
text
stringlengths 23
371k
| source
stringlengths 32
152
|
|---|---|
Manual Configuration
This guide will show you how to configure a custom structure for your dataset repository.
A dataset with a supported structure and [file formats](./datasets-adding#file-formats) automatically has a Dataset Viewer on its dataset page on the Hub. You can use YAML to define the splits, configurations and builder parameters that are used by the Viewer.
It is also possible to define multiple configurations for the same dataset (e.g. if the dataset has various independent files).
## Define your splits and subsets in YAML
## Splits
If you have multiple files and want to define which file goes into which split, you can use YAML at the top of your README.md.
For example, given a repository like this one:
```
my_dataset_repository/
├── README.md
├── data.csv
└── holdout.csv
```
You can define a configuration for your splits by adding the `configs` field in the YAML block at the top of your README.md:
```yaml
---
configs:
- config_name: default
data_files:
- split: train
path: "data.csv"
- split: test
path: "holdout.csv"
---
```
You can select multiple files per split using a list of paths:
```
my_dataset_repository/
├── README.md
├── data/
│ ├── abc.csv
│ └── def.csv
└── holdout/
└── ghi.csv
```
```yaml
---
configs:
- config_name: default
data_files:
- split: train
path:
- "data/abc.csv"
- "data/def.csv"
- split: test
path: "holdout/ghi.csv"
---
```
Or you can use glob patterns to automatically list all the files you need:
```yaml
---
configs:
- config_name: default
data_files:
- split: train
path: "data/*.csv"
- split: test
path: "holdout/*.csv"
---
```
<Tip warning={true}>
Note that `config_name` field is required even if you have a single configuration.
</Tip>
## Multiple Configurations
Your dataset might have several subsets of data that you want to be able to use separately.
For example each configuration has its own dropdown in the Dataset Viewer the Hugging Face Hub.
In that case you can define a list of configurations inside the `configs` field in YAML:
```
my_dataset_repository/
├── README.md
├── main_data.csv
└── additional_data.csv
```
```yaml
---
configs:
- config_name: main_data
data_files: "main_data.csv"
- config_name: additional_data
data_files: "additional_data.csv"
---
```
## Builder parameters
Not only `data_files`, but other builder-specific parameters can be passed via YAML, allowing for more flexibility on how to load the data while not requiring any custom code. For example, define which separator to use in which configuration to load your `csv` files:
```yaml
---
configs:
- config_name: tab
data_files: "main_data.csv"
sep: "\t"
- config_name: comma
data_files: "additional_data.csv"
sep: ","
---
```
Refer to the [specific builders' documentation](../datasets/package_reference/builder_classes) to see what configuration parameters they have.
<Tip>
You can set a default configuration using `default: true`
```yaml
- config_name: main_data
data_files: "main_data.csv"
default: true
```
</Tip>
|
huggingface/hub-docs/blob/main/docs/hub/datasets-manual-configuration.md
|
Gradio Demo: filter_records
```
!pip install -q gradio
```
```
import gradio as gr
def filter_records(records, gender):
return records[records["gender"] == gender]
demo = gr.Interface(
filter_records,
[
gr.Dataframe(
headers=["name", "age", "gender"],
datatype=["str", "number", "str"],
row_count=5,
col_count=(3, "fixed"),
),
gr.Dropdown(["M", "F", "O"]),
],
"dataframe",
description="Enter gender as 'M', 'F', or 'O' for other.",
)
if __name__ == "__main__":
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/filter_records/run.ipynb
|
--
title: Image Classification with AutoTrain
thumbnail: /blog/assets/105_autotrain-image-classification/thumbnail.png
authors:
- user: nimaboscarino
---
# Image Classification with AutoTrain
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
So you’ve heard all about the cool things that are happening in the machine learning world, and you want to join in. There’s just one problem – you don’t know how to code! 😱 Or maybe you’re a seasoned software engineer who wants to add some ML to your side-project, but you don’t have the time to pick up a whole new tech stack! For many people, the technical barriers to picking up machine learning feel insurmountable. That’s why Hugging Face created [AutoTrain](https://huggingface.co/autotrain), and with the latest feature we’ve just added, we’re making “no-code” machine learning better than ever. Best of all, you can create your first project for ✨ free! ✨
[Hugging Face AutoTrain](https://huggingface.co/autotrain) lets you train models with **zero** configuration needed. Just choose your task (translation? how about question answering?), upload your data, and let Hugging Face do the rest of the work! By letting AutoTrain experiment with number of different models, there's even a good chance that you'll end up with a model that performs better than a model that's been hand-trained by an engineer 🤯 We’ve been expanding the number of tasks that we support, and we’re proud to announce that **you can now use AutoTrain for Computer Vision**! Image Classification is the latest task we’ve added, with more on the way. But what does this mean for you?
[Image Classification](https://huggingface.co/tasks/image-classification) models learn to *categorize* images, meaning that you can train one of these models to label any image. Do you want a model that can recognize signatures? Distinguish bird species? Identify plant diseases? As long as you can find an appropriate dataset, an image classification model has you covered.
## How can you train your own image classifier?
If you haven’t [created a Hugging Face account](https://huggingface.co/join) yet, now’s the time! Following that, make your way over to the [AutoTrain homepage](https://huggingface.co/autotrain) and click on “Create new project” to get started. You’ll be asked to fill in some basic info about your project. In the screenshot below you’ll see that I created a project named `butterflies-classification`, and I chose the “Image Classification” task. I’ve also chosen the “Automatic” model option, since I want to let AutoTrain do the work of finding the best model architectures for my project.
<div class="flex justify-center">
<figure class="image table text-center m-0 w-1/2">
<medium-zoom background="rgba(0,0,0,.7)" alt="The 'New Project' form for AutoTrain, filled out for a new Image Classification project named 'butterflies-classification'." src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/autotrain-image-classification/new-project.png"></medium-zoom>
</figure>
</div>
Once AutoTrain creates your project, you just need to connect your data. If you have the data locally, you can drag and drop the folder into the window. Since we can also use [any of the image classification datasets on the Hugging Face Hub](https://huggingface.co/datasets?task_categories=task_categories:image-classification), in this example I’ve decided to use the [NimaBoscarino/butterflies](https://huggingface.co/datasets/NimaBoscarino/butterflies) dataset. You can select separate training and validation datasets if available, or you can ask AutoTrain to split the data for you.
<div class="grid grid-cols-2 gap-4">
<figure class="image table text-center m-0 w-full">
</figure>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="A form showing configurations to select for the imported dataset, including split types and data columns." src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/autotrain-image-classification/add-dataset.png"></medium-zoom>
</figure>
</div>
Once the data has been added, simply choose the number of model candidates that you’d like AutoModel to try out, review the expected training cost (training with 5 candidate models and less than 500 images is free 🤩), and start training!
<div class="grid grid-cols-2 gap-4">
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Screenshot showing the model-selection options. Users can choose various numbers of candidate models, and the final training budget is displayed." src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/autotrain-image-classification/select-models.png"></medium-zoom>
</figure>
<div>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Five candidate models are being trained, one of which has already completed training." src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/autotrain-image-classification/training-in-progress.png"></medium-zoom>
</figure>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="All the candidate models have finished training, with one in the 'stopped' state." src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/autotrain-image-classification/training-complete.png"></medium-zoom>
</figure>
</div>
</div>
In the screenshots above you can see that my project started 5 different models, which each reached different accuracy scores. One of them wasn’t performing very well at all, so AutoTrain went ahead and stopped it so that it wouldn’t waste resources. The very best model hit 84% accuracy, with effectively zero effort on my end 😍 To wrap it all up, you can visit your freshly trained models on the Hub and play around with them through the integrated [inference widget](https://huggingface.co/docs/hub/models-widgets). For example, check out my butterfly classifier model over at [NimaBoscarino/butterflies](https://huggingface.co/NimaBoscarino/butterflies) 🦋
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="An automatically generated model card for the butterflies-classification model, showing validation metrics and an embedded inference widget for image classification. The widget is displaying a picture of a butterfly, which has been identified as a Malachite butterfly." src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/autotrain-image-classification/model-card.png"></medium-zoom>
</figure>
We’re so excited to see what you build with AutoTrain! Don’t forget to join the community over at [hf.co/join/discord](https://huggingface.co/join/discord), and reach out to us if you need any help 🤗
|
huggingface/blog/blob/main/autotrain-image-classification.md
|
sing the Python debugger in a terminal. In this video, we'll learn how to use the Python debugger in a terminal. For this example, we are running code from the token classification section, downloading the Conll dataset before loading a tokenizer to preprocess it. Checkout the section of the course linked below for more information. Once this is done, we try to batch together some features of the training dataset by padding them and returning a tensor, then we get the following error. We use PyTorch here but you will get the same error with TensorFlow. As we have seen in the "How to debug an error?" video, the error message is at the end and it indicates we should use padding... which we are actually trying to do. So this is not useful and we will need to go a little deeper to debug the problem. Fortunately, you can use the Python debugger quite easily in a terminal by launching your script with python -m pdb instead of just python. When executing that command, you are sent to the first instruction of your script. You can run just the next instruction by typing n, or continue to the error by directly typing c. Once there, you go to the very bottom of the traceback, and you can type commands. The first two commands you should learn are u and d (for up and down), which allow you to go up in the Traceback or down. Going up twice, we get to the point the error was reached. The third command to learn is p, for print. It allows you to print any value you want. For instance here, we can see the value of return_tensors or batch_outputs to try to understand what triggered the error. The batch outputs dictionary is a bit hard to see, so let's dive into smaller pieces of it. Inside the debugger you can not only print any variable but also evaluate any expression, so we can look independently at the inputs or labels. Those labels are definitely weird: they are of various size, which we can actually confirm by printing the sizes. No wonder the tokenizer wasn't able to create a tensor with them! This is because the pad method only takes care of the tokenizer outputs: input IDs, attention mask and token type IDs, so we have to pad the labels ourselves before trying to create a tensor with them. Once you are ready to exit the Python debugger, you can press q for quit. Another way we can access the Python debugger is to set a "set_trace" instruction where we want in the script. It will interrupt the execution and launch the Python debugger at this place, and we can inspect all the variables before the next instruction is executed. Typing n executes the next instruction, which takes us back inside the traceback. One way to fix the error is to manually pad all labels to the longest, or we can use the data collator designed for this.
|
huggingface/course/blob/main/subtitles/en/raw/chapter8/02c_debug-terminal.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Overview
The APIs in this section are more experimental and prone to breaking changes. Most of them are used internally for development, but they may also be useful to you if you're interested in building a diffusion model with some custom parts or if you're interested in some of our helper utilities for working with 🤗 Diffusers.
|
huggingface/diffusers/blob/main/docs/source/en/api/internal_classes_overview.md
|
Static HTML Spaces
Spaces also accommodate custom HTML for your app instead of using Streamlit or Gradio. Set `sdk: static` inside the `YAML` block at the top of your Spaces **README.md** file. Then you can place your HTML code within an **index.html** file.
Here are some examples of Spaces using custom HTML:
* [Smarter NPC](https://huggingface.co/spaces/mishig/smarter_npc): Display a PlayCanvas project with an iframe in Spaces.
* [Huggingfab](https://huggingface.co/spaces/pierreant-p/huggingfab): Display a Sketchfab model in Spaces.
|
huggingface/hub-docs/blob/main/docs/hub/spaces-sdks-static.md
|
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# DistilBERT
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=distilbert">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-distilbert-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/distilbert-base-uncased">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
<a href="https://huggingface.co/papers/1910.01108">
<img alt="Paper page" src="https://img.shields.io/badge/Paper%20page-1910.01108-green">
</a>
</div>
## Overview
The DistilBERT model was proposed in the blog post [Smaller, faster, cheaper, lighter: Introducing DistilBERT, a
distilled version of BERT](https://medium.com/huggingface/distilbert-8cf3380435b5), and the paper [DistilBERT, a
distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108). DistilBERT is a
small, fast, cheap and light Transformer model trained by distilling BERT base. It has 40% less parameters than
*bert-base-uncased*, runs 60% faster while preserving over 95% of BERT's performances as measured on the GLUE language
understanding benchmark.
The abstract from the paper is the following:
*As Transfer Learning from large-scale pre-trained models becomes more prevalent in Natural Language Processing (NLP),
operating these large models in on-the-edge and/or under constrained computational training or inference budgets
remains challenging. In this work, we propose a method to pre-train a smaller general-purpose language representation
model, called DistilBERT, which can then be fine-tuned with good performances on a wide range of tasks like its larger
counterparts. While most prior work investigated the use of distillation for building task-specific models, we leverage
knowledge distillation during the pretraining phase and show that it is possible to reduce the size of a BERT model by
40%, while retaining 97% of its language understanding capabilities and being 60% faster. To leverage the inductive
biases learned by larger models during pretraining, we introduce a triple loss combining language modeling,
distillation and cosine-distance losses. Our smaller, faster and lighter model is cheaper to pre-train and we
demonstrate its capabilities for on-device computations in a proof-of-concept experiment and a comparative on-device
study.*
This model was contributed by [victorsanh](https://huggingface.co/victorsanh). This model jax version was
contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation).
## Usage tips
- DistilBERT doesn't have `token_type_ids`, you don't need to indicate which token belongs to which segment. Just
separate your segments with the separation token `tokenizer.sep_token` (or `[SEP]`).
- DistilBERT doesn't have options to select the input positions (`position_ids` input). This could be added if
necessary though, just let us know if you need this option.
- Same as BERT but smaller. Trained by distillation of the pretrained BERT model, meaning it’s been trained to predict the same probabilities as the larger model. The actual objective is a combination of:
* finding the same probabilities as the teacher model
* predicting the masked tokens correctly (but no next-sentence objective)
* a cosine similarity between the hidden states of the student and the teacher model
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DistilBERT. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<PipelineTag pipeline="text-classification"/>
- A blog post on [Getting Started with Sentiment Analysis using Python](https://huggingface.co/blog/sentiment-analysis-python) with DistilBERT.
- A blog post on how to [train DistilBERT with Blurr for sequence classification](https://huggingface.co/blog/fastai).
- A blog post on how to use [Ray to tune DistilBERT hyperparameters](https://huggingface.co/blog/ray-tune).
- A blog post on how to [train DistilBERT with Hugging Face and Amazon SageMaker](https://huggingface.co/blog/the-partnership-amazon-sagemaker-and-hugging-face).
- A notebook on how to [finetune DistilBERT for multi-label classification](https://colab.research.google.com/github/DhavalTaunk08/Transformers_scripts/blob/master/Transformers_multilabel_distilbert.ipynb). 🌎
- A notebook on how to [finetune DistilBERT for multiclass classification with PyTorch](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_multiclass_classification.ipynb). 🌎
- A notebook on how to [finetune DistilBERT for text classification in TensorFlow](https://colab.research.google.com/github/peterbayerle/huggingface_notebook/blob/main/distilbert_tf.ipynb). 🌎
- [`DistilBertForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb).
- [`TFDistilBertForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb).
- [`FlaxDistilBertForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification_flax.ipynb).
- [Text classification task guide](../tasks/sequence_classification)
<PipelineTag pipeline="token-classification"/>
- [`DistilBertForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb).
- [`TFDistilBertForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/token-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb).
- [`FlaxDistilBertForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/token-classification).
- [Token classification](https://huggingface.co/course/chapter7/2?fw=pt) chapter of the 🤗 Hugging Face Course.
- [Token classification task guide](../tasks/token_classification)
<PipelineTag pipeline="fill-mask"/>
- [`DistilBertForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#robertabertdistilbert-and-masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
- [`TFDistilBertForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_mlmpy) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
- [`FlaxDistilBertForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb).
- [Masked language modeling](https://huggingface.co/course/chapter7/3?fw=pt) chapter of the 🤗 Hugging Face Course.
- [Masked language modeling task guide](../tasks/masked_language_modeling)
<PipelineTag pipeline="question-answering"/>
- [`DistilBertForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb).
- [`TFDistilBertForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb).
- [`FlaxDistilBertForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/question-answering).
- [Question answering](https://huggingface.co/course/chapter7/7?fw=pt) chapter of the 🤗 Hugging Face Course.
- [Question answering task guide](../tasks/question_answering)
**Multiple choice**
- [`DistilBertForMultipleChoice`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/multiple-choice) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb).
- [`TFDistilBertForMultipleChoice`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/multiple-choice) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb).
- [Multiple choice task guide](../tasks/multiple_choice)
⚗️ Optimization
- A blog post on how to [quantize DistilBERT with 🤗 Optimum and Intel](https://huggingface.co/blog/intel).
- A blog post on how [Optimizing Transformers for GPUs with 🤗 Optimum](https://www.philschmid.de/optimizing-transformers-with-optimum-gpu).
- A blog post on [Optimizing Transformers with Hugging Face Optimum](https://www.philschmid.de/optimizing-transformers-with-optimum).
⚡️ Inference
- A blog post on how to [Accelerate BERT inference with Hugging Face Transformers and AWS Inferentia](https://huggingface.co/blog/bert-inferentia-sagemaker) with DistilBERT.
- A blog post on [Serverless Inference with Hugging Face's Transformers, DistilBERT and Amazon SageMaker](https://www.philschmid.de/sagemaker-serverless-huggingface-distilbert).
🚀 Deploy
- A blog post on how to [deploy DistilBERT on Google Cloud](https://huggingface.co/blog/how-to-deploy-a-pipeline-to-google-clouds).
- A blog post on how to [deploy DistilBERT with Amazon SageMaker](https://huggingface.co/blog/deploy-hugging-face-models-easily-with-amazon-sagemaker).
- A blog post on how to [Deploy BERT with Hugging Face Transformers, Amazon SageMaker and Terraform module](https://www.philschmid.de/terraform-huggingface-amazon-sagemaker).
## Combining DistilBERT and Flash Attention 2
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
```bash
pip install -U flash-attn --no-build-isolation
```
Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16`)
To load and run a model using Flash Attention 2, refer to the snippet below:
```python
>>> import torch
>>> from transformers import AutoTokenizer, AutoModel
>>> device = "cuda" # the device to load the model onto
>>> tokenizer = AutoTokenizer.from_pretrained('distilbert-base-uncased')
>>> model = AutoModel.from_pretrained("distilbert-base-uncased", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
>>> text = "Replace me by any text you'd like."
>>> encoded_input = tokenizer(text, return_tensors='pt').to(device)
>>> model.to(device)
>>> output = model(**encoded_input)
```
## DistilBertConfig
[[autodoc]] DistilBertConfig
## DistilBertTokenizer
[[autodoc]] DistilBertTokenizer
## DistilBertTokenizerFast
[[autodoc]] DistilBertTokenizerFast
<frameworkcontent>
<pt>
## DistilBertModel
[[autodoc]] DistilBertModel
- forward
## DistilBertForMaskedLM
[[autodoc]] DistilBertForMaskedLM
- forward
## DistilBertForSequenceClassification
[[autodoc]] DistilBertForSequenceClassification
- forward
## DistilBertForMultipleChoice
[[autodoc]] DistilBertForMultipleChoice
- forward
## DistilBertForTokenClassification
[[autodoc]] DistilBertForTokenClassification
- forward
## DistilBertForQuestionAnswering
[[autodoc]] DistilBertForQuestionAnswering
- forward
</pt>
<tf>
## TFDistilBertModel
[[autodoc]] TFDistilBertModel
- call
## TFDistilBertForMaskedLM
[[autodoc]] TFDistilBertForMaskedLM
- call
## TFDistilBertForSequenceClassification
[[autodoc]] TFDistilBertForSequenceClassification
- call
## TFDistilBertForMultipleChoice
[[autodoc]] TFDistilBertForMultipleChoice
- call
## TFDistilBertForTokenClassification
[[autodoc]] TFDistilBertForTokenClassification
- call
## TFDistilBertForQuestionAnswering
[[autodoc]] TFDistilBertForQuestionAnswering
- call
</tf>
<jax>
## FlaxDistilBertModel
[[autodoc]] FlaxDistilBertModel
- __call__
## FlaxDistilBertForMaskedLM
[[autodoc]] FlaxDistilBertForMaskedLM
- __call__
## FlaxDistilBertForSequenceClassification
[[autodoc]] FlaxDistilBertForSequenceClassification
- __call__
## FlaxDistilBertForMultipleChoice
[[autodoc]] FlaxDistilBertForMultipleChoice
- __call__
## FlaxDistilBertForTokenClassification
[[autodoc]] FlaxDistilBertForTokenClassification
- __call__
## FlaxDistilBertForQuestionAnswering
[[autodoc]] FlaxDistilBertForQuestionAnswering
- __call__
</jax>
</frameworkcontent>
|
huggingface/transformers/blob/main/docs/source/en/model_doc/distilbert.md
|
n this video, we will learn the first things to do when you get an error. Let's say we want to use the question answering pipeline on a particular model and we get the following error. Errors in Python can appear overwhelming because you get so much information printed out, but that's because Python is trying to help you the best it can to solve your problem. In this video we will see how to interpret the error report we get. The first thing to notice at the very top is that Python shows you with a clear arrow the line of code that triggered the error. So you don't have to fiddle with your code and remove random lines to figure out where the error comes from, you have the answer in front right here. The arrows you see below are the parts of the code Python tried to execute while running the instruction: here we are inside the pipeline function and the error came on this line while trying to execute the function check_tasks, which then raised the KeyError we see displayed. Note that Python tells you exactly where the functions it's executing live, so if you feel adventurous, you can even go inspect the source code. This whole thing is called the traceback. If you are running your code on Colab, the Traceback is automatically minimized, so you have to click to expand it. At the very end of the traceback, you finally get the actual error message. The first thing you should do when encountering an error is to read that error message. Here it's telling us it doesn't know the question answering task, and helpfully gives us the list of supported tasks... in which we can see that question answering is. Looking more closely though, we used an underscore to separate the two words when the task is written with a minus, so we should fix that! Now let's retry our code with the task properly written and what is happening today? Another error! As we saw before, we go look at the bottom to read the actual error message. It's telling us that we should check our model is a correct model identifier, so let's hop on to hf.co/models. We can see our model listed there in the ones available for question answering. The difference is that it's spelled distilbert with one l, and we used two. So let's fix that. We finally get our results! If your error is more complex, you might need to use the Python debugger, check out the videos linked below to learn how!
|
huggingface/course/blob/main/subtitles/en/raw/chapter8/02a_error.md
|
@gradio/dropdown
## 0.4.3
### Patch Changes
- Updated dependencies [[`828fb9e`](https://github.com/gradio-app/gradio/commit/828fb9e6ce15b6ea08318675a2361117596a1b5d), [`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144)]:
- @gradio/statustracker@0.4.3
- @gradio/atoms@0.4.1
## 0.4.2
### Features
- [#6399](https://github.com/gradio-app/gradio/pull/6399) [`053bec9`](https://github.com/gradio-app/gradio/commit/053bec98be1127e083414024e02cf0bebb0b5142) - Improve CSS token documentation in Storybook. Thanks [@hannahblair](https://github.com/hannahblair)!
### Fixes
- [#6694](https://github.com/gradio-app/gradio/pull/6694) [`dfc61ec`](https://github.com/gradio-app/gradio/commit/dfc61ec4d09da72ddd6e7ab726820529621dbd38) - Fix dropdown blur bug when values are provided as tuples. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.4.1
### Patch Changes
- Updated dependencies [[`206af31`](https://github.com/gradio-app/gradio/commit/206af31d7c1a31013364a44e9b40cf8df304ba50)]:
- @gradio/icons@0.3.1
- @gradio/atoms@0.3.1
- @gradio/statustracker@0.4.1
## 0.4.0
### Features
- [#6517](https://github.com/gradio-app/gradio/pull/6517) [`901f3eebd`](https://github.com/gradio-app/gradio/commit/901f3eebda0a67fa8f3050d80f7f7b5800c7f566) - Allow reselecting the original option in `gr.Dropdown` after value has changed programmatically. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.3.3
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/atoms@0.3.0
- @gradio/icons@0.3.0
- @gradio/statustracker@0.4.0
## 0.3.2
### Fixes
- [#6425](https://github.com/gradio-app/gradio/pull/6425) [`b3ba17dd1`](https://github.com/gradio-app/gradio/commit/b3ba17dd1167d254756d93f1fb01e8be071819b6) - Update the selected indices in `Dropdown` when value changes programmatically. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.3.1
### Patch Changes
- Updated dependencies [[`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780), [`fad92c29d`](https://github.com/gradio-app/gradio/commit/fad92c29dc1f5cd84341aae417c495b33e01245f)]:
- @gradio/atoms@0.2.1
- @gradio/statustracker@0.3.1
## 0.3.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
## 0.3.0-beta.8
### Features
- [#6136](https://github.com/gradio-app/gradio/pull/6136) [`667802a6c`](https://github.com/gradio-app/gradio/commit/667802a6cdbfb2ce454a3be5a78e0990b194548a) - JS Component Documentation. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6149](https://github.com/gradio-app/gradio/pull/6149) [`90318b1dd`](https://github.com/gradio-app/gradio/commit/90318b1dd118ae08a695a50e7c556226234ab6dc) - swap `mode` on the frontned to `interactive` to match the backend. Thanks [@pngwn](https://github.com/pngwn)!
### Fixes
- [#6148](https://github.com/gradio-app/gradio/pull/6148) [`0000a1916`](https://github.com/gradio-app/gradio/commit/0000a191688c5480c977c80acdd0c9023865d57e) - fix dropdown arrow size. Thanks [@pngwn](https://github.com/pngwn)!
## 0.3.0-beta.7
### Features
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
### Fixes
- [#6065](https://github.com/gradio-app/gradio/pull/6065) [`7d07001e8`](https://github.com/gradio-app/gradio/commit/7d07001e8e7ca9cbd2251632667b3a043de49f49) - fix storybook. Thanks [@pngwn](https://github.com/pngwn)!
## 0.3.0-beta.6
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.3.3
### Fixes
- [#5839](https://github.com/gradio-app/gradio/pull/5839) [`b83064da0`](https://github.com/gradio-app/gradio/commit/b83064da0005ca055fc15ee478cf064bf91702a4) - Fix error when scrolling dropdown with scrollbar. Thanks [@Kit-p](https://github.com/Kit-p)!
## 0.3.2
### Patch Changes
- Updated dependencies []:
- @gradio/utils@0.1.2
- @gradio/atoms@0.1.4
- @gradio/statustracker@0.2.2
## 0.3.1
### Patch Changes
- Updated dependencies [[`8f0fed857`](https://github.com/gradio-app/gradio/commit/8f0fed857d156830626eb48b469d54d211a582d2)]:
- @gradio/icons@0.2.0
- @gradio/atoms@0.1.3
- @gradio/statustracker@0.2.1
## 0.3.0
### Features
- [#5554](https://github.com/gradio-app/gradio/pull/5554) [`75ddeb390`](https://github.com/gradio-app/gradio/commit/75ddeb390d665d4484667390a97442081b49a423) - Accessibility Improvements. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.2.2
### Fixes
- [#5544](https://github.com/gradio-app/gradio/pull/5544) [`a0cc9ac9`](https://github.com/gradio-app/gradio/commit/a0cc9ac931554e06dcb091158c9b9ac0cc580b6c) - Fixes dropdown breaking if a user types in invalid value and presses enter. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.2.1
### Fixes
- [#5525](https://github.com/gradio-app/gradio/pull/5525) [`21f1db40`](https://github.com/gradio-app/gradio/commit/21f1db40de6d1717eba97a550e11422a457ba7e9) - Ensure input value saves on dropdown blur. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.2.0
### Features
- [#5384](https://github.com/gradio-app/gradio/pull/5384) [`ddc02268`](https://github.com/gradio-app/gradio/commit/ddc02268f731bd2ed04b7a5854accf3383f9a0da) - Allows the `gr.Dropdown` to have separate names and values, as well as enables `allow_custom_value` for multiselect dropdown. Thanks [@abidlabs](https://github.com/abidlabs)!
### Fixes
- [#5508](https://github.com/gradio-app/gradio/pull/5508) [`05715f55`](https://github.com/gradio-app/gradio/commit/05715f5599ae3e928d3183c7b0a7f5291f843a96) - Adds a `filterable` parameter to `gr.Dropdown` that controls whether user can type to filter choices. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.1.3
### Patch Changes
- Updated dependencies [[`afac0006`](https://github.com/gradio-app/gradio/commit/afac0006337ce2840cf497cd65691f2f60ee5912)]:
- @gradio/statustracker@0.2.0
- @gradio/utils@0.1.1
- @gradio/atoms@0.1.2
## 0.1.2
### Fixes
- [#5360](https://github.com/gradio-app/gradio/pull/5360) [`64666525`](https://github.com/gradio-app/gradio/commit/6466652583e3c620df995fb865ef3511a34cb676) - Cancel Dropdown Filter. Thanks [@deckar01](https://github.com/deckar01)!
## 0.1.1
### Fixes
- [#5323](https://github.com/gradio-app/gradio/pull/5323) [`e32b0928`](https://github.com/gradio-app/gradio/commit/e32b0928d2d00342ca917ebb10c379ffc2ec200d) - ensure dropdown stays open when identical data is passed in. Thanks [@pngwn](https://github.com/pngwn)!
## 0.1.0
### Highlights
#### Improve startup performance and markdown support ([#5279](https://github.com/gradio-app/gradio/pull/5279) [`fe057300`](https://github.com/gradio-app/gradio/commit/fe057300f0672c62dab9d9b4501054ac5d45a4ec))
##### Improved markdown support
We now have better support for markdown in `gr.Markdown` and `gr.Dataframe`. Including syntax highlighting and Github Flavoured Markdown. We also have more consistent markdown behaviour and styling.
##### Various performance improvements
These improvements will be particularly beneficial to large applications.
- Rather than attaching events manually, they are now delegated, leading to a significant performance improvement and addressing a performance regression introduced in a recent version of Gradio. App startup for large applications is now around twice as fast.
- Optimised the mounting of individual components, leading to a modest performance improvement during startup (~30%).
- Corrected an issue that was causing markdown to re-render infinitely.
- Ensured that the `gr.3DModel` does re-render prematurely.
Thanks [@pngwn](https://github.com/pngwn)!
### Features
- [#5215](https://github.com/gradio-app/gradio/pull/5215) [`fbdad78a`](https://github.com/gradio-app/gradio/commit/fbdad78af4c47454cbb570f88cc14bf4479bbceb) - Lazy load interactive or static variants of a component individually, rather than loading both variants regardless. This change will improve performance for many applications. Thanks [@pngwn](https://github.com/pngwn)!
- [#5216](https://github.com/gradio-app/gradio/pull/5216) [`4b58ea6d`](https://github.com/gradio-app/gradio/commit/4b58ea6d98e7a43b3f30d8a4cb6f379bc2eca6a8) - Update i18n tokens and locale files. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.0.2
### Fixes
- [#5062](https://github.com/gradio-app/gradio/pull/5062) [`7d897165`](https://github.com/gradio-app/gradio/commit/7d89716519d0751072792c9bbda668ffeb597296) - `gr.Dropdown` now has correct behavior in static mode as well as when an option is selected. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5039](https://github.com/gradio-app/gradio/pull/5039) [`620e4645`](https://github.com/gradio-app/gradio/commit/620e46452729d6d4877b3fab84a65daf2f2b7bc6) - `gr.Dropdown()` now supports values with arbitrary characters and doesn't clear value when re-focused. Thanks [@abidlabs](https://github.com/abidlabs)!
|
gradio-app/gradio/blob/main/js/dropdown/CHANGELOG.md
|
Tasks
## What's a task?
Tasks, or pipeline types, describe the "shape" of each model's API (inputs and outputs) and are used to determine which Inference API and widget we want to display for any given model.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/tasks.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/tasks-dark.png"/>
</div>
This classification is relatively coarse-grained (you can always add more fine-grained task names in your model tags), so **you should rarely have to create a new task**. If you want to add support for a new task, this document explains the required steps.
## Overview
Having a new task integrated into the Hub means that:
* Users can search for all models – and datasets – of a given task.
* The Inference API supports the task.
* Users can try out models directly with the widget. 🏆
Note that you don't need to implement all the steps by yourself. Adding a new task is a community effort, and multiple people can contribute. 🧑🤝🧑
To begin the process, open a new issue in the [huggingface_hub](https://github.com/huggingface/huggingface_hub/issues) repository. Please use the "Adding a new task" template. ⚠️Before doing any coding, it's suggested to go over this document. ⚠️
The first step is to upload a model for your proposed task. Once you have a model in the Hub for the new task, the next step is to enable it in the Inference API. There are three types of support that you can choose from:
* 🤗 using a `transformers` model
* 🐳 using a model from an [officially supported library](./models-libraries)
* 🖨️ using a model with custom inference code. This experimental option has downsides, so we recommend using one of the other approaches.
Finally, you can add a couple of UI elements, such as the task icon and the widget, that complete the integration in the Hub. 📷
Some steps are orthogonal; you don't need to do them in order. **You don't need the Inference API to add the icon.** This means that, even if there isn't full integration yet, users can still search for models of a given task.
## Adding new tasks to the Hub
### Using Hugging Face transformers library
If your model is a `transformers`-based model, there is a 1:1 mapping between the Inference API task and a `pipeline` class. Here are some example PRs from the `transformers` library:
* [Adding ImageClassificationPipeline](https://github.com/huggingface/transformers/pull/11598)
* [Adding AudioClassificationPipeline](https://github.com/huggingface/transformers/pull/13342)
Once the pipeline is submitted and deployed, you should be able to use the Inference API for your model.
### Using Community Inference API with a supported library
The Hub also supports over 10 open-source libraries in the [Community Inference API](https://github.com/huggingface/api-inference-community).
**Adding a new task is relatively straightforward and requires 2 PRs:**
* PR 1: Add the new task to the API [validation](https://github.com/huggingface/api-inference-community/blob/main/api_inference_community/validation.py). This code ensures that the inference input is valid for a given task. Some PR examples:
* [Add text-to-image](https://github.com/huggingface/huggingface_hub/commit/5f040a117cf2a44d704621012eb41c01b103cfca#diff-db8bbac95c077540d79900384cfd524d451e629275cbb5de7a31fc1cd5d6c189)
* [Add audio-classification](https://github.com/huggingface/huggingface_hub/commit/141e30588a2031d4d5798eaa2c1250d1d1b75905#diff-db8bbac95c077540d79900384cfd524d451e629275cbb5de7a31fc1cd5d6c189)
* [Add tabular-classification](https://github.com/huggingface/huggingface_hub/commit/dbea604a45df163d3f0b4b1d897e4b0fb951c650#diff-db8bbac95c077540d79900384cfd524d451e629275cbb5de7a31fc1cd5d6c189)
* PR 2: Add the new task to a library docker image. You should also add a template to [`docker_images/common/app/pipelines`](https://github.com/huggingface/api-inference-community/tree/main/docker_images/common/app/pipelines) to facilitate integrating the task in other libraries. Here is an example PR:
* [Add text-classification to spaCy](https://github.com/huggingface/huggingface_hub/commit/6926fd9bec23cb963ce3f58ec53496083997f0fa#diff-3f1083a92ca0047b50f9ad2d04f0fe8dfaeee0e26ab71eb8835e365359a1d0dc)
### Adding Community Inference API for a quick prototype
**My model is not supported by any library. Am I doomed? 😱**
We recommend using [Hugging Face Spaces](./spaces) for these use cases.
### UI elements
The Hub allows users to filter models by a given task. To do this, you need to add the task to several places. You'll also get to pick an icon for the task!
1. Add the task type to `Types.ts`
In [huggingface.js/packages/tasks/src/pipelines.ts](https://github.com/huggingface/huggingface.js/blob/main/packages/tasks/src/pipelines.ts), you need to do a couple of things
* Add the type to `PIPELINE_DATA`. Note that pipeline types are sorted into different categories (NLP, Audio, Computer Vision, and others).
* You will also need to fill minor changes in [huggingface.js/packages/tasks/src/tasks/index.ts](https://github.com/huggingface/huggingface.js/blob/main/packages/tasks/src/tasks/index.ts)
2. Choose an icon
You can add an icon in the [lib/Icons](https://github.com/huggingface/huggingface.js/tree/main/packages/widgets/src/lib/components/Icons) directory. We usually choose carbon icons from https://icones.js.org/collection/carbon. Also add the icon to [PipelineIcon](https://github.com/huggingface/huggingface.js/blob/main/packages/widgets/src/lib/components/PipelineIcon/PipelineIcon.svelte).
### Widget
Once the task is in production, what could be more exciting than implementing some way for users to play directly with the models in their browser? 🤩 You can find all the widgets [here](https://huggingface.co/spaces/huggingfacejs/inference-widgets).
If you would be interested in contributing with a widget, you can look at the [implementation](https://github.com/huggingface/huggingface.js/tree/main/packages/widgets) of all the widgets.
|
huggingface/hub-docs/blob/main/docs/hub/models-tasks.md
|
Gradio Demo: autocomplete
### This text generation demo works like autocomplete. There's only one textbox and it's used for both the input and the output. The demo loads the model as an interface, and uses that interface as an API. It then uses blocks to create the UI. All of this is done in less than 10 lines of code.
```
!pip install -q gradio
```
```
import gradio as gr
import os
# save your HF API token from https:/hf.co/settings/tokens as an env variable to avoid rate limiting
hf_token = os.getenv("hf_token")
# load a model from https://hf.co/models as an interface, then use it as an api
# you can remove the hf_token parameter if you don't care about rate limiting.
api = gr.load("huggingface/gpt2-xl", hf_token=hf_token)
def complete_with_gpt(text):
return text[:-50] + api(text[-50:])
with gr.Blocks() as demo:
textbox = gr.Textbox(placeholder="Type here...", lines=4)
btn = gr.Button("Autocomplete")
# define what will run when the button is clicked, here the textbox is used as both an input and an output
btn.click(fn=complete_with_gpt, inputs=textbox, outputs=textbox, queue=False)
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/autocomplete/run.ipynb
|
Gradio Demo: generate_english_german
```
!pip install -q gradio transformers torch
```
```
import gradio as gr
from transformers import pipeline
english_translator = gr.load(name="spaces/gradio/english_translator")
english_generator = pipeline("text-generation", model="distilgpt2")
def generate_text(text):
english_text = english_generator(text)[0]["generated_text"]
german_text = english_translator(english_text)
return english_text, german_text
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
seed = gr.Text(label="Input Phrase")
with gr.Column():
english = gr.Text(label="Generated English Text")
german = gr.Text(label="Generated German Text")
btn = gr.Button("Generate")
btn.click(generate_text, inputs=[seed], outputs=[english, german])
gr.Examples(["My name is Clara and I am"], inputs=[seed])
if __name__ == "__main__":
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/generate_english_german/run.ipynb
|
!---
Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Summarization example
This script shows an example of training a *summarization* model with the 🤗 Transformers library.
For straightforward use-cases you may be able to use these scripts without modification, although we have also
included comments in the code to indicate areas that you may need to adapt to your own projects.
### Multi-GPU and TPU usage
By default, these scripts use a `MirroredStrategy` and will use multiple GPUs effectively if they are available. TPUs
can also be used by passing the name of the TPU resource with the `--tpu` argument.
### Example command
```
python run_summarization.py \
--model_name_or_path facebook/bart-base \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
|
huggingface/transformers/blob/main/examples/tensorflow/summarization/README.md
|
--
title: "Fine-Tune XLSR-Wav2Vec2 for low-resource ASR with 🤗 Transformers"
thumbnail: /blog/assets/xlsr_wav2vec2.png
authors:
- user: patrickvonplaten
---
# Fine-tuning XLS-R for Multi-Lingual ASR with 🤗 Transformers
<a target="_blank" href="https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_Tune_XLS_R_on_Common_Voice.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
***New (11/2021)***: *This blog post has been updated to feature XLSR\'s
successor, called [XLS-R](https://huggingface.co/models?other=xls_r)*.
**Wav2Vec2** is a pretrained model for Automatic Speech Recognition
(ASR) and was released in [September
2020](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/)
by *Alexei Baevski, Michael Auli, and Alex Conneau*. Soon after the
superior performance of Wav2Vec2 was demonstrated on one of the most
popular English datasets for ASR, called
[LibriSpeech](https://huggingface.co/datasets/librispeech_asr),
*Facebook AI* presented a multi-lingual version of Wav2Vec2, called
[XLSR](https://arxiv.org/abs/2006.13979). XLSR stands for *cross-lingual
speech representations* and refers to model\'s ability to learn speech
representations that are useful across multiple languages.
XLSR\'s successor, simply called **XLS-R** (refering to the
[*\'\'XLM-R*](https://ai.facebook.com/blog/-xlm-r-state-of-the-art-cross-lingual-understanding-through-self-supervision/)
*for Speech\'\'*), was released in [November 2021](https://ai.facebook.com/blog/xls-r-self-supervised-speech-processing-for-128-languages) by *Arun
Babu, Changhan Wang, Andros Tjandra, et al.* XLS-R used almost **half a
million** hours of audio data in 128 languages for self-supervised
pre-training and comes in sizes ranging from 300 milion up to **two
billion** parameters. You can find the pretrained checkpoints on the 🤗
Hub:
- [**Wav2Vec2-XLS-R-300M**](https://huggingface.co/facebook/wav2vec2-xls-r-300m)
- [**Wav2Vec2-XLS-R-1B**](https://huggingface.co/facebook/wav2vec2-xls-r-1b)
- [**Wav2Vec2-XLS-R-2B**](https://huggingface.co/facebook/wav2vec2-xls-r-2b)
Similar to [BERT\'s masked language modeling
objective](http://jalammar.github.io/illustrated-bert/), XLS-R learns
contextualized speech representations by randomly masking feature
vectors before passing them to a transformer network during
self-supervised pre-training (*i.e.* diagram on the left below).
For fine-tuning, a single linear layer is added on top of the
pre-trained network to train the model on labeled data of audio
downstream tasks such as speech recognition, speech translation and
audio classification (*i.e.* diagram on the right below).

XLS-R shows impressive improvements over previous state-of-the-art
results on both speech recognition, speech translation and
speaker/language identification, *cf.* with Table 3-6, Table 7-10, and
Table 11-12 respectively of the official [paper](https://ai.facebook.com/blog/xls-r-self-supervised-speech-processing-for-128-languages).
Setup
--------------
In this blog, we will give an in-detail explanation of how XLS-R -
more specifically the pre-trained checkpoint
[**Wav2Vec2-XLS-R-300M**](https://huggingface.co/facebook/wav2vec2-xls-r-300m) - can be fine-tuned for ASR.
For demonstration purposes, we fine-tune the model on the low resource
ASR dataset of [Common
Voice](https://huggingface.co/datasets/common_voice) that contains only
*ca.* 4h of validated training data.
XLS-R is fine-tuned using Connectionist Temporal Classification (CTC),
which is an algorithm that is used to train neural networks for
sequence-to-sequence problems, such as ASR and handwriting recognition.
I highly recommend reading the well-written blog post [*Sequence
Modeling with CTC (2017)*](https://distill.pub/2017/ctc/) by Awni
Hannun.
Before we start, let\'s install `datasets` and `transformers`. Also, we
need the `torchaudio` to load audio files and `jiwer` to evaluate our
fine-tuned model using the [word error rate
(WER)](https://huggingface.co/metrics/wer) metric \\( {}^1 \\).
```python
!pip install datasets==1.18.3
!pip install transformers==4.11.3
!pip install huggingface_hub==0.1
!pip install torchaudio
!pip install librosa
!pip install jiwer
```
We strongly suggest to upload your training checkpoints directly to the
[Hugging Face Hub](https://huggingface.co/) while training. The [Hugging Face
Hub](https://huggingface.co/) has integrated version control so you can
be sure that no model checkpoint is getting lost during training.
To do so you have to store your authentication token from the Hugging
Face website (sign up [here](https://huggingface.co/join) if you
haven\'t already!)
```python
from huggingface_hub import notebook_login
notebook_login()
```
**Print Output:**
```bash
Login successful
Your token has been saved to /root/.huggingface/token
```
Then you need to install Git-LFS to upload your model checkpoints:
```bash
apt install git-lfs
```
------------------------------------------------------------------------
\\( {}^1 \\) In the [paper](https://arxiv.org/pdf/2006.13979.pdf), the model
was evaluated using the phoneme error rate (PER), but by far the most
common metric in ASR is the word error rate (WER). To keep this notebook
as general as possible we decided to evaluate the model using WER.
Prepare Data, Tokenizer, Feature Extractor
------------------------------------------
ASR models transcribe speech to text, which means that we both need a
feature extractor that processes the speech signal to the model\'s input
format, *e.g.* a feature vector, and a tokenizer that processes the
model\'s output format to text.
In 🤗 Transformers, the XLS-R model is thus accompanied by both a
tokenizer, called
[Wav2Vec2CTCTokenizer](https://huggingface.co/transformers/master/model_doc/wav2vec2.html#wav2vec2ctctokenizer),
and a feature extractor, called
[Wav2Vec2FeatureExtractor](https://huggingface.co/transformers/master/model_doc/wav2vec2.html#wav2vec2featureextractor).
Let\'s start by creating the tokenizer to decode the predicted output
classes to the output transcription.
### Create `Wav2Vec2CTCTokenizer`
A pre-trained XLS-R model maps the speech signal to a sequence of
context representations as illustrated in the figure above. However, for
speech recognition the model has to to map this sequence of context
representations to its corresponding transcription which means that a
linear layer has to be added on top of the transformer block (shown in
yellow in the diagram above). This linear layer is used to classify
each context representation to a token class analogous to how
a linear layer is added on top of BERT\'s embeddings
for further classification after pre-training (*cf.* with *\'BERT\'* section of the following [blog
post](https://huggingface.co/blog/warm-starting-encoder-decoder)).
after pretraining a linear layer is added on top of BERT\'s embeddings
for further classification - *cf.* with *\'BERT\'* section of this [blog
post](https://huggingface.co/blog/warm-starting-encoder-decoder).
The output size of this layer corresponds to the number of tokens in the
vocabulary, which does **not** depend on XLS-R\'s pretraining task, but
only on the labeled dataset used for fine-tuning. So in the first step,
we will take a look at the chosen dataset of Common Voice and define a
vocabulary based on the transcriptions.
First, let\'s go to Common Voice [official
website](https://commonvoice.mozilla.org/en/datasets) and pick a
language to fine-tune XLS-R on. For this notebook, we will use Turkish.
For each language-specific dataset, you can find a language code
corresponding to your chosen language. On [Common
Voice](https://commonvoice.mozilla.org/en/datasets), look for the field
\"Version\". The language code then corresponds to the prefix before the
underscore. For Turkish, *e.g.* the language code is `"tr"`.
Great, now we can use 🤗 Datasets\' simple API to download the data. The
dataset name is `"common_voice"`, the configuration name corresponds to
the language code, which is `"tr"` in our case.
Common Voice has many different splits including `invalidated`, which
refers to data that was not rated as \"clean enough\" to be considered
useful. In this notebook, we will only make use of the splits `"train"`,
`"validation"` and `"test"`.
Because the Turkish dataset is so small, we will merge both the
validation and training data into a training dataset and only use the
test data for validation.
```python
from datasets import load_dataset, load_metric, Audio
common_voice_train = load_dataset("common_voice", "tr", split="train+validation")
common_voice_test = load_dataset("common_voice", "tr", split="test")
```
Many ASR datasets only provide the target text, `'sentence'` for each
audio array `'audio'` and file `'path'`. Common Voice actually provides
much more information about each audio file, such as the `'accent'`,
etc. Keeping the notebook as general as possible, we only consider the
transcribed text for fine-tuning.
```python
common_voice_train = common_voice_train.remove_columns(["accent", "age", "client_id", "down_votes", "gender", "locale", "segment", "up_votes"])
common_voice_test = common_voice_test.remove_columns(["accent", "age", "client_id", "down_votes", "gender", "locale", "segment", "up_votes"])
```
Let\'s write a short function to display some random samples of the
dataset and run it a couple of times to get a feeling for the
transcriptions.
```python
from datasets import ClassLabel
import random
import pandas as pd
from IPython.display import display, HTML
def show_random_elements(dataset, num_examples=10):
assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset."
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
display(HTML(df.to_html()))
```
**Print Output:**
| Idx | Sentence |
|----------|:-------------:|
| 1 | Jonuz, kısa süreli görevi kabul eden tek adaydı. |
| 2 | Biz umudumuzu bu mücadeleden almaktayız. |
| 3 | Sergide beş Hırvat yeniliği sergilendi. |
| 4 | Herşey adıyla bilinmeli. |
| 5 | Kuruluş özelleştirmeye hazır. |
| 6 | Yerleşim yerlerinin manzarası harika. |
| 7 | Olayların failleri bulunamadı. |
| 8 | Fakat bu çabalar boşa çıktı. |
| 9 | Projenin değeri iki virgül yetmiş yedi milyon avro. |
| 10 | Büyük yeniden yapım projesi dört aşamaya bölündü. |
Alright! The transcriptions look fairly clean. Having translated the
transcribed sentences, it seems that the language corresponds more to
written-out text than noisy dialogue. This makes sense considering that
[Common Voice](https://huggingface.co/datasets/common_voice) is a
crowd-sourced read speech corpus.
We can see that the transcriptions contain some special characters, such
as `,.?!;:`. Without a language model, it is much harder to classify
speech chunks to such special characters because they don\'t really
correspond to a characteristic sound unit. *E.g.*, the letter `"s"` has
a more or less clear sound, whereas the special character `"."` does
not. Also in order to understand the meaning of a speech signal, it is
usually not necessary to include special characters in the
transcription.
Let\'s simply remove all characters that don\'t contribute to the
meaning of a word and cannot really be represented by an acoustic sound
and normalize the text.
```python
import re
chars_to_remove_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\']'
def remove_special_characters(batch):
batch["sentence"] = re.sub(chars_to_remove_regex, '', batch["sentence"]).lower()
return batch
```
```python
common_voice_train = common_voice_train.map(remove_special_characters)
common_voice_test = common_voice_test.map(remove_special_characters)
```
Let\'s look at the processed text labels again.
```python
show_random_elements(common_voice_train.remove_columns(["path","audio"]))
```
**Print Output:**
| Idx | Transcription |
|----------|:-------------:|
| 1 | birisi beyazlar için dediler |
| 2 | maktouf'un cezası haziran ayında sona erdi |
| 3 | orijinalin aksine kıyafetler çıkarılmadı |
| 4 | bunların toplam değeri yüz milyon avroyu buluyor |
| 5 | masada en az iki seçenek bulunuyor |
| 6 | bu hiç de haksız bir heveslilik değil |
| 7 | bu durum bin dokuz yüz doksanlarda ülkenin bölünmesiyle değişti |
| 8 | söz konusu süre altı ay |
| 9 | ancak bedel çok daha yüksek olabilir |
| 10 | başkent fira bir tepenin üzerinde yer alıyor |
Good! This looks better. We have removed most special characters from
transcriptions and normalized them to lower-case only.
Before finalizing the pre-processing, it is always advantageous to
consult a native speaker of the target language to see whether the text
can be further simplified. For this blog post,
[Merve](https://twitter.com/mervenoyann) was kind enough to take a quick
look and noted that \"hatted\" characters - like `â` - aren\'t really
used anymore in Turkish and can be replaced by their \"un-hatted\"
equivalent, *e.g.* `a`.
This means that we should replace a sentence like
`"yargı sistemi hâlâ sağlıksız"` to `"yargı sistemi hala sağlıksız"`.
Let\'s write another short mapping function to further simplify the text
labels. Remember, the simpler the text labels, the easier it is for the
model to learn to predict those labels.
```python
def replace_hatted_characters(batch):
batch["sentence"] = re.sub('[â]', 'a', batch["sentence"])
batch["sentence"] = re.sub('[î]', 'i', batch["sentence"])
batch["sentence"] = re.sub('[ô]', 'o', batch["sentence"])
batch["sentence"] = re.sub('[û]', 'u', batch["sentence"])
return batch
```
```python
common_voice_train = common_voice_train.map(replace_hatted_characters)
common_voice_test = common_voice_test.map(replace_hatted_characters)
```
In CTC, it is common to classify speech chunks into letters, so we will
do the same here. Let\'s extract all distinct letters of the training
and test data and build our vocabulary from this set of letters.
We write a mapping function that concatenates all transcriptions into
one long transcription and then transforms the string into a set of
chars. It is important to pass the argument `batched=True` to the
`map(...)` function so that the mapping function has access to all
transcriptions at once.
```python
def extract_all_chars(batch):
all_text = " ".join(batch["sentence"])
vocab = list(set(all_text))
return {"vocab": [vocab], "all_text": [all_text]}
```
```python
vocab_train = common_voice_train.map(extract_all_chars, batched=True, batch_size=-1, keep_in_memory=True, remove_columns=common_voice_train.column_names)
vocab_test = common_voice_test.map(extract_all_chars, batched=True, batch_size=-1, keep_in_memory=True, remove_columns=common_voice_test.column_names)
```
Now, we create the union of all distinct letters in the training dataset
and test dataset and convert the resulting list into an enumerated
dictionary.
```python
vocab_list = list(set(vocab_train["vocab"][0]) | set(vocab_test["vocab"][0]))
```
```python
vocab_dict = {v: k for k, v in enumerate(sorted(vocab_list))}
vocab_dict
```
**Print Output:**
```bash
{
' ': 0,
'a': 1,
'b': 2,
'c': 3,
'd': 4,
'e': 5,
'f': 6,
'g': 7,
'h': 8,
'i': 9,
'j': 10,
'k': 11,
'l': 12,
'm': 13,
'n': 14,
'o': 15,
'p': 16,
'q': 17,
'r': 18,
's': 19,
't': 20,
'u': 21,
'v': 22,
'w': 23,
'x': 24,
'y': 25,
'z': 26,
'ç': 27,
'ë': 28,
'ö': 29,
'ü': 30,
'ğ': 31,
'ı': 32,
'ş': 33,
'̇': 34
}
```
Cool, we see that all letters of the alphabet occur in the dataset
(which is not really surprising) and we also extracted the special
characters `""` and `'`. Note that we did not exclude those special
characters because:
The model has to learn to predict when a word is finished or else the
model prediction would always be a sequence of chars which would make it
impossible to separate words from each other.
One should always keep in mind that pre-processing is a very important
step before training your model. E.g., we don\'t want our model to
differentiate between `a` and `A` just because we forgot to normalize
the data. The difference between `a` and `A` does not depend on the
\"sound\" of the letter at all, but more on grammatical rules - *e.g.*
use a capitalized letter at the beginning of the sentence. So it is
sensible to remove the difference between capitalized and
non-capitalized letters so that the model has an easier time learning to
transcribe speech.
To make it clearer that `" "` has its own token class, we give it a more
visible character `|`. In addition, we also add an \"unknown\" token so
that the model can later deal with characters not encountered in Common
Voice\'s training set.
```python
vocab_dict["|"] = vocab_dict[" "]
del vocab_dict[" "]
```
Finally, we also add a padding token that corresponds to CTC\'s \"*blank
token*\". The \"blank token\" is a core component of the CTC algorithm.
For more information, please take a look at the \"Alignment\" section
[here](https://distill.pub/2017/ctc/).
```python
vocab_dict["[UNK]"] = len(vocab_dict)
vocab_dict["[PAD]"] = len(vocab_dict)
len(vocab_dict)
```
Cool, now our vocabulary is complete and consists of 39 tokens, which
means that the linear layer that we will add on top of the pretrained
XLS-R checkpoint will have an output dimension of 39.
Let\'s now save the vocabulary as a json file.
```python
import json
with open('vocab.json', 'w') as vocab_file:
json.dump(vocab_dict, vocab_file)
```
In a final step, we use the json file to load the vocabulary into an
instance of the `Wav2Vec2CTCTokenizer` class.
```python
from transformers import Wav2Vec2CTCTokenizer
tokenizer = Wav2Vec2CTCTokenizer.from_pretrained("./", unk_token="[UNK]", pad_token="[PAD]", word_delimiter_token="|")
```
If one wants to re-use the just created tokenizer with the fine-tuned
model of this notebook, it is strongly advised to upload the `tokenizer`
to the [Hugging Face Hub](https://huggingface.co/). Let\'s call the repo to which
we will upload the files `"wav2vec2-large-xlsr-turkish-demo-colab"`:
```python
repo_name = "wav2vec2-large-xls-r-300m-tr-colab"
```
and upload the tokenizer to the [🤗 Hub](https://huggingface.co/).
```python
tokenizer.push_to_hub(repo_name)
```
Great, you can see the just created repository under
`https://huggingface.co/<your-username>/wav2vec2-large-xls-r-300m-tr-colab`
### Create `Wav2Vec2FeatureExtractor`
Speech is a continuous signal, and, to be treated by computers, it first
has to be discretized, which is usually called **sampling**. The
sampling rate hereby plays an important role since it defines how many
data points of the speech signal are measured per second. Therefore,
sampling with a higher sampling rate results in a better approximation
of the *real* speech signal but also necessitates more values per
second.
A pretrained checkpoint expects its input data to have been sampled more
or less from the same distribution as the data it was trained on. The
same speech signals sampled at two different rates have a very different
distribution. For example, doubling the sampling rate results in data points
being twice as long. Thus, before fine-tuning a pretrained checkpoint of
an ASR model, it is crucial to verify that the sampling rate of the data
that was used to pretrain the model matches the sampling rate of the
dataset used to fine-tune the model.
XLS-R was pretrained on audio data of
[Babel](http://www.reading.ac.uk/AcaDepts/ll/speechlab/babel/r),
[Multilingual LibriSpeech
(MLS)](https://huggingface.co/datasets/multilingual_librispeech),
[Common Voice](https://huggingface.co/datasets/common_voice),
[VoxPopuli](https://arxiv.org/abs/2101.00390), and
[VoxLingua107](https://arxiv.org/abs/2011.12998) at a sampling rate of
16kHz. Common Voice, in its original form, has a sampling rate of 48kHz,
thus we will have to downsample the fine-tuning data to 16kHz in the
following.
A `Wav2Vec2FeatureExtractor` object requires the following parameters to
be instantiated:
- `feature_size`: Speech models take a sequence of feature vectors as
an input. While the length of this sequence obviously varies, the
feature size should not. In the case of Wav2Vec2, the feature size
is 1 because the model was trained on the raw speech signal \\( {}^2 \\).
- `sampling_rate`: The sampling rate at which the model is trained on.
- `padding_value`: For batched inference, shorter inputs need to be
padded with a specific value
- `do_normalize`: Whether the input should be
*zero-mean-unit-variance* normalized or not. Usually, speech models
perform better when normalizing the input
- `return_attention_mask`: Whether the model should make use of an
`attention_mask` for batched inference. In general, XLS-R models
checkpoints should **always** use the `attention_mask`.
```python
from transformers import Wav2Vec2FeatureExtractor
feature_extractor = Wav2Vec2FeatureExtractor(feature_size=1, sampling_rate=16000, padding_value=0.0, do_normalize=True, return_attention_mask=True)
```
Great, XLS-R\'s feature extraction pipeline is thereby fully defined!
For improved user-friendliness, the feature extractor and tokenizer are
*wrapped* into a single `Wav2Vec2Processor` class so that one only needs
a `model` and `processor` object.
```python
from transformers import Wav2Vec2Processor
processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
```
Next, we can prepare the dataset.
### Preprocess Data
So far, we have not looked at the actual values of the speech signal but
just the transcription. In addition to `sentence`, our datasets include
two more column names `path` and `audio`. `path` states the absolute
path of the audio file. Let\'s take a look.
```python
common_voice_train[0]["path"]
```
XLS-R expects the input in the format of a 1-dimensional array of 16
kHz. This means that the audio file has to be loaded and resampled.
Thankfully, `datasets` does this automatically by calling the other
column `audio`. Let try it out.
```python
common_voice_train[0]["audio"]
```
```bash
{'array': array([ 0.0000000e+00, 0.0000000e+00, 0.0000000e+00, ...,
-8.8930130e-05, -3.8027763e-05, -2.9146671e-05], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/05be0c29807a73c9b099873d2f5975dae6d05e9f7d577458a2466ecb9a2b0c6b/cv-corpus-6.1-2020-12-11/tr/clips/common_voice_tr_21921195.mp3',
'sampling_rate': 48000}
```
Great, we can see that the audio file has automatically been loaded.
This is thanks to the new [`"Audio"`
feature](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=audio#datasets.Audio)
introduced in `datasets == 1.18.3`, which loads and resamples audio
files on-the-fly upon calling.
In the example above we can see that the audio data is loaded with a
sampling rate of 48kHz whereas 16kHz are expected by the model. We can
set the audio feature to the correct sampling rate by making use of
[`cast_column`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=cast_column#datasets.DatasetDict.cast_column):
```python
common_voice_train = common_voice_train.cast_column("audio", Audio(sampling_rate=16_000))
common_voice_test = common_voice_test.cast_column("audio", Audio(sampling_rate=16_000))
```
Let\'s take a look at `"audio"` again.
```python
common_voice_train[0]["audio"]
```
```bash
{'array': array([ 0.0000000e+00, 0.0000000e+00, 0.0000000e+00, ...,
-7.4556941e-05, -1.4621433e-05, -5.7861507e-05], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/05be0c29807a73c9b099873d2f5975dae6d05e9f7d577458a2466ecb9a2b0c6b/cv-corpus-6.1-2020-12-11/tr/clips/common_voice_tr_21921195.mp3',
'sampling_rate': 16000}
```
This seemed to have worked! Let\'s listen to a couple of audio files to
better understand the dataset and verify that the audio was correctly
loaded.
```python
import IPython.display as ipd
import numpy as np
import random
rand_int = random.randint(0, len(common_voice_train)-1)
print(common_voice_train[rand_int]["sentence"])
ipd.Audio(data=common_voice_train[rand_int]["audio"]["array"], autoplay=True, rate=16000)
```
**Print Output:**
```bash
sunulan bütün teklifler i̇ngilizce idi
```
It seems like the data is now correctly loaded and resampled.
It can be heard, that the speakers change along with their speaking
rate, accent, and background environment, etc. Overall, the recordings
sound acceptably clear though, which is to be expected from a
crowd-sourced read speech corpus.
Let\'s do a final check that the data is correctly prepared, by printing
the shape of the speech input, its transcription, and the corresponding
sampling rate.
```python
rand_int = random.randint(0, len(common_voice_train)-1)
print("Target text:", common_voice_train[rand_int]["sentence"])
print("Input array shape:", common_voice_train[rand_int]["audio"]["array"].shape)
print("Sampling rate:", common_voice_train[rand_int]["audio"]["sampling_rate"])
```
**Print Output:**
```bash
Target text: makedonya bu yıl otuz adet tyetmiş iki tankı aldı
Input array shape: (71040,)
Sampling rate: 16000
```
Good! Everything looks fine - the data is a 1-dimensional array, the
sampling rate always corresponds to 16kHz, and the target text is
normalized.
Finally, we can leverage `Wav2Vec2Processor` to process the data to the
format expected by `Wav2Vec2ForCTC` for training. To do so let\'s make
use of Dataset\'s
[`map(...)`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=map#datasets.DatasetDict.map)
function.
First, we load and resample the audio data, simply by calling
`batch["audio"]`. Second, we extract the `input_values` from the loaded
audio file. In our case, the `Wav2Vec2Processor` only normalizes the
data. For other speech models, however, this step can include more
complex feature extraction, such as [Log-Mel feature
extraction](https://en.wikipedia.org/wiki/Mel-frequency_cepstrum).
Third, we encode the transcriptions to label ids.
**Note**: This mapping function is a good example of how the
`Wav2Vec2Processor` class should be used. In \"normal\" context, calling
`processor(...)` is redirected to `Wav2Vec2FeatureExtractor`\'s call
method. When wrapping the processor into the `as_target_processor`
context, however, the same method is redirected to
`Wav2Vec2CTCTokenizer`\'s call method. For more information please check
the
[docs](https://huggingface.co/transformers/master/model_doc/wav2vec2.html#transformers.Wav2Vec2Processor.__call__).
```python
def prepare_dataset(batch):
audio = batch["audio"]
# batched output is "un-batched"
batch["input_values"] = processor(audio["array"], sampling_rate=audio["sampling_rate"]).input_values[0]
batch["input_length"] = len(batch["input_values"])
with processor.as_target_processor():
batch["labels"] = processor(batch["sentence"]).input_ids
return batch
```
Let\'s apply the data preparation function to all examples.
```python
common_voice_train = common_voice_train.map(prepare_dataset, remove_columns=common_voice_train.column_names)
common_voice_test = common_voice_test.map(prepare_dataset, remove_columns=common_voice_test.column_names)
```
**Note**: Currently `datasets` make use of
[`torchaudio`](https://pytorch.org/audio/stable/index.html) and
[`librosa`](https://librosa.org/doc/latest/index.html) for audio loading
and resampling. If you wish to implement your own costumized data
loading/sampling, feel free to just make use of the `"path"` column
instead and disregard the `"audio"` column.
Long input sequences require a lot of memory. XLS-R is based on
`self-attention`. The memory requirement scales quadratically with the
input length for long input sequences (*cf.* with
[this](https://www.reddit.com/r/MachineLearning/comments/genjvb/d_why_is_the_maximum_input_sequence_length_of/)
reddit post). In case this demo crashes with an \"Out-of-memory\" error
for you, you might want to uncomment the following lines to filter all
sequences that are longer than 5 seconds for training.
```python
#max_input_length_in_sec = 5.0
#common_voice_train = common_voice_train.filter(lambda x: x < max_input_length_in_sec * processor.feature_extractor.sampling_rate, input_columns=["input_length"])
```
Awesome, now we are ready to start training!
Training
--------
The data is processed so that we are ready to start setting up the
training pipeline. We will make use of 🤗\'s
[Trainer](https://huggingface.co/transformers/master/main_classes/trainer.html?highlight=trainer)
for which we essentially need to do the following:
- Define a data collator. In contrast to most NLP models, XLS-R has a
much larger input length than output length. *E.g.*, a sample of
input length 50000 has an output length of no more than 100. Given
the large input sizes, it is much more efficient to pad the training
batches dynamically meaning that all training samples should only be
padded to the longest sample in their batch and not the overall
longest sample. Therefore, fine-tuning XLS-R requires a special
padding data collator, which we will define below
- Evaluation metric. During training, the model should be evaluated on
the word error rate. We should define a `compute_metrics` function
accordingly
- Load a pretrained checkpoint. We need to load a pretrained
checkpoint and configure it correctly for training.
- Define the training configuration.
After having fine-tuned the model, we will correctly evaluate it on the
test data and verify that it has indeed learned to correctly transcribe
speech.
### Set-up Trainer
Let\'s start by defining the data collator. The code for the data
collator was copied from [this
example](https://github.com/huggingface/transformers/blob/7e61d56a45c19284cfda0cee8995fb552f6b1f4e/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py#L219).
Without going into too many details, in contrast to the common data
collators, this data collator treats the `input_values` and `labels`
differently and thus applies to separate padding functions on them
(again making use of XLS-R processor\'s context manager). This is
necessary because in speech input and output are of different modalities
meaning that they should not be treated by the same padding function.
Analogous to the common data collators, the padding tokens in the labels
with `-100` so that those tokens are **not** taken into account when
computing the loss.
```python
import torch
from dataclasses import dataclass, field
from typing import Any, Dict, List, Optional, Union
@dataclass
class DataCollatorCTCWithPadding:
"""
Data collator that will dynamically pad the inputs received.
Args:
processor (:class:`~transformers.Wav2Vec2Processor`)
The processor used for proccessing the data.
padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
among:
* :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
sequence if provided).
* :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
maximum acceptable input length for the model if that argument is not provided.
* :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
different lengths).
"""
processor: Wav2Vec2Processor
padding: Union[bool, str] = True
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lengths and need
# different padding methods
input_features = [{"input_values": feature["input_values"]} for feature in features]
label_features = [{"input_ids": feature["labels"]} for feature in features]
batch = self.processor.pad(
input_features,
padding=self.padding,
return_tensors="pt",
)
with self.processor.as_target_processor():
labels_batch = self.processor.pad(
label_features,
padding=self.padding,
return_tensors="pt",
)
# replace padding with -100 to ignore loss correctly
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
batch["labels"] = labels
return batch
```
```python
data_collator = DataCollatorCTCWithPadding(processor=processor, padding=True)
```
Next, the evaluation metric is defined. As mentioned earlier, the
predominant metric in ASR is the word error rate (WER), hence we will
use it in this notebook as well.
```python
wer_metric = load_metric("wer")
```
The model will return a sequence of logit vectors:
\\( \mathbf{y}_1, \ldots, \mathbf{y}_m \\) with
\\( \mathbf{y}_1 = f_{\theta}(x_1, \ldots, x_n)[0] \\) and \\( n >> m \\).
A logit vector \\( \mathbf{y}_1 \\) contains the log-odds for each word in the
vocabulary we defined earlier, thus \\( \text{len}(\mathbf{y}_i) = \\)
`config.vocab_size`. We are interested in the most likely prediction of
the model and thus take the `argmax(...)` of the logits. Also, we
transform the encoded labels back to the original string by replacing
`-100` with the `pad_token_id` and decoding the ids while making sure
that consecutive tokens are **not** grouped to the same token in CTC
style \\( {}^1 \\).
```python
def compute_metrics(pred):
pred_logits = pred.predictions
pred_ids = np.argmax(pred_logits, axis=-1)
pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
pred_str = processor.batch_decode(pred_ids)
# we do not want to group tokens when computing the metrics
label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
wer = wer_metric.compute(predictions=pred_str, references=label_str)
return {"wer": wer}
```
Now, we can load the pretrained checkpoint of
[Wav2Vec2-XLS-R-300M](https://huggingface.co/facebook/wav2vec2-xls-r-300m).
The tokenizer\'s `pad_token_id` must be to define the model\'s
`pad_token_id` or in the case of `Wav2Vec2ForCTC` also CTC\'s *blank
token* \\( {}^2 \\). To save GPU memory, we enable PyTorch\'s [gradient
checkpointing](https://pytorch.org/docs/stable/checkpoint.html) and also
set the loss reduction to \"*mean*\".
Because the dataset is quite small (\~6h of training data) and because
Common Voice is quite noisy, fine-tuning Facebook\'s
[wav2vec2-xls-r-300m checkpoint](FILL%20ME) seems to require some
hyper-parameter tuning. Therefore, I had to play around a bit with
different values for dropout,
[SpecAugment](https://arxiv.org/abs/1904.08779)\'s masking dropout rate,
layer dropout, and the learning rate until training seemed to be stable
enough.
**Note**: When using this notebook to train XLS-R on another language of
Common Voice those hyper-parameter settings might not work very well.
Feel free to adapt those depending on your use case.
```python
from transformers import Wav2Vec2ForCTC
model = Wav2Vec2ForCTC.from_pretrained(
"facebook/wav2vec2-xls-r-300m",
attention_dropout=0.0,
hidden_dropout=0.0,
feat_proj_dropout=0.0,
mask_time_prob=0.05,
layerdrop=0.0,
ctc_loss_reduction="mean",
pad_token_id=processor.tokenizer.pad_token_id,
vocab_size=len(processor.tokenizer),
)
```
The first component of XLS-R consists of a stack of CNN layers that are
used to extract acoustically meaningful - but contextually independent -
features from the raw speech signal. This part of the model has already
been sufficiently trained during pretraining and as stated in the
[paper](https://arxiv.org/pdf/2006.13979.pdf) does not need to be
fine-tuned anymore. Thus, we can set the `requires_grad` to `False` for
all parameters of the *feature extraction* part.
```python
model.freeze_feature_extractor()
```
In a final step, we define all parameters related to training. To give
more explanation on some of the parameters:
- `group_by_length` makes training more efficient by grouping training
samples of similar input length into one batch. This can
significantly speed up training time by heavily reducing the overall
number of useless padding tokens that are passed through the model
- `learning_rate` and `weight_decay` were heuristically tuned until
fine-tuning has become stable. Note that those parameters strongly
depend on the Common Voice dataset and might be suboptimal for other
speech datasets.
For more explanations on other parameters, one can take a look at the
[docs](https://huggingface.co/transformers/master/main_classes/trainer.html?highlight=trainer#trainingarguments).
During training, a checkpoint will be uploaded asynchronously to the Hub
every 400 training steps. It allows you to also play around with the
demo widget even while your model is still training.
**Note**: If one does not want to upload the model checkpoints to the
Hub, simply set `push_to_hub=False`.
```python
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir=repo_name,
group_by_length=True,
per_device_train_batch_size=16,
gradient_accumulation_steps=2,
evaluation_strategy="steps",
num_train_epochs=30,
gradient_checkpointing=True,
fp16=True,
save_steps=400,
eval_steps=400,
logging_steps=400,
learning_rate=3e-4,
warmup_steps=500,
save_total_limit=2,
push_to_hub=True,
)
```
Now, all instances can be passed to Trainer and we are ready to start
training!
```python
from transformers import Trainer
trainer = Trainer(
model=model,
data_collator=data_collator,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=common_voice_train,
eval_dataset=common_voice_test,
tokenizer=processor.feature_extractor,
)
```
------------------------------------------------------------------------
\\( {}^1 \\) To allow models to become independent of the speaker rate, in
CTC, consecutive tokens that are identical are simply grouped as a
single token. However, the encoded labels should not be grouped when
decoding since they don\'t correspond to the predicted tokens of the
model, which is why the `group_tokens=False` parameter has to be passed.
If we wouldn\'t pass this parameter a word like `"hello"` would
incorrectly be encoded, and decoded as `"helo"`.
\\( {}^2 \\) The blank token allows the model to predict a word, such as
`"hello"` by forcing it to insert the blank token between the two l\'s.
A CTC-conform prediction of `"hello"` of our model would be
`[PAD] [PAD] "h" "e" "e" "l" "l" [PAD] "l" "o" "o" [PAD]`.
### Training
Training will take multiple hours depending on the GPU allocated to this
notebook. While the trained model yields somewhat satisfying results on
*Common Voice*\'s test data of Turkish, it is by no means an optimally
fine-tuned model. The purpose of this notebook is just to demonstrate
how to fine-tune XLS-R XLSR-Wav2Vec2\'s on an ASR dataset.
Depending on what GPU was allocated to your google colab it might be
possible that you are seeing an `"out-of-memory"` error here. In this
case, it\'s probably best to reduce `per_device_train_batch_size` to 8
or even less and increase
[`gradient_accumulation`](https://huggingface.co/transformers/master/main_classes/trainer.html#trainingarguments).
```python
trainer.train()
```
**Print Output:**
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.8842 | 3.67 | 400 | 0.6794 | 0.7000 |
| 0.4115 | 7.34 | 800 | 0.4304 | 0.4548 |
| 0.1946 | 11.01 | 1200 | 0.4466 | 0.4216 |
| 0.1308 | 14.68 | 1600 | 0.4526 | 0.3961 |
| 0.0997 | 18.35 | 2000 | 0.4567 | 0.3696 |
| 0.0784 | 22.02 | 2400 | 0.4193 | 0.3442 |
| 0.0633 | 25.69 | 2800 | 0.4153 | 0.3347 |
| 0.0498 | 29.36 | 3200 | 0.4077 | 0.3195 |
The training loss and validation WER go down nicely.
You can now upload the result of the training to the Hub, just execute
this instruction:
```python
trainer.push_to_hub()
```
You can now share this model with all your friends, family, favorite
pets: they can all load it with the identifier
\"your-username/the-name-you-picked\" so for instance:
```python
from transformers import AutoModelForCTC, Wav2Vec2Processor
model = AutoModelForCTC.from_pretrained("patrickvonplaten/wav2vec2-large-xls-r-300m-tr-colab")
processor = Wav2Vec2Processor.from_pretrained("patrickvonplaten/wav2vec2-large-xls-r-300m-tr-colab")
```
For more examples of how XLS-R can be fine-tuned, please take a look at the official
[🤗 Transformers examples](https://github.com/huggingface/transformers/tree/master/examples/pytorch/speech-recognition#examples).
### Evaluation
As a final check, let\'s load the model and verify that it indeed has
learned to transcribe Turkish speech.
Let\'s first load the pretrained checkpoint.
```python
model = Wav2Vec2ForCTC.from_pretrained(repo_name).to("cuda")
processor = Wav2Vec2Processor.from_pretrained(repo_name)
```
Now, we will just take the first example of the test set, run it through
the model and take the `argmax(...)` of the logits to retrieve the
predicted token ids.
```python
input_dict = processor(common_voice_test[0]["input_values"], return_tensors="pt", padding=True)
logits = model(input_dict.input_values.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)[0]
```
It is strongly recommended to pass the ``sampling_rate`` argument to this function.Failing to do so can result in silent errors that might be hard to debug.
We adapted `common_voice_test` quite a bit so that the dataset instance
does not contain the original sentence label anymore. Thus, we re-use
the original dataset to get the label of the first example.
```python
common_voice_test_transcription = load_dataset("common_voice", "tr", data_dir="./cv-corpus-6.1-2020-12-11", split="test")
```
Finally, we can decode the example.
```python
print("Prediction:")
print(processor.decode(pred_ids))
print("\nReference:")
print(common_voice_test_transcription[0]["sentence"].lower())
```
**Print Output:**
| pred_str | target_text |
|----------|:-------------:|
| hatta küçük şeyleri için bir büyt bir şeyleri kolluyor veyınıki çuk şeyler için bir bir mizi inciltiyoruz | hayatta küçük şeyleri kovalıyor ve yine küçük şeyler için birbirimizi incitiyoruz. |
Alright! The transcription can definitely be recognized from our
prediction, but it is not perfect yet. Training the model a bit longer,
spending more time on the data preprocessing, and especially using a
language model for decoding would certainly improve the model\'s overall
performance.
For a demonstration model on a low-resource language, the results are
quite acceptable however 🤗.
|
huggingface/blog/blob/main/fine-tune-xlsr-wav2vec2.md
|
Installation
<tokenizerslangcontent>
<python>
🤗 Tokenizers is tested on Python 3.5+.
You should install 🤗 Tokenizers in a [virtual environment](https://docs.python.org/3/library/venv.html). If you're
unfamiliar with Python virtual environments, check out the [user
guide](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
Create a virtual environment with the version of Python you're going to
use and activate it.
## Installation with pip
🤗 Tokenizers can be installed using pip as follows:
```bash
pip install tokenizers
```
## Installation from sources
To use this method, you need to have the Rust language installed. You
can follow [the official
guide](https://www.rust-lang.org/learn/get-started) for more
information.
If you are using a unix based OS, the installation should be as simple
as running:
```bash
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
```
Or you can easiy update it with the following command:
```bash
rustup update
```
Once rust is installed, we can start retrieving the sources for 🤗
Tokenizers:
```bash
git clone https://github.com/huggingface/tokenizers
```
Then we go into the python bindings folder:
```bash
cd tokenizers/bindings/python
```
At this point you should have your [virtual environment]() already
activated. In order to compile 🤗 Tokenizers, you need to:
```bash
pip install -e .
```
</python>
<rust>
## Crates.io
🤗 Tokenizers is available on [crates.io](https://crates.io/crates/tokenizers).
You just need to add it to your `Cargo.toml`:
```bash
cargo add tokenizers
```
</rust>
<node>
## Installation with npm
You can simply install 🤗 Tokenizers with npm using:
```bash
npm install tokenizers
```
</node>
</tokenizerslangcontent>
|
huggingface/tokenizers/blob/main/docs/source-doc-builder/installation.mdx
|
Mastering NLP[[mastering-nlp]]
<CourseFloatingBanner
chapter={7}
classNames="absolute z-10 right-0 top-0"
/>
If you've made it this far in the course, congratulations -- you now have all the knowledge and tools you need to tackle (almost) any NLP task with 🤗 Transformers and the Hugging Face ecosystem!
We have seen a lot of different data collators, so we made this little video to help you find which one to use for each task:
<Youtube id="-RPeakdlHYo"/>
After completing this lightning tour through the core NLP tasks, you should:
* Know which architectures (encoder, decoder, or encoder-decoder) are best suited for each task
* Understand the difference between pretraining and fine-tuning a language model
* Know how to train Transformer models using either the `Trainer` API and distributed training features of 🤗 Accelerate or TensorFlow and Keras, depending on which track you've been following
* Understand the meaning and limitations of metrics like ROUGE and BLEU for text generation tasks
* Know how to interact with your fine-tuned models, both on the Hub and using the `pipeline` from 🤗 Transformers
Despite all this knowledge, there will come a time when you'll either encounter a difficult bug in your code or have a question about how to solve a particular NLP problem. Fortunately, the Hugging Face community is here to help you! In the final chapter of this part of the course, we'll explore how you can debug your Transformer models and ask for help effectively.
|
huggingface/course/blob/main/chapters/en/chapter7/8.mdx
|
Collections
Use Collections to group repositories from the Hub (Models, Datasets, Spaces and Papers) on a dedicated page.
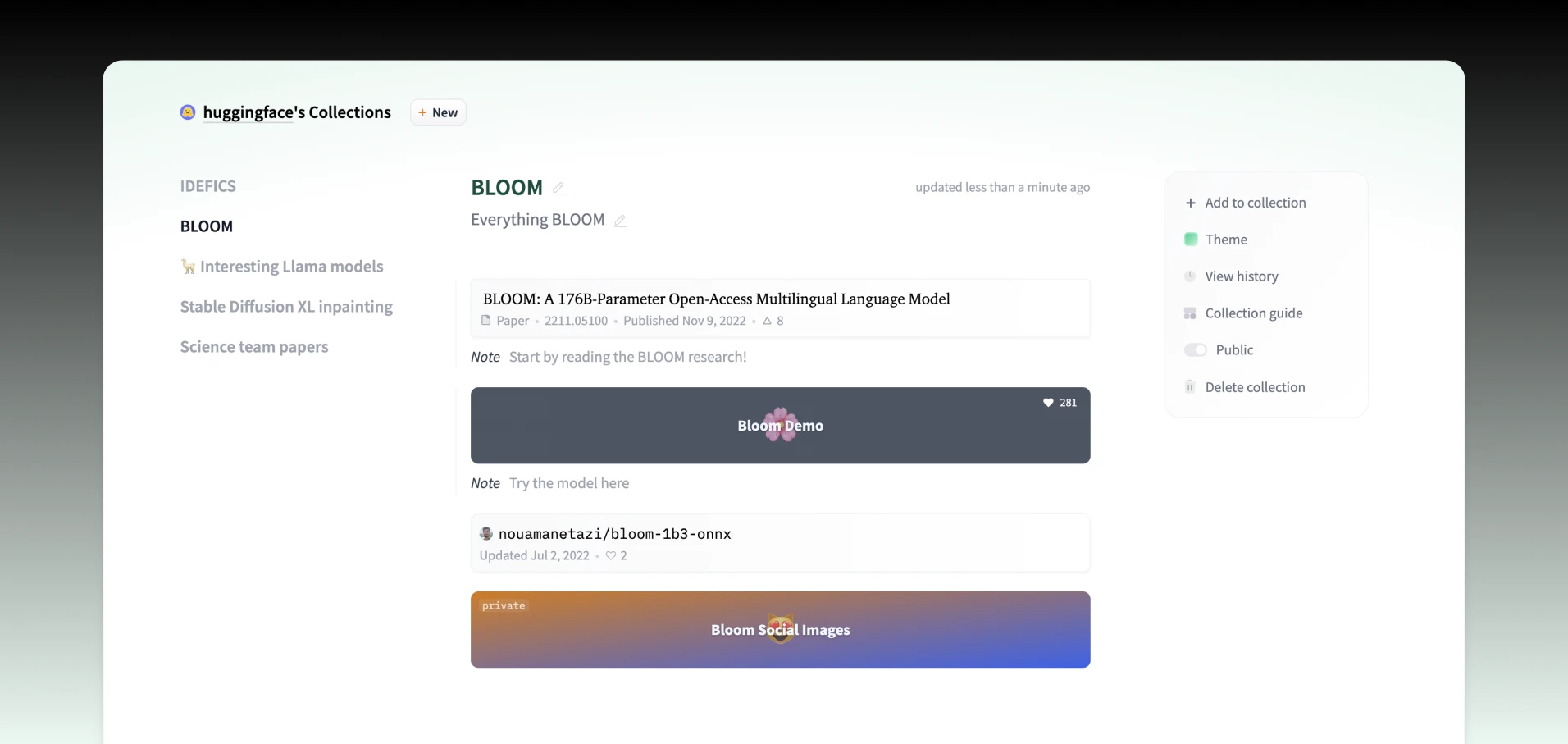
Collections have many use cases:
- Highlight specific repositories on your personal or organizational profile.
