 54.89123, 3.91234, 2.12345],
# ... other columns
})
# Setting the precision of numbers to 2 decimal places
s = df.style.format("{:.2f}")
# Displaying the styled dataframe in Gradio
with gr.Blocks() as demo:
gr.DataFrame(s)
demo.launch()
```
In this script, the format method of the Styler object is used to set the precision of numbers to two decimal places. Much cleaner now:
## Note about Interactivity
One thing to keep in mind is that the gradio `DataFrame` component only accepts `Styler` objects when it is non-interactive (i.e. in "static" mode). If the `DataFrame` component is interactive, then the styling information is ignored and instead the raw table values are shown instead.
The `DataFrame` component is by default non-interactive, unless it is used as an input to an event. In which case, you can force the component to be non-interactive by setting the `interactive` prop like this:
```python
c = gr.DataFrame(styler, interactive=False)
```
## Conclusion 🎉
This is just a taste of what's possible using the `gradio.DataFrame` component with the `Styler` class from `pandas`. Try it out and let us know what you think!
|
gradio-app/gradio/blob/main/guides/07_tabular-data-science-and-plots/styling-the-gradio-dataframe.md
|
Testing new Hugging Face Deep Learning Container.
This document explains the testing strategy for releasing the new Hugging Face Deep Learning Container. AWS maintains 14 days of currency with framework releases. Besides framework releases, AWS release train is bi-weekly on Monday. Code cutoff date for any changes is the Wednesday before release-Monday.
## Test Case 1: Releasing a New Version (Minor/Major) of 🤗 Transformers
### Requirements: Test should run on Release Candidate for new `transformers` release to validate the new release is compatible with the DLCs. To run these tests you need credentials for the HF SageMaker AWS Account. You can ask @philschmid or @n1t0 to get access.
### Run Tests:
Before we can run the tests we need to adjust the `requirements.txt` for PyTorch under `/tests/sagemaker/scripts/pytorch` and for TensorFlow under `/tests/sagemaker/scripts/pytorch`. We adjust the branch to the new RC-tag.
```
git+https://github.com/huggingface/transformers.git@v4.5.0.rc0 # install main or adjust ist with vX.X.X for installing version specific-transforms
```
After we adjusted the `requirements.txt` we can run Amazon SageMaker tests with:
```bash
AWS_PROFILE=<enter-your-profile> make test-sagemaker
```
These tests take around 10-15 minutes to finish. Preferably make a screenshot of the successfully ran tests.
### After Transformers Release:
After we have released the Release Candidate we need to create a PR at the [Deep Learning Container Repository](https://github.com/aws/deep-learning-containers).
**Creating the update PR:**
1. Update the two latest `buildspec.yaml` config for [PyTorch](https://github.com/aws/deep-learning-containers/tree/master/huggingface/pytorch) and [TensorFlow](https://github.com/aws/deep-learning-containers/tree/master/huggingface/tensorflow). The two latest `buildspec.yaml` are the `buildspec.yaml` without a version tag and the one with the highest framework version, e.g. `buildspec-1-7-1.yml` and not `buildspec-1-6.yml`.
To update the `buildspec.yaml` we need to adjust either the `transformers_version` or the `datasets_version` or both. Example for upgrading to `transformers 4.5.0` and `datasets 1.6.0`.
```yaml
account_id: &ACCOUNT_ID <set-$ACCOUNT_ID-in-environment>
region: ®ION <set-$REGION-in-environment>
base_framework: &BASE_FRAMEWORK pytorch
framework: &FRAMEWORK !join [ "huggingface_", *BASE_FRAMEWORK]
version: &VERSION 1.6.0
short_version: &SHORT_VERSION 1.6
repository_info:
training_repository: &TRAINING_REPOSITORY
image_type: &TRAINING_IMAGE_TYPE training
root: !join [ "huggingface/", *BASE_FRAMEWORK, "/", *TRAINING_IMAGE_TYPE ]
repository_name: &REPOSITORY_NAME !join ["pr", "-", "huggingface", "-", *BASE_FRAMEWORK, "-", *TRAINING_IMAGE_TYPE]
repository: &REPOSITORY !join [ *ACCOUNT_ID, .dkr.ecr., *REGION, .amazonaws.com/,
*REPOSITORY_NAME ]
images:
BuildHuggingFacePytorchGpuPy37Cu110TrainingDockerImage:
<<: *TRAINING_REPOSITORY
build: &HUGGINGFACE_PYTORCH_GPU_TRAINING_PY3 false
image_size_baseline: &IMAGE_SIZE_BASELINE 15000
device_type: &DEVICE_TYPE gpu
python_version: &DOCKER_PYTHON_VERSION py3
tag_python_version: &TAG_PYTHON_VERSION py36
cuda_version: &CUDA_VERSION cu110
os_version: &OS_VERSION ubuntu18.04
transformers_version: &TRANSFORMERS_VERSION 4.5.0 # this was adjusted from 4.4.2 to 4.5.0
datasets_version: &DATASETS_VERSION 1.6.0 # this was adjusted from 1.5.0 to 1.6.0
tag: !join [ *VERSION, '-', 'transformers', *TRANSFORMERS_VERSION, '-', *DEVICE_TYPE, '-', *TAG_PYTHON_VERSION, '-',
*CUDA_VERSION, '-', *OS_VERSION ]
docker_file: !join [ docker/, *SHORT_VERSION, /, *DOCKER_PYTHON_VERSION, /,
*CUDA_VERSION, /Dockerfile., *DEVICE_TYPE ]
```
2. In the PR comment describe what test, we ran and with which package versions. Here you can copy the table from [Current Tests](#current-tests).
2. In the PR comment describe what test we ran and with which framework versions. Here you can copy the table from [Current Tests](#current-tests). You can take a look at this [PR](https://github.com/aws/deep-learning-containers/pull/1016), which information are needed.
## Test Case 2: Releasing a New AWS Framework DLC
## Execute Tests
### Requirements:
AWS is going to release new DLCs for PyTorch and/or TensorFlow. The Tests should run on the new framework versions with current `transformers` release to validate the new framework release is compatible with the `transformers` version. To run these tests you need credentials for the HF SageMaker AWS Account. You can ask @philschmid or @n1t0 to get access. AWS will notify us with a new issue in the repository pointing to their framework upgrade PR.
### Run Tests:
Before we can run the tests we need to adjust the `requirements.txt` for Pytorch under `/tests/sagemaker/scripts/pytorch` and for Tensorflow under `/tests/sagemaker/scripts/pytorch`. We add the new framework version to it.
```
torch==1.8.1 # for pytorch
tensorflow-gpu==2.5.0 # for tensorflow
```
After we adjusted the `requirements.txt` we can run Amazon SageMaker tests with.
```bash
AWS_PROFILE=<enter-your-profile> make test-sagemaker
```
These tests take around 10-15 minutes to finish. Preferably make a screenshot of the successfully ran tests.
### After successful Tests:
After we have successfully run tests for the new framework version we need to create a PR at the [Deep Learning Container Repository](https://github.com/aws/deep-learning-containers).
**Creating the update PR:**
1. Create a new `buildspec.yaml` config for [PyTorch](https://github.com/aws/deep-learning-containers/tree/master/huggingface/pytorch) and [TensorFlow](https://github.com/aws/deep-learning-containers/tree/master/huggingface/tensorflow) and rename the old `buildspec.yaml` to `buildespec-x.x.x`, where `x.x.x` is the base framework version, e.g. if pytorch 1.6.0 is the latest version in `buildspec.yaml` the file should be renamed to `buildspec-yaml-1-6.yaml`.
To create the new `buildspec.yaml` we need to adjust the `version` and the `short_version`. Example for upgrading to `pytorch 1.7.1`.
```yaml
account_id: &ACCOUNT_ID <set-$ACCOUNT_ID-in-environment>
region: ®ION <set-$REGION-in-environment>
base_framework: &BASE_FRAMEWORK pytorch
framework: &FRAMEWORK !join [ "huggingface_", *BASE_FRAMEWORK]
version: &VERSION 1.7.1 # this was adjusted from 1.6.0 to 1.7.1
short_version: &SHORT_VERSION 1.7 # this was adjusted from 1.6 to 1.7
repository_info:
training_repository: &TRAINING_REPOSITORY
image_type: &TRAINING_IMAGE_TYPE training
root: !join [ "huggingface/", *BASE_FRAMEWORK, "/", *TRAINING_IMAGE_TYPE ]
repository_name: &REPOSITORY_NAME !join ["pr", "-", "huggingface", "-", *BASE_FRAMEWORK, "-", *TRAINING_IMAGE_TYPE]
repository: &REPOSITORY !join [ *ACCOUNT_ID, .dkr.ecr., *REGION, .amazonaws.com/,
*REPOSITORY_NAME ]
images:
BuildHuggingFacePytorchGpuPy37Cu110TrainingDockerImage:
<<: *TRAINING_REPOSITORY
build: &HUGGINGFACE_PYTORCH_GPU_TRAINING_PY3 false
image_size_baseline: &IMAGE_SIZE_BASELINE 15000
device_type: &DEVICE_TYPE gpu
python_version: &DOCKER_PYTHON_VERSION py3
tag_python_version: &TAG_PYTHON_VERSION py36
cuda_version: &CUDA_VERSION cu110
os_version: &OS_VERSION ubuntu18.04
transformers_version: &TRANSFORMERS_VERSION 4.4.2
datasets_version: &DATASETS_VERSION 1.5.0
tag: !join [ *VERSION, '-', 'transformers', *TRANSFORMERS_VERSION, '-', *DEVICE_TYPE, '-', *TAG_PYTHON_VERSION, '-',
*CUDA_VERSION, '-', *OS_VERSION ]
docker_file: !join [ docker/, *SHORT_VERSION, /, *DOCKER_PYTHON_VERSION, /,
*CUDA_VERSION, /Dockerfile., *DEVICE_TYPE ]
```
2. In the PR comment describe what test we ran and with which framework versions. Here you can copy the table from [Current Tests](#current-tests). You can take a look at this [PR](https://github.com/aws/deep-learning-containers/pull/1025), which information are needed.
## Current Tests
| ID | Description | Platform | #GPUS | Collected & evaluated metrics |
|-------------------------------------|-------------------------------------------------------------------|-----------------------------|-------|------------------------------------------|
| pytorch-transfromers-test-single | test bert finetuning using BERT fromtransformerlib+PT | SageMaker createTrainingJob | 1 | train_runtime, eval_accuracy & eval_loss |
| pytorch-transfromers-test-2-ddp | test bert finetuning using BERT from transformer lib+ PT DPP | SageMaker createTrainingJob | 16 | train_runtime, eval_accuracy & eval_loss |
| pytorch-transfromers-test-2-smd | test bert finetuning using BERT from transformer lib+ PT SM DDP | SageMaker createTrainingJob | 16 | train_runtime, eval_accuracy & eval_loss |
| pytorch-transfromers-test-1-smp | test roberta finetuning using BERT from transformer lib+ PT SM MP | SageMaker createTrainingJob | 8 | train_runtime, eval_accuracy & eval_loss |
| tensorflow-transfromers-test-single | Test bert finetuning using BERT from transformer lib+TF | SageMaker createTrainingJob | 1 | train_runtime, eval_accuracy & eval_loss |
| tensorflow-transfromers-test-2-smd | test bert finetuning using BERT from transformer lib+ TF SM DDP | SageMaker createTrainingJob | 16 | train_runtime, eval_accuracy & eval_loss |
|
huggingface/transformers/blob/main/tests/sagemaker/README.md
|
Custom Python Spaces
<Tip>
Spaces now support arbitrary Dockerfiles so you can host any Python app directly using [Docker Spaces](./spaces-sdks-docker).
</Tip>
While not an official workflow, you are able to run your own Python + interface stack in Spaces by selecting Gradio as your SDK and serving a frontend on port `7680`. See the [templates](https://huggingface.co/templates#spaces) for examples.
Spaces are served in iframes, which by default restrict links from opening in the parent page. The simplest solution is to open them in a new window:
```HTML
<a href="https://hf.space" rel="noopener" target="_blank">Spaces</a>
```
Usually, the height of Spaces is automatically adjusted when using the Gradio library interface. However, if you provide your own frontend in the Gradio SDK and the content height is larger than the viewport, you'll need to add an [iFrame Resizer script](https://cdnjs.com/libraries/iframe-resizer), so the content is scrollable in the iframe:
```HTML
<script src="https://cdnjs.cloudflare.com/ajax/libs/iframe-resizer/4.3.2/iframeResizer.contentWindow.min.js"></script>
```
As an example, here is the same Space with and without the script:
- https://huggingface.co/spaces/ronvolutional/http-server
- https://huggingface.co/spaces/ronvolutional/iframe-test
|
huggingface/hub-docs/blob/main/docs/hub/spaces-sdks-python.md
|
Image Classification with Vision Transformers
Related spaces: https://huggingface.co/spaces/abidlabs/vision-transformer
Tags: VISION, TRANSFORMERS, HUB
## Introduction
Image classification is a central task in computer vision. Building better classifiers to classify what object is present in a picture is an active area of research, as it has applications stretching from facial recognition to manufacturing quality control.
State-of-the-art image classifiers are based on the _transformers_ architectures, originally popularized for NLP tasks. Such architectures are typically called vision transformers (ViT). Such models are perfect to use with Gradio's _image_ input component, so in this tutorial we will build a web demo to classify images using Gradio. We will be able to build the whole web application in a **single line of Python**, and it will look like the demo on the bottom of the page.
Let's get started!
### Prerequisites
Make sure you have the `gradio` Python package already [installed](/getting_started).
## Step 1 — Choosing a Vision Image Classification Model
First, we will need an image classification model. For this tutorial, we will use a model from the [Hugging Face Model Hub](https://huggingface.co/models?pipeline_tag=image-classification). The Hub contains thousands of models covering dozens of different machine learning tasks.
Expand the Tasks category on the left sidebar and select "Image Classification" as our task of interest. You will then see all of the models on the Hub that are designed to classify images.
At the time of writing, the most popular one is `google/vit-base-patch16-224`, which has been trained on ImageNet images at a resolution of 224x224 pixels. We will use this model for our demo.
## Step 2 — Loading the Vision Transformer Model with Gradio
When using a model from the Hugging Face Hub, we do not need to define the input or output components for the demo. Similarly, we do not need to be concerned with the details of preprocessing or postprocessing.
All of these are automatically inferred from the model tags.
Besides the import statement, it only takes a single line of Python to load and launch the demo.
We use the `gr.Interface.load()` method and pass in the path to the model including the `huggingface/` to designate that it is from the Hugging Face Hub.
```python
import gradio as gr
gr.Interface.load(
"huggingface/google/vit-base-patch16-224",
examples=["alligator.jpg", "laptop.jpg"]).launch()
```
Notice that we have added one more parameter, the `examples`, which allows us to prepopulate our interfaces with a few predefined examples.
This produces the following interface, which you can try right here in your browser. When you input an image, it is automatically preprocessed and sent to the Hugging Face Hub API, where it is passed through the model and returned as a human-interpretable prediction. Try uploading your own image!
<gradio-app space="gradio/vision-transformer">
---
And you're done! In one line of code, you have built a web demo for an image classifier. If you'd like to share with others, try setting `share=True` when you `launch()` the Interface!
|
gradio-app/gradio/blob/main/guides/06_integrating-other-frameworks/image-classification-with-vision-transformers.md
|
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Wav2Vec2Phoneme
## Overview
The Wav2Vec2Phoneme model was proposed in [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition (Xu et al.,
2021](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
The abstract from the paper is the following:
*Recent progress in self-training, self-supervised pretraining and unsupervised learning enabled well performing speech
recognition systems without any labeled data. However, in many cases there is labeled data available for related
languages which is not utilized by these methods. This paper extends previous work on zero-shot cross-lingual transfer
learning by fine-tuning a multilingually pretrained wav2vec 2.0 model to transcribe unseen languages. This is done by
mapping phonemes of the training languages to the target language using articulatory features. Experiments show that
this simple method significantly outperforms prior work which introduced task-specific architectures and used only part
of a monolingually pretrained model.*
Relevant checkpoints can be found under https://huggingface.co/models?other=phoneme-recognition.
This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten)
The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
## Usage tips
- Wav2Vec2Phoneme uses the exact same architecture as Wav2Vec2
- Wav2Vec2Phoneme is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
- Wav2Vec2Phoneme model was trained using connectionist temporal classification (CTC) so the model output has to be
decoded using [`Wav2Vec2PhonemeCTCTokenizer`].
- Wav2Vec2Phoneme can be fine-tuned on multiple language at once and decode unseen languages in a single forward pass
to a sequence of phonemes
- By default, the model outputs a sequence of phonemes. In order to transform the phonemes to a sequence of words one
should make use of a dictionary and language model.
<Tip>
Wav2Vec2Phoneme's architecture is based on the Wav2Vec2 model, for API reference, check out [`Wav2Vec2`](wav2vec2)'s documentation page
except for the tokenizer.
</Tip>
## Wav2Vec2PhonemeCTCTokenizer
[[autodoc]] Wav2Vec2PhonemeCTCTokenizer
- __call__
- batch_decode
- decode
- phonemize
|
huggingface/transformers/blob/main/docs/source/en/model_doc/wav2vec2_phoneme.md
|
Gradio Demo: text_generation
### This text generation demo takes in input text and returns generated text. It uses the Transformers library to set up the model and has two examples.
```
!pip install -q gradio git+https://github.com/huggingface/transformers gradio torch
```
```
import gradio as gr
from transformers import pipeline
generator = pipeline('text-generation', model='gpt2')
def generate(text):
result = generator(text, max_length=30, num_return_sequences=1)
return result[0]["generated_text"]
examples = [
["The Moon's orbit around Earth has"],
["The smooth Borealis basin in the Northern Hemisphere covers 40%"],
]
demo = gr.Interface(
fn=generate,
inputs=gr.Textbox(lines=5, label="Input Text"),
outputs=gr.Textbox(label="Generated Text"),
examples=examples
)
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/text_generation/run.ipynb
|
Gradio Demo: diffusers_with_batching
```
!pip install -q gradio torch transformers diffusers
```
```
import torch
from diffusers import DiffusionPipeline
import gradio as gr
generator = DiffusionPipeline.from_pretrained("CompVis/ldm-text2im-large-256")
# move to GPU if available
if torch.cuda.is_available():
generator = generator.to("cuda")
def generate(prompts):
images = generator(list(prompts)).images
return [images]
demo = gr.Interface(generate,
"textbox",
"image",
batch=True,
max_batch_size=4 # Set the batch size based on your CPU/GPU memory
).queue()
if __name__ == "__main__":
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/diffusers_with_batching/run.ipynb
|
Paper Pages
Paper pages allow people to find artifacts related to a paper such as models, datasets and apps/demos (Spaces). Paper pages also enable the community to discuss about the paper.
<div class="flex justify-center">
<img class="block dark:hidden" width="300" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/papers-discussions.png"/>
<img class="hidden dark:block" width="300" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/papers-discussions-dark.png"/>
</div>
## Linking a Paper to a model, dataset or Space
If the repository card (`README.md`) includes a link to a paper on arXiv, the Hugging Face Hub will extract the arXiv ID and include it in the repository's tags. Clicking on the arxiv tag will let you:
* Visit the Paper page.
* Filter for other models or datasets on the Hub that cite the same paper.
<div class="flex justify-center">
<img class="block dark:hidden" width="300" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-arxiv.png"/>
<img class="hidden dark:block" width="300" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-arxiv-dark.png"/>
</div>
## Claiming authorship to a Paper
The Hub will attempt to automatically match paper to users based on their email.
<div class="flex justify-center">
<img class="block dark:hidden" width="300" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/papers-authors.png"/>
<img class="hidden dark:block" width="300" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/papers-authors-dark.png"/>
</div>
If your paper is not linked to your account, you can click in your name in the corresponding Paper page and click "claim authorship". This will automatically re-direct to your paper settings where you can confirm the request. The admin team will validate your request soon. Once confirmed, the Paper page will show as verified.
<div class="flex justify-center">
<img class="block dark:hidden" width="300" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/papers-settings.png"/>
<img class="hidden dark:block" width="300" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/papers-settings-dark.png"/>
</div>
## Frequently Asked Questions
### Can I control which Paper pages show in my profile?
Yes! You can visit your Papers in [settings](https://huggingface.co/settings/papers), where you will see a list of verified papers. There, you can click the "Show on profile" checkbox to hide/show it in your profile.
### Do you support ACL anthology?
We're starting with Arxiv as it accounts for 95% of the paper URLs Hugging Face users have linked in their repos organically. We'll check how this evolve and potentially extend to other paper hosts in the future.
### Can I have a Paper page even if I have no model/dataset/Space?
Yes. You can go to [the main Papers page](https://huggingface.co/papers), click search and write the name of the paper or the full Arxiv id. If the paper does not exist, you will get an option to index it. You can also just visit the page `hf.co/papers/xxxx.yyyyy` replacing with the arxiv id of the paper you wish to index.
|
huggingface/hub-docs/blob/main/docs/hub/paper-pages.md
|
Hands-on [[hands-on]]
<CourseFloatingBanner classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/deep-rl-class/blob/main/notebooks/unit3/unit3.ipynb"}
]}
askForHelpUrl="http://hf.co/join/discord" />
Now that you've studied the theory behind Deep Q-Learning, **you’re ready to train your Deep Q-Learning agent to play Atari Games**. We'll start with Space Invaders, but you'll be able to use any Atari game you want 🔥
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit4/atari-envs.gif" alt="Environments"/>
We're using the [RL-Baselines-3 Zoo integration](https://github.com/DLR-RM/rl-baselines3-zoo), a vanilla version of Deep Q-Learning with no extensions such as Double-DQN, Dueling-DQN, or Prioritized Experience Replay.
Also, **if you want to learn to implement Deep Q-Learning by yourself after this hands-on**, you definitely should look at the CleanRL implementation: https://github.com/vwxyzjn/cleanrl/blob/master/cleanrl/dqn_atari.py
To validate this hands-on for the certification process, you need to push your trained model to the Hub and **get a result of >= 200**.
To find your result, go to the leaderboard and find your model, **the result = mean_reward - std of reward**
**If you don't find your model, go to the bottom of the page and click on the refresh button.**
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
And you can check your progress here 👉 https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
**To start the hands-on click on Open In Colab button** 👇 :
[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit3/unit3.ipynb)
# Unit 3: Deep Q-Learning with Atari Games 👾 using RL Baselines3 Zoo
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit4/thumbnail.jpg" alt="Unit 3 Thumbnail">
In this hands-on, **you'll train a Deep Q-Learning agent** playing Space Invaders using [RL Baselines3 Zoo](https://github.com/DLR-RM/rl-baselines3-zoo), a training framework based on [Stable-Baselines3](https://stable-baselines3.readthedocs.io/en/master/) that provides scripts for training, evaluating agents, tuning hyperparameters, plotting results and recording videos.
We're using the [RL-Baselines-3 Zoo integration, a vanilla version of Deep Q-Learning](https://stable-baselines3.readthedocs.io/en/master/modules/dqn.html) with no extensions such as Double-DQN, Dueling-DQN, and Prioritized Experience Replay.
### 🎮 Environments:
- [SpacesInvadersNoFrameskip-v4](https://gymnasium.farama.org/environments/atari/space_invaders/)
You can see the difference between Space Invaders versions here 👉 https://gymnasium.farama.org/environments/atari/space_invaders/#variants
### 📚 RL-Library:
- [RL-Baselines3-Zoo](https://github.com/DLR-RM/rl-baselines3-zoo)
## Objectives of this hands-on 🏆
At the end of the hands-on, you will:
- Be able to understand deeper **how RL Baselines3 Zoo works**.
- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥.
## Prerequisites 🏗️
Before diving into the hands-on, you need to:
🔲 📚 **[Study Deep Q-Learning by reading Unit 3](https://huggingface.co/deep-rl-course/unit3/introduction)** 🤗
We're constantly trying to improve our tutorials, so **if you find some issues in this hands-on**, please [open an issue on the Github Repo](https://github.com/huggingface/deep-rl-class/issues).
# Let's train a Deep Q-Learning agent playing Atari' Space Invaders 👾 and upload it to the Hub.
We strongly recommend students **to use Google Colab for the hands-on exercises instead of running them on their personal computers**.
By using Google Colab, **you can focus on learning and experimenting without worrying about the technical aspects of setting up your environments**.
To validate this hands-on for the certification process, you need to push your trained model to the Hub and **get a result of >= 200**.
To find your result, go to the leaderboard and find your model, **the result = mean_reward - std of reward**
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
## Set the GPU 💪
- To **accelerate the agent's training, we'll use a GPU**. To do that, go to `Runtime > Change Runtime type`
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/gpu-step1.jpg" alt="GPU Step 1">
- `Hardware Accelerator > GPU`
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/gpu-step2.jpg" alt="GPU Step 2">
# Install RL-Baselines3 Zoo and its dependencies 📚
If you see `ERROR: pip's dependency resolver does not currently take into account all the packages that are installed.` **this is normal and it's not a critical error** there's a conflict of version. But the packages we need are installed.
```python
# For now we install this update of RL-Baselines3 Zoo
pip install git+https://github.com/DLR-RM/rl-baselines3-zoo@update/hf
```
IF AND ONLY IF THE VERSION ABOVE DOES NOT EXIST ANYMORE. UNCOMMENT AND INSTALL THE ONE BELOW
```python
#pip install rl_zoo3==2.0.0a9
```
```bash
apt-get install swig cmake ffmpeg
```
To be able to use Atari games in Gymnasium we need to install atari package. And accept-rom-license to download the rom files (games files).
```python
!pip install gymnasium[atari]
!pip install gymnasium[accept-rom-license]
```
## Create a virtual display 🔽
During the hands-on, we'll need to generate a replay video. To do so, if you train it on a headless machine, **we need to have a virtual screen to be able to render the environment** (and thus record the frames).
Hence the following cell will install the librairies and create and run a virtual screen 🖥
```bash
apt install python-opengl
apt install ffmpeg
apt install xvfb
pip3 install pyvirtualdisplay
```
```python
# Virtual display
from pyvirtualdisplay import Display
virtual_display = Display(visible=0, size=(1400, 900))
virtual_display.start()
```
## Train our Deep Q-Learning Agent to Play Space Invaders 👾
To train an agent with RL-Baselines3-Zoo, we just need to do two things:
1. Create a hyperparameter config file that will contain our training hyperparameters called `dqn.yml`.
This is a template example:
```
SpaceInvadersNoFrameskip-v4:
env_wrapper:
- stable_baselines3.common.atari_wrappers.AtariWrapper
frame_stack: 4
policy: 'CnnPolicy'
n_timesteps: !!float 1e7
buffer_size: 100000
learning_rate: !!float 1e-4
batch_size: 32
learning_starts: 100000
target_update_interval: 1000
train_freq: 4
gradient_steps: 1
exploration_fraction: 0.1
exploration_final_eps: 0.01
# If True, you need to deactivate handle_timeout_termination
# in the replay_buffer_kwargs
optimize_memory_usage: False
```
Here we see that:
- We use the `Atari Wrapper` that preprocess the input (Frame reduction ,grayscale, stack 4 frames)
- We use `CnnPolicy`, since we use Convolutional layers to process the frames
- We train it for 10 million `n_timesteps`
- Memory (Experience Replay) size is 100000, aka the amount of experience steps you saved to train again your agent with.
💡 My advice is to **reduce the training timesteps to 1M,** which will take about 90 minutes on a P100. `!nvidia-smi` will tell you what GPU you're using. At 10 million steps, this will take about 9 hours. I recommend running this on your local computer (or somewhere else). Just click on: `File>Download`.
In terms of hyperparameters optimization, my advice is to focus on these 3 hyperparameters:
- `learning_rate`
- `buffer_size (Experience Memory size)`
- `batch_size`
As a good practice, you need to **check the documentation to understand what each hyperparameters does**: https://stable-baselines3.readthedocs.io/en/master/modules/dqn.html#parameters
2. We start the training and save the models on `logs` folder 📁
- Define the algorithm after `--algo`, where we save the model after `-f` and where the hyperparameter config is after `-c`.
```bash
python -m rl_zoo3.train --algo ________ --env SpaceInvadersNoFrameskip-v4 -f _________ -c _________
```
#### Solution
```bash
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -c dqn.yml
```
## Let's evaluate our agent 👀
- RL-Baselines3-Zoo provides `enjoy.py`, a python script to evaluate our agent. In most RL libraries, we call the evaluation script `enjoy.py`.
- Let's evaluate it for 5000 timesteps 🔥
```bash
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 --no-render --n-timesteps _________ --folder logs/
```
#### Solution
```bash
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 --no-render --n-timesteps 5000 --folder logs/
```
## Publish our trained model on the Hub 🚀
Now that we saw we got good results after the training, we can publish our trained model on the hub 🤗 with one line of code.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit3/space-invaders-model.gif" alt="Space Invaders model">
By using `rl_zoo3.push_to_hub` **you evaluate, record a replay, generate a model card of your agent and push it to the hub**.
This way:
- You can **showcase our work** 🔥
- You can **visualize your agent playing** 👀
- You can **share with the community an agent that others can use** 💾
- You can **access a leaderboard 🏆 to see how well your agent is performing compared to your classmates** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
To be able to share your model with the community there are three more steps to follow:
1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join
2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.
- Create a new token (https://huggingface.co/settings/tokens) **with write role**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/create-token.jpg" alt="Create HF Token">
- Copy the token
- Run the cell below and past the token
```bash
from huggingface_hub import notebook_login # To log to our Hugging Face account to be able to upload models to the Hub.
notebook_login()
!git config --global credential.helper store
```
If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
3️⃣ We're now ready to push our trained agent to the 🤗 Hub 🔥
Let's run push_to_hub.py file to upload our trained agent to the Hub.
`--repo-name `: The name of the repo
`-orga`: Your Hugging Face username
`-f`: Where the trained model folder is (in our case `logs`)
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit3/select-id.png" alt="Select Id">
```bash
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 --repo-name _____________________ -orga _____________________ -f logs/
```
#### Solution
```bash
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 --repo-name dqn-SpaceInvadersNoFrameskip-v4 -orga ThomasSimonini -f logs/
```
###.
Congrats 🥳 you've just trained and uploaded your first Deep Q-Learning agent using RL-Baselines-3 Zoo. The script above should have displayed a link to a model repository such as https://huggingface.co/ThomasSimonini/dqn-SpaceInvadersNoFrameskip-v4. When you go to this link, you can:
- See a **video preview of your agent** at the right.
- Click "Files and versions" to see all the files in the repository.
- Click "Use in stable-baselines3" to get a code snippet that shows how to load the model.
- A model card (`README.md` file) which gives a description of the model and the hyperparameters you used.
Under the hood, the Hub uses git-based repositories (don't worry if you don't know what git is), which means you can update the model with new versions as you experiment and improve your agent.
**Compare the results of your agents with your classmates** using the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) 🏆
## Load a powerful trained model 🔥
- The Stable-Baselines3 team uploaded **more than 150 trained Deep Reinforcement Learning agents on the Hub**.
You can find them here: 👉 https://huggingface.co/sb3
Some examples:
- Asteroids: https://huggingface.co/sb3/dqn-AsteroidsNoFrameskip-v4
- Beam Rider: https://huggingface.co/sb3/dqn-BeamRiderNoFrameskip-v4
- Breakout: https://huggingface.co/sb3/dqn-BreakoutNoFrameskip-v4
- Road Runner: https://huggingface.co/sb3/dqn-RoadRunnerNoFrameskip-v4
Let's load an agent playing Beam Rider: https://huggingface.co/sb3/dqn-BeamRiderNoFrameskip-v4
1. We download the model using `rl_zoo3.load_from_hub`, and place it in a new folder that we can call `rl_trained`
```bash
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env BeamRiderNoFrameskip-v4 -orga sb3 -f rl_trained/
```
2. Let's evaluate if for 5000 timesteps
```bash
python -m rl_zoo3.enjoy --algo dqn --env BeamRiderNoFrameskip-v4 -n 5000 -f rl_trained/ --no-render
```
Why not trying to train your own **Deep Q-Learning Agent playing BeamRiderNoFrameskip-v4? 🏆.**
If you want to try, check https://huggingface.co/sb3/dqn-BeamRiderNoFrameskip-v4#hyperparameters **in the model card, you have the hyperparameters of the trained agent.**
But finding hyperparameters can be a daunting task. Fortunately, we'll see in the next Unit, how we can **use Optuna for optimizing the Hyperparameters 🔥.**
## Some additional challenges 🏆
The best way to learn **is to try things by your own**!
In the [Leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) you will find your agents. Can you get to the top?
Here's a list of environments you can try to train your agent with:
- BeamRiderNoFrameskip-v4
- BreakoutNoFrameskip-v4
- EnduroNoFrameskip-v4
- PongNoFrameskip-v4
Also, **if you want to learn to implement Deep Q-Learning by yourself**, you definitely should look at CleanRL implementation: https://github.com/vwxyzjn/cleanrl/blob/master/cleanrl/dqn_atari.py
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit4/atari-envs.gif" alt="Environments"/>
________________________________________________________________________
Congrats on finishing this chapter!
If you’re still feel confused with all these elements...it's totally normal! **This was the same for me and for all people who studied RL.**
Take time to really **grasp the material before continuing and try the additional challenges**. It’s important to master these elements and having a solid foundations.
In the next unit, **we’re going to learn about [Optuna](https://optuna.org/)**. One of the most critical task in Deep Reinforcement Learning is to find a good set of training hyperparameters. And Optuna is a library that helps you to automate the search.
### This is a course built with you 👷🏿♀️
Finally, we want to improve and update the course iteratively with your feedback. If you have some, please fill this form 👉 https://forms.gle/3HgA7bEHwAmmLfwh9
We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the Github Repo](https://github.com/huggingface/deep-rl-class/issues).
See you on Bonus unit 2! 🔥
### Keep Learning, Stay Awesome 🤗
|
huggingface/deep-rl-class/blob/main/units/en/unit3/hands-on.mdx
|
Gradio Demo: depth_estimation
### A demo for predicting the depth of an image and generating a 3D model of it.
```
!pip install -q gradio torch git+https://github.com/nielsrogge/transformers.git@add_dpt_redesign#egg=transformers numpy Pillow jinja2 open3d
```
```
# Downloading files from the demo repo
import os
os.mkdir('examples')
!wget -q -O examples/1-jonathan-borba-CgWTqYxHEkg-unsplash.jpg https://github.com/gradio-app/gradio/raw/main/demo/depth_estimation/examples/1-jonathan-borba-CgWTqYxHEkg-unsplash.jpg
!wget -q https://github.com/gradio-app/gradio/raw/main/demo/depth_estimation/packages.txt
```
```
import gradio as gr
from transformers import DPTFeatureExtractor, DPTForDepthEstimation
import torch
import numpy as np
from PIL import Image
import open3d as o3d
from pathlib import Path
feature_extractor = DPTFeatureExtractor.from_pretrained("Intel/dpt-large")
model = DPTForDepthEstimation.from_pretrained("Intel/dpt-large")
def process_image(image_path):
image_path = Path(image_path)
image_raw = Image.open(image_path)
image = image_raw.resize(
(800, int(800 * image_raw.size[1] / image_raw.size[0])),
Image.Resampling.LANCZOS)
# prepare image for the model
encoding = feature_extractor(image, return_tensors="pt")
# forward pass
with torch.no_grad():
outputs = model(**encoding)
predicted_depth = outputs.predicted_depth
# interpolate to original size
prediction = torch.nn.functional.interpolate(
predicted_depth.unsqueeze(1),
size=image.size[::-1],
mode="bicubic",
align_corners=False,
).squeeze()
output = prediction.cpu().numpy()
depth_image = (output * 255 / np.max(output)).astype('uint8')
try:
gltf_path = create_3d_obj(np.array(image), depth_image, image_path)
img = Image.fromarray(depth_image)
return [img, gltf_path, gltf_path]
except Exception:
gltf_path = create_3d_obj(
np.array(image), depth_image, image_path, depth=8)
img = Image.fromarray(depth_image)
return [img, gltf_path, gltf_path]
except:
print("Error reconstructing 3D model")
raise Exception("Error reconstructing 3D model")
def create_3d_obj(rgb_image, depth_image, image_path, depth=10):
depth_o3d = o3d.geometry.Image(depth_image)
image_o3d = o3d.geometry.Image(rgb_image)
rgbd_image = o3d.geometry.RGBDImage.create_from_color_and_depth(
image_o3d, depth_o3d, convert_rgb_to_intensity=False)
w = int(depth_image.shape[1])
h = int(depth_image.shape[0])
camera_intrinsic = o3d.camera.PinholeCameraIntrinsic()
camera_intrinsic.set_intrinsics(w, h, 500, 500, w/2, h/2)
pcd = o3d.geometry.PointCloud.create_from_rgbd_image(
rgbd_image, camera_intrinsic)
print('normals')
pcd.normals = o3d.utility.Vector3dVector(
np.zeros((1, 3))) # invalidate existing normals
pcd.estimate_normals(
search_param=o3d.geometry.KDTreeSearchParamHybrid(radius=0.01, max_nn=30))
pcd.orient_normals_towards_camera_location(
camera_location=np.array([0., 0., 1000.]))
pcd.transform([[1, 0, 0, 0],
[0, -1, 0, 0],
[0, 0, -1, 0],
[0, 0, 0, 1]])
pcd.transform([[-1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]])
print('run Poisson surface reconstruction')
with o3d.utility.VerbosityContextManager(o3d.utility.VerbosityLevel.Debug):
mesh_raw, densities = o3d.geometry.TriangleMesh.create_from_point_cloud_poisson(
pcd, depth=depth, width=0, scale=1.1, linear_fit=True)
voxel_size = max(mesh_raw.get_max_bound() - mesh_raw.get_min_bound()) / 256
print(f'voxel_size = {voxel_size:e}')
mesh = mesh_raw.simplify_vertex_clustering(
voxel_size=voxel_size,
contraction=o3d.geometry.SimplificationContraction.Average)
# vertices_to_remove = densities < np.quantile(densities, 0.001)
# mesh.remove_vertices_by_mask(vertices_to_remove)
bbox = pcd.get_axis_aligned_bounding_box()
mesh_crop = mesh.crop(bbox)
gltf_path = f'./{image_path.stem}.gltf'
o3d.io.write_triangle_mesh(
gltf_path, mesh_crop, write_triangle_uvs=True)
return gltf_path
title = "Demo: zero-shot depth estimation with DPT + 3D Point Cloud"
description = "This demo is a variation from the original <a href='https://huggingface.co/spaces/nielsr/dpt-depth-estimation' target='_blank'>DPT Demo</a>. It uses the DPT model to predict the depth of an image and then uses 3D Point Cloud to create a 3D object."
examples = [["examples/1-jonathan-borba-CgWTqYxHEkg-unsplash.jpg"]]
iface = gr.Interface(fn=process_image,
inputs=[gr.Image(
type="filepath", label="Input Image")],
outputs=[gr.Image(label="predicted depth", type="pil"),
gr.Model3D(label="3d mesh reconstruction", clear_color=[
1.0, 1.0, 1.0, 1.0]),
gr.File(label="3d gLTF")],
title=title,
description=description,
examples=examples,
allow_flagging="never",
cache_examples=False)
iface.launch(debug=True)
```
|
gradio-app/gradio/blob/main/demo/depth_estimation/run.ipynb
|
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Configuration
The base class [`PretrainedConfig`] implements the common methods for loading/saving a configuration
either from a local file or directory, or from a pretrained model configuration provided by the library (downloaded
from HuggingFace's AWS S3 repository).
Each derived config class implements model specific attributes. Common attributes present in all config classes are:
`hidden_size`, `num_attention_heads`, and `num_hidden_layers`. Text models further implement:
`vocab_size`.
## PretrainedConfig
[[autodoc]] PretrainedConfig
- push_to_hub
- all
|
huggingface/transformers/blob/main/docs/source/en/main_classes/configuration.md
|
DuckDB
[DuckDB](https://github.com/duckdb/duckdb) is an in-process SQL [OLAP](https://en.wikipedia.org/wiki/Online_analytical_processing) database management system.
Since it supports [fsspec](https://filesystem-spec.readthedocs.io) to read and write remote data, you can use the Hugging Face paths ([`hf://`](https://huggingface.co/docs/huggingface_hub/guides/hf_file_system#integrations)) to read and write data on the Hub:
First you need to [Login with your Hugging Face account](../huggingface_hub/quick-start#login), for example using:
```
huggingface-cli login
```
Then you can [Create a dataset repository](../huggingface_hub/quick-start#create-a-repository), for example using:
```python
from huggingface_hub import HfApi
HfApi().create_repo(repo_id="username/my_dataset", repo_type="dataset")
```
Finally, you can use [Hugging Face paths]([Hugging Face paths](https://huggingface.co/docs/huggingface_hub/guides/hf_file_system#integrations)) in DuckDB:
```python
>>> from huggingface_hub import HfFileSystem
>>> import duckdb
>>> fs = HfFileSystem()
>>> duckdb.register_filesystem(fs)
>>> duckdb.sql("COPY tbl TO 'hf://datasets/username/my_dataset/data.parquet' (FORMAT PARQUET);")
```
This creates a file `data.parquet` in the dataset repository `username/my_dataset` containing your dataset in Parquet format.
You can reload it later:
```python
>>> from huggingface_hub import HfFileSystem
>>> import duckdb
>>> fs = HfFileSystem()
>>> duckdb.register_filesystem(fs)
>>> df = duckdb.query("SELECT * FROM 'hf://datasets/username/my_dataset/data.parquet' LIMIT 10;").df()
```
To have more information on the Hugging Face paths and how they are implemented, please refer to the [the client library's documentation on the HfFileSystem](https://huggingface.co/docs/huggingface_hub/guides/hf_file_system).
|
huggingface/hub-docs/blob/main/docs/hub/datasets-duckdb.md
|
``python
import argparse
import json
import logging
import math
import os
import random
from pathlib import Path
from tqdm import tqdm
import datasets
from datasets import load_dataset, DatasetDict
import evaluate
import torch
from torch import nn
from torch.utils.data import DataLoader
import transformers
from transformers import AutoTokenizer, AutoModel, default_data_collator, SchedulerType, get_scheduler
from transformers.utils import check_min_version, get_full_repo_name, send_example_telemetry
from transformers.utils.versions import require_version
from huggingface_hub import Repository, create_repo
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import set_seed
from peft import PeftModel
import hnswlib
```
```python
class AutoModelForSentenceEmbedding(nn.Module):
def __init__(self, model_name, tokenizer, normalize=True):
super(AutoModelForSentenceEmbedding, self).__init__()
self.model = AutoModel.from_pretrained(model_name) # , load_in_8bit=True, device_map={"":0})
self.normalize = normalize
self.tokenizer = tokenizer
def forward(self, **kwargs):
model_output = self.model(**kwargs)
embeddings = self.mean_pooling(model_output, kwargs["attention_mask"])
if self.normalize:
embeddings = torch.nn.functional.normalize(embeddings, p=2, dim=1)
return embeddings
def mean_pooling(self, model_output, attention_mask):
token_embeddings = model_output[0] # First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
def __getattr__(self, name: str):
"""Forward missing attributes to the wrapped module."""
try:
return super().__getattr__(name) # defer to nn.Module's logic
except AttributeError:
return getattr(self.model, name)
def get_cosing_embeddings(query_embs, product_embs):
return torch.sum(query_embs * product_embs, axis=1)
```
```python
model_name_or_path = "intfloat/e5-large-v2"
peft_model_id = "smangrul/peft_lora_e5_semantic_search"
dataset_name = "smangrul/amazon_esci"
max_length = 70
batch_size = 256
```
```python
import pandas as pd
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
dataset = load_dataset(dataset_name)
train_product_dataset = dataset["train"].to_pandas()[["product_title"]]
val_product_dataset = dataset["validation"].to_pandas()[["product_title"]]
product_dataset_for_indexing = pd.concat([train_product_dataset, val_product_dataset])
product_dataset_for_indexing = product_dataset_for_indexing.drop_duplicates()
product_dataset_for_indexing.reset_index(drop=True, inplace=True)
product_dataset_for_indexing.reset_index(inplace=True)
```
```python
product_dataset_for_indexing
```
```python
pd.set_option("max_colwidth", 300)
product_dataset_for_indexing.sample(10)
```
```python
from datasets import Dataset
dataset = Dataset.from_pandas(product_dataset_for_indexing)
def preprocess_function(examples):
products = examples["product_title"]
result = tokenizer(products, padding="max_length", max_length=70, truncation=True)
return result
processed_dataset = dataset.map(
preprocess_function,
batched=True,
remove_columns=dataset.column_names,
desc="Running tokenizer on dataset",
)
processed_dataset
```
```python
# base model
model = AutoModelForSentenceEmbedding(model_name_or_path, tokenizer)
# peft config and wrapping
model = PeftModel.from_pretrained(model, peft_model_id)
print(model)
```
```python
dataloader = DataLoader(
processed_dataset,
shuffle=False,
collate_fn=default_data_collator,
batch_size=batch_size,
pin_memory=True,
)
```
```python
next(iter(dataloader))
```
```python
ids_to_products_dict = {i: p for i, p in zip(dataset["index"], dataset["product_title"])}
ids_to_products_dict
```
```python
device = "cuda"
model.to(device)
model.eval()
model = model.merge_and_unload()
```
```python
import numpy as np
num_products = len(dataset)
d = 1024
product_embeddings_array = np.zeros((num_products, d))
for step, batch in enumerate(tqdm(dataloader)):
with torch.no_grad():
with torch.amp.autocast(dtype=torch.bfloat16, device_type="cuda"):
product_embs = model(**{k: v.to(device) for k, v in batch.items()}).detach().float().cpu()
start_index = step * batch_size
end_index = start_index + batch_size if (start_index + batch_size) < num_products else num_products
product_embeddings_array[start_index:end_index] = product_embs
del product_embs, batch
```
```python
def construct_search_index(dim, num_elements, data):
# Declaring index
search_index = hnswlib.Index(space="ip", dim=dim) # possible options are l2, cosine or ip
# Initializing index - the maximum number of elements should be known beforehand
search_index.init_index(max_elements=num_elements, ef_construction=200, M=100)
# Element insertion (can be called several times):
ids = np.arange(num_elements)
search_index.add_items(data, ids)
return search_index
```
```python
product_search_index = construct_search_index(d, num_products, product_embeddings_array)
```
```python
def get_query_embeddings(query, model, tokenizer, device):
inputs = tokenizer(query, padding="max_length", max_length=70, truncation=True, return_tensors="pt")
model.eval()
with torch.no_grad():
query_embs = model(**{k: v.to(device) for k, v in inputs.items()}).detach().cpu()
return query_embs[0]
def get_nearest_neighbours(k, search_index, query_embeddings, ids_to_products_dict, threshold=0.7):
# Controlling the recall by setting ef:
search_index.set_ef(100) # ef should always be > k
# Query dataset, k - number of the closest elements (returns 2 numpy arrays)
labels, distances = search_index.knn_query(query_embeddings, k=k)
return [
(ids_to_products_dict[label], (1 - distance))
for label, distance in zip(labels[0], distances[0])
if (1 - distance) >= threshold
]
```
```python
query = "NLP and ML books"
k = 10
query_embeddings = get_query_embeddings(query, model, tokenizer, device)
search_results = get_nearest_neighbours(k, product_search_index, query_embeddings, ids_to_products_dict, threshold=0.7)
print(f"{query=}")
for product, cosine_sim_score in search_results:
print(f"cosine_sim_score={round(cosine_sim_score,2)} {product=}")
```
|
huggingface/peft/blob/main/examples/feature_extraction/peft_lora_embedding_semantic_similarity_inference.ipynb
|
Using Gradio for Tabular Data Science Workflows
Related spaces: https://huggingface.co/spaces/scikit-learn/gradio-skops-integration, https://huggingface.co/spaces/scikit-learn/tabular-playground, https://huggingface.co/spaces/merve/gradio-analysis-dashboard
## Introduction
Tabular data science is the most widely used domain of machine learning, with problems ranging from customer segmentation to churn prediction. Throughout various stages of the tabular data science workflow, communicating your work to stakeholders or clients can be cumbersome; which prevents data scientists from focusing on what matters, such as data analysis and model building. Data scientists can end up spending hours building a dashboard that takes in dataframe and returning plots, or returning a prediction or plot of clusters in a dataset. In this guide, we'll go through how to use `gradio` to improve your data science workflows. We will also talk about how to use `gradio` and [skops](https://skops.readthedocs.io/en/stable/) to build interfaces with only one line of code!
### Prerequisites
Make sure you have the `gradio` Python package already [installed](/getting_started).
## Let's Create a Simple Interface!
We will take a look at how we can create a simple UI that predicts failures based on product information.
```python
import gradio as gr
import pandas as pd
import joblib
import datasets
inputs = [gr.Dataframe(row_count = (2, "dynamic"), col_count=(4,"dynamic"), label="Input Data", interactive=1)]
outputs = [gr.Dataframe(row_count = (2, "dynamic"), col_count=(1, "fixed"), label="Predictions", headers=["Failures"])]
model = joblib.load("model.pkl")
# we will give our dataframe as example
df = datasets.load_dataset("merve/supersoaker-failures")
df = df["train"].to_pandas()
def infer(input_dataframe):
return pd.DataFrame(model.predict(input_dataframe))
gr.Interface(fn = infer, inputs = inputs, outputs = outputs, examples = [[df.head(2)]]).launch()
```
Let's break down above code.
- `fn`: the inference function that takes input dataframe and returns predictions.
- `inputs`: the component we take our input with. We define our input as dataframe with 2 rows and 4 columns, which initially will look like an empty dataframe with the aforementioned shape. When the `row_count` is set to `dynamic`, you don't have to rely on the dataset you're inputting to pre-defined component.
- `outputs`: The dataframe component that stores outputs. This UI can take single or multiple samples to infer, and returns 0 or 1 for each sample in one column, so we give `row_count` as 2 and `col_count` as 1 above. `headers` is a list made of header names for dataframe.
- `examples`: You can either pass the input by dragging and dropping a CSV file, or a pandas DataFrame through examples, which headers will be automatically taken by the interface.
We will now create an example for a minimal data visualization dashboard. You can find a more comprehensive version in the related Spaces.
<gradio-app space="gradio/tabular-playground"></gradio-app>
```python
import gradio as gr
import pandas as pd
import datasets
import seaborn as sns
import matplotlib.pyplot as plt
df = datasets.load_dataset("merve/supersoaker-failures")
df = df["train"].to_pandas()
df.dropna(axis=0, inplace=True)
def plot(df):
plt.scatter(df.measurement_13, df.measurement_15, c = df.loading,alpha=0.5)
plt.savefig("scatter.png")
df['failure'].value_counts().plot(kind='bar')
plt.savefig("bar.png")
sns.heatmap(df.select_dtypes(include="number").corr())
plt.savefig("corr.png")
plots = ["corr.png","scatter.png", "bar.png"]
return plots
inputs = [gr.Dataframe(label="Supersoaker Production Data")]
outputs = [gr.Gallery(label="Profiling Dashboard", columns=(1,3))]
gr.Interface(plot, inputs=inputs, outputs=outputs, examples=[df.head(100)], title="Supersoaker Failures Analysis Dashboard").launch()
```
<gradio-app space="gradio/gradio-analysis-dashboard-minimal"></gradio-app>
We will use the same dataset we used to train our model, but we will make a dashboard to visualize it this time.
- `fn`: The function that will create plots based on data.
- `inputs`: We use the same `Dataframe` component we used above.
- `outputs`: The `Gallery` component is used to keep our visualizations.
- `examples`: We will have the dataset itself as the example.
## Easily load tabular data interfaces with one line of code using skops
`skops` is a library built on top of `huggingface_hub` and `sklearn`. With the recent `gradio` integration of `skops`, you can build tabular data interfaces with one line of code!
```python
import gradio as gr
# title and description are optional
title = "Supersoaker Defective Product Prediction"
description = "This model predicts Supersoaker production line failures. Drag and drop any slice from dataset or edit values as you wish in below dataframe component."
gr.load("huggingface/scikit-learn/tabular-playground", title=title, description=description).launch()
```
<gradio-app space="gradio/gradio-skops-integration"></gradio-app>
`sklearn` models pushed to Hugging Face Hub using `skops` include a `config.json` file that contains an example input with column names, the task being solved (that can either be `tabular-classification` or `tabular-regression`). From the task type, `gradio` constructs the `Interface` and consumes column names and the example input to build it. You can [refer to skops documentation on hosting models on Hub](https://skops.readthedocs.io/en/latest/auto_examples/plot_hf_hub.html#sphx-glr-auto-examples-plot-hf-hub-py) to learn how to push your models to Hub using `skops`.
|
gradio-app/gradio/blob/main/guides/07_tabular-data-science-and-plots/using-gradio-for-tabular-workflows.md
|
More ways to create Spaces
## Duplicating a Space
You can duplicate a Space by clicking the three dots at the top right and selecting **Duplicate this Space**. Learn more about it [here]](./spaces-overview#duplicating-a-space).
## Creating a Space from a model
New! You can now create a Gradio demo directly from most model pages, using the "Deploy -> Spaces" button.
<video src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/model-page-deploy-to-spaces.mp4" controls autoplay muted loop />
As another example of how to create a Space from a set of models, the [Model Comparator Space Builder](https://huggingface.co/spaces/farukozderim/Model-Comparator-Space-Builder) from [@farukozderim](https://huggingface.co/farukozderim) can be used to create a Space directly from any model hosted on the Hub.
|
huggingface/hub-docs/blob/main/docs/hub/spaces-more-ways-to-create.md
|
Controlling Layout
By default, Components in Blocks are arranged vertically. Let's take a look at how we can rearrange Components. Under the hood, this layout structure uses the [flexbox model of web development](https://developer.mozilla.org/en-US/docs/Web/CSS/CSS_Flexible_Box_Layout/Basic_Concepts_of_Flexbox).
## Rows
Elements within a `with gr.Row` clause will all be displayed horizontally. For example, to display two Buttons side by side:
```python
with gr.Blocks() as demo:
with gr.Row():
btn1 = gr.Button("Button 1")
btn2 = gr.Button("Button 2")
```
To make every element in a Row have the same height, use the `equal_height` argument of the `style` method.
```python
with gr.Blocks() as demo:
with gr.Row(equal_height=True):
textbox = gr.Textbox()
btn2 = gr.Button("Button 2")
```
The widths of elements in a Row can be controlled via a combination of `scale` and `min_width` arguments that are present in every Component.
- `scale` is an integer that defines how an element will take up space in a Row. If scale is set to `0`, and element will not expand to take up space. If scale is set to `1` or greater, the element well expand. Multiple elements in a row will expand proportional to their scale. Below, `btn1` will expand twice as much as `btn2`, while `btn0` will not expand at all:
```python
with gr.Blocks() as demo:
with gr.Row():
btn0 = gr.Button("Button 0", scale=0)
btn1 = gr.Button("Button 1", scale=1)
btn2 = gr.Button("Button 2", scale=2)
```
- `min_width` will set the minimum width the element will take. The Row will wrap if there isn't sufficient space to satisfy all `min_width` values.
Learn more about Rows in the [docs](https://gradio.app/docs/#row).
## Columns and Nesting
Components within a Column will be placed vertically atop each other. Since the vertical layout is the default layout for Blocks apps anyway, to be useful, Columns are usually nested within Rows. For example:
$code_rows_and_columns
$demo_rows_and_columns
See how the first column has two Textboxes arranged vertically. The second column has an Image and Button arranged vertically. Notice how the relative widths of the two columns is set by the `scale` parameter. The column with twice the `scale` value takes up twice the width.
Learn more about Columns in the [docs](https://gradio.app/docs/#column).
# Dimensions
You can control the height and width of various components, where the parameters are available. These parameters accept either a number (interpreted as pixels) or a string. Using a string allows the direct application of any CSS unit to the encapsulating Block element, catering to more specifc design requirements. When omitted, Gradio uses default dimensions suited for most use cases.
Below is an example illustrating the use of viewport width (vw):
```python
import gradio as gr
with gr.Blocks() as demo:
im = gr.ImageEditor(
width="50vw",
)
demo.launch()
```
When using percentage values for dimensions, you may want to define a parent component with an absolute unit (e.g. `px` or `vw`). This approach ensures that child components with relative dimensions are sized appropriately:
```python
import gradio as gr
css = """
.container {
height: 100vh;
}
"""
with gr.Blocks(css=css) as demo:
with gr.Column(elem_classes=["container"]):
name = gr.Chatbot(value=[["1", "2"]], height="70%")
demo.launch()
```
In this example, the Column layout component is given a height of 100% of the viewport height (100vh), and the Chatbot component inside it takes up 70% of the Column's height.
You can apply any valid CSS unit for these parameters. For a comprehensive list of CSS units, refer to [this guide](https://www.w3schools.com/cssref/css_units.php). We recommend you always consider responsiveness and test your interfaces on various screen sizes to ensure a consistent user experience.
## Tabs and Accordions
You can also create Tabs using the `with gr.Tab('tab_name'):` clause. Any component created inside of a `with gr.Tab('tab_name'):` context appears in that tab. Consecutive Tab clauses are grouped together so that a single tab can be selected at one time, and only the components within that Tab's context are shown.
For example:
$code_blocks_flipper
$demo_blocks_flipper
Also note the `gr.Accordion('label')` in this example. The Accordion is a layout that can be toggled open or closed. Like `Tabs`, it is a layout element that can selectively hide or show content. Any components that are defined inside of a `with gr.Accordion('label'):` will be hidden or shown when the accordion's toggle icon is clicked.
Learn more about [Tabs](https://gradio.app/docs/#tab) and [Accordions](https://gradio.app/docs/#accordion) in the docs.
## Visibility
Both Components and Layout elements have a `visible` argument that can set initially and also updated. Setting `gr.Column(visible=...)` on a Column can be used to show or hide a set of Components.
$code_blocks_form
$demo_blocks_form
## Variable Number of Outputs
By adjusting the visibility of components in a dynamic way, it is possible to create
demos with Gradio that support a _variable numbers of outputs_. Here's a very simple example
where the number of output textboxes is controlled by an input slider:
$code_variable_outputs
$demo_variable_outputs
## Defining and Rendering Components Separately
In some cases, you might want to define components before you actually render them in your UI. For instance, you might want to show an examples section using `gr.Examples` above the corresponding `gr.Textbox` input. Since `gr.Examples` requires as a parameter the input component object, you will need to first define the input component, but then render it later, after you have defined the `gr.Examples` object.
The solution to this is to define the `gr.Textbox` outside of the `gr.Blocks()` scope and use the component's `.render()` method wherever you'd like it placed in the UI.
Here's a full code example:
```python
input_textbox = gr.Textbox()
with gr.Blocks() as demo:
gr.Examples(["hello", "bonjour", "merhaba"], input_textbox)
input_textbox.render()
```
|
gradio-app/gradio/blob/main/guides/03_building-with-blocks/02_controlling-layout.md
|
Shiny on Spaces
[Shiny](https://shiny.posit.co/) is an open-source framework for building simple, beautiful, and performant data applications.
The goal when developing Shiny was to build something simple enough to teach someone in an afternoon but extensible enough to power large, mission-critical applications.
You can create a useful Shiny app in a few minutes, but if the scope of your project grows, you can be sure that Shiny can accommodate that application.
The main feature that differentiates Shiny from other frameworks is its reactive execution model.
When you write a Shiny app, the framework infers the relationship between inputs, outputs, and intermediary calculations and uses those relationships to render only the things that need to change as a result of a user's action.
The result is that users can easily develop efficient, extensible applications without explicitly caching data or writing callback functions.
## Shiny for Python
[Shiny for Python](https://shiny.rstudio.com/py/) is a pure Python implementation of Shiny.
This gives you access to all of the great features of Shiny like reactivity, complex layouts, and modules without needing to use R.
Shiny for Python is ideal for Hugging Face applications because it integrates smoothly with other Hugging Face tools.
To get started deploying a Space, click this button to select your hardware and specify if you want a public or private Space.
The Space template will populate a few files to get your app started.
<a href="https://huggingface.co/new-space?template=posit/shiny-for-python-template"> <img src="https://huggingface.co/datasets/huggingface/badges/resolve/main/deploy-to-spaces-lg.svg"/> </a>
_app.py_
This file defines your app's logic. To learn more about how to modify this file, see [the Shiny for Python documentation](https://shiny.rstudio.com/py/docs/overview.html).
As your app gets more complex, it's a good idea to break your application logic up into [modules](https://shiny.rstudio.com/py/docs/workflow-modules.html).
_Dockerfile_
The Dockerfile for a Shiny for Python app is very minimal because the library doesn't have many system dependencies, but you may need to modify this file if your application has additional system dependencies.
The one essential feature of this file is that it exposes and runs the app on the port specified in the space README file (which is 7860 by default).
__requirements.txt__
The Space will automatically install dependencies listed in the requirements.txt file.
Note that you must include shiny in this file.
## Shiny for R
[Shiny for R](https://shiny.rstudio.com/) is a popular and well-established application framework in the R community and is a great choice if you want to host an R app on Hugging Face infrastructure or make use of some of the great [Shiny R extensions](https://github.com/nanxstats/awesome-shiny-extensions).
To integrate Hugging Face tools into an R app, you can either use [httr2](https://httr2.r-lib.org/) to call Hugging Face APIs, or [reticulate](https://rstudio.github.io/reticulate/) to call one of the Hugging Face Python SDKs.
To deploy an R Shiny Space, click this button and fill out the space metadata.
This will populate the Space with all the files you need to get started.
<a href="https://huggingface.co/new-space?template=posit/shiny-for-r-template"> <img src="https://huggingface.co/datasets/huggingface/badges/resolve/main/deploy-to-spaces-lg.svg"/> </a>
_app.R_
This file contains all of your application logic. If you prefer, you can break this file up into `ui.R` and `server.R`.
_Dockerfile_
The Dockerfile builds off of the the [rocker shiny](https://hub.docker.com/r/rocker/shiny) image. You'll need to modify this file to use additional packages.
If you are using a lot of tidyverse packages we recommend switching the base image to [rocker/shinyverse](https://hub.docker.com/r/rocker/shiny-verse).
You can install additional R packages by adding them under the `RUN install2.r` section of the dockerfile, and github packages can be installed by adding the repository under `RUN installGithub.r`.
There are two main requirements for this Dockerfile:
- First, the file must expose the port that you have listed in the README. The default is 7860 and we recommend not changing this port unless you have a reason to.
- Second, for the moment you must use the development version of [httpuv](https://github.com/rstudio/httpuv) which resolves an issue with app timeouts on Hugging Face.
|
huggingface/hub-docs/blob/main/docs/hub/spaces-sdks-docker-shiny.md
|
Introduction to PPO with Sample-Factory
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/thumbnail2.png" alt="thumbnail"/>
In this second part of Unit 8, we'll get deeper into PPO optimization by using [Sample-Factory](https://samplefactory.dev/), an **asynchronous implementation of the PPO algorithm**, to train our agent to play [vizdoom](https://vizdoom.cs.put.edu.pl/) (an open source version of Doom).
In the notebook, **you'll train your agent to play the Health Gathering level**, where the agent must collect health packs to avoid dying. After that, you can **train your agent to play more complex levels, such as Deathmatch**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit10/environments.png" alt="Environment"/>
Sound exciting? Let's get started! 🚀
The hands-on is made by [Edward Beeching](https://twitter.com/edwardbeeching), a Machine Learning Research Scientist at Hugging Face. He worked on Godot Reinforcement Learning Agents, an open-source interface for developing environments and agents in the Godot Game Engine.
|
huggingface/deep-rl-class/blob/main/units/en/unit8/introduction-sf.mdx
|
gradio
## 4.11.0
### Features
- [#6842](https://github.com/gradio-app/gradio/pull/6842) [`846d52d`](https://github.com/gradio-app/gradio/commit/846d52d1c92d429077382ce494eea27fd062d9f6) - Fix md highlight. Thanks [@pngwn](https://github.com/pngwn)!
- [#6831](https://github.com/gradio-app/gradio/pull/6831) [`f3abde8`](https://github.com/gradio-app/gradio/commit/f3abde80884d96ad69b825020c46486d9dd5cac5) - Add an option to enable header links for markdown. Thanks [@pngwn](https://github.com/pngwn)!
- [#6814](https://github.com/gradio-app/gradio/pull/6814) [`828fb9e`](https://github.com/gradio-app/gradio/commit/828fb9e6ce15b6ea08318675a2361117596a1b5d) - Refactor queue so that there are separate queues for each concurrency id. Thanks [@aliabid94](https://github.com/aliabid94)!
- [#6809](https://github.com/gradio-app/gradio/pull/6809) [`1401d99`](https://github.com/gradio-app/gradio/commit/1401d99ade46d87da75b5f5808a3354c49f1d1ea) - Fix `ImageEditor` interaction story. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6803](https://github.com/gradio-app/gradio/pull/6803) [`77c9003`](https://github.com/gradio-app/gradio/commit/77c900311e2ba37b8f849ce088ceb48aa196af18) - Fixes issue 5781: Enables specifying a caching directory for Examples. Thanks [@cswamy](https://github.com/cswamy)!
- [#6823](https://github.com/gradio-app/gradio/pull/6823) [`67a2b7f`](https://github.com/gradio-app/gradio/commit/67a2b7f12cb06355fcc41e40d47e8b2ad211d7d1) - Fixed duplicate word ("this this"). Thanks [@Cassini-chris](https://github.com/Cassini-chris)!
- [#6833](https://github.com/gradio-app/gradio/pull/6833) [`1b9d423`](https://github.com/gradio-app/gradio/commit/1b9d4234d6c25ef250d882c7b90e1f4039ed2d76) - Prevent file traversals. Thanks [@abidlabs](https://github.com/abidlabs)!
### Fixes
- [#6829](https://github.com/gradio-app/gradio/pull/6829) [`50496f9`](https://github.com/gradio-app/gradio/commit/50496f967f8209032b753912a4379eb9cea66627) - Adjust rounding logic when precision is `None` in `gr.Number()`. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6766](https://github.com/gradio-app/gradio/pull/6766) [`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144) - Improve source selection UX. Thanks [@hannahblair](https://github.com/hannahblair)!
## 4.10.0
### Features
- [#6798](https://github.com/gradio-app/gradio/pull/6798) [`245d58e`](https://github.com/gradio-app/gradio/commit/245d58eff788e8d44a59d37a2d9b26d0f08a62b4) - Improve how server/js client handle unexpected errors. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6794](https://github.com/gradio-app/gradio/pull/6794) [`7ba8c5d`](https://github.com/gradio-app/gradio/commit/7ba8c5da45b004edd12c0460be9222f5b5f5f055) - Fix SSRF vulnerability on `/file=` route. Thanks [@abidlabs](https://github.com/abidlabs)!
### Fixes
- [#6799](https://github.com/gradio-app/gradio/pull/6799) [`c352811`](https://github.com/gradio-app/gradio/commit/c352811f76d4126613ece0a584f8c552fdd8d1f6) - Adds docstrings for `gr.WaveformOptions`, `gr.Brush`, and `gr.Eraser`, fixes examples for `ImageEditor`, and allows individual images to be used as the initial `value` for `ImageEditor`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6808](https://github.com/gradio-app/gradio/pull/6808) [`6b130e2`](https://github.com/gradio-app/gradio/commit/6b130e26b9a6061e7984923b355a04a5484a1c96) - Ensure LoginButton `value` text is displayed. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6810](https://github.com/gradio-app/gradio/pull/6810) [`526fb6c`](https://github.com/gradio-app/gradio/commit/526fb6c446468f1567d614c83266bb5f5797ce9c) - Fix `gr.load()` so that it works with the SSE v1 protocol. Thanks [@abidlabs](https://github.com/abidlabs)!
## 4.9.1
### Features
- [#6781](https://github.com/gradio-app/gradio/pull/6781) [`a807ede`](https://github.com/gradio-app/gradio/commit/a807ede818e0690949aca41020e75a96f0110ece) - Fix backend tests on Windows. Thanks [@abidlabs](https://github.com/abidlabs)!
### Fixes
- [#6525](https://github.com/gradio-app/gradio/pull/6525) [`5d51fbc`](https://github.com/gradio-app/gradio/commit/5d51fbce7826da840a2fd4940feb5d9ad6f1bc5a) - Fixes Drag and Drop for Upload. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#6780](https://github.com/gradio-app/gradio/pull/6780) [`51e241a`](https://github.com/gradio-app/gradio/commit/51e241addd20dad9a0cdf3e72f747cab112815d1) - Fix flaky CI tests (again 😓 ). Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6693](https://github.com/gradio-app/gradio/pull/6693) [`34f9431`](https://github.com/gradio-app/gradio/commit/34f943101bf7dd6b8a8974a6131c1ed7c4a0dac0) - Python client properly handles hearbeat and log messages. Also handles responses longer than 65k. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 4.9.0
### Features
- [#6726](https://github.com/gradio-app/gradio/pull/6726) [`21cfb0a`](https://github.com/gradio-app/gradio/commit/21cfb0acc309bb1a392f4d8a8e42f6be864c5978) - Remove the styles from the Image/Video primitive components and Fix the container styles. Thanks [@whitphx](https://github.com/whitphx)!
- [#6398](https://github.com/gradio-app/gradio/pull/6398) [`67ddd40`](https://github.com/gradio-app/gradio/commit/67ddd40b4b70d3a37cb1637c33620f8d197dbee0) - Lite v4. Thanks [@whitphx](https://github.com/whitphx)!
- [#6399](https://github.com/gradio-app/gradio/pull/6399) [`053bec9`](https://github.com/gradio-app/gradio/commit/053bec98be1127e083414024e02cf0bebb0b5142) - Improve CSS token documentation in Storybook. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6745](https://github.com/gradio-app/gradio/pull/6745) [`3240d04`](https://github.com/gradio-app/gradio/commit/3240d042e907a3f2f679c2310c0dc6a688d2c07e) - Add `editable` parameter to Audio. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6616](https://github.com/gradio-app/gradio/pull/6616) [`9a0bd27`](https://github.com/gradio-app/gradio/commit/9a0bd27502894e2488b4732be081cb2027aa636e) - Add support for OAuth tokens. Thanks [@Wauplin](https://github.com/Wauplin)!
- [#6738](https://github.com/gradio-app/gradio/pull/6738) [`f3c4d78`](https://github.com/gradio-app/gradio/commit/f3c4d78b710854b94d9a15db78178e504a02c680) - reload on css changes + fix css specificity. Thanks [@pngwn](https://github.com/pngwn)!
- [#6671](https://github.com/gradio-app/gradio/pull/6671) [`299f5e2`](https://github.com/gradio-app/gradio/commit/299f5e238bb6fb3f51376ef8b73fc44351859bbe) - Update HF token used in CI tests. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6680](https://github.com/gradio-app/gradio/pull/6680) [`cfd5700`](https://github.com/gradio-app/gradio/commit/cfd57005bce715271c3073ecd322890b8d30f594) - Cause `gr.ClearButton` to reset the value of `gr.State`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6603](https://github.com/gradio-app/gradio/pull/6603) [`6b1401c`](https://github.com/gradio-app/gradio/commit/6b1401c514c2ec012b0a50c72a6ec81cb673bf1d) - chore(deps): update dependency marked to v11. Thanks [@renovate](https://github.com/apps/renovate)!
- [#6666](https://github.com/gradio-app/gradio/pull/6666) [`30c9fbb`](https://github.com/gradio-app/gradio/commit/30c9fbb5c74f0dc879e85dbdb6778c0782aeff38) - Set gradio api server from env. Thanks [@aisensiy](https://github.com/aisensiy)!
- [#6677](https://github.com/gradio-app/gradio/pull/6677) [`51b54b3`](https://github.com/gradio-app/gradio/commit/51b54b3411934ce46a27e7d525dd90b43c9fc016) - Tweak to our bug issue template. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6598](https://github.com/gradio-app/gradio/pull/6598) [`7cbf96e`](https://github.com/gradio-app/gradio/commit/7cbf96e0bdd12db7ecac7bf99694df0a912e5864) - Issue 5245: consolidate usage of requests and httpx. Thanks [@cswamy](https://github.com/cswamy)!
- [#6704](https://github.com/gradio-app/gradio/pull/6704) [`24e0481`](https://github.com/gradio-app/gradio/commit/24e048196e8f7bd309ef5c597d4ffc6ca4ed55d0) - Hotfix: update `huggingface_hub` dependency version. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6432](https://github.com/gradio-app/gradio/pull/6432) [`bdf81fe`](https://github.com/gradio-app/gradio/commit/bdf81fead86e1d5a29e6b036f1fff677f6480e6b) - Lite: Set the home dir path per appId at each runtime. Thanks [@whitphx](https://github.com/whitphx)!
- [#6569](https://github.com/gradio-app/gradio/pull/6569) [`4d1cbbc`](https://github.com/gradio-app/gradio/commit/4d1cbbcf30833ef1de2d2d2710c7492a379a9a00) - Allow passing height and width as string in `Blocks.svelte`. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6416](https://github.com/gradio-app/gradio/pull/6416) [`5177132`](https://github.com/gradio-app/gradio/commit/5177132d718c77f6d47869b4334afae6380394cb) - Lite: Fix the `isMessagePort()` type guard in js/wasm/src/worker-proxy.ts. Thanks [@whitphx](https://github.com/whitphx)!
- [#6543](https://github.com/gradio-app/gradio/pull/6543) [`8a70e83`](https://github.com/gradio-app/gradio/commit/8a70e83db9c7751b46058cdd2514e6bddeef6210) - switch from black to ruff formatter. Thanks [@DarhkVoyd](https://github.com/DarhkVoyd)!
### Fixes
- [#6709](https://github.com/gradio-app/gradio/pull/6709) [`6a9151d`](https://github.com/gradio-app/gradio/commit/6a9151d5c9432c724098da7d88a539aaaf5ffe88) - Remove progress animation on streaming. Thanks [@aliabid94](https://github.com/aliabid94)!
- [#6660](https://github.com/gradio-app/gradio/pull/6660) [`5238053`](https://github.com/gradio-app/gradio/commit/523805360bbf292d9d82443b1f521528beba68bb) - Fix reload mode warning about not being able to find the app. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6672](https://github.com/gradio-app/gradio/pull/6672) [`1234c37`](https://github.com/gradio-app/gradio/commit/1234c3732b52327a00b917af2ef75821771e2c92) - use gr.Error for audio length errors. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6676](https://github.com/gradio-app/gradio/pull/6676) [`fe40308`](https://github.com/gradio-app/gradio/commit/fe40308894efb2c6ff18e5e328163f6641b7476c) - Rotate Images to Upright Position in preprocess. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6487](https://github.com/gradio-app/gradio/pull/6487) [`9a5811d`](https://github.com/gradio-app/gradio/commit/9a5811df9218b622af59ba243a937a9c36ba00f9) - Fix the download button of the `gr.Gallery()` component to work. Thanks [@whitphx](https://github.com/whitphx)!
- [#6689](https://github.com/gradio-app/gradio/pull/6689) [`c9673ca`](https://github.com/gradio-app/gradio/commit/c9673cacd6470296ee01d7717e2080986e750572) - Fix directory-only glob for FileExplorer. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6639](https://github.com/gradio-app/gradio/pull/6639) [`9a6ff70`](https://github.com/gradio-app/gradio/commit/9a6ff704cd8429289c5376d3af5e4b8492df4773) - Fix issue with `head` param when adding more than one script tag. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#6556](https://github.com/gradio-app/gradio/pull/6556) [`d76bcaa`](https://github.com/gradio-app/gradio/commit/d76bcaaaf0734aaf49a680f94ea9d4d22a602e70) - Fix api event drops. Thanks [@aliabid94](https://github.com/aliabid94)!
- [#6754](https://github.com/gradio-app/gradio/pull/6754) [`a1b966e`](https://github.com/gradio-app/gradio/commit/a1b966edf761a20ef30e688b1ea1641a5ef1c860) - Fixed an issue where files could not be filed. Thanks [@duolabmeng6](https://github.com/duolabmeng6)!
- [#6694](https://github.com/gradio-app/gradio/pull/6694) [`dfc61ec`](https://github.com/gradio-app/gradio/commit/dfc61ec4d09da72ddd6e7ab726820529621dbd38) - Fix dropdown blur bug when values are provided as tuples. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6691](https://github.com/gradio-app/gradio/pull/6691) [`128ab5d`](https://github.com/gradio-app/gradio/commit/128ab5d65b51390e706a515a1708fe6c88659209) - Ensure checked files persist after FileExplorer rerenders. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6698](https://github.com/gradio-app/gradio/pull/6698) [`798eca5`](https://github.com/gradio-app/gradio/commit/798eca524d44289c536c47eec7c4fdce9fe81905) - Fit video media within Video component. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6759](https://github.com/gradio-app/gradio/pull/6759) [`28a7aa9`](https://github.com/gradio-app/gradio/commit/28a7aa917f6a0d57af2c18261d1c01ff76423030) - Mount on a FastAPI app with lifespan manager. Thanks [@Xmaster6y](https://github.com/Xmaster6y)!
## 4.8.0
### Features
- [#6624](https://github.com/gradio-app/gradio/pull/6624) [`1751f14`](https://github.com/gradio-app/gradio/commit/1751f14c1b26c72c0fcc6ba4c69c060c7a199e5d) - Remove 2 slider demos from docs. Thanks [@aliabd](https://github.com/aliabd)!
- [#6622](https://github.com/gradio-app/gradio/pull/6622) [`4396f3f`](https://github.com/gradio-app/gradio/commit/4396f3f8f0984d7fcd7e1b88a793af86c7d4e5bb) - Fix encoding issue #6364 of reload mode. Thanks [@curiousRay](https://github.com/curiousRay)!
- [#5885](https://github.com/gradio-app/gradio/pull/5885) [`9919b8a`](https://github.com/gradio-app/gradio/commit/9919b8ab43bee3d1d7cc65fd641fc8bc9725e102) - Fix the docstring decoration. Thanks [@whitphx](https://github.com/whitphx)!
- [#6565](https://github.com/gradio-app/gradio/pull/6565) [`9bf1ad4`](https://github.com/gradio-app/gradio/commit/9bf1ad43eac543c9991e59f37e1910f217f8d739) - Fix uploaded file wasn't moved to custom temp dir at different disks. Thanks [@dodysw](https://github.com/dodysw)!
- [#6584](https://github.com/gradio-app/gradio/pull/6584) [`9bcb1da`](https://github.com/gradio-app/gradio/commit/9bcb1da189a9738d023ef6daad8c6c827e3f6371) - Feat: make UploadButton accept icon. Thanks [@Justin-Xiang](https://github.com/Justin-Xiang)!
- [#6512](https://github.com/gradio-app/gradio/pull/6512) [`4f040c7`](https://github.com/gradio-app/gradio/commit/4f040c752bb3b0586a4e16eca25a1e5f596eee48) - Update zh-CN.json. Thanks [@cibimo](https://github.com/cibimo)!
### Fixes
- [#6607](https://github.com/gradio-app/gradio/pull/6607) [`13ace03`](https://github.com/gradio-app/gradio/commit/13ace035ed58f14f8f5ce584d94b81c56f83b5d4) - Update file_explorer.py - Fixing error if nothing selected in file_count=single mode (return None rather). Thanks [@v-chabaux](https://github.com/v-chabaux)!
- [#6574](https://github.com/gradio-app/gradio/pull/6574) [`2b625ad`](https://github.com/gradio-app/gradio/commit/2b625ad9403c3449b34a8a3da68ae48c4347c2db) - Ensure Chatbot messages are properly aligned when `rtl` is true. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6635](https://github.com/gradio-app/gradio/pull/6635) [`b639e04`](https://github.com/gradio-app/gradio/commit/b639e040741e6c0d9104271c81415d7befbd8cf3) - Quick Image + Text Component Fixes. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#6572](https://github.com/gradio-app/gradio/pull/6572) [`206af31`](https://github.com/gradio-app/gradio/commit/206af31d7c1a31013364a44e9b40cf8df304ba50) - Improve like/dislike functionality. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6566](https://github.com/gradio-app/gradio/pull/6566) [`d548202`](https://github.com/gradio-app/gradio/commit/d548202d2b5bd8a99e3ebc5bf56820b0282ce0f5) - Improve video trimming and error handling. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6653](https://github.com/gradio-app/gradio/pull/6653) [`d92c819`](https://github.com/gradio-app/gradio/commit/d92c8194191d0e3530d6780a72d6f5c4c545e175) - Add concurrency_limit to ChatInterface, add IDE support for concurrency_limit. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6551](https://github.com/gradio-app/gradio/pull/6551) [`8fc562a`](https://github.com/gradio-app/gradio/commit/8fc562a8abc0932fc312ac33bcc015f6cf2700f6) - Add `show_recording_waveform` to Audio. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6550](https://github.com/gradio-app/gradio/pull/6550) [`3156598`](https://github.com/gradio-app/gradio/commit/315659817e5e67a04a1375d35ea6fa58d20622d2) - Make FileExplorer work on python 3.8 and 3.9. Also make it update on changes to root, glob, or glob_dir. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6602](https://github.com/gradio-app/gradio/pull/6602) [`b8034a1`](https://github.com/gradio-app/gradio/commit/b8034a1e72c3aac649ee0ad9178ffdbaaa60fc61) - Fix: Gradio Client work with private Spaces. Thanks [@abidlabs](https://github.com/abidlabs)!
## 4.7.1
### Features
- [#6537](https://github.com/gradio-app/gradio/pull/6537) [`6d3fecfa4`](https://github.com/gradio-app/gradio/commit/6d3fecfa42dde1c70a60c397434c88db77289be6) - chore(deps): update all non-major dependencies. Thanks [@renovate](https://github.com/apps/renovate)!
### Fixes
- [#6530](https://github.com/gradio-app/gradio/pull/6530) [`13ef0f0ca`](https://github.com/gradio-app/gradio/commit/13ef0f0caa13e5a1cea70d572684122419419599) - Quick fix: Make component interactive when it is in focus. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
## 4.6.0
### Features
- [#6532](https://github.com/gradio-app/gradio/pull/6532) [`96290d304`](https://github.com/gradio-app/gradio/commit/96290d304a61064b52c10a54b2feeb09ca007542) - tweak deps. Thanks [@pngwn](https://github.com/pngwn)!
- [#6511](https://github.com/gradio-app/gradio/pull/6511) [`71f1a1f99`](https://github.com/gradio-app/gradio/commit/71f1a1f9931489d465c2c1302a5c8d768a3cd23a) - Mark `FileData.orig_name` optional on the frontend aligning the type definition on the Python side. Thanks [@whitphx](https://github.com/whitphx)!
- [#6520](https://github.com/gradio-app/gradio/pull/6520) [`f94db6b73`](https://github.com/gradio-app/gradio/commit/f94db6b7319be902428887867500311a6a32a165) - File table style with accessible file name texts. Thanks [@whitphx](https://github.com/whitphx)!
- [#6523](https://github.com/gradio-app/gradio/pull/6523) [`63f466882`](https://github.com/gradio-app/gradio/commit/63f466882104453b56a7f52c6bea5b5d497ec698) - Fix typo in base.py. Thanks [@eltociear](https://github.com/eltociear)!
- [#6296](https://github.com/gradio-app/gradio/pull/6296) [`46f13f496`](https://github.com/gradio-app/gradio/commit/46f13f4968c8177e318c9d75f2eed1ed55c2c042) - chore(deps): update all non-major dependencies. Thanks [@renovate](https://github.com/apps/renovate)!
- [#6517](https://github.com/gradio-app/gradio/pull/6517) [`901f3eebd`](https://github.com/gradio-app/gradio/commit/901f3eebda0a67fa8f3050d80f7f7b5800c7f566) - Allow reselecting the original option in `gr.Dropdown` after value has changed programmatically. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6538](https://github.com/gradio-app/gradio/pull/6538) [`147926196`](https://github.com/gradio-app/gradio/commit/147926196a074d3fe62e59b5a80997e133c0f707) - Some tweaks to `ImageEditor`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6518](https://github.com/gradio-app/gradio/pull/6518) [`d4e3a5189`](https://github.com/gradio-app/gradio/commit/d4e3a518905620c184a0315ff3bdfbf5e7945bd6) - Allows setting parameters of `gr.ChatInterface`'s `Accordion`. Thanks [@abidlabs](https://github.com/abidlabs)!
### Fixes
- [#6528](https://github.com/gradio-app/gradio/pull/6528) [`f53b01cbf`](https://github.com/gradio-app/gradio/commit/f53b01cbfbfccec66e0cda1d428ef72f05a3dfc0) - Fix Theme Dropdown in deployed theme space. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6546](https://github.com/gradio-app/gradio/pull/6546) [`a424fdbb2`](https://github.com/gradio-app/gradio/commit/a424fdbb2389219661b9a73197f4cc095a08cfe9) - Ensure audio waveform `autoplay` updates. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6536](https://github.com/gradio-app/gradio/pull/6536) [`1bbd6cab3`](https://github.com/gradio-app/gradio/commit/1bbd6cab3f0abe183b514b82061f0937c8480966) - Fix undefined `data` TypeError in Blocks. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6500](https://github.com/gradio-app/gradio/pull/6500) [`830b6c0e6`](https://github.com/gradio-app/gradio/commit/830b6c0e6e52c4fa33fddfa4d3f6162e29801f74) - Process and convert .svg files in `Image`. Thanks [@hannahblair](https://github.com/hannahblair)!
## 4.5.0
### Highlights
#### New `ImageEditor` component ([#6169](https://github.com/gradio-app/gradio/pull/6169) [`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8))
A brand new component, completely separate from `Image` that provides simple editing capabilities.
- Set background images from file uploads, webcam, or just paste!
- Crop images with an improved cropping UI. App authors can event set specific crop size, or crop ratios (`1:1`, etc)
- Paint on top of any image (or no image) and erase any mistakes!
- The ImageEditor supports layers, confining draw and erase actions to that layer.
- More flexible access to data. The image component returns a composite image representing the final state of the canvas as well as providing the background and all layers as individual images.
- Fully customisable. All features can be enabled and disabled. Even the brush color swatches can be customised.
<video src="https://user-images.githubusercontent.com/12937446/284027169-31188926-fd16-4a1c-8718-998e7aae4695.mp4" autoplay muted></video>
```py
def fn(im):
im["composite"] # the full canvas
im["background"] # the background image
im["layers"] # a list of individual layers
im = gr.ImageEditor(
# decide which sources you'd like to accept
sources=["upload", "webcam", "clipboard"],
# set a cropsize constraint, can either be a ratio or a concrete [width, height]
crop_size="1:1",
# enable crop (or disable it)
transforms=["crop"],
# customise the brush
brush=Brush(
default_size="25", # or leave it as 'auto'
color_mode="fixed", # 'fixed' hides the user swatches and colorpicker, 'defaults' shows it
default_color="hotpink", # html names are supported
colors=[
"rgba(0, 150, 150, 1)", # rgb(a)
"#fff", # hex rgb
"hsl(360, 120, 120)" # in fact any valid colorstring
]
),
brush=Eraser(default_size="25")
)
```
Thanks [@pngwn](https://github.com/pngwn)!
### Fixes
- [#6497](https://github.com/gradio-app/gradio/pull/6497) [`1baed201b`](https://github.com/gradio-app/gradio/commit/1baed201b12ecb5791146aed9a86b576c3595130) - Fix SourceFileReloader to watch the module with a qualified name to avoid importing a module with the same name from a different path. Thanks [@whitphx](https://github.com/whitphx)!
- [#6502](https://github.com/gradio-app/gradio/pull/6502) [`070f71c93`](https://github.com/gradio-app/gradio/commit/070f71c933d846ce8e2fe11cdd9bc0f3f897f29f) - Ensure image editor crop and draw cursor works as expected when the scroll position changes. Thanks [@pngwn](https://github.com/pngwn)!
## 4.4.1
### Features
- [#6467](https://github.com/gradio-app/gradio/pull/6467) [`739e3a5a0`](https://github.com/gradio-app/gradio/commit/739e3a5a09771a4a386cab0c6605156cf9fda7f6) - Fix dev mode. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 4.4.0
### Features
- [#6428](https://github.com/gradio-app/gradio/pull/6428) [`ac4ca59c9`](https://github.com/gradio-app/gradio/commit/ac4ca59c929bbe0bdf92155766883797d4e01ea0) - Extract video filenames correctly from URLs. Thanks [@112292454](https://github.com/112292454)!
- [#6461](https://github.com/gradio-app/gradio/pull/6461) [`6b53330a5`](https://github.com/gradio-app/gradio/commit/6b53330a5be53579d9128aea4858713082ce302d) - UploadButton tests. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6439](https://github.com/gradio-app/gradio/pull/6439) [`a1e3c61f4`](https://github.com/gradio-app/gradio/commit/a1e3c61f41b16166656b46254a201b37abcf20a8) - Allow setting a `default_concurrency_limit` other than 1. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6455](https://github.com/gradio-app/gradio/pull/6455) [`179f5bcde`](https://github.com/gradio-app/gradio/commit/179f5bcde16539bb9e828685d95dcd2167d3a215) - Add py.typed to gradio backend. Thanks [@aleneum](https://github.com/aleneum)!
- [#6436](https://github.com/gradio-app/gradio/pull/6436) [`58e3ca826`](https://github.com/gradio-app/gradio/commit/58e3ca8260a6635e10e7a7f141221c4f746e9386) - Custom Component CLI Improvements. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6462](https://github.com/gradio-app/gradio/pull/6462) [`2761b6d19`](https://github.com/gradio-app/gradio/commit/2761b6d197acc1c6a2fd9534e7633b463bd3f1e0) - Catch ValueError, KeyError when saving PIL Image. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6423](https://github.com/gradio-app/gradio/pull/6423) [`62d35c3d1`](https://github.com/gradio-app/gradio/commit/62d35c3d1b3e9d6e39bddbb32ff6b6cf9f1f7f72) - Issue 2085: Transformers object detection pipeline added. Thanks [@cswamy](https://github.com/cswamy)!
- [#6456](https://github.com/gradio-app/gradio/pull/6456) [`3953a1467`](https://github.com/gradio-app/gradio/commit/3953a146750b09161b50d972590cae8bf980990c) - Preserve original image extension in backend processing. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6427](https://github.com/gradio-app/gradio/pull/6427) [`e0fc14659`](https://github.com/gradio-app/gradio/commit/e0fc146598ba9b081bc5fa9616d0a41c2aba2427) - Allow google analytics to work on Spaces (and other iframe situations). Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6419](https://github.com/gradio-app/gradio/pull/6419) [`1959471a8`](https://github.com/gradio-app/gradio/commit/1959471a8d939275c7b9184913a5a6f92e567604) - Add download tests for audio/video. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6424](https://github.com/gradio-app/gradio/pull/6424) [`2727f45fb`](https://github.com/gradio-app/gradio/commit/2727f45fb0c9c3116a7e1a3f88cb3a401c4c7e93) - Do not show warnings when renaming api_names. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6437](https://github.com/gradio-app/gradio/pull/6437) [`727ae2597`](https://github.com/gradio-app/gradio/commit/727ae2597603f026d74d5acafac8709326300836) - chore: rename api_key to hf_token. Thanks [@NickCrews](https://github.com/NickCrews)!
### Fixes
- [#6441](https://github.com/gradio-app/gradio/pull/6441) [`2f805a7dd`](https://github.com/gradio-app/gradio/commit/2f805a7dd3d2b64b098f659dadd5d01258290521) - Small but important bugfixes for gr.Image: The upload event was not triggering at all. The paste-from-clipboard was not triggering an upload event. The clear button was not triggering a change event. The change event was triggering infinitely. Uploaded images were not preserving their original names. Uploading a new image should clear out the previous image. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6454](https://github.com/gradio-app/gradio/pull/6454) [`2777f326e`](https://github.com/gradio-app/gradio/commit/2777f326e595541fbec8ce14f56340b9e740f1da) - Ensure Audio ouput events are dispatched. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6254](https://github.com/gradio-app/gradio/pull/6254) [`f816136a0`](https://github.com/gradio-app/gradio/commit/f816136a039fa6011be9c4fb14f573e4050a681a) - Add volume control to Audio. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6457](https://github.com/gradio-app/gradio/pull/6457) [`d00fcf89d`](https://github.com/gradio-app/gradio/commit/d00fcf89d1c3ecbc910e81bb1311479ec2b73e4e) - Gradio custom component dev mode now detects changes to Example.svelte file. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6418](https://github.com/gradio-app/gradio/pull/6418) [`bce6ca109`](https://github.com/gradio-app/gradio/commit/bce6ca109feadd6ba94a69843689cefc381dd054) - Send more than one heartbeat message. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6425](https://github.com/gradio-app/gradio/pull/6425) [`b3ba17dd1`](https://github.com/gradio-app/gradio/commit/b3ba17dd1167d254756d93f1fb01e8be071819b6) - Update the selected indices in `Dropdown` when value changes programmatically. Thanks [@abidlabs](https://github.com/abidlabs)!
## 4.3.0
### Features
- [#6395](https://github.com/gradio-app/gradio/pull/6395) [`8ef48f852`](https://github.com/gradio-app/gradio/commit/8ef48f85241a0f06f4bcdaa0a2010917b3a536be) - Async functions and async generator functions with the `every` option to work. Thanks [@whitphx](https://github.com/whitphx)!
- [#6403](https://github.com/gradio-app/gradio/pull/6403) [`9cfeb4f17`](https://github.com/gradio-app/gradio/commit/9cfeb4f17e76efad7772e0cbe53dfb3e8310f565) - Remove websockets dependency. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6406](https://github.com/gradio-app/gradio/pull/6406) [`0401c77f3`](https://github.com/gradio-app/gradio/commit/0401c77f3d35763b79e040dbe876e69083defd36) - Move ffmpeg to `Video` deps. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6099](https://github.com/gradio-app/gradio/pull/6099) [`d84209703`](https://github.com/gradio-app/gradio/commit/d84209703b7a0728cdb49221e543500ddb6a8d33) - Lite: SharedWorker mode. Thanks [@whitphx](https://github.com/whitphx)!
### Fixes
- [#6412](https://github.com/gradio-app/gradio/pull/6412) [`649f3ceb6`](https://github.com/gradio-app/gradio/commit/649f3ceb6c784c82fa88bdb7f04535f6419b14dd) - Added docs on gr.Examples. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6378](https://github.com/gradio-app/gradio/pull/6378) [`d31d8c6ad`](https://github.com/gradio-app/gradio/commit/d31d8c6ad888aa4f094820d07288e9d0e2778521) - Allows `sources` to be a string for `gr.Image`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6382](https://github.com/gradio-app/gradio/pull/6382) [`2090aad73`](https://github.com/gradio-app/gradio/commit/2090aad731b186ef0a3f63ec2b4d1a6e3acb1754) - Move wavesurfer dep to js/audio. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6383](https://github.com/gradio-app/gradio/pull/6383) [`324867f63`](https://github.com/gradio-app/gradio/commit/324867f63c920113d89a565892aa596cf8b1e486) - Fix event target. Thanks [@aliabid94](https://github.com/aliabid94)!
- [#6405](https://github.com/gradio-app/gradio/pull/6405) [`03491ef49`](https://github.com/gradio-app/gradio/commit/03491ef49708753fc51566c3dc17df09ae98fb98) - Fix docstrings and default value for `api_name`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6386](https://github.com/gradio-app/gradio/pull/6386) [`e76a9e8fc`](https://github.com/gradio-app/gradio/commit/e76a9e8fcbbfc393298de2aa539f2b152c0d6400) - Fix Chatbot Pending Message Issues. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#6414](https://github.com/gradio-app/gradio/pull/6414) [`da1e31832`](https://github.com/gradio-app/gradio/commit/da1e31832f85ec76540e474ae35badfde8a18b6f) - Fix Model3D download button and other issues. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6379](https://github.com/gradio-app/gradio/pull/6379) [`de998b281`](https://github.com/gradio-app/gradio/commit/de998b28127ecef10c403890ff08674f527a3708) - Processes `avatar_images` for `gr.Chatbot` and `icon` for `gr.Button` correctly, so that respective files are moved to cache. Thanks [@abidlabs](https://github.com/abidlabs)!
## 4.2.0
### Features
- [#6333](https://github.com/gradio-app/gradio/pull/6333) [`42f76aeeb`](https://github.com/gradio-app/gradio/commit/42f76aeeb7b7263abccc038b699fb7fae7fe2313) - Add AsyncGenerator to the check-list of `dependencies.types.generator`. Thanks [@whitphx](https://github.com/whitphx)!
- [#6347](https://github.com/gradio-app/gradio/pull/6347) [`d64787b88`](https://github.com/gradio-app/gradio/commit/d64787b885a26ecb6771bfdd20aac33c8a90afe6) - Fix `colorFrom` in theme space readmes. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6363](https://github.com/gradio-app/gradio/pull/6363) [`4d3aad33a`](https://github.com/gradio-app/gradio/commit/4d3aad33a0b66639dbbb2928f305a79fb7789b2d) - Fix image upload. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6356](https://github.com/gradio-app/gradio/pull/6356) [`854b482f5`](https://github.com/gradio-app/gradio/commit/854b482f598e0dc47673846631643c079576da9c) - Redesign file upload. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6343](https://github.com/gradio-app/gradio/pull/6343) [`37dd335e5`](https://github.com/gradio-app/gradio/commit/37dd335e5f04a8e689dd7f23ae24ad1934ea08d8) - Fix audio streaming output issues in 4.0. Thanks [@aliabid94](https://github.com/aliabid94)!
- [#6307](https://github.com/gradio-app/gradio/pull/6307) [`f1409f95e`](https://github.com/gradio-app/gradio/commit/f1409f95ed39c5565bed6a601e41f94e30196a57) - Provide status updates on file uploads. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
### Fixes
- [#6368](https://github.com/gradio-app/gradio/pull/6368) [`8a3f45c26`](https://github.com/gradio-app/gradio/commit/8a3f45c2612a36112d797465e14cd6f1801ccbd9) - Fix component update bug. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6322](https://github.com/gradio-app/gradio/pull/6322) [`6204ccac5`](https://github.com/gradio-app/gradio/commit/6204ccac5967763e0ebde550d04d12584243a120) - Fixes `gr.load()` so it works properly with Images and Examples. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6323](https://github.com/gradio-app/gradio/pull/6323) [`55fda81fa`](https://github.com/gradio-app/gradio/commit/55fda81fa5918b48952729232d6e2fc55af9351d) - Textbox and Code Component Blur/Focus Fixes. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
## 4.1.2
### Features
- [#6318](https://github.com/gradio-app/gradio/pull/6318) [`d3b53a457`](https://github.com/gradio-app/gradio/commit/d3b53a4577ea05cd27e37ce7fec952028c18ed45) - Fix for stylized DataFrame. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6326](https://github.com/gradio-app/gradio/pull/6326) [`ed546f2e1`](https://github.com/gradio-app/gradio/commit/ed546f2e13915849b0306d017c40933b856bb792) - Fix Model3D template. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
### Fixes
- [#6310](https://github.com/gradio-app/gradio/pull/6310) [`dfdaf1092`](https://github.com/gradio-app/gradio/commit/dfdaf109263b7b88c125558028ee9609f817fd10) - Fix data model for `gr.DataFrame`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6316](https://github.com/gradio-app/gradio/pull/6316) [`4b1011bab`](https://github.com/gradio-app/gradio/commit/4b1011bab03c0b6a09329e0beb9c1b17b2189878) - Maintain text selection in `Chatbot` button elements. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6327](https://github.com/gradio-app/gradio/pull/6327) [`bca6c2c80`](https://github.com/gradio-app/gradio/commit/bca6c2c80f7e5062427019de45c282238388af95) - Restore query parameters in request. Thanks [@aliabid94](https://github.com/aliabid94)!
- [#6317](https://github.com/gradio-app/gradio/pull/6317) [`19af2806a`](https://github.com/gradio-app/gradio/commit/19af2806a58419cc551d2d1d6d8987df0db91ccb) - Add autoplay to `waveform_settings`. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6294](https://github.com/gradio-app/gradio/pull/6294) [`7ab73df48`](https://github.com/gradio-app/gradio/commit/7ab73df48ea9dc876c1eaedfb424fcead6326dc9) - fix regarding callable function error. Thanks [@SrijanSahaySrivastava](https://github.com/SrijanSahaySrivastava)!
- [#6279](https://github.com/gradio-app/gradio/pull/6279) [`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780) - Ensure source selection does not get hidden in overflow. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6311](https://github.com/gradio-app/gradio/pull/6311) [`176c4d140`](https://github.com/gradio-app/gradio/commit/176c4d140000b1be698b6caf0d0efd26a5c7897d) - Temporary fix to be able to load themes from Hub. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6314](https://github.com/gradio-app/gradio/pull/6314) [`fad92c29d`](https://github.com/gradio-app/gradio/commit/fad92c29dc1f5cd84341aae417c495b33e01245f) - Improve default source behaviour in Audio. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6320](https://github.com/gradio-app/gradio/pull/6320) [`570866a3b`](https://github.com/gradio-app/gradio/commit/570866a3bd95a45a197afec38b982bbc6c7cd0a0) - Hide show API link when in gradio lite. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6309](https://github.com/gradio-app/gradio/pull/6309) [`c56128781`](https://github.com/gradio-app/gradio/commit/c561287812797aa1b6b464b0e76419350570ba83) - Fix updating choices in `gr.Dropdown` and updates related to other components. Thanks [@abidlabs](https://github.com/abidlabs)!
