
text
stringlengths 23
371k
| source
stringlengths 32
152
|
|---|---|
--
title: NIST_MT
emoji: 🤗
colorFrom: purple
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
- machine-translation
description:
DARPA commissioned NIST to develop an MT evaluation facility based on the BLEU score.
---
# Metric Card for NIST's MT metric
## Metric Description
DARPA commissioned NIST to develop an MT evaluation facility based on the BLEU
score. The official script used by NIST to compute BLEU and NIST score is
mteval-14.pl. The main differences are:
- BLEU uses geometric mean of the ngram overlaps, NIST uses arithmetic mean.
- NIST has a different brevity penalty
- NIST score from mteval-14.pl has a self-contained tokenizer (in the Hugging Face implementation we rely on NLTK's
implementation of the NIST-specific tokenizer)
## Intended Uses
NIST was developed for machine translation evaluation.
## How to Use
```python
import evaluate
nist_mt = evaluate.load("nist_mt")
hypothesis1 = "It is a guide to action which ensures that the military always obeys the commands of the party"
reference1 = "It is a guide to action that ensures that the military will forever heed Party commands"
reference2 = "It is the guiding principle which guarantees the military forces always being under the command of the Party"
nist_mt.compute(hypothesis1, [reference1, reference2])
# {'nist_mt': 3.3709935957649324}
```
### Inputs
- **predictions**: tokenized predictions to score. For sentence-level NIST, a list of tokens (str);
for corpus-level NIST, a list (sentences) of lists of tokens (str)
- **references**: potentially multiple tokenized references for each prediction. For sentence-level NIST, a
list (multiple potential references) of list of tokens (str); for corpus-level NIST, a list (corpus) of lists
(multiple potential references) of lists of tokens (str)
- **n**: highest n-gram order
- **tokenize_kwargs**: arguments passed to the tokenizer (see: https://github.com/nltk/nltk/blob/90fa546ea600194f2799ee51eaf1b729c128711e/nltk/tokenize/nist.py#L139)
### Output Values
- **nist_mt** (`float`): NIST score
Output Example:
```python
{'nist_mt': 3.3709935957649324}
```
## Citation
```bibtex
@inproceedings{10.5555/1289189.1289273,
author = {Doddington, George},
title = {Automatic Evaluation of Machine Translation Quality Using N-Gram Co-Occurrence Statistics},
year = {2002},
publisher = {Morgan Kaufmann Publishers Inc.},
address = {San Francisco, CA, USA},
booktitle = {Proceedings of the Second International Conference on Human Language Technology Research},
pages = {138–145},
numpages = {8},
location = {San Diego, California},
series = {HLT '02}
}
```
## Further References
This Hugging Face implementation uses [the NLTK implementation](https://github.com/nltk/nltk/blob/develop/nltk/translate/nist_score.py)
|
huggingface/evaluate/blob/main/metrics/nist_mt/README.md
|
SSL ResNet
**Residual Networks**, or **ResNets**, learn residual functions with reference to the layer inputs, instead of learning unreferenced functions. Instead of hoping each few stacked layers directly fit a desired underlying mapping, residual nets let these layers fit a residual mapping. They stack [residual blocks](https://paperswithcode.com/method/residual-block) ontop of each other to form network: e.g. a ResNet-50 has fifty layers using these blocks.
The model in this collection utilises semi-supervised learning to improve the performance of the model. The approach brings important gains to standard architectures for image, video and fine-grained classification.
Please note the CC-BY-NC 4.0 license on theses weights, non-commercial use only.
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('ssl_resnet18', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `ssl_resnet18`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('ssl_resnet18', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/abs-1905-00546,
author = {I. Zeki Yalniz and
Herv{\'{e}} J{\'{e}}gou and
Kan Chen and
Manohar Paluri and
Dhruv Mahajan},
title = {Billion-scale semi-supervised learning for image classification},
journal = {CoRR},
volume = {abs/1905.00546},
year = {2019},
url = {http://arxiv.org/abs/1905.00546},
archivePrefix = {arXiv},
eprint = {1905.00546},
timestamp = {Mon, 28 Sep 2020 08:19:37 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-1905-00546.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<!--
Type: model-index
Collections:
- Name: SSL ResNet
Paper:
Title: Billion-scale semi-supervised learning for image classification
URL: https://paperswithcode.com/paper/billion-scale-semi-supervised-learning-for
Models:
- Name: ssl_resnet18
In Collection: SSL ResNet
Metadata:
FLOPs: 2337073152
Parameters: 11690000
File Size: 46811375
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
- YFCC-100M
Training Resources: 64x GPUs
ID: ssl_resnet18
LR: 0.0015
Epochs: 30
Layers: 18
Crop Pct: '0.875'
Batch Size: 1536
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/resnet.py#L894
Weights: https://dl.fbaipublicfiles.com/semiweaksupervision/model_files/semi_supervised_resnet18-d92f0530.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 72.62%
Top 5 Accuracy: 91.42%
- Name: ssl_resnet50
In Collection: SSL ResNet
Metadata:
FLOPs: 5282531328
Parameters: 25560000
File Size: 102480594
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
- YFCC-100M
Training Resources: 64x GPUs
ID: ssl_resnet50
LR: 0.0015
Epochs: 30
Layers: 50
Crop Pct: '0.875'
Batch Size: 1536
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/resnet.py#L904
Weights: https://dl.fbaipublicfiles.com/semiweaksupervision/model_files/semi_supervised_resnet50-08389792.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.24%
Top 5 Accuracy: 94.83%
-->
|
huggingface/pytorch-image-models/blob/main/hfdocs/source/models/ssl-resnet.mdx
|
--
title: What's new in Diffusers? 🎨
thumbnail: /blog/assets/102_diffusers_2nd_month/inpainting.png
authors:
- user: osanseviero
---
# What's new in Diffusers? 🎨
A month and a half ago we released `diffusers`, a library that provides a modular toolbox for diffusion models across modalities. A couple of weeks later, we released support for Stable Diffusion, a high quality text-to-image model, with a free demo for anyone to try out. Apart from burning lots of GPUs, in the last three weeks the team has decided to add one or two new features to the library that we hope the community enjoys! This blog post gives a high-level overview of the new features in `diffusers` version 0.3! Remember to give a ⭐ to the [GitHub repository](https://github.com/huggingface/diffusers).
- [Image to Image pipelines](#image-to-image-pipeline)
- [Textual Inversion](#textual-inversion)
- [Inpainting](#experimental-inpainting-pipeline)
- [Optimizations for Smaller GPUs](#optimizations-for-smaller-gpus)
- [Run on Mac](#diffusers-in-mac-os)
- [ONNX Exporter](#experimental-onnx-exporter-and-pipeline)
- [New docs](#new-docs)
- [Community](#community)
- [Generate videos with SD latent space](#stable-diffusion-videos)
- [Model Explainability](#diffusers-interpret)
- [Japanese Stable Diffusion](#japanese-stable-diffusion)
- [High quality fine-tuned model](#waifu-diffusion)
- [Cross Attention Control with Stable Diffusion](#cross-attention-control)
- [Reusable seeds](#reusable-seeds)
## Image to Image pipeline
One of the most requested features was to have image to image generation. This pipeline allows you to input an image and a prompt, and it will generate an image based on that!
Let's see some code based on the official Colab [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/image_2_image_using_diffusers.ipynb).
```python
from diffusers import StableDiffusionImg2ImgPipeline
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True
)
# Download an initial image
# ...
init_image = preprocess(init_img)
prompt = "A fantasy landscape, trending on artstation"
images = pipe(prompt=prompt, init_image=init_image, strength=0.75, guidance_scale=7.5, generator=generator)["sample"]
```
Don't have time for code? No worries, we also created a [Space demo](https://huggingface.co/spaces/huggingface/diffuse-the-rest) where you can try it out directly
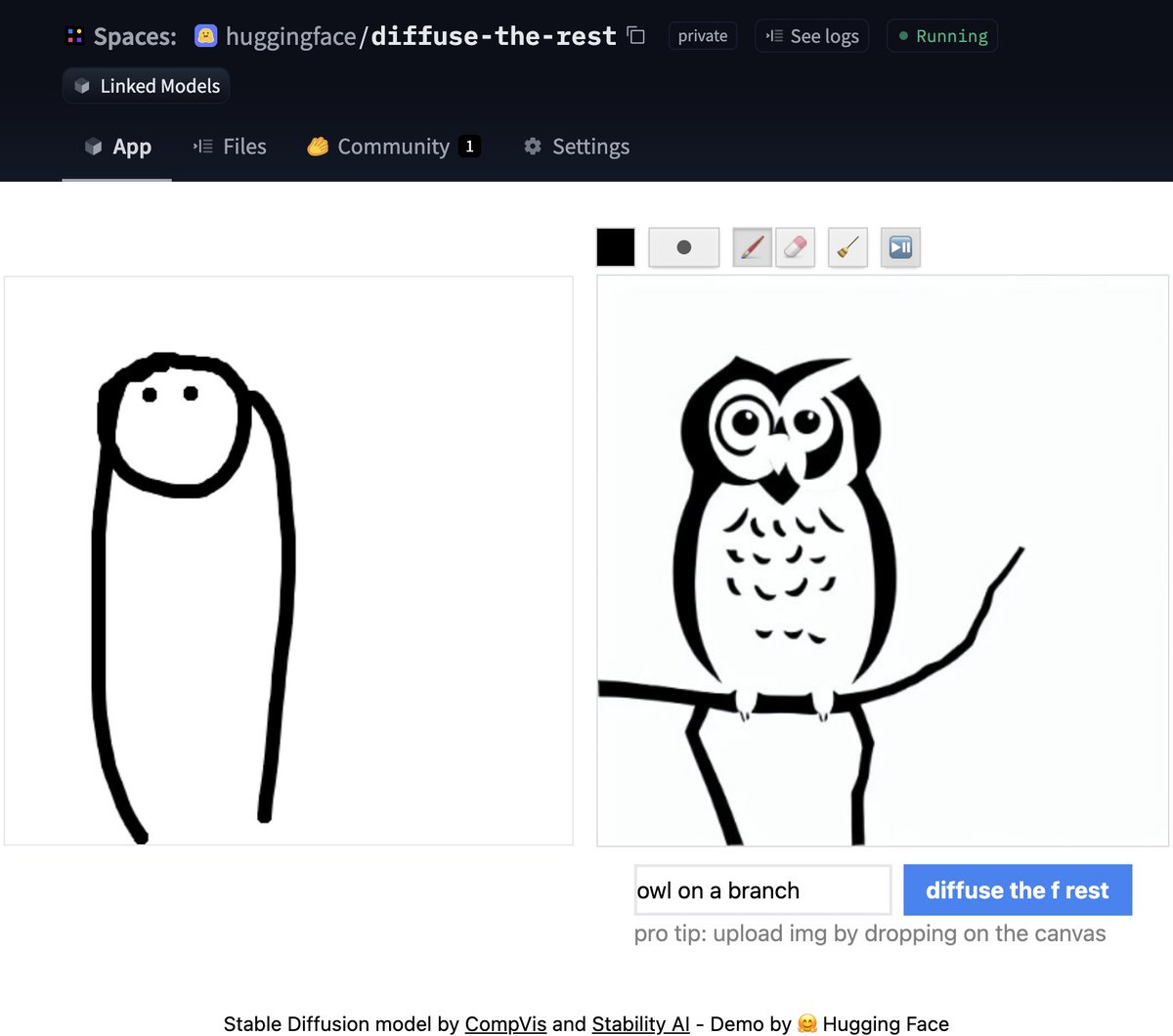
## Textual Inversion
Textual Inversion lets you personalize a Stable Diffusion model on your own images with just 3-5 samples. With this tool, you can train a model on a concept, and then share the concept with the rest of the community!
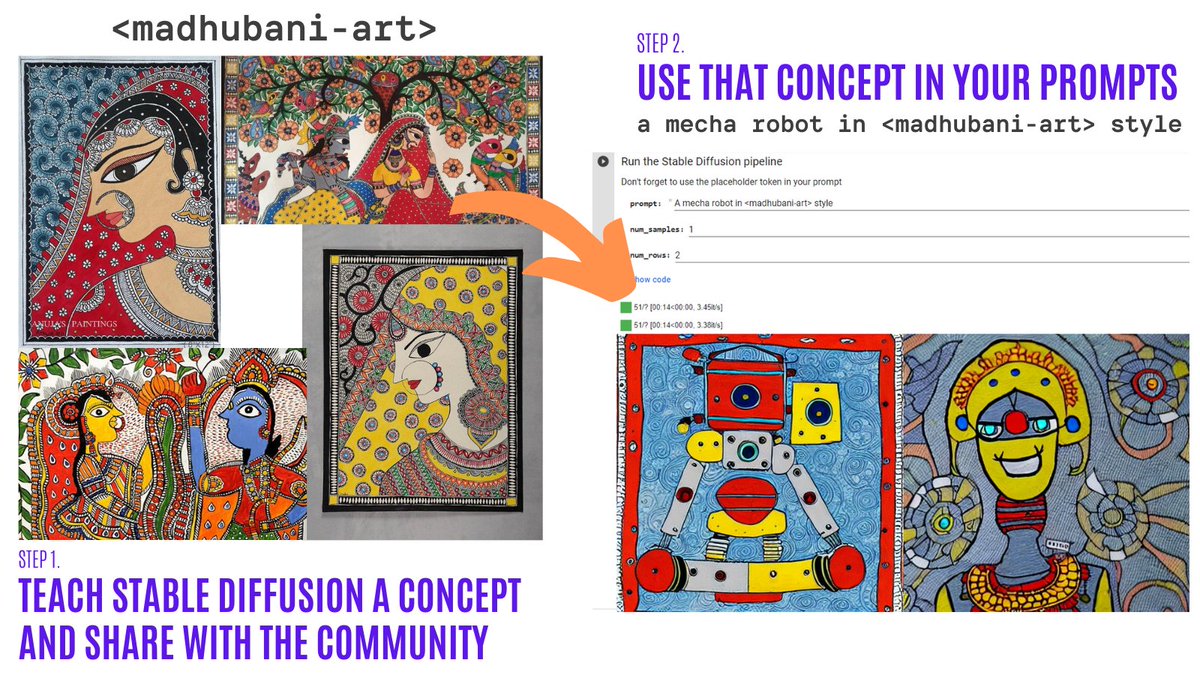
In just a couple of days, the community shared over 200 concepts! Check them out!
* [Organization](https://huggingface.co/sd-concepts-library) with the concepts.
* [Navigator Colab](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion_textual_inversion_library_navigator.ipynb): Browse visually and use over 150 concepts created by the community.
* [Training Colab](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb): Teach Stable Diffusion a new concept and share it with the rest of the community.
* [Inference Colab](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb): Run Stable Diffusion with the learned concepts.
## Experimental inpainting pipeline
Inpainting allows to provide an image, then select an area in the image (or provide a mask), and use Stable Diffusion to replace the mask. Here is an example:
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/diffusers-2nd-month/inpainting.png" alt="Example inpaint of owl being generated from an initial image and a prompt"/>
</figure>
You can try out a minimal Colab [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/in_painting_with_stable_diffusion_using_diffusers.ipynb) or check out the code below. A demo is coming soon!
```python
from diffusers import StableDiffusionInpaintPipeline
pipe = StableDiffusionInpaintPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True
).to(device)
images = pipe(
prompt=["a cat sitting on a bench"] * 3,
init_image=init_image,
mask_image=mask_image,
strength=0.75,
guidance_scale=7.5,
generator=None
).images
```
Please note this is experimental, so there is room for improvement.
## Optimizations for smaller GPUs
After some improvements, the diffusion models can take much less VRAM. 🔥 For example, Stable Diffusion only takes 3.2GB! This yields the exact same results at the expense of 10% of speed. Here is how to use these optimizations
```python
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True
)
pipe = pipe.to("cuda")
pipe.enable_attention_slicing()
```
This is super exciting as this will reduce even more the barrier to use these models!
## Diffusers in Mac OS
🍎 That's right! Another widely requested feature was just released! Read the full instructions in the [official docs](https://huggingface.co/docs/diffusers/optimization/mps) (including performance comparisons, specs, and more).
Using the PyTorch mps device, people with M1/M2 hardware can run inference with Stable Diffusion. 🤯 This requires minimal setup for users, try it out!
```python
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=True)
pipe = pipe.to("mps")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
```
## Experimental ONNX exporter and pipeline
The new experimental pipeline allows users to run Stable Diffusion on any hardware that supports ONNX. Here is an example of how to use it (note that the `onnx` revision is being used)
```python
from diffusers import StableDiffusionOnnxPipeline
pipe = StableDiffusionOnnxPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="onnx",
provider="CPUExecutionProvider",
use_auth_token=True,
)
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
```
Alternatively, you can also convert your SD checkpoints to ONNX directly with the exporter script.
```
python scripts/convert_stable_diffusion_checkpoint_to_onnx.py --model_path="CompVis/stable-diffusion-v1-4" --output_path="./stable_diffusion_onnx"
```
## New docs
All of the previous features are very cool. As maintainers of open-source libraries, we know about the importance of high quality documentation to make it as easy as possible for anyone to try out the library.
💅 Because of this, we did a Docs sprint and we're very excited to do a first release of our [documentation](https://huggingface.co/docs/diffusers/v0.3.0/en/index). This is a first version, so there are many things we plan to add (and contributions are always welcome!).
Some highlights of the docs:
* Techniques for [optimization](https://huggingface.co/docs/diffusers/optimization/fp16)
* The [training overview](https://huggingface.co/docs/diffusers/training/overview)
* A [contributing guide](https://huggingface.co/docs/diffusers/conceptual/contribution)
* In-depth API docs for [schedulers](https://huggingface.co/docs/diffusers/api/schedulers)
* In-depth API docs for [pipelines](https://huggingface.co/docs/diffusers/api/pipelines/overview)
## Community
And while we were doing all of the above, the community did not stay idle! Here are some highlights (although not exhaustive) of what has been done out there
### Stable Diffusion Videos
Create 🔥 videos with Stable Diffusion by exploring the latent space and morphing between text prompts. You can:
* Dream different versions of the same prompt
* Morph between different prompts
The [Stable Diffusion Videos](https://github.com/nateraw/stable-diffusion-videos) tool is pip-installable, comes with a Colab notebook and a Gradio notebook, and is super easy to use!
Here is an example
```python
from stable_diffusion_videos import walk
video_path = walk(['a cat', 'a dog'], [42, 1337], num_steps=3, make_video=True)
```
### Diffusers Interpret
[Diffusers interpret](https://github.com/JoaoLages/diffusers-interpret) is an explainability tool built on top of `diffusers`. It has cool features such as:
* See all the images in the diffusion process
* Analyze how each token in the prompt influences the generation
* Analyze within specified bounding boxes if you want to understand a part of the image
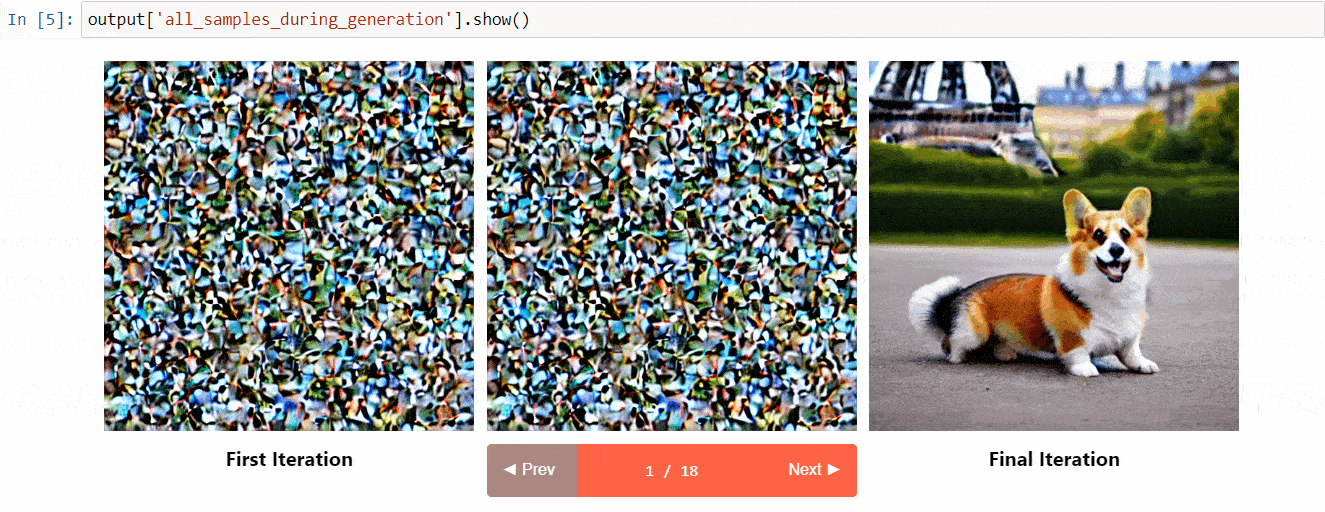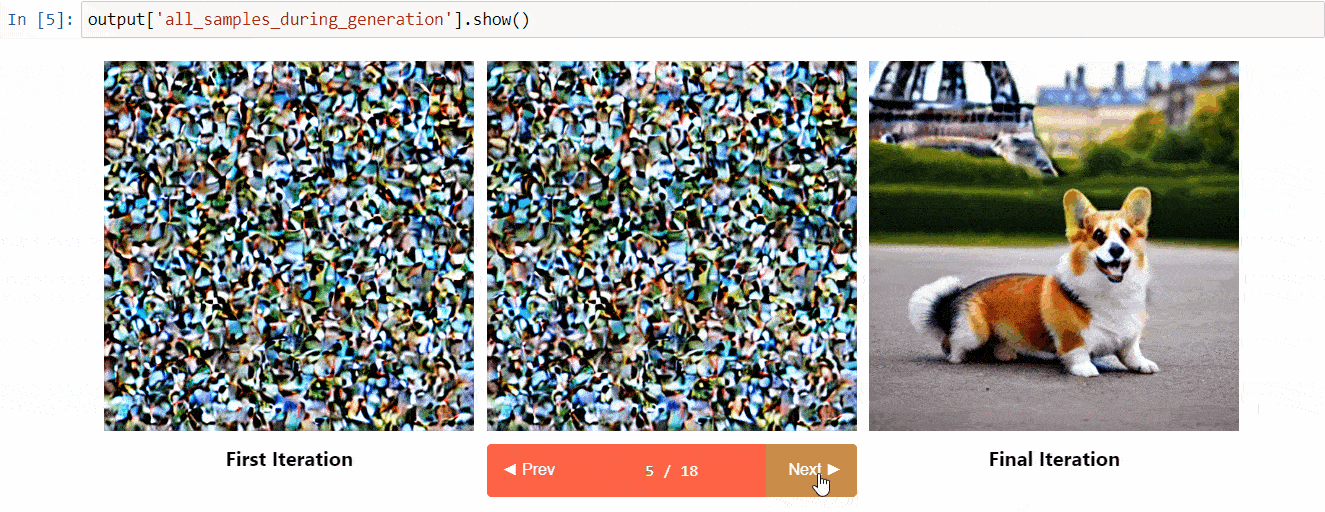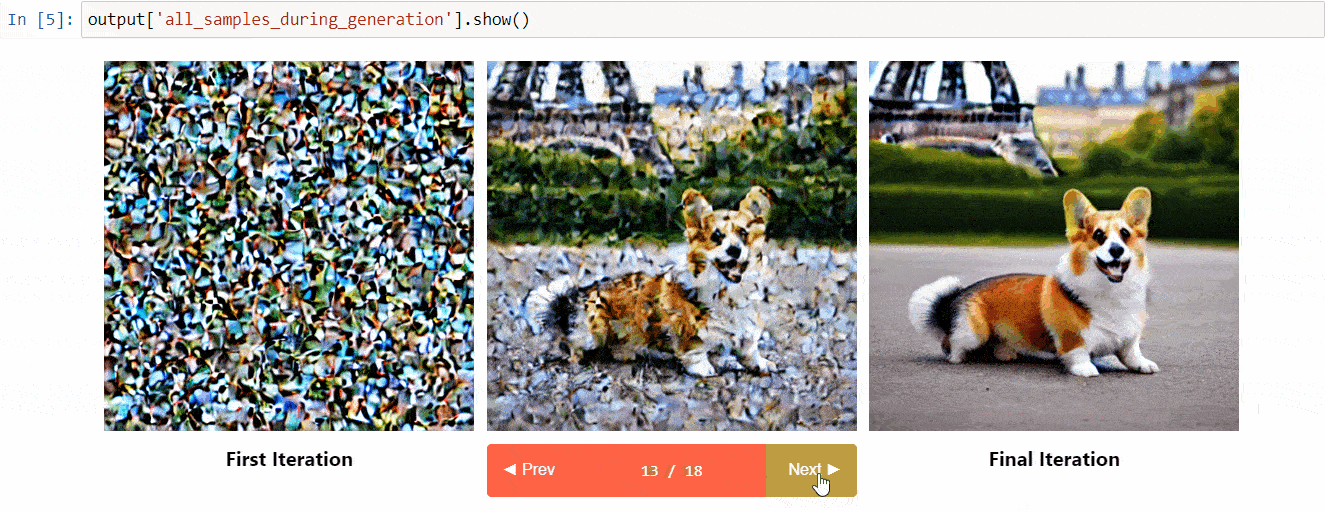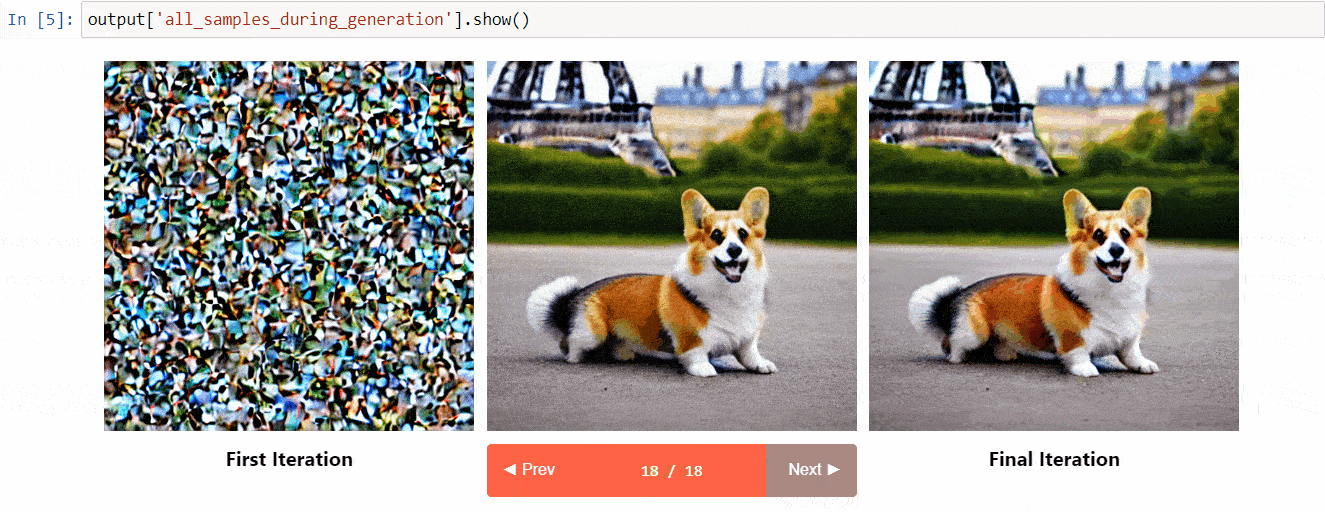
(Image from the tool repository)
```python
# pass pipeline to the explainer class
explainer = StableDiffusionPipelineExplainer(pipe)
# generate an image with `explainer`
prompt = "Corgi with the Eiffel Tower"
output = explainer(
prompt,
num_inference_steps=15
)
output.normalized_token_attributions # (token, attribution_percentage)
#[('corgi', 40),
# ('with', 5),
# ('the', 5),
# ('eiffel', 25),
# ('tower', 25)]
```
### Japanese Stable Diffusion
The name says it all! The goal of JSD was to train a model that also captures information about the culture, identity and unique expressions. It was trained with 100 million images with Japanese captions. You can read more about how the model was trained in the [model card](https://huggingface.co/rinna/japanese-stable-diffusion)
### Waifu Diffusion
[Waifu Diffusion](https://huggingface.co/hakurei/waifu-diffusion) is a fine-tuned SD model for high-quality anime images generation.
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/diffusers-2nd-month/waifu.png" alt="Images of high quality anime"/>
</figure>
(Image from the tool repository)
### Cross Attention Control
[Cross Attention Control](https://github.com/bloc97/CrossAttentionControl) allows fine control of the prompts by modifying the attention maps of the diffusion models. Some cool things you can do:
* Replace a target in the prompt (e.g. replace cat by dog)
* Reduce or increase the importance of words in the prompt (e.g. if you want less attention to be given to "rocks")
* Easily inject styles
And much more! Check out the repo.