- Separate key repositories from others for your profile visitors.
- Showcase and share a complete project with its paper(s), dataset(s), model(s) and Space(s).
- Bookmark things you find on the Hub in categories.
- Have a dedicated page of curated things to share with others.
This is just a list of possible uses, but remember that collections are just a way of grouping things, so use them in the way that best fits your use case.
## Creating a new collection
There are several ways to create a collection:
- For personal collections: Use the **+ New** button on your logged-in homepage (1).
- For organization collections: Use the **+ New** button available on organizations page (2).

It's also possible to create a collection on the fly when adding the first item from a repository page, select **+ Create new collection** from the dropdown menu.
You'll need to enter a title and short description for your collection to be created.
## Adding items to a collection
There are 2 ways to add items to a collection:
- From any repository page: Use the context menu available on any repository page then select **Add to collection** to add it to a collection (1).
- From the collection page: If you know the name of the repository you want to add, use the **+ add to collection** option in the right-hand menu (2).
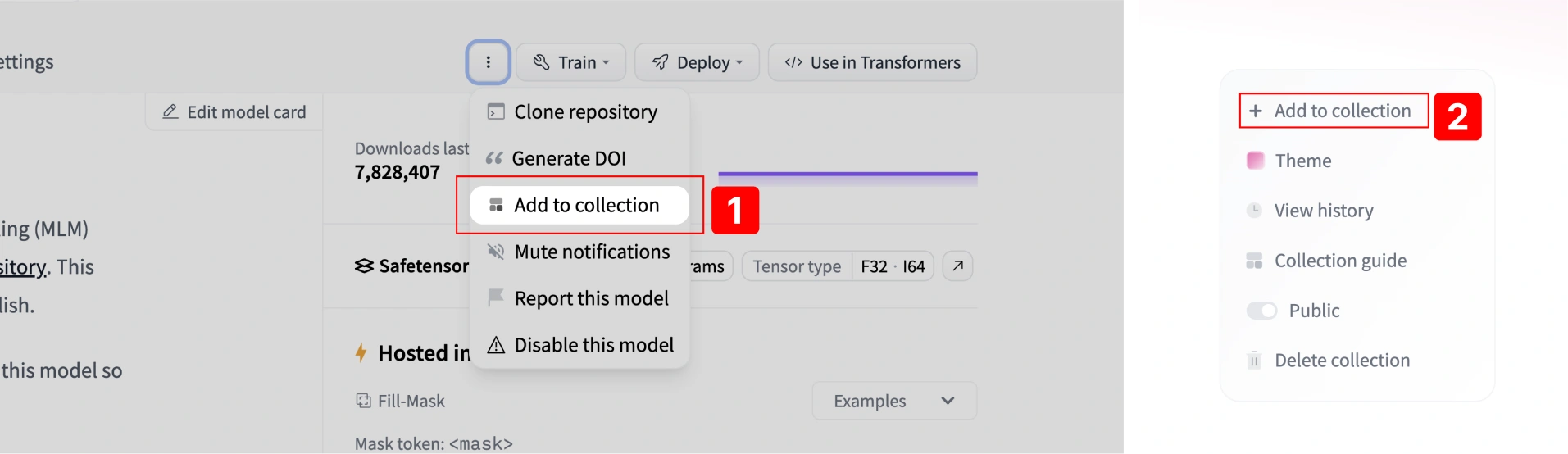
It's possible to add external repositories to your collections, not just your own.
## Collaborating on collections
Organization collections are a great way to build collections together. Any member of the organization can add, edit and remove items from the collection.
Use the **history feature** to keep track of who has edited the collection.
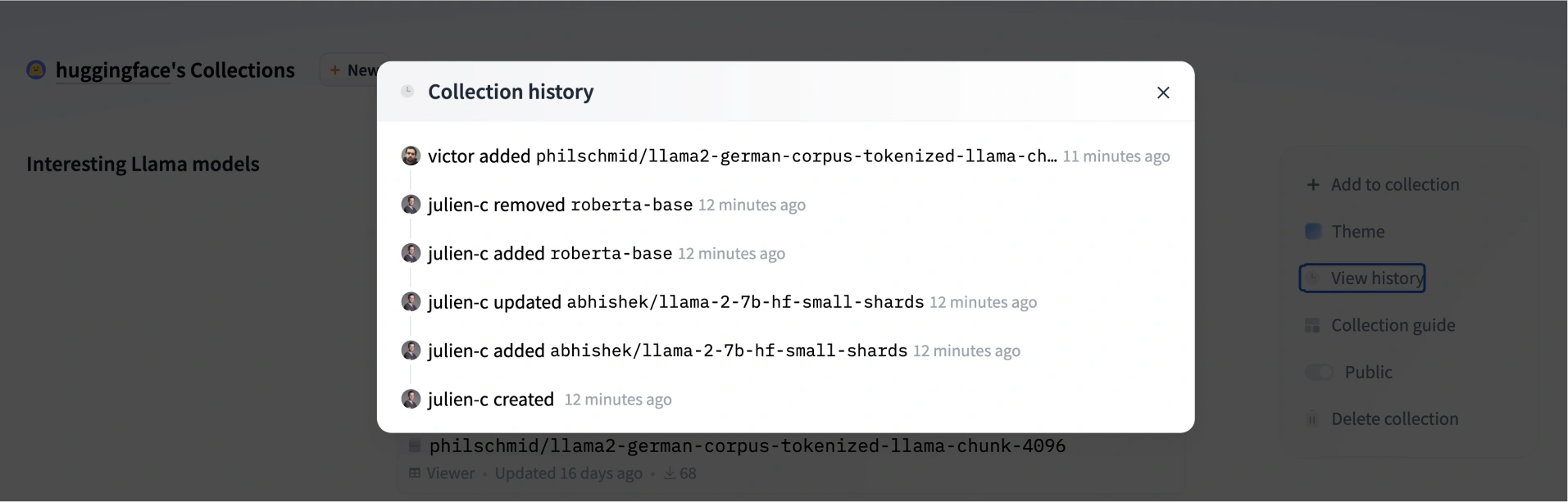
## Collection options
### Collection visibility
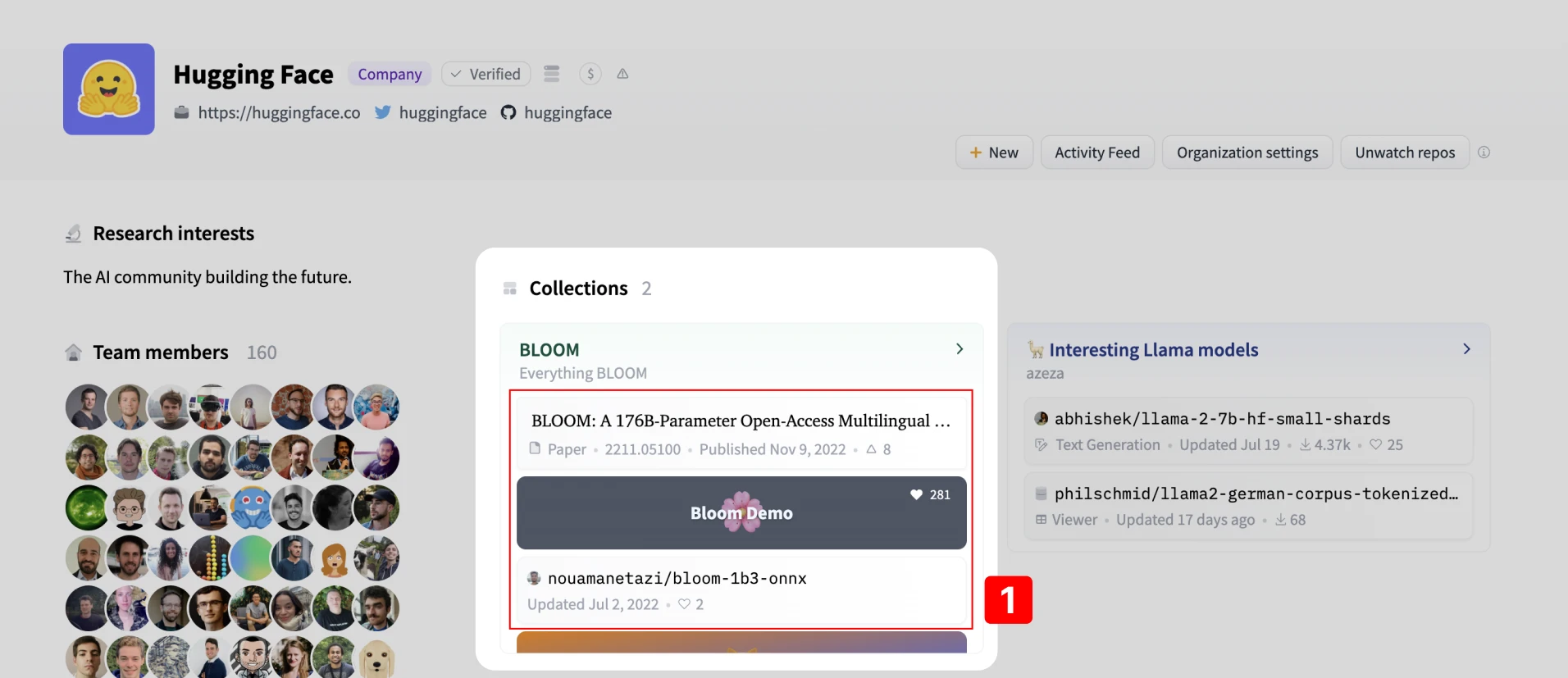
**Public** collections appear at the top of your profile or organization page and can be viewed by anyone. The first 3 items in each collection are visible directly in the collection preview (1). To see more, the user must click to go to the collection page.
Set your collection to **private** if you don't want it to be accessible via its URL (it will not be displayed on your profile/organization page). For organizations, private collections are only available to members of the organization.
### Ordering your collections and their items
You can use the drag and drop handles in the collections list (on the left side of your collections page) to change the order of your collections (1). The first two collections will be directly visible on your profile/organization pages.
You can also sort repositories within a collection by dragging the handles next to each item (2).
### Deleting items from a collection
To delete an item from a collection, click the trash icon in the menu that shows up on the right when you hover over an item (1).
To delete the whole collection, click delete on the right-hand menu (2) - you'll need to confirm this action.
### Adding notes to collection's items
It's possible to add a note to any item in a collection to give it more context (for others, or as a reminder to yourself). You can add notes by clicking the pencil icon when you hover over an item with your mouse. Notes are plain text and don't support markdown, to keep things clean and simple. URLs in notes are converted into clickable links.
### Adding images to a collection item
Similarily, you can attach images to a collection item. This is useful for showcasing the output of a model, the content of a dataset, attaching an infographic for context, etc.
To start adding images to your collection, you can click on the image icon in the contextual menu of an item. The menu shows up when you hover over an item with your mouse.
Then, add images by dragging and dropping images from your computer. You can also click on the gray zone to select image files from your computer's file system.
You can re-order images by drag-and-dropping them. Clicking on an image will open it in full-screen mode.

## Your feedback on collections
We're working on improving collections, so if you have any bugs, questions, or new features you'd like to see added, please post a message in the [dedicated discussion](https://huggingface.co/spaces/huggingface/HuggingDiscussions/discussions/12).
|
huggingface/hub-docs/blob/main/docs/hub/collections.md
|
--
title: "Advantage Actor Critic (A2C)"
thumbnail: /blog/assets/89_deep_rl_a2c/thumbnail.gif
authors:
- user: ThomasSimonini
---
# Advantage Actor Critic (A2C)
<h2>Unit 7, of the <a href="https://github.com/huggingface/deep-rl-class">Deep Reinforcement Learning Class with Hugging Face 🤗</a></h2>
⚠️ A **new updated version of this article is available here** 👉 [https://huggingface.co/deep-rl-course/unit1/introduction](https://huggingface.co/deep-rl-course/unit6/introduction)
*This article is part of the Deep Reinforcement Learning Class. A free course from beginner to expert. Check the syllabus [here.](https://huggingface.co/deep-rl-course/unit0/introduction)*
<img src="assets/89_deep_rl_a2c/thumbnail.jpg" alt="Thumbnail"/>
---
⚠️ A **new updated version of this article is available here** 👉 [https://huggingface.co/deep-rl-course/unit1/introduction](https://huggingface.co/deep-rl-course/unit6/introduction)
*This article is part of the Deep Reinforcement Learning Class. A free course from beginner to expert. Check the syllabus [here.](https://huggingface.co/deep-rl-course/unit0/introduction)*
[In Unit 5](https://huggingface.co/blog/deep-rl-pg), we learned about our first Policy-Based algorithm called **Reinforce**.
In Policy-Based methods, **we aim to optimize the policy directly without using a value function**. More precisely, Reinforce is part of a subclass of *Policy-Based Methods* called *Policy-Gradient methods*. This subclass optimizes the policy directly by **estimating the weights of the optimal policy using Gradient Ascent**.
We saw that Reinforce worked well. However, because we use Monte-Carlo sampling to estimate return (we use an entire episode to calculate the return), **we have significant variance in policy gradient estimation**.
Remember that the policy gradient estimation is **the direction of the steepest increase in return**. Aka, how to update our policy weights so that actions that lead to good returns have a higher probability of being taken. The Monte Carlo variance, which we will further study in this unit, **leads to slower training since we need a lot of samples to mitigate it**.
Today we'll study **Actor-Critic methods**, a hybrid architecture combining a value-based and policy-based methods that help to stabilize the training by reducing the variance:
- *An Actor* that controls **how our agent behaves** (policy-based method)
- *A Critic* that measures **how good the action taken is** (value-based method)
We'll study one of these hybrid methods called Advantage Actor Critic (A2C), **and train our agent using Stable-Baselines3 in robotic environments**. Where we'll train two agents to walk:
- A bipedal walker 🚶
- A spider 🕷️
<img src="https://github.com/huggingface/deep-rl-class/blob/main/unit7/assets/img/pybullet-envs.gif?raw=true" alt="Robotics environments"/>
Sounds exciting? Let's get started!
- [The Problem of Variance in Reinforce](https://huggingface.co/blog/deep-rl-a2c#the-problem-of-variance-in-reinforce)
- [Advantage Actor Critic (A2C)](https://huggingface.co/blog/deep-rl-a2c#advantage-actor-critic-a2c)
- [Reducing variance with Actor-Critic methods](https://huggingface.co/blog/deep-rl-a2c#reducing-variance-with-actor-critic-methods)
- [The Actor-Critic Process](https://huggingface.co/blog/deep-rl-a2c#the-actor-critic-process)
- [Advantage Actor Critic](https://huggingface.co/blog/deep-rl-a2c#advantage-actor-critic-a2c-1)
- [Advantage Actor Critic (A2C) using Robotics Simulations with PyBullet 🤖](https://huggingface.co/blog/deep-rl-a2c#advantage-actor-critic-a2c-using-robotics-simulations-with-pybullet-%F0%9F%A4%96)
## The Problem of Variance in Reinforce
In Reinforce, we want to **increase the probability of actions in a trajectory proportional to how high the return is**.
<img src="https://huggingface.co/blog/assets/85_policy_gradient/pg.jpg" alt="Reinforce"/>
- If the **return is high**, we will **push up** the probabilities of the (state, action) combinations.
- Else, if the **return is low**, it will **push down** the probabilities of the (state, action) combinations.
This return \\(R(\tau)\\) is calculated using a *Monte-Carlo sampling*. Indeed, we collect a trajectory and calculate the discounted return, **and use this score to increase or decrease the probability of every action taken in that trajectory**. If the return is good, all actions will be “reinforced” by increasing their likelihood of being taken.
\\(R(\tau) = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ...\\)
The advantage of this method is that **it’s unbiased. Since we’re not estimating the return**, we use only the true return we obtain.
But the problem is that **the variance is high, since trajectories can lead to different returns** due to stochasticity of the environment (random events during episode) and stochasticity of the policy. Consequently, the same starting state can lead to very different returns.
Because of this, **the return starting at the same state can vary significantly across episodes**.
<img src="assets/89_deep_rl_a2c/variance.jpg" alt="variance"/>
The solution is to mitigate the variance by **using a large number of trajectories, hoping that the variance introduced in any one trajectory will be reduced in aggregate and provide a "true" estimation of the return.**
However, increasing the batch size significantly **reduces sample efficiency**. So we need to find additional mechanisms to reduce the variance.
---
If you want to dive deeper into the question of variance and bias tradeoff in Deep Reinforcement Learning, you can check these two articles:
- [Making Sense of the Bias / Variance Trade-off in (Deep) Reinforcement Learning](https://blog.mlreview.com/making-sense-of-the-bias-variance-trade-off-in-deep-reinforcement-learning-79cf1e83d565)
- [Bias-variance Tradeoff in Reinforcement Learning](https://www.endtoend.ai/blog/bias-variance-tradeoff-in-reinforcement-learning/)
---
## Advantage Actor Critic (A2C)
### Reducing variance with Actor-Critic methods
The solution to reducing the variance of Reinforce algorithm and training our agent faster and better is to use a combination of policy-based and value-based methods: *the Actor-Critic method*.
To understand the Actor-Critic, imagine you play a video game. You can play with a friend that will provide you some feedback. You’re the Actor, and your friend is the Critic.
<img src="assets/89_deep_rl_a2c/ac.jpg" alt="Actor Critic"/>
You don’t know how to play at the beginning, **so you try some actions randomly**. The Critic observes your action and **provides feedback**.
Learning from this feedback, **you’ll update your policy and be better at playing that game.**
On the other hand, your friend (Critic) will also update their way to provide feedback so it can be better next time.
This is the idea behind Actor-Critic. We learn two function approximations:
- *A policy* that **controls how our agent acts**: \\( \pi_{\theta}(s,a) \\)
- *A value function* to assist the policy update by measuring how good the action taken is: \\( \hat{q}_{w}(s,a) \\)
### The Actor-Critic Process
Now that we have seen the Actor Critic's big picture, let's dive deeper to understand how Actor and Critic improve together during the training.
As we saw, with Actor-Critic methods there are two function approximations (two neural networks):
- *Actor*, a **policy function** parameterized by theta: \\( \pi_{\theta}(s,a) \\)
- *Critic*, a **value function** parameterized by w: \\( \hat{q}_{w}(s,a) \\)
Let's see the training process to understand how Actor and Critic are optimized:
- At each timestep, t, we get the current state \\( S_t\\) from the environment and **pass it as input through our Actor and Critic**.
- Our Policy takes the state and **outputs an action** \\( A_t \\).
<img src="assets/89_deep_rl_a2c/step1.jpg" alt="Step 1 Actor Critic"/>
- The Critic takes that action also as input and, using \\( S_t\\) and \\( A_t \\), **computes the value of taking that action at that state: the Q-value**.
<img src="assets/89_deep_rl_a2c/step2.jpg" alt="Step 2 Actor Critic"/>
- The action \\( A_t\\) performed in the environment outputs a new state \\( S_{t+1}\\) and a reward \\( R_{t+1} \\) .
<img src="assets/89_deep_rl_a2c/step3.jpg" alt="Step 3 Actor Critic"/>
- The Actor updates its policy parameters using the Q value.
<img src="assets/89_deep_rl_a2c/step4.jpg" alt="Step 4 Actor Critic"/>
- Thanks to its updated parameters, the Actor produces the next action to take at \\( A_{t+1} \\) given the new state \\( S_{t+1} \\).
- The Critic then updates its value parameters.
<img src="assets/89_deep_rl_a2c/step5.jpg" alt="Step 5 Actor Critic"/>
### Advantage Actor Critic (A2C)
We can stabilize learning further by **using the Advantage function as Critic instead of the Action value function**.
The idea is that the Advantage function calculates **how better taking that action at a state is compared to the average value of the state**. It’s subtracting the mean value of the state from the state action pair:
<img src="assets/89_deep_rl_a2c/advantage1.jpg" alt="Advantage Function"/>
In other words, this function calculates **the extra reward we get if we take this action at that state compared to the mean reward we get at that state**.
The extra reward is what's beyond the expected value of that state.
- If A(s,a) > 0: our gradient is **pushed in that direction**.
- If A(s,a) < 0 (our action does worse than the average value of that state), **our gradient is pushed in the opposite direction**.
The problem with implementing this advantage function is that it requires two value functions — \\( Q(s,a)\\) and \\( V(s)\\). Fortunately, **we can use the TD error as a good estimator of the advantage function.**
<img src="assets/89_deep_rl_a2c/advantage2.jpg" alt="Advantage Function"/>
## Advantage Actor Critic (A2C) using Robotics Simulations with PyBullet 🤖
Now that you've studied the theory behind Advantage Actor Critic (A2C), **you're ready to train your A2C agent** using Stable-Baselines3 in robotic environments.
<img src="https://github.com/huggingface/deep-rl-class/blob/main/unit7/assets/img/pybullet-envs.gif?raw=true" alt="Robotics environments"/>
Start the tutorial here 👉 [https://colab.research.google.com/github/huggingface/deep-rl-class/blob/main/unit7/unit7.ipynb](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/main/unit7/unit7.ipynb)
The leaderboard to compare your results with your classmates 🏆 👉 **[https://huggingface.co/spaces/chrisjay/Deep-Reinforcement-Learning-Leaderboard](https://huggingface.co/spaces/chrisjay/Deep-Reinforcement-Learning-Leaderboard)**
## Conclusion
Congrats on finishing this chapter! There was a lot of information. And congrats on finishing the tutorial. 🥳.
It's **normal if you still feel confused** with all these elements. **This was the same for me and for all people who studied RL.**
Take time to grasp the material before continuing. Look also at the additional reading materials we provided in this article and the syllabus to go deeper 👉 **[https://github.com/huggingface/deep-rl-class/blob/main/unit7/README.md](https://github.com/huggingface/deep-rl-class/blob/main/unit7/README.md)**
Don't hesitate to train your agent in other environments. The **best way to learn is to try things on your own!**
In the next unit, we will learn to improve Actor-Critic Methods with Proximal Policy Optimization.
And don't forget to share with your friends who want to learn 🤗!
Finally, with your feedback, we want **to improve and update the course iteratively**. If you have some, please fill this form 👉 **[https://forms.gle/3HgA7bEHwAmmLfwh9](https://forms.gle/3HgA7bEHwAmmLfwh9)**
### **Keep learning, stay awesome 🤗,**
|
huggingface/blog/blob/main/deep-rl-a2c.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Optimizing LLMs for Speed and Memory
[[open-in-colab]]
Large Language Models (LLMs) such as GPT3/4, [Falcon](https://huggingface.co/tiiuae/falcon-40b), and [Llama](https://huggingface.co/meta-llama/Llama-2-70b-hf) are rapidly advancing in their ability to tackle human-centric tasks, establishing themselves as essential tools in modern knowledge-based industries.
Deploying these models in real-world tasks remains challenging, however:
- To exhibit near-human text understanding and generation capabilities, LLMs currently require to be composed of billions of parameters (see [Kaplan et al](https://arxiv.org/abs/2001.08361), [Wei et. al](https://arxiv.org/abs/2206.07682)). This consequently amplifies the memory demands for inference.
- In many real-world tasks, LLMs need to be given extensive contextual information. This necessitates the model's capability to manage very long input sequences during inference.
The crux of these challenges lies in augmenting the computational and memory capabilities of LLMs, especially when handling expansive input sequences.
In this guide, we will go over the effective techniques for efficient LLM deployment:
1. **Lower Precision:** Research has shown that operating at reduced numerical precision, namely [8-bit and 4-bit](./main_classes/quantization.md) can achieve computational advantages without a considerable decline in model performance.
2. **Flash Attention:** Flash Attention is a variation of the attention algorithm that not only provides a more memory-efficient approach but also realizes increased efficiency due to optimized GPU memory utilization.
3. **Architectural Innovations:** Considering that LLMs are always deployed in the same way during inference, namely autoregressive text generation with a long input context, specialized model architectures have been proposed that allow for more efficient inference. The most important advancement in model architectures hereby are [Alibi](https://arxiv.org/abs/2108.12409), [Rotary embeddings](https://arxiv.org/abs/2104.09864), [Multi-Query Attention (MQA)](https://arxiv.org/abs/1911.02150) and [Grouped-Query-Attention (GQA)]((https://arxiv.org/abs/2305.13245)).
Throughout this guide, we will offer an analysis of auto-regressive generation from a tensor's perspective. We delve into the pros and cons of adopting lower precision, provide a comprehensive exploration of the latest attention algorithms, and discuss improved LLM architectures. While doing so, we run practical examples showcasing each of the feature improvements.
## 1. Lower Precision
Memory requirements of LLMs can be best understood by seeing the LLM as a set of weight matrices and vectors and the text inputs as a sequence of vectors. In the following, the definition *weights* will be used to signify all model weight matrices and vectors.
At the time of writing this guide, LLMs consist of at least a couple billion parameters. Each parameter thereby is made of a decimal number, e.g. `4.5689` which is usually stored in either [float32](https://en.wikipedia.org/wiki/Single-precision_floating-point_format), [bfloat16](https://en.wikipedia.org/wiki/Bfloat16_floating-point_format), or [float16](https://en.wikipedia.org/wiki/Half-precision_floating-point_format) format. This allows us to easily compute the memory requirement to load the LLM into memory:
> *Loading the weights of a model having X billion parameters requires roughly 4 * X GB of VRAM in float32 precision*
Nowadays, models are however rarely trained in full float32 precision, but usually in bfloat16 precision or less frequently in float16 precision. Therefore the rule of thumb becomes:
> *Loading the weights of a model having X billion parameters requires roughly 2 * X GB of VRAM in bfloat16/float16 precision*
For shorter text inputs (less than 1024 tokens), the memory requirement for inference is very much dominated by the memory requirement to load the weights. Therefore, for now, let's assume that the memory requirement for inference is equal to the memory requirement to load the model into the GPU VRAM.
To give some examples of how much VRAM it roughly takes to load a model in bfloat16:
- **GPT3** requires 2 \* 175 GB = **350 GB** VRAM
- [**Bloom**](https://huggingface.co/bigscience/bloom) requires 2 \* 176 GB = **352 GB** VRAM
- [**Llama-2-70b**](https://huggingface.co/meta-llama/Llama-2-70b-hf) requires 2 \* 70 GB = **140 GB** VRAM
- [**Falcon-40b**](https://huggingface.co/tiiuae/falcon-40b) requires 2 \* 40 GB = **80 GB** VRAM
- [**MPT-30b**](https://huggingface.co/mosaicml/mpt-30b) requires 2 \* 30 GB = **60 GB** VRAM
- [**bigcode/starcoder**](https://huggingface.co/bigcode/starcoder) requires 2 \* 15.5 = **31 GB** VRAM
As of writing this document, the largest GPU chip on the market is the A100 & H100 offering 80GB of VRAM. Most of the models listed before require more than 80GB just to be loaded and therefore necessarily require [tensor parallelism](https://huggingface.co/docs/transformers/perf_train_gpu_many#tensor-parallelism) and/or [pipeline parallelism](https://huggingface.co/docs/transformers/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism).
🤗 Transformers does not support tensor parallelism out of the box as it requires the model architecture to be written in a specific way. If you're interested in writing models in a tensor-parallelism-friendly way, feel free to have a look at [the text-generation-inference library](https://github.com/huggingface/text-generation-inference/tree/main/server/text_generation_server/models/custom_modeling).
Naive pipeline parallelism is supported out of the box. For this, simply load the model with `device="auto"` which will automatically place the different layers on the available GPUs as explained [here](https://huggingface.co/docs/accelerate/v0.22.0/en/concept_guides/big_model_inference).
Note, however that while very effective, this naive pipeline parallelism does not tackle the issues of GPU idling. For this more advanced pipeline parallelism is required as explained [here](https://huggingface.co/docs/transformers/en/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism).
If you have access to an 8 x 80GB A100 node, you could load BLOOM as follows
```bash
!pip install transformers accelerate bitsandbytes optimum
```
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("bigscience/bloom", device_map="auto", pad_token_id=0)
```
By using `device_map="auto"` the attention layers would be equally distributed over all available GPUs.
In this guide, we will use [bigcode/octocoder](https://huggingface.co/bigcode/octocoder) as it can be run on a single 40 GB A100 GPU device chip. Note that all memory and speed optimizations that we will apply going forward, are equally applicable to models that require model or tensor parallelism.
Since the model is loaded in bfloat16 precision, using our rule of thumb above, we would expect the memory requirement to run inference with `bigcode/octocoder` to be around 31 GB VRAM. Let's give it a try.
We first load the model and tokenizer and then pass both to Transformers' [pipeline](https://huggingface.co/docs/transformers/main_classes/pipelines) object.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
import torch
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto", pad_token_id=0)
tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
```
```python
prompt = "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer:"
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result
```
**Output**:
```
Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single
```
Nice, we can now directly use the result to convert bytes into Gigabytes.
```python
def bytes_to_giga_bytes(bytes):
return bytes / 1024 / 1024 / 1024
```
Let's call [`torch.cuda.max_memory_allocated`](https://pytorch.org/docs/stable/generated/torch.cuda.max_memory_allocated.html) to measure the peak GPU memory allocation.
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**Output**:
```bash
29.0260648727417
```
Close enough to our back-of-the-envelope computation! We can see the number is not exactly correct as going from bytes to kilobytes requires a multiplication of 1024 instead of 1000. Therefore the back-of-the-envelope formula can also be understood as an "at most X GB" computation.
Note that if we had tried to run the model in full float32 precision, a whopping 64 GB of VRAM would have been required.
> Almost all models are trained in bfloat16 nowadays, there is no reason to run the model in full float32 precision if [your GPU supports bfloat16](https://discuss.pytorch.org/t/bfloat16-native-support/117155/5). Float32 won't give better inference results than the precision that was used to train the model.
If you are unsure in which format the model weights are stored on the Hub, you can always look into the checkpoint's config under `"torch_dtype"`, *e.g.* [here](https://huggingface.co/meta-llama/Llama-2-7b-hf/blob/6fdf2e60f86ff2481f2241aaee459f85b5b0bbb9/config.json#L21). It is recommended to set the model to the same precision type as written in the config when loading with `from_pretrained(..., torch_dtype=...)` except when the original type is float32 in which case one can use both `float16` or `bfloat16` for inference.
Let's define a `flush(...)` function to free all allocated memory so that we can accurately measure the peak allocated GPU memory.
```python
del pipe
del model
import gc
import torch
def flush():
gc.collect()
torch.cuda.empty_cache()
torch.cuda.reset_peak_memory_stats()
```
Let's call it now for the next experiment.
```python
flush()
```
In the recent version of the accelerate library, you can also use an utility method called `release_memory()`
```python
from accelerate.utils import release_memory
# ...
release_memory(model)
```
Now what if your GPU does not have 32 GB of VRAM? It has been found that model weights can be quantized to 8-bit or 4-bits without a significant loss in performance (see [Dettmers et al.](https://arxiv.org/abs/2208.07339)).
Model can be quantized to even 3 or 2 bits with an acceptable loss in performance as shown in the recent [GPTQ paper](https://arxiv.org/abs/2210.17323) 🤯.
Without going into too many details, quantization schemes aim at reducing the precision of weights while trying to keep the model's inference results as accurate as possible (*a.k.a* as close as possible to bfloat16).
Note that quantization works especially well for text generation since all we care about is choosing the *set of most likely next tokens* and don't really care about the exact values of the next token *logit* distribution.
All that matters is that the next token *logit* distribution stays roughly the same so that an `argmax` or `topk` operation gives the same results.
There are various quantization techniques, which we won't discuss in detail here, but in general, all quantization techniques work as follows:
- 1. Quantize all weights to the target precision
- 2. Load the quantized weights, and pass the input sequence of vectors in bfloat16 precision
- 3. Dynamically dequantize weights to bfloat16 to perform the computation with their input vectors in bfloat16 precision
In a nutshell, this means that *inputs-weight matrix* multiplications, with \\( X \\) being the *inputs*, \\( W \\) being a weight matrix and \\( Y \\) being the output:
$$ Y = X * W $$
are changed to
$$ Y = X * \text{dequantize}(W) $$
for every matrix multiplication. Dequantization and re-quantization is performed sequentially for all weight matrices as the inputs run through the network graph.
Therefore, inference time is often **not** reduced when using quantized weights, but rather increases.
Enough theory, let's give it a try! To quantize the weights with Transformers, you need to make sure that
the [`bitsandbytes`](https://github.com/TimDettmers/bitsandbytes) library is installed.
```bash
!pip install bitsandbytes
```
We can then load models in 8-bit quantization by simply adding a `load_in_8bit=True` flag to `from_pretrained`.
```python
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_8bit=True, pad_token_id=0)
```
Now, let's run our example again and measure the memory usage.
```python
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result
```
**Output**:
```
Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single
```
Nice, we're getting the same result as before, so no loss in accuracy! Let's look at how much memory was used this time.
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**Output**:
```
15.219234466552734
```
Significantly less! We're down to just a bit over 15 GBs and could therefore run this model on consumer GPUs like the 4090.
We're seeing a very nice gain in memory efficiency and more or less no degradation to the model's output. However, we can also notice a slight slow-down during inference.
We delete the models and flush the memory again.
```python
del model
del pipe
```
```python
flush()
```
Let's see what peak GPU memory consumption 4-bit quantization gives. Quantizing the model to 4-bit can be done with the same API as before - this time by passing `load_in_4bit=True` instead of `load_in_8bit=True`.
```python
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_4bit=True, low_cpu_mem_usage=True, pad_token_id=0)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result
```
**Output**:
```
Here is a Python function that transforms bytes to Giga bytes:\n\n```\ndef bytes_to_gigabytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single argument
```
We're almost seeing the same output text as before - just the `python` is missing just before the code snippet. Let's see how much memory was required.
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**Output**:
```
9.543574333190918
```
Just 9.5GB! That's really not a lot for a >15 billion parameter model.
While we see very little degradation in accuracy for our model here, 4-bit quantization can in practice often lead to different results compared to 8-bit quantization or full `bfloat16` inference. It is up to the user to try it out.
Also note that inference here was again a bit slower compared to 8-bit quantization which is due to the more aggressive quantization method used for 4-bit quantization leading to \\( \text{quantize} \\) and \\( \text{dequantize} \\) taking longer during inference.
```python
del model
del pipe
```
```python
flush()
```
Overall, we saw that running OctoCoder in 8-bit precision reduced the required GPU VRAM from 32G GPU VRAM to only 15GB and running the model in 4-bit precision further reduces the required GPU VRAM to just a bit over 9GB.
4-bit quantization allows the model to be run on GPUs such as RTX3090, V100, and T4 which are quite accessible for most people.
For more information on quantization and to see how one can quantize models to require even less GPU VRAM memory than 4-bit, we recommend looking into the [`AutoGPTQ`](https://huggingface.co/docs/transformers/main/en/main_classes/quantization#autogptq-integration%60) implementation.
> As a conclusion, it is important to remember that model quantization trades improved memory efficiency against accuracy and in some cases inference time.
If GPU memory is not a constraint for your use case, there is often no need to look into quantization. However many GPUs simply can't run LLMs without quantization methods and in this case, 4-bit and 8-bit quantization schemes are extremely useful tools.
For more in-detail usage information, we strongly recommend taking a look at the [Transformers Quantization Docs](https://huggingface.co/docs/transformers/main_classes/quantization#general-usage).
Next, let's look into how we can improve computational and memory efficiency by using better algorithms and an improved model architecture.
## 2. Flash Attention
Today's top-performing LLMs share more or less the same fundamental architecture that consists of feed-forward layers, activation layers, layer normalization layers, and most crucially, self-attention layers.
Self-attention layers are central to Large Language Models (LLMs) in that they enable the model to understand the contextual relationships between input tokens.
However, the peak GPU memory consumption for self-attention layers grows *quadratically* both in compute and memory complexity with number of input tokens (also called *sequence length*) that we denote in the following by \\( N \\) .
While this is not really noticeable for shorter input sequences (of up to 1000 input tokens), it becomes a serious problem for longer input sequences (at around 16000 input tokens).
Let's take a closer look. The formula to compute the output \\( \mathbf{O} \\) of a self-attention layer for an input \\( \mathbf{X} \\) of length \\( N \\) is:
$$ \textbf{O} = \text{Attn}(\mathbf{X}) = \mathbf{V} \times \text{Softmax}(\mathbf{QK}^T) \text{ with } \mathbf{Q} = \mathbf{W}_q \mathbf{X}, \mathbf{V} = \mathbf{W}_v \mathbf{X}, \mathbf{K} = \mathbf{W}_k \mathbf{X} $$
\\( \mathbf{X} = (\mathbf{x}_1, ... \mathbf{x}_{N}) \\) is thereby the input sequence to the attention layer. The projections \\( \mathbf{Q} \\) and \\( \mathbf{K} \\) will each consist of \\( N \\) vectors resulting in the \\( \mathbf{QK}^T \\) being of size \\( N^2 \\) .
LLMs usually have multiple attention heads, thus doing multiple self-attention computations in parallel.
Assuming, the LLM has 40 attention heads and runs in bfloat16 precision, we can calculate the memory requirement to store the \\( \mathbf{QK^T} \\) matrices to be \\( 40 * 2 * N^2 \\) bytes. For \\( N=1000 \\) only around 50 MB of VRAM are needed, however, for \\( N=16000 \\) we would need 19 GB of VRAM, and for \\( N=100,000 \\) we would need almost 1TB just to store the \\( \mathbf{QK}^T \\) matrices.
Long story short, the default self-attention algorithm quickly becomes prohibitively memory-expensive for large input contexts.
As LLMs improve in text comprehension and generation, they are applied to increasingly complex tasks. While models once handled the translation or summarization of a few sentences, they now manage entire pages, demanding the capability to process extensive input lengths.
How can we get rid of the exorbitant memory requirements for large input lengths? We need a new way to compute the self-attention mechanism that gets rid of the \\( QK^T \\) matrix. [Tri Dao et al.](https://arxiv.org/abs/2205.14135) developed exactly such a new algorithm and called it **Flash Attention**.
In a nutshell, Flash Attention breaks the \\(\mathbf{V} \times \text{Softmax}(\mathbf{QK}^T\\)) computation apart and instead computes smaller chunks of the output by iterating over multiple softmax computation steps:
$$ \textbf{O}_i \leftarrow s^a_{ij} * \textbf{O}_i + s^b_{ij} * \mathbf{V}_{j} \times \text{Softmax}(\mathbf{QK}^T_{i,j}) \text{ for multiple } i, j \text{ iterations} $$
with \\( s^a_{ij} \\) and \\( s^b_{ij} \\) being some softmax normalization statistics that need to be recomputed for every \\( i \\) and \\( j \\) .
Please note that the whole Flash Attention is a bit more complex and is greatly simplified here as going in too much depth is out of scope for this guide. The reader is invited to take a look at the well-written [Flash Attention paper](https://arxiv.org/abs/2205.14135) for more details.
The main takeaway here is:
> By keeping track of softmax normalization statistics and by using some smart mathematics, Flash Attention gives **numerical identical** outputs compared to the default self-attention layer at a memory cost that only increases linearly with \\( N \\) .
Looking at the formula, one would intuitively say that Flash Attention must be much slower compared to the default self-attention formula as more computation needs to be done. Indeed Flash Attention requires more FLOPs compared to normal attention as the softmax normalization statistics have to constantly be recomputed (see [paper](https://arxiv.org/abs/2205.14135) for more details if interested)
> However, Flash Attention is much faster in inference compared to default attention which comes from its ability to significantly reduce the demands on the slower, high-bandwidth memory of the GPU (VRAM), focusing instead on the faster on-chip memory (SRAM).
Essentially, Flash Attention makes sure that all intermediate write and read operations can be done using the fast *on-chip* SRAM memory instead of having to access the slower VRAM memory to compute the output vector \\( \mathbf{O} \\) .
In practice, there is currently absolutely no reason to **not** use Flash Attention if available. The algorithm gives mathematically the same outputs, and is both faster and more memory-efficient.
Let's look at a practical example.
Our OctoCoder model now gets a significantly longer input prompt which includes a so-called *system prompt*. System prompts are used to steer the LLM into a better assistant that is tailored to the users' task.
In the following, we use a system prompt that will make OctoCoder a better coding assistant.
```python
system_prompt = """Below are a series of dialogues between various people and an AI technical assistant.
The assistant tries to be helpful, polite, honest, sophisticated, emotionally aware, and humble but knowledgeable.
The assistant is happy to help with code questions and will do their best to understand exactly what is needed.
It also tries to avoid giving false or misleading information, and it caveats when it isn't entirely sure about the right answer.
That said, the assistant is practical really does its best, and doesn't let caution get too much in the way of being useful.
The Starcoder models are a series of 15.5B parameter models trained on 80+ programming languages from The Stack (v1.2) (excluding opt-out requests).
The model uses Multi Query Attention, was trained using the Fill-in-the-Middle objective, and with 8,192 tokens context window for a trillion tokens of heavily deduplicated data.
-----
Question: Write a function that takes two lists and returns a list that has alternating elements from each input list.
Answer: Sure. Here is a function that does that.
def alternating(list1, list2):
results = []
for i in range(len(list1)):
results.append(list1[i])
results.append(list2[i])
return results
Question: Can you write some test cases for this function?
Answer: Sure, here are some tests.
assert alternating([10, 20, 30], [1, 2, 3]) == [10, 1, 20, 2, 30, 3]
assert alternating([True, False], [4, 5]) == [True, 4, False, 5]
assert alternating([], []) == []
Question: Modify the function so that it returns all input elements when the lists have uneven length. The elements from the longer list should be at the end.
Answer: Here is the modified function.
def alternating(list1, list2):
results = []
for i in range(min(len(list1), len(list2))):
results.append(list1[i])
results.append(list2[i])
if len(list1) > len(list2):
results.extend(list1[i+1:])
else:
results.extend(list2[i+1:])
return results
-----
"""
```
For demonstration purposes, we duplicate the system prompt by ten so that the input length is long enough to observe Flash Attention's memory savings.
We append the original text prompt `"Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here"`
```python
long_prompt = 10 * system_prompt + prompt
```
We instantiate our model again in bfloat16 precision.
```python
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
```
Let's now run the model just like before *without Flash Attention* and measure the peak GPU memory requirement and inference time.
```python
import time
start_time = time.time()
result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
print(f"Generated in {time.time() - start_time} seconds.")
result
```
**Output**:
```
Generated in 10.96854019165039 seconds.
Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndef
````
We're getting the same output as before, however this time, the model repeats the answer multiple times until it's 60 tokens cut-off. This is not surprising as we've repeated the system prompt ten times for demonstration purposes and thus cued the model to repeat itself.
**Note** that the system prompt should not be repeated ten times in real-world applications - one time is enough!
Let's measure the peak GPU memory requirement.
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**Output**:
```bash
37.668193340301514
```
As we can see the peak GPU memory requirement is now significantly higher than in the beginning, which is largely due to the longer input sequence. Also the generation takes a little over a minute now.
We call `flush()` to free GPU memory for our next experiment.
```python
flush()
```
For comparison, let's run the same function, but enable Flash Attention instead.
To do so, we convert the model to [BetterTransformer](https://huggingface.co/docs/optimum/bettertransformer/overview) and by doing so enabling PyTorch's [SDPA self-attention](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention) which in turn is able to use Flash Attention.
```python
model.to_bettertransformer()
```
Now we run the exact same code snippet as before and under the hood Transformers will make use of Flash Attention.
```py
start_time = time.time()
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
print(f"Generated in {time.time() - start_time} seconds.")
result
```
**Output**:
```
Generated in 3.0211617946624756 seconds.
Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndef
```
We're getting the exact same result as before, but can observe a very significant speed-up thanks to Flash Attention.
Let's measure the memory consumption one last time.
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**Output**:
```
32.617331981658936
```
And we're almost back to our original 29GB peak GPU memory from the beginning.
We can observe that we only use roughly 100MB more GPU memory when passing a very long input sequence with Flash Attention compared to passing a short input sequence as done in the beginning.
```py
flush()
```
For more information on how to use Flash Attention, please have a look at [this doc page](https://huggingface.co/docs/transformers/en/perf_infer_gpu_one#flashattention-2).
## 3. Architectural Innovations
So far we have looked into improving computational and memory efficiency by:
- Casting the weights to a lower precision format
- Replacing the self-attention algorithm with a more memory- and compute efficient version
Let's now look into how we can change the architecture of an LLM so that it is most effective and efficient for task that require long text inputs, *e.g.*:
- Retrieval augmented Questions Answering,
- Summarization,
- Chat
Note that *chat* not only requires the LLM to handle long text inputs, but it also necessitates that the LLM is able to efficiently handle the back-and-forth dialogue between user and assistant (such as ChatGPT).
Once trained, the fundamental LLM architecture is difficult to change, so it is important to make considerations about the LLM's tasks beforehand and accordingly optimize the model's architecture.
There are two important components of the model architecture that quickly become memory and/or performance bottlenecks for large input sequences.
- The positional embeddings
- The key-value cache
Let's go over each component in more detail
### 3.1 Improving positional embeddings of LLMs
Self-attention puts each token in relation to each other's tokens.
As an example, the \\( \text{Softmax}(\mathbf{QK}^T) \\) matrix of the text input sequence *"Hello", "I", "love", "you"* could look as follows:
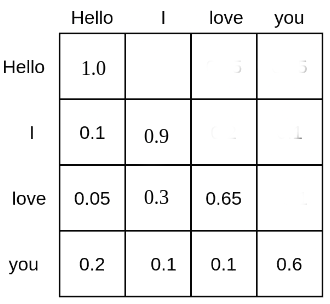
Each word token is given a probability mass at which it attends all other word tokens and, therefore is put into relation with all other word tokens. E.g. the word *"love"* attends to the word *"Hello"* with 5%, to *"I"* with 30%, and to itself with 65%.
A LLM based on self-attention, but without position embeddings would have great difficulties in understanding the positions of the text inputs to each other.
This is because the probability score computed by \\( \mathbf{QK}^T \\) relates each word token to each other word token in \\( O(1) \\) computations regardless of their relative positional distance to each other.
Therefore, for the LLM without position embeddings each token appears to have the same distance to all other tokens, *e.g.* differentiating between *"Hello I love you"* and *"You love I hello"* would be very challenging.
For the LLM to understand sentence order, an additional *cue* is needed and is usually applied in the form of *positional encodings* (or also called *positional embeddings*).
Positional encodings, encode the position of each token into a numerical presentation that the LLM can leverage to better understand sentence order.
The authors of the [*Attention Is All You Need*](https://arxiv.org/abs/1706.03762) paper introduced sinusoidal positional embeddings \\( \mathbf{P} = \mathbf{p}_1, \ldots, \mathbf{p}_N \\) .
where each vector \\( \mathbf{p}_i \\) is computed as a sinusoidal function of its position \\( i \\) .
The positional encodings are then simply added to the input sequence vectors \\( \mathbf{\hat{X}} = \mathbf{\hat{x}}_1, \ldots, \mathbf{\hat{x}}_N \\) = \\( \mathbf{x}_1 + \mathbf{p}_1, \ldots, \mathbf{x}_N + \mathbf{p}_N \\) thereby cueing the model to better learn sentence order.
Instead of using fixed position embeddings, others (such as [Devlin et al.](https://arxiv.org/abs/1810.04805)) used learned positional encodings for which the positional embeddings
\\( \mathbf{P} \\) are learned during training.
Sinusoidal and learned position embeddings used to be the predominant methods to encode sentence order into LLMs, but a couple of problems related to these positional encodings were found:
1. Sinusoidal and learned position embeddings are both absolute positional embeddings, *i.e.* encoding a unique embedding for each position id: \\( 0, \ldots, N \\) . As shown by [Huang et al.](https://arxiv.org/abs/2009.13658) and [Su et al.](https://arxiv.org/abs/2104.09864), absolute positional embeddings lead to poor LLM performance for long text inputs. For long text inputs, it is advantageous if the model learns the relative positional distance input tokens have to each other instead of their absolute position.
2. When using learned position embeddings, the LLM has to be trained on a fixed input length \\( N \\), which makes it difficult to extrapolate to an input length longer than what it was trained on.
Recently, relative positional embeddings that can tackle the above mentioned problems have become more popular, most notably:
- [Rotary Position Embedding (RoPE)](https://arxiv.org/abs/2104.09864)
- [ALiBi](https://arxiv.org/abs/2108.12409)
Both *RoPE* and *ALiBi* argue that it's best to cue the LLM about sentence order directly in the self-attention algorithm as it's there that word tokens are put into relation with each other. More specifically, sentence order should be cued by modifying the \\( \mathbf{QK}^T \\) computation.
Without going into too many details, *RoPE* notes that positional information can be encoded into query-key pairs, *e.g.* \\( \mathbf{q}_i \\) and \\( \mathbf{x}_j \\) by rotating each vector by an angle \\( \theta * i \\) and \\( \theta * j \\) respectively with \\( i, j \\) describing each vectors sentence position:
$$ \mathbf{\hat{q}}_i^T \mathbf{\hat{x}}_j = \mathbf{{q}}_i^T \mathbf{R}_{\theta, i -j} \mathbf{{x}}_j. $$
\\( \mathbf{R}_{\theta, i - j} \\) thereby represents a rotational matrix. \\( \theta \\) is *not* learned during training, but instead set to a pre-defined value that depends on the maximum input sequence length during training.
> By doing so, the propability score between \\( \mathbf{q}_i \\) and \\( \mathbf{q}_j \\) is only affected if \\( i \ne j \\) and solely depends on the relative distance \\( i - j \\) regardless of each vector's specific positions \\( i \\) and \\( j \\) .
*RoPE* is used in multiple of today's most important LLMs, such as:
- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
- [**Llama**](https://arxiv.org/abs/2302.13971)
- [**PaLM**](https://arxiv.org/abs/2204.02311)
As an alternative, *ALiBi* proposes a much simpler relative position encoding scheme. The relative distance that input tokens have to each other is added as a negative integer scaled by a pre-defined value `m` to each query-key entry of the \\( \mathbf{QK}^T \\) matrix right before the softmax computation.
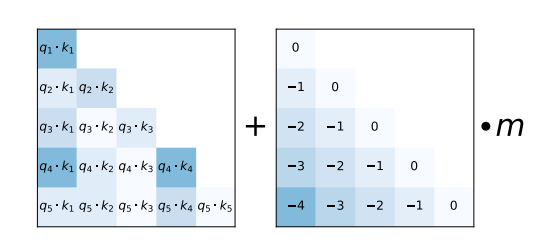
As shown in the [ALiBi](https://arxiv.org/abs/2108.12409) paper, this simple relative positional encoding allows the model to retain a high performance even at very long text input sequences.
*ALiBi* is used in multiple of today's most important LLMs, such as:
- [**MPT**](https://huggingface.co/mosaicml/mpt-30b)
- [**BLOOM**](https://huggingface.co/bigscience/bloom)
Both *RoPE* and *ALiBi* position encodings can extrapolate to input lengths not seen during training whereas it has been shown that extrapolation works much better out-of-the-box for *ALiBi* as compared to *RoPE*.
For ALiBi, one simply increases the values of the lower triangular position matrix to match the length of the input sequence.
For *RoPE*, keeping the same \\( \theta \\) that was used during training leads to poor results when passing text inputs much longer than those seen during training, *c.f* [Press et al.](https://arxiv.org/abs/2108.12409). However, the community has found a couple of effective tricks that adapt \\( \theta \\), thereby allowing *RoPE* position embeddings to work well for extrapolated text input sequences (see [here](https://github.com/huggingface/transformers/pull/24653)).
> Both RoPE and ALiBi are relative positional embeddings that are *not* learned during training, but instead are based on the following intuitions:
- Positional cues about the text inputs should be given directly to the \\( QK^T \\) matrix of the self-attention layer
- The LLM should be incentivized to learn a constant *relative* distance positional encodings have to each other
- The further text input tokens are from each other, the lower the probability of their query-value probability. Both RoPE and ALiBi lower the query-key probability of tokens far away from each other. RoPE by decreasing their vector product by increasing the angle between the query-key vectors. ALiBi by adding large negative numbers to the vector product
In conclusion, LLMs that are intended to be deployed in tasks that require handling large text inputs are better trained with relative positional embeddings, such as RoPE and ALiBi. Also note that even if an LLM with RoPE and ALiBi has been trained only on a fixed length of say \\( N_1 = 2048 \\) it can still be used in practice with text inputs much larger than \\( N_1 \\), like \\( N_2 = 8192 > N_1 \\) by extrapolating the positional embeddings.
### 3.2 The key-value cache
Auto-regressive text generation with LLMs works by iteratively putting in an input sequence, sampling the next token, appending the next token to the input sequence, and continuing to do so until the LLM produces a token that signifies that the generation has finished.
Please have a look at [Transformer's Generate Text Tutorial](https://huggingface.co/docs/transformers/llm_tutorial#generate-text) to get a more visual explanation of how auto-regressive generation works.
Let's run a quick code snippet to show how auto-regressive works in practice. We will simply take the most likely next token via `torch.argmax`.
```python
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
next_logits = model(input_ids)["logits"][:, -1:]
next_token_id = torch.argmax(next_logits,dim=-1)
input_ids = torch.cat([input_ids, next_token_id], dim=-1)
print("shape of input_ids", input_ids.shape)
generated_text = tokenizer.batch_decode(input_ids[:, -5:])
generated_text
```
**Output**:
```
shape of input_ids torch.Size([1, 21])
shape of input_ids torch.Size([1, 22])
shape of input_ids torch.Size([1, 23])
shape of input_ids torch.Size([1, 24])
shape of input_ids torch.Size([1, 25])
[' Here is a Python function']
```
As we can see every time we increase the text input tokens by the just sampled token.
With very few exceptions, LLMs are trained using the [causal language modeling objective](https://huggingface.co/docs/transformers/tasks/language_modeling#causal-language-modeling) and therefore mask the upper triangle matrix of the attention score - this is why in the two diagrams above the attention scores are left blank (*a.k.a* have 0 probability). For a quick recap on causal language modeling you can refer to the [*Illustrated Self Attention blog*](https://jalammar.github.io/illustrated-gpt2/#part-2-illustrated-self-attention).
As a consequence, tokens *never* depend on previous tokens, more specifically the \\( \mathbf{q}_i \\) vector is never put in relation with any key, values vectors \\( \mathbf{k}_j, \mathbf{v}_j \\) if \\( j > i \\) . Instead \\( \mathbf{q}_i \\) only attends to previous key-value vectors \\( \mathbf{k}_{m < i}, \mathbf{v}_{m < i} \text{ , for } m \in \{0, \ldots i - 1\} \\). In order to reduce unnecessary computation, one can therefore cache each layer's key-value vectors for all previous timesteps.
In the following, we will tell the LLM to make use of the key-value cache by retrieving and forwarding it for each forward pass.
In Transformers, we can retrieve the key-value cache by passing the `use_cache` flag to the `forward` call and can then pass it with the current token.
```python
past_key_values = None # past_key_values is the key-value cache
generated_tokens = []
next_token_id = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
next_logits, past_key_values = model(next_token_id, past_key_values=past_key_values, use_cache=True).to_tuple()
next_logits = next_logits[:, -1:]
next_token_id = torch.argmax(next_logits, dim=-1)
print("shape of input_ids", next_token_id.shape)
print("length of key-value cache", len(past_key_values[0][0])) # past_key_values are of shape [num_layers, 0 for k, 1 for v, batch_size, length, hidden_dim]
generated_tokens.append(next_token_id.item())
generated_text = tokenizer.batch_decode(generated_tokens)
generated_text
```
**Output**:
```
shape of input_ids torch.Size([1, 1])
length of key-value cache 20
shape of input_ids torch.Size([1, 1])
length of key-value cache 21
shape of input_ids torch.Size([1, 1])
length of key-value cache 22
shape of input_ids torch.Size([1, 1])
length of key-value cache 23
shape of input_ids torch.Size([1, 1])
length of key-value cache 24
[' Here', ' is', ' a', ' Python', ' function']
```
As one can see, when using the key-value cache the text input tokens are *not* increased in length, but remain a single input vector. The length of the key-value cache on the other hand is increased by one at every decoding step.
> Making use of the key-value cache means that the \\( \mathbf{QK}^T \\) is essentially reduced to \\( \mathbf{q}_c\mathbf{K}^T \\) with \\( \mathbf{q}_c \\) being the query projection of the currently passed input token which is *always* just a single vector.
Using the key-value cache has two advantages:
- Significant increase in computational efficiency as less computations are performed compared to computing the full \\( \mathbf{QK}^T \\) matrix. This leads to an increase in inference speed
- The maximum required memory is not increased quadratically with the number of generated tokens, but only increases linearly.
> One should *always* make use of the key-value cache as it leads to identical results and a significant speed-up for longer input sequences. Transformers has the key-value cache enabled by default when making use of the text pipeline or the [`generate` method](https://huggingface.co/docs/transformers/main_classes/text_generation).
<Tip warning={true}>
Note that, despite our advice to use key-value caches, your LLM output may be slightly different when you use them. This is a property of the matrix multiplication kernels themselves -- you can read more about it [here](https://github.com/huggingface/transformers/issues/25420#issuecomment-1775317535).
</Tip>
#### 3.2.1 Multi-round conversation
The key-value cache is especially useful for applications such as chat where multiple passes of auto-regressive decoding are required. Let's look at an example.
```
User: How many people live in France?
Assistant: Roughly 75 million people live in France
User: And how many are in Germany?
Assistant: Germany has ca. 81 million inhabitants
```
In this chat, the LLM runs auto-regressive decoding twice:
1. The first time, the key-value cache is empty and the input prompt is `"User: How many people live in France?"` and the model auto-regressively generates the text `"Roughly 75 million people live in France"` while increasing the key-value cache at every decoding step.
2. The second time the input prompt is `"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many in Germany?"`. Thanks to the cache, all key-value vectors for the first two sentences are already computed. Therefore the input prompt only consists of `"User: And how many in Germany?"`. While processing the shortened input prompt, it's computed key-value vectors are concatenated to the key-value cache of the first decoding. The second Assistant's answer `"Germany has ca. 81 million inhabitants"` is then auto-regressively generated with the key-value cache consisting of encoded key-value vectors of `"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many are in Germany?"`.
Two things should be noted here:
1. Keeping all the context is crucial for LLMs deployed in chat so that the LLM understands all the previous context of the conversation. E.g. for the example above the LLM needs to understand that the user refers to the population when asking `"And how many are in Germany"`.
2. The key-value cache is extremely useful for chat as it allows us to continuously grow the encoded chat history instead of having to re-encode the chat history again from scratch (as e.g. would be the case when using an encoder-decoder architecture).
In `transformers`, a `generate` call will return `past_key_values` when `return_dict_in_generate=True` is passed, in addition to the default `use_cache=True`. Note that it is not yet available through the `pipeline` interface.
```python
# Generation as usual
prompt = system_prompt + "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here"
model_inputs = tokenizer(prompt, return_tensors='pt')
generation_output = model.generate(**model_inputs, max_new_tokens=60, return_dict_in_generate=True)
decoded_output = tokenizer.batch_decode(generation_output.sequences)[0]
# Piping the returned `past_key_values` to speed up the next conversation round
prompt = decoded_output + "\nQuestion: How can I modify the function above to return Mega bytes instead?\n\nAnswer: Here"
model_inputs = tokenizer(prompt, return_tensors='pt')
generation_output = model.generate(
**model_inputs,
past_key_values=generation_output.past_key_values,
max_new_tokens=60,
return_dict_in_generate=True
)
tokenizer.batch_decode(generation_output.sequences)[0][len(prompt):]
```
**Output**:
```
is a modified version of the function that returns Mega bytes instead.
def bytes_to_megabytes(bytes):
return bytes / 1024 / 1024
Answer: The function takes a number of bytes as input and returns the number of
```
Great, no additional time is spent recomputing the same key and values for the attention layer! There is however one catch. While the required peak memory for the \\( \mathbf{QK}^T \\) matrix is significantly reduced, holding the key-value cache in memory can become very memory expensive for long input sequences or multi-turn chat. Remember that the key-value cache needs to store the key-value vectors for all previous input vectors \\( \mathbf{x}_i \text{, for } i \in \{1, \ldots, c - 1\} \\) for all self-attention layers and for all attention heads.
Let's compute the number of float values that need to be stored in the key-value cache for the LLM `bigcode/octocoder` that we used before.
The number of float values amounts to two times the sequence length times the number of attention heads times the attention head dimension and times the number of layers.
Computing this for our LLM at a hypothetical input sequence length of 16000 gives:
```python
config = model.config
2 * 16_000 * config.n_layer * config.n_head * config.n_embd // config.n_head
```
**Output**:
```
7864320000
```
Roughly 8 billion float values! Storing 8 billion float values in `float16` precision requires around 15 GB of RAM which is circa half as much as the model weights themselves!
Researchers have proposed two methods that allow to significantly reduce the memory cost of storing the key-value cache, which are explored in the next subsections.
#### 3.2.2 Multi-Query-Attention (MQA)
[Multi-Query-Attention](https://arxiv.org/abs/1911.02150) was proposed in Noam Shazeer's *Fast Transformer Decoding: One Write-Head is All You Need* paper. As the title says, Noam found out that instead of using `n_head` key-value projections weights, one can use a single head-value projection weight pair that is shared across all attention heads without that the model's performance significantly degrades.
> By using a single head-value projection weight pair, the key value vectors \\( \mathbf{k}_i, \mathbf{v}_i \\) have to be identical across all attention heads which in turn means that we only need to store 1 key-value projection pair in the cache instead of `n_head` ones.
As most LLMs use between 20 and 100 attention heads, MQA significantly reduces the memory consumption of the key-value cache. For the LLM used in this notebook we could therefore reduce the required memory consumption from 15 GB to less than 400 MB at an input sequence length of 16000.
In addition to memory savings, MQA also leads to improved computational efficiency as explained in the following.
In auto-regressive decoding, large key-value vectors need to be reloaded, concatenated with the current key-value vector pair to be then fed into the \\( \mathbf{q}_c\mathbf{K}^T \\) computation at every step. For auto-regressive decoding, the required memory bandwidth for the constant reloading can become a serious time bottleneck. By reducing the size of the key-value vectors less memory needs to be accessed, thus reducing the memory bandwidth bottleneck. For more detail, please have a look at [Noam's paper](https://arxiv.org/abs/1911.02150).
The important part to understand here is that reducing the number of key-value attention heads to 1 only makes sense if a key-value cache is used. The peak memory consumption of the model for a single forward pass without key-value cache stays unchanged as every attention head still has a unique query vector so that each attention head still has a different \\( \mathbf{QK}^T \\) matrix.
MQA has seen wide adoption by the community and is now used by many of the most popular LLMs:
- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
- [**PaLM**](https://arxiv.org/abs/2204.02311)
- [**MPT**](https://huggingface.co/mosaicml/mpt-30b)
- [**BLOOM**](https://huggingface.co/bigscience/bloom)
Also, the checkpoint used in this notebook - `bigcode/octocoder` - makes use of MQA.
#### 3.2.3 Grouped-Query-Attention (GQA)
[Grouped-Query-Attention](https://arxiv.org/abs/2305.13245), as proposed by Ainslie et al. from Google, found that using MQA can often lead to quality degradation compared to using vanilla multi-key-value head projections. The paper argues that more model performance can be kept by less drastically reducing the number of query head projection weights. Instead of using just a single key-value projection weight, `n < n_head` key-value projection weights should be used. By choosing `n` to a significantly smaller value than `n_head`, such as 2,4 or 8 almost all of the memory and speed gains from MQA can be kept while sacrificing less model capacity and thus arguably less performance.
Moreover, the authors of GQA found out that existing model checkpoints can be *uptrained* to have a GQA architecture with as little as 5% of the original pre-training compute. While 5% of the original pre-training compute can still be a massive amount, GQA *uptraining* allows existing checkpoints to be useful for longer input sequences.
GQA was only recently proposed which is why there is less adoption at the time of writing this notebook.
The most notable application of GQA is [Llama-v2](https://huggingface.co/meta-llama/Llama-2-70b-hf).
> As a conclusion, it is strongly recommended to make use of either GQA or MQA if the LLM is deployed with auto-regressive decoding and is required to handle large input sequences as is the case for example for chat.
## Conclusion
The research community is constantly coming up with new, nifty ways to speed up inference time for ever-larger LLMs. As an example, one such promising research direction is [speculative decoding](https://arxiv.org/abs/2211.17192) where "easy tokens" are generated by smaller, faster language models and only "hard tokens" are generated by the LLM itself. Going into more detail is out of the scope of this notebook, but can be read upon in this [nice blog post](https://huggingface.co/blog/assisted-generation).
The reason massive LLMs such as GPT3/4, Llama-2-70b, Claude, PaLM can run so quickly in chat-interfaces such as [Hugging Face Chat](https://huggingface.co/chat/) or ChatGPT is to a big part thanks to the above-mentioned improvements in precision, algorithms, and architecture.
Going forward, accelerators such as GPUs, TPUs, etc... will only get faster and allow for more memory, but one should nevertheless always make sure to use the best available algorithms and architectures to get the most bang for your buck 🤗
|
huggingface/transformers/blob/main/docs/source/en/llm_tutorial_optimization.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Working with custom models
Some fine-tuning techniques, such as prompt tuning, are specific to language models. That means in 🤗 PEFT, it is
assumed a 🤗 Transformers model is being used. However, other fine-tuning techniques - like
[LoRA](../conceptual_guides/lora) - are not restricted to specific model types.
In this guide, we will see how LoRA can be applied to a multilayer perceptron and a computer vision model from the [timm](https://huggingface.co/docs/timm/index) library.
## Multilayer perceptron
Let's assume that we want to fine-tune a multilayer perceptron with LoRA. Here is the definition:
```python
from torch import nn
class MLP(nn.Module):
def __init__(self, num_units_hidden=2000):
super().__init__()
self.seq = nn.Sequential(
nn.Linear(20, num_units_hidden),
nn.ReLU(),
nn.Linear(num_units_hidden, num_units_hidden),
nn.ReLU(),
nn.Linear(num_units_hidden, 2),
nn.LogSoftmax(dim=-1),
)
def forward(self, X):
return self.seq(X)
```
This is a straightforward multilayer perceptron with an input layer, a hidden layer, and an output layer.
<Tip>
For this toy example, we choose an exceedingly large number of hidden units to highlight the efficiency gains
from PEFT, but those gains are in line with more realistic examples.
</Tip>
There are a few linear layers in this model that could be tuned with LoRA. When working with common 🤗 Transformers
models, PEFT will know which layers to apply LoRA to, but in this case, it is up to us as a user to choose the layers.
To determine the names of the layers to tune:
```python
print([(n, type(m)) for n, m in MLP().named_modules()])
```
This should print:
```
[('', __main__.MLP),
('seq', torch.nn.modules.container.Sequential),
('seq.0', torch.nn.modules.linear.Linear),
('seq.1', torch.nn.modules.activation.ReLU),
('seq.2', torch.nn.modules.linear.Linear),
('seq.3', torch.nn.modules.activation.ReLU),
('seq.4', torch.nn.modules.linear.Linear),
('seq.5', torch.nn.modules.activation.LogSoftmax)]
```
Let's say we want to apply LoRA to the input layer and to the hidden layer, those are `'seq.0'` and `'seq.2'`. Moreover,
let's assume we want to update the output layer without LoRA, that would be `'seq.4'`. The corresponding config would
be:
```python
from peft import LoraConfig
config = LoraConfig(
target_modules=["seq.0", "seq.2"],
modules_to_save=["seq.4"],
)
```
With that, we can create our PEFT model and check the fraction of parameters trained:
```python
from peft import get_peft_model
model = MLP()
peft_model = get_peft_model(model, config)
peft_model.print_trainable_parameters()
# prints trainable params: 56,164 || all params: 4,100,164 || trainable%: 1.369798866581922
```
Finally, we can use any training framework we like, or write our own fit loop, to train the `peft_model`.
For a complete example, check out [this notebook](https://github.com/huggingface/peft/blob/main/examples/multilayer_perceptron/multilayer_perceptron_lora.ipynb).
## timm models
The [timm](https://huggingface.co/docs/timm/index) library contains a large number of pretrained computer vision models.
Those can also be fine-tuned with PEFT. Let's check out how this works in practice.
To start, ensure that timm is installed in the Python environment:
```bash
python -m pip install -U timm
```
Next we load a timm model for an image classification task:
```python
import timm
num_classes = ...
model_id = "timm/poolformer_m36.sail_in1k"
model = timm.create_model(model_id, pretrained=True, num_classes=num_classes)
```
Again, we need to make a decision about what layers to apply LoRA to. Since LoRA supports 2D conv layers, and since
those are a major building block of this model, we should apply LoRA to the 2D conv layers. To identify the names of
those layers, let's look at all the layer names:
```python
print([(n, type(m)) for n, m in MLP().named_modules()])
```
This will print a very long list, we'll only show the first few:
```
[('', timm.models.metaformer.MetaFormer),
('stem', timm.models.metaformer.Stem),
('stem.conv', torch.nn.modules.conv.Conv2d),
('stem.norm', torch.nn.modules.linear.Identity),
('stages', torch.nn.modules.container.Sequential),
('stages.0', timm.models.metaformer.MetaFormerStage),
('stages.0.downsample', torch.nn.modules.linear.Identity),
('stages.0.blocks', torch.nn.modules.container.Sequential),
('stages.0.blocks.0', timm.models.metaformer.MetaFormerBlock),
('stages.0.blocks.0.norm1', timm.layers.norm.GroupNorm1),
('stages.0.blocks.0.token_mixer', timm.models.metaformer.Pooling),
('stages.0.blocks.0.token_mixer.pool', torch.nn.modules.pooling.AvgPool2d),
('stages.0.blocks.0.drop_path1', torch.nn.modules.linear.Identity),
('stages.0.blocks.0.layer_scale1', timm.models.metaformer.Scale),
('stages.0.blocks.0.res_scale1', torch.nn.modules.linear.Identity),
('stages.0.blocks.0.norm2', timm.layers.norm.GroupNorm1),
('stages.0.blocks.0.mlp', timm.layers.mlp.Mlp),
('stages.0.blocks.0.mlp.fc1', torch.nn.modules.conv.Conv2d),
('stages.0.blocks.0.mlp.act', torch.nn.modules.activation.GELU),
('stages.0.blocks.0.mlp.drop1', torch.nn.modules.dropout.Dropout),
('stages.0.blocks.0.mlp.norm', torch.nn.modules.linear.Identity),
('stages.0.blocks.0.mlp.fc2', torch.nn.modules.conv.Conv2d),
('stages.0.blocks.0.mlp.drop2', torch.nn.modules.dropout.Dropout),
('stages.0.blocks.0.drop_path2', torch.nn.modules.linear.Identity),
('stages.0.blocks.0.layer_scale2', timm.models.metaformer.Scale),
('stages.0.blocks.0.res_scale2', torch.nn.modules.linear.Identity),
('stages.0.blocks.1', timm.models.metaformer.MetaFormerBlock),
('stages.0.blocks.1.norm1', timm.layers.norm.GroupNorm1),
('stages.0.blocks.1.token_mixer', timm.models.metaformer.Pooling),
('stages.0.blocks.1.token_mixer.pool', torch.nn.modules.pooling.AvgPool2d),
...
('head.global_pool.flatten', torch.nn.modules.linear.Identity),
('head.norm', timm.layers.norm.LayerNorm2d),
('head.flatten', torch.nn.modules.flatten.Flatten),
('head.drop', torch.nn.modules.linear.Identity),
('head.fc', torch.nn.modules.linear.Linear)]
]
```
Upon closer inspection, we see that the 2D conv layers have names such as `"stages.0.blocks.0.mlp.fc1"` and
`"stages.0.blocks.0.mlp.fc2"`. How can we match those layer names specifically? You can write a [regular
expressions](https://docs.python.org/3/library/re.html) to match the layer names. For our case, the regex
`r".*\.mlp\.fc\d"` should do the job.
Furthermore, as in the first example, we should ensure that the output layer, in this case the classification head, is
also updated. Looking at the end of the list printed above, we can see that it's named `'head.fc'`. With that in mind,
here is our LoRA config:
```python
config = LoraConfig(target_modules=r".*\.mlp\.fc\d", modules_to_save=["head.fc"])
```
Then we only need to create the PEFT model by passing our base model and the config to `get_peft_model`:
```python
peft_model = get_peft_model(model, config)
peft_model.print_trainable_parameters()
# prints trainable params: 1,064,454 || all params: 56,467,974 || trainable%: 1.88505789139876
```
This shows us that we only need to train less than 2% of all parameters, which is a huge efficiency gain.
For a complete example, check out [this notebook](https://github.com/huggingface/peft/blob/main/examples/image_classification/image_classification_timm_peft_lora.ipynb).
## New transformers architectures
When new popular transformers architectures are released, we do our best to quickly add them to PEFT. If you come across a transformers model that is not supported out of the box, don't worry, it will most likely still work if the config is set correctly. Specifically, you have to identify the layers that should be adapted and set them correctly when initializing the corresponding config class, e.g. `LoraConfig`. Here are some tips to help with this.
As a first step, it is a good idea is to check the existing models for inspiration. You can find them inside of [constants.py](https://github.com/huggingface/peft/blob/main/src/peft/utils/constants.py) in the PEFT repository. Often, you'll find a similar architecture that uses the same names. For example, if the new model architecture is a variation of the "mistral" model and you want to apply LoRA, you can see that the entry for "mistral" in `TRANSFORMERS_MODELS_TO_LORA_TARGET_MODULES_MAPPING` contains `["q_proj", "v_proj"]`. This tells you that for "mistral" models, the `target_modules` for LoRA should be `["q_proj", "v_proj"]`:
```python
from peft import LoraConfig, get_peft_model
my_mistral_model = ...
config = LoraConfig(
target_modules=["q_proj", "v_proj"],
..., # other LoRA arguments
)
peft_model = get_peft_model(my_mistral_model, config)
```
If that doesn't help, check the existing modules in your model architecture with the `named_modules` method and try to identify the attention layers, especially the key, query, and value layers. Those will often have names such as `c_attn`, `query`, `q_proj`, etc. The key layer is not always adapted, and ideally, you should check whether including it results in better performance.
Additionally, linear layers are common targets to be adapted (e.g. in [QLoRA paper](https://arxiv.org/abs/2305.14314), authors suggest to adapt them as well). Their names will often contain the strings `fc` or `dense`.
If you want to add a new model to PEFT, please create an entry in [constants.py](https://github.com/huggingface/peft/blob/main/src/peft/utils/constants.py) and open a pull request on the [repository](https://github.com/huggingface/peft/pulls). Don't forget to update the [README](https://github.com/huggingface/peft#models-support-matrix) as well.
|
huggingface/peft/blob/main/docs/source/developer_guides/custom_models.md
|
Gradio Demo: gallery_component_events
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
cheetahs = [
"https://gradio-builds.s3.amazonaws.com/assets/cheetah-003.jpg",
"https://gradio-builds.s3.amazonaws.com/assets/lite-logo.png",
"https://gradio-builds.s3.amazonaws.com/assets/TheCheethcat.jpg",
]
with gr.Row():
with gr.Column():
btn = gr.Button()
with gr.Column():
gallery = gr.Gallery()
with gr.Column():
select_output = gr.Textbox(label="Select Data")
btn.click(lambda: cheetahs, None, [gallery])
def select(select_data: gr.SelectData):
return select_data.value['image']['url']
gallery.select(select, None, select_output)
if __name__ == "__main__":
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/gallery_component_events/run.ipynb
|
Gradio Demo: theme_builder
```
!pip install -q gradio
```
```
import gradio as gr
demo = gr.themes.builder
if __name__ == "__main__":
demo()
```
|
gradio-app/gradio/blob/main/demo/theme_builder/run.ipynb
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Inpainting
[[open-in-colab]]
Inpainting replaces or edits specific areas of an image. This makes it a useful tool for image restoration like removing defects and artifacts, or even replacing an image area with something entirely new. Inpainting relies on a mask to determine which regions of an image to fill in; the area to inpaint is represented by white pixels and the area to keep is represented by black pixels. The white pixels are filled in by the prompt.
With 🤗 Diffusers, here is how you can do inpainting:
1. Load an inpainting checkpoint with the [`AutoPipelineForInpainting`] class. This'll automatically detect the appropriate pipeline class to load based on the checkpoint:
```py
import torch
from diffusers import AutoPipelineForInpainting
from diffusers.utils import load_image, make_image_grid
pipeline = AutoPipelineForInpainting.from_pretrained(
"kandinsky-community/kandinsky-2-2-decoder-inpaint", torch_dtype=torch.float16
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
```
<Tip>
You'll notice throughout the guide, we use [`~DiffusionPipeline.enable_model_cpu_offload`] and [`~DiffusionPipeline.enable_xformers_memory_efficient_attention`], to save memory and increase inference speed. If you're using PyTorch 2.0, it's not necessary to call [`~DiffusionPipeline.enable_xformers_memory_efficient_attention`] on your pipeline because it'll already be using PyTorch 2.0's native [scaled-dot product attention](../optimization/torch2.0#scaled-dot-product-attention).
</Tip>
2. Load the base and mask images:
```py
init_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint.png")
mask_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint_mask.png")
```
3. Create a prompt to inpaint the image with and pass it to the pipeline with the base and mask images:
```py
prompt = "a black cat with glowing eyes, cute, adorable, disney, pixar, highly detailed, 8k"
negative_prompt = "bad anatomy, deformed, ugly, disfigured"
image = pipeline(prompt=prompt, negative_prompt=negative_prompt, image=init_image, mask_image=mask_image).images[0]
make_image_grid([init_image, mask_image, image], rows=1, cols=3)
```
<div class="flex gap-4">
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">base image</figcaption>
</div>
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint_mask.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">mask image</figcaption>
</div>
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint-cat.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">generated image</figcaption>
</div>
</div>
## Create a mask image
Throughout this guide, the mask image is provided in all of the code examples for convenience. You can inpaint on your own images, but you'll need to create a mask image for it. Use the Space below to easily create a mask image.
Upload a base image to inpaint on and use the sketch tool to draw a mask. Once you're done, click **Run** to generate and download the mask image.
<iframe
src="https://stevhliu-inpaint-mask-maker.hf.space"
frameborder="0"
width="850"
height="450"
></iframe>
## Popular models
[Stable Diffusion Inpainting](https://huggingface.co/runwayml/stable-diffusion-inpainting), [Stable Diffusion XL (SDXL) Inpainting](https://huggingface.co/diffusers/stable-diffusion-xl-1.0-inpainting-0.1), and [Kandinsky 2.2 Inpainting](https://huggingface.co/kandinsky-community/kandinsky-2-2-decoder-inpaint) are among the most popular models for inpainting. SDXL typically produces higher resolution images than Stable Diffusion v1.5, and Kandinsky 2.2 is also capable of generating high-quality images.
### Stable Diffusion Inpainting
Stable Diffusion Inpainting is a latent diffusion model finetuned on 512x512 images on inpainting. It is a good starting point because it is relatively fast and generates good quality images. To use this model for inpainting, you'll need to pass a prompt, base and mask image to the pipeline:
```py
import torch
from diffusers import AutoPipelineForInpainting
from diffusers.utils import load_image, make_image_grid
pipeline = AutoPipelineForInpainting.from_pretrained(
"runwayml/stable-diffusion-inpainting", torch_dtype=torch.float16, variant="fp16"
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
# load base and mask image
init_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint.png")
mask_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint_mask.png")
generator = torch.Generator("cuda").manual_seed(92)
prompt = "concept art digital painting of an elven castle, inspired by lord of the rings, highly detailed, 8k"
image = pipeline(prompt=prompt, image=init_image, mask_image=mask_image, generator=generator).images[0]
make_image_grid([init_image, mask_image, image], rows=1, cols=3)
```
### Stable Diffusion XL (SDXL) Inpainting
SDXL is a larger and more powerful version of Stable Diffusion v1.5. This model can follow a two-stage model process (though each model can also be used alone); the base model generates an image, and a refiner model takes that image and further enhances its details and quality. Take a look at the [SDXL](sdxl) guide for a more comprehensive guide on how to use SDXL and configure it's parameters.
```py
import torch
from diffusers import AutoPipelineForInpainting
from diffusers.utils import load_image, make_image_grid
pipeline = AutoPipelineForInpainting.from_pretrained(
"diffusers/stable-diffusion-xl-1.0-inpainting-0.1", torch_dtype=torch.float16, variant="fp16"
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
# load base and mask image
init_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint.png")
mask_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint_mask.png")
generator = torch.Generator("cuda").manual_seed(92)
prompt = "concept art digital painting of an elven castle, inspired by lord of the rings, highly detailed, 8k"
image = pipeline(prompt=prompt, image=init_image, mask_image=mask_image, generator=generator).images[0]
make_image_grid([init_image, mask_image, image], rows=1, cols=3)
```
### Kandinsky 2.2 Inpainting
The Kandinsky model family is similar to SDXL because it uses two models as well; the image prior model creates image embeddings, and the diffusion model generates images from them. You can load the image prior and diffusion model separately, but the easiest way to use Kandinsky 2.2 is to load it into the [`AutoPipelineForInpainting`] class which uses the [`KandinskyV22InpaintCombinedPipeline`] under the hood.
```py
import torch
from diffusers import AutoPipelineForInpainting
from diffusers.utils import load_image, make_image_grid
pipeline = AutoPipelineForInpainting.from_pretrained(
"kandinsky-community/kandinsky-2-2-decoder-inpaint", torch_dtype=torch.float16
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
# load base and mask image
init_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint.png")
mask_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint_mask.png")
generator = torch.Generator("cuda").manual_seed(92)
prompt = "concept art digital painting of an elven castle, inspired by lord of the rings, highly detailed, 8k"
image = pipeline(prompt=prompt, image=init_image, mask_image=mask_image, generator=generator).images[0]
make_image_grid([init_image, mask_image, image], rows=1, cols=3)
```
<div class="flex flex-row gap-4">
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">base image</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint-sdv1.5.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">Stable Diffusion Inpainting</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint-sdxl.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">Stable Diffusion XL Inpainting</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint-kandinsky.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">Kandinsky 2.2 Inpainting</figcaption>
</div>
</div>
## Non-inpaint specific checkpoints
So far, this guide has used inpaint specific checkpoints such as [runwayml/stable-diffusion-inpainting](https://huggingface.co/runwayml/stable-diffusion-inpainting). But you can also use regular checkpoints like [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5). Let's compare the results of the two checkpoints.
The image on the left is generated from a regular checkpoint, and the image on the right is from an inpaint checkpoint. You'll immediately notice the image on the left is not as clean, and you can still see the outline of the area the model is supposed to inpaint. The image on the right is much cleaner and the inpainted area appears more natural.