## 4.1.1
### Fixes
- [#6288](https://github.com/gradio-app/gradio/pull/6288) [`92278729e`](https://github.com/gradio-app/gradio/commit/92278729ee008126af15ffe6be399236211b2f34) - Gallery preview fix and optionally skip download of urls in postprcess. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6289](https://github.com/gradio-app/gradio/pull/6289) [`5668036ee`](https://github.com/gradio-app/gradio/commit/5668036eef89051c1dbc5a74dc20988a3012ccbd) - Fix file upload on windows. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6290](https://github.com/gradio-app/gradio/pull/6290) [`e8216be94`](https://github.com/gradio-app/gradio/commit/e8216be948f76ce064595183d11e9148badf9421) - ensure `gr.Dataframe` updates as expected. Thanks [@pngwn](https://github.com/pngwn)!
## 4.1.0
### Features
- [#6261](https://github.com/gradio-app/gradio/pull/6261) [`8bbeca0e7`](https://github.com/gradio-app/gradio/commit/8bbeca0e772a5a2853d02a058b35abb2c15ffaf1) - Improve Embed and CDN handling and fix a couple of related bugs. Thanks [@pngwn](https://github.com/pngwn)!
- [#6241](https://github.com/gradio-app/gradio/pull/6241) [`61c155e9b`](https://github.com/gradio-app/gradio/commit/61c155e9ba0f8f7ebd5a2a71687597dafb842219) - Remove session if browser closed on mobile. Thanks [@aliabid94](https://github.com/aliabid94)!
- [#6227](https://github.com/gradio-app/gradio/pull/6227) [`4840b4bc2`](https://github.com/gradio-app/gradio/commit/4840b4bc297703d317cad9c0f566e857a20b9375) - Add that api routes are automatically named to CHANGELOG. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6240](https://github.com/gradio-app/gradio/pull/6240) [`dd901c1b0`](https://github.com/gradio-app/gradio/commit/dd901c1b0af73a78fca8b6875b2bb00f84071ac8) - Model3D panning, improved UX. Thanks [@dylanebert](https://github.com/dylanebert)!
- [#6272](https://github.com/gradio-app/gradio/pull/6272) [`12d8e90a1`](https://github.com/gradio-app/gradio/commit/12d8e90a1646374b46eb8258be7356c868d1cca3) - Fixes input `Image` component with `streaming=True`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6268](https://github.com/gradio-app/gradio/pull/6268) [`de36820ef`](https://github.com/gradio-app/gradio/commit/de36820ef51097b47937b41fb76e4038aaa369cb) - Fix various issues with demos on website. Thanks [@aliabd](https://github.com/aliabd)!
- [#6232](https://github.com/gradio-app/gradio/pull/6232) [`ac4f2bcde`](https://github.com/gradio-app/gradio/commit/ac4f2bcded61672bfe1d54c279d527de2eabdb7a) - Remove **kwargs from queue. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6255](https://github.com/gradio-app/gradio/pull/6255) [`e3ede2ff7`](https://github.com/gradio-app/gradio/commit/e3ede2ff7d4a36fb21bb0b146b8d5ad239c0e086) - Ensure Model 3D updates when attributes change. Thanks [@hannahblair](https://github.com/hannahblair)!
### Fixes
- [#6266](https://github.com/gradio-app/gradio/pull/6266) [`e32bac894`](https://github.com/gradio-app/gradio/commit/e32bac8944c85e0ec4831963299889d6bbfa0351) - Fix updating interactive prop. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6213](https://github.com/gradio-app/gradio/pull/6213) [`27194a987`](https://github.com/gradio-app/gradio/commit/27194a987fa7ba1234b5fc0ce8bf7fabef7033a9) - Ensure the statustracker for `gr.Image` displays in static mode. Thanks [@pngwn](https://github.com/pngwn)!
- [#6234](https://github.com/gradio-app/gradio/pull/6234) [`aaa55ce85`](https://github.com/gradio-app/gradio/commit/aaa55ce85e12f95aba9299445e9c5e59824da18e) - Video/Audio fixes. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6236](https://github.com/gradio-app/gradio/pull/6236) [`6bce259c5`](https://github.com/gradio-app/gradio/commit/6bce259c5db7b21b327c2067e74ea20417bc89ec) - Ensure `gr.CheckboxGroup` updates as expected. Thanks [@pngwn](https://github.com/pngwn)!
- [#6262](https://github.com/gradio-app/gradio/pull/6262) [`afb72bd19`](https://github.com/gradio-app/gradio/commit/afb72bd1970e6c43ddba0638fe9861330bdabb64) - Fix bug where radio.select passes the previous value to the function instead of the selected value. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6231](https://github.com/gradio-app/gradio/pull/6231) [`3e31c1752`](https://github.com/gradio-app/gradio/commit/3e31c1752e0e5bf90339b816f9895529d9368bbd) - Add likeable to config for Chatbot. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6249](https://github.com/gradio-app/gradio/pull/6249) [`2cffcf3c3`](https://github.com/gradio-app/gradio/commit/2cffcf3c39acd782f314f8a406100ae22e0809b7) - ensure radios have different names. Thanks [@pngwn](https://github.com/pngwn)!
- [#6229](https://github.com/gradio-app/gradio/pull/6229) [`5cddd6588`](https://github.com/gradio-app/gradio/commit/5cddd658809d147fafef5e9502ccfab5bd105aa6) - Fixes: Initial message is overwrtitten in chat interface. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#6277](https://github.com/gradio-app/gradio/pull/6277) [`5fe091367`](https://github.com/gradio-app/gradio/commit/5fe091367fbe0eecdd504aa734ca1c70b0621f52) - handle selected_index prop change for gallery. Thanks [@pngwn](https://github.com/pngwn)!
- [#6211](https://github.com/gradio-app/gradio/pull/6211) [`a4a931dd3`](https://github.com/gradio-app/gradio/commit/a4a931dd39a48bceac50486558b049ca7b874195) - fix`FileExplorer` preprocess. Thanks [@pngwn](https://github.com/pngwn)!
- [#5876](https://github.com/gradio-app/gradio/pull/5876) [`d7a1a6559`](https://github.com/gradio-app/gradio/commit/d7a1a6559005e6a1e0be03a3bd5212d1bc60d1ee) - Fix file overflow and add keyboard navigation to `FileExplorer`. Thanks [@hannahblair](https://github.com/hannahblair)!
## 4.0.2
### Fixes
- [#6191](https://github.com/gradio-app/gradio/pull/6191) [`b555bc09f`](https://github.com/gradio-app/gradio/commit/b555bc09ffe8e58b10da6227e2f11a0c084aa71d) - fix cdn build. Thanks [@pngwn](https://github.com/pngwn)!
## 4.0.1
### Features
- [#6137](https://github.com/gradio-app/gradio/pull/6137) [`2ba14b284`](https://github.com/gradio-app/gradio/commit/2ba14b284f908aa13859f4337167a157075a68eb) - JS Param. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#6181](https://github.com/gradio-app/gradio/pull/6181) [`62ec2075c`](https://github.com/gradio-app/gradio/commit/62ec2075ccad8025a7721a08d0f29eb5a4f87fad) - modify preprocess to use pydantic models. Thanks [@abidlabs](https://github.com/abidlabs)!
## 4.0.0
### Highlights
4.0 is a big release, so here are the main highlights:
**1. Custom Components**:
We've introduced the ability to create and publish you own custom `gradio` components. A custom Gradio component is a combination of Python and JavaScript (specifically, Svelte) that you can write to fully customize a Gradio component. A custom component can be used just like a regular Gradio component (with `gr.Interface`, `gr.Blocks`, etc.) and can be published so that other users can use it within their apps. To get started with Custom Components, [read our quickstart guide here](https://www.gradio.app/guides/five-minute-guide).
<img src="https://media2.giphy.com/media/v1.Y2lkPTc5MGI3NjExMm9pbzhvaTd1MTFlM3FrMmRweTh1ZWZiMmpvemhpNnVvaXVoeDZ2byZlcD12MV9pbnRlcm5hbF9naWZfYnlfaWQmY3Q9Zw/V3N5jnv0D1eKbPYins/giphy.gif">
**2. Redesigned Media Components and Accessibility**:
We redesigned our media components (`gr.Audio`, `gr.Image`, and `gr.Video`) from scratch and improved accessibilty across the board. All components are now keyboard navigable and include better colors to be usable by a wider audience.
<img src="https://media0.giphy.com/media/Kv1bAN7MX3ya5krkEU/giphy.gif">
**3. Server Side Events**:
Gradio's built-in queuing system is now the default for every Gradio app. We now use Server Side Events instead of Websockets for the queue. SSE means everything is served over HTTP and has better device support and better scaling than websockets.
<img style="width:50%" src="https://i.imgur.com/ewUIuUc.png">
**4. Custom Share Servers**:
Gradio share links can now run on custom domains. You can now set up your own server to serve Gradio share links. To get started, [read our guide here](https://github.com/huggingface/frp/).
<img style="width:50%" src="https://i.imgur.com/VFWVsqn.png">
5. We now support adding arbitrary JS to your apps using the `js` parameter in Blocks, and arbitrary modifications to the <head> of your app using the `head` parameter in Blocks
6. We no longer expose a user's working directory by default when you release a Gradio app. There are some other improvements around security as well.
7. Previously, a Gradio app's API endpoints were exposed, allowing you to bypass the queue. As a Gradio developer, you needed to set `api_open=False` to prevent this misuse. We've now made this the default.
8. You can now control whether a user should be able to trigger the same event multiple times (by using the `trigger_mode` parameter of each event)
9. You now have fine-grained control over how many times each event can be running concurrently in the backend (using the `concurrency_limit` parameter of each event)
10. We no longer serialize images into base64 before sending them to the server or on the way back. This should make any Gradio app that includes `gr.Image` components much faster.
### Breaking Changes
Gradio 4.0 is a new major version, and includes breaking changes from 3.x. Here's a list of all the breaking changes, along with migration steps where appropriate.
**Components**:
* Removes `**kwarg` from every component, meaning that components cannot accept arbitrary (unused) parameters. Previously, warnings would be thrown.
* Removes deprecated parameters. For example, `plain` is no longer an alias for `secondary` for the `variant` argument in the `gr.Button` class
* Removes the deprecated `Carousel` class and `StatusTracker` class and `Box` layout class
* Removes the deprecated `Variable` alias for `State`
* Removes the deprecated `.style()` methods from component classes
* Removes the deprecated `.update()` method from component classes
* Removes `get_interpretation_neighbors()` and `get_interpretation_scores()` from component classes
* Removes `deprecation.py` -- this was designed for internal usage so unlikely to break gradio apps
* Moves save to cache methods from component methods to standalone functions in processing_utils
* Renames `source` param in `gr.Audio` and `gr.Video` to `sources`
* Removes `show_edit_button` param from `gr.Audio`
* The `tool=` argument in `gr.Image()` has been removed. As of `gradio==4.5.0`, we have a new `gr.ImageEditor` component that takes its place. The `ImageEditor` component is a streamlined component that allows you to do basic manipulation of images. It supports setting a background image (which can be uploaded, pasted, or recorded through a webcam), as well the ability to "edit" the background image by using a brush to create strokes and an eraser to erase strokes in layers on top of the background image. See the **Migrating to Gradio 4.0** section below.
**Other changes related to the `gradio` library**:
* Removes the deprecated `status_tracker` parameter from events
* Removes the deprecated `HuggingFaceDatasetJSONSaver` class
* Now `Blocks.load()` can only be use an is instance method to attach an event that runs when the page loads. To use the class method, use `gr.load()` instead
* Similarly, `Interface.load()` has been removed
* If you are runnin Gradio 4.x, you can not `gr.load` a Space that is running Gradio 3.x. However, you can still use the client libraries (see changes to the client libraries below).
* Removes deprecated parameters, such as `enable_queue` from `launch()`
* Many of the positional arguments in launch() are now keyword only, and show_tips has been removed
* Changes the format of flagged data to json instead of filepath for media and chatbot
* Removes `gr.Series` and `gr.Parallel`
* All API endpoints are named by deafult. If `api_name=None`, the api name is the name of the python function.
**Changes related to the Client libraries**:
* When using the gradio Client libraries in 3.x with any component that returned JSON data (including `gr.Chatbot`, `gr.Label`, and `gr.JSON`), the data would get saved to a file and the filepath would be returned. Similarly, you would have to pass input JSON as a filepath. Now, the JSON data is passed and returned directly, making it easier to work with these components using the clients.
### Migrating to Gradio 4.0
Here are some concrete tips to help migrate to Gradio 4.0:
#### **Using `allowed_paths`**
Since the working directory is now not served by default, if you reference local files within your CSS or in a `gr.HTML` component using the `/file=` route, you will need to explicitly allow access to those files (or their parent directories) using the `allowed_paths` parameter in `launch()`
For example, if your code looks like this:
```py
import gradio as gr
with gr.Blocks() as demo:
gr.HTML("<img src='/file=image.png' alt='image One'>")
demo.launch()
```
In order for the HTML component to be able to serve `image.png`, you will need to add `image.png` in `allowed_paths` like this:
```py
import gradio as gr
with gr.Blocks() as demo:
gr.HTML("<img src='/file=image.png' alt='image One'>")
demo.launch(allowed_paths=["image.png"])
```
or if you want to expose all files in your working directory as was the case in Gradio 3.x (not recommended if you plan to share your app with others), you could do:
```py
import gradio as gr
with gr.Blocks() as demo:
gr.HTML("<img src='/file=image.png' alt='image One'>")
demo.launch(allowed_paths=["."])
```
#### **Using `concurrency_limit` instead of `concurrency_count`**
Previously, in Gradio 3.x, there was a single global `concurrency_count` parameter that controlled how many threads could execute tasks from the queue simultaneously. By default `concurrency_count` was 1, which meant that only a single event could be executed at a time (to avoid OOM errors when working with prediction functions that utilized a large amount of memory or GPU usage). You could bypass the queue by setting `queue=False`.
In Gradio 4.0, the `concurrency_count` parameter has been removed. You can still control the number of total threads by using the `max_threads` parameter. The default value of this parameter is `40`, but you don't have worry (as much) about OOM errors, because even though there are 40 threads, we use a single-worker-single-event model, which means each worker thread only executes a specific function. So effectively, each function has its own "concurrency count" of 1. If you'd like to change this behavior, you can do so by setting a parameter `concurrency_limit`, which is now a parameter of *each event*, not a global parameter. By default this is `1` for each event, but you can set it to a higher value, or to `None` if you'd like to allow an arbitrary number of executions of this event simultaneously. Events can also be grouped together using the `concurrency_id` parameter so that they share the same limit, and by default, events that call the same function share the same `concurrency_id`.
Lastly, it should be noted that the default value of the `concurrency_limit` of all events in a Blocks (which is normally 1) can be changed using the `default_concurrency_limit` parameter in `Blocks.queue()`. You can set this to a higher integer or to `None`. This in turn sets the `concurrency_limit` of all events that don't have an explicit `conurrency_limit` specified.
To summarize migration:
* For events that execute quickly or don't use much CPU or GPU resources, you should set `concurrency_limit=None` in Gradio 4.0. (Previously you would set `queue=False`.)
* For events that take significant resources (like the prediction function of your machine learning model), and you only want 1 execution of this function at a time, you don't have to set any parameters.
* For events that take significant resources (like the prediction function of your machine learning model), and you only want `X` executions of this function at a time, you should set `concurrency_limit=X` parameter in the event trigger.(Previously you would set a global `concurrency_count=X`.)
**The new `ImageEditor` component**
In Gradio 4.0, the `tool=` argument in `gr.Image()` was removed. It has been replaced, as of Gradio 4.5.0, with a new `gr.ImageEditor()` component. The `ImageEditor` component is a streamlined component that allows you to do basic manipulation of images. It supports setting a background image (which can be uploaded, pasted, or recorded through a webcam), as well the ability to "edit" the background by using a brush to create strokes and an eraser to erase strokes in layers on top of the background image.
The `ImageEditor` component is much more performant and also offers much more flexibility to customize the component, particularly through the new `brush` and `eraser` arguments, which take `Brush` and `Eraser` objects respectively.
Here are some examples of how you might migrate from `Image(tool=...)` to `gr.ImageEditor()`.
* To create a sketchpad input that supports writing black strokes on a white background, you might have previously written:
```py
gr.Image(source="canvas", tools="sketch")
```
Now, you should write:
```py
gr.ImageEditor(sources=(), brush=gr.Brush(colors=["#000000"]))
```
Note: you can supply a list of supported stroke colors in `gr.Brush`, as well as control whether users can choose their own colors by setting the `color_mode` parameter of `gr.Brush` to be either `"fixed"` or `"defaults"`.
* If you want to create a sketchpad where users can draw in any color, simply omit the `brush` parameter. In other words, where previously, you would do:
```py
gr.Image(source="canvas", tools="color-sketch")
```
Now, you should write:
```py
gr.ImageEditor(sources=())
```
* If you want to allow users to choose a background image and then draw on the image, previously, you would do:
```py
gr.Image(source="upload", tools="color-sketch")
```
Now, this is the default behavior of the `ImageEditor` component, so you should just write:
```py
gr.ImageEditor()
```
Unlike the `Image` component, which passes the input image as a single value into the prediction function, the `ImageEditor` passes a dictionary consisting of three key-value pairs:
* the key `"background"`, whose value is the background image
* the key `"layers"`, which consists of a list of values, with the strokes in each layer corresponding to one list element.
* the key `"composite"`, whose value is to the complete image consisting of background image and all of the strokes.
The type of each value can be set by the `type` parameter (`"filepath"`, `"pil"`, or `"numpy"`, with the default being `"numpy"`), just like in the `Image` component.
Please see the documentation of the `gr.ImageEditor` component for more details: https://www.gradio.app/docs/imageeditor
### Features
- [#6184](https://github.com/gradio-app/gradio/pull/6184) [`86edc0199`](https://github.com/gradio-app/gradio/commit/86edc01995d9f888bac093c44c3d4535fe6483b3) - Remove gr.mix. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - fix circular dependency with client + upload. Thanks [@pngwn](https://github.com/pngwn)!
- [#6177](https://github.com/gradio-app/gradio/pull/6177) [`59f5a4e30`](https://github.com/gradio-app/gradio/commit/59f5a4e30ed9da1c6d6f6ab0886285150b3e89ec) - Part I: Remove serializes. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Don't serve files in working directory by default. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Small change to make `api_open=False` by default. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Add json schema unit tests. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Remove duplicate `elem_ids` from components. Thanks [@pngwn](https://github.com/pngwn)!
- [#6182](https://github.com/gradio-app/gradio/pull/6182) [`911829ac2`](https://github.com/gradio-app/gradio/commit/911829ac278080fc81155d4b75502692e72fd3de) - Allow data at queue join. Thanks [@aliabid94](https://github.com/aliabid94)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Moves `gradio_cached_folder` inside the gradio temp direcotry. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - V4: Fix constructor_args. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Remove interpretation for good. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Improve Audio Component. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - pass props to example components and to example outputs. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Clean root url. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Adds the ability to build the frontend and backend of custom components in preparation for publishing to pypi using `gradio_component build`. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Fix selectable prop in the backend. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Set api=False for cancel events. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Improve Video Component. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Try to trigger a major beta release. Thanks [@pngwn](https://github.com/pngwn)!
- [#6172](https://github.com/gradio-app/gradio/pull/6172) [`79c8156eb`](https://github.com/gradio-app/gradio/commit/79c8156ebbf35369dc9cfb1522f88df3cd49c89c) - Queue concurrency count. Thanks [@aliabid94](https://github.com/aliabid94)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Image v4. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Open source FRP server and allow `gradio` to connect to custom share servers. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - File upload optimization. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Removes deprecated arguments and parameters from v4. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - V4: Use async version of shutil in upload route. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - V4: Set cache dir for some component tests. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Proposal: sample demo for custom components should be a `gr.Interface`. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - fix cc build. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - --overwrite deletes previous content. Thanks [@pngwn](https://github.com/pngwn)!
- [#6171](https://github.com/gradio-app/gradio/pull/6171) [`28322422c`](https://github.com/gradio-app/gradio/commit/28322422cb9d8d3e471e439ad602959662e79312) - strip dangling svelte imports. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Swap websockets for SSE. Thanks [@pngwn](https://github.com/pngwn)!
- [#6153](https://github.com/gradio-app/gradio/pull/6153) [`1162ed621`](https://github.com/gradio-app/gradio/commit/1162ed6217fe58d66a1923834c390150599ad81f) - Remove `show_edit_button` param in Audio. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6124](https://github.com/gradio-app/gradio/pull/6124) [`a7435ba9e`](https://github.com/gradio-app/gradio/commit/a7435ba9e6f8b88a838e80893eb8fedf60ccda67) - Fix static issues with Lite on v4. Thanks [@aliabd](https://github.com/aliabd)!
- [#6143](https://github.com/gradio-app/gradio/pull/6143) [`e4f7b4b40`](https://github.com/gradio-app/gradio/commit/e4f7b4b409323b01aa01b39e15ce6139e29aa073) - fix circular dependency with client + upload. Thanks [@pngwn](https://github.com/pngwn)!
- [#6136](https://github.com/gradio-app/gradio/pull/6136) [`667802a6c`](https://github.com/gradio-app/gradio/commit/667802a6cdbfb2ce454a3be5a78e0990b194548a) - JS Component Documentation. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6142](https://github.com/gradio-app/gradio/pull/6142) [`103416d17`](https://github.com/gradio-app/gradio/commit/103416d17f021c82f5ff0583dcc2d80906ad279e) - JS READMEs and Storybook on Docs. Thanks [@aliabd](https://github.com/aliabd)!
- [#6094](https://github.com/gradio-app/gradio/pull/6094) [`c476bd5a5`](https://github.com/gradio-app/gradio/commit/c476bd5a5b70836163b9c69bf4bfe068b17fbe13) - Image v4. Thanks [@pngwn](https://github.com/pngwn)!
- [#6149](https://github.com/gradio-app/gradio/pull/6149) [`90318b1dd`](https://github.com/gradio-app/gradio/commit/90318b1dd118ae08a695a50e7c556226234ab6dc) - swap `mode` on the frontned to `interactive` to match the backend. Thanks [@pngwn](https://github.com/pngwn)!
- [#6128](https://github.com/gradio-app/gradio/pull/6128) [`9c3bf3175`](https://github.com/gradio-app/gradio/commit/9c3bf31751a414093d103e5a115772f3ef1a67aa) - Don't serve files in working directory by default. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6138](https://github.com/gradio-app/gradio/pull/6138) [`d2dfc1b9a`](https://github.com/gradio-app/gradio/commit/d2dfc1b9a9bd4940f70b62066b1aeaa905b9c7a9) - Small change to make `api_open=False` by default. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6152](https://github.com/gradio-app/gradio/pull/6152) [`982bff2fd`](https://github.com/gradio-app/gradio/commit/982bff2fdd938b798c400fb90d1cf0caf7278894) - Remove duplicate `elem_ids` from components. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6155](https://github.com/gradio-app/gradio/pull/6155) [`f71ea09ae`](https://github.com/gradio-app/gradio/commit/f71ea09ae796b85e9fe35956d426f0a19ee48f85) - Moves `gradio_cached_folder` inside the gradio temp direcotry. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6154](https://github.com/gradio-app/gradio/pull/6154) [`a8ef6d5dc`](https://github.com/gradio-app/gradio/commit/a8ef6d5dc97b35cc1da589d1a653209a3c327d98) - Remove interpretation for good. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6135](https://github.com/gradio-app/gradio/pull/6135) [`bce37ac74`](https://github.com/gradio-app/gradio/commit/bce37ac744496537e71546d2bb889bf248dcf5d3) - Fix selectable prop in the backend. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6118](https://github.com/gradio-app/gradio/pull/6118) [`88bccfdba`](https://github.com/gradio-app/gradio/commit/88bccfdba3df2df4b2747ea5d649ed528047cf50) - Improve Video Component. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6126](https://github.com/gradio-app/gradio/pull/6126) [`865a22d5c`](https://github.com/gradio-app/gradio/commit/865a22d5c60fd97aeca968e55580b403743a23ec) - Refactor `Blocks.load()` so that it is in the same style as the other listeners. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6098](https://github.com/gradio-app/gradio/pull/6098) [`c3bc515bf`](https://github.com/gradio-app/gradio/commit/c3bc515bf7d430427182143f7fb047bb4b9f4e5e) - Gradio custom component publish. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6157](https://github.com/gradio-app/gradio/pull/6157) [`db143bdd1`](https://github.com/gradio-app/gradio/commit/db143bdd13b830f3bfd513bbfbc0cd1403522b84) - Make output components not editable if they are being updated. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#6091](https://github.com/gradio-app/gradio/pull/6091) [`d5d29c947`](https://github.com/gradio-app/gradio/commit/d5d29c947467e54a8514790894ffffba1c796772) - Open source FRP server and allow `gradio` to connect to custom share servers. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6129](https://github.com/gradio-app/gradio/pull/6129) [`0d261c6ec`](https://github.com/gradio-app/gradio/commit/0d261c6ec1e783e284336023885f67b2ce04084c) - Fix fallback demo app template code. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6140](https://github.com/gradio-app/gradio/pull/6140) [`71bf2702c`](https://github.com/gradio-app/gradio/commit/71bf2702cd5b810c89e2e53452532650acdcfb87) - Fix video. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6069](https://github.com/gradio-app/gradio/pull/6069) [`bf127e124`](https://github.com/gradio-app/gradio/commit/bf127e1241a41401e144874ea468dff8474eb505) - Swap websockets for SSE. Thanks [@aliabid94](https://github.com/aliabid94)!
- [#6082](https://github.com/gradio-app/gradio/pull/6082) [`037e5af33`](https://github.com/gradio-app/gradio/commit/037e5af3363c5b321b95efc955ee8d6ec0f4504e) - WIP: Fix docs. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6071](https://github.com/gradio-app/gradio/pull/6071) [`f08da1a6f`](https://github.com/gradio-app/gradio/commit/f08da1a6f288f6ab8ec40534d5a9e2c64bed4b3b) - Fixes markdown rendering in examples. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5970](https://github.com/gradio-app/gradio/pull/5970) [`0c571c044`](https://github.com/gradio-app/gradio/commit/0c571c044035989d6fe33fc01fee63d1780635cb) - Add json schema unit tests. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6093](https://github.com/gradio-app/gradio/pull/6093) [`fadc057bb`](https://github.com/gradio-app/gradio/commit/fadc057bb7016f90dd94049c79fc10d38150c561) - V4: Fix constructor_args. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#5966](https://github.com/gradio-app/gradio/pull/5966) [`9cad2127b`](https://github.com/gradio-app/gradio/commit/9cad2127b965023687470b3abfe620e188a9da6e) - Improve Audio Component. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6014](https://github.com/gradio-app/gradio/pull/6014) [`cad537aac`](https://github.com/gradio-app/gradio/commit/cad537aac57998560c9f44a37499be734de66349) - pass props to example components and to example outputs. Thanks [@pngwn](https://github.com/pngwn)!
- [#5955](https://github.com/gradio-app/gradio/pull/5955) [`825c9cddc`](https://github.com/gradio-app/gradio/commit/825c9cddc83a09457d8c85ebeecb4bc705572d82) - Fix dev mode model3D. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6107](https://github.com/gradio-app/gradio/pull/6107) [`9a40de7bf`](https://github.com/gradio-app/gradio/commit/9a40de7bff5844c8a135e73c7d175eb02b63a966) - Fix: Move to cache in init postprocess + Fallback Fixes. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6018](https://github.com/gradio-app/gradio/pull/6018) [`184834d02`](https://github.com/gradio-app/gradio/commit/184834d02d448bff387eeb3aef64d9517962f146) - Add a cli command to list available templates. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6092](https://github.com/gradio-app/gradio/pull/6092) [`11d67ae75`](https://github.com/gradio-app/gradio/commit/11d67ae7529e0838565e4131b185c413489c5aa6) - Add a stand-alone install command and tidy-up the fallback template. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6026](https://github.com/gradio-app/gradio/pull/6026) [`338969af2`](https://github.com/gradio-app/gradio/commit/338969af290de032f9cdc204dab8a50be3bf3cc5) - V4: Single-file implementation of form components. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6114](https://github.com/gradio-app/gradio/pull/6114) [`39227b6fa`](https://github.com/gradio-app/gradio/commit/39227b6fac274d5f5b301bc14039571c1bfe510c) - Try to trigger a major beta release. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6060](https://github.com/gradio-app/gradio/pull/6060) [`447dfe06b`](https://github.com/gradio-app/gradio/commit/447dfe06bf19324d88696eb646fd1c5f1c4e86ed) - Clean up backend of `File` and `UploadButton` and change the return type of `preprocess()` from TemporaryFIle to string filepath. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6073](https://github.com/gradio-app/gradio/pull/6073) [`abff6fb75`](https://github.com/gradio-app/gradio/commit/abff6fb758bd310053a23c938bf1dd8fbdc5d333) - Fix remaining xfail tests in backend. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6089](https://github.com/gradio-app/gradio/pull/6089) [`cd8146ba0`](https://github.com/gradio-app/gradio/commit/cd8146ba053fbcb56cf5052e658e4570d457fb8a) - Update logos for v4. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5961](https://github.com/gradio-app/gradio/pull/5961) [`be2ed5e13`](https://github.com/gradio-app/gradio/commit/be2ed5e13222cbe5013b63b36685987518034a76) - File upload optimization. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#5968](https://github.com/gradio-app/gradio/pull/5968) [`6b0bb5e6a`](https://github.com/gradio-app/gradio/commit/6b0bb5e6a252ce8c4ef38455a9f56f1dcda56ab0) - Removes deprecated arguments and parameters from v4. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6027](https://github.com/gradio-app/gradio/pull/6027) [`de18102b8`](https://github.com/gradio-app/gradio/commit/de18102b8ca38c1d6d6edfa8c0571b81089166bb) - V4: Fix component update bug. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#5996](https://github.com/gradio-app/gradio/pull/5996) [`9cf40f76f`](https://github.com/gradio-app/gradio/commit/9cf40f76fed1c0f84b5a5336a9b0100f8a9b4ee3) - V4: Simple dropdown. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#5990](https://github.com/gradio-app/gradio/pull/5990) [`85056de5c`](https://github.com/gradio-app/gradio/commit/85056de5cd4e90a10cbfcefab74037dbc622b26b) - V4: Simple textbox. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6044](https://github.com/gradio-app/gradio/pull/6044) [`9053c95a1`](https://github.com/gradio-app/gradio/commit/9053c95a10de12aef572018ee37c71106d2da675) - Simplify File Component. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6077](https://github.com/gradio-app/gradio/pull/6077) [`35a227fbf`](https://github.com/gradio-app/gradio/commit/35a227fbfb0b0eb11806c0382c5f6910dc9777cf) - Proposal: sample demo for custom components should be a `gr.Interface`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6079](https://github.com/gradio-app/gradio/pull/6079) [`3b2d9eaa3`](https://github.com/gradio-app/gradio/commit/3b2d9eaa3e84de3e4a0799e4585a94510d665f26) - fix cc build. Thanks [@pngwn](https://github.com/pngwn)!
### Fixes
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Pending events behavior. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Reinstate types that were removed in error in #5832. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Fixes: slider bar are too thin on FireFox. Thanks [@pngwn](https://github.com/pngwn)!
- [#6146](https://github.com/gradio-app/gradio/pull/6146) [`40a171ea6`](https://github.com/gradio-app/gradio/commit/40a171ea60c74afa9519d6cb159def16ce68e1ca) - Fix image double change bug. Thanks [@pngwn](https://github.com/pngwn)!
- [#6148](https://github.com/gradio-app/gradio/pull/6148) [`0000a1916`](https://github.com/gradio-app/gradio/commit/0000a191688c5480c977c80acdd0c9023865d57e) - fix dropdown arrow size. Thanks [@pngwn](https://github.com/pngwn)!
- [#6067](https://github.com/gradio-app/gradio/pull/6067) [`bf38e5f06`](https://github.com/gradio-app/gradio/commit/bf38e5f06a7039be913614901c308794fea83ae0) - remove dupe component. Thanks [@pngwn](https://github.com/pngwn)!
- [#6065](https://github.com/gradio-app/gradio/pull/6065) [`7d07001e8`](https://github.com/gradio-app/gradio/commit/7d07001e8e7ca9cbd2251632667b3a043de49f49) - fix storybook. Thanks [@pngwn](https://github.com/pngwn)!
- [#5826](https://github.com/gradio-app/gradio/pull/5826) [`ce036c5d4`](https://github.com/gradio-app/gradio/commit/ce036c5d47e741e29812654bcc641ea6be876504) - Pending events behavior. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#6046](https://github.com/gradio-app/gradio/pull/6046) [`dbb7de5e0`](https://github.com/gradio-app/gradio/commit/dbb7de5e02c53fee05889d696d764d212cb96c74) - fix tests. Thanks [@pngwn](https://github.com/pngwn)!
- [#6042](https://github.com/gradio-app/gradio/pull/6042) [`e27997fe6`](https://github.com/gradio-app/gradio/commit/e27997fe6c2bcfebc7015fc26100cee9625eb13a) - Fix `root` when user is unauthenticated so that login page appears correctly. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6076](https://github.com/gradio-app/gradio/pull/6076) [`f3f98f923`](https://github.com/gradio-app/gradio/commit/f3f98f923c9db506284b8440e18a3ac7ddd8398b) - Lite error handler. Thanks [@whitphx](https://github.com/whitphx)!
- [#5984](https://github.com/gradio-app/gradio/pull/5984) [`66549d8d2`](https://github.com/gradio-app/gradio/commit/66549d8d256b1845c8c5efa0384695b36cb46eab) - Fixes: slider bar are too thin on FireFox. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
## 3.45.0-beta.13
### Features
- [#5964](https://github.com/gradio-app/gradio/pull/5964) [`5fbda0bd2`](https://github.com/gradio-app/gradio/commit/5fbda0bd2b2bbb2282249b8875d54acf87cd7e84) - Wasm release. Thanks [@pngwn](https://github.com/pngwn)!
## 3.45.0-beta.12
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`85ba6de13`](https://github.com/gradio-app/gradio/commit/85ba6de136a45b3e92c74e410bb27e3cbe7138d7) - V4: Some misc fixes. Thanks [@pngwn](https://github.com/pngwn)!
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`85ba6de13`](https://github.com/gradio-app/gradio/commit/85ba6de136a45b3e92c74e410bb27e3cbe7138d7) - Add host to dev mode for vite. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`d2314e53b`](https://github.com/gradio-app/gradio/commit/d2314e53bc088ff6f307a122a9a01bafcdcff5c2) - BugFix: Make FileExplorer Component Templateable. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`85ba6de13`](https://github.com/gradio-app/gradio/commit/85ba6de136a45b3e92c74e410bb27e3cbe7138d7) - Use tags to identify custom component dirs and ignore uninstalled components. Thanks [@pngwn](https://github.com/pngwn)!
- [#5956](https://github.com/gradio-app/gradio/pull/5956) [`f769876e0`](https://github.com/gradio-app/gradio/commit/f769876e0fa62336425c4e8ada5e09f38353ff01) - Apply formatter (and small refactoring) to the Lite-related frontend code. Thanks [@whitphx](https://github.com/whitphx)!
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`85ba6de13`](https://github.com/gradio-app/gradio/commit/85ba6de136a45b3e92c74e410bb27e3cbe7138d7) - Adds the ability to build the frontend and backend of custom components in preparation for publishing to pypi using `gradio_component build`. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`85ba6de13`](https://github.com/gradio-app/gradio/commit/85ba6de136a45b3e92c74e410bb27e3cbe7138d7) - Fix deployed demos on v4 branch. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`85ba6de13`](https://github.com/gradio-app/gradio/commit/85ba6de136a45b3e92c74e410bb27e3cbe7138d7) - Set api=False for cancel events. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`85ba6de13`](https://github.com/gradio-app/gradio/commit/85ba6de136a45b3e92c74e410bb27e3cbe7138d7) - Use full path to executables in CLI. Thanks [@pngwn](https://github.com/pngwn)!
- [#5949](https://github.com/gradio-app/gradio/pull/5949) [`1c390f101`](https://github.com/gradio-app/gradio/commit/1c390f10199142a41722ba493a0c86b58245da15) - Merge main again. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`85ba6de13`](https://github.com/gradio-app/gradio/commit/85ba6de136a45b3e92c74e410bb27e3cbe7138d7) - Simplify how files are handled in components in 4.0. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`85ba6de13`](https://github.com/gradio-app/gradio/commit/85ba6de136a45b3e92c74e410bb27e3cbe7138d7) - Name Endpoints if api_name is None. Thanks [@pngwn](https://github.com/pngwn)!
- [#5937](https://github.com/gradio-app/gradio/pull/5937) [`dcf13d750`](https://github.com/gradio-app/gradio/commit/dcf13d750b1465f905e062a1368ba754446cc23f) - V4: Update Component pyi file. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`85ba6de13`](https://github.com/gradio-app/gradio/commit/85ba6de136a45b3e92c74e410bb27e3cbe7138d7) - Rename gradio_component to gradio component. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`85ba6de13`](https://github.com/gradio-app/gradio/commit/85ba6de136a45b3e92c74e410bb27e3cbe7138d7) - V4: Use async version of shutil in upload route. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`85ba6de13`](https://github.com/gradio-app/gradio/commit/85ba6de136a45b3e92c74e410bb27e3cbe7138d7) - V4: Set cache dir for some component tests. Thanks [@pngwn](https://github.com/pngwn)!
- [#5894](https://github.com/gradio-app/gradio/pull/5894) [`fee3d527e`](https://github.com/gradio-app/gradio/commit/fee3d527e83a615109cf937f6ca0a37662af2bb6) - Adds `column_widths` to `gr.Dataframe` and hide overflowing text when `wrap=False`. Thanks [@abidlabs](https://github.com/abidlabs)!
### Fixes
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`85ba6de13`](https://github.com/gradio-app/gradio/commit/85ba6de136a45b3e92c74e410bb27e3cbe7138d7) - Better logs in dev mode. Thanks [@pngwn](https://github.com/pngwn)!
- [#5946](https://github.com/gradio-app/gradio/pull/5946) [`d0cc6b136`](https://github.com/gradio-app/gradio/commit/d0cc6b136fd59121f74d0c5a1a4b51740ffaa838) - fixup. Thanks [@pngwn](https://github.com/pngwn)!
- [#5944](https://github.com/gradio-app/gradio/pull/5944) [`465f58957`](https://github.com/gradio-app/gradio/commit/465f58957f70c7cf3e894beef8a117b28339e3c1) - Show empty JSON icon when `value` is `null`. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`85ba6de13`](https://github.com/gradio-app/gradio/commit/85ba6de136a45b3e92c74e410bb27e3cbe7138d7) - Reinstate types that were removed in error in #5832. Thanks [@pngwn](https://github.com/pngwn)!
## 3.48.0
### Features
- [#5627](https://github.com/gradio-app/gradio/pull/5627) [`b67115e8e`](https://github.com/gradio-app/gradio/commit/b67115e8e6e489fffd5271ea830211863241ddc5) - Lite: Make the Examples component display media files using pseudo HTTP requests to the Wasm server. Thanks [@whitphx](https://github.com/whitphx)!
- [#5821](https://github.com/gradio-app/gradio/pull/5821) [`1aa186220`](https://github.com/gradio-app/gradio/commit/1aa186220dfa8ee3621b818c4cdf4d7b9d690b40) - Lite: Fix Examples.create() to be a normal func so it can be called in the Wasm env. Thanks [@whitphx](https://github.com/whitphx)!
- [#5886](https://github.com/gradio-app/gradio/pull/5886) [`121f25b2d`](https://github.com/gradio-app/gradio/commit/121f25b2d50a33e1e06721b79e20b4f5651987ba) - Lite: Fix is_self_host() to detect `127.0.0.1` as localhost as well. Thanks [@whitphx](https://github.com/whitphx)!
- [#5915](https://github.com/gradio-app/gradio/pull/5915) [`e24163e15`](https://github.com/gradio-app/gradio/commit/e24163e15afdfc51ec8cb00a0dc46c2318b245be) - Added dimensionality check to avoid bad array dimensions. Thanks [@THEGAMECHANGER416](https://github.com/THEGAMECHANGER416)!
- [#5835](https://github.com/gradio-app/gradio/pull/5835) [`46334780d`](https://github.com/gradio-app/gradio/commit/46334780dbbb7e83f31971d45a7047ee156a0578) - Mention that audio is normalized when converting to wav in docs. Thanks [@aileenvl](https://github.com/aileenvl)!
- [#5877](https://github.com/gradio-app/gradio/pull/5877) [`a55b80942`](https://github.com/gradio-app/gradio/commit/a55b8094231ae462ac53f52bbdb460c1286ffabb) - Add styling (e.g. font colors and background colors) support to `gr.DataFrame` through the `pd.Styler` object. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5819](https://github.com/gradio-app/gradio/pull/5819) [`5f1cbc436`](https://github.com/gradio-app/gradio/commit/5f1cbc4363b09302334e9bc864587f8ef398550d) - Add support for gr.Request to gr.ChatInterface. Thanks [@DarhkVoyd](https://github.com/DarhkVoyd)!
- [#5901](https://github.com/gradio-app/gradio/pull/5901) [`c4e3a9274`](https://github.com/gradio-app/gradio/commit/c4e3a92743a3b41edad8b45c5d5b0ccbc2674a30) - Fix curly brackets in docstrings. Thanks [@whitphx](https://github.com/whitphx)!
- [#5934](https://github.com/gradio-app/gradio/pull/5934) [`8d909624f`](https://github.com/gradio-app/gradio/commit/8d909624f61a49536e3c0f71cb2d9efe91216219) - Fix styling issues with Audio, Image and Video components. Thanks [@aliabd](https://github.com/aliabd)!
- [#5864](https://github.com/gradio-app/gradio/pull/5864) [`e70805d54`](https://github.com/gradio-app/gradio/commit/e70805d54cc792452545f5d8eccc1aa0212a4695) - Change `BlockLabel` element to use `<label>`. Thanks [@aileenvl](https://github.com/aileenvl)!
- [#5862](https://github.com/gradio-app/gradio/pull/5862) [`c07207e0b`](https://github.com/gradio-app/gradio/commit/c07207e0bc98cc32b6db629c432fadf877e451ff) - Remove deprecated `.update()` usage from Interface internals. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5905](https://github.com/gradio-app/gradio/pull/5905) [`b450cef15`](https://github.com/gradio-app/gradio/commit/b450cef15685c934ba7c4e4d57cbed233e925fb1) - Fix type the docstring of the Code component. Thanks [@whitphx](https://github.com/whitphx)!
### Fixes
- [#5840](https://github.com/gradio-app/gradio/pull/5840) [`4e62b8493`](https://github.com/gradio-app/gradio/commit/4e62b8493dfce50bafafe49f1a5deb929d822103) - Ensure websocket polyfill doesn't load if there is already a `global.Webocket` property set. Thanks [@Jay2theWhy](https://github.com/Jay2theWhy)!
- [#5839](https://github.com/gradio-app/gradio/pull/5839) [`b83064da0`](https://github.com/gradio-app/gradio/commit/b83064da0005ca055fc15ee478cf064bf91702a4) - Fix error when scrolling dropdown with scrollbar. Thanks [@Kit-p](https://github.com/Kit-p)!
- [#5822](https://github.com/gradio-app/gradio/pull/5822) [`7b63db271`](https://github.com/gradio-app/gradio/commit/7b63db27161ab538f20cf8523fc04c9c3b604a98) - Convert async methods in the Examples class into normal sync methods. Thanks [@whitphx](https://github.com/whitphx)!
- [#5904](https://github.com/gradio-app/gradio/pull/5904) [`891d42e9b`](https://github.com/gradio-app/gradio/commit/891d42e9baa7ab85ede2a5eadb56c274b0ed2785) - Define Font.__repr__() to be printed in the doc in a readable format. Thanks [@whitphx](https://github.com/whitphx)!
- [#5811](https://github.com/gradio-app/gradio/pull/5811) [`1d5b15a2d`](https://github.com/gradio-app/gradio/commit/1d5b15a2d24387154f2cfb40a36de25b331471d3) - Assert refactor in external.py. Thanks [@harry-urek](https://github.com/harry-urek)!
- [#5827](https://github.com/gradio-app/gradio/pull/5827) [`48e09ee88`](https://github.com/gradio-app/gradio/commit/48e09ee88799efa38a5cc9b1b61e462f72ec6093) - Quick fix: Chatbot change event. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#5890](https://github.com/gradio-app/gradio/pull/5890) [`c4ba832b3`](https://github.com/gradio-app/gradio/commit/c4ba832b318dad5e8bf565cfa0daf93ca188498f) - Remove deprecation warning from `gr.update` and clean up associated code. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5897](https://github.com/gradio-app/gradio/pull/5897) [`0592c301d`](https://github.com/gradio-app/gradio/commit/0592c301df9cd949b52159c85b7042f38d113e86) - Fix Dataframe `line_breaks`. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#5878](https://github.com/gradio-app/gradio/pull/5878) [`fbce277e5`](https://github.com/gradio-app/gradio/commit/fbce277e50c5885371fd49c68adf8565c25c1d39) - Keep Markdown rendered lists within dataframe cells. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5930](https://github.com/gradio-app/gradio/pull/5930) [`361823896`](https://github.com/gradio-app/gradio/commit/3618238960d54df65c34895f4eb69d08acc3f9b6) - Fix dataframe `line_breaks`. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
## 3.47.1
### Fixes
- [#5816](https://github.com/gradio-app/gradio/pull/5816) [`796145e2c`](https://github.com/gradio-app/gradio/commit/796145e2c48c4087bec17f8ec0be4ceee47170cb) - Fix calls to the component server so that `gr.FileExplorer` works on Spaces. Thanks [@abidlabs](https://github.com/abidlabs)!
## 3.47.0
### Highlights
#### new `FileExplorer` component ([#5672](https://github.com/gradio-app/gradio/pull/5672) [`e4a307ed6`](https://github.com/gradio-app/gradio/commit/e4a307ed6cde3bbdf4ff2f17655739addeec941e))
Thanks to a new capability that allows components to communicate directly with the server _without_ passing data via the value, we have created a new `FileExplorer` component.
This component allows you to populate the explorer by passing a glob, but only provides the selected file(s) in your prediction function.
Users can then navigate the virtual filesystem and select files which will be accessible in your predict function. This component will allow developers to build more complex spaces, with more flexible input options.

For more information check the [`FileExplorer` documentation](https://gradio.app/docs/fileexplorer).
Thanks [@aliabid94](https://github.com/aliabid94)!
### Features
- [#5780](https://github.com/gradio-app/gradio/pull/5780) [`ed0f9a21b`](https://github.com/gradio-app/gradio/commit/ed0f9a21b04ad6b941b63d2ce45100dbd1abd5c5) - Adds `change()` event to `gr.Gallery`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5783](https://github.com/gradio-app/gradio/pull/5783) [`4567788bd`](https://github.com/gradio-app/gradio/commit/4567788bd1fc25df9322902ba748012e392b520a) - Adds the ability to set the `selected_index` in a `gr.Gallery`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5787](https://github.com/gradio-app/gradio/pull/5787) [`caeee8bf7`](https://github.com/gradio-app/gradio/commit/caeee8bf7821fd5fe2f936ed82483bed00f613ec) - ensure the client does not depend on `window` when running in a node environment. Thanks [@gibiee](https://github.com/gibiee)!
### Fixes
- [#5798](https://github.com/gradio-app/gradio/pull/5798) [`a0d3cc45c`](https://github.com/gradio-app/gradio/commit/a0d3cc45c6db48dc0db423c229b8fb285623cdc4) - Fix `gr.SelectData` so that the target attribute is correctly attached, and the filedata is included in the data attribute with `gr.Gallery`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5795](https://github.com/gradio-app/gradio/pull/5795) [`957ba5cfd`](https://github.com/gradio-app/gradio/commit/957ba5cfde18e09caedf31236a2064923cd7b282) - Prevent bokeh from injecting bokeh js multiple times. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5790](https://github.com/gradio-app/gradio/pull/5790) [`37e70842d`](https://github.com/gradio-app/gradio/commit/37e70842d59f5aed6fab0086b1abf4b8d991f1c9) - added try except block in `state.py`. Thanks [@SrijanSahaySrivastava](https://github.com/SrijanSahaySrivastava)!
- [#5794](https://github.com/gradio-app/gradio/pull/5794) [`f096c3ae1`](https://github.com/gradio-app/gradio/commit/f096c3ae168c0df00f90fe131c1e48c572e0574b) - Throw helpful error when media devices are not found. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#5776](https://github.com/gradio-app/gradio/pull/5776) [`c0fef4454`](https://github.com/gradio-app/gradio/commit/c0fef44541bfa61568bdcfcdfc7d7d79869ab1df) - Revert replica proxy logic and instead implement using the `root` variable. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 3.46.1
### Features
- [#5124](https://github.com/gradio-app/gradio/pull/5124) [`6e56a0d9b`](https://github.com/gradio-app/gradio/commit/6e56a0d9b0c863e76c69e1183d9d40196922b4cd) - Lite: Websocket queueing. Thanks [@whitphx](https://github.com/whitphx)!
### Fixes
- [#5775](https://github.com/gradio-app/gradio/pull/5775) [`e2874bc3c`](https://github.com/gradio-app/gradio/commit/e2874bc3cb1397574f77dbd7f0408ed4e6792970) - fix pending chatbot message styling and ensure messages with value `None` don't render. Thanks [@hannahblair](https://github.com/hannahblair)!
## 3.46.0
### Features
- [#5699](https://github.com/gradio-app/gradio/pull/5699) [`8f0fed857`](https://github.com/gradio-app/gradio/commit/8f0fed857d156830626eb48b469d54d211a582d2) - Improve chatbot accessibility and UX. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#5569](https://github.com/gradio-app/gradio/pull/5569) [`2a5b9e03b`](https://github.com/gradio-app/gradio/commit/2a5b9e03b15ea324d641fe6982f26d81b1ca7210) - Added support for pandas `Styler` object to `gr.DataFrame` (initially just sets the `display_value`). Thanks [@abidlabs](https://github.com/abidlabs)!
### Fixes
- [#5735](https://github.com/gradio-app/gradio/pull/5735) [`abb5e9df4`](https://github.com/gradio-app/gradio/commit/abb5e9df47989b2c56c2c312d74944678f9f2d4e) - Ensure images with no caption download in gallery. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#5754](https://github.com/gradio-app/gradio/pull/5754) [`502054848`](https://github.com/gradio-app/gradio/commit/502054848fdbe39fc03ec42445242b4e49b7affc) - Fix Gallery `columns` and `rows` params. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5755](https://github.com/gradio-app/gradio/pull/5755) [`e842a561a`](https://github.com/gradio-app/gradio/commit/e842a561af4394f8109291ee5725bcf74743e816) - Fix new line issue in chatbot. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#5731](https://github.com/gradio-app/gradio/pull/5731) [`c9af4f794`](https://github.com/gradio-app/gradio/commit/c9af4f794060e218193935d7213f0991a374f502) - Added timeout and error handling for frpc tunnel. Thanks [@cansik](https://github.com/cansik)!
- [#5766](https://github.com/gradio-app/gradio/pull/5766) [`ef96d3512`](https://github.com/gradio-app/gradio/commit/ef96d351229272738fc3c9680f7111f159590341) - Don't raise warnings when returning an updated component in a dictionary. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5767](https://github.com/gradio-app/gradio/pull/5767) [`caf6d9c0e`](https://github.com/gradio-app/gradio/commit/caf6d9c0e1f5b867cc20f2b4f6abb5ef47503a5f) - Set share=True for all Gradio apps in Colab by default. Thanks [@abidlabs](https://github.com/abidlabs)!
## 3.45.2
### Features
- [#5722](https://github.com/gradio-app/gradio/pull/5722) [`dba651904`](https://github.com/gradio-app/gradio/commit/dba651904c97dcddcaae2691540ac430d3eefd18) - Fix for deepcopy errors when running the replica-related logic on Spaces. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5721](https://github.com/gradio-app/gradio/pull/5721) [`84e03fe50`](https://github.com/gradio-app/gradio/commit/84e03fe506e08f1f81bac6d504c9fba7924f2d93) - Adds copy buttons to website, and better descriptions to API Docs. Thanks [@aliabd](https://github.com/aliabd)!
### Fixes
- [#5714](https://github.com/gradio-app/gradio/pull/5714) [`a0fc5a296`](https://github.com/gradio-app/gradio/commit/a0fc5a29678baa2d9ba997a2124cadebecfb2c36) - Make Tab and Tabs updatable. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5713](https://github.com/gradio-app/gradio/pull/5713) [`c10dabd6b`](https://github.com/gradio-app/gradio/commit/c10dabd6b18b49259441eb5f956a19046f466339) - Fixes gr.select() Method Issues with Dataframe Cells. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#5693](https://github.com/gradio-app/gradio/pull/5693) [`c2b31c396`](https://github.com/gradio-app/gradio/commit/c2b31c396f6d260cdf93377b715aee7ff162df75) - Context-based Progress tracker. Thanks [@cbensimon](https://github.com/cbensimon)!
- [#5705](https://github.com/gradio-app/gradio/pull/5705) [`78e7cf516`](https://github.com/gradio-app/gradio/commit/78e7cf5163e8d205e8999428fce4c02dbdece25f) - ensure internal data has updated before dispatching `success` or `then` events. Thanks [@pngwn](https://github.com/pngwn)!
- [#5668](https://github.com/gradio-app/gradio/pull/5668) [`d626c21e9`](https://github.com/gradio-app/gradio/commit/d626c21e91df026b04fdb3ee5c7dba74a261cfd3) - Fully resolve generated filepaths when running on Hugging Face Spaces with multiple replicas. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5711](https://github.com/gradio-app/gradio/pull/5711) [`aefb556ac`](https://github.com/gradio-app/gradio/commit/aefb556ac6dbadc320c618b11bb48371ef19dd61) - prevent internal log_message error from `/api/predict`. Thanks [@cbensimon](https://github.com/cbensimon)!
- [#5726](https://github.com/gradio-app/gradio/pull/5726) [`96c4b97c7`](https://github.com/gradio-app/gradio/commit/96c4b97c742311e90a87d8e8ee562c6ad765e9f0) - Adjust translation. Thanks [@ylhsieh](https://github.com/ylhsieh)!
- [#5732](https://github.com/gradio-app/gradio/pull/5732) [`3a48490bc`](https://github.com/gradio-app/gradio/commit/3a48490bc5e4136ec9bc0354b0d6fb6c04280505) - Add a bare `Component` type to the acceptable type list of `gr.load()`'s `inputs` and `outputs`. Thanks [@whitphx](https://github.com/whitphx)!
## 3.45.1
### Fixes
- [#5701](https://github.com/gradio-app/gradio/pull/5701) [`ee8eec1e5`](https://github.com/gradio-app/gradio/commit/ee8eec1e5e544a0127e0aa68c2522a7085b8ada5) - Fix for regression in rendering empty Markdown. Thanks [@abidlabs](https://github.com/abidlabs)!
## 3.45.0
### Features
- [#5675](https://github.com/gradio-app/gradio/pull/5675) [`b619e6f6e`](https://github.com/gradio-app/gradio/commit/b619e6f6e4ca55334fb86da53790e45a8f978566) - Reorganize Docs Navbar and Fill in Gaps. Thanks [@aliabd](https://github.com/aliabd)!
- [#5669](https://github.com/gradio-app/gradio/pull/5669) [`c5e969559`](https://github.com/gradio-app/gradio/commit/c5e969559612f956afcdb0c6f7b22ab8275bc49a) - Fix small issues in docs and guides. Thanks [@aliabd](https://github.com/aliabd)!
- [#5682](https://github.com/gradio-app/gradio/pull/5682) [`c57f1b75e`](https://github.com/gradio-app/gradio/commit/c57f1b75e272c76b0af4d6bd0c7f44743ff34f26) - Fix functional tests. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5681](https://github.com/gradio-app/gradio/pull/5681) [`40de3d217`](https://github.com/gradio-app/gradio/commit/40de3d2178b61ebe424b6f6228f94c0c6f679bea) - add query parameters to the `gr.Request` object through the `query_params` attribute. Thanks [@DarhkVoyd](https://github.com/DarhkVoyd)!
- [#5653](https://github.com/gradio-app/gradio/pull/5653) [`ea0e00b20`](https://github.com/gradio-app/gradio/commit/ea0e00b207b4b90a10e9d054c4202d4e705a29ba) - Prevent Clients from accessing API endpoints that set `api_name=False`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5639](https://github.com/gradio-app/gradio/pull/5639) [`e1874aff8`](https://github.com/gradio-app/gradio/commit/e1874aff814d13b23f3e59ef239cc13e18ad3fa7) - Add `gr.on` listener method. Thanks [@aliabid94](https://github.com/aliabid94)!
- [#5652](https://github.com/gradio-app/gradio/pull/5652) [`2e25d4305`](https://github.com/gradio-app/gradio/commit/2e25d430582264945ae3316acd04c4453a25ce38) - Pause autoscrolling if a user scrolls up in a `gr.Textbox` and resume autoscrolling if they go all the way down. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5642](https://github.com/gradio-app/gradio/pull/5642) [`21c7225bd`](https://github.com/gradio-app/gradio/commit/21c7225bda057117a9d3311854323520218720b5) - Improve plot rendering. Thanks [@aliabid94](https://github.com/aliabid94)!
- [#5677](https://github.com/gradio-app/gradio/pull/5677) [`9f9af327c`](https://github.com/gradio-app/gradio/commit/9f9af327c9115356433ec837f349d6286730fb97) - [Refactoring] Convert async functions that don't contain `await` statements to normal functions. Thanks [@whitphx](https://github.com/whitphx)!
- [#5660](https://github.com/gradio-app/gradio/pull/5660) [`d76555a12`](https://github.com/gradio-app/gradio/commit/d76555a122b545f0df7c9e7c1ca7bd2a6e262c86) - Fix secondary hue bug in gr.themes.builder(). Thanks [@hellofreckles](https://github.com/hellofreckles)!
- [#5697](https://github.com/gradio-app/gradio/pull/5697) [`f4e4f82b5`](https://github.com/gradio-app/gradio/commit/f4e4f82b58a65efca9030a7e8e7c5ace60d8cc10) - Increase Slider clickable area. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#5671](https://github.com/gradio-app/gradio/pull/5671) [`6a36c3b78`](https://github.com/gradio-app/gradio/commit/6a36c3b786700600d3826ce1e0629cc5308ddd47) - chore(deps): update dependency @types/prismjs to v1.26.1. Thanks [@renovate](https://github.com/apps/renovate)!
- [#5240](https://github.com/gradio-app/gradio/pull/5240) [`da05e59a5`](https://github.com/gradio-app/gradio/commit/da05e59a53bbad15e5755a47f46685da18e1031e) - Cleanup of .update and .get_config per component. Thanks [@aliabid94](https://github.com/aliabid94)!/n get_config is removed, the config used is simply any attribute that is in the Block that shares a name with one of the constructor paramaters./n update is not removed for backwards compatibility, but deprecated. Instead return the component itself. Created a updateable decorator that simply checks to see if we're in an update, and if so, skips the constructor and wraps the args and kwargs in an update dictionary. easy peasy.
- [#5635](https://github.com/gradio-app/gradio/pull/5635) [`38fafb9e2`](https://github.com/gradio-app/gradio/commit/38fafb9e2a5509b444942e1d5dd48dffa20066f4) - Fix typos in Gallery docs. Thanks [@atesgoral](https://github.com/atesgoral)!
- [#5590](https://github.com/gradio-app/gradio/pull/5590) [`d1ad1f671`](https://github.com/gradio-app/gradio/commit/d1ad1f671caef9f226eb3965f39164c256d8615c) - Attach `elem_classes` selectors to layout elements, and an id to the Tab button (for targeting via CSS/JS). Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5554](https://github.com/gradio-app/gradio/pull/5554) [`75ddeb390`](https://github.com/gradio-app/gradio/commit/75ddeb390d665d4484667390a97442081b49a423) - Accessibility Improvements. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#5598](https://github.com/gradio-app/gradio/pull/5598) [`6b1714386`](https://github.com/gradio-app/gradio/commit/6b17143868bdd2c1400af1199a01c1c0d5c27477) - Upgrade Pyodide to 0.24.0 and install the native orjson package. Thanks [@whitphx](https://github.com/whitphx)!
### Fixes
- [#5625](https://github.com/gradio-app/gradio/pull/5625) [`9ccc4794a`](https://github.com/gradio-app/gradio/commit/9ccc4794a72ce8319417119f6c370e7af3ffca6d) - Use ContextVar instead of threading.local(). Thanks [@cbensimon](https://github.com/cbensimon)!
- [#5602](https://github.com/gradio-app/gradio/pull/5602) [`54d21d3f1`](https://github.com/gradio-app/gradio/commit/54d21d3f18f2ddd4e796d149a0b41461f49c711b) - Ensure `HighlightedText` with `merge_elements` loads without a value. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#5636](https://github.com/gradio-app/gradio/pull/5636) [`fb5964fb8`](https://github.com/gradio-app/gradio/commit/fb5964fb88082e7b956853b543c468116811cab9) - Fix bug in example cache loading event. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#5633](https://github.com/gradio-app/gradio/pull/5633) [`341402337`](https://github.com/gradio-app/gradio/commit/34140233794c29d4722020e13c2d045da642dfae) - Allow Gradio apps containing `gr.Radio()`, `gr.Checkboxgroup()`, or `gr.Dropdown()` to be loaded with `gr.load()`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5616](https://github.com/gradio-app/gradio/pull/5616) [`7c34b434a`](https://github.com/gradio-app/gradio/commit/7c34b434aae0eb85f112a1dc8d66cefc7e2296b2) - Fix width and height issues that would cut off content in `gr.DataFrame`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5604](https://github.com/gradio-app/gradio/pull/5604) [`faad01f8e`](https://github.com/gradio-app/gradio/commit/faad01f8e10ef6d18249b1a4587477c59b74adb2) - Add `render_markdown` parameter to chatbot. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#5593](https://github.com/gradio-app/gradio/pull/5593) [`88d43bd12`](https://github.com/gradio-app/gradio/commit/88d43bd124792d216da445adef932a2b02f5f416) - Fixes avatar image in chatbot being squashed. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#5690](https://github.com/gradio-app/gradio/pull/5690) [`6b8c8afd9`](https://github.com/gradio-app/gradio/commit/6b8c8afd981fea984da568e9a0bd8bfc2a9c06c4) - Fix incorrect behavior of `gr.load()` with `gr.Examples`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5696](https://github.com/gradio-app/gradio/pull/5696) [`e51fcd5d5`](https://github.com/gradio-app/gradio/commit/e51fcd5d54315e8b65ee40e3de4dab17579ff6d5) - setting share=True on Spaces or in wasm should warn instead of raising error. Thanks [@abidlabs](https://github.com/abidlabs)!
## 3.44.4
### Features
- [#5514](https://github.com/gradio-app/gradio/pull/5514) [`52f783175`](https://github.com/gradio-app/gradio/commit/52f7831751b432411e109bd41add4ab286023a8e) - refactor: Use package.json for version management. Thanks [@DarhkVoyd](https://github.com/DarhkVoyd)!
- [#5535](https://github.com/gradio-app/gradio/pull/5535) [`d29b1ab74`](https://github.com/gradio-app/gradio/commit/d29b1ab740784d8c70f9ab7bc38bbbf7dd3ff737) - Makes sliders consistent across all browsers. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
### Fixes
- [#5587](https://github.com/gradio-app/gradio/pull/5587) [`e0d61b8ba`](https://github.com/gradio-app/gradio/commit/e0d61b8baa0f6293f53b9bdb1647d42f9ae2583a) - Fix `.clear()` events for audio and image. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#5534](https://github.com/gradio-app/gradio/pull/5534) [`d9e9ae43f`](https://github.com/gradio-app/gradio/commit/d9e9ae43f5c52c1f729af5a20e5d4f754689d429) - Guide fixes, esp. streaming audio. Thanks [@aliabid94](https://github.com/aliabid94)!
- [#5588](https://github.com/gradio-app/gradio/pull/5588) [`acdeff57e`](https://github.com/gradio-app/gradio/commit/acdeff57ece4672f943c374d537eaf47d3ec034f) - Allow multiple instances of Gradio with authentication to run on different ports. Thanks [@abidlabs](https://github.com/abidlabs)!
## 3.44.3
### Fixes
- [#5562](https://github.com/gradio-app/gradio/pull/5562) [`50d9747d0`](https://github.com/gradio-app/gradio/commit/50d9747d061962cff7f60a8da648bb3781794102) - chore(deps): update dependency iframe-resizer to v4.3.7. Thanks [@renovate](https://github.com/apps/renovate)!
- [#5550](https://github.com/gradio-app/gradio/pull/5550) [`4ed5902e7`](https://github.com/gradio-app/gradio/commit/4ed5902e7dda2d95cd43e4ccaaef520ddd8eba57) - Adding basque language. Thanks [@EkhiAzur](https://github.com/EkhiAzur)!
- [#5547](https://github.com/gradio-app/gradio/pull/5547) [`290f51871`](https://github.com/gradio-app/gradio/commit/290f5187160cdbd7a786494fe3c19b0e70abe167) - typo in UploadButton's docstring. Thanks [@chaeheum3](https://github.com/chaeheum3)!
- [#5553](https://github.com/gradio-app/gradio/pull/5553) [`d1bf23cd2`](https://github.com/gradio-app/gradio/commit/d1bf23cd2c6da3692d7753856bfe7564d84778e0) - Modify Image examples docstring. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#5563](https://github.com/gradio-app/gradio/pull/5563) [`ba64082ed`](https://github.com/gradio-app/gradio/commit/ba64082ed80c1ed9113497ae089e63f032dbcc75) - preprocess for components when type='index'. Thanks [@abidlabs](https://github.com/abidlabs)!
## 3.44.2
### Fixes
- [#5537](https://github.com/gradio-app/gradio/pull/5537) [`301c7878`](https://github.com/gradio-app/gradio/commit/301c7878217f9fc531c0f28330b394f02955811b) - allow gr.Image() examples to take urls. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5544](https://github.com/gradio-app/gradio/pull/5544) [`a0cc9ac9`](https://github.com/gradio-app/gradio/commit/a0cc9ac931554e06dcb091158c9b9ac0cc580b6c) - Fixes dropdown breaking if a user types in invalid value and presses enter. Thanks [@abidlabs](https://github.com/abidlabs)!
## 3.44.1
### Fixes
- [#5516](https://github.com/gradio-app/gradio/pull/5516) [`c5fe8eba`](https://github.com/gradio-app/gradio/commit/c5fe8ebadbf206e2f4199ccde4606e331a22148a) - Fix docstring of dropdown. Thanks [@hysts](https://github.com/hysts)!
- [#5529](https://github.com/gradio-app/gradio/pull/5529) [`81c9ca9a`](https://github.com/gradio-app/gradio/commit/81c9ca9a2e00d19334f632fec32081d36ad54c7f) - Fix `.update()` method in `gr.Dropdown()` to handle `choices`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5528](https://github.com/gradio-app/gradio/pull/5528) [`dc86e4a7`](https://github.com/gradio-app/gradio/commit/dc86e4a7e1c40b910c74558e6f88fddf9b3292bc) - Lazy load all images. Thanks [@aliabid94](https://github.com/aliabid94)!
- [#5525](https://github.com/gradio-app/gradio/pull/5525) [`21f1db40`](https://github.com/gradio-app/gradio/commit/21f1db40de6d1717eba97a550e11422a457ba7e9) - Ensure input value saves on dropdown blur. Thanks [@hannahblair](https://github.com/hannahblair)!
## 3.44.0
### Features
- [#5505](https://github.com/gradio-app/gradio/pull/5505) [`9ee20f49`](https://github.com/gradio-app/gradio/commit/9ee20f499f62c1fe5af6b8f84918b3a334eb1c8d) - Validate i18n file names with ISO-639x. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#5475](https://github.com/gradio-app/gradio/pull/5475) [`c60b89b0`](https://github.com/gradio-app/gradio/commit/c60b89b0a54758a27277f0a6aa20d0653647c7c8) - Adding Central Kurdish. Thanks [@Hrazhan](https://github.com/Hrazhan)!
- [#5400](https://github.com/gradio-app/gradio/pull/5400) [`d112e261`](https://github.com/gradio-app/gradio/commit/d112e2611b0fc79ecedfaed367571f3157211387) - Allow interactive input in `gr.HighlightedText`. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#5488](https://github.com/gradio-app/gradio/pull/5488) [`8909e42a`](https://github.com/gradio-app/gradio/commit/8909e42a7c6272358ad413588d27a5124d151205) - Adds `autoscroll` param to `gr.Textbox()`. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#5384](https://github.com/gradio-app/gradio/pull/5384) [`ddc02268`](https://github.com/gradio-app/gradio/commit/ddc02268f731bd2ed04b7a5854accf3383f9a0da) - Allows the `gr.Dropdown` to have separate names and values, as well as enables `allow_custom_value` for multiselect dropdown. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5473](https://github.com/gradio-app/gradio/pull/5473) [`b271e738`](https://github.com/gradio-app/gradio/commit/b271e738860ca238ecdee2991f49b505c7559016) - Remove except asyncio.CancelledError which is no longer necessary due to 53d7025. Thanks [@whitphx](https://github.com/whitphx)!
- [#5474](https://github.com/gradio-app/gradio/pull/5474) [`041560f9`](https://github.com/gradio-app/gradio/commit/041560f9f11ca2560005b467bb412ee1becfc2b2) - Fix queueing.call_prediction to retrieve the default response class in the same manner as FastAPI's implementation. Thanks [@whitphx](https://github.com/whitphx)!
- [#5510](https://github.com/gradio-app/gradio/pull/5510) [`afcf3c48`](https://github.com/gradio-app/gradio/commit/afcf3c48e82712067d6d00a0caedb1562eb986f8) - Do not expose existence of files outside of working directory. Thanks [@abidlabs](https://github.com/abidlabs)!
### Fixes
- [#5459](https://github.com/gradio-app/gradio/pull/5459) [`bd2fda77`](https://github.com/gradio-app/gradio/commit/bd2fda77fc98d815f4fb670f535af453ebee9b80) - Dispatch `stop_recording` event in Audio. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#5508](https://github.com/gradio-app/gradio/pull/5508) [`05715f55`](https://github.com/gradio-app/gradio/commit/05715f5599ae3e928d3183c7b0a7f5291f843a96) - Adds a `filterable` parameter to `gr.Dropdown` that controls whether user can type to filter choices. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5470](https://github.com/gradio-app/gradio/pull/5470) [`a4e010a9`](https://github.com/gradio-app/gradio/commit/a4e010a96f1d8a52b3ac645e03fe472b9c3cbbb1) - Fix share button position. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#5496](https://github.com/gradio-app/gradio/pull/5496) [`82ec4d26`](https://github.com/gradio-app/gradio/commit/82ec4d2622a43c31b248b78e9410e2ac918f6035) - Allow interface with components to be run inside blocks. Thanks [@abidlabs](https://github.com/abidlabs)!
## 3.43.2
### Fixes
- [#5456](https://github.com/gradio-app/gradio/pull/5456) [`6e381c4f`](https://github.com/gradio-app/gradio/commit/6e381c4f146cc8177a4e2b8e39f914f09cd7ff0c) - ensure dataframe doesn't steal focus. Thanks [@pngwn](https://github.com/pngwn)!
## 3.43.1
### Fixes
- [#5445](https://github.com/gradio-app/gradio/pull/5445) [`67bb7bcb`](https://github.com/gradio-app/gradio/commit/67bb7bcb6a95b7a00a8bdf612cf147850d919a44) - ensure dataframe doesn't scroll unless needed. Thanks [@pngwn](https://github.com/pngwn)!
- [#5447](https://github.com/gradio-app/gradio/pull/5447) [`7a4a89e5`](https://github.com/gradio-app/gradio/commit/7a4a89e5ca1dedb39e5366867501584b0c636bbb) - ensure iframe is correct size on spaces. Thanks [@pngwn](https://github.com/pngwn)!
## 3.43.0
### Features
- [#5165](https://github.com/gradio-app/gradio/pull/5165) [`c77f05ab`](https://github.com/gradio-app/gradio/commit/c77f05abb65b2828c9c19af4ec0a0c09412f9f6a) - Fix the Queue to call API endpoints without internal HTTP routing. Thanks [@whitphx](https://github.com/whitphx)!
- [#5427](https://github.com/gradio-app/gradio/pull/5427) [`aad7acd7`](https://github.com/gradio-app/gradio/commit/aad7acd7128dca05b227ecbba06db9f94d65b088) - Add sort to bar plot. Thanks [@Chaitanya134](https://github.com/Chaitanya134)!
- [#5342](https://github.com/gradio-app/gradio/pull/5342) [`afac0006`](https://github.com/gradio-app/gradio/commit/afac0006337ce2840cf497cd65691f2f60ee5912) - significantly improve the performance of `gr.Dataframe` for large datasets. Thanks [@pngwn](https://github.com/pngwn)!
- [#5417](https://github.com/gradio-app/gradio/pull/5417) [`d14d63e3`](https://github.com/gradio-app/gradio/commit/d14d63e30c4af3f9c2a664fd11b0a01943a8300c) - Auto scroll to bottom of textbox. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
### Fixes
- [#5412](https://github.com/gradio-app/gradio/pull/5412) [`26fef8c7`](https://github.com/gradio-app/gradio/commit/26fef8c7f85a006c7e25cdbed1792df19c512d02) - Skip view_api request in js client when auth enabled. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#5436](https://github.com/gradio-app/gradio/pull/5436) [`7ab4b70f`](https://github.com/gradio-app/gradio/commit/7ab4b70f6821afb4e85cef225d1235c19df8ebbf) - api_open does not take precedence over show_api. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 3.42.0
### Highlights
#### Like/Dislike Button for Chatbot ([#5391](https://github.com/gradio-app/gradio/pull/5391) [`abf1c57d`](https://github.com/gradio-app/gradio/commit/abf1c57d7d85de0df233ee3b38aeb38b638477db))
Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
#### Added the ability to attach event listeners via decorators ([#5395](https://github.com/gradio-app/gradio/pull/5395) [`55fed04f`](https://github.com/gradio-app/gradio/commit/55fed04f559becb9c24f22cc6292dc572d709886))
e.g.
```python
with gr.Blocks() as demo:
name = gr.Textbox(label="Name")
output = gr.Textbox(label="Output Box")
greet_btn = gr.Button("Greet")
@greet_btn.click(inputs=name, outputs=output)
def greet(name):
return "Hello " + name + "!"
```
Thanks [@aliabid94](https://github.com/aliabid94)!
### Features
- [#5334](https://github.com/gradio-app/gradio/pull/5334) [`c5bf9138`](https://github.com/gradio-app/gradio/commit/c5bf91385a632dc9f612499ee01166ac6ae509a9) - Add chat bubble width param. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#5267](https://github.com/gradio-app/gradio/pull/5267) [`119c8343`](https://github.com/gradio-app/gradio/commit/119c834331bfae60d4742c8f20e9cdecdd67e8c2) - Faster reload mode. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#5373](https://github.com/gradio-app/gradio/pull/5373) [`79d8f9d8`](https://github.com/gradio-app/gradio/commit/79d8f9d891901683c5a1b7486efb44eab2478c96) - Adds `height` and `zoom_speed` parameters to `Model3D` component, as well as a button to reset the camera position. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5370](https://github.com/gradio-app/gradio/pull/5370) [`61803c65`](https://github.com/gradio-app/gradio/commit/61803c6545e73fce47e8740bd46721ab9bb0ba5c) - chore(deps): update dependency extendable-media-recorder to v9. Thanks [@renovate](https://github.com/apps/renovate)!
- [#5266](https://github.com/gradio-app/gradio/pull/5266) [`4ccb9a86`](https://github.com/gradio-app/gradio/commit/4ccb9a86f194c6997f80a09880edc3c2b0554aab) - Makes it possible to set the initial camera position for the `Model3D` component as a tuple of (alpha, beta, radius). Thanks [@mbahri](https://github.com/mbahri)!
- [#5271](https://github.com/gradio-app/gradio/pull/5271) [`97c3c7b1`](https://github.com/gradio-app/gradio/commit/97c3c7b1730407f9e80566af9ecb4ca7cccf62ff) - Move scripts from old website to CI. Thanks [@aliabd](https://github.com/aliabd)!
- [#5369](https://github.com/gradio-app/gradio/pull/5369) [`b8968898`](https://github.com/gradio-app/gradio/commit/b89688984fa9c6be0db06e392e6935a544620764) - Fix typo in utils.py. Thanks [@eltociear](https://github.com/eltociear)!
### Fixes
- [#5304](https://github.com/gradio-app/gradio/pull/5304) [`05892302`](https://github.com/gradio-app/gradio/commit/05892302fb8fe2557d57834970a2b65aea97355b) - Adds kwarg to disable html sanitization in `gr.Chatbot()`. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#5366](https://github.com/gradio-app/gradio/pull/5366) [`0cc7e2dc`](https://github.com/gradio-app/gradio/commit/0cc7e2dcf60e216e0a30e2f85a9879ce3cb2a1bd) - Hide avatar when message none. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#5393](https://github.com/gradio-app/gradio/pull/5393) [`e4e7a431`](https://github.com/gradio-app/gradio/commit/e4e7a4319924aaf51dcb18d07d0c9953d4011074) - Renders LaTeX that is added to the page in `gr.Markdown`, `gr.Chatbot`, and `gr.DataFrame`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5394](https://github.com/gradio-app/gradio/pull/5394) [`4d94ea0a`](https://github.com/gradio-app/gradio/commit/4d94ea0a0cf2103cda19f48398a5634f8341d04d) - Adds horizontal scrolling to content that overflows in gr.Markdown. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5368](https://github.com/gradio-app/gradio/pull/5368) [`b27f7583`](https://github.com/gradio-app/gradio/commit/b27f7583254165b135bf1496a7d8c489a62ba96f) - Change markdown rendering to set breaks to false. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5360](https://github.com/gradio-app/gradio/pull/5360) [`64666525`](https://github.com/gradio-app/gradio/commit/6466652583e3c620df995fb865ef3511a34cb676) - Cancel Dropdown Filter. Thanks [@deckar01](https://github.com/deckar01)!
## 3.41.2
### Features
- [#5284](https://github.com/gradio-app/gradio/pull/5284) [`5f25eb68`](https://github.com/gradio-app/gradio/commit/5f25eb6836f6a78ce6208b53495a01e1fc1a1d2f) - Minor bug fix sweep. Thanks [@aliabid94](https://github.com/aliabid94)!/n - Our use of __exit__ was catching errors and corrupting the traceback of any component that failed to instantiate (try running blocks_kitchen_sink off main for an example). Now the __exit__ exits immediately if there's been an exception, so the original exception can be printed cleanly/n - HighlightedText was rendering weird, cleaned it up
### Fixes
- [#5319](https://github.com/gradio-app/gradio/pull/5319) [`3341148c`](https://github.com/gradio-app/gradio/commit/3341148c109b5458cc88435d27eb154210efc472) - Fix: wrap avatar-image in a div to clip its shape. Thanks [@Keldos-Li](https://github.com/Keldos-Li)!
- [#5340](https://github.com/gradio-app/gradio/pull/5340) [`df090e89`](https://github.com/gradio-app/gradio/commit/df090e89f74a16e4cb2b700a1e3263cabd2bdd91) - Fix Checkbox select dispatch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 3.41.1
### Fixes
- [#5324](https://github.com/gradio-app/gradio/pull/5324) [`31996c99`](https://github.com/gradio-app/gradio/commit/31996c991d6bfca8cef975eb8e3c9f61a7aced19) - ensure login form has correct styles. Thanks [@pngwn](https://github.com/pngwn)!
- [#5323](https://github.com/gradio-app/gradio/pull/5323) [`e32b0928`](https://github.com/gradio-app/gradio/commit/e32b0928d2d00342ca917ebb10c379ffc2ec200d) - ensure dropdown stays open when identical data is passed in. Thanks [@pngwn](https://github.com/pngwn)!
## 3.41.0
### Highlights
#### Improve startup performance and markdown support ([#5279](https://github.com/gradio-app/gradio/pull/5279) [`fe057300`](https://github.com/gradio-app/gradio/commit/fe057300f0672c62dab9d9b4501054ac5d45a4ec))
##### Improved markdown support
We now have better support for markdown in `gr.Markdown` and `gr.Dataframe`. Including syntax highlighting and Github Flavoured Markdown. We also have more consistent markdown behaviour and styling.
##### Various performance improvements
These improvements will be particularly beneficial to large applications.
- Rather than attaching events manually, they are now delegated, leading to a significant performance improvement and addressing a performance regression introduced in a recent version of Gradio. App startup for large applications is now around twice as fast.
- Optimised the mounting of individual components, leading to a modest performance improvement during startup (~30%).
- Corrected an issue that was causing markdown to re-render infinitely.
- Ensured that the `gr.3DModel` does re-render prematurely.
Thanks [@pngwn](https://github.com/pngwn)!
#### Enable streaming audio in python client ([#5248](https://github.com/gradio-app/gradio/pull/5248) [`390624d8`](https://github.com/gradio-app/gradio/commit/390624d8ad2b1308a5bf8384435fd0db98d8e29e))
The `gradio_client` now supports streaming file outputs 🌊
No new syntax! Connect to a gradio demo that supports streaming file outputs and call `predict` or `submit` as you normally would.
```python
import gradio_client as grc
client = grc.Client("gradio/stream_audio_out")
# Get the entire generated audio as a local file
client.predict("/Users/freddy/Pictures/bark_demo.mp4", api_name="/predict")
job = client.submit("/Users/freddy/Pictures/bark_demo.mp4", api_name="/predict")
# Get the entire generated audio as a local file
job.result()
# Each individual chunk
job.outputs()
```
Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
#### Add `render` function to `<gradio-app>` ([#5158](https://github.com/gradio-app/gradio/pull/5158) [`804fcc05`](https://github.com/gradio-app/gradio/commit/804fcc058e147f283ece67f1f353874e26235535))
We now have an event `render` on the <gradio-app> web component, which is triggered once the embedded space has finished rendering.
```html
<script>
function handleLoadComplete() {
console.log("Embedded space has finished rendering");
}
const gradioApp = document.querySelector("gradio-app");
gradioApp.addEventListener("render", handleLoadComplete);
</script>
```
Thanks [@hannahblair](https://github.com/hannahblair)!
### Features
- [#5268](https://github.com/gradio-app/gradio/pull/5268) [`f49028cf`](https://github.com/gradio-app/gradio/commit/f49028cfe3e21097001ddbda71c560b3d8b42e1c) - Move markdown & latex processing to the frontend for the gr.Markdown and gr.DataFrame components. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5215](https://github.com/gradio-app/gradio/pull/5215) [`fbdad78a`](https://github.com/gradio-app/gradio/commit/fbdad78af4c47454cbb570f88cc14bf4479bbceb) - Lazy load interactive or static variants of a component individually, rather than loading both variants regardless. This change will improve performance for many applications. Thanks [@pngwn](https://github.com/pngwn)!
- [#5216](https://github.com/gradio-app/gradio/pull/5216) [`4b58ea6d`](https://github.com/gradio-app/gradio/commit/4b58ea6d98e7a43b3f30d8a4cb6f379bc2eca6a8) - Update i18n tokens and locale files. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#5283](https://github.com/gradio-app/gradio/pull/5283) [`a7460557`](https://github.com/gradio-app/gradio/commit/a74605572dd0d6bb41df6b38b120d656370dd67d) - Add height parameter and scrolling to `gr.Dataframe`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5232](https://github.com/gradio-app/gradio/pull/5232) [`c57d4c23`](https://github.com/gradio-app/gradio/commit/c57d4c232a97e03b4671f9e9edc3af456438fe89) - `gr.Radio` and `gr.CheckboxGroup` can now accept different names and values. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5219](https://github.com/gradio-app/gradio/pull/5219) [`e8fd4e4e`](https://github.com/gradio-app/gradio/commit/e8fd4e4ec68a6c974bc8c84b61f4a0ec50a85bc6) - Add `api_name` parameter to `gr.Interface`. Additionally, completely hide api page if show_api=False. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#5280](https://github.com/gradio-app/gradio/pull/5280) [`a2f42e28`](https://github.com/gradio-app/gradio/commit/a2f42e28bd793bce4bed6d54164bb2a327a46fd5) - Allow updating the label of `gr.UpdateButton`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5112](https://github.com/gradio-app/gradio/pull/5112) [`1cefee7f`](https://github.com/gradio-app/gradio/commit/1cefee7fc05175aca23ba04b3a3fda7b97f49bf0) - chore(deps): update dependency marked to v7. Thanks [@renovate](https://github.com/apps/renovate)!
- [#5260](https://github.com/gradio-app/gradio/pull/5260) [`a773eaf7`](https://github.com/gradio-app/gradio/commit/a773eaf7504abb53b99885b3454dc1e027adbb42) - Stop passing inputs and preprocessing on iterators. Thanks [@aliabid94](https://github.com/aliabid94)!
- [#4943](https://github.com/gradio-app/gradio/pull/4943) [`947d615d`](https://github.com/gradio-app/gradio/commit/947d615db6f76519d0e8bc0d1a0d7edf89df267b) - Sign in with Hugging Face (OAuth support). Thanks [@Wauplin](https://github.com/Wauplin)!
- [#5298](https://github.com/gradio-app/gradio/pull/5298) [`cf167cd1`](https://github.com/gradio-app/gradio/commit/cf167cd1dd4acd9aee225ff1cb6fac0e849806ba) - Create event listener table for components on docs. Thanks [@aliabd](https://github.com/aliabd)!
- [#5173](https://github.com/gradio-app/gradio/pull/5173) [`730f0c1d`](https://github.com/gradio-app/gradio/commit/730f0c1d54792eb11359e40c9f2326e8a6e39203) - Ensure gradio client works as expected for functions that return nothing. Thanks [@raymondtri](https://github.com/raymondtri)!
- [#5188](https://github.com/gradio-app/gradio/pull/5188) [`b22e1888`](https://github.com/gradio-app/gradio/commit/b22e1888fcf0843520525c1e4b7e1fe73fdeb948) - Fix the images in the theme builder to use permanent URI. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5221](https://github.com/gradio-app/gradio/pull/5221) [`f344592a`](https://github.com/gradio-app/gradio/commit/f344592aeb1658013235ded154107f72d86f24e7) - Allows setting a height to `gr.File` and improves the UI of the component. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5265](https://github.com/gradio-app/gradio/pull/5265) [`06982212`](https://github.com/gradio-app/gradio/commit/06982212dfbd613853133d5d0eebd75577967027) - Removes scrollbar from File preview when not needed. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5305](https://github.com/gradio-app/gradio/pull/5305) [`15075241`](https://github.com/gradio-app/gradio/commit/15075241fa7ad3f7fd9ae2a91e54faf8f19a46f9) - Rotate axes labels on LinePlot, BarPlot, and ScatterPlot. Thanks [@Faiga91](https://github.com/Faiga91)!
- [#5258](https://github.com/gradio-app/gradio/pull/5258) [`92282cea`](https://github.com/gradio-app/gradio/commit/92282cea6afdf7e9930ece1046d8a63be34b3cea) - Chatbot Avatar Images. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#5244](https://github.com/gradio-app/gradio/pull/5244) [`b3e50db9`](https://github.com/gradio-app/gradio/commit/b3e50db92f452f376aa2cc081326d40bb69d6dd7) - Remove aiohttp dependency. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#5264](https://github.com/gradio-app/gradio/pull/5264) [`46a2b600`](https://github.com/gradio-app/gradio/commit/46a2b600a7ff030a9ea1560b882b3bf3ad266bbc) - ensure translations for audio work correctly. Thanks [@hannahblair](https://github.com/hannahblair)!
### Fixes
- [#5256](https://github.com/gradio-app/gradio/pull/5256) [`933db53e`](https://github.com/gradio-app/gradio/commit/933db53e93a1229fdf149556d61da5c4c7e1a331) - Better handling of empty dataframe in `gr.DataFrame`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5242](https://github.com/gradio-app/gradio/pull/5242) [`2b397791`](https://github.com/gradio-app/gradio/commit/2b397791fe2059e4beb72937ff0436f2d4d28b4b) - Fix message text overflow onto copy button in `gr.Chatbot`. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#5253](https://github.com/gradio-app/gradio/pull/5253) [`ddac7e4d`](https://github.com/gradio-app/gradio/commit/ddac7e4d0f55c3bdc6c3e9a9e24588b2563e4049) - Ensure File component uploads files to the server. Thanks [@pngwn](https://github.com/pngwn)!
- [#5179](https://github.com/gradio-app/gradio/pull/5179) [`6fb92b48`](https://github.com/gradio-app/gradio/commit/6fb92b48a916104db573602011a448b904d42e5e) - Fixes audio streaming issues. Thanks [@aliabid94](https://github.com/aliabid94)!
- [#5295](https://github.com/gradio-app/gradio/pull/5295) [`7b8fa8aa`](https://github.com/gradio-app/gradio/commit/7b8fa8aa58f95f5046b9add64b40368bd3f1b700) - Allow caching examples with streamed output. Thanks [@aliabid94](https://github.com/aliabid94)!
- [#5285](https://github.com/gradio-app/gradio/pull/5285) [`cdfd4217`](https://github.com/gradio-app/gradio/commit/cdfd42174a9c777eaee9c1209bf8e90d8c7791f2) - Tweaks to `icon` parameter in `gr.Button()`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5122](https://github.com/gradio-app/gradio/pull/5122) [`3b805346`](https://github.com/gradio-app/gradio/commit/3b8053469aca6c7a86a6731e641e4400fc34d7d3) - Allows code block in chatbot to scroll horizontally. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#5312](https://github.com/gradio-app/gradio/pull/5312) [`f769cb67`](https://github.com/gradio-app/gradio/commit/f769cb67149d8e209091508f06d87014acaed965) - only start listening for events after the components are mounted. Thanks [@pngwn](https://github.com/pngwn)!
- [#5254](https://github.com/gradio-app/gradio/pull/5254) [`c39f06e1`](https://github.com/gradio-app/gradio/commit/c39f06e16b9feea97984e4822df35a99c807461c) - Fix `.update()` for `gr.Radio()` and `gr.CheckboxGroup()`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5231](https://github.com/gradio-app/gradio/pull/5231) [`87f1c2b4`](https://github.com/gradio-app/gradio/commit/87f1c2b4ac7c685c43477215fa5b96b6cbeffa05) - Allow `gr.Interface.from_pipeline()` and `gr.load()` to work within `gr.Blocks()`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5238](https://github.com/gradio-app/gradio/pull/5238) [`de23e9f7`](https://github.com/gradio-app/gradio/commit/de23e9f7d67e685e791faf48a21f34121f6d094a) - Improve audio streaming. Thanks [@aliabid94](https://github.com/aliabid94)!/n - Proper audio streaming with WAV files. We now do the proper processing to stream out wav files as a single stream of audio without any cracks in the seams./n - Audio streaming with bytes. Stream any audio type by yielding out bytes, and it should work flawlessly.
- [#5313](https://github.com/gradio-app/gradio/pull/5313) [`54bcb724`](https://github.com/gradio-app/gradio/commit/54bcb72417b2781ad9d7500ea0f89aa9d80f7d8f) - Restores missing part of bottom border on file component. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5235](https://github.com/gradio-app/gradio/pull/5235) [`1ecf88ac`](https://github.com/gradio-app/gradio/commit/1ecf88ac5f20bc5a1c91792d1a68559575e6afd7) - fix #5229. Thanks [@breengles](https://github.com/breengles)!
- [#5276](https://github.com/gradio-app/gradio/pull/5276) [`502f1015`](https://github.com/gradio-app/gradio/commit/502f1015bf23b365bc32446dd2e549b0c5d0dc72) - Ensure `Blocks` translation copy renders correctly. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#5296](https://github.com/gradio-app/gradio/pull/5296) [`a0f22626`](https://github.com/gradio-app/gradio/commit/a0f22626f2aff297754414bbc83d5c4cfe086ea0) - `make_waveform()` twitter video resolution fix. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
## 3.40.0
### Highlights
#### Client.predict will now return the final output for streaming endpoints ([#5057](https://github.com/gradio-app/gradio/pull/5057) [`35856f8b`](https://github.com/gradio-app/gradio/commit/35856f8b54548cae7bd3b8d6a4de69e1748283b2))
### This is a breaking change (for gradio_client only)!
Previously, `Client.predict` would only return the first output of an endpoint that streamed results. This was causing confusion for developers that wanted to call these streaming demos via the client.
We realize that developers using the client don't know the internals of whether a demo streams or not, so we're changing the behavior of predict to match developer expectations.
Using `Client.predict` will now return the final output of a streaming endpoint. This will make it even easier to use gradio apps via the client.
Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
#### Gradio now supports streaming audio outputs
Allows users to use generators to stream audio out, yielding consecutive chunks of audio. Requires `streaming=True` to be set on the output audio.
```python
import gradio as gr
from pydub import AudioSegment
def stream_audio(audio_file):
audio = AudioSegment.from_mp3(audio_file)
i = 0
chunk_size = 3000
while chunk_size*i < len(audio):
chunk = audio[chunk_size*i:chunk_size*(i+1)]
i += 1
if chunk:
file = f"/tmp/{i}.mp3"
chunk.export(file, format="mp3")
yield file
demo = gr.Interface(
fn=stream_audio,
inputs=gr.Audio(type="filepath", label="Audio file to stream"),
outputs=gr.Audio(autoplay=True, streaming=True),
)
demo.queue().launch()
```
From the backend, streamed outputs are served from the `/stream/` endpoint instead of the `/file/` endpoint. Currently just used to serve audio streaming output. The output JSON will have `is_stream`: `true`, instead of `is_file`: `true` in the file data object. Thanks [@aliabid94](https://github.com/aliabid94)!
### Features
- [#5081](https://github.com/gradio-app/gradio/pull/5081) [`d7f83823`](https://github.com/gradio-app/gradio/commit/d7f83823fbd7604456b0127d689a63eed759807d) - solve how can I config root_path dynamically? #4968. Thanks [@eastonsuo](https://github.com/eastonsuo)!
- [#5025](https://github.com/gradio-app/gradio/pull/5025) [`6693660a`](https://github.com/gradio-app/gradio/commit/6693660a790996f8f481feaf22a8c49130d52d89) - Add download button to selected images in `Gallery`. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#5133](https://github.com/gradio-app/gradio/pull/5133) [`61129052`](https://github.com/gradio-app/gradio/commit/61129052ed1391a75c825c891d57fa0ad6c09fc8) - Update dependency esbuild to ^0.19.0. Thanks [@renovate](https://github.com/apps/renovate)!
- [#5125](https://github.com/gradio-app/gradio/pull/5125) [`80be7a1c`](https://github.com/gradio-app/gradio/commit/80be7a1ca44c0adef1668367b2cf36b65e52e576) - chatbot conversation nodes can contain a copy button. Thanks [@fazpu](https://github.com/fazpu)!
- [#5048](https://github.com/gradio-app/gradio/pull/5048) [`0b74a159`](https://github.com/gradio-app/gradio/commit/0b74a1595b30df744e32a2c358c07acb7fd1cfe5) - Use `importlib` in favor of deprecated `pkg_resources`. Thanks [@jayceslesar](https://github.com/jayceslesar)!
- [#5045](https://github.com/gradio-app/gradio/pull/5045) [`3b9494f5`](https://github.com/gradio-app/gradio/commit/3b9494f5c57e6b52e6a040ce8d6b5141f780e84d) - Lite: Fix the analytics module to use asyncio to work in the Wasm env. Thanks [@whitphx](https://github.com/whitphx)!
- [#5046](https://github.com/gradio-app/gradio/pull/5046) [`5244c587`](https://github.com/gradio-app/gradio/commit/5244c5873c355cf3e2f0acb7d67fda3177ef8b0b) - Allow new lines in `HighlightedText` with `/n` and preserve whitespace. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#5076](https://github.com/gradio-app/gradio/pull/5076) [`2745075a`](https://github.com/gradio-app/gradio/commit/2745075a26f80e0e16863d483401ff1b6c5ada7a) - Add deploy_discord to docs. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#5116](https://github.com/gradio-app/gradio/pull/5116) [`0dc49b4c`](https://github.com/gradio-app/gradio/commit/0dc49b4c517706f572240f285313a881089ced79) - Add support for async functions and async generators to `gr.ChatInterface`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5047](https://github.com/gradio-app/gradio/pull/5047) [`883ac364`](https://github.com/gradio-app/gradio/commit/883ac364f69d92128774ac446ce49bdf8415fd7b) - Add `step` param to `Number`. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#5137](https://github.com/gradio-app/gradio/pull/5137) [`22aa5eba`](https://github.com/gradio-app/gradio/commit/22aa5eba3fee3f14473e4b0fac29cf72fe31ef04) - Use font size `--text-md` for `<code>` in Chatbot messages. Thanks [@jaywonchung](https://github.com/jaywonchung)!
- [#5005](https://github.com/gradio-app/gradio/pull/5005) [`f5539c76`](https://github.com/gradio-app/gradio/commit/f5539c7618e31451420bd3228754774da14dc65f) - Enhancement: Add focus event to textbox and number component. Thanks [@JodyZ0203](https://github.com/JodyZ0203)!
- [#5104](https://github.com/gradio-app/gradio/pull/5104) [`34f6b22e`](https://github.com/gradio-app/gradio/commit/34f6b22efbfedfa569d452f3f99ed2e6593e3c21) - Strip leading and trailing spaces from username in login route. Thanks [@sweep-ai](https://github.com/apps/sweep-ai)!
- [#5149](https://github.com/gradio-app/gradio/pull/5149) [`144df459`](https://github.com/gradio-app/gradio/commit/144df459a3b7895e524defcfc4c03fbb8b083aca) - Add `show_edit_button` param to `gr.Audio`. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#5136](https://github.com/gradio-app/gradio/pull/5136) [`eaa1ce14`](https://github.com/gradio-app/gradio/commit/eaa1ce14ac41de1c23321e93f11f1b03a2f3c7f4) - Enhancing Tamil Translation: Language Refinement 🌟. Thanks [@sanjaiyan-dev](https://github.com/sanjaiyan-dev)!
- [#5035](https://github.com/gradio-app/gradio/pull/5035) [`8b4eb8ca`](https://github.com/gradio-app/gradio/commit/8b4eb8cac9ea07bde31b44e2006ca2b7b5f4de36) - JS Client: Fixes cannot read properties of null (reading 'is_file'). Thanks [@raymondtri](https://github.com/raymondtri)!
- [#5023](https://github.com/gradio-app/gradio/pull/5023) [`e6317d77`](https://github.com/gradio-app/gradio/commit/e6317d77f87d3dad638acca3dbc4a9228570e63c) - Update dependency extendable-media-recorder to v8. Thanks [@renovate](https://github.com/apps/renovate)!
- [#5085](https://github.com/gradio-app/gradio/pull/5085) [`13e47835`](https://github.com/gradio-app/gradio/commit/13e478353532c4af18cfa50772f8b6fb3c6c9818) - chore(deps): update dependency extendable-media-recorder to v8. Thanks [@renovate](https://github.com/apps/renovate)!
- [#5080](https://github.com/gradio-app/gradio/pull/5080) [`37caa2e0`](https://github.com/gradio-app/gradio/commit/37caa2e0fe95d6cab8beb174580fb557904f137f) - Add icon and link params to `gr.Button`. Thanks [@hannahblair](https://github.com/hannahblair)!
### Fixes
- [#5062](https://github.com/gradio-app/gradio/pull/5062) [`7d897165`](https://github.com/gradio-app/gradio/commit/7d89716519d0751072792c9bbda668ffeb597296) - `gr.Dropdown` now has correct behavior in static mode as well as when an option is selected. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5077](https://github.com/gradio-app/gradio/pull/5077) [`667875b2`](https://github.com/gradio-app/gradio/commit/667875b2441753e74d25bd9d3c8adedd8ede11cd) - Live audio streaming output
- [#5118](https://github.com/gradio-app/gradio/pull/5118) [`1b017e68`](https://github.com/gradio-app/gradio/commit/1b017e68f6a9623cc2ec085bd20e056229552028) - Add `interactive` args to `gr.ColorPicker`. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#5114](https://github.com/gradio-app/gradio/pull/5114) [`56d2609d`](https://github.com/gradio-app/gradio/commit/56d2609de93387a75dc82b1c06c1240c5b28c0b8) - Reset textbox value to empty string when value is None. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#5075](https://github.com/gradio-app/gradio/pull/5075) [`67265a58`](https://github.com/gradio-app/gradio/commit/67265a58027ef1f9e4c0eb849a532f72eaebde48) - Allow supporting >1000 files in `gr.File()` and `gr.UploadButton()`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5135](https://github.com/gradio-app/gradio/pull/5135) [`80727bbe`](https://github.com/gradio-app/gradio/commit/80727bbe2c6d631022054edf01515017691b3bdd) - Fix dataset features and dataset preview for HuggingFaceDatasetSaver. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#5039](https://github.com/gradio-app/gradio/pull/5039) [`620e4645`](https://github.com/gradio-app/gradio/commit/620e46452729d6d4877b3fab84a65daf2f2b7bc6) - `gr.Dropdown()` now supports values with arbitrary characters and doesn't clear value when re-focused. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5061](https://github.com/gradio-app/gradio/pull/5061) [`136adc9c`](https://github.com/gradio-app/gradio/commit/136adc9ccb23e5cb4d02d2e88f23f0b850041f98) - Ensure `gradio_client` is backwards compatible with `gradio==3.24.1`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5129](https://github.com/gradio-app/gradio/pull/5129) [`97d804c7`](https://github.com/gradio-app/gradio/commit/97d804c748be9acfe27b8369dd2d64d61f43c2e7) - [Spaces] ZeroGPU Queue fix. Thanks [@cbensimon](https://github.com/cbensimon)!