### Reusable Seeds
One of the most impressive early demos of Stable Diffusion was the reuse of seeds to tweak images. The idea is to use the seed of an image of interest to generate a new image, with a different prompt. This yields some cool results! Check out the [Colab](https://colab.research.google.com/github/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb)
## Thanks for reading!
I hope you enjoy reading this! Remember to give a Star in our [GitHub Repository](https://github.com/huggingface/diffusers) and join the [Hugging Face Discord Server](https://hf.co/join/discord), where we have a category of channels just for Diffusion models. Over there the latest news in the library are shared!
Feel free to open issues with feature requests and bug reports! Everything that has been achieved couldn't have been done without such an amazing community.
|
huggingface/blog/blob/main/diffusers-2nd-month.md
|
Adversarial Inception v3
**Inception v3** is a convolutional neural network architecture from the Inception family that makes several improvements including using [Label Smoothing](https://paperswithcode.com/method/label-smoothing), Factorized 7 x 7 convolutions, and the use of an [auxiliary classifer](https://paperswithcode.com/method/auxiliary-classifier) to propagate label information lower down the network (along with the use of batch normalization for layers in the sidehead). The key building block is an [Inception Module](https://paperswithcode.com/method/inception-v3-module).
This particular model was trained for study of adversarial examples (adversarial training).
The weights from this model were ported from [Tensorflow/Models](https://github.com/tensorflow/models).
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('adv_inception_v3', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `adv_inception_v3`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('adv_inception_v3', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/abs-1804-00097,
author = {Alexey Kurakin and
Ian J. Goodfellow and
Samy Bengio and
Yinpeng Dong and
Fangzhou Liao and
Ming Liang and
Tianyu Pang and
Jun Zhu and
Xiaolin Hu and
Cihang Xie and
Jianyu Wang and
Zhishuai Zhang and
Zhou Ren and
Alan L. Yuille and
Sangxia Huang and
Yao Zhao and
Yuzhe Zhao and
Zhonglin Han and
Junjiajia Long and
Yerkebulan Berdibekov and
Takuya Akiba and
Seiya Tokui and
Motoki Abe},
title = {Adversarial Attacks and Defences Competition},
journal = {CoRR},
volume = {abs/1804.00097},
year = {2018},
url = {http://arxiv.org/abs/1804.00097},
archivePrefix = {arXiv},
eprint = {1804.00097},
timestamp = {Thu, 31 Oct 2019 16:31:22 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1804-00097.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<!--
Type: model-index
Collections:
- Name: Adversarial Inception v3
Paper:
Title: Adversarial Attacks and Defences Competition
URL: https://paperswithcode.com/paper/adversarial-attacks-and-defences-competition
Models:
- Name: adv_inception_v3
In Collection: Adversarial Inception v3
Metadata:
FLOPs: 7352418880
Parameters: 23830000
File Size: 95549439
Architecture:
- 1x1 Convolution
- Auxiliary Classifier
- Average Pooling
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inception-v3 Module
- Max Pooling
- ReLU
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: adv_inception_v3
Crop Pct: '0.875'
Image Size: '299'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/inception_v3.py#L456
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/adv_inception_v3-9e27bd63.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.58%
Top 5 Accuracy: 93.74%
-->
|
huggingface/pytorch-image-models/blob/main/docs/models/adversarial-inception-v3.md
|
`@gradio/code`
```html
<script>
import { BaseCode, BaseCopy, BaseDownload, BaseWidget, BaseExample} from "gradio/code";
</script>
```
BaseCode
```javascript
export let classNames = "";
export let value = "";
export let dark_mode: boolean;
export let basic = true;
export let language: string;
export let lines = 5;
export let extensions: Extension[] = [];
export let useTab = true;
export let readonly = false;
export let placeholder: string | HTMLElement | null | undefined = undefined;
```
BaseCopy
```javascript
export let value: string;
```
BaseDownload
```javascript
export let value: string;
export let language: string;
```
BaseWidget
```javascript
export let value: string;
export let language: string;
```
BaseExample
```
export let value: string;
export let type: "gallery" | "table";
export let selected = false;
```
|
gradio-app/gradio/blob/main/js/code/README.md
|
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 安装
在开始之前,您需要通过安装适当的软件包来设置您的环境
huggingface_hub 在 Python 3.8 或更高版本上进行了测试,可以保证在这些版本上正常运行。如果您使用的是 Python 3.7 或更低版本,可能会出现兼容性问题
## 使用 pip 安装
我们建议将huggingface_hub安装在[虚拟环境](https://docs.python.org/3/library/venv.html)中.
如果你不熟悉 Python虚拟环境,可以看看这个[指南](https://packaging.python.org/en/latest/guides/installing-using-pip-and-virtual-environments/).
虚拟环境可以更容易地管理不同的项目,避免依赖项之间的兼容性问题
首先在你的项目目录中创建一个虚拟环境,请运行以下代码:
```bash
python -m venv .env
```
在Linux和macOS上,请运行以下代码激活虚拟环境:
```bash
source .env/bin/activate
```
在 Windows 上,请运行以下代码激活虚拟环境:
```bash
.env/Scripts/activate
```
现在您可以从[PyPi注册表](https://pypi.org/project/huggingface-hub/)安装 `huggingface_hub`:
```bash
pip install --upgrade huggingface_hub
```
完成后,[检查安装](#check-installation)是否正常工作
### 安装可选依赖项
`huggingface_hub`的某些依赖项是 [可选](https://setuptools.pypa.io/en/latest/userguide/dependency_management.html#optional-dependencies) 的,因为它们不是运行`huggingface_hub`的核心功能所必需的.但是,如果没有安装可选依赖项, `huggingface_hub` 的某些功能可能会无法使用
您可以通过`pip`安装可选依赖项,请运行以下代码:
```bash
# 安装 TensorFlow 特定功能的依赖项
# /!\ 注意:这不等同于 `pip install tensorflow`
pip install 'huggingface_hub[tensorflow]'
# 安装 TensorFlow 特定功能和 CLI 特定功能的依赖项
pip install 'huggingface_hub[cli,torch]'
```
这里列出了 `huggingface_hub` 的可选依赖项:
- `cli`:为 `huggingface_hub` 提供更方便的命令行界面
- `fastai`,` torch`, `tensorflow`: 运行框架特定功能所需的依赖项
- `dev`:用于为库做贡献的依赖项。包括 `testing`(用于运行测试)、`typing`(用于运行类型检查器)和 `quality`(用于运行 linter)
### 从源代码安装
在某些情况下,直接从源代码安装`huggingface_hub`会更有趣。因为您可以使用最新的主版本`main`而非最新的稳定版本
`main`版本更有利于跟进平台的最新开发进度,例如,在最近一次官方发布之后和最新的官方发布之前所修复的某个错误
但是,这意味着`main`版本可能不总是稳定的。我们会尽力让其正常运行,大多数问题通常会在几小时或一天内解决。如果您遇到问题,请创建一个 Issue ,以便我们可以更快地解决!
```bash
pip install git+https://github.com/huggingface/huggingface_hub # 使用pip从GitHub仓库安装Hugging Face Hub库
```
从源代码安装时,您还可以指定特定的分支。如果您想测试尚未合并的新功能或新错误修复,这很有用
```bash
pip install git+https://github.com/huggingface/huggingface_hub@my-feature-branch # 使用pip从指定的GitHub分支(my-feature-branch)安装Hugging Face Hub库
```
完成安装后,请[检查安装](#check-installation)是否正常工作
### 可编辑安装
从源代码安装允许您设置[可编辑安装](https://pip.pypa.io/en/stable/topics/local-project-installs/#editable-installs).如果您计划为`huggingface_hub`做出贡献并需要测试代码更改,这是一个更高级的安装方式。您需要在本机上克隆一个`huggingface_hub`的本地副本
```bash
# 第一,使用以下命令克隆代码库
git clone https://github.com/huggingface/huggingface_hub.git
# 然后,使用以下命令启动虚拟环境
cd huggingface_hub
pip install -e .
```
这些命令将你克隆存储库的文件夹与你的 Python 库路径链接起来。Python 现在将除了正常的库路径之外,还会在你克隆到的文件夹中查找。例如,如果你的 Python 包通常安装在`./.venv/lib/python3.11/site-packages/`中,Python 还会搜索你克隆的文件夹`./huggingface_hub/`
## 通过 conda 安装
如果你更熟悉它,你可以使用[conda-forge channel](https://anaconda.org/conda-forge/huggingface_hub)渠道来安装 `huggingface_hub`
请运行以下代码:
```bash
conda install -c conda-forge huggingface_hub
```
完成安装后,请[检查安装](#check-installation)是否正常工作
## 验证安装
安装完成后,通过运行以下命令检查`huggingface_hub`是否正常工作:
```bash
python -c "from huggingface_hub import model_info; print(model_info('gpt2'))"
```
这个命令将从 Hub 获取有关 [gpt2](https://huggingface.co/gpt2) 模型的信息。
输出应如下所示:
```text
Model Name: gpt2 模型名称
Tags: ['pytorch', 'tf', 'jax', 'tflite', 'rust', 'safetensors', 'gpt2', 'text-generation', 'en', 'doi:10.57967/hf/0039', 'transformers', 'exbert', 'license:mit', 'has_space'] 标签
Task: text-generation 任务:文本生成
```
## Windows局限性
为了实现让每个人都能使用机器学习的目标,我们构建了 `huggingface_hub`库,使其成为一个跨平台的库,尤其可以在 Unix 和 Windows 系统上正常工作。但是,在某些情况下,`huggingface_hub`在Windows上运行时会有一些限制。以下是一些已知问题的完整列表。如果您遇到任何未记录的问题,请打开 [Github上的issue](https://github.com/huggingface/huggingface_hub/issues/new/choose).让我们知道
- `huggingface_hub`的缓存系统依赖于符号链接来高效地缓存从Hub下载的文件。在Windows上,您必须激活开发者模式或以管理员身份运行您的脚本才能启用符号链接。如果它们没有被激活,缓存系统仍然可以工作,但效率较低。有关更多详细信息,请阅读[缓存限制](./guides/manage-cache#limitations)部分。
- Hub上的文件路径可能包含特殊字符(例如:`path/to?/my/file`)。Windows对[特殊字符](https://learn.microsoft.com/en-us/windows/win32/intl/character-sets-used-in-file-names)更加严格,这使得在Windows上下载这些文件变得不可能。希望这是罕见的情况。如果您认为这是一个错误,请联系存储库所有者或我们,以找出解决方案。
## 后记
一旦您在机器上正确安装了`huggingface_hub`,您可能需要[配置环境变量](package_reference/environment_variables)或者[查看我们的指南之一](guides/overview)以开始使用。
|
huggingface/huggingface_hub/blob/main/docs/source/cn/installation.md
|
p align="center">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://huggingface.co/datasets/safetensors/assets/raw/main/banner-dark.svg">
<source media="(prefers-color-scheme: light)" srcset="https://huggingface.co/datasets/safetensors/assets/raw/main/banner-light.svg">
<img alt="Hugging Face Safetensors Library" src="https://huggingface.co/datasets/safetensors/assets/raw/main/banner-light.svg" style="max-width: 100%;">
</picture>
<br/>
<br/>
</p>
Python
[](https://pypi.org/pypi/safetensors/)
[](https://huggingface.co/docs/safetensors/index)
[](https://codecov.io/gh/huggingface/safetensors)
[](https://pepy.tech/project/safetensors)
Rust
[](https://crates.io/crates/safetensors)
[](https://docs.rs/safetensors/)
[](https://codecov.io/gh/huggingface/safetensors)
[](https://deps.rs/repo/github/huggingface/safetensors?path=safetensors)
# safetensors
## Safetensors
This repository implements a new simple format for storing tensors
safely (as opposed to pickle) and that is still fast (zero-copy).
### Installation
#### Pip
You can install safetensors via the pip manager:
```bash
pip install safetensors
```
#### From source
For the sources, you need Rust
```bash
# Install Rust
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
# Make sure it's up to date and using stable channel
rustup update
git clone https://github.com/huggingface/safetensors
cd safetensors/bindings/python
pip install setuptools_rust
pip install -e .
```
### Getting started
```python
import torch
from safetensors import safe_open
from safetensors.torch import save_file
tensors = {
"weight1": torch.zeros((1024, 1024)),
"weight2": torch.zeros((1024, 1024))
}
save_file(tensors, "model.safetensors")
tensors = {}
with safe_open("model.safetensors", framework="pt", device="cpu") as f:
for key in f.keys():
tensors[key] = f.get_tensor(key)
```
[Python documentation](https://huggingface.co/docs/safetensors/index)
### Format
- 8 bytes: `N`, an unsigned little-endian 64-bit integer, containing the size of the header
- N bytes: a JSON UTF-8 string representing the header.
- The header data MUST begin with a `{` character (0x7B).
- The header data MAY be trailing padded with whitespace (0x20).
- The header is a dict like `{"TENSOR_NAME": {"dtype": "F16", "shape": [1, 16, 256], "data_offsets": [BEGIN, END]}, "NEXT_TENSOR_NAME": {...}, ...}`,
- `data_offsets` point to the tensor data relative to the beginning of the byte buffer (i.e. not an absolute position in the file),
with `BEGIN` as the starting offset and `END` as the one-past offset (so total tensor byte size = `END - BEGIN`).
- A special key `__metadata__` is allowed to contain free form string-to-string map. Arbitrary JSON is not allowed, all values must be strings.
- Rest of the file: byte-buffer.
Notes:
- Duplicate keys are disallowed. Not all parsers may respect this.
- In general the subset of JSON is implicitly decided by `serde_json` for
this library. Anything obscure might be modified at a later time, that odd ways
to represent integer, newlines and escapes in utf-8 strings. This would only
be done for safety concerns
- Tensor values are not checked against, in particular NaN and +/-Inf could
be in the file
- Empty tensors (tensors with 1 dimension being 0) are allowed.
They are not storing any data in the databuffer, yet retaining size in the header.
They don't really bring a lot of values but are accepted since they are valid tensors
from traditional tensor libraries perspective (torch, tensorflow, numpy, ..).
- 0-rank Tensors (tensors with shape `[]`) are allowed, they are merely a scalar.
- The byte buffer needs to be entirely indexed, and cannot contain holes. This prevents
the creation of polyglot files.
- Endianness: Little-endian.
moment.
- Order: 'C' or row-major.
### Yet another format ?
The main rationale for this crate is to remove the need to use
`pickle` on `PyTorch` which is used by default.
There are other formats out there used by machine learning and more general
formats.
Let's take a look at alternatives and why this format is deemed interesting.
This is my very personal and probably biased view:
| Format | Safe | Zero-copy | Lazy loading | No file size limit | Layout control | Flexibility | Bfloat16/Fp8
| ----------------------- | --- | --- | --- | --- | --- | --- | --- |
| pickle (PyTorch) | ✗ | ✗ | ✗ | 🗸 | ✗ | 🗸 | 🗸 |
| H5 (Tensorflow) | 🗸 | ✗ | 🗸 | 🗸 | ~ | ~ | ✗ |
| SavedModel (Tensorflow) | 🗸 | ✗ | ✗ | 🗸 | 🗸 | ✗ | 🗸 |
| MsgPack (flax) | 🗸 | 🗸 | ✗ | 🗸 | ✗ | ✗ | 🗸 |
| Protobuf (ONNX) | 🗸 | ✗ | ✗ | ✗ | ✗ | ✗ | 🗸 |
| Cap'n'Proto | 🗸 | 🗸 | ~ | 🗸 | 🗸 | ~ | ✗ |
| Arrow | ? | ? | ? | ? | ? | ? | ✗ |
| Numpy (npy,npz) | 🗸 | ? | ? | ✗ | 🗸 | ✗ | ✗ |
| pdparams (Paddle) | ✗ | ✗ | ✗ | 🗸 | ✗ | 🗸 | 🗸 |
| SafeTensors | 🗸 | 🗸 | 🗸 | 🗸 | 🗸 | ✗ | 🗸 |
- Safe: Can I use a file randomly downloaded and expect not to run arbitrary code ?
- Zero-copy: Does reading the file require more memory than the original file ?
- Lazy loading: Can I inspect the file without loading everything ? And loading only
some tensors in it without scanning the whole file (distributed setting) ?
- Layout control: Lazy loading, is not necessarily enough since if the information about tensors is spread out in your file, then even if the information is lazily accessible you might have to access most of your file to read the available tensors (incurring many DISK -> RAM copies). Controlling the layout to keep fast access to single tensors is important.
- No file size limit: Is there a limit to the file size ?
- Flexibility: Can I save custom code in the format and be able to use it later with zero extra code ? (~ means we can store more than pure tensors, but no custom code)
- Bfloat16/Fp8: Does the format support native bfloat16/fp8 (meaning no weird workarounds are
necessary)? This is becoming increasingly important in the ML world.
### Main oppositions
- Pickle: Unsafe, runs arbitrary code
- H5: Apparently now discouraged for TF/Keras. Seems like a great fit otherwise actually. Some classic use after free issues: <https://www.cvedetails.com/vulnerability-list/vendor_id-15991/product_id-35054/Hdfgroup-Hdf5.html>. On a very different level than pickle security-wise. Also 210k lines of code vs ~400 lines for this lib currently.
- SavedModel: Tensorflow specific (it contains TF graph information).
- MsgPack: No layout control to enable lazy loading (important for loading specific parts in distributed setting)
- Protobuf: Hard 2Go max file size limit
- Cap'n'proto: Float16 support is not present [link](https://capnproto.org/language.html#built-in-types) so using a manual wrapper over a byte-buffer would be necessary. Layout control seems possible but not trivial as buffers have limitations [link](https://stackoverflow.com/questions/48458839/capnproto-maximum-filesize).
- Numpy (npz): No `bfloat16` support. Vulnerable to zip bombs (DOS). Not zero-copy.
- Arrow: No `bfloat16` support. Seem to require decoding [link](https://arrow.apache.org/docs/python/parquet.html#reading-parquet-and-memory-mapping)
### Notes
- Zero-copy: No format is really zero-copy in ML, it needs to go from disk to RAM/GPU RAM (that takes time). On CPU, if the file is already in cache, then it can
truly be zero-copy, whereas on GPU there is not such disk cache, so a copy is always required
but you can bypass allocating all the tensors on CPU at any given point.
SafeTensors is not zero-copy for the header. The choice of JSON is pretty arbitrary, but since deserialization is <<< of the time required to load the actual tensor data and is readable I went that way, (also space is <<< to the tensor data).
- Endianness: Little-endian. This can be modified later, but it feels really unnecessary at the
moment.
- Order: 'C' or row-major. This seems to have won. We can add that information later if needed.
- Stride: No striding, all tensors need to be packed before being serialized. I have yet to see a case where it seems useful to have a strided tensor stored in serialized format.
### Benefits
Since we can invent a new format we can propose additional benefits:
- Prevent DOS attacks: We can craft the format in such a way that it's almost
impossible to use malicious files to DOS attack a user. Currently, there's a limit
on the size of the header of 100MB to prevent parsing extremely large JSON.
Also when reading the file, there's a guarantee that addresses in the file
do not overlap in any way, meaning when you're loading a file you should never
exceed the size of the file in memory
- Faster load: PyTorch seems to be the fastest file to load out in the major
ML formats. However, it does seem to have an extra copy on CPU, which we
can bypass in this lib by using `torch.UntypedStorage.from_file`.
Currently, CPU loading times are extremely fast with this lib compared to pickle.
GPU loading times are as fast or faster than PyTorch equivalent.
Loading first on CPU with memmapping with torch, and then moving all tensors to GPU seems
to be faster too somehow (similar behavior in torch pickle)
- Lazy loading: in distributed (multi-node or multi-gpu) settings, it's nice to be able to
load only part of the tensors on the various models. For
[BLOOM](https://huggingface.co/bigscience/bloom) using this format enabled
to load the model on 8 GPUs from 10mn with regular PyTorch weights down to 45s.
This really speeds up feedbacks loops when developing on the model. For instance
you don't have to have separate copies of the weights when changing the distribution
strategy (for instance Pipeline Parallelism vs Tensor Parallelism).
License: Apache-2.0
|
huggingface/safetensors/blob/main/README.md
|
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Auto Classes
In many cases, the architecture you want to use can be guessed from the name or the path of the pretrained model you
are supplying to the `from_pretrained()` method. AutoClasses are here to do this job for you so that you
automatically retrieve the relevant model given the name/path to the pretrained weights/config/vocabulary.
Instantiating one of [`AutoConfig`], [`AutoModel`], and
[`AutoTokenizer`] will directly create a class of the relevant architecture. For instance
```python
model = AutoModel.from_pretrained("bert-base-cased")
```
will create a model that is an instance of [`BertModel`].
There is one class of `AutoModel` for each task, and for each backend (PyTorch, TensorFlow, or Flax).
## Extending the Auto Classes
Each of the auto classes has a method to be extended with your custom classes. For instance, if you have defined a
custom class of model `NewModel`, make sure you have a `NewModelConfig` then you can add those to the auto
classes like this:
```python
from transformers import AutoConfig, AutoModel
AutoConfig.register("new-model", NewModelConfig)
AutoModel.register(NewModelConfig, NewModel)
```
You will then be able to use the auto classes like you would usually do!
<Tip warning={true}>
If your `NewModelConfig` is a subclass of [`~transformers.PretrainedConfig`], make sure its
`model_type` attribute is set to the same key you use when registering the config (here `"new-model"`).
Likewise, if your `NewModel` is a subclass of [`PreTrainedModel`], make sure its
`config_class` attribute is set to the same class you use when registering the model (here
`NewModelConfig`).
</Tip>
## AutoConfig
[[autodoc]] AutoConfig
## AutoTokenizer
[[autodoc]] AutoTokenizer
## AutoFeatureExtractor
[[autodoc]] AutoFeatureExtractor
## AutoImageProcessor
[[autodoc]] AutoImageProcessor
## AutoProcessor
[[autodoc]] AutoProcessor
## Generic model classes
The following auto classes are available for instantiating a base model class without a specific head.
### AutoModel
[[autodoc]] AutoModel
### TFAutoModel
[[autodoc]] TFAutoModel
### FlaxAutoModel
[[autodoc]] FlaxAutoModel
## Generic pretraining classes
The following auto classes are available for instantiating a model with a pretraining head.
### AutoModelForPreTraining
[[autodoc]] AutoModelForPreTraining
### TFAutoModelForPreTraining
[[autodoc]] TFAutoModelForPreTraining
### FlaxAutoModelForPreTraining
[[autodoc]] FlaxAutoModelForPreTraining
## Natural Language Processing
The following auto classes are available for the following natural language processing tasks.
### AutoModelForCausalLM
[[autodoc]] AutoModelForCausalLM
### TFAutoModelForCausalLM
[[autodoc]] TFAutoModelForCausalLM
### FlaxAutoModelForCausalLM
[[autodoc]] FlaxAutoModelForCausalLM
### AutoModelForMaskedLM
[[autodoc]] AutoModelForMaskedLM
### TFAutoModelForMaskedLM
[[autodoc]] TFAutoModelForMaskedLM
### FlaxAutoModelForMaskedLM
[[autodoc]] FlaxAutoModelForMaskedLM
### AutoModelForMaskGeneration
[[autodoc]] AutoModelForMaskGeneration
### TFAutoModelForMaskGeneration
[[autodoc]] TFAutoModelForMaskGeneration
### AutoModelForSeq2SeqLM
[[autodoc]] AutoModelForSeq2SeqLM
### TFAutoModelForSeq2SeqLM
[[autodoc]] TFAutoModelForSeq2SeqLM
### FlaxAutoModelForSeq2SeqLM
[[autodoc]] FlaxAutoModelForSeq2SeqLM
### AutoModelForSequenceClassification
[[autodoc]] AutoModelForSequenceClassification
### TFAutoModelForSequenceClassification
[[autodoc]] TFAutoModelForSequenceClassification
### FlaxAutoModelForSequenceClassification
[[autodoc]] FlaxAutoModelForSequenceClassification
### AutoModelForMultipleChoice
[[autodoc]] AutoModelForMultipleChoice
### TFAutoModelForMultipleChoice
[[autodoc]] TFAutoModelForMultipleChoice
### FlaxAutoModelForMultipleChoice
[[autodoc]] FlaxAutoModelForMultipleChoice
### AutoModelForNextSentencePrediction
[[autodoc]] AutoModelForNextSentencePrediction
### TFAutoModelForNextSentencePrediction
[[autodoc]] TFAutoModelForNextSentencePrediction
### FlaxAutoModelForNextSentencePrediction
[[autodoc]] FlaxAutoModelForNextSentencePrediction
### AutoModelForTokenClassification
[[autodoc]] AutoModelForTokenClassification
### TFAutoModelForTokenClassification
[[autodoc]] TFAutoModelForTokenClassification
### FlaxAutoModelForTokenClassification
[[autodoc]] FlaxAutoModelForTokenClassification
### AutoModelForQuestionAnswering
[[autodoc]] AutoModelForQuestionAnswering
### TFAutoModelForQuestionAnswering
[[autodoc]] TFAutoModelForQuestionAnswering
### FlaxAutoModelForQuestionAnswering
[[autodoc]] FlaxAutoModelForQuestionAnswering
### AutoModelForTextEncoding
[[autodoc]] AutoModelForTextEncoding
### TFAutoModelForTextEncoding
[[autodoc]] TFAutoModelForTextEncoding
## Computer vision
The following auto classes are available for the following computer vision tasks.
### AutoModelForDepthEstimation
[[autodoc]] AutoModelForDepthEstimation
### AutoModelForImageClassification
[[autodoc]] AutoModelForImageClassification
### TFAutoModelForImageClassification
[[autodoc]] TFAutoModelForImageClassification
### FlaxAutoModelForImageClassification
[[autodoc]] FlaxAutoModelForImageClassification
### AutoModelForVideoClassification
[[autodoc]] AutoModelForVideoClassification
### AutoModelForMaskedImageModeling
[[autodoc]] AutoModelForMaskedImageModeling
### TFAutoModelForMaskedImageModeling
[[autodoc]] TFAutoModelForMaskedImageModeling
### AutoModelForObjectDetection
[[autodoc]] AutoModelForObjectDetection
### AutoModelForImageSegmentation
[[autodoc]] AutoModelForImageSegmentation
### AutoModelForImageToImage
[[autodoc]] AutoModelForImageToImage
### AutoModelForSemanticSegmentation
[[autodoc]] AutoModelForSemanticSegmentation
### TFAutoModelForSemanticSegmentation
[[autodoc]] TFAutoModelForSemanticSegmentation
### AutoModelForInstanceSegmentation
[[autodoc]] AutoModelForInstanceSegmentation
### AutoModelForUniversalSegmentation
[[autodoc]] AutoModelForUniversalSegmentation
### AutoModelForZeroShotImageClassification
[[autodoc]] AutoModelForZeroShotImageClassification
### TFAutoModelForZeroShotImageClassification
[[autodoc]] TFAutoModelForZeroShotImageClassification
### AutoModelForZeroShotObjectDetection
[[autodoc]] AutoModelForZeroShotObjectDetection
## Audio
The following auto classes are available for the following audio tasks.
### AutoModelForAudioClassification
[[autodoc]] AutoModelForAudioClassification
### AutoModelForAudioFrameClassification
[[autodoc]] TFAutoModelForAudioClassification
### TFAutoModelForAudioFrameClassification
[[autodoc]] AutoModelForAudioFrameClassification
### AutoModelForCTC
[[autodoc]] AutoModelForCTC
### AutoModelForSpeechSeq2Seq
[[autodoc]] AutoModelForSpeechSeq2Seq
### TFAutoModelForSpeechSeq2Seq
[[autodoc]] TFAutoModelForSpeechSeq2Seq
### FlaxAutoModelForSpeechSeq2Seq
[[autodoc]] FlaxAutoModelForSpeechSeq2Seq
### AutoModelForAudioXVector
[[autodoc]] AutoModelForAudioXVector
### AutoModelForTextToSpectrogram
[[autodoc]] AutoModelForTextToSpectrogram
### AutoModelForTextToWaveform
[[autodoc]] AutoModelForTextToWaveform
## Multimodal
The following auto classes are available for the following multimodal tasks.