<hfoptions id="regular-specific">
<hfoption id="runwayml/stable-diffusion-v1-5">
```py
import torch
from diffusers import AutoPipelineForInpainting
from diffusers.utils import load_image, make_image_grid
pipeline = AutoPipelineForInpainting.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, variant="fp16"
).to("cuda")
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
# load base and mask image
init_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint.png")
mask_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint_mask.png")
generator = torch.Generator("cuda").manual_seed(92)
prompt = "concept art digital painting of an elven castle, inspired by lord of the rings, highly detailed, 8k"
image = pipeline(prompt=prompt, image=init_image, mask_image=mask_image, generator=generator).images[0]
make_image_grid([init_image, image], rows=1, cols=2)
```
</hfoption>
<hfoption id="runwayml/stable-diffusion-inpainting">
```py
import torch
from diffusers import AutoPipelineForInpainting
from diffusers.utils import load_image, make_image_grid
pipeline = AutoPipelineForInpainting.from_pretrained(
"runwayml/stable-diffusion-inpainting", torch_dtype=torch.float16, variant="fp16"
).to("cuda")
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
# load base and mask image
init_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint.png")
mask_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint_mask.png")
generator = torch.Generator("cuda").manual_seed(92)
prompt = "concept art digital painting of an elven castle, inspired by lord of the rings, highly detailed, 8k"
image = pipeline(prompt=prompt, image=init_image, mask_image=mask_image, generator=generator).images[0]
make_image_grid([init_image, image], rows=1, cols=2)
```
</hfoption>
</hfoptions>
<div class="flex gap-4">
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/non-inpaint-specific.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">runwayml/stable-diffusion-v1-5</figcaption>
</div>
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint-specific.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">runwayml/stable-diffusion-inpainting</figcaption>
</div>
</div>
However, for more basic tasks like erasing an object from an image (like the rocks in the road for example), a regular checkpoint yields pretty good results. There isn't as noticeable of difference between the regular and inpaint checkpoint.
<hfoptions id="inpaint">
<hfoption id="runwayml/stable-diffusion-v1-5">
```py
import torch
from diffusers import AutoPipelineForInpainting
from diffusers.utils import load_image, make_image_grid
pipeline = AutoPipelineForInpainting.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, variant="fp16"
).to("cuda")
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
# load base and mask image
init_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint.png")
mask_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/road-mask.png")
image = pipeline(prompt="road", image=init_image, mask_image=mask_image).images[0]
make_image_grid([init_image, image], rows=1, cols=2)
```
</hfoption>
<hfoption id="runwayml/stable-diffusion-inpaint">
```py
import torch
from diffusers import AutoPipelineForInpainting
from diffusers.utils import load_image, make_image_grid
pipeline = AutoPipelineForInpainting.from_pretrained(
"runwayml/stable-diffusion-inpainting", torch_dtype=torch.float16, variant="fp16"
).to("cuda")
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
# load base and mask image
init_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint.png")
mask_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/road-mask.png")
image = pipeline(prompt="road", image=init_image, mask_image=mask_image).images[0]
make_image_grid([init_image, image], rows=1, cols=2)
```
</hfoption>
</hfoptions>
<div class="flex gap-4">
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/regular-inpaint-basic.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">runwayml/stable-diffusion-v1-5</figcaption>
</div>
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/specific-inpaint-basic.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">runwayml/stable-diffusion-inpainting</figcaption>
</div>
</div>
The trade-off of using a non-inpaint specific checkpoint is the overall image quality may be lower, but it generally tends to preserve the mask area (that is why you can see the mask outline). The inpaint specific checkpoints are intentionally trained to generate higher quality inpainted images, and that includes creating a more natural transition between the masked and unmasked areas. As a result, these checkpoints are more likely to change your unmasked area.
If preserving the unmasked area is important for your task, you can use the code below to force the unmasked area of an image to remain the same at the expense of some more unnatural transitions between the masked and unmasked areas.
```py
import PIL
import numpy as np
import torch
from diffusers import AutoPipelineForInpainting
from diffusers.utils import load_image, make_image_grid
device = "cuda"
pipeline = AutoPipelineForInpainting.from_pretrained(
"runwayml/stable-diffusion-inpainting",
torch_dtype=torch.float16,
)
pipeline = pipeline.to(device)
img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
init_image = load_image(img_url).resize((512, 512))
mask_image = load_image(mask_url).resize((512, 512))
prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
repainted_image = pipeline(prompt=prompt, image=init_image, mask_image=mask_image).images[0]
repainted_image.save("repainted_image.png")
# Convert mask to grayscale NumPy array
mask_image_arr = np.array(mask_image.convert("L"))
# Add a channel dimension to the end of the grayscale mask
mask_image_arr = mask_image_arr[:, :, None]
# Binarize the mask: 1s correspond to the pixels which are repainted
mask_image_arr = mask_image_arr.astype(np.float32) / 255.0
mask_image_arr[mask_image_arr < 0.5] = 0
mask_image_arr[mask_image_arr >= 0.5] = 1
# Take the masked pixels from the repainted image and the unmasked pixels from the initial image
unmasked_unchanged_image_arr = (1 - mask_image_arr) * init_image + mask_image_arr * repainted_image
unmasked_unchanged_image = PIL.Image.fromarray(unmasked_unchanged_image_arr.round().astype("uint8"))
unmasked_unchanged_image.save("force_unmasked_unchanged.png")
make_image_grid([init_image, mask_image, repainted_image, unmasked_unchanged_image], rows=2, cols=2)
```
## Configure pipeline parameters
Image features - like quality and "creativity" - are dependent on pipeline parameters. Knowing what these parameters do is important for getting the results you want. Let's take a look at the most important parameters and see how changing them affects the output.
### Strength
`strength` is a measure of how much noise is added to the base image, which influences how similar the output is to the base image.
* 📈 a high `strength` value means more noise is added to an image and the denoising process takes longer, but you'll get higher quality images that are more different from the base image
* 📉 a low `strength` value means less noise is added to an image and the denoising process is faster, but the image quality may not be as great and the generated image resembles the base image more
```py
import torch
from diffusers import AutoPipelineForInpainting
from diffusers.utils import load_image, make_image_grid
pipeline = AutoPipelineForInpainting.from_pretrained(
"runwayml/stable-diffusion-inpainting", torch_dtype=torch.float16, variant="fp16"
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
# load base and mask image
init_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint.png")
mask_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint_mask.png")
prompt = "concept art digital painting of an elven castle, inspired by lord of the rings, highly detailed, 8k"
image = pipeline(prompt=prompt, image=init_image, mask_image=mask_image, strength=0.6).images[0]
make_image_grid([init_image, mask_image, image], rows=1, cols=3)
```
<div class="flex flex-row gap-4">
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint-strength-0.6.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">strength = 0.6</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint-strength-0.8.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">strength = 0.8</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint-strength-1.0.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">strength = 1.0</figcaption>
</div>
</div>
### Guidance scale
`guidance_scale` affects how aligned the text prompt and generated image are.
* 📈 a high `guidance_scale` value means the prompt and generated image are closely aligned, so the output is a stricter interpretation of the prompt
* 📉 a low `guidance_scale` value means the prompt and generated image are more loosely aligned, so the output may be more varied from the prompt
You can use `strength` and `guidance_scale` together for more control over how expressive the model is. For example, a combination high `strength` and `guidance_scale` values gives the model the most creative freedom.
```py
import torch
from diffusers import AutoPipelineForInpainting
from diffusers.utils import load_image, make_image_grid
pipeline = AutoPipelineForInpainting.from_pretrained(
"runwayml/stable-diffusion-inpainting", torch_dtype=torch.float16, variant="fp16"
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
# load base and mask image
init_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint.png")
mask_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint_mask.png")
prompt = "concept art digital painting of an elven castle, inspired by lord of the rings, highly detailed, 8k"
image = pipeline(prompt=prompt, image=init_image, mask_image=mask_image, guidance_scale=2.5).images[0]
make_image_grid([init_image, mask_image, image], rows=1, cols=3)
```
<div class="flex flex-row gap-4">
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint-guidance-2.5.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">guidance_scale = 2.5</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint-guidance-7.5.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">guidance_scale = 7.5</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint-guidance-12.5.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">guidance_scale = 12.5</figcaption>
</div>
</div>
### Negative prompt
A negative prompt assumes the opposite role of a prompt; it guides the model away from generating certain things in an image. This is useful for quickly improving image quality and preventing the model from generating things you don't want.
```py
import torch
from diffusers import AutoPipelineForInpainting
from diffusers.utils import load_image, make_image_grid
pipeline = AutoPipelineForInpainting.from_pretrained(
"runwayml/stable-diffusion-inpainting", torch_dtype=torch.float16, variant="fp16"
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
# load base and mask image
init_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint.png")
mask_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint_mask.png")
prompt = "concept art digital painting of an elven castle, inspired by lord of the rings, highly detailed, 8k"
negative_prompt = "bad architecture, unstable, poor details, blurry"
image = pipeline(prompt=prompt, negative_prompt=negative_prompt, image=init_image, mask_image=mask_image).images[0]
make_image_grid([init_image, mask_image, image], rows=1, cols=3)
```
<div class="flex justify-center">
<figure>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint-negative.png" />
<figcaption class="text-center">negative_prompt = "bad architecture, unstable, poor details, blurry"</figcaption>
</figure>
</div>
## Chained inpainting pipelines
[`AutoPipelineForInpainting`] can be chained with other 🤗 Diffusers pipelines to edit their outputs. This is often useful for improving the output quality from your other diffusion pipelines, and if you're using multiple pipelines, it can be more memory-efficient to chain them together to keep the outputs in latent space and reuse the same pipeline components.
### Text-to-image-to-inpaint
Chaining a text-to-image and inpainting pipeline allows you to inpaint the generated image, and you don't have to provide a base image to begin with. This makes it convenient to edit your favorite text-to-image outputs without having to generate an entirely new image.
Start with the text-to-image pipeline to create a castle:
```py
import torch
from diffusers import AutoPipelineForText2Image, AutoPipelineForInpainting
from diffusers.utils import load_image, make_image_grid
pipeline = AutoPipelineForText2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
text2image = pipeline("concept art digital painting of an elven castle, inspired by lord of the rings, highly detailed, 8k").images[0]
```
Load the mask image of the output from above:
```py
mask_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint_text-chain-mask.png")
```
And let's inpaint the masked area with a waterfall:
```py
pipeline = AutoPipelineForInpainting.from_pretrained(
"kandinsky-community/kandinsky-2-2-decoder-inpaint", torch_dtype=torch.float16
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
prompt = "digital painting of a fantasy waterfall, cloudy"
image = pipeline(prompt=prompt, image=text2image, mask_image=mask_image).images[0]
make_image_grid([text2image, mask_image, image], rows=1, cols=3)
```
<div class="flex flex-row gap-4">
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint-text-chain.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">text-to-image</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint-text-chain-out.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">inpaint</figcaption>
</div>
</div>
### Inpaint-to-image-to-image
You can also chain an inpainting pipeline before another pipeline like image-to-image or an upscaler to improve the quality.
Begin by inpainting an image:
```py
import torch
from diffusers import AutoPipelineForInpainting, AutoPipelineForImage2Image
from diffusers.utils import load_image, make_image_grid
pipeline = AutoPipelineForInpainting.from_pretrained(
"runwayml/stable-diffusion-inpainting", torch_dtype=torch.float16, variant="fp16"
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
# load base and mask image
init_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint.png")
mask_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint_mask.png")
prompt = "concept art digital painting of an elven castle, inspired by lord of the rings, highly detailed, 8k"
image_inpainting = pipeline(prompt=prompt, image=init_image, mask_image=mask_image).images[0]
# resize image to 1024x1024 for SDXL
image_inpainting = image_inpainting.resize((1024, 1024))
```
Now let's pass the image to another inpainting pipeline with SDXL's refiner model to enhance the image details and quality:
```py
pipeline = AutoPipelineForInpainting.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0", torch_dtype=torch.float16, variant="fp16"
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
image = pipeline(prompt=prompt, image=image_inpainting, mask_image=mask_image, output_type="latent").images[0]
```
<Tip>
It is important to specify `output_type="latent"` in the pipeline to keep all the outputs in latent space to avoid an unnecessary decode-encode step. This only works if the chained pipelines are using the same VAE. For example, in the [Text-to-image-to-inpaint](#text-to-image-to-inpaint) section, Kandinsky 2.2 uses a different VAE class than the Stable Diffusion model so it won't work. But if you use Stable Diffusion v1.5 for both pipelines, then you can keep everything in latent space because they both use [`AutoencoderKL`].
</Tip>
Finally, you can pass this image to an image-to-image pipeline to put the finishing touches on it. It is more efficient to use the [`~AutoPipelineForImage2Image.from_pipe`] method to reuse the existing pipeline components, and avoid unnecessarily loading all the pipeline components into memory again.
```py
pipeline = AutoPipelineForImage2Image.from_pipe(pipeline)
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
image = pipeline(prompt=prompt, image=image).images[0]
make_image_grid([init_image, mask_image, image_inpainting, image], rows=2, cols=2)
```
<div class="flex flex-row gap-4">
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">initial image</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint-to-image-chain.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">inpaint</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint-to-image-final.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">image-to-image</figcaption>
</div>
</div>
Image-to-image and inpainting are actually very similar tasks. Image-to-image generates a new image that resembles the existing provided image. Inpainting does the same thing, but it only transforms the image area defined by the mask and the rest of the image is unchanged. You can think of inpainting as a more precise tool for making specific changes and image-to-image has a broader scope for making more sweeping changes.
## Control image generation
Getting an image to look exactly the way you want is challenging because the denoising process is random. While you can control certain aspects of generation by configuring parameters like `negative_prompt`, there are better and more efficient methods for controlling image generation.
### Prompt weighting
Prompt weighting provides a quantifiable way to scale the representation of concepts in a prompt. You can use it to increase or decrease the magnitude of the text embedding vector for each concept in the prompt, which subsequently determines how much of each concept is generated. The [Compel](https://github.com/damian0815/compel) library offers an intuitive syntax for scaling the prompt weights and generating the embeddings. Learn how to create the embeddings in the [Prompt weighting](../using-diffusers/weighted_prompts) guide.
Once you've generated the embeddings, pass them to the `prompt_embeds` (and `negative_prompt_embeds` if you're using a negative prompt) parameter in the [`AutoPipelineForInpainting`]. The embeddings replace the `prompt` parameter:
```py
import torch
from diffusers import AutoPipelineForInpainting
from diffusers.utils import make_image_grid
pipeline = AutoPipelineForInpainting.from_pretrained(
"runwayml/stable-diffusion-inpainting", torch_dtype=torch.float16,
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
image = pipeline(prompt_embeds=prompt_embeds, # generated from Compel
negative_prompt_embeds=negative_prompt_embeds, # generated from Compel
image=init_image,
mask_image=mask_image
).images[0]
make_image_grid([init_image, mask_image, image], rows=1, cols=3)
```
### ControlNet
ControlNet models are used with other diffusion models like Stable Diffusion, and they provide an even more flexible and accurate way to control how an image is generated. A ControlNet accepts an additional conditioning image input that guides the diffusion model to preserve the features in it.
For example, let's condition an image with a ControlNet pretrained on inpaint images:
```py
import torch
import numpy as np
from diffusers import ControlNetModel, StableDiffusionControlNetInpaintPipeline
from diffusers.utils import load_image, make_image_grid
# load ControlNet
controlnet = ControlNetModel.from_pretrained("lllyasviel/control_v11p_sd15_inpaint", torch_dtype=torch.float16, variant="fp16")
# pass ControlNet to the pipeline
pipeline = StableDiffusionControlNetInpaintPipeline.from_pretrained(
"runwayml/stable-diffusion-inpainting", controlnet=controlnet, torch_dtype=torch.float16, variant="fp16"
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
# load base and mask image
init_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint.png")
mask_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint_mask.png")
# prepare control image
def make_inpaint_condition(init_image, mask_image):
init_image = np.array(init_image.convert("RGB")).astype(np.float32) / 255.0
mask_image = np.array(mask_image.convert("L")).astype(np.float32) / 255.0
assert init_image.shape[0:1] == mask_image.shape[0:1], "image and image_mask must have the same image size"
init_image[mask_image > 0.5] = -1.0 # set as masked pixel
init_image = np.expand_dims(init_image, 0).transpose(0, 3, 1, 2)
init_image = torch.from_numpy(init_image)
return init_image
control_image = make_inpaint_condition(init_image, mask_image)
```
Now generate an image from the base, mask and control images. You'll notice features of the base image are strongly preserved in the generated image.
```py
prompt = "concept art digital painting of an elven castle, inspired by lord of the rings, highly detailed, 8k"
image = pipeline(prompt=prompt, image=init_image, mask_image=mask_image, control_image=control_image).images[0]
make_image_grid([init_image, mask_image, PIL.Image.fromarray(np.uint8(control_image[0][0])).convert('RGB'), image], rows=2, cols=2)
```
You can take this a step further and chain it with an image-to-image pipeline to apply a new [style](https://huggingface.co/nitrosocke/elden-ring-diffusion):
```py
from diffusers import AutoPipelineForImage2Image
pipeline = AutoPipelineForImage2Image.from_pretrained(
"nitrosocke/elden-ring-diffusion", torch_dtype=torch.float16,
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
prompt = "elden ring style castle" # include the token "elden ring style" in the prompt
negative_prompt = "bad architecture, deformed, disfigured, poor details"
image_elden_ring = pipeline(prompt, negative_prompt=negative_prompt, image=image).images[0]
make_image_grid([init_image, mask_image, image, image_elden_ring], rows=2, cols=2)
```
<div class="flex flex-row gap-4">
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">initial image</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint-controlnet.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">ControlNet inpaint</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint-img2img.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">image-to-image</figcaption>
</div>
</div>
## Optimize
It can be difficult and slow to run diffusion models if you're resource constrained, but it doesn't have to be with a few optimization tricks. One of the biggest (and easiest) optimizations you can enable is switching to memory-efficient attention. If you're using PyTorch 2.0, [scaled-dot product attention](../optimization/torch2.0#scaled-dot-product-attention) is automatically enabled and you don't need to do anything else. For non-PyTorch 2.0 users, you can install and use [xFormers](../optimization/xformers)'s implementation of memory-efficient attention. Both options reduce memory usage and accelerate inference.
You can also offload the model to the CPU to save even more memory:
```diff
+ pipeline.enable_xformers_memory_efficient_attention()
+ pipeline.enable_model_cpu_offload()
```
To speed-up your inference code even more, use [`torch_compile`](../optimization/torch2.0#torchcompile). You should wrap `torch.compile` around the most intensive component in the pipeline which is typically the UNet:
```py
pipeline.unet = torch.compile(pipeline.unet, mode="reduce-overhead", fullgraph=True)
```
Learn more in the [Reduce memory usage](../optimization/memory) and [Torch 2.0](../optimization/torch2.0) guides.
|
huggingface/diffusers/blob/main/docs/source/en/using-diffusers/inpaint.md
|
--
{{card_data}}
---
# {{ model_name | default("MyModelName", true)}}
{{ some_data }}
|
huggingface/huggingface_hub/blob/main/tests/fixtures/cards/sample_template.md
|
Noisy Student (EfficientNet)
**Noisy Student Training** is a semi-supervised learning approach. It extends the idea of self-training
and distillation with the use of equal-or-larger student models and noise added to the student during learning. It has three main steps:
1. train a teacher model on labeled images
2. use the teacher to generate pseudo labels on unlabeled images
3. train a student model on the combination of labeled images and pseudo labeled images.
The algorithm is iterated a few times by treating the student as a teacher to relabel the unlabeled data and training a new student.
Noisy Student Training seeks to improve on self-training and distillation in two ways. First, it makes the student larger than, or at least equal to, the teacher so the student can better learn from a larger dataset. Second, it adds noise to the student so the noised student is forced to learn harder from the pseudo labels. To noise the student, it uses input noise such as RandAugment data augmentation, and model noise such as dropout and stochastic depth during training.
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('tf_efficientnet_b0_ns', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `tf_efficientnet_b0_ns`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('tf_efficientnet_b0_ns', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{xie2020selftraining,
title={Self-training with Noisy Student improves ImageNet classification},
author={Qizhe Xie and Minh-Thang Luong and Eduard Hovy and Quoc V. Le},
year={2020},
eprint={1911.04252},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
<!--
Type: model-index
Collections:
- Name: Noisy Student
Paper:
Title: Self-training with Noisy Student improves ImageNet classification
URL: https://paperswithcode.com/paper/self-training-with-noisy-student-improves
Models:
- Name: tf_efficientnet_b0_ns
In Collection: Noisy Student
Metadata:
FLOPs: 488688572
Parameters: 5290000
File Size: 21386709
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- FixRes
- Label Smoothing
- Noisy Student
- RMSProp
- RandAugment
- Weight Decay
Training Data:
- ImageNet
- JFT-300M
Training Resources: Cloud TPU v3 Pod
ID: tf_efficientnet_b0_ns
LR: 0.128
Epochs: 700
Dropout: 0.5
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 2048
Image Size: '224'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Stochastic Depth Survival: 0.8
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1427
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b0_ns-c0e6a31c.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.66%
Top 5 Accuracy: 94.37%
- Name: tf_efficientnet_b1_ns
In Collection: Noisy Student
Metadata:
FLOPs: 883633200
Parameters: 7790000
File Size: 31516408
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- FixRes
- Label Smoothing
- Noisy Student
- RMSProp
- RandAugment
- Weight Decay
Training Data:
- ImageNet
- JFT-300M
Training Resources: Cloud TPU v3 Pod
ID: tf_efficientnet_b1_ns
LR: 0.128
Epochs: 700
Dropout: 0.5
Crop Pct: '0.882'
Momentum: 0.9
Batch Size: 2048
Image Size: '240'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Stochastic Depth Survival: 0.8
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1437
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b1_ns-99dd0c41.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.39%
Top 5 Accuracy: 95.74%
- Name: tf_efficientnet_b2_ns
In Collection: Noisy Student
Metadata:
FLOPs: 1234321170
Parameters: 9110000
File Size: 36801803
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- FixRes
- Label Smoothing
- Noisy Student
- RMSProp
- RandAugment
- Weight Decay
Training Data:
- ImageNet
- JFT-300M
Training Resources: Cloud TPU v3 Pod
ID: tf_efficientnet_b2_ns
LR: 0.128
Epochs: 700
Dropout: 0.5
Crop Pct: '0.89'
Momentum: 0.9
Batch Size: 2048
Image Size: '260'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Stochastic Depth Survival: 0.8
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1447
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b2_ns-00306e48.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 82.39%
Top 5 Accuracy: 96.24%
- Name: tf_efficientnet_b3_ns
In Collection: Noisy Student
Metadata:
FLOPs: 2275247568
Parameters: 12230000
File Size: 49385734
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- FixRes
- Label Smoothing
- Noisy Student
- RMSProp
- RandAugment
- Weight Decay
Training Data:
- ImageNet
- JFT-300M
Training Resources: Cloud TPU v3 Pod
ID: tf_efficientnet_b3_ns
LR: 0.128
Epochs: 700
Dropout: 0.5
Crop Pct: '0.904'
Momentum: 0.9
Batch Size: 2048
Image Size: '300'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Stochastic Depth Survival: 0.8
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1457
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b3_ns-9d44bf68.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 84.04%
Top 5 Accuracy: 96.91%
- Name: tf_efficientnet_b4_ns
In Collection: Noisy Student
Metadata:
FLOPs: 5749638672
Parameters: 19340000
File Size: 77995057
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- FixRes
- Label Smoothing
- Noisy Student
- RMSProp
- RandAugment
- Weight Decay
Training Data:
- ImageNet
- JFT-300M
Training Resources: Cloud TPU v3 Pod
ID: tf_efficientnet_b4_ns
LR: 0.128
Epochs: 700
Dropout: 0.5
Crop Pct: '0.922'
Momentum: 0.9
Batch Size: 2048
Image Size: '380'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Stochastic Depth Survival: 0.8
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1467
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b4_ns-d6313a46.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 85.15%
Top 5 Accuracy: 97.47%
- Name: tf_efficientnet_b5_ns
In Collection: Noisy Student
Metadata:
FLOPs: 13176501888
Parameters: 30390000
File Size: 122404944
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- FixRes
- Label Smoothing
- Noisy Student
- RMSProp
- RandAugment
- Weight Decay
Training Data:
- ImageNet
- JFT-300M
Training Resources: Cloud TPU v3 Pod
ID: tf_efficientnet_b5_ns
LR: 0.128
Epochs: 350
Dropout: 0.5
Crop Pct: '0.934'
Momentum: 0.9
Batch Size: 2048
Image Size: '456'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Stochastic Depth Survival: 0.8
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1477
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b5_ns-6f26d0cf.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 86.08%
Top 5 Accuracy: 97.75%
- Name: tf_efficientnet_b6_ns
In Collection: Noisy Student
Metadata:
FLOPs: 24180518488
Parameters: 43040000
File Size: 173239537
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- FixRes
- Label Smoothing
- Noisy Student
- RMSProp
- RandAugment
- Weight Decay
Training Data:
- ImageNet
- JFT-300M
Training Resources: Cloud TPU v3 Pod
ID: tf_efficientnet_b6_ns
LR: 0.128
Epochs: 350
Dropout: 0.5
Crop Pct: '0.942'
Momentum: 0.9
Batch Size: 2048
Image Size: '528'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Stochastic Depth Survival: 0.8
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1487
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b6_ns-51548356.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 86.45%
Top 5 Accuracy: 97.88%
- Name: tf_efficientnet_b7_ns
In Collection: Noisy Student
Metadata:
FLOPs: 48205304880
Parameters: 66349999
File Size: 266853140
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- FixRes
- Label Smoothing
- Noisy Student
- RMSProp
- RandAugment
- Weight Decay
Training Data:
- ImageNet
- JFT-300M
Training Resources: Cloud TPU v3 Pod
ID: tf_efficientnet_b7_ns
LR: 0.128
Epochs: 350
Dropout: 0.5
Crop Pct: '0.949'
Momentum: 0.9
Batch Size: 2048
Image Size: '600'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Stochastic Depth Survival: 0.8
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1498
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b7_ns-1dbc32de.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 86.83%
Top 5 Accuracy: 98.08%
- Name: tf_efficientnet_l2_ns
In Collection: Noisy Student
Metadata:
FLOPs: 611646113804
Parameters: 480310000
File Size: 1925950424
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- FixRes
- Label Smoothing
- Noisy Student
- RMSProp
- RandAugment
- Weight Decay
Training Data:
- ImageNet
- JFT-300M
Training Resources: Cloud TPU v3 Pod
Training Time: 6 days
ID: tf_efficientnet_l2_ns
LR: 0.128
Epochs: 350
Dropout: 0.5
Crop Pct: '0.96'
Momentum: 0.9
Batch Size: 2048
Image Size: '800'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Stochastic Depth Survival: 0.8
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1520
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_l2_ns-df73bb44.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 88.35%
Top 5 Accuracy: 98.66%
-->
|
huggingface/pytorch-image-models/blob/main/docs/models/noisy-student.md
|
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Adding support for an unsupported architecture
If you wish to export a model whose architecture is not already supported by the library, these are the main steps to follow:
1. Implement a custom ONNX configuration.
2. Register the ONNX configuration in the [`~optimum.exporters.TasksManager`].
2. Export the model to ONNX.
3. Validate the outputs of the original and exported models.
In this section, we'll look at how BERT was implemented to show what's involved with each step.
## Implementing a custom ONNX configuration
Let's start with the ONNX configuration object. We provide a 3-level [class hierarchy](/exporters/onnx/package_reference/configuration),
and to add support for a model, inheriting from the right middle-end class will be the way to go most of the time. You might have to
implement a middle-end class yourself if you are adding an architecture handling a modality and/or case never seen before.
<Tip>
A good way to implement a custom ONNX configuration is to look at the existing configuration implementations in the
`optimum/exporters/onnx/model_configs.py` file.
Also, if the architecture you are trying to add is (very) similar to an architecture that is already supported
(for instance adding support for ALBERT when BERT is already supported), trying to simply inheriting from this class
might work.
</Tip>
When inheriting from a middle-end class, look for the one handling the same modality / category of models as the one you
are trying to support.
### Example: Adding support for BERT
Since BERT is an encoder-based model for text, its configuration inherits from the middle-end class [`~optimum.exporters.onnx.config.TextEncoderOnnxConfig`].
In `optimum/exporters/onnx/model_configs.py`:
```python
# This class is actually in optimum/exporters/onnx/config.py
class TextEncoderOnnxConfig(OnnxConfig):
# Describes how to generate the dummy inputs.
DUMMY_INPUT_GENERATOR_CLASSES = (DummyTextInputGenerator,)
class BertOnnxConfig(TextEncoderOnnxConfig):
# Specifies how to normalize the BertConfig, this is needed to access common attributes
# during dummy input generation.
NORMALIZED_CONFIG_CLASS = NormalizedTextConfig
# Sets the absolute tolerance to when validating the exported ONNX model against the
# reference model.
ATOL_FOR_VALIDATION = 1e-4
@property
def inputs(self) -> Dict[str, Dict[int, str]]:
if self.task == "multiple-choice":
dynamic_axis = {0: "batch_size", 1: "num_choices", 2: "sequence_length"}
else:
dynamic_axis = {0: "batch_size", 1: "sequence_length"}
return {
"input_ids": dynamic_axis,
"attention_mask": dynamic_axis,
"token_type_ids": dynamic_axis,
}
```
First let's explain what `TextEncoderOnnxConfig` is all about. While most of the features are already implemented in `OnnxConfig`,
this class is modality-agnostic, meaning that it does not know what kind of inputs it should handle. The way input generation is
handled is via the `DUMMY_INPUT_GENERATOR_CLASSES` attribute, which is a tuple of [`~optimum.utils.input_generators.DummyInputGenerator`]s.
Here we are making a modality-aware configuration inheriting from `OnnxConfig` by specifying
`DUMMY_INPUT_GENERATOR_CLASSES = (DummyTextInputGenerator,)`.
Then comes the model-specific class, `BertOnnxConfig`. Two class attributes are specified here:
- `NORMALIZED_CONFIG_CLASS`: this must be a [`~optimum.utils.normalized_config.NormalizedConfig`], it basically allows
the input generator to access the model config attributes in a generic way.
- `ATOL_FOR_VALIDATION`: it is used when validating the exported model against the original one, this is the absolute
acceptable tolerance for the output values difference.
Every configuration object must implement the [`~optimum.exporters.onnx.OnnxConfig.inputs`] property and return a mapping, where each key corresponds to an
input name, and each value indicates the axes in that input that are dynamic.
For BERT, we can see that three inputs are required: `input_ids`, `attention_mask` and `token_type_ids`.
These inputs have the same shape of `(batch_size, sequence_length)` (except for the `multiple-choice` task) which is
why we see the same axes used in the configuration.
Once you have implemented an ONNX configuration, you can instantiate it by providing the base model's configuration as follows:
```python
>>> from transformers import AutoConfig
>>> from optimum.exporters.onnx.model_configs import BertOnnxConfig
>>> config = AutoConfig.from_pretrained("bert-base-uncased")
>>> onnx_config = BertOnnxConfig(config)
```
The resulting object has several useful properties. For example, you can view the ONNX
operator set that will be used during the export:
```python
>>> print(onnx_config.DEFAULT_ONNX_OPSET)
11
```
You can also view the outputs associated with the model as follows:
```python
>>> print(onnx_config.outputs)
OrderedDict([('last_hidden_state', {0: 'batch_size', 1: 'sequence_length'})])
```
Notice that the outputs property follows the same structure as the inputs; it returns an
`OrderedDict` of named outputs and their shapes. The output structure is linked to the
choice of task that the configuration is initialised with. By default, the ONNX
configuration is initialized with the `default` task that corresponds to exporting a
model loaded with the `AutoModel` class. If you want to export a model for another task,
just provide a different task to the `task` argument when you initialize the ONNX
configuration. For example, if we wished to export BERT with a sequence
classification head, we could use:
```python
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("bert-base-uncased")
>>> onnx_config_for_seq_clf = BertOnnxConfig(config, task="text-classification")
>>> print(onnx_config_for_seq_clf.outputs)
OrderedDict([('logits', {0: 'batch_size'})])
```
<Tip>
Check out [`BartOnnxConfig`] for an advanced example.
</Tip>
## Registering the ONNX configuration in the TasksManager
The [`~optimum.exporters.tasks.TasksManager`] is the main entry-point to load a model given a name and a task,
and to get the proper configuration for a given (architecture, backend) couple. When adding support for the export to ONNX,
registering the configuration to the `TasksManager` will make the export available in the command line tool.
To do that, add an entry in the `_SUPPORTED_MODEL_TYPE` attribute:
- If the model is already supported for other backends than ONNX, it will already have an entry, so you will only need to
add an `onnx` key specifying the name of the configuration class.
- Otherwise, you will have to add the whole entry.
For BERT, it looks as follows:
```python
"bert": supported_tasks_mapping(
"default",
"fill-mask",
"text-generation",
"text-classification",
"multiple-choice",
"token-classification",
"question-answering",
onnx="BertOnnxConfig",
)
```
## Exporting the model
Once you have implemented the ONNX configuration, the next step is to export the model.
Here we can use the `export()` function provided by the `optimum.exporters.onnx` package.
This function expects the ONNX configuration, along with the base model, and the path to save the exported file:
```python
>>> from pathlib import Path
>>> from optimum.exporters import TasksManager
>>> from optimum.exporters.onnx import export
>>> from transformers import AutoModel
>>> base_model = AutoModel.from_pretrained("bert-base-uncased")
>>> onnx_path = Path("model.onnx")
>>> onnx_config_constructor = TasksManager.get_exporter_config_constructor("onnx", base_model)
>>> onnx_config = onnx_config_constructor(base_model.config)
>>> onnx_inputs, onnx_outputs = export(base_model, onnx_config, onnx_path, onnx_config.DEFAULT_ONNX_OPSET)
```
The `onnx_inputs` and `onnx_outputs` returned by the `export()` function are lists of the keys defined in the [`~optimum.exporters.onnx.OnnxConfig.inputs`]
and [`~optimum.exporters.onnx.OnnxConfig.inputs`] properties of the configuration. Once the model is exported, you can test that the model is well formed as follows:
```python
>>> import onnx
>>> onnx_model = onnx.load("model.onnx")
>>> onnx.checker.check_model(onnx_model)
```
<Tip>
If your model is larger than 2GB, you will see that many additional files are created during the export. This is
_expected_ because ONNX uses [Protocol Buffers](https://developers.google.com/protocol-buffers/) to store the model
and these have a size limit of 2GB. See the [ONNX documentation](https://github.com/onnx/onnx/blob/master/docs/ExternalData.md)
for instructions on how to load models with external data.
</Tip>
## Validating the model outputs
The final step is to validate that the outputs from the base and exported model agree within some absolute tolerance.
Here we can use the `validate_model_outputs()` function provided by the `optimum.exporters.onnx` package:
```python
>>> from optimum.exporters.onnx import validate_model_outputs
>>> validate_model_outputs(
... onnx_config, base_model, onnx_path, onnx_outputs, onnx_config.ATOL_FOR_VALIDATION
... )
```
## Contributing the new configuration to 🤗 Optimum
Now that the support for the architectures has been implemented, and validated, there are two things left:
1. Add your model architecture to the tests in `tests/exporters/test_onnx_export.py`
2. Create a PR on the [`optimum` repo](https://github.com/huggingface/optimum)
Thanks for you contribution!
|
huggingface/optimum/blob/main/docs/source/exporters/onnx/usage_guides/contribute.mdx
|
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# LED
## Overview
The LED model was proposed in [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz
Beltagy, Matthew E. Peters, Arman Cohan.
The abstract from the paper is the following:
*Transformer-based models are unable to process long sequences due to their self-attention operation, which scales
quadratically with the sequence length. To address this limitation, we introduce the Longformer with an attention
mechanism that scales linearly with sequence length, making it easy to process documents of thousands of tokens or
longer. Longformer's attention mechanism is a drop-in replacement for the standard self-attention and combines a local
windowed attention with a task motivated global attention. Following prior work on long-sequence transformers, we
evaluate Longformer on character-level language modeling and achieve state-of-the-art results on text8 and enwik8. In
contrast to most prior work, we also pretrain Longformer and finetune it on a variety of downstream tasks. Our
pretrained Longformer consistently outperforms RoBERTa on long document tasks and sets new state-of-the-art results on
WikiHop and TriviaQA. We finally introduce the Longformer-Encoder-Decoder (LED), a Longformer variant for supporting
long document generative sequence-to-sequence tasks, and demonstrate its effectiveness on the arXiv summarization
dataset.*
## Usage tips
- [`LEDForConditionalGeneration`] is an extension of
[`BartForConditionalGeneration`] exchanging the traditional *self-attention* layer with
*Longformer*'s *chunked self-attention* layer. [`LEDTokenizer`] is an alias of
[`BartTokenizer`].
- LED works very well on long-range *sequence-to-sequence* tasks where the `input_ids` largely exceed a length of
1024 tokens.
- LED pads the `input_ids` to be a multiple of `config.attention_window` if required. Therefore a small speed-up is
gained, when [`LEDTokenizer`] is used with the `pad_to_multiple_of` argument.
- LED makes use of *global attention* by means of the `global_attention_mask` (see
[`LongformerModel`]). For summarization, it is advised to put *global attention* only on the first
`<s>` token. For question answering, it is advised to put *global attention* on all tokens of the question.
- To fine-tune LED on all 16384, *gradient checkpointing* can be enabled in case training leads to out-of-memory (OOM)
errors. This can be done by executing `model.gradient_checkpointing_enable()`.
Moreover, the `use_cache=False`
flag can be used to disable the caching mechanism to save memory.
- LED is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
## Resources
- [A notebook showing how to evaluate LED](https://colab.research.google.com/drive/12INTTR6n64TzS4RrXZxMSXfrOd9Xzamo?usp=sharing).
- [A notebook showing how to fine-tune LED](https://colab.research.google.com/drive/12LjJazBl7Gam0XBPy_y0CTOJZeZ34c2v?usp=sharing).
- [Text classification task guide](../tasks/sequence_classification)
- [Question answering task guide](../tasks/question_answering)
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## LEDConfig
[[autodoc]] LEDConfig
## LEDTokenizer
[[autodoc]] LEDTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## LEDTokenizerFast
[[autodoc]] LEDTokenizerFast
## LED specific outputs
[[autodoc]] models.led.modeling_led.LEDEncoderBaseModelOutput
[[autodoc]] models.led.modeling_led.LEDSeq2SeqModelOutput
[[autodoc]] models.led.modeling_led.LEDSeq2SeqLMOutput
[[autodoc]] models.led.modeling_led.LEDSeq2SeqSequenceClassifierOutput
[[autodoc]] models.led.modeling_led.LEDSeq2SeqQuestionAnsweringModelOutput
[[autodoc]] models.led.modeling_tf_led.TFLEDEncoderBaseModelOutput
[[autodoc]] models.led.modeling_tf_led.TFLEDSeq2SeqModelOutput
[[autodoc]] models.led.modeling_tf_led.TFLEDSeq2SeqLMOutput
<frameworkcontent>
<pt>
## LEDModel
[[autodoc]] LEDModel
- forward
## LEDForConditionalGeneration
[[autodoc]] LEDForConditionalGeneration
- forward
## LEDForSequenceClassification
[[autodoc]] LEDForSequenceClassification
- forward
## LEDForQuestionAnswering
[[autodoc]] LEDForQuestionAnswering
- forward
</pt>
<tf>
## TFLEDModel
[[autodoc]] TFLEDModel
- call
## TFLEDForConditionalGeneration
[[autodoc]] TFLEDForConditionalGeneration
- call
</tf>
</frameworkcontent>
|
huggingface/transformers/blob/main/docs/source/en/model_doc/led.md
|
--
title: "Faster Training and Inference: Habana Gaudi®2 vs Nvidia A100 80GB"
thumbnail: /blog/assets/habana-gaudi-2-benchmark/thumbnail.png
authors:
- user: regisss
---
# Faster Training and Inference: Habana Gaudi®-2 vs Nvidia A100 80GB
In this article, you will learn how to use [Habana® Gaudi®2](https://habana.ai/training/gaudi2/) to accelerate model training and inference, and train bigger models with 🤗 [Optimum Habana](https://huggingface.co/docs/optimum/habana/index). Then, we present several benchmarks including BERT pre-training, Stable Diffusion inference and T5-3B fine-tuning, to assess the performance differences between first generation Gaudi, Gaudi2 and Nvidia A100 80GB. Spoiler alert - Gaudi2 is about twice faster than Nvidia A100 80GB for both training and inference!
[Gaudi2](https://habana.ai/training/gaudi2/) is the second generation AI hardware accelerator designed by Habana Labs. A single server contains 8 accelerator devices with 96GB of memory each (versus 32GB on first generation Gaudi and 80GB on A100 80GB). The Habana SDK, [SynapseAI](https://developer.habana.ai/), is common to both first-gen Gaudi and Gaudi2.
That means that 🤗 Optimum Habana, which offers a very user-friendly interface between the 🤗 Transformers and 🤗 Diffusers libraries and SynapseAI, **works the exact same way on Gaudi2 as on first-gen Gaudi!**
So if you already have ready-to-use training or inference workflows for first-gen Gaudi, we encourage you to try them on Gaudi2, as they will work without any single change.
## How to Get Access to Gaudi2?
One of the easy, cost-efficient ways that Intel and Habana have made Gaudi2 available is on the Intel Developer Cloud. To start using Gaudi2 there, you should follow the following steps:
1. Go to the [Intel Developer Cloud landing page](https://www.intel.com/content/www/us/en/developer/tools/devcloud/services.html) and sign in to your account or register if you do not have one.
2. Go to the [Intel Developer Cloud management console](https://scheduler.cloud.intel.com/#/systems).
3. Select *Habana Gaudi2 Deep Learning Server featuring eight Gaudi2 HL-225H mezzanine cards and latest Intel® Xeon® Processors* and click on *Launch Instance* in the lower right corner as shown below.
<figure class="image table text-center m-0 w-full">
<img src="assets/habana-gaudi-2-benchmark/launch_instance.png" alt="Cloud Architecture"/>
</figure>
4. You can then request an instance:
<figure class="image table text-center m-0 w-full">
<img src="assets/habana-gaudi-2-benchmark/request_instance.png" alt="Cloud Architecture"/>
</figure>
5. Once your request is validated, re-do step 3 and click on *Add OpenSSH Publickey* to add a payment method (credit card or promotion code) and a SSH public key that you can generate with `ssh-keygen -t rsa -b 4096 -f ~/.ssh/id_rsa`. You may be redirected to step 3 each time you add a payment method or a SSH public key.
6. Re-do step 3 and then click on *Launch Instance*. You will have to accept the proposed general conditions to actually launch the instance.
7. Go to the [Intel Developer Cloud management console](https://scheduler.cloud.intel.com/#/systems) and click on the tab called *View Instances*.
8. You can copy the SSH command to access your Gaudi2 instance remotely!
> If you terminate the instance and want to use Gaudi2 again, you will have to re-do the whole process.
You can find more information about this process [here](https://scheduler.cloud.intel.com/public/Intel_Developer_Cloud_Getting_Started.html).
## Benchmarks
Several benchmarks were performed to assess the abilities of first-gen Gaudi, Gaudi2 and A100 80GB for both training and inference, and for models of various sizes.
### Pre-Training BERT
A few months ago, [Philipp Schmid](https://huggingface.co/philschmid), technical lead at Hugging Face, presented [how to pre-train BERT on Gaudi with 🤗 Optimum Habana](https://huggingface.co/blog/pretraining-bert). 65k training steps were performed with a batch size of 32 samples per device (so 8*32=256 in total) for a total training time of 8 hours and 53 minutes (you can see the TensorBoard logs of this run [here](https://huggingface.co/philschmid/bert-base-uncased-2022-habana-test-6/tensorboard?scroll=1#scalars)).
We re-ran the same script with the same hyperparameters on Gaudi2 and got a total training time of 2 hours and 55 minutes (see the logs [here](https://huggingface.co/regisss/bert-pretraining-gaudi-2-batch-size-32/tensorboard?scroll=1#scalars)). **That makes a x3.04 speedup on Gaudi2 without changing anything.**
Since Gaudi2 has roughly 3 times more memory per device compared to first-gen Gaudi, it is possible to leverage this greater capacity to have bigger batches. This will give HPUs more work to do and will also enable developers to try a range of hyperparameter values that was not reachable with first-gen Gaudi. With a batch size of 64 samples per device (512 in total), we got with 20k steps a similar loss convergence to the 65k steps of the previous runs. That makes a total training time of 1 hour and 33 minutes (see the logs [here](https://huggingface.co/regisss/bert-pretraining-gaudi-2-batch-size-64/tensorboard?scroll=1#scalars)). The throughput is x1.16 higher with this configuration, while this new batch size strongly accelerates convergence.
**Overall, with Gaudi2, the total training time is reduced by a 5.75 factor and the throughput is x3.53 higher compared to first-gen Gaudi**.
**Gaudi2 also offers a speedup over A100**: 1580.2 samples/s versus 981.6 for a batch size of 32 and 1835.8 samples/s versus 1082.6 for a batch size of 64, which is consistent with the x1.8 speedup [announced by Habana](https://habana.ai/training/gaudi2/) on the phase 1 of BERT pre-training with a batch size of 64.
The following table displays the throughputs we got for first-gen Gaudi, Gaudi2 and Nvidia A100 80GB GPUs:
<center>
| | First-gen Gaudi (BS=32) | Gaudi2 (BS=32) | Gaudi2 (BS=64) | A100 (BS=32) | A100 (BS=64) |
|:-:|:-----------------------:|:--------------:|:--------------:|:-------:|:---------------------:|
| Throughput (samples/s) | 520.2 | 1580.2 | 1835.8 | 981.6 | 1082.6 |
| Speedup | x1.0 | x3.04 | x3.53 | x1.89 | x2.08 |
</center>
*BS* is the batch size per device. The Gaudi runs were performed in mixed precision (bf16/fp32) and the A100 runs in fp16. All runs were *distributed* runs on *8 devices*.
### Generating Images from Text with Stable Diffusion
One of the main new features of 🤗 Optimum Habana release 1.3 is [the support for Stable Diffusion](https://huggingface.co/docs/optimum/habana/usage_guides/stable_diffusion). It is now very easy to generate images from text on Gaudi. Unlike with 🤗 Diffusers on GPUs, images are generated by batches. Due to model compilation times, the first two batches will be slower than the following iterations. In this benchmark, these first two iterations were discarded to compute the throughputs for both first-gen Gaudi and Gaudi2.
[This script](https://github.com/huggingface/optimum-habana/tree/main/examples/stable-diffusion) was run for a batch size of 8 samples. It uses the [`Habana/stable-diffusion`](https://huggingface.co/Habana/stable-diffusion) Gaudi configuration.
The results we got, which are consistent with the numbers published by Habana [here](https://developer.habana.ai/resources/habana-models-performance/), are displayed in the table below.
**Gaudi2 showcases latencies that are x3.51 faster than first-gen Gaudi (3.25s versus 0.925s) and x2.84 faster than Nvidia A100 (2.63s versus 0.925s).** It can also support bigger batch sizes.
<center>
| | First-gen Gaudi (BS=8) | Gaudi2 (BS=8) | A100 (BS=1) |
|:---------------:|:----------------------:|:-------------:|:-----------:|
| Latency (s/img) | 3.25 | 0.925 | 2.63 |
| Speedup | x1.0 | x3.51 | x1.24 |
</center>
*Update: the figures above were updated as SynapseAI 1.10 and Optimum Habana 1.6 bring an additional speedup on first-gen Gaudi and Gaudi2.*
*BS* is the batch size.
The Gaudi runs were performed in *bfloat16* precision and the A100 runs in *fp16* precision (more information [here](https://huggingface.co/docs/diffusers/optimization/fp16)). All runs were *single-device* runs.
### Fine-tuning T5-3B
With 96 GB of memory per device, Gaudi2 enables running much bigger models. For instance, we managed to fine-tune T5-3B (containing 3 billion parameters) with gradient checkpointing being the only applied memory optimization. This is not possible on first-gen Gaudi.
[Here](https://huggingface.co/regisss/t5-3b-summarization-gaudi-2/tensorboard?scroll=1#scalars) are the logs of this run where the model was fine-tuned on the CNN DailyMail dataset for text summarization using [this script](https://github.com/huggingface/optimum-habana/tree/main/examples/summarization).
The results we achieved are presented in the table below. **Gaudi2 is x2.44 faster than A100 80GB.** We observe that we cannot fit a batch size larger than 1 on Gaudi2 here. This is due to the memory space taken by the graph where operations are accumulated during the first iteration of the run. Habana is working on optimizing the memory footprint in future releases of SynapseAI. We are looking forward to expanding this benchmark using newer versions of Habana's SDK and also using [DeepSpeed](https://www.deepspeed.ai/) to see if the same trend holds.
<center>
| | First-gen Gaudi | Gaudi2 (BS=1) | A100 (BS=16) |
|:-:|:-------:|:--------------:|:------------:|
| Throughput (samples/s) | N/A | 19.7 | 8.07 |
| Speedup | / | x2.44 | x1.0 |
</center>
*BS* is the batch size per device. Gaudi2 and A100 runs were performed in fp32 with gradient checkpointing enabled. All runs were *distributed* runs on *8 devices*.
## Conclusion
In this article, we discuss our first experience with Gaudi2. The transition from first generation Gaudi to Gaudi2 is completely seamless since SynapseAI, Habana's SDK, is fully compatible with both. This means that new optimizations proposed by future releases will benefit both of them.
You have seen that Habana Gaudi2 significantly improves performance over first generation Gaudi and delivers about twice the throughput speed as Nvidia A100 80GB for both training and inference.
You also know now how to setup a Gaudi2 instance through the Intel Developer Zone. Check out the [examples](https://github.com/huggingface/optimum-habana/tree/main/examples) you can easily run on it with 🤗 Optimum Habana.
If you are interested in accelerating your Machine Learning training and inference workflows using the latest AI hardware accelerators and software libraries, check out our [Expert Acceleration Program](https://huggingface.co/support). To learn more about Habana solutions, [read about our partnership here](https://huggingface.co/hardware/habana) and [contact them](https://habana.ai/contact-us/). To learn more about Hugging Face efforts to make AI hardware accelerators easy to use, check out our [Hardware Partner Program](https://huggingface.co/hardware).
### Related Topics
- [Getting Started on Transformers with Habana Gaudi](https://huggingface.co/blog/getting-started-habana)
- [Accelerate Transformer Model Training with Hugging Face and Habana Labs](https://developer.habana.ai/events/accelerate-transformer-model-training-with-hugging-face-and-habana-labs/)
---
Thanks for reading! If you have any questions, feel free to contact me, either through [Github](https://github.com/huggingface/optimum-habana) or on the [forum](https://discuss.huggingface.co/c/optimum/59). You can also connect with me on [LinkedIn](https://www.linkedin.com/in/regispierrard/).
|
huggingface/blog/blob/main/habana-gaudi-2-benchmark.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Quicktour
PEFT offers parameter-efficient methods for finetuning large pretrained models. The traditional paradigm is to finetune all of a model's parameters for each downstream task, but this is becoming exceedingly costly and impractical because of the enormous number of parameters in models today. Instead, it is more efficient to train a smaller number of prompt parameters or use a reparametrization method like low-rank adaptation (LoRA) to reduce the number of trainable parameters.
This quicktour will show you PEFT's main features and how you can train or run inference on large models that would typically be inaccessible on consumer devices.
## Train
Each PEFT method is defined by a [`PeftConfig`] class that stores all the important parameters for building a [`PeftModel`]. For example, to train with LoRA, load and create a [`LoraConfig`] class and specify the following parameters:
- `task_type`: the task to train for (sequence-to-sequence language modeling in this case)
- `inference_mode`: whether you're using the model for inference or not
- `r`: the dimension of the low-rank matrices
- `lora_alpha`: the scaling factor for the low-rank matrices
- `lora_dropout`: the dropout probability of the LoRA layers
```python
from peft import LoraConfig, TaskType
peft_config = LoraConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1)
```
<Tip>
See the [`LoraConfig`] reference for more details about other parameters you can adjust, such as the modules to target or the bias type.
</Tip>
Once the [`LoraConfig`] is setup, create a [`PeftModel`] with the [`get_peft_model`] function. It takes a base model - which you can load from the Transformers library - and the [`LoraConfig`] containing the parameters for how to configure a model for training with LoRA.
Load the base model you want to finetune.
```python
from transformers import AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/mt0-large")
```
Wrap the base model and `peft_config` with the [`get_peft_model`] function to create a [`PeftModel`]. To get a sense of the number of trainable parameters in your model, use the [`print_trainable_parameters`] method.
```python
from peft import get_peft_model
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
"output: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282"
```
Out of [bigscience/mt0-large's](https://huggingface.co/bigscience/mt0-large) 1.2B parameters, you're only training 0.19% of them!
That is it 🎉! Now you can train the model with the Transformers [`~transformers.Trainer`], Accelerate, or any custom PyTorch training loop.
For example, to train with the [`~transformers.Trainer`] class, setup a [`~transformers.TrainingArguments`] class with some training hyperparameters.
```py
training_args = TrainingArguments(
output_dir="your-name/bigscience/mt0-large-lora",
learning_rate=1e-3,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
num_train_epochs=2,
weight_decay=0.01,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
)
```
Pass the model, training arguments, dataset, tokenizer, and any other necessary component to the [`~transformers.Trainer`], and call [`~transformers.Trainer.train`] to start training.
```py
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
trainer.train()
```
### Save model
After your model is finished training, you can save your model to a directory using the [`~transformers.PreTrainedModel.save_pretrained`] function.
```py
model.save_pretrained("output_dir")
```
You can also save your model to the Hub (make sure you're logged in to your Hugging Face account first) with the [`~transformers.PreTrainedModel.push_to_hub`] function.
```python
from huggingface_hub import notebook_login
notebook_login()
model.push_to_hub("your-name/bigscience/mt0-large-lora")
```
Both methods only save the extra PEFT weights that were trained, meaning it is super efficient to store, transfer, and load. For example, this [facebook/opt-350m](https://huggingface.co/ybelkada/opt-350m-lora) model trained with LoRA only contains two files: `adapter_config.json` and `adapter_model.safetensors`. The `adapter_model.safetensors` file is just 6.3MB!
<div class="flex flex-col justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/PEFT-hub-screenshot.png"/>
<figcaption class="text-center">The adapter weights for a opt-350m model stored on the Hub are only ~6MB compared to the full size of the model weights, which can be ~700MB.</figcaption>
</div>
## Inference
<Tip>
Take a look at the [AutoPeftModel](package_reference/auto_class) API reference for a complete list of available `AutoPeftModel` classes.
</Tip>
Easily load any PEFT-trained model for inference with the [`AutoPeftModel`] class and the [`~transformers.PreTrainedModel.from_pretrained`] method:
```py
from peft import AutoPeftModelForCausalLM
from transformers import AutoTokenizer
import torch
model = AutoPeftModelForCausalLM.from_pretrained("ybelkada/opt-350m-lora")
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
model = model.to("cuda")
model.eval()
inputs = tokenizer("Preheat the oven to 350 degrees and place the cookie dough", return_tensors="pt")
outputs = model.generate(input_ids=inputs["input_ids"].to("cuda"), max_new_tokens=50)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True)[0])
"Preheat the oven to 350 degrees and place the cookie dough in the center of the oven. In a large bowl, combine the flour, baking powder, baking soda, salt, and cinnamon. In a separate bowl, combine the egg yolks, sugar, and vanilla."
```
For other tasks that aren't explicitly supported with an `AutoPeftModelFor` class - such as automatic speech recognition - you can still use the base [`AutoPeftModel`] class to load a model for the task.
```py
from peft import AutoPeftModel
model = AutoPeftModel.from_pretrained("smangrul/openai-whisper-large-v2-LORA-colab")
```
## Next steps
Now that you've seen how to train a model with one of the PEFT methods, we encourage you to try out some of the other methods like prompt tuning. The steps are very similar to the ones shown in the quicktour:
1. prepare a [`PeftConfig`] for a PEFT method
2. use the [`get_peft_model`] method to create a [`PeftModel`] from the configuration and base model
Then you can train it however you like! To load a PEFT model for inference, you can use the [`AutoPeftModel`] class.
Feel free to also take a look at the task guides if you're interested in training a model with another PEFT method for a specific task such as semantic segmentation, multilingual automatic speech recognition, DreamBooth, token classification, and more.
|
huggingface/peft/blob/main/docs/source/quicktour.md
|
!---
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<h1 align="center"> <p>🤗 PEFT</p></h1>
<h3 align="center">
<p>State-of-the-art Parameter-Efficient Fine-Tuning (PEFT) methods</p>
</h3>
Parameter-Efficient Fine-Tuning (PEFT) methods enable efficient adaptation of pre-trained language models (PLMs) to various downstream applications without fine-tuning all the model's parameters. Fine-tuning large-scale PLMs is often prohibitively costly. In this regard, PEFT methods only fine-tune a small number of (extra) model parameters, thereby greatly decreasing the computational and storage costs. Recent State-of-the-Art PEFT techniques achieve performance comparable to that of full fine-tuning.
Seamlessly integrated with 🤗 Accelerate for large scale models leveraging DeepSpeed and Big Model Inference.
Supported methods:
1. LoRA: [LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS](https://arxiv.org/abs/2106.09685)
2. Prefix Tuning: [Prefix-Tuning: Optimizing Continuous Prompts for Generation](https://aclanthology.org/2021.acl-long.353/), [P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks](https://arxiv.org/pdf/2110.07602.pdf)
3. P-Tuning: [GPT Understands, Too](https://arxiv.org/abs/2103.10385)
4. Prompt Tuning: [The Power of Scale for Parameter-Efficient Prompt Tuning](https://arxiv.org/abs/2104.08691)
5. AdaLoRA: [Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning](https://arxiv.org/abs/2303.10512)
6. $(IA)^3$: [Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning](https://arxiv.org/abs/2205.05638)
7. MultiTask Prompt Tuning: [Multitask Prompt Tuning Enables Parameter-Efficient Transfer Learning](https://arxiv.org/abs/2303.02861)
8. LoHa: [FedPara: Low-Rank Hadamard Product for Communication-Efficient Federated Learning](https://arxiv.org/abs/2108.06098)
9. LoKr: [KronA: Parameter Efficient Tuning with Kronecker Adapter](https://arxiv.org/abs/2212.10650) based on [Navigating Text-To-Image Customization:From LyCORIS Fine-Tuning to Model Evaluation](https://arxiv.org/abs/2309.14859) implementation
10. LoftQ: [LoftQ: LoRA-Fine-Tuning-aware Quantization for Large Language Models](https://arxiv.org/abs/2310.08659)
11. OFT: [Controlling Text-to-Image Diffusion by Orthogonal Finetuning](https://arxiv.org/abs/2306.07280)
## Getting started
```python
from transformers import AutoModelForSeq2SeqLM
from peft import get_peft_config, get_peft_model, LoraConfig, TaskType
model_name_or_path = "bigscience/mt0-large"
tokenizer_name_or_path = "bigscience/mt0-large"
peft_config = LoraConfig(
task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
# output: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282
```
## Use Cases
### Get comparable performance to full finetuning by adapting LLMs to downstream tasks using consumer hardware
GPU memory required for adapting LLMs on the few-shot dataset [`ought/raft/twitter_complaints`](https://huggingface.co/datasets/ought/raft/viewer/twitter_complaints). Here, settings considered
are full finetuning, PEFT-LoRA using plain PyTorch and PEFT-LoRA using DeepSpeed with CPU Offloading.
Hardware: Single A100 80GB GPU with CPU RAM above 64GB
| Model | Full Finetuning | PEFT-LoRA PyTorch | PEFT-LoRA DeepSpeed with CPU Offloading |
| --------- | ---- | ---- | ---- |
| bigscience/T0_3B (3B params) | 47.14GB GPU / 2.96GB CPU | 14.4GB GPU / 2.96GB CPU | 9.8GB GPU / 17.8GB CPU |
| bigscience/mt0-xxl (12B params) | OOM GPU | 56GB GPU / 3GB CPU | 22GB GPU / 52GB CPU |
| bigscience/bloomz-7b1 (7B params) | OOM GPU | 32GB GPU / 3.8GB CPU | 18.1GB GPU / 35GB CPU |
Performance of PEFT-LoRA tuned [`bigscience/T0_3B`](https://huggingface.co/bigscience/T0_3B) on [`ought/raft/twitter_complaints`](https://huggingface.co/datasets/ought/raft/viewer/twitter_complaints) leaderboard.
A point to note is that we didn't try to squeeze performance by playing around with input instruction templates, LoRA hyperparams and other training related hyperparams. Also, we didn't use the larger 13B [mt0-xxl](https://huggingface.co/bigscience/mt0-xxl) model.
So, we are already seeing comparable performance to SoTA with parameter efficient tuning. Also, the final additional checkpoint size is just `19MB` in comparison to `11GB` size of the backbone [`bigscience/T0_3B`](https://huggingface.co/bigscience/T0_3B) model, but one still has to load the original full size model.
| Submission Name | Accuracy |
| --------- | ---- |
| Human baseline (crowdsourced) | 0.897 |
| Flan-T5 | 0.892 |
| lora-t0-3b | 0.863 |
**Therefore, we can see that performance comparable to SoTA is achievable by PEFT methods with consumer hardware such as 16GB and 24GB GPUs.**
An insightful blogpost explaining the advantages of using PEFT for fine-tuning FlanT5-XXL: [https://www.philschmid.de/fine-tune-flan-t5-peft](https://www.philschmid.de/fine-tune-flan-t5-peft)
### Parameter Efficient Tuning of Diffusion Models
GPU memory required by different settings during training is given below. The final checkpoint size is `8.8 MB`.
Hardware: Single A100 80GB GPU with CPU RAM above 64GB
| Model | Full Finetuning | PEFT-LoRA | PEFT-LoRA with Gradient Checkpointing |
| --------- | ---- | ---- | ---- |
| CompVis/stable-diffusion-v1-4 | 27.5GB GPU / 3.97GB CPU | 15.5GB GPU / 3.84GB CPU | 8.12GB GPU / 3.77GB CPU |
**Training**
An example of using LoRA for parameter efficient dreambooth training is given in [`examples/lora_dreambooth/train_dreambooth.py`](examples/lora_dreambooth/train_dreambooth.py)
```bash
export MODEL_NAME= "CompVis/stable-diffusion-v1-4" #"stabilityai/stable-diffusion-2-1"
export INSTANCE_DIR="path-to-instance-images"
export CLASS_DIR="path-to-class-images"
export OUTPUT_DIR="path-to-save-model"
accelerate launch train_dreambooth.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--class_data_dir=$CLASS_DIR \
--output_dir=$OUTPUT_DIR \
--train_text_encoder \
--with_prior_preservation --prior_loss_weight=1.0 \
--instance_prompt="a photo of sks dog" \
--class_prompt="a photo of dog" \
--resolution=512 \
--train_batch_size=1 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--num_class_images=200 \
--use_lora \
--lora_r 16 \
--lora_alpha 27 \
--lora_text_encoder_r 16 \
--lora_text_encoder_alpha 17 \
--learning_rate=1e-4 \
--gradient_accumulation_steps=1 \
--gradient_checkpointing \
--max_train_steps=800
```
Try out the 🤗 Gradio Space which should run seamlessly on a T4 instance:
[smangrul/peft-lora-sd-dreambooth](https://huggingface.co/spaces/smangrul/peft-lora-sd-dreambooth).
**NEW** ✨ Multi Adapter support and combining multiple LoRA adapters in a weighted combination

**NEW** ✨ Dreambooth training for Stable Diffusion using LoHa and LoKr adapters [`examples/stable_diffusion/train_dreambooth.py`](examples/stable_diffusion/train_dreambooth.py)
### Parameter Efficient Tuning of LLMs for RLHF components such as Ranker and Policy
- Here is an example in [trl](https://github.com/lvwerra/trl) library using PEFT+INT8 for tuning policy model: [gpt2-sentiment_peft.py](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt2-sentiment_peft.py) and corresponding [Blog](https://huggingface.co/blog/trl-peft)
- Example using PEFT for Instruction finetuning, reward model and policy : [stack_llama](https://github.com/lvwerra/trl/tree/main/examples/research_projects/stack_llama/scripts) and corresponding [Blog](https://huggingface.co/blog/stackllama)
### INT8 training of large models in Colab using PEFT LoRA and bitsandbytes
- Here is now a demo on how to fine tune [OPT-6.7b](https://huggingface.co/facebook/opt-6.7b) (14GB in fp16) in a Google Colab: [](https://colab.research.google.com/drive/1jCkpikz0J2o20FBQmYmAGdiKmJGOMo-o?usp=sharing)
- Here is now a demo on how to fine tune [whisper-large](https://huggingface.co/openai/whisper-large-v2) (1.5B params) (14GB in fp16) in a Google Colab: [](https://colab.research.google.com/drive/1DOkD_5OUjFa0r5Ik3SgywJLJtEo2qLxO?usp=sharing) and [](https://colab.research.google.com/drive/1vhF8yueFqha3Y3CpTHN6q9EVcII9EYzs?usp=sharing)
### Save compute and storage even for medium and small models
Save storage by avoiding full finetuning of models on each of the downstream tasks/datasets,
With PEFT methods, users only need to store tiny checkpoints in the order of `MBs` all the while retaining
performance comparable to full finetuning.
An example of using LoRA for the task of adapting `LayoutLMForTokenClassification` on `FUNSD` dataset is given in `~examples/token_classification/PEFT_LoRA_LayoutLMForTokenClassification_on_FUNSD.py`. We can observe that with only `0.62 %` of parameters being trainable, we achieve performance (F1 0.777) comparable to full finetuning (F1 0.786) (without any hyperparam tuning runs for extracting more performance), and the checkpoint of this is only `2.8MB`. Now, if there are `N` such datasets, just have these PEFT models one for each dataset and save a lot of storage without having to worry about the problem of catastrophic forgetting or overfitting of backbone/base model.
Another example is fine-tuning [`roberta-large`](https://huggingface.co/roberta-large) on [`MRPC` GLUE](https://huggingface.co/datasets/glue/viewer/mrpc) dataset using different PEFT methods. The notebooks are given in `~examples/sequence_classification`.
## PEFT + 🤗 Accelerate
PEFT models work with 🤗 Accelerate out of the box. Use 🤗 Accelerate for Distributed training on various hardware such as GPUs, Apple Silicon devices, etc during training.
Use 🤗 Accelerate for inferencing on consumer hardware with small resources.
### Example of PEFT model training using 🤗 Accelerate's DeepSpeed integration
DeepSpeed version required `v0.8.0`. An example is provided in `~examples/conditional_generation/peft_lora_seq2seq_accelerate_ds_zero3_offload.py`.
a. First, run `accelerate config --config_file ds_zero3_cpu.yaml` and answer the questionnaire.
Below are the contents of the config file.
```yaml
compute_environment: LOCAL_MACHINE
deepspeed_config:
gradient_accumulation_steps: 1
gradient_clipping: 1.0
offload_optimizer_device: cpu
offload_param_device: cpu
zero3_init_flag: true
zero3_save_16bit_model: true
zero_stage: 3
distributed_type: DEEPSPEED
downcast_bf16: 'no'
dynamo_backend: 'NO'
fsdp_config: {}
machine_rank: 0
main_training_function: main
megatron_lm_config: {}
mixed_precision: 'no'
num_machines: 1
num_processes: 1
rdzv_backend: static
same_network: true
use_cpu: false
```
b. run the below command to launch the example script
```bash
accelerate launch --config_file ds_zero3_cpu.yaml examples/peft_lora_seq2seq_accelerate_ds_zero3_offload.py
```
c. output logs:
```bash
GPU Memory before entering the train : 1916
GPU Memory consumed at the end of the train (end-begin): 66
GPU Peak Memory consumed during the train (max-begin): 7488
GPU Total Peak Memory consumed during the train (max): 9404
CPU Memory before entering the train : 19411
CPU Memory consumed at the end of the train (end-begin): 0
CPU Peak Memory consumed during the train (max-begin): 0
CPU Total Peak Memory consumed during the train (max): 19411
epoch=4: train_ppl=tensor(1.0705, device='cuda:0') train_epoch_loss=tensor(0.0681, device='cuda:0')
100%|████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:27<00:00, 3.92s/it]
GPU Memory before entering the eval : 1982
GPU Memory consumed at the end of the eval (end-begin): -66
GPU Peak Memory consumed during the eval (max-begin): 672
GPU Total Peak Memory consumed during the eval (max): 2654
CPU Memory before entering the eval : 19411
CPU Memory consumed at the end of the eval (end-begin): 0
CPU Peak Memory consumed during the eval (max-begin): 0
CPU Total Peak Memory consumed during the eval (max): 19411
accuracy=100.0
eval_preds[:10]=['no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint', 'no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint']
dataset['train'][label_column][:10]=['no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint', 'no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint']
```
### Example of PEFT model inference using 🤗 Accelerate's Big Model Inferencing capabilities
An example is provided in [this notebook](https://github.com/huggingface/peft/blob/main/examples/causal_language_modeling/peft_lora_clm_accelerate_big_model_inference.ipynb).
## Models support matrix
Find models that are supported out of the box below. Note that PEFT works with almost all models -- if it is not listed, you just need to [do some manual configuration](https://huggingface.co/docs/peft/developer_guides/custom_models).
### Causal Language Modeling
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
|--------------| ---- | ---- | ---- | ---- | ---- |
| GPT-2 | ✅ | ✅ | ✅ | ✅ | ✅ |
| Bloom | ✅ | ✅ | ✅ | ✅ | ✅ |
| OPT | ✅ | ✅ | ✅ | ✅ | ✅ |
| GPT-Neo | ✅ | ✅ | ✅ | ✅ | ✅ |
| GPT-J | ✅ | ✅ | ✅ | ✅ | ✅ |
| GPT-NeoX-20B | ✅ | ✅ | ✅ | ✅ | ✅ |
| LLaMA | ✅ | ✅ | ✅ | ✅ | ✅ |
| ChatGLM | ✅ | ✅ | ✅ | ✅ | ✅ |
| Mistral | ✅ | | | | |
### Conditional Generation
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
| --------- | ---- | ---- | ---- | ---- | ---- |
| T5 | ✅ | ✅ | ✅ | ✅ | ✅ |
| BART | ✅ | ✅ | ✅ | ✅ | ✅ |
### Sequence Classification
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
| --------- | ---- | ---- | ---- | ---- | ---- |
| BERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
| GPT-2 | ✅ | ✅ | ✅ | ✅ | |
| Bloom | ✅ | ✅ | ✅ | ✅ | |
| OPT | ✅ | ✅ | ✅ | ✅ | |
| GPT-Neo | ✅ | ✅ | ✅ | ✅ | |
| GPT-J | ✅ | ✅ | ✅ | ✅ | |
| Deberta | ✅ | | ✅ | ✅ | |
| Deberta-v2 | ✅ | | ✅ | ✅ | |
### Token Classification
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
| --------- | ---- | ---- | ---- | ---- | ---- |
| BERT | ✅ | ✅ | | | |
| RoBERTa | ✅ | ✅ | | | |
| GPT-2 | ✅ | ✅ | | | |
| Bloom | ✅ | ✅ | | | |
| OPT | ✅ | ✅ | | | |
| GPT-Neo | ✅ | ✅ | | | |
| GPT-J | ✅ | ✅ | | | |
| Deberta | ✅ | | | | |
| Deberta-v2 | ✅ | | | | |
### Text-to-Image Generation
| Model | LoRA | LoHa | LoKr | OFT | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
| --------- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- |
| Stable Diffusion | ✅ | ✅ | ✅ | ✅ | | | |
### Image Classification
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
| --------- | ---- | ---- | ---- | ---- | ---- |
| ViT | ✅ | | | | |
| Swin | ✅ | | | | |
### Image to text (Multi-modal models)
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3
| --------- | ---- | ---- | ---- | ---- | ---- |
| Blip-2 | ✅ | | | | |
___Note that we have tested LoRA for [ViT](https://huggingface.co/docs/transformers/model_doc/vit) and [Swin](https://huggingface.co/docs/transformers/model_doc/swin) for fine-tuning on image classification. However, it should be possible to use LoRA for any compatible model [provided](https://huggingface.co/models?pipeline_tag=image-classification&sort=downloads&search=vit) by 🤗 Transformers. Check out the respective
examples to learn more. If you run into problems, please open an issue.___
The same principle applies to our [segmentation models](https://huggingface.co/models?pipeline_tag=image-segmentation&sort=downloads) as well.
### Semantic Segmentation
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
| --------- | ---- | ---- | ---- | ---- | ---- |
| SegFormer | ✅ | | | | |
## Caveats:
1. Below is an example of using PyTorch FSDP for training. However, it doesn't lead to
any GPU memory savings. Please refer issue [[FSDP] FSDP with CPU offload consumes 1.65X more GPU memory when training models with most of the params frozen](https://github.com/pytorch/pytorch/issues/91165).
```python
from peft.utils.other import fsdp_auto_wrap_policy
...
if os.environ.get("ACCELERATE_USE_FSDP", None) is not None:
accelerator.state.fsdp_plugin.auto_wrap_policy = fsdp_auto_wrap_policy(model)
model = accelerator.prepare(model)
```
Example of parameter efficient tuning with [`mt0-xxl`](https://huggingface.co/bigscience/mt0-xxl) base model using 🤗 Accelerate is provided in `~examples/conditional_generation/peft_lora_seq2seq_accelerate_fsdp.py`.
a. First, run `accelerate config --config_file fsdp_config.yaml` and answer the questionnaire.
Below are the contents of the config file.
```yaml
command_file: null
commands: null
compute_environment: LOCAL_MACHINE
deepspeed_config: {}
distributed_type: FSDP
downcast_bf16: 'no'
dynamo_backend: 'NO'
fsdp_config:
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_backward_prefetch_policy: BACKWARD_PRE
fsdp_offload_params: true
fsdp_sharding_strategy: 1
fsdp_state_dict_type: FULL_STATE_DICT
fsdp_transformer_layer_cls_to_wrap: T5Block
gpu_ids: null
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
megatron_lm_config: {}
mixed_precision: 'no'
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_name: null
tpu_zone: null
use_cpu: false
```
b. run the below command to launch the example script
```bash
accelerate launch --config_file fsdp_config.yaml examples/peft_lora_seq2seq_accelerate_fsdp.py
```
2. When using ZeRO3 with zero3_init_flag=True, if you find the gpu memory increase with training steps. we might need to update deepspeed after [deepspeed commit 42858a9891422abc](https://github.com/microsoft/DeepSpeed/commit/42858a9891422abcecaa12c1bd432d28d33eb0d4) . The related issue is [[BUG] Peft Training with Zero.Init() and Zero3 will increase GPU memory every forward step ](https://github.com/microsoft/DeepSpeed/issues/3002)
## 🤗 PEFT as a utility library
### Injecting adapters directly into the model
Inject trainable adapters on any `torch` model using `inject_adapter_in_model` method. Note the method will make no further change to the model.
```python
import torch
from peft import inject_adapter_in_model, LoraConfig
class DummyModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.embedding = torch.nn.Embedding(10, 10)
self.linear = torch.nn.Linear(10, 10)
self.lm_head = torch.nn.Linear(10, 10)
def forward(self, input_ids):
x = self.embedding(input_ids)
x = self.linear(x)
x = self.lm_head(x)
return x
lora_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
target_modules=["linear"],
)
model = DummyModel()
model = inject_adapter_in_model(lora_config, model)
dummy_inputs = torch.LongTensor([[0, 1, 2, 3, 4, 5, 6, 7]])
dummy_outputs = model(dummy_inputs)
```
Learn more about the [low level API in the docs](https://huggingface.co/docs/peft/developer_guides/low_level_api).
### Mixing different adapter types
Ususally, it is not possible to combine different adapter types in the same model, e.g. combining LoRA with AdaLoRA, LoHa, or LoKr. Using a mixed model, this can, however, be achieved:
```python
from peft import PeftMixedModel
model = AutoModelForCausalLM.from_pretrained("hf-internal-testing/tiny-random-OPTForCausalLM").eval()
peft_model = PeftMixedModel.from_pretrained(model, <path-to-adapter-0>, "adapter0")
peft_model.load_adapter(<path-to-adapter-1>, "adapter1")
peft_model.set_adapter(["adapter0", "adapter1"])
result = peft_model(**inputs)
```
The main intent is to load already trained adapters and use this only for inference. However, it is also possible to create a PEFT model for training by passing `mixed=True` to `get_peft_model`:
```python
from peft import get_peft_model, LoraConfig, LoKrConfig
base_model = ...
config0 = LoraConfig(...)
config1 = LoKrConfig(...)
peft_model = get_peft_model(base_model, config0, "adapter0", mixed=True)
peft_model.add_adapter(config1, "adapter1")
peft_model.set_adapter(["adapter0", "adapter1"])
for batch in dataloader:
...
```
## Contributing
If you would like to contribute to PEFT, please check out our [contributing guide](https://huggingface.co/docs/peft/developer_guides/contributing).
## Citing 🤗 PEFT
If you use 🤗 PEFT in your publication, please cite it by using the following BibTeX entry.
```bibtex
@Misc{peft,
title = {PEFT: State-of-the-art Parameter-Efficient Fine-Tuning methods},
author = {Sourab Mangrulkar and Sylvain Gugger and Lysandre Debut and Younes Belkada and Sayak Paul and Benjamin Bossan},
howpublished = {\url{https://github.com/huggingface/peft}},
year = {2022}
}
```
|
huggingface/peft/blob/main/README.md
|
List splits and configurations
Datasets typically have splits and may also have configurations. A _split_ is a subset of the dataset, like `train` and `test`, that are used during different stages of training and evaluating a model. A _configuration_ is a sub-dataset contained within a larger dataset. Configurations are especially common in multilingual speech datasets where there may be a different configuration for each language. If you're interested in learning more about splits and configurations, check out the [Load a dataset from the Hub tutorial](https://huggingface.co/docs/datasets/main/en/load_hub)!
This guide shows you how to use Datasets Server's `/splits` endpoint to retrieve a dataset's splits and configurations programmatically. Feel free to also try it out with [Postman](https://www.postman.com/huggingface/workspace/hugging-face-apis/request/23242779-f0cde3b9-c2ee-4062-aaca-65c4cfdd96f8), [RapidAPI](https://rapidapi.com/hugging-face-hugging-face-default/api/hugging-face-datasets-api), or [ReDoc](https://redocly.github.io/redoc/?url=https://datasets-server.huggingface.co/openapi.json#operation/listSplits)
The `/splits` endpoint accepts the dataset name as its query parameter:
<inferencesnippet>
<python>
```python
import requests
headers = {"Authorization": f"Bearer {API_TOKEN}"}
API_URL = "https://datasets-server.huggingface.co/splits?dataset=duorc"
def query():
response = requests.get(API_URL, headers=headers)
return response.json()
data = query()
```
</python>
<js>
```js
import fetch from "node-fetch";
async function query(data) {
const response = await fetch(
"https://datasets-server.huggingface.co/splits?dataset=duorc",
{
headers: { Authorization: `Bearer ${API_TOKEN}` },
method: "GET"
}
);
const result = await response.json();
return result;
}
query().then((response) => {
console.log(JSON.stringify(response));
});
```
</js>
<curl>
```curl
curl https://datasets-server.huggingface.co/splits?dataset=duorc \
-X GET \
-H "Authorization: Bearer ${API_TOKEN}"
```
</curl>
</inferencesnippet>
The endpoint response is a JSON containing a list of the dataset's splits and configurations. For example, the [duorc](https://huggingface.co/datasets/duorc) dataset has six splits and two configurations:
```json
{
"splits": [
{ "dataset": "duorc", "config": "ParaphraseRC", "split": "train" },
{ "dataset": "duorc", "config": "ParaphraseRC", "split": "validation" },
{ "dataset": "duorc", "config": "ParaphraseRC", "split": "test" },
{ "dataset": "duorc", "config": "SelfRC", "split": "train" },
{ "dataset": "duorc", "config": "SelfRC", "split": "validation" },
{ "dataset": "duorc", "config": "SelfRC", "split": "test" }
],
"pending": [],
"failed": []
}
```
|
huggingface/datasets-server/blob/main/docs/source/splits.mdx
|
--
title: "Parameter-Efficient Fine-Tuning using 🤗 PEFT"
thumbnail: /blog/assets/130_peft/thumbnail.png
authors:
- user: smangrul
- user: sayakpaul
---
# 🤗 PEFT: Parameter-Efficient Fine-Tuning of Billion-Scale Models on Low-Resource Hardware
## Motivation
Large Language Models (LLMs) based on the transformer architecture, like GPT, T5, and BERT have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. They have also started foraying into other domains, such as Computer Vision (CV) (VIT, Stable Diffusion, LayoutLM) and Audio (Whisper, XLS-R). The conventional paradigm is large-scale pretraining on generic web-scale data, followed by fine-tuning to downstream tasks. Fine-tuning these pretrained LLMs on downstream datasets results in huge performance gains when compared to using the pretrained LLMs out-of-the-box (zero-shot inference, for example).
However, as models get larger and larger, full fine-tuning becomes infeasible to train on consumer hardware. In addition, storing and deploying fine-tuned models independently for each downstream task becomes very expensive, because fine-tuned models are the same size as the original pretrained model. Parameter-Efficient Fine-tuning (PEFT) approaches are meant to address both problems!
PEFT approaches only fine-tune a small number of (extra) model parameters while freezing most parameters of the pretrained LLMs, thereby greatly decreasing the computational and storage costs. This also overcomes the issues of [catastrophic forgetting](https://arxiv.org/abs/1312.6211), a behaviour observed during the full finetuning of LLMs. PEFT approaches have also shown to be better than fine-tuning in the low-data regimes and generalize better to out-of-domain scenarios. It can be applied to various modalities, e.g., [image classification](https://github.com/huggingface/peft/tree/main/examples/image_classification) and [stable diffusion dreambooth](https://github.com/huggingface/peft/tree/main/examples/lora_dreambooth).
It also helps in portability wherein users can tune models using PEFT methods to get tiny checkpoints worth a few MBs compared to the large checkpoints of full fine-tuning, e.g., `bigscience/mt0-xxl` takes up 40GB of storage and full fine-tuning will lead to 40GB checkpoints for each downstream dataset whereas using PEFT methods it would be just a few MBs for each downstream dataset all the while achieving comparable performance to full fine-tuning. The small trained weights from PEFT approaches are added on top of the pretrained LLM. So the same LLM can be used for multiple tasks by adding small weights without having to replace the entire model.
**In short, PEFT approaches enable you to get performance comparable to full fine-tuning while only having a small number of trainable parameters.**
Today, we are excited to introduce the [🤗 PEFT](https://github.com/huggingface/peft) library, which provides the latest Parameter-Efficient Fine-tuning techniques seamlessly integrated with 🤗 Transformers and 🤗 Accelerate. This enables using the most popular and performant models from Transformers coupled with the simplicity and scalability of Accelerate. Below are the currently supported PEFT methods, with more coming soon:
1. LoRA: [LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS](https://arxiv.org/pdf/2106.09685.pdf)
2. Prefix Tuning: [P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks](https://arxiv.org/pdf/2110.07602.pdf)
3. Prompt Tuning: [The Power of Scale for Parameter-Efficient Prompt Tuning](https://arxiv.org/pdf/2104.08691.pdf)
4. P-Tuning: [GPT Understands, Too](https://arxiv.org/pdf/2103.10385.pdf)
## Use Cases
We explore many interesting use cases [here](https://github.com/huggingface/peft#use-cases). These are a few of the most interesting ones:
1. Using 🤗 PEFT LoRA for tuning `bigscience/T0_3B` model (3 Billion parameters) on consumer hardware with 11GB of RAM, such as Nvidia GeForce RTX 2080 Ti, Nvidia GeForce RTX 3080, etc using 🤗 Accelerate's DeepSpeed integration: [peft_lora_seq2seq_accelerate_ds_zero3_offload.py](https://github.com/huggingface/peft/blob/main/examples/conditional_generation/peft_lora_seq2seq_accelerate_ds_zero3_offload.py). This means you can tune such large LLMs in Google Colab.
2. Taking the previous example a notch up by enabling INT8 tuning of the `OPT-6.7b` model (6.7 Billion parameters) in Google Colab using 🤗 PEFT LoRA and [bitsandbytes](https://github.com/TimDettmers/bitsandbytes): [](https://colab.research.google.com/drive/1jCkpikz0J2o20FBQmYmAGdiKmJGOMo-o?usp=sharing)
3. Stable Diffusion Dreambooth training using 🤗 PEFT on consumer hardware with 11GB of RAM, such as Nvidia GeForce RTX 2080 Ti, Nvidia GeForce RTX 3080, etc. Try out the Space demo, which should run seamlessly on a T4 instance (16GB GPU): [smangrul/peft-lora-sd-dreambooth](https://huggingface.co/spaces/smangrul/peft-lora-sd-dreambooth).
