
text
stringlengths 23
371k
| source
stringlengths 32
152
|
|---|---|
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Quickstart
The [Hugging Face Hub](https://huggingface.co/) is the go-to place for sharing machine learning
models, demos, datasets, and metrics. `huggingface_hub` library helps you interact with
the Hub without leaving your development environment. You can create and manage
repositories easily, download and upload files, and get useful model and dataset
metadata from the Hub.
## Installation
To get started, install the `huggingface_hub` library:
```bash
pip install --upgrade huggingface_hub
```
For more details, check out the [installation](installation) guide.
## Download files
Repositories on the Hub are git version controlled, and users can download a single file
or the whole repository. You can use the [`hf_hub_download`] function to download files.
This function will download and cache a file on your local disk. The next time you need
that file, it will load from your cache, so you don't need to re-download it.
You will need the repository id and the filename of the file you want to download. For
example, to download the [Pegasus](https://huggingface.co/google/pegasus-xsum) model
configuration file:
```py
>>> from huggingface_hub import hf_hub_download
>>> hf_hub_download(repo_id="google/pegasus-xsum", filename="config.json")
```
To download a specific version of the file, use the `revision` parameter to specify the
branch name, tag, or commit hash. If you choose to use the commit hash, it must be the
full-length hash instead of the shorter 7-character commit hash:
```py
>>> from huggingface_hub import hf_hub_download
>>> hf_hub_download(
... repo_id="google/pegasus-xsum",
... filename="config.json",
... revision="4d33b01d79672f27f001f6abade33f22d993b151"
... )
```
For more details and options, see the API reference for [`hf_hub_download`].
<a id="login"></a> <!-- backward compatible anchor -->
## Authentication
In a lot of cases, you must be authenticated with a Hugging Face account to interact with
the Hub: download private repos, upload files, create PRs,...
[Create an account](https://huggingface.co/join) if you don't already have one, and then sign in
to get your [User Access Token](https://huggingface.co/docs/hub/security-tokens) from
your [Settings page](https://huggingface.co/settings/tokens). The User Access Token is
used to authenticate your identity to the Hub.
<Tip>
Tokens can have `read` or `write` permissions. Make sure to have a `write` access token if you want to create or edit a repository. Otherwise, it's best to generate a `read` token to reduce risk in case your token is inadvertently leaked.
</Tip>
### Login command
The easiest way to authenticate is to save the token on your machine. You can do that from the terminal using the [`login`] command:
```bash
huggingface-cli login
```
The command will tell you if you are already logged in and prompt you for your token. The token is then validated and saved in your `HF_HOME` directory (defaults to `~/.cache/huggingface/token`). Any script or library interacting with the Hub will use this token when sending requests.
Alternatively, you can programmatically login using [`login`] in a notebook or a script:
```py
>>> from huggingface_hub import login
>>> login()
```
You can only be logged in to one account at a time. Logging in to a new account will automatically log you out of the previous one. To determine your currently active account, simply run the `huggingface-cli whoami` command.
<Tip warning={true}>
Once logged in, all requests to the Hub - even methods that don't necessarily require authentication - will use your access token by default. If you want to disable the implicit use of your token, you should set `HF_HUB_DISABLE_IMPLICIT_TOKEN=1` as an environment variable (see [reference](../package_reference/environment_variables#hfhubdisableimplicittoken)).
</Tip>
### Environment variable
The environment variable `HF_TOKEN` can also be used to authenticate yourself. This is especially useful in a Space where you can set `HF_TOKEN` as a [Space secret](https://huggingface.co/docs/hub/spaces-overview#managing-secrets).
<Tip>
**NEW:** Google Colaboratory lets you define [private keys](https://twitter.com/GoogleColab/status/1719798406195867814) for your notebooks. Define a `HF_TOKEN` secret to be automatically authenticated!
</Tip>
Authentication via an environment variable or a secret has priority over the token stored on your machine.
### Method parameters
Finally, it is also possible to authenticate by passing your token to any method that accepts `token` as a parameter.
```
from transformers import whoami
user = whoami(token=...)
```
This is usually discouraged except in an environment where you don't want to store your token permanently or if you need to handle several tokens at once.
<Tip warning={true}>
Please be careful when passing tokens as a parameter. It is always best practice to load the token from a secure vault instead of hardcoding it in your codebase or notebook. Hardcoded tokens present a major leak risk if you share your code inadvertently.
</Tip>
## Create a repository
Once you've registered and logged in, create a repository with the [`create_repo`]
function:
```py
>>> from huggingface_hub import HfApi
>>> api = HfApi()
>>> api.create_repo(repo_id="super-cool-model")
```
If you want your repository to be private, then:
```py
>>> from huggingface_hub import HfApi
>>> api = HfApi()
>>> api.create_repo(repo_id="super-cool-model", private=True)
```
Private repositories will not be visible to anyone except yourself.
<Tip>
To create a repository or to push content to the Hub, you must provide a User Access
Token that has the `write` permission. You can choose the permission when creating the
token in your [Settings page](https://huggingface.co/settings/tokens).
</Tip>
## Upload files
Use the [`upload_file`] function to add a file to your newly created repository. You
need to specify:
1. The path of the file to upload.
2. The path of the file in the repository.
3. The repository id of where you want to add the file.
```py
>>> from huggingface_hub import HfApi
>>> api = HfApi()
>>> api.upload_file(
... path_or_fileobj="/home/lysandre/dummy-test/README.md",
... path_in_repo="README.md",
... repo_id="lysandre/test-model",
... )
```
To upload more than one file at a time, take a look at the [Upload](./guides/upload) guide
which will introduce you to several methods for uploading files (with or without git).
## Next steps
The `huggingface_hub` library provides an easy way for users to interact with the Hub
with Python. To learn more about how you can manage your files and repositories on the
Hub, we recommend reading our [how-to guides](./guides/overview) to:
- [Manage your repository](./guides/repository).
- [Download](./guides/download) files from the Hub.
- [Upload](./guides/upload) files to the Hub.
- [Search the Hub](./guides/search) for your desired model or dataset.
- [Access the Inference API](./guides/inference) for fast inference. | huggingface/huggingface_hub/blob/main/docs/source/en/quick-start.md |
Metric Card for Code Eval
## Metric description
The CodeEval metric estimates the pass@k metric for code synthesis.
It implements the evaluation harness for the HumanEval problem solving dataset described in the paper ["Evaluating Large Language Models Trained on Code"](https://arxiv.org/abs/2107.03374).
## How to use
The Code Eval metric calculates how good are predictions given a set of references. Its arguments are:
`predictions`: a list of candidates to evaluate. Each candidate should be a list of strings with several code candidates to solve the problem.
`references`: a list with a test for each prediction. Each test should evaluate the correctness of a code candidate.
`k`: number of code candidates to consider in the evaluation. The default value is `[1, 10, 100]`.
`num_workers`: the number of workers used to evaluate the candidate programs (The default value is `4`).
`timeout`: The maximum time taken to produce a prediction before it is considered a "timeout". The default value is `3.0` (i.e. 3 seconds).
```python
from datasets import load_metric
code_eval = load_metric("code_eval")
test_cases = ["assert add(2,3)==5"]
candidates = [["def add(a,b): return a*b", "def add(a, b): return a+b"]]
pass_at_k, results = code_eval.compute(references=test_cases, predictions=candidates, k=[1, 2])
```
N.B.
This metric exists to run untrusted model-generated code. Users are strongly encouraged not to do so outside of a robust security sandbox. Before running this metric and once you've taken the necessary precautions, you will need to set the `HF_ALLOW_CODE_EVAL` environment variable. Use it at your own risk:
```python
import os
os.environ["HF_ALLOW_CODE_EVAL"] = "1"`
```
## Output values
The Code Eval metric outputs two things:
`pass_at_k`: a dictionary with the pass rates for each k value defined in the arguments.
`results`: a dictionary with granular results of each unit test.
### Values from popular papers
The [original CODEX paper](https://arxiv.org/pdf/2107.03374.pdf) reported that the CODEX-12B model had a pass@k score of 28.8% at `k=1`, 46.8% at `k=10` and 72.3% at `k=100`. However, since the CODEX model is not open source, it is hard to verify these numbers.
## Examples
Full match at `k=1`:
```python
from datasets import load_metric
code_eval = load_metric("code_eval")
test_cases = ["assert add(2,3)==5"]
candidates = [["def add(a, b): return a+b"]]
pass_at_k, results = code_eval.compute(references=test_cases, predictions=candidates, k=[1])
print(pass_at_k)
{'pass@1': 1.0}
```
No match for k = 1:
```python
from datasets import load_metric
code_eval = load_metric("code_eval")
test_cases = ["assert add(2,3)==5"]
candidates = [["def add(a,b): return a*b"]]
pass_at_k, results = code_eval.compute(references=test_cases, predictions=candidates, k=[1])
print(pass_at_k)
{'pass@1': 0.0}
```
Partial match at k=1, full match at k=2:
```python
from datasets import load_metric
code_eval = load_metric("code_eval")
test_cases = ["assert add(2,3)==5"]
candidates = [["def add(a, b): return a+b", "def add(a,b): return a*b"]]
pass_at_k, results = code_eval.compute(references=test_cases, predictions=candidates, k=[1, 2])
print(pass_at_k)
{'pass@1': 0.5, 'pass@2': 1.0}
```
## Limitations and bias
As per the warning included in the metric code itself:
> This program exists to execute untrusted model-generated code. Although it is highly unlikely that model-generated code will do something overtly malicious in response to this test suite, model-generated code may act destructively due to a lack of model capability or alignment. Users are strongly encouraged to sandbox this evaluation suite so that it does not perform destructive actions on their host or network. For more information on how OpenAI sandboxes its code, see the accompanying paper. Once you have read this disclaimer and taken appropriate precautions, uncomment the following line and proceed at your own risk:
More information about the limitations of the code can be found on the [Human Eval Github repository](https://github.com/openai/human-eval).
## Citation
```bibtex
@misc{chen2021evaluating,
title={Evaluating Large Language Models Trained on Code},
author={Mark Chen and Jerry Tworek and Heewoo Jun and Qiming Yuan \
and Henrique Ponde de Oliveira Pinto and Jared Kaplan and Harri Edwards \
and Yuri Burda and Nicholas Joseph and Greg Brockman and Alex Ray \
and Raul Puri and Gretchen Krueger and Michael Petrov and Heidy Khlaaf \
and Girish Sastry and Pamela Mishkin and Brooke Chan and Scott Gray \
and Nick Ryder and Mikhail Pavlov and Alethea Power and Lukasz Kaiser \
and Mohammad Bavarian and Clemens Winter and Philippe Tillet \
and Felipe Petroski Such and Dave Cummings and Matthias Plappert \
and Fotios Chantzis and Elizabeth Barnes and Ariel Herbert-Voss \
and William Hebgen Guss and Alex Nichol and Alex Paino and Nikolas Tezak \
and Jie Tang and Igor Babuschkin and Suchir Balaji and Shantanu Jain \
and William Saunders and Christopher Hesse and Andrew N. Carr \
and Jan Leike and Josh Achiam and Vedant Misra and Evan Morikawa \
and Alec Radford and Matthew Knight and Miles Brundage and Mira Murati \
and Katie Mayer and Peter Welinder and Bob McGrew and Dario Amodei \
and Sam McCandlish and Ilya Sutskever and Wojciech Zaremba},
year={2021},
eprint={2107.03374},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
## Further References
- [Human Eval Github repository](https://github.com/openai/human-eval)
- [OpenAI Codex website](https://openai.com/blog/openai-codex/)
| huggingface/datasets/blob/main/metrics/code_eval/README.md |
Interface State
So far, we've assumed that your demos are *stateless*: that they do not persist information beyond a single function call. What if you want to modify the behavior of your demo based on previous interactions with the demo? There are two approaches in Gradio: *global state* and *session state*.
## Global State
If the state is something that should be accessible to all function calls and all users, you can create a variable outside the function call and access it inside the function. For example, you may load a large model outside the function and use it inside the function so that every function call does not need to reload the model.
$code_score_tracker
In the code above, the `scores` array is shared between all users. If multiple users are accessing this demo, their scores will all be added to the same list, and the returned top 3 scores will be collected from this shared reference.
## Session State
Another type of data persistence Gradio supports is session state, where data persists across multiple submits within a page session. However, data is _not_ shared between different users of your model. To store data in a session state, you need to do three things:
1. Pass in an extra parameter into your function, which represents the state of the interface.
2. At the end of the function, return the updated value of the state as an extra return value.
3. Add the `'state'` input and `'state'` output components when creating your `Interface`
A chatbot is an example where you would need session state - you want access to a users previous submissions, but you cannot store chat history in a global variable, because then chat history would get jumbled between different users.
$code_chatbot_dialogpt
$demo_chatbot_dialogpt
Notice how the state persists across submits within each page, but if you load this demo in another tab (or refresh the page), the demos will not share chat history.
The default value of `state` is None. If you pass a default value to the state parameter of the function, it is used as the default value of the state instead. The `Interface` class only supports a single input and outputs state variable, though it can be a list with multiple elements. For more complex use cases, you can use Blocks, [which supports multiple `State` variables](/guides/state-in-blocks/).
| gradio-app/gradio/blob/main/guides/02_building-interfaces/03_interface-state.md |
Hands-on [[hands-on]]
Now that you've learned to use Optuna, here are some ideas to apply what you've learned:
1️⃣ **Beat your LunarLander-v2 agent results**, by using Optuna to find a better set of hyperparameters. You can also try with another environment, such as MountainCar-v0 and CartPole-v1.
2️⃣ **Beat your SpaceInvaders agent results**.
By doing this, you'll see how valuable and powerful Optuna can be in training better agents.
Have fun!
Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then please 👉 [fill out this form](https://forms.gle/BzKXWzLAGZESGNaE9)
### Keep Learning, stay awesome 🤗
| huggingface/deep-rl-class/blob/main/units/en/unitbonus2/hands-on.mdx |
--
title: "Creating open machine learning datasets? Share them on the Hugging Face Hub!"
thumbnail: /blog/assets/researcher-dataset-sharing/thumbnail.png
authors:
- user: davanstrien
---
# Creating open machine learning datasets? Share them on the Hugging Face Hub!
## Who is this blog post for?
Are you a researcher doing data-intensive research or using machine learning as a research tool? As part of this research, you have likely created datasets for training and evaluating machine learning models, and like many researchers, you may be sharing these datasets via Google Drive, OneDrive, or your own personal server. In this post, we’ll outline why you might want to consider sharing these datasets on the Hugging Face Hub instead.
This post outlines:
- Why researchers should openly share their data (feel free to skip this section if you are already convinced about this!)
- What the Hugging Face Hub offers for researchers who want to share their datasets.
- Resources for getting started with sharing your datasets on the Hugging Face Hub.
## Why share your data?
Machine learning is increasingly utilized across various disciplines, enhancing research efficiency in tackling diverse problems. Data remains crucial for training and evaluating models, especially when developing new machine-learning methods for specific tasks or domains. Large Language Models may not perform well on specialized tasks like bio-medical entity extraction, and computer vision models might struggle with classifying domain specific images.
Domain-specific datasets are vital for evaluating and training machine learning models, helping to overcome the limitations of existing models. Creating these datasets, however, is challenging, requiring significant time, resources, and domain expertise, particularly for annotating data. Maximizing the impact of this data is crucial for the benefit of both the researchers involved and their respective fields.
The Hugging Face Hub can help achieve this maximum impact.
## What is the Hugging Face Hub?
The [Hugging Face Hub](https://huggingface.co/) has become the central hub for sharing open machine learning models, datasets and demos, hosting over 360,000 models and 70,000 datasets. The Hub enables people – including researchers – to access state-of-the-art machine learning models and datasets in a few lines of code.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/researcher-dataset-sharing/hub-datasets.png" alt="Screenshot of datasets in the Hugging Face Hub"><br>
<em>Datasets on the Hugging Face Hub.</em>
</p>
## What does the Hugging Face Hub offer for data sharing?
This blog post won’t cover all of the features and benefits of hosting datasets on the Hugging Face Hub but will instead highlight some that are particularly relevant for researchers.
### Visibility for your work
The Hugging Face Hub has become the central Hub for people to collaborate on open machine learning. Making your datasets available via the Hugging Face Hub ensures it is visible to a wide audience of machine learning researchers. The Hub makes it possible to expose links between datasets, models and demos which makes it easier to see how people are using your datasets for training models and creating demos.
### Tools for exploring and working with datasets
There are a growing number of tools being created which make it easier to understand datasets hosted on the Hugging Face Hub.
### Tools for loading datasets hosted on the Hugging Face Hub
Datasets shared on the Hugging Face Hub can be loaded via a variety of tools. The [`datasets`](https://huggingface.co/docs/datasets/) library is a Python library which can directly load datasets from the huggingface hub via a `load_dataset` command. The `datasets` library is optimized for working with large datasets (including datasets which won't fit into memory) and supporting machine learning workflows.
Alongside this many of the datasets on the Hub can also be loaded directly into [`Pandas`](https://pandas.pydata.org/), [`Polars`](https://www.pola.rs/), and [`DuckDB`](https://duckdb.org/). This [page](https://huggingface.co/docs/datasets-server/parquet_process) provides a more detailed overview of the different ways you can load datasets from the Hub.
#### Datasets Viewer
The datasets viewer allows people to explore and interact with datasets hosted on the Hub directly in the browser by visiting the dataset repository on the Hugging Face Hub. This makes it much easier for others to view and explore your data without first having to download it. The datasets viewer also allows you to search and filter datasets, which can be valuable to potential dataset users, understanding the nature of a dataset more quickly.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/researcher-dataset-sharing/datasets-viewer.png" alt="Screenshot of a dataset viewer on the Hub showing a named entity recognition dataset"><br>
<em>The dataset viewer for the multiconer_v2 Named Entity Recognition dataset.</em>
</p>
### Community tools
Alongside the datasets viewer there are a growing number of community created tools for exploring datasets on the Hub.
#### Spotlight
[`Spotlight`](https://github.com/Renumics/spotlight) is a tool that allows you to interactively explore datasets on the Hub with one line of code.
<p align="center"><a href="https://github.com/Renumics/spotlight"><img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/scalable-data-inspection/speech_commands_vis_s.gif" width="100%"/></a></p>
You can learn more about how you can use this tool in this [blog post](https://huggingface.co/blog/scalable-data-inspection).
#### Lilac
[`Lilac`](https://lilacml.com/) is a tool that aims to help you "curate better data for LLMs" and allows you to explore natural language datasets more easily. The tool allows you to semantically search your dataset (search by meaning), cluster data and gain high-level insights into your dataset.
<div style="text-align: center;">
<iframe
src="https://lilacai-lilac.hf.space"
frameborder="0"
width="850"
height="450"
></iframe>
<em>A Spaces demo of the lilac tool.</em>
</div>
You can explore the `Lilac` tool further in a [demo](https://lilacai-lilac.hf.space/).
This growing number of tools for exploring datasets on the Hub makes it easier for people to explore and understand your datasets and can help promote your datasets to a wider audience.
### Support for large datasets
The Hub can host large datasets; it currently hosts datasets with multiple TBs of data.The datasets library, which users can use to download and process datasets from the Hub, supports streaming, making it possible to work with large datasets without downloading the entire dataset upfront. This can be invaluable for allowing researchers with less computational resources to work with your datasets, or to select small portions of a huge dataset for testing, development or prototyping.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/researcher-dataset-sharing/filesize.png" alt="Screenshot of the file size information for a dataset"><br>
<em>The Hugging Face Hub can host the large datasets often created for machine learning research.</em>
</p>
## API and client library interaction with the Hub
Interacting with the Hugging Face Hub via an [API](https://huggingface.co/docs/hub/api) or the [`huggingface_hub`](https://huggingface.co/docs/huggingface_hub/index) Python library is possible. This includes creating new repositories, uploading data programmatically and creating and modifying metadata for datasets. This can be powerful for research workflows where new data or annotations continue to be created. The client library also makes uploading large datasets much more accessible.
## Community
The Hugging Face Hub is already home to a large community of researchers, developers, artists, and others interested in using and contributing to an ecosystem of open-source machine learning. Making your datasets accessible to this community increases their visibility, opens them up to new types of users and places your datasets within the context of a larger ecosystem of models, datasets and libraries.
The Hub also has features which allow communities to collaborate more easily. This includes a discussion page for each dataset, model and Space hosted on the Hub. This means users of your datasets can quickly ask questions and discuss ideas for working with a dataset.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/researcher-dataset-sharing/discussion.png" alt="Screenshot of a discussion for a dataset on the Hub."><br>
<em>The Hub makes it easy to ask questions and discuss datasets.</em>
</p>
### Other important features for researchers
Some other features of the Hub may be of particular interest to researchers wanting to share their machine learning datasets on the Hub:
- [Organizations](https://huggingface.co/organizations) allow you to collaborate with other people and share models, datasets and demos under a single organization. This can be an excellent way of highlighting the work of a particular research project or institute.
- [Gated repositories](https://huggingface.co/docs/hub/datasets-gated) allow you to add some access restrictions to accessing your dataset.
- Download metrics are available for datasets on the Hub; this can be useful for communicating the impact of your researchers to funders and hiring committees.
- [Digital Object Identifiers (DOI)](https://huggingface.co/docs/hub/doi): it’s possible to register a persistent identifier for your dataset.
### How can I share my dataset on the Hugging Face Hub?
Here are some resources to help you get started with sharing your datasets on the Hugging Face Hub:
- General guidance on [creating](https://huggingface.co/docs/datasets/create_dataset) and [sharing datasets on the Hub](https://huggingface.co/docs/datasets/upload_dataset)
- Guides for particular modalities:
- Creating an [audio dataset](https://huggingface.co/docs/datasets/audio_dataset)
- Creating an [image dataset](https://huggingface.co/docs/datasets/image_dataset)
- Guidance on [structuring your repository](https://huggingface.co/docs/datasets/repository_structure) so a dataset can be automatically loaded from the Hub.
The following pages will be useful if you want to share large datasets:
- [Repository limitations and recommendations](https://huggingface.co/docs/hub/repositories-recommendations) provides general guidance on some of the considerations you'll want to make when sharing large datasets.
- The [Tips and tricks for large uploads](https://huggingface.co/docs/huggingface_hub/guides/upload#tips-and-tricks-for-large-uploads) page provides some guidance on how to upload large datasets to the Hub.
If you want any further help uploading a dataset to the Hub or want to upload a particularly large dataset, please contact datasets@huggingface.co.
| huggingface/blog/blob/main/researcher-dataset-sharing.md |
Gradio Demo: tabbed_interface_lite
```
!pip install -q gradio
```
```
import gradio as gr
hello_world = gr.Interface(lambda name: "Hello " + name, "text", "text")
bye_world = gr.Interface(lambda name: "Bye " + name, "text", "text")
demo = gr.TabbedInterface([hello_world, bye_world], ["Hello World", "Bye World"])
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/tabbed_interface_lite/run.ipynb |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Installation
🤗 Diffusers is tested on Python 3.8+, PyTorch 1.7.0+, and Flax. Follow the installation instructions below for the deep learning library you are using:
- [PyTorch](https://pytorch.org/get-started/locally/) installation instructions
- [Flax](https://flax.readthedocs.io/en/latest/) installation instructions
## Install with pip
You should install 🤗 Diffusers in a [virtual environment](https://docs.python.org/3/library/venv.html).
If you're unfamiliar with Python virtual environments, take a look at this [guide](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
A virtual environment makes it easier to manage different projects and avoid compatibility issues between dependencies.
Start by creating a virtual environment in your project directory:
```bash
python -m venv .env
```
Activate the virtual environment:
```bash
source .env/bin/activate
```
You should also install 🤗 Transformers because 🤗 Diffusers relies on its models:
<frameworkcontent>
<pt>
```bash
pip install diffusers["torch"] transformers
```
</pt>
<jax>
```bash
pip install diffusers["flax"] transformers
```
</jax>
</frameworkcontent>
## Install with conda
After activating your virtual environment, with `conda` (maintained by the community):
```bash
conda install -c conda-forge diffusers
```
## Install from source
Before installing 🤗 Diffusers from source, make sure you have PyTorch and 🤗 Accelerate installed.
To install 🤗 Accelerate:
```bash
pip install accelerate
```
Then install 🤗 Diffusers from source:
```bash
pip install git+https://github.com/huggingface/diffusers
```
This command installs the bleeding edge `main` version rather than the latest `stable` version.
The `main` version is useful for staying up-to-date with the latest developments.
For instance, if a bug has been fixed since the last official release but a new release hasn't been rolled out yet.
However, this means the `main` version may not always be stable.
We strive to keep the `main` version operational, and most issues are usually resolved within a few hours or a day.
If you run into a problem, please open an [Issue](https://github.com/huggingface/diffusers/issues/new/choose) so we can fix it even sooner!
## Editable install
You will need an editable install if you'd like to:
* Use the `main` version of the source code.
* Contribute to 🤗 Diffusers and need to test changes in the code.
Clone the repository and install 🤗 Diffusers with the following commands:
```bash
git clone https://github.com/huggingface/diffusers.git
cd diffusers
```
<frameworkcontent>
<pt>
```bash
pip install -e ".[torch]"
```
</pt>
<jax>
```bash
pip install -e ".[flax]"
```
</jax>
</frameworkcontent>
These commands will link the folder you cloned the repository to and your Python library paths.
Python will now look inside the folder you cloned to in addition to the normal library paths.
For example, if your Python packages are typically installed in `~/anaconda3/envs/main/lib/python3.8/site-packages/`, Python will also search the `~/diffusers/` folder you cloned to.
<Tip warning={true}>
You must keep the `diffusers` folder if you want to keep using the library.
</Tip>
Now you can easily update your clone to the latest version of 🤗 Diffusers with the following command:
```bash
cd ~/diffusers/
git pull
```
Your Python environment will find the `main` version of 🤗 Diffusers on the next run.
## Cache
Model weights and files are downloaded from the Hub to a cache which is usually your home directory. You can change the cache location by specifying the `HF_HOME` or `HUGGINFACE_HUB_CACHE` environment variables or configuring the `cache_dir` parameter in methods like [`~DiffusionPipeline.from_pretrained`].
Cached files allow you to run 🤗 Diffusers offline. To prevent 🤗 Diffusers from connecting to the internet, set the `HF_HUB_OFFLINE` environment variable to `True` and 🤗 Diffusers will only load previously downloaded files in the cache.
```shell
export HF_HUB_OFFLINE=True
```
For more details about managing and cleaning the cache, take a look at the [caching](https://huggingface.co/docs/huggingface_hub/guides/manage-cache) guide.
## Telemetry logging
Our library gathers telemetry information during [`~DiffusionPipeline.from_pretrained`] requests.
The data gathered includes the version of 🤗 Diffusers and PyTorch/Flax, the requested model or pipeline class,
and the path to a pretrained checkpoint if it is hosted on the Hugging Face Hub.
This usage data helps us debug issues and prioritize new features.
Telemetry is only sent when loading models and pipelines from the Hub,
and it is not collected if you're loading local files.
We understand that not everyone wants to share additional information,and we respect your privacy.
You can disable telemetry collection by setting the `DISABLE_TELEMETRY` environment variable from your terminal:
On Linux/MacOS:
```bash
export DISABLE_TELEMETRY=YES
```
On Windows:
```bash
set DISABLE_TELEMETRY=YES
```
| huggingface/diffusers/blob/main/docs/source/en/installation.md |
Gradio Demo: theme_extended_step_1
```
!pip install -q gradio
```
```
import gradio as gr
import time
with gr.Blocks(theme=gr.themes.Default(primary_hue="red", secondary_hue="pink")) as demo:
textbox = gr.Textbox(label="Name")
slider = gr.Slider(label="Count", minimum=0, maximum=100, step=1)
with gr.Row():
button = gr.Button("Submit", variant="primary")
clear = gr.Button("Clear")
output = gr.Textbox(label="Output")
def repeat(name, count):
time.sleep(3)
return name * count
button.click(repeat, [textbox, slider], output)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/theme_extended_step_1/run.ipynb |
--
title: "Assisted Generation: a new direction toward low-latency text generation"
thumbnail: /blog/assets/assisted-generation/thumbnail.png
authors:
- user: joaogante
---
# Assisted Generation: a new direction toward low-latency text generation
Large language models are all the rage these days, with many companies investing significant resources to scale them up and unlock new capabilities. However, as humans with ever-decreasing attention spans, we also dislike their slow response times. Latency is critical for a good user experience, and smaller models are often used despite their lower quality (e.g. in [code completion](https://ai.googleblog.com/2022/07/ml-enhanced-code-completion-improves.html)).
Why is text generation so slow? What’s preventing you from deploying low-latency large language models without going bankrupt? In this blog post, we will revisit the bottlenecks for autoregressive text generation and introduce a new decoding method to tackle the latency problem. You’ll see that by using our new method, assisted generation, you can reduce latency up to 10x in commodity hardware!
## Understanding text generation latency
The core of modern text generation is straightforward to understand. Let’s look at the central piece, the ML model. Its input contains a text sequence, which includes the text generated so far, and potentially other model-specific components (for instance, Whisper also has an audio input). The model takes the input and runs a forward pass: the input is fed to the model and passed sequentially along its layers until the unnormalized log probabilities for the next token are predicted (also known as logits). A token may consist of entire words, sub-words, or even individual characters, depending on the model. The [illustrated GPT-2](https://jalammar.github.io/illustrated-gpt2/) is a great reference if you’d like to dive deeper into this part of text generation.
<!-- [GIF 1 -- FWD PASS] -->
<figure class="image table text-center m-0 w-full">
<video
style="max-width: 90%; margin: auto;"
autoplay loop muted playsinline
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_1_1080p.mov"
></video>
</figure>
A model forward pass gets you the logits for the next token, which you can freely manipulate (e.g. set the probability of undesirable words or sequences to 0). The following step in text generation is to select the next token from these logits. Common strategies include picking the most likely token, known as greedy decoding, or sampling from their distribution, also called multinomial sampling. Chaining model forward passes with next token selection iteratively gets you text generation. This explanation is the tip of the iceberg when it comes to decoding methods; please refer to [our blog post on text generation](https://huggingface.co/blog/how-to-generate) for an in-depth exploration.
<!-- [GIF 2 -- TEXT GENERATION] -->
<figure class="image table text-center m-0 w-full">
<video
style="max-width: 90%; margin: auto;"
autoplay loop muted playsinline
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_2_1080p.mov"
></video>
</figure>
From the description above, the latency bottleneck in text generation is clear: running a model forward pass for large models is slow, and you may need to do hundreds of them in a sequence. But let’s dive deeper: why are forward passes slow? Forward passes are typically dominated by matrix multiplications and, after a quick visit to the [corresponding wikipedia section](https://en.wikipedia.org/wiki/Matrix_multiplication_algorithm#Communication-avoiding_and_distributed_algorithms), you can tell that memory bandwidth is the limitation in this operation (e.g. from the GPU RAM to the GPU compute cores). In other words, *the bottleneck in the forward pass comes from loading the model layer weights into the computation cores of your device, not from performing the computations themselves*.
At the moment, you have three main avenues you can explore to get the most out of text generation, all tackling the performance of the model forward pass. First, you have the hardware-specific model optimizations. For instance, your device may be compatible with [Flash Attention](https://github.com/HazyResearch/flash-attention), which speeds up the attention layer through a reorder of the operations, or [INT8 quantization](https://huggingface.co/blog/hf-bitsandbytes-integration), which reduces the size of the model weights.
Second, when you know you’ll get concurrent text generation requests, you can batch the inputs and massively increase the throughput with a small latency penalty. The model layer weights loaded into the device are now used on several input rows in parallel, which means that you’ll get more tokens out for approximately the same memory bandwidth burden. The catch with batching is that you need additional device memory (or to offload the memory somewhere) – at the end of this spectrum, you can see projects like [FlexGen](https://github.com/FMInference/FlexGen) which optimize throughput at the expense of latency.
```python
# Example showcasing the impact of batched generation. Measurement device: RTX3090
from transformers import AutoModelForCausalLM, AutoTokenizer
import time
tokenizer = AutoTokenizer.from_pretrained("distilgpt2")
model = AutoModelForCausalLM.from_pretrained("distilgpt2").to("cuda")
inputs = tokenizer(["Hello world"], return_tensors="pt").to("cuda")
def print_tokens_per_second(batch_size):
new_tokens = 100
cumulative_time = 0
# warmup
model.generate(
**inputs, do_sample=True, max_new_tokens=new_tokens, num_return_sequences=batch_size
)
for _ in range(10):
start = time.time()
model.generate(
**inputs, do_sample=True, max_new_tokens=new_tokens, num_return_sequences=batch_size
)
cumulative_time += time.time() - start
print(f"Tokens per second: {new_tokens * batch_size * 10 / cumulative_time:.1f}")
print_tokens_per_second(1) # Tokens per second: 418.3
print_tokens_per_second(64) # Tokens per second: 16266.2 (~39x more tokens per second)
```
Finally, if you have multiple devices available to you, you can distribute the workload using [Tensor Parallelism](https://huggingface.co/docs/transformers/main/en/perf_train_gpu_many#tensor-parallelism) and obtain lower latency. With Tensor Parallelism, you split the memory bandwidth burden across multiple devices, but you now have to consider inter-device communication bottlenecks in addition to the monetary cost of running multiple devices. The benefits depend largely on the model size: models that easily fit on a single consumer device see very limited benefits. Taking the results from this [DeepSpeed blog post](https://www.microsoft.com/en-us/research/blog/deepspeed-accelerating-large-scale-model-inference-and-training-via-system-optimizations-and-compression/), you see that you can spread a 17B parameter model across 4 GPUs to reduce the latency by 1.5x (Figure 7).
These three types of improvements can be used in tandem, resulting in [high throughput solutions](https://github.com/huggingface/text-generation-inference). However, after applying hardware-specific optimizations, there are limited options to reduce latency – and the existing options are expensive. Let’s fix that!
## Language decoder forward pass, revisited
You’ve read above that each model forward pass yields the logits for the next token, but that’s actually an incomplete description. During text generation, the typical iteration consists in the model receiving as input the latest generated token, plus cached internal computations for all other previous inputs, returning the next token logits. Caching is used to avoid redundant computations, resulting in faster forward passes, but it’s not mandatory (and can be used partially). When caching is disabled, the input contains the entire sequence of tokens generated so far and the output contains the logits corresponding to the next token for *all positions* in the sequence! The logits at position N correspond to the distribution for the next token if the input consisted of the first N tokens, ignoring all subsequent tokens in the sequence. In the particular case of greedy decoding, if you pass the generated sequence as input and apply the argmax operator to the resulting logits, you will obtain the generated sequence back.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
tok = AutoTokenizer.from_pretrained("distilgpt2")
model = AutoModelForCausalLM.from_pretrained("distilgpt2")
inputs = tok(["The"], return_tensors="pt")
generated = model.generate(**inputs, do_sample=False, max_new_tokens=10)
forward_confirmation = model(generated).logits.argmax(-1)
# We exclude the opposing tips from each sequence: the forward pass returns
# the logits for the next token, so it is shifted by one position.
print(generated[0, 1:].tolist() == forward_confirmation[0, :-1].tolist()) # True
```
This means that you can use a model forward pass for a different purpose: in addition to feeding some tokens to predict the next one, you can also pass a sequence to the model and double-check whether the model would generate that same sequence (or part of it).
<!-- [GIF 3 -- FWD CONFIRMATION] -->
<figure class="image table text-center m-0 w-full">
<video
style="max-width: 90%; margin: auto;"
autoplay loop muted playsinline
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_3_1080p.mov"
></video>
</figure>
Let’s consider for a second that you have access to a magical latency-free oracle model that generates the same sequence as your model, for any given input. For argument’s sake, it can’t be used directly, it’s limited to being an assistant to your generation procedure. Using the property described above, you could use this assistant model to get candidate output tokens followed by a forward pass with your model to confirm that they are indeed correct. In this utopian scenario, the latency of text generation would be reduced from `O(n)` to `O(1)`, with `n` being the number of generated tokens. For long generations, we're talking about several orders of magnitude.
Walking a step towards reality, let's assume the assistant model has lost its oracle properties. Now it’s a latency-free model that gets some of the candidate tokens wrong, according to your model. Due to the autoregressive nature of the task, as soon as the assistant gets a token wrong, all subsequent candidates must be invalidated. However, that does not prevent you from querying the assistant again, after correcting the wrong token with your model, and repeating this process iteratively. Even if the assistant fails a few tokens, text generation would have an order of magnitude less latency than in its original form.
Obviously, there are no latency-free assistant models. Nevertheless, it is relatively easy to find a model that approximates some other model’s text generation outputs – smaller versions of the same architecture trained similarly often fit this property. Moreover, when the difference in model sizes becomes significant, the cost of using the smaller model as an assistant becomes an afterthought after factoring in the benefits of skipping a few forward passes! You now understand the core of _assisted generation_.
## Greedy decoding with assisted generation
Assisted generation is a balancing act. You want the assistant to quickly generate a candidate sequence while being as accurate as possible. If the assistant has poor quality, your get the cost of using the assistant model with little to no benefits. On the other hand, optimizing the quality of the candidate sequences may imply the use of slow assistants, resulting in a net slowdown. While we can't automate the selection of the assistant model for you, we’ve included an additional requirement and a heuristic to ensure the time spent with the assistant stays in check.
First, the requirement – the assistant must have the exact same tokenizer as your model. If this requirement was not in place, expensive token decoding and re-encoding steps would have to be added. Furthermore, these additional steps would have to happen on the CPU, which in turn may need slow inter-device data transfers. Fast usage of the assistant is critical for the benefits of assisted generation to show up.
Finally, the heuristic. By this point, you have probably noticed the similarities between the movie Inception and assisted generation – you are, after all, running text generation inside text generation. There will be one assistant model forward pass per candidate token, and we know that forward passes are expensive. While you can’t know in advance the number of tokens that the assistant model will get right, you can keep track of this information and use it to limit the number of candidate tokens requested to the assistant – some sections of the output are easier to anticipate than others.
Wrapping all up, here’s our original implementation of the assisted generation loop ([code](https://github.com/huggingface/transformers/blob/849367ccf741d8c58aa88ccfe1d52d8636eaf2b7/src/transformers/generation/utils.py#L4064)):
1. Use greedy decoding to generate a certain number of candidate tokens with the assistant model, producing `candidates`. The number of produced candidate tokens is initialized to `5` the first time assisted generation is called.
2. Using our model, do a forward pass with `candidates`, obtaining `logits`.
3. Use the token selection method (`.argmax()` for greedy search or `.multinomial()` for sampling) to get the `next_tokens` from `logits`.
4. Compare `next_tokens` to `candidates` and get the number of matching tokens. Remember that this comparison has to be done with left-to-right causality: after the first mismatch, all candidates are invalidated.
5. Use the number of matches to slice things up and discard variables related to unconfirmed candidate tokens. In essence, in `next_tokens`, keep the matching tokens plus the first divergent token (which our model generates from a valid candidate subsequence).
6. Adjust the number of candidate tokens to be produced in the next iteration — our original heuristic increases it by `2` if ALL tokens match and decreases it by `1` otherwise.
<!-- [GIF 4 -- ASSISTED GENERATION] -->
<figure class="image table text-center m-0 w-full">
<video
style="max-width: 90%; margin: auto;"
autoplay loop muted playsinline
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_4_1080p.mov"
></video>
</figure>
We’ve designed the API in 🤗 Transformers such that this process is hassle-free for you. All you need to do is to pass the assistant model under the new `assistant_model` keyword argument and reap the latency gains! At the time of the release of this blog post, assisted generation is limited to a batch size of `1`.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
prompt = "Alice and Bob"
checkpoint = "EleutherAI/pythia-1.4b-deduped"
assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer(prompt, return_tensors="pt").to(device)
model = AutoModelForCausalLM.from_pretrained(checkpoint).to(device)
assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint).to(device)
outputs = model.generate(**inputs, assistant_model=assistant_model)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
# ['Alice and Bob are sitting in a bar. Alice is drinking a beer and Bob is drinking a']
```
Is the additional internal complexity worth it? Let’s have a look at the latency numbers for the greedy decoding case (results for sampling are in the next section), considering a batch size of `1`. These results were pulled directly out of 🤗 Transformers without any additional optimizations, so you should be able to reproduce them in your setup.
<!-- [SPACE WITH GREEDY DECODING PERFORMANCE NUMBERS] -->
<script
type="module"
src="https://gradio.s3-us-west-2.amazonaws.com/3.28.2/gradio.js"
></script>
<gradio-app theme_mode="light" space="joaogante/assisted_generation_benchmarks"></gradio-app>
Glancing at the collected numbers, we see that assisted generation can deliver significant latency reductions in diverse settings, but it is not a silver bullet – you should benchmark it before applying it to your use case. We can conclude that assisted generation:
1. 🤏 Requires access to an assistant model that is at least an order of magnitude smaller than your model (the bigger the difference, the better);
2. 🚀 Gets up to 3x speedups in the presence of INT8 and up to 2x otherwise, when the model fits in the GPU memory;
3. 🤯 If you’re playing with models that do not fit in your GPU and are relying on memory offloading, you can see up to 10x speedups;
4. 📄 Shines in input-grounded tasks, like automatic speech recognition or summarization.
## Sample with assisted generation
Greedy decoding is suited for input-grounded tasks (automatic speech recognition, translation, summarization, ...) or factual knowledge-seeking. Open-ended tasks requiring large levels of creativity, such as most uses of a language model as a chatbot, should use sampling instead. Assisted generation is naturally designed for greedy decoding, but that doesn’t mean that you can’t use assisted generation with multinomial sampling!
Drawing samples from a probability distribution for the next token will cause our greedy assistant to fail more often, reducing its latency benefits. However, we can control how sharp the probability distribution for the next tokens is, using the temperature coefficient that’s present in most sampling-based applications. At one extreme, with temperatures close to 0, sampling will approximate greedy decoding, favoring the most likely token. At the other extreme, with the temperature set to values much larger than 1, sampling will be chaotic, drawing from a uniform distribution. Low temperatures are, therefore, more favorable to your assistant model, retaining most of the latency benefits from assisted generation, as we can see below.
<!-- [TEMPERATURE RESULTS, SHOW THAT LATENCY INCREASES STEADILY WITH TEMP] -->
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/temperature.png"/>
</div>
Why don't you see it for yourself, so get a feeling of assisted generation?
<!-- [DEMO] -->
<gradio-app theme_mode="light" space="joaogante/assisted_generation_demo"></gradio-app>
## Future directions
Assisted generation shows that modern text generation strategies are ripe for optimization. Understanding that it is currently a memory-bound problem, not a compute-bound problem, allows us to apply simple heuristics to get the most out of the available memory bandwidth, alleviating the bottleneck. We believe that further refinement of the use of assistant models will get us even bigger latency reductions - for instance, we may be able to skip a few more forward passes if we request the assistant to generate several candidate continuations. Naturally, releasing high-quality small models to be used as assistants will be critical to realizing and amplifying the benefits.
Initially released under our 🤗 Transformers library, to be used with the `.generate()` function, we expect to offer it throughout the Hugging Face universe. Its implementation is also completely open-source so, if you’re working on text generation and not using our tools, feel free to use it as a reference.
Finally, assisted generation resurfaces a crucial question in text generation. The field has been evolving with the constraint where all new tokens are the result of a fixed amount of compute, for a given model. One token per homogeneous forward pass, in pure autoregressive fashion. This blog post reinforces the idea that it shouldn’t be the case: large subsections of the generated output can also be equally generated by models that are a fraction of the size. For that, we’ll need new model architectures and decoding methods – we’re excited to see what the future holds!
## Related Work
After the original release of this blog post, it came to my attention that other works have explored the same core principle (use a forward pass to validate longer continuations). In particular, have a look at the following works:
- [Blockwise Parallel Decoding](https://proceedings.neurips.cc/paper/2018/file/c4127b9194fe8562c64dc0f5bf2c93bc-Paper.pdf), by Google Brain
- [Speculative Sampling](https://arxiv.org/abs/2302.01318), by DeepMind
## Citation
```bibtex
@misc {gante2023assisted,
author = { {Joao Gante} },
title = { Assisted Generation: a new direction toward low-latency text generation },
year = 2023,
url = { https://huggingface.co/blog/assisted-generation },
doi = { 10.57967/hf/0638 },
publisher = { Hugging Face Blog }
}
```
## Acknowledgements
I'd like to thank Sylvain Gugger, Nicolas Patry, and Lewis Tunstall for sharing many valuable suggestions to improve this blog post. Finally, kudos to Chunte Lee for designing the gorgeous cover you can see in our web page.
| huggingface/blog/blob/main/assisted-generation.md |
使用 GAN 创建您自己的朋友
spaces/NimaBoscarino/cryptopunks, https://huggingface.co/spaces/nateraw/cryptopunks-generator
Tags: GAN, IMAGE, HUB
由 <a href="https://huggingface.co/NimaBoscarino">Nima Boscarino</a> 和 <a href="https://huggingface.co/nateraw">Nate Raw</a> 贡献
## 简介
最近,加密货币、NFTs 和 Web3 运动似乎都非常流行!数字资产以惊人的金额在市场上上市,几乎每个名人都推出了自己的 NFT 收藏。虽然您的加密资产可能是应税的,例如在加拿大(https://www.canada.ca/en/revenue-agency/programs/about-canada-revenue-agency-cra/compliance/digital-currency/cryptocurrency-guide.html),但今天我们将探索一些有趣且无税的方法来生成自己的一系列过程生成的 CryptoPunks(https://www.larvalabs.com/cryptopunks)。
生成对抗网络(GANs),通常称为 GANs,是一类特定的深度学习模型,旨在通过学习输入数据集来创建(生成!)与原始训练集中的元素具有令人信服的相似性的新材料。众所周知,网站[thispersondoesnotexist.com](https://thispersondoesnotexist.com/)通过名为 StyleGAN2 的模型生成了栩栩如生但是合成的人物图像而迅速走红。GANs 在机器学习领域获得了人们的关注,现在被用于生成各种图像、文本甚至音乐!
今天我们将简要介绍 GAN 的高级直觉,然后我们将围绕一个预训练的 GAN 构建一个小型演示,看看这一切都是怎么回事。下面是我们将要组合的东西的一瞥:
<iframe src="https://nimaboscarino-cryptopunks.hf.space" frameBorder="0" height="855" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
### 先决条件
确保已经[安装](/getting_started)了 `gradio` Python 包。要使用预训练模型,请还安装 `torch` 和 `torchvision`。
## GANs:简介
最初在[Goodfellow 等人 2014 年的论文](https://arxiv.org/abs/1406.2661)中提出,GANs 由互相竞争的神经网络组成,旨在相互智能地欺骗对方。一种网络,称为“生成器”,负责生成图像。另一个网络,称为“鉴别器”,从生成器一次接收一张图像,以及来自训练数据集的 **real 真实**图像。然后,鉴别器必须猜测:哪张图像是假的?
生成器不断训练以创建对鉴别器更难以识别的图像,而鉴别器每次正确检测到伪造图像时,都会为生成器设置更高的门槛。随着网络之间的这种竞争(**adversarial 对抗性!**),生成的图像改善到了对人眼来说无法区分的地步!
如果您想更深入地了解 GANs,可以参考[Analytics Vidhya 上的这篇优秀文章](https://www.analyticsvidhya.com/blog/2021/06/a-detailed-explanation-of-gan-with-implementation-using-tensorflow-and-keras/)或这个[PyTorch 教程](https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html)。不过,现在我们将深入看一下演示!
## 步骤 1 - 创建生成器模型
要使用 GAN 生成新图像,只需要生成器模型。生成器可以使用许多不同的架构,但是对于这个演示,我们将使用一个预训练的 GAN 生成器模型,其架构如下:
```python
from torch import nn
class Generator(nn.Module):
# 有关nc,nz和ngf的解释,请参见下面的链接
# https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html#inputs
def __init__(self, nc=4, nz=100, ngf=64):
super(Generator, self).__init__()
self.network = nn.Sequential(
nn.ConvTranspose2d(nz, ngf * 4, 3, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
nn.ConvTranspose2d(ngf * 4, ngf * 2, 3, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 0, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
nn.ConvTranspose2d(ngf, nc, 4, 2, 1, bias=False),
nn.Tanh(),
)
def forward(self, input):
output = self.network(input)
return output
```
我们正在使用来自[此 repo 的 @teddykoker](https://github.com/teddykoker/cryptopunks-gan/blob/main/train.py#L90)的生成器模型,您还可以在那里看到原始的鉴别器模型结构。
在实例化模型之后,我们将加载来自 Hugging Face Hub 的权重,存储在[nateraw/cryptopunks-gan](https://huggingface.co/nateraw/cryptopunks-gan)中:
```python
from huggingface_hub import hf_hub_download
import torch
model = Generator()
weights_path = hf_hub_download('nateraw/cryptopunks-gan', 'generator.pth')
model.load_state_dict(torch.load(weights_path, map_location=torch.device('cpu'))) # 如果有可用的GPU,请使用'cuda'
```
## 步骤 2 - 定义“predict”函数
`predict` 函数是使 Gradio 工作的关键!我们通过 Gradio 界面选择的任何输入都将通过我们的 `predict` 函数传递,该函数应对输入进行操作并生成我们可以通过 Gradio 输出组件显示的输出。对于 GANs,常见的做法是将随机噪声传入我们的模型作为输入,因此我们将生成一张随机数的张量并将其传递给模型。然后,我们可以使用 `torchvision` 的 `save_image` 函数将模型的输出保存为 `png` 文件,并返回文件名:
```python
from torchvision.utils import save_image
def predict(seed):
num_punks = 4
torch.manual_seed(seed)
z = torch.randn(num_punks, 100, 1, 1)
punks = model(z)
save_image(punks, "punks.png", normalize=True)
return 'punks.png'
```
我们给 `predict` 函数一个 `seed` 参数,这样我们就可以使用一个种子固定随机张量生成。然后,我们可以通过传入相同的种子再次查看生成的 punks。
_注意!_ 我们的模型需要一个 100x1x1 的输入张量进行单次推理,或者 (BatchSize)x100x1x1 来生成一批图像。在这个演示中,我们每次生成 4 个 punk。
## 第三步—创建一个 Gradio 接口
此时,您甚至可以运行您拥有的代码 `predict(<SOME_NUMBER>)`,并在您的文件系统中找到新生成的 punk 在 `./punks.png`。然而,为了制作一个真正的交互演示,我们将用 Gradio 构建一个简单的界面。我们的目标是:
- 设置一个滑块输入,以便用户可以选择“seed”值
- 使用图像组件作为输出,展示生成的 punk
- 使用我们的 `predict()` 函数来接受种子并生成图像
通过使用 `gr.Interface()`,我们可以使用一个函数调用来定义所有这些 :
```python
import gradio as gr
gr.Interface(
predict,
inputs=[
gr.Slider(0, 1000, label='Seed', default=42),
],
outputs="image",
).launch()
```
启动界面后,您应该会看到像这样的东西 :
<iframe src="https://nimaboscarino-cryptopunks-1.hf.space" frameBorder="0" height="365" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
## 第四步—更多 punk!
每次生成 4 个 punk 是一个好的开始,但是也许我们想控制每次想生成多少。通过简单地向我们传递给 `gr.Interface` 的 `inputs` 列表添加另一项即可向我们的 Gradio 界面添加更多输入 :
```python
gr.Interface(
predict,
inputs=[
gr.Slider(0, 1000, label='Seed', default=42),
gr.Slider(4, 64, label='Number of Punks', step=1, default=10), # 添加另一个滑块!
],
outputs="image",
).launch()
```
新的输入将传递给我们的 `predict()` 函数,所以我们必须对该函数进行一些更改,以接受一个新的参数 :
```python
def predict(seed, num_punks):
torch.manual_seed(seed)
z = torch.randn(num_punks, 100, 1, 1)
punks = model(z)
save_image(punks, "punks.png", normalize=True)
return 'punks.png'
```
当您重新启动界面时,您应该会看到一个第二个滑块,它可以让您控制 punk 的数量!
## 第五步-完善它
您的 Gradio 应用已经准备好运行了,但是您可以添加一些额外的功能来使其真正准备好发光 ✨
我们可以添加一些用户可以轻松尝试的示例,通过将其添加到 `gr.Interface` 中实现 :
```python
gr.Interface(
# ...
# 将所有内容保持不变,然后添加
examples=[[123, 15], [42, 29], [456, 8], [1337, 35]],
).launch(cache_examples=True) # cache_examples是可选的
```
`examples` 参数接受一个列表的列表,其中子列表中的每个项目的顺序与我们列出的 `inputs` 的顺序相同。所以在我们的例子中,`[seed, num_punks]`。试一试吧!
您还可以尝试在 `gr.Interface` 中添加 `title`、`description` 和 `article`。每个参数都接受一个字符串,所以试试看发生了什么👀 `article` 也接受 HTML,如[前面的指南](./key_features/#descriptive-content)所述!
当您完成所有操作后,您可能会得到类似于这样的结果 :
<iframe src="https://nimaboscarino-cryptopunks.hf.space" frameBorder="0" height="855" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
供参考,这是我们的完整代码 :
```python
import torch
from torch import nn
from huggingface_hub import hf_hub_download
from torchvision.utils import save_image
import gradio as gr
class Generator(nn.Module):
# 关于nc、nz和ngf的解释,请参见下面的链接
# https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html#inputs
def __init__(self, nc=4, nz=100, ngf=64):
super(Generator, self).__init__()
self.network = nn.Sequential(
nn.ConvTranspose2d(nz, ngf * 4, 3, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
nn.ConvTranspose2d(ngf * 4, ngf * 2, 3, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 0, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
nn.ConvTranspose2d(ngf, nc, 4, 2, 1, bias=False),
nn.Tanh(),
)
def forward(self, input):
output = self.network(input)
return output
model = Generator()
weights_path = hf_hub_download('nateraw/cryptopunks-gan', 'generator.pth')
model.load_state_dict(torch.load(weights_path, map_location=torch.device('cpu'))) # 如果您有可用的GPU,使用'cuda'
def predict(seed, num_punks):
torch.manual_seed(seed)
z = torch.randn(num_punks, 100, 1, 1)
punks = model(z)
save_image(punks, "punks.png", normalize=True)
return 'punks.png'
gr.Interface(
predict,
inputs=[
gr.Slider(0, 1000, label='Seed', default=42),
gr.Slider(4, 64, label='Number of Punks', step=1, default=10),
],
outputs="image",
examples=[[123, 15], [42, 29], [456, 8], [1337, 35]],
).launch(cache_examples=True)
```
---
恭喜!你已经成功构建了自己的基于 GAN 的 CryptoPunks 生成器,配备了一个时尚的 Gradio 界面,使任何人都能轻松使用。现在你可以在 Hub 上[寻找更多的 GANs](https://huggingface.co/models?other=gan)(或者自己训练)并继续制作更多令人赞叹的演示项目。🤗
| gradio-app/gradio/blob/main/guides/cn/07_other-tutorials/create-your-own-friends-with-a-gan.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# ViTDet
## Overview
The ViTDet model was proposed in [Exploring Plain Vision Transformer Backbones for Object Detection](https://arxiv.org/abs/2203.16527) by Yanghao Li, Hanzi Mao, Ross Girshick, Kaiming He.
VitDet leverages the plain [Vision Transformer](vit) for the task of object detection.
The abstract from the paper is the following:
*We explore the plain, non-hierarchical Vision Transformer (ViT) as a backbone network for object detection. This design enables the original ViT architecture to be fine-tuned for object detection without needing to redesign a hierarchical backbone for pre-training. With minimal adaptations for fine-tuning, our plain-backbone detector can achieve competitive results. Surprisingly, we observe: (i) it is sufficient to build a simple feature pyramid from a single-scale feature map (without the common FPN design) and (ii) it is sufficient to use window attention (without shifting) aided with very few cross-window propagation blocks. With plain ViT backbones pre-trained as Masked Autoencoders (MAE), our detector, named ViTDet, can compete with the previous leading methods that were all based on hierarchical backbones, reaching up to 61.3 AP_box on the COCO dataset using only ImageNet-1K pre-training. We hope our study will draw attention to research on plain-backbone detectors.*
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/facebookresearch/detectron2/tree/main/projects/ViTDet).
Tips:
- At the moment, only the backbone is available.
## VitDetConfig
[[autodoc]] VitDetConfig
## VitDetModel
[[autodoc]] VitDetModel
- forward | huggingface/transformers/blob/main/docs/source/en/model_doc/vitdet.md |
AdvProp (EfficientNet)
**AdvProp** is an adversarial training scheme which treats adversarial examples as additional examples, to prevent overfitting. Key to the method is the usage of a separate auxiliary batch norm for adversarial examples, as they have different underlying distributions to normal examples.
The weights from this model were ported from [Tensorflow/TPU](https://github.com/tensorflow/tpu).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('tf_efficientnet_b0_ap', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `tf_efficientnet_b0_ap`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('tf_efficientnet_b0_ap', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{xie2020adversarial,
title={Adversarial Examples Improve Image Recognition},
author={Cihang Xie and Mingxing Tan and Boqing Gong and Jiang Wang and Alan Yuille and Quoc V. Le},
year={2020},
eprint={1911.09665},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: AdvProp
Paper:
Title: Adversarial Examples Improve Image Recognition
URL: https://paperswithcode.com/paper/adversarial-examples-improve-image
Models:
- Name: tf_efficientnet_b0_ap
In Collection: AdvProp
Metadata:
FLOPs: 488688572
Parameters: 5290000
File Size: 21385973
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AdvProp
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b0_ap
LR: 0.256
Epochs: 350
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 2048
Image Size: '224'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1334
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b0_ap-f262efe1.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.1%
Top 5 Accuracy: 93.26%
- Name: tf_efficientnet_b1_ap
In Collection: AdvProp
Metadata:
FLOPs: 883633200
Parameters: 7790000
File Size: 31515350
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AdvProp
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b1_ap
LR: 0.256
Epochs: 350
Crop Pct: '0.882'
Momentum: 0.9
Batch Size: 2048
Image Size: '240'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1344
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b1_ap-44ef0a3d.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.28%
Top 5 Accuracy: 94.3%
- Name: tf_efficientnet_b2_ap
In Collection: AdvProp
Metadata:
FLOPs: 1234321170
Parameters: 9110000
File Size: 36800745
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AdvProp
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b2_ap
LR: 0.256
Epochs: 350
Crop Pct: '0.89'
Momentum: 0.9
Batch Size: 2048
Image Size: '260'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1354
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b2_ap-2f8e7636.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.3%
Top 5 Accuracy: 95.03%
- Name: tf_efficientnet_b3_ap
In Collection: AdvProp
Metadata:
FLOPs: 2275247568
Parameters: 12230000
File Size: 49384538
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AdvProp
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b3_ap
LR: 0.256
Epochs: 350
Crop Pct: '0.904'
Momentum: 0.9
Batch Size: 2048
Image Size: '300'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1364
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b3_ap-aad25bdd.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.82%
Top 5 Accuracy: 95.62%
- Name: tf_efficientnet_b4_ap
In Collection: AdvProp
Metadata:
FLOPs: 5749638672
Parameters: 19340000
File Size: 77993585
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AdvProp
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b4_ap
LR: 0.256
Epochs: 350
Crop Pct: '0.922'
Momentum: 0.9
Batch Size: 2048
Image Size: '380'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1374
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b4_ap-dedb23e6.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 83.26%
Top 5 Accuracy: 96.39%
- Name: tf_efficientnet_b5_ap
In Collection: AdvProp
Metadata:
FLOPs: 13176501888
Parameters: 30390000
File Size: 122403150
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AdvProp
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b5_ap
LR: 0.256
Epochs: 350
Crop Pct: '0.934'
Momentum: 0.9
Batch Size: 2048
Image Size: '456'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1384
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b5_ap-9e82fae8.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 84.25%
Top 5 Accuracy: 96.97%
- Name: tf_efficientnet_b6_ap
In Collection: AdvProp
Metadata:
FLOPs: 24180518488
Parameters: 43040000
File Size: 173237466
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AdvProp
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b6_ap
LR: 0.256
Epochs: 350
Crop Pct: '0.942'
Momentum: 0.9
Batch Size: 2048
Image Size: '528'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1394
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b6_ap-4ffb161f.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 84.79%
Top 5 Accuracy: 97.14%
- Name: tf_efficientnet_b7_ap
In Collection: AdvProp
Metadata:
FLOPs: 48205304880
Parameters: 66349999
File Size: 266850607
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AdvProp
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b7_ap
LR: 0.256
Epochs: 350
Crop Pct: '0.949'
Momentum: 0.9
Batch Size: 2048
Image Size: '600'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1405
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b7_ap-ddb28fec.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 85.12%
Top 5 Accuracy: 97.25%
- Name: tf_efficientnet_b8_ap
In Collection: AdvProp
Metadata:
FLOPs: 80962956270
Parameters: 87410000
File Size: 351412563
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AdvProp
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b8_ap
LR: 0.128
Epochs: 350
Crop Pct: '0.954'
Momentum: 0.9
Batch Size: 2048
Image Size: '672'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1416
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b8_ap-00e169fa.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 85.37%
Top 5 Accuracy: 97.3%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/advprop.mdx |
!-- DISABLE-FRONTMATTER-SECTIONS -->
# End-of-chapter quiz[[end-of-chapter-quiz]]
<CourseFloatingBanner
chapter={1}
classNames="absolute z-10 right-0 top-0"
/>
This chapter covered a lot of ground! Don't worry if you didn't grasp all the details; the next chapters will help you understand how things work under the hood.
First, though, let's test what you learned in this chapter!
### 1. Explore the Hub and look for the `roberta-large-mnli` checkpoint. What task does it perform?
<Question
choices={[
{
text: "Summarization",
explain: "Look again on the <a href=\"https://huggingface.co/roberta-large-mnli\">roberta-large-mnli page</a>."
},
{
text: "Text classification",
explain: "More precisely, it classifies if two sentences are logically linked across three labels (contradiction, neutral, entailment) — a task also called <em>natural language inference</em>.",
correct: true
},
{
text: "Text generation",
explain: "Look again on the <a href=\"https://huggingface.co/roberta-large-mnli\">roberta-large-mnli page</a>."
}
]}
/>
### 2. What will the following code return?
```py
from transformers import pipeline
ner = pipeline("ner", grouped_entities=True)
ner("My name is Sylvain and I work at Hugging Face in Brooklyn.")
```
<Question
choices={[
{
text: "It will return classification scores for this sentence, with labels \"positive\" or \"negative\".",
explain: "This is incorrect — this would be a <code>sentiment-analysis</code> pipeline."
},
{
text: "It will return a generated text completing this sentence.",
explain: "This is incorrect — it would be a <code>text-generation</code> pipeline.",
},
{
text: "It will return the words representing persons, organizations or locations.",
explain: "Furthermore, with <code>grouped_entities=True</code>, it will group together the words belonging to the same entity, like \"Hugging Face\".",
correct: true
}
]}
/>
### 3. What should replace ... in this code sample?
```py
from transformers import pipeline
filler = pipeline("fill-mask", model="bert-base-cased")
result = filler("...")
```
<Question
choices={[
{
text: "This <mask> has been waiting for you.",
explain: "This is incorrect. Check out the <code>bert-base-cased</code> model card and try to spot your mistake."
},
{
text: "This [MASK] has been waiting for you.",
explain: "Correct! This model's mask token is [MASK].",
correct: true
},
{
text: "This man has been waiting for you.",
explain: "This is incorrect. This pipeline fills in masked words, so it needs a mask token somewhere."
}
]}
/>
### 4. Why will this code fail?
```py
from transformers import pipeline
classifier = pipeline("zero-shot-classification")
result = classifier("This is a course about the Transformers library")
```
<Question
choices={[
{
text: "This pipeline requires that labels be given to classify this text.",
explain: "Right — the correct code needs to include <code>candidate_labels=[...]</code>.",
correct: true
},
{
text: "This pipeline requires several sentences, not just one.",
explain: "This is incorrect, though when properly used, this pipeline can take a list of sentences to process (like all other pipelines)."
},
{
text: "The 🤗 Transformers library is broken, as usual.",
explain: "We won't dignify this answer with a comment!"
},
{
text: "This pipeline requires longer inputs; this one is too short.",
explain: "This is incorrect. Note that a very long text will be truncated when processed by this pipeline."
}
]}
/>
### 5. What does "transfer learning" mean?
<Question
choices={[
{
text: "Transferring the knowledge of a pretrained model to a new model by training it on the same dataset.",
explain: "No, that would be two versions of the same model."
},
{
text: "Transferring the knowledge of a pretrained model to a new model by initializing the second model with the first model's weights.",
explain: "Correct: when the second model is trained on a new task, it *transfers* the knowledge of the first model.",
correct: true
},
{
text: "Transferring the knowledge of a pretrained model to a new model by building the second model with the same architecture as the first model.",
explain: "The architecture is just the way the model is built; there is no knowledge shared or transferred in this case."
}
]}
/>
### 6. True or false? A language model usually does not need labels for its pretraining.
<Question
choices={[
{
text: "True",
explain: "The pretraining is usually <em>self-supervised</em>, which means the labels are created automatically from the inputs (like predicting the next word or filling in some masked words).",
correct: true
},
{
text: "False",
explain: "This is not the correct answer."
}
]}
/>
### 7. Select the sentence that best describes the terms "model", "architecture", and "weights".
<Question
choices={[
{
text: "If a model is a building, its architecture is the blueprint and the weights are the people living inside.",
explain: "Following this metaphor, the weights would be the bricks and other materials used to construct the building."
},
{
text: "An architecture is a map to build a model and its weights are the cities represented on the map.",
explain: "The problem with this metaphor is that a map usually represents one existing reality (there is only one city in France named Paris). For a given architecture, multiple weights are possible."
},
{
text: "An architecture is a succession of mathematical functions to build a model and its weights are those functions parameters.",
explain: "The same set of mathematical functions (architecture) can be used to build different models by using different parameters (weights).",
correct: true
}
]}
/>
### 8. Which of these types of models would you use for completing prompts with generated text?
<Question
choices={[
{
text: "An encoder model",
explain: "An encoder model generates a representation of the whole sentence that is better suited for tasks like classification."
},
{
text: "A decoder model",
explain: "Decoder models are perfectly suited for text generation from a prompt.",
correct: true
},
{
text: "A sequence-to-sequence model",
explain: "Sequence-to-sequence models are better suited for tasks where you want to generate sentences in relation to the input sentences, not a given prompt."
}
]}
/>
### 9. Which of those types of models would you use for summarizing texts?
<Question
choices={[
{
text: "An encoder model",
explain: "An encoder model generates a representation of the whole sentence that is better suited for tasks like classification."
},
{
text: "A decoder model",
explain: "Decoder models are good for generating output text (like summaries), but they don't have the ability to exploit a context like the whole text to summarize."
},
{
text: "A sequence-to-sequence model",
explain: "Sequence-to-sequence models are perfectly suited for a summarization task.",
correct: true
}
]}
/>
### 10. Which of these types of models would you use for classifying text inputs according to certain labels?
<Question
choices={[
{
text: "An encoder model",
explain: "An encoder model generates a representation of the whole sentence which is perfectly suited for a task like classification.",
correct: true
},
{
text: "A decoder model",
explain: "Decoder models are good for generating output texts, not extracting a label out of a sentence."
},
{
text: "A sequence-to-sequence model",
explain: "Sequence-to-sequence models are better suited for tasks where you want to generate text based on an input sentence, not a label.",
}
]}
/>
### 11. What possible source can the bias observed in a model have?
<Question
choices={[
{
text: "The model is a fine-tuned version of a pretrained model and it picked up its bias from it.",
explain: "When applying Transfer Learning, the bias in the pretrained model used persists in the fine-tuned model.",
correct: true
},
{
text: "The data the model was trained on is biased.",
explain: "This is the most obvious source of bias, but not the only one.",
correct: true
},
{
text: "The metric the model was optimizing for is biased.",
explain: "A less obvious source of bias is the way the model is trained. Your model will blindly optimize for whatever metric you chose, without any second thoughts.",
correct: true
}
]}
/>
| huggingface/course/blob/main/chapters/en/chapter1/10.mdx |
n this video we will see how you can create your own tokenizer from scratch! To create your own tokenizer you will have to think about each of the operations involved in tokenization, namely: normalization, pre-tokenization, model, post-processing and decoding. If you don't know what normalization, pre-tokenization and the model are, I advise you to go and see the videos linked below. The post processing gathers all the modifications that we will carry out on the tokenized text. It can include the addition of special tokens, the creation of an attention mask but also the generation of a list of token ids. The decoding operation occurs at the very end and will allow passing from the sequence of ids in a sentence. For example, in our example, we can see that the hashtags have been removed and the tokens composing the word "today" have been grouped together. In a fast tokenizer, all these components are gathered in the backend_tokenizer attribute. As you can see with this small code snippet, it is an instance of a tokenizer from the tokenizers library. So, to create your own transformers tokenizer you will have to follow these steps: first create a training dataset; second create and train a tokenizer with the tokenizers library and third load this tokenizer into transformers tokenizer. To understand these steps, I propose that we recreate a BERT tokenizer. The first thing to do is to create a dataset. With this code snippet you can create an iterator on the dataset wikitext-2-raw-v1 which is a rather small dataset in English. We attack here the big part: the design of our tokenizer with the tokenizers library. We start by initializing a tokenizer instance with a WordPiece model because it is the model used by BERT. Then we can define our normalizer. We will define it as a succession of 2 normalizations used to clean up characters not visible in the text, 1 lowercasing normalization and 2 normalizations used to remove accents. For the pre-tokenization, we will chain two pre_tokenizer. The first one separating the text at the level of spaces and the second one isolating the punctuation marks. Now, we can define the trainer that will allow us to train the WordPiece model chosen at the beginning. To carry out the training, we will have to choose a vocabulary size, here we choose twenty-five thousand and also announce the special tokens that we absolutely want to add to our vocabulary. In one line of code, we can train our WordPiece model using the iterator we defined earlier. Once the model has been trained, we can retrieve the ids of the special class and separation tokens because we will need them to post-process our sequence. Thanks to the TemplateProcessing class, we can add the CLS token at the beginning of each sequence and the SEP token at the end of the sequence and between two sentences if we tokenize a text pair. Finally, we just have to define our decoder which will allow us to remove the hashtags at the beginning of the tokens that must be reattached to the previous token. And there it ist, you have all the necessary lines of code to define your own tokenizer. Now that we have a brand new tokenizer with the tokenizers library we just have to load it into a fast tokenizer from the transformers library. Here again we have several possibilities. We can load it in the generic class "PreTrainedTokenizerFast" or in the BertTokenizerFast class since we have built a bert type tokenizer here. I hope this video has helped you understand how you can create your own tokenizer and that you are ready to navigate the tokenizers library documentation to choose the components for your brand-new tokenizer! | huggingface/course/blob/main/subtitles/en/raw/chapter6/09_building-a-tokenizer.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Schedulers
🤗 Diffusers provides many scheduler functions for the diffusion process. A scheduler takes a model's output (the sample which the diffusion process is iterating on) and a timestep to return a denoised sample. The timestep is important because it dictates where in the diffusion process the step is; data is generated by iterating forward *n* timesteps and inference occurs by propagating backward through the timesteps. Based on the timestep, a scheduler may be *discrete* in which case the timestep is an `int` or *continuous* in which case the timestep is a `float`.
Depending on the context, a scheduler defines how to iteratively add noise to an image or how to update a sample based on a model's output:
- during *training*, a scheduler adds noise (there are different algorithms for how to add noise) to a sample to train a diffusion model
- during *inference*, a scheduler defines how to update a sample based on a pretrained model's output
Many schedulers are implemented from the [k-diffusion](https://github.com/crowsonkb/k-diffusion) library by [Katherine Crowson](https://github.com/crowsonkb/), and they're also widely used in A1111. To help you map the schedulers from k-diffusion and A1111 to the schedulers in 🤗 Diffusers, take a look at the table below:
| A1111/k-diffusion | 🤗 Diffusers | Usage |
|---------------------|-------------------------------------|---------------------------------------------------------------------------------------------------------------|
| DPM++ 2M | [`DPMSolverMultistepScheduler`] | |
| DPM++ 2M Karras | [`DPMSolverMultistepScheduler`] | init with `use_karras_sigmas=True` |
| DPM++ 2M SDE | [`DPMSolverMultistepScheduler`] | init with `algorithm_type="sde-dpmsolver++"` |
| DPM++ 2M SDE Karras | [`DPMSolverMultistepScheduler`] | init with `use_karras_sigmas=True` and `algorithm_type="sde-dpmsolver++"` |
| DPM++ 2S a | N/A | very similar to `DPMSolverSinglestepScheduler` |
| DPM++ 2S a Karras | N/A | very similar to `DPMSolverSinglestepScheduler(use_karras_sigmas=True, ...)` |
| DPM++ SDE | [`DPMSolverSinglestepScheduler`] | |
| DPM++ SDE Karras | [`DPMSolverSinglestepScheduler`] | init with `use_karras_sigmas=True` |
| DPM2 | [`KDPM2DiscreteScheduler`] | |
| DPM2 Karras | [`KDPM2DiscreteScheduler`] | init with `use_karras_sigmas=True` |
| DPM2 a | [`KDPM2AncestralDiscreteScheduler`] | |
| DPM2 a Karras | [`KDPM2AncestralDiscreteScheduler`] | init with `use_karras_sigmas=True` |
| DPM adaptive | N/A | |
| DPM fast | N/A | |
| Euler | [`EulerDiscreteScheduler`] | |
| Euler a | [`EulerAncestralDiscreteScheduler`] | |
| Heun | [`HeunDiscreteScheduler`] | |
| LMS | [`LMSDiscreteScheduler`] | |
| LMS Karras | [`LMSDiscreteScheduler`] | init with `use_karras_sigmas=True` |
| N/A | [`DEISMultistepScheduler`] | |
| N/A | [`UniPCMultistepScheduler`] | |
All schedulers are built from the base [`SchedulerMixin`] class which implements low level utilities shared by all schedulers.
## SchedulerMixin
[[autodoc]] SchedulerMixin
## SchedulerOutput
[[autodoc]] schedulers.scheduling_utils.SchedulerOutput
## KarrasDiffusionSchedulers
[`KarrasDiffusionSchedulers`] are a broad generalization of schedulers in 🤗 Diffusers. The schedulers in this class are distinguished at a high level by their noise sampling strategy, the type of network and scaling, the training strategy, and how the loss is weighed.