- [#5140](https://github.com/gradio-app/gradio/pull/5140) [`cd1353fa`](https://github.com/gradio-app/gradio/commit/cd1353fa3eb1b015f5860ca5d5a8e8d1aa4a831c) - Fixes the display of minutes in the video player. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5111](https://github.com/gradio-app/gradio/pull/5111) [`b84a35b7`](https://github.com/gradio-app/gradio/commit/b84a35b7b91eca947f787648ceb361b1d023427b) - Add icon and link to DuplicateButton. Thanks [@aliabd](https://github.com/aliabd)!
- [#5030](https://github.com/gradio-app/gradio/pull/5030) [`f6c491b0`](https://github.com/gradio-app/gradio/commit/f6c491b079d335af633dd854c68eb26f9e61c552) - highlightedtext throws an error basing on model. Thanks [@rajeunoia](https://github.com/rajeunoia)!
## 3.39.0
### Highlights
#### Create Discord Bots from Gradio Apps 🤖 ([#4960](https://github.com/gradio-app/gradio/pull/4960) [`46e4ef67`](https://github.com/gradio-app/gradio/commit/46e4ef67d287dd68a91473b73172b29cbad064bc))
We're excited to announce that Gradio can now automatically create a discord bot from any `gr.ChatInterface` app.
It's as easy as importing `gradio_client`, connecting to the app, and calling `deploy_discord`!
_🦙 Turning Llama 2 70b into a discord bot 🦙_
```python
import gradio_client as grc
grc.Client("ysharma/Explore_llamav2_with_TGI").deploy_discord(to_id="llama2-70b-discord-bot")
```
<img src="https://gradio-builds.s3.amazonaws.com/demo-files/discordbots/guide/llama_chat.gif">
#### Getting started with template spaces
To help get you started, we have created an organization on Hugging Face called [gradio-discord-bots](https://huggingface.co/gradio-discord-bots) with template spaces you can use to turn state of the art LLMs powered by Gradio to discord bots.
Currently we have template spaces for:
- [Llama-2-70b-chat-hf](https://huggingface.co/spaces/gradio-discord-bots/Llama-2-70b-chat-hf) powered by a FREE Hugging Face Inference Endpoint!
- [Llama-2-13b-chat-hf](https://huggingface.co/spaces/gradio-discord-bots/Llama-2-13b-chat-hf) powered by Hugging Face Inference Endpoints.
- [Llama-2-13b-chat-hf](https://huggingface.co/spaces/gradio-discord-bots/llama-2-13b-chat-transformers) powered by Hugging Face transformers.
- [falcon-7b-instruct](https://huggingface.co/spaces/gradio-discord-bots/falcon-7b-instruct) powered by Hugging Face Inference Endpoints.
- [gpt-3.5-turbo](https://huggingface.co/spaces/gradio-discord-bots/gpt-35-turbo), powered by openai. Requires an OpenAI key.
But once again, you can deploy ANY `gr.ChatInterface` app exposed on the internet! So don't hesitate to try it on your own Chatbots.
❗️ Additional Note ❗️: Technically, any gradio app that exposes an api route that takes in a single string and outputs a single string can be deployed to discord. But `gr.ChatInterface` apps naturally lend themselves to discord's chat functionality so we suggest you start with those.
Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
### Features
- [#4995](https://github.com/gradio-app/gradio/pull/4995) [`3f8c210b`](https://github.com/gradio-app/gradio/commit/3f8c210b01ef1ceaaf8ee73be4bf246b5b745bbf) - Implement left and right click in `Gallery` component and show implicit images in `Gallery` grid. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#4993](https://github.com/gradio-app/gradio/pull/4993) [`dc07a9f9`](https://github.com/gradio-app/gradio/commit/dc07a9f947de44b419d8384987a02dcf94977851) - Bringing back the "Add download button for audio" PR by [@leuryr](https://github.com/leuryr). Thanks [@abidlabs](https://github.com/abidlabs)!
- [#4979](https://github.com/gradio-app/gradio/pull/4979) [`44ac8ad0`](https://github.com/gradio-app/gradio/commit/44ac8ad08d82ea12c503dde5c78f999eb0452de2) - Allow setting sketch color default. Thanks [@aliabid94](https://github.com/aliabid94)!
- [#4985](https://github.com/gradio-app/gradio/pull/4985) [`b74f8453`](https://github.com/gradio-app/gradio/commit/b74f8453034328f0e42da8e41785f5eb039b45d7) - Adds `additional_inputs` to `gr.ChatInterface`. Thanks [@abidlabs](https://github.com/abidlabs)!
### Fixes
- [#4997](https://github.com/gradio-app/gradio/pull/4997) [`41c83070`](https://github.com/gradio-app/gradio/commit/41c83070b01632084e7d29123048a96c1e261407) - Add CSS resets and specifiers to play nice with HF blog. Thanks [@aliabid94](https://github.com/aliabid94)!
## 3.38
### New Features:
- Provide a parameter `animate` (`False` by default) in `gr.make_waveform()` which animates the overlayed waveform by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 4918](https://github.com/gradio-app/gradio/pull/4918)
- Add `show_download_button` param to allow the download button in static Image components to be hidden by [@hannahblair](https://github.com/hannahblair) in [PR 4959](https://github.com/gradio-app/gradio/pull/4959)
- Added autofocus argument to Textbox by [@aliabid94](https://github.com/aliabid94) in [PR 4978](https://github.com/gradio-app/gradio/pull/4978)
- The `gr.ChatInterface` UI now converts the "Submit" button to a "Stop" button in ChatInterface while streaming, which can be used to pause generation. By [@abidlabs](https://github.com/abidlabs) in [PR 4971](https://github.com/gradio-app/gradio/pull/4971).
- Add a `border_color_accent_subdued` theme variable to add a subdued border color to accented items. This is used by chatbot user messages. Set the value of this variable in `Default` theme to `*primary_200`. By [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4989](https://github.com/gradio-app/gradio/pull/4989)
- Add default sketch color argument `brush_color`. Also, masks drawn on images are now slightly translucent (and mask color can also be set via brush_color). By [@aliabid94](https://github.com/aliabid94) in [PR 4979](https://github.com/gradio-app/gradio/pull/4979)
### Bug Fixes:
- Fixes `cancels` for generators so that if a generator is canceled before it is complete, subsequent runs of the event do not continue from the previous iteration, but rather start from the beginning. By [@abidlabs](https://github.com/abidlabs) in [PR 4969](https://github.com/gradio-app/gradio/pull/4969).
- Use `gr.State` in `gr.ChatInterface` to reduce latency by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4976](https://github.com/gradio-app/gradio/pull/4976)
- Fix bug with `gr.Interface` where component labels inferred from handler parameters were including special args like `gr.Request` or `gr.EventData`. By [@cbensimon](https://github.com/cbensimon) in [PR 4956](https://github.com/gradio-app/gradio/pull/4956)
### Breaking Changes:
No changes to highlight.
### Other Changes:
- Apply pyright to the `components` directory by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4948](https://github.com/gradio-app/gradio/pull/4948)
- Improved look of ChatInterface by [@aliabid94](https://github.com/aliabid94) in [PR 4978](https://github.com/gradio-app/gradio/pull/4978)
## 3.37
### New Features:
Introducing a new `gr.ChatInterface` abstraction, which allows Gradio users to build fully functioning Chat interfaces very easily. The only required parameter is a chat function `fn`, which accepts a (string) user input `message` and a (list of lists) chat `history` and returns a (string) response. Here's a toy example:
```py
import gradio as gr
def echo(message, history):
return message
demo = gr.ChatInterface(fn=echo, examples=["hello", "hola", "merhaba"], title="Echo Bot")
demo.launch()
```
Which produces:
<img width="1291" alt="image" src="https://github.com/gradio-app/gradio/assets/1778297/ae94fd72-c2bb-406e-9e8d-7b9c12e80119">
And a corresponding easy-to-use API at `/chat`:
<img width="1164" alt="image" src="https://github.com/gradio-app/gradio/assets/1778297/7b10d6db-6476-4e2e-bebd-ecda802c3b8f">
The `gr.ChatInterface` abstraction works nicely with various LLM libraries, such as `langchain`. See the [dedicated guide](https://gradio.app/guides/creating-a-chatbot-fast) for more examples using `gr.ChatInterface`. Collective team effort in [PR 4869](https://github.com/gradio-app/gradio/pull/4869)
- Chatbot messages now show hyperlinks to download files uploaded to `gr.Chatbot()` by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 4848](https://github.com/gradio-app/gradio/pull/4848)
- Cached examples now work with generators and async generators by [@abidlabs](https://github.com/abidlabs) in [PR 4927](https://github.com/gradio-app/gradio/pull/4927)
- Add RTL support to `gr.Markdown`, `gr.Chatbot`, `gr.Textbox` (via the `rtl` boolean parameter) and text-alignment to `gr.Textbox`(via the string `text_align` parameter) by [@abidlabs](https://github.com/abidlabs) in [PR 4933](https://github.com/gradio-app/gradio/pull/4933)
Examples of usage:
```py
with gr.Blocks() as demo:
gr.Textbox(interactive=True, text_align="right")
demo.launch()
```
```py
with gr.Blocks() as demo:
gr.Markdown("سلام", rtl=True)
demo.launch()
```
- The `get_api_info` method of `Blocks` now supports layout output components [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4871](https://github.com/gradio-app/gradio/pull/4871)
- Added the support for the new command `gradio environment`to make it easier for people to file bug reports if we shipped an easy command to list the OS, gradio version, and versions of gradio/gradio-client dependencies. bu [@varshneydevansh](https://github.com/varshneydevansh) in [PR 4915](https://github.com/gradio-app/gradio/pull/4915).
### Bug Fixes:
- The `.change()` event is fixed in `Video` and `Image` so that it only fires once by [@abidlabs](https://github.com/abidlabs) in [PR 4793](https://github.com/gradio-app/gradio/pull/4793)
- The `.change()` event is fixed in `Audio` so that fires when the component value is programmatically updated by [@abidlabs](https://github.com/abidlabs) in [PR 4793](https://github.com/gradio-app/gradio/pull/4793)
* Add missing `display: flex` property to `Row` so that flex styling is applied to children by [@hannahblair] in [PR 4896](https://github.com/gradio-app/gradio/pull/4896)
* Fixed bug where `gr.Video` could not preprocess urls by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4904](https://github.com/gradio-app/gradio/pull/4904)
* Fixed copy button rendering in API page on Safari by [@aliabid94](https://github.com/aliabid94) in [PR 4924](https://github.com/gradio-app/gradio/pull/4924)
* Fixed `gr.Group` and `container=False`. `container` parameter only available for `Textbox`, `Number`, and `Dropdown`, the only elements where it makes sense. By [@aliabid94](https://github.com/aliabid94) in [PR 4916](https://github.com/gradio-app/gradio/pull/4916)
* Fixed broken image link in auto-generated `app.py` from `ThemeClass.push_to_hub` by [@deepkyu](https://github.com/deepkyu) in [PR 4944](https://github.com/gradio-app/gradio/pull/4944)
### Other Changes:
- Warning on mobile that if a user leaves the tab, websocket connection may break. On broken connection, tries to rejoin queue and displays error conveying connection broke. By [@aliabid94](https://github.com/aliabid94) in [PR 4742](https://github.com/gradio-app/gradio/pull/4742)
- Remove blocking network calls made before the local URL gets printed - these slow down the display of the local URL, especially when no internet is available. [@aliabid94](https://github.com/aliabid94) in [PR 4905](https://github.com/gradio-app/gradio/pull/4905).
- Pinned dependencies to major versions to reduce the likelihood of a broken `gradio` due to changes in downstream dependencies by [@abidlabs](https://github.com/abidlabs) in [PR 4885](https://github.com/gradio-app/gradio/pull/4885)
- Queue `max_size` defaults to parent Blocks `max_thread` when running on Spaces with ZeroGPU hardware. By [@cbensimon](https://github.com/cbensimon) in [PR 4937](https://github.com/gradio-app/gradio/pull/4937)
### Breaking Changes:
Motivated by the release of `pydantic==2.0`, which included breaking changes that broke a large number of Gradio apps, we've pinned many gradio dependencies. Note that pinned dependencies can cause downstream conflicts, so this may be a breaking change. That being said, we've kept the pins pretty loose, and we're expecting change to be better for the long-term stability of Gradio apps.
## 3.36.1
### New Features:
- Hotfix to support pydantic v1 and v2 by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4835](https://github.com/gradio-app/gradio/pull/4835)
### Bug Fixes:
- Fix bug where `gr.File` change event was not triggered when the value was changed by another event by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4811](https://github.com/gradio-app/gradio/pull/4811)
### Other Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
## 3.36.0
### New Features:
- The `gr.Video`, `gr.Audio`, `gr.Image`, `gr.Chatbot`, and `gr.Gallery` components now include a share icon when deployed on Spaces. This behavior can be modified by setting the `show_share_button` parameter in the component classes. by [@aliabid94](https://github.com/aliabid94) in [PR 4651](https://github.com/gradio-app/gradio/pull/4651)
- Allow the web component `space`, `src`, and `host` attributes to be updated dynamically by [@pngwn](https://github.com/pngwn) in [PR 4461](https://github.com/gradio-app/gradio/pull/4461)
- Suggestion for Spaces Duplication built into Gradio, by [@aliabid94](https://github.com/aliabid94) in [PR 4458](https://github.com/gradio-app/gradio/pull/4458)
- The `api_name` parameter now accepts `False` as a value, which means it does not show up in named or unnamed endpoints. By [@abidlabs](https://github.com/aliabid94) in [PR 4683](https://github.com/gradio-app/gradio/pull/4683)
- Added support for `pathlib.Path` in `gr.Video`, `gr.Gallery`, and `gr.Chatbot` by [sunilkumardash9](https://github.com/sunilkumardash9) in [PR 4581](https://github.com/gradio-app/gradio/pull/4581).
### Bug Fixes:
- Updated components with `info` attribute to update when `update()` is called on them. by [@jebarpg](https://github.com/jebarpg) in [PR 4715](https://github.com/gradio-app/gradio/pull/4715).
- Ensure the `Image` components undo button works mode is `mask` or `color-sketch` by [@amyorz](https://github.com/AmyOrz) in [PR 4692](https://github.com/gradio-app/gradio/pull/4692)
- Load the iframe resizer external asset asynchronously, by [@akx](https://github.com/akx) in [PR 4336](https://github.com/gradio-app/gradio/pull/4336)
- Restored missing imports in `gr.components` by [@abidlabs](https://github.com/abidlabs) in [PR 4566](https://github.com/gradio-app/gradio/pull/4566)
- Fix bug where `select` event was not triggered in `gr.Gallery` if `height` was set to be large with `allow_preview=False` by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4551](https://github.com/gradio-app/gradio/pull/4551)
- Fix bug where setting `visible=False` in `gr.Group` event did not work by [@abidlabs](https://github.com/abidlabs) in [PR 4567](https://github.com/gradio-app/gradio/pull/4567)
- Fix `make_waveform` to work with paths that contain spaces [@akx](https://github.com/akx) in [PR 4570](https://github.com/gradio-app/gradio/pull/4570) & [PR 4578](https://github.com/gradio-app/gradio/pull/4578)
- Send captured data in `stop_recording` event for `gr.Audio` and `gr.Video` components by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4554](https://github.com/gradio-app/gradio/pull/4554)
- Fix bug in `gr.Gallery` where `height` and `object_fit` parameters where being ignored by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4576](https://github.com/gradio-app/gradio/pull/4576)
- Fixes an HTML sanitization issue in DOMPurify where links in markdown were not opening in a new window by [@hannahblair] in [PR 4577](https://github.com/gradio-app/gradio/pull/4577)
- Fixed Dropdown height rendering in Columns by [@aliabid94](https://github.com/aliabid94) in [PR 4584](https://github.com/gradio-app/gradio/pull/4584)
- Fixed bug where `AnnotatedImage` css styling was causing the annotation masks to not be displayed correctly by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4628](https://github.com/gradio-app/gradio/pull/4628)
- Ensure that Gradio does not silently fail when running on a port that is occupied by [@abidlabs](https://github.com/abidlabs) in [PR 4624](https://github.com/gradio-app/gradio/pull/4624).
- Fix double upload bug that caused lag in file uploads by [@aliabid94](https://github.com/aliabid94) in [PR 4661](https://github.com/gradio-app/gradio/pull/4661)
- `Progress` component now appears even when no `iterable` is specified in `tqdm` constructor by [@itrushkin](https://github.com/itrushkin) in [PR 4475](https://github.com/gradio-app/gradio/pull/4475)
- Deprecation warnings now point at the user code using those deprecated features, instead of Gradio internals, by (https://github.com/akx) in [PR 4694](https://github.com/gradio-app/gradio/pull/4694)
- Adapt column widths in gr.Examples based on content by [@pngwn](https://github.com/pngwn) & [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 4700](https://github.com/gradio-app/gradio/pull/4700)
- The `plot` parameter deprecation warnings should now only be emitted for `Image` components by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4709](https://github.com/gradio-app/gradio/pull/4709)
- Removed uncessessary `type` deprecation warning by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4709](https://github.com/gradio-app/gradio/pull/4709)
- Ensure Audio autoplays works when `autoplay=True` and the video source is dynamically updated [@pngwn](https://github.com/pngwn) in [PR 4705](https://github.com/gradio-app/gradio/pull/4705)
- When an error modal is shown in spaces, ensure we scroll to the top so it can be seen by [@pngwn](https://github.com/pngwn) in [PR 4712](https://github.com/gradio-app/gradio/pull/4712)
- Update depedencies by [@pngwn](https://github.com/pngwn) in [PR 4675](https://github.com/gradio-app/gradio/pull/4675)
- Fixes `gr.Dropdown` being cutoff at the bottom by [@abidlabs](https://github.com/abidlabs) in [PR 4691](https://github.com/gradio-app/gradio/pull/4691).
- Scroll top when clicking "View API" in spaces by [@pngwn](https://github.com/pngwn) in [PR 4714](https://github.com/gradio-app/gradio/pull/4714)
- Fix bug where `show_label` was hiding the entire component for `gr.Label` by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4713](https://github.com/gradio-app/gradio/pull/4713)
- Don't crash when uploaded image has broken EXIF data, by [@akx](https://github.com/akx) in [PR 4764](https://github.com/gradio-app/gradio/pull/4764)
- Place toast messages at the top of the screen by [@pngwn](https://github.com/pngwn) in [PR 4796](https://github.com/gradio-app/gradio/pull/4796)
- Fix regressed styling of Login page when auth is enabled by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4797](https://github.com/gradio-app/gradio/pull/4797)
- Prevent broken scrolling to output on Spaces by [@aliabid94](https://github.com/aliabid94) in [PR 4822](https://github.com/gradio-app/gradio/pull/4822)
### Other Changes:
- Add `.git-blame-ignore-revs` by [@akx](https://github.com/akx) in [PR 4586](https://github.com/gradio-app/gradio/pull/4586)
- Update frontend dependencies in [PR 4601](https://github.com/gradio-app/gradio/pull/4601)
- Use `typing.Literal` where possible in gradio library and client by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4608](https://github.com/gradio-app/gradio/pull/4608)
- Remove unnecessary mock json files for frontend E2E tests by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 4625](https://github.com/gradio-app/gradio/pull/4625)
- Update dependencies by [@pngwn](https://github.com/pngwn) in [PR 4643](https://github.com/gradio-app/gradio/pull/4643)
- The theme builder now launches successfully, and the API docs are cleaned up. By [@abidlabs](https://github.com/aliabid94) in [PR 4683](https://github.com/gradio-app/gradio/pull/4683)
- Remove `cleared_value` from some components as its no longer used internally by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4685](https://github.com/gradio-app/gradio/pull/4685)
- Better errors when you define two Blocks and reference components in one Blocks from the events in the other Blocks [@abidlabs](https://github.com/abidlabs) in [PR 4738](https://github.com/gradio-app/gradio/pull/4738).
- Better message when share link is not created by [@abidlabs](https://github.com/abidlabs) in [PR 4773](https://github.com/gradio-app/gradio/pull/4773).
- Improve accessibility around selected images in gr.Gallery component by [@hannahblair](https://github.com/hannahblair) in [PR 4790](https://github.com/gradio-app/gradio/pull/4790)
### Breaking Changes:
[PR 4683](https://github.com/gradio-app/gradio/pull/4683) removes the explict named endpoint "load_examples" from gr.Interface that was introduced in [PR 4456](https://github.com/gradio-app/gradio/pull/4456).
## 3.35.2
### New Features:
No changes to highlight.
### Bug Fixes:
- Fix chatbot streaming by [@aliabid94](https://github.com/aliabid94) in [PR 4537](https://github.com/gradio-app/gradio/pull/4537)
- Fix chatbot height and scrolling by [@aliabid94](https://github.com/aliabid94) in [PR 4540](https://github.com/gradio-app/gradio/pull/4540)
### Other Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
## 3.35.1
### New Features:
No changes to highlight.
### Bug Fixes:
- Fix chatbot streaming by [@aliabid94](https://github.com/aliabid94) in [PR 4537](https://github.com/gradio-app/gradio/pull/4537)
- Fix error modal position and text size by [@pngwn](https://github.com/pngwn) in [PR 4538](https://github.com/gradio-app/gradio/pull/4538).
### Other Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
## 3.35.0
### New Features:
- A `gr.ClearButton` which allows users to easily clear the values of components by [@abidlabs](https://github.com/abidlabs) in [PR 4456](https://github.com/gradio-app/gradio/pull/4456)
Example usage:
```py
import gradio as gr
with gr.Blocks() as demo:
chatbot = gr.Chatbot([("Hello", "How are you?")])
with gr.Row():
textbox = gr.Textbox(scale=3, interactive=True)
gr.ClearButton([textbox, chatbot], scale=1)
demo.launch()
```
- Min and max value for gr.Number by [@artegoser](https://github.com/artegoser) and [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 3991](https://github.com/gradio-app/gradio/pull/3991)
- Add `start_recording` and `stop_recording` events to `Video` and `Audio` components by [@pngwn](https://github.com/pngwn) in [PR 4422](https://github.com/gradio-app/gradio/pull/4422)
- Allow any function to generate an error message and allow multiple messages to appear at a time. Other error modal improvements such as auto dismiss after a time limit and a new layout on mobile [@pngwn](https://github.com/pngwn) in [PR 4459](https://github.com/gradio-app/gradio/pull/4459).
- Add `autoplay` kwarg to `Video` and `Audio` components by [@pngwn](https://github.com/pngwn) in [PR 4453](https://github.com/gradio-app/gradio/pull/4453)
- Add `allow_preview` parameter to `Gallery` to control whether a detailed preview is displayed on click by
[@freddyaboulton](https://github.com/freddyaboulton) in [PR 4470](https://github.com/gradio-app/gradio/pull/4470)
- Add `latex_delimiters` parameter to `Chatbot` to control the delimiters used for LaTeX and to disable LaTeX in the `Chatbot` by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 4516](https://github.com/gradio-app/gradio/pull/4516)
- Can now issue `gr.Warning` and `gr.Info` modals. Simply put the code `gr.Warning("Your warning message")` or `gr.Info("Your info message")` as a standalone line in your function. By [@aliabid94](https://github.com/aliabid94) in [PR 4518](https://github.com/gradio-app/gradio/pull/4518).
Example:
```python
def start_process(name):
gr.Info("Starting process")
if name is None:
gr.Warning("Name is empty")
...
if success == False:
raise gr.Error("Process failed")
```
### Bug Fixes:
- Add support for PAUSED state in the JS client by [@abidlabs](https://github.com/abidlabs) in [PR 4438](https://github.com/gradio-app/gradio/pull/4438)
- Ensure Tabs only occupy the space required by [@pngwn](https://github.com/pngwn) in [PR 4419](https://github.com/gradio-app/gradio/pull/4419)
- Ensure components have the correct empty sizes to prevent empty containers from collapsing by [@pngwn](https://github.com/pngwn) in [PR 4447](https://github.com/gradio-app/gradio/pull/4447).
- Frontend code no longer crashes when there is a relative URL in an `<a>` element, by [@akx](https://github.com/akx) in [PR 4449](https://github.com/gradio-app/gradio/pull/4449).
- Fix bug where setting `format='mp4'` on a video component would cause the function to error out if the uploaded video was not playable by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4467](https://github.com/gradio-app/gradio/pull/4467)
- Fix `_js` parameter to work even without backend function, by [@aliabid94](https://github.com/aliabid94) in [PR 4486](https://github.com/gradio-app/gradio/pull/4486).
- Fix new line issue with `gr.Chatbot()` by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 4491](https://github.com/gradio-app/gradio/pull/4491)
- Fixes issue with Clear button not working for `Label` component by [@abidlabs](https://github.com/abidlabs) in [PR 4456](https://github.com/gradio-app/gradio/pull/4456)
- Restores the ability to pass in a tuple (sample rate, audio array) to gr.Audio() by [@abidlabs](https://github.com/abidlabs) in [PR 4525](https://github.com/gradio-app/gradio/pull/4525)
- Ensure code is correctly formatted and copy button is always present in Chatbot by [@pngwn](https://github.com/pngwn) in [PR 4527](https://github.com/gradio-app/gradio/pull/4527)
- `show_label` will not automatically be set to `True` in `gr.BarPlot.update` by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4531](https://github.com/gradio-app/gradio/pull/4531)
- `gr.BarPlot` group text now respects darkmode by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4531](https://github.com/gradio-app/gradio/pull/4531)
- Fix dispatched errors from within components [@aliabid94](https://github.com/aliabid94) in [PR 4786](https://github.com/gradio-app/gradio/pull/4786)
### Other Changes:
- Change styling of status and toast error components by [@hannahblair](https://github.com/hannahblair) in [PR 4454](https://github.com/gradio-app/gradio/pull/4454).
- Clean up unnecessary `new Promise()`s by [@akx](https://github.com/akx) in [PR 4442](https://github.com/gradio-app/gradio/pull/4442).
- Minor UI cleanup for Examples and Dataframe components [@aliabid94](https://github.com/aliabid94) in [PR 4455](https://github.com/gradio-app/gradio/pull/4455).
- Minor UI cleanup for Examples and Dataframe components [@aliabid94](https://github.com/aliabid94) in [PR 4455](https://github.com/gradio-app/gradio/pull/4455).
- Add Catalan translation [@jordimas](https://github.com/jordimas) in [PR 4483](https://github.com/gradio-app/gradio/pull/4483).
- The API endpoint that loads examples upon click has been given an explicit name ("/load_examples") by [@abidlabs](https://github.com/abidlabs) in [PR 4456](https://github.com/gradio-app/gradio/pull/4456).
- Allows configuration of FastAPI app when calling `mount_gradio_app`, by [@charlesfrye](https://github.com/charlesfrye) in [PR4519](https://github.com/gradio-app/gradio/pull/4519).
### Breaking Changes:
- The behavior of the `Clear` button has been changed for `Slider`, `CheckboxGroup`, `Radio`, `Dropdown` components by [@abidlabs](https://github.com/abidlabs) in [PR 4456](https://github.com/gradio-app/gradio/pull/4456). The Clear button now sets the value of these components to be empty as opposed to the original default set by the developer. This is to make them in line with the rest of the Gradio components.
- Python 3.7 end of life is June 27 2023. Gradio will no longer support python 3.7 by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4484](https://github.com/gradio-app/gradio/pull/4484)
- Removed `$` as a default LaTeX delimiter for the `Chatbot` by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 4516](https://github.com/gradio-app/gradio/pull/4516). The specific LaTeX delimeters can be set using the new `latex_delimiters` parameter in `Chatbot`.
## 3.34.0
### New Features:
- The `gr.UploadButton` component now supports the `variant` and `interactive` parameters by [@abidlabs](https://github.com/abidlabs) in [PR 4436](https://github.com/gradio-app/gradio/pull/4436).
### Bug Fixes:
- Remove target="\_blank" override on anchor tags with internal targets by [@hannahblair](https://github.com/hannahblair) in [PR 4405](https://github.com/gradio-app/gradio/pull/4405)
- Fixed bug where `gr.File(file_count='multiple')` could not be cached as output by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4421](https://github.com/gradio-app/gradio/pull/4421)
- Restricts the domains that can be proxied via `/proxy` route by [@abidlabs](https://github.com/abidlabs) in [PR 4406](https://github.com/gradio-app/gradio/pull/4406).
- Fixes issue where `gr.UploadButton` could not be used to upload the same file twice by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 4437](https://github.com/gradio-app/gradio/pull/4437)
- Fixes bug where `/proxy` route was being incorrectly constructed by the frontend by [@abidlabs](https://github.com/abidlabs) in [PR 4430](https://github.com/gradio-app/gradio/pull/4430).
- Fix z-index of status component by [@hannahblair](https://github.com/hannahblair) in [PR 4429](https://github.com/gradio-app/gradio/pull/4429)
- Fix video rendering in Safari by [@aliabid94](https://github.com/aliabid94) in [PR 4433](https://github.com/gradio-app/gradio/pull/4433).
- The output directory for files downloaded when calling Blocks as a function is now set to a temporary directory by default (instead of the working directory in some cases) by [@abidlabs](https://github.com/abidlabs) in [PR 4501](https://github.com/gradio-app/gradio/pull/4501)
### Other Changes:
- When running on Spaces, handler functions will be transformed by the [PySpaces](https://pypi.org/project/spaces/) library in order to make them work with specific hardware. It will have no effect on standalone Gradio apps or regular Gradio Spaces and can be globally deactivated as follows : `import spaces; spaces.disable_gradio_auto_wrap()` by [@cbensimon](https://github.com/cbensimon) in [PR 4389](https://github.com/gradio-app/gradio/pull/4389).
- Deprecated `.style` parameter and moved arguments to constructor. Added support for `.update()` to all arguments initially in style. Added `scale` and `min_width` support to every Component. By [@aliabid94](https://github.com/aliabid94) in [PR 4374](https://github.com/gradio-app/gradio/pull/4374)
### Breaking Changes:
No changes to highlight.
## 3.33.1
### New Features:
No changes to highlight.
### Bug Fixes:
- Allow `every` to work with generators by [@dkjshk](https://github.com/dkjshk) in [PR 4434](https://github.com/gradio-app/gradio/pull/4434)
- Fix z-index of status component by [@hannahblair](https://github.com/hannahblair) in [PR 4429](https://github.com/gradio-app/gradio/pull/4429)
- Allow gradio to work offline, by [@aliabid94](https://github.com/aliabid94) in [PR 4398](https://github.com/gradio-app/gradio/pull/4398).
- Fixed `validate_url` to check for 403 errors and use a GET request in place of a HEAD by [@alvindaiyan](https://github.com/alvindaiyan) in [PR 4388](https://github.com/gradio-app/gradio/pull/4388).
### Other Changes:
- More explicit error message when share link binary is blocked by antivirus by [@abidlabs](https://github.com/abidlabs) in [PR 4380](https://github.com/gradio-app/gradio/pull/4380).
### Breaking Changes:
No changes to highlight.
## 3.33.0
### New Features:
- Introduced `gradio deploy` to launch a Gradio app to Spaces directly from your terminal. By [@aliabid94](https://github.com/aliabid94) in [PR 4033](https://github.com/gradio-app/gradio/pull/4033).
- Introduce `show_progress='corner'` argument to event listeners, which will not cover the output components with the progress animation, but instead show it in the corner of the components. By [@aliabid94](https://github.com/aliabid94) in [PR 4396](https://github.com/gradio-app/gradio/pull/4396).
### Bug Fixes:
- Fix bug where Label change event was triggering itself by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4371](https://github.com/gradio-app/gradio/pull/4371)
- Make `Blocks.load` behave like other event listeners (allows chaining `then` off of it) [@anentropic](https://github.com/anentropic/) in [PR 4304](https://github.com/gradio-app/gradio/pull/4304)
- Respect `interactive=True` in output components of a `gr.Interface` by [@abidlabs](https://github.com/abidlabs) in [PR 4356](https://github.com/gradio-app/gradio/pull/4356).
- Remove unused frontend code by [@akx](https://github.com/akx) in [PR 4275](https://github.com/gradio-app/gradio/pull/4275)
- Fixes favicon path on Windows by [@abidlabs](https://github.com/abidlabs) in [PR 4369](https://github.com/gradio-app/gradio/pull/4369).
- Prevent path traversal in `/file` routes by [@abidlabs](https://github.com/abidlabs) in [PR 4370](https://github.com/gradio-app/gradio/pull/4370).
- Do not send HF token to other domains via `/proxy` route by [@abidlabs](https://github.com/abidlabs) in [PR 4368](https://github.com/gradio-app/gradio/pull/4368).
- Replace default `markedjs` sanitize function with DOMPurify sanitizer for `gr.Chatbot()` by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 4360](https://github.com/gradio-app/gradio/pull/4360)
- Prevent the creation of duplicate copy buttons in the chatbot and ensure copy buttons work in non-secure contexts by [@binary-husky](https://github.com/binary-husky) in [PR 4350](https://github.com/gradio-app/gradio/pull/4350).
### Other Changes:
- Remove flicker of loading bar by adding opacity transition, by [@aliabid94](https://github.com/aliabid94) in [PR 4349](https://github.com/gradio-app/gradio/pull/4349).
- Performance optimization in the frontend's Blocks code by [@akx](https://github.com/akx) in [PR 4334](https://github.com/gradio-app/gradio/pull/4334)
- Upgrade the pnpm lock file format version from v6.0 to v6.1 by [@whitphx](https://github.com/whitphx) in [PR 4393](https://github.com/gradio-app/gradio/pull/4393)
### Breaking Changes:
- The `/file=` route no longer allows accessing dotfiles or files in "dot directories" by [@akx](https://github.com/akx) in [PR 4303](https://github.com/gradio-app/gradio/pull/4303)
## 3.32.0
### New Features:
- `Interface.launch()` and `Blocks.launch()` now accept an `app_kwargs` argument to allow customizing the configuration of the underlying FastAPI app, by [@akx](https://github.com/akx) in [PR 4282](https://github.com/gradio-app/gradio/pull/4282)
### Bug Fixes:
- Fixed Gallery/AnnotatedImage components not respecting GRADIO_DEFAULT_DIR variable by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4256](https://github.com/gradio-app/gradio/pull/4256)
- Fixed Gallery/AnnotatedImage components resaving identical images by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4256](https://github.com/gradio-app/gradio/pull/4256)
- Fixed Audio/Video/File components creating empty tempfiles on each run by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4256](https://github.com/gradio-app/gradio/pull/4256)
- Fixed the behavior of the `run_on_click` parameter in `gr.Examples` by [@abidlabs](https://github.com/abidlabs) in [PR 4258](https://github.com/gradio-app/gradio/pull/4258).
- Ensure error modal displays when the queue is enabled by [@pngwn](https://github.com/pngwn) in [PR 4273](https://github.com/gradio-app/gradio/pull/4273)
- Ensure js client respcts the full root when making requests to the server by [@pngwn](https://github.com/pngwn) in [PR 4271](https://github.com/gradio-app/gradio/pull/4271)
### Other Changes:
- Refactor web component `initial_height` attribute by [@whitphx](https://github.com/whitphx) in [PR 4223](https://github.com/gradio-app/gradio/pull/4223)
- Relocate `mount_css` fn to remove circular dependency [@whitphx](https://github.com/whitphx) in [PR 4222](https://github.com/gradio-app/gradio/pull/4222)
- Upgrade Black to 23.3 by [@akx](https://github.com/akx) in [PR 4259](https://github.com/gradio-app/gradio/pull/4259)
- Add frontend LaTeX support in `gr.Chatbot()` using `KaTeX` by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 4285](https://github.com/gradio-app/gradio/pull/4285).
### Breaking Changes:
No changes to highlight.
## 3.31.0
### New Features:
- The reloader command (`gradio app.py`) can now accept command line arguments by [@micky2be](https://github.com/micky2be) in [PR 4119](https://github.com/gradio-app/gradio/pull/4119)
- Added `format` argument to `Audio` component by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4178](https://github.com/gradio-app/gradio/pull/4178)
- Add JS client code snippets to use via api page by [@aliabd](https://github.com/aliabd) in [PR 3927](https://github.com/gradio-app/gradio/pull/3927).
- Update to the JS client by [@pngwn](https://github.com/pngwn) in [PR 4202](https://github.com/gradio-app/gradio/pull/4202)
### Bug Fixes:
- Fix "TypeError: issubclass() arg 1 must be a class" When use Optional[Types] by [@lingfengchencn](https://github.com/lingfengchencn) in [PR 4200](https://github.com/gradio-app/gradio/pull/4200).
- Gradio will no longer send any analytics or call home if analytics are disabled with the GRADIO_ANALYTICS_ENABLED environment variable. By [@akx](https://github.com/akx) in [PR 4194](https://github.com/gradio-app/gradio/pull/4194) and [PR 4236](https://github.com/gradio-app/gradio/pull/4236)
- The deprecation warnings for kwargs now show the actual stack level for the invocation, by [@akx](https://github.com/akx) in [PR 4203](https://github.com/gradio-app/gradio/pull/4203).
- Fix "TypeError: issubclass() arg 1 must be a class" When use Optional[Types] by [@lingfengchencn](https://github.com/lingfengchencn) in [PR 4200](https://github.com/gradio-app/gradio/pull/4200).
- Ensure cancelling functions work correctly by [@pngwn](https://github.com/pngwn) in [PR 4225](https://github.com/gradio-app/gradio/pull/4225)
- Fixes a bug with typing.get_type_hints() on Python 3.9 by [@abidlabs](https://github.com/abidlabs) in [PR 4228](https://github.com/gradio-app/gradio/pull/4228).
- Fixes JSONDecodeError by [@davidai](https://github.com/davidai) in [PR 4241](https://github.com/gradio-app/gradio/pull/4241)
- Fix `chatbot_dialogpt` demo by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 4238](https://github.com/gradio-app/gradio/pull/4238).
### Other Changes:
- Change `gr.Chatbot()` markdown parsing to frontend using `marked` library and `prism` by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 4150](https://github.com/gradio-app/gradio/pull/4150)
- Update the js client by [@pngwn](https://github.com/pngwn) in [PR 3899](https://github.com/gradio-app/gradio/pull/3899)
- Fix documentation for the shape of the numpy array produced by the `Image` component by [@der3318](https://github.com/der3318) in [PR 4204](https://github.com/gradio-app/gradio/pull/4204).
- Updates the timeout for websocket messaging from 1 second to 5 seconds by [@abidlabs](https://github.com/abidlabs) in [PR 4235](https://github.com/gradio-app/gradio/pull/4235)
### Breaking Changes:
No changes to highlight.
## 3.30.0
### New Features:
- Adds a `root_path` parameter to `launch()` that allows running Gradio applications on subpaths (e.g. www.example.com/app) behind a proxy, by [@abidlabs](https://github.com/abidlabs) in [PR 4133](https://github.com/gradio-app/gradio/pull/4133)
- Fix dropdown change listener to trigger on change when updated as an output by [@aliabid94](https://github.com/aliabid94) in [PR 4128](https://github.com/gradio-app/gradio/pull/4128).
- Add `.input` event listener, which is only triggered when a user changes the component value (as compared to `.change`, which is also triggered when a component updates as the result of a function trigger), by [@aliabid94](https://github.com/aliabid94) in [PR 4157](https://github.com/gradio-app/gradio/pull/4157).
### Bug Fixes:
- Records username when flagging by [@abidlabs](https://github.com/abidlabs) in [PR 4135](https://github.com/gradio-app/gradio/pull/4135)
- Fix website build issue by [@aliabd](https://github.com/aliabd) in [PR 4142](https://github.com/gradio-app/gradio/pull/4142)
- Fix lang agnostic type info for `gr.File(file_count='multiple')` output components by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4153](https://github.com/gradio-app/gradio/pull/4153)
### Other Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
## 3.29.0
### New Features:
- Returning language agnostic types in the `/info` route by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4039](https://github.com/gradio-app/gradio/pull/4039)
### Bug Fixes:
- Allow users to upload audio files in Audio component on iOS by by [@aliabid94](https://github.com/aliabid94) in [PR 4071](https://github.com/gradio-app/gradio/pull/4071).
- Fixes the gradio theme builder error that appeared on launch by [@aliabid94](https://github.com/aliabid94) and [@abidlabs](https://github.com/abidlabs) in [PR 4080](https://github.com/gradio-app/gradio/pull/4080)
- Keep Accordion content in DOM by [@aliabid94](https://github.com/aliabid94) in [PR 4070](https://github.com/gradio-app/gradio/pull/4073)
- Fixed bug where type hints in functions caused the event handler to crash by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4068](https://github.com/gradio-app/gradio/pull/4068)
- Fix dropdown default value not appearing by [@aliabid94](https://github.com/aliabid94) in [PR 4072](https://github.com/gradio-app/gradio/pull/4072).
- Soft theme label color fix by [@aliabid94](https://github.com/aliabid94) in [PR 4070](https://github.com/gradio-app/gradio/pull/4070)
- Fix `gr.Slider` `release` event not triggering on mobile by [@space-nuko](https://github.com/space-nuko) in [PR 4098](https://github.com/gradio-app/gradio/pull/4098)
- Removes extraneous `State` component info from the `/info` route by [@abidlabs](https://github.com/freddyaboulton) in [PR 4107](https://github.com/gradio-app/gradio/pull/4107)
- Make .then() work even if first event fails by [@aliabid94](https://github.com/aliabid94) in [PR 4115](https://github.com/gradio-app/gradio/pull/4115).
### Documentation Changes:
No changes to highlight.
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- Allow users to submit with enter in Interfaces with textbox / number inputs [@aliabid94](https://github.com/aliabid94) in [PR 4090](https://github.com/gradio-app/gradio/pull/4090).
- Updates gradio's requirements.txt to requires uvicorn>=0.14.0 by [@abidlabs](https://github.com/abidlabs) in [PR 4086](https://github.com/gradio-app/gradio/pull/4086)
- Updates some error messaging by [@abidlabs](https://github.com/abidlabs) in [PR 4086](https://github.com/gradio-app/gradio/pull/4086)
- Renames simplified Chinese translation file from `zh-cn.json` to `zh-CN.json` by [@abidlabs](https://github.com/abidlabs) in [PR 4086](https://github.com/gradio-app/gradio/pull/4086)
### Contributors Shoutout:
No changes to highlight.
## 3.28.3
### New Features:
No changes to highlight.
### Bug Fixes:
- Fixes issue with indentation in `gr.Code()` component with streaming by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 4043](https://github.com/gradio-app/gradio/pull/4043)
### Documentation Changes:
No changes to highlight.
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
### Contributors Shoutout:
No changes to highlight.
## 3.28.2
### Bug Fixes
- Code component visual updates by [@pngwn](https://github.com/pngwn) in [PR 4051](https://github.com/gradio-app/gradio/pull/4051)
### New Features:
- Add support for `visual-question-answering`, `document-question-answering`, and `image-to-text` using `gr.Interface.load("models/...")` and `gr.Interface.from_pipeline` by [@osanseviero](https://github.com/osanseviero) in [PR 3887](https://github.com/gradio-app/gradio/pull/3887)
- Add code block support in `gr.Chatbot()`, by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 4048](https://github.com/gradio-app/gradio/pull/4048)
- Adds the ability to blocklist filepaths (and also improves the allowlist mechanism) by [@abidlabs](https://github.com/abidlabs) in [PR 4047](https://github.com/gradio-app/gradio/pull/4047).
- Adds the ability to specify the upload directory via an environment variable by [@abidlabs](https://github.com/abidlabs) in [PR 4047](https://github.com/gradio-app/gradio/pull/4047).
### Bug Fixes:
- Fixes issue with `matplotlib` not rendering correctly if the backend was not set to `Agg` by [@abidlabs](https://github.com/abidlabs) in [PR 4029](https://github.com/gradio-app/gradio/pull/4029)
- Fixes bug where rendering the same `gr.State` across different Interfaces/Blocks within larger Blocks would not work by [@abidlabs](https://github.com/abidlabs) in [PR 4030](https://github.com/gradio-app/gradio/pull/4030)
- Code component visual updates by [@pngwn](https://github.com/pngwn) in [PR 4051](https://github.com/gradio-app/gradio/pull/4051)
### Documentation Changes:
- Adds a Guide on how to use the Python Client within a FastAPI app, by [@abidlabs](https://github.com/abidlabs) in [PR 3892](https://github.com/gradio-app/gradio/pull/3892)
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
- `gr.HuggingFaceDatasetSaver` behavior changed internally. The `flagging/` folder is not a `.git/` folder anymore when using it. `organization` parameter is now ignored in favor of passing a full dataset id as `dataset_name` (e.g. `"username/my-dataset"`).
- New lines (`\n`) are not automatically converted to `<br>` in `gr.Markdown()` or `gr.Chatbot()`. For multiple new lines, a developer must add multiple `<br>` tags.
### Full Changelog:
- Safer version of `gr.HuggingFaceDatasetSaver` using HTTP methods instead of git pull/push by [@Wauplin](https://github.com/Wauplin) in [PR 3973](https://github.com/gradio-app/gradio/pull/3973)
### Contributors Shoutout:
No changes to highlight.
## 3.28.1
### New Features:
- Add a "clear mask" button to `gr.Image` sketch modes, by [@space-nuko](https://github.com/space-nuko) in [PR 3615](https://github.com/gradio-app/gradio/pull/3615)
### Bug Fixes:
- Fix dropdown default value not appearing by [@aliabid94](https://github.com/aliabid94) in [PR 3996](https://github.com/gradio-app/gradio/pull/3996).
- Fix faded coloring of output textboxes in iOS / Safari by [@aliabid94](https://github.com/aliabid94) in [PR 3993](https://github.com/gradio-app/gradio/pull/3993)
### Documentation Changes:
No changes to highlight.
### Testing and Infrastructure Changes:
- CI: Simplified Python CI workflow by [@akx](https://github.com/akx) in [PR 3982](https://github.com/gradio-app/gradio/pull/3982)
- Upgrade pyright to 1.1.305 by [@akx](https://github.com/akx) in [PR 4042](https://github.com/gradio-app/gradio/pull/4042)
- More Ruff rules are enabled and lint errors fixed by [@akx](https://github.com/akx) in [PR 4038](https://github.com/gradio-app/gradio/pull/4038)
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
### Contributors Shoutout:
No changes to highlight.
## 3.28.0
### Bug Fixes:
- Fix duplicate play commands in full-screen mode of 'video'. by [@tomchang25](https://github.com/tomchang25) in [PR 3968](https://github.com/gradio-app/gradio/pull/3968).
- Fix the issue of the UI stuck caused by the 'selected' of DataFrame not being reset. by [@tomchang25](https://github.com/tomchang25) in [PR 3916](https://github.com/gradio-app/gradio/pull/3916).
- Fix issue where `gr.Video()` would not work inside a `gr.Tab()` by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 3891](https://github.com/gradio-app/gradio/pull/3891)
- Fixed issue with old_value check in File. by [@tomchang25](https://github.com/tomchang25) in [PR 3859](https://github.com/gradio-app/gradio/pull/3859).
- Fixed bug where all bokeh plots appeared in the same div by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3896](https://github.com/gradio-app/gradio/pull/3896)
- Fixed image outputs to automatically take full output image height, unless explicitly set, by [@aliabid94](https://github.com/aliabid94) in [PR 3905](https://github.com/gradio-app/gradio/pull/3905)
- Fix issue in `gr.Gallery()` where setting height causes aspect ratio of images to collapse by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 3830](https://github.com/gradio-app/gradio/pull/3830)
- Fix issue where requesting for a non-existing file would trigger a 500 error by [@micky2be](https://github.com/micky2be) in `[PR 3895](https://github.com/gradio-app/gradio/pull/3895)`.
- Fix bugs with abspath about symlinks, and unresolvable path on Windows by [@micky2be](https://github.com/micky2be) in `[PR 3895](https://github.com/gradio-app/gradio/pull/3895)`.
- Fixes type in client `Status` enum by [@10zinten](https://github.com/10zinten) in [PR 3931](https://github.com/gradio-app/gradio/pull/3931)
- Fix `gr.ChatBot` to handle image url [tye-singwa](https://github.com/tye-signwa) in [PR 3953](https://github.com/gradio-app/gradio/pull/3953)
- Move Google Tag Manager related initialization code to analytics-enabled block by [@akx](https://github.com/akx) in [PR 3956](https://github.com/gradio-app/gradio/pull/3956)
- Fix bug where port was not reused if the demo was closed and then re-launched by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3896](https://github.com/gradio-app/gradio/pull/3959)
- Fixes issue where dropdown does not position itself at selected element when opened [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 3639](https://github.com/gradio-app/gradio/pull/3639)
### Documentation Changes:
- Make use of `gr` consistent across the docs by [@duerrsimon](https://github.com/duerrsimon) in [PR 3901](https://github.com/gradio-app/gradio/pull/3901)
- Fixed typo in theming-guide.md by [@eltociear](https://github.com/eltociear) in [PR 3952](https://github.com/gradio-app/gradio/pull/3952)
### Testing and Infrastructure Changes:
- CI: Python backend lint is only run once, by [@akx](https://github.com/akx) in [PR 3960](https://github.com/gradio-app/gradio/pull/3960)
- Format invocations and concatenations were replaced by f-strings where possible by [@akx](https://github.com/akx) in [PR 3984](https://github.com/gradio-app/gradio/pull/3984)
- Linting rules were made more strict and issues fixed by [@akx](https://github.com/akx) in [PR 3979](https://github.com/gradio-app/gradio/pull/3979).
### Breaking Changes:
- Some re-exports in `gradio.themes` utilities (introduced in 3.24.0) have been eradicated.
By [@akx](https://github.com/akx) in [PR 3958](https://github.com/gradio-app/gradio/pull/3958)
### Full Changelog:
- Add DESCRIPTION.md to image_segmentation demo by [@aliabd](https://github.com/aliabd) in [PR 3866](https://github.com/gradio-app/gradio/pull/3866)
- Fix error in running `gr.themes.builder()` by [@deepkyu](https://github.com/deepkyu) in [PR 3869](https://github.com/gradio-app/gradio/pull/3869)
- Fixed a JavaScript TypeError when loading custom JS with `_js` and setting `outputs` to `None` in `gradio.Blocks()` by [@DavG25](https://github.com/DavG25) in [PR 3883](https://github.com/gradio-app/gradio/pull/3883)
- Fixed bg_background_fill theme property to expand to whole background, block_radius to affect form elements as well, and added block_label_shadow theme property by [@aliabid94](https://github.com/aliabid94) in [PR 3590](https://github.com/gradio-app/gradio/pull/3590)
### Contributors Shoutout:
No changes to highlight.
## 3.27.0
### New Features:
###### AnnotatedImage Component
New AnnotatedImage component allows users to highlight regions of an image, either by providing bounding boxes, or 0-1 pixel masks. This component is useful for tasks such as image segmentation, object detection, and image captioning.
Example usage:
```python
with gr.Blocks() as demo:
img = gr.Image()
img_section = gr.AnnotatedImage()
def mask(img):
top_left_corner = [0, 0, 20, 20]
random_mask = np.random.randint(0, 2, img.shape[:2])
return (img, [(top_left_corner, "left corner"), (random_mask, "random")])
img.change(mask, img, img_section)
```
See the [image_segmentation demo](https://github.com/gradio-app/gradio/tree/main/demo/image_segmentation) for a full example. By [@aliabid94](https://github.com/aliabid94) in [PR 3836](https://github.com/gradio-app/gradio/pull/3836)
### Bug Fixes:
No changes to highlight.
### Documentation Changes:
No changes to highlight.
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
### Contributors Shoutout:
No changes to highlight.
## 3.26.0
### New Features:
###### `Video` component supports subtitles
- Allow the video component to accept subtitles as input, by [@tomchang25](https://github.com/tomchang25) in [PR 3673](https://github.com/gradio-app/gradio/pull/3673). To provide subtitles, simply return a tuple consisting of `(path_to_video, path_to_subtitles)` from your function. Both `.srt` and `.vtt` formats are supported:
```py
with gr.Blocks() as demo:
gr.Video(("video.mp4", "captions.srt"))
```
### Bug Fixes:
- Fix code markdown support in `gr.Chatbot()` component by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 3816](https://github.com/gradio-app/gradio/pull/3816)
### Documentation Changes:
- Updates the "view API" page in Gradio apps to use the `gradio_client` library by [@aliabd](https://github.com/aliabd) in [PR 3765](https://github.com/gradio-app/gradio/pull/3765)
- Read more about how to use the `gradio_client` library here: https://gradio.app/getting-started-with-the-python-client/
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
### Contributors Shoutout:
No changes to highlight.
## 3.25.0
### New Features:
- Improve error messages when number of inputs/outputs to event handlers mismatch, by [@space-nuko](https://github.com/space-nuko) in [PR 3519](https://github.com/gradio-app/gradio/pull/3519)
- Add `select` listener to Images, allowing users to click on any part of an image and get the coordinates of the click by [@aliabid94](https://github.com/aliabid94) in [PR 3786](https://github.com/gradio-app/gradio/pull/3786).
```python
with gr.Blocks() as demo:
img = gr.Image()
textbox = gr.Textbox()
def select_handler(img, evt: gr.SelectData):
selected_pixel = img[evt.index[1], evt.index[0]]
return f"Selected pixel: {selected_pixel}"
img.select(select_handler, img, textbox)
```
### Bug Fixes:
- Increase timeout for sending analytics data by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 3647](https://github.com/gradio-app/gradio/pull/3647)
- Fix bug where http token was not accessed over websocket connections by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3735](https://github.com/gradio-app/gradio/pull/3735)
- Add ability to specify `rows`, `columns` and `object-fit` in `style()` for `gr.Gallery()` component by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 3586](https://github.com/gradio-app/gradio/pull/3586)
- Fix bug where recording an audio file through the microphone resulted in a corrupted file name by [@abidlabs](https://github.com/abidlabs) in [PR 3770](https://github.com/gradio-app/gradio/pull/3770)
- Added "ssl_verify" to blocks.launch method to allow for use of self-signed certs by [@garrettsutula](https://github.com/garrettsutula) in [PR 3873](https://github.com/gradio-app/gradio/pull/3873)
- Fix bug where iterators where not being reset for processes that terminated early by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3777](https://github.com/gradio-app/gradio/pull/3777)
- Fix bug where the upload button was not properly handling the `file_count='multiple'` case by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3782](https://github.com/gradio-app/gradio/pull/3782)
- Fix bug where use Via API button was giving error by [@Devang-C](https://github.com/Devang-C) in [PR 3783](https://github.com/gradio-app/gradio/pull/3783)
### Documentation Changes:
- Fix invalid argument docstrings, by [@akx](https://github.com/akx) in [PR 3740](https://github.com/gradio-app/gradio/pull/3740)
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- Fixed IPv6 listening to work with bracket [::1] notation, by [@dsully](https://github.com/dsully) in [PR 3695](https://github.com/gradio-app/gradio/pull/3695)
### Contributors Shoutout:
No changes to highlight.
## 3.24.1
### New Features:
- No changes to highlight.
### Bug Fixes:
- Fixes Chatbot issue where new lines were being created every time a message was sent back and forth by [@aliabid94](https://github.com/aliabid94) in [PR 3717](https://github.com/gradio-app/gradio/pull/3717).
- Fixes data updating in DataFrame invoking a `select` event once the dataframe has been selected. By [@yiyuezhuo](https://github.com/yiyuezhuo) in [PR 3861](https://github.com/gradio-app/gradio/pull/3861)
- Fixes false positive warning which is due to too strict type checking by [@yiyuezhuo](https://github.com/yiyuezhuo) in [PR 3837](https://github.com/gradio-app/gradio/pull/3837).
### Documentation Changes:
No changes to highlight.
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
### Contributors Shoutout:
No changes to highlight.
## 3.24.0
### New Features:
- Trigger the release event when Slider number input is released or unfocused by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3589](https://github.com/gradio-app/gradio/pull/3589)
- Created Theme Builder, which allows users to create themes without writing any code, by [@aliabid94](https://github.com/aliabid94) in [PR 3664](https://github.com/gradio-app/gradio/pull/3664). Launch by:
```python
import gradio as gr
gr.themes.builder()
```
- The `Dropdown` component now has a `allow_custom_value` parameter that lets users type in custom values not in the original list of choices.
- The `Colorpicker` component now has a `.blur()` event
###### Added a download button for videos! 📥
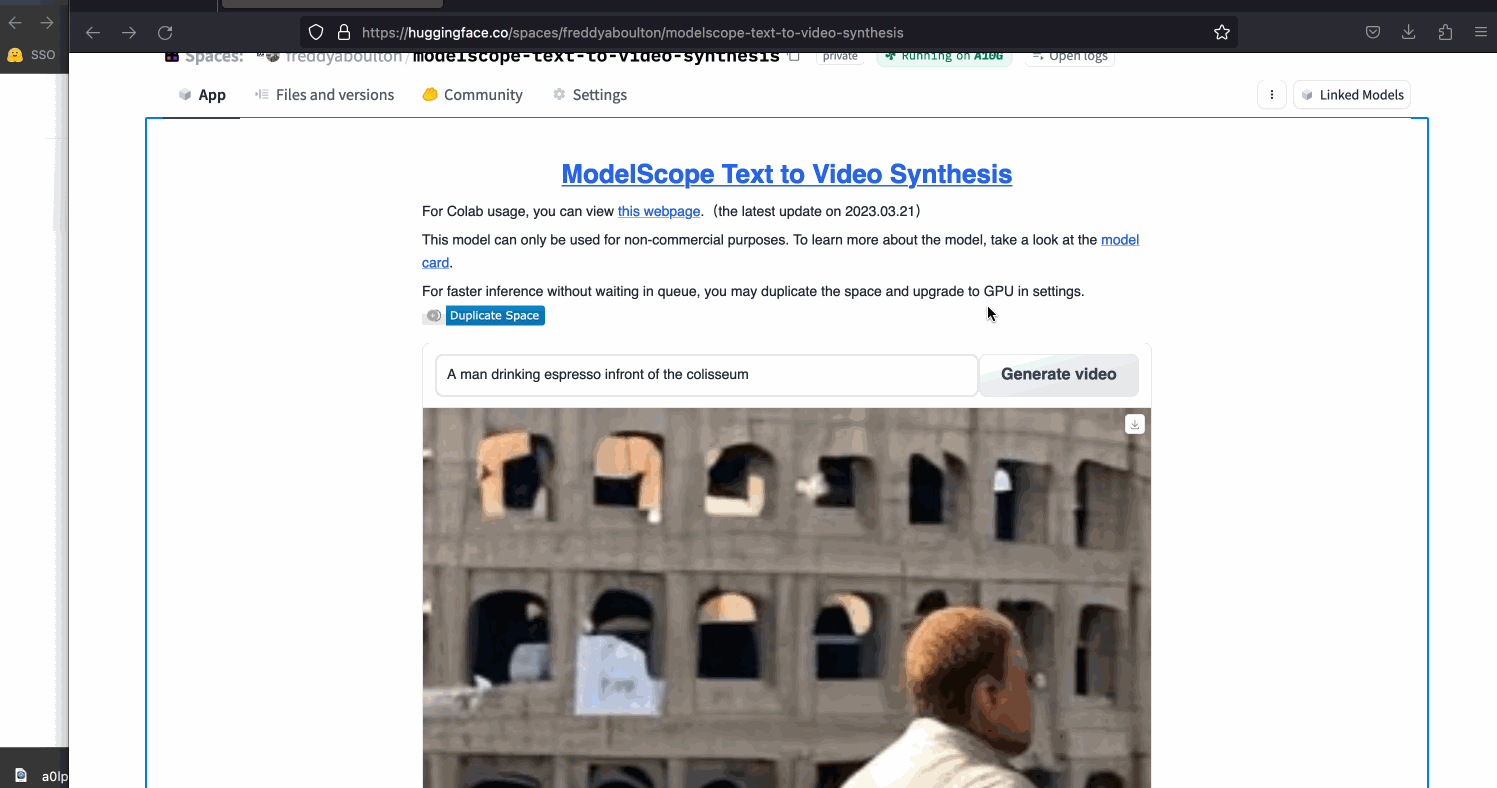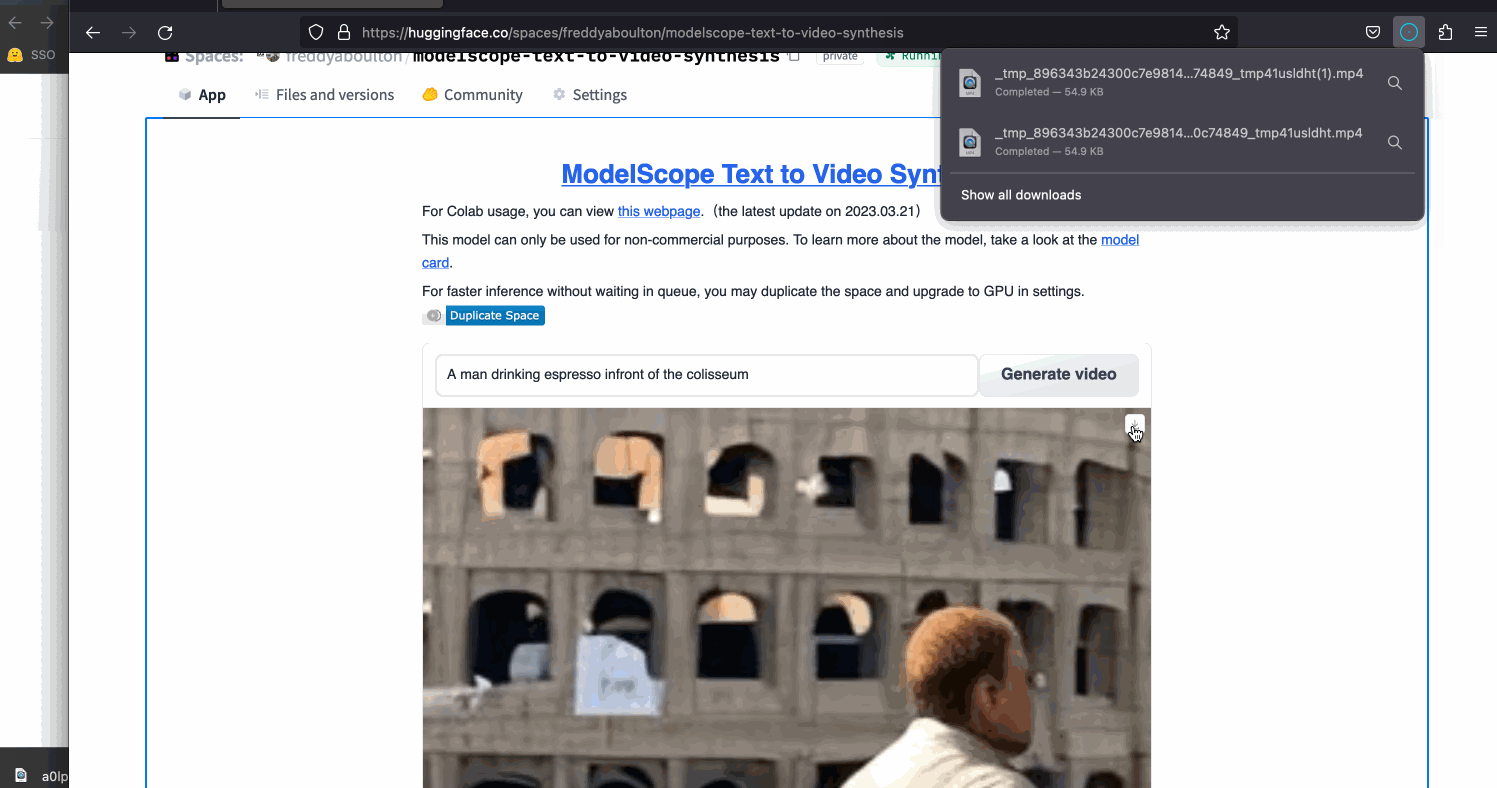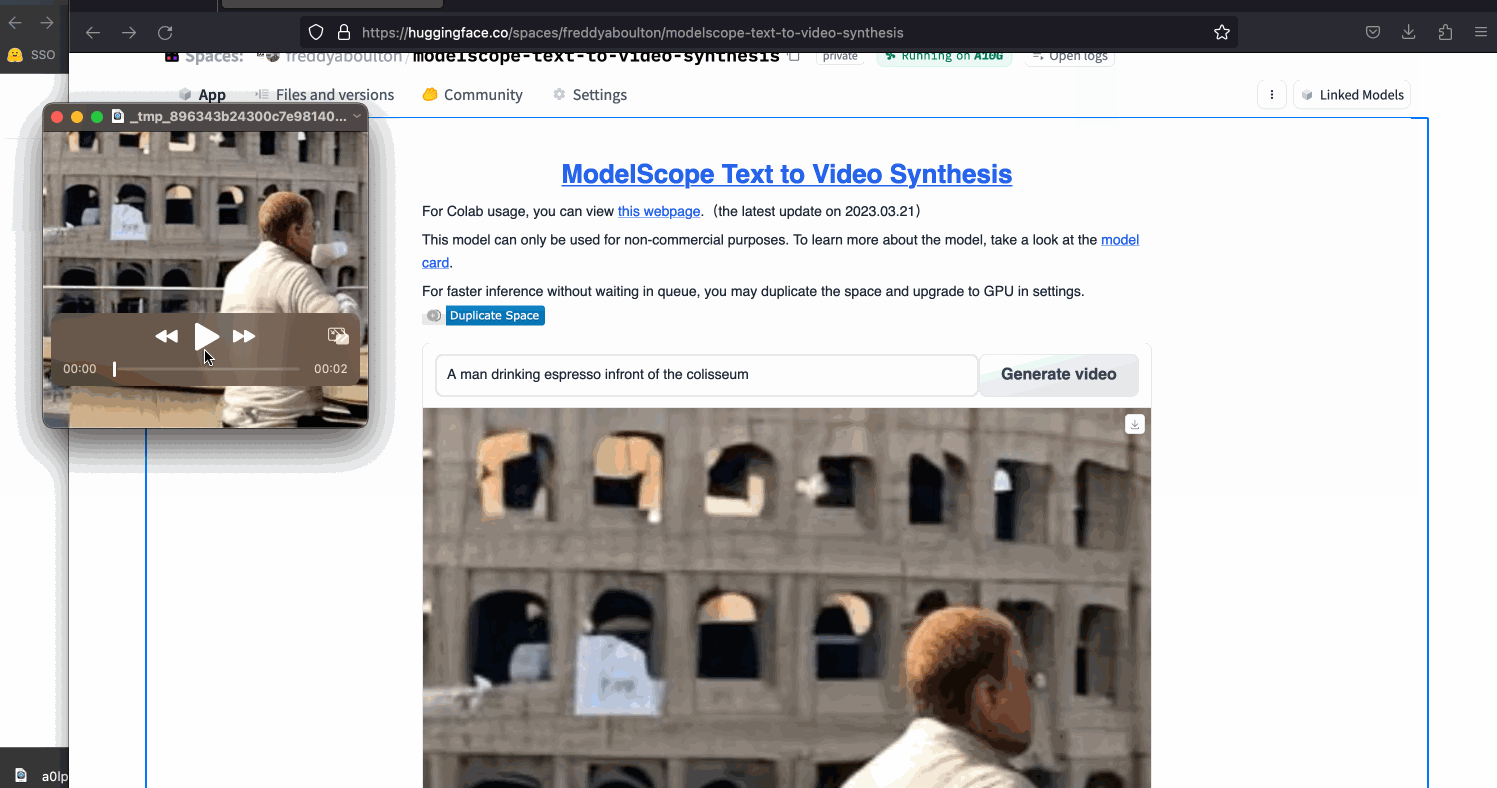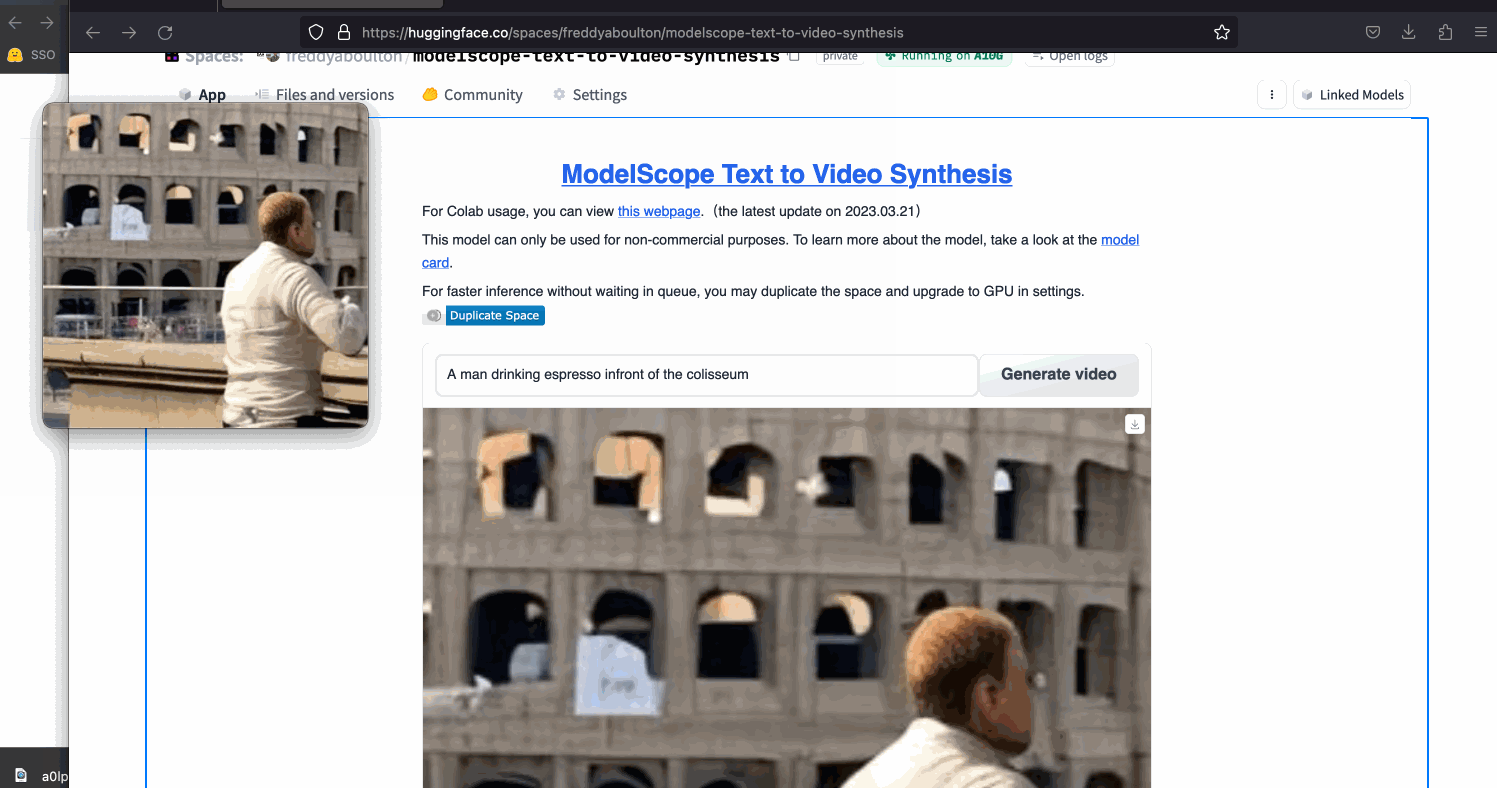
By [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3581](https://github.com/gradio-app/gradio/pull/3581).
- Trigger the release event when Slider number input is released or unfocused by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3589](https://github.com/gradio-app/gradio/pull/3589)
### Bug Fixes:
- Fixed bug where text for altair plots was not legible in dark mode by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3555](https://github.com/gradio-app/gradio/pull/3555)
- Fixes `Chatbot` and `Image` components so that files passed during processing are added to a directory where they can be served from, by [@abidlabs](https://github.com/abidlabs) in [PR 3523](https://github.com/gradio-app/gradio/pull/3523)
- Use Gradio API server to send telemetry using `huggingface_hub` [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 3488](https://github.com/gradio-app/gradio/pull/3488)
- Fixes an an issue where if the Blocks scope was not exited, then State could be shared across sessions, by [@abidlabs](https://github.com/abidlabs) in [PR 3600](https://github.com/gradio-app/gradio/pull/3600)
- Ensures that `gr.load()` loads and applies the upstream theme, by [@abidlabs](https://github.com/abidlabs) in [PR 3641](https://github.com/gradio-app/gradio/pull/3641)
- Fixed bug where "or" was not being localized in file upload text by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3599](https://github.com/gradio-app/gradio/pull/3599)
- Fixed bug where chatbot does not autoscroll inside of a tab, row or column by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 3637](https://github.com/gradio-app/gradio/pull/3637)
- Fixed bug where textbox shrinks when `lines` set to larger than 20 by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 3637](https://github.com/gradio-app/gradio/pull/3637)
- Ensure CSS has fully loaded before rendering the application, by [@pngwn](https://github.com/pngwn) in [PR 3573](https://github.com/gradio-app/gradio/pull/3573)
- Support using an empty list as `gr.Dataframe` value, by [@space-nuko](https://github.com/space-nuko) in [PR 3646](https://github.com/gradio-app/gradio/pull/3646)
- Fixed `gr.Image` not filling the entire element size, by [@space-nuko](https://github.com/space-nuko) in [PR 3649](https://github.com/gradio-app/gradio/pull/3649)
- Make `gr.Code` support the `lines` property, by [@space-nuko](https://github.com/space-nuko) in [PR 3651](https://github.com/gradio-app/gradio/pull/3651)
- Fixes certain `_js` return values being double wrapped in an array, by [@space-nuko](https://github.com/space-nuko) in [PR 3594](https://github.com/gradio-app/gradio/pull/3594)
- Correct the documentation of `gr.File` component to state that its preprocessing method converts the uploaded file to a temporary file, by @RussellLuo in [PR 3660](https://github.com/gradio-app/gradio/pull/3660)
- Fixed bug in Serializer ValueError text by [@osanseviero](https://github.com/osanseviero) in [PR 3669](https://github.com/gradio-app/gradio/pull/3669)
- Fix default parameter argument and `gr.Progress` used in same function, by [@space-nuko](https://github.com/space-nuko) in [PR 3671](https://github.com/gradio-app/gradio/pull/3671)
- Hide `Remove All` button in `gr.Dropdown` single-select mode by [@space-nuko](https://github.com/space-nuko) in [PR 3678](https://github.com/gradio-app/gradio/pull/3678)
- Fix broken spaces in docs by [@aliabd](https://github.com/aliabd) in [PR 3698](https://github.com/gradio-app/gradio/pull/3698)
- Fix items in `gr.Dropdown` besides the selected item receiving a checkmark, by [@space-nuko](https://github.com/space-nuko) in [PR 3644](https://github.com/gradio-app/gradio/pull/3644)
- Fix several `gr.Dropdown` issues and improve usability, by [@space-nuko](https://github.com/space-nuko) in [PR 3705](https://github.com/gradio-app/gradio/pull/3705)
### Documentation Changes:
- Makes some fixes to the Theme Guide related to naming of variables, by [@abidlabs](https://github.com/abidlabs) in [PR 3561](https://github.com/gradio-app/gradio/pull/3561)
- Documented `HuggingFaceDatasetJSONSaver` by [@osanseviero](https://github.com/osanseviero) in [PR 3604](https://github.com/gradio-app/gradio/pull/3604)
- Makes some additions to documentation of `Audio` and `State` components, and fixes the `pictionary` demo by [@abidlabs](https://github.com/abidlabs) in [PR 3611](https://github.com/gradio-app/gradio/pull/3611)
- Fix outdated sharing your app guide by [@aliabd](https://github.com/aliabd) in [PR 3699](https://github.com/gradio-app/gradio/pull/3699)
### Testing and Infrastructure Changes:
- Removed heavily-mocked tests related to comet_ml, wandb, and mlflow as they added a significant amount of test dependencies that prevented installation of test dependencies on Windows environments. By [@abidlabs](https://github.com/abidlabs) in [PR 3608](https://github.com/gradio-app/gradio/pull/3608)
- Added Windows continuous integration, by [@space-nuko](https://github.com/space-nuko) in [PR 3628](https://github.com/gradio-app/gradio/pull/3628)
- Switched linting from flake8 + isort to `ruff`, by [@akx](https://github.com/akx) in [PR 3710](https://github.com/gradio-app/gradio/pull/3710)
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- Mobile responsive iframes in themes guide by [@aliabd](https://github.com/aliabd) in [PR 3562](https://github.com/gradio-app/gradio/pull/3562)
- Remove extra $demo from theme guide by [@aliabd](https://github.com/aliabd) in [PR 3563](https://github.com/gradio-app/gradio/pull/3563)
- Set the theme name to be the upstream repo name when loading from the hub by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3595](https://github.com/gradio-app/gradio/pull/3595)
- Copy everything in website Dockerfile, fix build issues by [@aliabd](https://github.com/aliabd) in [PR 3659](https://github.com/gradio-app/gradio/pull/3659)
- Raise error when an event is queued but the queue is not configured by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3640](https://github.com/gradio-app/gradio/pull/3640)
- Allows users to apss in a string name for a built-in theme, by [@abidlabs](https://github.com/abidlabs) in [PR 3641](https://github.com/gradio-app/gradio/pull/3641)
- Added `orig_name` to Video output in the backend so that the front end can set the right name for downloaded video files by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3700](https://github.com/gradio-app/gradio/pull/3700)
### Contributors Shoutout:
No changes to highlight.
## 3.23.0
### New Features:
###### Theme Sharing!
Once you have created a theme, you can upload it to the HuggingFace Hub to let others view it, use it, and build off of it! You can also download, reuse, and remix other peoples' themes. See https://gradio.app/theming-guide/ for more details.
By [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3428](https://github.com/gradio-app/gradio/pull/3428)
### Bug Fixes:
- Removes leading spaces from all lines of code uniformly in the `gr.Code()` component. By [@abidlabs](https://github.com/abidlabs) in [PR 3556](https://github.com/gradio-app/gradio/pull/3556)
- Fixed broken login page, by [@aliabid94](https://github.com/aliabid94) in [PR 3529](https://github.com/gradio-app/gradio/pull/3529)
### Documentation Changes:
No changes to highlight.
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- Fix rendering of dropdowns to take more space, and related bugs, by [@aliabid94](https://github.com/aliabid94) in [PR 3549](https://github.com/gradio-app/gradio/pull/3549)
### Contributors Shoutout:
No changes to highlight.
## 3.22.1
### New Features:
No changes to highlight.
### Bug Fixes:
- Restore label bars by [@aliabid94](https://github.com/aliabid94) in [PR 3507](https://github.com/gradio-app/gradio/pull/3507)
### Documentation Changes:
No changes to highlight.
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
### Contributors Shoutout:
No changes to highlight.
## 3.22.0
### New Features:
###### Official Theme release
Gradio now supports a new theme system, which allows you to customize the look and feel of your app. You can now use the `theme=` kwarg to pass in a prebuilt theme, or customize your own! See https://gradio.app/theming-guide/ for more details. By [@aliabid94](https://github.com/aliabid94) in [PR 3470](https://github.com/gradio-app/gradio/pull/3470) and [PR 3497](https://github.com/gradio-app/gradio/pull/3497)
###### `elem_classes`
Add keyword argument `elem_classes` to Components to control class names of components, in the same manner as existing `elem_id`.
By [@aliabid94](https://github.com/aliabid94) in [PR 3466](https://github.com/gradio-app/gradio/pull/3466)
### Bug Fixes:
- Fixes the File.upload() event trigger which broke as part of the change in how we uploaded files by [@abidlabs](https://github.com/abidlabs) in [PR 3462](https://github.com/gradio-app/gradio/pull/3462)
- Fixed issue with `gr.Request` object failing to handle dictionaries when nested keys couldn't be converted to variable names [#3454](https://github.com/gradio-app/gradio/issues/3454) by [@radames](https://github.com/radames) in [PR 3459](https://github.com/gradio-app/gradio/pull/3459)
- Fixed bug where css and client api was not working properly when mounted in a subpath by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3482](https://github.com/gradio-app/gradio/pull/3482)
### Documentation Changes:
- Document gr.Error in the docs by [@aliabd](https://github.com/aliabd) in [PR 3465](https://github.com/gradio-app/gradio/pull/3465)
### Testing and Infrastructure Changes:
- Pinned `pyright==1.1.298` for stability by [@abidlabs](https://github.com/abidlabs) in [PR 3475](https://github.com/gradio-app/gradio/pull/3475)
- Removed `IOComponent.add_interactive_to_config()` by [@space-nuko](https://github.com/space-nuko) in [PR 3476](https://github.com/gradio-app/gradio/pull/3476)
- Removed `IOComponent.generate_sample()` by [@space-nuko](https://github.com/space-nuko) in [PR 3475](https://github.com/gradio-app/gradio/pull/3483)
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- Revert primary button background color in dark mode by [@aliabid94](https://github.com/aliabid94) in [PR 3468](https://github.com/gradio-app/gradio/pull/3468)
### Contributors Shoutout:
No changes to highlight.
## 3.21.0
### New Features:
###### Theme Sharing 🎨 🤝
You can now share your gradio themes with the world!
After creating a theme, you can upload it to the HuggingFace Hub to let others view it, use it, and build off of it!
###### Uploading
There are two ways to upload a theme, via the theme class instance or the command line.
1. Via the class instance
```python
my_theme.push_to_hub(repo_name="my_theme",
version="0.2.0",
hf_token="...")
```
2. Via the command line
First save the theme to disk
```python
my_theme.dump(filename="my_theme.json")
```
Then use the `upload_theme` command:
```bash
upload_theme\
"my_theme.json"\
"my_theme"\
"0.2.0"\
"<hf-token>"
```
The `version` must be a valid [semantic version](https://www.geeksforgeeks.org/introduction-semantic-versioning/) string.
This creates a space on the huggingface hub to host the theme files and show potential users a preview of your theme.
An example theme space is here: https://huggingface.co/spaces/freddyaboulton/dracula_revamped
###### Downloading
To use a theme from the hub, use the `from_hub` method on the `ThemeClass` and pass it to your app:
```python
my_theme = gr.Theme.from_hub("freddyaboulton/my_theme")
with gr.Blocks(theme=my_theme) as demo:
....
```
You can also pass the theme string directly to `Blocks` or `Interface` (`gr.Blocks(theme="freddyaboulton/my_theme")`)
You can pin your app to an upstream theme version by using semantic versioning expressions.
For example, the following would ensure the theme we load from the `my_theme` repo was between versions `0.1.0` and `0.2.0`:
```python
with gr.Blocks(theme="freddyaboulton/my_theme@>=0.1.0,<0.2.0") as demo:
....
```
by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3428](https://github.com/gradio-app/gradio/pull/3428)
###### Code component 🦾
New code component allows you to enter, edit and display code with full syntax highlighting by [@pngwn](https://github.com/pngwn) in [PR 3421](https://github.com/gradio-app/gradio/pull/3421)
###### The `Chatbot` component now supports audio, video, and images
The `Chatbot` component now supports audio, video, and images with a simple syntax: simply
pass in a tuple with the URL or filepath (the second optional element of the tuple is alt text), and the image/audio/video will be displayed:
```python
gr.Chatbot([
(("driving.mp4",), "cool video"),
(("cantina.wav",), "cool audio"),
(("lion.jpg", "A lion"), "cool pic"),
]).style(height=800)
```
<img width="1054" alt="image" src="https://user-images.githubusercontent.com/1778297/224116682-5908db47-f0fa-405c-82ab-9c7453e8c4f1.png">
Note: images were previously supported via Markdown syntax and that is still supported for backwards compatibility. By [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 3413](https://github.com/gradio-app/gradio/pull/3413)
- Allow consecutive function triggers with `.then` and `.success` by [@aliabid94](https://github.com/aliabid94) in [PR 3430](https://github.com/gradio-app/gradio/pull/3430)
- New code component allows you to enter, edit and display code with full syntax highlighting by [@pngwn](https://github.com/pngwn) in [PR 3421](https://github.com/gradio-app/gradio/pull/3421)
- Added the `.select()` event listener, which also includes event data that can be passed as an argument to a function with type hint `gr.SelectData`. The following components support the `.select()` event listener: Chatbot, CheckboxGroup, Dataframe, Dropdown, File, Gallery, HighlightedText, Label, Radio, TabItem, Tab, Textbox. Example usage:
```python
import gradio as gr
with gr.Blocks() as demo:
gallery = gr.Gallery(["images/1.jpg", "images/2.jpg", "images/3.jpg"])
selected_index = gr.Textbox()
def on_select(evt: gr.SelectData):
return evt.index
gallery.select(on_select, None, selected_index)
```
By [@aliabid94](https://github.com/aliabid94) in [PR 3399](https://github.com/gradio-app/gradio/pull/3399)
- The `Textbox` component now includes a copy button by [@abidlabs](https://github.com/abidlabs) in [PR 3452](https://github.com/gradio-app/gradio/pull/3452)
### Bug Fixes:
- Use `huggingface_hub` to send telemetry on `interface` and `blocks`; eventually to replace segment by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 3342](https://github.com/gradio-app/gradio/pull/3342)
- Ensure load events created by components (randomize for slider, callable values) are never queued unless every is passed by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3391](https://github.com/gradio-app/gradio/pull/3391)
- Prevent in-place updates of `generic_update` by shallow copying by [@gitgithan](https://github.com/gitgithan) in [PR 3405](https://github.com/gradio-app/gradio/pull/3405) to fix [#3282](https://github.com/gradio-app/gradio/issues/3282)
- Fix bug caused by not importing `BlockContext` in `utils.py` by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3424](https://github.com/gradio-app/gradio/pull/3424)
- Ensure dropdown does not highlight partial matches by [@pngwn](https://github.com/pngwn) in [PR 3421](https://github.com/gradio-app/gradio/pull/3421)
- Fix mic button display by [@aliabid94](https://github.com/aliabid94) in [PR 3456](https://github.com/gradio-app/gradio/pull/3456)
### Documentation Changes:
- Added a section on security and access when sharing Gradio apps by [@abidlabs](https://github.com/abidlabs) in [PR 3408](https://github.com/gradio-app/gradio/pull/3408)
- Add Chinese README by [@uanu2002](https://github.com/uanu2002) in [PR 3394](https://github.com/gradio-app/gradio/pull/3394)
- Adds documentation for web components by [@abidlabs](https://github.com/abidlabs) in [PR 3407](https://github.com/gradio-app/gradio/pull/3407)
- Fixed link in Chinese readme by [@eltociear](https://github.com/eltociear) in [PR 3417](https://github.com/gradio-app/gradio/pull/3417)
- Document Blocks methods by [@aliabd](https://github.com/aliabd) in [PR 3427](https://github.com/gradio-app/gradio/pull/3427)
- Fixed bug where event handlers were not showing up in documentation by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3434](https://github.com/gradio-app/gradio/pull/3434)
### Testing and Infrastructure Changes:
- Fixes tests that were failing locally but passing on CI by [@abidlabs](https://github.com/abidlabs) in [PR 3411](https://github.com/gradio-app/gradio/pull/3411)
- Remove codecov from the repo by [@aliabd](https://github.com/aliabd) in [PR 3415](https://github.com/gradio-app/gradio/pull/3415)
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- Prevent in-place updates of `generic_update` by shallow copying by [@gitgithan](https://github.com/gitgithan) in [PR 3405](https://github.com/gradio-app/gradio/pull/3405) to fix [#3282](https://github.com/gradio-app/gradio/issues/3282)
- Persist file names of files uploaded through any Gradio component by [@abidlabs](https://github.com/abidlabs) in [PR 3412](https://github.com/gradio-app/gradio/pull/3412)
- Fix markdown embedded component in docs by [@aliabd](https://github.com/aliabd) in [PR 3410](https://github.com/gradio-app/gradio/pull/3410)
- Clean up event listeners code by [@aliabid94](https://github.com/aliabid94) in [PR 3420](https://github.com/gradio-app/gradio/pull/3420)
- Fix css issue with spaces logo by [@aliabd](https://github.com/aliabd) in [PR 3422](https://github.com/gradio-app/gradio/pull/3422)
- Makes a few fixes to the `JSON` component (show_label parameter, icons) in [@abidlabs](https://github.com/abidlabs) in [PR 3451](https://github.com/gradio-app/gradio/pull/3451)
### Contributors Shoutout:
No changes to highlight.
## 3.20.1
### New Features:
- Add `height` kwarg to style in `gr.Chatbot()` component by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 3369](https://github.com/gradio-app/gradio/pull/3369)
```python
chatbot = gr.Chatbot().style(height=500)
```
### Bug Fixes:
- Ensure uploaded images are always shown in the sketch tool by [@pngwn](https://github.com/pngwn) in [PR 3386](https://github.com/gradio-app/gradio/pull/3386)
- Fixes bug where when if fn is a non-static class member, then self should be ignored as the first param of the fn by [@or25](https://github.com/or25) in [PR #3227](https://github.com/gradio-app/gradio/pull/3227)
### Documentation Changes:
No changes to highlight.
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
### Contributors Shoutout:
No changes to highlight.
## 3.20.0
### New Features:
###### Release event for Slider
Now you can trigger your python function to run when the slider is released as opposed to every slider change value!
Simply use the `release` method on the slider
```python
slider.release(function, inputs=[...], outputs=[...], api_name="predict")
```
By [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3353](https://github.com/gradio-app/gradio/pull/3353)
###### Dropdown Component Updates
The standard dropdown component now supports searching for choices. Also when `multiselect` is `True`, you can specify `max_choices` to set the maximum number of choices you want the user to be able to select from the dropdown component.
```python
gr.Dropdown(label="Choose your favorite colors", choices=["red", "blue", "green", "yellow", "orange"], multiselect=True, max_choices=2)
```
by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 3211](https://github.com/gradio-app/gradio/pull/3211)
###### Download button for images 🖼️
Output images will now automatically have a download button displayed to make it easier to save and share
the results of Machine Learning art models.
By [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3297](https://github.com/gradio-app/gradio/pull/3297)
- Updated image upload component to accept all image formats, including lossless formats like .webp by [@fienestar](https://github.com/fienestar) in [PR 3225](https://github.com/gradio-app/gradio/pull/3225)
- Adds a disabled mode to the `gr.Button` component by setting `interactive=False` by [@abidlabs](https://github.com/abidlabs) in [PR 3266](https://github.com/gradio-app/gradio/pull/3266) and [PR 3288](https://github.com/gradio-app/gradio/pull/3288)
- Adds visual feedback to the when the Flag button is clicked, by [@abidlabs](https://github.com/abidlabs) in [PR 3289](https://github.com/gradio-app/gradio/pull/3289)
- Adds ability to set `flagging_options` display text and saved flag separately by [@abidlabs](https://github.com/abidlabs) in [PR 3289](https://github.com/gradio-app/gradio/pull/3289)
- Allow the setting of `brush_radius` for the `Image` component both as a default and via `Image.update()` by [@pngwn](https://github.com/pngwn) in [PR 3277](https://github.com/gradio-app/gradio/pull/3277)
- Added `info=` argument to form components to enable extra context provided to users, by [@aliabid94](https://github.com/aliabid94) in [PR 3291](https://github.com/gradio-app/gradio/pull/3291)
- Allow developers to access the username of a logged-in user from the `gr.Request()` object using the `.username` attribute by [@abidlabs](https://github.com/abidlabs) in [PR 3296](https://github.com/gradio-app/gradio/pull/3296)
- Add `preview` option to `Gallery.style` that launches the gallery in preview mode when first loaded by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3345](https://github.com/gradio-app/gradio/pull/3345)
### Bug Fixes:
- Ensure `mirror_webcam` is always respected by [@pngwn](https://github.com/pngwn) in [PR 3245](https://github.com/gradio-app/gradio/pull/3245)
- Fix issue where updated markdown links were not being opened in a new tab by [@gante](https://github.com/gante) in [PR 3236](https://github.com/gradio-app/gradio/pull/3236)
- API Docs Fixes by [@aliabd](https://github.com/aliabd) in [PR 3287](https://github.com/gradio-app/gradio/pull/3287)
- Added a timeout to queue messages as some demos were experiencing infinitely growing queues from active jobs waiting forever for clients to respond by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3196](https://github.com/gradio-app/gradio/pull/3196)
- Fixes the height of rendered LaTeX images so that they match the height of surrounding text by [@abidlabs](https://github.com/abidlabs) in [PR 3258](https://github.com/gradio-app/gradio/pull/3258) and in [PR 3276](https://github.com/gradio-app/gradio/pull/3276)
- Fix bug where matplotlib images where always too small on the front end by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3274](https://github.com/gradio-app/gradio/pull/3274)
- Remove embed's `initial_height` when loading is complete so the embed finds its natural height once it is loaded [@pngwn](https://github.com/pngwn) in [PR 3292](https://github.com/gradio-app/gradio/pull/3292)
- Prevent Sketch from crashing when a default image is provided by [@pngwn](https://github.com/pngwn) in [PR 3277](https://github.com/gradio-app/gradio/pull/3277)
- Respect the `shape` argument on the front end when creating Image Sketches by [@pngwn](https://github.com/pngwn) in [PR 3277](https://github.com/gradio-app/gradio/pull/3277)
- Fix infinite loop caused by setting `Dropdown's` value to be `[]` and adding a change event on the dropdown by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3295](https://github.com/gradio-app/gradio/pull/3295)
- Fix change event listed twice in image docs by [@aliabd](https://github.com/aliabd) in [PR 3318](https://github.com/gradio-app/gradio/pull/3318)
- Fix bug that cause UI to be vertically centered at all times by [@pngwn](https://github.com/pngwn) in [PR 3336](https://github.com/gradio-app/gradio/pull/3336)
- Fix bug where `height` set in `Gallery.style` was not respected by the front-end by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3343](https://github.com/gradio-app/gradio/pull/3343)
- Ensure markdown lists are rendered correctly by [@pngwn](https://github.com/pngwn) in [PR 3341](https://github.com/gradio-app/gradio/pull/3341)
- Ensure that the initial empty value for `gr.Dropdown(Multiselect=True)` is an empty list and the initial value for `gr.Dropdown(Multiselect=False)` is an empty string by [@pngwn](https://github.com/pngwn) in [PR 3338](https://github.com/gradio-app/gradio/pull/3338)
- Ensure uploaded images respect the shape property when the canvas is also enabled by [@pngwn](https://github.com/pngwn) in [PR 3351](https://github.com/gradio-app/gradio/pull/3351)
- Ensure that Google Analytics works correctly when gradio apps are created with `analytics_enabled=True` by [@abidlabs](https://github.com/abidlabs) in [PR 3349](https://github.com/gradio-app/gradio/pull/3349)
- Fix bug where files were being re-uploaded after updates by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3375](https://github.com/gradio-app/gradio/pull/3375)
- Fix error when using backen_fn and custom js at the same time by [@jialeicui](https://github.com/jialeicui) in [PR 3358](https://github.com/gradio-app/gradio/pull/3358)
- Support new embeds for huggingface spaces subdomains by [@pngwn](https://github.com/pngwn) in [PR 3367](https://github.com/gradio-app/gradio/pull/3367)
### Documentation Changes:
- Added the `types` field to the dependency field in the config by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3315](https://github.com/gradio-app/gradio/pull/3315)
- Gradio Status Page by [@aliabd](https://github.com/aliabd) in [PR 3331](https://github.com/gradio-app/gradio/pull/3331)
- Adds a Guide on setting up a dashboard from Supabase data using the `gr.BarPlot`
component by [@abidlabs](https://github.com/abidlabs) in [PR 3275](https://github.com/gradio-app/gradio/pull/3275)
### Testing and Infrastructure Changes:
- Adds a script to benchmark the performance of the queue and adds some instructions on how to use it. By [@freddyaboulton](https://github.com/freddyaboulton) and [@abidlabs](https://github.com/abidlabs) in [PR 3272](https://github.com/gradio-app/gradio/pull/3272)
- Flaky python tests no longer cancel non-flaky tests by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3344](https://github.com/gradio-app/gradio/pull/3344)
### Breaking Changes:
- Chatbot bubble colors can no longer be set by `chatbot.style(color_map=)` by [@aliabid94] in [PR 3370](https://github.com/gradio-app/gradio/pull/3370)
### Full Changelog:
- Fixed comment typo in components.py by [@eltociear](https://github.com/eltociear) in [PR 3235](https://github.com/gradio-app/gradio/pull/3235)
- Cleaned up chatbot ui look and feel by [@aliabid94] in [PR 3370](https://github.com/gradio-app/gradio/pull/3370)
### Contributors Shoutout:
No changes to highlight.
## 3.19.1
### New Features:
No changes to highlight.
### Bug Fixes:
- UI fixes including footer and API docs by [@aliabid94](https://github.com/aliabid94) in [PR 3242](https://github.com/gradio-app/gradio/pull/3242)
- Updated image upload component to accept all image formats, including lossless formats like .webp by [@fienestar](https://github.com/fienestar) in [PR 3225](https://github.com/gradio-app/gradio/pull/3225)
### Documentation Changes:
No changes to highlight.
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- Added backend support for themes by [@aliabid94](https://github.com/aliabid94) in [PR 2931](https://github.com/gradio-app/gradio/pull/2931)
- Added support for button sizes "lg" (default) and "sm".
### Contributors Shoutout:
No changes to highlight.
## 3.19.0
### New Features:
###### Improved embedding experience
When embedding a spaces-hosted gradio app as a web component, you now get an improved UI linking back to the original space, better error handling and more intelligent load performance. No changes are required to your code to benefit from this enhanced experience; simply upgrade your gradio SDK to the latest version.
This behaviour is configurable. You can disable the info panel at the bottom by passing `info="false"`. You can disable the container entirely by passing `container="false"`.
Error statuses are reported in the UI with an easy way for end-users to report problems to the original space author via the community tab of that Hugginface space:
By default, gradio apps are lazy loaded, vastly improving performance when there are several demos on the page. Metadata is loaded ahead of time, but the space will only be loaded and rendered when it is in view.
This behaviour is configurable. You can pass `eager="true"` to load and render the space regardless of whether or not it is currently on the screen.
by [@pngwn](https://github.com/pngwn) in [PR 3205](https://github.com/gradio-app/gradio/pull/3205)
###### New `gr.BarPlot` component! 📊
Create interactive bar plots from a high-level interface with `gr.BarPlot`.
No need to remember matplotlib syntax anymore!
Example usage:
```python
import gradio as gr
import pandas as pd
simple = pd.DataFrame({
'a': ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I'],
'b': [28, 55, 43, 91, 81, 53, 19, 87, 52]
})
with gr.Blocks() as demo:
gr.BarPlot(
simple,
x="a",
y="b",
title="Simple Bar Plot with made up data",
tooltip=['a', 'b'],
)
demo.launch()
```
By [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3157](https://github.com/gradio-app/gradio/pull/3157)
###### Bokeh plots are back! 🌠
Fixed a bug that prevented bokeh plots from being displayed on the front end and extended support for both 2.x and 3.x versions of bokeh!
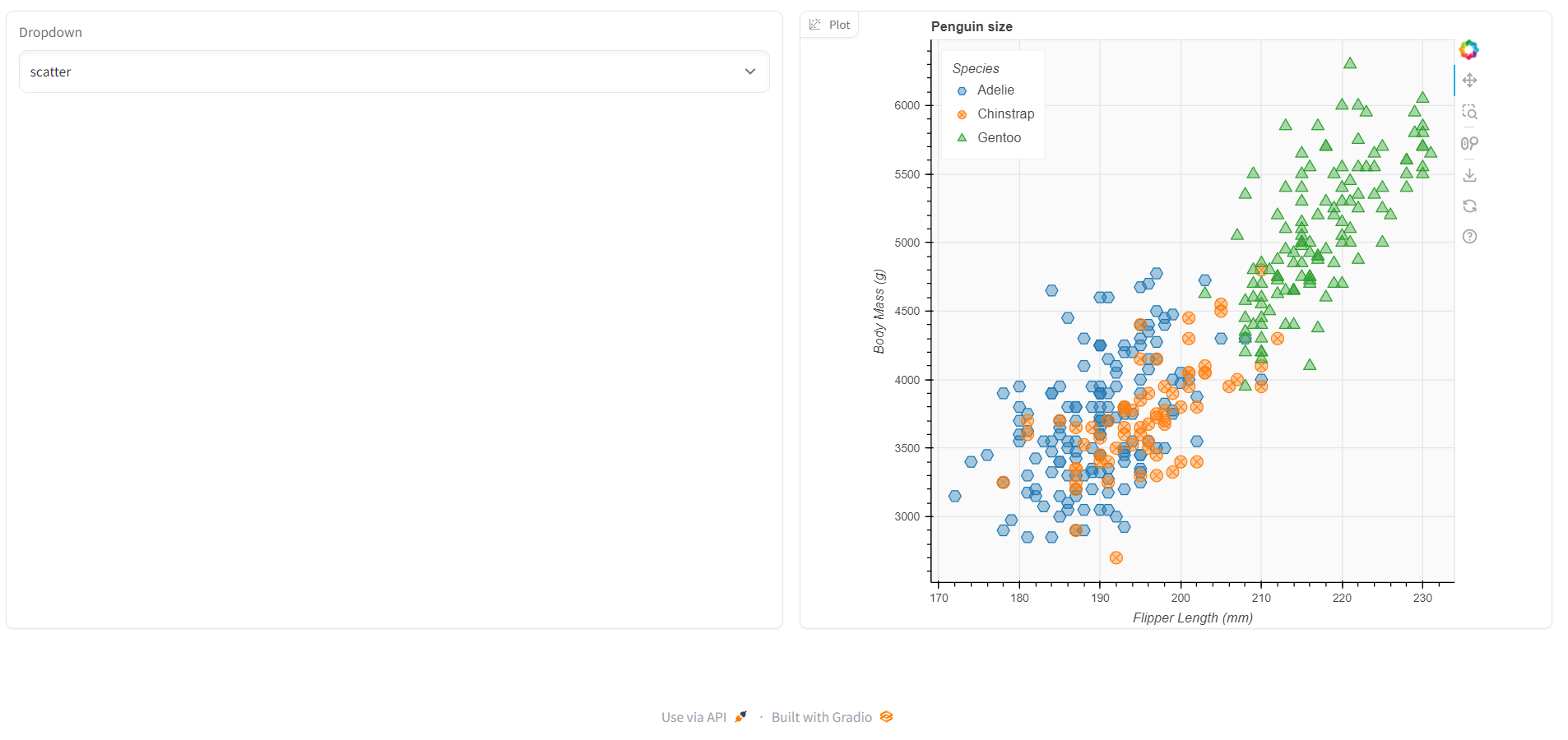
By [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3212](https://github.com/gradio-app/gradio/pull/3212)
### Bug Fixes:
- Adds ability to add a single message from the bot or user side. Ex: specify `None` as the second value in the tuple, to add a single message in the chatbot from the "bot" side.