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/peft_lora_dreambooth_gradio_space.png" alt="peft lora dreambooth gradio space"><br>
<em>PEFT LoRA Dreambooth Gradio Space</em>
</p>
## Training your model using 🤗 PEFT
Let's consider the case of fine-tuning [`bigscience/mt0-large`](https://huggingface.co/bigscience/mt0-large) using LoRA.
1. Let's get the necessary imports
```diff
from transformers import AutoModelForSeq2SeqLM
+ from peft import get_peft_model, LoraConfig, TaskType
model_name_or_path = "bigscience/mt0-large"
tokenizer_name_or_path = "bigscience/mt0-large"
```
2. Creating config corresponding to the PEFT method
```py
peft_config = LoraConfig(
task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
)
```
3. Wrapping base 🤗 Transformers model by calling `get_peft_model`
```diff
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
+ model = get_peft_model(model, peft_config)
+ model.print_trainable_parameters()
# output: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282
```
That's it! The rest of the training loop remains the same. Please refer example [peft_lora_seq2seq.ipynb](https://github.com/huggingface/peft/blob/main/examples/conditional_generation/peft_lora_seq2seq.ipynb) for an end-to-end example.
4. When you are ready to save the model for inference, just do the following.
```py
model.save_pretrained("output_dir")
# model.push_to_hub("my_awesome_peft_model") also works
```
This will only save the incremental PEFT weights that were trained. For example, you can find the `bigscience/T0_3B` tuned using LoRA on the `twitter_complaints` raft dataset here: [smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM](https://huggingface.co/smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM). Notice that it only contains 2 files: adapter_config.json and adapter_model.bin with the latter being just 19MB.
5. To load it for inference, follow the snippet below:
```diff
from transformers import AutoModelForSeq2SeqLM
+ from peft import PeftModel, PeftConfig
peft_model_id = "smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)
+ model = PeftModel.from_pretrained(model, peft_model_id)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
model = model.to(device)
model.eval()
inputs = tokenizer("Tweet text : @HondaCustSvc Your customer service has been horrible during the recall process. I will never purchase a Honda again. Label :", return_tensors="pt")
with torch.no_grad():
outputs = model.generate(input_ids=inputs["input_ids"].to("cuda"), max_new_tokens=10)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True)[0])
# 'complaint'
```
## Next steps
We've released PEFT as an efficient way of tuning large LLMs on downstream tasks and domains, saving a lot of compute and storage while achieving comparable performance to full finetuning. In the coming months, we'll be exploring more PEFT methods, such as (IA)3 and bottleneck adapters. Also, we'll focus on new use cases such as INT8 training of [`whisper-large`](https://huggingface.co/openai/whisper-large) model in Google Colab and tuning of RLHF components such as policy and ranker using PEFT approaches.
In the meantime, we're excited to see how industry practitioners apply PEFT to their use cases - if you have any questions or feedback, open an issue on our [GitHub repo](https://github.com/huggingface/peft) 🤗.
Happy Parameter-Efficient Fine-Tuning!
|
huggingface/blog/blob/main/peft.md
|
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# DePlot
## Overview
DePlot was proposed in the paper [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) from Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
The abstract of the paper states the following:
*Visual language such as charts and plots is ubiquitous in the human world. Comprehending plots and charts requires strong reasoning skills. Prior state-of-the-art (SOTA) models require at least tens of thousands of training examples and their reasoning capabilities are still much limited, especially on complex human-written queries. This paper presents the first one-shot solution to visual language reasoning. We decompose the challenge of visual language reasoning into two steps: (1) plot-to-text translation, and (2) reasoning over the translated text. The key in this method is a modality conversion module, named as DePlot, which translates the image of a plot or chart to a linearized table. The output of DePlot can then be directly used to prompt a pretrained large language model (LLM), exploiting the few-shot reasoning capabilities of LLMs. To obtain DePlot, we standardize the plot-to-table task by establishing unified task formats and metrics, and train DePlot end-to-end on this task. DePlot can then be used off-the-shelf together with LLMs in a plug-and-play fashion. Compared with a SOTA model finetuned on more than >28k data points, DePlot+LLM with just one-shot prompting achieves a 24.0% improvement over finetuned SOTA on human-written queries from the task of chart QA.*
DePlot is a model that is trained using `Pix2Struct` architecture. You can find more information about `Pix2Struct` in the [Pix2Struct documentation](https://huggingface.co/docs/transformers/main/en/model_doc/pix2struct).
DePlot is a Visual Question Answering subset of `Pix2Struct` architecture. It renders the input question on the image and predicts the answer.
## Usage example
Currently one checkpoint is available for DePlot:
- `google/deplot`: DePlot fine-tuned on ChartQA dataset
```python
from transformers import AutoProcessor, Pix2StructForConditionalGeneration
import requests
from PIL import Image
model = Pix2StructForConditionalGeneration.from_pretrained("google/deplot")
processor = AutoProcessor.from_pretrained("google/deplot")
url = "https://raw.githubusercontent.com/vis-nlp/ChartQA/main/ChartQA%20Dataset/val/png/5090.png"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, text="Generate underlying data table of the figure below:", return_tensors="pt")
predictions = model.generate(**inputs, max_new_tokens=512)
print(processor.decode(predictions[0], skip_special_tokens=True))
```
## Fine-tuning
To fine-tune DePlot, refer to the pix2struct [fine-tuning notebook](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_pix2struct.ipynb). For `Pix2Struct` models, we have found out that fine-tuning the model with Adafactor and cosine learning rate scheduler leads to faster convergence:
```python
from transformers.optimization import Adafactor, get_cosine_schedule_with_warmup
optimizer = Adafactor(self.parameters(), scale_parameter=False, relative_step=False, lr=0.01, weight_decay=1e-05)
scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=1000, num_training_steps=40000)
```
<Tip>
DePlot is a model trained using `Pix2Struct` architecture. For API reference, see [`Pix2Struct` documentation](pix2struct).
</Tip>
|
huggingface/transformers/blob/main/docs/source/en/model_doc/deplot.md
|
`tokenizers-darwin-x64`
This is the **x86_64-apple-darwin** binary for `tokenizers`
|
huggingface/tokenizers/blob/main/bindings/node/npm/darwin-x64/README.md
|
Gradio Demo: blocks_inputs
```
!pip install -q gradio
```
```
# Downloading files from the demo repo
import os
!wget -q https://github.com/gradio-app/gradio/raw/main/demo/blocks_inputs/lion.jpg
```
```
import gradio as gr
import os
def combine(a, b):
return a + " " + b
def mirror(x):
return x
with gr.Blocks() as demo:
txt = gr.Textbox(label="Input", lines=2)
txt_2 = gr.Textbox(label="Input 2")
txt_3 = gr.Textbox(value="", label="Output")
btn = gr.Button(value="Submit")
btn.click(combine, inputs=[txt, txt_2], outputs=[txt_3])
with gr.Row():
im = gr.Image()
im_2 = gr.Image()
btn = gr.Button(value="Mirror Image")
btn.click(mirror, inputs=[im], outputs=[im_2])
gr.Markdown("## Text Examples")
gr.Examples(
[["hi", "Adam"], ["hello", "Eve"]],
[txt, txt_2],
txt_3,
combine,
cache_examples=True,
)
gr.Markdown("## Image Examples")
gr.Examples(
examples=[os.path.join(os.path.abspath(''), "lion.jpg")],
inputs=im,
outputs=im_2,
fn=mirror,
cache_examples=True,
)
if __name__ == "__main__":
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/blocks_inputs/run.ipynb
|
*NOTE**: This example is outdated and is not longer actively maintained. Please
follow the new instructions of fine-tuning Wav2Vec2 [here](https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-recognition/README.md)
## Fine-tuning Wav2Vec2
The `run_asr.py` script allows one to fine-tune pretrained Wav2Vec2 models that can be found [here](https://huggingface.co/models?search=facebook/wav2vec2).
This finetuning script can also be run as a google colab [TODO: here]( ).
### Fine-Tuning with TIMIT
Let's take a look at the [script](./finetune_base_timit_asr.sh) used to fine-tune [wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base)
with the [TIMIT dataset](https://huggingface.co/datasets/timit_asr):
```bash
#!/usr/bin/env bash
python run_asr.py \
--output_dir="./wav2vec2-base-timit-asr" \
--num_train_epochs="30" \
--per_device_train_batch_size="20" \
--per_device_eval_batch_size="20" \
--evaluation_strategy="steps" \
--save_steps="500" \
--eval_steps="100" \
--logging_steps="50" \
--learning_rate="5e-4" \
--warmup_steps="3000" \
--model_name_or_path="facebook/wav2vec2-base" \
--fp16 \
--dataset_name="timit_asr" \
--train_split_name="train" \
--validation_split_name="test" \
--orthography="timit" \
--preprocessing_num_workers="$(nproc)" \
--group_by_length \
--freeze_feature_extractor \
--verbose_logging \
```
The resulting model and inference examples can be found [here](https://huggingface.co/elgeish/wav2vec2-base-timit-asr).
Some of the arguments above may look unfamiliar, let's break down what's going on:
`--orthography="timit"` applies certain text preprocessing rules, for tokenization and normalization, to clean up the dataset.
In this case, we use the following instance of `Orthography`:
```python
Orthography(
do_lower_case=True,
# break compounds like "quarter-century-old" and replace pauses "--"
translation_table=str.maketrans({"-": " "}),
)
```
The instance above is used as follows:
* creates a tokenizer with `do_lower_case=True` (ignores casing for input and lowercases output when decoding)
* replaces `"-"` with `" "` to break compounds like `"quarter-century-old"` and to clean up suspended hyphens
* cleans up consecutive whitespaces (replaces them with a single space: `" "`)
* removes characters not in vocabulary (lacking respective sound units)
`--verbose_logging` logs text preprocessing updates and when evaluating, using the validation split every `eval_steps`,
logs references and predictions.
### Fine-Tuning with Arabic Speech Corpus
Other datasets, like the [Arabic Speech Corpus dataset](https://huggingface.co/datasets/arabic_speech_corpus),
require more work! Let's take a look at the [script](./finetune_large_xlsr_53_arabic_speech_corpus.sh)
used to fine-tune [wav2vec2-large-xlsr-53](https://huggingface.co/elgeish/wav2vec2-large-xlsr-53-arabic):
```bash
#!/usr/bin/env bash
python run_asr.py \
--output_dir="./wav2vec2-large-xlsr-53-arabic-speech-corpus" \
--num_train_epochs="50" \
--per_device_train_batch_size="1" \
--per_device_eval_batch_size="1" \
--gradient_accumulation_steps="8" \
--evaluation_strategy="steps" \
--save_steps="500" \
--eval_steps="100" \
--logging_steps="50" \
--learning_rate="5e-4" \
--warmup_steps="3000" \
--model_name_or_path="elgeish/wav2vec2-large-xlsr-53-arabic" \
--fp16 \
--dataset_name="arabic_speech_corpus" \
--train_split_name="train" \
--validation_split_name="test" \
--max_duration_in_seconds="15" \
--orthography="buckwalter" \
--preprocessing_num_workers="$(nproc)" \
--group_by_length \
--freeze_feature_extractor \
--target_feature_extractor_sampling_rate \
--verbose_logging \
```
First, let's understand how this dataset represents Arabic text; it uses a format called
[Buckwalter transliteration](https://en.wikipedia.org/wiki/Buckwalter_transliteration).
We use the [lang-trans](https://github.com/kariminf/lang-trans) package to convert back to Arabic when logging.
The Buckwalter format only includes ASCII characters, some of which are non-alpha (e.g., `">"` maps to `"أ"`).
`--orthography="buckwalter"` applies certain text preprocessing rules, for tokenization and normalization, to clean up the dataset. In this case, we use the following instance of `Orthography`:
```python
Orthography(
vocab_file=pathlib.Path(__file__).parent.joinpath("vocab/buckwalter.json"),
word_delimiter_token="/", # "|" is Arabic letter alef with madda above
words_to_remove={"sil"}, # fixing "sil" in arabic_speech_corpus dataset
untransliterator=arabic.buckwalter.untransliterate,
translation_table=str.maketrans(translation_table = {
"-": " ", # sometimes used to represent pauses
"^": "v", # fixing "tha" in arabic_speech_corpus dataset
}),
)
```
The instance above is used as follows:
* creates a tokenizer with Buckwalter vocabulary and `word_delimiter_token="/"`
* replaces `"-"` with `" "` to clean up hyphens and fixes the orthography for `"ث"`
* removes words used as indicators (in this case, `"sil"` is used for silence)
* cleans up consecutive whitespaces (replaces them with a single space: `" "`)
* removes characters not in vocabulary (lacking respective sound units)
`--verbose_logging` logs text preprocessing updates and when evaluating, using the validation split every `eval_steps`,
logs references and predictions. Using the Buckwalter format, text is also logged in Arabic abjad.
`--target_feature_extractor_sampling_rate` resamples audio to target feature extractor's sampling rate (16kHz).
`--max_duration_in_seconds="15"` filters out examples whose audio is longer than the specified limit,
which helps with capping GPU memory usage.
### DeepSpeed Integration
To learn how to deploy Deepspeed Integration please refer to [this guide](https://huggingface.co/transformers/main/main_classes/deepspeed.html#deepspeed-trainer-integration).
But to get started quickly all you need is to install:
```
pip install deepspeed
```
and then use the default configuration files in this directory:
* `ds_config_wav2vec2_zero2.json`
* `ds_config_wav2vec2_zero3.json`
Here are examples of how you can use DeepSpeed:
(edit the value for `--num_gpus` to match the number of GPUs you have)
ZeRO-2:
```
PYTHONPATH=../../../src deepspeed --num_gpus 2 \
run_asr.py \
--output_dir=output_dir --num_train_epochs=2 --per_device_train_batch_size=2 \
--per_device_eval_batch_size=2 --evaluation_strategy=steps --save_steps=500 --eval_steps=100 \
--logging_steps=5 --learning_rate=5e-4 --warmup_steps=3000 \
--model_name_or_path=patrickvonplaten/wav2vec2_tiny_random_robust \
--dataset_name=hf-internal-testing/librispeech_asr_dummy --dataset_config_name=clean \
--train_split_name=validation --validation_split_name=validation --orthography=timit \
--preprocessing_num_workers=1 --group_by_length --freeze_feature_extractor --verbose_logging \
--deepspeed ds_config_wav2vec2_zero2.json
```
For ZeRO-2 with more than 1 gpu you need to use (which is already in the example configuration file):
```
"zero_optimization": {
...
"find_unused_parameters": true,
...
}
```
ZeRO-3:
```
PYTHONPATH=../../../src deepspeed --num_gpus 2 \
run_asr.py \
--output_dir=output_dir --num_train_epochs=2 --per_device_train_batch_size=2 \
--per_device_eval_batch_size=2 --evaluation_strategy=steps --save_steps=500 --eval_steps=100 \
--logging_steps=5 --learning_rate=5e-4 --warmup_steps=3000 \
--model_name_or_path=patrickvonplaten/wav2vec2_tiny_random_robust \
--dataset_name=hf-internal-testing/librispeech_asr_dummy --dataset_config_name=clean \
--train_split_name=validation --validation_split_name=validation --orthography=timit \
--preprocessing_num_workers=1 --group_by_length --freeze_feature_extractor --verbose_logging \
--deepspeed ds_config_wav2vec2_zero3.json
```
### Pretraining Wav2Vec2
The `run_pretrain.py` script allows one to pretrain a Wav2Vec2 model from scratch using Wav2Vec2's contrastive loss objective (see official [paper](https://arxiv.org/abs/2006.11477) for more information).
It is recommended to pre-train Wav2Vec2 with Trainer + Deepspeed (please refer to [this guide](https://huggingface.co/transformers/main/main_classes/deepspeed.html#deepspeed-trainer-integration) for more information).
Here is an example of how you can use DeepSpeed ZeRO-2 to pretrain a small Wav2Vec2 model:
```
PYTHONPATH=../../../src deepspeed --num_gpus 4 run_pretrain.py \
--output_dir="./wav2vec2-base-libri-100h" \
--num_train_epochs="3" \
--per_device_train_batch_size="32" \
--per_device_eval_batch_size="32" \
--gradient_accumulation_steps="2" \
--save_total_limit="3" \
--save_steps="500" \
--logging_steps="10" \
--learning_rate="5e-4" \
--weight_decay="0.01" \
--warmup_steps="3000" \
--model_name_or_path="patrickvonplaten/wav2vec2-base-libri-100h" \
--dataset_name="librispeech_asr" \
--dataset_config_name="clean" \
--train_split_name="train.100" \
--preprocessing_num_workers="4" \
--max_duration_in_seconds="10.0" \
--group_by_length \
--verbose_logging \
--fp16 \
--deepspeed ds_config_wav2vec2_zero2.json \
```
### Forced Alignment
Character level forced alignment for audio and text pairs with wav2vec2 models finetuned on ASR task for a specific language.
Inspired by [this](https://pytorch.org/tutorials/intermediate/forced_alignment_with_torchaudio_tutorial.html) Pytorch tutorial.
#### Input Formats
Input format in script.txt Input format in wavs directroy
0000 sentence1 0000.wav
0001 sentence2 0001.wav
#### Output Format
Output directory will contain 0000.txt and 0001.txt. Each file will have format like below
char score start_ms end_ms
h 0.25 1440 1520
#### Run command
```
python alignment.py \
--model_name="arijitx/wav2vec2-xls-r-300m-bengali" \
--wav_dir="./wavs"
--text_file="script.txt" \
--input_wavs_sr=48000 \
--output_dir="./out_alignment" \
--cuda
```
|
huggingface/transformers/blob/main/examples/research_projects/wav2vec2/README.md
|
Gradio Demo: html_component
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
gr.HTML(value="<p style='margin-top: 1rem, margin-bottom: 1rem'>This <em>example</em> was <strong>written</strong> in <a href='https://en.wikipedia.org/wiki/HTML' _target='blank'>HTML</a> </p>")
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/html_component/run.ipynb
|
Run training on Amazon SageMaker
<iframe width="700" height="394" src="https://www.youtube.com/embed/ok3hetb42gU" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
This guide will show you how to train a 🤗 Transformers model with the `HuggingFace` SageMaker Python SDK. Learn how to:
- [Install and setup your training environment](#installation-and-setup).
- [Prepare a training script](#prepare-a-transformers-fine-tuning-script).
- [Create a Hugging Face Estimator](#create-a-hugging-face-estimator).
- [Run training with the `fit` method](#execute-training).
- [Access your trained model](#access-trained-model).
- [Perform distributed training](#distributed-training).
- [Create a spot instance](#spot-instances).
- [Load a training script from a GitHub repository](#git-repository).
- [Collect training metrics](#sagemaker-metrics).
## Installation and setup
Before you can train a 🤗 Transformers model with SageMaker, you need to sign up for an AWS account. If you don't have an AWS account yet, learn more [here](https://docs.aws.amazon.com/sagemaker/latest/dg/gs-set-up.html).
Once you have an AWS account, get started using one of the following:
- [SageMaker Studio](https://docs.aws.amazon.com/sagemaker/latest/dg/gs-studio-onboard.html)
- [SageMaker notebook instance](https://docs.aws.amazon.com/sagemaker/latest/dg/gs-console.html)
- Local environment
To start training locally, you need to setup an appropriate [IAM role](https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-roles.html).
Upgrade to the latest `sagemaker` version:
```bash
pip install sagemaker --upgrade
```
**SageMaker environment**
Setup your SageMaker environment as shown below:
```python
import sagemaker
sess = sagemaker.Session()
role = sagemaker.get_execution_role()
```
_Note: The execution role is only available when running a notebook within SageMaker. If you run `get_execution_role` in a notebook not on SageMaker, expect a `region` error._
**Local environment**
Setup your local environment as shown below:
```python
import sagemaker
import boto3
iam_client = boto3.client('iam')
role = iam_client.get_role(RoleName='role-name-of-your-iam-role-with-right-permissions')['Role']['Arn']
sess = sagemaker.Session()
```
## Prepare a 🤗 Transformers fine-tuning script
Our training script is very similar to a training script you might run outside of SageMaker. However, you can access useful properties about the training environment through various environment variables (see [here](https://github.com/aws/sagemaker-training-toolkit/blob/master/ENVIRONMENT_VARIABLES.md) for a complete list), such as:
- `SM_MODEL_DIR`: A string representing the path to which the training job writes the model artifacts. After training, artifacts in this directory are uploaded to S3 for model hosting. `SM_MODEL_DIR` is always set to `/opt/ml/model`.
- `SM_NUM_GPUS`: An integer representing the number of GPUs available to the host.
- `SM_CHANNEL_XXXX:` A string representing the path to the directory that contains the input data for the specified channel. For example, when you specify `train` and `test` in the Hugging Face Estimator `fit` method, the environment variables are set to `SM_CHANNEL_TRAIN` and `SM_CHANNEL_TEST`.
The `hyperparameters` defined in the [Hugging Face Estimator](#create-an-huggingface-estimator) are passed as named arguments and processed by `ArgumentParser()`.
```python
import transformers
import datasets
import argparse
import os
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# hyperparameters sent by the client are passed as command-line arguments to the script
parser.add_argument("--epochs", type=int, default=3)
parser.add_argument("--per_device_train_batch_size", type=int, default=32)
parser.add_argument("--model_name_or_path", type=str)
# data, model, and output directories
parser.add_argument("--model-dir", type=str, default=os.environ["SM_MODEL_DIR"])
parser.add_argument("--training_dir", type=str, default=os.environ["SM_CHANNEL_TRAIN"])
parser.add_argument("--test_dir", type=str, default=os.environ["SM_CHANNEL_TEST"])
```
_Note that SageMaker doesn’t support argparse actions. For example, if you want to use a boolean hyperparameter, specify `type` as `bool` in your script and provide an explicit `True` or `False` value._
Look [train.py file](https://github.com/huggingface/notebooks/blob/main/sagemaker/01_getting_started_pytorch/scripts/train.py) for a complete example of a 🤗 Transformers training script.
## Training Output Management
If `output_dir` in the `TrainingArguments` is set to '/opt/ml/model' the Trainer saves all training artifacts, including logs, checkpoints, and models. Amazon SageMaker archives the whole '/opt/ml/model' directory as `model.tar.gz` and uploads it at the end of the training job to Amazon S3. Depending on your Hyperparameters and `TrainingArguments` this could lead to a large artifact (> 5GB), which can slow down deployment for Amazon SageMaker Inference.
You can control how checkpoints, logs, and artifacts are saved by customization the [TrainingArguments](https://huggingface.co/docs/transformers/main/en/main_classes/trainer#transformers.TrainingArguments). For example by providing `save_total_limit` as `TrainingArgument` you can control the limit of the total amount of checkpoints. Deletes the older checkpoints in `output_dir` if new ones are saved and the maximum limit is reached.
In addition to the options already mentioned above, there is another option to save the training artifacts during the training session. Amazon SageMaker supports [Checkpointing](https://docs.aws.amazon.com/sagemaker/latest/dg/model-checkpoints.html), which allows you to continuously save your artifacts during training to Amazon S3 rather than at the end of your training. To enable [Checkpointing](https://docs.aws.amazon.com/sagemaker/latest/dg/model-checkpoints.html) you need to provide the `checkpoint_s3_uri` parameter pointing to an Amazon S3 location in the `HuggingFace` estimator and set `output_dir` to `/opt/ml/checkpoints`.
_Note: If you set `output_dir` to `/opt/ml/checkpoints` make sure to call `trainer.save_model("/opt/ml/model")` or model.save_pretrained("/opt/ml/model")/`tokenizer.save_pretrained("/opt/ml/model")` at the end of your training to be able to deploy your model seamlessly to Amazon SageMaker for Inference._
## Create a Hugging Face Estimator
Run 🤗 Transformers training scripts on SageMaker by creating a [Hugging Face Estimator](https://sagemaker.readthedocs.io/en/stable/frameworks/huggingface/sagemaker.huggingface.html#huggingface-estimator). The Estimator handles end-to-end SageMaker training. There are several parameters you should define in the Estimator:
1. `entry_point` specifies which fine-tuning script to use.
2. `instance_type` specifies an Amazon instance to launch. Refer [here](https://aws.amazon.com/sagemaker/pricing/) for a complete list of instance types.
3. `hyperparameters` specifies training hyperparameters. View additional available hyperparameters in [train.py file](https://github.com/huggingface/notebooks/blob/main/sagemaker/01_getting_started_pytorch/scripts/train.py).
The following code sample shows how to train with a custom script `train.py` with three hyperparameters (`epochs`, `per_device_train_batch_size`, and `model_name_or_path`):
```python
from sagemaker.huggingface import HuggingFace
# hyperparameters which are passed to the training job
hyperparameters={'epochs': 1,
'per_device_train_batch_size': 32,
'model_name_or_path': 'distilbert-base-uncased'
}
# create the Estimator
huggingface_estimator = HuggingFace(
entry_point='train.py',
source_dir='./scripts',
instance_type='ml.p3.2xlarge',
instance_count=1,
role=role,
transformers_version='4.26',
pytorch_version='1.13',
py_version='py39',
hyperparameters = hyperparameters
)
```
If you are running a `TrainingJob` locally, define `instance_type='local'` or `instance_type='local_gpu'` for GPU usage. Note that this will not work with SageMaker Studio.
## Execute training
Start your `TrainingJob` by calling `fit` on a Hugging Face Estimator. Specify your input training data in `fit`. The input training data can be a:
- S3 URI such as `s3://my-bucket/my-training-data`.
- `FileSystemInput` for Amazon Elastic File System or FSx for Lustre. See [here](https://sagemaker.readthedocs.io/en/stable/overview.html?highlight=FileSystemInput#use-file-systems-as-training-inputs) for more details about using these file systems as input.
Call `fit` to begin training:
```python
huggingface_estimator.fit(
{'train': 's3://sagemaker-us-east-1-558105141721/samples/datasets/imdb/train',
'test': 's3://sagemaker-us-east-1-558105141721/samples/datasets/imdb/test'}
)
```
SageMaker starts and manages all the required EC2 instances and initiates the `TrainingJob` by running:
```bash
/opt/conda/bin/python train.py --epochs 1 --model_name_or_path distilbert-base-uncased --per_device_train_batch_size 32
```
## Access trained model
Once training is complete, you can access your model through the [AWS console](https://console.aws.amazon.com/console/home?nc2=h_ct&src=header-signin) or download it directly from S3.
```python
from sagemaker.s3 import S3Downloader
S3Downloader.download(
s3_uri=huggingface_estimator.model_data, # S3 URI where the trained model is located
local_path='.', # local path where *.targ.gz is saved
sagemaker_session=sess # SageMaker session used for training the model
)
```
## Distributed training
SageMaker provides two strategies for distributed training: data parallelism and model parallelism. Data parallelism splits a training set across several GPUs, while model parallelism splits a model across several GPUs.
### Data parallelism
The Hugging Face [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) supports SageMaker's data parallelism library. If your training script uses the Trainer API, you only need to define the distribution parameter in the Hugging Face Estimator:
```python
# configuration for running training on smdistributed data parallel
distribution = {'smdistributed':{'dataparallel':{ 'enabled': True }}}
# create the Estimator
huggingface_estimator = HuggingFace(
entry_point='train.py',
source_dir='./scripts',
instance_type='ml.p3dn.24xlarge',
instance_count=2,
role=role,
transformers_version='4.26.0',
pytorch_version='1.13.1',
py_version='py39',
hyperparameters = hyperparameters,
distribution = distribution
)
```
📓 Open the [sagemaker-notebook.ipynb notebook](https://github.com/huggingface/notebooks/blob/main/sagemaker/07_tensorflow_distributed_training_data_parallelism/sagemaker-notebook.ipynb) for an example of how to run the data parallelism library with TensorFlow.
### Model parallelism
The Hugging Face [Trainer] also supports SageMaker's model parallelism library. If your training script uses the Trainer API, you only need to define the distribution parameter in the Hugging Face Estimator (see [here](https://sagemaker.readthedocs.io/en/stable/api/training/smd_model_parallel_general.html?highlight=modelparallel#required-sagemaker-python-sdk-parameters) for more detailed information about using model parallelism):
```python
# configuration for running training on smdistributed model parallel
mpi_options = {
"enabled" : True,
"processes_per_host" : 8
}
smp_options = {
"enabled":True,
"parameters": {
"microbatches": 4,
"placement_strategy": "spread",
"pipeline": "interleaved",
"optimize": "speed",
"partitions": 4,
"ddp": True,
}
}
distribution={
"smdistributed": {"modelparallel": smp_options},
"mpi": mpi_options
}
# create the Estimator
huggingface_estimator = HuggingFace(
entry_point='train.py',
source_dir='./scripts',
instance_type='ml.p3dn.24xlarge',
instance_count=2,
role=role,
transformers_version='4.26.0',
pytorch_version='1.13.1',
py_version='py39',
hyperparameters = hyperparameters,
distribution = distribution
)
```
📓 Open the [sagemaker-notebook.ipynb notebook](https://github.com/huggingface/notebooks/blob/main/sagemaker/04_distributed_training_model_parallelism/sagemaker-notebook.ipynb) for an example of how to run the model parallelism library.
## Spot instances
The Hugging Face extension for the SageMaker Python SDK means we can benefit from [fully-managed EC2 spot instances](https://docs.aws.amazon.com/sagemaker/latest/dg/model-managed-spot-training.html). This can help you save up to 90% of training costs!
_Note: Unless your training job completes quickly, we recommend you use [checkpointing](https://docs.aws.amazon.com/sagemaker/latest/dg/model-checkpoints.html) with managed spot training. In this case, you need to define the `checkpoint_s3_uri`._
Set `use_spot_instances=True` and define your `max_wait` and `max_run` time in the Estimator to use spot instances:
```python
# hyperparameters which are passed to the training job
hyperparameters={'epochs': 1,
'train_batch_size': 32,
'model_name':'distilbert-base-uncased',
'output_dir':'/opt/ml/checkpoints'
}
# create the Estimator
huggingface_estimator = HuggingFace(
entry_point='train.py',
source_dir='./scripts',
instance_type='ml.p3.2xlarge',
instance_count=1,
checkpoint_s3_uri=f's3://{sess.default_bucket()}/checkpoints'
use_spot_instances=True,
# max_wait should be equal to or greater than max_run in seconds
max_wait=3600,
max_run=1000,
role=role,
transformers_version='4.26',
pytorch_version='1.13',
py_version='py39',
hyperparameters = hyperparameters
)
# Training seconds: 874
# Billable seconds: 262
# Managed Spot Training savings: 70.0%
```
📓 Open the [sagemaker-notebook.ipynb notebook](https://github.com/huggingface/notebooks/blob/main/sagemaker/05_spot_instances/sagemaker-notebook.ipynb) for an example of how to use spot instances.
## Git repository
The Hugging Face Estimator can load a training script [stored in a GitHub repository](https://sagemaker.readthedocs.io/en/stable/overview.html#use-scripts-stored-in-a-git-repository). Provide the relative path to the training script in `entry_point` and the relative path to the directory in `source_dir`.
If you are using `git_config` to run the [🤗 Transformers example scripts](https://github.com/huggingface/transformers/tree/main/examples), you need to configure the correct `'branch'` in `transformers_version` (e.g. if you use `transformers_version='4.4.2` you have to use `'branch':'v4.4.2'`).
_Tip: Save your model to S3 by setting `output_dir=/opt/ml/model` in the hyperparameter of your training script._
```python
# configure git settings
git_config = {'repo': 'https://github.com/huggingface/transformers.git','branch': 'v4.4.2'} # v4.4.2 refers to the transformers_version you use in the estimator
# create the Estimator
huggingface_estimator = HuggingFace(
entry_point='run_glue.py',
source_dir='./examples/pytorch/text-classification',
git_config=git_config,
instance_type='ml.p3.2xlarge',
instance_count=1,
role=role,
transformers_version='4.26',
pytorch_version='1.13',
py_version='py39',
hyperparameters=hyperparameters
)
```
## SageMaker metrics
[SageMaker metrics](https://docs.aws.amazon.com/sagemaker/latest/dg/training-metrics.html#define-train-metrics) automatically parses training job logs for metrics and sends them to CloudWatch. If you want SageMaker to parse the logs, you must specify the metric's name and a regular expression for SageMaker to use to find the metric.
```python
# define metrics definitions
metric_definitions = [
{"Name": "train_runtime", "Regex": "train_runtime.*=\D*(.*?)$"},
{"Name": "eval_accuracy", "Regex": "eval_accuracy.*=\D*(.*?)$"},
{"Name": "eval_loss", "Regex": "eval_loss.*=\D*(.*?)$"},
]
# create the Estimator
huggingface_estimator = HuggingFace(
entry_point='train.py',
source_dir='./scripts',
instance_type='ml.p3.2xlarge',
instance_count=1,
role=role,
transformers_version='4.26',
pytorch_version='1.13',
py_version='py39',
metric_definitions=metric_definitions,
hyperparameters = hyperparameters)
```
📓 Open the [notebook](https://github.com/huggingface/notebooks/blob/main/sagemaker/06_sagemaker_metrics/sagemaker-notebook.ipynb) for an example of how to capture metrics in SageMaker.
|
huggingface/hub-docs/blob/main/docs/sagemaker/train.md
|
--
title: "MTEB: Massive Text Embedding Benchmark"
thumbnail: /blog/assets/110_mteb/thumbnail.png
authors:
- user: Muennighoff
---
# MTEB: Massive Text Embedding Benchmark
MTEB is a massive benchmark for measuring the performance of text embedding models on diverse embedding tasks.
The 🥇 [leaderboard](https://huggingface.co/spaces/mteb/leaderboard) provides a holistic view of the best text embedding models out there on a variety of tasks.
The 📝 [paper](https://arxiv.org/abs/2210.07316) gives background on the tasks and datasets in MTEB and analyzes leaderboard results!
The 💻 [Github repo](https://github.com/embeddings-benchmark/mteb) contains the code for benchmarking and submitting any model of your choice to the leaderboard.
<p align="center">
<a href="https://huggingface.co/spaces/mteb/leaderboard"><img src="assets/110_mteb/leaderboard.png" alt="MTEB Leaderboard"></a>
</p>
## Why Text Embeddings?
Text Embeddings are vector representations of text that encode semantic information. As machines require numerical inputs to perform computations, text embeddings are a crucial component of many downstream NLP applications. For example, Google uses text embeddings to [power their search engine](https://cloud.google.com/blog/topics/developers-practitioners/find-anything-blazingly-fast-googles-vector-search-technology). Text Embeddings can also be used for finding [patterns in large amount of text via clustering](https://txt.cohere.ai/combing-for-insight-in-10-000-hacker-news-posts-with-text-clustering/) or as inputs to text classification models, such as in our recent [SetFit](https://huggingface.co/blog/setfit) work. The quality of text embeddings, however, is highly dependent on the embedding model used. MTEB is designed to help you find the best embedding model out there for a variety of tasks!
## MTEB
🐋 **Massive**: MTEB includes 56 datasets across 8 tasks and currently summarizes >2000 results on the [leaderboard](https://huggingface.co/spaces/mteb/leaderboard).
🌎 **Multilingual**: MTEB contains up to 112 different languages! We have benchmarked several multilingual models on Bitext Mining, Classification, and STS.
🦚 **Extensible**: Be it new tasks, datasets, metrics, or leaderboard additions, any contribution is very welcome. Check out the GitHub repository to [submit to the leaderboard](https://github.com/embeddings-benchmark/mteb#leaderboard) or [solve open issues](https://github.com/embeddings-benchmark/mteb/issues). We hope you join us on the journey of finding the best text embedding model!
<p align="center">
<img src="assets/110_mteb/mteb_diagram_white_background.png" alt="MTEB Taxonomy">
</p>
<p align="center">
<em>Overview of tasks and datasets in MTEB. Multilingual datasets are marked with a purple shade.</em>
</p>
## Models
For the initial benchmarking of MTEB, we focused on models claiming state-of-the-art results and popular models on the Hub. This led to a high representation of transformers. 🤖
<p align="center">
<img src="assets/110_mteb/benchmark.png" alt="MTEB Speed Benchmark">
</p>
<p align="center">
<em>Models by average English MTEB score (y) vs speed (x) vs embedding size (circle size).</em>
</p>
We grouped models into the following three attributes to simplify finding the best model for your task:
**🏎 Maximum speed** Models like [Glove](https://huggingface.co/sentence-transformers/average_word_embeddings_glove.6B.300d) offer high speed, but suffer from a lack of context awareness resulting in low average MTEB scores.
**⚖️ Speed and performance** Slightly slower, but significantly stronger, [all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) or [all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) provide a good balance between speed and performance.
**💪 Maximum performance** Multi-billion parameter models like [ST5-XXL](https://huggingface.co/sentence-transformers/sentence-t5-xxl), [GTR-XXL](https://huggingface.co/sentence-transformers/gtr-t5-xxl) or [SGPT-5.8B-msmarco](https://huggingface.co/Muennighoff/SGPT-5.8B-weightedmean-msmarco-specb-bitfit) dominate on MTEB. They tend to also produce bigger embeddings like [SGPT-5.8B-msmarco](https://huggingface.co/Muennighoff/SGPT-5.8B-weightedmean-msmarco-specb-bitfit) which produces 4096 dimensional embeddings requiring more storage!
Model performance varies a lot depending on the task and dataset, so we recommend checking the various tabs of the [leaderboard](https://huggingface.co/spaces/mteb/leaderboard) before deciding which model to use!
## Benchmark your model
Using the [MTEB library](https://github.com/embeddings-benchmark/mteb), you can benchmark any model that produces embeddings and add its results to the public leaderboard. Let's run through a quick example!
First, install the library:
```sh
pip install mteb
```
Next, benchmark a model on a dataset, for example [komninos word embeddings](https://huggingface.co/sentence-transformers/average_word_embeddings_komninos) on [Banking77](https://huggingface.co/datasets/mteb/banking77).
```python
from mteb import MTEB
from sentence_transformers import SentenceTransformer
model_name = "average_word_embeddings_komninos"
model = SentenceTransformer(model_name)
evaluation = MTEB(tasks=["Banking77Classification"])
results = evaluation.run(model, output_folder=f"results/{model_name}")
```
This should produce a `results/average_word_embeddings_komninos/Banking77Classification.json` file!
Now you can submit the results to the leaderboard by adding it to the metadata of the `README.md` of any model on the Hub.
Run our [automatic script](https://github.com/embeddings-benchmark/mteb/blob/main/scripts/mteb_meta.py) to generate the metadata:
```sh
python mteb_meta.py results/average_word_embeddings_komninos
```
The script will produce a `mteb_metadata.md` file that looks like this:
```sh
---
tags:
- mteb
model-index:
- name: average_word_embeddings_komninos
results:
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 66.76623376623377
- type: f1
value: 66.59096432882667
---
```
Now add the metadata to the top of a `README.md` of any model on the Hub, like this [SGPT-5.8B-msmarco](https://huggingface.co/Muennighoff/SGPT-5.8B-weightedmean-msmarco-specb-bitfit/blob/main/README.md) model, and it will show up on the [leaderboard](https://huggingface.co/spaces/mteb/leaderboard) after refreshing!
## Next steps
Go out there and benchmark any model you like! Let us know if you have questions or feedback by opening an issue on our [GitHub repo](https://github.com/embeddings-benchmark/mteb) or the [leaderboard community tab](https://huggingface.co/spaces/mteb/leaderboard/discussions) 🤗
Happy embedding!
## Credits
Huge thanks to the following who contributed to the article or to the MTEB codebase (listed in alphabetical order): Steven Liu, Loïc Magne, Nils Reimers and Nouamane Tazi.
|
huggingface/blog/blob/main/mteb.md
|
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Optimization
## Transformation
[[autodoc]] fx.optimization.Transformation
- all
- __call__
## Reversible transformation
[[autodoc]] fx.optimization.ReversibleTransformation
- all
- __call__
[[autodoc]] fx.optimization.compose
### Transformations
[[autodoc]] fx.optimization.MergeLinears
- all
[[autodoc]] fx.optimization.FuseBiasInLinear
- all
[[autodoc]] fx.optimization.ChangeTrueDivToMulByInverse
- all
[[autodoc]] fx.optimization.FuseBatchNorm2dInConv2d
- all
[[autodoc]] fx.optimization.FuseBatchNorm1dInLinear
- all
|
huggingface/optimum/blob/main/docs/source/torch_fx/package_reference/optimization.mdx
|
--
title: Deploying 🤗 ViT on Vertex AI
thumbnail: /blog/assets/97_vertex_ai/image1.png
authors:
- user: sayakpaul
guest: true
- user: chansung
guest: true
---
# Deploying 🤗 ViT on Vertex AI
<a target="_blank" href="https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/112_vertex_ai_vision.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
In the previous posts, we showed how to deploy a [<u>Vision Transformers
(ViT) model</u>](https://huggingface.co/docs/transformers/main/en/model_doc/vit)
from 🤗 Transformers [locally](https://huggingface.co/blog/tf-serving-vision) and
on a [Kubernetes cluster](https://huggingface.co/blog/deploy-tfserving-kubernetes). This post will
show you how to deploy the same model on the [<u>Vertex AI platform</u>](https://cloud.google.com/vertex-ai).
You’ll achieve the same scalability level as Kubernetes-based deployment but with
significantly less code.
This post builds on top of the previous two posts linked above. You’re
advised to check them out if you haven’t already.
You can find a completely worked-out example in the Colab Notebook
linked at the beginning of the post.
# What is Vertex AI?
According to [<u>Google Cloud</u>](https://www.youtube.com/watch?v=766OilR6xWc):
> Vertex AI provides tools to support your entire ML workflow, across
different model types and varying levels of ML expertise.
Concerning model deployment, Vertex AI provides a few important features
with a unified API design:
- Authentication
- Autoscaling based on traffic
- Model versioning
- Traffic splitting between different versions of a model
- Rate limiting
- Model monitoring and logging
- Support for online and batch predictions
For TensorFlow models, it offers various off-the-shelf utilities, which
you’ll get to in this post. But it also has similar support for other
frameworks like
[<u>PyTorch</u>](https://cloud.google.com/blog/topics/developers-practitioners/pytorch-google-cloud-how-deploy-pytorch-models-vertex-ai)
and [<u>scikit-learn</u>](https://codelabs.developers.google.com/vertex-cpr-sklearn).
To use Vertex AI, you’ll need a [<u>billing-enabled Google Cloud
Platform (GCP) project</u>](https://cloud.google.com/billing/docs/how-to/modify-project)
and the following services enabled:
- Vertex AI
- Cloud Storage
# Revisiting the Serving Model
You’ll use the same [<u>ViT B/16 model implemented in TensorFlow</u>](https://huggingface.co/docs/transformers/main/en/model_doc/vit#transformers.TFViTForImageClassification) as you did in the last two posts. You serialized the model with
corresponding pre-processing and post-processing operations embedded to
reduce [<u>training-serving skew</u>](https://developers.google.com/machine-learning/guides/rules-of-ml#:~:text=Training%2Dserving%20skew%20is%20a,train%20and%20when%20you%20serve.).
Please refer to the [<u>first post</u>](https://huggingface.co/blog/tf-serving-vision) that discusses
this in detail. The signature of the final serialized `SavedModel` looks like:
```bash
The given SavedModel SignatureDef contains the following input(s):
inputs['string_input'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_string_input:0
The given SavedModel SignatureDef contains the following output(s):
outputs['confidence'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: StatefulPartitionedCall:0
outputs['label'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: StatefulPartitionedCall:1
Method name is: tensorflow/serving/predict
```
The model will accept [<u>base64 encoded</u>](https://www.base64encode.org/) strings of images, perform
pre-processing, run inference, and finally perform the post-processing
steps. The strings are base64 encoded to prevent any
modifications during network transmission. Pre-processing includes
resizing the input image to 224x224 resolution, standardizing it to the
`[-1, 1]` range, and transposing it to the `channels_first` memory
layout. Postprocessing includes mapping the predicted logits to string
labels.
To perform a deployment on Vertex AI, you need to keep the model
artifacts in a [<u>Google Cloud Storage (GCS) bucket</u>](https://cloud.google.com/storage/docs/json_api/v1/buckets).
The accompanying Colab Notebook shows how to create a GCS bucket and
save the model artifacts into it.
# Deployment workflow with Vertex AI
The figure below gives a pictorial workflow of deploying an already
trained TensorFlow model on Vertex AI.

Let’s now discuss what the Vertex AI Model Registry and Endpoint are.
## Vertex AI Model Registry
Vertex AI Model Registry is a fully managed machine learning model
registry. There are a couple of things to note about what fully managed
means here. First, you don’t need to worry about how and where models
are stored. Second, it manages different versions of the same model.
These features are important for machine learning in production.
Building a model registry that guarantees high availability and security
is nontrivial. Also, there are often situations where you want to roll
back the current model to a past version since we can not
control the inside of a black box machine learning model. Vertex AI
Model Registry allows us to achieve these without much difficulty.
The currently supported model types include `SavedModel` from
TensorFlow, scikit-learn, and XGBoost.
## Vertex AI Endpoint
From the user’s perspective, Vertex AI Endpoint simply provides an
endpoint to receive requests and send responses back. However, it has a
lot of things under the hood for machine learning operators to
configure. Here are some of the configurations that you can choose:
- Version of a model
- Specification of VM in terms of CPU, memory, and accelerators
- Min/Max number of compute nodes
- Traffic split percentage
- Model monitoring window length and its objectives
- Prediction requests sampling rate
# Performing the Deployment
The [`google-cloud-aiplatform`](https://pypi.org/project/google-cloud-aiplatform/)
Python SDK provides easy APIs to manage the lifecycle of a deployment on
Vertex AI. It is divided into four steps:
1. uploading a model
2. creating an endpoint
3. deploying the model to the endpoint
4. making prediction requests.
Throughout these steps, you will
need `ModelServiceClient`, `EndpointServiceClient`, and
`PredictionServiceClient` modules from the `google-cloud-aiplatform`
Python SDK to interact with Vertex AI.

**1.** The first step in the workflow is to upload the `SavedModel` to
Vertex AI’s model registry:
```py
tf28_gpu_model_dict = {
"display_name": "ViT Base TF2.8 GPU model",
"artifact_uri": f"{GCS_BUCKET}/{LOCAL_MODEL_DIR}",
"container_spec": {
"image_uri": "us-docker.pkg.dev/vertex-ai/prediction/tf2-gpu.2-8:latest",
},
}
tf28_gpu_model = (
model_service_client.upload_model(parent=PARENT, model=tf28_gpu_model_dict)
.result(timeout=180)
.model
)
```
Let’s unpack the code piece by piece:
- `GCS_BUCKET` denotes the path of your GCS bucket where the model
artifacts are located (e.g., `gs://hf-tf-vision`).
- In `container_spec`, you provide the URI of a Docker image that will
be used to serve predictions. Vertex AI
provides [pre-built images]((https://cloud.google.com/vertex-ai/docs/predictions/pre-built-containers)) to serve TensorFlow models, but you can also use your custom Docker images when using a different framework
([<u>an example</u>](https://cloud.google.com/blog/topics/developers-practitioners/pytorch-google-cloud-how-deploy-pytorch-models-vertex-ai)).
- `model_service_client` is a
[`ModelServiceClient`](https://cloud.google.com/python/docs/reference/aiplatform/latest/google.cloud.aiplatform_v1.services.model_service.ModelServiceClient)
object that exposes the methods to upload a model to the Vertex AI
Model Registry.
- `PARENT` is set to `f"projects/{PROJECT_ID}/locations/{REGION}"`
that lets Vertex AI determine where the model is going to be scoped
inside GCP.
**2.** Then you need to create a Vertex AI Endpoint:
```py
tf28_gpu_endpoint_dict = {
"display_name": "ViT Base TF2.8 GPU endpoint",
}
tf28_gpu_endpoint = (
endpoint_service_client.create_endpoint(
parent=PARENT, endpoint=tf28_gpu_endpoint_dict
)
.result(timeout=300)
.name
)
```
Here you’re using an `endpoint_service_client` which is an
[`EndpointServiceClient`](https://cloud.google.com/vertex-ai/docs/samples/aiplatform-create-endpoint-sample)
object. It lets you create and configure your Vertex AI Endpoint.
**3.** Now you’re down to performing the actual deployment!
```py
tf28_gpu_deployed_model_dict = {
"model": tf28_gpu_model,
"display_name": "ViT Base TF2.8 GPU deployed model",
"dedicated_resources": {
"min_replica_count": 1,
"max_replica_count": 1,
"machine_spec": {
"machine_type": DEPLOY_COMPUTE, # "n1-standard-8"
"accelerator_type": DEPLOY_GPU, # aip.AcceleratorType.NVIDIA_TESLA_T4
"accelerator_count": 1,
},
},
}
tf28_gpu_deployed_model = endpoint_service_client.deploy_model(
endpoint=tf28_gpu_endpoint,
deployed_model=tf28_gpu_deployed_model_dict,
traffic_split={"0": 100},
).result()
```
Here, you’re chaining together the model you uploaded to the Vertex AI
Model Registry and the Endpoint you created in the above steps. You’re
first defining the configurations of the deployment under
`tf28_gpu_deployed_model_dict`.
Under `dedicated_resources` you’re configuring:
- `min_replica_count` and `max_replica_count` that handle the
autoscaling aspects of your deployment.
- `machine_spec` lets you define the configurations of the deployment
hardware:
- `machine_type` is the base machine type that will be used to run
the Docker image. The underlying autoscaler will scale this
machine as per the traffic load. You can choose one from the
[supported machine types](https://cloud.google.com/vertex-ai/docs/predictions/configure-compute#machine-types).
- `accelerator_type` is the hardware accelerator that will be used
to perform inference.
- `accelerator_count` denotes the number of hardware accelerators to
attach to each replica.
**Note** that providing an accelerator is not a requirement to deploy
models on Vertex AI.
Next, you deploy the endpoint using the above specifications:
```py
tf28_gpu_deployed_model = endpoint_service_client.deploy_model(
endpoint=tf28_gpu_endpoint,
deployed_model=tf28_gpu_deployed_model_dict,
traffic_split={"0": 100},
).result()
```
Notice how you’re defining the traffic split for the model. If you had
multiple versions of the model, you could have defined a dictionary
where the keys would denote the model version and values would denote
the percentage of traffic the model is supposed to serve.
With a Model Registry and a dedicated
[<u>interface</u>](https://console.cloud.google.com/vertex-ai/endpoints)
to manage Endpoints, Vertex AI lets you easily control the important
aspects of the deployment.
It takes about 15 - 30 minutes for Vertex AI to scope the deployment.
Once it’s done, you should be able to see it on the
[<u>console</u>](https://console.cloud.google.com/vertex-ai/endpoints).
# Performing Predictions
If your deployment was successful, you can test the deployed
Endpoint by making a prediction request.
First, prepare a base64 encoded image string:
```py
import base64
import tensorflow as tf
image_path = tf.keras.utils.get_file(
"image.jpg", "http://images.cocodataset.org/val2017/000000039769.jpg"
)
bytes = tf.io.read_file(image_path)
b64str = base64.b64encode(bytes.numpy()).decode("utf-8")
```
**4.** The following utility first prepares a list of instances (only
one instance in this case) and then uses a prediction service client (of
type [`PredictionServiceClient`](https://cloud.google.com/python/docs/reference/automl/latest/google.cloud.automl_v1beta1.services.prediction_service.PredictionServiceClient)).
`serving_input` is the name of the input signature key of the served
model. In this case, the `serving_input` is `string_input`, which
you can verify from the `SavedModel` signature output shown above.
```
from google.protobuf import json_format
from google.protobuf.struct_pb2 import Value
def predict_image(image, endpoint, serving_input):
# The format of each instance should conform to
# the deployed model's prediction input schema.
instances_list = [{serving_input: {"b64": image}}]
instances = [json_format.ParseDict(s, Value()) for s in instances_list]
print(
prediction_service_client.predict(
endpoint=endpoint,
instances=instances,
)
)
predict_image(b64str, tf28_gpu_endpoint, serving_input)
```
For TensorFlow models deployed on Vertex AI, the request payload needs
to be formatted in a certain way. For models like ViT that deal with
binary data like images, they need to be base64 encoded. According to
the [<u>official guide</u>](https://cloud.google.com/vertex-ai/docs/predictions/online-predictions-custom-models#encoding-binary-data),
the request payload for each instance needs to be like so:
```py
{serving_input: {"b64": base64.b64encode(jpeg_data).decode()}}
```
The `predict_image()` utility prepares the request payload conforming
to this specification.
If everything goes well with the deployment, when you call
`predict_image()`, you should get an output like so:
```bash
predictions {
struct_value {
fields {
key: "confidence"
value {
number_value: 0.896659553
}
}
fields {
key: "label"
value {
string_value: "Egyptian cat"
}
}
}
}
deployed_model_id: "5163311002082607104"
model: "projects/29880397572/locations/us-central1/models/7235960789184544768"
model_display_name: "ViT Base TF2.8 GPU model"
```
Note, however, this is not the only way to obtain predictions using a
Vertex AI Endpoint. If you head over to the Endpoint console and select
your endpoint, it will show you two different ways to obtain
predictions:

It’s also possible to avoid cURL requests and obtain predictions
programmatically without using the Vertex AI SDK. Refer to
[<u>this notebook</u>](https://github.com/sayakpaul/deploy-hf-tf-vision-models/blob/main/hf_vision_model_vertex_ai/test-vertex-ai-endpoint.ipynb)
to learn more.
Now that you’ve learned how to use Vertex AI to deploy a TensorFlow
model, let’s now discuss some beneficial features provided by Vertex AI.
These help you get deeper insights into your deployment.
# Monitoring with Vertex AI
Vertex AI also lets you monitor your model without any configuration.
From the Endpoint console, you can get details about the performance of
the Endpoint and the utilization of the allocated resources.


As seen in the above chart, for a brief amount of time, the accelerator
duty cycle (utilization) was about 100% which is a sight for sore eyes.
For the rest of the time, there weren’t any requests to process hence
things were idle.
This type of monitoring helps you quickly flag the currently deployed
Endpoint and make adjustments as necessary. It’s also possible to
request monitoring of model explanations. Refer
[<u>here</u>](https://cloud.google.com/vertex-ai/docs/explainable-ai/overview)
to learn more.
# Local Load Testing
We conducted a local load test to better understand the limits of the
Endpoint with [<u>Locust</u>](https://locust.io/). The table below
summarizes the request statistics:

Among all the different statistics shown in the table, `Average (ms)`
refers to the average latency of the Endpoint. Locust fired off about
**17230 requests**, and the reported average latency is **646
Milliseconds**, which is impressive. In practice, you’d want to simulate
more real traffic by conducting the load test in a distributed manner.
Refer [<u>here</u>](https://cloud.google.com/architecture/load-testing-and-monitoring-aiplatform-models)
to learn more.
[<u>This directory</u>](https://github.com/sayakpaul/deploy-hf-tf-vision-models/tree/main/hf_vision_model_vertex_ai/locust)
has all the information needed to know how we conducted the load test.
# Pricing
You can use the [<u>GCP cost estimator</u>](https://cloud.google.com/products/calculator) to estimate the cost of usage,
and the exact hourly pricing table can be found [<u>here</u>](https://cloud.google.com/vertex-ai/pricing#custom-trained_models).
It is worth noting that you are only charged when the node is processing
the actual prediction requests, and you need to calculate the price with
and without GPUs.
For the Vertex Prediction for a custom-trained model, we can choose
[N1 machine types from `n1-standard-2` to `n1-highcpu-32`](https://cloud.google.com/vertex-ai/pricing#custom-trained_models).
You used `n1-standard-8` for this post which is equipped with 8
vCPUs and 32GBs of RAM.
<div align="center">
| **Machine Type** | **Hourly Pricing (USD)** |
|:-----------------------------:|:--------------------------:|
| n1-standard-8 (8vCPU, 30GB) | $ 0.4372 |
</div>
Also, when you attach accelerators to the compute node, you will be
charged extra by the type of accelerator you want. We used
`NVIDIA_TESLA_T4` for this blog post, but almost all modern
accelerators, including TPUs are supported. You can find further
information [<u>here</u>](https://cloud.google.com/vertex-ai/pricing#custom-trained_models).
<div align="center">
| **Accelerator Type** | **Hourly Pricing (USD)** |
|:----------------------:|:--------------------------:|
| NVIDIA_TESLA_T4 | $ 0.4024 |
</div>
# Call for Action
The collection of TensorFlow vision models in 🤗 Transformers is growing. It now supports
state-of-the-art semantic segmentation with
[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer#transformers.TFSegformerForSemanticSegmentation).
We encourage you to extend the deployment workflow you learned in this post to semantic segmentation models like SegFormer.
# Conclusion
In this post, you learned how to deploy a Vision Transformer model with
the Vertex AI platform using the easy APIs it provides. You also learned
how Vertex AI’s features benefit the model deployment process by enabling
you to focus on declarative configurations and removing the complex
parts. Vertex AI also supports deployment of PyTorch models via custom
prediction routes. Refer
[<u>here</u>](https://cloud.google.com/blog/topics/developers-practitioners/pytorch-google-cloud-how-deploy-pytorch-models-vertex-ai)
for more details.
The series first introduced you to TensorFlow Serving for locally deploying
a vision model from 🤗 Transformers. In the second post, you learned how to scale
that local deployment with Docker and Kubernetes. We hope this series on the
online deployment of TensorFlow vision models was beneficial for you to take your
ML toolbox to the next level. We can’t wait to see what you build with these tools.
# Acknowledgements
Thanks to the ML Developer Relations Program team at Google, which
provided us with GCP credits for conducting the experiments.
Parts of the deployment code were referred from
[<u>this notebook</u>](https://github.com/GoogleCloudPlatform/vertex-ai-samples/tree/main/notebooks/community/vertex_endpoints/optimized_tensorflow_runtime) of the official [<u>GitHub repository</u>](https://github.com/GoogleCloudPlatform/vertex-ai-samples)
of Vertex AI code samples.
|
huggingface/blog/blob/main/deploy-vertex-ai.md
|
--
title: 'Few-shot learning in practice: GPT-Neo and the 🤗 Accelerated Inference API'
# thumbnail: /blog/assets/22_few_shot_learning_gpt_neo_and_inference_api/thumbnail.png
authors:
- user: philschmid
---
# Few-shot learning in practice: GPT-Neo and the 🤗 Accelerated Inference API
In many Machine Learning applications, the amount of available labeled data is a barrier to producing a high-performing model. The latest developments in NLP show that you can overcome this limitation by providing a few examples at inference time with a large language model - a technique known as Few-Shot Learning. In this blog post, we'll explain what Few-Shot Learning is, and explore how a large language model called GPT-Neo, and the 🤗 Accelerated Inference API, can be used to generate your own predictions.
## What is Few-Shot Learning?
Few-Shot Learning refers to the practice of feeding a machine learning model with a very small amount of training data to guide its predictions, like a few examples at inference time, as opposed to standard fine-tuning techniques which require a relatively large amount of training data for the pre-trained model to adapt to the desired task with accuracy.
This technique has been mostly used in computer vision, but with some of the latest Language Models, like [EleutherAI GPT-Neo](https://www.eleuther.ai/research/projects/gpt-neo/) and [OpenAI GPT-3](https://openai.com/blog/gpt-3-apps/), we can now use it in Natural Language Processing (NLP).
In NLP, Few-Shot Learning can be used with Large Language Models, which have learned to perform a wide number of tasks implicitly during their pre-training on large text datasets. This enables the model to generalize, that is to understand related but previously unseen tasks, with just a few examples.
Few-Shot NLP examples consist of three main components:
- **Task Description**: A short description of what the model should do, e.g. "Translate English to French"
- **Examples**: A few examples showing the model what it is expected to predict, e.g. "sea otter => loutre de mer"
- **Prompt**: The beginning of a new example, which the model should complete by generating the missing text, e.g. "cheese => "

<small>Image from <a href="https://arxiv.org/abs/2005.14165" target="_blank">Language Models are Few-Shot Learners</a></small>
Creating these few-shot examples can be tricky, since you need to articulate the “task” you want the model to perform through them. A common issue is that models, especially smaller ones, are very sensitive to the way the examples are written.
An approach to optimize Few-Shot Learning in production is to learn a common representation for a task and then train task-specific classifiers on top of this representation.
OpenAI showed in the [GPT-3 Paper](https://arxiv.org/abs/2005.14165) that the few-shot prompting ability improves with the number of language model parameters.

<small>Image from <a href="https://arxiv.org/abs/2005.14165" target="_blank">Language Models are Few-Shot Learners</a></small>
Let's now take a look at how at how GPT-Neo and the 🤗 Accelerated Inference API can be used to generate your own Few-Shot Learning predictions!
---
## What is GPT-Neo?
GPT-Neo is a family of transformer-based language models from [EleutherAI](https://www.eleuther.ai/projects/gpt-neo/) based on the GPT architecture. [EleutherAI](https://www.eleuther.ai)'s primary goal is to train a model that is equivalent in size to GPT-3 and make it available to the public under an open license.
All of the currently available GPT-Neo checkpoints are trained with the Pile dataset, a large text corpus that is extensively documented in ([Gao et al., 2021](https://arxiv.org/abs/2101.00027)). As such, it is expected to function better on the text that matches the distribution of its training text; we recommend keeping this in mind when designing your examples.
---
## 🤗 Accelerated Inference API
The [Accelerated Inference API](https://huggingface.co/inference-api) is our hosted service to run inference on any of the 10,000+ models publicly available on the 🤗 Model Hub, or your own private models, via simple API calls. The API includes acceleration on CPU and GPU with [up to 100x speedup](https://huggingface.co/blog/accelerated-inference) compared to out of the box deployment of Transformers.
To integrate Few-Shot Learning predictions with `GPT-Neo` in your own apps, you can use the 🤗 Accelerated Inference API with the code snippet below. You can find your API Token [here](https://huggingface.co/settings/token), if you don't have an account you can get started [here](https://huggingface.co/pricing).
```python
import json
import requests
API_TOKEN = ""
def query(payload='',parameters=None,options={'use_cache': False}):
API_URL = "https://api-inference.huggingface.co/models/EleutherAI/gpt-neo-2.7B"
headers = {"Authorization": f"Bearer {API_TOKEN}"}
body = {"inputs":payload,'parameters':parameters,'options':options}
response = requests.request("POST", API_URL, headers=headers, data= json.dumps(body))
try:
response.raise_for_status()
except requests.exceptions.HTTPError:
return "Error:"+" ".join(response.json()['error'])
else:
return response.json()[0]['generated_text']
parameters = {
'max_new_tokens':25, # number of generated tokens
'temperature': 0.5, # controlling the randomness of generations
'end_sequence': "###" # stopping sequence for generation
}
prompt="...." # few-shot prompt
data = query(prompt,parameters,options)
```
---
## Practical Insights
Here are some practical insights, which help you get started using `GPT-Neo` and the 🤗 Accelerated Inference API.
Since `GPT-Neo` (2.7B) is about 60x smaller than `GPT-3` (175B), it does not generalize as well to zero-shot problems and needs 3-4 examples to achieve good results. When you provide more examples `GPT-Neo` understands the task and takes the `end_sequence` into account, which allows us to control the generated text pretty well.

The hyperparameter `End Sequence`, `Token Length` & `Temperature` can be used to control the `text-generation` of the model and you can use this to your advantage to solve the task you need. The `Temperature` controlls the randomness of your generations, lower temperature results in less random generations and higher temperature results in more random generations.

In the example, you can see how important it is to define your hyperparameter. These can make the difference between solving your task or failing miserably.
---
## Responsible Use
Few-Shot Learning is a powerful technique but also presents unique pitfalls that need to be taken into account when designing uses cases.
To illustrate this, let's consider the default `Sentiment Analysis` setting provided in the widget. After seeing three examples of sentiment classification, the model makes the following predictions 4 times out of 5, with `temperature` set to 0.1:
> ###
> Tweet: "I'm a disabled happy person"
> Sentiment: Negative
What could go wrong? Imagine that you are using sentiment analysis to aggregate reviews of products on an online shopping website: a possible outcome could be that items useful to people with disabilities would be automatically down-ranked - a form of automated discrimination. For more on this specific issue, we recommend the ACL 2020 paper [Social Biases in NLP Models as Barriers for Persons with Disabilities](https://www.aclweb.org/anthology/2020.acl-main.487.pdf). Because Few-Shot Learning relies more directly on information and associations picked up from pre-training, it makes it more sensitive to this type of failures.
How to minimize the risk of harm? Here are some practical recommendations.
### Best practices for responsible use
- Make sure people know which parts of their user experience depend on the outputs of the ML system
- If possible, give users the ability to opt-out
- Provide a mechanism for users to give feedback on the model decision, and to override it
- Monitor feedback, especially model failures, for groups of users that may be disproportionately affected
What needs most to be avoided is to use the model to automatically make decisions for, or about, a user, without opportunity for a human to provide input or correct the output. Several regulations, such as [GDPR](https://gdpr-info.eu/) in Europe, require that users be provided an explanation for automatic decisions made about them.
---
To use GPT-Neo or any Hugging Face model in your own application, you can [start a free trial](https://huggingface.co/pricing) of the 🤗 Accelerated Inference API.
If you need help mitigating bias in models and AI systems, or leveraging Few-Shot Learning, the 🤗 Expert Acceleration Program can [offer your team direct premium support from the Hugging Face team](https://huggingface.co/support).
|
huggingface/blog/blob/main/few-shot-learning-gpt-neo-and-inference-api.md
|
Evaluate predictions
<Tip warning={true}>
Metrics is deprecated in 🤗 Datasets. To learn more about how to use metrics, take a look at the library 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index)! In addition to metrics, you can find more tools for evaluating models and datasets.
</Tip>
🤗 Datasets provides various common and NLP-specific [metrics](https://huggingface.co/metrics) for you to measure your models performance. In this section of the tutorials, you will load a metric and use it to evaluate your models predictions.
You can see what metrics are available with [`list_metrics`]:
```py
>>> from datasets import list_metrics
>>> metrics_list = list_metrics()
>>> len(metrics_list)
28
>>> print(metrics_list)
['accuracy', 'bertscore', 'bleu', 'bleurt', 'cer', 'comet', 'coval', 'cuad', 'f1', 'gleu', 'glue', 'indic_glue', 'matthews_correlation', 'meteor', 'pearsonr', 'precision', 'recall', 'rouge', 'sacrebleu', 'sari', 'seqeval', 'spearmanr', 'squad', 'squad_v2', 'super_glue', 'wer', 'wiki_split', 'xnli']
```
## Load metric
It is very easy to load a metric with 🤗 Datasets. In fact, you will notice that it is very similar to loading a dataset! Load a metric from the Hub with [`load_metric`]:
```py
>>> from datasets import load_metric
>>> metric = load_metric('glue', 'mrpc')
```
This will load the metric associated with the MRPC dataset from the GLUE benchmark.
## Select a configuration
If you are using a benchmark dataset, you need to select a metric that is associated with the configuration you are using. Select a metric configuration by providing the configuration name:
```py
>>> metric = load_metric('glue', 'mrpc')
```
## Metrics object
Before you begin using a [`Metric`] object, you should get to know it a little better. As with a dataset, you can return some basic information about a metric. For example, access the `inputs_description` parameter in [`datasets.MetricInfo`] to get more information about a metrics expected input format and some usage examples:
```py
>>> print(metric.inputs_description)
Compute GLUE evaluation metric associated to each GLUE dataset.
Args:
predictions: list of predictions to score.
Each translation should be tokenized into a list of tokens.
references: list of lists of references for each translation.
Each reference should be tokenized into a list of tokens.
Returns: depending on the GLUE subset, one or several of:
"accuracy": Accuracy
"f1": F1 score
"pearson": Pearson Correlation
"spearmanr": Spearman Correlation
"matthews_correlation": Matthew Correlation
Examples:
>>> glue_metric = datasets.load_metric('glue', 'sst2') # 'sst2' or any of ["mnli", "mnli_mismatched", "mnli_matched", "qnli", "rte", "wnli", "hans"]
>>> references = [0, 1]
>>> predictions = [0, 1]
>>> results = glue_metric.compute(predictions=predictions, references=references)
>>> print(results)
{'accuracy': 1.0}
...
>>> glue_metric = datasets.load_metric('glue', 'mrpc') # 'mrpc' or 'qqp'
>>> references = [0, 1]
>>> predictions = [0, 1]
>>> results = glue_metric.compute(predictions=predictions, references=references)
>>> print(results)
{'accuracy': 1.0, 'f1': 1.0}
...
```
Notice for the MRPC configuration, the metric expects the input format to be zero or one. For a complete list of attributes you can return with your metric, take a look at [`MetricInfo`].
## Compute metric
Once you have loaded a metric, you are ready to use it to evaluate a models predictions. Provide the model predictions and references to [`~datasets.Metric.compute`]:
```py
>>> model_predictions = model(model_inputs)
>>> final_score = metric.compute(predictions=model_predictions, references=gold_references)
```
|
huggingface/datasets/blob/main/docs/source/metrics.mdx
|
--
title: ROC AUC
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
This metric computes the area under the curve (AUC) for the Receiver Operating Characteristic Curve (ROC). The return values represent how well the model used is predicting the correct classes, based on the input data. A score of `0.5` means that the model is predicting exactly at chance, i.e. the model's predictions are correct at the same rate as if the predictions were being decided by the flip of a fair coin or the roll of a fair die. A score above `0.5` indicates that the model is doing better than chance, while a score below `0.5` indicates that the model is doing worse than chance.
This metric has three separate use cases:
- binary: The case in which there are only two different label classes, and each example gets only one label. This is the default implementation.
- multiclass: The case in which there can be more than two different label classes, but each example still gets only one label.
- multilabel: The case in which there can be more than two different label classes, and each example can have more than one label.
---
# Metric Card for ROC AUC
## Metric Description
This metric computes the area under the curve (AUC) for the Receiver Operating Characteristic Curve (ROC). The return values represent how well the model used is predicting the correct classes, based on the input data. A score of `0.5` means that the model is predicting exactly at chance, i.e. the model's predictions are correct at the same rate as if the predictions were being decided by the flip of a fair coin or the roll of a fair die. A score above `0.5` indicates that the model is doing better than chance, while a score below `0.5` indicates that the model is doing worse than chance.
This metric has three separate use cases:
- **binary**: The case in which there are only two different label classes, and each example gets only one label. This is the default implementation.
- **multiclass**: The case in which there can be more than two different label classes, but each example still gets only one label.
- **multilabel**: The case in which there can be more than two different label classes, and each example can have more than one label.
## How to Use
At minimum, this metric requires references and prediction scores:
```python
>>> roc_auc_score = evaluate.load("roc_auc")
>>> refs = [1, 0, 1, 1, 0, 0]
>>> pred_scores = [0.5, 0.2, 0.99, 0.3, 0.1, 0.7]
>>> results = roc_auc_score.compute(references=refs, prediction_scores=pred_scores)
>>> print(round(results['roc_auc'], 2))
0.78
```
The default implementation of this metric is the **binary** implementation. If employing the **multiclass** or **multilabel** use cases, the keyword `"multiclass"` or `"multilabel"` must be specified when loading the metric:
- In the **multiclass** case, the metric is loaded with:
```python
>>> roc_auc_score = evaluate.load("roc_auc", "multiclass")
```
- In the **multilabel** case, the metric is loaded with:
```python
>>> roc_auc_score = evaluate.load("roc_auc", "multilabel")
```
See the [Examples Section Below](#examples_section) for more extensive examples.
### Inputs
- **`references`** (array-like of shape (n_samples,) or (n_samples, n_classes)): Ground truth labels. Expects different inputs based on use case:
- binary: expects an array-like of shape (n_samples,)
- multiclass: expects an array-like of shape (n_samples,)
- multilabel: expects an array-like of shape (n_samples, n_classes)
- **`prediction_scores`** (array-like of shape (n_samples,) or (n_samples, n_classes)): Model predictions. Expects different inputs based on use case:
- binary: expects an array-like of shape (n_samples,)
- multiclass: expects an array-like of shape (n_samples, n_classes). The probability estimates must sum to 1 across the possible classes.
- multilabel: expects an array-like of shape (n_samples, n_classes)
- **`average`** (`str`): Type of average, and is ignored in the binary use case. Defaults to `'macro'`. Options are:
- `'micro'`: Calculates metrics globally by considering each element of the label indicator matrix as a label. Only works with the multilabel use case.
- `'macro'`: Calculate metrics for each label, and find their unweighted mean. This does not take label imbalance into account.
- `'weighted'`: Calculate metrics for each label, and find their average, weighted by support (i.e. the number of true instances for each label).
- `'samples'`: Calculate metrics for each instance, and find their average. Only works with the multilabel use case.
- `None`: No average is calculated, and scores for each class are returned. Only works with the multilabels use case.
- **`sample_weight`** (array-like of shape (n_samples,)): Sample weights. Defaults to None.
- **`max_fpr`** (`float`): If not None, the standardized partial AUC over the range [0, `max_fpr`] is returned. Must be greater than `0` and less than or equal to `1`. Defaults to `None`. Note: For the multiclass use case, `max_fpr` should be either `None` or `1.0` as ROC AUC partial computation is not currently supported for `multiclass`.
- **`multi_class`** (`str`): Only used for multiclass targets, in which case it is required. Determines the type of configuration to use. Options are:
- `'ovr'`: Stands for One-vs-rest. Computes the AUC of each class against the rest. This treats the multiclass case in the same way as the multilabel case. Sensitive to class imbalance even when `average == 'macro'`, because class imbalance affects the composition of each of the 'rest' groupings.
- `'ovo'`: Stands for One-vs-one. Computes the average AUC of all possible pairwise combinations of classes. Insensitive to class imbalance when `average == 'macro'`.
- **`labels`** (array-like of shape (n_classes,)): Only used for multiclass targets. List of labels that index the classes in `prediction_scores`. If `None`, the numerical or lexicographical order of the labels in `prediction_scores` is used. Defaults to `None`.
### Output Values
This metric returns a dict containing the `roc_auc` score. The score is a `float`, unless it is the multilabel case with `average=None`, in which case the score is a numpy `array` with entries of type `float`.
The output therefore generally takes the following format:
```python
{'roc_auc': 0.778}
```
In contrast, though, the output takes the following format in the multilabel case when `average=None`:
```python
{'roc_auc': array([0.83333333, 0.375, 0.94444444])}
```
ROC AUC scores can take on any value between `0` and `1`, inclusive.
#### Values from Popular Papers
### <a name="examples_section"></a>Examples
Example 1, the **binary** use case:
```python
>>> roc_auc_score = evaluate.load("roc_auc")
>>> refs = [1, 0, 1, 1, 0, 0]
>>> pred_scores = [0.5, 0.2, 0.99, 0.3, 0.1, 0.7]
>>> results = roc_auc_score.compute(references=refs, prediction_scores=pred_scores)
>>> print(round(results['roc_auc'], 2))
0.78
```
Example 2, the **multiclass** use case:
```python
>>> roc_auc_score = evaluate.load("roc_auc", "multiclass")
>>> refs = [1, 0, 1, 2, 2, 0]
>>> pred_scores = [[0.3, 0.5, 0.2],
... [0.7, 0.2, 0.1],
... [0.005, 0.99, 0.005],
... [0.2, 0.3, 0.5],
... [0.1, 0.1, 0.8],
... [0.1, 0.7, 0.2]]
>>> results = roc_auc_score.compute(references=refs,
... prediction_scores=pred_scores,
... multi_class='ovr')
>>> print(round(results['roc_auc'], 2))
0.85
```
Example 3, the **multilabel** use case:
```python
>>> roc_auc_score = evaluate.load("roc_auc", "multilabel")
>>> refs = [[1, 1, 0],
... [1, 1, 0],
... [0, 1, 0],
... [0, 0, 1],
... [0, 1, 1],
... [1, 0, 1]]
>>> pred_scores = [[0.3, 0.5, 0.2],
... [0.7, 0.2, 0.1],
... [0.005, 0.99, 0.005],
... [0.2, 0.3, 0.5],
... [0.1, 0.1, 0.8],
... [0.1, 0.7, 0.2]]
>>> results = roc_auc_score.compute(references=refs,
... prediction_scores=pred_scores,
... average=None)
>>> print([round(res, 2) for res in results['roc_auc'])
[0.83, 0.38, 0.94]
```
## Limitations and Bias
## Citation
```bibtex
@article{doi:10.1177/0272989X8900900307,
author = {Donna Katzman McClish},
title ={Analyzing a Portion of the ROC Curve},
journal = {Medical Decision Making},
volume = {9},
number = {3},
pages = {190-195},
year = {1989},
doi = {10.1177/0272989X8900900307},
note ={PMID: 2668680},
URL = {https://doi.org/10.1177/0272989X8900900307},
eprint = {https://doi.org/10.1177/0272989X8900900307}
}
```
```bibtex
@article{10.1023/A:1010920819831,
author = {Hand, David J. and Till, Robert J.},
title = {A Simple Generalisation of the Area Under the ROC Curve for Multiple Class Classification Problems},
year = {2001},
issue_date = {November 2001},
publisher = {Kluwer Academic Publishers},
address = {USA},
volume = {45},
number = {2},
issn = {0885-6125},
url = {https://doi.org/10.1023/A:1010920819831},
doi = {10.1023/A:1010920819831},
journal = {Mach. Learn.},
month = {oct},
pages = {171–186},
numpages = {16},
keywords = {Gini index, AUC, error rate, ROC curve, receiver operating characteristic}
}
```
```bibtex
@article{scikit-learn,
title={Scikit-learn: Machine Learning in {P}ython},
author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V. and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P. and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.},
journal={Journal of Machine Learning Research},
volume={12},
pages={2825--2830},
year={2011}
}
```
## Further References
This implementation is a wrapper around the [Scikit-learn implementation](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.roc_auc_score.html). Much of the documentation here was adapted from their existing documentation, as well.
The [Guide to ROC and AUC](https://youtu.be/iCZJfO-7C5Q) video from the channel Data Science Bits is also very informative.
|
huggingface/evaluate/blob/main/metrics/roc_auc/README.md
|
Create custom Inference Handler
Hugging Face Endpoints supports all of the Transformers and Sentence-Transformers tasks and can support custom tasks, including custom pre- & post-processing. The customization can be done through a [handler.py](https://huggingface.co/philschmid/distilbert-onnx-banking77/blob/main/handler.py) file in your model repository on the Hugging Face Hub.
The [handler.py](https://huggingface.co/philschmid/distilbert-onnx-banking77/blob/main/handler.py) needs to implement the [EndpointHandler](https://huggingface.co/philschmid/distilbert-onnx-banking77/blob/main/handler.py) class with a `__init__` and a `__call__` method.
If you want to use custom dependencies, e.g. [optimum](https://raw.githubusercontent.com/huggingface/optimum), the dependencies must be listed in a `requirements.txt` as described above in “add custom dependencies.”
## Custom Handler Examples
There are already several public examples on the [Hugging Face Hub](https://huggingface.co/models?other=endpoints-template) where you can take insipiration or directly use them. The repositories are tagged with `endpoints-template` and can be found under this [link](https://huggingface.co/models?other=endpoints-template).
Included examples are for:
* [Optimum and ONNX Runtime](https://huggingface.co/philschmid/distilbert-onnx-banking77)
* [Image Embeddings with BLIP](https://huggingface.co/florentgbelidji/blip_image_embeddings)
* [TrOCR for OCR Detection](https://huggingface.co/philschmid/trocr-base-printed)
* [Optimized Sentence Transformers with Optimum](https://huggingface.co/philschmid/all-MiniLM-L6-v2-optimum-embeddings)
* [Pyannote Speaker diarization](https://huggingface.co/philschmid/pyannote-speaker-diarization-endpoint)
* [LayoutLM](https://huggingface.co/philschmid/layoutlm-funsd)
* [Flair NER](https://huggingface.co/philschmid/flair-ner-english-ontonotes-large)
* [GPT-J 6B Single GPU](https://huggingface.co/philschmid/gpt-j-6B-fp16-sharded)
* [Donut Document understanding](https://huggingface.co/philschmid/donut-base-finetuned-cord-v2)
* [SetFit classifier](https://huggingface.co/philschmid/setfit-ag-news-endpoint)
## Tutorial
Before creating a Custom Handler, you need a Hugging Face Model repository with your model weights and an Access Token with _WRITE_ access to the repository. To find, create and manage Access Tokens, click [here](https://huggingface.co/settings/tokens).
If you want to write a Custom Handler for an existing model from the community, you can use the [repo_duplicator](https://huggingface.co/spaces/osanseviero/repo_duplicator) to create a repository fork.
The code can also be found in this [Notebook](https://colab.research.google.com/drive/1hANJeRa1PK1gZaUorobnQGu4bFj4_4Rf?usp=sharing).
You can also search for already existing Custom Handlers here: [https://huggingface.co/models?other=endpoints-template](https://huggingface.co/models?other=endpoints-template)
### 1. Set up Development Environment
The easiest way to develop our custom handler is to set up a local development environment, to implement, test, and iterate there, and then deploy it as an Inference Endpoint. The first step is to install all required development dependencies.
_needed to create the custom handler, not needed for inference_
```
# install git-lfs to interact with the repository
sudo apt-get update
sudo apt-get install git-lfs
# install transformers (not needed since it is installed by default in the container)
pip install transformers[sklearn,sentencepiece,audio,vision]
```
After we have installed our libraries we will clone our repository to our development environment.
We will use [philschmid/distilbert-base-uncased-emotion](https://huggingface.co/philschmid/distilbert-base-uncased-emotion) during the tutorial.
```
git lfs install
git clone https://huggingface.co/philschmid/distilbert-base-uncased-emotion
```
To be able to push our CP later you need to login into our HF account. This can be done by using the `huggingface-cli`.
_Note: Make sure to configure git config as well._
```
# setup cli with token
huggingface-cli login
git config --global credential.helper store
```
### 2. Create EndpointHandler (CP)
After we have set up our environment, we can start creating your custom handler. The custom handler is a Python class (`EndpointHandler`) inside a `handler.py` file in our repository. The `EndpointHandler` needs to implement an `__init__` and a `__call__` method.
- The `__init__` method will be called when starting the Endpoint and will receive 1 argument, a string with the path to your model weights. This allows you to load your model correctly.
- The `__call__` method will be called on every request and receive a dictionary with your request body as a python dictionary. It will always contain the `inputs` key.
The first step is to create our `handler.py` in the local clone of our repository.
```
!cd distilbert-base-uncased-emotion && touch handler.py
```
In there, you define your `EndpointHandler` class with the `__init__` and `__call__ `method.
```python
from typing import Dict, List, Any
class EndpointHandler():
def __init__(self, path=""):
# Preload all the elements you are going to need at inference.
# pseudo:
# self.model= load_model(path)
def __call__(self, data: Dict[str, Any]) -> List[Dict[str, Any]]:
"""
data args:
inputs (:obj: `str` | `PIL.Image` | `np.array`)
kwargs
Return:
A :obj:`list` | `dict`: will be serialized and returned
"""
# pseudo
# self.model(input)
```
### 3. Customize EndpointHandler
Now, you can add all of the custom logic you want to use during initialization or inference to your CP. You can already find multiple [Custom Handler on the Hub](https://huggingface.co/models?other=endpoints-template) if you need some inspiration. In our example, we will add a custom condition based on additional payload information.
*The model we are using in the tutorial is fine-tuned to detect emotions. We will add an additional payload field for the date, and will use an external package to check if it is a holiday, to add a condition so that when the input date is a holiday, the model returns “happy” - since everyone is happy when there are holidays *🌴🎉😆
First, we need to create a new `requirements.txt` and add our [holiday detection package](https://pypi.org/project/holidays/) and make sure we have it installed in our development environment as well.