### AutoModelForTableQuestionAnswering
[[autodoc]] AutoModelForTableQuestionAnswering
### TFAutoModelForTableQuestionAnswering
[[autodoc]] TFAutoModelForTableQuestionAnswering
### AutoModelForDocumentQuestionAnswering
[[autodoc]] AutoModelForDocumentQuestionAnswering
### TFAutoModelForDocumentQuestionAnswering
[[autodoc]] TFAutoModelForDocumentQuestionAnswering
### AutoModelForVisualQuestionAnswering
[[autodoc]] AutoModelForVisualQuestionAnswering
### AutoModelForVision2Seq
[[autodoc]] AutoModelForVision2Seq
### TFAutoModelForVision2Seq
[[autodoc]] TFAutoModelForVision2Seq
### FlaxAutoModelForVision2Seq
[[autodoc]] FlaxAutoModelForVision2Seq
|
huggingface/transformers/blob/main/docs/source/en/model_doc/auto.md
|
Gradio Demo: gif_maker
```
!pip install -q gradio opencv-python
```
```
import cv2
import gradio as gr
def gif_maker(img_files):
img_array = []
for filename in img_files:
img = cv2.imread(filename.name)
height, width, _ = img.shape
size = (width,height)
img_array.append(img)
output_file = "test.mp4"
out = cv2.VideoWriter(output_file,cv2.VideoWriter_fourcc(*'h264'), 15, size)
for i in range(len(img_array)):
out.write(img_array[i])
out.release()
return output_file
demo = gr.Interface(gif_maker, inputs=gr.File(file_count="multiple"), outputs=gr.Video())
if __name__ == "__main__":
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/gif_maker/run.ipynb
|
SWSL ResNet
**Residual Networks**, or **ResNets**, learn residual functions with reference to the layer inputs, instead of learning unreferenced functions. Instead of hoping each few stacked layers directly fit a desired underlying mapping, residual nets let these layers fit a residual mapping. They stack [residual blocks](https://paperswithcode.com/method/residual-block) ontop of each other to form network: e.g. a ResNet-50 has fifty layers using these blocks.
The models in this collection utilise semi-weakly supervised learning to improve the performance of the model. The approach brings important gains to standard architectures for image, video and fine-grained classification.
Please note the CC-BY-NC 4.0 license on theses weights, non-commercial use only.
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('swsl_resnet18', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `swsl_resnet18`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('swsl_resnet18', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/abs-1905-00546,
author = {I. Zeki Yalniz and
Herv{\'{e}} J{\'{e}}gou and
Kan Chen and
Manohar Paluri and
Dhruv Mahajan},
title = {Billion-scale semi-supervised learning for image classification},
journal = {CoRR},
volume = {abs/1905.00546},
year = {2019},
url = {http://arxiv.org/abs/1905.00546},
archivePrefix = {arXiv},
eprint = {1905.00546},
timestamp = {Mon, 28 Sep 2020 08:19:37 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-1905-00546.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<!--
Type: model-index
Collections:
- Name: SWSL ResNet
Paper:
Title: Billion-scale semi-supervised learning for image classification
URL: https://paperswithcode.com/paper/billion-scale-semi-supervised-learning-for
Models:
- Name: swsl_resnet18
In Collection: SWSL ResNet
Metadata:
FLOPs: 2337073152
Parameters: 11690000
File Size: 46811375
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- IG-1B-Targeted
- ImageNet
Training Resources: 64x GPUs
ID: swsl_resnet18
LR: 0.0015
Epochs: 30
Layers: 18
Crop Pct: '0.875'
Batch Size: 1536
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/resnet.py#L954
Weights: https://dl.fbaipublicfiles.com/semiweaksupervision/model_files/semi_weakly_supervised_resnet18-118f1556.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 73.28%
Top 5 Accuracy: 91.76%
- Name: swsl_resnet50
In Collection: SWSL ResNet
Metadata:
FLOPs: 5282531328
Parameters: 25560000
File Size: 102480594
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- IG-1B-Targeted
- ImageNet
Training Resources: 64x GPUs
ID: swsl_resnet50
LR: 0.0015
Epochs: 30
Layers: 50
Crop Pct: '0.875'
Batch Size: 1536
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/resnet.py#L965
Weights: https://dl.fbaipublicfiles.com/semiweaksupervision/model_files/semi_weakly_supervised_resnet50-16a12f1b.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.14%
Top 5 Accuracy: 95.97%
-->
|
huggingface/pytorch-image-models/blob/main/docs/models/swsl-resnet.md
|
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# CamemBERT
## Overview
The CamemBERT model was proposed in [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by
Louis Martin, Benjamin Muller, Pedro Javier Ortiz Suárez, Yoann Dupont, Laurent Romary, Éric Villemonte de la
Clergerie, Djamé Seddah, and Benoît Sagot. It is based on Facebook's RoBERTa model released in 2019. It is a model
trained on 138GB of French text.
The abstract from the paper is the following:
*Pretrained language models are now ubiquitous in Natural Language Processing. Despite their success, most available
models have either been trained on English data or on the concatenation of data in multiple languages. This makes
practical use of such models --in all languages except English-- very limited. Aiming to address this issue for French,
we release CamemBERT, a French version of the Bi-directional Encoders for Transformers (BERT). We measure the
performance of CamemBERT compared to multilingual models in multiple downstream tasks, namely part-of-speech tagging,
dependency parsing, named-entity recognition, and natural language inference. CamemBERT improves the state of the art
for most of the tasks considered. We release the pretrained model for CamemBERT hoping to foster research and
downstream applications for French NLP.*
This model was contributed by [camembert](https://huggingface.co/camembert). The original code can be found [here](https://camembert-model.fr/).
<Tip>
This implementation is the same as RoBERTa. Refer to the [documentation of RoBERTa](roberta) for usage examples as well
as the information relative to the inputs and outputs.
</Tip>
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## CamembertConfig
[[autodoc]] CamembertConfig
## CamembertTokenizer
[[autodoc]] CamembertTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## CamembertTokenizerFast
[[autodoc]] CamembertTokenizerFast
<frameworkcontent>
<pt>
## CamembertModel
[[autodoc]] CamembertModel
## CamembertForCausalLM
[[autodoc]] CamembertForCausalLM
## CamembertForMaskedLM
[[autodoc]] CamembertForMaskedLM
## CamembertForSequenceClassification
[[autodoc]] CamembertForSequenceClassification
## CamembertForMultipleChoice
[[autodoc]] CamembertForMultipleChoice
## CamembertForTokenClassification
[[autodoc]] CamembertForTokenClassification
## CamembertForQuestionAnswering
[[autodoc]] CamembertForQuestionAnswering
</pt>
<tf>
## TFCamembertModel
[[autodoc]] TFCamembertModel
## TFCamembertForCasualLM
[[autodoc]] TFCamembertForCausalLM
## TFCamembertForMaskedLM
[[autodoc]] TFCamembertForMaskedLM
## TFCamembertForSequenceClassification
[[autodoc]] TFCamembertForSequenceClassification
## TFCamembertForMultipleChoice
[[autodoc]] TFCamembertForMultipleChoice
## TFCamembertForTokenClassification
[[autodoc]] TFCamembertForTokenClassification
## TFCamembertForQuestionAnswering
[[autodoc]] TFCamembertForQuestionAnswering
</tf>
</frameworkcontent>
|
huggingface/transformers/blob/main/docs/source/en/model_doc/camembert.md
|
(Tensorflow) EfficientNet
**EfficientNet** is a convolutional neural network architecture and scaling method that uniformly scales all dimensions of depth/width/resolution using a *compound coefficient*. Unlike conventional practice that arbitrary scales these factors, the EfficientNet scaling method uniformly scales network width, depth, and resolution with a set of fixed scaling coefficients. For example, if we want to use $2^N$ times more computational resources, then we can simply increase the network depth by $\alpha ^ N$, width by $\beta ^ N$, and image size by $\gamma ^ N$, where $\alpha, \beta, \gamma$ are constant coefficients determined by a small grid search on the original small model. EfficientNet uses a compound coefficient $\phi$ to uniformly scales network width, depth, and resolution in a principled way.
The compound scaling method is justified by the intuition that if the input image is bigger, then the network needs more layers to increase the receptive field and more channels to capture more fine-grained patterns on the bigger image.
The base EfficientNet-B0 network is based on the inverted bottleneck residual blocks of [MobileNetV2](https://paperswithcode.com/method/mobilenetv2), in addition to [squeeze-and-excitation blocks](https://paperswithcode.com/method/squeeze-and-excitation-block).
The weights from this model were ported from [Tensorflow/TPU](https://github.com/tensorflow/tpu).
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('tf_efficientnet_b0', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `tf_efficientnet_b0`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('tf_efficientnet_b0', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{tan2020efficientnet,
title={EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks},
author={Mingxing Tan and Quoc V. Le},
year={2020},
eprint={1905.11946},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
<!--
Type: model-index
Collections:
- Name: TF EfficientNet
Paper:
Title: 'EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks'
URL: https://paperswithcode.com/paper/efficientnet-rethinking-model-scaling-for
Models:
- Name: tf_efficientnet_b0
In Collection: TF EfficientNet
Metadata:
FLOPs: 488688572
Parameters: 5290000
File Size: 21383997
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
Training Resources: TPUv3 Cloud TPU
ID: tf_efficientnet_b0
LR: 0.256
Epochs: 350
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 2048
Image Size: '224'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1241
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b0_aa-827b6e33.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 76.85%
Top 5 Accuracy: 93.23%
- Name: tf_efficientnet_b1
In Collection: TF EfficientNet
Metadata:
FLOPs: 883633200
Parameters: 7790000
File Size: 31512534
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b1
LR: 0.256
Epochs: 350
Crop Pct: '0.882'
Momentum: 0.9
Batch Size: 2048
Image Size: '240'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1251
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b1_aa-ea7a6ee0.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.84%
Top 5 Accuracy: 94.2%
- Name: tf_efficientnet_b2
In Collection: TF EfficientNet
Metadata:
FLOPs: 1234321170
Parameters: 9110000
File Size: 36797929
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b2
LR: 0.256
Epochs: 350
Crop Pct: '0.89'
Momentum: 0.9
Batch Size: 2048
Image Size: '260'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1261
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b2_aa-60c94f97.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.07%
Top 5 Accuracy: 94.9%
- Name: tf_efficientnet_b3
In Collection: TF EfficientNet
Metadata:
FLOPs: 2275247568
Parameters: 12230000
File Size: 49381362
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b3
LR: 0.256
Epochs: 350
Crop Pct: '0.904'
Momentum: 0.9
Batch Size: 2048
Image Size: '300'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1271
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b3_aa-84b4657e.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.65%
Top 5 Accuracy: 95.72%
- Name: tf_efficientnet_b4
In Collection: TF EfficientNet
Metadata:
FLOPs: 5749638672
Parameters: 19340000
File Size: 77989689
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
Training Resources: TPUv3 Cloud TPU
ID: tf_efficientnet_b4
LR: 0.256
Epochs: 350
Crop Pct: '0.922'
Momentum: 0.9
Batch Size: 2048
Image Size: '380'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1281
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b4_aa-818f208c.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 83.03%
Top 5 Accuracy: 96.3%
- Name: tf_efficientnet_b5
In Collection: TF EfficientNet
Metadata:
FLOPs: 13176501888
Parameters: 30390000
File Size: 122403150
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b5
LR: 0.256
Epochs: 350
Crop Pct: '0.934'
Momentum: 0.9
Batch Size: 2048
Image Size: '456'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1291
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b5_ra-9a3e5369.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 83.81%
Top 5 Accuracy: 96.75%
- Name: tf_efficientnet_b6
In Collection: TF EfficientNet
Metadata:
FLOPs: 24180518488
Parameters: 43040000
File Size: 173232007
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b6
LR: 0.256
Epochs: 350
Crop Pct: '0.942'
Momentum: 0.9
Batch Size: 2048
Image Size: '528'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1301
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b6_aa-80ba17e4.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 84.11%
Top 5 Accuracy: 96.89%
- Name: tf_efficientnet_b7
In Collection: TF EfficientNet
Metadata:
FLOPs: 48205304880
Parameters: 66349999
File Size: 266850607
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b7
LR: 0.256
Epochs: 350
Crop Pct: '0.949'
Momentum: 0.9
Batch Size: 2048
Image Size: '600'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1312
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b7_ra-6c08e654.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 84.93%
Top 5 Accuracy: 97.2%
- Name: tf_efficientnet_b8
In Collection: TF EfficientNet
Metadata:
FLOPs: 80962956270
Parameters: 87410000
File Size: 351379853
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b8
LR: 0.256
Epochs: 350
Crop Pct: '0.954'
Momentum: 0.9
Batch Size: 2048
Image Size: '672'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1323
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b8_ra-572d5dd9.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 85.35%
Top 5 Accuracy: 97.39%
- Name: tf_efficientnet_el
In Collection: TF EfficientNet
Metadata:
FLOPs: 9356616096
Parameters: 10590000
File Size: 42800271
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: tf_efficientnet_el
Crop Pct: '0.904'
Image Size: '300'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1551
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_el-5143854e.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.45%
Top 5 Accuracy: 95.17%
- Name: tf_efficientnet_em
In Collection: TF EfficientNet
Metadata:
FLOPs: 3636607040
Parameters: 6900000
File Size: 27933644
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: tf_efficientnet_em
Crop Pct: '0.882'
Image Size: '240'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1541
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_em-e78cfe58.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.71%
Top 5 Accuracy: 94.33%
- Name: tf_efficientnet_es
In Collection: TF EfficientNet
Metadata:
FLOPs: 2057577472
Parameters: 5440000
File Size: 22008479
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: tf_efficientnet_es
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1531
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_es-ca1afbfe.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.28%
Top 5 Accuracy: 93.6%
- Name: tf_efficientnet_l2_ns_475
In Collection: TF EfficientNet
Metadata:
FLOPs: 217795669644
Parameters: 480310000
File Size: 1925950424
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- FixRes
- Label Smoothing
- Noisy Student
- RMSProp
- RandAugment
- Weight Decay
Training Data:
- ImageNet
- JFT-300M
Training Resources: TPUv3 Cloud TPU
ID: tf_efficientnet_l2_ns_475
LR: 0.128
Epochs: 350
Dropout: 0.5
Crop Pct: '0.936'
Momentum: 0.9
Batch Size: 2048
Image Size: '475'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Stochastic Depth Survival: 0.8
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1509
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_l2_ns_475-bebbd00a.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 88.24%
Top 5 Accuracy: 98.55%
-->
|
huggingface/pytorch-image-models/blob/main/docs/models/tf-efficientnet.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Improve image quality with deterministic generation
[[open-in-colab]]
A common way to improve the quality of generated images is with *deterministic batch generation*, generate a batch of images and select one image to improve with a more detailed prompt in a second round of inference. The key is to pass a list of [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html#generator)'s to the pipeline for batched image generation, and tie each `Generator` to a seed so you can reuse it for an image.
Let's use [`runwayml/stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5) for example, and generate several versions of the following prompt:
```py
prompt = "Labrador in the style of Vermeer"
```
Instantiate a pipeline with [`DiffusionPipeline.from_pretrained`] and place it on a GPU (if available):
```python
import torch
from diffusers import DiffusionPipeline
from diffusers.utils import make_image_grid
pipe = DiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, use_safetensors=True
)
pipe = pipe.to("cuda")
```
Now, define four different `Generator`s and assign each `Generator` a seed (`0` to `3`) so you can reuse a `Generator` later for a specific image:
```python
generator = [torch.Generator(device="cuda").manual_seed(i) for i in range(4)]
```
<Tip warning={true}>
To create a batched seed, you should use a list comprehension that iterates over the length specified in `range()`. This creates a unique `Generator` object for each image in the batch. If you only multiply the `Generator` by the batch size, this only creates one `Generator` object that is used sequentially for each image in the batch.
For example, if you want to use the same seed to create 4 identical images:
```py
❌ [torch.Generator().manual_seed(seed)] * 4
✅ [torch.Generator().manual_seed(seed) for _ in range(4)]
```
</Tip>
Generate the images and have a look:
```python
images = pipe(prompt, generator=generator, num_images_per_prompt=4).images
make_image_grid(images, rows=2, cols=2)
```

In this example, you'll improve upon the first image - but in reality, you can use any image you want (even the image with double sets of eyes!). The first image used the `Generator` with seed `0`, so you'll reuse that `Generator` for the second round of inference. To improve the quality of the image, add some additional text to the prompt:
```python
prompt = [prompt + t for t in [", highly realistic", ", artsy", ", trending", ", colorful"]]
generator = [torch.Generator(device="cuda").manual_seed(0) for i in range(4)]
```
Create four generators with seed `0`, and generate another batch of images, all of which should look like the first image from the previous round!
```python
images = pipe(prompt, generator=generator).images
make_image_grid(images, rows=2, cols=2)
```

|
huggingface/diffusers/blob/main/docs/source/en/using-diffusers/reusing_seeds.md
|
--
{card_data}
---
# {{ pretty_name | default("Dataset Name", true)}}
{{ some_data }}
|
huggingface/huggingface_hub/blob/main/tests/fixtures/cards/sample_datasetcard_template.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Distilled Stable Diffusion inference
[[open-in-colab]]
Stable Diffusion inference can be a computationally intensive process because it must iteratively denoise the latents to generate an image. To reduce the computational burden, you can use a *distilled* version of the Stable Diffusion model from [Nota AI](https://huggingface.co/nota-ai). The distilled version of their Stable Diffusion model eliminates some of the residual and attention blocks from the UNet, reducing the model size by 51% and improving latency on CPU/GPU by 43%.
<Tip>
Read this [blog post](https://huggingface.co/blog/sd_distillation) to learn more about how knowledge distillation training works to produce a faster, smaller, and cheaper generative model.
</Tip>
Let's load the distilled Stable Diffusion model and compare it against the original Stable Diffusion model:
```py
from diffusers import StableDiffusionPipeline
import torch
distilled = StableDiffusionPipeline.from_pretrained(
"nota-ai/bk-sdm-small", torch_dtype=torch.float16, use_safetensors=True,
).to("cuda")
original = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16, use_safetensors=True,
).to("cuda")
```
Given a prompt, get the inference time for the original model:
```py
import time
seed = 2023
generator = torch.manual_seed(seed)
NUM_ITERS_TO_RUN = 3
NUM_INFERENCE_STEPS = 25
NUM_IMAGES_PER_PROMPT = 4
prompt = "a golden vase with different flowers"
start = time.time_ns()
for _ in range(NUM_ITERS_TO_RUN):
images = original(
prompt,
num_inference_steps=NUM_INFERENCE_STEPS,
generator=generator,
num_images_per_prompt=NUM_IMAGES_PER_PROMPT
).images
end = time.time_ns()
original_sd = f"{(end - start) / 1e6:.1f}"
print(f"Execution time -- {original_sd} ms\n")
"Execution time -- 45781.5 ms"
```
Time the distilled model inference:
```py
start = time.time_ns()
for _ in range(NUM_ITERS_TO_RUN):
images = distilled(
prompt,
num_inference_steps=NUM_INFERENCE_STEPS,
generator=generator,
num_images_per_prompt=NUM_IMAGES_PER_PROMPT
).images
end = time.time_ns()
distilled_sd = f"{(end - start) / 1e6:.1f}"
print(f"Execution time -- {distilled_sd} ms\n")
"Execution time -- 29884.2 ms"
```
<div class="flex gap-4">
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/original_sd.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">original Stable Diffusion (45781.5 ms)</figcaption>
</div>
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/distilled_sd.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">distilled Stable Diffusion (29884.2 ms)</figcaption>
</div>
</div>
## Tiny AutoEncoder
To speed inference up even more, use a tiny distilled version of the [Stable Diffusion VAE](https://huggingface.co/sayakpaul/taesdxl-diffusers) to denoise the latents into images. Replace the VAE in the distilled Stable Diffusion model with the tiny VAE:
```py
from diffusers import AutoencoderTiny
distilled.vae = AutoencoderTiny.from_pretrained(
"sayakpaul/taesd-diffusers", torch_dtype=torch.float16, use_safetensors=True,
).to("cuda")
```
Time the distilled model and distilled VAE inference:
```py
start = time.time_ns()
for _ in range(NUM_ITERS_TO_RUN):
images = distilled(
prompt,
num_inference_steps=NUM_INFERENCE_STEPS,
generator=generator,
num_images_per_prompt=NUM_IMAGES_PER_PROMPT
).images
end = time.time_ns()
distilled_tiny_sd = f"{(end - start) / 1e6:.1f}"
print(f"Execution time -- {distilled_tiny_sd} ms\n")
"Execution time -- 27165.7 ms"
```
<div class="flex justify-center">
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/distilled_sd_vae.png" />
<figcaption class="mt-2 text-center text-sm text-gray-500">distilled Stable Diffusion + Tiny AutoEncoder (27165.7 ms)</figcaption>
</div>
</div>
|
huggingface/diffusers/blob/main/docs/source/en/using-diffusers/distilled_sd.md
|
Datasets server API - search service
> /search endpoint
> /filter endpoint
## Configuration
The service can be configured using environment variables. They are grouped by scope.
### Duckdb index full text search
- `DUCKDB_INDEX_CACHE_DIRECTORY`: directory where the temporal duckdb index files are downloaded. Defaults to empty.
- `DUCKDB_INDEX_TARGET_REVISION`: the git revision of the dataset where the index file is stored in the dataset repository.
### API service
See [../../libs/libapi/README.md](../../libs/libapi/README.md) for more information about the API configuration.
### Common
See [../../libs/libcommon/README.md](../../libs/libcommon/README.md) for more information about the common configuration.
## Endpoints
See https://huggingface.co/docs/datasets-server
- /healthcheck: ensure the app is running
- /metrics: return a list of metrics in the Prometheus format
- /search: get a slice of a search result over a dataset split
- /filter: filter rows of a dataset split
|
huggingface/datasets-server/blob/main/services/search/README.md
|
# Token classification
Based on the scripts [`run_ner.py`](https://github.com/huggingface/transformers/blob/main/examples/legacy/token-classification/run_ner.py).
The following examples are covered in this section:
* NER on the GermEval 2014 (German NER) dataset
* Emerging and Rare Entities task: WNUT’17 (English NER) dataset
Details and results for the fine-tuning provided by @stefan-it.
### GermEval 2014 (German NER) dataset
#### Data (Download and pre-processing steps)
Data can be obtained from the [GermEval 2014](https://sites.google.com/site/germeval2014ner/data) shared task page.
Here are the commands for downloading and pre-processing train, dev and test datasets. The original data format has four (tab-separated) columns, in a pre-processing step only the two relevant columns (token and outer span NER annotation) are extracted:
```bash
curl -L 'https://drive.google.com/uc?export=download&id=1Jjhbal535VVz2ap4v4r_rN1UEHTdLK5P' \
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > train.txt.tmp
curl -L 'https://drive.google.com/uc?export=download&id=1ZfRcQThdtAR5PPRjIDtrVP7BtXSCUBbm' \
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > dev.txt.tmp
curl -L 'https://drive.google.com/uc?export=download&id=1u9mb7kNJHWQCWyweMDRMuTFoOHOfeBTH' \
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > test.txt.tmp
```
The GermEval 2014 dataset contains some strange "control character" tokens like `'\x96', '\u200e', '\x95', '\xad' or '\x80'`.
One problem with these tokens is, that `BertTokenizer` returns an empty token for them, resulting in misaligned `InputExample`s.
The `preprocess.py` script located in the `scripts` folder a) filters these tokens and b) splits longer sentences into smaller ones (once the max. subtoken length is reached).
Let's define some variables that we need for further pre-processing steps and training the model:
```bash
export MAX_LENGTH=128
export BERT_MODEL=bert-base-multilingual-cased
```
Run the pre-processing script on training, dev and test datasets:
```bash
python3 scripts/preprocess.py train.txt.tmp $BERT_MODEL $MAX_LENGTH > train.txt
python3 scripts/preprocess.py dev.txt.tmp $BERT_MODEL $MAX_LENGTH > dev.txt
python3 scripts/preprocess.py test.txt.tmp $BERT_MODEL $MAX_LENGTH > test.txt
```
The GermEval 2014 dataset has much more labels than CoNLL-2002/2003 datasets, so an own set of labels must be used:
```bash
cat train.txt dev.txt test.txt | cut -d " " -f 2 | grep -v "^$"| sort | uniq > labels.txt
```
#### Prepare the run
Additional environment variables must be set:
```bash
export OUTPUT_DIR=germeval-model
export BATCH_SIZE=32
export NUM_EPOCHS=3
export SAVE_STEPS=750
export SEED=1
```
#### Run the Pytorch version
To start training, just run:
```bash
python3 run_ner.py --data_dir ./ \
--labels ./labels.txt \
--model_name_or_path $BERT_MODEL \
--output_dir $OUTPUT_DIR \
--max_seq_length $MAX_LENGTH \
--num_train_epochs $NUM_EPOCHS \
--per_device_train_batch_size $BATCH_SIZE \
--save_steps $SAVE_STEPS \
--seed $SEED \
--do_train \
--do_eval \
--do_predict
```
If your GPU supports half-precision training, just add the `--fp16` flag. After training, the model will be both evaluated on development and test datasets.
#### JSON-based configuration file
Instead of passing all parameters via commandline arguments, the `run_ner.py` script also supports reading parameters from a json-based configuration file:
```json
{
"data_dir": ".",
"labels": "./labels.txt",
"model_name_or_path": "bert-base-multilingual-cased",
"output_dir": "germeval-model",
"max_seq_length": 128,
"num_train_epochs": 3,
"per_device_train_batch_size": 32,
"save_steps": 750,
"seed": 1,
"do_train": true,
"do_eval": true,
"do_predict": true
}
```
It must be saved with a `.json` extension and can be used by running `python3 run_ner.py config.json`.
#### Evaluation
Evaluation on development dataset outputs the following for our example:
```bash
10/04/2019 00:42:06 - INFO - __main__ - ***** Eval results *****
10/04/2019 00:42:06 - INFO - __main__ - f1 = 0.8623348017621146
10/04/2019 00:42:06 - INFO - __main__ - loss = 0.07183869666975543
10/04/2019 00:42:06 - INFO - __main__ - precision = 0.8467916366258111
10/04/2019 00:42:06 - INFO - __main__ - recall = 0.8784592370979806
```
On the test dataset the following results could be achieved:
```bash
10/04/2019 00:42:42 - INFO - __main__ - ***** Eval results *****
10/04/2019 00:42:42 - INFO - __main__ - f1 = 0.8614389652384803
10/04/2019 00:42:42 - INFO - __main__ - loss = 0.07064602487454782
10/04/2019 00:42:42 - INFO - __main__ - precision = 0.8604651162790697
10/04/2019 00:42:42 - INFO - __main__ - recall = 0.8624150210424085
```
#### Run the Tensorflow 2 version
To start training, just run:
```bash
python3 run_tf_ner.py --data_dir ./ \
--labels ./labels.txt \
--model_name_or_path $BERT_MODEL \
--output_dir $OUTPUT_DIR \
--max_seq_length $MAX_LENGTH \
--num_train_epochs $NUM_EPOCHS \
--per_device_train_batch_size $BATCH_SIZE \
--save_steps $SAVE_STEPS \
--seed $SEED \
--do_train \
--do_eval \
--do_predict
```
Such as the Pytorch version, if your GPU supports half-precision training, just add the `--fp16` flag. After training, the model will be both evaluated on development and test datasets.
#### Evaluation
Evaluation on development dataset outputs the following for our example:
```bash
precision recall f1-score support
LOCderiv 0.7619 0.6154 0.6809 52
PERpart 0.8724 0.8997 0.8858 4057
OTHpart 0.9360 0.9466 0.9413 711
ORGpart 0.7015 0.6989 0.7002 269
LOCpart 0.7668 0.8488 0.8057 496
LOC 0.8745 0.9191 0.8963 235
ORGderiv 0.7723 0.8571 0.8125 91
OTHderiv 0.4800 0.6667 0.5581 18
OTH 0.5789 0.6875 0.6286 16
PERderiv 0.5385 0.3889 0.4516 18
PER 0.5000 0.5000 0.5000 2
ORG 0.0000 0.0000 0.0000 3
micro avg 0.8574 0.8862 0.8715 5968
macro avg 0.8575 0.8862 0.8713 5968
```
On the test dataset the following results could be achieved:
```bash
precision recall f1-score support
PERpart 0.8847 0.8944 0.8896 9397
OTHpart 0.9376 0.9353 0.9365 1639
ORGpart 0.7307 0.7044 0.7173 697
LOC 0.9133 0.9394 0.9262 561
LOCpart 0.8058 0.8157 0.8107 1150
ORG 0.0000 0.0000 0.0000 8
OTHderiv 0.5882 0.4762 0.5263 42
PERderiv 0.6571 0.5227 0.5823 44
OTH 0.4906 0.6667 0.5652 39
ORGderiv 0.7016 0.7791 0.7383 172
LOCderiv 0.8256 0.6514 0.7282 109
PER 0.0000 0.0000 0.0000 11
micro avg 0.8722 0.8774 0.8748 13869
macro avg 0.8712 0.8774 0.8740 13869
```
### Emerging and Rare Entities task: WNUT’17 (English NER) dataset
Description of the WNUT’17 task from the [shared task website](http://noisy-text.github.io/2017/index.html):
> The WNUT’17 shared task focuses on identifying unusual, previously-unseen entities in the context of emerging discussions.
> Named entities form the basis of many modern approaches to other tasks (like event clustering and summarization), but recall on
> them is a real problem in noisy text - even among annotators. This drop tends to be due to novel entities and surface forms.
Six labels are available in the dataset. An overview can be found on this [page](http://noisy-text.github.io/2017/files/).
#### Data (Download and pre-processing steps)
The dataset can be downloaded from the [official GitHub](https://github.com/leondz/emerging_entities_17) repository.
