
text
stringlengths 23
371k
| source
stringlengths 32
152
|
|---|---|
Conclusion
**Congrats on finishing this unit**! There was a lot of information.
And congrats on finishing the tutorial. You've just coded your first Deep Reinforcement Learning agent from scratch using PyTorch and shared it on the Hub 🥳.
Don't hesitate to iterate on this unit **by improving the implementation for more complex environments** (for instance, what about changing the network to a Convolutional Neural Network to handle
frames as observation)?
In the next unit, **we're going to learn more about Unity MLAgents**, by training agents in Unity environments. This way, you will be ready to participate in the **AI vs AI challenges where you'll train your agents
to compete against other agents in a snowball fight and a soccer game.**
Sound fun? See you next time!
Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then please 👉 [fill this form](https://forms.gle/BzKXWzLAGZESGNaE9)
### Keep Learning, stay awesome 🤗
|
huggingface/deep-rl-class/blob/main/units/en/unit4/conclusion.mdx
|
--
title: MASE
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
Mean Absolute Scaled Error (MASE) is the mean absolute error of the forecast values, divided by the mean absolute error of the in-sample one-step naive forecast on the training set.
---
# Metric Card for MASE
## Metric Description
Mean Absolute Scaled Error (MASE) is the mean absolute error of the forecast values, divided by the mean absolute error of the in-sample one-step naive forecast. For prediction $x_i$ and corresponding ground truth $y_i$ as well as training data $z_t$ with seasonality $p$ the metric is given by:
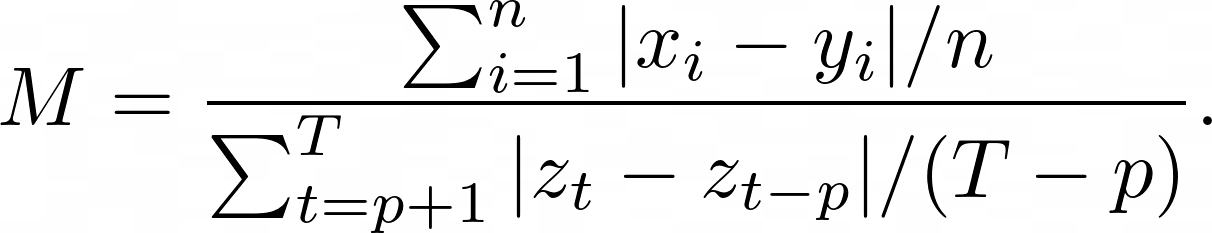
This metric is:
* independent of the scale of the data;
* has predictable behavior when predicted/ground-truth data is near zero;
* symmetric;
* interpretable, as values greater than one indicate that in-sample one-step forecasts from the naïve method perform better than the forecast values under consideration.
## How to Use
At minimum, this metric requires predictions, references and training data as inputs.
```python
>>> mase_metric = evaluate.load("mase")
>>> predictions = [2.5, 0.0, 2, 8]
>>> references = [3, -0.5, 2, 7]
>>> training = [5, 0.5, 4, 6, 3, 5, 2]
>>> results = mase_metric.compute(predictions=predictions, references=references, training=training)
```
### Inputs
Mandatory inputs:
- `predictions`: numeric array-like of shape (`n_samples,`) or (`n_samples`, `n_outputs`), representing the estimated target values.
- `references`: numeric array-like of shape (`n_samples,`) or (`n_samples`, `n_outputs`), representing the ground truth (correct) target values.
- `training`: numeric array-like of shape (`n_train_samples,`) or (`n_train_samples`, `n_outputs`), representing the in sample training data.
Optional arguments:
- `periodicity`: the seasonal periodicity of training data. The default is 1.
- `sample_weight`: numeric array-like of shape (`n_samples,`) representing sample weights. The default is `None`.
- `multioutput`: `raw_values`, `uniform_average` or numeric array-like of shape (`n_outputs,`), which defines the aggregation of multiple output values. The default value is `uniform_average`.
- `raw_values` returns a full set of errors in case of multioutput input.
- `uniform_average` means that the errors of all outputs are averaged with uniform weight.
- the array-like value defines weights used to average errors.
### Output Values
This metric outputs a dictionary, containing the mean absolute error score, which is of type:
- `float`: if multioutput is `uniform_average` or an ndarray of weights, then the weighted average of all output errors is returned.
- numeric array-like of shape (`n_outputs,`): if multioutput is `raw_values`, then the score is returned for each output separately.
Each MASE `float` value ranges from `0.0` to `1.0`, with the best value being 0.0.
Output Example(s):
```python
{'mase': 0.5}
```
If `multioutput="raw_values"`:
```python
{'mase': array([0.5, 1. ])}
```
#### Values from Popular Papers
### Examples
Example with the `uniform_average` config:
```python
>>> mase_metric = evaluate.load("mase")
>>> predictions = [2.5, 0.0, 2, 8]
>>> references = [3, -0.5, 2, 7]
>>> training = [5, 0.5, 4, 6, 3, 5, 2]
>>> results = mase_metric.compute(predictions=predictions, references=references, training=training)
>>> print(results)
{'mase': 0.1833...}
```
Example with multi-dimensional lists, and the `raw_values` config:
```python
>>> mase_metric = evaluate.load("mase", "multilist")
>>> predictions = [[0.5, 1], [-1, 1], [7, -6]]
>>> references = [[0.1, 2], [-1, 2], [8, -5]]
>>> training = [[0.5, 1], [-1, 1], [7, -6]]
>>> results = mase_metric.compute(predictions=predictions, references=references, training=training)
>>> print(results)
{'mase': 0.1818...}
>>> results = mase_metric.compute(predictions=predictions, references=references, training=training, multioutput='raw_values')
>>> print(results)
{'mase': array([0.1052..., 0.2857...])}
```
## Limitations and Bias
## Citation(s)
```bibtex
@article{HYNDMAN2006679,
title = {Another look at measures of forecast accuracy},
journal = {International Journal of Forecasting},
volume = {22},
number = {4},
pages = {679--688},
year = {2006},
issn = {0169-2070},
doi = {https://doi.org/10.1016/j.ijforecast.2006.03.001},
url = {https://www.sciencedirect.com/science/article/pii/S0169207006000239},
author = {Rob J. Hyndman and Anne B. Koehler},
}
```
## Further References
- [Mean absolute scaled error - Wikipedia](https://en.wikipedia.org/wiki/Mean_absolute_scaled_errorr)
|
huggingface/evaluate/blob/main/metrics/mase/README.md
|
Metric Card for XTREME-S
## Metric Description
The XTREME-S metric aims to evaluate model performance on the Cross-lingual TRansfer Evaluation of Multilingual Encoders for Speech (XTREME-S) benchmark.
This benchmark was designed to evaluate speech representations across languages, tasks, domains and data regimes. It covers 102 languages from 10+ language families, 3 different domains and 4 task families: speech recognition, translation, classification and retrieval.
## How to Use
There are two steps: (1) loading the XTREME-S metric relevant to the subset of the benchmark being used for evaluation; and (2) calculating the metric.
1. **Loading the relevant XTREME-S metric** : the subsets of XTREME-S are the following: `mls`, `voxpopuli`, `covost2`, `fleurs-asr`, `fleurs-lang_id`, `minds14` and `babel`. More information about the different subsets can be found on the [XTREME-S benchmark page](https://huggingface.co/datasets/google/xtreme_s).
```python
>>> from datasets import load_metric
>>> xtreme_s_metric = datasets.load_metric('xtreme_s', 'mls')
```
2. **Calculating the metric**: the metric takes two inputs :
- `predictions`: a list of predictions to score, with each prediction a `str`.
- `references`: a list of lists of references for each translation, with each reference a `str`.
```python
>>> references = ["it is sunny here", "paper and pen are essentials"]
>>> predictions = ["it's sunny", "paper pen are essential"]
>>> results = xtreme_s_metric.compute(predictions=predictions, references=references)
```
It also has two optional arguments:
- `bleu_kwargs`: a `dict` of keywords to be passed when computing the `bleu` metric for the `covost2` subset. Keywords can be one of `smooth_method`, `smooth_value`, `force`, `lowercase`, `tokenize`, `use_effective_order`.
- `wer_kwargs`: optional dict of keywords to be passed when computing `wer` and `cer`, which are computed for the `mls`, `fleurs-asr`, `voxpopuli`, and `babel` subsets. Keywords are `concatenate_texts`.
## Output values
The output of the metric depends on the XTREME-S subset chosen, consisting of a dictionary that contains one or several of the following metrics:
- `accuracy`: the proportion of correct predictions among the total number of cases processed, with a range between 0 and 1 (see [accuracy](https://huggingface.co/metrics/accuracy) for more information). This is returned for the `fleurs-lang_id` and `minds14` subsets.
- `f1`: the harmonic mean of the precision and recall (see [F1 score](https://huggingface.co/metrics/f1) for more information). Its range is 0-1 -- its lowest possible value is 0, if either the precision or the recall is 0, and its highest possible value is 1.0, which means perfect precision and recall. It is returned for the `minds14` subset.
- `wer`: Word error rate (WER) is a common metric of the performance of an automatic speech recognition system. The lower the value, the better the performance of the ASR system, with a WER of 0 being a perfect score (see [WER score](https://huggingface.co/metrics/wer) for more information). It is returned for the `mls`, `fleurs-asr`, `voxpopuli` and `babel` subsets of the benchmark.
- `cer`: Character error rate (CER) is similar to WER, but operates on character instead of word. The lower the CER value, the better the performance of the ASR system, with a CER of 0 being a perfect score (see [CER score](https://huggingface.co/metrics/cer) for more information). It is returned for the `mls`, `fleurs-asr`, `voxpopuli` and `babel` subsets of the benchmark.
- `bleu`: the BLEU score, calculated according to the SacreBLEU metric approach. It can take any value between 0.0 and 100.0, inclusive, with higher values being better (see [SacreBLEU](https://huggingface.co/metrics/sacrebleu) for more details). This is returned for the `covost2` subset.
### Values from popular papers
The [original XTREME-S paper](https://arxiv.org/pdf/2203.10752.pdf) reported average WERs ranging from 9.2 to 14.6, a BLEU score of 20.6, an accuracy of 73.3 and F1 score of 86.9, depending on the subsets of the dataset tested on.
## Examples
For the `mls` subset (which outputs `wer` and `cer`):
```python
>>> from datasets import load_metric
>>> xtreme_s_metric = datasets.load_metric('xtreme_s', 'mls')
>>> references = ["it is sunny here", "paper and pen are essentials"]
>>> predictions = ["it's sunny", "paper pen are essential"]
>>> results = xtreme_s_metric.compute(predictions=predictions, references=references)
>>> print({k: round(v, 2) for k, v in results.items()})
{'wer': 0.56, 'cer': 0.27}
```
For the `covost2` subset (which outputs `bleu`):
```python
>>> from datasets import load_metric
>>> xtreme_s_metric = datasets.load_metric('xtreme_s', 'covost2')
>>> references = ["bonjour paris", "il est necessaire de faire du sport de temps en temp"]
>>> predictions = ["bonjour paris", "il est important de faire du sport souvent"]
>>> results = xtreme_s_metric.compute(predictions=predictions, references=references)
>>> print({k: round(v, 2) for k, v in results.items()})
{'bleu': 31.65}
```
For the `fleurs-lang_id` subset (which outputs `accuracy`):
```python
>>> from datasets import load_metric
>>> xtreme_s_metric = datasets.load_metric('xtreme_s', 'fleurs-lang_id')
>>> references = [0, 1, 0, 0, 1]
>>> predictions = [0, 1, 1, 0, 0]
>>> results = xtreme_s_metric.compute(predictions=predictions, references=references)
>>> print({k: round(v, 2) for k, v in results.items()})
{'accuracy': 0.6}
```
For the `minds14` subset (which outputs `f1` and `accuracy`):
```python
>>> from datasets import load_metric
>>> xtreme_s_metric = datasets.load_metric('xtreme_s', 'minds14')
>>> references = [0, 1, 0, 0, 1]
>>> predictions = [0, 1, 1, 0, 0]
>>> results = xtreme_s_metric.compute(predictions=predictions, references=references)
>>> print({k: round(v, 2) for k, v in results.items()})
{'f1': 0.58, 'accuracy': 0.6}
```
## Limitations and bias
This metric works only with datasets that have the same format as the [XTREME-S dataset](https://huggingface.co/datasets/google/xtreme_s).
While the XTREME-S dataset is meant to represent a variety of languages and tasks, it has inherent biases: it is missing many languages that are important and under-represented in NLP datasets.
It also has a particular focus on read-speech because common evaluation benchmarks like CoVoST-2 or LibriSpeech evaluate on this type of speech, which results in a mismatch between performance obtained in a read-speech setting and a more noisy setting (in production or live deployment, for instance).
## Citation
```bibtex
@article{conneau2022xtreme,
title={XTREME-S: Evaluating Cross-lingual Speech Representations},
author={Conneau, Alexis and Bapna, Ankur and Zhang, Yu and Ma, Min and von Platen, Patrick and Lozhkov, Anton and Cherry, Colin and Jia, Ye and Rivera, Clara and Kale, Mihir and others},
journal={arXiv preprint arXiv:2203.10752},
year={2022}
}
```
## Further References
- [XTREME-S dataset](https://huggingface.co/datasets/google/xtreme_s)
- [XTREME-S github repository](https://github.com/google-research/xtreme)
|
huggingface/datasets/blob/main/metrics/xtreme_s/README.md
|
ResNet
**Residual Networks**, or **ResNets**, learn residual functions with reference to the layer inputs, instead of learning unreferenced functions. Instead of hoping each few stacked layers directly fit a desired underlying mapping, residual nets let these layers fit a residual mapping. They stack [residual blocks](https://paperswithcode.com/method/residual-block) ontop of each other to form network: e.g. a ResNet-50 has fifty layers using these blocks.
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('resnet18', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `resnet18`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('resnet18', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/HeZRS15,
author = {Kaiming He and
Xiangyu Zhang and
Shaoqing Ren and
Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {CoRR},
volume = {abs/1512.03385},
year = {2015},
url = {http://arxiv.org/abs/1512.03385},
archivePrefix = {arXiv},
eprint = {1512.03385},
timestamp = {Wed, 17 Apr 2019 17:23:45 +0200},
biburl = {https://dblp.org/rec/journals/corr/HeZRS15.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<!--
Type: model-index
Collections:
- Name: ResNet
Paper:
Title: Deep Residual Learning for Image Recognition
URL: https://paperswithcode.com/paper/deep-residual-learning-for-image-recognition
Models:
- Name: resnet18
In Collection: ResNet
Metadata:
FLOPs: 2337073152
Parameters: 11690000
File Size: 46827520
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: resnet18
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnet.py#L641
Weights: https://download.pytorch.org/models/resnet18-5c106cde.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 69.74%
Top 5 Accuracy: 89.09%
- Name: resnet26
In Collection: ResNet
Metadata:
FLOPs: 3026804736
Parameters: 16000000
File Size: 64129972
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: resnet26
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnet.py#L675
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/resnet26-9aa10e23.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.29%
Top 5 Accuracy: 92.57%
- Name: resnet34
In Collection: ResNet
Metadata:
FLOPs: 4718469120
Parameters: 21800000
File Size: 87290831
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: resnet34
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnet.py#L658
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/resnet34-43635321.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.11%
Top 5 Accuracy: 92.28%
- Name: resnet50
In Collection: ResNet
Metadata:
FLOPs: 5282531328
Parameters: 25560000
File Size: 102488165
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: resnet50
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnet.py#L691
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/resnet50_ram-a26f946b.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.04%
Top 5 Accuracy: 94.39%
- Name: resnetblur50
In Collection: ResNet
Metadata:
FLOPs: 6621606912
Parameters: 25560000
File Size: 102488165
Architecture:
- 1x1 Convolution
- Batch Normalization
- Blur Pooling
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: resnetblur50
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnet.py#L1160
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/resnetblur50-84f4748f.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.29%
Top 5 Accuracy: 94.64%
- Name: tv_resnet101
In Collection: ResNet
Metadata:
FLOPs: 10068547584
Parameters: 44550000
File Size: 178728960
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: tv_resnet101
LR: 0.1
Epochs: 90
Crop Pct: '0.875'
LR Gamma: 0.1
Momentum: 0.9
Batch Size: 32
Image Size: '224'
LR Step Size: 30
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/resnet.py#L761
Weights: https://download.pytorch.org/models/resnet101-5d3b4d8f.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.37%
Top 5 Accuracy: 93.56%
- Name: tv_resnet152
In Collection: ResNet
Metadata:
FLOPs: 14857660416
Parameters: 60190000
File Size: 241530880
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: tv_resnet152
LR: 0.1
Epochs: 90
Crop Pct: '0.875'
LR Gamma: 0.1
Momentum: 0.9
Batch Size: 32
Image Size: '224'
LR Step Size: 30
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/resnet.py#L769
Weights: https://download.pytorch.org/models/resnet152-b121ed2d.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.32%
Top 5 Accuracy: 94.05%
- Name: tv_resnet34
In Collection: ResNet
Metadata:
FLOPs: 4718469120
Parameters: 21800000
File Size: 87306240
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: tv_resnet34
LR: 0.1
Epochs: 90
Crop Pct: '0.875'
LR Gamma: 0.1
Momentum: 0.9
Batch Size: 32
Image Size: '224'
LR Step Size: 30
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/resnet.py#L745
Weights: https://download.pytorch.org/models/resnet34-333f7ec4.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 73.3%
Top 5 Accuracy: 91.42%
- Name: tv_resnet50
In Collection: ResNet
Metadata:
FLOPs: 5282531328
Parameters: 25560000
File Size: 102502400
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: tv_resnet50
LR: 0.1
Epochs: 90
Crop Pct: '0.875'
LR Gamma: 0.1
Momentum: 0.9
Batch Size: 32
Image Size: '224'
LR Step Size: 30
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/resnet.py#L753
Weights: https://download.pytorch.org/models/resnet50-19c8e357.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 76.16%
Top 5 Accuracy: 92.88%
-->
|
huggingface/pytorch-image-models/blob/main/hfdocs/source/models/resnet.mdx
|
Visualize the Clipped Surrogate Objective Function
Don't worry. **It's normal if this seems complex to handle right now**. But we're going to see what this Clipped Surrogate Objective Function looks like, and this will help you to visualize better what's going on.
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/recap.jpg" alt="PPO"/>
<figcaption><a href="https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf">Table from "Towards Delivering a Coherent Self-Contained
Explanation of Proximal Policy Optimization" by Daniel Bick</a></figcaption>
</figure>
We have six different situations. Remember first that we take the minimum between the clipped and unclipped objectives.
## Case 1 and 2: the ratio is between the range
In situations 1 and 2, **the clipping does not apply since the ratio is between the range** \\( [1 - \epsilon, 1 + \epsilon] \\)
In situation 1, we have a positive advantage: the **action is better than the average** of all the actions in that state. Therefore, we should encourage our current policy to increase the probability of taking that action in that state.
Since the ratio is between intervals, **we can increase our policy's probability of taking that action at that state.**
In situation 2, we have a negative advantage: the action is worse than the average of all actions at that state. Therefore, we should discourage our current policy from taking that action in that state.
Since the ratio is between intervals, **we can decrease the probability that our policy takes that action at that state.**
## Case 3 and 4: the ratio is below the range
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/recap.jpg" alt="PPO"/>
<figcaption><a href="https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf">Table from "Towards Delivering a Coherent Self-Contained
Explanation of Proximal Policy Optimization" by Daniel Bick</a></figcaption>
</figure>
If the probability ratio is lower than \\( [1 - \epsilon] \\), the probability of taking that action at that state is much lower than with the old policy.
If, like in situation 3, the advantage estimate is positive (A>0), then **you want to increase the probability of taking that action at that state.**
But if, like situation 4, the advantage estimate is negative, **we don't want to decrease further** the probability of taking that action at that state. Therefore, the gradient is = 0 (since we're on a flat line), so we don't update our weights.
## Case 5 and 6: the ratio is above the range
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/recap.jpg" alt="PPO"/>
<figcaption><a href="https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf">Table from "Towards Delivering a Coherent Self-Contained
Explanation of Proximal Policy Optimization" by Daniel Bick</a></figcaption>
</figure>
If the probability ratio is higher than \\( [1 + \epsilon] \\), the probability of taking that action at that state in the current policy is **much higher than in the former policy.**
If, like in situation 5, the advantage is positive, **we don't want to get too greedy**. We already have a higher probability of taking that action at that state than the former policy. Therefore, the gradient is = 0 (since we're on a flat line), so we don't update our weights.
If, like in situation 6, the advantage is negative, we want to decrease the probability of taking that action at that state.
So if we recap, **we only update the policy with the unclipped objective part**. When the minimum is the clipped objective part, we don't update our policy weights since the gradient will equal 0.
So we update our policy only if:
- Our ratio is in the range \\( [1 - \epsilon, 1 + \epsilon] \\)
- Our ratio is outside the range, but **the advantage leads to getting closer to the range**
- Being below the ratio but the advantage is > 0
- Being above the ratio but the advantage is < 0
**You might wonder why, when the minimum is the clipped ratio, the gradient is 0.** When the ratio is clipped, the derivative in this case will not be the derivative of the \\( r_t(\theta) * A_t \\) but the derivative of either \\( (1 - \epsilon)* A_t\\) or the derivative of \\( (1 + \epsilon)* A_t\\) which both = 0.
To summarize, thanks to this clipped surrogate objective, **we restrict the range that the current policy can vary from the old one.** Because we remove the incentive for the probability ratio to move outside of the interval since the clip forces the gradient to be zero. If the ratio is > \\( 1 + \epsilon \\) or < \\( 1 - \epsilon \\) the gradient will be equal to 0.
The final Clipped Surrogate Objective Loss for PPO Actor-Critic style looks like this, it's a combination of Clipped Surrogate Objective function, Value Loss Function and Entropy bonus:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/ppo-objective.jpg" alt="PPO objective"/>
That was quite complex. Take time to understand these situations by looking at the table and the graph. **You must understand why this makes sense.** If you want to go deeper, the best resource is the article [Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization" by Daniel Bick, especially part 3.4](https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf).
|
huggingface/deep-rl-class/blob/main/units/en/unit8/visualize.mdx
|
Metric Card for WER
## Metric description
Word error rate (WER) is a common metric of the performance of an automatic speech recognition (ASR) system.
The general difficulty of measuring the performance of ASR systems lies in the fact that the recognized word sequence can have a different length from the reference word sequence (supposedly the correct one). The WER is derived from the [Levenshtein distance](https://en.wikipedia.org/wiki/Levenshtein_distance), working at the word level.
This problem is solved by first aligning the recognized word sequence with the reference (spoken) word sequence using dynamic string alignment. Examination of this issue is seen through a theory called the power law that states the correlation between [perplexity](https://huggingface.co/metrics/perplexity) and word error rate (see [this article](https://www.cs.cmu.edu/~roni/papers/eval-metrics-bntuw-9802.pdf) for further information).
Word error rate can then be computed as:
`WER = (S + D + I) / N = (S + D + I) / (S + D + C)`
where
`S` is the number of substitutions,
`D` is the number of deletions,
`I` is the number of insertions,
`C` is the number of correct words,
`N` is the number of words in the reference (`N=S+D+C`).
## How to use
The metric takes two inputs: references (a list of references for each speech input) and predictions (a list of transcriptions to score).
```python
from datasets import load_metric
wer = load_metric("wer")
wer_score = wer.compute(predictions=predictions, references=references)
```
## Output values
This metric outputs a float representing the word error rate.
```
print(wer_score)
0.5
```
This value indicates the average number of errors per reference word.
The **lower** the value, the **better** the performance of the ASR system, with a WER of 0 being a perfect score.
### Values from popular papers
This metric is highly dependent on the content and quality of the dataset, and therefore users can expect very different values for the same model but on different datasets.
For example, datasets such as [LibriSpeech](https://huggingface.co/datasets/librispeech_asr) report a WER in the 1.8-3.3 range, whereas ASR models evaluated on [Timit](https://huggingface.co/datasets/timit_asr) report a WER in the 8.3-20.4 range.
See the leaderboards for [LibriSpeech](https://paperswithcode.com/sota/speech-recognition-on-librispeech-test-clean) and [Timit](https://paperswithcode.com/sota/speech-recognition-on-timit) for the most recent values.
## Examples
Perfect match between prediction and reference:
```python
from datasets import load_metric
wer = load_metric("wer")
predictions = ["hello world", "good night moon"]
references = ["hello world", "good night moon"]
wer_score = wer.compute(predictions=predictions, references=references)
print(wer_score)
0.0
```
Partial match between prediction and reference:
```python
from datasets import load_metric
wer = load_metric("wer")
predictions = ["this is the prediction", "there is an other sample"]
references = ["this is the reference", "there is another one"]
wer_score = wer.compute(predictions=predictions, references=references)
print(wer_score)
0.5
```
No match between prediction and reference:
```python
from datasets import load_metric
wer = load_metric("wer")
predictions = ["hello world", "good night moon"]
references = ["hi everyone", "have a great day"]
wer_score = wer.compute(predictions=predictions, references=references)
print(wer_score)
1.0
```
## Limitations and bias
WER is a valuable tool for comparing different systems as well as for evaluating improvements within one system. This kind of measurement, however, provides no details on the nature of translation errors and further work is therefore required to identify the main source(s) of error and to focus any research effort.
## Citation
```bibtex
@inproceedings{woodard1982,
author = {Woodard, J.P. and Nelson, J.T.,
year = {1982},
journal = Ẅorkshop on standardisation for speech I/O technology, Naval Air Development Center, Warminster, PA},
title = {An information theoretic measure of speech recognition performance}
}
```
```bibtex
@inproceedings{morris2004,
author = {Morris, Andrew and Maier, Viktoria and Green, Phil},
year = {2004},
month = {01},
pages = {},
title = {From WER and RIL to MER and WIL: improved evaluation measures for connected speech recognition.}
}
```
## Further References
- [Word Error Rate -- Wikipedia](https://en.wikipedia.org/wiki/Word_error_rate)
- [Hugging Face Tasks -- Automatic Speech Recognition](https://huggingface.co/tasks/automatic-speech-recognition)
|
huggingface/datasets/blob/main/metrics/wer/README.md
|
Share a dataset to the Hub
The [Hub](https://huggingface.co/datasets) is home to an extensive collection of community-curated and popular research datasets. We encourage you to share your dataset to the Hub to help grow the ML community and accelerate progress for everyone. All contributions are welcome; adding a dataset is just a drag and drop away!
Start by [creating a Hugging Face Hub account](https://huggingface.co/join) if you don't have one yet.
## Upload with the Hub UI
The Hub's web-based interface allows users without any developer experience to upload a dataset.
### Create a repository
A repository hosts all your dataset files, including the revision history, making storing more than one dataset version possible.
1. Click on your profile and select **New Dataset** to create a new dataset repository.
2. Pick a name for your dataset, and choose whether it is a public or private dataset. A public dataset is visible to anyone, whereas a private dataset can only be viewed by you or members of your organization.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/create_repo.png"/>
</div>
### Upload dataset
1. Once you've created a repository, navigate to the **Files and versions** tab to add a file. Select **Add file** to upload your dataset files. We support many text, audio, and image data extensions such as `.csv`, `.mp3`, and `.jpg` among many others. For text data extensions like `.csv`, `.json`, `.jsonl`, and `.txt`, we recommend compressing them before uploading to the Hub (to `.zip` or `.gz` file extension for example).
Text file extensions are not tracked by Git LFS by default, and if they're greater than 10MB, they will not be committed and uploaded. Take a look at the `.gitattributes` file in your repository for a complete list of tracked file extensions. For this tutorial, you can use the following sample `.csv` files since they're small: <a href="https://huggingface.co/datasets/stevhliu/demo/raw/main/train.csv" download>train.csv</a>, <a href="https://huggingface.co/datasets/stevhliu/demo/raw/main/test.csv" download>test.csv</a>.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/upload_files.png"/>
</div>
2. Drag and drop your dataset files and add a brief descriptive commit message.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/commit_files.png"/>
</div>
3. After uploading your dataset files, they are stored in your dataset repository.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/files_stored.png"/>
</div>
### Create a Dataset card
Adding a Dataset card is super valuable for helping users find your dataset and understand how to use it responsibly.
1. Click on **Create Dataset Card** to create a Dataset card. This button creates a `README.md` file in your repository.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/dataset_card.png"/>
</div>
2. At the top, you'll see the **Metadata UI** with several fields to select from like license, language, and task categories. These are the most important tags for helping users discover your dataset on the Hub. When you select an option from each field, they'll be automatically added to the top of the dataset card.
You can also look at the [Dataset Card specifications](https://github.com/huggingface/hub-docs/blob/main/datasetcard.md?plain=1), which has a complete set of (but not required) tag options like `annotations_creators`, to help you choose the appropriate tags.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/metadata_ui.png"/>
</div>
3. Click on the **Import dataset card template** link at the top of the editor to automatically create a dataset card template. Filling out the template is a great way to introduce your dataset to the community and help users understand how to use it. For a detailed example of what a good Dataset card should look like, take a look at the [CNN DailyMail Dataset card](https://huggingface.co/datasets/cnn_dailymail).
### Load dataset
Once your dataset is stored on the Hub, anyone can load it with the [`load_dataset`] function:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("stevhliu/demo")
```
## Upload with Python
Users who prefer to upload a dataset programmatically can use the [huggingface_hub](https://huggingface.co/docs/huggingface_hub/index) library. This library allows users to interact with the Hub from Python.
1. Begin by installing the library:
```bash
pip install huggingface_hub
```
2. To upload a dataset on the Hub in Python, you need to log in to your Hugging Face account:
```bash
huggingface-cli login
```
3. Use the [`push_to_hub()`](https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.DatasetDict.push_to_hub) function to help you add, commit, and push a file to your repository:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("stevhliu/demo")
# dataset = dataset.map(...) # do all your processing here
>>> dataset.push_to_hub("stevhliu/processed_demo")
```
To set your dataset as private, set the `private` parameter to `True`. This parameter will only work if you are creating a repository for the first time.
```py
>>> dataset.push_to_hub("stevhliu/private_processed_demo", private=True)
```
To add a new configuration (or subset) to a dataset or to add a new split (train/validation/test), please refer to the [`Dataset.push_to_hub`] documentation.
### Privacy
A private dataset is only accessible by you. Similarly, if you share a dataset within your organization, then members of the organization can also access the dataset.
Load a private dataset by providing your authentication token to the `token` parameter:
```py
>>> from datasets import load_dataset
# Load a private individual dataset
>>> dataset = load_dataset("stevhliu/demo", token=True)
# Load a private organization dataset
>>> dataset = load_dataset("organization/dataset_name", token=True)
```
## What's next?
Congratulations, you've completed the tutorials! 🥳
From here, you can go on to:
- Learn more about how to use 🤗 Datasets other functions to [process your dataset](process).
- [Stream large datasets](stream) without downloading it locally.
- [Define your dataset splits and configurations](repository_structure) or [loading script](dataset_script) and share your dataset with the community.
If you have any questions about 🤗 Datasets, feel free to join and ask the community on our [forum](https://discuss.huggingface.co/c/datasets/10).
|
huggingface/datasets/blob/main/docs/source/upload_dataset.mdx
|
--
title: sMAPE
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
Symmetric Mean Absolute Percentage Error (sMAPE) is the symmetric mean percentage error difference between the predicted and actual values defined by Chen and Yang (2004).
---
# Metric Card for sMAPE
## Metric Description
Symmetric Mean Absolute Error (sMAPE) is the symmetric mean of the percentage error of difference between the predicted $x_i$ and actual $y_i$ numeric values:
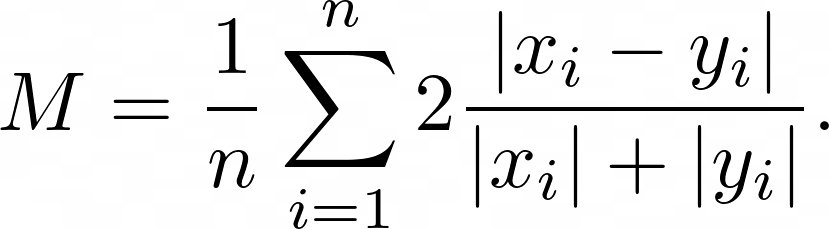
## How to Use
At minimum, this metric requires predictions and references as inputs.
```python
>>> smape_metric = evaluate.load("smape")
>>> predictions = [2.5, 0.0, 2, 8]
>>> references = [3, -0.5, 2, 7]
>>> results = smape_metric.compute(predictions=predictions, references=references)
```
### Inputs
Mandatory inputs:
- `predictions`: numeric array-like of shape (`n_samples,`) or (`n_samples`, `n_outputs`), representing the estimated target values.
- `references`: numeric array-like of shape (`n_samples,`) or (`n_samples`, `n_outputs`), representing the ground truth (correct) target values.
Optional arguments:
- `sample_weight`: numeric array-like of shape (`n_samples,`) representing sample weights. The default is `None`.
- `multioutput`: `raw_values`, `uniform_average` or numeric array-like of shape (`n_outputs,`), which defines the aggregation of multiple output values. The default value is `uniform_average`.
- `raw_values` returns a full set of errors in case of multioutput input.
- `uniform_average` means that the errors of all outputs are averaged with uniform weight.
- the array-like value defines weights used to average errors.
### Output Values
This metric outputs a dictionary, containing the mean absolute error score, which is of type:
- `float`: if multioutput is `uniform_average` or an ndarray of weights, then the weighted average of all output errors is returned.
- numeric array-like of shape (`n_outputs,`): if multioutput is `raw_values`, then the score is returned for each output separately.
Each sMAPE `float` value ranges from `0.0` to `2.0`, with the best value being 0.0.
Output Example(s):
```python
{'smape': 0.5}
```
If `multioutput="raw_values"`:
```python
{'smape': array([0.5, 1.5 ])}
```
#### Values from Popular Papers
### Examples
Example with the `uniform_average` config:
```python
>>> smape_metric = evaluate.load("smape")
>>> predictions = [2.5, 0.0, 2, 8]
>>> references = [3, -0.5, 2, 7]
>>> results = smape_metric.compute(predictions=predictions, references=references)
>>> print(results)
{'smape': 0.5787...}
```
Example with multi-dimensional lists, and the `raw_values` config:
```python
>>> smape_metric = evaluate.load("smape", "multilist")
>>> predictions = [[0.5, 1], [-1, 1], [7, -6]]
>>> references = [[0.1, 2], [-1, 2], [8, -5]]
>>> results = smape_metric.compute(predictions=predictions, references=references)
>>> print(results)
{'smape': 0.8874...}
>>> results = smape_metric.compute(predictions=predictions, references=references, multioutput='raw_values')
>>> print(results)
{'smape': array([1.3749..., 0.4])}
```
## Limitations and Bias
This metric is called a measure of "percentage error" even though there is no multiplier of 100. The range is between (0, 2) with it being two when the target and prediction are both zero.
## Citation(s)
```bibtex
@article{article,
author = {Chen, Zhuo and Yang, Yuhong},
year = {2004},
month = {04},
pages = {},
title = {Assessing forecast accuracy measures}
}
```
## Further References
- [Symmetric Mean absolute percentage error - Wikipedia](https://en.wikipedia.org/wiki/Symmetric_mean_absolute_percentage_error)
|
huggingface/evaluate/blob/main/metrics/smape/README.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Prefix tuning
[Prefix tuning](https://hf.co/papers/2101.00190) prefixes a series of task-specific vectors to the input sequence that can be learned while keeping the pretrained model frozen. The prefix parameters are inserted in all of the model layers.
The abstract from the paper is:
*Fine-tuning is the de facto way to leverage large pretrained language models to perform downstream tasks. However, it modifies all the language model parameters and therefore necessitates storing a full copy for each task. In this paper, we propose prefix-tuning, a lightweight alternative to fine-tuning for natural language generation tasks, which keeps language model parameters frozen, but optimizes a small continuous task-specific vector (called the prefix). Prefix-tuning draws inspiration from prompting, allowing subsequent tokens to attend to this prefix as if it were "virtual tokens". We apply prefix-tuning to GPT-2 for table-to-text generation and to BART for summarization. We find that by learning only 0.1\% of the parameters, prefix-tuning obtains comparable performance in the full data setting, outperforms fine-tuning in low-data settings, and extrapolates better to examples with topics unseen during training*.
## PrefixTuningConfig
[[autodoc]] tuners.prefix_tuning.config.PrefixTuningConfig
## PrefixEncoder
[[autodoc]] tuners.prefix_tuning.model.PrefixEncoder
|
huggingface/peft/blob/main/docs/source/package_reference/prefix_tuning.md
|
--
title: "Announcing the 🤗 AI Research Residency Program"
thumbnail: /blog/assets/57_ai_residency/residency-thumbnail.jpg
authors:
- user: douwekiela
---
# Announcing the 🤗 AI Research Residency Program 🎉 🎉 🎉
The 🤗 Research Residency Program is a 9-month opportunity to launch or advance your career in machine learning research 🚀. The goal of the residency is to help you grow into an impactful AI researcher. Residents will work alongside Researchers from our Science Team. Together, you will pick a research problem and then develop new machine learning techniques to solve it in an open & collaborative way, with the hope of ultimately publishing your work and making it visible to a wide audience.
Applicants from all backgrounds are welcome! Ideally, you have some research experience and are excited about our mission to democratize responsible machine learning. The progress of our field has the potential to exacerbate existing disparities in ways that disproportionately hurt the most marginalized people in society — including people of color, people from working-class backgrounds, women, and LGBTQ+ people. These communities must be centered in the work we do as a research community. So we strongly encourage proposals from people whose personal experience reflects these identities.. We encourage applications relating to AI that demonstrate a clear and positive societal impact.
## How to Apply
Since the focus of your work will be on developing Machine Learning techniques, your application should show evidence of programming skills and of prerequisite courses, like calculus or linear algebra, or links to an open-source project that demonstrates programming and mathematical ability.
More importantly, your application needs to present interest in effecting positive change through AI in any number of creative ways. This can stem from a topic that is of particular interest to you and your proposal would capture concrete ways in which machine learning can contribute. Thinking through the entire pipeline, from understanding where ML tools are needed to gathering data and deploying the resulting approach, can help make your project more impactful.
We are actively working to build a culture that values diversity, equity, and inclusivity. We are intentionally building a workplace where people feel respected and supported—regardless of who you are or where you come from. We believe this is foundational to building a great company and community. Hugging Face is an equal opportunity employer and we do not discriminate on the basis of race, religion, color, national origin, gender, sexual orientation, age, marital status, veteran status, or disability status.
[Submit your application here](https://apply.workable.com/huggingface/j/1B77519961).
## FAQs
* **Can I complete the program part-time?**<br>No. The Residency is only offered as a full-time position.
* **I have been out of school for several years. Can I apply?**<br>Yes. We will consider applications from various backgrounds.
* **Can I be enrolled as a student at a university or work for another employer during the residency?**<br>No, the residency can’t be completed simultaneously with any other obligations.
* **Will I receive benefits during the Residency?**<br>Yes, residents are eligible for most benefits, including medical (depending on location).
* **Will I be required to relocate for this residency?**<br>Absolutely not! We are a distributed team and you are welcome to work from wherever you are currently located.
* **Is there a deadline?**<br>Applications close on April 3rd, 2022!
|
huggingface/blog/blob/main/ai-residency.md
|
@gradio/plot
## 0.2.6
### Patch Changes
- Updated dependencies [[`828fb9e`](https://github.com/gradio-app/gradio/commit/828fb9e6ce15b6ea08318675a2361117596a1b5d), [`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144)]:
- @gradio/statustracker@0.4.3
- @gradio/atoms@0.4.1
## 0.2.5
### Patch Changes
- Updated dependencies [[`053bec9`](https://github.com/gradio-app/gradio/commit/053bec98be1127e083414024e02cf0bebb0b5142), [`4d1cbbc`](https://github.com/gradio-app/gradio/commit/4d1cbbcf30833ef1de2d2d2710c7492a379a9a00)]:
- @gradio/icons@0.3.2
- @gradio/atoms@0.4.0
- @gradio/statustracker@0.4.2
## 0.2.4
### Patch Changes
- Updated dependencies [[`206af31`](https://github.com/gradio-app/gradio/commit/206af31d7c1a31013364a44e9b40cf8df304ba50)]:
- @gradio/icons@0.3.1
- @gradio/atoms@0.3.1
- @gradio/statustracker@0.4.1
## 0.2.3
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/atoms@0.3.0
- @gradio/icons@0.3.0
- @gradio/statustracker@0.4.0
## 0.2.2
### Patch Changes
- Updated dependencies [[`f816136a0`](https://github.com/gradio-app/gradio/commit/f816136a039fa6011be9c4fb14f573e4050a681a)]:
- @gradio/atoms@0.2.2
- @gradio/icons@0.2.1
- @gradio/statustracker@0.3.2
## 0.2.1
### Patch Changes
- Updated dependencies [[`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780), [`fad92c29d`](https://github.com/gradio-app/gradio/commit/fad92c29dc1f5cd84341aae417c495b33e01245f)]:
- @gradio/atoms@0.2.1
- @gradio/statustracker@0.3.1
## 0.2.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
## 0.2.0-beta.8
### Patch Changes
- Updated dependencies [[`667802a6c`](https://github.com/gradio-app/gradio/commit/667802a6cdbfb2ce454a3be5a78e0990b194548a), [`c476bd5a5`](https://github.com/gradio-app/gradio/commit/c476bd5a5b70836163b9c69bf4bfe068b17fbe13)]:
- @gradio/atoms@0.2.0-beta.6
- @gradio/statustracker@0.3.0-beta.8
- @gradio/utils@0.2.0-beta.6
- @gradio/icons@0.2.0-beta.3
## 0.2.0-beta.7
### Features
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.2.0-beta.6
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.2.3
### Patch Changes
- Updated dependencies [[`e70805d54`](https://github.com/gradio-app/gradio/commit/e70805d54cc792452545f5d8eccc1aa0212a4695)]:
- @gradio/atoms@0.2.0
- @gradio/statustracker@0.2.3
## 0.2.2
### Fixes
- [#5795](https://github.com/gradio-app/gradio/pull/5795) [`957ba5cfd`](https://github.com/gradio-app/gradio/commit/957ba5cfde18e09caedf31236a2064923cd7b282) - Prevent bokeh from injecting bokeh js multiple times. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.2.1
### Patch Changes
- Updated dependencies [[`8f0fed857`](https://github.com/gradio-app/gradio/commit/8f0fed857d156830626eb48b469d54d211a582d2)]:
- @gradio/icons@0.2.0
- @gradio/atoms@0.1.3
- @gradio/statustracker@0.2.1
## 0.2.0
### Features
- [#5642](https://github.com/gradio-app/gradio/pull/5642) [`21c7225bd`](https://github.com/gradio-app/gradio/commit/21c7225bda057117a9d3311854323520218720b5) - Improve plot rendering. Thanks [@aliabid94](https://github.com/aliabid94)!
- [#5554](https://github.com/gradio-app/gradio/pull/5554) [`75ddeb390`](https://github.com/gradio-app/gradio/commit/75ddeb390d665d4484667390a97442081b49a423) - Accessibility Improvements. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.1.2
### Patch Changes
- Updated dependencies [[`afac0006`](https://github.com/gradio-app/gradio/commit/afac0006337ce2840cf497cd65691f2f60ee5912)]:
- @gradio/statustracker@0.2.0
- @gradio/theme@0.1.0
- @gradio/utils@0.1.1
- @gradio/atoms@0.1.2
## 0.1.1
### Patch Changes
- Updated dependencies [[`abf1c57d`](https://github.com/gradio-app/gradio/commit/abf1c57d7d85de0df233ee3b38aeb38b638477db)]:
- @gradio/icons@0.1.0
- @gradio/utils@0.1.0
- @gradio/atoms@0.1.1
- @gradio/statustracker@0.1.1
## 0.1.0
### Highlights
#### Improve startup performance and markdown support ([#5279](https://github.com/gradio-app/gradio/pull/5279) [`fe057300`](https://github.com/gradio-app/gradio/commit/fe057300f0672c62dab9d9b4501054ac5d45a4ec))
##### Improved markdown support
We now have better support for markdown in `gr.Markdown` and `gr.Dataframe`. Including syntax highlighting and Github Flavoured Markdown. We also have more consistent markdown behaviour and styling.
##### Various performance improvements
These improvements will be particularly beneficial to large applications.
- Rather than attaching events manually, they are now delegated, leading to a significant performance improvement and addressing a performance regression introduced in a recent version of Gradio. App startup for large applications is now around twice as fast.
- Optimised the mounting of individual components, leading to a modest performance improvement during startup (~30%).
- Corrected an issue that was causing markdown to re-render infinitely.
- Ensured that the `gr.3DModel` does re-render prematurely.
Thanks [@pngwn](https://github.com/pngwn)!
### Features
- [#5215](https://github.com/gradio-app/gradio/pull/5215) [`fbdad78a`](https://github.com/gradio-app/gradio/commit/fbdad78af4c47454cbb570f88cc14bf4479bbceb) - Lazy load interactive or static variants of a component individually, rather than loading both variants regardless. This change will improve performance for many applications. Thanks [@pngwn](https://github.com/pngwn)!
- [#5216](https://github.com/gradio-app/gradio/pull/5216) [`4b58ea6d`](https://github.com/gradio-app/gradio/commit/4b58ea6d98e7a43b3f30d8a4cb6f379bc2eca6a8) - Update i18n tokens and locale files. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.0.2
### Patch Changes
- Updated dependencies [[`41c83070`](https://github.com/gradio-app/gradio/commit/41c83070b01632084e7d29123048a96c1e261407)]:
- @gradio/theme@0.0.2
- @gradio/utils@0.0.2
- @gradio/atoms@0.0.2
|
gradio-app/gradio/blob/main/js/plot/CHANGELOG.md
|
Organizations, Security, and the Hub API
## Contents
- [Organizations](./organizations)
- [Managing Organizations](./organizations-managing)
- [Organization Cards](./organizations-cards)
- [Access control in organizations](./organizations-security)
- [Moderation](./moderation)
- [Billing](./billing)
- [Digital Object Identifier (DOI)](./doi)
- [Security](./security)
- [User Access Tokens](./security-tokens)
- [Signing commits with GPG](./security-gpg)
- [Malware Scanning](./security-malware)
- [Pickle Scanning](./security-pickle)
- [Hub API Endpoints](./api)
- [Webhooks](./webhooks)
|
huggingface/hub-docs/blob/main/docs/hub/other.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Consistency Models
Consistency Models were proposed in [Consistency Models](https://huggingface.co/papers/2303.01469) by Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever.
The abstract from the paper is:
*Diffusion models have significantly advanced the fields of image, audio, and video generation, but they depend on an iterative sampling process that causes slow generation. To overcome this limitation, we propose consistency models, a new family of models that generate high quality samples by directly mapping noise to data. They support fast one-step generation by design, while still allowing multistep sampling to trade compute for sample quality. They also support zero-shot data editing, such as image inpainting, colorization, and super-resolution, without requiring explicit training on these tasks. Consistency models can be trained either by distilling pre-trained diffusion models, or as standalone generative models altogether. Through extensive experiments, we demonstrate that they outperform existing distillation techniques for diffusion models in one- and few-step sampling, achieving the new state-of-the-art FID of 3.55 on CIFAR-10 and 6.20 on ImageNet 64x64 for one-step generation. When trained in isolation, consistency models become a new family of generative models that can outperform existing one-step, non-adversarial generative models on standard benchmarks such as CIFAR-10, ImageNet 64x64 and LSUN 256x256.*
The original codebase can be found at [openai/consistency_models](https://github.com/openai/consistency_models), and additional checkpoints are available at [openai](https://huggingface.co/openai).
The pipeline was contributed by [dg845](https://github.com/dg845) and [ayushtues](https://huggingface.co/ayushtues). ❤️
## Tips
For an additional speed-up, use `torch.compile` to generate multiple images in <1 second:
```diff
import torch
from diffusers import ConsistencyModelPipeline
device = "cuda"
# Load the cd_bedroom256_lpips checkpoint.
model_id_or_path = "openai/diffusers-cd_bedroom256_lpips"
pipe = ConsistencyModelPipeline.from_pretrained(model_id_or_path, torch_dtype=torch.float16)
pipe.to(device)
+ pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
# Multistep sampling
# Timesteps can be explicitly specified; the particular timesteps below are from the original GitHub repo:
# https://github.com/openai/consistency_models/blob/main/scripts/launch.sh#L83
for _ in range(10):
image = pipe(timesteps=[17, 0]).images[0]
image.show()
```
## ConsistencyModelPipeline
[[autodoc]] ConsistencyModelPipeline
- all
- __call__
## ImagePipelineOutput
[[autodoc]] pipelines.ImagePipelineOutput
|
huggingface/diffusers/blob/main/docs/source/en/api/pipelines/consistency_models.md
|
Welcome to the 🤗 Deep Reinforcement Learning Course [[introduction]]
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit0/thumbnail.jpg" alt="Deep RL Course thumbnail" width="100%"/>
Welcome to the most fascinating topic in Artificial Intelligence: **Deep Reinforcement Learning**.
This course will **teach you about Deep Reinforcement Learning from beginner to expert**. It’s completely free and open-source!
In this introduction unit you’ll:
- Learn more about the **course content**.
- **Define the path** you’re going to take (either self-audit or certification process).
- Learn more about the **AI vs. AI challenges** you're going to participate in.
- Learn more **about us**.
- **Create your Hugging Face account** (it’s free).
- **Sign-up to our Discord server**, the place where you can chat with your classmates and us (the Hugging Face team).
Let’s get started!
## What to expect? [[expect]]
In this course, you will:
- 📖 Study Deep Reinforcement Learning in **theory and practice.**
- 🧑💻 Learn to **use famous Deep RL libraries** such as [Stable Baselines3](https://stable-baselines3.readthedocs.io/en/master/), [RL Baselines3 Zoo](https://github.com/DLR-RM/rl-baselines3-zoo), [Sample Factory](https://samplefactory.dev/) and [CleanRL](https://github.com/vwxyzjn/cleanrl).
- 🤖 **Train agents in unique environments** such as [SnowballFight](https://huggingface.co/spaces/ThomasSimonini/SnowballFight), [Huggy the Doggo 🐶](https://huggingface.co/spaces/ThomasSimonini/Huggy), [VizDoom (Doom)](https://vizdoom.cs.put.edu.pl/) and classical ones such as [Space Invaders](https://gymnasium.farama.org/environments/atari/space_invaders/), [PyBullet](https://pybullet.org/wordpress/) and more.
- 💾 Share your **trained agents with one line of code to the Hub** and also download powerful agents from the community.
- 🏆 Participate in challenges where you will **evaluate your agents against other teams. You'll also get to play against the agents you'll train.**
- 🎓 **Earn a certificate of completion** by completing 80% of the assignments.
And more!
At the end of this course, **you’ll get a solid foundation from the basics to the SOTA (state-of-the-art) of methods**.
Don’t forget to **<a href="http://eepurl.com/ic5ZUD">sign up to the course</a>** (we are collecting your email to be able to **send you the links when each Unit is published and give you information about the challenges and updates).**
Sign up 👉 <a href="http://eepurl.com/ic5ZUD">here</a>
## What does the course look like? [[course-look-like]]
The course is composed of:
- *A theory part*: where you learn a **concept in theory**.
- *A hands-on*: where you’ll learn **to use famous Deep RL libraries** to train your agents in unique environments. These hands-on will be **Google Colab notebooks with companion tutorial videos** if you prefer learning with video format!
- *Challenges*: you'll get to put your agent to compete against other agents in different challenges. There will also be [a leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) for you to compare the agents' performance.
## What's the syllabus? [[syllabus]]
This is the course's syllabus:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit0/syllabus1.jpg" alt="Syllabus Part 1" width="100%"/>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit0/syllabus2.jpg" alt="Syllabus Part 2" width="100%"/>
## Two paths: choose your own adventure [[two-paths]]
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit0/two-paths.jpg" alt="Two paths" width="100%"/>
You can choose to follow this course either:
- *To get a certificate of completion*: you need to complete 80% of the assignments.
- *To get a certificate of honors*: you need to complete 100% of the assignments.
- *As a simple audit*: you can participate in all challenges and do assignments if you want.
There's **no deadlines, the course is self-paced**.
Both paths **are completely free**.
Whatever path you choose, we advise you **to follow the recommended pace to enjoy the course and challenges with your fellow classmates.**
You don't need to tell us which path you choose. **If you get more than 80% of the assignments done, you'll get a certificate.**
## The Certification Process [[certification-process]]
The certification process is **completely free**:
- *To get a certificate of completion*: you need to complete 80% of the assignments.
- *To get a certificate of honors*: you need to complete 100% of the assignments.
Again, there's **no deadline** since the course is self paced. But our advice **is to follow the recommended pace section**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit0/certification.jpg" alt="Course certification" width="100%"/>
## How to get most of the course? [[advice]]
To get most of the course, we have some advice:
1. <a href="https://discord.gg/ydHrjt3WP5">Join study groups in Discord </a>: studying in groups is always easier. To do that, you need to join our discord server. If you're new to Discord, no worries! We have some tools that will help you learn about it.
2. **Do the quizzes and assignments**: the best way to learn is to do and test yourself.
3. **Define a schedule to stay in sync**: you can use our recommended pace schedule below or create yours.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit0/advice.jpg" alt="Course advice" width="100%"/>
## What tools do I need? [[tools]]
You need only 3 things:
- *A computer* with an internet connection.
- *Google Colab (free version)*: most of our hands-on will use Google Colab, the **free version is enough.**
- A *Hugging Face Account*: to push and load models. If you don’t have an account yet, you can create one **[here](https://hf.co/join)** (it’s free).
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit0/tools.jpg" alt="Course tools needed" width="100%"/>
## What is the recommended pace? [[recommended-pace]]
Each chapter in this course is designed **to be completed in 1 week, with approximately 3-4 hours of work per week**. However, you can take as much time as necessary to complete the course. If you want to dive into a topic more in-depth, we'll provide additional resources to help you achieve that.
## Who are we [[who-are-we]]
About the author:
- <a href="https://twitter.com/ThomasSimonini">Thomas Simonini</a> is a Developer Advocate at Hugging Face 🤗 specializing in Deep Reinforcement Learning. He founded the Deep Reinforcement Learning Course in 2018, which became one of the most used courses in Deep RL.
About the team:
- <a href="https://twitter.com/osanseviero">Omar Sanseviero</a> is a Machine Learning Engineer at Hugging Face where he works in the intersection of ML, Community and Open Source. Previously, Omar worked as a Software Engineer at Google in the teams of Assistant and TensorFlow Graphics. He is from Peru and likes llamas 🦙.
- <a href="https://twitter.com/RisingSayak"> Sayak Paul</a> is a Developer Advocate Engineer at Hugging Face. He's interested in the area of representation learning (self-supervision, semi-supervision, model robustness). And he loves watching crime and action thrillers 🔪.
## What are the challenges in this course? [[challenges]]
In this new version of the course, you have two types of challenges:
- [A leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) to compare your agent's performance to other classmates'.
- [AI vs. AI challenges](https://huggingface.co/learn/deep-rl-course/unit7/introduction?fw=pt) where you can train your agent and compete against other classmates' agents.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit0/challenges.jpg" alt="Challenges" width="100%"/>
## I found a bug, or I want to improve the course [[contribute]]
Contributions are welcomed 🤗
- If you *found a bug 🐛 in a notebook*, please <a href="https://github.com/huggingface/deep-rl-class/issues">open an issue</a> and **describe the problem**.
- If you *want to improve the course*, you can <a href="https://github.com/huggingface/deep-rl-class/pulls">open a Pull Request.</a>
## I still have questions [[questions]]
Please ask your question in our <a href="https://discord.gg/ydHrjt3WP5">discord server #rl-discussions.</a>
|
huggingface/deep-rl-class/blob/main/units/en/unit0/introduction.mdx
|
Using timm at Hugging Face
`timm`, also known as [pytorch-image-models](https://github.com/rwightman/pytorch-image-models), is an open-source collection of state-of-the-art PyTorch image models, pretrained weights, and utility scripts for training, inference, and validation.
This documentation focuses on `timm` functionality in the Hugging Face Hub instead of the `timm` library itself. For detailed information about the `timm` library, visit [its documentation](https://huggingface.co/docs/timm).
You can find a number of `timm` models on the Hub using the filters on the left of the [models page](https://huggingface.co/models?library=timm&sort=downloads).
All models on the Hub come with several useful features:
1. An automatically generated model card, which model authors can complete with [information about their model](./model-cards).
2. Metadata tags help users discover the relevant `timm` models.
3. An [interactive widget](./models-widgets) you can use to play with the model directly in the browser.
4. An [Inference API](./models-inference) that allows users to make inference requests.
## Using existing models from the Hub
Any `timm` model from the Hugging Face Hub can be loaded with a single line of code as long as you have `timm` installed! Once you've selected a model from the Hub, pass the model's ID prefixed with `hf-hub:` to `timm`'s `create_model` method to download and instantiate the model.
```py
import timm
# Loading https://huggingface.co/timm/eca_nfnet_l0
model = timm.create_model("hf-hub:timm/eca_nfnet_l0", pretrained=True)
```
If you want to see how to load a specific model, you can click **Use in timm** and you will be given a working snippet to load it!
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-timm_snippet1.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-timm_snippet1-dark.png"/>
</div>
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-timm_snippet2.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-timm_snippet2-dark.png"/>
</div>
### Inference
The snippet below shows how you can perform inference on a `timm` model loaded from the Hub:
```py
import timm
import torch
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
# Load from Hub 🔥
model = timm.create_model(
'hf-hub:nateraw/resnet50-oxford-iiit-pet',
pretrained=True
)
# Set model to eval mode for inference
model.eval()
# Create Transform
transform = create_transform(**resolve_data_config(model.pretrained_cfg, model=model))
# Get the labels from the model config
labels = model.pretrained_cfg['labels']
top_k = min(len(labels), 5)
# Use your own image file here...
image = Image.open('boxer.jpg').convert('RGB')
# Process PIL image with transforms and add a batch dimension
x = transform(image).unsqueeze(0)
# Pass inputs to model forward function to get outputs
out = model(x)
# Apply softmax to get predicted probabilities for each class
probabilities = torch.nn.functional.softmax(out[0], dim=0)
# Grab the values and indices of top 5 predicted classes
values, indices = torch.topk(probabilities, top_k)
# Prepare a nice dict of top k predictions
predictions = [
{"label": labels[i], "score": v.item()}
for i, v in zip(indices, values)
]
print(predictions)
```
This should leave you with a list of predictions, like this:
```py
[
{'label': 'american_pit_bull_terrier', 'score': 0.9999998807907104},
{'label': 'staffordshire_bull_terrier', 'score': 1.0000000149011612e-07},
{'label': 'miniature_pinscher', 'score': 1.0000000149011612e-07},
{'label': 'chihuahua', 'score': 1.0000000149011612e-07},
{'label': 'beagle', 'score': 1.0000000149011612e-07}
]
```
## Sharing your models
You can share your `timm` models directly to the Hugging Face Hub. This will publish a new version of your model to the Hugging Face Hub, creating a model repo for you if it doesn't already exist.
Before pushing a model, make sure that you've logged in to Hugging Face:
```sh
python -m pip install huggingface_hub
huggingface-cli login
```
Alternatively, if you prefer working from a Jupyter or Colaboratory notebook, once you've installed `huggingface_hub` you can log in with:
```py
from huggingface_hub import notebook_login
notebook_login()
```
Then, push your model using the `push_to_hf_hub` method:
```py
import timm
# Build or load a model, e.g. timm's pretrained resnet18
model = timm.create_model('resnet18', pretrained=True, num_classes=4)
###########################
# [Fine tune your model...]
###########################
# Push it to the 🤗 Hub
timm.models.hub.push_to_hf_hub(
model,
'resnet18-random-classifier',
model_config={'labels': ['a', 'b', 'c', 'd']}
)
# Load your model from the Hub
model_reloaded = timm.create_model(
'hf-hub:<your-username>/resnet18-random-classifier',
pretrained=True
)
```
## Inference Widget and API
All `timm` models on the Hub are automatically equipped with an [inference widget](./models-widgets), pictured below for [nateraw/timm-resnet50-beans](https://huggingface.co/nateraw/timm-resnet50-beans). Additionally, `timm` models are available through the [Inference API](./models-inference), which you can access through HTTP with cURL, Python's `requests` library, or your preferred method for making network requests.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-timm_widget.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-timm_widget-dark.png"/>
</div>
```sh
curl https://api-inference.huggingface.co/models/nateraw/timm-resnet50-beans \
-X POST \
--data-binary '@beans.jpeg' \
-H "Authorization: Bearer {$HF_API_TOKEN}"
# [{"label":"angular_leaf_spot","score":0.9845947027206421},{"label":"bean_rust","score":0.01368315052241087},{"label":"healthy","score":0.001722085871733725}]
```
## Additional resources
* timm (pytorch-image-models) [GitHub Repo](https://github.com/rwightman/pytorch-image-models).