The different schedulers in this class, depending on the ordinary differential equations (ODE) solver type, fall into the above taxonomy and provide a good abstraction for the design of the main schedulers implemented in 🤗 Diffusers. The schedulers in this class are given [here](https://github.com/huggingface/diffusers/blob/a69754bb879ed55b9b6dc9dd0b3cf4fa4124c765/src/diffusers/schedulers/scheduling_utils.py#L32).
## PushToHubMixin
[[autodoc]] utils.PushToHubMixin
| huggingface/diffusers/blob/main/docs/source/en/api/schedulers/overview.md |
Gradio Blocks Party[[gradio-blocks-party]]
Along with the release of the Gradio chapter of the course, Hugging Face hosted a community event on building cool machine learning demos using the new Gradio Blocks feature.
You can find all the demos that the community created under the [`Gradio-Blocks`](https://huggingface.co/Gradio-Blocks) organisation on the Hub. Here's a few examples from the winners:
**Natural language to SQL**
<iframe src="https://curranj-words-to-sql.hf.space" frameBorder="0" height="640" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
| huggingface/course/blob/main/chapters/en/events/3.mdx |
MobileNet v2
**MobileNetV2** is a convolutional neural network architecture that seeks to perform well on mobile devices. It is based on an [inverted residual structure](https://paperswithcode.com/method/inverted-residual-block) where the residual connections are between the bottleneck layers. The intermediate expansion layer uses lightweight depthwise convolutions to filter features as a source of non-linearity. As a whole, the architecture of MobileNetV2 contains the initial fully convolution layer with 32 filters, followed by 19 residual bottleneck layers.
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('mobilenetv2_100', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `mobilenetv2_100`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('mobilenetv2_100', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/abs-1801-04381,
author = {Mark Sandler and
Andrew G. Howard and
Menglong Zhu and
Andrey Zhmoginov and
Liang{-}Chieh Chen},
title = {Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification,
Detection and Segmentation},
journal = {CoRR},
volume = {abs/1801.04381},
year = {2018},
url = {http://arxiv.org/abs/1801.04381},
archivePrefix = {arXiv},
eprint = {1801.04381},
timestamp = {Tue, 12 Jan 2021 15:30:06 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1801-04381.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<!--
Type: model-index
Collections:
- Name: MobileNet V2
Paper:
Title: 'MobileNetV2: Inverted Residuals and Linear Bottlenecks'
URL: https://paperswithcode.com/paper/mobilenetv2-inverted-residuals-and-linear
Models:
- Name: mobilenetv2_100
In Collection: MobileNet V2
Metadata:
FLOPs: 401920448
Parameters: 3500000
File Size: 14202571
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Depthwise Separable Convolution
- Dropout
- Inverted Residual Block
- Max Pooling
- ReLU6
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- RMSProp
- Weight Decay
Training Data:
- ImageNet
Training Resources: 16x GPUs
ID: mobilenetv2_100
LR: 0.045
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1536
Image Size: '224'
Weight Decay: 4.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L955
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mobilenetv2_100_ra-b33bc2c4.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 72.95%
Top 5 Accuracy: 91.0%
- Name: mobilenetv2_110d
In Collection: MobileNet V2
Metadata:
FLOPs: 573958832
Parameters: 4520000
File Size: 18316431
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Depthwise Separable Convolution
- Dropout
- Inverted Residual Block
- Max Pooling
- ReLU6
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- RMSProp
- Weight Decay
Training Data:
- ImageNet
Training Resources: 16x GPUs
ID: mobilenetv2_110d
LR: 0.045
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1536
Image Size: '224'
Weight Decay: 4.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L969
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mobilenetv2_110d_ra-77090ade.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.05%
Top 5 Accuracy: 92.19%
- Name: mobilenetv2_120d
In Collection: MobileNet V2
Metadata:
FLOPs: 888510048
Parameters: 5830000
File Size: 23651121
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Depthwise Separable Convolution
- Dropout
- Inverted Residual Block
- Max Pooling
- ReLU6
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- RMSProp
- Weight Decay
Training Data:
- ImageNet
Training Resources: 16x GPUs
ID: mobilenetv2_120d
LR: 0.045
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1536
Image Size: '224'
Weight Decay: 4.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L977
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mobilenetv2_120d_ra-5987e2ed.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.28%
Top 5 Accuracy: 93.51%
- Name: mobilenetv2_140
In Collection: MobileNet V2
Metadata:
FLOPs: 770196784
Parameters: 6110000
File Size: 24673555
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Depthwise Separable Convolution
- Dropout
- Inverted Residual Block
- Max Pooling
- ReLU6
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- RMSProp
- Weight Decay
Training Data:
- ImageNet
Training Resources: 16x GPUs
ID: mobilenetv2_140
LR: 0.045
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1536
Image Size: '224'
Weight Decay: 4.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L962
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mobilenetv2_140_ra-21a4e913.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 76.51%
Top 5 Accuracy: 93.0%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/mobilenet-v2.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# DEISMultistepScheduler
Diffusion Exponential Integrator Sampler (DEIS) is proposed in [Fast Sampling of Diffusion Models with Exponential Integrator](https://huggingface.co/papers/2204.13902) by Qinsheng Zhang and Yongxin Chen. `DEISMultistepScheduler` is a fast high order solver for diffusion ordinary differential equations (ODEs).
This implementation modifies the polynomial fitting formula in log-rho space instead of the original linear `t` space in the DEIS paper. The modification enjoys closed-form coefficients for exponential multistep update instead of replying on the numerical solver.
The abstract from the paper is:
*The past few years have witnessed the great success of Diffusion models~(DMs) in generating high-fidelity samples in generative modeling tasks. A major limitation of the DM is its notoriously slow sampling procedure which normally requires hundreds to thousands of time discretization steps of the learned diffusion process to reach the desired accuracy. Our goal is to develop a fast sampling method for DMs with a much less number of steps while retaining high sample quality. To this end, we systematically analyze the sampling procedure in DMs and identify key factors that affect the sample quality, among which the method of discretization is most crucial. By carefully examining the learned diffusion process, we propose Diffusion Exponential Integrator Sampler~(DEIS). It is based on the Exponential Integrator designed for discretizing ordinary differential equations (ODEs) and leverages a semilinear structure of the learned diffusion process to reduce the discretization error. The proposed method can be applied to any DMs and can generate high-fidelity samples in as few as 10 steps. In our experiments, it takes about 3 minutes on one A6000 GPU to generate 50k images from CIFAR10. Moreover, by directly using pre-trained DMs, we achieve the state-of-art sampling performance when the number of score function evaluation~(NFE) is limited, e.g., 4.17 FID with 10 NFEs, 3.37 FID, and 9.74 IS with only 15 NFEs on CIFAR10. Code is available at [this https URL](https://github.com/qsh-zh/deis).*
## Tips
It is recommended to set `solver_order` to 2 or 3, while `solver_order=1` is equivalent to [`DDIMScheduler`].
Dynamic thresholding from [Imagen](https://huggingface.co/papers/2205.11487) is supported, and for pixel-space
diffusion models, you can set `thresholding=True` to use the dynamic thresholding.
## DEISMultistepScheduler
[[autodoc]] DEISMultistepScheduler
## SchedulerOutput
[[autodoc]] schedulers.scheduling_utils.SchedulerOutput
| huggingface/diffusers/blob/main/docs/source/en/api/schedulers/deis.md |
Training a new tokenizer from an old one[[training-a-new-tokenizer-from-an-old-one]]
<CourseFloatingBanner chapter={6}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter6/section2.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter6/section2.ipynb"},
]} />
If a language model is not available in the language you are interested in, or if your corpus is very different from the one your language model was trained on, you will most likely want to retrain the model from scratch using a tokenizer adapted to your data. That will require training a new tokenizer on your dataset. But what exactly does that mean? When we first looked at tokenizers in [Chapter 2](/course/chapter2), we saw that most Transformer models use a _subword tokenization algorithm_. To identify which subwords are of interest and occur most frequently in the corpus at hand, the tokenizer needs to take a hard look at all the texts in the corpus -- a process we call *training*. The exact rules that govern this training depend on the type of tokenizer used, and we'll go over the three main algorithms later in this chapter.
<Youtube id="DJimQynXZsQ"/>
<Tip warning={true}>
⚠️ Training a tokenizer is not the same as training a model! Model training uses stochastic gradient descent to make the loss a little bit smaller for each batch. It's randomized by nature (meaning you have to set some seeds to get the same results when doing the same training twice). Training a tokenizer is a statistical process that tries to identify which subwords are the best to pick for a given corpus, and the exact rules used to pick them depend on the tokenization algorithm. It's deterministic, meaning you always get the same results when training with the same algorithm on the same corpus.
</Tip>
## Assembling a corpus[[assembling-a-corpus]]
There's a very simple API in 🤗 Transformers that you can use to train a new tokenizer with the same characteristics as an existing one: `AutoTokenizer.train_new_from_iterator()`. To see this in action, let’s say we want to train GPT-2 from scratch, but in a language other than English. Our first task will be to gather lots of data in that language in a training corpus. To provide examples everyone will be able to understand, we won't use a language like Russian or Chinese here, but rather a specialized English language: Python code.
The [🤗 Datasets](https://github.com/huggingface/datasets) library can help us assemble a corpus of Python source code. We'll use the usual `load_dataset()` function to download and cache the [CodeSearchNet](https://huggingface.co/datasets/code_search_net) dataset. This dataset was created for the [CodeSearchNet challenge](https://wandb.ai/github/CodeSearchNet/benchmark) and contains millions of functions from open source libraries on GitHub in several programming languages. Here, we will load the Python part of this dataset:
```py
from datasets import load_dataset
# This can take a few minutes to load, so grab a coffee or tea while you wait!
raw_datasets = load_dataset("code_search_net", "python")
```
We can have a look at the training split to see which columns we have access to:
```py
raw_datasets["train"]
```
```python out
Dataset({
features: ['repository_name', 'func_path_in_repository', 'func_name', 'whole_func_string', 'language',
'func_code_string', 'func_code_tokens', 'func_documentation_string', 'func_documentation_tokens', 'split_name',
'func_code_url'
],
num_rows: 412178
})
```
We can see the dataset separates docstrings from code and suggests a tokenization of both. Here. we'll just use the `whole_func_string` column to train our tokenizer. We can look at an example of one these functions by indexing into the `train` split:
```py
print(raw_datasets["train"][123456]["whole_func_string"])
```
which should print the following:
```out
def handle_simple_responses(
self, timeout_ms=None, info_cb=DEFAULT_MESSAGE_CALLBACK):
"""Accepts normal responses from the device.
Args:
timeout_ms: Timeout in milliseconds to wait for each response.
info_cb: Optional callback for text sent from the bootloader.
Returns:
OKAY packet's message.
"""
return self._accept_responses('OKAY', info_cb, timeout_ms=timeout_ms)
```
The first thing we need to do is transform the dataset into an _iterator_ of lists of texts -- for instance, a list of list of texts. Using lists of texts will enable our tokenizer to go faster (training on batches of texts instead of processing individual texts one by one), and it should be an iterator if we want to avoid having everything in memory at once. If your corpus is huge, you will want to take advantage of the fact that 🤗 Datasets does not load everything into RAM but stores the elements of the dataset on disk.
Doing the following would create a list of lists of 1,000 texts each, but would load everything in memory:
```py
# Don't uncomment the following line unless your dataset is small!
# training_corpus = [raw_datasets["train"][i: i + 1000]["whole_func_string"] for i in range(0, len(raw_datasets["train"]), 1000)]
```
Using a Python generator, we can avoid Python loading anything into memory until it's actually necessary. To create such a generator, you just to need to replace the brackets with parentheses:
```py
training_corpus = (
raw_datasets["train"][i : i + 1000]["whole_func_string"]
for i in range(0, len(raw_datasets["train"]), 1000)
)
```
This line of code doesn't fetch any elements of the dataset; it just creates an object you can use in a Python `for` loop. The texts will only be loaded when you need them (that is, when you're at the step of the `for` loop that requires them), and only 1,000 texts at a time will be loaded. This way you won't exhaust all your memory even if you are processing a huge dataset.
The problem with a generator object is that it can only be used once. So, instead of this giving us the list of the first 10 digits twice:
```py
gen = (i for i in range(10))
print(list(gen))
print(list(gen))
```
we get them once and then an empty list:
```python out
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[]
```
That's why we define a function that returns a generator instead:
```py
def get_training_corpus():
return (
raw_datasets["train"][i : i + 1000]["whole_func_string"]
for i in range(0, len(raw_datasets["train"]), 1000)
)
training_corpus = get_training_corpus()
```
You can also define your generator inside a `for` loop by using the `yield` statement:
```py
def get_training_corpus():
dataset = raw_datasets["train"]
for start_idx in range(0, len(dataset), 1000):
samples = dataset[start_idx : start_idx + 1000]
yield samples["whole_func_string"]
```
which will produce the exact same generator as before, but allows you to use more complex logic than you can in a list comprehension.
## Training a new tokenizer[[training-a-new-tokenizer]]
Now that we have our corpus in the form of an iterator of batches of texts, we are ready to train a new tokenizer. To do this, we first need to load the tokenizer we want to pair with our model (here, GPT-2):
```py
from transformers import AutoTokenizer
old_tokenizer = AutoTokenizer.from_pretrained("gpt2")
```
Even though we are going to train a new tokenizer, it's a good idea to do this to avoid starting entirely from scratch. This way, we won't have to specify anything about the tokenization algorithm or the special tokens we want to use; our new tokenizer will be exactly the same as GPT-2, and the only thing that will change is the vocabulary, which will be determined by the training on our corpus.
First let's have a look at how this tokenizer would treat an example function:
```py
example = '''def add_numbers(a, b):
"""Add the two numbers `a` and `b`."""
return a + b'''
tokens = old_tokenizer.tokenize(example)
tokens
```
```python out
['def', 'Ġadd', '_', 'n', 'umbers', '(', 'a', ',', 'Ġb', '):', 'Ċ', 'Ġ', 'Ġ', 'Ġ', 'Ġ"""', 'Add', 'Ġthe', 'Ġtwo',
'Ġnumbers', 'Ġ`', 'a', '`', 'Ġand', 'Ġ`', 'b', '`', '."', '""', 'Ċ', 'Ġ', 'Ġ', 'Ġ', 'Ġreturn', 'Ġa', 'Ġ+', 'Ġb']
```
This tokenizer has a few special symbols, like `Ġ` and `Ċ`, which denote spaces and newlines, respectively. As we can see, this is not too efficient: the tokenizer returns individual tokens for each space, when it could group together indentation levels (since having sets of four or eight spaces is going to be very common in code). It also split the function name a bit weirdly, not being used to seeing words with the `_` character.
Let's train a new tokenizer and see if it solves those issues. For this, we'll use the method `train_new_from_iterator()`:
```py
tokenizer = old_tokenizer.train_new_from_iterator(training_corpus, 52000)
```
This command might take a bit of time if your corpus is very large, but for this dataset of 1.6 GB of texts it's blazing fast (1 minute 16 seconds on an AMD Ryzen 9 3900X CPU with 12 cores).
Note that `AutoTokenizer.train_new_from_iterator()` only works if the tokenizer you are using is a "fast" tokenizer. As you'll see in the next section, the 🤗 Transformers library contains two types of tokenizers: some are written purely in Python and others (the fast ones) are backed by the 🤗 Tokenizers library, which is written in the [Rust](https://www.rust-lang.org) programming language. Python is the language most often used for data science and deep learning applications, but when anything needs to be parallelized to be fast, it has to be written in another language. For instance, the matrix multiplications that are at the core of the model computation are written in CUDA, an optimized C library for GPUs.
Training a brand new tokenizer in pure Python would be excruciatingly slow, which is why we developed the 🤗 Tokenizers library. Note that just as you didn't have to learn the CUDA language to be able to execute your model on a batch of inputs on a GPU, you won't need to learn Rust to use a fast tokenizer. The 🤗 Tokenizers library provides Python bindings for many methods that internally call some piece of code in Rust; for example, to parallelize the training of your new tokenizer or, as we saw in [Chapter 3](/course/chapter3), the tokenization of a batch of inputs.
Most of the Transformer models have a fast tokenizer available (there are some exceptions that you can check [here](https://huggingface.co/transformers/#supported-frameworks)), and the `AutoTokenizer` API always selects the fast tokenizer for you if it's available. In the next section we'll take a look at some of the other special features fast tokenizers have, which will be really useful for tasks like token classification and question answering. Before diving into that, however, let's try our brand new tokenizer on the previous example:
```py
tokens = tokenizer.tokenize(example)
tokens
```
```python out
['def', 'Ġadd', '_', 'numbers', '(', 'a', ',', 'Ġb', '):', 'ĊĠĠĠ', 'Ġ"""', 'Add', 'Ġthe', 'Ġtwo', 'Ġnumbers', 'Ġ`',
'a', '`', 'Ġand', 'Ġ`', 'b', '`."""', 'ĊĠĠĠ', 'Ġreturn', 'Ġa', 'Ġ+', 'Ġb']
```
Here we again see the special symbols `Ġ` and `Ċ` that denote spaces and newlines, but we can also see that our tokenizer learned some tokens that are highly specific to a corpus of Python functions: for example, there is a `ĊĠĠĠ` token that represents an indentation, and a `Ġ"""` token that represents the three quotes that start a docstring. The tokenizer also correctly split the function name on `_`. This is quite a compact representation; comparatively, using the plain English tokenizer on the same example will give us a longer sentence:
```py
print(len(tokens))
print(len(old_tokenizer.tokenize(example)))
```
```python out
27
36
```
Let's look at another example:
```python
example = """class LinearLayer():
def __init__(self, input_size, output_size):
self.weight = torch.randn(input_size, output_size)
self.bias = torch.zeros(output_size)
def __call__(self, x):
return x @ self.weights + self.bias
"""
tokenizer.tokenize(example)
```
```python out
['class', 'ĠLinear', 'Layer', '():', 'ĊĠĠĠ', 'Ġdef', 'Ġ__', 'init', '__(', 'self', ',', 'Ġinput', '_', 'size', ',',
'Ġoutput', '_', 'size', '):', 'ĊĠĠĠĠĠĠĠ', 'Ġself', '.', 'weight', 'Ġ=', 'Ġtorch', '.', 'randn', '(', 'input', '_',
'size', ',', 'Ġoutput', '_', 'size', ')', 'ĊĠĠĠĠĠĠĠ', 'Ġself', '.', 'bias', 'Ġ=', 'Ġtorch', '.', 'zeros', '(',
'output', '_', 'size', ')', 'ĊĊĠĠĠ', 'Ġdef', 'Ġ__', 'call', '__(', 'self', ',', 'Ġx', '):', 'ĊĠĠĠĠĠĠĠ',
'Ġreturn', 'Ġx', 'Ġ@', 'Ġself', '.', 'weights', 'Ġ+', 'Ġself', '.', 'bias', 'ĊĠĠĠĠ']
```
In addition to the token corresponding to an indentation, here we can also see a token for a double indentation: `ĊĠĠĠĠĠĠĠ`. The special Python words like `class`, `init`, `call`, `self`, and `return` are each tokenized as one token, and we can see that as well as splitting on `_` and `.` the tokenizer correctly splits even camel-cased names: `LinearLayer` is tokenized as `["ĠLinear", "Layer"]`.
## Saving the tokenizer[[saving-the-tokenizer]]
To make sure we can use it later, we need to save our new tokenizer. Like for models, this is done with the `save_pretrained()` method:
```py
tokenizer.save_pretrained("code-search-net-tokenizer")
```
This will create a new folder named *code-search-net-tokenizer*, which will contain all the files the tokenizer needs to be reloaded. If you want to share this tokenizer with your colleagues and friends, you can upload it to the Hub by logging into your account. If you're working in a notebook, there's a convenience function to help you with this:
```python
from huggingface_hub import notebook_login
notebook_login()
```
This will display a widget where you can enter your Hugging Face login credentials. If you aren't working in a notebook, just type the following line in your terminal:
```bash
huggingface-cli login
```
Once you've logged in, you can push your tokenizer by executing the following command:
```py
tokenizer.push_to_hub("code-search-net-tokenizer")
```
This will create a new repository in your namespace with the name `code-search-net-tokenizer`, containing the tokenizer file. You can then load the tokenizer from anywhere with the `from_pretrained()` method:
```py
# Replace "huggingface-course" below with your actual namespace to use your own tokenizer
tokenizer = AutoTokenizer.from_pretrained("huggingface-course/code-search-net-tokenizer")
```
You're now all set for training a language model from scratch and fine-tuning it on your task at hand! We'll get to that in [Chapter 7](/course/chapter7), but first, in the rest of this chapter we'll take a closer look at fast tokenizers and explore in detail what actually happens when we call the method `train_new_from_iterator()`.
| huggingface/course/blob/main/chapters/en/chapter6/2.mdx |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# 💻 Installation
🤗 Simulate can be installed in python using pip:
```
pip install simulate
```
🤗 Simulate comes with additional support for reinforcement learning libraries, including gym:
```
pip install simulate[gym]
```
stable baselines 3:
```
pip install simulate[sb3]
```
and sample-factory (experimental):
```
pip install simulate[sf]
```
Verify that 🤗 Simulate is working correctly by showing a simple scene:
```
import simulate as sm
scene = sm.Scene(engine="Unity")
scene += sm.LightSun() + sm.Box()
scene.show()
```
| huggingface/simulate/blob/main/docs/source/installation.mdx |
FrameworkSwitchCourse {fw} />
<!-- DISABLE-FRONTMATTER-SECTIONS -->
# End-of-chapter quiz[[end-of-chapter-quiz]]
<CourseFloatingBanner
chapter={3}
classNames="absolute z-10 right-0 top-0"
/>
Test what you learned in this chapter!
### 1. The `emotion` dataset contains Twitter messages labeled with emotions. Search for it in the [Hub](https://huggingface.co/datasets), and read the dataset card. Which of these is not one of its basic emotions?
<Question
choices={[
{
text: "Joy",
explain: "Try again — this emotion is present in that dataset!"
},
{
text: "Love",
explain: "Try again — this emotion is present in that dataset!"
},
{
text: "Confusion",
explain: "Correct! Confusion is not one of the six basic emotions.",
correct: true
},
{
text: "Surprise",
explain: "Surprise! Try another one!"
}
]}
/>
### 2. Search for the `ar_sarcasm` dataset in the [Hub](https://huggingface.co/datasets). Which task does it support?
<Question
choices={[
{
text: "Sentiment classification",
explain: "That's right! You can tell thanks to the tags.",
correct: true
},
{
text: "Machine translation",
explain: "That's not it — take another look at the <a href='https://huggingface.co/datasets/ar_sarcasm'>dataset card</a>!"
},
{
text: "Named entity recognition",
explain: "That's not it — take another look at the <a href='https://huggingface.co/datasets/ar_sarcasm'>dataset card</a>!"
},
{
text: "Question answering",
explain: "Alas, this question was not answered correctly. Try again!"
}
]}
/>
### 3. How does the BERT model expect a pair of sentences to be processed?
<Question
choices={[
{
text: "Tokens_of_sentence_1 [SEP] Tokens_of_sentence_2",
explain: "A <code>[SEP]</code> special token is needed to separate the two sentences, but that's not the only thing!"
},
{
text: "[CLS] Tokens_of_sentence_1 Tokens_of_sentence_2",
explain: "A <code>[CLS]</code> special token is required at the beginning, but that's not the only thing!"
},
{
text: "[CLS] Tokens_of_sentence_1 [SEP] Tokens_of_sentence_2 [SEP]",
explain: "That's correct!",
correct: true
},
{
text: "[CLS] Tokens_of_sentence_1 [SEP] Tokens_of_sentence_2",
explain: "A <code>[CLS]</code> special token is needed at the beginning as well as a <code>[SEP]</code> special token to separate the two sentences, but that's not all!"
}
]}
/>
{#if fw === 'pt'}
### 4. What are the benefits of the `Dataset.map()` method?
<Question
choices={[
{
text: "The results of the function are cached, so it won't take any time if we re-execute the code.",
explain: "That is indeed one of the neat benefits of this method! It's not the only one, though...",
correct: true
},
{
text: "It can apply multiprocessing to go faster than applying the function on each element of the dataset.",
explain: "This is a neat feature of this method, but it's not the only one!",
correct: true
},
{
text: "It does not load the whole dataset into memory, saving the results as soon as one element is processed.",
explain: "That's one advantage of this method. There are others, though!",
correct: true
},
]}
/>
### 5. What does dynamic padding mean?
<Question
choices={[
{
text: "It's when you pad the inputs for each batch to the maximum length in the whole dataset.",
explain: "It does imply padding when creating the batch, but not to the maximum length in the whole dataset."
},
{
text: "It's when you pad your inputs when the batch is created, to the maximum length of the sentences inside that batch.",
explain: "That's correct! The \"dynamic\" part comes from the fact that the size of each batch is determined at the time of creation, and all your batches might have different shapes as a result.",
correct: true
},
{
text: "It's when you pad your inputs so that each sentence has the same number of tokens as the previous one in the dataset.",
explain: "That's incorrect, plus it doesn't make sense to look at the order in the dataset since we shuffle it during training."
},
]}
/>
### 6. What is the purpose of a collate function?
<Question
choices={[
{
text: "It ensures all the sequences in the dataset have the same length.",
explain: "A collate function is involved in handling individual batches, not the whole dataset. Additionally, we're talking about generic collate functions, not <code>DataCollatorWithPadding</code> specifically."
},
{
text: "It puts together all the samples in a batch.",
explain: "Correct! You can pass the collate function as an argument of a <code>DataLoader</code>. We used the <code>DataCollatorWithPadding</code> function, which pads all items in a batch so they have the same length.",
correct: true
},
{
text: "It preprocesses the whole dataset.",
explain: "That would be a preprocessing function, not a collate function."
},
{
text: "It truncates the sequences in the dataset.",
explain: "A collate function is involved in handling individual batches, not the whole dataset. If you're interested in truncating, you can use the <code>truncate</code> argument of <code>tokenizer</code>."
}
]}
/>
### 7. What happens when you instantiate one of the `AutoModelForXxx` classes with a pretrained language model (such as `bert-base-uncased`) that corresponds to a different task than the one for which it was trained?
<Question
choices={[
{
text: "Nothing, but you get a warning.",
explain: "You do get a warning, but that's not all!"
},
{
text: "The head of the pretrained model is discarded and a new head suitable for the task is inserted instead.",
explain: "Correct. For example, when we used <code>AutoModelForSequenceClassification</code> with <code>bert-base-uncased</code>, we got warnings when instantiating the model. The pretrained head is not used for the sequence classification task, so it's discarded and a new head is instantiated with random weights.",
correct: true
},
{
text: "The head of the pretrained model is discarded.",
explain: "Something else needs to happen. Try again!"
},
{
text: "Nothing, since the model can still be fine-tuned for the different task.",
explain: "The head of the pretrained model was not trained to solve this task, so we should discard the head!"
}
]}
/>
### 8. What's the purpose of `TrainingArguments`?
<Question
choices={[
{
text: "It contains all the hyperparameters used for training and evaluation with the <code>Trainer</code>.",
explain: "Correct!",
correct: true
},
{
text: "It specifies the size of the model.",
explain: "The model size is defined by the model configuration, not the class <code>TrainingArguments</code>."
},
{
text: "It just contains the hyperparameters used for evaluation.",
explain: "In the example, we specified where the model and its checkpoints will be saved. Try again!"
},
{
text: "It just contains the hyperparameters used for training.",
explain: "In the example, we used an <code>evaluation_strategy</code> as well, so this impacts evaluation. Try again!"
}
]}
/>
### 9. Why should you use the 🤗 Accelerate library?
<Question
choices={[
{
text: "It provides access to faster models.",
explain: "No, the 🤗 Accelerate library does not provide any models."
},
{
text: "It provides a high-level API so I don't have to implement my own training loop.",
explain: "This is what we did with <code>Trainer</code>, not the 🤗 Accelerate library. Try again!"
},
{
text: "It makes our training loops work on distributed strategies.",
explain: "Correct! With 🤗 Accelerate, your training loops will work for multiple GPUs and TPUs.",
correct: true
},
{
text: "It provides more optimization functions.",
explain: "No, the 🤗 Accelerate library does not provide any optimization functions."
}
]}
/>
{:else}
### 4. What happens when you instantiate one of the `TFAutoModelForXxx` classes with a pretrained language model (such as `bert-base-uncased`) that corresponds to a different task than the one for which it was trained?
<Question
choices={[
{
text: "Nothing, but you get a warning.",
explain: "You do get a warning, but that's not all!"
},
{
text: "The head of the pretrained model is discarded and a new head suitable for the task is inserted instead.",
explain: "Correct. For example, when we used <code>TFAutoModelForSequenceClassification</code> with <code>bert-base-uncased</code>, we got warnings when instantiating the model. The pretrained head is not used for the sequence classification task, so it's discarded and a new head is instantiated with random weights.",
correct: true
},
{
text: "The head of the pretrained model is discarded.",
explain: "Something else needs to happen. Try again!"
},
{
text: "Nothing, since the model can still be fine-tuned for the different task.",
explain: "The head of the pretrained model was not trained to solve this task, so we should discard the head!"
}
]}
/>
### 5. The TensorFlow models from `transformers` are already Keras models. What benefit does this offer?
<Question
choices={[
{
text: "The models work on a TPU out of the box.",
explain: "Almost! There are some small additional changes required. For example, you need to run everything in a <code>TPUStrategy</code> scope, including the initialization of the model."
},
{
text: "You can leverage existing methods such as <code>compile()</code>, <code>fit()</code>, and <code>predict()</code>.",
explain: "Correct! Once you have the data, training on it requires very little work.",
correct: true
},
{
text: "You get to learn Keras as well as transformers.",
explain: "Correct, but we're looking for something else :)",
correct: true
},
{
text: "You can easily compute metrics related to the dataset.",
explain: "Keras helps us with training and evaluating the model, not computing dataset-related metrics."
}
]}
/>
### 6. How can you define your own custom metric?
<Question
choices={[
{
text: "By subclassing <code>tf.keras.metrics.Metric</code>.",
explain: "Great!",
correct: true
},
{
text: "Using the Keras functional API.",
explain: "Try again!"
},
{
text: "By using a callable with signature <code>metric_fn(y_true, y_pred)</code>.",
explain: "Correct!",
correct: true
},
{
text: "By Googling it.",
explain: "That's not the answer we're looking for, but it should help you find it.",
correct: true
}
]}
/>
{/if}
| huggingface/course/blob/main/chapters/en/chapter3/6.mdx |
Gradio Demo: blocks_flipper
```
!pip install -q gradio
```
```
import numpy as np
import gradio as gr
def flip_text(x):
return x[::-1]
def flip_image(x):
return np.fliplr(x)
with gr.Blocks() as demo:
gr.Markdown("Flip text or image files using this demo.")
with gr.Tab("Flip Text"):
text_input = gr.Textbox()
text_output = gr.Textbox()
text_button = gr.Button("Flip")
with gr.Tab("Flip Image"):
with gr.Row():
image_input = gr.Image()
image_output = gr.Image()
image_button = gr.Button("Flip")
with gr.Accordion("Open for More!"):
gr.Markdown("Look at me...")
text_button.click(flip_text, inputs=text_input, outputs=text_output)
image_button.click(flip_image, inputs=image_input, outputs=image_output)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/blocks_flipper/run.ipynb |
Create a dataset
Sometimes, you may need to create a dataset if you're working with your own data. Creating a dataset with 🤗 Datasets confers all the advantages of the library to your dataset: fast loading and processing, [stream enormous datasets](stream), [memory-mapping](https://huggingface.co/course/chapter5/4?fw=pt#the-magic-of-memory-mapping), and more. You can easily and rapidly create a dataset with 🤗 Datasets low-code approaches, reducing the time it takes to start training a model. In many cases, it is as easy as [dragging and dropping](upload_dataset#upload-with-the-hub-ui) your data files into a dataset repository on the Hub.
In this tutorial, you'll learn how to use 🤗 Datasets low-code methods for creating all types of datasets:
* Folder-based builders for quickly creating an image or audio dataset
* `from_` methods for creating datasets from local files
## Folder-based builders
There are two folder-based builders, [`ImageFolder`] and [`AudioFolder`]. These are low-code methods for quickly creating an image or speech and audio dataset with several thousand examples. They are great for rapidly prototyping computer vision and speech models before scaling to a larger dataset. Folder-based builders takes your data and automatically generates the dataset's features, splits, and labels. Under the hood:
* [`ImageFolder`] uses the [`~datasets.Image`] feature to decode an image file. Many image extension formats are supported, such as jpg and png, but other formats are also supported. You can check the complete [list](https://github.com/huggingface/datasets/blob/b5672a956d5de864e6f5550e493527d962d6ae55/src/datasets/packaged_modules/imagefolder/imagefolder.py#L39) of supported image extensions.
* [`AudioFolder`] uses the [`~datasets.Audio`] feature to decode an audio file. Audio extensions such as wav and mp3 are supported, and you can check the complete [list](https://github.com/huggingface/datasets/blob/b5672a956d5de864e6f5550e493527d962d6ae55/src/datasets/packaged_modules/audiofolder/audiofolder.py#L39) of supported audio extensions.
The dataset splits are generated from the repository structure, and the label names are automatically inferred from the directory name.
For example, if your image dataset (it is the same for an audio dataset) is stored like this:
```
pokemon/train/grass/bulbasaur.png
pokemon/train/fire/charmander.png
pokemon/train/water/squirtle.png
pokemon/test/grass/ivysaur.png
pokemon/test/fire/charmeleon.png
pokemon/test/water/wartortle.png
```
Then this is how the folder-based builder generates an example:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/folder-based-builder.png"/>
</div>
Create the image dataset by specifying `imagefolder` in [`load_dataset`]:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("imagefolder", data_dir="/path/to/pokemon")
```
An audio dataset is created in the same way, except you specify `audiofolder` in [`load_dataset`] instead:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("audiofolder", data_dir="/path/to/folder")
```
Any additional information about your dataset, such as text captions or transcriptions, can be included with a `metadata.csv` file in the folder containing your dataset. The metadata file needs to have a `file_name` column that links the image or audio file to its corresponding metadata:
```
file_name, text
bulbasaur.png, There is a plant seed on its back right from the day this Pokémon is born.
charmander.png, It has a preference for hot things.
squirtle.png, When it retracts its long neck into its shell, it squirts out water with vigorous force.
```
To learn more about each of these folder-based builders, check out the and <a href="https://huggingface.co/docs/datasets/image_dataset#imagefolder"><span class="underline decoration-yellow-400 decoration-2 font-semibold">ImageFolder</span></a> or <a href="https://huggingface.co/docs/datasets/audio_dataset#audiofolder"><span class="underline decoration-pink-400 decoration-2 font-semibold">AudioFolder</span></a> guides.
## From local files
You can also create a dataset from local files by specifying the path to the data files. There are two ways you can create a dataset using the `from_` methods:
* The [`~Dataset.from_generator`] method is the most memory-efficient way to create a dataset from a [generator](https://wiki.python.org/moin/Generators) due to a generators iterative behavior. This is especially useful when you're working with a really large dataset that may not fit in memory, since the dataset is generated on disk progressively and then memory-mapped.
```py
>>> from datasets import Dataset
>>> def gen():
... yield {"pokemon": "bulbasaur", "type": "grass"}
... yield {"pokemon": "squirtle", "type": "water"}
>>> ds = Dataset.from_generator(gen)
>>> ds[0]
{"pokemon": "bulbasaur", "type": "grass"}
```
A generator-based [`IterableDataset`] needs to be iterated over with a `for` loop for example:
```py
>>> from datasets import IterableDataset
>>> ds = IterableDataset.from_generator(gen)
>>> for example in ds:
... print(example)
{"pokemon": "bulbasaur", "type": "grass"}
{"pokemon": "squirtle", "type": "water"}
```
* The [`~Dataset.from_dict`] method is a straightforward way to create a dataset from a dictionary:
```py
>>> from datasets import Dataset
>>> ds = Dataset.from_dict({"pokemon": ["bulbasaur", "squirtle"], "type": ["grass", "water"]})
>>> ds[0]
{"pokemon": "bulbasaur", "type": "grass"}
```
To create an image or audio dataset, chain the [`~Dataset.cast_column`] method with [`~Dataset.from_dict`] and specify the column and feature type. For example, to create an audio dataset:
```py
>>> audio_dataset = Dataset.from_dict({"audio": ["path/to/audio_1", ..., "path/to/audio_n"]}).cast_column("audio", Audio())
```
## Next steps
We didn't mention this in the tutorial, but you can also create a dataset with a loading script. A loading script is a more manual and code-intensive method for creating a dataset, but it also gives you the most flexibility and control over how a dataset is generated. It lets you configure additional options such as creating multiple configurations within a dataset, or enabling your dataset to be streamed.
To learn more about how to write loading scripts, take a look at the <a href="https://huggingface.co/docs/datasets/main/en/image_dataset#loading-script"><span class="underline decoration-yellow-400 decoration-2 font-semibold">image loading script</span></a>, <a href="https://huggingface.co/docs/datasets/main/en/audio_dataset"><span class="underline decoration-pink-400 decoration-2 font-semibold">audio loading script</span></a>, and <a href="https://huggingface.co/docs/datasets/main/en/dataset_script"><span class="underline decoration-green-400 decoration-2 font-semibold">text loading script</span></a> guides.
Now that you know how to create a dataset, consider sharing it on the Hub so the community can also benefit from your work! Go on to the next section to learn how to share your dataset.
| huggingface/datasets/blob/main/docs/source/create_dataset.mdx |
TResNet
A **TResNet** is a variant on a [ResNet](https://paperswithcode.com/method/resnet) that aim to boost accuracy while maintaining GPU training and inference efficiency. They contain several design tricks including a SpaceToDepth stem, [Anti-Alias downsampling](https://paperswithcode.com/method/anti-alias-downsampling), In-Place Activated BatchNorm, Blocks selection and [squeeze-and-excitation layers](https://paperswithcode.com/method/squeeze-and-excitation-block).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('tresnet_l', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `tresnet_l`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('tresnet_l', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{ridnik2020tresnet,
title={TResNet: High Performance GPU-Dedicated Architecture},
author={Tal Ridnik and Hussam Lawen and Asaf Noy and Emanuel Ben Baruch and Gilad Sharir and Itamar Friedman},
year={2020},
eprint={2003.13630},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: TResNet
Paper:
Title: 'TResNet: High Performance GPU-Dedicated Architecture'
URL: https://paperswithcode.com/paper/tresnet-high-performance-gpu-dedicated
Models:
- Name: tresnet_l
In Collection: TResNet
Metadata:
FLOPs: 10873416792
Parameters: 53456696
File Size: 224440219
Architecture:
- 1x1 Convolution
- Anti-Alias Downsampling
- Convolution
- Global Average Pooling
- InPlace-ABN
- Leaky ReLU
- ReLU
- Residual Connection
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Cutout
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA 100 GPUs
ID: tresnet_l
LR: 0.01
Epochs: 300
Crop Pct: '0.875'
Momentum: 0.9
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/tresnet.py#L267
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-tresnet/tresnet_l_81_5-235b486c.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.49%
Top 5 Accuracy: 95.62%
- Name: tresnet_l_448
In Collection: TResNet
Metadata:
FLOPs: 43488238584
Parameters: 53456696
File Size: 224440219
Architecture:
- 1x1 Convolution
- Anti-Alias Downsampling
- Convolution
- Global Average Pooling
- InPlace-ABN
- Leaky ReLU
- ReLU
- Residual Connection
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Cutout
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA 100 GPUs
ID: tresnet_l_448
LR: 0.01
Epochs: 300
Crop Pct: '0.875'
Momentum: 0.9
Image Size: '448'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/tresnet.py#L285
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-tresnet/tresnet_l_448-940d0cd1.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 82.26%
Top 5 Accuracy: 95.98%
- Name: tresnet_m
In Collection: TResNet
Metadata:
FLOPs: 5733048064
Parameters: 41282200
File Size: 125861314
Architecture:
- 1x1 Convolution
- Anti-Alias Downsampling
- Convolution
- Global Average Pooling
- InPlace-ABN
- Leaky ReLU
- ReLU
- Residual Connection
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Cutout
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA 100 GPUs
Training Time: < 24 hours
ID: tresnet_m
LR: 0.01
Epochs: 300
Crop Pct: '0.875'
Momentum: 0.9
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/tresnet.py#L261
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-tresnet/tresnet_m_80_8-dbc13962.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.8%
Top 5 Accuracy: 94.86%
- Name: tresnet_m_448
In Collection: TResNet
Metadata:
FLOPs: 22929743104
Parameters: 29278464
File Size: 125861314
Architecture:
- 1x1 Convolution
- Anti-Alias Downsampling
- Convolution
- Global Average Pooling
- InPlace-ABN
- Leaky ReLU
- ReLU
- Residual Connection
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Cutout
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA 100 GPUs
ID: tresnet_m_448
LR: 0.01
Epochs: 300
Crop Pct: '0.875'
Momentum: 0.9
Image Size: '448'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/tresnet.py#L279
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-tresnet/tresnet_m_448-bc359d10.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.72%
Top 5 Accuracy: 95.57%
- Name: tresnet_xl
In Collection: TResNet
Metadata:
FLOPs: 15162534034
Parameters: 75646610
File Size: 314378965
Architecture:
- 1x1 Convolution
- Anti-Alias Downsampling
- Convolution
- Global Average Pooling
- InPlace-ABN
- Leaky ReLU
- ReLU
- Residual Connection
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Cutout
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA 100 GPUs
ID: tresnet_xl
LR: 0.01
Epochs: 300
Crop Pct: '0.875'
Momentum: 0.9
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/tresnet.py#L273
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-tresnet/tresnet_xl_82_0-a2d51b00.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 82.05%
Top 5 Accuracy: 95.93%
- Name: tresnet_xl_448
In Collection: TResNet
Metadata:
FLOPs: 60641712730
Parameters: 75646610
File Size: 224440219
Architecture:
- 1x1 Convolution
- Anti-Alias Downsampling
- Convolution
- Global Average Pooling
- InPlace-ABN
- Leaky ReLU
- ReLU
- Residual Connection
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Cutout
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA 100 GPUs
ID: tresnet_xl_448
LR: 0.01
Epochs: 300
Crop Pct: '0.875'
Momentum: 0.9
Image Size: '448'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/tresnet.py#L291
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-tresnet/tresnet_l_448-940d0cd1.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 83.06%
Top 5 Accuracy: 96.19%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/tresnet.mdx |
Visualization methods
Methods for visualizing evaluations results:
## Radar Plot
[[autodoc]] evaluate.visualization.radar_plot
| huggingface/evaluate/blob/main/docs/source/package_reference/visualization_methods.mdx |
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Debugging
Training on multiple GPUs can be a tricky endeavor whether you're running into installation issues or communication problems between your GPUs. This debugging guide covers some issues you may run into and how to resolve them.
## DeepSpeed CUDA installation
If you're using DeepSpeed, you've probably already installed it with the following command.
```bash
pip install deepspeed
```
DeepSpeed compiles CUDA C++ code and it can be a potential source of errors when building PyTorch extensions that require CUDA. These errors depend on how CUDA is installed on your system, and this section focuses on PyTorch built with *CUDA 10.2*.
<Tip>
For any other installation issues, please [open an issue](https://github.com/microsoft/DeepSpeed/issues) with the DeepSpeed team.
</Tip>
### Non-identical CUDA toolkits
PyTorch comes with its own CUDA toolkit, but to use DeepSpeed with PyTorch, you need to have an identical version of CUDA installed system-wide. For example, if you installed PyTorch with `cudatoolkit==10.2` in your Python environment, then you'll also need to have CUDA 10.2 installed system-wide. If you don't have CUDA installed system-wide, you should install it first.
The exact location may vary from system to system, but `usr/local/cuda-10.2` is the most common location on many Unix systems. When CUDA is correctly setup and added to your `PATH` environment variable, you can find the installation location with the following command:
```bash
which nvcc
```
### Multiple CUDA toolkits
You may also have more than one CUDA toolkit installed system-wide.
```bash
/usr/local/cuda-10.2
/usr/local/cuda-11.0
```
Typically, package installers set the paths to whatever the last version was installed. If the package build fails because it can't find the right CUDA version (despite it being installed system-wide already), then you need to configure the `PATH` and `LD_LIBRARY_PATH` environment variables to point to the correct path.
Take a look at the contents of these environment variables first:
```bash
echo $PATH
echo $LD_LIBRARY_PATH
```
`PATH` lists the locations of the executables and `LD_LIBRARY_PATH` lists where to look for shared libraries. Earlier entries are prioritized over later ones, and `:` is used to separate multiple entries. To tell the build program where to find the specific CUDA toolkit you want, insert the correct path to list first. This command prepends rather than overwrites the existing values.
```bash
# adjust the version and full path if needed
export PATH=/usr/local/cuda-10.2/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64:$LD_LIBRARY_PATH
```
In addition, you should also check the directories you assign actually exist. The `lib64` sub-directory contains various CUDA `.so` objects (like `libcudart.so`) and while it is unlikely your system names them differently, you should check the actual names and change them accordingly.
### Older CUDA versions
Sometimes, older CUDA versions may refuse to build with newer compilers. For example, if you have `gcc-9` but CUDA wants `gcc-7`. Usually, installing the latest CUDA toolkit enables support for the newer compiler.
You could also install an older version of the compiler in addition to the one you're currently using (or it may already be installed but it's not used by default and the build system can't see it). To resolve this, you can create a symlink to give the build system visibility to the older compiler.
```bash
# adapt the path to your system
sudo ln -s /usr/bin/gcc-7 /usr/local/cuda-10.2/bin/gcc
sudo ln -s /usr/bin/g++-7 /usr/local/cuda-10.2/bin/g++
```
## Multi-GPU Network Issues Debug
When training or inferencing with `DistributedDataParallel` and multiple GPU, if you run into issue of inter-communication between processes and/or nodes, you can use the following script to diagnose network issues.
```bash
wget https://raw.githubusercontent.com/huggingface/transformers/main/scripts/distributed/torch-distributed-gpu-test.py
```
For example to test how 2 GPUs interact do:
```bash
python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py
```
If both processes can talk to each and allocate GPU memory each will print an OK status.
For more GPUs or nodes adjust the arguments in the script.
You will find a lot more details inside the diagnostics script and even a recipe to how you could run it in a SLURM environment.
An additional level of debug is to add `NCCL_DEBUG=INFO` environment variable as follows:
```bash
NCCL_DEBUG=INFO python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py
```
This will dump a lot of NCCL-related debug information, which you can then search online if you find that some problems are reported. Or if you're not sure how to interpret the output you can share the log file in an Issue.
## Underflow and Overflow Detection
<Tip>
This feature is currently available for PyTorch-only.
</Tip>
<Tip>
For multi-GPU training it requires DDP (`torch.distributed.launch`).
</Tip>
<Tip>
This feature can be used with any `nn.Module`-based model.
</Tip>
If you start getting `loss=NaN` or the model inhibits some other abnormal behavior due to `inf` or `nan` in
activations or weights one needs to discover where the first underflow or overflow happens and what led to it. Luckily
you can accomplish that easily by activating a special module that will do the detection automatically.
If you're using [`Trainer`], you just need to add:
```bash
--debug underflow_overflow
```
to the normal command line arguments, or pass `debug="underflow_overflow"` when creating the
[`TrainingArguments`] object.
If you're using your own training loop or another Trainer you can accomplish the same with:
```python
from transformers.debug_utils import DebugUnderflowOverflow
debug_overflow = DebugUnderflowOverflow(model)
```
[`~debug_utils.DebugUnderflowOverflow`] inserts hooks into the model that immediately after each
forward call will test input and output variables and also the corresponding module's weights. As soon as `inf` or
`nan` is detected in at least one element of the activations or weights, the program will assert and print a report
like this (this was caught with `google/mt5-small` under fp16 mixed precision):
```
Detected inf/nan during batch_number=0
Last 21 forward frames:
abs min abs max metadata
encoder.block.1.layer.1.DenseReluDense.dropout Dropout
0.00e+00 2.57e+02 input[0]
0.00e+00 2.85e+02 output
[...]
encoder.block.2.layer.0 T5LayerSelfAttention
6.78e-04 3.15e+03 input[0]
2.65e-04 3.42e+03 output[0]
None output[1]
2.25e-01 1.00e+04 output[2]
encoder.block.2.layer.1.layer_norm T5LayerNorm
8.69e-02 4.18e-01 weight
2.65e-04 3.42e+03 input[0]
1.79e-06 4.65e+00 output
encoder.block.2.layer.1.DenseReluDense.wi_0 Linear
2.17e-07 4.50e+00 weight
1.79e-06 4.65e+00 input[0]
2.68e-06 3.70e+01 output
encoder.block.2.layer.1.DenseReluDense.wi_1 Linear
8.08e-07 2.66e+01 weight
1.79e-06 4.65e+00 input[0]
1.27e-04 2.37e+02 output
encoder.block.2.layer.1.DenseReluDense.dropout Dropout
0.00e+00 8.76e+03 input[0]
0.00e+00 9.74e+03 output
encoder.block.2.layer.1.DenseReluDense.wo Linear
1.01e-06 6.44e+00 weight
0.00e+00 9.74e+03 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.DenseReluDense T5DenseGatedGeluDense
1.79e-06 4.65e+00 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.dropout Dropout
3.18e-04 6.27e+04 input[0]
0.00e+00 inf output
```
The example output has been trimmed in the middle for brevity.
The second column shows the value of the absolute largest element, so if you have a closer look at the last few frames,
the inputs and outputs were in the range of `1e4`. So when this training was done under fp16 mixed precision the very
last step overflowed (since under `fp16` the largest number before `inf` is `64e3`). To avoid overflows under
`fp16` the activations must remain way below `1e4`, because `1e4 * 1e4 = 1e8` so any matrix multiplication with
large activations is going to lead to a numerical overflow condition.
At the very start of the trace you can discover at which batch number the problem occurred (here `Detected inf/nan during batch_number=0` means the problem occurred on the first batch).
Each reported frame starts by declaring the fully qualified entry for the corresponding module this frame is reporting
for. If we look just at this frame:
```
encoder.block.2.layer.1.layer_norm T5LayerNorm
8.69e-02 4.18e-01 weight
2.65e-04 3.42e+03 input[0]
1.79e-06 4.65e+00 output
```
Here, `encoder.block.2.layer.1.layer_norm` indicates that it was a layer norm for the first layer, of the second
block of the encoder. And the specific calls of the `forward` is `T5LayerNorm`.
Let's look at the last few frames of that report:
```
Detected inf/nan during batch_number=0
Last 21 forward frames:
abs min abs max metadata
[...]
encoder.block.2.layer.1.DenseReluDense.wi_0 Linear
2.17e-07 4.50e+00 weight
1.79e-06 4.65e+00 input[0]
2.68e-06 3.70e+01 output
encoder.block.2.layer.1.DenseReluDense.wi_1 Linear
8.08e-07 2.66e+01 weight
1.79e-06 4.65e+00 input[0]
1.27e-04 2.37e+02 output
encoder.block.2.layer.1.DenseReluDense.wo Linear
1.01e-06 6.44e+00 weight
0.00e+00 9.74e+03 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.DenseReluDense T5DenseGatedGeluDense
1.79e-06 4.65e+00 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.dropout Dropout
3.18e-04 6.27e+04 input[0]
0.00e+00 inf output
```
The last frame reports for `Dropout.forward` function with the first entry for the only input and the second for the
only output. You can see that it was called from an attribute `dropout` inside `DenseReluDense` class. We can see
that it happened during the first layer, of the 2nd block, during the very first batch. Finally, the absolute largest
input elements was `6.27e+04` and same for the output was `inf`.
You can see here, that `T5DenseGatedGeluDense.forward` resulted in output activations, whose absolute max value was
around 62.7K, which is very close to fp16's top limit of 64K. In the next frame we have `Dropout` which renormalizes
the weights, after it zeroed some of the elements, which pushes the absolute max value to more than 64K, and we get an
overflow (`inf`).
As you can see it's the previous frames that we need to look into when the numbers start going into very large for fp16
numbers.
Let's match the report to the code from `models/t5/modeling_t5.py`:
```python
class T5DenseGatedGeluDense(nn.Module):
def __init__(self, config):
super().__init__()
self.wi_0 = nn.Linear(config.d_model, config.d_ff, bias=False)
self.wi_1 = nn.Linear(config.d_model, config.d_ff, bias=False)
self.wo = nn.Linear(config.d_ff, config.d_model, bias=False)
self.dropout = nn.Dropout(config.dropout_rate)
self.gelu_act = ACT2FN["gelu_new"]
def forward(self, hidden_states):
hidden_gelu = self.gelu_act(self.wi_0(hidden_states))
hidden_linear = self.wi_1(hidden_states)
hidden_states = hidden_gelu * hidden_linear
hidden_states = self.dropout(hidden_states)
hidden_states = self.wo(hidden_states)
return hidden_states
```
Now it's easy to see the `dropout` call, and all the previous calls as well.
Since the detection is happening in a forward hook, these reports are printed immediately after each `forward`
returns.
Going back to the full report, to act on it and to fix the problem, we need to go a few frames up where the numbers
started to go up and most likely switch to the `fp32` mode here, so that the numbers don't overflow when multiplied
or summed up. Of course, there might be other solutions. For example, we could turn off `amp` temporarily if it's
enabled, after moving the original `forward` into a helper wrapper, like so:
```python
def _forward(self, hidden_states):
hidden_gelu = self.gelu_act(self.wi_0(hidden_states))
hidden_linear = self.wi_1(hidden_states)
hidden_states = hidden_gelu * hidden_linear
hidden_states = self.dropout(hidden_states)
hidden_states = self.wo(hidden_states)
return hidden_states
import torch
def forward(self, hidden_states):
if torch.is_autocast_enabled():
with torch.cuda.amp.autocast(enabled=False):
return self._forward(hidden_states)
else:
return self._forward(hidden_states)
```
Since the automatic detector only reports on inputs and outputs of full frames, once you know where to look, you may
want to analyse the intermediary stages of any specific `forward` function as well. In such a case you can use the
`detect_overflow` helper function to inject the detector where you want it, for example:
```python
from debug_utils import detect_overflow
class T5LayerFF(nn.Module):
[...]
def forward(self, hidden_states):
forwarded_states = self.layer_norm(hidden_states)
detect_overflow(forwarded_states, "after layer_norm")
forwarded_states = self.DenseReluDense(forwarded_states)
detect_overflow(forwarded_states, "after DenseReluDense")
return hidden_states + self.dropout(forwarded_states)
```
You can see that we added 2 of these and now we track if `inf` or `nan` for `forwarded_states` was detected
somewhere in between.
Actually, the detector already reports these because each of the calls in the example above is a `nn.Module`, but
let's say if you had some local direct calculations this is how you'd do that.
Additionally, if you're instantiating the debugger in your own code, you can adjust the number of frames printed from
its default, e.g.:
```python
from transformers.debug_utils import DebugUnderflowOverflow
debug_overflow = DebugUnderflowOverflow(model, max_frames_to_save=100)
```
### Specific batch absolute min and max value tracing
The same debugging class can be used for per-batch tracing with the underflow/overflow detection feature turned off.
Let's say you want to watch the absolute min and max values for all the ingredients of each `forward` call of a given
batch, and only do that for batches 1 and 3. Then you instantiate this class as:
```python
debug_overflow = DebugUnderflowOverflow(model, trace_batch_nums=[1, 3])
```
And now full batches 1 and 3 will be traced using the same format as the underflow/overflow detector does.
Batches are 0-indexed.
This is helpful if you know that the program starts misbehaving after a certain batch number, so you can fast-forward
right to that area. Here is a sample truncated output for such configuration:
```
*** Starting batch number=1 ***
abs min abs max metadata
shared Embedding
1.01e-06 7.92e+02 weight
0.00e+00 2.47e+04 input[0]
5.36e-05 7.92e+02 output
[...]
decoder.dropout Dropout
1.60e-07 2.27e+01 input[0]
0.00e+00 2.52e+01 output
decoder T5Stack
not a tensor output
lm_head Linear
1.01e-06 7.92e+02 weight
0.00e+00 1.11e+00 input[0]
6.06e-02 8.39e+01 output
T5ForConditionalGeneration
not a tensor output
*** Starting batch number=3 ***
abs min abs max metadata
shared Embedding
1.01e-06 7.92e+02 weight
0.00e+00 2.78e+04 input[0]
5.36e-05 7.92e+02 output
[...]
```
Here you will get a huge number of frames dumped - as many as there were forward calls in your model, so it may or may
not what you want, but sometimes it can be easier to use for debugging purposes than a normal debugger. For example, if
a problem starts happening at batch number 150. So you can dump traces for batches 149 and 150 and compare where
numbers started to diverge.
You can also specify the batch number after which to stop the training, with:
```python
debug_overflow = DebugUnderflowOverflow(model, trace_batch_nums=[1, 3], abort_after_batch_num=3)
```
| huggingface/transformers/blob/main/docs/source/en/debugging.md |
# Textual Inversion fine-tuning example
[Textual inversion](https://arxiv.org/abs/2208.01618) is a method to personalize text2image models like stable diffusion on your own images using just 3-5 examples.
The `textual_inversion.py` script shows how to implement the training procedure and adapt it for stable diffusion.
## Running on Colab
Colab for training
[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb)
Colab for inference
[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb)
## Running locally with PyTorch
### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then cd in the example folder and run
```bash
pip install -r requirements.txt
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
### Cat toy example
You need to accept the model license before downloading or using the weights. In this example we'll use model version `v1-5`, so you'll need to visit [its card](https://huggingface.co/runwayml/stable-diffusion-v1-5), read the license and tick the checkbox if you agree.
You have to be a registered user in 🤗 Hugging Face Hub, and you'll also need to use an access token for the code to work. For more information on access tokens, please refer to [this section of the documentation](https://huggingface.co/docs/hub/security-tokens).
Run the following command to authenticate your token
```bash
huggingface-cli login
```
If you have already cloned the repo, then you won't need to go through these steps.
<br>
Now let's get our dataset. For this example we will use some cat images: https://huggingface.co/datasets/diffusers/cat_toy_example .
Let's first download it locally:
```py
from huggingface_hub import snapshot_download
local_dir = "./cat"
snapshot_download("diffusers/cat_toy_example", local_dir=local_dir, repo_type="dataset", ignore_patterns=".gitattributes")
```
This will be our training data.
Now we can launch the training using
## Use ONNXRuntime to accelerate training
In order to leverage onnxruntime to accelerate training, please use textual_inversion.py
The command to train on custom data with onnxruntime:
```bash
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export DATA_DIR="path-to-dir-containing-images"
accelerate launch textual_inversion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$DATA_DIR \
--learnable_property="object" \
--placeholder_token="<cat-toy>" --initializer_token="toy" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=3000 \
--learning_rate=5.0e-04 --scale_lr \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--output_dir="textual_inversion_cat"
```
Please contact Prathik Rao (prathikr), Sunghoon Choi (hanbitmyths), Ashwini Khade (askhade), or Peng Wang (pengwa) on github with any questions. | huggingface/diffusers/blob/main/examples/research_projects/onnxruntime/textual_inversion/README.md |
# Information Gain Filtration(IGF)
Authors @Tuko @mraunak
This folder contains the code how to implement IGF for finetuning on GPT-2.
## What is IGF?
Here we present a general fine-tuning method that we call information gain filtration for improving the overall training efficiency and final
performance of language model fine-tuning(see paper below). The method is an alternative fine-tuning method that trains
a secondary model (e.g., a simple convolutional network) to predict the amount of information
gained over a given pre-trained model. The secondary model is lightweight and trained to
predict the Information Gain measure. Information Gain is defined as the change in a loss
function for a model before and after an SGD update with a sample (Equation X in the paper).
A small subset of the training set named the “objective” set, is used to measure information
gain on the pre-trained model, and consequently to train the secondary model. After
training, the model is used for filtering samples for the fine-tuning process. Therefore,
a high information gain value would suggest a sample is informative, whereas a low value
would suggest a non-informative sample that should be filtered out. Thus, a thresholding
strategy is defined to select informative samples. With such a strategy, samples are filtered
and once enough samples are selected to form a mini-batch and a usual fine-tuning/optimization
step is applied. The filtration process is repeated until the fine-tuning process is over.
Paper [Selecting Informative Contexts Improves Language Model Finetuning](https://arxiv.org/abs/2005.00175)
# Results
Several experiments were conducted to show the robustness of the IGF method versus the
standard fine-tuning process. For example, we achieve a median perplexity of 54.0 on the
Books dataset compared to 57.3 for standard fine-tuning on GPT-2 Small. The code was
implemented using the Transformers library and Pytorch. While the method may seem more
expensive, we saw enough evidence that it may lead to a performance benefit in the final models.

Figure 1: Comparing IGF to Standard Fine-tuning:
IGF with constant (p < 10−3 , t-test) and shifting(p < 10−6 , t-test) thresholding significantly outperform standard fine-tuning. The left-hand figure shows
test-set perplexity after each fine-tuning batch, averaged over 50 runs (error bars denote ± one standard error). The right-hand figure shows the perplexity of each
method after 60 batches. IGF with shifting thresholding (red) clearly improves over standard batched fine-tuning with Adam
## How to use this project?
To fine-tune a transformer model with IGF on a language modeling task, use the following script:
- `model_name_or_path`: Path to pretrained model or model identifier from huggingface.co/models
- `data_file`: A jbl file containing tokenized data which can be split as objective dataset,
train_dataset and test_dataset
- `igf_data_file`: A jbl file containing the context and information gain pairs to train secondary learner.
- `context_len`: The maximum total input sequence length after tokenization. Sequences longer
than this will be truncated, sequences shorter will be padded.
- `size_objective_set`: Number of articles that are long enough to be used as our objective set"
- `min_len`: The minimum length of the article to be used as objective set
- `trim`: Truncate the example if it exceeds context length
- `eval_freq`: Secondary model evaluation can be triggered at eval_freq
- `max_steps`: To calculate training epochs
- `number`: The number of examples split to be used as objective_set/test_data
- `secondary_learner_batch_size`: The batch size of training data for secondary learner
- `secondary_learner_max_epochs`: The number of epochs to train secondary learner
- `recopy_model`: Reset the model to the original pretrained GPT-2 weights after each iteration
- `eval_interval`: Decay the selectivity of our secondary learner filter from"
1 standard deviation above average to 1 below average after eval_interval(10) batches"
```python
python run_clm_igf.py\
--model_name_or_path "gpt2" \
--data_file="data/tokenized_stories_train_wikitext103" \
--igf_data_file="data/IGF_values" \
--context_len 32 \
--size_objective_set 100 \
--min_len 1026 \
--trim True \
--eval_freq 100 \
--max_steps 1000 \
--secondary_learner_batch_size 128 \
--secondary_learner_max_epochs 15 \
--number 100 \
--recopy_model \
--eval_interval 10 \
```
## Citation
If you find the resource useful, please cite the following paper
```
@inproceedings{antonello-etal-2021-selecting,
title = "Selecting Informative Contexts Improves Language Model Fine-tuning",
author = "Antonello, Richard and Beckage, Nicole and Turek, Javier and Huth, Alexander",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.87",
doi = "10.18653/v1/2021.acl-long.87",
pages = "1072--1085",
}
```
| huggingface/transformers/blob/main/examples/research_projects/information-gain-filtration/README.md |
Get the number of rows and the size in bytes
This guide shows you how to use Datasets Server's `/size` endpoint to retrieve a dataset's size programmatically. Feel free to also try it out with [ReDoc](https://redocly.github.io/redoc/?url=https://datasets-server.huggingface.co/openapi.json#operation/getSize).
The `/size` endpoint accepts the dataset name as its query parameter:
<inferencesnippet>
<python>
```python
import requests
headers = {"Authorization": f"Bearer {API_TOKEN}"}
API_URL = "https://datasets-server.huggingface.co/size?dataset=duorc"
def query():
response = requests.get(API_URL, headers=headers)
return response.json()
data = query()
```
</python>
<js>
```js
import fetch from "node-fetch";
async function query(data) {
const response = await fetch(
"https://datasets-server.huggingface.co/size?dataset=duorc",
{
headers: { Authorization: `Bearer ${API_TOKEN}` },
method: "GET"
}
);
const result = await response.json();
return result;
}
query().then((response) => {
console.log(JSON.stringify(response));
});
```
</js>
<curl>
```curl
curl https://datasets-server.huggingface.co/size?dataset=duorc \
-X GET \
-H "Authorization: Bearer ${API_TOKEN}"
```
</curl>
</inferencesnippet>
The endpoint response is a JSON containing the size of the dataset, as well as each of its configurations and splits. It provides the number of rows, the number of colums (where applicable) and the size in bytes for the different forms of the data: original files, size in memory (RAM) and auto-converted parquet files. For example, the [duorc](https://huggingface.co/datasets/duorc) dataset has 187.213 rows along all its configurations and splits, for a total of 97MB.
```json
{
"size": {
"dataset": {
"dataset": "duorc",
"num_bytes_original_files": 97383710,
"num_bytes_parquet_files": 58710973,
"num_bytes_memory": 1059067116,
"num_rows": 187213
},
"configs": [
{
"dataset": "duorc",
"config": "ParaphraseRC",
"num_bytes_original_files": 62921050,
"num_bytes_parquet_files": 37709127,
"num_bytes_memory": 718409158,
"num_rows": 100972,
"num_columns": 7
},
{
"dataset": "duorc",
"config": "SelfRC",
"num_bytes_original_files": 34462660,
"num_bytes_parquet_files": 21001846,
"num_bytes_memory": 340657958,
"num_rows": 86241,
"num_columns": 7
}
],
"splits": [
{
"dataset": "duorc",
"config": "ParaphraseRC",
"split": "train",
"num_bytes_parquet_files": 26005668,
"num_bytes_memory": 496682909,
"num_rows": 69524,
"num_columns": 7
},
{
"dataset": "duorc",
"config": "ParaphraseRC",
"split": "validation",
"num_bytes_parquet_files": 5566868,
"num_bytes_memory": 106510489,
"num_rows": 15591,
"num_columns": 7
},
{
"dataset": "duorc",
"config": "ParaphraseRC",
"split": "test",
"num_bytes_parquet_files": 6136591,
"num_bytes_memory": 115215760,
"num_rows": 15857,
"num_columns": 7
},
{
"dataset": "duorc",
"config": "SelfRC",
"split": "train",
"num_bytes_parquet_files": 14851720,
"num_bytes_memory": 239852729,
"num_rows": 60721,
"num_columns": 7
},
{
"dataset": "duorc",
"config": "SelfRC",
"split": "validation",
"num_bytes_parquet_files": 3114390,
"num_bytes_memory": 51662519,
"num_rows": 12961,
"num_columns": 7
},
{
"dataset": "duorc",
"config": "SelfRC",
"split": "test",
"num_bytes_parquet_files": 3035736,
"num_bytes_memory": 49142710,
"num_rows": 12559,
"num_columns": 7
}
]
},
"pending": [],
"failed": [],
"partial": false
}
```
If the size has `partial: true` it means that the actual size of the dataset couldn't been determined because it's too big.
In that case the number of rows and bytes can be inferior to the actual numbers.
| huggingface/datasets-server/blob/main/docs/source/size.mdx |
--
title: "Introducing the Private Hub: A New Way to Build With Machine Learning"
thumbnail: /blog/assets/92_introducing_private_hub/thumbnail.png
authors:
- user: federicopascual
---
# Introducing the Private Hub: A New Way to Build With Machine Learning
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
<br>
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 10px;">
June 2023 Update:
The Private Hub is now called <b>Enterprise Hub</b>.
The Enterprise Hub is a hosted solution that combines the best of Cloud Managed services (SaaS) and Enterprise security. It lets customers deploy specific services like <b>Inference Endpoints</b> on a wide scope of compute options, from on-cloud to on-prem. It offers advanced user administration and access controls through SSO.
Get in touch with our [Enterprise team](/support) to find the best solution for your company.
</div>
Machine learning is changing how companies are building technology. From powering a new generation of disruptive products to enabling smarter features in well-known applications we all use and love, ML is at the core of the development process.
But with every technology shift comes new challenges.
Around [90% of machine learning models never make it into production](https://venturebeat.com/2019/07/19/why-do-87-of-data-science-projects-never-make-it-into-production/). Unfamiliar tools and non-standard workflows slow down ML development. Efforts get duplicated as models and datasets aren't shared internally, and similar artifacts are built from scratch across teams all the time. Data scientists find it hard to show their technical work to business stakeholders, who struggle to share precise and timely feedback. And machine learning teams waste time on Docker/Kubernetes and optimizing models for production.
With this in mind, we launched the [Private Hub](https://huggingface.co/platform) (PH), a new way to build with machine learning. From research to production, it provides a unified set of tools to accelerate each step of the machine learning lifecycle in a secure and compliant way. PH brings various ML tools together in one place, making collaborating in machine learning simpler, more fun and productive.
In this blog post, we will deep dive into what is the Private Hub, why it's useful, and how customers are accelerating their ML roadmaps with it.
Read along or feel free to jump to the section that sparks 🌟 your interest:
1. [What is the Hugging Face Hub?](#1-what-is-the-hugging-face-hub)
2. [What is the Private Hub?](#2-what-is-the-private-hub)
3. [How are companies using the Private Hub to accelerate their ML roadmap?](#3-how-are-companies-using-the-private-hub-to-accelerate-their-ml-roadmap)
Let's get started! 🚀
## 1. What is the Hugging Face Hub?
Before diving into the Private Hub, let's first take a look at the Hugging Face Hub, which is a central part of the PH.
The [Hugging Face Hub](https://huggingface.co/docs/hub/index) offers over 60K models, 6K datasets, and 6K ML demo apps, all open source and publicly available, in an online platform where people can easily collaborate and build ML together. The Hub works as a central place where anyone can explore, experiment, collaborate and build technology with machine learning.
On the Hugging Face Hub, you’ll be able to create or discover the following ML assets:
- [Models](https://huggingface.co/models): hosting the latest state-of-the-art models for NLP, computer vision, speech, time-series, biology, reinforcement learning, chemistry and more.
- [Datasets](https://huggingface.co/datasets): featuring a wide variety of data for different domains, modalities and languages.
- [Spaces](https://huggingface.co/spaces): interactive apps for showcasing ML models directly in your browser.
Each model, dataset or space uploaded to the Hub is a [Git-based repository](https://huggingface.co/docs/hub/repositories), which are version-controlled places that can contain all your files. You can use the traditional git commands to pull, push, clone, and/or manipulate your files. You can see the commit history for your models, datasets and spaces, and see who did what and when.
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Commit history on a machine learning model" src="assets/92_introducing_private_hub/commit-history.png"></medium-zoom>
<figcaption>Commit history on a model</figcaption>
</figure>
The Hugging Face Hub is also a central place for feedback and development in machine learning. Teams use [pull requests and discussions](https://huggingface.co/docs/hub/repositories-pull-requests-discussions) to support peer reviews on models, datasets, and spaces, improve collaboration and accelerate their ML work.
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Pull requests and discussions on a model" src="assets/92_introducing_private_hub/pull-requests-and-discussions.png"></medium-zoom>
<figcaption>Pull requests and discussions on a model</figcaption>
</figure>
The Hub allows users to create [Organizations](https://huggingface.co/docs/hub/organizations), that is, team accounts to manage models, datasets, and spaces collaboratively. An organization’s repositories will be featured on the organization’s page and admins can set roles to control access to these repositories. Every member of the organization can contribute to models, datasets and spaces given the right permissions. Here at Hugging Face, we believe having the right tools to collaborate drastically accelerates machine learning development! 🔥
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Organization in the Hub for BigScience" src="assets/92_introducing_private_hub/organizations.png"></medium-zoom>
<figcaption>Organization in the Hub for <a href="https://huggingface.co/bigscience">BigScience</a></figcaption>
</figure>
Now that we have covered the basics, let's dive into the specific characteristics of models, datasets and spaces hosted on the Hugging Face Hub.
### Models
[Transfer learning](https://www.youtube.com/watch?v=BqqfQnyjmgg&ab_channel=HuggingFace) has changed the way companies approach machine learning problems. Traditionally, companies needed to train models from scratch, which requires a lot of time, data, and resources. Now machine learning teams can use a pre-trained model and [fine-tune it for their own use case](https://huggingface.co/course/chapter3/1?fw=pt) in a fast and cost-effective way. This dramatically accelerates the process of getting accurate and performant models.
On the Hub, you can find 60,000+ state-of-the-art open source pre-trained models for NLP, computer vision, speech, time-series, biology, reinforcement learning, chemistry and more. You can use the search bar or filter by tasks, libraries, licenses and other tags to find the right model for your particular use case:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="60,000+ models available on the Hub" src="assets/92_introducing_private_hub/models.png"></medium-zoom>
<figcaption>60,000+ models available on the Hub</figcaption>
</figure>
These models span 180 languages and support up to 25 ML libraries (including Transformers, Keras, spaCy, Timm and others), so there is a lot of flexibility in terms of the type of models, languages and libraries.
Each model has a [model card](https://huggingface.co/docs/hub/models-cards), a simple markdown file with a description of the model itself. This includes what it's intended for, what data that model has been trained on, code samples, information on potential bias and potential risks associated with the model, metrics, related research papers, you name it. Model cards are a great way to understand what the model is about, but they also are useful for identifying the right pre-trained model as a starting point for your ML project:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Model card" src="assets/92_introducing_private_hub/model-card.png"></medium-zoom>
<figcaption>Model card</figcaption>
</figure>
Besides improving models' discoverability and reusability, model cards also make it easier for model risk management (MRM) processes. ML teams are often required to provide information about the machine learning models they build so compliance teams can identify, measure and mitigate model risks. Through model cards, organizations can set up a template with all the required information and streamline the MRM conversations between the ML and compliance teams right within the models.