The following commands show how to prepare the dataset for fine-tuning:
```bash
mkdir -p data_wnut_17
curl -L 'https://github.com/leondz/emerging_entities_17/raw/master/wnut17train.conll' | tr '\t' ' ' > data_wnut_17/train.txt.tmp
curl -L 'https://github.com/leondz/emerging_entities_17/raw/master/emerging.dev.conll' | tr '\t' ' ' > data_wnut_17/dev.txt.tmp
curl -L 'https://raw.githubusercontent.com/leondz/emerging_entities_17/master/emerging.test.annotated' | tr '\t' ' ' > data_wnut_17/test.txt.tmp
```
Let's define some variables that we need for further pre-processing steps:
```bash
export MAX_LENGTH=128
export BERT_MODEL=bert-large-cased
```
Here we use the English BERT large model for fine-tuning.
The `preprocess.py` scripts splits longer sentences into smaller ones (once the max. subtoken length is reached):
```bash
python3 scripts/preprocess.py data_wnut_17/train.txt.tmp $BERT_MODEL $MAX_LENGTH > data_wnut_17/train.txt
python3 scripts/preprocess.py data_wnut_17/dev.txt.tmp $BERT_MODEL $MAX_LENGTH > data_wnut_17/dev.txt
python3 scripts/preprocess.py data_wnut_17/test.txt.tmp $BERT_MODEL $MAX_LENGTH > data_wnut_17/test.txt
```
In the last pre-processing step, the `labels.txt` file needs to be generated. This file contains all available labels:
```bash
cat data_wnut_17/train.txt data_wnut_17/dev.txt data_wnut_17/test.txt | cut -d " " -f 2 | grep -v "^$"| sort | uniq > data_wnut_17/labels.txt
```
#### Run the Pytorch version
Fine-tuning with the PyTorch version can be started using the `run_ner.py` script. In this example we use a JSON-based configuration file.
This configuration file looks like:
```json
{
"data_dir": "./data_wnut_17",
"labels": "./data_wnut_17/labels.txt",
"model_name_or_path": "bert-large-cased",
"output_dir": "wnut-17-model-1",
"max_seq_length": 128,
"num_train_epochs": 3,
"per_device_train_batch_size": 32,
"save_steps": 425,
"seed": 1,
"do_train": true,
"do_eval": true,
"do_predict": true,
"fp16": false
}
```
If your GPU supports half-precision training, please set `fp16` to `true`.
Save this JSON-based configuration under `wnut_17.json`. The fine-tuning can be started with `python3 run_ner_old.py wnut_17.json`.
#### Evaluation
Evaluation on development dataset outputs the following:
```bash
05/29/2020 23:33:44 - INFO - __main__ - ***** Eval results *****
05/29/2020 23:33:44 - INFO - __main__ - eval_loss = 0.26505235286212275
05/29/2020 23:33:44 - INFO - __main__ - eval_precision = 0.7008264462809918
05/29/2020 23:33:44 - INFO - __main__ - eval_recall = 0.507177033492823
05/29/2020 23:33:44 - INFO - __main__ - eval_f1 = 0.5884802220680084
05/29/2020 23:33:44 - INFO - __main__ - epoch = 3.0
```
On the test dataset the following results could be achieved:
```bash
05/29/2020 23:33:44 - INFO - transformers.trainer - ***** Running Prediction *****
05/29/2020 23:34:02 - INFO - __main__ - eval_loss = 0.30948806500973547
05/29/2020 23:34:02 - INFO - __main__ - eval_precision = 0.5840108401084011
05/29/2020 23:34:02 - INFO - __main__ - eval_recall = 0.3994439295644115
05/29/2020 23:34:02 - INFO - __main__ - eval_f1 = 0.47440836543753434
```
WNUT’17 is a very difficult task. Current state-of-the-art results on this dataset can be found [here](https://nlpprogress.com/english/named_entity_recognition.html).
|
huggingface/transformers/blob/main/examples/legacy/token-classification/README.md
|
hat is domain adaptation? When fine-tuning a pretrained model on a new dataset, the fine-tuned model we obtain will make predictions that are attuned to this new dataset. When the two models are trained with the same task, we can then compare their predictions on the same input. The predictions of the two models will be different, in a way that reflects the differences between the two datasets, a phenomenon we call domain adaptation. Let's look at an example with mask language modeling, by comparing the outputs of the pretrained distilBERT model with the version fine-tuned in chapter 7 of the course (linked below). The pretrained model makes generic predictions, whereas the fine-tuned model has its first two predictions linked to cinema. Since it was fine-tuned on a movie reviews dataset, it's perfectly normal to see it adapted its suggestions like this. Notice how it keeps the same predictions as the pretrained model afterward. Even if the fine-tuned model adapts to the new dataset, it's not forgetting what it was pretrained on. This is another example on a translation task. On top we use a pretrained French/English model and at the bottom, the version we fine-tuned in chapter 7. The top model is pretrained on lots of texts, and leaves technical English terms like plugin and email unchanged in the translation (both are perfectly understood by French people). The dataset picked for the fine-tuning is a dataset of technical texts where special attention was picked to translate everything in French. As a result, the fine-tuned model picked that habit and translated both plugin and email.
|
huggingface/course/blob/main/subtitles/en/raw/chapter7/03c_domain-adaptation.md
|
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Audio classification
[[open-in-colab]]
<Youtube id="KWwzcmG98Ds"/>
Audio classification - just like with text - assigns a class label output from the input data. The only difference is instead of text inputs, you have raw audio waveforms. Some practical applications of audio classification include identifying speaker intent, language classification, and even animal species by their sounds.
This guide will show you how to:
1. Finetune [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base) on the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset to classify speaker intent.
2. Use your finetuned model for inference.
<Tip>
The task illustrated in this tutorial is supported by the following model architectures:
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
[Audio Spectrogram Transformer](../model_doc/audio-spectrogram-transformer), [Data2VecAudio](../model_doc/data2vec-audio), [Hubert](../model_doc/hubert), [SEW](../model_doc/sew), [SEW-D](../model_doc/sew-d), [UniSpeech](../model_doc/unispeech), [UniSpeechSat](../model_doc/unispeech-sat), [Wav2Vec2](../model_doc/wav2vec2), [Wav2Vec2-Conformer](../model_doc/wav2vec2-conformer), [WavLM](../model_doc/wavlm), [Whisper](../model_doc/whisper)
<!--End of the generated tip-->
</Tip>
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers datasets evaluate
```
We encourage you to login to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to login:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Load MInDS-14 dataset
Start by loading the MInDS-14 dataset from the 🤗 Datasets library:
```py
>>> from datasets import load_dataset, Audio
>>> minds = load_dataset("PolyAI/minds14", name="en-US", split="train")
```
Split the dataset's `train` split into a smaller train and test set with the [`~datasets.Dataset.train_test_split`] method. This'll give you a chance to experiment and make sure everything works before spending more time on the full dataset.
```py
>>> minds = minds.train_test_split(test_size=0.2)
```
Then take a look at the dataset:
```py
>>> minds
DatasetDict({
train: Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 450
})
test: Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 113
})
})
```
While the dataset contains a lot of useful information, like `lang_id` and `english_transcription`, you'll focus on the `audio` and `intent_class` in this guide. Remove the other columns with the [`~datasets.Dataset.remove_columns`] method:
```py
>>> minds = minds.remove_columns(["path", "transcription", "english_transcription", "lang_id"])
```
Take a look at an example now:
```py
>>> minds["train"][0]
{'audio': {'array': array([ 0. , 0. , 0. , ..., -0.00048828,
-0.00024414, -0.00024414], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602b9a5fbb1e6d0fbce91f52.wav',
'sampling_rate': 8000},
'intent_class': 2}
```
There are two fields:
- `audio`: a 1-dimensional `array` of the speech signal that must be called to load and resample the audio file.
- `intent_class`: represents the class id of the speaker's intent.
To make it easier for the model to get the label name from the label id, create a dictionary that maps the label name to an integer and vice versa:
```py
>>> labels = minds["train"].features["intent_class"].names
>>> label2id, id2label = dict(), dict()
>>> for i, label in enumerate(labels):
... label2id[label] = str(i)
... id2label[str(i)] = label
```
Now you can convert the label id to a label name:
```py
>>> id2label[str(2)]
'app_error'
```
## Preprocess
The next step is to load a Wav2Vec2 feature extractor to process the audio signal:
```py
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base")
```
The MInDS-14 dataset has a sampling rate of 8000khz (you can find this information in it's [dataset card](https://huggingface.co/datasets/PolyAI/minds14)), which means you'll need to resample the dataset to 16000kHz to use the pretrained Wav2Vec2 model:
```py
>>> minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
>>> minds["train"][0]
{'audio': {'array': array([ 2.2098757e-05, 4.6582241e-05, -2.2803260e-05, ...,
-2.8419291e-04, -2.3305941e-04, -1.1425107e-04], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602b9a5fbb1e6d0fbce91f52.wav',
'sampling_rate': 16000},
'intent_class': 2}
```
Now create a preprocessing function that:
1. Calls the `audio` column to load, and if necessary, resample the audio file.
2. Checks if the sampling rate of the audio file matches the sampling rate of the audio data a model was pretrained with. You can find this information in the Wav2Vec2 [model card](https://huggingface.co/facebook/wav2vec2-base).
3. Set a maximum input length to batch longer inputs without truncating them.
```py
>>> def preprocess_function(examples):
... audio_arrays = [x["array"] for x in examples["audio"]]
... inputs = feature_extractor(
... audio_arrays, sampling_rate=feature_extractor.sampling_rate, max_length=16000, truncation=True
... )
... return inputs
```
To apply the preprocessing function over the entire dataset, use 🤗 Datasets [`~datasets.Dataset.map`] function. You can speed up `map` by setting `batched=True` to process multiple elements of the dataset at once. Remove the columns you don't need, and rename `intent_class` to `label` because that's the name the model expects:
```py
>>> encoded_minds = minds.map(preprocess_function, remove_columns="audio", batched=True)
>>> encoded_minds = encoded_minds.rename_column("intent_class", "label")
```
## Evaluate
Including a metric during training is often helpful for evaluating your model's performance. You can quickly load a evaluation method with the 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) library. For this task, load the [accuracy](https://huggingface.co/spaces/evaluate-metric/accuracy) metric (see the 🤗 Evaluate [quick tour](https://huggingface.co/docs/evaluate/a_quick_tour) to learn more about how to load and compute a metric):
```py
>>> import evaluate
>>> accuracy = evaluate.load("accuracy")
```
Then create a function that passes your predictions and labels to [`~evaluate.EvaluationModule.compute`] to calculate the accuracy:
```py
>>> import numpy as np
>>> def compute_metrics(eval_pred):
... predictions = np.argmax(eval_pred.predictions, axis=1)
... return accuracy.compute(predictions=predictions, references=eval_pred.label_ids)
```
Your `compute_metrics` function is ready to go now, and you'll return to it when you setup your training.
## Train
<frameworkcontent>
<pt>
<Tip>
If you aren't familiar with finetuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#train-with-pytorch-trainer)!
</Tip>
You're ready to start training your model now! Load Wav2Vec2 with [`AutoModelForAudioClassification`] along with the number of expected labels, and the label mappings:
```py
>>> from transformers import AutoModelForAudioClassification, TrainingArguments, Trainer
>>> num_labels = len(id2label)
>>> model = AutoModelForAudioClassification.from_pretrained(
... "facebook/wav2vec2-base", num_labels=num_labels, label2id=label2id, id2label=id2label
... )
```
At this point, only three steps remain:
1. Define your training hyperparameters in [`TrainingArguments`]. The only required parameter is `output_dir` which specifies where to save your model. You'll push this model to the Hub by setting `push_to_hub=True` (you need to be signed in to Hugging Face to upload your model). At the end of each epoch, the [`Trainer`] will evaluate the accuracy and save the training checkpoint.
2. Pass the training arguments to [`Trainer`] along with the model, dataset, tokenizer, data collator, and `compute_metrics` function.
3. Call [`~Trainer.train`] to finetune your model.
```py
>>> training_args = TrainingArguments(
... output_dir="my_awesome_mind_model",
... evaluation_strategy="epoch",
... save_strategy="epoch",
... learning_rate=3e-5,
... per_device_train_batch_size=32,
... gradient_accumulation_steps=4,
... per_device_eval_batch_size=32,
... num_train_epochs=10,
... warmup_ratio=0.1,
... logging_steps=10,
... load_best_model_at_end=True,
... metric_for_best_model="accuracy",
... push_to_hub=True,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=encoded_minds["train"],
... eval_dataset=encoded_minds["test"],
... tokenizer=feature_extractor,
... compute_metrics=compute_metrics,
... )
>>> trainer.train()
```
Once training is completed, share your model to the Hub with the [`~transformers.Trainer.push_to_hub`] method so everyone can use your model:
```py
>>> trainer.push_to_hub()
```
</pt>
</frameworkcontent>
<Tip>
For a more in-depth example of how to finetune a model for audio classification, take a look at the corresponding [PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/audio_classification.ipynb).
</Tip>
## Inference
Great, now that you've finetuned a model, you can use it for inference!
Load an audio file you'd like to run inference on. Remember to resample the sampling rate of the audio file to match the sampling rate of the model if you need to!
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train")
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> audio_file = dataset[0]["audio"]["path"]
```
The simplest way to try out your finetuned model for inference is to use it in a [`pipeline`]. Instantiate a `pipeline` for audio classification with your model, and pass your audio file to it:
```py
>>> from transformers import pipeline
>>> classifier = pipeline("audio-classification", model="stevhliu/my_awesome_minds_model")
>>> classifier(audio_file)
[
{'score': 0.09766869246959686, 'label': 'cash_deposit'},
{'score': 0.07998877018690109, 'label': 'app_error'},
{'score': 0.0781070664525032, 'label': 'joint_account'},
{'score': 0.07667109370231628, 'label': 'pay_bill'},
{'score': 0.0755252093076706, 'label': 'balance'}
]
```
You can also manually replicate the results of the `pipeline` if you'd like:
<frameworkcontent>
<pt>
Load a feature extractor to preprocess the audio file and return the `input` as PyTorch tensors:
```py
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("stevhliu/my_awesome_minds_model")
>>> inputs = feature_extractor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
```
Pass your inputs to the model and return the logits:
```py
>>> from transformers import AutoModelForAudioClassification
>>> model = AutoModelForAudioClassification.from_pretrained("stevhliu/my_awesome_minds_model")
>>> with torch.no_grad():
... logits = model(**inputs).logits
```
Get the class with the highest probability, and use the model's `id2label` mapping to convert it to a label:
```py
>>> import torch
>>> predicted_class_ids = torch.argmax(logits).item()
>>> predicted_label = model.config.id2label[predicted_class_ids]
>>> predicted_label
'cash_deposit'
```
</pt>
</frameworkcontent>
|
huggingface/transformers/blob/main/docs/source/en/tasks/audio_classification.md
|
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BERTweet
## Overview
The BERTweet model was proposed in [BERTweet: A pre-trained language model for English Tweets](https://www.aclweb.org/anthology/2020.emnlp-demos.2.pdf) by Dat Quoc Nguyen, Thanh Vu, Anh Tuan Nguyen.
The abstract from the paper is the following:
*We present BERTweet, the first public large-scale pre-trained language model for English Tweets. Our BERTweet, having
the same architecture as BERT-base (Devlin et al., 2019), is trained using the RoBERTa pre-training procedure (Liu et
al., 2019). Experiments show that BERTweet outperforms strong baselines RoBERTa-base and XLM-R-base (Conneau et al.,
2020), producing better performance results than the previous state-of-the-art models on three Tweet NLP tasks:
Part-of-speech tagging, Named-entity recognition and text classification.*
This model was contributed by [dqnguyen](https://huggingface.co/dqnguyen). The original code can be found [here](https://github.com/VinAIResearch/BERTweet).
## Usage example
```python
>>> import torch
>>> from transformers import AutoModel, AutoTokenizer
>>> bertweet = AutoModel.from_pretrained("vinai/bertweet-base")
>>> # For transformers v4.x+:
>>> tokenizer = AutoTokenizer.from_pretrained("vinai/bertweet-base", use_fast=False)
>>> # For transformers v3.x:
>>> # tokenizer = AutoTokenizer.from_pretrained("vinai/bertweet-base")
>>> # INPUT TWEET IS ALREADY NORMALIZED!
>>> line = "SC has first two presumptive cases of coronavirus , DHEC confirms HTTPURL via @USER :cry:"
>>> input_ids = torch.tensor([tokenizer.encode(line)])
>>> with torch.no_grad():
... features = bertweet(input_ids) # Models outputs are now tuples
>>> # With TensorFlow 2.0+:
>>> # from transformers import TFAutoModel
>>> # bertweet = TFAutoModel.from_pretrained("vinai/bertweet-base")
```
<Tip>
This implementation is the same as BERT, except for tokenization method. Refer to [BERT documentation](bert) for
API reference information.
</Tip>
## BertweetTokenizer
[[autodoc]] BertweetTokenizer
|
huggingface/transformers/blob/main/docs/source/en/model_doc/bertweet.md
|
Gradio Demo: file_explorer_component_events
```
!pip install -q gradio
```
```
# Downloading files from the demo repo
import os
os.mkdir('dir1')
!wget -q -O dir1/bar.txt https://github.com/gradio-app/gradio/raw/main/demo/file_explorer_component_events/dir1/bar.txt
!wget -q -O dir1/foo.txt https://github.com/gradio-app/gradio/raw/main/demo/file_explorer_component_events/dir1/foo.txt
os.mkdir('dir2')
!wget -q -O dir2/baz.png https://github.com/gradio-app/gradio/raw/main/demo/file_explorer_component_events/dir2/baz.png
!wget -q -O dir2/foo.png https://github.com/gradio-app/gradio/raw/main/demo/file_explorer_component_events/dir2/foo.png
os.mkdir('dir3')
!wget -q -O dir3/dir3_foo.txt https://github.com/gradio-app/gradio/raw/main/demo/file_explorer_component_events/dir3/dir3_foo.txt
!wget -q -O dir3/dir4 https://github.com/gradio-app/gradio/raw/main/demo/file_explorer_component_events/dir3/dir4
```
```
import gradio as gr
from pathlib import Path
base_root = Path(__file__).parent.resolve()
with gr.Blocks() as demo:
with gr.Row():
dd = gr.Dropdown(label="Select File Explorer Root",
value=str(base_root / "dir1"),
choices=[str(base_root / "dir1"), str(base_root / "dir2"),
str(base_root / "dir3")])
with gr.Group():
dir_only_glob = gr.Checkbox(label="Show only directories", value=False)
ignore_dir_in_glob = gr.Checkbox(label="Ignore directories in glob", value=False)
fe = gr.FileExplorer(root=str(base_root / "dir1"),
glob="**/*", interactive=True)
textbox = gr.Textbox(label="Selected Directory")
run = gr.Button("Run")
dir_only_glob.select(lambda s: gr.FileExplorer(glob="**/" if s else "**/*.*",
file_count="multiple",
root=str(base_root / "dir3")) ,
inputs=[dir_only_glob], outputs=[fe])
ignore_dir_in_glob.select(lambda s: gr.FileExplorer(glob="**/*",
ignore_glob="**/",
root=str(base_root / "dir3")),
inputs=[ignore_dir_in_glob], outputs=[fe])
dd.select(lambda s: gr.FileExplorer(root=s), inputs=[dd], outputs=[fe])
run.click(lambda s: ",".join(s) if isinstance(s, list) else s, inputs=[fe], outputs=[textbox])
with gr.Row():
a = gr.Textbox(elem_id="input-box")
a.change(lambda x: x, inputs=[a])
if __name__ == "__main__":
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/file_explorer_component_events/run.ipynb
|
--
title: "Announcing the Hugging Face Fellowship Program"
thumbnail: /blog/assets/62_fellowship/fellowship-thumbnail.png
authors:
- user: merve
- user: espejelomar
---
# Announcing the Hugging Face Fellowship Program
The Fellowship is a network of exceptional people from different backgrounds who contribute to the Machine Learning open-source ecosystem 🚀. The goal of the program is to empower key contributors to enable them to scale their impact while inspiring others to contribute as well.
## How the Fellowship works 🙌🏻
This is Hugging Face supporting the amazing work of contributors! Being a Fellow works differently for everyone. The key question here is:
❓ **What would contributors need to have more impact? How can Hugging Face support them so they can do that project they have always wanted to do?**
Fellows of all backgrounds are welcome! The progress of Machine Learning depends on grassroots contributions. Each person has a unique set of skills and knowledge that can be used to democratize the field in a variety of ways. Each Fellow achieves impact differently and that is perfect 🌈. Hugging Face supports them to continue creating and sharing the way that fits their needs the best.
## What are the benefits of being part of the Fellowship? 🤩
The benefits will be based on the interests of each individual. Some examples of how Hugging Face supports Fellows:
💾 Computing and resources
🎁 Merchandise and assets.
✨ Official recognition from Hugging Face.
## How to become a Fellow
Fellows are currently nominated by members of the Hugging Face team or by another Fellow. How can prospects get noticed? The main criterion is that they have contributed to the democratization of open-source Machine Learning.
How? In the ways that they prefer. Here are some examples of the first Fellows:
- **María Grandury** - Created the [largest Spanish-speaking NLP community](https://somosnlp.org/) and organized a Hackathon that achieved 23 Spaces, 23 datasets, and 33 models that advanced the SOTA for Spanish ([see the Organization](https://huggingface.co/hackathon-pln-es) in the Hub). 👩🏼🎤
- **Manuel Romero** - Contributed [over 300 models](https://huggingface.co/mrm8488) to the Hugging Face Hub. He has trained multiple SOTA models in Spanish. 🤴🏻
- **Aritra Roy Gosthipathy**: Contributed new architectures for TensorFlow to the Transformers library, improved Keras tooling, and helped create the Keras working group (for example, see his [Vision Transformers tutorial](https://twitter.com/RisingSayak/status/1515918406171914240)). 🦹🏻
- **Vaibhav Srivastav** - Advocacy in the field of speech. He has led the [ML4Audio working group](https://github.com/Vaibhavs10/ml-with-audio) ([see the recordings](https://www.youtube.com/playlist?list=PLo2EIpI_JMQtOQK_B4G97yn1QWZ4Xi4Tu)) and paper discussion sessions. 🦹🏻
- **Bram Vanroy** - Helped many contributors and the Hugging Face team from the beginning. He has reported several [issues](https://github.com/huggingface/transformers/issues/1332) and merged [pull requests](https://github.com/huggingface/transformers/pull/1346) in the Transformers library since September 2019. 🦸🏼
- **Christopher Akiki** - Contributed to sprints, workshops, [Big Science](https://t.co/oIRne5fZYb), and cool demos! Check out some of his recent projects like his [TF-coder](https://t.co/NtTmO6ngHP) and the [income stats explorer](https://t.co/dNMO7lHAIR). 🦹🏻♀️
- **Ceyda Çınarel** - Contributed to many successful Hugging Face and Spaces models in various sprints. Check out her [ButterflyGAN Space](https://huggingface.co/spaces/huggan/butterfly-gan) or [search for reaction GIFs with CLIP](https://huggingface.co/spaces/flax-community/clip-reply-demo). 👸🏻
Additionally, there are strategic areas where Hugging Face is looking for open-source contributions. These areas will be added and updated frequently on the [Fellowship Doc with specific projects](https://docs.google.com/document/d/11mh36a4fgBlj8sh3_KoP2TckuPcnD-_S_UAtsEWgs50/edit). Prospects should not hesitate to write in the #looking-for-collaborators channel in the [Hugging Face Discord](https://t.co/1n75wi976V?amp=1) if they want to undertake a project in these areas, support or be considered as a Fellow. Additionally, refer to the **Where and how can I contribute?** question below.
If you are currently a student, consider applying to the [Student Ambassador Program](https://huggingface.co/blog/ambassadors). The application deadline is June 13, 2022.
Hugging Face is actively working to build a culture that values diversity, equity, and inclusion. Hugging Face intentionally creates a community where people feel respected and supported, regardless of who they are or where they come from. This is critical to building the future of open Machine Learning. The Fellowship will not discriminate based on race, religion, color, national origin, gender, sexual orientation, age, marital status, veteran status, or disability status.
## Frequently Asked Questions
* **I am just starting to contribute. Can I be a fellow?**
Fellows are nominated based on their open-source and community contributions. If you want to participate in the Fellowship, the best way to start is to begin contributing! If you are a student, the [Student Ambassador Program](https://huggingface.co/blog/ambassadors) might be more suitable for you (the application deadline is June 13, 2022).
* **Where and how can I contribute?**
It depends on your interests. Here are some ideas of areas where you can contribute, but you should work on things that get **you** excited!
- Share exciting models with the community through the Hub. These can be for Computer Vision, Reinforcement Learning, and any other ML domain!
- Create tutorials and projects using different open-source libraries—for example, Stable-Baselines 3, fastai, or Keras.
- Organize local sprints to promote open source Machine Learning in different languages or niches. For example, the [Somos NLP Hackathon](https://huggingface.co/hackathon-pln-es) focused on Spanish speakers. The [HugGAN sprint](https://github.com/huggingface/community-events/tree/main/huggan) focused on generative models.
- Translate the [Hugging Face Course](https://github.com/huggingface/course#-languages-and-translations), the [Transformers documentation](https://github.com/huggingface/transformers/blob/main/docs/TRANSLATING.md) or the [Educational Toolkit](https://github.com/huggingface/education-toolkit/blob/main/TRANSLATING.md).
- [Doc with specific projects](https://docs.google.com/document/d/11mh36a4fgBlj8sh3_KoP2TckuPcnD-_S_UAtsEWgs50/edit) where contributions would be valuable. The Hugging Face team will frequently update the doc with new projects.
Please share in the #looking-for-contributors channel on the [Hugging Face Discord](https://hf.co/join/discord) if you want to work on a particular project.
* **Will I be an employee of Hugging Face?**
No, the Fellowship does not mean you are an employee of Hugging Face. However, feel free to mention in any forum, including LinkedIn, that you are a Hugging Face Fellow. Hugging Face is growing and this could be a good path for a bigger relationship in the future 😎. Check the [Hugging Face job board](https://hf.co/jobs) for updated opportunities.
* **Will I receive benefits during the Fellowship?**
Yes, the benefits will depend on the particular needs and projects that each Fellow wants to undertake.
* **Is there a deadline?**
No. Admission to the program is ongoing and contingent on the nomination of a current Fellow or member of the Hugging Face team. Please note that being nominated may not be enough to be admitted as a Fellow.
|
huggingface/blog/blob/main/fellowship.md
|
Moderation
<Tip>
Check out the [Code of Conduct](https://huggingface.co/code-of-conduct) and the [Content Guidelines](https://huggingface.co/content-guidelines).
</Tip>
## Reporting a repository
To report a repository, you can click the three dots at the top right of a repository. Afterwards, you can click "Report the repository". This will allow you to explain what's the reason behind the report (Ethical issue, legal issue, not working, or other) and a description for the report. Once you do this, a **public discussion** will be opened.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/repository-report.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/repository-report-dark.png"/>
</div>
## Reporting a comment
To report a comment, you can click the three dots at the top right of a comment. That will submit a request for the Hugging Face team to review.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/comment-report.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/comment-report-dark.png"/>
</div>
|
huggingface/hub-docs/blob/main/docs/hub/moderation.md
|
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Articulation Bodies
There are two primary types of articulation supported by Simulate:
1. `Prismatic` joints: slide along a specified axis,
2. `Revolute` joints: rotate about a specified axis.
*Note* that these are currently only implemented in **Unity**.
[[autodoc]] ArticulationBodyComponent
|
huggingface/simulate/blob/main/docs/source/api/joints.mdx
|
Livebook on Spaces
**Livebook** is an open-source tool for writing interactive code notebooks in [Elixir](https://elixir-lang.org/). It's part of a growing collection of Elixir tools for [numerical computing](https://github.com/elixir-nx/nx), [data science](https://github.com/elixir-nx/explorer), and [Machine Learning](https://github.com/elixir-nx/bumblebee).
Some of Livebook's most exciting features are:
- **Reproducible workflows**: Livebook runs your code in a predictable order, all the way down to package management
- **Smart cells**: perform complex tasks, such as data manipulation and running machine learning models, with a few clicks using Livebook's extensible notebook cells
- **Elixir powered**: use the power of the Elixir programming language to write concurrent and distributed notebooks that scale beyond your machine
To learn more about it, watch this [15-minute video](https://www.youtube.com/watch?v=EhSNXWkji6o). Or visit [Livebook's website](https://livebook.dev/). Or follow its [Twitter](https://twitter.com/livebookdev) and [blog](https://news.livebook.dev/) to keep up with new features and updates.
## Your first Livebook Space
You can get Livebook up and running in a Space with just a few clicks. Click the button below to start creating a new Space using Livebook's Docker template:
<a href="http://huggingface.co/new-space?template=livebook-dev/livebook" target="_blank">
<img src="https://huggingface.co/datasets/huggingface/badges/resolve/main/deploy-to-spaces-lg.svg" alt="">
</a>
Then:
1. Give your Space a name
2. Set the password of your Livebook
3. Set its visibility to public
4. Create your Space
This will start building your Space using Livebook's Docker image.