* timm [documentation](https://huggingface.co/docs/timm).
* Additional documentation at [timmdocs](https://timm.fast.ai) by [Aman Arora](https://github.com/amaarora).
* [Getting Started with PyTorch Image Models (timm): A Practitioner’s Guide](https://towardsdatascience.com/getting-started-with-pytorch-image-models-timm-a-practitioners-guide-4e77b4bf9055) by [Chris Hughes](https://github.com/Chris-hughes10).
|
huggingface/hub-docs/blob/main/docs/hub/timm.md
|
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# CPU inference
With some optimizations, it is possible to efficiently run large model inference on a CPU. One of these optimization techniques involves compiling the PyTorch code into an intermediate format for high-performance environments like C++. The other technique fuses multiple operations into one kernel to reduce the overhead of running each operation separately.
You'll learn how to use [BetterTransformer](https://pytorch.org/blog/a-better-transformer-for-fast-transformer-encoder-inference/) for faster inference, and how to convert your PyTorch code to [TorchScript](https://pytorch.org/tutorials/beginner/Intro_to_TorchScript_tutorial.html). If you're using an Intel CPU, you can also use [graph optimizations](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/features.html#graph-optimization) from [Intel Extension for PyTorch](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/index.html) to boost inference speed even more. Finally, learn how to use 🤗 Optimum to accelerate inference with ONNX Runtime or OpenVINO (if you're using an Intel CPU).
## BetterTransformer
BetterTransformer accelerates inference with its fastpath (native PyTorch specialized implementation of Transformer functions) execution. The two optimizations in the fastpath execution are:
1. fusion, which combines multiple sequential operations into a single "kernel" to reduce the number of computation steps
2. skipping the inherent sparsity of padding tokens to avoid unnecessary computation with nested tensors
BetterTransformer also converts all attention operations to use the more memory-efficient [scaled dot product attention](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention).
<Tip>
BetterTransformer is not supported for all models. Check this [list](https://huggingface.co/docs/optimum/bettertransformer/overview#supported-models) to see if a model supports BetterTransformer.
</Tip>
Before you start, make sure you have 🤗 Optimum [installed](https://huggingface.co/docs/optimum/installation).
Enable BetterTransformer with the [`PreTrainedModel.to_bettertransformer`] method:
```py
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("bigcode/starcoder")
model.to_bettertransformer()
```
## TorchScript
TorchScript is an intermediate PyTorch model representation that can be run in production environments where performance is important. You can train a model in PyTorch and then export it to TorchScript to free the model from Python performance constraints. PyTorch [traces](https://pytorch.org/docs/stable/generated/torch.jit.trace.html) a model to return a [`ScriptFunction`] that is optimized with just-in-time compilation (JIT). Compared to the default eager mode, JIT mode in PyTorch typically yields better performance for inference using optimization techniques like operator fusion.
For a gentle introduction to TorchScript, see the [Introduction to PyTorch TorchScript](https://pytorch.org/tutorials/beginner/Intro_to_TorchScript_tutorial.html) tutorial.
With the [`Trainer`] class, you can enable JIT mode for CPU inference by setting the `--jit_mode_eval` flag:
```bash
python run_qa.py \
--model_name_or_path csarron/bert-base-uncased-squad-v1 \
--dataset_name squad \
--do_eval \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/ \
--no_cuda \
--jit_mode_eval
```
<Tip warning={true}>
For PyTorch >= 1.14.0, JIT-mode could benefit any model for prediction and evaluaion since the dict input is supported in `jit.trace`.
For PyTorch < 1.14.0, JIT-mode could benefit a model if its forward parameter order matches the tuple input order in `jit.trace`, such as a question-answering model. If the forward parameter order does not match the tuple input order in `jit.trace`, like a text classification model, `jit.trace` will fail and we are capturing this with the exception here to make it fallback. Logging is used to notify users.
</Tip>
## IPEX graph optimization
Intel® Extension for PyTorch (IPEX) provides further optimizations in JIT mode for Intel CPUs, and we recommend combining it with TorchScript for even faster performance. The IPEX [graph optimization](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/features/graph_optimization.html) fuses operations like Multi-head attention, Concat Linear, Linear + Add, Linear + Gelu, Add + LayerNorm, and more.
To take advantage of these graph optimizations, make sure you have IPEX [installed](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/installation.html):
```bash
pip install intel_extension_for_pytorch
```
Set the `--use_ipex` and `--jit_mode_eval` flags in the [`Trainer`] class to enable JIT mode with the graph optimizations:
```bash
python run_qa.py \
--model_name_or_path csarron/bert-base-uncased-squad-v1 \
--dataset_name squad \
--do_eval \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/ \
--no_cuda \
--use_ipex \
--jit_mode_eval
```
## 🤗 Optimum
<Tip>
Learn more details about using ORT with 🤗 Optimum in the [Optimum Inference with ONNX Runtime](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/models) guide. This section only provides a brief and simple example.
</Tip>
ONNX Runtime (ORT) is a model accelerator that runs inference on CPUs by default. ORT is supported by 🤗 Optimum which can be used in 🤗 Transformers, without making too many changes to your code. You only need to replace the 🤗 Transformers `AutoClass` with its equivalent [`~optimum.onnxruntime.ORTModel`] for the task you're solving, and load a checkpoint in the ONNX format.
For example, if you're running inference on a question answering task, load the [optimum/roberta-base-squad2](https://huggingface.co/optimum/roberta-base-squad2) checkpoint which contains a `model.onnx` file:
```py
from transformers import AutoTokenizer, pipeline
from optimum.onnxruntime import ORTModelForQuestionAnswering
model = ORTModelForQuestionAnswering.from_pretrained("optimum/roberta-base-squad2")
tokenizer = AutoTokenizer.from_pretrained("deepset/roberta-base-squad2")
onnx_qa = pipeline("question-answering", model=model, tokenizer=tokenizer)
question = "What's my name?"
context = "My name is Philipp and I live in Nuremberg."
pred = onnx_qa(question, context)
```
If you have an Intel CPU, take a look at 🤗 [Optimum Intel](https://huggingface.co/docs/optimum/intel/index) which supports a variety of compression techniques (quantization, pruning, knowledge distillation) and tools for converting models to the [OpenVINO](https://huggingface.co/docs/optimum/intel/inference) format for higher performance inference.
|
huggingface/transformers/blob/main/docs/source/en/perf_infer_cpu.md
|
Gradio Demo: chatbot_component
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
gr.Chatbot(value=[["Hello World","Hey Gradio!"],["❤️","😍"],["🔥","🤗"]])
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/chatbot_component/run.ipynb
|
Gradio Demo: interface_random_slider
```
!pip install -q gradio
```
```
import gradio as gr
def func(slider_1, slider_2, *args):
return slider_1 + slider_2 * 5
demo = gr.Interface(
func,
[
gr.Slider(minimum=1.5, maximum=250000.89, randomize=True, label="Random Big Range"),
gr.Slider(minimum=-1, maximum=1, randomize=True, step=0.05, label="Random only multiple of 0.05 allowed"),
gr.Slider(minimum=0, maximum=1, randomize=True, step=0.25, label="Random only multiples of 0.25 allowed"),
gr.Slider(minimum=-100, maximum=100, randomize=True, step=3, label="Random between -100 and 100 step 3"),
gr.Slider(minimum=-100, maximum=100, randomize=True, label="Random between -100 and 100"),
gr.Slider(value=0.25, minimum=5, maximum=30, step=-1),
],
"number",
)
if __name__ == "__main__":
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/interface_random_slider/run.ipynb
|
Saving methods
Methods for saving evaluations results:
## Save
[[autodoc]] evaluate.save
|
huggingface/evaluate/blob/main/docs/source/package_reference/saving_methods.mdx
|
Introduction[[introduction]]
Welcome to the Hugging Face course! This introduction will guide you through setting up a working environment. If you're just starting the course, we recommend you first take a look at [Chapter 1](/course/chapter1), then come back and set up your environment so you can try the code yourself.
All the libraries that we'll be using in this course are available as Python packages, so here we'll show you how to set up a Python environment and install the specific libraries you'll need.
We'll cover two ways of setting up your working environment, using a Colab notebook or a Python virtual environment. Feel free to choose the one that resonates with you the most. For beginners, we strongly recommend that you get started by using a Colab notebook.
Note that we will not be covering the Windows system. If you're running on Windows, we recommend following along using a Colab notebook. If you're using a Linux distribution or macOS, you can use either approach described here.
Most of the course relies on you having a Hugging Face account. We recommend creating one now: [create an account](https://huggingface.co/join).
## Using a Google Colab notebook[[using-a-google-colab-notebook]]
Using a Colab notebook is the simplest possible setup; boot up a notebook in your browser and get straight to coding!
If you're not familiar with Colab, we recommend you start by following the [introduction](https://colab.research.google.com/notebooks/intro.ipynb). Colab allows you to use some accelerating hardware, like GPUs or TPUs, and it is free for smaller workloads.
Once you're comfortable moving around in Colab, create a new notebook and get started with the setup:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter0/new_colab.png" alt="An empty colab notebook" width="80%"/>
</div>
The next step is to install the libraries that we'll be using in this course. We'll use `pip` for the installation, which is the package manager for Python. In notebooks, you can run system commands by preceding them with the `!` character, so you can install the 🤗 Transformers library as follows:
```
!pip install transformers
```
You can make sure the package was correctly installed by importing it within your Python runtime:
```
import transformers
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter0/install.gif" alt="A gif showing the result of the two commands above: installation and import" width="80%"/>
</div>
This installs a very light version of 🤗 Transformers. In particular, no specific machine learning frameworks (like PyTorch or TensorFlow) are installed. Since we'll be using a lot of different features of the library, we recommend installing the development version, which comes with all the required dependencies for pretty much any imaginable use case:
```
!pip install transformers[sentencepiece]
```
This will take a bit of time, but then you'll be ready to go for the rest of the course!
## Using a Python virtual environment[[using-a-python-virtual-environment]]
If you prefer to use a Python virtual environment, the first step is to install Python on your system. We recommend following [this guide](https://realpython.com/installing-python/) to get started.
Once you have Python installed, you should be able to run Python commands in your terminal. You can start by running the following command to ensure that it is correctly installed before proceeding to the next steps: `python --version`. This should print out the Python version now available on your system.
When running a Python command in your terminal, such as `python --version`, you should think of the program running your command as the "main" Python on your system. We recommend keeping this main installation free of any packages, and using it to create separate environments for each application you work on — this way, each application can have its own dependencies and packages, and you won't need to worry about potential compatibility issues with other applications.
In Python this is done with [*virtual environments*](https://docs.python.org/3/tutorial/venv.html), which are self-contained directory trees that each contain a Python installation with a particular Python version alongside all the packages the application needs. Creating such a virtual environment can be done with a number of different tools, but we'll use the official Python package for that purpose, which is called [`venv`](https://docs.python.org/3/library/venv.html#module-venv).
First, create the directory you'd like your application to live in — for example, you might want to make a new directory called *transformers-course* at the root of your home directory:
```
mkdir ~/transformers-course
cd ~/transformers-course
```
From inside this directory, create a virtual environment using the Python `venv` module:
```
python -m venv .env
```
You should now have a directory called *.env* in your otherwise empty folder:
```
ls -a
```
```out
. .. .env
```
You can jump in and out of your virtual environment with the `activate` and `deactivate` scripts:
```
# Activate the virtual environment
source .env/bin/activate
# Deactivate the virtual environment
source .env/bin/deactivate
```
You can make sure that the environment is activated by running the `which python` command: if it points to the virtual environment, then you have successfully activated it!
```
which python
```
```out
/home/<user>/transformers-course/.env/bin/python
```
### Installing dependencies[[installing-dependencies]]
As in the previous section on using Google Colab instances, you'll now need to install the packages required to continue. Again, you can install the development version of 🤗 Transformers using the `pip` package manager:
```
pip install "transformers[sentencepiece]"
```
You're now all set up and ready to go!
|
huggingface/course/blob/main/chapters/en/chapter0/1.mdx
|
!--Copyright 2023 The HuggingFace and Baidu Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ErnieM
## Overview
The ErnieM model was proposed in [ERNIE-M: Enhanced Multilingual Representation by Aligning
Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun,
Hao Tian, Hua Wu, Haifeng Wang.
The abstract from the paper is the following:
*Recent studies have demonstrated that pre-trained cross-lingual models achieve impressive performance in downstream cross-lingual tasks. This improvement benefits from learning a large amount of monolingual and parallel corpora. Although it is generally acknowledged that parallel corpora are critical for improving the model performance, existing methods are often constrained by the size of parallel corpora, especially for lowresource languages. In this paper, we propose ERNIE-M, a new training method that encourages the model to align the representation of multiple languages with monolingual corpora, to overcome the constraint that the parallel corpus size places on the model performance. Our key insight is to integrate back-translation into the pre-training process. We generate pseudo-parallel sentence pairs on a monolingual corpus to enable the learning of semantic alignments between different languages, thereby enhancing the semantic modeling of cross-lingual models. Experimental results show that ERNIE-M outperforms existing cross-lingual models and delivers new state-of-the-art results in various cross-lingual downstream tasks.*
This model was contributed by [Susnato Dhar](https://huggingface.co/susnato). The original code can be found [here](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/paddlenlp/transformers/ernie_m).
## Usage tips
- Ernie-M is a BERT-like model so it is a stacked Transformer Encoder.
- Instead of using MaskedLM for pretraining (like BERT) the authors used two novel techniques: `Cross-attention Masked Language Modeling` and `Back-translation Masked Language Modeling`. For now these two LMHead objectives are not implemented here.
- It is a multilingual language model.
- Next Sentence Prediction was not used in pretraining process.
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Multiple choice task guide](../tasks/multiple_choice)
## ErnieMConfig
[[autodoc]] ErnieMConfig
## ErnieMTokenizer
[[autodoc]] ErnieMTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## ErnieMModel
[[autodoc]] ErnieMModel
- forward
## ErnieMForSequenceClassification
[[autodoc]] ErnieMForSequenceClassification
- forward
## ErnieMForMultipleChoice
[[autodoc]] ErnieMForMultipleChoice
- forward
## ErnieMForTokenClassification
[[autodoc]] ErnieMForTokenClassification
- forward
## ErnieMForQuestionAnswering
[[autodoc]] ErnieMForQuestionAnswering
- forward
## ErnieMForInformationExtraction
[[autodoc]] ErnieMForInformationExtraction
- forward
|
huggingface/transformers/blob/main/docs/source/en/model_doc/ernie_m.md
|
Hands on
<CourseFloatingBanner classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/deep-rl-class/blob/main/notebooks/unit4/unit4.ipynb"}
]}
askForHelpUrl="http://hf.co/join/discord" />
Now that we've studied the theory behind Reinforce, **you’re ready to code your Reinforce agent with PyTorch**. And you'll test its robustness using CartPole-v1 and PixelCopter,.
You'll then be able to iterate and improve this implementation for more advanced environments.
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/envs.gif" alt="Environments"/>
</figure>
To validate this hands-on for the certification process, you need to push your trained models to the Hub and:
- Get a result of >= 350 for `Cartpole-v1`
- Get a result of >= 5 for `PixelCopter`.
To find your result, go to the leaderboard and find your model, **the result = mean_reward - std of reward**. **If you don't see your model on the leaderboard, go at the bottom of the leaderboard page and click on the refresh button**.
**If you don't find your model, go to the bottom of the page and click on the refresh button.**
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
And you can check your progress here 👉 https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
**To start the hands-on click on Open In Colab button** 👇 :
[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit4/unit4.ipynb)
We strongly **recommend students use Google Colab for the hands-on exercises** instead of running them on their personal computers.
By using Google Colab, **you can focus on learning and experimenting without worrying about the technical aspects** of setting up your environments.
# Unit 4: Code your first Deep Reinforcement Learning Algorithm with PyTorch: Reinforce. And test its robustness 💪
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/thumbnail.png" alt="thumbnail"/>
In this notebook, you'll code your first Deep Reinforcement Learning algorithm from scratch: Reinforce (also called Monte Carlo Policy Gradient).
Reinforce is a *Policy-based method*: a Deep Reinforcement Learning algorithm that tries **to optimize the policy directly without using an action-value function**.
More precisely, Reinforce is a *Policy-gradient method*, a subclass of *Policy-based methods* that aims **to optimize the policy directly by estimating the weights of the optimal policy using gradient ascent**.
To test its robustness, we're going to train it in 2 different simple environments:
- Cartpole-v1
- PixelcopterEnv
⬇️ Here is an example of what **you will achieve at the end of this notebook.** ⬇️
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/envs.gif" alt="Environments"/>
### 🎮 Environments:
- [CartPole-v1](https://www.gymlibrary.dev/environments/classic_control/cart_pole/)
- [PixelCopter](https://pygame-learning-environment.readthedocs.io/en/latest/user/games/pixelcopter.html)
### 📚 RL-Library:
- Python
- PyTorch
We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues).
## Objectives of this notebook 🏆
At the end of the notebook, you will:
- Be able to **code a Reinforce algorithm from scratch using PyTorch.**
- Be able to **test the robustness of your agent using simple environments.**
- Be able to **push your trained agent to the Hub** with a nice video replay and an evaluation score 🔥.
## Prerequisites 🏗️
Before diving into the notebook, you need to:
🔲 📚 [Study Policy Gradients by reading Unit 4](https://huggingface.co/deep-rl-course/unit4/introduction)
# Let's code Reinforce algorithm from scratch 🔥
## Some advice 💡
It's better to run this colab in a copy on your Google Drive, so that **if it times out** you still have the saved notebook on your Google Drive and do not need to fill everything in from scratch.
To do that you can either do `Ctrl + S` or `File > Save a copy in Google Drive.`
## Set the GPU 💪
- To **accelerate the agent's training, we'll use a GPU**. To do that, go to `Runtime > Change Runtime type`
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/gpu-step1.jpg" alt="GPU Step 1">
- `Hardware Accelerator > GPU`
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/gpu-step2.jpg" alt="GPU Step 2">
## Create a virtual display 🖥
During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames).
The following cell will install the librairies and create and run a virtual screen 🖥
```python
%%capture
!apt install python-opengl
!apt install ffmpeg
!apt install xvfb
!pip install pyvirtualdisplay
!pip install pyglet==1.5.1
```
```python
# Virtual display
from pyvirtualdisplay import Display
virtual_display = Display(visible=0, size=(1400, 900))
virtual_display.start()
```
## Install the dependencies 🔽
The first step is to install the dependencies. We’ll install multiple ones:
- `gym`
- `gym-games`: Extra gym environments made with PyGame.
- `huggingface_hub`: The Hub works as a central place where anyone can share and explore models and datasets. It has versioning, metrics, visualizations, and other features that will allow you to easily collaborate with others.
You may be wondering why we install gym and not gymnasium, a more recent version of gym? **Because the gym-games we are using are not updated yet with gymnasium**.
The differences you'll encounter here:
- In `gym` we don't have `terminated` and `truncated` but only `done`.
- In `gym` using `env.step()` returns `state, reward, done, info`
You can learn more about the differences between Gym and Gymnasium here 👉 https://gymnasium.farama.org/content/migration-guide/
You can see here all the Reinforce models available 👉 https://huggingface.co/models?other=reinforce
And you can find all the Deep Reinforcement Learning models here 👉 https://huggingface.co/models?pipeline_tag=reinforcement-learning
```bash
!pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit4/requirements-unit4.txt
```
## Import the packages 📦
In addition to importing the installed libraries, we also import:
- `imageio`: A library that will help us to generate a replay video
```python
import numpy as np
from collections import deque
import matplotlib.pyplot as plt
%matplotlib inline
# PyTorch
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
# Gym
import gym
import gym_pygame
# Hugging Face Hub
from huggingface_hub import notebook_login # To log to our Hugging Face account to be able to upload models to the Hub.
import imageio
```
## Check if we have a GPU
- Let's check if we have a GPU
- If it's the case you should see `device:cuda0`
```python
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
```
```python
print(device)
```
We're now ready to implement our Reinforce algorithm 🔥
# First agent: Playing CartPole-v1 🤖
## Create the CartPole environment and understand how it works
### [The environment 🎮](https://www.gymlibrary.dev/environments/classic_control/cart_pole/)
### Why do we use a simple environment like CartPole-v1?
As explained in [Reinforcement Learning Tips and Tricks](https://stable-baselines3.readthedocs.io/en/master/guide/rl_tips.html), when you implement your agent from scratch, you need **to be sure that it works correctly and find bugs with easy environments before going deeper** as finding bugs will be much easier in simple environments.
> Try to have some “sign of life” on toy problems
> Validate the implementation by making it run on harder and harder envs (you can compare results against the RL zoo). You usually need to run hyperparameter optimization for that step.
### The CartPole-v1 environment
> A pole is attached by an un-actuated joint to a cart, which moves along a frictionless track. The pendulum is placed upright on the cart and the goal is to balance the pole by applying forces in the left and right direction on the cart.
So, we start with CartPole-v1. The goal is to push the cart left or right **so that the pole stays in the equilibrium.**
The episode ends if:
- The pole Angle is greater than ±12°
- The Cart Position is greater than ±2.4
- The episode length is greater than 500
We get a reward 💰 of +1 every timestep that the Pole stays in the equilibrium.
```python
env_id = "CartPole-v1"
# Create the env
env = gym.make(env_id)
# Create the evaluation env
eval_env = gym.make(env_id)
# Get the state space and action space
s_size = env.observation_space.shape[0]
a_size = env.action_space.n
```
```python
print("_____OBSERVATION SPACE_____ \n")
print("The State Space is: ", s_size)
print("Sample observation", env.observation_space.sample()) # Get a random observation
```
```python
print("\n _____ACTION SPACE_____ \n")
print("The Action Space is: ", a_size)
print("Action Space Sample", env.action_space.sample()) # Take a random action
```
## Let's build the Reinforce Architecture
This implementation is based on three implementations:
- [PyTorch official Reinforcement Learning example](https://github.com/pytorch/examples/blob/main/reinforcement_learning/reinforce.py)
- [Udacity Reinforce](https://github.com/udacity/deep-reinforcement-learning/blob/master/reinforce/REINFORCE.ipynb)
- [Improvement of the integration by Chris1nexus](https://github.com/huggingface/deep-rl-class/pull/95)
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/reinforce.png" alt="Reinforce"/>
So we want:
- Two fully connected layers (fc1 and fc2).
- To use ReLU as activation function of fc1
- To use Softmax to output a probability distribution over actions
```python
class Policy(nn.Module):
def __init__(self, s_size, a_size, h_size):
super(Policy, self).__init__()
# Create two fully connected layers
def forward(self, x):
# Define the forward pass
# state goes to fc1 then we apply ReLU activation function
# fc1 outputs goes to fc2
# We output the softmax
def act(self, state):
"""
Given a state, take action
"""
state = torch.from_numpy(state).float().unsqueeze(0).to(device)
probs = self.forward(state).cpu()
m = Categorical(probs)
action = np.argmax(m)
return action.item(), m.log_prob(action)
```
### Solution
```python
class Policy(nn.Module):
def __init__(self, s_size, a_size, h_size):
super(Policy, self).__init__()
self.fc1 = nn.Linear(s_size, h_size)
self.fc2 = nn.Linear(h_size, a_size)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.softmax(x, dim=1)
def act(self, state):
state = torch.from_numpy(state).float().unsqueeze(0).to(device)
probs = self.forward(state).cpu()
m = Categorical(probs)
action = np.argmax(m)
return action.item(), m.log_prob(action)
```
I made a mistake, can you guess where?
- To find out let's make a forward pass:
```python
debug_policy = Policy(s_size, a_size, 64).to(device)
debug_policy.act(env.reset())
```
- Here we see that the error says `ValueError: The value argument to log_prob must be a Tensor`
- It means that `action` in `m.log_prob(action)` must be a Tensor **but it's not.**
- Do you know why? Check the act function and try to see why it does not work.
Advice 💡: Something is wrong in this implementation. Remember that for the act function **we want to sample an action from the probability distribution over actions**.
### (Real) Solution
```python
class Policy(nn.Module):
def __init__(self, s_size, a_size, h_size):
super(Policy, self).__init__()
self.fc1 = nn.Linear(s_size, h_size)
self.fc2 = nn.Linear(h_size, a_size)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.softmax(x, dim=1)
def act(self, state):
state = torch.from_numpy(state).float().unsqueeze(0).to(device)
probs = self.forward(state).cpu()
m = Categorical(probs)
action = m.sample()
return action.item(), m.log_prob(action)
```
By using CartPole, it was easier to debug since **we know that the bug comes from our integration and not from our simple environment**.
- Since **we want to sample an action from the probability distribution over actions**, we can't use `action = np.argmax(m)` since it will always output the action that has the highest probability.
- We need to replace this with `action = m.sample()` which will sample an action from the probability distribution P(.|s)
### Let's build the Reinforce Training Algorithm
This is the Reinforce algorithm pseudocode:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/pg_pseudocode.png" alt="Policy gradient pseudocode"/>
- When we calculate the return Gt (line 6), we see that we calculate the sum of discounted rewards **starting at timestep t**.
- Why? Because our policy should only **reinforce actions on the basis of the consequences**: so rewards obtained before taking an action are useless (since they were not because of the action), **only the ones that come after the action matters**.
- Before coding this you should read this section [don't let the past distract you](https://spinningup.openai.com/en/latest/spinningup/rl_intro3.html#don-t-let-the-past-distract-you) that explains why we use reward-to-go policy gradient.
We use an interesting technique coded by [Chris1nexus](https://github.com/Chris1nexus) to **compute the return at each timestep efficiently**. The comments explained the procedure. Don't hesitate also [to check the PR explanation](https://github.com/huggingface/deep-rl-class/pull/95)
But overall the idea is to **compute the return at each timestep efficiently**.
The second question you may ask is **why do we minimize the loss**? Didn't we talk about Gradient Ascent, not Gradient Descent earlier?
- We want to maximize our utility function $J(\theta)$, but in PyTorch and TensorFlow, it's better to **minimize an objective function.**
- So let's say we want to reinforce action 3 at a certain timestep. Before training this action P is 0.25.
- So we want to modify \\(theta \\) such that \\(\pi_\theta(a_3|s; \theta) > 0.25 \\)
- Because all P must sum to 1, max \\(pi_\theta(a_3|s; \theta)\\) will **minimize other action probability.**
- So we should tell PyTorch **to min \\(1 - \pi_\theta(a_3|s; \theta)\\).**
- This loss function approaches 0 as \\(\pi_\theta(a_3|s; \theta)\\) nears 1.
- So we are encouraging the gradient to max \\(\pi_\theta(a_3|s; \theta)\\)
```python
def reinforce(policy, optimizer, n_training_episodes, max_t, gamma, print_every):
# Help us to calculate the score during the training
scores_deque = deque(maxlen=100)
scores = []
# Line 3 of pseudocode
for i_episode in range(1, n_training_episodes+1):
saved_log_probs = []
rewards = []
state = # TODO: reset the environment
# Line 4 of pseudocode
for t in range(max_t):
action, log_prob = # TODO get the action
saved_log_probs.append(log_prob)
state, reward, done, _ = # TODO: take an env step
rewards.append(reward)
if done:
break
scores_deque.append(sum(rewards))
scores.append(sum(rewards))
# Line 6 of pseudocode: calculate the return
returns = deque(maxlen=max_t)
n_steps = len(rewards)
# Compute the discounted returns at each timestep,
# as the sum of the gamma-discounted return at time t (G_t) + the reward at time t
# In O(N) time, where N is the number of time steps
# (this definition of the discounted return G_t follows the definition of this quantity
# shown at page 44 of Sutton&Barto 2017 2nd draft)
# G_t = r_(t+1) + r_(t+2) + ...
# Given this formulation, the returns at each timestep t can be computed
# by re-using the computed future returns G_(t+1) to compute the current return G_t
# G_t = r_(t+1) + gamma*G_(t+1)
# G_(t-1) = r_t + gamma* G_t
# (this follows a dynamic programming approach, with which we memorize solutions in order
# to avoid computing them multiple times)
# This is correct since the above is equivalent to (see also page 46 of Sutton&Barto 2017 2nd draft)
# G_(t-1) = r_t + gamma*r_(t+1) + gamma*gamma*r_(t+2) + ...
## Given the above, we calculate the returns at timestep t as:
# gamma[t] * return[t] + reward[t]
#
## We compute this starting from the last timestep to the first, in order
## to employ the formula presented above and avoid redundant computations that would be needed
## if we were to do it from first to last.
## Hence, the queue "returns" will hold the returns in chronological order, from t=0 to t=n_steps
## thanks to the appendleft() function which allows to append to the position 0 in constant time O(1)
## a normal python list would instead require O(N) to do this.
for t in range(n_steps)[::-1]:
disc_return_t = (returns[0] if len(returns)>0 else 0)
returns.appendleft( ) # TODO: complete here
## standardization of the returns is employed to make training more stable
eps = np.finfo(np.float32).eps.item()
## eps is the smallest representable float, which is
# added to the standard deviation of the returns to avoid numerical instabilities
returns = torch.tensor(returns)
returns = (returns - returns.mean()) / (returns.std() + eps)
# Line 7:
policy_loss = []
for log_prob, disc_return in zip(saved_log_probs, returns):
policy_loss.append(-log_prob * disc_return)
policy_loss = torch.cat(policy_loss).sum()
# Line 8: PyTorch prefers gradient descent
optimizer.zero_grad()
policy_loss.backward()
optimizer.step()
if i_episode % print_every == 0:
print('Episode {}\tAverage Score: {:.2f}'.format(i_episode, np.mean(scores_deque)))
return scores
```
#### Solution
```python
def reinforce(policy, optimizer, n_training_episodes, max_t, gamma, print_every):
# Help us to calculate the score during the training
scores_deque = deque(maxlen=100)
scores = []
# Line 3 of pseudocode
for i_episode in range(1, n_training_episodes + 1):
saved_log_probs = []
rewards = []
state = env.reset()
# Line 4 of pseudocode
for t in range(max_t):
action, log_prob = policy.act(state)
saved_log_probs.append(log_prob)
state, reward, done, _ = env.step(action)
rewards.append(reward)
if done:
break
scores_deque.append(sum(rewards))
scores.append(sum(rewards))
# Line 6 of pseudocode: calculate the return
returns = deque(maxlen=max_t)
n_steps = len(rewards)
# Compute the discounted returns at each timestep,
# as
# the sum of the gamma-discounted return at time t (G_t) + the reward at time t
#
# In O(N) time, where N is the number of time steps
# (this definition of the discounted return G_t follows the definition of this quantity
# shown at page 44 of Sutton&Barto 2017 2nd draft)
# G_t = r_(t+1) + r_(t+2) + ...
# Given this formulation, the returns at each timestep t can be computed
# by re-using the computed future returns G_(t+1) to compute the current return G_t
# G_t = r_(t+1) + gamma*G_(t+1)
# G_(t-1) = r_t + gamma* G_t
# (this follows a dynamic programming approach, with which we memorize solutions in order
# to avoid computing them multiple times)
# This is correct since the above is equivalent to (see also page 46 of Sutton&Barto 2017 2nd draft)
# G_(t-1) = r_t + gamma*r_(t+1) + gamma*gamma*r_(t+2) + ...
## Given the above, we calculate the returns at timestep t as:
# gamma[t] * return[t] + reward[t]
#
## We compute this starting from the last timestep to the first, in order
## to employ the formula presented above and avoid redundant computations that would be needed
## if we were to do it from first to last.
## Hence, the queue "returns" will hold the returns in chronological order, from t=0 to t=n_steps
## thanks to the appendleft() function which allows to append to the position 0 in constant time O(1)
## a normal python list would instead require O(N) to do this.
for t in range(n_steps)[::-1]:
disc_return_t = returns[0] if len(returns) > 0 else 0
returns.appendleft(gamma * disc_return_t + rewards[t])
## standardization of the returns is employed to make training more stable
eps = np.finfo(np.float32).eps.item()
## eps is the smallest representable float, which is
# added to the standard deviation of the returns to avoid numerical instabilities
returns = torch.tensor(returns)
returns = (returns - returns.mean()) / (returns.std() + eps)
# Line 7:
policy_loss = []
for log_prob, disc_return in zip(saved_log_probs, returns):
policy_loss.append(-log_prob * disc_return)
policy_loss = torch.cat(policy_loss).sum()
# Line 8: PyTorch prefers gradient descent
optimizer.zero_grad()
policy_loss.backward()
optimizer.step()
if i_episode % print_every == 0:
print("Episode {}\tAverage Score: {:.2f}".format(i_episode, np.mean(scores_deque)))
return scores
```
## Train it
- We're now ready to train our agent.
- But first, we define a variable containing all the training hyperparameters.
- You can change the training parameters (and should 😉)
```python
cartpole_hyperparameters = {
"h_size": 16,
"n_training_episodes": 1000,
"n_evaluation_episodes": 10,
"max_t": 1000,
"gamma": 1.0,
"lr": 1e-2,
"env_id": env_id,
"state_space": s_size,
"action_space": a_size,
}
```
```python
# Create policy and place it to the device
cartpole_policy = Policy(
cartpole_hyperparameters["state_space"],
cartpole_hyperparameters["action_space"],
cartpole_hyperparameters["h_size"],
).to(device)
cartpole_optimizer = optim.Adam(cartpole_policy.parameters(), lr=cartpole_hyperparameters["lr"])
```
```python
scores = reinforce(
cartpole_policy,
cartpole_optimizer,
cartpole_hyperparameters["n_training_episodes"],
cartpole_hyperparameters["max_t"],
cartpole_hyperparameters["gamma"],
100,
)
```
## Define evaluation method 📝
- Here we define the evaluation method that we're going to use to test our Reinforce agent.
```python
def evaluate_agent(env, max_steps, n_eval_episodes, policy):
"""
Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.
:param env: The evaluation environment
:param n_eval_episodes: Number of episode to evaluate the agent
:param policy: The Reinforce agent
"""
episode_rewards = []
for episode in range(n_eval_episodes):
state = env.reset()
step = 0
done = False
total_rewards_ep = 0
for step in range(max_steps):
action, _ = policy.act(state)
new_state, reward, done, info = env.step(action)
total_rewards_ep += reward
if done:
break
state = new_state
episode_rewards.append(total_rewards_ep)
mean_reward = np.mean(episode_rewards)
std_reward = np.std(episode_rewards)
return mean_reward, std_reward
```
## Evaluate our agent 📈
```python
evaluate_agent(
eval_env, cartpole_hyperparameters["max_t"], cartpole_hyperparameters["n_evaluation_episodes"], cartpole_policy
)
```
### Publish our trained model on the Hub 🔥
Now that we saw we got good results after the training, we can publish our trained model on the hub 🤗 with one line of code.
Here's an example of a Model Card:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/modelcard.png"/>
### Push to the Hub
#### Do not modify this code
```python
from huggingface_hub import HfApi, snapshot_download
from huggingface_hub.repocard import metadata_eval_result, metadata_save
from pathlib import Path
import datetime
import json
import imageio
import tempfile
import os
```
```python
def record_video(env, policy, out_directory, fps=30):
"""
Generate a replay video of the agent
:param env
:param Qtable: Qtable of our agent
:param out_directory
:param fps: how many frame per seconds (with taxi-v3 and frozenlake-v1 we use 1)
"""
images = []
done = False
state = env.reset()
img = env.render(mode="rgb_array")
images.append(img)
while not done:
# Take the action (index) that have the maximum expected future reward given that state
action, _ = policy.act(state)
state, reward, done, info = env.step(action) # We directly put next_state = state for recording logic
img = env.render(mode="rgb_array")
images.append(img)
imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)
```
```python
def push_to_hub(repo_id,
model,
hyperparameters,
eval_env,
video_fps=30
):
"""
Evaluate, Generate a video and Upload a model to Hugging Face Hub.
This method does the complete pipeline:
- It evaluates the model
- It generates the model card
- It generates a replay video of the agent
- It pushes everything to the Hub
:param repo_id: repo_id: id of the model repository from the Hugging Face Hub
:param model: the pytorch model we want to save
:param hyperparameters: training hyperparameters
:param eval_env: evaluation environment
:param video_fps: how many frame per seconds to record our video replay
"""
_, repo_name = repo_id.split("/")
api = HfApi()
# Step 1: Create the repo
repo_url = api.create_repo(
repo_id=repo_id,
exist_ok=True,
)
with tempfile.TemporaryDirectory() as tmpdirname:
local_directory = Path(tmpdirname)
# Step 2: Save the model
torch.save(model, local_directory / "model.pt")
# Step 3: Save the hyperparameters to JSON
with open(local_directory / "hyperparameters.json", "w") as outfile:
json.dump(hyperparameters, outfile)
# Step 4: Evaluate the model and build JSON
mean_reward, std_reward = evaluate_agent(eval_env,
hyperparameters["max_t"],
hyperparameters["n_evaluation_episodes"],
model)
# Get datetime
eval_datetime = datetime.datetime.now()
eval_form_datetime = eval_datetime.isoformat()
evaluate_data = {
"env_id": hyperparameters["env_id"],
"mean_reward": mean_reward,
"n_evaluation_episodes": hyperparameters["n_evaluation_episodes"],
"eval_datetime": eval_form_datetime,
}
# Write a JSON file
with open(local_directory / "results.json", "w") as outfile:
json.dump(evaluate_data, outfile)
# Step 5: Create the model card
env_name = hyperparameters["env_id"]
metadata = {}
metadata["tags"] = [
env_name,
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class"
]
# Add metrics
eval = metadata_eval_result(
model_pretty_name=repo_name,
task_pretty_name="reinforcement-learning",
task_id="reinforcement-learning",
metrics_pretty_name="mean_reward",
metrics_id="mean_reward",
metrics_value=f"{mean_reward:.2f} +/- {std_reward:.2f}",
dataset_pretty_name=env_name,
dataset_id=env_name,
)
# Merges both dictionaries
metadata = {**metadata, **eval}
model_card = f"""
# **Reinforce** Agent playing **{env_id}**
This is a trained model of a **Reinforce** agent playing **{env_id}** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
"""
readme_path = local_directory / "README.md"
readme = ""
if readme_path.exists():
with readme_path.open("r", encoding="utf8") as f:
readme = f.read()
else:
readme = model_card
with readme_path.open("w", encoding="utf-8") as f:
f.write(readme)
# Save our metrics to Readme metadata
metadata_save(readme_path, metadata)
# Step 6: Record a video
video_path = local_directory / "replay.mp4"
record_video(env, model, video_path, video_fps)
# Step 7. Push everything to the Hub
api.upload_folder(
repo_id=repo_id,
folder_path=local_directory,
path_in_repo=".",
)
print(f"Your model is pushed to the Hub. You can view your model here: {repo_url}")
```
By using `push_to_hub`, **you evaluate, record a replay, generate a model card of your agent, and push it to the Hub**.
This way:
- You can **showcase our work** 🔥
- You can **visualize your agent playing** 👀
- You can **share an agent with the community that others can use** 💾
- You can **access a leaderboard 🏆 to see how well your agent is performing compared to your classmates** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
To be able to share your model with the community there are three more steps to follow:
1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join
2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.
- Create a new token (https://huggingface.co/settings/tokens) **with write role**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/create-token.jpg" alt="Create HF Token">
```python
notebook_login()
```
If you don't want to use Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login` (or `login`)
3️⃣ We're now ready to push our trained agent to the 🤗 Hub 🔥 using `package_to_hub()` function
```python
repo_id = "" # TODO Define your repo id {username/Reinforce-{model-id}}
push_to_hub(
repo_id,
cartpole_policy, # The model we want to save
cartpole_hyperparameters, # Hyperparameters
eval_env, # Evaluation environment
video_fps=30
)
```
Now that we tested the robustness of our implementation, let's try a more complex environment: PixelCopter 🚁
## Second agent: PixelCopter 🚁
### Study the PixelCopter environment 👀
- [The Environment documentation](https://pygame-learning-environment.readthedocs.io/en/latest/user/games/pixelcopter.html)
```python
env_id = "Pixelcopter-PLE-v0"
env = gym.make(env_id)
eval_env = gym.make(env_id)
s_size = env.observation_space.shape[0]
a_size = env.action_space.n
```
```python
print("_____OBSERVATION SPACE_____ \n")
print("The State Space is: ", s_size)
print("Sample observation", env.observation_space.sample()) # Get a random observation
```
```python
print("\n _____ACTION SPACE_____ \n")
print("The Action Space is: ", a_size)
print("Action Space Sample", env.action_space.sample()) # Take a random action
```
The observation space (7) 👀:
- player y position
- player velocity
- player distance to floor
- player distance to ceiling
- next block x distance to player
- next blocks top y location
- next blocks bottom y location
The action space(2) 🎮:
- Up (press accelerator)
- Do nothing (don't press accelerator)
The reward function 💰:
- For each vertical block it passes, it gains a positive reward of +1. Each time a terminal state is reached it receives a negative reward of -1.
### Define the new Policy 🧠
- We need to have a deeper neural network since the environment is more complex
```python
class Policy(nn.Module):
def __init__(self, s_size, a_size, h_size):
super(Policy, self).__init__()
# Define the three layers here
def forward(self, x):
# Define the forward process here
return F.softmax(x, dim=1)
def act(self, state):
state = torch.from_numpy(state).float().unsqueeze(0).to(device)
probs = self.forward(state).cpu()
m = Categorical(probs)
action = m.sample()
return action.item(), m.log_prob(action)
```
#### Solution
```python
class Policy(nn.Module):
def __init__(self, s_size, a_size, h_size):
super(Policy, self).__init__()
self.fc1 = nn.Linear(s_size, h_size)
self.fc2 = nn.Linear(h_size, h_size * 2)
self.fc3 = nn.Linear(h_size * 2, a_size)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return F.softmax(x, dim=1)
def act(self, state):
state = torch.from_numpy(state).float().unsqueeze(0).to(device)
probs = self.forward(state).cpu()
m = Categorical(probs)
action = m.sample()
return action.item(), m.log_prob(action)
```
### Define the hyperparameters ⚙️
- Because this environment is more complex.
- Especially for the hidden size, we need more neurons.
```python
pixelcopter_hyperparameters = {
"h_size": 64,
"n_training_episodes": 50000,
"n_evaluation_episodes": 10,
"max_t": 10000,
"gamma": 0.99,
"lr": 1e-4,
"env_id": env_id,
"state_space": s_size,
"action_space": a_size,
}
```
### Train it
- We're now ready to train our agent 🔥.
```python
# Create policy and place it to the device
# torch.manual_seed(50)
pixelcopter_policy = Policy(
pixelcopter_hyperparameters["state_space"],
pixelcopter_hyperparameters["action_space"],
pixelcopter_hyperparameters["h_size"],
).to(device)
pixelcopter_optimizer = optim.Adam(pixelcopter_policy.parameters(), lr=pixelcopter_hyperparameters["lr"])
```
```python
scores = reinforce(
pixelcopter_policy,
pixelcopter_optimizer,
pixelcopter_hyperparameters["n_training_episodes"],
pixelcopter_hyperparameters["max_t"],
pixelcopter_hyperparameters["gamma"],
1000,
)
```
### Publish our trained model on the Hub 🔥
```python
repo_id = "" # TODO Define your repo id {username/Reinforce-{model-id}}
push_to_hub(
repo_id,
pixelcopter_policy, # The model we want to save
pixelcopter_hyperparameters, # Hyperparameters
eval_env, # Evaluation environment
video_fps=30
)
```
## Some additional challenges 🏆
The best way to learn **is to try things on your own**! As you saw, the current agent is not doing great. As a first suggestion, you can train for more steps. But also try to find better parameters.
In the [Leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) you will find your agents. Can you get to the top?
Here are some ideas to climb up the leaderboard:
* Train more steps
* Try different hyperparameters by looking at what your classmates have done 👉 https://huggingface.co/models?other=reinforce
* **Push your new trained model** on the Hub 🔥
* **Improving the implementation for more complex environments** (for instance, what about changing the network to a Convolutional Neural Network to handle
frames as observation)?
________________________________________________________________________
**Congrats on finishing this unit**! There was a lot of information.
And congrats on finishing the tutorial. You've just coded your first Deep Reinforcement Learning agent from scratch using PyTorch and shared it on the Hub 🥳.
Don't hesitate to iterate on this unit **by improving the implementation for more complex environments** (for instance, what about changing the network to a Convolutional Neural Network to handle
frames as observation)?
In the next unit, **we're going to learn more about Unity MLAgents**, by training agents in Unity environments. This way, you will be ready to participate in the **AI vs AI challenges where you'll train your agents
to compete against other agents in a snowball fight and a soccer game.**
Sound fun? See you next time!
Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then please 👉 [fill this form](https://forms.gle/BzKXWzLAGZESGNaE9)
See you in Unit 5! 🔥
### Keep Learning, stay awesome 🤗
|
huggingface/deep-rl-class/blob/main/units/en/unit4/hands-on.mdx
|
Setup [[setup]]
After all this information, it's time to get started. We're going to do two things:
1. **Create your Hugging Face account** if it's not already done
2. **Sign up to Discord and introduce yourself** (don't be shy 🤗)
### Let's create my Hugging Face account
(If it's not already done) create an account to HF <a href="https://huggingface.co/join">here</a>
### Let's join our Discord server
You can now sign up for our Discord Server. This is the place where you **can chat with the community and with us, create and join study groups to grow with each other and more**
👉🏻 Join our discord server <a href="https://discord.gg/ydHrjt3WP5">here.</a>
When you join, remember to introduce yourself in #introduce-yourself and sign-up for reinforcement channels in #role-assignments.
We have multiple RL-related channels:
- `rl-announcements`: where we give the latest information about the course.
- `rl-discussions`: where you can chat about RL and share information.
- `rl-study-group`: where you can create and join study groups.
- `rl-i-made-this`: where you can share your projects and models.
If this is your first time using Discord, we wrote a Discord 101 to get the best practices. Check the next section.
Congratulations! **You've just finished the on-boarding**. You're now ready to start to learn Deep Reinforcement Learning. Have fun!
### Keep Learning, stay awesome 🤗
|
huggingface/deep-rl-class/blob/main/units/en/unit0/setup.mdx
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# AutoPipeline
`AutoPipeline` is designed to:
1. make it easy for you to load a checkpoint for a task without knowing the specific pipeline class to use
2. use multiple pipelines in your workflow
Based on the task, the `AutoPipeline` class automatically retrieves the relevant pipeline given the name or path to the pretrained weights with the `from_pretrained()` method.
To seamlessly switch between tasks with the same checkpoint without reallocating additional memory, use the `from_pipe()` method to transfer the components from the original pipeline to the new one.
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, use_safetensors=True
).to("cuda")
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipeline(prompt, num_inference_steps=25).images[0]
```
<Tip>
Check out the [AutoPipeline](../../tutorials/autopipeline) tutorial to learn how to use this API!
</Tip>
`AutoPipeline` supports text-to-image, image-to-image, and inpainting for the following diffusion models:
- [Stable Diffusion](./stable_diffusion/overview)
- [ControlNet](./controlnet)
- [Stable Diffusion XL (SDXL)](./stable_diffusion/stable_diffusion_xl)
- [DeepFloyd IF](./deepfloyd_if)
- [Kandinsky 2.1](./kandinsky)
- [Kandinsky 2.2](./kandinsky_v22)
## AutoPipelineForText2Image
[[autodoc]] AutoPipelineForText2Image
- all
- from_pretrained
- from_pipe
## AutoPipelineForImage2Image
[[autodoc]] AutoPipelineForImage2Image
- all
- from_pretrained
- from_pipe
## AutoPipelineForInpainting
[[autodoc]] AutoPipelineForInpainting
- all
- from_pretrained
- from_pipe
|
huggingface/diffusers/blob/main/docs/source/en/api/pipelines/auto_pipeline.md
|
NASNet
**NASNet** is a type of convolutional neural network discovered through neural architecture search. The building blocks consist of normal and reduction cells.
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('nasnetalarge', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `nasnetalarge`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('nasnetalarge', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{zoph2018learning,
title={Learning Transferable Architectures for Scalable Image Recognition},
author={Barret Zoph and Vijay Vasudevan and Jonathon Shlens and Quoc V. Le},
year={2018},
eprint={1707.07012},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: NASNet
Paper:
Title: Learning Transferable Architectures for Scalable Image Recognition
URL: https://paperswithcode.com/paper/learning-transferable-architectures-for
Models:
- Name: nasnetalarge
In Collection: NASNet
Metadata:
FLOPs: 30242402862
Parameters: 88750000
File Size: 356056626
Architecture:
- Average Pooling
- Batch Normalization
- Convolution
- Depthwise Separable Convolution
- Dropout
- ReLU
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- RMSProp
- Weight Decay
Training Data:
- ImageNet
Training Resources: 50x Tesla K40 GPUs
ID: nasnetalarge
Dropout: 0.5
Crop Pct: '0.911'
Momentum: 0.9
Image Size: '331'
Interpolation: bicubic
Label Smoothing: 0.1
RMSProp \\( \epsilon \\): 1.0
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/nasnet.py#L562
Weights: http://data.lip6.fr/cadene/pretrainedmodels/nasnetalarge-a1897284.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 82.63%
Top 5 Accuracy: 96.05%
-->
|
huggingface/pytorch-image-models/blob/main/hfdocs/source/models/nasnet.mdx
|
his demo identifies musical instruments from an audio file. It uses Gradio's Audio and Label components.
|
gradio-app/gradio/blob/main/demo/musical_instrument_identification/DESCRIPTION.md
|
--
title: "Hugging Face Reads, Feb. 2021 - Long-range Transformers"
thumbnail: /blog/assets/14_long_range_transformers/EfficientTransformerTaxonomy.png
authors:
- user: VictorSanh
---
<figure>
<img src="/blog/assets/14_long_range_transformers/EfficientTransformerTaxonomy.png" alt="Efficient Transformers taxonomy"/>
<figcaption>Efficient Transformers taxonomy from Efficient Transformers: a Survey by Tay et al.</figcaption>
</figure>
# Hugging Face Reads, Feb. 2021 - Long-range Transformers
Co-written by Teven Le Scao, Patrick Von Platen, Suraj Patil, Yacine Jernite and Victor Sanh.
> Each month, we will choose a topic to focus on, reading a set of four papers recently published on the subject. We will then write a short blog post summarizing their findings and the common trends between them, and questions we had for follow-up work after reading them. The first topic for January 2021 was [Sparsity and Pruning](https://discuss.huggingface.co/t/hugging-face-reads-01-2021-sparsity-and-pruning/3144), in February 2021 we addressed Long-Range Attention in Transformers.
## Introduction
After the rise of large transformer models in 2018 and 2019, two trends have quickly emerged to bring their compute requirements down. First, conditional computation, quantization, distillation, and pruning have unlocked inference of large models in compute-constrained environments; we’ve already touched upon this in part in our [last reading group post](https://discuss.huggingface.co/t/hugging-face-reads-01-2021-sparsity-and-pruning/3144). The research community then moved to reduce the cost of pre-training.
In particular, one issue has been at the center of the efforts: the quadratic cost in memory and time of transformer models with regard to the sequence length. In order to allow efficient training of very large models, 2020 saw an onslaught of papers to address that bottleneck and scale transformers beyond the usual 512- or 1024- sequence lengths that were the default in NLP at the start of the year.
This topic has been a key part of our research discussions from the start, and our own Patrick Von Platen has already dedicated [a 4-part series to Reformer](https://huggingface.co/blog/reformer). In this reading group, rather than trying to cover every approach (there are so many!), we’ll focus on four main ideas:
* Custom attention patterns (with [Longformer](https://arxiv.org/abs/2004.05150))
* Recurrence (with [Compressive Transformer](https://arxiv.org/abs/1911.05507))
* Low-rank approximations (with [Linformer](https://arxiv.org/abs/2006.04768))
* Kernel approximations (with [Performer](https://arxiv.org/abs/2009.14794))
For exhaustive views of the subject, check out [Efficient Transfomers: A Survey](https://arxiv.org/abs/2009.06732) and [Long Range Arena](https://arxiv.org/abs/2011.04006).
## Summaries
### [Longformer - The Long-Document Transformer](https://arxiv.org/abs/2004.05150)
Iz Beltagy, Matthew E. Peters, Arman Cohan
Longformer addresses the memory bottleneck of transformers by replacing conventional self-attention with a combination of windowed/local/sparse (cf. [Sparse Transformers (2019)](https://arxiv.org/abs/1904.10509)) attention and global attention that scales linearly with the sequence length. As opposed to previous long-range transformer models (e.g. [Transformer-XL (2019)](https://arxiv.org/abs/1901.02860), [Reformer (2020)](https://arxiv.org/abs/2001.04451), [Adaptive Attention Span (2019)](https://arxiv.org/abs/1905.07799)), Longformer’s self-attention layer is designed as a drop-in replacement for the standard self-attention, thus making it possible to leverage pre-trained checkpoints for further pre-training and/or fine-tuning on long sequence tasks.
The standard self-attention matrix (Figure a) scales quadratically with the input length:
<figure>
<img src="/blog/assets/14_long_range_transformers/Longformer.png" alt="Longformer attention"/>
<figcaption>Figure taken from Longformer</figcaption>
</figure>
Longformer uses different attention patterns for autoregressive language modeling, encoder pre-training & fine-tuning, and sequence-to-sequence tasks.
* For autoregressive language modeling, the strongest results are obtained by replacing causal self-attention (a la GPT2) with dilated windowed self-attention (Figure c). With \\(n\\) being the sequence length and \\(w\\) being the window length, this attention pattern reduces the memory consumption from \\(n^2\\) to \\(wn\\), which under the assumption that \\(w << n\\), scales linearly with the sequence length.
* For encoder pre-training, Longformer replaces the bi-directional self-attention (a la BERT) with a combination of local windowed and global bi-directional self-attention (Figure d). This reduces the memory consumption from \\(n^2\\) to \\(w n + g n\\) with \\(g\\) being the number of tokens that are attended to globally, which again scales linearly with the sequence length.
* For sequence-to-sequence models, only the encoder layers (a la BART) are replaced with a combination of local and global bi-directional self-attention (Figure d) because for most seq2seq tasks, only the encoder processes very large inputs (e.g. summarization). The memory consumption is thus reduced from \\(n_s^2+ n_s n_t +n_t^2\\) to \\(w n_s +gn_s +n_s n_t +n_t^2\\) with \\(n_s\\) and \\(n_t\\) being the source (encoder input) and target (decoder input) lengths respectively. For Longformer Encoder-Decoder to be efficient, it is assumed that \\(n_s\\) is much bigger than \\(n_t\\).
#### Main findings
* The authors proposed the dilated windowed self-attention (Figure c) and showed that it yields better results on language modeling compared to just windowed/sparse self-attention (Figure b). The window sizes are increased through the layers. This pattern further outperforms previous architectures (such as Transformer-XL, or adaptive span attention) on downstream benchmarks.
* Global attention allows the information to flow through the whole sequence and applying the global attention to task-motivated tokens (such as the tokens of the question in QA, CLS token for sentence classification) leads to stronger performance on downstream tasks. Using this global pattern, Longformer can be successfully applied to document-level NLP tasks in the transfer learning setting.
* Standard pre-trained models can be adapted to long-range inputs by simply replacing the standard self-attention with the long-range self-attention proposed in this paper and then fine-tuning on the downstream task. This avoids costly pre-training specific to long-range inputs.
#### Follow-up questions
* The increasing size (throughout the layers) of the dilated windowed self-attention echoes findings in computer vision on increasing the receptive field of stacked CNN. How do these two findings relate? What are the transposable learnings?
* Longformer’s Encoder-Decoder architecture works well for tasks that do not require a long target length (e.g. summarization). However, how would it work for long-range seq2seq tasks which require a long target length (e.g. document translation, speech recognition, etc.) especially considering the cross-attention layer of encoder-decoder’s models?
* In practice, the sliding window self-attention relies on many indexing operations to ensure a symmetric query-key weights matrix. Those operations are very slow on TPUs which highlights the question of the applicability of such patterns on other hardware.
### [Compressive Transformers for Long-Range Sequence Modelling](https://arxiv.org/abs/1911.05507)
Jack W. Rae, Anna Potapenko, Siddhant M. Jayakumar, Timothy P. Lillicrap
[Transformer-XL (2019)](https://arxiv.org/abs/1901.02860) showed that caching previously computed layer activations in a memory can boost performance on language modeling tasks (such as *enwik8*). Instead of just attending the current \\(n\\) input tokens, the model can also attend to the past \\(n_m\\) tokens, with \\(n_m\\) being the memory size of the model. Transformer-XL has a memory complexity of \\(O(n^2+ n n_m)\\), which shows that memory cost can increase significantly for very large \\(n_m\\). Hence, Transformer-XL has to eventually discard past activations from the memory when the number of cached activations gets larger than \\(n_m\\). Compressive Transformer addresses this problem by adding an additional compressed memory to efficiently cache past activations that would have otherwise eventually been discarded. This way the model can learn better long-range sequence dependencies having access to significantly more past activations.
<figure>
<img src="/blog/assets/14_long_range_transformers/CompressiveTransformer.png" alt="Compressive Tranformer recurrence"/>
<figcaption>Figure taken from Compressive Transfomer</figcaption>
</figure>
A compression factor \\(c\\) (equal to 3 in the illustration) is chosen to decide the rate at which past activations are compressed. The authors experiment with different compression functions \\(f_c\\) such as max/mean pooling (parameter-free) and 1D convolution (trainable layer). The compression function is trained with backpropagation through time or local auxiliary compression losses. In addition to the current input of length \\(n\\), the model attends to \\(n_m\\) cached activations in the regular memory and \\(n_{cm}\\) compressed memory activations allowing a long temporal dependency of \\(l × (n_m + c n_{cm})\\), with \\(l\\) being the number of attention layers. This increases Transformer-XL’s range by additional \\(l × c × n_{cm}\\) tokens and the memory cost amounts to \\(O(n^2+ n n_m+ n n_{cm})\\). Experiments are conducted on Reinforcement learning, audio generation, and natural language processing. The authors also introduce a new long-range language modeling benchmark called [PG19](https://huggingface.co/datasets/pg19).
#### Main findings
* Compressive Transformer significantly outperforms the state-of-the-art perplexity on language modeling, namely on the enwik8 and WikiText-103 datasets. In particular, compressed memory plays a crucial role in modeling rare words occurring on long sequences.
* The authors show that the model learns to preserve salient information by increasingly attending the compressed memory instead of the regular memory, which goes against the trend of older memories being accessed less frequently.
* All compression functions (average pooling, max pooling, 1D convolution) yield similar results confirming that memory compression is an effective way to store past information.
#### Follow-up questions
* Compressive Transformer requires a special optimization schedule in which the effective batch size is progressively increased to avoid significant performance degradation for lower learning rates. This effect is not well understood and calls into more analysis.
* The Compressive Transformer has many more hyperparameters compared to a simple model like BERT or GPT2: the compression rate, the compression function and loss, the regular and compressed memory sizes, etc. It is not clear whether those parameters generalize well across different tasks (other than language modeling) or similar to the learning rate, make the training also very brittle.
* It would be interesting to probe the regular memory and compressed memory to analyze what kind of information is memorized through the long sequences. Shedding light on the most salient pieces of information can inform methods such as [Funnel Transformer](https://arxiv.org/abs/2006.03236) which reduces the redundancy in maintaining a full-length token-level sequence.
### [Linformer: Self-Attention with Linear Complexity](https://arxiv.org/abs/2006.04768)
Sinong Wang, Belinda Z. Li, Madian Khabsa, Han Fang, Hao Ma
The goal is to reduce the complexity of the self-attention with respect to the sequence length \\(n\\)) from quadratic to linear. This paper makes the observation that the attention matrices are low rank (i.e. they don’t contain \\(n × n\\) worth of information) and explores the possibility of using high-dimensional data compression techniques to build more memory efficient transformers.
The theoretical foundations of the proposed approach are based on the Johnson-Lindenstrauss lemma. Let’s consider \\(m\\)) points in a high-dimensional space. We want to project them to a low-dimensional space while preserving the structure of the dataset (i.e. the mutual distances between points) with a margin of error \\(\varepsilon\\). The Johnson-Lindenstrauss lemma states we can choose a small dimension \\(k \sim 8 \log(m) / \varepsilon^2\\) and find a suitable projection into Rk in polynomial time by simply trying random orthogonal projections.