```python
gr.Chatbot([("Hi, I'm DialoGPT. Try asking me a question.", None)])
```
By [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 3165](https://github.com/gradio-app/gradio/pull/3165)
- Fixes `gr.utils.delete_none` to only remove props whose values are `None` from the config by [@abidlabs](https://github.com/abidlabs) in [PR 3188](https://github.com/gradio-app/gradio/pull/3188)
- Fix bug where embedded demos were not loading files properly by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3177](https://github.com/gradio-app/gradio/pull/3177)
- The `change` event is now triggered when users click the 'Clear All' button of the multiselect DropDown component by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3195](https://github.com/gradio-app/gradio/pull/3195)
- Stops File component from freezing when a large file is uploaded by [@aliabid94](https://github.com/aliabid94) in [PR 3191](https://github.com/gradio-app/gradio/pull/3191)
- Support Chinese pinyin in Dataframe by [@aliabid94](https://github.com/aliabid94) in [PR 3206](https://github.com/gradio-app/gradio/pull/3206)
- The `clear` event is now triggered when images are cleared by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3218](https://github.com/gradio-app/gradio/pull/3218)
- Fix bug where auth cookies where not sent when connecting to an app via http by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3223](https://github.com/gradio-app/gradio/pull/3223)
- Ensure latext CSS is always applied in light and dark mode by [@pngwn](https://github.com/pngwn) in [PR 3233](https://github.com/gradio-app/gradio/pull/3233)
### Documentation Changes:
- Sort components in docs by alphabetic order by [@aliabd](https://github.com/aliabd) in [PR 3152](https://github.com/gradio-app/gradio/pull/3152)
- Changes to W&B guide by [@scottire](https://github.com/scottire) in [PR 3153](https://github.com/gradio-app/gradio/pull/3153)
- Keep pnginfo metadata for gallery by [@wfng92](https://github.com/wfng92) in [PR 3150](https://github.com/gradio-app/gradio/pull/3150)
- Add a section on how to run a Gradio app locally [@osanseviero](https://github.com/osanseviero) in [PR 3170](https://github.com/gradio-app/gradio/pull/3170)
- Fixed typos in gradio events function documentation by [@vidalmaxime](https://github.com/vidalmaxime) in [PR 3168](https://github.com/gradio-app/gradio/pull/3168)
- Added an example using Gradio's batch mode with the diffusers library by [@abidlabs](https://github.com/abidlabs) in [PR 3224](https://github.com/gradio-app/gradio/pull/3224)
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- Fix demos page css and add close demos button by [@aliabd](https://github.com/aliabd) in [PR 3151](https://github.com/gradio-app/gradio/pull/3151)
- Caches temp files from base64 input data by giving them a deterministic path based on the contents of data by [@abidlabs](https://github.com/abidlabs) in [PR 3197](https://github.com/gradio-app/gradio/pull/3197)
- Better warnings (when there is a mismatch between the number of output components and values returned by a function, or when the `File` component or `UploadButton` component includes a `file_types` parameter along with `file_count=="dir"`) by [@abidlabs](https://github.com/abidlabs) in [PR 3194](https://github.com/gradio-app/gradio/pull/3194)
- Raises a `gr.Error` instead of a regular Python error when you use `gr.Interface.load()` to load a model and there's an error querying the HF API by [@abidlabs](https://github.com/abidlabs) in [PR 3194](https://github.com/gradio-app/gradio/pull/3194)
- Fixed gradio share links so that they are persistent and do not reset if network
connection is disrupted by by [XciD](https://github.com/XciD), [Wauplin](https://github.com/Wauplin), and [@abidlabs](https://github.com/abidlabs) in [PR 3149](https://github.com/gradio-app/gradio/pull/3149) and a follow-up to allow it to work for users upgrading from a previous Gradio version in [PR 3221](https://github.com/gradio-app/gradio/pull/3221)
### Contributors Shoutout:
No changes to highlight.
## 3.18.0
### New Features:
###### Revamped Stop Button for Interfaces 🛑
If your Interface function is a generator, there used to be a separate `Stop` button displayed next
to the `Submit` button.
We've revamed the `Submit` button so that it turns into a `Stop` button during the generation process.
Clicking on the `Stop` button will cancel the generation and turn it back to a `Submit` button.
The `Stop` button will automatically turn back to a `Submit` button at the end of the generation if you don't use it!
By [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3124](https://github.com/gradio-app/gradio/pull/3124)
###### Queue now works with reload mode!
You can now call `queue` on your `demo` outside of the `if __name__ == "__main__"` block and
run the script in reload mode with the `gradio` command.
Any changes to the `app.py` file will be reflected in the webpage automatically and the queue will work
properly!
By [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3089](https://github.com/gradio-app/gradio/pull/3089)
###### Allow serving files from additional directories
```python
demo = gr.Interface(...)
demo.launch(
file_directories=["/var/lib/demo/path/to/resources"]
)
```
By [@maxaudron](https://github.com/maxaudron) in [PR 3075](https://github.com/gradio-app/gradio/pull/3075)
### Bug Fixes:
- Fixes URL resolution on Windows by [@abidlabs](https://github.com/abidlabs) in [PR 3108](https://github.com/gradio-app/gradio/pull/3108)
- Example caching now works with components without a label attribute (e.g. `Column`) by [@abidlabs](https://github.com/abidlabs) in [PR 3123](https://github.com/gradio-app/gradio/pull/3123)
- Ensure the Video component correctly resets the UI state when a new video source is loaded and reduce choppiness of UI by [@pngwn](https://github.com/abidlabs) in [PR 3117](https://github.com/gradio-app/gradio/pull/3117)
- Fixes loading private Spaces by [@abidlabs](https://github.com/abidlabs) in [PR 3068](https://github.com/gradio-app/gradio/pull/3068)
- Added a warning when attempting to launch an `Interface` via the `%%blocks` jupyter notebook magic command by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3126](https://github.com/gradio-app/gradio/pull/3126)
- Fixes bug where interactive output image cannot be set when in edit mode by [@dawoodkhan82](https://github.com/@dawoodkhan82) in [PR 3135](https://github.com/gradio-app/gradio/pull/3135)
- A share link will automatically be created when running on Sagemaker notebooks so that the front-end is properly displayed by [@abidlabs](https://github.com/abidlabs) in [PR 3137](https://github.com/gradio-app/gradio/pull/3137)
- Fixes a few dropdown component issues; hide checkmark next to options as expected, and keyboard hover is visible by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 3145]https://github.com/gradio-app/gradio/pull/3145)
- Fixed bug where example pagination buttons were not visible in dark mode or displayed under the examples table. By [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3144](https://github.com/gradio-app/gradio/pull/3144)
- Fixed bug where the font color of axis labels and titles for native plots did not respond to dark mode preferences. By [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3146](https://github.com/gradio-app/gradio/pull/3146)
### Documentation Changes:
- Added a guide on the 4 kinds of Gradio Interfaces by [@yvrjsharma](https://github.com/yvrjsharma) and [@abidlabs](https://github.com/abidlabs) in [PR 3003](https://github.com/gradio-app/gradio/pull/3003)
- Explained that the parameters in `launch` will not be respected when using reload mode, e.g. `gradio` command by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3089](https://github.com/gradio-app/gradio/pull/3089)
- Added a demo to show how to set up variable numbers of outputs in Gradio by [@abidlabs](https://github.com/abidlabs) in [PR 3127](https://github.com/gradio-app/gradio/pull/3127)
- Updated docs to reflect that the `equal_height` parameter should be passed to the `.style()` method of `gr.Row()` by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3125](https://github.com/gradio-app/gradio/pull/3125)
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- Changed URL of final image for `fake_diffusion` demos by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3120](https://github.com/gradio-app/gradio/pull/3120)
### Contributors Shoutout:
No changes to highlight.
## 3.17.1
### New Features:
###### iOS image rotation fixed 🔄
Previously photos uploaded via iOS would be rotated after processing. This has been fixed by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3089](https://github.com/gradio-app/gradio/pull/3091)
######### Before
######### After
###### Run on Kaggle kernels 🧪
A share link will automatically be created when running on Kaggle kernels (notebooks) so that the front-end is properly displayed.
By [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3101](https://github.com/gradio-app/gradio/pull/3101)
### Bug Fixes:
- Fix bug where examples were not rendered correctly for demos created with Blocks api that had multiple input compinents by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3090](https://github.com/gradio-app/gradio/pull/3090)
- Fix change event listener for JSON, HighlightedText, Chatbot by [@aliabid94](https://github.com/aliabid94) in [PR 3095](https://github.com/gradio-app/gradio/pull/3095)
- Fixes bug where video and file change event not working [@tomchang25](https://github.com/tomchang25) in [PR 3098](https://github.com/gradio-app/gradio/pull/3098)
- Fixes bug where static_video play and pause event not working [@tomchang25](https://github.com/tomchang25) in [PR 3098](https://github.com/gradio-app/gradio/pull/3098)
- Fixed `Gallery.style(grid=...)` by by [@aliabd](https://github.com/aliabd) in [PR 3107](https://github.com/gradio-app/gradio/pull/3107)
### Documentation Changes:
- Update chatbot guide to include blocks demo and markdown support section by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 3023](https://github.com/gradio-app/gradio/pull/3023)
* Fix a broken link in the Quick Start guide, by [@cakiki](https://github.com/cakiki) in [PR 3109](https://github.com/gradio-app/gradio/pull/3109)
* Better docs navigation on mobile by [@aliabd](https://github.com/aliabd) in [PR 3112](https://github.com/gradio-app/gradio/pull/3112)
* Add a guide on using Gradio with [Comet](https://comet.com/), by [@DN6](https://github.com/DN6/) in [PR 3058](https://github.com/gradio-app/gradio/pull/3058)
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- Set minimum `markdown-it-py` version to `2.0.0` so that the dollar math plugin is compatible by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3102](https://github.com/gradio-app/gradio/pull/3102)
### Contributors Shoutout:
No changes to highlight.
## 3.17.0
### New Features:
###### Extended support for Interface.load! 🏗️
You can now load `image-to-text` and `conversational` pipelines from the hub!
###### Image-to-text Demo
```python
io = gr.Interface.load("models/nlpconnect/vit-gpt2-image-captioning",
api_key="<optional-api-key>")
io.launch()
```
<img width="1087" alt="image" src="https://user-images.githubusercontent.com/41651716/213260197-dc5d80b4-6e50-4b3a-a764-94980930ac38.png">
###### conversational Demo
```python
chatbot = gr.Interface.load("models/microsoft/DialoGPT-medium",
api_key="<optional-api-key>")
chatbot.launch()
```
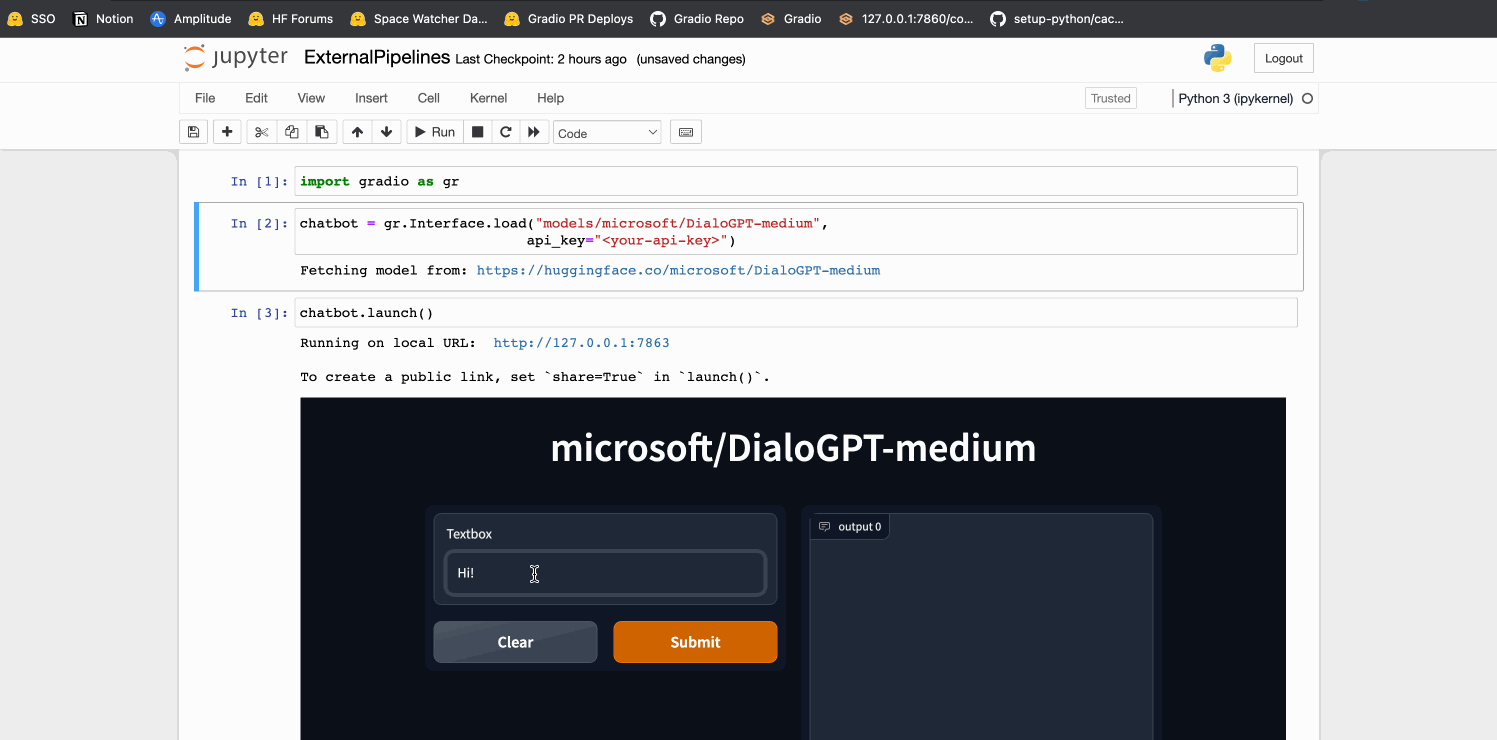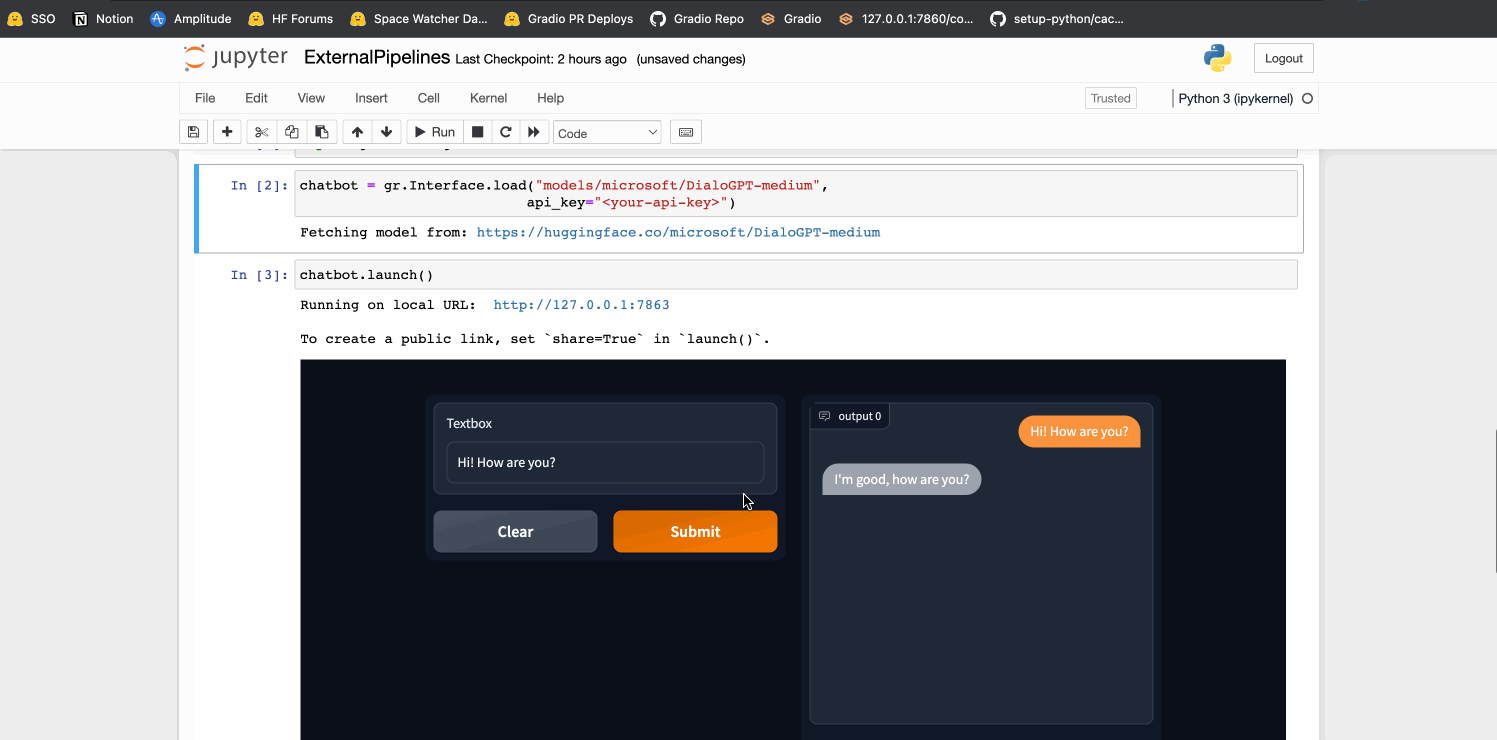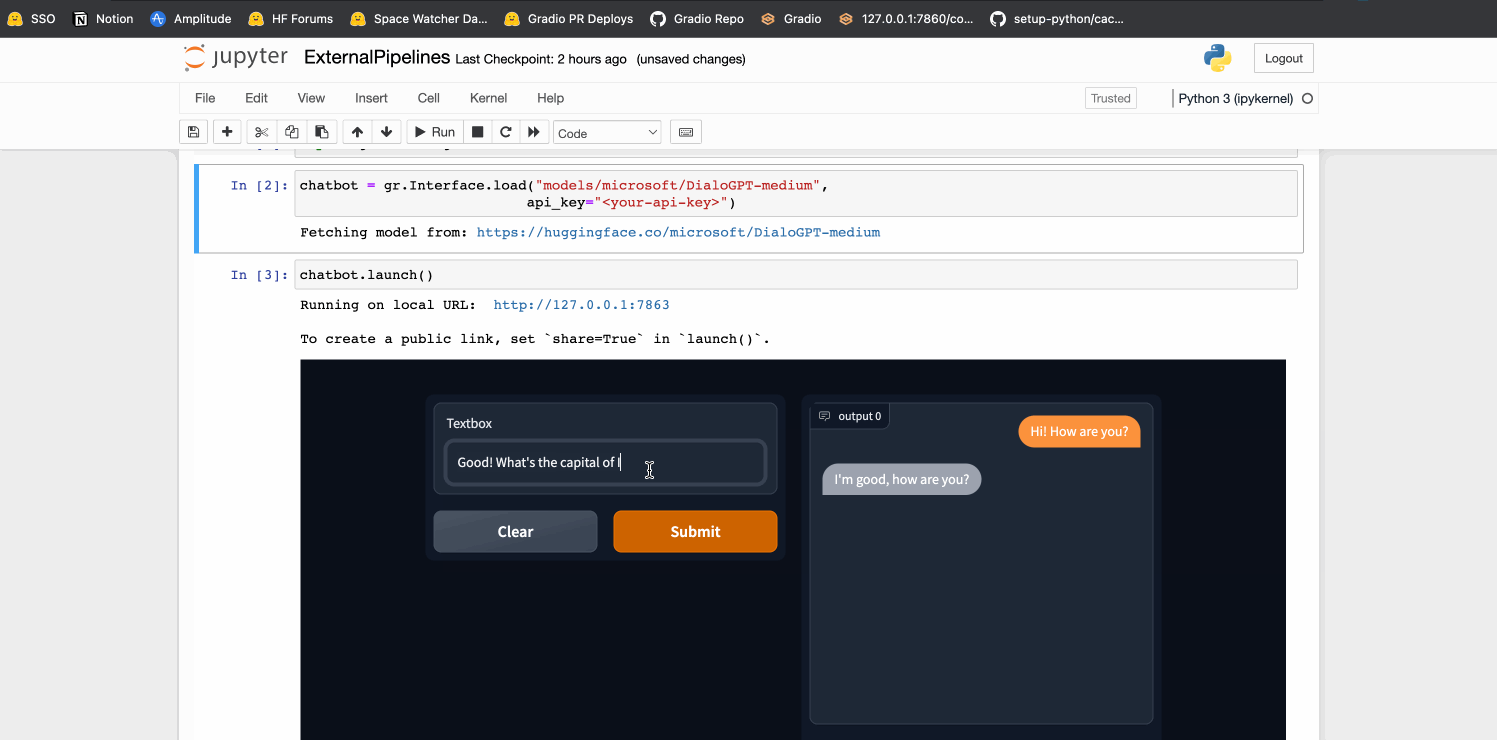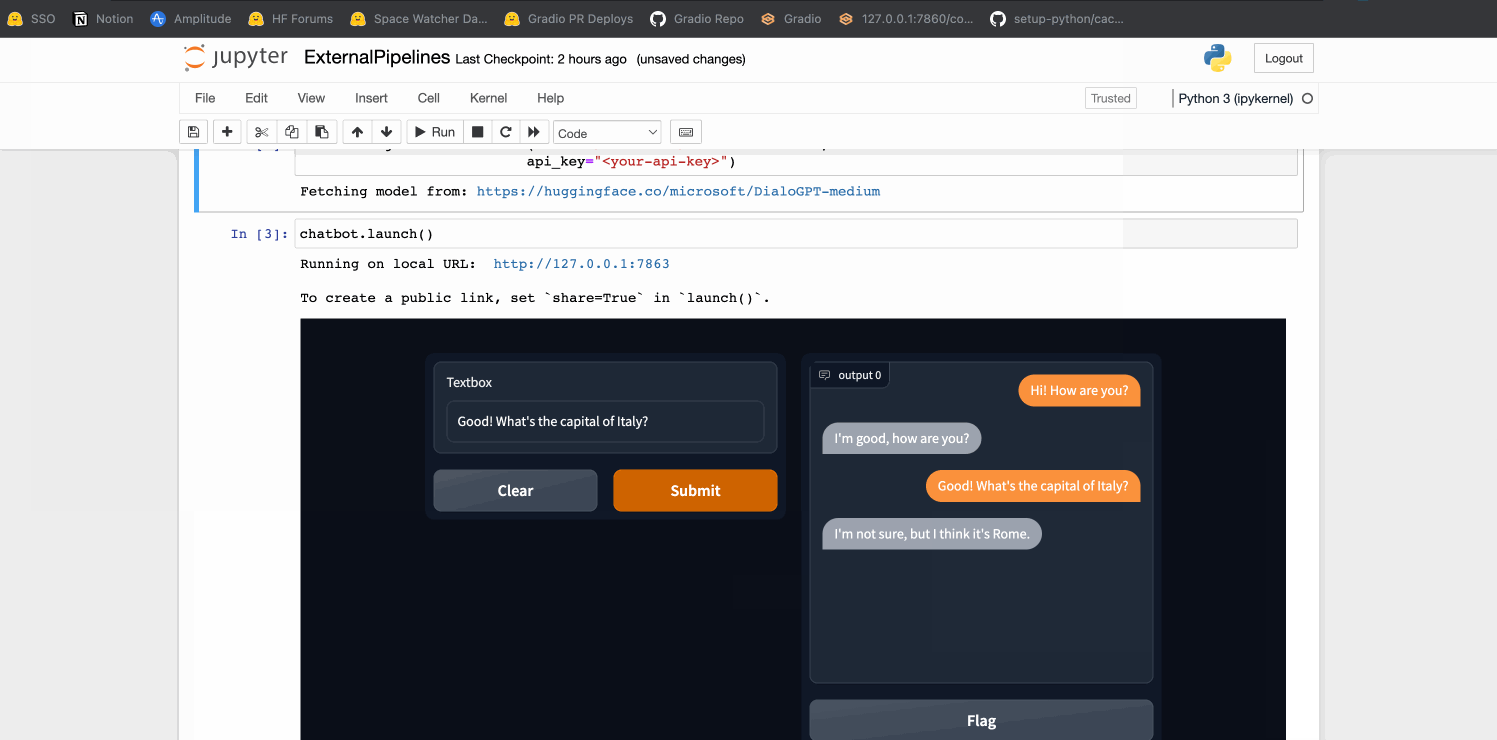
By [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3011](https://github.com/gradio-app/gradio/pull/3011)
###### Download Button added to Model3D Output Component 📥
No need for an additional file output component to enable model3d file downloads anymore. We now added a download button to the model3d component itself.
<img width="739" alt="Screenshot 2023-01-18 at 3 52 45 PM" src="https://user-images.githubusercontent.com/12725292/213294198-5f4fda35-bde7-450c-864f-d5683e7fa29a.png">
By [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 3014](https://github.com/gradio-app/gradio/pull/3014)
###### Fixing Auth on Spaces 🔑
Authentication on spaces works now! Third party cookies must be enabled on your browser to be able
to log in. Some browsers disable third party cookies by default (Safari, Chrome Incognito).
### Bug Fixes:
- Fixes bug where interpretation event was not configured correctly by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2993](https://github.com/gradio-app/gradio/pull/2993)
- Fix relative import bug in reload mode by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2992](https://github.com/gradio-app/gradio/pull/2992)
- Fixes bug where png files were not being recognized when uploading images by [@abidlabs](https://github.com/abidlabs) in [PR 3002](https://github.com/gradio-app/gradio/pull/3002)
- Fixes bug where external Spaces could not be loaded and used as functions if they returned files by [@abidlabs](https://github.com/abidlabs) in [PR 3004](https://github.com/gradio-app/gradio/pull/3004)
- Fix bug where file serialization output was not JSON serializable by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2999](https://github.com/gradio-app/gradio/pull/2999)
- Fixes bug where png files were not being recognized when uploading images by [@abidlabs](https://github.com/abidlabs) in [PR 3002](https://github.com/gradio-app/gradio/pull/3002)
- Fixes bug where temporary uploaded files were not being added to temp sets by [@abidlabs](https://github.com/abidlabs) in [PR 3005](https://github.com/gradio-app/gradio/pull/3005)
- Fixes issue where markdown support in chatbot breaks older demos [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 3006](https://github.com/gradio-app/gradio/pull/3006)
- Fixes the `/file/` route that was broken in a recent change in [PR 3010](https://github.com/gradio-app/gradio/pull/3010)
- Fix bug where the Image component could not serialize image urls by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2957](https://github.com/gradio-app/gradio/pull/2957)
- Fix forwarding for guides after SEO renaming by [@aliabd](https://github.com/aliabd) in [PR 3017](https://github.com/gradio-app/gradio/pull/3017)
- Switch all pages on the website to use latest stable gradio by [@aliabd](https://github.com/aliabd) in [PR 3016](https://github.com/gradio-app/gradio/pull/3016)
- Fix bug related to deprecated parameters in `huggingface_hub` for the HuggingFaceDatasetSaver in [PR 3025](https://github.com/gradio-app/gradio/pull/3025)
- Added better support for symlinks in the way absolute paths are resolved by [@abidlabs](https://github.com/abidlabs) in [PR 3037](https://github.com/gradio-app/gradio/pull/3037)
- Fix several minor frontend bugs (loading animation, examples as gallery) frontend [@aliabid94](https://github.com/3026) in [PR 2961](https://github.com/gradio-app/gradio/pull/3026).
- Fixes bug that the chatbot sample code does not work with certain input value by [@petrov826](https://github.com/petrov826) in [PR 3039](https://github.com/gradio-app/gradio/pull/3039).
- Fix shadows for form element and ensure focus styles more visible in dark mode [@pngwn](https://github.com/pngwn) in [PR 3042](https://github.com/gradio-app/gradio/pull/3042).
- Fixed bug where the Checkbox and Dropdown change events were not triggered in response to other component changes by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3045](https://github.com/gradio-app/gradio/pull/3045)
- Fix bug where the queue was not properly restarted after launching a `closed` app by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3022](https://github.com/gradio-app/gradio/pull/3022)
- Adding missing embedded components on docs by [@aliabd](https://github.com/aliabd) in [PR 3027](https://github.com/gradio-app/gradio/pull/3027)
- Fixes bug where app would crash if the `file_types` parameter of `gr.File` or `gr.UploadButton` was not a list by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3048](https://github.com/gradio-app/gradio/pull/3048)
- Ensure CSS mounts correctly regardless of how many Gradio instances are on the page [@pngwn](https://github.com/pngwn) in [PR 3059](https://github.com/gradio-app/gradio/pull/3059).
- Fix bug where input component was not hidden in the frontend for `UploadButton` by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3053](https://github.com/gradio-app/gradio/pull/3053)
- Fixes issue where after clicking submit or undo, the sketch output wouldn't clear. [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 3047](https://github.com/gradio-app/gradio/pull/3047)
- Ensure spaces embedded via the web component always use the correct URLs for server requests and change ports for testing to avoid strange collisions when users are working with embedded apps locally by [@pngwn](https://github.com/pngwn) in [PR 3065](https://github.com/gradio-app/gradio/pull/3065)
- Preserve selected image of Gallery through updated by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3061](https://github.com/gradio-app/gradio/pull/3061)
- Fix bug where auth was not respected on HF spaces by [@freddyaboulton](https://github.com/freddyaboulton) and [@aliabid94](https://github.com/aliabid94) in [PR 3049](https://github.com/gradio-app/gradio/pull/3049)
- Fixes bug where tabs selected attribute not working if manually change tab by [@tomchang25](https://github.com/tomchang25) in [3055](https://github.com/gradio-app/gradio/pull/3055)
- Change chatbot to show dots on progress, and fix bug where chatbot would not stick to bottom in the case of images by [@aliabid94](https://github.com/aliabid94) in [PR 3067](https://github.com/gradio-app/gradio/pull/3079)
### Documentation Changes:
- SEO improvements to guides by[@aliabd](https://github.com/aliabd) in [PR 2915](https://github.com/gradio-app/gradio/pull/2915)
- Use `gr.LinePlot` for the `blocks_kinematics` demo by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2998](https://github.com/gradio-app/gradio/pull/2998)
- Updated the `interface_series_load` to include some inline markdown code by [@abidlabs](https://github.com/abidlabs) in [PR 3051](https://github.com/gradio-app/gradio/pull/3051)
### Testing and Infrastructure Changes:
- Adds a GitHub action to test if any large files (> 5MB) are present by [@abidlabs](https://github.com/abidlabs) in [PR 3013](https://github.com/gradio-app/gradio/pull/3013)
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- Rewrote frontend using CSS variables for themes by [@pngwn](https://github.com/pngwn) in [PR 2840](https://github.com/gradio-app/gradio/pull/2840)
- Moved telemetry requests to run on background threads by [@abidlabs](https://github.com/abidlabs) in [PR 3054](https://github.com/gradio-app/gradio/pull/3054)
### Contributors Shoutout:
No changes to highlight.
## 3.16.2
### New Features:
No changes to highlight.
### Bug Fixes:
- Fixed file upload fails for files with zero size by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 2923](https://github.com/gradio-app/gradio/pull/2923)
- Fixed bug where `mount_gradio_app` would not launch if the queue was enabled in a gradio app by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2939](https://github.com/gradio-app/gradio/pull/2939)
- Fix custom long CSS handling in Blocks by [@anton-l](https://github.com/anton-l) in [PR 2953](https://github.com/gradio-app/gradio/pull/2953)
- Recovers the dropdown change event by [@abidlabs](https://github.com/abidlabs) in [PR 2954](https://github.com/gradio-app/gradio/pull/2954).
- Fix audio file output by [@aliabid94](https://github.com/aliabid94) in [PR 2961](https://github.com/gradio-app/gradio/pull/2961).
- Fixed bug where file extensions of really long files were not kept after download by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2929](https://github.com/gradio-app/gradio/pull/2929)
- Fix bug where outputs for examples where not being returned by the backend by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2955](https://github.com/gradio-app/gradio/pull/2955)
- Fix bug in `blocks_plug` demo that prevented switching tabs programmatically with python [@TashaSkyUp](https://github.com/https://github.com/TashaSkyUp) in [PR 2971](https://github.com/gradio-app/gradio/pull/2971).
### Documentation Changes:
No changes to highlight.
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
### Contributors Shoutout:
No changes to highlight.
## 3.16.1
### New Features:
No changes to highlight.
### Bug Fixes:
- Fix audio file output by [@aliabid94](https://github.com/aliabid94) in [PR 2950](https://github.com/gradio-app/gradio/pull/2950).
### Documentation Changes:
No changes to highlight.
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
### Contributors Shoutout:
No changes to highlight.
## 3.16.0
### New Features:
###### Send custom progress updates by adding a `gr.Progress` argument after the input arguments to any function. Example:
```python
def reverse(word, progress=gr.Progress()):
progress(0, desc="Starting")
time.sleep(1)
new_string = ""
for letter in progress.tqdm(word, desc="Reversing"):
time.sleep(0.25)
new_string = letter + new_string
return new_string
demo = gr.Interface(reverse, gr.Text(), gr.Text())
```
Progress indicator bar by [@aliabid94](https://github.com/aliabid94) in [PR 2750](https://github.com/gradio-app/gradio/pull/2750).
- Added `title` argument to `TabbedInterface` by @MohamedAliRashad in [#2888](https://github.com/gradio-app/gradio/pull/2888)
- Add support for specifying file extensions for `gr.File` and `gr.UploadButton`, using `file_types` parameter (e.g `gr.File(file_count="multiple", file_types=["text", ".json", ".csv"])`) by @dawoodkhan82 in [#2901](https://github.com/gradio-app/gradio/pull/2901)
- Added `multiselect` option to `Dropdown` by @dawoodkhan82 in [#2871](https://github.com/gradio-app/gradio/pull/2871)
###### With `multiselect` set to `true` a user can now select multiple options from the `gr.Dropdown` component.
```python
gr.Dropdown(["angola", "pakistan", "canada"], multiselect=True, value=["angola"])
```
<img width="610" alt="Screenshot 2023-01-03 at 4 14 36 PM" src="https://user-images.githubusercontent.com/12725292/210442547-c86975c9-4b4f-4b8e-8803-9d96e6a8583a.png">
### Bug Fixes:
- Fixed bug where an error opening an audio file led to a crash by [@FelixDombek](https://github.com/FelixDombek) in [PR 2898](https://github.com/gradio-app/gradio/pull/2898)
- Fixed bug where setting `default_enabled=False` made it so that the entire queue did not start by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2876](https://github.com/gradio-app/gradio/pull/2876)
- Fixed bug where csv preview for DataFrame examples would show filename instead of file contents by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2877](https://github.com/gradio-app/gradio/pull/2877)
- Fixed bug where an error raised after yielding iterative output would not be displayed in the browser by
[@JaySmithWpg](https://github.com/JaySmithWpg) in [PR 2889](https://github.com/gradio-app/gradio/pull/2889)
- Fixed bug in `blocks_style` demo that was preventing it from launching by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2890](https://github.com/gradio-app/gradio/pull/2890)
- Fixed bug where files could not be downloaded by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2926](https://github.com/gradio-app/gradio/pull/2926)
- Fixed bug where cached examples were not displaying properly by [@a-rogalska](https://github.com/a-rogalska) in [PR 2974](https://github.com/gradio-app/gradio/pull/2974)
### Documentation Changes:
- Added a Guide on using Google Sheets to create a real-time dashboard with Gradio's `DataFrame` and `LinePlot` component, by [@abidlabs](https://github.com/abidlabs) in [PR 2816](https://github.com/gradio-app/gradio/pull/2816)
- Add a components - events matrix on the docs by [@aliabd](https://github.com/aliabd) in [PR 2921](https://github.com/gradio-app/gradio/pull/2921)
### Testing and Infrastructure Changes:
- Deployed PRs from forks to spaces by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2895](https://github.com/gradio-app/gradio/pull/2895)
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- The `default_enabled` parameter of the `Blocks.queue` method has no effect by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2876](https://github.com/gradio-app/gradio/pull/2876)
- Added typing to several Python files in codebase by [@abidlabs](https://github.com/abidlabs) in [PR 2887](https://github.com/gradio-app/gradio/pull/2887)
- Excluding untracked files from demo notebook check action by [@aliabd](https://github.com/aliabd) in [PR 2897](https://github.com/gradio-app/gradio/pull/2897)
- Optimize images and gifs by [@aliabd](https://github.com/aliabd) in [PR 2922](https://github.com/gradio-app/gradio/pull/2922)
- Updated typing by [@1nF0rmed](https://github.com/1nF0rmed) in [PR 2904](https://github.com/gradio-app/gradio/pull/2904)
### Contributors Shoutout:
- @JaySmithWpg for making their first contribution to gradio!
- @MohamedAliRashad for making their first contribution to gradio!
## 3.15.0
### New Features:
Gradio's newest plotting component `gr.LinePlot`! 📈
With this component you can easily create time series visualizations with customizable
appearance for your demos and dashboards ... all without having to know an external plotting library.
For an example of the api see below:
```python
gr.LinePlot(stocks,
x="date",
y="price",
color="symbol",
color_legend_position="bottom",
width=600, height=400, title="Stock Prices")
```
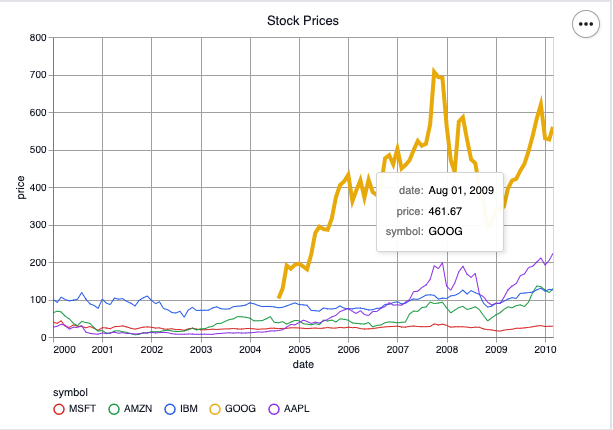
By [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2807](https://github.com/gradio-app/gradio/pull/2807)
### Bug Fixes:
- Fixed bug where the `examples_per_page` parameter of the `Examples` component was not passed to the internal `Dataset` component by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2861](https://github.com/gradio-app/gradio/pull/2861)
- Fixes loading Spaces that have components with default values by [@abidlabs](https://github.com/abidlabs) in [PR 2855](https://github.com/gradio-app/gradio/pull/2855)
- Fixes flagging when `allow_flagging="auto"` in `gr.Interface()` by [@abidlabs](https://github.com/abidlabs) in [PR 2695](https://github.com/gradio-app/gradio/pull/2695)
- Fixed bug where passing a non-list value to `gr.CheckboxGroup` would crash the entire app by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2866](https://github.com/gradio-app/gradio/pull/2866)
### Documentation Changes:
- Added a Guide on using BigQuery with Gradio's `DataFrame` and `ScatterPlot` component,
by [@abidlabs](https://github.com/abidlabs) in [PR 2794](https://github.com/gradio-app/gradio/pull/2794)
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- Fixed importing gradio can cause PIL.Image.registered_extensions() to break by `[@aliencaocao](https://github.com/aliencaocao)` in `[PR 2846](https://github.com/gradio-app/gradio/pull/2846)`
- Fix css glitch and navigation in docs by [@aliabd](https://github.com/aliabd) in [PR 2856](https://github.com/gradio-app/gradio/pull/2856)
- Added the ability to set `x_lim`, `y_lim` and legend positions for `gr.ScatterPlot` by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2807](https://github.com/gradio-app/gradio/pull/2807)
- Remove footers and min-height the correct way by [@aliabd](https://github.com/aliabd) in [PR 2860](https://github.com/gradio-app/gradio/pull/2860)
### Contributors Shoutout:
No changes to highlight.
## 3.14.0
### New Features:
###### Add Waveform Visual Support to Audio
Adds a `gr.make_waveform()` function that creates a waveform video by combining an audio and an optional background image by [@dawoodkhan82](http://github.com/dawoodkhan82) and [@aliabid94](http://github.com/aliabid94) in [PR 2706](https://github.com/gradio-app/gradio/pull/2706. Helpful for making audio outputs much more shareable.
###### Allows Every Component to Accept an `every` Parameter
When a component's initial value is a function, the `every` parameter re-runs the function every `every` seconds. By [@abidlabs](https://github.com/abidlabs) in [PR 2806](https://github.com/gradio-app/gradio/pull/2806). Here's a code example:
```py
import gradio as gr
with gr.Blocks() as demo:
df = gr.DataFrame(run_query, every=60*60)
demo.queue().launch()
```
### Bug Fixes:
- Fixed issue where too many temporary files were created, all with randomly generated
filepaths. Now fewer temporary files are created and are assigned a path that is a
hash based on the file contents by [@abidlabs](https://github.com/abidlabs) in [PR 2758](https://github.com/gradio-app/gradio/pull/2758)
### Documentation Changes:
No changes to highlight.
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
### Contributors Shoutout:
No changes to highlight.
## 3.13.2
### New Features:
No changes to highlight.
### Bug Fixes:
\*No changes to highlight.
-
### Documentation Changes:
- Improves documentation of several queuing-related parameters by [@abidlabs](https://github.com/abidlabs) in [PR 2825](https://github.com/gradio-app/gradio/pull/2825)
### Testing and Infrastructure Changes:
- Remove h11 pinning by [@ecederstrand](https://github.com/ecederstrand) in [PR 2820](https://github.com/gradio-app/gradio/pull/2820)
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
### Contributors Shoutout:
No changes to highlight.
## 3.13.1
### New Features:
###### New Shareable Links
Replaces tunneling logic based on ssh port-forwarding to that based on `frp` by [XciD](https://github.com/XciD) and [Wauplin](https://github.com/Wauplin) in [PR 2509](https://github.com/gradio-app/gradio/pull/2509)
You don't need to do anything differently, but when you set `share=True` in `launch()`,
you'll get this message and a public link that look a little bit different:
```bash
Setting up a public link... we have recently upgraded the way public links are generated. If you encounter any problems, please downgrade to gradio version 3.13.0
.
Running on public URL: https://bec81a83-5b5c-471e.gradio.live
```
These links are a more secure and scalable way to create shareable demos!
### Bug Fixes:
- Allows `gr.Dataframe()` to take a `pandas.DataFrame` that includes numpy array and other types as its initial value, by [@abidlabs](https://github.com/abidlabs) in [PR 2804](https://github.com/gradio-app/gradio/pull/2804)
- Add `altair` to requirements.txt by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2811](https://github.com/gradio-app/gradio/pull/2811)
- Added aria-labels to icon buttons that are built into UI components by [@emilyuhde](http://github.com/emilyuhde) in [PR 2791](https://github.com/gradio-app/gradio/pull/2791)
### Documentation Changes:
- Fixed some typos in the "Plot Component for Maps" guide by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2811](https://github.com/gradio-app/gradio/pull/2811)
### Testing and Infrastructure Changes:
- Fixed test for IP address by [@abidlabs](https://github.com/abidlabs) in [PR 2808](https://github.com/gradio-app/gradio/pull/2808)
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- Fixed typo in parameter `visible` in classes in `templates.py` by [@abidlabs](https://github.com/abidlabs) in [PR 2805](https://github.com/gradio-app/gradio/pull/2805)
- Switched external service for getting IP address from `https://api.ipify.org` to `https://checkip.amazonaws.com/` by [@abidlabs](https://github.com/abidlabs) in [PR 2810](https://github.com/gradio-app/gradio/pull/2810)
### Contributors Shoutout:
No changes to highlight.
- Fixed typo in parameter `visible` in classes in `templates.py` by [@abidlabs](https://github.com/abidlabs) in [PR 2805](https://github.com/gradio-app/gradio/pull/2805)
- Switched external service for getting IP address from `https://api.ipify.org` to `https://checkip.amazonaws.com/` by [@abidlabs](https://github.com/abidlabs) in [PR 2810](https://github.com/gradio-app/gradio/pull/2810)
## 3.13.0
### New Features:
###### Scatter plot component
It is now possible to create a scatter plot natively in Gradio!
The `gr.ScatterPlot` component accepts a pandas dataframe and some optional configuration parameters
and will automatically create a plot for you!
This is the first of many native plotting components in Gradio!
For an example of how to use `gr.ScatterPlot` see below:
```python
import gradio as gr
from vega_datasets import data
cars = data.cars()
with gr.Blocks() as demo:
gr.ScatterPlot(show_label=False,
value=cars,
x="Horsepower",
y="Miles_per_Gallon",
color="Origin",
tooltip="Name",
title="Car Data",
y_title="Miles per Gallon",
color_legend_title="Origin of Car").style(container=False)
demo.launch()
```
<img width="404" alt="image" src="https://user-images.githubusercontent.com/41651716/206737726-4c4da5f0-dee8-4f0a-b1e1-e2b75c4638e9.png">
By [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2764](https://github.com/gradio-app/gradio/pull/2764)
###### Support for altair plots
The `Plot` component can now accept altair plots as values!
Simply return an altair plot from your event listener and gradio will display it in the front-end.
See the example below:
```python
import gradio as gr
import altair as alt
from vega_datasets import data
cars = data.cars()
chart = (
alt.Chart(cars)
.mark_point()
.encode(
x="Horsepower",
y="Miles_per_Gallon",
color="Origin",
)
)
with gr.Blocks() as demo:
gr.Plot(value=chart)
demo.launch()
```
<img width="1366" alt="image" src="https://user-images.githubusercontent.com/41651716/204660697-f994316f-5ca7-4e8a-93bc-eb5e0d556c91.png">
By [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2741](https://github.com/gradio-app/gradio/pull/2741)
###### Set the background color of a Label component
The `Label` component now accepts a `color` argument by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2736](https://github.com/gradio-app/gradio/pull/2736).
The `color` argument should either be a valid css color name or hexadecimal string.
You can update the color with `gr.Label.update`!
This lets you create Alert and Warning boxes with the `Label` component. See below:
```python
import gradio as gr
import random
def update_color(value):
if value < 0:
# This is bad so use red
return "#FF0000"
elif 0 <= value <= 20:
# Ok but pay attention (use orange)
return "#ff9966"
else:
# Nothing to worry about
return None
def update_value():
choice = random.choice(['good', 'bad', 'so-so'])
color = update_color(choice)
return gr.Label.update(value=choice, color=color)
with gr.Blocks() as demo:
label = gr.Label(value=-10)
demo.load(lambda: update_value(), inputs=None, outputs=[label], every=1)
demo.queue().launch()
```
###### Add Brazilian Portuguese translation
Add Brazilian Portuguese translation (pt-BR.json) by [@pstwh](http://github.com/pstwh) in [PR 2753](https://github.com/gradio-app/gradio/pull/2753):
<img width="951" alt="image" src="https://user-images.githubusercontent.com/1778297/206615305-4c52031e-3f7d-4df2-8805-a79894206911.png">
### Bug Fixes:
- Fixed issue where image thumbnails were not showing when an example directory was provided
by [@abidlabs](https://github.com/abidlabs) in [PR 2745](https://github.com/gradio-app/gradio/pull/2745)
- Fixed bug loading audio input models from the hub by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2779](https://github.com/gradio-app/gradio/pull/2779).
- Fixed issue where entities were not merged when highlighted text was generated from the
dictionary inputs [@payoto](https://github.com/payoto) in [PR 2767](https://github.com/gradio-app/gradio/pull/2767)
- Fixed bug where generating events did not finish running even if the websocket connection was closed by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2783](https://github.com/gradio-app/gradio/pull/2783).
### Documentation Changes:
No changes to highlight.
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- Images in the chatbot component are now resized if they exceed a max width by [@abidlabs](https://github.com/abidlabs) in [PR 2748](https://github.com/gradio-app/gradio/pull/2748)
- Missing parameters have been added to `gr.Blocks().load()` by [@abidlabs](https://github.com/abidlabs) in [PR 2755](https://github.com/gradio-app/gradio/pull/2755)
- Deindex share URLs from search by [@aliabd](https://github.com/aliabd) in [PR 2772](https://github.com/gradio-app/gradio/pull/2772)
- Redirect old links and fix broken ones by [@aliabd](https://github.com/aliabd) in [PR 2774](https://github.com/gradio-app/gradio/pull/2774)
### Contributors Shoutout:
No changes to highlight.
## 3.12.0
### New Features:
###### The `Chatbot` component now supports a subset of Markdown (including bold, italics, code, images)
You can now pass in some Markdown to the Chatbot component and it will show up,
meaning that you can pass in images as well! by [@abidlabs](https://github.com/abidlabs) in [PR 2731](https://github.com/gradio-app/gradio/pull/2731)
Here's a simple example that references a local image `lion.jpg` that is in the same
folder as the Python script:
```py
import gradio as gr
with gr.Blocks() as demo:
gr.Chatbot([("hi", "hello **abubakar**"), ("", "cool pic")])
demo.launch()
```

To see a more realistic example, see the new demo `/demo/chatbot_multimodal/run.py`.
###### Latex support
Added mathtext (a subset of latex) support to gr.Markdown. Added by [@kashif](https://github.com/kashif) and [@aliabid94](https://github.com/aliabid94) in [PR 2696](https://github.com/gradio-app/gradio/pull/2696).
Example of how it can be used:
```python
gr.Markdown(
r"""
# Hello World! $\frac{\sqrt{x + y}}{4}$ is today's lesson.
""")
```
###### Update Accordion properties from the backend
You can now update the Accordion `label` and `open` status with `gr.Accordion.update` by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2690](https://github.com/gradio-app/gradio/pull/2690)
```python
import gradio as gr
with gr.Blocks() as demo:
with gr.Accordion(label="Open for greeting", open=False) as accordion:
gr.Textbox("Hello!")
open_btn = gr.Button(value="Open Accordion")
close_btn = gr.Button(value="Close Accordion")
open_btn.click(
lambda: gr.Accordion.update(open=True, label="Open Accordion"),
inputs=None,
outputs=[accordion],
)
close_btn.click(
lambda: gr.Accordion.update(open=False, label="Closed Accordion"),
inputs=None,
outputs=[accordion],
)
demo.launch()
```
### Bug Fixes:
- Fixed bug where requests timeout is missing from utils.version_check() by [@yujiehecs](https://github.com/yujiehecs) in [PR 2729](https://github.com/gradio-app/gradio/pull/2729)
- Fixed bug where so that the `File` component can properly preprocess files to "binary" byte-string format by [CoffeeVampir3](https://github.com/CoffeeVampir3) in [PR 2727](https://github.com/gradio-app/gradio/pull/2727)
- Fixed bug to ensure that filenames are less than 200 characters even for non-English languages by [@SkyTNT](https://github.com/SkyTNT) in [PR 2685](https://github.com/gradio-app/gradio/pull/2685)
### Documentation Changes:
- Performance improvements to docs on mobile by [@aliabd](https://github.com/aliabd) in [PR 2730](https://github.com/gradio-app/gradio/pull/2730)
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- Make try examples button more prominent by [@aliabd](https://github.com/aliabd) in [PR 2705](https://github.com/gradio-app/gradio/pull/2705)
- Fix id clashes in docs by [@aliabd](https://github.com/aliabd) in [PR 2713](https://github.com/gradio-app/gradio/pull/2713)
- Fix typos in guide docs by [@andridns](https://github.com/andridns) in [PR 2722](https://github.com/gradio-app/gradio/pull/2722)
- Add option to `include_audio` in Video component. When `True`, for `source="webcam"` this will record audio and video, for `source="upload"` this will retain the audio in an uploaded video by [@mandargogate](https://github.com/MandarGogate) in [PR 2721](https://github.com/gradio-app/gradio/pull/2721)
### Contributors Shoutout:
- [@andridns](https://github.com/andridns) made their first contribution in [PR 2722](https://github.com/gradio-app/gradio/pull/2722)!
## 3.11.0
### New Features:
###### Upload Button
There is now a new component called the `UploadButton` which is a file upload component but in button form! You can also specify what file types it should accept in the form of a list (ex: `image`, `video`, `audio`, `text`, or generic `file`). Added by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 2591](https://github.com/gradio-app/gradio/pull/2591).
Example of how it can be used:
```python
import gradio as gr
def upload_file(files):
file_paths = [file.name for file in files]
return file_paths
with gr.Blocks() as demo:
file_output = gr.File()
upload_button = gr.UploadButton("Click to Upload a File", file_types=["image", "video"], file_count="multiple")
upload_button.upload(upload_file, upload_button, file_output)
demo.launch()
```
###### Revamped API documentation page
New API Docs page with in-browser playground and updated aesthetics. [@gary149](https://github.com/gary149) in [PR 2652](https://github.com/gradio-app/gradio/pull/2652)
###### Revamped Login page
Previously our login page had its own CSS, had no dark mode, and had an ugly json message on the wrong credentials. Made the page more aesthetically consistent, added dark mode support, and a nicer error message. [@aliabid94](https://github.com/aliabid94) in [PR 2684](https://github.com/gradio-app/gradio/pull/2684)
###### Accessing the Requests Object Directly
You can now access the Request object directly in your Python function by [@abidlabs](https://github.com/abidlabs) in [PR 2641](https://github.com/gradio-app/gradio/pull/2641). This means that you can access request headers, the client IP address, and so on. In order to use it, add a parameter to your function and set its type hint to be `gr.Request`. Here's a simple example:
```py
import gradio as gr
def echo(name, request: gr.Request):
if request:
print("Request headers dictionary:", request.headers)
print("IP address:", request.client.host)
return name
io = gr.Interface(echo, "textbox", "textbox").launch()
```
### Bug Fixes:
- Fixed bug that limited files from being sent over websockets to 16MB. The new limit
is now 1GB by [@abidlabs](https://github.com/abidlabs) in [PR 2709](https://github.com/gradio-app/gradio/pull/2709)
### Documentation Changes:
- Updated documentation for embedding Gradio demos on Spaces as web components by
[@julien-c](https://github.com/julien-c) in [PR 2698](https://github.com/gradio-app/gradio/pull/2698)
- Updated IFrames in Guides to use the host URL instead of the Space name to be consistent with the new method for embedding Spaces, by
[@julien-c](https://github.com/julien-c) in [PR 2692](https://github.com/gradio-app/gradio/pull/2692)
- Colab buttons on every demo in the website! Just click open in colab, and run the demo there.
https://user-images.githubusercontent.com/9021060/202878400-cb16ed47-f4dd-4cb0-b2f0-102a9ff64135.mov
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- Better warnings and error messages for `gr.Interface.load()` by [@abidlabs](https://github.com/abidlabs) in [PR 2694](https://github.com/gradio-app/gradio/pull/2694)
- Add open in colab buttons to demos in docs and /demos by [@aliabd](https://github.com/aliabd) in [PR 2608](https://github.com/gradio-app/gradio/pull/2608)
- Apply different formatting for the types in component docstrings by [@aliabd](https://github.com/aliabd) in [PR 2707](https://github.com/gradio-app/gradio/pull/2707)
### Contributors Shoutout:
No changes to highlight.
## 3.10.1
### New Features:
No changes to highlight.
### Bug Fixes:
- Passes kwargs into `gr.Interface.load()` by [@abidlabs](https://github.com/abidlabs) in [PR 2669](https://github.com/gradio-app/gradio/pull/2669)
### Documentation Changes:
No changes to highlight.
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- Clean up printed statements in Embedded Colab Mode by [@aliabid94](https://github.com/aliabid94) in [PR 2612](https://github.com/gradio-app/gradio/pull/2612)
### Contributors Shoutout:
No changes to highlight.
## 3.10.0
- Add support for `'password'` and `'email'` types to `Textbox`. [@pngwn](https://github.com/pngwn) in [PR 2653](https://github.com/gradio-app/gradio/pull/2653)
- `gr.Textbox` component will now raise an exception if `type` is not "text", "email", or "password" [@pngwn](https://github.com/pngwn) in [PR 2653](https://github.com/gradio-app/gradio/pull/2653). This will cause demos using the deprecated `gr.Textbox(type="number")` to raise an exception.
### Bug Fixes:
- Updated the minimum FastApi used in tests to version 0.87 by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2647](https://github.com/gradio-app/gradio/pull/2647)
- Fixed bug where interfaces with examples could not be loaded with `gr.Interface.load` by [@freddyaboulton](https://github.com/freddyaboulton) [PR 2640](https://github.com/gradio-app/gradio/pull/2640)
- Fixed bug where the `interactive` property of a component could not be updated by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2639](https://github.com/gradio-app/gradio/pull/2639)
- Fixed bug where some URLs were not being recognized as valid URLs and thus were not
loading correctly in various components by [@abidlabs](https://github.com/abidlabs) in [PR 2659](https://github.com/gradio-app/gradio/pull/2659)
### Documentation Changes:
- Fix some typos in the embedded demo names in "05_using_blocks_like_functions.md" by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2656](https://github.com/gradio-app/gradio/pull/2656)
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- Add support for `'password'` and `'email'` types to `Textbox`. [@pngwn](https://github.com/pngwn) in [PR 2653](https://github.com/gradio-app/gradio/pull/2653)
### Contributors Shoutout:
No changes to highlight.
## 3.9.1
### New Features:
No changes to highlight.
### Bug Fixes:
- Only set a min height on md and html when loading by [@pngwn](https://github.com/pngwn) in [PR 2623](https://github.com/gradio-app/gradio/pull/2623)
### Documentation Changes:
- See docs for the latest gradio commit to main as well the latest pip release:
- Modified the "Connecting To a Database Guide" to use `pd.read_sql` as opposed to low-level postgres connector by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2604](https://github.com/gradio-app/gradio/pull/2604)
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- Dropdown for seeing docs as latest or main by [@aliabd](https://github.com/aliabd) in [PR 2544](https://github.com/gradio-app/gradio/pull/2544)
- Allow `gr.Templates` to accept parameters to override the defaults by [@abidlabs](https://github.com/abidlabs) in [PR 2600](https://github.com/gradio-app/gradio/pull/2600)
- Components now throw a `ValueError()` if constructed with invalid parameters for `type` or `source` (for components that take those parameters) in [PR 2610](https://github.com/gradio-app/gradio/pull/2610)
- Allow auth with using queue by [@GLGDLY](https://github.com/GLGDLY) in [PR 2611](https://github.com/gradio-app/gradio/pull/2611)
### Contributors Shoutout:
No changes to highlight.
## 3.9
### New Features:
- Gradio is now embedded directly in colab without requiring the share link by [@aliabid94](https://github.com/aliabid94) in [PR 2455](https://github.com/gradio-app/gradio/pull/2455)
###### Calling functions by api_name in loaded apps
When you load an upstream app with `gr.Blocks.load`, you can now specify which fn
to call with the `api_name` parameter.
```python
import gradio as gr
english_translator = gr.Blocks.load(name="spaces/gradio/english-translator")
german = english_translator("My name is Freddy", api_name='translate-to-german')
```
The `api_name` parameter will take precedence over the `fn_index` parameter.
### Bug Fixes:
- Fixed bug where None could not be used for File,Model3D, and Audio examples by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2588](https://github.com/gradio-app/gradio/pull/2588)
- Fixed links in Plotly map guide + demo by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 2578](https://github.com/gradio-app/gradio/pull/2578)
- `gr.Blocks.load()` now correctly loads example files from Spaces [@abidlabs](https://github.com/abidlabs) in [PR 2594](https://github.com/gradio-app/gradio/pull/2594)
- Fixed bug when image clear started upload dialog [@mezotaken](https://github.com/mezotaken) in [PR 2577](https://github.com/gradio-app/gradio/pull/2577)
### Documentation Changes:
- Added a Guide on how to configure the queue for maximum performance by [@abidlabs](https://github.com/abidlabs) in [PR 2558](https://github.com/gradio-app/gradio/pull/2558)
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- Add `api_name` to `Blocks.__call__` by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2593](https://github.com/gradio-app/gradio/pull/2593)
- Update queue with using deque & update requirements by [@GLGDLY](https://github.com/GLGDLY) in [PR 2428](https://github.com/gradio-app/gradio/pull/2428)
### Contributors Shoutout:
No changes to highlight.
## 3.8.2
### Bug Fixes:
- Ensure gradio apps embedded via spaces use the correct endpoint for predictions. [@pngwn](https://github.com/pngwn) in [PR 2567](https://github.com/gradio-app/gradio/pull/2567)
- Ensure gradio apps embedded via spaces use the correct websocket protocol. [@pngwn](https://github.com/pngwn) in [PR 2571](https://github.com/gradio-app/gradio/pull/2571)
### New Features:
###### Running Events Continuously
Gradio now supports the ability to run an event continuously on a fixed schedule. To use this feature,
pass `every=# of seconds` to the event definition. This will run the event every given number of seconds!
This can be used to:
- Create live visualizations that show the most up to date data
- Refresh the state of the frontend automatically in response to changes in the backend
Here is an example of a live plot that refreshes every half second:
```python
import math
import gradio as gr
import plotly.express as px
import numpy as np
plot_end = 2 * math.pi
def get_plot(period=1):
global plot_end
x = np.arange(plot_end - 2 * math.pi, plot_end, 0.02)
y = np.sin(2*math.pi*period * x)
fig = px.line(x=x, y=y)
plot_end += 2 * math.pi
return fig
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
gr.Markdown("Change the value of the slider to automatically update the plot")
period = gr.Slider(label="Period of plot", value=1, minimum=0, maximum=10, step=1)
plot = gr.Plot(label="Plot (updates every half second)")
dep = demo.load(get_plot, None, plot, every=0.5)
period.change(get_plot, period, plot, every=0.5, cancels=[dep])
demo.queue().launch()
```
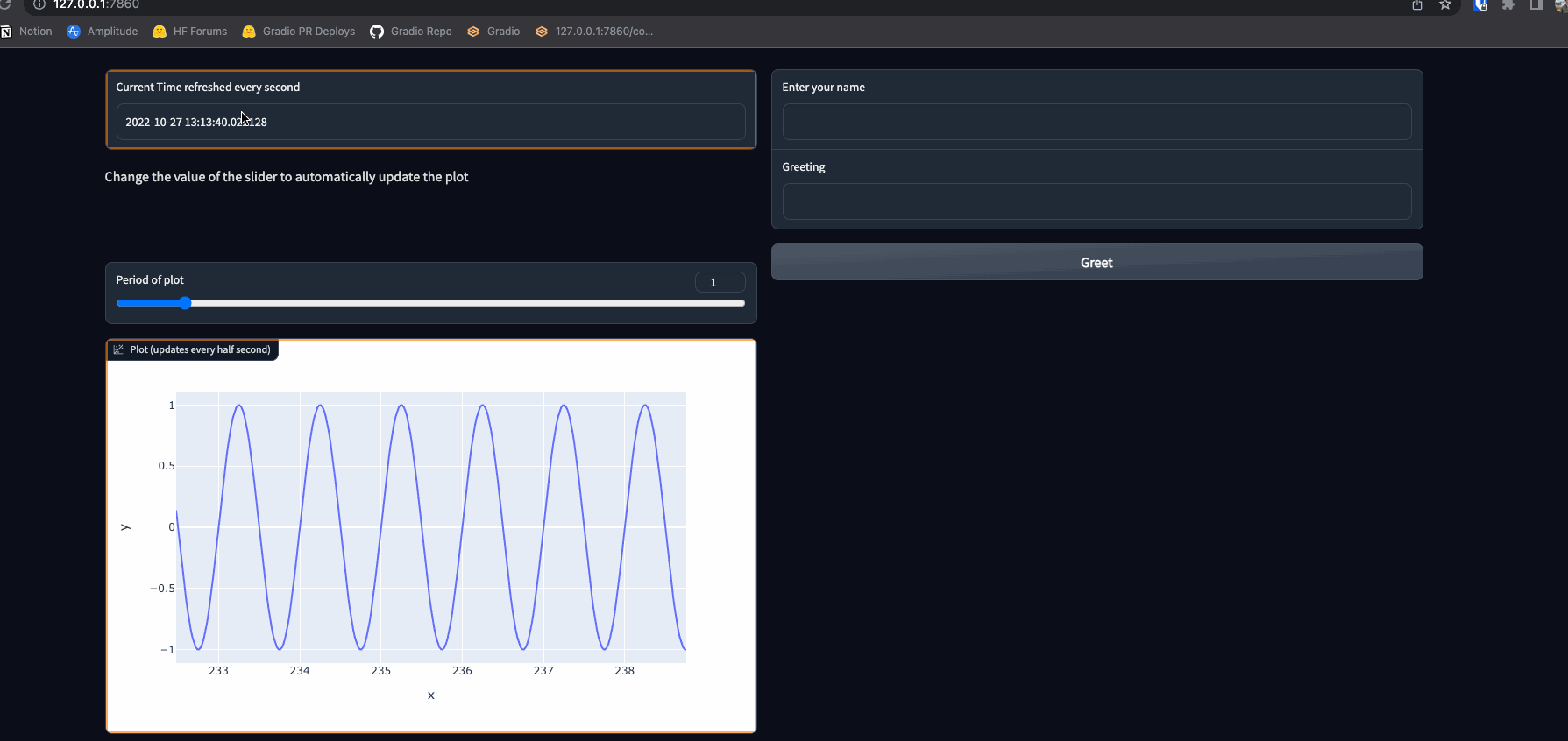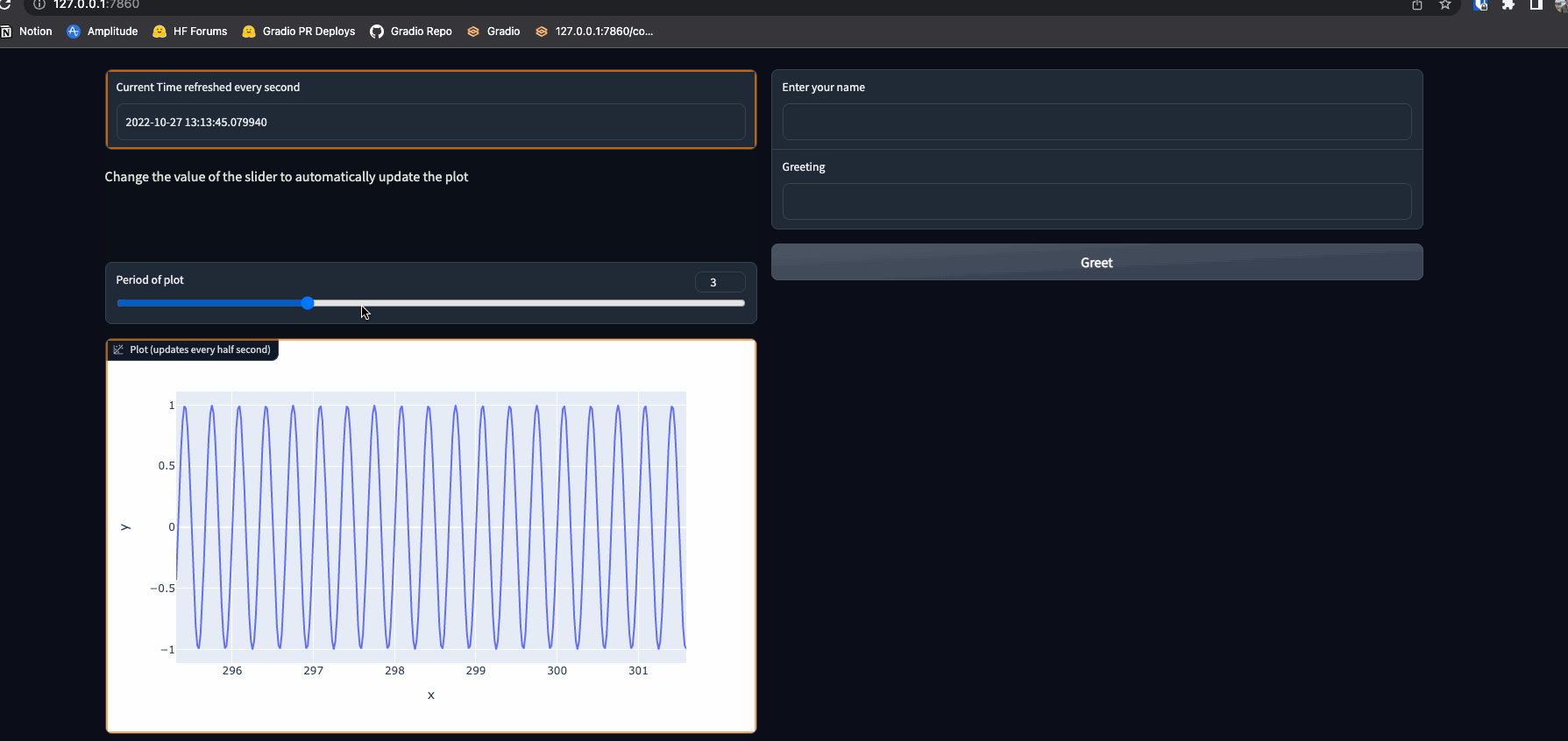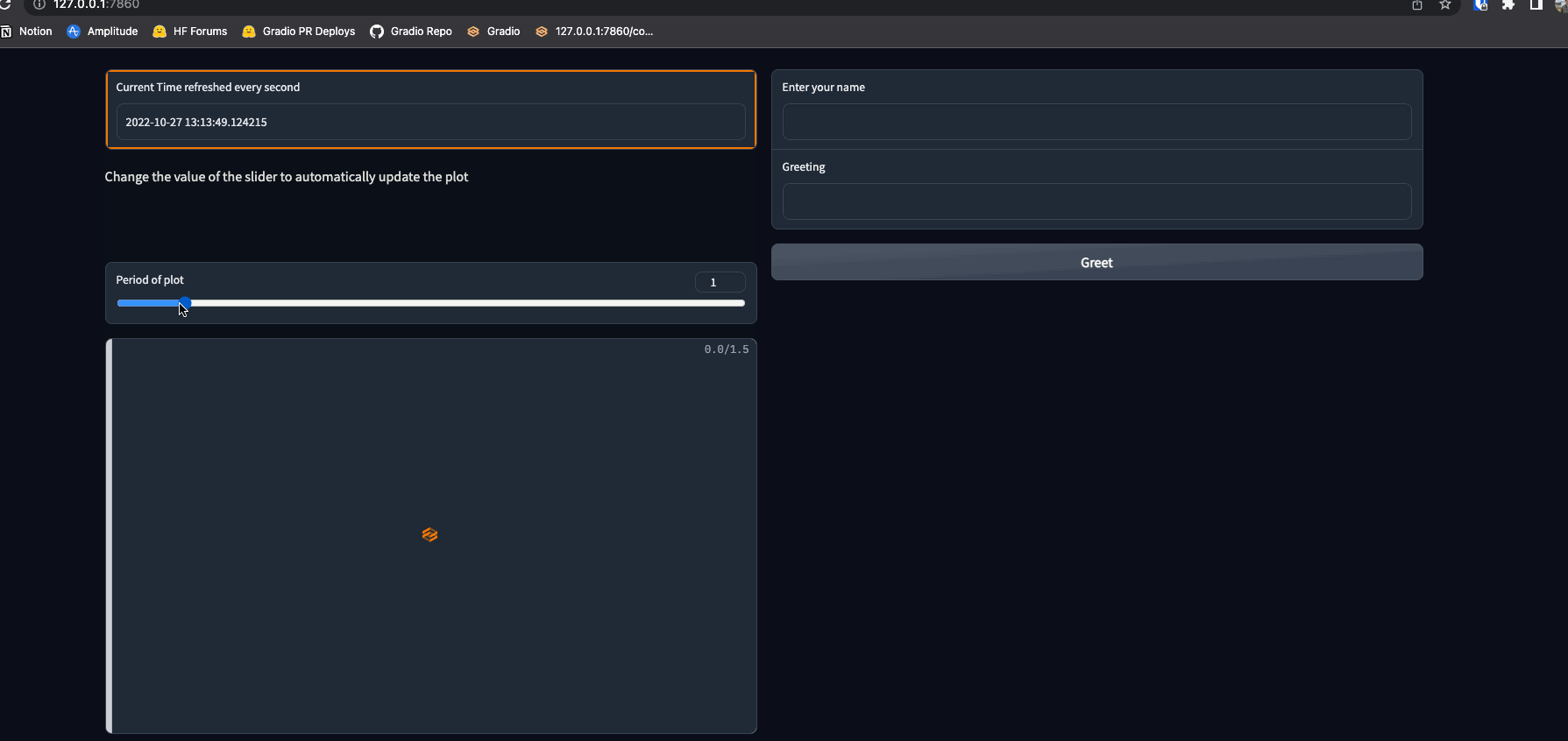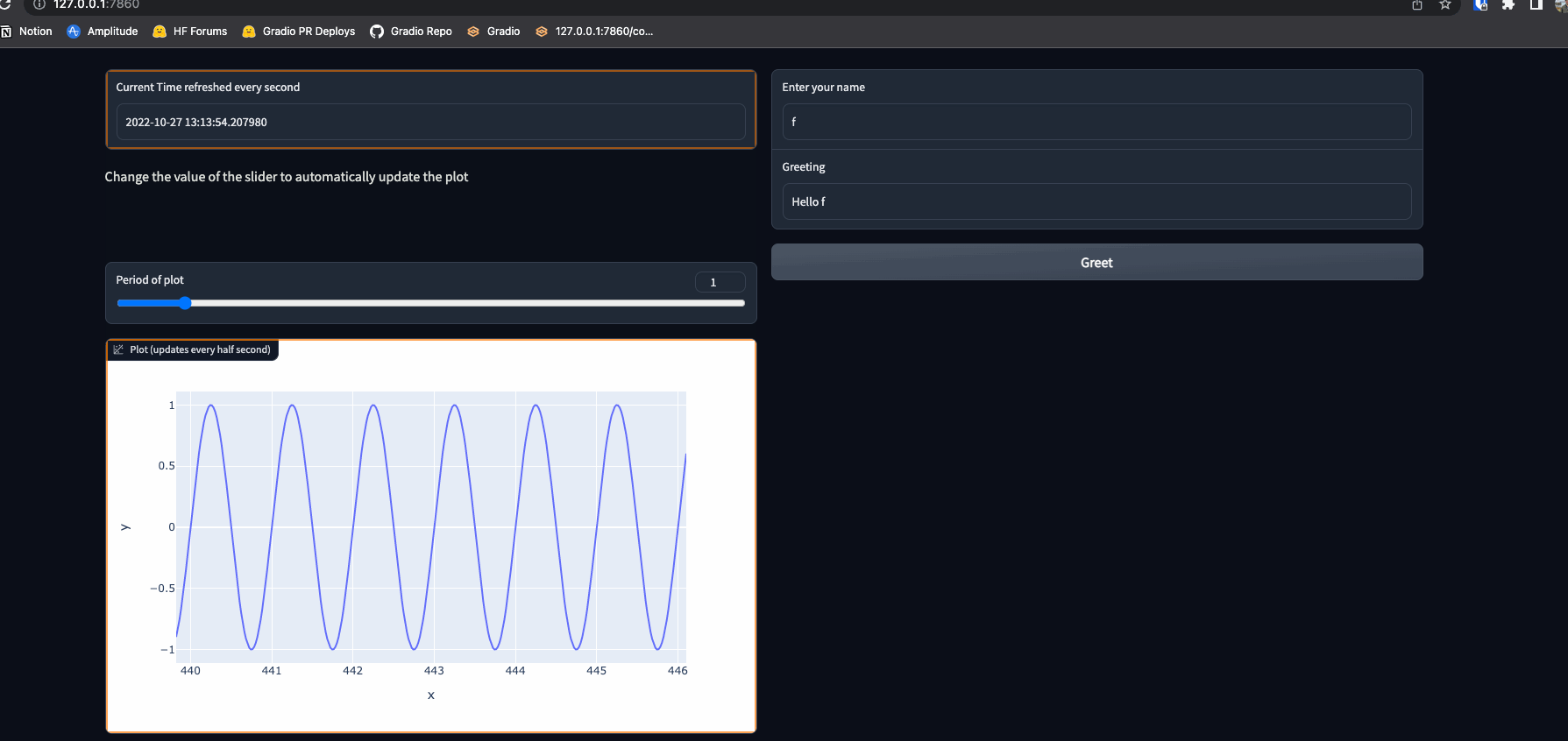
### Bug Fixes:
No changes to highlight.
### Documentation Changes:
- Explained how to set up `queue` and `auth` when working with reload mode by by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3089](https://github.com/gradio-app/gradio/pull/3089)
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- Allows loading private Spaces by passing an an `api_key` to `gr.Interface.load()`
by [@abidlabs](https://github.com/abidlabs) in [PR 2568](https://github.com/gradio-app/gradio/pull/2568)
### Contributors Shoutout:
No changes to highlight.
## 3.8
### New Features:
- Allows event listeners to accept a single dictionary as its argument, where the keys are the components and the values are the component values. This is set by passing the input components in the event listener as a set instead of a list. [@aliabid94](https://github.com/aliabid94) in [PR 2550](https://github.com/gradio-app/gradio/pull/2550)
### Bug Fixes:
- Fix whitespace issue when using plotly. [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 2548](https://github.com/gradio-app/gradio/pull/2548)
- Apply appropriate alt text to all gallery images. [@camenduru](https://github.com/camenduru) in [PR 2358](https://github.com/gradio-app/gradio/pull/2538)
- Removed erroneous tkinter import in gradio.blocks by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2555](https://github.com/gradio-app/gradio/pull/2555)
### Documentation Changes:
No changes to highlight.
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- Added the `every` keyword to event listeners that runs events on a fixed schedule by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2512](https://github.com/gradio-app/gradio/pull/2512)
- Fix whitespace issue when using plotly. [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 2548](https://github.com/gradio-app/gradio/pull/2548)
- Apply appropriate alt text to all gallery images. [@camenduru](https://github.com/camenduru) in [PR 2358](https://github.com/gradio-app/gradio/pull/2538)
### Contributors Shoutout:
No changes to highlight.
## 3.7
### New Features:
###### Batched Functions
Gradio now supports the ability to pass _batched_ functions. Batched functions are just
functions which take in a list of inputs and return a list of predictions.
For example, here is a batched function that takes in two lists of inputs (a list of
words and a list of ints), and returns a list of trimmed words as output:
```py
import time
def trim_words(words, lens):
trimmed_words = []
time.sleep(5)
for w, l in zip(words, lens):
trimmed_words.append(w[:l])
return [trimmed_words]
```
The advantage of using batched functions is that if you enable queuing, the Gradio
server can automatically _batch_ incoming requests and process them in parallel,
potentially speeding up your demo. Here's what the Gradio code looks like (notice
the `batch=True` and `max_batch_size=16` -- both of these parameters can be passed
into event triggers or into the `Interface` class)
```py
import gradio as gr
with gr.Blocks() as demo:
with gr.Row():
word = gr.Textbox(label="word", value="abc")
leng = gr.Number(label="leng", precision=0, value=1)
output = gr.Textbox(label="Output")
with gr.Row():
run = gr.Button()
event = run.click(trim_words, [word, leng], output, batch=True, max_batch_size=16)
demo.queue()
demo.launch()
```
In the example above, 16 requests could be processed in parallel (for a total inference
time of 5 seconds), instead of each request being processed separately (for a total
inference time of 80 seconds).
###### Upload Event
`Video`, `Audio`, `Image`, and `File` components now support a `upload()` event that is triggered when a user uploads a file into any of these components.
Example usage:
```py
import gradio as gr
with gr.Blocks() as demo:
with gr.Row():
input_video = gr.Video()
output_video = gr.Video()
# Clears the output video when an input video is uploaded
input_video.upload(lambda : None, None, output_video)
```
### Bug Fixes:
- Fixes issue where plotly animations, interactivity, titles, legends, were not working properly. [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 2486](https://github.com/gradio-app/gradio/pull/2486)
- Prevent requests to the `/api` endpoint from skipping the queue if the queue is enabled for that event by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2493](https://github.com/gradio-app/gradio/pull/2493)
- Fixes a bug with `cancels` in event triggers so that it works properly if multiple
Blocks are rendered by [@abidlabs](https://github.com/abidlabs) in [PR 2530](https://github.com/gradio-app/gradio/pull/2530)
- Prevent invalid targets of events from crashing the whole application. [@pngwn](https://github.com/pngwn) in [PR 2534](https://github.com/gradio-app/gradio/pull/2534)
- Properly dequeue cancelled events when multiple apps are rendered by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2540](https://github.com/gradio-app/gradio/pull/2540)
- Fixes videos being cropped due to height/width params not being used [@hannahblair](https://github.com/hannahblair) in [PR 4946](https://github.com/gradio-app/gradio/pull/4946)
### Documentation Changes:
- Added an example interactive dashboard to the "Tabular & Plots" section of the Demos page by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2508](https://github.com/gradio-app/gradio/pull/2508)
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- Fixes the error message if a user builds Gradio locally and tries to use `share=True` by [@abidlabs](https://github.com/abidlabs) in [PR 2502](https://github.com/gradio-app/gradio/pull/2502)
- Allows the render() function to return self by [@Raul9595](https://github.com/Raul9595) in [PR 2514](https://github.com/gradio-app/gradio/pull/2514)
- Fixes issue where plotly animations, interactivity, titles, legends, were not working properly. [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 2486](https://github.com/gradio-app/gradio/pull/2486)
- Gradio now supports batched functions by [@abidlabs](https://github.com/abidlabs) in [PR 2218](https://github.com/gradio-app/gradio/pull/2218)
- Add `upload` event for `Video`, `Audio`, `Image`, and `File` components [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 2448](https://github.com/gradio-app/gradio/pull/2456)
- Changes websocket path for Spaces as it is no longer necessary to have a different URL for websocket connections on Spaces by [@abidlabs](https://github.com/abidlabs) in [PR 2528](https://github.com/gradio-app/gradio/pull/2528)
- Clearer error message when events are defined outside of a Blocks scope, and a warning if you
try to use `Series` or `Parallel` with `Blocks` by [@abidlabs](https://github.com/abidlabs) in [PR 2543](https://github.com/gradio-app/gradio/pull/2543)
- Adds support for audio samples that are in `float64`, `float16`, or `uint16` formats by [@abidlabs](https://github.com/abidlabs) in [PR 2545](https://github.com/gradio-app/gradio/pull/2545)
### Contributors Shoutout:
No changes to highlight.
## 3.6
### New Features:
###### Cancelling Running Events
Running events can be cancelled when other events are triggered! To test this feature, pass the `cancels` parameter to the event listener.
For this feature to work, the queue must be enabled.
Code:
```python
import time
import gradio as gr
def fake_diffusion(steps):
for i in range(steps):
time.sleep(1)
yield str(i)
def long_prediction(*args, **kwargs):
time.sleep(10)
return 42
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
n = gr.Slider(1, 10, value=9, step=1, label="Number Steps")
run = gr.Button()
output = gr.Textbox(label="Iterative Output")
stop = gr.Button(value="Stop Iterating")
with gr.Column():
prediction = gr.Number(label="Expensive Calculation")
run_pred = gr.Button(value="Run Expensive Calculation")
with gr.Column():
cancel_on_change = gr.Textbox(label="Cancel Iteration and Expensive Calculation on Change")
click_event = run.click(fake_diffusion, n, output)
stop.click(fn=None, inputs=None, outputs=None, cancels=[click_event])
pred_event = run_pred.click(fn=long_prediction, inputs=None, outputs=prediction)
cancel_on_change.change(None, None, None, cancels=[click_event, pred_event])
demo.queue(concurrency_count=1, max_size=20).launch()
```
For interfaces, a stop button will be added automatically if the function uses a `yield` statement.
```python
import gradio as gr
import time
def iteration(steps):
for i in range(steps):
time.sleep(0.5)
yield i
gr.Interface(iteration,
inputs=gr.Slider(minimum=1, maximum=10, step=1, value=5),
outputs=gr.Number()).queue().launch()
```
### Bug Fixes:
- Add loading status tracker UI to HTML and Markdown components. [@pngwn](https://github.com/pngwn) in [PR 2474](https://github.com/gradio-app/gradio/pull/2474)
- Fixed videos being mirrored in the front-end if source is not webcam by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2475](https://github.com/gradio-app/gradio/pull/2475)
- Add clear button for timeseries component [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 2487](https://github.com/gradio-app/gradio/pull/2487)
- Removes special characters from temporary filenames so that the files can be served by components [@abidlabs](https://github.com/abidlabs) in [PR 2480](https://github.com/gradio-app/gradio/pull/2480)
- Fixed infinite reload loop when mounting gradio as a sub application by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2477](https://github.com/gradio-app/gradio/pull/2477)
### Documentation Changes:
- Adds a demo to show how a sound alert can be played upon completion of a prediction by [@abidlabs](https://github.com/abidlabs) in [PR 2478](https://github.com/gradio-app/gradio/pull/2478)
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- Enable running events to be cancelled from other events by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2433](https://github.com/gradio-app/gradio/pull/2433)
- Small fix for version check before reuploading demos by [@aliabd](https://github.com/aliabd) in [PR 2469](https://github.com/gradio-app/gradio/pull/2469)
- Add loading status tracker UI to HTML and Markdown components. [@pngwn](https://github.com/pngwn) in [PR 2400](https://github.com/gradio-app/gradio/pull/2474)
- Add clear button for timeseries component [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 2487](https://github.com/gradio-app/gradio/pull/2487)
### Contributors Shoutout:
No changes to highlight.
## 3.5
### Bug Fixes:
- Ensure that Gradio does not take control of the HTML page title when embedding a gradio app as a web component, this behaviour flipped by adding `control_page_title="true"` to the webcomponent. [@pngwn](https://github.com/pngwn) in [PR 2400](https://github.com/gradio-app/gradio/pull/2400)
- Decreased latency in iterative-output demos by making the iteration asynchronous [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2409](https://github.com/gradio-app/gradio/pull/2409)
- Fixed queue getting stuck under very high load by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2374](https://github.com/gradio-app/gradio/pull/2374)
- Ensure that components always behave as if `interactive=True` were set when the following conditions are true:
- no default value is provided,
- they are not set as the input or output of an event,
- `interactive` kwarg is not set.
[@pngwn](https://github.com/pngwn) in [PR 2459](https://github.com/gradio-app/gradio/pull/2459)
### New Features:
- When an `Image` component is set to `source="upload"`, it is now possible to drag and drop and image to replace a previously uploaded image by [@pngwn](https://github.com/pngwn) in [PR 1711](https://github.com/gradio-app/gradio/issues/1711)
- The `gr.Dataset` component now accepts `HTML` and `Markdown` components by [@abidlabs](https://github.com/abidlabs) in [PR 2437](https://github.com/gradio-app/gradio/pull/2437)
### Documentation Changes:
- Improved documentation for the `gr.Dataset` component by [@abidlabs](https://github.com/abidlabs) in [PR 2437](https://github.com/gradio-app/gradio/pull/2437)
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
- The `Carousel` component is officially deprecated. Since gradio 3.0, code containing the `Carousel` component would throw warnings. As of the next release, the `Carousel` component will raise an exception.
### Full Changelog:
- Speeds up Gallery component by using temporary files instead of base64 representation in the front-end by [@proxyphi](https://github.com/proxyphi), [@pngwn](https://github.com/pngwn), and [@abidlabs](https://github.com/abidlabs) in [PR 2265](https://github.com/gradio-app/gradio/pull/2265)
- Fixed some embedded demos in the guides by not loading the gradio web component in some guides by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2403](https://github.com/gradio-app/gradio/pull/2403)
- When an `Image` component is set to `source="upload"`, it is now possible to drag and drop and image to replace a previously uploaded image by [@pngwn](https://github.com/pngwn) in [PR 2400](https://github.com/gradio-app/gradio/pull/2410)
- Improve documentation of the `Blocks.load()` event by [@abidlabs](https://github.com/abidlabs) in [PR 2413](https://github.com/gradio-app/gradio/pull/2413)
- Decreased latency in iterative-output demos by making the iteration asynchronous [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2409](https://github.com/gradio-app/gradio/pull/2409)
- Updated share link message to reference new Spaces Hardware [@abidlabs](https://github.com/abidlabs) in [PR 2423](https://github.com/gradio-app/gradio/pull/2423)
- Automatically restart spaces if they're down by [@aliabd](https://github.com/aliabd) in [PR 2405](https://github.com/gradio-app/gradio/pull/2405)
- Carousel component is now deprecated by [@abidlabs](https://github.com/abidlabs) in [PR 2434](https://github.com/gradio-app/gradio/pull/2434)
- Build Gradio from source in ui tests by by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2440](https://github.com/gradio-app/gradio/pull/2440)
- Change "return ValueError" to "raise ValueError" by [@vzakharov](https://github.com/vzakharov) in [PR 2445](https://github.com/gradio-app/gradio/pull/2445)
- Add guide on creating a map demo using the `gr.Plot()` component [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 2402](https://github.com/gradio-app/gradio/pull/2402)
- Add blur event for `Textbox` and `Number` components [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 2448](https://github.com/gradio-app/gradio/pull/2448)
- Stops a gradio launch from hogging a port even after it's been killed [@aliabid94](https://github.com/aliabid94) in [PR 2453](https://github.com/gradio-app/gradio/pull/2453)
- Fix embedded interfaces on touch screen devices by [@aliabd](https://github.com/aliabd) in [PR 2457](https://github.com/gradio-app/gradio/pull/2457)
- Upload all demos to spaces by [@aliabd](https://github.com/aliabd) in [PR 2281](https://github.com/gradio-app/gradio/pull/2281)
### Contributors Shoutout:
No changes to highlight.
## 3.4.1
### New Features:
###### 1. See Past and Upcoming Changes in the Release History 👀
You can now see gradio's release history directly on the website, and also keep track of upcoming changes. Just go [here](https://gradio.app/changelog/).
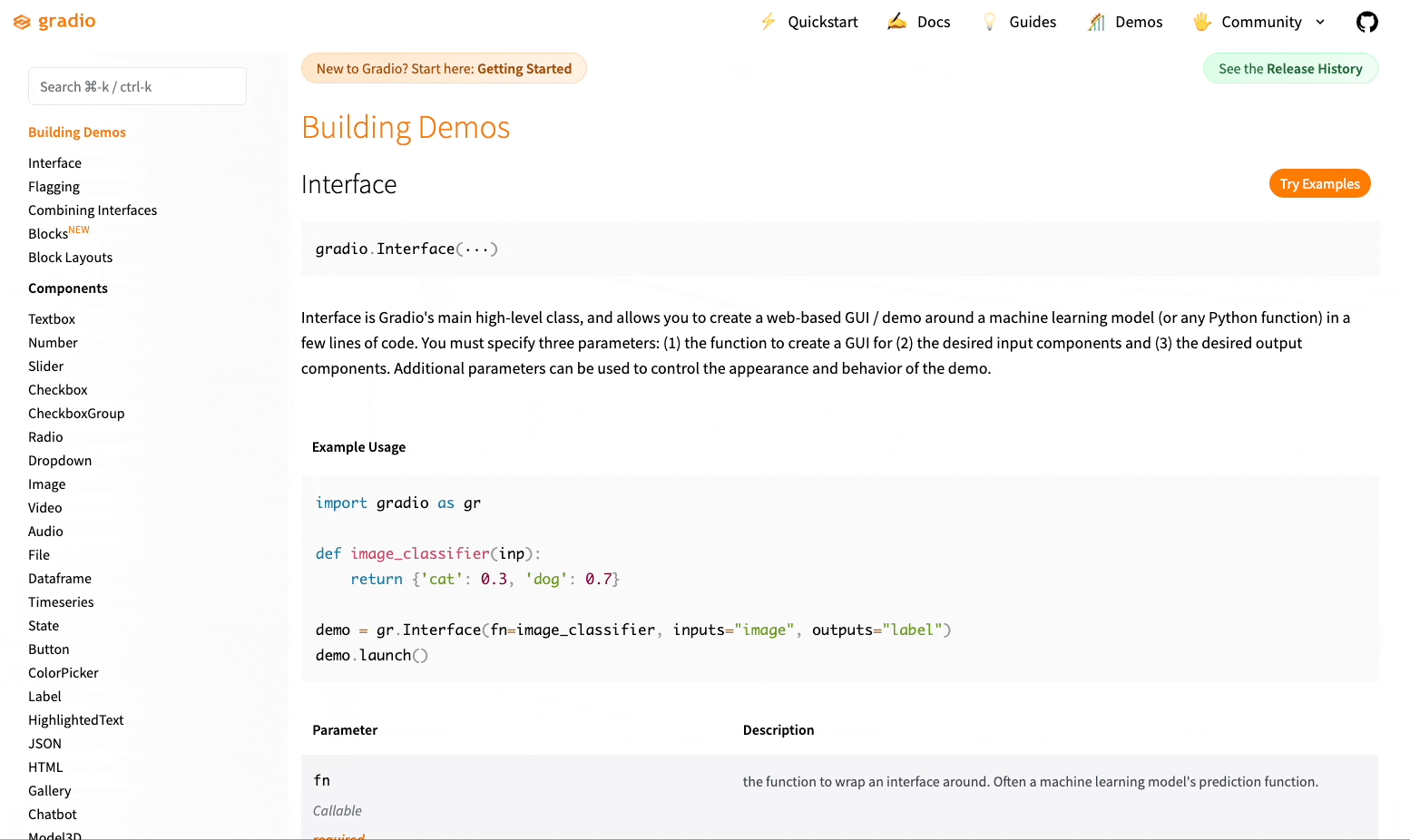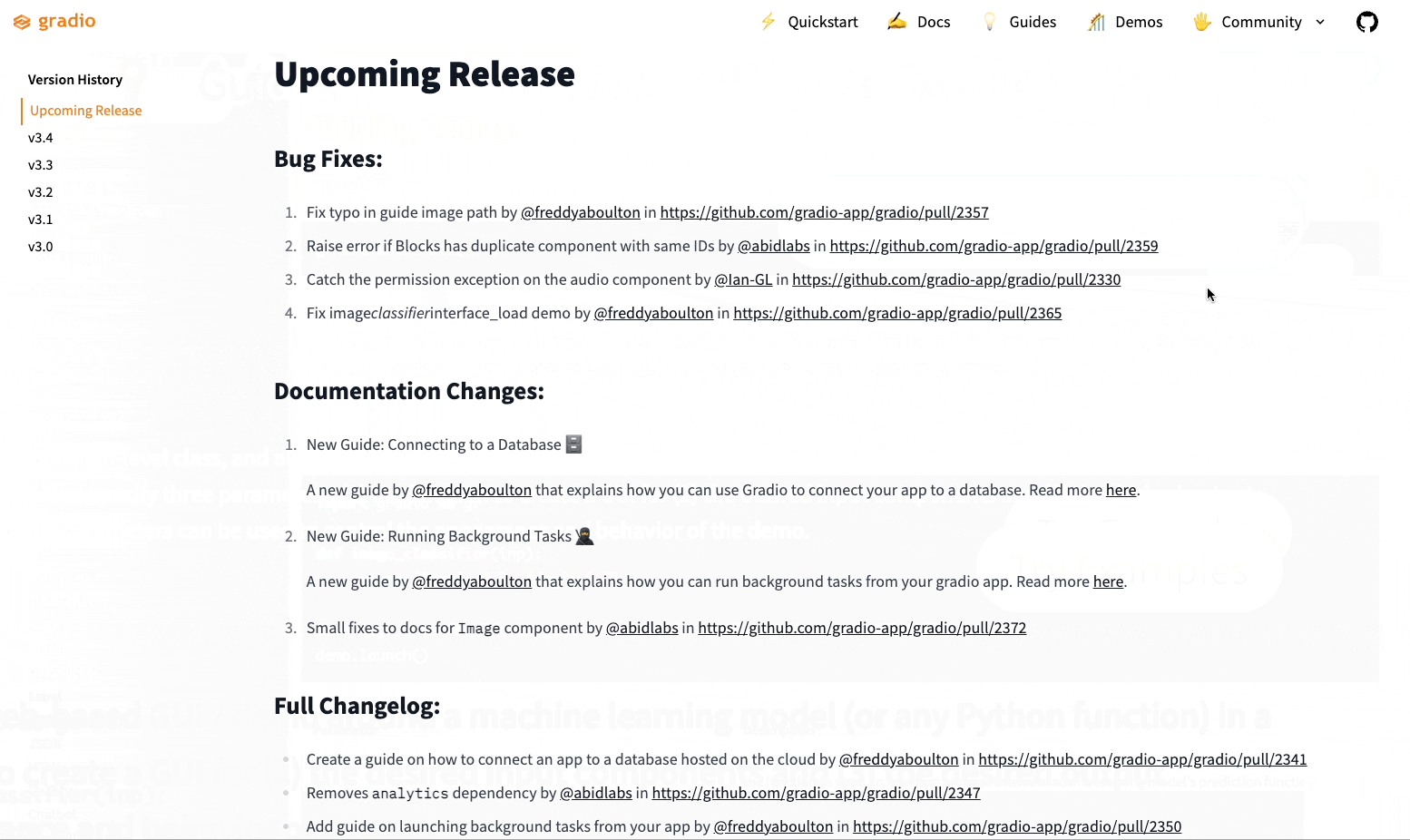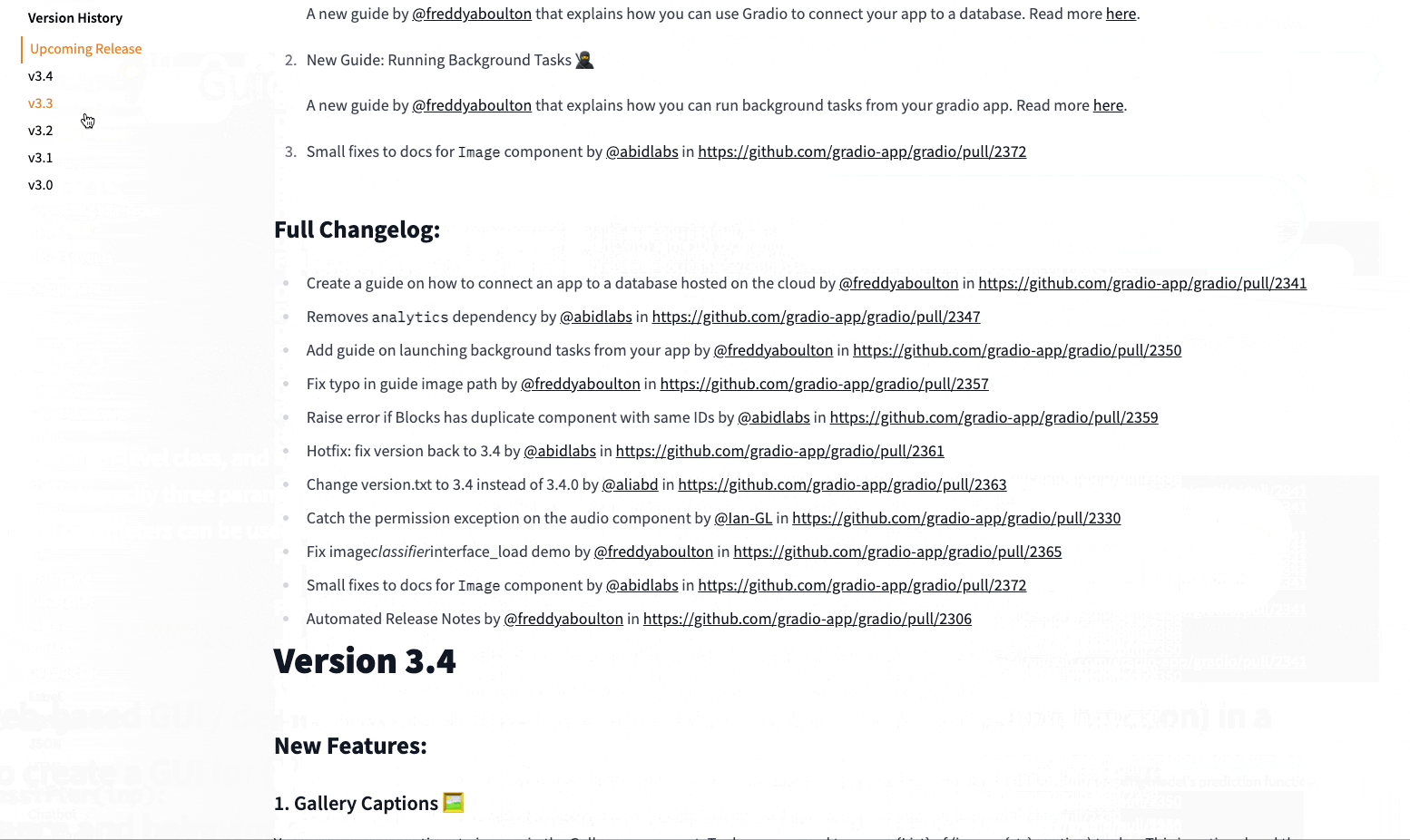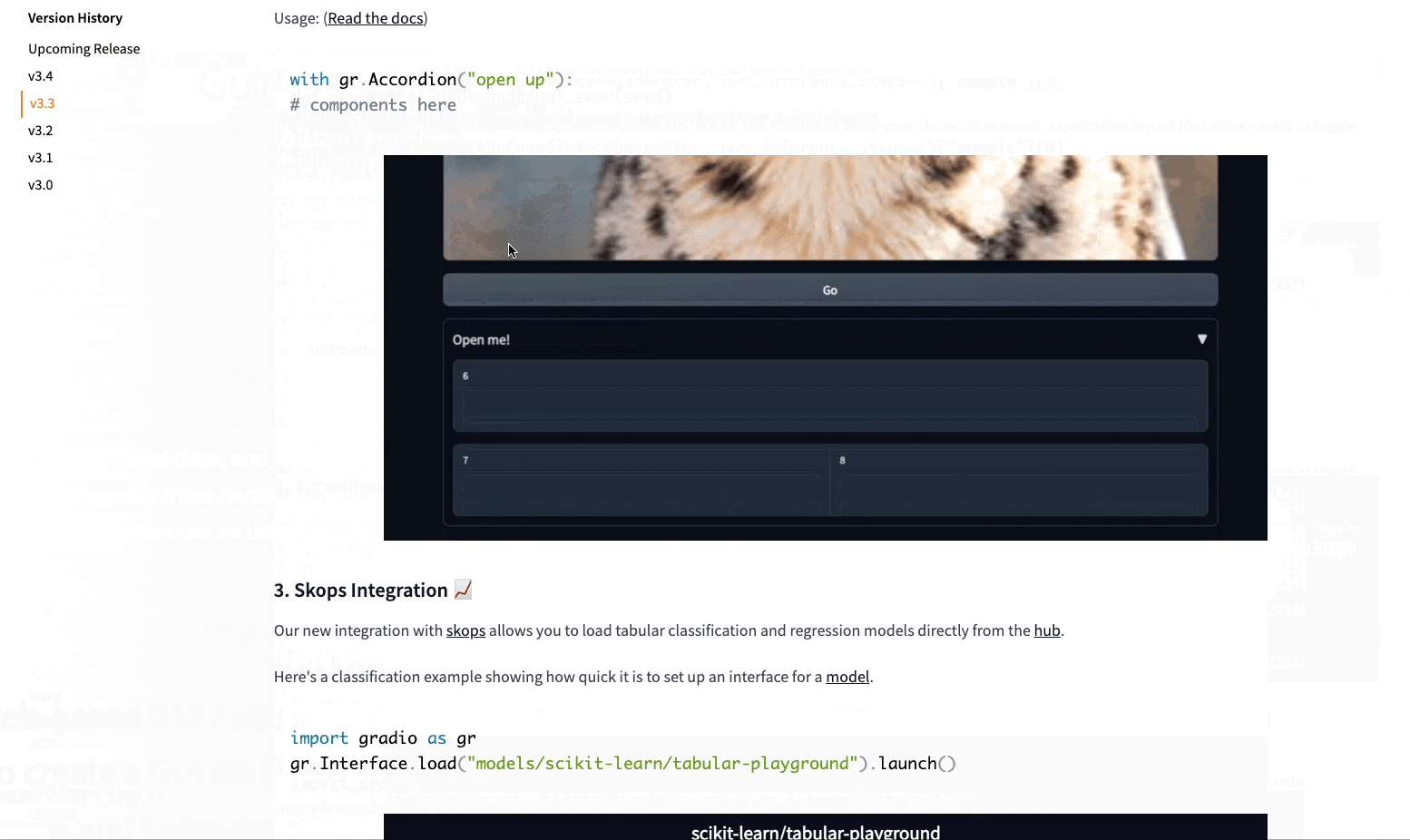
### Bug Fixes:
1. Fix typo in guide image path by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2357](https://github.com/gradio-app/gradio/pull/2357)
2. Raise error if Blocks has duplicate component with same IDs by [@abidlabs](https://github.com/abidlabs) in [PR 2359](https://github.com/gradio-app/gradio/pull/2359)
3. Catch the permission exception on the audio component by [@Ian-GL](https://github.com/Ian-GL) in [PR 2330](https://github.com/gradio-app/gradio/pull/2330)
4. Fix image_classifier_interface_load demo by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2365](https://github.com/gradio-app/gradio/pull/2365)
5. Fix combining adjacent components without gaps by introducing `gr.Row(variant="compact")` by [@aliabid94](https://github.com/aliabid94) in [PR 2291](https://github.com/gradio-app/gradio/pull/2291) This comes with deprecation of the following arguments for `Component.style`: `round`, `margin`, `border`.