The Hub also provides an [Inference Widget](https://huggingface.co/docs/hub/models-widgets) to easily test models right from your browser! It's a really good way to get a feeling if a particular model is a good fit and something you wanna dive into:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Inference widget" src="assets/92_introducing_private_hub/inference-widget.png"></medium-zoom>
<figcaption>Inference widget</figcaption>
</figure>
### Datasets
Data is a key part of building machine learning models; without the right data, you won't get accurate models. The 🤗 Hub hosts more than [6,000 open source, ready-to-use datasets for ML models](https://huggingface.co/datasets) with fast, easy-to-use and efficient data manipulation tools. Like with models, you can find the right dataset for your use case by using the search bar or filtering by tags. For example, you can easily find 96 models for sentiment analysis by filtering by the task "sentiment-classification":
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Datasets available for sentiment classification" src="assets/92_introducing_private_hub/filtering-datasets.png"></medium-zoom>
<figcaption>Datasets available for sentiment classification</figcaption>
</figure>
Similar to models, datasets uploaded to the 🤗 Hub have [Dataset Cards](https://huggingface.co/docs/hub/datasets-cards#dataset-cards) to help users understand the contents of the dataset, how the dataset should be used, how it was created and know relevant considerations for using the dataset. You can use the [Dataset Viewer](https://huggingface.co/docs/hub/datasets-viewer) to easily view the data and quickly understand if a particular dataset is useful for your machine learning project:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Super Glue dataset preview" src="assets/92_introducing_private_hub/dataset-preview.png"></medium-zoom>
<figcaption>Super Glue dataset preview</figcaption>
</figure>
### Spaces
A few months ago, we introduced a new feature on the 🤗 Hub called [Spaces](https://huggingface.co/spaces/launch). It's a simple way to build and host machine learning apps. Spaces allow you to easily showcase your ML models to business stakeholders and get the feedback you need to move your ML project forward.
If you've been generating funny images with [DALL-E mini](https://huggingface.co/spaces/dalle-mini/dalle-mini), then you have used Spaces. This space showcase the [DALL-E mini model](https://huggingface.co/dalle-mini/dalle-mini), a machine learning model to generate images based on text prompts:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Space for DALL-E mini" src="assets/92_introducing_private_hub/dalle-mini.png"></medium-zoom>
<figcaption>Space for DALL-E mini</figcaption>
</figure>
## 2. What is the Private Hub?
The [Private Hub](https://huggingface.co/platform) allows companies to use Hugging Face’s complete ecosystem in their own private and compliant environment to accelerate their machine learning development. It brings ML tools for every step of the ML lifecycle together in one place to make collaborating in ML simpler and more productive, while having a compliant environment that companies need for building ML securely:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="The Private Hub" src="assets/92_introducing_private_hub/private-hub.png"></medium-zoom>
<figcaption>The Private Hub</figcaption>
</figure>
With the Private Hub, data scientists can seamlessly work with [Transformers](https://github.com/huggingface/transformers), [Datasets](https://github.com/huggingface/datasets) and other [open source libraries](https://github.com/huggingface) with models, datasets and spaces privately and securely hosted on your own servers, and get machine learning done faster by leveraging the Hub features:
- [AutoTrain](https://huggingface.co/autotrain): you can use our AutoML no-code solution to train state-of-the-art models, automatically fine-tuned, evaluated and deployed in your own servers.
- [Evaluate](https://huggingface.co/spaces/autoevaluate/model-evaluator): evaluate any model on any dataset on the Private Hub with any metric without writing a single line of code.
- [Spaces](https://huggingface.co/spaces/launch): easily host an ML demo app to show your ML work to business stakeholders, get feedback early and build faster.
- [Inference API](https://huggingface.co/inference-api): every private model created on the Private Hub is deployed for inference in your own infrastructure via simple API calls.
- [PRs and Discussions](https://huggingface.co/blog/community-update): support peer reviews on models, datasets, and spaces to improve collaboration across teams.
From research to production, your data never leaves your servers. The Private Hub runs in your own compliant server. It provides enterprise security features like security scans, audit trail, SSO, and control access to keep your models and data secure.
We provide flexible options for deploying your Private Hub in your private, compliant environment, including:
- **Managed Private Hub (SaaS)**: runs in segregated virtual private servers (VPCs) owned by Hugging Face. You can enjoy the full Hugging Face experience on your own private Hub without having to manage any infrastructure.
- **On-cloud Private Hub**: runs in a cloud account on AWS, Azure or GCP owned by the customer. This deployment option gives you full administrative control of the underlying cloud infrastructure and lets you achieve stronger security and compliance.
- **On-prem Private Hub**: on-premise deployment of the Hugging Face Hub on your own infrastructure. For customers with strict compliance rules and/or workloads where they don't want or are not allowed to run on a public cloud.
Now that we have covered the basics of what the Private Hub is, let's go over how companies are using it to accelerate their ML development.
## 3. How Are Companies Using the Private Hub to Accelerate Their ML Roadmap?
[🤗 Transformers](https://github.com/huggingface/transformers) is one of the [fastest growing open source projects of all time](https://star-history.com/#tensorflow/tensorflow&nodejs/node&kubernetes/kubernetes&pytorch/pytorch&huggingface/transformers&Timeline). We now offer [25+ open source libraries](https://github.com/huggingface) and over 10,000 companies are now using Hugging Face to build technology with machine learning.
Being at the heart of the open source AI community, we had thousands of conversations with machine learning and data science teams, giving us a unique perspective on the most common problems and challenges companies are facing when building machine learning.
Through these conversations, we discovered that the current workflow for building machine learning is broken. Duplicated efforts, poor feedback loops, high friction to collaborate across teams, non-standard processes and tools, and difficulty optimizing models for production are common and slow down ML development.
We built the Private Hub to change this. Like Git and GitHub forever changed how companies build software, the Private Hub changes how companies build machine learning:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Before and after using The Private Hub" src="assets/92_introducing_private_hub/before-and-after.png"></medium-zoom>
<figcaption>Before and after using The Private Hub</figcaption>
</figure>
In this section, we'll go through a demo example of how customers are leveraging the PH to accelerate their ML lifecycle. We will go over the step-by-step process of building an ML app to automatically analyze financial analyst 🏦 reports.
First, we will search for a pre-trained model relevant to our use case and fine-tune it on a custom dataset for sentiment analysis. Next, we will build an ML web app to show how this model works to business stakeholders. Finally, we will use the Inference API to run inferences with an infrastructure that can handle production-level loads. All artifacts for this ML demo app can be found in this [organization on the Hub](https://huggingface.co/FinanceInc).
### Training accurate models faster
#### Leveraging a pre-trained model from the Hub
Instead of training models from scratch, transfer learning now allows you to build more accurate models 10x faster ⚡️by fine-tuning pre-trained models available on the Hub for your particular use case.
For our demo example, one of the requirements for building this ML app for financial analysts is doing sentiment analysis. Business stakeholders want to automatically get a sense of a company's performance as soon as financial docs and analyst reports are available.
So as a first step towards creating this ML app, we dive into the [🤗 Hub](https://huggingface.co/models) and explore what pre-trained models are available that we can fine-tune for sentiment analysis. The search bar and tags will let us filter and discover relevant models very quickly. Soon enough, we come across [FinBERT](https://huggingface.co/yiyanghkust/finbert-pretrain), a BERT model pre-trained on corporate reports, earnings call transcripts and financial analyst reports:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Finbert model" src="assets/92_introducing_private_hub/finbert-pretrain.png"></medium-zoom>
<figcaption>Finbert model</figcaption>
</figure>
We [clone the model](https://huggingface.co/FinanceInc/finbert-pretrain) in our own Private Hub, so it's available to other teammates. We also add the required information to the model card to streamline the model risk management process with the compliance team.
#### Fine-tuning a pre-trained model with a custom dataset
Now that we have a great pre-trained model for financial data, the next step is to fine-tune it using our own data for doing sentiment analysis!
So, we first upload a [custom dataset for sentiment analysis](https://huggingface.co/datasets/FinanceInc/auditor_sentiment) that we built internally with the team to our Private Hub. This dataset has several thousand sentences from financial news in English and proprietary financial data manually categorized by our team according to their sentiment. This data contains sensitive information, so our compliance team only allows us to upload this data on our own servers. Luckily, this is not an issue as we run the Private Hub on our own AWS instance.
Then, we use [AutoTrain](https://huggingface.co/autotrain) to quickly fine-tune the FinBert model with our custom sentiment analysis dataset. We can do this straight from the datasets page on our Private Hub:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Fine-tuning a pre-trained model with AutoTrain" src="assets/92_introducing_private_hub/train-in-autotrain.png"></medium-zoom>
<figcaption>Fine-tuning a pre-trained model with AutoTrain</figcaption>
</figure>
Next, we select "manual" as the model choice and choose our [cloned Finbert model](https://huggingface.co/FinanceInc/finbert-pretrain) as the model to fine-tune with our dataset:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Creating a new project with AutoTrain" src="assets/92_introducing_private_hub/autotrain-new-project.png"></medium-zoom>
<figcaption>Creating a new project with AutoTrain</figcaption>
</figure>
Finally, we select the number of candidate models to train with our data. We choose 25 models and voila! After a few minutes, AutoTrain has automatically fine-tuned 25 finbert models with our own sentiment analysis data, showing the performance metrics for all the different models 🔥🔥🔥
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="25 fine-tuned models with AutoTrain" src="assets/92_introducing_private_hub/autotrain-trained-models.png"></medium-zoom>
<figcaption>25 fine-tuned models with AutoTrain</figcaption>
</figure>
Besides the performance metrics, we can easily test the [fine-tuned models](https://huggingface.co/FinanceInc/auditor_sentiment_finetuned) using the inference widget right from our browser to get a sense of how good they are:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Testing the fine-tuned models with the Inference Widget" src="assets/92_introducing_private_hub/auto-train-inference-widget.png"></medium-zoom>
<figcaption>Testing the fine-tuned models with the Inference Widget</figcaption>
</figure>
### Easily demo models to relevant stakeholders
Now that we have trained our custom model for analyzing financial documents, as a next step, we want to build a machine learning demo with [Spaces](https://huggingface.co/spaces/launch) to validate our MVP with our business stakeholders. This demo app will use our custom sentiment analysis model, as well as a second FinBERT model we fine-tuned for [detecting forward-looking statements](https://huggingface.co/FinanceInc/finbert_fls) from financial reports. This interactive demo app will allow us to get feedback sooner, iterate faster, and improve the models so we can use them in production. ✅
In less than 20 minutes, we were able to build an [interactive demo app](https://huggingface.co/spaces/FinanceInc/Financial_Analyst_AI) that any business stakeholder can easily test right from their browsers:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Space for our financial demo app" src="assets/92_introducing_private_hub/financial-analyst-space.png"></medium-zoom>
<figcaption>Space for our financial demo app</figcaption>
</figure>
If you take a look at the [app.py file](https://huggingface.co/spaces/FinanceInc/Financial_Analyst_AI/blob/main/app.py), you'll see it's quite simple:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Code for our ML demo app" src="assets/92_introducing_private_hub/spaces-code.png"></medium-zoom>
<figcaption>Code for our ML demo app</figcaption>
</figure>
51 lines of code are all it took to get this ML demo app up and running! 🤯
### Scale inferences while staying out of MLOps
By now, our business stakeholders have provided great feedback that allowed us to improve these models. Compliance teams assessed potential risks through the information provided via the model cards and green-lighted our project for production. Now, we are ready to put these models to work and start analyzing financial reports at scale! 🎉
Instead of wasting time on Docker/Kubernetes, setting up a server for running these models or optimizing models for production, all we need to do is to leverage the [Inference API](https://huggingface.co/inference-api). We don't need to worry about deployment or scalability issues, we can easily integrate our custom models via simple API calls.
Models uploaded to the Hub and/or created with AutoTrain are instantly deployed to production, ready to make inferences at scale and in real-time. And all it takes to run inferences is 12 lines of code!
To get the code snippet to run inferences with our [sentiment analysis model](https://huggingface.co/FinanceInc/auditor_sentiment_finetuned), we click on "Deploy" and "Accelerated Inference":
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Leveraging the Inference API to run inferences on our custom model" src="assets/92_introducing_private_hub/deploy.png"></medium-zoom>
<figcaption>Leveraging the Inference API to run inferences on our custom model</figcaption>
</figure>
This will show us the following code to make HTTP requests to the Inference API and start analyzing data with our custom model:
```python
import requests
API_URL = "https://api-inference.huggingface.co/models/FinanceInc/auditor_sentiment_finetuned"
headers = {"Authorization": "Bearer xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
output = query({
"inputs": "Operating profit jumped to EUR 47 million from EUR 6.6 million",
})
```
With just 12 lines of code, we are up and running in running inferences with an infrastructure that can handle production-level loads at scale and in real-time 🚀. Pretty cool, right?
## Last Words
Machine learning is becoming the default way to build technology, mostly thanks to open-source and open-science.
But building machine learning is still hard. Many ML projects are rushed and never make it to production. ML development is slowed down by non-standard workflows. ML teams get frustrated with duplicated work, low collaboration across teams, and a fragmented ecosystem of ML tooling.
At Hugging Face, we believe there is a better way to build machine learning. And this is why we created the [Private Hub](https://huggingface.co/platform). We think that providing a unified set of tools for every step of the machine learning development and the right tools to collaborate will lead to better ML work, bring more ML solutions to production, and help ML teams spark innovation.
Interested in learning more? [Request a demo](https://huggingface.co/platform#form) to see how you can leverage the Private Hub to accelerate ML development within your organization.
| huggingface/blog/blob/main/introducing-private-hub.md |
et's have a look inside the token classification pipeline. In the pipeline video, we looked at the different applications the Transformers library supports out of the box, one of them being token classification, for instance predicting for each word in a sentence whether they correspond to a person, an organization or a location. We can even group together the tokens corresponding to the same entity, for instance all the tokens that formed the word Sylvain here, or Hugging and Face. The token classification pipeline works the same way as the text classification pipeline we studied in a previous video. There are three steps: the tokenization, the model, and the post processing. The first two steps are identical to the text classification pipeline, except we use an auto token classification model instead of a sequence classification one. We tokenize our text then feed it to the model. Instead of getting one number for each possible label for the whole sentence, we get one number for each of the possible 9 labels for every token in the sentence, here 19. Like all the other models of the Transformers library, our model outputs logits, which we turn into predictions by using a SoftMax. We also get the predicted label for each token by taking the maximum prediction (since the softmax function preserves the order, we could have done it on the logits if we had no need of the predictions). The model config contains the label mapping in its id2label field. Using it, we can map every token to its corresponding label. The label O correspond to "no entity", which is why we didn't see it in our results in the first slide. On top of the label and the probability, those results included the start and end character in the sentence. We will need to use the offset mapping of the tokenizer to get those (look at the video linked below if you don't know about them already). Then, looping through each token that has a label distinct from O, we can build the list of results we got with our first pipeline. The last step is to group together tokens that correspond to the same entity. This is why we had two labels for each type of entity: I-PER and B-PER for instance. It allows us to know if a token is in the same entity as the previous one.() Note that there are two ways of labelling used for token classification, one (in pink here) uses the B-PER label at the beginning of each new entity, but the other (in blue) only uses it to separate two adjacent entities of the same type. In both cases, we can flag a new entity each time we see a new label appearing (either with the I or B prefix) then take all the following tokens labelled the same, with an I-flag. This, coupled with the offset mapping to get the start and end characters allows us to get the span of texts for each entity. | huggingface/course/blob/main/subtitles/en/raw/chapter6/03c_tokenization-pipeline-tf.md |
Managing Spaces with CircleCI Workflows
You can keep your app in sync with your GitHub repository with a **CircleCI workflow**.
[CircleCI](https://circleci.com) is a continuous integration and continuous delivery (CI/CD) platform that helps automate the software development process. A [CircleCI workflow](https://circleci.com/docs/workflows/) is a set of automated tasks defined in a configuration file, orchestrated by CircleCI, to streamline the process of building, testing, and deploying software applications.
*Note: For files larger than 10MB, Spaces requires Git-LFS. If you don't want to use Git-LFS, you may need to review your files and check your history. Use a tool like [BFG Repo-Cleaner](https://rtyley.github.io/bfg-repo-cleaner/) to remove any large files from your history. BFG Repo-Cleaner will keep a local copy of your repository as a backup.*
First, set up your GitHub repository and Spaces app together. Add your Spaces app as an additional remote to your existing Git repository.
```bash
git remote add space https://huggingface.co/spaces/HF_USERNAME/SPACE_NAME
```
Then force push to sync everything for the first time:
```bash
git push --force space main
```
Next, set up a [CircleCI workflow](https://circleci.com/docs/workflows/) to push your `main` git branch to Spaces.
In the example below:
* Replace `HF_USERNAME` with your username and `SPACE_NAME` with your Space name.
* [Create a context in CircleCI](https://circleci.com/docs/contexts/) and add an env variable into it called *HF_PERSONAL_TOKEN* (you can give it any name, use the key you create in place of HF_PERSONAL_TOKEN) and the value as your Hugging Face API token. You can find your Hugging Face API token under **API Tokens** on [your Hugging Face profile](https://huggingface.co/settings/tokens).
```yaml
version: 2.1
workflows:
main:
jobs:
- sync-to-huggingface:
context:
- HuggingFace
filters:
branches:
only:
- main
jobs:
sync-to-huggingface:
docker:
- image: alpine
resource_class: small
steps:
- run:
name: install git
command: apk update && apk add openssh-client git
- checkout
- run:
name: push to Huggingface hub
command: |
git config user.email "<your-email@here>"
git config user.name "<your-identifier>"
git push -f https://HF_USERNAME:${HF_PERSONAL_TOKEN}@huggingface.co/spaces/HF_USERNAME/SPACE_NAME main
``` | huggingface/hub-docs/blob/main/docs/hub/spaces-circleci.md |
--
title: TER
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
TER (Translation Edit Rate, also called Translation Error Rate) is a metric to quantify the edit operations that a
hypothesis requires to match a reference translation. We use the implementation that is already present in sacrebleu
(https://github.com/mjpost/sacreBLEU#ter), which in turn is inspired by the TERCOM implementation, which can be found
here: https://github.com/jhclark/tercom.
The implementation here is slightly different from sacrebleu in terms of the required input format. The length of
the references and hypotheses lists need to be the same, so you may need to transpose your references compared to
sacrebleu's required input format. See https://github.com/huggingface/datasets/issues/3154#issuecomment-950746534
See the README.md file at https://github.com/mjpost/sacreBLEU#ter for more information.
---
# Metric Card for TER
## Metric Description
TER (Translation Edit Rate, also called Translation Error Rate) is a metric to quantify the edit operations that a hypothesis requires to match a reference translation. We use the implementation that is already present in [sacrebleu](https://github.com/mjpost/sacreBLEU#ter), which in turn is inspired by the [TERCOM implementation](https://github.com/jhclark/tercom).
The implementation here is slightly different from sacrebleu in terms of the required input format. The length of the references and hypotheses lists need to be the same, so you may need to transpose your references compared to sacrebleu's required input format. See [this github issue](https://github.com/huggingface/datasets/issues/3154#issuecomment-950746534).
See the README.md file at https://github.com/mjpost/sacreBLEU#ter for more information.
## How to Use
This metric takes, at minimum, predicted sentences and reference sentences:
```python
>>> predictions = ["does this sentence match??",
... "what about this sentence?",
... "What did the TER metric user say to the developer?"]
>>> references = [["does this sentence match", "does this sentence match!?!"],
... ["wHaT aBoUt ThIs SeNtEnCe?", "wHaT aBoUt ThIs SeNtEnCe?"],
... ["Your jokes are...", "...TERrible"]]
>>> ter = evaluate.load("ter")
>>> results = ter.compute(predictions=predictions,
... references=references,
... case_sensitive=True)
>>> print(results)
{'score': 150.0, 'num_edits': 15, 'ref_length': 10.0}
```
### Inputs
This metric takes the following as input:
- **`predictions`** (`list` of `str`): The system stream (a sequence of segments).
- **`references`** (`list` of `list` of `str`): A list of one or more reference streams (each a sequence of segments).
- **`normalized`** (`boolean`): If `True`, applies basic tokenization and normalization to sentences. Defaults to `False`.
- **`ignore_punct`** (`boolean`): If `True`, applies basic tokenization and normalization to sentences. Defaults to `False`.
- **`support_zh_ja_chars`** (`boolean`): If `True`, tokenization/normalization supports processing of Chinese characters, as well as Japanese Kanji, Hiragana, Katakana, and Phonetic Extensions of Katakana. Only applies if `normalized = True`. Defaults to `False`.
- **`case_sensitive`** (`boolean`): If `False`, makes all predictions and references lowercase to ignore differences in case. Defaults to `False`.
### Output Values
This metric returns the following:
- **`score`** (`float`): TER score (num_edits / sum_ref_lengths * 100)
- **`num_edits`** (`int`): The cumulative number of edits
- **`ref_length`** (`float`): The cumulative average reference length
The output takes the following form:
```python
{'score': ter_score, 'num_edits': num_edits, 'ref_length': ref_length}
```
The metric can take on any value `0` and above. `0` is a perfect score, meaning the predictions exactly match the references and no edits were necessary. Higher scores are worse. Scores above 100 mean that the cumulative number of edits, `num_edits`, is higher than the cumulative length of the references, `ref_length`.
#### Values from Popular Papers
### Examples
Basic example with only predictions and references as inputs:
```python
>>> predictions = ["does this sentence match??",
... "what about this sentence?"]
>>> references = [["does this sentence match", "does this sentence match!?!"],
... ["wHaT aBoUt ThIs SeNtEnCe?", "wHaT aBoUt ThIs SeNtEnCe?"]]
>>> ter = evaluate.load("ter")
>>> results = ter.compute(predictions=predictions,
... references=references,
... case_sensitive=True)
>>> print(results)
{'score': 62.5, 'num_edits': 5, 'ref_length': 8.0}
```
Example with `normalization = True`:
```python
>>> predictions = ["does this sentence match??",
... "what about this sentence?"]
>>> references = [["does this sentence match", "does this sentence match!?!"],
... ["wHaT aBoUt ThIs SeNtEnCe?", "wHaT aBoUt ThIs SeNtEnCe?"]]
>>> ter = evaluate.load("ter")
>>> results = ter.compute(predictions=predictions,
... references=references,
... normalized=True,
... case_sensitive=True)
>>> print(results)
{'score': 57.14285714285714, 'num_edits': 6, 'ref_length': 10.5}
```
Example ignoring punctuation and capitalization, and everything matches:
```python
>>> predictions = ["does this sentence match??",
... "what about this sentence?"]
>>> references = [["does this sentence match", "does this sentence match!?!"],
... ["wHaT aBoUt ThIs SeNtEnCe?", "wHaT aBoUt ThIs SeNtEnCe?"]]
>>> ter = evaluate.load("ter")
>>> results = ter.compute(predictions=predictions,
... references=references,
... ignore_punct=True,
... case_sensitive=False)
>>> print(results)
{'score': 0.0, 'num_edits': 0, 'ref_length': 8.0}
```
Example ignoring punctuation and capitalization, but with an extra (incorrect) sample:
```python
>>> predictions = ["does this sentence match??",
... "what about this sentence?",
... "What did the TER metric user say to the developer?"]
>>> references = [["does this sentence match", "does this sentence match!?!"],
... ["wHaT aBoUt ThIs SeNtEnCe?", "wHaT aBoUt ThIs SeNtEnCe?"],
... ["Your jokes are...", "...TERrible"]]
>>> ter = evaluate.load("ter")
>>> results = ter.compute(predictions=predictions,
... references=references,
... ignore_punct=True,
... case_sensitive=False)
>>> print(results)
{'score': 100.0, 'num_edits': 10, 'ref_length': 10.0}
```
## Limitations and Bias
## Citation
```bibtex
@inproceedings{snover-etal-2006-study,
title = "A Study of Translation Edit Rate with Targeted Human Annotation",
author = "Snover, Matthew and
Dorr, Bonnie and
Schwartz, Rich and
Micciulla, Linnea and
Makhoul, John",
booktitle = "Proceedings of the 7th Conference of the Association for Machine Translation in the Americas: Technical Papers",
month = aug # " 8-12",
year = "2006",
address = "Cambridge, Massachusetts, USA",
publisher = "Association for Machine Translation in the Americas",
url = "https://aclanthology.org/2006.amta-papers.25",
pages = "223--231",
}
@inproceedings{post-2018-call,
title = "A Call for Clarity in Reporting {BLEU} Scores",
author = "Post, Matt",
booktitle = "Proceedings of the Third Conference on Machine Translation: Research Papers",
month = oct,
year = "2018",
address = "Belgium, Brussels",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/W18-6319",
pages = "186--191",
}
```
## Further References
- See [the sacreBLEU github repo](https://github.com/mjpost/sacreBLEU#ter) for more information.
| huggingface/evaluate/blob/main/metrics/ter/README.md |
--
title: "Speculative Decoding for 2x Faster Whisper Inference"
thumbnail: /blog/assets/whisper-speculative-decoding/thumbnail.png
authors:
- user: sanchit-gandhi
---
# Speculative Decoding for 2x Faster Whisper Inference
<a target="_blank" href="https://colab.research.google.com/github/sanchit-gandhi/notebooks/blob/main/speculative_decoding.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
Open AI's [Whisper](https://openai.com/research/whisper) is a general
purpose speech transcription model that achieves state-of-the-art results across a range of different benchmarks and
audio conditions. The latest [large-v3](https://huggingface.co/openai/whisper-large-v3) model tops the
[OpenASR Leaderboard](https://huggingface.co/spaces/hf-audio/open_asr_leaderboard), ranking as the best open-source
speech transcription model for English. The model also demonstrates strong multilingual performance, achieving less than
30% word error rate (WER) on 42 of the 58 languages tested in the Common Voice 15 dataset.
While the transcription accuracy is exceptional, the inference time is very slow. A 1 hour audio clip takes upwards of
6 minutes to transcribe on a 16GB T4 GPU, even after leveraging inference optimisations like [flash attention](https://huggingface.co/docs/transformers/perf_infer_gpu_one#flashattention-2),
half-precision, and [chunking](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.AutomaticSpeechRecognitionPipeline.chunk_length_s).
In this blog post, we demonstrate how Speculative Decoding can be employed to reduce the
inference time of Whisper by a **factor of 2**, while mathematically ensuring exactly the **same outputs** are achieved
from the model. As a result, this method provides a perfect drop-in replacement for existing Whisper pipelines, since it
provides free 2x speed-up while maintaining the same accuracy. For a more streamlined version of the blog post
with fewer explanations but all the code, see the accompanying [Google Colab](https://colab.research.google.com/github/sanchit-gandhi/notebooks/blob/main/speculative_decoding.ipynb).
## Speculative Decoding
Speculative Decoding was proposed in [Fast Inference from Transformers via Speculative Decoding](https://arxiv.org/abs/2211.17192)
by Yaniv Leviathan et. al. from Google. It works on the premise that a faster, **assistant model** very often generates the same tokens as a larger **main model**.
First, the assistant model auto-regressively generates a sequence of \\( N \\) *candidate tokens*, \\( \hat{\boldsymbol{y}}_{1:N} \\).
In the diagram below, the assistant model generates a sequence of 5 candidate tokens: `The quick brown sock jumps`.
<figure class="image table text-center m-0 w-full">
<video
style="max-width: 90%; margin: auto;"
controls playsinline
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/whisper-speculative-decoding/split_1.mp4"
></video>
</figure>
While these candidate tokens are generated quickly, they may differ from those predicted by the main model. Therefore,
in the second step, the candidate tokens are passed to the main model to be "verified". The main model takes the
candidate tokens as input and performs a **single forward pass**. The outputs of the main model are the "correct"
token for each step in the token sequence \\( \boldsymbol{y}_{1:N} \\).
<figure class="image table text-center m-0 w-full">
<video
style="max-width: 90%; margin: auto;"
controls playsinline
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/whisper-speculative-decoding/split_2.mp4"
></video>
</figure>
In the diagram above, we see that the first three tokens predicted by the main model agree with those from the assistant
model: <span style="color:green">The quick brown</span>. However, the fourth candidate token from the assistant model,
<span style="color:red">sock</span>, mismatches with the correct token from the main model, <span style="color:green">fox</span>.
We know that all candidate tokens up to the first mismatch are correct (<span style="color:green">The quick brown</span>),
since these agree with the predictions from the main model. However, after the first mismatch, the candidate tokens
diverge from the actual tokens predicted by the main model. Therefore, we can replace the first incorrect candidate
token (<span style="color:red">sock</span>) with the correct token from the main model (<span style="color:green">fox</span>),
and discard all predicted tokens that come after this, since these have diverged. The corrected sequence, `The quick brown fox`,
now forms the new input to the assistant model:
<figure class="image table text-center m-0 w-full">
<video
style="max-width: 90%; margin: auto;"
controls playsinline
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/whisper-speculative-decoding/split_3.mp4"
></video>
</figure>
The inference process then repeats, the assistant model generating a new set of \\( N \\) candidate tokens, which are verified
in a single forward pass by the main model.
<figure class="image table text-center m-0 w-full">
<video
style="max-width: 90%; margin: auto;"
controls playsinline
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/whisper-speculative-decoding/split_4.mp4"
></video>
</figure>
Since we auto-regressively generate using the fast, assistant model, and only perform verification forward passes with
the slow, main model, the decoding process is sped-up substantially. Furthermore, the verification forward passes
performed by the main model ensures that **exactly the same outputs** are achieved as if we were using the main model standalone.
This makes speculative decoding a perfect drop-in for existing Whisper pipelines, since one can be certain that the
same quality will be attained.
To get the biggest improvement in latency, the assistant model should be significantly faster than the main model,
while predicting the same token distribution as often as possible. In practice, these two attributes form a trade-off:
the faster a model is, the less accurate it is. However, since 70-80% of all predicted tokens tend to be "easier" tokens,
this trade-off is heavily biased towards selecting a faster model, rather than a more accurate one. Thus, the assistant
model should be at least 3x faster than the main model (the more the better), while predicting all the "easy" tokens
in the examples correctly. The remaining 20-30% of more "difficult" tokens can then be verified by the larger, main model.
The only constraint for selecting an assistant model is that it must share the same vocabulary as the main model. That is
to say, the assistant model must use one-to-one the same tokenizer as the main model.
Therefore, if we want to use speculative decoding with a multilingual variant of Whisper, e.g. [large-v2](https://huggingface.co/openai/whisper-large-v2)
(multilingual), we need to select a multilingual variant of Whisper as the assistant model, e.g. [tiny](https://huggingface.co/openai/tiny).
Whereas, if we want to use speculative decoding with and English-only version of Whisper, e.g. [medium.en](https://huggingface.co/openai/whisper-medium.en),
we need an English-only of version as the assistant model, e.g. [tiny.en](https://huggingface.co/openai/tiny.en).
At the current time, Whisper [large-v3](https://huggingface.co/openai/whisper-large-v3) is an exception, since
it is the only Whisper checkpoint with an expanded vocabulary size, and thus is not compatible with previous Whisper
checkpoints.
Now that we know the background behind speculative decoding, we're ready to dive into the practical implementation. In
the [🤗 Transformers](https://huggingface.co/docs/transformers/index) library, speculative decoding is implemented as
the "assisted generation" inference strategy. For more details about the implementation, the reader is advised to read
Joao Gante's excellent blog post on [Assisted Generation](https://huggingface.co/blog/assisted-generation).
## English Speech Transcription
### Baseline Implementation
We start by benchmarking Whisper [large-v2](https://huggingface.co/openai/whisper-large-v2) to get our baseline number
for inference speed. We can load the main model and it's corresponding processor via the convenient
[`AutoModelForSpeechSeq2Seq`](https://huggingface.co/docs/transformers/model_doc/auto#transformers.AutoModelForSpeechSeq2Seq)
and [`AutoProcessor`](https://huggingface.co/docs/transformers/model_doc/auto#transformers.AutoProcessor) classes. We'll
load the model in `float16` precision and make sure that loading time takes as little time as possible by passing
[`low_cpu_mem_usage=True`](https://huggingface.co/docs/transformers/main_classes/model#large-model-loading). In addition,
we want to make sure that the model is loaded in [safetensors](https://huggingface.co/docs/diffusers/main/en/using-diffusers/using_safetensors)
format by passing [`use_safetensors=True`](https://huggingface.co/docs/transformers/main_classes/model#transformers.PreTrainedModel.from_pretrained.use_safetensors).
Finally, we'll pass the argument `attn_implementation="sdpa"` to benefit from Flash Attention speed-ups through PyTorch's
[SDPA attention kernel](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html):
```python
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "openai/whisper-large-v2"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
use_safetensors=True,
attn_implementation="sdpa",
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
```
Let's load the English speech transcription dataset that we will use for benchmarking. We'll load a small dataset
consisting of 73 samples from the [LibriSpeech ASR](https://huggingface.co/datasets/librispeech_asr) validation-clean
dataset. This amounts to ~9MB of data, so it's very lightweight and quick to download on device:
```python
from datasets import load_dataset
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
```
For the benchmark, we only want to measure the generation time, so let's write a short helper function that measures
this step. The following function will return both the decoded tokens and the time it took to run the model:
```python
import time
def generate_with_time(model, inputs, **kwargs):
start_time = time.time()
outputs = model.generate(**inputs, **kwargs)
generation_time = time.time() - start_time
return outputs, generation_time
```
We can now iterate over the audio samples in our dataset and sum up the overall generation time:
```python
from tqdm import tqdm
all_time = 0
predictions = []
references = []
for sample in tqdm(dataset):
audio = sample["audio"]
inputs = processor(audio["array"], sampling_rate=audio["sampling_rate"], return_tensors="pt")
inputs = inputs.to(device=device, dtype=torch.float16)
output, gen_time = generate_with_time(model, inputs)
all_time += gen_time
predictions.append(processor.batch_decode(output, skip_special_tokens=True, normalize=True)[0])
references.append(processor.tokenizer._normalize(sample["text"]))
print(all_time)
```
**Output:**
```
100%|██████████| 73/73 [01:37<00:00, 1.33s/it]
72.99542546272278
```
Alright! We see that transcribing the 73 samples took 73 seconds. Let's check the WER of the predictions:
```python
from evaluate import load
wer = load("wer")
print(wer.compute(predictions=predictions, references=references))
```
**Output:**
0.03507271171941831
```
Our final baseline number is 73 seconds for a WER of 3.5%.
### Speculative Decoding
Now let's load the assistant model for speculative decoding. In this example, we'll use a distilled variant of Whisper,
[distil-large-v2](https://huggingface.co/distil-whisper/distil-large-v2). The distilled model copies the entire encoder
from Whisper, but only 2 of the 32 decoder layers. As such, it runs 6x faster than Whisper, while performing to within
1% WER on out-of-distribution test sets. This makes it the perfect choice as an assistant model, since it has both
high transcription accuracy and fast generation \\({}^1\\).
Since Distil-Whisper uses exactly the same encoder as the Whisper model, we can share the encoder across the main and
assistant models. We then only have to load the 2-layer decoder from Distil-Whisper as a "decoder-only" model. We can do
this through the convenient [`AutoModelForCausalLM`](https://huggingface.co/docs/transformers/model_doc/auto#transformers.AutoModelForCausalLM)
auto class. In practice, this results in only an 8% increase to VRAM over using the main model alone.
```python
from transformers import AutoModelForCausalLM
assistant_model_id = "distil-whisper/distil-large-v2"
assistant_model = AutoModelForCausalLM.from_pretrained(
assistant_model_id,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
use_safetensors=True,
attn_implementation="sdpa",
)
assistant_model.to(device);
```
------------------------------------------------------------------------
\\({}^1\\) We intend to release an improved variant of Distil-Whisper with a stronger alignment in the token distribution
that will improve speculative decoding performance further. Follow the [Distil-Whisper repository](https://github.com/huggingface/distil-whisper)
for updates.
------------------------------------------------------------------------
We can define a modified function for our speculative decoding benchmark. The only difference from the previous function
is that we pass the assistant model to our call to `.generate`:
```python
def assisted_generate_with_time(model, inputs, **kwargs):
start_time = time.time()
outputs = model.generate(**inputs, assistant_model=assistant_model, **kwargs)
generation_time = time.time() - start_time
return outputs, generation_time
```
Let's run the benchmark with speculative decoding, using Distil-Whisper as the assistant to Whisper:
```python
all_time = 0
predictions = []
references = []
for sample in tqdm(dataset):
audio = sample["audio"]
inputs = processor(audio["array"], sampling_rate=audio["sampling_rate"], return_tensors="pt")
inputs = inputs.to(device=device, dtype=torch.float16)
output, gen_time = assisted_generate_with_time(model, inputs)
all_time += gen_time
predictions.append(processor.batch_decode(output, skip_special_tokens=True, normalize=True)[0])
references.append(processor.tokenizer._normalize(sample["text"]))
print(all_time)
```
**Outputs:**
```
100%|██████████| 73/73 [00:38<00:00, 1.88it/s]
32.69683289527893
```
With speculative decoding, the inference time was just 33 seconds, 2.2x faster than before! Let's verify we have the same
WER:
```python
print(wer.compute(predictions=predictions, references=references))
```
**Outputs:**
```
0.03507271171941831
```
Perfect! 3.5% WER again, as we have identical outputs to using the main model standalone.
Speculative decoding can also be used with the easy 🤗 Transformers [pipeline](https://huggingface.co/docs/transformers/pipeline_tutorial) API for inference. Below, we instantiate the pipeline using the model and processor, and then use it to
transcribe the first sample from the toy dataset. This can be extended to transcribe audio samples of arbitrary length,
including with the use of batching:
```python
from transformers import pipeline
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
chunk_length_s=15,
batch_size=4,
generate_kwargs={"assistant_model": assistant_model},
torch_dtype=torch_dtype,
device=device,
)
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
```
**Outputs:**
```
Mr. Quilter is the apostle of the middle classes and we are glad to welcome his gospel.
```
An end-to-end code snippet for running speculative decoding with Whisper and Distil-Whisper can be found on the [Distil-Whisper model card](https://huggingface.co/distil-whisper/distil-large-v2#speculative-decoding).
It combines the stages of inference covered in this notebook into a single code example.
## Multilingual Speech Transcription
Distil-Whisper is the perfect assistant model for English speech transcription, since it performs to within 1% WER of the
original Whisper model, while being 6x faster over short and long-form audio samples. However, the official Distil-Whisper
checkpoints are English only, meaning they cannot be used for multilingual speech transcription.
To use speculative decoding for multilingual speech transcription, one could either use one of the [official multilingual Whisper checkpoints](https://huggingface.co/openai/whisper-large-v2#model-details),
or a fine-tuned variant of Whisper. At the time of writing, there are over 5,000 [fine-tuned Whisper checkpoints](https://huggingface.co/models?other=whisper)
on the Hugging Face Hub in over 100 languages. These provide an excellent starting point for selecting assistant Whisper
checkpoints that perform very well on a single language. In this example, we'll use the smallest official multilingual
checkpoint, Whisper [tiny](https://huggingface.co/openai/whisper-tiny). Feel free to experiment with different checkpoints
fine-tuned in your language!
Let's load the weights for our new assistant model, Whisper tiny. Since the encoder in Whisper tiny differs from that in
large-v2, this time we'll load both the encoder and decoder using the `AutoModelForSpeechSeq2Seq` class:
```python
assistant_model_id = "openai/whisper-tiny"
assistant_model = AutoModelForSpeechSeq2Seq.from_pretrained(
assistant_model_id,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
use_safetensors=True,
attn_implementation="sdpa",
)
assistant_model.to(device);
```
For our benchmarking dataset, we'll load 73 samples from the Dutch ("nl") split of the [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) dataset:
```python
dataset = load_dataset("sanchit-gandhi/voxpopuli_dummy", "nl", split="validation")
```
Great! We can now re-run our benchmark for our baseline Whisper large-v2 model as before. The only change we make is that
we pass the language and task arguments to our generate function, in order to ensure we perform speech transcription
(not speech translation). Speculative decoding is fully compatible with both the speech transcription and translation tasks. Simply
set the task argument as required below:
```python
all_time = 0
predictions = []
references = []
for sample in tqdm(dataset):
audio = sample["audio"]
inputs = processor(audio["array"], sampling_rate=audio["sampling_rate"], return_tensors="pt")
inputs = inputs.to(device=device, dtype=torch.float16)
output, gen_time = generate_with_time(model, inputs, language="nl", task="transcribe")
all_time += gen_time
predictions.append(processor.batch_decode(output, skip_special_tokens=True, normalize=True)[0])
references.append(processor.tokenizer._normalize(sample["normalized_text"]))
wer_result = wer.compute(predictions=predictions, references=references)
print("Time:", all_time)
print("WER:", wer_result)
```
**Outputs:**
```
100%|██████████| 73/73 [02:05<00:00, 1.72s/it]
Time: 116.50992178916931
WER: 0.127190136275146
```
Right! We have our baseline time of 117 seconds and a WER of 12.8%. Let's re-run the generation process using speculative decoding:
```python
all_time = 0
predictions = []
references = []
for sample in tqdm(dataset):
audio = sample["audio"]
inputs = processor(audio["array"], sampling_rate=audio["sampling_rate"], return_tensors="pt")
inputs = inputs.to(device=device, dtype=torch.float16)
output, gen_time = assisted_generate_with_time(model, inputs, language="nl", task="transcribe")
all_time += gen_time
predictions.append(processor.batch_decode(output, skip_special_tokens=True, normalize=True)[0])
references.append(processor.tokenizer._normalize(sample["normalized_text"]))
wer_result = wer.compute(predictions=predictions, references=references)
print("Time:", all_time)
print("WER:", wer_result)
```
**Outputs:**
```
100%|██████████| 73/73 [01:08<00:00, 1.06it/s]
Time: 62.10229682922363
WER: 0.127190136275146
```
Again, we achieve 12.8% WER, but this time in just 62 seconds of inference time, representing a speed-up of 1.9x.
Given the low overhead of loading the assistant model and the mathematical property that exactly the same outputs are
achieved, speculative decoding offers the perfect drop-in replacement to existing Whisper pipelines.
## Strategies for Efficient Speculative Decoding
In this final section, we cover two strategies for ensuring the fastest possible inference time with speculative decoding.
#### Assistant Model
Our objective is to select an assistant model that is at least 3x faster than the main model **and** transcribes at least
70-80% of the predicted tokens correctly, typically the "easier" tokens in the examples. If you have a particular
language in which you want to transcribe, an effective strategy is to train two Whisper models of different sizes, and
use one as the assistant to the other:
* First, fine-tune Whisper [large-v3](https://huggingface.co/openai/whisper-large-v3) to act as your main model
* Second, distil Whisper [large-v3](https://huggingface.co/openai/whisper-large-v3) on the same dataset to act as a fast assistant model
Fine-tuning and distillation can improve the WER performance of both the main and assistant models on your chosen language,
while maximising the alignment in the token distributions. A complete guide to Whisper fine-tuning can be found
[here](https://huggingface.co/blog/fine-tune-whisper), and distillation [here](https://github.com/huggingface/distil-whisper/tree/main/training).
#### Batch Size
It is worth noting that the largest speed gains with speculative decoding come with a batch size of 1. For batched
speculative decoding, all candidate tokens **across the batch** must match the validation tokens in order for the tokens
to be accepted. If a token in the batch at a given position does not agree, all candidate tokens that proceed the position
are discarded. Consequently, speculative decoding favours lower batch sizes. In practice, we find that speculative decoding
provides a speed-up until a batch size of 4. Above batch size 4, speculative decoding returns slower inference than the
main model alone. For full results, refer to Section D.3 of the [Distil-Whisper paper](https://arxiv.org/pdf/2311.00430.pdf).
## Conclusion
In this blog post, we covered the inference strategy of speculative decoding, as applied to the Whisper model for speech
transcription. We demonstrated how 2x speed-ups can be achieved, while mathematically ensuring the same outputs as using
the original model alone. We encourage you to try speculative decoding as a drop-in replacement for existing Whisper
pipelines, given the low overhead of using the additional assistant model and the guarantee of the same transcription results.
## Acknowledgements
Blog post by [Sanchit Gandhi](https://huggingface.co/sanchit-gandhi). Many thanks to [Patrick von Platen](https://huggingface.co/patrickvonplaten)
and [Pedro Cuenca](https://huggingface.co/pcuenq) for their constructive comments, and to [Joao Gante](https://huggingface.co/joaogante)
for the assisted generation implementation in 🤗 Transformers. | huggingface/blog/blob/main/whisper-speculative-decoding.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# T5
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=t5">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-t5-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/t5-base">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
<a href="https://huggingface.co/papers/1910.10683">
<img alt="Paper page" src="https://img.shields.io/badge/Paper%20page-1910.10683-green">
</a>
</div>
## Overview
The T5 model was presented in [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/pdf/1910.10683.pdf) by [Colin Raffel](https://huggingface.co/craffel), Noam Shazeer, [Adam Roberts](https://huggingface.co/adarob), Katherine Lee, Sharan Narang,
Michael Matena, Yanqi Zhou, Wei Li, [Peter J. Liu](https://huggingface.co/peterjliu).
The abstract from the paper is the following:
*Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream
task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning
has given rise to a diversity of approaches, methodology, and practice. In this paper, we explore the landscape of
transfer learning techniques for NLP by introducing a unified framework that converts every language problem into a
text-to-text format. Our systematic study compares pretraining objectives, architectures, unlabeled datasets, transfer
approaches, and other factors on dozens of language understanding tasks. By combining the insights from our exploration
with scale and our new "Colossal Clean Crawled Corpus", we achieve state-of-the-art results on many benchmarks covering
summarization, question answering, text classification, and more. To facilitate future work on transfer learning for
NLP, we release our dataset, pre-trained models, and code.*
All checkpoints can be found on the [hub](https://huggingface.co/models?search=t5).
This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/google-research/text-to-text-transfer-transformer).
## Usage tips
- T5 is an encoder-decoder model pre-trained on a multi-task mixture of unsupervised and supervised tasks and for which
each task is converted into a text-to-text format. T5 works well on a variety of tasks out-of-the-box by prepending a
different prefix to the input corresponding to each task, e.g., for translation: *translate English to German: ...*,
for summarization: *summarize: ...*.
- The pretraining includes both supervised and self-supervised training. Supervised training is conducted on downstream tasks provided by the GLUE and SuperGLUE benchmarks (converting them into text-to-text tasks as explained above).
- Self-supervised training uses corrupted tokens, by randomly removing 15% of the tokens and replacing them with individual sentinel tokens (if several consecutive tokens are marked for removal, the whole group is replaced with a single sentinel token). The input of the encoder is the corrupted sentence, the input of the decoder is the original sentence and the target is then the dropped out tokens delimited by their sentinel tokens.
- T5 uses relative scalar embeddings. Encoder input padding can be done on the left and on the right.
- See the [training](#training), [inference](#inference) and [scripts](#scripts) sections below for all details regarding usage.
T5 comes in different sizes:
- [t5-small](https://huggingface.co/t5-small)
- [t5-base](https://huggingface.co/t5-base)
- [t5-large](https://huggingface.co/t5-large)
- [t5-3b](https://huggingface.co/t5-3b)
- [t5-11b](https://huggingface.co/t5-11b).
Based on the original T5 model, Google has released some follow-up works:
- **T5v1.1**: T5v1.1 is an improved version of T5 with some architectural tweaks, and is pre-trained on C4 only without
mixing in the supervised tasks. Refer to the documentation of T5v1.1 which can be found [here](t5v1.1).
- **mT5**: mT5 is a multilingual T5 model. It is pre-trained on the mC4 corpus, which includes 101 languages. Refer to
the documentation of mT5 which can be found [here](mt5).
- **byT5**: byT5 is a T5 model pre-trained on byte sequences rather than SentencePiece subword token sequences. Refer
to the documentation of byT5 which can be found [here](byt5).
- **UL2**: UL2 is a T5 like model pretrained on various denoising objectives
- **Flan-T5**: Flan is a pretraining methods that is based on prompting. The Flan-T5 are T5 models trained on the Flan collection of
datasets which include: `taskmaster2`, `djaym7/wiki_dialog`, `deepmind/code_contests`, `lambada`, `gsm8k`, `aqua_rat`, `esnli`, `quasc` and `qed`.
- **FLan-UL2** : the UL2 model finetuned using the "Flan" prompt tuning and dataset collection.
- **UMT5**: UmT5 is a multilingual T5 model trained on an improved and refreshed mC4 multilingual corpus, 29 trillion characters across 107 language, using a new sampling method, UniMax. Refer to
the documentation of mT5 which can be found [here](umt5).
## Training
T5 is an encoder-decoder model and converts all NLP problems into a text-to-text format. It is trained using teacher
forcing. This means that for training, we always need an input sequence and a corresponding target sequence. The input
sequence is fed to the model using `input_ids`. The target sequence is shifted to the right, i.e., prepended by a
start-sequence token and fed to the decoder using the `decoder_input_ids`. In teacher-forcing style, the target
sequence is then appended by the EOS token and corresponds to the `labels`. The PAD token is hereby used as the
start-sequence token. T5 can be trained / fine-tuned both in a supervised and unsupervised fashion.
One can use [`T5ForConditionalGeneration`] (or the Tensorflow/Flax variant), which includes the
language modeling head on top of the decoder.
- Unsupervised denoising training
In this setup, spans of the input sequence are masked by so-called sentinel tokens (*a.k.a* unique mask tokens) and
the output sequence is formed as a concatenation of the same sentinel tokens and the *real* masked tokens. Each
sentinel token represents a unique mask token for this sentence and should start with `<extra_id_0>`,
`<extra_id_1>`, ... up to `<extra_id_99>`. As a default, 100 sentinel tokens are available in
[`T5Tokenizer`].
For instance, the sentence "The cute dog walks in the park" with the masks put on "cute dog" and "the" should be
processed as follows:
```python
>>> from transformers import T5Tokenizer, T5ForConditionalGeneration
>>> tokenizer = T5Tokenizer.from_pretrained("t5-small")
>>> model = T5ForConditionalGeneration.from_pretrained("t5-small")
>>> input_ids = tokenizer("The <extra_id_0> walks in <extra_id_1> park", return_tensors="pt").input_ids
>>> labels = tokenizer("<extra_id_0> cute dog <extra_id_1> the <extra_id_2>", return_tensors="pt").input_ids
>>> # the forward function automatically creates the correct decoder_input_ids
>>> loss = model(input_ids=input_ids, labels=labels).loss
>>> loss.item()
3.7837
```
If you're interested in pre-training T5 on a new corpus, check out the [run_t5_mlm_flax.py](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling) script in the Examples
directory.
- Supervised training
In this setup, the input sequence and output sequence are a standard sequence-to-sequence input-output mapping.
Suppose that we want to fine-tune the model for translation for example, and we have a training example: the input
sequence "The house is wonderful." and output sequence "Das Haus ist wunderbar.", then they should be prepared for
the model as follows:
```python
>>> from transformers import T5Tokenizer, T5ForConditionalGeneration
>>> tokenizer = T5Tokenizer.from_pretrained("t5-small")
>>> model = T5ForConditionalGeneration.from_pretrained("t5-small")
>>> input_ids = tokenizer("translate English to German: The house is wonderful.", return_tensors="pt").input_ids
>>> labels = tokenizer("Das Haus ist wunderbar.", return_tensors="pt").input_ids
>>> # the forward function automatically creates the correct decoder_input_ids
>>> loss = model(input_ids=input_ids, labels=labels).loss
>>> loss.item()
0.2542
```
As you can see, only 2 inputs are required for the model in order to compute a loss: `input_ids` (which are the
`input_ids` of the encoded input sequence) and `labels` (which are the `input_ids` of the encoded
target sequence). The model will automatically create the `decoder_input_ids` based on the `labels`, by
shifting them one position to the right and prepending the `config.decoder_start_token_id`, which for T5 is
equal to 0 (i.e. the id of the pad token). Also note the task prefix: we prepend the input sequence with 'translate
English to German: ' before encoding it. This will help in improving the performance, as this task prefix was used
during T5's pre-training.
However, the example above only shows a single training example. In practice, one trains deep learning models in
batches. This entails that we must pad/truncate examples to the same length. For encoder-decoder models, one
typically defines a `max_source_length` and `max_target_length`, which determine the maximum length of the
input and output sequences respectively (otherwise they are truncated). These should be carefully set depending on
the task.
In addition, we must make sure that padding token id's of the `labels` are not taken into account by the loss
function. In PyTorch and Tensorflow, this can be done by replacing them with -100, which is the `ignore_index`
of the `CrossEntropyLoss`. In Flax, one can use the `decoder_attention_mask` to ignore padded tokens from
the loss (see the [Flax summarization script](https://github.com/huggingface/transformers/tree/main/examples/flax/summarization) for details). We also pass
`attention_mask` as additional input to the model, which makes sure that padding tokens of the inputs are
ignored. The code example below illustrates all of this.
```python
>>> from transformers import T5Tokenizer, T5ForConditionalGeneration
>>> import torch
>>> tokenizer = T5Tokenizer.from_pretrained("t5-small")
>>> model = T5ForConditionalGeneration.from_pretrained("t5-small")
>>> # the following 2 hyperparameters are task-specific
>>> max_source_length = 512
>>> max_target_length = 128
>>> # Suppose we have the following 2 training examples:
>>> input_sequence_1 = "Welcome to NYC"
>>> output_sequence_1 = "Bienvenue à NYC"
>>> input_sequence_2 = "HuggingFace is a company"
>>> output_sequence_2 = "HuggingFace est une entreprise"
>>> # encode the inputs
>>> task_prefix = "translate English to French: "
>>> input_sequences = [input_sequence_1, input_sequence_2]
>>> encoding = tokenizer(
... [task_prefix + sequence for sequence in input_sequences],
... padding="longest",
... max_length=max_source_length,
... truncation=True,
... return_tensors="pt",
... )
>>> input_ids, attention_mask = encoding.input_ids, encoding.attention_mask
>>> # encode the targets
>>> target_encoding = tokenizer(
... [output_sequence_1, output_sequence_2],
... padding="longest",
... max_length=max_target_length,
... truncation=True,
... return_tensors="pt",
... )
>>> labels = target_encoding.input_ids
>>> # replace padding token id's of the labels by -100 so it's ignored by the loss
>>> labels[labels == tokenizer.pad_token_id] = -100
>>> # forward pass
>>> loss = model(input_ids=input_ids, attention_mask=attention_mask, labels=labels).loss
>>> loss.item()
0.188
```
Additional training tips:
- T5 models need a slightly higher learning rate than the default one set in the `Trainer` when using the AdamW
optimizer. Typically, 1e-4 and 3e-4 work well for most problems (classification, summarization, translation, question
answering, question generation). Note that T5 was pre-trained using the AdaFactor optimizer.
According to [this forum post](https://discuss.huggingface.co/t/t5-finetuning-tips/684), task prefixes matter when
(1) doing multi-task training (2) your task is similar or related to one of the supervised tasks used in T5's
pre-training mixture (see Appendix D of the [paper](https://arxiv.org/pdf/1910.10683.pdf) for the task prefixes
used).
If training on TPU, it is recommended to pad all examples of the dataset to the same length or make use of
*pad_to_multiple_of* to have a small number of predefined bucket sizes to fit all examples in. Dynamically padding
batches to the longest example is not recommended on TPU as it triggers a recompilation for every batch shape that is
encountered during training thus significantly slowing down the training. only padding up to the longest example in a
batch) leads to very slow training on TPU.
## Inference
At inference time, it is recommended to use [`~generation.GenerationMixin.generate`]. This
method takes care of encoding the input and feeding the encoded hidden states via cross-attention layers to the decoder
and auto-regressively generates the decoder output. Check out [this blog post](https://huggingface.co/blog/how-to-generate) to know all the details about generating text with Transformers.
There's also [this blog post](https://huggingface.co/blog/encoder-decoder#encoder-decoder) which explains how
generation works in general in encoder-decoder models.
```python
>>> from transformers import T5Tokenizer, T5ForConditionalGeneration
>>> tokenizer = T5Tokenizer.from_pretrained("t5-small")
>>> model = T5ForConditionalGeneration.from_pretrained("t5-small")
>>> input_ids = tokenizer("translate English to German: The house is wonderful.", return_tensors="pt").input_ids
>>> outputs = model.generate(input_ids)
>>> print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Das Haus ist wunderbar.
```
Note that T5 uses the `pad_token_id` as the `decoder_start_token_id`, so when doing generation without using
[`~generation.GenerationMixin.generate`], make sure you start it with the `pad_token_id`.
The example above only shows a single example. You can also do batched inference, like so:
```python
>>> from transformers import T5Tokenizer, T5ForConditionalGeneration
>>> tokenizer = T5Tokenizer.from_pretrained("t5-small")
>>> model = T5ForConditionalGeneration.from_pretrained("t5-small")
>>> task_prefix = "translate English to German: "
>>> # use different length sentences to test batching
>>> sentences = ["The house is wonderful.", "I like to work in NYC."]
>>> inputs = tokenizer([task_prefix + sentence for sentence in sentences], return_tensors="pt", padding=True)
>>> output_sequences = model.generate(
... input_ids=inputs["input_ids"],
... attention_mask=inputs["attention_mask"],
... do_sample=False, # disable sampling to test if batching affects output
... )
>>> print(tokenizer.batch_decode(output_sequences, skip_special_tokens=True))
['Das Haus ist wunderbar.', 'Ich arbeite gerne in NYC.']
```
Because T5 has been trained with the span-mask denoising objective,
it can be used to predict the sentinel (masked-out) tokens during inference.
The predicted tokens will then be placed between the sentinel tokens.
```python
>>> from transformers import T5Tokenizer, T5ForConditionalGeneration
>>> tokenizer = T5Tokenizer.from_pretrained("t5-small")
>>> model = T5ForConditionalGeneration.from_pretrained("t5-small")
>>> input_ids = tokenizer("The <extra_id_0> walks in <extra_id_1> park", return_tensors="pt").input_ids
>>> sequence_ids = model.generate(input_ids)
>>> sequences = tokenizer.batch_decode(sequence_ids)
>>> sequences
['<pad><extra_id_0> park offers<extra_id_1> the<extra_id_2> park.</s>']
```
## Performance
If you'd like a faster training and inference performance, install [NVIDIA APEX](https://github.com/NVIDIA/apex#quick-start) for NVIDIA GPUs, or [ROCm APEX](https://github.com/ROCmSoftwarePlatform/apex) for AMD GPUs and then the model will automatically use `apex.normalization.FusedRMSNorm` instead of `T5LayerNorm`. The former uses an optimized fused kernel which is several times faster than the latter.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with T5. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<PipelineTag pipeline="text-classification"/>
- A notebook for how to [finetune T5 for classification and multiple choice](https://colab.research.google.com/github/patil-suraj/exploring-T5/blob/master/t5_fine_tuning.ipynb).
- A notebook for how to [finetune T5 for sentiment span extraction](https://colab.research.google.com/github/enzoampil/t5-intro/blob/master/t5_qa_training_pytorch_span_extraction.ipynb). 🌎
<PipelineTag pipeline="token-classification"/>
- A notebook for how to [finetune T5 for named entity recognition](https://colab.research.google.com/drive/1obr78FY_cBmWY5ODViCmzdY6O1KB65Vc?usp=sharing). 🌎
<PipelineTag pipeline="text-generation"/>
- A notebook for [Finetuning CodeT5 for generating docstrings from Ruby code](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/T5/Fine_tune_CodeT5_for_generating_docstrings_from_Ruby_code.ipynb).
<PipelineTag pipeline="summarization"/>
- A notebook to [Finetune T5-base-dutch to perform Dutch abstractive summarization on a TPU](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/T5/Fine_tuning_Dutch_T5_base_on_CNN_Daily_Mail_for_summarization_(on_TPU_using_HuggingFace_Accelerate).ipynb).
- A notebook for how to [finetune T5 for summarization in PyTorch and track experiments with WandB](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_summarization_wandb.ipynb#scrollTo=OKRpFvYhBauC). 🌎
- A blog post on [Distributed Training: Train BART/T5 for Summarization using 🤗 Transformers and Amazon SageMaker](https://huggingface.co/blog/sagemaker-distributed-training-seq2seq).
- [`T5ForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization.ipynb).
- [`TFT5ForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization-tf.ipynb).
- [`FlaxT5ForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/summarization).
- [Summarization](https://huggingface.co/course/chapter7/5?fw=pt#summarization) chapter of the 🤗 Hugging Face course.
- [Summarization task guide](../tasks/summarization)
<PipelineTag pipeline="fill-mask"/>
- [`FlaxT5ForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#t5-like-span-masked-language-modeling) for training T5 with a span-masked language model objective. The script also shows how to train a T5 tokenizer. [`FlaxT5ForConditionalGeneration`] is also supported by this [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb).
<PipelineTag pipeline="translation"/>
- [`T5ForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/translation) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation.ipynb).
- [`TFT5ForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/translation) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation-tf.ipynb).
- [Translation task guide](../tasks/translation)
<PipelineTag pipeline="question-answering"/>
- A notebook on how to [finetune T5 for question answering with TensorFlow 2](https://colab.research.google.com/github/snapthat/TF-T5-text-to-text/blob/master/snapthatT5/notebooks/TF-T5-Datasets%20Training.ipynb). 🌎
- A notebook on how to [finetune T5 for question answering on a TPU](https://colab.research.google.com/github/patil-suraj/exploring-T5/blob/master/T5_on_TPU.ipynb#scrollTo=QLGiFCDqvuil).
🚀 **Deploy**
- A blog post on how to deploy [T5 11B for inference for less than $500](https://www.philschmid.de/deploy-t5-11b).
## T5Config
[[autodoc]] T5Config
## T5Tokenizer
[[autodoc]] T5Tokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## T5TokenizerFast
[[autodoc]] T5TokenizerFast
<frameworkcontent>
<pt>
## T5Model
[[autodoc]] T5Model
- forward
## T5ForConditionalGeneration
[[autodoc]] T5ForConditionalGeneration
- forward
## T5EncoderModel
[[autodoc]] T5EncoderModel
- forward
## T5ForSequenceClassification
[[autodoc]] T5ForSequenceClassification
- forward
## T5ForQuestionAnswering
[[autodoc]] T5ForQuestionAnswering
- forward
</pt>
<tf>
## TFT5Model
[[autodoc]] TFT5Model
- call
## TFT5ForConditionalGeneration
[[autodoc]] TFT5ForConditionalGeneration
- call
## TFT5EncoderModel
[[autodoc]] TFT5EncoderModel
- call
</tf>
<jax>
## FlaxT5Model
[[autodoc]] FlaxT5Model
- __call__
- encode
- decode
## FlaxT5ForConditionalGeneration
[[autodoc]] FlaxT5ForConditionalGeneration
- __call__
- encode
- decode
## FlaxT5EncoderModel
[[autodoc]] FlaxT5EncoderModel
- __call__
</jax>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/t5.md |
FrameworkSwitchCourse {fw} />
# Fine-tuning a model with Keras[[fine-tuning-a-model-with-keras]]
<CourseFloatingBanner chapter={3}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter3/section3_tf.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter3/section3_tf.ipynb"},
]} />
Once you've done all the data preprocessing work in the last section, you have just a few steps left to train the model. Note, however, that the `model.fit()` command will run very slowly on a CPU. If you don't have a GPU set up, you can get access to free GPUs or TPUs on [Google Colab](https://colab.research.google.com/).
The code examples below assume you have already executed the examples in the previous section. Here is a short summary recapping what you need:
```py
from datasets import load_dataset
from transformers import AutoTokenizer, DataCollatorWithPadding
import numpy as np
raw_datasets = load_dataset("glue", "mrpc")
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
tf_train_dataset = tokenized_datasets["train"].to_tf_dataset(
columns=["attention_mask", "input_ids", "token_type_ids"],
label_cols=["labels"],
shuffle=True,
collate_fn=data_collator,
batch_size=8,
)
tf_validation_dataset = tokenized_datasets["validation"].to_tf_dataset(
columns=["attention_mask", "input_ids", "token_type_ids"],
label_cols=["labels"],
shuffle=False,
collate_fn=data_collator,
batch_size=8,
)
```
### Training[[training]]
TensorFlow models imported from 🤗 Transformers are already Keras models. Here is a short introduction to Keras.
<Youtube id="rnTGBy2ax1c"/>
That means that once we have our data, very little work is required to begin training on it.
<Youtube id="AUozVp78dhk"/>
As in the [previous chapter](/course/chapter2), we will use the `TFAutoModelForSequenceClassification` class, with two labels:
```py
from transformers import TFAutoModelForSequenceClassification
model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
```
You will notice that unlike in [Chapter 2](/course/chapter2), you get a warning after instantiating this pretrained model. This is because BERT has not been pretrained on classifying pairs of sentences, so the head of the pretrained model has been discarded and a new head suitable for sequence classification has been inserted instead. The warnings indicate that some weights were not used (the ones corresponding to the dropped pretraining head) and that some others were randomly initialized (the ones for the new head). It concludes by encouraging you to train the model, which is exactly what we are going to do now.
To fine-tune the model on our dataset, we just have to `compile()` our model and then pass our data to the `fit()` method. This will start the fine-tuning process (which should take a couple of minutes on a GPU) and report training loss as it goes, plus the validation loss at the end of each epoch.
<Tip>
Note that 🤗 Transformers models have a special ability that most Keras models don't - they can automatically use an appropriate loss which they compute internally. They will use this loss by default if you don't set a loss argument in `compile()`. Note that to use the internal loss you'll need to pass your labels as part of the input, not as a separate label, which is the normal way to use labels with Keras models. You'll see examples of this in Part 2 of the course, where defining the correct loss function can be tricky. For sequence classification, however, a standard Keras loss function works fine, so that's what we'll use here.
</Tip>
```py
from tensorflow.keras.losses import SparseCategoricalCrossentropy
model.compile(
optimizer="adam",
loss=SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"],
)
model.fit(
tf_train_dataset,
validation_data=tf_validation_dataset,
)
```
<Tip warning={true}>
Note a very common pitfall here — you *can* just pass the name of the loss as a string to Keras, but by default Keras will assume that you have already applied a softmax to your outputs. Many models, however, output the values right before the softmax is applied, which are also known as the *logits*. We need to tell the loss function that that's what our model does, and the only way to do that is to call it directly, rather than by name with a string.
</Tip>
### Improving training performance[[improving-training-performance]]
<Youtube id="cpzq6ESSM5c"/>
If you try the above code, it certainly runs, but you'll find that the loss declines only slowly or sporadically. The primary cause
is the *learning rate*. As with the loss, when we pass Keras the name of an optimizer as a string, Keras initializes
that optimizer with default values for all parameters, including learning rate. From long experience, though, we know
that transformer models benefit from a much lower learning rate than the default for Adam, which is 1e-3, also written
as 10 to the power of -3, or 0.001. 5e-5 (0.00005), which is some twenty times lower, is a much better starting point.
In addition to lowering the learning rate, we have a second trick up our sleeve: We can slowly reduce the learning rate
over the course of training. In the literature, you will sometimes see this referred to as *decaying* or *annealing*
the learning rate. In Keras, the best way to do this is to use a *learning rate scheduler*. A good one to use is
`PolynomialDecay` — despite the name, with default settings it simply linearly decays the learning rate from the initial
value to the final value over the course of training, which is exactly what we want. In order to use a scheduler correctly,
though, we need to tell it how long training is going to be. We compute that as `num_train_steps` below.
```py
from tensorflow.keras.optimizers.schedules import PolynomialDecay
batch_size = 8
num_epochs = 3
# The number of training steps is the number of samples in the dataset, divided by the batch size then multiplied
# by the total number of epochs. Note that the tf_train_dataset here is a batched tf.data.Dataset,
# not the original Hugging Face Dataset, so its len() is already num_samples // batch_size.
num_train_steps = len(tf_train_dataset) * num_epochs
lr_scheduler = PolynomialDecay(
initial_learning_rate=5e-5, end_learning_rate=0.0, decay_steps=num_train_steps
)
from tensorflow.keras.optimizers import Adam
opt = Adam(learning_rate=lr_scheduler)
```
<Tip>
The 🤗 Transformers library also has a `create_optimizer()` function that will create an `AdamW` optimizer with learning rate decay. This is a convenient shortcut that you'll see in detail in future sections of the course.
</Tip>
Now we have our all-new optimizer, and we can try training with it. First, let's reload the model, to reset the changes to the weights from the training run we just did, and then we can compile it with the new optimizer:
```py
import tensorflow as tf
model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
model.compile(optimizer=opt, loss=loss, metrics=["accuracy"])
```
Now, we fit again:
```py
model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3)
```
<Tip>
💡 If you want to automatically upload your model to the Hub during training, you can pass along a `PushToHubCallback` in the `model.fit()` method. We will learn more about this in [Chapter 4](/course/chapter4/3)
</Tip>
### Model predictions[[model-predictions]]
<Youtube id="nx10eh4CoOs"/>
Training and watching the loss go down is all very nice, but what if we want to actually get outputs from the trained model, either to compute some metrics, or to use the model in production? To do that, we can just use the `predict()` method. This will return the *logits* from the output head of the model, one per class.
```py
preds = model.predict(tf_validation_dataset)["logits"]
```
We can convert these logits into the model's class predictions by using `argmax` to find the highest logit, which corresponds to the most likely class:
```py
class_preds = np.argmax(preds, axis=1)
print(preds.shape, class_preds.shape)
```
```python out
(408, 2) (408,)
```
Now, let's use those `preds` to compute some metrics! We can load the metrics associated with the MRPC dataset as easily as we loaded the dataset, this time with the `evaluate.load()` function. The object returned has a `compute()` method we can use to do the metric calculation:
```py
import evaluate
metric = evaluate.load("glue", "mrpc")
metric.compute(predictions=class_preds, references=raw_datasets["validation"]["label"])
```
```python out
{'accuracy': 0.8578431372549019, 'f1': 0.8996539792387542}
```
The exact results you get may vary, as the random initialization of the model head might change the metrics it achieved. Here, we can see our model has an accuracy of 85.78% on the validation set and an F1 score of 89.97. Those are the two metrics used to evaluate results on the MRPC dataset for the GLUE benchmark. The table in the [BERT paper](https://arxiv.org/pdf/1810.04805.pdf) reported an F1 score of 88.9 for the base model. That was the `uncased` model while we are currently using the `cased` model, which explains the better result.
This concludes the introduction to fine-tuning using the Keras API. An example of doing this for most common NLP tasks will be given in [Chapter 7](/course/chapter7). If you would like to hone your skills on the Keras API, try to fine-tune a model on the GLUE SST-2 dataset, using the data processing you did in section 2.
| huggingface/course/blob/main/chapters/en/chapter3/3_tf.mdx |
!---
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Automatic Speech Recognition - Flax Examples
## Sequence to Sequence
The script [`run_flax_speech_recognition_seq2seq.py`](https://github.com/huggingface/transformers/blob/main/examples/flax/speech-recognition/run_flax_speech_recognition_seq2seq.py)
can be used to fine-tune any [Flax Speech Sequence-to-Sequence Model](https://huggingface.co/docs/transformers/main/en/model_doc/auto#transformers.FlaxAutoModelForSpeechSeq2Seq)
for automatic speech recognition on one of the [official speech recognition datasets](https://huggingface.co/datasets?task_ids=task_ids:automatic-speech-recognition)
or a custom dataset. This includes the Whisper model from OpenAI, or a warm-started Speech-Encoder-Decoder Model,
an example for which is included below.
### Whisper Model
We can load all components of the Whisper model directly from the pretrained checkpoint, including the pretrained model
weights, feature extractor and tokenizer. We simply have to specify the id of fine-tuning dataset and the necessary
training hyperparameters.
The following example shows how to fine-tune the [Whisper small](https://huggingface.co/openai/whisper-small) checkpoint
on the Hindi subset of the [Common Voice 13](https://huggingface.co/datasets/mozilla-foundation/common_voice_13_0) dataset.
Note that before running this script you must accept the dataset's [terms of use](https://huggingface.co/datasets/mozilla-foundation/common_voice_13_0)
and register your Hugging Face Hub token on your device by running `huggingface-hub login`.