Linformer projects the sequence length into a smaller dimension by learning a low-rank decomposition of the attention context matrix. The matrix multiplication of the self-attention can be then cleverly re-written such that no matrix of size \\(n × n\\) needs to be ever computed and stored.
Standard transformer:
$$\text{Attention}(Q, K, V) = \text{softmax}(Q * K) * V$$
(n * h) (n * n) (n * h)
Linformer:
$$\text{LinAttention}(Q, K, V) = \text{softmax}(Q * K * W^K) * W^V * V$$
(n * h) (n * d) (d * n) (n * h)
#### Main findings
* The self-attention matrix is low-rank which implies that most of its information can be recovered by its first few highest eigenvalues and can be approximated by a low-rank matrix.
* Lot of works focus on reducing the dimensionality of the hidden states. This paper shows that reducing the sequence length with learned projections can be a strong alternative while shrinking the memory complexity of the self-attention from quadratic to linear.
* Increasing the sequence length doesn’t affect the inference speed (time-clock) of Linformer, when transformers have a linear increase. Moreover, the convergence speed (number of updates) is not impacted by Linformer's self-attention.
<figure>
<img src="/blog/assets/14_long_range_transformers/Linformer.png" alt="Linformer performance"/>
<figcaption>Figure taken from Linformer</figcaption>
</figure>
#### Follow-up questions
* Even though the projections matrices are shared between layers, the approach presented here comes in contrast with the Johnson-Lindenstrauss that states that random orthogonal projections are sufficient (in polynomial time). Would random projections have worked here? This is reminiscent of Reformer which uses random projections in locally sensitive hashing to reduce the memory complexity of the self-attention.
### [Rethinking Attention with Performers](https://arxiv.org/abs/2009.14794)
Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, David Belanger, Lucy Colwell, Adrian Weller
The goal is (again!) to reduce the complexity of the self-attention with respect to the sequence length \\(n\\)) from quadratic to linear. In contrast to other papers, the authors note that the sparsity and low-rankness priors of the self-attention may not hold in other modalities (speech, protein sequence modeling). Thus the paper explores methods to reduce the memory burden of the self-attention without any priors on the attention matrix.
The authors observe that if we could perform the matrix multiplication \\(K × V\\) through the softmax ( \\(\text{softmax}(Q × K) × V\\) ), we wouldn’t have to compute the \\(Q x K\\) matrix of size \\(n x n\\) which is the memory bottleneck. They use random feature maps (aka random projections) to approximate the softmax by:
$$\text{softmax}(Q * K) \sim Q’ * K’ = \phi(Q) * \phi(K)$$
, where \\(phi\\) is a non-linear suitable function. And then:
$$\text{Attention}(Q, K, V) \sim \phi(Q) * (\phi(K) * V)$$
Taking inspiration from machine learning papers from the early 2000s, the authors introduce **FAVOR+** (**F**ast **A**ttention **V**ia **O**rthogonal **R**andom positive (**+**) **F**eatures) a procedure to find unbiased or nearly-unbiased estimations of the self-attention matrix, with uniform convergence and low estimation variance.
#### Main findings
* The FAVOR+ procedure can be used to approximate self-attention matrices with high accuracy, without any priors on the form of the attention matrix, making it applicable as a drop-in replacement of standard self-attention and leading to strong performances in multiple applications and modalities.
* The very thorough mathematical investigation of how-to and not-to approximate softmax highlights the relevance of principled methods developed in the early 2000s even in the deep learning era.
* FAVOR+ can also be applied to efficiently model other kernelizable attention mechanisms beyond softmax.
#### Follow-up questions
* Even if the approximation of the attention mechanism is tight, small errors propagate through the transformer layers. This raises the question of the convergence and stability of fine-tuning a pre-trained network with FAVOR+ as an approximation of self-attention.
* The FAVOR+ algorithm is the combination of multiple components. It is not clear which of these components have the most empirical impact on the performance, especially in view of the variety of modalities considered in this work.
## Reading group discussion
The developments in pre-trained transformer-based language models for natural language understanding and generation are impressive. Making these systems efficient for production purposes has become a very active research area. This emphasizes that we still have much to learn and build both on the methodological and practical sides to enable efficient and general deep learning based systems, in particular for applications that require modeling long-range inputs.
The four papers above offer different ways to deal with the quadratic memory complexity of the self-attention mechanism, usually by reducing it to linear complexity. Linformer and Longformer both rely on the observation that the self-attention matrix does not contain \\(n × n\\) worth of information (the attention matrix is low-rank and sparse). Performer gives a principled method to approximate the softmax-attention kernel (and any kernelizable attention mechanisms beyond softmax). Compressive Transformer offers an orthogonal approach to model long range dependencies based on recurrence.
These different inductive biases have implications in terms of computational speed and generalization beyond the training setup. In particular, Linformer and Longformer lead to different trade-offs: Longformer explicitly designs the sparse attention patterns of the self-attention (fixed patterns) while Linformer learns the low-rank matrix factorization of the self-attention matrix. In our experiments, Longformer is less efficient than Linformer, and is currently highly dependent on implementation details. On the other hand, Linformer’s decomposition only works for fixed context length (fixed at training) and cannot generalize to longer sequences without specific adaptation. Moreover, it cannot cache previous activations which can be extremely useful in the generative setup. Interestingly, Performer is conceptually different: it learns to approximate the softmax attention kernel without relying on any sparsity or low-rank assumption. The question of how these inductive biases compare to each other for varying quantities of training data remains.
All these works highlight the importance of long-range inputs modeling in natural language. In the industry, it is common to encounter use-cases such as document translation, document classification or document summarization which require modeling very long sequences in an efficient and robust way. Recently, zero-shot examples priming (a la GPT3) has also emerged as a promising alternative to standard fine-tuning, and increasing the number of priming examples (and thus the context size) steadily increases the performance and robustness. Finally, it is common in other modalities such as speech or protein modeling to encounter long sequences beyond the standard 512 time steps.
Modeling long inputs is not antithetical to modeling short inputs but instead should be thought from the perspective of a continuum from shorter to longer sequences. [Shortformer](https://arxiv.org/abs/2012.15832), Longformer and BERT provide evidence that training the model on short sequences and gradually increasing sequence lengths lead to an accelerated training and stronger downstream performance. This observation is coherent with the intuition that the long-range dependencies acquired when little data is available can rely on spurious correlations instead of robust language understanding. This echoes some experiments Teven Le Scao has run on language modeling: LSTMs are stronger learners in the low data regime compared to transformers and give better perplexities on small-scale language modeling benchmarks such as Penn Treebank.
From a practical point of view, the question of positional embeddings is also a crucial methodological aspect with computational efficiency trade-offs. Relative positional embeddings (introduced in Transformer-XL and used in Compressive Transformers) are appealing because they can easily be extended to yet-unseen sequence lengths, but at the same time, relative positional embeddings are computationally expensive. On the other side, absolute positional embeddings (used in Longformer and Linformer) are less flexible for sequences longer than the ones seen during training, but are computationally more efficient. Interestingly, [Shortformer](https://arxiv.org/abs/2012.15832) introduces a simple alternative by adding the positional information to the queries and keys of the self-attention mechanism instead of adding it to the token embeddings. The method is called position-infused attention and is shown to be very efficient while producing strong results.
## @Hugging Face 🤗: Long-range modeling
The Longformer implementation and the associated open-source checkpoints are available through the Transformers library and the [model hub](https://huggingface.co/models?search=longformer). Performer and Big Bird, which is a long-range model based on sparse attention, are currently in the works as part of our [call for models](https://twitter.com/huggingface/status/1359903233976762368), an effort involving the community in order to promote open-source contributions. We would be pumped to hear from you if you’ve wondered how to contribute to `transformers` but did not know where to start!
For further reading, we recommend checking Patrick Platen’s blog on [Reformer](https://arxiv.org/abs/2001.04451), Teven Le Scao’s post on [Johnson-Lindenstrauss approximation](https://tevenlescao.github.io/blog/fastpages/jupyter/2020/06/18/JL-Lemma-+-Linformer.html), [Efficient Transfomers: A Survey](https://arxiv.org/abs/2009.06732), and [Long Range Arena: A Benchmark for Efficient Transformers](https://arxiv.org/abs/2011.04006).
Next month, we'll cover self-training methods and applications. See you in March!
|
huggingface/blog/blob/main/long-range-transformers.md
|
--
title: "VQ-Diffusion"
thumbnail: /blog/assets/117_vq_diffusion/thumbnail.png
authors:
- user: williamberman
---
# VQ-Diffusion
Vector Quantized Diffusion (VQ-Diffusion) is a conditional latent diffusion model developed by the University of Science and Technology of China and Microsoft. Unlike most commonly studied diffusion models, VQ-Diffusion's noising and denoising processes operate on a quantized latent space, i.e., the latent space is composed of a discrete set of vectors. Discrete diffusion models are less explored than their continuous counterparts and offer an interesting point of comparison with autoregressive (AR) models.
- [Hugging Face model card](https://huggingface.co/microsoft/vq-diffusion-ithq)
- [Hugging Face Spaces](https://huggingface.co/spaces/patrickvonplaten/vq-vs-stable-diffusion)
- [Original Implementation](https://github.com/microsoft/VQ-Diffusion)
- [Paper](https://arxiv.org/abs/2111.14822)
### Demo
🧨 Diffusers lets you run VQ-Diffusion with just a few lines of code.
Install dependencies
```bash
pip install 'diffusers[torch]' transformers ftfy
```
Load the pipeline
```python
from diffusers import VQDiffusionPipeline
pipe = VQDiffusionPipeline.from_pretrained("microsoft/vq-diffusion-ithq")
```
If you want to use FP16 weights
```python
from diffusers import VQDiffusionPipeline
import torch
pipe = VQDiffusionPipeline.from_pretrained("microsoft/vq-diffusion-ithq", torch_dtype=torch.float16, revision="fp16")
```
Move to GPU
```python
pipe.to("cuda")
```
Run the pipeline!
```python
prompt = "A teddy bear playing in the pool."
image = pipe(prompt).images[0]
```

### Architecture

#### VQ-VAE
Images are encoded into a set of discrete "tokens" or embedding vectors using a VQ-VAE encoder. To do so, images are split in patches, and then each patch is replaced by the closest entry from a codebook with a fixed-size vocabulary. This reduces the dimensionality of the input pixel space. VQ-Diffusion uses the VQGAN variant from [Taming Transformers](https://arxiv.org/abs/2012.09841). This [blog post](https://ml.berkeley.edu/blog/posts/vq-vae/) is a good resource for better understanding VQ-VAEs.
VQ-Diffusion uses a pre-trained VQ-VAE which was frozen during the diffusion training process.
#### Forward process
In the forward diffusion process, each latent token can stay the same, be resampled to a different latent vector (each with equal probability), or be masked. Once a latent token is masked, it will stay masked. \\( \alpha_t \\), \\( \beta_t \\), and \\( \gamma_t \\) are hyperparameters that control the forward diffusion process from step \\( t-1 \\) to step \\( t \\). \\( \gamma_t \\) is the probability an unmasked token becomes masked. \\( \alpha_t + \beta_t \\) is the probability an unmasked token stays the same. The token can transition to any individual non-masked latent vector with a probability of \\( \beta_t \\). In other words, \\( \alpha_t + K \beta_t + \gamma_t = 1 \\) where \\( K \\) is the number of non-masked latent vectors. See section 4.1 of the paper for more details.
#### Approximating the reverse process
An encoder-decoder transformer approximates the classes of the un-noised latents, \\( x_0 \\), conditioned on the prompt, \\( y \\). The encoder is a CLIP text encoder with frozen weights. The decoder transformer provides unmasked global attention to all latent pixels and outputs the log probabilities of the categorical distribution over vector embeddings. The decoder transformer predicts the entire distribution of un-noised latents in one forward pass, providing global self-attention over \\( x_t \\). Framing the problem as conditional sequence to sequence over discrete values provides some intuition for why the encoder-decoder transformer is a good fit.
The AR models section provides additional context on VQ-Diffusion's architecture in comparison to AR transformer based models.
[Taming Transformers](https://arxiv.org/abs/2012.09841) provides a good discussion on converting raw pixels to discrete tokens in a compressed latent space so that transformers become computationally feasible for image data.
### VQ-Diffusion in Context
#### Diffusion Models
Contemporary diffusion models are mostly continuous. In the forward process, continuous diffusion models iteratively add Gaussian noise. The reverse process is approximated via \\( p_{\theta}(x_{t-1} | x_t) = N(x_{t-1}; \mu_{\theta}(x_t, t), \Sigma_{\theta}(x_t, t)) \\). In the simpler case of [DDPM](https://arxiv.org/abs/2006.11239), the covariance matrix is fixed, a U-Net is trained to predict the noise in \\( x_t \\), and \\( x_{t-1} \\) is derived from the noise.
The approximate reverse process is structurally similar to the discrete reverse process. However in the discrete case, there is no clear analog for predicting the noise in \\( x_t \\), and directly predicting the distribution for \\( x_0 \\) is a more clear objective.
There is a smaller amount of literature covering discrete diffusion models than continuous diffusion models. [Deep Unsupervised Learning using Nonequilibrium Thermodynamics](https://arxiv.org/abs/1503.03585) introduces a diffusion model over a binomial distribution. [Argmax Flows and Multinomial Diffusion](https://arxiv.org/abs/2102.05379) extends discrete diffusion to multinomial distributions and trains a transformer for predicting the unnoised distribution for a language modeling task. [Structured Denoising Diffusion Models in Discrete State-Spaces](https://arxiv.org/abs/2107.03006) generalizes multinomial diffusion with alternative noising processes -- uniform, absorbing, discretized Gaussian, and token embedding distance. Alternative noising processes are also possible in continuous diffusion models, but as noted in the paper, only additive Gaussian noise has received significant attention.
#### Autoregressive Models
It's perhaps more interesting to compare VQ-Diffusion to AR models as they more frequently feature transformers making predictions over discrete distributions. While transformers have demonstrated success in AR modeling, they still suffer from linear decreases in inference speed for increased image resolution, error accumulation, and directional bias. VQ-Diffusion improves on all three pain points.
AR image generative models are characterized by factoring the image probability such that each pixel is conditioned on the previous pixels in a raster scan order (left to right, top to bottom) i.e.
\\( p(x) = \prod_i p(x_i | x_{i-1}, x_{i-2}, ... x_{2}, x_{1}) \\). As a result, the models can be trained by directly maximizing the log-likelihood. Additionally, AR models which operate on actual pixel (non-latent) values, predict channel values from a discrete multinomial distribution i.e. first the red channel value is sampled from a 256 way softmax, and then the green channel prediction is conditioned on the red channel value.
AR image generative models have evolved architecturally with much work towards making transformers computationally feasible. Prior to transformer based models, [PixelRNN](https://arxiv.org/abs/1601.06759), [PixelCNN](https://arxiv.org/abs/1606.05328), and [PixelCNN++](https://arxiv.org/abs/1701.05517) were the state of the art.
[Image Transformer](https://arxiv.org/abs/1802.05751) provides a good discussion on the non-transformer based models and the transition to transformer based models (see paper for omitted citations).
> Training recurrent neural networks to sequentially predict each pixel of even a small image is computationally very challenging. Thus, parallelizable models that use convolutional neural networks such as the PixelCNN have recently received much more attention, and have now surpassed the PixelRNN in quality.
>
> One disadvantage of CNNs compared to RNNs is their typically fairly limited receptive field. This can adversely affect their ability to model long-range phenomena common in images, such as symmetry and occlusion, especially with a small number of layers. Growing the receptive field has been shown to improve quality significantly (Salimans et al.). Doing so, however, comes at a significant cost in number of parameters and consequently computational performance and can make training such models more challenging.
>
> ... self-attention can achieve a better balance in the trade-off between the virtually unlimited receptive field of the necessarily sequential PixelRNN and the limited receptive field of the much more parallelizable PixelCNN and its various extensions.
[Image Transformer](https://arxiv.org/abs/1802.05751) uses transformers by restricting self attention over local neighborhoods of pixels.
[Taming Transformers](https://arxiv.org/abs/2012.09841) and [DALL-E 1](https://arxiv.org/abs/2102.12092) combine convolutions and transformers. Both train a VQ-VAE to learn a discrete latent space, and then a transformer is trained in the compressed latent space. The transformer context is global but masked, because attention is provided over all previously predicted latent pixels, but the model is still AR so attention cannot be provided over not yet predicted pixels.
[ImageBART](https://arxiv.org/abs/2108.08827) combines convolutions, transformers, and diffusion processes. It learns a discrete latent space that is further compressed with a short multinomial diffusion process. Separate encoder-decoder transformers are then trained to reverse each step in the diffusion process. The encoder transformer provides global context on \\( x_t \\) while the decoder transformer autoregressively predicts latent pixels in \\( x_{t-1} \\). As a result, each pixel receives global cross attention on the more noised image. Between 2-5 diffusion steps are used with more steps for more complex datasets.
Despite having made tremendous strides, AR models still suffer from linear decreases in inference speed for increased image resolution, error accumulation, and directional bias. For equivalently sized AR transformer models, the big-O of VQ-Diffusion's inference is better so long as the number of diffusion steps is less than the number of latent pixels. For the ITHQ dataset, the latent resolution is 32x32 and the model is trained up to 100 diffusion steps for an ~10x big-O improvement. In practice, VQ-Diffusion "can be 15 times faster than AR methods while achieving a better image quality" (see [paper](https://arxiv.org/abs/2111.14822) for more details). Additionally, VQ-Diffusion does not require teacher-forcing and instead learns to correct incorrectly predicted tokens. During training, noised images are both masked and have latent pixels replaced with random tokens. VQ-Diffusion is also able to provide global context on \\( x_t \\) while predicting \\( x_{t-1} \\).
### Further steps with VQ-Diffusion and 🧨 Diffusers
So far, we've only ported the VQ-Diffusion model trained on the ITHQ dataset. There are also [released VQ-Diffusion models](https://github.com/microsoft/VQ-Diffusion#pretrained-model) trained on CUB-200, Oxford-102, MSCOCO, Conceptual Captions, LAION-400M, and ImageNet.
VQ-Diffusion also supports a faster inference strategy. The network reparameterization relies on the posterior of the diffusion process conditioned on the un-noised image being tractable. A similar formula applies when using a time stride, \\( \Delta t \\), that skips a number of reverse diffusion steps, \\( p_\theta (x_{t - \Delta t } | x_t, y) = \sum_{\tilde{x}_0=1}^{K}{q(x_{t - \Delta t} | x_t, \tilde{x}_0)} p_\theta(\tilde{x}_0 | x_t, y) \\).
[Improved Vector Quantized Diffusion Models](https://arxiv.org/abs/2205.16007) improves upon VQ-Diffusion's sample quality with discrete classifier-free guidance and an alternative inference strategy to address the "joint distribution issue" -- see section 3.2 for more details. Discrete classifier-free guidance is merged into diffusers but the alternative inference strategy has not been added yet.
Contributions are welcome!
|
huggingface/blog/blob/main/vq-diffusion.md
|
--
title: Zero-shot image segmentation with CLIPSeg
thumbnail: /blog/assets/123_clipseg-zero-shot/thumb.png
authors:
- user: segments-tobias
guest: true
- user: nielsr
---
# Zero-shot image segmentation with CLIPSeg
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
<a target="_blank" href="https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/123_clipseg-zero-shot.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
**This guide shows how you can use [CLIPSeg](https://huggingface.co/docs/transformers/main/en/model_doc/clipseg), a zero-shot image segmentation model, using [`🤗 transformers`](https://huggingface.co/transformers). CLIPSeg creates rough segmentation masks that can be used for robot perception, image inpainting, and many other tasks. If you need more precise segmentation masks, we’ll show how you can refine the results of CLIPSeg on [Segments.ai](https://segments.ai/?utm_source=hf&utm_medium=blog&utm_campaign=clipseg).**
Image segmentation is a well-known task within the field of computer vision. It allows a computer to not only know what is in an image (classification), where objects are in the image (detection), but also what the outlines of those objects are. Knowing the outlines of objects is essential in fields such as robotics and autonomous driving. For example, a robot has to know the shape of an object to grab it correctly. Segmentation can also be combined with [image inpainting](https://t.co/5q8YHSOfx7) to allow users to describe which part of the image they want to replace.
One limitation of most image segmentation models is that they only work with a fixed list of categories. For example, you cannot simply use a segmentation model trained on oranges to segment apples. To teach the segmentation model an additional category, you have to label data of the new category and train a new model, which can be costly and time-consuming. But what if there was a model that can already segment almost any kind of object, without any further training? That’s exactly what [CLIPSeg](https://arxiv.org/abs/2112.10003), a zero-shot segmentation model, achieves.
Currently, CLIPSeg still has its limitations. For example, the model uses images of 352 x 352 pixels, so the output is quite low-resolution. This means we cannot expect pixel-perfect results when we work with images from modern cameras. If we want more precise segmentations, we can fine-tune a state-of-the-art segmentation model, as shown in [our previous blog post](https://huggingface.co/blog/fine-tune-segformer). In that case, we can still use CLIPSeg to generate some rough labels, and then refine them in a labeling tool such as [Segments.ai](https://segments.ai/?utm_source=hf&utm_medium=blog&utm_campaign=clipseg). Before we describe how to do that, let’s first take a look at how CLIPSeg works.
## CLIP: the magic model behind CLIPSeg
[CLIP](https://huggingface.co/docs/transformers/main/en/model_doc/clip), which stands for **C**ontrastive **L**anguage–**I**mage **P**re-training, is a model developed by OpenAI in 2021. You can give CLIP an image or a piece of text, and CLIP will output an abstract *representation* of your input. This abstract representation, also called an *embedding*, is really just a vector (a list of numbers). You can think of this vector as a point in high-dimensional space. CLIP is trained so that the representations of similar pictures and texts are similar as well. This means that if we input an image and a text description that fits that image, the representations of the image and the text will be similar (i.e., the high-dimensional points will be close together).
At first, this might not seem very useful, but it is actually very powerful. As an example, let’s take a quick look at how CLIP can be used to classify images without ever having been trained on that task. To classify an image, we input the image and the different categories we want to choose from to CLIP (e.g. we input an image and the words “apple”, “orange”, …). CLIP then gives us back an embedding of the image and of each category. Now, we simply have to check which category embedding is closest to the embedding of the image, et voilà! Feels like magic, doesn’t it?
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Overview of the CLIPSeg model" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/clip-tv-example.png"></medium-zoom>
<figcaption>Example of image classification using CLIP (<a href="https://openai.com/blog/clip/">source</a>).</figcaption>
</figure>
What’s more, CLIP is not only useful for classification, but it can also be used for [image search](https://huggingface.co/spaces/DrishtiSharma/Text-to-Image-search-using-CLIP) (can you see how this is similar to classification?), [text-to-image models](https://huggingface.co/spaces/kamiyamai/stable-diffusion-webui) ([DALL-E 2](https://openai.com/dall-e-2/) is powered by CLIP), [object detection](https://segments.ai/zeroshot?utm_source=hf&utm_medium=blog&utm_campaign=clipseg) ([OWL-ViT](https://arxiv.org/abs/2205.06230)), and most importantly for us: image segmentation. Now you see why CLIP was truly a breakthrough in machine learning.
The reason why CLIP works so well is that the model was trained on a huge dataset of images with text captions. The dataset contained a whopping 400 million image-text pairs taken from the internet. These images contain a wide variety of objects and concepts, and CLIP is great at creating a representation for each of them.
## CLIPSeg: image segmentation with CLIP
[CLIPSeg](https://arxiv.org/abs/2112.10003) is a model that uses CLIP representations to create image segmentation masks. It was published by Timo Lüddecke and Alexander Ecker. They achieved zero-shot image segmentation by training a Transformer-based decoder on top of the CLIP model, which is kept frozen. The decoder takes in the CLIP representation of an image, and the CLIP representation of the thing you want to segment. Using these two inputs, the CLIPSeg decoder creates a binary segmentation mask. To be more precise, the decoder doesn’t only use the final CLIP representation of the image we want to segment, but it also uses the outputs of some of the layers of CLIP.
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Overview of the CLIPSeg model" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/clipseg-overview.png"></medium-zoom>
<figcaption><a href="https://arxiv.org/abs/2112.10003">Source</a></figcaption>
</figure>
The decoder is trained on the [PhraseCut dataset](https://arxiv.org/abs/2008.01187), which contains over 340,000 phrases with corresponding image segmentation masks. The authors also experimented with various augmentations to expand the size of the dataset. The goal here is not only to be able to segment the categories that are present in the dataset, but also to segment unseen categories. Experiments indeed show that the decoder can generalize to unseen categories.
One interesting feature of CLIPSeg is that both the query (the image we want to segment) and the prompt (the thing we want to segment in the image) are input as CLIP embeddings. The CLIP embedding for the prompt can either come from a piece of text (the category name), **or from another image**. This means you can segment oranges in a photo by giving CLIPSeg an example image of an orange.
This technique, which is called "visual prompting", is really helpful when the thing you want to segment is hard to describe. For example, if you want to segment a logo in a picture of a t-shirt, it's not easy to describe the shape of the logo, but CLIPSeg allows you to simply use the image of the logo as the prompt.
The CLIPSeg paper contains some tips on improving the effectiveness of visual prompting. They find that cropping the query image (so that it only contains the object you want to segment) helps a lot. Blurring and darkening the background of the query image also helps a little bit. In the next section, we'll show how you can try out visual prompting yourself using [`🤗 transformers`](https://huggingface.co/transformers).
## Using CLIPSeg with Hugging Face Transformers
Using Hugging Face Transformers, you can easily download and run a
pre-trained CLIPSeg model on your images. Let's start by installing
transformers.
```python
!pip install -q transformers
```
To download the model, simply instantiate it.
```python
from transformers import CLIPSegProcessor, CLIPSegForImageSegmentation
processor = CLIPSegProcessor.from_pretrained("CIDAS/clipseg-rd64-refined")
model = CLIPSegForImageSegmentation.from_pretrained("CIDAS/clipseg-rd64-refined")
```
Now we can load an image to try out the segmentation. We\'ll choose a
picture of a delicious breakfast taken by [Calum
Lewis](https://unsplash.com/@calumlewis).
```python
from PIL import Image
import requests
url = "https://unsplash.com/photos/8Nc_oQsc2qQ/download?ixid=MnwxMjA3fDB8MXxhbGx8fHx8fHx8fHwxNjcxMjAwNzI0&force=true&w=640"
image = Image.open(requests.get(url, stream=True).raw)
image
```
<figure class="image table text-center m-0 w-6/12">
<medium-zoom background="rgba(0,0,0,.7)" alt="A picture of a pancake breakfast." src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/73d97c93dc0f5545378e433e956509b8acafb8d9.png"></medium-zoom>
</figure>
### Text prompting
Let's start by defining some text categories we want to segment.
```python
prompts = ["cutlery", "pancakes", "blueberries", "orange juice"]
```
Now that we have our inputs, we can process them and input them to the
model.
```python
import torch
inputs = processor(text=prompts, images=[image] * len(prompts), padding="max_length", return_tensors="pt")
# predict
with torch.no_grad():
outputs = model(**inputs)
preds = outputs.logits.unsqueeze(1)
```
Finally, let's visualize the output.
```python
import matplotlib.pyplot as plt
_, ax = plt.subplots(1, len(prompts) + 1, figsize=(3*(len(prompts) + 1), 4))
[a.axis('off') for a in ax.flatten()]
ax[0].imshow(image)
[ax[i+1].imshow(torch.sigmoid(preds[i][0])) for i in range(len(prompts))];
[ax[i+1].text(0, -15, prompt) for i, prompt in enumerate(prompts)];
```
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="The masks of the different categories in the breakfast image." src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/14c048ea92645544c1bbbc9e55f3c620eaab8886.png"></medium-zoom>
</figure>
### Visual prompting
As mentioned before, we can also use images as the input prompts (i.e.
in place of the category names). This can be especially useful if it\'s
not easy to describe the thing you want to segment. For this example,
we\'ll use a picture of a coffee cup taken by [Daniel
Hooper](https://unsplash.com/@dan_fromyesmorecontent).
```python
url = "https://unsplash.com/photos/Ki7sAc8gOGE/download?ixid=MnwxMjA3fDB8MXxzZWFyY2h8MTJ8fGNvZmZlJTIwdG8lMjBnb3xlbnwwfHx8fDE2NzExOTgzNDQ&force=true&w=640"
prompt = Image.open(requests.get(url, stream=True).raw)
prompt
```
<figure class="image table text-center m-0 w-6/12">
<medium-zoom background="rgba(0,0,0,.7)" alt="A picture of a paper coffee cup." src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/7931f9db82ab07af7d161f0cfbfc347645da6646.png"></medium-zoom>
</figure>
We can now process the input image and prompt image and input them to
the model.
```python
encoded_image = processor(images=[image], return_tensors="pt")
encoded_prompt = processor(images=[prompt], return_tensors="pt")
# predict
with torch.no_grad():
outputs = model(**encoded_image, conditional_pixel_values=encoded_prompt.pixel_values)
preds = outputs.logits.unsqueeze(1)
preds = torch.transpose(preds, 0, 1)
```
Then, we can visualize the results as before.
```python
_, ax = plt.subplots(1, 2, figsize=(6, 4))
[a.axis('off') for a in ax.flatten()]
ax[0].imshow(image)
ax[1].imshow(torch.sigmoid(preds[0]))
```
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="The mask of the coffee cup in the breakfast image." src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/fbde45fc65907d17de38b0db3eb262bdec1f1784.png"></medium-zoom>
</figure>
Let's try one last time by using the visual prompting tips described in
the paper, i.e. cropping the image and darkening the background.
```python
url = "https://i.imgur.com/mRSORqz.jpg"
alternative_prompt = Image.open(requests.get(url, stream=True).raw)
alternative_prompt
```
<figure class="image table text-center m-0 w-6/12">
<medium-zoom background="rgba(0,0,0,.7)" alt="A cropped version of the image of the coffee cup with a darker background." src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/915a97da22131e0ab6ff4daa78ffe3f1889e3386.png"></medium-zoom>
</figure>
```python
encoded_alternative_prompt = processor(images=[alternative_prompt], return_tensors="pt")
# predict
with torch.no_grad():
outputs = model(**encoded_image, conditional_pixel_values=encoded_alternative_prompt.pixel_values)
preds = outputs.logits.unsqueeze(1)
preds = torch.transpose(preds, 0, 1)
```
```python
_, ax = plt.subplots(1, 2, figsize=(6, 4))
[a.axis('off') for a in ax.flatten()]
ax[0].imshow(image)
ax[1].imshow(torch.sigmoid(preds[0]))
```
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="The mask of the coffee cup in the breakfast image." src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/7f75badfc245fc3a75e0e05058b8c4b6a3a991fa.png"></medium-zoom>
</figure>
In this case, the result is pretty much the same. This is probably
because the coffee cup was already separated well from the background in
the original image.
## Using CLIPSeg to pre-label images on Segments.ai
As you can see, the results from CLIPSeg are a little fuzzy and very
low-res. If we want to obtain better results, you can fine-tune a
state-of-the-art segmentation model, as explained in [our previous
blogpost](https://huggingface.co/blog/fine-tune-segformer). To finetune
the model, we\'ll need labeled data. In this section, we\'ll show you
how you can use CLIPSeg to create some rough segmentation masks and then
refine them on
[Segments.ai](https://segments.ai/?utm_source=hf&utm_medium=blog&utm_campaign=clipseg),
a labeling platform with smart labeling tools for image segmentation.
First, create an account at
[https://segments.ai/join](https://segments.ai/join?utm_source=hf&utm_medium=blog&utm_campaign=clipseg)
and install the Segments Python SDK. Then you can initialize the
Segments.ai Python client using an API key. This key can be found on
[the account page](https://segments.ai/account?utm_source=hf&utm_medium=blog&utm_campaign=clipseg).
```python
!pip install -q segments-ai
```
```python
from segments import SegmentsClient
from getpass import getpass
api_key = getpass('Enter your API key: ')
segments_client = SegmentsClient(api_key)
```
Next, let\'s load an image from a dataset using the Segments client.
We\'ll use the [a2d2 self-driving
dataset](https://www.a2d2.audi/a2d2/en.html). You can also create your
own dataset by following [these
instructions](https://docs.segments.ai/tutorials/getting-started?utm_source=hf&utm_medium=blog&utm_campaign=clipseg).
```python
samples = segments_client.get_samples("admin-tobias/clipseg")
# Use the last image as an example
sample = samples[1]
image = Image.open(requests.get(sample.attributes.image.url, stream=True).raw)
image
```
<figure class="image table text-center m-0 w-9/12">
<medium-zoom background="rgba(0,0,0,.7)" alt="A picture of a street with cars from the a2d2 dataset." src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/a0ca3accab5a40547f16b2abc05edd4558818bdf.png"></medium-zoom>
</figure>
We also need to get the category names from the dataset attributes.
```python
dataset = segments_client.get_dataset("admin-tobias/clipseg")
category_names = [category.name for category in dataset.task_attributes.categories]
```
Now we can use CLIPSeg on the image as before. This time, we\'ll also
scale up the outputs so that they match the input image\'s size.
```python
from torch import nn
inputs = processor(text=category_names, images=[image] * len(category_names), padding="max_length", return_tensors="pt")
# predict
with torch.no_grad():
outputs = model(**inputs)
# resize the outputs
preds = nn.functional.interpolate(
outputs.logits.unsqueeze(1),
size=(image.size[1], image.size[0]),
mode="bilinear"
)
```
And we can visualize the results again.
```python
len_cats = len(category_names)
_, ax = plt.subplots(1, len_cats + 1, figsize=(3*(len_cats + 1), 4))
[a.axis('off') for a in ax.flatten()]
ax[0].imshow(image)
[ax[i+1].imshow(torch.sigmoid(preds[i][0])) for i in range(len_cats)];
[ax[i+1].text(0, -15, category_name) for i, category_name in enumerate(category_names)];
```
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="The masks of the different categories in the street image." src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/7782da300097ce4dcb3891257db7cc97ccf1deb3.png"></medium-zoom>
</figure>
Now we have to combine the predictions to a single segmented image.
We\'ll simply do this by taking the category with the greatest sigmoid
value for each patch. We\'ll also make sure that all the values under a
certain threshold do not count.
```python
threshold = 0.1
flat_preds = torch.sigmoid(preds.squeeze()).reshape((preds.shape[0], -1))
# Initialize a dummy "unlabeled" mask with the threshold
flat_preds_with_treshold = torch.full((preds.shape[0] + 1, flat_preds.shape[-1]), threshold)
flat_preds_with_treshold[1:preds.shape[0]+1,:] = flat_preds
# Get the top mask index for each pixel
inds = torch.topk(flat_preds_with_treshold, 1, dim=0).indices.reshape((preds.shape[-2], preds.shape[-1]))
```
Let\'s quickly visualize the result.
```python
plt.imshow(inds)
```
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="A combined segmentation label of the street image." src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/b92dc12452108a0b2769ddfc1d7f79909e65144b.png"></medium-zoom>
</figure>
Lastly, we can upload the prediction to Segments.ai. To do that, we\'ll
first convert the bitmap to a png file, then we\'ll upload this file to
the Segments, and finally we\'ll add the label to the sample.
```python
from segments.utils import bitmap2file
import numpy as np
inds_np = inds.numpy().astype(np.uint32)
unique_inds = np.unique(inds_np).tolist()
f = bitmap2file(inds_np, is_segmentation_bitmap=True)
asset = segments_client.upload_asset(f, "clipseg_prediction.png")
attributes = {
'format_version': '0.1',
'annotations': [{"id": i, "category_id": i} for i in unique_inds if i != 0],
'segmentation_bitmap': { 'url': asset.url },
}
segments_client.add_label(sample.uuid, 'ground-truth', attributes)
```
If you take a look at the [uploaded prediction on
Segments.ai](https://segments.ai/admin-tobias/clipseg/samples/71a80d39-8cf3-4768-a097-e81e0b677517/ground-truth),
you can see that it\'s not perfect. However, you can manually correct
the biggest mistakes, and then you can use the corrected dataset to
train a better model than CLIPSeg.
<figure class="image table text-center m-0 w-9/12">
<medium-zoom background="rgba(0,0,0,.7)" alt="Thumbnails of the final segmentation labels on Segments.ai." src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/segments-thumbs.png"></medium-zoom>
</figure>
## Conclusion
CLIPSeg is a zero-shot segmentation model that works with both text and image prompts. The model adds a decoder to CLIP and can segment almost anything. However, the output segmentation masks are still very low-res for now, so you’ll probably still want to fine-tune a different segmentation model if accuracy is important.
Note that there's more research on zero-shot segmentation currently being conducted, so you can expect more models to be added in the near future. One example is [GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit), which is already available in 🤗 Transformers. To stay up to date with the latest news in segmentation research, you can follow us on Twitter: [@TobiasCornille](https://twitter.com/tobiascornille), [@NielsRogge](https://twitter.com/nielsrogge), and [@huggingface](https://twitter.com/huggingface).
If you’re interested in learning how to fine-tune a state-of-the-art segmentation model, check out our previous blog post: [https://huggingface.co/blog/fine-tune-segformer](https://huggingface.co/blog/fine-tune-segformer).
|
huggingface/blog/blob/main/clipseg-zero-shot.md
|
Gradio Demo: blocks_js_load
```
!pip install -q gradio
```
```
import gradio as gr
def welcome(name):
return f"Welcome to Gradio, {name}!"
js = """
function createGradioAnimation() {
var container = document.createElement('div');
container.id = 'gradio-animation';
container.style.fontSize = '2em';
container.style.fontWeight = 'bold';
container.style.textAlign = 'center';
container.style.marginBottom = '20px';
var text = 'Welcome to Gradio!';
for (var i = 0; i < text.length; i++) {
(function(i){
setTimeout(function(){
var letter = document.createElement('span');
letter.style.opacity = '0';
letter.style.transition = 'opacity 0.5s';
letter.innerText = text[i];
container.appendChild(letter);
setTimeout(function() {
letter.style.opacity = '1';
}, 50);
}, i * 250);
})(i);
}
var gradioContainer = document.querySelector('.gradio-container');
gradioContainer.insertBefore(container, gradioContainer.firstChild);
return 'Animation created';
}
"""
with gr.Blocks(js=js) as demo:
inp = gr.Textbox(placeholder="What is your name?")
out = gr.Textbox()
inp.change(welcome, inp, out)
if __name__ == "__main__":
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/blocks_js_load/run.ipynb
|
Image Dataset
This guide will show you how to configure your dataset repository with image files. You can find accompanying examples of repositories in this [Image datasets examples collection](https://huggingface.co/collections/datasets-examples/image-dataset-6568e7cf28639db76eb92d65).
A dataset with a supported structure and [file formats](./datasets-adding#file-formats) automatically has a Dataset Viewer on its page on the Hub. Any additional information about your dataset - such as captions or bounding boxes for object detection - is automatically loaded as long as you include this information in a metadata file (`metadata.csv`/`metadata.jsonl`).
## Only images
If your dataset only consists of one column with images, you can simply store your image files at the root:
```
my_dataset_repository/
├── 1.jpg
├── 2.jpg
├── 3.jpg
└── 4.jpg
```
or in a subdirectory:
```
my_dataset_repository/
└── images
├── 1.jpg
├── 2.jpg
├── 3.jpg
└── 4.jpg
```
Multiple [formats](./datasets-adding#file-formats) are supported at the same time, including PNG, JPEG, TIFF and WebP.
```
my_dataset_repository/
└── images
├── 1.jpg
├── 2.png
├── 3.tiff
└── 4.webp
```
If you have several splits, you can put your images into directories named accordingly:
```
my_dataset_repository/
├── train
│ ├── 1.jpg
│ └── 2.jpg
└── test
├── 3.jpg
└── 4.jpg
```
See [File names and splits](./datasets-file-names-and-splits) for more information and other ways to organize data by splits.
## Additional columns
If there is additional information you'd like to include about your dataset, like text captions or bounding boxes, add it as a `metadata.csv` file in your repository. This lets you quickly create datasets for different computer vision tasks like text captioning or object detection.
```
my_dataset_repository/
└── train
├── 1.jpg
├── 2.jpg
├── 3.jpg
├── 4.jpg
└── metadata.csv
```
Your `metadata.csv` file must have a `file_name` column which links image files with their metadata:
```csv
file_name,text
1.jpg,a drawing of a green pokemon with red eyes
2.jpg,a green and yellow toy with a red nose
3.jpg,a red and white ball with an angry look on its face
4.jpg,a cartoon ball with a smile on it's face
```
You can also use a [JSONL](https://jsonlines.org/) file `metadata.jsonl`:
```jsonl
{"file_name": "1.jpg","text": "a drawing of a green pokemon with red eyes"}
{"file_name": "2.jpg","text": "a green and yellow toy with a red nose"}
{"file_name": "3.jpg","text": "a red and white ball with an angry look on its face"}
{"file_name": "4.jpg","text": "a cartoon ball with a smile on it's face"}
```
## Relative paths
Metadata file must be located either in the same directory with the images it is linked to, or in any parent directory, like in this example:
```
my_dataset_repository/
└── train
├── images
│ ├── 1.jpg
│ ├── 2.jpg
│ ├── 3.jpg
│ └── 4.jpg
└── metadata.csv
```
In this case, the `file_name` column must be a full relative path to the images, not just the filename:
```csv
file_name,text
images/1.jpg,a drawing of a green pokemon with red eyes
images/2.jpg,a green and yellow toy with a red nose
images/3.jpg,a red and white ball with an angry look on its face
images/4.jpg,a cartoon ball with a smile on it's face
```
Metadata file cannot be put in subdirectories of a directory with the images.
## Image classification
For image classification datasets, you can also use a simple setup: use directories to name the image classes. Store your image files in a directory structure like:
```
my_dataset_repository/
├── green
│ ├── 1.jpg
│ └── 2.jpg
└── red
├── 3.jpg
└── 4.jpg
```
The dataset created with this structure contains two columns: `image` and `label` (with values `green` and `red`).
You can also provide multiple splits. To do so, your dataset directory should have the following structure (see [File names and splits](./datasets-file-names-and-splits) for more information):
```
my_dataset_repository/
├── test
│ ├── green
│ │ └── 2.jpg
│ └── red
│ └── 4.jpg
└── train
├── green
│ └── 1.jpg
└── red
└── 3.jpg
```
You can disable this automatic addition of the `label` column in the [YAML configuration](./datasets-manual-configuration). If your directory names have no special meaning, set `drop_labels: true` in the README header:
```yaml
configs:
- config_name: default
drop_labels: true
```
## Parquet format
Instead of uploading the images and metadata as individual files, you can embed everything inside a [Parquet](https://parquet.apache.org/) file. This is useful if you have a large number of images, if you want to embed multiple image columns, or if you want to store additional information about the images in the same file. Parquet is also useful for storing data such as raw bytes, which is not supported by JSON/CSV.
```
my_dataset_repository/
└── train.parquet
```
Note that for the user convenience, every dataset hosted in the Hub is automatically converted to Parquet format. Read more about it in the [Parquet format](./datasets-viewer#access-the-parquet-files) documentation.
|
huggingface/hub-docs/blob/main/docs/hub/datasets-image.md
|
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# X-CLIP
## Overview
The X-CLIP model was proposed in [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
X-CLIP is a minimal extension of [CLIP](clip) for video. The model consists of a text encoder, a cross-frame vision encoder, a multi-frame integration Transformer, and a video-specific prompt generator.
The abstract from the paper is the following:
*Contrastive language-image pretraining has shown great success in learning visual-textual joint representation from web-scale data, demonstrating remarkable "zero-shot" generalization ability for various image tasks. However, how to effectively expand such new language-image pretraining methods to video domains is still an open problem. In this work, we present a simple yet effective approach that adapts the pretrained language-image models to video recognition directly, instead of pretraining a new model from scratch. More concretely, to capture the long-range dependencies of frames along the temporal dimension, we propose a cross-frame attention mechanism that explicitly exchanges information across frames. Such module is lightweight and can be plugged into pretrained language-image models seamlessly. Moreover, we propose a video-specific prompting scheme, which leverages video content information for generating discriminative textual prompts. Extensive experiments demonstrate that our approach is effective and can be generalized to different video recognition scenarios. In particular, under fully-supervised settings, our approach achieves a top-1 accuracy of 87.1% on Kinectics-400, while using 12 times fewer FLOPs compared with Swin-L and ViViT-H. In zero-shot experiments, our approach surpasses the current state-of-the-art methods by +7.6% and +14.9% in terms of top-1 accuracy under two popular protocols. In few-shot scenarios, our approach outperforms previous best methods by +32.1% and +23.1% when the labeled data is extremely limited.*
Tips:
- Usage of X-CLIP is identical to [CLIP](clip).
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/xclip_architecture.png"
alt="drawing" width="600"/>
<small> X-CLIP architecture. Taken from the <a href="https://arxiv.org/abs/2208.02816">original paper.</a> </small>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/microsoft/VideoX/tree/master/X-CLIP).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with X-CLIP.
- Demo notebooks for X-CLIP can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/X-CLIP).
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## XCLIPProcessor
[[autodoc]] XCLIPProcessor
## XCLIPConfig
[[autodoc]] XCLIPConfig
- from_text_vision_configs
## XCLIPTextConfig
[[autodoc]] XCLIPTextConfig
## XCLIPVisionConfig
[[autodoc]] XCLIPVisionConfig
## XCLIPModel
[[autodoc]] XCLIPModel
- forward
- get_text_features
- get_video_features
## XCLIPTextModel
[[autodoc]] XCLIPTextModel
- forward
## XCLIPVisionModel
[[autodoc]] XCLIPVisionModel
- forward
|
huggingface/transformers/blob/main/docs/source/en/model_doc/xclip.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# LMSDiscreteScheduler
`LMSDiscreteScheduler` is a linear multistep scheduler for discrete beta schedules. The scheduler is ported from and created by [Katherine Crowson](https://github.com/crowsonkb/), and the original implementation can be found at [crowsonkb/k-diffusion](https://github.com/crowsonkb/k-diffusion/blob/481677d114f6ea445aa009cf5bd7a9cdee909e47/k_diffusion/sampling.py#L181).
## LMSDiscreteScheduler
[[autodoc]] LMSDiscreteScheduler
## LMSDiscreteSchedulerOutput
[[autodoc]] schedulers.scheduling_lms_discrete.LMSDiscreteSchedulerOutput
|
huggingface/diffusers/blob/main/docs/source/en/api/schedulers/lms_discrete.md
|
--
title: "Getting Started with Sentiment Analysis on Twitter"
thumbnail: /blog/assets/85_sentiment_analysis_twitter/thumbnail.png
authors:
- user: federicopascual
---
# Getting Started with Sentiment Analysis on Twitter
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
Sentiment analysis is the automatic process of classifying text data according to their polarity, such as positive, negative and neutral. Companies leverage sentiment analysis of tweets to get a sense of how customers are talking about their products and services, get insights to drive business decisions, and identify product issues and potential PR crises early on.
In this guide, we will cover everything you need to learn to get started with sentiment analysis on Twitter. We'll share a step-by-step process to do sentiment analysis, for both, coders and non-coders. If you are a coder, you'll learn how to use the [Inference API](https://huggingface.co/inference-api), a plug & play machine learning API for doing sentiment analysis of tweets at scale in just a few lines of code. If you don't know how to code, don't worry! We'll also cover how to do sentiment analysis with Zapier, a no-code tool that will enable you to gather tweets, analyze them with the Inference API, and finally send the results to Google Sheets ⚡️
Read along or jump to the section that sparks 🌟 your interest:
1. [What is sentiment analysis?](#what-is-sentiment-analysis)
2. [How to do Twitter sentiment analysis with code?](#how-to-do-twitter-sentiment-analysis-with-code)
3. [How to do Twitter sentiment analysis without coding?](#how-to-do-twitter-sentiment-analysis-without-coding)
Buckle up and enjoy the ride! 🤗
## What is Sentiment Analysis?
Sentiment analysis uses [machine learning](https://en.wikipedia.org/wiki/Machine_learning) to automatically identify how people are talking about a given topic. The most common use of sentiment analysis is detecting the polarity of text data, that is, automatically identifying if a tweet, product review or support ticket is talking positively, negatively, or neutral about something.
As an example, let's check out some tweets mentioning [@Salesforce](https://twitter.com/Salesforce) and see how they would be tagged by a sentiment analysis model:
- *"The more I use @salesforce the more I dislike it. It's slow and full of bugs. There are elements of the UI that look like they haven't been updated since 2006. Current frustration: app exchange pages won't stop refreshing every 10 seconds"* --> This first tweet would be tagged as "Negative".
- *"That’s what I love about @salesforce. That it’s about relationships and about caring about people and it’s not only about business and money. Thanks for caring about #TrailblazerCommunity"* --> In contrast, this tweet would be classified as "Positive".
- *"Coming Home: #Dreamforce Returns to San Francisco for 20th Anniversary. Learn more: http[]()://bit.ly/3AgwO0H via @Salesforce"* --> Lastly, this tweet would be tagged as "Neutral" as it doesn't contain an opinion or polarity.
Up until recently, analyzing tweets mentioning a brand, product or service was a very manual, hard and tedious process; it required someone to manually go over relevant tweets, and read and label them according to their sentiment. As you can imagine, not only this doesn't scale, it is expensive and very time-consuming, but it is also prone to human error.
Luckily, recent advancements in AI allowed companies to use machine learning models for sentiment analysis of tweets that are as good as humans. By using machine learning, companies can analyze tweets in real-time 24/7, do it at scale and analyze thousands of tweets in seconds, and more importantly, get the insights they are looking for when they need them.
Why do sentiment analysis on Twitter? Companies use this for a wide variety of use cases, but the two of the most common use cases are analyzing user feedback and monitoring mentions to detect potential issues early on.
**Analyze Feedback on Twitter**
Listening to customers is key for detecting insights on how you can improve your product or service. Although there are multiple sources of feedback, such as surveys or public reviews, Twitter offers raw, unfiltered feedback on what your audience thinks about your offering.
By analyzing how people talk about your brand on Twitter, you can understand whether they like a new feature you just launched. You can also get a sense if your pricing is clear for your target audience. You can also see what aspects of your offering are the most liked and disliked to make business decisions (e.g. customers loving the simplicity of the user interface but hate how slow customer support is).
**Monitor Twitter Mentions to Detect Issues**
Twitter has become the default way to share a bad customer experience and express frustrations whenever something goes wrong while using a product or service. This is why companies monitor how users mention their brand on Twitter to detect any issues early on.
By implementing a sentiment analysis model that analyzes incoming mentions in real-time, you can automatically be alerted about sudden spikes of negative mentions. Most times, this is caused is an ongoing situation that needs to be addressed asap (e.g. an app not working because of server outages or a really bad experience with a customer support representative).
Now that we covered what is sentiment analysis and why it's useful, let's get our hands dirty and actually do sentiment analysis of tweets!💥
## How to do Twitter sentiment analysis with code?
Nowadays, getting started with sentiment analysis on Twitter is quite easy and straightforward 🙌
With a few lines of code, you can automatically get tweets, run sentiment analysis and visualize the results. And you can learn how to do all these things in just a few minutes!
In this section, we'll show you how to do it with a cool little project: we'll do sentiment analysis of tweets mentioning [Notion](https://twitter.com/notionhq)!
First, you'll use [Tweepy](https://www.tweepy.org/), an open source Python library to get tweets mentioning @NotionHQ using the [Twitter API](https://developer.twitter.com/en/docs/twitter-api). Then you'll use the [Inference API](https://huggingface.co/inference-api) for doing sentiment analysis. Once you get the sentiment analysis results, you will create some charts to visualize the results and detect some interesting insights.
You can use this [Google Colab notebook](https://colab.research.google.com/drive/1R92sbqKMI0QivJhHOp1T03UDaPUhhr6x?usp=sharing) to follow this tutorial.
Let's get started with it! 💪
1. Install Dependencies
As a first step, you'll need to install the required dependencies. You'll use [Tweepy](https://www.tweepy.org/) for gathering tweets, [Matplotlib](https://matplotlib.org/) for building some charts and [WordCloud](https://amueller.github.io/word_cloud/) for building a visualization with the most common keywords:
```python
!pip install -q transformers tweepy matplotlib wordcloud
```
2. Setting up Twitter credentials
Then, you need to set up the [Twitter API credentials](https://developer.twitter.com/en/docs/twitter-api) so you can authenticate with Twitter and then gather tweets automatically using their API:
```python
import tweepy
# Add Twitter API key and secret
consumer_key = "XXXXXX"
consumer_secret = "XXXXXX"
# Handling authentication with Twitter
auth = tweepy.AppAuthHandler(consumer_key, consumer_secret)
# Create a wrapper for the Twitter API
api = tweepy.API(auth, wait_on_rate_limit=True, wait_on_rate_limit_notify=True)
```
3. Search for tweets using Tweepy
Now you are ready to start collecting data from Twitter! 🎉 You will use [Tweepy Cursor](https://docs.tweepy.org/en/v3.5.0/cursor_tutorial.html) to automatically collect 1,000 tweets mentioning Notion:
```python
# Helper function for handling pagination in our search and handle rate limits
def limit_handled(cursor):
while True:
try:
yield cursor.next()
except tweepy.RateLimitError:
print('Reached rate limite. Sleeping for >15 minutes')
time.sleep(15 * 61)
except StopIteration:
break
# Define the term you will be using for searching tweets
query = '@NotionHQ'
query = query + ' -filter:retweets'
# Define how many tweets to get from the Twitter API
count = 1000
# Search for tweets using Tweepy
search = limit_handled(tweepy.Cursor(api.search,
q=query,
tweet_mode='extended',
lang='en',
result_type="recent").items(count))
# Process the results from the search using Tweepy
tweets = []
for result in search:
tweet_content = result.full_text
tweets.append(tweet_content) # Only saving the tweet content.
```
4. Analyzing tweets with sentiment analysis
Now that you have data, you are ready to analyze the tweets with sentiment analysis! 💥
You will be using [Inference API](https://huggingface.co/inference-api), an easy-to-use API for integrating machine learning models via simple API calls. With the Inference API, you can use state-of-the-art models for sentiment analysis without the hassle of building infrastructure for machine learning or dealing with model scalability. You can serve the latest (and greatest!) open source models for sentiment analysis while staying out of MLOps. 🤩
For using the Inference API, first you will need to define your `model id` and your `Hugging Face API Token`:
- The `model ID` is to specify which model you want to use for making predictions. Hugging Face has more than [400 models for sentiment analysis in multiple languages](https://huggingface.co/models?pipeline_tag=text-classification&sort=downloads&search=sentiment), including various models specifically fine-tuned for sentiment analysis of tweets. For this particular tutorial, you will use [twitter-roberta-base-sentiment-latest](https://huggingface.co/cardiffnlp/twitter-roberta-base-sentiment-latest), a sentiment analysis model trained on ≈124 million tweets and fine-tuned for sentiment analysis.
- You'll also need to specify your `Hugging Face token`; you can get one for free by signing up [here](https://huggingface.co/join) and then copying your token on this [page](https://huggingface.co/settings/tokens).
```python
model = "cardiffnlp/twitter-roberta-base-sentiment-latest"
hf_token = "XXXXXX"
```
Next, you will create the API call using the `model id` and `hf_token`:
```python
API_URL = "https://api-inference.huggingface.co/models/" + model
headers = {"Authorization": "Bearer %s" % (hf_token)}
def analysis(data):
payload = dict(inputs=data, options=dict(wait_for_model=True))
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
```
Now, you are ready to do sentiment analysis on each tweet. 🔥🔥🔥
```python
tweets_analysis = []
for tweet in tweets:
try:
sentiment_result = analysis(tweet)[0]
top_sentiment = max(sentiment_result, key=lambda x: x['score']) # Get the sentiment with the higher score
tweets_analysis.append({'tweet': tweet, 'sentiment': top_sentiment['label']})
except Exception as e:
print(e)
```
5. Explore the results of sentiment analysis
Wondering if people on Twitter are talking positively or negatively about Notion? Or what do users discuss when talking positively or negatively about Notion? We'll use some data visualization to explore the results of the sentiment analysis and find out!
First, let's see examples of tweets that were labeled for each sentiment to get a sense of the different polarities of these tweets:
```python
import pandas as pd
# Load the data in a dataframe
pd.set_option('max_colwidth', None)
pd.set_option('display.width', 3000)
df = pd.DataFrame(tweets_analysis)
# Show a tweet for each sentiment
display(df[df["sentiment"] == 'Positive'].head(1))
display(df[df["sentiment"] == 'Neutral'].head(1))
display(df[df["sentiment"] == 'Negative'].head(1))
```
Results:
```
@thenotionbar @hypefury @NotionHQ That’s genuinely smart. So basically you’ve setup your posting queue to by a recurrent recycling of top content that runs 100% automatic? Sentiment: Positive
@itskeeplearning @NotionHQ How you've linked gallery cards? Sentiment: Neutral
@NotionHQ Running into an issue here recently were content is not showing on on web but still in the app. This happens for all of our pages. https://t.co/3J3AnGzDau. Sentiment: Negative
```
Next, you'll count the number of tweets that were tagged as positive, negative and neutral:
```python
sentiment_counts = df.groupby(['sentiment']).size()
print(sentiment_counts)
```
Remarkably, most of the tweets about Notion are positive:
```
sentiment
Negative 82
Neutral 420
Positive 498
```
Then, let's create a pie chart to visualize each sentiment in relative terms:
```python
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(6,6), dpi=100)
ax = plt.subplot(111)
sentiment_counts.plot.pie(ax=ax, autopct='%1.1f%%', startangle=270, fontsize=12, label="")
```
It's cool to see that 50% of all tweets are positive and only 8.2% are negative:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Sentiment analysis results of tweets mentioning Notion" src="assets/85_sentiment_analysis_twitter/sentiment-pie.png"></medium-zoom>
<figcaption>Sentiment analysis results of tweets mentioning Notion</figcaption>
</figure>
As a last step, let's create some wordclouds to see which words are the most used for each sentiment:
```python
from wordcloud import WordCloud
from wordcloud import STOPWORDS
# Wordcloud with positive tweets
positive_tweets = df['tweet'][df["sentiment"] == 'Positive']
stop_words = ["https", "co", "RT"] + list(STOPWORDS)
positive_wordcloud = WordCloud(max_font_size=50, max_words=50, background_color="white", stopwords = stop_words).generate(str(positive_tweets))
plt.figure()
plt.title("Positive Tweets - Wordcloud")
plt.imshow(positive_wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
# Wordcloud with negative tweets
negative_tweets = df['tweet'][df["sentiment"] == 'Negative']
stop_words = ["https", "co", "RT"] + list(STOPWORDS)
negative_wordcloud = WordCloud(max_font_size=50, max_words=50, background_color="white", stopwords = stop_words).generate(str(negative_tweets))
plt.figure()
plt.title("Negative Tweets - Wordcloud")
plt.imshow(negative_wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
```
Curiously, some of the words that stand out from the positive tweets include "notes", "cron", and "paid":
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Sentiment analysis results of tweets mentioning Notion" src="assets/85_sentiment_analysis_twitter/positive-tweets.png"></medium-zoom>
<figcaption>Word cloud for positive tweets</figcaption>
</figure>
In contrast, "figma", "enterprise" and "account" are some of the most used words from the negatives tweets:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Sentiment analysis results of tweets mentioning Notion" src="assets/85_sentiment_analysis_twitter/negative-tweets.png"></medium-zoom>
<figcaption>Word cloud for negative tweets</figcaption>
</figure>
That was fun, right?
With just a few lines of code, you were able to automatically gather tweets mentioning Notion using Tweepy, analyze them with a sentiment analysis model using the [Inference API](https://huggingface.co/inference-api), and finally create some visualizations to analyze the results. 💥
Are you interested in doing more? As a next step, you could use a second [text classifier](https://huggingface.co/tasks/text-classification) to classify each tweet by their theme or topic. This way, each tweet will be labeled with both sentiment and topic, and you can get more granular insights (e.g. are users praising how easy to use is Notion but are complaining about their pricing or customer support?).
## How to do Twitter sentiment analysis without coding?
To get started with sentiment analysis, you don't need to be a developer or know how to code. 🤯
There are some amazing no-code solutions that will enable you to easily do sentiment analysis in just a few minutes.
In this section, you will use [Zapier](https://zapier.com/), a no-code tool that enables users to connect 5,000+ apps with an easy to use user interface. You will create a [Zap](https://zapier.com/help/create/basics/create-zaps), that is triggered whenever someone mentions Notion on Twitter. Then the Zap will use the [Inference API](https://huggingface.co/inference-api) to analyze the tweet with a sentiment analysis model and finally it will save the results on Google Sheets:
1. Step 1 (trigger): Getting the tweets.
2. Step 2: Analyze tweets with sentiment analysis.
3. Step 3: Save the results on Google Sheets.
No worries, it won't take much time; in under 10 minutes, you'll create and activate the zap, and will start seeing the sentiment analysis results pop up in Google Sheets.