The visibility of the Space must be set to public for the Smart cells feature in Livebook to function properly. However, your Livebook instance will be protected by Livebook authentication.
<Tip>
<a href="https://news.livebook.dev/v0.6-automate-and-learn-with-smart-cells-mxJJe" target="_blank">Smart cell</a> is a type of Livebook cell that provides a UI component for accomplishing a specific task. The code for the task is generated automatically based on the user's interactions with the UI, allowing for faster completion of high-level tasks without writing code from scratch.
</Tip>
Once the app build is finished, go to the "App" tab in your Space and log in to your Livebook using the password you previously set:
That's it! Now you can start using Livebook inside your Space.
If this is your first time using Livebook, you can learn how to use it with its interactive notebooks within Livebook itself:
## Livebook integration with Hugging Face Models
Livebook has an [official integration with Hugging Face models](https://livebook.dev/integrations/hugging-face). With this feature, you can run various Machine Learning models within Livebook with just a few clicks.
Here's a quick video showing how to do that:
<Youtube id="IcR60pVKeGY"/>
## How to configure Livebook to use the GPU
If your Space Hardware is configured to use a GPU accelerator, you can configure Livebook to leverage it.
Go to the Settings page of your Space and create a secret called `XLA_TARGET` with the value `cuda118`.
Restart your Space and start using Livebook with a GPU.
## How to update Livebook's version
To update Livebook to its latest version, go to the Settings page of your Space and click on "Factory reboot this Space":
## Caveats
The following caveats apply to running Livebook inside a Space:
- The Space's visibility setting must be public. Otherwise, Smart cells won't work. That said, your Livebook instance will still be behind Livebook authentication since you've set the `LIVEBOOK_PASSWORD` secret.
- Livebook global configurations will be lost once the Space restarts. Consider using the [desktop app](https://livebook.dev/#install) if you find yourself in need of persisting configuration across deployments.
## Feedback and support
If you have improvement suggestions or need specific support, please join the [Livebook community on GitHub](https://github.com/livebook-dev/livebook/discussions).
|
huggingface/hub-docs/blob/main/docs/hub/spaces-sdks-docker-livebook.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Text generation strategies
Text generation is essential to many NLP tasks, such as open-ended text generation, summarization, translation, and
more. It also plays a role in a variety of mixed-modality applications that have text as an output like speech-to-text
and vision-to-text. Some of the models that can generate text include
GPT2, XLNet, OpenAI GPT, CTRL, TransformerXL, XLM, Bart, T5, GIT, Whisper.
Check out a few examples that use [`~transformers.generation_utils.GenerationMixin.generate`] method to produce
text outputs for different tasks:
* [Text summarization](./tasks/summarization#inference)
* [Image captioning](./model_doc/git#transformers.GitForCausalLM.forward.example)
* [Audio transcription](./model_doc/whisper#transformers.WhisperForConditionalGeneration.forward.example)
Note that the inputs to the generate method depend on the model's modality. They are returned by the model's preprocessor
class, such as AutoTokenizer or AutoProcessor. If a model's preprocessor creates more than one kind of input, pass all
the inputs to generate(). You can learn more about the individual model's preprocessor in the corresponding model's documentation.
The process of selecting output tokens to generate text is known as decoding, and you can customize the decoding strategy
that the `generate()` method will use. Modifying a decoding strategy does not change the values of any trainable parameters.
However, it can have a noticeable impact on the quality of the generated output. It can help reduce repetition in the text
and make it more coherent.
This guide describes:
* default generation configuration
* common decoding strategies and their main parameters
* saving and sharing custom generation configurations with your fine-tuned model on 🤗 Hub
## Default text generation configuration
A decoding strategy for a model is defined in its generation configuration. When using pre-trained models for inference
within a [`pipeline`], the models call the `PreTrainedModel.generate()` method that applies a default generation
configuration under the hood. The default configuration is also used when no custom configuration has been saved with
the model.
When you load a model explicitly, you can inspect the generation configuration that comes with it through
`model.generation_config`:
```python
>>> from transformers import AutoModelForCausalLM
>>> model = AutoModelForCausalLM.from_pretrained("distilgpt2")
>>> model.generation_config
GenerationConfig {
"bos_token_id": 50256,
"eos_token_id": 50256,
}
```
Printing out the `model.generation_config` reveals only the values that are different from the default generation
configuration, and does not list any of the default values.
The default generation configuration limits the size of the output combined with the input prompt to a maximum of 20
tokens to avoid running into resource limitations. The default decoding strategy is greedy search, which is the simplest decoding strategy that picks a token with the highest probability as the next token. For many tasks
and small output sizes this works well. However, when used to generate longer outputs, greedy search can start
producing highly repetitive results.
## Customize text generation
You can override any `generation_config` by passing the parameters and their values directly to the [`generate`] method:
```python
>>> my_model.generate(**inputs, num_beams=4, do_sample=True) # doctest: +SKIP
```
Even if the default decoding strategy mostly works for your task, you can still tweak a few things. Some of the
commonly adjusted parameters include:
- `max_new_tokens`: the maximum number of tokens to generate. In other words, the size of the output sequence, not
including the tokens in the prompt. As an alternative to using the output's length as a stopping criteria, you can choose
to stop generation whenever the full generation exceeds some amount of time. To learn more, check [`StoppingCriteria`].
- `num_beams`: by specifying a number of beams higher than 1, you are effectively switching from greedy search to
beam search. This strategy evaluates several hypotheses at each time step and eventually chooses the hypothesis that
has the overall highest probability for the entire sequence. This has the advantage of identifying high-probability
sequences that start with a lower probability initial tokens and would've been ignored by the greedy search.
- `do_sample`: if set to `True`, this parameter enables decoding strategies such as multinomial sampling, beam-search
multinomial sampling, Top-K sampling and Top-p sampling. All these strategies select the next token from the probability
distribution over the entire vocabulary with various strategy-specific adjustments.
- `num_return_sequences`: the number of sequence candidates to return for each input. This option is only available for
the decoding strategies that support multiple sequence candidates, e.g. variations of beam search and sampling. Decoding
strategies like greedy search and contrastive search return a single output sequence.
## Save a custom decoding strategy with your model
If you would like to share your fine-tuned model with a specific generation configuration, you can:
* Create a [`GenerationConfig`] class instance
* Specify the decoding strategy parameters
* Save your generation configuration with [`GenerationConfig.save_pretrained`], making sure to leave its `config_file_name` argument empty
* Set `push_to_hub` to `True` to upload your config to the model's repo
```python
>>> from transformers import AutoModelForCausalLM, GenerationConfig
>>> model = AutoModelForCausalLM.from_pretrained("my_account/my_model") # doctest: +SKIP
>>> generation_config = GenerationConfig(
... max_new_tokens=50, do_sample=True, top_k=50, eos_token_id=model.config.eos_token_id
... )
>>> generation_config.save_pretrained("my_account/my_model", push_to_hub=True) # doctest: +SKIP
```
You can also store several generation configurations in a single directory, making use of the `config_file_name`
argument in [`GenerationConfig.save_pretrained`]. You can later instantiate them with [`GenerationConfig.from_pretrained`]. This is useful if you want to
store several generation configurations for a single model (e.g. one for creative text generation with sampling, and
one for summarization with beam search). You must have the right Hub permissions to add configuration files to a model.
```python
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, GenerationConfig
>>> tokenizer = AutoTokenizer.from_pretrained("t5-small")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("t5-small")
>>> translation_generation_config = GenerationConfig(
... num_beams=4,
... early_stopping=True,
... decoder_start_token_id=0,
... eos_token_id=model.config.eos_token_id,
... pad_token=model.config.pad_token_id,
... )
>>> # Tip: add `push_to_hub=True` to push to the Hub
>>> translation_generation_config.save_pretrained("/tmp", "translation_generation_config.json")
>>> # You could then use the named generation config file to parameterize generation
>>> generation_config = GenerationConfig.from_pretrained("/tmp", "translation_generation_config.json")
>>> inputs = tokenizer("translate English to French: Configuration files are easy to use!", return_tensors="pt")
>>> outputs = model.generate(**inputs, generation_config=generation_config)
>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
['Les fichiers de configuration sont faciles à utiliser!']
```
## Streaming
The `generate()` supports streaming, through its `streamer` input. The `streamer` input is compatible with any instance
from a class that has the following methods: `put()` and `end()`. Internally, `put()` is used to push new tokens and
`end()` is used to flag the end of text generation.
<Tip warning={true}>
The API for the streamer classes is still under development and may change in the future.
</Tip>
In practice, you can craft your own streaming class for all sorts of purposes! We also have basic streaming classes
ready for you to use. For example, you can use the [`TextStreamer`] class to stream the output of `generate()` into
your screen, one word at a time:
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
>>> tok = AutoTokenizer.from_pretrained("gpt2")
>>> model = AutoModelForCausalLM.from_pretrained("gpt2")
>>> inputs = tok(["An increasing sequence: one,"], return_tensors="pt")
>>> streamer = TextStreamer(tok)
>>> # Despite returning the usual output, the streamer will also print the generated text to stdout.
>>> _ = model.generate(**inputs, streamer=streamer, max_new_tokens=20)
An increasing sequence: one, two, three, four, five, six, seven, eight, nine, ten, eleven,
```
## Decoding strategies
Certain combinations of the `generate()` parameters, and ultimately `generation_config`, can be used to enable specific
decoding strategies. If you are new to this concept, we recommend reading [this blog post that illustrates how common decoding strategies work](https://huggingface.co/blog/how-to-generate).
Here, we'll show some of the parameters that control the decoding strategies and illustrate how you can use them.
### Greedy Search
[`generate`] uses greedy search decoding by default so you don't have to pass any parameters to enable it. This means the parameters `num_beams` is set to 1 and `do_sample=False`.
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> prompt = "I look forward to"
>>> checkpoint = "distilgpt2"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['I look forward to seeing you all again!\n\n\n\n\n\n\n\n\n\n\n']
```
### Contrastive search
The contrastive search decoding strategy was proposed in the 2022 paper [A Contrastive Framework for Neural Text Generation](https://arxiv.org/abs/2202.06417).
It demonstrates superior results for generating non-repetitive yet coherent long outputs. To learn how contrastive search
works, check out [this blog post](https://huggingface.co/blog/introducing-csearch).
The two main parameters that enable and control the behavior of contrastive search are `penalty_alpha` and `top_k`:
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
>>> checkpoint = "gpt2-large"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> prompt = "Hugging Face Company is"
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> outputs = model.generate(**inputs, penalty_alpha=0.6, top_k=4, max_new_tokens=100)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Hugging Face Company is a family owned and operated business. We pride ourselves on being the best
in the business and our customer service is second to none.\n\nIf you have any questions about our
products or services, feel free to contact us at any time. We look forward to hearing from you!']
```
### Multinomial sampling
As opposed to greedy search that always chooses a token with the highest probability as the
next token, multinomial sampling (also called ancestral sampling) randomly selects the next token based on the probability distribution over the entire
vocabulary given by the model. Every token with a non-zero probability has a chance of being selected, thus reducing the
risk of repetition.
To enable multinomial sampling set `do_sample=True` and `num_beams=1`.
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
>>> set_seed(0) # For reproducibility
>>> checkpoint = "gpt2-large"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> prompt = "Today was an amazing day because"
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> outputs = model.generate(**inputs, do_sample=True, num_beams=1, max_new_tokens=100)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Today was an amazing day because when you go to the World Cup and you don\'t, or when you don\'t get invited,
that\'s a terrible feeling."']
```
### Beam-search decoding
Unlike greedy search, beam-search decoding keeps several hypotheses at each time step and eventually chooses
the hypothesis that has the overall highest probability for the entire sequence. This has the advantage of identifying high-probability
sequences that start with lower probability initial tokens and would've been ignored by the greedy search.
To enable this decoding strategy, specify the `num_beams` (aka number of hypotheses to keep track of) that is greater than 1.
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> prompt = "It is astonishing how one can"
>>> checkpoint = "gpt2-medium"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs, num_beams=5, max_new_tokens=50)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['It is astonishing how one can have such a profound impact on the lives of so many people in such a short period of
time."\n\nHe added: "I am very proud of the work I have been able to do in the last few years.\n\n"I have']
```
### Beam-search multinomial sampling
As the name implies, this decoding strategy combines beam search with multinomial sampling. You need to specify
the `num_beams` greater than 1, and set `do_sample=True` to use this decoding strategy.
```python
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, set_seed
>>> set_seed(0) # For reproducibility
>>> prompt = "translate English to German: The house is wonderful."
>>> checkpoint = "t5-small"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs, num_beams=5, do_sample=True)
>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
'Das Haus ist wunderbar.'
```
### Diverse beam search decoding
The diverse beam search decoding strategy is an extension of the beam search strategy that allows for generating a more diverse
set of beam sequences to choose from. To learn how it works, refer to [Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models](https://arxiv.org/pdf/1610.02424.pdf).
This approach has three main parameters: `num_beams`, `num_beam_groups`, and `diversity_penalty`.
The diversity penalty ensures the outputs are distinct across groups, and beam search is used within each group.
```python
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> checkpoint = "google/pegasus-xsum"
>>> prompt = (
... "The Permaculture Design Principles are a set of universal design principles "
... "that can be applied to any location, climate and culture, and they allow us to design "
... "the most efficient and sustainable human habitation and food production systems. "
... "Permaculture is a design system that encompasses a wide variety of disciplines, such "
... "as ecology, landscape design, environmental science and energy conservation, and the "
... "Permaculture design principles are drawn from these various disciplines. Each individual "
... "design principle itself embodies a complete conceptual framework based on sound "
... "scientific principles. When we bring all these separate principles together, we can "
... "create a design system that both looks at whole systems, the parts that these systems "
... "consist of, and how those parts interact with each other to create a complex, dynamic, "
... "living system. Each design principle serves as a tool that allows us to integrate all "
... "the separate parts of a design, referred to as elements, into a functional, synergistic, "
... "whole system, where the elements harmoniously interact and work together in the most "
... "efficient way possible."
... )
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs, num_beams=5, num_beam_groups=5, max_new_tokens=30, diversity_penalty=1.0)
>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
'The Design Principles are a set of universal design principles that can be applied to any location, climate and
culture, and they allow us to design the'
```
This guide illustrates the main parameters that enable various decoding strategies. More advanced parameters exist for the
[`generate`] method, which gives you even further control over the [`generate`] method's behavior.
For the complete list of the available parameters, refer to the [API documentation](./main_classes/text_generation.md).
### Speculative Decoding
Speculative decoding (also known as assisted decoding) is a modification of the decoding strategies above, that uses an
assistant model (ideally a much smaller one) with the same tokenizer, to generate a few candidate tokens. The main
model then validates the candidate tokens in a single forward pass, which speeds up the decoding process. If
`do_sample=True`, then the token validation with resampling introduced in the
[speculative decoding paper](https://arxiv.org/pdf/2211.17192.pdf) is used.
Currently, only greedy search and sampling are supported with assisted decoding, and assisted decoding doesn't support batched inputs.
To learn more about assisted decoding, check [this blog post](https://huggingface.co/blog/assisted-generation).
To enable assisted decoding, set the `assistant_model` argument with a model.
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> prompt = "Alice and Bob"
>>> checkpoint = "EleutherAI/pythia-1.4b-deduped"
>>> assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
>>> outputs = model.generate(**inputs, assistant_model=assistant_model)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Alice and Bob are sitting in a bar. Alice is drinking a beer and Bob is drinking a']
```
When using assisted decoding with sampling methods, you can use the `temperature` argument to control the randomness,
just like in multinomial sampling. However, in assisted decoding, reducing the temperature may help improve the latency.
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
>>> set_seed(42) # For reproducibility
>>> prompt = "Alice and Bob"
>>> checkpoint = "EleutherAI/pythia-1.4b-deduped"
>>> assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
>>> outputs = model.generate(**inputs, assistant_model=assistant_model, do_sample=True, temperature=0.5)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Alice and Bob are going to the same party. It is a small party, in a small']
```
|
huggingface/transformers/blob/main/docs/source/en/generation_strategies.md
|
Gradio Demo: stream_audio
```
!pip install -q gradio
```
```
import gradio as gr
import numpy as np
import time
def add_to_stream(audio, instream):
time.sleep(1)
if audio is None:
return gr.Audio(), instream
if instream is None:
ret = audio
else:
ret = (audio[0], np.concatenate((instream[1], audio[1])))
return ret, ret
with gr.Blocks() as demo:
inp = gr.Audio(sources=["microphone"])
out = gr.Audio()
stream = gr.State()
clear = gr.Button("Clear")
inp.stream(add_to_stream, [inp, stream], [out, stream])
clear.click(lambda: [None, None, None], None, [inp, out, stream])
if __name__ == "__main__":
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/stream_audio/run.ipynb
|
ESE-VoVNet
**VoVNet** is a convolutional neural network that seeks to make [DenseNet](https://paperswithcode.com/method/densenet) more efficient by concatenating all features only once in the last feature map, which makes input size constant and enables enlarging new output channel.
Read about [one-shot aggregation here](https://paperswithcode.com/method/one-shot-aggregation).
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('ese_vovnet19b_dw', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `ese_vovnet19b_dw`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('ese_vovnet19b_dw', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{lee2019energy,
title={An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection},
author={Youngwan Lee and Joong-won Hwang and Sangrok Lee and Yuseok Bae and Jongyoul Park},
year={2019},
eprint={1904.09730},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: ESE VovNet
Paper:
Title: 'CenterMask : Real-Time Anchor-Free Instance Segmentation'
URL: https://paperswithcode.com/paper/centermask-real-time-anchor-free-instance-1
Models:
- Name: ese_vovnet19b_dw
In Collection: ESE VovNet
Metadata:
FLOPs: 1711959904
Parameters: 6540000
File Size: 26243175
Architecture:
- Batch Normalization
- Convolution
- Max Pooling
- One-Shot Aggregation
- ReLU
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: ese_vovnet19b_dw
Layers: 19
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/vovnet.py#L361
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/ese_vovnet19b_dw-a8741004.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 76.82%
Top 5 Accuracy: 93.28%
- Name: ese_vovnet39b
In Collection: ESE VovNet
Metadata:
FLOPs: 9089259008
Parameters: 24570000
File Size: 98397138
Architecture:
- Batch Normalization
- Convolution
- Max Pooling
- One-Shot Aggregation
- ReLU
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: ese_vovnet39b
Layers: 39
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/vovnet.py#L371
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/ese_vovnet39b-f912fe73.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.31%
Top 5 Accuracy: 94.72%
-->
|
huggingface/pytorch-image-models/blob/main/docs/models/ese-vovnet.md
|
--
title: "How 🤗 Accelerate runs very large models thanks to PyTorch"
thumbnail: /blog/assets/104_accelerate-large-models/thumbnail.png
authors:
- user: sgugger
---
# How 🤗 Accelerate runs very large models thanks to PyTorch
## Load and run large models
Meta AI and BigScience recently open-sourced very large language models which won't fit into memory (RAM or GPU) of most consumer hardware. At Hugging Face, part of our mission is to make even those large models accessible, so we developed tools to allow you to run those models even if you don't own a supercomputer. All the examples picked in this blog post run on a free Colab instance (with limited RAM and disk space) if you have access to more disk space, don't hesitate to pick larger checkpoints.
Here is how we can run OPT-6.7B:
```python
import torch
from transformers import pipeline
# This works on a base Colab instance.
# Pick a larger checkpoint if you have time to wait and enough disk space!
checkpoint = "facebook/opt-6.7b"
generator = pipeline("text-generation", model=checkpoint, device_map="auto", torch_dtype=torch.float16)
# Perform inference
generator("More and more large language models are opensourced so Hugging Face has")
```
We'll explain what each of those arguments do in a moment, but first just consider the traditional model loading pipeline in PyTorch: it usually consists of:
1. Create the model
2. Load in memory its weights (in an object usually called `state_dict`)
3. Load those weights in the created model
4. Move the model on the device for inference
While that has worked pretty well in the past years, very large models make this approach challenging. Here the model picked has 6.7 *billion* parameters. In the default precision, it means that just step 1 (creating the model) will take roughly **26.8GB** in RAM (1 parameter in float32 takes 4 bytes in memory). This can't even fit in the RAM you get on Colab.
Then step 2 will load in memory a second copy of the model (so another 26.8GB in RAM in default precision). If you were trying to load the largest models, for example BLOOM or OPT-176B (which both have 176 billion parameters), like this, you would need 1.4 **terabytes** of CPU RAM. That is a bit excessive! And all of this to just move the model on one (or several) GPU(s) at step 4.
Clearly we need something smarter. In this blog post, we'll explain how Accelerate leverages PyTorch features to load and run inference with very large models, even if they don't fit in RAM or one GPU. In a nutshell, it changes the process above like this:
1. Create an empty (e.g. without weights) model
2. Decide where each layer is going to go (when multiple devices are available)
3. Load in memory parts of its weights
4. Load those weights in the empty model
5. Move the weights on the device for inference
6. Repeat from step 3 for the next weights until all the weights are loaded
## Creating an empty model
PyTorch 1.9 introduced a new kind of device called the *meta* device. This allows us to create tensor without any data attached to them: a tensor on the meta device only needs a shape. As long as you are on the meta device, you can thus create arbitrarily large tensors without having to worry about CPU (or GPU) RAM.
For instance, the following code will crash on Colab:
```python
import torch
large_tensor = torch.randn(100000, 100000)
```
as this large tensor requires `4 * 10**10` bytes (the default precision is FP32, so each element of the tensor takes 4 bytes) thus 40GB of RAM. The same on the meta device works just fine however:
```python
import torch
large_tensor = torch.randn(100000, 100000, device="meta")
```
If you try to display this tensor, here is what PyTorch will print:
```
tensor(..., device='meta', size=(100000, 100000))
```
As we said before, there is no data associated with this tensor, just a shape.
You can instantiate a model directly on the meta device:
```python
large_model = torch.nn.Linear(100000, 100000, device="meta")
```
But for an existing model, this syntax would require you to rewrite all your modeling code so that each submodule accepts and passes along a `device` keyword argument. Since this was impractical for the 150 models of the Transformers library, we developed a context manager that will instantiate an empty model for you.
Here is how you can instantiate an empty version of BLOOM:
```python
from accelerate import init_empty_weights
from transformers import AutoConfig, AutoModelForCausalLM
config = AutoConfig.from_pretrained("bigscience/bloom")
with init_empty_weights():
model = AutoModelForCausalLM.from_config(config)
```
This works on any model, but you get back a shell you can't use directly: some operations are implemented for the meta device, but not all yet. Here for instance, you can use the `large_model` defined above with an input, but not the BLOOM model. Even when using it, the output will be a tensor of the meta device, so you will get the shape of the result, but nothing more.
As further work on this, the PyTorch team is working on a new [class `FakeTensor`](https://pytorch.org/torchdistx/latest/fake_tensor.html), which is a bit like tensors on the meta device, but with the device information (on top of shape and dtype)
Since we know the shape of each weight, we can however know how much memory they will all consume once we load the pretrained tensors fully. Therefore, we can make a decision on how to split our model across CPUs and GPUs.
## Computing a device map
Before we start loading the pretrained weights, we will need to know where we want to put them. This way we can free the CPU RAM each time we have put a weight in its right place. This can be done with the empty model on the meta device, since we only need to know the shape of each tensor and its dtype to compute how much space it will take in memory.
Accelerate provides a function to automatically determine a *device map* from an empty model. It will try to maximize the use of all available GPUs, then CPU RAM, and finally flag the weights that don't fit for disk offload. Let's have a look using [OPT-13b](https://huggingface.co/facebook/opt-13b).
```python
from accelerate import infer_auto_device_map, init_empty_weights
from transformers import AutoConfig, AutoModelForCausalLM
config = AutoConfig.from_pretrained("facebook/opt-13b")
with init_empty_weights():
model = AutoModelForCausalLM.from_config(config)
device_map = infer_auto_device_map(model)
```
This will return a dictionary mapping modules or weights to a device. On a machine with one Titan RTX for instance, we get the following:
```python out
{'model.decoder.embed_tokens': 0,
'model.decoder.embed_positions': 0,
'model.decoder.final_layer_norm': 0,
'model.decoder.layers.0': 0,
'model.decoder.layers.1': 0,
...
'model.decoder.layers.9': 0,
'model.decoder.layers.10.self_attn': 0,
'model.decoder.layers.10.activation_fn': 0,
'model.decoder.layers.10.self_attn_layer_norm': 0,
'model.decoder.layers.10.fc1': 'cpu',
'model.decoder.layers.10.fc2': 'cpu',
'model.decoder.layers.10.final_layer_norm': 'cpu',
'model.decoder.layers.11': 'cpu',
...
'model.decoder.layers.17': 'cpu',
'model.decoder.layers.18.self_attn': 'cpu',
'model.decoder.layers.18.activation_fn': 'cpu',
'model.decoder.layers.18.self_attn_layer_norm': 'cpu',
'model.decoder.layers.18.fc1': 'disk',
'model.decoder.layers.18.fc2': 'disk',
'model.decoder.layers.18.final_layer_norm': 'disk',
'model.decoder.layers.19': 'disk',
...
'model.decoder.layers.39': 'disk',
'lm_head': 'disk'}
```
Accelerate evaluated that the embeddings and the decoder up until the 9th block could all fit on the GPU (device 0), then part of the 10th block needs to be on the CPU, as well as the following weights until the 17th layer. Then the 18th layer is split between the CPU and the disk and the following layers must all be offloaded to disk
Actually using this device map later on won't work, because the layers composing this model have residual connections (where the input of the block is added to the output of the block) so all of a given layer should be on the same device. We can indicate this to Accelerate by passing a list of module names that shouldn't be split with the `no_split_module_classes` keyword argument:
```python
device_map = infer_auto_device_map(model, no_split_module_classes=["OPTDecoderLayer"])
```
This will then return
```python out
'model.decoder.embed_tokens': 0,
'model.decoder.embed_positions': 0,
'model.decoder.final_layer_norm': 0,
'model.decoder.layers.0': 0,
'model.decoder.layers.1': 0,
...
'model.decoder.layers.9': 0,
'model.decoder.layers.10': 'cpu',
'model.decoder.layers.11': 'cpu',
...
'model.decoder.layers.17': 'cpu',
'model.decoder.layers.18': 'disk',
...
'model.decoder.layers.39': 'disk',
'lm_head': 'disk'}
```
Now, each layer is always on the same device.
In Transformers, when using `device_map` in the `from_pretrained()` method or in a `pipeline`, those classes of blocks to leave on the same device are automatically provided, so you don't need to worry about them. Note that you have the following options for `device_map` (only relevant when you have more than one GPU):
- `"auto"` or `"balanced"`: Accelerate will split the weights so that each GPU is used equally;
- `"balanced_low_0"`: Accelerate will split the weights so that each GPU is used equally except the first one, where it will try to have as little weights as possible (useful when you want to work with the outputs of the model on one GPU, for instance when using the `generate` function);
- `"sequential"`: Accelerate will fill the GPUs in order (so the last ones might not be used at all).
You can also pass your own `device_map` as long as it follows the format we saw before (dictionary layer/module names to device).
Finally, note that the results of the `device_map` you receive depend on the selected dtype (as different types of floats take a different amount of space). Providing `dtype="float16"` will give us different results:
```python
device_map = infer_auto_device_map(model, no_split_module_classes=["OPTDecoderLayer"], dtype="float16")
```
In this precision, we can fit the model up to layer 21 on the GPU:
```python out
{'model.decoder.embed_tokens': 0,
'model.decoder.embed_positions': 0,
'model.decoder.final_layer_norm': 0,
'model.decoder.layers.0': 0,
'model.decoder.layers.1': 0,
...
'model.decoder.layers.21': 0,
'model.decoder.layers.22': 'cpu',
...
'model.decoder.layers.37': 'cpu',
'model.decoder.layers.38': 'disk',
'model.decoder.layers.39': 'disk',
'lm_head': 'disk'}
```
Now that we know where each weight is supposed to go, we can progressively load the pretrained weights inside the model.
## Sharding state dicts
Traditionally, PyTorch models are saved in a whole file containing a map from parameter name to weight. This map is often called a `state_dict`. Here is an excerpt from the [PyTorch documentation](https://pytorch.org/tutorials/beginner/basics/saveloadrun_tutorial.html) on saving on loading:
```python
# Save the model weights
torch.save(my_model.state_dict(), 'model_weights.pth')
# Reload them
new_model = ModelClass()
new_model.load_state_dict(torch.load('model_weights.pth'))
```
This works pretty well for models with less than 1 billion parameters, but for larger models, this is very taxing in RAM. The BLOOM model has 176 billions parameters; even with the weights saved in bfloat16 to save space, it still represents 352GB as a whole. While the super computer that trained this model might have this amount of memory available, requiring this for inference is unrealistic.