```bash
python run_flax_speech_recognition_seq2seq.py \
--model_name_or_path="openai/whisper-small" \
--dataset_name="mozilla-foundation/common_voice_13_0" \
--dataset_config_name="hi" \
--language="hindi" \
--train_split_name="train+validation" \
--eval_split_name="test" \
--output_dir="./whisper-small-hi-flax" \
--per_device_train_batch_size="16" \
--per_device_eval_batch_size="16" \
--num_train_epochs="10" \
--learning_rate="1e-4" \
--warmup_steps="500" \
--logging_steps="25" \
--generation_max_length="40" \
--preprocessing_num_workers="32" \
--dataloader_num_workers="32" \
--max_duration_in_seconds="30" \
--text_column_name="sentence" \
--overwrite_output_dir \
--do_train \
--do_eval \
--predict_with_generate \
--push_to_hub \
--use_auth_token
```
On a TPU v4-8, training should take approximately 25 minutes, with a final cross-entropy loss of 0.02 and word error
rate of **34%**. See the checkpoint [sanchit-gandhi/whisper-small-hi-flax](https://huggingface.co/sanchit-gandhi/whisper-small-hi-flax)
for an example training run.
| huggingface/transformers/blob/main/examples/flax/speech-recognition/README.md |
he post-processing step in a question answering task. When doing question answering, the processing of the initial dataset implies splitting examples in several features, which may or may not contain the answer. Passing those features through the model will give us logits for the start and end positions, since our labels are the indices of the tokens that correspond to the start and end the answer. We must then somehow convert those logits into an answer, and then pick one of the various answers each feature gives to be THE answer for a given example. For the processing step, you should refer to the video linked below. It's not very different for validation, we just need to add a few lines to keep track of two things: instead of discarding the offset mapping, we keep them, and also include in them the information of where the context is by setting the offsets of the special tokens and the question to None. Then we also keep track of the example ID for each feature, to be able to map back feature to the examples that they originated from. If you don't want to compute the validation loss, you won't need to include all the special code that we used to create the labels. With this done, we can apply that preprocessing function using the map method. We take the SQUAD dataset like in the preprocessing for question-answering video. Once this is done, the next step is to create our model. We use the default model behind the question-answering pipeline here, but you should use any model you want to evaluate. We will run a manual evaluation loop, so we create a PyTorch DataLoader with our features. With it, we can compute and gather all the start and end logits like this, with a standard PyTorch evaluation loop. With this done, we can really dive into the post-processing. We will need a map from examples to features, which we can create like this. Now, for the main part of the post-processing, let's see how to extract an answer from the logits. We could just take the best index for the start and end logits and be done, but if our model predicts something impossible, like tokens in the question, we will look at more of the logits. Note that in the question-answering pipeline, we attributed score to each answer based on the probabilities, which we did not compute here. In terms of logits, the multiplication we had in the scores becomes an addition. To go fast, we don't look at all possible start and end logits, but the twenty best ones. We ignore the logits that spawn impossible answers or answer that are too long. As we saw in the preprocessing, the labels (0, 0) correspond to no answer, otherwise we use the offsets to get the answer inside the context. Let's have a look at the predicted answer for the first feature, which is the answer with the best score (or the best logit score since the SoftMax is an increasing function). The model got it right! Next we just have to loop this for every example, picking for each the answer with the best logit score in all the features the example generated. Now you know how to get answers from your model predictions! | huggingface/course/blob/main/subtitles/en/raw/chapter7/07b_question-answering-post-processing-pt.md |
@gradio/annotatedimage
## 0.3.13
### Patch Changes
- Updated dependencies [[`828fb9e`](https://github.com/gradio-app/gradio/commit/828fb9e6ce15b6ea08318675a2361117596a1b5d), [`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144)]:
- @gradio/client@0.9.3
- @gradio/statustracker@0.4.3
- @gradio/atoms@0.4.1
- @gradio/upload@0.5.6
## 0.3.12
### Patch Changes
- Updated dependencies [[`245d58e`](https://github.com/gradio-app/gradio/commit/245d58eff788e8d44a59d37a2d9b26d0f08a62b4)]:
- @gradio/client@0.9.2
- @gradio/upload@0.5.5
## 0.3.11
### Patch Changes
- Updated dependencies [[`5d51fbc`](https://github.com/gradio-app/gradio/commit/5d51fbce7826da840a2fd4940feb5d9ad6f1bc5a), [`34f9431`](https://github.com/gradio-app/gradio/commit/34f943101bf7dd6b8a8974a6131c1ed7c4a0dac0)]:
- @gradio/upload@0.5.4
- @gradio/client@0.9.1
## 0.3.10
### Patch Changes
- Updated dependencies [[`6a9151d`](https://github.com/gradio-app/gradio/commit/6a9151d5c9432c724098da7d88a539aaaf5ffe88), [`d76bcaa`](https://github.com/gradio-app/gradio/commit/d76bcaaaf0734aaf49a680f94ea9d4d22a602e70), [`67ddd40`](https://github.com/gradio-app/gradio/commit/67ddd40b4b70d3a37cb1637c33620f8d197dbee0), [`053bec9`](https://github.com/gradio-app/gradio/commit/053bec98be1127e083414024e02cf0bebb0b5142), [`4d1cbbc`](https://github.com/gradio-app/gradio/commit/4d1cbbcf30833ef1de2d2d2710c7492a379a9a00)]:
- @gradio/upload@0.5.3
- @gradio/client@0.9.0
- @gradio/icons@0.3.2
- @gradio/atoms@0.4.0
- @gradio/statustracker@0.4.2
## 0.3.9
### Patch Changes
- Updated dependencies [[`206af31`](https://github.com/gradio-app/gradio/commit/206af31d7c1a31013364a44e9b40cf8df304ba50)]:
- @gradio/icons@0.3.1
- @gradio/atoms@0.3.1
- @gradio/statustracker@0.4.1
- @gradio/upload@0.5.2
## 0.3.8
### Patch Changes
- Updated dependencies [[`71f1a1f99`](https://github.com/gradio-app/gradio/commit/71f1a1f9931489d465c2c1302a5c8d768a3cd23a)]:
- @gradio/client@0.8.2
- @gradio/upload@0.5.1
## 0.3.7
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/atoms@0.3.0
- @gradio/icons@0.3.0
- @gradio/statustracker@0.4.0
- @gradio/upload@0.5.0
## 0.3.6
### Patch Changes
- Updated dependencies [[`2f805a7dd`](https://github.com/gradio-app/gradio/commit/2f805a7dd3d2b64b098f659dadd5d01258290521), [`f816136a0`](https://github.com/gradio-app/gradio/commit/f816136a039fa6011be9c4fb14f573e4050a681a)]:
- @gradio/upload@0.4.2
- @gradio/atoms@0.2.2
- @gradio/icons@0.2.1
- @gradio/statustracker@0.3.2
## 0.3.5
### Patch Changes
- Updated dependencies [[`324867f63`](https://github.com/gradio-app/gradio/commit/324867f63c920113d89a565892aa596cf8b1e486)]:
- @gradio/client@0.8.1
- @gradio/upload@0.4.1
## 0.3.4
### Patch Changes
- Updated dependencies [[`854b482f5`](https://github.com/gradio-app/gradio/commit/854b482f598e0dc47673846631643c079576da9c), [`f1409f95e`](https://github.com/gradio-app/gradio/commit/f1409f95ed39c5565bed6a601e41f94e30196a57)]:
- @gradio/upload@0.4.0
- @gradio/client@0.8.0
## 0.3.3
### Patch Changes
- Updated dependencies [[`bca6c2c80`](https://github.com/gradio-app/gradio/commit/bca6c2c80f7e5062427019de45c282238388af95), [`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780), [`fad92c29d`](https://github.com/gradio-app/gradio/commit/fad92c29dc1f5cd84341aae417c495b33e01245f)]:
- @gradio/client@0.7.2
- @gradio/atoms@0.2.1
- @gradio/upload@0.3.3
- @gradio/statustracker@0.3.1
## 0.3.2
### Patch Changes
- Updated dependencies [[`aaa55ce85`](https://github.com/gradio-app/gradio/commit/aaa55ce85e12f95aba9299445e9c5e59824da18e)]:
- @gradio/upload@0.3.2
## 0.3.1
### Patch Changes
- Updated dependencies [[`2ba14b284`](https://github.com/gradio-app/gradio/commit/2ba14b284f908aa13859f4337167a157075a68eb)]:
- @gradio/client@0.7.1
- @gradio/upload@0.3.1
## 0.3.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - fix circular dependency with client + upload. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Clean root url. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Image v4. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
## 0.3.0-beta.2
### Features
- [#6143](https://github.com/gradio-app/gradio/pull/6143) [`e4f7b4b40`](https://github.com/gradio-app/gradio/commit/e4f7b4b409323b01aa01b39e15ce6139e29aa073) - fix circular dependency with client + upload. Thanks [@pngwn](https://github.com/pngwn)!
- [#6094](https://github.com/gradio-app/gradio/pull/6094) [`c476bd5a5`](https://github.com/gradio-app/gradio/commit/c476bd5a5b70836163b9c69bf4bfe068b17fbe13) - Image v4. Thanks [@pngwn](https://github.com/pngwn)!
## 0.3.0-beta.1
### Features
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.3.0-beta.0
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
## 0.2.3
### Patch Changes
- Updated dependencies [[`e70805d54`](https://github.com/gradio-app/gradio/commit/e70805d54cc792452545f5d8eccc1aa0212a4695)]:
- @gradio/atoms@0.2.0
- @gradio/statustracker@0.2.3
- @gradio/upload@0.3.3
## 0.2.2
### Patch Changes
- Updated dependencies []:
- @gradio/utils@0.1.2
- @gradio/atoms@0.1.4
- @gradio/statustracker@0.2.2
- @gradio/upload@0.3.2
## 0.2.1
### Patch Changes
- Updated dependencies [[`8f0fed857`](https://github.com/gradio-app/gradio/commit/8f0fed857d156830626eb48b469d54d211a582d2)]:
- @gradio/icons@0.2.0
- @gradio/atoms@0.1.3
- @gradio/statustracker@0.2.1
- @gradio/upload@0.3.1
## 0.2.0
### Features
- [#5554](https://github.com/gradio-app/gradio/pull/5554) [`75ddeb390`](https://github.com/gradio-app/gradio/commit/75ddeb390d665d4484667390a97442081b49a423) - Accessibility Improvements. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.1.2
### Patch Changes
- Updated dependencies [[`afac0006`](https://github.com/gradio-app/gradio/commit/afac0006337ce2840cf497cd65691f2f60ee5912)]:
- @gradio/statustracker@0.2.0
- @gradio/utils@0.1.1
- @gradio/atoms@0.1.2
- @gradio/upload@0.2.1
## 0.1.1
### Patch Changes
- Updated dependencies [[`abf1c57d`](https://github.com/gradio-app/gradio/commit/abf1c57d7d85de0df233ee3b38aeb38b638477db), [`79d8f9d8`](https://github.com/gradio-app/gradio/commit/79d8f9d891901683c5a1b7486efb44eab2478c96)]:
- @gradio/icons@0.1.0
- @gradio/utils@0.1.0
- @gradio/upload@0.2.0
- @gradio/atoms@0.1.1
- @gradio/statustracker@0.1.1
## 0.1.0
### Highlights
#### Improve startup performance and markdown support ([#5279](https://github.com/gradio-app/gradio/pull/5279) [`fe057300`](https://github.com/gradio-app/gradio/commit/fe057300f0672c62dab9d9b4501054ac5d45a4ec))
##### Improved markdown support
We now have better support for markdown in `gr.Markdown` and `gr.Dataframe`. Including syntax highlighting and Github Flavoured Markdown. We also have more consistent markdown behaviour and styling.
##### Various performance improvements
These improvements will be particularly beneficial to large applications.
- Rather than attaching events manually, they are now delegated, leading to a significant performance improvement and addressing a performance regression introduced in a recent version of Gradio. App startup for large applications is now around twice as fast.
- Optimised the mounting of individual components, leading to a modest performance improvement during startup (~30%).
- Corrected an issue that was causing markdown to re-render infinitely.
- Ensured that the `gr.3DModel` does re-render prematurely.
Thanks [@pngwn](https://github.com/pngwn)!
### Features
- [#5215](https://github.com/gradio-app/gradio/pull/5215) [`fbdad78a`](https://github.com/gradio-app/gradio/commit/fbdad78af4c47454cbb570f88cc14bf4479bbceb) - Lazy load interactive or static variants of a component individually, rather than loading both variants regardless. This change will improve performance for many applications. Thanks [@pngwn](https://github.com/pngwn)!
- [#5216](https://github.com/gradio-app/gradio/pull/5216) [`4b58ea6d`](https://github.com/gradio-app/gradio/commit/4b58ea6d98e7a43b3f30d8a4cb6f379bc2eca6a8) - Update i18n tokens and locale files. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.0.2
### Patch Changes
- Updated dependencies [[`667875b2`](https://github.com/gradio-app/gradio/commit/667875b2441753e74d25bd9d3c8adedd8ede11cd)]:
- @gradio/upload@0.0.3
| gradio-app/gradio/blob/main/js/annotatedimage/CHANGELOG.md |
Gradio Demo: stt_or_tts
```
!pip install -q gradio
```
```
import gradio as gr
tts_examples = [
"I love learning machine learning",
"How do you do?",
]
tts_demo = gr.load(
"huggingface/facebook/fastspeech2-en-ljspeech",
title=None,
examples=tts_examples,
description="Give me something to say!",
cache_examples=False
)
stt_demo = gr.load(
"huggingface/facebook/wav2vec2-base-960h",
title=None,
inputs="mic",
description="Let me try to guess what you're saying!",
)
demo = gr.TabbedInterface([tts_demo, stt_demo], ["Text-to-speech", "Speech-to-text"])
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/stt_or_tts/run.ipynb |
--
title: "Snorkel AI x Hugging Face: unlock foundation models for enterprises"
thumbnail: /blog/assets/78_ml_director_insights/snorkel.png
authors:
- user: Violette
---
# Snorkel AI x Hugging Face: unlock foundation models for enterprises
_This article is a cross-post from an originally published post on April 6, 2023 [in Snorkel's blog](https://snorkel.ai/snorkel-hugging-face-unlock-foundation-models-for-enterprise/), by Friea Berg ._
As OpenAI releases [GPT-4](https://openai.com/research/gpt-4) and Google debuts [Bard](https://gizmodo.com/google-bard-chatgpt-ai-rival-released-1850248162) in beta, enterprises around the world are excited to leverage the power of foundation models. As that excitement builds, so does the realization that most companies and organizations are not equipped to properly take advantage of foundation models.
Foundation models pose a unique set of challenges for enterprises. Their larger-than-ever size makes them difficult and expensive for companies to host themselves, and using off-the-shelf FMs for production use cases could mean poor performance or substantial governance and compliance risks.
Snorkel AI bridges the gap between foundation models and practical enterprise use cases and has [yielded impressive results](https://snorkel.ai/how-pixability-uses-foundation-models-to-accelerate-nlp-application-development-by-months/) for AI innovators like Pixability. We’re teaming with [Hugging Face](https://huggingface.co/), best known for its enormous repository of ready-to-use open-source models, to provide enterprises with even more flexibility and choice as they develop AI applications.
## Foundation models in Snorkel Flow
The Snorkel Flow development platform enables users to [adapt foundation models](https://snorkel.ai/snorkel-flow/foundation-model-development/) for their specific use cases. Application development begins by inspecting the predictions of a selected foundation model “out of the box” on their data. These predictions become an initial version of training labels for those data points. Snorkel Flow helps users to identify error modes in that model and correct them efficiently via [programmatic labeling](https://snorkel.ai/programmatic-labeling/), which can include updating training labels with heuristics or [prompts](https://snorkel.ai/combining-foundation-models-with-weak-supervision/). The base foundation model can then be fine-tuned on the updated labels and evaluated once again, with this iterative “detect and correct” process continuing until the adapted foundation model is sufficiently high quality to deploy.
Hugging Face helps enable this powerful development process by making more than 150,000 open-source models immediately available from a single source. Many of those models are specialized on domain-specific data, like the BioBERT and SciBERT models used to demonstrate [how ML can be used to spot adverse drug events](https://snorkel.ai/adverse-drug-events-how-to-spot-them-with-machine-learning/). One – or better yet, [multiple](https://snorkel.ai/combining-foundation-models-with-weak-supervision/) – specialized base models can give users a jump-start on initial predictions, prompts for improving labels, or fine-tuning a final model for deployment.
## How does Hugging Face help?
Snorkel AI’s partnership with Hugging Face supercharges Snorkel Flow’s foundation model capabilities. Initially we only made a small number of foundation models available. Each one required a dedicated service, making it prohibitively expensive and difficult for us to offer enterprises the flexibility to capitalize on the rapidly growing variety of models available. Adopting Hugging Face’s Inference Endpoint service enabled us to expand the number of foundation models our users could tap into while keeping costs manageable.
Hugging Face’s service allows users to create a model API in a few clicks and begin using it immediately. Crucially, the new service has “pause and resume” capabilities that allow us to activate a model API when a client needs it, and put it to sleep when they don’t.
"We were pleasantly surprised to see how straightforward Hugging Face Inference Endpoint service was to set up.. All the configuration options were pretty self-explanatory, but we also had access to all the options we needed in terms of what cloud to run on, what security level we needed, etc."
– Snorkel CTO and Co-founder Braden Hancock
<iframe width="100%" style="aspect-ratio: 16 / 9;" src="https://www.youtube-nocookie.com/embed/woblG7iZPSw" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
## How does this help Snorkel customers?
Few enterprises have the resources to train their own foundation models from scratch. While many may have the in-house expertise to fine-tune their own version of a foundation model, they may struggle to gather the volume of data needed for that task. Snorkel’s data-centric platform for developing foundation models and alignment with leading industry innovators like Hugging Face help put the power of foundation models at our users’ fingertips.
#### "With Snorkel AI and Hugging Face Inference Endpoints, companies will accelerate their data-centric AI applications with open source at the core. Machine Learning is becoming the default way of building technology, and building from open source allows companies to build the right solution for their use case and take control of the experience they offer to their customers. We are excited to see Snorkel AI enable automated data labeling for the enterprise building from open-source Hugging Face models and Inference Endpoints, our machine learning production service.”
Clement Delangue, co-founder and CEO, Hugging Face
## Conclusion
Together, Snorkel and Hugging Face make it easier than ever for large companies, government agencies, and AI innovators to get value from foundation models. The ability to use Hugging Face’s comprehensive hub of foundation models means that users can pick the models that best align with their business needs without having to invest in the resources required to train them. This integration is a significant step forward in making foundation models more accessible to enterprises around the world.
_If you’re interested in Hugging Face Inference Endpoints for your company, please contact us [here](https://huggingface.co/inference-endpoints/enterprise) - our team will contact you to discuss your requirements!_
| huggingface/blog/blob/main/snorkel-case-study.md |
gradio_client
## 0.7.3
### Fixes
- [#6693](https://github.com/gradio-app/gradio/pull/6693) [`34f9431`](https://github.com/gradio-app/gradio/commit/34f943101bf7dd6b8a8974a6131c1ed7c4a0dac0) - Python client properly handles hearbeat and log messages. Also handles responses longer than 65k. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.7.2
### Features
- [#6598](https://github.com/gradio-app/gradio/pull/6598) [`7cbf96e`](https://github.com/gradio-app/gradio/commit/7cbf96e0bdd12db7ecac7bf99694df0a912e5864) - Issue 5245: consolidate usage of requests and httpx. Thanks [@cswamy](https://github.com/cswamy)!
- [#6704](https://github.com/gradio-app/gradio/pull/6704) [`24e0481`](https://github.com/gradio-app/gradio/commit/24e048196e8f7bd309ef5c597d4ffc6ca4ed55d0) - Hotfix: update `huggingface_hub` dependency version. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6543](https://github.com/gradio-app/gradio/pull/6543) [`8a70e83`](https://github.com/gradio-app/gradio/commit/8a70e83db9c7751b46058cdd2514e6bddeef6210) - switch from black to ruff formatter. Thanks [@DarhkVoyd](https://github.com/DarhkVoyd)!
### Fixes
- [#6556](https://github.com/gradio-app/gradio/pull/6556) [`d76bcaa`](https://github.com/gradio-app/gradio/commit/d76bcaaaf0734aaf49a680f94ea9d4d22a602e70) - Fix api event drops. Thanks [@aliabid94](https://github.com/aliabid94)!
## 0.7.1
### Fixes
- [#6602](https://github.com/gradio-app/gradio/pull/6602) [`b8034a1`](https://github.com/gradio-app/gradio/commit/b8034a1e72c3aac649ee0ad9178ffdbaaa60fc61) - Fix: Gradio Client work with private Spaces. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.7.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Add json schema unit tests. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Image v4. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Swap websockets for SSE. Thanks [@pngwn](https://github.com/pngwn)!
## 0.7.0-beta.2
### Features
- [#6094](https://github.com/gradio-app/gradio/pull/6094) [`c476bd5a5`](https://github.com/gradio-app/gradio/commit/c476bd5a5b70836163b9c69bf4bfe068b17fbe13) - Image v4. Thanks [@pngwn](https://github.com/pngwn)!
- [#6069](https://github.com/gradio-app/gradio/pull/6069) [`bf127e124`](https://github.com/gradio-app/gradio/commit/bf127e1241a41401e144874ea468dff8474eb505) - Swap websockets for SSE. Thanks [@aliabid94](https://github.com/aliabid94)!
## 0.7.0-beta.1
### Features
- [#6082](https://github.com/gradio-app/gradio/pull/6082) [`037e5af33`](https://github.com/gradio-app/gradio/commit/037e5af3363c5b321b95efc955ee8d6ec0f4504e) - WIP: Fix docs. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#5970](https://github.com/gradio-app/gradio/pull/5970) [`0c571c044`](https://github.com/gradio-app/gradio/commit/0c571c044035989d6fe33fc01fee63d1780635cb) - Add json schema unit tests. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6073](https://github.com/gradio-app/gradio/pull/6073) [`abff6fb75`](https://github.com/gradio-app/gradio/commit/abff6fb758bd310053a23c938bf1dd8fbdc5d333) - Fix remaining xfail tests in backend. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.7.0-beta.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`85ba6de13`](https://github.com/gradio-app/gradio/commit/85ba6de136a45b3e92c74e410bb27e3cbe7138d7) - Simplify how files are handled in components in 4.0. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`85ba6de13`](https://github.com/gradio-app/gradio/commit/85ba6de136a45b3e92c74e410bb27e3cbe7138d7) - Rename gradio_component to gradio component. Thanks [@pngwn](https://github.com/pngwn)!
## 0.6.1
### Fixes
- [#5811](https://github.com/gradio-app/gradio/pull/5811) [`1d5b15a2d`](https://github.com/gradio-app/gradio/commit/1d5b15a2d24387154f2cfb40a36de25b331471d3) - Assert refactor in external.py. Thanks [@harry-urek](https://github.com/harry-urek)!
## 0.6.0
### Highlights
#### new `FileExplorer` component ([#5672](https://github.com/gradio-app/gradio/pull/5672) [`e4a307ed6`](https://github.com/gradio-app/gradio/commit/e4a307ed6cde3bbdf4ff2f17655739addeec941e))
Thanks to a new capability that allows components to communicate directly with the server _without_ passing data via the value, we have created a new `FileExplorer` component.
This component allows you to populate the explorer by passing a glob, but only provides the selected file(s) in your prediction function.
Users can then navigate the virtual filesystem and select files which will be accessible in your predict function. This component will allow developers to build more complex spaces, with more flexible input options.

For more information check the [`FileExplorer` documentation](https://gradio.app/docs/fileexplorer).
Thanks [@aliabid94](https://github.com/aliabid94)!
## 0.5.3
### Features
- [#5721](https://github.com/gradio-app/gradio/pull/5721) [`84e03fe50`](https://github.com/gradio-app/gradio/commit/84e03fe506e08f1f81bac6d504c9fba7924f2d93) - Adds copy buttons to website, and better descriptions to API Docs. Thanks [@aliabd](https://github.com/aliabd)!
## 0.5.2
### Features
- [#5653](https://github.com/gradio-app/gradio/pull/5653) [`ea0e00b20`](https://github.com/gradio-app/gradio/commit/ea0e00b207b4b90a10e9d054c4202d4e705a29ba) - Prevent Clients from accessing API endpoints that set `api_name=False`. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.5.1
### Features
- [#5514](https://github.com/gradio-app/gradio/pull/5514) [`52f783175`](https://github.com/gradio-app/gradio/commit/52f7831751b432411e109bd41add4ab286023a8e) - refactor: Use package.json for version management. Thanks [@DarhkVoyd](https://github.com/DarhkVoyd)!
## 0.5.0
### Highlights
#### Enable streaming audio in python client ([#5248](https://github.com/gradio-app/gradio/pull/5248) [`390624d8`](https://github.com/gradio-app/gradio/commit/390624d8ad2b1308a5bf8384435fd0db98d8e29e))
The `gradio_client` now supports streaming file outputs 🌊
No new syntax! Connect to a gradio demo that supports streaming file outputs and call `predict` or `submit` as you normally would.
```python
import gradio_client as grc
client = grc.Client("gradio/stream_audio_out")
# Get the entire generated audio as a local file
client.predict("/Users/freddy/Pictures/bark_demo.mp4", api_name="/predict")
job = client.submit("/Users/freddy/Pictures/bark_demo.mp4", api_name="/predict")
# Get the entire generated audio as a local file
job.result()
# Each individual chunk
job.outputs()
```
Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
### Fixes
- [#5295](https://github.com/gradio-app/gradio/pull/5295) [`7b8fa8aa`](https://github.com/gradio-app/gradio/commit/7b8fa8aa58f95f5046b9add64b40368bd3f1b700) - Allow caching examples with streamed output. Thanks [@aliabid94](https://github.com/aliabid94)!
## 0.4.0
### Highlights
#### Client.predict will now return the final output for streaming endpoints ([#5057](https://github.com/gradio-app/gradio/pull/5057) [`35856f8b`](https://github.com/gradio-app/gradio/commit/35856f8b54548cae7bd3b8d6a4de69e1748283b2))
### This is a breaking change (for gradio_client only)!
Previously, `Client.predict` would only return the first output of an endpoint that streamed results. This was causing confusion for developers that wanted to call these streaming demos via the client.
We realize that developers using the client don't know the internals of whether a demo streams or not, so we're changing the behavior of predict to match developer expectations.
Using `Client.predict` will now return the final output of a streaming endpoint. This will make it even easier to use gradio apps via the client.
Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
### Features
- [#5076](https://github.com/gradio-app/gradio/pull/5076) [`2745075a`](https://github.com/gradio-app/gradio/commit/2745075a26f80e0e16863d483401ff1b6c5ada7a) - Add deploy_discord to docs. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
### Fixes
- [#5061](https://github.com/gradio-app/gradio/pull/5061) [`136adc9c`](https://github.com/gradio-app/gradio/commit/136adc9ccb23e5cb4d02d2e88f23f0b850041f98) - Ensure `gradio_client` is backwards compatible with `gradio==3.24.1`. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.3.0
### Highlights
#### Create Discord Bots from Gradio Apps 🤖 ([#4960](https://github.com/gradio-app/gradio/pull/4960) [`46e4ef67`](https://github.com/gradio-app/gradio/commit/46e4ef67d287dd68a91473b73172b29cbad064bc))
We're excited to announce that Gradio can now automatically create a discord bot from any `gr.ChatInterface` app.
It's as easy as importing `gradio_client`, connecting to the app, and calling `deploy_discord`!
_🦙 Turning Llama 2 70b into a discord bot 🦙_
```python
import gradio_client as grc
grc.Client("ysharma/Explore_llamav2_with_TGI").deploy_discord(to_id="llama2-70b-discord-bot")
```
<img src="https://gradio-builds.s3.amazonaws.com/demo-files/discordbots/guide/llama_chat.gif">
#### Getting started with template spaces
To help get you started, we have created an organization on Hugging Face called [gradio-discord-bots](https://huggingface.co/gradio-discord-bots) with template spaces you can use to turn state of the art LLMs powered by Gradio to discord bots.
Currently we have template spaces for:
- [Llama-2-70b-chat-hf](https://huggingface.co/spaces/gradio-discord-bots/Llama-2-70b-chat-hf) powered by a FREE Hugging Face Inference Endpoint!
- [Llama-2-13b-chat-hf](https://huggingface.co/spaces/gradio-discord-bots/Llama-2-13b-chat-hf) powered by Hugging Face Inference Endpoints.
- [Llama-2-13b-chat-hf](https://huggingface.co/spaces/gradio-discord-bots/llama-2-13b-chat-transformers) powered by Hugging Face transformers.
- [falcon-7b-instruct](https://huggingface.co/spaces/gradio-discord-bots/falcon-7b-instruct) powered by Hugging Face Inference Endpoints.
- [gpt-3.5-turbo](https://huggingface.co/spaces/gradio-discord-bots/gpt-35-turbo), powered by openai. Requires an OpenAI key.
But once again, you can deploy ANY `gr.ChatInterface` app exposed on the internet! So don't hesitate to try it on your own Chatbots.
❗️ Additional Note ❗️: Technically, any gradio app that exposes an api route that takes in a single string and outputs a single string can be deployed to discord. But `gr.ChatInterface` apps naturally lend themselves to discord's chat functionality so we suggest you start with those.
Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
### New Features:
- Endpoints that return layout components are now properly handled in the `submit` and `view_api` methods. Output layout components are not returned by the API but all other components are (excluding `gr.State`). By [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4871](https://github.com/gradio-app/gradio/pull/4871)
### Bug Fixes:
No changes to highlight
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
# 0.2.9
### New Features:
No changes to highlight
### Bug Fixes:
- Fix bug determining the api name when a demo has `api_name=False` by [@freddyboulton](https://github.com/freddyaboulton) in [PR 4886](https://github.com/gradio-app/gradio/pull/4886)
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- Pinned dependencies to major versions to reduce the likelihood of a broken `gradio_client` due to changes in downstream dependencies by [@abidlabs](https://github.com/abidlabs) in [PR 4885](https://github.com/gradio-app/gradio/pull/4885)
# 0.2.8
### New Features:
- Support loading gradio apps where `api_name=False` by [@abidlabs](https://github.com/abidlabs) in [PR 4683](https://github.com/gradio-app/gradio/pull/4683)
### Bug Fixes:
- Fix bug where space duplication would error if the demo has cpu-basic hardware by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4583](https://github.com/gradio-app/gradio/pull/4583)
- Fixes and optimizations to URL/download functions by [@akx](https://github.com/akx) in [PR 4695](https://github.com/gradio-app/gradio/pull/4695)
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
# 0.2.7
### New Features:
- The output directory for files downloaded via the Client can now be set by the `output_dir` parameter in `Client` by [@abidlabs](https://github.com/abidlabs) in [PR 4501](https://github.com/gradio-app/gradio/pull/4501)
### Bug Fixes:
- The output directory for files downloaded via the Client are now set to a temporary directory by default (instead of the working directory in some cases) by [@abidlabs](https://github.com/abidlabs) in [PR 4501](https://github.com/gradio-app/gradio/pull/4501)
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
# 0.2.6
### New Features:
No changes to highlight.
### Bug Fixes:
- Fixed bug file deserialization didn't preserve all file extensions by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4440](https://github.com/gradio-app/gradio/pull/4440)
- Fixed bug where mounted apps could not be called via the client by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4435](https://github.com/gradio-app/gradio/pull/4435)
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
# 0.2.5
### New Features:
No changes to highlight.
### Bug Fixes:
- Fixes parameter names not showing underscores by [@abidlabs](https://github.com/abidlabs) in [PR 4230](https://github.com/gradio-app/gradio/pull/4230)
- Fixes issue in which state was not handled correctly if `serialize=False` by [@abidlabs](https://github.com/abidlabs) in [PR 4230](https://github.com/gradio-app/gradio/pull/4230)
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
# 0.2.4
### Bug Fixes:
- Fixes missing serialization classes for several components: `Barplot`, `Lineplot`, `Scatterplot`, `AnnotatedImage`, `Interpretation` by [@abidlabs](https://github.com/abidlabs) in [PR 4167](https://github.com/gradio-app/gradio/pull/4167)
### Documentation Changes:
No changes to highlight.
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
### Contributors Shoutout:
No changes to highlight.
# 0.2.3
### New Features:
No changes to highlight.
### Bug Fixes:
- Fix example inputs for `gr.File(file_count='multiple')` output components by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4153](https://github.com/gradio-app/gradio/pull/4153)
### Documentation Changes:
No changes to highlight.
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
### Contributors Shoutout:
No changes to highlight.
# 0.2.2
### New Features:
No changes to highlight.
### Bug Fixes:
- Only send request to `/info` route if demo version is above `3.28.3` by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4109](https://github.com/gradio-app/gradio/pull/4109)
### Other Changes:
- Fix bug in test from gradio 3.29.0 refactor by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4138](https://github.com/gradio-app/gradio/pull/4138)
### Breaking Changes:
No changes to highlight.
# 0.2.1
### New Features:
No changes to highlight.
### Bug Fixes:
Removes extraneous `State` component info from the `Client.view_api()` method by [@abidlabs](https://github.com/freddyaboulton) in [PR 4107](https://github.com/gradio-app/gradio/pull/4107)
### Documentation Changes:
No changes to highlight.
### Testing and Infrastructure Changes:
Separates flaky tests from non-flaky tests by [@abidlabs](https://github.com/freddyaboulton) in [PR 4107](https://github.com/gradio-app/gradio/pull/4107)
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
### Contributors Shoutout:
No changes to highlight.
# 0.1.4
### New Features:
- Progress Updates from `gr.Progress()` can be accessed via `job.status().progress_data` by @freddyaboulton](https://github.com/freddyaboulton) in [PR 3924](https://github.com/gradio-app/gradio/pull/3924)
### Bug Fixes:
- Fixed bug where unnamed routes where displayed with `api_name` instead of `fn_index` in `view_api` by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3972](https://github.com/gradio-app/gradio/pull/3972)
### Documentation Changes:
No changes to highlight.
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
### Contributors Shoutout:
No changes to highlight.
# 0.1.3
### New Features:
No changes to highlight.
### Bug Fixes:
- Fixed bug where `Video` components in latest gradio were not able to be deserialized by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3860](https://github.com/gradio-app/gradio/pull/3860)
### Documentation Changes:
No changes to highlight.
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
### Contributors Shoutout:
No changes to highlight.
# 0.1.2
First public release of the Gradio Client library! The `gradio_client` Python library that makes it very easy to use any Gradio app as an API.
As an example, consider this [Hugging Face Space that transcribes audio files](https://huggingface.co/spaces/abidlabs/whisper) that are recorded from the microphone.
Using the `gradio_client` library, we can easily use the Gradio as an API to transcribe audio files programmatically.
Here's the entire code to do it:
```python
from gradio_client import Client
client = Client("abidlabs/whisper")
client.predict("audio_sample.wav")
>> "This is a test of the whisper speech recognition model."
```
Read more about how to use the `gradio_client` library here: https://gradio.app/getting-started-with-the-python-client/ | gradio-app/gradio/blob/main/client/python/CHANGELOG.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Utilities for Generation
This page lists all the utility functions used by [`~generation.GenerationMixin.generate`],
[`~generation.GenerationMixin.greedy_search`],
[`~generation.GenerationMixin.contrastive_search`],
[`~generation.GenerationMixin.sample`],
[`~generation.GenerationMixin.beam_search`],
[`~generation.GenerationMixin.beam_sample`],
[`~generation.GenerationMixin.group_beam_search`], and
[`~generation.GenerationMixin.constrained_beam_search`].
Most of those are only useful if you are studying the code of the generate methods in the library.
## Generate Outputs
The output of [`~generation.GenerationMixin.generate`] is an instance of a subclass of
[`~utils.ModelOutput`]. This output is a data structure containing all the information returned
by [`~generation.GenerationMixin.generate`], but that can also be used as tuple or dictionary.
Here's an example:
```python
from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
inputs = tokenizer("Hello, my dog is cute and ", return_tensors="pt")
generation_output = model.generate(**inputs, return_dict_in_generate=True, output_scores=True)
```
The `generation_output` object is a [`~generation.GreedySearchDecoderOnlyOutput`], as we can
see in the documentation of that class below, it means it has the following attributes:
- `sequences`: the generated sequences of tokens
- `scores` (optional): the prediction scores of the language modelling head, for each generation step
- `hidden_states` (optional): the hidden states of the model, for each generation step
- `attentions` (optional): the attention weights of the model, for each generation step
Here we have the `scores` since we passed along `output_scores=True`, but we don't have `hidden_states` and
`attentions` because we didn't pass `output_hidden_states=True` or `output_attentions=True`.
You can access each attribute as you would usually do, and if that attribute has not been returned by the model, you
will get `None`. Here for instance `generation_output.scores` are all the generated prediction scores of the
language modeling head, and `generation_output.attentions` is `None`.
When using our `generation_output` object as a tuple, it only keeps the attributes that don't have `None` values.
Here, for instance, it has two elements, `loss` then `logits`, so
```python
generation_output[:2]
```
will return the tuple `(generation_output.sequences, generation_output.scores)` for instance.
When using our `generation_output` object as a dictionary, it only keeps the attributes that don't have `None`
values. Here, for instance, it has two keys that are `sequences` and `scores`.
We document here all output types.
### PyTorch
[[autodoc]] generation.GreedySearchEncoderDecoderOutput
[[autodoc]] generation.GreedySearchDecoderOnlyOutput
[[autodoc]] generation.SampleEncoderDecoderOutput
[[autodoc]] generation.SampleDecoderOnlyOutput
[[autodoc]] generation.BeamSearchEncoderDecoderOutput
[[autodoc]] generation.BeamSearchDecoderOnlyOutput
[[autodoc]] generation.BeamSampleEncoderDecoderOutput
[[autodoc]] generation.BeamSampleDecoderOnlyOutput
[[autodoc]] generation.ContrastiveSearchEncoderDecoderOutput
[[autodoc]] generation.ContrastiveSearchDecoderOnlyOutput
### TensorFlow
[[autodoc]] generation.TFGreedySearchEncoderDecoderOutput
[[autodoc]] generation.TFGreedySearchDecoderOnlyOutput
[[autodoc]] generation.TFSampleEncoderDecoderOutput
[[autodoc]] generation.TFSampleDecoderOnlyOutput
[[autodoc]] generation.TFBeamSearchEncoderDecoderOutput
[[autodoc]] generation.TFBeamSearchDecoderOnlyOutput
[[autodoc]] generation.TFBeamSampleEncoderDecoderOutput
[[autodoc]] generation.TFBeamSampleDecoderOnlyOutput
[[autodoc]] generation.TFContrastiveSearchEncoderDecoderOutput
[[autodoc]] generation.TFContrastiveSearchDecoderOnlyOutput
### FLAX
[[autodoc]] generation.FlaxSampleOutput
[[autodoc]] generation.FlaxGreedySearchOutput
[[autodoc]] generation.FlaxBeamSearchOutput
## LogitsProcessor
A [`LogitsProcessor`] can be used to modify the prediction scores of a language model head for
generation.
### PyTorch
[[autodoc]] AlternatingCodebooksLogitsProcessor
- __call__
[[autodoc]] ClassifierFreeGuidanceLogitsProcessor
- __call__
[[autodoc]] EncoderNoRepeatNGramLogitsProcessor
- __call__
[[autodoc]] EncoderRepetitionPenaltyLogitsProcessor
- __call__
[[autodoc]] EpsilonLogitsWarper
- __call__
[[autodoc]] EtaLogitsWarper
- __call__
[[autodoc]] ExponentialDecayLengthPenalty
- __call__
[[autodoc]] ForcedBOSTokenLogitsProcessor
- __call__
[[autodoc]] ForcedEOSTokenLogitsProcessor
- __call__
[[autodoc]] ForceTokensLogitsProcessor
- __call__
[[autodoc]] HammingDiversityLogitsProcessor
- __call__
[[autodoc]] InfNanRemoveLogitsProcessor
- __call__
[[autodoc]] LogitNormalization
- __call__
[[autodoc]] LogitsProcessor
- __call__
[[autodoc]] LogitsProcessorList
- __call__
[[autodoc]] LogitsWarper
- __call__
[[autodoc]] MinLengthLogitsProcessor
- __call__
[[autodoc]] MinNewTokensLengthLogitsProcessor
- __call__
[[autodoc]] NoBadWordsLogitsProcessor
- __call__
[[autodoc]] NoRepeatNGramLogitsProcessor
- __call__
[[autodoc]] PrefixConstrainedLogitsProcessor
- __call__
[[autodoc]] RepetitionPenaltyLogitsProcessor
- __call__
[[autodoc]] SequenceBiasLogitsProcessor
- __call__
[[autodoc]] SuppressTokensAtBeginLogitsProcessor
- __call__
[[autodoc]] SuppressTokensLogitsProcessor
- __call__
[[autodoc]] TemperatureLogitsWarper
- __call__
[[autodoc]] TopKLogitsWarper
- __call__
[[autodoc]] TopPLogitsWarper
- __call__
[[autodoc]] TypicalLogitsWarper
- __call__
[[autodoc]] UnbatchedClassifierFreeGuidanceLogitsProcessor
- __call__
[[autodoc]] WhisperTimeStampLogitsProcessor
- __call__
### TensorFlow
[[autodoc]] TFForcedBOSTokenLogitsProcessor
- __call__
[[autodoc]] TFForcedEOSTokenLogitsProcessor
- __call__
[[autodoc]] TFForceTokensLogitsProcessor
- __call__
[[autodoc]] TFLogitsProcessor
- __call__
[[autodoc]] TFLogitsProcessorList
- __call__
[[autodoc]] TFLogitsWarper
- __call__
[[autodoc]] TFMinLengthLogitsProcessor
- __call__
[[autodoc]] TFNoBadWordsLogitsProcessor
- __call__
[[autodoc]] TFNoRepeatNGramLogitsProcessor
- __call__
[[autodoc]] TFRepetitionPenaltyLogitsProcessor
- __call__
[[autodoc]] TFSuppressTokensAtBeginLogitsProcessor
- __call__
[[autodoc]] TFSuppressTokensLogitsProcessor
- __call__
[[autodoc]] TFTemperatureLogitsWarper
- __call__
[[autodoc]] TFTopKLogitsWarper
- __call__
[[autodoc]] TFTopPLogitsWarper
- __call__
### FLAX
[[autodoc]] FlaxForcedBOSTokenLogitsProcessor
- __call__
[[autodoc]] FlaxForcedEOSTokenLogitsProcessor
- __call__
[[autodoc]] FlaxForceTokensLogitsProcessor
- __call__
[[autodoc]] FlaxLogitsProcessor
- __call__
[[autodoc]] FlaxLogitsProcessorList
- __call__
[[autodoc]] FlaxLogitsWarper
- __call__
[[autodoc]] FlaxMinLengthLogitsProcessor
- __call__
[[autodoc]] FlaxSuppressTokensAtBeginLogitsProcessor
- __call__
[[autodoc]] FlaxSuppressTokensLogitsProcessor
- __call__
[[autodoc]] FlaxTemperatureLogitsWarper
- __call__
[[autodoc]] FlaxTopKLogitsWarper
- __call__
[[autodoc]] FlaxTopPLogitsWarper
- __call__
[[autodoc]] FlaxWhisperTimeStampLogitsProcessor
- __call__
## StoppingCriteria
A [`StoppingCriteria`] can be used to change when to stop generation (other than EOS token). Please note that this is exclusivelly available to our PyTorch implementations.
[[autodoc]] StoppingCriteria
- __call__
[[autodoc]] StoppingCriteriaList
- __call__
[[autodoc]] MaxLengthCriteria
- __call__
[[autodoc]] MaxTimeCriteria
- __call__
## Constraints
A [`Constraint`] can be used to force the generation to include specific tokens or sequences in the output. Please note that this is exclusivelly available to our PyTorch implementations.
[[autodoc]] Constraint
[[autodoc]] PhrasalConstraint
[[autodoc]] DisjunctiveConstraint
[[autodoc]] ConstraintListState
## BeamSearch
[[autodoc]] BeamScorer
- process
- finalize
[[autodoc]] BeamSearchScorer
- process
- finalize
[[autodoc]] ConstrainedBeamSearchScorer
- process
- finalize
## Utilities
[[autodoc]] top_k_top_p_filtering
[[autodoc]] tf_top_k_top_p_filtering
## Streamers
[[autodoc]] TextStreamer
[[autodoc]] TextIteratorStreamer
## Caches
[[autodoc]] Cache
- update
[[autodoc]] DynamicCache
- update
- get_seq_length
- reorder_cache
- to_legacy_cache
- from_legacy_cache
[[autodoc]] SinkCache
- update
- get_seq_length
- reorder_cache
| huggingface/transformers/blob/main/docs/source/en/internal/generation_utils.md |
--
title: "An Introduction to Q-Learning Part 2/2"
thumbnail: /blog/assets/73_deep_rl_q_part2/thumbnail.gif
authors:
- user: ThomasSimonini
---
# An Introduction to Q-Learning Part 2/2
<h2>Unit 2, part 2 of the <a href="https://github.com/huggingface/deep-rl-class">Deep Reinforcement Learning Class with Hugging Face 🤗</a></h2>
⚠️ A **new updated version of this article is available here** 👉 [https://huggingface.co/deep-rl-course/unit1/introduction](https://huggingface.co/deep-rl-course/unit2/q-learning)
*This article is part of the Deep Reinforcement Learning Class. A free course from beginner to expert. Check the syllabus [here.](https://huggingface.co/deep-rl-course/unit0/introduction)*
<img src="assets/73_deep_rl_q_part2/thumbnail.gif" alt="Thumbnail"/>
---
⚠️ A **new updated version of this article is available here** 👉 [https://huggingface.co/deep-rl-course/unit1/introduction](https://huggingface.co/deep-rl-course/unit2/q-learning)
*This article is part of the Deep Reinforcement Learning Class. A free course from beginner to expert. Check the syllabus [here.](https://huggingface.co/deep-rl-course/unit0/introduction)*
[In the first part of this unit](https://huggingface.co/blog/deep-rl-q-part1), **we learned about the value-based methods and the difference between Monte Carlo and Temporal Difference Learning**.
So, in the second part, we’ll **study Q-Learning**, **and implement our first RL agent from scratch**, a Q-Learning agent, and will train it in two environments:
1. Frozen Lake v1 ❄️: where our agent will need to **go from the starting state (S) to the goal state (G)** by walking only on frozen tiles (F) and avoiding holes (H).
2. An autonomous taxi 🚕: where the agent will need **to learn to navigate** a city to **transport its passengers from point A to point B.**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/envs.gif" alt="Environments"/>
</figure>
This unit is fundamental if you want to be able to work on Deep Q-Learning (Unit 3).
So let’s get started! 🚀
- [Introducing Q-Learning](#introducing-q-learning)
- [What is Q-Learning?](#what-is-q-learning)
- [The Q-Learning algorithm](#the-q-learning-algorithm)
- [Off-policy vs. On-policy](#off-policy-vs-on-policy)
- [A Q-Learning example](#a-q-learning-example)
## **Introducing Q-Learning**
### **What is Q-Learning?**
Q-Learning is an **off-policy value-based method that uses a TD approach to train its action-value function:**
- *Off-policy*: we'll talk about that at the end of this chapter.
- *Value-based method*: finds the optimal policy indirectly by training a value or action-value function that will tell us **the value of each state or each state-action pair.**
- *Uses a TD approach:* **updates its action-value function at each step instead of at the end of the episode.**
**Q-Learning is the algorithm we use to train our Q-Function**, an **action-value function** that determines the value of being at a particular state and taking a specific action at that state.
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Q-function.jpg" alt="Q-function"/>
<figcaption>Given a state and action, our Q Function outputs a state-action value (also called Q-value)</figcaption>
</figure>
The **Q comes from "the Quality" of that action at that state.**
Internally, our Q-function has **a Q-table, a table where each cell corresponds to a state-action value pair value.** Think of this Q-table as **the memory or cheat sheet of our Q-function.**
If we take this maze example:
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Maze-1.jpg" alt="Maze example"/>
</figure>
The Q-Table is initialized. That's why all values are = 0. This table **contains, for each state, the four state-action values.**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Maze-2.jpg" alt="Maze example"/>
</figure>
Here we see that the **state-action value of the initial state and going up is 0:**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Maze-3.jpg" alt="Maze example"/>
</figure>
Therefore, Q-function contains a Q-table **that has the value of each-state action pair.** And given a state and action, **our Q-Function will search inside its Q-table to output the value.**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Q-function-2.jpg" alt="Q-function"/>
<figcaption>Given a state and action pair, our Q-function will search inside its Q-table to output the state-action pair value (the Q value).</figcaption>
</figure>
If we recap, *Q-Learning* **is the RL algorithm that:**
- Trains *Q-Function* (an **action-value function**) which internally is a *Q-table* **that contains all the state-action pair values.**
- Given a state and action, our Q-Function **will search into its Q-table the corresponding value.**
- When the training is done, **we have an optimal Q-function, which means we have optimal Q-Table.**
- And if we **have an optimal Q-function**, we **have an optimal policy** since we **know for each state what is the best action to take.**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/link-value-policy.jpg" alt="Link value policy"/>
</figure>
But, in the beginning, **our Q-Table is useless since it gives arbitrary values for each state-action pair** (most of the time, we initialize the Q-Table to 0 values). But, as we'll **explore the environment and update our Q-Table, it will give us better and better approximations.**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Q-learning-1.jpg" alt="Q-learning"/>
<figcaption>We see here that with the training, our Q-Table is better since, thanks to it, we can know the value of each state-action pair.</figcaption>
</figure>
So now that we understand what Q-Learning, Q-Function, and Q-Table are, **let's dive deeper into the Q-Learning algorithm**.
### **The Q-Learning algorithm**
This is the Q-Learning pseudocode; let's study each part and **see how it works with a simple example before implementing it.** Don't be intimidated by it, it's simpler than it looks! We'll go over each step.
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Q-learning-2.jpg" alt="Q-learning"/>
</figure>
**Step 1: We initialize the Q-Table**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Q-learning-3.jpg" alt="Q-learning"/>
</figure>
We need to initialize the Q-Table for each state-action pair. **Most of the time, we initialize with values of 0.**
**Step 2: Choose action using Epsilon Greedy Strategy**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Q-learning-4.jpg" alt="Q-learning"/>
</figure>
Epsilon Greedy Strategy is a policy that handles the exploration/exploitation trade-off.
The idea is that we define epsilon ɛ = 1.0:
- *With probability 1 — ɛ* : we do **exploitation** (aka our agent selects the action with the highest state-action pair value).
- With probability ɛ: **we do exploration** (trying random action).
At the beginning of the training, **the probability of doing exploration will be huge since ɛ is very high, so most of the time, we'll explore.** But as the training goes on, and consequently our **Q-Table gets better and better in its estimations, we progressively reduce the epsilon value** since we will need less and less exploration and more exploitation.
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Q-learning-5.jpg" alt="Q-learning"/>
</figure>
**Step 3: Perform action At, gets reward Rt+1 and next state St+1**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Q-learning-6.jpg" alt="Q-learning"/>
</figure>
**Step 4: Update Q(St, At)**
Remember that in TD Learning, we update our policy or value function (depending on the RL method we choose) **after one step of the interaction.**
To produce our TD target, **we used the immediate reward \\(R_{t+1}\\) plus the discounted value of the next state best state-action pair** (we call that bootstrap).
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Q-learning-7.jpg" alt="Q-learning"/>
</figure>
Therefore, our \\(Q(S_t, A_t)\\) **update formula goes like this:**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Q-learning-8.jpg" alt="Q-learning"/>
</figure>
It means that to update our \\(Q(S_t, A_t)\\):
- We need \\(S_t, A_t, R_{t+1}, S_{t+1}\\).
- To update our Q-value at a given state-action pair, we use the TD target.
How do we form the TD target?
1. We obtain the reward after taking the action \\(R_{t+1}\\).
2. To get the **best next-state-action pair value**, we use a greedy policy to select the next best action. Note that this is not an epsilon greedy policy, this will always take the action with the highest state-action value.
Then when the update of this Q-value is done. We start in a new_state and select our action **using our epsilon-greedy policy again.**
**It's why we say that this is an off-policy algorithm.**
### **Off-policy vs On-policy**
The difference is subtle:
- *Off-policy*: using **a different policy for acting and updating.**
For instance, with Q-Learning, the Epsilon greedy policy (acting policy), is different from the greedy policy that is **used to select the best next-state action value to update our Q-value (updating policy).**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/off-on-1.jpg" alt="Off-on policy"/>
<figcaption>Acting Policy</figcaption>
</figure>
Is different from the policy we use during the training part:
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/off-on-2.jpg" alt="Off-on policy"/>
<figcaption>Updating policy</figcaption>
</figure>
- *On-policy:* using the **same policy for acting and updating.**
For instance, with Sarsa, another value-based algorithm, **the Epsilon-Greedy Policy selects the next_state-action pair, not a greedy policy.**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/off-on-3.jpg" alt="Off-on policy"/>
<figcaption>Sarsa</figcaption>
</figure>
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/off-on-4.jpg" alt="Off-on policy"/>
</figure>
## **A Q-Learning example**
To better understand Q-Learning, let's take a simple example:
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Maze-Example-2.jpg" alt="Maze-Example"/>
</figure>
- You're a mouse in this tiny maze. You always **start at the same starting point.**
- The goal is **to eat the big pile of cheese at the bottom right-hand corner** and avoid the poison. After all, who doesn't like cheese?
- The episode ends if we eat the poison, **eat the big pile of cheese or if we spent more than five steps.**
- The learning rate is 0.1
- The gamma (discount rate) is 0.99
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/q-ex-1.jpg" alt="Maze-Example"/>
</figure>
The reward function goes like this:
- **+0:** Going to a state with no cheese in it.
- **+1:** Going to a state with a small cheese in it.
- **+10:** Going to the state with the big pile of cheese.
- **-10:** Going to the state with the poison and thus die.
- **+0** If we spend more than five steps.
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/q-ex-2.jpg" alt="Maze-Example"/>
</figure>
To train our agent to have an optimal policy (so a policy that goes right, right, down), **we will use the Q-Learning algorithm**.
**Step 1: We initialize the Q-Table**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Example-1.jpg" alt="Maze-Example"/>
</figure>
So, for now, **our Q-Table is useless**; we need **to train our Q-function using the Q-Learning algorithm.**
Let's do it for 2 training timesteps:
Training timestep 1:
**Step 2: Choose action using Epsilon Greedy Strategy**
Because epsilon is big = 1.0, I take a random action, in this case, I go right.
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/q-ex-3.jpg" alt="Maze-Example"/>
</figure>
**Step 3: Perform action At, gets Rt+1 and St+1**
By going right, I've got a small cheese, so \\(R_{t+1} = 1\\), and I'm in a new state.
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/q-ex-4.jpg" alt="Maze-Example"/>
</figure>
**Step 4: Update \\(Q(S_t, A_t)\\)**
We can now update \\(Q(S_t, A_t)\\) using our formula.
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/q-ex-5.jpg" alt="Maze-Example"/>
</figure>
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Example-4.jpg" alt="Maze-Example"/>
</figure>
Training timestep 2:
**Step 2: Choose action using Epsilon Greedy Strategy**
**I take a random action again, since epsilon is big 0.99** (since we decay it a little bit because as the training progress, we want less and less exploration).
I took action down. **Not a good action since it leads me to the poison.**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/q-ex-6.jpg" alt="Maze-Example"/>
</figure>
**Step 3: Perform action At, gets \\(R_{t+1}\\) and St+1**
Because I go to the poison state, **I get \\(R_{t+1} = -10\\), and I die.**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/q-ex-7.jpg" alt="Maze-Example"/>
</figure>
**Step 4: Update \\(Q(S_t, A_t)\\)**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/q-ex-8.jpg" alt="Maze-Example"/>
</figure>
Because we're dead, we start a new episode. But what we see here is that **with two explorations steps, my agent became smarter.**
As we continue exploring and exploiting the environment and updating Q-values using TD target, **Q-Table will give us better and better approximations. And thus, at the end of the training, we'll get an estimate of the optimal Q-Function.**
---
Now that we **studied the theory of Q-Learning**, let's **implement it from scratch**. A Q-Learning agent that we will train in two environments:
1. *Frozen-Lake-v1* ❄️ (non-slippery version): where our agent will need to **go from the starting state (S) to the goal state (G)** by walking only on frozen tiles (F) and avoiding holes (H).
2. *An autonomous taxi* 🚕 will need **to learn to navigate** a city to **transport its passengers from point A to point B.**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/envs.gif" alt="Environments"/>
</figure>
Start the tutorial here 👉 https://colab.research.google.com/github/huggingface/deep-rl-class/blob/main/unit2/unit2.ipynb
The leaderboard 👉 https://huggingface.co/spaces/chrisjay/Deep-Reinforcement-Learning-Leaderboard
---
Congrats on finishing this chapter! There was a lot of information. And congrats on finishing the tutorials. You’ve just implemented your first RL agent from scratch and shared it on the Hub 🥳.
Implementing from scratch when you study a new architecture **is important to understand how it works.**
That’s **normal if you still feel confused** with all these elements. **This was the same for me and for all people who studied RL.**
Take time to really grasp the material before continuing.
And since the best way to learn and avoid the illusion of competence is **to test yourself**. We wrote a quiz to help you find where **you need to reinforce your study**.
Check your knowledge here 👉 https://github.com/huggingface/deep-rl-class/blob/main/unit2/quiz2.md
It’s essential to master these elements and having a solid foundations before entering the **fun part.**
Don't hesitate to modify the implementation, try ways to improve it and change environments, **the best way to learn is to try things on your own!**
We published additional readings in the syllabus if you want to go deeper 👉 https://github.com/huggingface/deep-rl-class/blob/main/unit2/README.md
<a href="https://huggingface.co/blog/deep-rl-dqn">In the next unit, we’re going to learn about Deep-Q-Learning.</a>
And don't forget to share with your friends who want to learn 🤗 !
Finally, we want **to improve and update the course iteratively with your feedback**. If you have some, please fill this form 👉 https://forms.gle/3HgA7bEHwAmmLfwh9
### Keep learning, stay awesome,
| huggingface/blog/blob/main/deep-rl-q-part2.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# XLNet
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=xlnet">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-xlnet-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/xlnet-base-cased">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
The XLNet model was proposed in [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov,
Quoc V. Le. XLnet is an extension of the Transformer-XL model pre-trained using an autoregressive method to learn
bidirectional contexts by maximizing the expected likelihood over all permutations of the input sequence factorization
order.
The abstract from the paper is the following:
*With the capability of modeling bidirectional contexts, denoising autoencoding based pretraining like BERT achieves
better performance than pretraining approaches based on autoregressive language modeling. However, relying on
corrupting the input with masks, BERT neglects dependency between the masked positions and suffers from a
pretrain-finetune discrepancy. In light of these pros and cons, we propose XLNet, a generalized autoregressive
pretraining method that (1) enables learning bidirectional contexts by maximizing the expected likelihood over all
permutations of the factorization order and (2) overcomes the limitations of BERT thanks to its autoregressive
formulation. Furthermore, XLNet integrates ideas from Transformer-XL, the state-of-the-art autoregressive model, into
pretraining. Empirically, under comparable experiment settings, XLNet outperforms BERT on 20 tasks, often by a large
margin, including question answering, natural language inference, sentiment analysis, and document ranking.*
This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/zihangdai/xlnet/).
## Usage tips
- The specific attention pattern can be controlled at training and test time using the `perm_mask` input.
- Due to the difficulty of training a fully auto-regressive model over various factorization order, XLNet is pretrained
using only a sub-set of the output tokens as target which are selected with the `target_mapping` input.
- To use XLNet for sequential decoding (i.e. not in fully bi-directional setting), use the `perm_mask` and
`target_mapping` inputs to control the attention span and outputs (see examples in
*examples/pytorch/text-generation/run_generation.py*)
- XLNet is one of the few models that has no sequence length limit.
- XLNet is not a traditional autoregressive model but uses a training strategy that builds on that. It permutes the tokens in the sentence, then allows the model to use the last n tokens to predict the token n+1. Since this is all done with a mask, the sentence is actually fed in the model in the right order, but instead of masking the first n tokens for n+1, XLNet uses a mask that hides the previous tokens in some given permutation of 1,…,sequence length.
- XLNet also uses the same recurrence mechanism as Transformer-XL to build long-term dependencies.
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## XLNetConfig
[[autodoc]] XLNetConfig
## XLNetTokenizer
[[autodoc]] XLNetTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## XLNetTokenizerFast
[[autodoc]] XLNetTokenizerFast
## XLNet specific outputs
[[autodoc]] models.xlnet.modeling_xlnet.XLNetModelOutput
[[autodoc]] models.xlnet.modeling_xlnet.XLNetLMHeadModelOutput
[[autodoc]] models.xlnet.modeling_xlnet.XLNetForSequenceClassificationOutput
[[autodoc]] models.xlnet.modeling_xlnet.XLNetForMultipleChoiceOutput
[[autodoc]] models.xlnet.modeling_xlnet.XLNetForTokenClassificationOutput
[[autodoc]] models.xlnet.modeling_xlnet.XLNetForQuestionAnsweringSimpleOutput
[[autodoc]] models.xlnet.modeling_xlnet.XLNetForQuestionAnsweringOutput
[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetModelOutput
[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetLMHeadModelOutput
[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetForSequenceClassificationOutput
[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetForMultipleChoiceOutput
[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetForTokenClassificationOutput
[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetForQuestionAnsweringSimpleOutput
<frameworkcontent>
<pt>
## XLNetModel
[[autodoc]] XLNetModel
- forward
## XLNetLMHeadModel
[[autodoc]] XLNetLMHeadModel
- forward
## XLNetForSequenceClassification
[[autodoc]] XLNetForSequenceClassification
- forward
## XLNetForMultipleChoice
[[autodoc]] XLNetForMultipleChoice
- forward
## XLNetForTokenClassification
[[autodoc]] XLNetForTokenClassification
- forward
## XLNetForQuestionAnsweringSimple
[[autodoc]] XLNetForQuestionAnsweringSimple
- forward
## XLNetForQuestionAnswering
[[autodoc]] XLNetForQuestionAnswering
- forward
</pt>
<tf>
## TFXLNetModel
[[autodoc]] TFXLNetModel
- call
## TFXLNetLMHeadModel
[[autodoc]] TFXLNetLMHeadModel
- call
## TFXLNetForSequenceClassification
[[autodoc]] TFXLNetForSequenceClassification
- call
## TFLNetForMultipleChoice
[[autodoc]] TFXLNetForMultipleChoice
- call
## TFXLNetForTokenClassification
[[autodoc]] TFXLNetForTokenClassification
- call
## TFXLNetForQuestionAnsweringSimple
[[autodoc]] TFXLNetForQuestionAnsweringSimple
- call
</tf>
</frameworkcontent> | huggingface/transformers/blob/main/docs/source/en/model_doc/xlnet.md |
[The Hugging Face Deep Reinforcement Learning Course 🤗 (v2.0)](https://huggingface.co/deep-rl-course/unit0/introduction)
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit0/thumbnail.jpg" alt="Thumbnail"/>
If you like the course, don't hesitate to **⭐ star this repository. This helps us 🤗**.
This repository contains the Deep Reinforcement Learning Course mdx files and notebooks. **The website is here**: https://huggingface.co/deep-rl-course/unit0/introduction?fw=pt
- The syllabus 📚: https://simoninithomas.github.io/deep-rl-course
- The course 📚: https://huggingface.co/deep-rl-course/unit0/introduction?fw=pt
- **Sign up here** ➡️➡️➡️ http://eepurl.com/ic5ZUD
## Citing the project
To cite this repository in publications:
```bibtex
@misc{deep-rl-course,
author = {Simonini, Thomas and Sanseviero, Omar},
title = {The Hugging Face Deep Reinforcement Learning Class},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/huggingface/deep-rl-class}},
}
```
| huggingface/deep-rl-class/blob/main/README.md |
--
title: "Overview of natively supported quantization schemes in 🤗 Transformers"
thumbnail: /blog/assets/163_overview_quantization_transformers/thumbnail.jpg
authors:
- user: ybelkada
- user: marcsun13
- user: IlyasMoutawwakil
- user: clefourrier
- user: fxmarty
---
# Overview of natively supported quantization schemes in 🤗 Transformers
We aim to give a clear overview of the pros and cons of each quantization scheme supported in transformers to help you decide which one you should go for.
Currently, quantizing models are used for two main purposes:
- Running inference of a large model on a smaller device
- Fine-tune adapters on top of quantized models
So far, two integration efforts have been made and are **natively** supported in transformers : *bitsandbytes* and *auto-gptq*.
Note that some additional quantization schemes are also supported in the [🤗 optimum library](https://github.com/huggingface/optimum), but this is out of scope for this blogpost.
To learn more about each of the supported schemes, please have a look at one of the resources shared below. Please also have a look at the appropriate sections of the documentation.
Note also that the details shared below are only valid for `PyTorch` models, this is currently out of scope for Tensorflow and Flax/JAX models.
## Table of contents
- [Resources](#resources)
- [Comparing bitsandbytes and auto-gptq](#Comparing-bitsandbytes-and-auto-gptq)
- [Diving into speed benchmarks](#Diving-into-speed-benchmarks)
- [Conclusion and final words](#conclusion-and-final-words)
- [Acknowledgements](#acknowledgements)
## Resources
- [GPTQ blogpost](https://huggingface.co/blog/gptq-integration) – gives an overview on what is the GPTQ quantization method and how to use it.
- [bistandbytes 4-bit quantization blogpost](https://huggingface.co/blog/4bit-transformers-bitsandbytes) - This blogpost introduces 4-bit quantization and QLoRa, an efficient finetuning approach.
- [bistandbytes 8-bit quantization blogpost](https://huggingface.co/blog/hf-bitsandbytes-integration) - This blogpost explains how 8-bit quantization works with bitsandbytes.
- [Basic usage Google Colab notebook for GPTQ](https://colab.research.google.com/drive/1_TIrmuKOFhuRRiTWN94iLKUFu6ZX4ceb?usp=sharing) - This notebook shows how to quantize your transformers model with the GPTQ method, how to do inference, and how to do fine-tuning with the quantized model.
- [Basic usage Google Colab notebook for bitsandbytes](https://colab.research.google.com/drive/1ge2F1QSK8Q7h0hn3YKuBCOAS0bK8E0wf?usp=sharing) - This notebook shows how to use 4-bit models in inference with all their variants, and how to run GPT-neo-X (a 20B parameter model) on a free Google Colab instance.
- [Merve's blogpost on quantization](https://huggingface.co/blog/merve/quantization) - This blogpost provides a gentle introduction to quantization and the quantization methods supported natively in transformers.
## Comparing bitsandbytes and auto-gptq
In this section, we will go over the pros and cons of bitsandbytes and gptq quantization. Note that these are based on the feedback from the community and they can evolve over time as some of these features are in the roadmap of the respective libraries.
### What are the benefits of bitsandbytes?
**easy**: bitsandbytes still remains the easiest way to quantize any model as it does not require calibrating the quantized model with input data (also called zero-shot quantization). It is possible to quantize any model out of the box as long as it contains `torch.nn.Linear` modules. Whenever a new architecture is added in transformers, as long as they can be loaded with accelerate’s `device_map=”auto”`, users can benefit from bitsandbytes quantization straight out of the box with minimal performance degradation. Quantization is performed on model load, no need to run any post-processing or preparation step.
**cross-modality interoperability**: As the only condition to quantize a model is to contain a `torch.nn.Linear` layer, quantization works out of the box for any modality, making it possible to load models such as Whisper, ViT, Blip2, etc. in 8-bit or 4-bit out of the box.
**0 performance degradation when merging adapters**: (Read more about adapters and PEFT in [this blogpost](https://huggingface.co/blog/peft) if you are not familiar with it). If you train adapters on top of the quantized base model, the adapters can be merged on top of of the base model for deployment, with no inference performance degradation. You can also [merge](https://github.com/huggingface/peft/pull/851/files) the adapters on top of the dequantized model ! This is not supported for GPTQ.
### What are the benefits of autoGPTQ?
**fast for text generation**: GPTQ quantized models are fast compared to bitsandbytes quantized models for [text generation](https://huggingface.co/docs/transformers/main_classes/text_generation). We will address the speed comparison in an appropriate section.
**n-bit support**: The GPTQ algorithm makes it possible to quantize models up to 2 bits! However, this might come with severe quality degradation. The recommended number of bits is 4, which seems to be a great tradeoff for GPTQ at this time.
**easily-serializable**: GPTQ models support serialization for any number of bits. Loading models from TheBloke namespace: https://huggingface.co/TheBloke (look for those that end with the `-GPTQ` suffix) is supported out of the box, as long as you have the required packages installed. Bitsandbytes supports 8-bit serialization but does not support 4-bit serialization as of today.
**AMD support**: The integration should work out of the box for AMD GPUs!
### What are the potential rooms of improvements of bitsandbytes?
**slower than GPTQ for text generation**: bitsandbytes 4-bit models are slow compared to GPTQ when using [`generate`](https://huggingface.co/docs/transformers/main_classes/text_generation).
**4-bit weights are not serializable**: Currently, 4-bit models cannot be serialized. This is a frequent community request, and we believe it should be addressed very soon by the bitsandbytes maintainers as it's in their roadmap!
### What are the potential rooms of improvements of autoGPTQ?
**calibration dataset**: The need of a calibration dataset might discourage some users to go for GPTQ. Furthermore, it can take several hours to quantize the model (e.g. 4 GPU hours for a 175B scale model [according to the paper](https://arxiv.org/pdf/2210.17323.pdf) - section 2)
**works only for language models (for now)**: As of today, the API for quantizing a model with auto-GPTQ has been designed to support only language models. It should be possible to quantize non-text (or multimodal) models using the GPTQ algorithm, but the process has not been elaborated in the original paper or in the auto-gptq repository. If the community is excited about this topic this might be considered in the future.
## Diving into speed benchmarks
We decided to provide an extensive benchmark for both inference and fine-tuning adapters using bitsandbytes and auto-gptq on different hardware. The inference benchmark should give users an idea of the speed difference they might get between the different approaches we propose for inference, and the adapter fine-tuning benchmark should give a clear idea to users when it comes to deciding which approach to use when fine-tuning adapters on top of bitsandbytes and GPTQ base models.
We will use the following setup:
- bitsandbytes: 4-bit quantization with `bnb_4bit_compute_dtype=torch.float16`. Make sure to use `bitsandbytes>=0.41.1` for fast 4-bit kernels.
- auto-gptq: 4-bit quantization with exllama kernels. You will need `auto-gptq>=0.4.0` to use ex-llama kernels.
### Inference speed (forward pass only)
This benchmark measures only the prefill step, which corresponds to the forward pass during training. It was run on a single NVIDIA A100-SXM4-80GB GPU with a prompt length of 512. The model we used was `meta-llama/Llama-2-13b-hf`.
with batch size = 1:
|quantization |act_order|bits|group_size|kernel|Load time (s)|Per-token latency (ms)|Throughput (tok/s)|Peak memory (MB)|
|-----|---------|----|----------|------|-------------|----------------------|------------------|----------------|
|fp16|None |None|None |None |26.0 |36.958 |27.058 |29152.98 |
|gptq |False |4 |128 |exllama|36.2 |33.711 |29.663 |10484.34 |
|bitsandbytes|None |4|None |None |37.64 |52.00 |19.23 |11018.36 |
with batch size = 16:
|quantization |act_order|bits|group_size|kernel|Load time (s)|Per-token latency (ms)|Throughput (tok/s)|Peak memory (MB)|
|-----|---------|----|----------|------|-------------|----------------------|------------------|----------------|
|fp16|None |None|None |None |26.0 |69.94 |228.76 |53986.51 |
|gptq |False |4 |128 |exllama|36.2 |95.41 |167.68 |34777.04 |
|bitsandbytes|None |4|None |None |37.64 |113.98 |140.38 |35532.37 |
From the benchmark, we can see that bitsandbyes and GPTQ are equivalent, with GPTQ being slightly faster for large batch size. Check this [link](https://github.com/huggingface/optimum/blob/main/tests/benchmark/README.md#prefill-only-benchmark-results) to have more details on these benchmarks.
### Generate speed
The following benchmarks measure the generation speed of the model during inference. The benchmarking script can be found [here](https://gist.github.com/younesbelkada/e576c0d5047c0c3f65b10944bc4c651c) for reproducibility.
#### use_cache
Let's test `use_cache` to better understand the impact of caching the hidden state during the generation.
The benchmark was run on an A100 with a prompt length of 30 and we generated exactly 30 tokens. The model we used was `meta-llama/Llama-2-7b-hf`.
with `use_cache=True`
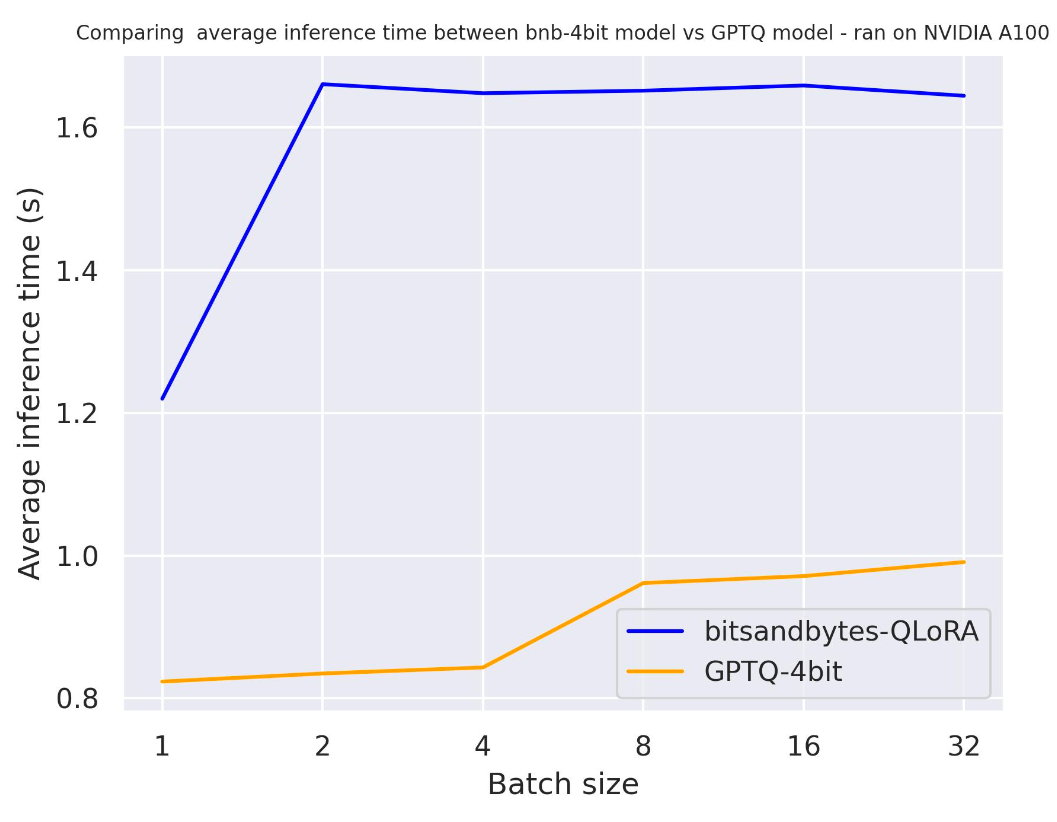
with `use_cache=False`
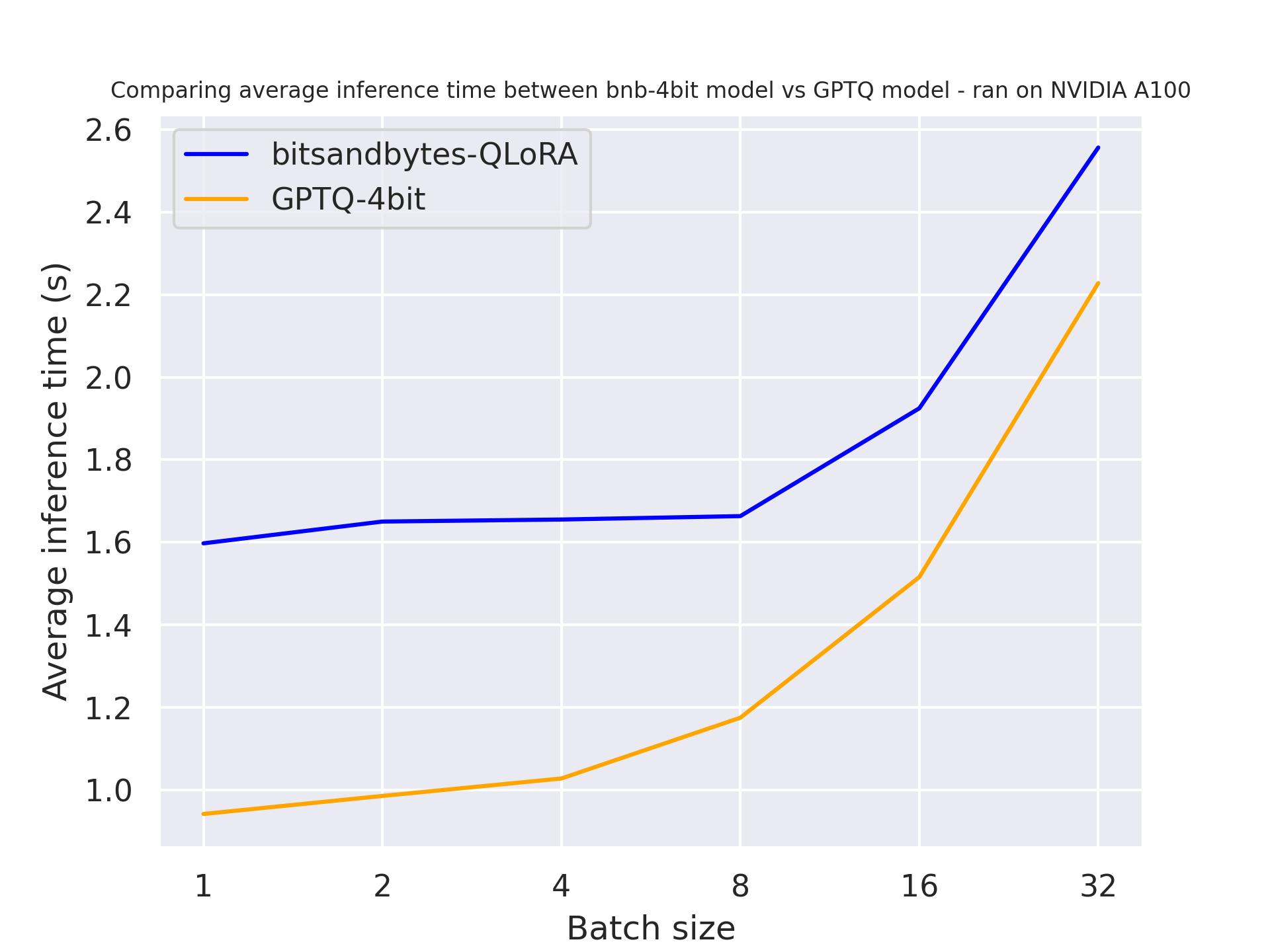
From the two benchmarks, we conclude that generation is faster when we use attention caching, as expected. Moreover, GPTQ is, in general, faster than bitsandbytes. For example, with `batch_size=4` and `use_cache=True`, it is twice as fast! Therefore let’s use `use_cache` for the next benchmarks. Note that `use_cache` will consume more memory.