Let's get started! 🚀
### Step 1: Getting the Tweets
To get started, you'll need to [create a Zap](https://zapier.com/webintent/create-zap), and configure the first step of your Zap, also called the *"Trigger"* step. In your case, you will need to set it up so that it triggers the Zap whenever someone mentions Notion on Twitter. To set it up, follow the following steps:
- First select "Twitter" and select "Search mention" as event on "Choose app & event".
- Then connect your Twitter account to Zapier.
- Set up the trigger by specifying "NotionHQ" as the search term for this trigger.
- Finally test the trigger to make sure it gather tweets and runs correctly.
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Sentiment analysis results of tweets mentioning Notion" src="assets/85_sentiment_analysis_twitter/zapier-getting-tweets-cropped-cut-optimized.gif"></medium-zoom>
<figcaption>Step 1 on the Zap</figcaption>
</figure>
### Step 2: Analyze Tweets with Sentiment Analysis
Now that your Zap can gather tweets mentioning Notion, let's add a second step to do the sentiment analysis. 🤗
You will be using [Inference API](https://huggingface.co/inference-api), an easy-to-use API for integrating machine learning models. For using the Inference API, you will need to define your "model id" and your "Hugging Face API Token":
- The `model ID` is to tell the Inference API which model you want to use for making predictions. For this guide, you will use [twitter-roberta-base-sentiment-latest](https://huggingface.co/cardiffnlp/twitter-roberta-base-sentiment-latest), a sentiment analysis model trained on ≈124 million tweets and fine-tuned for sentiment analysis. You can explore the more than [400 models for sentiment analysis available on the Hugging Face Hub](https://huggingface.co/models?pipeline_tag=text-classification&sort=downloads&search=sentiment) in case you want to use a different model (e.g. doing sentiment analysis on a different language).
- You'll also need to specify your `Hugging Face token`; you can get one for free by signing up [here](https://huggingface.co/join) and then copying your token on this [page](https://huggingface.co/settings/tokens).
Once you have your model ID and your Hugging Face token ID, go back to your Zap and follow these instructions to set up the second step of the zap:
1. First select "Code by Zapier" and "Run python" in "Choose app and event".
2. On "Set up action", you will need to first add the tweet "full text" as "input_data". Then you will need to add these [28 lines of python code](https://gist.github.com/feconroses/0e064f463b9a0227ba73195f6376c8ed) in the "Code" section. This code will allow the Zap to call the Inference API and make the predictions with sentiment analysis. Before adding this code to your zap, please make sure that you do the following:
- Change line 5 and add your Hugging Face token, that is, instead of `hf_token = "ADD_YOUR_HUGGING_FACE_TOKEN_HERE"`, you will need to change it to something like`hf_token = "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"`
- If you want to use a different sentiment analysis model, you will need to change line 4 and specify the id of the new model here. For example, instead of using the default model, you could use [this model](https://huggingface.co/finiteautomata/beto-sentiment-analysis?text=Te+quiero.+Te+amo.) to do sentiment analysis on tweets in Spanish by changing this line `model = "cardiffnlp/twitter-roberta-base-sentiment-latest"` to `model = "finiteautomata/beto-sentiment-analysis"`.
3. Finally, test this step to make sure it makes predictions and runs correctly.
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Sentiment analysis results of tweets mentioning Notion" src="assets/85_sentiment_analysis_twitter/zapier-analyze-tweets-cropped-cut-optimized.gif"></medium-zoom>
<figcaption>Step 2 on the Zap</figcaption>
</figure>
### Step 3: Save the results on Google Sheets
As the last step to your Zap, you will save the results of the sentiment analysis on a spreadsheet on Google Sheets and visualize the results. 📊
First, [create a new spreadsheet on Google Sheets](https://docs.google.com/spreadsheets/u/0/create), and define the following columns:
- **Tweet**: this column will contain the text of the tweet.
- **Sentiment**: will have the label of the sentiment analysis results (e.g. positive, negative and neutral).
- **Score**: will store the value that reflects how confident the model is with its prediction.
- **Date**: will contain the date of the tweet (which can be handy for creating graphs and charts over time).
Then, follow these instructions to configure this last step:
1. Select Google Sheets as an app, and "Create Spreadsheet Row" as the event in "Choose app & Event".
2. Then connect your Google Sheets account to Zapier.
3. Next, you'll need to set up the action. First, you'll need to specify the Google Drive value (e.g. My Drive), then select the spreadsheet, and finally the worksheet where you want Zapier to automatically write new rows. Once you are done with this, you will need to map each column on the spreadsheet with the values you want to use when your zap automatically writes a new row on your file. If you have created the columns we suggested before, this will look like the following (column → value):
- Tweet → Full Text (value from the step 1 of the zap)
- Sentiment → Sentiment Label (value from step 2)
- Sentiment Score → Sentiment Score (value from step 2)
- Date → Created At (value from step 1)
4. Finally, test this last step to make sure it can add a new row to your spreadsheet. After confirming it's working, you can delete this row on your spreadsheet.
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Sentiment analysis results of tweets mentioning Notion" src="assets/85_sentiment_analysis_twitter/zapier-add-to-google-sheets-cropped-cut.gif"></medium-zoom>
<figcaption>Step 3 on the Zap</figcaption>
</figure>
### 4. Turn on your Zap
At this point, you have completed all the steps of your zap! 🔥
Now, you just need to turn it on so it can start gathering tweets, analyzing them with sentiment analysis, and store the results on Google Sheets. ⚡️
To turn it on, just click on "Publish" button at the bottom of your screen:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Sentiment analysis results of tweets mentioning Notion" src="assets/85_sentiment_analysis_twitter/zap-turn-on-cut-optimized.gif"></medium-zoom>
<figcaption>Turning on the Zap</figcaption>
</figure>
After a few minutes, you will see how your spreadsheet starts populating with tweets and the results of sentiment analysis. You can also create a graph that can be updated in real-time as tweets come in:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Sentiment analysis results of tweets mentioning Notion" src="assets/85_sentiment_analysis_twitter/google-sheets-results-cropped-cut.gif"></medium-zoom>
<figcaption>Tweets popping up on Google Sheets</figcaption>
</figure>
Super cool, right? 🚀
## Wrap up
Twitter is the public town hall where people share their thoughts about all kinds of topics. From people talking about politics, sports or tech, users sharing their feedback about a new shiny app, or passengers complaining to an Airline about a canceled flight, the amount of data on Twitter is massive. Sentiment analysis allows making sense of all that data in real-time to uncover insights that can drive business decisions.
Luckily, tools like the [Inference API](https://huggingface.co/inference-api) makes it super easy to get started with sentiment analysis on Twitter. No matter if you know or don't know how to code and/or you don't have experience with machine learning, in a few minutes, you can set up a process that can gather tweets in real-time, analyze them with a state-of-the-art model for sentiment analysis, and explore the results with some cool visualizations. 🔥🔥🔥
If you have questions, you can ask them in the [Hugging Face forum](https://discuss.huggingface.co/) so the Hugging Face community can help you out and others can benefit from seeing the discussion. You can also join our [Discord](https://discord.gg/YRAq8fMnUG) server to talk with us and the entire Hugging Face community.
|
huggingface/blog/blob/main/sentiment-analysis-twitter.md
|
--
title: Exact Match
emoji: 🤗
colorFrom: blue
colorTo: green
sdk: gradio
sdk_version: 3.0.2
app_file: app.py
pinned: false
tags:
- evaluate
- comparison
description: >-
Returns the rate at which the predictions of one model exactly match those of another model.
---
# Comparison Card for Exact Match
## Comparison description
Given two model predictions the exact match score is 1 if they are the exact same, and is 0 otherwise. The overall exact match score is the average.
- **Example 1**: The exact match score if prediction 1.0 is [0, 1] is 0, given prediction 2 is [0, 1].
- **Example 2**: The exact match score if prediction 0.0 is [0, 1] is 0, given prediction 2 is [1, 0].
- **Example 3**: The exact match score if prediction 0.5 is [0, 1] is 0, given prediction 2 is [1, 1].
## How to use
At minimum, this metric takes as input predictions and references:
```python
>>> exact_match = evaluate.load("exact_match", module_type="comparison")
>>> results = exact_match.compute(predictions1=[0, 1, 1], predictions2=[1, 1, 1])
>>> print(results)
{'exact_match': 0.66}
```
## Output values
Returns a float between 0.0 and 1.0 inclusive.
## Examples
```python
>>> exact_match = evaluate.load("exact_match", module_type="comparison")
>>> results = exact_match.compute(predictions1=[0, 0, 0], predictions2=[1, 1, 1])
>>> print(results)
{'exact_match': 1.0}
```
```python
>>> exact_match = evaluate.load("exact_match", module_type="comparison")
>>> results = exact_match.compute(predictions1=[0, 1, 1], predictions2=[1, 1, 1])
>>> print(results)
{'exact_match': 0.66}
```
## Limitations and bias
## Citations
|
huggingface/evaluate/blob/main/comparisons/exact_match/README.md
|
!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# VisionTextDualEncoder and CLIP model training examples
The following example showcases how to train a CLIP-like vision-text dual encoder model
using a pre-trained vision and text encoder.
Such a model can be used for natural language image search and potentially zero-shot image classification.
The model is inspired by [CLIP](https://openai.com/blog/clip/), introduced by Alec Radford et al.
The idea is to train a vision encoder and a text encoder jointly to project the representation of images and their
captions into the same embedding space, such that the caption embeddings are located near the embeddings
of the images they describe.
### Download COCO dataset (2017)
This example uses COCO dataset (2017) through a custom dataset script, which requires users to manually download the
COCO dataset before training.
```bash
mkdir data
cd data
wget http://images.cocodataset.org/zips/train2017.zip
wget http://images.cocodataset.org/zips/val2017.zip
wget http://images.cocodataset.org/zips/test2017.zip
wget http://images.cocodataset.org/annotations/annotations_trainval2017.zip
wget http://images.cocodataset.org/annotations/image_info_test2017.zip
cd ..
```
Having downloaded COCO dataset manually you should be able to load with the `ydshieh/coc_dataset_script` dataset loading script:
```py
import os
import datasets
COCO_DIR = os.path.join(os.getcwd(), "data")
ds = datasets.load_dataset("ydshieh/coco_dataset_script", "2017", data_dir=COCO_DIR)
```
### Create a model from a vision encoder model and a text encoder model
Next, we create a [VisionTextDualEncoderModel](https://huggingface.co/docs/transformers/model_doc/vision-text-dual-encoder#visiontextdualencoder).
The `VisionTextDualEncoderModel` class lets you load any vision and text encoder model to create a dual encoder.
Here is an example of how to load the model using pre-trained vision and text models.
```python3
from transformers import (
VisionTextDualEncoderModel,
VisionTextDualEncoderProcessor,
AutoTokenizer,
AutoImageProcessor
)
model = VisionTextDualEncoderModel.from_vision_text_pretrained(
"openai/clip-vit-base-patch32", "roberta-base"
)
tokenizer = AutoTokenizer.from_pretrained("roberta-base")
image_processor = AutoImageProcessor.from_pretrained("openai/clip-vit-base-patch32")
processor = VisionTextDualEncoderProcessor(image_processor, tokenizer)
# save the model and processor
model.save_pretrained("clip-roberta")
processor.save_pretrained("clip-roberta")
```
This loads both the text and vision encoders using pre-trained weights, the projection layers are randomly
initialized except for CLIP's vision model. If you use CLIP to initialize the vision model then the vision projection weights are also
loaded using the pre-trained weights.
### Train the model
Finally, we can run the example script to train the model:
```bash
python examples/pytorch/contrastive-image-text/run_clip.py \
--output_dir ./clip-roberta-finetuned \
--model_name_or_path ./clip-roberta \
--data_dir $PWD/data \
--dataset_name ydshieh/coco_dataset_script \
--dataset_config_name=2017 \
--image_column image_path \
--caption_column caption \
--remove_unused_columns=False \
--do_train --do_eval \
--per_device_train_batch_size="64" \
--per_device_eval_batch_size="64" \
--learning_rate="5e-5" --warmup_steps="0" --weight_decay 0.1 \
--overwrite_output_dir \
--push_to_hub
```
|
huggingface/transformers/blob/main/examples/pytorch/contrastive-image-text/README.md
|
Gradio Demo: image_mod_default_image
```
!pip install -q gradio
```
```
# Downloading files from the demo repo
import os
os.mkdir('images')
!wget -q -O images/cheetah1.jpg https://github.com/gradio-app/gradio/raw/main/demo/image_mod_default_image/images/cheetah1.jpg
!wget -q -O images/lion.jpg https://github.com/gradio-app/gradio/raw/main/demo/image_mod_default_image/images/lion.jpg
!wget -q -O images/logo.png https://github.com/gradio-app/gradio/raw/main/demo/image_mod_default_image/images/logo.png
```
```
import gradio as gr
import os
def image_mod(image):
return image.rotate(45)
cheetah = os.path.join(os.path.abspath(''), "images/cheetah1.jpg")
demo = gr.Interface(image_mod, gr.Image(type="pil", value=cheetah), "image",
flagging_options=["blurry", "incorrect", "other"], examples=[
os.path.join(os.path.abspath(''), "images/lion.jpg"),
os.path.join(os.path.abspath(''), "images/logo.png")
])
if __name__ == "__main__":
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/image_mod_default_image/run.ipynb
|
n this video we take a look at the data processing necessary to train causal language models. Causal Language Modeling is the task of predicting the next token based on the previous token. Another term for Causal Language Modeling is Autoregressive Modeling. In the example that you see here the next token could for example be NLP or machine learning. A popular example of a Causal Language Model is the GPT family of models. To train such models such as GPT-2 we usually start with a large corpus of text files. These files can webpages scraped from the internet such as the Common Crawl dataset or they can be Python files from GitHub like you can see here. As a first step we need to tokenize these files such that we can feed them through a model. Here we show the tokenized texts as bars of various length illustrating the different sequence lengths. Normally, the text files come in various sizes and which results in various sequence length of the tokenized texts. Transformer models have a limited context length and depending on the data source it is possible that the tokenized texts are much longer than this context length. In this case we could just truncate the sequence to the context length but this would mean that we loose everything after the context length. Using the return overflowing tokens flag in the we can use the tokenizer to create chunks with each one being the size of the context length. Sometimes it can happen that the last chunk is too short if there aren’t enough tokens to fill it. In this case we would like to remove it. With the return_length keyword we also get the length of each chunk from the tokenizer. This function shows all the steps necessary to prepare the dataset. First we tokenize the dataset with the flags I just mentioned. Then we go through each chunk and if its length matches the context length we add it to the inputs we return. We can apply this function to the whole dataset and we make sure to use batches and remove the existing columns. We need to remove columns because we can create multiple samples per text and the shapes in the dataset would not match. If the context length is of similar length as the files this approach doesn't so well anymore. In this example both sample 1 and 2 are shorter than the context size and would be discarded with the previous approach. In this case it is better to first tokenize each sample without truncation and then concatenate the tokenized samples with an end of string, or EOS for short, token in between. Finally we can chunk this long sequence with the context length and we don’t loose any sequences because they are too short. So far we have only talked about the inputs for causal language modeling but not the labels needed for supervised training. When we do causal language modeling we don’t require any extra labels for the input sequences as the input sequences themselves are the labels. In this example when we feed the token “Trans” to the next token we want the model to predict is “formers”. In the next step we feed “Trans” and “formers” to the model and the label is the token “are”. This pattern continues and as you can see the input sequence is the label just shifted by one. Since the model only makes a prediction after the first token, the first element of the input sequence, in this case “Trans”, is not used as a label. Similarly, we do not have a label for the last token in the sequence since there is no token after the sequence ends. Let’s have a look at what we need to do to create the labels for causal language modeling in code.If we want to calculate the loss on a batch we can just pass the input_ids as labels and all the shifting is handled in the model internally. And the dataset is also ready to be used directly in the Trainer or keras.fit if you are using TensorFlow. So you see there is no magic involved in processing data for causal language modeling and only requires a few simple steps!
|
huggingface/course/blob/main/subtitles/en/raw/chapter7/06a_clm-processing.md
|
(Gluon) Inception v3
**Inception v3** is a convolutional neural network architecture from the Inception family that makes several improvements including using [Label Smoothing](https://paperswithcode.com/method/label-smoothing), Factorized 7 x 7 convolutions, and the use of an [auxiliary classifer](https://paperswithcode.com/method/auxiliary-classifier) to propagate label information lower down the network (along with the use of batch normalization for layers in the sidehead). The key building block is an [Inception Module](https://paperswithcode.com/method/inception-v3-module).
The weights from this model were ported from [Gluon](https://cv.gluon.ai/model_zoo/classification.html).
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('gluon_inception_v3', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `gluon_inception_v3`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('gluon_inception_v3', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/SzegedyVISW15,
author = {Christian Szegedy and
Vincent Vanhoucke and
Sergey Ioffe and
Jonathon Shlens and
Zbigniew Wojna},
title = {Rethinking the Inception Architecture for Computer Vision},
journal = {CoRR},
volume = {abs/1512.00567},
year = {2015},
url = {http://arxiv.org/abs/1512.00567},
archivePrefix = {arXiv},
eprint = {1512.00567},
timestamp = {Mon, 13 Aug 2018 16:49:07 +0200},
biburl = {https://dblp.org/rec/journals/corr/SzegedyVISW15.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<!--
Type: model-index
Collections:
- Name: Gloun Inception v3
Paper:
Title: Rethinking the Inception Architecture for Computer Vision
URL: https://paperswithcode.com/paper/rethinking-the-inception-architecture-for
Models:
- Name: gluon_inception_v3
In Collection: Gloun Inception v3
Metadata:
FLOPs: 7352418880
Parameters: 23830000
File Size: 95567055
Architecture:
- 1x1 Convolution
- Auxiliary Classifier
- Average Pooling
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inception-v3 Module
- Max Pooling
- ReLU
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_inception_v3
Crop Pct: '0.875'
Image Size: '299'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/inception_v3.py#L464
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/gluon_inception_v3-9f746940.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.8%
Top 5 Accuracy: 94.38%
-->
|
huggingface/pytorch-image-models/blob/main/docs/models/gloun-inception-v3.md
|
Gradio Demo: on_listener_basic
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
name = gr.Textbox(label="Name")
output = gr.Textbox(label="Output Box")
greet_btn = gr.Button("Greet")
trigger = gr.Textbox(label="Trigger Box")
trigger2 = gr.Textbox(label="Trigger Box")
def greet(name, evt_data: gr.EventData):
return "Hello " + name + "!", evt_data.target.__class__.__name__
def clear_name(evt_data: gr.EventData):
return "", evt_data.target.__class__.__name__
gr.on(
triggers=[name.submit, greet_btn.click],
fn=greet,
inputs=name,
outputs=[output, trigger],
).then(clear_name, outputs=[name, trigger2])
if __name__ == "__main__":
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/on_listener_basic/run.ipynb
|
hat is the BLEU metric? For many NLP tasks we can use common metrics like accuracy or F1 score, but what do you do when you want to measure the quality of text that's generated from a model like GPT-2? In this video, we'll take a look at a widely used metric for machine translation called BLEU, which is short for BiLingual Evaluation Understudy. The basic idea behind BLEU is to assign a single numerical score to a translation that tells us how "good" it is compared to one or more reference translations. In this example we have a sentence in Spanish that has been translated into English by some model. If we compare the generated translation to some reference human translations, we can see that the model is pretty good, but has made a common error: the Spanish word "tengo" means "have" in English and this 1-1 translation is not quite natural. So how can we measure the quality of a generated translation in an automatic way? The approach that BLEU takes is to compare the n-grams of the generated translation to the n-grams of the references. An n-gram is just a fancy way of saying "a chunk of n words", so let's start with unigrams, which correspond to the individual words in a sentence. In this example you can see that four of the words in the generated translation are also found in one of the reference translations. Now that we've found our matches, one way to assign a score to the translation is to compute the precision of the unigrams. This means we just count the number of matching words in the generated and reference translations and normalize the count by dividing by the number of word in the generation. In this example, we found 4 matching words and our generation has 5 words, so our unigram precision is 4/5 or 0.8. In general precision ranges from 0 to 1, and higher precision scores mean a better translation. One problem with unigram precision is that translation models sometimes get stuck in repetitive patterns and repeat the same word several times. If we just count the number of word matches, we can get really high precision scores even though the translation is terrible from a human perspective! For example, if our model just generates the word "six", we get a perfect unigram precision score. To handle this, BLEU uses a modified precision that clips the number of times to count a word, based on the maximum number of times it appears in the reference translation. In this example, the word "six" only appears once in the reference, so we clip the numerator to one and the modified unigram precision now gives a much lower score. Another problem with unigram precision is that it doesn't take into account the order of the words in the translations. For example, suppose we had Yoda translate our Spanish sentence, then we might get something backwards like "years six thirty have I". In this case, the modified unigram precision gives a high precision which is not what we want. So to deal with word ordering problems, BLEU actually computes the precision for several different n-grams and then averages the result. For example, if we compare 4-grams, then we can see there are no matching chunks of 4 words in translations and so the 4-gram precision is 0. To compute BLEU scores in Hugging Face Datasets is very simple: just use the load_metric() function, provide your model's predictions along with the references and you're good to go! The output contains several fields of interest. The precisions field contains all the individual precision scores for each n-gram. The BLEU score itself is then calculated by taking the geometric mean of the precision scores. By default, the mean of all four n-gram precisions is reported, a metric that is sometimes also called BLEU-4. In this example we can see the BLEU score is zero because the 4-gram precision was zero. The BLEU metric has some nice properties, but it is far from a perfect metric. The good properties are that it's easy to compute and widely used in research so you can compare your model against others on a benchmark. On the other hand, there are several problems with BLEU, including the fact it doesn't incorporate semantics and struggles on non-English languages. Another problem with BLEU is that it assumes the human translations have already been tokenized and this makes it hard to compare models with different tokenizers. Measuring the quality of texts is still a difficult, open problem in NLP research. For machine translation, the current recommendation is to use the SacreBLEU metric which addresses the tokenization limitations of BLEU. As you can see in this example, computing the SacreBLEU score is almost identical to the BLEU one. The main difference is that we now pass a list of texts instead of a list of words for the translations, and SacreBLEU takes care of the tokenization under the hood.
|
huggingface/course/blob/main/subtitles/en/raw/chapter7/04b_bleu.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Tiny AutoEncoder
Tiny AutoEncoder for Stable Diffusion (TAESD) was introduced in [madebyollin/taesd](https://github.com/madebyollin/taesd) by Ollin Boer Bohan. It is a tiny distilled version of Stable Diffusion's VAE that can quickly decode the latents in a [`StableDiffusionPipeline`] or [`StableDiffusionXLPipeline`] almost instantly.
To use with Stable Diffusion v-2.1:
```python
import torch
from diffusers import DiffusionPipeline, AutoencoderTiny
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-1-base", torch_dtype=torch.float16
)
pipe.vae = AutoencoderTiny.from_pretrained("madebyollin/taesd", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "slice of delicious New York-style berry cheesecake"
image = pipe(prompt, num_inference_steps=25).images[0]
image
```
To use with Stable Diffusion XL 1.0
```python
import torch
from diffusers import DiffusionPipeline, AutoencoderTiny
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16
)
pipe.vae = AutoencoderTiny.from_pretrained("madebyollin/taesdxl", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "slice of delicious New York-style berry cheesecake"
image = pipe(prompt, num_inference_steps=25).images[0]
image
```
## AutoencoderTiny
[[autodoc]] AutoencoderTiny
## AutoencoderTinyOutput
[[autodoc]] models.autoencoders.autoencoder_tiny.AutoencoderTinyOutput
|
huggingface/diffusers/blob/main/docs/source/en/api/models/autoencoder_tiny.md
|
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
Setup transformers following instructions in README.md, (I would fork first).
```bash
git clone git@github.com:huggingface/transformers.git
cd transformers
pip install -e .
pip install pandas GitPython wget
```
Get required metadata
```
curl https://cdn-datasets.huggingface.co/language_codes/language-codes-3b2.csv > language-codes-3b2.csv
curl https://cdn-datasets.huggingface.co/language_codes/iso-639-3.csv > iso-639-3.csv
```
Install Tatoeba-Challenge repo inside transformers
```bash
git clone git@github.com:Helsinki-NLP/Tatoeba-Challenge.git
```
To convert a few models, call the conversion script from command line:
```bash
python src/transformers/models/marian/convert_marian_tatoeba_to_pytorch.py --models heb-eng eng-heb --save_dir converted
```
To convert lots of models you can pass your list of Tatoeba model names to `resolver.convert_models` in a python client or script.
```python
from transformers.convert_marian_tatoeba_to_pytorch import TatoebaConverter
resolver = TatoebaConverter(save_dir='converted')
resolver.convert_models(['heb-eng', 'eng-heb'])
```
### Upload converted models
Since version v3.5.0, the model sharing workflow is switched to git-based system . Refer to [model sharing doc](https://huggingface.co/transformers/main/model_sharing.html#model-sharing-and-uploading) for more details.
To upload all converted models,
1. Install [git-lfs](https://git-lfs.github.com/).
2. Login to `huggingface-cli`
```bash
huggingface-cli login
```
3. Run the `upload_models` script
```bash
./scripts/tatoeba/upload_models.sh
```
### Modifications
- To change naming logic, change the code near `os.rename`. The model card creation code may also need to change.
- To change model card content, you must modify `TatoebaCodeResolver.write_model_card`
|
huggingface/transformers/blob/main/scripts/tatoeba/README.md
|
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Tokenizer
A tokenizer is in charge of preparing the inputs for a model. The library contains tokenizers for all the models. Most
of the tokenizers are available in two flavors: a full python implementation and a "Fast" implementation based on the
Rust library [🤗 Tokenizers](https://github.com/huggingface/tokenizers). The "Fast" implementations allows:
1. a significant speed-up in particular when doing batched tokenization and
2. additional methods to map between the original string (character and words) and the token space (e.g. getting the
index of the token comprising a given character or the span of characters corresponding to a given token).
The base classes [`PreTrainedTokenizer`] and [`PreTrainedTokenizerFast`]
implement the common methods for encoding string inputs in model inputs (see below) and instantiating/saving python and
"Fast" tokenizers either from a local file or directory or from a pretrained tokenizer provided by the library
(downloaded from HuggingFace's AWS S3 repository). They both rely on
[`~tokenization_utils_base.PreTrainedTokenizerBase`] that contains the common methods, and
[`~tokenization_utils_base.SpecialTokensMixin`].
[`PreTrainedTokenizer`] and [`PreTrainedTokenizerFast`] thus implement the main
methods for using all the tokenizers:
- Tokenizing (splitting strings in sub-word token strings), converting tokens strings to ids and back, and
encoding/decoding (i.e., tokenizing and converting to integers).
- Adding new tokens to the vocabulary in a way that is independent of the underlying structure (BPE, SentencePiece...).
- Managing special tokens (like mask, beginning-of-sentence, etc.): adding them, assigning them to attributes in the
tokenizer for easy access and making sure they are not split during tokenization.
[`BatchEncoding`] holds the output of the
[`~tokenization_utils_base.PreTrainedTokenizerBase`]'s encoding methods (`__call__`,
`encode_plus` and `batch_encode_plus`) and is derived from a Python dictionary. When the tokenizer is a pure python
tokenizer, this class behaves just like a standard python dictionary and holds the various model inputs computed by
these methods (`input_ids`, `attention_mask`...). When the tokenizer is a "Fast" tokenizer (i.e., backed by
HuggingFace [tokenizers library](https://github.com/huggingface/tokenizers)), this class provides in addition
several advanced alignment methods which can be used to map between the original string (character and words) and the
token space (e.g., getting the index of the token comprising a given character or the span of characters corresponding
to a given token).
## PreTrainedTokenizer
[[autodoc]] PreTrainedTokenizer
- __call__
- add_tokens
- add_special_tokens
- apply_chat_template
- batch_decode
- decode
- encode
- push_to_hub
- all
## PreTrainedTokenizerFast
The [`PreTrainedTokenizerFast`] depend on the [tokenizers](https://huggingface.co/docs/tokenizers) library. The tokenizers obtained from the 🤗 tokenizers library can be
loaded very simply into 🤗 transformers. Take a look at the [Using tokenizers from 🤗 tokenizers](../fast_tokenizers) page to understand how this is done.
[[autodoc]] PreTrainedTokenizerFast
- __call__
- add_tokens
- add_special_tokens
- apply_chat_template
- batch_decode
- decode
- encode
- push_to_hub
- all
## BatchEncoding
[[autodoc]] BatchEncoding
|
huggingface/transformers/blob/main/docs/source/en/main_classes/tokenizer.md
|
elcome to the Hugging Face Course! This course has been designed to teach you all about the Hugging Face ecosystem: how to use the dataset and model hub as well as all our open source libraries. Here is the Table of Contents. As you can see, it's divided in three sections which become progressively more advanced. At this stage, the first two sections have been released. The first will teach you the basics of how to use a Transformer model, fine-tune it on your own dataset and share the result with the community. The second will dive deeper into our libraries and teach you how to tackle any NLP task. We are actively working on the last one and hope to have it ready for you for the spring of 2022. The first chapter requires no technical knowledge and is a good introduction to learn what Transformers models can do and how they could be of use to you or your company. The next chapters require a good knowledge of Python and some basic knowledge of Machine Learning and Deep Learning. If you don't know what a training and validation set is or what gradient descent means, you should look at an introductory course such as the ones published by deeplearning.ai or fast.ai. It's also best if you have some basics in one Deep Learning Framework (PyTorch or TensorFlow). Each part of the material introduced in this course has a version in both those frameworks, so you will be able to pick the one you are most comfortable with. This is the team that developed this course. I'll now let each of the speakers introduce themselves briefly.
|
huggingface/course/blob/main/subtitles/en/raw/chapter1/01_welcome.md
|
--
title: "Huggy Lingo: Using Machine Learning to Improve Language Metadata on the Hugging Face Hub"
thumbnail: blog/assets/156_huggylingo/Huggy_Lingo.png
authors:
- user: davanstrien
---
## Huggy Lingo: Using Machine Learning to Improve Language Metadata on the Hugging Face Hub
**tl;dr**: We're using machine learning to detect the language of Hub datasets with no language metadata, and [librarian-bots](https://huggingface.co/librarian-bots) to make pull requests to add this metadata.
The Hugging Face Hub has become the repository where the community shares machine learning models, datasets, and applications. As the number of datasets grows, metadata becomes increasingly important as a tool for finding the right resource for your use case.
In this blog post, I'm excited to share some early experiments which seek to use machine learning to improve the metadata for datasets hosted on the Hugging Face Hub.
### Language metadata for datasets on the Hub
There are currently ~50K public datasets on the Hugging Face Hub. Metadata about the language used in a dataset can be specified using a [YAML](https://en.wikipedia.org/wiki/YAML) field at the top of the [dataset card](https://huggingface.co/docs/datasets/upload_dataset#create-a-dataset-card).
All public datasets specify 1,716 unique languages via a language tag in their metadata. Note that some of them will be the result of languages being specified in different ways i.e. `en` vs `eng` vs `english` vs `English`.
For example, the [IMDB dataset](https://huggingface.co/datasets/imdb) specifies `en` in the YAML metadata (indicating English):
* Section of the YAML metadata for the IMDB dataset*
It is perhaps unsurprising that English is by far the most common language for datasets on the Hub, with around 19% of datasets on the Hub listing their language as `en` (not including any variations of `en`, so the actual percentage is likely much higher).
*The frequency and percentage frequency for datasets on the Hugging Face Hub*
What does the distribution of languages look like if we exclude English? We can see that there is a grouping of a few dominant languages and after that there is a pretty smooth fall in the frequencies at which languages appear.
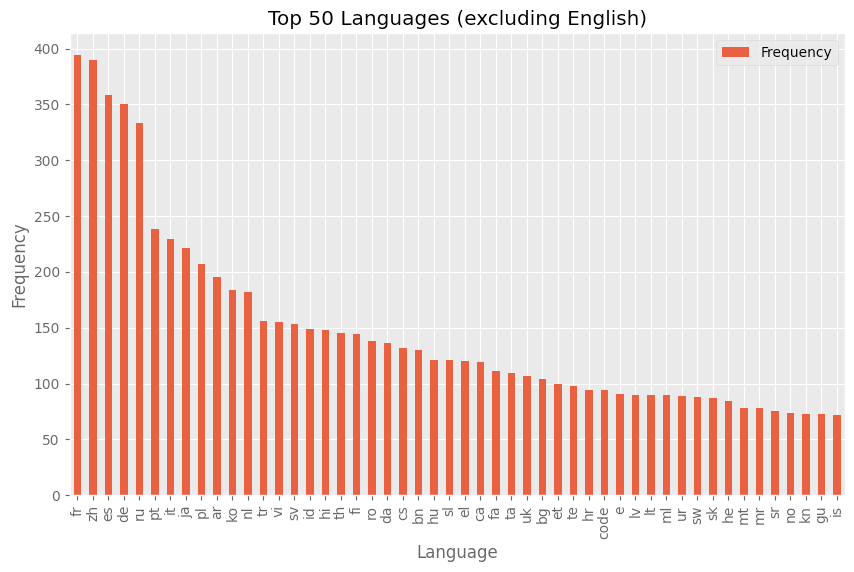
*Distribution of language tags for datasets on the hub excluding English*
However, there is a major caveat to this. Most datasets (around 87%) do not specify any language at all!
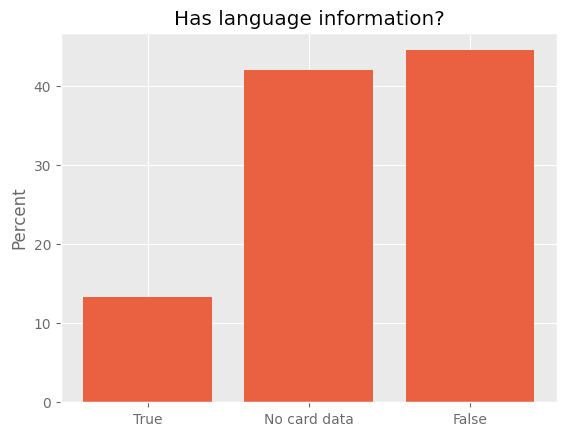
*The percent of datasets which have language metadata. True indicates language metadata is specified, False means no language data is listed. No card data means that there isn't any metadata or it couldn't be loaded by the `huggingface_hub` Python library.*
#### Why is language metadata important?
Language metadata can be a vital tool for finding relevant datasets. The Hugging Face Hub allows you to filter datasets by language. For example, if we want to find datasets with Dutch language we can use [a filter](https://huggingface.co/datasets?language=language:nl&sort=trending) on the Hub to include only datasets with Dutch data.
Currently this filter returns 184 datasets. However, there are datasets on the Hub which include Dutch but don't specify this in the metadata. These datasets become more difficult to find, particularly as the number of datasets on the Hub grows.
Many people want to be able to find datasets for a particular language. One of the major barriers to training good open source LLMs for a particular language is a lack of high quality training data.
If we switch to the task of finding relevant machine learning models, knowing what languages were included in the training data for a model can help us find models for the language we are interested in. This relies on the dataset specifying this information.
Finally, knowing what languages are represented on the Hub (and which are not), helps us understand the language biases of the Hub and helps inform community efforts to address gaps in particular languages.
### Predicting the languages of datasets using machine learning
We’ve already seen that many of the datasets on the Hugging Face Hub haven’t included metadata for the language used. However, since these datasets are already shared openly, perhaps we can look at the dataset and try to identify the language using machine learning.
#### Getting the data
One way we could access some examples from a dataset is by using the datasets library to download the datasets i.e.
```python
from datasets import load_dataset
dataset = load_dataset("biglam/on_the_books")
```
However, for some of the datasets on the Hub, we might be keen not to download the whole dataset. We could instead try to load a sample of the dataset. However, depending on how the dataset was created, we might still end up downloading more data than we’d need onto the machine we’re working on.
Luckily, many datasets on the Hub are available via the [datasets server](https://huggingface.co/docs/datasets-server/index). The datasets server is an API that allows us to access datasets hosted on the Hub without downloading the dataset locally. The Datasets Server powers the Datasets Viewer preview you will see for many datasets hosted on the Hub.
For this first experiment with predicting language for datasets, we define a list of column names and data types likely to contain textual content i.e. `text` or `prompt` column names and `string` features are likely to be relevant `image` is not. This means we can avoid predicting the language for datasets where language information is less relevant, for example, image classification datasets. We use the Datasets Server to get 20 rows of text data to pass to a machine learning model (we could modify this to take more or fewer examples from the dataset).
This approach means that for the majority of datasets on the Hub we can quickly request the contents of likely text columns for the first 20 rows in a dataset.
#### Predicting the language of a dataset
Once we have some examples of text from a dataset, we need to predict the language. There are various options here, but for this work, we used the [facebook/fasttext-language-identification](https://huggingface.co/facebook/fasttext-language-identification) fastText model created by [Meta](https://huggingface.co/facebook) as part of the [No Language Left Behind](https://ai.facebook.com/research/no-language-left-behind/) work. This model can detect 217 languages which will likely represent the majority of languages for datasets hosted on the Hub.
We pass 20 examples to the model representing rows from a dataset. This results in 20 individual language predictions (one per row) for each dataset.
Once we have these predictions, we do some additional filtering to determine if we will accept the predictions as a metadata suggestion. This roughly consists of:
- Grouping the predictions for each dataset by language: some datasets return predictions for multiple languages. We group these predictions by the language predicted i.e. if a dataset returns predictions for English and Dutch, we group the English and Dutch predictions together.
- For datasets with multiple languages predicted, we count how many predictions we have for each language. If a language is predicted less than 20% of the time, we discard this prediction. i.e. if we have 18 predictions for English and only 2 for Dutch we discard the Dutch predictions.
- We calculate the mean score for all predictions for a language. If the mean score associated with a languages prediction is below 80% we discard this prediction.
Once we’ve done this filtering, we have a further step of deciding how to use these predictions. The fastText language prediction model returns predictions as an [ISO 639-3](https://en.wikipedia.org/wiki/ISO_639-3) code (an international standard for language codes) along with a script type. i.e. `kor_Hang` is the ISO 693-3 language code for Korean (kor) + Hangul script (Hang) a [ISO 15924](https://en.wikipedia.org/wiki/ISO_15924) code representing the script of a language.
We discard the script information since this isn't currently captured consistently as metadata on the Hub and, where possible, we convert the language prediction returned by the model from [ISO 639-3](https://en.wikipedia.org/wiki/ISO_639-3) to [ISO 639-1](https://en.wikipedia.org/wiki/ISO_639-1) language codes. This is largely done because these language codes have better support in the Hub UI for navigating datasets.
For some ISO 639-3 codes, there is no ISO 639-1 equivalent. For these cases we manually specify a mapping if we deem it to make sense, for example Standard Arabic (`arb`) is mapped to Arabic (`ar`). Where an obvious mapping is not possible, we currently don't suggest metadata for this dataset. In future iterations of this work we may take a different approach. It is important to recognise this approach does come with downsides, since it reduces the diversity of languages which might be suggested and also relies on subjective judgments about what languages can be mapped to others.
But the process doesn't stop here. After all, what use is predicting the language of the datasets if we can't share that information with the rest of the community?
### Using Librarian-Bot to Update Metadata
To ensure this valuable language metadata is incorporated back into the Hub, we turn to Librarian-Bot! Librarian-Bot takes the language predictions generated by Meta's [facebook/fasttext-language-identification](https://huggingface.co/facebook/fasttext-language-identification) fastText model and opens pull requests to add this information to the metadata of each respective dataset.
This automated system not only updates the datasets with language information, but also does it swiftly and efficiently, without requiring manual work from humans. Once these pull requests are approved and merged, the language metadata becomes available for all users, significantly enhancing the usability of the Hugging Face Hub. You can keep track of what the librarian-bot is doing [here](https://huggingface.co/librarian-bot/activity/community)!
#### Next steps
As the number of datasets on the Hub grows, metadata becomes increasingly important. Language metadata, in particular, can be incredibly valuable for identifying the correct dataset for your use case.
With the assistance of the Datasets Server and the [Librarian-Bots](https://huggingface.co/librarian-bots), we can update our dataset metadata at a scale that wouldn't be possible manually. As a result, we're enriching the Hub and making it an even more powerful tool for data scientists, linguists, and AI enthusiasts around the world.
As the machine learning librarian at Hugging Face, I continue exploring opportunities for automatic metadata enrichment for machine learning artefacts hosted on the Hub. Feel free to reach out (daniel at thiswebsite dot co) if you have ideas or want to collaborate on this effort!
|
huggingface/blog/blob/main/huggylingo.md
|
--
title: "Jupyter X Hugging Face"
thumbnail: /blog/assets/135_notebooks-hub/before_after_notebook_rendering.png
authors:
- user: davanstrien
- user: reach-vb
- user: merve
---
# Jupyter X Hugging Face
**We’re excited to announce improved support for Jupyter notebooks hosted on the Hugging Face Hub!**
From serving as an essential learning resource to being a key tool used for model development, Jupyter notebooks have become a key component across many areas of machine learning. Notebooks' interactive and visual nature lets you get feedback quickly as you develop models, datasets, and demos. For many, their first exposure to training machine learning models is via a Jupyter notebook, and many practitioners use notebooks as a critical tool for developing and communicating their work.
Hugging Face is a collaborative Machine Learning platform in which the community has shared over 150,000 models, 25,000 datasets, and 30,000 ML apps. The Hub has model and dataset versioning tools, including model cards and client-side libraries to automate the versioning process. However, only including a model card with hyperparameters is not enough to provide the best reproducibility; this is where notebooks can help. Alongside these models, datasets, and demos, the Hub hosts over 7,000 notebooks. These notebooks often document the development process of a model or a dataset and can provide guidance and tutorials showing how others can use these resources. We’re therefore excited about our improved support for notebook hosting on the Hub.
## What have we changed?
Under the hood, Jupyter notebook files (usually shared with an `ipynb` extension) are JSON files. While viewing these files directly is possible, it's not a format intended to be read by humans. We have now added rendering support for notebooks hosted on the Hub. This means that notebooks will now be displayed in a human-readable format.
<figure>
<img src="/blog/assets/135_notebooks-hub/before_after_notebook_rendering.png" alt="A side-by-side comparison showing a screenshot of a notebook that hasn’t been rendered on the left and a rendered version on the right. The non-rendered image shows part of a JSON file containing notebook cells that are difficult to read. The rendered version shows a notebook hosted on the Hugging Face hub showing the notebook rendered in a human-readable format. The screenshot shows some of the context of the Hugging Face Hub hosting, such as the branch and a window showing the rendered notebook. The rendered notebook has some example Markdown and code snippets showing the notebook output. "/>
<figcaption>Before and after rendering of notebooks hosted on the hub.</figcaption>
</figure>
## Why are we excited to host more notebooks on the Hub?
- Notebooks help document how people can use your models and datasets; sharing notebooks in the same place as your models and datasets makes it easier for others to use the resources you have created and shared on the Hub.
- Many people use the Hub to develop a Machine Learning portfolio. You can now supplement this portfolio with Jupyter Notebooks too.
- Support for one-click direct opening notebooks hosted on the Hub in [Google Colab](https://medium.com/google-colab/hugging-face-notebooks-x-colab-722d91e05e7c), making notebooks on the Hub an even more powerful experience. Look out for future announcements!
|
huggingface/blog/blob/main/notebooks-hub.md
|
--
title: "Gradio is joining Hugging Face!"
thumbnail: /blog/assets/42_gradio_joins_hf/thumbnail.png
authors:
- user: abidlabs
---
# Gradio is joining Hugging Face!
<p> </p>
_Gradio is joining Hugging Face! By acquiring Gradio, a machine learning startup, Hugging Face will be able to offer users, developers, and data scientists the tools needed to get to high level results and create better models and tools..._
Hmm, paragraphs about acquisitions like the one above are so common that an algorithm could write them. In
fact, one did!! This first paragraph was written with the [Acquisition Post Generator](https://huggingface.co/spaces/abidlabs/The-Acquisition-Post-Generator), a machine learning demo on **Hugging Face Spaces**. You can run it yourself in your browser: provide the names of any two companies and you'll get a reasonable-sounding start to an article announcing their acquisition!
The Acquisition Post Generator was built using our open-source Gradio library -- it is just one of our recent collaborations with Hugging Face. And I'm excited to announce that these collaborations are culminating in... 🥁 **Hugging Face's acquisition of Gradio** (so yes, that first paragraph might have been written by
an algorithm but it's true!)
<img class="max-w-full mx-auto my-6" style="width: 54rem" src="/blog/assets/42_gradio_joins_hf/screenshot.png">
As one of the founders of Gradio, I couldn't be more excited about the next step in our journey. I still remember clearly how we started in 2019: as a PhD student at Stanford, I struggled to share a medical computer vision model with one of my collaborators, who was a doctor. I needed him to test my machine learning model, but he didn't know Python and couldn't easily run the model on his own images. I envisioned a tool that could make it super simple for machine learning engineers to build and share demos of computer vision models, which in turn would lead to better feedback and more reliable models 🔁
I recruited my talented housemates Ali Abdalla, Ali Abid, and Dawood Khan to release the first version of Gradio in 2019. We steadily expanded to cover more areas of machine learning including text, speech, and video. We found that it wasn't just researchers who needed to share machine learning models: interdisciplinary teams in industry, from startups to public companies, were building models and needed to debug them internally or showcase them externally. Gradio could help with both. Since we first released the library, more than 300,000 demos have been built with Gradio. We couldn't have done this without our community of contributors, our supportive investors, and the amazing Ahsen Khaliq who joined our company this year.
Demos and GUIs built with Gradio give the power of machine learning to more and more people because they allow non-technical users to access, use, and give feedback on models. And our acquisition by Hugging Face is the next step in this ongoing journey of accessibility. Hugging Face has already radically democratized machine learning so that any software engineer can use state-of-the-art models with a few lines of code. By working together with Hugging Face, we're taking this even further so that machine learning is accessible to literally anyone with an internet connection and a browser. With Hugging Face, we are going to keep growing Gradio and make it the best way to share your machine learning model with anyone, anywhere 🚀
In addition to the shared mission of Gradio and Hugging Face, what delights me is the team that we are joining. Hugging Face's remarkable culture of openness and innovation is well-known. Over the past few months, I've gotten to know the founders as well: they are wonderful people who genuinely care about every single person at Hugging Face and are willing to go to bat for them. On behalf of the entire Gradio team, we couldn't be more thrilled to be working with them to build the future of machine learning 🤗
Also: [we are hiring!!](https://apply.workable.com/huggingface/) ❤️
|
huggingface/blog/blob/main/gradio-joins-hf.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Image classification using LoRA
This guide demonstrates how to use LoRA, a low-rank approximation technique, to fine-tune an image classification model.
By using LoRA from 🤗 PEFT, we can reduce the number of trainable parameters in the model to only 0.77% of the original.
LoRA achieves this reduction by adding low-rank "update matrices" to specific blocks of the model, such as the attention
blocks. During fine-tuning, only these matrices are trained, while the original model parameters are left unchanged.
At inference time, the update matrices are merged with the original model parameters to produce the final classification result.
For more information on LoRA, please refer to the [original LoRA paper](https://arxiv.org/abs/2106.09685).
## Install dependencies
Install the libraries required for model training:
```bash
!pip install transformers accelerate evaluate datasets peft -q
```
Check the versions of all required libraries to make sure you are up to date:
```python
import transformers
import accelerate
import peft
print(f"Transformers version: {transformers.__version__}")
print(f"Accelerate version: {accelerate.__version__}")
print(f"PEFT version: {peft.__version__}")
"Transformers version: 4.27.4"
"Accelerate version: 0.18.0"
"PEFT version: 0.2.0"
```
## Authenticate to share your model
To share the fine-tuned model at the end of the training with the community, authenticate using your 🤗 token.
You can obtain your token from your [account settings](https://huggingface.co/settings/token).
```python
from huggingface_hub import notebook_login
notebook_login()
```
## Select a model checkpoint to fine-tune
Choose a model checkpoint from any of the model architectures supported for [image classification](https://huggingface.co/models?pipeline_tag=image-classification&sort=downloads). When in doubt, refer to
the [image classification task guide](https://huggingface.co/docs/transformers/v4.27.2/en/tasks/image_classification) in
🤗 Transformers documentation.
```python
model_checkpoint = "google/vit-base-patch16-224-in21k"
```
## Load a dataset
To keep this example's runtime short, let's only load the first 5000 instances from the training set of the [Food-101 dataset](https://huggingface.co/datasets/food101):
```python
from datasets import load_dataset
dataset = load_dataset("food101", split="train[:5000]")
```
## Dataset preparation
To prepare the dataset for training and evaluation, create `label2id` and `id2label` dictionaries. These will come in
handy when performing inference and for metadata information:
```python
labels = dataset.features["label"].names
label2id, id2label = dict(), dict()
for i, label in enumerate(labels):
label2id[label] = i
id2label[i] = label
id2label[2]
"baklava"
```
Next, load the image processor of the model you're fine-tuning:
```python
from transformers import AutoImageProcessor
image_processor = AutoImageProcessor.from_pretrained(model_checkpoint)
```
The `image_processor` contains useful information on which size the training and evaluation images should be resized
to, as well as values that should be used to normalize the pixel values. Using the `image_processor`, prepare transformation
functions for the datasets. These functions will include data augmentation and pixel scaling:
```python
from torchvision.transforms import (
CenterCrop,
Compose,
Normalize,
RandomHorizontalFlip,
RandomResizedCrop,
Resize,
ToTensor,
)
normalize = Normalize(mean=image_processor.image_mean, std=image_processor.image_std)
train_transforms = Compose(
[
RandomResizedCrop(image_processor.size["height"]),
RandomHorizontalFlip(),
ToTensor(),
normalize,
]
)
val_transforms = Compose(
[
Resize(image_processor.size["height"]),
CenterCrop(image_processor.size["height"]),
ToTensor(),
normalize,
]
)
def preprocess_train(example_batch):
"""Apply train_transforms across a batch."""
example_batch["pixel_values"] = [train_transforms(image.convert("RGB")) for image in example_batch["image"]]
return example_batch
def preprocess_val(example_batch):
"""Apply val_transforms across a batch."""
example_batch["pixel_values"] = [val_transforms(image.convert("RGB")) for image in example_batch["image"]]
return example_batch
```
Split the dataset into training and validation sets:
```python
splits = dataset.train_test_split(test_size=0.1)
train_ds = splits["train"]
val_ds = splits["test"]
```
Finally, set the transformation functions for the datasets accordingly:
```python
train_ds.set_transform(preprocess_train)
val_ds.set_transform(preprocess_val)
```
## Load and prepare a model
Before loading the model, let's define a helper function to check the total number of parameters a model has, as well
as how many of them are trainable.
```python
def print_trainable_parameters(model):
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param:.2f}"
)
```
It's important to initialize the original model correctly as it will be used as a base to create the `PeftModel` you'll
actually fine-tune. Specify the `label2id` and `id2label` so that [`~transformers.AutoModelForImageClassification`] can append a classification
head to the underlying model, adapted for this dataset. You should see the following output:
```
Some weights of ViTForImageClassification were not initialized from the model checkpoint at google/vit-base-patch16-224-in21k and are newly initialized: ['classifier.weight', 'classifier.bias']
```
```python
from transformers import AutoModelForImageClassification, TrainingArguments, Trainer
model = AutoModelForImageClassification.from_pretrained(
model_checkpoint,
label2id=label2id,
id2label=id2label,
ignore_mismatched_sizes=True, # provide this in case you're planning to fine-tune an already fine-tuned checkpoint
)
```
Before creating a `PeftModel`, you can check the number of trainable parameters in the original model:
```python
print_trainable_parameters(model)
"trainable params: 85876325 || all params: 85876325 || trainable%: 100.00"
```
Next, use `get_peft_model` to wrap the base model so that "update" matrices are added to the respective places.
```python
from peft import LoraConfig, get_peft_model
config = LoraConfig(
r=16,
lora_alpha=16,
target_modules=["query", "value"],
lora_dropout=0.1,
bias="none",
modules_to_save=["classifier"],
)
lora_model = get_peft_model(model, config)
print_trainable_parameters(lora_model)
"trainable params: 667493 || all params: 86466149 || trainable%: 0.77"
```
Let's unpack what's going on here.
To use LoRA, you need to specify the target modules in `LoraConfig` so that `get_peft_model()` knows which modules
inside our model need to be amended with LoRA matrices. In this example, we're only interested in targeting the query and
value matrices of the attention blocks of the base model. Since the parameters corresponding to these matrices are "named"
"query" and "value" respectively, we specify them accordingly in the `target_modules` argument of `LoraConfig`.
We also specify `modules_to_save`. After wrapping the base model with `get_peft_model()` along with the `config`, we get
a new model where only the LoRA parameters are trainable (so-called "update matrices") while the pre-trained parameters
are kept frozen. However, we want the classifier parameters to be trained too when fine-tuning the base model on our
custom dataset. To ensure that the classifier parameters are also trained, we specify `modules_to_save`. This also
ensures that these modules are serialized alongside the LoRA trainable parameters when using utilities like `save_pretrained()`
and `push_to_hub()`.
Here's what the other parameters mean:
- `r`: The dimension used by the LoRA update matrices.
- `alpha`: Scaling factor.
- `bias`: Specifies if the `bias` parameters should be trained. `None` denotes none of the `bias` parameters will be trained.
`r` and `alpha` together control the total number of final trainable parameters when using LoRA, giving you the flexibility
to balance a trade-off between end performance and compute efficiency.
By looking at the number of trainable parameters, you can see how many parameters we're actually training. Since the goal is
to achieve parameter-efficient fine-tuning, you should expect to see fewer trainable parameters in the `lora_model`
in comparison to the original model, which is indeed the case here.
## Define training arguments
For model fine-tuning, use [`~transformers.Trainer`]. It accepts
several arguments which you can wrap using [`~transformers.TrainingArguments`].
```python
from transformers import TrainingArguments, Trainer
model_name = model_checkpoint.split("/")[-1]
batch_size = 128
args = TrainingArguments(
f"{model_name}-finetuned-lora-food101",
remove_unused_columns=False,
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=5e-3,
per_device_train_batch_size=batch_size,
gradient_accumulation_steps=4,
per_device_eval_batch_size=batch_size,
fp16=True,
num_train_epochs=5,
logging_steps=10,
load_best_model_at_end=True,
metric_for_best_model="accuracy",
push_to_hub=True,
label_names=["labels"],
)
```
Compared to non-PEFT methods, you can use a larger batch size since there are fewer parameters to train.
You can also set a larger learning rate than the normal (1e-5 for example).
This can potentially also reduce the need to conduct expensive hyperparameter tuning experiments.
## Prepare evaluation metric
```python
import numpy as np
import evaluate
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
"""Computes accuracy on a batch of predictions"""
predictions = np.argmax(eval_pred.predictions, axis=1)
return metric.compute(predictions=predictions, references=eval_pred.label_ids)
```
The `compute_metrics` function takes a named tuple as input: `predictions`, which are the logits of the model as Numpy arrays,
and `label_ids`, which are the ground-truth labels as Numpy arrays.
## Define collation function
A collation function is used by [`~transformers.Trainer`] to gather a batch of training and evaluation examples and prepare them in a
format that is acceptable by the underlying model.
```python
import torch
def collate_fn(examples):
pixel_values = torch.stack([example["pixel_values"] for example in examples])
labels = torch.tensor([example["label"] for example in examples])
return {"pixel_values": pixel_values, "labels": labels}
```
## Train and evaluate
Bring everything together - model, training arguments, data, collation function, etc. Then, start the training!
```python
trainer = Trainer(
lora_model,
args,
train_dataset=train_ds,
eval_dataset=val_ds,
tokenizer=image_processor,
compute_metrics=compute_metrics,
data_collator=collate_fn,
)
train_results = trainer.train()
```
In just a few minutes, the fine-tuned model shows 96% validation accuracy even on this small
subset of the training dataset.
```python
trainer.evaluate(val_ds)
{
"eval_loss": 0.14475855231285095,
"eval_accuracy": 0.96,
"eval_runtime": 3.5725,
"eval_samples_per_second": 139.958,
"eval_steps_per_second": 1.12,
"epoch": 5.0,
}
```
## Share your model and run inference
Once the fine-tuning is done, share the LoRA parameters with the community like so:
```python
repo_name = f"sayakpaul/{model_name}-finetuned-lora-food101"
lora_model.push_to_hub(repo_name)
```
When calling [`~transformers.PreTrainedModel.push_to_hub`] on the `lora_model`, only the LoRA parameters along with any modules specified in `modules_to_save`
are saved. Take a look at the [trained LoRA parameters](https://huggingface.co/sayakpaul/vit-base-patch16-224-in21k-finetuned-lora-food101/blob/main/adapter_model.bin).
You'll see that it's only 2.6 MB! This greatly helps with portability, especially when using a very large model to fine-tune (such as [BLOOM](https://huggingface.co/bigscience/bloom)).
Next, let's see how to load the LoRA updated parameters along with our base model for inference. When you wrap a base model
with `PeftModel`, modifications are done *in-place*. To mitigate any concerns that might stem from in-place modifications,
initialize the base model just like you did earlier and construct the inference model.
```python
from peft import PeftConfig, PeftModel
config = PeftConfig.from_pretrained(repo_name)
model = AutoModelForImageClassification.from_pretrained(
config.base_model_name_or_path,
label2id=label2id,
id2label=id2label,
ignore_mismatched_sizes=True, # provide this in case you're planning to fine-tune an already fine-tuned checkpoint
)
# Load the LoRA model
inference_model = PeftModel.from_pretrained(model, repo_name)
```
Let's now fetch an example image for inference.
```python
from PIL import Image
import requests
url = "https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/beignets.jpeg"
image = Image.open(requests.get(url, stream=True).raw)
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/beignets.jpeg" alt="image of beignets"/>
</div>
First, instantiate an `image_processor` from the underlying model repo.
```python
image_processor = AutoImageProcessor.from_pretrained(repo_name)
```
Then, prepare the example for inference.
```python
encoding = image_processor(image.convert("RGB"), return_tensors="pt")
```
Finally, run inference!
```python
with torch.no_grad():
outputs = inference_model(**encoding)
logits = outputs.logits
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", inference_model.config.id2label[predicted_class_idx])
"Predicted class: beignets"
```
|
huggingface/peft/blob/main/docs/source/task_guides/image_classification_lora.md
|
--
title: "Generating Stories: AI for Game Development #5"
thumbnail: /blog/assets/124_ml-for-games/thumbnail5.png
authors:
- user: dylanebert
---
# Generating Stories: AI for Game Development #5
**Welcome to AI for Game Development!** In this series, we'll be using AI tools to create a fully functional farming game in just 5 days. By the end of this series, you will have learned how you can incorporate a variety of AI tools into your game development workflow. I will show you how you can use AI tools for:
1. Art Style
2. Game Design
3. 3D Assets
4. 2D Assets
5. Story
Want the quick video version? You can watch it [here](https://www.tiktok.com/@individualkex/video/7197505390353960235). Otherwise, if you want the technical details, keep reading!
**Note:** This post makes several references to [Part 2](https://huggingface.co/blog/ml-for-games-2), where we used ChatGPT for Game Design. Read Part 2 for additional context on how ChatGPT works, including a brief overview of language models and their limitations.
## Day 5: Story
In [Part 4](https://huggingface.co/blog/ml-for-games-4) of this tutorial series, we talked about how you can use Stable Diffusion and Image2Image as a tool in your 2D Asset workflow.
In this final part, we'll be using AI for Story. First, I'll walk through my [process](#process) for the farming game, calling attention to ⚠️ **Limitations** to watch out for. Then, I'll talk about relevant technologies and [where we're headed](#where-were-headed) in the context of game development. Finally, I'll [conclude](#conclusion) with the final game.
### Process
**Requirements:** I'm using [ChatGPT](https://openai.com/blog/chatgpt/) throughout this process. For more information on ChatGPT and language modeling in general, I recommend reading [Part 2](https://huggingface.co/blog/ml-for-games-2) of the series. ChatGPT isn't the only viable solution, with many emerging competitors, including open-source dialog agents. Read ahead to learn more about [the emerging landscape](#the-emerging-landscape) of dialog agents.
1. **Ask ChatGPT to write a story.** I provide plenty of context about my game, then ask ChatGPT to write a story summary.