```
!echo "holidays" >> requirements.txt
!pip install -r requirements.txt
```
Next, we have to adjust our `handler.py` and `EndpointHandler` to match our condition.
```python
from typing import Dict, List, Any
from transformers import pipeline
import holidays
class EndpointHandler():
def __init__(self, path=""):
self.pipeline = pipeline("text-classification",model=path)
self.holidays = holidays.US()
def __call__(self, data: Dict[str, Any]) -> List[Dict[str, Any]]:
"""
data args:
inputs (:obj: `str`)
date (:obj: `str`)
Return:
A :obj:`list` | `dict`: will be serialized and returned
"""
# get inputs
inputs = data.pop("inputs",data)
date = data.pop("date", None)
# check if date exists and if it is a holiday
if date is not None and date in self.holidays:
return [{"label": "happy", "score": 1}]
# run normal prediction
prediction = self.pipeline(inputs)
return prediction
```
### 4. Test EndpointHandler
To test our EndpointHandler, we can simplify import, initialize and test it. Therefore we only need to prepare a sample payload.
```python
from handler import EndpointHandler
# init handler
my_handler = EndpointHandler(path=".")
# prepare sample payload
non_holiday_payload = {"inputs": "I am quite excited how this will turn out", "date": "2022-08-08"}
holiday_payload = {"inputs": "Today is a though day", "date": "2022-07-04"}
# test the handler
non_holiday_pred=my_handler(non_holiday_payload)
holiday_payload=my_handler(holiday_payload)
# show results
print("non_holiday_pred", non_holiday_pred)
print("holiday_payload", holiday_payload)
# non_holiday_pred [{'label': 'joy', 'score': 0.9985942244529724}]
# holiday_payload [{'label': 'happy', 'score': 1}]
```
It works!!!! 🎉
_Note: If you are using a notebook you might have to restart your kernel when you make changes to the handler.py since it is not automatically re-imported._
### 5. Push the Custom Handler to your repository
After you have successfully tested your handler locally, you can push it to your repository by simply using basic git commands.
```
# add all our new files
!git add *
# commit our files
!git commit -m "add custom handler"
# push the files to the hub
!git push
```
Now, you should see your `handler.py` and `requirements.txt` in your repository in the [“Files and version”](https://huggingface.co/philschmid/distilbert-base-uncased-emotion/tree/main) tab.
### 6. Deploy your Custom Handler as an Inference Endpoint
The last step is to deploy your Custom Handler as an Inference Endpoint. You can deploy your Custom Handler like you would a regular Inference Endpoint. Add your repository, select your cloud and region, your instance and security setting, and deploy.
When creating your Endpoint, the Inference Endpoint Service will check for an available and valid `handler.py`, and will use it for serving requests no matter which “Task” you select.
_Note: In your [Inference Endpoints dashboard](https://ui.endpoints.huggingface.co/), the Task for this Endpoint should now be set to Custom_
|
huggingface/hf-endpoints-documentation/blob/main/docs/source/guides/custom_handler.mdx
|
--
title: "Director of Machine Learning Insights [Part 3: Finance Edition]"
thumbnail: /blog/assets/78_ml_director_insights/thumbnail.png
authors:
- user: britneymuller
---
# Director of Machine Learning Insights [Part 3: Finance Edition]
_If you're interested in building ML solutions faster visit [hf.co/support](https://huggingface.co/support?utm_source=article&utm_medium=blog&utm_campaign=ml_director_insights_3) today!_
👋 Welcome back to our Director of ML Insights Series, Finance Edition! If you missed earlier Editions you can find them here:
- [Director of Machine Learning Insights [Part 1]](https://huggingface.co/blog/ml-director-insights)
- [Director of Machine Learning Insights [Part 2 : SaaS Edition]](https://huggingface.co/blog/ml-director-insights-2)
Machine Learning Directors within finance face the unique challenges of navigating legacy systems, deploying interpretable models, and maintaining customer trust, all while being highly regulated (with lots of government oversight). Each of these challenges requires deep industry knowledge and technical expertise to pilot effectively. The following experts from U.S. Bank, the Royal Bank of Canada, Moody's Analytics and ex Research Scientist at Bloomberg AI all help uncover unique gems within the Machine Learning x Finance sector.
You’ll hear from a juniors Greek National Tennis Champion, a published author with over 100+ patents, and a cycle polo player who regularly played at the world’s oldest polo club (the Calcutta Polo Club). All turned financial ML experts.
🚀 Buckle up Goose, here are the top insights from financial ML Mavericks:
_Disclaimer: All views are from individuals and not from any past or current employers._
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/78_ml_director_insights/Ioannis-Bakagiannis.jpeg"></a>
### [Ioannis Bakagiannis](https://www.linkedin.com/in/bakagiannisioannis//) - Director of Machine Learning, Marketing Science at [RBC](https://www.rbcroyalbank.com/personal.html)
**Background:** Passionate Machine Learning Expert with experience in delivering scalable, production-grade, and state-of-the-art Machine Learning solutions. Ioannis is also the Host of [Bak Up Podcast](https://www.youtube.com/channel/UCHK-YMcyzw2TwKonKoFtiug) and seeks to make an impact on the world through AI.
**Fun Fact:** Ioannis was a juniors Greek national tennis champion.🏆
**RBC:** The world’s leading organizations look to RBC Capital Markets as an innovative, trusted partner in capital markets, banking and finance.
#### **1. How has ML made a positive impact on finance?**
We all know that ML is a disrupting force in all industries while continuously creating new business opportunities. Many financial products have been created or altered due to ML such as personalized insurance and targeted marketing.
Disruptions and profit are great but my favorite financial impact has been the ML-initiated conversation around trust in financial decision making.
In the past, financial decisions like loan approval, rate determination, portfolio management, etc. have all been done by humans with relevant expertise. Essentially, people trusted “other people” or “experts” for financial decisions (and often without question).
When ML attempted to automate that decision-making process, people asked, “Why should we trust a model?”. Models appeared to be black boxes of doom coming to replace honest working people. But that argument has initiated the conversation of trust in financial decision-making and ethics, regardless of who or what is involved.
As an industry, we are still defining this conversation but with more transparency, thanks to ML in finance.
#### **2. What are the biggest ML challenges within finance?**
I can’t speak for companies but established financial institutions experience one continuous struggle, like all long-lived organizations: Legacy Systems.
Financial organizations have been around for a while and they have evolved over time but today they have found themselves somehow as ‘tech companies’. Such organizations need to be part of cutting-edge technologies so they can compete with newcomer rivals but at the same time maintain the robustness that makes our financial world work.
This internal battle is skewed by the risk appetite of the institutions. Financial risk increases linearly (usually) with the scale of the solution you provide since we are talking about money. But on top of that, there are other forms of risk that a system failure will incur such as Regulatory and Reputational risk. This compounded risk along with the complexity of migrating a huge, mature system to a new tech stack is, at least in my opinion, the biggest challenge in adopting cutting-edge technologies such as ML.
#### **3. What’s a common mistake you see people make trying to integrate ML into financial applications?**
ML, even with all its recent attention, is still a relatively new field in software engineering. The deployment of ML applications is often not a well-defined process. The artist/engineer can deliver an ML application but the world around it is still not familiar with the technical process. At that intersection of technical and non-technical worlds, I have seen the most “mistakes”.
It is hard to optimize for the right Business and ML KPIs and define the right objective function or the desired labels. I have seen applications go to waste due to undesired prediction windows or because they predict the wrong labels.
The worst outcome comes when the misalignment is not uncovered in the development step and makes it into production.
Then applications can create unwanted user behavior or simply measure/predict the wrong thing. Unfortunately, we tend to equip the ML teams with tools and computing but not with solid processes and communication buffers. And mistakes at the beginning of an ill-defined process grow with every step.
#### **4. What excites you most about the future of ML?**
It is difficult not to get excited with everything new that comes out of ML. The field changes so frequently that it’s refreshing.
Currently, we are good at solving individual problems: computer vision, the next word prediction, data point generation, etc, but we haven’t been able to address multiple problems at the same time. I’m excited to see how we can model such behaviors in mathematical expressions that currently seem to contradict each other. Hope we get there soon!
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/78_ml_director_insights/Debanjan-Mahata.jpeg"></a>
### [Debanjan Mahata](https://www.linkedin.com/in/debanjanmahata/) - Director of AI & ML at [Moody's Analytics](https://www.moodysanalytics.com/) / Ex Research Scientist @ Bloomberg AI
**Background:** Debanjan is Director of Machine Learning in the AI Team at Moody's Analytics and also serves as an Adjunct Faculty at IIIT-Delhi, India. He is an active researcher and is currently interested in various information extraction problems and domain adaptation techniques in NLP. He has a track record of formulating and applying machine learning to various use cases. He actively participates in the program committee of different top tier conference venues in machine learning.
**Fun Fact:** Debanjan played cycle polo at the world's oldest polo club (the Calcutta Polo Club) when he was a kid.
**Moody's Analytics:** Provides financial intelligence and analytical tools supporting our clients’ growth, efficiency and risk management objectives.
#### **1. How has ML made a positive impact on finance?**
Machine learning (ML) has made a significant positive impact in the finance industry in many ways. For example, it has helped in combating financial crimes and identifying fraudulent transactions. Machine learning has been a crucial tool in applications such as Know Your Customer (KYC) screening and Anti Money Laundering (AML). With an increase in AML fines by financial institutions worldwide, ever changing realm of sanctions, and greater complexity in money laundering, banks are increasing their investments in KYC and AML technologies, many of which are powered by ML. ML is revolutionizing multiple facets of this sector, especially bringing huge efficiency gains by automating various processes and assisting analysts to do their jobs more efficiently and accurately.
One of the key useful traits of ML is that it can learn from and find hidden patterns in large volumes of data. With a focus on digitization, the financial sector is producing digital data more than ever, which makes it challenging for humans to comprehend, process and make decisions. ML is enabling humans in making sense of the data, glean information from them, and make well-informed decisions. At Moody's Analytics, we are using ML and helping our clients to better manage risk and meet business and industry demands.
#### **2. What are the biggest ML challenges within finance?**
1. Reducing the False Positives without impacting the True Positives - A number of applications using ML in the regtech space rely on alerts. With strict regulatory measures and big financial implications of a wrong decision, human investigations can be time consuming and demanding. ML certainly helps in these scenarios in assisting human analysts to arrive at the right decisions. But if a ML system results in a lot of False Positives, it makes an analysts' job harder. Coming up with the right balance is an important challenge for ML in finance.
2. Gap between ML in basic research and education and ML in finance - Due to the regulated nature of the finance industry, we see limited exchange of ideas, data, and resources between the basic research and the finance sector, in the area of ML. There are few exceptions of course. This has led to scarcity of developing ML research that cater to the needs of the finance industry. I think more efforts must be made to decrease this gap. Otherwise, it will be increasingly challenging for the finance industry to leverage the latest ML advances.
3. Legacy infrastructure and databases - Many financial institutions still carry legacy infrastructure with them which makes it challenging for applying modern ML technologies and especially to integrate them. The finance industry would benefit from borrowing key ideas, culture and best practices from the tech industry when it comes to developing new infrastructure and enabling the ML professionals to innovate and make more impact. There are certainly challenges related to operationalizing ML across the industry.
4. Data and model governance - More data and model governance efforts need to be made in this sector. As we collect more and more data there should be more increase in the efforts to collect high quality data and the right data. Extra precautions need to be taken when ML models are involved in decisioning. Proper model governance measures and frameworks needs to be developed for different financial applications. A big challenge in this space is the lack of tools and technologies to operationalize data and model governance that are often needed for ML systems operating in this sector. More efforts should also be made in understanding bias in the data that train the models and how to make it a common practice to mitigate them in the overall process. Ensuring auditability, model and data lineage has been challenging for ML teams.
5. Explainability and Interpretability - Developing models which are highly accurate as well as interpretable and explainable is a big challenge. Modern deep learning models often outperform more traditional models; however, they lack explainability and interpretability. Most of the applications in finance demands explainability. Adopting the latest developments in this area and ensuring the development of interpretable models with explainable predictions have been a challenge.
#### **3. What’s a common mistake you see people make trying to integrate ML into financial applications?**
- Not understanding the data well and the raw predictions made by the ML models trained on them.
- Not analyzing failed efforts and learning from them.
- Not understanding the end application and how it will be used.
- Trying complex techniques when simpler solutions might suffice.
#### **4. What excites you most about the future of ML?**
I am really blown away by how modern ML models have been learning rich representations of text, audio, images, videos, code and so on using self-supervised learning on large amounts of data. The future is certainly multi-modal and there has been consistent progress in understanding multi-modal content through the lens of ML. I think this is going to play a crucial role in the near future and I am excited by it and looking forward to being a part of these advances.
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/78_ml_director_insights/Soumitri-Kolavennu.jpeg"></a>
### [Soumitri Kolavennu](https://www.linkedin.com/in/soumitri-kolavennu-2b47376/) - Artificial Intelligence Leader - Enterprise Analytics & AI at [U.S. Bank](https://www.usbank.com/index.html)
**Background:** Soumitri Kolavennu is a SVP and head of AI research in U.S. Bank’s enterprise analytics and AI organization. He is currently focused on deep learning based NLP, vision & audio analytics, graph neural networks, sensor/knowledge fusion, time-series data with application to automation, information extraction, fraud detection and anti-money laundering in financial systems.
Previously, he held the position of Fellows Leader & Senior Fellow, while working at Honeywell International Inc. where he had worked on IoT and control systems applied to smart home, smart cities, industrial and automotive systems.
**Fun Fact:** Soumitri is a prolific inventor with 100+ issued U.S. patents in varied fields including control systems, Internet of Things, wireless networking, optimization, turbocharging, speech recognition, machine learning and AI. He also has around 30 publications, [authored a book](https://www.elsevier.com/books/industrial-wireless-sensor-networks/budampati/978-1-78242-230-3), book chapters and was elected member of NIST’s smart grid committee.
**U.S. Bank:** The largest regional bank in the United States, U.S. Bank blends its relationship teams, branches and ATM networks with digital tools that allow customers to bank when, where and how they prefer.
#### **1. How has ML made a positive impact on finance?**
Machine learning and artificial intelligence have made a profound and positive impact on finance in general and banking in particular. There are many applications in banking where many factors (features) are to be considered when making a decision and ML has traditionally helped in this respect. For example, the credit score we all universally rely on is derived from a machine learning algorithm.
Over the years ML has interestingly also helped remove human bias from decisions and provided a consistent algorithmic approach to decisions. For example, in credit card/loan underwriting and mortgages, modern AI techniques can take more factors (free form text, behavioral trends, social and financial interactions) into account for decisions while also detecting fraud.
#### **2. What are the biggest ML challenges within finance?**
The finance and banking industry brings a lot of challenges due to the nature of the industry. First of all, it is a highly regulated industry with government oversight in many aspects. The data that is often used is very personal and identifiable data (social security numbers, bank statements, tax records, etc). Hence there is a lot of care taken to create machine learning and AI models that are private and unbiased. Many government regulations require any models to be explainable. For example, if a loan is denied, there is a fundamental need to explain why it is denied.
The data on the other hand, which may be scarce in other industries is abundant in the financial industry. (Mortgage records have to be kept for 30 years for example). The current trend for digitization of data and the explosion of more sophisticated AI/ML techniques has created a unique opportunity for the application of these advances.
#### **3. What’s a common mistake you see people make trying to integrate ML into financial applications?**
One of the most common mistakes people make is to use a model or a technique without understanding the underlying working principles, advantages, and shortcomings of the model. People tend to think of AI/ML models as a ‘black box’. In finance, it is especially important to understand the model and to be able to explain its’ output. Another mistake is not comprehensively testing the model on a representative input space. Model performance, validation, inference capacities, and model monitoring (retraining intervals) are all important to consider when choosing a model.
#### **4. What excites you most about the future of ML?**
Now is a great time to be in applied ML and AI. The techniques in AI/ML are certainly refining if not redefining many scientific disciplines. I am very excited about how all the developments that are currently underway will reshape the future.
When I first started working in NLP, I was in awe of the ability of neural networks/language models to generate a number or vector (which we now call embeddings) that represents a word, a sentence with the associated grammar, or even a paragraph. We are constantly in search of more and more appropriate and contextual embeddings.
We have advanced far beyond a “simple” embedding for a text to “multimodal” embeddings that are even more awe-inspiring to me. I am most excited and look forward to generating and playing with these new embeddings enabling more exciting applications in the future.
---
🤗 Thank you for joining us in this third installment of ML Director Insights. Stay tuned for more insights from ML Directors.
Big thanks to Soumitri Kolavennu, Debanjan Mahata, and Ioannis Bakagiannis for their brilliant insights and participation in this piece. We look forward to watching your continued success and will be cheering you on each step of the way. 🎉
If you're' interested in accelerating your ML roadmap with Hugging Face Experts please visit [hf.co/support](https://huggingface.co/support?utm_source=article&utm_medium=blog&utm_campaign=ml_director_insights_3) to learn more.
|
huggingface/blog/blob/main/ml-director-insights-3.md
|
# How to release
# Before the release
Simple checklist on how to make releases for `tokenizers`.
- Freeze `master` branch.
- Run all tests (Check CI has properly run)
- If any significant work, check benchmarks:
- `cd tokenizers && cargo bench` (needs to be run on latest release tag to measure difference if it's your first time)
- Run all `transformers` tests. (`transformers` is a big user of `tokenizers` we need
to make sure we don't break it, testing is one way to make sure nothing unforeseen
has been done.)
- Run all fast tests at the VERY least (not just the tokenization tests). (`RUN_PIPELINE_TESTS=1 CUDA_VISIBLE_DEVICES=-1 pytest -sv tests/`)
- When all *fast* tests work, then we can also (it's recommended) run the whole `transformers`
test suite.
- Rebase this [PR](https://github.com/huggingface/transformers/pull/16708).
This will create new docker images ready to run the tests suites with `tokenizers` from the main branch.
- Wait for actions to finish
- Rebase this [PR](https://github.com/huggingface/transformers/pull/16712)
This will run the actual full test suite.
- Check the results.
- **If any breaking change has been done**, make sure the version can safely be increased for transformers users (`tokenizers` version need to make sure users don't upgrade before `transformers` has). [link](https://github.com/huggingface/transformers/blob/main/setup.py#L154)
For instance `tokenizers>=0.10,<0.11` so we can safely upgrade to `0.11` without impacting
current users
- Then start a new PR containing all desired code changes from the following steps.
- You will `Create release` after the code modifications are on `master`.
# Rust
- `tokenizers` (rust, python & node) versions don't have to be in sync but it's
very common to release for all versions at once for new features.
- Edit `Cargo.toml` to reflect new version
- Edit `CHANGELOG.md`:
- Add relevant PRs that were added (python PRs do not belong for instance).
- Add links at the end of the files.
- Go to [Releases](https://github.com/huggingface/tokenizers/releases)
- Create new Release:
- Mark it as pre-release
- Use new version name with a new tag (create on publish) `vX.X.X`.
- Copy paste the new part of the `CHANGELOG.md`
- ⚠️ Click on `Publish release`. This will start the whole process of building a uploading
the new version on `crates.io`, there's no going back after this
- Go to the [Actions](https://github.com/huggingface/tokenizers/actions) tab and check everything works smoothly.
- If anything fails, you need to fix the CI/CD to make it work again. Since your package was not uploaded to the repository properly, you can try again.
# Python
- Edit `bindings/python/setup.py` to reflect new version.
- Edit `bindings/python/py_src/tokenizers/__init__.py` to reflect new version.
- Edit `CHANGELOG.md`:
- Add relevant PRs that were added (node PRs do not belong for instance).
- Add links at the end of the files.
- Go to [Releases](https://github.com/huggingface/tokenizers/releases)
- Create new Release:
- Mark it as pre-release
- Use new version name with a new tag (create on publish) `python-vX.X.X`.
- Copy paste the new part of the `CHANGELOG.md`
- ⚠️ Click on `Publish release`. This will start the whole process of building a uploading
the new version on `pypi`, there's no going back after this
- Go to the [Actions](https://github.com/huggingface/tokenizers/actions) tab and check everything works smoothly.
- If anything fails, you need to fix the CI/CD to make it work again. Since your package was not uploaded to the repository properly, you can try again.
- This CI/CD has 3 distinct builds, `Pypi`(normal), `conda` and `extra`. `Extra` is REALLY slow (~4h), this is normal since it has to rebuild many things, but enables the wheel to be available for old Linuxes
# Node
- Edit `bindings/node/package.json` to reflect new version.
- Edit `CHANGELOG.md`:
- Add relevant PRs that were added (python PRs do not belong for instance).
- Add links at the end of the files.
- Go to [Releases](https://github.com/huggingface/tokenizers/releases)
- Create new Release:
- Mark it as pre-release
- Use new version name with a new tag (create on publish) `node-vX.X.X`.
- Copy paste the new part of the `CHANGELOG.md`
- ⚠️ Click on `Publish release`. This will start the whole process of building a uploading
the new version on `npm`, there's no going back after this
- Go to the [Actions](https://github.com/huggingface/tokenizers/actions) tab and check everything works smoothly.
- If anything fails, you need to fix the CI/CD to make it work again. Since your package was not uploaded to the repository properly, you can try again.
# Testing the CI/CD for release
If you want to make modifications to the CI/CD of the release GH actions, you need
to :
- **Comment the part that uploads the artifacts** to `crates.io`, `PyPi` or `npm`.
- Change the trigger mecanism so it can trigger every time you push to your branch.
- Keep pushing your changes until the artifacts are properly created.
|
huggingface/tokenizers/blob/main/RELEASE.md
|
Torch shared tensors
## TL;DR
Using specific functions, which should work in most cases for you.
This is not without side effects.
```python
from safetensors.torch import load_model, save_model
save_model(model, "model.safetensors")
# Instead of save_file(model.state_dict(), "model.safetensors")
load_model(model, "model.safetensors")
# Instead of model.load_state_dict(load_file("model.safetensors"))
```
## What are shared tensors ?
Pytorch uses shared tensors for some computation.
This is extremely interesting to reduce memory usage in general.
One very classic use case is in transformers the `embeddings` are shared with
`lm_head`. By using the same matrix, the model uses less parameters, and gradients
flow much better to the `embeddings` (which is the start of the model, so they don't
flow easily there, whereas `lm_head` is at the tail of the model, so gradients are
extremely good over there, since they are the same tensors, they both benefit)
```python
from torch import nn
class Model(nn.Module):
def __init__(self):
super().__init__()
self.a = nn.Linear(100, 100)
self.b = self.a
def forward(self, x):
return self.b(self.a(x))
model = Model()
print(model.state_dict())
# odict_keys(['a.weight', 'a.bias', 'b.weight', 'b.bias'])
torch.save(model.state_dict(), "model.bin")
# This file is now 41k instead of ~80k, because A and B are the same weight hence only 1 is saved on disk with both `a` and `b` pointing to the same buffer
```
## Why are shared tensors not saved in `safetensors` ?
Multiple reasons for that:
- *Not all frameworks support them* for instance `tensorflow` does not.
So if someone saves shared tensors in torch, there is no way to
load them in a similar fashion so we could not keep the same `Dict[str, Tensor]`
API.
- *It makes lazy loading very quickly.*
Lazy loading is the ability to load only some tensors, or part of tensors for
a given file. This is trivial to do without sharing tensors but with tensor sharing
```python
with safe_open("model.safetensors", framework="pt") as f:
a = f.get_tensor("a")
b = f.get_tensor("b")
```
Now it's impossible with this given code to "reshare" buffers after the fact.
Once we give the `a` tensor we have no way to give back the same memory when
you ask for `b`. (In this particular example we could keep track of given buffers
but this is not the case in general, since you could do arbitrary work with `a`
like sending it to another device before asking for `b`)
- *It can lead to much larger file than necessary*.
If you are saving a shared tensor which is only a fraction of a larger tensor,
then saving it with pytorch leads to saving the entire buffer instead of saving
just what is needed.
```python
a = torch.zeros((100, 100))
b = a[:1, :]
torch.save({"b": b}, "model.bin")
# File is 41k instead of the expected 400 bytes
# In practice it could happen that you save several 10GB instead of 1GB.
```
Now with all those reasons being mentioned, nothing is set in stone in there.
Shared tensors do not cause unsafety, or denial of service potential, so this
decision could be revisited if current workarounds are not satisfactory.
## How does it work ?
The design is rather simple.
We're going to look for all shared tensors, then looking for all tensors
covering the entire buffer (there can be multiple such tensors).
That gives us multiple names which can be saved, we simply choose the first one
During `load_model`, we are loading a bit like `load_state_dict` does, except
we're looking into the model itself, to check for shared buffers, and ignoring
the "missed keys" which were actually covered by virtue of buffer sharing (they
were properly loaded since there was a buffer that loaded under the hood).
Every other error is raised as-is
**Caveat**: This means we're dropping some keys within the file. meaning if you're
checking for the keys saved on disk, you will see some "missing tensors" or if you're
using `load_state_dict`. Unless we start supporting shared tensors directly in
the format there's no real way around it.
|
huggingface/safetensors/blob/main/docs/source/torch_shared_tensors.mdx
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
<Tip warning={true}>
🧪 This pipeline is for research purposes only.
</Tip>
# Text-to-video
[ModelScope Text-to-Video Technical Report](https://arxiv.org/abs/2308.06571) is by Jiuniu Wang, Hangjie Yuan, Dayou Chen, Yingya Zhang, Xiang Wang, Shiwei Zhang.
The abstract from the paper is:
*This paper introduces ModelScopeT2V, a text-to-video synthesis model that evolves from a text-to-image synthesis model (i.e., Stable Diffusion). ModelScopeT2V incorporates spatio-temporal blocks to ensure consistent frame generation and smooth movement transitions. The model could adapt to varying frame numbers during training and inference, rendering it suitable for both image-text and video-text datasets. ModelScopeT2V brings together three components (i.e., VQGAN, a text encoder, and a denoising UNet), totally comprising 1.7 billion parameters, in which 0.5 billion parameters are dedicated to temporal capabilities. The model demonstrates superior performance over state-of-the-art methods across three evaluation metrics. The code and an online demo are available at https://modelscope.cn/models/damo/text-to-video-synthesis/summary.*
You can find additional information about Text-to-Video on the [project page](https://modelscope.cn/models/damo/text-to-video-synthesis/summary), [original codebase](https://github.com/modelscope/modelscope/), and try it out in a [demo](https://huggingface.co/spaces/damo-vilab/modelscope-text-to-video-synthesis). Official checkpoints can be found at [damo-vilab](https://huggingface.co/damo-vilab) and [cerspense](https://huggingface.co/cerspense).
## Usage example
### `text-to-video-ms-1.7b`
Let's start by generating a short video with the default length of 16 frames (2s at 8 fps):
```python
import torch
from diffusers import DiffusionPipeline
from diffusers.utils import export_to_video
pipe = DiffusionPipeline.from_pretrained("damo-vilab/text-to-video-ms-1.7b", torch_dtype=torch.float16, variant="fp16")
pipe = pipe.to("cuda")
prompt = "Spiderman is surfing"
video_frames = pipe(prompt).frames
video_path = export_to_video(video_frames)
video_path
```
Diffusers supports different optimization techniques to improve the latency
and memory footprint of a pipeline. Since videos are often more memory-heavy than images,
we can enable CPU offloading and VAE slicing to keep the memory footprint at bay.
Let's generate a video of 8 seconds (64 frames) on the same GPU using CPU offloading and VAE slicing:
```python
import torch
from diffusers import DiffusionPipeline
from diffusers.utils import export_to_video
pipe = DiffusionPipeline.from_pretrained("damo-vilab/text-to-video-ms-1.7b", torch_dtype=torch.float16, variant="fp16")
pipe.enable_model_cpu_offload()
# memory optimization
pipe.enable_vae_slicing()
prompt = "Darth Vader surfing a wave"
video_frames = pipe(prompt, num_frames=64).frames
video_path = export_to_video(video_frames)
video_path
```
It just takes **7 GBs of GPU memory** to generate the 64 video frames using PyTorch 2.0, "fp16" precision and the techniques mentioned above.
We can also use a different scheduler easily, using the same method we'd use for Stable Diffusion:
```python
import torch
from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
from diffusers.utils import export_to_video
pipe = DiffusionPipeline.from_pretrained("damo-vilab/text-to-video-ms-1.7b", torch_dtype=torch.float16, variant="fp16")
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
prompt = "Spiderman is surfing"
video_frames = pipe(prompt, num_inference_steps=25).frames
video_path = export_to_video(video_frames)
video_path
```
Here are some sample outputs:
<table>
<tr>
<td><center>
An astronaut riding a horse.
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/astr.gif"
alt="An astronaut riding a horse."
style="width: 300px;" />
</center></td>
<td ><center>
Darth vader surfing in waves.
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/vader.gif"
alt="Darth vader surfing in waves."
style="width: 300px;" />
</center></td>
</tr>
</table>
### `cerspense/zeroscope_v2_576w` & `cerspense/zeroscope_v2_XL`
Zeroscope are watermark-free model and have been trained on specific sizes such as `576x320` and `1024x576`.
One should first generate a video using the lower resolution checkpoint [`cerspense/zeroscope_v2_576w`](https://huggingface.co/cerspense/zeroscope_v2_576w) with [`TextToVideoSDPipeline`],
which can then be upscaled using [`VideoToVideoSDPipeline`] and [`cerspense/zeroscope_v2_XL`](https://huggingface.co/cerspense/zeroscope_v2_XL).
```py
import torch
from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
from diffusers.utils import export_to_video
from PIL import Image
pipe = DiffusionPipeline.from_pretrained("cerspense/zeroscope_v2_576w", torch_dtype=torch.float16)
pipe.enable_model_cpu_offload()
# memory optimization
pipe.unet.enable_forward_chunking(chunk_size=1, dim=1)
pipe.enable_vae_slicing()
prompt = "Darth Vader surfing a wave"
video_frames = pipe(prompt, num_frames=24).frames
video_path = export_to_video(video_frames)
video_path
```
Now the video can be upscaled:
```py
pipe = DiffusionPipeline.from_pretrained("cerspense/zeroscope_v2_XL", torch_dtype=torch.float16)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
# memory optimization
pipe.unet.enable_forward_chunking(chunk_size=1, dim=1)
pipe.enable_vae_slicing()
video = [Image.fromarray(frame).resize((1024, 576)) for frame in video_frames]
video_frames = pipe(prompt, video=video, strength=0.6).frames
video_path = export_to_video(video_frames)
video_path
```
Here are some sample outputs:
<table>
<tr>
<td ><center>
Darth vader surfing in waves.
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/darthvader_cerpense.gif"
alt="Darth vader surfing in waves."
style="width: 576px;" />
</center></td>
</tr>
</table>
<Tip>
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
</Tip>
## TextToVideoSDPipeline
[[autodoc]] TextToVideoSDPipeline
- all
- __call__
## VideoToVideoSDPipeline
[[autodoc]] VideoToVideoSDPipeline
- all
- __call__
## TextToVideoSDPipelineOutput
[[autodoc]] pipelines.text_to_video_synthesis.TextToVideoSDPipelineOutput
|
huggingface/diffusers/blob/main/docs/source/en/api/pipelines/text_to_video.md
|
Gradio Demo: checkboxgroup_component
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
gr.CheckboxGroup(choices=["First Choice", "Second Choice", "Third Choice"])
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/checkboxgroup_component/run.ipynb
|
--
title: "Instruction-tuning Stable Diffusion with InstructPix2Pix"
thumbnail: assets/instruction_tuning_sd/thumbnail.png
authors:
- user: sayakpaul
---
# Instruction-tuning Stable Diffusion with InstructPix2Pix
This post explores instruction-tuning to teach [Stable Diffusion](https://huggingface.co/blog/stable_diffusion) to follow instructions to translate or process input images. With this method, we can prompt Stable Diffusion using an input image and an “instruction”, such as - *Apply a cartoon filter to the natural image*.
| 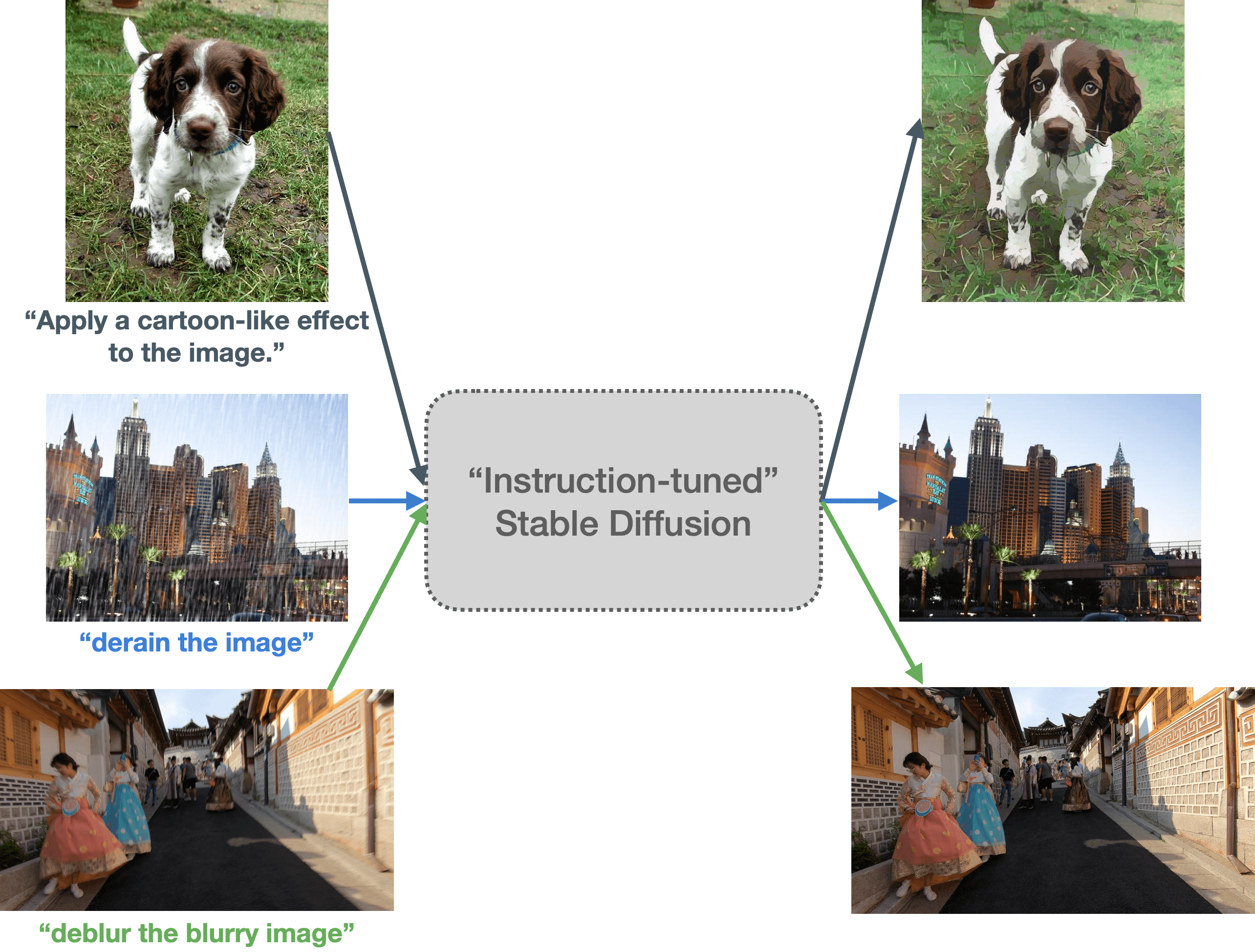 |
|:--:|
| **Figure 1**: We explore the instruction-tuning capabilities of Stable Diffusion. In this figure, we prompt an instruction-tuned Stable Diffusion system with prompts involving different transformations and input images. The tuned system seems to be able to learn these transformations stated in the input prompts. Figure best viewed in color and zoomed in. |
This idea of teaching Stable Diffusion to follow user instructions to perform **edits** on input images was introduced in [InstructPix2Pix: Learning to Follow Image Editing Instructions](https://huggingface.co/papers/2211.09800). We discuss how to extend the InstructPix2Pix training strategy to follow more specific instructions related to tasks in image translation (such as cartoonization) and low-level image processing (such as image deraining). We cover:
- [Introduction to instruction-tuning](#introduction-and-motivation)
- [The motivation behind this work](#introduction-and-motivation)
- [Dataset preparation](#dataset-preparation)
- [Training experiments and results](#training-experiments-and-results)
- [Potential applications and limitations](#potential-applications-and-limitations)
- [Open questions](#open-questions)
Our code, pre-trained models, and datasets can be found [here](https://github.com/huggingface/instruction-tuned-sd).
## Introduction and motivation
Instruction-tuning is a supervised way of teaching language models to follow instructions to solve a task. It was introduced in [Fine-tuned Language Models Are Zero-Shot Learners](https://huggingface.co/papers/2109.01652) (FLAN) by Google. From recent times, you might recall works like [Alpaca](https://crfm.stanford.edu/2023/03/13/alpaca.html) and [FLAN V2](https://huggingface.co/papers/2210.11416), which are good examples of how beneficial instruction-tuning can be for various tasks.
The figure below shows a formulation of instruction-tuning (also called “instruction-finetuning”). In the [FLAN V2 paper](https://huggingface.co/papers/2210.11416), the authors take a pre-trained language model ([T5](https://huggingface.co/docs/transformers/model_doc/t5), for example) and fine-tune it on a dataset of exemplars, as shown in the figure below.
| 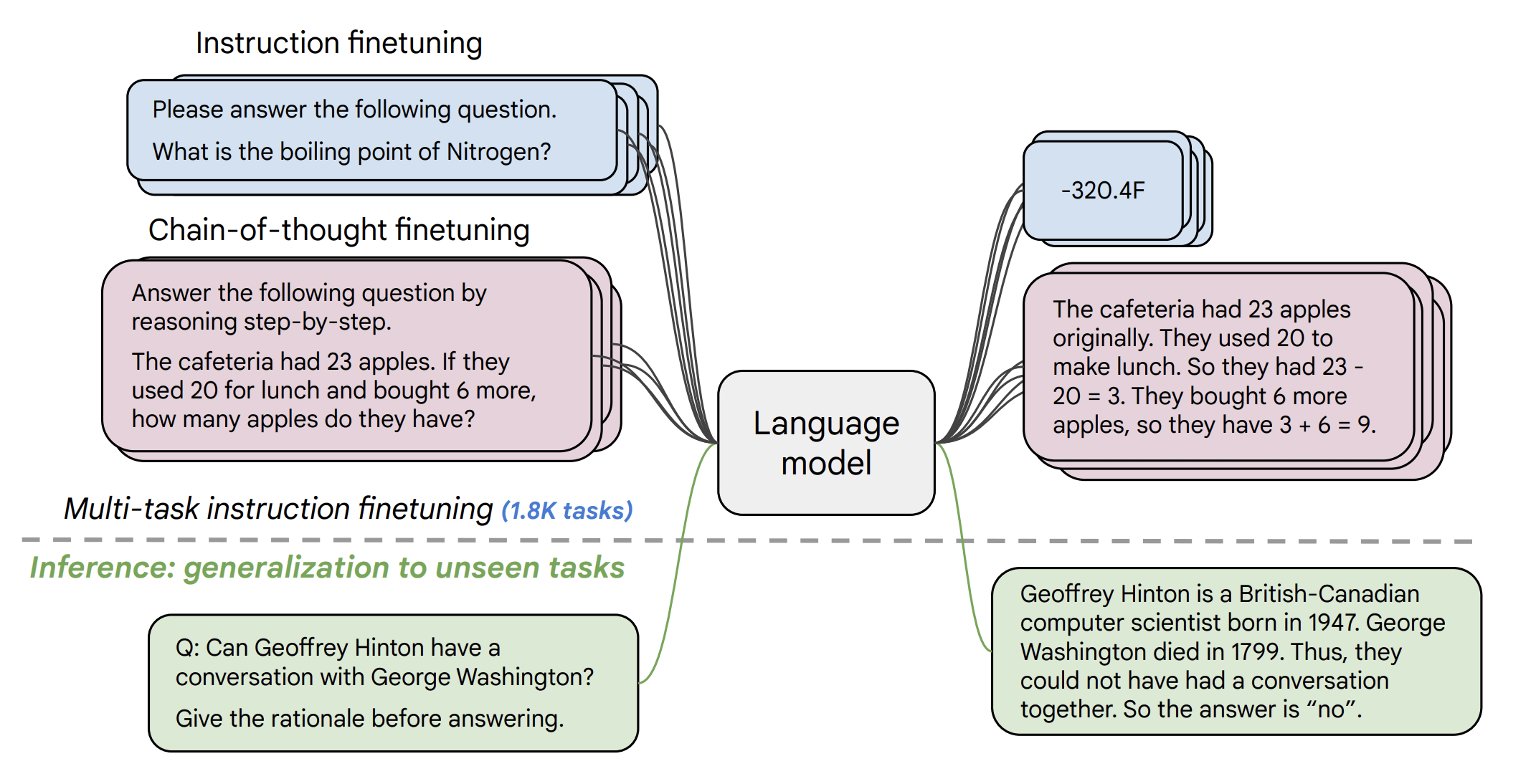 |
|:--:|
| **Figure 2**: FLAN V2 schematic (figure taken from the FLAN V2 paper). |
With this approach, one can create exemplars covering many different tasks, which makes instruction-tuning a multi-task training objective:
| **Input** | **Label** | **Task** |
|---|---|---|
| Predict the sentiment of the<br>following sentence: “The movie<br>was pretty amazing. I could not<br>turn around my eyes even for a<br>second.” | Positive | Sentiment analysis /<br>Sequence classification |
| Please answer the following<br>question. <br>What is the boiling point of<br>Nitrogen? | 320.4F | Question answering |
| Translate the following<br>English sentence into German: “I have<br>a cat.” | Ich habe eine Katze. | Machine translation |
| … | … | … |
| | | | |
Using a similar philosophy, the authors of FLAN V2 conduct instruction-tuning on a mixture of thousands of tasks and achieve zero-shot generalization to unseen tasks:
| 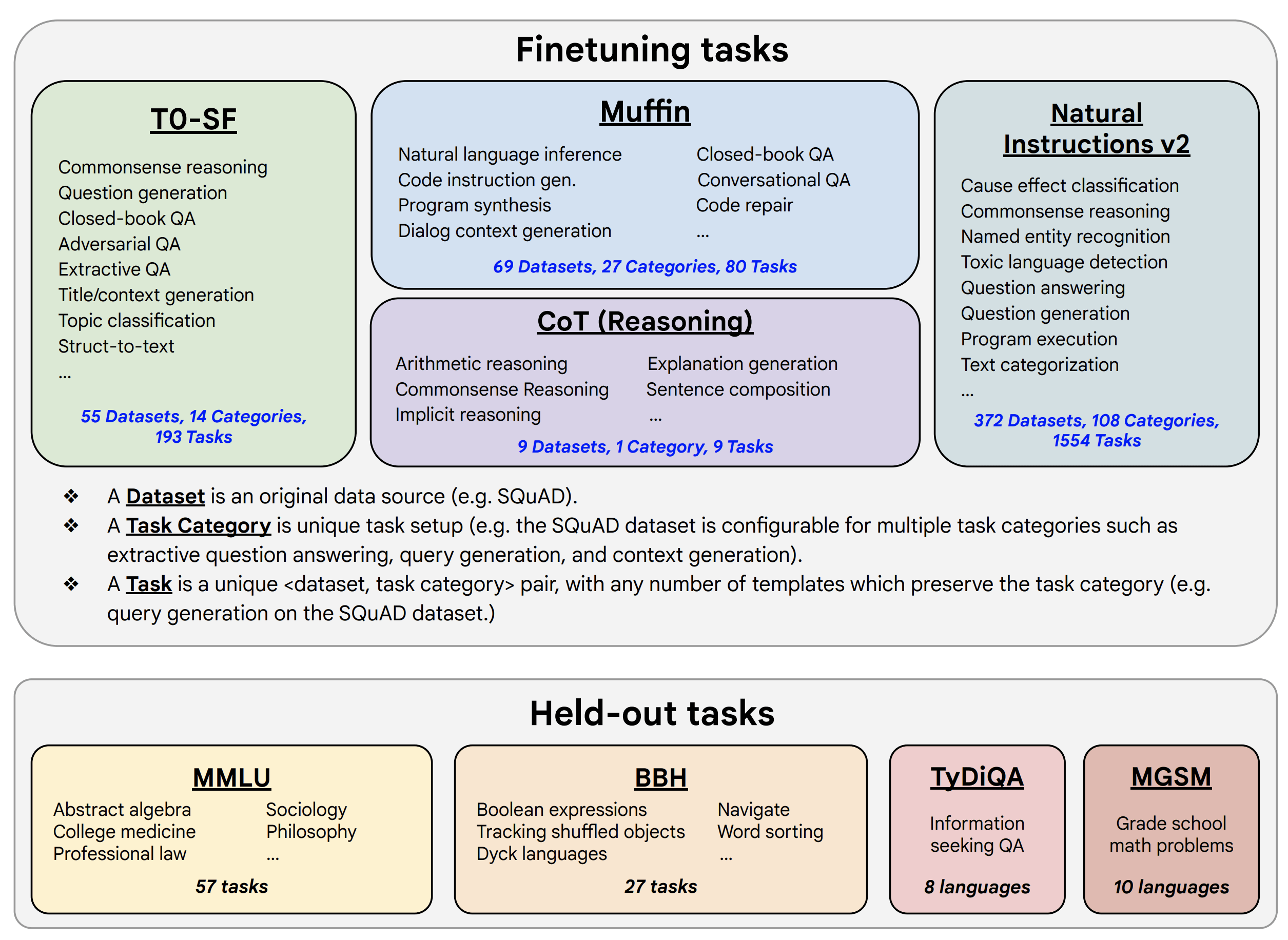 |
|:--:|
| **Figure 3**: FLAN V2 training and test task mixtures (figure taken from the FLAN V2 paper). |
Our motivation behind this work comes partly from the FLAN line of work and partly from InstructPix2Pix. We wanted to explore if it’s possible to prompt Stable Diffusion with specific instructions and input images to process them as per our needs.
The [pre-trained InstructPix2Pix models](https://huggingface.co/timbrooks/instruct-pix2pix) are good at following general instructions, but they may fall short of following instructions involving specific transformations:
|  |
|:--:|
| **Figure 4**: We observe that for the input images (left column), our models (right column) more faithfully perform “cartoonization” compared to the pre-trained InstructPix2Pix models (middle column). It is interesting to note the results of the first row where the pre-trained InstructPix2Pix models almost fail significantly. Figure best viewed in color and zoomed in. See original [here](https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/Instruction-tuning-sd/cartoonization_results.png). |
But we can still leverage the findings from InstructPix2Pix to suit our customizations.
On the other hand, paired datasets for tasks like [cartoonization](https://github.com/SystemErrorWang/White-box-Cartoonization), [image denoising](https://paperswithcode.com/dataset/sidd), [image deraining](https://paperswithcode.com/dataset/raindrop), etc. are available publicly, which we can use to build instruction-prompted datasets taking inspiration from FLAN V2. Doing so allows us to transfer the instruction-templating ideas explored in FLAN V2 to this work.
## Dataset preparation
### Cartoonization
In our early experiments, we prompted InstructPix2Pix to perform cartoonization and the results were not up to our expectations. We tried various inference-time hyperparameter combinations (such as image guidance scale and the number of inference steps), but the results still were not compelling. This motivated us to approach the problem differently.
As hinted in the previous section, we wanted to benefit from both worlds:
**(1)** training methodology of InstructPix2Pix and
**(2)** the flexibility of creating instruction-prompted dataset templates from FLAN.
We started by creating an instruction-prompted dataset for the task of cartoonization. Figure 5 presents our dataset creation pipeline:
| 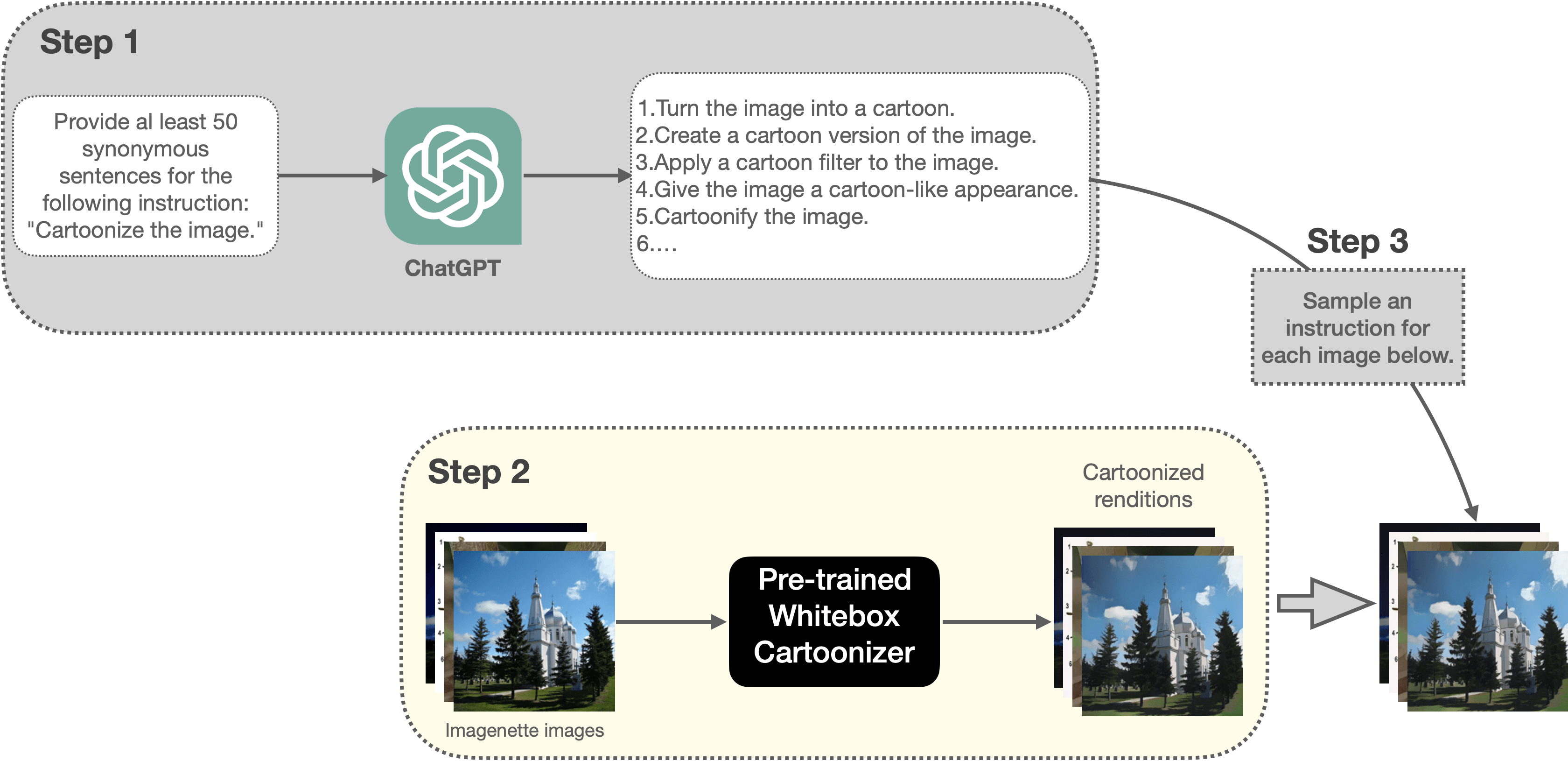 |
|:--:|
| **Figure 5**: A depiction of our dataset creation pipeline for cartoonization (best viewed in color and zoomed in). |
In particular, we:
1. Ask [ChatGPT](https://openai.com/blog/chatgpt) to generate 50 synonymous sentences for the following instruction: "Cartoonize the image.”
2. We then use a random sub-set (5000 samples) of the [Imagenette dataset](https://github.com/fastai/imagenette) and leverage a pre-trained [Whitebox CartoonGAN](https://github.com/SystemErrorWang/White-box-Cartoonization) model to produce the cartoonized renditions of those images. The cartoonized renditions are the labels we want our model to learn from. So, in a way, this corresponds to transferring the biases learned by the Whitebox CartoonGAN model to our model.
3. Then we create our exemplars in the following format:
| 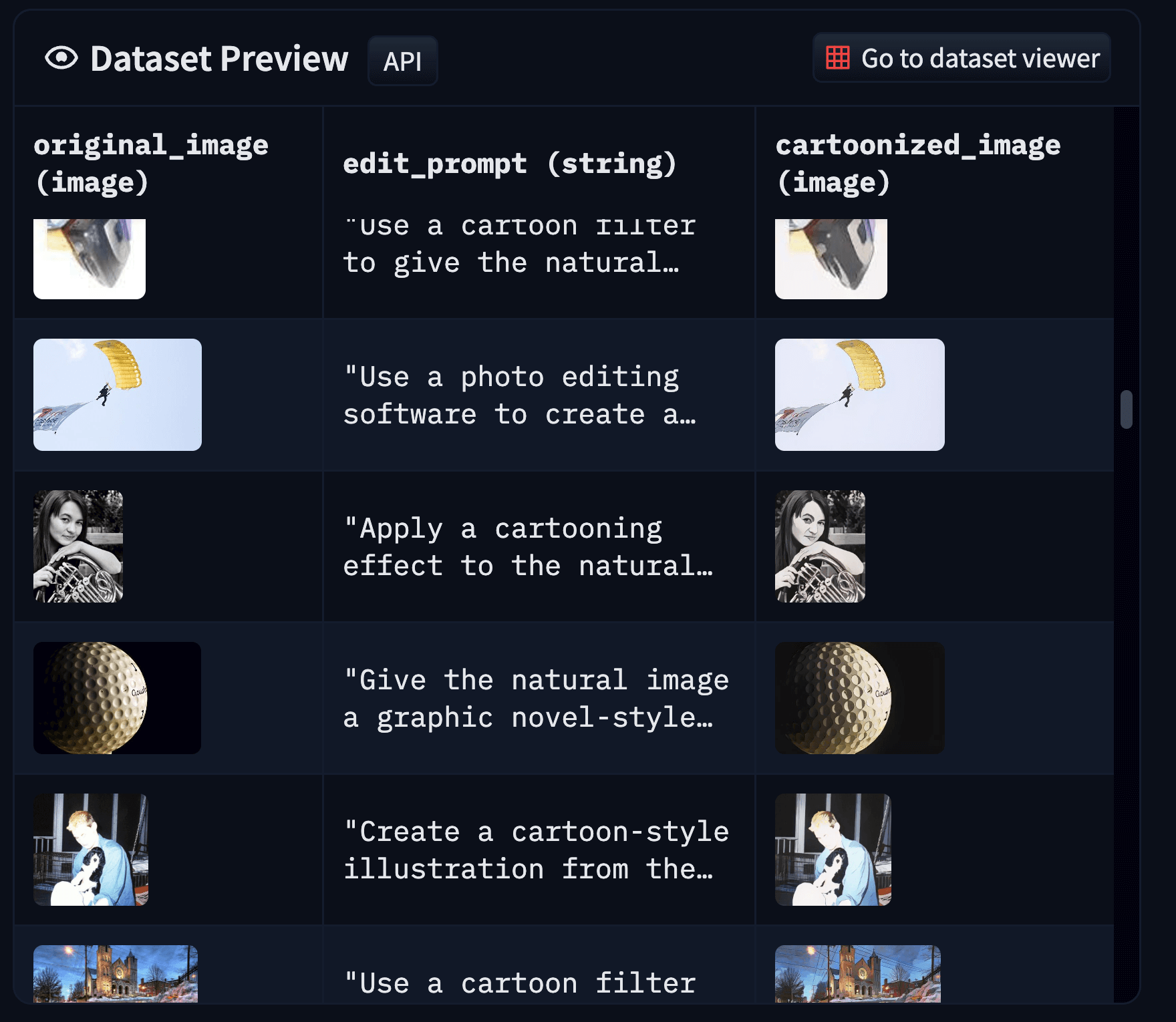 |
|:--:|
| **Figure 6**: Samples from the final cartoonization dataset (best viewed in color and zoomed in). |
Our final dataset for cartoonization can be found [here](https://huggingface.co/datasets/instruction-tuning-vision/cartoonizer-dataset). For more details on how the dataset was prepared, refer to [this directory](https://github.com/huggingface/instruction-tuned-sd/tree/main/data_preparation). We experimented with this dataset by fine-tuning InstructPix2Pix and got promising results (more details in the “Training experiments and results” section).
We then proceeded to see if we could generalize this approach to low-level image processing tasks such as image deraining, image denoising, and image deblurring.
### Low-level image processing
We focus on the common low-level image processing tasks explored in [MAXIM](https://huggingface.co/papers/2201.02973). In particular, we conduct our experiments for the following tasks: deraining, denoising, low-light image enhancement, and deblurring.
We took different number of samples from the following datasets for each task and constructed a single dataset with prompts added like so:
| **Task** | **Prompt** | **Dataset** | **Number of samples** |
|---|---|---|---|
| Deblurring | “deblur the blurry image” | [REDS](https://seungjunnah.github.io/Datasets/reds.html) (`train_blur`<br>and `train_sharp`) | 1200 |
| Deraining | “derain the image” | [Rain13k](https://github.com/megvii-model/HINet#image-restoration-tasks) | 686 |
| Denoising | “denoise the noisy image” | [SIDD](https://www.eecs.yorku.ca/~kamel/sidd/) | 8 |
| Low-light<br>image enhancement | "enhance the low-light image” | [LOL](https://paperswithcode.com/dataset/lol) | 23 |
| | | | |
Datasets mentioned above typically come as input-output pairs, so we do not have to worry about the ground-truth. Our final dataset is available [here](https://huggingface.co/datasets/instruction-tuning-vision/instruct-tuned-image-processing). The final dataset looks like so:
| 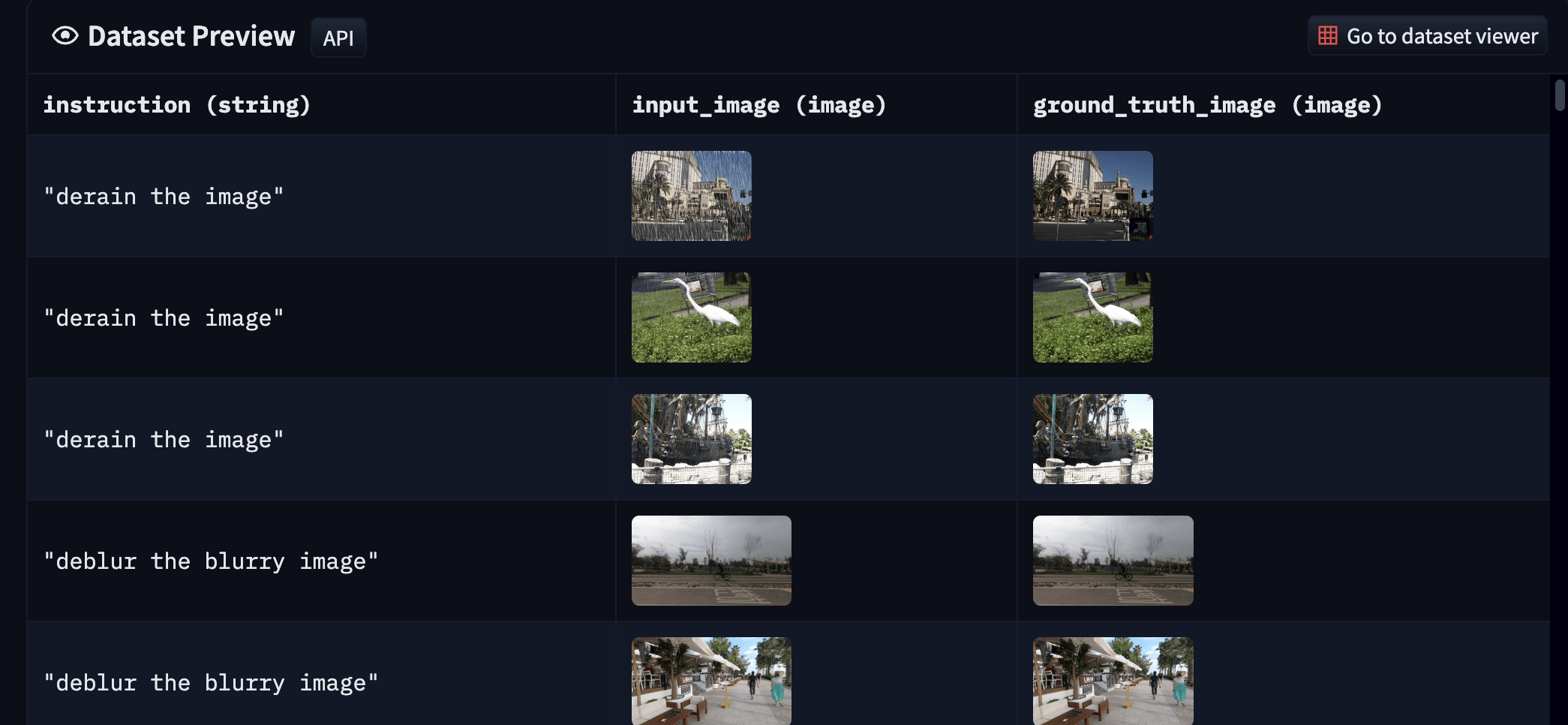 |
|:--:|
| **Figure 7**: Samples from the final low-level image processing dataset (best viewed in color and zoomed in). |
Overall, this setup helps draw parallels from the FLAN setup, where we create a mixture of different tasks. This also helps us train a single model one time, performing well to the different tasks we have in the mixture. This varies significantly from what is typically done in low-level image processing. Works like MAXIM introduce a single model architecture capable of modeling the different low-level image processing tasks, but training happens independently on the individual datasets.
## Training experiments and results
We based our training experiments on [this script](https://github.com/huggingface/diffusers/blob/main/examples/instruct_pix2pix/train_instruct_pix2pix.py). Our training logs (including validation samples and training hyperparameters) are available on Weight and Biases:
- [Cartoonization](https://wandb.ai/sayakpaul/instruction-tuning-sd/runs/wszjpb1b) ([hyperparameters](https://wandb.ai/sayakpaul/instruction-tuning-sd/runs/wszjpb1b/overview?workspace=))
- [Low-level image processing](https://wandb.ai/sayakpaul/instruction-tuning-sd/runs/2kg5wohb) ([hyperparameters](https://wandb.ai/sayakpaul/instruction-tuning-sd/runs/2kg5wohb/overview?workspace=))
When training, we explored two options:
1. Fine-tuning from an existing [InstructPix2Pix checkpoint](https://huggingface.co/timbrooks/instruct-pix2pix)
2. Fine-tuning from an existing [Stable Diffusion checkpoint](https://huggingface.co/runwayml/stable-diffusion-v1-5) using the InstructPix2Pix training methodology
In our experiments, we found out that the first option helps us adapt to our datasets faster (in terms of generation quality).
For more details on the training and hyperparameters, we encourage you to check out [our code](https://github.com/huggingface/instruction-tuned-sd) and the respective run pages on Weights and Biases.
### Cartoonization results
For testing the [instruction-tuned cartoonization model](https://huggingface.co/instruction-tuning-sd/cartoonizer), we compared the outputs as follows:
|  |
|:--:|
| **Figure 8**: We compare the results of our instruction-tuned cartoonization model (last column) with that of a [CartoonGAN](https://github.com/SystemErrorWang/White-box-Cartoonization) model (column two) and the pre-trained InstructPix2Pix model (column three). It’s evident that the instruction-tuned model can more faithfully match the outputs of the CartoonGAN model. Figure best viewed in color and zoomed in. See original [here](https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/Instruction-tuning-sd/cartoonization_full_results.png). |
To gather these results, we sampled images from the `validation` split of ImageNette. We used the following prompt when using our model and the pre-trained InstructPix2Pix model: *“Generate a cartoonized version of the image”.* For these two models, we kept the `image_guidance_scale` and `guidance_scale` to 1.5 and 7.0, respectively, and number of inference steps to 20. Indeed more experimentation is needed around these hyperparameters to study how they affect the results of the pre-trained InstructPix2Pix model, in particular.
More comparative results are available [here](https://wandb.ai/sayakpaul/instruction-tuning-sd/runs/g6cvggw2). Our code for comparing these models is available [here](https://github.com/huggingface/instruction-tuned-sd/blob/main/validation/compare_models.py).
Our model, however, [fails to produce](https://wandb.ai/sayakpaul/instruction-tuning-sd/runs/g6cvggw2) the expected outputs for the classes from ImageNette, which it has not seen enough during training. This is somewhat expected, and we believe this could be mitigated by scaling the training dataset.
### Low-level image processing results
For low-level image processing ([our model](https://huggingface.co/instruction-tuning-sd/low-level-img-proc)), we follow the same inference-time hyperparameters as above:
- Number of inference steps: 20
- Image guidance scale: 1.5
- Guidance scale: 7.0
For deraining, our model provides compelling results when compared to the ground-truth and the output of the pre-trained InstructPix2Pix model:
|  |
|:--:|
| **Figure 9**: Deraining results (best viewed in color and zoomed in). Inference prompt: “derain the image” (same as the training set). See original [here](https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/Instruction-tuning-sd/deraining_results.png). |
However, for low-light image enhancement, it leaves a lot to be desired:
|  |
|:--:|
| **Figure 10**: Low-light image enhancement results (best viewed in color and zoomed in). Inference prompt: “enhance the low-light image” (same as the training set). See original [here](https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/Instruction-tuning-sd/image_enhancement_results.png). |
This failure, perhaps, can be attributed to our model not seeing enough exemplars for the task and possibly from better training. We notice similar findings for deblurring as well:
|  |
|:--:|
| **Figure 11**: Deblurring results (best viewed in color and zoomed in). Inference prompt: “deblur the image” (same as the training set). See original [here](https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/Instruction-tuning-sd/deblurring_results.png). |
We believe there is an opportunity for the community to explore how much the task mixture for low-level image processing affects the end results. *Does increasing the task mixture with more representative samples help improve the end results?* We leave this question for the community to explore further.
You can try out the interactive demo below to make Stable Diffusion follow specific instructions:
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.29.0/gradio.js"></script>
<gradio-app theme_mode="light" src="https://instruction-tuning-sd-instruction-tuned-sd.hf.space"></gradio-app>
## Potential applications and limitations
In the world of image editing, there is a disconnect between what a domain expert has in mind (the tasks to be performed) and the actions needed to be applied in editing tools (such as [Lightroom](https://www.adobe.com/in/products/photoshop-lightroom.html)). Having an easy way of translating natural language goals to low-level image editing primitives would be a seamless user experience. With the introduction of mechanisms like InstructPix2Pix, it’s safe to say that we’re getting closer to that realm.
However, challenges still remain:
- These systems need to work for large high-resolution original images.
- Diffusion models often invent or re-interpret an instruction to perform the modifications in the image space. For a realistic image editing application, this is unacceptable.
## Open questions
We acknowledge that our experiments are preliminary. We did not go deep into ablating the apparent factors in our experiments. Hence, here we enlist a few open questions that popped up during our experiments:
- ***What happens we scale up the datasets?*** How does that impact the quality of the generated samples? We experimented with a handful of examples. For comparison, InstructPix2Pix was trained on more than 30000 samples.
- ***What is the impact of training for longer, especially when the task mixture is broader?*** In our experiments, we did not conduct hyperparameter tuning, let alone an ablation on the number of training steps.
- ***How does this approach generalize to a broader mixture of tasks commonly done in the “instruction-tuning” world?*** We only covered four tasks for low-level image processing: deraining, deblurring, denoising, and low-light image enhancement. Does adding more tasks to the mixture with more representative samples help the model generalize to unseen tasks or, perhaps, a combination of tasks (example: “Deblur the image and denoise it”)?
- ***Does using different variations of the same instruction on-the-fly help improve performance?*** For cartoonization, we randomly sampled an instruction from the set of ChatGPT-generated synonymous instructions **during** dataset creation. But what happens when we perform random sampling during training instead?
For low-level image processing, we used fixed instructions. What happens when we follow a similar methodology of using synonymous instructions for each task and input image?
- ***What happens when we use ControlNet training setup, instead?*** [ControlNet](https://huggingface.co/papers/2302.05543) also allows adapting a pre-trained text-to-image diffusion model to be conditioned on additional images (such as semantic segmentation maps, canny edge maps, etc.). If you’re interested, then you can use the datasets presented in this post and perform ControlNet training referring to [this post](https://huggingface.co/blog/train-your-controlnet).
## Conclusion
In this post, we presented our exploration of “instruction-tuning” of Stable Diffusion. While pre-trained InstructPix2Pix are good at following general image editing instructions, they may break when presented with more specific instructions. To mitigate that, we discussed how we prepared our datasets for further fine-tuning InstructPix2Pix and presented our results. As noted above, our results are still preliminary. But we hope this work provides a basis for the researchers working on similar problems and they feel motivated to explore the open questions further.
## Links
- Training and inference code: [https://github.com/huggingface/instruction-tuned-sd](https://github.com/huggingface/instruction-tuned-sd)
- Demo: [https://huggingface.co/spaces/instruction-tuning-sd/instruction-tuned-sd](https://huggingface.co/spaces/instruction-tuning-sd/instruction-tuned-sd)
- InstructPix2Pix: [https://huggingface.co/timbrooks/instruct-pix2pix](https://huggingface.co/timbrooks/instruct-pix2pix)
- Datasets and models from this post: [https://huggingface.co/instruction-tuning-sd](https://huggingface.co/instruction-tuning-sd)
*Thanks to [Alara Dirik](https://www.linkedin.com/in/alaradirik/) and [Zhengzhong Tu](https://www.linkedin.com/in/zhengzhongtu) for the helpful discussions. Thanks to [Pedro Cuenca](https://twitter.com/pcuenq?lang=en) and [Kashif Rasul](https://twitter.com/krasul?lang=en) for their helpful reviews on the post.*
## Citation
To cite this work, please use the following citation:
```bibtex
@article{
Paul2023instruction-tuning-sd,
author = {Paul, Sayak},
title = {Instruction-tuning Stable Diffusion with InstructPix2Pix},
journal = {Hugging Face Blog},
year = {2023},
note = {https://huggingface.co/blog/instruction-tuning-sd},
}
```
|
huggingface/blog/blob/main/instruction-tuning-sd.md
|
Gradio Demo: state_component
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
gr.State()
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/state_component/run.ipynb
|
Introduction [[introduction]]
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit0/thumbnail.png" alt="Thumbnail"/>
Since the beginning of this course, we learned to train agents in a *single-agent system* where our agent was alone in its environment: it was **not cooperating or collaborating with other agents**.
This worked great, and the single-agent system is useful for many applications.
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit10/patchwork.jpg" alt="Patchwork"/>
<figcaption>
A patchwork of all the environments you’ve trained your agents on since the beginning of the course
</figcaption>
</figure>
But, as humans, **we live in a multi-agent world**. Our intelligence comes from interaction with other agents. And so, our **goal is to create agents that can interact with other humans and other agents**.
Consequently, we must study how to train deep reinforcement learning agents in a *multi-agents system* to build robust agents that can adapt, collaborate, or compete.
So today we’re going to **learn the basics of the fascinating topic of multi-agents reinforcement learning (MARL)**.
And the most exciting part is that, during this unit, you’re going to train your first agents in a multi-agents system: **a 2vs2 soccer team that needs to beat the opponent team**.
And you’re going to participate in **AI vs. AI challenge** where your trained agent will compete against other classmates’ agents every day and be ranked on a [new leaderboard](https://huggingface.co/spaces/huggingface-projects/AIvsAI-SoccerTwos).
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit10/soccertwos.gif" alt="SoccerTwos"/>
<figcaption>This environment was made by the <a href="https://github.com/Unity-Technologies/ml-agents">Unity MLAgents Team</a></figcaption>
</figure>
So let’s get started!
|
huggingface/deep-rl-class/blob/main/units/en/unit7/introduction.mdx
|
RLHF
Reinforcement learning from human feedback (RLHF) is a **methodology for integrating human data labels into a RL-based optimization process**.
It is motivated by the **challenge of modeling human preferences**.
For many questions, even if you could try and write down an equation for one ideal, humans differ on their preferences.
Updating models **based on measured data is an avenue to try and alleviate these inherently human ML problems**.
## Start Learning about RLHF
To start learning about RLHF:
1. Read this introduction: [Illustrating Reinforcement Learning from Human Feedback (RLHF)](https://huggingface.co/blog/rlhf).
2. Watch the recorded live we did some weeks ago, where Nathan covered the basics of Reinforcement Learning from Human Feedback (RLHF) and how this technology is being used to enable state-of-the-art ML tools like ChatGPT.
Most of the talk is an overview of the interconnected ML models. It covers the basics of Natural Language Processing and RL and how RLHF is used on large language models. We then conclude with open questions in RLHF.
<Youtube id="2MBJOuVq380" />
3. Read other blogs on this topic, such as [Closed-API vs Open-source continues: RLHF, ChatGPT, data moats](https://robotic.substack.com/p/rlhf-chatgpt-data-moats). Let us know if there are more you like!
## Additional readings
*Note, this is copied from the Illustrating RLHF blog post above*.
Here is a list of the most prevalent papers on RLHF to date. The field was recently popularized with the emergence of DeepRL (around 2017) and has grown into a broader study of the applications of LLMs from many large technology companies.
Here are some papers on RLHF that pre-date the LM focus:
- [TAMER: Training an Agent Manually via Evaluative Reinforcement](https://www.cs.utexas.edu/~pstone/Papers/bib2html-links/ICDL08-knox.pdf) (Knox and Stone 2008): Proposed a learned agent where humans provided scores on the actions taken iteratively to learn a reward model.
- [Interactive Learning from Policy-Dependent Human Feedback](http://proceedings.mlr.press/v70/macglashan17a/macglashan17a.pdf) (MacGlashan et al. 2017): Proposed an actor-critic algorithm, COACH, where human feedback (both positive and negative) is used to tune the advantage function.
- [Deep Reinforcement Learning from Human Preferences](https://proceedings.neurips.cc/paper/2017/hash/d5e2c0adad503c91f91df240d0cd4e49-Abstract.html) (Christiano et al. 2017): RLHF applied on preferences between Atari trajectories.
- [Deep TAMER: Interactive Agent Shaping in High-Dimensional State Spaces](https://ojs.aaai.org/index.php/AAAI/article/view/11485) (Warnell et al. 2018): Extends the TAMER framework where a deep neural network is used to model the reward prediction.
And here is a snapshot of the growing set of papers that show RLHF's performance for LMs:
- [Fine-Tuning Language Models from Human Preferences](https://arxiv.org/abs/1909.08593) (Zieglar et al. 2019): An early paper that studies the impact of reward learning on four specific tasks.
- [Learning to summarize with human feedback](https://proceedings.neurips.cc/paper/2020/hash/1f89885d556929e98d3ef9b86448f951-Abstract.html) (Stiennon et al., 2020): RLHF applied to the task of summarizing text. Also, [Recursively Summarizing Books with Human Feedback](https://arxiv.org/abs/2109.10862) (OpenAI Alignment Team 2021), follow on work summarizing books.
- [WebGPT: Browser-assisted question-answering with human feedback](https://arxiv.org/abs/2112.09332) (OpenAI, 2021): Using RLHF to train an agent to navigate the web.
- InstructGPT: [Training language models to follow instructions with human feedback](https://arxiv.org/abs/2203.02155) (OpenAI Alignment Team 2022): RLHF applied to a general language model [[Blog post](https://openai.com/blog/instruction-following/) on InstructGPT].
- GopherCite: [Teaching language models to support answers with verified quotes](https://www.deepmind.com/publications/gophercite-teaching-language-models-to-support-answers-with-verified-quotes) (Menick et al. 2022): Train a LM with RLHF to return answers with specific citations.
- Sparrow: [Improving alignment of dialogue agents via targeted human judgements](https://arxiv.org/abs/2209.14375) (Glaese et al. 2022): Fine-tuning a dialogue agent with RLHF
- [ChatGPT: Optimizing Language Models for Dialogue](https://openai.com/blog/chatgpt/) (OpenAI 2022): Training a LM with RLHF for suitable use as an all-purpose chat bot.
- [Scaling Laws for Reward Model Overoptimization](https://arxiv.org/abs/2210.10760) (Gao et al. 2022): studies the scaling properties of the learned preference model in RLHF.
- [Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback](https://arxiv.org/abs/2204.05862) (Anthropic, 2022): A detailed documentation of training a LM assistant with RLHF.
- [Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned](https://arxiv.org/abs/2209.07858) (Ganguli et al. 2022): A detailed documentation of efforts to “discover, measure, and attempt to reduce [language models] potentially harmful outputs.”
- [Dynamic Planning in Open-Ended Dialogue using Reinforcement Learning](https://arxiv.org/abs/2208.02294) (Cohen at al. 2022): Using RL to enhance the conversational skill of an open-ended dialogue agent.
- [Is Reinforcement Learning (Not) for Natural Language Processing?: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization](https://arxiv.org/abs/2210.01241) (Ramamurthy and Ammanabrolu et al. 2022): Discusses the design space of open-source tools in RLHF and proposes a new algorithm NLPO (Natural Language Policy Optimization) as an alternative to PPO.
## Author
This section was written by <a href="https://twitter.com/natolambert"> Nathan Lambert </a>
|
huggingface/deep-rl-class/blob/main/units/en/unitbonus3/rlhf.mdx
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# X-MOD
## Overview
The X-MOD model was proposed in [Lifting the Curse of Multilinguality by Pre-training Modular Transformers](http://dx.doi.org/10.18653/v1/2022.naacl-main.255) by Jonas Pfeiffer, Naman Goyal, Xi Lin, Xian Li, James Cross, Sebastian Riedel, and Mikel Artetxe.
X-MOD extends multilingual masked language models like [XLM-R](xlm-roberta) to include language-specific modular components (_language adapters_) during pre-training. For fine-tuning, the language adapters in each transformer layer are frozen.
The abstract from the paper is the following:
*Multilingual pre-trained models are known to suffer from the curse of multilinguality, which causes per-language performance to drop as they cover more languages. We address this issue by introducing language-specific modules, which allows us to grow the total capacity of the model, while keeping the total number of trainable parameters per language constant. In contrast with prior work that learns language-specific components post-hoc, we pre-train the modules of our Cross-lingual Modular (X-MOD) models from the start. Our experiments on natural language inference, named entity recognition and question answering show that our approach not only mitigates the negative interference between languages, but also enables positive transfer, resulting in improved monolingual and cross-lingual performance. Furthermore, our approach enables adding languages post-hoc with no measurable drop in performance, no longer limiting the model usage to the set of pre-trained languages.*
This model was contributed by [jvamvas](https://huggingface.co/jvamvas).
The original code can be found [here](https://github.com/facebookresearch/fairseq/tree/58cc6cca18f15e6d56e3f60c959fe4f878960a60/fairseq/models/xmod) and the original documentation is found [here](https://github.com/facebookresearch/fairseq/tree/58cc6cca18f15e6d56e3f60c959fe4f878960a60/examples/xmod).
## Usage tips
Tips:
- X-MOD is similar to [XLM-R](xlm-roberta), but a difference is that the input language needs to be specified so that the correct language adapter can be activated.
- The main models – base and large – have adapters for 81 languages.
## Adapter Usage
### Input language
There are two ways to specify the input language:
1. By setting a default language before using the model:
```python
from transformers import XmodModel
model = XmodModel.from_pretrained("facebook/xmod-base")
model.set_default_language("en_XX")
```
2. By explicitly passing the index of the language adapter for each sample:
```python
import torch
input_ids = torch.tensor(
[
[0, 581, 10269, 83, 99942, 136, 60742, 23, 70, 80583, 18276, 2],
[0, 1310, 49083, 443, 269, 71, 5486, 165, 60429, 660, 23, 2],
]
)
lang_ids = torch.LongTensor(
[
0, # en_XX
8, # de_DE
]
)
output = model(input_ids, lang_ids=lang_ids)
```
### Fine-tuning
The paper recommends that the embedding layer and the language adapters are frozen during fine-tuning. A method for doing this is provided:
```python
model.freeze_embeddings_and_language_adapters()
# Fine-tune the model ...
```
### Cross-lingual transfer
After fine-tuning, zero-shot cross-lingual transfer can be tested by activating the language adapter of the target language:
```python
model.set_default_language("de_DE")
# Evaluate the model on German examples ...
```
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## XmodConfig
[[autodoc]] XmodConfig
## XmodModel
[[autodoc]] XmodModel
- forward
## XmodForCausalLM
[[autodoc]] XmodForCausalLM
- forward
## XmodForMaskedLM
[[autodoc]] XmodForMaskedLM
- forward
## XmodForSequenceClassification
[[autodoc]] XmodForSequenceClassification
- forward
## XmodForMultipleChoice
[[autodoc]] XmodForMultipleChoice
- forward
## XmodForTokenClassification
[[autodoc]] XmodForTokenClassification
- forward
## XmodForQuestionAnswering
[[autodoc]] XmodForQuestionAnswering
- forward
|
huggingface/transformers/blob/main/docs/source/en/model_doc/xmod.md
|
Noisy Student (EfficientNet)
**Noisy Student Training** is a semi-supervised learning approach. It extends the idea of self-training
and distillation with the use of equal-or-larger student models and noise added to the student during learning. It has three main steps:
1. train a teacher model on labeled images
2. use the teacher to generate pseudo labels on unlabeled images
3. train a student model on the combination of labeled images and pseudo labeled images.
The algorithm is iterated a few times by treating the student as a teacher to relabel the unlabeled data and training a new student.
Noisy Student Training seeks to improve on self-training and distillation in two ways. First, it makes the student larger than, or at least equal to, the teacher so the student can better learn from a larger dataset. Second, it adds noise to the student so the noised student is forced to learn harder from the pseudo labels. To noise the student, it uses input noise such as RandAugment data augmentation, and model noise such as dropout and stochastic depth during training.