#### Hardware
In the following benchmark, we will try different hardware to see the impact on the quantized model. We used a prompt length of 30 and we generated exactly 30 tokens. The model we used was `meta-llama/Llama-2-7b-hf`.
with a NVIDIA A100:

with a NVIDIA T4:
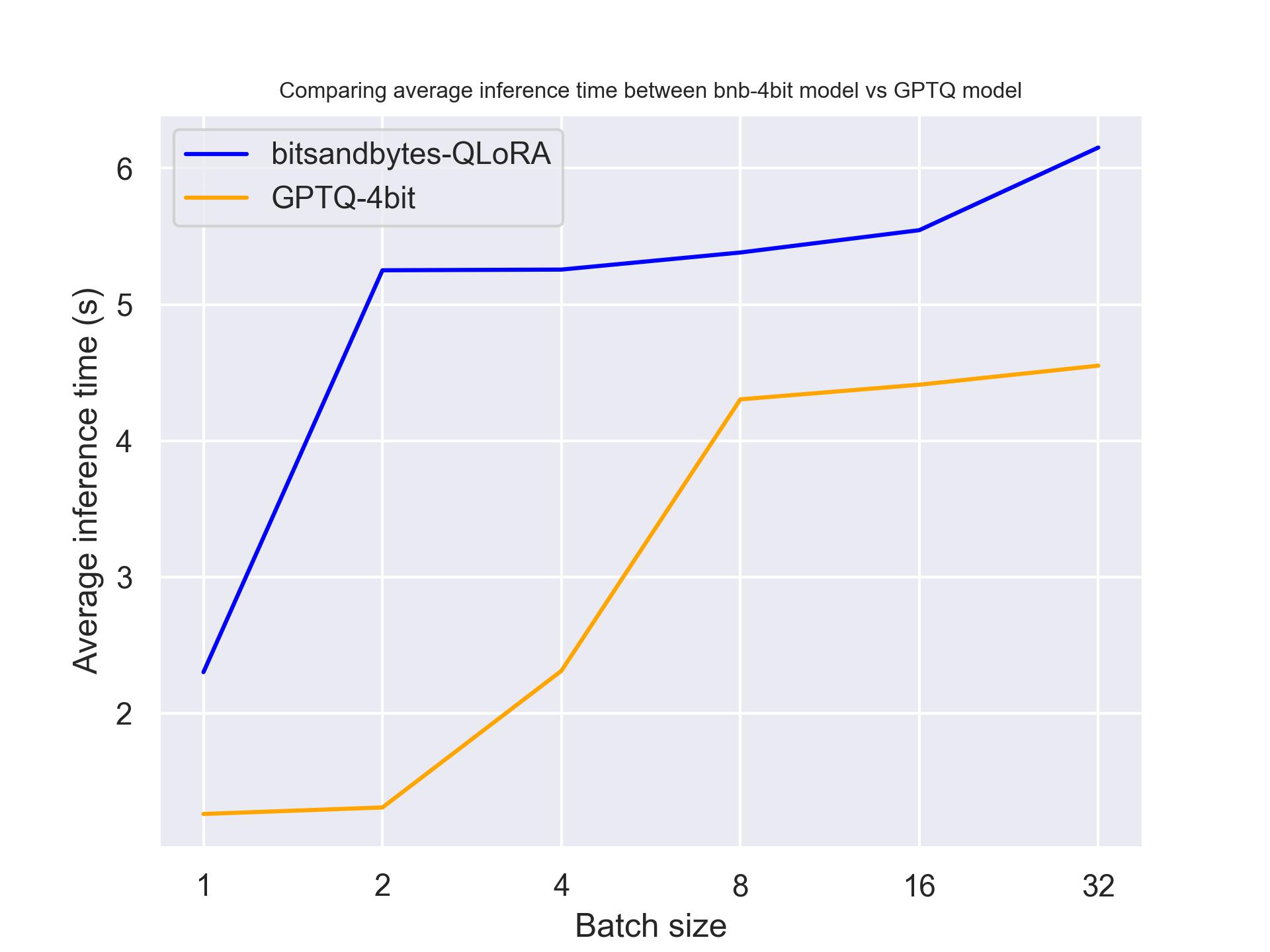
with a Titan RTX:
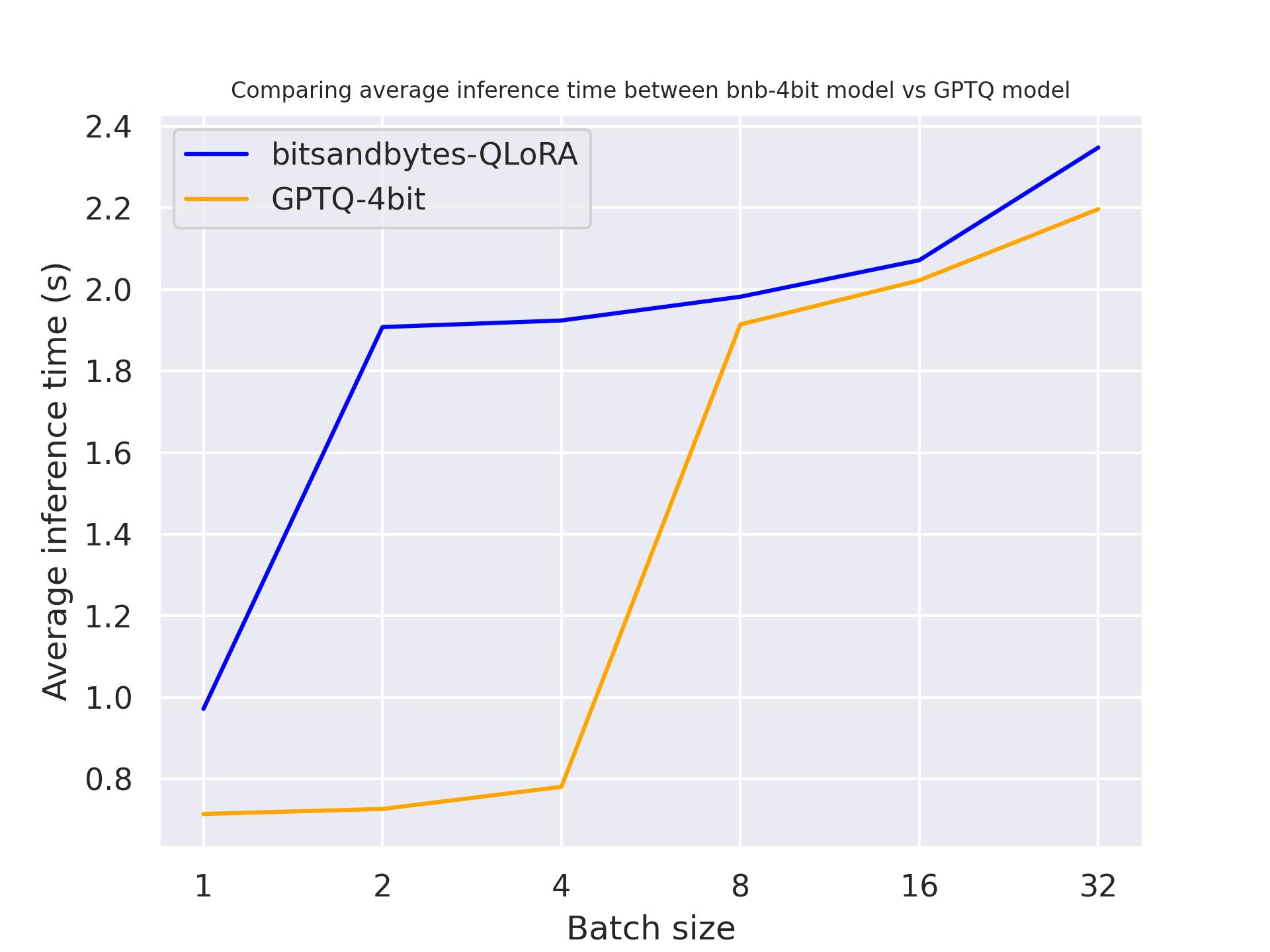
From the benchmark above, we can conclude that GPTQ is faster than bitsandbytes for those three GPUs.
#### Generation length
In the following benchmark, we will try different generation lengths to see their impact on the quantized model. It was run on a A100 and we used a prompt length of 30, and varied the number of generated tokens. The model we used was `meta-llama/Llama-2-7b-hf`.
with 30 tokens generated:

with 512 tokens generated:
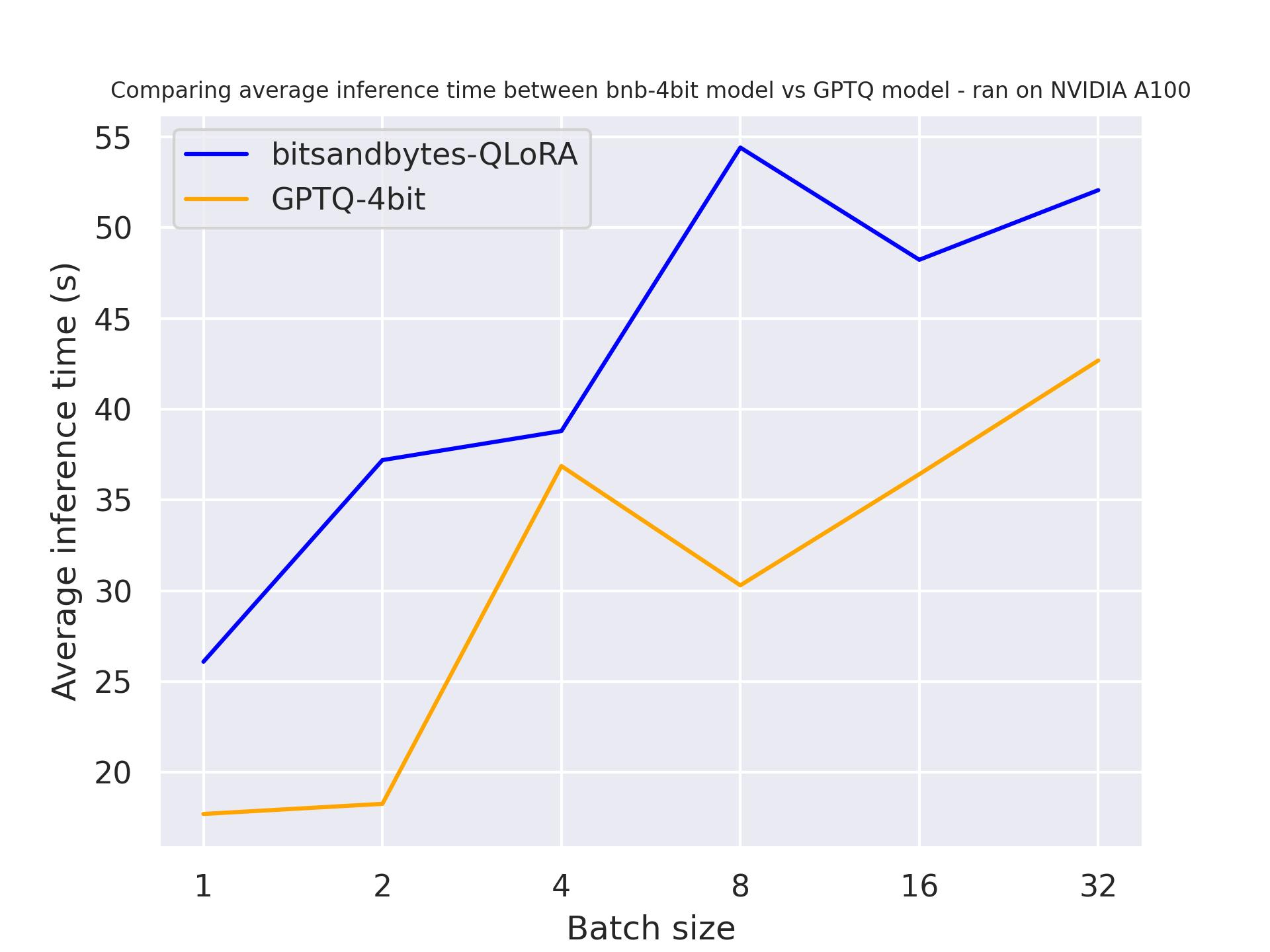
From the benchmark above, we can conclude that GPTQ is faster than bitsandbytes independently of the generation length.
### Adapter fine-tuning (forward + backward)
It is not possible to perform pure training on a quantized model. However, you can fine-tune quantized models by leveraging parameter efficient fine tuning methods (PEFT) and train adapters on top of them. The fine-tuning method will rely on a recent method called "Low Rank Adapters" (LoRA): instead of fine-tuning the entire model you just have to fine-tune these adapters and load them properly inside the model. Let's compare the fine-tuning speed!
The benchmark was run on a NVIDIA A100 GPU and we used `meta-llama/Llama-2-7b-hf` model from the Hub. Note that for GPTQ model, we had to disable the exllama kernels as exllama is not supported for fine-tuning.
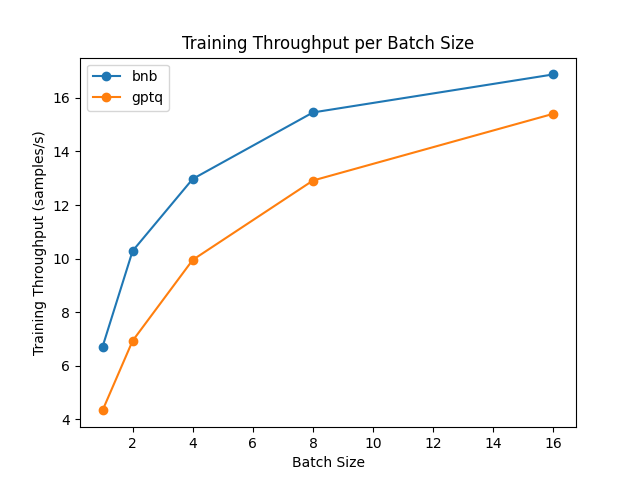
From the result, we conclude that bitsandbytes is faster than GPTQ for fine-tuning.
### Performance degradation
Quantization is great for reducing memory consumption. However, it does come with performance degradation. Let's compare the performance using the [Open-LLM leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) !
with 7b model:
| model_id | Average | ARC | Hellaswag | MMLU | TruthfulQA |
|------------------------------------|---------|-------|-----------|-------|------------|
| meta-llama/llama-2-7b-hf | **54.32** | 53.07 | 78.59 | 46.87 | 38.76 |
| meta-llama/llama-2-7b-hf-bnb-4bit | **53.4** | 53.07 | 77.74 | 43.8 | 38.98 |
| TheBloke/Llama-2-7B-GPTQ | **53.23** | 52.05 | 77.59 | 43.99 | 39.32 |
with 13b model:
| model_id | Average | ARC | Hellaswag | MMLU | TruthfulQA |
|------------------------------------|---------|-------|-----------|-------|------------|
| meta-llama/llama-2-13b-hf | **58.66** | 59.39 | 82.13 | 55.74 | 37.38 |
| TheBloke/Llama-2-13B-GPTQ (revision = 'gptq-4bit-128g-actorder_True')| **58.03** | 59.13 | 81.48 | 54.45 | 37.07 |
| TheBloke/Llama-2-13B-GPTQ | **57.56** | 57.25 | 81.66 | 54.81 | 36.56 |
| meta-llama/llama-2-13b-hf-bnb-4bit | **56.9** | 58.11 | 80.97 | 54.34 | 34.17 |
From the results above, we conclude that there is less degradation in bigger models. More interestingly, the degradation is minimal!
## Conclusion and final words
In this blogpost, we compared bitsandbytes and GPTQ quantization across multiple setups. We saw that bitsandbytes is better suited for fine-tuning while GPTQ is better for generation. From this observation, one way to get better merged models would be to:
- (1) quantize the base model using bitsandbytes (zero-shot quantization)
- (2) add and fine-tune the adapters
- (3) merge the trained adapters on top of the base model or the [dequantized model](https://github.com/huggingface/peft/pull/851/files) !
- (4) quantize the merged model using GPTQ and use it for deployment
We hope that this overview will make it easier for everyone to use LLMs in their applications and usecases, and we are looking forward to seeing what you will build with it!
## Acknowledgements
We would like to thank [Ilyas](https://huggingface.co/IlyasMoutawwakil), [Clémentine](https://huggingface.co/clefourrier) and [Felix](https://huggingface.co/fxmarty) for their help on the benchmarking.
Finally, we would like to thank [Pedro Cuenca](https://github.com/pcuenca) for his help with the writing of this blogpost.
| huggingface/blog/blob/main/overview-quantization-transformers.md |
ESE-VoVNet
**VoVNet** is a convolutional neural network that seeks to make [DenseNet](https://paperswithcode.com/method/densenet) more efficient by concatenating all features only once in the last feature map, which makes input size constant and enables enlarging new output channel.
Read about [one-shot aggregation here](https://paperswithcode.com/method/one-shot-aggregation).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('ese_vovnet19b_dw', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `ese_vovnet19b_dw`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('ese_vovnet19b_dw', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{lee2019energy,
title={An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection},
author={Youngwan Lee and Joong-won Hwang and Sangrok Lee and Yuseok Bae and Jongyoul Park},
year={2019},
eprint={1904.09730},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: ESE VovNet
Paper:
Title: 'CenterMask : Real-Time Anchor-Free Instance Segmentation'
URL: https://paperswithcode.com/paper/centermask-real-time-anchor-free-instance-1
Models:
- Name: ese_vovnet19b_dw
In Collection: ESE VovNet
Metadata:
FLOPs: 1711959904
Parameters: 6540000
File Size: 26243175
Architecture:
- Batch Normalization
- Convolution
- Max Pooling
- One-Shot Aggregation
- ReLU
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: ese_vovnet19b_dw
Layers: 19
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/vovnet.py#L361
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/ese_vovnet19b_dw-a8741004.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 76.82%
Top 5 Accuracy: 93.28%
- Name: ese_vovnet39b
In Collection: ESE VovNet
Metadata:
FLOPs: 9089259008
Parameters: 24570000
File Size: 98397138
Architecture:
- Batch Normalization
- Convolution
- Max Pooling
- One-Shot Aggregation
- ReLU
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: ese_vovnet39b
Layers: 39
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/vovnet.py#L371
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/ese_vovnet39b-f912fe73.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.31%
Top 5 Accuracy: 94.72%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/ese-vovnet.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# DDPM
[Denoising Diffusion Probabilistic Models](https://huggingface.co/papers/2006.11239) (DDPM) by Jonathan Ho, Ajay Jain and Pieter Abbeel proposes a diffusion based model of the same name. In the 🤗 Diffusers library, DDPM refers to the *discrete denoising scheduler* from the paper as well as the pipeline.
The abstract from the paper is:
*We present high quality image synthesis results using diffusion probabilistic models, a class of latent variable models inspired by considerations from nonequilibrium thermodynamics. Our best results are obtained by training on a weighted variational bound designed according to a novel connection between diffusion probabilistic models and denoising score matching with Langevin dynamics, and our models naturally admit a progressive lossy decompression scheme that can be interpreted as a generalization of autoregressive decoding. On the unconditional CIFAR10 dataset, we obtain an Inception score of 9.46 and a state-of-the-art FID score of 3.17. On 256x256 LSUN, we obtain sample quality similar to ProgressiveGAN.*
The original codebase can be found at [hohonathanho/diffusion](https://github.com/hojonathanho/diffusion).
<Tip>
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
</Tip>
# DDPMPipeline
[[autodoc]] DDPMPipeline
- all
- __call__
## ImagePipelineOutput
[[autodoc]] pipelines.ImagePipelineOutput
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/ddpm.md |
Docker Spaces
Spaces accommodate custom [Docker containers](https://docs.docker.com/get-started/) for apps outside the scope of Streamlit and Gradio. Docker Spaces allow users to go beyond the limits of what was previously possible with the standard SDKs. From FastAPI and Go endpoints to Phoenix apps and ML Ops tools, Docker Spaces can help in many different setups.
## Setting up Docker Spaces
Selecting **Docker** as the SDK when [creating a new Space](https://huggingface.co/new-space) will initialize your Space by setting the `sdk` property to `docker` in your `README.md` file's YAML block. Alternatively, given an existing Space repository, set `sdk: docker` inside the `YAML` block at the top of your Spaces **README.md** file. You can also change the default exposed port `7860` by setting `app_port: 7860`. Afterwards, you can create a usual `Dockerfile`.
```Yaml
---
title: Basic Docker SDK Space
emoji: 🐳
colorFrom: purple
colorTo: gray
sdk: docker
app_port: 7860
---
```
Internally you could have as many open ports as you want. For instance, you can install Elasticsearch inside your Space and call it internally on its default port 9200.
If you want to expose apps served on multiple ports to the outside world, a workaround is to use a reverse proxy like Nginx to dispatch requests from the broader internet (on a single port) to different internal ports.
## Secrets and Variables Management
<a id="secret-management"></a>
You can manage a Space's environment variables in the Space Settings. Read more [here](./spaces-overview#managing-secrets).
### Variables
#### Buildtime
Variables are passed as `build-arg`s when building your Docker Space. Read [Docker's dedicated documentation](https://docs.docker.com/engine/reference/builder/#arg) for a complete guide on how to use this in the Dockerfile.
```Dockerfile
# Declare your environment variables with the ARG directive
ARG MODEL_REPO_NAME
FROM python:latest
# [...]
# You can use them like environment variables
RUN predict.py $MODEL_REPO_NAME
```
#### Runtime
Variables are injected in the container's environment at runtime.
### Secrets
#### Buildtime
In Docker Spaces, the secrets management is different for security reasons. Once you create a secret in the [Settings tab](./spaces-overview#managing-secrets), you can expose the secret by adding the following line in your Dockerfile:
For example, if `SECRET_EXAMPLE` is the name of the secret you created in the Settings tab, you can read it at build time by mounting it to a file, then reading it with `$(cat /run/secrets/SECRET_EXAMPLE)`.
See an example below:
```Dockerfile
# Expose the secret SECRET_EXAMPLE at buildtime and use its value as git remote URL
RUN --mount=type=secret,id=SECRET_EXAMPLE,mode=0444,required=true \
git init && \
git remote add origin $(cat /run/secrets/SECRET_EXAMPLE)
```
```Dockerfile
# Expose the secret SECRET_EXAMPLE at buildtime and use its value as a Bearer token for a curl request
RUN --mount=type=secret,id=SECRET_EXAMPLE,mode=0444,required=true \
curl test -H 'Authorization: Bearer $(cat /run/secrets/SECRET_EXAMPLE)'
```
#### Runtime
Same as for public Variables, at runtime, you can access the secrets as environment variables. For example, in Python you would use `os.environ.get("SECRET_EXAMPLE")`. Check out this [example](https://huggingface.co/spaces/DockerTemplates/secret-example) of a Docker Space that uses secrets.
## Permissions
The container runs with user ID 1000. To avoid permission issues you should create a user and set its `WORKDIR` before any `COPY` or download.
```Dockerfile
# Set up a new user named "user" with user ID 1000
RUN useradd -m -u 1000 user
# Switch to the "user" user
USER user
# Set home to the user's home directory
ENV HOME=/home/user \
PATH=/home/user/.local/bin:$PATH
# Set the working directory to the user's home directory
WORKDIR $HOME/app
# Try and run pip command after setting the user with `USER user` to avoid permission issues with Python
RUN pip install --no-cache-dir --upgrade pip
# Copy the current directory contents into the container at $HOME/app setting the owner to the user
COPY --chown=user . $HOME/app
# Download a checkpoint
RUN mkdir content
ADD --chown=user https://<SOME_ASSET_URL> content/<SOME_ASSET_NAME>
```
<Tip warning="{true}">
Always specify the `--chown=user` with `ADD` and `COPY` to ensure the new files are owned by your user.
</Tip>
If you still face permission issues, you might need to use `chmod` or `chown` in your `Dockerfile` to grant the right permissions. For example, if you want to use the directory `/data`, you can do:
```Dockerfile
RUN mkdir -p /data
RUN chmod 777 /data
```
You should always avoid superfluous chowns.
<Tip warning={true}>
Updating metadata for a file creates a new copy stored in the new layer. Therefore, a recursive chown can result in a very large image due to the duplication of all affected files.
</Tip>
Rather than fixing permission by running `chown`:
```
COPY checkpoint .
RUN chown -R user checkpoint
```
you should always do:
```
COPY --chown=user checkpoint .
```
(same goes for `ADD` command)
## Data Persistence
The data written on disk is lost whenever your Docker Space restarts, unless you opt-in for a [persistent storage](./spaces-storage) upgrade.
If you opt-in for a persistent storage upgrade, you can use the `/data` directory to store data. This directory is mounted on a persistent volume, which means that the data written in this directory will be persisted across restarts.
<Tip warning="{true}">
At the moment, `/data` volume is only available at runtime, i.e. you cannot use `/data` during the build step of your Dockerfile.
</Tip>
You can also use our Datasets Hub for specific cases, where you can store state and data in a git LFS repository. You can find an example of persistence [here](https://huggingface.co/spaces/Wauplin/space_to_dataset_saver), which uses the [`huggingface_hub` library](https://huggingface.co/docs/huggingface_hub/index) for programmatically uploading files to a dataset repository. This Space example along with [this guide](https://huggingface.co/docs/huggingface_hub/main/en/guides/upload#scheduled-uploads) will help you define which solution fits best your data type.
Finally, in some cases, you might want to use an external storage solution from your Space's code like an external hosted DB, S3, etc.
### Docker container with GPU
You can run Docker containers with GPU support by using one of our GPU-flavored [Spaces Hardware](./spaces-gpus).
We recommend using the [`nvidia/cuda`](https://hub.docker.com/r/nvidia/cuda) from Docker Hub as a base image, which comes with CUDA and cuDNN pre-installed.
<Tip warning="{true}">
During Docker buildtime, you don't have access to a GPU hardware. Therefore, you should not try to run any GPU-related command during the build step of your Dockerfile. For example, you can't run `nvidia-smi` or `torch.cuda.is_available()` building an image. Read more [here](https://github.com/NVIDIA/nvidia-docker/wiki/nvidia-docker#description).
</Tip>
## Read More
- [Full Docker demo example](spaces-sdks-docker-first-demo)
- [List of Docker Spaces examples](spaces-sdks-docker-examples)
- [Spaces Examples](https://huggingface.co/SpacesExamples)
| huggingface/hub-docs/blob/main/docs/hub/spaces-sdks-docker.md |
Kandinsky2.2 text-to-image fine-tuning
Kandinsky 2.2 includes a prior pipeline that generates image embeddings from text prompts, and a decoder pipeline that generates the output image based on the image embeddings. We provide `train_text_to_image_prior.py` and `train_text_to_image_decoder.py` scripts to show you how to fine-tune the Kandinsky prior and decoder models separately based on your own dataset. To achieve the best results, you should fine-tune **_both_** your prior and decoder models.
___Note___:
___This script is experimental. The script fine-tunes the whole model and often times the model overfits and runs into issues like catastrophic forgetting. It's recommended to try different hyperparameters to get the best result on your dataset.___
## Running locally with PyTorch
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then cd in the example folder and run
```bash
pip install -r requirements.txt
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
For this example we want to directly store the trained LoRA embeddings on the Hub, so we need to be logged in and add the --push_to_hub flag.
___
### Pokemon example
For all our examples, we will directly store the trained weights on the Hub, so we need to be logged in and add the `--push_to_hub` flag. In order to do that, you have to be a registered user on the 🤗 Hugging Face Hub, and you'll also need to use an access token for the code to work. For more information on access tokens, please refer to the [User Access Tokens](https://huggingface.co/docs/hub/security-tokens) guide.
Run the following command to authenticate your token
```bash
huggingface-cli login
```
We also use [Weights and Biases](https://docs.wandb.ai/quickstart) logging by default, because it is really useful to monitor the training progress by regularly generating sample images during training. To install wandb, run
```bash
pip install wandb
```
To disable wandb logging, remove the `--report_to=="wandb"` and `--validation_prompts="A robot pokemon, 4k photo"` flags from below examples
#### Fine-tune decoder
<br>
<!-- accelerate_snippet_start -->
```bash
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch --mixed_precision="fp16" train_text_to_image_decoder.py \
--dataset_name=$DATASET_NAME \
--resolution=768 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--checkpoints_total_limit=3 \
--lr_scheduler="constant" --lr_warmup_steps=0 \
--validation_prompts="A robot pokemon, 4k photo" \
--report_to="wandb" \
--push_to_hub \
--output_dir="kandi2-decoder-pokemon-model"
```
<!-- accelerate_snippet_end -->
To train on your own training files, prepare the dataset according to the format required by `datasets`. You can find the instructions for how to do that in the [ImageFolder with metadata](https://huggingface.co/docs/datasets/en/image_load#imagefolder-with-metadata) guide.
If you wish to use custom loading logic, you should modify the script and we have left pointers for that in the training script.
```bash
export TRAIN_DIR="path_to_your_dataset"
accelerate launch --mixed_precision="fp16" train_text_to_image_decoder.py \
--train_data_dir=$TRAIN_DIR \
--resolution=768 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--checkpoints_total_limit=3 \
--lr_scheduler="constant" --lr_warmup_steps=0 \
--validation_prompts="A robot pokemon, 4k photo" \
--report_to="wandb" \
--push_to_hub \
--output_dir="kandi22-decoder-pokemon-model"
```
Once the training is finished the model will be saved in the `output_dir` specified in the command. In this example it's `kandi22-decoder-pokemon-model`. To load the fine-tuned model for inference just pass that path to `AutoPipelineForText2Image`
```python
from diffusers import AutoPipelineForText2Image
import torch
pipe = AutoPipelineForText2Image.from_pretrained(output_dir, torch_dtype=torch.float16)
pipe.enable_model_cpu_offload()
prompt='A robot pokemon, 4k photo'
images = pipe(prompt=prompt).images
images[0].save("robot-pokemon.png")
```
Checkpoints only save the unet, so to run inference from a checkpoint, just load the unet
```python
from diffusers import AutoPipelineForText2Image, UNet2DConditionModel
model_path = "path_to_saved_model"
unet = UNet2DConditionModel.from_pretrained(model_path + "/checkpoint-<N>/unet")
pipe = AutoPipelineForText2Image.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", unet=unet, torch_dtype=torch.float16)
pipe.enable_model_cpu_offload()
image = pipe(prompt="A robot pokemon, 4k photo").images[0]
image.save("robot-pokemon.png")
```
#### Fine-tune prior
You can fine-tune the Kandinsky prior model with `train_text_to_image_prior.py` script. Note that we currently do not support `--gradient_checkpointing` for prior model fine-tuning.
<br>
<!-- accelerate_snippet_start -->
```bash
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch --mixed_precision="fp16" train_text_to_image_prior.py \
--dataset_name=$DATASET_NAME \
--resolution=768 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--checkpoints_total_limit=3 \
--lr_scheduler="constant" --lr_warmup_steps=0 \
--validation_prompts="A robot pokemon, 4k photo" \
--report_to="wandb" \
--push_to_hub \
--output_dir="kandi2-prior-pokemon-model"
```
<!-- accelerate_snippet_end -->
To perform inference with the fine-tuned prior model, you will need to first create a prior pipeline by passing the `output_dir` to `DiffusionPipeline`. Then create a `KandinskyV22CombinedPipeline` from a pretrained or fine-tuned decoder checkpoint along with all the modules of the prior pipeline you just created.
```python
from diffusers import AutoPipelineForText2Image, DiffusionPipeline
import torch
pipe_prior = DiffusionPipeline.from_pretrained(output_dir, torch_dtype=torch.float16)
prior_components = {"prior_" + k: v for k,v in pipe_prior.components.items()}
pipe = AutoPipelineForText2Image.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", **prior_components, torch_dtype=torch.float16)
pipe.enable_model_cpu_offload()
prompt='A robot pokemon, 4k photo'
images = pipe(prompt=prompt, negative_prompt=negative_prompt).images
images[0]
```
If you want to use a fine-tuned decoder checkpoint along with your fine-tuned prior checkpoint, you can simply replace the "kandinsky-community/kandinsky-2-2-decoder" in above code with your custom model repo name. Note that in order to be able to create a `KandinskyV22CombinedPipeline`, your model repository need to have a prior tag. If you have created your model repo using our training script, the prior tag is automatically included.
#### Training with multiple GPUs
`accelerate` allows for seamless multi-GPU training. Follow the instructions [here](https://huggingface.co/docs/accelerate/basic_tutorials/launch)
for running distributed training with `accelerate`. Here is an example command:
```bash
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch --mixed_precision="fp16" --multi_gpu train_text_to_image_decoder.py \
--dataset_name=$DATASET_NAME \
--resolution=768 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--checkpoints_total_limit=3 \
--lr_scheduler="constant" --lr_warmup_steps=0 \
--validation_prompts="A robot pokemon, 4k photo" \
--report_to="wandb" \
--push_to_hub \
--output_dir="kandi2-decoder-pokemon-model"
```
#### Training with Min-SNR weighting
We support training with the Min-SNR weighting strategy proposed in [Efficient Diffusion Training via Min-SNR Weighting Strategy](https://arxiv.org/abs/2303.09556) which helps achieve faster convergence
by rebalancing the loss. Enable the `--snr_gamma` argument and set it to the recommended
value of 5.0.
## Training with LoRA
Low-Rank Adaption of Large Language Models was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
In a nutshell, LoRA allows adapting pretrained models by adding pairs of rank-decomposition matrices to existing weights and **only** training those newly added weights. This has a couple of advantages:
- Previous pretrained weights are kept frozen so that model is not prone to [catastrophic forgetting](https://www.pnas.org/doi/10.1073/pnas.1611835114).
- Rank-decomposition matrices have significantly fewer parameters than original model, which means that trained LoRA weights are easily portable.
- LoRA attention layers allow to control to which extent the model is adapted toward new training images via a `scale` parameter.
[cloneofsimo](https://github.com/cloneofsimo) was the first to try out LoRA training for Stable Diffusion in the popular [lora](https://github.com/cloneofsimo/lora) GitHub repository.
With LoRA, it's possible to fine-tune Kandinsky 2.2 on a custom image-caption pair dataset
on consumer GPUs like Tesla T4, Tesla V100.
### Training
First, you need to set up your development environment as explained in the [installation](#installing-the-dependencies). Make sure to set the `MODEL_NAME` and `DATASET_NAME` environment variables. Here, we will use [Kandinsky 2.2](https://huggingface.co/kandinsky-community/kandinsky-2-2-decoder) and the [Pokemons dataset](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions).
#### Train decoder
```bash
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch --mixed_precision="fp16" train_text_to_image_decoder_lora.py \
--dataset_name=$DATASET_NAME --caption_column="text" \
--resolution=768 \
--train_batch_size=1 \
--num_train_epochs=100 --checkpointing_steps=5000 \
--learning_rate=1e-04 --lr_scheduler="constant" --lr_warmup_steps=0 \
--seed=42 \
--rank=4 \
--gradient_checkpointing \
--output_dir="kandi22-decoder-pokemon-lora" \
--validation_prompt="cute dragon creature" --report_to="wandb" \
--push_to_hub \
```
#### Train prior
```bash
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch --mixed_precision="fp16" train_text_to_image_prior_lora.py \
--dataset_name=$DATASET_NAME --caption_column="text" \
--resolution=768 \
--train_batch_size=1 \
--num_train_epochs=100 --checkpointing_steps=5000 \
--learning_rate=1e-04 --lr_scheduler="constant" --lr_warmup_steps=0 \
--seed=42 \
--rank=4 \
--output_dir="kandi22-prior-pokemon-lora" \
--validation_prompt="cute dragon creature" --report_to="wandb" \
--push_to_hub \
```
**___Note: When using LoRA we can use a much higher learning rate compared to non-LoRA fine-tuning. Here we use *1e-4* instead of the usual *1e-5*. Also, by using LoRA, it's possible to run above scripts in consumer GPUs like T4 or V100.___**
### Inference
#### Inference using fine-tuned LoRA checkpoint for decoder
Once you have trained a Kandinsky decoder model using the above command, inference can be done with the `AutoPipelineForText2Image` after loading the trained LoRA weights. You need to pass the `output_dir` for loading the LoRA weights, which in this case is `kandi22-decoder-pokemon-lora`.
```python
from diffusers import AutoPipelineForText2Image
import torch
pipe = AutoPipelineForText2Image.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16)
pipe.unet.load_attn_procs(output_dir)
pipe.enable_model_cpu_offload()
prompt='A robot pokemon, 4k photo'
image = pipe(prompt=prompt).images[0]
image.save("robot_pokemon.png")
```
#### Inference using fine-tuned LoRA checkpoint for prior
```python
from diffusers import AutoPipelineForText2Image
import torch
pipe = AutoPipelineForText2Image.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16)
pipe.prior_prior.load_attn_procs(output_dir)
pipe.enable_model_cpu_offload()
prompt='A robot pokemon, 4k photo'
image = pipe(prompt=prompt).images[0]
image.save("robot_pokemon.png")
image
```
### Training with xFormers:
You can enable memory efficient attention by [installing xFormers](https://huggingface.co/docs/diffusers/main/en/optimization/xformers) and passing the `--enable_xformers_memory_efficient_attention` argument to the script.
xFormers training is not available for fine-tuning the prior model.
**Note**:
According to [this issue](https://github.com/huggingface/diffusers/issues/2234#issuecomment-1416931212), xFormers `v0.0.16` cannot be used for training in some GPUs. If you observe that problem, please install a development version as indicated in that comment. | huggingface/diffusers/blob/main/examples/kandinsky2_2/text_to_image/README.md |
How do Unity ML-Agents work? [[how-mlagents-works]]
Before training our agent, we need to understand **what ML-Agents is and how it works**.
## What is Unity ML-Agents? [[what-is-mlagents]]
[Unity ML-Agents](https://github.com/Unity-Technologies/ml-agents) is a toolkit for the game engine Unity that **allows us to create environments using Unity or use pre-made environments to train our agents**.
It’s developed by [Unity Technologies](https://unity.com/), the developers of Unity, one of the most famous Game Engines used by the creators of Firewatch, Cuphead, and Cities: Skylines.
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit5/firewatch.jpeg" alt="Firewatch"/>
<figcaption>Firewatch was made with Unity</figcaption>
</figure>
## The six components [[six-components]]
With Unity ML-Agents, you have six essential components:
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit5/mlagents-1.png" alt="MLAgents"/>
<figcaption>Source: <a href="https://unity-technologies.github.io/ml-agents/">Unity ML-Agents Documentation</a> </figcaption>
</figure>
- The first is the *Learning Environment*, which contains **the Unity scene (the environment) and the environment elements** (game characters).
- The second is the *Python Low-level API*, which contains **the low-level Python interface for interacting and manipulating the environment**. It’s the API we use to launch the training.
- Then, we have the *External Communicator* that **connects the Learning Environment (made with C#) with the low level Python API (Python)**.
- The *Python trainers*: the **Reinforcement algorithms made with PyTorch (PPO, SAC…)**.
- The *Gym wrapper*: to encapsulate the RL environment in a gym wrapper.
- The *PettingZoo wrapper*: PettingZoo is the multi-agents version of the gym wrapper.
## Inside the Learning Component [[inside-learning-component]]
Inside the Learning Component, we have **two important elements**:
- The first is the *agent component*, the actor of the scene. We’ll **train the agent by optimizing its policy** (which will tell us what action to take in each state). The policy is called the *Brain*.
- Finally, there is the *Academy*. This component **orchestrates agents and their decision-making processes**. Think of this Academy as a teacher who handles Python API requests.
To better understand its role, let’s remember the RL process. This can be modeled as a loop that works like this:
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/RL_process.jpg" alt="The RL process" width="100%">
<figcaption>The RL Process: a loop of state, action, reward and next state</figcaption>
<figcaption>Source: <a href="http://incompleteideas.net/book/RLbook2020.pdf">Reinforcement Learning: An Introduction, Richard Sutton and Andrew G. Barto</a></figcaption>
</figure>
Now, let’s imagine an agent learning to play a platform game. The RL process looks like this:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/RL_process_game.jpg" alt="The RL process" width="100%">
- Our Agent receives **state \\(S_0\\)** from the **Environment** — we receive the first frame of our game (Environment).
- Based on that **state \\(S_0\\),** the Agent takes **action \\(A_0\\)** — our Agent will move to the right.
- The environment goes to a **new** **state \\(S_1\\)** — new frame.
- The environment gives some **reward \\(R_1\\)** to the Agent — we’re not dead *(Positive Reward +1)*.
This RL loop outputs a sequence of **state, action, reward and next state.** The goal of the agent is to **maximize the expected cumulative reward**.
The Academy will be the one that will **send the order to our Agents and ensure that agents are in sync**:
- Collect Observations
- Select your action using your policy
- Take the Action
- Reset if you reached the max step or if you’re done.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit5/academy.png" alt="The MLAgents Academy" width="100%">
Now that we understand how ML-Agents works, **we’re ready to train our agents.**
| huggingface/deep-rl-class/blob/main/units/en/unit5/how-mlagents-works.mdx |
e don't yet support training T2I-Adapters on Stable Diffusion yet. For training T2I-Adapters on Stable Diffusion XL, refer [here](./README_sdxl.md). | huggingface/diffusers/blob/main/examples/t2i_adapter/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Document Question Answering
[[open-in-colab]]
Document Question Answering, also referred to as Document Visual Question Answering, is a task that involves providing
answers to questions posed about document images. The input to models supporting this task is typically a combination of an image and
a question, and the output is an answer expressed in natural language. These models utilize multiple modalities, including
text, the positions of words (bounding boxes), and the image itself.
This guide illustrates how to:
- Fine-tune [LayoutLMv2](../model_doc/layoutlmv2) on the [DocVQA dataset](https://huggingface.co/datasets/nielsr/docvqa_1200_examples_donut).
- Use your fine-tuned model for inference.
<Tip>
The task illustrated in this tutorial is supported by the following model architectures:
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
[LayoutLM](../model_doc/layoutlm), [LayoutLMv2](../model_doc/layoutlmv2), [LayoutLMv3](../model_doc/layoutlmv3)
<!--End of the generated tip-->
</Tip>
LayoutLMv2 solves the document question-answering task by adding a question-answering head on top of the final hidden
states of the tokens, to predict the positions of the start and end tokens of the
answer. In other words, the problem is treated as extractive question answering: given the context, extract which piece
of information answers the question. The context comes from the output of an OCR engine, here it is Google's Tesseract.
Before you begin, make sure you have all the necessary libraries installed. LayoutLMv2 depends on detectron2, torchvision and tesseract.
```bash
pip install -q transformers datasets
```
```bash
pip install 'git+https://github.com/facebookresearch/detectron2.git'
pip install torchvision
```
```bash
sudo apt install tesseract-ocr
pip install -q pytesseract
```
Once you have installed all of the dependencies, restart your runtime.
We encourage you to share your model with the community. Log in to your Hugging Face account to upload it to the 🤗 Hub.
When prompted, enter your token to log in:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
Let's define some global variables.
```py
>>> model_checkpoint = "microsoft/layoutlmv2-base-uncased"
>>> batch_size = 4
```
## Load the data
In this guide we use a small sample of preprocessed DocVQA that you can find on 🤗 Hub. If you'd like to use the full
DocVQA dataset, you can register and download it on [DocVQA homepage](https://rrc.cvc.uab.es/?ch=17). If you do so, to
proceed with this guide check out [how to load files into a 🤗 dataset](https://huggingface.co/docs/datasets/loading#local-and-remote-files).
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("nielsr/docvqa_1200_examples")
>>> dataset
DatasetDict({
train: Dataset({
features: ['id', 'image', 'query', 'answers', 'words', 'bounding_boxes', 'answer'],
num_rows: 1000
})
test: Dataset({
features: ['id', 'image', 'query', 'answers', 'words', 'bounding_boxes', 'answer'],
num_rows: 200
})
})
```
As you can see, the dataset is split into train and test sets already. Take a look at a random example to familiarize
yourself with the features.
```py
>>> dataset["train"].features
```
Here's what the individual fields represent:
* `id`: the example's id
* `image`: a PIL.Image.Image object containing the document image
* `query`: the question string - natural language asked question, in several languages
* `answers`: a list of correct answers provided by human annotators
* `words` and `bounding_boxes`: the results of OCR, which we will not use here
* `answer`: an answer matched by a different model which we will not use here
Let's leave only English questions, and drop the `answer` feature which appears to contain predictions by another model.
We'll also take the first of the answers from the set provided by the annotators. Alternatively, you can randomly sample it.
```py
>>> updated_dataset = dataset.map(lambda example: {"question": example["query"]["en"]}, remove_columns=["query"])
>>> updated_dataset = updated_dataset.map(
... lambda example: {"answer": example["answers"][0]}, remove_columns=["answer", "answers"]
... )
```
Note that the LayoutLMv2 checkpoint that we use in this guide has been trained with `max_position_embeddings = 512` (you can
find this information in the [checkpoint's `config.json` file](https://huggingface.co/microsoft/layoutlmv2-base-uncased/blob/main/config.json#L18)).
We can truncate the examples but to avoid the situation where the answer might be at the end of a large document and end up truncated,
here we'll remove the few examples where the embedding is likely to end up longer than 512.
If most of the documents in your dataset are long, you can implement a sliding window strategy - check out [this notebook](https://github.com/huggingface/notebooks/blob/main/examples/question_answering.ipynb) for details.
```py
>>> updated_dataset = updated_dataset.filter(lambda x: len(x["words"]) + len(x["question"].split()) < 512)
```
At this point let's also remove the OCR features from this dataset. These are a result of OCR for fine-tuning a different
model. They would still require some processing if we wanted to use them, as they do not match the input requirements
of the model we use in this guide. Instead, we can use the [`LayoutLMv2Processor`] on the original data for both OCR and
tokenization. This way we'll get the inputs that match model's expected input. If you want to process images manually,
check out the [`LayoutLMv2` model documentation](../model_doc/layoutlmv2) to learn what input format the model expects.
```py
>>> updated_dataset = updated_dataset.remove_columns("words")
>>> updated_dataset = updated_dataset.remove_columns("bounding_boxes")
```
Finally, the data exploration won't be complete if we don't peek at an image example.
```py
>>> updated_dataset["train"][11]["image"]
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/docvqa_example.jpg" alt="DocVQA Image Example"/>
</div>
## Preprocess the data
The Document Question Answering task is a multimodal task, and you need to make sure that the inputs from each modality
are preprocessed according to the model's expectations. Let's start by loading the [`LayoutLMv2Processor`], which internally combines an image processor that can handle image data and a tokenizer that can encode text data.
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
```
### Preprocessing document images
First, let's prepare the document images for the model with the help of the `image_processor` from the processor.
By default, image processor resizes the images to 224x224, makes sure they have the correct order of color channels,
applies OCR with tesseract to get words and normalized bounding boxes. In this tutorial, all of these defaults are exactly what we need.
Write a function that applies the default image processing to a batch of images and returns the results of OCR.
```py
>>> image_processor = processor.image_processor
>>> def get_ocr_words_and_boxes(examples):
... images = [image.convert("RGB") for image in examples["image"]]
... encoded_inputs = image_processor(images)
... examples["image"] = encoded_inputs.pixel_values
... examples["words"] = encoded_inputs.words
... examples["boxes"] = encoded_inputs.boxes
... return examples
```
To apply this preprocessing to the entire dataset in a fast way, use [`~datasets.Dataset.map`].
```py
>>> dataset_with_ocr = updated_dataset.map(get_ocr_words_and_boxes, batched=True, batch_size=2)
```
### Preprocessing text data
Once we have applied OCR to the images, we need to encode the text part of the dataset to prepare it for the model.
This involves converting the words and boxes that we got in the previous step to token-level `input_ids`, `attention_mask`,
`token_type_ids` and `bbox`. For preprocessing text, we'll need the `tokenizer` from the processor.
```py
>>> tokenizer = processor.tokenizer
```
On top of the preprocessing mentioned above, we also need to add the labels for the model. For `xxxForQuestionAnswering` models
in 🤗 Transformers, the labels consist of the `start_positions` and `end_positions`, indicating which token is at the
start and which token is at the end of the answer.
Let's start with that. Define a helper function that can find a sublist (the answer split into words) in a larger list (the words list).
This function will take two lists as input, `words_list` and `answer_list`. It will then iterate over the `words_list` and check
if the current word in the `words_list` (words_list[i]) is equal to the first word of answer_list (answer_list[0]) and if
the sublist of `words_list` starting from the current word and of the same length as `answer_list` is equal `to answer_list`.
If this condition is true, it means that a match has been found, and the function will record the match, its starting index (idx),
and its ending index (idx + len(answer_list) - 1). If more than one match was found, the function will return only the first one.
If no match is found, the function returns (`None`, 0, and 0).
```py
>>> def subfinder(words_list, answer_list):
... matches = []
... start_indices = []
... end_indices = []
... for idx, i in enumerate(range(len(words_list))):
... if words_list[i] == answer_list[0] and words_list[i : i + len(answer_list)] == answer_list:
... matches.append(answer_list)
... start_indices.append(idx)
... end_indices.append(idx + len(answer_list) - 1)
... if matches:
... return matches[0], start_indices[0], end_indices[0]
... else:
... return None, 0, 0
```
To illustrate how this function finds the position of the answer, let's use it on an example:
```py
>>> example = dataset_with_ocr["train"][1]
>>> words = [word.lower() for word in example["words"]]
>>> match, word_idx_start, word_idx_end = subfinder(words, example["answer"].lower().split())
>>> print("Question: ", example["question"])
>>> print("Words:", words)
>>> print("Answer: ", example["answer"])
>>> print("start_index", word_idx_start)
>>> print("end_index", word_idx_end)
Question: Who is in cc in this letter?
Words: ['wie', 'baw', 'brown', '&', 'williamson', 'tobacco', 'corporation', 'research', '&', 'development', 'internal', 'correspondence', 'to:', 'r.', 'h.', 'honeycutt', 'ce:', 't.f.', 'riehl', 'from:', '.', 'c.j.', 'cook', 'date:', 'may', '8,', '1995', 'subject:', 'review', 'of', 'existing', 'brainstorming', 'ideas/483', 'the', 'major', 'function', 'of', 'the', 'product', 'innovation', 'graup', 'is', 'to', 'develop', 'marketable', 'nove!', 'products', 'that', 'would', 'be', 'profitable', 'to', 'manufacture', 'and', 'sell.', 'novel', 'is', 'defined', 'as:', 'of', 'a', 'new', 'kind,', 'or', 'different', 'from', 'anything', 'seen', 'or', 'known', 'before.', 'innovation', 'is', 'defined', 'as:', 'something', 'new', 'or', 'different', 'introduced;', 'act', 'of', 'innovating;', 'introduction', 'of', 'new', 'things', 'or', 'methods.', 'the', 'products', 'may', 'incorporate', 'the', 'latest', 'technologies,', 'materials', 'and', 'know-how', 'available', 'to', 'give', 'then', 'a', 'unique', 'taste', 'or', 'look.', 'the', 'first', 'task', 'of', 'the', 'product', 'innovation', 'group', 'was', 'to', 'assemble,', 'review', 'and', 'categorize', 'a', 'list', 'of', 'existing', 'brainstorming', 'ideas.', 'ideas', 'were', 'grouped', 'into', 'two', 'major', 'categories', 'labeled', 'appearance', 'and', 'taste/aroma.', 'these', 'categories', 'are', 'used', 'for', 'novel', 'products', 'that', 'may', 'differ', 'from', 'a', 'visual', 'and/or', 'taste/aroma', 'point', 'of', 'view', 'compared', 'to', 'canventional', 'cigarettes.', 'other', 'categories', 'include', 'a', 'combination', 'of', 'the', 'above,', 'filters,', 'packaging', 'and', 'brand', 'extensions.', 'appearance', 'this', 'category', 'is', 'used', 'for', 'novel', 'cigarette', 'constructions', 'that', 'yield', 'visually', 'different', 'products', 'with', 'minimal', 'changes', 'in', 'smoke', 'chemistry', 'two', 'cigarettes', 'in', 'cne.', 'emulti-plug', 'te', 'build', 'yaur', 'awn', 'cigarette.', 'eswitchable', 'menthol', 'or', 'non', 'menthol', 'cigarette.', '*cigarettes', 'with', 'interspaced', 'perforations', 'to', 'enable', 'smoker', 'to', 'separate', 'unburned', 'section', 'for', 'future', 'smoking.', '«short', 'cigarette,', 'tobacco', 'section', '30', 'mm.', '«extremely', 'fast', 'buming', 'cigarette.', '«novel', 'cigarette', 'constructions', 'that', 'permit', 'a', 'significant', 'reduction', 'iretobacco', 'weight', 'while', 'maintaining', 'smoking', 'mechanics', 'and', 'visual', 'characteristics.', 'higher', 'basis', 'weight', 'paper:', 'potential', 'reduction', 'in', 'tobacco', 'weight.', '«more', 'rigid', 'tobacco', 'column;', 'stiffing', 'agent', 'for', 'tobacco;', 'e.g.', 'starch', '*colored', 'tow', 'and', 'cigarette', 'papers;', 'seasonal', 'promotions,', 'e.g.', 'pastel', 'colored', 'cigarettes', 'for', 'easter', 'or', 'in', 'an', 'ebony', 'and', 'ivory', 'brand', 'containing', 'a', 'mixture', 'of', 'all', 'black', '(black', 'paper', 'and', 'tow)', 'and', 'ail', 'white', 'cigarettes.', '499150498']
Answer: T.F. Riehl
start_index 17
end_index 18
```
Once examples are encoded, however, they will look like this:
```py
>>> encoding = tokenizer(example["question"], example["words"], example["boxes"])
>>> tokenizer.decode(encoding["input_ids"])
[CLS] who is in cc in this letter? [SEP] wie baw brown & williamson tobacco corporation research & development ...
```
We'll need to find the position of the answer in the encoded input.
* `token_type_ids` tells us which tokens are part of the question, and which ones are part of the document's words.
* `tokenizer.cls_token_id` will help find the special token at the beginning of the input.
* `word_ids` will help match the answer found in the original `words` to the same answer in the full encoded input and determine
the start/end position of the answer in the encoded input.
With that in mind, let's create a function to encode a batch of examples in the dataset:
```py
>>> def encode_dataset(examples, max_length=512):
... questions = examples["question"]
... words = examples["words"]
... boxes = examples["boxes"]
... answers = examples["answer"]
... # encode the batch of examples and initialize the start_positions and end_positions
... encoding = tokenizer(questions, words, boxes, max_length=max_length, padding="max_length", truncation=True)
... start_positions = []
... end_positions = []
... # loop through the examples in the batch
... for i in range(len(questions)):
... cls_index = encoding["input_ids"][i].index(tokenizer.cls_token_id)
... # find the position of the answer in example's words
... words_example = [word.lower() for word in words[i]]
... answer = answers[i]
... match, word_idx_start, word_idx_end = subfinder(words_example, answer.lower().split())
... if match:
... # if match is found, use `token_type_ids` to find where words start in the encoding
... token_type_ids = encoding["token_type_ids"][i]
... token_start_index = 0
... while token_type_ids[token_start_index] != 1:
... token_start_index += 1
... token_end_index = len(encoding["input_ids"][i]) - 1
... while token_type_ids[token_end_index] != 1:
... token_end_index -= 1
... word_ids = encoding.word_ids(i)[token_start_index : token_end_index + 1]
... start_position = cls_index
... end_position = cls_index
... # loop over word_ids and increase `token_start_index` until it matches the answer position in words
... # once it matches, save the `token_start_index` as the `start_position` of the answer in the encoding
... for id in word_ids:
... if id == word_idx_start:
... start_position = token_start_index
... else:
... token_start_index += 1
... # similarly loop over `word_ids` starting from the end to find the `end_position` of the answer
... for id in word_ids[::-1]:
... if id == word_idx_end:
... end_position = token_end_index
... else:
... token_end_index -= 1
... start_positions.append(start_position)
... end_positions.append(end_position)
... else:
... start_positions.append(cls_index)
... end_positions.append(cls_index)
... encoding["image"] = examples["image"]
... encoding["start_positions"] = start_positions
... encoding["end_positions"] = end_positions
... return encoding
```
Now that we have this preprocessing function, we can encode the entire dataset:
```py
>>> encoded_train_dataset = dataset_with_ocr["train"].map(
... encode_dataset, batched=True, batch_size=2, remove_columns=dataset_with_ocr["train"].column_names
... )
>>> encoded_test_dataset = dataset_with_ocr["test"].map(
... encode_dataset, batched=True, batch_size=2, remove_columns=dataset_with_ocr["test"].column_names
... )
```
Let's check what the features of the encoded dataset look like:
```py
>>> encoded_train_dataset.features
{'image': Sequence(feature=Sequence(feature=Sequence(feature=Value(dtype='uint8', id=None), length=-1, id=None), length=-1, id=None), length=-1, id=None),
'input_ids': Sequence(feature=Value(dtype='int32', id=None), length=-1, id=None),
'token_type_ids': Sequence(feature=Value(dtype='int8', id=None), length=-1, id=None),
'attention_mask': Sequence(feature=Value(dtype='int8', id=None), length=-1, id=None),
'bbox': Sequence(feature=Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None), length=-1, id=None),
'start_positions': Value(dtype='int64', id=None),
'end_positions': Value(dtype='int64', id=None)}
```
## Evaluation
Evaluation for document question answering requires a significant amount of postprocessing. To avoid taking up too much
of your time, this guide skips the evaluation step. The [`Trainer`] still calculates the evaluation loss during training so
you're not completely in the dark about your model's performance. Extractive question answering is typically evaluated using F1/exact match.
If you'd like to implement it yourself, check out the [Question Answering chapter](https://huggingface.co/course/chapter7/7?fw=pt#postprocessing)
of the Hugging Face course for inspiration.
## Train
Congratulations! You've successfully navigated the toughest part of this guide and now you are ready to train your own model.
Training involves the following steps:
* Load the model with [`AutoModelForDocumentQuestionAnswering`] using the same checkpoint as in the preprocessing.
* Define your training hyperparameters in [`TrainingArguments`].
* Define a function to batch examples together, here the [`DefaultDataCollator`] will do just fine
* Pass the training arguments to [`Trainer`] along with the model, dataset, and data collator.
* Call [`~Trainer.train`] to finetune your model.
```py
>>> from transformers import AutoModelForDocumentQuestionAnswering
>>> model = AutoModelForDocumentQuestionAnswering.from_pretrained(model_checkpoint)
```
In the [`TrainingArguments`] use `output_dir` to specify where to save your model, and configure hyperparameters as you see fit.
If you wish to share your model with the community, set `push_to_hub` to `True` (you must be signed in to Hugging Face to upload your model).
In this case the `output_dir` will also be the name of the repo where your model checkpoint will be pushed.
```py
>>> from transformers import TrainingArguments
>>> # REPLACE THIS WITH YOUR REPO ID
>>> repo_id = "MariaK/layoutlmv2-base-uncased_finetuned_docvqa"
>>> training_args = TrainingArguments(
... output_dir=repo_id,
... per_device_train_batch_size=4,
... num_train_epochs=20,
... save_steps=200,
... logging_steps=50,
... evaluation_strategy="steps",
... learning_rate=5e-5,
... save_total_limit=2,
... remove_unused_columns=False,
... push_to_hub=True,
... )
```
Define a simple data collator to batch examples together.
```py
>>> from transformers import DefaultDataCollator
>>> data_collator = DefaultDataCollator()
```
Finally, bring everything together, and call [`~Trainer.train`]:
```py
>>> from transformers import Trainer
>>> trainer = Trainer(
... model=model,
... args=training_args,
... data_collator=data_collator,
... train_dataset=encoded_train_dataset,
... eval_dataset=encoded_test_dataset,
... tokenizer=processor,
... )
>>> trainer.train()
```
To add the final model to 🤗 Hub, create a model card and call `push_to_hub`:
```py
>>> trainer.create_model_card()
>>> trainer.push_to_hub()
```
## Inference
Now that you have finetuned a LayoutLMv2 model, and uploaded it to the 🤗 Hub, you can use it for inference. The simplest
way to try out your finetuned model for inference is to use it in a [`Pipeline`].
Let's take an example:
```py
>>> example = dataset["test"][2]
>>> question = example["query"]["en"]
>>> image = example["image"]
>>> print(question)
>>> print(example["answers"])
'Who is ‘presiding’ TRRF GENERAL SESSION (PART 1)?'
['TRRF Vice President', 'lee a. waller']
```
Next, instantiate a pipeline for
document question answering with your model, and pass the image + question combination to it.
```py
>>> from transformers import pipeline
>>> qa_pipeline = pipeline("document-question-answering", model="MariaK/layoutlmv2-base-uncased_finetuned_docvqa")
>>> qa_pipeline(image, question)
[{'score': 0.9949808120727539,
'answer': 'Lee A. Waller',
'start': 55,
'end': 57}]
```
You can also manually replicate the results of the pipeline if you'd like:
1. Take an image and a question, prepare them for the model using the processor from your model.
2. Forward the result or preprocessing through the model.
3. The model returns `start_logits` and `end_logits`, which indicate which token is at the start of the answer and
which token is at the end of the answer. Both have shape (batch_size, sequence_length).
4. Take an argmax on the last dimension of both the `start_logits` and `end_logits` to get the predicted `start_idx` and `end_idx`.
5. Decode the answer with the tokenizer.
```py
>>> import torch
>>> from transformers import AutoProcessor
>>> from transformers import AutoModelForDocumentQuestionAnswering
>>> processor = AutoProcessor.from_pretrained("MariaK/layoutlmv2-base-uncased_finetuned_docvqa")
>>> model = AutoModelForDocumentQuestionAnswering.from_pretrained("MariaK/layoutlmv2-base-uncased_finetuned_docvqa")
>>> with torch.no_grad():
... encoding = processor(image.convert("RGB"), question, return_tensors="pt")
... outputs = model(**encoding)
... start_logits = outputs.start_logits
... end_logits = outputs.end_logits
... predicted_start_idx = start_logits.argmax(-1).item()
... predicted_end_idx = end_logits.argmax(-1).item()
>>> processor.tokenizer.decode(encoding.input_ids.squeeze()[predicted_start_idx : predicted_end_idx + 1])
'lee a. waller'
``` | huggingface/transformers/blob/main/docs/source/en/tasks/document_question_answering.md |
--
title: Toxicity
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.0.2
app_file: app.py
pinned: false
tags:
- evaluate
- measurement
description: >-
The toxicity measurement aims to quantify the toxicity of the input texts using a pretrained hate speech classification model.
---
# Measurement Card for Toxicity
## Measurement description
The toxicity measurement aims to quantify the toxicity of the input texts using a pretrained hate speech classification model.
## How to use
The default model used is [roberta-hate-speech-dynabench-r4](https://huggingface.co/facebook/roberta-hate-speech-dynabench-r4-target). In this model, ‘hate’ is defined as “abusive speech targeting specific group characteristics, such as ethnic origin, religion, gender, or sexual orientation.” Definitions used by other classifiers may vary.
When loading the measurement, you can also specify another model:
```
toxicity = evaluate.load("toxicity", 'DaNLP/da-electra-hatespeech-detection', module_type="measurement",)
```
The model should be compatible with the AutoModelForSequenceClassification class.
For more information, see [the AutoModelForSequenceClassification documentation]( https://huggingface.co/docs/transformers/master/en/model_doc/auto#transformers.AutoModelForSequenceClassification).
Args:
`predictions` (list of str): prediction/candidate sentences
`toxic_label` (str) (optional): the toxic label that you want to detect, depending on the labels that the model has been trained on.
This can be found using the `id2label` function, e.g.:
```python
>>> model = AutoModelForSequenceClassification.from_pretrained("DaNLP/da-electra-hatespeech-detection")
>>> model.config.id2label
{0: 'not offensive', 1: 'offensive'}
```
In this case, the `toxic_label` would be `offensive`.
`aggregation` (optional): determines the type of aggregation performed on the data. If set to `None`, the scores for each prediction are returned.
Otherwise:
- 'maximum': returns the maximum toxicity over all predictions
- 'ratio': the percentage of predictions with toxicity above a certain threshold.
`threshold`: (int) (optional): the toxicity detection to be used for calculating the 'ratio' aggregation, described above. The default threshold is 0.5, based on the one established by [RealToxicityPrompts](https://arxiv.org/abs/2009.11462).
## Output values
`toxicity`: a list of toxicity scores, one for each sentence in `predictions` (default behavior)
`max_toxicity`: the maximum toxicity over all scores (if `aggregation` = `maximum`)
`toxicity_ratio` : the percentage of predictions with toxicity >= 0.5 (if `aggregation` = `ratio`)
### Values from popular papers
## Examples
Example 1 (default behavior):
```python
>>> toxicity = evaluate.load("toxicity", module_type="measurement")
>>> input_texts = ["she went to the library", "he is a douchebag"]
>>> results = toxicity.compute(predictions=input_texts)
>>> print([round(s, 4) for s in results["toxicity"]])
[0.0002, 0.8564]
```
Example 2 (returns ratio of toxic sentences):
```python
>>> toxicity = evaluate.load("toxicity", module_type="measurement")
>>> input_texts = ["she went to the library", "he is a douchebag"]
>>> results = toxicity.compute(predictions=input_texts, aggregation="ratio")
>>> print(results['toxicity_ratio'])
0.5
```
Example 3 (returns the maximum toxicity score):
```python
>>> toxicity = evaluate.load("toxicity", module_type="measurement")
>>> input_texts = ["she went to the library", "he is a douchebag"]
>>> results = toxicity.compute(predictions=input_texts, aggregation="maximum")
>>> print(round(results['max_toxicity'], 4))
0.8564
```
Example 4 (uses a custom model):
```python
>>> toxicity = evaluate.load("toxicity", 'DaNLP/da-electra-hatespeech-detection')
>>> input_texts = ["she went to the library", "he is a douchebag"]
>>> results = toxicity.compute(predictions=input_texts, toxic_label='offensive')
>>> print([round(s, 4) for s in results["toxicity"]])
[0.0176, 0.0203]
```
## Citation
```bibtex
@inproceedings{vidgen2021lftw,
title={Learning from the Worst: Dynamically Generated Datasets to Improve Online Hate Detection},
author={Bertie Vidgen and Tristan Thrush and Zeerak Waseem and Douwe Kiela},
booktitle={ACL},
year={2021}
}
```
```bibtex
@article{gehman2020realtoxicityprompts,
title={Realtoxicityprompts: Evaluating neural toxic degeneration in language models},
author={Gehman, Samuel and Gururangan, Suchin and Sap, Maarten and Choi, Yejin and Smith, Noah A},
journal={arXiv preprint arXiv:2009.11462},
year={2020}
}
```
## Further References
| huggingface/evaluate/blob/main/measurements/toxicity/README.md |
CSP-ResNet
**CSPResNet** is a convolutional neural network where we apply the Cross Stage Partial Network (CSPNet) approach to [ResNet](https://paperswithcode.com/method/resnet). The CSPNet partitions the feature map of the base layer into two parts and then merges them through a cross-stage hierarchy. The use of a split and merge strategy allows for more gradient flow through the network.
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('cspresnet50', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `cspresnet50`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('cspresnet50', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{wang2019cspnet,
title={CSPNet: A New Backbone that can Enhance Learning Capability of CNN},
author={Chien-Yao Wang and Hong-Yuan Mark Liao and I-Hau Yeh and Yueh-Hua Wu and Ping-Yang Chen and Jun-Wei Hsieh},
year={2019},
eprint={1911.11929},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: CSP ResNet
Paper:
Title: 'CSPNet: A New Backbone that can Enhance Learning Capability of CNN'
URL: https://paperswithcode.com/paper/cspnet-a-new-backbone-that-can-enhance
Models:
- Name: cspresnet50
In Collection: CSP ResNet
Metadata:
FLOPs: 5924992000
Parameters: 21620000
File Size: 86679303
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- Polynomial Learning Rate Decay
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: cspresnet50
LR: 0.1
Layers: 50
Crop Pct: '0.887'
Momentum: 0.9
Batch Size: 128
Image Size: '256'
Weight Decay: 0.005
Interpolation: bilinear
Training Steps: 8000000
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/cspnet.py#L415
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/cspresnet50_ra-d3e8d487.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.57%
Top 5 Accuracy: 94.71%
--> | huggingface/pytorch-image-models/blob/main/docs/models/csp-resnet.md |
--
title: 'Train and Fine-Tune Sentence Transformers Models'
thumbnail: /blog/assets/95_training_st_models/thumbnail.png
authors:
- user: espejelomar
---
# Train and Fine-Tune Sentence Transformers Models
Check out this tutorial with the Notebook Companion:
<a target="_blank" href="https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/95_Training_Sentence_Transformers.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
---
---
Training or fine-tuning a Sentence Transformers model highly depends on the available data and the target task. The key is twofold:
1. Understand how to input data into the model and prepare your dataset accordingly.
2. Know the different loss functions and how they relate to the dataset.
In this tutorial, you will:
1. Understand how Sentence Transformers models work by creating one from "scratch" or fine-tuning one from the Hugging Face Hub.
2. Learn the different formats your dataset could have.
3. Review the different loss functions you can choose based on your dataset format.
4. Train or fine-tune your model.
5. Share your model to the Hugging Face Hub.
6. Learn when Sentence Transformers models may not be the best choice.
## How Sentence Transformers models work
In a Sentence Transformer model, you map a variable-length text (or image pixels) to a fixed-size embedding representing that input's meaning. To get started with embeddings, check out our [previous tutorial](https://huggingface.co/blog/getting-started-with-embeddings). This post focuses on text.
This is how the Sentence Transformers models work:
1. **Layer 1** – The input text is passed through a pre-trained Transformer model that can be obtained directly from the [Hugging Face Hub](https://huggingface.co/models?pipeline_tag=fill-mask&sort=downloads). This tutorial will use the "[distilroberta-base](https://huggingface.co/distilroberta-base)" model. The Transformer outputs are contextualized word embeddings for all input tokens; imagine an embedding for each token of the text.
2. **Layer 2** - The embeddings go through a pooling layer to get a single fixed-length embedding for all the text. For example, mean pooling averages the embeddings generated by the model.
This figure summarizes the process:

Remember to install the Sentence Transformers library with `pip install -U sentence-transformers`. In code, this two-step process is simple:
```py
from sentence_transformers import SentenceTransformer, models
## Step 1: use an existing language model
word_embedding_model = models.Transformer('distilroberta-base')
## Step 2: use a pool function over the token embeddings
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension())
## Join steps 1 and 2 using the modules argument
model = SentenceTransformer(modules=[word_embedding_model, pooling_model])
```
From the code above, you can see that Sentence Transformers models are made up of modules, that is, a list of layers that are executed consecutively. The input text enters the first module, and the final output comes from the last component. As simple as it looks, the above model is a typical architecture for Sentence Transformers models. If necessary, additional layers can be added, for example, dense, bag of words, and convolutional.
Why not use a Transformer model, like BERT or Roberta, out of the box to create embeddings for entire sentences and texts? There are at least two reasons.
1. Pre-trained Transformers require heavy computation to perform semantic search tasks. For example, finding the most similar pair in a collection of 10,000 sentences [requires about 50 million inference computations (~65 hours) with BERT](https://arxiv.org/abs/1908.10084). In contrast, a BERT Sentence Transformers model reduces the time to about 5 seconds.
2. Once trained, Transformers create poor sentence representations out of the box. A BERT model with its token embeddings averaged to create a sentence embedding [performs worse than the GloVe embeddings](https://arxiv.org/abs/1908.10084) developed in 2014.
In this section we are creating a Sentence Transformers model from scratch. If you want to fine-tune an existing Sentence Transformers model, you can skip the steps above and import it from the Hugging Face Hub. You can find most of the Sentence Transformers models in the ["Sentence Similarity"](https://huggingface.co/models?pipeline_tag=sentence-similarity) task. Here we load the "sentence-transformers/all-MiniLM-L6-v2" model:
```py
from sentence_transformers import SentenceTransformer
model_id = "sentence-transformers/all-MiniLM-L6-v2"
model = SentenceTransformer(model_id)
```
Now for the most critical part: the dataset format.