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/chatgpt1.png" alt="ChatGPT for Story #1">
</div>
ChatGPT then responds with a story summary that is extremely similar to the story of the game [Stardew Valley](https://www.stardewvalley.net/).
> ⚠️ **Limitation:** Language models are susceptible to reproducing existing stories.
This highlights the importance of using language models as a tool, rather than as a replacement for human creativity. In this case, relying solely on ChatGPT would result in a very unoriginal story.
2. **Refine the results.** As with Image2Image in [Part 4](https://huggingface.co/blog/ml-for-games-4), the real power of these tools comes from back-and-forth collaboration. So, I ask ChatGPT directly to be more original.
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/chatgpt2.png" alt="ChatGPT for Story #2">
</div>
This is already much better. I continue to refine the result, such as asking to remove elements of magic since the game doesn't contain magic. After a few rounds of back-and-forth, I reach a description I'm happy with. Then, it's a matter of generating the actual content that tells this story.
3. **Write the content.** Once I'm happy with the story summary, I ask ChatGPT to write the in-game story content. In the case of this farming game, the only written content is the description of the game, and the description of the items in the shop.
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/chatgpt3.png" alt="ChatGPT for Story #3">
</div>
Not bad. However, there is definitely no help from experienced farmers in the game, nor challenges or adventures to discover.
4. **Refine the content.** I continue to refine the generated content to better fit the game.
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/chatgpt4.png" alt="ChatGPT for Story #4">
</div>
I'm happy with this result. So, should I use it directly? Maybe. Since this is a free game being developed for an AI tutorial, probably. However, it may not be straightforward for commercial products, having potential unintended legal, ethical, and commercial ramifications.
> ⚠️ **Limitation:** Using outputs from language models directly may have unintended legal, ethical, and commercial ramifications.
Some potential unintended ramifications of using outputs directly are as follows:
- <u>Legal:</u> The legal landscape surrounding Generative AI is currently very unclear, with several ongoing lawsuits.
- <u>Ethical:</u> Language models can produce plagiarized or biased outputs. For more information, check out the [Ethics and Society Newsletter](https://huggingface.co/blog/ethics-soc-2).
- <u>Commercial:</u> [Some](https://www.searchenginejournal.com/google-says-ai-generated-content-is-against-guidelines/444916/) sources have stated that AI-generated content may be deprioritized by search engines. This [may not](https://seo.ai/blog/google-is-not-against-ai-content) be the case for most non-spam content, but is worth considering. Tools such as [AI Content Detector](https://writer.com/ai-content-detector/) can be used to check whether content may be detected as AI-generated. There is ongoing research on language model [watermarking](https://arxiv.org/abs/2301.10226) which may mark text as AI-generated.
Given these limitations, the safest approach may be to use language models like ChatGPT for brainstorming but write the final content by hand.
5. **Scale the content.** I continue to use ChatGPT to flesh out descriptions for the items in the store.
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/chatgpt5.png" alt="ChatGPT for Story #5">
</div>
For my simple farming game, this may be an effective approach to producing all the story content for the game. However, this may quickly run into scaling limitations. ChatGPT isn't well-suited to very long cohesive storytelling. Even after generating a few item descriptions for the farming game, the results begin to drift in quality and fall into repetition.
> ⚠️ **Limitation:** Language models are susceptible to repetition.
To wrap up this section, here are some tips from my own experience that may help with using AI for Story:
- **Ask for outlines.** As mentioned, quality may deteriorate with long-form content. Developing high-level story outlines tends to work much better.
- **Brainstorm small ideas.** Use language models to help flesh out ideas that don't require the full story context. For example, describe a character and use the AI to help brainstorm details about that character.
- **Refine content.** Write your actual story content, and ask for suggestions on ways to improve that content. Even if you don't use the result, it may give you ideas on how to improve the content.
Despite the limitations I've discussed, dialog agents are an incredibly useful tool for game development, and it's only the beginning. Let's talk about the emerging landscape of dialog agents and their potential impact on game development.
### Where We're Headed
#### The Emerging Landscape
My [process](#process) focused on how ChatGPT can be used for story. However, ChatGPT isn't the only solution available. [Character.AI](https://beta.character.ai/) provides access to dialog agents that are customized to characters with different personalities, including an [agent](https://beta.character.ai/chat?char=9ZSDyg3OuPbFgDqGwy3RpsXqJblE4S1fKA_oU3yvfTM) that is specialized for creative writing.
There are many other models which are not yet publicly accessible. Check out [this](https://huggingface.co/blog/dialog-agents) recent blog post on dialog agents, including a comparison with other existing models. These include:
- [Google's LaMDA](https://arxiv.org/abs/2201.08239) and [Bard](https://blog.google/technology/ai/bard-google-ai-search-updates/)
- [Meta's BlenderBot](https://arxiv.org/abs/2208.03188)
- [DeepMind's Sparrow](https://arxiv.org/abs/2209.14375)
- [Anthropic's Assistant](https://arxiv.org/abs/2204.05862).
While many prevalent contenders are closed-source, there are also open-source dialog agent efforts, such as [LAION's OpenAssistant](https://github.com/LAION-AI/Open-Assistant), reported efforts from [CarperAI](https://carper.ai), and the open source release of [Google's FLAN-T5 XXL](https://huggingface.co/google/flan-t5-xxl). These can be combined with open-source tools like [LangChain](https://github.com/hwchase17/langchain), which allow language model inputs and outputs to be chained, helping to work toward open dialog agents.
Just as the open-source release of Stable Diffusion has rapidly risen to a wide variety of innovations that have inspired this series, the open-source community will be key to exciting language-centric applications in game development that are yet to be seen. To keep up with these developments, feel free to follow me on [Twitter](https://twitter.com/dylan_ebert_). In the meantime, let's discuss some of these potential developments.
#### In-Game Development
**NPCs:** Aside from the clear uses of language models and dialog agents in the game development workflow, there is an exciting in-game potential for this technology that has not yet been realized. The most clear case of this is AI-powered NPCs. There are already startups built around the idea. Personally, I don't quite see how language models, as they currently are, can be applied to create compelling NPCs. However, I definitely don't think it's far off. I'll let you know.
**Controls.** What if you could control a game by talking to it? This is actually not too hard to do right now, though it hasn't been put into common practice. Would you be interested in learning how to do this? Stay tuned.
### Conclusion
Want to play the final farming game? Check it out [here](https://huggingface.co/spaces/dylanebert/FarmingGame) or on [itch.io](https://individualkex.itch.io/farming-game).
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/game.png" alt="Final Farming Game">
</div>
Thank you for reading the AI for Game Development series! This series is only the beginning of AI for Game Development at Hugging Face, with more to come. Have questions? Want to get more involved? Join the [Hugging Face Discord](https://hf.co/join/discord)!
|
huggingface/blog/blob/main/ml-for-games-5.md
|
(Gluon) SENet
A **SENet** is a convolutional neural network architecture that employs [squeeze-and-excitation blocks](https://paperswithcode.com/method/squeeze-and-excitation-block) to enable the network to perform dynamic channel-wise feature recalibration.
The weights from this model were ported from [Gluon](https://cv.gluon.ai/model_zoo/classification.html).
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('gluon_senet154', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `gluon_senet154`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('gluon_senet154', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{hu2019squeezeandexcitation,
title={Squeeze-and-Excitation Networks},
author={Jie Hu and Li Shen and Samuel Albanie and Gang Sun and Enhua Wu},
year={2019},
eprint={1709.01507},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: Gloun SENet
Paper:
Title: Squeeze-and-Excitation Networks
URL: https://paperswithcode.com/paper/squeeze-and-excitation-networks
Models:
- Name: gluon_senet154
In Collection: Gloun SENet
Metadata:
FLOPs: 26681705136
Parameters: 115090000
File Size: 461546622
Architecture:
- Convolution
- Dense Connections
- Global Average Pooling
- Max Pooling
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_senet154
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L239
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_senet154-70a1a3c0.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.23%
Top 5 Accuracy: 95.35%
-->
|
huggingface/pytorch-image-models/blob/main/docs/models/gloun-senet.md
|
--
title: "Making automatic speech recognition work on large files with Wav2Vec2 in 🤗 Transformers"
thumbnail: /blog/assets/49_asr_chunking/thumbnail.png
authors:
- user: Narsil
---
# Making automatic speech recognition work on large files with Wav2Vec2 in 🤗 Transformers
```
Tl;dr: This post explains how to use the specificities of the Connectionist
Temporal Classification (CTC) architecture in order to achieve very good
quality automatic speech recognition (ASR) even on arbitrarily long files or
during live inference.
```
**Wav2Vec2** is a popular pre-trained model for speech recognition.
Released in [September 2020](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/)
by Meta AI Research, the novel architecture catalyzed progress in
self-supervised pretraining for speech recognition, *e.g.* [*G. Ng et
al.*, 2021](https://arxiv.org/pdf/2104.03416.pdf), [*Chen et al*,
2021](https://arxiv.org/abs/2110.13900), [*Hsu et al.*,
2021](https://arxiv.org/abs/2106.07447) and [*Babu et al.*,
2021](https://arxiv.org/abs/2111.09296). On the Hugging Face Hub,
Wav2Vec2's most popular pre-trained checkpoint currently amounts to
over [**250,000** monthly
downloads](https://huggingface.co/facebook/wav2vec2-base-960h).
**Wav2Vec2** is at its core a **transformers** models and one caveat
of **transformers** is that it usually has a finite amount of sequence
length it can handle. Either because it uses **position encodings** (not
the case here) or simply because the cost of attention in transformers
is actually O(n²) in sequence_length, meaning that using very large
sequence_length explodes in complexity/memory. So you cannot run with finite hardware
(even a very large GPU like A100), simply run Wav2Vec2 on an hour long
file. Your program will crash. Let's try it !
```bash
pip install transformers
```
```python
from transformers import pipeline
# This will work on any of the thousands of models at
# https://huggingface.co/models?pipeline_tag=automatic-speech-recognition
pipe = pipeline(model="facebook/wav2vec2-base-960h")
# The Public Domain LibriVox file used for the test
#!wget https://ia902600.us.archive.org/8/items/thecantervilleghostversion_2_1501_librivox/thecantervilleghostversion2_01_wilde_128kb.mp3 -o very_long_file.mp3
pipe("very_long_file.mp3")
# Crash out of memory !
pipe("very_long_file.mp3", chunk_length_s=10)
# This works and prints a very long string !
# This whole blogpost will explain how to make things work
```
Simple Chunking
---------------
The simplest way to achieve inference on very long files would be to simply chunk
the initial audio into shorter samples, let's say 10 seconds each, run inference on those, and end up
with a final reconstruction. This is efficient computationally but usually leads
to subpar results, the reason being that in order to do good inference, the model
needs some context, so around the chunking border, inference tends to be of poor
quality.
Look at the following diagram:

There are ways to try and work around the problem in a general fashion, but
they are never entirely robust. You can try to chunk only when you encounter
silence but you may have a non silent audio for a long time (a song, or noisy
café audio). You can also try to cut only when there's no voice but it requires
another model and this is not an entirely solved problem. You could also have
a continous voice for a very long time.
As it turns out, CTC structure, which is used by Wav2Vec2, can be exploited
in order to achieve very robust speech recognition even on very long files
without falling into those pitfalls.
Chunking with stride
--------------------
Wav2Vec2 uses the [CTC algorithm](https://distill.pub/2017/ctc/), which means that every frame of audio is mapped
to a single letter prediction (logit).

That's the main feature we're going to use in order to add a `stride`.
This [link](https://www.quora.com/What-does-stride-mean-in-the-context-of-convolutional-neural-networks) explains it
in the image context, but it's the same concept for audio.
Because of this property, we can:
- Start doing inference on **overlapping** chunks
so that the model actually has proper context in the center.
- **Drop** the inferenced logits on the side.
- Chain the **logits** without their dropped sides to recover something extremely close to what the model would have
predicted on the full length audio.

This is not **technically** 100% the same thing as running the model on the whole
file so it is not enabled by default, but as you saw in the earlier example you
need only to add `chunk_length_s` to your `pipeline` for it to work.
In practice, we observed that most of the bad inference is kept within
the strides, which get dropped before inference, leading to a proper
inference of the full text.
Let's note that you can choose every argument of this technique:
```python
from transformers import pipeline
pipe = pipeline(model="facebook/wav2vec2-base-960h")
# stride_length_s is a tuple of the left and right stride length.
# With only 1 number, both sides get the same stride, by default
# the stride_length on one side is 1/6th of the chunk_length_s
output = pipe("very_long_file.mp3", chunk_length_s=10, stride_length_s=(4, 2))
```
Chunking with stride on LM augmented models
-------------------------------------------
In [transformers](https://github.com/huggingface/transformers), we also
added support for adding LM to Wav2Vec2 in order to boost the WER performance
of the models without even finetuning. [See this excellent blogpost explaining
how it works](https://huggingface.co/blog/wav2vec2-with-ngram).
It turns out, that the LM works directly on the logits themselves, so we
can actually apply the exact same technique as before without any modification !
So chunking large files on these LM boosted models still works out of the box.
Live inference
--------------
A very nice perk of using a CTC model like Wav2vec2, is that it is a single
pass model, so it is **very** fast. Especially on GPU. We can exploit that in order
to do live inference.
The principle is exactly the same as regular striding, but this time we can
feed the pipeline data **as it is coming in** and simply use striding on
full chunks of length 10s for instance with 1s striding to get proper context.
That requires running much more inference steps than simple file chunking, but it can make the
live experience much better because the model can print things as you are
speaking, without having to wait for X seconds before seeing something displayed.
|
huggingface/blog/blob/main/asr-chunking.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Troubleshooting
If you encounter any issue when using PEFT, please check the following list of common issues and their solutions.
## Examples don't work
Examples often rely on the most recent package versions, so please ensure they're up-to-date. In particular, check the version of the following packages:
- `peft`
- `transformers`
- `accelerate`
- `torch`
In general, you can update the package version by running this command inside your Python environment:
```bash
python -m pip install -U <package_name>
```
Installing PEFT from source is useful for keeping up with the latest developments:
```bash
python -m pip install git+https://github.com/huggingface/peft
```
## Bad results from a loaded PEFT model
There can be several reasons for getting a poor result from a loaded PEFT model, which are listed below. If you're still unable to troubleshoot the problem, see if anyone else had a similar [issue](https://github.com/huggingface/peft/issues) on GitHub, and if you can't find any, open a new issue.
When opening an issue, it helps a lot if you provide a minimal code example that reproduces the issue. Also, please report if the loaded model performs at the same level as the model did before fine-tuning, if it performs at a random level, or if it is only slightly worse than expected. This information helps us identify the problem more quickly.
### Random deviations
If your model outputs are not exactly the same as previous runs, there could be an issue with random elements. For example:
1. please ensure it is in `.eval()` mode, which is important, for instance, if the model uses dropout
2. if you use [`~transformers.GenerationMixin.generate`] on a language model, there could be random sampling, so obtaining the same result requires setting a random seed
3. if you used quantization and merged the weights, small deviations are expected due to rounding errors
### Incorrectly loaded model
Please ensure that you load the model correctly. A common error is trying to load a _trained_ model with `get_peft_model`, which is incorrect. Instead, the loading code should look like this:
```python
from peft import PeftModel, PeftConfig
base_model = ... # to load the base model, use the same code as when you trained it
config = PeftConfig.from_pretrained(peft_model_id)
peft_model = PeftModel.from_pretrained(base_model, peft_model_id)
```
### Randomly initialized layers
For some tasks, it is important to correctly configure `modules_to_save` in the config to account for randomly initialized layers.
As an example, this is necessary if you use LoRA to fine-tune a language model for sequence classification because 🤗 Transformers adds a randomly initialized classification head on top of the model. If you do not add this layer to `modules_to_save`, the classification head won't be saved. The next time you load the model, you'll get a _different_ randomly initialized classification head, resulting in completely different results.
In PEFT, we try to correctly guess the `modules_to_save` if you provide the `task_type` argument in the config. This should work for transformers models that follow the standard naming scheme. It is always a good idea to double check though because we can't guarantee all models follow the naming scheme.
When you load a transformers model that has randomly initialized layers, you should see a warning along the lines of:
```
Some weights of <MODEL> were not initialized from the model checkpoint at <ID> and are newly initialized: [<LAYER_NAMES>].
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
```
The mentioned layers should be added to `modules_to_save` in the config to avoid the described problem.
|
huggingface/peft/blob/main/docs/source/developer_guides/troubleshooting.md
|
Introduction[[introduction]]
<CourseFloatingBanner
chapter={1}
classNames="absolute z-10 right-0 top-0"
/>
## Welcome to the 🤗 Course![[welcome-to-the-course]]
<Youtube id="00GKzGyWFEs" />
This course will teach you about natural language processing (NLP) using libraries from the [Hugging Face](https://huggingface.co/) ecosystem — [🤗 Transformers](https://github.com/huggingface/transformers), [🤗 Datasets](https://github.com/huggingface/datasets), [🤗 Tokenizers](https://github.com/huggingface/tokenizers), and [🤗 Accelerate](https://github.com/huggingface/accelerate) — as well as the [Hugging Face Hub](https://huggingface.co/models). It's completely free and without ads.
## What to expect?[[what-to-expect]]
Here is a brief overview of the course:
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter1/summary.svg" alt="Brief overview of the chapters of the course.">
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter1/summary-dark.svg" alt="Brief overview of the chapters of the course.">
</div>
- Chapters 1 to 4 provide an introduction to the main concepts of the 🤗 Transformers library. By the end of this part of the course, you will be familiar with how Transformer models work and will know how to use a model from the [Hugging Face Hub](https://huggingface.co/models), fine-tune it on a dataset, and share your results on the Hub!
- Chapters 5 to 8 teach the basics of 🤗 Datasets and 🤗 Tokenizers before diving into classic NLP tasks. By the end of this part, you will be able to tackle the most common NLP problems by yourself.
- Chapters 9 to 12 go beyond NLP, and explore how Transformer models can be used to tackle tasks in speech processing and computer vision. Along the way, you'll learn how to build and share demos of your models, and optimize them for production environments. By the end of this part, you will be ready to apply 🤗 Transformers to (almost) any machine learning problem!
This course:
* Requires a good knowledge of Python
* Is better taken after an introductory deep learning course, such as [fast.ai's](https://www.fast.ai/) [Practical Deep Learning for Coders](https://course.fast.ai/) or one of the programs developed by [DeepLearning.AI](https://www.deeplearning.ai/)
* Does not expect prior [PyTorch](https://pytorch.org/) or [TensorFlow](https://www.tensorflow.org/) knowledge, though some familiarity with either of those will help
After you've completed this course, we recommend checking out DeepLearning.AI's [Natural Language Processing Specialization](https://www.coursera.org/specializations/natural-language-processing?utm_source=deeplearning-ai&utm_medium=institutions&utm_campaign=20211011-nlp-2-hugging_face-page-nlp-refresh), which covers a wide range of traditional NLP models like naive Bayes and LSTMs that are well worth knowing about!
## Who are we?[[who-are-we]]
About the authors:
[**Abubakar Abid**](https://huggingface.co/abidlabs) completed his PhD at Stanford in applied machine learning. During his PhD, he founded [Gradio](https://github.com/gradio-app/gradio), an open-source Python library that has been used to build over 600,000 machine learning demos. Gradio was acquired by Hugging Face, which is where Abubakar now serves as a machine learning team lead.
[**Matthew Carrigan**](https://huggingface.co/Rocketknight1) is a Machine Learning Engineer at Hugging Face. He lives in Dublin, Ireland and previously worked as an ML engineer at Parse.ly and before that as a post-doctoral researcher at Trinity College Dublin. He does not believe we're going to get to AGI by scaling existing architectures, but has high hopes for robot immortality regardless.
[**Lysandre Debut**](https://huggingface.co/lysandre) is a Machine Learning Engineer at Hugging Face and has been working on the 🤗 Transformers library since the very early development stages. His aim is to make NLP accessible for everyone by developing tools with a very simple API.
[**Sylvain Gugger**](https://huggingface.co/sgugger) is a Research Engineer at Hugging Face and one of the core maintainers of the 🤗 Transformers library. Previously he was a Research Scientist at fast.ai, and he co-wrote _[Deep Learning for Coders with fastai and PyTorch](https://learning.oreilly.com/library/view/deep-learning-for/9781492045519/)_ with Jeremy Howard. The main focus of his research is on making deep learning more accessible, by designing and improving techniques that allow models to train fast on limited resources.
[**Dawood Khan**](https://huggingface.co/dawoodkhan82) is a Machine Learning Engineer at Hugging Face. He's from NYC and graduated from New York University studying Computer Science. After working as an iOS Engineer for a few years, Dawood quit to start Gradio with his fellow co-founders. Gradio was eventually acquired by Hugging Face.
[**Merve Noyan**](https://huggingface.co/merve) is a developer advocate at Hugging Face, working on developing tools and building content around them to democratize machine learning for everyone.
[**Lucile Saulnier**](https://huggingface.co/SaulLu) is a machine learning engineer at Hugging Face, developing and supporting the use of open source tools. She is also actively involved in many research projects in the field of Natural Language Processing such as collaborative training and BigScience.
[**Lewis Tunstall**](https://huggingface.co/lewtun) is a machine learning engineer at Hugging Face, focused on developing open-source tools and making them accessible to the wider community. He is also a co-author of the O’Reilly book [Natural Language Processing with Transformers](https://www.oreilly.com/library/view/natural-language-processing/9781098136789/).
[**Leandro von Werra**](https://huggingface.co/lvwerra) is a machine learning engineer in the open-source team at Hugging Face and also a co-author of the O’Reilly book [Natural Language Processing with Transformers](https://www.oreilly.com/library/view/natural-language-processing/9781098136789/). He has several years of industry experience bringing NLP projects to production by working across the whole machine learning stack..
## FAQ[[faq]]
Here are some answers to frequently asked questions:
- **Does taking this course lead to a certification?**
Currently we do not have any certification for this course. However, we are working on a certification program for the Hugging Face ecosystem -- stay tuned!
- **How much time should I spend on this course?**
Each chapter in this course is designed to be completed in 1 week, with approximately 6-8 hours of work per week. However, you can take as much time as you need to complete the course.
- **Where can I ask a question if I have one?**
If you have a question about any section of the course, just click on the "*Ask a question*" banner at the top of the page to be automatically redirected to the right section of the [Hugging Face forums](https://discuss.huggingface.co/):
<img src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter1/forum-button.png" alt="Link to the Hugging Face forums" width="75%">
Note that a list of [project ideas](https://discuss.huggingface.co/c/course/course-event/25) is also available on the forums if you wish to practice more once you have completed the course.
- **Where can I get the code for the course?**
For each section, click on the banner at the top of the page to run the code in either Google Colab or Amazon SageMaker Studio Lab:
<img src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter1/notebook-buttons.png" alt="Link to the Hugging Face course notebooks" width="75%">
The Jupyter notebooks containing all the code from the course are hosted on the [`huggingface/notebooks`](https://github.com/huggingface/notebooks) repo. If you wish to generate them locally, check out the instructions in the [`course`](https://github.com/huggingface/course#-jupyter-notebooks) repo on GitHub.
- **How can I contribute to the course?**
There are many ways to contribute to the course! If you find a typo or a bug, please open an issue on the [`course`](https://github.com/huggingface/course) repo. If you would like to help translate the course into your native language, check out the instructions [here](https://github.com/huggingface/course#translating-the-course-into-your-language).
- ** What were the choices made for each translation?**
Each translation has a glossary and `TRANSLATING.txt` file that details the choices that were made for machine learning jargon etc. You can find an example for German [here](https://github.com/huggingface/course/blob/main/chapters/de/TRANSLATING.txt).
- **Can I reuse this course?**
Of course! The course is released under the permissive [Apache 2 license](https://www.apache.org/licenses/LICENSE-2.0.html). This means that you must give appropriate credit, provide a link to the license, and indicate if changes were made. You may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your use. If you would like to cite the course, please use the following BibTeX:
```
@misc{huggingfacecourse,
author = {Hugging Face},
title = {The Hugging Face Course, 2022},
howpublished = "\url{https://huggingface.co/course}",
year = {2022},
note = "[Online; accessed <today>]"
}
```
## Let's Go
Are you ready to roll? In this chapter, you will learn:
* How to use the `pipeline()` function to solve NLP tasks such as text generation and classification
* About the Transformer architecture
* How to distinguish between encoder, decoder, and encoder-decoder architectures and use cases
|
huggingface/course/blob/main/chapters/en/chapter1/1.mdx
|
Second Quiz [[quiz2]]
The best way to learn and [to avoid the illusion of competence](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
### Q1: What is Q-Learning?
<Question
choices={[
{
text: "The algorithm we use to train our Q-function",
explain: "",
correct: true
},
{
text: "A value function",
explain: "It's an action-value function since it determines the value of being at a particular state and taking a specific action at that state",
},
{
text: "An algorithm that determines the value of being at a particular state and taking a specific action at that state",
explain: "",
correct: true
},
{
text: "A table",
explain: "Q-function is not a Q-table. The Q-function is the algorithm that will feed the Q-table."
}
]}
/>
### Q2: What is a Q-table?
<Question
choices={[
{
text: "An algorithm we use in Q-Learning",
explain: "",
},
{
text: "Q-table is the internal memory of our agent",
explain: "",
correct: true
},
{
text: "In Q-table each cell corresponds a state value",
explain: "Each cell corresponds to a state-action value pair value. Not a state value.",
}
]}
/>
### Q3: Why if we have an optimal Q-function Q* we have an optimal policy?
<details>
<summary>Solution</summary>
Because if we have an optimal Q-function, we have an optimal policy since we know for each state what is the best action to take.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/link-value-policy.jpg" alt="link value policy"/>
</details>
### Q4: Can you explain what is Epsilon-Greedy Strategy?
<details>
<summary>Solution</summary>
Epsilon Greedy Strategy is a policy that handles the exploration/exploitation trade-off.
The idea is that we define epsilon ɛ = 1.0:
- With *probability 1 — ɛ* : we do exploitation (aka our agent selects the action with the highest state-action pair value).
- With *probability ɛ* : we do exploration (trying random action).
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Q-learning-4.jpg" alt="Epsilon Greedy"/>
</details>
### Q5: How do we update the Q value of a state, action pair?
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/q-update-ex.jpg" alt="Q Update exercise"/>
<details>
<summary>Solution</summary>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/q-update-solution.jpg" alt="Q Update exercise"/>
</details>
### Q6: What's the difference between on-policy and off-policy
<details>
<summary>Solution</summary>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/off-on-4.jpg" alt="On/off policy"/>
</details>
Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read again the chapter to reinforce (😏) your knowledge.
|
huggingface/deep-rl-class/blob/main/units/en/unit2/quiz2.mdx
|
ote: the following transcripts are associated with Merve Noyan's videos in the Hugging Face Tasks playlist: https://www.youtube.com/playlist?list=PLo2EIpI_JMQtyEr-sLJSy5_SnLCb4vtQf
Token Classification video
Welcome to the Hugging Face tasks series! In this video we’ll take a look at the token classification task.
Token classification is the task of assigning a label to each token in a sentence. There are various token classification tasks and the most common are Named Entity Recognition and Part-of-Speech Tagging.
Let’s take a quick look at the Named Entity Recognition task. The goal of this task is to find the entities in a piece of text, such as person, location, or organization. This task is formulated as labelling each token with one class for each entity, and another class for tokens that have no entity.
Another token classification task is part-of-speech tagging. The goal of this task is to label the words for a particular part of a speech, such as noun, pronoun, adjective, verb and so on. This task is formulated as labelling each token with parts of speech.
Token classification models are evaluated on Accuracy, Recall, Precision and F1-Score. The metrics are calculated for each of the classes. We calculate true positive, true negative and false positives to calculate precision and recall, and take their harmonic mean to get F1-Score. Then we calculate it for every class and take the overall average to evaluate our model.
An example dataset used for this task is ConLL2003. Here, each token belongs to a certain named entity class, denoted as the indices of the list containing the labels.
You can extract important information from invoices using named entity recognition models, such as date, organization name or address.
For more information about the Token classification task, check out the Hugging Face course.
Question Answering video
Welcome to the Hugging Face tasks series. In this video, we will take a look at the Question Answering task.
Question answering is the task of extracting an answer in a given document.
Question answering models take a context, which is the document you want to search in, and a question and return an answer. Note that the answer is not generated, but extracted from the context. This type of question answering is called extractive.
The task is evaluated on two metrics, exact match and F1-Score.
As the name implies, exact match looks for an exact match between the predicted answer and the correct answer.
A common metric used is the F1-Score, which is calculated over tokens that are predicted correctly and incorrectly. It is calculated over the average of two metrics called precision and recall which are metrics that are used widely in classification problems.
An example dataset used for this task is called SQuAD. This dataset contains contexts, questions and the answers that are obtained from English Wikipedia articles.
You can use question answering models to automatically answer the questions asked by your customers. You simply need a document containing information about your business and query through that document with the questions asked by your customers.
For more information about the Question Answering task, check out the Hugging Face course.
Causal Language Modeling video
Welcome to the Hugging Face tasks series! In this video we’ll take a look at Causal Language Modeling.
Causal language modeling is the task of predicting the next
word in a sentence, given all the previous words. This task is very similar to the autocorrect function that you might have on your phone.
These models take a sequence to be completed and outputs the complete sequence.
Classification metrics can’t be used as there’s no single correct answer for completion. Instead, we evaluate the distribution of the text completed by the model.
A common metric to do so is the cross-entropy loss. Perplexity is also a widely used metric and it is calculated as the exponential of the cross-entropy loss.
You can use any dataset with plain text and tokenize the text to prepare the data.
Causal language models can be used to generate code.
For more information about the Causal Language Modeling task, check out the Hugging Face course.
Masked Language Modeling video
Welcome to the Hugging Face tasks series! In this video we’ll take a look at Masked Language Modeling.
Masked language modeling is the task of predicting which words should fill in the blanks of a sentence.
These models take a masked text as the input and output the possible values for that mask.
Masked language modeling is handy before fine-tuning your model for your task. For example, if you need to use a model in a specific domain, say, biomedical documents, models like BERT will treat your domain-specific words as rare tokens. If you train a masked language model using your biomedical corpus and then fine tune your model on a downstream task, you will have a better performance.
Classification metrics can’t be used as there’s no single correct answer to mask values. Instead, we evaluate the distribution of the mask values.
A common metric to do so is the cross-entropy loss. Perplexity is also a widely used metric and it is calculated as the exponential of the cross-entropy loss.
You can use any dataset with plain text and tokenize the text to mask the data.
For more information about the Masked Language Modeling, check out the Hugging Face course.
Summarization video
Welcome to the Hugging Face tasks series. In this video, we will take a look at the Text Summarization task.
Summarization is a task of producing a shorter version of a document while preserving the relevant and important information in the document.
Summarization models take a document to be summarized and output the summarized text.
This task is evaluated on the ROUGE score. It’s based on the overlap between the produced sequence and the correct sequence.
You might see this as ROUGE-1, which is the overlap of single tokens and ROUGE-2, the overlap of subsequent token pairs. ROUGE-N refers to the overlap of n subsequent tokens. Here we see an example of how overlaps take place.
An example dataset used for this task is called Extreme Summarization, XSUM. This dataset contains texts and their summarized versions.
You can use summarization models to summarize research papers which would enable researchers to easily pick papers for their reading list.
For more information about the Summarization task, check out the Hugging Face course.
Translation video
Welcome to the Hugging Face tasks series. In this video, we will take a look at the Translation task.
Translation is the task of translating text from one language to another.
These models take a text in the source language and output the translation of that text in the target language.
The task is evaluated on the BLEU score.
The score ranges from 0 to 1, in which 1 means the translation perfectly matched and 0 did not match at all.
BLEU is calculated over subsequent tokens called n-grams. Unigram refers to a single token while bi-gram refers to token pairs and n-grams refer to n subsequent tokens.
Machine translation datasets contain pairs of text in a language and translation of the text in another language.
These models can help you build conversational agents across different languages.
One option is to translate the training data used for the chatbot and train a separate chatbot.
You can put one translation model from your user’s language to the language your chatbot is trained on, translate the user inputs and do intent classification, take the output of the chatbot and translate it from the language your chatbot was trained on to the user’s language.
For more information about the Translation task, check out the Hugging Face course.
|
huggingface/course/blob/main/subtitles/en/raw/tasks.md
|
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Using pipelines for a webserver
<Tip>
Creating an inference engine is a complex topic, and the "best" solution
will most likely depend on your problem space. Are you on CPU or GPU? Do
you want the lowest latency, the highest throughput, support for
many models, or just highly optimize 1 specific model?
There are many ways to tackle this topic, so what we are going to present is a good default
to get started which may not necessarily be the most optimal solution for you.
</Tip>
The key thing to understand is that we can use an iterator, just like you would [on a
dataset](pipeline_tutorial#using-pipelines-on-a-dataset), since a webserver is basically a system that waits for requests and
treats them as they come in.
Usually webservers are multiplexed (multithreaded, async, etc..) to handle various
requests concurrently. Pipelines on the other hand (and mostly the underlying models)
are not really great for parallelism; they take up a lot of RAM, so it's best to give them all the available resources when they are running or it's a compute-intensive job.
We are going to solve that by having the webserver handle the light load of receiving
and sending requests, and having a single thread handling the actual work.
This example is going to use `starlette`. The actual framework is not really
important, but you might have to tune or change the code if you are using another
one to achieve the same effect.
Create `server.py`:
```py
from starlette.applications import Starlette
from starlette.responses import JSONResponse
from starlette.routing import Route
from transformers import pipeline
import asyncio
async def homepage(request):
payload = await request.body()
string = payload.decode("utf-8")
response_q = asyncio.Queue()
await request.app.model_queue.put((string, response_q))
output = await response_q.get()
return JSONResponse(output)
async def server_loop(q):
pipe = pipeline(model="bert-base-uncased")
while True:
(string, response_q) = await q.get()
out = pipe(string)
await response_q.put(out)
app = Starlette(
routes=[
Route("/", homepage, methods=["POST"]),
],
)
@app.on_event("startup")
async def startup_event():
q = asyncio.Queue()
app.model_queue = q
asyncio.create_task(server_loop(q))
```
Now you can start it with:
```bash
uvicorn server:app
```
And you can query it:
```bash
curl -X POST -d "test [MASK]" http://localhost:8000/
#[{"score":0.7742936015129089,"token":1012,"token_str":".","sequence":"test."},...]
```
And there you go, now you have a good idea of how to create a webserver!
What is really important is that we load the model only **once**, so there are no copies
of the model on the webserver. This way, no unnecessary RAM is being used.
Then the queuing mechanism allows you to do fancy stuff like maybe accumulating a few
items before inferring to use dynamic batching:
<Tip warning={true}>
The code sample below is intentionally written like pseudo-code for readability.
Do not run this without checking if it makes sense for your system resources!
</Tip>
```py
(string, rq) = await q.get()
strings = []
queues = []
while True:
try:
(string, rq) = await asyncio.wait_for(q.get(), timeout=0.001) # 1ms
except asyncio.exceptions.TimeoutError:
break
strings.append(string)
queues.append(rq)
strings
outs = pipe(strings, batch_size=len(strings))
for rq, out in zip(queues, outs):
await rq.put(out)
```
Again, the proposed code is optimized for readability, not for being the best code.
First of all, there's no batch size limit which is usually not a
great idea. Next, the timeout is reset on every queue fetch, meaning you could
wait much more than 1ms before running the inference (delaying the first request
by that much).
It would be better to have a single 1ms deadline.
This will always wait for 1ms even if the queue is empty, which might not be the
best since you probably want to start doing inference if there's nothing in the queue.
But maybe it does make sense if batching is really crucial for your use case.
Again, there's really no one best solution.
## Few things you might want to consider
### Error checking
There's a lot that can go wrong in production: out of memory, out of space,
loading the model might fail, the query might be wrong, the query might be
correct but still fail to run because of a model misconfiguration, and so on.
Generally, it's good if the server outputs the errors to the user, so
adding a lot of `try..except` statements to show those errors is a good
idea. But keep in mind it may also be a security risk to reveal all those errors depending
on your security context.
### Circuit breaking
Webservers usually look better when they do circuit breaking. It means they
return proper errors when they're overloaded instead of just waiting for the query indefinitely. Return a 503 error instead of waiting for a super long time or a 504 after a long time.
This is relatively easy to implement in the proposed code since there is a single queue.
Looking at the queue size is a basic way to start returning errors before your
webserver fails under load.
### Blocking the main thread
Currently PyTorch is not async aware, and computation will block the main
thread while running. That means it would be better if PyTorch was forced to run
on its own thread/process. This wasn't done here because the code is a lot more
complex (mostly because threads and async and queues don't play nice together).
But ultimately it does the same thing.
This would be important if the inference of single items were long (> 1s) because
in this case, it means every query during inference would have to wait for 1s before
even receiving an error.
### Dynamic batching
In general, batching is not necessarily an improvement over passing 1 item at
a time (see [batching details](./main_classes/pipelines#pipeline-batching) for more information). But it can be very effective
when used in the correct setting. In the API, there is no dynamic
batching by default (too much opportunity for a slowdown). But for BLOOM inference -
which is a very large model - dynamic batching is **essential** to provide a decent experience for everyone.
|
huggingface/transformers/blob/main/docs/source/en/pipeline_webserver.md
|
Gradio Demo: reversible_flow
```
!pip install -q gradio
```
```
import gradio as gr
def increase(num):
return num + 1
with gr.Blocks() as demo:
a = gr.Number(label="a")
b = gr.Number(label="b")
atob = gr.Button("a > b")
btoa = gr.Button("b > a")
atob.click(increase, a, b)
btoa.click(increase, b, a)
if __name__ == "__main__":
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/reversible_flow/run.ipynb
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Latent Consistency Distillation
[Latent Consistency Models (LCMs)](https://hf.co/papers/2310.04378) are able to generate high-quality images in just a few steps, representing a big leap forward because many pipelines require at least 25+ steps. LCMs are produced by applying the latent consistency distillation method to any Stable Diffusion model. This method works by applying *one-stage guided distillation* to the latent space, and incorporating a *skipping-step* method to consistently skip timesteps to accelerate the distillation process (refer to section 4.1, 4.2, and 4.3 of the paper for more details).
If you're training on a GPU with limited vRAM, try enabling `gradient_checkpointing`, `gradient_accumulation_steps`, and `mixed_precision` to reduce memory-usage and speedup training. You can reduce your memory-usage even more by enabling memory-efficient attention with [xFormers](../optimization/xformers) and [bitsandbytes'](https://github.com/TimDettmers/bitsandbytes) 8-bit optimizer.
This guide will explore the [train_lcm_distill_sd_wds.py](https://github.com/huggingface/diffusers/blob/main/examples/consistency_distillation/train_lcm_distill_sd_wds.py) script to help you become more familiar with it, and how you can adapt it for your own use-case.
Before running the script, make sure you install the library from source:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then navigate to the example folder containing the training script and install the required dependencies for the script you're using:
```bash
cd examples/consistency_distillation
pip install -r requirements.txt
```
<Tip>
🤗 Accelerate is a library for helping you train on multiple GPUs/TPUs or with mixed-precision. It'll automatically configure your training setup based on your hardware and environment. Take a look at the 🤗 Accelerate [Quick tour](https://huggingface.co/docs/accelerate/quicktour) to learn more.
</Tip>
Initialize an 🤗 Accelerate environment (try enabling `torch.compile` to significantly speedup training):
```bash
accelerate config
```
To setup a default 🤗 Accelerate environment without choosing any configurations:
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell, like a notebook, you can use:
```bash
from accelerate.utils import write_basic_config
write_basic_config()
```
Lastly, if you want to train a model on your own dataset, take a look at the [Create a dataset for training](create_dataset) guide to learn how to create a dataset that works with the training script.
## Script parameters
<Tip>
The following sections highlight parts of the training script that are important for understanding how to modify it, but it doesn't cover every aspect of the script in detail. If you're interested in learning more, feel free to read through the [script](https://github.com/huggingface/diffusers/blob/main/examples/consistency_distillation/train_lcm_distill_sd_wds.py) and let us know if you have any questions or concerns.
</Tip>
The training script provides many parameters to help you customize your training run. All of the parameters and their descriptions are found in the [`parse_args()`](https://github.com/huggingface/diffusers/blob/3b37488fa3280aed6a95de044d7a42ffdcb565ef/examples/consistency_distillation/train_lcm_distill_sd_wds.py#L419) function. This function provides default values for each parameter, such as the training batch size and learning rate, but you can also set your own values in the training command if you'd like.
For example, to speedup training with mixed precision using the fp16 format, add the `--mixed_precision` parameter to the training command:
```bash
accelerate launch train_lcm_distill_sd_wds.py \
--mixed_precision="fp16"
```
Most of the parameters are identical to the parameters in the [Text-to-image](text2image#script-parameters) training guide, so you'll focus on the parameters that are relevant to latent consistency distillation in this guide.
- `--pretrained_teacher_model`: the path to a pretrained latent diffusion model to use as the teacher model
- `--pretrained_vae_model_name_or_path`: path to a pretrained VAE; the SDXL VAE is known to suffer from numerical instability, so this parameter allows you to specify an alternative VAE (like this [VAE]((https://huggingface.co/madebyollin/sdxl-vae-fp16-fix)) by madebyollin which works in fp16)
- `--w_min` and `--w_max`: the minimum and maximum guidance scale values for guidance scale sampling
- `--num_ddim_timesteps`: the number of timesteps for DDIM sampling
- `--loss_type`: the type of loss (L2 or Huber) to calculate for latent consistency distillation; Huber loss is generally preferred because it's more robust to outliers
- `--huber_c`: the Huber loss parameter
## Training script
The training script starts by creating a dataset class - [`Text2ImageDataset`](https://github.com/huggingface/diffusers/blob/3b37488fa3280aed6a95de044d7a42ffdcb565ef/examples/consistency_distillation/train_lcm_distill_sd_wds.py#L141) - for preprocessing the images and creating a training dataset.
```py
def transform(example):
image = example["image"]
image = TF.resize(image, resolution, interpolation=transforms.InterpolationMode.BILINEAR)
c_top, c_left, _, _ = transforms.RandomCrop.get_params(image, output_size=(resolution, resolution))
image = TF.crop(image, c_top, c_left, resolution, resolution)
image = TF.to_tensor(image)
image = TF.normalize(image, [0.5], [0.5])
example["image"] = image
return example
```
For improved performance on reading and writing large datasets stored in the cloud, this script uses the [WebDataset](https://github.com/webdataset/webdataset) format to create a preprocessing pipeline to apply transforms and create a dataset and dataloader for training. Images are processed and fed to the training loop without having to download the full dataset first.
```py
processing_pipeline = [
wds.decode("pil", handler=wds.ignore_and_continue),
wds.rename(image="jpg;png;jpeg;webp", text="text;txt;caption", handler=wds.warn_and_continue),
wds.map(filter_keys({"image", "text"})),
wds.map(transform),
wds.to_tuple("image", "text"),
]
```
In the [`main()`](https://github.com/huggingface/diffusers/blob/3b37488fa3280aed6a95de044d7a42ffdcb565ef/examples/consistency_distillation/train_lcm_distill_sd_wds.py#L768) function, all the necessary components like the noise scheduler, tokenizers, text encoders, and VAE are loaded. The teacher UNet is also loaded here and then you can create a student UNet from the teacher UNet. The student UNet is updated by the optimizer during training.
```py
teacher_unet = UNet2DConditionModel.from_pretrained(
args.pretrained_teacher_model, subfolder="unet", revision=args.teacher_revision
)
unet = UNet2DConditionModel(**teacher_unet.config)
unet.load_state_dict(teacher_unet.state_dict(), strict=False)
unet.train()
```
Now you can create the [optimizer](https://github.com/huggingface/diffusers/blob/3b37488fa3280aed6a95de044d7a42ffdcb565ef/examples/consistency_distillation/train_lcm_distill_sd_wds.py#L979) to update the UNet parameters:
```py
optimizer = optimizer_class(
unet.parameters(),
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
```
Create the [dataset](https://github.com/huggingface/diffusers/blob/3b37488fa3280aed6a95de044d7a42ffdcb565ef/examples/consistency_distillation/train_lcm_distill_sd_wds.py#L994):
```py
dataset = Text2ImageDataset(
train_shards_path_or_url=args.train_shards_path_or_url,
num_train_examples=args.max_train_samples,
per_gpu_batch_size=args.train_batch_size,
global_batch_size=args.train_batch_size * accelerator.num_processes,
num_workers=args.dataloader_num_workers,
resolution=args.resolution,
shuffle_buffer_size=1000,
pin_memory=True,
persistent_workers=True,
)
train_dataloader = dataset.train_dataloader
```
Next, you're ready to setup the [training loop](https://github.com/huggingface/diffusers/blob/3b37488fa3280aed6a95de044d7a42ffdcb565ef/examples/consistency_distillation/train_lcm_distill_sd_wds.py#L1049) and implement the latent consistency distillation method (see Algorithm 1 in the paper for more details). This section of the script takes care of adding noise to the latents, sampling and creating a guidance scale embedding, and predicting the original image from the noise.
```py
pred_x_0 = predicted_origin(
noise_pred,
start_timesteps,
noisy_model_input,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
model_pred = c_skip_start * noisy_model_input + c_out_start * pred_x_0
```
It gets the [teacher model predictions](https://github.com/huggingface/diffusers/blob/3b37488fa3280aed6a95de044d7a42ffdcb565ef/examples/consistency_distillation/train_lcm_distill_sd_wds.py#L1172) and the [LCM predictions](https://github.com/huggingface/diffusers/blob/3b37488fa3280aed6a95de044d7a42ffdcb565ef/examples/consistency_distillation/train_lcm_distill_sd_wds.py#L1209) next, calculates the loss, and then backpropagates it to the LCM.
```py
if args.loss_type == "l2":
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
elif args.loss_type == "huber":
loss = torch.mean(
torch.sqrt((model_pred.float() - target.float()) ** 2 + args.huber_c**2) - args.huber_c
)
```
If you want to learn more about how the training loop works, check out the [Understanding pipelines, models and schedulers tutorial](../using-diffusers/write_own_pipeline) which breaks down the basic pattern of the denoising process.
## Launch the script
Now you're ready to launch the training script and start distilling!
For this guide, you'll use the `--train_shards_path_or_url` to specify the path to the [Conceptual Captions 12M](https://github.com/google-research-datasets/conceptual-12m) dataset stored on the Hub [here](https://huggingface.co/datasets/laion/conceptual-captions-12m-webdataset). Set the `MODEL_DIR` environment variable to the name of the teacher model and `OUTPUT_DIR` to where you want to save the model.
```bash
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="path/to/saved/model"
accelerate launch train_lcm_distill_sd_wds.py \
--pretrained_teacher_model=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--mixed_precision=fp16 \
--resolution=512 \
--learning_rate=1e-6 --loss_type="huber" --ema_decay=0.95 --adam_weight_decay=0.0 \
--max_train_steps=1000 \
--max_train_samples=4000000 \
--dataloader_num_workers=8 \
--train_shards_path_or_url="pipe:curl -L -s https://huggingface.co/datasets/laion/conceptual-captions-12m-webdataset/resolve/main/data/{00000..01099}.tar?download=true" \
--validation_steps=200 \
--checkpointing_steps=200 --checkpoints_total_limit=10 \
--train_batch_size=12 \
--gradient_checkpointing --enable_xformers_memory_efficient_attention \
--gradient_accumulation_steps=1 \
--use_8bit_adam \
--resume_from_checkpoint=latest \
--report_to=wandb \
--seed=453645634 \
--push_to_hub
```
Once training is complete, you can use your new LCM for inference.
```py
from diffusers import UNet2DConditionModel, DiffusionPipeline, LCMScheduler
import torch
unet = UNet2DConditionModel.from_pretrained("your-username/your-model", torch_dtype=torch.float16, variant="fp16")
pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", unet=unet, torch_dtype=torch.float16, variant="fp16")
pipeline.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
pipeline.to("cuda")
prompt = "sushi rolls in the form of panda heads, sushi platter"
image = pipeline(prompt, num_inference_steps=4, guidance_scale=1.0).images[0]
```
## LoRA
LoRA is a training technique for significantly reducing the number of trainable parameters. As a result, training is faster and it is easier to store the resulting weights because they are a lot smaller (~100MBs). Use the [train_lcm_distill_lora_sd_wds.py](https://github.com/huggingface/diffusers/blob/main/examples/consistency_distillation/train_lcm_distill_lora_sd_wds.py) or [train_lcm_distill_lora_sdxl.wds.py](https://github.com/huggingface/diffusers/blob/main/examples/consistency_distillation/train_lcm_distill_lora_sdxl_wds.py) script to train with LoRA.
The LoRA training script is discussed in more detail in the [LoRA training](lora) guide.
## Stable Diffusion XL
Stable Diffusion XL (SDXL) is a powerful text-to-image model that generates high-resolution images, and it adds a second text-encoder to its architecture. Use the [train_lcm_distill_sdxl_wds.py](https://github.com/huggingface/diffusers/blob/main/examples/consistency_distillation/train_lcm_distill_sdxl_wds.py) script to train a SDXL model with LoRA.
The SDXL training script is discussed in more detail in the [SDXL training](sdxl) guide.
## Next steps
Congratulations on distilling a LCM model! To learn more about LCM, the following may be helpful:
- Learn how to use [LCMs for inference](../using-diffusers/lcm) for text-to-image, image-to-image, and with LoRA checkpoints.
- Read the [SDXL in 4 steps with Latent Consistency LoRAs](https://huggingface.co/blog/lcm_lora) blog post to learn more about SDXL LCM-LoRA's for super fast inference, quality comparisons, benchmarks, and more.
|
huggingface/diffusers/blob/main/docs/source/en/training/lcm_distill.md
|
Deploy models to Amazon SageMaker
Deploying a 🤗 Transformers models in SageMaker for inference is as easy as:
```python
from sagemaker.huggingface import HuggingFaceModel
# create Hugging Face Model Class and deploy it as SageMaker endpoint
huggingface_model = HuggingFaceModel(...).deploy()
```
This guide will show you how to deploy models with zero-code using the [Inference Toolkit](https://github.com/aws/sagemaker-huggingface-inference-toolkit). The Inference Toolkit builds on top of the [`pipeline` feature](https://huggingface.co/docs/transformers/main_classes/pipelines) from 🤗 Transformers. Learn how to:
- [Install and setup the Inference Toolkit](#installation-and-setup).
- [Deploy a 🤗 Transformers model trained in SageMaker](#deploy-a-transformer-model-trained-in-sagemaker).
- [Deploy a 🤗 Transformers model from the Hugging Face [model Hub](https://huggingface.co/models)](#deploy-a-model-from-the-hub).
- [Run a Batch Transform Job using 🤗 Transformers and Amazon SageMaker](#run-batch-transform-with-transformers-and-sagemaker).
- [Create a custom inference module](#user-defined-code-and-modules).
## Installation and setup
Before deploying a 🤗 Transformers model to SageMaker, you need to sign up for an AWS account. If you don't have an AWS account yet, learn more [here](https://docs.aws.amazon.com/sagemaker/latest/dg/gs-set-up.html).
Once you have an AWS account, get started using one of the following:
- [SageMaker Studio](https://docs.aws.amazon.com/sagemaker/latest/dg/gs-studio-onboard.html)
- [SageMaker notebook instance](https://docs.aws.amazon.com/sagemaker/latest/dg/gs-console.html)
- Local environment
To start training locally, you need to setup an appropriate [IAM role](https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-roles.html).
Upgrade to the latest `sagemaker` version.
```bash
pip install sagemaker --upgrade
```
**SageMaker environment**
Setup your SageMaker environment as shown below:
```python
import sagemaker
sess = sagemaker.Session()
role = sagemaker.get_execution_role()
```
_Note: The execution role is only available when running a notebook within SageMaker. If you run `get_execution_role` in a notebook not on SageMaker, expect a `region` error._
**Local environment**
Setup your local environment as shown below:
```python
import sagemaker
import boto3
iam_client = boto3.client('iam')
role = iam_client.get_role(RoleName='role-name-of-your-iam-role-with-right-permissions')['Role']['Arn']
sess = sagemaker.Session()
```
## Deploy a 🤗 Transformers model trained in SageMaker
<iframe width="700" height="394" src="https://www.youtube.com/embed/pfBGgSGnYLs" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
There are two ways to deploy your Hugging Face model trained in SageMaker:
- Deploy it after your training has finished.
- Deploy your saved model at a later time from S3 with the `model_data`.
📓 Open the [deploy_transformer_model_from_s3.ipynb notebook](https://github.com/huggingface/notebooks/blob/main/sagemaker/10_deploy_model_from_s3/deploy_transformer_model_from_s3.ipynb) for an example of how to deploy a model from S3 to SageMaker for inference.
### Deploy after training
To deploy your model directly after training, ensure all required files are saved in your training script, including the tokenizer and the model.
If you use the Hugging Face `Trainer`, you can pass your tokenizer as an argument to the `Trainer`. It will be automatically saved when you call `trainer.save_model()`.
```python
from sagemaker.huggingface import HuggingFace
############ pseudo code start ############
# create Hugging Face Estimator for training
huggingface_estimator = HuggingFace(....)
# start the train job with our uploaded datasets as input
huggingface_estimator.fit(...)
############ pseudo code end ############
# deploy model to SageMaker Inference
predictor = hf_estimator.deploy(initial_instance_count=1, instance_type="ml.m5.xlarge")
# example request: you always need to define "inputs"
data = {
"inputs": "Camera - You are awarded a SiPix Digital Camera! call 09061221066 fromm landline. Delivery within 28 days."
}
# request
predictor.predict(data)
```
After you run your request you can delete the endpoint as shown:
```python
# delete endpoint
predictor.delete_endpoint()
```
### Deploy with `model_data`
If you've already trained your model and want to deploy it at a later time, use the `model_data` argument to specify the location of your tokenizer and model weights.
```python
from sagemaker.huggingface.model import HuggingFaceModel
# create Hugging Face Model Class
huggingface_model = HuggingFaceModel(
model_data="s3://models/my-bert-model/model.tar.gz", # path to your trained SageMaker model
role=role, # IAM role with permissions to create an endpoint
transformers_version="4.26", # Transformers version used
pytorch_version="1.13", # PyTorch version used
py_version='py39', # Python version used
)
# deploy model to SageMaker Inference
predictor = huggingface_model.deploy(
initial_instance_count=1,
instance_type="ml.m5.xlarge"
)
# example request: you always need to define "inputs"
data = {
"inputs": "Camera - You are awarded a SiPix Digital Camera! call 09061221066 fromm landline. Delivery within 28 days."
}
# request
predictor.predict(data)
```
After you run our request, you can delete the endpoint again with:
```python
# delete endpoint
predictor.delete_endpoint()
```
### Create a model artifact for deployment
For later deployment, you can create a `model.tar.gz` file that contains all the required files, such as:
- `pytorch_model.bin`
- `tf_model.h5`
- `tokenizer.json`
- `tokenizer_config.json`
For example, your file should look like this:
```bash
model.tar.gz/
|- pytorch_model.bin
|- vocab.txt
|- tokenizer_config.json
|- config.json
|- special_tokens_map.json
```
Create your own `model.tar.gz` from a model from the 🤗 Hub:
1. Download a model:
```bash
git lfs install
git clone git@hf.co:{repository}
```
2. Create a `tar` file:
```bash
cd {repository}
tar zcvf model.tar.gz *
```
3. Upload `model.tar.gz` to S3:
```bash
aws s3 cp model.tar.gz <s3://{my-s3-path}>
```
Now you can provide the S3 URI to the `model_data` argument to deploy your model later.
## Deploy a model from the 🤗 Hub
<iframe width="700" height="394" src="https://www.youtube.com/embed/l9QZuazbzWM" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
To deploy a model directly from the 🤗 Hub to SageMaker, define two environment variables when you create a `HuggingFaceModel`:
- `HF_MODEL_ID` defines the model ID which is automatically loaded from [huggingface.co/models](http://huggingface.co/models) when you create a SageMaker endpoint. Access 10,000+ models on he 🤗 Hub through this environment variable.
- `HF_TASK` defines the task for the 🤗 Transformers `pipeline`. A complete list of tasks can be found [here](https://huggingface.co/docs/transformers/main_classes/pipelines).
```python
from sagemaker.huggingface.model import HuggingFaceModel
# Hub model configuration <https://huggingface.co/models>
hub = {
'HF_MODEL_ID':'distilbert-base-uncased-distilled-squad', # model_id from hf.co/models
'HF_TASK':'question-answering' # NLP task you want to use for predictions
}
# create Hugging Face Model Class
huggingface_model = HuggingFaceModel(
env=hub, # configuration for loading model from Hub
role=role, # IAM role with permissions to create an endpoint
transformers_version="4.26", # Transformers version used
pytorch_version="1.13", # PyTorch version used
py_version='py39', # Python version used
)
# deploy model to SageMaker Inference
predictor = huggingface_model.deploy(
initial_instance_count=1,
instance_type="ml.m5.xlarge"
)
# example request: you always need to define "inputs"
data = {
"inputs": {
"question": "What is used for inference?",
"context": "My Name is Philipp and I live in Nuremberg. This model is used with sagemaker for inference."
}
}
# request
predictor.predict(data)
```
After you run our request, you can delete the endpoint again with:
```python
# delete endpoint
predictor.delete_endpoint()
```
📓 Open the [deploy_transformer_model_from_hf_hub.ipynb notebook](https://github.com/huggingface/notebooks/blob/main/sagemaker/11_deploy_model_from_hf_hub/deploy_transformer_model_from_hf_hub.ipynb) for an example of how to deploy a model from the 🤗 Hub to SageMaker for inference.
## Run batch transform with 🤗 Transformers and SageMaker
<iframe width="700" height="394" src="https://www.youtube.com/embed/lnTixz0tUBg" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
After training a model, you can use [SageMaker batch transform](https://docs.aws.amazon.com/sagemaker/latest/dg/how-it-works-batch.html) to perform inference with the model. Batch transform accepts your inference data as an S3 URI and then SageMaker will take care of downloading the data, running the prediction, and uploading the results to S3. For more details about batch transform, take a look [here](https://docs.aws.amazon.com/sagemaker/latest/dg/batch-transform.html).
⚠️ The Hugging Face Inference DLC currently only supports `.jsonl` for batch transform due to the complex structure of textual data.
_Note: Make sure your `inputs` fit the `max_length` of the model during preprocessing._
If you trained a model using the Hugging Face Estimator, call the `transformer()` method to create a transform job for a model based on the training job (see [here](https://sagemaker.readthedocs.io/en/stable/overview.html#sagemaker-batch-transform) for more details):
```python
batch_job = huggingface_estimator.transformer(
instance_count=1,
instance_type='ml.p3.2xlarge',
strategy='SingleRecord')
batch_job.transform(
data='s3://s3-uri-to-batch-data',
content_type='application/json',
split_type='Line')
```
If you want to run your batch transform job later or with a model from the 🤗 Hub, create a `HuggingFaceModel` instance and then call the `transformer()` method:
```python
from sagemaker.huggingface.model import HuggingFaceModel
# Hub model configuration <https://huggingface.co/models>
hub = {
'HF_MODEL_ID':'distilbert-base-uncased-finetuned-sst-2-english',
'HF_TASK':'text-classification'
}
# create Hugging Face Model Class
huggingface_model = HuggingFaceModel(
env=hub, # configuration for loading model from Hub
role=role, # IAM role with permissions to create an endpoint
transformers_version="4.26", # Transformers version used
pytorch_version="1.13", # PyTorch version used
py_version='py39', # Python version used
)
# create transformer to run a batch job
batch_job = huggingface_model.transformer(
instance_count=1,
instance_type='ml.p3.2xlarge',
strategy='SingleRecord'
)
# starts batch transform job and uses S3 data as input
batch_job.transform(
data='s3://sagemaker-s3-demo-test/samples/input.jsonl',
content_type='application/json',
split_type='Line'
)
```
The `input.jsonl` looks like this:
```jsonl
{"inputs":"this movie is terrible"}
{"inputs":"this movie is amazing"}
{"inputs":"SageMaker is pretty cool"}
{"inputs":"SageMaker is pretty cool"}
{"inputs":"this movie is terrible"}
{"inputs":"this movie is amazing"}
```
📓 Open the [sagemaker-notebook.ipynb notebook](https://github.com/huggingface/notebooks/blob/main/sagemaker/12_batch_transform_inference/sagemaker-notebook.ipynb) for an example of how to run a batch transform job for inference.