6. Fix audio streaming, which was previously choppy in [PR 2351](https://github.com/gradio-app/gradio/pull/2351). Big thanks to [@yannickfunk](https://github.com/yannickfunk) for the proposed solution.
7. Fix bug where new typeable slider doesn't respect the minimum and maximum values [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 2380](https://github.com/gradio-app/gradio/pull/2380)
### Documentation Changes:
1. New Guide: Connecting to a Database 🗄️
A new guide by [@freddyaboulton](https://github.com/freddyaboulton) that explains how you can use Gradio to connect your app to a database. Read more [here](https://gradio.app/connecting_to_a_database/).
2. New Guide: Running Background Tasks 🥷
A new guide by [@freddyaboulton](https://github.com/freddyaboulton) that explains how you can run background tasks from your gradio app. Read more [here](https://gradio.app/running_background_tasks/).
3. Small fixes to docs for `Image` component by [@abidlabs](https://github.com/abidlabs) in [PR 2372](https://github.com/gradio-app/gradio/pull/2372)
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- Create a guide on how to connect an app to a database hosted on the cloud by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2341](https://github.com/gradio-app/gradio/pull/2341)
- Removes `analytics` dependency by [@abidlabs](https://github.com/abidlabs) in [PR 2347](https://github.com/gradio-app/gradio/pull/2347)
- Add guide on launching background tasks from your app by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2350](https://github.com/gradio-app/gradio/pull/2350)
- Fix typo in guide image path by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2357](https://github.com/gradio-app/gradio/pull/2357)
- Raise error if Blocks has duplicate component with same IDs by [@abidlabs](https://github.com/abidlabs) in [PR 2359](https://github.com/gradio-app/gradio/pull/2359)
- Hotfix: fix version back to 3.4 by [@abidlabs](https://github.com/abidlabs) in [PR 2361](https://github.com/gradio-app/gradio/pull/2361)
- Change version.txt to 3.4 instead of 3.4.0 by [@aliabd](https://github.com/aliabd) in [PR 2363](https://github.com/gradio-app/gradio/pull/2363)
- Catch the permission exception on the audio component by [@Ian-GL](https://github.com/Ian-GL) in [PR 2330](https://github.com/gradio-app/gradio/pull/2330)
- Fix image_classifier_interface_load demo by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2365](https://github.com/gradio-app/gradio/pull/2365)
- Small fixes to docs for `Image` component by [@abidlabs](https://github.com/abidlabs) in [PR 2372](https://github.com/gradio-app/gradio/pull/2372)
- Automated Release Notes by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2306](https://github.com/gradio-app/gradio/pull/2306)
- Fixed small typos in the docs [@julien-c](https://github.com/julien-c) in [PR 2373](https://github.com/gradio-app/gradio/pull/2373)
- Adds ability to disable pre/post-processing for examples [@abidlabs](https://github.com/abidlabs) in [PR 2383](https://github.com/gradio-app/gradio/pull/2383)
- Copy changelog file in website docker by [@aliabd](https://github.com/aliabd) in [PR 2384](https://github.com/gradio-app/gradio/pull/2384)
- Lets users provide a `gr.update()` dictionary even if post-processing is disabled [@abidlabs](https://github.com/abidlabs) in [PR 2385](https://github.com/gradio-app/gradio/pull/2385)
- Fix bug where errors would cause apps run in reload mode to hang forever by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2394](https://github.com/gradio-app/gradio/pull/2394)
- Fix bug where new typeable slider doesn't respect the minimum and maximum values [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 2380](https://github.com/gradio-app/gradio/pull/2380)
### Contributors Shoutout:
No changes to highlight.
## 3.4
### New Features:
###### 1. Gallery Captions 🖼️
You can now pass captions to images in the Gallery component. To do so you need to pass a {List} of (image, {str} caption) tuples. This is optional and the component also accepts just a list of the images.
Here's an example:
```python
import gradio as gr
images_with_captions = [
("https://images.unsplash.com/photo-1551969014-7d2c4cddf0b6", "Cheetah by David Groves"),
("https://images.unsplash.com/photo-1546182990-dffeafbe841d", "Lion by Francesco"),
("https://images.unsplash.com/photo-1561731216-c3a4d99437d5", "Tiger by Mike Marrah")
]
with gr.Blocks() as demo:
gr.Gallery(value=images_with_captions)
demo.launch()
```
<img src="https://user-images.githubusercontent.com/9021060/192399521-7360b1a9-7ce0-443e-8e94-863a230a7dbe.gif" alt="gallery_captions" width="1000"/>
###### 2. Type Values into the Slider 🔢
You can now type values directly on the Slider component! Here's what it looks like:
###### 3. Better Sketching and Inpainting 🎨
We've made a lot of changes to our Image component so that it can support better sketching and inpainting.
Now supports:
- A standalone black-and-white sketch
```python
import gradio as gr
demo = gr.Interface(lambda x: x, gr.Sketchpad(), gr.Image())
demo.launch()
```
- A standalone color sketch
```python
import gradio as gr
demo = gr.Interface(lambda x: x, gr.Paint(), gr.Image())
demo.launch()
```

- An uploadable image with black-and-white or color sketching
```python
import gradio as gr
demo = gr.Interface(lambda x: x, gr.Image(source='upload', tool='color-sketch'), gr.Image()) # for black and white, tool = 'sketch'
demo.launch()
```
- Webcam with black-and-white or color sketching
```python
import gradio as gr
demo = gr.Interface(lambda x: x, gr.Image(source='webcam', tool='color-sketch'), gr.Image()) # for black and white, tool = 'sketch'
demo.launch()
```
As well as other fixes
### Bug Fixes:
1. Fix bug where max concurrency count is not respected in queue by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2286](https://github.com/gradio-app/gradio/pull/2286)
2. fix : queue could be blocked by [@SkyTNT](https://github.com/SkyTNT) in [PR 2288](https://github.com/gradio-app/gradio/pull/2288)
3. Supports `gr.update()` in example caching by [@abidlabs](https://github.com/abidlabs) in [PR 2309](https://github.com/gradio-app/gradio/pull/2309)
4. Clipboard fix for iframes by [@abidlabs](https://github.com/abidlabs) in [PR 2321](https://github.com/gradio-app/gradio/pull/2321)
5. Fix: Dataframe column headers are reset when you add a new column by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 2318](https://github.com/gradio-app/gradio/pull/2318)
6. Added support for URLs for Video, Audio, and Image by [@abidlabs](https://github.com/abidlabs) in [PR 2256](https://github.com/gradio-app/gradio/pull/2256)
7. Add documentation about how to create and use the Gradio FastAPI app by [@abidlabs](https://github.com/abidlabs) in [PR 2263](https://github.com/gradio-app/gradio/pull/2263)
### Documentation Changes:
1. Adding a Playground Tab to the Website by [@aliabd](https://github.com/aliabd) in [PR 1860](https://github.com/gradio-app/gradio/pull/1860)
2. Gradio for Tabular Data Science Workflows Guide by [@merveenoyan](https://github.com/merveenoyan) in [PR 2199](https://github.com/gradio-app/gradio/pull/2199)
3. Promotes `postprocess` and `preprocess` to documented parameters by [@abidlabs](https://github.com/abidlabs) in [PR 2293](https://github.com/gradio-app/gradio/pull/2293)
4. Update 2)key_features.md by [@voidxd](https://github.com/voidxd) in [PR 2326](https://github.com/gradio-app/gradio/pull/2326)
5. Add docs to blocks context postprocessing function by [@Ian-GL](https://github.com/Ian-GL) in [PR 2332](https://github.com/gradio-app/gradio/pull/2332)
### Testing and Infrastructure Changes
1. Website fixes and refactoring by [@aliabd](https://github.com/aliabd) in [PR 2280](https://github.com/gradio-app/gradio/pull/2280)
2. Don't deploy to spaces on release by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2313](https://github.com/gradio-app/gradio/pull/2313)
### Full Changelog:
- Website fixes and refactoring by [@aliabd](https://github.com/aliabd) in [PR 2280](https://github.com/gradio-app/gradio/pull/2280)
- Fix bug where max concurrency count is not respected in queue by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2286](https://github.com/gradio-app/gradio/pull/2286)
- Promotes `postprocess` and `preprocess` to documented parameters by [@abidlabs](https://github.com/abidlabs) in [PR 2293](https://github.com/gradio-app/gradio/pull/2293)
- Raise warning when trying to cache examples but not all inputs have examples by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2279](https://github.com/gradio-app/gradio/pull/2279)
- fix : queue could be blocked by [@SkyTNT](https://github.com/SkyTNT) in [PR 2288](https://github.com/gradio-app/gradio/pull/2288)
- Don't deploy to spaces on release by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2313](https://github.com/gradio-app/gradio/pull/2313)
- Supports `gr.update()` in example caching by [@abidlabs](https://github.com/abidlabs) in [PR 2309](https://github.com/gradio-app/gradio/pull/2309)
- Respect Upstream Queue when loading interfaces/blocks from Spaces by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2294](https://github.com/gradio-app/gradio/pull/2294)
- Clipboard fix for iframes by [@abidlabs](https://github.com/abidlabs) in [PR 2321](https://github.com/gradio-app/gradio/pull/2321)
- Sketching + Inpainting Capabilities to Gradio by [@abidlabs](https://github.com/abidlabs) in [PR 2144](https://github.com/gradio-app/gradio/pull/2144)
- Update 2)key_features.md by [@voidxd](https://github.com/voidxd) in [PR 2326](https://github.com/gradio-app/gradio/pull/2326)
- release 3.4b3 by [@abidlabs](https://github.com/abidlabs) in [PR 2328](https://github.com/gradio-app/gradio/pull/2328)
- Fix: Dataframe column headers are reset when you add a new column by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 2318](https://github.com/gradio-app/gradio/pull/2318)
- Start queue when gradio is a sub application by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2319](https://github.com/gradio-app/gradio/pull/2319)
- Fix Web Tracker Script by [@aliabd](https://github.com/aliabd) in [PR 2308](https://github.com/gradio-app/gradio/pull/2308)
- Add docs to blocks context postprocessing function by [@Ian-GL](https://github.com/Ian-GL) in [PR 2332](https://github.com/gradio-app/gradio/pull/2332)
- Fix typo in iterator variable name in run_predict function by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2340](https://github.com/gradio-app/gradio/pull/2340)
- Add captions to galleries by [@aliabid94](https://github.com/aliabid94) in [PR 2284](https://github.com/gradio-app/gradio/pull/2284)
- Typeable value on gradio.Slider by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 2329](https://github.com/gradio-app/gradio/pull/2329)
### Contributors Shoutout:
- [@SkyTNT](https://github.com/SkyTNT) made their first contribution in [PR 2288](https://github.com/gradio-app/gradio/pull/2288)
- [@voidxd](https://github.com/voidxd) made their first contribution in [PR 2326](https://github.com/gradio-app/gradio/pull/2326)
## 3.3
### New Features:
###### 1. Iterative Outputs ⏳
You can now create an iterative output simply by having your function return a generator!
Here's (part of) an example that was used to generate the interface below it. [See full code](https://colab.research.google.com/drive/1m9bWS6B82CT7bw-m4L6AJR8za7fEK7Ov?usp=sharing).
```python
def predict(steps, seed):
generator = torch.manual_seed(seed)
for i in range(1,steps):
yield pipeline(generator=generator, num_inference_steps=i)["sample"][0]
```

###### 2. Accordion Layout 🆕
This version of Gradio introduces a new layout component to Blocks: the Accordion. Wrap your elements in a neat, expandable layout that allows users to toggle them as needed.
Usage: ([Read the docs](https://gradio.app/docs/#accordion))
```python
with gr.Accordion("open up"):
# components here
```
###### 3. Skops Integration 📈
Our new integration with [skops](https://huggingface.co/blog/skops) allows you to load tabular classification and regression models directly from the [hub](https://huggingface.co/models).
Here's a classification example showing how quick it is to set up an interface for a [model](https://huggingface.co/scikit-learn/tabular-playground).
```python
import gradio as gr
gr.Interface.load("models/scikit-learn/tabular-playground").launch()
```
### Bug Fixes:
No changes to highlight.
### Documentation Changes:
No changes to highlight.
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- safari fixes by [@pngwn](https://github.com/pngwn) in [PR 2138](https://github.com/gradio-app/gradio/pull/2138)
- Fix roundedness and form borders by [@aliabid94](https://github.com/aliabid94) in [PR 2147](https://github.com/gradio-app/gradio/pull/2147)
- Better processing of example data prior to creating dataset component by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2147](https://github.com/gradio-app/gradio/pull/2147)
- Show error on Connection drops by [@aliabid94](https://github.com/aliabid94) in [PR 2147](https://github.com/gradio-app/gradio/pull/2147)
- 3.2 release! by [@abidlabs](https://github.com/abidlabs) in [PR 2139](https://github.com/gradio-app/gradio/pull/2139)
- Fixed Named API Requests by [@abidlabs](https://github.com/abidlabs) in [PR 2151](https://github.com/gradio-app/gradio/pull/2151)
- Quick Fix: Cannot upload Model3D image after clearing it by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 2168](https://github.com/gradio-app/gradio/pull/2168)
- Fixed misleading log when server_name is '0.0.0.0' by [@lamhoangtung](https://github.com/lamhoangtung) in [PR 2176](https://github.com/gradio-app/gradio/pull/2176)
- Keep embedded PngInfo metadata by [@cobryan05](https://github.com/cobryan05) in [PR 2170](https://github.com/gradio-app/gradio/pull/2170)
- Skops integration: Load tabular classification and regression models from the hub by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2126](https://github.com/gradio-app/gradio/pull/2126)
- Respect original filename when cached example files are downloaded by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2145](https://github.com/gradio-app/gradio/pull/2145)
- Add manual trigger to deploy to pypi by [@abidlabs](https://github.com/abidlabs) in [PR 2192](https://github.com/gradio-app/gradio/pull/2192)
- Fix bugs with gr.update by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2157](https://github.com/gradio-app/gradio/pull/2157)
- Make queue per app by [@aliabid94](https://github.com/aliabid94) in [PR 2193](https://github.com/gradio-app/gradio/pull/2193)
- Preserve Labels In Interpretation Components by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2166](https://github.com/gradio-app/gradio/pull/2166)
- Quick Fix: Multiple file download not working by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 2169](https://github.com/gradio-app/gradio/pull/2169)
- use correct MIME type for js-script file by [@daspartho](https://github.com/daspartho) in [PR 2200](https://github.com/gradio-app/gradio/pull/2200)
- Add accordion component by [@aliabid94](https://github.com/aliabid94) in [PR 2208](https://github.com/gradio-app/gradio/pull/2208)
### Contributors Shoutout:
- [@lamhoangtung](https://github.com/lamhoangtung) made their first contribution in [PR 2176](https://github.com/gradio-app/gradio/pull/2176)
- [@cobryan05](https://github.com/cobryan05) made their first contribution in [PR 2170](https://github.com/gradio-app/gradio/pull/2170)
- [@daspartho](https://github.com/daspartho) made their first contribution in [PR 2200](https://github.com/gradio-app/gradio/pull/2200)
## 3.2
### New Features:
###### 1. Improvements to Queuing 🥇
We've implemented a brand new queuing system based on **web sockets** instead of HTTP long polling. Among other things, this allows us to manage queue sizes better on Hugging Face Spaces. There are also additional queue-related parameters you can add:
- Now supports concurrent workers (parallelization)
```python
demo = gr.Interface(...)
demo.queue(concurrency_count=3)
demo.launch()
```
- Configure a maximum queue size
```python
demo = gr.Interface(...)
demo.queue(max_size=100)
demo.launch()
```
- If a user closes their tab / browser, they leave the queue, which means the demo will run faster for everyone else
###### 2. Fixes to Examples
- Dataframe examples will render properly, and look much clearer in the UI: (thanks to PR #2125)
- Image and Video thumbnails are cropped to look neater and more uniform: (thanks to PR #2109)
- Other fixes in PR #2131 and #2064 make it easier to design and use Examples
###### 3. Component Fixes 🧱
- Specify the width and height of an image in its style tag (thanks to PR #2133)
```python
components.Image().style(height=260, width=300)
```
- Automatic conversion of videos so they are playable in the browser (thanks to PR #2003). Gradio will check if a video's format is playable in the browser and, if it isn't, will automatically convert it to a format that is (mp4).
- Pass in a json filepath to the Label component (thanks to PR #2083)
- Randomize the default value of a Slider (thanks to PR #1935)
- Improvements to State in PR #2100
###### 4. Ability to Randomize Input Sliders and Reload Data whenever the Page Loads
- In some cases, you want to be able to show a different set of input data to every user as they load the page app. For example, you might want to randomize the value of a "seed" `Slider` input. Or you might want to show a `Textbox` with the current date. We now supporting passing _functions_ as the default value in input components. When you pass in a function, it gets **re-evaluated** every time someone loads the demo, allowing you to reload / change data for different users.
Here's an example loading the current date time into an input Textbox:
```python
import gradio as gr
import datetime
with gr.Blocks() as demo:
gr.Textbox(datetime.datetime.now)
demo.launch()
```
Note that we don't evaluate the function -- `datetime.datetime.now()` -- we pass in the function itself to get this behavior -- `datetime.datetime.now`
Because randomizing the initial value of `Slider` is a common use case, we've added a `randomize` keyword argument you can use to randomize its initial value:
```python
import gradio as gr
demo = gr.Interface(lambda x:x, gr.Slider(0, 10, randomize=True), "number")
demo.launch()
```
###### 5. New Guide 🖊️
- [Gradio and W&B Integration](https://gradio.app/Gradio_and_Wandb_Integration/)
### Full Changelog:
- Reset components to original state by setting value to None by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2044](https://github.com/gradio-app/gradio/pull/2044)
- Cleaning up the way data is processed for components by [@abidlabs](https://github.com/abidlabs) in [PR 1967](https://github.com/gradio-app/gradio/pull/1967)
- version 3.1.8b by [@abidlabs](https://github.com/abidlabs) in [PR 2063](https://github.com/gradio-app/gradio/pull/2063)
- Wandb guide by [@AK391](https://github.com/AK391) in [PR 1898](https://github.com/gradio-app/gradio/pull/1898)
- Add a flagging callback to save json files to a hugging face dataset by [@chrisemezue](https://github.com/chrisemezue) in [PR 1821](https://github.com/gradio-app/gradio/pull/1821)
- Add data science demos to landing page by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2067](https://github.com/gradio-app/gradio/pull/2067)
- Hide time series + xgboost demos by default by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2079](https://github.com/gradio-app/gradio/pull/2079)
- Encourage people to keep trying when queue full by [@apolinario](https://github.com/apolinario) in [PR 2076](https://github.com/gradio-app/gradio/pull/2076)
- Updated our analytics on creation of Blocks/Interface by [@abidlabs](https://github.com/abidlabs) in [PR 2082](https://github.com/gradio-app/gradio/pull/2082)
- `Label` component now accepts file paths to `.json` files by [@abidlabs](https://github.com/abidlabs) in [PR 2083](https://github.com/gradio-app/gradio/pull/2083)
- Fix issues related to demos in Spaces by [@abidlabs](https://github.com/abidlabs) in [PR 2086](https://github.com/gradio-app/gradio/pull/2086)
- Fix TimeSeries examples not properly displayed in UI by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 2064](https://github.com/gradio-app/gradio/pull/2064)
- Fix infinite requests when doing tab item select by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2070](https://github.com/gradio-app/gradio/pull/2070)
- Accept deprecated `file` route as well by [@abidlabs](https://github.com/abidlabs) in [PR 2099](https://github.com/gradio-app/gradio/pull/2099)
- Allow frontend method execution on Block.load event by [@codedealer](https://github.com/codedealer) in [PR 2108](https://github.com/gradio-app/gradio/pull/2108)
- Improvements to `State` by [@abidlabs](https://github.com/abidlabs) in [PR 2100](https://github.com/gradio-app/gradio/pull/2100)
- Catch IndexError, KeyError in video_is_playable by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2113](https://github.com/gradio-app/gradio/pull/2113)
- Fix: Download button does not respect the filepath returned by the function by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 2073](https://github.com/gradio-app/gradio/pull/2073)
- Refactoring Layout: Adding column widths, forms, and more. by [@aliabid94](https://github.com/aliabid94) in [PR 2097](https://github.com/gradio-app/gradio/pull/2097)
- Update CONTRIBUTING.md by [@abidlabs](https://github.com/abidlabs) in [PR 2118](https://github.com/gradio-app/gradio/pull/2118)
- 2092 df ex by [@pngwn](https://github.com/pngwn) in [PR 2125](https://github.com/gradio-app/gradio/pull/2125)
- feat(samples table/gallery): Crop thumbs to square by [@ronvoluted](https://github.com/ronvoluted) in [PR 2109](https://github.com/gradio-app/gradio/pull/2109)
- Some enhancements to `gr.Examples` by [@abidlabs](https://github.com/abidlabs) in [PR 2131](https://github.com/gradio-app/gradio/pull/2131)
- Image size fix by [@aliabid94](https://github.com/aliabid94) in [PR 2133](https://github.com/gradio-app/gradio/pull/2133)
### Contributors Shoutout:
- [@chrisemezue](https://github.com/chrisemezue) made their first contribution in [PR 1821](https://github.com/gradio-app/gradio/pull/1821)
- [@apolinario](https://github.com/apolinario) made their first contribution in [PR 2076](https://github.com/gradio-app/gradio/pull/2076)
- [@codedealer](https://github.com/codedealer) made their first contribution in [PR 2108](https://github.com/gradio-app/gradio/pull/2108)
## 3.1
### New Features:
###### 1. Embedding Demos on Any Website 💻
With PR #1444, Gradio is now distributed as a web component. This means demos can be natively embedded on websites. You'll just need to add two lines: one to load the gradio javascript, and one to link to the demos backend.
Here's a simple example that embeds the demo from a Hugging Face space:
```html
<script
type="module"
src="https://gradio.s3-us-west-2.amazonaws.com/3.0.18/gradio.js"
></script>
<gradio-app space="abidlabs/pytorch-image-classifier"></gradio-app>
```
But you can also embed demos that are running anywhere, you just need to link the demo to `src` instead of `space`. In fact, all the demos on the gradio website are embedded this way:
<img width="1268" alt="Screen Shot 2022-07-14 at 2 41 44 PM" src="https://user-images.githubusercontent.com/9021060/178997124-b2f05af2-c18f-4716-bf1b-cb971d012636.png">
Read more in the [Embedding Gradio Demos](https://gradio.app/embedding_gradio_demos) guide.
###### 2. Reload Mode 👨💻
Reload mode helps developers create gradio demos faster by automatically reloading the demo whenever the code changes. It can support development on Python IDEs (VS Code, PyCharm, etc), the terminal, as well as Jupyter notebooks.
If your demo code is in a script named `app.py`, instead of running `python app.py` you can now run `gradio app.py` and that will launch the demo in reload mode:
```bash
Launching in reload mode on: http://127.0.0.1:7860 (Press CTRL+C to quit)
Watching...
WARNING: The --reload flag should not be used in production on Windows.
```
If you're working from a Jupyter or Colab Notebook, use these magic commands instead: `%load_ext gradio` when you import gradio, and `%%blocks` in the top of the cell with the demo code. Here's an example that shows how much faster the development becomes:
###### 3. Inpainting Support on `gr.Image()` 🎨
We updated the Image component to add support for inpainting demos. It works by adding `tool="sketch"` as a parameter, that passes both an image and a sketchable mask to your prediction function.
Here's an example from the [LAMA space](https://huggingface.co/spaces/akhaliq/lama):
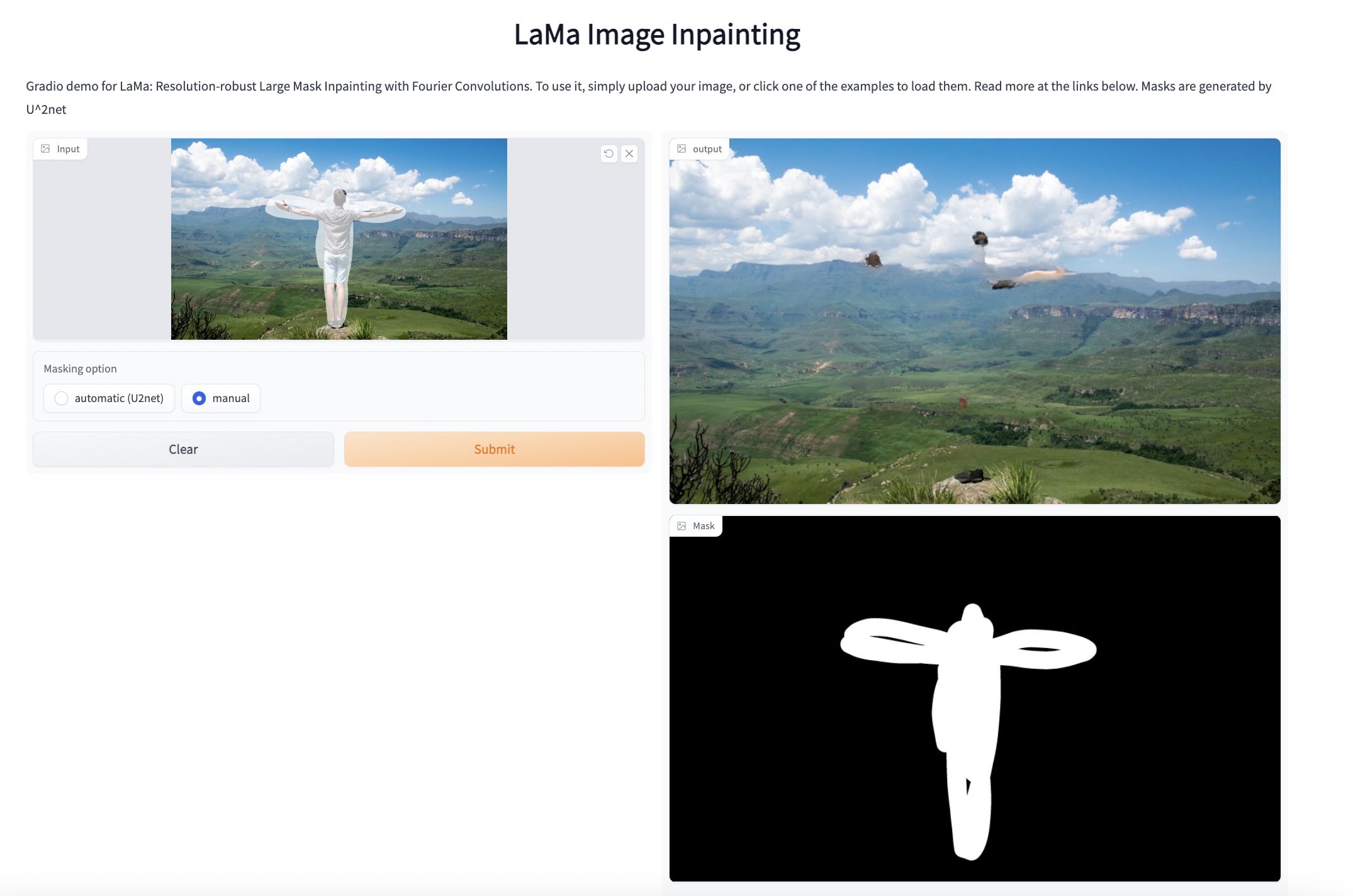
###### 4. Markdown and HTML support in Dataframes 🔢
We upgraded the Dataframe component in PR #1684 to support rendering Markdown and HTML inside the cells.
This means you can build Dataframes that look like the following:
###### 5. `gr.Examples()` for Blocks 🧱
We've added the `gr.Examples` component helper to allow you to add examples to any Blocks demo. This class is a wrapper over the `gr.Dataset` component.
<img width="1271" alt="Screen Shot 2022-07-14 at 2 23 50 PM" src="https://user-images.githubusercontent.com/9021060/178992715-c8bc7550-bc3d-4ddc-9fcb-548c159cd153.png">
gr.Examples takes two required parameters:
- `examples` which takes in a nested list
- `inputs` which takes in a component or list of components
You can read more in the [Examples docs](https://gradio.app/docs/#examples) or the [Adding Examples to your Demos guide](https://gradio.app/adding_examples_to_your_app/).
###### 6. Fixes to Audio Streaming
With [PR 1828](https://github.com/gradio-app/gradio/pull/1828) we now hide the status loading animation, as well as remove the echo in streaming. Check out the [stream_audio](https://github.com/gradio-app/gradio/blob/main/demo/stream_audio/run.py) demo for more or read through our [Real Time Speech Recognition](https://gradio.app/real_time_speech_recognition/) guide.
<img width="785" alt="Screen Shot 2022-07-19 at 6 02 35 PM" src="https://user-images.githubusercontent.com/9021060/179808136-9e84502c-f9ee-4f30-b5e9-1086f678fe91.png">
### Full Changelog:
- File component: list multiple files and allow for download #1446 by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 1681](https://github.com/gradio-app/gradio/pull/1681)
- Add ColorPicker to docs by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 1768](https://github.com/gradio-app/gradio/pull/1768)
- Mock out requests in TestRequest unit tests by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 1794](https://github.com/gradio-app/gradio/pull/1794)
- Add requirements.txt and test_files to source dist by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 1817](https://github.com/gradio-app/gradio/pull/1817)
- refactor: f-string for tunneling.py by [@nhankiet](https://github.com/nhankiet) in [PR 1819](https://github.com/gradio-app/gradio/pull/1819)
- Miscellaneous formatting improvements to website by [@aliabd](https://github.com/aliabd) in [PR 1754](https://github.com/gradio-app/gradio/pull/1754)
- `integrate()` method moved to `Blocks` by [@abidlabs](https://github.com/abidlabs) in [PR 1776](https://github.com/gradio-app/gradio/pull/1776)
- Add python-3.7 tests by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 1818](https://github.com/gradio-app/gradio/pull/1818)
- Copy test dir in website dockers by [@aliabd](https://github.com/aliabd) in [PR 1827](https://github.com/gradio-app/gradio/pull/1827)
- Add info to docs on how to set default values for components by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 1788](https://github.com/gradio-app/gradio/pull/1788)
- Embedding Components on Docs by [@aliabd](https://github.com/aliabd) in [PR 1726](https://github.com/gradio-app/gradio/pull/1726)
- Remove usage of deprecated gr.inputs and gr.outputs from website by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 1796](https://github.com/gradio-app/gradio/pull/1796)
- Some cleanups to the docs page by [@abidlabs](https://github.com/abidlabs) in [PR 1822](https://github.com/gradio-app/gradio/pull/1822)
### Contributors Shoutout:
- [@nhankiet](https://github.com/nhankiet) made their first contribution in [PR 1819](https://github.com/gradio-app/gradio/pull/1819)
## 3.0
###### 🔥 Gradio 3.0 is the biggest update to the library, ever.
### New Features:
###### 1. Blocks 🧱
Blocks is a new, low-level API that allows you to have full control over the data flows and layout of your application. It allows you to build very complex, multi-step applications. For example, you might want to:
- Group together related demos as multiple tabs in one web app
- Change the layout of your demo instead of just having all of the inputs on the left and outputs on the right
- Have multi-step interfaces, in which the output of one model becomes the input to the next model, or have more flexible data flows in general
- Change a component's properties (for example, the choices in a Dropdown) or its visibility based on user input
Here's a simple example that creates the demo below it:
```python
import gradio as gr
def update(name):
return f"Welcome to Gradio, {name}!"
demo = gr.Blocks()
with demo:
gr.Markdown(
"""
# Hello World!
Start typing below to see the output.
""")
inp = gr.Textbox(placeholder="What is your name?")
out = gr.Textbox()
inp.change(fn=update,
inputs=inp,
outputs=out)
demo.launch()
```
Read our [Introduction to Blocks](http://gradio.app/introduction_to_blocks/) guide for more, and join the 🎈 [Gradio Blocks Party](https://huggingface.co/spaces/Gradio-Blocks/README)!
###### 2. Our Revamped Design 🎨
We've upgraded our design across the entire library: from components, and layouts all the way to dark mode.
###### 3. A New Website 💻
We've upgraded [gradio.app](https://gradio.app) to make it cleaner, faster and easier to use. Our docs now come with components and demos embedded directly on the page. So you can quickly get up to speed with what you're looking for.
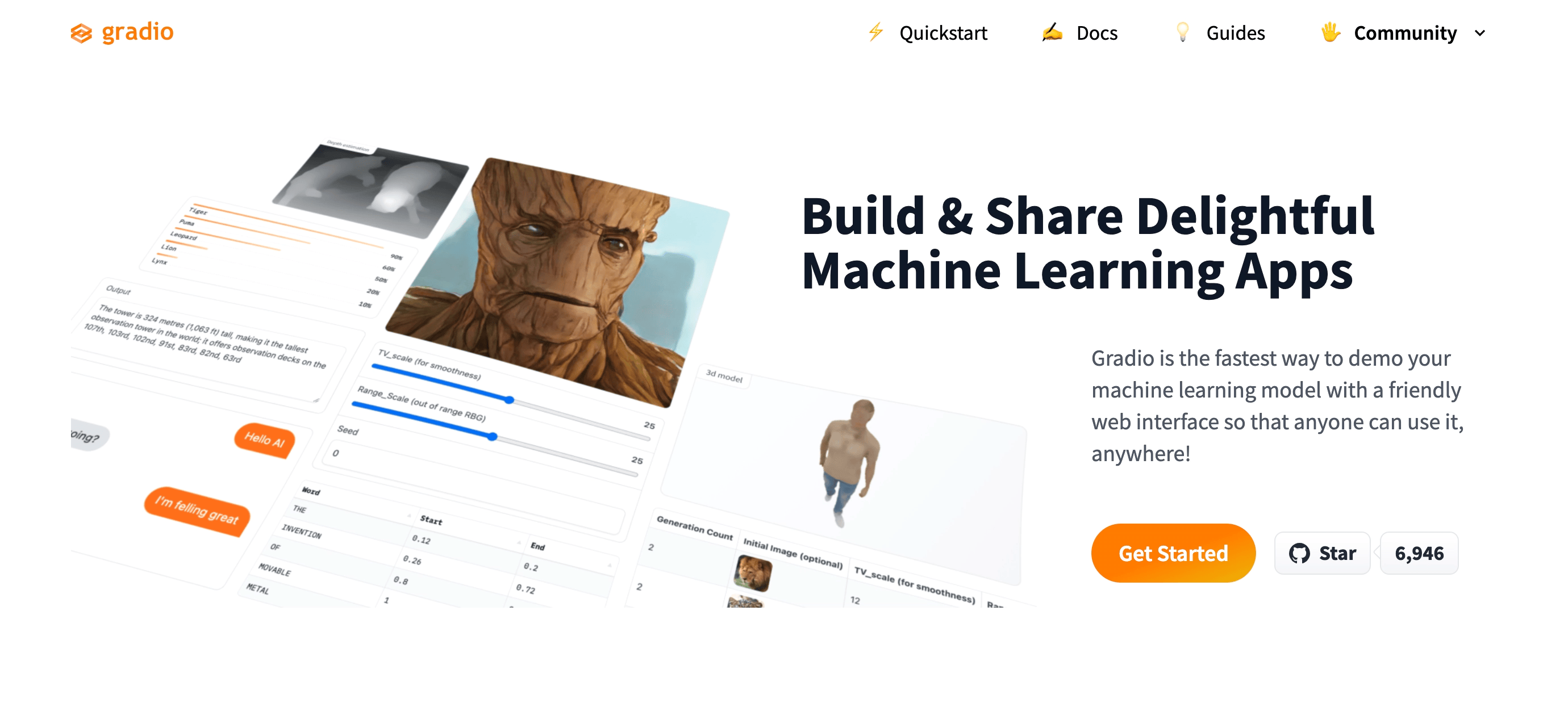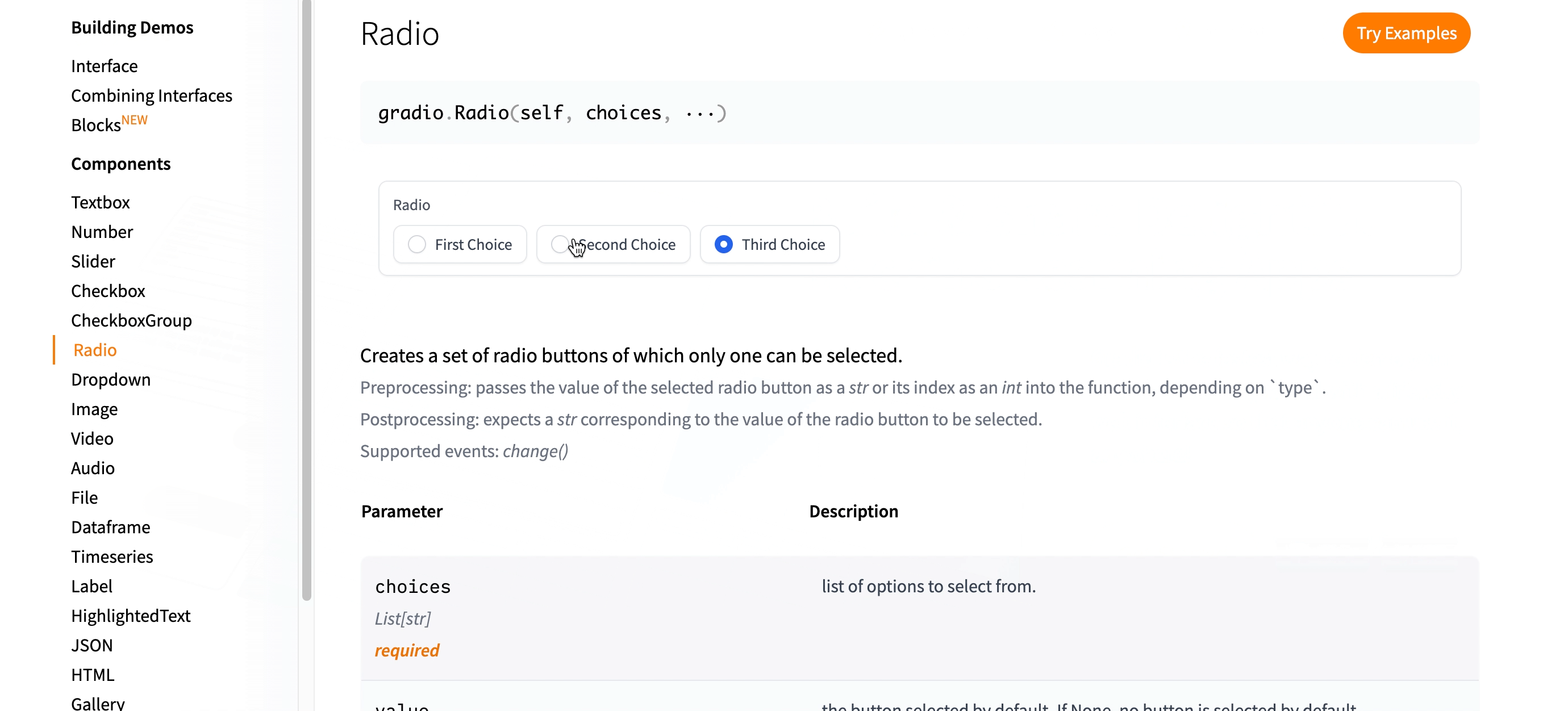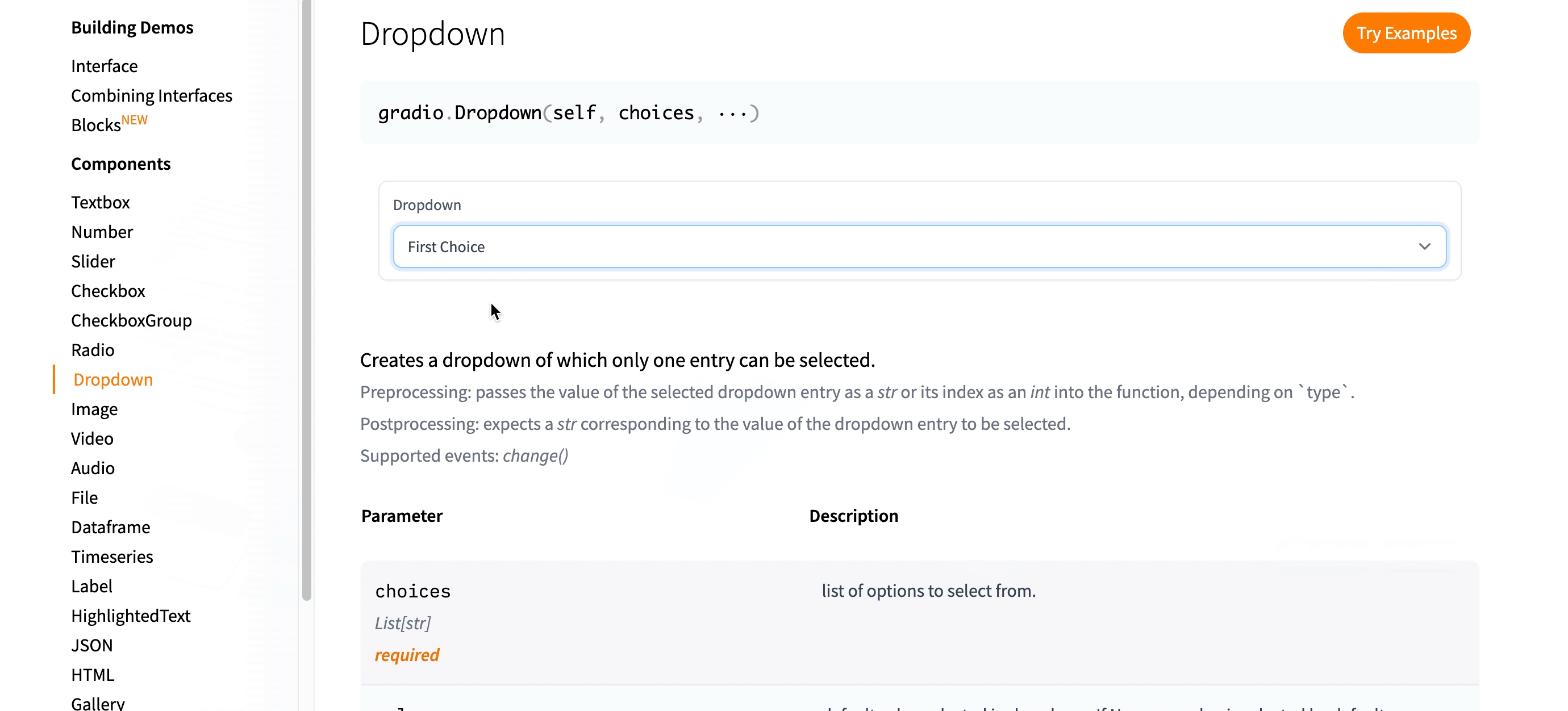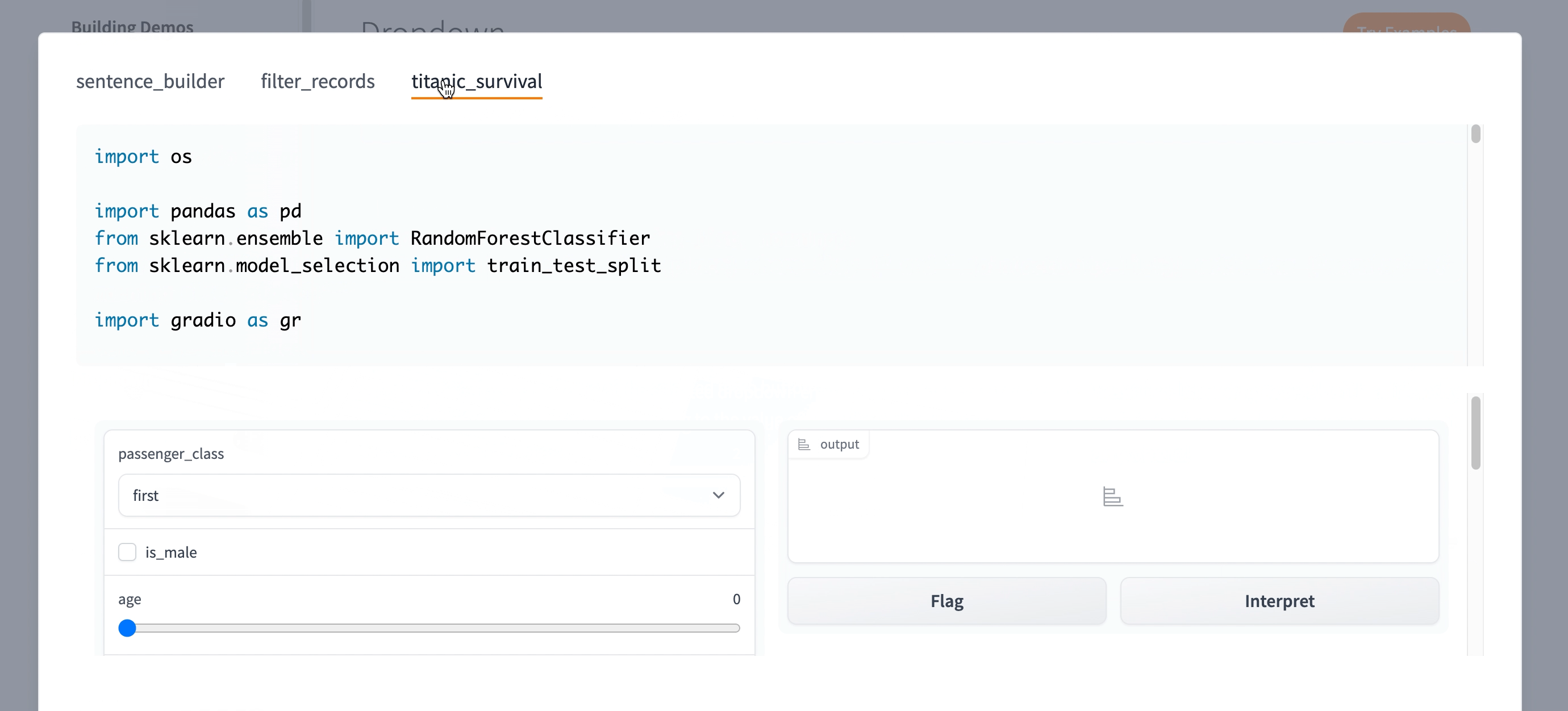
###### 4. New Components: Model3D, Dataset, and More..
We've introduced a lot of new components in `3.0`, including `Model3D`, `Dataset`, `Markdown`, `Button` and `Gallery`. You can find all the components and play around with them [here](https://gradio.app/docs/#components).
### Full Changelog:
- Gradio dash fe by [@pngwn](https://github.com/pngwn) in [PR 807](https://github.com/gradio-app/gradio/pull/807)
- Blocks components by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 765](https://github.com/gradio-app/gradio/pull/765)
- Blocks components V2 by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 843](https://github.com/gradio-app/gradio/pull/843)
- Blocks-Backend-Events by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 844](https://github.com/gradio-app/gradio/pull/844)
- Interfaces from Blocks by [@aliabid94](https://github.com/aliabid94) in [PR 849](https://github.com/gradio-app/gradio/pull/849)
- Blocks dev by [@aliabid94](https://github.com/aliabid94) in [PR 853](https://github.com/gradio-app/gradio/pull/853)
- Started updating demos to use the new `gradio.components` syntax by [@abidlabs](https://github.com/abidlabs) in [PR 848](https://github.com/gradio-app/gradio/pull/848)
- add test infra + add browser tests to CI by [@pngwn](https://github.com/pngwn) in [PR 852](https://github.com/gradio-app/gradio/pull/852)
- 854 textbox by [@pngwn](https://github.com/pngwn) in [PR 859](https://github.com/gradio-app/gradio/pull/859)
- Getting old Python unit tests to pass on `blocks-dev` by [@abidlabs](https://github.com/abidlabs) in [PR 861](https://github.com/gradio-app/gradio/pull/861)
- initialise chatbot with empty array of messages by [@pngwn](https://github.com/pngwn) in [PR 867](https://github.com/gradio-app/gradio/pull/867)
- add test for output to input by [@pngwn](https://github.com/pngwn) in [PR 866](https://github.com/gradio-app/gradio/pull/866)
- More Interface -> Blocks features by [@aliabid94](https://github.com/aliabid94) in [PR 864](https://github.com/gradio-app/gradio/pull/864)
- Fixing external.py in blocks-dev to reflect the new HF Spaces paths by [@abidlabs](https://github.com/abidlabs) in [PR 879](https://github.com/gradio-app/gradio/pull/879)
- backend_default_value_refactoring by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 871](https://github.com/gradio-app/gradio/pull/871)
- fix default_value by [@pngwn](https://github.com/pngwn) in [PR 869](https://github.com/gradio-app/gradio/pull/869)
- fix buttons by [@aliabid94](https://github.com/aliabid94) in [PR 883](https://github.com/gradio-app/gradio/pull/883)
- Checking and updating more demos to use 3.0 syntax by [@abidlabs](https://github.com/abidlabs) in [PR 892](https://github.com/gradio-app/gradio/pull/892)
- Blocks Tests by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 902](https://github.com/gradio-app/gradio/pull/902)
- Interface fix by [@pngwn](https://github.com/pngwn) in [PR 901](https://github.com/gradio-app/gradio/pull/901)
- Quick fix: Issue 893 by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 907](https://github.com/gradio-app/gradio/pull/907)
- 3d Image Component by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 775](https://github.com/gradio-app/gradio/pull/775)
- fix endpoint url in prod by [@pngwn](https://github.com/pngwn) in [PR 911](https://github.com/gradio-app/gradio/pull/911)
- rename Model3d to Image3D by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 912](https://github.com/gradio-app/gradio/pull/912)
- update pypi to 2.9.1 by [@abidlabs](https://github.com/abidlabs) in [PR 916](https://github.com/gradio-app/gradio/pull/916)
- blocks-with-fix by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 917](https://github.com/gradio-app/gradio/pull/917)
- Restore Interpretation, Live, Auth, Queueing by [@aliabid94](https://github.com/aliabid94) in [PR 915](https://github.com/gradio-app/gradio/pull/915)
- Allow `Blocks` instances to be used like a `Block` in other `Blocks` by [@abidlabs](https://github.com/abidlabs) in [PR 919](https://github.com/gradio-app/gradio/pull/919)
- Redesign 1 by [@pngwn](https://github.com/pngwn) in [PR 918](https://github.com/gradio-app/gradio/pull/918)
- blocks-components-tests by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 904](https://github.com/gradio-app/gradio/pull/904)
- fix unit + browser tests by [@pngwn](https://github.com/pngwn) in [PR 926](https://github.com/gradio-app/gradio/pull/926)
- blocks-move-test-data by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 927](https://github.com/gradio-app/gradio/pull/927)
- remove debounce from form inputs by [@pngwn](https://github.com/pngwn) in [PR 932](https://github.com/gradio-app/gradio/pull/932)
- reimplement webcam video by [@pngwn](https://github.com/pngwn) in [PR 928](https://github.com/gradio-app/gradio/pull/928)
- blocks-move-test-data by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 941](https://github.com/gradio-app/gradio/pull/941)
- allow audio components to take a string value by [@pngwn](https://github.com/pngwn) in [PR 930](https://github.com/gradio-app/gradio/pull/930)
- static mode for textbox by [@pngwn](https://github.com/pngwn) in [PR 929](https://github.com/gradio-app/gradio/pull/929)
- fix file upload text by [@pngwn](https://github.com/pngwn) in [PR 931](https://github.com/gradio-app/gradio/pull/931)
- tabbed-interface-rewritten by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 958](https://github.com/gradio-app/gradio/pull/958)
- Gan demo fix by [@abidlabs](https://github.com/abidlabs) in [PR 965](https://github.com/gradio-app/gradio/pull/965)
- Blocks analytics by [@abidlabs](https://github.com/abidlabs) in [PR 947](https://github.com/gradio-app/gradio/pull/947)
- Blocks page load by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 963](https://github.com/gradio-app/gradio/pull/963)
- add frontend for page load events by [@pngwn](https://github.com/pngwn) in [PR 967](https://github.com/gradio-app/gradio/pull/967)
- fix i18n and some tweaks by [@pngwn](https://github.com/pngwn) in [PR 966](https://github.com/gradio-app/gradio/pull/966)
- add jinja2 to reqs by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 969](https://github.com/gradio-app/gradio/pull/969)
- Cleaning up `Launchable()` by [@abidlabs](https://github.com/abidlabs) in [PR 968](https://github.com/gradio-app/gradio/pull/968)
- Fix #944 by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 971](https://github.com/gradio-app/gradio/pull/971)
- New Blocks Demo: neural instrument cloning by [@abidlabs](https://github.com/abidlabs) in [PR 975](https://github.com/gradio-app/gradio/pull/975)
- Add huggingface_hub client library by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 973](https://github.com/gradio-app/gradio/pull/973)
- State and variables by [@aliabid94](https://github.com/aliabid94) in [PR 977](https://github.com/gradio-app/gradio/pull/977)
- update-components by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 986](https://github.com/gradio-app/gradio/pull/986)
- ensure dataframe updates as expected by [@pngwn](https://github.com/pngwn) in [PR 981](https://github.com/gradio-app/gradio/pull/981)
- test-guideline by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 990](https://github.com/gradio-app/gradio/pull/990)
- Issue #785: add footer by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 972](https://github.com/gradio-app/gradio/pull/972)
- indentation fix by [@abidlabs](https://github.com/abidlabs) in [PR 993](https://github.com/gradio-app/gradio/pull/993)
- missing quote by [@aliabd](https://github.com/aliabd) in [PR 996](https://github.com/gradio-app/gradio/pull/996)
- added interactive parameter to components by [@abidlabs](https://github.com/abidlabs) in [PR 992](https://github.com/gradio-app/gradio/pull/992)
- custom-components by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 985](https://github.com/gradio-app/gradio/pull/985)
- Refactor component shortcuts by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 995](https://github.com/gradio-app/gradio/pull/995)
- Plot Component by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 805](https://github.com/gradio-app/gradio/pull/805)
- updated PyPi version to 2.9.2 by [@abidlabs](https://github.com/abidlabs) in [PR 1002](https://github.com/gradio-app/gradio/pull/1002)
- Release 2.9.3 by [@abidlabs](https://github.com/abidlabs) in [PR 1003](https://github.com/gradio-app/gradio/pull/1003)
- Image3D Examples Fix by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 1001](https://github.com/gradio-app/gradio/pull/1001)
- release 2.9.4 by [@abidlabs](https://github.com/abidlabs) in [PR 1006](https://github.com/gradio-app/gradio/pull/1006)
- templates import hotfix by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 1008](https://github.com/gradio-app/gradio/pull/1008)
- Progress indicator bar by [@aliabid94](https://github.com/aliabid94) in [PR 997](https://github.com/gradio-app/gradio/pull/997)
- Fixed image input for absolute path by [@JefferyChiang](https://github.com/JefferyChiang) in [PR 1004](https://github.com/gradio-app/gradio/pull/1004)
- Model3D + Plot Components by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 1010](https://github.com/gradio-app/gradio/pull/1010)
- Gradio Guides: Creating CryptoPunks with GANs by [@NimaBoscarino](https://github.com/NimaBoscarino) in [PR 1000](https://github.com/gradio-app/gradio/pull/1000)
- [BIG PR] Gradio blocks & redesigned components by [@abidlabs](https://github.com/abidlabs) in [PR 880](https://github.com/gradio-app/gradio/pull/880)
- fixed failing test on main by [@abidlabs](https://github.com/abidlabs) in [PR 1023](https://github.com/gradio-app/gradio/pull/1023)
- Use smaller ASR model in external test by [@abidlabs](https://github.com/abidlabs) in [PR 1024](https://github.com/gradio-app/gradio/pull/1024)
- updated PyPi version to 2.9.0b by [@abidlabs](https://github.com/abidlabs) in [PR 1026](https://github.com/gradio-app/gradio/pull/1026)
- Fixing import issues so that the package successfully installs on colab notebooks by [@abidlabs](https://github.com/abidlabs) in [PR 1027](https://github.com/gradio-app/gradio/pull/1027)
- Update website tracker slackbot by [@aliabd](https://github.com/aliabd) in [PR 1037](https://github.com/gradio-app/gradio/pull/1037)
- textbox-autoheight by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 1009](https://github.com/gradio-app/gradio/pull/1009)
- Model3D Examples fixes by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 1035](https://github.com/gradio-app/gradio/pull/1035)
- GAN Gradio Guide: Adjustments to iframe heights by [@NimaBoscarino](https://github.com/NimaBoscarino) in [PR 1042](https://github.com/gradio-app/gradio/pull/1042)
- added better default labels to form components by [@abidlabs](https://github.com/abidlabs) in [PR 1040](https://github.com/gradio-app/gradio/pull/1040)
- Slackbot web tracker fix by [@aliabd](https://github.com/aliabd) in [PR 1043](https://github.com/gradio-app/gradio/pull/1043)
- Plot fixes by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 1044](https://github.com/gradio-app/gradio/pull/1044)
- Small fixes to the demos by [@abidlabs](https://github.com/abidlabs) in [PR 1030](https://github.com/gradio-app/gradio/pull/1030)
- fixing demo issue with website by [@aliabd](https://github.com/aliabd) in [PR 1047](https://github.com/gradio-app/gradio/pull/1047)
- [hotfix] HighlightedText by [@aliabid94](https://github.com/aliabid94) in [PR 1046](https://github.com/gradio-app/gradio/pull/1046)
- Update text by [@ronvoluted](https://github.com/ronvoluted) in [PR 1050](https://github.com/gradio-app/gradio/pull/1050)
- Update CONTRIBUTING.md by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 1052](https://github.com/gradio-app/gradio/pull/1052)
- fix(ui): Increase contrast for footer by [@ronvoluted](https://github.com/ronvoluted) in [PR 1048](https://github.com/gradio-app/gradio/pull/1048)
- UI design update by [@gary149](https://github.com/gary149) in [PR 1041](https://github.com/gradio-app/gradio/pull/1041)
- updated PyPi version to 2.9.0b8 by [@abidlabs](https://github.com/abidlabs) in [PR 1059](https://github.com/gradio-app/gradio/pull/1059)
- Running, testing, and fixing demos by [@abidlabs](https://github.com/abidlabs) in [PR 1060](https://github.com/gradio-app/gradio/pull/1060)
- Form layout by [@pngwn](https://github.com/pngwn) in [PR 1054](https://github.com/gradio-app/gradio/pull/1054)
- inputless-interfaces by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 1038](https://github.com/gradio-app/gradio/pull/1038)
- Update PULL_REQUEST_TEMPLATE.md by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 1068](https://github.com/gradio-app/gradio/pull/1068)
- Upgrading node memory to 4gb in website Docker by [@aliabd](https://github.com/aliabd) in [PR 1069](https://github.com/gradio-app/gradio/pull/1069)
- Website reload error by [@aliabd](https://github.com/aliabd) in [PR 1079](https://github.com/gradio-app/gradio/pull/1079)
- fixed favicon issue by [@abidlabs](https://github.com/abidlabs) in [PR 1064](https://github.com/gradio-app/gradio/pull/1064)
- remove-queue-from-events by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 1056](https://github.com/gradio-app/gradio/pull/1056)
- Enable vertex colors for OBJs files by [@radames](https://github.com/radames) in [PR 1074](https://github.com/gradio-app/gradio/pull/1074)
- Dark text by [@ronvoluted](https://github.com/ronvoluted) in [PR 1049](https://github.com/gradio-app/gradio/pull/1049)
- Scroll to output by [@pngwn](https://github.com/pngwn) in [PR 1077](https://github.com/gradio-app/gradio/pull/1077)
- Explicitly list pnpm version 6 in contributing guide by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 1085](https://github.com/gradio-app/gradio/pull/1085)
- hotfix for encrypt issue by [@abidlabs](https://github.com/abidlabs) in [PR 1096](https://github.com/gradio-app/gradio/pull/1096)
- Release 2.9b9 by [@abidlabs](https://github.com/abidlabs) in [PR 1098](https://github.com/gradio-app/gradio/pull/1098)
- tweak node circleci settings by [@pngwn](https://github.com/pngwn) in [PR 1091](https://github.com/gradio-app/gradio/pull/1091)
- Website Reload Error by [@aliabd](https://github.com/aliabd) in [PR 1099](https://github.com/gradio-app/gradio/pull/1099)
- Website Reload: README in demos docker by [@aliabd](https://github.com/aliabd) in [PR 1100](https://github.com/gradio-app/gradio/pull/1100)
- Flagging fixes by [@abidlabs](https://github.com/abidlabs) in [PR 1081](https://github.com/gradio-app/gradio/pull/1081)
- Backend for optional labels by [@abidlabs](https://github.com/abidlabs) in [PR 1080](https://github.com/gradio-app/gradio/pull/1080)
- Optional labels fe by [@pngwn](https://github.com/pngwn) in [PR 1105](https://github.com/gradio-app/gradio/pull/1105)
- clean-deprecated-parameters by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 1090](https://github.com/gradio-app/gradio/pull/1090)
- Blocks rendering fix by [@abidlabs](https://github.com/abidlabs) in [PR 1102](https://github.com/gradio-app/gradio/pull/1102)
- Redos #1106 by [@abidlabs](https://github.com/abidlabs) in [PR 1112](https://github.com/gradio-app/gradio/pull/1112)
- Interface types: handle input-only, output-only, and unified interfaces by [@abidlabs](https://github.com/abidlabs) in [PR 1108](https://github.com/gradio-app/gradio/pull/1108)
- Hotfix + New pypi release 2.9b11 by [@abidlabs](https://github.com/abidlabs) in [PR 1118](https://github.com/gradio-app/gradio/pull/1118)
- issue-checkbox by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 1122](https://github.com/gradio-app/gradio/pull/1122)
- issue-checkbox-hotfix by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 1127](https://github.com/gradio-app/gradio/pull/1127)
- Fix demos in website by [@aliabd](https://github.com/aliabd) in [PR 1130](https://github.com/gradio-app/gradio/pull/1130)
- Guide for Gradio ONNX model zoo on Huggingface by [@AK391](https://github.com/AK391) in [PR 1073](https://github.com/gradio-app/gradio/pull/1073)
- ONNX guide fixes by [@aliabd](https://github.com/aliabd) in [PR 1131](https://github.com/gradio-app/gradio/pull/1131)
- Stacked form inputs css by [@gary149](https://github.com/gary149) in [PR 1134](https://github.com/gradio-app/gradio/pull/1134)
- made default value in textbox empty string by [@abidlabs](https://github.com/abidlabs) in [PR 1135](https://github.com/gradio-app/gradio/pull/1135)
- Examples UI by [@gary149](https://github.com/gary149) in [PR 1121](https://github.com/gradio-app/gradio/pull/1121)
- Chatbot custom color support by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 1092](https://github.com/gradio-app/gradio/pull/1092)
- highlighted text colors by [@pngwn](https://github.com/pngwn) in [PR 1119](https://github.com/gradio-app/gradio/pull/1119)
- pin to pnpm 6 for now by [@pngwn](https://github.com/pngwn) in [PR 1147](https://github.com/gradio-app/gradio/pull/1147)
- Restore queue in Blocks by [@aliabid94](https://github.com/aliabid94) in [PR 1137](https://github.com/gradio-app/gradio/pull/1137)
- add select event for tabitems by [@pngwn](https://github.com/pngwn) in [PR 1154](https://github.com/gradio-app/gradio/pull/1154)
- max_lines + autoheight for textbox by [@pngwn](https://github.com/pngwn) in [PR 1153](https://github.com/gradio-app/gradio/pull/1153)
- use color palette for chatbot by [@pngwn](https://github.com/pngwn) in [PR 1152](https://github.com/gradio-app/gradio/pull/1152)
- Timeseries improvements by [@pngwn](https://github.com/pngwn) in [PR 1149](https://github.com/gradio-app/gradio/pull/1149)
- move styling for interface panels to frontend by [@pngwn](https://github.com/pngwn) in [PR 1146](https://github.com/gradio-app/gradio/pull/1146)
- html tweaks by [@pngwn](https://github.com/pngwn) in [PR 1145](https://github.com/gradio-app/gradio/pull/1145)
- Issue #768: Support passing none to resize and crop image by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 1144](https://github.com/gradio-app/gradio/pull/1144)
- image gallery component + img css by [@aliabid94](https://github.com/aliabid94) in [PR 1140](https://github.com/gradio-app/gradio/pull/1140)
- networking tweak by [@abidlabs](https://github.com/abidlabs) in [PR 1143](https://github.com/gradio-app/gradio/pull/1143)
- Allow enabling queue per event listener by [@aliabid94](https://github.com/aliabid94) in [PR 1155](https://github.com/gradio-app/gradio/pull/1155)
- config hotfix and v. 2.9b23 by [@abidlabs](https://github.com/abidlabs) in [PR 1158](https://github.com/gradio-app/gradio/pull/1158)
- Custom JS calls by [@aliabid94](https://github.com/aliabid94) in [PR 1082](https://github.com/gradio-app/gradio/pull/1082)
- Small fixes: queue default fix, ffmpeg installation message by [@abidlabs](https://github.com/abidlabs) in [PR 1159](https://github.com/gradio-app/gradio/pull/1159)
- formatting by [@abidlabs](https://github.com/abidlabs) in [PR 1161](https://github.com/gradio-app/gradio/pull/1161)
- enable flex grow for gr-box by [@radames](https://github.com/radames) in [PR 1165](https://github.com/gradio-app/gradio/pull/1165)
- 1148 loading by [@pngwn](https://github.com/pngwn) in [PR 1164](https://github.com/gradio-app/gradio/pull/1164)
- Put enable_queue kwarg back in launch() by [@aliabid94](https://github.com/aliabid94) in [PR 1167](https://github.com/gradio-app/gradio/pull/1167)
- A few small fixes by [@abidlabs](https://github.com/abidlabs) in [PR 1171](https://github.com/gradio-app/gradio/pull/1171)
- Hotfix for dropdown component by [@abidlabs](https://github.com/abidlabs) in [PR 1172](https://github.com/gradio-app/gradio/pull/1172)
- use secondary buttons in interface by [@pngwn](https://github.com/pngwn) in [PR 1173](https://github.com/gradio-app/gradio/pull/1173)
- 1183 component height by [@pngwn](https://github.com/pngwn) in [PR 1185](https://github.com/gradio-app/gradio/pull/1185)
- 962 dataframe by [@pngwn](https://github.com/pngwn) in [PR 1186](https://github.com/gradio-app/gradio/pull/1186)
- update-contributing by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 1188](https://github.com/gradio-app/gradio/pull/1188)
- Table tweaks by [@pngwn](https://github.com/pngwn) in [PR 1195](https://github.com/gradio-app/gradio/pull/1195)
- wrap tab content in column by [@pngwn](https://github.com/pngwn) in [PR 1200](https://github.com/gradio-app/gradio/pull/1200)
- WIP: Add dark mode support by [@gary149](https://github.com/gary149) in [PR 1187](https://github.com/gradio-app/gradio/pull/1187)
- Restored /api/predict/ endpoint for Interfaces by [@abidlabs](https://github.com/abidlabs) in [PR 1199](https://github.com/gradio-app/gradio/pull/1199)
- hltext-label by [@pngwn](https://github.com/pngwn) in [PR 1204](https://github.com/gradio-app/gradio/pull/1204)
- add copy functionality to json by [@pngwn](https://github.com/pngwn) in [PR 1205](https://github.com/gradio-app/gradio/pull/1205)
- Update component config by [@aliabid94](https://github.com/aliabid94) in [PR 1089](https://github.com/gradio-app/gradio/pull/1089)
- fix placeholder prompt by [@pngwn](https://github.com/pngwn) in [PR 1215](https://github.com/gradio-app/gradio/pull/1215)
- ensure webcam video value is propagated correctly by [@pngwn](https://github.com/pngwn) in [PR 1218](https://github.com/gradio-app/gradio/pull/1218)
- Automatic word-break in highlighted text, combine_adjacent support by [@aliabid94](https://github.com/aliabid94) in [PR 1209](https://github.com/gradio-app/gradio/pull/1209)
- async-function-support by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 1190](https://github.com/gradio-app/gradio/pull/1190)
- Sharing fix for assets by [@aliabid94](https://github.com/aliabid94) in [PR 1208](https://github.com/gradio-app/gradio/pull/1208)
- Hotfixes for course demos by [@abidlabs](https://github.com/abidlabs) in [PR 1222](https://github.com/gradio-app/gradio/pull/1222)
- Allow Custom CSS by [@aliabid94](https://github.com/aliabid94) in [PR 1170](https://github.com/gradio-app/gradio/pull/1170)
- share-hotfix by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 1226](https://github.com/gradio-app/gradio/pull/1226)
- tweaks by [@pngwn](https://github.com/pngwn) in [PR 1229](https://github.com/gradio-app/gradio/pull/1229)
- white space for class concatenation by [@radames](https://github.com/radames) in [PR 1228](https://github.com/gradio-app/gradio/pull/1228)
- Tweaks by [@pngwn](https://github.com/pngwn) in [PR 1230](https://github.com/gradio-app/gradio/pull/1230)
- css tweaks by [@pngwn](https://github.com/pngwn) in [PR 1235](https://github.com/gradio-app/gradio/pull/1235)
- ensure defaults height match for media inputs by [@pngwn](https://github.com/pngwn) in [PR 1236](https://github.com/gradio-app/gradio/pull/1236)
- Default Label label value by [@radames](https://github.com/radames) in [PR 1239](https://github.com/gradio-app/gradio/pull/1239)
- update-shortcut-syntax by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 1234](https://github.com/gradio-app/gradio/pull/1234)
- Update version.txt by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 1244](https://github.com/gradio-app/gradio/pull/1244)
- Layout bugs by [@pngwn](https://github.com/pngwn) in [PR 1246](https://github.com/gradio-app/gradio/pull/1246)
- Update demo by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 1253](https://github.com/gradio-app/gradio/pull/1253)
- Button default name by [@FarukOzderim](https://github.com/FarukOzderim) in [PR 1243](https://github.com/gradio-app/gradio/pull/1243)
- Labels spacing by [@gary149](https://github.com/gary149) in [PR 1254](https://github.com/gradio-app/gradio/pull/1254)
- add global loader for gradio app by [@pngwn](https://github.com/pngwn) in [PR 1251](https://github.com/gradio-app/gradio/pull/1251)
- ui apis for dalle-mini by [@pngwn](https://github.com/pngwn) in [PR 1258](https://github.com/gradio-app/gradio/pull/1258)
- Add precision to Number, backend only by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 1125](https://github.com/gradio-app/gradio/pull/1125)
- Website Design Changes by [@abidlabs](https://github.com/abidlabs) in [PR 1015](https://github.com/gradio-app/gradio/pull/1015)
- Small fixes for multiple demos compatible with 3.0 by [@radames](https://github.com/radames) in [PR 1257](https://github.com/gradio-app/gradio/pull/1257)
- Issue #1160: Model 3D component not destroyed correctly by [@dawoodkhan82](https://github.com/dawoodkhan82) in [PR 1219](https://github.com/gradio-app/gradio/pull/1219)
- Fixes to components by [@abidlabs](https://github.com/abidlabs) in [PR 1260](https://github.com/gradio-app/gradio/pull/1260)
- layout docs by [@abidlabs](https://github.com/abidlabs) in [PR 1263](https://github.com/gradio-app/gradio/pull/1263)
- Static forms by [@pngwn](https://github.com/pngwn) in [PR 1264](https://github.com/gradio-app/gradio/pull/1264)
- Cdn assets by [@pngwn](https://github.com/pngwn) in [PR 1265](https://github.com/gradio-app/gradio/pull/1265)
- update logo by [@gary149](https://github.com/gary149) in [PR 1266](https://github.com/gradio-app/gradio/pull/1266)
- fix slider by [@aliabid94](https://github.com/aliabid94) in [PR 1268](https://github.com/gradio-app/gradio/pull/1268)
- maybe fix auth in iframes by [@pngwn](https://github.com/pngwn) in [PR 1261](https://github.com/gradio-app/gradio/pull/1261)
- Improves "Getting Started" guide by [@abidlabs](https://github.com/abidlabs) in [PR 1269](https://github.com/gradio-app/gradio/pull/1269)
- Add embedded demos to website by [@aliabid94](https://github.com/aliabid94) in [PR 1270](https://github.com/gradio-app/gradio/pull/1270)
- Label hotfixes by [@abidlabs](https://github.com/abidlabs) in [PR 1281](https://github.com/gradio-app/gradio/pull/1281)
- General tweaks by [@pngwn](https://github.com/pngwn) in [PR 1276](https://github.com/gradio-app/gradio/pull/1276)
- only affect links within the document by [@pngwn](https://github.com/pngwn) in [PR 1282](https://github.com/gradio-app/gradio/pull/1282)
- release 3.0b9 by [@abidlabs](https://github.com/abidlabs) in [PR 1283](https://github.com/gradio-app/gradio/pull/1283)
- Dm by [@pngwn](https://github.com/pngwn) in [PR 1284](https://github.com/gradio-app/gradio/pull/1284)
- Website fixes by [@aliabd](https://github.com/aliabd) in [PR 1286](https://github.com/gradio-app/gradio/pull/1286)
- Create Streamables by [@aliabid94](https://github.com/aliabid94) in [PR 1279](https://github.com/gradio-app/gradio/pull/1279)
- ensure table works on mobile by [@pngwn](https://github.com/pngwn) in [PR 1277](https://github.com/gradio-app/gradio/pull/1277)
- changes by [@aliabid94](https://github.com/aliabid94) in [PR 1287](https://github.com/gradio-app/gradio/pull/1287)
- demo alignment on landing page by [@aliabd](https://github.com/aliabd) in [PR 1288](https://github.com/gradio-app/gradio/pull/1288)
- New meta img by [@aliabd](https://github.com/aliabd) in [PR 1289](https://github.com/gradio-app/gradio/pull/1289)
- updated PyPi version to 3.0 by [@abidlabs](https://github.com/abidlabs) in [PR 1290](https://github.com/gradio-app/gradio/pull/1290)
- Fix site by [@aliabid94](https://github.com/aliabid94) in [PR 1291](https://github.com/gradio-app/gradio/pull/1291)
- Mobile responsive guides by [@aliabd](https://github.com/aliabd) in [PR 1293](https://github.com/gradio-app/gradio/pull/1293)
- Update readme by [@abidlabs](https://github.com/abidlabs) in [PR 1292](https://github.com/gradio-app/gradio/pull/1292)
- gif by [@abidlabs](https://github.com/abidlabs) in [PR 1296](https://github.com/gradio-app/gradio/pull/1296)
- Allow decoding headerless b64 string [@1lint](https://github.com/1lint) in [PR 4031](https://github.com/gradio-app/gradio/pull/4031)
### Contributors Shoutout:
- [@JefferyChiang](https://github.com/JefferyChiang) made their first contribution in [PR 1004](https://github.com/gradio-app/gradio/pull/1004)
- [@NimaBoscarino](https://github.com/NimaBoscarino) made their first contribution in [PR 1000](https://github.com/gradio-app/gradio/pull/1000)
- [@ronvoluted](https://github.com/ronvoluted) made their first contribution in [PR 1050](https://github.com/gradio-app/gradio/pull/1050)
- [@radames](https://github.com/radames) made their first contribution in [PR 1074](https://github.com/gradio-app/gradio/pull/1074)
- [@freddyaboulton](https://github.com/freddyaboulton) made their first contribution in [PR 1085](https://github.com/gradio-app/gradio/pull/1085)
- [@liteli1987gmail](https://github.com/liteli1987gmail) & [@chenglu](https://github.com/chenglu) made their first contribution in [PR 4767](https://github.com/gradio-app/gradio/pull/4767)
|
gradio-app/gradio/blob/main/gradio/CHANGELOG.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Falcon
## Overview
Falcon is a class of causal decoder-only models built by [TII](https://www.tii.ae/). The largest Falcon checkpoints
have been trained on >=1T tokens of text, with a particular emphasis on the [RefinedWeb](https://arxiv.org/abs/2306.01116)
corpus. They are made available under the Apache 2.0 license.
Falcon's architecture is modern and optimized for inference, with multi-query attention and support for efficient
attention variants like `FlashAttention`. Both 'base' models trained only as causal language models as well as
'instruct' models that have received further fine-tuning are available.
Falcon models are (as of 2023) some of the largest and most powerful open-source language models,
and consistently rank highly in the [OpenLLM leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
## Converting custom checkpoints
<Tip>
Falcon models were initially added to the Hugging Face Hub as custom code checkpoints. However, Falcon is now fully
supported in the Transformers library. If you fine-tuned a model from a custom code checkpoint, we recommend converting
your checkpoint to the new in-library format, as this should give significant improvements to stability and
performance, especially for generation, as well as removing the need to use `trust_remote_code=True`!
</Tip>
You can convert custom code checkpoints to full Transformers checkpoints using the `convert_custom_code_checkpoint.py`
script located in the
[Falcon model directory](https://github.com/huggingface/transformers/tree/main/src/transformers/models/falcon)
of the Transformers library. To use this script, simply call it with
`python convert_custom_code_checkpoint.py --checkpoint_dir my_model`. This will convert your checkpoint in-place, and
you can immediately load it from the directory afterwards with e.g. `from_pretrained()`. If your model hasn't been
uploaded to the Hub, we recommend making a backup before attempting the conversion, just in case!
## FalconConfig
[[autodoc]] FalconConfig
- all
## FalconModel
[[autodoc]] FalconModel
- forward
## FalconForCausalLM
[[autodoc]] FalconForCausalLM
- forward
## FalconForSequenceClassification
[[autodoc]] FalconForSequenceClassification
- forward
## FalconForTokenClassification
[[autodoc]] FalconForTokenClassification
- forward
## FalconForQuestionAnswering
[[autodoc]] FalconForQuestionAnswering
- forward
|
huggingface/transformers/blob/main/docs/source/en/model_doc/falcon.md
|
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# GLPN
<Tip>
This is a recently introduced model so the API hasn't been tested extensively. There may be some bugs or slight
breaking changes to fix it in the future. If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title).
</Tip>
## Overview
The GLPN model was proposed in [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
GLPN combines [SegFormer](segformer)'s hierarchical mix-Transformer with a lightweight decoder for monocular depth estimation. The proposed decoder shows better performance than the previously proposed decoders, with considerably
less computational complexity.
The abstract from the paper is the following:
*Depth estimation from a single image is an important task that can be applied to various fields in computer vision, and has grown rapidly with the development of convolutional neural networks. In this paper, we propose a novel structure and training strategy for monocular depth estimation to further improve the prediction accuracy of the network. We deploy a hierarchical transformer encoder to capture and convey the global context, and design a lightweight yet powerful decoder to generate an estimated depth map while considering local connectivity. By constructing connected paths between multi-scale local features and the global decoding stream with our proposed selective feature fusion module, the network can integrate both representations and recover fine details. In addition, the proposed decoder shows better performance than the previously proposed decoders, with considerably less computational complexity. Furthermore, we improve the depth-specific augmentation method by utilizing an important observation in depth estimation to enhance the model. Our network achieves state-of-the-art performance over the challenging depth dataset NYU Depth V2. Extensive experiments have been conducted to validate and show the effectiveness of the proposed approach. Finally, our model shows better generalisation ability and robustness than other comparative models.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/glpn_architecture.jpg"
alt="drawing" width="600"/>
<small> Summary of the approach. Taken from the <a href="https://arxiv.org/abs/2201.07436" target="_blank">original paper</a>. </small>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/vinvino02/GLPDepth).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with GLPN.
- Demo notebooks for [`GLPNForDepthEstimation`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/GLPN).
- [Monocular depth estimation task guide](../tasks/monocular_depth_estimation)
## GLPNConfig
[[autodoc]] GLPNConfig
## GLPNFeatureExtractor
[[autodoc]] GLPNFeatureExtractor
- __call__
## GLPNImageProcessor
[[autodoc]] GLPNImageProcessor
- preprocess
## GLPNModel
[[autodoc]] GLPNModel
- forward
## GLPNForDepthEstimation
[[autodoc]] GLPNForDepthEstimation
- forward
|
huggingface/transformers/blob/main/docs/source/en/model_doc/glpn.md
|
--
title: "Spread Your Wings: Falcon 180B is here"
thumbnail: /blog/assets/162_falcon_180b/thumbnail.jpg
authors:
- user: philschmid
- user: osanseviero
- user: pcuenq
- user: lvwerra
- user: slippylolo
---
# Spread Your Wings: Falcon 180B is here
## Introduction
**Today, we're excited to welcome [TII's](https://falconllm.tii.ae/) Falcon 180B to HuggingFace!** Falcon 180B sets a new state-of-the-art for open models. It is the largest openly available language model, with 180 billion parameters, and was trained on a massive 3.5 trillion tokens using TII's [RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb) dataset. This represents the longest single-epoch pretraining for an open model.
You can find the model on the Hugging Face Hub ([base](https://huggingface.co/tiiuae/falcon-180B) and [chat](https://huggingface.co/tiiuae/falcon-180B-chat) model) and interact with the model on the [Falcon Chat Demo Space](https://huggingface.co/spaces/tiiuae/falcon-180b-chat).
In terms of capabilities, Falcon 180B achieves state-of-the-art results across natural language tasks. It tops the leaderboard for (pre-trained) open-access models and rivals proprietary models like PaLM-2. While difficult to rank definitively yet, it is considered on par with PaLM-2 Large, making Falcon 180B one of the most capable LLMs publicly known.
In this blog post, we explore what makes Falcon 180B so good by looking at some evaluation results and show how you can use the model.
* [What is Falcon-180B?](#what-is-falcon-180b)
* [How good is Falcon 180B?](#how-good-is-falcon-180b)
* [How to use Falcon 180B?](#how-to-use-falcon-180b)
* [Demo](#demo)
* [Hardware requirements](#hardware-requirements)
* [Prompt format](#prompt-format)
* [Transformers](#transformers)
* [Additional Resources](#additional-resources)
## What is Falcon-180B?
Falcon 180B is a model released by [TII](https://falconllm.tii.ae/) that follows previous releases in the Falcon family.
Architecture-wise, Falcon 180B is a scaled-up version of [Falcon 40B](https://huggingface.co/tiiuae/falcon-40b) and builds on its innovations such as multiquery attention for improved scalability. We recommend reviewing the [initial blog post](https://huggingface.co/blog/falcon) introducing Falcon to dive into the architecture. Falcon 180B was trained on 3.5 trillion tokens on up to 4096 GPUs simultaneously, using Amazon SageMaker for a total of ~7,000,000 GPU hours. This means Falcon 180B is 2.5 times larger than Llama 2 and was trained with 4x more compute.
The dataset for Falcon 180B consists predominantly of web data from [RefinedWeb](https://arxiv.org/abs/2306.01116) (\~85%). In addition, it has been trained on a mix of curated data such as conversations, technical papers, and a small fraction of code (\~3%). This pretraining dataset is big enough that even 3.5 trillion tokens constitute less than an epoch.
The released [chat model](https://huggingface.co/tiiuae/falcon-180B-chat) is fine-tuned on chat and instruction datasets with a mix of several large-scale conversational datasets.
‼️ Commercial use:
Falcon 180b can be commercially used but under very restrictive conditions, excluding any "hosting use". We recommend to check the [license](https://huggingface.co/spaces/tiiuae/falcon-180b-license/blob/main/LICENSE.txt) and consult your legal team if you are interested in using it for commercial purposes.
## How good is Falcon 180B?
Falcon 180B is the best openly released LLM today, outperforming Llama 2 70B and OpenAI’s GPT-3.5 on MMLU, and is on par with Google's PaLM 2-Large on HellaSwag, LAMBADA, WebQuestions, Winogrande, PIQA, ARC, BoolQ, CB, COPA, RTE, WiC, WSC, ReCoRD. Falcon 180B typically sits somewhere between GPT 3.5 and GPT4 depending on the evaluation benchmark and further finetuning from the community will be very interesting to follow now that it's openly released.
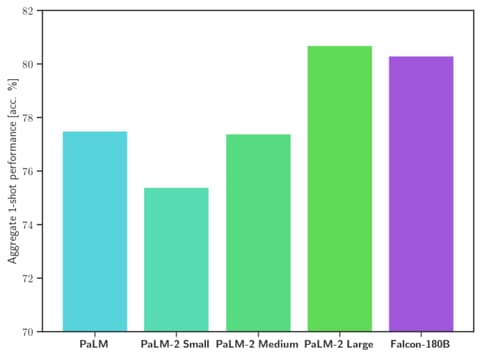
With 68.74 on the Hugging Face Leaderboard, Falcon 180B is the highest-scoring openly released pre-trained LLM, surpassing Meta’s LLaMA 2 (67.35).
| Model | Size | Leaderboard score | Commercial use or license | Pretraining length |
| ------- | ---- | ----------------- | ------------------------- | ------------------ |
| Falcon | 180B | 68.74 | 🟠 | 3,500B |
| Llama 2 | 70B | 67.35 | 🟠 | 2,000B |
| LLaMA | 65B | 64.23 | 🔴 | 1,400B |
| Falcon | 40B | 61.48 | 🟢 | 1,000B |
| MPT | 30B | 56.15 | 🟢 | 1,000B |
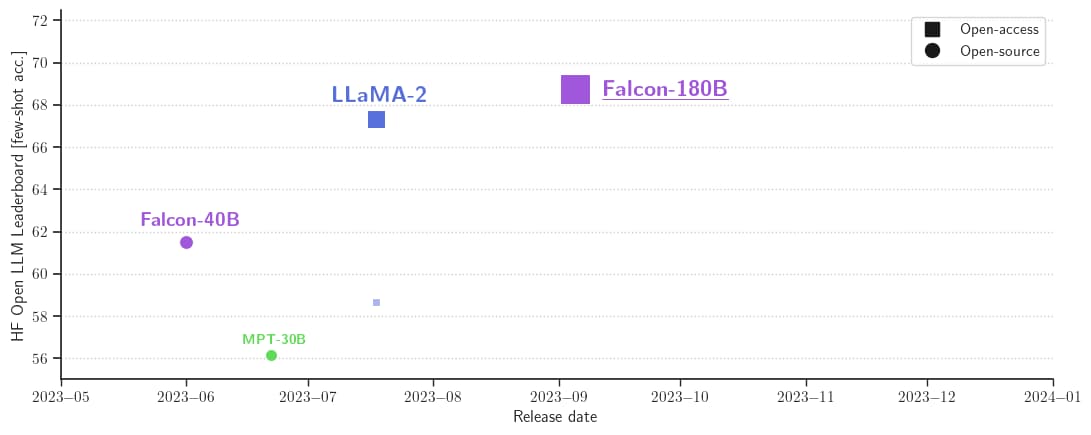
The quantized Falcon models preserve similar metrics across benchmarks. The results were similar when evaluating `torch.float16`, `8bit`, and `4bit`. See results in the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
## How to use Falcon 180B?
Falcon 180B is available in the Hugging Face ecosystem, starting with Transformers version 4.33.
### Demo
You can easily try the Big Falcon Model (180 billion parameters!) in [this Space](https://huggingface.co/spaces/tiiuae/falcon-180b-demo) or in the playground embedded below:
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.42.0/gradio.js"> </script>
<gradio-app theme_mode="light" space="tiiuae/falcon-180b-chat"></gradio-app>
### Hardware requirements
We ran several tests on the hardware needed to run the model for different use cases. Those are not the minimum numbers, but the minimum numbers for the configurations we had access to.
| | Type | Kind | Memory | Example |
| ----------- | --------- | ---------------- | ------------------- | --------------- |
| Falcon 180B | Training | Full fine-tuning | 5120GB | 8x 8x A100 80GB |
| Falcon 180B | Training | LoRA with ZeRO-3 | 1280GB | 2x 8x A100 80GB |
| Falcon 180B | Training | QLoRA | 160GB | 2x A100 80GB |
| Falcon 180B | Inference | BF16/FP16 | 640GB | 8x A100 80GB |
| Falcon 180B | Inference | GPTQ/int4 | 320GB | 8x A100 40GB |
### Prompt format
The base model has no prompt format. Remember that it’s not a conversational model or trained with instructions, so don’t expect it to generate conversational responses—the pretrained model is a great platform for further finetuning, but you probably shouldn’t driectly use it out of the box. The Chat model has a very simple conversation structure.
```bash
System: Add an optional system prompt here
User: This is the user input
Falcon: This is what the model generates
User: This might be a second turn input
Falcon: and so on
```
### Transformers
With the release of Transformers 4.33, you can use Falcon 180B and leverage all the tools in the HF ecosystem, such as:
- training and inference scripts and examples
- safe file format (safetensors)
- integrations with tools such as bitsandbytes (4-bit quantization), PEFT (parameter efficient fine-tuning) and GPTQ
- assisted generation (also known as “speculative decoding”)
- RoPE scaling support for larger context lengths
- rich and powerful generation parameters
Use of the model requires you to accept its license and terms of use. Please, make sure you are logged into your Hugging Face account and ensure you have the latest version of `transformers`:
```bash
pip install --upgrade transformers
huggingface-cli login
```
#### bfloat16
This is how you’d use the base model in `bfloat16`. Falcon 180B is a big model, so please take into account the hardware requirements summarized in the table above.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "tiiuae/falcon-180B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
prompt = "My name is Pedro, I live in"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
do_sample=True,
temperature=0.6,
top_p=0.9,
max_new_tokens=50,
)
output = output[0].to("cpu")
print(tokenizer.decode(output)
```
This could produce an output such as:
```
My name is Pedro, I live in Portugal and I am 25 years old. I am a graphic designer, but I am also passionate about photography and video.
I love to travel and I am always looking for new adventures. I love to meet new people and explore new places.
```
#### 8-bit and 4-bit with `bitsandbytes`
The 8-bit and 4-bit quantized versions of Falcon 180B show almost no difference in evaluation with respect to the `bfloat16` reference! This is very good news for inference, as you can confidently use a quantized version to reduce hardware requirements. Keep in mind, though, that 8-bit inference is *much faster* than running the model in `4-bit`.
To use quantization, you need to install the `bitsandbytes` library and simply enable the corresponding flag when loading the model:
```python
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
load_in_8bit=True,
device_map="auto",
)
```
#### Chat Model
As mentioned above, the version of the model fine-tuned to follow conversations used a very straightforward training template. We have to follow the same pattern in order to run chat-style inference. For reference, you can take a look at the [format_prompt](https://huggingface.co/spaces/tiiuae/falcon-180b-demo/blob/main/app.py#L28) function in the Chat demo, which looks like this:
```python
def format_prompt(message, history, system_prompt):
prompt = ""
if system_prompt:
prompt += f"System: {system_prompt}\n"
for user_prompt, bot_response in history:
prompt += f"User: {user_prompt}\n"
prompt += f"Falcon: {bot_response}\n"
prompt += f"User: {message}\nFalcon:"
return prompt
```
As you can see, interactions from the user and responses by the model are preceded by `User: ` and `Falcon: ` separators. We concatenate them together to form a prompt containing the conversation's whole history. We can provide a system prompt to tweak the generation style.
## Additional Resources
- [Models](https://huggingface.co/models?other=falcon&sort=trending&search=180)
- [Demo](https://huggingface.co/spaces/tiiuae/falcon-180b-chat)
- [The Falcon has landed in the Hugging Face ecosystem](https://huggingface.co/blog/falcon)
- [Official Announcement](https://falconllm.tii.ae/)
## Acknowledgments
Releasing such a model with support and evaluations in the ecosystem would not be possible without the contributions of many community members, including [Clémentine](https://huggingface.co/clefourrier) and [Eleuther Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) for LLM evaluations; [Loubna](https://huggingface.co/loubnabnl) and [BigCode](https://huggingface.co/bigcode) for code evaluations; [Nicolas](https://hf.co/narsil) for Inference support; [Lysandre](https://huggingface.co/lysandre), [Matt](https://huggingface.co/Rocketknight1), [Daniel](https://huggingface.co/DanielHesslow), [Amy](https://huggingface.co/amyeroberts), [Joao](https://huggingface.co/joaogante), and [Arthur](https://huggingface.co/ArthurZ) for integrating Falcon into transformers. Thanks to [Baptiste](https://huggingface.co/BapBap) and [Patrick](https://huggingface.co/patrickvonplaten) for the open-source demo. Thanks to [Thom](https://huggingface.co/thomwolf), [Lewis](https://huggingface.co/lewtun), [TheBloke](https://huggingface.co/thebloke), [Nouamane](https://huggingface.co/nouamanetazi), [Tim Dettmers](https://huggingface.co/timdettmers) for multiple contributions enabling this to get out. Finally, thanks to the HF Cluster for enabling running LLM evaluations as well as providing inference for a free, open-source demo of the model.
|
huggingface/blog/blob/main/falcon-180b.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ALIGN
## Overview
The ALIGN model was proposed in [Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://arxiv.org/abs/2102.05918) by Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig. ALIGN is a multi-modal vision and language model. It can be used for image-text similarity and for zero-shot image classification. ALIGN features a dual-encoder architecture with [EfficientNet](efficientnet) as its vision encoder and [BERT](bert) as its text encoder, and learns to align visual and text representations with contrastive learning. Unlike previous work, ALIGN leverages a massive noisy dataset and shows that the scale of the corpus can be used to achieve SOTA representations with a simple recipe.
The abstract from the paper is the following:
*Pre-trained representations are becoming crucial for many NLP and perception tasks. While representation learning in NLP has transitioned to training on raw text without human annotations, visual and vision-language representations still rely heavily on curated training datasets that are expensive or require expert knowledge. For vision applications, representations are mostly learned using datasets with explicit class labels such as ImageNet or OpenImages. For vision-language, popular datasets like Conceptual Captions, MSCOCO, or CLIP all involve a non-trivial data collection (and cleaning) process. This costly curation process limits the size of datasets and hence hinders the scaling of trained models. In this paper, we leverage a noisy dataset of over one billion image alt-text pairs, obtained without expensive filtering or post-processing steps in the Conceptual Captions dataset. A simple dual-encoder architecture learns to align visual and language representations of the image and text pairs using a contrastive loss. We show that the scale of our corpus can make up for its noise and leads to state-of-the-art representations even with such a simple learning scheme. Our visual representation achieves strong performance when transferred to classification tasks such as ImageNet and VTAB. The aligned visual and language representations enables zero-shot image classification and also set new state-of-the-art results on Flickr30K and MSCOCO image-text retrieval benchmarks, even when compared with more sophisticated cross-attention models. The representations also enable cross-modality search with complex text and text + image queries.*
This model was contributed by [Alara Dirik](https://huggingface.co/adirik).
The original code is not released, this implementation is based on the Kakao Brain implementation based on the original paper.
## Usage example
ALIGN uses EfficientNet to get visual features and BERT to get the text features. Both the text and visual features are then projected to a latent space with identical dimension. The dot product between the projected image and text features is then used as a similarity score.
[`AlignProcessor`] wraps [`EfficientNetImageProcessor`] and [`BertTokenizer`] into a single instance to both encode the text and preprocess the images. The following example shows how to get the image-text similarity scores using [`AlignProcessor`] and [`AlignModel`].
```python
import requests
import torch
from PIL import Image
from transformers import AlignProcessor, AlignModel
processor = AlignProcessor.from_pretrained("kakaobrain/align-base")
model = AlignModel.from_pretrained("kakaobrain/align-base")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
candidate_labels = ["an image of a cat", "an image of a dog"]
inputs = processor(text=candidate_labels, images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# this is the image-text similarity score
logits_per_image = outputs.logits_per_image
# we can take the softmax to get the label probabilities
probs = logits_per_image.softmax(dim=1)
print(probs)
```
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ALIGN.
- A blog post on [ALIGN and the COYO-700M dataset](https://huggingface.co/blog/vit-align).
- A zero-shot image classification [demo](https://huggingface.co/spaces/adirik/ALIGN-zero-shot-image-classification).
- [Model card](https://huggingface.co/kakaobrain/align-base) of `kakaobrain/align-base` model.
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it. The resource should ideally demonstrate something new instead of duplicating an existing resource.