This is why large models on the Hugging Face Hub are not saved and shared with one big file containing all the weights, but **several** of them. If you go to the [BLOOM model page](https://huggingface.co/bigscience/bloom/tree/main) for instance, you will see there is 72 files named `pytorch_model_xxxxx-of-00072.bin`, which each contain part of the model weights. Using this format, we can load one part of the state dict in memory, put the weights inside the model, move them on the right device, then discard this state dict part before going to the next. Instead of requiring to have enough RAM to accommodate the whole model, we only need enough RAM to get the biggest checkpoint part, which we call a **shard**, so 7.19GB in the case of BLOOM.
We call the checkpoints saved in several files like BLOOM *sharded checkpoints*, and we have standardized their format as such:
- One file (called `pytorch_model.bin.index.json`) contains some metadata and a map parameter name to file name, indicating where to find each weight
- All the other files are standard PyTorch state dicts, they just contain a part of the model instead of the whole one. You can have a look at the content of the index file [here](https://huggingface.co/bigscience/bloom/blob/main/pytorch_model.bin.index.json).
To load such a sharded checkpoint into a model, we just need to loop over the various shards. Accelerate provides a function called `load_checkpoint_in_model` that will do this for you if you have cloned one of the repos of the Hub, or you can directly use the `from_pretrained` method of Transformers, which will handle the downloading and caching for you:
```python
import torch
from transformers import AutoModelForCausalLM
# Will error
checkpoint = "facebook/opt-13b"
model = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto", torch_dtype=torch.float16)
```
If the device map computed automatically requires some weights to be offloaded on disk because you don't have enough GPU and CPU RAM, you will get an error indicating you need to pass an folder where the weights that should be stored on disk will be offloaded:
```python out
ValueError: The current `device_map` had weights offloaded to the disk. Please provide an
`offload_folder` for them.
```
Adding this argument should resolve the error:
```python
import torch
from transformers import AutoModelForCausalLM
# Will go out of RAM on Colab
checkpoint = "facebook/opt-13b"
model = AutoModelForCausalLM.from_pretrained(
checkpoint, device_map="auto", offload_folder="offload", torch_dtype=torch.float16
)
```
Note that if you are trying to load a very large model that require some disk offload on top of CPU offload, you might run out of RAM when the last shards of the checkpoint are loaded, since there is the part of the model staying on CPU taking space. If that is the case, use the option `offload_state_dict=True` to temporarily offload the part of the model staying on CPU while the weights are all loaded, and reload it in RAM once all the weights have been processed
```python
import torch
from transformers import AutoModelForCausalLM
checkpoint = "facebook/opt-13b"
model = AutoModelForCausalLM.from_pretrained(
checkpoint, device_map="auto", offload_folder="offload", offload_state_dict = True, torch_dtype=torch.float16
)
```
This will fit in Colab, but will be so close to using all the RAM available that it will go out of RAM when you try to generate a prediction. To get a model we can use, we need to offload one more layer on the disk. We can do so by taking the `device_map` computed in the previous section, adapting it a bit, then passing it to the `from_pretrained` call:
```python
import torch
from transformers import AutoModelForCausalLM
checkpoint = "facebook/opt-13b"
device_map["model.decoder.layers.37"] = "disk"
model = AutoModelForCausalLM.from_pretrained(
checkpoint, device_map=device_map, offload_folder="offload", offload_state_dict = True, torch_dtype=torch.float16
)
```
## Running a model split on several devices
One last part we haven't touched is how Accelerate enables your model to run with its weight spread across several GPUs, CPU RAM, and the disk folder. This is done very simply using hooks.
> [hooks](https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.register_forward_hook) are a PyTorch API that adds functions executed just before each forward called
We couldn't use this directly since they only support models with regular arguments and no keyword arguments in their forward pass, but we took the same idea. Once the model is loaded, the `dispatch_model` function will add hooks to every module and submodule that are executed before and after each forward pass. They will:
- make sure all the inputs of the module are on the same device as the weights;
- if the weights have been offloaded to the CPU, move them to GPU 0 before the forward pass and back to the CPU just after;
- if the weights have been offloaded to disk, load them in RAM then on the GPU 0 before the forward pass and free this memory just after.
The whole process is summarized in the following video:
<iframe width="560" height="315" src="https://www.youtube.com/embed/MWCSGj9jEAo" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
This way, your model can be loaded and run even if you don't have enough GPU RAM and CPU RAM. The only thing you need is disk space (and lots of patience!) While this solution is pretty naive if you have multiple GPUs (there is no clever pipeline parallelism involved, just using the GPUs sequentially) it still yields [pretty decent results for BLOOM](https://huggingface.co/blog/bloom-inference-pytorch-scripts). And it allows you to run the model on smaller setups (albeit more slowly).
To learn more about Accelerate big model inference, see the [documentation](https://huggingface.co/docs/accelerate/usage_guides/big_modeling).
|
huggingface/blog/blob/main/accelerate-large-models.md
|
Datasets server databases migrations
> Scripts to migrate the datasets server databases
## Configuration
The script can be configured using environment variables. They are grouped by scope.
### Migration script
Set environment variables to configure the job (`DATABASE_MIGRATIONS_` prefix):
- `DATABASE_MIGRATIONS_MONGO_DATABASE`: the name of the database used for storing the migrations history. Defaults to `"datasets_server_maintenance"`.
- `DATABASE_MIGRATIONS_MONGO_URL`: the URL used to connect to the mongo db server. Defaults to `"mongodb://localhost:27017"`.
### Common
See [../../libs/libcommon/README.md](../../libs/libcommon/README.md) for more information about the common configuration.
## Launch
```shell
make run
```
|
huggingface/datasets-server/blob/main/jobs/mongodb_migration/README.md
|
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Pipelines
The pipelines are a great and easy way to use models for inference. These pipelines are objects that abstract most of
the complex code from the library, offering a simple API dedicated to several tasks, including Named Entity
Recognition, Masked Language Modeling, Sentiment Analysis, Feature Extraction and Question Answering. See the
[task summary](../task_summary) for examples of use.
There are two categories of pipeline abstractions to be aware about:
- The [`pipeline`] which is the most powerful object encapsulating all other pipelines.
- Task-specific pipelines are available for [audio](#audio), [computer vision](#computer-vision), [natural language processing](#natural-language-processing), and [multimodal](#multimodal) tasks.
## The pipeline abstraction
The *pipeline* abstraction is a wrapper around all the other available pipelines. It is instantiated as any other
pipeline but can provide additional quality of life.
Simple call on one item:
```python
>>> pipe = pipeline("text-classification")
>>> pipe("This restaurant is awesome")
[{'label': 'POSITIVE', 'score': 0.9998743534088135}]
```
If you want to use a specific model from the [hub](https://huggingface.co) you can ignore the task if the model on
the hub already defines it:
```python
>>> pipe = pipeline(model="roberta-large-mnli")
>>> pipe("This restaurant is awesome")
[{'label': 'NEUTRAL', 'score': 0.7313136458396912}]
```
To call a pipeline on many items, you can call it with a *list*.
```python
>>> pipe = pipeline("text-classification")
>>> pipe(["This restaurant is awesome", "This restaurant is awful"])
[{'label': 'POSITIVE', 'score': 0.9998743534088135},
{'label': 'NEGATIVE', 'score': 0.9996669292449951}]
```
To iterate over full datasets it is recommended to use a `dataset` directly. This means you don't need to allocate
the whole dataset at once, nor do you need to do batching yourself. This should work just as fast as custom loops on
GPU. If it doesn't don't hesitate to create an issue.
```python
import datasets
from transformers import pipeline
from transformers.pipelines.pt_utils import KeyDataset
from tqdm.auto import tqdm
pipe = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h", device=0)
dataset = datasets.load_dataset("superb", name="asr", split="test")
# KeyDataset (only *pt*) will simply return the item in the dict returned by the dataset item
# as we're not interested in the *target* part of the dataset. For sentence pair use KeyPairDataset
for out in tqdm(pipe(KeyDataset(dataset, "file"))):
print(out)
# {"text": "NUMBER TEN FRESH NELLY IS WAITING ON YOU GOOD NIGHT HUSBAND"}
# {"text": ....}
# ....
```
For ease of use, a generator is also possible:
```python
from transformers import pipeline
pipe = pipeline("text-classification")
def data():
while True:
# This could come from a dataset, a database, a queue or HTTP request
# in a server
# Caveat: because this is iterative, you cannot use `num_workers > 1` variable
# to use multiple threads to preprocess data. You can still have 1 thread that
# does the preprocessing while the main runs the big inference
yield "This is a test"
for out in pipe(data()):
print(out)
# {"text": "NUMBER TEN FRESH NELLY IS WAITING ON YOU GOOD NIGHT HUSBAND"}
# {"text": ....}
# ....
```
[[autodoc]] pipeline
## Pipeline batching
All pipelines can use batching. This will work
whenever the pipeline uses its streaming ability (so when passing lists or `Dataset` or `generator`).
```python
from transformers import pipeline
from transformers.pipelines.pt_utils import KeyDataset
import datasets
dataset = datasets.load_dataset("imdb", name="plain_text", split="unsupervised")
pipe = pipeline("text-classification", device=0)
for out in pipe(KeyDataset(dataset, "text"), batch_size=8, truncation="only_first"):
print(out)
# [{'label': 'POSITIVE', 'score': 0.9998743534088135}]
# Exactly the same output as before, but the content are passed
# as batches to the model
```
<Tip warning={true}>
However, this is not automatically a win for performance. It can be either a 10x speedup or 5x slowdown depending
on hardware, data and the actual model being used.
Example where it's mostly a speedup:
</Tip>
```python
from transformers import pipeline
from torch.utils.data import Dataset
from tqdm.auto import tqdm
pipe = pipeline("text-classification", device=0)
class MyDataset(Dataset):
def __len__(self):
return 5000
def __getitem__(self, i):
return "This is a test"
dataset = MyDataset()
for batch_size in [1, 8, 64, 256]:
print("-" * 30)
print(f"Streaming batch_size={batch_size}")
for out in tqdm(pipe(dataset, batch_size=batch_size), total=len(dataset)):
pass
```
```
# On GTX 970
------------------------------
Streaming no batching
100%|██████████████████████████████████████████████████████████████████████| 5000/5000 [00:26<00:00, 187.52it/s]
------------------------------
Streaming batch_size=8
100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:04<00:00, 1205.95it/s]
------------------------------
Streaming batch_size=64
100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:02<00:00, 2478.24it/s]
------------------------------
Streaming batch_size=256
100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:01<00:00, 2554.43it/s]
(diminishing returns, saturated the GPU)
```
Example where it's most a slowdown:
```python
class MyDataset(Dataset):
def __len__(self):
return 5000
def __getitem__(self, i):
if i % 64 == 0:
n = 100
else:
n = 1
return "This is a test" * n
```
This is a occasional very long sentence compared to the other. In that case, the **whole** batch will need to be 400
tokens long, so the whole batch will be [64, 400] instead of [64, 4], leading to the high slowdown. Even worse, on
bigger batches, the program simply crashes.
```
------------------------------
Streaming no batching
100%|█████████████████████████████████████████████████████████████████████| 1000/1000 [00:05<00:00, 183.69it/s]
------------------------------
Streaming batch_size=8
100%|█████████████████████████████████████████████████████████████████████| 1000/1000 [00:03<00:00, 265.74it/s]
------------------------------
Streaming batch_size=64
100%|██████████████████████████████████████████████████████████████████████| 1000/1000 [00:26<00:00, 37.80it/s]
------------------------------
Streaming batch_size=256
0%| | 0/1000 [00:00<?, ?it/s]
Traceback (most recent call last):
File "/home/nicolas/src/transformers/test.py", line 42, in <module>
for out in tqdm(pipe(dataset, batch_size=256), total=len(dataset)):
....
q = q / math.sqrt(dim_per_head) # (bs, n_heads, q_length, dim_per_head)
RuntimeError: CUDA out of memory. Tried to allocate 376.00 MiB (GPU 0; 3.95 GiB total capacity; 1.72 GiB already allocated; 354.88 MiB free; 2.46 GiB reserved in total by PyTorch)
```
There are no good (general) solutions for this problem, and your mileage may vary depending on your use cases. Rule of
thumb:
For users, a rule of thumb is:
- **Measure performance on your load, with your hardware. Measure, measure, and keep measuring. Real numbers are the
only way to go.**
- If you are latency constrained (live product doing inference), don't batch.
- If you are using CPU, don't batch.
- If you are using throughput (you want to run your model on a bunch of static data), on GPU, then:
- If you have no clue about the size of the sequence_length ("natural" data), by default don't batch, measure and
try tentatively to add it, add OOM checks to recover when it will fail (and it will at some point if you don't
control the sequence_length.)
- If your sequence_length is super regular, then batching is more likely to be VERY interesting, measure and push
it until you get OOMs.
- The larger the GPU the more likely batching is going to be more interesting
- As soon as you enable batching, make sure you can handle OOMs nicely.
## Pipeline chunk batching
`zero-shot-classification` and `question-answering` are slightly specific in the sense, that a single input might yield
multiple forward pass of a model. Under normal circumstances, this would yield issues with `batch_size` argument.
In order to circumvent this issue, both of these pipelines are a bit specific, they are `ChunkPipeline` instead of
regular `Pipeline`. In short:
```python
preprocessed = pipe.preprocess(inputs)
model_outputs = pipe.forward(preprocessed)
outputs = pipe.postprocess(model_outputs)
```
Now becomes:
```python
all_model_outputs = []
for preprocessed in pipe.preprocess(inputs):
model_outputs = pipe.forward(preprocessed)
all_model_outputs.append(model_outputs)
outputs = pipe.postprocess(all_model_outputs)
```
This should be very transparent to your code because the pipelines are used in
the same way.
This is a simplified view, since the pipeline can handle automatically the batch to ! Meaning you don't have to care
about how many forward passes you inputs are actually going to trigger, you can optimize the `batch_size`
independently of the inputs. The caveats from the previous section still apply.
## Pipeline custom code
If you want to override a specific pipeline.
Don't hesitate to create an issue for your task at hand, the goal of the pipeline is to be easy to use and support most
cases, so `transformers` could maybe support your use case.
If you want to try simply you can:
- Subclass your pipeline of choice
```python
class MyPipeline(TextClassificationPipeline):
def postprocess():
# Your code goes here
scores = scores * 100
# And here
my_pipeline = MyPipeline(model=model, tokenizer=tokenizer, ...)
# or if you use *pipeline* function, then:
my_pipeline = pipeline(model="xxxx", pipeline_class=MyPipeline)
```
That should enable you to do all the custom code you want.
## Implementing a pipeline
[Implementing a new pipeline](../add_new_pipeline)
## Audio
Pipelines available for audio tasks include the following.
### AudioClassificationPipeline
[[autodoc]] AudioClassificationPipeline
- __call__
- all
### AutomaticSpeechRecognitionPipeline
[[autodoc]] AutomaticSpeechRecognitionPipeline
- __call__
- all
### TextToAudioPipeline
[[autodoc]] TextToAudioPipeline
- __call__
- all
### ZeroShotAudioClassificationPipeline
[[autodoc]] ZeroShotAudioClassificationPipeline
- __call__
- all
## Computer vision
Pipelines available for computer vision tasks include the following.
### DepthEstimationPipeline
[[autodoc]] DepthEstimationPipeline
- __call__
- all
### ImageClassificationPipeline
[[autodoc]] ImageClassificationPipeline
- __call__
- all
### ImageSegmentationPipeline
[[autodoc]] ImageSegmentationPipeline
- __call__
- all
### ImageToImagePipeline
[[autodoc]] ImageToImagePipeline
- __call__
- all
### ObjectDetectionPipeline
[[autodoc]] ObjectDetectionPipeline
- __call__
- all
### VideoClassificationPipeline
[[autodoc]] VideoClassificationPipeline
- __call__
- all
### ZeroShotImageClassificationPipeline
[[autodoc]] ZeroShotImageClassificationPipeline
- __call__
- all
### ZeroShotObjectDetectionPipeline
[[autodoc]] ZeroShotObjectDetectionPipeline
- __call__
- all
## Natural Language Processing
Pipelines available for natural language processing tasks include the following.
### ConversationalPipeline
[[autodoc]] Conversation
[[autodoc]] ConversationalPipeline
- __call__
- all
### FillMaskPipeline
[[autodoc]] FillMaskPipeline
- __call__
- all
### QuestionAnsweringPipeline
[[autodoc]] QuestionAnsweringPipeline
- __call__
- all
### SummarizationPipeline
[[autodoc]] SummarizationPipeline
- __call__
- all
### TableQuestionAnsweringPipeline
[[autodoc]] TableQuestionAnsweringPipeline
- __call__
### TextClassificationPipeline
[[autodoc]] TextClassificationPipeline
- __call__
- all
### TextGenerationPipeline
[[autodoc]] TextGenerationPipeline
- __call__
- all
### Text2TextGenerationPipeline
[[autodoc]] Text2TextGenerationPipeline
- __call__
- all
### TokenClassificationPipeline
[[autodoc]] TokenClassificationPipeline
- __call__
- all
### TranslationPipeline
[[autodoc]] TranslationPipeline
- __call__
- all
### ZeroShotClassificationPipeline
[[autodoc]] ZeroShotClassificationPipeline
- __call__
- all
## Multimodal
Pipelines available for multimodal tasks include the following.
### DocumentQuestionAnsweringPipeline
[[autodoc]] DocumentQuestionAnsweringPipeline
- __call__
- all
### FeatureExtractionPipeline
[[autodoc]] FeatureExtractionPipeline
- __call__
- all
### ImageToTextPipeline
[[autodoc]] ImageToTextPipeline
- __call__
- all
### MaskGenerationPipeline
[[autodoc]] MaskGenerationPipeline
- __call__
- all
### VisualQuestionAnsweringPipeline
[[autodoc]] VisualQuestionAnsweringPipeline
- __call__
- all
## Parent class: `Pipeline`
[[autodoc]] Pipeline
|
huggingface/transformers/blob/main/docs/source/en/main_classes/pipelines.md
|
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 🤗 Hub 客户端库
通过`huggingface_hub` 库,您可以与面向机器学习开发者和协作者的平台 [Hugging Face Hub](https://huggingface.co/)进行交互,找到适用于您所在项目的预训练模型和数据集,体验在平台托管的数百个机器学习应用,还可以创建或分享自己的模型和数据集并于社区共享。以上所有都可以用Python在`huggingface_hub` 库中轻松实现。
阅读[快速入门指南](快速入门指南)以开始使用huggingface_hub库。您将学习如何从Hub下载文件,创建存储库以及将文件上传到Hub。继续阅读以了解更多关于如何在🤗Hub上管理您的存储库,如何参与讨论或者甚至如何访问推理API的信息。
<div class="mt-10">
<div class="w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-2 md:gap-y-4 md:gap-x-5">
`<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./guides/overview">`
`<div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">`How-to guides`</div>`
`<p class="text-gray-700">`Practical guides to help you achieve a specific goal. Take a look at these guides to learn how to use huggingface_hub to solve real-world problems.`</p>`
`</a>`
`<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./package_reference/overview">`
`<div class="w-full text-center bg-gradient-to-br from-purple-400 to-purple-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">`Reference`</div>`
`<p class="text-gray-700">`Exhaustive and technical description of huggingface_hub classes and methods.`</p>`
`</a>`
`<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./concepts/git_vs_http">`
`<div class="w-full text-center bg-gradient-to-br from-pink-400 to-pink-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">`Conceptual guides`</div>`
`<p class="text-gray-700">`High-level explanations for building a better understanding of huggingface_hub philosophy.`</p>`
`</a>`
</div>
</div>
通过 `huggingface_hub`库,您可以与面向机器学习开发者和协作者的平台 [Hugging Face Hub](https://huggingface.co/)进行交互,找到适用于您所在项目的预训练模型和数据集,体验在平台托管的数百个机器学习应用,还可以创建或分享自己的模型和数据集并于社区共享。以上所有都可以用Python在 `huggingface_hub`库中轻松实现。
<!--
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./tutorials/overview"
><div class="w-full text-center bg-gradient-to-br from-blue-400 to-blue-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">Tutorials</div>
<p class="text-gray-700">Learn the basics and become familiar with using huggingface_hub to programmatically interact with the 🤗 Hub!</p>
</a> -->
## 贡献
所有对 huggingface_hub 的贡献都受到欢迎和同等重视!🤗 除了在代码中添加或修复现有问题外,您还可以通过确保其准确且最新来帮助改进文档,在问题上帮助回答问题,并请求您认为可以改进库的新功能。请查看[贡献指南](https://github.com/huggingface/huggingface_hub/blob/main/CONTRIBUTING.md) 了解有关如何提交新问题或功能请求、如何提交拉取请求以及如何测试您的贡献以确保一切正常运行的更多信息。
当然,贡献者也应该尊重我们的[行为准则](https://github.com/huggingface/huggingface_hub/blob/main/CODE_OF_CONDUCT.md),以便为每个人创建一个包容和欢迎的协作空间。
|
huggingface/huggingface_hub/blob/main/docs/source/cn/index.md
|
Gradio Demo: gallery_selections
```
!pip install -q gradio
```
```
import gradio as gr
import numpy as np
with gr.Blocks() as demo:
imgs = gr.State()
gallery = gr.Gallery(allow_preview=False)
def deselect_images():
return gr.Gallery(selected_index=None)
def generate_images():
images = []
for _ in range(9):
image = np.ones((100, 100, 3), dtype=np.uint8) * np.random.randint(
0, 255, 3
) # image is a solid single color
images.append(image)
return images, images
demo.load(generate_images, None, [gallery, imgs])
with gr.Row():
selected = gr.Number(show_label=False)
darken_btn = gr.Button("Darken selected")
deselect_button = gr.Button("Deselect")
deselect_button.click(deselect_images, None, gallery)
def get_select_index(evt: gr.SelectData):
return evt.index
gallery.select(get_select_index, None, selected)
def darken_img(imgs, index):
index = int(index)
imgs[index] = np.round(imgs[index] * 0.8).astype(np.uint8)
return imgs, imgs
darken_btn.click(darken_img, [imgs, selected], [imgs, gallery])
if __name__ == "__main__":
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/gallery_selections/run.ipynb
|
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# CLIPSeg
## Overview
The CLIPSeg model was proposed in [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke
and Alexander Ecker. CLIPSeg adds a minimal decoder on top of a frozen [CLIP](clip) model for zero- and one-shot image segmentation.
The abstract from the paper is the following:
*Image segmentation is usually addressed by training a
model for a fixed set of object classes. Incorporating additional classes or more complex queries later is expensive
as it requires re-training the model on a dataset that encompasses these expressions. Here we propose a system
that can generate image segmentations based on arbitrary
prompts at test time. A prompt can be either a text or an
image. This approach enables us to create a unified model
(trained once) for three common segmentation tasks, which
come with distinct challenges: referring expression segmentation, zero-shot segmentation and one-shot segmentation.
We build upon the CLIP model as a backbone which we extend with a transformer-based decoder that enables dense
prediction. After training on an extended version of the
PhraseCut dataset, our system generates a binary segmentation map for an image based on a free-text prompt or on
an additional image expressing the query. We analyze different variants of the latter image-based prompts in detail.
This novel hybrid input allows for dynamic adaptation not
only to the three segmentation tasks mentioned above, but
to any binary segmentation task where a text or image query
can be formulated. Finally, we find our system to adapt well
to generalized queries involving affordances or properties*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/clipseg_architecture.png"
alt="drawing" width="600"/>
<small> CLIPSeg overview. Taken from the <a href="https://arxiv.org/abs/2112.10003">original paper.</a> </small>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/timojl/clipseg).
## Usage tips
- [`CLIPSegForImageSegmentation`] adds a decoder on top of [`CLIPSegModel`]. The latter is identical to [`CLIPModel`].
- [`CLIPSegForImageSegmentation`] can generate image segmentations based on arbitrary prompts at test time. A prompt can be either a text
(provided to the model as `input_ids`) or an image (provided to the model as `conditional_pixel_values`). One can also provide custom
conditional embeddings (provided to the model as `conditional_embeddings`).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with CLIPSeg. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<PipelineTag pipeline="image-segmentation"/>
- A notebook that illustrates [zero-shot image segmentation with CLIPSeg](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/CLIPSeg/Zero_shot_image_segmentation_with_CLIPSeg.ipynb).
## CLIPSegConfig
[[autodoc]] CLIPSegConfig
- from_text_vision_configs
## CLIPSegTextConfig
[[autodoc]] CLIPSegTextConfig
## CLIPSegVisionConfig
[[autodoc]] CLIPSegVisionConfig
## CLIPSegProcessor
[[autodoc]] CLIPSegProcessor
## CLIPSegModel
[[autodoc]] CLIPSegModel
- forward
- get_text_features
- get_image_features
## CLIPSegTextModel
[[autodoc]] CLIPSegTextModel
- forward
## CLIPSegVisionModel
[[autodoc]] CLIPSegVisionModel
- forward
## CLIPSegForImageSegmentation
[[autodoc]] CLIPSegForImageSegmentation
- forward
|
huggingface/transformers/blob/main/docs/source/en/model_doc/clipseg.md
|
Gradio Demo: stream_asr
```
!pip install -q gradio torch torchaudio transformers
```
```
import gradio as gr
from transformers import pipeline
import numpy as np
transcriber = pipeline("automatic-speech-recognition", model="openai/whisper-base.en")
def transcribe(stream, new_chunk):
sr, y = new_chunk
y = y.astype(np.float32)
y /= np.max(np.abs(y))
if stream is not None:
stream = np.concatenate([stream, y])
else:
stream = y
return stream, transcriber({"sampling_rate": sr, "raw": stream})["text"]
demo = gr.Interface(
transcribe,
["state", gr.Audio(sources=["microphone"], streaming=True)],
["state", "text"],
live=True,
)
if __name__ == "__main__":
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/stream_asr/run.ipynb
|
his demo takes in 12 inputs from the user in dropdowns and sliders and predicts income. It also has a separate button for explaining the prediction.
|
gradio-app/gradio/blob/main/demo/xgboost-income-prediction-with-explainability/DESCRIPTION.md
|
Installation
Before you start, you'll need to setup your environment and install the appropriate packages. 🤗 Datasets is tested on **Python 3.7+**.
<Tip>
If you want to use 🤗 Datasets with TensorFlow or PyTorch, you'll need to install them separately. Refer to the [TensorFlow installation page](https://www.tensorflow.org/install/pip#tensorflow-2-packages-are-available) or the [PyTorch installation page](https://pytorch.org/get-started/locally/#start-locally) for the specific install command for your framework.
</Tip>
## Virtual environment
You should install 🤗 Datasets in a [virtual environment](https://docs.python.org/3/library/venv.html) to keep things tidy and avoid dependency conflicts.
1. Create and navigate to your project directory:
```bash
mkdir ~/my-project
cd ~/my-project
```
2. Start a virtual environment inside your directory:
```bash
python -m venv .env
```
3. Activate and deactivate the virtual environment with the following commands:
```bash
# Activate the virtual environment
source .env/bin/activate
# Deactivate the virtual environment
source .env/bin/deactivate
```
Once you've created your virtual environment, you can install 🤗 Datasets in it.
## pip
The most straightforward way to install 🤗 Datasets is with pip:
```bash
pip install datasets
```
Run the following command to check if 🤗 Datasets has been properly installed:
```bash
python -c "from datasets import load_dataset; print(load_dataset('squad', split='train')[0])"
```
This command downloads version 1 of the [Stanford Question Answering Dataset (SQuAD)](https://rajpurkar.github.io/SQuAD-explorer/), loads the training split, and prints the first training example. You should see:
```python
{'answers': {'answer_start': [515], 'text': ['Saint Bernadette Soubirous']}, 'context': 'Architecturally, the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend "Venite Ad Me Omnes". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.', 'id': '5733be284776f41900661182', 'question': 'To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?', 'title': 'University_of_Notre_Dame'}
```
## Audio
To work with audio datasets, you need to install the [`Audio`] feature as an extra dependency:
```bash
pip install datasets[audio]
```
<Tip warning={true}>
To decode mp3 files, you need to have at least version 1.1.0 of the `libsndfile` system library. Usually, it's bundled with the python [`soundfile`](https://github.com/bastibe/python-soundfile) package, which is installed as an extra audio dependency for 🤗 Datasets.
For Linux, the required version of `libsndfile` is bundled with `soundfile` starting from version 0.12.0. You can run the following command to determine which version of `libsndfile` is being used by `soundfile`:
```bash
python -c "import soundfile; print(soundfile.__libsndfile_version__)"
```
</Tip>
## Vision
To work with image datasets, you need to install the [`Image`] feature as an extra dependency:
```bash
pip install datasets[vision]
```
## source
Building 🤗 Datasets from source lets you make changes to the code base. To install from the source, clone the repository and install with the following commands:
```bash
git clone https://github.com/huggingface/datasets.git
cd datasets
pip install -e .
```
Again, you can check if 🤗 Datasets was properly installed with the following command:
```bash
python -c "from datasets import load_dataset; print(load_dataset('squad', split='train')[0])"
```
## conda
🤗 Datasets can also be installed from conda, a package management system:
```bash
conda install -c huggingface -c conda-forge datasets
```
|
huggingface/datasets/blob/main/docs/source/installation.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Value-guided planning
<Tip warning={true}>
🧪 This is an experimental pipeline for reinforcement learning!