## User defined code and modules
The Hugging Face Inference Toolkit allows the user to override the default methods of the `HuggingFaceHandlerService`. You will need to create a folder named `code/` with an `inference.py` file in it. See [here](#create-a-model-artifact-for-deployment) for more details on how to archive your model artifacts. For example:
```bash
model.tar.gz/
|- pytorch_model.bin
|- ....
|- code/
|- inference.py
|- requirements.txt
```
The `inference.py` file contains your custom inference module, and the `requirements.txt` file contains additional dependencies that should be added. The custom module can override the following methods:
* `model_fn(model_dir)` overrides the default method for loading a model. The return value `model` will be used in `predict` for predictions. `predict` receives argument the `model_dir`, the path to your unzipped `model.tar.gz`.
* `transform_fn(model, data, content_type, accept_type)` overrides the default transform function with your custom implementation. You will need to implement your own `preprocess`, `predict` and `postprocess` steps in the `transform_fn`. This method can't be combined with `input_fn`, `predict_fn` or `output_fn` mentioned below.
* `input_fn(input_data, content_type)` overrides the default method for preprocessing. The return value `data` will be used in `predict` for predictions. The inputs are:
- `input_data` is the raw body of your request.
- `content_type` is the content type from the request header.
* `predict_fn(processed_data, model)` overrides the default method for predictions. The return value `predictions` will be used in `postprocess`. The input is `processed_data`, the result from `preprocess`.
* `output_fn(prediction, accept)` overrides the default method for postprocessing. The return value `result` will be the response of your request (e.g.`JSON`). The inputs are:
- `predictions` is the result from `predict`.
- `accept` is the return accept type from the HTTP Request, e.g. `application/json`.
Here is an example of a custom inference module with `model_fn`, `input_fn`, `predict_fn`, and `output_fn`:
```python
from sagemaker_huggingface_inference_toolkit import decoder_encoder
def model_fn(model_dir):
# implement custom code to load the model
loaded_model = ...
return loaded_model
def input_fn(input_data, content_type):
# decode the input data (e.g. JSON string -> dict)
data = decoder_encoder.decode(input_data, content_type)
return data
def predict_fn(data, model):
# call your custom model with the data
outputs = model(data , ... )
return predictions
def output_fn(prediction, accept):
# convert the model output to the desired output format (e.g. dict -> JSON string)
response = decoder_encoder.encode(prediction, accept)
return response
```
Customize your inference module with only `model_fn` and `transform_fn`:
```python
from sagemaker_huggingface_inference_toolkit import decoder_encoder
def model_fn(model_dir):
# implement custom code to load the model
loaded_model = ...
return loaded_model
def transform_fn(model, input_data, content_type, accept):
# decode the input data (e.g. JSON string -> dict)
data = decoder_encoder.decode(input_data, content_type)
# call your custom model with the data
outputs = model(data , ... )
# convert the model output to the desired output format (e.g. dict -> JSON string)
response = decoder_encoder.encode(output, accept)
return response
```
|
huggingface/hub-docs/blob/main/docs/sagemaker/inference.md
|
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Speech2Text
## Overview
The Speech2Text model was proposed in [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino. It's a
transformer-based seq2seq (encoder-decoder) model designed for end-to-end Automatic Speech Recognition (ASR) and Speech
Translation (ST). It uses a convolutional downsampler to reduce the length of speech inputs by 3/4th before they are
fed into the encoder. The model is trained with standard autoregressive cross-entropy loss and generates the
transcripts/translations autoregressively. Speech2Text has been fine-tuned on several datasets for ASR and ST:
[LibriSpeech](http://www.openslr.org/12), [CoVoST 2](https://github.com/facebookresearch/covost), [MuST-C](https://ict.fbk.eu/must-c/).
This model was contributed by [valhalla](https://huggingface.co/valhalla). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text).
## Inference
Speech2Text is a speech model that accepts a float tensor of log-mel filter-bank features extracted from the speech
signal. It's a transformer-based seq2seq model, so the transcripts/translations are generated autoregressively. The
`generate()` method can be used for inference.
The [`Speech2TextFeatureExtractor`] class is responsible for extracting the log-mel filter-bank
features. The [`Speech2TextProcessor`] wraps [`Speech2TextFeatureExtractor`] and
[`Speech2TextTokenizer`] into a single instance to both extract the input features and decode the
predicted token ids.
The feature extractor depends on `torchaudio` and the tokenizer depends on `sentencepiece` so be sure to
install those packages before running the examples. You could either install those as extra speech dependencies with
`pip install transformers"[speech, sentencepiece]"` or install the packages separately with `pip install torchaudio sentencepiece`. Also `torchaudio` requires the development version of the [libsndfile](http://www.mega-nerd.com/libsndfile/) package which can be installed via a system package manager. On Ubuntu it can
be installed as follows: `apt install libsndfile1-dev`
- ASR and Speech Translation
```python
>>> import torch
>>> from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
>>> from datasets import load_dataset
>>> model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-small-librispeech-asr")
>>> processor = Speech2TextProcessor.from_pretrained("facebook/s2t-small-librispeech-asr")
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
>>> inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["sampling_rate"], return_tensors="pt")
>>> generated_ids = model.generate(inputs["input_features"], attention_mask=inputs["attention_mask"])
>>> transcription = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> transcription
['mister quilter is the apostle of the middle classes and we are glad to welcome his gospel']
```
- Multilingual speech translation
For multilingual speech translation models, `eos_token_id` is used as the `decoder_start_token_id` and
the target language id is forced as the first generated token. To force the target language id as the first
generated token, pass the `forced_bos_token_id` parameter to the `generate()` method. The following
example shows how to transate English speech to French text using the *facebook/s2t-medium-mustc-multilingual-st*
checkpoint.
```python
>>> import torch
>>> from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
>>> from datasets import load_dataset
>>> model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-medium-mustc-multilingual-st")
>>> processor = Speech2TextProcessor.from_pretrained("facebook/s2t-medium-mustc-multilingual-st")
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
>>> inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["sampling_rate"], return_tensors="pt")
>>> generated_ids = model.generate(
... inputs["input_features"],
... attention_mask=inputs["attention_mask"],
... forced_bos_token_id=processor.tokenizer.lang_code_to_id["fr"],
... )
>>> translation = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> translation
["(Vidéo) Si M. Kilder est l'apossible des classes moyennes, et nous sommes heureux d'être accueillis dans son évangile."]
```
See the [model hub](https://huggingface.co/models?filter=speech_to_text) to look for Speech2Text checkpoints.
## Speech2TextConfig
[[autodoc]] Speech2TextConfig
## Speech2TextTokenizer
[[autodoc]] Speech2TextTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## Speech2TextFeatureExtractor
[[autodoc]] Speech2TextFeatureExtractor
- __call__
## Speech2TextProcessor
[[autodoc]] Speech2TextProcessor
- __call__
- from_pretrained
- save_pretrained
- batch_decode
- decode
<frameworkcontent>
<pt>
## Speech2TextModel
[[autodoc]] Speech2TextModel
- forward
## Speech2TextForConditionalGeneration
[[autodoc]] Speech2TextForConditionalGeneration
- forward
</pt>
<tf>
## TFSpeech2TextModel
[[autodoc]] TFSpeech2TextModel
- call
## TFSpeech2TextForConditionalGeneration
[[autodoc]] TFSpeech2TextForConditionalGeneration
- call
</tf>
</frameworkcontent>
|
huggingface/transformers/blob/main/docs/source/en/model_doc/speech_to_text.md
|
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# VAN
<Tip warning={true}>
This model is in maintenance mode only, we don't accept any new PRs changing its code.
If you run into any issues running this model, please reinstall the last version that supported this model: v4.30.0.
You can do so by running the following command: `pip install -U transformers==4.30.0`.
</Tip>
## Overview
The VAN model was proposed in [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
This paper introduces a new attention layer based on convolution operations able to capture both local and distant relationships. This is done by combining normal and large kernel convolution layers. The latter uses a dilated convolution to capture distant correlations.
The abstract from the paper is the following:
*While originally designed for natural language processing tasks, the self-attention mechanism has recently taken various computer vision areas by storm. However, the 2D nature of images brings three challenges for applying self-attention in computer vision. (1) Treating images as 1D sequences neglects their 2D structures. (2) The quadratic complexity is too expensive for high-resolution images. (3) It only captures spatial adaptability but ignores channel adaptability. In this paper, we propose a novel large kernel attention (LKA) module to enable self-adaptive and long-range correlations in self-attention while avoiding the above issues. We further introduce a novel neural network based on LKA, namely Visual Attention Network (VAN). While extremely simple, VAN outperforms the state-of-the-art vision transformers and convolutional neural networks with a large margin in extensive experiments, including image classification, object detection, semantic segmentation, instance segmentation, etc. Code is available at [this https URL](https://github.com/Visual-Attention-Network/VAN-Classification).*
Tips:
- VAN does not have an embedding layer, thus the `hidden_states` will have a length equal to the number of stages.
The figure below illustrates the architecture of a Visual Aattention Layer. Taken from the [original paper](https://arxiv.org/abs/2202.09741).
<img width="600" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/van_architecture.png"/>
This model was contributed by [Francesco](https://huggingface.co/Francesco). The original code can be found [here](https://github.com/Visual-Attention-Network/VAN-Classification).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with VAN.
<PipelineTag pipeline="image-classification"/>
- [`VanForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## VanConfig
[[autodoc]] VanConfig
## VanModel
[[autodoc]] VanModel
- forward
## VanForImageClassification
[[autodoc]] VanForImageClassification
- forward
|
huggingface/transformers/blob/main/docs/source/en/model_doc/van.md
|
--
title: Perplexity
emoji: 🤗
colorFrom: green
colorTo: purple
sdk: gradio
sdk_version: 3.0.2
app_file: app.py
pinned: false
tags:
- evaluate
- measurement
description: >-
Perplexity (PPL) can be used to evaluate the extent to which a dataset is similar to the distribution of text that a given model was trained on.
It is defined as the exponentiated average negative log-likelihood of a sequence, calculated with exponent base `e`.
For more information on perplexity, see [this tutorial](https://huggingface.co/docs/transformers/perplexity).
---
# Measurement Card for Perplexity
## Measurement Description
Given a model and an input text sequence, perplexity measures how likely the model is to generate the input text sequence.
As a measurement, it can be used to evaluate how well text matches the distribution of text that the input model was trained on.
In this case, `model_id` should be the trained model, and `data` should be the text to be evaluated.
This implementation of perplexity is calculated with log base `e`, as in `perplexity = e**(sum(losses) / num_tokenized_tokens)`, following recent convention in deep learning frameworks.
## Intended Uses
Dataset analysis or exploration.
## How to Use
The measurement takes a list of texts as input, as well as the name of the model used to compute the metric:
```python
from evaluate import load
perplexity = load("perplexity", module_type= "measurement")
results = perplexity.compute(data=input_texts, model_id='gpt2')
```
### Inputs
- **model_id** (str): model used for calculating Perplexity. NOTE: Perplexity can only be calculated for causal language models.
- This includes models such as gpt2, causal variations of bert, causal versions of t5, and more (the full list can be found in the AutoModelForCausalLM documentation here: https://huggingface.co/docs/transformers/master/en/model_doc/auto#transformers.AutoModelForCausalLM )
- **data** (list of str): input text, where each separate text snippet is one list entry.
- **batch_size** (int): the batch size to run texts through the model. Defaults to 16.
- **add_start_token** (bool): whether to add the start token to the texts, so the perplexity can include the probability of the first word. Defaults to True.
- **device** (str): device to run on, defaults to `cuda` when available
### Output Values
This metric outputs a dictionary with the perplexity scores for the text input in the list, and the average perplexity.
If one of the input texts is longer than the max input length of the model, then it is truncated to the max length for the perplexity computation.
```
{'perplexities': [8.182524681091309, 33.42122268676758, 27.012239456176758], 'mean_perplexity': 22.871995608011883}
```
The range of this metric is [0, inf). A lower score is better.
#### Values from Popular Papers
### Examples
Calculating perplexity on input_texts defined here:
```python
perplexity = evaluate.load("perplexity", module_type="measurement")
input_texts = ["lorem ipsum", "Happy Birthday!", "Bienvenue"]
results = perplexity.compute(model_id='gpt2',
add_start_token=False,
data=input_texts)
print(list(results.keys()))
>>>['perplexities', 'mean_perplexity']
print(round(results["mean_perplexity"], 2))
>>>646.75
print(round(results["perplexities"][0], 2))
>>>32.25
```
Calculating perplexity on input_texts loaded in from a dataset:
```python
perplexity = evaluate.load("perplexity", module_type= "measurement")
input_texts = datasets.load_dataset("wikitext",
"wikitext-2-raw-v1",
split="test")["text"][:50]
input_texts = [s for s in input_texts if s!='']
results = perplexity.compute(model_id='gpt2',
data=input_texts)
print(list(results.keys()))
>>>['perplexities', 'mean_perplexity']
print(round(results["mean_perplexity"], 2))
>>>576.76
print(round(results["perplexities"][0], 2))
>>>889.28
```
## Limitations and Bias
Note that the output value is based heavily on what text the model was trained on. This means that perplexity scores are not comparable between models or datasets.
## Citation
```bibtex
@article{jelinek1977perplexity,
title={Perplexity—a measure of the difficulty of speech recognition tasks},
author={Jelinek, Fred and Mercer, Robert L and Bahl, Lalit R and Baker, James K},
journal={The Journal of the Acoustical Society of America},
volume={62},
number={S1},
pages={S63--S63},
year={1977},
publisher={Acoustical Society of America}
}
```
## Further References
- [Hugging Face Perplexity Blog Post](https://huggingface.co/docs/transformers/perplexity)
|
huggingface/evaluate/blob/main/measurements/perplexity/README.md
|
Custom Diffusion training example
[Custom Diffusion](https://arxiv.org/abs/2212.04488) is a method to customize text-to-image models like Stable Diffusion given just a few (4~5) images of a subject.
The `train_custom_diffusion.py` script shows how to implement the training procedure and adapt it for stable diffusion.
## Running locally with PyTorch
### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install -e .
```
Then cd in the example folder and run
```bash
pip install -r requirements.txt
pip install clip-retrieval
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
Or for a default accelerate configuration without answering questions about your environment
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell e.g. a notebook
```python
from accelerate.utils import write_basic_config
write_basic_config()
```
### Cat example 😺
Now let's get our dataset. Download dataset from [here](https://www.cs.cmu.edu/~custom-diffusion/assets/data.zip) and unzip it.
We also collect 200 real images using `clip-retrieval` which are combined with the target images in the training dataset as a regularization. This prevents overfitting to the given target image. The following flags enable the regularization `with_prior_preservation`, `real_prior` with `prior_loss_weight=1.`.
The `class_prompt` should be the category name same as target image. The collected real images are with text captions similar to the `class_prompt`. The retrieved image are saved in `class_data_dir`. You can disable `real_prior` to use generated images as regularization. To collect the real images use this command first before training.
```bash
pip install clip-retrieval
python retrieve.py --class_prompt cat --class_data_dir real_reg/samples_cat --num_class_images 200
```
**___Note: Change the `resolution` to 768 if you are using the [stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) 768x768 model.___**
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export OUTPUT_DIR="path-to-save-model"
export INSTANCE_DIR="./data/cat"
accelerate launch train_custom_diffusion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--output_dir=$OUTPUT_DIR \
--class_data_dir=./real_reg/samples_cat/ \
--with_prior_preservation --real_prior --prior_loss_weight=1.0 \
--class_prompt="cat" --num_class_images=200 \
--instance_prompt="photo of a <new1> cat" \
--resolution=512 \
--train_batch_size=2 \
--learning_rate=1e-5 \
--lr_warmup_steps=0 \
--max_train_steps=250 \
--scale_lr --hflip \
--modifier_token "<new1>"
```
**Use `--enable_xformers_memory_efficient_attention` for faster training with lower VRAM requirement (16GB per GPU). Follow [this guide](https://github.com/facebookresearch/xformers) for installation instructions.**
To track your experiments using Weights and Biases (`wandb`) and to save intermediate results (which we HIGHLY recommend), follow these steps:
* Install `wandb`: `pip install wandb`.
* Authorize: `wandb login`.
* Then specify a `validation_prompt` and set `report_to` to `wandb` while launching training. You can also configure the following related arguments:
* `num_validation_images`
* `validation_steps`
Here is an example command:
```bash
accelerate launch train_custom_diffusion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--output_dir=$OUTPUT_DIR \
--class_data_dir=./real_reg/samples_cat/ \
--with_prior_preservation --real_prior --prior_loss_weight=1.0 \
--class_prompt="cat" --num_class_images=200 \
--instance_prompt="photo of a <new1> cat" \
--resolution=512 \
--train_batch_size=2 \
--learning_rate=1e-5 \
--lr_warmup_steps=0 \
--max_train_steps=250 \
--scale_lr --hflip \
--modifier_token "<new1>" \
--validation_prompt="<new1> cat sitting in a bucket" \
--report_to="wandb"
```
Here is an example [Weights and Biases page](https://wandb.ai/sayakpaul/custom-diffusion/runs/26ghrcau) where you can check out the intermediate results along with other training details.
If you specify `--push_to_hub`, the learned parameters will be pushed to a repository on the Hugging Face Hub. Here is an [example repository](https://huggingface.co/sayakpaul/custom-diffusion-cat).
### Training on multiple concepts 🐱🪵
Provide a [json](https://github.com/adobe-research/custom-diffusion/blob/main/assets/concept_list.json) file with the info about each concept, similar to [this](https://github.com/ShivamShrirao/diffusers/blob/main/examples/dreambooth/train_dreambooth.py).
To collect the real images run this command for each concept in the json file.
```bash
pip install clip-retrieval
python retrieve.py --class_prompt {} --class_data_dir {} --num_class_images 200
```
And then we're ready to start training!
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export OUTPUT_DIR="path-to-save-model"
accelerate launch train_custom_diffusion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--output_dir=$OUTPUT_DIR \
--concepts_list=./concept_list.json \
--with_prior_preservation --real_prior --prior_loss_weight=1.0 \
--resolution=512 \
--train_batch_size=2 \
--learning_rate=1e-5 \
--lr_warmup_steps=0 \
--max_train_steps=500 \
--num_class_images=200 \
--scale_lr --hflip \
--modifier_token "<new1>+<new2>"
```
Here is an example [Weights and Biases page](https://wandb.ai/sayakpaul/custom-diffusion/runs/3990tzkg) where you can check out the intermediate results along with other training details.
### Training on human faces
For fine-tuning on human faces we found the following configuration to work better: `learning_rate=5e-6`, `max_train_steps=1000 to 2000`, and `freeze_model=crossattn` with at least 15-20 images.
To collect the real images use this command first before training.
```bash
pip install clip-retrieval
python retrieve.py --class_prompt person --class_data_dir real_reg/samples_person --num_class_images 200
```
Then start training!
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export OUTPUT_DIR="path-to-save-model"
export INSTANCE_DIR="path-to-images"
accelerate launch train_custom_diffusion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--output_dir=$OUTPUT_DIR \
--class_data_dir=./real_reg/samples_person/ \
--with_prior_preservation --real_prior --prior_loss_weight=1.0 \
--class_prompt="person" --num_class_images=200 \
--instance_prompt="photo of a <new1> person" \
--resolution=512 \
--train_batch_size=2 \
--learning_rate=5e-6 \
--lr_warmup_steps=0 \
--max_train_steps=1000 \
--scale_lr --hflip --noaug \
--freeze_model crossattn \
--modifier_token "<new1>" \
--enable_xformers_memory_efficient_attention
```
## Inference
Once you have trained a model using the above command, you can run inference using the below command. Make sure to include the `modifier token` (e.g. \<new1\> in above example) in your prompt.
```python
import torch
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16
).to("cuda")
pipe.unet.load_attn_procs(
"path-to-save-model", weight_name="pytorch_custom_diffusion_weights.bin"
)
pipe.load_textual_inversion("path-to-save-model", weight_name="<new1>.bin")
image = pipe(
"<new1> cat sitting in a bucket",
num_inference_steps=100,
guidance_scale=6.0,
eta=1.0,
).images[0]
image.save("cat.png")
```
It's possible to directly load these parameters from a Hub repository:
```python
import torch
from huggingface_hub.repocard import RepoCard
from diffusers import DiffusionPipeline
model_id = "sayakpaul/custom-diffusion-cat"
card = RepoCard.load(model_id)
base_model_id = card.data.to_dict()["base_model"]
pipe = DiffusionPipeline.from_pretrained(base_model_id, torch_dtype=torch.float16).to(
"cuda")
pipe.unet.load_attn_procs(model_id, weight_name="pytorch_custom_diffusion_weights.bin")
pipe.load_textual_inversion(model_id, weight_name="<new1>.bin")
image = pipe(
"<new1> cat sitting in a bucket",
num_inference_steps=100,
guidance_scale=6.0,
eta=1.0,
).images[0]
image.save("cat.png")
```
Here is an example of performing inference with multiple concepts:
```python
import torch
from huggingface_hub.repocard import RepoCard
from diffusers import DiffusionPipeline
model_id = "sayakpaul/custom-diffusion-cat-wooden-pot"
card = RepoCard.load(model_id)
base_model_id = card.data.to_dict()["base_model"]
pipe = DiffusionPipeline.from_pretrained(base_model_id, torch_dtype=torch.float16).to(
"cuda")
pipe.unet.load_attn_procs(model_id, weight_name="pytorch_custom_diffusion_weights.bin")
pipe.load_textual_inversion(model_id, weight_name="<new1>.bin")
pipe.load_textual_inversion(model_id, weight_name="<new2>.bin")
image = pipe(
"the <new1> cat sculpture in the style of a <new2> wooden pot",
num_inference_steps=100,
guidance_scale=6.0,
eta=1.0,
).images[0]
image.save("multi-subject.png")
```
Here, `cat` and `wooden pot` refer to the multiple concepts.
### Inference from a training checkpoint
You can also perform inference from one of the complete checkpoint saved during the training process, if you used the `--checkpointing_steps` argument.
TODO.
## Set grads to none
To save even more memory, pass the `--set_grads_to_none` argument to the script. This will set grads to None instead of zero. However, be aware that it changes certain behaviors, so if you start experiencing any problems, remove this argument.
More info: https://pytorch.org/docs/stable/generated/torch.optim.Optimizer.zero_grad.html
## Experimental results
You can refer to [our webpage](https://www.cs.cmu.edu/~custom-diffusion/) that discusses our experiments in detail. We also released a more extensive dataset of 101 concepts for evaluating model customization methods. For more details please refer to our [dataset webpage](https://www.cs.cmu.edu/~custom-diffusion/dataset.html).
|
huggingface/diffusers/blob/main/examples/custom_diffusion/README.md
|
`tokenizers-linux-x64-musl`
This is the **x86_64-unknown-linux-musl** binary for `tokenizers`
|
huggingface/tokenizers/blob/main/bindings/node/npm/linux-x64-musl/README.md
|
Server infrastructure
The [Datasets Server](https://github.com/huggingface/datasets-server) has two main components that work together to return queries about a dataset instantly:
- a user-facing web API for exploring and returning information about a dataset
- a server runs the queries ahead of time and caches them in a database
While most of the documentation is focused on the web API, the server is crucial because it performs all the time-consuming preprocessing and stores the results so the web API can retrieve and serve them to the user. This saves a user time because instead of generating the response every time it gets requested, Datasets Server can return the preprocessed results instantly from the cache.
There are three elements that keep the server running: the job queue, workers, and the cache.
## Job queue
The job queue is a list of jobs stored in a Mongo database that should be completed by the workers. The jobs are practically identical to the endpoints the user uses; only the server runs the jobs ahead of time, and the user gets the results when they use the endpoint.
There are three jobs:
- `/splits` corresponds to the `/splits` endpoint. It refreshes a dataset and then returns that dataset's splits and configurations. For every split in the dataset, it'll create a new job.
- `/first-rows` corresponds to the `/first-rows` endpoint. It gets the first 100 rows and columns of a dataset split.
- `/parquet` corresponds to the `/parquet` endpoint. It downloads the whole dataset, converts it to [parquet](https://parquet.apache.org/) and publishes the parquet files to the Hub.
You might've noticed the `/rows` and `/search` endpoints don't have a job in the queue. The responses from these endpoints are generated on demand.
## Workers
Workers are responsible for executing the jobs in the queue. They complete the actual preprocessing requests, such as getting a list of splits and configurations. The workers can be controlled by configurable environment variables, like the minimum or the maximum number of rows returned by a worker or the maximum number of jobs to start per dataset user or organization.
Take a look at the [workers configuration](https://github.com/huggingface/datasets-server/tree/main/services/worker#configuration) for a complete list of the environment variables if you're interested in learning more.
## Cache
Once the workers complete a job, the results are stored - or _cached_ - in a Mongo database. When a user makes a request with an endpoint like `/first-rows`, Datasets Server retrieves the preprocessed response from the cache, and serves it to the user. This eliminates the time a user would've waited if the server hadn't already completed the job and stored the response.
As a result, users can get their requested information about a dataset (even large ones) nearly instantaneously!
|
huggingface/datasets-server/blob/main/docs/source/server.mdx
|
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Table Transformer
## Overview
The Table Transformer model was proposed in [PubTables-1M: Towards comprehensive table extraction from unstructured documents](https://arxiv.org/abs/2110.00061) by
Brandon Smock, Rohith Pesala, Robin Abraham. The authors introduce a new dataset, PubTables-1M, to benchmark progress in table extraction from unstructured documents,
as well as table structure recognition and functional analysis. The authors train 2 [DETR](detr) models, one for table detection and one for table structure recognition, dubbed Table Transformers.
The abstract from the paper is the following:
*Recently, significant progress has been made applying machine learning to the problem of table structure inference and extraction from unstructured documents.
However, one of the greatest challenges remains the creation of datasets with complete, unambiguous ground truth at scale. To address this, we develop a new, more
comprehensive dataset for table extraction, called PubTables-1M. PubTables-1M contains nearly one million tables from scientific articles, supports multiple input
modalities, and contains detailed header and location information for table structures, making it useful for a wide variety of modeling approaches. It also addresses a significant
source of ground truth inconsistency observed in prior datasets called oversegmentation, using a novel canonicalization procedure. We demonstrate that these improvements lead to a
significant increase in training performance and a more reliable estimate of model performance at evaluation for table structure recognition. Further, we show that transformer-based
object detection models trained on PubTables-1M produce excellent results for all three tasks of detection, structure recognition, and functional analysis without the need for any
special customization for these tasks.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/table_transformer_architecture.jpeg"
alt="drawing" width="600"/>
<small> Table detection and table structure recognition clarified. Taken from the <a href="https://arxiv.org/abs/2110.00061">original paper</a>. </small>
The authors released 2 models, one for [table detection](https://huggingface.co/microsoft/table-transformer-detection) in
documents, one for [table structure recognition](https://huggingface.co/microsoft/table-transformer-structure-recognition)
(the task of recognizing the individual rows, columns etc. in a table).
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be
found [here](https://github.com/microsoft/table-transformer).
## Resources
<PipelineTag pipeline="object-detection"/>
- A demo notebook for the Table Transformer can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Table%20Transformer).
- It turns out padding of images is quite important for detection. An interesting Github thread with replies from the authors can be found [here](https://github.com/microsoft/table-transformer/issues/68).
## TableTransformerConfig
[[autodoc]] TableTransformerConfig
## TableTransformerModel
[[autodoc]] TableTransformerModel
- forward
## TableTransformerForObjectDetection
[[autodoc]] TableTransformerForObjectDetection
- forward
|
huggingface/transformers/blob/main/docs/source/en/model_doc/table-transformer.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# UNetMotionModel
The [UNet](https://huggingface.co/papers/1505.04597) model was originally introduced by Ronneberger et al for biomedical image segmentation, but it is also commonly used in 🤗 Diffusers because it outputs images that are the same size as the input. It is one of the most important components of a diffusion system because it facilitates the actual diffusion process. There are several variants of the UNet model in 🤗 Diffusers, depending on it's number of dimensions and whether it is a conditional model or not. This is a 2D UNet model.
The abstract from the paper is:
*There is large consent that successful training of deep networks requires many thousand annotated training samples. In this paper, we present a network and training strategy that relies on the strong use of data augmentation to use the available annotated samples more efficiently. The architecture consists of a contracting path to capture context and a symmetric expanding path that enables precise localization. We show that such a network can be trained end-to-end from very few images and outperforms the prior best method (a sliding-window convolutional network) on the ISBI challenge for segmentation of neuronal structures in electron microscopic stacks. Using the same network trained on transmitted light microscopy images (phase contrast and DIC) we won the ISBI cell tracking challenge 2015 in these categories by a large margin. Moreover, the network is fast. Segmentation of a 512x512 image takes less than a second on a recent GPU. The full implementation (based on Caffe) and the trained networks are available at http://lmb.informatik.uni-freiburg.de/people/ronneber/u-net.*
## UNetMotionModel
[[autodoc]] UNetMotionModel
## UNet3DConditionOutput
[[autodoc]] models.unet_3d_condition.UNet3DConditionOutput
|
huggingface/diffusers/blob/main/docs/source/en/api/models/unet-motion.md
|
Two main approaches for solving RL problems [[two-methods]]
<Tip>
Now that we learned the RL framework, how do we solve the RL problem?
</Tip>
In other words, how do we build an RL agent that can **select the actions that maximize its expected cumulative reward?**
## The Policy π: the agent’s brain [[policy]]
The Policy **π** is the **brain of our Agent**, it’s the function that tells us what **action to take given the state we are in.** So it **defines the agent’s behavior** at a given time.
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/policy_1.jpg" alt="Policy" />
<figcaption>Think of policy as the brain of our agent, the function that will tell us the action to take given a state</figcaption>
</figure>
This Policy **is the function we want to learn**, our goal is to find the optimal policy π\*, the policy that **maximizes expected return** when the agent acts according to it. We find this π\* **through training.**
There are two approaches to train our agent to find this optimal policy π\*:
- **Directly,** by teaching the agent to learn which **action to take,** given the current state: **Policy-Based Methods.**
- Indirectly, **teach the agent to learn which state is more valuable** and then take the action that **leads to the more valuable states**: Value-Based Methods.
## Policy-Based Methods [[policy-based]]
In Policy-Based methods, **we learn a policy function directly.**
This function will define a mapping from each state to the best corresponding action. Alternatively, it could define **a probability distribution over the set of possible actions at that state.**
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/policy_2.jpg" alt="Policy" />
<figcaption>As we can see here, the policy (deterministic) <b>directly indicates the action to take for each step.</b></figcaption>
</figure>
We have two types of policies:
- *Deterministic*: a policy at a given state **will always return the same action.**
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/policy_3.jpg" alt="Policy"/>
<figcaption>action = policy(state)</figcaption>
</figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/policy_4.jpg" alt="Policy" width="100%"/>
- *Stochastic*: outputs **a probability distribution over actions.**
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/policy_5.jpg" alt="Policy"/>
<figcaption>policy(actions | state) = probability distribution over the set of actions given the current state</figcaption>
</figure>
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/policy-based.png" alt="Policy Based"/>
<figcaption>Given an initial state, our stochastic policy will output probability distributions over the possible actions at that state.</figcaption>
</figure>
If we recap:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/pbm_1.jpg" alt="Pbm recap" width="100%" />
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/pbm_2.jpg" alt="Pbm recap" width="100%" />
## Value-based methods [[value-based]]
In value-based methods, instead of learning a policy function, we **learn a value function** that maps a state to the expected value **of being at that state.**
The value of a state is the **expected discounted return** the agent can get if it **starts in that state, and then acts according to our policy.**
“Act according to our policy” just means that our policy is **“going to the state with the highest value”.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/value_1.jpg" alt="Value based RL" width="100%" />
Here we see that our value function **defined values for each possible state.**
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/value_2.jpg" alt="Value based RL"/>
<figcaption>Thanks to our value function, at each step our policy will select the state with the biggest value defined by the value function: -7, then -6, then -5 (and so on) to attain the goal.</figcaption>
</figure>
Thanks to our value function, at each step our policy will select the state with the biggest value defined by the value function: -7, then -6, then -5 (and so on) to attain the goal.
If we recap:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/vbm_1.jpg" alt="Vbm recap" width="100%" />
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/vbm_2.jpg" alt="Vbm recap" width="100%" />
|
huggingface/deep-rl-class/blob/main/units/en/unit1/two-methods.mdx
|
Single Sign-On (SSO)
The Hugging Face Hub gives you the ability to implement mandatory Single Sign-On (SSO) for your organization.
We support both SAML 2.0 and OpenID Connect (OIDC) protocols.
<Tip warning={true}>
This feature is part of the <a href="https://huggingface.co/enterprise" target="_blank">Enterprise Hub</a>.
</Tip>
## How does it work?
When Single Sign-On is enabled, the members of your organization must authenticate through your Identity Provider (IdP) to access any content under the organization's namespace. Public content will still be available to users who are not members of the organization.
**We use email addresses to identify SSO users. Make sure that your organizational email address (e.g. your company email) has been added to [your user account](https://huggingface.co/settings/account).**
When users log in, they will be prompted to complete the Single Sign-On authentication flow with a banner similar to the following:
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/security-sso-prompt.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/security-sso-prompt-dark.png"/>
</div>
Single Sign-On only applies to your organization. Members may belong to other organizations on Hugging Face.
We support [role mapping](#role-mapping): you can automatically assign [roles](./organizations-security#access-control-in-organizations) to organization members based on attributes provided by your Identity Provider.
### Supported Identity Providers
You can easily integrate Hugging Face Hub with a variety of Identity Providers, such as Okta, OneLogin or Azure Active Directory (Azure AD). Hugging Face Hub can work with any OIDC-compliant or SAML Identity Provider.
## How to configure OIDC/SAML provider in the Hub
We have some guides available to help with configuring based on your chosen SSO provider, or to take inspiration from:
- [How to configure OIDC with Okta in the Hub](./security-sso-okta-oidc)
- [How to configure SAML with Okta in the Hub](./security-sso-okta-saml)
- [How to configure SAML with Azure in the Hub](./security-sso-azure-saml)
### Users Management
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-settings-users.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-settings-users-dark.png"/>
</div>
#### Session Timeout
This value sets the duration of the session for members of your organization.
After this time, members will be prompted to re-authenticate with your Identity Provider to access the organization's resources.
The default value is 7 days.
#### Role Mapping
When enabled, Role Mapping allows you to dynamically assign [roles](./organizations-security#access-control-in-organizations) to organization members based on data provided by your Identity Provider.
This section allows you to define a mapping from your IdP's user profile data from your IdP to the assigned role in Hugging Face.
- IdP Role Attribute Mapping
A JSON path to an attribute in your user's IdP profile data.
- Role Mapping
A mapping from the IdP attribute value to the assigned role in the Hugging Face organization.
You must map at least one admin role.
If there is no match, a user will be assigned the default role for your organization. The default role can be customized in the `Members` section of the organization's settings.
Role synchronization is performed on login.
|
huggingface/hub-docs/blob/main/docs/hub/security-sso.md
|
as recorded adlib - need to generate transcript with Whisper :)
|
huggingface/course/blob/main/subtitles/en/raw/chapter1/04a_the-carbon-footprint.md
|
Big data? 🤗 Datasets to the rescue![[big-data-datasets-to-the-rescue]]
<CourseFloatingBanner chapter={5}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter5/section4.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter5/section4.ipynb"},
]} />
Nowadays it is not uncommon to find yourself working with multi-gigabyte datasets, especially if you're planning to pretrain a transformer like BERT or GPT-2 from scratch. In these cases, even _loading_ the data can be a challenge. For example, the WebText corpus used to pretrain GPT-2 consists of over 8 million documents and 40 GB of text -- loading this into your laptop's RAM is likely to give it a heart attack!
Fortunately, 🤗 Datasets has been designed to overcome these limitations. It frees you from memory management problems by treating datasets as _memory-mapped_ files, and from hard drive limits by _streaming_ the entries in a corpus.
<Youtube id="JwISwTCPPWo"/>
In this section we'll explore these features of 🤗 Datasets with a huge 825 GB corpus known as [the Pile](https://pile.eleuther.ai). Let's get started!
## What is the Pile?[[what-is-the-pile]]
The Pile is an English text corpus that was created by [EleutherAI](https://www.eleuther.ai) for training large-scale language models. It includes a diverse range of datasets, spanning scientific articles, GitHub code repositories, and filtered web text. The training corpus is available in [14 GB chunks](https://the-eye.eu/public/AI/pile/), and you can also download several of the [individual components](https://the-eye.eu/public/AI/pile_preliminary_components/). Let's start by taking a look at the PubMed Abstracts dataset, which is a corpus of abstracts from 15 million biomedical publications on [PubMed](https://pubmed.ncbi.nlm.nih.gov/). The dataset is in [JSON Lines format](https://jsonlines.org) and is compressed using the `zstandard` library, so first we need to install that:
```py
!pip install zstandard
```
Next, we can load the dataset using the method for remote files that we learned in [section 2](/course/chapter5/2):
```py
from datasets import load_dataset
# This takes a few minutes to run, so go grab a tea or coffee while you wait :)
data_files = "https://the-eye.eu/public/AI/pile_preliminary_components/PUBMED_title_abstracts_2019_baseline.jsonl.zst"
pubmed_dataset = load_dataset("json", data_files=data_files, split="train")
pubmed_dataset
```
```python out
Dataset({
features: ['meta', 'text'],
num_rows: 15518009
})
```
We can see that there are 15,518,009 rows and 2 columns in our dataset -- that's a lot!
<Tip>
✎ By default, 🤗 Datasets will decompress the files needed to load a dataset. If you want to preserve hard drive space, you can pass `DownloadConfig(delete_extracted=True)` to the `download_config` argument of `load_dataset()`. See the [documentation](https://huggingface.co/docs/datasets/package_reference/builder_classes.html?#datasets.utils.DownloadConfig) for more details.
</Tip>
Let's inspect the contents of the first example:
```py
pubmed_dataset[0]
```
```python out
{'meta': {'pmid': 11409574, 'language': 'eng'},
'text': 'Epidemiology of hypoxaemia in children with acute lower respiratory infection.\nTo determine the prevalence of hypoxaemia in children aged under 5 years suffering acute lower respiratory infections (ALRI), the risk factors for hypoxaemia in children under 5 years of age with ALRI, and the association of hypoxaemia with an increased risk of dying in children of the same age ...'}
```
Okay, this looks like the abstract from a medical article. Now let's see how much RAM we've used to load the dataset!
## The magic of memory mapping[[the-magic-of-memory-mapping]]
A simple way to measure memory usage in Python is with the [`psutil`](https://psutil.readthedocs.io/en/latest/) library, which can be installed with `pip` as follows:
```python
!pip install psutil
```
It provides a `Process` class that allows us to check the memory usage of the current process as follows:
```py
import psutil
# Process.memory_info is expressed in bytes, so convert to megabytes
print(f"RAM used: {psutil.Process().memory_info().rss / (1024 * 1024):.2f} MB")
```
```python out
RAM used: 5678.33 MB
```
Here the `rss` attribute refers to the _resident set size_, which is the fraction of memory that a process occupies in RAM. This measurement also includes the memory used by the Python interpreter and the libraries we've loaded, so the actual amount of memory used to load the dataset is a bit smaller. For comparison, let's see how large the dataset is on disk, using the `dataset_size` attribute. Since the result is expressed in bytes like before, we need to manually convert it to gigabytes:
```py
print(f"Number of files in dataset : {pubmed_dataset.dataset_size}")
size_gb = pubmed_dataset.dataset_size / (1024**3)
print(f"Dataset size (cache file) : {size_gb:.2f} GB")
```
```python out
Number of files in dataset : 20979437051
Dataset size (cache file) : 19.54 GB
```
Nice -- despite it being almost 20 GB large, we're able to load and access the dataset with much less RAM!
<Tip>
✏️ **Try it out!** Pick one of the [subsets](https://the-eye.eu/public/AI/pile_preliminary_components/) from the Pile that is larger than your laptop or desktop's RAM, load it with 🤗 Datasets, and measure the amount of RAM used. Note that to get an accurate measurement, you'll want to do this in a new process. You can find the decompressed sizes of each subset in Table 1 of [the Pile paper](https://arxiv.org/abs/2101.00027).
</Tip>
If you're familiar with Pandas, this result might come as a surprise because of Wes Kinney's famous [rule of thumb](https://wesmckinney.com/blog/apache-arrow-pandas-internals/) that you typically need 5 to 10 times as much RAM as the size of your dataset. So how does 🤗 Datasets solve this memory management problem? 🤗 Datasets treats each dataset as a [memory-mapped file](https://en.wikipedia.org/wiki/Memory-mapped_file), which provides a mapping between RAM and filesystem storage that allows the library to access and operate on elements of the dataset without needing to fully load it into memory.
Memory-mapped files can also be shared across multiple processes, which enables methods like `Dataset.map()` to be parallelized without needing to move or copy the dataset. Under the hood, these capabilities are all realized by the [Apache Arrow](https://arrow.apache.org) memory format and [`pyarrow`](https://arrow.apache.org/docs/python/index.html) library, which make the data loading and processing lightning fast. (For more details about Apache Arrow and comparisons to Pandas, check out [Dejan Simic's blog post](https://towardsdatascience.com/apache-arrow-read-dataframe-with-zero-memory-69634092b1a).) To see this in action, let's run a little speed test by iterating over all the elements in the PubMed Abstracts dataset:
```py
import timeit
code_snippet = """batch_size = 1000
for idx in range(0, len(pubmed_dataset), batch_size):
_ = pubmed_dataset[idx:idx + batch_size]
"""
time = timeit.timeit(stmt=code_snippet, number=1, globals=globals())
print(
f"Iterated over {len(pubmed_dataset)} examples (about {size_gb:.1f} GB) in "
f"{time:.1f}s, i.e. {size_gb/time:.3f} GB/s"
)
```
```python out
'Iterated over 15518009 examples (about 19.5 GB) in 64.2s, i.e. 0.304 GB/s'
```
Here we've used Python's `timeit` module to measure the execution time taken by `code_snippet`. You'll typically be able to iterate over a dataset at speed of a few tenths of a GB/s to several GB/s. This works great for the vast majority of applications, but sometimes you'll have to work with a dataset that is too large to even store on your laptop's hard drive. For example, if we tried to download the Pile in its entirety, we'd need 825 GB of free disk space! To handle these cases, 🤗 Datasets provides a streaming feature that allows us to download and access elements on the fly, without needing to download the whole dataset. Let's take a look at how this works.
<Tip>
💡 In Jupyter notebooks you can also time cells using the [`%%timeit` magic function](https://ipython.readthedocs.io/en/stable/interactive/magics.html#magic-timeit).
</Tip>
## Streaming datasets[[streaming-datasets]]
To enable dataset streaming you just need to pass the `streaming=True` argument to the `load_dataset()` function. For example, let's load the PubMed Abstracts dataset again, but in streaming mode:
```py
pubmed_dataset_streamed = load_dataset(
"json", data_files=data_files, split="train", streaming=True
)
```
Instead of the familiar `Dataset` that we've encountered elsewhere in this chapter, the object returned with `streaming=True` is an `IterableDataset`. As the name suggests, to access the elements of an `IterableDataset` we need to iterate over it. We can access the first element of our streamed dataset as follows:
```py
next(iter(pubmed_dataset_streamed))
```
```python out
{'meta': {'pmid': 11409574, 'language': 'eng'},
'text': 'Epidemiology of hypoxaemia in children with acute lower respiratory infection.\nTo determine the prevalence of hypoxaemia in children aged under 5 years suffering acute lower respiratory infections (ALRI), the risk factors for hypoxaemia in children under 5 years of age with ALRI, and the association of hypoxaemia with an increased risk of dying in children of the same age ...'}
```
The elements from a streamed dataset can be processed on the fly using `IterableDataset.map()`, which is useful during training if you need to tokenize the inputs. The process is exactly the same as the one we used to tokenize our dataset in [Chapter 3](/course/chapter3), with the only difference being that outputs are returned one by one:
```py
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
tokenized_dataset = pubmed_dataset_streamed.map(lambda x: tokenizer(x["text"]))
next(iter(tokenized_dataset))
```
```python out
{'input_ids': [101, 4958, 5178, 4328, 6779, ...], 'attention_mask': [1, 1, 1, 1, 1, ...]}
```
<Tip>
💡 To speed up tokenization with streaming you can pass `batched=True`, as we saw in the last section. It will process the examples batch by batch; the default batch size is 1,000 and can be specified with the `batch_size` argument.
</Tip>
You can also shuffle a streamed dataset using `IterableDataset.shuffle()`, but unlike `Dataset.shuffle()` this only shuffles the elements in a predefined `buffer_size`:
```py
shuffled_dataset = pubmed_dataset_streamed.shuffle(buffer_size=10_000, seed=42)
next(iter(shuffled_dataset))
```
```python out
{'meta': {'pmid': 11410799, 'language': 'eng'},
'text': 'Randomized study of dose or schedule modification of granulocyte colony-stimulating factor in platinum-based chemotherapy for elderly patients with lung cancer ...'}
```
In this example, we selected a random example from the first 10,000 examples in the buffer. Once an example is accessed, its spot in the buffer is filled with the next example in the corpus (i.e., the 10,001st example in the case above). You can also select elements from a streamed dataset using the `IterableDataset.take()` and `IterableDataset.skip()` functions, which act in a similar way to `Dataset.select()`. For example, to select the first 5 examples in the PubMed Abstracts dataset we can do the following:
```py
dataset_head = pubmed_dataset_streamed.take(5)
list(dataset_head)
```
```python out
[{'meta': {'pmid': 11409574, 'language': 'eng'},
'text': 'Epidemiology of hypoxaemia in children with acute lower respiratory infection ...'},
{'meta': {'pmid': 11409575, 'language': 'eng'},
'text': 'Clinical signs of hypoxaemia in children with acute lower respiratory infection: indicators of oxygen therapy ...'},
{'meta': {'pmid': 11409576, 'language': 'eng'},
'text': "Hypoxaemia in children with severe pneumonia in Papua New Guinea ..."},
{'meta': {'pmid': 11409577, 'language': 'eng'},
'text': 'Oxygen concentrators and cylinders ...'},
{'meta': {'pmid': 11409578, 'language': 'eng'},
'text': 'Oxygen supply in rural africa: a personal experience ...'}]
```
Similarly, you can use the `IterableDataset.skip()` function to create training and validation splits from a shuffled dataset as follows:
```py
# Skip the first 1,000 examples and include the rest in the training set
train_dataset = shuffled_dataset.skip(1000)
# Take the first 1,000 examples for the validation set
validation_dataset = shuffled_dataset.take(1000)
```
Let's round out our exploration of dataset streaming with a common application: combining multiple datasets together to create a single corpus. 🤗 Datasets provides an `interleave_datasets()` function that converts a list of `IterableDataset` objects into a single `IterableDataset`, where the elements of the new dataset are obtained by alternating among the source examples. This function is especially useful when you're trying to combine large datasets, so as an example let's stream the FreeLaw subset of the Pile, which is a 51 GB dataset of legal opinions from US courts:
```py
law_dataset_streamed = load_dataset(
"json",
data_files="https://the-eye.eu/public/AI/pile_preliminary_components/FreeLaw_Opinions.jsonl.zst",
split="train",
streaming=True,
)
next(iter(law_dataset_streamed))
```
```python out
{'meta': {'case_ID': '110921.json',
'case_jurisdiction': 'scotus.tar.gz',
'date_created': '2010-04-28T17:12:49Z'},
'text': '\n461 U.S. 238 (1983)\nOLIM ET AL.\nv.\nWAKINEKONA\nNo. 81-1581.\nSupreme Court of United States.\nArgued January 19, 1983.\nDecided April 26, 1983.\nCERTIORARI TO THE UNITED STATES COURT OF APPEALS FOR THE NINTH CIRCUIT\n*239 Michael A. Lilly, First Deputy Attorney General of Hawaii, argued the cause for petitioners. With him on the brief was James H. Dannenberg, Deputy Attorney General...'}
```
This dataset is large enough to stress the RAM of most laptops, yet we've been able to load and access it without breaking a sweat! Let's now combine the examples from the FreeLaw and PubMed Abstracts datasets with the `interleave_datasets()` function:
```py
from itertools import islice
from datasets import interleave_datasets
combined_dataset = interleave_datasets([pubmed_dataset_streamed, law_dataset_streamed])
list(islice(combined_dataset, 2))
```
```python out
[{'meta': {'pmid': 11409574, 'language': 'eng'},
'text': 'Epidemiology of hypoxaemia in children with acute lower respiratory infection ...'},
{'meta': {'case_ID': '110921.json',
'case_jurisdiction': 'scotus.tar.gz',
'date_created': '2010-04-28T17:12:49Z'},
'text': '\n461 U.S. 238 (1983)\nOLIM ET AL.\nv.\nWAKINEKONA\nNo. 81-1581.\nSupreme Court of United States.\nArgued January 19, 1983.\nDecided April 26, 1983.\nCERTIORARI TO THE UNITED STATES COURT OF APPEALS FOR THE NINTH CIRCUIT\n*239 Michael A. Lilly, First Deputy Attorney General of Hawaii, argued the cause for petitioners. With him on the brief was James H. Dannenberg, Deputy Attorney General...'}]
```
Here we've used the `islice()` function from Python's `itertools` module to select the first two examples from the combined dataset, and we can see that they match the first examples from each of the two source datasets.
Finally, if you want to stream the Pile in its 825 GB entirety, you can grab all the prepared files as follows:
```py
base_url = "https://the-eye.eu/public/AI/pile/"
data_files = {
"train": [base_url + "train/" + f"{idx:02d}.jsonl.zst" for idx in range(30)],
"validation": base_url + "val.jsonl.zst",
"test": base_url + "test.jsonl.zst",
}
pile_dataset = load_dataset("json", data_files=data_files, streaming=True)
next(iter(pile_dataset["train"]))
```
```python out
{'meta': {'pile_set_name': 'Pile-CC'},
'text': 'It is done, and submitted. You can play “Survival of the Tastiest” on Android, and on the web...'}
```
<Tip>
✏️ **Try it out!** Use one of the large Common Crawl corpora like [`mc4`](https://huggingface.co/datasets/mc4) or [`oscar`](https://huggingface.co/datasets/oscar) to create a streaming multilingual dataset that represents the spoken proportions of languages in a country of your choice. For example, the four national languages in Switzerland are German, French, Italian, and Romansh, so you could try creating a Swiss corpus by sampling the Oscar subsets according to their spoken proportion.
</Tip>
You now have all the tools you need to load and process datasets of all shapes and sizes -- but unless you're exceptionally lucky, there will come a point in your NLP journey where you'll have to actually create a dataset to solve the problem at hand. That's the topic of the next section!
|
huggingface/course/blob/main/chapters/en/chapter5/4.mdx
|
@gradio/checkboxgroup
## 0.3.7
### Patch Changes
- Updated dependencies [[`828fb9e`](https://github.com/gradio-app/gradio/commit/828fb9e6ce15b6ea08318675a2361117596a1b5d), [`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144)]:
- @gradio/statustracker@0.4.3
- @gradio/atoms@0.4.1
## 0.3.6
### Patch Changes
- Updated dependencies [[`4d1cbbc`](https://github.com/gradio-app/gradio/commit/4d1cbbcf30833ef1de2d2d2710c7492a379a9a00)]:
- @gradio/atoms@0.4.0
- @gradio/statustracker@0.4.2
## 0.3.5
### Patch Changes
- Updated dependencies []:
- @gradio/atoms@0.3.1
- @gradio/statustracker@0.4.1
## 0.3.4
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/atoms@0.3.0
- @gradio/statustracker@0.4.0
## 0.3.3
### Patch Changes
- Updated dependencies [[`f816136a0`](https://github.com/gradio-app/gradio/commit/f816136a039fa6011be9c4fb14f573e4050a681a)]:
- @gradio/atoms@0.2.2
- @gradio/statustracker@0.3.2
## 0.3.2
### Patch Changes
- Updated dependencies [[`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780), [`fad92c29d`](https://github.com/gradio-app/gradio/commit/fad92c29dc1f5cd84341aae417c495b33e01245f)]:
- @gradio/atoms@0.2.1
- @gradio/statustracker@0.3.1
## 0.3.1
### Fixes
- [#6236](https://github.com/gradio-app/gradio/pull/6236) [`6bce259c5`](https://github.com/gradio-app/gradio/commit/6bce259c5db7b21b327c2067e74ea20417bc89ec) - Ensure `gr.CheckboxGroup` updates as expected. Thanks [@pngwn](https://github.com/pngwn)!
## 0.3.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
## 0.3.0-beta.8
### Features
- [#6149](https://github.com/gradio-app/gradio/pull/6149) [`90318b1dd`](https://github.com/gradio-app/gradio/commit/90318b1dd118ae08a695a50e7c556226234ab6dc) - swap `mode` on the frontned to `interactive` to match the backend. Thanks [@pngwn](https://github.com/pngwn)!
## 0.3.0-beta.7
### Features
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6026](https://github.com/gradio-app/gradio/pull/6026) [`338969af2`](https://github.com/gradio-app/gradio/commit/338969af290de032f9cdc204dab8a50be3bf3cc5) - V4: Single-file implementation of form components. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.3.0-beta.6
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.3.3
### Patch Changes
- Updated dependencies [[`e70805d54`](https://github.com/gradio-app/gradio/commit/e70805d54cc792452545f5d8eccc1aa0212a4695)]:
- @gradio/atoms@0.2.0
- @gradio/statustracker@0.2.3
## 0.3.2
### Patch Changes
- Updated dependencies []:
- @gradio/utils@0.1.2
- @gradio/atoms@0.1.4
- @gradio/statustracker@0.2.2
## 0.3.1
### Patch Changes
- Updated dependencies []:
- @gradio/atoms@0.1.3
- @gradio/statustracker@0.2.1
## 0.3.0
### Features
- [#5554](https://github.com/gradio-app/gradio/pull/5554) [`75ddeb390`](https://github.com/gradio-app/gradio/commit/75ddeb390d665d4484667390a97442081b49a423) - Accessibility Improvements. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.2.0
### Features
- [#5384](https://github.com/gradio-app/gradio/pull/5384) [`ddc02268`](https://github.com/gradio-app/gradio/commit/ddc02268f731bd2ed04b7a5854accf3383f9a0da) - Allows the `gr.Dropdown` to have separate names and values, as well as enables `allow_custom_value` for multiselect dropdown. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.1.2
### Patch Changes
- Updated dependencies [[`afac0006`](https://github.com/gradio-app/gradio/commit/afac0006337ce2840cf497cd65691f2f60ee5912)]:
- @gradio/statustracker@0.2.0
- @gradio/utils@0.1.1
- @gradio/atoms@0.1.2
## 0.1.1
### Patch Changes
- Updated dependencies [[`abf1c57d`](https://github.com/gradio-app/gradio/commit/abf1c57d7d85de0df233ee3b38aeb38b638477db)]:
- @gradio/utils@0.1.0
- @gradio/atoms@0.1.1
- @gradio/statustracker@0.1.1
## 0.1.0
### Highlights
#### Improve startup performance and markdown support ([#5279](https://github.com/gradio-app/gradio/pull/5279) [`fe057300`](https://github.com/gradio-app/gradio/commit/fe057300f0672c62dab9d9b4501054ac5d45a4ec))
##### Improved markdown support
We now have better support for markdown in `gr.Markdown` and `gr.Dataframe`. Including syntax highlighting and Github Flavoured Markdown. We also have more consistent markdown behaviour and styling.
##### Various performance improvements
These improvements will be particularly beneficial to large applications.
- Rather than attaching events manually, they are now delegated, leading to a significant performance improvement and addressing a performance regression introduced in a recent version of Gradio. App startup for large applications is now around twice as fast.
- Optimised the mounting of individual components, leading to a modest performance improvement during startup (~30%).
- Corrected an issue that was causing markdown to re-render infinitely.
- Ensured that the `gr.3DModel` does re-render prematurely.
Thanks [@pngwn](https://github.com/pngwn)!
### Features
- [#5215](https://github.com/gradio-app/gradio/pull/5215) [`fbdad78a`](https://github.com/gradio-app/gradio/commit/fbdad78af4c47454cbb570f88cc14bf4479bbceb) - Lazy load interactive or static variants of a component individually, rather than loading both variants regardless. This change will improve performance for many applications. Thanks [@pngwn](https://github.com/pngwn)!
- [#5216](https://github.com/gradio-app/gradio/pull/5216) [`4b58ea6d`](https://github.com/gradio-app/gradio/commit/4b58ea6d98e7a43b3f30d8a4cb6f379bc2eca6a8) - Update i18n tokens and locale files. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#5232](https://github.com/gradio-app/gradio/pull/5232) [`c57d4c23`](https://github.com/gradio-app/gradio/commit/c57d4c232a97e03b4671f9e9edc3af456438fe89) - `gr.Radio` and `gr.CheckboxGroup` can now accept different names and values. Thanks [@abidlabs](https://github.com/abidlabs)!
|
gradio-app/gradio/blob/main/js/checkboxgroup/CHANGELOG.md
|
The Exploration/Exploitation trade-off [[exp-exp-tradeoff]]
Finally, before looking at the different methods to solve Reinforcement Learning problems, we must cover one more very important topic: *the exploration/exploitation trade-off.*
- *Exploration* is exploring the environment by trying random actions in order to **find more information about the environment.**
- *Exploitation* is **exploiting known information to maximize the reward.**
Remember, the goal of our RL agent is to maximize the expected cumulative reward. However, **we can fall into a common trap**.
Let’s take an example:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/exp_1.jpg" alt="Exploration" width="100%">
In this game, our mouse can have an **infinite amount of small cheese** (+1 each). But at the top of the maze, there is a gigantic sum of cheese (+1000).
However, if we only focus on exploitation, our agent will never reach the gigantic sum of cheese. Instead, it will only exploit **the nearest source of rewards,** even if this source is small (exploitation).
But if our agent does a little bit of exploration, it can **discover the big reward** (the pile of big cheese).
This is what we call the exploration/exploitation trade-off. We need to balance how much we **explore the environment** and how much we **exploit what we know about the environment.**
Therefore, we must **define a rule that helps to handle this trade-off**. We’ll see the different ways to handle it in the future units.
If it’s still confusing, **think of a real problem: the choice of picking a restaurant:**
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/exp_2.jpg" alt="Exploration">
<figcaption>Source: <a href="https://inst.eecs.berkeley.edu/~cs188/sp20/assets/lecture/lec15_6up.pdf"> Berkley AI Course</a>
</figcaption>
</figure>
- *Exploitation*: You go to the same one that you know is good every day and **take the risk to miss another better restaurant.**
- *Exploration*: Try restaurants you never went to before, with the risk of having a bad experience **but the probable opportunity of a fantastic experience.**
To recap:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/expexpltradeoff.jpg" alt="Exploration Exploitation Tradeoff" width="100%">
|
huggingface/deep-rl-class/blob/main/units/en/unit1/exp-exp-tradeoff.mdx
|
et's see how we can preprocess our data for masked language modeling. As a reminder, masked language modeling is when a model needs to fill the blanks in a sentence. To do this, you just need texts, no labels, as this is a self-supervised problem. To apply this on your own data, just make sure you have all your texts gathered in one column of your dataset. Before we start randomly masking things, we will need to somehow make all those texts the same length to batch them together. The first way to make all the texts the same length is the one we used in text classification. let's pad the short texts and truncate the long ones. As we have seen when we processed data for text classification, this is all done by our tokenizer with the right options for padding and truncation. This will however make us lose a lot of texts if the examples in our dataset are very long, compared to the context length we picked. Here, all the portion in gray is lost. This is why a second way to generate samples of text with the same length is to chunk our text in pieces of context lengths, instead of discarding everything after the first chunk. There will probably be a remainder of length smaller than the context size, which we can choose to keep and pad or ignore. Here is how we can apply this in practice, by just adding the return overflowing tokens option in our tokenizer call. Note how this gives us a bigger dataset! This second way of chunking is ideal if all your texts are very long, but it won't work as nicely if you have a variety of lengths in the texts. In this case, the best option is to concatenate all your tokenized texts in one big stream, with a special tokens to indicate when you pass from one document to the other, and only then split the big stream into chunks. Here is how it can be done with code, with one loop to concatenate all the texts and another one to chunk it. Notice how it reduces the number of samples in our dataset here, there must have been quite a few short entries! Once this is done, the masking is the easy part. There is a data collator designed specifically for this in the Transformers library. You can use it directly in the Trainer, or when converting your datasets to tensorflow datasets before doing Keras.fit, with the to_tf_dataset method.
|
huggingface/course/blob/main/subtitles/en/raw/chapter7/03a_mlm-processing.md
|
# Sequence to Sequence Training and Evaluation
This directory contains examples for finetuning and evaluating transformers on summarization and translation tasks.