## AlignConfig
[[autodoc]] AlignConfig
- from_text_vision_configs
## AlignTextConfig
[[autodoc]] AlignTextConfig
## AlignVisionConfig
[[autodoc]] AlignVisionConfig
## AlignProcessor
[[autodoc]] AlignProcessor
## AlignModel
[[autodoc]] AlignModel
- forward
- get_text_features
- get_image_features
## AlignTextModel
[[autodoc]] AlignTextModel
- forward
## AlignVisionModel
[[autodoc]] AlignVisionModel
- forward
|
huggingface/transformers/blob/main/docs/source/en/model_doc/align.md
|
--
title: Swift 🧨Diffusers - Fast Stable Diffusion for Mac
thumbnail: /blog/assets/fast-mac-diffusers/thumbnail.png
authors:
- user: pcuenq
- user: reach-vb
---
# Swift 🧨Diffusers: Fast Stable Diffusion for Mac
Transform your text into stunning images with ease using Diffusers for Mac, a native app powered by state-of-the-art diffusion models. It leverages a bouquet of SoTA Text-to-Image models contributed by the community to the Hugging Face Hub, and converted to Core ML for blazingly fast performance. Our latest version, 1.1, is now available on the [Mac App Store](https://apps.apple.com/app/diffusers/id1666309574) with significant performance upgrades and user-friendly interface tweaks. It's a solid foundation for future feature updates. Plus, the app is fully open source with a permissive [license](https://github.com/huggingface/swift-coreml-diffusers/blob/main/LICENSE), so you can build on it too! Check out our GitHub repository at https://github.com/huggingface/swift-coreml-diffusers for more information.
<img style="border:none;" alt="Screenshot showing Diffusers for Mac UI" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/fast-mac-diffusers/UI.png" />
## What exactly is 🧨Diffusers for Mac anyway?
The Diffusers app ([App Store](https://apps.apple.com/app/diffusers/id1666309574), [source code](https://github.com/huggingface/swift-coreml-diffusers)) is the Mac counterpart to our [🧨`diffusers` library](https://github.com/huggingface/diffusers). This library is written in Python with PyTorch, and uses a modular design to train and run diffusion models. It supports many different models and tasks, and is highly configurable and well optimized. It runs on Mac, too, using PyTorch's [`mps` accelerator](https://huggingface.co/docs/diffusers/optimization/mps), which is an alternative to `cuda` on Apple Silicon.
Why would you want to run a native Mac app then? There are many reasons:
- It uses Core ML models, instead of the original PyTorch ones. This is important because they allow for [additional optimizations](https://machinelearning.apple.com/research/stable-diffusion-coreml-apple-silicon) relevant to the specifics of Apple hardware, and because Core ML models can run on all the compute devices in your system: the CPU, the GPU and the Neural Engine, _at once_ – the Core ML framework will decide what portions of your model to run on each device to make it as fast as possible. PyTorch's `mps` device cannot use the Neural Engine.
- It's a Mac app! We try to follow Apple's design language and guidelines so it feels at home on your Mac. No need to use the command line, create virtual environments or fix dependencies.
- It's local and private. You don't need credits for online services and won't experience long queues – just generate all the images you want and use them for fun or work. Privacy is guaranteed: your prompts and images are yours to use, and will never leave your computer (unless you choose to share them).
- [It's open source](https://github.com/huggingface/swift-coreml-diffusers), and it uses Swift, Swift UI and the latest languages and technologies for Mac and iOS development. If you are technically inclined, you can use Xcode to extend the code as you like. We welcome your contributions, too!
## Performance Benchmarks
**TL;DR:** Depending on your computer Text-to-Image Generation can be up to **twice as fast** on Diffusers 1.1. ⚡️
We've done a lot of testing on several Macs to determine the best combinations of compute devices that yield optimum performance. For some computers it's best to use the GPU, while others work better when the Neural Engine, or ANE, is engaged.
Come check out our benchmarks. All the combinations use the CPU in addition to either the GPU or the ANE.
| Model name | Benchmark | M1 8 GB | M1 16 GB | M2 24 GB | M1 Max 64 GB |
|:---------------------------------:|-----------|:-------:|:---------:|:--------:|:------------:|
| Cores (performance/GPU/ANE) | | 4/8/16 | 4/8/16 | 4/8/16 | 8/32/16 |
| Stable Diffusion 1.5 | | | | | |
| | GPU | 32.9 | 32.8 | 21.9 | 9 |
| | ANE | 18.8 | 18.7 | 13.1 | 20.4 |
| Stable Diffusion 2 Base | | | | | |
| | GPU | 30.2 | 30.2 | 19.4 | 8.3 |
| | ANE | 14.5 | 14.4 | 10.5 | 15.3 |
| Stable Diffusion 2.1 Base | | | | | |
| | GPU | 29.6 | 29.4 | 19.5 | 8.3 |
| | ANE | 14.3 | 14.3 | 10.5 | 15.3 |
| OFA-Sys/small-stable-diffusion-v0 | | | | | |
| | GPU | 22.1 | 22.5 | 14.5 | 6.3 |
| | ANE | 12.3 | 12.7 | 9.1 | 13.2 |
We found that the amount of memory does not seem to play a big factor on performance, but the number of CPU and GPU cores does. For example, on a M1 Max laptop, the generation with GPU is a lot faster than with ANE. That's likely because it has 4 times the number of GPU cores (and twice as many CPU performance cores) than the standard M1 processor, for the same amount of neural engine cores. Conversely, the standard M1 processors found in Mac Minis are **twice as fast** using ANE than GPU. Interestingly, we tested the use of _both_ GPU and ANE accelerators together, and found that it does not improve performance with respect to the best results obtained with just one of them. The cut point seems to be around the hardware characteristics of the M1 Pro chip (8 performance cores, 14 or 16 GPU cores), which we don't have access to at the moment.
🧨Diffusers version 1.1 automatically selects the best accelerator based on the computer where the app runs. Some device configurations, like the "Pro" variants, are not offered by any cloud services we know of, so our heuristics could be improved for them. If you'd like to help us gather data to keep improving the out-of-the-box experience of our app, read on!
## Community Call for Benchmark Data
We are interested in running more comprehensive performance benchmarks on Mac devices. If you'd like to help, we've created [this GitHub issue](https://github.com/huggingface/swift-coreml-diffusers/issues/31) where you can post your results. We'll use them to optimize performance on an upcoming version of the app. We are particularly interested in M1 Pro, M2 Pro and M2 Max architectures 🤗
<img style="border:none;display:block;margin-left:auto;margin-right:auto;" alt="Screenshot showing the Advanced Compute Units picker" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/fast-mac-diffusers/Advanced.png" />
## Other Improvements in Version 1.1
In addition to the performance optimization and fixing a few bugs, we have focused on adding new features while trying to keep the UI as simple and clean as possible. Most of them are obvious (guidance scale, optionally disable the safety checker, allow generations to be canceled). Our favorite ones are the model download indicators, and a shortcut to reuse the seed from a previous generation in order to tweak the generation parameters.
Version 1.1 also includes additional information about what the different generation settings do. We want 🧨Diffusers for Mac to make image generation as approachable as possible to all Mac users, not just technologists.
## Next Steps
We believe there's a lot of untapped potential for image generation in the Apple ecosystem. In future updates we want to focus on the following:
- Easy access to additional models from the Hub. Run any Dreambooth or fine-tuned model from the app, in a Mac-like way.
- Release a version for iOS and iPadOS.
There are many more ideas that we are considering. If you'd like to suggest your own, you are most welcome to do so [in our GitHub repo](https://github.com/huggingface/swift-coreml-diffusers).
|
huggingface/blog/blob/main/fast-mac-diffusers.md
|
# Ensemble Adversarial Inception ResNet v2
**Inception-ResNet-v2** is a convolutional neural architecture that builds on the Inception family of architectures but incorporates [residual connections](https://paperswithcode.com/method/residual-connection) (replacing the filter concatenation stage of the Inception architecture).
This particular model was trained for study of adversarial examples (adversarial training).
The weights from this model were ported from [Tensorflow/Models](https://github.com/tensorflow/models).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('ens_adv_inception_resnet_v2', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `ens_adv_inception_resnet_v2`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('ens_adv_inception_resnet_v2', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/abs-1804-00097,
author = {Alexey Kurakin and
Ian J. Goodfellow and
Samy Bengio and
Yinpeng Dong and
Fangzhou Liao and
Ming Liang and
Tianyu Pang and
Jun Zhu and
Xiaolin Hu and
Cihang Xie and
Jianyu Wang and
Zhishuai Zhang and
Zhou Ren and
Alan L. Yuille and
Sangxia Huang and
Yao Zhao and
Yuzhe Zhao and
Zhonglin Han and
Junjiajia Long and
Yerkebulan Berdibekov and
Takuya Akiba and
Seiya Tokui and
Motoki Abe},
title = {Adversarial Attacks and Defences Competition},
journal = {CoRR},
volume = {abs/1804.00097},
year = {2018},
url = {http://arxiv.org/abs/1804.00097},
archivePrefix = {arXiv},
eprint = {1804.00097},
timestamp = {Thu, 31 Oct 2019 16:31:22 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1804-00097.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<!--
Type: model-index
Collections:
- Name: Ensemble Adversarial
Paper:
Title: Adversarial Attacks and Defences Competition
URL: https://paperswithcode.com/paper/adversarial-attacks-and-defences-competition
Models:
- Name: ens_adv_inception_resnet_v2
In Collection: Ensemble Adversarial
Metadata:
FLOPs: 16959133120
Parameters: 55850000
File Size: 223774238
Architecture:
- 1x1 Convolution
- Auxiliary Classifier
- Average Pooling
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inception-v3 Module
- Max Pooling
- ReLU
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: ens_adv_inception_resnet_v2
Crop Pct: '0.897'
Image Size: '299'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/inception_resnet_v2.py#L351
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/ens_adv_inception_resnet_v2-2592a550.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 1.0%
Top 5 Accuracy: 17.32%
-->
|
huggingface/pytorch-image-models/blob/main/hfdocs/source/models/ensemble-adversarial.mdx
|
Build a Custom Multimodal Chatbot - Part 1
This is the first in a two part series where we build a custom Multimodal Chatbot component.
In part 1, we will modify the Gradio Chatbot component to display text and media files (video, audio, image) in the same message.
In part 2, we will build a custom Textbox component that will be able to send multimodal messages (text and media files) to the chatbot.
You can follow along with the author of this post as he implements the chatbot component in the following YouTube video!
<iframe width="560" height="315" src="https://www.youtube.com/embed/IVJkOHTBPn0?si=bs-sBv43X-RVA8ly" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe>
Here's a preview of what our multimodal chatbot component will look like:
## Part 1 - Creating our project
For this demo we will be tweaking the existing Gradio `Chatbot` component to display text and media files in the same message.
Let's create a new custom component directory by templating off of the `Chatbot` component source code.
```bash
gradio cc create MultimodalChatbot --template Chatbot
```
And we're ready to go!
Tip: Make sure to modify the `Author` key in the `pyproject.toml` file.
## Part 2a - The backend data_model
Open up the `multimodalchatbot.py` file in your favorite code editor and let's get started modifying the backend of our component.
The first thing we will do is create the `data_model` of our component.
The `data_model` is the data format that your python component will receive and send to the javascript client running the UI.
You can read more about the `data_model` in the [backend guide](./backend).
For our component, each chatbot message will consist of two keys: a `text` key that displays the text message and an optional list of media files that can be displayed underneath the text.
Import the `FileData` and `GradioModel` classes from `gradio.data_classes` and modify the existing `ChatbotData` class to look like the following:
```python
class FileMessage(GradioModel):
file: FileData
alt_text: Optional[str] = None
class MultimodalMessage(GradioModel):
text: Optional[str] = None
files: Optional[List[FileMessage]] = None
class ChatbotData(GradioRootModel):
root: List[Tuple[Optional[MultimodalMessage], Optional[MultimodalMessage]]]
class MultimodalChatbot(Component):
...
data_model = ChatbotData
```
Tip: The `data_model`s are implemented using `Pydantic V2`. Read the documentation [here](https://docs.pydantic.dev/latest/).
We've done the hardest part already!
## Part 2b - The pre and postprocess methods
For the `preprocess` method, we will keep it simple and pass a list of `MultimodalMessage`s to the python functions that use this component as input.
This will let users of our component access the chatbot data with `.text` and `.files` attributes.
This is a design choice that you can modify in your implementation!
We can return the list of messages with the `root` property of the `ChatbotData` like so:
```python
def preprocess(
self,
payload: ChatbotData | None,
) -> List[MultimodalMessage] | None:
if payload is None:
return payload
return payload.root
```
Tip: Learn about the reasoning behind the `preprocess` and `postprocess` methods in the [key concepts guide](./key-component-concepts)
In the `postprocess` method we will coerce each message returned by the python function to be a `MultimodalMessage` class.
We will also clean up any indentation in the `text` field so that it can be properly displayed as markdown in the frontend.
We can leave the `postprocess` method as is and modify the `_postprocess_chat_messages`
```python
def _postprocess_chat_messages(
self, chat_message: MultimodalMessage | dict | None
) -> MultimodalMessage | None:
if chat_message is None:
return None
if isinstance(chat_message, dict):
chat_message = MultimodalMessage(**chat_message)
chat_message.text = inspect.cleandoc(chat_message.text or "")
for file_ in chat_message.files:
file_.file.mime_type = client_utils.get_mimetype(file_.file.path)
return chat_message
```
Before we wrap up with the backend code, let's modify the `example_inputs` method to return a valid dictionary representation of the `ChatbotData`:
```python
def example_inputs(self) -> Any:
return [[{"text": "Hello!", "files": []}, None]]
```
Congrats - the backend is complete!
## Part 3a - The Index.svelte file
The frontend for the `Chatbot` component is divided into two parts - the `Index.svelte` file and the `shared/Chatbot.svelte` file.
The `Index.svelte` file applies some processing to the data received from the server and then delegates the rendering of the conversation to the `shared/Chatbot.svelte` file.
First we will modify the `Index.svelte` file to apply processing to the new data type the backend will return.
Let's begin by porting our custom types from our python `data_model` to typescript.
Open `frontend/shared/utils.ts` and add the following type definitions at the top of the file:
```ts
export type FileMessage = {
file: FileData;
alt_text?: string;
};
export type MultimodalMessage = {
text: string;
files?: FileMessage[];
}
```
Now let's import them in `Index.svelte` and modify the type annotations for `value` and `_value`.
```ts
import type { FileMessage, MultimodalMessage } from "./shared/utils";
export let value: [
MultimodalMessage | null,
MultimodalMessage | null
][] = [];
let _value: [
MultimodalMessage | null,
MultimodalMessage | null
][];
```
We need to normalize each message to make sure each file has a proper URL to fetch its contents from.
We also need to format any embedded file links in the `text` key.
Let's add a `process_message` utility function and apply it whenever the `value` changes.
```ts
function process_message(msg: MultimodalMessage | null): MultimodalMessage | null {
if (msg === null) {
return msg;
}
msg.text = redirect_src_url(msg.text);
msg.files = msg.files.map(normalize_messages);
return msg;
}
$: _value = value
? value.map(([user_msg, bot_msg]) => [
process_message(user_msg),
process_message(bot_msg)
])
: [];
```
## Part 3b - the Chatbot.svelte file
Let's begin similarly to the `Index.svelte` file and let's first modify the type annotations.
Import `Mulimodal` message at the top of the `<script>` section and use it to type the `value` and `old_value` variables.
```ts
import type { MultimodalMessage } from "./utils";
export let value:
| [
MultimodalMessage | null,
MultimodalMessage | null
][]
| null;
let old_value:
| [
MultimodalMessage | null,
MultimodalMessage | null
][]
| null = null;
```
We also need to modify the `handle_select` and `handle_like` functions:
```ts
function handle_select(
i: number,
j: number,
message: MultimodalMessage | null
): void {
dispatch("select", {
index: [i, j],
value: message
});
}
function handle_like(
i: number,
j: number,
message: MultimodalMessage | null,
liked: boolean
): void {
dispatch("like", {
index: [i, j],
value: message,
liked: liked
});
}
```
Now for the fun part, actually rendering the text and files in the same message!
You should see some code like the following that determines whether a file or a markdown message should be displayed depending on the type of the message:
```ts
{#if typeof message === "string"}
<Markdown
{message}
{latex_delimiters}
{sanitize_html}
{render_markdown}
{line_breaks}
on:load={scroll}
/>
{:else if message !== null && message.file?.mime_type?.includes("audio")}
<audio
data-testid="chatbot-audio"
controls
preload="metadata"
...
```
We will modify this code to always display the text message and then loop through the files and display all of them that are present:
```ts
<Markdown
message={message.text}
{latex_delimiters}
{sanitize_html}
{render_markdown}
{line_breaks}
on:load={scroll}
/>
{#each message.files as file, k}
{#if file !== null && file.file.mime_type?.includes("audio")}
<audio
data-testid="chatbot-audio"
controls
preload="metadata"
src={file.file?.url}
title={file.alt_text}
on:play
on:pause
on:ended
/>
{:else if message !== null && file.file?.mime_type?.includes("video")}
<video
data-testid="chatbot-video"
controls
src={file.file?.url}
title={file.alt_text}
preload="auto"
on:play
on:pause
on:ended
>
<track kind="captions" />
</video>
{:else if message !== null && file.file?.mime_type?.includes("image")}
<img
data-testid="chatbot-image"
src={file.file?.url}
alt={file.alt_text}
/>
{:else if message !== null && file.file?.url !== null}
<a
data-testid="chatbot-file"
href={file.file?.url}
target="_blank"
download={window.__is_colab__
? null
: file.file?.orig_name || file.file?.path}
>
{file.file?.orig_name || file.file?.path}
</a>
{:else if pending_message && j === 1}
<Pending {layout} />
{/if}
{/each}
```
We did it! 🎉
## Part 4 - The demo
For this tutorial, let's keep the demo simple and just display a static conversation between a hypothetical user and a bot.
This demo will show how both the user and the bot can send files.
In part 2 of this tutorial series we will build a fully functional chatbot demo!
The demo code will look like the following:
```python
import gradio as gr
from gradio_multimodalchatbot import MultimodalChatbot
from gradio.data_classes import FileData
user_msg1 = {"text": "Hello, what is in this image?",
"files": [{"file": FileData(path="https://gradio-builds.s3.amazonaws.com/diffusion_image/cute_dog.jpg")}]
}
bot_msg1 = {"text": "It is a very cute dog",
"files": []}
user_msg2 = {"text": "Describe this audio clip please.",
"files": [{"file": FileData(path="cantina.wav")}]}
bot_msg2 = {"text": "It is the cantina song from Star Wars",
"files": []}
user_msg3 = {"text": "Give me a video clip please.",
"files": []}
bot_msg3 = {"text": "Here is a video clip of the world",
"files": [{"file": FileData(path="world.mp4")},
{"file": FileData(path="cantina.wav")}]}
conversation = [[user_msg1, bot_msg1], [user_msg2, bot_msg2], [user_msg3, bot_msg3]]
with gr.Blocks() as demo:
MultimodalChatbot(value=conversation, height=800)
demo.launch()
```
Tip: Change the filepaths so that they correspond to files on your machine. Also, if you are running in development mode, make sure the files are located in the top level of your custom component directory.
## Part 5 - Deploying and Conclusion
Let's build and deploy our demo with `gradio cc build` and `gradio cc deploy`!
You can check out our component deployed to [HuggingFace Spaces](https://huggingface.co/spaces/freddyaboulton/gradio_multimodalchatbot) and all of the source code is available [here](https://huggingface.co/spaces/freddyaboulton/gradio_multimodalchatbot/tree/main/src).
See you in the next installment of this series!
|
gradio-app/gradio/blob/main/guides/05_custom-components/08_multimodal-chatbot-part1.md
|
n a lot of our examples, you're going to see DataCollators popping up over and over. They're used in both PyTorch and TensorFlow workflows, and maybe even in JAX, but no-one really knows what's happening in JAX. We have a research team working on that, so maybe they'll tell us soon. But what are data collators? Data collators collate data. More specifically, they put together a list of samples into a single training minibatch. For some tasks, the data collator can be very straightforward. For example, when you're doing sequence classification, all you really need from your data collator is that it pads your samples to the same length and concatenates them into a single Tensor. But for other workflows, data collators can be more complex, as they handle some of the preprocessing needed for that particular task. For PyTorch users, you usually pass the DataCollator to your Trainer object. In TensorFlow, the easiest way to use a DataCollator is to pass it to the to_tf_dataset method of your dataset. You'll see these approaches used in the examples and notebooks throughout this course. In both cases, you end up with an iterable that's going to output collated batches, ready for training. Note that all of our collators take a return_tensors argument - you can set this to "pt" to get PyTorch Tensors, "tf" to get TensorFlow Tensors, or "np" to get Numpy arrays. For backward compatibility reasons, the default value is "pt", so PyTorch users don't even have to set this argument most of the time, and so are often totally unaware that this option exists. This is a valuable lesson about how the beneficiaries of privilege are often the most blind to its existence. So now let's see some specific DataCollators in action, though remember that if none of them do what you need, you can always write your own! First, we'll see the "basic" data collators. These are DefaultDataCollator and DataCollatorWithPadding. These are the ones you should use if your labels are straightforward and your data doesn't need any special processing before being ready for training. Most sequence classification tasks, for example, would use one of these data collators. Remember that because different models have different padding tokens, DataCollatorWithPadding will need your model's Tokenizer so it knows how to pad sequences properly! So how do you choose one of these? Simple: As you can see here, if you have variable sequence lengths then you should use DataCollatorWithPadding, which will pad all your sequences to the same length. If you're sure all your sequences are the same length then you can use the even simpler DefaultDataCollator, but it'll give you an error if that assumption is wrong! Moving on, though, many of the other data collators are often designed to handle one specific task, and that's the case with DataCollatorForTokenClassification and DataCollatorForSeqToSeq. These tasks need special collators because the labels are variable in length. In token classification there's one label for each token, and that means the length of the labels can be variable, while in SeqToSeq the labels are also a sequence of tokens that can have variable length. In both of these cases, we handle that by padding the labels too, as you can see here. Inputs and the labels will need to be padded if we want to join samples of variable length into the same minibatch, and that's exactly what the data collators will do. The final data collator I want to show you is the DataCollatorForLanguageModeling. It's very important, firstly because language models are so foundational to everything we do in NLP, and secondly because it has two modes that do two very different things. You choose which mode you want with the mlm argument - set it to True for masked language modeling, and False for causal language modeling. Collating data for causal language modeling is actually quite straightforward - the model is just making predictions for what token comes next, so your labels are more or less just a copy of your inputs, and the collator handles that and ensures your inputs and labels are padded correctly. When you set mlm to True, though, you get quite different behaviour! That's because masked language modeling requires the labels to be, well... masked. So what does that look like? Recall that in masked language modeling, the model is not predicting "the next word"; instead we randomly mask out multiple tokens and the model makes predictions for all of them at once. The process of random masking is surprisingly complex, though - that's because if we follow the protocol from the original BERT paper, we need to replace some tokens with a masking token, other tokens with a random token and then keep a third set of tokens unchanged. This isn't the lecture to go into *why* we do that - you should check out the original BERT paper if you're curious. The main thing to know here is that it can be a real pain to implement yourself, but DataCollatorForLanguageModeling will do it for you. And that's it! That covers the most commonly used data collators and the tasks they're used for.
|
huggingface/course/blob/main/subtitles/en/raw/chapter7/08_data-collators.md
|
Creating a Real-Time Dashboard from BigQuery Data
Tags: TABULAR, DASHBOARD, PLOTS
[Google BigQuery](https://cloud.google.com/bigquery) is a cloud-based service for processing very large data sets. It is a serverless and highly scalable data warehousing solution that enables users to analyze data [using SQL-like queries](https://www.oreilly.com/library/view/google-bigquery-the/9781492044451/ch01.html).
In this tutorial, we will show you how to query a BigQuery dataset in Python and display the data in a dashboard that updates in real time using `gradio`. The dashboard will look like this:
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/gradio-guides/bigquery-dashboard.gif">
We'll cover the following steps in this Guide:
1. Setting up your BigQuery credentials
2. Using the BigQuery client
3. Building the real-time dashboard (in just _7 lines of Python_)
We'll be working with the [New York Times' COVID dataset](https://www.nytimes.com/interactive/2021/us/covid-cases.html) that is available as a public dataset on BigQuery. The dataset, named `covid19_nyt.us_counties` contains the latest information about the number of confirmed cases and deaths from COVID across US counties.
**Prerequisites**: This Guide uses [Gradio Blocks](/guides/quickstart/#blocks-more-flexibility-and-control), so make your are familiar with the Blocks class.
## Setting up your BigQuery Credentials
To use Gradio with BigQuery, you will need to obtain your BigQuery credentials and use them with the [BigQuery Python client](https://pypi.org/project/google-cloud-bigquery/). If you already have BigQuery credentials (as a `.json` file), you can skip this section. If not, you can do this for free in just a couple of minutes.
1. First, log in to your Google Cloud account and go to the Google Cloud Console (https://console.cloud.google.com/)
2. In the Cloud Console, click on the hamburger menu in the top-left corner and select "APIs & Services" from the menu. If you do not have an existing project, you will need to create one.
3. Then, click the "+ Enabled APIs & services" button, which allows you to enable specific services for your project. Search for "BigQuery API", click on it, and click the "Enable" button. If you see the "Manage" button, then the BigQuery is already enabled, and you're all set.
4. In the APIs & Services menu, click on the "Credentials" tab and then click on the "Create credentials" button.
5. In the "Create credentials" dialog, select "Service account key" as the type of credentials to create, and give it a name. Also grant the service account permissions by giving it a role such as "BigQuery User", which will allow you to run queries.
6. After selecting the service account, select the "JSON" key type and then click on the "Create" button. This will download the JSON key file containing your credentials to your computer. It will look something like this:
```json
{
"type": "service_account",
"project_id": "your project",
"private_key_id": "your private key id",
"private_key": "private key",
"client_email": "email",
"client_id": "client id",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://accounts.google.com/o/oauth2/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/email_id"
}
```
## Using the BigQuery Client
Once you have the credentials, you will need to use the BigQuery Python client to authenticate using your credentials. To do this, you will need to install the BigQuery Python client by running the following command in the terminal:
```bash
pip install google-cloud-bigquery[pandas]
```
You'll notice that we've installed the pandas add-on, which will be helpful for processing the BigQuery dataset as a pandas dataframe. Once the client is installed, you can authenticate using your credentials by running the following code:
```py
from google.cloud import bigquery
client = bigquery.Client.from_service_account_json("path/to/key.json")
```
With your credentials authenticated, you can now use the BigQuery Python client to interact with your BigQuery datasets.
Here is an example of a function which queries the `covid19_nyt.us_counties` dataset in BigQuery to show the top 20 counties with the most confirmed cases as of the current day:
```py
import numpy as np
QUERY = (
'SELECT * FROM `bigquery-public-data.covid19_nyt.us_counties` '
'ORDER BY date DESC,confirmed_cases DESC '
'LIMIT 20')
def run_query():
query_job = client.query(QUERY)
query_result = query_job.result()
df = query_result.to_dataframe()
# Select a subset of columns
df = df[["confirmed_cases", "deaths", "county", "state_name"]]
# Convert numeric columns to standard numpy types
df = df.astype({"deaths": np.int64, "confirmed_cases": np.int64})
return df
```
## Building the Real-Time Dashboard
Once you have a function to query the data, you can use the `gr.DataFrame` component from the Gradio library to display the results in a tabular format. This is a useful way to inspect the data and make sure that it has been queried correctly.
Here is an example of how to use the `gr.DataFrame` component to display the results. By passing in the `run_query` function to `gr.DataFrame`, we instruct Gradio to run the function as soon as the page loads and show the results. In addition, you also pass in the keyword `every` to tell the dashboard to refresh every hour (60\*60 seconds).
```py
import gradio as gr
with gr.Blocks() as demo:
gr.DataFrame(run_query, every=60*60)
demo.queue().launch() # Run the demo using queuing
```
Perhaps you'd like to add a visualization to our dashboard. You can use the `gr.ScatterPlot()` component to visualize the data in a scatter plot. This allows you to see the relationship between different variables such as case count and case deaths in the dataset and can be useful for exploring the data and gaining insights. Again, we can do this in real-time
by passing in the `every` parameter.
Here is a complete example showing how to use the `gr.ScatterPlot` to visualize in addition to displaying data with the `gr.DataFrame`
```py
import gradio as gr
with gr.Blocks() as demo:
gr.Markdown("# 💉 Covid Dashboard (Updated Hourly)")
with gr.Row():
gr.DataFrame(run_query, every=60*60)
gr.ScatterPlot(run_query, every=60*60, x="confirmed_cases",
y="deaths", tooltip="county", width=500, height=500)
demo.queue().launch() # Run the demo with queuing enabled
```
|
gradio-app/gradio/blob/main/guides/07_tabular-data-science-and-plots/creating-a-dashboard-from-bigquery-data.md
|
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Philosophy
🤗 Transformers is an opinionated library built for:
- machine learning researchers and educators seeking to use, study or extend large-scale Transformers models.
- hands-on practitioners who want to fine-tune those models or serve them in production, or both.
- engineers who just want to download a pretrained model and use it to solve a given machine learning task.
The library was designed with two strong goals in mind:
1. Be as easy and fast to use as possible:
- We strongly limited the number of user-facing abstractions to learn, in fact, there are almost no abstractions,
just three standard classes required to use each model: [configuration](main_classes/configuration),
[models](main_classes/model), and a preprocessing class ([tokenizer](main_classes/tokenizer) for NLP, [image processor](main_classes/image_processor) for vision, [feature extractor](main_classes/feature_extractor) for audio, and [processor](main_classes/processors) for multimodal inputs).
- All of these classes can be initialized in a simple and unified way from pretrained instances by using a common
`from_pretrained()` method which downloads (if needed), caches and
loads the related class instance and associated data (configurations' hyperparameters, tokenizers' vocabulary,
and models' weights) from a pretrained checkpoint provided on [Hugging Face Hub](https://huggingface.co/models) or your own saved checkpoint.
- On top of those three base classes, the library provides two APIs: [`pipeline`] for quickly
using a model for inference on a given task and [`Trainer`] to quickly train or fine-tune a PyTorch model (all TensorFlow models are compatible with `Keras.fit`).
- As a consequence, this library is NOT a modular toolbox of building blocks for neural nets. If you want to
extend or build upon the library, just use regular Python, PyTorch, TensorFlow, Keras modules and inherit from the base
classes of the library to reuse functionalities like model loading and saving. If you'd like to learn more about our coding philosophy for models, check out our [Repeat Yourself](https://huggingface.co/blog/transformers-design-philosophy) blog post.
2. Provide state-of-the-art models with performances as close as possible to the original models:
- We provide at least one example for each architecture which reproduces a result provided by the official authors
of said architecture.
- The code is usually as close to the original code base as possible which means some PyTorch code may be not as
*pytorchic* as it could be as a result of being converted TensorFlow code and vice versa.
A few other goals:
- Expose the models' internals as consistently as possible:
- We give access, using a single API, to the full hidden-states and attention weights.
- The preprocessing classes and base model APIs are standardized to easily switch between models.
- Incorporate a subjective selection of promising tools for fine-tuning and investigating these models:
- A simple and consistent way to add new tokens to the vocabulary and embeddings for fine-tuning.
- Simple ways to mask and prune Transformer heads.
- Easily switch between PyTorch, TensorFlow 2.0 and Flax, allowing training with one framework and inference with another.
## Main concepts
The library is built around three types of classes for each model:
- **Model classes** can be PyTorch models ([torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)), Keras models ([tf.keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model)) or JAX/Flax models ([flax.linen.Module](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html)) that work with the pretrained weights provided in the library.
- **Configuration classes** store the hyperparameters required to build a model (such as the number of layers and hidden size). You don't always need to instantiate these yourself. In particular, if you are using a pretrained model without any modification, creating the model will automatically take care of instantiating the configuration (which is part of the model).
- **Preprocessing classes** convert the raw data into a format accepted by the model. A [tokenizer](main_classes/tokenizer) stores the vocabulary for each model and provide methods for encoding and decoding strings in a list of token embedding indices to be fed to a model. [Image processors](main_classes/image_processor) preprocess vision inputs, [feature extractors](main_classes/feature_extractor) preprocess audio inputs, and a [processor](main_classes/processors) handles multimodal inputs.
All these classes can be instantiated from pretrained instances, saved locally, and shared on the Hub with three methods:
- `from_pretrained()` lets you instantiate a model, configuration, and preprocessing class from a pretrained version either
provided by the library itself (the supported models can be found on the [Model Hub](https://huggingface.co/models)) or
stored locally (or on a server) by the user.
- `save_pretrained()` lets you save a model, configuration, and preprocessing class locally so that it can be reloaded using
`from_pretrained()`.
- `push_to_hub()` lets you share a model, configuration, and a preprocessing class to the Hub, so it is easily accessible to everyone.
|
huggingface/transformers/blob/main/docs/source/en/philosophy.md
|
Load text data
This guide shows you how to load text datasets. To learn how to load any type of dataset, take a look at the <a class="underline decoration-sky-400 decoration-2 font-semibold" href="./loading">general loading guide</a>.
Text files are one of the most common file types for storing a dataset. By default, 🤗 Datasets samples a text file line by line to build the dataset.
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("text", data_files={"train": ["my_text_1.txt", "my_text_2.txt"], "test": "my_test_file.txt"})
# Load from a directory
>>> dataset = load_dataset("text", data_dir="path/to/text/dataset")
```
To sample a text file by paragraph or even an entire document, use the `sample_by` parameter:
```py
# Sample by paragraph
>>> dataset = load_dataset("text", data_files={"train": "my_train_file.txt", "test": "my_test_file.txt"}, sample_by="paragraph")
# Sample by document
>>> dataset = load_dataset("text", data_files={"train": "my_train_file.txt", "test": "my_test_file.txt"}, sample_by="document")
```
You can also use grep patterns to load specific files:
```py
>>> from datasets import load_dataset
>>> c4_subset = load_dataset("allenai/c4", data_files="en/c4-train.0000*-of-01024.json.gz")
```
To load remote text files via HTTP, pass the URLs instead:
```py
>>> dataset = load_dataset("text", data_files="https://huggingface.co/datasets/lhoestq/test/resolve/main/some_text.txt")
```
|
huggingface/datasets/blob/main/docs/source/nlp_load.mdx
|
!-- DISABLE-FRONTMATTER-SECTIONS -->
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/safetensors/safetensors-logo-light.svg"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/safetensors/safetensors-logo-dark.svg"/>
</div>
# Safetensors
Safetensors is a new simple format for storing tensors safely (as opposed to pickle) and that is still fast (zero-copy). Safetensors is really [fast 🚀](./speed).
## Installation
with pip:
```
pip install safetensors
```
with conda:
```
conda install -c huggingface safetensors
```
## Usage
### Load tensors
```python
from safetensors import safe_open
tensors = {}
with safe_open("model.safetensors", framework="pt", device=0) as f:
for k in f.keys():
tensors[k] = f.get_tensor(k)
```
Loading only part of the tensors (interesting when running on multiple GPU)
```python
from safetensors import safe_open
tensors = {}
with safe_open("model.safetensors", framework="pt", device=0) as f:
tensor_slice = f.get_slice("embedding")
vocab_size, hidden_dim = tensor_slice.get_shape()
tensor = tensor_slice[:, :hidden_dim]
```
### Save tensors
```python
import torch
from safetensors.torch import save_file
tensors = {
"embedding": torch.zeros((2, 2)),
"attention": torch.zeros((2, 3))
}
save_file(tensors, "model.safetensors")
```
## Format
Let's say you have safetensors file named `model.safetensors`, then `model.safetensors` will have the following internal format:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/safetensors/safetensors-format.svg"/>
</div>
## Featured Projects
Safetensors is being used widely at leading AI enterprises, such as [Hugging Face](https://huggingface.co/), [EleutherAI](https://www.eleuther.ai/), and [StabilityAI](https://stability.ai/). Here is a non-exhaustive list of projects that are using safetensors:
* [huggingface/transformers](https://github.com/huggingface/transformers)
* [AUTOMATIC1111/stable-diffusion-webui](https://github.com/AUTOMATIC1111/stable-diffusion-webui)
* [Llama-cpp](https://github.com/ggerganov/llama.cpp/blob/e6a46b0ed1884c77267dc70693183e3b7164e0e0/convert.py#L537)
* [microsoft/TaskMatrix](https://github.com/microsoft/TaskMatrix)
* [hpcaitech/ColossalAI](https://github.com/hpcaitech/ColossalAI)
* [huggingface/pytorch-image-models](https://github.com/huggingface/pytorch-image-models)
* [CivitAI](https://civitai.com/)
* [huggingface/diffusers](https://github.com/huggingface/diffusers)
* [coreylowman/dfdx](https://github.com/coreylowman/dfdx)
* [invoke-ai/InvokeAI](https://github.com/invoke-ai/InvokeAI)
* [oobabooga/text-generation-webui](https://github.com/oobabooga/text-generation-webui)
* [Sanster/lama-cleaner](https://github.com/Sanster/lama-cleaner)
* [PaddlePaddle/PaddleNLP](https://github.com/PaddlePaddle/PaddleNLP)
* [AIGC-Audio/AudioGPT](https://github.com/AIGC-Audio/AudioGPT)
* [brycedrennan/imaginAIry](https://github.com/brycedrennan/imaginAIry)
* [comfyanonymous/ComfyUI](https://github.com/comfyanonymous/ComfyUI)
* [LianjiaTech/BELLE](https://github.com/LianjiaTech/BELLE)
* [alvarobartt/safejax](https://github.com/alvarobartt/safejax)
* [MaartenGr/BERTopic](https://github.com/MaartenGr/BERTopic)
* [LaurentMazare/tch-rs](https://github.com/LaurentMazare/tch-rs)
* [chainyo/tensorshare](https://github.com/chainyo/tensorshare)
|
huggingface/safetensors/blob/main/docs/source/index.mdx
|
Integrations with the Hugging Face Hub[[integrations-with-the-hugging-face-hub]]
<CourseFloatingBanner chapter={9}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter9/section5.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter9/section5.ipynb"},
]} />
To make your life even easier, Gradio integrates directly with Hugging Face Hub and Hugging Face Spaces.
You can load demos from the Hub and Spaces with only *one line of code*.
### Loading models from the Hugging Face Hub[[loading-models-from-the-hugging-face-hub]]
To start with, choose one of the thousands of models Hugging Face offers through the Hub, as described in [Chapter 4](/course/chapter4/2).
Using the special `Interface.load()` method, you pass `"model/"` (or, equivalently, `"huggingface/"`)
followed by the model name.
For example, here is the code to build a demo for [GPT-J](https://huggingface.co/EleutherAI/gpt-j-6B), a large language model, add a couple of example inputs:
```py
import gradio as gr
title = "GPT-J-6B"
description = "Gradio Demo for GPT-J 6B, a transformer model trained using Ben Wang's Mesh Transformer JAX. 'GPT-J' refers to the class of model, while '6B' represents the number of trainable parameters. To use it, simply add your text, or click one of the examples to load them. Read more at the links below."
article = "<p style='text-align: center'><a href='https://github.com/kingoflolz/mesh-transformer-jax' target='_blank'>GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model</a></p>"
gr.Interface.load(
"huggingface/EleutherAI/gpt-j-6B",
inputs=gr.Textbox(lines=5, label="Input Text"),
title=title,
description=description,
article=article,
).launch()
```
The code above will produce the interface below:
<iframe src="https://course-demos-gpt-j-6B.hf.space" frameBorder="0" height="750" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
Loading a model in this way uses Hugging Face's [Inference API](https://huggingface.co/inference-api),
instead of loading the model in memory. This is ideal for huge models like GPT-J or T0pp which
require lots of RAM.
### Loading from Hugging Face Spaces[[loading-from-hugging-face-spaces]]
To load any Space from the Hugging Face Hub and recreate it locally, you can pass `spaces/` to the `Interface`, followed by the name of the Space.
Remember the demo from section 1 that removes the background of an image? Let's load it from Hugging Face Spaces:
```py
gr.Interface.load("spaces/abidlabs/remove-bg").launch()
```
<iframe src="https://course-demos-remove-bg-original.hf.space" frameBorder="0" height="650" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
One of the cool things about loading demos from the Hub or Spaces is that you customize them
by overriding any of the
parameters. Here, we add a title and get it to work with a webcam instead:
```py
gr.Interface.load(
"spaces/abidlabs/remove-bg", inputs="webcam", title="Remove your webcam background!"
).launch()
```
<iframe src="https://course-demos-Remove-bg.hf.space" frameBorder="0" height="550" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
Now that we've explored a few ways to integrate Gradio with the Hugging Face Hub, let's take a look at some advanced features of the `Interface` class. That's the topic of the next section!
|
huggingface/course/blob/main/chapters/en/chapter9/5.mdx
|
Encode Inputs
<tokenizerslangcontent>
<python>
These types represent all the different kinds of input that a [`~tokenizers.Tokenizer`] accepts
when using [`~tokenizers.Tokenizer.encode_batch`].
## TextEncodeInput[[[[tokenizers.TextEncodeInput]]]]
<code>tokenizers.TextEncodeInput</code>
Represents a textual input for encoding. Can be either:
- A single sequence: [TextInputSequence](/docs/tokenizers/api/input-sequences#tokenizers.TextInputSequence)
- A pair of sequences:
- A Tuple of [TextInputSequence](/docs/tokenizers/api/input-sequences#tokenizers.TextInputSequence)
- Or a List of [TextInputSequence](/docs/tokenizers/api/input-sequences#tokenizers.TextInputSequence) of size 2
alias of `Union[str, Tuple[str, str], List[str]]`.
## PreTokenizedEncodeInput[[[[tokenizers.PreTokenizedEncodeInput]]]]
<code>tokenizers.PreTokenizedEncodeInput</code>
Represents a pre-tokenized input for encoding. Can be either:
- A single sequence: [PreTokenizedInputSequence](/docs/tokenizers/api/input-sequences#tokenizers.PreTokenizedInputSequence)
- A pair of sequences:
- A Tuple of [PreTokenizedInputSequence](/docs/tokenizers/api/input-sequences#tokenizers.PreTokenizedInputSequence)
- Or a List of [PreTokenizedInputSequence](/docs/tokenizers/api/input-sequences#tokenizers.PreTokenizedInputSequence) of size 2
alias of `Union[List[str], Tuple[str], Tuple[Union[List[str], Tuple[str]], Union[List[str], Tuple[str]]], List[Union[List[str], Tuple[str]]]]`.
## EncodeInput[[[[tokenizers.EncodeInput]]]]
<code>tokenizers.EncodeInput</code>
Represents all the possible types of input for encoding. Can be:
- When `is_pretokenized=False`: [TextEncodeInput](#tokenizers.TextEncodeInput)
- When `is_pretokenized=True`: [PreTokenizedEncodeInput](#tokenizers.PreTokenizedEncodeInput)
alias of `Union[str, Tuple[str, str], List[str], Tuple[str], Tuple[Union[List[str], Tuple[str]], Union[List[str], Tuple[str]]], List[Union[List[str], Tuple[str]]]]`.
</python>
<rust>
The Rust API Reference is available directly on the [Docs.rs](https://docs.rs/tokenizers/latest/tokenizers/) website.
</rust>
<node>
The node API has not been documented yet.
</node>
</tokenizerslangcontent>
|
huggingface/tokenizers/blob/main/docs/source-doc-builder/api/encode-inputs.mdx
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Preprocess
[[open-in-colab]]
Before you can train a model on a dataset, it needs to be preprocessed into the expected model input format. Whether your data is text, images, or audio, they need to be converted and assembled into batches of tensors. 🤗 Transformers provides a set of preprocessing classes to help prepare your data for the model. In this tutorial, you'll learn that for:
* Text, use a [Tokenizer](./main_classes/tokenizer) to convert text into a sequence of tokens, create a numerical representation of the tokens, and assemble them into tensors.
* Speech and audio, use a [Feature extractor](./main_classes/feature_extractor) to extract sequential features from audio waveforms and convert them into tensors.
* Image inputs use a [ImageProcessor](./main_classes/image) to convert images into tensors.
* Multimodal inputs, use a [Processor](./main_classes/processors) to combine a tokenizer and a feature extractor or image processor.
<Tip>
`AutoProcessor` **always** works and automatically chooses the correct class for the model you're using, whether you're using a tokenizer, image processor, feature extractor or processor.
</Tip>
Before you begin, install 🤗 Datasets so you can load some datasets to experiment with:
```bash
pip install datasets
```
## Natural Language Processing
<Youtube id="Yffk5aydLzg"/>
The main tool for preprocessing textual data is a [tokenizer](main_classes/tokenizer). A tokenizer splits text into *tokens* according to a set of rules. The tokens are converted into numbers and then tensors, which become the model inputs. Any additional inputs required by the model are added by the tokenizer.
<Tip>
If you plan on using a pretrained model, it's important to use the associated pretrained tokenizer. This ensures the text is split the same way as the pretraining corpus, and uses the same corresponding tokens-to-index (usually referred to as the *vocab*) during pretraining.
</Tip>
Get started by loading a pretrained tokenizer with the [`AutoTokenizer.from_pretrained`] method. This downloads the *vocab* a model was pretrained with:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
```
Then pass your text to the tokenizer:
```py
>>> encoded_input = tokenizer("Do not meddle in the affairs of wizards, for they are subtle and quick to anger.")
>>> print(encoded_input)
{'input_ids': [101, 2079, 2025, 19960, 10362, 1999, 1996, 3821, 1997, 16657, 1010, 2005, 2027, 2024, 11259, 1998, 4248, 2000, 4963, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
The tokenizer returns a dictionary with three important items:
* [input_ids](glossary#input-ids) are the indices corresponding to each token in the sentence.
* [attention_mask](glossary#attention-mask) indicates whether a token should be attended to or not.
* [token_type_ids](glossary#token-type-ids) identifies which sequence a token belongs to when there is more than one sequence.
Return your input by decoding the `input_ids`:
```py
>>> tokenizer.decode(encoded_input["input_ids"])
'[CLS] Do not meddle in the affairs of wizards, for they are subtle and quick to anger. [SEP]'
```
As you can see, the tokenizer added two special tokens - `CLS` and `SEP` (classifier and separator) - to the sentence. Not all models need
special tokens, but if they do, the tokenizer automatically adds them for you.
If there are several sentences you want to preprocess, pass them as a list to the tokenizer:
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_inputs = tokenizer(batch_sentences)
>>> print(encoded_inputs)
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1]]}
```
### Pad
Sentences aren't always the same length which can be an issue because tensors, the model inputs, need to have a uniform shape. Padding is a strategy for ensuring tensors are rectangular by adding a special *padding token* to shorter sentences.
Set the `padding` parameter to `True` to pad the shorter sequences in the batch to match the longest sequence:
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch_sentences, padding=True)
>>> print(encoded_input)
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
```
The first and third sentences are now padded with `0`'s because they are shorter.
### Truncation
On the other end of the spectrum, sometimes a sequence may be too long for a model to handle. In this case, you'll need to truncate the sequence to a shorter length.
Set the `truncation` parameter to `True` to truncate a sequence to the maximum length accepted by the model:
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True)
>>> print(encoded_input)
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
```
<Tip>
Check out the [Padding and truncation](./pad_truncation) concept guide to learn more different padding and truncation arguments.
</Tip>
### Build tensors
Finally, you want the tokenizer to return the actual tensors that get fed to the model.
Set the `return_tensors` parameter to either `pt` for PyTorch, or `tf` for TensorFlow:
<frameworkcontent>
<pt>
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="pt")
>>> print(encoded_input)
{'input_ids': tensor([[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]])}
```
</pt>
<tf>
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="tf")
>>> print(encoded_input)
{'input_ids': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
array([[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
dtype=int32)>,
'token_type_ids': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=int32)>,
'attention_mask': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
array([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=int32)>}
```
</tf>
</frameworkcontent>
## Audio
For audio tasks, you'll need a [feature extractor](main_classes/feature_extractor) to prepare your dataset for the model. The feature extractor is designed to extract features from raw audio data, and convert them into tensors.
Load the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset (see the 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub) for more details on how to load a dataset) to see how you can use a feature extractor with audio datasets:
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train")
```
Access the first element of the `audio` column to take a look at the input. Calling the `audio` column automatically loads and resamples the audio file:
```py
>>> dataset[0]["audio"]
{'array': array([ 0. , 0.00024414, -0.00024414, ..., -0.00024414,
0. , 0. ], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
'sampling_rate': 8000}
```
This returns three items:
* `array` is the speech signal loaded - and potentially resampled - as a 1D array.
* `path` points to the location of the audio file.
* `sampling_rate` refers to how many data points in the speech signal are measured per second.
For this tutorial, you'll use the [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base) model. Take a look at the model card, and you'll learn Wav2Vec2 is pretrained on 16kHz sampled speech audio. It is important your audio data's sampling rate matches the sampling rate of the dataset used to pretrain the model. If your data's sampling rate isn't the same, then you need to resample your data.
1. Use 🤗 Datasets' [`~datasets.Dataset.cast_column`] method to upsample the sampling rate to 16kHz:
```py
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16_000))
```
2. Call the `audio` column again to resample the audio file:
```py
>>> dataset[0]["audio"]
{'array': array([ 2.3443763e-05, 2.1729663e-04, 2.2145823e-04, ...,
3.8356509e-05, -7.3497440e-06, -2.1754686e-05], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
'sampling_rate': 16000}
```
Next, load a feature extractor to normalize and pad the input. When padding textual data, a `0` is added for shorter sequences. The same idea applies to audio data. The feature extractor adds a `0` - interpreted as silence - to `array`.
Load the feature extractor with [`AutoFeatureExtractor.from_pretrained`]:
```py
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base")
```
Pass the audio `array` to the feature extractor. We also recommend adding the `sampling_rate` argument in the feature extractor in order to better debug any silent errors that may occur.
```py
>>> audio_input = [dataset[0]["audio"]["array"]]
>>> feature_extractor(audio_input, sampling_rate=16000)
{'input_values': [array([ 3.8106556e-04, 2.7506407e-03, 2.8015103e-03, ...,
5.6335266e-04, 4.6588284e-06, -1.7142107e-04], dtype=float32)]}
```
Just like the tokenizer, you can apply padding or truncation to handle variable sequences in a batch. Take a look at the sequence length of these two audio samples:
```py
>>> dataset[0]["audio"]["array"].shape
(173398,)
>>> dataset[1]["audio"]["array"].shape
(106496,)
```
Create a function to preprocess the dataset so the audio samples are the same lengths. Specify a maximum sample length, and the feature extractor will either pad or truncate the sequences to match it:
```py
>>> def preprocess_function(examples):
... audio_arrays = [x["array"] for x in examples["audio"]]
... inputs = feature_extractor(
... audio_arrays,
... sampling_rate=16000,
... padding=True,
... max_length=100000,
... truncation=True,
... )
... return inputs
```
Apply the `preprocess_function` to the first few examples in the dataset:
```py
>>> processed_dataset = preprocess_function(dataset[:5])
```
The sample lengths are now the same and match the specified maximum length. You can pass your processed dataset to the model now!
```py
>>> processed_dataset["input_values"][0].shape
(100000,)
>>> processed_dataset["input_values"][1].shape
(100000,)
```
## Computer vision
For computer vision tasks, you'll need an [image processor](main_classes/image_processor) to prepare your dataset for the model.
Image preprocessing consists of several steps that convert images into the input expected by the model. These steps
include but are not limited to resizing, normalizing, color channel correction, and converting images to tensors.
<Tip>
Image preprocessing often follows some form of image augmentation. Both image preprocessing and image augmentation
transform image data, but they serve different purposes:
* Image augmentation alters images in a way that can help prevent overfitting and increase the robustness of the model. You can get creative in how you augment your data - adjust brightness and colors, crop, rotate, resize, zoom, etc. However, be mindful not to change the meaning of the images with your augmentations.
* Image preprocessing guarantees that the images match the model’s expected input format. When fine-tuning a computer vision model, images must be preprocessed exactly as when the model was initially trained.
You can use any library you like for image augmentation. For image preprocessing, use the `ImageProcessor` associated with the model.
</Tip>
Load the [food101](https://huggingface.co/datasets/food101) dataset (see the 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub) for more details on how to load a dataset) to see how you can use an image processor with computer vision datasets:
<Tip>
Use 🤗 Datasets `split` parameter to only load a small sample from the training split since the dataset is quite large!
</Tip>
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("food101", split="train[:100]")
```
Next, take a look at the image with 🤗 Datasets [`Image`](https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=image#datasets.Image) feature:
```py
>>> dataset[0]["image"]
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/vision-preprocess-tutorial.png"/>
</div>
Load the image processor with [`AutoImageProcessor.from_pretrained`]:
```py
>>> from transformers import AutoImageProcessor
>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
```
First, let's add some image augmentation. You can use any library you prefer, but in this tutorial, we'll use torchvision's [`transforms`](https://pytorch.org/vision/stable/transforms.html) module. If you're interested in using another data augmentation library, learn how in the [Albumentations](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_albumentations.ipynb) or [Kornia notebooks](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_kornia.ipynb).
1. Here we use [`Compose`](https://pytorch.org/vision/master/generated/torchvision.transforms.Compose.html) to chain together a couple of
transforms - [`RandomResizedCrop`](https://pytorch.org/vision/main/generated/torchvision.transforms.RandomResizedCrop.html) and [`ColorJitter`](https://pytorch.org/vision/main/generated/torchvision.transforms.ColorJitter.html).
Note that for resizing, we can get the image size requirements from the `image_processor`. For some models, an exact height and
width are expected, for others only the `shortest_edge` is defined.
```py
>>> from torchvision.transforms import RandomResizedCrop, ColorJitter, Compose
>>> size = (
... image_processor.size["shortest_edge"]
... if "shortest_edge" in image_processor.size
... else (image_processor.size["height"], image_processor.size["width"])
... )
>>> _transforms = Compose([RandomResizedCrop(size), ColorJitter(brightness=0.5, hue=0.5)])
```
2. The model accepts [`pixel_values`](model_doc/visionencoderdecoder#transformers.VisionEncoderDecoderModel.forward.pixel_values)
as its input. `ImageProcessor` can take care of normalizing the images, and generating appropriate tensors.
Create a function that combines image augmentation and image preprocessing for a batch of images and generates `pixel_values`:
```py
>>> def transforms(examples):
... images = [_transforms(img.convert("RGB")) for img in examples["image"]]
... examples["pixel_values"] = image_processor(images, do_resize=False, return_tensors="pt")["pixel_values"]
... return examples
```
<Tip>
In the example above we set `do_resize=False` because we have already resized the images in the image augmentation transformation,
and leveraged the `size` attribute from the appropriate `image_processor`. If you do not resize images during image augmentation,
leave this parameter out. By default, `ImageProcessor` will handle the resizing.
If you wish to normalize images as a part of the augmentation transformation, use the `image_processor.image_mean`,
and `image_processor.image_std` values.
</Tip>
3. Then use 🤗 Datasets[`~datasets.Dataset.set_transform`] to apply the transforms on the fly:
```py
>>> dataset.set_transform(transforms)
```
4. Now when you access the image, you'll notice the image processor has added `pixel_values`. You can pass your processed dataset to the model now!
```py
>>> dataset[0].keys()
```
Here is what the image looks like after the transforms are applied. The image has been randomly cropped and it's color properties are different.
```py
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> img = dataset[0]["pixel_values"]
>>> plt.imshow(img.permute(1, 2, 0))
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/preprocessed_image.png"/>
</div>
<Tip>
For tasks like object detection, semantic segmentation, instance segmentation, and panoptic segmentation, `ImageProcessor`
offers post processing methods. These methods convert model's raw outputs into meaningful predictions such as bounding boxes,
or segmentation maps.
</Tip>
### Pad
In some cases, for instance, when fine-tuning [DETR](./model_doc/detr), the model applies scale augmentation at training
time. This may cause images to be different sizes in a batch. You can use [`DetrImageProcessor.pad`]
from [`DetrImageProcessor`] and define a custom `collate_fn` to batch images together.
```py
>>> def collate_fn(batch):
... pixel_values = [item["pixel_values"] for item in batch]
... encoding = image_processor.pad(pixel_values, return_tensors="pt")
... labels = [item["labels"] for item in batch]
... batch = {}
... batch["pixel_values"] = encoding["pixel_values"]
... batch["pixel_mask"] = encoding["pixel_mask"]
... batch["labels"] = labels
... return batch
```
## Multimodal
For tasks involving multimodal inputs, you'll need a [processor](main_classes/processors) to prepare your dataset for the model. A processor couples together two processing objects such as as tokenizer and feature extractor.
Load the [LJ Speech](https://huggingface.co/datasets/lj_speech) dataset (see the 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub) for more details on how to load a dataset) to see how you can use a processor for automatic speech recognition (ASR):
```py
>>> from datasets import load_dataset
>>> lj_speech = load_dataset("lj_speech", split="train")
```
For ASR, you're mainly focused on `audio` and `text` so you can remove the other columns:
```py
>>> lj_speech = lj_speech.map(remove_columns=["file", "id", "normalized_text"])
```
Now take a look at the `audio` and `text` columns:
```py
>>> lj_speech[0]["audio"]
{'array': array([-7.3242188e-04, -7.6293945e-04, -6.4086914e-04, ...,
7.3242188e-04, 2.1362305e-04, 6.1035156e-05], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/917ece08c95cf0c4115e45294e3cd0dee724a1165b7fc11798369308a465bd26/LJSpeech-1.1/wavs/LJ001-0001.wav',
'sampling_rate': 22050}
>>> lj_speech[0]["text"]
'Printing, in the only sense with which we are at present concerned, differs from most if not from all the arts and crafts represented in the Exhibition'
```
Remember you should always [resample](preprocessing#audio) your audio dataset's sampling rate to match the sampling rate of the dataset used to pretrain a model!
```py
>>> lj_speech = lj_speech.cast_column("audio", Audio(sampling_rate=16_000))
```
Load a processor with [`AutoProcessor.from_pretrained`]:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
```
1. Create a function to process the audio data contained in `array` to `input_values`, and tokenize `text` to `labels`. These are the inputs to the model:
```py
>>> def prepare_dataset(example):
... audio = example["audio"]
... example.update(processor(audio=audio["array"], text=example["text"], sampling_rate=16000))
... return example
```
2. Apply the `prepare_dataset` function to a sample:
```py
>>> prepare_dataset(lj_speech[0])
```
The processor has now added `input_values` and `labels`, and the sampling rate has also been correctly downsampled to 16kHz. You can pass your processed dataset to the model now!
|
huggingface/transformers/blob/main/docs/source/en/preprocessing.md
|
Using ML-Agents at Hugging Face
`ml-agents` is an open-source toolkit that enables games and simulations made with Unity to serve as environments for training intelligent agents.
## Exploring ML-Agents in the Hub
You can find `ml-agents` models by filtering at the left of the [models page](https://huggingface.co/models?library=ml-agents).
All models on the Hub come up with useful features:
1. An automatically generated model card with a description, a training configuration, and more.
2. Metadata tags that help for discoverability.
3. Tensorboard summary files to visualize the training metrics.
4. A link to the Spaces web demo where you can visualize your agent playing in your browser.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/ml-agents-demo.gif"/>
</div>
## Install the library
To install the `ml-agents` library, you need to clone the repo:
```
# Clone the repository
git clone https://github.com/Unity-Technologies/ml-agents
# Go inside the repository and install the package
cd ml-agents
pip3 install -e ./ml-agents-envs
pip3 install -e ./ml-agents
```
## Using existing models
You can simply download a model from the Hub using `mlagents-load-from-hf`.
```
mlagents-load-from-hf --repo-id="ThomasSimonini/MLAgents-Pyramids" --local-dir="./downloads"
```
You need to define two parameters:
- `--repo-id`: the name of the Hugging Face repo you want to download.
- `--local-dir`: the path to download the model.
## Visualize an agent playing
You can easily watch any model playing directly in your browser:
1. Go to your model repo.
2. In the `Watch Your Agent Play` section, click on the link.
3. In the demo, on step 1, choose your model repository, which is the model id.
4. In step 2, choose what model you want to replay.
## Sharing your models
You can easily upload your models using `mlagents-push-to-hf`:
```
mlagents-push-to-hf --run-id="First Training" --local-dir="results/First Training" --repo-id="ThomasSimonini/MLAgents-Pyramids" --commit-message="Pyramids"
```
You need to define four parameters:
- `--run-id`: the name of the training run id.
- `--local-dir`: where the model was saved.
- `--repo-id`: the name of the Hugging Face repo you want to create or update. It’s `<your huggingface username>/<the repo name>`.
- `--commit-message`.
## Additional resources
* ML-Agents [documentation](https://github.com/Unity-Technologies/ml-agents/blob/develop/docs/Hugging-Face-Integration.md)
* Official Unity ML-Agents Spaces [demos](https://huggingface.co/unity)
|
huggingface/hub-docs/blob/main/docs/hub/ml-agents.md
|
--
title: "Director of Machine Learning Insights"
thumbnail: /blog/assets/61_ml_director_insights/thumbnail.png
authors:
- user: britneymuller
---
# Director of Machine Learning Insights [Part 1]
Few seats at the Machine Learning table span both technical skills, problem solving and business acumen like Directors of Machine Learning
Directors of Machine Learning and/or Data Science are often expected to design ML systems, have deep knowledge of mathematics, familiarity with ML frameworks, rich data architecture understanding, experience applying ML to real-world applications, solid communication skills, and often expected to keep on top of industry developments. A tall order!
<a href="https://huggingface.co/platform?utm_source=article&utm_medium=blog&utm_campaign=ml_director_insights_1"><img width="100%" style=
"margin:auto" src="/blog/assets/61_ml_director_insights/private-model-hub.png"></a>
For these reasons, we’ve tapped into this unique group of ML Directors for a series of articles highlighting their thoughts on current ML insights and industry trends ranging from Healthcare to Finance, eCommerce, SaaS, Research, Media, and more. For example, one Director will note how ML can be used to reduce empty deadheading truck driving (which occurs ~20% of the time) down to just 19% would cut carbon emissions by ~100,000 Americans. Note: This is back of napkin math, done by an ex-rocket Scientist however, so we’ll take it.
In this first installment, you’ll hear from a researcher (who’s using ground penetrating radar to detect buried landmines), an ex-Rocket Scientist, a Dzongkha fluent amateur gamer (Kuzu = Hello!), an ex-van living Scientist, a high-performance Data Science team coach who’s still very hands-on, a data practitioner who values relationships, family, dogs, and pizza. —All of whom are currently Directors of Machine Learning with rich field insights.
🚀 Let’s meet some top Machine Learning Directors and hear what they have to say about Machine Learning’s impact on their prospective industries:
<img class="mx-auto" style="float: left;" padding="5px" src="/blog/assets/61_ml_director_insights/Archi-Mitra.jpeg"></a>
### [Archi Mitra](https://www.linkedin.com/in/archimitra/) - Director of Machine Learning at [Buzzfeed](https://www.buzzfeed.com/)
**Background:** Bringing balance to the promise of ML for business. People over Process. Strategy over Hope. AI Ethics over AI Profits. Brown New Yorker.
**Fun Fact:** I can speak [Dzongkha](https://en.wikipedia.org/wiki/Dzongkha) (google it!) and am a supporter of [Youth for Seva](https://www.youthforseva.org/Donation).
**Buzzfeed:** An American Internet media, news and entertainment company with a focus on digital media.
#### **1. How has ML made a positive impact on Media?**
_Privacy first personalization for customers:_ Every user is unique and while their long-term interests are stable, their short-term interests are stochastic. They expect their relationship with the Media to reflect this. The combination of advancement in hardware acceleration and Deep Learning for recommendations has unlocked the ability to start deciphering this nuance and serve users with the right content at the right time at the right touchpoint.
_Assistive tools for makers:_ Makers are the limited assets in media and preserving their creative bandwidth by ML driven human-in-the-loop assistive tools have seen an outsized impact. Something as simple as automatically suggesting an appropriate title, image, video, and/or product that can go along with the content they are creating unlocks a collaborative machine-human flywheel.
_Tightened testing:_ In a capital intensive media venture, there is a need to shorten the time between collecting information on what resonates with users and immediately acting on it. With a wide variety of Bayesian techniques and advancements in reinforcement learning, we have been able to drastically reduce not only the time but the cost associated with it.
#### **2. What are the biggest ML challenges within Media?**
_Privacy, editorial voice, and equitable coverage:_ Media is a key pillar in the democratic world now more than ever. ML needs to respect that and operate within constraints that are not strictly considered table stakes in any other domain or industry. Finding a balance between editorially curated content & programming vs ML driven recommendations continues to be a challenge. Another unique challenge to BuzzFeed is we believe that the internet should be free which means we don't track our users like others can.
#### **3. What’s a common mistake you see people make trying to integrate ML into Media?**
Ignoring “the makers” of media: Media is prevalent because it houses a voice that has a deep influence on people. The editors, content creators, writers & makers are the larynx of that voice and the business and building ML that enables them, extends their impact and works in harmony with them is the key ingredient to success.
#### **4. What excites you most about the future of ML?**
Hopefully, small data-driven general-purpose multi-modal multi-task real-time ML systems that create step-function improvements in drug discovery, high precision surgery, climate control systems & immersive metaverse experiences. Realistically, more accessible, low-effort meta-learning techniques for highly accurate text and image generation.
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/61_ml_director_insights/Li-Tan.jpeg"></a>
### [Li Tan](http://linkedin.com/in/iamtanli/) - Director of Machine Learning & AI at [Johnson & Johnson](https://www.jnj.com/)
**Background:** Li is an AI/ML veteran with 15+ years of experience leading high-profile Data Science teams within industry leaders like Johnson & Johnson, Microsoft, and Amazon.
**Fun Fact:** Li continues to be curious, is always learning, and enjoys hands-on programming.
**Johnson & Johnson:** A Multinational corporation that develops medical devices, pharmaceuticals, and consumer packaged goods.
#### **1. How has ML made a positive impact on Pharmaceuticals?**
AI/ML applications have exploded in the pharmaceuticals space the past few years and are making many long-term positive impacts. Pharmaceuticals and healthcare have many use cases that can leverage AI/ML.
Applications range from research, and real-world evidence, to smart manufacturing and quality assurance. The technologies used are also very broad: NLP/NLU, CV, AIIoT, Reinforcement Learning, etc. even things like AlphaFold.
#### **2. What are the biggest ML challenges within Pharmaceuticals?**
The biggest ML challenge within pharma and healthcare is how to ensure equality and diversity in AI applications. For example, how to make sure the training set has good representations of all ethnic groups. Due to the nature of healthcare and pharma, this problem can have a much greater impact compared to applications in some other fields.
#### **3. What’s a common mistake you see people make trying to integrate ML into Pharmaceuticals?**
Wouldn’t say this is necessarily a mistake, but I see many people gravitate toward extreme perspectives when it comes to AI applications in healthcare; either too conservative or too aggressive.
Some people are resistant due to high regulatory requirements. We had to qualify many of our AI applications with strict GxP validation. It may require a fair amount of work, but we believe the effort is worthwhile. On the opposite end of the spectrum, there are many people who think AI/Deep Learning models can outperform humans in many applications and run completely autonomously.
As practitioners, we know that currently, neither is true.
ML models can be incredibly valuable but still make mistakes. So I recommend a more progressive approach. The key is to have a framework that can leverage the power of AI while having goalkeepers in place. [FDA has taken actions](https://www.fda.gov/medical-devices/software-medical-device-samd/artificial-intelligence-and-machine-learning-software-medical-device) to regulate how AI/ML should be used in software as a medical device and I believe that’s a positive step forward for our industry.
#### **4. What excites you most about the future of ML?**
The intersections between AI/ML and other hard sciences and technologies. I’m excited to see what’s to come.
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/61_ml_director_insights/Alina-Zare.jpeg"></a>
### [Alina Zare](https://www.linkedin.com/in/alina-zare/) - Director of the Machine Learning & Sensing Laboratory at the [University of Florida](https://faculty.eng.ufl.edu/machine-learning/people/faculty/)
**Background:** Alina Zare teaches and conducts research in the area of machine learning and artificial intelligence as a Professor in the Electrical and Computer Engineering Department at the University of Florida and Director of the Machine Learning and Sensing Lab. Dr. Zare’s research has focused primarily on developing new machine learning algorithms to automatically understand and process data and imagery.
Her research work has included automated plant root phenotyping, sub-pixel hyperspectral image analysis, target detection, and underwater scene understanding using synthetic aperture sonar, LIDAR data analysis, Ground Penetrating Radar analysis, and buried landmine and explosive hazard detection.
**Fun Fact:** Alina is a rower. She joined the crew team in high school, rowed throughout college and grad school, was head coach of the University of Missouri team while she was an assistant professor, and then rowed as a masters rower when she joined the faculty at UF.
**Machine Learning & Sensing Laboratory:** A University of Florida laboratory that develops machine learning methods for autonomously analyzing and understanding sensor data.
#### **1. How has ML made a positive impact on Science**
ML has made a positive impact in a number of ways from helping to automate tedious and/or slow tasks or providing new ways to examine and look at various questions. One example from my work in ML for plant science is that we have developed ML approaches to automate plant root segmentation and characterization in imagery. This task was previously a bottleneck for plant scientists looking at root imagery. By automating this step through ML we can conduct these analyses at a much higher throughput and begin to use this data to investigate plant biology research questions at scale.
#### **2. What are the biggest ML challenges within Scientific research?**
There are many challenges. One example is when using ML for Science research, we have to think carefully through the data collection and curation protocols. In some cases, the protocols we used for non-ML analysis are not appropriate or effective. The quality of the data and how representative it is of what we expect to see in the application can make a huge impact on the performance, reliability, and trustworthiness of an ML-based system.
#### **3. What’s a common mistake you see people make trying to integrate ML into Science?**
Related to the question above, one common mistake is misinterpreting results or performance to be a function of just the ML system and not also considering the data collection, curation, calibration, and normalization protocols.
#### **4. What excites you most about the future of ML?**
There are a lot of really exciting directions. A lot of my research currently is in spaces where we have a huge amount of prior knowledge and empirically derived models. For example, I have ongoing work using ML for forest ecology research. The forestry community has a rich body of prior knowledge and current purely data-driven ML systems are not leveraging. I think hybrid methods that seamlessly blend prior knowledge with ML approaches will be an interesting and exciting path forward.
An example may be understanding how likely two species are to co-occur in an area. Or what species distribution we could expect given certain environmental conditions. These could potentially be used w/ data-driven methods to make predictions in changing conditions.
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/61_ml_director_insights/Nathan-Cahill.jpeg"></a>
### [Nathan Cahill](https://www.linkedin.com/in/nathan-m-cahill/) Ph.D. - Director of Machine Learning at [Xpress Technologies](https://xpresstechfreight.com/)
**Background:** Nathan is a passionate machine learning leader with 7 years of experience in research and development, and three years experience creating business value by shipping ML models to prod. He specializes in finding and strategically prioritizing the business' biggest pain points: unlocking the power of data earlier on in the growth curve.
**Fun Fact:** Before getting into transportation and logistics I was engineering rockets at Northrop Grumman. #RocketScience
**Xpress Technologies:** A digital freight matching technology to connect Shippers, Brokers and Carriers to bring efficiency and automation to the Transportation Industry.
#### **1. How has ML made a positive impact on Logistics/Transportation?**
The transportation industry is incredibly fragmented. The top players in the game have less than 1% market share. As a result, there exist inefficiencies that can be solved by digital solutions.
For example, when you see a semi-truck driving on the road, there is currently a 20% chance that the truck is driving with nothing in the back. Yes, 20% of the miles a tractor-trailer drives are from the last drop off of their previous load to their next pickup. The chances are that there is another truck driving empty (or "deadheading") in the other direction.
With machine learning and optimization this deadhead percent can be reduced significantly, and just taking that number from 20% to 19% percent would cut the equivalent carbon emissions of 100,000 Americans.
Note: the carbon emissions of 100k Americans were my own back of the napkin math.
#### **2. What are the biggest ML challenges within Logistics?**
The big challenge within logistics is due to the fact that the industry is so fragmented: there is no shared pool of data that would allow technology solutions to "see" the big picture. For example a large fraction of brokerage loads, maybe a majority, costs are negotiated on a load by load basis making them highly volatile. This makes pricing a very difficult problem to solve. If the industry became more transparent and shared data more freely, so much more would become possible.
#### **3. What’s a common mistake you see people make trying to integrate ML into Logistics?**
I think that the most common mistake I see is people doing ML and Data Science in a vacuum.
Most ML applications within logistics will significantly change the dynamics of the problem if they are being used so it's important to develop models iteratively with the business and make sure that performance in reality matches what you expect in training.
An example of this is in pricing where if you underprice a lane slightly, your prices may be too competitive which will create an influx of freight on that lane. This, in turn, may cause costs to go up as the brokers struggle to find capacity for those loads, exacerbating the issue.
#### **4. What excites you the most about the future of ML?**
I think the thing that excites me most about ML is the opportunity to make people better at their jobs.
As ML begins to be ubiquitous in business, it will be able to help speed up decisions and automate redundant work. This will accelerate the pace of innovation and create immense economic value. I can’t wait to see what problems we solve in the next 10 years aided by data science and ML!
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/61_ml_director_insights/Nicolas-Bertagnolli.png"></a>
### [Nicolas Bertagnolli](https://www.linkedin.com/in/nicolas-bertagnolli-058aba81/) - Director of Machine Learning at [BEN](https://ben.productplacement.com/)
**Background:** Nic is a scientist and engineer working to improve human communication through machine learning. He’s spent the last decade applying ML/NLP to solve data problems in the medical space from uncovering novel patterns in cancer genomes to leveraging billions of clinical notes to reduce costs and improve outcomes.
At BEN, Nic innovates intelligent technologies that scale human capabilities to reach people. See his [CV](http://www.nbertagnolli.com/assets/Bertagnolli_CV.pdf), [research](http://www.nbertagnolli.com/), and [Medium articles here](https://nbertagnolli.medium.com/).
**Fun Fact:** Nic lived in a van and traveled around the western United States for three years before starting work at BEN.
**BEN:** An entertainment AI company that places brands inside influencer, streaming, TV, and film content to connect brands with audiences in a way that advertisements cannot.
#### **1. How has ML made a positive impact on Marketing?**
In so many ways! It’s completely changing the landscape. Marketing is a field steeped in tradition based on gut feelings. In the past 20 years, there has been a move to more and more statistically informed marketing decisions but many brands are still relying on the gut instincts of their marketing departments. ML is revolutionizing this. With the ability to analyze data about which advertisements perform well we can make really informed decisions about how and who we market to.
At BEN, ML has really helped us take the guesswork out of a lot of the process when dealing with influencer marketing. Data helps shine a light through the fog of bias and subjectivity so that we can make informed decisions.
That’s just the obvious stuff! ML is also making it possible to make safer marketing decisions for brands. For example, it’s illegal to advertise alcohol to people under the age of 21. Using machine learning we can identify influencers whose audiences are mainly above 21. This scales our ability to help alcohol brands, and also brands who are worried about their image being associated with alcohol.
#### **2. What are the biggest ML challenges within Marketing?**
As with most things in Machine Learning the problems often aren’t really with the models themselves. With tools like [Hugging Face](http://huggingface.co), [torch hub](https://pytorch.org/docs/stable/hub.html), etc. so many great and flexible models are available to work with.
The real challenges have to do with collecting, cleaning, and managing the data. If we want to talk about the hard ML-y bits of the job, some of it comes down to the fact that there is a lot of noise in what people view and enjoy. Understanding things like virality are really really hard.
Understanding what makes a creator/influencer successful over time is really hard. There is a lot of weird preference information buried in some pretty noisy difficult-to-acquire data. These problems come down to having really solid communication between data, ML, and business teams, and building models which augment and collaborate with humans instead of fully automating away their roles.
#### **3. What’s a common mistake you see people make trying to integrate ML into Marketing?**
I don’t think this is exclusive to marketing but prioritizing machine learning and data science over good infrastructure is a big problem I see often. Organizations hear about ML and want to get a piece of the pie so they hire some data scientists only to find out that they don’t have any infrastructure to service their new fancy pants models. A ton of the value of ML is in the infrastructure around the models and if you’ve got trained models but no infrastructure you’re hosed.
One of the really nice things about BEN is we invested heavily in our data infrastructure and built the horse before the cart. Now Data Scientists can build models that get served to our end users quickly instead of having to figure out every step of that pipeline themselves. Invest in data engineering before hiring lots of ML folks.
#### **4. What excites you most about the future of ML?**
There is so much exciting stuff going on. I think the pace and democratization of the field is perhaps what I find most exciting. I remember almost 10 years ago writing my first seq2seq model for language translation. It was hundreds of lines of code, took forever to train and was pretty challenging. Now you can basically build a system to translate any language to any other language in under 100 lines of python code. It’s insane! This trend is most likely to continue and as the ML infrastructure gets better and better it will be easier and easier for people without deep domain expertise to deploy and serve models to other people.
Much like in the beginning of the internet, software developers were few and far between and you needed a skilled team to set up a website. Then things like Django, Rails, etc. came out making website building easy but serving it was hard. We’re kind of at this place where building the models is easy but serving them reliably, monitoring them reliably, etc. is still challenging. I think in the next few years the barrier to entry is going to come WAY down here and basically, any high schooler could deploy a deep transformer to some cloud infrastructure and start serving useful results to the general population. This is really exciting because it means we’ll start to see more and more tangible innovation, much like the explosion of online services. So many cool things!
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/61_ml_director_insights/Eric-Golinko.jpeg"></a>
### [Eric Golinko](https://www.linkedin.com/in/eric-golinko/) - Director of Machine Learning at [E Source](https://www.esource.com/)
**Background:** Experienced data practitioner and team builder. I’ve worked in many industries across companies of different sizes. I’m a problem solver, by training a mathematician and computer scientist. But, above all, I value relationships, family, dogs, travel and pizza.
**Fun Fact:** Eric adores nachos!
**E Source:** Provides independent market intelligence, consulting, and predictive data science to utilities, major energy users, and other key players in the retail energy marketplace.
#### **1. How has ML made a positive impact on the Energy/Utility industry?**
Access to business insight. Provided a pre-requisite is great data. Utilities have many data relationships within their data portfolio from customers to devices, more specifically, this speaks to monthly billing amounts and enrollment in energy savings programs. Data like that could be stored in a relational database, whereas device or asset data we can think of as the pieces of machinery that make our grid. Bridging those types of data is non-trivial.
In addition, third-party data spatial/gis and weather are extremely important. Through the lens of machine learning, we are able to find and explore features and outcomes that have a real impact.
#### **2. What are the biggest ML challenges within Utilities?**
There is a demystification that needs to happen. What machine learning can do and where it needs to be monitored or could fall short. The utility industry has established ways of operating, machine learning can be perceived as a disruptor. Because of this, departments can be slow to adopt any new technology or paradigm. However, if the practitioner is able to prove results, then results create traction and a larger appetite to adopt. Additional challenges are on-premise data and access to the cloud and infrastructure. It’s a gradual process and has a learning curve that requires patience.
#### **3. What’s a common mistake you see people make trying to integrate ML into Utilities?**
Not unique to utilizes, but moving too fast and neglecting good data quality and simple quality checks. Aside from this machine learning is practiced among many groups in some direct or indirect way. A challenge is integrating best development practices across teams. This also means model tracking and being able to persist experiments and continuous discovery.
#### **4. What excites you most about the future of ML?**
I’ve been doing this for over a decade, and I somehow still feel like a novice. I feel fortunate to have been part of teams where I’d be lucky to be called the average member. My feeling is that the next ten years and beyond will be more focused on data engineering to see even a larger number of use cases covered by machine learning.
---
🤗 Thank you for joining us in this first installment of ML Director Insights. Stay tuned for more insights from ML Directors in SaaS, Finance, and e-Commerce.
Big thanks to Eric Golinko, Nicolas Bertagnolli, Nathan Cahill, Alina Zare, Li Tan, and Archi Mitra for their brilliant insights and participation in this piece. We look forward to watching each of your continued successes and will be cheering you on each step of the way. 🎉
Lastly, if you or your team are interested in accelerating your ML roadmap with Hugging Face Experts please visit [hf.co/support](https://huggingface.co/support?utm_source=article&utm_medium=blog&utm_campaign=ml_director_insights_1) to learn more.
|
huggingface/blog/blob/main/ml-director-insights.md
|
The Deep Q-Learning Algorithm [[deep-q-algorithm]]
We learned that Deep Q-Learning **uses a deep neural network to approximate the different Q-values for each possible action at a state** (value-function estimation).
The difference is that, during the training phase, instead of updating the Q-value of a state-action pair directly as we have done with Q-Learning:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/q-ex-5.jpg" alt="Q Loss"/>
in Deep Q-Learning, we create a **loss function that compares our Q-value prediction and the Q-target and uses gradient descent to update the weights of our Deep Q-Network to approximate our Q-values better**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit4/Q-target.jpg" alt="Q-target"/>
The Deep Q-Learning training algorithm has *two phases*:
- **Sampling**: we perform actions and **store the observed experience tuples in a replay memory**.
- **Training**: Select a **small batch of tuples randomly and learn from this batch using a gradient descent update step**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit4/sampling-training.jpg" alt="Sampling Training"/>
This is not the only difference compared with Q-Learning. Deep Q-Learning training **might suffer from instability**, mainly because of combining a non-linear Q-value function (Neural Network) and bootstrapping (when we update targets with existing estimates and not an actual complete return).
To help us stabilize the training, we implement three different solutions:
1. *Experience Replay* to make more **efficient use of experiences**.
2. *Fixed Q-Target* **to stabilize the training**.
3. *Double Deep Q-Learning*, to **handle the problem of the overestimation of Q-values**.
Let's go through them!
## Experience Replay to make more efficient use of experiences [[exp-replay]]
Why do we create a replay memory?
Experience Replay in Deep Q-Learning has two functions:
1. **Make more efficient use of the experiences during the training**.
Usually, in online reinforcement learning, the agent interacts with the environment, gets experiences (state, action, reward, and next state), learns from them (updates the neural network), and discards them. This is not efficient.
Experience replay helps by **using the experiences of the training more efficiently**. We use a replay buffer that saves experience samples **that we can reuse during the training.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit4/experience-replay.jpg" alt="Experience Replay"/>
⇒ This allows the agent to **learn from the same experiences multiple times**.
2. **Avoid forgetting previous experiences (aka catastrophic interference, or catastrophic forgetting) and reduce the correlation between experiences**.
- **[catastrophic forgetting](https://en.wikipedia.org/wiki/Catastrophic_interference)**: The problem we get if we give sequential samples of experiences to our neural network is that it tends to forget **the previous experiences as it gets new experiences.** For instance, if the agent is in the first level and then in the second, which is different, it can forget how to behave and play in the first level.
The solution is to create a Replay Buffer that stores experience tuples while interacting with the environment and then sample a small batch of tuples. This prevents **the network from only learning about what it has done immediately before.**
Experience replay also has other benefits. By randomly sampling the experiences, we remove correlation in the observation sequences and avoid **action values from oscillating or diverging catastrophically.**
In the Deep Q-Learning pseudocode, we **initialize a replay memory buffer D with capacity N** (N is a hyperparameter that you can define). We then store experiences in the memory and sample a batch of experiences to feed the Deep Q-Network during the training phase.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit4/experience-replay-pseudocode.jpg" alt="Experience Replay Pseudocode"/>
## Fixed Q-Target to stabilize the training [[fixed-q]]
When we want to calculate the TD error (aka the loss), we calculate the **difference between the TD target (Q-Target) and the current Q-value (estimation of Q)**.
But we **don’t have any idea of the real TD target**. We need to estimate it. Using the Bellman equation, we saw that the TD target is just the reward of taking that action at that state plus the discounted highest Q value for the next state.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit4/Q-target.jpg" alt="Q-target"/>
However, the problem is that we are using the same parameters (weights) for estimating the TD target **and** the Q-value. Consequently, there is a significant correlation between the TD target and the parameters we are changing.
Therefore, at every step of training, **both our Q-values and the target values shift.** We’re getting closer to our target, but the target is also moving. It’s like chasing a moving target! This can lead to significant oscillation in training.
It’s like if you were a cowboy (the Q estimation) and you wanted to catch a cow (the Q-target). Your goal is to get closer (reduce the error).
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit4/qtarget-1.jpg" alt="Q-target"/>
At each time step, you’re trying to approach the cow, which also moves at each time step (because you use the same parameters).
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit4/qtarget-2.jpg" alt="Q-target"/>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit4/qtarget-3.jpg" alt="Q-target"/>
This leads to a bizarre path of chasing (a significant oscillation in training).
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit4/qtarget-4.jpg" alt="Q-target"/>
Instead, what we see in the pseudo-code is that we:
- Use a **separate network with fixed parameters** for estimating the TD Target
- **Copy the parameters from our Deep Q-Network every C steps** to update the target network.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit4/fixed-q-target-pseudocode.jpg" alt="Fixed Q-target Pseudocode"/>
## Double DQN [[double-dqn]]
Double DQNs, or Double Deep Q-Learning neural networks, were introduced [by Hado van Hasselt](https://papers.nips.cc/paper/3964-double-q-learning). This method **handles the problem of the overestimation of Q-values.**
To understand this problem, remember how we calculate the TD Target:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/TD-1.jpg" alt="TD target"/>
We face a simple problem by calculating the TD target: how are we sure that **the best action for the next state is the action with the highest Q-value?**
We know that the accuracy of Q-values depends on what action we tried **and** what neighboring states we explored.
Consequently, we don’t have enough information about the best action to take at the beginning of the training. Therefore, taking the maximum Q-value (which is noisy) as the best action to take can lead to false positives. If non-optimal actions are regularly **given a higher Q value than the optimal best action, the learning will be complicated.**
The solution is: when we compute the Q target, we use two networks to decouple the action selection from the target Q-value generation. We:
- Use our **DQN network** to select the best action to take for the next state (the action with the highest Q-value).
- Use our **Target network** to calculate the target Q-value of taking that action at the next state.
Therefore, Double DQN helps us reduce the overestimation of Q-values and, as a consequence, helps us train faster and with more stable learning.
Since these three improvements in Deep Q-Learning, many more have been added, such as Prioritized Experience Replay and Dueling Deep Q-Learning. They’re out of the scope of this course but if you’re interested, check the links we put in the reading list.
|
huggingface/deep-rl-class/blob/main/units/en/unit3/deep-q-algorithm.mdx
|
Gradio Demo: sepia_filter
```
!pip install -q gradio
```
```
import numpy as np
import gradio as gr
def sepia(input_img):
sepia_filter = np.array([
[0.393, 0.769, 0.189],
[0.349, 0.686, 0.168],
[0.272, 0.534, 0.131]
])
sepia_img = input_img.dot(sepia_filter.T)
sepia_img /= sepia_img.max()
return sepia_img
demo = gr.Interface(sepia, gr.Image(), "image")
if __name__ == "__main__":
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/sepia_filter/run.ipynb
|
--
title: "My Journey to a serverless transformers pipeline on Google Cloud"
thumbnail: /blog/assets/14_how_to_deploy_a_pipeline_to_google_clouds/thumbnail.png
authors:
- user: Maxence
guest: true
---
# My Journey to a serverless transformers pipeline on <br>Google Cloud
> ##### A guest blog post by community member <a href="/Maxence">Maxence Dominici</a>
This article will discuss my journey to deploy the `transformers` _sentiment-analysis_ pipeline on [Google Cloud](https://cloud.google.com). We will start with a quick introduction to `transformers` and then move to the technical part of the implementation. Finally, we'll summarize this implementation and review what we have achieved.
## The Goal

I wanted to create a micro-service that automatically detects whether a customer review left in Discord is positive or negative. This would allow me to treat the comment accordingly and improve the customer experience. For instance, if the review was negative, I could create a feature which would contact the customer, apologize for the poor quality of service, and inform him/her that our support team will contact him/her as soon as possible to assist him and hopefully fix the problem. Since I don't plan to get more than 2,000 requests per month, I didn't impose any performance constraints regarding the time and the scalability.
## The Transformers library
I was a bit confused at the beginning when I downloaded the .h5 file. I thought it would be compatible with `tensorflow.keras.models.load_model`, but this wasn't the case. After a few minutes of research I was able to figure out that the file was a weights checkpoint rather than a Keras model.
After that, I tried out the API that Hugging Face offers and read a bit more about the pipeline feature they offer. Since the results of the API & the pipeline were great, I decided that I could serve the model through the pipeline on my own server.
Below is the [official example](https://github.com/huggingface/transformers#quick-tour) from the Transformers GitHub page.
```python
from transformers import pipeline
# Allocate a pipeline for sentiment-analysis
classifier = pipeline('sentiment-analysis')
classifier('We are very happy to include pipeline into the transformers repository.')
[{'label': 'POSITIVE', 'score': 0.9978193640708923}]
```
## Deploy transformers to Google Cloud
> GCP is chosen as it is the cloud environment I am using in my personal organization.
### Step 1 - Research
I already knew that I could use an API-Service like `flask` to serve a `transformers` model. I searched in the Google Cloud AI documentation and found a service to host Tensorflow models named [AI-Platform Prediction](https://cloud.google.com/ai-platform/prediction/docs). I also found [App Engine](https://cloud.google.com/appengine) and [Cloud Run](https://cloud.google.com/run) there, but I was concerned about the memory usage for App Engine and was not very familiar with Docker.
### Step 2 - Test on AI-Platform Prediction
As the model is not a "pure TensorFlow" saved model but a checkpoint, and I couldn't turn it into a "pure TensorFlow model", I figured out that the example on [this page](https://cloud.google.com/ai-platform/prediction/docs/deploying-models) wouldn't work.
From there I saw that I could write some custom code, allowing me to load the `pipeline` instead of having to handle the model, which seemed is easier. I also learned that I could define a pre-prediction & post-prediction action, which could be useful in the future for pre- or post-processing the data for customers' needs.
I followed Google's guide but encountered an issue as the service is still in beta and everything is not stable. This issue is detailed [here](https://github.com/huggingface/transformers/issues/9926).
### Step 3 - Test on App Engine
I moved to Google's [App Engine](https://cloud.google.com/appengine) as it's a service that I am familiar with, but encountered an installation issue with TensorFlow due to a missing system dependency file. I then tried with PyTorch which worked with an F4_1G instance, but it couldn't handle more than 2 requests on the same instance, which isn't really great performance-wise.
### Step 4 - Test on Cloud Run
Lastly, I moved to [Cloud Run](https://cloud.google.com/run) with a docker image. I followed [this guide](https://cloud.google.com/run/docs/quickstarts/build-and-deploy#python) to get an idea of how it works. In Cloud Run, I could configure a higher memory and more vCPUs to perform the prediction with PyTorch. I ditched Tensorflow as PyTorch seems to load the model faster.
## Implementation of the serverless pipeline
The final solution consists of four different components:
- `main.py` handling the request to the pipeline
- `Dockerfile` used to create the image that will be deployed on Cloud Run.
- Model folder having the `pytorch_model.bin`, `config.json` and `vocab.txt`.
- Model : [DistilBERT base uncased finetuned SST-2
](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english)
- To download the model folder, follow the instructions in the button. 
- You don't need to keep the `rust_model.ot` or the `tf_model.h5` as we will use [PyTorch](https://pytorch.org/).
- `requirement.txt` for installing the dependencies
The content on the `main.py` is really simple. The idea is to receive a `GET` request containing two fields. First the review that needs to be analysed, second the API key to "protect" the service. The second parameter is optional, I used it to avoid setting up the oAuth2 of Cloud Run. After these arguments are provided, we load the pipeline which is built based on the model `distilbert-base-uncased-finetuned-sst-2-english` (provided above). In the end, the best match is returned to the client.
```python
import os
from flask import Flask, jsonify, request
from transformers import pipeline
app = Flask(__name__)
model_path = "./model"
@app.route('/')
def classify_review():
review = request.args.get('review')
api_key = request.args.get('api_key')
if review is None or api_key != "MyCustomerApiKey":
return jsonify(code=403, message="bad request")
classify = pipeline("sentiment-analysis", model=model_path, tokenizer=model_path)
return classify("that was great")[0]
if __name__ == '__main__':
# This is used when running locally only. When deploying to Google Cloud
# Run, a webserver process such as Gunicorn will serve the app.
app.run(debug=False, host="0.0.0.0", port=int(os.environ.get("PORT", 8080)))
```
Then the `DockerFile` which will be used to create a docker image of the service. We specify that our service runs with python:3.7, plus that we need to install our requirements. Then we use `gunicorn` to handle our process on the port `5000`.
```dockerfile
# Use Python37
FROM python:3.7
# Allow statements and log messages to immediately appear in the Knative logs
ENV PYTHONUNBUFFERED True
# Copy requirements.txt to the docker image and install packages
COPY requirements.txt /
RUN pip install -r requirements.txt
# Set the WORKDIR to be the folder
COPY . /app
# Expose port 5000
EXPOSE 5000
ENV PORT 5000
WORKDIR /app
# Use gunicorn as the entrypoint
CMD exec gunicorn --bind :$PORT main:app --workers 1 --threads 1 --timeout 0
```
It is important to note the arguments `--workers 1 --threads 1` which means that I want to execute my app on only one worker (= 1 process) with a single thread. This is because I don't want to have 2 instances up at once because it might increase the billing. One of the downsides is that it will take more time to process if the service receives two requests at once. After that, I put the limit to one thread due to the memory usage needed for loading the model into the pipeline. If I were using 4 threads, I might have 4 Gb / 4 = 1 Gb only to perform the full process, which is not enough and would lead to a memory error.
Finally, the `requirement.txt` file
```python
Flask==1.1.2
torch===1.7.1
transformers~=4.2.0
gunicorn>=20.0.0
```
## Deployment instructions
First, you will need to meet some requirements such as having a project on Google Cloud, enabling the billing and installing the `gcloud` cli. You can find more details about it in the [Google's guide - Before you begin](https://cloud.google.com/run/docs/quickstarts/build-and-deploy#before-you-begin),
Second, we need to build the docker image and deploy it to cloud run by selecting the correct project (replace `PROJECT-ID`) and set the name of the instance such as `ai-customer-review`. You can find more information about the deployment on [Google's guide - Deploying to](https://cloud.google.com/run/docs/quickstarts/build-and-deploy#deploying_to).
```shell
gcloud builds submit --tag gcr.io/PROJECT-ID/ai-customer-review
gcloud run deploy --image gcr.io/PROJECT-ID/ai-customer-review --platform managed
```
After a few minutes, you will also need to upgrade the memory allocated to your Cloud Run instance from 256 MB to 4 Gb. To do so, head over to the [Cloud Run Console](https://console.cloud.google.com/run) of your project.
There you should find your instance, click on it.

After that you will have a blue button labelled "edit and deploy new revision" on top of the screen, click on it and you'll be prompt many configuration fields. At the bottom you should find a "Capacity" section where you can specify the memory.

## Performances

Handling a request takes less than five seconds from the moment you send the request including loading the model into the pipeline, and prediction. The cold start might take up an additional 10 seconds more or less.
We can improve the request handling performance by warming the model, it means loading it on start-up instead on each request (global variable for example), by doing so, we win time and memory usage.
## Costs
I simulated the cost based on the Cloud Run instance configuration with [Google pricing simulator](https://cloud.google.com/products/calculator#id=cd314cba-1d9a-4bc6-a7c0-740bbf6c8a78)

For my micro-service, I am planning to near 1,000 requests per month, optimistically. 500 may more likely for my usage. That's why I considered 2,000 requests as an upper bound when designing my microservice.
Due to that low number of requests, I didn't bother so much regarding the scalability but might come back into it if my billing increases.
Nevertheless, it's important to stress that you will pay the storage for each Gigabyte of your build image. It's roughly €0.10 per Gb per month, which is fine if you don't keep all your versions on the cloud since my version is slightly above 1 Gb (Pytorch for 700 Mb & the model for 250 Mb).
## Conclusion
By using Transformers' sentiment analysis pipeline, I saved a non-negligible amount of time. Instead of training/fine-tuning a model, I could find one ready to be used in production and start the deployment in my system. I might fine-tune it in the future, but as shown on my test, the accuracy is already amazing!
I would have liked a "pure TensorFlow" model, or at least a way to load it in TensorFlow without Transformers dependencies to use the AI platform. It would also be great to have a lite version.
|
huggingface/blog/blob/main/how-to-deploy-a-pipeline-to-google-clouds.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# LLM prompting guide
[[open-in-colab]]
Large Language Models such as Falcon, LLaMA, etc. are pretrained transformer models initially trained to predict the
next token given some input text. They typically have billions of parameters and have been trained on trillions of
tokens for an extended period of time. As a result, these models become quite powerful and versatile, and you can use
them to solve multiple NLP tasks out of the box by instructing the models with natural language prompts.
Designing such prompts to ensure the optimal output is often called "prompt engineering". Prompt engineering is an
iterative process that requires a fair amount of experimentation. Natural languages are much more flexible and expressive
than programming languages, however, they can also introduce some ambiguity. At the same time, prompts in natural language
are quite sensitive to changes. Even minor modifications in prompts can lead to wildly different outputs.
While there is no exact recipe for creating prompts to match all cases, researchers have worked out a number of best
practices that help to achieve optimal results more consistently.
This guide covers the prompt engineering best practices to help you craft better LLM prompts and solve various NLP tasks.
You'll learn:
- [Basics of prompting](#basic-prompts)
- [Best practices of LLM prompting](#best-practices-of-llm-prompting)
- [Advanced prompting techniques: few-shot prompting and chain-of-thought](#advanced-prompting-techniques)
- [When to fine-tune instead of prompting](#prompting-vs-fine-tuning)
<Tip>
Prompt engineering is only a part of the LLM output optimization process. Another essential component is choosing the
optimal text generation strategy. You can customize how your LLM selects each of the subsequent tokens when generating
the text without modifying any of the trainable parameters. By tweaking the text generation parameters, you can reduce
repetition in the generated text and make it more coherent and human-sounding.
Text generation strategies and parameters are out of scope for this guide, but you can learn more about these topics in
the following guides:
* [Generation with LLMs](../llm_tutorial)
* [Text generation strategies](../generation_strategies)
</Tip>
## Basics of prompting
### Types of models
The majority of modern LLMs are decoder-only transformers. Some examples include: [LLaMA](../model_doc/llama),
[Llama2](../model_doc/llama2), [Falcon](../model_doc/falcon), [GPT2](../model_doc/gpt2). However, you may encounter
encoder-decoder transformer LLMs as well, for instance, [Flan-T5](../model_doc/flan-t5) and [BART](../model_doc/bart).
Encoder-decoder-style models are typically used in generative tasks where the output **heavily** relies on the input, for
example, in translation and summarization. The decoder-only models are used for all other types of generative tasks.
When using a pipeline to generate text with an LLM, it's important to know what type of LLM you are using, because
they use different pipelines.
Run inference with decoder-only models with the `text-generation` pipeline:
```python
>>> from transformers import pipeline
>>> import torch
>>> torch.manual_seed(0) # doctest: +IGNORE_RESULT
>>> generator = pipeline('text-generation', model = 'gpt2')
>>> prompt = "Hello, I'm a language model"
>>> generator(prompt, max_length = 30)
[{'generated_text': "Hello, I'm a language model expert, so I'm a big believer in the concept that I know very well and then I try to look into"}]
```
To run inference with an encoder-decoder, use the `text2text-generation` pipeline:
```python
>>> text2text_generator = pipeline("text2text-generation", model = 'google/flan-t5-base')
>>> prompt = "Translate from English to French: I'm very happy to see you"
>>> text2text_generator(prompt)
[{'generated_text': 'Je suis très heureuse de vous rencontrer.'}]
```
### Base vs instruct/chat models
Most of the recent LLM checkpoints available on 🤗 Hub come in two versions: base and instruct (or chat). For example,
[`tiiuae/falcon-7b`](https://huggingface.co/tiiuae/falcon-7b) and [`tiiuae/falcon-7b-instruct`](https://huggingface.co/tiiuae/falcon-7b-instruct).
Base models are excellent at completing the text when given an initial prompt, however, they are not ideal for NLP tasks
where they need to follow instructions, or for conversational use. This is where the instruct (chat) versions come in.
These checkpoints are the result of further fine-tuning of the pre-trained base versions on instructions and conversational data.
This additional fine-tuning makes them a better choice for many NLP tasks.
Let's illustrate some simple prompts that you can use with [`tiiuae/falcon-7b-instruct`](https://huggingface.co/tiiuae/falcon-7b-instruct)
to solve some common NLP tasks.
### NLP tasks
First, let's set up the environment:
```bash
pip install -q transformers accelerate
```
Next, let's load the model with the appropriate pipeline (`"text-generation"`):
```python
>>> from transformers import pipeline, AutoTokenizer
>>> import torch
>>> torch.manual_seed(0) # doctest: +IGNORE_RESULT
>>> model = "tiiuae/falcon-7b-instruct"
>>> tokenizer = AutoTokenizer.from_pretrained(model)
>>> pipe = pipeline(
... "text-generation",
... model=model,
... tokenizer=tokenizer,
... torch_dtype=torch.bfloat16,
... device_map="auto",
... )
```
<Tip>
Note that Falcon models were trained using the `bfloat16` datatype, so we recommend you use the same. This requires a recent
version of CUDA and works best on modern cards.
</Tip>
Now that we have the model loaded via the pipeline, let's explore how you can use prompts to solve NLP tasks.
#### Text classification
One of the most common forms of text classification is sentiment analysis, which assigns a label like "positive", "negative",
or "neutral" to a sequence of text. Let's write a prompt that instructs the model to classify a given text (a movie review).
We'll start by giving the instruction, and then specifying the text to classify. Note that instead of leaving it at that, we're
also adding the beginning of the response - `"Sentiment: "`:
```python
>>> torch.manual_seed(0) # doctest: +IGNORE_RESULT
>>> prompt = """Classify the text into neutral, negative or positive.