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('tf_efficientnet_b0_ns', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `tf_efficientnet_b0_ns`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('tf_efficientnet_b0_ns', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{xie2020selftraining,
title={Self-training with Noisy Student improves ImageNet classification},
author={Qizhe Xie and Minh-Thang Luong and Eduard Hovy and Quoc V. Le},
year={2020},
eprint={1911.04252},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
<!--
Type: model-index
Collections:
- Name: Noisy Student
Paper:
Title: Self-training with Noisy Student improves ImageNet classification
URL: https://paperswithcode.com/paper/self-training-with-noisy-student-improves
Models:
- Name: tf_efficientnet_b0_ns
In Collection: Noisy Student
Metadata:
FLOPs: 488688572
Parameters: 5290000
File Size: 21386709
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- FixRes
- Label Smoothing
- Noisy Student
- RMSProp
- RandAugment
- Weight Decay
Training Data:
- ImageNet
- JFT-300M
Training Resources: Cloud TPU v3 Pod
ID: tf_efficientnet_b0_ns
LR: 0.128
Epochs: 700
Dropout: 0.5
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 2048
Image Size: '224'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Stochastic Depth Survival: 0.8
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1427
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b0_ns-c0e6a31c.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.66%
Top 5 Accuracy: 94.37%
- Name: tf_efficientnet_b1_ns
In Collection: Noisy Student
Metadata:
FLOPs: 883633200
Parameters: 7790000
File Size: 31516408
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- FixRes
- Label Smoothing
- Noisy Student
- RMSProp
- RandAugment
- Weight Decay
Training Data:
- ImageNet
- JFT-300M
Training Resources: Cloud TPU v3 Pod
ID: tf_efficientnet_b1_ns
LR: 0.128
Epochs: 700
Dropout: 0.5
Crop Pct: '0.882'
Momentum: 0.9
Batch Size: 2048
Image Size: '240'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Stochastic Depth Survival: 0.8
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1437
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b1_ns-99dd0c41.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.39%
Top 5 Accuracy: 95.74%
- Name: tf_efficientnet_b2_ns
In Collection: Noisy Student
Metadata:
FLOPs: 1234321170
Parameters: 9110000
File Size: 36801803
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- FixRes
- Label Smoothing
- Noisy Student
- RMSProp
- RandAugment
- Weight Decay
Training Data:
- ImageNet
- JFT-300M
Training Resources: Cloud TPU v3 Pod
ID: tf_efficientnet_b2_ns
LR: 0.128
Epochs: 700
Dropout: 0.5
Crop Pct: '0.89'
Momentum: 0.9
Batch Size: 2048
Image Size: '260'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Stochastic Depth Survival: 0.8
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1447
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b2_ns-00306e48.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 82.39%
Top 5 Accuracy: 96.24%
- Name: tf_efficientnet_b3_ns
In Collection: Noisy Student
Metadata:
FLOPs: 2275247568
Parameters: 12230000
File Size: 49385734
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- FixRes
- Label Smoothing
- Noisy Student
- RMSProp
- RandAugment
- Weight Decay
Training Data:
- ImageNet
- JFT-300M
Training Resources: Cloud TPU v3 Pod
ID: tf_efficientnet_b3_ns
LR: 0.128
Epochs: 700
Dropout: 0.5
Crop Pct: '0.904'
Momentum: 0.9
Batch Size: 2048
Image Size: '300'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Stochastic Depth Survival: 0.8
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1457
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b3_ns-9d44bf68.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 84.04%
Top 5 Accuracy: 96.91%
- Name: tf_efficientnet_b4_ns
In Collection: Noisy Student
Metadata:
FLOPs: 5749638672
Parameters: 19340000
File Size: 77995057
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- FixRes
- Label Smoothing
- Noisy Student
- RMSProp
- RandAugment
- Weight Decay
Training Data:
- ImageNet
- JFT-300M
Training Resources: Cloud TPU v3 Pod
ID: tf_efficientnet_b4_ns
LR: 0.128
Epochs: 700
Dropout: 0.5
Crop Pct: '0.922'
Momentum: 0.9
Batch Size: 2048
Image Size: '380'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Stochastic Depth Survival: 0.8
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1467
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b4_ns-d6313a46.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 85.15%
Top 5 Accuracy: 97.47%
- Name: tf_efficientnet_b5_ns
In Collection: Noisy Student
Metadata:
FLOPs: 13176501888
Parameters: 30390000
File Size: 122404944
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- FixRes
- Label Smoothing
- Noisy Student
- RMSProp
- RandAugment
- Weight Decay
Training Data:
- ImageNet
- JFT-300M
Training Resources: Cloud TPU v3 Pod
ID: tf_efficientnet_b5_ns
LR: 0.128
Epochs: 350
Dropout: 0.5
Crop Pct: '0.934'
Momentum: 0.9
Batch Size: 2048
Image Size: '456'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Stochastic Depth Survival: 0.8
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1477
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b5_ns-6f26d0cf.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 86.08%
Top 5 Accuracy: 97.75%
- Name: tf_efficientnet_b6_ns
In Collection: Noisy Student
Metadata:
FLOPs: 24180518488
Parameters: 43040000
File Size: 173239537
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- FixRes
- Label Smoothing
- Noisy Student
- RMSProp
- RandAugment
- Weight Decay
Training Data:
- ImageNet
- JFT-300M
Training Resources: Cloud TPU v3 Pod
ID: tf_efficientnet_b6_ns
LR: 0.128
Epochs: 350
Dropout: 0.5
Crop Pct: '0.942'
Momentum: 0.9
Batch Size: 2048
Image Size: '528'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Stochastic Depth Survival: 0.8
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1487
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b6_ns-51548356.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 86.45%
Top 5 Accuracy: 97.88%
- Name: tf_efficientnet_b7_ns
In Collection: Noisy Student
Metadata:
FLOPs: 48205304880
Parameters: 66349999
File Size: 266853140
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- FixRes
- Label Smoothing
- Noisy Student
- RMSProp
- RandAugment
- Weight Decay
Training Data:
- ImageNet
- JFT-300M
Training Resources: Cloud TPU v3 Pod
ID: tf_efficientnet_b7_ns
LR: 0.128
Epochs: 350
Dropout: 0.5
Crop Pct: '0.949'
Momentum: 0.9
Batch Size: 2048
Image Size: '600'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Stochastic Depth Survival: 0.8
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1498
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b7_ns-1dbc32de.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 86.83%
Top 5 Accuracy: 98.08%
- Name: tf_efficientnet_l2_ns
In Collection: Noisy Student
Metadata:
FLOPs: 611646113804
Parameters: 480310000
File Size: 1925950424
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- FixRes
- Label Smoothing
- Noisy Student
- RMSProp
- RandAugment
- Weight Decay
Training Data:
- ImageNet
- JFT-300M
Training Resources: Cloud TPU v3 Pod
Training Time: 6 days
ID: tf_efficientnet_l2_ns
LR: 0.128
Epochs: 350
Dropout: 0.5
Crop Pct: '0.96'
Momentum: 0.9
Batch Size: 2048
Image Size: '800'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Stochastic Depth Survival: 0.8
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1520
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_l2_ns-df73bb44.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 88.35%
Top 5 Accuracy: 98.66%
-->
|
huggingface/pytorch-image-models/blob/main/hfdocs/source/models/noisy-student.mdx
|
`@gradio/textbox`
```html
<script>
import { BaseTextbox, BaseExample } from "@gradio/textbox";
</script>
```
BaseTextbox
```javascript
export let value = "";
export let value_is_output = false;
export let lines = 1;
export let placeholder = "Type here...";
export let label: string;
export let info: string | undefined = undefined;
export let disabled = false;
export let show_label = true;
export let container = true;
export let max_lines: number;
export let type: "text" | "password" | "email" = "text";
export let show_copy_button = false;
export let rtl = false;
export let autofocus = false;
export let text_align: "left" | "right" | undefined = undefined;
export let autoscroll = true;
```
BaseExample
```javascript
export let value: string;
export let type: "gallery" | "table";
export let selected = false;
```
|
gradio-app/gradio/blob/main/js/textbox/README.md
|
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Inference
Inference is the process of using a trained model to make predictions on new data. As this process can be compute-intensive,
running on a dedicated server can be an interesting option. The `huggingface_hub` library provides an easy way to call a
service that runs inference for hosted models. There are several services you can connect to:
- [Inference API](https://huggingface.co/docs/api-inference/index): a service that allows you to run accelerated inference
on Hugging Face's infrastructure for free. This service is a fast way to get started, test different models, and
prototype AI products.
- [Inference Endpoints](https://huggingface.co/inference-endpoints): a product to easily deploy models to production.
Inference is run by Hugging Face in a dedicated, fully managed infrastructure on a cloud provider of your choice.
These services can be called with the [`InferenceClient`] object. Please refer to [this guide](../guides/inference)
for more information on how to use it.
## Inference Client
[[autodoc]] InferenceClient
## Async Inference Client
An async version of the client is also provided, based on `asyncio` and `aiohttp`.
To use it, you can either install `aiohttp` directly or use the `[inference]` extra:
```sh
pip install --upgrade huggingface_hub[inference]
# or
# pip install aiohttp
```
[[autodoc]] AsyncInferenceClient
## InferenceTimeoutError
[[autodoc]] InferenceTimeoutError
## Return types
For most tasks, the return value has a built-in type (string, list, image...). Here is a list for the more complex types.
### ClassificationOutput
[[autodoc]] huggingface_hub.inference._types.ClassificationOutput
### ConversationalOutputConversation
[[autodoc]] huggingface_hub.inference._types.ConversationalOutputConversation
### ConversationalOutput
[[autodoc]] huggingface_hub.inference._types.ConversationalOutput
### ImageSegmentationOutput
[[autodoc]] huggingface_hub.inference._types.ImageSegmentationOutput
### ModelStatus
[[autodoc]] huggingface_hub.inference._common.ModelStatus
### TokenClassificationOutput
[[autodoc]] huggingface_hub.inference._types.TokenClassificationOutput
### Text generation types
[`~InferenceClient.text_generation`] task has a greater support than other tasks in `InferenceClient`. In
particular, user inputs and server outputs are validated using [Pydantic](https://docs.pydantic.dev/latest/)
if this package is installed. Therefore, we recommend installing it (`pip install pydantic`)
for a better user experience.
You can find below the dataclasses used to validate data and in particular [`~huggingface_hub.inference._text_generation.TextGenerationParameters`] (input),
[`~huggingface_hub.inference._text_generation.TextGenerationResponse`] (output) and
[`~huggingface_hub.inference._text_generation.TextGenerationStreamResponse`] (streaming output).
[[autodoc]] huggingface_hub.inference._text_generation.TextGenerationParameters
[[autodoc]] huggingface_hub.inference._text_generation.TextGenerationResponse
[[autodoc]] huggingface_hub.inference._text_generation.TextGenerationStreamResponse
[[autodoc]] huggingface_hub.inference._text_generation.InputToken
[[autodoc]] huggingface_hub.inference._text_generation.Token
[[autodoc]] huggingface_hub.inference._text_generation.FinishReason
[[autodoc]] huggingface_hub.inference._text_generation.BestOfSequence
[[autodoc]] huggingface_hub.inference._text_generation.Details
[[autodoc]] huggingface_hub.inference._text_generation.StreamDetails
## InferenceAPI
[`InferenceAPI`] is the legacy way to call the Inference API. The interface is more simplistic and requires knowing
the input parameters and output format for each task. It also lacks the ability to connect to other services like
Inference Endpoints or AWS SageMaker. [`InferenceAPI`] will soon be deprecated so we recommend using [`InferenceClient`]
whenever possible. Check out [this guide](../guides/inference#legacy-inferenceapi-client) to learn how to switch from
[`InferenceAPI`] to [`InferenceClient`] in your scripts.
[[autodoc]] InferenceApi
- __init__
- __call__
- all
|
huggingface/huggingface_hub/blob/main/docs/source/en/package_reference/inference_client.md
|
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Logging
🤗 Transformers has a centralized logging system, so that you can setup the verbosity of the library easily.
Currently the default verbosity of the library is `WARNING`.
To change the level of verbosity, just use one of the direct setters. For instance, here is how to change the verbosity
to the INFO level.
```python
import transformers
transformers.logging.set_verbosity_info()
```
You can also use the environment variable `TRANSFORMERS_VERBOSITY` to override the default verbosity. You can set it
to one of the following: `debug`, `info`, `warning`, `error`, `critical`. For example:
```bash
TRANSFORMERS_VERBOSITY=error ./myprogram.py
```
Additionally, some `warnings` can be disabled by setting the environment variable
`TRANSFORMERS_NO_ADVISORY_WARNINGS` to a true value, like *1*. This will disable any warning that is logged using
[`logger.warning_advice`]. For example:
```bash
TRANSFORMERS_NO_ADVISORY_WARNINGS=1 ./myprogram.py
```
Here is an example of how to use the same logger as the library in your own module or script:
```python
from transformers.utils import logging
logging.set_verbosity_info()
logger = logging.get_logger("transformers")
logger.info("INFO")
logger.warning("WARN")
```
All the methods of this logging module are documented below, the main ones are
[`logging.get_verbosity`] to get the current level of verbosity in the logger and
[`logging.set_verbosity`] to set the verbosity to the level of your choice. In order (from the least
verbose to the most verbose), those levels (with their corresponding int values in parenthesis) are:
- `transformers.logging.CRITICAL` or `transformers.logging.FATAL` (int value, 50): only report the most
critical errors.
- `transformers.logging.ERROR` (int value, 40): only report errors.
- `transformers.logging.WARNING` or `transformers.logging.WARN` (int value, 30): only reports error and
warnings. This the default level used by the library.
- `transformers.logging.INFO` (int value, 20): reports error, warnings and basic information.
- `transformers.logging.DEBUG` (int value, 10): report all information.
By default, `tqdm` progress bars will be displayed during model download. [`logging.disable_progress_bar`] and [`logging.enable_progress_bar`] can be used to suppress or unsuppress this behavior.
## `logging` vs `warnings`
Python has two logging systems that are often used in conjunction: `logging`, which is explained above, and `warnings`,
which allows further classification of warnings in specific buckets, e.g., `FutureWarning` for a feature or path
that has already been deprecated and `DeprecationWarning` to indicate an upcoming deprecation.
We use both in the `transformers` library. We leverage and adapt `logging`'s `captureWarning` method to allow
management of these warning messages by the verbosity setters above.
What does that mean for developers of the library? We should respect the following heuristic:
- `warnings` should be favored for developers of the library and libraries dependent on `transformers`
- `logging` should be used for end-users of the library using it in every-day projects
See reference of the `captureWarnings` method below.
[[autodoc]] logging.captureWarnings
## Base setters
[[autodoc]] logging.set_verbosity_error
[[autodoc]] logging.set_verbosity_warning
[[autodoc]] logging.set_verbosity_info
[[autodoc]] logging.set_verbosity_debug
## Other functions
[[autodoc]] logging.get_verbosity
[[autodoc]] logging.set_verbosity
[[autodoc]] logging.get_logger
[[autodoc]] logging.enable_default_handler
[[autodoc]] logging.disable_default_handler
[[autodoc]] logging.enable_explicit_format
[[autodoc]] logging.reset_format
[[autodoc]] logging.enable_progress_bar
[[autodoc]] logging.disable_progress_bar
|
huggingface/transformers/blob/main/docs/source/en/main_classes/logging.md
|
Gradio Demo: clear_components
```
!pip install -q gradio
```
```
# Downloading files from the demo repo
import os
!wget -q https://github.com/gradio-app/gradio/raw/main/demo/clear_components/__init__.py
```
```
import gradio as gr
from datetime import datetime
import os
import random
import string
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
def random_plot():
start_year = 2020
x = np.arange(start_year, start_year + 5)
year_count = x.shape[0]
plt_format = "-"
fig = plt.figure()
ax = fig.add_subplot(111)
series = np.arange(0, year_count, dtype=float)
series = series**2
series += np.random.rand(year_count)
ax.plot(x, series, plt_format)
return fig
images = [
"https://images.unsplash.com/photo-1507003211169-0a1dd7228f2d?ixlib=rb-1.2.1&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=387&q=80",
"https://images.unsplash.com/photo-1554151228-14d9def656e4?ixlib=rb-1.2.1&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=386&q=80",
"https://images.unsplash.com/photo-1542909168-82c3e7fdca5c?ixlib=rb-1.2.1&ixid=MnwxMjA3fDB8MHxzZWFyY2h8MXx8aHVtYW4lMjBmYWNlfGVufDB8fDB8fA%3D%3D&w=1000&q=80",
]
file_dir = os.path.join(os.path.abspath(''), "..", "kitchen_sink", "files")
model3d_dir = os.path.join(os.path.abspath(''), "..", "model3D", "files")
highlighted_text_output_1 = [
{
"entity": "I-LOC",
"score": 0.9988978,
"index": 2,
"word": "Chicago",
"start": 5,
"end": 12,
},
{
"entity": "I-MISC",
"score": 0.9958592,
"index": 5,
"word": "Pakistani",
"start": 22,
"end": 31,
},
]
highlighted_text_output_2 = [
{
"entity": "I-LOC",
"score": 0.9988978,
"index": 2,
"word": "Chicago",
"start": 5,
"end": 12,
},
{
"entity": "I-LOC",
"score": 0.9958592,
"index": 5,
"word": "Pakistan",
"start": 22,
"end": 30,
},
]
highlighted_text = "Does Chicago have any Pakistani restaurants"
def random_model3d():
model_3d = random.choice(
[os.path.join(model3d_dir, model) for model in os.listdir(model3d_dir) if model != "source.txt"]
)
return model_3d
components = [
gr.Textbox(value=lambda: datetime.now(), label="Current Time"),
gr.Number(value=lambda: random.random(), label="Random Percentage"),
gr.Slider(minimum=0, maximum=100, randomize=True, label="Slider with randomize"),
gr.Slider(
minimum=0,
maximum=1,
value=lambda: random.random(),
label="Slider with value func",
),
gr.Checkbox(value=lambda: random.random() > 0.5, label="Random Checkbox"),
gr.CheckboxGroup(
choices=["a", "b", "c", "d"],
value=lambda: random.choice(["a", "b", "c", "d"]),
label="Random CheckboxGroup",
),
gr.Radio(
choices=list(string.ascii_lowercase),
value=lambda: random.choice(string.ascii_lowercase),
),
gr.Dropdown(
choices=["a", "b", "c", "d", "e"],
value=lambda: random.choice(["a", "b", "c"]),
),
gr.Image(
value=lambda: random.choice(images)
),
gr.Video(value=lambda: os.path.join(file_dir, "world.mp4")),
gr.Audio(value=lambda: os.path.join(file_dir, "cantina.wav")),
gr.File(
value=lambda: random.choice(
[os.path.join(file_dir, img) for img in os.listdir(file_dir)]
)
),
gr.Dataframe(
value=lambda: pd.DataFrame({"random_number_rows": range(5)}, columns=["one", "two", "three"])
),
gr.ColorPicker(value=lambda: random.choice(["#000000", "#ff0000", "#0000FF"])),
gr.Label(value=lambda: random.choice(["Pedestrian", "Car", "Cyclist"])),
gr.HighlightedText(
value=lambda: random.choice(
[
{"text": highlighted_text, "entities": highlighted_text_output_1},
{"text": highlighted_text, "entities": highlighted_text_output_2},
]
),
),
gr.JSON(value=lambda: random.choice([{"a": 1}, {"b": 2}])),
gr.HTML(
value=lambda: random.choice(
[
'<p style="color:red;">I am red</p>',
'<p style="color:blue;">I am blue</p>',
]
)
),
gr.Gallery(
value=lambda: images
),
gr.Model3D(value=random_model3d),
gr.Plot(value=random_plot),
gr.Markdown(value=lambda: f"### {random.choice(['Hello', 'Hi', 'Goodbye!'])}"),
]
def evaluate_values(*args):
are_false = []
for a in args:
if isinstance(a, (pd.DataFrame, np.ndarray)):
are_false.append(not a.any().any())
elif isinstance(a, str) and a.startswith("#"):
are_false.append(a == "#000000")
else:
are_false.append(not a)
return all(are_false)
with gr.Blocks() as demo:
for i, component in enumerate(components):
component.label = f"component_{str(i).zfill(2)}"
component.render()
clear = gr.ClearButton(value="Clear", components=components)
result = gr.Textbox(label="Are all cleared?")
hide = gr.Button(value="Hide")
reveal = gr.Button(value="Reveal")
hide.click(
lambda: [c.__class__(visible=False) for c in components],
inputs=[],
outputs=components
)
reveal.click(
lambda: [c.__class__(visible=True) for c in components],
inputs=[],
outputs=components
)
get_value = gr.Button(value="Get Values")
get_value.click(evaluate_values, components, result)
if __name__ == "__main__":
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/clear_components/run.ipynb
|
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Callbacks
Callbacks are objects that can customize the behavior of the training loop in the PyTorch
[`Trainer`] (this feature is not yet implemented in TensorFlow) that can inspect the training loop
state (for progress reporting, logging on TensorBoard or other ML platforms...) and take decisions (like early
stopping).
Callbacks are "read only" pieces of code, apart from the [`TrainerControl`] object they return, they
cannot change anything in the training loop. For customizations that require changes in the training loop, you should
subclass [`Trainer`] and override the methods you need (see [trainer](trainer) for examples).
By default, `TrainingArguments.report_to` is set to `"all"`, so a [`Trainer`] will use the following callbacks.
- [`DefaultFlowCallback`] which handles the default behavior for logging, saving and evaluation.
- [`PrinterCallback`] or [`ProgressCallback`] to display progress and print the
logs (the first one is used if you deactivate tqdm through the [`TrainingArguments`], otherwise
it's the second one).
- [`~integrations.TensorBoardCallback`] if tensorboard is accessible (either through PyTorch >= 1.4
or tensorboardX).
- [`~integrations.WandbCallback`] if [wandb](https://www.wandb.com/) is installed.
- [`~integrations.CometCallback`] if [comet_ml](https://www.comet.ml/site/) is installed.
- [`~integrations.MLflowCallback`] if [mlflow](https://www.mlflow.org/) is installed.
- [`~integrations.NeptuneCallback`] if [neptune](https://neptune.ai/) is installed.
- [`~integrations.AzureMLCallback`] if [azureml-sdk](https://pypi.org/project/azureml-sdk/) is
installed.
- [`~integrations.CodeCarbonCallback`] if [codecarbon](https://pypi.org/project/codecarbon/) is
installed.
- [`~integrations.ClearMLCallback`] if [clearml](https://github.com/allegroai/clearml) is installed.
- [`~integrations.DagsHubCallback`] if [dagshub](https://dagshub.com/) is installed.
- [`~integrations.FlyteCallback`] if [flyte](https://flyte.org/) is installed.
- [`~integrations.DVCLiveCallback`] if [dvclive](https://dvc.org/doc/dvclive) is installed.
If a package is installed but you don't wish to use the accompanying integration, you can change `TrainingArguments.report_to` to a list of just those integrations you want to use (e.g. `["azure_ml", "wandb"]`).
The main class that implements callbacks is [`TrainerCallback`]. It gets the
[`TrainingArguments`] used to instantiate the [`Trainer`], can access that
Trainer's internal state via [`TrainerState`], and can take some actions on the training loop via
[`TrainerControl`].
## Available Callbacks
Here is the list of the available [`TrainerCallback`] in the library:
[[autodoc]] integrations.CometCallback
- setup
[[autodoc]] DefaultFlowCallback
[[autodoc]] PrinterCallback
[[autodoc]] ProgressCallback
[[autodoc]] EarlyStoppingCallback
[[autodoc]] integrations.TensorBoardCallback
[[autodoc]] integrations.WandbCallback
- setup
[[autodoc]] integrations.MLflowCallback
- setup
[[autodoc]] integrations.AzureMLCallback
[[autodoc]] integrations.CodeCarbonCallback
[[autodoc]] integrations.NeptuneCallback
[[autodoc]] integrations.ClearMLCallback
[[autodoc]] integrations.DagsHubCallback
[[autodoc]] integrations.FlyteCallback
[[autodoc]] integrations.DVCLiveCallback
- setup
## TrainerCallback
[[autodoc]] TrainerCallback
Here is an example of how to register a custom callback with the PyTorch [`Trainer`]:
```python
class MyCallback(TrainerCallback):
"A callback that prints a message at the beginning of training"
def on_train_begin(self, args, state, control, **kwargs):
print("Starting training")
trainer = Trainer(
model,
args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
callbacks=[MyCallback], # We can either pass the callback class this way or an instance of it (MyCallback())
)
```
Another way to register a callback is to call `trainer.add_callback()` as follows:
```python
trainer = Trainer(...)
trainer.add_callback(MyCallback)
# Alternatively, we can pass an instance of the callback class
trainer.add_callback(MyCallback())
```
## TrainerState
[[autodoc]] TrainerState
## TrainerControl
[[autodoc]] TrainerControl
|
huggingface/transformers/blob/main/docs/source/en/main_classes/callback.md
|
ow to add BigBird to 🤗 Transformers?
=====================================
Mentor: [Patrick](https://github.com/patrickvonplaten)
Begin: 12.02.2020
Estimated End: 19.03.2020
Contributor: [Vasudev](https://github.com/thevasudevgupta)
Adding a new model is often difficult and requires an in-depth knowledge
of the 🤗 Transformers library and ideally also of the model's original
repository. At Hugging Face, we are trying to empower the community more
and more to add models independently.
The following sections explain in detail how to add BigBird
to Transformers. You will work closely with Patrick to
integrate BigBird into Transformers. By doing so, you will both gain a
theoretical and deep practical understanding of BigBird.
But more importantly, you will have made a major
open-source contribution to Transformers. Along the way, you will:
- get insights into open-source best practices
- understand the design principles of one of the most popular NLP
libraries
- learn how to do efficiently test large NLP models
- learn how to integrate Python utilities like `black`, `ruff`,
`make fix-copies` into a library to always ensure clean and readable
code
To start, let's try to get a general overview of the Transformers
library.
General overview of 🤗 Transformers
----------------------------------
First, you should get a general overview of 🤗 Transformers. Transformers
is a very opinionated library, so there is a chance that
you don't agree with some of the library's philosophies or design
choices. From our experience, however, we found that the fundamental
design choices and philosophies of the library are crucial to
efficiently scale Transformers while keeping maintenance costs at a
reasonable level.
A good first starting point to better understand the library is to read
the [documentation of our philosophy](https://huggingface.co/transformers/philosophy.html).
As a result of our way of working, there are some choices that we try to apply to all models:
- Composition is generally favored over abstraction
- Duplicating code is not always bad if it strongly improves the
readability or accessibility of a model
- Model files are as self-contained as possible so that when you read
the code of a specific model, you ideally only have to look into the
respective `modeling_....py` file.
In our opinion, the library's code is not just a means to provide a
product, *e.g.*, the ability to use BERT for inference, but also as the
very product that we want to improve. Hence, when adding a model, the
user is not only the person that will use your model, but also everybody
that will read, try to understand, and possibly tweak your code.
With this in mind, let's go a bit deeper into the general library
design.
### Overview of models
To successfully add a model, it is important to understand the
interaction between your model and its config,
`PreTrainedModel`, and `PretrainedConfig`. For
exemplary purposes, we will call the PyTorch model to be added to 🤗 Transformers
`BrandNewBert`.
Let's take a look:
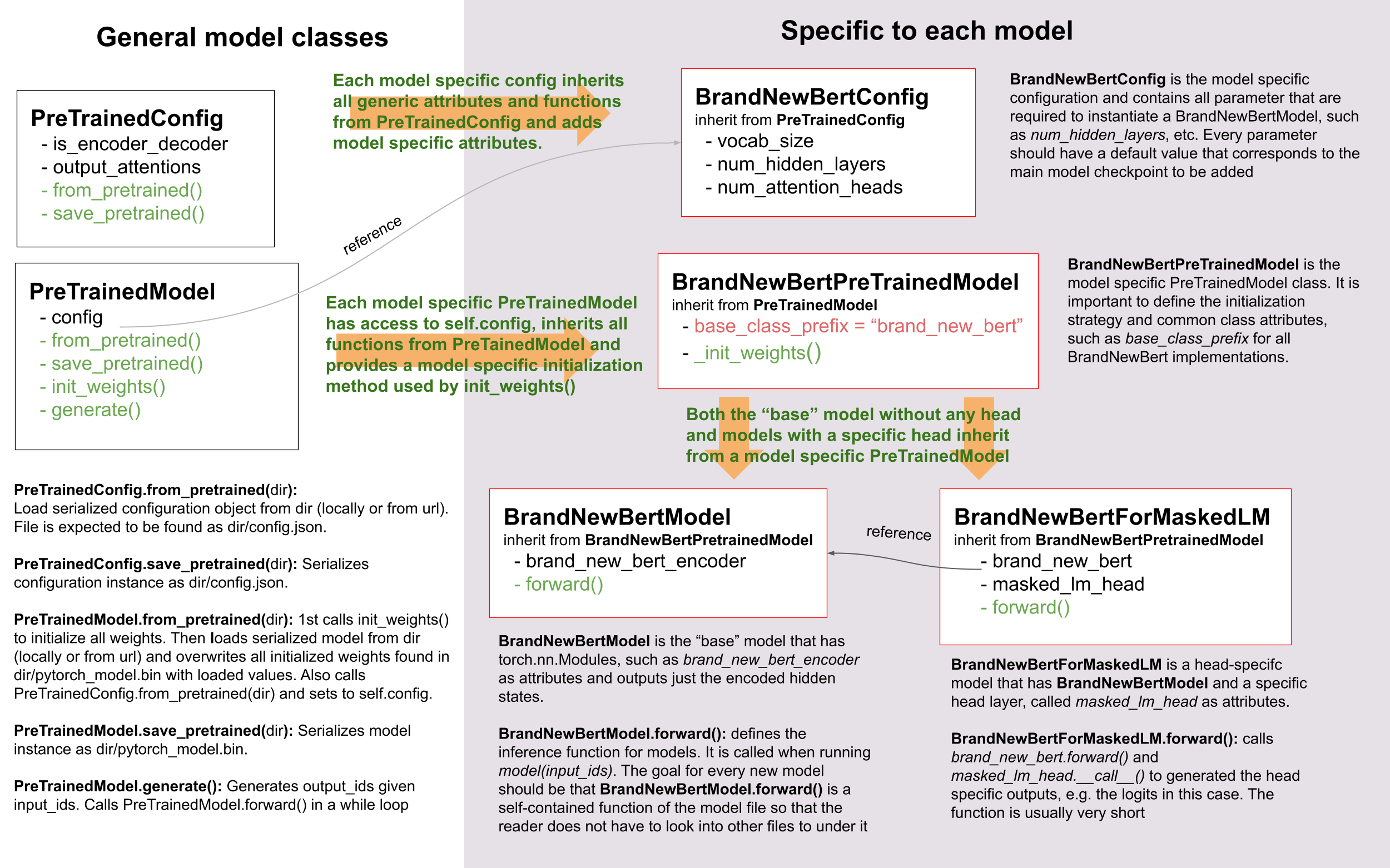
As you can see, we do make use of inheritance in 🤗 Transformers, but we
keep the level of abstraction to an absolute minimum. There are never
more than two levels of abstraction for any model in the library.
`BrandNewBertModel` inherits from
`BrandNewBertPreTrainedModel` which in
turn inherits from `PreTrainedModel` and that's it.
As a general rule, we want to make sure
that a new model only depends on `PreTrainedModel`. The
important functionalities that are automatically provided to every new
model are
`PreTrainedModel.from_pretrained` and `PreTrainedModel.save_pretrained`, which are
used for serialization and deserialization. All
of the other important functionalities, such as
`BrandNewBertModel.forward` should be
completely defined in the new `modeling_brand_new_bert.py` module. Next,
we want to make sure that a model with a specific head layer, such as
`BrandNewBertForMaskedLM` does not inherit
from `BrandNewBertModel`, but rather uses
`BrandNewBertModel` as a component that
can be called in its forward pass to keep the level of abstraction low.
Every new model requires a configuration class, called
`BrandNewBertConfig`. This configuration
is always stored as an attribute in
`PreTrainedModel`, and
thus can be accessed via the `config` attribute for all classes
inheriting from `BrandNewBertPreTrainedModel`
```python
# assuming that `brand_new_bert` belongs to the organization `brandy`
model = BrandNewBertModel.from_pretrained("brandy/brand_new_bert")
model.config # model has access to its config
```
Similar to the model, the configuration inherits basic serialization and
deserialization functionalities from
`PretrainedConfig`. Note
that the configuration and the model are always serialized into two
different formats - the model to a `pytorch_model.bin` file
and the configuration to a `config.json` file. Calling
`PreTrainedModel.save_pretrained` will automatically call
`PretrainedConfig.save_pretrained`, so that both model and configuration are saved.
### Overview of tokenizers
Not quite ready yet :-( This section will be added soon!
Step-by-step recipe to add a model to 🤗 Transformers
----------------------------------------------------
Everyone has different preferences of how to port a model so it can be
very helpful for you to take a look at summaries of how other
contributors ported models to Hugging Face. Here is a list of community
blog posts on how to port a model:
1. [Porting GPT2
Model](https://medium.com/huggingface/from-tensorflow-to-pytorch-265f40ef2a28)
by [Thomas](https://huggingface.co/thomwolf)
2. [Porting WMT19 MT Model](https://huggingface.co/blog/porting-fsmt)
by [Stas](https://huggingface.co/stas)
From experience, we can tell you that the most important things to keep
in mind when adding a model are:
- Don't reinvent the wheel! Most parts of the code you will add for
the new 🤗 Transformers model already exist somewhere in 🤗
Transformers. Take some time to find similar, already existing
models and tokenizers you can copy from.
[grep](https://www.gnu.org/software/grep/) and
[rg](https://github.com/BurntSushi/ripgrep) are your friends. Note
that it might very well happen that your model's tokenizer is based
on one model implementation, and your model's modeling code on
another one. *E.g.*, FSMT's modeling code is based on BART, while
FSMT's tokenizer code is based on XLM.
- It's more of an engineering challenge than a scientific challenge.
You should spend more time on creating an efficient debugging
environment than trying to understand all theoretical aspects of the
model in the paper.
- Ask for help when you're stuck! Models are the core component of 🤗
Transformers so we, at Hugging Face, are more than happy to help
you at every step to add your model. Don't hesitate to ask if you
notice you are not making progress.
In the following, we try to give you a general recipe that we found most
useful when porting a model to 🤗 Transformers.
The following list is a summary of everything that has to be done to add
a model and can be used by you as a To-Do List:
1. [ ] (Optional) Understood theoretical aspects
2. [ ] Prepared transformers dev environment
3. [ ] Set up debugging environment of the original repository
4. [ ] Created script that successfully runs forward pass using
original repository and checkpoint
5. [ ] Successfully opened a PR and added the model skeleton to Transformers
6. [ ] Successfully converted original checkpoint to Transformers
checkpoint
7. [ ] Successfully ran forward pass in Transformers that gives
identical output to original checkpoint
8. [ ] Finished model tests in Transformers
9. [ ] Successfully added Tokenizer in Transformers
10. [ ] Run end-to-end integration tests
11. [ ] Finished docs
12. [ ] Uploaded model weights to the hub
13. [ ] Submitted the pull request for review
14. [ ] (Optional) Added a demo notebook
To begin with, we usually recommend to start by getting a good
theoretical understanding of `BigBird`. However, if you prefer to
understand the theoretical aspects of the model *on-the-job*, then it is
totally fine to directly dive into the `BigBird`'s code-base. This
option might suit you better, if your engineering skills are better than
your theoretical skill, if you have trouble understanding
`BigBird`'s paper, or if you just enjoy programming much more than
reading scientific papers.
### 1. (Optional) Theoretical aspects of BigBird
You should take some time to read *BigBird's* paper, if such
descriptive work exists. There might be large sections of the paper that
are difficult to understand. If this is the case, this is fine - don't
worry! The goal is not to get a deep theoretical understanding of the
paper, but to extract the necessary information required to effectively
re-implement the model in 🤗 Transformers. That being said, you don't
have to spend too much time on the theoretical aspects, but rather focus
on the practical ones, namely:
- What type of model is *BigBird*? BERT-like encoder-only
model? GPT2-like decoder-only model? BART-like encoder-decoder
model? Look at the `model_summary` if
you're not familiar with the differences between those.
- What are the applications of *BigBird*? Text
classification? Text generation? Seq2Seq tasks, *e.g.,*
summarization?
- What is the novel feature of the model making it different from
BERT/GPT-2/BART?
- Which of the already existing [🤗 Transformers
models](https://huggingface.co/transformers/#contents) is most
similar to *BigBird*?
- What type of tokenizer is used? A sentencepiece tokenizer? Word
piece tokenizer? Is it the same tokenizer as used for BERT or BART?
After you feel like you have gotten a good overview of the architecture
of the model, you might want to write to Patrick with any
questions you might have. This might include questions regarding the
model's architecture, its attention layer, etc. We will be more than
happy to help you.
#### Additional resources
Before diving into the code, here are some additional resources that might be worth taking a look at:
- [Yannic Kilcher's paper summary](https://www.youtube.com/watch?v=WVPE62Gk3EM&ab_channel=YannicKilcher)
- [Yannic Kilcher's summary of Longformer](https://www.youtube.com/watch?v=_8KNb5iqblE&ab_channel=YannicKilcher) - Longformer and BigBird are **very** similar models. Since Longformer has already been ported to 🤗 Transformers, it is useful to understand the differences between the two models
- [Blog post](https://medium.com/dsc-msit/is-google-bigbird-gonna-be-the-new-leader-in-nlp-domain-8c95cecc30f8) - A relatively superficial blog post about BigBird. Might be a good starting point to understand BigBird
#### Make sure you've understood the fundamental aspects of BigBird
Alright, now you should be ready to take a closer look into the actual code of BigBird.
You should have understood the following aspects of BigBird by now:
- BigBird provides a new attention layer for long-range sequence modelling that can be used
as a drop-in replacement for already existing architectures. This means that every transformer-based model architecture can replace its [Self-attention layer](https://towardsdatascience.com/illustrated-self-attention-2d627e33b20a) with BigBird's self-attention layer.
- BigBird's self-attention layer is composed of three mechanisms: block sparse (local) self-attention, global self-attention, random self-attention
- BigBird's block sparse (local) self-attention is different from Longformer's local self-attention. How so? Why does that matter? => Can be deployed on TPU much easier this way
- BigBird can be implemented for both an encoder-only model **and**
for an encoder-decoder model, which means that we can reuse lots of [code from RoBERTa](https://github.com/huggingface/transformers/blob/main/src/transformers/models/roberta/modeling_roberta.py) and [from PEGASUS](https://github.com/huggingface/transformers/blob/main/src/transformers/models/pegasus/modeling_pegasus.py) at a later stage.
If any of the mentioned aspects above are **not** clear to you, now is a great time to talk to Patrick.
### 2. Next prepare your environment
1. Fork the [repository](https://github.com/huggingface/transformers)
by clicking on the 'Fork' button on the repository's page. This
creates a copy of the code under your GitHub user account.
2. Clone your `transformers` fork to your local disk, and add the base
repository as a remote:
```bash
git clone https://github.com/[your Github handle]/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git
```
3. Set up a development environment, for instance by running the
following command:
```bash
python -m venv .env
source .env/bin/activate
pip install -e ".[dev]"
```
and return to the parent directory
```bash
cd ..
```
4. We recommend adding the PyTorch version of *BigBird* to
Transformers. To install PyTorch, please follow the instructions [here](https://pytorch.org/get-started/locally/).
**Note:** You don't need to have CUDA installed. Making the new model
work on CPU is sufficient.
5. To port *BigBird*, you will also need access to its
original repository:
```bash
git clone https://github.com/google-research/bigbird.git
cd big_bird
pip install -e .
```
Now you have set up a development environment to port *BigBird*
to 🤗 Transformers.
### Run a pretrained checkpoint using the original repository
**3. Set up debugging environment**
At first, you will work on the original *BigBird* repository.
Often, the original implementation is very "researchy". Meaning that
documentation might be lacking and the code can be difficult to
understand. But this should be exactly your motivation to reimplement
*BigBird*. At Hugging Face, one of our main goals is to *make
people stand on the shoulders of giants* which translates here very well
into taking a working model and rewriting it to make it as **accessible,
user-friendly, and beautiful** as possible. This is the number-one
motivation to re-implement models into 🤗 Transformers - trying to make
complex new NLP technology accessible to **everybody**.
You should start thereby by diving into the [original repository](https://github.com/google-research/bigbird).
Successfully running the official pretrained model in the original
repository is often **the most difficult** step. From our experience, it
is very important to spend some time getting familiar with the original
code-base. You need to figure out the following:
- Where to find the pretrained weights?
- How to load the pretrained weights into the corresponding model?
- How to run the tokenizer independently from the model?
- Trace one forward pass so that you know which classes and functions
are required for a simple forward pass. Usually, you only have to
reimplement those functions.
- Be able to locate the important components of the model: Where is
the model's class? Are there model sub-classes, *e.g.*,
EncoderModel, DecoderModel? Where is the self-attention layer? Are
there multiple different attention layers, *e.g.*, *self-attention*,
*cross-attention*...?
- How can you debug the model in the original environment of the repo?
Do you have to add `print` statements, can you work with
an interactive debugger like [ipdb](https://pypi.org/project/ipdb/), or should you use
an efficient IDE to debug the model, like PyCharm?
It is very important that before you start the porting process, that you
can **efficiently** debug code in the original repository! Also,
remember that you are working with an open-source library, so do not
hesitate to open an issue, or even a pull request in the original
repository. The maintainers of this repository are most likely very
happy about someone looking into their code!
At this point, it is really up to you which debugging environment and
strategy you prefer to use to debug the original model. We strongly
advise against setting up a costly GPU environment, but simply work on a
CPU both when starting to dive into the original repository and also
when starting to write the 🤗 Transformers implementation of the model.
Only at the very end, when the model has already been successfully
ported to 🤗 Transformers, one should verify that the model also works as
expected on GPU.
In general, there are two possible debugging environments for running
the original model
- [Jupyter notebooks](https://jupyter.org/) / [google colab](https://colab.research.google.com/notebooks/intro.ipynb)
- Local python scripts.
Jupyter notebooks have the advantage that they allow for cell-by-cell
execution which can be helpful to better split logical components from
one another and to have faster debugging cycles as intermediate results
can be stored. Also, notebooks are often easier to share with other
contributors, which might be very helpful if you want to ask the Hugging
Face team for help. If you are familiar with Jupyter notebooks, we
strongly recommend you to work with them.
The obvious disadvantage of Jupyter notebooks is that if you are not
used to working with them you will have to spend some time adjusting to
the new programming environment and that you might not be able to use
your known debugging tools anymore, like `ipdb`.
**4. Successfully run forward pass**
For each code-base, a good first step is always to load a **small**
pretrained checkpoint and to be able to reproduce a single forward pass
using a dummy integer vector of input IDs as an input. Such a script
could look something like this:
```python
from bigbird.core import modeling
model = modeling.BertModel(bert_config)
from bigbird.core import utils
params = utils.BigBirdConfig(vocab_size=32000, hidden_size=512,
num_hidden_layers=8, num_attention_heads=6, intermediate_size=1024)
ckpt_path = 'gs://bigbird-transformer/pretrain/bigbr_base/model.ckpt-0'
ckpt_reader = tf.compat.v1.train.NewCheckpointReader(ckpt_path)
model.set_weights([ckpt_reader.get_tensor(v.name[:-2]) for v in tqdm(model.trainable_weights, position=0)])
input_ids = tf.constant([[31, 51, 99], [15, 5, 0]])
_, pooled_output = model(input_ids=input_ids, token_type_ids=token_type_ids)
...
```
Next, regarding the debugging strategy, there are generally a few from
which to choose from:
- Decompose the original model into many small testable components and
run a forward pass on each of those for verification
- Decompose the original model only into the original *tokenizer* and
the original *model*, run a forward pass on those, and use
intermediate print statements or breakpoints for verification
Again, it is up to you which strategy to choose. Often, one or the other
is advantageous depending on the original code base.
If the original code-base allows you to decompose the model into smaller
sub-components, *e.g.*, if the original code-base can easily be run in
eager mode, it is usually worth the effort to do so. There are some
important advantages to taking the more difficult road in the beginning:
- at a later stage when comparing the original model to the Hugging
Face implementation, you can verify automatically for each component
individually that the corresponding component of the 🤗 Transformers
implementation matches instead of relying on visual comparison via
print statements
- it can give you some rope to decompose the big problem of porting a
model into smaller problems of just porting individual components
and thus structure your work better
- separating the model into logical meaningful components will help
you to get a better overview of the model's design and thus to
better understand the model
- at a later stage those component-by-component tests help you to
ensure that no regression occurs as you continue changing your code
[Lysandre's](https://gist.github.com/LysandreJik/db4c948f6b4483960de5cbac598ad4ed)
integration checks for ELECTRA gives a nice example of how this can be
done.
However, if the original code-base is very complex or only allows
intermediate components to be run in a compiled mode, it might be too
time-consuming or even impossible to separate the model into smaller
testable sub-components. A good example is [T5's
MeshTensorFlow](https://github.com/tensorflow/mesh/tree/master/mesh_tensorflow)
library which is very complex and does not offer a simple way to
decompose the model into its sub-components. For such libraries, one
often relies on verifying print statements.
No matter which strategy you choose, the recommended procedure is often
the same in that you should start to debug the starting layers first and
the ending layers last.
It is recommended that you retrieve the output, either by print
statements or sub-component functions, of the following layers in the
following order:
1. Retrieve the input IDs passed to the model
2. Retrieve the word embeddings
3. Retrieve the input of the first Transformer layer
4. Retrieve the output of the first Transformer layer
5. Retrieve the output of the following n - 1 Transformer layers
6. Retrieve the output of the whole BigBird Model
Input IDs should thereby consists of an array of integers, *e.g.*,
`input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]`
The outputs of the following layers often consist of multi-dimensional
float arrays and can look like this:
```bash
[[
[-0.1465, -0.6501, 0.1993, ..., 0.1451, 0.3430, 0.6024],
[-0.4417, -0.5920, 0.3450, ..., -0.3062, 0.6182, 0.7132],
[-0.5009, -0.7122, 0.4548, ..., -0.3662, 0.6091, 0.7648],
...,
[-0.5613, -0.6332, 0.4324, ..., -0.3792, 0.7372, 0.9288],
[-0.5416, -0.6345, 0.4180, ..., -0.3564, 0.6992, 0.9191],
[-0.5334, -0.6403, 0.4271, ..., -0.3339, 0.6533, 0.8694]]],
```
We expect that every model added to 🤗 Transformers passes a couple of
integration tests, meaning that the original model and the reimplemented
version in 🤗 Transformers have to give the exact same output up to a
precision of 0.001! Since it is normal that the exact same model written
in different libraries can give a slightly different output depending on
the library framework, we accept an error tolerance of 1e-3 (0.001). It
is not enough if the model gives nearly the same output, they have to be
the almost identical. Therefore, you will certainly compare the
intermediate outputs of the 🤗 Transformers version multiple times
against the intermediate outputs of the original implementation of
*BigBird* in which case an **efficient** debugging environment
of the original repository is absolutely important. Here is some advice
to make your debugging environment as efficient as possible.
- Find the best way of debugging intermediate results. Is the original
repository written in PyTorch? Then you should probably take the
time to write a longer script that decomposes the original model
into smaller sub-components to retrieve intermediate values. Is the
original repository written in Tensorflow 1? Then you might have to
rely on TensorFlow print operations like
[tf.print](https://www.tensorflow.org/api_docs/python/tf/print) to
output intermediate values. Is the original repository written in
Jax? Then make sure that the model is **not jitted** when running
the forward pass, *e.g.*, check-out [this
link](https://github.com/google/jax/issues/196).
- Use the smallest pretrained checkpoint you can find. The smaller the
checkpoint, the faster your debug cycle becomes. It is not efficient
if your pretrained model is so big that your forward pass takes more
than 10 seconds. In case only very large checkpoints are available,
it might make more sense to create a dummy model in the new
environment with randomly initialized weights and save those weights
for comparison with the 🤗 Transformers version of your model
- Make sure you are using the easiest way of calling a forward pass in
the original repository. Ideally, you want to find the function in
the original repository that **only** calls a single forward pass,
*i.e.* that is often called `predict`, `evaluate`, `forward` or
`__call__`. You don't want to debug a function that calls `forward`
multiple times, *e.g.*, to generate text, like
`autoregressive_sample`, `generate`.
- Try to separate the tokenization from the model's
forward pass. If the original repository shows
examples where you have to input a string, then try to find out
where in the forward call the string input is changed to input ids
and start from this point. This might mean that you have to possibly
write a small script yourself or change the original code so that
you can directly input the ids instead of an input string.
- Make sure that the model in your debugging setup is **not** in
training mode, which often causes the model to yield random outputs
due to multiple dropout layers in the model. Make sure that the
forward pass in your debugging environment is **deterministic** so
that the dropout layers are not used. Or use
`transformers.utils.set_seed` if the old and new
implementations are in the same framework.
#### (Important) More details on how to create a debugging environment for BigBird
- BigBird has multiple pretrained checkpoints that should eventually all be ported to
🤗 Transformers. The pretrained checkpoints can be found [here](https://console.cloud.google.com/storage/browser/bigbird-transformer/pretrain;tab=objects?prefix=&forceOnObjectsSortingFiltering=false).
Those checkpoints include both pretrained weights for encoder-only (BERT/RoBERTa) under the folder `bigbr_base` and encoder-decoder (PEGASUS) under the folder `bigbp_large`.
You should start by porting the `bigbr_base` model. The encoder-decoder model
can be ported afterward.
for an encoder-decoder architecture as well as an encoder-only architecture.
- BigBird was written in tf.compat meaning that a mixture of a TensorFlow 1 and
TensorFlow 2 API was used.
- The most important part of the BigBird code-base is [bigbird.bigbird.core](https://github.com/google-research/bigbird/tree/master/bigbird/core) which includes all logic necessary
to implement BigBird.
- The first goal should be to successfully run a forward pass using the RoBERTa checkpoint `bigbr_base/model.ckpt-0.data-00000-of-00001` and `bigbr_base/model.ckpt-0.index`.
### Port BigBird to 🤗 Transformers
Next, you can finally start adding new code to 🤗 Transformers. Go into
the clone of your 🤗 Transformers' fork:
cd transformers
In the special case that you are adding a model whose architecture
exactly matches the model architecture of an existing model you only
have to add a conversion script as described in [this
section](#write-a-conversion-script). In this case, you can just re-use
the whole model architecture of the already existing model.
Otherwise, let's start generating a new model with the amazing
Cookiecutter!
**Use the Cookiecutter to automatically generate the model's code**
To begin with head over to the [🤗 Transformers
templates](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model)
to make use of our `cookiecutter` implementation to automatically
generate all the relevant files for your model. Again, we recommend only
adding the PyTorch version of the model at first. Make sure you follow
the instructions of the `README.md` on the [🤗 Transformers
templates](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model)
carefully.
Since you will first implement the Encoder-only/RoBERTa-like version of BigBird you should
select the `is_encoder_decoder_model = False` option in the cookiecutter. Also, it is recommended
that you implement the model only in PyTorch in the beginning and select "Standalone" as the
tokenizer type for now.
**Open a Pull Request on the main huggingface/transformers repo**
Before starting to adapt the automatically generated code, now is the
time to open a "Work in progress (WIP)" pull request, *e.g.*, "\[WIP\]
Add *BigBird*", in 🤗 Transformers so that you and the Hugging
Face team can work side-by-side on integrating the model into 🤗
Transformers.
You should do the following:
1. Create a branch with a descriptive name from your main branch
```
git checkout -b add_big_bird
```
2. Commit the automatically generated code:
```
git add .
git commit
```
3. Fetch and rebase to current main
```
git fetch upstream
git rebase upstream/main
```
4. Push the changes to your account using:
```
git push -u origin a-descriptive-name-for-my-changes
```
5. Once you are satisfied, go to the webpage of your fork on GitHub.
Click on "Pull request". Make sure to add the GitHub handle of Patrick
as one reviewer, so that the Hugging Face team gets notified for future changes.
6. Change the PR into a draft by clicking on "Convert to draft" on the
right of the GitHub pull request web page.
In the following, whenever you have done some progress, don't forget to
commit your work and push it to your account so that it shows in the
pull request. Additionally, you should make sure to update your work
with the current main from time to time by doing:
git fetch upstream
git merge upstream/main
In general, all questions you might have regarding the model or your
implementation should be asked in your PR and discussed/solved in the
PR. This way, Patrick will always be notified when you are
committing new code or if you have a question. It is often very helpful
to point Patrick to your added code so that the Hugging
Face team can efficiently understand your problem or question.
To do so, you can go to the "Files changed" tab where you see all of
your changes, go to a line regarding which you want to ask a question,
and click on the "+" symbol to add a comment. Whenever a question or
problem has been solved, you can click on the "Resolve" button of the
created comment.
In the same way, Patrick will open comments when reviewing
your code. We recommend asking most questions on GitHub on your PR. For
some very general questions that are not very useful for the public,
feel free to ping Patrick by Slack or email.
**5. Adapt the generated models code for BigBird**
At first, we will focus only on the model itself and not care about the
tokenizer. All the relevant code should be found in the generated files
`src/transformers/models/big_bird/modeling_big_bird.py` and
`src/transformers/models/big_bird/configuration_big_bird.py`.
Now you can finally start coding :). The generated code in
`src/transformers/models/big_bird/modeling_big_bird.py` will
either have the same architecture as BERT if it's an encoder-only model
or BART if it's an encoder-decoder model. At this point, you should
remind yourself what you've learned in the beginning about the
theoretical aspects of the model: *How is the model different from BERT
or BART?*\". Implement those changes which often means to change the
*self-attention* layer, the order of the normalization layer, etc...
Again, it is often useful to look at the similar architecture of already
existing models in Transformers to get a better feeling of how your
model should be implemented.
**Note** that at this point, you don't have to be very sure that your
code is fully correct or clean. Rather, it is advised to add a first
*unclean*, copy-pasted version of the original code to
`src/transformers/models/big_bird/modeling_big_bird.py`
until you feel like all the necessary code is added. From our
experience, it is much more efficient to quickly add a first version of
the required code and improve/correct the code iteratively with the
conversion script as described in the next section. The only thing that
has to work at this point is that you can instantiate the 🤗 Transformers
implementation of *BigBird*, *i.e.* the following command
should work:
```python
from transformers import BigBirdModel, BigBirdConfig
model = BigBirdModel(BigBirdConfig())
```
The above command will create a model according to the default
parameters as defined in `BigBirdConfig()` with random weights,
thus making sure that the `init()` methods of all components works.
Note that for BigBird you have to change the attention layer. BigBird's attention
layer is quite complex as you can see [here](https://github.com/google-research/bigbird/blob/103a3345f94bf6364749b51189ed93024ca5ef26/bigbird/core/attention.py#L560). Don't
feel discouraged by this! In a first step you should simply make sure that
the layer `BigBirdAttention` has the correct weights as can be found in the
pretrained checkpoints. This means that you have to make sure that in the
`__init__(self, ...)` function of `BigBirdAttention`, all submodules include all
necessary `nn.Module` layers. Only at a later stage do we need to fully rewrite
the complex attention function.
**6. Write a conversion script**
Next, you should write a conversion script that lets you convert the
checkpoint you used to debug *BigBird* in the original
repository to a checkpoint compatible with your just created 🤗
Transformers implementation of *BigBird*. It is not advised to
write the conversion script from scratch, but rather to look through
already existing conversion scripts in 🤗 Transformers for one that has
been used to convert a similar model that was written in the same
framework as *BigBird*. Usually, it is enough to copy an
already existing conversion script and slightly adapt it for your use
case. Don't hesitate to ask Patrick to point you to a
similar already existing conversion script for your model.
- A good starting point to convert the original TF BigBird implementation to the PT Hugging Face implementation is probably BERT's conversion script
[here](https://github.com/huggingface/transformers/blob/7acfa95afb8194f8f9c1f4d2c6028224dbed35a2/src/transformers/models/bert/modeling_bert.py#L91)
You can copy paste the conversion function into `modeling_big_bird.py` and then adapt it
to your needs.
In the following, we'll quickly explain how PyTorch models store layer
weights and define layer names. In PyTorch, the name of a layer is
defined by the name of the class attribute you give the layer. Let's
define a dummy model in PyTorch, called `SimpleModel` as follows:
```python
from torch import nn
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.dense = nn.Linear(10, 10)
self.intermediate = nn.Linear(10, 10)
self.layer_norm = nn.LayerNorm(10)
```
Now we can create an instance of this model definition which will fill
all weights: `dense`, `intermediate`, `layer_norm` with random weights.
We can print the model to see its architecture
```python
model = SimpleModel()
print(model)
```
This will print out the following:
```bash
SimpleModel(
(dense): Linear(in_features=10, out_features=10, bias=True)
(intermediate): Linear(in_features=10, out_features=10, bias=True)
(layer_norm): LayerNorm((10,), eps=1e-05, elementwise_affine=True)
)
```
We can see that the layer names are defined by the name of the class
attribute in PyTorch. You can print out the weight values of a specific
layer:
```python
print(model.dense.weight.data)
```
to see that the weights were randomly initialized
```bash
tensor([[-0.0818, 0.2207, -0.0749, -0.0030, 0.0045, -0.1569, -0.1598, 0.0212,
-0.2077, 0.2157],
[ 0.1044, 0.0201, 0.0990, 0.2482, 0.3116, 0.2509, 0.2866, -0.2190,
0.2166, -0.0212],
[-0.2000, 0.1107, -0.1999, -0.3119, 0.1559, 0.0993, 0.1776, -0.1950,
-0.1023, -0.0447],
[-0.0888, -0.1092, 0.2281, 0.0336, 0.1817, -0.0115, 0.2096, 0.1415,
-0.1876, -0.2467],
[ 0.2208, -0.2352, -0.1426, -0.2636, -0.2889, -0.2061, -0.2849, -0.0465,
0.2577, 0.0402],
[ 0.1502, 0.2465, 0.2566, 0.0693, 0.2352, -0.0530, 0.1859, -0.0604,
0.2132, 0.1680],
[ 0.1733, -0.2407, -0.1721, 0.1484, 0.0358, -0.0633, -0.0721, -0.0090,
0.2707, -0.2509],
[-0.1173, 0.1561, 0.2945, 0.0595, -0.1996, 0.2988, -0.0802, 0.0407,
0.1829, -0.1568],
[-0.1164, -0.2228, -0.0403, 0.0428, 0.1339, 0.0047, 0.1967, 0.2923,
0.0333, -0.0536],
[-0.1492, -0.1616, 0.1057, 0.1950, -0.2807, -0.2710, -0.1586, 0.0739,
0.2220, 0.2358]]).
```
In the conversion script, you should fill those randomly initialized
weights with the exact weights of the corresponding layer in the
checkpoint. *E.g.*,
```python
# retrieve matching layer weights, e.g. by
# recursive algorithm
layer_name = "dense"
pretrained_weight = array_of_dense_layer
model_pointer = getattr(model, "dense")
model_pointer.weight.data = torch.from_numpy(pretrained_weight)
```
While doing so, you must verify that each randomly initialized weight of
your PyTorch model and its corresponding pretrained checkpoint weight
exactly match in both **shape and name**. To do so, it is **necessary**
to add assert statements for the shape and print out the names of the
checkpoints weights. *E.g.*, you should add statements like:
```python
assert (
model_pointer.weight.shape == pretrained_weight.shape
), f"Pointer shape of random weight {model_pointer.shape} and array shape of checkpoint weight {pretrained_weight.shape} mismatched"
```
Besides, you should also print out the names of both weights to make
sure they match, *e.g.*,
```python
logger.info(f"Initialize PyTorch weight {layer_name} from {pretrained_weight.name}")
```
If either the shape or the name doesn't match, you probably assigned
the wrong checkpoint weight to a randomly initialized layer of the 🤗
Transformers implementation.
An incorrect shape is most likely due to an incorrect setting of the
config parameters in `BigBirdConfig()` that do not exactly match
those that were used for the checkpoint you want to convert. However, it
could also be that PyTorch's implementation of a layer requires the
weight to be transposed beforehand.
Finally, you should also check that **all** required weights are
initialized and print out all checkpoint weights that were not used for
initialization to make sure the model is correctly converted. It is
completely normal, that the conversion trials fail with either a wrong
shape statement or wrong name assignment. This is most likely because
either you used incorrect parameters in `BigBirdConfig()`, have a
wrong architecture in the 🤗 Transformers implementation, you have a bug
in the `init()` functions of one of the components of the 🤗 Transformers
implementation or you need to transpose one of the checkpoint weights.
This step should be iterated with the previous step until all weights of
the checkpoint are correctly loaded in the Transformers model. Having
correctly loaded the checkpoint into the 🤗 Transformers implementation,
you can then save the model under a folder of your choice
`/path/to/converted/checkpoint/folder` that should then contain both a
`pytorch_model.bin` file and a `config.json` file:
```python
model.save_pretrained("/path/to/converted/checkpoint/folder")
```
**7. Implement the forward pass**
Having managed to correctly load the pretrained weights into the 🤗
Transformers implementation, you should now make sure that the forward
pass is correctly implemented. In [Get familiar with the original
repository](#run-a-pretrained-checkpoint-using-the-original-repository),
you have already created a script that runs a forward pass of the model
using the original repository. Now you should write an analogous script
using the 🤗 Transformers implementation instead of the original one. It
should look as follows:
[Here the model name might have to be adapted, *e.g.*, maybe BigBirdForConditionalGeneration instead of BigBirdModel]
```python
model = BigBirdModel.from_pretrained("/path/to/converted/checkpoint/folder")
input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]
output = model(input_ids).last_hidden_states
```
It is very likely that the 🤗 Transformers implementation and the
original model implementation don't give the exact same output the very
first time or that the forward pass throws an error. Don't be
disappointed - it's expected! First, you should make sure that the
forward pass doesn't throw any errors. It often happens that the wrong
dimensions are used leading to a `"Dimensionality mismatch"`
error or that the wrong data type object is used, *e.g.*, `torch.long`
instead of `torch.float32`. Don't hesitate to ask Patrick
for help, if you don't manage to solve certain errors.
The final part to make sure the 🤗 Transformers implementation works
correctly is to ensure that the outputs are equivalent to a precision of
`1e-3`. First, you should ensure that the output shapes are identical,
*i.e.* `outputs.shape` should yield the same value for the script of the
🤗 Transformers implementation and the original implementation. Next, you
should make sure that the output values are identical as well. This one
of the most difficult parts of adding a new model. Common mistakes why
the outputs are not identical are:
- Some layers were not added, *i.e.* an activation layer
was not added, or the residual connection was forgotten
- The word embedding matrix was not tied
- The wrong positional embeddings are used because the original
implementation uses on offset
- Dropout is applied during the forward pass. To fix this make sure
`model.training is False` and that no dropout layer is
falsely activated during the forward pass, *i.e.* pass
`self.training` to [PyTorch's functional
dropout](https://pytorch.org/docs/stable/nn.functional.html?highlight=dropout#torch.nn.functional.dropout)
The best way to fix the problem is usually to look at the forward pass
of the original implementation and the 🤗 Transformers implementation
side-by-side and check if there are any differences. Ideally, you should
debug/print out intermediate outputs of both implementations of the
forward pass to find the exact position in the network where the 🤗
Transformers implementation shows a different output than the original
implementation. First, make sure that the hard-coded `input_ids` in both
scripts are identical. Next, verify that the outputs of the first
transformation of the `input_ids` (usually the word embeddings) are
identical. And then work your way up to the very last layer of the
network. At some point, you will notice a difference between the two
implementations, which should point you to the bug in the 🤗 Transformers
implementation. From our experience, a simple and efficient way is to
add many print statements in both the original implementation and 🤗
Transformers implementation, at the same positions in the network
respectively, and to successively remove print statements showing the
same values for intermediate presentions.
When you're confident that both implementations yield the same output,
verifying the outputs with
`torch.allclose(original_output, output, atol=1e-3)`, you're done with
the most difficult part! Congratulations - the work left to be done
should be a cakewalk 😊.
**8. Adding all necessary model tests**
At this point, you have successfully added a new model. However, it is
very much possible that the model does not yet fully comply with the
required design. To make sure, the implementation is fully compatible
with 🤗 Transformers, all common tests should pass. The Cookiecutter
should have automatically added a test file for your model, probably
under the same `tests/test_modeling_big_bird.py`. Run this test
file to verify that all common tests pass:
```python
pytest tests/test_modeling_big_bird.py
```
Having fixed all common tests, it is now crucial to ensure that all the
nice work you have done is well tested, so that
- a) The community can easily understand your work by looking at
specific tests of *BigBird*
- b) Future changes to your model will not break any important
feature of the model.
At first, integration tests should be added. Those integration tests
essentially do the same as the debugging scripts you used earlier to
implement the model to 🤗 Transformers. A template of those model tests
is already added by the Cookiecutter, called
`BigBirdModelIntegrationTests` and only has to be filled out by
you. To ensure that those tests are passing, run
```python
RUN_SLOW=1 pytest -sv tests/test_modeling_big_bird.py::BigBirdModelIntegrationTests
```
**Note**: In case you are using Windows, you should replace `RUN_SLOW=1` with
`SET RUN_SLOW=1`
Second, all features that are special to *BigBird* should be
tested additionally in a separate test under
`BigBirdModelTester`/`BigBirdModelTest`. This part is often
forgotten but is extremely useful in two ways:
- It helps to transfer the knowledge you have acquired during the
model addition to the community by showing how the special features
of *BigBird* should work.
- Future contributors can quickly test changes to the model by running
those special tests.
BigBird has quite a complex attention layer, so it is very important
to add more tests verifying the all parts of BigBird's self-attention layer
works as expected. This means that there should be at least 3 additional tests:
- 1. Verify that the sparse attention works correctly
- 2. Verify that the global attention works correctly
- 3. Verify that the random attention works correctly
**9. Implement the tokenizer**
Next, we should add the tokenizer of *BigBird*. Usually, the
tokenizer is equivalent or very similar to an already existing tokenizer
of 🤗 Transformers.
In the case of BigBird you should be able to just rely on an already existing tokenizer.
If not mistaken, BigBird uses the same tokenizer that was used for `BertGenerationTokenizer`,
which is based on `sentencepiece`. So you should be able to just set the config parameter
`tokenizer_class` to `BertGenerationTokenizer` without having to implement any new tokenizer.
It is very important to find/extract the original tokenizer file and to
manage to load this file into the 🤗 Transformers' implementation of the
tokenizer.
For BigBird, the tokenizer (sentencepiece) files can be found [here](https://github.com/google-research/bigbird/blob/master/bigbird/vocab/gpt2.model), which you should be able to load
as easily as:
```python
from transformers import BertGenerationTokenizer
tokenizer = BertGenerationTokenizer("/path/to/gpt2.model/file")
```
To ensure that the tokenizer works correctly, it is recommended to first
create a script in the original repository that inputs a string and
returns the `input_ids`. It could look similar to this (in pseudo-code):
```bash
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
model = BigBirdModel.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = model.tokenize(input_str)
```
You might have to take a deeper look again into the original repository
to find the correct tokenizer function or you might even have to do
changes to your clone of the original repository to only output the
`input_ids`. Having written a functional tokenization script that uses
the original repository, an analogous script for 🤗 Transformers should
be created. It should look similar to this:
```python
from transformers import BertGenerationTokenizer
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
tokenizer = BertGenerationTokenizer.from_pretrained("/path/big/bird/folder")
input_ids = tokenizer(input_str).input_ids
```
When both `input_ids` yield the same values, as a final step a tokenizer
test file should also be added.
Since BigBird is most likely fully based on `BertGenerationTokenizer`,
you should only add a couple of "slow" integration tests. However, in this
case you do **not** need to add any `BigBirdTokenizationTest`.
**10. Run End-to-end integration tests**
Having added the tokenizer, you should also add a couple of end-to-end
integration tests using both the model and the tokenizer to
`tests/test_modeling_big_bird.py` in 🤗 Transformers. Such a test
should show on a meaningful text-to-text sample that the 🤗 Transformers
implementation works as expected. A meaningful text-to-text sample can
include, *e.g.*, a source-to-target-translation pair, an
article-to-summary pair, a question-to-answer pair, etc... If none of
the ported checkpoints has been fine-tuned on a downstream task it is
enough to simply rely on the model tests. In a final step to ensure that
the model is fully functional, it is advised that you also run all tests
on GPU. It can happen that you forgot to add some `.to(self.device)`
statements to internal tensors of the model, which in such a test would
show in an error. In case you have no access to a GPU, the Hugging Face
team can take care of running those tests for you.
**11. Add Docstring**
Now, all the necessary functionality for *BigBird* is added -
you're almost done! The only thing left to add is a nice docstring and
a doc page. The Cookiecutter should have added a template file called
`docs/source/model_doc/big_bird.rst` that you should fill out.
Users of your model will usually first look at this page before using
your model. Hence, the documentation must be understandable and concise.
It is very useful for the community to add some *Tips* to show how the
model should be used. Don't hesitate to ping Patrick
regarding the docstrings.
Next, make sure that the docstring added to
`src/transformers/models/big_bird/modeling_big_bird.py` is
correct and included all necessary inputs and outputs. It is always to
good to remind oneself that documentation should be treated at least as
carefully as the code in 🤗 Transformers since the documentation is
usually the first contact point of the community with the model.
**Code refactor**
Great, now you have added all the necessary code for *BigBird*.
At this point, you should correct some potential incorrect code style by
running:
```bash
make style
```
and verify that your coding style passes the quality check:
```bash
make quality
```
There are a couple of other very strict design tests in 🤗 Transformers
that might still be failing, which shows up in the tests of your pull
request. This is often because of some missing information in the
docstring or some incorrect naming. Patrick will surely
help you if you're stuck here.
Lastly, it is always a good idea to refactor one's code after having
ensured that the code works correctly. With all tests passing, now it's
a good time to go over the added code again and do some refactoring.
You have now finished the coding part, congratulation! 🎉 You are
Awesome! 😎
**12. Upload the models to the model hub**
In this final part, you should convert and upload all checkpoints to the
model hub and add a model card for each uploaded model checkpoint. You
should work alongside Patrick here to decide on a fitting
name for each checkpoint and to get the required access rights to be
able to upload the model under the author's organization of
*BigBird*.
It is worth spending some time to create fitting model cards for each
checkpoint. The model cards should highlight the specific
characteristics of this particular checkpoint, *e.g.*, On which dataset
was the checkpoint pretrained/fine-tuned on? On what down-stream task
should the model be used? And also include some code on how to correctly
use the model.
**13. (Optional) Add notebook**
It is very helpful to add a notebook that showcases in-detail how
*BigBird* can be used for inference and/or fine-tuned on a
downstream task. This is not mandatory to merge your PR, but very useful
for the community.
**14. Submit your finished PR**
You're done programming now and can move to the last step, which is
getting your PR merged into main. Usually, Patrick
should have helped you already at this point, but it is worth taking
some time to give your finished PR a nice description and eventually add
comments to your code, if you want to point out certain design choices
to your reviewer.
### Share your work!!
Now, it's time to get some credit from the community for your work!
Having completed a model addition is a major contribution to
Transformers and the whole NLP community. Your code and the ported
pre-trained models will certainly be used by hundreds and possibly even
thousands of developers and researchers. You should be proud of your
work and share your achievement with the community.
**You have made another model that is super easy to access for everyone
in the community! 🤯**
|
huggingface/transformers/blob/main/templates/adding_a_new_model/open_model_proposals/ADD_BIG_BIRD.md
|
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Run Inference on servers
Inference is the process of using a trained model to make predictions on new data. As this process can be compute-intensive,
running on a dedicated server can be an interesting option. The `huggingface_hub` library provides an easy way to call a
service that runs inference for hosted models. There are several services you can connect to:
- [Inference API](https://huggingface.co/docs/api-inference/index): a service that allows you to run accelerated inference
on Hugging Face's infrastructure for free. This service is a fast way to get started, test different models, and
prototype AI products.
- [Inference Endpoints](https://huggingface.co/docs/inference-endpoints/index): a product to easily deploy models to production.
Inference is run by Hugging Face in a dedicated, fully managed infrastructure on a cloud provider of your choice.
These services can be called with the [`InferenceClient`] object. It acts as a replacement for the legacy
[`InferenceApi`] client, adding specific support for tasks and handling inference on both
[Inference API](https://huggingface.co/docs/api-inference/index) and [Inference Endpoints](https://huggingface.co/docs/inference-endpoints/index).
Learn how to migrate to the new client in the [Legacy InferenceAPI client](#legacy-inferenceapi-client) section.
<Tip>
[`InferenceClient`] is a Python client making HTTP calls to our APIs. If you want to make the HTTP calls directly using
your preferred tool (curl, postman,...), please refer to the [Inference API](https://huggingface.co/docs/api-inference/index)
or to the [Inference Endpoints](https://huggingface.co/docs/inference-endpoints/index) documentation pages.
For web development, a [JS client](https://huggingface.co/docs/huggingface.js/inference/README) has been released.
If you are interested in game development, you might have a look at our [C# project](https://github.com/huggingface/unity-api).
</Tip>
## Getting started
Let's get started with a text-to-image task:
```python
>>> from huggingface_hub import InferenceClient
>>> client = InferenceClient()
>>> image = client.text_to_image("An astronaut riding a horse on the moon.")
>>> image.save("astronaut.png")
```
We initialized an [`InferenceClient`] with the default parameters. The only thing you need to know is the [task](#supported-tasks) you want
to perform. By default, the client will connect to the Inference API and select a model to complete the task. In our
example, we generated an image from a text prompt. The returned value is a `PIL.Image` object that can be saved to a
file.
<Tip warning={true}>
The API is designed to be simple. Not all parameters and options are available or described for the end user. Check out
[this page](https://huggingface.co/docs/api-inference/detailed_parameters) if you are interested in learning more about
all the parameters available for each task.
</Tip>
### Using a specific model
What if you want to use a specific model? You can specify it either as a parameter or directly at an instance level:
```python
>>> from huggingface_hub import InferenceClient
# Initialize client for a specific model
>>> client = InferenceClient(model="prompthero/openjourney-v4")
>>> client.text_to_image(...)
# Or use a generic client but pass your model as an argument
>>> client = InferenceClient()
>>> client.text_to_image(..., model="prompthero/openjourney-v4")
```
<Tip>
There are more than 200k models on the Hugging Face Hub! Each task in the [`InferenceClient`] comes with a recommended
model. Be aware that the HF recommendation can change over time without prior notice. Therefore it is best to explicitly
set a model once you are decided. Also, in most cases you'll be interested in finding a model specific to _your_ needs.
Visit the [Models](https://huggingface.co/models) page on the Hub to explore your possibilities.
</Tip>
### Using a specific URL
The examples we saw above use the free-hosted Inference API. This proves to be very useful for prototyping
and testing things quickly. Once you're ready to deploy your model to production, you'll need to use a dedicated infrastructure.
That's where [Inference Endpoints](https://huggingface.co/docs/inference-endpoints/index) comes into play. It allows you to deploy
any model and expose it as a private API. Once deployed, you'll get a URL that you can connect to using exactly the same
code as before, changing only the `model` parameter:
```python
>>> from huggingface_hub import InferenceClient
>>> client = InferenceClient(model="https://uu149rez6gw9ehej.eu-west-1.aws.endpoints.huggingface.cloud/deepfloyd-if")
# or
>>> client = InferenceClient()
>>> client.text_to_image(..., model="https://uu149rez6gw9ehej.eu-west-1.aws.endpoints.huggingface.cloud/deepfloyd-if")
```
### Authentication
Calls made with the [`InferenceClient`] can be authenticated using a [User Access Token](https://huggingface.co/docs/hub/security-tokens).
By default, it will use the token saved on your machine if you are logged in (check out
[how to authenticate](https://huggingface.co/docs/huggingface_hub/quick-start#authentication)). If you are not logged in, you can pass
your token as an instance parameter:
```python
>>> from huggingface_hub import InferenceClient
>>> client = InferenceClient(token="hf_***")
```
<Tip>
Authentication is NOT mandatory when using the Inference API. However, authenticated users get a higher free-tier to
play with the service. Token is also mandatory if you want to run inference on your private models or on private
endpoints.
</Tip>
## Supported tasks
[`InferenceClient`]'s goal is to provide the easiest interface to run inference on Hugging Face models. It
has a simple API that supports the most common tasks. Here is a list of the currently supported tasks:
| Domain | Task | Supported | Documentation |
|--------|--------------------------------|--------------|------------------------------------|
| Audio | [Audio Classification](https://huggingface.co/tasks/audio-classification) | ✅ | [`~InferenceClient.audio_classification`] |
| | [Automatic Speech Recognition](https://huggingface.co/tasks/automatic-speech-recognition) | ✅ | [`~InferenceClient.automatic_speech_recognition`] |
| | [Text-to-Speech](https://huggingface.co/tasks/text-to-speech) | ✅ | [`~InferenceClient.text_to_speech`] |
| Computer Vision | [Image Classification](https://huggingface.co/tasks/image-classification) | ✅ | [`~InferenceClient.image_classification`] |
| | [Image Segmentation](https://huggingface.co/tasks/image-segmentation) | ✅ | [`~InferenceClient.image_segmentation`] |
| | [Image-to-Image](https://huggingface.co/tasks/image-to-image) | ✅ | [`~InferenceClient.image_to_image`] |
| | [Image-to-Text](https://huggingface.co/tasks/image-to-text) | ✅ | [`~InferenceClient.image_to_text`] |
| | [Object Detection](https://huggingface.co/tasks/object-detection) | ✅ | [`~InferenceClient.object_detection`] |
| | [Text-to-Image](https://huggingface.co/tasks/text-to-image) | ✅ | [`~InferenceClient.text_to_image`] |
| | [Zero-Shot-Image-Classification](https://huggingface.co/tasks/zero-shot-image-classification) | ✅ | [`~InferenceClient.zero_shot_image_classification`] |
| Multimodal | [Documentation Question Answering](https://huggingface.co/tasks/document-question-answering) | ✅ | [`~InferenceClient.document_question_answering`]
| | [Visual Question Answering](https://huggingface.co/tasks/visual-question-answering) | ✅ | [`~InferenceClient.visual_question_answering`] |
| NLP | [Conversational](https://huggingface.co/tasks/conversational) | ✅ | [`~InferenceClient.conversational`] |
| | [Feature Extraction](https://huggingface.co/tasks/feature-extraction) | ✅ | [`~InferenceClient.feature_extraction`] |
| | [Fill Mask](https://huggingface.co/tasks/fill-mask) | ✅ | [`~InferenceClient.fill_mask`] |
| | [Question Answering](https://huggingface.co/tasks/question-answering) | ✅ | [`~InferenceClient.question_answering`]
| | [Sentence Similarity](https://huggingface.co/tasks/sentence-similarity) | ✅ | [`~InferenceClient.sentence_similarity`] |
| | [Summarization](https://huggingface.co/tasks/summarization) | ✅ | [`~InferenceClient.summarization`] |
| | [Table Question Answering](https://huggingface.co/tasks/table-question-answering) | ✅ | [`~InferenceClient.table_question_answering`] |
| | [Text Classification](https://huggingface.co/tasks/text-classification) | ✅ | [`~InferenceClient.text_classification`] |
| | [Text Generation](https://huggingface.co/tasks/text-generation) | ✅ | [`~InferenceClient.text_generation`] |
| | [Token Classification](https://huggingface.co/tasks/token-classification) | ✅ | [`~InferenceClient.token_classification`] |
| | [Translation](https://huggingface.co/tasks/translation) | ✅ | [`~InferenceClient.translation`] |
| | [Zero Shot Classification](https://huggingface.co/tasks/zero-shot-classification) | ✅ | [`~InferenceClient.zero_shot_classification`] |
| Tabular | [Tabular Classification](https://huggingface.co/tasks/tabular-classification) | ✅ | [`~InferenceClient.tabular_classification`] |
| | [Tabular Regression](https://huggingface.co/tasks/tabular-regression) | ✅ | [`~InferenceClient.tabular_regression`] |
<Tip>
Check out the [Tasks](https://huggingface.co/tasks) page to learn more about each task, how to use them, and the
most popular models for each task.
</Tip>
## Custom requests
However, it is not always possible to cover all use cases. For custom requests, the [`InferenceClient.post`] method
gives you the flexibility to send any request to the Inference API. For example, you can specify how to parse the inputs
and outputs. In the example below, the generated image is returned as raw bytes instead of parsing it as a `PIL Image`.
This can be helpful if you don't have `Pillow` installed in your setup and just care about the binary content of the
image. [`InferenceClient.post`] is also useful to handle tasks that are not yet officially supported.
```python
>>> from huggingface_hub import InferenceClient
>>> client = InferenceClient()
>>> response = client.post(json={"inputs": "An astronaut riding a horse on the moon."}, model="stabilityai/stable-diffusion-2-1")
>>> response.content # raw bytes
b'...'
```
## Async client
An async version of the client is also provided, based on `asyncio` and `aiohttp`. You can either install `aiohttp`
directly or use the `[inference]` extra:
```sh
pip install --upgrade huggingface_hub[inference]
# or
# pip install aiohttp
```
After installation all async API endpoints are available via [`AsyncInferenceClient`]. Its initialization and APIs are
strictly the same as the sync-only version.
```py
# Code must be run in a asyncio concurrent context.
# $ python -m asyncio
>>> from huggingface_hub import AsyncInferenceClient
>>> client = AsyncInferenceClient()
>>> image = await client.text_to_image("An astronaut riding a horse on the moon.")
>>> image.save("astronaut.png")
>>> async for token in await client.text_generation("The Huggingface Hub is", stream=True):
... print(token, end="")
a platform for sharing and discussing ML-related content.
```
For more information about the `asyncio` module, please refer to the [official documentation](https://docs.python.org/3/library/asyncio.html).
## Advanced tips
In the above section, we saw the main aspects of [`InferenceClient`]. Let's dive into some more advanced tips.
### Timeout
When doing inference, there are two main causes for a timeout:
- The inference process takes a long time to complete.
- The model is not available, for example when Inference API is loading it for the first time.
[`InferenceClient`] has a global `timeout` parameter to handle those two aspects. By default, it is set to `None`,
meaning that the client will wait indefinitely for the inference to complete. If you want more control in your workflow,
you can set it to a specific value in seconds. If the timeout delay expires, an [`InferenceTimeoutError`] is raised.
You can catch it and handle it in your code:
```python
>>> from huggingface_hub import InferenceClient, InferenceTimeoutError
>>> client = InferenceClient(timeout=30)
>>> try:
... client.text_to_image(...)
... except InferenceTimeoutError:
... print("Inference timed out after 30s.")
```
### Binary inputs
Some tasks require binary inputs, for example, when dealing with images or audio files. In this case, [`InferenceClient`]
tries to be as permissive as possible and accept different types:
- raw `bytes`
- a file-like object, opened as binary (`with open("audio.flac", "rb") as f: ...`)
- a path (`str` or `Path`) pointing to a local file
- a URL (`str`) pointing to a remote file (e.g. `https://...`). In this case, the file will be downloaded locally before
sending it to the Inference API.
```py
>>> from huggingface_hub import InferenceClient
>>> client = InferenceClient()
>>> client.image_classification("https://upload.wikimedia.org/wikipedia/commons/thumb/4/43/Cute_dog.jpg/320px-Cute_dog.jpg")
[{'score': 0.9779096841812134, 'label': 'Blenheim spaniel'}, ...]
```
## Legacy InferenceAPI client
[`InferenceClient`] acts as a replacement for the legacy [`InferenceApi`] client. It adds specific support for tasks and
handles inference on both [Inference API](https://huggingface.co/docs/api-inference/index) and [Inference Endpoints](https://huggingface.co/docs/inference-endpoints/index).
Here is a short guide to help you migrate from [`InferenceApi`] to [`InferenceClient`].
### Initialization
Change from
```python
>>> from huggingface_hub import InferenceApi
>>> inference = InferenceApi(repo_id="bert-base-uncased", token=API_TOKEN)
```
to
```python
>>> from huggingface_hub import InferenceClient
>>> inference = InferenceClient(model="bert-base-uncased", token=API_TOKEN)
```
### Run on a specific task
Change from
```python
>>> from huggingface_hub import InferenceApi
>>> inference = InferenceApi(repo_id="paraphrase-xlm-r-multilingual-v1", task="feature-extraction")
>>> inference(...)
```
to
```python
>>> from huggingface_hub import InferenceClient
>>> inference = InferenceClient()
>>> inference.feature_extraction(..., model="paraphrase-xlm-r-multilingual-v1")
```
<Tip>
This is the recommended way to adapt your code to [`InferenceClient`]. It lets you benefit from the task-specific
methods like `feature_extraction`.
</Tip>
### Run custom request
Change from
```python
>>> from huggingface_hub import InferenceApi
>>> inference = InferenceApi(repo_id="bert-base-uncased")
>>> inference(inputs="The goal of life is [MASK].")
[{'sequence': 'the goal of life is life.', 'score': 0.10933292657136917, 'token': 2166, 'token_str': 'life'}]
```
to
```python
>>> from huggingface_hub import InferenceClient
>>> client = InferenceClient()
>>> response = client.post(json={"inputs": "The goal of life is [MASK]."}, model="bert-base-uncased")
>>> response.json()
[{'sequence': 'the goal of life is life.', 'score': 0.10933292657136917, 'token': 2166, 'token_str': 'life'}]
```
### Run with parameters
Change from
```python
>>> from huggingface_hub import InferenceApi
>>> inference = InferenceApi(repo_id="typeform/distilbert-base-uncased-mnli")
>>> inputs = "Hi, I recently bought a device from your company but it is not working as advertised and I would like to get reimbursed!"