</Tip>
This pipeline is based on the [Planning with Diffusion for Flexible Behavior Synthesis](https://huggingface.co/papers/2205.09991) paper by Michael Janner, Yilun Du, Joshua B. Tenenbaum, Sergey Levine.
The abstract from the paper is:
*Model-based reinforcement learning methods often use learning only for the purpose of estimating an approximate dynamics model, offloading the rest of the decision-making work to classical trajectory optimizers. While conceptually simple, this combination has a number of empirical shortcomings, suggesting that learned models may not be well-suited to standard trajectory optimization. In this paper, we consider what it would look like to fold as much of the trajectory optimization pipeline as possible into the modeling problem, such that sampling from the model and planning with it become nearly identical. The core of our technical approach lies in a diffusion probabilistic model that plans by iteratively denoising trajectories. We show how classifier-guided sampling and image inpainting can be reinterpreted as coherent planning strategies, explore the unusual and useful properties of diffusion-based planning methods, and demonstrate the effectiveness of our framework in control settings that emphasize long-horizon decision-making and test-time flexibility.*
You can find additional information about the model on the [project page](https://diffusion-planning.github.io/), the [original codebase](https://github.com/jannerm/diffuser), or try it out in a demo [notebook](https://colab.research.google.com/drive/1rXm8CX4ZdN5qivjJ2lhwhkOmt_m0CvU0#scrollTo=6HXJvhyqcITc&uniqifier=1).
The script to run the model is available [here](https://github.com/huggingface/diffusers/tree/main/examples/reinforcement_learning).
<Tip>
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
</Tip>
## ValueGuidedRLPipeline
[[autodoc]] diffusers.experimental.ValueGuidedRLPipeline
|
huggingface/diffusers/blob/main/docs/source/en/api/pipelines/value_guided_sampling.md
|
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BERT
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=bert">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-bert-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/bert-base-uncased">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
The BERT model was proposed in [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova. It's a
bidirectional transformer pretrained using a combination of masked language modeling objective and next sentence
prediction on a large corpus comprising the Toronto Book Corpus and Wikipedia.
The abstract from the paper is the following:
*We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations
from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional
representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result,
the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models
for a wide range of tasks, such as question answering and language inference, without substantial task-specific
architecture modifications.*
*BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural
language processing tasks, including pushing the GLUE score to 80.5% (7.7% point absolute improvement), MultiNLI
accuracy to 86.7% (4.6% absolute improvement), SQuAD v1.1 question answering Test F1 to 93.2 (1.5 point absolute
improvement) and SQuAD v2.0 Test F1 to 83.1 (5.1 point absolute improvement).*
This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/google-research/bert).
## Usage tips
- BERT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
- BERT was trained with the masked language modeling (MLM) and next sentence prediction (NSP) objectives. It is
efficient at predicting masked tokens and at NLU in general, but is not optimal for text generation.
- Corrupts the inputs by using random masking, more precisely, during pretraining, a given percentage of tokens (usually 15%) is masked by:
* a special mask token with probability 0.8
* a random token different from the one masked with probability 0.1
* the same token with probability 0.1
- The model must predict the original sentence, but has a second objective: inputs are two sentences A and B (with a separation token in between). With probability 50%, the sentences are consecutive in the corpus, in the remaining 50% they are not related. The model has to predict if the sentences are consecutive or not.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BERT. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<PipelineTag pipeline="text-classification"/>
- A blog post on [BERT Text Classification in a different language](https://www.philschmid.de/bert-text-classification-in-a-different-language).
- A notebook for [Finetuning BERT (and friends) for multi-label text classification](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/BERT/Fine_tuning_BERT_(and_friends)_for_multi_label_text_classification.ipynb).
- A notebook on how to [Finetune BERT for multi-label classification using PyTorch](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb). 🌎
- A notebook on how to [warm-start an EncoderDecoder model with BERT for summarization](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/BERT2BERT_for_CNN_Dailymail.ipynb).
- [`BertForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb).
- [`TFBertForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb).
- [`FlaxBertForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification_flax.ipynb).
- [Text classification task guide](../tasks/sequence_classification)
<PipelineTag pipeline="token-classification"/>
- A blog post on how to use [Hugging Face Transformers with Keras: Fine-tune a non-English BERT for Named Entity Recognition](https://www.philschmid.de/huggingface-transformers-keras-tf).
- A notebook for [Finetuning BERT for named-entity recognition](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/Custom_Named_Entity_Recognition_with_BERT_only_first_wordpiece.ipynb) using only the first wordpiece of each word in the word label during tokenization. To propagate the label of the word to all wordpieces, see this [version](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/BERT/Custom_Named_Entity_Recognition_with_BERT.ipynb) of the notebook instead.
- [`BertForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb).
- [`TFBertForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/token-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb).
- [`FlaxBertForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/token-classification).
- [Token classification](https://huggingface.co/course/chapter7/2?fw=pt) chapter of the 🤗 Hugging Face Course.
- [Token classification task guide](../tasks/token_classification)
<PipelineTag pipeline="fill-mask"/>
- [`BertForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#robertabertdistilbert-and-masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
- [`TFBertForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_mlmpy) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
- [`FlaxBertForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb).
- [Masked language modeling](https://huggingface.co/course/chapter7/3?fw=pt) chapter of the 🤗 Hugging Face Course.
- [Masked language modeling task guide](../tasks/masked_language_modeling)
<PipelineTag pipeline="question-answering"/>
- [`BertForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb).
- [`TFBertForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb).
- [`FlaxBertForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/question-answering).
- [Question answering](https://huggingface.co/course/chapter7/7?fw=pt) chapter of the 🤗 Hugging Face Course.
- [Question answering task guide](../tasks/question_answering)
**Multiple choice**
- [`BertForMultipleChoice`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/multiple-choice) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb).
- [`TFBertForMultipleChoice`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/multiple-choice) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb).
- [Multiple choice task guide](../tasks/multiple_choice)
⚡️ **Inference**
- A blog post on how to [Accelerate BERT inference with Hugging Face Transformers and AWS Inferentia](https://huggingface.co/blog/bert-inferentia-sagemaker).
- A blog post on how to [Accelerate BERT inference with DeepSpeed-Inference on GPUs](https://www.philschmid.de/bert-deepspeed-inference).
⚙️ **Pretraining**
- A blog post on [Pre-Training BERT with Hugging Face Transformers and Habana Gaudi](https://www.philschmid.de/pre-training-bert-habana).
🚀 **Deploy**
- A blog post on how to [Convert Transformers to ONNX with Hugging Face Optimum](https://www.philschmid.de/convert-transformers-to-onnx).
- A blog post on how to [Setup Deep Learning environment for Hugging Face Transformers with Habana Gaudi on AWS](https://www.philschmid.de/getting-started-habana-gaudi#conclusion).
- A blog post on [Autoscaling BERT with Hugging Face Transformers, Amazon SageMaker and Terraform module](https://www.philschmid.de/terraform-huggingface-amazon-sagemaker-advanced).
- A blog post on [Serverless BERT with HuggingFace, AWS Lambda, and Docker](https://www.philschmid.de/serverless-bert-with-huggingface-aws-lambda-docker).
- A blog post on [Hugging Face Transformers BERT fine-tuning using Amazon SageMaker and Training Compiler](https://www.philschmid.de/huggingface-amazon-sagemaker-training-compiler).
- A blog post on [Task-specific knowledge distillation for BERT using Transformers & Amazon SageMaker](https://www.philschmid.de/knowledge-distillation-bert-transformers).
## BertConfig
[[autodoc]] BertConfig
- all
## BertTokenizer
[[autodoc]] BertTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
<frameworkcontent>
<pt>
## BertTokenizerFast
[[autodoc]] BertTokenizerFast
</pt>
<tf>
## TFBertTokenizer
[[autodoc]] TFBertTokenizer
</tf>
</frameworkcontent>
## Bert specific outputs
[[autodoc]] models.bert.modeling_bert.BertForPreTrainingOutput
[[autodoc]] models.bert.modeling_tf_bert.TFBertForPreTrainingOutput
[[autodoc]] models.bert.modeling_flax_bert.FlaxBertForPreTrainingOutput
<frameworkcontent>
<pt>
## BertModel
[[autodoc]] BertModel
- forward
## BertForPreTraining
[[autodoc]] BertForPreTraining
- forward
## BertLMHeadModel
[[autodoc]] BertLMHeadModel
- forward
## BertForMaskedLM
[[autodoc]] BertForMaskedLM
- forward
## BertForNextSentencePrediction
[[autodoc]] BertForNextSentencePrediction
- forward
## BertForSequenceClassification
[[autodoc]] BertForSequenceClassification
- forward
## BertForMultipleChoice
[[autodoc]] BertForMultipleChoice
- forward
## BertForTokenClassification
[[autodoc]] BertForTokenClassification
- forward
## BertForQuestionAnswering
[[autodoc]] BertForQuestionAnswering
- forward
</pt>
<tf>
## TFBertModel
[[autodoc]] TFBertModel
- call
## TFBertForPreTraining
[[autodoc]] TFBertForPreTraining
- call
## TFBertModelLMHeadModel
[[autodoc]] TFBertLMHeadModel
- call
## TFBertForMaskedLM
[[autodoc]] TFBertForMaskedLM
- call
## TFBertForNextSentencePrediction
[[autodoc]] TFBertForNextSentencePrediction
- call
## TFBertForSequenceClassification
[[autodoc]] TFBertForSequenceClassification
- call
## TFBertForMultipleChoice
[[autodoc]] TFBertForMultipleChoice
- call
## TFBertForTokenClassification
[[autodoc]] TFBertForTokenClassification
- call
## TFBertForQuestionAnswering
[[autodoc]] TFBertForQuestionAnswering
- call
</tf>
<jax>
## FlaxBertModel
[[autodoc]] FlaxBertModel
- __call__
## FlaxBertForPreTraining
[[autodoc]] FlaxBertForPreTraining
- __call__
## FlaxBertForCausalLM
[[autodoc]] FlaxBertForCausalLM
- __call__
## FlaxBertForMaskedLM
[[autodoc]] FlaxBertForMaskedLM
- __call__
## FlaxBertForNextSentencePrediction
[[autodoc]] FlaxBertForNextSentencePrediction
- __call__
## FlaxBertForSequenceClassification
[[autodoc]] FlaxBertForSequenceClassification
- __call__
## FlaxBertForMultipleChoice
[[autodoc]] FlaxBertForMultipleChoice
- __call__
## FlaxBertForTokenClassification
[[autodoc]] FlaxBertForTokenClassification
- __call__
## FlaxBertForQuestionAnswering
[[autodoc]] FlaxBertForQuestionAnswering
- __call__
</jax>
</frameworkcontent>
|
huggingface/transformers/blob/main/docs/source/en/model_doc/bert.md
|
`@gradio/label`
```html
<script>
import { BaseLabel } from "@gradio/label";
</script>
```
BaseLabel
```javascript
export let value: {
label?: string;
confidences?: { label: string; confidence: number }[];
};
export let color: string | undefined = undefined;
export let selectable = false;
```
|
gradio-app/gradio/blob/main/js/label/README.md
|
Contributing a Guide
Want to help teach Gradio? Consider contributing a Guide! 🤗
Broadly speaking, there are two types of guides:
- **Use cases**: guides that cover step-by-step how to build a particular type of machine learning demo or app using Gradio. Here's an example: [_Creating a Chatbot_](https://github.com/gradio-app/gradio/blob/master/guides/creating_a_chatbot.md)
- **Feature explanation**: guides that describe in detail a particular feature of Gradio. Here's an example: [_Using Flagging_](https://github.com/gradio-app/gradio/blob/master/guides/using_flagging.md)
We encourage you to submit either type of Guide! (Looking for ideas? We may also have open [issues](https://github.com/gradio-app/gradio/issues?q=is%3Aopen+is%3Aissue+label%3Aguides) where users have asked for guides on particular topics)
## Guide Structure
As you can see with the previous examples, Guides are standard markdown documents. They usually:
- start with an Introduction section describing the topic
- include subheadings to make articles easy to navigate
- include real code snippets that make it easy to follow along and implement the Guide
- include embedded Gradio demos to make them more interactive and provide immediate demonstrations of the topic being discussed. These Gradio demos are hosted on [Hugging Face Spaces](https://huggingface.co/spaces) and are embedded using the standard \<iframe\> tag.
## How to Contribute a Guide
1. Clone or fork this `gradio` repo
2. Add a new markdown document with a descriptive title to the `/guides` folder
3. Write your Guide in standard markdown! Embed Gradio demos wherever helpful
4. Add a list of `related_spaces` at the top of the markdown document (see the previously linked Guides for how to do this)
5. Add 3 `tags` at the top of the markdown document to help users find your guide (again, see the previously linked Guides for how to do this)
6. Open a PR to have your guide reviewed
That's it! We're looking forward to reading your Guide 🥳
|
gradio-app/gradio/blob/main/guides/cn/CONTRIBUTING.md
|
(Gluon) Xception
**Xception** is a convolutional neural network architecture that relies solely on [depthwise separable convolution](https://paperswithcode.com/method/depthwise-separable-convolution) layers.
The weights from this model were ported from [Gluon](https://cv.gluon.ai/model_zoo/classification.html).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('gluon_xception65', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `gluon_xception65`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('gluon_xception65', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{chollet2017xception,
title={Xception: Deep Learning with Depthwise Separable Convolutions},
author={François Chollet},
year={2017},
eprint={1610.02357},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: Gloun Xception
Paper:
Title: 'Xception: Deep Learning with Depthwise Separable Convolutions'
URL: https://paperswithcode.com/paper/xception-deep-learning-with-depthwise
Models:
- Name: gluon_xception65
In Collection: Gloun Xception
Metadata:
FLOPs: 17594889728
Parameters: 39920000
File Size: 160551306
Architecture:
- 1x1 Convolution
- Convolution
- Dense Connections
- Depthwise Separable Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_xception65
Crop Pct: '0.903'
Image Size: '299'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_xception.py#L241
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/gluon_xception-7015a15c.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.7%
Top 5 Accuracy: 94.87%
-->
|
huggingface/pytorch-image-models/blob/main/hfdocs/source/models/gloun-xception.mdx
|
alculate taxes using Textbox, Radio, and Dataframe components
|
gradio-app/gradio/blob/main/demo/tax_calculator/DESCRIPTION.md
|
--
title: 'The Partnership: Amazon SageMaker and Hugging Face'
thumbnail: /blog/assets/17_the_partnership_amazon_sagemaker_and_hugging_face/thumbnail.png
---
<img src="/blog/assets/17_the_partnership_amazon_sagemaker_and_hugging_face/cover.png" alt="hugging-face-and-aws-logo" class="w-full">
> Look at these smiles!
# **The Partnership: Amazon SageMaker and Hugging Face**
Today, we announce a strategic partnership between Hugging Face and [Amazon](https://huggingface.co/amazon) to make it easier for companies to leverage State of the Art Machine Learning models, and ship cutting-edge NLP features faster.
Through this partnership, Hugging Face is leveraging Amazon Web Services as its Preferred Cloud Provider to deliver services to its customers.
As a first step to enable our common customers, Hugging Face and Amazon are introducing new Hugging Face Deep Learning Containers (DLCs) to make it easier than ever to train Hugging Face Transformer models in [Amazon SageMaker](https://aws.amazon.com/sagemaker/).
To learn how to access and use the new Hugging Face DLCs with the Amazon SageMaker Python SDK, check out the guides and resources below.
> _On July 8th, 2021 we extended the Amazon SageMaker integration to add easy deployment and inference of Transformers models. If you want to learn how you can [deploy Hugging Face models easily with Amazon SageMaker](https://huggingface.co/blog/deploy-hugging-face-models-easily-with-amazon-sagemaker) take a look at the [new blog post](https://huggingface.co/blog/deploy-hugging-face-models-easily-with-amazon-sagemaker) and the [documentation](https://huggingface.co/docs/sagemaker/inference)._
---
## **Features & Benefits 🔥**
## One Command is All you Need
With the new Hugging Face Deep Learning Containers available in Amazon SageMaker, training cutting-edge Transformers-based NLP models has never been simpler. There are variants specially optimized for TensorFlow and PyTorch, for single-GPU, single-node multi-GPU and multi-node clusters.
## Accelerating Machine Learning from Science to Production
In addition to Hugging Face DLCs, we created a first-class Hugging Face extension to the SageMaker Python-sdk to accelerate data science teams, reducing the time required to set up and run experiments from days to minutes.
You can use the Hugging Face DLCs with the Automatic Model Tuning capability of Amazon SageMaker, in order to automatically optimize your training hyperparameters and quickly increase the accuracy of your models.
Thanks to the SageMaker Studio web-based Integrated Development Environment (IDE), you can easily track and compare your experiments and your training artifacts.
## Built-in Performance
With the Hugging Face DLCs, SageMaker customers will benefit from built-in performance optimizations for PyTorch or TensorFlow, to train NLP models faster, and with the flexibility to choose the training infrastructure with the best price/performance ratio for your workload.
The Hugging Face DLCs are fully integrated with the [SageMaker distributed training libraries](https://docs.aws.amazon.com/sagemaker/latest/dg/distributed-training.html), to train models faster than was ever possible before, using the latest generation of instances available on Amazon EC2.
---
## **Resources, Documentation & Samples 📄**
Below you can find all the important resources to all published blog posts, videos, documentation, and sample Notebooks/scripts.
## Blog/Video
- [AWS: Embracing natural language processing with Hugging Face](https://aws.amazon.com/de/blogs/opensource/embracing-natural-language-processing-with-hugging-face/)
- [Deploy Hugging Face models easily with Amazon SageMaker](https://huggingface.co/blog/deploy-hugging-face-models-easily-with-amazon-sagemaker)
- [AWS and Hugging Face collaborate to simplify and accelerate adoption of natural language processing models](https://aws.amazon.com/blogs/machine-learning/aws-and-hugging-face-collaborate-to-simplify-and-accelerate-adoption-of-natural-language-processing-models/)
- [Walkthrough: End-to-End Text Classification](https://youtu.be/ok3hetb42gU)
- [Working with Hugging Face models on Amazon SageMaker](https://youtu.be/leyrCgLAGjMn)
- [Distributed Training: Train BART/T5 for Summarization using 🤗 Transformers and Amazon SageMaker](https://huggingface.co/blog/sagemaker-distributed-training-seq2seq)
- [Deploy a Hugging Face Transformers Model from S3 to Amazon SageMaker](https://youtu.be/pfBGgSGnYLs)
- [Deploy a Hugging Face Transformers Model from the Model Hub to Amazon SageMaker](https://youtu.be/l9QZuazbzWM)
## Documentation
- [Hugging Face documentation for Amazon SageMaker](https://huggingface.co/docs/sagemaker/main)
- [Run training on Amazon SageMaker](https://huggingface.co/docs/sagemaker/train)
- [Deploy models to Amazon SageMaker](https://huggingface.co/docs/sagemaker/inference)
- [Frequently Asked Questions](https://huggingface.co/docs/sagemaker/faq)
- [Amazon SageMaker documentation for Hugging Face](https://docs.aws.amazon.com/sagemaker/latest/dg/hugging-face.html)
- [Python SDK SageMaker documentation for Hugging Face](https://sagemaker.readthedocs.io/en/stable/frameworks/huggingface/index.html)
- [Deep Learning Container](https://github.com/aws/deep-learning-containers/blob/master/available_images.md#huggingface-training-containers)
- [SageMaker's Distributed Data Parallel Library](https://docs.aws.amazon.com/sagemaker/latest/dg/data-parallel.html)
- [SageMaker's Distributed Model Parallel Library](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel.html)
## Sample Notebook
- [all Notebooks](https://github.com/huggingface/notebooks/tree/master/sagemaker)
- [Getting Started Pytorch](https://github.com/huggingface/notebooks/blob/master/sagemaker/01_getting_started_pytorch/sagemaker-notebook.ipynb)
- [Getting Started Tensorflow](https://github.com/huggingface/notebooks/blob/master/sagemaker/02_getting_started_tensorflow/sagemaker-notebook.ipynb)
- [Distributed Training Data Parallelism](https://github.com/huggingface/notebooks/blob/master/sagemaker/03_distributed_training_data_parallelism/sagemaker-notebook.ipynb)
- [Distributed Training Model Parallelism](https://github.com/huggingface/notebooks/blob/master/sagemaker/04_distributed_training_model_parallelism/sagemaker-notebook.ipynb)
- [Spot Instances and continue training](https://github.com/huggingface/notebooks/blob/master/sagemaker/05_spot_instances/sagemaker-notebook.ipynb)
- [SageMaker Metrics](https://github.com/huggingface/notebooks/blob/master/sagemaker/06_sagemaker_metrics/sagemaker-notebook.ipynb)
- [Distributed Training Data Parallelism Tensorflow](https://github.com/huggingface/notebooks/blob/master/sagemaker/07_tensorflow_distributed_training_data_parallelism/sagemaker-notebook.ipynb)
- [Distributed Training Summarization](https://github.com/huggingface/notebooks/blob/master/sagemaker/08_distributed_summarization_bart_t5/sagemaker-notebook.ipynb)
- [Image Classification with Vision Transformer](https://github.com/huggingface/notebooks/blob/master/sagemaker/09_image_classification_vision_transformer/sagemaker-notebook.ipynb)
- [Deploy one of the 10,000+ Hugging Face Transformers to Amazon SageMaker for Inference](https://github.com/huggingface/notebooks/blob/master/sagemaker/11_deploy_model_from_hf_hub/deploy_transformer_model_from_hf_hub.ipynb)
- [Deploy a Hugging Face Transformer model from S3 to SageMaker for inference](https://github.com/huggingface/notebooks/blob/master/sagemaker/10_deploy_model_from_s3/deploy_transformer_model_from_s3.ipynb)
---
## **Getting started: End-to-End Text Classification 🧭**
In this getting started guide, we will use the new Hugging Face DLCs and Amazon SageMaker extension to train a transformer model on binary text classification using the transformers and datasets libraries.
We will use an Amazon SageMaker Notebook Instance for the example. You can learn [here how to set up a Notebook Instance](https://docs.aws.amazon.com/sagemaker/latest/dg/nbi.html).
**What are we going to do:**
- set up a development environment and install sagemaker
- create the training script `train.py`
- preprocess our data and upload it to [Amazon S3](https://docs.aws.amazon.com/AmazonS3/latest/userguide/Welcome.html)
- create a [HuggingFace Estimator](https://huggingface.co/transformers/sagemaker.html) and train our model
## Set up a development environment and install sagemaker
As mentioned above we are going to use SageMaker Notebook Instances for this. To get started you need to jump into your Jupyer Notebook or JupyterLab and create a new Notebook with the conda_pytorch_p36 kernel.
_**Note:** The use of Jupyter is optional: We could also launch SageMaker Training jobs from anywhere we have an SDK installed, connectivity to the cloud and appropriate permissions, such as a Laptop, another IDE or a task scheduler like Airflow or AWS Step Functions._
After that we can install the required dependencies
```bash
pip install "sagemaker>=2.31.0" "transformers==4.6.1" "datasets[s3]==1.6.2" --upgrade
```
To run training on SageMaker we need to create a sagemaker Session and provide an IAM role with the right permission. This IAM role will be later attached to the TrainingJob enabling it to download data, e.g. from Amazon S3.
```python
import sagemaker
sess = sagemaker.Session()
# sagemaker session bucket -> used for uploading data, models and logs
# sagemaker will automatically create this bucket if it not exists
sagemaker_session_bucket=None
if sagemaker_session_bucket is None and sess is not None:
# set to default bucket if a bucket name is not given
sagemaker_session_bucket = sess.default_bucket()
role = sagemaker.get_execution_role()
sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)
print(f"sagemaker role arn: {role}")
print(f"sagemaker bucket: {sess.default_bucket()}")
print(f"sagemaker session region: {sess.boto_region_name}")
```
## Create the training script `train.py`
In a SageMaker `TrainingJob` we are executing a python script with named arguments. In this example, we use PyTorch together with transformers. The script will
- pass the incoming parameters (hyperparameters from HuggingFace Estimator)
- load our dataset
- define our compute metrics function
- set up our `Trainer`
- run training with `trainer.train()`
- evaluate the training and save our model at the end to S3.
```bash
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
from datasets import load_from_disk
import random
import logging
import sys
import argparse
import os
import torch
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# hyperparameters sent by the client are passed as command-line arguments to the script.
parser.add_argument("--epochs", type=int, default=3)
parser.add_argument("--train-batch-size", type=int, default=32)
parser.add_argument("--eval-batch-size", type=int, default=64)
parser.add_argument("--warmup_steps", type=int, default=500)
parser.add_argument("--model_name", type=str)
parser.add_argument("--learning_rate", type=str, default=5e-5)
# Data, model, and output directories
parser.add_argument("--output-data-dir", type=str, default=os.environ["SM_OUTPUT_DATA_DIR"])
parser.add_argument("--model-dir", type=str, default=os.environ["SM_MODEL_DIR"])
parser.add_argument("--n_gpus", type=str, default=os.environ["SM_NUM_GPUS"])
parser.add_argument("--training_dir", type=str, default=os.environ["SM_CHANNEL_TRAIN"])
parser.add_argument("--test_dir", type=str, default=os.environ["SM_CHANNEL_TEST"])
args, _ = parser.parse_known_args()
# Set up logging
logger = logging.getLogger(__name__)
logging.basicConfig(
level=logging.getLevelName("INFO"),
handlers=[logging.StreamHandler(sys.stdout)],
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s",
)
# load datasets
train_dataset = load_from_disk(args.training_dir)
test_dataset = load_from_disk(args.test_dir)
logger.info(f" loaded train_dataset length is: {len(train_dataset)}")
logger.info(f" loaded test_dataset length is: {len(test_dataset)}")
# compute metrics function for binary classification
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average="binary")
acc = accuracy_score(labels, preds)
return {"accuracy": acc, "f1": f1, "precision": precision, "recall": recall}
# download model from model hub
model = AutoModelForSequenceClassification.from_pretrained(args.model_name)
# define training args
training_args = TrainingArguments(
output_dir=args.model_dir,
num_train_epochs=args.epochs,
per_device_train_batch_size=args.train_batch_size,
per_device_eval_batch_size=args.eval_batch_size,
warmup_steps=args.warmup_steps,
evaluation_strategy="epoch",
logging_dir=f"{args.output_data_dir}/logs",
learning_rate=float(args.learning_rate),
)
# create Trainer instance
trainer = Trainer(
model=model,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=train_dataset,
eval_dataset=test_dataset,
)
# train model
trainer.train()
# evaluate model
eval_result = trainer.evaluate(eval_dataset=test_dataset)
# writes eval result to file which can be accessed later in s3 output
with open(os.path.join(args.output_data_dir, "eval_results.txt"), "w") as writer:
print(f"***** Eval results *****")
for key, value in sorted(eval_result.items()):
writer.write(f"{key} = {value}\\n")
# Saves the model to s3; default is /opt/ml/model which SageMaker sends to S3
trainer.save_model(args.model_dir)
```
## Preprocess our data and upload it to s3
We use the `datasets` library to download and preprocess our `imdb` dataset. After preprocessing, the dataset will be uploaded to the current session’s default s3 bucket `sess.default_bucket()` used within our training job. The `imdb` dataset consists of 25000 training and 25000 testing highly polar movie reviews.
```python
import botocore
from datasets import load_dataset
from transformers import AutoTokenizer
from datasets.filesystems import S3FileSystem
# tokenizer used in preprocessing
tokenizer_name = 'distilbert-base-uncased'
# filesystem client for s3
s3 = S3FileSystem()
# dataset used
dataset_name = 'imdb'
# s3 key prefix for the data
s3_prefix = 'datasets/imdb'
# load dataset
dataset = load_dataset(dataset_name)
# download tokenizer
tokenizer = AutoTokenizer.from_pretrained(tokenizer_name)
# tokenizer helper function
def tokenize(batch):
return tokenizer(batch['text'], padding='max_length', truncation=True)
# load dataset
train_dataset, test_dataset = load_dataset('imdb', split=['train', 'test'])
test_dataset = test_dataset.shuffle().select(range(10000)) # smaller the size for test dataset to 10k
# tokenize dataset
train_dataset = train_dataset.map(tokenize, batched=True, batch_size=len(train_dataset))
test_dataset = test_dataset.map(tokenize, batched=True, batch_size=len(test_dataset))
# set format for pytorch
train_dataset = train_dataset.rename_column("label", "labels")
train_dataset.set_format('torch', columns=['input_ids', 'attention_mask', 'labels'])
test_dataset = test_dataset.rename_column("label", "labels")
test_dataset.set_format('torch', columns=['input_ids', 'attention_mask', 'labels'])
# save train_dataset to s3
training_input_path = f's3://{sess.default_bucket()}/{s3_prefix}/train'
train_dataset.save_to_disk(training_input_path,fs=s3)
# save test_dataset to s3
test_input_path = f's3://{sess.default_bucket()}/{s3_prefix}/test'
test_dataset.save_to_disk(test_input_path,fs=s3)
```
## Create a HuggingFace Estimator and train our model
In order to create a SageMaker `Trainingjob` we can use a HuggingFace Estimator. The Estimator handles the end-to-end Amazon SageMaker training. In an Estimator, we define which fine-tuning script should be used as `entry_point`, which `instance_type` should be used, which hyperparameters are passed in. In addition to this, a number of advanced controls are available, such as customizing the output and checkpointing locations, specifying the local storage size or network configuration.