Author: Sam Shleifer (https://github.com/sshleifer)
### Supported Architectures
- `BartForConditionalGeneration` (and anything that inherits from it)
- `MarianMTModel`
- `PegasusForConditionalGeneration`
- `MBartForConditionalGeneration`
- `FSMTForConditionalGeneration`
- `T5ForConditionalGeneration`
# Note
⚠️ This project should be run with pytorch-lightning==1.0.4 which has a potential security vulnerability
## Datasets
#### XSUM
```bash
cd examples/contrib/pytorch-lightning/seq2seq
wget https://cdn-datasets.huggingface.co/summarization/xsum.tar.gz
tar -xzvf xsum.tar.gz
export XSUM_DIR=${PWD}/xsum
```
this should make a directory called `xsum/` with files like `test.source`.
To use your own data, copy that files format. Each article to be summarized is on its own line.
#### CNN/DailyMail
```bash
cd examples/contrib/pytorch-lightning/seq2seq
wget https://cdn-datasets.huggingface.co/summarization/cnn_dm_v2.tgz
tar -xzvf cnn_dm_v2.tgz # empty lines removed
mv cnn_cln cnn_dm
export CNN_DIR=${PWD}/cnn_dm
```
this should make a directory called `cnn_dm/` with 6 files.
#### WMT16 English-Romanian Translation Data
download with this command:
```bash
wget https://cdn-datasets.huggingface.co/translation/wmt_en_ro.tar.gz
tar -xzvf wmt_en_ro.tar.gz
export ENRO_DIR=${PWD}/wmt_en_ro
```
this should make a directory called `wmt_en_ro/` with 6 files.
#### WMT English-German
```bash
wget https://cdn-datasets.huggingface.co/translation/wmt_en_de.tgz
tar -xzvf wmt_en_de.tgz
export DATA_DIR=${PWD}/wmt_en_de
```
#### FSMT datasets (wmt)
Refer to the scripts starting with `eval_` under:
https://github.com/huggingface/transformers/tree/main/scripts/fsmt
#### Pegasus (multiple datasets)
Multiple eval datasets are available for download from:
https://github.com/stas00/porting/tree/master/datasets/pegasus
#### Your Data
If you are using your own data, it must be formatted as one directory with 6 files:
```
train.source
train.target
val.source
val.target
test.source
test.target
```
The `.source` files are the input, the `.target` files are the desired output.
### Potential issues
- native AMP (`--fp16` and no apex) may lead to a huge memory leak and require 10x gpu memory. This has been fixed in pytorch-nightly and the minimal official version to have this fix will be pytorch-1.8. Until then if you have to use mixed precision please use AMP only with pytorch-nightly or NVIDIA's apex. Reference: https://github.com/huggingface/transformers/issues/8403
### Tips and Tricks
General Tips:
- since you need to run from this folder, and likely need to modify code, the easiest workflow is fork transformers, clone your fork, and run `pip install -e .` before you get started.
- try `--freeze_encoder` or `--freeze_embeds` for faster training/larger batch size. (3hr per epoch with bs=8, see the "xsum_shared_task" command below)
- `fp16_opt_level=O1` (the default works best).
- In addition to the pytorch-lightning .ckpt checkpoint, a transformers checkpoint will be saved.
Load it with `BartForConditionalGeneration.from_pretrained(f'{output_dir}/best_tfmr)`.
- At the moment, `--do_predict` does not work in a multi-gpu setting. You need to use `evaluate_checkpoint` or the `run_eval.py` code.
- This warning can be safely ignored:
> "Some weights of BartForConditionalGeneration were not initialized from the model checkpoint at facebook/bart-large-xsum and are newly initialized: ['final_logits_bias']"
- Both finetuning and eval are 30% faster with `--fp16`. For that you need to [install apex](https://github.com/NVIDIA/apex#quick-start).
- Read scripts before you run them!
Summarization Tips:
- (summ) 1 epoch at batch size 1 for bart-large takes 24 hours and requires 13GB GPU RAM with fp16 on an NVIDIA-V100.
- If you want to run experiments on improving the summarization finetuning process, try the XSUM Shared Task (below). It's faster to train than CNNDM because the summaries are shorter.
- For CNN/DailyMail, the default `val_max_target_length` and `test_max_target_length` will truncate the ground truth labels, resulting in slightly higher rouge scores. To get accurate rouge scores, you should rerun calculate_rouge on the `{output_dir}/test_generations.txt` file saved by `trainer.test()`
- `--max_target_length=60 --val_max_target_length=60 --test_max_target_length=100 ` is a reasonable setting for XSUM.
- `wandb` can be used by specifying `--logger_name wandb`. It is useful for reproducibility. Specify the environment variable `WANDB_PROJECT='hf_xsum'` to do the XSUM shared task.
- If you are finetuning on your own dataset, start from `distilbart-cnn-12-6` if you want long summaries and `distilbart-xsum-12-6` if you want short summaries.
(It rarely makes sense to start from `bart-large` unless you are a researching finetuning methods).
**Update 2018-07-18**
Datasets: `LegacySeq2SeqDataset` will be used for all tokenizers without a `prepare_seq2seq_batch` method. Otherwise, `Seq2SeqDataset` will be used.
Future work/help wanted: A new dataset to support multilingual tasks.
### Finetuning Scripts
All finetuning bash scripts call finetune.py (or distillation.py) with reasonable command line arguments. They usually require extra command line arguments to work.
To see all the possible command line options, run:
```bash
./finetune.py --help
```
### Finetuning Training Params
To override the pretrained model's training params, you can pass them to `./finetune.sh`:
```bash
./finetune.sh \
[...]
--encoder_layerdrop 0.1 \
--decoder_layerdrop 0.1 \
--dropout 0.1 \
--attention_dropout 0.1 \
```
### Summarization Finetuning
Run/modify `finetune.sh`
The following command should work on a 16GB GPU:
```bash
./finetune.sh \
--data_dir $XSUM_DIR \
--train_batch_size=1 \
--eval_batch_size=1 \
--output_dir=xsum_results \
--num_train_epochs 6 \
--model_name_or_path facebook/bart-large
```
There is a starter finetuning script for pegasus at `finetune_pegasus_xsum.sh`.
### Translation Finetuning
First, follow the wmt_en_ro download instructions.
Then you can finetune mbart_cc25 on english-romanian with the following command.
**Recommendation:** Read and potentially modify the fairly opinionated defaults in `train_mbart_cc25_enro.sh` script before running it.
Best performing command:
```bash
# optionally
export ENRO_DIR='wmt_en_ro' # Download instructions above
# export WANDB_PROJECT="MT" # optional
export MAX_LEN=128
export BS=4
./train_mbart_cc25_enro.sh --output_dir enro_finetune_baseline --label_smoothing 0.1 --fp16_opt_level=O1 --logger_name wandb --sortish_sampler
```
This should take < 6h/epoch on a 16GB v100 and achieve test BLEU above 26
To get results in line with fairseq, you need to do some postprocessing. (see `romanian_postprocessing.md`)
MultiGPU command
(using 8 GPUS as an example)
```bash
export ENRO_DIR='wmt_en_ro' # Download instructions above
# export WANDB_PROJECT="MT" # optional
export MAX_LEN=128
export BS=4
./train_mbart_cc25_enro.sh --output_dir enro_finetune_baseline --gpus 8 --logger_name wandb
```
### Finetuning Outputs
As you train, `output_dir` will be filled with files, that look kind of like this (comments are mine).
Some of them are metrics, some of them are checkpoints, some of them are metadata. Here is a quick tour:
```bash
output_dir
├── best_tfmr # this is a huggingface checkpoint generated by save_pretrained. It is the same model as the PL .ckpt file below
│ ├── config.json
│ ├── merges.txt
│ ├── pytorch_model.bin
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── vocab.json
├── git_log.json # repo, branch, and commit hash
├── val_avg_rouge2=0.1984-step_count=11.ckpt # this is a pytorch lightning checkpoint associated with the best val score. (it will be called BLEU for MT)
├── metrics.json # new validation metrics will continually be appended to this
├── student # this is a huggingface checkpoint generated by SummarizationDistiller. It is the student before it gets finetuned.
│ ├── config.json
│ └── pytorch_model.bin
├── test_generations.txt
# ^^ are the summaries or translations produced by your best checkpoint on the test data. Populated when training is done
├── test_results.txt # a convenience file with the test set metrics. This data is also in metrics.json['test']
├── hparams.pkl # the command line args passed after some light preprocessing. Should be saved fairly quickly.
```
After training, you can recover the best checkpoint by running
```python
from transformers import AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained(f'{output_dir}/best_tfmr')
```
### Converting pytorch-lightning checkpoints
pytorch lightning ``-do_predict`` often fails, after you are done training, the best way to evaluate your model is to convert it.
This should be done for you, with a file called `{save_dir}/best_tfmr`.
If that file doesn't exist but you have a lightning `.ckpt` file, you can run
```bash
python convert_pl_checkpoint_to_hf.py PATH_TO_CKPT randomly_initialized_hf_model_path save_dir/best_tfmr
```
Then either `run_eval` or `run_distributed_eval` with `save_dir/best_tfmr` (see previous sections)
# Experimental Features
These features are harder to use and not always useful.
### Dynamic Batch Size for MT
`finetune.py` has a command line arg `--max_tokens_per_batch` that allows batches to be dynamically sized.
This feature can only be used:
- with fairseq installed
- on 1 GPU
- without sortish sampler
- after calling `./save_len_file.py $tok $data_dir`
For example,
```bash
./save_len_file.py Helsinki-NLP/opus-mt-en-ro wmt_en_ro
./dynamic_bs_example.sh --max_tokens_per_batch=2000 --output_dir benchmark_dynamic_bs
```
splits `wmt_en_ro/train` into 11,197 uneven lengthed batches and can finish 1 epoch in 8 minutes on a v100.
For comparison,
```bash
./dynamic_bs_example.sh --sortish_sampler --train_batch_size 48
```
uses 12,723 batches of length 48 and takes slightly more time 9.5 minutes.
The feature is still experimental, because:
+ we can make it much more robust if we have memory mapped/preprocessed datasets.
+ The speedup over sortish sampler is not that large at the moment.
# DistilBART
<!---It should be called distilling bart and pegasus, but I don't want to break the link in the paper.-->
This section describes all code and artifacts from our [Paper](http://arxiv.org/abs/2010.13002)

+ For the CNN/DailyMail dataset, (relatively longer, more extractive summaries), we found a simple technique that works, which we call "Shrink and Fine-tune", or SFT.
you just copy alternating layers from `facebook/bart-large-cnn` and fine-tune more on the cnn/dm data. `sshleifer/distill-pegasus-cnn-16-4`, `sshleifer/distilbart-cnn-12-6` and all other checkpoints under `sshleifer` that start with `distilbart-cnn` were trained this way.
+ For the XSUM dataset, training on pseudo-labels worked best for Pegasus (`sshleifer/distill-pegasus-16-4`), while training with KD worked best for `distilbart-xsum-12-6`
+ For `sshleifer/dbart-xsum-12-3`
+ We ran 100s experiments, and didn't want to document 100s of commands. If you want a command to replicate a figure from the paper that is not documented below, feel free to ask on the [forums](https://discuss.huggingface.co/t/seq2seq-distillation-methodology-questions/1270) and tag `@sshleifer`.
+ You can see the performance tradeoffs of model sizes [here](https://docs.google.com/spreadsheets/d/1EkhDMwVO02m8jCD1cG3RoFPLicpcL1GQHTQjfvDYgIM/edit#gid=0).
and more granular timing results [here](https://docs.google.com/spreadsheets/d/1EkhDMwVO02m8jCD1cG3RoFPLicpcL1GQHTQjfvDYgIM/edit#gid=1753259047&range=B2:I23).
### Evaluation
use [run_distributed_eval](./run_distributed_eval.py), with the following convenient alias
```bash
deval () {
proc=$1
m=$2
dd=$3
sd=$4
shift
shift
shift
shift
python -m torch.distributed.launch --nproc_per_node=$proc run_distributed_eval.py \
--model_name $m --save_dir $sd --data_dir $dd $@
}
```
On a 1 GPU system, here are four commands (that assume `xsum`, `cnn_dm` are downloaded, cmd-F for those links in this file).
`distilBART`:
```bash
deval 1 sshleifer/distilbart-xsum-12-3 xsum dbart_12_3_xsum_eval --fp16 # --help for more choices.
deval 1 sshleifer/distilbart-cnn_dm-12-6 cnn_dm dbart_12_6_cnn_eval --fp16
```
`distill-pegasus`:
```bash
deval 1 sshleifer/distill-pegasus-cnn-16-4 cnn_dm dpx_cnn_eval
deval 1 sshleifer/distill-pegasus-xsum-16-4 xsum dpx_xsum_eval
```
### Distillation
+ For all of the following commands, you can get roughly equivalent result and faster run times by passing `--num_beams=4`. That's not what we did for the paper.
+ Besides the KD section, you can also run commands with the built-in transformers trainer. See, for example, [builtin_trainer/train_distilbart_cnn.sh](./builtin_trainer/train_distilbart_cnn.sh).
+ Large performance deviations (> 5X slower or more than 0.5 Rouge-2 worse), should be reported.
+ Multi-gpu (controlled with `--gpus` should work, but might require more epochs).
#### Recommended Workflow
+ Get your dataset in the right format. (see 6 files above).
+ Find a teacher model [Pegasus](https://huggingface.co/models?search=pegasus) (slower, better ROUGE) or `facebook/bart-large-xsum`/`facebook/bart-large-cnn` (faster, slightly lower.).
Choose the checkpoint where the corresponding dataset is most similar (or identical to) your dataset.
+ Follow the sections in order below. You can stop after SFT if you are satisfied, or move on to pseudo-labeling if you want more performance.
+ student size: If you want a close to free 50% speedup, cut the decoder in half. If you want a larger speedup, cut it in 4.
+ If your SFT run starts at a validation ROUGE-2 that is more than 10 pts below the teacher's validation ROUGE-2, you have a bug. Switching to a more expensive technique will not help. Try setting a breakpoint and looking at generation and truncation defaults/hyper-parameters, and share your experience on the forums!
#### Initialization
We use [make_student.py](./make_student.py) to copy alternating layers from the teacher, and save the resulting model to disk
```bash
python make_student.py facebook/bart-large-xsum --save_path dbart_xsum_12_3 -e 12 -d 3
```
or for `pegasus-xsum`
```bash
python make_student.py google/pegasus-xsum --save_path dpx_xsum_16_4 --e 16 --d 4
```
we now have an initialized student saved to `dbart_xsum_12_3`, which we will use for the following commands.
+ Extension: To replicate more complicated initialize experiments in section 6.1, or try your own. Use the `create_student_by_copying_alternating_layers` function.
#### Pegasus
+ The following commands are written for BART and will require, at minimum, the following modifications
+ reduce batch size, and increase gradient accumulation steps so that the product `gpus * batch size * gradient_accumulation_steps = 256`. We used `--learning-rate` = 1e-4 * gradient accumulation steps.
+ don't use fp16
+ `--tokenizer_name google/pegasus-large`
### SFT (No Teacher Distillation)
You don't need `distillation.py`, you can just run:
```bash
python finetune.py \
--data_dir xsum \
--freeze_encoder --freeze_embeds \
--learning_rate=3e-4 \
--do_train \
--do_predict \
--fp16 --fp16_opt_level=O1 \
--val_check_interval 0.1 --n_val 1000 --eval_beams 2 --length_penalty=0.5 \
--max_target_length=60 --val_max_target_length=60 --test_max_target_length=100 \
--model_name_or_path dbart_xsum_12_3 \
--train_batch_size=64 --eval_batch_size=64 \
--sortish_sampler \
--num_train_epochs=6 \
--warmup_steps 500 \
--output_dir distilbart_xsum_sft_12_3 --gpus 1
```
+ Note: The command that produced `sshleifer/distilbart-cnn-12-6` is at [train_distilbart_cnn.sh](./[train_distilbart_cnn.sh)
```bash
./train_distilbart_cnn.sh
```
<!--- runtime: 6H on NVIDIA RTX 24GB GPU -->
+ Tip: You can get the same simple distillation logic by using `distillation.py --no_teacher ` followed by identical arguments as the ones in `train_distilbart_cnn.sh`.
If you are using `wandb` and comparing the two distillation methods, using this entry point will make your logs consistent,
because you will have the same hyper-parameters logged in every run.
### Pseudo-Labeling
+ You don't need `distillation.py`.
+ Instructions to generate pseudo-labels and use pre-computed pseudo-labels can be found [here](./precomputed_pseudo_labels.md).
Simply run `finetune.py` with one of those pseudo-label datasets as `--data_dir` (`DATA`, below).
```bash
python finetune.py \
--teacher facebook/bart-large-xsum --data_dir DATA \
--freeze_encoder --freeze_embeds \
--learning_rate=3e-4 \
--do_train \
--do_predict \
--fp16 --fp16_opt_level=O1 \
--val_check_interval 0.1 --n_val 1000 --eval_beams 2 --length_penalty=0.5 \
--max_target_length=60 --val_max_target_length=60 --test_max_target_length=100 \
--model_name_or_path dbart_xsum_12_3 \
--train_batch_size=32 --eval_batch_size=32 \
--sortish_sampler \
--num_train_epochs=5 \
--warmup_steps 500 \
--output_dir dbart_xsum_12_3_PL --gpus 1 --logger_name wandb
```
To combine datasets, as in Section 6.2, try something like:
```bash
curl -S https://cdn-datasets.huggingface.co/pseudo/xsum/bart_xsum_pl.tgz | tar -xvz -C .
curl -S https://cdn-datasets.huggingface.co/pseudo/xsum/pegasus_xsum.tgz | tar -xvz -C .
curl -S https://cdn-datasets.huggingface.co/summarization/xsum.tar.gz | tar -xvz -C .
mkdir all_pl
cat bart_xsum_pl/train.source pegasus_xsum/train.source xsum/train.source > all_pl/train.source
cat bart_xsum_pl/train.target pegasus_xsum/train.target xsum/train.target > all_pl/train.target
cp xsum/val* all_pl
cp xsum/test* all_pl
```
then use `all_pl` as DATA in the command above.
#### Direct Knowledge Distillation (KD)
+ In this method, we use try to enforce that the student and teacher produce similar encoder_outputs, logits, and hidden_states using `SummarizationDistiller`.
+ This method was used for `sshleifer/distilbart-xsum-12-6`, `6-6`, and `9-6` checkpoints were produced.
+ You must use [`distillation.py`](./distillation.py). Note that this command initializes the student for you.
The command that produced `sshleifer/distilbart-xsum-12-6` is at [./train_distilbart_xsum.sh](train_distilbart_xsum.sh)
```bash
./train_distilbart_xsum.sh --logger_name wandb --gpus 1
```
+ Expected ROUGE-2 between 21.3 and 21.6, run time ~13H.
+ direct KD + Pegasus is VERY slow and works best with `--supervise_forward --normalize_hidden`.
<!--- runtime: 13H on V-100 16GB GPU. -->
### Citation
```bibtex
@misc{shleifer2020pretrained,
title={Pre-trained Summarization Distillation},
author={Sam Shleifer and Alexander M. Rush},
year={2020},
eprint={2010.13002},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@article{Wolf2019HuggingFacesTS,
title={HuggingFace's Transformers: State-of-the-art Natural Language Processing},
author={Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush},
journal={ArXiv},
year={2019},
volume={abs/1910.03771}
}
```
|
huggingface/transformers/blob/main/examples/research_projects/seq2seq-distillation/README.md
|
--
title: "Red-Teaming Large Language Models"
thumbnail: /blog/assets/red-teaming/thumbnail.png
authors:
- user: nazneen
- user: natolambert
- user: lewtun
---
# Red-Teaming Large Language Models
*Warning: This article is about red-teaming and as such contains examples of model generation that may be offensive or upsetting.*
Large language models (LLMs) trained on an enormous amount of text data are very good at generating realistic text. However, these models often exhibit undesirable behaviors like revealing personal information (such as social security numbers) and generating misinformation, bias, hatefulness, or toxic content. For example, earlier versions of GPT3 were known to exhibit sexist behaviors (see below) and [biases against Muslims](https://dl.acm.org/doi/abs/10.1145/3461702.3462624),
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/red-teaming/gpt3.png"/>
</p>
Once we uncover such undesirable outcomes when using an LLM, we can develop strategies to steer it away from them, as in [Generative Discriminator Guided Sequence Generation (GeDi)](https://arxiv.org/pdf/2009.06367.pdf) or [Plug and Play Language Models (PPLM)](https://arxiv.org/pdf/1912.02164.pdf) for guiding generation in GPT3. Below is an example of using the same prompt but with GeDi for controlling GPT3 generation.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/red-teaming/gedi.png"/>
</p>
Even recent versions of GPT3 produce similarly offensive text when attacked with prompt injection that can become a security concern for downstream applications as discussed in [this blog](https://simonwillison.net/2022/Sep/12/prompt-injection/).
**Red-teaming** *is a form of evaluation that elicits model vulnerabilities that might lead to undesirable behaviors.* Jailbreaking is another term for red-teaming wherein the LLM is manipulated to break away from its guardrails. [Microsoft’s Chatbot Tay](https://blogs.microsoft.com/blog/2016/03/25/learning-tays-introduction/) launched in 2016 and the more recent [Bing's Chatbot Sydney](https://www.nytimes.com/2023/02/16/technology/bing-chatbot-transcript.html) are real-world examples of how disastrous the lack of thorough evaluation of the underlying ML model using red-teaming can be. The origins of the idea of a red-team traces back to adversary simulations and wargames performed by militaries.
The goal of red-teaming language models is to craft a prompt that would trigger the model to generate text that is likely to cause harm. Red-teaming shares some similarities and differences with the more well-known form of evaluation in ML called *adversarial attacks*. The similarity is that both red-teaming and adversarial attacks share the same goal of “attacking” or “fooling” the model to generate content that would be undesirable in a real-world use case. However, adversarial attacks can be unintelligible to humans, for example, by prefixing the string “aaabbbcc” to each prompt because it deteriorates model performance. Many examples of such attacks on various NLP classification and generation tasks is discussed in [Wallace et al., ‘19](https://arxiv.org/abs/1908.07125). Red-teaming prompts, on the other hand, look like regular, natural language prompts.
Red-teaming can reveal model limitations that can cause upsetting user experiences or enable harm by aiding violence or other unlawful activity for a user with malicious intentions. The outputs from red-teaming (just like adversarial attacks) are generally used to train the model to be less likely to cause harm or steer it away from undesirable outputs.
Since red-teaming requires creative thinking of possible model failures, it is a problem with a large search space making it resource intensive. A workaround would be to augment the LLM with a classifier trained to predict whether a given prompt contains topics or phrases that can possibly lead to offensive generations and if the classifier predicts the prompt would lead to a potentially offensive text, generate a canned response. Such a strategy would err on the side of caution. But that would be very restrictive and cause the model to be frequently evasive. So, there is tension between the model being *helpful* (by following instructions) and being *harmless* (or at least less likely to enable harm).
The red team can be a human-in-the-loop or an LM that is testing another LM for harmful outputs. Coming up with red-teaming prompts for models that are fine-tuned for safety and alignment (such as via RLHF or SFT) requires creative thinking in the form of *roleplay attacks* wherein the LLM is instructed to behave as a malicious character [as in Ganguli et al., ‘22](https://arxiv.org/pdf/2209.07858.pdf). Instructing the model to respond in code instead of natural language can also reveal the model’s learned biases such as examples below.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/red-teaming/jb1.png"/>
</p>
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/red-teaming/jb0.png"/>
</p>
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/red-teaming/jb2.png"/>
</p>
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/red-teaming/jb3.png"/>
</p>
See [this](https://twitter.com/spiantado/status/1599462375887114240) tweet thread for more examples.
Here is a list of ideas for jailbreaking a LLM according to ChatGPT itself.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/red-teaming/jailbreak.png"/>
</p>
Red-teaming LLMs is still a nascent research area and the aforementioned strategies could still work in jailbreaking these models, or they have aided the deployment of at-scale machine learning products. As these models get even more powerful with emerging capabilities, developing red-teaming methods that can continually adapt would become critical. Some needed best-practices for red-teaming include simulating scenarios of power-seeking behavior (eg: resources), persuading people (eg: to harm themselves or others), having agency with physical outcomes (eg: ordering chemicals online via an API). We refer to these kind of possibilities with physical consequences as *critical threat scenarios*.
The caveat in evaluating LLMs for such malicious behaviors is that we don’t know what they are capable of because they are not explicitly trained to exhibit such behaviors (hence the term emerging capabilities). Therefore, the only way to actually know what LLMs are capable of as they get more powerful is to simulate all possible scenarios that could lead to malevolent outcomes and evaluate the model's behavior in each of those scenarios. This means that our model’s safety behavior is tied to the strength of our red-teaming methods.
Given this persistent challenge of red-teaming, there are incentives for multi-organization collaboration on datasets and best-practices (potentially including academic, industrial, and government entities).
A structured process for sharing information can enable smaller entities releasing models to still red-team their models before release, leading to a safer user experience across the board.
**Open source datasets for Red-teaming:**
1. Meta’s [Bot Adversarial Dialog dataset](https://github.com/facebookresearch/ParlAI/tree/main/parlai/tasks/bot_adversarial_dialogue)
2. Anthropic’s [red-teaming attempts](https://huggingface.co/datasets/Anthropic/hh-rlhf/tree/main/red-team-attempts)
3. AI2’s [RealToxicityPrompts](https://huggingface.co/datasets/allenai/real-toxicity-prompts)
**Findings from past work on red-teaming LLMs** (from [Anthropic's Ganguli et al. 2022](https://arxiv.org/abs/2209.07858) and [Perez et al. 2022](https://arxiv.org/abs/2202.03286))
1. Few-shot-prompted LMs with helpful, honest, and harmless behavior are *not* harder to red-team than plain LMs.
2. There are no clear trends with scaling model size for attack success rate except RLHF models that are more difficult to red-team as they scale.
3. Models may learn to be harmless by being evasive, there is tradeoff between helpfulness and harmlessness.
4. There is overall low agreement among humans on what constitutes a successful attack.
5. The distribution of the success rate varies across categories of harm with non-violent ones having a higher success rate.
6. Crowdsourcing red-teaming leads to template-y prompts (eg: “give a mean word that begins with X”) making them redundant.
**Future directions:**
1. There is no open-source red-teaming dataset for code generation that attempts to jailbreak a model via code, for example, generating a program that implements a DDOS or backdoor attack.
2. Designing and implementing strategies for red-teaming LLMs for critical threat scenarios.
3. Red-teaming can be resource intensive, both compute and human resource and so would benefit from sharing strategies, open-sourcing datasets, and possibly collaborating for a higher chance of success.
4. Evaluating the tradeoffs between evasiveness and helpfulness.
5. Enumerate the choices based on the above tradeoff and explore the pareto front for red-teaming (similar to [Anthropic's Constitutional AI](https://arxiv.org/pdf/2212.08073.pdf) work)
These limitations and future directions make it clear that red-teaming is an under-explored and crucial component of the modern LLM workflow.
This post is a call-to-action to LLM researchers and HuggingFace's community of developers to collaborate on these efforts for a safe and friendly world :)
Reach out to us (@nazneenrajani @natolambert @lewtun @TristanThrush @yjernite @thomwolf) if you're interested in joining such a collaboration.
*Acknowledgement:* We'd like to thank [Yacine Jernite](https://huggingface.co/yjernite) for his helpful suggestions on correct usage of terms in this blogpost.
|
huggingface/blog/blob/main/red-teaming.md
|
Gradio Demo: digit_classifier
```
!pip install -q gradio tensorflow
```
```
from urllib.request import urlretrieve
import tensorflow as tf
import gradio as gr
urlretrieve(
"https://gr-models.s3-us-west-2.amazonaws.com/mnist-model.h5", "mnist-model.h5"
)
model = tf.keras.models.load_model("mnist-model.h5")
def recognize_digit(image):
image = image.reshape(1, -1)
prediction = model.predict(image).tolist()[0]
return {str(i): prediction[i] for i in range(10)}
im = gr.Image(shape=(28, 28), image_mode="L", invert_colors=False, source="canvas")
demo = gr.Interface(
recognize_digit,
im,
gr.Label(num_top_classes=3),
live=True,
capture_session=True,
)
if __name__ == "__main__":
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/digit_classifier/run.ipynb
|
Metric Card for SQuAD
## Metric description
This metric wraps the official scoring script for version 1 of the [Stanford Question Answering Dataset (SQuAD)](https://huggingface.co/datasets/squad).
SQuAD is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable.
## How to use
The metric takes two files or two lists of question-answers dictionaries as inputs : one with the predictions of the model and the other with the references to be compared to:
```python
from datasets import load_metric
squad_metric = load_metric("squad")
results = squad_metric.compute(predictions=predictions, references=references)
```
## Output values
This metric outputs a dictionary with two values: the average exact match score and the average [F1 score](https://huggingface.co/metrics/f1).
```
{'exact_match': 100.0, 'f1': 100.0}
```
The range of `exact_match` is 0-100, where 0.0 means no answers were matched and 100.0 means all answers were matched.
The range of `f1` is 0-1 -- its lowest possible value is 0, if either the precision or the recall is 0, and its highest possible value is 1.0, which means perfect precision and recall.
### Values from popular papers
The [original SQuAD paper](https://nlp.stanford.edu/pubs/rajpurkar2016squad.pdf) reported an F1 score of 51.0% and an Exact Match score of 40.0%. They also report that human performance on the dataset represents an F1 score of 90.5% and an Exact Match score of 80.3%.
For more recent model performance, see the [dataset leaderboard](https://paperswithcode.com/dataset/squad).
## Examples
Maximal values for both exact match and F1 (perfect match):
```python
from datasets import load_metric
squad_metric = load_metric("squad")
predictions = [{'prediction_text': '1976', 'id': '56e10a3be3433e1400422b22'}]
references = [{'answers': {'answer_start': [97], 'text': ['1976']}, 'id': '56e10a3be3433e1400422b22'}]
results = squad_metric.compute(predictions=predictions, references=references)
results
{'exact_match': 100.0, 'f1': 100.0}
```
Minimal values for both exact match and F1 (no match):
```python
from datasets import load_metric
squad_metric = load_metric("squad")
predictions = [{'prediction_text': '1999', 'id': '56e10a3be3433e1400422b22'}]
references = [{'answers': {'answer_start': [97], 'text': ['1976']}, 'id': '56e10a3be3433e1400422b22'}]
results = squad_metric.compute(predictions=predictions, references=references)
results
{'exact_match': 0.0, 'f1': 0.0}
```
Partial match (2 out of 3 answers correct) :
```python
from datasets import load_metric
squad_metric = load_metric("squad")
predictions = [{'prediction_text': '1976', 'id': '56e10a3be3433e1400422b22'}, {'prediction_text': 'Beyonce', 'id': '56d2051ce7d4791d0090260b'}, {'prediction_text': 'climate change', 'id': '5733b5344776f419006610e1'}]
references = [{'answers': {'answer_start': [97], 'text': ['1976']}, 'id': '56e10a3be3433e1400422b22'}, {'answers': {'answer_start': [233], 'text': ['Beyoncé and Bruno Mars']}, 'id': '56d2051ce7d4791d0090260b'}, {'answers': {'answer_start': [891], 'text': ['climate change']}, 'id': '5733b5344776f419006610e1'}]
results = squad_metric.compute(predictions=predictions, references=references)
results
{'exact_match': 66.66666666666667, 'f1': 66.66666666666667}
```
## Limitations and bias
This metric works only with datasets that have the same format as [SQuAD v.1 dataset](https://huggingface.co/datasets/squad).
The SQuAD dataset does contain a certain amount of noise, such as duplicate questions as well as missing answers, but these represent a minority of the 100,000 question-answer pairs. Also, neither exact match nor F1 score reflect whether models do better on certain types of questions (e.g. who questions) or those that cover a certain gender or geographical area -- carrying out more in-depth error analysis can complement these numbers.
## Citation
@inproceedings{Rajpurkar2016SQuAD10,
title={SQuAD: 100, 000+ Questions for Machine Comprehension of Text},
author={Pranav Rajpurkar and Jian Zhang and Konstantin Lopyrev and Percy Liang},
booktitle={EMNLP},
year={2016}
}
## Further References
- [The Stanford Question Answering Dataset: Background, Challenges, Progress (blog post)](https://rajpurkar.github.io/mlx/qa-and-squad/)
- [Hugging Face Course -- Question Answering](https://huggingface.co/course/chapter7/7)
|
huggingface/datasets/blob/main/metrics/squad/README.md
|
Vision Transformer (ViT)
The **Vision Transformer** is a model for image classification that employs a Transformer-like architecture over patches of the image. This includes the use of [Multi-Head Attention](https://paperswithcode.com/method/multi-head-attention), [Scaled Dot-Product Attention](https://paperswithcode.com/method/scaled) and other architectural features seen in the [Transformer](https://paperswithcode.com/method/transformer) architecture traditionally used for NLP.
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('vit_base_patch16_224', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `vit_base_patch16_224`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('vit_base_patch16_224', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{dosovitskiy2020image,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Alexey Dosovitskiy and Lucas Beyer and Alexander Kolesnikov and Dirk Weissenborn and Xiaohua Zhai and Thomas Unterthiner and Mostafa Dehghani and Matthias Minderer and Georg Heigold and Sylvain Gelly and Jakob Uszkoreit and Neil Houlsby},
year={2020},
eprint={2010.11929},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: Vision Transformer
Paper:
Title: 'An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale'
URL: https://paperswithcode.com/paper/an-image-is-worth-16x16-words-transformers-1
Models:
- Name: vit_base_patch16_224
In Collection: Vision Transformer
Metadata:
FLOPs: 67394605056
Parameters: 86570000
File Size: 346292833
Architecture:
- Attention Dropout
- Convolution
- Dense Connections
- Dropout
- GELU
- Layer Normalization
- Multi-Head Attention
- Scaled Dot-Product Attention
- Tanh Activation
Tasks:
- Image Classification
Training Techniques:
- Cosine Annealing
- Gradient Clipping
- SGD with Momentum
Training Data:
- ImageNet
- JFT-300M
Training Resources: TPUv3
ID: vit_base_patch16_224
LR: 0.0008
Epochs: 90
Dropout: 0.0
Crop Pct: '0.9'
Batch Size: 4096
Image Size: '224'
Warmup Steps: 10000
Weight Decay: 0.03
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/5f9aff395c224492e9e44248b15f44b5cc095d9c/timm/models/vision_transformer.py#L503
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_base_p16_224-80ecf9dd.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.78%
Top 5 Accuracy: 96.13%
- Name: vit_base_patch16_384
In Collection: Vision Transformer
Metadata:
FLOPs: 49348245504
Parameters: 86860000
File Size: 347460194
Architecture:
- Attention Dropout
- Convolution
- Dense Connections
- Dropout
- GELU
- Layer Normalization
- Multi-Head Attention
- Scaled Dot-Product Attention
- Tanh Activation
Tasks:
- Image Classification
Training Techniques:
- Cosine Annealing
- Gradient Clipping
- SGD with Momentum
Training Data:
- ImageNet
- JFT-300M
Training Resources: TPUv3
ID: vit_base_patch16_384
Crop Pct: '1.0'
Momentum: 0.9
Batch Size: 512
Image Size: '384'
Weight Decay: 0.0
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/5f9aff395c224492e9e44248b15f44b5cc095d9c/timm/models/vision_transformer.py#L522
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_base_p16_384-83fb41ba.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 84.2%
Top 5 Accuracy: 97.22%
- Name: vit_base_patch32_384
In Collection: Vision Transformer
Metadata:
FLOPs: 12656142336
Parameters: 88300000
File Size: 353210979
Architecture:
- Attention Dropout
- Convolution
- Dense Connections
- Dropout
- GELU
- Layer Normalization
- Multi-Head Attention
- Scaled Dot-Product Attention
- Tanh Activation
Tasks:
- Image Classification
Training Techniques:
- Cosine Annealing
- Gradient Clipping
- SGD with Momentum
Training Data:
- ImageNet
- JFT-300M
Training Resources: TPUv3
ID: vit_base_patch32_384
Crop Pct: '1.0'
Momentum: 0.9
Batch Size: 512
Image Size: '384'
Weight Decay: 0.0
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/5f9aff395c224492e9e44248b15f44b5cc095d9c/timm/models/vision_transformer.py#L532
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_base_p32_384-830016f5.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.66%
Top 5 Accuracy: 96.13%
- Name: vit_base_resnet50_384
In Collection: Vision Transformer
Metadata:
FLOPs: 49461491712
Parameters: 98950000
File Size: 395854632
Architecture:
- Attention Dropout
- Convolution
- Dense Connections
- Dropout
- GELU
- Layer Normalization
- Multi-Head Attention
- Scaled Dot-Product Attention
- Tanh Activation
Tasks:
- Image Classification
Training Techniques:
- Cosine Annealing
- Gradient Clipping
- SGD with Momentum
Training Data:
- ImageNet
- JFT-300M
Training Resources: TPUv3
ID: vit_base_resnet50_384
Crop Pct: '1.0'
Momentum: 0.9
Batch Size: 512
Image Size: '384'
Weight Decay: 0.0
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/5f9aff395c224492e9e44248b15f44b5cc095d9c/timm/models/vision_transformer.py#L653
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_base_resnet50_384-9fd3c705.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 84.99%
Top 5 Accuracy: 97.3%
- Name: vit_large_patch16_224
In Collection: Vision Transformer
Metadata:
FLOPs: 119294746624
Parameters: 304330000
File Size: 1217350532
Architecture:
- Attention Dropout
- Convolution
- Dense Connections
- Dropout
- GELU
- Layer Normalization
- Multi-Head Attention
- Scaled Dot-Product Attention
- Tanh Activation
Tasks:
- Image Classification
Training Techniques:
- Cosine Annealing
- Gradient Clipping
- SGD with Momentum
Training Data:
- ImageNet
- JFT-300M
Training Resources: TPUv3
ID: vit_large_patch16_224
Crop Pct: '0.9'
Momentum: 0.9
Batch Size: 512
Image Size: '224'
Weight Decay: 0.0
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/5f9aff395c224492e9e44248b15f44b5cc095d9c/timm/models/vision_transformer.py#L542
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_large_p16_224-4ee7a4dc.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 83.06%
Top 5 Accuracy: 96.44%
- Name: vit_large_patch16_384
In Collection: Vision Transformer
Metadata:
FLOPs: 174702764032
Parameters: 304720000
File Size: 1218907013
Architecture:
- Attention Dropout
- Convolution
- Dense Connections
- Dropout
- GELU
- Layer Normalization
- Multi-Head Attention
- Scaled Dot-Product Attention
- Tanh Activation
Tasks:
- Image Classification
Training Techniques:
- Cosine Annealing
- Gradient Clipping
- SGD with Momentum
Training Data:
- ImageNet
- JFT-300M
Training Resources: TPUv3
ID: vit_large_patch16_384
Crop Pct: '1.0'
Momentum: 0.9
Batch Size: 512
Image Size: '384'
Weight Decay: 0.0
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/5f9aff395c224492e9e44248b15f44b5cc095d9c/timm/models/vision_transformer.py#L561
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_large_p16_384-b3be5167.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 85.17%
Top 5 Accuracy: 97.36%
- Name: vit_small_patch16_224
In Collection: Vision Transformer
Metadata:
FLOPs: 28236450816
Parameters: 48750000
File Size: 195031454
Architecture:
- Attention Dropout
- Convolution
- Dense Connections
- Dropout
- GELU
- Layer Normalization
- Multi-Head Attention
- Scaled Dot-Product Attention
- Tanh Activation
Tasks:
- Image Classification
Training Techniques:
- Cosine Annealing
- Gradient Clipping
- SGD with Momentum
Training Data:
- ImageNet
- JFT-300M
Training Resources: TPUv3
ID: vit_small_patch16_224
Crop Pct: '0.9'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/5f9aff395c224492e9e44248b15f44b5cc095d9c/timm/models/vision_transformer.py#L490
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/vit_small_p16_224-15ec54c9.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.85%
Top 5 Accuracy: 93.42%
-->
|
huggingface/pytorch-image-models/blob/main/docs/models/vision-transformer.md
|
--
title: Accuracy
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
Accuracy is the proportion of correct predictions among the total number of cases processed. It can be computed with:
Accuracy = (TP + TN) / (TP + TN + FP + FN)
Where:
TP: True positive
TN: True negative
FP: False positive
FN: False negative
---
# Metric Card for Accuracy
## Metric Description
Accuracy is the proportion of correct predictions among the total number of cases processed. It can be computed with:
Accuracy = (TP + TN) / (TP + TN + FP + FN)
Where:
TP: True positive
TN: True negative
FP: False positive
FN: False negative
## How to Use
At minimum, this metric requires predictions and references as inputs.
```python
>>> accuracy_metric = evaluate.load("accuracy")
>>> results = accuracy_metric.compute(references=[0, 1], predictions=[0, 1])
>>> print(results)
{'accuracy': 1.0}
```
### Inputs
- **predictions** (`list` of `int`): Predicted labels.
- **references** (`list` of `int`): Ground truth labels.
- **normalize** (`boolean`): If set to False, returns the number of correctly classified samples. Otherwise, returns the fraction of correctly classified samples. Defaults to True.
- **sample_weight** (`list` of `float`): Sample weights Defaults to None.
### Output Values
- **accuracy**(`float` or `int`): Accuracy score. Minimum possible value is 0. Maximum possible value is 1.0, or the number of examples input, if `normalize` is set to `True`.. A higher score means higher accuracy.
Output Example(s):
```python
{'accuracy': 1.0}
```
This metric outputs a dictionary, containing the accuracy score.
#### Values from Popular Papers
Top-1 or top-5 accuracy is often used to report performance on supervised classification tasks such as image classification (e.g. on [ImageNet](https://paperswithcode.com/sota/image-classification-on-imagenet)) or sentiment analysis (e.g. on [IMDB](https://paperswithcode.com/sota/text-classification-on-imdb)).
### Examples
Example 1-A simple example
```python
>>> accuracy_metric = evaluate.load("accuracy")
>>> results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0])
>>> print(results)
{'accuracy': 0.5}
```
Example 2-The same as Example 1, except with `normalize` set to `False`.
```python
>>> accuracy_metric = evaluate.load("accuracy")
>>> results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0], normalize=False)
>>> print(results)
{'accuracy': 3.0}
```
Example 3-The same as Example 1, except with `sample_weight` set.
```python
>>> accuracy_metric = evaluate.load("accuracy")
>>> results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0], sample_weight=[0.5, 2, 0.7, 0.5, 9, 0.4])
>>> print(results)
{'accuracy': 0.8778625954198473}
```
## Limitations and Bias
This metric can be easily misleading, especially in the case of unbalanced classes. For example, a high accuracy might be because a model is doing well, but if the data is unbalanced, it might also be because the model is only accurately labeling the high-frequency class. In such cases, a more detailed analysis of the model's behavior, or the use of a different metric entirely, is necessary to determine how well the model is actually performing.
## Citation(s)
```bibtex
@article{scikit-learn,
title={Scikit-learn: Machine Learning in {P}ython},
author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V.
and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P.
and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and
Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.},
journal={Journal of Machine Learning Research},
volume={12},
pages={2825--2830},
year={2011}
}
```
## Further References
|
huggingface/evaluate/blob/main/metrics/accuracy/README.md
|
--
title: "2023, year of open LLMs"
thumbnail: /blog/assets/cv_state/thumbnail.png
authors:
- user: clefourrier
---
# 2023, year of open LLMs
2023 has seen a surge of public interest in Large Language Models (LLMs), and now that most people have an idea of what they are and can do, the public debates around open versus closed source have reached a wide audience as well. At Hugging Face, we follow open models with great interest, as they allow research to be reproducible, empower the community to participate in the development of AI models, permit the easier scrutiny of model biases and limitations, and lower the overall carbon impact of our field by favoring checkpoint reuse (among [many other benefits](https://huggingface.co/papers/2302.04844)).
So let's do a retrospective of the year in open LLMs!
*To keep this document manageable in length, we won't look at code models.*
## 🍜 Recipe for a pretrained Large Language Model
First, how do you get a Large Language Model? (Feel free to skim this section if you already know!)
The model **architecture** (its code) describes its specific implementation and mathematical shape: it is a list of all its parameters, as well as how they interact with inputs. At the moment, most highly performing LLMs are variations on the "decoder-only" Transformer architecture (more details in the [original transformers paper](https://huggingface.co/papers/1706.03762)).
The **training dataset** contains all examples and documents on which the model is trained (aka the parameters are learned), therefore, the specific patterns learned. Most of the time, these documents contain text, either in natural language (ex: French, English, Chinese), a programming language (ex: Python, C), or any kind of structured data expressible as text (ex: tables in markdown or latex, equations, ...).
A **tokenizer** defines how the text from the training dataset is converted to numbers (as a model is a mathematical function and therefore needs numbers as inputs). Tokenization is done by transforming text into sub-units called tokens (which can be words, sub-words, or characters, depending on tokenization methods). The vocabulary size of the tokenizer indicates how many different tokens it knows, typically between 32k and 200k. The size of a dataset is often measured as the **number of tokens** it contains once split in a sequence of these individual, "atomistic" units, and these days range from several hundred billion tokens to several trillion tokens!
**Training hyperparameters** then define how the model is trained. How much should the parameters change to fit each new example? How fast should the model be updated?
Once these parameters have been selected, you only need 1) a lot of computing power to train the model and 2) competent (and kind) people to run and monitor the training. The training itself will consist in instantiating the architecture (creating the matrices on the hardware used for training) and running the training algorithm on the training dataset with the above mentioned hyperparameters. The result is a set of model **weights**. These are the model parameters after learning and what most people mean when discussing access to an open pretrained model. These weights can then be used **inference**, i.e., for prediction on new inputs, for instance, to generate text.
Pretrained LLMs can also be specialized or adapted for a specific task after pretraining, particularly when the weights are openly released. They are then used as a starting point for use cases and applications through a process called **fine-tuning**. Fine-tuning involves applying additional training steps on the model on a different –often more specialized and smaller– dataset to optimize it for a specific application. Even though this step has a cost in terms of compute power needed, it is usually much less costly than training a model from scratch, both financially and environmentally. This is one reason high-quality open-source pretrained models are very interesting, as they can be freely used and built upon by the community even when the practitioners have only access to a limited computing budget.
## 🗝️ 2022, from a race for size to a race for data
What open models were available to the community before 2023?
Until early 2022, the trend in machine learning was that the bigger a model was (i.e. the more parameters it had), the better its performance. In particular, it seemed that models going above specific size thresholds jumped in capabilities, two concepts which were dubbed `emergent abilities` and `scaling laws`. Pretrained open-source model families published in 2022 mostly followed this paradigm.
1. [BLOOM](https://huggingface.co/papers/2211.05100) (BigScience Large Open-science Open-access Multilingual Language Model)
BLOOM is a family of [models](https://huggingface.co/bigscience/bloom) released by BigScience, a collaborative effort including 1000 researchers across 60 countries and 250 institutions, coordinated by Hugging Face, in collaboration with the French organizations GENCI and IDRIS. These models use decoder-only transformers, with minor modifications (post embedding normalization,[^1] and the use of ALiBi positional embeddings [^2]). The biggest model of this family is a 176B parameters model, trained on 350B tokens of multilingual data in 46 human languages and 13 programming languages. Most of the training data was released, and details of its sources, curation, and processing were published. It is the biggest open source massively multilingual model to date.
2. [OPT](https://huggingface.co/papers/2205.01068) (Open Pre-trained Transformer)
The OPT [model](https://huggingface.co/facebook/opt-66b) family was released by Meta. These models use a decoder-only transformers architecture, following the tricks of the GPT-3 paper (a specific weights initialization, pre-normalization), with some changes to the attention mechanism (alternating dense and locally banded attention layers). The biggest model of this family is a 175B parameters model trained on 180B tokens of data from mostly public sources (books, social data through Reddit, news, Wikipedia, and other various internet sources). This model family was of comparable performance to GPT-3 models, using coding optimization to make it less compute-intensive.
3. [GLM-130B](https://huggingface.co/papers/2210.02414) (General Language Model)
[GLM-130B](https://huggingface.co/THUDM/glm-roberta-large) was released by Tsinghua University and Zhipu.AI. It uses a full transformer architecture with some changes (post-layer-normalisation with DeepNorm, rotary embeddings). The 130B parameters model was trained on 400B tokens of English and Chinese internet data (The Pile, Wudao Corpora, and other Chinese corpora). It was also of comparable performance to GPT-3 models.
4. Smaller or more specialized open LLM
Some smaller open-source models were also released, mostly for research purposes: Meta released the [Galactica](https://huggingface.co/papers/2211.09085) series, LLM of up to [120B](https://huggingface.co/facebook/galactica-120b) parameters, pre-trained on 106B tokens of scientific literature, and EleutherAI released the [GPT-NeoX-20B](https://huggingface.co/EleutherAI/gpt-neox-20b) model, an entirely open source (architecture, weights, data included) decoder transformer model trained on 500B tokens (using RoPE and some changes to attention and initialization), to provide a full artifact for scientific investigations.
These huge models were exciting but also very expensive to run! When performing inference (computing predictions from a model), the model needs to be loaded in memory, but a 100B parameters model will typically require 220GB of memory to be loaded (we explain this process below), which is very large, and not accessible to most organization and practitioners!
However, in March 2022, a [new paper](https://huggingface.co/papers/2203.15556) by DeepMind came out, investigating what the optimal ratio of tokens to model parameters is for a given compute budget. In other words, if you only have an amount X of money to spend on model training, what should the respective model and data sizes be? The authors found out that, overall, for the average compute budget being spent on LLMs, models should be smaller but trained on considerably more data. Their own model, Chinchilla (not open source), was a 70B parameters model (a third of the size of the above models) but trained on 1.4T tokens of data (between 3 and 4 times more data). It had similar or better performance than its bigger counterparts, both open and closed source.
This paradigm shift, while probably already known in closed labs took the open science community by storm.
## 🌊 2023, a year of open releases
### The rise of small Large Language Models
2023 saw a wave of decoder style transformers arise, with new pretrained models released every month, and soon every week or even day: LLaMA (by Meta) in February, Pythia (by Eleuther AI) in April, MPT (by MosaicML) in May, X-GEN (by Salesforce) and Falcon (by TIIUAE) in June, Llama 2 (by Meta) in July. Qwen (by Alibaba) and Mistral (by Mistral.AI) in September, Yi (by 01-ai) in November, DeciLM (by Deci), Phi-2, and SOLAR (by Upstage) in December.
All these releases a) included model weights (under varyingly open licenses) and b) had good performance for models on the smaller side (between 3B and 70B parameters), and therefore, they were instantly adopted by the community. Almost all of these models use the decoder transformer architecture, with various tweaks (ALiBi or RoPE, RMS pre-normalization, SwiGLU), as well as some changes to the attention functions (Flash-Attention, GQA, sliding windows) and different code base implementations to optimize for training or inference speed. These tweaks are likely to affect the performance and training speed to some extent; however, as all the architectures have been released publicly with the weights, the core differences that remain are the training data and the licensing of the models.
The first model family in this series was the [LLaMA](https://huggingface.co/papers/2302.13971) family, released by Meta AI. The explicit objective of the researchers was to train a set of models of various sizes with the best possible performances for a given computing budget. For one of the first times, the research team explicitly decided to consider not only the training budget but also the inference cost (for a given performance objective, how much does it cost to run inference with the model). In this perspective, they decided to train smaller models on even more data and for more steps than was usually done, thereby reaching higher performances at a smaller model size (the trade-off being training compute efficiency). The biggest model in the Llama 1 family is a 65B parameters model trained on 1.4T tokens, while the smaller models (resp. 6 and 13B parameters) were trained on 1T tokens. The small 13B LLaMA model outperformed GPT-3 on most benchmarks, and the biggest LLaMA model was state of the art when it came out. The weights were released with a non-commercial license though, limiting the adoption by the community.
The [Pythia](https://huggingface.co/papers/2304.01373) models were released by the open-source non-profit lab Eleuther AI, and were a [suite of LLMs](https://huggingface.co/collections/EleutherAI/pythia-scaling-suite-64fb5dfa8c21ebb3db7ad2e1) of different sizes, trained on completely public data, provided to help researchers to understand the different steps of LLM training.
The [MPT models](https://www.mosaicml.com/blog/mpt-7b), which came out a couple of months later, released by MosaicML, were close in performance but with a license allowing commercial use, and the details of their training mix. The first MPT model was a [7B model](https://huggingface.co/mosaicml/mpt-7b), followed up by 30B versions in June, both trained on 1T tokens of English and code (using data from C4, CommonCrawl, The Stack, S2ORC).
The MPT models were quickly followed by the 7 and 30B [models](https://huggingface.co/tiiuae/falcon-7b) from the [Falcon series](https://huggingface.co/collections/tiiuae/falcon-64fb432660017eeec9837b5a), released by TIIUAE, and trained on 1 to 1.5T tokens of English and code (RefinedWeb, Project Gutemberg, Reddit, StackOverflow, Github, arXiv, Wikipedia, among other sources) - later in the year, a gigantic 180B model was also released. The Falcon models, data, and training process were detailed in a technical report and a [later research paper](https://huggingface.co/papers/2311.16867).
Where previous models were public about their data, from then on, following releases gave close to no information about what was used to train the models, and their efforts cannot be reproduced - however, they provide starting points for the community through the weights released.
Early in the summer came the [X-Gen](https://huggingface.co/papers/2309.03450) [models](https://huggingface.co/Salesforce/xgen-7b-4k-base) from Salesforce, 7B parameters models trained on 1.5T tokens of "natural language and code", in several steps, following a data scheduling system (not all data is introduced at the same time to the model).
X-Gen was a bit over-shadowed by the much visible new [LLaMA-2](https://huggingface.co/papers/2307.09288) family from Meta, a range of [7 to 70B models](https://huggingface.co/meta-llama/Llama-2-7b) trained on 2T tokens "from publicly available sources", with a permissive community license and an extensive process of finetuning from human-preferences (RLHF), so-called alignment procedure.
A couple of months later, the first [model](https://huggingface.co/mistralai/Mistral-7B-v0.1) from the newly created startup Mistral, the so-called [Mistral-7B](https://huggingface.co/papers/2310.06825) was released, trained on an undisclosed number of tokens from data "extracted from the open Web". The end of 2023 was busy with model releases with a second larger model from Mistral (Mixtral 8x7B), a first impressive [model](https://huggingface.co/Deci/DeciLM-7B) from Deci.AI called [DeciLM](https://deci.ai/blog/introducing-DeciLM-7B-the-fastest-and-most-accurate-7b-large-language-model-to-date) as well as a larger merge of models from upstage, [SOLAR](https://huggingface.co/upstage/SOLAR-10.7B-v1.0) also trained on undisclosed amount and sources of data. All these models carried steady increases on the leaderboards and open benchmarks.
In parallel, a notable event of the end of the year 2023 was the rise of performances and a number of models trained in China and openly released. Two bilingual English-Chinese model series were released: [Qwen](https://huggingface.co/papers/2309.16609), from Alibaba, [models](https://huggingface.co/Qwen/Qwen-72B) of 7 to 70B parameters trained on 2.4T tokens, and [Yi](https://huggingface.co/01-ai/Yi-34B), from 01-AI, models of 6 to 34B parameters, trained on 3T tokens. The performance of these models was a step ahead of previous models both on open leaderboards like the [Open LLM leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) and some of the most difficult benchmarks like [Skill-Mix](https://huggingface.co/papers/2310.17567). Another strong contender from late 2023 was the DeepSeek coding model from [DeepSeek AI](https://huggingface.co/deepseek-ai) trained from scratch on 2T tokens, with a composition of 87% code and 13% natural language in both English and Chinese (mostly a code model).
### Dialog models everywhere
Compared to 2022, almost all pretrained models released in 2023 came with both a pre-trained version and a dialog-finetuned version, using one of several existing approaches. While approaches for adapting models to chat-setting were developed in 2022 and before, wide adoption of these techniques really took off in 2023, emphasizing the growing use of these chat models by the general public as well as the growing manual evaluation of the models by chatting with them ("vibe-check" evaluation). We detail the most well-known approaches to adapt pretrained models for chat here, but many variations exist!
**Chat-based fine-tuning** is a variant of supervised fine-tuning, where the annotated data is chat data (multiturn dialogue-like data, much like what you would find on social media) that you fine-tune your model on. You use the same technique as when training your model: for decoder transformers, you teach your model to predict the next words one by one (called an auto-regressive approach).
**Instruction fine-tuning** (IFT) follows the same approach but with instruction datasets, which contain a collection of query-like prompts plus answers (with optional additional input if needed). These datasets teach the models how to follow an instruction and can be human or LLM-generated.
Using large-scale model-outputs synthetic datasets (datasets which are composed of model generations, e.g., generations from GPT-4 either from instructions of from interactions between users and said model) is one of the ways to accomplish instruction and chat finetuning. This is often called `distillation` as it involves taking the knowledge from a high-performing model to train or fine-tune a smaller model.
Both these methods are relatively easy to implement: you just need to find or generate related datasets and then fine-tune your model using the same technique as when training. A great number of instruct datasets were published last year, which improved model performance in dialogue-like setups. For more information on this topic, you can read an intro blog [here](https://huggingface.co/blog/dialog-agents). However, the models, though better, can still not match what humans expect.
**Reinforcement learning from human feedback** (RLHF) is a specific approach that aims to align what the model predicts to what humans like best (depending on specific criteria). It was (at the beginning of the year) a new technique for fine-tuning. From a given prompt, the model generates several possible answers; humans rank these answers; the rankings are used to train what is called a preference model (which learns to give a score reflecting human preference for answers); the preference model is then used to fine-tune the language model using reinforcement learning. For more detailed information, see this [blog post](https://huggingface.co/blog/rlhf), the [original RLHF paper](https://huggingface.co/papers/1909.08593), or the Anthropic paper on [RLHF](https://huggingface.co/papers/2204.05862). It's a costly method (annotating/ranking + training a new model + fine-tuning is quite expensive) that has been mostly used to align models for safety objectives. A less costly variation of this method has been developed that uses a high-quality LLM to rank model outputs instead of humans: **reinforcement learning from AI feedback** (RLAIF).
**Direct preference optimization** (DPO) is another variation of RLHF, but does not require the training and use of a separate preference model - the method requires the same human or AI ranking dataset but uses this data to update the model directly by looking at the difference between its original policy (way of predicting) and the optimal one (which would predict the best-ranked answers). In other words, the aligned model is also the preference model, which makes the optimization procedure a lot simpler while giving what seems to be equivalent final performances.
So, to come back to our wave of small open weights models from (mostly) private companies, a lot of them were released with fine-tuned counterparts: MPT-7B also came with an instruct and a chat version, instruct-tuned versions of Falcon and XGen models were released at the end of the year, Llama-2, Qwen and Yi were released with chat versions and DeciLM with an instruct version. The release of Llama-2 was particularly notable due to the strong focus on safety, both in the pretraining and fine-tuning models.
### What about the community?
While chat-models and instruction fine-tuned models were usually provided directly with new models releases, the community and researchers didn't take them for granted, and a wide and healthy community of model fine-tuners bloomed over the fruitful grounds provided by these base-models. Usually creating new datasets and finetuning models on them to show good performances and quality of the newly released data.
At the beginning of 2023, a few datasets for instruction/chat finetuning were already released. For instance, for human preferences, the [WebGPT](https://huggingface.co/datasets/openai/webgpt_comparisons) dataset by OpenAI, [HH-RLHF dataset](https://github.com/anthropics/hh-rlhf) by Anthropic, and [Summarize](https://huggingface.co/datasets/openai/summarize_from_feedback) by OpenAI were pioneer in this direction. Examples of instruction datasets are the [Public Pool of Prompts](https://huggingface.co/datasets/bigscience/P3) by BigScience, [FLAN](https://github.com/google-research/FLAN) 1 and 2 by Google, [Natural Instructions](https://github.com/allenai/natural-instructions) by AllenAI, [Self Instruct](https://github.com/yizhongw/self-instruct), a framework to generate automatic instructions by researchers from different affiliations, [SuperNatural instructions](https://aclanthology.org/2022.emnlp-main.340/), an expert created instruction benchmark sometimes used as fine-tuning data, [Unnatural instructions](https://aclanthology.org/2023.acl-long.806.pdf), an automatically generated instruction dataset by Tel Aviv University and Meta, among others.