## How to prepare your dataset for training a Sentence Transformers model
To train a Sentence Transformers model, you need to inform it somehow that two sentences have a certain degree of similarity. Therefore, each example in the data requires a label or structure that allows the model to understand whether two sentences are similar or different.
Unfortunately, there is no single way to prepare your data to train a Sentence Transformers model. It largely depends on your goals and the structure of your data. If you don't have an explicit label, which is the most likely scenario, you can derive it from the design of the documents where you obtained the sentences. For example, two sentences in the same report should be more comparable than two sentences in different reports. Neighboring sentences might be more comparable than non-neighboring sentences.
Furthermore, the structure of your data will influence which loss function you can use. This will be discussed in the next section.
Remember the [Notebook Companion](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/95_Training_Sentence_Transformers.ipynb) for this post has all the code already implemented.
Most dataset configurations will take one of four forms (below you will see examples of each case):
- Case 1: The example is a pair of sentences and a label indicating how similar they are. The label can be either an integer or a float. This case applies to datasets originally prepared for Natural Language Inference (NLI), since they contain pairs of sentences with a label indicating whether they infer each other or not.
- Case 2: The example is a pair of positive (similar) sentences **without** a label. For example, pairs of paraphrases, pairs of full texts and their summaries, pairs of duplicate questions, pairs of (`query`, `response`), or pairs of (`source_language`, `target_language`). Natural Language Inference datasets can also be formatted this way by pairing entailing sentences. Having your data in this format can be great since you can use the `MultipleNegativesRankingLoss`, one of the most used loss functions for Sentence Transformers models.
- Case 3: The example is a sentence with an integer label. This data format is easily converted by loss functions into three sentences (triplets) where the first is an "anchor", the second a "positive" of the same class as the anchor, and the third a "negative" of a different class. Each sentence has an integer label indicating the class to which it belongs.
- Case 4: The example is a triplet (anchor, positive, negative) without classes or labels for the sentences.
As an example, in this tutorial you will train a Sentence Transformer using a dataset in the fourth case. You will then fine-tune it using the second case dataset configuration (please refer to the [Notebook Companion](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/95_Training_Sentence_Transformers.ipynb) for this blog).
Note that Sentence Transformers models can be trained with human labeling (cases 1 and 3) or with labels automatically deduced from text formatting (mainly case 2; although case 4 does not require labels, it is more difficult to find data in a triplet unless you process it as the [`MegaBatchMarginLoss`](https://www.sbert.net/docs/package_reference/losses.html#megabatchmarginloss) function does).
There are datasets on the Hugging Face Hub for each of the above cases. Additionally, the datasets in the Hub have a Dataset Preview functionality that allows you to view the structure of datasets before downloading them. Here are sample data sets for each of these cases:
- Case 1: The same setup as for Natural Language Inference can be used if you have (or fabricate) a label indicating the degree of similarity between two sentences; for example {0,1,2} where 0 is contradiction and 2 is entailment. Review the structure of the [SNLI dataset](https://huggingface.co/datasets/snli).
- Case 2: The [Sentence Compression dataset](https://huggingface.co/datasets/embedding-data/sentence-compression) has examples made up of positive pairs. If your dataset has more than two positive sentences per example, for example quintets as in the [COCO Captions](https://huggingface.co/datasets/embedding-data/coco_captions_quintets) or the [Flickr30k Captions](https://huggingface.co/datasets/embedding-data/flickr30k_captions_quintets) datasets, you can format the examples as to have different combinations of positive pairs.
- Case 3: The [TREC dataset](https://huggingface.co/datasets/trec) has integer labels indicating the class of each sentence. Each example in the [Yahoo Answers Topics dataset](https://huggingface.co/datasets/yahoo_answers_topics) contains three sentences and a label indicating its topic; thus, each example can be divided into three.
- Case 4: The [Quora Triplets dataset](https://huggingface.co/datasets/embedding-data/QQP_triplets) has triplets (anchor, positive, negative) without labels.
The next step is converting the dataset into a format the Sentence Transformers model can understand. The model cannot accept raw lists of strings. Each example must be converted to a `sentence_transformers.InputExample` class and then to a `torch.utils.data.DataLoader` class to batch and shuffle the examples.
Install Hugging Face Datasets with `pip install datasets`. Then import a dataset with the `load_dataset` function:
```py
from datasets import load_dataset
dataset_id = "embedding-data/QQP_triplets"
dataset = load_dataset(dataset_id)
```
This guide uses an unlabeled triplets dataset, the fourth case above.
With the `datasets` library you can explore the dataset:
```py
print(f"- The {dataset_id} dataset has {dataset['train'].num_rows} examples.")
print(f"- Each example is a {type(dataset['train'][0])} with a {type(dataset['train'][0]['set'])} as value.")
print(f"- Examples look like this: {dataset['train'][0]}")
```
Output:
```py
- The embedding-data/QQP_triplets dataset has 101762 examples.
- Each example is a <class 'dict'> with a <class 'dict'> as value.
- Examples look like this: {'set': {'query': 'Why in India do we not have one on one political debate as in USA?', 'pos': ['Why can't we have a public debate between politicians in India like the one in US?'], 'neg': ['Can people on Quora stop India Pakistan debate? We are sick and tired seeing this everyday in bulk?'...]
```
You can see that `query` (the anchor) has a single sentence, `pos` (positive) is a list of sentences (the one we print has only one sentence), and `neg` (negative) has a list of multiple sentences.
Convert the examples into `InputExample`'s. For simplicity, (1) only one of the positives and one of the negatives in the [embedding-data/QQP_triplets]((https://huggingface.co/datasets/embedding-data/QQP_triplets)) dataset will be used. (2) We will only employ 1/2 of the available examples. You can obtain much better results by increasing the number of examples.
```py
from sentence_transformers import InputExample
train_examples = []
train_data = dataset['train']['set']
# For agility we only 1/2 of our available data
n_examples = dataset['train'].num_rows // 2
for i in range(n_examples):
example = train_data[i]
train_examples.append(InputExample(texts=[example['query'], example['pos'][0], example['neg'][0]]))
```
Convert the training examples to a `Dataloader`.
```py
from torch.utils.data import DataLoader
train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=16)
```
The next step is to choose a suitable loss function that can be used with the data format.
## Loss functions for training a Sentence Transformers model
Remember the four different formats your data could be in? Each will have a different loss function associated with it.
Case 1: Pair of sentences and a label indicating how similar they are. The loss function optimizes such that (1) the sentences with the closest labels are near in the vector space, and (2) the sentences with the farthest labels are as far as possible. The loss function depends on the format of the label. If its an integer use [`ContrastiveLoss`](https://www.sbert.net/docs/package_reference/losses.html#contrastiveloss) or [`SoftmaxLoss`](https://www.sbert.net/docs/package_reference/losses.html#softmaxloss); if its a float you can use [`CosineSimilarityLoss`](https://www.sbert.net/docs/package_reference/losses.html#cosinesimilarityloss).
Case 2: If you only have two similar sentences (two positives) with no labels, then you can use the [`MultipleNegativesRankingLoss`](https://www.sbert.net/docs/package_reference/losses.html#multiplenegativesrankingloss) function. The [`MegaBatchMarginLoss`](https://www.sbert.net/docs/package_reference/losses.html#megabatchmarginloss) can also be used, and it would convert your examples to triplets `(anchor_i, positive_i, positive_j)` where `positive_j` serves as the negative.
Case 3: When your samples are triplets of the form `[anchor, positive, negative]` and you have an integer label for each, a loss function optimizes the model so that the anchor and positive sentences are closer together in vector space than the anchor and negative sentences. You can use [`BatchHardTripletLoss`](https://www.sbert.net/docs/package_reference/losses.html#batchhardtripletloss), which requires the data to be labeled with integers (e.g., labels 1, 2, 3) assuming that samples with the same label are similar. Therefore, anchors and positives must have the same label, while negatives must have a different one. Alternatively, you can use [`BatchAllTripletLoss`](https://www.sbert.net/docs/package_reference/losses.html#batchalltripletloss), [`BatchHardSoftMarginTripletLoss`](https://www.sbert.net/docs/package_reference/losses.html#batchhardsoftmargintripletloss), or [`BatchSemiHardTripletLoss`](https://www.sbert.net/docs/package_reference/losses.html#batchsemihardtripletloss). The differences between them is beyond the scope of this tutorial, but can be reviewed in the Sentence Transformers documentation.
Case 4: If you don't have a label for each sentence in the triplets, you should use [`TripletLoss`](https://www.sbert.net/docs/package_reference/losses.html#tripletloss). This loss minimizes the distance between the anchor and the positive sentences while maximizing the distance between the anchor and the negative sentences.
This figure summarizes the different types of datasets formats, example dataets in the Hub, and their adequate loss functions.

The hardest part is choosing a suitable loss function conceptually. In the code, there are only two lines:
```py
from sentence_transformers import losses
train_loss = losses.TripletLoss(model=model)
```
Once the dataset is in the desired format and a suitable loss function is in place, fitting and training a Sentence Transformers is simple.
## How to train or fine-tune a Sentence Transformer model
> "SentenceTransformers was designed so that fine-tuning your own sentence/text embeddings models is easy. It provides most of the building blocks you can stick together to tune embeddings for your specific task." - [Sentence Transformers Documentation](https://www.sbert.net/docs/training/overview.html#training-overview).
This is what the training or fine-tuning looks like:
```py
model.fit(train_objectives=[(train_dataloader, train_loss)], epochs=10)
```
Remember that if you are fine-tuning an existing Sentence Transformers model (see [Notebook Companion](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/95_Training_Sentence_Transformers.ipynb)), you can directly call the `fit` method from it. If this is a new Sentence Transformers model, you must first define it as you did in the "How Sentence Transformers models work" section.
That's it; you have a new or improved Sentence Transformers model! Do you want to share it to the Hugging Face Hub?
First, log in to the Hugging Face Hub. You will need to create a `write` token in your [Account Settings](http://hf.co/settings/tokens). Then there are two options to log in:
1. Type `huggingface-cli login` in your terminal and enter your token.
2. If in a python notebook, you can use `notebook_login`.
```py
from huggingface_hub import notebook_login
notebook_login()
```
Then, you can share your models by calling the `save_to_hub` method from the trained model. By default, the model will be uploaded to your account. Still, you can upload to an organization by passing it in the `organization` parameter. `save_to_hub` automatically generates a model card, an inference widget, example code snippets, and more details. You can automatically add to the Hub’s model card a list of datasets you used to train the model with the argument `train_datasets`:
```py
model.save_to_hub(
"distilroberta-base-sentence-transformer",
organization= # Add your username
train_datasets=["embedding-data/QQP_triplets"],
)
```
In the [Notebook Companion](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/95_Training_Sentence_Transformers.ipynb) I fine-tuned this same model using the [embedding-data/sentence-compression](https://huggingface.co/datasets/embedding-data/sentence-compression) dataset and the [`MultipleNegativesRankingLoss`](https://www.sbert.net/docs/package_reference/losses.html#multiplenegativesrankingloss) loss.
## What are the limits of Sentence Transformers?
Sentence Transformers models work much better than the simple Transformers models for semantic search. However, where do the Sentence Transformers models not work well? If your task is classification, then using sentence embeddings is the wrong approach. In that case, the 🤗 [Transformers library](https://huggingface.co/docs/transformers/tasks/sequence_classification) would be a better choice.
## Extra Resources
- [Getting Started With Embeddings](https://huggingface.co/blog/getting-started-with-embeddings).
- [Understanding Semantic Search](https://huggingface.co/spaces/sentence-transformers/Sentence_Transformers_for_semantic_search).
- [Start your first Sentence Transformers model](https://huggingface.co/blog/your-first-ml-project).
- [Generate playlists using Sentence Transformers](https://huggingface.co/blog/playlist-generator).
- [Hugging Face + Sentence Transformers docs](https://www.sbert.net/docs/hugging_face.html).
Thanks for reading! Happy embedding making.
| huggingface/blog/blob/main/how-to-train-sentence-transformers.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# How to accelerate training with ONNX Runtime
Optimum integrates ONNX Runtime Training through an `ORTTrainer` API that extends `Trainer` in [Transformers](https://huggingface.co/docs/transformers/index).
With this extension, training time can be reduced by more than 35% for many popular Hugging Face models compared to PyTorch under eager mode.
[`ORTTrainer`] and [`ORTSeq2SeqTrainer`] APIs make it easy to compose __[ONNX Runtime (ORT)](https://onnxruntime.ai/)__ with other features in [`Trainer`](https://huggingface.co/docs/transformers/main_classes/trainer).
It contains feature-complete training loop and evaluation loop, and supports hyperparameter search, mixed-precision training and distributed training with multiple [NVIDIA](https://techcommunity.microsoft.com/t5/ai-machine-learning-blog/accelerate-pytorch-transformer-model-training-with-onnx-runtime/ba-p/2540471)
and [AMD](https://cloudblogs.microsoft.com/opensource/2021/07/13/onnx-runtime-release-1-8-1-previews-support-for-accelerated-training-on-amd-gpus-with-the-amd-rocm-open-software-platform/) GPUs.
With the ONNX Runtime backend, [`ORTTrainer`] and [`ORTSeq2SeqTrainer`] take advantage of:
* Computation graph optimizations: constant foldings, node eliminations, node fusions
* Efficient memory planning
* Kernel optimization
* ORT fused Adam optimizer: batches the elementwise updates applied to all the model's parameters into one or a few kernel launches
* More efficient FP16 optimizer: eliminates a great deal of device to host memory copies
* Mixed precision training
Test it out to achieve __lower latency, higher throughput, and larger maximum batch size__ while training models in 🤗 Transformers!
## Performance
The chart below shows impressive acceleration __from 39% to 130%__ for Hugging Face models with Optimum when __using ONNX Runtime and DeepSpeed ZeRO Stage 1__ for training.
The performance measurements were done on selected Hugging Face models with PyTorch as the baseline run, only ONNX Runtime for training as the second run, and ONNX
Runtime + DeepSpeed ZeRO Stage 1 as the final run, showing maximum gains. The Optimizer used for the baseline PyTorch runs is the AdamW optimizer and the ORT Training
runs use the Fused Adam Optimizer(available in `ORTTrainingArguments`). The runs were performed on a single Nvidia A100 node with 8 GPUs.
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/optimum/documentation-images/resolve/main/onnxruntime/onnxruntime-training-benchmark.png" alt="ONNX Runtime Training Benchmark"/>
</figure>
The version information used for these runs is as follows:
```
PyTorch: 1.14.0.dev20221103+cu116; ORT: 1.14.0.dev20221103001+cu116; DeepSpeed: 0.6.6; HuggingFace: 4.24.0.dev0; Optimum: 1.4.1.dev0; Cuda: 11.6.2
```
## Start by setting up the environment
To use ONNX Runtime for training, you need a machine with at least one NVIDIA or AMD GPU.
To use `ORTTrainer` or `ORTSeq2SeqTrainer`, you need to install ONNX Runtime Training module and Optimum.
### Install ONNX Runtime
To set up the environment, we __strongly recommend__ you install the dependencies with Docker to ensure that the versions are correct and well
configured. You can find dockerfiles with various combinations [here](https://github.com/huggingface/optimum/tree/main/examples/onnxruntime/training/docker).
#### Setup for NVIDIA GPU
Here below we take the installation of `onnxruntime-training 1.14.0` as an example:
* If you want to install `onnxruntime-training 1.14.0` via [Dockerfile](https://github.com/huggingface/optimum/blob/main/examples/onnxruntime/training/docker/Dockerfile-ort1.14.0-cu116):
```bash
docker build -f Dockerfile-ort1.14.0-cu116 -t ort/train:1.14.0 .
```
* If you want to install the dependencies beyond in a local Python environment. You can pip install them once you have [CUDA 11.6](https://docs.nvidia.com/cuda/archive/11.6.2/) and [cuDNN 8](https://developer.nvidia.com/cudnn) well installed.
```bash
pip install onnx ninja
pip install torch==1.13.1+cu116 torchvision==0.14.1 -f https://download.pytorch.org/whl/cu116/torch_stable.html
pip install onnxruntime-training==1.14.0 -f https://download.onnxruntime.ai/onnxruntime_stable_cu116.html
pip install torch-ort
pip install --upgrade protobuf==3.20.2
```
And run post-installation configuration:
```bash
python -m torch_ort.configure
```
#### Setup for AMD GPU
Here below we take the installation of `onnxruntime-training` nightly as an example:
* If you want to install `onnxruntime-training` via [Dockerfile](https://github.com/huggingface/optimum/blob/main/examples/onnxruntime/training/docker/Dockerfile-ort-nightly-rocm57):
```bash
docker build -f Dockerfile-ort-nightly-rocm57 -t ort/train:nightly .
```
* If you want to install the dependencies beyond in a local Python environment. You can pip install them once you have [ROCM 5.7](https://rocmdocs.amd.com/en/latest/deploy/linux/quick_start.html) well installed.
```bash
pip install onnx ninja
pip3 install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/rocm5.7
pip install pip install --pre onnxruntime-training -f https://download.onnxruntime.ai/onnxruntime_nightly_rocm57.html
pip install torch-ort
pip install --upgrade protobuf==3.20.2
```
And run post-installation configuration:
```bash
python -m torch_ort.configure
```
### Install Optimum
You can install Optimum via pypi:
```bash
pip install optimum
```
Or install from source:
```bash
pip install git+https://github.com/huggingface/optimum.git
```
This command installs the current main dev version of Optimum, which could include latest developments(new features, bug fixes). However, the
main version might not be very stable. If you run into any problem, please open an [issue](https://github.com/huggingface/optimum/issues) so
that we can fix it as soon as possible.
## ORTTrainer
The [`ORTTrainer`] class inherits the [`Trainer`](https://huggingface.co/docs/transformers/main/en/main_classes/trainer#trainer)
of Transformers. You can easily adapt the codes by replacing `Trainer` of transformers with `ORTTrainer` to take advantage of the acceleration
empowered by ONNX Runtime. Here is an example of how to use `ORTTrainer` compared with `Trainer`:
```diff
-from transformers import Trainer, TrainingArguments
+from optimum.onnxruntime import ORTTrainer, ORTTrainingArguments
# Step 1: Define training arguments
-training_args = TrainingArguments(
+training_args = ORTTrainingArguments(
output_dir="path/to/save/folder/",
- optim = "adamw_hf",
+ optim="adamw_ort_fused",
...
)
# Step 2: Create your ONNX Runtime Trainer
-trainer = Trainer(
+trainer = ORTTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
+ feature="text-classification",
...
)
# Step 3: Use ONNX Runtime for training!🤗
trainer.train()
```
Check out more detailed [example scripts](https://github.com/huggingface/optimum/tree/main/examples/onnxruntime/training) in the optimum repository.
## ORTSeq2SeqTrainer
The [`ORTSeq2SeqTrainer`] class is similar to the [`Seq2SeqTrainer`](https://huggingface.co/docs/transformers/main/en/main_classes/trainer#transformers.Seq2SeqTrainer)
of Transformers. You can easily adapt the codes by replacing `Seq2SeqTrainer` of transformers with `ORTSeq2SeqTrainer` to take advantage of the acceleration
empowered by ONNX Runtime. Here is an example of how to use `ORTSeq2SeqTrainer` compared with `Seq2SeqTrainer`:
```diff
-from transformers import Seq2SeqTrainer, Seq2SeqTrainingArguments
+from optimum.onnxruntime import ORTSeq2SeqTrainer, ORTSeq2SeqTrainingArguments
# Step 1: Define training arguments
-training_args = Seq2SeqTrainingArguments(
+training_args = ORTSeq2SeqTrainingArguments(
output_dir="path/to/save/folder/",
- optim = "adamw_hf",
+ optim="adamw_ort_fused",
...
)
# Step 2: Create your ONNX Runtime Seq2SeqTrainer
-trainer = Seq2SeqTrainer(
+trainer = ORTSeq2SeqTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
+ feature="text2text-generation",
...
)
# Step 3: Use ONNX Runtime for training!🤗
trainer.train()
```
Check out more detailed [example scripts](https://github.com/huggingface/optimum/tree/main/examples/onnxruntime/training) in the optimum repository.
## ORTTrainingArguments
The [`ORTTrainingArguments`] class inherits the [`TrainingArguments`](https://huggingface.co/docs/transformers/main/en/main_classes/trainer#transformers.TrainingArguments)
class in Transformers. Besides the optimizers implemented in Transformers, it allows you to use the optimizers implemented in ONNX Runtime.
Replace `Seq2SeqTrainingArguments` with `ORTSeq2SeqTrainingArguments`:
```diff
-from transformers import TrainingArguments
+from optimum.onnxruntime import ORTTrainingArguments
-training_args = TrainingArguments(
+training_args = ORTTrainingArguments(
output_dir="path/to/save/folder/",
num_train_epochs=1,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
warmup_steps=500,
weight_decay=0.01,
logging_dir="path/to/save/folder/",
- optim = "adamw_hf",
+ optim="adamw_ort_fused", # Fused Adam optimizer implemented by ORT
)
```
<Tip warning={false}>
DeepSpeed is supported by ONNX Runtime(only ZeRO stage 1 and 2 for the moment).
You can find some [DeepSpeed configuration examples](https://github.com/huggingface/optimum/tree/main/tests/onnxruntime/ds_configs)
in the Optimum repository.
</Tip>
## ORTSeq2SeqTrainingArguments
The [`ORTSeq2SeqTrainingArguments`] class inherits the [`Seq2SeqTrainingArguments`](https://huggingface.co/docs/transformers/main/en/main_classes/trainer#transformers.Seq2SeqTrainingArguments)
class in Transformers. Besides the optimizers implemented in Transformers, it allows you to use the optimizers implemented in ONNX Runtime.
Replace `Seq2SeqTrainingArguments` with `ORTSeq2SeqTrainingArguments`:
```diff
-from transformers import Seq2SeqTrainingArguments
+from optimum.onnxruntime import ORTSeq2SeqTrainingArguments
-training_args = Seq2SeqTrainingArguments(
+training_args = ORTSeq2SeqTrainingArguments(
output_dir="path/to/save/folder/",
num_train_epochs=1,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
warmup_steps=500,
weight_decay=0.01,
logging_dir="path/to/save/folder/",
- optim = "adamw_hf",
+ optim="adamw_ort_fused", # Fused Adam optimizer implemented by ORT
)
```
<Tip warning={false}>
DeepSpeed is supported by ONNX Runtime(only ZeRO stage 1 and 2 for the moment).
You can find some [DeepSpeed configuration examples](https://github.com/huggingface/optimum/tree/main/tests/onnxruntime/ds_configs)
in the Optimum repository.
</Tip>
## ORTModule+StableDiffusion
Optimum supports accelerating Hugging Face Diffusers with ONNX Runtime in [this example](https://github.com/huggingface/optimum/tree/main/examples/onnxruntime/training/stable-diffusion/text-to-image).
The core changes required to enable ONNX Runtime Training are summarized below:
```diff
import torch
from diffusers import AutoencoderKL, UNet2DConditionModel
from transformers import CLIPTextModel
+from onnxruntime.training.ortmodule import ORTModule
+from onnxruntime.training.optim.fp16_optimizer import FP16_Optimizer as ORT_FP16_Optimizer
unet = UNet2DConditionModel.from_pretrained(
"CompVis/stable-diffusion-v1-4",
subfolder="unet",
...
)
text_encoder = CLIPTextModel.from_pretrained(
"CompVis/stable-diffusion-v1-4",
subfolder="text_encoder",
...
)
vae = AutoencoderKL.from_pretrained(
"CompVis/stable-diffusion-v1-4",
subfolder="vae",
...
)
optimizer = torch.optim.AdamW(
unet.parameters(),
...
)
+vae = ORTModule(vae)
+text_encoder = ORTModule(text_encoder)
+unet = ORTModule(unet)
+optimizer = ORT_FP16_Optimizer(optimizer)
```
## Other Resources
* Blog posts
* [Optimum + ONNX Runtime: Easier, Faster training for your Hugging Face models](https://huggingface.co/blog/optimum-onnxruntime-training)
* [Accelerate PyTorch transformer model training with ONNX Runtime - a deep dive](https://techcommunity.microsoft.com/t5/ai-machine-learning-blog/accelerate-pytorch-transformer-model-training-with-onnx-runtime/ba-p/2540471)
* [ONNX Runtime Training Technical Deep Dive](https://techcommunity.microsoft.com/t5/ai-machine-learning-blog/onnx-runtime-training-technical-deep-dive/ba-p/1398310)
* [Optimum github](https://github.com/huggingface/optimum)
* [ONNX Runtime github](https://github.com/microsoft/onnxruntime)
* [Torch ORT github](https://github.com/pytorch/ort)
* [Download ONNX Runtime stable versions](https://download.onnxruntime.ai/)
If you have any problems or questions regarding `ORTTrainer`, please file an issue with [Optimum Github](https://github.com/huggingface/optimum)
or discuss with us on [HuggingFace's community forum](https://discuss.huggingface.co/c/optimum/), cheers 🤗 ! | huggingface/optimum/blob/main/docs/source/onnxruntime/usage_guides/trainer.mdx |
AdvProp (EfficientNet)
**AdvProp** is an adversarial training scheme which treats adversarial examples as additional examples, to prevent overfitting. Key to the method is the usage of a separate auxiliary batch norm for adversarial examples, as they have different underlying distributions to normal examples.
The weights from this model were ported from [Tensorflow/TPU](https://github.com/tensorflow/tpu).
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('tf_efficientnet_b0_ap', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `tf_efficientnet_b0_ap`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('tf_efficientnet_b0_ap', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{xie2020adversarial,
title={Adversarial Examples Improve Image Recognition},
author={Cihang Xie and Mingxing Tan and Boqing Gong and Jiang Wang and Alan Yuille and Quoc V. Le},
year={2020},
eprint={1911.09665},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: AdvProp
Paper:
Title: Adversarial Examples Improve Image Recognition
URL: https://paperswithcode.com/paper/adversarial-examples-improve-image
Models:
- Name: tf_efficientnet_b0_ap
In Collection: AdvProp
Metadata:
FLOPs: 488688572
Parameters: 5290000
File Size: 21385973
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AdvProp
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b0_ap
LR: 0.256
Epochs: 350
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 2048
Image Size: '224'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1334
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b0_ap-f262efe1.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.1%
Top 5 Accuracy: 93.26%
- Name: tf_efficientnet_b1_ap
In Collection: AdvProp
Metadata:
FLOPs: 883633200
Parameters: 7790000
File Size: 31515350
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AdvProp
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b1_ap
LR: 0.256
Epochs: 350
Crop Pct: '0.882'
Momentum: 0.9
Batch Size: 2048
Image Size: '240'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1344
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b1_ap-44ef0a3d.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.28%
Top 5 Accuracy: 94.3%
- Name: tf_efficientnet_b2_ap
In Collection: AdvProp
Metadata:
FLOPs: 1234321170
Parameters: 9110000
File Size: 36800745
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AdvProp
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b2_ap
LR: 0.256
Epochs: 350
Crop Pct: '0.89'
Momentum: 0.9
Batch Size: 2048
Image Size: '260'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1354
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b2_ap-2f8e7636.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.3%
Top 5 Accuracy: 95.03%
- Name: tf_efficientnet_b3_ap
In Collection: AdvProp
Metadata:
FLOPs: 2275247568
Parameters: 12230000
File Size: 49384538
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AdvProp
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b3_ap
LR: 0.256
Epochs: 350
Crop Pct: '0.904'
Momentum: 0.9
Batch Size: 2048
Image Size: '300'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1364
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b3_ap-aad25bdd.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.82%
Top 5 Accuracy: 95.62%
- Name: tf_efficientnet_b4_ap
In Collection: AdvProp
Metadata:
FLOPs: 5749638672
Parameters: 19340000
File Size: 77993585
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AdvProp
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b4_ap
LR: 0.256
Epochs: 350
Crop Pct: '0.922'
Momentum: 0.9
Batch Size: 2048
Image Size: '380'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1374
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b4_ap-dedb23e6.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 83.26%
Top 5 Accuracy: 96.39%
- Name: tf_efficientnet_b5_ap
In Collection: AdvProp
Metadata:
FLOPs: 13176501888
Parameters: 30390000
File Size: 122403150
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AdvProp
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b5_ap
LR: 0.256
Epochs: 350
Crop Pct: '0.934'
Momentum: 0.9
Batch Size: 2048
Image Size: '456'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1384
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b5_ap-9e82fae8.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 84.25%
Top 5 Accuracy: 96.97%
- Name: tf_efficientnet_b6_ap
In Collection: AdvProp
Metadata:
FLOPs: 24180518488
Parameters: 43040000
File Size: 173237466
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AdvProp
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b6_ap
LR: 0.256
Epochs: 350
Crop Pct: '0.942'
Momentum: 0.9
Batch Size: 2048
Image Size: '528'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1394
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b6_ap-4ffb161f.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 84.79%
Top 5 Accuracy: 97.14%
- Name: tf_efficientnet_b7_ap
In Collection: AdvProp
Metadata:
FLOPs: 48205304880
Parameters: 66349999
File Size: 266850607
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AdvProp
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b7_ap
LR: 0.256
Epochs: 350
Crop Pct: '0.949'
Momentum: 0.9
Batch Size: 2048
Image Size: '600'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1405
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b7_ap-ddb28fec.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 85.12%
Top 5 Accuracy: 97.25%
- Name: tf_efficientnet_b8_ap
In Collection: AdvProp
Metadata:
FLOPs: 80962956270
Parameters: 87410000
File Size: 351412563
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AdvProp
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b8_ap
LR: 0.128
Epochs: 350
Crop Pct: '0.954'
Momentum: 0.9
Batch Size: 2048
Image Size: '672'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1416
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b8_ap-00e169fa.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 85.37%
Top 5 Accuracy: 97.3%
--> | huggingface/pytorch-image-models/blob/main/docs/models/advprop.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BORT
<Tip warning={true}>
This model is in maintenance mode only, we do not accept any new PRs changing its code.
If you run into any issues running this model, please reinstall the last version that supported this model: v4.30.0.
You can do so by running the following command: `pip install -U transformers==4.30.0`.
</Tip>
## Overview
The BORT model was proposed in [Optimal Subarchitecture Extraction for BERT](https://arxiv.org/abs/2010.10499) by
Adrian de Wynter and Daniel J. Perry. It is an optimal subset of architectural parameters for the BERT, which the
authors refer to as "Bort".
The abstract from the paper is the following:
*We extract an optimal subset of architectural parameters for the BERT architecture from Devlin et al. (2018) by
applying recent breakthroughs in algorithms for neural architecture search. This optimal subset, which we refer to as
"Bort", is demonstrably smaller, having an effective (that is, not counting the embedding layer) size of 5.5% the
original BERT-large architecture, and 16% of the net size. Bort is also able to be pretrained in 288 GPU hours, which
is 1.2% of the time required to pretrain the highest-performing BERT parametric architectural variant, RoBERTa-large
(Liu et al., 2019), and about 33% of that of the world-record, in GPU hours, required to train BERT-large on the same
hardware. It is also 7.9x faster on a CPU, as well as being better performing than other compressed variants of the
architecture, and some of the non-compressed variants: it obtains performance improvements of between 0.3% and 31%,
absolute, with respect to BERT-large, on multiple public natural language understanding (NLU) benchmarks.*
This model was contributed by [stefan-it](https://huggingface.co/stefan-it). The original code can be found [here](https://github.com/alexa/bort/).
## Usage tips
- BORT's model architecture is based on BERT, refer to [BERT's documentation page](bert) for the
model's API reference as well as usage examples.
- BORT uses the RoBERTa tokenizer instead of the BERT tokenizer, refer to [RoBERTa's documentation page](roberta) for the tokenizer's API reference as well as usage examples.
- BORT requires a specific fine-tuning algorithm, called [Agora](https://adewynter.github.io/notes/bort_algorithms_and_applications.html#fine-tuning-with-algebraic-topology) ,
that is sadly not open-sourced yet. It would be very useful for the community, if someone tries to implement the
algorithm to make BORT fine-tuning work.
| huggingface/transformers/blob/main/docs/source/en/model_doc/bort.md |
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Question answering
The script [`run_qa.py`](https://github.com/huggingface/optimum/blob/main/examples/onnxruntime/quantization/question-answering/run_qa.py)
allows us to apply different quantization approaches (such as dynamic and static quantization) as well as graph
optimizations using [ONNX Runtime](https://github.com/microsoft/onnxruntime) for question answering tasks.
Note that if your dataset contains samples with no possible answers (like SQuAD version 2), you need to pass along
the flag `--version_2_with_negative`.
The following example applies post-training dynamic quantization on a DistilBERT fine-tuned on the SQuAD1.0 dataset.
```bash
python run_qa.py \
--model_name_or_path distilbert-base-uncased-distilled-squad \
--dataset_name squad \
--quantization_approach dynamic \
--do_eval \
--output_dir /tmp/quantized_distilbert_squad
```
In order to apply dynamic or static quantization, `quantization_approach` must be set to respectively `dynamic` or `static`.
| huggingface/optimum/blob/main/examples/onnxruntime/quantization/question-answering/README.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ALBERT
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=albert">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-albert-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/albert-base-v2">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
The ALBERT model was proposed in [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942) by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma,
Radu Soricut. It presents two parameter-reduction techniques to lower memory consumption and increase the training
speed of BERT:
- Splitting the embedding matrix into two smaller matrices.
- Using repeating layers split among groups.
The abstract from the paper is the following:
*Increasing model size when pretraining natural language representations often results in improved performance on
downstream tasks. However, at some point further model increases become harder due to GPU/TPU memory limitations,
longer training times, and unexpected model degradation. To address these problems, we present two parameter-reduction
techniques to lower memory consumption and increase the training speed of BERT. Comprehensive empirical evidence shows
that our proposed methods lead to models that scale much better compared to the original BERT. We also use a
self-supervised loss that focuses on modeling inter-sentence coherence, and show it consistently helps downstream tasks
with multi-sentence inputs. As a result, our best model establishes new state-of-the-art results on the GLUE, RACE, and
SQuAD benchmarks while having fewer parameters compared to BERT-large.*
This model was contributed by [lysandre](https://huggingface.co/lysandre). This model jax version was contributed by
[kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/google-research/ALBERT).
## Usage tips
- ALBERT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather
than the left.
- ALBERT uses repeating layers which results in a small memory footprint, however the computational cost remains
similar to a BERT-like architecture with the same number of hidden layers as it has to iterate through the same
number of (repeating) layers.
- Embedding size E is different from hidden size H justified because the embeddings are context independent (one embedding vector represents one token), whereas hidden states are context dependent (one hidden state represents a sequence of tokens) so it's more logical to have H >> E. Also, the embedding matrix is large since it's V x E (V being the vocab size). If E < H, it has less parameters.
- Layers are split in groups that share parameters (to save memory).
Next sentence prediction is replaced by a sentence ordering prediction: in the inputs, we have two sentences A and B (that are consecutive) and we either feed A followed by B or B followed by A. The model must predict if they have been swapped or not.
This model was contributed by [lysandre](https://huggingface.co/lysandre). This model jax version was contributed by
[kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/google-research/ALBERT).
## Resources
The resources provided in the following sections consist of a list of official Hugging Face and community (indicated by 🌎) resources to help you get started with AlBERT. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<PipelineTag pipeline="text-classification"/>
- [`AlbertForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification).
- [`TFAlbertForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/text-classification).
- [`FlaxAlbertForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification_flax.ipynb).
- Check the [Text classification task guide](../tasks/sequence_classification) on how to use the model.
<PipelineTag pipeline="token-classification"/>
- [`AlbertForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification).
- [`TFAlbertForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/token-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb).
- [`FlaxAlbertForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/token-classification).
- [Token classification](https://huggingface.co/course/chapter7/2?fw=pt) chapter of the 🤗 Hugging Face Course.
- Check the [Token classification task guide](../tasks/token_classification) on how to use the model.
<PipelineTag pipeline="fill-mask"/>
- [`AlbertForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#robertabertdistilbert-and-masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
- [`TFAlbertForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_mlmpy) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
- [`FlaxAlbertForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb).
- [Masked language modeling](https://huggingface.co/course/chapter7/3?fw=pt) chapter of the 🤗 Hugging Face Course.
- Check the [Masked language modeling task guide](../tasks/masked_language_modeling) on how to use the model.
<PipelineTag pipeline="question-answering"/>
- [`AlbertForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb).
- [`TFAlbertForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb).
- [`FlaxAlbertForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/question-answering).
- [Question answering](https://huggingface.co/course/chapter7/7?fw=pt) chapter of the 🤗 Hugging Face Course.
- Check the [Question answering task guide](../tasks/question_answering) on how to use the model.
**Multiple choice**
- [`AlbertForMultipleChoice`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/multiple-choice) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb).
- [`TFAlbertForMultipleChoice`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/multiple-choice) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb).
- Check the [Multiple choice task guide](../tasks/multiple_choice) on how to use the model.
## AlbertConfig
[[autodoc]] AlbertConfig
## AlbertTokenizer
[[autodoc]] AlbertTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## AlbertTokenizerFast
[[autodoc]] AlbertTokenizerFast
## Albert specific outputs
[[autodoc]] models.albert.modeling_albert.AlbertForPreTrainingOutput
[[autodoc]] models.albert.modeling_tf_albert.TFAlbertForPreTrainingOutput
<frameworkcontent>
<pt>
## AlbertModel
[[autodoc]] AlbertModel
- forward
## AlbertForPreTraining
[[autodoc]] AlbertForPreTraining
- forward
## AlbertForMaskedLM
[[autodoc]] AlbertForMaskedLM
- forward
## AlbertForSequenceClassification
[[autodoc]] AlbertForSequenceClassification
- forward
## AlbertForMultipleChoice
[[autodoc]] AlbertForMultipleChoice
## AlbertForTokenClassification
[[autodoc]] AlbertForTokenClassification
- forward
## AlbertForQuestionAnswering
[[autodoc]] AlbertForQuestionAnswering
- forward
</pt>
<tf>
## TFAlbertModel
[[autodoc]] TFAlbertModel
- call
## TFAlbertForPreTraining
[[autodoc]] TFAlbertForPreTraining
- call
## TFAlbertForMaskedLM
[[autodoc]] TFAlbertForMaskedLM
- call
## TFAlbertForSequenceClassification
[[autodoc]] TFAlbertForSequenceClassification
- call
## TFAlbertForMultipleChoice
[[autodoc]] TFAlbertForMultipleChoice
- call
## TFAlbertForTokenClassification
[[autodoc]] TFAlbertForTokenClassification
- call
## TFAlbertForQuestionAnswering
[[autodoc]] TFAlbertForQuestionAnswering
- call
</tf>
<jax>
## FlaxAlbertModel
[[autodoc]] FlaxAlbertModel
- __call__
## FlaxAlbertForPreTraining
[[autodoc]] FlaxAlbertForPreTraining
- __call__
## FlaxAlbertForMaskedLM
[[autodoc]] FlaxAlbertForMaskedLM
- __call__
## FlaxAlbertForSequenceClassification
[[autodoc]] FlaxAlbertForSequenceClassification
- __call__
## FlaxAlbertForMultipleChoice
[[autodoc]] FlaxAlbertForMultipleChoice
- __call__
## FlaxAlbertForTokenClassification
[[autodoc]] FlaxAlbertForTokenClassification
- __call__
## FlaxAlbertForQuestionAnswering
[[autodoc]] FlaxAlbertForQuestionAnswering
- __call__
</jax>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/albert.md |
Asking for help on the forums[[asking-for-help-on-the-forums]]
<CourseFloatingBanner chapter={8}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter8/section3.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter8/section3.ipynb"},
]} />
<Youtube id="S2EEG3JIt2A"/>
The [Hugging Face forums](https://discuss.huggingface.co) are a great place to get help from the open source team and wider Hugging Face community. Here's what the main page looks like on any given day:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter8/forums.png" alt="The Hugging Face forums." width="100%"/>
</div>
On the lefthand side you can see all the categories that the various topics are grouped into, while the righthand side shows the most recent topics. A topic is a post that contains a title, category, and description; it's quite similar to the GitHub issues format that we saw when creating our own dataset in [Chapter 5](/course/chapter5). As the name suggests, the [Beginners](https://discuss.huggingface.co/c/beginners/5) category is primarily intended for people just starting out with the Hugging Face libraries and ecosystem. Any question on any of the libraries is welcome there, be it to debug some code or to ask for help about how to do something. (That said, if your question concerns one library in particular, you should probably head to the corresponding library category on the forum.)
Similarly, the [Intermediate](https://discuss.huggingface.co/c/intermediate/6) and [Research](https://discuss.huggingface.co/c/research/7) categories are for more advanced questions, for example about the libraries or some cool new NLP research that you'd like to discuss.
And naturally, we should also mention the [Course](https://discuss.huggingface.co/c/course/20) category, where you can ask any questions you have that are related to the Hugging Face course!
Once you have selected a category, you'll be ready to write your first topic. You can find some [guidelines](https://discuss.huggingface.co/t/how-to-request-support/3128) in the forum on how to do this, and in this section we'll take a look at some features that make up a good topic.
## Writing a good forum post[[writing-a-good-forum-post]]
As a running example, let's suppose that we're trying to generate embeddings from Wikipedia articles to create a custom search engine. As usual, we load the tokenizer and model as follows:
```python
from transformers import AutoTokenizer, AutoModel
model_checkpoint = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
model = AutoModel.from_pretrained(model_checkpoint)
```
Now suppose we try to embed a whole section of the [Wikipedia article](https://en.wikipedia.org/wiki/Transformers) on Transformers (the franchise, not the library!):
```python
text = """
Generation One is a retroactive term for the Transformers characters that
appeared between 1984 and 1993. The Transformers began with the 1980s Japanese
toy lines Micro Change and Diaclone. They presented robots able to transform
into everyday vehicles, electronic items or weapons. Hasbro bought the Micro
Change and Diaclone toys, and partnered with Takara. Marvel Comics was hired by
Hasbro to create the backstory; editor-in-chief Jim Shooter wrote an overall
story, and gave the task of creating the characthers to writer Dennis O'Neil.
Unhappy with O'Neil's work (although O'Neil created the name "Optimus Prime"),
Shooter chose Bob Budiansky to create the characters.
The Transformers mecha were largely designed by Shōji Kawamori, the creator of
the Japanese mecha anime franchise Macross (which was adapted into the Robotech
franchise in North America). Kawamori came up with the idea of transforming
mechs while working on the Diaclone and Macross franchises in the early 1980s
(such as the VF-1 Valkyrie in Macross and Robotech), with his Diaclone mechs
later providing the basis for Transformers.
The primary concept of Generation One is that the heroic Optimus Prime, the
villainous Megatron, and their finest soldiers crash land on pre-historic Earth
in the Ark and the Nemesis before awakening in 1985, Cybertron hurtling through
the Neutral zone as an effect of the war. The Marvel comic was originally part
of the main Marvel Universe, with appearances from Spider-Man and Nick Fury,
plus some cameos, as well as a visit to the Savage Land.
The Transformers TV series began around the same time. Produced by Sunbow
Productions and Marvel Productions, later Hasbro Productions, from the start it
contradicted Budiansky's backstories. The TV series shows the Autobots looking
for new energy sources, and crash landing as the Decepticons attack. Marvel
interpreted the Autobots as destroying a rogue asteroid approaching Cybertron.
Shockwave is loyal to Megatron in the TV series, keeping Cybertron in a
stalemate during his absence, but in the comic book he attempts to take command
of the Decepticons. The TV series would also differ wildly from the origins
Budiansky had created for the Dinobots, the Decepticon turned Autobot Jetfire
(known as Skyfire on TV), the Constructicons (who combine to form
Devastator),[19][20] and Omega Supreme. The Marvel comic establishes early on
that Prime wields the Creation Matrix, which gives life to machines. In the
second season, the two-part episode The Key to Vector Sigma introduced the
ancient Vector Sigma computer, which served the same original purpose as the
Creation Matrix (giving life to Transformers), and its guardian Alpha Trion.
"""
inputs = tokenizer(text, return_tensors="pt")
logits = model(**inputs).logits
```
```python output
IndexError: index out of range in self
```
Uh-oh, we've hit a problem -- and the error message is far more cryptic than the ones we saw in [section 2](/course/chapter8/section2)! We can't make head or tails of the full traceback, so we decide to turn to the Hugging Face forums for help. How might we craft the topic?
To get started, we need to click the "New Topic" button at the upper-right corner (note that to create a topic, we'll need to be logged in):
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter8/forums-new-topic.png" alt="Creating a new forum topic." width="100%"/>
</div>
This brings up a writing interface where we can input the title of our topic, select a category, and draft the content:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter8/forum-topic01.png" alt="The interface for creating a forum topic." width="100%"/>
</div>
Since the error seems to be exclusively about 🤗 Transformers, we'll select this for the category. Our first attempt at explaining the problem might look something like this:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter8/forum-topic02.png" alt="Drafting the content for a new forum topic." width="100%"/>
</div>
Although this topic contains the error message we need help with, there are a few problems with the way it is written:
1. The title is not very descriptive, so anyone browsing the forum won't be able to tell what the topic is about without reading the body as well.
2. The body doesn't provide enough information about _where_ the error is coming from and _how_ to reproduce it.
3. The topic tags a few people directly with a somewhat demanding tone.
Topics like this one are not likely to get a fast answer (if they get one at all), so let's look at how we can improve it. We'll start with the first issue of picking a good title.
### Choosing a descriptive title[[choosing-a-descriptive-title]]
If you're trying to get help with a bug in your code, a good rule of thumb is to include enough information in the title so that others can quickly determine whether they think they can answer your question or not. In our running example, we know the name of the exception that's being raised and have some hints that it's triggered in the forward pass of the model, where we call `model(**inputs)`. To communicate this, one possible title could be:
> Source of IndexError in the AutoModel forward pass?
This title tells the reader _where_ you think the bug is coming from, and if they've encountered an `IndexError` before, there's a good chance they'll know how to debug it. Of course, the title can be anything you want, and other variations like:
> Why does my model produce an IndexError?
could also be fine. Now that we've got a descriptive title, let's take a look at improving the body.
### Formatting your code snippets[[formatting-your-code-snippets]]
Reading source code is hard enough in an IDE, but it's even harder when the code is copied and pasted as plain text! Fortunately, the Hugging Face forums support the use of Markdown, so you should always enclose your code blocks with three backticks (```) so it's more easily readable. Let's do this to prettify the error message -- and while we're at it, let's make the body a bit more polite than our original version:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter8/forum-topic03.png" alt="Our revised forum topic, with proper code formatting." width="100%"/>
</div>
As you can see in the screenshot, enclosing the code blocks in backticks converts the raw text into formatted code, complete with color styling! Also note that single backticks can be used to format inline variables, like we've done for `distilbert-base-uncased`. This topic is looking much better, and with a bit of luck we might find someone in the community who can guess what the error is about. However, instead of relying on luck, let's make life easier by including the traceback in its full gory detail!
### Including the full traceback[[including-the-full-traceback]]
Since the last line of the traceback is often enough to debug your own code, it can be tempting to just provide that in your topic to "save space." Although well intentioned, this actually makes it _harder_ for others to debug the problem since the information that's higher up in the traceback can be really useful too. So, a good practice is to copy and paste the _whole_ traceback, while making sure that it's nicely formatted. Since these tracebacks can get rather long, some people prefer to show them after they've explained the source code. Let's do this. Now, our forum topic looks like the following:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter8/forum-topic04.png" alt="Our example forum topic, with the complete traceback." width="100%"/>
</div>
This is much more informative, and a careful reader might be able to point out that the problem seems to be due to passing a long input because of this line in the traceback:
> Token indices sequence length is longer than the specified maximum sequence length for this model (583 > 512).
However, we can make things even easier for them by providing the actual code that triggered the error. Let's do that now.
### Providing a reproducible example[[providing-a-reproducible-example]]
If you've ever tried to debug someone else's code, you've probably first tried to recreate the problem they've reported so you can start working your way through the traceback to pinpoint the error. It's no different when it comes to getting (or giving) assistance on the forums, so it really helps if you can provide a small example that reproduces the error. Half the time, simply walking through this exercise will help you figure out what's going wrong. In any case, the missing piece of our example is to show the _inputs_ that we provided to the model. Doing that gives us something like the following completed example:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter8/forum-topic05.png" alt="The final version of our forum topic." width="100%"/>
</div>
This topic now contains quite a lot of information, and it's written in a way that is much more likely to attract the attention of the community and get a helpful answer. With these basic guidelines, you can now create great topics to find the answers to your 🤗 Transformers questions!
| huggingface/course/blob/main/chapters/en/chapter8/3.mdx |
Gradio and W&B Integration
相关空间:https://huggingface.co/spaces/akhaliq/JoJoGAN
标签:WANDB, SPACES
由 Gradio 团队贡献
## 介绍
在本指南中,我们将引导您完成以下内容:
- Gradio、Hugging Face Spaces 和 Wandb 的介绍
- 如何使用 Wandb 集成为 JoJoGAN 设置 Gradio 演示
- 如何在 Hugging Face 的 Wandb 组织中追踪实验并贡献您自己的 Gradio 演示
下面是一个使用 Wandb 跟踪训练和实验的模型示例,请在下方尝试 JoJoGAN 演示。
<iframe src="https://akhaliq-jojogan.hf.space" frameBorder="0" height="810" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
## 什么是 Wandb?
Weights and Biases (W&B) 允许数据科学家和机器学习科学家在从训练到生产的每个阶段跟踪他们的机器学习实验。任何指标都可以对样本进行聚合,并在可自定义和可搜索的仪表板中显示,如下所示:
<img alt="Screen Shot 2022-08-01 at 5 54 59 PM" src="https://user-images.githubusercontent.com/81195143/182252755-4a0e1ca8-fd25-40ff-8c91-c9da38aaa9ec.png">
## 什么是 Hugging Face Spaces 和 Gradio?
### Gradio
Gradio 让用户可以使用几行 Python 代码将其机器学习模型演示为 Web 应用程序。Gradio 将任何 Python 函数(例如机器学习模型的推断函数)包装成一个用户界面,这些演示可以在 jupyter 笔记本、colab 笔记本中启动,也可以嵌入到您自己的网站中,免费托管在 Hugging Face Spaces 上。
在这里开始 [here](https://gradio.app/getting_started)
### Hugging Face Spaces
Hugging Face Spaces 是 Gradio 演示的免费托管选项。Spaces 有 3 个 SDK 选项:Gradio、Streamlit 和静态 HTML 演示。Spaces 可以是公共的或私有的,工作流程类似于 github 存储库。目前在 Hugging Face 上有 2000 多个 Spaces。了解更多关于 Spaces 的信息 [here](https://huggingface.co/spaces/launch)。
## 为 JoJoGAN 设置 Gradio 演示
现在,让我们引导您如何在自己的环境中完成此操作。我们假设您对 W&B 和 Gradio 还不太了解,只是为了本教程的目的。
让我们开始吧!
1. 创建 W&B 账号
如果您还没有 W&B 账号,请按照[这些快速说明](https://app.wandb.ai/login)创建免费账号。这不应该超过几分钟的时间。一旦完成(或者如果您已经有一个账户),接下来,我们将运行一个快速的 colab。
2. 打开 Colab 安装 Gradio 和 W&B
我们将按照 JoJoGAN 存储库中提供的 colab 进行操作,稍作修改以更有效地使用 Wandb 和 Gradio。
[](https://colab.research.google.com/github/mchong6/JoJoGAN/blob/main/stylize.ipynb)
在顶部安装 Gradio 和 Wandb:
```sh
pip install gradio wandb
```
3. 微调 StyleGAN 和 W&B 实验跟踪
下一步将打开一个 W&B 仪表板,以跟踪实验,并显示一个 Gradio 演示提供的预训练模型,您可以从下拉菜单中选择。这是您需要的代码:
```python
alpha = 1.0
alpha = 1-alpha
preserve_color = True
num_iter = 100
log_interval = 50
samples = []
column_names = ["Reference (y)", "Style Code(w)", "Real Face Image(x)"]
wandb.init(project="JoJoGAN")
config = wandb.config
config.num_iter = num_iter
config.preserve_color = preserve_color
wandb.log(
{"Style reference": [wandb.Image(transforms.ToPILImage()(target_im))]},
step=0)
# 加载判别器用于感知损失
discriminator = Discriminator(1024, 2).eval().to(device)
ckpt = torch.load('models/stylegan2-ffhq-config-f.pt', map_location=lambda storage, loc: storage)
discriminator.load_state_dict(ckpt["d"], strict=False)
# 重置生成器
del generator
generator = deepcopy(original_generator)
g_optim = optim.Adam(generator.parameters(), lr=2e-3, betas=(0, 0.99))
# 用于生成一族合理真实图像-> 假图像的更换图层
if preserve_color:
id_swap = [9,11,15,16,17]
else:
id_swap = list(range(7, generator.n_latent))
for idx in tqdm(range(num_iter)):
mean_w = generator.get_latent(torch.randn([latents.size(0), latent_dim]).to(device)).unsqueeze(1).repeat(1, generator.n_latent, 1)
in_latent = latents.clone()
in_latent[:, id_swap] = alpha*latents[:, id_swap] + (1-alpha)*mean_w[:, id_swap]
img = generator(in_latent, input_is_latent=True)
with torch.no_grad():
real_feat = discriminator(targets)
fake_feat = discriminator(img)
loss = sum([F.l1_loss(a, b) for a, b in zip(fake_feat, real_feat)])/len(fake_feat)
wandb.log({"loss": loss}, step=idx)
if idx % log_interval == 0:
generator.eval()
my_sample = generator(my_w, input_is_latent=True)
generator.train()
my_sample = transforms.ToPILImage()(utils.make_grid(my_sample, normalize=True, range=(-1, 1)))
wandb.log(
{"Current stylization": [wandb.Image(my_sample)]},
step=idx)
table_data = [
wandb.Image(transforms.ToPILImage()(target_im)),
wandb.Image(img),
wandb.Image(my_sample),
]
samples.append(table_data)
g_optim.zero_grad()
loss.backward()
g_optim.step()
out_table = wandb.Table(data=samples, columns=column_names)
wandb.log({" 当前样本数 ": out_table})
```
4. 保存、下载和加载模型
以下是如何保存和下载您的模型。
```python
from PIL import Image
import torch
torch.backends.cudnn.benchmark = True
from torchvision import transforms, utils
from util import *
import math
import random
import numpy as np
from torch import nn, autograd, optim
from torch.nn import functional as F
from tqdm import tqdm
import lpips
from model import *
from e4e_projection import projection as e4e_projection
from copy import deepcopy
import imageio
import os
import sys
import torchvision.transforms as transforms
from argparse import Namespace
from e4e.models.psp import pSp
from util import *
from huggingface_hub import hf_hub_download
from google.colab import files
torch.save({"g": generator.state_dict()}, "your-model-name.pt")
files.download('your-model-name.pt')
latent_dim = 512
device="cuda"
model_path_s = hf_hub_download(repo_id="akhaliq/jojogan-stylegan2-ffhq-config-f", filename="stylegan2-ffhq-config-f.pt")
original_generator = Generator(1024, latent_dim, 8, 2).to(device)
ckpt = torch.load(model_path_s, map_location=lambda storage, loc: storage)
original_generator.load_state_dict(ckpt["g_ema"], strict=False)
mean_latent = original_generator.mean_latent(10000)
generator = deepcopy(original_generator)
ckpt = torch.load("/content/JoJoGAN/your-model-name.pt", map_location=lambda storage, loc: storage)
generator.load_state_dict(ckpt["g"], strict=False)
generator.eval()
plt.rcParams['figure.dpi'] = 150
transform = transforms.Compose(
[
transforms.Resize((1024, 1024)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]
)
def inference(img):
img.save('out.jpg')
aligned_face = align_face('out.jpg')
my_w = e4e_projection(aligned_face, "out.pt", device).unsqueeze(0)
with torch.no_grad():
my_sample = generator(my_w, input_is_latent=True)
npimage = my_sample[0].cpu().permute(1, 2, 0).detach().numpy()
imageio.imwrite('filename.jpeg', npimage)
return 'filename.jpeg'
```
5. 构建 Gradio 演示
```python
import gradio as gr
title = "JoJoGAN"
description = "JoJoGAN 的 Gradio 演示:一次性面部风格化。要使用它,只需上传您的图像,或单击示例之一加载它们。在下面的链接中阅读更多信息。"
demo = gr.Interface(
inference,
gr.Image(type="pil"),
gr.Image(type=" 文件 "),
title=title,
description=description
)
demo.launch(share=True)
```
6. 将 Gradio 集成到 W&B 仪表板
最后一步——将 Gradio 演示与 W&B 仪表板集成,只需要一行额外的代码 :
```python
demo.integrate(wandb=wandb)
```
调用集成之后,将创建一个演示,您可以将其集成到仪表板或报告中
在 W&B 之外,使用 gradio-app 标记允许任何人直接将 Gradio 演示嵌入到其博客、网站、文档等中的 HF spaces 上 :
```html
<gradio-app space="akhaliq/JoJoGAN"> <gradio-app>
```
7.(可选)在 Gradio 应用程序中嵌入 W&B 图
也可以在 Gradio 应用程序中嵌入 W&B 图。为此,您可以创建一个 W&B 报告,并在一个 `gr.HTML` 块中将其嵌入到 Gradio 应用程序中。
报告需要是公开的,您需要在 iFrame 中包装 URL,如下所示 :
The Report will need to be public and you will need to wrap the URL within an iFrame like this:
```python
import gradio as gr
def wandb_report(url):
iframe = f'<iframe src={url} style="border:none;height:1024px;width:100%">'
return gr.HTML(iframe)
with gr.Blocks() as demo:
report_url = 'https://wandb.ai/_scott/pytorch-sweeps-demo/reports/loss-22-10-07-16-00-17---VmlldzoyNzU2NzAx'
report = wandb_report(report_url)
demo.launch(share=True)
```
## 结论
希望您喜欢此嵌入 Gradio 演示到 W&B 报告的简短演示!感谢您一直阅读到最后。回顾一下 :
- 仅需要一个单一参考图像即可对 JoJoGAN 进行微调,通常在 GPU 上需要约 1 分钟。训练完成后,可以将样式应用于任何输入图像。在论文中阅读更多内容。
- W&B 可以通过添加几行代码来跟踪实验,您可以在单个集中的仪表板中可视化、排序和理解您的实验。
- Gradio 则在用户友好的界面中演示模型,可以在网络上任何地方共享。
## 如何在 Wandb 组织的 HF spaces 上 贡献 Gradio 演示
- 在 Hugging Face 上创建一个帐户[此处](https://huggingface.co/join)。
- 在您的用户名下添加 Gradio 演示,请参阅[此教程](https://huggingface.co/course/chapter9/4?fw=pt) 以在 Hugging Face 上设置 Gradio 演示。
- 申请加入 wandb 组织[此处](https://huggingface.co/wandb)。
- 批准后,将模型从自己的用户名转移到 Wandb 组织中。
| gradio-app/gradio/blob/main/guides/cn/04_integrating-other-frameworks/Gradio-and-Wandb-Integration.md |
Gradio Demo: dataset
```
!pip install -q gradio
```
```
# Downloading files from the demo repo
import os
os.mkdir('files')
!wget -q -O files/Bunny.obj https://github.com/gradio-app/gradio/raw/main/demo/dataset/files/Bunny.obj
!wget -q -O files/cantina.wav https://github.com/gradio-app/gradio/raw/main/demo/dataset/files/cantina.wav
!wget -q -O files/cheetah1.jpg https://github.com/gradio-app/gradio/raw/main/demo/dataset/files/cheetah1.jpg
!wget -q -O files/time.csv https://github.com/gradio-app/gradio/raw/main/demo/dataset/files/time.csv
!wget -q -O files/titanic.csv https://github.com/gradio-app/gradio/raw/main/demo/dataset/files/titanic.csv
!wget -q -O files/world.mp4 https://github.com/gradio-app/gradio/raw/main/demo/dataset/files/world.mp4
```
```
import gradio as gr
import os
import numpy as np
txt = "the quick brown fox"
num = 10
img = os.path.join(os.path.abspath(''), "files/cheetah1.jpg")
vid = os.path.join(os.path.abspath(''), "files/world.mp4")
audio = os.path.join(os.path.abspath(''), "files/cantina.wav")
csv = os.path.join(os.path.abspath(''), "files/time.csv")
model = os.path.join(os.path.abspath(''), "files/Bunny.obj")
dataframe = [[1, 2, 3, 4], [4, 5, 6, 7], [8, 9, 1, 2], [3, 4, 5, 6]]
with gr.Blocks() as demo:
gr.Markdown("# Dataset previews")
a = gr.Audio(visible=False)
gr.Dataset(
components=[a],
label="Audio",
samples=[
[audio],
[audio],
[audio],
[audio],
[audio],
[audio],
],
)
c = gr.Checkbox(visible=False)
gr.Dataset(
label="Checkbox",
components=[c],
samples=[[True], [True], [False], [True], [False], [False]],
)
c_2 = gr.CheckboxGroup(visible=False, choices=['a', 'b', 'c'])
gr.Dataset(
label="CheckboxGroup",
components=[c_2],
samples=[
[["a"]],
[["a", "b"]],
[["a", "b", "c"]],
[["b"]],
[["c"]],
[["a", "c"]],
],
)
c_3 = gr.ColorPicker(visible=False)
gr.Dataset(
label="ColorPicker",
components=[c_3],
samples=[
["#FFFFFF"],
["#000000"],
["#FFFFFF"],
["#000000"],
["#FFFFFF"],
["#000000"],
],
)
d = gr.DataFrame(visible=False)
gr.Dataset(
components=[d],
label="Dataframe",
samples=[
[np.zeros((3, 3)).tolist()],
[np.ones((2, 2)).tolist()],
[np.random.randint(0, 10, (3, 10)).tolist()],
[np.random.randint(0, 10, (10, 3)).tolist()],
[np.random.randint(0, 10, (10, 10)).tolist()],
],
)
d_2 = gr.Dropdown(visible=False, choices=["one", "two", "three"])
gr.Dataset(
components=[d_2],
label="Dropdown",
samples=[["one"], ["two"], ["three"], ["one"], ["two"], ["three"]],
)
f = gr.File(visible=False)
gr.Dataset(
components=[f],
label="File",
samples=[
[csv],
[csv],
[csv],
[csv],
[csv],
[csv],
],
)
h = gr.HTML(visible=False)
gr.Dataset(
components=[h],
label="HTML",
samples=[
["<h1>hi</h2>"],
["<h1>hi</h2>"],
["<h1>hi</h2>"],
["<h1>hi</h2>"],
["<h1>hi</h2>"],
["<h1>hi</h2>"],
],
)
i = gr.Image(visible=False)
gr.Dataset(
components=[i],
label="Image",
samples=[[img], [img], [img], [img], [img], [img]],
)
m = gr.Markdown(visible=False)
gr.Dataset(
components=[m],
label="Markdown",
samples=[
["# hi"],
["# hi"],
["# hi"],
["# hi"],
["# hi"],
["# hi"],
],
)
m_2 = gr.Model3D(visible=False)
gr.Dataset(
components=[m_2],
label="Model3D",
samples=[[model], [model], [model], [model], [model], [model]],
)
n = gr.Number(visible=False)
gr.Dataset(
label="Number",
components=[n],
samples=[[1], [1], [1], [1], [1], [1]],
)
r = gr.Radio(visible=False, choices=["one", "two", "three"])
gr.Dataset(
components=[r],
label="Radio",
samples=[["one"], ["two"], ["three"], ["one"], ["two"], ["three"]],
)
s = gr.Slider(visible=False)
gr.Dataset(
label="Slider",
components=[s],
samples=[[1], [1], [1], [1], [1], [1]],
)
t = gr.Textbox(visible=False)
gr.Dataset(
label="Textbox",
components=[t],
samples=[
["Some value"],
["Some value"],
["Some value"],
["Some value"],
["Some value"],
["Some value"],
],
)
v = gr.Video(visible=False)
gr.Dataset(
components=[v],
label="Video",
samples=[[vid], [vid], [vid], [vid], [vid], [vid]],
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/dataset/run.ipynb |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# IA3
Infused Adapter by Inhibiting and Amplifying Inner Activations, or [IA3](https://hf.co/papers/2205.05638), is a method that adds three learned vectors to rescale the keys and values of the self-attention and encoder-decoder attention layers, and the intermediate activation of the position-wise feed-forward network.
The abstract from the paper is:
*Few-shot in-context learning (ICL) enables pre-trained language models to perform a previously-unseen task without any gradient-based training by feeding a small number of training examples as part of the input. ICL incurs substantial computational, memory, and storage costs because it involves processing all of the training examples every time a prediction is made. Parameter-efficient fine-tuning (PEFT) (e.g. adapter modules, prompt tuning, sparse update methods, etc.) offers an alternative paradigm where a small set of parameters are trained to enable a model to perform the new task. In this paper, we rigorously compare few-shot ICL and PEFT and demonstrate that the latter offers better accuracy as well as dramatically lower computational costs. Along the way, we introduce a new PEFT method called (IA)^3 that scales activations by learned vectors, attaining stronger performance while only introducing a relatively tiny amount of new parameters. We also propose a simple recipe based on the T0 model called T-Few that can be applied to new tasks without task-specific tuning or modifications. We validate the effectiveness of T-Few on completely unseen tasks by applying it to the RAFT benchmark, attaining super-human performance for the first time and outperforming the state-of-the-art by 6% absolute. All of the code used in our experiments is publicly available*.
## IA3Config
[[autodoc]] tuners.ia3.config.IA3Config
## IA3Model
[[autodoc]] tuners.ia3.model.IA3Model | huggingface/peft/blob/main/docs/source/package_reference/ia3.md |
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# LoRA for token classification
Low-Rank Adaptation (LoRA) is a reparametrization method that aims to reduce the number of trainable parameters with low-rank representations. The weight matrix is broken down into low-rank matrices that are trained and updated. All the pretrained model parameters remain frozen. After training, the low-rank matrices are added back to the original weights. This makes it more efficient to store and train a LoRA model because there are significantly fewer parameters.
<Tip>
💡 Read [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) to learn more about LoRA.
</Tip>
This guide will show you how to train a [`roberta-large`](https://huggingface.co/roberta-large) model with LoRA on the [BioNLP2004](https://huggingface.co/datasets/tner/bionlp2004) dataset for token classification.
Before you begin, make sure you have all the necessary libraries installed:
```bash
!pip install -q peft transformers datasets evaluate seqeval
```
## Setup
Let's start by importing all the necessary libraries you'll need:
- 🤗 Transformers for loading the base `roberta-large` model and tokenizer, and handling the training loop
- 🤗 Datasets for loading and preparing the `bionlp2004` dataset for training
- 🤗 Evaluate for evaluating the model's performance
- 🤗 PEFT for setting up the LoRA configuration and creating the PEFT model
```py
from datasets import load_dataset
from transformers import (
AutoModelForTokenClassification,
AutoTokenizer,
DataCollatorForTokenClassification,
TrainingArguments,
Trainer,
)
from peft import get_peft_config, PeftModel, PeftConfig, get_peft_model, LoraConfig, TaskType
import evaluate
import torch
import numpy as np
model_checkpoint = "roberta-large"
lr = 1e-3
batch_size = 16
num_epochs = 10
```
## Load dataset and metric
The [BioNLP2004](https://huggingface.co/datasets/tner/bionlp2004) dataset includes tokens and tags for biological structures like DNA, RNA and proteins. Load the dataset:
```py
bionlp = load_dataset("tner/bionlp2004")
bionlp["train"][0]
{
"tokens": [
"Since",
"HUVECs",
"released",
"superoxide",
"anions",
"in",
"response",
"to",
"TNF",
",",
"and",
"H2O2",
"induces",
"VCAM-1",
",",
"PDTC",
"may",
"act",
"as",
"a",
"radical",
"scavenger",
".",
],
"tags": [0, 7, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0],
}
```
The `tags` values are defined in the label ids [dictionary](https://huggingface.co/datasets/tner/bionlp2004#label-id). The letter that prefixes each label indicates the token position: `B` is for the first token of an entity, `I` is for a token inside the entity, and `0` is for a token that is not part of an entity.
```py
{
"O": 0,
"B-DNA": 1,
"I-DNA": 2,
"B-protein": 3,
"I-protein": 4,
"B-cell_type": 5,
"I-cell_type": 6,
"B-cell_line": 7,
"I-cell_line": 8,
"B-RNA": 9,
"I-RNA": 10,
}
```
Then load the [`seqeval`](https://huggingface.co/spaces/evaluate-metric/seqeval) framework which includes several metrics - precision, accuracy, F1, and recall - for evaluating sequence labeling tasks.
```py
seqeval = evaluate.load("seqeval")
```
Now you can write an evaluation function to compute the metrics from the model predictions and labels, and return the precision, recall, F1, and accuracy scores:
```py
label_list = [
"O",
"B-DNA",
"I-DNA",
"B-protein",
"I-protein",
"B-cell_type",
"I-cell_type",
"B-cell_line",
"I-cell_line",
"B-RNA",
"I-RNA",
]
def compute_metrics(p):
predictions, labels = p
predictions = np.argmax(predictions, axis=2)
true_predictions = [
[label_list[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
true_labels = [
[label_list[l] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
results = seqeval.compute(predictions=true_predictions, references=true_labels)
return {
"precision": results["overall_precision"],
"recall": results["overall_recall"],
"f1": results["overall_f1"],
"accuracy": results["overall_accuracy"],
}
```
## Preprocess dataset
Initialize a tokenizer and make sure you set `is_split_into_words=True` because the text sequence has already been split into words. However, this doesn't mean it is tokenized yet (even though it may look like it!), and you'll need to further tokenize the words into subwords.
```py
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, add_prefix_space=True)
```
You'll also need to write a function to:
1. Map each token to their respective word with the [`~transformers.BatchEncoding.word_ids`] method.
2. Ignore the special tokens by setting them to `-100`.
3. Label the first token of a given entity.
```py
def tokenize_and_align_labels(examples):
tokenized_inputs = tokenizer(examples["tokens"], truncation=True, is_split_into_words=True)
labels = []
for i, label in enumerate(examples[f"tags"]):
word_ids = tokenized_inputs.word_ids(batch_index=i)
previous_word_idx = None
label_ids = []
for word_idx in word_ids:
if word_idx is None:
label_ids.append(-100)
elif word_idx != previous_word_idx:
label_ids.append(label[word_idx])
else:
label_ids.append(-100)
previous_word_idx = word_idx
labels.append(label_ids)
tokenized_inputs["labels"] = labels
return tokenized_inputs
```
Use [`~datasets.Dataset.map`] to apply the `tokenize_and_align_labels` function to the dataset:
```py
tokenized_bionlp = bionlp.map(tokenize_and_align_labels, batched=True)
```
Finally, create a data collator to pad the examples to the longest length in a batch:
```py
data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)
```
## Train
Now you're ready to create a [`PeftModel`]. Start by loading the base `roberta-large` model, the number of expected labels, and the `id2label` and `label2id` dictionaries:
```py
id2label = {
0: "O",
1: "B-DNA",
2: "I-DNA",
3: "B-protein",
4: "I-protein",
5: "B-cell_type",
6: "I-cell_type",
7: "B-cell_line",
8: "I-cell_line",
9: "B-RNA",
10: "I-RNA",
}
label2id = {
"O": 0,
"B-DNA": 1,
"I-DNA": 2,
"B-protein": 3,
"I-protein": 4,
"B-cell_type": 5,
"I-cell_type": 6,
"B-cell_line": 7,
"I-cell_line": 8,
"B-RNA": 9,
"I-RNA": 10,
}
model = AutoModelForTokenClassification.from_pretrained(
model_checkpoint, num_labels=11, id2label=id2label, label2id=label2id
)
```
Define the [`LoraConfig`] with:
- `task_type`, token classification (`TaskType.TOKEN_CLS`)
- `r`, the dimension of the low-rank matrices
- `lora_alpha`, scaling factor for the weight matrices
- `lora_dropout`, dropout probability of the LoRA layers
- `bias`, set to `all` to train all bias parameters
<Tip>
💡 The weight matrix is scaled by `lora_alpha/r`, and a higher `lora_alpha` value assigns more weight to the LoRA activations. For performance, we recommend setting `bias` to `None` first, and then `lora_only`, before trying `all`.
</Tip>
```py
peft_config = LoraConfig(
task_type=TaskType.TOKEN_CLS, inference_mode=False, r=16, lora_alpha=16, lora_dropout=0.1, bias="all"
)
```
Pass the base model and `peft_config` to the [`get_peft_model`] function to create a [`PeftModel`]. You can check out how much more efficient training the [`PeftModel`] is compared to fully training the base model by printing out the trainable parameters:
```py
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
"trainable params: 1855499 || all params: 355894283 || trainable%: 0.5213624069370061"
```
From the 🤗 Transformers library, create a [`~transformers.TrainingArguments`] class and specify where you want to save the model to, the training hyperparameters, how to evaluate the model, and when to save the checkpoints:
```py
training_args = TrainingArguments(
output_dir="roberta-large-lora-token-classification",
learning_rate=lr,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=num_epochs,
weight_decay=0.01,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
)
```
Pass the model, `TrainingArguments`, datasets, tokenizer, data collator and evaluation function to the [`~transformers.Trainer`] class. The `Trainer` handles the training loop for you, and when you're ready, call [`~transformers.Trainer.train`] to begin!