SageMaker takes care of starting and managing all the required Amazon EC2 instances for us with the Hugging Face DLC, it uploads the provided fine-tuning script, for example, our `train.py`, then downloads the data from the S3 bucket, `sess.default_bucket()`, into the container. Once the data is ready, the training job will start automatically by running.
```bash
/opt/conda/bin/python train.py --epochs 1 --model_name distilbert-base-uncased --train_batch_size 32
```
The hyperparameters you define in the HuggingFace Estimator are passed in as named arguments.
```python
from sagemaker.huggingface import HuggingFace
# hyperparameters, which are passed into the training job
hyperparameters={'epochs': 1,
'train_batch_size': 32,
'model_name':'distilbert-base-uncased'
}
# create the Estimator
huggingface_estimator = HuggingFace(
entry_point='train.py',
source_dir='./scripts',
instance_type='ml.p3.2xlarge',
instance_count=1,
role=role,
transformers_version='4.6',
pytorch_version='1.7',
py_version='py36',
hyperparameters = hyperparameters
)
```
To start our training we call the .fit() method and pass our S3 uri as input.
```python
# starting the train job with our uploaded datasets as input
huggingface_estimator.fit({'train': training_input_path, 'test': test_input_path})
```
---
## **Additional Features 🚀**
In addition to the Deep Learning Container and the SageMaker SDK, we have implemented other additional features.
## Distributed Training: Data-Parallel
You can use [SageMaker Data Parallelism Library](https://aws.amazon.com/blogs/aws/managed-data-parallelism-in-amazon-sagemaker-simplifies-training-on-large-datasets/) out of the box for distributed training. We added the functionality of Data Parallelism directly into the Trainer. If your train.py uses the Trainer API you only need to define the distribution parameter in the HuggingFace Estimator.
- [Example Notebook PyTorch](https://github.com/huggingface/notebooks/blob/master/sagemaker/04_distributed_training_model_parallelism/sagemaker-notebook.ipynb)
- [Example Notebook TensorFlow](https://github.com/huggingface/notebooks/blob/master/sagemaker/07_tensorflow_distributed_training_data_parallelism/sagemaker-notebook.ipynb)
```python
# configuration for running training on smdistributed Data Parallel
distribution = {'smdistributed':{'dataparallel':{ 'enabled': True }}}
# create the Estimator
huggingface_estimator = HuggingFace(
entry_point='train.py',
source_dir='./scripts',
instance_type='ml.p3dn.24xlarge',
instance_count=2,
role=role,
transformers_version='4.4.2',
pytorch_version='1.6.0',
py_version='py36',
hyperparameters = hyperparameters
distribution = distribution
)
```
The "Getting started: End-to-End Text Classification 🧭" example can be used for distributed training without any changes.
## Distributed Training: Model Parallel
You can use [SageMaker Model Parallelism Library](https://aws.amazon.com/blogs/aws/amazon-sagemaker-simplifies-training-deep-learning-models-with-billions-of-parameters/) out of the box for distributed training. We added the functionality of Model Parallelism directly into the [Trainer](https://huggingface.co/transformers/main_classes/trainer.html). If your `train.py` uses the [Trainer](https://huggingface.co/transformers/main_classes/trainer.html) API you only need to define the distribution parameter in the HuggingFace Estimator.
For detailed information about the adjustments take a look [here](https://sagemaker.readthedocs.io/en/stable/api/training/smd_model_parallel_general.html?highlight=modelparallel#required-sagemaker-python-sdk-parameters).
- [Example Notebook](https://github.com/huggingface/notebooks/blob/master/sagemaker/04_distributed_training_model_parallelism/sagemaker-notebook.ipynb)
```python
# configuration for running training on smdistributed Model Parallel
mpi_options = {
"enabled" : True,
"processes_per_host" : 8
}
smp_options = {
"enabled":True,
"parameters": {
"microbatches": 4,
"placement_strategy": "spread",
"pipeline": "interleaved",
"optimize": "speed",
"partitions": 4,
"ddp": True,
}
}
distribution={
"smdistributed": {"modelparallel": smp_options},
"mpi": mpi_options
}
# create the Estimator
huggingface_estimator = HuggingFace(
entry_point='train.py',
source_dir='./scripts',
instance_type='ml.p3dn.24xlarge',
instance_count=2,
role=role,
transformers_version='4.4.2',
pytorch_version='1.6.0',
py_version='py36',
hyperparameters = hyperparameters,
distribution = distribution
)
```
## Spot instances
With the creation of HuggingFace Framework extension for the SageMaker Python SDK we can also leverage the benefit of [fully-managed EC2 spot instances](https://docs.aws.amazon.com/sagemaker/latest/dg/model-managed-spot-training.html) and save up to 90% of our training cost.
_Note: Unless your training job will complete quickly, we recommend you use [checkpointing](https://docs.aws.amazon.com/sagemaker/latest/dg/model-checkpoints.html) with managed spot training, therefore you need to define the `checkpoint_s3_uri`._
To use spot instances with the `HuggingFace` Estimator we have to set the `use_spot_instances` parameter to `True` and define your `max_wait` and `max_run` time. You can read more about [the managed spot training lifecycle here](https://docs.aws.amazon.com/sagemaker/latest/dg/model-managed-spot-training.html).
- [Example Notebook](https://github.com/huggingface/notebooks/blob/master/sagemaker/05_spot_instances/sagemaker-notebook.ipynb)
```python
# hyperparameters, which are passed into the training job
hyperparameters={'epochs': 1,
'train_batch_size': 32,
'model_name':'distilbert-base-uncased',
'output_dir':'/opt/ml/checkpoints'
}
# create the Estimator
huggingface_estimator = HuggingFace(
entry_point='train.py',
source_dir='./scripts',
instance_type='ml.p3.2xlarge',
instance_count=1,
checkpoint_s3_uri=f's3://{sess.default_bucket()}/checkpoints'
use_spot_instances=True,
max_wait=3600, # This should be equal to or greater than max_run in seconds'
max_run=1000,
role=role,
transformers_version='4.4',
pytorch_version='1.6',
py_version='py36',
hyperparameters = hyperparameters
)
# Training seconds: 874
# Billable seconds: 105
# Managed Spot Training savings: 88.0%
```
## Git Repositories
When you create an `HuggingFace` Estimator, you can specify a [training script that is stored in a GitHub](https://sagemaker.readthedocs.io/en/stable/overview.html#use-scripts-stored-in-a-git-repository) repository as the entry point for the estimator, so that you don’t have to download the scripts locally. If Git support is enabled, then `entry_point` and `source_dir` should be relative paths in the Git repo if provided.
As an example to use `git_config` with an [example script from the transformers repository](https://github.com/huggingface/transformers/tree/master/examples/text-classification).
_Be aware that you need to define `output_dir` as a hyperparameter for the script to save your model to S3 after training. Suggestion: define output_dir as `/opt/ml/model` since it is the default `SM_MODEL_DIR` and will be uploaded to S3._
- [Example Notebook](https://github.com/huggingface/notebooks/blob/master/sagemaker/02_getting_started_tensorflow/sagemaker-notebook.ipynb)
```python
# configure git settings
git_config = {'repo': 'https://github.com/huggingface/transformers.git','branch': 'master'}
# create the Estimator
huggingface_estimator = HuggingFace(
entry_point='run_glue.py',
source_dir='./examples/text-classification',
git_config=git_config,
instance_type='ml.p3.2xlarge',
instance_count=1,
role=role,
transformers_version='4.4',
pytorch_version='1.6',
py_version='py36',
hyperparameters=hyperparameters
)
```
## SageMaker Metrics
[SageMaker Metrics](https://docs.aws.amazon.com/sagemaker/latest/dg/training-metrics.html#define-train-metrics) can automatically parse the logs for metrics and send those metrics to CloudWatch. If you want SageMaker to parse logs you have to specify the metrics that you want SageMaker to send to CloudWatch when you configure the training job. You specify the name of the metrics that you want to send and the regular expressions that SageMaker uses to parse the logs that your algorithm emits to find those metrics.
- [Example Notebook](https://github.com/huggingface/notebooks/blob/master/sagemaker/06_sagemaker_metrics/sagemaker-notebook.ipynb)
```python
# define metrics definitions
metric_definitions = [
{"Name": "train_runtime", "Regex": "train_runtime.*=\D*(.*?)$"},
{"Name": "eval_accuracy", "Regex": "eval_accuracy.*=\D*(.*?)$"},
{"Name": "eval_loss", "Regex": "eval_loss.*=\D*(.*?)$"},
]
# create the Estimator
huggingface_estimator = HuggingFace(
entry_point='train.py',
source_dir='./scripts',
instance_type='ml.p3.2xlarge',
instance_count=1,
role=role,
transformers_version='4.4',
pytorch_version='1.6',
py_version='py36',
metric_definitions=metric_definitions,
hyperparameters = hyperparameters
)
```
---
## **FAQ 🎯**
You can find the complete [Frequently Asked Questions](https://huggingface.co/docs/sagemaker/faq) in the [documentation](https://huggingface.co/docs/sagemaker/faq).
_Q: What are Deep Learning Containers?_
A: Deep Learning Containers (DLCs) are Docker images pre-installed with deep learning frameworks and libraries (e.g. transformers, datasets, tokenizers) to make it easy to train models by letting you skip the complicated process of building and optimizing your environments from scratch.
_Q: Do I have to use the SageMaker Python SDK to use the Hugging Face Deep Learning Containers?_
A: You can use the HF DLC without the SageMaker Python SDK and launch SageMaker Training jobs with other SDKs, such as the [AWS CLI](https://docs.aws.amazon.com/cli/latest/reference/sagemaker/create-training-job.html) or [boto3](https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker.html#SageMaker.Client.create_training_job). The DLCs are also available through Amazon ECR and can be pulled and used in any environment of choice.
_Q: Why should I use the Hugging Face Deep Learning Containers?_
A: The DLCs are fully tested, maintained, optimized deep learning environments that require no installation, configuration, or maintenance.
_Q: Why should I use SageMaker Training to train Hugging Face models?_
A: SageMaker Training provides numerous benefits that will boost your productivity with Hugging Face : (1) first it is cost-effective: the training instances live only for the duration of your job and are paid per second. No risk anymore to leave GPU instances up all night: the training cluster stops right at the end of your job! It also supports EC2 Spot capacity, which enables up to 90% cost reduction. (2) SageMaker also comes with a lot of built-in automation that facilitates teamwork and MLOps: training metadata and logs are automatically persisted to a serverless managed metastore, and I/O with S3 (for datasets, checkpoints and model artifacts) is fully managed. Finally, SageMaker also allows to drastically scale up and out: you can launch multiple training jobs in parallel, but also launch large-scale distributed training jobs
_Q: Once I've trained my model with Amazon SageMaker, can I use it with 🤗/Transformers ?_
A: Yes, you can download your trained model from S3 and directly use it with transformers or upload it to the [Hugging Face Model Hub](https://huggingface.co/models).
_Q: How is my data and code secured by Amazon SageMaker?_
A: Amazon SageMaker provides numerous security mechanisms including [encryption at rest](https://docs.aws.amazon.com/sagemaker/latest/dg/encryption-at-rest-nbi.html) and [in transit](https://docs.aws.amazon.com/sagemaker/latest/dg/encryption-in-transit.html), [Virtual Private Cloud (VPC) connectivity](https://docs.aws.amazon.com/sagemaker/latest/dg/interface-vpc-endpoint.html) and [Identity and Access Management (IAM)](https://docs.aws.amazon.com/sagemaker/latest/dg/security_iam_service-with-iam.html). To learn more about security in the AWS cloud and with Amazon SageMaker, you can visit [Security in Amazon SageMaker](https://docs.aws.amazon.com/sagemaker/latest/dg/security_iam_service-with-iam.html) and [AWS Cloud Security](https://docs.aws.amazon.com/sagemaker/latest/dg/security_iam_service-with-iam.html).
_Q: Is this available in my region?_
A: For a list of the supported regions, please visit the [AWS region table](https://aws.amazon.com/about-aws/global-infrastructure/regional-product-services/) for all AWS global infrastructure.
_Q: Do I need to pay for a license from Hugging Face to use the DLCs?_
A: No - the Hugging Face DLCs are open source and licensed under Apache 2.0.
_Q: How can I run inference on my trained models?_
A: You have multiple options to run inference on your trained models. One option is to use Hugging Face [Accelerated Inference-API](https://api-inference.huggingface.co/docs/python/html/index.html) hosted service: start by [uploading the trained models to your Hugging Face account](https://huggingface.co/new) to deploy them publicly, or privately. Another great option is to use [SageMaker Inference](https://docs.aws.amazon.com/sagemaker/latest/dg/your-algorithms-inference-main.html) to run your own inference code in Amazon SageMaker. We are working on offering an integrated solution for Amazon SageMaker with Hugging Face Inference DLCs in the future - stay tuned!
_Q: Do you offer premium support or support SLAs for this solution?_
A: AWS Technical Support tiers are available from AWS and cover development and production issues for AWS products and services - please refer to AWS Support for specifics and scope.
If you have questions which the Hugging Face community can help answer and/or benefit from, please [post them in the Hugging Face forum](https://discuss.huggingface.co/c/sagemaker/17).
If you need premium support from the Hugging Face team to accelerate your NLP roadmap, our Expert Acceleration Program offers direct guidance from our open source, science and ML Engineering team - [contact us to learn more](mailto:api-enterprise@huggingface.co).
_Q: What are you planning next through this partnership?_
A: Our common goal is to democratize state of the art Machine Learning. We will continue to innovate to make it easier for researchers, data scientists and ML practitioners to manage, train and run state of the art models. If you have feature requests for integration in AWS with Hugging Face, please [let us know in the Hugging Face community forum](https://discuss.huggingface.co/c/sagemaker/17).
_Q: I use Hugging Face with Azure Machine Learning or Google Cloud Platform, what does this partnership mean for me?_
A: A foundational goal for Hugging Face is to make the latest AI accessible to as many people as possible, whichever framework or development environment they work in. While we are focusing integration efforts with Amazon Web Services as our Preferred Cloud Provider, we will continue to work hard to serve all Hugging Face users and customers, no matter what compute environment they run on.
|
huggingface/blog/blob/main/the-partnership-amazon-sagemaker-and-hugging-face.md
|
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Export to TorchScript
<Tip>
This is the very beginning of our experiments with TorchScript and we are still
exploring its capabilities with variable-input-size models. It is a focus of interest to
us and we will deepen our analysis in upcoming releases, with more code examples, a more
flexible implementation, and benchmarks comparing Python-based codes with compiled
TorchScript.
</Tip>
According to the [TorchScript documentation](https://pytorch.org/docs/stable/jit.html):
> TorchScript is a way to create serializable and optimizable models from PyTorch code.
There are two PyTorch modules, [JIT and
TRACE](https://pytorch.org/docs/stable/jit.html), that allow developers to export their
models to be reused in other programs like efficiency-oriented C++ programs.
We provide an interface that allows you to export 🤗 Transformers models to TorchScript
so they can be reused in a different environment than PyTorch-based Python programs.
Here, we explain how to export and use our models using TorchScript.
Exporting a model requires two things:
- model instantiation with the `torchscript` flag
- a forward pass with dummy inputs
These necessities imply several things developers should be careful about as detailed
below.
## TorchScript flag and tied weights
The `torchscript` flag is necessary because most of the 🤗 Transformers language models
have tied weights between their `Embedding` layer and their `Decoding` layer.
TorchScript does not allow you to export models that have tied weights, so it is
necessary to untie and clone the weights beforehand.
Models instantiated with the `torchscript` flag have their `Embedding` layer and
`Decoding` layer separated, which means that they should not be trained down the line.
Training would desynchronize the two layers, leading to unexpected results.
This is not the case for models that do not have a language model head, as those do not
have tied weights. These models can be safely exported without the `torchscript` flag.
## Dummy inputs and standard lengths
The dummy inputs are used for a models forward pass. While the inputs' values are
propagated through the layers, PyTorch keeps track of the different operations executed
on each tensor. These recorded operations are then used to create the *trace* of the
model.
The trace is created relative to the inputs' dimensions. It is therefore constrained by
the dimensions of the dummy input, and will not work for any other sequence length or
batch size. When trying with a different size, the following error is raised:
```
`The expanded size of the tensor (3) must match the existing size (7) at non-singleton dimension 2`
```
We recommended you trace the model with a dummy input size at least as large as the
largest input that will be fed to the model during inference. Padding can help fill the
missing values. However, since the model is traced with a larger input size, the
dimensions of the matrix will also be large, resulting in more calculations.
Be careful of the total number of operations done on each input and follow the
performance closely when exporting varying sequence-length models.
## Using TorchScript in Python
This section demonstrates how to save and load models as well as how to use the trace
for inference.
### Saving a model
To export a `BertModel` with TorchScript, instantiate `BertModel` from the `BertConfig`
class and then save it to disk under the filename `traced_bert.pt`:
```python
from transformers import BertModel, BertTokenizer, BertConfig
import torch
enc = BertTokenizer.from_pretrained("bert-base-uncased")
# Tokenizing input text
text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
tokenized_text = enc.tokenize(text)
# Masking one of the input tokens
masked_index = 8
tokenized_text[masked_index] = "[MASK]"
indexed_tokens = enc.convert_tokens_to_ids(tokenized_text)
segments_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
# Creating a dummy input
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_ids])
dummy_input = [tokens_tensor, segments_tensors]
# Initializing the model with the torchscript flag
# Flag set to True even though it is not necessary as this model does not have an LM Head.
config = BertConfig(
vocab_size_or_config_json_file=32000,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
torchscript=True,
)
# Instantiating the model
model = BertModel(config)
# The model needs to be in evaluation mode
model.eval()
# If you are instantiating the model with *from_pretrained* you can also easily set the TorchScript flag
model = BertModel.from_pretrained("bert-base-uncased", torchscript=True)
# Creating the trace
traced_model = torch.jit.trace(model, [tokens_tensor, segments_tensors])
torch.jit.save(traced_model, "traced_bert.pt")
```
### Loading a model
Now you can load the previously saved `BertModel`, `traced_bert.pt`, from disk and use
it on the previously initialised `dummy_input`:
```python
loaded_model = torch.jit.load("traced_bert.pt")
loaded_model.eval()
all_encoder_layers, pooled_output = loaded_model(*dummy_input)
```
### Using a traced model for inference
Use the traced model for inference by using its `__call__` dunder method:
```python
traced_model(tokens_tensor, segments_tensors)
```
## Deploy Hugging Face TorchScript models to AWS with the Neuron SDK
AWS introduced the [Amazon EC2 Inf1](https://aws.amazon.com/ec2/instance-types/inf1/)
instance family for low cost, high performance machine learning inference in the cloud.
The Inf1 instances are powered by the AWS Inferentia chip, a custom-built hardware
accelerator, specializing in deep learning inferencing workloads. [AWS
Neuron](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/#) is the SDK for
Inferentia that supports tracing and optimizing transformers models for deployment on
Inf1. The Neuron SDK provides:
1. Easy-to-use API with one line of code change to trace and optimize a TorchScript
model for inference in the cloud.
2. Out of the box performance optimizations for [improved
cost-performance](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/benchmark/>).
3. Support for Hugging Face transformers models built with either
[PyTorch](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/bert_tutorial/tutorial_pretrained_bert.html)
or
[TensorFlow](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/tensorflow/huggingface_bert/huggingface_bert.html).
### Implications
Transformers models based on the [BERT (Bidirectional Encoder Representations from
Transformers)](https://huggingface.co/docs/transformers/main/model_doc/bert)
architecture, or its variants such as
[distilBERT](https://huggingface.co/docs/transformers/main/model_doc/distilbert) and
[roBERTa](https://huggingface.co/docs/transformers/main/model_doc/roberta) run best on
Inf1 for non-generative tasks such as extractive question answering, sequence
classification, and token classification. However, text generation tasks can still be
adapted to run on Inf1 according to this [AWS Neuron MarianMT
tutorial](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/transformers-marianmt.html).
More information about models that can be converted out of the box on Inferentia can be
found in the [Model Architecture
Fit](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/models/models-inferentia.html#models-inferentia)
section of the Neuron documentation.
### Dependencies
Using AWS Neuron to convert models requires a [Neuron SDK
environment](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/neuron-frameworks/pytorch-neuron/index.html#installation-guide)
which comes preconfigured on [AWS Deep Learning
AMI](https://docs.aws.amazon.com/dlami/latest/devguide/tutorial-inferentia-launching.html).
### Converting a model for AWS Neuron
Convert a model for AWS NEURON using the same code from [Using TorchScript in
Python](torchscript#using-torchscript-in-python) to trace a `BertModel`. Import the
`torch.neuron` framework extension to access the components of the Neuron SDK through a
Python API:
```python
from transformers import BertModel, BertTokenizer, BertConfig
import torch
import torch.neuron
```
You only need to modify the following line:
```diff
- torch.jit.trace(model, [tokens_tensor, segments_tensors])
+ torch.neuron.trace(model, [token_tensor, segments_tensors])
```
This enables the Neuron SDK to trace the model and optimize it for Inf1 instances.
To learn more about AWS Neuron SDK features, tools, example tutorials and latest
updates, please see the [AWS NeuronSDK
documentation](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/index.html).
|
huggingface/transformers/blob/main/docs/source/en/torchscript.md
|
--
title: "Introducing Optimum: The Optimization Toolkit for Transformers at Scale"
authors:
- user: mfuntowicz
- user: echarlaix
- user: michaelbenayoun
- user: jeffboudier
---
# Introducing 🤗 Optimum: The Optimization Toolkit for Transformers at Scale
This post is the first step of a journey for Hugging Face to democratize
state-of-the-art **Machine Learning production performance**.
To get there, we will work hand in hand with our
Hardware Partners, as we have with Intel below.
Join us in this journey, and follow [Optimum](https://github.com/huggingface/optimum), our new open source library!
## Why 🤗 Optimum?
### 🤯 Scaling Transformers is hard
What do Tesla, Google, Microsoft and Facebook all have in common?
Well many things, but one of them is they all run billions of Transformer model predictions
every day. Transformers for AutoPilot to drive your Tesla (lucky you!),
for Gmail to complete your sentences,
for Facebook to translate your posts on the fly,
for Bing to answer your natural language queries.
[Transformers](https://github.com/huggingface/transformers) have brought a step change improvement
in the accuracy of Machine Learning models, have conquered NLP and are now expanding
to other modalities starting with [Speech](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition&sort=downloads)
and [Vision](https://huggingface.co/models?pipeline_tag=image-classification&sort=downloads).
But taking these massive models into production, and making them run fast at scale is a huge challenge
for any Machine Learning Engineering team.
What if you don’t have hundreds of highly skilled Machine Learning Engineers on payroll like the above companies?
Through Optimum, our new open source library, we aim to build the definitive toolkit for Transformers production performance,
and enable maximum efficiency to train and run models on specific hardware.
### 🏭 Optimum puts Transformers to work
To get optimal performance training and serving models, the model acceleration techniques need to be specifically compatible with the targeted hardware.
Each hardware platform offers specific software tooling,
[features and knobs that can have a huge impact on performance](https://huggingface.co/blog/bert-cpu-scaling-part-1).
Similarly, to take advantage of advanced model acceleration techniques like sparsity and quantization, optimized kernels need to be compatible with the operators on silicon,
and specific to the neural network graph derived from the model architecture.
Diving into this 3-dimensional compatibility matrix and how to use model acceleration libraries is daunting work,
which few Machine Learning Engineers have experience on.
[Optimum](https://github.com/huggingface/optimum) aims to make this work easy, providing performance optimization tools targeting efficient AI hardware,
built in collaboration with our Hardware Partners, and turn Machine Learning Engineers into ML Optimization wizards.
With the [Transformers](https://github.com/huggingface/transformers) library, we made it easy for researchers and engineers to use state-of-the-art models,
abstracting away the complexity of frameworks, architectures and pipelines.
With the [Optimum](https://github.com/huggingface/optimum) library, we are making it easy for engineers to leverage all the available hardware features at their disposal,
abstracting away the complexity of model acceleration on hardware platforms.
## 🤗 Optimum in practice: how to quantize a model for Intel Xeon CPU
### 🤔 Why quantization is important but tricky to get right
Pre-trained language models such as BERT have achieved state-of-the-art results on a wide range of natural language processing tasks,
other Transformer based models such as ViT and Speech2Text have achieved state-of-the-art results on computer vision and speech tasks respectively:
transformers are everywhere in the Machine Learning world and are here to stay.
However, putting transformer-based models into production can be tricky and expensive as they need a lot of compute power to work.
To solve this many techniques exist, the most popular being quantization.
Unfortunately, in most cases quantizing a model requires a lot of work, for many reasons:
1. The model needs to be edited: some ops need to be replaced by their quantized counterparts, new ops need to be inserted (quantization and dequantization nodes),
and others need to be adapted to the fact that weights and activations will be quantized.
This part can be very time-consuming because frameworks such as PyTorch work in eager mode, meaning that the changes mentioned above need to be added to the model implementation itself.
PyTorch now provides a tool called `torch.fx` that allows you to trace and transform your model without having to actually change the model implementation, but it is tricky to use when tracing is not supported for your model out of the box.
On top of the actual editing, it is also necessary to find which parts of the model need to be edited,
which ops have an available quantized kernel counterpart and which ops don't, and so on.
2. Once the model has been edited, there are many parameters to play with to find the best quantization settings:
- Which kind of observers should I use for range calibration?
- Which quantization scheme should I use?
- Which quantization related data types (int8, uint8, int16) are supported on my target device?
3. Balance the trade-off between quantization and an acceptable accuracy loss.
4. Export the quantized model for the target device.
Although PyTorch and TensorFlow made great progress in making things easy for quantization,
the complexities of transformer based models makes it hard to use the provided tools out of the box and get something working without putting up a ton of effort.
### 💡 How Intel is solving quantization and more with Neural Compressor
Intel® [Neural Compressor](https://github.com/intel/neural-compressor) (formerly referred to as Low Precision Optimization Tool or LPOT) is an open-source python library designed to help users deploy low-precision inference solutions.
The latter applies low-precision recipes for deep-learning models to achieve optimal product objectives,
such as inference performance and memory usage, with expected performance criteria.
Neural Compressor supports post-training quantization, quantization-aware training and dynamic quantization.
In order to specify the quantization approach, objective and performance criteria, the user must provide a configuration yaml file specifying the tuning parameters.
The configuration file can either be hosted on the Hugging Face's Model Hub or can be given through a local directory path.
### 🔥 How to easily quantize Transformers for Intel Xeon CPUs with Optimum

## Follow 🤗 Optimum: a journey to democratize ML production performance
### ⚡️State of the Art Hardware
Optimum will focus on achieving optimal production performance on dedicated hardware, where software and hardware acceleration techniques can be applied for maximum efficiency.
We will work hand in hand with our Hardware Partners to enable, test and maintain acceleration, and deliver it in an easy and accessible way through Optimum, as we did with Intel and Neural Compressor.
We will soon announce new Hardware Partners who have joined us on our journey toward Machine Learning efficiency.
### 🔮 State-of-the-Art Models
The collaboration with our Hardware Partners will yield hardware-specific optimized model configurations and artifacts,
which we will make available to the AI community via the Hugging Face [Model Hub](https://huggingface.co/models).
We hope that Optimum and hardware-optimized models will accelerate the adoption of efficiency in production workloads,
which represent most of the aggregate energy spent on Machine Learning.
And most of all, we hope that Optimum will accelerate the adoption of Transformers at scale, not just for the biggest tech companies, but for all of us.
### 🌟 A journey of collaboration: join us, follow our progress
Every journey starts with a first step, and ours was the public release of Optimum.
Join us and make your first step by [giving the library a Star](https://github.com/huggingface/optimum),
so you can follow along as we introduce new supported hardware, acceleration techniques and optimized models.
If you would like to see new hardware and features be supported in Optimum,
or you are interested in joining us to work at the intersection of software and hardware, please reach out to us at hardware@huggingface.co
|
huggingface/blog/blob/main/hardware-partners-program.md
|
Gradio Demo: json_component
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
gr.JSON(value={"Key 1": "Value 1", "Key 2": {"Key 3": "Value 2", "Key 4": "Value 3"}, "Key 5": ["Item 1", "Item 2", "Item 3"]})
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/json_component/run.ipynb
|
Subsets and Splits
Transformers Source Texts
This query retrieves specific examples from the dataset related to transformers, providing a limited view of the data with basic filtering.