>>> params = {"candidate_labels":["refund", "legal", "faq"]}
>>> inference(inputs, params)
{'sequence': 'Hi, I recently bought a device from your company but it is not working as advertised and I would like to get reimbursed!', 'labels': ['refund', 'faq', 'legal'], 'scores': [0.9378499388694763, 0.04914155602455139, 0.013008488342165947]}
```
to
```python
>>> from huggingface_hub import InferenceClient
>>> client = InferenceClient()
>>> inputs = "Hi, I recently bought a device from your company but it is not working as advertised and I would like to get reimbursed!"
>>> params = {"candidate_labels":["refund", "legal", "faq"]}
>>> response = client.post(json={"inputs": inputs, "parameters": params}, model="typeform/distilbert-base-uncased-mnli")
>>> response.json()
{'sequence': 'Hi, I recently bought a device from your company but it is not working as advertised and I would like to get reimbursed!', 'labels': ['refund', 'faq', 'legal'], 'scores': [0.9378499388694763, 0.04914155602455139, 0.013008488342165947]}
```
|
huggingface/huggingface_hub/blob/main/docs/source/en/guides/inference.md
|
Datasets server API
> API on 🤗 datasets
## Configuration
The service can be configured using environment variables. They are grouped by scope.
### API service
See [../../libs/libapi/README.md](../../libs/libapi/README.md) for more information about the API configuration.
### Common
See [../../libs/libcommon/README.md](../../libs/libcommon/README.md) for more information about the common configuration.
## Endpoints
See https://huggingface.co/docs/datasets-server
- /healthcheck: Ensure the app is running
- /metrics: Return a list of metrics in the Prometheus format
- /webhook: Add, update or remove a dataset
- /is-valid: Tell if a dataset is [valid](https://huggingface.co/docs/datasets-server/valid)
- /splits: List the [splits](https://huggingface.co/docs/datasets-server/splits) names for a dataset
- /first-rows: Extract the [first rows](https://huggingface.co/docs/datasets-server/first_rows) for a dataset split
- /parquet: List the [parquet files](https://huggingface.co/docs/datasets-server/parquet) auto-converted for a dataset
|
huggingface/datasets-server/blob/main/services/api/README.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Attention Processor
An attention processor is a class for applying different types of attention mechanisms.
## AttnProcessor
[[autodoc]] models.attention_processor.AttnProcessor
## AttnProcessor2_0
[[autodoc]] models.attention_processor.AttnProcessor2_0
## FusedAttnProcessor2_0
[[autodoc]] models.attention_processor.FusedAttnProcessor2_0
## LoRAAttnProcessor
[[autodoc]] models.attention_processor.LoRAAttnProcessor
## LoRAAttnProcessor2_0
[[autodoc]] models.attention_processor.LoRAAttnProcessor2_0
## CustomDiffusionAttnProcessor
[[autodoc]] models.attention_processor.CustomDiffusionAttnProcessor
## CustomDiffusionAttnProcessor2_0
[[autodoc]] models.attention_processor.CustomDiffusionAttnProcessor2_0
## AttnAddedKVProcessor
[[autodoc]] models.attention_processor.AttnAddedKVProcessor
## AttnAddedKVProcessor2_0
[[autodoc]] models.attention_processor.AttnAddedKVProcessor2_0
## LoRAAttnAddedKVProcessor
[[autodoc]] models.attention_processor.LoRAAttnAddedKVProcessor
## XFormersAttnProcessor
[[autodoc]] models.attention_processor.XFormersAttnProcessor
## LoRAXFormersAttnProcessor
[[autodoc]] models.attention_processor.LoRAXFormersAttnProcessor
## CustomDiffusionXFormersAttnProcessor
[[autodoc]] models.attention_processor.CustomDiffusionXFormersAttnProcessor
## SlicedAttnProcessor
[[autodoc]] models.attention_processor.SlicedAttnProcessor
## SlicedAttnAddedKVProcessor
[[autodoc]] models.attention_processor.SlicedAttnAddedKVProcessor
|
huggingface/diffusers/blob/main/docs/source/en/api/attnprocessor.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# DPMSolverMultistepInverse
`DPMSolverMultistepInverse` is the inverted scheduler from [DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps](https://huggingface.co/papers/2206.00927) and [DPM-Solver++: Fast Solver for Guided Sampling of Diffusion Probabilistic Models](https://huggingface.co/papers/2211.01095) by Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu.
The implementation is mostly based on the DDIM inversion definition of [Null-text Inversion for Editing Real Images using Guided Diffusion Models](https://huggingface.co/papers/2211.09794) and notebook implementation of the [`DiffEdit`] latent inversion from [Xiang-cd/DiffEdit-stable-diffusion](https://github.com/Xiang-cd/DiffEdit-stable-diffusion/blob/main/diffedit.ipynb).
## Tips
Dynamic thresholding from [Imagen](https://huggingface.co/papers/2205.11487) is supported, and for pixel-space
diffusion models, you can set both `algorithm_type="dpmsolver++"` and `thresholding=True` to use the dynamic
thresholding. This thresholding method is unsuitable for latent-space diffusion models such as
Stable Diffusion.
## DPMSolverMultistepInverseScheduler
[[autodoc]] DPMSolverMultistepInverseScheduler
## SchedulerOutput
[[autodoc]] schedulers.scheduling_utils.SchedulerOutput
|
huggingface/diffusers/blob/main/docs/source/en/api/schedulers/multistep_dpm_solver_inverse.md
|
快速开始
**先决条件**:Gradio 需要 Python 3.8 或更高版本,就是这样!
## Gradio 是做什么的?
与他人分享您的机器学习模型、API 或数据科学流程的*最佳方式之一*是创建一个**交互式应用程序**,让您的用户或同事可以在他们的浏览器中尝试演示。
Gradio 允许您**使用 Python 构建演示并共享这些演示**。通常只需几行代码!那么我们开始吧。
## Hello, World
要通过一个简单的“Hello, World”示例运行 Gradio,请遵循以下三个步骤:
1. 使用 pip 安装 Gradio:
```bash
pip install gradio
```
2. 将下面的代码作为 Python 脚本运行或在 Jupyter Notebook 中运行(或者 [Google Colab](https://colab.research.google.com/drive/18ODkJvyxHutTN0P5APWyGFO_xwNcgHDZ?usp=sharing)):
$code_hello_world
我们将导入的名称缩短为 `gr`,以便以后在使用 Gradio 的代码中更容易理解。这是一种广泛采用的约定,您应该遵循,以便与您的代码一起工作的任何人都可以轻松理解。
3. 在 Jupyter Notebook 中,该演示将自动显示;如果从脚本运行,则会在浏览器中弹出,网址为 [http://localhost:7860](http://localhost:7860):
$demo_hello_world
在本地开发时,如果您想将代码作为 Python 脚本运行,您可以使用 Gradio CLI 以**重载模式**启动应用程序,这将提供无缝和快速的开发。了解有关[自动重载指南](https://gradio.app/developing-faster-with-reload-mode/)中重新加载的更多信息。
```bash
gradio app.py
```
注意:您也可以运行 `python app.py`,但它不会提供自动重新加载机制。
## `Interface` 类
您会注意到为了创建演示,我们创建了一个 `gr.Interface`。`Interface` 类可以将任何 Python 函数与用户界面配对。在上面的示例中,我们看到了一个简单的基于文本的函数,但该函数可以是任何内容,从音乐生成器到税款计算器再到预训练的机器学习模型的预测函数。
`Interface` 类的核心是使用三个必需参数进行初始化:
- `fn`:要在其周围包装 UI 的函数
- `inputs`:用于输入的组件(例如 `"text"`、`"image"` 或 `"audio"`)
- `outputs`:用于输出的组件(例如 `"text"`、`"image"` 或 `"label"`)
让我们更详细地了解用于提供输入和输出的组件。
## 组件属性 (Components Attributes)
我们在前面的示例中看到了一些简单的 `Textbox` 组件,但是如果您想更改 UI 组件的外观或行为怎么办?
假设您想自定义输入文本字段 - 例如,您希望它更大并具有文本占位符。如果我们使用实际的 `Textbox` 类而不是使用字符串快捷方式,您可以通过组件属性获得更多的自定义功能。
$code_hello_world_2
$demo_hello_world_2
## 多个输入和输出组件
假设您有一个更复杂的函数,具有多个输入和输出。在下面的示例中,我们定义了一个接受字符串、布尔值和数字,并返回字符串和数字的函数。请看一下如何传递输入和输出组件的列表。
$code_hello_world_3
$demo_hello_world_3
只需将组件包装在列表中。`inputs` 列表中的每个组件对应函数的一个参数,顺序相同。`outputs` 列表中的每个组件对应函数返回的一个值,同样是顺序。
## 图像示例
Gradio 支持许多类型的组件,例如 `Image`、`DataFrame`、`Video` 或 `Label`。让我们尝试一个图像到图像的函数,以了解这些组件的感觉!
$code_sepia_filter
$demo_sepia_filter
使用 `Image` 组件作为输入时,您的函数将接收到一个形状为`(高度,宽度,3)` 的 NumPy 数组,其中最后一个维度表示 RGB 值。我们还将返回一个图像,形式为 NumPy 数组。
您还可以使用 `type=` 关键字参数设置组件使用的数据类型。例如,如果您希望函数接受图像文件路径而不是 NumPy 数组,输入 `Image` 组件可以写成:
```python
gr.Image(type="filepath", shape=...)
```
还要注意,我们的输入 `Image` 组件附带有一个编辑按钮🖉,允许裁剪和缩放图像。通过这种方式操作图像可以帮助揭示机器学习模型中的偏见或隐藏的缺陷!
您可以在[Gradio 文档](https://gradio.app/docs)中阅读有关许多组件以及如何使用它们的更多信息。
## Blocks:更灵活和可控
Gradio 提供了两个类来构建应用程序:
1. **Interface**,提供了用于创建演示的高级抽象,我们到目前为止一直在讨论。
2. **Blocks**,用于以更灵活的布局和数据流设计 Web 应用程序的低级 API。Blocks 允许您执行诸如特性多个数据流和演示,控制组件在页面上的出现位置,处理复杂的数据流(例如,输出可以作为其他函数的输入),并基于用户交互更新组件的属性 / 可见性等操作 - 仍然全部使用 Python。如果您需要这种可定制性,请尝试使用 `Blocks`!
## Hello, Blocks
让我们看一个简单的示例。请注意,此处的 API 与 `Interface` 不同。
$code_hello_blocks
$demo_hello_blocks
需要注意的事项:
- `Blocks` 可以使用 `with` 子句创建,此子句中创建的任何组件都会自动添加到应用程序中。
- 组件以按创建顺序垂直放置在应用程序中。(稍后我们将介绍自定义布局!)
- 创建了一个 `Button`,然后在此按钮上添加了一个 `click` 事件监听器。对于这个 API,应该很熟悉!与 `Interface` 类似,`click` 方法接受一个 Python 函数、输入组件和输出组件。
## 更复杂的应用
下面是一个应用程序,以让您对 `Blocks` 可以实现的更多内容有所了解:
$code_blocks_flipper
$demo_blocks_flipper
这里有更多的东西!在[building with blocks](https://gradio.app/building_with_blocks)部分中,我们将介绍如何创建像这样的复杂的 `Blocks` 应用程序。
恭喜,您已经熟悉了 Gradio 的基础知识! 🥳 转到我们的[下一个指南](https://gradio.app/key_features)了解更多关于 Gradio 的主要功能。
|
gradio-app/gradio/blob/main/guides/cn/01_getting-started/01_quickstart.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# GPTBigCode
## Overview
The GPTBigCode model was proposed in [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) by BigCode. The listed authors are: Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
The abstract from the paper is the following:
*The BigCode project is an open-scientific collaboration working on the responsible development of large language models for code. This tech report describes the progress of the collaboration until December 2022, outlining the current state of the Personally Identifiable Information (PII) redaction pipeline, the experiments conducted to de-risk the model architecture, and the experiments investigating better preprocessing methods for the training data. We train 1.1B parameter models on the Java, JavaScript, and Python subsets of The Stack and evaluate them on the MultiPL-E text-to-code benchmark. We find that more aggressive filtering of near-duplicates can further boost performance and, surprisingly, that selecting files from repositories with 5+ GitHub stars deteriorates performance significantly. Our best model outperforms previous open-source multilingual code generation models (InCoder-6.7B and CodeGen-Multi-2.7B) in both left-to-right generation and infilling on the Java, JavaScript, and Python portions of MultiPL-E, despite being a substantially smaller model. All models are released under an OpenRAIL license at [this https URL.](https://huggingface.co/bigcode)*
The model is an optimized [GPT2 model](https://huggingface.co/docs/transformers/model_doc/gpt2) with support for Multi-Query Attention.
## Implementation details
The main differences compared to GPT2.
- Added support for Multi-Query Attention.
- Use `gelu_pytorch_tanh` instead of classic `gelu`.
- Avoid unnecessary synchronizations (this has since been added to GPT2 in #20061, but wasn't in the reference codebase).
- Use Linear layers instead of Conv1D (good speedup but makes the checkpoints incompatible).
- Merge `_attn` and `_upcast_and_reordered_attn`. Always merge the matmul with scaling. Rename `reorder_and_upcast_attn`->`attention_softmax_in_fp32`
- Cache the attention mask value to avoid recreating it every time.
- Use jit to fuse the attention fp32 casting, masking, softmax, and scaling.
- Combine the attention and causal masks into a single one, pre-computed for the whole model instead of every layer.
- Merge the key and value caches into one (this changes the format of layer_past/ present, does it risk creating problems?)
- Use the memory layout (self.num_heads, 3, self.head_dim) instead of `(3, self.num_heads, self.head_dim)` for the QKV tensor with MHA. (prevents an overhead with the merged key and values, but makes the checkpoints incompatible with the original gpt2 model).
You can read more about the optimizations in the [original pull request](https://github.com/huggingface/transformers/pull/22575)
## Combining Starcoder and Flash Attention 2
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
```bash
pip install -U flash-attn --no-build-isolation
```
Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16``)
To load and run a model using Flash Attention 2, refer to the snippet below:
```python
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> device = "cuda" # the device to load the model onto
>>> model = AutoModelForCausalLM.from_pretrained("bigcode/gpt_bigcode-santacoder", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
>>> tokenizer = AutoTokenizer.from_pretrained("bigcode/gpt_bigcode-santacoder")
>>> prompt = "def hello_world():"
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=30, do_sample=False)
>>> tokenizer.batch_decode(generated_ids)[0]
'def hello_world():\n print("hello world")\n\nif __name__ == "__main__":\n print("hello world")\n<|endoftext|>'
```
### Expected speedups
Below is a expected speedup diagram that compares pure inference time between the native implementation in transformers using `bigcode/starcoder` checkpoint and the Flash Attention 2 version of the model using two different sequence lengths.
<div style="text-align: center">
<img src="https://huggingface.co/datasets/ybelkada/documentation-images/resolve/main/starcoder-speedup.png">
</div>
## GPTBigCodeConfig
[[autodoc]] GPTBigCodeConfig
## GPTBigCodeModel
[[autodoc]] GPTBigCodeModel
- forward
## GPTBigCodeForCausalLM
[[autodoc]] GPTBigCodeForCausalLM
- forward
## GPTBigCodeForSequenceClassification
[[autodoc]] GPTBigCodeForSequenceClassification
- forward
## GPTBigCodeForTokenClassification
[[autodoc]] GPTBigCodeForTokenClassification
- forward
|
huggingface/transformers/blob/main/docs/source/en/model_doc/gpt_bigcode.md
|
Managing organizations
## Creating an organization
Visit the [New Organization](https://hf.co/organizations/new) form to create an organization.
## Managing members
New members can be added to an organization by visiting the **Organization settings** and clicking on the **Members** tab. There, you'll be able to generate an invite link, add members individually, or send out email invitations in bulk. If the **Allow requests to join from the organization page** setting is enabled, you'll also be able to approve or reject any pending requests on the **Members** page.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/organizations-members.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/organizations-members-dark.png"/>
</div>
You can also revoke a user's membership or change their role on this page.
## Organization domain name
Under the **Account** tab in the Organization settings, you can set an **Organization domain name**. Specifying a domain name will allow any user with a matching email address on the Hugging Face Hub to join your organization.
|
huggingface/hub-docs/blob/main/docs/hub/organizations-managing.md
|
Examples
In this folder we showcase some examples to use code models for downstream tasks.
## Complexity prediction
In this task we want to predict the complexity of Java programs in [CodeComplex](https://huggingface.co/datasets/codeparrot/codecomplex) dataset. Using Hugging Face `trainer`, we finetuned [multilingual CodeParrot](https://huggingface.co/codeparrot/codeparrot-small-multi) and [UniXcoder](https://huggingface.co/microsoft/unixcoder-base-nine) on it, and we used the latter to build this Java complexity prediction [space](https://huggingface.co/spaces/codeparrot/code-complexity-predictor) on Hugging Face hub.
To fine-tune a model on this dataset you can use the following commands:
```python
python train_complexity_predictor.py \
--model_ckpt microsoft/unixcoder-base-nine \
--num_epochs 60 \
--num_warmup_steps 10 \
--batch_size 8 \
--learning_rate 5e-4
```
## Code generation: text to python
In this task we want to train a model to generate code from english text. We finetuned Codeparrot-small on [github-jupyter-text-to-code](https://huggingface.co/datasets/codeparrot/github-jupyter-text-to-code), a dataset where the samples are a succession of docstrings and their Python code, originally extracted from Jupyter notebooks parsed in this [dataset](https://huggingface.co/datasets/codeparrot/github-jupyter-parsed).
To fine-tune a model on this dataset we use the same [script](https://github.com/huggingface/transformers/blob/main/examples/research_projects/codeparrot/scripts/codeparrot_training.py) as the pretraining of codeparrot:
```python
accelerate launch scripts/codeparrot_training.py \
--model_ckpt codeparrot/codeparrot-small \
--dataset_name_train codeparrot/github-jupyter-text-to-code \
--dataset_name_valid codeparrot/github-jupyter-text-to-code \
--train_batch_size 12 \
--valid_batch_size 12 \
--learning_rate 5e-4 \
--num_warmup_steps 100 \
--gradient_accumulation 1 \
--gradient_checkpointing False \
--max_train_steps 3000 \
--save_checkpoint_steps 200 \
--save_dir jupyter-text-to-python
```
## Code explanation: python to text
In this task we want to train a model to explain python code. We finetuned Codeparrot-small on [github-jupyter-code-to-text](https://huggingface.co/datasets/codeparrot/github-jupyter-code-to-text), a dataset where the samples are a succession of Python code and its explanation as a docstring, we just inverted the order of text and code pairs in github-jupyter-code-to-text dataset and added the delimiters "Explanation:" and "End of explanation" inside the doctrings.
To fine-tune a model on this dataset we use the same [script](https://github.com/huggingface/transformers/blob/main/examples/research_projects/codeparrot/scripts/codeparrot_training.py) as the pretraining of codeparrot:
```python
accelerate launch scripts/codeparrot_training.py \
--model_ckpt codeparrot/codeparrot-small \
--dataset_name_train codeparrot/github-jupyter-code-to-text \
--dataset_name_valid codeparrot/github-jupyter-code-to-text \
--train_batch_size 12 \
--valid_batch_size 12 \
--learning_rate 5e-4 \
--num_warmup_steps 100 \
--gradient_accumulation 1 \
--gradient_checkpointing False \
--max_train_steps 3000 \
--save_checkpoint_steps 200 \
--save_dir jupyter-python-to-text
```
|
huggingface/transformers/blob/main/examples/research_projects/codeparrot/examples/README.md
|
@gradio/storybook
## 0.2.0
### Features
- [#6451](https://github.com/gradio-app/gradio/pull/6451) [`d92de491b`](https://github.com/gradio-app/gradio/commit/d92de491bf2fbdbbb57fe5bc23165c4933afe182) - Optimise Chromatic workflow. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.1.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Improve Audio Component. Thanks [@pngwn](https://github.com/pngwn)!
## 0.1.0-beta.0
### Features
- [#5966](https://github.com/gradio-app/gradio/pull/5966) [`9cad2127b`](https://github.com/gradio-app/gradio/commit/9cad2127b965023687470b3abfe620e188a9da6e) - Improve Audio Component. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6089](https://github.com/gradio-app/gradio/pull/6089) [`cd8146ba0`](https://github.com/gradio-app/gradio/commit/cd8146ba053fbcb56cf5052e658e4570d457fb8a) - Update logos for v4. Thanks [@abidlabs](https://github.com/abidlabs)!
### Fixes
- [#6065](https://github.com/gradio-app/gradio/pull/6065) [`7d07001e8`](https://github.com/gradio-app/gradio/commit/7d07001e8e7ca9cbd2251632667b3a043de49f49) - fix storybook. Thanks [@pngwn](https://github.com/pngwn)!
- [#6046](https://github.com/gradio-app/gradio/pull/6046) [`dbb7de5e0`](https://github.com/gradio-app/gradio/commit/dbb7de5e02c53fee05889d696d764d212cb96c74) - fix tests. Thanks [@pngwn](https://github.com/pngwn)!
|
gradio-app/gradio/blob/main/js/storybook/CHANGELOG.md
|
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Splinter
## Overview
The Splinter model was proposed in [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy. Splinter
is an encoder-only transformer (similar to BERT) pretrained using the recurring span selection task on a large corpus
comprising Wikipedia and the Toronto Book Corpus.
The abstract from the paper is the following:
In several question answering benchmarks, pretrained models have reached human parity through fine-tuning on an order
of 100,000 annotated questions and answers. We explore the more realistic few-shot setting, where only a few hundred
training examples are available, and observe that standard models perform poorly, highlighting the discrepancy between
current pretraining objectives and question answering. We propose a new pretraining scheme tailored for question
answering: recurring span selection. Given a passage with multiple sets of recurring spans, we mask in each set all
recurring spans but one, and ask the model to select the correct span in the passage for each masked span. Masked spans
are replaced with a special token, viewed as a question representation, that is later used during fine-tuning to select
the answer span. The resulting model obtains surprisingly good results on multiple benchmarks (e.g., 72.7 F1 on SQuAD
with only 128 training examples), while maintaining competitive performance in the high-resource setting.
This model was contributed by [yuvalkirstain](https://huggingface.co/yuvalkirstain) and [oriram](https://huggingface.co/oriram). The original code can be found [here](https://github.com/oriram/splinter).
## Usage tips
- Splinter was trained to predict answers spans conditioned on a special [QUESTION] token. These tokens contextualize
to question representations which are used to predict the answers. This layer is called QASS, and is the default
behaviour in the [`SplinterForQuestionAnswering`] class. Therefore:
- Use [`SplinterTokenizer`] (rather than [`BertTokenizer`]), as it already
contains this special token. Also, its default behavior is to use this token when two sequences are given (for
example, in the *run_qa.py* script).
- If you plan on using Splinter outside *run_qa.py*, please keep in mind the question token - it might be important for
the success of your model, especially in a few-shot setting.
- Please note there are two different checkpoints for each size of Splinter. Both are basically the same, except that
one also has the pretrained weights of the QASS layer (*tau/splinter-base-qass* and *tau/splinter-large-qass*) and one
doesn't (*tau/splinter-base* and *tau/splinter-large*). This is done to support randomly initializing this layer at
fine-tuning, as it is shown to yield better results for some cases in the paper.
## Resources
- [Question answering task guide](../tasks/question-answering)
## SplinterConfig
[[autodoc]] SplinterConfig
## SplinterTokenizer
[[autodoc]] SplinterTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## SplinterTokenizerFast
[[autodoc]] SplinterTokenizerFast
## SplinterModel
[[autodoc]] SplinterModel
- forward
## SplinterForQuestionAnswering
[[autodoc]] SplinterForQuestionAnswering
- forward
## SplinterForPreTraining
[[autodoc]] SplinterForPreTraining
- forward
|
huggingface/transformers/blob/main/docs/source/en/model_doc/splinter.md
|
!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Token classification
## NER Tasks
By running the script [`run_ner.py`](https://github.com/huggingface/optimum/blob/main/examples/onnxruntime/training/token-classification/run_ner.py),
we will be able to leverage the [`ONNX Runtime`](https://github.com/microsoft/onnxruntime) accelerator to fine-tune the models from the
[HuggingFace hub](https://huggingface.co/models) for token classification tasks such as Named Entity Recognition (NER).
__The following example applies the acceleration features powered by ONNX Runtime.__
### ONNX Runtime Training
The following example fine-tunes a BERT on the sst-2 task.
```bash
torchrun --nproc_per_node=NUM_GPUS_YOU_HAVE run_ner.py \
--model_name_or_path bert-base-cased \
--dataset_name conll2003 \
--do_train \
--do_eval \
--output_dir /tmp/ort_bert_conll2003/
```
### Performance
We get the following results for [bert-large-cased](https://huggingface.co/bert-large-cased) model mixed precision training(fp16) on the previous
task under PyTorch and ONNX Runtime backends. A single Nvidia A100 card was used to run the experiment for 7 epochs:
| Model | Backend | Runtime(s) | Train samples(/s) |
| ---------------- | ------------ | ---------- | ----------------- |
| bert-large-cased | PyTorch | 711.5 | 138.1 |
| bert-large-cased | ONNX Runtime | 637.2 | 154.3 |
We observe the gain of ONNX Runtime compared to PyTorch as follow:
| | Latency | Throughput |
| ----- | ------- | ---------- |
| Gain | 10.45% | 11.67% |
__Note__
> *To enable ONNX Runtime training, your devices need to be equipped with GPU. Install the dependencies either with our prepared*
*[Dockerfiles](https://github.com/huggingface/optimum/blob/main/examples/onnxruntime/training/docker/) or follow the instructions*
*in [`torch_ort`](https://github.com/pytorch/ort/blob/main/torch_ort/docker/README.md).*
> *The inference will use PyTorch by default, if you want to use ONNX Runtime backend instead, add the flag `--inference_with_ort`.*
---
|
huggingface/optimum/blob/main/examples/onnxruntime/training/token-classification/README.md
|
(Tensorflow) MixNet
**MixNet** is a type of convolutional neural network discovered via AutoML that utilises [MixConvs](https://paperswithcode.com/method/mixconv) instead of regular [depthwise convolutions](https://paperswithcode.com/method/depthwise-convolution).
The weights from this model were ported from [Tensorflow/TPU](https://github.com/tensorflow/tpu).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('tf_mixnet_l', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `tf_mixnet_l`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('tf_mixnet_l', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{tan2019mixconv,
title={MixConv: Mixed Depthwise Convolutional Kernels},
author={Mingxing Tan and Quoc V. Le},
year={2019},
eprint={1907.09595},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: TF MixNet
Paper:
Title: 'MixConv: Mixed Depthwise Convolutional Kernels'
URL: https://paperswithcode.com/paper/mixnet-mixed-depthwise-convolutional-kernels
Models:
- Name: tf_mixnet_l
In Collection: TF MixNet
Metadata:
FLOPs: 688674516
Parameters: 7330000
File Size: 29620756
Architecture:
- Batch Normalization
- Dense Connections
- Dropout
- Global Average Pooling
- Grouped Convolution
- MixConv
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- MNAS
Training Data:
- ImageNet
ID: tf_mixnet_l
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1720
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_mixnet_l-6c92e0c8.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.78%
Top 5 Accuracy: 94.0%
- Name: tf_mixnet_m
In Collection: TF MixNet
Metadata:
FLOPs: 416633502
Parameters: 5010000
File Size: 20310871
Architecture:
- Batch Normalization
- Dense Connections
- Dropout
- Global Average Pooling
- Grouped Convolution
- MixConv
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- MNAS
Training Data:
- ImageNet
ID: tf_mixnet_m
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1709
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_mixnet_m-0f4d8805.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 76.96%
Top 5 Accuracy: 93.16%
- Name: tf_mixnet_s
In Collection: TF MixNet
Metadata:
FLOPs: 302587678
Parameters: 4130000
File Size: 16738218
Architecture:
- Batch Normalization
- Dense Connections
- Dropout
- Global Average Pooling
- Grouped Convolution
- MixConv
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- MNAS
Training Data:
- ImageNet
ID: tf_mixnet_s
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1698
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_mixnet_s-89d3354b.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.68%
Top 5 Accuracy: 92.64%
-->
|
huggingface/pytorch-image-models/blob/main/hfdocs/source/models/tf-mixnet.mdx
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Push files to the Hub
[[open-in-colab]]
🤗 Diffusers provides a [`~diffusers.utils.PushToHubMixin`] for uploading your model, scheduler, or pipeline to the Hub. It is an easy way to store your files on the Hub, and also allows you to share your work with others. Under the hood, the [`~diffusers.utils.PushToHubMixin`]:
1. creates a repository on the Hub
2. saves your model, scheduler, or pipeline files so they can be reloaded later
3. uploads folder containing these files to the Hub
This guide will show you how to use the [`~diffusers.utils.PushToHubMixin`] to upload your files to the Hub.
You'll need to log in to your Hub account with your access [token](https://huggingface.co/settings/tokens) first:
```py
from huggingface_hub import notebook_login
notebook_login()
```
## Models
To push a model to the Hub, call [`~diffusers.utils.PushToHubMixin.push_to_hub`] and specify the repository id of the model to be stored on the Hub:
```py
from diffusers import ControlNetModel
controlnet = ControlNetModel(
block_out_channels=(32, 64),
layers_per_block=2,
in_channels=4,
down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
cross_attention_dim=32,
conditioning_embedding_out_channels=(16, 32),
)
controlnet.push_to_hub("my-controlnet-model")
```
For models, you can also specify the [*variant*](loading#checkpoint-variants) of the weights to push to the Hub. For example, to push `fp16` weights:
```py
controlnet.push_to_hub("my-controlnet-model", variant="fp16")
```
The [`~diffusers.utils.PushToHubMixin.push_to_hub`] function saves the model's `config.json` file and the weights are automatically saved in the `safetensors` format.
Now you can reload the model from your repository on the Hub:
```py
model = ControlNetModel.from_pretrained("your-namespace/my-controlnet-model")
```
## Scheduler
To push a scheduler to the Hub, call [`~diffusers.utils.PushToHubMixin.push_to_hub`] and specify the repository id of the scheduler to be stored on the Hub:
```py
from diffusers import DDIMScheduler
scheduler = DDIMScheduler(
beta_start=0.00085,
beta_end=0.012,
beta_schedule="scaled_linear",
clip_sample=False,
set_alpha_to_one=False,
)
scheduler.push_to_hub("my-controlnet-scheduler")
```
The [`~diffusers.utils.PushToHubMixin.push_to_hub`] function saves the scheduler's `scheduler_config.json` file to the specified repository.
Now you can reload the scheduler from your repository on the Hub:
```py
scheduler = DDIMScheduler.from_pretrained("your-namepsace/my-controlnet-scheduler")
```
## Pipeline
You can also push an entire pipeline with all it's components to the Hub. For example, initialize the components of a [`StableDiffusionPipeline`] with the parameters you want:
```py
from diffusers import (
UNet2DConditionModel,
AutoencoderKL,
DDIMScheduler,
StableDiffusionPipeline,
)
from transformers import CLIPTextModel, CLIPTextConfig, CLIPTokenizer
unet = UNet2DConditionModel(
block_out_channels=(32, 64),
layers_per_block=2,
sample_size=32,
in_channels=4,
out_channels=4,
down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
cross_attention_dim=32,
)
scheduler = DDIMScheduler(
beta_start=0.00085,
beta_end=0.012,
beta_schedule="scaled_linear",
clip_sample=False,
set_alpha_to_one=False,
)
vae = AutoencoderKL(
block_out_channels=[32, 64],
in_channels=3,
out_channels=3,
down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
latent_channels=4,
)
text_encoder_config = CLIPTextConfig(
bos_token_id=0,
eos_token_id=2,
hidden_size=32,
intermediate_size=37,
layer_norm_eps=1e-05,
num_attention_heads=4,
num_hidden_layers=5,
pad_token_id=1,
vocab_size=1000,
)
text_encoder = CLIPTextModel(text_encoder_config)
tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
```
Pass all of the components to the [`StableDiffusionPipeline`] and call [`~diffusers.utils.PushToHubMixin.push_to_hub`] to push the pipeline to the Hub:
```py
components = {
"unet": unet,
"scheduler": scheduler,
"vae": vae,
"text_encoder": text_encoder,
"tokenizer": tokenizer,
"safety_checker": None,
"feature_extractor": None,
}
pipeline = StableDiffusionPipeline(**components)
pipeline.push_to_hub("my-pipeline")
```
The [`~diffusers.utils.PushToHubMixin.push_to_hub`] function saves each component to a subfolder in the repository. Now you can reload the pipeline from your repository on the Hub:
```py
pipeline = StableDiffusionPipeline.from_pretrained("your-namespace/my-pipeline")
```
## Privacy
Set `private=True` in the [`~diffusers.utils.PushToHubMixin.push_to_hub`] function to keep your model, scheduler, or pipeline files private:
```py
controlnet.push_to_hub("my-controlnet-model-private", private=True)
```
Private repositories are only visible to you, and other users won't be able to clone the repository and your repository won't appear in search results. Even if a user has the URL to your private repository, they'll receive a `404 - Sorry, we can't find the page you are looking for`. You must be [logged in](https://huggingface.co/docs/huggingface_hub/quick-start#login) to load a model from a private repository.
|
huggingface/diffusers/blob/main/docs/source/en/using-diffusers/push_to_hub.md
|
Sharing Your App
How to share your Gradio app:
1. [Sharing demos with the share parameter](#sharing-demos)
2. [Hosting on HF Spaces](#hosting-on-hf-spaces)
3. [Embedding hosted spaces](#embedding-hosted-spaces)
4. [Using the API page](#api-page)
5. [Authentication](#authentication)
6. [Accessing network requests](#accessing-the-network-request-directly)
7. [Mounting within FastAPI](#mounting-within-another-fast-api-app)
8. [Security and file access](#security-and-file-access)
## Sharing Demos
Gradio demos can be easily shared publicly by setting `share=True` in the `launch()` method. Like this:
```python
import gradio as gr
def greet(name):
return "Hello " + name + "!"
demo = gr.Interface(fn=greet, inputs="textbox", outputs="textbox")
demo.launch(share=True) # Share your demo with just 1 extra parameter 🚀
```
This generates a public, shareable link that you can send to anybody! When you send this link, the user on the other side can try out the model in their browser. Because the processing happens on your device (as long as your device stays on), you don't have to worry about any packaging any dependencies.

A share link usually looks something like this: **https://07ff8706ab.gradio.live**. Although the link is served through the Gradio Share Servers, these servers are only a proxy for your local server, and do not store any data sent through your app. Share links expire after 72 hours. (it is [also possible to set up your own Share Server](https://github.com/huggingface/frp/) on your own cloud server to overcome this restriction.)
Tip: Keep in mind that share links are publicly accessible, meaning that anyone can use your model for prediction! Therefore, make sure not to expose any sensitive information through the functions you write, or allow any critical changes to occur on your device. Or you can [add authentication to your Gradio app](#authentication) as discussed below.
Note that by default, `share=False`, which means that your server is only running locally. (This is the default, except in Google Colab notebooks, where share links are automatically created). As an alternative to using share links, you can use use [SSH port-forwarding](https://www.ssh.com/ssh/tunneling/example) to share your local server with specific users.
## Hosting on HF Spaces
If you'd like to have a permanent link to your Gradio demo on the internet, use Hugging Face Spaces. [Hugging Face Spaces](http://huggingface.co/spaces/) provides the infrastructure to permanently host your machine learning model for free!
After you have [created a free Hugging Face account](https://huggingface.co/join), you have two methods to deploy your Gradio app to Hugging Face Spaces:
1. From terminal: run `gradio deploy` in your app directory. The CLI will gather some basic metadata and then launch your app. To update your space, you can re-run this command or enable the Github Actions option to automatically update the Spaces on `git push`.
2. From your browser: Drag and drop a folder containing your Gradio model and all related files [here](https://huggingface.co/new-space). See [this guide how to host on Hugging Face Spaces](https://huggingface.co/blog/gradio-spaces) for more information, or watch the embedded video:
<video autoplay muted loop>
<source src="https://github.com/gradio-app/gradio/blob/main/guides/assets/hf_demo.mp4?raw=true" type="video/mp4" />
</video>
## Embedding Hosted Spaces
Once you have hosted your app on Hugging Face Spaces (or on your own server), you may want to embed the demo on a different website, such as your blog or your portfolio. Embedding an interactive demo allows people to try out the machine learning model that you have built, without needing to download or install anything — right in their browser! The best part is that you can embed interactive demos even in static websites, such as GitHub pages.
There are two ways to embed your Gradio demos. You can find quick links to both options directly on the Hugging Face Space page, in the "Embed this Space" dropdown option:

### Embedding with Web Components
Web components typically offer a better experience to users than IFrames. Web components load lazily, meaning that they won't slow down the loading time of your website, and they automatically adjust their height based on the size of the Gradio app.
To embed with Web Components:
1. Import the gradio JS library into into your site by adding the script below in your site (replace {GRADIO_VERSION} in the URL with the library version of Gradio you are using).
```html
<script
type="module"
src="https://gradio.s3-us-west-2.amazonaws.com/{GRADIO_VERSION}/gradio.js"
></script>
```
2. Add
```html
<gradio-app src="https://$your_space_host.hf.space"></gradio-app>
```
element where you want to place the app. Set the `src=` attribute to your Space's embed URL, which you can find in the "Embed this Space" button. For example:
```html
<gradio-app
src="https://abidlabs-pytorch-image-classifier.hf.space"
></gradio-app>
```
<script>
fetch("https://pypi.org/pypi/gradio/json"
).then(r => r.json()
).then(obj => {
let v = obj.info.version;
content = document.querySelector('.prose');
content.innerHTML = content.innerHTML.replaceAll("{GRADIO_VERSION}", v);
});
</script>
You can see examples of how web components look <a href="https://www.gradio.app">on the Gradio landing page</a>.
You can also customize the appearance and behavior of your web component with attributes that you pass into the `<gradio-app>` tag:
- `src`: as we've seen, the `src` attributes links to the URL of the hosted Gradio demo that you would like to embed
- `space`: an optional shorthand if your Gradio demo is hosted on Hugging Face Space. Accepts a `username/space_name` instead of a full URL. Example: `gradio/Echocardiogram-Segmentation`. If this attribute attribute is provided, then `src` does not need to be provided.
- `control_page_title`: a boolean designating whether the html title of the page should be set to the title of the Gradio app (by default `"false"`)
- `initial_height`: the initial height of the web component while it is loading the Gradio app, (by default `"300px"`). Note that the final height is set based on the size of the Gradio app.
- `container`: whether to show the border frame and information about where the Space is hosted (by default `"true"`)
- `info`: whether to show just the information about where the Space is hosted underneath the embedded app (by default `"true"`)
- `autoscroll`: whether to autoscroll to the output when prediction has finished (by default `"false"`)
- `eager`: whether to load the Gradio app as soon as the page loads (by default `"false"`)
- `theme_mode`: whether to use the `dark`, `light`, or default `system` theme mode (by default `"system"`)
- `render`: an event that is triggered once the embedded space has finished rendering.
Here's an example of how to use these attributes to create a Gradio app that does not lazy load and has an initial height of 0px.
```html
<gradio-app
space="gradio/Echocardiogram-Segmentation"
eager="true"
initial_height="0px"
></gradio-app>
```
Here's another example of how to use the `render` event. An event listener is used to capture the `render` event and will call the `handleLoadComplete()` function once rendering is complete.
```html
<script>
function handleLoadComplete() {
console.log("Embedded space has finished rendering");
}
const gradioApp = document.querySelector("gradio-app");
gradioApp.addEventListener("render", handleLoadComplete);
</script>
```
_Note: While Gradio's CSS will never impact the embedding page, the embedding page can affect the style of the embedded Gradio app. Make sure that any CSS in the parent page isn't so general that it could also apply to the embedded Gradio app and cause the styling to break. Element selectors such as `header { ... }` and `footer { ... }` will be the most likely to cause issues._
### Embedding with IFrames
To embed with IFrames instead (if you cannot add javascript to your website, for example), add this element:
```html
<iframe src="https://$your_space_host.hf.space"></iframe>
```
Again, you can find the `src=` attribute to your Space's embed URL, which you can find in the "Embed this Space" button.
Note: if you use IFrames, you'll probably want to add a fixed `height` attribute and set `style="border:0;"` to remove the boreder. In addition, if your app requires permissions such as access to the webcam or the microphone, you'll need to provide that as well using the `allow` attribute.
## API Page
You can use almost any Gradio app as an API! In the footer of a Gradio app [like this one](https://huggingface.co/spaces/gradio/hello_world), you'll see a "Use via API" link.

This is a page that lists the endpoints that can be used to query the Gradio app, via our supported clients: either [the Python client](https://gradio.app/guides/getting-started-with-the-python-client/), or [the JavaScript client](https://gradio.app/guides/getting-started-with-the-js-client/). For each endpoint, Gradio automatically generates the parameters and their types, as well as example inputs.
The endpoints are automatically created when you launch a Gradio `Interface`. If you are using Gradio `Blocks`, you can also set up a Gradio API page, though we recommend that you explicitly name each event listener, such as
```python
btn.click(add, [num1, num2], output, api_name="addition")
```
This will add and document the endpoint `/api/addition/` to the automatically generated API page. Otherwise, your API endpoints will appear as "unnamed" endpoints.
## Authentication
### Password-protected app
You may wish to put an authentication page in front of your app to limit who can open your app. With the `auth=` keyword argument in the `launch()` method, you can provide a tuple with a username and password, or a list of acceptable username/password tuples; Here's an example that provides password-based authentication for a single user named "admin":
```python
demo.launch(auth=("admin", "pass1234"))
```
For more complex authentication handling, you can even pass a function that takes a username and password as arguments, and returns True to allow authentication, False otherwise. This can be used for, among other things, making requests to 3rd-party authentication services.
Here's an example of a function that accepts any login where the username and password are the same:
```python
def same_auth(username, password):
return username == password
demo.launch(auth=same_auth)
```
For authentication to work properly, third party cookies must be enabled in your browser.
This is not the case by default for Safari, Chrome Incognito Mode.
### OAuth (Login via Hugging Face)
Gradio supports OAuth login via Hugging Face. This feature is currently **experimental** and only available on Spaces.
It allows you to add a _"Sign in with Hugging Face"_ button to your demo. Check out [this Space](https://huggingface.co/spaces/Wauplin/gradio-oauth-demo) for a live demo.
To enable OAuth, you must set `hf_oauth: true` as a Space metadata in your README.md file. This will register your Space
as an OAuth application on Hugging Face. Next, you can use `gr.LoginButton` and `gr.LogoutButton` to add login and logout buttons to
your Gradio app. Once a user is logged in with their HF account, you can retrieve their profile by adding a parameter of type
`gr.OAuthProfile` to any Gradio function. The user profile will be automatically injected as a parameter value. If you want
to perform actions on behalf of the user (e.g. list user's private repos, create repo, etc.), you can retrieve the user
token by adding a parameter of type `gr.OAuthToken`. You must define which scopes you will use in your Space metadata
(see [documentation](https://huggingface.co/docs/hub/spaces-oauth#scopes) for more details).
Here is a short example:
```py
import gradio as gr
def hello(profile: gr.OAuthProfile | None) -> str:
if profile is None:
return "I don't know you."
return f"Hello {profile.name}"
def list_organizations(oauth_token: gr.OAuthToken | None) -> str:
if oauth_token is None:
return "Please log in to list organizations."
org_names = [org["name"] for org in whoami(oauth_token.token)["orgs"]]
return f"You belong to {', '.join(org_names)}."
with gr.Blocks() as demo:
gr.LoginButton()
gr.LogoutButton()
m1 = gr.Markdown()
m2 = gr.Markdown()
demo.load(hello, inputs=None, outputs=m1)
demo.load(list_organizations, inputs=None, outputs=m2)
```
When the user clicks on the login button, they get redirected in a new page to authorize your Space.
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/gradio-guides/oauth_sign_in.png" style="width:300px; max-width:80%">
</center>
Users can revoke access to their profile at any time in their [settings](https://huggingface.co/settings/connected-applications).
As seen above, OAuth features are available only when your app runs in a Space. However, you often need to test your app
locally before deploying it. To help with that, the `gr.LoginButton` is mocked. When a user clicks on it, they are
automatically logged in with a fake user profile. This allows you to debug your app before deploying it to a Space.
## Accessing the Network Request Directly
When a user makes a prediction to your app, you may need the underlying network request, in order to get the request headers (e.g. for advanced authentication), log the client's IP address, getting the query parameters, or for other reasons. Gradio supports this in a similar manner to FastAPI: simply add a function parameter whose type hint is `gr.Request` and Gradio will pass in the network request as that parameter. Here is an example:
```python
import gradio as gr
def echo(text, request: gr.Request):
if request:
print("Request headers dictionary:", request.headers)
print("IP address:", request.client.host)
print("Query parameters:", dict(request.query_params))
return text
io = gr.Interface(echo, "textbox", "textbox").launch()
```
Note: if your function is called directly instead of through the UI (this happens, for
example, when examples are cached, or when the Gradio app is called via API), then `request` will be `None`.
You should handle this case explicitly to ensure that your app does not throw any errors. That is why
we have the explicit check `if request`.
## Mounting Within Another FastAPI App
In some cases, you might have an existing FastAPI app, and you'd like to add a path for a Gradio demo.
You can easily do this with `gradio.mount_gradio_app()`.
Here's a complete example:
$code_custom_path
Note that this approach also allows you run your Gradio apps on custom paths (`http://localhost:8000/gradio` in the example above).
## Security and File Access
Sharing your Gradio app with others (by hosting it on Spaces, on your own server, or through temporary share links) **exposes** certain files on the host machine to users of your Gradio app.
In particular, Gradio apps ALLOW users to access to three kinds of files:
- **Temporary files created by Gradio.** These are files that are created by Gradio as part of running your prediction function. For example, if your prediction function returns a video file, then Gradio will save that video to a temporary cache on your device and then send the path to the file to the front end. You can customize the location of temporary cache files created by Gradio by setting the environment variable `GRADIO_TEMP_DIR` to an absolute path, such as `/home/usr/scripts/project/temp/`.
- **Cached examples created by Gradio.** These are files that are created by Gradio as part of caching examples for faster runtimes, if you set `cache_examples=True` in `gr.Interface()` or in `gr.Examples()`. By default, these files are saved in the `gradio_cached_examples/` subdirectory within your app's working directory. You can customize the location of cached example files created by Gradio by setting the environment variable `GRADIO_EXAMPLES_CACHE` to an absolute path or a path relative to your working directory.
- **Files that you explicitly allow via the `allowed_paths` parameter in `launch()`**. This parameter allows you to pass in a list of additional directories or exact filepaths you'd like to allow users to have access to. (By default, this parameter is an empty list).
Gradio DOES NOT ALLOW access to:
- **Files that you explicitly block via the `blocked_paths` parameter in `launch()`**. You can pass in a list of additional directories or exact filepaths to the `blocked_paths` parameter in `launch()`. This parameter takes precedence over the files that Gradio exposes by default or by the `allowed_paths`.
- **Any other paths on the host machine**. Users should NOT be able to access other arbitrary paths on the host.
Please make sure you are running the latest version of `gradio` for these security settings to apply.
|
gradio-app/gradio/blob/main/guides/01_getting-started/03_sharing-your-app.md
|
`@gradio/tooltip`
```javascript
import { Tooltip } from "@gradio/tooltip";
```
```javascript
export let text: string;
export let x: number;
export let y: number;
export let color: string;
```
|
gradio-app/gradio/blob/main/js/tooltip/README.md
|
enerate a plot based on 5 inputs.
|
gradio-app/gradio/blob/main/demo/outbreak_forecast/DESCRIPTION.md
|
FrameworkSwitchCourse {fw} />
# Semantic search with FAISS[[semantic-search-with-faiss]]
{#if fw === 'pt'}
<CourseFloatingBanner chapter={5}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter5/section6_pt.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter5/section6_pt.ipynb"},
]} />
{:else}
<CourseFloatingBanner chapter={5}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter5/section6_tf.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter5/section6_tf.ipynb"},
]} />
{/if}
In [section 5](/course/chapter5/5), we created a dataset of GitHub issues and comments from the 🤗 Datasets repository. In this section we'll use this information to build a search engine that can help us find answers to our most pressing questions about the library!
<Youtube id="OATCgQtNX2o"/>
## Using embeddings for semantic search[[using-embeddings-for-semantic-search]]
As we saw in [Chapter 1](/course/chapter1), Transformer-based language models represent each token in a span of text as an _embedding vector_. It turns out that one can "pool" the individual embeddings to create a vector representation for whole sentences, paragraphs, or (in some cases) documents. These embeddings can then be used to find similar documents in the corpus by computing the dot-product similarity (or some other similarity metric) between each embedding and returning the documents with the greatest overlap.
In this section we'll use embeddings to develop a semantic search engine. These search engines offer several advantages over conventional approaches that are based on matching keywords in a query with the documents.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter5/semantic-search.svg" alt="Semantic search."/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter5/semantic-search-dark.svg" alt="Semantic search."/>
</div>
## Loading and preparing the dataset[[loading-and-preparing-the-dataset]]
The first thing we need to do is download our dataset of GitHub issues, so let's use `load_dataset()` function as usual:
```py
from datasets import load_dataset
issues_dataset = load_dataset("lewtun/github-issues", split="train")
issues_dataset
```
```python out
Dataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
num_rows: 2855
})
```
Here we've specified the default `train` split in `load_dataset()`, so it returns a `Dataset` instead of a `DatasetDict`. The first order of business is to filter out the pull requests, as these tend to be rarely used for answering user queries and will introduce noise in our search engine. As should be familiar by now, we can use the `Dataset.filter()` function to exclude these rows in our dataset. While we're at it, let's also filter out rows with no comments, since these provide no answers to user queries:
```py
issues_dataset = issues_dataset.filter(
lambda x: (x["is_pull_request"] == False and len(x["comments"]) > 0)
)
issues_dataset
```
```python out
Dataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
num_rows: 771
})
```
We can see that there are a lot of columns in our dataset, most of which we don't need to build our search engine. From a search perspective, the most informative columns are `title`, `body`, and `comments`, while `html_url` provides us with a link back to the source issue. Let's use the `Dataset.remove_columns()` function to drop the rest:
```py
columns = issues_dataset.column_names
columns_to_keep = ["title", "body", "html_url", "comments"]
columns_to_remove = set(columns_to_keep).symmetric_difference(columns)
issues_dataset = issues_dataset.remove_columns(columns_to_remove)
issues_dataset
```
```python out
Dataset({
features: ['html_url', 'title', 'comments', 'body'],
num_rows: 771
})
```
To create our embeddings we'll augment each comment with the issue's title and body, since these fields often include useful contextual information. Because our `comments` column is currently a list of comments for each issue, we need to "explode" the column so that each row consists of an `(html_url, title, body, comment)` tuple. In Pandas we can do this with the [`DataFrame.explode()` function](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.explode.html), which creates a new row for each element in a list-like column, while replicating all the other column values. To see this in action, let's first switch to the Pandas `DataFrame` format:
```py
issues_dataset.set_format("pandas")
df = issues_dataset[:]
```
If we inspect the first row in this `DataFrame` we can see there are four comments associated with this issue:
```py
df["comments"][0].tolist()
```
```python out
['the bug code locate in :\r\n if data_args.task_name is not None:\r\n # Downloading and loading a dataset from the hub.\r\n datasets = load_dataset("glue", data_args.task_name, cache_dir=model_args.cache_dir)',
'Hi @jinec,\r\n\r\nFrom time to time we get this kind of `ConnectionError` coming from the github.com website: https://raw.githubusercontent.com\r\n\r\nNormally, it should work if you wait a little and then retry.\r\n\r\nCould you please confirm if the problem persists?',
'cannot connect,even by Web browser,please check that there is some problems。',
'I can access https://raw.githubusercontent.com/huggingface/datasets/1.7.0/datasets/glue/glue.py without problem...']
```
When we explode `df`, we expect to get one row for each of these comments. Let's check if that's the case:
```py
comments_df = df.explode("comments", ignore_index=True)
comments_df.head(4)
```
<table border="1" class="dataframe" style="table-layout: fixed; word-wrap:break-word; width: 100%;">
<thead>
<tr style="text-align: right;">
<th></th>
<th>html_url</th>
<th>title</th>
<th>comments</th>
<th>body</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>https://github.com/huggingface/datasets/issues/2787</td>
<td>ConnectionError: Couldn't reach https://raw.githubusercontent.com</td>
<td>the bug code locate in :\r\n if data_args.task_name is not None...</td>
<td>Hello,\r\nI am trying to run run_glue.py and it gives me this error...</td>
</tr>
<tr>
<th>1</th>
<td>https://github.com/huggingface/datasets/issues/2787</td>
<td>ConnectionError: Couldn't reach https://raw.githubusercontent.com</td>
<td>Hi @jinec,\r\n\r\nFrom time to time we get this kind of `ConnectionError` coming from the github.com website: https://raw.githubusercontent.com...</td>
<td>Hello,\r\nI am trying to run run_glue.py and it gives me this error...</td>
</tr>
<tr>
<th>2</th>
<td>https://github.com/huggingface/datasets/issues/2787</td>
<td>ConnectionError: Couldn't reach https://raw.githubusercontent.com</td>
<td>cannot connect,even by Web browser,please check that there is some problems。</td>
<td>Hello,\r\nI am trying to run run_glue.py and it gives me this error...</td>
</tr>
<tr>
<th>3</th>
<td>https://github.com/huggingface/datasets/issues/2787</td>
<td>ConnectionError: Couldn't reach https://raw.githubusercontent.com</td>
<td>I can access https://raw.githubusercontent.com/huggingface/datasets/1.7.0/datasets/glue/glue.py without problem...</td>
<td>Hello,\r\nI am trying to run run_glue.py and it gives me this error...</td>
</tr>
</tbody>
</table>
Great, we can see the rows have been replicated, with the `comments` column containing the individual comments! Now that we're finished with Pandas, we can quickly switch back to a `Dataset` by loading the `DataFrame` in memory:
```py
from datasets import Dataset
comments_dataset = Dataset.from_pandas(comments_df)
comments_dataset
```
```python out
Dataset({
features: ['html_url', 'title', 'comments', 'body'],
num_rows: 2842
})
```
Okay, this has given us a few thousand comments to work with!
<Tip>
✏️ **Try it out!** See if you can use `Dataset.map()` to explode the `comments` column of `issues_dataset` _without_ resorting to the use of Pandas. This is a little tricky; you might find the ["Batch mapping"](https://huggingface.co/docs/datasets/v1.12.1/about_map_batch.html?batch-mapping#batch-mapping) section of the 🤗 Datasets documentation useful for this task.
</Tip>
Now that we have one comment per row, let's create a new `comments_length` column that contains the number of words per comment:
```py
comments_dataset = comments_dataset.map(
lambda x: {"comment_length": len(x["comments"].split())}
)
```
We can use this new column to filter out short comments, which typically include things like "cc @lewtun" or "Thanks!" that are not relevant for our search engine. There's no precise number to select for the filter, but around 15 words seems like a good start:
```py
comments_dataset = comments_dataset.filter(lambda x: x["comment_length"] > 15)
comments_dataset
```
```python out
Dataset({
features: ['html_url', 'title', 'comments', 'body', 'comment_length'],
num_rows: 2098
})
```
Having cleaned up our dataset a bit, let's concatenate the issue title, description, and comments together in a new `text` column. As usual, we'll write a simple function that we can pass to `Dataset.map()`:
```py
def concatenate_text(examples):
return {
"text": examples["title"]
+ " \n "
+ examples["body"]
+ " \n "
+ examples["comments"]
}
comments_dataset = comments_dataset.map(concatenate_text)
```
We're finally ready to create some embeddings! Let's take a look.
## Creating text embeddings[[creating-text-embeddings]]
We saw in [Chapter 2](/course/chapter2) that we can obtain token embeddings by using the `AutoModel` class. All we need to do is pick a suitable checkpoint to load the model from. Fortunately, there's a library called `sentence-transformers` that is dedicated to creating embeddings. As described in the library's [documentation](https://www.sbert.net/examples/applications/semantic-search/README.html#symmetric-vs-asymmetric-semantic-search), our use case is an example of _asymmetric semantic search_ because we have a short query whose answer we'd like to find in a longer document, like a an issue comment. The handy [model overview table](https://www.sbert.net/docs/pretrained_models.html#model-overview) in the documentation indicates that the `multi-qa-mpnet-base-dot-v1` checkpoint has the best performance for semantic search, so we'll use that for our application. We'll also load the tokenizer using the same checkpoint:
{#if fw === 'pt'}
```py
from transformers import AutoTokenizer, AutoModel
model_ckpt = "sentence-transformers/multi-qa-mpnet-base-dot-v1"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
model = AutoModel.from_pretrained(model_ckpt)
```
To speed up the embedding process, it helps to place the model and inputs on a GPU device, so let's do that now:
```py
import torch
device = torch.device("cuda")
model.to(device)
```
{:else}
```py
from transformers import AutoTokenizer, TFAutoModel
model_ckpt = "sentence-transformers/multi-qa-mpnet-base-dot-v1"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
model = TFAutoModel.from_pretrained(model_ckpt, from_pt=True)
```
Note that we've set `from_pt=True` as an argument of the `from_pretrained()` method. That's because the `multi-qa-mpnet-base-dot-v1` checkpoint only has PyTorch weights, so setting `from_pt=True` will automatically convert them to the TensorFlow format for us. As you can see, it is very simple to switch between frameworks in 🤗 Transformers!
{/if}
As we mentioned earlier, we'd like to represent each entry in our GitHub issues corpus as a single vector, so we need to "pool" or average our token embeddings in some way. One popular approach is to perform *CLS pooling* on our model's outputs, where we simply collect the last hidden state for the special `[CLS]` token. The following function does the trick for us:
```py
def cls_pooling(model_output):
return model_output.last_hidden_state[:, 0]
```
Next, we'll create a helper function that will tokenize a list of documents, place the tensors on the GPU, feed them to the model, and finally apply CLS pooling to the outputs:
{#if fw === 'pt'}
```py
def get_embeddings(text_list):
encoded_input = tokenizer(
text_list, padding=True, truncation=True, return_tensors="pt"
)
encoded_input = {k: v.to(device) for k, v in encoded_input.items()}
model_output = model(**encoded_input)
return cls_pooling(model_output)
```
We can test the function works by feeding it the first text entry in our corpus and inspecting the output shape:
```py
embedding = get_embeddings(comments_dataset["text"][0])
embedding.shape
```
```python out
torch.Size([1, 768])
```
Great, we've converted the first entry in our corpus into a 768-dimensional vector! We can use `Dataset.map()` to apply our `get_embeddings()` function to each row in our corpus, so let's create a new `embeddings` column as follows:
```py
embeddings_dataset = comments_dataset.map(
lambda x: {"embeddings": get_embeddings(x["text"]).detach().cpu().numpy()[0]}
)
```
{:else}
```py
def get_embeddings(text_list):
encoded_input = tokenizer(
text_list, padding=True, truncation=True, return_tensors="tf"
)
encoded_input = {k: v for k, v in encoded_input.items()}
model_output = model(**encoded_input)
return cls_pooling(model_output)
```
We can test the function works by feeding it the first text entry in our corpus and inspecting the output shape:
```py
embedding = get_embeddings(comments_dataset["text"][0])
embedding.shape
```
```python out
TensorShape([1, 768])
```
Great, we've converted the first entry in our corpus into a 768-dimensional vector! We can use `Dataset.map()` to apply our `get_embeddings()` function to each row in our corpus, so let's create a new `embeddings` column as follows:
```py
embeddings_dataset = comments_dataset.map(
lambda x: {"embeddings": get_embeddings(x["text"]).numpy()[0]}
)
```
{/if}
Notice that we've converted the embeddings to NumPy arrays -- that's because 🤗 Datasets requires this format when we try to index them with FAISS, which we'll do next.
## Using FAISS for efficient similarity search[[using-faiss-for-efficient-similarity-search]]
Now that we have a dataset of embeddings, we need some way to search over them. To do this, we'll use a special data structure in 🤗 Datasets called a _FAISS index_. [FAISS](https://faiss.ai/) (short for Facebook AI Similarity Search) is a library that provides efficient algorithms to quickly search and cluster embedding vectors.
The basic idea behind FAISS is to create a special data structure called an _index_ that allows one to find which embeddings are similar to an input embedding. Creating a FAISS index in 🤗 Datasets is simple -- we use the `Dataset.add_faiss_index()` function and specify which column of our dataset we'd like to index:
```py
embeddings_dataset.add_faiss_index(column="embeddings")
```
We can now perform queries on this index by doing a nearest neighbor lookup with the `Dataset.get_nearest_examples()` function. Let's test this out by first embedding a question as follows:
{#if fw === 'pt'}
```py
question = "How can I load a dataset offline?"
question_embedding = get_embeddings([question]).cpu().detach().numpy()
question_embedding.shape
```
```python out
torch.Size([1, 768])
```
{:else}
```py
question = "How can I load a dataset offline?"
question_embedding = get_embeddings([question]).numpy()
question_embedding.shape
```
```python out
(1, 768)
```
{/if}
Just like with the documents, we now have a 768-dimensional vector representing the query, which we can compare against the whole corpus to find the most similar embeddings:
```py
scores, samples = embeddings_dataset.get_nearest_examples(
"embeddings", question_embedding, k=5
)
```
The `Dataset.get_nearest_examples()` function returns a tuple of scores that rank the overlap between the query and the document, and a corresponding set of samples (here, the 5 best matches). Let's collect these in a `pandas.DataFrame` so we can easily sort them:
```py
import pandas as pd
samples_df = pd.DataFrame.from_dict(samples)
samples_df["scores"] = scores
samples_df.sort_values("scores", ascending=False, inplace=True)
```
Now we can iterate over the first few rows to see how well our query matched the available comments:
```py
for _, row in samples_df.iterrows():
print(f"COMMENT: {row.comments}")
print(f"SCORE: {row.scores}")
print(f"TITLE: {row.title}")
print(f"URL: {row.html_url}")
print("=" * 50)
print()
```
```python out
"""
COMMENT: Requiring online connection is a deal breaker in some cases unfortunately so it'd be great if offline mode is added similar to how `transformers` loads models offline fine.
@mandubian's second bullet point suggests that there's a workaround allowing you to use your offline (custom?) dataset with `datasets`. Could you please elaborate on how that should look like?
SCORE: 25.505046844482422
TITLE: Discussion using datasets in offline mode
URL: https://github.com/huggingface/datasets/issues/824
==================================================
COMMENT: The local dataset builders (csv, text , json and pandas) are now part of the `datasets` package since #1726 :)
You can now use them offline
\`\`\`python
datasets = load_dataset("text", data_files=data_files)
\`\`\`
We'll do a new release soon
SCORE: 24.555509567260742
TITLE: Discussion using datasets in offline mode
URL: https://github.com/huggingface/datasets/issues/824
==================================================
COMMENT: I opened a PR that allows to reload modules that have already been loaded once even if there's no internet.
Let me know if you know other ways that can make the offline mode experience better. I'd be happy to add them :)
I already note the "freeze" modules option, to prevent local modules updates. It would be a cool feature.
----------
> @mandubian's second bullet point suggests that there's a workaround allowing you to use your offline (custom?) dataset with `datasets`. Could you please elaborate on how that should look like?
Indeed `load_dataset` allows to load remote dataset script (squad, glue, etc.) but also you own local ones.
For example if you have a dataset script at `./my_dataset/my_dataset.py` then you can do
\`\`\`python
load_dataset("./my_dataset")
\`\`\`
and the dataset script will generate your dataset once and for all.
----------
About I'm looking into having `csv`, `json`, `text`, `pandas` dataset builders already included in the `datasets` package, so that they are available offline by default, as opposed to the other datasets that require the script to be downloaded.
cf #1724
SCORE: 24.14896583557129
TITLE: Discussion using datasets in offline mode
URL: https://github.com/huggingface/datasets/issues/824
==================================================
COMMENT: > here is my way to load a dataset offline, but it **requires** an online machine
>
> 1. (online machine)
>
> ```
>
> import datasets
>
> data = datasets.load_dataset(...)
>
> data.save_to_disk(/YOUR/DATASET/DIR)
>
> ```
>
> 2. copy the dir from online to the offline machine
>
> 3. (offline machine)
>
> ```
>
> import datasets
>
> data = datasets.load_from_disk(/SAVED/DATA/DIR)
>
> ```
>
>
>
> HTH.
SCORE: 22.893993377685547
TITLE: Discussion using datasets in offline mode
URL: https://github.com/huggingface/datasets/issues/824
==================================================
COMMENT: here is my way to load a dataset offline, but it **requires** an online machine
1. (online machine)
\`\`\`
import datasets
data = datasets.load_dataset(...)
data.save_to_disk(/YOUR/DATASET/DIR)
\`\`\`
2. copy the dir from online to the offline machine
3. (offline machine)
\`\`\`
import datasets
data = datasets.load_from_disk(/SAVED/DATA/DIR)
\`\`\`
HTH.
SCORE: 22.406635284423828
TITLE: Discussion using datasets in offline mode
URL: https://github.com/huggingface/datasets/issues/824
==================================================
"""
```
Not bad! Our second hit seems to match the query.
<Tip>
✏️ **Try it out!** Create your own query and see whether you can find an answer in the retrieved documents. You might have to increase the `k` parameter in `Dataset.get_nearest_examples()` to broaden the search.
</Tip>
|
huggingface/course/blob/main/chapters/en/chapter5/6.mdx
|
Gradio Demo: stock_forecast
```
!pip install -q gradio numpy matplotlib
```
```
import matplotlib.pyplot as plt
import numpy as np
import gradio as gr
def plot_forecast(final_year, companies, noise, show_legend, point_style):
start_year = 2020
x = np.arange(start_year, final_year + 1)
year_count = x.shape[0]
plt_format = ({"cross": "X", "line": "-", "circle": "o--"})[point_style]
fig = plt.figure()
ax = fig.add_subplot(111)
for i, company in enumerate(companies):
series = np.arange(0, year_count, dtype=float)
series = series**2 * (i + 1)
series += np.random.rand(year_count) * noise
ax.plot(x, series, plt_format)
if show_legend:
plt.legend(companies)
return fig
demo = gr.Interface(
plot_forecast,
[
gr.Radio([2025, 2030, 2035, 2040], label="Project to:"),
gr.CheckboxGroup(["Google", "Microsoft", "Gradio"], label="Company Selection"),
gr.Slider(1, 100, label="Noise Level"),
gr.Checkbox(label="Show Legend"),
gr.Dropdown(["cross", "line", "circle"], label="Style"),
],
gr.Plot(label="forecast"),
)
if __name__ == "__main__":
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/stock_forecast/run.ipynb
|
Batch mapping
Combining the utility of [`Dataset.map`] with batch mode is very powerful. It allows you to speed up processing, and freely control the size of the generated dataset.
## Need for speed
The primary objective of batch mapping is to speed up processing. Often times, it is faster to work with batches of data instead of single examples. Naturally, batch mapping lends itself to tokenization. For example, the 🤗 [Tokenizers](https://huggingface.co/docs/tokenizers/python/latest/) library works faster with batches because it parallelizes the tokenization of all the examples in a batch.
## Input size != output size
The ability to control the size of the generated dataset can be leveraged for many interesting use-cases. In the How-to [map](#map) section, there are examples of using batch mapping to:
- Split long sentences into shorter chunks.
- Augment a dataset with additional tokens.
It is helpful to understand how this works, so you can come up with your own ways to use batch mapping. At this point, you may be wondering how you can control the size of the generated dataset. The answer is: **the mapped function does not have to return an output batch of the same size**.
In other words, your mapped function input can be a batch of size `N` and return a batch of size `M`. The output `M` can be greater than or less than `N`. This means you can concatenate your examples, divide it up, and even add more examples!
However, remember that all values in the output dictionary must contain the **same number of elements** as the other fields in the output dictionary. Otherwise, it is not possible to define the number of examples in the output returned by the mapped function. The number can vary between successive batches processed by the mapped function. For a single batch though, all values of the output dictionary should have the same length (i.e., the number of elements).
For example, from a dataset of 1 column and 3 rows, if you use `map` to return a new column with twice as many rows, then you will have an error.
In this case, you end up with one column with 3 rows, and one column with 6 rows. As you can see, the table will not be valid:
```py
>>> from datasets import Dataset
>>> dataset = Dataset.from_dict({"a": [0, 1, 2]})
>>> dataset.map(lambda batch: {"b": batch["a"] * 2}, batched=True) # new column with 6 elements: [0, 1, 2, 0, 1, 2]
'ArrowInvalid: Column 1 named b expected length 3 but got length 6'
```
To make it valid, you have to drop one of the columns:
```py
>>> from datasets import Dataset
>>> dataset = Dataset.from_dict({"a": [0, 1, 2]})
>>> dataset_with_duplicates = dataset.map(lambda batch: {"b": batch["a"] * 2}, remove_columns=["a"], batched=True)
>>> len(dataset_with_duplicates)
6
```
|
huggingface/datasets/blob/main/docs/source/about_map_batch.mdx
|
he Push to Hub API. Let's have a look at the push_to_hub API. You will need to be logged in with your Hugging Face account, which you can do by executing this first cell or typing huggingface-cli login in a terminal. Just enter your username and password and click login, which will store an authentication token in the cache of the machine you're using. Now, let's launch the fine-tuning of a BERT model on the GLUE COLA dataset. We won't go over the fine-tuning code because you can find it in any Transformers tutorial, or by looking at the videos linked below. What interests us here, is how we can leverage the Model Hub during training. This is done with the push_to_hub=True passed in your TrainingArguments . This will automatically upload your model to the Hub each time it is saved (so every epoch in our case), which allows you to resume training from a different machine if the current one gets interrupted. The model will be uploaded in your namespace, with the name of the output directory as a repository name. You can pick another name by passing it to the hub_model_id argument, and you can also push inside an organization you are a member of by passing a full repository name. With that done, we can just launch training and wait a little bit. Note that the model is pushed asynchronously, meaning that the training continues while your model is uploaded to the Hub. When your first commit is finished, you can go inspect your model on the Hub and even start playing with its inference widget while it's training! There is something wrong with the labels, but we will fix this later on in this video. When the training is finished, we should do one last push with trainer.push_to_hub for two reasons. One this will make sure we are uploading the final version of our models if we didn't already (for instance if we saved every n steps instead of every epoch). Two, this will draft a model card that will be the landing page of your model repo. Going back to the model page, you can see the Trainer included some metadata that is interpreted by the Hugging Face website in the model card. On top of informations about the training, the intermediate results or the hyperparameter used, we get the values of the metrics automatically displayed in a small widget, and a link to a leaderboard in Paper with Code. The Tensorboard runs have also been pushed to this repo, and we can look at them directly from the Model Hub. If you were not using the Trainer API to fine-tune your model, you can use the push_to_hub method on the model and tokenizer directly. Let's test this to fix our labels in the inference widget! The inference widget was using default names for labels because we did not indicate the correspondence between integers and label names. We can fix in the configuration by setting the label2id and id2label fields to their proper value then we can push the fixed config to our repo using the push_to_hub method. Once this is done and we can check on the website the model is now showing the proper labels! Now that the model is on the hub, we can use it from anywhere with the from_pretrained method. We just have to use the identifier from the hub and we can see that the model configuration and weights are automatically downloaded. We can use this model as we would any other Transformers model, for instance by loading it in a pipeline. Try the push_to_hub API on your next training to easily share your model with the rest of the world!
|
huggingface/course/blob/main/subtitles/en/raw/chapter4/03b_push-to-hub-pt.md
|
--
title: "Deploying the AI Comic Factory using the Inference API"
thumbnail: /blog/assets/165_ai_comic_factory/thumbnail.jpg
authors:
- user: jbilcke-hf
---
# Deploying the AI Comic Factory using the Inference API
We recently announced [Inference for PROs](https://huggingface.co/blog/inference-pro), our new offering that makes larger models accessible to a broader audience. This opportunity opens up new possibilities for running end-user applications using Hugging Face as a platform.
An example of such an application is the [AI Comic Factory](https://huggingface.co/spaces/jbilcke-hf/ai-comic-factory) - a Space that has proved incredibly popular. Thousands of users have tried it to create their own AI comic panels, fostering its own community of regular users. They share their creations, with some even opening pull requests.
In this tutorial, we'll show you how to fork and configure the AI Comic Factory to avoid long wait times and deploy it to your own private space using the Inference API. It does not require strong technical skills, but some knowledge of APIs, environment variables and a general understanding of LLMs & Stable Diffusion are recommended.
## Getting started
First, ensure that you sign up for a [PRO Hugging Face account](https://huggingface.co/subscribe/pro), as this will grant you access to the Llama-2 and SDXL models.
## How the AI Comic Factory works
The AI Comic Factory is a bit different from other Spaces running on Hugging Face: it is a NextJS application, deployed using Docker, and is based on a client-server approach, requiring two APIs to work:
- a Language Model API (Currently [Llama-2](https://huggingface.co/docs/transformers/model_doc/llama2))
- a Stable Diffusion API (currently [SDXL 1.0](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl))
## Duplicating the Space
To duplicate the AI Comic Factory, go to the Space and [click on "Duplicate"](https://huggingface.co/spaces/jbilcke-hf/ai-comic-factory?duplicate=true):
You'll observe that the Space owner, name, and visibility are already filled in for you, so you can leave those values as is.
Your copy of the Space will run inside a Docker container that doesn't require many resources, so you can use the smallest instance. The official AI Comic Factory Space utilizes a bigger CPU instance, as it caters to a large user base.
To operate the AI Comic Factory under your account, you need to configure your Hugging Face token:
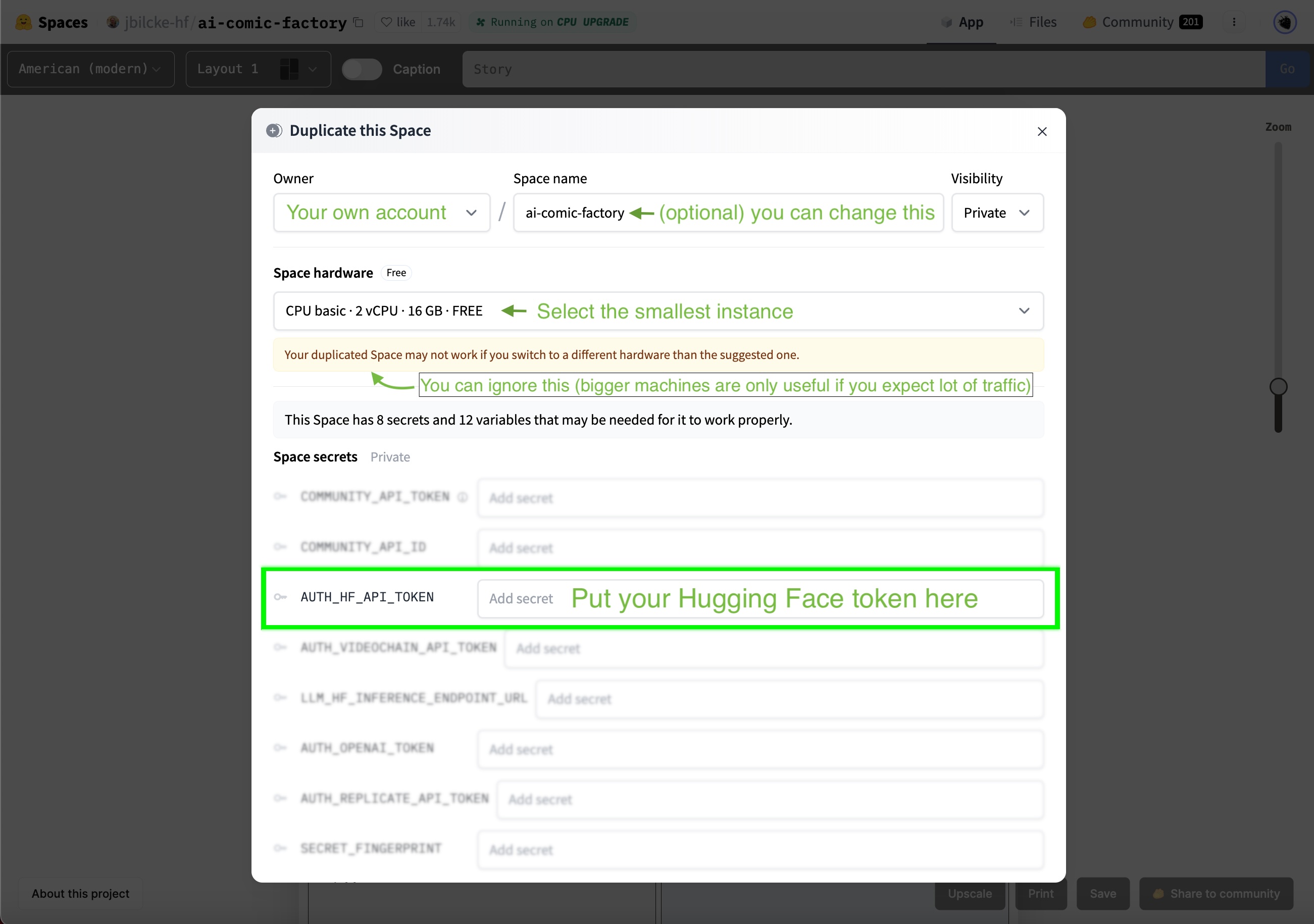
## Selecting the LLM and SD engines
The AI Comic Factory supports various backend engines, which can be configured using two environment variables:
- `LLM_ENGINE` to configure the language model (possible values are `INFERENCE_API`, `INFERENCE_ENDPOINT`, `OPENAI`)
- `RENDERING_ENGINE` to configure the image generation engine (possible values are `INFERENCE_API`, `INFERENCE_ENDPOINT`, `REPLICATE`, `VIDEOCHAIN`).
We'll focus on making the AI Comic Factory work on the Inference API, so they both need to be set to `INFERENCE_API`:

You can find more information about alternative engines and vendors in the project's [README](https://huggingface.co/spaces/jbilcke-hf/ai-comic-factory/blob/main/README.md) and the [.env](https://huggingface.co/spaces/jbilcke-hf/ai-comic-factory/blob/main/README.md) config file.
## Configuring the models
The AI Comic Factory comes with the following models pre-configured:
- `LLM_HF_INFERENCE_API_MODEL`: default value is `meta-llama/Llama-2-70b-chat-hf`
- `RENDERING_HF_RENDERING_INFERENCE_API_MODEL`: default value is `stabilityai/stable-diffusion-xl-base-1.0`
Your PRO Hugging Face account already gives you access to those models, so you don't have anything to do or change.
## Going further
Support for the Inference API in the AI Comic Factory is in its early stages, and some features, such as using the refiner step for SDXL or implementing upscaling, haven't been ported over yet.
Nonetheless, we hope this information will enable you to start forking and tweaking the AI Comic Factory to suit your requirements.
Feel free to experiment and try other models from the community, and happy hacking!
|
huggingface/blog/blob/main/ai-comic-factory.md
|
!-- DISABLE-FRONTMATTER-SECTIONS -->
# End-of-chapter quiz[[end-of-chapter-quiz]]
<CourseFloatingBanner
chapter={6}
classNames="absolute z-10 right-0 top-0"
/>
Let's test what you learned in this chapter!
### 1. When should you train a new tokenizer?
<Question
choices={[
{
text: "When your dataset is similar to that used by an existing pretrained model, and you want to pretrain a new model",
explain: "In this case, to save time and compute resources, a better choice would be to use the same tokenizer as the pretrained model and fine-tune that model instead."
},
{
text: "When your dataset is similar to that used by an existing pretrained model, and you want to fine-tune a new model using this pretrained model",
explain: "To fine-tune a model from a pretrained model, you should always use the same tokenizer."
},
{
text: "When your dataset is different from the one used by an existing pretrained model, and you want to pretrain a new model",
explain: "Correct! In this case there's no advantage to using the same tokenizer.",
correct: true
},
{
text: "When your dataset is different from the one used by an existing pretrained model, but you want to fine-tune a new model using this pretrained model",
explain: "To fine-tune a model from a pretrained model, you should always use the same tokenizer."
}
]}
/>
### 2. What is the advantage of using a generator of lists of texts compared to a list of lists of texts when using `train_new_from_iterator()`?
<Question
choices={[
{
text: "That's the only type the method <code>train_new_from_iterator()</code> accepts.",
explain: "A list of lists of texts is a particular kind of generator of lists of texts, so the method will accept this too. Try again!"
},
{
text: "You will avoid loading the whole dataset into memory at once.",
explain: "Right! Each batch of texts will be released from memory when you iterate, and the gain will be especially visible if you use 🤗 Datasets to store your texts.",
correct: true
},
{
text: "This will allow the 🤗 Tokenizers library to use multiprocessing.",
explain: "No, it will use multiprocessing either way."
},
{
text: "The tokenizer you train will generate better texts.",
explain: "The tokenizer does not generate text -- are you confusing it with a language model?"
}
]}
/>
### 3. What are the advantages of using a "fast" tokenizer?
<Question
choices={[
{
text: "It can process inputs faster than a slow tokenizer when you batch lots of inputs together.",
explain: "Correct! Thanks to parallelism implemented in Rust, it will be faster on batches of inputs. What other benefit can you think of?",
correct: true
},
{
text: "Fast tokenizers always tokenize faster than their slow counterparts.",
explain: "A fast tokenizer can actually be slower when you only give it one or very few texts, since it can't use parallelism."
},
{
text: "It can apply padding and truncation.",
explain: "True, but slow tokenizers also do that."
},
{
text: "It has some additional features allowing you to map tokens to the span of text that created them.",
explain: "Indeed -- those are called offset mappings. That's not the only advantage, though.",
correct: true
}
]}
/>
### 4. How does the `token-classification` pipeline handle entities that span over several tokens?
<Question
choices={[
{
text: "The entities with the same label are merged into one entity.",
explain: "That's oversimplifying things a little. Try again!"
},
{
text: "There is a label for the beginning of an entity and a label for the continuation of an entity.",
explain: "Correct!",
correct: true
},
{
text: "In a given word, as long as the first token has the label of the entity, the whole word is considered labeled with that entity.",
explain: "That's one strategy to handle entities. What other answers here apply?",
correct: true
},
{
text: "When a token has the label of a given entity, any other following token with the same label is considered part of the same entity, unless it's labeled as the start of a new entity.",
explain: "That's the most common way to group entities together -- it's not the only right answer, though.",
correct: true
}
]}
/>
### 5. How does the `question-answering` pipeline handle long contexts?
<Question
choices={[
{
text: "It doesn't really, as it truncates the long context at the maximum length accepted by the model.",
explain: "There is a trick you can use to handle long contexts. Do you remember what it is?"
},
{
text: "It splits the context into several parts and averages the results obtained.",
explain: "No, it wouldn't make sense to average the results, as some parts of the context won't include the answer."
},
{
text: "It splits the context into several parts (with overlap) and finds the maximum score for an answer in each part.",
explain: "That's the correct answer!",
correct: true
},
{
text: "It splits the context into several parts (without overlap, for efficiency) and finds the maximum score for an answer in each part.",
explain: "No, it includes some overlap between the parts to avoid a situation where the answer would be split across two parts."
}
]}
/>
### 6. What is normalization?
<Question
choices={[
{
text: "It's any cleanup the tokenizer performs on the texts in the initial stages.",
explain: "That's correct -- for instance, it might involve removing accents or whitespace, or lowercasing the inputs.",
correct: true
},
{
text: "It's a data augmentation technique that involves making the text more normal by removing rare words.",
explain: "That's incorrect! Try again."
},
{
text: "It's the final post-processing step where the tokenizer adds the special tokens.",
explain: "That stage is simply called post-processing."
},
{
text: "It's when the embeddings are made with mean 0 and standard deviation 1, by subtracting the mean and dividing by the std.",
explain: "That process is commonly called normalization when applied to pixel values in computer vision, but it's not what normalization means in NLP."