... Text: This movie is definitely one of my favorite movies of its kind. The interaction between respectable and morally strong characters is an ode to chivalry and the honor code amongst thieves and policemen.
... Sentiment:
... """
>>> sequences = pipe(
... prompt,
... max_new_tokens=10,
... )
>>> for seq in sequences:
... print(f"Result: {seq['generated_text']}")
Result: Classify the text into neutral, negative or positive.
Text: This movie is definitely one of my favorite movies of its kind. The interaction between respectable and morally strong characters is an ode to chivalry and the honor code amongst thieves and policemen.
Sentiment:
Positive
```
As a result, the output contains a classification label from the list we have provided in the instructions, and it is a correct one!
<Tip>
You may notice that in addition to the prompt, we pass a `max_new_tokens` parameter. It controls the number of tokens the
model shall generate, and it is one of the many text generation parameters that you can learn about
in [Text generation strategies](../generation_strategies) guide.
</Tip>
#### Named Entity Recognition
Named Entity Recognition (NER) is a task of finding named entities in a piece of text, such as a person, location, or organization.
Let's modify the instructions in the prompt to make the LLM perform this task. Here, let's also set `return_full_text = False`
so that output doesn't contain the prompt:
```python
>>> torch.manual_seed(1) # doctest: +IGNORE_RESULT
>>> prompt = """Return a list of named entities in the text.
... Text: The Golden State Warriors are an American professional basketball team based in San Francisco.
... Named entities:
... """
>>> sequences = pipe(
... prompt,
... max_new_tokens=15,
... return_full_text = False,
... )
>>> for seq in sequences:
... print(f"{seq['generated_text']}")
- Golden State Warriors
- San Francisco
```
As you can see, the model correctly identified two named entities from the given text.
#### Translation
Another task LLMs can perform is translation. You can choose to use encoder-decoder models for this task, however, here,
for the simplicity of the examples, we'll keep using Falcon-7b-instruct, which does a decent job. Once again, here's how
you can write a basic prompt to instruct a model to translate a piece of text from English to Italian:
```python
>>> torch.manual_seed(2) # doctest: +IGNORE_RESULT
>>> prompt = """Translate the English text to Italian.
... Text: Sometimes, I've believed as many as six impossible things before breakfast.
... Translation:
... """
>>> sequences = pipe(
... prompt,
... max_new_tokens=20,
... do_sample=True,
... top_k=10,
... return_full_text = False,
... )
>>> for seq in sequences:
... print(f"{seq['generated_text']}")
A volte, ho creduto a sei impossibili cose prima di colazione.
```
Here we've added a `do_sample=True` and `top_k=10` to allow the model to be a bit more flexible when generating output.
#### Text summarization
Similar to the translation, text summarization is another generative task where the output **heavily** relies on the input,
and encoder-decoder models can be a better choice. However, decoder-style models can be used for this task as well.
Previously, we have placed the instructions at the very beginning of the prompt. However, the very end of the prompt can
also be a suitable location for instructions. Typically, it's better to place the instruction on one of the extreme ends.
```python
>>> torch.manual_seed(3) # doctest: +IGNORE_RESULT
>>> prompt = """Permaculture is a design process mimicking the diversity, functionality and resilience of natural ecosystems. The principles and practices are drawn from traditional ecological knowledge of indigenous cultures combined with modern scientific understanding and technological innovations. Permaculture design provides a framework helping individuals and communities develop innovative, creative and effective strategies for meeting basic needs while preparing for and mitigating the projected impacts of climate change.
... Write a summary of the above text.
... Summary:
... """
>>> sequences = pipe(
... prompt,
... max_new_tokens=30,
... do_sample=True,
... top_k=10,
... return_full_text = False,
... )
>>> for seq in sequences:
... print(f"{seq['generated_text']}")
Permaculture is an ecological design mimicking natural ecosystems to meet basic needs and prepare for climate change. It is based on traditional knowledge and scientific understanding.
```
#### Question answering
For question answering task we can structure the prompt into the following logical components: instructions, context, question, and
the leading word or phrase (`"Answer:"`) to nudge the model to start generating the answer:
```python
>>> torch.manual_seed(4) # doctest: +IGNORE_RESULT
>>> prompt = """Answer the question using the context below.
... Context: Gazpacho is a cold soup and drink made of raw, blended vegetables. Most gazpacho includes stale bread, tomato, cucumbers, onion, bell peppers, garlic, olive oil, wine vinegar, water, and salt. Northern recipes often include cumin and/or pimentón (smoked sweet paprika). Traditionally, gazpacho was made by pounding the vegetables in a mortar with a pestle; this more laborious method is still sometimes used as it helps keep the gazpacho cool and avoids the foam and silky consistency of smoothie versions made in blenders or food processors.
... Question: What modern tool is used to make gazpacho?
... Answer:
... """
>>> sequences = pipe(
... prompt,
... max_new_tokens=10,
... do_sample=True,
... top_k=10,
... return_full_text = False,
... )
>>> for seq in sequences:
... print(f"Result: {seq['generated_text']}")
Result: Modern tools are used, such as immersion blenders
```
#### Reasoning
Reasoning is one of the most difficult tasks for LLMs, and achieving good results often requires applying advanced prompting techniques, like
[Chain-of-though](#chain-of-thought).
Let's try if we can make a model reason about a simple arithmetics task with a basic prompt:
```python
>>> torch.manual_seed(5) # doctest: +IGNORE_RESULT
>>> prompt = """There are 5 groups of students in the class. Each group has 4 students. How many students are there in the class?"""
>>> sequences = pipe(
... prompt,
... max_new_tokens=30,
... do_sample=True,
... top_k=10,
... return_full_text = False,
... )
>>> for seq in sequences:
... print(f"Result: {seq['generated_text']}")
Result:
There are a total of 5 groups, so there are 5 x 4=20 students in the class.
```
Correct! Let's increase the complexity a little and see if we can still get away with a basic prompt:
```python
>>> torch.manual_seed(6) # doctest: +IGNORE_RESULT
>>> prompt = """I baked 15 muffins. I ate 2 muffins and gave 5 muffins to a neighbor. My partner then bought 6 more muffins and ate 2. How many muffins do we now have?"""
>>> sequences = pipe(
... prompt,
... max_new_tokens=10,
... do_sample=True,
... top_k=10,
... return_full_text = False,
... )
>>> for seq in sequences:
... print(f"Result: {seq['generated_text']}")
Result:
The total number of muffins now is 21
```
This is a wrong answer, it should be 12. In this case, this can be due to the prompt being too basic, or due to the choice
of model, after all we've picked the smallest version of Falcon. Reasoning is difficult for models of all sizes, but larger
models are likely to perform better.
## Best practices of LLM prompting
In this section of the guide we have compiled a list of best practices that tend to improve the prompt results:
* When choosing the model to work with, the latest and most capable models are likely to perform better.
* Start with a simple and short prompt, and iterate from there.
* Put the instructions at the beginning of the prompt, or at the very end. When working with large context, models apply various optimizations to prevent Attention complexity from scaling quadratically. This may make a model more attentive to the beginning or end of a prompt than the middle.
* Clearly separate instructions from the text they apply to - more on this in the next section.
* Be specific and descriptive about the task and the desired outcome - its format, length, style, language, etc.
* Avoid ambiguous descriptions and instructions.
* Favor instructions that say "what to do" instead of those that say "what not to do".
* "Lead" the output in the right direction by writing the first word (or even begin the first sentence for the model).
* Use advanced techniques like [Few-shot prompting](#few-shot-prompting) and [Chain-of-thought](#chain-of-thought)
* Test your prompts with different models to assess their robustness.
* Version and track the performance of your prompts.
## Advanced prompting techniques
### Few-shot prompting
The basic prompts in the sections above are the examples of "zero-shot" prompts, meaning, the model has been given
instructions and context, but no examples with solutions. LLMs that have been fine-tuned on instruction datasets, generally
perform well on such "zero-shot" tasks. However, you may find that your task has more complexity or nuance, and, perhaps,
you have some requirements for the output that the model doesn't catch on just from the instructions. In this case, you can
try the technique called few-shot prompting.
In few-shot prompting, we provide examples in the prompt giving the model more context to improve the performance.
The examples condition the model to generate the output following the patterns in the examples.
Here's an example:
```python
>>> torch.manual_seed(0) # doctest: +IGNORE_RESULT
>>> prompt = """Text: The first human went into space and orbited the Earth on April 12, 1961.
... Date: 04/12/1961
... Text: The first-ever televised presidential debate in the United States took place on September 28, 1960, between presidential candidates John F. Kennedy and Richard Nixon.
... Date:"""
>>> sequences = pipe(
... prompt,
... max_new_tokens=8,
... do_sample=True,
... top_k=10,
... )
>>> for seq in sequences:
... print(f"Result: {seq['generated_text']}")
Result: Text: The first human went into space and orbited the Earth on April 12, 1961.
Date: 04/12/1961
Text: The first-ever televised presidential debate in the United States took place on September 28, 1960, between presidential candidates John F. Kennedy and Richard Nixon.
Date: 09/28/1960
```
In the above code snippet we used a single example to demonstrate the desired output to the model, so this can be called a
"one-shot" prompting. However, depending on the task complexity you may need to use more than one example.
Limitations of the few-shot prompting technique:
- While LLMs can pick up on the patterns in the examples, these technique doesn't work well on complex reasoning tasks
- Few-shot prompting requires creating lengthy prompts. Prompts with large number of tokens can increase computation and latency. There's also a limit to the length of the prompts.
- Sometimes when given a number of examples, models can learn patterns that you didn't intend them to learn, e.g. that the third movie review is always negative.
### Chain-of-thought
Chain-of-thought (CoT) prompting is a technique that nudges a model to produce intermediate reasoning steps thus improving
the results on complex reasoning tasks.
There are two ways of steering a model to producing the reasoning steps:
- few-shot prompting by illustrating examples with detailed answers to questions, showing the model how to work through a problem.
- by instructing the model to reason by adding phrases like "Let's think step by step" or "Take a deep breath and work through the problem step by step."
If we apply the CoT technique to the muffins example from the [reasoning section](#reasoning) and use a larger model,
such as (`tiiuae/falcon-180B-chat`) which you can play with in the [HuggingChat](https://huggingface.co/chat/),
we'll get a significant improvement on the reasoning result:
```text
Let's go through this step-by-step:
1. You start with 15 muffins.
2. You eat 2 muffins, leaving you with 13 muffins.
3. You give 5 muffins to your neighbor, leaving you with 8 muffins.
4. Your partner buys 6 more muffins, bringing the total number of muffins to 14.
5. Your partner eats 2 muffins, leaving you with 12 muffins.
Therefore, you now have 12 muffins.
```
## Prompting vs fine-tuning
You can achieve great results by optimizing your prompts, however, you may still ponder whether fine-tuning a model
would work better for your case. Here are some scenarios when fine-tuning a smaller model may be a preferred option:
- Your domain is wildly different from what LLMs were pre-trained on and extensive prompt optimization did not yield sufficient results.
- You need your model to work well in a low-resource language.
- You need the model to be trained on sensitive data that is under strict regulations.
- You have to use a small model due to cost, privacy, infrastructure or other limitations.
In all of the above examples, you will need to make sure that you either already have or can easily obtain a large enough
domain-specific dataset at a reasonable cost to fine-tune a model. You will also need to have enough time and resources
to fine-tune a model.
If the above examples are not the case for you, optimizing prompts can prove to be more beneficial.
|
huggingface/transformers/blob/main/docs/source/en/tasks/prompting.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# XLA Integration for TensorFlow Models
[[open-in-colab]]
Accelerated Linear Algebra, dubbed XLA, is a compiler for accelerating the runtime of TensorFlow Models. From the [official documentation](https://www.tensorflow.org/xla):
XLA (Accelerated Linear Algebra) is a domain-specific compiler for linear algebra that can accelerate TensorFlow models with potentially no source code changes.
Using XLA in TensorFlow is simple – it comes packaged inside the `tensorflow` library, and it can be triggered with the `jit_compile` argument in any graph-creating function such as [`tf.function`](https://www.tensorflow.org/guide/intro_to_graphs). When using Keras methods like `fit()` and `predict()`, you can enable XLA simply by passing the `jit_compile` argument to `model.compile()`. However, XLA is not limited to these methods - it can also be used to accelerate any arbitrary `tf.function`.
Several TensorFlow methods in 🤗 Transformers have been rewritten to be XLA-compatible, including text generation for models such as [GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2), [T5](https://huggingface.co/docs/transformers/model_doc/t5) and [OPT](https://huggingface.co/docs/transformers/model_doc/opt), as well as speech processing for models such as [Whisper](https://huggingface.co/docs/transformers/model_doc/whisper).
While the exact amount of speed-up is very much model-dependent, for TensorFlow text generation models inside 🤗 Transformers, we noticed a speed-up of ~100x. This document will explain how you can use XLA for these models to get the maximum amount of performance. We’ll also provide links to additional resources if you’re interested to learn more about the benchmarks and our design philosophy behind the XLA integration.
## Running TF functions with XLA
Let us consider the following model in TensorFlow:
```py
import tensorflow as tf
model = tf.keras.Sequential(
[tf.keras.layers.Dense(10, input_shape=(10,), activation="relu"), tf.keras.layers.Dense(5, activation="softmax")]
)
```
The above model accepts inputs having a dimension of `(10, )`. We can use the model for running a forward pass like so:
```py
# Generate random inputs for the model.
batch_size = 16
input_vector_dim = 10
random_inputs = tf.random.normal((batch_size, input_vector_dim))
# Run a forward pass.
_ = model(random_inputs)
```
In order to run the forward pass with an XLA-compiled function, we’d need to do:
```py
xla_fn = tf.function(model, jit_compile=True)
_ = xla_fn(random_inputs)
```
The default `call()` function of the `model` is used for compiling the XLA graph. But if there’s any other model function you want to compile into XLA that’s also possible with:
```py
my_xla_fn = tf.function(model.my_xla_fn, jit_compile=True)
```
## Running a TF text generation model with XLA from 🤗 Transformers
To enable XLA-accelerated generation within 🤗 Transformers, you need to have a recent version of `transformers` installed. You can install it by running:
```bash
pip install transformers --upgrade
```
And then you can run the following code:
```py
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
# Will error if the minimal version of Transformers is not installed.
from transformers.utils import check_min_version
check_min_version("4.21.0")
tokenizer = AutoTokenizer.from_pretrained("gpt2", padding_side="left", pad_token="</s>")
model = TFAutoModelForCausalLM.from_pretrained("gpt2")
input_string = ["TensorFlow is"]
# One line to create an XLA generation function
xla_generate = tf.function(model.generate, jit_compile=True)
tokenized_input = tokenizer(input_string, return_tensors="tf")
generated_tokens = xla_generate(**tokenized_input, num_beams=2)
decoded_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)
print(f"Generated -- {decoded_text}")
# Generated -- TensorFlow is an open-source, open-source, distributed-source application # framework for the
```
As you can notice, enabling XLA on `generate()` is just a single line of code. The rest of the code remains unchanged. However, there are a couple of gotchas in the above code snippet that are specific to XLA. You need to be aware of those to realize the speed-ups that XLA can bring in. We discuss these in the following section.
## Gotchas to be aware of
When you are executing an XLA-enabled function (like `xla_generate()` above) for the first time, it will internally try to infer the computation graph, which is time-consuming. This process is known as [“tracing”](https://www.tensorflow.org/guide/intro_to_graphs#when_is_a_function_tracing).
You might notice that the generation time is not fast. Successive calls of `xla_generate()` (or any other XLA-enabled function) won’t have to infer the computation graph, given the inputs to the function follow the same shape with which the computation graph was initially built. While this is not a problem for modalities with fixed input shapes (e.g., images), you must pay attention if you are working with variable input shape modalities (e.g., text).
To ensure `xla_generate()` always operates with the same input shapes, you can specify the `padding` arguments when calling the tokenizer.
```py
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("gpt2", padding_side="left", pad_token="</s>")
model = TFAutoModelForCausalLM.from_pretrained("gpt2")
input_string = ["TensorFlow is"]
xla_generate = tf.function(model.generate, jit_compile=True)
# Here, we call the tokenizer with padding options.
tokenized_input = tokenizer(input_string, pad_to_multiple_of=8, padding=True, return_tensors="tf")
generated_tokens = xla_generate(**tokenized_input, num_beams=2)
decoded_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)
print(f"Generated -- {decoded_text}")
```
This way, you can ensure that the inputs to `xla_generate()` will always receive inputs with the shape it was traced with and thus leading to speed-ups in the generation time. You can verify this with the code below:
```py
import time
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("gpt2", padding_side="left", pad_token="</s>")
model = TFAutoModelForCausalLM.from_pretrained("gpt2")
xla_generate = tf.function(model.generate, jit_compile=True)
for input_string in ["TensorFlow is", "TensorFlow is a", "TFLite is a"]:
tokenized_input = tokenizer(input_string, pad_to_multiple_of=8, padding=True, return_tensors="tf")
start = time.time_ns()
generated_tokens = xla_generate(**tokenized_input, num_beams=2)
end = time.time_ns()
print(f"Execution time -- {(end - start) / 1e6:.1f} ms\n")
```
On a Tesla T4 GPU, you can expect the outputs like so:
```bash
Execution time -- 30819.6 ms
Execution time -- 79.0 ms
Execution time -- 78.9 ms
```
The first call to `xla_generate()` is time-consuming because of tracing, but the successive calls are orders of magnitude faster. Keep in mind that any change in the generation options at any point with trigger re-tracing and thus leading to slow-downs in the generation time.
We didn’t cover all the text generation options 🤗 Transformers provides in this document. We encourage you to read the documentation for advanced use cases.
## Additional Resources
Here, we leave you with some additional resources if you want to delve deeper into XLA in 🤗 Transformers and in general.
* [This Colab Notebook](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/91_tf_xla_generate.ipynb) provides an interactive demonstration if you want to fiddle with the XLA-compatible encoder-decoder (like [T5](https://huggingface.co/docs/transformers/model_doc/t5)) and decoder-only (like [GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2)) text generation models.
* [This blog post](https://huggingface.co/blog/tf-xla-generate) provides an overview of the comparison benchmarks for XLA-compatible models along with a friendly introduction to XLA in TensorFlow.
* [This blog post](https://blog.tensorflow.org/2022/11/how-hugging-face-improved-text-generation-performance-with-xla.html) discusses our design philosophy behind adding XLA support to the TensorFlow models in 🤗 Transformers.
* Recommended posts for learning more about XLA and TensorFlow graphs in general:
* [XLA: Optimizing Compiler for Machine Learning](https://www.tensorflow.org/xla)
* [Introduction to graphs and tf.function](https://www.tensorflow.org/guide/intro_to_graphs)
* [Better performance with tf.function](https://www.tensorflow.org/guide/function)
|
huggingface/transformers/blob/main/docs/source/en/tf_xla.md
|
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Examples
This folder contains actively maintained examples of use of 🤗 Transformers using the PyTorch backend, organized by ML task.
## The Big Table of Tasks
Here is the list of all our examples:
- with information on whether they are **built on top of `Trainer`** (if not, they still work, they might
just lack some features),
- whether or not they have a version using the [🤗 Accelerate](https://github.com/huggingface/accelerate) library.
- whether or not they leverage the [🤗 Datasets](https://github.com/huggingface/datasets) library.
- links to **Colab notebooks** to walk through the scripts and run them easily,
<!--
Coming soon!
- links to **Cloud deployments** to be able to deploy large-scale trainings in the Cloud with little to no setup.
-->
| Task | Example datasets | Trainer support | 🤗 Accelerate | 🤗 Datasets | Colab
|---|---|:---:|:---:|:---:|:---:|
| [**`language-modeling`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling) | [WikiText-2](https://huggingface.co/datasets/wikitext) | ✅ | ✅ | ✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)
| [**`multiple-choice`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/multiple-choice) | [SWAG](https://huggingface.co/datasets/swag) | ✅ | ✅ | ✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb)
| [**`question-answering`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering) | [SQuAD](https://huggingface.co/datasets/squad) | ✅ | ✅ | ✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb)
| [**`summarization`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) | [XSum](https://huggingface.co/datasets/xsum) | ✅ | ✅ | ✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization.ipynb)
| [**`text-classification`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification) | [GLUE](https://huggingface.co/datasets/glue) | ✅ | ✅ | ✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb)
| [**`text-generation`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-generation) | - | n/a | - | - | [](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/02_how_to_generate.ipynb)
| [**`token-classification`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification) | [CoNLL NER](https://huggingface.co/datasets/conll2003) | ✅ |✅ | ✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb)
| [**`translation`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/translation) | [WMT](https://huggingface.co/datasets/wmt17) | ✅ | ✅ |✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation.ipynb)
| [**`speech-recognition`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/speech-recognition) | [TIMIT](https://huggingface.co/datasets/timit_asr) | ✅ | - |✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/speech_recognition.ipynb)
| [**`multi-lingual speech-recognition`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/speech-recognition) | [Common Voice](https://huggingface.co/datasets/common_voice) | ✅ | - |✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multi_lingual_speech_recognition.ipynb)
| [**`audio-classification`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/audio-classification) | [SUPERB KS](https://huggingface.co/datasets/superb) | ✅ | - |✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/audio_classification.ipynb)
| [**`image-pretraining`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining) | [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k) | ✅ | - |✅ | /
| [**`image-classification`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) | [CIFAR-10](https://huggingface.co/datasets/cifar10) | ✅ | ✅ |✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)
| [**`semantic-segmentation`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/semantic-segmentation) | [SCENE_PARSE_150](https://huggingface.co/datasets/scene_parse_150) | ✅ | ✅ |✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/semantic_segmentation.ipynb)
## Running quick tests
Most examples are equipped with a mechanism to truncate the number of dataset samples to the desired length. This is useful for debugging purposes, for example to quickly check that all stages of the programs can complete, before running the same setup on the full dataset which may take hours to complete.
For example here is how to truncate all three splits to just 50 samples each:
```
examples/pytorch/token-classification/run_ner.py \
--max_train_samples 50 \
--max_eval_samples 50 \
--max_predict_samples 50 \
[...]
```
Most example scripts should have the first two command line arguments and some have the third one. You can quickly check if a given example supports any of these by passing a `-h` option, e.g.:
```
examples/pytorch/token-classification/run_ner.py -h
```
## Resuming training
You can resume training from a previous checkpoint like this:
1. Pass `--output_dir previous_output_dir` without `--overwrite_output_dir` to resume training from the latest checkpoint in `output_dir` (what you would use if the training was interrupted, for instance).
2. Pass `--resume_from_checkpoint path_to_a_specific_checkpoint` to resume training from that checkpoint folder.
Should you want to turn an example into a notebook where you'd no longer have access to the command
line, 🤗 Trainer supports resuming from a checkpoint via `trainer.train(resume_from_checkpoint)`.
1. If `resume_from_checkpoint` is `True` it will look for the last checkpoint in the value of `output_dir` passed via `TrainingArguments`.
2. If `resume_from_checkpoint` is a path to a specific checkpoint it will use that saved checkpoint folder to resume the training from.
### Upload the trained/fine-tuned model to the Hub
All the example scripts support automatic upload of your final model to the [Model Hub](https://huggingface.co/models) by adding a `--push_to_hub` argument. It will then create a repository with your username slash the name of the folder you are using as `output_dir`. For instance, `"sgugger/test-mrpc"` if your username is `sgugger` and you are working in the folder `~/tmp/test-mrpc`.
To specify a given repository name, use the `--hub_model_id` argument. You will need to specify the whole repository name (including your username), for instance `--hub_model_id sgugger/finetuned-bert-mrpc`. To upload to an organization you are a member of, just use the name of that organization instead of your username: `--hub_model_id huggingface/finetuned-bert-mrpc`.
A few notes on this integration:
- you will need to be logged in to the Hugging Face website locally for it to work, the easiest way to achieve this is to run `huggingface-cli login` and then type your username and password when prompted. You can also pass along your authentication token with the `--hub_token` argument.
- the `output_dir` you pick will either need to be a new folder or a local clone of the distant repository you are using.
## Distributed training and mixed precision
All the PyTorch scripts mentioned above work out of the box with distributed training and mixed precision, thanks to
the [Trainer API](https://huggingface.co/transformers/main_classes/trainer.html). To launch one of them on _n_ GPUs,
use the following command:
```bash
torchrun \
--nproc_per_node number_of_gpu_you_have path_to_script.py \
--all_arguments_of_the_script
```
As an example, here is how you would fine-tune the BERT large model (with whole word masking) on the text
classification MNLI task using the `run_glue` script, with 8 GPUs:
```bash
torchrun \
--nproc_per_node 8 pytorch/text-classification/run_glue.py \
--model_name_or_path bert-large-uncased-whole-word-masking \
--task_name mnli \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 8 \
--learning_rate 2e-5 \
--num_train_epochs 3.0 \
--output_dir /tmp/mnli_output/
```
If you have a GPU with mixed precision capabilities (architecture Pascal or more recent), you can use mixed precision
training with PyTorch 1.6.0 or latest, or by installing the [Apex](https://github.com/NVIDIA/apex) library for previous
versions. Just add the flag `--fp16` to your command launching one of the scripts mentioned above!
Using mixed precision training usually results in 2x-speedup for training with the same final results (as shown in
[this table](https://github.com/huggingface/transformers/tree/main/examples/text-classification#mixed-precision-training)
for text classification).
## Running on TPUs
When using Tensorflow, TPUs are supported out of the box as a `tf.distribute.Strategy`.
When using PyTorch, we support TPUs thanks to `pytorch/xla`. For more context and information on how to setup your TPU environment refer to Google's documentation and to the
very detailed [pytorch/xla README](https://github.com/pytorch/xla/blob/master/README.md).
In this repo, we provide a very simple launcher script named
[xla_spawn.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/xla_spawn.py) that lets you run our
example scripts on multiple TPU cores without any boilerplate. Just pass a `--num_cores` flag to this script, then your
regular training script with its arguments (this is similar to the `torch.distributed.launch` helper for
`torch.distributed`):
```bash
python xla_spawn.py --num_cores num_tpu_you_have \
path_to_script.py \
--all_arguments_of_the_script
```
As an example, here is how you would fine-tune the BERT large model (with whole word masking) on the text
classification MNLI task using the `run_glue` script, with 8 TPUs (from this folder):
```bash
python xla_spawn.py --num_cores 8 \
text-classification/run_glue.py \
--model_name_or_path bert-large-uncased-whole-word-masking \
--task_name mnli \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 8 \
--learning_rate 2e-5 \
--num_train_epochs 3.0 \
--output_dir /tmp/mnli_output/
```
## Using Accelerate
Most PyTorch example scripts have a version using the [🤗 Accelerate](https://github.com/huggingface/accelerate) library
that exposes the training loop so it's easy for you to customize or tweak them to your needs. They all require you to
install `accelerate` with the latest development version
```bash
pip install git+https://github.com/huggingface/accelerate
```
Then you can easily launch any of the scripts by running
```bash
accelerate config
```
and reply to the questions asked. Then
```bash
accelerate test
```
that will check everything is ready for training. Finally, you can launch training with
```bash
accelerate launch path_to_script.py --args_to_script
```
## Logging & Experiment tracking
You can easily log and monitor your runs code. The following are currently supported:
* [TensorBoard](https://www.tensorflow.org/tensorboard)
* [Weights & Biases](https://docs.wandb.ai/integrations/huggingface)
* [Comet ML](https://www.comet.ml/docs/python-sdk/huggingface/)
* [Neptune](https://docs.neptune.ai/integrations-and-supported-tools/model-training/hugging-face)
* [ClearML](https://clear.ml/docs/latest/docs/getting_started/ds/ds_first_steps)
* [DVCLive](https://dvc.org/doc/dvclive/ml-frameworks/huggingface)
### Weights & Biases
To use Weights & Biases, install the wandb package with:
```bash
pip install wandb
```
Then log in the command line:
```bash
wandb login
```
If you are in Jupyter or Colab, you should login with:
```python
import wandb
wandb.login()
```
To enable logging to W&B, include `"wandb"` in the `report_to` of your `TrainingArguments` or script. Or just pass along `--report_to_all` if you have `wandb` installed.
Whenever you use `Trainer` or `TFTrainer` classes, your losses, evaluation metrics, model topology and gradients (for `Trainer` only) will automatically be logged.
Advanced configuration is possible by setting environment variables:
| Environment Variable | Value |
|---|---|
| WANDB_LOG_MODEL | Log the model as artifact (log the model as artifact at the end of training) (`false` by default) |
| WANDB_WATCH | one of `gradients` (default) to log histograms of gradients, `all` to log histograms of both gradients and parameters, or `false` for no histogram logging |
| WANDB_PROJECT | Organize runs by project |
Set run names with `run_name` argument present in scripts or as part of `TrainingArguments`.
Additional configuration options are available through generic [wandb environment variables](https://docs.wandb.com/library/environment-variables).
Refer to related [documentation & examples](https://docs.wandb.ai/integrations/huggingface).
### Comet.ml
To use `comet_ml`, install the Python package with:
```bash
pip install comet_ml
```
or if in a Conda environment:
```bash
conda install -c comet_ml -c anaconda -c conda-forge comet_ml
```
### Neptune
First, install the Neptune client library. You can do it with either `pip` or `conda`:
`pip`:
```bash
pip install neptune
```
`conda`:
```bash
conda install -c conda-forge neptune
```
Next, in your model training script, import `NeptuneCallback`:
```python
from transformers.integrations import NeptuneCallback
```
To enable Neptune logging, in your `TrainingArguments`, set the `report_to` argument to `"neptune"`:
```python
training_args = TrainingArguments(
"quick-training-distilbert-mrpc",
evaluation_strategy="steps",
eval_steps=20,
report_to="neptune",
)
trainer = Trainer(
model,
training_args,
...
)
```
**Note:** This method requires saving your Neptune credentials as environment variables (see the bottom of the section).
Alternatively, for more logging options, create a Neptune callback:
```python
neptune_callback = NeptuneCallback()
```
To add more detail to the tracked run, you can supply optional arguments to `NeptuneCallback`.
Some examples:
```python
neptune_callback = NeptuneCallback(
name = "DistilBERT",
description = "DistilBERT fine-tuned on GLUE/MRPC",
tags = ["args-callback", "fine-tune", "MRPC"], # tags help you manage runs in Neptune
base_namespace="callback", # the default is "finetuning"
log_checkpoints = "best", # other options are "last", "same", and None
capture_hardware_metrics = False, # additional keyword arguments for a Neptune run
)
```
Pass the callback to the Trainer:
```python
training_args = TrainingArguments(..., report_to=None)
trainer = Trainer(
model,
training_args,
...
callbacks=[neptune_callback],
)
```
Now, when you start the training with `trainer.train()`, your metadata will be logged in Neptune.
**Note:** Although you can pass your **Neptune API token** and **project name** as arguments when creating the callback, the recommended way is to save them as environment variables:
| Environment variable | Value |
| :------------------- | :--------------------------------------------------- |
| `NEPTUNE_API_TOKEN` | Your Neptune API token. To find and copy it, click your Neptune avatar and select **Get your API token**. |
| `NEPTUNE_PROJECT` | The full name of your Neptune project (`workspace-name/project-name`). To find and copy it, head to **project settings** → **Properties**. |
For detailed instructions and examples, see the [Neptune docs](https://docs.neptune.ai/integrations/transformers/).
### ClearML
To use ClearML, install the clearml package with:
```bash
pip install clearml
```
Then [create new credentials]() from the ClearML Server. You can get a free hosted server [here]() or [self-host your own]()!
After creating your new credentials, you can either copy the local snippet which you can paste after running:
```bash
clearml-init
```
Or you can copy the jupyter snippet if you are in Jupyter or Colab:
```python
%env CLEARML_WEB_HOST=https://app.clear.ml
%env CLEARML_API_HOST=https://api.clear.ml
%env CLEARML_FILES_HOST=https://files.clear.ml
%env CLEARML_API_ACCESS_KEY=***
%env CLEARML_API_SECRET_KEY=***
```
To enable logging to ClearML, include `"clearml"` in the `report_to` of your `TrainingArguments` or script. Or just pass along `--report_to all` if you have `clearml` already installed.
Advanced configuration is possible by setting environment variables:
| Environment Variable | Value |
|---|---|
| CLEARML_PROJECT | Name of the project in ClearML. (default: `"HuggingFace Transformers"`) |
| CLEARML_TASK | Name of the task in ClearML. (default: `"Trainer"`) |
Additional configuration options are available through generic [clearml environment variables](https://clear.ml/docs/latest/docs/configs/env_vars).
|
huggingface/transformers/blob/main/examples/pytorch/README.md
|
Metric Card for TER
## Metric Description
TER (Translation Edit Rate, also called Translation Error Rate) is a metric to quantify the edit operations that a hypothesis requires to match a reference translation. We use the implementation that is already present in [sacrebleu](https://github.com/mjpost/sacreBLEU#ter), which in turn is inspired by the [TERCOM implementation](https://github.com/jhclark/tercom).
The implementation here is slightly different from sacrebleu in terms of the required input format. The length of the references and hypotheses lists need to be the same, so you may need to transpose your references compared to sacrebleu's required input format. See [this github issue](https://github.com/huggingface/datasets/issues/3154#issuecomment-950746534).
See the README.md file at https://github.com/mjpost/sacreBLEU#ter for more information.
## How to Use
This metric takes, at minimum, predicted sentences and reference sentences:
```python
>>> predictions = ["does this sentence match??",
... "what about this sentence?",
... "What did the TER metric user say to the developer?"]
>>> references = [["does this sentence match", "does this sentence match!?!"],
... ["wHaT aBoUt ThIs SeNtEnCe?", "wHaT aBoUt ThIs SeNtEnCe?"],
... ["Your jokes are...", "...TERrible"]]
>>> ter = datasets.load_metric("ter")
>>> results = ter.compute(predictions=predictions,
... references=references,
... case_sensitive=True)
>>> print(results)
{'score': 150.0, 'num_edits': 15, 'ref_length': 10.0}
```
### Inputs
This metric takes the following as input:
- **`predictions`** (`list` of `str`): The system stream (a sequence of segments).
- **`references`** (`list` of `list` of `str`): A list of one or more reference streams (each a sequence of segments).
- **`normalized`** (`boolean`): If `True`, applies basic tokenization and normalization to sentences. Defaults to `False`.
- **`ignore_punct`** (`boolean`): If `True`, applies basic tokenization and normalization to sentences. Defaults to `False`.
- **`support_zh_ja_chars`** (`boolean`): If `True`, tokenization/normalization supports processing of Chinese characters, as well as Japanese Kanji, Hiragana, Katakana, and Phonetic Extensions of Katakana. Only applies if `normalized = True`. Defaults to `False`.
- **`case_sensitive`** (`boolean`): If `False`, makes all predictions and references lowercase to ignore differences in case. Defaults to `False`.
### Output Values
This metric returns the following:
- **`score`** (`float`): TER score (num_edits / sum_ref_lengths * 100)
- **`num_edits`** (`int`): The cumulative number of edits
- **`ref_length`** (`float`): The cumulative average reference length
The output takes the following form:
```python
{'score': ter_score, 'num_edits': num_edits, 'ref_length': ref_length}
```
The metric can take on any value `0` and above. `0` is a perfect score, meaning the predictions exactly match the references and no edits were necessary. Higher scores are worse. Scores above 100 mean that the cumulative number of edits, `num_edits`, is higher than the cumulative length of the references, `ref_length`.
#### Values from Popular Papers
### Examples
Basic example with only predictions and references as inputs:
```python
>>> predictions = ["does this sentence match??",
... "what about this sentence?"]
>>> references = [["does this sentence match", "does this sentence match!?!"],
... ["wHaT aBoUt ThIs SeNtEnCe?", "wHaT aBoUt ThIs SeNtEnCe?"]]
>>> ter = datasets.load_metric("ter")
>>> results = ter.compute(predictions=predictions,
... references=references,
... case_sensitive=True)
>>> print(results)
{'score': 62.5, 'num_edits': 5, 'ref_length': 8.0}
```
Example with `normalization = True`:
```python
>>> predictions = ["does this sentence match??",
... "what about this sentence?"]
>>> references = [["does this sentence match", "does this sentence match!?!"],
... ["wHaT aBoUt ThIs SeNtEnCe?", "wHaT aBoUt ThIs SeNtEnCe?"]]
>>> ter = datasets.load_metric("ter")
>>> results = ter.compute(predictions=predictions,
... references=references,
... normalized=True,
... case_sensitive=True)
>>> print(results)
{'score': 57.14285714285714, 'num_edits': 6, 'ref_length': 10.5}
```
Example ignoring punctuation and capitalization, and everything matches:
```python
>>> predictions = ["does this sentence match??",
... "what about this sentence?"]
>>> references = [["does this sentence match", "does this sentence match!?!"],
... ["wHaT aBoUt ThIs SeNtEnCe?", "wHaT aBoUt ThIs SeNtEnCe?"]]
>>> ter = datasets.load_metric("ter")
>>> results = ter.compute(predictions=predictions,
... references=references,
... ignore_punct=True,
... case_sensitive=False)
>>> print(results)
{'score': 0.0, 'num_edits': 0, 'ref_length': 8.0}
```
Example ignoring punctuation and capitalization, but with an extra (incorrect) sample:
```python
>>> predictions = ["does this sentence match??",
... "what about this sentence?",
... "What did the TER metric user say to the developer?"]
>>> references = [["does this sentence match", "does this sentence match!?!"],
... ["wHaT aBoUt ThIs SeNtEnCe?", "wHaT aBoUt ThIs SeNtEnCe?"],
... ["Your jokes are...", "...TERrible"]]
>>> ter = datasets.load_metric("ter")
>>> results = ter.compute(predictions=predictions,
... references=references,
... ignore_punct=True,
... case_sensitive=False)
>>> print(results)
{'score': 100.0, 'num_edits': 10, 'ref_length': 10.0}
```
## Limitations and Bias
## Citation
```bibtex
@inproceedings{snover-etal-2006-study,
title = "A Study of Translation Edit Rate with Targeted Human Annotation",
author = "Snover, Matthew and
Dorr, Bonnie and
Schwartz, Rich and
Micciulla, Linnea and
Makhoul, John",
booktitle = "Proceedings of the 7th Conference of the Association for Machine Translation in the Americas: Technical Papers",
month = aug # " 8-12",
year = "2006",
address = "Cambridge, Massachusetts, USA",
publisher = "Association for Machine Translation in the Americas",
url = "https://aclanthology.org/2006.amta-papers.25",
pages = "223--231",
}
@inproceedings{post-2018-call,
title = "A Call for Clarity in Reporting {BLEU} Scores",
author = "Post, Matt",
booktitle = "Proceedings of the Third Conference on Machine Translation: Research Papers",
month = oct,
year = "2018",
address = "Belgium, Brussels",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/W18-6319",
pages = "186--191",
}
```
## Further References
- See [the sacreBLEU github repo](https://github.com/mjpost/sacreBLEU#ter) for more information.
|
huggingface/datasets/blob/main/metrics/ter/README.md
|
!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Custom hardware for training
The hardware you use to run model training and inference can have a big effect on performance. For a deep dive into GPUs make sure to check out Tim Dettmer's excellent [blog post](https://timdettmers.com/2020/09/07/which-gpu-for-deep-learning/).
Let's have a look at some practical advice for GPU setups.
## GPU
When you train bigger models you have essentially three options:
- bigger GPUs
- more GPUs
- more CPU and NVMe (offloaded to by [DeepSpeed-Infinity](main_classes/deepspeed#nvme-support))
Let's start at the case where you have a single GPU.
### Power and Cooling
If you bought an expensive high end GPU make sure you give it the correct power and sufficient cooling.
**Power**:
Some high end consumer GPU cards have 2 and sometimes 3 PCI-E 8-Pin power sockets. Make sure you have as many independent 12V PCI-E 8-Pin cables plugged into the card as there are sockets. Do not use the 2 splits at one end of the same cable (also known as pigtail cable). That is if you have 2 sockets on the GPU, you want 2 PCI-E 8-Pin cables going from your PSU to the card and not one that has 2 PCI-E 8-Pin connectors at the end! You won't get the full performance out of your card otherwise.
Each PCI-E 8-Pin power cable needs to be plugged into a 12V rail on the PSU side and can supply up to 150W of power.
Some other cards may use a PCI-E 12-Pin connectors, and these can deliver up to 500-600W of power.
Low end cards may use 6-Pin connectors, which supply up to 75W of power.
Additionally you want the high-end PSU that has stable voltage. Some lower quality ones may not give the card the stable voltage it needs to function at its peak.
And of course the PSU needs to have enough unused Watts to power the card.
**Cooling**:
When a GPU gets overheated it will start throttling down and will not deliver full performance and it can even shutdown if it gets too hot.
It's hard to tell the exact best temperature to strive for when a GPU is heavily loaded, but probably anything under +80C is good, but lower is better - perhaps 70-75C is an excellent range to be in. The throttling down is likely to start at around 84-90C. But other than throttling performance a prolonged very high temperature is likely to reduce the lifespan of a GPU.
Next let's have a look at one of the most important aspects when having multiple GPUs: connectivity.
### Multi-GPU Connectivity
If you use multiple GPUs the way cards are inter-connected can have a huge impact on the total training time. If the GPUs are on the same physical node, you can run:
```
nvidia-smi topo -m
```
and it will tell you how the GPUs are inter-connected. On a machine with dual-GPU and which are connected with NVLink, you will most likely see something like:
```
GPU0 GPU1 CPU Affinity NUMA Affinity
GPU0 X NV2 0-23 N/A
GPU1 NV2 X 0-23 N/A
```
on a different machine w/o NVLink we may see:
```
GPU0 GPU1 CPU Affinity NUMA Affinity
GPU0 X PHB 0-11 N/A
GPU1 PHB X 0-11 N/A
```
The report includes this legend:
```
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinks
```
So the first report `NV2` tells us the GPUs are interconnected with 2 NVLinks, and the second report `PHB` we have a typical consumer-level PCIe+Bridge setup.
Check what type of connectivity you have on your setup. Some of these will make the communication between cards faster (e.g. NVLink), others slower (e.g. PHB).
Depending on the type of scalability solution used, the connectivity speed could have a major or a minor impact. If the GPUs need to sync rarely, as in DDP, the impact of a slower connection will be less significant. If the GPUs need to send messages to each other often, as in ZeRO-DP, then faster connectivity becomes super important to achieve faster training.
#### NVlink
[NVLink](https://en.wikipedia.org/wiki/NVLink) is a wire-based serial multi-lane near-range communications link developed by Nvidia.
Each new generation provides a faster bandwidth, e.g. here is a quote from [Nvidia Ampere GA102 GPU Architecture](https://www.nvidia.com/content/dam/en-zz/Solutions/geforce/ampere/pdf/NVIDIA-ampere-GA102-GPU-Architecture-Whitepaper-V1.pdf):
> Third-Generation NVLink®
> GA102 GPUs utilize NVIDIA’s third-generation NVLink interface, which includes four x4 links,
> with each link providing 14.0625 GB/sec bandwidth in each direction between two GPUs. Four
> links provide 56.25 GB/sec bandwidth in each direction, and 112.5 GB/sec total bandwidth
> between two GPUs. Two RTX 3090 GPUs can be connected together for SLI using NVLink.
> (Note that 3-Way and 4-Way SLI configurations are not supported.)
So the higher `X` you get in the report of `NVX` in the output of `nvidia-smi topo -m` the better. The generation will depend on your GPU architecture.
Let's compare the execution of a gpt2 language model training over a small sample of wikitext.
The results are:
| NVlink | Time |
| ----- | ---: |
| Y | 101s |
| N | 131s |
You can see that NVLink completes the training ~23% faster. In the second benchmark we use `NCCL_P2P_DISABLE=1` to tell the GPUs not to use NVLink.
Here is the full benchmark code and outputs:
```bash
# DDP w/ NVLink
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 torchrun \
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train \
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 101.9003, 'train_samples_per_second': 1.963, 'epoch': 0.69}
# DDP w/o NVLink
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 NCCL_P2P_DISABLE=1 torchrun \
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 131.4367, 'train_samples_per_second': 1.522, 'epoch': 0.69}
```
Hardware: 2x TITAN RTX 24GB each + NVlink with 2 NVLinks (`NV2` in `nvidia-smi topo -m`)
Software: `pytorch-1.8-to-be` + `cuda-11.0` / `transformers==4.3.0.dev0`
|
huggingface/transformers/blob/main/docs/source/en/perf_hardware.md
|
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# MaskFormer
<Tip>
This is a recently introduced model so the API hasn't been tested extensively. There may be some bugs or slight
breaking changes to fix it in the future. If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title).
</Tip>
## Overview
The MaskFormer model was proposed in [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov. MaskFormer addresses semantic segmentation with a mask classification paradigm instead of performing classic pixel-level classification.
The abstract from the paper is the following:
*Modern approaches typically formulate semantic segmentation as a per-pixel classification task, while instance-level segmentation is handled with an alternative mask classification. Our key insight: mask classification is sufficiently general to solve both semantic- and instance-level segmentation tasks in a unified manner using the exact same model, loss, and training procedure. Following this observation, we propose MaskFormer, a simple mask classification model which predicts a set of binary masks, each associated with a single global class label prediction. Overall, the proposed mask classification-based method simplifies the landscape of effective approaches to semantic and panoptic segmentation tasks and shows excellent empirical results. In particular, we observe that MaskFormer outperforms per-pixel classification baselines when the number of classes is large. Our mask classification-based method outperforms both current state-of-the-art semantic (55.6 mIoU on ADE20K) and panoptic segmentation (52.7 PQ on COCO) models.*
The figure below illustrates the architecture of MaskFormer. Taken from the [original paper](https://arxiv.org/abs/2107.06278).
<img width="600" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/maskformer_architecture.png"/>
This model was contributed by [francesco](https://huggingface.co/francesco). The original code can be found [here](https://github.com/facebookresearch/MaskFormer).
## Usage tips
- MaskFormer's Transformer decoder is identical to the decoder of [DETR](detr). During training, the authors of DETR did find it helpful to use auxiliary losses in the decoder, especially to help the model output the correct number of objects of each class. If you set the parameter `use_auxilary_loss` of [`MaskFormerConfig`] to `True`, then prediction feedforward neural networks and Hungarian losses are added after each decoder layer (with the FFNs sharing parameters).
- If you want to train the model in a distributed environment across multiple nodes, then one should update the
`get_num_masks` function inside in the `MaskFormerLoss` class of `modeling_maskformer.py`. When training on multiple nodes, this should be
set to the average number of target masks across all nodes, as can be seen in the original implementation [here](https://github.com/facebookresearch/MaskFormer/blob/da3e60d85fdeedcb31476b5edd7d328826ce56cc/mask_former/modeling/criterion.py#L169).
- One can use [`MaskFormerImageProcessor`] to prepare images for the model and optional targets for the model.
- To get the final segmentation, depending on the task, you can call [`~MaskFormerImageProcessor.post_process_semantic_segmentation`] or [`~MaskFormerImageProcessor.post_process_panoptic_segmentation`]. Both tasks can be solved using [`MaskFormerForInstanceSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
## Resources
<PipelineTag pipeline="image-segmentation"/>
- All notebooks that illustrate inference as well as fine-tuning on custom data with MaskFormer can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/MaskFormer).
## MaskFormer specific outputs
[[autodoc]] models.maskformer.modeling_maskformer.MaskFormerModelOutput
[[autodoc]] models.maskformer.modeling_maskformer.MaskFormerForInstanceSegmentationOutput
## MaskFormerConfig
[[autodoc]] MaskFormerConfig
## MaskFormerImageProcessor
[[autodoc]] MaskFormerImageProcessor
- preprocess
- encode_inputs
- post_process_semantic_segmentation
- post_process_instance_segmentation
- post_process_panoptic_segmentation
## MaskFormerFeatureExtractor
[[autodoc]] MaskFormerFeatureExtractor
- __call__
- encode_inputs
- post_process_semantic_segmentation
- post_process_instance_segmentation
- post_process_panoptic_segmentation
## MaskFormerModel
[[autodoc]] MaskFormerModel
- forward
## MaskFormerForInstanceSegmentation
[[autodoc]] MaskFormerForInstanceSegmentation
- forward
|
huggingface/transformers/blob/main/docs/source/en/model_doc/maskformer.md
|
--
title: "Machine Learning Experts - Margaret Mitchell"
thumbnail: /blog/assets/57_meg_mitchell_interview/thumbnail.png
authors:
- user: britneymuller
---
# Machine Learning Experts - Margaret Mitchell
Hey friends! Welcome to Machine Learning Experts. I'm your host, Britney Muller and today’s guest is none other than [Margaret Mitchell](https://twitter.com/mmitchell_ai) (Meg for short). Meg founded & co-led Google’s Ethical AI Group, is a pioneer in the field of Machine Learning, has published over 50 papers, and is a leading researcher in Ethical AI.
You’ll hear Meg talk about the moment she realized the importance of ethical AI (an incredible story!), how ML teams can be more aware of harmful data bias, and the power (and performance) benefits of inclusion and diversity in ML.
<a href="https://huggingface.co/support?utm_source=blog&utm_medium=blog&utm_campaign=ml_experts&utm_content=meg_interview_article"><img src="/blog/assets/57_meg_mitchell_interview/Meg-cta.png"></a>
Very excited to introduce this powerful episode to you! Here’s my conversation with Meg Mitchell:
<iframe width="100%" style="aspect-ratio: 16 / 9;"src="https://www.youtube.com/embed/FpIxYGyJBbs" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
## Transcription:
*Note: Transcription has been slightly modified/reformatted to deliver the highest-quality reading experience.*
### Could you share a little bit about your background and what brought you to Hugging Face?
**Dr. Margaret Mitchell’s Background:**
- Bachelor’s in Linguistics at Reed College - Worked on NLP
- Worked on assistive and augmentative technology after her Bachelor’s and also during her graduate studies
- Master’s in Computational Linguistics at the University of Washington
- PhD in Computer Science
**Meg:** I did heavy statistical work as a postdoc at Johns Hopkins and then went to Microsoft Research where I continued doing vision to language generation that led to working on an app for people who are blind to navigate the world a bit easier called [Seeing AI](https://www.microsoft.com/en-us/ai/seeing-ai).
After a few years at Microsoft, I left to work at Google to focus on big data problems inherent in deep learning. That’s where I started focusing on things like fairness, rigorous evaluation for different kinds of issues, and bias. While at Google, I founded and co-led the Ethical AI Team which focuses on inclusion and transparency.
After four years at Google, I came over to Hugging Face where I was able to jump in and focus on coding.
I’m helping to create protocols for ethical AI research, inclusive hiring, systems, and setting up a good culture here at Hugging Face.
### When did you recognize the importance of Ethical AI?
**Meg:** This occurred when I was working at Microsoft while I was working on the assistance technology, Seeing AI. In general, I was working on generating language from images and I started to see was how lopsided data was. Data represents a subset of the world and it influences what a model will say.
So I began to run into issues where white people would be described as ‘people’ and black people would be described as ‘black people’ as if white was a default and black was a marked characteristic. That was concerning to me.
There was also an ah-ha moment when I was feeding my system a sequence of images, getting it to talk more about a story of what is happening. And I fed it some images of this massive blast where a lot of people worked, called the ‘Hebstad blast’. You could see that the person taking the picture was on the second or third story looking out on the blast. The blast was very close to this person. It was a very dire and intense moment and when I fed this to the system the system’s output was that “ this is awesome, this is a great view, this is beautiful’. And I thought.. this is a great view of this horrible scene but the important part here is that people may be dying. This is a massive destructive explosion.
But the thing is, when you’re learning from images people don’t tend to take photos of terrible things, they take photos of sunsets, fireworks, etc., and a visual recognition model had learned on these images and believed that color in the sky was a positive, beautiful thing.
At that moment, I realized that if a model with that sort of thinking had access to actions it would be just one hop away from a system that would blow up buildings because it thought it was beautiful.
This was a moment for me when I realized I didn’t want to keep making these systems do better on benchmarks, I wanted to fundamentally shift how we were looking at these problems, how we were approaching data and analysis of data, how we were evaluating and all of the factors we were leaving out with these straightforward pipelines.
So that really became my shift into ethical AI work.
### In what applications is data ethics most important?
**Meg:** Human-centric technology that deals with people and identity (face recognition, pedestrian recognition). In NLP this would pertain more to the privacy of individuals, how individuals are talked about, and the biases models pick up with regards to descriptors used for people.
### How can ML teams be more aware of harmful bias?
**Meg:** A primary issue is that these concepts haven't been taught and most teams simply aren’t aware. Another problem is the lack of a lexicon to contextualize and communicate what is going on.
For example:
- This is what marginalization is
- This is what a power differential is
- Here is what inclusion is
- Here is how stereotypes work
Having a better understanding of these pillars is really important.
Another issue is the culture behind machine learning. It’s taken a bit of an ‘Alpha’ or ‘macho’ approach where the focus is on ‘beating’ the last numbers, making things ‘faster’, ‘bigger’, etc. There are lots of parallels that can be made to human anatomy.
There’s also a very hostile competitiveness that comes out where you find that women are disproportionately treated as less than.
Since women are often much more familiar with discrimination women are focusing a lot more on ethics, stereotypes, sexism, etc. within AI. This means it gets associated with women more and seen as less than which makes the culture a lot harder to penetrate.
It’s generally assumed that I’m not technical. It’s something I have to prove over and over again. I’m called a linguist, an ethicist because these are things I care about and know about but that is treated as less-than. People say or think, “You don’t program, you don’t know about statistics, you are not as important,” and it’s often not until I start talking about things technically that people take me seriously which is unfortunate.
There is a massive cultural barrier in ML.
### Lack of diversity and inclusion hurts everyone
**Meg:** Diversity is when you have a lot of races, ethnicities, genders, abilities, statuses at the table.
Inclusion is when each person feels comfortable talking, they feel welcome.
One of the best ways to be more inclusive is to not be exclusive. Feels fairly obvious but is often missed. People get left out of meetings because we don’t find them helpful or find them annoying or combative (which is a function of various biases). To be inclusive you need to not be exclusive so when scheduling a meeting pay attention to the demographic makeup of the people you’re inviting. If your meeting is all-male, that’s a problem.
It’s incredibly valuable to become more aware and intentional about the demographic makeup of the people you’re including in an email. But you’ll notice in tech, a lot of meetings are all male, and if you bring it up that can be met with a lot of hostility. Air on the side of including people.
We all have biases but there are tactics to break some of those patterns. When writing an email I’ll go through their gender and ethnicities to ensure I’m being inclusive. It’s a very conscious effort. That sort of thinking through demographics helps. However, mention this before someone sends an email or schedules a meeting. People tend to not respond as well when you mention these things after the fact.
### Diversity in AI - Isn’t there proof that having a more diverse set of people on an ML project results in better outcomes?
**Meg:** Yes, since you have different perspectives you have a different distribution over options and thus, more options. One of the fundamental aspects of machine learning is that when you start training you can use a randomized starting point and what kind of distribution you want to sample from.
Most engineers can agree that you don’t want to sample from one little piece of the distribution to have the best chance of finding a local optimum.
You need to translate this approach to the people sitting at the table.
Just how you want to have a Gaussian approach over different start states, so too do you want that at the table when you’re starting projects because it gives you this larger search space making it easier to attain a local optimum.
### Can you talk about Model Cards and how that project came to be?
**Meg:** This project started at Google when I first started working on fairness and what a rigorous evaluation of fairness would look like.
In order to do that you need to have an understanding of context and understanding of who would use it. This revolved around how to approach model biases and it wasn’t getting a lot of pick up.
I was talking to [Timnit Gebru](https://twitter.com/timnitGebru) who was at that time someone in the field with similar interest to me and she was talking about this idea of datasheets; a kind of documentation for data (based on her experience at Apple) doing engineering where you tend to have specifications of hardware. But we don’t have something similar for data and she was talking about how crazy that is.
So Timnit had this idea of datasheets for datasets. It struck me that by having an ‘artifact’ people in tech who are motivated by launches would care a lot more about it. So if we say you have to produce this artifact and it will count as a launch suddenly people would be more incentivized to do it.
The way we came up with the name was that a comparable word to ‘data sheet’ that could be used for models was card (plus it was shorter). Also decided to call it ‘model cards’ because the name was very generic and would have longevity over time.
Timnit’s paper was called [‘Data Sheets for Datasets’](https://arxiv.org/abs/1803.09010). So we called ours [‘Model Cards for Model Reporting’](https://arxiv.org/abs/1810.03993) and once we had the published paper people started taking us more seriously. Couldn’t have done this without Timnit Gebru’s brilliance suggesting “You need an artifact, a standardized thing that people will want to produce.”
### Where are model cards headed?
**Meg:** There’s a pretty big barrier to entry to do model cards in a way that is well informed by ethics. Partly because the people who need to fill this out are often engineers and developers who want to launch their model and don’t want to sit around thinking about documentation and ethics.
Part of why I wanted to join Hugging Face is because it gave me an opportunity to standardize how these processes could be filled out and automated as much as possible. One thing I really like about Hugging Face is there is a focus on creating end-to-end machine learning processes that are as smooth as possible. Would love to do something like that with model cards where you could have something largely automatically generated as a function of different questions asked or even based on model specifications directly.
We want to work towards having model cards as filled out as possible and interactive. Interactivity would allow you to see the difference in false-negative rate as you move the decision threshold. Normally with classification systems, you set some threshold at which you say yes or no, like .7, but in practice, you actually want to vary the decision threshold to trade off different errors.
A static report of how well it works isn’t as informative as you want it to be because you want to know how well it works as different decision thresholds are chosen, and you could use that to decide what decision threshold to be used with your system. So we created a model card where you could interactively change the decision threshold and see how the numbers change. Moving towards that direction in further automation and interactivity is the way to go.
### Decision thresholds & model transparency
**Meg:** When Amazon first started putting out facial recognition and facial analysis technology it was found that the gender classification was disproportionately bad for black women and Amazon responded by saying “this was done using the wrong decision threshold”. And then one of the police agencies who had been using one of these systems had been asked what decision threshold they had been using and said, “Oh we’re not using a decision threshold,”.
Which was like oh you really don’t understand how this works and are using this out of the box with default parameter settings?! That is a problem. So minimally having this documentary brings awareness to decisions around the various types of parameters.
Machine learning models are so different from other things we put out into the public. Toys, medicine, and cars have all sorts of regulations to ensure products are safe and work as intended. We don’t have that in machine learning, partly because it’s new so the laws and regulations don’t exist yet. It’s a bit like the wild west, and that’s what we’re trying to change with model cards.
### What are you working on at Hugging Face?
- Working on a few different tools designed for engineers.
- Working on philosophical and social science research: Just did a deep dive into UDHR (Universal Declaration of Human Rights) and how those can be applied with AI. Trying to help bridge the gaps between AI, ML, law, and philosophy.
- Trying to develop some statistical methods that are helpful for testing systems as well as understanding datasets.
- We also recently [put out a tool](https://huggingface.co/spaces/huggingface/data-measurements-tool) that shows how well a language maps to Zipfian distributions (how natural language tends to go) so you can test how well your model is matching with natural language that way.
- Working a lot on the culture stuff: spending a lot of time on hiring and what processes we should have in place to be more inclusive.
- Working on [Big Science](https://bigscience.huggingface.co/): a massive effort with people from all around the world, not just hugging face working on data governance (how can big data be used and examined without having it proliferate all over the world/being tracked with how it’s used).
- Occasionally I’ll do an interview or talk to a Senator, so it’s all over the place.
- Try to answer emails sometimes.
*Note: Everyone at Hugging Face wears several hats.* :)
### Meg’s impact on AI
Meg is featured in the book [Genius Makers ‘The Mavericks who brought AI to Google, Facebook, and the World’](https://www.amazon.com/Genius-Makers-Mavericks-Brought-Facebook/dp/1524742678). Cade Metz interviewed Meg for this while she was at Google.
Meg’s pioneering research, systems, and work have played a pivotal role in the history of AI. (we are so lucky to have her at Hugging Face!)
### Rapid Fire Questions:
### Best piece of advice for someone looking to get into AI?
**Meg:** Depends on who the person is. If they have marginalized characteristics I would give very different advice. For example, if it was a woman I would say, 'Don’t listen to your supervisors saying you aren’t good at this. Chances are you are just thinking about things differently than they are used to so have confidence in yourself.'
If it’s someone with more majority characteristics I’d say, 'Forget about the pipeline problem, pay attention to the people around you and make sure that you hold them up so that the pipeline you’re in now becomes less of a problem.'
Also, 'Evaluate your systems'.
### What industries are you most excited to see ML applied (or ML Ethics be applied)
**Meg:** The health and assistive domains continue to be areas I care a lot about and see a ton of potential.
Also want to see systems that help people understand their own biases. Lots of technology is being created to screen job candidates for job interviews but I feel that technology should really be focused on the interviewer and how they might be coming at the situation with different biases. Would love to have more technology that assists humans to be more inclusive instead of assisting humans to exclude people.
### You frequently include incredible examples of biased models in your Keynotes and interviews. One in particular that I love is the criminal detection model you've talked about that was using patterns of mouth angles to identify criminals (which you swiftly debunked).
**Meg:** Yes, [the example is that] they were making this claim that there was this angle theta that was more indicative of criminals when it was a smaller angle. However, I was looking at the math and I realized that what they were talking about was a smile! Where you would have a wider angle for a smile vs a smaller angle associated with a straight face. They really missed the boat on what they were actually capturing there. Experimenter's bias: wanting to find things that aren’t there.
### Should people be afraid of AI taking over the world?
**Meg:** There are a lot of things to be afraid of with AI. I like to see it as we have a distribution over different kinds of outcomes, some more positive than others, so there’s not one set one that we can know. There are a lot of different things where AI can be super helpful and more task-based over more generalized intelligence. You can see it going in another direction, similar to what I mentioned earlier about a model thinking something destructive is beautiful is one hop away from a system that is able to press a button to set off a missile. Don’t think people should be scared per se, but they should think about the best and worst-case scenarios and try to mitigate or stop the worst outcomes.
I think the biggest thing right now is these systems can widen the divide between the haves and have nots. Further giving power to people who have power and further worsening things for people who don’t. The people designing these systems tend to be people with more power and wealth and they design things for their kinds of interest. I think that’s happening right now and something to think about in the future.
Hopefully, we can focus on the things that are most beneficial and continue heading in that direction.
### Fav ML papers?
**Meg:** Most recently I’ve really loved what [Abeba Birhane](https://abebabirhane.github.io) has been doing on [values that are encoded in machine learning](https://arxiv.org/abs/2106.15590). My own team at Google had been working on [data genealogies](https://journals.sagepub.com/doi/full/10.1177/20539517211035955), bringing critical analysis on how ML data is handled which they have a few papers on - for example, [Data and its (dis)contents: A survey of dataset development and use in machine learning research](https://arxiv.org/abs/2012.05345). Really love that work and might be biased because it included my team and direct reports, I’m very proud of them but it really is fundamentally good work.
Earlier papers that I’m interested in are more reflective of what I was doing at that time. Really love the work of [Herbert Clark](https://neurotree.org/beta/publications.php?pid=4636) who was a psycholinguistics/communications person and he did a lot of work that is easily ported to computational models about how humans communicate. Really love his work and cite him a lot throughout my thesis.
### Anything else you would like to mention?
**Meg:** One of the things I’m working on, that I think other people should be working on, is lowering the barrier of entry to AI for people with different academic backgrounds.
We have a lot of people developing technology, which is great, but we don’t have a lot of people in a situation where they can really question the technology because there is often a bottleneck.
For example, if you want to know about data directly you have to be able to log into a server and write a SQL query. So there is a bottleneck where engineers have to do it and I want to remove that barrier. How can we take things that are fundamentally technical code stuff and open it up so people can directly query the data without knowing how to program?
We will be able to make better technology when we remove the barriers that require engineers to be in the middle.
### Outro
**Britney:** Meg had a hard stop on the hour but I was able to ask her my last question offline: What’s something you’ve been interested in lately? Meg’s response: "How to propagate and grow plants in synthetic/controlled settings." Just when I thought she couldn’t get any cooler. 🤯
I’ll leave you with a recent quote from Meg in a [Science News article on Ethical AI](https://www.sciencenews.org/article/computer-science-history-ethics-future-robots-ai):
*“The most pressing problem is the diversity and inclusion of who’s at the table from the start. All the other issues fall out from there.” -Meg Mitchell.*
Thank you for listening to Machine Learning Experts!
<a href="https://huggingface.co/support?utm_source=blog&utm_medium=blog&utm_campaign=ml_experts&utm_content=meg_interview_article"><img src="/blog/assets/57_meg_mitchell_interview/Meg-cta.png"></a>
**Honorable mentions + links:**
- [Emily Bender](https://twitter.com/emilymbender?lang=en)
- [Ehud Reiter](https://mobile.twitter.com/ehudreiter)
- [Abeba Birhane](https://abebabirhane.github.io/)
- [Seeing AI](https://www.microsoft.com/en-us/ai/seeing-ai)
- [Data Sheets for Datasets](https://arxiv.org/abs/1803.09010)
- [Model Cards](https://modelcards.withgoogle.com/about)
- [Model Cards Paper](https://arxiv.org/abs/1810.03993)
- [Abeba Birhane](https://arxiv.org/search/cs?searchtype=author&query=Birhane%2C+A)
- [The Values Encoded in Machine Learning Research](https://arxiv.org/abs/2106.15590)
- [Data and its (dis)contents:](https://arxiv.org/abs/2012.05345)
- [Herbert Clark](https://neurotree.org/beta/publications.php?pid=4636)
**Follow Meg Online:**
- [Twitter](https://twitter.com/mmitchell_ai)
- [Website](http://www.m-mitchell.com)
- [LinkedIn](https://www.linkedin.com/in/margaret-mitchell-9b13429)
|
huggingface/blog/blob/main/meg-mitchell-interview.md
|
(Gluon) ResNeXt
A **ResNeXt** repeats a [building block](https://paperswithcode.com/method/resnext-block) that aggregates a set of transformations with the same topology. Compared to a [ResNet](https://paperswithcode.com/method/resnet), it exposes a new dimension, *cardinality* (the size of the set of transformations) \\( C \\), as an essential factor in addition to the dimensions of depth and width.
The weights from this model were ported from [Gluon](https://cv.gluon.ai/model_zoo/classification.html).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('gluon_resnext101_32x4d', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `gluon_resnext101_32x4d`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('gluon_resnext101_32x4d', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/XieGDTH16,
author = {Saining Xie and
Ross B. Girshick and
Piotr Doll{\'{a}}r and
Zhuowen Tu and
Kaiming He},
title = {Aggregated Residual Transformations for Deep Neural Networks},
journal = {CoRR},
volume = {abs/1611.05431},
year = {2016},
url = {http://arxiv.org/abs/1611.05431},
archivePrefix = {arXiv},
eprint = {1611.05431},
timestamp = {Mon, 13 Aug 2018 16:45:58 +0200},
biburl = {https://dblp.org/rec/journals/corr/XieGDTH16.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<!--
Type: model-index
Collections:
- Name: Gloun ResNeXt
Paper:
Title: Aggregated Residual Transformations for Deep Neural Networks
URL: https://paperswithcode.com/paper/aggregated-residual-transformations-for-deep
Models:
- Name: gluon_resnext101_32x4d
In Collection: Gloun ResNeXt
Metadata:
FLOPs: 10298145792
Parameters: 44180000
File Size: 177367414
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnext101_32x4d
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L193
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnext101_32x4d-b253c8c4.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.33%
Top 5 Accuracy: 94.91%
- Name: gluon_resnext101_64x4d
In Collection: Gloun ResNeXt
Metadata:
FLOPs: 19954172928
Parameters: 83460000
File Size: 334737852
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnext101_64x4d
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L201
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnext101_64x4d-f9a8e184.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.63%
Top 5 Accuracy: 95.0%
- Name: gluon_resnext50_32x4d
In Collection: Gloun ResNeXt
Metadata:
FLOPs: 5472648192
Parameters: 25030000
File Size: 100441719
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnext50_32x4d
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L185
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnext50_32x4d-e6a097c1.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.35%
Top 5 Accuracy: 94.42%
-->
|
huggingface/pytorch-image-models/blob/main/hfdocs/source/models/gloun-resnext.mdx
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Stable Video Diffusion
[[open-in-colab]]
[Stable Video Diffusion](https://static1.squarespace.com/static/6213c340453c3f502425776e/t/655ce779b9d47d342a93c890/1700587395994/stable_video_diffusion.pdf) is a powerful image-to-video generation model that can generate high resolution (576x1024) 2-4 second videos conditioned on the input image.
This guide will show you how to use SVD to short generate videos from images.
Before you begin, make sure you have the following libraries installed:
```py
!pip install -q -U diffusers transformers accelerate
```
## Image to Video Generation
The are two variants of SVD. [SVD](https://huggingface.co/stabilityai/stable-video-diffusion-img2vid)
and [SVD-XT](https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt). The svd checkpoint is trained to generate 14 frames and the svd-xt checkpoint is further
finetuned to generate 25 frames.
We will use the `svd-xt` checkpoint for this guide.
```python
import torch
from diffusers import StableVideoDiffusionPipeline
from diffusers.utils import load_image, export_to_video
pipe = StableVideoDiffusionPipeline.from_pretrained(
"stabilityai/stable-video-diffusion-img2vid-xt", torch_dtype=torch.float16, variant="fp16"
)
pipe.enable_model_cpu_offload()
# Load the conditioning image
image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/svd/rocket.png?download=true")
image = image.resize((1024, 576))
generator = torch.manual_seed(42)
frames = pipe(image, decode_chunk_size=8, generator=generator).frames[0]
export_to_video(frames, "generated.mp4", fps=7)
```
<video controls width="1024" height="576">
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/svd/rocket_generated.webm" type="video/webm" />
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/svd/rocket_generated.mp4" type="video/mp4" />
</video>
<Tip>
Since generating videos is more memory intensive we can use the `decode_chunk_size` argument to control how many frames are decoded at once. This will reduce the memory usage. It's recommended to tweak this value based on your GPU memory.
Setting `decode_chunk_size=1` will decode one frame at a time and will use the least amount of memory but the video might have some flickering.
Additionally, we also use [model cpu offloading](../../optimization/memory#model-offloading) to reduce the memory usage.
</Tip>
### Torch.compile
You can achieve a 20-25% speed-up at the expense of slightly increased memory by compiling the UNet as follows:
```diff
- pipe.enable_model_cpu_offload()
+ pipe.to("cuda")
+ pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
```
### Low-memory
Video generation is very memory intensive as we have to essentially generate `num_frames` all at once. The mechanism is very comparable to text-to-image generation with a high batch size. To reduce the memory requirement you have multiple options. The following options trade inference speed against lower memory requirement:
- enable model offloading: Each component of the pipeline is offloaded to CPU once it's not needed anymore.
- enable feed-forward chunking: The feed-forward layer runs in a loop instead of running with a single huge feed-forward batch size
- reduce `decode_chunk_size`: This means that the VAE decodes frames in chunks instead of decoding them all together. **Note**: In addition to leading to a small slowdown, this method also slightly leads to video quality deterioration
You can enable them as follows:
```diff
-pipe.enable_model_cpu_offload()
-frames = pipe(image, decode_chunk_size=8, generator=generator).frames[0]
+pipe.enable_model_cpu_offload()
+pipe.unet.enable_forward_chunking()
+frames = pipe(image, decode_chunk_size=2, generator=generator, num_frames=25).frames[0]
```
Including all these tricks should lower the memory requirement to less than 8GB VRAM.
### Micro-conditioning
Along with conditioning image Stable Diffusion Video also allows providing micro-conditioning that allows more control over the generated video.
It accepts the following arguments:
- `fps`: The frames per second of the generated video.
- `motion_bucket_id`: The motion bucket id to use for the generated video. This can be used to control the motion of the generated video. Increasing the motion bucket id will increase the motion of the generated video.
- `noise_aug_strength`: The amount of noise added to the conditioning image. The higher the values the less the video will resemble the conditioning image. Increasing this value will also increase the motion of the generated video.
Here is an example of using micro-conditioning to generate a video with more motion.
```python
import torch
from diffusers import StableVideoDiffusionPipeline
from diffusers.utils import load_image, export_to_video
pipe = StableVideoDiffusionPipeline.from_pretrained(
"stabilityai/stable-video-diffusion-img2vid-xt", torch_dtype=torch.float16, variant="fp16"
)
pipe.enable_model_cpu_offload()
# Load the conditioning image
image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/svd/rocket.png?download=true")
image = image.resize((1024, 576))
generator = torch.manual_seed(42)
frames = pipe(image, decode_chunk_size=8, generator=generator, motion_bucket_id=180, noise_aug_strength=0.1).frames[0]
export_to_video(frames, "generated.mp4", fps=7)
```
<video width="1024" height="576" controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/svd/rocket_generated_motion.mp4" type="video/mp4">
</video>
|
huggingface/diffusers/blob/main/docs/source/en/using-diffusers/svd.md
|
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Hybrid Vision Transformer (ViT Hybrid)
## Overview
The hybrid Vision Transformer (ViT) model was proposed in [An Image is Worth 16x16 Words: Transformers for Image Recognition
at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk
Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob
Uszkoreit, Neil Houlsby. It's the first paper that successfully trains a Transformer encoder on ImageNet, attaining
very good results compared to familiar convolutional architectures. ViT hybrid is a slight variant of the [plain Vision Transformer](vit),
by leveraging a convolutional backbone (specifically, [BiT](bit)) whose features are used as initial "tokens" for the Transformer.
The abstract from the paper is the following:
*While the Transformer architecture has become the de-facto standard for natural language processing tasks, its
applications to computer vision remain limited. In vision, attention is either applied in conjunction with
convolutional networks, or used to replace certain components of convolutional networks while keeping their overall
structure in place. We show that this reliance on CNNs is not necessary and a pure transformer applied directly to
sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of
data and transferred to multiple mid-sized or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.),
Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring
substantially fewer computational resources to train.*
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code (written in JAX) can be
found [here](https://github.com/google-research/vision_transformer).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViT Hybrid.
<PipelineTag pipeline="image-classification"/>
- [`ViTHybridForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## ViTHybridConfig
[[autodoc]] ViTHybridConfig
## ViTHybridImageProcessor
[[autodoc]] ViTHybridImageProcessor
- preprocess
## ViTHybridModel
[[autodoc]] ViTHybridModel
- forward
## ViTHybridForImageClassification
[[autodoc]] ViTHybridForImageClassification
- forward
|
huggingface/transformers/blob/main/docs/source/en/model_doc/vit_hybrid.md
|
--
# Example metadata to be added to a model card.
# Full model card template at https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md
language:
- {lang_0} # Example: fr
- {lang_1} # Example: en
license: {license} # Example: apache-2.0 or any license from https://hf.co/docs/hub/repositories-licenses
license_name: {license_name} # If license = other (license not in https://hf.co/docs/hub/repositories-licenses), specify an id for it here, like `my-license-1.0`.
license_link: {license_link} # If license = other, specify "LICENSE" or "LICENSE.md" to link to a file of that name inside the repo, or a URL to a remote file.
library_name: {library_name} # Optional. Example: keras or any library from https://github.com/huggingface/huggingface.js/blob/main/packages/tasks/src/model-libraries.ts
tags:
- {tag_0} # Example: audio
- {tag_1} # Example: automatic-speech-recognition
- {tag_2} # Example: speech
- {tag_3} # Example to specify a library: allennlp
datasets:
- {dataset_0} # Example: common_voice. Use dataset id from https://hf.co/datasets
metrics:
- {metric_0} # Example: wer. Use metric id from https://hf.co/metrics
base_model: {base_model} # Example: stabilityai/stable-diffusion-xl-base-1.0. Can also be a list (for merges)
# Optional. Add this if you want to encode your eval results in a structured way.
model-index:
- name: {model_id}
results:
- task:
type: {task_type} # Required. Example: automatic-speech-recognition
name: {task_name} # Optional. Example: Speech Recognition
dataset:
type: {dataset_type} # Required. Example: common_voice. Use dataset id from https://hf.co/datasets
name: {dataset_name} # Required. A pretty name for the dataset. Example: Common Voice (French)
config: {dataset_config} # Optional. The name of the dataset configuration used in `load_dataset()`. Example: fr in `load_dataset("common_voice", "fr")`. See the `datasets` docs for more info: https://huggingface.co/docs/datasets/package_reference/loading_methods#datasets.load_dataset.name
split: {dataset_split} # Optional. Example: test
revision: {dataset_revision} # Optional. Example: 5503434ddd753f426f4b38109466949a1217c2bb
args:
{arg_0}: {value_0} # Optional. Additional arguments to `load_dataset()`. Example for wikipedia: language: en
{arg_1}: {value_1} # Optional. Example for wikipedia: date: 20220301
metrics:
- type: {metric_type} # Required. Example: wer. Use metric id from https://hf.co/metrics
value: {metric_value} # Required. Example: 20.90
name: {metric_name} # Optional. Example: Test WER
config: {metric_config} # Optional. The name of the metric configuration used in `load_metric()`. Example: bleurt-large-512 in `load_metric("bleurt", "bleurt-large-512")`. See the `datasets` docs for more info: https://huggingface.co/docs/datasets/v2.1.0/en/loading#load-configurations
args:
{arg_0}: {value_0} # Optional. The arguments passed during `Metric.compute()`. Example for `bleu`: max_order: 4
verifyToken: {verify_token} # Optional. If present, this is a signature that can be used to prove that evaluation was generated by Hugging Face (vs. self-reported).
source: # Optional. The source for this result.
name: {source_name} # Optional. The name of the source. Example: Open LLM Leaderboard.
url: {source_url} # Required if source is provided. A link to the source. Example: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard.
---
This markdown file contains the spec for the modelcard metadata regarding evaluation parameters. When present, and only then, 'model-index', 'datasets' and 'license' contents will be verified when git pushing changes to your README.md file.
Valid license identifiers can be found in [our docs](https://huggingface.co/docs/hub/repositories-licenses).
For the full model card template, see: [modelcard_template.md file](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md).
|
huggingface/hub-docs/blob/main/modelcard.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Dance Diffusion
[Dance Diffusion](https://github.com/Harmonai-org/sample-generator) is by Zach Evans.
Dance Diffusion is the first in a suite of generative audio tools for producers and musicians released by [Harmonai](https://github.com/Harmonai-org).
<Tip>
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
</Tip>
## DanceDiffusionPipeline
[[autodoc]] DanceDiffusionPipeline
- all
- __call__
## AudioPipelineOutput
[[autodoc]] pipelines.AudioPipelineOutput
|
huggingface/diffusers/blob/main/docs/source/en/api/pipelines/dance_diffusion.md
|
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Multiple choice
The script [`run_swag.py`](https://github.com/huggingface/optimum/blob/main/examples/onnxruntime/quantization/multiple-choice/run_swag.py) allows us to apply different quantization approaches (such as dynamic and static quantization) using the [ONNX Runtime](https://github.com/microsoft/onnxruntime) quantization tool for multiple choice tasks.
The following example applies post-training dynamic quantization on a BERT fine-tuned on the SWAG dataset.
```bash
python run_swag.py \
--model_name_or_path ehdwns1516/bert-base-uncased_SWAG \
--quantization_approach dynamic \
--do_eval \
--output_dir /tmp/quantized_bert_swag
```
In order to apply dynamic or static quantization, `quantization_approach` must be set to respectively `dynamic` or `static`.
|
huggingface/optimum/blob/main/examples/onnxruntime/quantization/multiple-choice/README.md
|
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# LayoutLMv3
## Overview
The LayoutLMv3 model was proposed in [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
LayoutLMv3 simplifies [LayoutLMv2](layoutlmv2) by using patch embeddings (as in [ViT](vit)) instead of leveraging a CNN backbone, and pre-trains the model on 3 objectives: masked language modeling (MLM), masked image modeling (MIM)
and word-patch alignment (WPA).
The abstract from the paper is the following:
*Self-supervised pre-training techniques have achieved remarkable progress in Document AI. Most multimodal pre-trained models use a masked language modeling objective to learn bidirectional representations on the text modality, but they differ in pre-training objectives for the image modality. This discrepancy adds difficulty to multimodal representation learning. In this paper, we propose LayoutLMv3 to pre-train multimodal Transformers for Document AI with unified text and image masking. Additionally, LayoutLMv3 is pre-trained with a word-patch alignment objective to learn cross-modal alignment by predicting whether the corresponding image patch of a text word is masked. The simple unified architecture and training objectives make LayoutLMv3 a general-purpose pre-trained model for both text-centric and image-centric Document AI tasks. Experimental results show that LayoutLMv3 achieves state-of-the-art performance not only in text-centric tasks, including form understanding, receipt understanding, and document visual question answering, but also in image-centric tasks such as document image classification and document layout analysis.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/layoutlmv3_architecture.png"
alt="drawing" width="600"/>
<small> LayoutLMv3 architecture. Taken from the <a href="https://arxiv.org/abs/2204.08387">original paper</a>. </small>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version of this model was added by [chriskoo](https://huggingface.co/chriskoo), [tokec](https://huggingface.co/tokec), and [lre](https://huggingface.co/lre). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/layoutlmv3).
## Usage tips
- In terms of data processing, LayoutLMv3 is identical to its predecessor [LayoutLMv2](layoutlmv2), except that:
- images need to be resized and normalized with channels in regular RGB format. LayoutLMv2 on the other hand normalizes the images internally and expects the channels in BGR format.
- text is tokenized using byte-pair encoding (BPE), as opposed to WordPiece.
Due to these differences in data preprocessing, one can use [`LayoutLMv3Processor`] which internally combines a [`LayoutLMv3ImageProcessor`] (for the image modality) and a [`LayoutLMv3Tokenizer`]/[`LayoutLMv3TokenizerFast`] (for the text modality) to prepare all data for the model.
- Regarding usage of [`LayoutLMv3Processor`], we refer to the [usage guide](layoutlmv2#usage-layoutlmv2processor) of its predecessor.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LayoutLMv3. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<Tip>
LayoutLMv3 is nearly identical to LayoutLMv2, so we've also included LayoutLMv2 resources you can adapt for LayoutLMv3 tasks. For these notebooks, take care to use [`LayoutLMv2Processor`] instead when preparing data for the model!
</Tip>
- Demo notebooks for LayoutLMv3 can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LayoutLMv3).
- Demo scripts can be found [here](https://github.com/huggingface/transformers/tree/main/examples/research_projects/layoutlmv3).
<PipelineTag pipeline="text-classification"/>
- [`LayoutLMv2ForSequenceClassification`] is supported by this [notebook](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv2/RVL-CDIP/Fine_tuning_LayoutLMv2ForSequenceClassification_on_RVL_CDIP.ipynb).
- [Text classification task guide](../tasks/sequence_classification)
<PipelineTag pipeline="token-classification"/>
- [`LayoutLMv3ForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/research_projects/layoutlmv3) and [notebook](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv3/Fine_tune_LayoutLMv3_on_FUNSD_(HuggingFace_Trainer).ipynb).
- A [notebook](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv2/FUNSD/Inference_with_LayoutLMv2ForTokenClassification.ipynb) for how to perform inference with [`LayoutLMv2ForTokenClassification`] and a [notebook](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv2/FUNSD/True_inference_with_LayoutLMv2ForTokenClassification_%2B_Gradio_demo.ipynb) for how to perform inference when no labels are available with [`LayoutLMv2ForTokenClassification`].
- A [notebook](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv2/FUNSD/Fine_tuning_LayoutLMv2ForTokenClassification_on_FUNSD_using_HuggingFace_Trainer.ipynb) for how to finetune [`LayoutLMv2ForTokenClassification`] with the 🤗 Trainer.
- [Token classification task guide](../tasks/token_classification)
<PipelineTag pipeline="question-answering"/>
- [`LayoutLMv2ForQuestionAnswering`] is supported by this [notebook](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv2/DocVQA/Fine_tuning_LayoutLMv2ForQuestionAnswering_on_DocVQA.ipynb).
- [Question answering task guide](../tasks/question_answering)
**Document question answering**
- [Document question answering task guide](../tasks/document_question_answering)
## LayoutLMv3Config
[[autodoc]] LayoutLMv3Config
## LayoutLMv3FeatureExtractor
[[autodoc]] LayoutLMv3FeatureExtractor
- __call__
## LayoutLMv3ImageProcessor
[[autodoc]] LayoutLMv3ImageProcessor
- preprocess
## LayoutLMv3Tokenizer
[[autodoc]] LayoutLMv3Tokenizer
- __call__
- save_vocabulary
## LayoutLMv3TokenizerFast
[[autodoc]] LayoutLMv3TokenizerFast
- __call__
## LayoutLMv3Processor
[[autodoc]] LayoutLMv3Processor
- __call__
<frameworkcontent>
<pt>
## LayoutLMv3Model
[[autodoc]] LayoutLMv3Model
- forward
## LayoutLMv3ForSequenceClassification
[[autodoc]] LayoutLMv3ForSequenceClassification
- forward
## LayoutLMv3ForTokenClassification
[[autodoc]] LayoutLMv3ForTokenClassification
- forward
## LayoutLMv3ForQuestionAnswering
[[autodoc]] LayoutLMv3ForQuestionAnswering
- forward
</pt>
<tf>
## TFLayoutLMv3Model
[[autodoc]] TFLayoutLMv3Model
- call
## TFLayoutLMv3ForSequenceClassification
[[autodoc]] TFLayoutLMv3ForSequenceClassification
- call
## TFLayoutLMv3ForTokenClassification
[[autodoc]] TFLayoutLMv3ForTokenClassification
- call
## TFLayoutLMv3ForQuestionAnswering
[[autodoc]] TFLayoutLMv3ForQuestionAnswering
- call
</tf>
</frameworkcontent>
|
huggingface/transformers/blob/main/docs/source/en/model_doc/layoutlmv3.md
|
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# 🤗 Benchmark results
Here, you can find a list of the different benchmark results created by the community.
If you would like to list benchmark results on your favorite models of the [model hub](https://huggingface.co/models) here, please open a Pull Request and add it below.
| Benchmark description | Results | Environment info | Author |
|:----------|:-------------|:-------------|------:|
| PyTorch Benchmark on inference for `bert-base-cased` |[memory](https://github.com/patrickvonplaten/files_to_link_to/blob/master/bert_benchmark/inference_memory.csv) | [env](https://github.com/patrickvonplaten/files_to_link_to/blob/master/bert_benchmark/env.csv) | [Partick von Platen](https://github.com/patrickvonplaten) |
| PyTorch Benchmark on inference for `bert-base-cased` |[time](https://github.com/patrickvonplaten/files_to_link_to/blob/master/bert_benchmark/inference_time.csv) | [env](https://github.com/patrickvonplaten/files_to_link_to/blob/master/bert_benchmark/env.csv) | [Partick von Platen](https://github.com/patrickvonplaten) |
|
huggingface/transformers/blob/main/examples/tensorflow/benchmarking/README.md
|
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# XGLM
## Overview
The XGLM model was proposed in [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668)
by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal,
Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo,
Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
The abstract from the paper is the following:
*Large-scale autoregressive language models such as GPT-3 are few-shot learners that can perform a wide range of language
tasks without fine-tuning. While these models are known to be able to jointly represent many different languages,
their training data is dominated by English, potentially limiting their cross-lingual generalization.
In this work, we train multilingual autoregressive language models on a balanced corpus covering a diverse set of languages,
and study their few- and zero-shot learning capabilities in a wide range of tasks. Our largest model with 7.5 billion parameters
sets new state of the art in few-shot learning in more than 20 representative languages, outperforming GPT-3 of comparable size
in multilingual commonsense reasoning (with +7.4% absolute accuracy improvement in 0-shot settings and +9.4% in 4-shot settings)
and natural language inference (+5.4% in each of 0-shot and 4-shot settings). On the FLORES-101 machine translation benchmark,
our model outperforms GPT-3 on 171 out of 182 translation directions with 32 training examples, while surpassing the
official supervised baseline in 45 directions. We present a detailed analysis of where the model succeeds and fails,
showing in particular that it enables cross-lingual in-context learning on some tasks, while there is still room for improvement
on surface form robustness and adaptation to tasks that do not have a natural cloze form. Finally, we evaluate our models
in social value tasks such as hate speech detection in five languages and find it has limitations similar to comparable sized GPT-3 models.*
This model was contributed by [Suraj](https://huggingface.co/valhalla). The original code can be found [here](https://github.com/pytorch/fairseq/tree/main/examples/xglm).
## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
## XGLMConfig
[[autodoc]] XGLMConfig
## XGLMTokenizer
[[autodoc]] XGLMTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## XGLMTokenizerFast
[[autodoc]] XGLMTokenizerFast
<frameworkcontent>
<pt>
## XGLMModel
[[autodoc]] XGLMModel
- forward
## XGLMForCausalLM
[[autodoc]] XGLMForCausalLM
- forward
</pt>
<tf>
## TFXGLMModel
[[autodoc]] TFXGLMModel
- call
## TFXGLMForCausalLM
[[autodoc]] TFXGLMForCausalLM
- call
</tf>
<jax>
## FlaxXGLMModel
[[autodoc]] FlaxXGLMModel
- __call__
## FlaxXGLMForCausalLM
[[autodoc]] FlaxXGLMForCausalLM
- __call__
</jax>
</frameworkcontent>
|
huggingface/transformers/blob/main/docs/source/en/model_doc/xglm.md
|
--
title: "Accelerating PyTorch distributed fine-tuning with Intel technologies"
thumbnail: /blog/assets/36_accelerating_pytorch/04_four_nodes.png
authors:
- user: juliensimon
---
# Accelerating PyTorch distributed fine-tuning with Intel technologies
For all their amazing performance, state of the art deep learning models often take a long time to train. In order to speed up training jobs, engineering teams rely on distributed training, a divide-and-conquer technique where clustered servers each keep a copy of the model, train it on a subset of the training set, and exchange results to converge to a final model.
Graphical Processing Units (GPUs) have long been the _de facto_ choice to train deep learning models. However, the rise of transfer learning is changing the game. Models are now rarely trained from scratch on humungous datasets. Instead, they are frequently fine-tuned on specific (and smaller) datasets, in order to build specialized models that are more accurate than the base model for particular tasks. As these training jobs are much shorter, using a CPU-based cluster can prove to be an interesting option that keeps both training time and cost under control.
### What this post is about
In this post, you will learn how to accelerate [PyTorch](https://pytorch.org) training jobs by distributing them on a cluster of Intel Xeon Scalable CPU servers, powered by the Ice Lake architecture and running performance-optimized software libraries. We will build the cluster from scratch using virtual machines, and you should be able to easily replicate the demo on your own infrastructure, either in the cloud or on premise.
Running a text classification job, we will fine-tune a [BERT](https://huggingface.co/bert-base-cased) model on the [MRPC](https://www.microsoft.com/en-us/download/details.aspx?id=52398) dataset (one of the tasks included in the [GLUE](https://gluebenchmark.com/) benchmark). The MRPC dataset contains 5,800 sentence pairs extracted from news sources, with a label telling us whether the two sentences in each pair are semantically equivalent. We picked this dataset for its reasonable training time, and trying other GLUE tasks is just a parameter away.
Once the cluster is up and running, we will run a baseline job on a single server. Then, we will scale it to 2 servers and 4 servers and measure the speed-up.
Along the way, we will cover the following topics:
* Listing the required infrastructure and software building blocks,
* Setting up our cluster,
* Installing dependencies,
* Running a single-node job,
* Running a distributed job.
Let's get to work!
### Using Intel servers
For best performance, we will use Intel servers based on the Ice Lake architecture, which supports hardware features such as Intel AVX-512 and Intel Vector Neural Network Instructions (VNNI). These features accelerate operations typically found in deep learning training and inference. You can learn more about them in this [presentation](https://www.intel.com/content/dam/www/public/us/en/documents/product-overviews/dl-boost-product-overview.pdf) (PDF).
All three major cloud providers offer virtual machines powered by Intel Ice Lake CPUs:
- Amazon Web Services: Amazon EC2 [M6i](https://aws.amazon.com/blogs/aws/new-amazon-ec2-m6i-instances-powered-by-the-latest-generation-intel-xeon-scalable-processors/)
and [C6i](https://aws.amazon.com/blogs/aws/new-amazon-ec2-c6i-instances-powered-by-the-latest-generation-intel-xeon-scalable-processors/) instances.
- Azure: [Dv5/Dsv5-series](https://docs.microsoft.com/en-us/azure/virtual-machines/dv5-dsv5-series), [Ddv5/Ddsv5-series](https://docs.microsoft.com/en-us/azure/virtual-machines/ddv5-ddsv5-series) and [Edv5/Edsv5-series](https://docs.microsoft.com/en-us/azure/virtual-machines/edv5-edsv5-series) virtual machines.
- Google Cloud Platform: [N2](https://cloud.google.com/blog/products/compute/compute-engine-n2-vms-now-available-with-intel-ice-lake) Compute Engine virtual machines.
Of course, you can also use your own servers. If they are based on the Cascade Lake architecture (Ice Lake's predecessor), they're good to go as Cascade Lake also includes AVX-512 and VNNI.
### Using Intel performance libraries
To leverage AVX-512 and VNNI in PyTorch, Intel has designed the [Intel extension for PyTorch](https://github.com/intel/intel-extension-for-pytorch). This software library provides out of the box speedup for training and inference, so we should definitely install it.
When it comes to distributed training, the main performance bottleneck is often networking. Indeed, the different nodes in the cluster need to periodically exchange model state information to stay in sync. As transformers are large models with billions of parameters (sometimes much more), the volume of information is significant, and things only get worse as the number of nodes increase. Thus, it's important to use a communication library optimized for deep learning.
In fact, PyTorch includes the [```torch.distributed```](https://pytorch.org/tutorials/intermediate/dist_tuto.html) package, which supports different communication backends. Here, we'll use the Intel oneAPI Collective Communications Library [(oneCCL)](https://github.com/oneapi-src/oneCCL), an efficient implementation of communication patterns used in deep learning ([all-reduce](https://en.wikipedia.org/wiki/Collective_operation), etc.). You can learn about the performance of oneCCL versus other backends in this PyTorch [blog post](https://pytorch.medium.com/optimizing-dlrm-by-using-pytorch-with-oneccl-backend-9f85b8ef6929).
Now that we're clear on building blocks, let's talk about the overall setup of our training cluster.
### Setting up our cluster
In this demo, I'm using Amazon EC2 instances running Amazon Linux 2 (c6i.16xlarge, 64 vCPUs, 128GB RAM, 25Gbit/s networking). Setup will be different in other environments, but steps should be very similar.
Please keep in mind that you will need 4 identical instances, so you may want to plan for some sort of automation to avoid running the same setup 4 times. Here, I will set up one instance manually, create a new Amazon Machine Image [(AMI)](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/AMIs.html) from this instance, and use this AMI to launch three identical instances.
From a networking perspective, we will need the following setup:
* Open port 22 for ```ssh``` access on all instances for setup and debugging.
* Configure [password-less](https://www.redhat.com/sysadmin/passwordless-ssh) ```ssh``` between the master instance (the one you'll launch training from) and all other instances (__master included__).
* Open all TCP ports on all instances for oneCCL communication inside the cluster. __Please make sure NOT to open these ports to the external world__. AWS provides a convenient way to do this by only allowing connections from instances running a particular [security group](https://docs.aws.amazon.com/vpc/latest/userguide/VPC_SecurityGroups.html). Here's how my setup looks.
<kbd>
<img src="assets/36_accelerating_pytorch/01_security_group.png">
</kbd>
Now, let's provision the first instance manually. I first create the instance itself, attach the security group above, and add 128GB of storage. To optimize costs, I have launched it as a [spot instance](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-spot-instances.html).
Once the instance is up, I connect to it with ```ssh``` in order to install dependencies.
### Installing dependencies
Here are the steps we will follow:
* Install Intel toolkits,
* Install the Anaconda distribution,
* Create a new ```conda``` environment,
* Install PyTorch and the Intel extension for PyTorch,
* Compile and install oneCCL,
* Install the ```transformers``` library.
It looks like a lot, but there's nothing complicated. Here we go!
__Installing Intel toolkits__
First, we download and install the Intel [OneAPI base toolkit](https://www.intel.com/content/www/us/en/developer/tools/oneapi/base-toolkit-download.html?operatingsystem=linux&distributions=webdownload&options=offline) as well as the [AI toolkit](https://www.intel.com/content/www/us/en/developer/tools/oneapi/ai-analytics-toolkit-download.html?operatingsystem=linux&distributions=webdownload&options=offline). You can learn about them on the Intel [website](https://www.intel.com/content/www/us/en/developer/tools/oneapi/toolkits.html#gs.gmojrp).
```
wget https://registrationcenter-download.intel.com/akdlm/irc_nas/18236/l_BaseKit_p_2021.4.0.3422_offline.sh
sudo bash l_BaseKit_p_2021.4.0.3422_offline.sh
wget https://registrationcenter-download.intel.com/akdlm/irc_nas/18235/l_AIKit_p_2021.4.0.1460_offline.sh
sudo bash l_AIKit_p_2021.4.0.1460_offline.sh
```
__Installing Anaconda__
Then, we [download](https://www.anaconda.com/products/individual) and install the Anaconda distribution.
```
wget https://repo.anaconda.com/archive/Anaconda3-2021.05-Linux-x86_64.sh
sh Anaconda3-2021.05-Linux-x86_64.sh
```
__Creating a new conda environment__
We log out and log in again to refresh paths. Then, we create a new ```conda``` environment to keep things neat and tidy.
```
yes | conda create -n transformer python=3.7.9 -c anaconda
eval "$(conda shell.bash hook)"
conda activate transformer
yes | conda install pip cmake
```
__Installing PyTorch and the Intel extension for PyTorch__
Next, we install PyTorch 1.9 and the Intel extension toolkit. __Versions must match__.
```
yes | conda install pytorch==1.9.0 cpuonly -c pytorch
pip install torch_ipex==1.9.0 -f https://software.intel.com/ipex-whl-stable
```
__Compiling and installing oneCCL__
Then, we install some native dependencies required to compile oneCCL.
```
sudo yum -y update
sudo yum install -y git cmake3 gcc gcc-c++
```
Next, we clone the oneCCL repository, build the library and install it. __Again, versions must match__.
```
source /opt/intel/oneapi/mkl/latest/env/vars.sh
git clone https://github.com/intel/torch-ccl.git
cd torch-ccl
git checkout ccl_torch1.9
git submodule sync
git submodule update --init --recursive
python setup.py install
cd ..
```
__Installing the transformers library__
Next, we install the ```transformers``` library and dependencies required to run GLUE tasks.
```
pip install transformers datasets
yes | conda install scipy scikit-learn
```
Finally, we clone a fork of the ```transformers```repository containing the example we're going to run.
```
git clone https://github.com/kding1/transformers.git
cd transformers
git checkout dist-sigopt
```
We're done! Let's run a single-node job.
### Launching a single-node job
To get a baseline, let's launch a single-node job running the ```run_glue.py``` script in ```transformers/examples/pytorch/text-classification```. This should work on any of the instances, and it's a good sanity check before proceeding to distributed training.
```
python run_glue.py \
--model_name_or_path bert-base-cased --task_name mrpc \
--do_train --do_eval --max_seq_length 128 \
--per_device_train_batch_size 32 --learning_rate 2e-5 --num_train_epochs 3 \
--output_dir /tmp/mrpc/ --overwrite_output_dir True
```
<kbd>
<img src="assets/36_accelerating_pytorch/02_single_node.png">
</kbd>
This job takes __7 minutes and 46 seconds__. Now, let's set up distributed jobs with oneCCL and speed things up!
### Setting up a distributed job with oneCCL
Three steps are required to run a distributed training job:
* List the nodes of the training cluster,
* Define environment variables,
* Modify the training script.
__Listing the nodes of the training cluster__
On the master instance, in ```transformers/examples/pytorch/text-classification```, we create a text file named ```hostfile```. This file stores the names of the nodes in the cluster (IP addresses would work too). The first line should point to the master instance.
Here's my file:
```
ip-172-31-28-17.ec2.internal
ip-172-31-30-87.ec2.internal
ip-172-31-29-11.ec2.internal
ip-172-31-20-77.ec2.internal
```
__Defining environment variables__
Next, we need to set some environment variables on the master node, most notably its IP address. You can find more information on oneCCL variables in the [documentation](https://oneapi-src.github.io/oneCCL/env-variables.html).
```
for nic in eth0 eib0 hib0 enp94s0f0; do
master_addr=$(ifconfig $nic 2>/dev/null | grep netmask | awk '{print $2}'| cut -f2 -d:)
if [ "$master_addr" ]; then
break
fi
done
export MASTER_ADDR=$master_addr
source /home/ec2-user/anaconda3/envs/transformer/lib/python3.7/site-packages/torch_ccl-1.3.0+43f48a1-py3.7-linux-x86_64.egg/torch_ccl/env/setvars.sh
export LD_LIBRARY_PATH=/home/ec2-user/anaconda3/envs/transformer/lib/python3.7/site-packages/torch_ccl-1.3.0+43f48a1-py3.7-linux-x86_64.egg/:$LD_LIBRARY_PATH
export LD_PRELOAD="${CONDA_PREFIX}/lib/libtcmalloc.so:${CONDA_PREFIX}/lib/libiomp5.so"
export CCL_WORKER_COUNT=4
export CCL_WORKER_AFFINITY="0,1,2,3,32,33,34,35"
export CCL_ATL_TRANSPORT=ofi
export ATL_PROGRESS_MODE=0
```
__Modifying the training script__
The following changes have already been applied to our training script (```run_glue.py```) in order to enable distributed training. You would need to apply similar changes when using your own training code.