```py
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_bionlp["train"],
eval_dataset=tokenized_bionlp["validation"],
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
trainer.train()
```
## Share model
Once training is complete, you can store and share your model on the Hub if you'd like. Log in to your Hugging Face account and enter your token when prompted:
```py
from huggingface_hub import notebook_login
notebook_login()
```
Upload the model to a specific model repository on the Hub with the [`~transformers.PreTrainedModel.push_to_hub`] method:
```py
model.push_to_hub("your-name/roberta-large-lora-token-classification")
```
## Inference
To use your model for inference, load the configuration and model:
```py
peft_model_id = "stevhliu/roberta-large-lora-token-classification"
config = PeftConfig.from_pretrained(peft_model_id)
inference_model = AutoModelForTokenClassification.from_pretrained(
config.base_model_name_or_path, num_labels=11, id2label=id2label, label2id=label2id
)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
model = PeftModel.from_pretrained(inference_model, peft_model_id)
```
Get some text to tokenize:
```py
text = "The activation of IL-2 gene expression and NF-kappa B through CD28 requires reactive oxygen production by 5-lipoxygenase."
inputs = tokenizer(text, return_tensors="pt")
```
Pass the inputs to the model, and print out the model prediction for each token:
```py
with torch.no_grad():
logits = model(**inputs).logits
tokens = inputs.tokens()
predictions = torch.argmax(logits, dim=2)
for token, prediction in zip(tokens, predictions[0].numpy()):
print((token, model.config.id2label[prediction]))
("<s>", "O")
("The", "O")
("Ġactivation", "O")
("Ġof", "O")
("ĠIL", "B-DNA")
("-", "O")
("2", "I-DNA")
("Ġgene", "O")
("Ġexpression", "O")
("Ġand", "O")
("ĠNF", "B-protein")
("-", "O")
("k", "I-protein")
("appa", "I-protein")
("ĠB", "I-protein")
("Ġthrough", "O")
("ĠCD", "B-protein")
("28", "I-protein")
("Ġrequires", "O")
("Ġreactive", "O")
("Ġoxygen", "O")
("Ġproduction", "O")
("Ġby", "O")
("Ġ5", "B-protein")
("-", "O")
("lip", "I-protein")
("oxy", "I-protein")
("gen", "I-protein")
("ase", "I-protein")
(".", "O")
("</s>", "O")
``` | huggingface/peft/blob/main/docs/source/task_guides/token-classification-lora.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Token classification
[[open-in-colab]]
<Youtube id="wVHdVlPScxA"/>
Token classification assigns a label to individual tokens in a sentence. One of the most common token classification tasks is Named Entity Recognition (NER). NER attempts to find a label for each entity in a sentence, such as a person, location, or organization.
This guide will show you how to:
1. Finetune [DistilBERT](https://huggingface.co/distilbert-base-uncased) on the [WNUT 17](https://huggingface.co/datasets/wnut_17) dataset to detect new entities.
2. Use your finetuned model for inference.
<Tip>
The task illustrated in this tutorial is supported by the following model architectures:
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
[ALBERT](../model_doc/albert), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [BioGpt](../model_doc/biogpt), [BLOOM](../model_doc/bloom), [BROS](../model_doc/bros), [CamemBERT](../model_doc/camembert), [CANINE](../model_doc/canine), [ConvBERT](../model_doc/convbert), [Data2VecText](../model_doc/data2vec-text), [DeBERTa](../model_doc/deberta), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ErnieM](../model_doc/ernie_m), [ESM](../model_doc/esm), [Falcon](../model_doc/falcon), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [I-BERT](../model_doc/ibert), [LayoutLM](../model_doc/layoutlm), [LayoutLMv2](../model_doc/layoutlmv2), [LayoutLMv3](../model_doc/layoutlmv3), [LiLT](../model_doc/lilt), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [MarkupLM](../model_doc/markuplm), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [MPT](../model_doc/mpt), [MRA](../model_doc/mra), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [Phi](../model_doc/phi), [QDQBert](../model_doc/qdqbert), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [SqueezeBERT](../model_doc/squeezebert), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
<!--End of the generated tip-->
</Tip>
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers datasets evaluate seqeval
```
We encourage you to login to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to login:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Load WNUT 17 dataset
Start by loading the WNUT 17 dataset from the 🤗 Datasets library:
```py
>>> from datasets import load_dataset
>>> wnut = load_dataset("wnut_17")
```
Then take a look at an example:
```py
>>> wnut["train"][0]
{'id': '0',
'ner_tags': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 7, 8, 8, 0, 7, 0, 0, 0, 0, 0, 0, 0, 0],
'tokens': ['@paulwalk', 'It', "'s", 'the', 'view', 'from', 'where', 'I', "'m", 'living', 'for', 'two', 'weeks', '.', 'Empire', 'State', 'Building', '=', 'ESB', '.', 'Pretty', 'bad', 'storm', 'here', 'last', 'evening', '.']
}
```
Each number in `ner_tags` represents an entity. Convert the numbers to their label names to find out what the entities are:
```py
>>> label_list = wnut["train"].features[f"ner_tags"].feature.names
>>> label_list
[
"O",
"B-corporation",
"I-corporation",
"B-creative-work",
"I-creative-work",
"B-group",
"I-group",
"B-location",
"I-location",
"B-person",
"I-person",
"B-product",
"I-product",
]
```
The letter that prefixes each `ner_tag` indicates the token position of the entity:
- `B-` indicates the beginning of an entity.
- `I-` indicates a token is contained inside the same entity (for example, the `State` token is a part of an entity like
`Empire State Building`).
- `0` indicates the token doesn't correspond to any entity.
## Preprocess
<Youtube id="iY2AZYdZAr0"/>
The next step is to load a DistilBERT tokenizer to preprocess the `tokens` field:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
```
As you saw in the example `tokens` field above, it looks like the input has already been tokenized. But the input actually hasn't been tokenized yet and you'll need to set `is_split_into_words=True` to tokenize the words into subwords. For example:
```py
>>> example = wnut["train"][0]
>>> tokenized_input = tokenizer(example["tokens"], is_split_into_words=True)
>>> tokens = tokenizer.convert_ids_to_tokens(tokenized_input["input_ids"])
>>> tokens
['[CLS]', '@', 'paul', '##walk', 'it', "'", 's', 'the', 'view', 'from', 'where', 'i', "'", 'm', 'living', 'for', 'two', 'weeks', '.', 'empire', 'state', 'building', '=', 'es', '##b', '.', 'pretty', 'bad', 'storm', 'here', 'last', 'evening', '.', '[SEP]']
```
However, this adds some special tokens `[CLS]` and `[SEP]` and the subword tokenization creates a mismatch between the input and labels. A single word corresponding to a single label may now be split into two subwords. You'll need to realign the tokens and labels by:
1. Mapping all tokens to their corresponding word with the [`word_ids`](https://huggingface.co/docs/transformers/main_classes/tokenizer#transformers.BatchEncoding.word_ids) method.
2. Assigning the label `-100` to the special tokens `[CLS]` and `[SEP]` so they're ignored by the PyTorch loss function (see [CrossEntropyLoss](https://pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html)).
3. Only labeling the first token of a given word. Assign `-100` to other subtokens from the same word.
Here is how you can create a function to realign the tokens and labels, and truncate sequences to be no longer than DistilBERT's maximum input length:
```py
>>> def tokenize_and_align_labels(examples):
... tokenized_inputs = tokenizer(examples["tokens"], truncation=True, is_split_into_words=True)
... labels = []
... for i, label in enumerate(examples[f"ner_tags"]):
... word_ids = tokenized_inputs.word_ids(batch_index=i) # Map tokens to their respective word.
... previous_word_idx = None
... label_ids = []
... for word_idx in word_ids: # Set the special tokens to -100.
... if word_idx is None:
... label_ids.append(-100)
... elif word_idx != previous_word_idx: # Only label the first token of a given word.
... label_ids.append(label[word_idx])
... else:
... label_ids.append(-100)
... previous_word_idx = word_idx
... labels.append(label_ids)
... tokenized_inputs["labels"] = labels
... return tokenized_inputs
```
To apply the preprocessing function over the entire dataset, use 🤗 Datasets [`~datasets.Dataset.map`] function. You can speed up the `map` function by setting `batched=True` to process multiple elements of the dataset at once:
```py
>>> tokenized_wnut = wnut.map(tokenize_and_align_labels, batched=True)
```
Now create a batch of examples using [`DataCollatorWithPadding`]. It's more efficient to *dynamically pad* the sentences to the longest length in a batch during collation, instead of padding the whole dataset to the maximum length.
<frameworkcontent>
<pt>
```py
>>> from transformers import DataCollatorForTokenClassification
>>> data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)
```
</pt>
<tf>
```py
>>> from transformers import DataCollatorForTokenClassification
>>> data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer, return_tensors="tf")
```
</tf>
</frameworkcontent>
## Evaluate
Including a metric during training is often helpful for evaluating your model's performance. You can quickly load a evaluation method with the 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) library. For this task, load the [seqeval](https://huggingface.co/spaces/evaluate-metric/seqeval) framework (see the 🤗 Evaluate [quick tour](https://huggingface.co/docs/evaluate/a_quick_tour) to learn more about how to load and compute a metric). Seqeval actually produces several scores: precision, recall, F1, and accuracy.
```py
>>> import evaluate
>>> seqeval = evaluate.load("seqeval")
```
Get the NER labels first, and then create a function that passes your true predictions and true labels to [`~evaluate.EvaluationModule.compute`] to calculate the scores:
```py
>>> import numpy as np
>>> labels = [label_list[i] for i in example[f"ner_tags"]]
>>> def compute_metrics(p):
... predictions, labels = p
... predictions = np.argmax(predictions, axis=2)
... true_predictions = [
... [label_list[p] for (p, l) in zip(prediction, label) if l != -100]
... for prediction, label in zip(predictions, labels)
... ]
... true_labels = [
... [label_list[l] for (p, l) in zip(prediction, label) if l != -100]
... for prediction, label in zip(predictions, labels)
... ]
... results = seqeval.compute(predictions=true_predictions, references=true_labels)
... return {
... "precision": results["overall_precision"],
... "recall": results["overall_recall"],
... "f1": results["overall_f1"],
... "accuracy": results["overall_accuracy"],
... }
```
Your `compute_metrics` function is ready to go now, and you'll return to it when you setup your training.
## Train
Before you start training your model, create a map of the expected ids to their labels with `id2label` and `label2id`:
```py
>>> id2label = {
... 0: "O",
... 1: "B-corporation",
... 2: "I-corporation",
... 3: "B-creative-work",
... 4: "I-creative-work",
... 5: "B-group",
... 6: "I-group",
... 7: "B-location",
... 8: "I-location",
... 9: "B-person",
... 10: "I-person",
... 11: "B-product",
... 12: "I-product",
... }
>>> label2id = {
... "O": 0,
... "B-corporation": 1,
... "I-corporation": 2,
... "B-creative-work": 3,
... "I-creative-work": 4,
... "B-group": 5,
... "I-group": 6,
... "B-location": 7,
... "I-location": 8,
... "B-person": 9,
... "I-person": 10,
... "B-product": 11,
... "I-product": 12,
... }
```
<frameworkcontent>
<pt>
<Tip>
If you aren't familiar with finetuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#train-with-pytorch-trainer)!
</Tip>
You're ready to start training your model now! Load DistilBERT with [`AutoModelForTokenClassification`] along with the number of expected labels, and the label mappings:
```py
>>> from transformers import AutoModelForTokenClassification, TrainingArguments, Trainer
>>> model = AutoModelForTokenClassification.from_pretrained(
... "distilbert-base-uncased", num_labels=13, id2label=id2label, label2id=label2id
... )
```
At this point, only three steps remain:
1. Define your training hyperparameters in [`TrainingArguments`]. The only required parameter is `output_dir` which specifies where to save your model. You'll push this model to the Hub by setting `push_to_hub=True` (you need to be signed in to Hugging Face to upload your model). At the end of each epoch, the [`Trainer`] will evaluate the seqeval scores and save the training checkpoint.
2. Pass the training arguments to [`Trainer`] along with the model, dataset, tokenizer, data collator, and `compute_metrics` function.
3. Call [`~Trainer.train`] to finetune your model.
```py
>>> training_args = TrainingArguments(
... output_dir="my_awesome_wnut_model",
... learning_rate=2e-5,
... per_device_train_batch_size=16,
... per_device_eval_batch_size=16,
... num_train_epochs=2,
... weight_decay=0.01,
... evaluation_strategy="epoch",
... save_strategy="epoch",
... load_best_model_at_end=True,
... push_to_hub=True,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=tokenized_wnut["train"],
... eval_dataset=tokenized_wnut["test"],
... tokenizer=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
>>> trainer.train()
```
Once training is completed, share your model to the Hub with the [`~transformers.Trainer.push_to_hub`] method so everyone can use your model:
```py
>>> trainer.push_to_hub()
```
</pt>
<tf>
<Tip>
If you aren't familiar with finetuning a model with Keras, take a look at the basic tutorial [here](../training#train-a-tensorflow-model-with-keras)!
</Tip>
To finetune a model in TensorFlow, start by setting up an optimizer function, learning rate schedule, and some training hyperparameters:
```py
>>> from transformers import create_optimizer
>>> batch_size = 16
>>> num_train_epochs = 3
>>> num_train_steps = (len(tokenized_wnut["train"]) // batch_size) * num_train_epochs
>>> optimizer, lr_schedule = create_optimizer(
... init_lr=2e-5,
... num_train_steps=num_train_steps,
... weight_decay_rate=0.01,
... num_warmup_steps=0,
... )
```
Then you can load DistilBERT with [`TFAutoModelForTokenClassification`] along with the number of expected labels, and the label mappings:
```py
>>> from transformers import TFAutoModelForTokenClassification
>>> model = TFAutoModelForTokenClassification.from_pretrained(
... "distilbert-base-uncased", num_labels=13, id2label=id2label, label2id=label2id
... )
```
Convert your datasets to the `tf.data.Dataset` format with [`~transformers.TFPreTrainedModel.prepare_tf_dataset`]:
```py
>>> tf_train_set = model.prepare_tf_dataset(
... tokenized_wnut["train"],
... shuffle=True,
... batch_size=16,
... collate_fn=data_collator,
... )
>>> tf_validation_set = model.prepare_tf_dataset(
... tokenized_wnut["validation"],
... shuffle=False,
... batch_size=16,
... collate_fn=data_collator,
... )
```
Configure the model for training with [`compile`](https://keras.io/api/models/model_training_apis/#compile-method). Note that Transformers models all have a default task-relevant loss function, so you don't need to specify one unless you want to:
```py
>>> import tensorflow as tf
>>> model.compile(optimizer=optimizer) # No loss argument!
```
The last two things to setup before you start training is to compute the seqeval scores from the predictions, and provide a way to push your model to the Hub. Both are done by using [Keras callbacks](../main_classes/keras_callbacks).
Pass your `compute_metrics` function to [`~transformers.KerasMetricCallback`]:
```py
>>> from transformers.keras_callbacks import KerasMetricCallback
>>> metric_callback = KerasMetricCallback(metric_fn=compute_metrics, eval_dataset=tf_validation_set)
```
Specify where to push your model and tokenizer in the [`~transformers.PushToHubCallback`]:
```py
>>> from transformers.keras_callbacks import PushToHubCallback
>>> push_to_hub_callback = PushToHubCallback(
... output_dir="my_awesome_wnut_model",
... tokenizer=tokenizer,
... )
```
Then bundle your callbacks together:
```py
>>> callbacks = [metric_callback, push_to_hub_callback]
```
Finally, you're ready to start training your model! Call [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) with your training and validation datasets, the number of epochs, and your callbacks to finetune the model:
```py
>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=3, callbacks=callbacks)
```
Once training is completed, your model is automatically uploaded to the Hub so everyone can use it!
</tf>
</frameworkcontent>
<Tip>
For a more in-depth example of how to finetune a model for token classification, take a look at the corresponding
[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb)
or [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb).
</Tip>
## Inference
Great, now that you've finetuned a model, you can use it for inference!
Grab some text you'd like to run inference on:
```py
>>> text = "The Golden State Warriors are an American professional basketball team based in San Francisco."
```
The simplest way to try out your finetuned model for inference is to use it in a [`pipeline`]. Instantiate a `pipeline` for NER with your model, and pass your text to it:
```py
>>> from transformers import pipeline
>>> classifier = pipeline("ner", model="stevhliu/my_awesome_wnut_model")
>>> classifier(text)
[{'entity': 'B-location',
'score': 0.42658573,
'index': 2,
'word': 'golden',
'start': 4,
'end': 10},
{'entity': 'I-location',
'score': 0.35856336,
'index': 3,
'word': 'state',
'start': 11,
'end': 16},
{'entity': 'B-group',
'score': 0.3064001,
'index': 4,
'word': 'warriors',
'start': 17,
'end': 25},
{'entity': 'B-location',
'score': 0.65523505,
'index': 13,
'word': 'san',
'start': 80,
'end': 83},
{'entity': 'B-location',
'score': 0.4668663,
'index': 14,
'word': 'francisco',
'start': 84,
'end': 93}]
```
You can also manually replicate the results of the `pipeline` if you'd like:
<frameworkcontent>
<pt>
Tokenize the text and return PyTorch tensors:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_wnut_model")
>>> inputs = tokenizer(text, return_tensors="pt")
```
Pass your inputs to the model and return the `logits`:
```py
>>> from transformers import AutoModelForTokenClassification
>>> model = AutoModelForTokenClassification.from_pretrained("stevhliu/my_awesome_wnut_model")
>>> with torch.no_grad():
... logits = model(**inputs).logits
```
Get the class with the highest probability, and use the model's `id2label` mapping to convert it to a text label:
```py
>>> predictions = torch.argmax(logits, dim=2)
>>> predicted_token_class = [model.config.id2label[t.item()] for t in predictions[0]]
>>> predicted_token_class
['O',
'O',
'B-location',
'I-location',
'B-group',
'O',
'O',
'O',
'O',
'O',
'O',
'O',
'O',
'B-location',
'B-location',
'O',
'O']
```
</pt>
<tf>
Tokenize the text and return TensorFlow tensors:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_wnut_model")
>>> inputs = tokenizer(text, return_tensors="tf")
```
Pass your inputs to the model and return the `logits`:
```py
>>> from transformers import TFAutoModelForTokenClassification
>>> model = TFAutoModelForTokenClassification.from_pretrained("stevhliu/my_awesome_wnut_model")
>>> logits = model(**inputs).logits
```
Get the class with the highest probability, and use the model's `id2label` mapping to convert it to a text label:
```py
>>> predicted_token_class_ids = tf.math.argmax(logits, axis=-1)
>>> predicted_token_class = [model.config.id2label[t] for t in predicted_token_class_ids[0].numpy().tolist()]
>>> predicted_token_class
['O',
'O',
'B-location',
'I-location',
'B-group',
'O',
'O',
'O',
'O',
'O',
'O',
'O',
'O',
'B-location',
'B-location',
'O',
'O']
```
</tf>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/tasks/token_classification.md |
## Saved Pseudo-Labels
These are the generations of various large models on various large **training** sets. All in all they took about 200 GPU hours to produce.
### Available Pseudo-labels
| Dataset | Model | Link | Rouge Scores | Notes
|---------|-----------------------------|----------------------------------------------------------------------------------------|--------------------|-------------------------------------------------------------------------------------------------------------
| XSUM | `facebook/bart-large-xsum` | [download](https://cdn-datasets.huggingface.co/pseudo/xsum/bart_xsum_pl.tgz) | 49.8/28.0/42.5 |
| XSUM | `google/pegasus-xsum` | [download](https://cdn-datasets.huggingface.co/pseudo/xsum/pegasus_xsum.tgz) | 53.3/32.7/46.5 |
| XSUM | `facebook/bart-large-xsum` | [download](https://cdn-datasets.huggingface.co/pseudo/xsum/xsum_pl2_bart.tgz) | | Bart pseudolabels filtered to those with Rouge2 > 10.0 w GT.
| CNN/DM | `sshleifer/pegasus-cnn-ft-v2` | [download](https://cdn-datasets.huggingface.co/pseudo/cnn_dm/pegasus_cnn_cnn_pls.tgz) | 47.316/26.65/44.56 | do not worry about the fact that train.source is one line shorter.
| CNN/DM | `facebook/bart-large-cnn` | [download](https://cdn-datasets.huggingface.co/pseudo/cnn_dm/cnn_bart_pl.tgz) | | 5K (2%) are missing, there should be 282173
| CNN/DM | `google/pegasus-xsum` | [download](https://cdn-datasets.huggingface.co/pseudo/cnn_dm/pegasus_xsum_on_cnn.tgz) | 21.5/6.76/25 | extra labels for xsum distillation Used max_source_length=512, (and all other pegasus-xsum configuration).
| EN-RO | `Helsinki-NLP/opus-mt-en-ro` | [download](https://cdn-datasets.huggingface.co/pseudo/wmt_en_ro/opus_mt_en_ro.tgz) | |
| EN-RO | `facebook/mbart-large-en-ro` | [download](https://cdn-datasets.huggingface.co/pseudo/wmt_en_ro/mbart_large_en_ro.tgz) | |
(EN_RO = WMT 2016 English-Romanian).
Example Download Command:
```bash
curl -S https://cdn-datasets.huggingface.co/pseudo/xsum/bart_xsum_pl.tgz | tar -xvz -C .
```
### Generating New Pseudolabels
Here is the command I used to generate the pseudolabels in the second row of the table, after downloading XSUM from [here](https://cdn-datasets.huggingface.co/summarization/xsum.tar.gz).
```bash
python -m torch.distributed.launch --nproc_per_node=8 run_distributed_eval.py \
--model_name google/pegasus-xsum \
--save_dir pegasus_xsum \
--data_dir xsum \
--bs 8 --sync_timeout 60000 \
--max_source_length 512 \
--type_path train
```
+ These commands takes a while to run. For example, `pegasus_cnn_cnn_pls.tgz` took 8 hours on 8 GPUs.
+ Pegasus does not work in fp16 :(, Bart, mBART and Marian do.
+ Even if you have 1 GPU, `run_distributed_eval.py` is 10-20% faster than `run_eval.py` because it uses `SortishSampler` to minimize padding computation.
### Contributions
Feel free to contribute your own pseudolabels via PR. Add a row to this table with a new google drive link (or other command line downloadable link).
| huggingface/transformers/blob/main/examples/research_projects/seq2seq-distillation/precomputed_pseudo_labels.md |
`@gradio/dropdown`
```html
<script>
import {BaseDropdown, BaseMultiselect, BaseExample } from "@gradio/dropdown";
</script>
```
BaseDropdown
```javascript
export let label: string;
export let info: string | undefined = undefined;
export let value: string | number | (string | number)[] | undefined = [];
export let value_is_output = false;
export let choices: [string, string | number][];
export let disabled = false;
export let show_label: boolean;
export let container = true;
export let allow_custom_value = false;
export let filterable = true;
```
BaseMultiselect
```javascript
export let label: string;
export let info: string | undefined = undefined;
export let value: string | number | (string | number)[] | undefined = [];
export let value_is_output = false;
export let max_choices: number | null = null;
export let choices: [string, string | number][];
export let disabled = false;
export let show_label: boolean;
export let container = true;
export let allow_custom_value = false;
export let filterable = true;
export let i18n: I18nFormatter;
```
BaseExample
```javascript
export let value: string;
export let type: "gallery" | "table";
export let selected = false;
``` | gradio-app/gradio/blob/main/js/dropdown/README.md |
Gradio Demo: fake_diffusion_with_gif
```
!pip install -q gradio
```
```
# Downloading files from the demo repo
import os
!wget -q https://github.com/gradio-app/gradio/raw/main/demo/fake_diffusion_with_gif/image.gif
```
```
import gradio as gr
import numpy as np
import time
import os
from PIL import Image
import requests
from io import BytesIO
def create_gif(images):
pil_images = []
for image in images:
if isinstance(image, str):
response = requests.get(image)
image = Image.open(BytesIO(response.content))
else:
image = Image.fromarray((image * 255).astype(np.uint8))
pil_images.append(image)
fp_out = os.path.join(os.path.abspath(''), "image.gif")
img = pil_images.pop(0)
img.save(fp=fp_out, format='GIF', append_images=pil_images,
save_all=True, duration=400, loop=0)
return fp_out
def fake_diffusion(steps):
images = []
for _ in range(steps):
time.sleep(1)
image = np.random.random((600, 600, 3))
images.append(image)
yield image, gr.Image(visible=False)
time.sleep(1)
image = "https://gradio-builds.s3.amazonaws.com/diffusion_image/cute_dog.jpg"
images.append(image)
gif_path = create_gif(images)
yield image, gr.Image(value=gif_path, visible=True)
demo = gr.Interface(fake_diffusion,
inputs=gr.Slider(1, 10, 3),
outputs=["image", gr.Image(label="All Images", visible=False)])
demo.queue()
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/fake_diffusion_with_gif/run.ipynb |
!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
## Summarization
By running the script [`run_summarization.py`](https://github.com/huggingface/optimum/blob/main/examples/onnxruntime/training/summarization/run_summarization.py),
you will be able to leverage the [`ONNX Runtime`](https://github.com/microsoft/onnxruntime) accelerator to fine-tune and evaluate models from the
[HuggingFace hub](https://huggingface.co/models) on summarization tasks.
### Supported models
Theoretically, all sequence-to-sequence models with [ONNXConfig](https://github.com/huggingface/transformers/blob/main/src/transformers/onnx/features.py) support in Transformers shall work, here are the models that the Optimum team has tested and validated.
* `Bart`
* `T5`
`run_summarization.py` is a lightweight example of how to download and preprocess a dataset from the 🤗 Datasets library or use your own files (jsonlines or csv), then fine-tune one of the architectures above on it.
__The following example applies the acceleration features powered by ONNX Runtime.__
### Onnx Runtime Training
The following example fine-tunes a BERT on the SQuAD 1.0 dataset.
```bash
torchrun --nproc_per_node=NUM_GPUS_YOU_HAVE run_summarization.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--do_train \
--do_eval \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--output_dir /tmp/ort_summarization_t5/ \
--overwrite_output_dir \
--predict_with_generate
```
__Note__
> *To enable ONNX Runtime training, your devices need to be equipped with GPU. Install the dependencies either with our prepared*
*[Dockerfiles](https://github.com/huggingface/optimum/blob/main/examples/onnxruntime/training/docker/) or follow the instructions*
*in [`torch_ort`](https://github.com/pytorch/ort/blob/main/torch_ort/docker/README.md).*
> *The inference will use PyTorch by default, if you want to use ONNX Runtime backend instead, add the flag `--inference_with_ort`.*
--- | huggingface/optimum/blob/main/examples/onnxruntime/training/summarization/README.md |
Webhook guide: build a Discussion bot based on BLOOM
<Tip>
Webhooks are now publicly available!
</Tip>
Here's a short guide on how to use Hugging Face Webhooks to build a bot that replies to Discussion comments on the Hub with a response generated by BLOOM, a multilingual language model, using the free Inference API.
## Create your Webhook in your user profile
First, let's create a Webhook from your [settings]( https://huggingface.co/settings/webhooks).
- Input a few target repositories that your Webhook will listen to.
- You can put a dummy Webhook URL for now, but defining your webhook will let you look at the events that will be sent to it (and you can replay them, which will be useful for debugging).
- Input a secret as it will be more secure.
- Subscribe to Community (PR & discussions) events, as we are building a Discussion bot.
Your Webhook will look like this:
## Create a new `Bot` user profile
In this guide, we create a separate user account to host a Space and to post comments:
<Tip>
When creating a bot that will interact with other users on the Hub, we ask that you clearly label the account as a "Bot" (see profile screenshot).
</Tip>
## Create a Space that will react to your Webhook
The third step is actually to listen to the Webhook events.
An easy way is to use a Space for this. We use the user account we created, but you could do it from your main user account if you wanted to.
The Space's code is [here](https://huggingface.co/spaces/discussion-bot/webhook/tree/main).
We used NodeJS and Typescript to implement it, but any language or framework would work equally well. Read more about Docker Spaces [here](https://huggingface.co/docs/hub/spaces-sdks-docker).
**The main `server.ts` file is [here](https://huggingface.co/spaces/discussion-bot/webhook/blob/main/server.ts)**
Let's walk through what happens in this file:
```ts
app.post("/", async (req, res) => {
if (req.header("X-Webhook-Secret") !== process.env.WEBHOOK_SECRET) {
console.error("incorrect secret");
return res.status(400).json({ error: "incorrect secret" });
}
...
```
Here, we listen to POST requests made to `/`, and then we check that the `X-Webhook-Secret` header is equal to the secret we had previously defined (you need to also set the `WEBHOOK_SECRET` secret in your Space's settings to be able to verify it).
```ts
const event = req.body.event;
if (
event.action === "create" &&
event.scope === "discussion.comment" &&
req.body.comment.content.includes(BOT_USERNAME)
) {
...
```
The event's payload is encoded as JSON. Here, we specify that we will run our Webhook only when:
- the event concerns a discussion comment
- the event is a creation, i.e. a new comment has been posted
- the comment's content contains `@discussion-bot`, i.e. our bot was just mentioned in a comment.
In that case, we will continue to the next step:
```ts
const INFERENCE_URL =
"https://api-inference.huggingface.co/models/bigscience/bloom";
const PROMPT = `Pretend that you are a bot that replies to discussions about machine learning, and reply to the following comment:\n`;
const response = await fetch(INFERENCE_URL, {
method: "POST",
body: JSON.stringify({ inputs: PROMPT + req.body.comment.content }),
});
if (response.ok) {
const output = await response.json();
const continuationText = output[0].generated_text.replace(
PROMPT + req.body.comment.content,
""
);
...
```
This is the coolest part: we call the Inference API for the BLOOM model, prompting it with `PROMPT`, and we get the continuation text, i.e., the part generated by the model.
Finally, we will post it as a reply in the same discussion thread:
```ts
const commentUrl = req.body.discussion.url.api + "/comment";
const commentApiResponse = await fetch(commentUrl, {
method: "POST",
headers: {
Authorization: `Bearer ${process.env.HF_TOKEN}`,
"Content-Type": "application/json",
},
body: JSON.stringify({ comment: continuationText }),
});
const apiOutput = await commentApiResponse.json();
```
## Configure your Webhook to send events to your Space
Last but not least, you'll need to configure your Webhook to send POST requests to your Space.
Let's first grab our Space's "direct URL" from the contextual menu. Click on "Embed this Space" and copy the "Direct URL".
Update your webhook to send requests to that URL:

## Result
| huggingface/hub-docs/blob/main/docs/hub/webhooks-guide-discussion-bot.md |
ow to batch inputs together? In this video, we will see how to batch input sequences together. In general, the sentences we want to pass through our model won't all have the same lengths. Here we are using the model we saw in the sentiment analysis pipeline and want to classify two sentences. When tokenizing them and mapping each token to its corresponding input IDs, we get two lists of different lengths. Trying to create a tensor or a NumPy array from those two lists will result in an error, because all arrays and tensors should be rectangular. One way to overcome this limit is to make the second sentence the same length as the first by adding a special token as many times as necessary. Another way would be to truncate the first sequence to the length of the second, but we would them lose a lot of information that might be necessary to properly classify the sentence. In general, we only truncate sentences when they are longer than the maximum length the model can handle. The value used to pad the second sentence should not be picked randomly: the model has been pretrained with a certain padding ID, which you can find in tokenizer.pad_token_id. Now that we have padded our sentences, we can make a batch with them. If we pass the two sentences to the model separately and batched together however, we notice that we don't get the same results for the sentence that is padded (here the second one). If you remember that Transformer models make heavy use of attention layers, this should not come as a total surprise: when computing the contextual representation of each token, the attention layers look at all the other words in the sentence. If we have just the sentence or the sentence with several padding tokens added, it's logical we don't get the same values. To get the same results with or without padding, we need to indicate to the attention layers that they should ignore those padding tokens. This is done by creating an attention mask, a tensor with the same shape as the input IDs, with zeros and ones. Ones indicate the tokens the attention layers should consider in the context and zeros the tokens they should ignore. Now passing this attention mask along with the input ids will give us the same results as when we sent the two sentences individually to the model! This is all done behind the scenes by the tokenizer when you apply it to several sentences with the flag padding=True. It will apply the padding with the proper value to the smaller sentences and create the appropriate attention mask. | huggingface/course/blob/main/subtitles/en/raw/chapter2/05_batching-inputs-pt.md |
Create an audio dataset
You can share a dataset with your team or with anyone in the community by creating a dataset repository on the Hugging Face Hub:
```py
from datasets import load_dataset
dataset = load_dataset("<username>/my_dataset")
```
There are several methods for creating and sharing an audio dataset:
* Create an audio dataset from local files in python with [`Dataset.push_to_hub`]. This is an easy way that requires only a few steps in python.
* Create an audio dataset repository with the `AudioFolder` builder. This is a no-code solution for quickly creating an audio dataset with several thousand audio files.
* Create an audio dataset by writing a loading script. This method is for advanced users and requires more effort and coding, but you have greater flexibility over how a dataset is defined, downloaded, and generated which can be useful for more complex or large scale audio datasets.
<Tip>
You can control access to your dataset by requiring users to share their contact information first. Check out the [Gated datasets](https://huggingface.co/docs/hub/datasets-gated) guide for more information about how to enable this feature on the Hub.
</Tip>
## Local files
You can load your own dataset using the paths to your audio files. Use the [`~Dataset.cast_column`] function to take a column of audio file paths, and cast it to the [`Audio`] feature:
```py
>>> audio_dataset = Dataset.from_dict({"audio": ["path/to/audio_1", "path/to/audio_2", ..., "path/to/audio_n"]}).cast_column("audio", Audio())
>>> audio_dataset[0]["audio"]
{'array': array([ 0. , 0.00024414, -0.00024414, ..., -0.00024414,
0. , 0. ], dtype=float32),
'path': 'path/to/audio_1',
'sampling_rate': 16000}
```
Then upload the dataset to the Hugging Face Hub using [`Dataset.push_to_hub`]:
```py
audio_dataset.push_to_hub("<username>/my_dataset")
```
This will create a dataset repository containing your audio dataset:
```
my_dataset/
├── README.md
└── data/
└── train-00000-of-00001.parquet
```
## AudioFolder
The `AudioFolder` is a dataset builder designed to quickly load an audio dataset with several thousand audio files without requiring you to write any code.
Any additional information about your dataset - such as transcription, speaker accent, or speaker intent - is automatically loaded by `AudioFolder` as long as you include this information in a metadata file (`metadata.csv`/`metadata.jsonl`).
<Tip>
💡 Take a look at the [Split pattern hierarchy](repository_structure#split-pattern-hierarchy) to learn more about how `AudioFolder` creates dataset splits based on your dataset repository structure.
</Tip>
Create a dataset repository on the Hugging Face Hub and upload your dataset directory following the `AudioFolder` structure:
```
my_dataset/
├── README.md
├── metadata.csv
└── data/
```
The `data` folder can be any name you want.
<Tip>
It can be helpful to store your metadata as a `jsonl` file if the data columns contain a more complex format (like a list of floats) to avoid parsing errors or reading complex values as strings.
</Tip>
The metadata file should include a `file_name` column to link an audio file to it's metadata:
```csv
file_name,transcription
data/first_audio_file.mp3,znowu się duch z ciałem zrośnie w młodocianej wstaniesz wiosnie i możesz skutkiem tych leków umierać wstawać wiek wieków dalej tam były przestrogi jak siekać głowę jak nogi
data/second_audio_file.mp3,już u źwierzyńca podwojów król zasiada przy nim książęta i panowie rada a gdzie wzniosły krążył ganek rycerze obok kochanek król skinął palcem zaczęto igrzysko
data/third_audio_file.mp3,pewnie kędyś w obłędzie ubite minęły szlaki zaczekajmy dzień jaki poślemy szukać wszędzie dziś jutro pewnie będzie posłali wszędzie sługi czekali dzień i drugi gdy nic nie doczekali z płaczem chcą jechać dali
```
Then you can store your dataset in a directory structure like this:
```
metadata.csv
data/first_audio_file.mp3
data/second_audio_file.mp3
data/third_audio_file.mp3
```
Users can now load your dataset and the associated metadata by specifying `audiofolder` in [`load_dataset`] and the dataset directory in `data_dir`:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("audiofolder", data_dir="/path/to/data")
>>> dataset["train"][0]
{'audio':
{'path': '/path/to/extracted/audio/first_audio_file.mp3',
'array': array([ 0.00088501, 0.0012207 , 0.00131226, ..., -0.00045776, -0.00054932, -0.00054932], dtype=float32),
'sampling_rate': 16000},
'transcription': 'znowu się duch z ciałem zrośnie w młodocianej wstaniesz wiosnie i możesz skutkiem tych leków umierać wstawać wiek wieków dalej tam były przestrogi jak siekać głowę jak nogi'
}
```
You can also use `audiofolder` to load datasets involving multiple splits. To do so, your dataset directory might have the following structure:
```
data/train/first_train_audio_file.mp3
data/train/second_train_audio_file.mp3
data/test/first_test_audio_file.mp3
data/test/second_test_audio_file.mp3
```
<Tip warning={true}>
Note that if audio files are located not right next to a metadata file, `file_name` column should be a full relative path to an audio file, not just its filename.
</Tip>
For audio datasets that don't have any associated metadata, `AudioFolder` automatically infers the class labels of the dataset based on the directory name. It might be useful for audio classification tasks. Your dataset directory might look like:
```
data/train/electronic/01.mp3
data/train/punk/01.mp3
data/test/electronic/09.mp3
data/test/punk/09.mp3
```
Load the dataset with `AudioFolder`, and it will create a `label` column from the directory name (language id):
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("audiofolder", data_dir="/path/to/data")
>>> dataset["train"][0]
{'audio':
{'path': '/path/to/electronic/01.mp3',
'array': array([ 3.9714024e-07, 7.3031038e-07, 7.5640685e-07, ...,
-1.1963668e-01, -1.1681189e-01, -1.1244172e-01], dtype=float32),
'sampling_rate': 44100},
'label': 0 # "electronic"
}
>>> dataset["train"][-1]
{'audio':
{'path': '/path/to/punk/01.mp3',
'array': array([0.15237972, 0.13222949, 0.10627693, ..., 0.41940814, 0.37578005,
0.33717662], dtype=float32),
'sampling_rate': 44100},
'label': 1 # "punk"
}
```
<Tip warning={true}>
If all audio files are contained in a single directory or if they are not on the same level of directory structure, `label` column won't be added automatically. If you need it, set `drop_labels=False` explicitly.
</Tip>
<Tip>
Some audio datasets, like those found in [Kaggle competitions](https://www.kaggle.com/competitions/kaggle-pog-series-s01e02/overview), have separate metadata files for each split. Provided the metadata features are the same for each split, `audiofolder` can be used to load all splits at once. If the metadata features differ across each split, you should load them with separate `load_dataset()` calls.
</Tip>
## Loading script
Write a dataset loading script to manually create a dataset.
It defines a dataset's splits and configurations, and handles downloading and generating the dataset examples.
The script should have the same name as your dataset folder or repository:
```
my_dataset/
├── README.md
├── my_dataset.py
└── data/
```
The `data` folder can be any name you want, it doesn't have to be `data`. This folder is optional, unless you're hosting your dataset on the Hub.
This directory structure allows your dataset to be loaded in one line:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("path/to/my_dataset")
```
This guide will show you how to create a dataset loading script for audio datasets, which is a bit different from <a class="underline decoration-green-400 decoration-2 font-semibold" href="./dataset_script">creating a loading script for text datasets</a>.
Audio datasets are commonly stored in `tar.gz` archives which requires a particular approach to support streaming mode. While streaming is not required, we highly encourage implementing streaming support in your audio dataset because:
1. Users without a lot of disk space can use your dataset without downloading it. Learn more about streaming in the [Stream](./stream) guide!
2. Users can preview a dataset in the dataset viewer.
Here is an example using TAR archives:
```
my_dataset/
├── README.md
├── my_dataset.py
└── data/
├── train.tar.gz
├── test.tar.gz
└── metadata.csv
```
In addition to learning how to create a streamable dataset, you'll also learn how to:
* Create a dataset builder class.
* Create dataset configurations.
* Add dataset metadata.
* Download and define the dataset splits.
* Generate the dataset.
* Upload the dataset to the Hub.
The best way to learn is to open up an existing audio dataset loading script, like [Vivos](https://huggingface.co/datasets/vivos/blob/main/vivos.py), and follow along!
<Tip warning=True>
This guide shows how to process audio data stored in TAR archives - the most frequent case for audio datasets. Check out [minds14](https://huggingface.co/datasets/PolyAI/minds14/blob/main/minds14.py) dataset for an example of an audio script which uses ZIP archives.
</Tip>
<Tip>
To help you get started, we created a loading script [template](https://github.com/huggingface/datasets/blob/main/templates/new_dataset_script.py) you can copy and use as a starting point!
</Tip>
### Create a dataset builder class
[`GeneratorBasedBuilder`] is the base class for datasets generated from a dictionary generator. Within this class, there are three methods to help create your dataset:
* `_info` stores information about your dataset like its description, license, and features.
* `_split_generators` downloads the dataset and defines its splits.
* `_generate_examples` generates the dataset's samples containing the audio data and other features specified in `info` for each split.
Start by creating your dataset class as a subclass of [`GeneratorBasedBuilder`] and add the three methods. Don't worry about filling in each of these methods yet, you'll develop those over the next few sections:
```py
class VivosDataset(datasets.GeneratorBasedBuilder):
"""VIVOS is a free Vietnamese speech corpus consisting of 15 hours of recording speech prepared for
Vietnamese Automatic Speech Recognition task."""
def _info(self):
def _split_generators(self, dl_manager):
def _generate_examples(self, prompts_path, path_to_clips, audio_files):
```
#### Multiple configurations
In some cases, a dataset may have more than one configuration. For example, [LibriVox Indonesia](https://huggingface.co/datasets/indonesian-nlp/librivox-indonesia) dataset has several configurations corresponding to different languages.
To create different configurations, use the [`BuilderConfig`] class to create a subclass of your dataset. The only required parameter is the `name` of the configuration, which must be passed to the configuration's superclass `__init__()`. Otherwise, you can specify any custom parameters you want in your configuration class.
```py
class LibriVoxIndonesiaConfig(datasets.BuilderConfig):
"""BuilderConfig for LibriVoxIndonesia."""
def __init__(self, name, version, **kwargs):
self.language = kwargs.pop("language", None)
self.release_date = kwargs.pop("release_date", None)
self.num_clips = kwargs.pop("num_clips", None)
self.num_speakers = kwargs.pop("num_speakers", None)
self.validated_hr = kwargs.pop("validated_hr", None)
self.total_hr = kwargs.pop("total_hr", None)
self.size_bytes = kwargs.pop("size_bytes", None)
self.size_human = size_str(self.size_bytes)
description = (
f"LibriVox-Indonesia speech to text dataset in {self.language} released on {self.release_date}. "
f"The dataset comprises {self.validated_hr} hours of transcribed speech data"
)
super(LibriVoxIndonesiaConfig, self).__init__(
name=name,
version=datasets.Version(version),
description=description,
**kwargs,
)
```
Define your configurations in the `BUILDER_CONFIGS` class variable inside [`GeneratorBasedBuilder`]. In this example, the author imports the languages from a separate `release_stats.py` [file](https://huggingface.co/datasets/indonesian-nlp/librivox-indonesia/blob/main/release_stats.py) from their repository, and then loops through each language to create a configuration:
```py
class LibriVoxIndonesia(datasets.GeneratorBasedBuilder):
DEFAULT_CONFIG_NAME = "all"
BUILDER_CONFIGS = [
LibriVoxIndonesiaConfig(
name=lang,
version=STATS["version"],
language=LANGUAGES[lang],
release_date=STATS["date"],
num_clips=lang_stats["clips"],
num_speakers=lang_stats["users"],
total_hr=float(lang_stats["totalHrs"]) if lang_stats["totalHrs"] else None,
size_bytes=int(lang_stats["size"]) if lang_stats["size"] else None,
)
for lang, lang_stats in STATS["locales"].items()
]
```
<Tip>
Typically, users need to specify a configuration to load in [`load_dataset`], otherwise a `ValueError` is raised. You can avoid this by setting a default dataset configuration to load in `DEFAULT_CONFIG_NAME`.
</Tip>
Now if users want to load the Balinese (`bal`) configuration, they can use the configuration name:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("indonesian-nlp/librivox-indonesia", "bal", split="train")
```
### Add dataset metadata
Adding information about your dataset helps users to learn more about it. This information is stored in the [`DatasetInfo`] class which is returned by the `info` method. Users can access this information by:
```py
>>> from datasets import load_dataset_builder
>>> ds_builder = load_dataset_builder("vivos")
>>> ds_builder.info
```
There is a lot of information you can include about your dataset, but some important ones are:
1. `description` provides a concise description of the dataset.
2. `features` specify the dataset column types. Since you're creating an audio loading script, you'll need to include the [`Audio`] feature and the `sampling_rate` of the dataset.
3. `homepage` provides a link to the dataset homepage.
4. `license` specify the permissions for using a dataset as defined by the license type.
5. `citation` is a BibTeX citation of the dataset.
<Tip>
You'll notice a lot of the dataset information is defined earlier in the loading script which can make it easier to read. There are also other [`~Dataset.Features`] you can input, so be sure to check out the full list and [features guide](./about_dataset_features) for more details.
</Tip>
```py
def _info(self):
return datasets.DatasetInfo(
description=_DESCRIPTION,
features=datasets.Features(
{
"speaker_id": datasets.Value("string"),
"path": datasets.Value("string"),
"audio": datasets.Audio(sampling_rate=16_000),
"sentence": datasets.Value("string"),
}
),
supervised_keys=None,
homepage=_HOMEPAGE,
license=_LICENSE,
citation=_CITATION,
)
```
### Download and define the dataset splits
Now that you've added some information about your dataset, the next step is to download the dataset and define the splits.
1. Use the [`~DownloadManager.download`] method to download metadata file at `_PROMPTS_URLS` and audio TAR archive at `_DATA_URL`. This method returns the path to the local file/archive. In streaming mode, it doesn't download the file(s) and just returns a URL to stream the data from. This method accepts:
* a relative path to a file inside a Hub dataset repository (for example, in the `data/` folder)
* a URL to a file hosted somewhere else
* a (nested) list or dictionary of file names or URLs
2. After you've downloaded the dataset, use the [`SplitGenerator`] to organize the audio files and sentence prompts in each split. Name each split with a standard name like: `Split.TRAIN`, `Split.TEST`, and `SPLIT.Validation`.
In the `gen_kwargs` parameter, specify the file path to the `prompts_path` and `path_to_clips`. For `audio_files`, you'll need to use [`~DownloadManager.iter_archive`] to iterate over the audio files in the TAR archive. This enables streaming for your dataset. All of these file paths are passed onto the next step where you'll actually generate the dataset.
```py
def _split_generators(self, dl_manager):
"""Returns SplitGenerators."""
prompts_paths = dl_manager.download(_PROMPTS_URLS)
archive = dl_manager.download(_DATA_URL)
train_dir = "vivos/train"
test_dir = "vivos/test"
return [
datasets.SplitGenerator(
name=datasets.Split.TRAIN,
gen_kwargs={
"prompts_path": prompts_paths["train"],
"path_to_clips": train_dir + "/waves",
"audio_files": dl_manager.iter_archive(archive),
},
),
datasets.SplitGenerator(
name=datasets.Split.TEST,
gen_kwargs={
"prompts_path": prompts_paths["test"],
"path_to_clips": test_dir + "/waves",
"audio_files": dl_manager.iter_archive(archive),
},
),
]
```
<Tip warning={true}>
This implementation does not extract downloaded archives. If you want to extract files after download, you need to additionally use [`~DownloadManager.extract`], see the [(Advanced) Extract TAR archives](#advanced-extract-tar-archives-locally) section.
</Tip>
### Generate the dataset
The last method in the [`GeneratorBasedBuilder`] class actually generates the samples in the dataset. It yields a dataset according to the structure specified in `features` from the `info` method. As you can see, `generate_examples` accepts the `prompts_path`, `path_to_clips`, and `audio_files` from the previous method as arguments.
Files inside TAR archives are accessed and yielded sequentially. This means you need to have the metadata associated with the audio files in the TAR file in hand first so you can yield it with its corresponding audio file.
```py
examples = {}
with open(prompts_path, encoding="utf-8") as f:
for row in f:
data = row.strip().split(" ", 1)
speaker_id = data[0].split("_")[0]
audio_path = "/".join([path_to_clips, speaker_id, data[0] + ".wav"])
examples[audio_path] = {
"speaker_id": speaker_id,
"path": audio_path,
"sentence": data[1],
}
```
Finally, iterate over files in `audio_files` and yield them along with their corresponding metadata. [`~DownloadManager.iter_archive`] yields a tuple of (`path`, `f`) where `path` is a **relative** path to a file inside TAR archive and `f` is a file object itself.
```py
inside_clips_dir = False
id_ = 0
for path, f in audio_files:
if path.startswith(path_to_clips):
inside_clips_dir = True
if path in examples:
audio = {"path": path, "bytes": f.read()}
yield id_, {**examples[path], "audio": audio}
id_ += 1
elif inside_clips_dir:
break
```
Put these two steps together, and the whole `_generate_examples` method looks like:
```py
def _generate_examples(self, prompts_path, path_to_clips, audio_files):
"""Yields examples as (key, example) tuples."""
examples = {}
with open(prompts_path, encoding="utf-8") as f:
for row in f:
data = row.strip().split(" ", 1)
speaker_id = data[0].split("_")[0]
audio_path = "/".join([path_to_clips, speaker_id, data[0] + ".wav"])
examples[audio_path] = {
"speaker_id": speaker_id,
"path": audio_path,
"sentence": data[1],
}
inside_clips_dir = False
id_ = 0
for path, f in audio_files:
if path.startswith(path_to_clips):
inside_clips_dir = True
if path in examples:
audio = {"path": path, "bytes": f.read()}
yield id_, {**examples[path], "audio": audio}
id_ += 1
elif inside_clips_dir:
break
```
### Upload the dataset to the Hub
Once your script is ready, [create a dataset card](./dataset_card) and [upload it to the Hub](./share).
Congratulations, you can now load your dataset from the Hub! 🥳
```py
>>> from datasets import load_dataset
>>> load_dataset("<username>/my_dataset")
```
### (Advanced) Extract TAR archives locally
In the example above downloaded archives are not extracted and therefore examples do not contain information about where they are stored locally.
To explain how to do the extraction in a way that it also supports streaming, we will briefly go through the [LibriVox Indonesia](https://huggingface.co/datasets/indonesian-nlp/librivox-indonesia/blob/main/librivox-indonesia.py) loading script.
#### Download and define the dataset splits
1. Use the [`~DownloadManager.download`] method to download the audio data at `_AUDIO_URL`.
2. To extract audio TAR archive locally, use the [`~DownloadManager.extract`]. You can use this method only in non-streaming mode (when `dl_manager.is_streaming=False`). This returns a local path to the extracted archive directory:
```py
local_extracted_archive = dl_manager.extract(audio_path) if not dl_manager.is_streaming else None
```
3. Use the [`~DownloadManager.iter_archive`] method to iterate over the archive at `audio_path`, just like in the Vivos example above. [`~DownloadManager.iter_archive`] doesn't provide any information about the full paths of files from the archive, even if it has been extracted. As a result, you need to pass the `local_extracted_archive` path to the next step in `gen_kwargs`, in order to preserve information about where the archive was extracted to. This is required to construct the correct paths to the local files when you generate the examples.
<Tip warning={true}>
The reason you need to use a combination of [`~DownloadManager.download`] and [`~DownloadManager.iter_archive`] is because files in TAR archives can't be accessed directly by their paths. Instead, you'll need to iterate over the files within the archive! You can use [`~DownloadManager.download_and_extract`] and [`~DownloadManager.extract`] with TAR archives only in non-streaming mode, otherwise it would throw an error.
</Tip>
4. Use the [`~DownloadManager.download_and_extract`] method to download the metadata file specified in `_METADATA_URL`. This method returns a path to a local file in non-streaming mode. In streaming mode, it doesn't download file locally and returns the same URL.
5. Now use the [`SplitGenerator`] to organize the audio files and metadata in each split. Name each split with a standard name like: `Split.TRAIN`, `Split.TEST`, and `SPLIT.Validation`.
In the `gen_kwargs` parameter, specify the file paths to `local_extracted_archive`, `audio_files`, `metadata_path`, and `path_to_clips`. Remember, for `audio_files`, you need to use [`~DownloadManager.iter_archive`] to iterate over the audio files in the TAR archives. This enables streaming for your dataset! All of these file paths are passed onto the next step where the dataset samples are generated.
```py
def _split_generators(self, dl_manager):
"""Returns SplitGenerators."""
dl_manager.download_config.ignore_url_params = True
audio_path = dl_manager.download(_AUDIO_URL)
local_extracted_archive = dl_manager.extract(audio_path) if not dl_manager.is_streaming else None
path_to_clips = "librivox-indonesia"
return [
datasets.SplitGenerator(
name=datasets.Split.TRAIN,
gen_kwargs={
"local_extracted_archive": local_extracted_archive,
"audio_files": dl_manager.iter_archive(audio_path),
"metadata_path": dl_manager.download_and_extract(_METADATA_URL + "/metadata_train.csv.gz"),
"path_to_clips": path_to_clips,
},
),
datasets.SplitGenerator(
name=datasets.Split.TEST,
gen_kwargs={
"local_extracted_archive": local_extracted_archive,
"audio_files": dl_manager.iter_archive(audio_path),
"metadata_path": dl_manager.download_and_extract(_METADATA_URL + "/metadata_test.csv.gz"),
"path_to_clips": path_to_clips,
},
),
]
```
#### Generate the dataset
Here `_generate_examples` accepts `local_extracted_archive`, `audio_files`, `metadata_path`, and `path_to_clips` from the previous method as arguments.
1. TAR files are accessed and yielded sequentially. This means you need to have the metadata in `metadata_path` associated with the audio files in the TAR file in hand first so that you can yield it with its corresponding audio file further:
```py
with open(metadata_path, "r", encoding="utf-8") as f:
reader = csv.DictReader(f)
for row in reader:
if self.config.name == "all" or self.config.name == row["language"]:
row["path"] = os.path.join(path_to_clips, row["path"])
# if data is incomplete, fill with empty values
for field in data_fields:
if field not in row:
row[field] = ""
metadata[row["path"]] = row
```
2. Now you can yield the files in `audio_files` archive. When you use [`~DownloadManager.iter_archive`], it yielded a tuple of (`path`, `f`) where `path` is a **relative path** to a file inside the archive, and `f` is the file object itself. To get the **full path** to the locally extracted file, join the path of the directory (`local_extracted_path`) where the archive is extracted to and the relative audio file path (`path`):
```py
for path, f in audio_files:
if path in metadata:
result = dict(metadata[path])
# set the audio feature and the path to the extracted file
path = os.path.join(local_extracted_archive, path) if local_extracted_archive else path
result["audio"] = {"path": path, "bytes": f.read()}
result["path"] = path
yield id_, result
id_ += 1
````
Put both of these steps together, and the whole `_generate_examples` method should look like:
```py
def _generate_examples(
self,
local_extracted_archive,
audio_files,
metadata_path,
path_to_clips,
):
"""Yields examples."""
data_fields = list(self._info().features.keys())
metadata = {}
with open(metadata_path, "r", encoding="utf-8") as f:
reader = csv.DictReader(f)
for row in reader:
if self.config.name == "all" or self.config.name == row["language"]:
row["path"] = os.path.join(path_to_clips, row["path"])
# if data is incomplete, fill with empty values
for field in data_fields:
if field not in row:
row[field] = ""
metadata[row["path"]] = row
id_ = 0
for path, f in audio_files:
if path in metadata:
result = dict(metadata[path])
# set the audio feature and the path to the extracted file
path = os.path.join(local_extracted_archive, path) if local_extracted_archive else path
result["audio"] = {"path": path, "bytes": f.read()}
result["path"] = path
yield id_, result
id_ += 1
```
| huggingface/datasets/blob/main/docs/source/audio_dataset.mdx |
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# 🤗 Benchmark results
Here, you can find a list of the different benchmark results created by the community.
If you would like to list benchmark results on your favorite models of the [model hub](https://huggingface.co/models) here, please open a Pull Request and add it below.
| Benchmark description | Results | Environment info | Author |
|:----------|:-------------|:-------------|------:|
| PyTorch Benchmark on inference for `bert-base-cased` |[memory](https://github.com/patrickvonplaten/files_to_link_to/blob/master/bert_benchmark/inference_memory.csv) | [env](https://github.com/patrickvonplaten/files_to_link_to/blob/master/bert_benchmark/env.csv) | [Partick von Platen](https://github.com/patrickvonplaten) |
| PyTorch Benchmark on inference for `bert-base-cased` |[time](https://github.com/patrickvonplaten/files_to_link_to/blob/master/bert_benchmark/inference_time.csv) | [env](https://github.com/patrickvonplaten/files_to_link_to/blob/master/bert_benchmark/env.csv) | [Partick von Platen](https://github.com/patrickvonplaten) |
| huggingface/transformers/blob/main/examples/legacy/benchmarking/README.md |
The Pyramid environment
The goal in this environment is to train our agent to **get the gold brick on the top of the Pyramid. To do that, it needs to press a button to spawn a Pyramid, navigate to the Pyramid, knock it over, and move to the gold brick at the top**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/pyramids.png" alt="Pyramids Environment"/>
## The reward function
The reward function is:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/pyramids-reward.png" alt="Pyramids Environment"/>
In terms of code, it looks like this
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/pyramids-reward-code.png" alt="Pyramids Reward"/>
To train this new agent that seeks that button and then the Pyramid to destroy, we’ll use a combination of two types of rewards:
- The *extrinsic one* given by the environment (illustration above).
- But also an *intrinsic* one called **curiosity**. This second will **push our agent to be curious, or in other terms, to better explore its environment**.
If you want to know more about curiosity, the next section (optional) will explain the basics.
## The observation space
In terms of observation, we **use 148 raycasts that can each detect objects** (switch, bricks, golden brick, and walls.)
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/pyramids_raycasts.png"/>
We also use a **boolean variable indicating the switch state** (did we turn on or off the switch to spawn the Pyramid) and a vector that **contains the agent’s speed**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/pyramids-obs-code.png" alt="Pyramids obs code"/>
## The action space
The action space is **discrete** with four possible actions:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/pyramids-action.png" alt="Pyramids Environment"/>
| huggingface/deep-rl-class/blob/main/units/en/unit5/pyramids.mdx |
(Legacy) SENet
A **SENet** is a convolutional neural network architecture that employs [squeeze-and-excitation blocks](https://paperswithcode.com/method/squeeze-and-excitation-block) to enable the network to perform dynamic channel-wise feature recalibration.
The weights from this model were ported from Gluon.
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('legacy_senet154', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `legacy_senet154`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('legacy_senet154', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{hu2019squeezeandexcitation,
title={Squeeze-and-Excitation Networks},
author={Jie Hu and Li Shen and Samuel Albanie and Gang Sun and Enhua Wu},
year={2019},
eprint={1709.01507},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: Legacy SENet
Paper:
Title: Squeeze-and-Excitation Networks
URL: https://paperswithcode.com/paper/squeeze-and-excitation-networks
Models:
- Name: legacy_senet154
In Collection: Legacy SENet
Metadata:
FLOPs: 26659556016
Parameters: 115090000
File Size: 461488402
Architecture:
- Convolution
- Dense Connections
- Global Average Pooling
- Max Pooling
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: legacy_senet154
LR: 0.6
Epochs: 100
Layers: 154
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/senet.py#L440
Weights: http://data.lip6.fr/cadene/pretrainedmodels/senet154-c7b49a05.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.33%
Top 5 Accuracy: 95.51%
--> | huggingface/pytorch-image-models/blob/main/docs/models/legacy-senet.md |
n this video, we will see how to debug an error you encounter when running trainer.train(). As an example, we will use this script that finetunes a bert model on the GLUE MNLI dataset. Checkout the videos linked below to see how we came to such a script, here we want to learn how to debug the problems in it. Running the script gives us an error pretty fast. It happens at the line where we feed the inputs to the model, according to the traceback. That tells us there is a problem there, but the problem could come from many different causes. To debug an error in a training, you need to make sure each step of the training pipeline works as intended. This means checking that the inputs of your dataset are correct, you can batch them together, feed them through the model to get a loss, then compute the gradients of that loss before performing an optimizer step. So let's start by looking at the training dataset this Trainer is using. There is definitely a problem there as we see texts and not numbers. The error message was telling us the model did not get input IDs and we do not have those in the dataset indeed. Looking back at our code, we can see we made a mistake and passed the wrong datasets to the Trainer. So let's fix that and run again. Now we have a new error. Inspecting the traceback tells us it happens when we try to create a batch, specifically to group the features in a tensor. We can confirm this by asking the Trainer to get us a batch of the training data loader, which reproduces the same error. Either by inspecting the inputs or debugging, we can then see they are not all of the same size. This is because we have not passed a data collator to do the padding in the Trainer and didn't pad when preprocessing the data either. Padding inside the Trainer is normally the default, but only if you provide your tokenizer to the Trainer, and we forgot to do that. So let's fix the issue and run again. This time we get a nasty CUDA error. They are very difficult to debug because for one, they put your kernel in a state that is not recoverable (so you have to restart your notebook from the beginning) and two, the traceback is completely useless for those. Here the traceback tells us the error happens when we do the gradient computation with loss.backward, but as we will see later on that is not the case. This is because everything that happens on the GPU is done asynchronously: when you execute the model call, what the program does is just stacking that in the queue of GPU, then (if the GPU didn't have any current job to do), the work will start on the GPU at the same time as the CPU will move to the next instruction. Continuing with the extraction of the loss, this is stacked into the GPU queue while the CPU moves to the instruction loss.backward. But the GPU still hasn't finished the forward pass of the model since all that took no time at all. The CPU stops moving forward, because loss.backward as an instruction telling it to wait for the GPUs to be finished, and when the GPU encounters an error, it gives with a cryptic message back to the CPU, who raises the error at the wrong place. So to debug this, we will need to execute the next steps of the training pipeline on the CPU. It is very easy to do, and we get a traceback we can trust this time. As we said before, the error happens during the forward pass of the model, and it's an index error. With a bit of debugging, we see we have labels ranging from 0 to 2, so three different values, but our outputs have a shape of batch size per 2. It looks like our model has the wrong number of labels! We can indeed confirm that, and now that we know it's easy to fix it in the code by adding num_labels=3 when we create the model. Now the training script will run to completion! We did not need it yet, but here is how we would debug the next step of the pipeline, gradient computation, as well as the optimizer step. With all of this, good luck debugging your own trainings! | huggingface/course/blob/main/subtitles/en/raw/chapter8/04_debug-pt.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Overview
🤗 Optimum enables exporting models from PyTorch or TensorFlow to different formats through its `exporters` module. For now, two exporting format are supported: ONNX and TFLite (TensorFlow Lite).
| huggingface/optimum/blob/main/docs/source/exporters/overview.mdx |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Audio Spectrogram Transformer
## Overview
The Audio Spectrogram Transformer model was proposed in [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
The Audio Spectrogram Transformer applies a [Vision Transformer](vit) to audio, by turning audio into an image (spectrogram). The model obtains state-of-the-art results
for audio classification.
The abstract from the paper is the following:
*In the past decade, convolutional neural networks (CNNs) have been widely adopted as the main building block for end-to-end audio classification models, which aim to learn a direct mapping from audio spectrograms to corresponding labels. To better capture long-range global context, a recent trend is to add a self-attention mechanism on top of the CNN, forming a CNN-attention hybrid model. However, it is unclear whether the reliance on a CNN is necessary, and if neural networks purely based on attention are sufficient to obtain good performance in audio classification. In this paper, we answer the question by introducing the Audio Spectrogram Transformer (AST), the first convolution-free, purely attention-based model for audio classification. We evaluate AST on various audio classification benchmarks, where it achieves new state-of-the-art results of 0.485 mAP on AudioSet, 95.6% accuracy on ESC-50, and 98.1% accuracy on Speech Commands V2.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/audio_spectogram_transformer_architecture.png"
alt="drawing" width="600"/>
<small> Audio Spectrogram Transformer architecture. Taken from the <a href="https://arxiv.org/abs/2104.01778">original paper</a>.</small>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/YuanGongND/ast).
## Usage tips
- When fine-tuning the Audio Spectrogram Transformer (AST) on your own dataset, it's recommended to take care of the input normalization (to make
sure the input has mean of 0 and std of 0.5). [`ASTFeatureExtractor`] takes care of this. Note that it uses the AudioSet
mean and std by default. You can check [`ast/src/get_norm_stats.py`](https://github.com/YuanGongND/ast/blob/master/src/get_norm_stats.py) to see how
the authors compute the stats for a downstream dataset.
- Note that the AST needs a low learning rate (the authors use a 10 times smaller learning rate compared to their CNN model proposed in the
[PSLA paper](https://arxiv.org/abs/2102.01243)) and converges quickly, so please search for a suitable learning rate and learning rate scheduler for your task.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with the Audio Spectrogram Transformer.
<PipelineTag pipeline="audio-classification"/>
- A notebook illustrating inference with AST for audio classification can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/AST).
- [`ASTForAudioClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/audio-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/audio_classification.ipynb).
- See also: [Audio classification](../tasks/audio_classification).
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## ASTConfig
[[autodoc]] ASTConfig
## ASTFeatureExtractor
[[autodoc]] ASTFeatureExtractor
- __call__
## ASTModel
[[autodoc]] ASTModel
- forward
## ASTForAudioClassification
[[autodoc]] ASTForAudioClassification
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/audio-spectrogram-transformer.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Hyperparameter Search using Trainer API
🤗 Transformers provides a [`Trainer`] class optimized for training 🤗 Transformers models, making it easier to start training without manually writing your own training loop. The [`Trainer`] provides API for hyperparameter search. This doc shows how to enable it in example.
## Hyperparameter Search backend
[`Trainer`] supports four hyperparameter search backends currently:
[optuna](https://optuna.org/), [sigopt](https://sigopt.com/), [raytune](https://docs.ray.io/en/latest/tune/index.html) and [wandb](https://wandb.ai/site/sweeps).
you should install them before using them as the hyperparameter search backend
```bash
pip install optuna/sigopt/wandb/ray[tune]
```
## How to enable Hyperparameter search in example
Define the hyperparameter search space, different backends need different format.
For sigopt, see sigopt [object_parameter](https://docs.sigopt.com/ai-module-api-references/api_reference/objects/object_parameter), it's like following:
```py
>>> def sigopt_hp_space(trial):
... return [
... {"bounds": {"min": 1e-6, "max": 1e-4}, "name": "learning_rate", "type": "double"},
... {
... "categorical_values": ["16", "32", "64", "128"],
... "name": "per_device_train_batch_size",
... "type": "categorical",
... },
... ]
```
For optuna, see optuna [object_parameter](https://optuna.readthedocs.io/en/stable/tutorial/10_key_features/002_configurations.html#sphx-glr-tutorial-10-key-features-002-configurations-py), it's like following:
```py
>>> def optuna_hp_space(trial):
... return {
... "learning_rate": trial.suggest_float("learning_rate", 1e-6, 1e-4, log=True),
... "per_device_train_batch_size": trial.suggest_categorical("per_device_train_batch_size", [16, 32, 64, 128]),
... }
```
Optuna provides multi-objective HPO. You can pass `direction` in `hyperparameter_search` and define your own compute_objective to return multiple objective values. The Pareto Front (`List[BestRun]`) will be returned in hyperparameter_search, you should refer to the test case `TrainerHyperParameterMultiObjectOptunaIntegrationTest` in [test_trainer](https://github.com/huggingface/transformers/blob/main/tests/trainer/test_trainer.py). It's like following
```py
>>> best_trials = trainer.hyperparameter_search(
... direction=["minimize", "maximize"],
... backend="optuna",
... hp_space=optuna_hp_space,
... n_trials=20,
... compute_objective=compute_objective,
... )
```
For raytune, see raytune [object_parameter](https://docs.ray.io/en/latest/tune/api/search_space.html), it's like following:
```py
>>> def ray_hp_space(trial):
... return {
... "learning_rate": tune.loguniform(1e-6, 1e-4),
... "per_device_train_batch_size": tune.choice([16, 32, 64, 128]),
... }
```
For wandb, see wandb [object_parameter](https://docs.wandb.ai/guides/sweeps/configuration), it's like following:
```py
>>> def wandb_hp_space(trial):
... return {
... "method": "random",
... "metric": {"name": "objective", "goal": "minimize"},
... "parameters": {
... "learning_rate": {"distribution": "uniform", "min": 1e-6, "max": 1e-4},
... "per_device_train_batch_size": {"values": [16, 32, 64, 128]},
... },
... }
```
Define a `model_init` function and pass it to the [`Trainer`], as an example:
```py
>>> def model_init(trial):
... return AutoModelForSequenceClassification.from_pretrained(
... model_args.model_name_or_path,
... from_tf=bool(".ckpt" in model_args.model_name_or_path),
... config=config,
... cache_dir=model_args.cache_dir,
... revision=model_args.model_revision,
... token=True if model_args.use_auth_token else None,
... )
```
Create a [`Trainer`] with your `model_init` function, training arguments, training and test datasets, and evaluation function:
```py
>>> trainer = Trainer(
... model=None,
... args=training_args,
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
... tokenizer=tokenizer,
... model_init=model_init,
... data_collator=data_collator,
... )
```
Call hyperparameter search, get the best trial parameters, backend could be `"optuna"`/`"sigopt"`/`"wandb"`/`"ray"`. direction can be`"minimize"` or `"maximize"`, which indicates whether to optimize greater or lower objective.
You could define your own compute_objective function, if not defined, the default compute_objective will be called, and the sum of eval metric like f1 is returned as objective value.
```py
>>> best_trial = trainer.hyperparameter_search(
... direction="maximize",
... backend="optuna",
... hp_space=optuna_hp_space,
... n_trials=20,
... compute_objective=compute_objective,
... )
```
## Hyperparameter search For DDP finetune
Currently, Hyperparameter search for DDP is enabled for optuna and sigopt. Only the rank-zero process will generate the search trial and pass the argument to other ranks.
| huggingface/transformers/blob/main/docs/source/en/hpo_train.md |
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 创建和管理存储库
Hugging Face Hub是一组 Git 存储库。[Git](https://git-scm.com/)是软件开发中广泛使用的工具,可以在协作工作时轻松对项目进行版本控制。本指南将向您展示如何与 Hub 上的存储库进行交互,特别关注以下内容:
- 创建和删除存储库
- 管理分支和标签
- 重命名您的存储库
- 更新您的存储库可见性
- 管理存储库的本地副本
<Tip warning={true}>
如果您习惯于使用类似于GitLab/GitHub/Bitbucket等平台,您可能首先想到使用 `git`命令行工具来克隆存储库(`git clone`)、提交更改(`git add` , ` git commit`)并推送它们(`git push`)。在使用 Hugging Face Hub 时,这是有效的。然而,软件工程和机器学习并不具有相同的要求和工作流程。模型存储库可能会维护大量模型权重文件以适应不同的框架和工具,因此克隆存储库会导致您维护大量占用空间的本地文件夹。因此,使用我们的自定义HTTP方法可能更有效。您可以阅读我们的[git与HTTP相比较](../concepts/git_vs_http)解释页面以获取更多详细信息
</Tip>
如果你想在Hub上创建和管理一个仓库,你的计算机必须处于登录状态。如果尚未登录,请参考[此部分](../quick-start#login)。在本指南的其余部分,我们将假设你的计算机已登录
## 仓库创建和删除
第一步是了解如何创建和删除仓库。你只能管理你拥有的仓库(在你的用户名命名空间下)或者你具有写入权限的组织中的仓库
### 创建一个仓库
使用 [`create_repo`] 创建一个空仓库,并通过 `repo_id`参数为其命名 `repo_id`是你的命名空间,后面跟着仓库名称:`username_or_org/repo_name`
运行以下代码,以创建仓库:
```py
>>> from huggingface_hub import create_repo
>>> create_repo("lysandre/test-model")
'https://huggingface.co/lysandre/test-model'
```
默认情况下,[`create_repo`] 会创建一个模型仓库。但是你可以使用 `repo_type`参数来指定其他仓库类型。例如,如果你想创建一个数据集仓库
请运行以下代码:
```py
>>> from huggingface_hub import create_repo
>>> create_repo("lysandre/test-dataset", repo_type="dataset")
'https://huggingface.co/datasets/lysandre/test-dataset'
```
创建仓库时,你可以使用 `private`参数设置仓库的可见性
请运行以下代码
```py
>>> from huggingface_hub import create_repo
>>> create_repo("lysandre/test-private", private=True)
```
如果你想在以后更改仓库的可见性,你可以使用[`update_repo_visibility`] 函数
### 删除一个仓库
使用 [`delete_repo`] 删除一个仓库。确保你确实想要删除仓库,因为这是一个不可逆转的过程!做完上述过程后,指定你想要删除的仓库的 `repo_id`
请运行以下代码:
```py
>>> delete_repo(repo_id="lysandre/my-corrupted-dataset", repo_type="dataset")
```
### 克隆一个仓库(仅适用于 Spaces)
在某些情况下,你可能想要复制别人的仓库并根据自己的用例进行调整。对于 Spaces,你可以使用 [`duplicate_space`] 方法来实现。它将复制整个仓库。
你仍然需要配置自己的设置(硬件和密钥)。查看我们的[管理你的Space指南](./manage-spaces)以获取更多详细信息。
请运行以下代码:
```py
>>> from huggingface_hub import duplicate_space
>>> duplicate_space("multimodalart/dreambooth-training", private=False)
RepoUrl('https://huggingface.co/spaces/nateraw/dreambooth-training',...)
```
## 上传和下载文件
既然您已经创建了您的存储库,您现在也可以推送更改至其中并从中下载文件
这两个主题有它们自己的指南。请[上传指南](./upload) 和[下载指南](./download)来学习如何使用您的存储库。
## 分支和标签
Git存储库通常使用分支来存储同一存储库的不同版本。标签也可以用于标记存储库的特定状态,例如,在发布版本这个情况下。更一般地说,分支和标签被称为[git引用](https://git-scm.com/book/en/v2/Git-Internals-Git-References).
### 创建分支和标签
你可以使用[`create_branch`]和[`create_tag`]来创建新的分支和标签:
请运行以下代码:
```py
>>> from huggingface_hub import create_branch, create_tag
# Create a branch on a Space repo from `main` branch
>>> create_branch("Matthijs/speecht5-tts-demo", repo_type="space", branch="handle-dog-speaker")
# Create a tag on a Dataset repo from `v0.1-release` branch
>>> create_branch("bigcode/the-stack", repo_type="dataset", revision="v0.1-release", tag="v0.1.1", tag_message="Bump release version.")