}
]}
/>
### 7. What is pre-tokenization for a subword tokenizer?
<Question
choices={[
{
text: "It's the step before the tokenization, where data augmentation (like random masking) is applied.",
explain: "No, that step is part of the preprocessing."
},
{
text: "It's the step before the tokenization, where the desired cleanup operations are applied to the text.",
explain: "No, that's the normalization step."
},
{
text: "It's the step before the tokenizer model is applied, to split the input into words.",
explain: "That's the correct answer!",
correct: true
},
{
text: "It's the step before the tokenizer model is applied, to split the input into tokens.",
explain: "No, splitting into tokens is the job of the tokenizer model."
}
]}
/>
### 8. Select the sentences that apply to the BPE model of tokenization.
<Question
choices={[
{
text: "BPE is a subword tokenization algorithm that starts with a small vocabulary and learns merge rules.",
explain: "That's the case indeed!",
correct: true
},
{
text: "BPE is a subword tokenization algorithm that starts with a big vocabulary and progressively removes tokens from it.",
explain: "No, that's the approach taken by a different tokenization algorithm."
},
{
text: "BPE tokenizers learn merge rules by merging the pair of tokens that is the most frequent.",
explain: "That's correct!",
correct: true
},
{
text: "A BPE tokenizer learns a merge rule by merging the pair of tokens that maximizes a score that privileges frequent pairs with less frequent individual parts.",
explain: "No, that's the strategy applied by another tokenization algorithm."
},
{
text: "BPE tokenizes words into subwords by splitting them into characters and then applying the merge rules.",
explain: "That's correct!",
correct: true
},
{
text: "BPE tokenizes words into subwords by finding the longest subword starting from the beginning that is in the vocabulary, then repeating the process for the rest of the text.",
explain: "No, that's another tokenization algorithm's way of doing things."
},
]}
/>
### 9. Select the sentences that apply to the WordPiece model of tokenization.
<Question
choices={[
{
text: "WordPiece is a subword tokenization algorithm that starts with a small vocabulary and learns merge rules.",
explain: "That's the case indeed!",
correct: true
},
{
text: "WordPiece is a subword tokenization algorithm that starts with a big vocabulary and progressively removes tokens from it.",
explain: "No, that's the approach taken by a different tokenization algorithm."
},
{
text: "WordPiece tokenizers learn merge rules by merging the pair of tokens that is the most frequent.",
explain: "No, that's the strategy applied by another tokenization algorithm."
},
{
text: "A WordPiece tokenizer learns a merge rule by merging the pair of tokens that maximizes a score that privileges frequent pairs with less frequent individual parts.",
explain: "That's correct!",
correct: true
},
{
text: "WordPiece tokenizes words into subwords by finding the most likely segmentation into tokens, according to the model.",
explain: "No, that's how another tokenization algorithm works."
},
{
text: "WordPiece tokenizes words into subwords by finding the longest subword starting from the beginning that is in the vocabulary, then repeating the process for the rest of the text.",
explain: "Yes, this is how WordPiece proceeds for the encoding.",
correct: true
},
]}
/>
### 10. Select the sentences that apply to the Unigram model of tokenization.
<Question
choices={[
{
text: "Unigram is a subword tokenization algorithm that starts with a small vocabulary and learns merge rules.",
explain: "No, that's the approach taken by a different tokenization algorithm."
},
{
text: "Unigram is a subword tokenization algorithm that starts with a big vocabulary and progressively removes tokens from it.",
explain: "That's correct!",
correct: true
},
{
text: "Unigram adapts its vocabulary by minimizing a loss computed over the whole corpus.",
explain: "That's correct!",
correct: true
},
{
text: "Unigram adapts its vocabulary by keeping the most frequent subwords.",
explain: "No, this incorrect."
},
{
text: "Unigram tokenizes words into subwords by finding the most likely segmentation into tokens, according to the model.",
explain: "That's correct!",
correct: true
},
{
text: "Unigram tokenizes words into subwords by splitting them into characters, then applying the merge rules.",
explain: "No, that's how another tokenization algorithm works."
},
]}
/>
|
huggingface/course/blob/main/chapters/en/chapter6/10.mdx
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Paint by Example
[Paint by Example: Exemplar-based Image Editing with Diffusion Models](https://huggingface.co/papers/2211.13227) is by Binxin Yang, Shuyang Gu, Bo Zhang, Ting Zhang, Xuejin Chen, Xiaoyan Sun, Dong Chen, Fang Wen.
The abstract from the paper is:
*Language-guided image editing has achieved great success recently. In this paper, for the first time, we investigate exemplar-guided image editing for more precise control. We achieve this goal by leveraging self-supervised training to disentangle and re-organize the source image and the exemplar. However, the naive approach will cause obvious fusing artifacts. We carefully analyze it and propose an information bottleneck and strong augmentations to avoid the trivial solution of directly copying and pasting the exemplar image. Meanwhile, to ensure the controllability of the editing process, we design an arbitrary shape mask for the exemplar image and leverage the classifier-free guidance to increase the similarity to the exemplar image. The whole framework involves a single forward of the diffusion model without any iterative optimization. We demonstrate that our method achieves an impressive performance and enables controllable editing on in-the-wild images with high fidelity.*
The original codebase can be found at [Fantasy-Studio/Paint-by-Example](https://github.com/Fantasy-Studio/Paint-by-Example), and you can try it out in a [demo](https://huggingface.co/spaces/Fantasy-Studio/Paint-by-Example).
## Tips
Paint by Example is supported by the official [Fantasy-Studio/Paint-by-Example](https://huggingface.co/Fantasy-Studio/Paint-by-Example) checkpoint. The checkpoint is warm-started from [CompVis/stable-diffusion-v1-4](https://huggingface.co/CompVis/stable-diffusion-v1-4) to inpaint partly masked images conditioned on example and reference images.
<Tip>
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
</Tip>
## PaintByExamplePipeline
[[autodoc]] PaintByExamplePipeline
- all
- __call__
## StableDiffusionPipelineOutput
[[autodoc]] pipelines.stable_diffusion.StableDiffusionPipelineOutput
|
huggingface/diffusers/blob/main/docs/source/en/api/pipelines/paint_by_example.md
|
FrameworkSwitchCourse {fw} />
# Training a causal language model from scratch[[training-a-causal-language-model-from-scratch]]
{#if fw === 'pt'}
<CourseFloatingBanner chapter={7}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter7/section6_pt.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter7/section6_pt.ipynb"},
]} />
{:else}
<CourseFloatingBanner chapter={7}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter7/section6_tf.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter7/section6_tf.ipynb"},
]} />
{/if}
Up until now, we've mostly been using pretrained models and fine-tuning them for new use cases by reusing the weights from pretraining. As we saw in [Chapter 1](/course/chapter1), this is commonly referred to as _transfer learning_, and it's a very successful strategy for applying Transformer models to most real-world use cases where labeled data is sparse. In this chapter, we'll take a different approach and train a completely new model from scratch. This is a good approach to take if you have a lot of data and it is very different from the pretraining data used for the available models. However, it also requires considerably more compute resources to pretrain a language model than just to fine-tune an existing one. Examples where it can make sense to train a new model include for datasets consisting of musical notes, molecular sequences such as DNA, or programming languages. The latter have recently gained traction thanks to tools such as TabNine and GitHub's Copilot, powered by OpenAI's Codex model, that can generate long sequences of code. This task of text generation is best addressed with auto-regressive or causal language models such as GPT-2.
In this section we will build a scaled-down version of a code generation model: we'll focus on one-line completions instead of full functions or classes, using a subset of Python code. When working with data in Python you are in frequent contact with the Python data science stack, consisting of the `matplotlib`, `seaborn`, `pandas`, and `scikit-learn` libraries. When using those frameworks it's common to need to look up specific commands, so it would be nice if we could use a model to complete these calls for us.
<Youtube id="Vpjb1lu0MDk"/>
In [Chapter 6](/course/chapter6) we created an efficient tokenizer to process Python source code, but what we still need is a large-scale dataset to pretrain a model on. Here, we'll apply our tokenizer to a corpus of Python code derived from GitHub repositories. We will then use the `Trainer` API and 🤗 Accelerate to train the model. Let's get to it!
<iframe src="https://course-demos-codeparrot-ds.hf.space" frameBorder="0" height="300" title="Gradio app" class="block dark:hidden container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
This is actually showcasing the model that was trained and uploaded to the Hub using the code shown in this section. You can find it [here](https://huggingface.co/huggingface-course/codeparrot-ds?text=plt.imshow%28). Note that since there is some randomization happening in the text generation, you will probably get a slightly different result.
## Gathering the data[[gathering-the-data]]
Python code is abundantly available from code repositories such as GitHub, which we can use to create a dataset by scraping for every Python repository. This was the approach taken in the [Transformers textbook](https://learning.oreilly.com/library/view/natural-language-processing/9781098136789/) to pretrain a large GPT-2 model. Using a GitHub dump of about 180 GB containing roughly 20 million Python files called `codeparrot`, the authors built a dataset that they then shared on the [Hugging Face Hub](https://huggingface.co/datasets/transformersbook/codeparrot).
However, training on the full corpus is time- and compute-consuming, and we only need the subset of the dataset concerned with the Python data science stack. So, let's start by filtering the `codeparrot` dataset for all files that include any of the libraries in this stack. Because of the dataset's size, we want to avoid downloading it; instead, we'll use the streaming feature to filter it on the fly. To help us filter the code samples using the libraries we mentioned earlier, we'll use the following function:
```py
def any_keyword_in_string(string, keywords):
for keyword in keywords:
if keyword in string:
return True
return False
```
Let's test it on two examples:
```py
filters = ["pandas", "sklearn", "matplotlib", "seaborn"]
example_1 = "import numpy as np"
example_2 = "import pandas as pd"
print(
any_keyword_in_string(example_1, filters), any_keyword_in_string(example_2, filters)
)
```
```python out
False True
```
We can use this to create a function that will stream the dataset and filter the elements we want:
```py
from collections import defaultdict
from tqdm import tqdm
from datasets import Dataset
def filter_streaming_dataset(dataset, filters):
filtered_dict = defaultdict(list)
total = 0
for sample in tqdm(iter(dataset)):
total += 1
if any_keyword_in_string(sample["content"], filters):
for k, v in sample.items():
filtered_dict[k].append(v)
print(f"{len(filtered_dict['content'])/total:.2%} of data after filtering.")
return Dataset.from_dict(filtered_dict)
```
Then we can simply apply this function to the streaming dataset:
```py
# This cell will take a very long time to execute, so you should skip it and go to
# the next one!
from datasets import load_dataset
split = "train" # "valid"
filters = ["pandas", "sklearn", "matplotlib", "seaborn"]
data = load_dataset(f"transformersbook/codeparrot-{split}", split=split, streaming=True)
filtered_data = filter_streaming_dataset(data, filters)
```
```python out
3.26% of data after filtering.
```
This leaves us with about 3% of the original dataset, which is still quite sizable -- the resulting dataset is 6 GB and consists of 600,000 Python scripts!
Filtering the full dataset can take 2-3h depending on your machine and bandwidth. If you don't want to go through this lengthy process yourself, we provide the filtered dataset on the Hub for you to download:
```py
from datasets import load_dataset, DatasetDict
ds_train = load_dataset("huggingface-course/codeparrot-ds-train", split="train")
ds_valid = load_dataset("huggingface-course/codeparrot-ds-valid", split="validation")
raw_datasets = DatasetDict(
{
"train": ds_train, # .shuffle().select(range(50000)),
"valid": ds_valid, # .shuffle().select(range(500))
}
)
raw_datasets
```
```python out
DatasetDict({
train: Dataset({
features: ['repo_name', 'path', 'copies', 'size', 'content', 'license'],
num_rows: 606720
})
valid: Dataset({
features: ['repo_name', 'path', 'copies', 'size', 'content', 'license'],
num_rows: 3322
})
})
```
<Tip>
Pretraining the language model will take a while. We suggest that you first run the training loop on a sample of the data by uncommenting the two partial lines above, and make sure that the training successfully completes and the models are stored. Nothing is more frustrating than a training run failing at the last step because you forgot to create a folder or because there's a typo at the end of the training loop!
</Tip>
Let's look at an example from the dataset. We'll just show the first 200 characters of each field:
```py
for key in raw_datasets["train"][0]:
print(f"{key.upper()}: {raw_datasets['train'][0][key][:200]}")
```
```python out
'REPO_NAME: kmike/scikit-learn'
'PATH: sklearn/utils/__init__.py'
'COPIES: 3'
'SIZE: 10094'
'''CONTENT: """
The :mod:`sklearn.utils` module includes various utilites.
"""
from collections import Sequence
import numpy as np
from scipy.sparse import issparse
import warnings
from .murmurhash import murm
LICENSE: bsd-3-clause'''
```
We can see that the `content` field contains the code that we want our model to train on. Now that we have a dataset, we need to prepare the texts so they're in a format suitable for pretraining.
## Preparing the dataset[[preparing-the-dataset]]
<Youtube id="ma1TrR7gE7I"/>
The first step will be to tokenize the data, so we can use it for training. Since our goal is to mainly autocomplete short function calls, we can keep the context size relatively small. This has the benefit that we can train the model much faster and it requires significantly less memory. If it is important for your application to have more context (for example, if you want the model to write unit tests based on a file with the function definition), make sure you increase that number, but also keep in mind that this comes with a greater GPU memory footprint. For now, let's fix the context size at 128 tokens, as opposed to the 1,024 or 2,048 used in GPT-2 or GPT-3, respectively.
Most documents contain many more than 128 tokens, so simply truncating the inputs to the maximum length would eliminate a large fraction of our dataset. Instead, we'll use the `return_overflowing_tokens` option to tokenize the whole input and split it into several chunks, as we did in [Chapter 6](/course/chapter6/4). We'll also use the `return_length` option to return the length of each created chunk automatically. Often the last chunk will be smaller than the context size, and we'll get rid of these pieces to avoid padding issues; we don't really need them as we have plenty of data anyway.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter7/chunking_texts.svg" alt="Chunking a large texts in several pieces."/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter7/chunking_texts-dark.svg" alt="Chunking a large texts in several pieces."/>
</div>
Let's see exactly how this works by looking at the first two examples:
```py
from transformers import AutoTokenizer
context_length = 128
tokenizer = AutoTokenizer.from_pretrained("huggingface-course/code-search-net-tokenizer")
outputs = tokenizer(
raw_datasets["train"][:2]["content"],
truncation=True,
max_length=context_length,
return_overflowing_tokens=True,
return_length=True,
)
print(f"Input IDs length: {len(outputs['input_ids'])}")
print(f"Input chunk lengths: {(outputs['length'])}")
print(f"Chunk mapping: {outputs['overflow_to_sample_mapping']}")
```
```python out
Input IDs length: 34
Input chunk lengths: [128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 117, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 41]
Chunk mapping: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
```
We can see that we get 34 segments in total from those two examples. Looking at the chunk lengths, we can see that the chunks at the ends of both documents have less than 128 tokens (117 and 41, respectively). These represent just a small fraction of the total chunks that we have, so we can safely throw them away. With the `overflow_to_sample_mapping` field, we can also reconstruct which chunks belonged to which input samples.
With this operation we're using a handy feature of the `Dataset.map()` function in 🤗 Datasets, which is that it does not require one-to-one maps; as we saw in [section 3](/course/chapter7/3), we can create batches with more or fewer elements than the input batch. This is useful when doing operations like data augmentation or data filtering that change the number of elements. In our case, when tokenizing each element into chunks of the specified context size, we create many samples from each document. We just need to make sure to delete the existing columns, since they have a conflicting size. If we wanted to keep them, we could repeat them appropriately and return them within the `Dataset.map()` call:
```py
def tokenize(element):
outputs = tokenizer(
element["content"],
truncation=True,
max_length=context_length,
return_overflowing_tokens=True,
return_length=True,
)
input_batch = []
for length, input_ids in zip(outputs["length"], outputs["input_ids"]):
if length == context_length:
input_batch.append(input_ids)
return {"input_ids": input_batch}
tokenized_datasets = raw_datasets.map(
tokenize, batched=True, remove_columns=raw_datasets["train"].column_names
)
tokenized_datasets
```
```python out
DatasetDict({
train: Dataset({
features: ['input_ids'],
num_rows: 16702061
})
valid: Dataset({
features: ['input_ids'],
num_rows: 93164
})
})
```
We now have 16.7 million examples with 128 tokens each, which corresponds to about 2.1 billion tokens in total. For reference, OpenAI's GPT-3 and Codex models are trained on 300 and 100 billion tokens, respectively, where the Codex models are initialized from the GPT-3 checkpoints. Our goal in this section is not to compete with these models, which can generate long, coherent texts, but to create a scaled-down version providing a quick autocomplete function for data scientists.
Now that we have the dataset ready, let's set up the model!
<Tip>
✏️ **Try it out!** Getting rid of all the chunks that are smaller than the context size wasn't a big issue here because we're using small context windows. As you increase the context size (or if you have a corpus of short documents), the fraction of chunks that are thrown away will also grow. A more efficient way to prepare the data is to join all the tokenized samples in a batch with an `eos_token_id` token in between, and then perform the chunking on the concatenated sequences. As an exercise, modify the `tokenize()` function to make use of that approach. Note that you'll want to set `truncation=False` and remove the other arguments from the tokenizer to get the full sequence of token IDs.
</Tip>
## Initializing a new model[[initializing-a-new-model]]
Our first step is to freshly initialize a GPT-2 model. We'll use the same configuration for our model as for the small GPT-2 model, so we load the pretrained configuration, make sure that the tokenizer size matches the model vocabulary size and pass the `bos` and `eos` (beginning and end of sequence) token IDs:
{#if fw === 'pt'}
```py
from transformers import AutoTokenizer, GPT2LMHeadModel, AutoConfig
config = AutoConfig.from_pretrained(
"gpt2",
vocab_size=len(tokenizer),
n_ctx=context_length,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
)
```
With that configuration, we can load a new model. Note that this is the first time we don't use the `from_pretrained()` function, since we're actually initializing a model ourself:
```py
model = GPT2LMHeadModel(config)
model_size = sum(t.numel() for t in model.parameters())
print(f"GPT-2 size: {model_size/1000**2:.1f}M parameters")
```
```python out
GPT-2 size: 124.2M parameters
```
{:else}
```py
from transformers import AutoTokenizer, TFGPT2LMHeadModel, AutoConfig
config = AutoConfig.from_pretrained(
"gpt2",
vocab_size=len(tokenizer),
n_ctx=context_length,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
)
```
With that configuration, we can load a new model. Note that this is the first time we don't use the `from_pretrained()` function, since we're actually initializing a model ourself:
```py
model = TFGPT2LMHeadModel(config)
model(model.dummy_inputs) # Builds the model
model.summary()
```
```python out
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
transformer (TFGPT2MainLayer multiple 124242432
=================================================================
Total params: 124,242,432
Trainable params: 124,242,432
Non-trainable params: 0
_________________________________________________________________
```
{/if}
Our model has 124M parameters that we'll have to tune. Before we can start training, we need to set up a data collator that will take care of creating the batches. We can use the `DataCollatorForLanguageModeling` collator, which is designed specifically for language modeling (as the name subtly suggests). Besides stacking and padding batches, it also takes care of creating the language model labels -- in causal language modeling the inputs serve as labels too (just shifted by one element), and this data collator creates them on the fly during training so we don't need to duplicate the `input_ids`.
Note that `DataCollatorForLanguageModeling` supports both masked language modeling (MLM) and causal language modeling (CLM). By default it prepares data for MLM, but we can switch to CLM by setting the argument `mlm=False`:
{#if fw === 'pt'}
```py
from transformers import DataCollatorForLanguageModeling
tokenizer.pad_token = tokenizer.eos_token
data_collator = DataCollatorForLanguageModeling(tokenizer, mlm=False)
```
{:else}
```py
from transformers import DataCollatorForLanguageModeling
tokenizer.pad_token = tokenizer.eos_token
data_collator = DataCollatorForLanguageModeling(tokenizer, mlm=False, return_tensors="tf")
```
{/if}
Let's have a look at an example:
```py
out = data_collator([tokenized_datasets["train"][i] for i in range(5)])
for key in out:
print(f"{key} shape: {out[key].shape}")
```
{#if fw === 'pt'}
```python out
input_ids shape: torch.Size([5, 128])
attention_mask shape: torch.Size([5, 128])
labels shape: torch.Size([5, 128])
```
{:else}
```python out
input_ids shape: (5, 128)
attention_mask shape: (5, 128)
labels shape: (5, 128)
```
{/if}
We can see that the examples have been stacked and all the tensors have the same shape.
{#if fw === 'tf'}
Now we can use the `prepare_tf_dataset()` method to convert our datasets to TensorFlow datasets with the data collator we created above:
```python
tf_train_dataset = model.prepare_tf_dataset(
tokenized_dataset["train"],
collate_fn=data_collator,
shuffle=True,
batch_size=32,
)
tf_eval_dataset = model.prepare_tf_dataset(
tokenized_dataset["valid"],
collate_fn=data_collator,
shuffle=False,
batch_size=32,
)
```
{/if}
<Tip warning={true}>
⚠️ Shifting the inputs and labels to align them happens inside the model, so the data collator just copies the inputs to create the labels.
</Tip>
Now we have everything in place to actually train our model -- that wasn't so much work after all! Before we start training we should log in to Hugging Face. If you're working in a notebook, you can do so with the following utility function:
```python
from huggingface_hub import notebook_login
notebook_login()
```
This will display a widget where you can enter your Hugging Face login credentials.
If you aren't working in a notebook, just type the following line in your terminal:
```bash
huggingface-cli login
```
{#if fw === 'pt'}
All that's left to do is configure the training arguments and fire up the `Trainer`. We'll use a cosine learning rate schedule with some warmup and an effective batch size of 256 (`per_device_train_batch_size` * `gradient_accumulation_steps`). Gradient accumulation is used when a single batch does not fit into memory, and incrementally builds up the gradient through several forward/backward passes. We'll see this in action when we create the training loop with 🤗 Accelerate.
```py
from transformers import Trainer, TrainingArguments
args = TrainingArguments(
output_dir="codeparrot-ds",
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
evaluation_strategy="steps",
eval_steps=5_000,
logging_steps=5_000,
gradient_accumulation_steps=8,
num_train_epochs=1,
weight_decay=0.1,
warmup_steps=1_000,
lr_scheduler_type="cosine",
learning_rate=5e-4,
save_steps=5_000,
fp16=True,
push_to_hub=True,
)
trainer = Trainer(
model=model,
tokenizer=tokenizer,
args=args,
data_collator=data_collator,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["valid"],
)
```
Now we can just start the `Trainer` and wait for training to finish. Depending on whether you run it on the full or a subset of the training set this will take 20 or 2 hours, respectively, so grab a few coffees and a good book to read!
```py
trainer.train()
```
After training completes, we can push the model and tokenizer to the Hub:
```py
trainer.push_to_hub()
```
{:else}
All that's left to do is configure the training hyperparameters and call `compile()` and `fit()`. We'll use a learning rate schedule with some warmup to improve the stability of training:
```py
from transformers import create_optimizer
import tensorflow as tf
num_train_steps = len(tf_train_dataset)
optimizer, schedule = create_optimizer(
init_lr=5e-5,
num_warmup_steps=1_000,
num_train_steps=num_train_steps,
weight_decay_rate=0.01,
)
model.compile(optimizer=optimizer)
# Train in mixed-precision float16
tf.keras.mixed_precision.set_global_policy("mixed_float16")
```
Now we can just call `model.fit()` and wait for training to finish. Depending on whether you run it on the full or a subset of the training set this will take 20 or 2 hours, respectively, so grab a few coffees and a good book to read! After training completes we can push the model and tokenizer to the Hub:
```py
from transformers.keras_callbacks import PushToHubCallback
callback = PushToHubCallback(output_dir="codeparrot-ds", tokenizer=tokenizer)
model.fit(tf_train_dataset, validation_data=tf_eval_dataset, callbacks=[callback])
```
{/if}
<Tip>
✏️ **Try it out!** It only took us about 30 lines of code in addition to the `TrainingArguments` to get from raw texts to training GPT-2. Try it out with your own dataset and see if you can get good results!
</Tip>
<Tip>
{#if fw === 'pt'}
💡 If you have access to a machine with multiple GPUs, try to run the code there. The `Trainer` automatically manages multiple machines, and this can speed up training tremendously.
{:else}
💡 If you have access to a machine with multiple GPUs, you can try using a `MirroredStrategy` context to substantially speed up training. You'll need to create a `tf.distribute.MirroredStrategy` object, and make sure that any `to_tf_dataset()` or `prepare_tf_dataset()` methods as well as model creation and the call to `fit()` are all run in its `scope()` context. You can see documentation on this [here](https://www.tensorflow.org/guide/distributed_training#use_tfdistributestrategy_with_keras_modelfit).
{/if}
</Tip>
## Code generation with a pipeline[[code-generation-with-a-pipeline]]
Now is the moment of truth: let's see how well the trained model actually works! We can see in the logs that the loss went down steadily, but to put the model to the test let's take a look at how well it works on some prompts. To do that we'll wrap the model in a text generation `pipeline`, and we'll put it on the GPU for fast generations if there is one available:
{#if fw === 'pt'}
```py
import torch
from transformers import pipeline
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
pipe = pipeline(
"text-generation", model="huggingface-course/codeparrot-ds", device=device
)
```
{:else}
```py
from transformers import pipeline
course_model = TFGPT2LMHeadModel.from_pretrained("huggingface-course/codeparrot-ds")
course_tokenizer = AutoTokenizer.from_pretrained("huggingface-course/codeparrot-ds")
pipe = pipeline(
"text-generation", model=course_model, tokenizer=course_tokenizer, device=0
)
```
{/if}
Let's start with the simple task of creating a scatter plot:
```py
txt = """\
# create some data
x = np.random.randn(100)
y = np.random.randn(100)
# create scatter plot with x, y
"""
print(pipe(txt, num_return_sequences=1)[0]["generated_text"])
```
```python out
# create some data
x = np.random.randn(100)
y = np.random.randn(100)
# create scatter plot with x, y
plt.scatter(x, y)
# create scatter
```
The result looks correct. Does it also work for a `pandas` operation? Let's see if we can create a `DataFrame` from two arrays:
```py
txt = """\
# create some data
x = np.random.randn(100)
y = np.random.randn(100)
# create dataframe from x and y
"""
print(pipe(txt, num_return_sequences=1)[0]["generated_text"])
```
```python out
# create some data
x = np.random.randn(100)
y = np.random.randn(100)
# create dataframe from x and y
df = pd.DataFrame({'x': x, 'y': y})
df.insert(0,'x', x)
for
```
Nice, that's the correct answer -- although it then inserts the column `x` again. Since the number of generated tokens is limited, the following `for` loop is cut off. Let's see if we can do something a bit more complex and have the model help us use the `groupby` operation:
```py
txt = """\
# dataframe with profession, income and name
df = pd.DataFrame({'profession': x, 'income':y, 'name': z})
# calculate the mean income per profession
"""
print(pipe(txt, num_return_sequences=1)[0]["generated_text"])
```
```python out
# dataframe with profession, income and name
df = pd.DataFrame({'profession': x, 'income':y, 'name': z})
# calculate the mean income per profession
profession = df.groupby(['profession']).mean()
# compute the
```
Not bad; that's the right way to do it. Finally, let's see if we can also use it for `scikit-learn` and set up a Random Forest model:
```py
txt = """
# import random forest regressor from scikit-learn
from sklearn.ensemble import RandomForestRegressor
# fit random forest model with 300 estimators on X, y:
"""
print(pipe(txt, num_return_sequences=1)[0]["generated_text"])
```
```python out
# import random forest regressor from scikit-learn
from sklearn.ensemble import RandomForestRegressor
# fit random forest model with 300 estimators on X, y:
rf = RandomForestRegressor(n_estimators=300, random_state=random_state, max_depth=3)
rf.fit(X, y)
rf
```
{#if fw === 'tf'}
Looking at these few examples, it seems that the model has learned some of the syntax of the Python data science stack. Of course, we would need to evaluate the model more thoroughly before deploying it in the real world, but this is still an impressive prototype.
{:else}
Looking at these few examples, it seems that the model has learned some of the syntax of the Python data science stack (of course, we would need to evaluate it more thoroughly before deploying the model in the real world). Sometimes it requires more customization of the model training to achieve the necessary performance for a given use case, however. For example, what if we would like to dynamically update the batch size or have a conditional training loop that skips bad examples on the fly? One option would be to subclass the `Trainer` and add the necessary changes, but sometimes it's simpler to write the training loop from scratch. That's where 🤗 Accelerate comes in.
{/if}
{#if fw === 'pt'}
## Training with 🤗 Accelerate[[training-with-accelerate]]
We've seen how to train a model with the `Trainer`, which can allow for some customization. However, sometimes we want full control over the training loop, or we want to make some exotic changes. In this case 🤗 Accelerate is a great choice, and in this section we'll go through the steps to use it to train our model. To make things more interesting, we'll also add a twist to the training loop.
<Youtube id="Hm8_PgVTFuc"/>
Since we are mainly interested in sensible autocompletion for the the data science libraries, it makes sense to give more weight to training samples that make more use of these libraries. We can easily identify these examples through the use of keywords such as `plt`, `pd`, `sk`, `fit`, and `predict`, which are the most frequent import names for `matplotlib.pyplot`, `pandas`, and `sklearn` as well as the fit/predict pattern of the latter. If these are each represented as a single token, we can easily check if they occur in the input sequence. Tokens can have a whitespace prefix, so we'll also check for those versions in the tokenizer vocabulary. To verify that it works, we'll add one test token which should be split into multiple tokens:
```py
keytoken_ids = []
for keyword in [
"plt",
"pd",
"sk",
"fit",
"predict",
" plt",
" pd",
" sk",
" fit",
" predict",
"testtest",
]:
ids = tokenizer([keyword]).input_ids[0]
if len(ids) == 1:
keytoken_ids.append(ids[0])
else:
print(f"Keyword has not single token: {keyword}")
```
```python out
'Keyword has not single token: testtest'
```
Great, that seems to work nicely! We can now write a custom loss function that takes the input sequence, the logits, and the key tokens we just selected as inputs. First we need to align the logits and inputs: the input sequence shifted by one to the right forms the labels, since the next token is the label for the current token. We can achieve this by starting the labels from the second token of the input sequence, since the model does not make a prediction for the first token anyway. Then we cut off the last logit, as we don't have a label for the token that follows the full input sequence. With that we can compute the loss per sample and count the occurrences of all keywords in each sample. Finally, we calculate the weighted average over all samples using the occurrences as weights. Since we don't want to throw away all the samples that have no keywords, we add 1 to the weights:
```py
from torch.nn import CrossEntropyLoss
import torch
def keytoken_weighted_loss(inputs, logits, keytoken_ids, alpha=1.0):
# Shift so that tokens < n predict n
shift_labels = inputs[..., 1:].contiguous()
shift_logits = logits[..., :-1, :].contiguous()
# Calculate per-token loss
loss_fct = CrossEntropyLoss(reduce=False)
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
# Resize and average loss per sample
loss_per_sample = loss.view(shift_logits.size(0), shift_logits.size(1)).mean(axis=1)
# Calculate and scale weighting
weights = torch.stack([(inputs == kt).float() for kt in keytoken_ids]).sum(
axis=[0, 2]
)
weights = alpha * (1.0 + weights)
# Calculate weighted average
weighted_loss = (loss_per_sample * weights).mean()
return weighted_loss
```
Before we can start training with this awesome new loss function, we need to prepare a few things:
- We need dataloaders to load the data in batches.
- We need to set up weight decay parameters.
- From time to time we want to evaluate, so it makes sense to wrap the evaluation code in a function.
Let's start with the dataloaders. We only need to set the dataset's format to `"torch"`, and then we can pass it to a PyTorch `DataLoader` with the appropriate batch size:
```py
from torch.utils.data.dataloader import DataLoader
tokenized_dataset.set_format("torch")
train_dataloader = DataLoader(tokenized_dataset["train"], batch_size=32, shuffle=True)
eval_dataloader = DataLoader(tokenized_dataset["valid"], batch_size=32)
```
Next, we group the parameters so that the optimizer knows which ones will get an additional weight decay. Usually, all bias and LayerNorm weights terms are exempt from this; here's how we can do this:
```py
weight_decay = 0.1
def get_grouped_params(model, no_decay=["bias", "LayerNorm.weight"]):
params_with_wd, params_without_wd = [], []
for n, p in model.named_parameters():
if any(nd in n for nd in no_decay):
params_without_wd.append(p)
else:
params_with_wd.append(p)
return [
{"params": params_with_wd, "weight_decay": weight_decay},
{"params": params_without_wd, "weight_decay": 0.0},
]
```
Since we want to evaluate the model regularly on the validation set during training, let's write a function for that as well. It just runs through the evaluation dataloader and gathers all the losses across processes:
```py
def evaluate():
model.eval()
losses = []
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
outputs = model(batch["input_ids"], labels=batch["input_ids"])
losses.append(accelerator.gather(outputs.loss))
loss = torch.mean(torch.cat(losses))
try:
perplexity = torch.exp(loss)
except OverflowError:
perplexity = float("inf")
return loss.item(), perplexity.item()
```
With the `evaluate()` function we can report loss and [perplexity](/course/chapter7/3) at regular intervals. Next, we redefine our model to make sure we train from scratch again:
```py
model = GPT2LMHeadModel(config)
```
We can then define our optimizer, using the function from before to split the parameters for weight decay:
```py
from torch.optim import AdamW
optimizer = AdamW(get_grouped_params(model), lr=5e-4)
```
Now let's prepare the model, optimizer, and dataloaders so we can start training:
```py
from accelerate import Accelerator
accelerator = Accelerator(fp16=True)
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader
)
```
<Tip>
🚨 If you're training on a TPU, you'll need to move all the code starting at the cell above into a dedicated training function. See [Chapter 3](/course/chapter3) for more details.
</Tip>
Now that we have sent our `train_dataloader` to `accelerator.prepare()`, we can use its length to compute the number of training steps. Remember that we should always do this after preparing the dataloader, as that method will change its length. We use a classic linear schedule from the learning rate to 0:
```py
from transformers import get_scheduler
num_train_epochs = 1
num_update_steps_per_epoch = len(train_dataloader)
num_training_steps = num_train_epochs * num_update_steps_per_epoch
lr_scheduler = get_scheduler(
name="linear",
optimizer=optimizer,
num_warmup_steps=1_000,
num_training_steps=num_training_steps,
)
```
Lastly, to push our model to the Hub, we will need to create a `Repository` object in a working folder. First log in to the Hugging Face Hub, if you aren't logged in already. We'll determine the repository name from the model ID we want to give our model (feel free to replace the `repo_name` with your own choice; it just needs to contain your username, which is what the function `get_full_repo_name()` does):
```py
from huggingface_hub import Repository, get_full_repo_name
model_name = "codeparrot-ds-accelerate"
repo_name = get_full_repo_name(model_name)
repo_name
```
```python out
'sgugger/codeparrot-ds-accelerate'
```
Then we can clone that repository in a local folder. If it already exists, this local folder should be an existing clone of the repository we are working with:
```py
output_dir = "codeparrot-ds-accelerate"
repo = Repository(output_dir, clone_from=repo_name)
```
We can now upload anything we save in `output_dir` by calling the `repo.push_to_hub()` method. This will help us upload the intermediate models at the end of each epoch.
Before we train, let's run a quick test to see if the evaluation function works properly:
```py
evaluate()
```
```python out
(10.934126853942871, 56057.14453125)
```
Those are very high values for loss and perplexity, but that's not surprising as we haven't trained the model yet. With that, we have everything prepared to write the core part of the training script: the training loop. In the training loop we iterate over the dataloader and pass the batches to the model. With the logits, we can then evaluate our custom loss function. We scale the loss by the number of gradient accumulation steps so as not to create larger losses when aggregating more steps. Before we optimize, we also clip the gradients for better convergence. Finally, every few steps we evaluate the model on the evaluation set with our new `evaluate()` function:
```py
from tqdm.notebook import tqdm
gradient_accumulation_steps = 8
eval_steps = 5_000
model.train()
completed_steps = 0
for epoch in range(num_train_epochs):
for step, batch in tqdm(
enumerate(train_dataloader, start=1), total=num_training_steps
):
logits = model(batch["input_ids"]).logits
loss = keytoken_weighted_loss(batch["input_ids"], logits, keytoken_ids)
if step % 100 == 0:
accelerator.print(
{
"samples": step * samples_per_step,
"steps": completed_steps,
"loss/train": loss.item() * gradient_accumulation_steps,
}
)
loss = loss / gradient_accumulation_steps
accelerator.backward(loss)
if step % gradient_accumulation_steps == 0:
accelerator.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
completed_steps += 1
if (step % (eval_steps * gradient_accumulation_steps)) == 0:
eval_loss, perplexity = evaluate()
accelerator.print({"loss/eval": eval_loss, "perplexity": perplexity})
model.train()
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
if accelerator.is_main_process:
tokenizer.save_pretrained(output_dir)
repo.push_to_hub(
commit_message=f"Training in progress step {step}", blocking=False
)
```
And that's it -- you now have your own custom training loop for causal language models such as GPT-2 that you can further customize to your needs.
<Tip>
✏️ **Try it out!** Either create your own custom loss function tailored to your use case, or add another custom step into the training loop.
</Tip>
<Tip>
✏️ **Try it out!** When running long training experiments it's a good idea to log important metrics using tools such as TensorBoard or Weights & Biases. Add proper logging to the training loop so you can always check how the training is going.
</Tip>
{/if}
|
huggingface/course/blob/main/chapters/en/chapter7/6.mdx
|
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Jukebox
## Overview
The Jukebox model was proposed in [Jukebox: A generative model for music](https://arxiv.org/pdf/2005.00341.pdf)
by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford,
Ilya Sutskever. It introduces a generative music model which can produce minute long samples that can be conditioned on
an artist, genres and lyrics.
The abstract from the paper is the following:
*We introduce Jukebox, a model that generates music with singing in the raw audio domain. We tackle the long context of raw audio using a multiscale VQ-VAE to compress it to discrete codes, and modeling those using autoregressive Transformers. We show that the combined model at scale can generate high-fidelity and diverse songs with coherence up to multiple minutes. We can condition on artist and genre to steer the musical and vocal style, and on unaligned lyrics to make the singing more controllable. We are releasing thousands of non cherry-picked samples, along with model weights and code.*
As shown on the following figure, Jukebox is made of 3 `priors` which are decoder only models. They follow the architecture described in [Generating Long Sequences with Sparse Transformers](https://arxiv.org/abs/1904.10509), modified to support longer context length.
First, a autoencoder is used to encode the text lyrics. Next, the first (also called `top_prior`) prior attends to the last hidden states extracted from the lyrics encoder. The priors are linked to the previous priors respectively via an `AudioConditionner` module. The`AudioConditioner` upsamples the outputs of the previous prior to raw tokens at a certain audio frame per second resolution.
The metadata such as *artist, genre and timing* are passed to each prior, in the form of a start token and positional embedding for the timing data. The hidden states are mapped to the closest codebook vector from the VQVAE in order to convert them to raw audio.

This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ).
The original code can be found [here](https://github.com/openai/jukebox).
## Usage tips
- This model only supports inference. This is for a few reasons, mostly because it requires a crazy amount of memory to train. Feel free to open a PR and add what's missing to have a full integration with the hugging face traineer!
- This model is very slow, and takes 8h to generate a minute long audio using the 5b top prior on a V100 GPU. In order automaticallay handle the device on which the model should execute, use `accelerate`.
- Contrary to the paper, the order of the priors goes from `0` to `1` as it felt more intuitive : we sample starting from `0`.
- Primed sampling (conditioning the sampling on raw audio) requires more memory than ancestral sampling and should be used with `fp16` set to `True`.
This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ).
The original code can be found [here](https://github.com/openai/jukebox).
## JukeboxConfig
[[autodoc]] JukeboxConfig
## JukeboxPriorConfig
[[autodoc]] JukeboxPriorConfig
## JukeboxVQVAEConfig
[[autodoc]] JukeboxVQVAEConfig
## JukeboxTokenizer
[[autodoc]] JukeboxTokenizer
- save_vocabulary
## JukeboxModel
[[autodoc]] JukeboxModel
- ancestral_sample
- primed_sample
- continue_sample
- upsample
- _sample
## JukeboxPrior
[[autodoc]] JukeboxPrior
- sample
- forward
## JukeboxVQVAE
[[autodoc]] JukeboxVQVAE
- forward
- encode
- decode
|
huggingface/transformers/blob/main/docs/source/en/model_doc/jukebox.md
|
simple dashboard showing pypi stats for python libraries. Updates on load, and has no buttons!
|
gradio-app/gradio/blob/main/demo/timeseries-forecasting-with-prophet/DESCRIPTION.md
|
Dreambooth for the inpainting model
This script was added by @thedarkzeno .
Please note that this script is not actively maintained, you can open an issue and tag @thedarkzeno or @patil-suraj though.
```bash
export MODEL_NAME="runwayml/stable-diffusion-inpainting"
export INSTANCE_DIR="path-to-instance-images"
export OUTPUT_DIR="path-to-save-model"
accelerate launch train_dreambooth_inpaint.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--output_dir=$OUTPUT_DIR \
--instance_prompt="a photo of sks dog" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=1 \
--learning_rate=5e-6 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=400
```
### Training with prior-preservation loss
Prior-preservation is used to avoid overfitting and language-drift. Refer to the paper to learn more about it. For prior-preservation we first generate images using the model with a class prompt and then use those during training along with our data.
According to the paper, it's recommended to generate `num_epochs * num_samples` images for prior-preservation. 200-300 works well for most cases.
```bash
export MODEL_NAME="runwayml/stable-diffusion-inpainting"
export INSTANCE_DIR="path-to-instance-images"
export CLASS_DIR="path-to-class-images"
export OUTPUT_DIR="path-to-save-model"
accelerate launch train_dreambooth_inpaint.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--class_data_dir=$CLASS_DIR \
--output_dir=$OUTPUT_DIR \
--with_prior_preservation --prior_loss_weight=1.0 \
--instance_prompt="a photo of sks dog" \
--class_prompt="a photo of dog" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=1 \
--learning_rate=5e-6 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--num_class_images=200 \
--max_train_steps=800
```
### Training with gradient checkpointing and 8-bit optimizer:
With the help of gradient checkpointing and the 8-bit optimizer from bitsandbytes it's possible to run train dreambooth on a 16GB GPU.
To install `bitandbytes` please refer to this [readme](https://github.com/TimDettmers/bitsandbytes#requirements--installation).
```bash
export MODEL_NAME="runwayml/stable-diffusion-inpainting"
export INSTANCE_DIR="path-to-instance-images"
export CLASS_DIR="path-to-class-images"
export OUTPUT_DIR="path-to-save-model"
accelerate launch train_dreambooth_inpaint.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--class_data_dir=$CLASS_DIR \
--output_dir=$OUTPUT_DIR \
--with_prior_preservation --prior_loss_weight=1.0 \
--instance_prompt="a photo of sks dog" \
--class_prompt="a photo of dog" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=2 --gradient_checkpointing \
--use_8bit_adam \
--learning_rate=5e-6 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--num_class_images=200 \
--max_train_steps=800
```
### Fine-tune text encoder with the UNet.
The script also allows to fine-tune the `text_encoder` along with the `unet`. It's been observed experimentally that fine-tuning `text_encoder` gives much better results especially on faces.
Pass the `--train_text_encoder` argument to the script to enable training `text_encoder`.
___Note: Training text encoder requires more memory, with this option the training won't fit on 16GB GPU. It needs at least 24GB VRAM.___
```bash
export MODEL_NAME="runwayml/stable-diffusion-inpainting"
export INSTANCE_DIR="path-to-instance-images"
export CLASS_DIR="path-to-class-images"
export OUTPUT_DIR="path-to-save-model"
accelerate launch train_dreambooth_inpaint.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_text_encoder \
--instance_data_dir=$INSTANCE_DIR \
--class_data_dir=$CLASS_DIR \
--output_dir=$OUTPUT_DIR \
--with_prior_preservation --prior_loss_weight=1.0 \
--instance_prompt="a photo of sks dog" \
--class_prompt="a photo of dog" \
--resolution=512 \
--train_batch_size=1 \
--use_8bit_adam \
--gradient_checkpointing \
--learning_rate=2e-6 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--num_class_images=200 \
--max_train_steps=800
```
|
huggingface/diffusers/blob/main/examples/research_projects/dreambooth_inpaint/README.md
|
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Neighborhood Attention Transformer
## Overview
NAT was proposed in [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143)
by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
It is a hierarchical vision transformer based on Neighborhood Attention, a sliding-window self attention pattern.
The abstract from the paper is the following:
*We present Neighborhood Attention (NA), the first efficient and scalable sliding-window attention mechanism for vision.
NA is a pixel-wise operation, localizing self attention (SA) to the nearest neighboring pixels, and therefore enjoys a
linear time and space complexity compared to the quadratic complexity of SA. The sliding-window pattern allows NA's
receptive field to grow without needing extra pixel shifts, and preserves translational equivariance, unlike
Swin Transformer's Window Self Attention (WSA). We develop NATTEN (Neighborhood Attention Extension), a Python package
with efficient C++ and CUDA kernels, which allows NA to run up to 40% faster than Swin's WSA while using up to 25% less
memory. We further present Neighborhood Attention Transformer (NAT), a new hierarchical transformer design based on NA
that boosts image classification and downstream vision performance. Experimental results on NAT are competitive;
NAT-Tiny reaches 83.2% top-1 accuracy on ImageNet, 51.4% mAP on MS-COCO and 48.4% mIoU on ADE20K, which is 1.9%
ImageNet accuracy, 1.0% COCO mAP, and 2.6% ADE20K mIoU improvement over a Swin model with similar size. *
<img
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/neighborhood-attention-pattern.jpg"
alt="drawing" width="600"/>
<small> Neighborhood Attention compared to other attention patterns.
Taken from the <a href="https://arxiv.org/abs/2204.07143">original paper</a>.</small>
This model was contributed by [Ali Hassani](https://huggingface.co/alihassanijr).
The original code can be found [here](https://github.com/SHI-Labs/Neighborhood-Attention-Transformer).
## Usage tips
- One can use the [`AutoImageProcessor`] API to prepare images for the model.
- NAT can be used as a *backbone*. When `output_hidden_states = True`,
it will output both `hidden_states` and `reshaped_hidden_states`.
The `reshaped_hidden_states` have a shape of `(batch, num_channels, height, width)` rather than
`(batch_size, height, width, num_channels)`.
Notes:
- NAT depends on [NATTEN](https://github.com/SHI-Labs/NATTEN/)'s implementation of Neighborhood Attention.
You can install it with pre-built wheels for Linux by referring to [shi-labs.com/natten](https://shi-labs.com/natten),
or build on your system by running `pip install natten`.
Note that the latter will likely take time to compile. NATTEN does not support Windows devices yet.
- Patch size of 4 is only supported at the moment.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with NAT.
<PipelineTag pipeline="image-classification"/>
- [`NatForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## NatConfig
[[autodoc]] NatConfig
## NatModel
[[autodoc]] NatModel
- forward
## NatForImageClassification
[[autodoc]] NatForImageClassification
- forward
|
huggingface/transformers/blob/main/docs/source/en/model_doc/nat.md
|
Pickle Scanning
Pickle is a widely used serialization format in ML. Most notably, it is the default format for PyTorch model weights.
There are dangerous arbitrary code execution attacks that can be perpetrated when you load a pickle file. We suggest loading models from users and organizations you trust, relying on signed commits, and/or loading models from TF or Jax formats with the `from_tf=True` auto-conversion mechanism. We also alleviate this issue by displaying/"vetting" the list of imports in any pickled file, directly on the Hub. Finally, we are experimenting with a new, simple serialization format for weights called [`safetensors`](https://github.com/huggingface/safetensors).
## What is a pickle?
From the [official docs](https://docs.python.org/3/library/pickle.html) :
> The `pickle` module implements binary protocols for serializing and de-serializing a Python object structure.
What this means is that pickle is a serializing protocol, something you use to efficiently share data amongst parties.
We call a pickle the binary file that was generated while pickling.
At its core, the pickle is basically a stack of instructions or opcodes. As you probably have guessed, it’s not human readable. The opcodes are generated when pickling and read sequentially at unpickling. Based on the opcode, a given action is executed.
Here’s a small example:
```python
import pickle
import pickletools
var = "data I want to share with a friend"
# store the pickle data in a file named 'payload.pkl'
with open('payload.pkl', 'wb') as f:
pickle.dump(var, f)
# disassemble the pickle
# and print the instructions to the command line
with open('payload.pkl', 'rb') as f:
pickletools.dis(f)
```
When you run this, it will create a pickle file and print the following instructions in your terminal:
```python
0: \x80 PROTO 4
2: \x95 FRAME 48
11: \x8c SHORT_BINUNICODE 'data I want to share with a friend'
57: \x94 MEMOIZE (as 0)
58: . STOP
highest protocol among opcodes = 4
```
Don’t worry too much about the instructions for now, just know that the [pickletools](https://docs.python.org/3/library/pickletools.html) module is very useful for analyzing pickles. It allows you to read the instructions in the file ***without*** executing any code.
Pickle is not simply a serialization protocol, it allows more flexibility by giving the ability to users to run python code at de-serialization time. Doesn’t sound good, does it?
## Why is it dangerous?
As we’ve stated above, de-serializing pickle means that code can be executed. But this comes with certain limitations: you can only reference functions and classes from the top level module; you cannot embed them in the pickle file itself.
Back to the drawing board:
```python
import pickle
import pickletools
class Data:
def __init__(self, important_stuff: str):
self.important_stuff = important_stuff
d = Data("42")
with open('payload.pkl', 'wb') as f:
pickle.dump(d, f)
```
When we run this script we get the `payload.pkl` again. When we check the file’s contents:
```bash
# cat payload.pkl
__main__Data)}important_stuff42sb.%
# hexyl payload.pkl
┌────────┬─────────────────────────┬─────────────────────────┬────────┬────────┐
│00000000│ 80 04 95 33 00 00 00 00 ┊ 00 00 00 8c 08 5f 5f 6d │ו×30000┊000ו__m│
│00000010│ 61 69 6e 5f 5f 94 8c 04 ┊ 44 61 74 61 94 93 94 29 │ain__×ו┊Data×××)│
│00000020│ 81 94 7d 94 8c 0f 69 6d ┊ 70 6f 72 74 61 6e 74 5f │××}×וim┊portant_│
│00000030│ 73 74 75 66 66 94 8c 02 ┊ 34 32 94 73 62 2e │stuff×ו┊42×sb. │
└────────┴─────────────────────────┴─────────────────────────┴────────┴────────┘
```
We can see that there isn’t much in there, a few opcodes and the associated data. You might be thinking, so what’s the problem with pickle?
Let’s try something else:
```python
from fickling.pickle import Pickled
import pickle
# Create a malicious pickle
data = "my friend needs to know this"
pickle_bin = pickle.dumps(data)
p = Pickled.load(pickle_bin)
p.insert_python_exec('print("you\'ve been pwned !")')
with open('payload.pkl', 'wb') as f:
p.dump(f)
# innocently unpickle and get your friend's data
with open('payload.pkl', 'rb') as f:
data = pickle.load(f)
print(data)
```
Here we’re using the [fickling](https://github.com/trailofbits/fickling) library for simplicity. It allows us to add pickle instructions to execute code contained in a string via the `exec` function. This is how you circumvent the fact that you cannot define functions or classes in your pickles: you run exec on python code saved as a string.
When you run this, it creates a `payload.pkl` and prints the following:
```
you've been pwned !
my friend needs to know this
```
If we check the contents of the pickle file, we get:
```bash
# cat payload.pkl
c__builtin__
exec
(Vprint("you've been pwned !")
tR my friend needs to know this.%
# hexyl payload.pkl
┌────────┬─────────────────────────┬─────────────────────────┬────────┬────────┐
│00000000│ 63 5f 5f 62 75 69 6c 74 ┊ 69 6e 5f 5f 0a 65 78 65 │c__built┊in___exe│
│00000010│ 63 0a 28 56 70 72 69 6e ┊ 74 28 22 79 6f 75 27 76 │c_(Vprin┊t("you'v│
│00000020│ 65 20 62 65 65 6e 20 70 ┊ 77 6e 65 64 20 21 22 29 │e been p┊wned !")│
│00000030│ 0a 74 52 80 04 95 20 00 ┊ 00 00 00 00 00 00 8c 1c │_tR×•× 0┊000000ו│
│00000040│ 6d 79 20 66 72 69 65 6e ┊ 64 20 6e 65 65 64 73 20 │my frien┊d needs │
│00000050│ 74 6f 20 6b 6e 6f 77 20 ┊ 74 68 69 73 94 2e │to know ┊this×. │
└────────┴─────────────────────────┴─────────────────────────┴────────┴────────┘
```
Basically, this is what’s happening when you unpickle:
```python
# ...
opcodes_stack = [exec_func, "malicious argument", "REDUCE"]
opcode = stack.pop()
if opcode == "REDUCE":
arg = opcodes_stack.pop()
callable = opcodes_stack.pop()
opcodes_stack.append(callable(arg))
# ...
```
The instructions that pose a threat are `STACK_GLOBAL`, `GLOBAL` and `REDUCE`.
`REDUCE` is what tells the unpickler to execute the function with the provided arguments and `*GLOBAL` instructions are telling the unpickler to `import` stuff.
To sum up, pickle is dangerous because:
- when importing a python module, arbitrary code can be executed
- you can import builtin functions like `eval` or `exec`, which can be used to execute arbitrary code
- when instantiating an object, the constructor may be called
This is why it is stated in most docs using pickle, do not unpickle data from untrusted sources.
## Mitigation Strategies
***Don’t use pickle***
Sound advice Luc, but pickle is used profusely and isn’t going anywhere soon: finding a new format everyone is happy with and initiating the change will take some time.
So what can we do for now?
### Load files from users and organizations you trust
On the Hub, you have the ability to [sign your commits with a GPG key](./security-gpg). This does **not** guarantee that your file is safe, but it does guarantee the origin of the file.
If you know and trust user A and the commit that includes the file on the Hub is signed by user A’s GPG key, it’s pretty safe to assume that you can trust the file.
### Load model weights from TF or Flax
TensorFlow and Flax checkpoints are not affected, and can be loaded within PyTorch architectures using the `from_tf` and `from_flax` kwargs for the `from_pretrained` method to circumvent this issue.
E.g.:
```python
from transformers import AutoModel
model = AutoModel.from_pretrained("bert-base-cased", from_flax=True)
```
### Use your own serialization format
- [MsgPack](https://msgpack.org/index.html)
- [Protobuf](https://developers.google.com/protocol-buffers)
- [Cap'n'proto](https://capnproto.org/)
- [Avro](https://avro.apache.org/)
- [safetensors](https://github.com/huggingface/safetensors)
This last format, `safetensors`, is a simple serialization format that we are working on and experimenting with currently! Please help or contribute if you can 🔥.
### Improve `torch.load/save`
There's an open discussion in progress at PyTorch on having a [Safe way of loading only weights from *.pt file by default](https://github.com/pytorch/pytorch/issues/52181) – please chime in there!
### Hub’s Security Scanner
#### What we have now
We have created a security scanner that scans every file pushed to the Hub and runs security checks. At the time of writing, it runs two types of scans:
- ClamAV scans
- Pickle Import scans
For ClamAV scans, files are run through the open-source antivirus [ClamAV](https://www.clamav.net). While this covers a good amount of dangerous files, it doesn’t cover pickle exploits.
We have implemented a Pickle Import scan, which extracts the list of imports referenced in a pickle file. Every time you upload a `pytorch_model.bin` or any other pickled file, this scan is run.
On the hub the list of imports will be displayed next to each file containing imports. If any import looks suspicious, it will be highlighted.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/security-pickle-imports.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/security-pickle-imports-dark.png"/>
</div>
We get this data thanks to [`pickletools.genops`](https://docs.python.org/3/library/pickletools.html#pickletools.genops) which allows us to read the file without executing potentially dangerous code.
Note that this is what allows to know if, when unpickling a file, it will `REDUCE` on a potentially dangerous function that was imported by `*GLOBAL`.
***Disclaimer***: this is not 100% foolproof. It is your responsibility as a user to check if something is safe or not. We are not actively auditing python packages for safety, the safe/unsafe imports lists we have are maintained in a best-effort manner.
Please contact us if you think something is not safe, and we flag it as such, by sending us an email to website at huggingface.co
#### Potential solutions
One could think of creating a custom [Unpickler](https://docs.python.org/3/library/pickle.html#pickle.Unpickler) in the likes of [this one](https://github.com/facebookresearch/CrypTen/blob/main/crypten/common/serial.py). But as we can see in this [sophisticated exploit](https://ctftime.org/writeup/16723), this won’t work.
Thankfully, there is always a trace of the `eval` import, so reading the opcodes directly should allow to catch malicious usage.
The current solution I propose is creating a file resembling a `.gitignore` but for imports.
This file would be a whitelist of imports that would make a `pytorch_model.bin` file flagged as dangerous if there are imports not included in the whitelist.
One could imagine having a regex-ish format where you could allow all numpy submodules for instance via a simple line like: `numpy.*`.
## Further Reading
[pickle - Python object serialization - Python 3.10.6 documentation](https://docs.python.org/3/library/pickle.html#what-can-be-pickled-and-unpickled)
[Dangerous Pickles - Malicious Python Serialization](https://intoli.com/blog/dangerous-pickles/)
[GitHub - trailofbits/fickling: A Python pickling decompiler and static analyzer](https://github.com/trailofbits/fickling)
[Exploiting Python pickles](https://davidhamann.de/2020/04/05/exploiting-python-pickle/)
[cpython/pickletools.py at 3.10 · python/cpython](https://github.com/python/cpython/blob/3.10/Lib/pickletools.py)
[cpython/pickle.py at 3.10 · python/cpython](https://github.com/python/cpython/blob/3.10/Lib/pickle.py)
[CrypTen/serial.py at main · facebookresearch/CrypTen](https://github.com/facebookresearch/CrypTen/blob/main/crypten/common/serial.py)
[CTFtime.org / Balsn CTF 2019 / pyshv1 / Writeup](https://ctftime.org/writeup/16723)
[Rehabilitating Python's pickle module](https://github.com/moreati/pickle-fuzz)
|
huggingface/hub-docs/blob/main/docs/hub/security-pickle.md
|
ow to ask a question on the Hugging Face forums?
If you have a general question or are looking to debug your code, the forums are the place to ask. In this video we will teach you how to write a good question, to maximize the chances you will get an answer.
First things first, to login on the forums, you need a Hugging Face account. If you haven't created one yet, go to hf.co and click Sign Up. There is also a direct link below.
Fill your email and password, then continue the steps ot pick a username and update a profile picture.
Once this is done, go to discuss.huggingface.co (linked below) and click Log In. Use the same login information as for the Hugging Face website.
You can search the forums by clicking on the magnifying glass. Someone may have already asked your question in a topic! If you find you can't post a new topic as a new user, it may be because of the antispam filters. Make sure you spend some time reading existing topics to deactivate it.
When you are sure your question hasn't been asked yet, click on the New Topic button.
For this example, we will use the following code,
that produces an error, as we saw in the "What to do when I get an error?" video.
The first step is to pick a category for our new topic. Since our error has to do with the Transformers library, we pick this category. New, choose a title that summarizes your error well. Don't be too vague or users that get the same error you did in the future won't be able to find your topic. Once you have finished typing your topic, make sure the question hasn't been answered in the topics Discourse suggests you. Click on the cross to remove that window when you have double-checked. This is an example of what not to do when posting an error: the message is very vague so no one else will be able to guess what went wrong for you, and it tags too many people. Tagging people (especially moderators) might have the opposite effect of what you want. As you send them a notification (and they get plenty), they will probably not bother replying to you, and users you didn't tag will probably ignore the question since they see tagged users. Only tag a user when you are completely certain they are the best placed to answer your question. Be precise in your text, and if you have an error coming from a specific piece of code, include that code in your post. To make sure your post looks good, place your question between three backticks like this. You can check on the right how your post will appear once posted. If your question is about an error, it's even better to include the full traceback. As explained in the "what to do when I get an error?' video, expand the traceback if you are on Colab. like for the code, put it between two lines containing three backticks for proper formatting. Our last advice is to remember to be nice, a please and a thank you will go a long way into getting others to help you. With all that done properly, your question should get an answer pretty quickly!
|
huggingface/course/blob/main/subtitles/en/raw/chapter8/03_forums.md
|
!---
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# 🤗 Datasets Notebooks
You can find here a list of the official notebooks provided by Hugging Face.
Also, we would like to list here interesting content created by the community.
If you wrote some notebook(s) leveraging 🤗 Datasets and would like it to be listed here, please open a
Pull Request so it can be included under the Community notebooks.
## Hugging Face's notebooks 🤗
### Documentation notebooks
You can open any page of the documentation as a notebook in Colab (there is a button directly on said pages) but they are also listed here if you need them:
| Notebook | Description | | |
|:----------|:-------------|:-------------|------:|
| [Quickstart](https://github.com/huggingface/notebooks/blob/main/datasets_doc/en/quickstart.ipynb) | A quick presentation on integrating Datasets into a model training workflow |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/datasets_doc/en/quickstart.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/datasets_doc/en/quickstart.ipynb)|
|
huggingface/datasets/blob/main/notebooks/README.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# LLaVa
## Overview
LLaVa is an open-source chatbot trained by fine-tuning LlamA/Vicuna on GPT-generated multimodal instruction-following data. It is an auto-regressive language model, based on the transformer architecture. In other words, it is an multi-modal version of LLMs fine-tuned for chat / instructions.
The LLaVa model was proposed in [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) and improved in [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/pdf/2310.03744) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
The abstract from the paper is the following:
*Large multimodal models (LMM) have recently shown encouraging progress with visual instruction tuning. In this note, we show that the fully-connected vision-language cross-modal connector in LLaVA is surprisingly powerful and data-efficient. With simple modifications to LLaVA, namely, using CLIP-ViT-L-336px with an MLP projection and adding academic-task-oriented VQA data with simple response formatting prompts, we establish stronger baselines that achieve state-of-the-art across 11 benchmarks. Our final 13B checkpoint uses merely 1.2M publicly available data, and finishes full training in ∼1 day on a single 8-A100 node. We hope this can make state-of-the-art LMM research more accessible. Code and model will be publicly available*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/llava_architecture.jpg"
alt="drawing" width="600"/>
<small> LLaVa architecture. Taken from the <a href="https://arxiv.org/abs/2304.08485">original paper.</a> </small>
This model was contributed by [ArthurZ](https://huggingface.co/ArthurZ) and [ybelkada](https://huggingface.co/ybelkada).
The original code can be found [here](https://github.com/haotian-liu/LLaVA/tree/main/llava).
## Usage tips
- We advise users to use `padding_side="left"` when computing batched generation as it leads to more accurate results. Simply make sure to call `processor.tokenizer.padding_side = "left"` before generating.
- Note the model has not been explicitly trained to process multiple images in the same prompt, although this is technically possible, you may experience inaccurate results.
- For better results, we recommend users to prompt the model with the correct prompt format:
```bash
"USER: <image>\n<prompt>ASSISTANT:"
```
For multiple turns conversation:
```bash
"USER: <image>\n<prompt1>ASSISTANT: <answer1>USER: <prompt2>ASSISTANT: <answer2>USER: <prompt3>ASSISTANT:"
```
### Using Flash Attention 2
Flash Attention 2 is an even faster, optimized version of the previous optimization, please refer to the [Flash Attention 2 section of performance docs](https://huggingface.co/docs/transformers/perf_infer_gpu_one).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BEiT.
<PipelineTag pipeline="image-to-text"/>
- A [Google Colab demo](https://colab.research.google.com/drive/1qsl6cd2c8gGtEW1xV5io7S8NHh-Cp1TV?usp=sharing) on how to run Llava on a free-tier Google colab instance leveraging 4-bit inference.
- A [similar notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LLaVa/Inference_with_LLaVa_for_multimodal_generation.ipynb) showcasing batched inference. 🌎
## LlavaConfig
[[autodoc]] LlavaConfig
## LlavaProcessor
[[autodoc]] LlavaProcessor
## LlavaForConditionalGeneration
[[autodoc]] LlavaForConditionalGeneration
- forward
|
huggingface/transformers/blob/main/docs/source/en/model_doc/llava.md
|
Create a dataset for training
There are many datasets on the [Hub](https://huggingface.co/datasets?task_categories=task_categories:text-to-image&sort=downloads) to train a model on, but if you can't find one you're interested in or want to use your own, you can create a dataset with the 🤗 [Datasets](hf.co/docs/datasets) library. The dataset structure depends on the task you want to train your model on. The most basic dataset structure is a directory of images for tasks like unconditional image generation. Another dataset structure may be a directory of images and a text file containing their corresponding text captions for tasks like text-to-image generation.
This guide will show you two ways to create a dataset to finetune on:
- provide a folder of images to the `--train_data_dir` argument
- upload a dataset to the Hub and pass the dataset repository id to the `--dataset_name` argument
<Tip>
💡 Learn more about how to create an image dataset for training in the [Create an image dataset](https://huggingface.co/docs/datasets/image_dataset) guide.
</Tip>
## Provide a dataset as a folder
For unconditional generation, you can provide your own dataset as a folder of images. The training script uses the [`ImageFolder`](https://huggingface.co/docs/datasets/en/image_dataset#imagefolder) builder from 🤗 Datasets to automatically build a dataset from the folder. Your directory structure should look like:
```bash
data_dir/xxx.png
data_dir/xxy.png
data_dir/[...]/xxz.png
```
Pass the path to the dataset directory to the `--train_data_dir` argument, and then you can start training:
```bash
accelerate launch train_unconditional.py \
--train_data_dir <path-to-train-directory> \
<other-arguments>
```
## Upload your data to the Hub
<Tip>
💡 For more details and context about creating and uploading a dataset to the Hub, take a look at the [Image search with 🤗 Datasets](https://huggingface.co/blog/image-search-datasets) post.
</Tip>
Start by creating a dataset with the [`ImageFolder`](https://huggingface.co/docs/datasets/image_load#imagefolder) feature, which creates an `image` column containing the PIL-encoded images.
You can use the `data_dir` or `data_files` parameters to specify the location of the dataset. The `data_files` parameter supports mapping specific files to dataset splits like `train` or `test`:
```python
from datasets import load_dataset
# example 1: local folder
dataset = load_dataset("imagefolder", data_dir="path_to_your_folder")
# example 2: local files (supported formats are tar, gzip, zip, xz, rar, zstd)
dataset = load_dataset("imagefolder", data_files="path_to_zip_file")
# example 3: remote files (supported formats are tar, gzip, zip, xz, rar, zstd)
dataset = load_dataset(
"imagefolder",
data_files="https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_3367a.zip",
)
# example 4: providing several splits
dataset = load_dataset(
"imagefolder", data_files={"train": ["path/to/file1", "path/to/file2"], "test": ["path/to/file3", "path/to/file4"]}
)
```
Then use the [`~datasets.Dataset.push_to_hub`] method to upload the dataset to the Hub:
```python
# assuming you have ran the huggingface-cli login command in a terminal
dataset.push_to_hub("name_of_your_dataset")
# if you want to push to a private repo, simply pass private=True:
dataset.push_to_hub("name_of_your_dataset", private=True)
```
Now the dataset is available for training by passing the dataset name to the `--dataset_name` argument:
```bash
accelerate launch --mixed_precision="fp16" train_text_to_image.py \
--pretrained_model_name_or_path="runwayml/stable-diffusion-v1-5" \
--dataset_name="name_of_your_dataset" \
<other-arguments>
```
## Next steps
Now that you've created a dataset, you can plug it into the `train_data_dir` (if your dataset is local) or `dataset_name` (if your dataset is on the Hub) arguments of a training script.
For your next steps, feel free to try and use your dataset to train a model for [unconditional generation](unconditional_training) or [text-to-image generation](text2image)!
|
huggingface/diffusers/blob/main/docs/source/en/training/create_dataset.md
|
Gradio Demo: neon-tts-plugin-coqui
### This demo converts text to speech in 14 languages.
```
!pip install -q gradio neon-tts-plugin-coqui==0.4.1a9
```
```
# Downloading files from the demo repo
import os
!wget -q https://github.com/gradio-app/gradio/raw/main/demo/neon-tts-plugin-coqui/packages.txt
```
```
import tempfile
import gradio as gr
from neon_tts_plugin_coqui import CoquiTTS
LANGUAGES = list(CoquiTTS.langs.keys())
coquiTTS = CoquiTTS()
def tts(text: str, language: str):
with tempfile.NamedTemporaryFile(suffix=".wav", delete=False) as fp:
coquiTTS.get_tts(text, fp, speaker = {"language" : language})
return fp.name
inputs = [gr.Textbox(label="Input", value=CoquiTTS.langs["en"]["sentence"], max_lines=3),
gr.Radio(label="Language", choices=LANGUAGES, value="en")]
outputs = gr.Audio(label="Output")
demo = gr.Interface(fn=tts, inputs=inputs, outputs=outputs)
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/neon-tts-plugin-coqui/run.ipynb
|
@gradio/tooltip
## 0.1.0
## 0.1.0-beta.2
### Features
- [#6136](https://github.com/gradio-app/gradio/pull/6136) [`667802a6c`](https://github.com/gradio-app/gradio/commit/667802a6cdbfb2ce454a3be5a78e0990b194548a) - JS Component Documentation. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.1.0-beta.1
### Fixes
- [#6046](https://github.com/gradio-app/gradio/pull/6046) [`dbb7de5e0`](https://github.com/gradio-app/gradio/commit/dbb7de5e02c53fee05889d696d764d212cb96c74) - fix tests. Thanks [@pngwn](https://github.com/pngwn)!
## 0.1.0-beta.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`681f10c31`](https://github.com/gradio-app/gradio/commit/681f10c315a75cc8cd0473c9a0167961af7696db) - release first version. Thanks [@pngwn](https://github.com/pngwn)!
|
gradio-app/gradio/blob/main/js/tooltip/CHANGELOG.md
|
``python
import argparse
import os
import torch
from torch.optim import AdamW
from torch.utils.data import DataLoader
from peft import (
get_peft_config,
get_peft_model,
get_peft_model_state_dict,
set_peft_model_state_dict,
LoraConfig,
PeftType,
PrefixTuningConfig,
PromptEncoderConfig,
)
import evaluate
from datasets import load_dataset
from transformers import AutoModelForSequenceClassification, AutoTokenizer, get_linear_schedule_with_warmup, set_seed
from tqdm import tqdm
```
```python
batch_size = 32
model_name_or_path = "roberta-large"
task = "mrpc"
peft_type = PeftType.LORA
device = "cuda"
num_epochs = 20
```
```python
peft_config = LoraConfig(task_type="SEQ_CLS", inference_mode=False, r=8, lora_alpha=16, lora_dropout=0.1)
lr = 3e-4
```
```python
if any(k in model_name_or_path for k in ("gpt", "opt", "bloom")):
padding_side = "left"
else:
padding_side = "right"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, padding_side=padding_side)
if getattr(tokenizer, "pad_token_id") is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
datasets = load_dataset("glue", task)
metric = evaluate.load("glue", task)
def tokenize_function(examples):
# max_length=None => use the model max length (it's actually the default)
outputs = tokenizer(examples["sentence1"], examples["sentence2"], truncation=True, max_length=None)
return outputs
tokenized_datasets = datasets.map(
tokenize_function,
batched=True,
remove_columns=["idx", "sentence1", "sentence2"],
)
# We also rename the 'label' column to 'labels' which is the expected name for labels by the models of the
# transformers library
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
def collate_fn(examples):
return tokenizer.pad(examples, padding="longest", return_tensors="pt")
# Instantiate dataloaders.
train_dataloader = DataLoader(tokenized_datasets["train"], shuffle=True, collate_fn=collate_fn, batch_size=batch_size)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], shuffle=False, collate_fn=collate_fn, batch_size=batch_size
)
```
```python
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
model
```
```python
optimizer = AdamW(params=model.parameters(), lr=lr)
# Instantiate scheduler
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=0.06 * (len(train_dataloader) * num_epochs),
num_training_steps=(len(train_dataloader) * num_epochs),
)
```
```python
model.to(device)
for epoch in range(num_epochs):
model.train()
for step, batch in enumerate(tqdm(train_dataloader)):
batch.to(device)
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
for step, batch in enumerate(tqdm(eval_dataloader)):
batch.to(device)
with torch.no_grad():
outputs = model(**batch)
predictions = outputs.logits.argmax(dim=-1)
predictions, references = predictions, batch["labels"]
metric.add_batch(
predictions=predictions,
references=references,
)
eval_metric = metric.compute()
print(f"epoch {epoch}:", eval_metric)
```
## Share adapters on the 🤗 Hub
```python
model.push_to_hub("smangrul/roberta-large-peft-lora", use_auth_token=True)
```
## Load adapters from the Hub
You can also directly load adapters from the Hub using the commands below:
```python
import torch
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
peft_model_id = "smangrul/roberta-large-peft-lora"
config = PeftConfig.from_pretrained(peft_model_id)
inference_model = AutoModelForSequenceClassification.from_pretrained(config.base_model_name_or_path)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
# Load the Lora model
inference_model = PeftModel.from_pretrained(inference_model, peft_model_id)
inference_model.to(device)
inference_model.eval()
for step, batch in enumerate(tqdm(eval_dataloader)):
batch.to(device)
with torch.no_grad():
outputs = inference_model(**batch)
predictions = outputs.logits.argmax(dim=-1)
predictions, references = predictions, batch["labels"]
metric.add_batch(
predictions=predictions,
references=references,
)
eval_metric = metric.compute()
print(eval_metric)
```
|
huggingface/peft/blob/main/examples/sequence_classification/LoRA.ipynb
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# InstructBLIP
## Overview
The InstructBLIP model was proposed in [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
InstructBLIP leverages the [BLIP-2](blip2) architecture for visual instruction tuning.
The abstract from the paper is the following:
*General-purpose language models that can solve various language-domain tasks have emerged driven by the pre-training and instruction-tuning pipeline. However, building general-purpose vision-language models is challenging due to the increased task discrepancy introduced by the additional visual input. Although vision-language pre-training has been widely studied, vision-language instruction tuning remains relatively less explored. In this paper, we conduct a systematic and comprehensive study on vision-language instruction tuning based on the pre-trained BLIP-2 models. We gather a wide variety of 26 publicly available datasets, transform them into instruction tuning format and categorize them into two clusters for held-in instruction tuning and held-out zero-shot evaluation. Additionally, we introduce instruction-aware visual feature extraction, a crucial method that enables the model to extract informative features tailored to the given instruction. The resulting InstructBLIP models achieve state-of-the-art zero-shot performance across all 13 held-out datasets, substantially outperforming BLIP-2 and the larger Flamingo. Our models also lead to state-of-the-art performance when finetuned on individual downstream tasks (e.g., 90.7% accuracy on ScienceQA IMG). Furthermore, we qualitatively demonstrate the advantages of InstructBLIP over concurrent multimodal models.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/instructblip_architecture.jpg"
alt="drawing" width="600"/>
<small> InstructBLIP architecture. Taken from the <a href="https://arxiv.org/abs/2305.06500">original paper.</a> </small>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/salesforce/LAVIS/tree/main/projects/instructblip).
## Usage tips
InstructBLIP uses the same architecture as [BLIP-2](blip2) with a tiny but important difference: it also feeds the text prompt (instruction) to the Q-Former.
## InstructBlipConfig
[[autodoc]] InstructBlipConfig
- from_vision_qformer_text_configs
## InstructBlipVisionConfig
[[autodoc]] InstructBlipVisionConfig
## InstructBlipQFormerConfig
[[autodoc]] InstructBlipQFormerConfig
## InstructBlipProcessor
[[autodoc]] InstructBlipProcessor
## InstructBlipVisionModel
[[autodoc]] InstructBlipVisionModel
- forward
## InstructBlipQFormerModel
[[autodoc]] InstructBlipQFormerModel
- forward
## InstructBlipForConditionalGeneration
[[autodoc]] InstructBlipForConditionalGeneration
- forward
- generate
|
huggingface/transformers/blob/main/docs/source/en/model_doc/instructblip.md
|
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Generating the documentation
To generate the documentation, you first have to build it. Several packages are necessary to build the doc,
you can install them with the following command, at the root of the code repository:
```bash
pip install -e ".[docs]"
```
Then you need to install our special tool that builds the documentation:
```bash
pip install git+https://github.com/huggingface/doc-builder
```
---
**NOTE**
You only need to generate the documentation to inspect it locally (if you're planning changes and want to
check how they look before committing for instance). You don't have to `git commit` the built documentation.
---
## Building the documentation
Once you have setup the `doc-builder` and additional packages, you can generate the documentation by typing
the following command:
```bash
doc-builder build datasets docs/source/ --build_dir ~/tmp/test-build
```
You can adapt the `--build_dir` to set any temporary folder that you prefer. This command will create it and generate
the MDX files that will be rendered as the documentation on the main website. You can inspect them in your favorite
Markdown editor.
## Previewing the documentation
To preview the docs, first install the `watchdog` module with:
```bash
pip install watchdog
```
Then run the following command:
```bash
doc-builder preview datasets docs/source/
```
The docs will be viewable at [http://localhost:3000](http://localhost:3000). You can also preview the docs once you have opened a PR. You will see a bot add a comment to a link where the documentation with your changes lives.
---
**NOTE**
The `preview` command only works with existing doc files. When you add a completely new file, you need to update `_toctree.yml` & restart `preview` command (`ctrl-c` to stop it & call `doc-builder preview ...` again).
## Adding a new element to the navigation bar
Accepted files are Markdown (.md or .mdx).
Create a file with its extension and put it in the source directory. You can then link it to the toc-tree by putting
the filename without the extension in the [`_toctree.yml`](https://github.com/huggingface/datasets/blob/main/docs/source/_toctree.yml) file.
## Renaming section headers and moving sections
It helps to keep the old links working when renaming the section header and/or moving sections from one document to another. This is because the old links are likely to be used in Issues, Forums and Social media and it'd make for a much more superior user experience if users reading those months later could still easily navigate to the originally intended information.
Therefore we simply keep a little map of moved sections at the end of the document where the original section was. The key is to preserve the original anchor.
So if you renamed a section from: "Section A" to "Section B", then you can add at the end of the file:
```
Sections that were moved:
[ <a href="#section-b">Section A</a><a id="section-a"></a> ]
```
and of course if you moved it to another file, then:
```
Sections that were moved:
[ <a href="../new-file#section-b">Section A</a><a id="section-a"></a> ]
```
Use the relative style to link to the new file so that the versioned docs continue to work.
For an example of a rich moved sections set please see the very end of [the transformers Trainer doc](https://github.com/huggingface/transformers/blob/main/docs/source/en/main_classes/trainer.md).
## Writing Documentation - Specification
The `huggingface/datasets` documentation follows the
[Google documentation](https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html) style for docstrings,
although we can write them directly in Markdown.
### Adding a new tutorial
Adding a new tutorial or section is done in two steps:
- Add a new file under `./source`. This file can either be ReStructuredText (.rst) or Markdown (.md).
- Link that file in `./source/_toctree.yml` on the correct toc-tree.
Make sure to put your new file under the proper section. If you have a doubt, feel free to ask in a Github Issue or PR.
### Writing source documentation
Values that should be put in `code` should either be surrounded by backticks: \`like so\`. Note that argument names
and objects like True, None or any strings should usually be put in `code`.
When mentioning a class, function or method, it is recommended to use our syntax for internal links so that our tool
adds a link to its documentation with this syntax: \[\`XXXClass\`\] or \[\`function\`\]. This requires the class or
function to be in the main package.
If you want to create a link to some internal class or function, you need to
provide its path. For instance: \[\`table.InMemoryTable\`\]. This will be converted into a link with
`table.InMemoryTable` in the description. To get rid of the path and only keep the name of the object you are
linking to in the description, add a ~: \[\`~table.InMemoryTable\`\] will generate a link with `InMemoryTable` in the description.
The same works for methods so you can either use \[\`XXXClass.method\`\] or \[~\`XXXClass.method\`\].
#### Defining arguments in a method
Arguments should be defined with the `Args:` (or `Arguments:` or `Parameters:`) prefix, followed by a line return and
an indentation. The argument should be followed by its type, with its shape if it is a tensor, a colon and its
description:
```
Args:
n_layers (`int`): The number of layers of the model.
```
If the description is too long to fit in one line, another indentation is necessary before writing the description
after the argument.
Here's an example showcasing everything so far:
```
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`AlbertTokenizer`]. See [`~PreTrainedTokenizer.encode`] and
[`~PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
```
For optional arguments or arguments with defaults we follow the following syntax: imagine we have a function with the
following signature:
```
def my_function(x: str = None, a: float = 1):
```
then its documentation should look like this:
```
Args:
x (`str`, *optional*):
This argument controls ...
a (`float`, *optional*, defaults to 1):
This argument is used to ...
```
Note that we always omit the "defaults to \`None\`" when None is the default for any argument. Also note that even
if the first line describing your argument type and its default gets long, you can't break it into several lines. You can
however write as many lines as you want in the indented description (see the example above with `input_ids`).
#### Writing a multi-line code block
Multi-line code blocks can be useful for displaying examples. They are done between two lines of three backticks as usual in Markdown:
````
```
# first line of code
# second line
# etc
```
````
#### Writing a return block
The return block should be introduced with the `Returns:` prefix, followed by a line return and an indentation.
The first line should be the type of the return, followed by a line return. No need to indent further for the elements
building the return.
Here's an example of a single value return:
```
Returns:
`List[int]`: A list of integers in the range [0, 1] --- 1 for a special token, 0 for a sequence token.
```
Here's an example of tuple return, comprising several objects:
```
Returns:
`tuple(torch.FloatTensor)` comprising various elements depending on the configuration ([`BertConfig`]) and inputs:
- ** loss** (*optional*, returned when `masked_lm_labels` is provided) `torch.FloatTensor` of shape `(1,)` --
Total loss as the sum of the masked language modeling loss and the next sequence prediction (classification) loss.
- **prediction_scores** (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`) --
Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
```
#### Adding an image
Due to the rapidly growing repository, it is important to make sure that no files that would significantly weigh down the repository are added. This includes images, videos and other non-text files. We prefer to leverage a hf.co hosted `dataset` like
the ones hosted on [`hf-internal-testing`](https://huggingface.co/hf-internal-testing) in which to place these files and reference
them by URL. We recommend putting them in the following dataset: [huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images).
If an external contribution, feel free to add the images to your PR and ask a Hugging Face member to migrate your images
to this dataset.
## Writing documentation examples
The syntax for Example docstrings can look as follows:
```
Example:
```py
>>> from datasets import load_dataset
>>> ds = load_dataset("rotten_tomatoes", split="validation")
>>> def add_prefix(example):
... example["text"] = "Review: " + example["text"]
... return example
>>> ds = ds.map(add_prefix)
>>> ds[0:3]["text"]
['Review: compassionately explores the seemingly irreconcilable situation between conservative christian parents and their estranged gay and lesbian children .',
'Review: the soundtrack alone is worth the price of admission .',
'Review: rodriguez does a splendid job of racial profiling hollywood style--casting excellent latin actors of all ages--a trend long overdue .']
# process a batch of examples
>>> ds = ds.map(lambda example: tokenizer(example["text"]), batched=True)
# set number of processors
>>> ds = ds.map(add_prefix, num_proc=4)
```
```
The docstring should give a minimal, clear example of how the respective class or function is to be used in practice and also include the expected (ideally sensible) output.
Often, readers will try out the example before even going through the function
or class definitions. Therefore, it is of utmost importance that the example
works as expected.
|
huggingface/datasets/blob/main/docs/README.md
|
Subsets and Splits
Transformers Source Texts
This query retrieves specific examples from the dataset related to transformers, providing a limited view of the data with basic filtering.