* Import the ```torch_ccl```package.
* Receive the address of the master node and the local rank of the node in the cluster.
```
+import torch_ccl
+
import datasets
import numpy as np
from datasets import load_dataset, load_metric
@@ -47,7 +49,7 @@ from transformers.utils.versions import require_version
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.13.0.dev0")
+# check_min_version("4.13.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/text-classification/requirements.txt")
@@ -191,6 +193,17 @@ def main():
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
+ # add local rank for cpu-dist
+ sys.argv.append("--local_rank")
+ sys.argv.append(str(os.environ.get("PMI_RANK", -1)))
+
+ # ccl specific environment variables
+ if "ccl" in sys.argv:
+ os.environ["MASTER_ADDR"] = os.environ.get("MASTER_ADDR", "127.0.0.1")
+ os.environ["MASTER_PORT"] = "29500"
+ os.environ["RANK"] = str(os.environ.get("PMI_RANK", -1))
+ os.environ["WORLD_SIZE"] = str(os.environ.get("PMI_SIZE", -1))
+
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
```
Setup is now complete. Let's scale our training job to 2 nodes and 4 nodes.
### Running a distributed job with oneCCL
On the __master node__, I use ```mpirun```to launch a 2-node job: ```-np``` (number of processes) is set to 2 and ```-ppn``` (process per node) is set to 1. Hence, the first two nodes in ```hostfile``` will be selected.
```
mpirun -f hostfile -np 2 -ppn 1 -genv I_MPI_PIN_DOMAIN=[0xfffffff0] \
-genv OMP_NUM_THREADS=28 python run_glue.py \
--model_name_or_path distilbert-base-uncased --task_name mrpc \
--do_train --do_eval --max_seq_length 128 --per_device_train_batch_size 32 \
--learning_rate 2e-5 --num_train_epochs 3 --output_dir /tmp/mrpc/ \
--overwrite_output_dir True --xpu_backend ccl --no_cuda True
```
Within seconds, a job starts on the first two nodes. The job completes in __4 minutes and 39 seconds__, a __1.7x__ speedup.
<kbd>
<img src="assets/36_accelerating_pytorch/03_two_nodes.png">
</kbd>
Setting ```-np``` to 4 and launching a new job, I now see one process running on each node of the cluster.
<kbd>
<img src="assets/36_accelerating_pytorch/04_four_nodes.png">
</kbd>
Training completes in __2 minutes and 36 seconds__, a __3x__ speedup.
One last thing. Changing ```--task_name``` to ```qqp```, I also ran the Quora Question Pairs GLUE task, which is based on a much larger [dataset](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) (over 400,000 training samples). The fine-tuning times were:
* Single-node: 11 hours 22 minutes,
* 2 nodes: 6 hours and 38 minutes (1.71x),
* 4 nodes: 3 hours and 51 minutes (2.95x).
It looks like the speedup is pretty consistent. Feel free to keep experimenting with different learning rates, batch sizes and oneCCL settings. I'm sure you can go even faster!
### Conclusion
In this post, you've learned how to build a distributed training cluster based on Intel CPUs and performance libraries, and how to use this cluster to speed up fine-tuning jobs. Indeed, transfer learning is putting CPU training back into the game, and you should definitely consider it when designing and building your next deep learning workflows.
Thanks for reading this long post. I hope you found it informative. Feedback and questions are welcome at _julsimon@huggingface.co_. Until next time, keep learning!
Julien
|
huggingface/blog/blob/main/accelerating-pytorch.md
|
SSL ResNet
**Residual Networks**, or **ResNets**, learn residual functions with reference to the layer inputs, instead of learning unreferenced functions. Instead of hoping each few stacked layers directly fit a desired underlying mapping, residual nets let these layers fit a residual mapping. They stack [residual blocks](https://paperswithcode.com/method/residual-block) ontop of each other to form network: e.g. a ResNet-50 has fifty layers using these blocks.
The model in this collection utilises semi-supervised learning to improve the performance of the model. The approach brings important gains to standard architectures for image, video and fine-grained classification.
Please note the CC-BY-NC 4.0 license on theses weights, non-commercial use only.
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('ssl_resnet18', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `ssl_resnet18`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('ssl_resnet18', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/abs-1905-00546,
author = {I. Zeki Yalniz and
Herv{\'{e}} J{\'{e}}gou and
Kan Chen and
Manohar Paluri and
Dhruv Mahajan},
title = {Billion-scale semi-supervised learning for image classification},
journal = {CoRR},
volume = {abs/1905.00546},
year = {2019},
url = {http://arxiv.org/abs/1905.00546},
archivePrefix = {arXiv},
eprint = {1905.00546},
timestamp = {Mon, 28 Sep 2020 08:19:37 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-1905-00546.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<!--
Type: model-index
Collections:
- Name: SSL ResNet
Paper:
Title: Billion-scale semi-supervised learning for image classification
URL: https://paperswithcode.com/paper/billion-scale-semi-supervised-learning-for
Models:
- Name: ssl_resnet18
In Collection: SSL ResNet
Metadata:
FLOPs: 2337073152
Parameters: 11690000
File Size: 46811375
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
- YFCC-100M
Training Resources: 64x GPUs
ID: ssl_resnet18
LR: 0.0015
Epochs: 30
Layers: 18
Crop Pct: '0.875'
Batch Size: 1536
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/resnet.py#L894
Weights: https://dl.fbaipublicfiles.com/semiweaksupervision/model_files/semi_supervised_resnet18-d92f0530.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 72.62%
Top 5 Accuracy: 91.42%
- Name: ssl_resnet50
In Collection: SSL ResNet
Metadata:
FLOPs: 5282531328
Parameters: 25560000
File Size: 102480594
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
- YFCC-100M
Training Resources: 64x GPUs
ID: ssl_resnet50
LR: 0.0015
Epochs: 30
Layers: 50
Crop Pct: '0.875'
Batch Size: 1536
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/resnet.py#L904
Weights: https://dl.fbaipublicfiles.com/semiweaksupervision/model_files/semi_supervised_resnet50-08389792.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.24%
Top 5 Accuracy: 94.83%
-->
|
huggingface/pytorch-image-models/blob/main/docs/models/ssl-resnet.md
|
A Q-Learning example [[q-learning-example]]
To better understand Q-Learning, let's take a simple example:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Maze-Example-2.jpg" alt="Maze-Example"/>
- You're a mouse in this tiny maze. You always **start at the same starting point.**
- The goal is **to eat the big pile of cheese at the bottom right-hand corner** and avoid the poison. After all, who doesn't like cheese?
- The episode ends if we eat the poison, **eat the big pile of cheese**, or if we take more than five steps.
- The learning rate is 0.1
- The discount rate (gamma) is 0.99
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/q-ex-1.jpg" alt="Maze-Example"/>
The reward function goes like this:
- **+0:** Going to a state with no cheese in it.
- **+1:** Going to a state with a small cheese in it.
- **+10:** Going to the state with the big pile of cheese.
- **-10:** Going to the state with the poison and thus dying.
- **+0** If we take more than five steps.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/q-ex-2.jpg" alt="Maze-Example"/>
To train our agent to have an optimal policy (so a policy that goes right, right, down), **we will use the Q-Learning algorithm**.
## Step 1: Initialize the Q-table [[step1]]
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Example-1.jpg" alt="Maze-Example"/>
So, for now, **our Q-table is useless**; we need **to train our Q-function using the Q-Learning algorithm.**
Let's do it for 2 training timesteps:
Training timestep 1:
## Step 2: Choose an action using the Epsilon Greedy Strategy [[step2]]
Because epsilon is big (= 1.0), I take a random action. In this case, I go right.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/q-ex-3.jpg" alt="Maze-Example"/>
## Step 3: Perform action At, get Rt+1 and St+1 [[step3]]
By going right, I get a small cheese, so \\(R_{t+1} = 1\\) and I'm in a new state.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/q-ex-4.jpg" alt="Maze-Example"/>
## Step 4: Update Q(St, At) [[step4]]
We can now update \\(Q(S_t, A_t)\\) using our formula.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/q-ex-5.jpg" alt="Maze-Example"/>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Example-4.jpg" alt="Maze-Example"/>
Training timestep 2:
## Step 2: Choose an action using the Epsilon Greedy Strategy [[step2-2]]
**I take a random action again, since epsilon=0.99 is big**. (Notice we decay epsilon a little bit because, as the training progress, we want less and less exploration).
I took the action 'down'. **This is not a good action since it leads me to the poison.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/q-ex-6.jpg" alt="Maze-Example"/>
## Step 3: Perform action At, get Rt+1 and St+1 [[step3-3]]
Because I ate poison, **I get \\(R_{t+1} = -10\\), and I die.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/q-ex-7.jpg" alt="Maze-Example"/>
## Step 4: Update Q(St, At) [[step4-4]]
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/q-ex-8.jpg" alt="Maze-Example"/>
Because we're dead, we start a new episode. But what we see here is that, **with two explorations steps, my agent became smarter.**
As we continue exploring and exploiting the environment and updating Q-values using the TD target, the **Q-table will give us a better and better approximation. At the end of the training, we'll get an estimate of the optimal Q-function.**
|
huggingface/deep-rl-class/blob/main/units/en/unit2/q-learning-example.mdx
|
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Git 与 HTTP 范式
`huggingface_hub`库是用于与Hugging Face Hub进行交互的库,Hugging Face Hub是一组基于Git的存储库(模型、数据集或Spaces)。使用 `huggingface_hub`有两种主要方式来访问Hub。
第一种方法,即所谓的“基于git”的方法,由[`Repository`]类驱动。这种方法使用了一个包装器,它在 `git`命令的基础上增加了专门与Hub交互的额外函数。第二种选择,称为“基于HTTP”的方法,涉及使用[`HfApi`]客户端进行HTTP请求。让我们来看一看每种方法的优缺点。
## 存储库:基于历史的 Git 方法
最初,`huggingface_hub`主要围绕 [`Repository`] 类构建。它为常见的 `git` 命令(如 `"git add"`、`"git commit"`、`"git push"`、`"git tag"`、`"git checkout"` 等)提供了 Python 包装器
该库还可以帮助设置凭据和跟踪大型文件,这些文件通常在机器学习存储库中使用。此外,该库允许您在后台执行其方法,使其在训练期间上传数据很有用。
使用 [`Repository`] 的最大优点是它允许你在本地机器上维护整个存储库的本地副本。这也可能是一个缺点,因为它需要你不断更新和维护这个本地副本。这类似于传统软件开发中,每个开发人员都维护自己的本地副本,并在开发功能时推送更改。但是,在机器学习的上下文中,这可能并不总是必要的,因为用户可能只需要下载推理所需的权重,或将权重从一种格式转换为另一种格式,而无需克隆整个存储库。
## HfApi: 一个功能强大且方便的HTTP客户端
`HfApi` 被开发为本地 git 存储库的替代方案,因为本地 git 存储库在处理大型模型或数据集时可能会很麻烦。`HfApi` 提供与基于 git 的方法相同的功能,例如下载和推送文件以及创建分支和标签,但无需本地文件夹来保持同步。
`HfApi`除了提供 `git` 已经提供的功能外,还提供其他功能,例如:
* 管理存储库
* 使用缓存下载文件以进行有效的重复使用
* 在 Hub 中搜索存储库和元数据
* 访问社区功能,如讨论、PR和评论
* 配置Spaces
## 我应该使用什么?以及何时使用?
总的来说,在大多数情况下,`HTTP 方法`是使用 huggingface_hub 的推荐方法。但是,在以下几种情况下,维护本地 git 克隆(使用 `Repository`)可能更有益:
如果您在本地机器上训练模型,使用传统的 git 工作流程并定期推送更新可能更有效。`Repository` 被优化为此类情况,因为它能够在后台运行。
如果您需要手动编辑大型文件,`git `是最佳选择,因为它只会将文件的差异发送到服务器。使用 `HfAPI` 客户端,每次编辑都会上传整个文件。请记住,大多数大型文件是二进制文件,因此无法从 git 差异中受益。
并非所有 git 命令都通过 [`HfApi`] 提供。有些可能永远不会被实现,但我们一直在努力改进并缩小差距。如果您没有看到您的用例被覆盖。
请在[Github](https://github.com/huggingface/huggingface_hub)打开一个 issue!我们欢迎反馈,以帮助我们与我们的用户一起构建 🤗 生态系统。
|
huggingface/huggingface_hub/blob/main/docs/source/cn/concepts/git_vs_http.md
|
`@gradio/image`
```html
<script>
import { BaseImageUploader, BaseStaticImage, Webcam, BaseExample } from "@gradio/image";
</script>
```
BaseImageUploader
```javascript
export let sources: ("clipboard" | "webcam" | "upload")[] = [
"upload",
"clipboard",
"webcam"
];
export let streaming = false;
export let pending = false;
export let mirror_webcam: boolean;
export let selectable = false;
export let root: string;
export let i18n: I18nFormatter;
```
BaseStaticImage
```javascript
export let value: null | FileData;
export let label: string | undefined = undefined;
export let show_label: boolean;
export let show_download_button = true;
export let selectable = false;
export let show_share_button = false;
export let root: string;
export let i18n: I18nFormatter;
```
Webcam
```javascript
export let streaming = false;
export let pending = false;
export let mode: "image" | "video" = "image";
export let mirror_webcam: boolean;
export let include_audio: boolean;
export let i18n: I18nFormatter;
```
BaseExample
```javascript
export let value: string;
export let samples_dir: string;
export let type: "gallery" | "table";
export let selected = false;
```
|
gradio-app/gradio/blob/main/js/image/README.md
|
Xception
**Xception** is a convolutional neural network architecture that relies solely on [depthwise separable convolution layers](https://paperswithcode.com/method/depthwise-separable-convolution).
The weights from this model were ported from [Tensorflow/Models](https://github.com/tensorflow/models).
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('xception', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `xception`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('xception', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/ZagoruykoK16,
@misc{chollet2017xception,
title={Xception: Deep Learning with Depthwise Separable Convolutions},
author={François Chollet},
year={2017},
eprint={1610.02357},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: Xception
Paper:
Title: 'Xception: Deep Learning with Depthwise Separable Convolutions'
URL: https://paperswithcode.com/paper/xception-deep-learning-with-depthwise
Models:
- Name: xception
In Collection: Xception
Metadata:
FLOPs: 10600506792
Parameters: 22860000
File Size: 91675053
Architecture:
- 1x1 Convolution
- Convolution
- Dense Connections
- Depthwise Separable Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: xception
Crop Pct: '0.897'
Image Size: '299'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/xception.py#L229
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-cadene/xception-43020ad28.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.05%
Top 5 Accuracy: 94.4%
- Name: xception41
In Collection: Xception
Metadata:
FLOPs: 11681983232
Parameters: 26970000
File Size: 108422028
Architecture:
- 1x1 Convolution
- Convolution
- Dense Connections
- Depthwise Separable Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: xception41
Crop Pct: '0.903'
Image Size: '299'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/xception_aligned.py#L181
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_xception_41-e6439c97.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.54%
Top 5 Accuracy: 94.28%
- Name: xception65
In Collection: Xception
Metadata:
FLOPs: 17585702144
Parameters: 39920000
File Size: 160536780
Architecture:
- 1x1 Convolution
- Convolution
- Dense Connections
- Depthwise Separable Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: xception65
Crop Pct: '0.903'
Image Size: '299'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/xception_aligned.py#L200
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_xception_65-c9ae96e8.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.55%
Top 5 Accuracy: 94.66%
- Name: xception71
In Collection: Xception
Metadata:
FLOPs: 22817346560
Parameters: 42340000
File Size: 170295556
Architecture:
- 1x1 Convolution
- Convolution
- Dense Connections
- Depthwise Separable Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: xception71
Crop Pct: '0.903'
Image Size: '299'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/xception_aligned.py#L219
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_xception_71-8eec7df1.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.88%
Top 5 Accuracy: 94.93%
-->
|
huggingface/pytorch-image-models/blob/main/docs/models/xception.md
|
``python
from transformers import AutoModelForCausalLM
from peft import PeftModel, PeftConfig
import torch
from datasets import load_dataset
import os
from transformers import AutoTokenizer
from torch.utils.data import DataLoader
from transformers import default_data_collator, get_linear_schedule_with_warmup
from tqdm import tqdm
from datasets import load_dataset
device = "cuda"
model_name_or_path = "bigscience/bloomz-7b1"
tokenizer_name_or_path = "bigscience/bloomz-7b1"
dataset_name = "twitter_complaints"
text_column = "Tweet text"
label_column = "text_label"
max_length = 64
lr = 1e-3
num_epochs = 50
batch_size = 8
```
```python
from datasets import load_dataset
dataset = load_dataset("ought/raft", dataset_name)
classes = [k.replace("_", " ") for k in dataset["train"].features["Label"].names]
print(classes)
dataset = dataset.map(
lambda x: {"text_label": [classes[label] for label in x["Label"]]},
batched=True,
num_proc=1,
)
print(dataset)
dataset["train"][0]
```
```python
# data preprocessing
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
target_max_length = max([len(tokenizer(class_label)["input_ids"]) for class_label in classes])
print(target_max_length)
def preprocess_function(examples):
batch_size = len(examples[text_column])
inputs = [f"{text_column} : {x} Label : " for x in examples[text_column]]
targets = [str(x) for x in examples[label_column]]
model_inputs = tokenizer(inputs)
labels = tokenizer(targets, add_special_tokens=False) # don't add bos token because we concatenate with inputs
for i in range(batch_size):
sample_input_ids = model_inputs["input_ids"][i]
label_input_ids = labels["input_ids"][i] + [tokenizer.eos_token_id]
# print(i, sample_input_ids, label_input_ids)
model_inputs["input_ids"][i] = sample_input_ids + label_input_ids
labels["input_ids"][i] = [-100] * len(sample_input_ids) + label_input_ids
model_inputs["attention_mask"][i] = [1] * len(model_inputs["input_ids"][i])
# print(model_inputs)
for i in range(batch_size):
sample_input_ids = model_inputs["input_ids"][i]
label_input_ids = labels["input_ids"][i]
model_inputs["input_ids"][i] = [tokenizer.pad_token_id] * (
max_length - len(sample_input_ids)
) + sample_input_ids
model_inputs["attention_mask"][i] = [0] * (max_length - len(sample_input_ids)) + model_inputs[
"attention_mask"
][i]
labels["input_ids"][i] = [-100] * (max_length - len(sample_input_ids)) + label_input_ids
model_inputs["input_ids"][i] = torch.tensor(model_inputs["input_ids"][i][:max_length])
model_inputs["attention_mask"][i] = torch.tensor(model_inputs["attention_mask"][i][:max_length])
labels["input_ids"][i] = torch.tensor(labels["input_ids"][i][:max_length])
model_inputs["labels"] = labels["input_ids"]
return model_inputs
processed_datasets = dataset.map(
preprocess_function,
batched=True,
num_proc=1,
remove_columns=dataset["train"].column_names,
load_from_cache_file=False,
desc="Running tokenizer on dataset",
)
train_dataset = processed_datasets["train"]
train_dataloader = DataLoader(
train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True
)
```
```python
def test_preprocess_function(examples):
batch_size = len(examples[text_column])
inputs = [f"{text_column} : {x} Label : " for x in examples[text_column]]
model_inputs = tokenizer(inputs)
# print(model_inputs)
for i in range(batch_size):
sample_input_ids = model_inputs["input_ids"][i]
model_inputs["input_ids"][i] = [tokenizer.pad_token_id] * (
max_length - len(sample_input_ids)
) + sample_input_ids
model_inputs["attention_mask"][i] = [0] * (max_length - len(sample_input_ids)) + model_inputs[
"attention_mask"
][i]
model_inputs["input_ids"][i] = torch.tensor(model_inputs["input_ids"][i][:max_length])
model_inputs["attention_mask"][i] = torch.tensor(model_inputs["attention_mask"][i][:max_length])
return model_inputs
processed_datasets = dataset.map(
test_preprocess_function,
batched=True,
num_proc=1,
remove_columns=dataset["train"].column_names,
load_from_cache_file=False,
desc="Running tokenizer on dataset",
)
eval_dataset = processed_datasets["train"]
test_dataset = processed_datasets["test"]
eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
test_dataloader = DataLoader(test_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
print(next(iter(eval_dataloader)))
print(next(iter(test_dataloader)))
```
You can load model from hub or local
- Load model from Hugging Face Hub, you can change to your own model id
```python
peft_model_id = "username/twitter_complaints_bigscience_bloomz-7b1_LORA_CAUSAL_LM"
```
- Or load model form local
```python
peft_model_id = "twitter_complaints_bigscience_bloomz-7b1_LORA_CAUSAL_LM"
```
```python
from peft import PeftModel, PeftConfig
max_memory = {0: "1GIB", 1: "1GIB", 2: "2GIB", 3: "10GIB", "cpu": "30GB"}
peft_model_id = "smangrul/twitter_complaints_bigscience_bloomz-7b1_LORA_CAUSAL_LM"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path, device_map="auto", max_memory=max_memory)
model = PeftModel.from_pretrained(model, peft_model_id, device_map="auto", max_memory=max_memory)
```
```python
# model
```
```python
model.hf_device_map
```
```python
model.eval()
i = 89
inputs = tokenizer(f'{text_column} : {dataset["test"][i]["Tweet text"]} Label : ', return_tensors="pt")
print(dataset["test"][i]["Tweet text"])
print(inputs)
with torch.no_grad():
outputs = model.generate(input_ids=inputs["input_ids"], max_new_tokens=10)
print(outputs)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
```
```python
model.eval()
eval_preds = []
for _, batch in enumerate(tqdm(eval_dataloader)):
batch = {k: v for k, v in batch.items() if k != "labels"}
with torch.no_grad():
outputs = model.generate(**batch, max_new_tokens=10)
preds = outputs[:, max_length:].detach().cpu().numpy()
eval_preds.extend(tokenizer.batch_decode(preds, skip_special_tokens=True))
```
```python
correct = 0
total = 0
for pred, true in zip(eval_preds, dataset["train"][label_column]):
if pred.strip() == true.strip():
correct += 1
total += 1
accuracy = correct / total * 100
print(f"{accuracy=}")
print(f"{eval_preds[:10]=}")
print(f"{dataset['train'][label_column][:10]=}")
```
```python
model.eval()
test_preds = []
for _, batch in enumerate(tqdm(test_dataloader)):
batch = {k: v for k, v in batch.items() if k != "labels"}
with torch.no_grad():
outputs = model.generate(**batch, max_new_tokens=10)
preds = outputs[:, max_length:].detach().cpu().numpy()
test_preds.extend(tokenizer.batch_decode(preds, skip_special_tokens=True))
if len(test_preds) > 100:
break
test_preds
```
|
huggingface/peft/blob/main/examples/causal_language_modeling/peft_lora_clm_accelerate_big_model_inference.ipynb
|
RealFill
[RealFill](https://arxiv.org/abs/2309.16668) is a method to personalize text2image inpainting models like stable diffusion inpainting given just a few(1~5) images of a scene.
The `train_realfill.py` script shows how to implement the training procedure for stable diffusion inpainting.
## Running locally with PyTorch
### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
cd to the realfill folder and run
```bash
cd realfill
pip install -r requirements.txt
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
Or for a default accelerate configuration without answering questions about your environment
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell e.g. a notebook
```python
from accelerate.utils import write_basic_config
write_basic_config()
```
When running `accelerate config`, if we specify torch compile mode to True there can be dramatic speedups.
### Toy example
Now let's fill the real. For this example, we will use some images of the flower girl example from the paper.
We already provide some images for testing in [this link](https://github.com/thuanz123/realfill/tree/main/data/flowerwoman)
You only have to launch the training using:
```bash
export MODEL_NAME="stabilityai/stable-diffusion-2-inpainting"
export TRAIN_DIR="data/flowerwoman"
export OUTPUT_DIR="flowerwoman-model"
accelerate launch train_realfill.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$TRAIN_DIR \
--output_dir=$OUTPUT_DIR \
--resolution=512 \
--train_batch_size=16 \
--gradient_accumulation_steps=1 \
--unet_learning_rate=2e-4 \
--text_encoder_learning_rate=4e-5 \
--lr_scheduler="constant" \
--lr_warmup_steps=100 \
--max_train_steps=2000 \
--lora_rank=8 \
--lora_dropout=0.1 \
--lora_alpha=16 \
```
### Training on a low-memory GPU:
It is possible to run realfill on a low-memory GPU by using the following optimizations:
- [gradient checkpointing and the 8-bit optimizer](#training-with-gradient-checkpointing-and-8-bit-optimizers)
- [xformers](#training-with-xformers)
- [setting grads to none](#set-grads-to-none)
```bash
export MODEL_NAME="stabilityai/stable-diffusion-2-inpainting"
export TRAIN_DIR="data/flowerwoman"
export OUTPUT_DIR="flowerwoman-model"
accelerate launch train_realfill.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$TRAIN_DIR \
--output_dir=$OUTPUT_DIR \
--resolution=512 \
--train_batch_size=16 \
--gradient_accumulation_steps=1 --gradient_checkpointing \
--use_8bit_adam \
--enable_xformers_memory_efficient_attention \
--set_grads_to_none \
--unet_learning_rate=2e-4 \
--text_encoder_learning_rate=4e-5 \
--lr_scheduler="constant" \
--lr_warmup_steps=100 \
--max_train_steps=2000 \
--lora_rank=8 \
--lora_dropout=0.1 \
--lora_alpha=16 \
```
### Training with gradient checkpointing and 8-bit optimizers:
With the help of gradient checkpointing and the 8-bit optimizer from bitsandbytes it's possible to run train realfill on a 16GB GPU.
To install `bitsandbytes` please refer to this [readme](https://github.com/TimDettmers/bitsandbytes#requirements--installation).
### Training with xformers:
You can enable memory efficient attention by [installing xFormers](https://github.com/facebookresearch/xformers#installing-xformers) and padding the `--enable_xformers_memory_efficient_attention` argument to the script.
### Set grads to none
To save even more memory, pass the `--set_grads_to_none` argument to the script. This will set grads to None instead of zero. However, be aware that it changes certain behaviors, so if you start experiencing any problems, remove this argument.
More info: https://pytorch.org/docs/stable/generated/torch.optim.Optimizer.zero_grad.html
## Acknowledge
This repo is built upon the code of DreamBooth from diffusers and we thank the developers for their great works and efforts to release source code. Furthermore, a special "thank you" to RealFill's authors for publishing such an amazing work.
|
huggingface/diffusers/blob/main/examples/research_projects/realfill/README.md
|
(Gluon) ResNet
**Residual Networks**, or **ResNets**, learn residual functions with reference to the layer inputs, instead of learning unreferenced functions. Instead of hoping each few stacked layers directly fit a desired underlying mapping, residual nets let these layers fit a residual mapping. They stack [residual blocks](https://paperswithcode.com/method/residual-block) ontop of each other to form network: e.g. a ResNet-50 has fifty layers using these blocks.
The weights from this model were ported from [Gluon](https://cv.gluon.ai/model_zoo/classification.html).
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('gluon_resnet101_v1b', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `gluon_resnet101_v1b`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('gluon_resnet101_v1b', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/HeZRS15,
author = {Kaiming He and
Xiangyu Zhang and
Shaoqing Ren and
Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {CoRR},
volume = {abs/1512.03385},
year = {2015},
url = {http://arxiv.org/abs/1512.03385},
archivePrefix = {arXiv},
eprint = {1512.03385},
timestamp = {Wed, 17 Apr 2019 17:23:45 +0200},
biburl = {https://dblp.org/rec/journals/corr/HeZRS15.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<!--
Type: model-index
Collections:
- Name: Gloun ResNet
Paper:
Title: Deep Residual Learning for Image Recognition
URL: https://paperswithcode.com/paper/deep-residual-learning-for-image-recognition
Models:
- Name: gluon_resnet101_v1b
In Collection: Gloun ResNet
Metadata:
FLOPs: 10068547584
Parameters: 44550000
File Size: 178723172
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet101_v1b
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L89
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet101_v1b-3b017079.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.3%
Top 5 Accuracy: 94.53%
- Name: gluon_resnet101_v1c
In Collection: Gloun ResNet
Metadata:
FLOPs: 10376567296
Parameters: 44570000
File Size: 178802575
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet101_v1c
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L113
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet101_v1c-1f26822a.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.53%
Top 5 Accuracy: 94.59%
- Name: gluon_resnet101_v1d
In Collection: Gloun ResNet
Metadata:
FLOPs: 10377018880
Parameters: 44570000
File Size: 178802755
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet101_v1d
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L138
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet101_v1d-0f9c8644.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.4%
Top 5 Accuracy: 95.02%
- Name: gluon_resnet101_v1s
In Collection: Gloun ResNet
Metadata:
FLOPs: 11805511680
Parameters: 44670000
File Size: 179221777
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet101_v1s
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L166
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet101_v1s-60fe0cc1.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.29%
Top 5 Accuracy: 95.16%
- Name: gluon_resnet152_v1b
In Collection: Gloun ResNet
Metadata:
FLOPs: 14857660416
Parameters: 60190000
File Size: 241534001
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet152_v1b
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L97
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet152_v1b-c1edb0dd.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.69%
Top 5 Accuracy: 94.73%
- Name: gluon_resnet152_v1c
In Collection: Gloun ResNet
Metadata:
FLOPs: 15165680128
Parameters: 60210000
File Size: 241613404
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet152_v1c
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L121
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet152_v1c-a3bb0b98.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.91%
Top 5 Accuracy: 94.85%
- Name: gluon_resnet152_v1d
In Collection: Gloun ResNet
Metadata:
FLOPs: 15166131712
Parameters: 60210000
File Size: 241613584
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet152_v1d
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L147
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet152_v1d-bd354e12.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.48%
Top 5 Accuracy: 95.2%
- Name: gluon_resnet152_v1s
In Collection: Gloun ResNet
Metadata:
FLOPs: 16594624512
Parameters: 60320000
File Size: 242032606
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet152_v1s
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L175
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet152_v1s-dcc41b81.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.02%
Top 5 Accuracy: 95.42%
- Name: gluon_resnet18_v1b
In Collection: Gloun ResNet
Metadata:
FLOPs: 2337073152
Parameters: 11690000
File Size: 46816736
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet18_v1b
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L65
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet18_v1b-0757602b.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 70.84%
Top 5 Accuracy: 89.76%
- Name: gluon_resnet34_v1b
In Collection: Gloun ResNet
Metadata:
FLOPs: 4718469120
Parameters: 21800000
File Size: 87295112
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet34_v1b
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L73
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet34_v1b-c6d82d59.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 74.59%
Top 5 Accuracy: 92.0%
- Name: gluon_resnet50_v1b
In Collection: Gloun ResNet
Metadata:
FLOPs: 5282531328
Parameters: 25560000
File Size: 102493763
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet50_v1b
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L81
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet50_v1b-0ebe02e2.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.58%
Top 5 Accuracy: 93.72%
- Name: gluon_resnet50_v1c
In Collection: Gloun ResNet
Metadata:
FLOPs: 5590551040
Parameters: 25580000
File Size: 102573166
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet50_v1c
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L105
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet50_v1c-48092f55.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.01%
Top 5 Accuracy: 93.99%
- Name: gluon_resnet50_v1d
In Collection: Gloun ResNet
Metadata:
FLOPs: 5591002624
Parameters: 25580000
File Size: 102573346
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet50_v1d
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L129
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet50_v1d-818a1b1b.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.06%
Top 5 Accuracy: 94.46%
- Name: gluon_resnet50_v1s
In Collection: Gloun ResNet
Metadata:
FLOPs: 7019495424
Parameters: 25680000
File Size: 102992368
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet50_v1s
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L156
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet50_v1s-1762acc0.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.7%
Top 5 Accuracy: 94.25%
-->
|
huggingface/pytorch-image-models/blob/main/docs/models/gloun-resnet.md
|
--
title: "Introducing new audio and vision documentation in 🤗 Datasets"
thumbnail: /blog/assets/87_datasets-docs-update/thumbnail.gif
authors:
- user: stevhliu
---
# Introducing new audio and vision documentation in 🤗 Datasets
Open and reproducible datasets are essential for advancing good machine learning. At the same time, datasets have grown tremendously in size as rocket fuel for large language models. In 2020, Hugging Face launched 🤗 Datasets, a library dedicated to:
1. Providing access to standardized datasets with a single line of code.
2. Tools for rapidly and efficiently processing large-scale datasets.
Thanks to the community, we added hundreds of NLP datasets in many languages and dialects during the [Datasets Sprint](https://discuss.huggingface.co/t/open-to-the-community-one-week-team-effort-to-reach-v2-0-of-hf-datasets-library/2176)! 🤗 ❤️
But text datasets are just the beginning. Data is represented in richer formats like 🎵 audio, 📸 images, and even a combination of audio and text or image and text. Models trained on these datasets enable awesome applications like describing what is in an image or answering questions about an image.
<div class="hidden xl:block">
<div style="display: flex; flex-direction: column; align-items: center;">
<iframe src="https://salesforce-blip.hf.space" frameBorder="0" width="1400" height="690" title="Gradio app" class="p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
</div>
</div>
The 🤗 Datasets team has been building tools and features to make working with these dataset types as simple as possible for the best developer experience. We added new documentation along the way to help you learn more about loading and processing audio and image datasets.
## Quickstart
The [Quickstart](https://huggingface.co/docs/datasets/quickstart) is one of the first places new users visit for a TLDR about a library’s features. That’s why we updated the Quickstart to include how you can use 🤗 Datasets to work with audio and image datasets. Choose a dataset modality you want to work with and see an end-to-end example of how to load and process the dataset to get it ready for training with either PyTorch or TensorFlow.
Also new in the Quickstart is the `to_tf_dataset` function which takes care of converting a dataset into a `tf.data.Dataset` like a mama bear taking care of her cubs. This means you don’t have to write any code to shuffle and load batches from your dataset to get it to play nicely with TensorFlow. Once you’ve converted your dataset into a `tf.data.Dataset`, you can train your model with the usual TensorFlow or Keras methods.
Check out the [Quickstart](https://huggingface.co/docs/datasets/quickstart) today to learn how to work with different dataset modalities and try out the new `to_tf_dataset` function!
<figure class="image table text-center m-0 w-full">
<img style="border:none;" alt="Cards with links to end-to-end examples for how to process audio, vision, and NLP datasets" src="assets/87_datasets-docs-update/quickstart.png" />
<figcaption>Choose your dataset adventure!</figcaption>
</figure>
## Dedicated guides
Each dataset modality has specific nuances on how to load and process them. For example, when you load an audio dataset, the audio signal is automatically decoded and resampled on-the-fly by the `Audio` feature. This is quite different from loading a text dataset!
To make all of the modality-specific documentation more discoverable, there are new dedicated sections with guides focused on showing you how to load and process each modality. If you’re looking for specific information about working with a dataset modality, take a look at these dedicated sections first. Meanwhile, functions that are non-specific and can be used broadly are documented in the General Usage section. Reorganizing the documentation in this way will allow us to better scale to other dataset types we plan to support in the future.
<figure class="image table text-center m-0 w-full">
<img style="border:none;" alt="An overview of the how-to guides page that displays five new sections of the guides: general usage, audio, vision, text, and dataset repository." src="assets/87_datasets-docs-update/overview.png" />
<figcaption>The guides are organized into sections that cover the most essential aspects of 🤗 Datasets.</figcaption>
</figure>
Check out the [dedicated guides](https://huggingface.co/docs/datasets/how_to) to learn more about loading and processing datasets for different modalities.
## ImageFolder
Typically, 🤗 Datasets users [write a dataset loading script](https://huggingface.co/docs/datasets/dataset_script) to download and generate a dataset with the appropriate `train` and `test` splits. With the `ImageFolder` dataset builder, you don’t need to write any code to download and generate an image dataset. Loading an image dataset for image classification is as simple as ensuring your dataset is organized in a folder like:
```py
folder/train/dog/golden_retriever.png
folder/train/dog/german_shepherd.png
folder/train/dog/chihuahua.png
folder/train/cat/maine_coon.png
folder/train/cat/bengal.png
folder/train/cat/birman.png
```
<figure class="image table text-center m-0 w-full">
<img style="border:none;" alt="A table of images of dogs and their associated label." src="assets/87_datasets-docs-update/good_boi_pics.png" />
<figcaption>Your 🐶 dataset should look something like this once you've uploaded it to the Hub and preview it.</figcaption>
</figure>
Image labels are generated in a `label` column based on the directory name. `ImageFolder` allows you to get started instantly with an image dataset, eliminating the time and effort required to write a dataset loading script.
But wait, it gets even better! If you have a file containing some metadata about your image dataset, `ImageFolder` can be used for other image tasks like image captioning and object detection. For example, object detection datasets commonly have *bounding boxes*, coordinates in an image that identify where an object is. `ImageFolder` can use this file to link the metadata about the bounding box and category for each image to the corresponding images in the folder:
```py
{"file_name": "0001.png", "objects": {"bbox": [[302.0, 109.0, 73.0, 52.0]], "categories": [0]}}
{"file_name": "0002.png", "objects": {"bbox": [[810.0, 100.0, 57.0, 28.0]], "categories": [1]}}
{"file_name": "0003.png", "objects": {"bbox": [[160.0, 31.0, 248.0, 616.0], [741.0, 68.0, 202.0, 401.0]], "categories": [2, 2]}}
dataset = load_dataset("imagefolder", data_dir="/path/to/folder", split="train")
dataset[0]["objects"]
{"bbox": [[302.0, 109.0, 73.0, 52.0]], "categories": [0]}
```
You can use `ImageFolder` to load an image dataset for nearly any type of image task if you have a metadata file with the required information. Check out the [ImageFolder](https://huggingface.co/docs/datasets/image_load) guide to learn more.
## What’s next?
Similar to how the first iteration of the 🤗 Datasets library standardized text datasets and made them super easy to download and process, we are very excited to bring this same level of user-friendliness to audio and image datasets. In doing so, we hope it’ll be easier for users to train, build, and evaluate models and applications across all different modalities.
In the coming months, we’ll continue to add new features and tools to support working with audio and image datasets. Word on the 🤗 Hugging Face street is that there’ll be something called `AudioFolder` coming soon! 🤫 While you wait, feel free to take a look at the [audio processing guide](https://huggingface.co/docs/datasets/audio_process) and then get hands-on with an audio dataset like [GigaSpeech](https://huggingface.co/datasets/speechcolab/gigaspeech).
---
Join the [forum](https://discuss.huggingface.co/) for any questions and feedback about working with audio and image datasets. If you discover any bugs, please open a [GitHub Issue](https://github.com/huggingface/datasets/issues/new/choose), so we can take care of it.
Feeling a little more adventurous? Contribute to the growing community-driven collection of audio and image datasets on the [Hub](https://huggingface.co/datasets)! [Create a dataset repository](https://huggingface.co/docs/datasets/upload_dataset) on the Hub and upload your dataset. If you need a hand, open a discussion on your repository’s **Community tab** and ping one of the 🤗 Datasets team members to help you cross the finish line!
|
huggingface/blog/blob/main/datasets-docs-update.md
|
`@gradio/audio`
```html
<script>
import { BaseStaticAudio, BaseInteractiveAudio, BasePlayer, BaseExample } from "@gradio/audio";
</script>
```
BaseExample:
```javascript
export let value: string;
export let type: "gallery" | "table";
export let selected = false;
```
BaseStaticAudio:
```javascript
export let value: null | { name: string; data: string } = null;
export let label: string;
export let name: string;
export let show_label = true;
export let autoplay: boolean;
export let show_download_button = true;
export let show_share_button = false;
export let i18n: I18nFormatter;
export let waveform_settings = {};
```
BaseInteractiveAudio:
```javascript
export let value: null | { name: string; data: string } = null;
export let label: string;
export let root: string;
export let show_label = true;
export let sources:
| ["microphone"]
| ["upload"]
| ["microphone", "upload"]
| ["upload", "microphone"] = ["microphone", "upload"];
export let pending = false;
export let streaming = false;
export let autoplay = false;
export let i18n: I18nFormatter;
export let waveform_settings = {};
export let dragging: boolean;
export let active_source: "microphone" | "upload";
export let handle_reset_value: () => void = () => {};
```
BasePlayer:
```javascript
export let value: null | { name: string; data: string } = null;
export let label: string;
export let autoplay: boolean;
export let i18n: I18nFormatter;
export let dispatch: (event: any, detail?: any) => void;
export let dispatch_blob: (
blobs: Uint8Array[] | Blob[],
event: "stream" | "change" | "stop_recording"
) => Promise<void> = () => Promise.resolve();
export let interactive = false;
export let waveform_settings = {};
export let mode = "";
export let handle_reset_value: () => void = () => {};
```
|
gradio-app/gradio/blob/main/js/audio/README.md
|
Congratulations
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/communication/thumbnail.png" alt="Thumbnail"/>
**Congratulations on finishing this course!** With perseverance, hard work, and determination, **you've acquired a solid background in Deep Reinforcement Learning**.
But finishing this course is **not the end of your journey**. It's just the beginning: don't hesitate to explore bonus unit 3, where we show you topics you may be interested in studying. And don't hesitate to **share what you're doing, and ask questions in the discord server**
**Thank you** for being part of this course. **I hope you liked this course as much as I loved writing it**.
Don't hesitate **to give us feedback on how we can improve the course** using [this form](https://forms.gle/BzKXWzLAGZESGNaE9)
And don't forget **to check in the next section how you can get (if you pass) your certificate of completion 🎓.**
One last thing, to keep in touch with the Reinforcement Learning Team and with me:
- [Follow me on Twitter](https://twitter.com/thomassimonini)
- [Follow Hugging Face Twitter account](https://twitter.com/huggingface)
- [Join the Hugging Face Discord](https://www.hf.co/join/discord)
## Keep Learning, Stay Awesome 🤗
Thomas Simonini,
|
huggingface/deep-rl-class/blob/main/units/en/communication/conclusion.mdx
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contains specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# MADLAD-400
## Overview
MADLAD-400 models were released in the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](MADLAD-400: A Multilingual And Document-Level Large Audited Dataset).
The abstract from the paper is the following:
*We introduce MADLAD-400, a manually audited, general domain 3T token monolingual dataset based on CommonCrawl, spanning 419 languages. We discuss
the limitations revealed by self-auditing MADLAD-400, and the role data auditing
had in the dataset creation process. We then train and release a 10.7B-parameter
multilingual machine translation model on 250 billion tokens covering over 450
languages using publicly available data, and find that it is competitive with models
that are significantly larger, and report the results on different domains. In addition, we train a 8B-parameter language model, and assess the results on few-shot
translation. We make the baseline models 1
available to the research community.*
This model was added by [Juarez Bochi](https://huggingface.co/jbochi). The original checkpoints can be found [here](https://github.com/google-research/google-research/tree/master/madlad_400).
This is a machine translation model that supports many low-resource languages, and that is competitive with models that are significantly larger.
One can directly use MADLAD-400 weights without finetuning the model:
```python
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/madlad400-3b-mt")
>>> tokenizer = AutoTokenizer.from_pretrained("google/madlad400-3b-mt")
>>> inputs = tokenizer("<2pt> I love pizza!", return_tensors="pt")
>>> outputs = model.generate(**inputs)
>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
['Eu amo pizza!']
```
Google has released the following variants:
- [google/madlad400-3b-mt](https://huggingface.co/google/madlad400-3b-mt)
- [google/madlad400-7b-mt](https://huggingface.co/google/madlad400-7b-mt)
- [google/madlad400-7b-mt-bt](https://huggingface.co/google/madlad400-7b-mt-bt)
- [google/madlad400-10b-mt](https://huggingface.co/google/madlad400-10b-mt)
The original checkpoints can be found [here](https://github.com/google-research/google-research/tree/master/madlad_400).
<Tip>
Refer to [T5's documentation page](t5) for all API references, code examples, and notebooks. For more details regarding training and evaluation of the MADLAD-400, refer to the model card.
</Tip>
|
huggingface/transformers/blob/main/docs/source/en/model_doc/madlad-400.md
|
Gradio Demo: blocks_multiple_event_triggers
```
!pip install -q gradio plotly pypistats
```
```
import gradio as gr
import pypistats
from datetime import date
from dateutil.relativedelta import relativedelta
import pandas as pd
def get_plot(lib, time):
data = pypistats.overall(lib, total=True, format="pandas")
data = data.groupby("category").get_group("with_mirrors").sort_values("date")
start_date = date.today() - relativedelta(months=int(time.split(" ")[0]))
data = data[(data['date'] > str(start_date))]
data.date = pd.to_datetime(pd.to_datetime(data.date))
return gr.LinePlot(value=data, x="date", y="downloads",
tooltip=['date', 'downloads'],
title=f"Pypi downloads of {lib} over last {time}",
overlay_point=True,
height=400,
width=900)
with gr.Blocks() as demo:
gr.Markdown(
"""
## Pypi Download Stats 📈
See live download stats for all of Hugging Face's open-source libraries 🤗
""")
with gr.Row():
lib = gr.Dropdown(["transformers", "datasets", "huggingface-hub", "gradio", "accelerate"],
value="gradio", label="Library")
time = gr.Dropdown(["3 months", "6 months", "9 months", "12 months"],
value="3 months", label="Downloads over the last...")
plt = gr.LinePlot()
# You can add multiple event triggers in 2 lines like this
for event in [lib.change, time.change, demo.load]:
event(get_plot, [lib, time], [plt])
if __name__ == "__main__":
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/blocks_multiple_event_triggers/run.ipynb
|
(Tensorflow) EfficientNet Lite
**EfficientNet** is a convolutional neural network architecture and scaling method that uniformly scales all dimensions of depth/width/resolution using a *compound coefficient*. Unlike conventional practice that arbitrary scales these factors, the EfficientNet scaling method uniformly scales network width, depth, and resolution with a set of fixed scaling coefficients. For example, if we want to use $2^N$ times more computational resources, then we can simply increase the network depth by $\alpha ^ N$, width by $\beta ^ N$, and image size by $\gamma ^ N$, where $\alpha, \beta, \gamma$ are constant coefficients determined by a small grid search on the original small model. EfficientNet uses a compound coefficient $\phi$ to uniformly scales network width, depth, and resolution in a principled way.
The compound scaling method is justified by the intuition that if the input image is bigger, then the network needs more layers to increase the receptive field and more channels to capture more fine-grained patterns on the bigger image.
The base EfficientNet-B0 network is based on the inverted bottleneck residual blocks of [MobileNetV2](https://paperswithcode.com/method/mobilenetv2).
EfficientNet-Lite makes EfficientNet more suitable for mobile devices by introducing [ReLU6](https://paperswithcode.com/method/relu6) activation functions and removing [squeeze-and-excitation blocks](https://paperswithcode.com/method/squeeze-and-excitation).
The weights from this model were ported from [Tensorflow/TPU](https://github.com/tensorflow/tpu).
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('tf_efficientnet_lite0', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `tf_efficientnet_lite0`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('tf_efficientnet_lite0', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{tan2020efficientnet,
title={EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks},
author={Mingxing Tan and Quoc V. Le},
year={2020},
eprint={1905.11946},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
<!--
Type: model-index
Collections:
- Name: TF EfficientNet Lite
Paper:
Title: 'EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks'
URL: https://paperswithcode.com/paper/efficientnet-rethinking-model-scaling-for
Models:
- Name: tf_efficientnet_lite0
In Collection: TF EfficientNet Lite
Metadata:
FLOPs: 488052032
Parameters: 4650000
File Size: 18820223
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- RELU6
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: tf_efficientnet_lite0
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1596
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_lite0-0aa007d2.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 74.83%
Top 5 Accuracy: 92.17%
- Name: tf_efficientnet_lite1
In Collection: TF EfficientNet Lite
Metadata:
FLOPs: 773639520
Parameters: 5420000
File Size: 21939331
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- RELU6
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: tf_efficientnet_lite1
Crop Pct: '0.882'
Image Size: '240'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1607
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_lite1-bde8b488.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 76.67%
Top 5 Accuracy: 93.24%
- Name: tf_efficientnet_lite2
In Collection: TF EfficientNet Lite
Metadata:
FLOPs: 1068494432
Parameters: 6090000
File Size: 24658687
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- RELU6
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: tf_efficientnet_lite2
Crop Pct: '0.89'
Image Size: '260'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1618
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_lite2-dcccb7df.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.48%
Top 5 Accuracy: 93.75%
- Name: tf_efficientnet_lite3
In Collection: TF EfficientNet Lite
Metadata:
FLOPs: 2011534304
Parameters: 8199999
File Size: 33161413
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- RELU6
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: tf_efficientnet_lite3
Crop Pct: '0.904'
Image Size: '300'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1629
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_lite3-b733e338.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.83%
Top 5 Accuracy: 94.91%
- Name: tf_efficientnet_lite4
In Collection: TF EfficientNet Lite
Metadata:
FLOPs: 5164802912
Parameters: 13010000
File Size: 52558819
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- RELU6
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: tf_efficientnet_lite4
Crop Pct: '0.92'
Image Size: '380'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1640
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_lite4-741542c3.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.54%
Top 5 Accuracy: 95.66%
-->
|
huggingface/pytorch-image-models/blob/main/docs/models/tf-efficientnet-lite.md
|
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# How to create a custom pipeline?
In this guide, we will see how to create a custom pipeline and share it on the [Hub](hf.co/models) or add it to the
🤗 Transformers library.
First and foremost, you need to decide the raw entries the pipeline will be able to take. It can be strings, raw bytes,
dictionaries or whatever seems to be the most likely desired input. Try to keep these inputs as pure Python as possible
as it makes compatibility easier (even through other languages via JSON). Those will be the `inputs` of the
pipeline (`preprocess`).
Then define the `outputs`. Same policy as the `inputs`. The simpler, the better. Those will be the outputs of
`postprocess` method.
Start by inheriting the base class `Pipeline` with the 4 methods needed to implement `preprocess`,
`_forward`, `postprocess`, and `_sanitize_parameters`.
```python
from transformers import Pipeline
class MyPipeline(Pipeline):
def _sanitize_parameters(self, **kwargs):
preprocess_kwargs = {}
if "maybe_arg" in kwargs:
preprocess_kwargs["maybe_arg"] = kwargs["maybe_arg"]
return preprocess_kwargs, {}, {}
def preprocess(self, inputs, maybe_arg=2):
model_input = Tensor(inputs["input_ids"])
return {"model_input": model_input}
def _forward(self, model_inputs):
# model_inputs == {"model_input": model_input}
outputs = self.model(**model_inputs)
# Maybe {"logits": Tensor(...)}
return outputs
def postprocess(self, model_outputs):
best_class = model_outputs["logits"].softmax(-1)
return best_class
```
The structure of this breakdown is to support relatively seamless support for CPU/GPU, while supporting doing
pre/postprocessing on the CPU on different threads
`preprocess` will take the originally defined inputs, and turn them into something feedable to the model. It might
contain more information and is usually a `Dict`.
`_forward` is the implementation detail and is not meant to be called directly. `forward` is the preferred
called method as it contains safeguards to make sure everything is working on the expected device. If anything is
linked to a real model it belongs in the `_forward` method, anything else is in the preprocess/postprocess.
`postprocess` methods will take the output of `_forward` and turn it into the final output that was decided
earlier.
`_sanitize_parameters` exists to allow users to pass any parameters whenever they wish, be it at initialization
time `pipeline(...., maybe_arg=4)` or at call time `pipe = pipeline(...); output = pipe(...., maybe_arg=4)`.
The returns of `_sanitize_parameters` are the 3 dicts of kwargs that will be passed directly to `preprocess`,
`_forward`, and `postprocess`. Don't fill anything if the caller didn't call with any extra parameter. That
allows to keep the default arguments in the function definition which is always more "natural".
A classic example would be a `top_k` argument in the post processing in classification tasks.
```python
>>> pipe = pipeline("my-new-task")
>>> pipe("This is a test")
[{"label": "1-star", "score": 0.8}, {"label": "2-star", "score": 0.1}, {"label": "3-star", "score": 0.05}
{"label": "4-star", "score": 0.025}, {"label": "5-star", "score": 0.025}]
>>> pipe("This is a test", top_k=2)
[{"label": "1-star", "score": 0.8}, {"label": "2-star", "score": 0.1}]
```
In order to achieve that, we'll update our `postprocess` method with a default parameter to `5`. and edit
`_sanitize_parameters` to allow this new parameter.
```python
def postprocess(self, model_outputs, top_k=5):
best_class = model_outputs["logits"].softmax(-1)
# Add logic to handle top_k
return best_class
def _sanitize_parameters(self, **kwargs):
preprocess_kwargs = {}
if "maybe_arg" in kwargs:
preprocess_kwargs["maybe_arg"] = kwargs["maybe_arg"]
postprocess_kwargs = {}
if "top_k" in kwargs:
postprocess_kwargs["top_k"] = kwargs["top_k"]
return preprocess_kwargs, {}, postprocess_kwargs
```
Try to keep the inputs/outputs very simple and ideally JSON-serializable as it makes the pipeline usage very easy
without requiring users to understand new kinds of objects. It's also relatively common to support many different types
of arguments for ease of use (audio files, which can be filenames, URLs or pure bytes)
## Adding it to the list of supported tasks
To register your `new-task` to the list of supported tasks, you have to add it to the `PIPELINE_REGISTRY`:
```python
from transformers.pipelines import PIPELINE_REGISTRY
PIPELINE_REGISTRY.register_pipeline(
"new-task",
pipeline_class=MyPipeline,
pt_model=AutoModelForSequenceClassification,
)
```
You can specify a default model if you want, in which case it should come with a specific revision (which can be the name of a branch or a commit hash, here we took `"abcdef"`) as well as the type:
```python
PIPELINE_REGISTRY.register_pipeline(
"new-task",
pipeline_class=MyPipeline,
pt_model=AutoModelForSequenceClassification,
default={"pt": ("user/awesome_model", "abcdef")},
type="text", # current support type: text, audio, image, multimodal
)
```
## Share your pipeline on the Hub
To share your custom pipeline on the Hub, you just have to save the custom code of your `Pipeline` subclass in a
python file. For instance, let's say we want to use a custom pipeline for sentence pair classification like this:
```py
import numpy as np
from transformers import Pipeline
def softmax(outputs):
maxes = np.max(outputs, axis=-1, keepdims=True)
shifted_exp = np.exp(outputs - maxes)
return shifted_exp / shifted_exp.sum(axis=-1, keepdims=True)
class PairClassificationPipeline(Pipeline):
def _sanitize_parameters(self, **kwargs):
preprocess_kwargs = {}
if "second_text" in kwargs:
preprocess_kwargs["second_text"] = kwargs["second_text"]
return preprocess_kwargs, {}, {}
def preprocess(self, text, second_text=None):
return self.tokenizer(text, text_pair=second_text, return_tensors=self.framework)
def _forward(self, model_inputs):
return self.model(**model_inputs)
def postprocess(self, model_outputs):
logits = model_outputs.logits[0].numpy()
probabilities = softmax(logits)
best_class = np.argmax(probabilities)
label = self.model.config.id2label[best_class]
score = probabilities[best_class].item()
logits = logits.tolist()
return {"label": label, "score": score, "logits": logits}
```
The implementation is framework agnostic, and will work for PyTorch and TensorFlow models. If we have saved this in
a file named `pair_classification.py`, we can then import it and register it like this:
```py
from pair_classification import PairClassificationPipeline
from transformers.pipelines import PIPELINE_REGISTRY
from transformers import AutoModelForSequenceClassification, TFAutoModelForSequenceClassification
PIPELINE_REGISTRY.register_pipeline(
"pair-classification",
pipeline_class=PairClassificationPipeline,
pt_model=AutoModelForSequenceClassification,
tf_model=TFAutoModelForSequenceClassification,
)
```
Once this is done, we can use it with a pretrained model. For instance `sgugger/finetuned-bert-mrpc` has been
fine-tuned on the MRPC dataset, which classifies pairs of sentences as paraphrases or not.
```py
from transformers import pipeline
classifier = pipeline("pair-classification", model="sgugger/finetuned-bert-mrpc")
```
Then we can share it on the Hub by using the `save_pretrained` method in a `Repository`:
```py
from huggingface_hub import Repository
repo = Repository("test-dynamic-pipeline", clone_from="{your_username}/test-dynamic-pipeline")
classifier.save_pretrained("test-dynamic-pipeline")
repo.push_to_hub()
```
This will copy the file where you defined `PairClassificationPipeline` inside the folder `"test-dynamic-pipeline"`,
along with saving the model and tokenizer of the pipeline, before pushing everything into the repository
`{your_username}/test-dynamic-pipeline`. After that, anyone can use it as long as they provide the option
`trust_remote_code=True`:
```py
from transformers import pipeline
classifier = pipeline(model="{your_username}/test-dynamic-pipeline", trust_remote_code=True)
```
## Add the pipeline to 🤗 Transformers
If you want to contribute your pipeline to 🤗 Transformers, you will need to add a new module in the `pipelines` submodule
with the code of your pipeline, then add it to the list of tasks defined in `pipelines/__init__.py`.
Then you will need to add tests. Create a new file `tests/test_pipelines_MY_PIPELINE.py` with examples of the other tests.
The `run_pipeline_test` function will be very generic and run on small random models on every possible
architecture as defined by `model_mapping` and `tf_model_mapping`.
This is very important to test future compatibility, meaning if someone adds a new model for
`XXXForQuestionAnswering` then the pipeline test will attempt to run on it. Because the models are random it's
impossible to check for actual values, that's why there is a helper `ANY` that will simply attempt to match the
output of the pipeline TYPE.
You also *need* to implement 2 (ideally 4) tests.
- `test_small_model_pt` : Define 1 small model for this pipeline (doesn't matter if the results don't make sense)
and test the pipeline outputs. The results should be the same as `test_small_model_tf`.
- `test_small_model_tf` : Define 1 small model for this pipeline (doesn't matter if the results don't make sense)
and test the pipeline outputs. The results should be the same as `test_small_model_pt`.
- `test_large_model_pt` (`optional`): Tests the pipeline on a real pipeline where the results are supposed to
make sense. These tests are slow and should be marked as such. Here the goal is to showcase the pipeline and to make
sure there is no drift in future releases.
- `test_large_model_tf` (`optional`): Tests the pipeline on a real pipeline where the results are supposed to
make sense. These tests are slow and should be marked as such. Here the goal is to showcase the pipeline and to make
sure there is no drift in future releases.
|
huggingface/transformers/blob/main/docs/source/en/add_new_pipeline.md
|
--
title: "Welcome Mixtral - a SOTA Mixture of Experts on Hugging Face"
thumbnail: /blog/assets/mixtral/thumbnail.jpg
authors:
- user: lewtun
- user: philschmid
- user: osanseviero
- user: pcuenq
- user: olivierdehaene
- user: lvwerra
- user: ybelkada
---
# Welcome Mixtral - a SOTA Mixture of Experts on Hugging Face
Mixtral 8x7b is an exciting large language model released by Mistral today, which sets a new state-of-the-art for open-access models and outperforms GPT-3.5 across many benchmarks. We’re excited to support the launch with a comprehensive integration of Mixtral in the Hugging Face ecosystem 🔥!
Among the features and integrations being released today, we have:
- [Models on the Hub](https://huggingface.co/models?search=mistralai/Mixtral), with their model cards and licenses (Apache 2.0)
- [🤗 Transformers integration](https://github.com/huggingface/transformers/releases/tag/v4.36.0)
- Integration with Inference Endpoints
- Integration with [Text Generation Inference](https://github.com/huggingface/text-generation-inference) for fast and efficient production-ready inference
- An example of fine-tuning Mixtral on a single GPU with 🤗 TRL.
## Table of Contents
- [What is Mixtral 8x7b](#what-is-mixtral-8x7b)
- [About the name](#about-the-name)
- [Prompt format](#prompt-format)
- [What we don't know](#what-we-dont-know)
- [Demo](#demo)
- [Inference](#inference)
- [Using 🤗 Transformers](#using-🤗-transformers)
- [Using Text Generation Inference](#using-text-generation-inference)
- [Fine-tuning with 🤗 TRL](#fine-tuning-with-🤗-trl)
- [Quantizing Mixtral](#quantizing-mixtral)
- [Load Mixtral with 4-bit quantization](#load-mixtral-with-4-bit-quantization)
- [Load Mixtral with GPTQ](#load-mixtral-with-gptq)
- [Disclaimers and ongoing work](#disclaimers-and-ongoing-work)
- [Additional Resources](#additional-resources)
- [Conclusion](#conclusion)
## What is Mixtral 8x7b?
Mixtral has a similar architecture to Mistral 7B, but comes with a twist: it’s actually 8 “expert” models in one, thanks to a technique called Mixture of Experts (MoE). For transformers models, the way this works is by replacing some Feed-Forward layers with a sparse MoE layer. A MoE layer contains a router network to select which experts process which tokens most efficiently. In the case of Mixtral, two experts are selected for each timestep, which allows the model to decode at the speed of a 12B parameter-dense model, despite containing 4x the number of effective parameters!
For more details on MoEs, see our accompanying blog post: [hf.co/blog/moe](https://huggingface.co/blog/moe)
**Mixtral release TL;DR;**
- Release of base and Instruct versions
- Supports a context length of 32k tokens.
- Outperforms Llama 2 70B and matches or beats GPT3.5 on most benchmarks
- Speaks English, French, German, Spanish, and Italian.
- Good at coding, with 40.2% on HumanEval
- Commercially permissive with an Apache 2.0 license
So how good are the Mixtral models? Here’s an overview of the base model and its performance compared to other open models on the [LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) (higher scores are better):
| Model | License | Commercial use? | Pretraining size [tokens] | Leaderboard score ⬇️ |
| --------------------------------------------------------------------------------- | --------------- | --------------- | ------------------------- | -------------------- |
| [mistralai/Mixtral-8x7B-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-v0.1) | Apache 2.0 | ✅ | unknown | 68.42 |
| [meta-llama/Llama-2-70b-hf](https://huggingface.co/meta-llama/Llama-2-70b-hf) | Llama 2 license | ✅ | 2,000B | 67.87 |
| [tiiuae/falcon-40b](https://huggingface.co/tiiuae/falcon-40b) | Apache 2.0 | ✅ | 1,000B | 61.5 |
| [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) | Apache 2.0 | ✅ | unknown | 60.97 |
| [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) | Llama 2 license | ✅ | 2,000B | 54.32 |
For instruct and chat models, evaluating on benchmarks like MT-Bench or AlpacaEval is better. Below, we show how [Mixtral Instruct](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) performs up against the top closed and open access models (higher scores are better):
| Model | Availability | Context window (tokens) | MT-Bench score ⬇️ |
| --------------------------------------------------------------------------------------------------- | --------------- | ----------------------- | ---------------- |
| [GPT-4 Turbo](https://openai.com/blog/new-models-and-developer-products-announced-at-devday) | Proprietary | 128k | 9.32 |
| [GPT-3.5-turbo-0613](https://platform.openai.com/docs/models/gpt-3-5) | Proprietary | 16k | 8.32 |
| [mistralai/Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) | Apache 2.0 | 32k | 8.30 |
| [Claude 2.1](https://www.anthropic.com/index/claude-2-1) | Proprietary | 200k | 8.18 |
| [openchat/openchat_3.5](https://huggingface.co/openchat/openchat_3.5) | Apache 2.0 | 8k | 7.81 |
| [HuggingFaceH4/zephyr-7b-beta](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta) | MIT | 8k | 7.34 |
| [meta-llama/Llama-2-70b-chat-hf](https://huggingface.co/meta-llama/Llama-2-70b-chat-hf) | Llama 2 license | 4k | 6.86 |
Impressively, Mixtral Instruct outperforms all other open-access models on MT-Bench and is the first one to achieve comparable performance with GPT-3.5!
### About the name
The Mixtral MoE is called **Mixtral-8x7B**, but it doesn't have 56B parameters. Shortly after the release, we found that some people were misled into thinking that the model behaves similarly to an ensemble of 8 models with 7B parameters each, but that's not how MoE models work. Only some layers of the model (the feed-forward blocks) are replicated; the rest of the parameters are the same as in a 7B model. The total number of parameters is not 56B, but about 45B. A better name [could have been `Mixtral-45-8e`](https://twitter.com/osanseviero/status/1734248798749159874) to better convey the architecture. For more details about how MoE works, please refer to [our "Mixture of Experts Explained" post](https://huggingface.co/blog/moe).
### Prompt format
The [base model](https://huggingface.co/mistralai/Mixtral-8x7B-v0.1) has no prompt format. Like other base models, it can be used to continue an input sequence with a plausible continuation or for zero-shot/few-shot inference. It’s also a great foundation for fine-tuning your own use case. The [Instruct model](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) has a very simple conversation structure.
```bash
<s> [INST] User Instruction 1 [/INST] Model answer 1</s> [INST] User instruction 2[/INST]
```
This format has to be exactly reproduced for effective use. We’ll show later how easy it is to reproduce the instruct prompt with the chat template available in `transformers`.
### What we don't know
Like the previous Mistral 7B release, there are several open questions about this new series of models. In particular, we have no information about the size of the dataset used for pretraining, its composition, or how it was preprocessed.
Similarly, for the Mixtral instruct model, no details have been shared about the fine-tuning datasets or the hyperparameters associated with SFT and DPO.
## Demo
You can chat with the Mixtral Instruct model on Hugging Face Chat! Check it out here: [https://huggingface.co/chat/?model=mistralai/Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/chat/?model=mistralai/Mixtral-8x7B-Instruct-v0.1).
## Inference
We provide two main ways to run inference with Mixtral models:
- Via the `pipeline()` function of 🤗 Transformers.
- With Text Generation Inference, which supports advanced features like continuous batching, tensor parallelism, and more, for blazing fast results.
For each method, it is possible to run the model in half-precision (float16) or with quantized weights. Since the Mixtral model is roughly equivalent in size to a 45B parameter dense model, we can estimate the minimum amount of VRAM needed as follows:
| Precision | Required VRAM |
| --------- | ------------- |
| float16 | >90 GB |
| 8-bit | >45 GB |
| 4-bit | >23 GB |
### Using 🤗 Transformers
With transformers [release 4.36](https://github.com/huggingface/transformers/releases/tag/v4.36.0), you can use Mixtral and leverage all the tools within the Hugging Face ecosystem, such as:
- training and inference scripts and examples
- safe file format (`safetensors`)
- integrations with tools such as bitsandbytes (4-bit quantization), PEFT (parameter efficient fine-tuning), and Flash Attention 2
- utilities and helpers to run generation with the model
- mechanisms to export the models to deploy
Make sure to use the latest `transformers` release:
```bash
pip install -U "transformers==4.36.0" --upgrade
```
In the following code snippet, we show how to run inference with 🤗 Transformers and 4-bit quantization. Due to the large size of the model, you’ll need a card with at least 30 GB of RAM to run it. This includes cards such as A100 (80 or 40GB versions), or A6000 (48 GB).
```python
from transformers import AutoTokenizer
import transformers
import torch
model = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
model_kwargs={"torch_dtype": torch.float16, "load_in_4bit": True},
)
messages = [{"role": "user", "content": "Explain what a Mixture of Experts is in less than 100 words."}]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
> \<s>[INST] Explain what a Mixture of Experts is in less than 100 words. [/INST] A
Mixture of Experts is an ensemble learning method that combines multiple models,
or "experts," to make more accurate predictions. Each expert specializes in a
different subset of the data, and a gating network determines the appropriate
expert to use for a given input. This approach allows the model to adapt to
complex, non-linear relationships in the data and improve overall performance.
>
### Using Text Generation Inference
**[Text Generation Inference](https://github.com/huggingface/text-generation-inference)** is a production-ready inference container developed by Hugging Face to enable easy deployment of large language models. It has features such as continuous batching, token streaming, tensor parallelism for fast inference on multiple GPUs, and production-ready logging and tracing.
You can deploy Mixtral on Hugging Face's [Inference Endpoints](https://ui.endpoints.huggingface.co/new?repository=mistralai%2FMixtral-8x7B-Instruct-v0.1&vendor=aws®ion=us-east-1&accelerator=gpu&instance_size=2xlarge&task=text-generation&no_suggested_compute=true&tgi=true&tgi_max_batch_total_tokens=1024000&tgi_max_total_tokens=32000), which uses Text Generation Inference as the backend. To deploy a Mixtral model, go to the [model page](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) and click on the [Deploy -> Inference Endpoints](https://ui.endpoints.huggingface.co/new?repository=meta-llama/Llama-2-7b-hf) widget.
*Note: You might need to request a quota upgrade via email to **[api-enterprise@huggingface.co](mailto:api-enterprise@huggingface.co)** to access A100s*
You can learn more on how to **[Deploy LLMs with Hugging Face Inference Endpoints in our blog](https://huggingface.co/blog/inference-endpoints-llm)**. The **[blog](https://huggingface.co/blog/inference-endpoints-llm)** includes information about supported hyperparameters and how to stream your response using Python and Javascript.
You can also run Text Generation Inference locally on 2x A100s (80GB) with Docker as follows:
```bash
docker run --gpus all --shm-size 1g -p 3000:80 -v /data:/data ghcr.io/huggingface/text-generation-inference:1.3.0 \
--model-id mistralai/Mixtral-8x7B-Instruct-v0.1 \
--num-shard 2 \
--max-batch-total-tokens 1024000 \
--max-total-tokens 32000
```
## Fine-tuning with 🤗 TRL
Training LLMs can be technically and computationally challenging. In this section, we look at the tools available in the Hugging Face ecosystem to efficiently train Mixtral on a single A100 GPU.
An example command to fine-tune Mixtral on OpenAssistant’s [chat dataset](https://huggingface.co/datasets/OpenAssistant/oasst_top1_2023-08-25) can be found below. To conserve memory, we make use of 4-bit quantization and [QLoRA](https://arxiv.org/abs/2305.14314) to target all the linear layers in the attention blocks. Note that unlike dense transformers, one should not target the MLP layers as they are sparse and don’t interact well with PEFT.
First, install the nightly version of 🤗 TRL and clone the repo to access the [training script](https://github.com/huggingface/trl/blob/main/examples/scripts/sft.py):
```bash
pip install -U transformers
pip install git+https://github.com/huggingface/trl
git clone https://github.com/huggingface/trl
cd trl
```
Then you can run the script:
```bash
accelerate launch --config_file examples/accelerate_configs/multi_gpu.yaml --num_processes=1 \
examples/scripts/sft.py \
--model_name mistralai/Mixtral-8x7B-v0.1 \
--dataset_name trl-lib/ultrachat_200k_chatml \
--batch_size 2 \
--gradient_accumulation_steps 1 \
--learning_rate 2e-4 \
--save_steps 200_000 \
--use_peft \
--peft_lora_r 16 --peft_lora_alpha 32 \
--target_modules q_proj k_proj v_proj o_proj \
--load_in_4bit
```
This takes about 48 hours to train on a single A100, but can be easily parallelised by tweaking `--num_processes` to the number of GPUs you have available.
## Quantizing Mixtral
As seen above, the challenge for this model is to make it run on consumer-type hardware for anyone to use it, as the model requires ~90GB just to be loaded in half-precision (`torch.float16`).
With the 🤗 transformers library, we support out-of-the-box inference with state-of-the-art quantization methods such as QLoRA and GPTQ. You can read more about the quantization methods we support in the [appropriate documentation section](https://huggingface.co/docs/transformers/quantization).
### Load Mixtral with 4-bit quantization
As demonstrated in the inference section, you can load Mixtral with 4-bit quantization by installing the `bitsandbytes` library (`pip install -U bitsandbytes`) and passing the flag `load_in_4bit=True` to the `from_pretrained` method. For better performance, we advise users to load the model with `bnb_4bit_compute_dtype=torch.float16`. Note you need a GPU device with at least 30GB VRAM to properly run the snippet below.
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=quantization_config)
prompt = "[INST] Explain what a Mixture of Experts is in less than 100 words. [/INST]"
inputs = tokenizer(prompt, return_tensors="pt").to(0)
output = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(output[0], skip_special_tokens=True))
```
This 4-bit quantization technique was introduced in the [QLoRA paper](https://huggingface.co/papers/2305.14314), you can read more about it in the corresponding section of [the documentation](https://huggingface.co/docs/transformers/quantization#4-bit) or in [this post](https://huggingface.co/blog/4bit-transformers-bitsandbytes).
### Load Mixtral with GPTQ
The GPTQ algorithm is a post-training quantization technique where each row of the weight matrix is quantized independently to find a version of the weights that minimizes the error. These weights are quantized to int4, but they’re restored to fp16 on the fly during inference. In contrast with 4-bit QLoRA, GPTQ needs the model to be calibrated with a dataset in order to be quantized. Ready-to-use GPTQ models are shared on the 🤗 Hub by [TheBloke](https://huggingface.co/TheBloke), so anyone can use them without having to calibrate them first.
For Mixtral, we had to tweak the calibration approach by making sure we **do not** quantize the expert gating layers for better performance. The final perplexity (lower is better) of the quantized model is `4.40` vs `4.25` for the half-precision model. The quantized model can be found [here](https://huggingface.co/TheBloke/Mixtral-8x7B-v0.1-GPTQ), and to run it with 🤗 transformers you first need to update the `auto-gptq` and `optimum` libraries:
```bash
pip install -U optimum auto-gptq
```
You also need to install transformers from source:
```bash
pip install -U git+https://github.com/huggingface/transformers.git
```
Once installed, simply load the GPTQ model with the `from_pretrained` method:
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
model_id = "TheBloke/Mixtral-8x7B-v0.1-GPTQ"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto")
prompt = "[INST] Explain what a Mixture of Experts is in less than 100 words. [/INST]"
inputs = tokenizer(prompt, return_tensors="pt").to(0)
output = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(output[0], skip_special_tokens=True))
```
Note that for both QLoRA and GPTQ you need at least 30 GB of GPU VRAM to fit the model. You can make it work with 24 GB if you use `device_map="auto"`, like in the example above, so some layers are offloaded to CPU.
## Disclaimers and ongoing work
- **Quantization**: Quantization of MoEs is an active area of research. Some initial experiments we've done with TheBloke are shown above, but we expect more progress as this architecture is known better! It will be exciting to see the development in the coming days and weeks in this area. Additionally, recent work such as [QMoE](https://arxiv.org/abs/2310.16795), which achieves sub-1-bit quantization for MoEs, could be applied here.
- **High VRAM usage**: MoEs run inference very quickly but still need a large amount of VRAM (and hence an expensive GPU). This makes it challenging to use it in local setups. MoEs are great for setups with many devices and large VRAM. Mixtral requires 90GB of VRAM in half-precision 🤯
## Additional Resources
- [Mixture of Experts Explained](https://huggingface.co/blog/moe)
- [Mixtral of experts](https://mistral.ai/news/mixtral-of-experts/)
- [Models on the Hub](https://huggingface.co/models?other=mixtral)
- [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
- [Chat demo on Hugging Chat](https://huggingface.co/chat/?model=mistralai/Mixtral-8x7B-Instruct-v0.1)
## Conclusion
We're very excited about Mixtral being released! In the coming days, be ready to learn more about ways to fine-tune and deploy Mixtral.
|
huggingface/blog/blob/main/mixtral.md
|
Training a masked language model end-to-end from scratch on TPUs
In this example, we're going to demonstrate how to train a TensorFlow model from 🤗 Transformers from scratch. If you're interested in some background theory on training Hugging Face models with TensorFlow on TPU, please check out our
[tutorial doc](https://huggingface.co/docs/transformers/main/perf_train_tpu_tf) on this topic!
If you're interested in smaller-scale TPU training from a pre-trained checkpoint, you can also check out the [TPU fine-tuning example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb).
This example will demonstrate pre-training language models at the 100M-1B parameter scale, similar to BERT or GPT-2. More concretely, we will show how to train a [RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta) (base model) from scratch on the [WikiText dataset (v1)](https://huggingface.co/datasets/wikitext).
We've tried to ensure that all the practices we show you here are scalable, though - with relatively few changes, the code could be scaled up to much larger models.
Google's gargantuan [PaLM model](https://arxiv.org/abs/2204.02311), with
over 500B parameters, is a good example of how far you can go with pure TPU training, though gathering the dataset and the budget to train at that scale is not an easy task!
### Table of contents
- [Setting up a TPU-VM](#setting-up-a-tpu-vm)
- [Training a tokenizer](#training-a-tokenizer)
- [Preparing the dataset](#preparing-the-dataset)
- [Training the model](#training-the-model)
- [Inference](#inference)
## Setting up a TPU-VM
Since this example focuses on using TPUs, the first step is to set up access to TPU hardware. For this example, we chose to use a TPU v3-8 VM. Follow [this guide](https://cloud.google.com/tpu/docs/run-calculation-tensorflow) to quickly create a TPU VM with TensorFlow pre-installed.
> 💡 **Note**: You don't need a TPU-enabled hardware for tokenizer training and TFRecord shard preparation.
## Training a tokenizer
To train a language model from scratch, the first step is to tokenize text. In most Hugging Face examples, we begin from a pre-trained model and use its tokenizer. However, in this example, we're going to train a tokenizer from scratch as well. The script for this is `train_unigram.py`. An example command is:
```bash
python train_unigram.py --batch_size 1000 --vocab_size 25000 --export_to_hub
```
The script will automatically load the `train` split of the WikiText dataset and train a [Unigram tokenizer](https://huggingface.co/course/chapter6/7?fw=pt) on it.
> 💡 **Note**: In order for `export_to_hub` to work, you must authenticate yourself with the `huggingface-cli`. Run `huggingface-cli login` and follow the on-screen instructions.
## Preparing the dataset
The next step is to prepare the dataset. This consists of loading a text dataset from the Hugging Face Hub, tokenizing it and grouping it into chunks of a fixed length ready for training. The script for this is `prepare_tfrecord_shards.py`.
The reason we create TFRecord output files from this step is that these files work well with [`tf.data` pipelines](https://www.tensorflow.org/guide/data_performance). This makes them very suitable for scalable TPU training - the dataset can easily be sharded and read in parallel just by tweaking a few parameters in the pipeline. An example command is:
```bash
python prepare_tfrecord_shards.py \
--tokenizer_name_or_path tf-tpu/unigram-tokenizer-wikitext \
--shard_size 5000 \
--split test
--max_length 128 \
--output_dir gs://tf-tpu-training-resources
```
**Notes**:
* While running the above script, you need to specify the `split` accordingly. The example command above will only filter the `test` split of the dataset.
* If you append `gs://` in your `output_dir` the TFRecord shards will be directly serialized to a Google Cloud Storage (GCS) bucket. Ensure that you have already [created the GCS bucket](https://cloud.google.com/storage/docs).
* If you're using a TPU node, you must stream data from a GCS bucket. Otherwise, if you're using a TPU VM,you can store the data locally. You may need to [attach](https://cloud.google.com/tpu/docs/setup-persistent-disk) a persistent storage to the VM.
* Additional CLI arguments are also supported. We encourage you to run `python prepare_tfrecord_shards.py -h` to know more about them.
## Training the model
Once that's done, the model is ready for training. By default, training takes place on TPU, but you can use the `--no_tpu` flag to train on CPU for testing purposes. An example command is:
```bash
python3 run_mlm.py \
--train_dataset gs://tf-tpu-training-resources/train/ \
--eval_dataset gs://tf-tpu-training-resources/validation/ \
--tokenizer tf-tpu/unigram-tokenizer-wikitext \
--output_dir trained_model
```
If you had specified a `hub_model_id` while launching training, then your model will be pushed to a model repository on the Hugging Face Hub. You can find such an example repository here:
[tf-tpu/roberta-base-epochs-500-no-wd](https://huggingface.co/tf-tpu/roberta-base-epochs-500-no-wd).
## Inference
Once the model is trained, you can use 🤗 Pipelines to perform inference:
```python
from transformers import pipeline
model_id = "tf-tpu/roberta-base-epochs-500-no-wd"
unmasker = pipeline("fill-mask", model=model_id, framework="tf")
unmasker("Goal of my life is to [MASK].")
[{'score': 0.1003185287117958,
'token': 52,
'token_str': 'be',
'sequence': 'Goal of my life is to be.'},
{'score': 0.032648514956235886,
'token': 5,
'token_str': '',
'sequence': 'Goal of my life is to .'},
{'score': 0.02152673341333866,
'token': 138,
'token_str': 'work',
'sequence': 'Goal of my life is to work.'},
{'score': 0.019547373056411743,
'token': 984,
'token_str': 'act',
'sequence': 'Goal of my life is to act.'},
{'score': 0.01939118467271328,
'token': 73,
'token_str': 'have',
'sequence': 'Goal of my life is to have.'}]
```
You can also try out inference using the [Inference Widget](https://huggingface.co/tf-tpu/roberta-base-epochs-500-no-wd?text=Goal+of+my+life+is+to+%5BMASK%5D.) from the model page.
|
huggingface/transformers/blob/main/examples/tensorflow/language-modeling-tpu/README.md
|
--
title: Hyperparameter Search with Transformers and Ray Tune
thumbnail: /blog/assets/06_ray_tune/ray-hf.jpg
authors:
- user: ray-project
guest: true
---
# Hyperparameter Search with Transformers and Ray Tune
##### A guest blog post by Richard Liaw from the Anyscale team
With cutting edge research implementations, thousands of trained models easily accessible, the Hugging Face [transformers](https://github.com/huggingface/transformers) library has become critical to the success and growth of natural language processing today.
For any machine learning model to achieve good performance, users often need to implement some form of parameter tuning. Yet, nearly everyone ([1](https://medium.com/@prakashakshay90/fine-tuning-bert-model-using-pytorch-f34148d58a37), [2](https://mccormickml.com/2019/07/22/BERT-fine-tuning/#advantages-of-fine-tuning)) either ends up disregarding hyperparameter tuning or opting to do a simplistic grid search with a small search space.
However, simple experiments are able to show the benefit of using an advanced tuning technique. Below is [a recent experiment run on a BERT](https://medium.com/distributed-computing-with-ray/hyperparameter-optimization-for-transformers-a-guide-c4e32c6c989b) model from [Hugging Face transformers](https://github.com/huggingface/transformers) on the [RTE dataset](https://aclweb.org/aclwiki/Textual_Entailment_Resource_Pool). Genetic optimization techniques like [PBT](https://docs.ray.io/en/latest/tune/api_docs/schedulers.html#population-based-training-tune-schedulers-populationbasedtraining) can provide large performance improvements compared to standard hyperparameter optimization techniques.
<table>
<tr>
<td><strong>Algorithm</strong>
</td>
<td><strong>Best Val Acc.</strong>
</td>
<td><strong>Best Test Acc.</strong>
</td>
<td><strong>Total GPU min</strong>
</td>
<td><strong>Total $ cost</strong>
</td>
</tr>
<tr>
<td>Grid Search
</td>
<td>74%
</td>
<td>65.4%
</td>
<td>45 min
</td>
<td>$2.30
</td>
</tr>
<tr>
<td>Bayesian Optimization +Early Stop
</td>
<td>77%
</td>
<td>66.9%
</td>
<td>104 min
</td>
<td>$5.30
</td>
</tr>
<tr>
<td>Population-based Training
</td>
<td>78%
</td>
<td>70.5%
</td>
<td>48 min
</td>
<td>$2.45
</td>
</tr>
</table>
If you’re leveraging [Transformers](https://github.com/huggingface/transformers), you’ll want to have a way to easily access powerful hyperparameter tuning solutions without giving up the customizability of the Transformers framework.

In the Transformers 3.1 release, [Hugging Face Transformers](https://github.com/huggingface/transformers) and [Ray Tune](https://docs.ray.io/en/latest/tune/index.html) teamed up to provide a simple yet powerful integration. [Ray Tune](https://docs.ray.io/en/latest/tune/index.html) is a popular Python library for hyperparameter tuning that provides many state-of-the-art algorithms out of the box, along with integrations with the best-of-class tooling, such as [Weights and Biases](https://wandb.ai/) and tensorboard.
To demonstrate this new [Hugging Face](https://github.com/huggingface/transformers) + [Ray Tune](https://docs.ray.io/en/latest/tune/index.html) integration, we leverage the [Hugging Face Datasets library](https://github.com/huggingface/datasets) to fine tune BERT on [MRPC](https://www.microsoft.com/en-us/download/details.aspx?id=52398).
To run this example, please first run:
**`pip install "ray[tune]" transformers datasets scipy sklearn torch`**
Simply plug in one of Ray’s standard tuning algorithms by just adding a few lines of code.
```python
from datasets import load_dataset, load_metric
from transformers import (AutoModelForSequenceClassification, AutoTokenizer,
Trainer, TrainingArguments)
tokenizer = AutoTokenizer.from_pretrained('distilbert-base-uncased')
dataset = load_dataset('glue', 'mrpc')
metric = load_metric('glue', 'mrpc')
def encode(examples):
outputs = tokenizer(
examples['sentence1'], examples['sentence2'], truncation=True)
return outputs
encoded_dataset = dataset.map(encode, batched=True)
def model_init():
return AutoModelForSequenceClassification.from_pretrained(
'distilbert-base-uncased', return_dict=True)
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = predictions.argmax(axis=-1)
return metric.compute(predictions=predictions, references=labels)
# Evaluate during training and a bit more often
# than the default to be able to prune bad trials early.
# Disabling tqdm is a matter of preference.
training_args = TrainingArguments(
"test", evaluation_strategy="steps", eval_steps=500, disable_tqdm=True)
trainer = Trainer(
args=training_args,
tokenizer=tokenizer,
train_dataset=encoded_dataset["train"],
eval_dataset=encoded_dataset["validation"],
model_init=model_init,
compute_metrics=compute_metrics,
)
# Default objective is the sum of all metrics
# when metrics are provided, so we have to maximize it.
trainer.hyperparameter_search(
direction="maximize",
backend="ray",
n_trials=10 # number of trials
)
```
By default, each trial will utilize 1 CPU, and optionally 1 GPU if available.
You can leverage multiple [GPUs for a parallel hyperparameter search](https://docs.ray.io/en/latest/tune/user-guide.html#resources-parallelism-gpus-distributed)
by passing in a `resources_per_trial` argument.
You can also easily swap different parameter tuning algorithms such as [HyperBand](https://docs.ray.io/en/latest/tune/api_docs/schedulers.html#asha-tune-schedulers-ashascheduler), [Bayesian Optimization](https://docs.ray.io/en/latest/tune/api_docs/suggestion.html), [Population-Based Training](https://docs.ray.io/en/latest/tune/api_docs/schedulers.html#population-based-training-tune-schedulers-populationbasedtraining):
To run this example, first run: **`pip install hyperopt`**
```python
from ray.tune.suggest.hyperopt import HyperOptSearch
from ray.tune.schedulers import ASHAScheduler
trainer = Trainer(
args=training_args,
tokenizer=tokenizer,
train_dataset=encoded_dataset["train"],
eval_dataset=encoded_dataset["validation"],
model_init=model_init,
compute_metrics=compute_metrics,
)
best_trial = trainer.hyperparameter_search(
direction="maximize",
backend="ray",
# Choose among many libraries:
# https://docs.ray.io/en/latest/tune/api_docs/suggestion.html
search_alg=HyperOptSearch(metric="objective", mode="max"),
# Choose among schedulers:
# https://docs.ray.io/en/latest/tune/api_docs/schedulers.html
scheduler=ASHAScheduler(metric="objective", mode="max"))
```
It also works with [Weights and Biases](https://wandb.ai/) out of the box!

### Try it out today:
* `pip install -U ray`
* `pip install -U transformers datasets`
* Check out the [Hugging Face documentation](https://huggingface.co/transformers/) and [Discussion thread](https://discuss.huggingface.co/t/using-hyperparameter-search-in-trainer/785/10)
* [End-to-end example of using Hugging Face hyperparameter search for text classification](https://github.com/huggingface/notebooks/blob/master/examples/text_classification.ipynb)
If you liked this blog post, be sure to check out:
* [Transformers + GLUE + Ray Tune example](https://docs.ray.io/en/latest/tune/examples/index.html#hugging-face-huggingface-transformers)
* Our [Weights and Biases report](https://wandb.ai/amogkam/transformers/reports/Hyperparameter-Optimization-for-Huggingface-Transformers--VmlldzoyMTc2ODI) on Hyperparameter Optimization for Transformers
* The [simplest way to serve your NLP model](https://medium.com/distributed-computing-with-ray/the-simplest-way-to-serve-your-nlp-model-in-production-with-pure-python-d42b6a97ad55) from scratch
|
huggingface/blog/blob/main/ray-tune.md
|
Models
[[autodoc]] timm.create_model
[[autodoc]] timm.list_models
|
huggingface/pytorch-image-models/blob/main/hfdocs/source/reference/models.mdx
|
FrameworkSwitchCourse {fw} />
# Fine-tuning a model with the Trainer API[[fine-tuning-a-model-with-the-trainer-api]]
<CourseFloatingBanner chapter={3}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter3/section3.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter3/section3.ipynb"},
]} />
<Youtube id="nvBXf7s7vTI"/>
🤗 Transformers provides a `Trainer` class to help you fine-tune any of the pretrained models it provides on your dataset. Once you've done all the data preprocessing work in the last section, you have just a few steps left to define the `Trainer`. The hardest part is likely to be preparing the environment to run `Trainer.train()`, as it will run very slowly on a CPU. If you don't have a GPU set up, you can get access to free GPUs or TPUs on [Google Colab](https://colab.research.google.com/).
The code examples below assume you have already executed the examples in the previous section. Here is a short summary recapping what you need:
```py
from datasets import load_dataset
from transformers import AutoTokenizer, DataCollatorWithPadding
raw_datasets = load_dataset("glue", "mrpc")
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
```
### Training[[training]]
The first step before we can define our `Trainer` is to define a `TrainingArguments` class that will contain all the hyperparameters the `Trainer` will use for training and evaluation. The only argument you have to provide is a directory where the trained model will be saved, as well as the checkpoints along the way. For all the rest, you can leave the defaults, which should work pretty well for a basic fine-tuning.
```py
from transformers import TrainingArguments
training_args = TrainingArguments("test-trainer")
```
<Tip>
💡 If you want to automatically upload your model to the Hub during training, pass along `push_to_hub=True` in the `TrainingArguments`. We will learn more about this in [Chapter 4](/course/chapter4/3)
</Tip>
The second step is to define our model. As in the [previous chapter](/course/chapter2), we will use the `AutoModelForSequenceClassification` class, with two labels:
```py
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
```
You will notice that unlike in [Chapter 2](/course/chapter2), you get a warning after instantiating this pretrained model. This is because BERT has not been pretrained on classifying pairs of sentences, so the head of the pretrained model has been discarded and a new head suitable for sequence classification has been added instead. The warnings indicate that some weights were not used (the ones corresponding to the dropped pretraining head) and that some others were randomly initialized (the ones for the new head). It concludes by encouraging you to train the model, which is exactly what we are going to do now.
Once we have our model, we can define a `Trainer` by passing it all the objects constructed up to now — the `model`, the `training_args`, the training and validation datasets, our `data_collator`, and our `tokenizer`:
```py
from transformers import Trainer
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
)
```
Note that when you pass the `tokenizer` as we did here, the default `data_collator` used by the `Trainer` will be a `DataCollatorWithPadding` as defined previously, so you can skip the line `data_collator=data_collator` in this call. It was still important to show you this part of the processing in section 2!
To fine-tune the model on our dataset, we just have to call the `train()` method of our `Trainer`:
```py
trainer.train()
```
This will start the fine-tuning (which should take a couple of minutes on a GPU) and report the training loss every 500 steps. It won't, however, tell you how well (or badly) your model is performing. This is because:
1. We didn't tell the `Trainer` to evaluate during training by setting `evaluation_strategy` to either `"steps"` (evaluate every `eval_steps`) or `"epoch"` (evaluate at the end of each epoch).
2. We didn't provide the `Trainer` with a `compute_metrics()` function to calculate a metric during said evaluation (otherwise the evaluation would just have printed the loss, which is not a very intuitive number).
### Evaluation[[evaluation]]
Let's see how we can build a useful `compute_metrics()` function and use it the next time we train. The function must take an `EvalPrediction` object (which is a named tuple with a `predictions` field and a `label_ids` field) and will return a dictionary mapping strings to floats (the strings being the names of the metrics returned, and the floats their values). To get some predictions from our model, we can use the `Trainer.predict()` command:
```py
predictions = trainer.predict(tokenized_datasets["validation"])
print(predictions.predictions.shape, predictions.label_ids.shape)
```
```python out
(408, 2) (408,)
```
The output of the `predict()` method is another named tuple with three fields: `predictions`, `label_ids`, and `metrics`. The `metrics` field will just contain the loss on the dataset passed, as well as some time metrics (how long it took to predict, in total and on average). Once we complete our `compute_metrics()` function and pass it to the `Trainer`, that field will also contain the metrics returned by `compute_metrics()`.
As you can see, `predictions` is a two-dimensional array with shape 408 x 2 (408 being the number of elements in the dataset we used). Those are the logits for each element of the dataset we passed to `predict()` (as you saw in the [previous chapter](/course/chapter2), all Transformer models return logits). To transform them into predictions that we can compare to our labels, we need to take the index with the maximum value on the second axis:
```py
import numpy as np
preds = np.argmax(predictions.predictions, axis=-1)
```
We can now compare those `preds` to the labels. To build our `compute_metric()` function, we will rely on the metrics from the 🤗 [Evaluate](https://github.com/huggingface/evaluate/) library. We can load the metrics associated with the MRPC dataset as easily as we loaded the dataset, this time with the `evaluate.load()` function. The object returned has a `compute()` method we can use to do the metric calculation:
```py
import evaluate
metric = evaluate.load("glue", "mrpc")
metric.compute(predictions=preds, references=predictions.label_ids)
```
```python out
{'accuracy': 0.8578431372549019, 'f1': 0.8996539792387542}
```
The exact results you get may vary, as the random initialization of the model head might change the metrics it achieved. Here, we can see our model has an accuracy of 85.78% on the validation set and an F1 score of 89.97. Those are the two metrics used to evaluate results on the MRPC dataset for the GLUE benchmark. The table in the [BERT paper](https://arxiv.org/pdf/1810.04805.pdf) reported an F1 score of 88.9 for the base model. That was the `uncased` model while we are currently using the `cased` model, which explains the better result.
Wrapping everything together, we get our `compute_metrics()` function:
```py
def compute_metrics(eval_preds):
metric = evaluate.load("glue", "mrpc")
logits, labels = eval_preds
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
```
And to see it used in action to report metrics at the end of each epoch, here is how we define a new `Trainer` with this `compute_metrics()` function:
```py
training_args = TrainingArguments("test-trainer", evaluation_strategy="epoch")
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
```
Note that we create a new `TrainingArguments` with its `evaluation_strategy` set to `"epoch"` and a new model — otherwise, we would just be continuing the training of the model we have already trained. To launch a new training run, we execute:
```py
trainer.train()
```
This time, it will report the validation loss and metrics at the end of each epoch on top of the training loss. Again, the exact accuracy/F1 score you reach might be a bit different from what we found, because of the random head initialization of the model, but it should be in the same ballpark.
The `Trainer` will work out of the box on multiple GPUs or TPUs and provides lots of options, like mixed-precision training (use `fp16 = True` in your training arguments). We will go over everything it supports in Chapter 10.
This concludes the introduction to fine-tuning using the `Trainer` API. An example of doing this for most common NLP tasks will be given in [Chapter 7](/course/chapter7), but for now let's look at how to do the same thing in pure PyTorch.
<Tip>
✏️ **Try it out!** Fine-tune a model on the GLUE SST-2 dataset, using the data processing you did in section 2.
</Tip>
|
huggingface/course/blob/main/chapters/en/chapter3/3.mdx
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Image captioning
[[open-in-colab]]
Image captioning is the task of predicting a caption for a given image. Common real world applications of it include
aiding visually impaired people that can help them navigate through different situations. Therefore, image captioning
helps to improve content accessibility for people by describing images to them.
This guide will show you how to:
* Fine-tune an image captioning model.
* Use the fine-tuned model for inference.
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers datasets evaluate -q
pip install jiwer -q
```
We encourage you to log in to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to log in:
```python
from huggingface_hub import notebook_login
notebook_login()
```
## Load the Pokémon BLIP captions dataset
Use the 🤗 Dataset library to load a dataset that consists of {image-caption} pairs. To create your own image captioning dataset
in PyTorch, you can follow [this notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/GIT/Fine_tune_GIT_on_an_image_captioning_dataset.ipynb).
```python
from datasets import load_dataset
ds = load_dataset("lambdalabs/pokemon-blip-captions")
ds
```
```bash
DatasetDict({
train: Dataset({
features: ['image', 'text'],
num_rows: 833
})
})
```
The dataset has two features, `image` and `text`.
<Tip>
Many image captioning datasets contain multiple captions per image. In those cases, a common strategy is to randomly sample a caption amongst the available ones during training.
</Tip>
Split the dataset’s train split into a train and test set with the [~datasets.Dataset.train_test_split] method:
```python
ds = ds["train"].train_test_split(test_size=0.1)
train_ds = ds["train"]
test_ds = ds["test"]
```
Let's visualize a couple of samples from the training set.
```python
from textwrap import wrap
import matplotlib.pyplot as plt
import numpy as np
def plot_images(images, captions):
plt.figure(figsize=(20, 20))
for i in range(len(images)):
ax = plt.subplot(1, len(images), i + 1)
caption = captions[i]
caption = "\n".join(wrap(caption, 12))
plt.title(caption)
plt.imshow(images[i])
plt.axis("off")
sample_images_to_visualize = [np.array(train_ds[i]["image"]) for i in range(5)]
sample_captions = [train_ds[i]["text"] for i in range(5)]
plot_images(sample_images_to_visualize, sample_captions)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/sample_training_images_image_cap.png" alt="Sample training images"/>
</div>
## Preprocess the dataset
Since the dataset has two modalities (image and text), the pre-processing pipeline will preprocess images and the captions.
To do so, load the processor class associated with the model you are about to fine-tune.
```python
from transformers import AutoProcessor
checkpoint = "microsoft/git-base"
processor = AutoProcessor.from_pretrained(checkpoint)
```
The processor will internally pre-process the image (which includes resizing, and pixel scaling) and tokenize the caption.
```python
def transforms(example_batch):
images = [x for x in example_batch["image"]]
captions = [x for x in example_batch["text"]]
inputs = processor(images=images, text=captions, padding="max_length")
inputs.update({"labels": inputs["input_ids"]})
return inputs
train_ds.set_transform(transforms)
test_ds.set_transform(transforms)
```
With the dataset ready, you can now set up the model for fine-tuning.
## Load a base model
Load the ["microsoft/git-base"](https://huggingface.co/microsoft/git-base) into a [`AutoModelForCausalLM`](https://huggingface.co/docs/transformers/model_doc/auto#transformers.AutoModelForCausalLM) object.
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(checkpoint)
```
## Evaluate
Image captioning models are typically evaluated with the [Rouge Score](https://huggingface.co/spaces/evaluate-metric/rouge) or [Word Error Rate](https://huggingface.co/spaces/evaluate-metric/wer). For this guide, you will use the Word Error Rate (WER).
We use the 🤗 Evaluate library to do so. For potential limitations and other gotchas of the WER, refer to [this guide](https://huggingface.co/spaces/evaluate-metric/wer).
```python
from evaluate import load
import torch
wer = load("wer")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predicted = logits.argmax(-1)
decoded_labels = processor.batch_decode(labels, skip_special_tokens=True)
decoded_predictions = processor.batch_decode(predicted, skip_special_tokens=True)
wer_score = wer.compute(predictions=decoded_predictions, references=decoded_labels)
return {"wer_score": wer_score}
```
## Train!
Now, you are ready to start fine-tuning the model. You will use the 🤗 [`Trainer`] for this.
First, define the training arguments using [`TrainingArguments`].
```python
from transformers import TrainingArguments, Trainer
model_name = checkpoint.split("/")[1]
training_args = TrainingArguments(
output_dir=f"{model_name}-pokemon",
learning_rate=5e-5,
num_train_epochs=50,
fp16=True,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
gradient_accumulation_steps=2,
save_total_limit=3,
evaluation_strategy="steps",
eval_steps=50,
save_strategy="steps",
save_steps=50,
logging_steps=50,
remove_unused_columns=False,
push_to_hub=True,
label_names=["labels"],
load_best_model_at_end=True,
)
```
Then pass them along with the datasets and the model to 🤗 Trainer.
```python
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_ds,
eval_dataset=test_ds,
compute_metrics=compute_metrics,
)
```
To start training, simply call [`~Trainer.train`] on the [`Trainer`] object.
```python
trainer.train()
```
You should see the training loss drop smoothly as training progresses.
Once training is completed, share your model to the Hub with the [`~Trainer.push_to_hub`] method so everyone can use your model:
```python
trainer.push_to_hub()
```
## Inference
Take a sample image from `test_ds` to test the model.
```python
from PIL import Image
import requests
url = "https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/pokemon.png"
image = Image.open(requests.get(url, stream=True).raw)
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/test_image_image_cap.png" alt="Test image"/>
</div>
Prepare image for the model.
```python
device = "cuda" if torch.cuda.is_available() else "cpu"
inputs = processor(images=image, return_tensors="pt").to(device)
pixel_values = inputs.pixel_values
```
Call [`generate`] and decode the predictions.
```python
generated_ids = model.generate(pixel_values=pixel_values, max_length=50)
generated_caption = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(generated_caption)
```
```bash
a drawing of a pink and blue pokemon
```
Looks like the fine-tuned model generated a pretty good caption!
|
huggingface/transformers/blob/main/docs/source/en/tasks/image_captioning.md
|
Subsets and Splits
Transformers Source Texts
This query retrieves specific examples from the dataset related to transformers, providing a limited view of the data with basic filtering.