```
同时,你可以以相同的方式使用 [`delete_branch`] 和 [`delete_tag`] 函数来删除分支或标签
### 列出所有的分支和标签
你还可以使用 [`list_repo_refs`] 列出存储库中的现有 Git 引用
请运行以下代码:
```py
>>> from huggingface_hub import list_repo_refs
>>> api.list_repo_refs("bigcode/the-stack", repo_type="dataset")
GitRefs(
branches=[
GitRefInfo(name='main', ref='refs/heads/main', target_commit='18edc1591d9ce72aa82f56c4431b3c969b210ae3'),
GitRefInfo(name='v1.1.a1', ref='refs/heads/v1.1.a1', target_commit='f9826b862d1567f3822d3d25649b0d6d22ace714')
],
converts=[],
tags=[
GitRefInfo(name='v1.0', ref='refs/tags/v1.0', target_commit='c37a8cd1e382064d8aced5e05543c5f7753834da')
]
)
```
## 修改存储库设置
存储库具有一些可配置的设置。大多数情况下,您通常会在浏览器中的存储库设置页面上手动配置这些设置。要配置存储库,您必须具有对其的写访问权限(拥有它或属于组织)。在本节中,我们将看到您还可以使用 `huggingface_hub` 在编程方式上配置的设置。
一些设置是特定于 Spaces(硬件、环境变量等)的。要配置这些设置,请参考我们的[管理Spaces](../guides/manage-spaces)指南。
### 更新可见性
一个存储库可以是公共的或私有的。私有存储库仅对您或存储库所在组织的成员可见。
请运行以下代码将存储库更改为私有:
```py
>>> from huggingface_hub import update_repo_visibility
>>> update_repo_visibility(repo_id=repo_id, private=True)
```
### 重命名您的存储库
您可以使用 [`move_repo`] 在 Hub 上重命名您的存储库。使用这种方法,您还可以将存储库从一个用户移动到一个组织。在这样做时,有一些[限制](https://hf.co/docs/hub/repositories-settings#renaming-or-transferring-a-repo)需要注意。例如,您不能将存储库转移到另一个用户。
请运行以下代码:
```py
>>> from huggingface_hub import move_repo
>>> move_repo(from_id="Wauplin/cool-model", to_id="huggingface/cool-model")
```
## 管理存储库的本地副本
上述所有操作都可以通过HTTP请求完成。然而,在某些情况下,您可能希望在本地拥有存储库的副本,并使用您熟悉的Git命令与之交互。
[`Repository`] 类允许您使用类似于Git命令的函数与Hub上的文件和存储库进行交互。它是对Git和Git-LFS方法的包装,以使用您已经了解和喜爱的Git命令。在开始之前,请确保已安装Git-LFS(请参阅[此处](https://git-lfs.github.com/)获取安装说明)。
### 使用本地存储库
使用本地存储库路径实例化一个 [`Repository`] 对象:
请运行以下代码:
```py
>>> from huggingface_hub import Repository
>>> repo = Repository(local_dir="<path>/<to>/<folder>")
```
### 克隆
`clone_from`参数将一个存储库从Hugging Face存储库ID克隆到由 `local_dir`参数指定的本地目录:
请运行以下代码:
```py
>>> from huggingface_hub import Repository
>>> repo = Repository(local_dir="w2v2", clone_from="facebook/wav2vec2-large-960h-lv60")
```
`clone_from`还可以使用URL克隆存储库:
请运行以下代码:
```py
>>> repo = Repository(local_dir="huggingface-hub", clone_from="https://huggingface.co/facebook/wav2vec2-large-960h-lv60")
```
你可以将`clone_from`参数与[`create_repo`]结合使用,以创建并克隆一个存储库:
请运行以下代码:
```py
>>> repo_url = create_repo(repo_id="repo_name")
>>> repo = Repository(local_dir="repo_local_path", clone_from=repo_url)
```
当你克隆一个存储库时,通过在克隆时指定`git_user`和`git_email`参数,你还可以为克隆的存储库配置Git用户名和电子邮件。当用户提交到该存储库时,Git将知道提交的作者是谁。
请运行以下代码:
```py
>>> repo = Repository(
... "my-dataset",
... clone_from="<user>/<dataset_id>",
... token=True,
... repo_type="dataset",
... git_user="MyName",
... git_email="me@cool.mail"
... )
```
### 分支
分支对于协作和实验而不影响当前文件和代码非常重要。使用[`~Repository.git_checkout`]来在不同的分支之间切换。例如,如果你想从 `branch1`切换到 `branch2`:
请运行以下代码:
```py
>>> from huggingface_hub import Repository
>>> repo = Repository(local_dir="huggingface-hub", clone_from="<user>/<dataset_id>", revision='branch1')
>>> repo.git_checkout("branch2")
```
### 拉取
[`~Repository.git_pull`] 允许你使用远程存储库的更改更新当前本地分支:
请运行以下代码:
```py
>>> from huggingface_hub import Repository
>>> repo.git_pull()
```
如果你希望本地的提交发生在你的分支被远程的新提交更新之后,请设置`rebase=True`:
```py
>>> repo.git_pull(rebase=True)
```
| huggingface/huggingface_hub/blob/main/docs/source/cn/guides/repository.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# DiT
## Overview
DiT was proposed in [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
DiT applies the self-supervised objective of [BEiT](beit) (BERT pre-training of Image Transformers) to 42 million document images, allowing for state-of-the-art results on tasks including:
- document image classification: the [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/) dataset (a collection of
400,000 images belonging to one of 16 classes).
- document layout analysis: the [PubLayNet](https://github.com/ibm-aur-nlp/PubLayNet) dataset (a collection of more
than 360,000 document images constructed by automatically parsing PubMed XML files).
- table detection: the [ICDAR 2019 cTDaR](https://github.com/cndplab-founder/ICDAR2019_cTDaR) dataset (a collection of
600 training images and 240 testing images).
The abstract from the paper is the following:
*Image Transformer has recently achieved significant progress for natural image understanding, either using supervised (ViT, DeiT, etc.) or self-supervised (BEiT, MAE, etc.) pre-training techniques. In this paper, we propose DiT, a self-supervised pre-trained Document Image Transformer model using large-scale unlabeled text images for Document AI tasks, which is essential since no supervised counterparts ever exist due to the lack of human labeled document images. We leverage DiT as the backbone network in a variety of vision-based Document AI tasks, including document image classification, document layout analysis, as well as table detection. Experiment results have illustrated that the self-supervised pre-trained DiT model achieves new state-of-the-art results on these downstream tasks, e.g. document image classification (91.11 → 92.69), document layout analysis (91.0 → 94.9) and table detection (94.23 → 96.55). *
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/dit_architecture.jpg"
alt="drawing" width="600"/>
<small> Summary of the approach. Taken from the [original paper](https://arxiv.org/abs/2203.02378). </small>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/dit).
## Usage tips
One can directly use the weights of DiT with the AutoModel API:
```python
from transformers import AutoModel
model = AutoModel.from_pretrained("microsoft/dit-base")
```
This will load the model pre-trained on masked image modeling. Note that this won't include the language modeling head on top, used to predict visual tokens.
To include the head, you can load the weights into a `BeitForMaskedImageModeling` model, like so:
```python
from transformers import BeitForMaskedImageModeling
model = BeitForMaskedImageModeling.from_pretrained("microsoft/dit-base")
```
You can also load a fine-tuned model from the [hub](https://huggingface.co/models?other=dit), like so:
```python
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained("microsoft/dit-base-finetuned-rvlcdip")
```
This particular checkpoint was fine-tuned on [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/), an important benchmark for document image classification.
A notebook that illustrates inference for document image classification can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DiT/Inference_with_DiT_(Document_Image_Transformer)_for_document_image_classification.ipynb).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DiT.
<PipelineTag pipeline="image-classification"/>
- [`BeitForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<Tip>
As DiT's architecture is equivalent to that of BEiT, one can refer to [BEiT's documentation page](beit) for all tips, code examples and notebooks.
</Tip>
| huggingface/transformers/blob/main/docs/source/en/model_doc/dit.md |
Gradio Demo: theme_soft
```
!pip install -q gradio
```
```
import gradio as gr
import time
with gr.Blocks(theme=gr.themes.Soft()) as demo:
textbox = gr.Textbox(label="Name")
slider = gr.Slider(label="Count", minimum=0, maximum=100, step=1)
with gr.Row():
button = gr.Button("Submit", variant="primary")
clear = gr.Button("Clear")
output = gr.Textbox(label="Output")
def repeat(name, count):
time.sleep(3)
return name * count
button.click(repeat, [textbox, slider], output)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/theme_soft/run.ipynb |
(Gluon) SENet
A **SENet** is a convolutional neural network architecture that employs [squeeze-and-excitation blocks](https://paperswithcode.com/method/squeeze-and-excitation-block) to enable the network to perform dynamic channel-wise feature recalibration.
The weights from this model were ported from [Gluon](https://cv.gluon.ai/model_zoo/classification.html).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('gluon_senet154', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `gluon_senet154`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('gluon_senet154', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{hu2019squeezeandexcitation,
title={Squeeze-and-Excitation Networks},
author={Jie Hu and Li Shen and Samuel Albanie and Gang Sun and Enhua Wu},
year={2019},
eprint={1709.01507},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: Gloun SENet
Paper:
Title: Squeeze-and-Excitation Networks
URL: https://paperswithcode.com/paper/squeeze-and-excitation-networks
Models:
- Name: gluon_senet154
In Collection: Gloun SENet
Metadata:
FLOPs: 26681705136
Parameters: 115090000
File Size: 461546622
Architecture:
- Convolution
- Dense Connections
- Global Average Pooling
- Max Pooling
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_senet154
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L239
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_senet154-70a1a3c0.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.23%
Top 5 Accuracy: 95.35%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/gloun-senet.mdx |
urrently the following model proposals are available:
- <s>[BigBird (Google)](./ADD_BIG_BIRD.md)</s>
| huggingface/transformers/blob/main/templates/adding_a_new_model/open_model_proposals/README.md |
Gradio Demo: radio_component
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
gr.Radio(choices=["First Choice", "Second Choice", "Third Choice"])
demo.launch()
```
| gradio-app/gradio/blob/main/demo/radio_component/run.ipynb |
--
title: "SDXL in 4 steps with Latent Consistency LoRAs"
thumbnail: /blog/assets/lcm_sdxl/lcm_thumbnail.png
authors:
- user: pcuenq
- user: valhalla
- user: SimianLuo
guest: true
- user: dg845
guest: true
- user: tyq1024
guest: true
- user: sayakpaul
- user: multimodalart
---
# SDXL in 4 steps with Latent Consistency LoRAs
[Latent Consistency Models (LCM)](https://huggingface.co/papers/2310.04378) are a way to decrease the number of steps required to generate an image with Stable Diffusion (or SDXL) by _distilling_ the original model into another version that requires fewer steps (4 to 8 instead of the original 25 to 50). Distillation is a type of training procedure that attempts to replicate the outputs from a source model using a new one. The distilled model may be designed to be smaller (that’s the case of [DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert) or the recently-released [Distil-Whisper](https://github.com/huggingface/distil-whisper)) or, in this case, require fewer steps to run. It’s usually a lengthy and costly process that requires huge amounts of data, patience, and a few GPUs.
Well, that was the status quo before today!
We are delighted to announce a new method that can essentially make Stable Diffusion and SDXL faster, as if they had been distilled using the LCM process! How does it sound to run _any_ SDXL model in about 1 second instead of 7 on a 3090, or 10x faster on Mac? Read on for details!
## Contents
- [Method Overview](#method-overview)
- [Why does this matter](#why-does-this-matter)
- [Fast Inference with SDXL LCM LoRAs](#fast-inference-with-sdxl-lcm-loras)
- [Quality Comparison](#quality-comparison)
- [Guidance Scale and Negative Prompts](#guidance-scale-and-negative-prompts)
- [Quality vs base SDXL](#quality-vs-base-sdxl)
- [LCM LoRAs with other Models](#lcm-loras-with-other-models)
- [Full Diffusers Integration](#full-diffusers-integration)
- [Benchmarks](#benchmarks)
- [LCM LoRAs and Models Released Today](#lcm-loras-and-models-released-today)
- [Bonus: Combine LCM LoRAs with regular SDXL LoRAs](#bonus-combine-lcm-loras-with-regular-sdxl-loras)
- [How to train LCM LoRAs](#how-to-train-lcm-loras)
- [Resources](#resources)
- [Credits](#credits)
## Method Overview
So, what’s the trick?
For latent consistency distillation, each model needs to be distilled separately. The core idea with LCM LoRA is to train just a small number of adapters, [known as LoRA layers](https://huggingface.co/docs/peft/conceptual_guides/lora), instead of the full model. The resulting LoRAs can then be applied to any fine-tuned version of the model without having to distil them separately. If you are itching to see how this looks in practice, just jump to the [next section](#fast-inference-with-sdxl-lcm-loras) to play with the inference code. If you want to train your own LoRAs, this is the process you’d use:
1. Select an available teacher model from the Hub. For example, you can use [SDXL (base)](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0), or any fine-tuned or dreamboothed version you like.
2. [Train a LCM LoRA](#how-to-train-lcm-models-and-loras) on the model. LoRA is a type of performance-efficient fine-tuning, or PEFT, that is much cheaper to accomplish than full model fine-tuning. For additional details on PEFT, please check [this blog post](https://huggingface.co/blog/peft) or [the diffusers LoRA documentation](https://huggingface.co/docs/diffusers/training/lora).
3. Use the LoRA with any SDXL diffusion model and the LCM scheduler; bingo! You get high-quality inference in just a few steps.
For more details on the process, please [download our paper](https://huggingface.co/latent-consistency/lcm-lora-sdxl/resolve/main/LCM-LoRA-Technical-Report.pdf).
## Why does this matter?
Fast inference of Stable Diffusion and SDXL enables new use-cases and workflows. To name a few:
- **Accessibility**: generative tools can be used effectively by more people, even if they don’t have access to the latest hardware.
- **Faster iteration**: get more images and multiple variants in a fraction of the time! This is great for artists and researchers; whether for personal or commercial use.
- Production workloads may be possible on different accelerators, including CPUs.
- Cheaper image generation services.
To gauge the speed difference we are talking about, generating a single 1024x1024 image on an M1 Mac with SDXL (base) takes about a minute. Using the LCM LoRA, we get great results in just ~6s (4 steps). This is an order of magnitude faster, and not having to wait for results is a game-changer. Using a 4090, we get almost instant response (less than 1s). This unlocks the use of SDXL in applications where real-time events are a requirement.
## Fast Inference with SDXL LCM LoRAs
The version of `diffusers` released today makes it very easy to use LCM LoRAs:
```py
from diffusers import DiffusionPipeline, LCMScheduler
import torch
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
lcm_lora_id = "latent-consistency/lcm-lora-sdxl"
pipe = DiffusionPipeline.from_pretrained(model_id, variant="fp16")
pipe.load_lora_weights(lcm_lora_id)
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
pipe.to(device="cuda", dtype=torch.float16)
prompt = "close-up photography of old man standing in the rain at night, in a street lit by lamps, leica 35mm summilux"
images = pipe(
prompt=prompt,
num_inference_steps=4,
guidance_scale=1,
).images[0]
```
Note how the code:
- Instantiates a standard diffusion pipeline with the SDXL 1.0 base model.
- Applies the LCM LoRA.
- Changes the scheduler to the LCMScheduler, which is the one used in latent consistency models.
- That’s it!
This would result in the following full-resolution image:
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/lcm-lora/lcm-1.jpg?download=true" alt="SDXL in 4 steps with LCM LoRA"><br>
<em>Image generated with SDXL in 4 steps using an LCM LoRA.</em>
</p>
### Quality Comparison
Let’s see how the number of steps impacts generation quality. The following code will generate images with 1 to 8 total inference steps:
```py
images = []
for steps in range(8):
generator = torch.Generator(device=pipe.device).manual_seed(1337)
image = pipe(
prompt=prompt,
num_inference_steps=steps+1,
guidance_scale=1,
generator=generator,
).images[0]
images.append(image)
```
These are the 8 images displayed in a grid:
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/lcm-lora/lcm-grid.jpg?download=true" alt="LCM LoRA generations with 1 to 8 steps"><br>
<em>LCM LoRA generations with 1 to 8 steps.</em>
</p>
As expected, using just **1** step produces an approximate shape without discernible features and lacking texture. However, results quickly improve, and they are usually very satisfactory in just 4 to 6 steps. Personally, I find the 8-step image in the previous test to be a bit too saturated and “cartoony” for my taste, so I’d probably choose between the ones with 5 and 6 steps in this example. Generation is so fast that you can create a bunch of different variants using just 4 steps, and then select the ones you like and iterate using a couple more steps and refined prompts as necessary.
### Guidance Scale and Negative Prompts
Note that in the previous examples we used a `guidance_scale` of `1`, which effectively disables it. This works well for most prompts, and it’s fastest, but ignores negative prompts. You can also explore using negative prompts by providing a guidance scale between `1` and `2` – we found that larger values don’t work.
### Quality vs base SDXL
How does this compare against the standard SDXL pipeline, in terms of quality? Let’s see an example!
We can quickly revert our pipeline to a standard SDXL pipeline by unloading the LoRA weights and switching to the default scheduler:
```py
from diffusers import EulerDiscreteScheduler
pipe.unload_lora_weights()
pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config)
```
Then we can run inference as usual for SDXL. We’ll gather results using varying number of steps:
```py
images = []
for steps in (1, 4, 8, 15, 20, 25, 30, 50):
generator = torch.Generator(device=pipe.device).manual_seed(1337)
image = pipe(
prompt=prompt,
num_inference_steps=steps,
generator=generator,
).images[0]
images.append(image)
```
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/lcm-lora/lcm-sdxl-grid.jpg?download=true" alt="SDXL results for various inference steps"><br>
<em>SDXL pipeline results (same prompt and random seed), using 1, 4, 8, 15, 20, 25, 30, and 50 steps.</em>
</p>
As you can see, images in this example are pretty much useless until ~20 steps (second row), and quality still increases niteceably with more steps. The details in the final image are amazing, but it took 50 steps to get there.
### LCM LoRAs with other models
This technique also works for any other fine-tuned SDXL or Stable Diffusion model. To demonstrate, let's see how to run inference on [`collage-diffusion`](https://huggingface.co/wavymulder/collage-diffusion), a model fine-tuned from [Stable Diffusion v1.5](https://huggingface.co/runwayml/stable-diffusion-v1-5) using Dreambooth.
The code is similar to the one we saw in the previous examples. We load the fine-tuned model, and then the LCM LoRA suitable for Stable Diffusion v1.5.
```py
from diffusers import DiffusionPipeline, LCMScheduler
import torch
model_id = "wavymulder/collage-diffusion"
lcm_lora_id = "latent-consistency/lcm-lora-sdv1-5"
pipe = DiffusionPipeline.from_pretrained(model_id, variant="fp16")
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
pipe.load_lora_weights(lcm_lora_id)
pipe.to(device="cuda", dtype=torch.float16)
prompt = "collage style kid sits looking at the night sky, full of stars"
generator = torch.Generator(device=pipe.device).manual_seed(1337)
images = pipe(
prompt=prompt,
generator=generator,
negative_prompt=negative_prompt,
num_inference_steps=4,
guidance_scale=1,
).images[0]
images
```
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/lcm-lora/collage.png?download=true" alt="LCM LoRA technique with a Dreambooth Stable Diffusion v1.5 model, allowing 4-step inference."><br>
<em>LCM LoRA technique with a Dreambooth Stable Diffusion v1.5 model, allowing 4-step inference.</em>
</p>
### Full Diffusers Integration
The integration of LCM in `diffusers` makes it possible to take advantage of many features and workflows that are part of the diffusers toolbox. For example:
- Out of the box `mps` support for Macs with Apple Silicon.
- Memory and performance optimizations like flash attention or `torch.compile()`.
- Additional memory saving strategies for low-RAM environments, including model offload.
- Workflows like ControlNet or image-to-image.
- Training and fine-tuning scripts.
## Benchmarks
This section is not meant to be exhaustive, but illustrative of the generation speed we achieve on various computers. Let us stress again how liberating it is to explore image generation so easily.
| Hardware | SDXL LoRA LCM (4 steps) | SDXL standard (25 steps) |
|----------------------------------------|-------------------------|--------------------------|
| Mac, M1 Max | 6.5s | 64s |
| 2080 Ti | 4.7s | 10.2s |
| 3090 | 1.4s | 7s |
| 4090 | 0.7s | 3.4s |
| T4 (Google Colab Free Tier) | 8.4s | 26.5s |
| A100 (80 GB) | 1.2s | 3.8s |
| Intel i9-10980XE CPU (1/36 cores used) | 29s | 219s |
These tests were run with a batch size of 1 in all cases, using [this script](https://huggingface.co/datasets/pcuenq/gists/blob/main/sayak_lcm_benchmark.py) by [Sayak Paul](https://huggingface.co/sayakpaul).
For cards with a lot of capacity, such as A100, performance increases significantly when generating multiple images at once, which is usually the case for production workloads.
## LCM LoRAs and Models Released Today
- [Latent Consistency Models LoRAs Collection](https://huggingface.co/collections/latent-consistency/latent-consistency-models-loras-654cdd24e111e16f0865fba6)
- [`latent-consistency/lcm-lora-sdxl`](https://huggingface.co/latent-consistency/lcm-lora-sdxl). LCM LoRA for [SDXL 1.0 base](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0), as seen in the examples above.
- [`latent-consistency/lcm-lora-sdv1-5`](https://huggingface.co/latent-consistency/lcm-lora-sdv1-5). LCM LoRA for [Stable Diffusion 1.5](https://huggingface.co/runwayml/stable-diffusion-v1-5).
- [`latent-consistency/lcm-lora-ssd-1b`](https://huggingface.co/latent-consistency/lcm-lora-ssd-1b). LCM LoRA for [`segmind/SSD-1B`](https://huggingface.co/segmind/SSD-1B), a distilled SDXL model that's 50% smaller and 60% faster than the original SDXL.
- [`latent-consistency/lcm-sdxl`](https://huggingface.co/latent-consistency/lcm-sdxl). Full fine-tuned consistency model derived from [SDXL 1.0 base](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0).
- [`latent-consistency/lcm-ssd-1b`](https://huggingface.co/latent-consistency/lcm-ssd-1b). Full fine-tuned consistency model derived from [`segmind/SSD-1B`](https://huggingface.co/segmind/SSD-1B).
## Bonus: Combine LCM LoRAs with regular SDXL LoRAs
Using the [diffusers + PEFT integration](https://huggingface.co/docs/diffusers/main/en/tutorials/using_peft_for_inference), you can combine LCM LoRAs with regular SDXL LoRAs, giving them the superpower to run LCM inference in only 4 steps.
Here we are going to combine `CiroN2022/toy_face` LoRA with the LCM LoRA:
```py
from diffusers import DiffusionPipeline, LCMScheduler
import torch
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
lcm_lora_id = "latent-consistency/lcm-lora-sdxl"
pipe = DiffusionPipeline.from_pretrained(model_id, variant="fp16")
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
pipe.load_lora_weights(lcm_lora_id)
pipe.load_lora_weights("CiroN2022/toy-face", weight_name="toy_face_sdxl.safetensors", adapter_name="toy")
pipe.set_adapters(["lora", "toy"], adapter_weights=[1.0, 0.8])
pipe.to(device="cuda", dtype=torch.float16)
prompt = "a toy_face man"
negative_prompt = "blurry, low quality, render, 3D, oversaturated"
images = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
num_inference_steps=4,
guidance_scale=0.5,
).images[0]
images
```
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/lcm-lora/lcm-toy.png?download=true" alt="Combining LoRAs for fast inference"><br>
<em>Standard and LCM LoRAs combined for fast (4 step) inference.</em>
</p>
Need ideas to explore some LoRAs? Check out our experimental [LoRA the Explorer (LCM version)](https://huggingface.co/spaces/latent-consistency/lcm-LoraTheExplorer) Space to test amazing creations by the community and get inspired!
## How to Train LCM Models and LoRAs
As part of the `diffusers` release today, we are providing training and fine-tuning scripts developed in collaboration with the LCM team authors. They allow users to:
- Perform full-model distillation of Stable Diffusion or SDXL models on large datasets such as Laion.
- Train LCM LoRAs, which is a much easier process. As we've shown in this post, it also makes it possible to run fast inference with Stable Diffusion, without having to go through distillation training.
For more details, please check the instructions for [SDXL](https://github.com/huggingface/diffusers/blob/main/examples/consistency_distillation/README_sdxl.md) or [Stable Diffusion](https://github.com/huggingface/diffusers/blob/main/examples/consistency_distillation/README.md) in the repo.
We hope these scripts inspire the community to try their own fine-tunes. Please, do let us know if you use them for your projects!
## Resources
- Latent Consistency Models [project page](https://latent-consistency-models.github.io), [paper](https://huggingface.co/papers/2310.04378).
- [LCM LoRAs](https://huggingface.co/collections/latent-consistency/latent-consistency-models-loras-654cdd24e111e16f0865fba6)
- [For SDXL](https://huggingface.co/latent-consistency/lcm-lora-sdxl).
- [For Stable Diffusion v1.5](https://huggingface.co/latent-consistency/lcm-lora-sdv1-5).
- [For Segmind's SSD-1B](https://huggingface.co/latent-consistency/lcm-lora-ssd-1b).
- [Technical Report](https://huggingface.co/latent-consistency/lcm-lora-sdxl/resolve/main/LCM-LoRA-Technical-Report.pdf).
- Demos
- [SDXL in 4 steps with Latent Consistency LoRAs](https://huggingface.co/spaces/latent-consistency/lcm-lora-for-sdxl)
- [Near real-time video stream](https://huggingface.co/spaces/latent-consistency/Real-Time-LCM-ControlNet-Lora-SD1.5)
- [LoRA the Explorer (experimental LCM version)](https://huggingface.co/spaces/latent-consistency/lcm-LoraTheExplorer)
- PEFT: [intro](https://huggingface.co/blog/peft), [repo](https://github.com/huggingface/peft)
- Training scripts
- [For Stable Diffusion 1.5](https://github.com/huggingface/diffusers/blob/main/examples/consistency_distillation/README.md)
- [For SDXL](https://github.com/huggingface/diffusers/blob/main/examples/consistency_distillation/README_sdxl.md)
## Credits
The amazing work on Latent Consistency Models was performed by the [LCM Team](https://latent-consistency-models.github.io), please make sure to check out their code, report and paper. This project is a collaboration between the [diffusers team](https://github.com/huggingface/diffusers), the LCM team, and community contributor [Daniel Gu](https://huggingface.co/dg845). We believe it's a testament to the enabling power of open source AI, the cornerstone that allows researchers, practitioners and tinkerers to explore new ideas and collaborate. We'd also like to thank [`@madebyollin`](https://huggingface.co/madebyollin) for their continued contributions to the community, including the `float16` autoencoder we use in our training scripts.
| huggingface/blog/blob/main/lcm_lora.md |
How Huggy works [[how-huggy-works]]
Huggy is a Deep Reinforcement Learning environment made by Hugging Face and based on [Puppo the Corgi, a project by the Unity MLAgents team](https://blog.unity.com/technology/puppo-the-corgi-cuteness-overload-with-the-unity-ml-agents-toolkit).
This environment was created using the [Unity game engine](https://unity.com/) and [MLAgents](https://github.com/Unity-Technologies/ml-agents). ML-Agents is a toolkit for the game engine from Unity that allows us to **create environments using Unity or use pre-made environments to train our agents**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/huggy.jpg" alt="Huggy" width="100%">
In this environment we aim to train Huggy to **fetch the stick we throw. This means he needs to move correctly toward the stick**.
## The State Space, what Huggy perceives. [[state-space]]
Huggy doesn't "see" his environment. Instead, we provide him information about the environment:
- The target (stick) position
- The relative position between himself and the target
- The orientation of his legs.
Given all this information, Huggy can **use his policy to determine which action to take next to fulfill his goal**.
## The Action Space, what moves Huggy can perform [[action-space]]
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/huggy-action.jpg" alt="Huggy action" width="100%">
**Joint motors drive Huggy's legs**. This means that to get the target, Huggy needs to **learn to rotate the joint motors of each of his legs correctly so he can move**.
## The Reward Function [[reward-function]]
The reward function is designed so that **Huggy will fulfill his goal**: fetch the stick.
Remember that one of the foundations of Reinforcement Learning is the *reward hypothesis*: a goal can be described as the **maximization of the expected cumulative reward**.
Here, our goal is that Huggy **goes towards the stick but without spinning too much**. Hence, our reward function must translate this goal.
Our reward function:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/reward.jpg" alt="Huggy reward function" width="100%">
- *Orientation bonus*: we **reward him for getting close to the target**.
- *Time penalty*: a fixed-time penalty given at every action to **force him to get to the stick as fast as possible**.
- *Rotation penalty*: we penalize Huggy if **he spins too much and turns too quickly**.
- *Getting to the target reward*: we reward Huggy for **reaching the target**.
If you want to see what this reward function looks like mathematically, check [Puppo the Corgi presentation](https://blog.unity.com/technology/puppo-the-corgi-cuteness-overload-with-the-unity-ml-agents-toolkit).
## Train Huggy
Huggy aims **to learn to run correctly and as fast as possible toward the goal**. To do that, at every step and given the environment observation, he needs to decide how to rotate each joint motor of his legs to move correctly (not spinning too much) and towards the goal.
The training loop looks like this:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/huggy-loop.jpg" alt="Huggy loop" width="100%">
The training environment looks like this:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/training-env.jpg" alt="Huggy training env" width="100%">
It's a place where a **stick is spawned randomly**. When Huggy reaches it, the stick get spawned somewhere else.
We built **multiple copies of the environment for the training**. This helps speed up the training by providing more diverse experiences.
Now that you have the big picture of the environment, you're ready to train Huggy to fetch the stick.
To do that, we're going to use [MLAgents](https://github.com/Unity-Technologies/ml-agents). Don't worry if you have never used it before. In this unit we'll use Google Colab to train Huggy, and then you'll be able to load your trained Huggy and play with him directly in the browser.
In a future unit, we will study MLAgents more in-depth and see how it works. But for now, we keep things simple by just using the provided implementation.
| huggingface/deep-rl-class/blob/main/units/en/unitbonus1/how-huggy-works.mdx |
Research projects
This folder contains various research projects using 🧨 Diffusers.
They are not really maintained by the core maintainers of this library and often require a specific version of Diffusers that is indicated in the requirements file of each folder.
Updating them to the most recent version of the library will require some work.
To use any of them, just run the command
```
pip install -r requirements.txt
```
inside the folder of your choice.
If you need help with any of those, please open an issue where you directly ping the author(s), as indicated at the top of the README of each folder.
| huggingface/diffusers/blob/main/examples/research_projects/README.md |
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# SegFormer
## Overview
The SegFormer model was proposed in [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping
Luo. The model consists of a hierarchical Transformer encoder and a lightweight all-MLP decode head to achieve great
results on image segmentation benchmarks such as ADE20K and Cityscapes.
The abstract from the paper is the following:
*We present SegFormer, a simple, efficient yet powerful semantic segmentation framework which unifies Transformers with
lightweight multilayer perception (MLP) decoders. SegFormer has two appealing features: 1) SegFormer comprises a novel
hierarchically structured Transformer encoder which outputs multiscale features. It does not need positional encoding,
thereby avoiding the interpolation of positional codes which leads to decreased performance when the testing resolution
differs from training. 2) SegFormer avoids complex decoders. The proposed MLP decoder aggregates information from
different layers, and thus combining both local attention and global attention to render powerful representations. We
show that this simple and lightweight design is the key to efficient segmentation on Transformers. We scale our
approach up to obtain a series of models from SegFormer-B0 to SegFormer-B5, reaching significantly better performance
and efficiency than previous counterparts. For example, SegFormer-B4 achieves 50.3% mIoU on ADE20K with 64M parameters,
being 5x smaller and 2.2% better than the previous best method. Our best model, SegFormer-B5, achieves 84.0% mIoU on
Cityscapes validation set and shows excellent zero-shot robustness on Cityscapes-C.*
The figure below illustrates the architecture of SegFormer. Taken from the [original paper](https://arxiv.org/abs/2105.15203).
<img width="600" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/segformer_architecture.png"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version
of the model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/NVlabs/SegFormer).
## Usage tips
- SegFormer consists of a hierarchical Transformer encoder, and a lightweight all-MLP decoder head.
[`SegformerModel`] is the hierarchical Transformer encoder (which in the paper is also referred to
as Mix Transformer or MiT). [`SegformerForSemanticSegmentation`] adds the all-MLP decoder head on
top to perform semantic segmentation of images. In addition, there's
[`SegformerForImageClassification`] which can be used to - you guessed it - classify images. The
authors of SegFormer first pre-trained the Transformer encoder on ImageNet-1k to classify images. Next, they throw
away the classification head, and replace it by the all-MLP decode head. Next, they fine-tune the model altogether on
ADE20K, Cityscapes and COCO-stuff, which are important benchmarks for semantic segmentation. All checkpoints can be
found on the [hub](https://huggingface.co/models?other=segformer).
- The quickest way to get started with SegFormer is by checking the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/SegFormer) (which showcase both inference and
fine-tuning on custom data). One can also check out the [blog post](https://huggingface.co/blog/fine-tune-segformer) introducing SegFormer and illustrating how it can be fine-tuned on custom data.
- TensorFlow users should refer to [this repository](https://github.com/deep-diver/segformer-tf-transformers) that shows off-the-shelf inference and fine-tuning.
- One can also check out [this interactive demo on Hugging Face Spaces](https://huggingface.co/spaces/chansung/segformer-tf-transformers)
to try out a SegFormer model on custom images.
- SegFormer works on any input size, as it pads the input to be divisible by `config.patch_sizes`.
- One can use [`SegformerImageProcessor`] to prepare images and corresponding segmentation maps
for the model. Note that this image processor is fairly basic and does not include all data augmentations used in
the original paper. The original preprocessing pipelines (for the ADE20k dataset for instance) can be found [here](https://github.com/NVlabs/SegFormer/blob/master/local_configs/_base_/datasets/ade20k_repeat.py). The most
important preprocessing step is that images and segmentation maps are randomly cropped and padded to the same size,
such as 512x512 or 640x640, after which they are normalized.
- One additional thing to keep in mind is that one can initialize [`SegformerImageProcessor`] with
`reduce_labels` set to `True` or `False`. In some datasets (like ADE20k), the 0 index is used in the annotated
segmentation maps for background. However, ADE20k doesn't include the "background" class in its 150 labels.
Therefore, `reduce_labels` is used to reduce all labels by 1, and to make sure no loss is computed for the
background class (i.e. it replaces 0 in the annotated maps by 255, which is the *ignore_index* of the loss function
used by [`SegformerForSemanticSegmentation`]). However, other datasets use the 0 index as
background class and include this class as part of all labels. In that case, `reduce_labels` should be set to
`False`, as loss should also be computed for the background class.
- As most models, SegFormer comes in different sizes, the details of which can be found in the table below
(taken from Table 7 of the [original paper](https://arxiv.org/abs/2105.15203)).
| **Model variant** | **Depths** | **Hidden sizes** | **Decoder hidden size** | **Params (M)** | **ImageNet-1k Top 1** |
| :---------------: | ------------- | ------------------- | :---------------------: | :------------: | :-------------------: |
| MiT-b0 | [2, 2, 2, 2] | [32, 64, 160, 256] | 256 | 3.7 | 70.5 |
| MiT-b1 | [2, 2, 2, 2] | [64, 128, 320, 512] | 256 | 14.0 | 78.7 |
| MiT-b2 | [3, 4, 6, 3] | [64, 128, 320, 512] | 768 | 25.4 | 81.6 |
| MiT-b3 | [3, 4, 18, 3] | [64, 128, 320, 512] | 768 | 45.2 | 83.1 |
| MiT-b4 | [3, 8, 27, 3] | [64, 128, 320, 512] | 768 | 62.6 | 83.6 |
| MiT-b5 | [3, 6, 40, 3] | [64, 128, 320, 512] | 768 | 82.0 | 83.8 |
Note that MiT in the above table refers to the Mix Transformer encoder backbone introduced in SegFormer. For
SegFormer's results on the segmentation datasets like ADE20k, refer to the [paper](https://arxiv.org/abs/2105.15203).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with SegFormer.
<PipelineTag pipeline="image-classification"/>
- [`SegformerForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- [Image classification task guide](../tasks/image_classification)
Semantic segmentation:
- [`SegformerForSemanticSegmentation`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/semantic-segmentation).
- A blog on fine-tuning SegFormer on a custom dataset can be found [here](https://huggingface.co/blog/fine-tune-segformer).
- More demo notebooks on SegFormer (both inference + fine-tuning on a custom dataset) can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/SegFormer).
- [`TFSegformerForSemanticSegmentation`] is supported by this [example notebook](https://github.com/huggingface/notebooks/blob/main/examples/semantic_segmentation-tf.ipynb).
- [Semantic segmentation task guide](../tasks/semantic_segmentation)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## SegformerConfig
[[autodoc]] SegformerConfig
## SegformerFeatureExtractor
[[autodoc]] SegformerFeatureExtractor
- __call__
- post_process_semantic_segmentation
## SegformerImageProcessor
[[autodoc]] SegformerImageProcessor
- preprocess
- post_process_semantic_segmentation
<frameworkcontent>
<pt>
## SegformerModel
[[autodoc]] SegformerModel
- forward
## SegformerDecodeHead
[[autodoc]] SegformerDecodeHead
- forward
## SegformerForImageClassification
[[autodoc]] SegformerForImageClassification
- forward
## SegformerForSemanticSegmentation
[[autodoc]] SegformerForSemanticSegmentation
- forward
</pt>
<tf>
## TFSegformerDecodeHead
[[autodoc]] TFSegformerDecodeHead
- call
## TFSegformerModel
[[autodoc]] TFSegformerModel
- call
## TFSegformerForImageClassification
[[autodoc]] TFSegformerForImageClassification
- call
## TFSegformerForSemanticSegmentation
[[autodoc]] TFSegformerForSemanticSegmentation
- call
</tf>
</frameworkcontent> | huggingface/transformers/blob/main/docs/source/en/model_doc/segformer.md |
Interesting Environments to try
Here we provide a list of interesting environments you can try to train your agents on:
## MineRL
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit12/minerl.jpg" alt="MineRL"/>
MineRL is a Python library that provides a Gym interface for interacting with the video game Minecraft, accompanied by datasets of human gameplay.
Every year there are challenges with this library. Check the [website](https://minerl.io/)
To start using this environment, check these resources:
- [What is MineRL?](https://www.youtube.com/watch?v=z6PTrGifupU)
- [First steps in MineRL](https://www.youtube.com/watch?v=8yIrWcyWGek)
- [MineRL documentation and tutorials](https://minerl.readthedocs.io/en/latest/)
## DonkeyCar Simulator
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit12/donkeycar.jpg" alt="Donkey Car"/>
Donkey is a Self Driving Car Platform for hobby remote control cars.
This simulator version is built on the Unity game platform. It uses their internal physics and graphics and connects to a donkey Python process to use our trained model to control the simulated Donkey (car).
To start using this environment, check these resources:
- [DonkeyCar Simulator documentation](https://docs.donkeycar.com/guide/deep_learning/simulator/)
- [Learn to Drive Smoothly (Antonin Raffin's tutorial) Part 1](https://www.youtube.com/watch?v=ngK33h00iBE)
- [Learn to Drive Smoothly (Antonin Raffin's tutorial) Part 2](https://www.youtube.com/watch?v=DUqssFvcSOY)
- [Learn to Drive Smoothly (Antonin Raffin's tutorial) Part 3](https://www.youtube.com/watch?v=v8j2bpcE4Rg)
- Pretrained agents:
- https://huggingface.co/araffin/tqc-donkey-mountain-track-v0
- https://huggingface.co/araffin/tqc-donkey-avc-sparkfun-v0
- https://huggingface.co/araffin/tqc-donkey-minimonaco-track-v0
## Starcraft II
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit12/alphastar.jpg" alt="Alphastar"/>
Starcraft II is a famous *real-time strategy game*. DeepMind has used this game for their Deep Reinforcement Learning research with [Alphastar](https://www.deepmind.com/blog/alphastar-mastering-the-real-time-strategy-game-starcraft-ii)
To start using this environment, check these resources:
- [Starcraft gym](http://starcraftgym.com/)
- [A. I. Learns to Play Starcraft 2 (Reinforcement Learning) tutorial](https://www.youtube.com/watch?v=q59wap1ELQ4)
## Author
This section was written by <a href="https://twitter.com/ThomasSimonini"> Thomas Simonini</a>
| huggingface/deep-rl-class/blob/main/units/en/unitbonus3/envs-to-try.mdx |
--
title: "Introducing Skops"
thumbnail: /blog/assets/94_skops/introducing_skops.png
authors:
- user: merve
- user: adrin
- user: BenjaminB
---
# Introducing Skops
## Introducing Skops
At Hugging Face, we are working on tackling various problems in open-source machine learning, including, hosting models securely and openly, enabling reproducibility, explainability and collaboration. We are thrilled to introduce you to our new library: Skops! With Skops, you can host your scikit-learn models on the Hugging Face Hub, create model cards for model documentation and collaborate with others.
Let's go through an end-to-end example: train a model first, and see step-by-step how to leverage Skops for sklearn in production.
```python
# let's import the libraries first
import sklearn
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
# Load the data and split
X, y = load_breast_cancer(as_frame=True, return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# Train the model
model = DecisionTreeClassifier().fit(X_train, y_train)
```
You can use any model filename and serialization method, like `pickle` or `joblib`. At the moment, our backend uses `joblib` to load the model. `hub_utils.init` creates a local folder containing the model in the given path, and the configuration file containing the specifications of the environment the model is trained in. The data and the task passed to the `init` will help Hugging Face Hub enable the inference widget on the model page as well as discoverability features to find the model.
```python
from skops import hub_utils
import pickle
# let's save the model
model_path = "example.pkl"
local_repo = "my-awesome-model"
with open(model_path, mode="bw") as f:
pickle.dump(model, file=f)
# we will now initialize a local repository
hub_utils.init(
model=model_path,
requirements=[f"scikit-learn={sklearn.__version__}"],
dst=local_repo,
task="tabular-classification",
data=X_test,
)
```
The repository now contains the serialized model and the configuration file.
The configuration contains the following:
- features of the model,
- the requirements of the model,
- an example input taken from `X_test` that we've passed,
- name of the model file,
- name of the task to be solved here.
We will now create the model card. The card should match the expected Hugging Face Hub format: a markdown part and a metadata section, which is a `yaml` section at the top. The keys to the metadata section are defined [here](https://huggingface.co/docs/hub/models-cards#model-card-metadata) and are used for the discoverability of the models.
The content of the model card is determined by a template that has a:
- `yaml` section on top for metadata (e.g. model license, library name, and more)
- markdown section with free text and sections to be filled (e.g. simple description of the model),
The following sections are extracted by `skops` to fill in the model card:
- Hyperparameters of the model,
- Interactive diagram of the model,
- For metadata, library name, task identifier (e.g. tabular-classification), and information required by the inference widget are filled.
We will walk you through how to programmatically pass information to fill the model card. You can check out our documentation on the default template provided by `skops`, and its sections [here](https://skops.readthedocs.io/en/latest/model_card.html) to see what the template expects and what it looks like [here](https://github.com/skops-dev/skops/blob/main/skops/card/default_template.md).
You can create the model card by instantiating the `Card` class from `skops`. During model serialization, the task name and library name are written to the configuration file. This information is also needed in the card's metadata, so you can use the `metadata_from_config` method to extract the metadata from the configuration file and pass it to the card when you create it. You can add information and metadata using `add`.
```python
from skops import card
# create the card
model_card = card.Card(model, metadata=card.metadata_from_config(Path(destination_folder)))
limitations = "This model is not ready to be used in production."
model_description = "This is a DecisionTreeClassifier model trained on breast cancer dataset."
model_card_authors = "skops_user"
get_started_code = "import pickle \nwith open(dtc_pkl_filename, 'rb') as file: \n clf = pickle.load(file)"
citation_bibtex = "bibtex\n@inproceedings{...,year={2020}}"
# we can add the information using add
model_card.add(
citation_bibtex=citation_bibtex,
get_started_code=get_started_code,
model_card_authors=model_card_authors,
limitations=limitations,
model_description=model_description,
)
# we can set the metadata part directly
model_card.metadata.license = "mit"
```
We will now evaluate the model and add a description of the evaluation method with `add`. The metrics are added by `add_metrics`, which will be parsed into a table.
```python
from sklearn.metrics import (ConfusionMatrixDisplay, confusion_matrix,
accuracy_score, f1_score)
# let's make a prediction and evaluate the model
y_pred = model.predict(X_test)
# we can pass metrics using add_metrics and pass details with add
model_card.add(eval_method="The model is evaluated using test split, on accuracy and F1 score with macro average.")
model_card.add_metrics(accuracy=accuracy_score(y_test, y_pred))
model_card.add_metrics(**{"f1 score": f1_score(y_test, y_pred, average="micro")})
```
We can also add any plot of our choice to the card using `add_plot` like below.
```python
import matplotlib.pyplot as plt
from pathlib import Path
# we will create a confusion matrix
cm = confusion_matrix(y_test, y_pred, labels=model.classes_)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=model.classes_)
disp.plot()
# save the plot
plt.savefig(Path(local_repo) / "confusion_matrix.png")
# the plot will be written to the model card under the name confusion_matrix
# we pass the path of the plot itself
model_card.add_plot(confusion_matrix="confusion_matrix.png")
```
Let's save the model card in the local repository. The file name here should be `README.md` since it is what Hugging Face Hub expects.
```python
model_card.save(Path(local_repo) / "README.md")
```
We can now push the repository to the Hugging Face Hub. For this, we will use `push` from `hub_utils`. Hugging Face Hub requires tokens for authentication, therefore you need to pass your token in either `notebook_login` if you're logging in from a notebook, or `huggingface-cli login` if you're logging in from the CLI.
```python
# if the repository doesn't exist remotely on the Hugging Face Hub, it will be created when we set create_remote to True
repo_id = "skops-user/my-awesome-model"
hub_utils.push(
repo_id=repo_id,
source=local_repo,
token=token,
commit_message="pushing files to the repo from the example!",
create_remote=True,
)
```
Once we push the model to the Hub, anyone can use it unless the repository is private. You can download the models using `download`. Apart from the model file, the repository contains the model configuration and the environment requirements.
```python
download_repo = "downloaded-model"
hub_utils.download(repo_id=repo_id, dst=download_repo)
```
The inference widget is enabled to make predictions in the repository.

If the requirements of your project have changed, you can use `update_env` to update the environment.
```python
hub_utils.update_env(path=local_repo, requirements=["scikit-learn"])
```
You can see the example repository pushed with above code [here](https://huggingface.co/scikit-learn/skops-blog-example).
We have prepared two examples to show how to save your models and use model card utilities. You can find them in the resources section below.
## Resources
- [Model card tutorial](https://skops.readthedocs.io/en/latest/auto_examples/plot_model_card.html)
- [hub_utils tutorial](https://skops.readthedocs.io/en/latest/auto_examples/plot_hf_hub.html)
- [skops documentation](https://skops.readthedocs.io/en/latest/modules/classes.html)
| huggingface/blog/blob/main/skops.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# ControlNet-XS
ControlNet-XS was introduced in [ControlNet-XS](https://vislearn.github.io/ControlNet-XS/) by Denis Zavadski and Carsten Rother. It is based on the observation that the control model in the [original ControlNet](https://huggingface.co/papers/2302.05543) can be made much smaller and still produce good results.
Like the original ControlNet model, you can provide an additional control image to condition and control Stable Diffusion generation. For example, if you provide a depth map, the ControlNet model generates an image that'll preserve the spatial information from the depth map. It is a more flexible and accurate way to control the image generation process.
ControlNet-XS generates images with comparable quality to a regular ControlNet, but it is 20-25% faster ([see benchmark](https://github.com/UmerHA/controlnet-xs-benchmark/blob/main/Speed%20Benchmark.ipynb) with StableDiffusion-XL) and uses ~45% less memory.
Here's the overview from the [project page](https://vislearn.github.io/ControlNet-XS/):
*With increasing computing capabilities, current model architectures appear to follow the trend of simply upscaling all components without validating the necessity for doing so. In this project we investigate the size and architectural design of ControlNet [Zhang et al., 2023] for controlling the image generation process with stable diffusion-based models. We show that a new architecture with as little as 1% of the parameters of the base model achieves state-of-the art results, considerably better than ControlNet in terms of FID score. Hence we call it ControlNet-XS. We provide the code for controlling StableDiffusion-XL [Podell et al., 2023] (Model B, 48M Parameters) and StableDiffusion 2.1 [Rombach et al. 2022] (Model B, 14M Parameters), all under openrail license.*
This model was contributed by [UmerHA](https://twitter.com/UmerHAdil). ❤️
<Tip>
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
</Tip>
## StableDiffusionControlNetXSPipeline
[[autodoc]] StableDiffusionControlNetXSPipeline
- all
- __call__
## StableDiffusionPipelineOutput
[[autodoc]] pipelines.stable_diffusion.StableDiffusionPipelineOutput
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/controlnetxs.md |
SWSL ResNeXt
A **ResNeXt** repeats a [building block](https://paperswithcode.com/method/resnext-block) that aggregates a set of transformations with the same topology. Compared to a [ResNet](https://paperswithcode.com/method/resnet), it exposes a new dimension, *cardinality* (the size of the set of transformations) \\( C \\), as an essential factor in addition to the dimensions of depth and width.
The models in this collection utilise semi-weakly supervised learning to improve the performance of the model. The approach brings important gains to standard architectures for image, video and fine-grained classification.
Please note the CC-BY-NC 4.0 license on theses weights, non-commercial use only.
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('swsl_resnext101_32x16d', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `swsl_resnext101_32x16d`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('swsl_resnext101_32x16d', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/abs-1905-00546,
author = {I. Zeki Yalniz and
Herv{\'{e}} J{\'{e}}gou and
Kan Chen and
Manohar Paluri and
Dhruv Mahajan},
title = {Billion-scale semi-supervised learning for image classification},
journal = {CoRR},
volume = {abs/1905.00546},
year = {2019},
url = {http://arxiv.org/abs/1905.00546},
archivePrefix = {arXiv},
eprint = {1905.00546},
timestamp = {Mon, 28 Sep 2020 08:19:37 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-1905-00546.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<!--
Type: model-index
Collections:
- Name: SWSL ResNext
Paper:
Title: Billion-scale semi-supervised learning for image classification
URL: https://paperswithcode.com/paper/billion-scale-semi-supervised-learning-for
Models:
- Name: swsl_resnext101_32x16d
In Collection: SWSL ResNext
Metadata:
FLOPs: 46623691776
Parameters: 194030000
File Size: 777518664
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- IG-1B-Targeted
- ImageNet
Training Resources: 64x GPUs
ID: swsl_resnext101_32x16d
LR: 0.0015
Epochs: 30
Layers: 101
Crop Pct: '0.875'
Batch Size: 1536
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/resnet.py#L1009
Weights: https://dl.fbaipublicfiles.com/semiweaksupervision/model_files/semi_weakly_supervised_resnext101_32x16-f3559a9c.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 83.34%
Top 5 Accuracy: 96.84%
- Name: swsl_resnext101_32x4d
In Collection: SWSL ResNext
Metadata:
FLOPs: 10298145792
Parameters: 44180000
File Size: 177341913
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- IG-1B-Targeted
- ImageNet
Training Resources: 64x GPUs
ID: swsl_resnext101_32x4d
LR: 0.0015
Epochs: 30
Layers: 101
Crop Pct: '0.875'
Batch Size: 1536
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/resnet.py#L987
Weights: https://dl.fbaipublicfiles.com/semiweaksupervision/model_files/semi_weakly_supervised_resnext101_32x4-3f87e46b.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 83.22%
Top 5 Accuracy: 96.77%
- Name: swsl_resnext101_32x8d
In Collection: SWSL ResNext
Metadata:
FLOPs: 21180417024
Parameters: 88790000
File Size: 356056638
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- IG-1B-Targeted
- ImageNet
Training Resources: 64x GPUs
ID: swsl_resnext101_32x8d
LR: 0.0015
Epochs: 30
Layers: 101
Crop Pct: '0.875'
Batch Size: 1536
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/resnet.py#L998
Weights: https://dl.fbaipublicfiles.com/semiweaksupervision/model_files/semi_weakly_supervised_resnext101_32x8-b4712904.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 84.27%
Top 5 Accuracy: 97.17%
- Name: swsl_resnext50_32x4d
In Collection: SWSL ResNext
Metadata:
FLOPs: 5472648192
Parameters: 25030000
File Size: 100428550
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- IG-1B-Targeted
- ImageNet
Training Resources: 64x GPUs
ID: swsl_resnext50_32x4d
LR: 0.0015
Epochs: 30
Layers: 50
Crop Pct: '0.875'
Batch Size: 1536
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/resnet.py#L976
Weights: https://dl.fbaipublicfiles.com/semiweaksupervision/model_files/semi_weakly_supervised_resnext50_32x4-72679e44.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 82.17%
Top 5 Accuracy: 96.23%
-->
| huggingface/pytorch-image-models/blob/main/hfdocs/source/models/swsl-resnext.mdx |
Encoder models[[encoder-models]]
<CourseFloatingBanner
chapter={1}
classNames="absolute z-10 right-0 top-0"
/>
<Youtube id="MUqNwgPjJvQ" />
Encoder models use only the encoder of a Transformer model. At each stage, the attention layers can access all the words in the initial sentence. These models are often characterized as having "bi-directional" attention, and are often called *auto-encoding models*.
The pretraining of these models usually revolves around somehow corrupting a given sentence (for instance, by masking random words in it) and tasking the model with finding or reconstructing the initial sentence.
Encoder models are best suited for tasks requiring an understanding of the full sentence, such as sentence classification, named entity recognition (and more generally word classification), and extractive question answering.
Representatives of this family of models include:
- [ALBERT](https://huggingface.co/docs/transformers/model_doc/albert)
- [BERT](https://huggingface.co/docs/transformers/model_doc/bert)
- [DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)
- [ELECTRA](https://huggingface.co/docs/transformers/model_doc/electra)
- [RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta)
| huggingface/course/blob/main/chapters/en/chapter1/5.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# SpeechT5
## Overview
The SpeechT5 model was proposed in [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
The abstract from the paper is the following:
*Motivated by the success of T5 (Text-To-Text Transfer Transformer) in pre-trained natural language processing models, we propose a unified-modal SpeechT5 framework that explores the encoder-decoder pre-training for self-supervised speech/text representation learning. The SpeechT5 framework consists of a shared encoder-decoder network and six modal-specific (speech/text) pre/post-nets. After preprocessing the input speech/text through the pre-nets, the shared encoder-decoder network models the sequence-to-sequence transformation, and then the post-nets generate the output in the speech/text modality based on the output of the decoder. Leveraging large-scale unlabeled speech and text data, we pre-train SpeechT5 to learn a unified-modal representation, hoping to improve the modeling capability for both speech and text. To align the textual and speech information into this unified semantic space, we propose a cross-modal vector quantization approach that randomly mixes up speech/text states with latent units as the interface between encoder and decoder. Extensive evaluations show the superiority of the proposed SpeechT5 framework on a wide variety of spoken language processing tasks, including automatic speech recognition, speech synthesis, speech translation, voice conversion, speech enhancement, and speaker identification.*
This model was contributed by [Matthijs](https://huggingface.co/Matthijs). The original code can be found [here](https://github.com/microsoft/SpeechT5).
## SpeechT5Config
[[autodoc]] SpeechT5Config
## SpeechT5HifiGanConfig
[[autodoc]] SpeechT5HifiGanConfig
## SpeechT5Tokenizer
[[autodoc]] SpeechT5Tokenizer
- __call__
- save_vocabulary
- decode
- batch_decode
## SpeechT5FeatureExtractor
[[autodoc]] SpeechT5FeatureExtractor
- __call__
## SpeechT5Processor
[[autodoc]] SpeechT5Processor
- __call__
- pad
- from_pretrained
- save_pretrained
- batch_decode
- decode
## SpeechT5Model
[[autodoc]] SpeechT5Model
- forward
## SpeechT5ForSpeechToText
[[autodoc]] SpeechT5ForSpeechToText
- forward
## SpeechT5ForTextToSpeech
[[autodoc]] SpeechT5ForTextToSpeech
- forward
- generate
## SpeechT5ForSpeechToSpeech
[[autodoc]] SpeechT5ForSpeechToSpeech
- forward
- generate_speech
## SpeechT5HifiGan
[[autodoc]] SpeechT5HifiGan
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/speecht5.md |
--
title: "Run a Chatgpt-like Chatbot on a Single GPU with ROCm"
thumbnail: /blog/assets/chatbot-amd-gpu/thumbnail.png
authors:
- user: andyll7772
guest: true
---
# Run a Chatgpt-like Chatbot on a Single GPU with ROCm
## Introduction
ChatGPT, OpenAI's groundbreaking language model, has become an
influential force in the realm of artificial intelligence, paving the
way for a multitude of AI applications across diverse sectors. With its
staggering ability to comprehend and generate human-like text, ChatGPT
has transformed industries, from customer support to creative writing,
and has even served as an invaluable research tool.
Various efforts have been made to provide
open-source large language models which demonstrate great capabilities
but in smaller sizes, such as
[OPT](https://huggingface.co/docs/transformers/model_doc/opt),
[LLAMA](https://github.com/facebookresearch/llama),
[Alpaca](https://github.com/tatsu-lab/stanford_alpaca) and
[Vicuna](https://github.com/lm-sys/FastChat).
In this blog, we will delve into the world of Vicuna, and explain how to
run the Vicuna 13B model on a single AMD GPU with ROCm.
**What is Vicuna?**
Vicuna is an open-source chatbot with 13 billion parameters, developed
by a team from UC Berkeley, CMU, Stanford, and UC San Diego. To create
Vicuna, a LLAMA base model was fine-tuned using about 70K user-shared
conversations collected from ShareGPT.com via public APIs. According to
initial assessments where GPT-4 is used as a reference, Vicuna-13B has
achieved over 90%\* quality compared to OpenAI ChatGPT.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/01.png" style="width: 60%; height: auto;">
</p>
It was released on [Github](https://github.com/lm-sys/FastChat) on Apr
11, just a few weeks ago. It is worth mentioning that the data set,
training code, evaluation metrics, training cost are known for Vicuna. Its total training cost was just
around \$300, making it a cost-effective solution for the general public.
For more details about Vicuna, please check out
<https://vicuna.lmsys.org>.
**Why do we need a quantized GPT model?**
Running Vicuna-13B model in fp16 requires around 28GB GPU RAM. To
further reduce the memory footprint, optimization techniques are
required. There is a recent research paper GPTQ published, which
proposed accurate post-training quantization for GPT models with lower
bit precision. As illustrated below, for models with parameters larger
than 10B, the 4-bit or 3-bit GPTQ can achieve comparable accuracy
with fp16.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/02.png" style="width: 70%; height: auto;">
</p>
Moreover, large parameters of these models also have a severely negative
effect on GPT latency because GPT token generation is more limited by
memory bandwidth (GB/s) than computation (TFLOPs or TOPs) itself. For this
reason, a quantized model does not degrade
token generation latency when the GPU is under a memory bound situation.
Refer to [the GPTQ quantization papers](<https://arxiv.org/abs/2210.17323>) and [github repo](<https://github.com/IST-DASLab/gptq>).
By leveraging this technique, several 4-bit quantized Vicuna models are
available from Hugging Face as follows,
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/03.png" style="width: 50%; height: auto;">
</p>
## Running Vicuna 13B Model on AMD GPU with ROCm
To run the Vicuna 13B model on an AMD GPU, we need to leverage the power
of ROCm (Radeon Open Compute), an open-source software platform that
provides AMD GPU acceleration for deep learning and high-performance
computing applications.
Here's a step-by-step guide on how to set up and run the Vicuna 13B
model on an AMD GPU with ROCm:
**System Requirements**
Before diving into the installation process, ensure that your system
meets the following requirements:
- An AMD GPU that supports ROCm (check the compatibility list on
docs.amd.com page)
- A Linux-based operating system, preferably Ubuntu 18.04 or 20.04
- Conda or Docker environment
- Python 3.6 or higher
For more information, please check out <https://docs.amd.com/bundle/ROCm-Installation-Guide-v5.4.3/page/Prerequisites.html>.
This example has been tested on [**Instinct
MI210**](https://www.amd.com/en/products/server-accelerators/amd-instinct-mi210)
and [**Radeon
RX6900XT**](https://www.amd.com/en/products/graphics/amd-radeon-rx-6900-xt)
GPUs with ROCm5.4.3 and Pytorch2.0.
**Quick Start**
**1 ROCm installation and Docker container setup (Host machine)**
**1.1 ROCm** **installation**
The following is for ROCm5.4.3 and Ubuntu 22.04. Please modify
according to your target ROCm and Ubuntu version from:
<https://docs.amd.com/bundle/ROCm-Installation-Guide-v5.4.3/page/How_to_Install_ROCm.html>
```
sudo apt update && sudo apt upgrade -y
wget https://repo.radeon.com/amdgpu-install/5.4.3/ubuntu/jammy/amdgpu-install_5.4.50403-1_all.deb
sudo apt-get install ./amdgpu-install_5.4.50403-1_all.deb
sudo amdgpu-install --usecase=hiplibsdk,rocm,dkms
sudo amdgpu-install --list-usecase
sudo reboot
```
**1.2 ROCm installation verification**
```
rocm-smi
sudo rocminfo
```
**1.3 Docker image pull and run a Docker container**
The following uses Pytorch2.0 on ROCm5.4.2. Please use the
appropriate docker image according to your target ROCm and Pytorch
version: <https://hub.docker.com/r/rocm/pytorch/tags>
```
docker pull rocm/pytorch:rocm5.4.2_ubuntu20.04_py3.8_pytorch_2.0.0_preview
sudo docker run --device=/dev/kfd --device=/dev/dri --group-add video \
--shm-size=8g --cap-add=SYS_PTRACE --security-opt seccomp=unconfined \
--ipc=host -it --name vicuna_test -v ${PWD}:/workspace -e USER=${USER} \
rocm/pytorch:rocm5.4.2_ubuntu20.04_py3.8_pytorch_2.0.0_preview
```
**2 Model** **quantization and Model inference (Inside the docker)**
You can either download quantized Vicuna-13b model from Huggingface or
quantize the floating-point model. Please check out **Appendix - GPTQ
model quantization** if you want to quantize the floating-point model.
**2.1 Download the quantized Vicuna-13b model**
Use download-model.py script from the following git repo.
```
git clone https://github.com/oobabooga/text-generation-webui.git
cd text-generation-webui
python download-model.py anon8231489123/vicuna-13b-GPTQ-4bit-128g
```
2. **Running the Vicuna 13B GPTQ Model on AMD GPU**
```
git clone https://github.com/oobabooga/GPTQ-for-LLaMa.git -b cuda
cd GPTQ-for-LLaMa
python setup_cuda.py install
```
These commands will compile and link HIPIFIED CUDA-equivalent kernel
binaries to
python as C extensions. The kernels of this implementation are composed
of dequantization + FP32 Matmul. If you want to use dequantization +
FP16 Matmul for additional speed-up, please check out **Appendix - GPTQ
Dequantization + FP16 Mamul kernel for AMD GPUs**
```
git clone https://github.com/oobabooga/GPTQ-for-LLaMa.git -b cuda
cd GPTQ-for-LLaMa/
python setup_cuda.py install
# model inference
python llama_inference.py ../../models/vicuna-13b --wbits 4 --load \
../../models/vicuna-13b/vicuna-13b_4_actorder.safetensors --groupsize 128 --text “You input text here”
```
Now that you have everything set up, it's time to run the Vicuna 13B
model on your AMD GPU. Use the commands above to run the model. Replace
*"Your input text here"* with the text you want to use as input for
the model. If everything is set up correctly, you should see the model
generating output text based on your input.
**3. Expose the quantized Vicuna model to the Web API server**
Change the path of GPTQ python modules (GPTQ-for-LLaMa) in the following
line:
<https://github.com/thisserand/FastChat/blob/4a57c928a906705404eae06f7a44b4da45828487/fastchat/serve/load_gptq_model.py#L7>
To launch Web UXUI from the gradio library, you need to set up the
controller, worker (Vicunal model worker), web_server by running them as
background jobs.
```
nohup python0 -W ignore::UserWarning -m fastchat.serve.controller &
nohup python0 -W ignore::UserWarning -m fastchat.serve.model_worker --model-path /path/to/quantized_vicuna_weights \
--model-name vicuna-13b-quantization --wbits 4 --groupsize 128 &
nohup python0 -W ignore::UserWarning -m fastchat.serve.gradio_web_server &
```
Now the 4-bit quantized Vicuna-13B model can be fitted in RX6900XT GPU
DDR memory, which has 16GB DDR. Only 7.52GB of DDR (46% of 16GB) is
needed to run 13B models whereas the model needs more than 28GB of DDR
space in fp16 datatype. The latency penalty and accuracy penalty are
also very minimal and the related metrics are provided at the end of
this article.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/04.png" style="width: 60%; height: auto;">
</p>
**Test the quantized Vicuna model in the Web API server**
Let us give it a try. First, let us use fp16 Vicuna model for language
translation.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/05.png" style="width: 80%; height: auto;">
</p>
It does a better job than me. Next, let us ask something about soccer. The answer looks good to me.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/06.png" style="width: 80%; height: auto;">
</p>
When we switch to the 4-bit model, for the same question, the answer is
a bit different. There is a duplicated “Lionel Messi” in it.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/07.png" style="width: 80%; height: auto;">
</p>
**Vicuna fp16 and 4bit quantized model comparison**
Test environment:
\- GPU: Instinct MI210, RX6900XT
\- python: 3.10
\- pytorch: 2.1.0a0+gitfa08e54
\- rocm: 5.4.3
**Metrics - Model size (GB)**
- Model parameter size. When the models are preloaded to GPU DDR, the
actual DDR size consumption is larger than model itself due to caching
for Input and output token spaces.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/08.png" style="width: 70%; height: auto;">
</p>
**Metrics – Accuracy (PPL: Perplexity)**
- Measured on 2048 examples of C4
(<https://paperswithcode.com/dataset/c4>) dataset
- Vicuna 13b – baseline: fp16 datatype parameter, fp16 Matmul
- Vicuna 13b – quant (4bit/fp32): 4bits datatype parameter, fp32 Matmul
- Vicuna 13b – quant (4bit/fp16): 4bits datatype parameter, fp16 Matmul
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/09.png" style="width: 70%; height: auto;">
</p>
**Metrics – Latency (Token generation latency, ms)**
- Measured during token generation phases.
- Vicuna 13b – baseline: fp16 datatype parameter, fp16 Matmul
- Vicuna 13b – quant (4bit/fp32): 4bits datatype parameter, fp32 Matmul
- Vicuna 13b – quant (4bit/fp16): 4bits datatype parameter, fp16 Matmul
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/10.png" style="width: 70%; height: auto;">
</p>
## Conclusion
Large language models (LLMs) have made significant advancements in
chatbot systems, as seen in OpenAI’s ChatGPT. Vicuna-13B, an open-source
LLM model has been developed and demonstrated excellent capability and quality.
By following this guide, you should now have a better understanding of
how to set up and run the Vicuna 13B model on an AMD GPU with ROCm. This
will enable you to unlock the full potential of this cutting-edge
language model for your research and personal projects.
Thanks for reading!
## Appendix - GPTQ model quantization
**Building Vicuna quantized model from the floating-point LLaMA model**
**a. Download LLaMA and Vicuna delta models from Huggingface**
The developers of Vicuna (lmsys) provide only delta-models that can be
applied to the LLaMA model. Download LLaMA in huggingface format and
Vicuna delta parameters from Huggingface individually. Currently, 7b and
13b delta models of Vicuna are available.
<https://huggingface.co/models?sort=downloads&search=huggyllama>
<https://huggingface.co/models?sort=downloads&search=lmsys>
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/13.png" style="width: 60%; height: auto;">
</p>
**b. Convert LLaMA to Vicuna by using Vicuna-delta model**
```
git clone https://github.com/lm-sys/FastChat
cd FastChat
```
Convert the LLaMA parameters by using this command:
(Note: do not use vicuna-{7b, 13b}-\*delta-v0 because it’s vocab_size is
different from that of LLaMA and the model cannot be converted)
```
python -m fastchat.model.apply_delta --base /path/to/llama-13b --delta lmsys/vicuna-13b-delta-v1.1 \
--target ./vicuna-13b
```
Now Vicuna-13b model is ready.
**c. Quantize Vicuna to 2/3/4 bits**
To apply the GPTQ to LLaMA and Vicuna,
```
git clone https://github.com/oobabooga/GPTQ-for-LLaMa -b cuda
cd GPTQ-for-LLaMa
```
(Note, do not use <https://github.com/qwopqwop200/GPTQ-for-LLaMa> for
now. Because 2,3,4bit quantization + MatMul kernels implemented in this
repo does not parallelize the dequant+matmul and hence shows lower token
generation performance)
Quantize Vicuna-13b model with this command. QAT is done based on c4
data-set but you can also use other data-sets, such as wikitext2
(Note. Change group size with different combinations as long as the
model accuracy increases significantly. Under some combination of wbit
and groupsize, model accuracy can be increased significantly.)
```
python llama.py ./Vicuna-13b c4 --wbits 4 --true-sequential --act-order \
--save_safetensors Vicuna-13b-4bit-act-order.safetensors
```
Now the model is ready and saved as
**Vicuna-13b-4bit-act-order.safetensors**.
**GPTQ Dequantization + FP16 Mamul kernel for AMD GPUs**
The more optimized kernel implementation in
<https://github.com/oobabooga/GPTQ-for-LLaMa/blob/57a26292ed583528d9941e79915824c5af012279/quant_cuda_kernel.cu#L891>
targets at A100 GPU and not compatible with ROCM5.4.3 HIPIFY
toolkits. It needs to be modified as follows. The same for
VecQuant2MatMulKernelFaster, VecQuant3MatMulKernelFaster,
VecQuant4MatMulKernelFaster kernels.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/14.png" style="width: 100%; height: auto;">
For convenience, All the modified codes are available in [Github Gist](https://gist.github.com/seungrokjung/110943b70503732c4a398607e1cbdd6c).
| huggingface/blog/blob/main/chatbot-amd-gpu.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Image-to-Image Task Guide
[[open-in-colab]]
Image-to-Image task is the task where an application receives an image and outputs another image. This has various subtasks, including image enhancement (super resolution, low light enhancement, deraining and so on), image inpainting, and more.
This guide will show you how to:
- Use an image-to-image pipeline for super resolution task,
- Run image-to-image models for same task without a pipeline.
Note that as of the time this guide is released, `image-to-image` pipeline only supports super resolution task.
Let's begin by installing the necessary libraries.
```bash
pip install transformers
```
We can now initialize the pipeline with a [Swin2SR model](https://huggingface.co/caidas/swin2SR-lightweight-x2-64). We can then infer with the pipeline by calling it with an image. As of now, only [Swin2SR models](https://huggingface.co/models?sort=trending&search=swin2sr) are supported in this pipeline.
```python
from transformers import pipeline
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
pipe = pipeline(task="image-to-image", model="caidas/swin2SR-lightweight-x2-64", device=device)
```
Now, let's load an image.
```python
from PIL import Image
import requests
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/cat.jpg"
image = Image.open(requests.get(url, stream=True).raw)
print(image.size)
```
```bash
# (532, 432)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/cat.jpg" alt="Photo of a cat"/>
</div>
We can now do inference with the pipeline. We will get an upscaled version of the cat image.
```python
upscaled = pipe(image)
print(upscaled.size)
```
```bash
# (1072, 880)
```
If you wish to do inference yourself with no pipeline, you can use the `Swin2SRForImageSuperResolution` and `Swin2SRImageProcessor` classes of transformers. We will use the same model checkpoint for this. Let's initialize the model and the processor.
```python
from transformers import Swin2SRForImageSuperResolution, Swin2SRImageProcessor
model = Swin2SRForImageSuperResolution.from_pretrained("caidas/swin2SR-lightweight-x2-64").to(device)
processor = Swin2SRImageProcessor("caidas/swin2SR-lightweight-x2-64")
```
`pipeline` abstracts away the preprocessing and postprocessing steps that we have to do ourselves, so let's preprocess the image. We will pass the image to the processor and then move the pixel values to GPU.
```python
pixel_values = processor(image, return_tensors="pt").pixel_values
print(pixel_values.shape)
pixel_values = pixel_values.to(device)
```
We can now infer the image by passing pixel values to the model.
```python
import torch
with torch.no_grad():
outputs = model(pixel_values)
```
Output is an object of type `ImageSuperResolutionOutput` that looks like below 👇
```
(loss=None, reconstruction=tensor([[[[0.8270, 0.8269, 0.8275, ..., 0.7463, 0.7446, 0.7453],
[0.8287, 0.8278, 0.8283, ..., 0.7451, 0.7448, 0.7457],
[0.8280, 0.8273, 0.8269, ..., 0.7447, 0.7446, 0.7452],
...,
[0.5923, 0.5933, 0.5924, ..., 0.0697, 0.0695, 0.0706],
[0.5926, 0.5932, 0.5926, ..., 0.0673, 0.0687, 0.0705],
[0.5927, 0.5914, 0.5922, ..., 0.0664, 0.0694, 0.0718]]]],
device='cuda:0'), hidden_states=None, attentions=None)
```
We need to get the `reconstruction` and post-process it for visualization. Let's see how it looks like.
```python
outputs.reconstruction.data.shape
# torch.Size([1, 3, 880, 1072])
```
We need to squeeze the output and get rid of axis 0, clip the values, then convert it to be numpy float. Then we will arrange axes to have the shape [1072, 880], and finally, bring the output back to range [0, 255].
```python
import numpy as np
# squeeze, take to CPU and clip the values
output = outputs.reconstruction.data.squeeze().cpu().clamp_(0, 1).numpy()
# rearrange the axes
output = np.moveaxis(output, source=0, destination=-1)
# bring values back to pixel values range
output = (output * 255.0).round().astype(np.uint8)
Image.fromarray(output)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/cat_upscaled.png" alt="Upscaled photo of a cat"/>
</div>
| huggingface/transformers/blob/main/docs/source/en/tasks/image_to_image.md |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.