❄️ Winter 2022/2023: In January this year, the [Human ChatGPT Instruction corpus](https://huggingface.co/datasets/Hello-SimpleAI/HC3) (HC3) was released by Chinese researchers from various institutions, and contained humans versus model answers to various questions. March was filled with releases: Stanford opened the [Alpaca](https://github.com/tatsu-lab/stanford_alpaca) model, which was the first instruction-following LLaMA model (7B), and the associated dataset, 52K instructions generated with an LLM. LAION (a non profit open source lab) released the [Open Instruction Generalist](https://laion.ai/blog/oig-dataset/) (OIG) dataset, 43M instructions both created with data augmentation and compiled from other pre-existing data sources. The same month, LMSYS org (at UC Berkeley) released [Vicuna](https://lmsys.org/blog/2023-03-30-vicuna/), also a LLaMA fine-tune (13B), this time on chat data: conversations between users and ChatGPT, shared publicly by the users themselves on [ShareGPT](https://share-gpt.com/). The [Guanaco](https://huggingface.co/datasets/JosephusCheung/GuanacoDataset) dataset, an extension of the Alpaca dataset (containing an added 500K entries in more languages), was also released, as well as the associated LLaMA-7B fine-tune.
🌱 Spring: In April, BAIR (Berkeley AI Research lab) released [Koala](https://bair.berkeley.edu/blog/2023/04/03/koala/), a chat-tuned LLaMA model, using several of the previous datasets (Alpaca, HH-RLHF, WebGPT, ShareGPT), and DataBricks released the [Dolly](https://huggingface.co/datasets/databricks/databricks-dolly-15k) dataset, a great human effort of 15K manually generated instructions as well as the associated model, a Pythia fine-tune. In May, Tsinghua University released [UltraChat](https://arxiv.org/abs/2305.14233), a dataset of 1.5M conversations containing instructions, and UltraLLaMA, a fine-tune on said dataset. Microsoft then released the [GPT4-LLM](https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM) dataset/framework to generate instructions with GPT4, and in June, Microsoft research shared a new method, [Orca](https://arxiv.org/pdf/2306.02707.pdf), to construct instruction datasets by using the reasoning trace of larger models (which explain their step by step reasoning) - it was soon reproduced by the community (notably Alignementlab.ai), who created [Open Orca](https://huggingface.co/Open-Orca) datasets, several million of entries, then used to fine-tune a number of models (Llama, Mistral, ...). In May and June, [Camel-AI](https://huggingface.co/camel-ai) released a number of instruction or chat datasets on different topics (more than 20K examples in each domain, physics, biology, chemistry, ...) obtained with GPT4. In June, too, the [Airoboros](https://github.com/jondurbin/airoboros) framework to fine-tune models using model-generated data (following the self-instruct approach) was released, along with a number of [instruct datasets](https://huggingface.co/jondurbin).
🌻Summer: In August, [UltraLM](https://github.com/thunlp/UltraChat) (a high-performing chat fine-tune of LLaMA) was released by OpenBMB, a Chinese non-profit, and in September, they released the associated preference dataset [UltraFeedback](https://huggingface.co/datasets/openbmb/UltraFeedback), a feedback dataset of inputs compared by GPT4 (with annotations). Throughout the summer, [NousResearch](https://huggingface.co/NousResearch), a collective, released several fine-tunes (notably the Hermes and Capybara collections) based on several private and public instruct datasets. In September, a student team from Tsinghua University released [OpenChat](https://huggingface.co/openchat/openchat_3.5), a LLaMA fine-tune using a new RL finetuning strategy.
🍂 Autumn: In October, Hugging Face released [Zephyr](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta), a Mistral fine-tune using DPO and AIF on UltraChat and UltraFeedback, and community members released [OpenHermes 2](https://huggingface.co/teknium/OpenHermes-2-Mistral-7B), a Mistral-7B fine-tuned on 900K entries either from the web or generated with Axolotl. Lmsys released LMSYS-Chat-1M, real-life user conversations with 25 LLMs. In November, OpenBuddy released OpenBuddy-Zephyr, a Zephyr fine-tuned multi-turn dialogue. In November, NVIDIA released [HelpSteer](https://huggingface.co/datasets/nvidia/HelpSteer), an alignment fine-tuning dataset providing prompts, associated model responses, and grades of said answers on several criteria, while Microsoft Research released the [Orca-2](https://huggingface.co/microsoft/Orca-2-13b) model, a Llama 2 fine-tuned on a new synthetic reasoning dataset. In December, Berkeley released [Starling](https://huggingface.co/berkeley-nest/Starling-LM-7B-alpha), a RLAIF fine-tuned of Open-Chat, and the associated dataset, [Nectar](https://huggingface.co/datasets/berkeley-nest/Nectar), 200K entries of comparison data.
As we can see, this whole year's development relies both on the creation of new datasets through the use of high-quality pretrained LLMs, as well as on all the open models released by the community, making the field go forward by leaps and bounds! And if you now see one of these names in a model name, you'll be able to get an idea of where it's coming from 🤗
*Some more specialized datasets (such as [MetaMath](https://meta-math.github.io/) or [MathInstruct](https://huggingface.co/datasets/TIGER-Lab/MathInstruct) math problem fine-tuning datasets, [Evol-Instruct](https://huggingface.co/datasets/WizardLM/WizardLM_evol_instruct_70k), math and code instructions, [CodeAlpaca](https://huggingface.co/datasets/sahil2801/CodeAlpaca-20k) and [CodeCapybara](https://github.com/FSoft-AI4Code/CodeCapybara) code instructions) were also released, but we won't cover them in detail here, though they have also been used to improve model performance on specific tasks. You can also see the [awesome instructions dataset](https://github.com/jianzhnie/awesome-instruction-datasets) for a compilation of other relevant datasets.*
## Democratizing access
### Merging: Extreme customization
In a typical open-source fashion, one of the landmark of the community is model/data merging. With each merge/commit, it can be more difficult to trace both the data used (as a number of released datasets are compilations of other datasets) and the models' history, as highly performing models are fine-tuned versions of fine-tuned versions of similar models (see Mistral's "child models tree" [here](https://huggingface.co/spaces/davanstrien/mistral-graph)). In this summary, we haven't had the time yet to talk about this amazing technique, so let's spend a couple of final words on it.
But what does it mean to merge a model?
**Model merging** is a way to fuse the weights of different models together in a single model to (ideally) combine the respective strengths of each model in a unified single model. A few techniques exist to do so that have been extended and often published mostly in community forums, a striking case of fully decentralized research happening all over the world between a community of practitioners, researchers, and hobbyists. One of the simplest published methods consists in averaging the parameters of a set of models sharing a common architecture ([example 1](https://huggingface.co/papers/2204.03044), [example 2](https://huggingface.co/papers/2109.01903)) but more complex parameter combinations exist, such as determining which parameters are the most influential in each model for a given task ([weighted averaging](https://huggingface.co/papers/2111.09832)), or considering parameters interference between models before selecting which parameters to keep when merging ([ties merging](https://huggingface.co/papers/2306.01708)).
These techniques allow anybody to easily generate combinations of models and are made especially easy by the fact that most models are nowadays variations on the same architecture. That's the reason some models submitted to the [open LLM leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) have names such as `llama2-zephyr-orca-ultra`. This particular example is likely a merge of `llama2` and `zephyr` models, fine-tuned on orca and ultra datasets. Usually, more details are to be found in the respective model card on the Hugging Face hub.
### PEFT: Personalization at the tip of your fingers
Sometimes, you may want more controlled personalization, without enough memory to load a whole model in memory to fine tune it. Did you know that you don't need to use an entire model when fine-tuning?
You might want to use what is called **parameter efficient fine-tuning** (PEFT).
This technique first freezes up the parameters of your pretrained model of interest, then adds a number of new parameters on top of it, called the adapters. What you then fine-tune on your task are only the (lightweight) adapter weights, considerably smaller than the original model. You then just need to share your small adapter weights (and the base model)! You'll find a list of interesting approaches for PEFT [here](https://github.com/huggingface/peft).
### Quantization: Models running everywhere
We've seen that well-performing models now come in all shapes and sizes… but even then, it doesn't mean that they are accessible to all! A 30B parameters model can require more than 66G of RAM just to load in memory (not even use), and not everyone in the community has the hardware necessary to do so.
That's where quantization comes in! Quantization is a special technique which reduces a model's size by changing the precision of its parameters.
What does it mean?
In a computer, numbers are stored with a given precision (such as `float32`, `float16`, `int8`, and so forth). A precision indicates both the number type (is it a floating point number or an integer) as well as on how much memory the number is stored: `float32` stores floating point numbers on 32 bits. For a more in-depth explanation, see [this link](https://huggingface.co/docs/optimum/concept_guides/quantization#going-further-how-do-machines-represent-numbers). So, the higher the precision, the more physical memory a number takes, as it will be stored on more bits.
So, if you reduce the precision, you reduce the memory each model parameter takes in storage, therefore reducing the model size! This also means that you reduce... the actual precision of the computations, which can reduce the model's performance. However, we found out that on bigger models, this performance degradation is actually very [limited](https://huggingface.co/blog/overview-quantization-transformers).
To go back to our above example, our 30B parameters model in `float16` requires a bit less than 66G of RAM, in `8bit` it only requires half that, so 33G of RAM, and it `4bit` we reach even half of this, so around 16G of RAM, making it considerably more accessible.
There are many ways to go from one precision to another, with many different "translation" schemes existing, each with its own benefits and drawbacks. Popular approaches include [bitsandbytes](https://huggingface.co/papers/2208.07339), [GPTQ](https://huggingface.co/papers/2210.17323), and [AWQ](https://huggingface.co/papers/2306.00978). Some users, such as [TheBloke](https://huggingface.co/TheBloke), are even converting popular models to make them accessible to the community. All are very recent and still developing, and we hope to see even more progress on this as time goes on.
## What's next?
The year is not over yet! And these final ~~months~~ ~~days~~ hours have already come with the share of surprises: will a new architecture finally overperform the simple and efficient Transformer?
New releases include
- A mixture of experts:
- [Mixtral](https://huggingface.co/mistralai/Mixtral-8x7B-v0.1), the model is made of 8 sub-models (transformer decoders), and for each input, a router picks the 2 best sub-models and sums their outputs.
- Several state space models (models that map input to output through a latent space and which can expressed as either an RNN or a CNN depending on the tasks):
- [Mamba](https://huggingface.co/papers/2312.00752), a state space model with an added selection mechanism
- [Striped Hyena](https://huggingface.co/togethercomputer/StripedHyena-Nous-7B), a state space model with fast convolutions kernel
It's still a bit too early to say if these new approaches will take over the Transformer, but state space models are quite promising!
## Takeaways
- This year has seen a rise of open releases from all kinds of actors (big companies, start ups, research labs), which empowered the community to start experimenting and exploring at a rate never seen before.
- Model announcement openness has seen ebbs and flow, from early releases this year being very open (dataset mixes, weights, architectures) to late releases indicating nothing about their training data, therefore being unreproducible.
- Open models emerged from many new places, including China, with several new actors positioning themselves as strong contenders in the LLM game.
- Personalization possibilities reached an all-time high, with new strategies for fine-tuning (RLHF, adapters, merging), which are only at their beginning.
- Smaller model sizes and upgrades in quantization made LLMs really accessible to many more people!
- New architectures have also appeared - will they finally replace the Transformer?
That's it folks!
I hope you enjoyed this year's review, learned a thing or two, and feel as enthusiastic about me about how much of AI progress now relies on open source and community effort! 🤗
[^1]: Post embedding normalisation is a trick to make learning more stable.
[^2]: ALiBi positional embeddings introduce a penalty when tokens too far away in a sequence are connected together by the model (where normal positional embeddings would just store information about the order and respective position of tokens in a sequence).
|
huggingface/blog/blob/main/2023-in-llms.md
|
@gradio/wasm
## 0.4.0
### Features
- [#6398](https://github.com/gradio-app/gradio/pull/6398) [`67ddd40`](https://github.com/gradio-app/gradio/commit/67ddd40b4b70d3a37cb1637c33620f8d197dbee0) - Lite v4. Thanks [@whitphx](https://github.com/whitphx)!
- [#6432](https://github.com/gradio-app/gradio/pull/6432) [`bdf81fe`](https://github.com/gradio-app/gradio/commit/bdf81fead86e1d5a29e6b036f1fff677f6480e6b) - Lite: Set the home dir path per appId at each runtime. Thanks [@whitphx](https://github.com/whitphx)!
- [#6416](https://github.com/gradio-app/gradio/pull/6416) [`5177132`](https://github.com/gradio-app/gradio/commit/5177132d718c77f6d47869b4334afae6380394cb) - Lite: Fix the `isMessagePort()` type guard in js/wasm/src/worker-proxy.ts. Thanks [@whitphx](https://github.com/whitphx)!
## 0.3.0
### Features
- [#6099](https://github.com/gradio-app/gradio/pull/6099) [`d84209703`](https://github.com/gradio-app/gradio/commit/d84209703b7a0728cdb49221e543500ddb6a8d33) - Lite: SharedWorker mode. Thanks [@whitphx](https://github.com/whitphx)!
## 0.2.0
## 0.2.0-beta.2
### Features
- [#6036](https://github.com/gradio-app/gradio/pull/6036) [`f2cd6cb7f`](https://github.com/gradio-app/gradio/commit/f2cd6cb7f4c118495fc4f4802363c051958bc940) - lite: install typing-extensions to avoid capping fastapi versions. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
### Fixes
- [#6076](https://github.com/gradio-app/gradio/pull/6076) [`f3f98f923`](https://github.com/gradio-app/gradio/commit/f3f98f923c9db506284b8440e18a3ac7ddd8398b) - Lite error handler. Thanks [@whitphx](https://github.com/whitphx)!
## 0.2.0-beta.1
### Features
- [#5963](https://github.com/gradio-app/gradio/pull/5963) [`174b73619`](https://github.com/gradio-app/gradio/commit/174b736194756e23f51bbaf6f850bac5f1ca95b5) - release wasm. Thanks [@pngwn](https://github.com/pngwn)!
- [#5964](https://github.com/gradio-app/gradio/pull/5964) [`5fbda0bd2`](https://github.com/gradio-app/gradio/commit/5fbda0bd2b2bbb2282249b8875d54acf87cd7e84) - Wasm release. Thanks [@pngwn](https://github.com/pngwn)!
## 0.2.0-beta.0
### Features
- [#5956](https://github.com/gradio-app/gradio/pull/5956) [`f769876e0`](https://github.com/gradio-app/gradio/commit/f769876e0fa62336425c4e8ada5e09f38353ff01) - Apply formatter (and small refactoring) to the Lite-related frontend code. Thanks [@whitphx](https://github.com/whitphx)!
- [#5958](https://github.com/gradio-app/gradio/pull/5958) [`6780d660b`](https://github.com/gradio-app/gradio/commit/6780d660bb8f3b969a4bd40644a49f3274a779a9) - Make the HTTP requests for the Wasm worker wait for the initial `run_code()` or `run_file()` to finish. Thanks [@whitphx](https://github.com/whitphx)!
## 0.1.0
### Features
- [#5868](https://github.com/gradio-app/gradio/pull/5868) [`4e0d87e9c`](https://github.com/gradio-app/gradio/commit/4e0d87e9c471fe90a344a3036d0faed9188ef6f3) - fix @gradio/lite dependencies. Thanks [@pngwn](https://github.com/pngwn)!
- [#5838](https://github.com/gradio-app/gradio/pull/5838) [`ead265c1b`](https://github.com/gradio-app/gradio/commit/ead265c1b98883f7971eb454b14fc81442e0589f) - Lite: Convert an error object caught in the worker to be cloneable. Thanks [@whitphx](https://github.com/whitphx)!
- [#5627](https://github.com/gradio-app/gradio/pull/5627) [`b67115e8e`](https://github.com/gradio-app/gradio/commit/b67115e8e6e489fffd5271ea830211863241ddc5) - Lite: Make the Examples component display media files using pseudo HTTP requests to the Wasm server. Thanks [@whitphx](https://github.com/whitphx)!
### Fixes
- [#5919](https://github.com/gradio-app/gradio/pull/5919) [`1724918f0`](https://github.com/gradio-app/gradio/commit/1724918f06845e9fd12b6dd82710dd05a969a1cf) - Lite: Add a break statement. Thanks [@whitphx](https://github.com/whitphx)!
## 0.0.4
### Features
- [#5124](https://github.com/gradio-app/gradio/pull/5124) [`6e56a0d9b`](https://github.com/gradio-app/gradio/commit/6e56a0d9b0c863e76c69e1183d9d40196922b4cd) - Lite: Websocket queueing. Thanks [@whitphx](https://github.com/whitphx)!
## 0.0.3
### Features
- [#5598](https://github.com/gradio-app/gradio/pull/5598) [`6b1714386`](https://github.com/gradio-app/gradio/commit/6b17143868bdd2c1400af1199a01c1c0d5c27477) - Upgrade Pyodide to 0.24.0 and install the native orjson package. Thanks [@whitphx](https://github.com/whitphx)!
## 0.0.2
### Fixes
- [#5538](https://github.com/gradio-app/gradio/pull/5538) [`b5c6f7b08`](https://github.com/gradio-app/gradio/commit/b5c6f7b086a6419f27c757ad9b2ac9ea679b749b) - chore(deps): update dependency pyodide to ^0.24.0. Thanks [@renovate](https://github.com/apps/renovate)!
|
gradio-app/gradio/blob/main/js/wasm/CHANGELOG.md
|
@gradio/checkbox
## 0.2.6
### Patch Changes
- Updated dependencies [[`828fb9e`](https://github.com/gradio-app/gradio/commit/828fb9e6ce15b6ea08318675a2361117596a1b5d), [`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144)]:
- @gradio/statustracker@0.4.3
- @gradio/atoms@0.4.1
## 0.2.5
### Patch Changes
- Updated dependencies [[`4d1cbbc`](https://github.com/gradio-app/gradio/commit/4d1cbbcf30833ef1de2d2d2710c7492a379a9a00)]:
- @gradio/atoms@0.4.0
- @gradio/statustracker@0.4.2
## 0.2.4
### Patch Changes
- Updated dependencies []:
- @gradio/atoms@0.3.1
- @gradio/statustracker@0.4.1
## 0.2.3
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/atoms@0.3.0
- @gradio/statustracker@0.4.0
## 0.2.2
### Patch Changes
- Updated dependencies [[`f816136a0`](https://github.com/gradio-app/gradio/commit/f816136a039fa6011be9c4fb14f573e4050a681a)]:
- @gradio/atoms@0.2.2
- @gradio/statustracker@0.3.2
## 0.2.1
### Patch Changes
- Updated dependencies [[`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780), [`fad92c29d`](https://github.com/gradio-app/gradio/commit/fad92c29dc1f5cd84341aae417c495b33e01245f)]:
- @gradio/atoms@0.2.1
- @gradio/statustracker@0.3.1
## 0.2.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
## 0.2.0-beta.8
### Features
- [#6136](https://github.com/gradio-app/gradio/pull/6136) [`667802a6c`](https://github.com/gradio-app/gradio/commit/667802a6cdbfb2ce454a3be5a78e0990b194548a) - JS Component Documentation. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6149](https://github.com/gradio-app/gradio/pull/6149) [`90318b1dd`](https://github.com/gradio-app/gradio/commit/90318b1dd118ae08a695a50e7c556226234ab6dc) - swap `mode` on the frontned to `interactive` to match the backend. Thanks [@pngwn](https://github.com/pngwn)!
## 0.2.0-beta.7
### Features
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6026](https://github.com/gradio-app/gradio/pull/6026) [`338969af2`](https://github.com/gradio-app/gradio/commit/338969af290de032f9cdc204dab8a50be3bf3cc5) - V4: Single-file implementation of form components. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.2.0-beta.6
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.2.3
### Patch Changes
- Updated dependencies [[`e70805d54`](https://github.com/gradio-app/gradio/commit/e70805d54cc792452545f5d8eccc1aa0212a4695)]:
- @gradio/atoms@0.2.0
- @gradio/statustracker@0.2.3
## 0.2.2
### Patch Changes
- Updated dependencies []:
- @gradio/utils@0.1.2
- @gradio/atoms@0.1.4
- @gradio/statustracker@0.2.2
## 0.2.1
### Patch Changes
- Updated dependencies []:
- @gradio/atoms@0.1.3
- @gradio/statustracker@0.2.1
## 0.2.0
### Features
- [#5554](https://github.com/gradio-app/gradio/pull/5554) [`75ddeb390`](https://github.com/gradio-app/gradio/commit/75ddeb390d665d4484667390a97442081b49a423) - Accessibility Improvements. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.1.3
### Patch Changes
- Updated dependencies [[`afac0006`](https://github.com/gradio-app/gradio/commit/afac0006337ce2840cf497cd65691f2f60ee5912)]:
- @gradio/statustracker@0.2.0
- @gradio/utils@0.1.1
- @gradio/atoms@0.1.2
## 0.1.2
### Patch Changes
- Updated dependencies [[`abf1c57d`](https://github.com/gradio-app/gradio/commit/abf1c57d7d85de0df233ee3b38aeb38b638477db)]:
- @gradio/utils@0.1.0
- @gradio/atoms@0.1.1
- @gradio/statustracker@0.1.1
## 0.1.1
### Fixes
- [#5340](https://github.com/gradio-app/gradio/pull/5340) [`df090e89`](https://github.com/gradio-app/gradio/commit/df090e89f74a16e4cb2b700a1e3263cabd2bdd91) - Fix Checkbox select dispatch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.1.0
### Highlights
#### Improve startup performance and markdown support ([#5279](https://github.com/gradio-app/gradio/pull/5279) [`fe057300`](https://github.com/gradio-app/gradio/commit/fe057300f0672c62dab9d9b4501054ac5d45a4ec))
##### Improved markdown support
We now have better support for markdown in `gr.Markdown` and `gr.Dataframe`. Including syntax highlighting and Github Flavoured Markdown. We also have more consistent markdown behaviour and styling.
##### Various performance improvements
These improvements will be particularly beneficial to large applications.
- Rather than attaching events manually, they are now delegated, leading to a significant performance improvement and addressing a performance regression introduced in a recent version of Gradio. App startup for large applications is now around twice as fast.
- Optimised the mounting of individual components, leading to a modest performance improvement during startup (~30%).
- Corrected an issue that was causing markdown to re-render infinitely.
- Ensured that the `gr.3DModel` does re-render prematurely.
Thanks [@pngwn](https://github.com/pngwn)!
### Features
- [#5215](https://github.com/gradio-app/gradio/pull/5215) [`fbdad78a`](https://github.com/gradio-app/gradio/commit/fbdad78af4c47454cbb570f88cc14bf4479bbceb) - Lazy load interactive or static variants of a component individually, rather than loading both variants regardless. This change will improve performance for many applications. Thanks [@pngwn](https://github.com/pngwn)!
- [#5216](https://github.com/gradio-app/gradio/pull/5216) [`4b58ea6d`](https://github.com/gradio-app/gradio/commit/4b58ea6d98e7a43b3f30d8a4cb6f379bc2eca6a8) - Update i18n tokens and locale files. Thanks [@hannahblair](https://github.com/hannahblair)!
|
gradio-app/gradio/blob/main/js/checkbox/CHANGELOG.md
|
--
title: "The N Implementation Details of RLHF with PPO"
thumbnail: /blog/assets/167_the_n_implementation_details_of_rlhf_with_ppo/thumbnail.png
authors:
- user: vwxyzjn
- user: tianlinliu0121
guest: true
- user: lvwerra
---
# The N Implementation Details of RLHF with PPO
RLHF / ChatGPT has been a popular research topic these days. In our quest to research more on RLHF, this blog post attempts to do a reproduction of OpenAI’s 2019 original RLHF codebase at [*openai/lm-human-preferences*](https://github.com/openai/lm-human-preferences). Despite its “tensorflow-1.x-ness,” OpenAI’s original codebase is very well-evaluated and benchmarked, making it a good place to study RLHF implementation engineering details.
We aim to:
1. reproduce OAI’s results in stylistic tasks and match the learning curves of [*openai/lm-human-preferences*](https://github.com/openai/lm-human-preferences).
2. present a checklist of implementation details, similar to the spirit of [*The 37 Implementation Details of Proximal Policy Optimization*](https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/); [*Debugging RL, Without the Agonizing Pain*](https://andyljones.com/posts/rl-debugging.html).
3. provide a simple-to-read and minimal reference implementation of RLHF;
This work is just for educational / learning purposes. For advanced users requiring more features, such as running larger models with PEFT, [*huggingface/trl*](https://github.com/huggingface/trl) would be a great choice.
- In [Matching Learning Curves](#matching-learning-curves), we show our main contribution: creating a codebase that can reproduce OAI’s results in the stylistic tasks and matching learning curves very closely with [*openai/lm-human-preferences*](https://github.com/openai/lm-human-preferences).
- We then take a technical deep dive into the implementation details that are relevant to reproducing OAI’s work. In [General Implementation Details](#general-implementation-details), we talk about basic details, such as how rewards/values are generated and how responses are generated. In [Reward Model Implementation Details](#reward-model-implementation-details), we talk about details such as reward normalization. In [Policy Training Implementation Details](#policy-training-implementation-details), we discuss details such as rejection sampling and reward “whitening”.
- In [**PyTorch Adam optimizer numerical issues w.r.t RLHF**](#pytorch-adam-optimizer-numerical-issues-wrt-rlhf), we highlight a very interesting implementation difference in Adam between TensorFlow and PyTorch, which causes an aggressive update in the model training.
- Next, we examine the effect of training different base models (e.g., gpt2-xl, falcon-1b,) given that the reward labels are produced with `gpt2-large`.
- Finally, we conclude our work with limitations and discussions.
**Here are the important links:**
- 💾 Our reproduction codebase [*https://github.com/vwxyzjn/lm-human-preference-details*](https://github.com/vwxyzjn/lm-human-preference-details)
- 🤗 Demo of RLHF model comparison: [*https://huggingface.co/spaces/lm-human-preference-details/rlhf-demo*](https://huggingface.co/spaces/lm-human-preference-details/rlhf-demo)
- 🐝 All w&b training logs [*https://wandb.ai/openrlbenchmark/lm_human_preference_details*](https://wandb.ai/openrlbenchmark/lm_human_preference_details)
# Matching Learning Curves
Our main contribution is to reproduce OAI’s results in stylistic tasks, such as sentiment and descriptiveness. As shown in the figure below, our codebase (orange curves) can produce nearly identical learning curves as OAI’s codebase (blue curves).
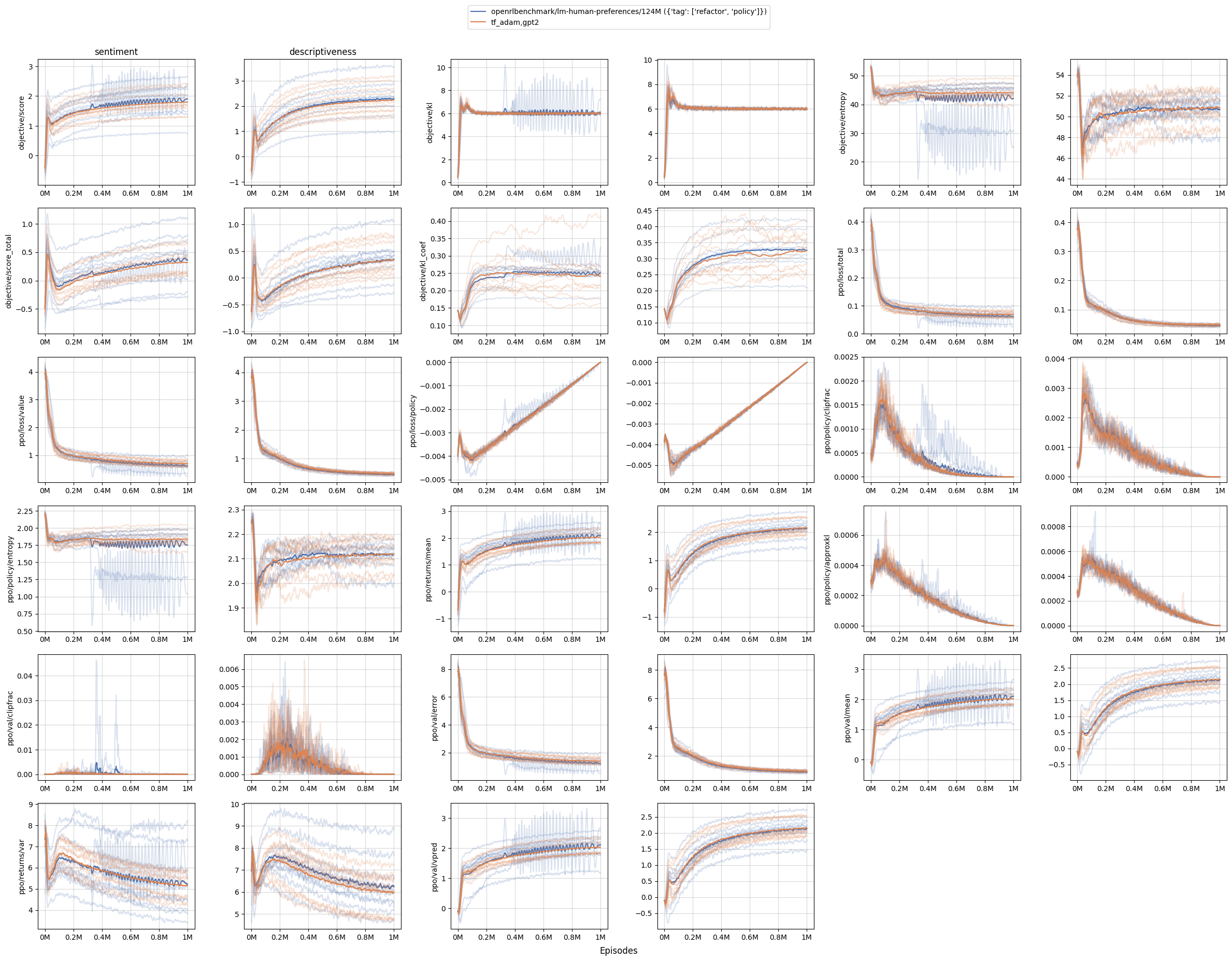
## A note on running openai/lm-human-preferences
To make a direct comparison, we ran the original RLHF code at [*openai/lm-human-preferences*](https://github.com/openai/lm-human-preferences), which will offer valuable metrics to help validate and diagnose our reproduction. We were able to set the original TensorFlow 1.x code up, but it requires a hyper-specific setup:
- OAI’s dataset was partially corrupted/lost (so we replaced them with similar HF datasets, which may or may not cause a performance difference)
- Specifically, its book dataset was lost during OpenAI’s GCP - Azure migration ([https://github.com/openai/lm-human-preferences/issues/17#issuecomment-1044051496](https://github.com/openai/lm-human-preferences/issues/17#issuecomment-1044051496)). I replaced the book dataset with Hugging Face’s `bookcorpus` dataset, which is, in principle, what OAI used.
- It can’t run on 1 V100 because it doesn’t implement gradient accumulation. Instead, it uses a large batch size and splits the batch across 8 GPUs, and will OOM on just 1 GPU.
- It can’t run on 8x A100 because it uses TensorFlow 1.x, which is incompatible with Cuda 8+
- It can’t run on 8x V100 (16GB) because it will OOM
- It can only run on 8x V100 (32GB), which is only offered by AWS as the `p3dn.24xlarge` instance.
# General Implementation Details
We now take a technical deep dive into the implementation details that are relevant to reproducing OAI’s work. In this section, we talk about basic details, such as how rewards/values are generated and how responses are generated. Here are these details in no particular order:
1. **The reward model and policy’s value head take input as the concatenation of `query` and `response`**
1. The reward model and policy’s value head do *not* only look at the response. Instead, it concatenates the `query` and `response` together as `query_response` ([lm_human_preferences/rewards.py#L105-L107](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/rewards.py#L105-L107)).
2. So, for example, if `query = "he was quiet for a minute, his eyes unreadable"`., and the `response = "He looked at his left hand, which held the arm that held his arm out in front of him."`, then the reward model and policy’s value do a forward pass on `query_response = "he was quiet for a minute, his eyes unreadable. He looked at his left hand, which held the arm that held his arm out in front of him."` and produced rewards and values of shape `(B, T, 1)`, where `B` is the batch size, `T` is the sequence length, and `1` is the reward head dimension of 1 ([lm_human_preferences/rewards.py#L105-L107](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/rewards.py#L105-L107), [lm_human_preferences/policy.py#L111](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/policy.py#L111)).
3. The `T` means that each token has a reward associated with it and its previous context. For example, the `eyes` token would have a reward corresponding to `he was quiet for a minute, his eyes`.
2. **Pad with a special padding token and truncate inputs.**
1. OAI sets a fixed input length for query `query_length`; it **pads** sequences that are too short with `pad_token` ([lm_human_preferences/language/datasets.py#L66-L67](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/datasets.py#L66-L67)) and **truncates** sequences that are too long ([lm_human_preferences/language/datasets.py#L57](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/datasets.py#L57)). See [here](https://huggingface.co/docs/transformers/pad_truncation) for a general introduction to the concept). When padding the inputs, OAI uses a token beyond the vocabulary ([lm_human_preferences/language/encodings.py#L56](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/encodings.py#L56)).
1. **Note on HF’s transformers — padding token.** According to ([transformers#2630#issuecomment-578159876](https://github.com/huggingface/transformers/issues/2630#issuecomment-578159876)), padding tokens were not used during the pre-training of GPT and GPT-2; therefore transformer’s gpt2 models have no official padding token associated with its tokenizer. A common practice is to set `tokenizer.pad_token = tokenizer.eos_token`, but in this work, we shall distinguish these two special tokens to match OAI’s original setting, so we will use `tokenizer.add_special_tokens({"pad_token": "[PAD]"})`.
Note that having no padding token is a default setting for decoder models, since they train with “packing” during pretraining, which means that many sequences are concatenated and separated by the EOS token and chunks of this sequence that always have the max length are fed to the model during pretraining.
2. When putting everything together, here is an example
```python
import transformers
tokenizer = transformers.AutoTokenizer.from_pretrained("gpt2", padding_side="right")
tokenizer.add_special_tokens({"pad_token": "[PAD]"})
query_length = 5
texts = [
"usually, he would",
"she thought about it",
]
tokens = []
for text in texts:
tokens.append(tokenizer.encode(text)[:query_length])
print("tokens", tokens)
inputs = tokenizer.pad(
{"input_ids": tokens},
padding="max_length",
max_length=query_length,
return_tensors="pt",
return_attention_mask=True,
)
print("inputs", inputs)
"""prints are
tokens [[23073, 11, 339, 561], [7091, 1807, 546, 340]]
inputs {'input_ids': tensor([[23073, 11, 339, 561, 50257],
[ 7091, 1807, 546, 340, 50257]]), 'attention_mask': tensor([[1, 1, 1, 1, 0],
[1, 1, 1, 1, 0]])}
"""
```
3. **Adjust position indices correspondingly for padding tokens**
1. When calculating the logits, OAI’s code works by masking out padding tokens properly. This is achieved by finding out the token indices corresponding to the padding tokens ([lm_human_preferences/language/model.py#L296-L297](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/model.py#L296-L297)), followed by adjusting their position indices correspondingly ([lm_human_preferences/language/model.py#L320](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/model.py#L320)).
2. For example, if the `query=[23073, 50259, 50259]` and `response=[11, 339, 561]`, where (`50259` is OAI’s padding token), it then creates position indices as `[[0 1 1 1 2 3]]` and logits as follows. Note how the logits corresponding to the padding tokens remain the same as before! This is the effect we should be aiming for in our reproduction.
```python
all_logits [[[ -35.28693 -34.2875 -38.16074 ... -41.595802 -41.082108
-35.36577 ]
[ -35.28693 -34.2875 -38.16074 ... -41.595802 -41.082108
-35.36577 ]
[ -35.28693 -34.2875 -38.16074 ... -41.595802 -41.082108
-35.36577 ]
[-111.303955 -110.94471 -112.90624 ... -113.13064 -113.7788
-109.17345 ]
[-111.51512 -109.61077 -114.90231 ... -118.43514 -111.56671
-112.12478 ]
[-122.69775 -121.84468 -128.27417 ... -132.28055 -130.39604
-125.707756]]] (1, 6, 50257)
```
3. **Note on HF’s transformers — `position_ids` and `padding_side`.** We can replicate the exact logits using Hugging Face’s transformer with 1) left padding and 2) pass in the appropriate `position_ids`:
```python
import torch
import transformers
tokenizer = transformers.AutoTokenizer.from_pretrained("gpt2", padding_side="right")
tokenizer.add_special_tokens({"pad_token": "[PAD]"})
pad_id = tokenizer.pad_token_id
query = torch.tensor([
[pad_id, pad_id, 23073],
])
response = torch.tensor([
[11, 339, 561],
])
temperature = 1.0
query = torch.tensor(query)
response = torch.tensor(response).long()
context_length = query.shape[1]
query_response = torch.cat((query, response), 1)
pretrained_model = transformers.AutoModelForCausalLM.from_pretrained("gpt2")
def forward(policy, query_responses, tokenizer):
attention_mask = query_responses != tokenizer.pad_token_id
position_ids = attention_mask.cumsum(1) - attention_mask.long() # exclusive cumsum
input_ids = query_responses.clone()
input_ids[~attention_mask] = 0
return policy(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
return_dict=True,
output_hidden_states=True,
)
output = forward(pretrained_model, query_response, tokenizer)
logits = output.logits
logits /= temperature
print(logits)
"""
tensor([[[ -26.9395, -26.4709, -30.0456, ..., -33.2208, -33.2884,
-27.4360],
[ -27.1677, -26.7330, -30.2386, ..., -33.6813, -33.6931,
-27.5928],
[ -35.2869, -34.2875, -38.1608, ..., -41.5958, -41.0821,
-35.3658],
[-111.3040, -110.9447, -112.9062, ..., -113.1306, -113.7788,
-109.1734],
[-111.5152, -109.6108, -114.9024, ..., -118.4352, -111.5668,
-112.1248],
[-122.6978, -121.8447, -128.2742, ..., -132.2805, -130.3961,
-125.7078]]], grad_fn=<DivBackward0>)
"""
```
4. **Note on HF’s transformers — `position_ids` during `generate`:** during generate we should not pass in `position_ids` because the `position_ids` are already adjusted in `transformers` (see [huggingface/transformers#/7552](https://github.com/huggingface/transformers/pull/7552).
Usually, we almost never pass `position_ids` in transformers. All the masking and shifting logic are already implemented e.g. in the `generate` function (need permanent code link).
4. **Response generation samples a fixed-length response without padding.**
1. During response generation, OAI uses `top_k=0, top_p=1.0` and just do categorical samples across the vocabulary ([lm_human_preferences/language/sample.py#L43](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/sample.py#L43)) and the code would keep sampling until a fixed-length response is generated ([lm_human_preferences/policy.py#L103](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/policy.py#L103)). Notably, even if it encounters EOS (end-of-sequence) tokens, it will keep sampling.
2. **Note on HF’s transformers — sampling could stop at `eos_token`:** in `transformers`, the generation could stop at `eos_token` ([src/transformers/generation/utils.py#L2248-L2256](https://github.com/huggingface/transformers/blob/67b85f24def79962ce075353c2627f78e0e53e9f/src/transformers/generation/utils.py#L2248-L2256)), which is not the same as OAI’s setting. To align the setting, we need to do set `pretrained_model.generation_config.eos_token_id = None, pretrained_model.generation_config.pad_token_id = None`. Note that `transformers.GenerationConfig(eos_token_id=None, pad_token_id=None, ...)` does not work because `pretrained_model.generation_config` would override and set a `eos_token`.
```python
import torch
import transformers
tokenizer = transformers.AutoTokenizer.from_pretrained("gpt2", padding_side="right")
tokenizer.add_special_tokens({"pad_token": "[PAD]"})
pad_id = tokenizer.pad_token_id
query = torch.tensor([
[pad_id, pad_id, 23073],
])
response = torch.tensor([
[11, 339, 561],
])
response_length = 4
temperature = 0.7
pretrained_model = transformers.AutoModelForCausalLM.from_pretrained("gpt2")
pretrained_model.generation_config.eos_token_id = None # disable `pad_token_id` and `eos_token_id` because we just want to
pretrained_model.generation_config.pad_token_id = None # generate tokens without truncation / padding
generation_config = transformers.GenerationConfig(
max_new_tokens=response_length,
min_new_tokens=response_length,
temperature=temperature,
top_k=0.0,
top_p=1.0,
do_sample=True,
)
context_length = query.shape[1]
attention_mask = query != tokenizer.pad_token_id
input_ids = query.clone()
input_ids[~attention_mask] = 0 # set padding tokens to 0
output = pretrained_model.generate(
input_ids=input_ids,
attention_mask=attention_mask,
# position_ids=attention_mask.cumsum(1) - attention_mask.long(), # generation collapsed if this was turned on.
generation_config=generation_config,
return_dict_in_generate=True,
)
print(output.sequences)
"""
tensor([[ 0, 0, 23073, 16851, 11, 475, 991]])
"""
```
3. Note that in a more recent codebase https://github.com/openai/summarize-from-feedback, OAI does stop sampling when encountering EOS token ([summarize_from_feedback/utils/experiment_helpers.py#L19](https://github.com/openai/summarize-from-feedback/blob/8af822a428c93432aa80ffbe5b065a8f93895669/summarize_from_feedback/utils/experiment_helpers.py#L19)). However in this work we aim to do a 1:1 replication, so we align the setting that could keep sampling even eos_token is encountered
5. **Learning rate annealing for reward model and policy training.**
1. As Ziegler et al. (2019) suggested, the reward model is trained for a single epoch to avoid overfitting the limited amount of human annotation data (e.g., the `descriptiveness` task only had about 5000 labels). During this single epoch, the learning rate is annealed to zero ([lm_human_preferences/train_reward.py#L249](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_reward.py#L249)).
2. Similar to reward model training, the learning rate is annealed to zero ([lm_human_preferences/train_policy.py#L172-L173](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L172-L173)).
6. **Use different seeds for different processes**
1. When spawning 8 GPU processes to do data parallelism, OAI sets a different random seed per process ([lm_human_preferences/utils/core.py#L108-L111](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/utils/core.py#L108-L111)). Implementation-wise, this is done via `local_seed = args.seed + process_rank * 100003`. The seed is going to make the model produce different responses and get different scores, for example.
1. Note: I believe the dataset shuffling has a bug — the dataset is shuffled using the same seed for some reason ([lm_human_preferences/lm_tasks.py#L94-L97](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/lm_tasks.py#L94-L97)).
# Reward Model Implementation Details
In this section, we discuss reward-model-specific implementation details. We talk about details such as reward normalization and layer initialization. Here are these details in no particular order:
1. **The reward model only outputs the value at the last token.**
1. Notice that the rewards obtained after the forward pass on the concatenation of `query` and `response` will have the shape `(B, T, 1)`, where `B` is the batch size, `T` is the sequence length (which is always the same; it is `query_length + response_length = 64 + 24 = 88` in OAI’s setting for stylistic tasks, see [launch.py#L9-L11](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/launch.py#L9-L11)), and `1` is the reward head dimension of 1. For RLHF purposes, the original codebase extracts the reward of the last token ([lm_human_preferences/rewards.py#L132](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/rewards.py#L132)), so that the rewards will only have shape `(B, 1)`.
2. Note that in a more recent codebase [*openai/summarize-from-feedback*](https://github.com/openai/summarize-from-feedback), OAI stops sampling when encountering EOS token ([summarize_from_feedback/utils/experiment_helpers.py#L19](https://github.com/openai/summarize-from-feedback/blob/8af822a428c93432aa80ffbe5b065a8f93895669/summarize_from_feedback/utils/experiment_helpers.py#L19)). When extracting rewards, it is going to identify the `last_response_index`, the index before the EOS token ([#L11-L13](https://github.com/openai/summarize-from-feedback/blob/8af822a428c93432aa80ffbe5b065a8f93895669/summarize_from_feedback/reward_model.py#L11-L13)), and extract the reward at that index ([summarize_from_feedback/reward_model.py#L59](https://github.com/openai/summarize-from-feedback/blob/8af822a428c93432aa80ffbe5b065a8f93895669/summarize_from_feedback/reward_model.py#L59)). However in this work we just stick with the original setting.
2. **Reward head layer initialization**
1. The weight of the reward head is initialized according to \\( \mathcal{N}\left(0,1 /\left(\sqrt{d_{\text {model }}+1}\right)\right) \\) ([lm_human_preferences/language/model.py#L368,](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/model.py#L368) [lm_human_preferences/language/model.py#L251-L252](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/model.py#L251-L252)). This aligns with the settings in Stiennon et al., 2020 ([summarize_from_feedback/query_response_model.py#L106-L107](https://github.com/openai/summarize-from-feedback/blob/8af822a428c93432aa80ffbe5b065a8f93895669/summarize_from_feedback/query_response_model.py#L106-L107)) (P.S., Stiennon et al., 2020 had a typo on page 17 saying the distribution is \\( \mathcal{N}\left(0,1 /\left(d_{\text {model }}+1\right)\right) \\) without the square root)
2. The bias of the reward head is set to 0 ([lm_human_preferences/language/model.py#L254](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/model.py#L254)).
3. **Reward model normalization before and after**
1. In the paper, Ziegler el al. (2019) mentioned that "to keep the scale of the reward model consistent across training, we normalize it so that it has mean 0 and variance 1 for \\( x \sim \mathcal{D}, y \sim \rho(·|x) \\).” To perform the normalization process, the code first creates a `reward_gain` and `reward_bias`, such that the reward can be calculated by `reward = reward * reward_gain + reward_bias` ([lm_human_preferences/rewards.py#L50-L51](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/rewards.py#L50-L51)).
2. When performing the normalization process, the code first sets `reward_gain=1, reward_bias=0` ([lm_human_preferences/train_reward.py#L211](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_reward.py#L211)), followed by collecting sampled queries from the target dataset (e.g., `bookcorpus, tldr, cnndm`), completed responses, and evaluated rewards. It then gets the **empirical mean and std** of the evaluated reward ([lm_human_preferences/train_reward.py#L162-L167](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_reward.py#L162-L167)) and tries to compute what the `reward_gain` and `reward_bias` should be.
3. Let us use \\( \mu_{\mathcal{D}} \\) to denote the empirical mean, \\( \sigma_{\mathcal{D}} \\) the empirical std, \\(g\\) the `reward_gain`, \\(b\\) `reward_bias`, \\( \mu_{\mathcal{T}} = 0\\) **target mean** and \\( \sigma_{\mathcal{T}}=1\\) **target std**. Then we have the following formula.
$$\begin{aligned}g*\mathcal{N}(\mu_{\mathcal{D}}, \sigma_{\mathcal{D}}) + b &= \mathcal{N}(g*\mu_{\mathcal{D}}, g*\sigma_{\mathcal{D}}) + b\\&= \mathcal{N}(g*\mu_{\mathcal{D}} + b, g*\sigma_{\mathcal{D}}) \\&= \mathcal{N}(\mu_{\mathcal{T}}, \sigma_{\mathcal{T}}) \\g &= \frac{\sigma_{\mathcal{T}}}{\sigma_{\mathcal{D}}} \\b &= \mu_{\mathcal{T}} - g*\mu_{\mathcal{D}}\end{aligned}$$
4. The normalization process is then applied **before** and **after** reward model training ([lm_human_preferences/train_reward.py#L232-L234](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_reward.py#L232-L234), [lm_human_preferences/train_reward.py#L252-L254](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_reward.py#L252-L254)).
5. Note that responses \\( y \sim \rho(·|x) \\) we generated for the normalization purpose are from the pre-trained language model \\(\rho \\). The model \\(\rho \\) is fixed as a reference and is not updated in reward learning ([lm_human_preferences/train_reward.py#L286C1-L286C31](https://github.com/openai/lm-human-preferences/blob/master/lm_human_preferences/train_reward.py#L286C1-L286C31)).
# Policy Training Implementation Details
In this section, we will delve into details, such as layer initialization, data post-processing, and dropout settings. We will also explore techniques, such as of rejection sampling and reward "whitening", and adaptive KL. Here are these details in no particular order:
1. **Scale the logits by sampling temperature.**
1. When calculating the log probability of responses, the model first outputs the logits of the tokens in the responses, followed by dividing the logits with the sampling temperature ([lm_human_preferences/policy.py#L121](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/policy.py#L121)). I.e., `logits /= self.temperature`
2. In an informal test, we found that without this scaling, the KL would rise faster than expected, and performance would deteriorate.
2. **Value head layer initialization**
1. The weight of the value head is initialized according to \\(\mathcal{N}\left(0,0\right)\\) ([lm_human_preferences/language/model.py#L368,](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/model.py#L368) [lm_human_preferences/language/model.py#L251-L252](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/model.py#L251-L252)). This is
2. The bias of the reward head is set to 0 ([lm_human_preferences/language/model.py#L254](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/model.py#L254)).
3. **Select query texts that start and end with a period**
1. This is done as part of the data preprocessing;
1. Tries to select text only after `start_text="."` ([lm_human_preferences/language/datasets.py#L51](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/datasets.py#L51))
2. Tries select text just before `end_text="."` ([lm_human_preferences/language/datasets.py#L61](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/datasets.py#L61))
3. Then pad the text ([lm_human_preferences/language/datasets.py#L66-L67](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/datasets.py#L66-L67))
2. When running `openai/lm-human-preferences`, OAI’s datasets were partially corrupted/lost ([openai/lm-human-preferences/issues/17#issuecomment-104405149](https://github.com/openai/lm-human-preferences/issues/17#issuecomment-1044051496)), so we had to replace them with similar HF datasets, which may or may not cause a performance difference)
3. For the book dataset, we used [https://huggingface.co/datasets/bookcorpus](https://huggingface.co/datasets/bookcorpus), which we find not necessary to extract sentences that start and end with periods because the dataset ) is already pre-processed this way (e.g., `"usually , he would be tearing around the living room , playing with his toys ."`) To this end, we set `start_text=None, end_text=None` for the `sentiment` and `descriptiveness` tasks.
4. **Disable dropout**
1. Ziegler et al. (2019) suggested, “We do not use dropout for policy training.” This is also done in the code ([lm_human_preferences/policy.py#L48](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/policy.py#L48)).
5. **Rejection sampling**
1. Ziegler et al. (2019) suggested, “We use rejection sampling to ensure there is a period between tokens 16 and 24 and then truncate at that period (This is a crude approximation for ‘end of sentence.’ We chose it because it is easy to integrate into the RL loop, and even a crude approximation is sufficient for the intended purpose of making the human evaluation task somewhat easier). During the RL finetuning, we penalize continuations that don’t have such a period by giving them a fixed reward of −1.”
2. Specifically, this is achieved with the following steps:
1. **Token truncation**: We want to truncate at the first occurrence of `truncate_token` that appears at or after position `truncate_after` in the responses ([lm_human_preferences/train_policy.py#L378](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L378))
1. Code comment: “central example: replace all tokens after truncate_token with padding_token”
2. **Run reward model on truncated response:** After the response has been truncated by the token truncation process, the code then runs the reward model on the **truncated response**.
3. **Rejection sampling**: if there is not a period between tokens 16 and 24, then replace the score of the response with a fixed low value (such as -1)([lm_human_preferences/train_policy.py#L384](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L384), [lm_human_preferences/train_policy.py#L384-L402](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L384-L402))
1. Code comment: “central example: ensure that the sample contains `truncate_token`"
2. Code comment: “only query humans on responses that pass that function“
4. To give some examples in `descriptiveness`:
. Notice the 1st and 3rd example has too many tokens after the period, so its score was replaced by -1. ](https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/rlhf_implementation_details/Untitled%201.png)
Samples extracted from our reproduction [https://wandb.ai/openrlbenchmark/lm_human_preference_details/runs/djf8yymv/logs](https://wandb.ai/openrlbenchmark/lm_human_preference_details/runs/djf8yymv/logs?workspace=user-costa-huang). Notice the 1st and 3rd example has too many tokens after the period, so its score was replaced by -1.
6. **Discount factor = 1**
1. The discount parameter \\(\gamma\\) is set to 1 ([lm_human_preferences/train_policy.py#L56](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L56)), which means that future rewards are given the same weight as immediate rewards.
7. **Terminology of the training loop: batches and minibatches in PPO**
1. OAI uses the following training loop ([lm_human_preferences/train_policy.py#L184-L192](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L184-L192)). Note: we additionally added the `micro_batch_size` to help deal with the case in gradient accumulation. At each epoch, it shuffles the batch indices.
```python
import numpy as np
batch_size = 8
nminibatches = 2
gradient_accumulation_steps = 2
mini_batch_size = batch_size // nminibatches
micro_batch_size = mini_batch_size // gradient_accumulation_steps
data = np.arange(batch_size).astype(np.float32)
print("data:", data)
print("batch_size:", batch_size)
print("mini_batch_size:", mini_batch_size)
print("micro_batch_size:", micro_batch_size)
for epoch in range(4):
batch_inds = np.random.permutation(batch_size)
print("epoch:", epoch, "batch_inds:", batch_inds)
for mini_batch_start in range(0, batch_size, mini_batch_size):
mini_batch_end = mini_batch_start + mini_batch_size
mini_batch_inds = batch_inds[mini_batch_start:mini_batch_end]
# `optimizer.zero_grad()` set optimizer to zero for gradient accumulation
for micro_batch_start in range(0, mini_batch_size, micro_batch_size):
micro_batch_end = micro_batch_start + micro_batch_size
micro_batch_inds = mini_batch_inds[micro_batch_start:micro_batch_end]
print("____⏩ a forward pass on", data[micro_batch_inds])
# `optimizer.step()`
print("⏪ a backward pass on", data[mini_batch_inds])
# data: [0. 1. 2. 3. 4. 5. 6. 7.]
# batch_size: 8
# mini_batch_size: 4
# micro_batch_size: 2
# epoch: 0 batch_inds: [6 4 0 7 3 5 1 2]
# ____⏩ a forward pass on [6. 4.]
# ____⏩ a forward pass on [0. 7.]
# ⏪ a backward pass on [6. 4. 0. 7.]
# ____⏩ a forward pass on [3. 5.]
# ____⏩ a forward pass on [1. 2.]
# ⏪ a backward pass on [3. 5. 1. 2.]
# epoch: 1 batch_inds: [6 7 3 2 0 4 5 1]
# ____⏩ a forward pass on [6. 7.]
# ____⏩ a forward pass on [3. 2.]
# ⏪ a backward pass on [6. 7. 3. 2.]
# ____⏩ a forward pass on [0. 4.]
# ____⏩ a forward pass on [5. 1.]
# ⏪ a backward pass on [0. 4. 5. 1.]
# epoch: 2 batch_inds: [1 4 5 6 0 7 3 2]
# ____⏩ a forward pass on [1. 4.]
# ____⏩ a forward pass on [5. 6.]
# ⏪ a backward pass on [1. 4. 5. 6.]
# ____⏩ a forward pass on [0. 7.]
# ____⏩ a forward pass on [3. 2.]
# ⏪ a backward pass on [0. 7. 3. 2.]
# epoch: 3 batch_inds: [7 2 4 1 3 0 6 5]
# ____⏩ a forward pass on [7. 2.]
# ____⏩ a forward pass on [4. 1.]
# ⏪ a backward pass on [7. 2. 4. 1.]
# ____⏩ a forward pass on [3. 0.]
# ____⏩ a forward pass on [6. 5.]
# ⏪ a backward pass on [3. 0. 6. 5.]
```
8. **Per-token KL penalty**
- The code adds a per-token KL penalty ([lm_human_preferences/train_policy.py#L150-L153](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L150-L153)) to the rewards, in order to discourage the policy to be very different from the original policy.
- Using the `"usually, he would"` as an example, it gets tokenized to `[23073, 11, 339, 561]`. Say we use `[23073]` as the query and `[11, 339, 561]` as the response. Then under the default `gpt2` parameters, the response tokens will have log probabilities of the reference policy `logprobs=[-3.3213, -4.9980, -3.8690]` .
- During the first PPO update epoch and minibatch update, so the active policy will have the same log probabilities `new_logprobs=[-3.3213, -4.9980, -3.8690]`. , so the per-token KL penalty would be `kl = new_logprobs - logprobs = [0., 0., 0.,]`
- However, after the first gradient backward pass, we could have `new_logprob=[3.3213, -4.9980, -3.8690]` , so the per-token KL penalty becomes `kl = new_logprobs - logprobs = [-0.3315, -0.0426, 0.6351]`
- Then the `non_score_reward = beta * kl` , where `beta` is the KL penalty coefficient \\(\beta\\), and it’s added to the `score` obtained from the reward model to create the `rewards` used for training. The `score` is only given at the end of episode; it could look like `[0.4,]` , and we have `rewards = [beta * -0.3315, beta * -0.0426, beta * 0.6351 + 0.4]`.
9. **Per-minibatch reward and advantage whitening, with optional mean shifting**
1. OAI implements a `whiten` function that looks like below, basically normalizing the `values` by subtracting its mean followed by dividing by its standard deviation. Optionally, `whiten` can shift back the mean of the whitened `values` with `shift_mean=True`.
```python
def whiten(values, shift_mean=True):
mean, var = torch.mean(values), torch.var(values, unbiased=False)
whitened = (values - mean) * torch.rsqrt(var + 1e-8)
if not shift_mean:
whitened += mean
return whitened
```
1. In each minibatch, OAI then whitens the reward `whiten(rewards, shift_mean=False)` without shifting the mean ([lm_human_preferences/train_policy.py#L325](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L325)) and whitens the advantages `whiten(advantages)` with the shifted mean ([lm_human_preferences/train_policy.py#L338](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L338)).
2. **Optimization note:** if the number of minibatches is one (which is the case in this reproduction) we only need to whiten rewards, calculate and whiten advantages once since their values won’t change.
3. **TensorFlow vs PyTorch note:** Different behavior of `tf.moments` vs `torch.var`: The behavior of whitening is different in torch vs tf because the variance calculation is different:
```jsx
import numpy as np
import tensorflow as tf
import torch
def whiten_tf(values, shift_mean=True):
mean, var = tf.nn.moments(values, axes=list(range(values.shape.rank)))
mean = tf.Print(mean, [mean], 'mean', summarize=100)
var = tf.Print(var, [var], 'var', summarize=100)
whitened = (values - mean) * tf.rsqrt(var + 1e-8)
if not shift_mean:
whitened += mean
return whitened
def whiten_pt(values, shift_mean=True, unbiased=True):
mean, var = torch.mean(values), torch.var(values, unbiased=unbiased)
print("mean", mean)
print("var", var)
whitened = (values - mean) * torch.rsqrt(var + 1e-8)
if not shift_mean:
whitened += mean
return whitened
rewards = np.array([
[1.2, 1.3, 1.4],
[1.5, 1.6, 1.7],
[1.8, 1.9, 2.0],
])
with tf.Session() as sess:
print(sess.run(whiten_tf(tf.constant(rewards, dtype=tf.float32), shift_mean=False)))
print(whiten_pt(torch.tensor(rewards), shift_mean=False, unbiased=True))
print(whiten_pt(torch.tensor(rewards), shift_mean=False, unbiased=False))
```
```jsx
mean[1.5999999]
var[0.0666666627]
[[0.05080712 0.4381051 0.8254035 ]
[1.2127019 1.6000004 1.9872988 ]
[2.3745968 2.7618952 3.1491938 ]]
mean tensor(1.6000, dtype=torch.float64)
var tensor(0.0750, dtype=torch.float64)
tensor([[0.1394, 0.5046, 0.8697],
[1.2349, 1.6000, 1.9651],
[2.3303, 2.6954, 3.0606]], dtype=torch.float64)
mean tensor(1.6000, dtype=torch.float64)
var tensor(0.0667, dtype=torch.float64)
tensor([[0.0508, 0.4381, 0.8254],
[1.2127, 1.6000, 1.9873],
[2.3746, 2.7619, 3.1492]], dtype=torch.float64)
```
10. **Clipped value function**
1. As done in the original PPO ([baselines/ppo2/model.py#L68-L75](https://github.com/openai/baselines/blob/ea25b9e8b234e6ee1bca43083f8f3cf974143998/baselines/ppo2/model.py#L68-L75)), the value function is clipped ([lm_human_preferences/train_policy.py#L343-L348](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L343-L348)) in a similar fashion as the policy objective.
11. **Adaptive KL**
- The KL divergence penalty coefficient \\(\beta\\) is modified adaptively based on the KL divergence between the current policy and the previous policy. If the KL divergence is outside a predefined target range, the penalty coefficient is adjusted to bring it closer to the target range ([lm_human_preferences/train_policy.py#L115-L124](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L115-L124)). It’s implemented as follows:
```python
class AdaptiveKLController:
def __init__(self, init_kl_coef, hparams):
self.value = init_kl_coef
self.hparams = hparams
def update(self, current, n_steps):
target = self.hparams.target
proportional_error = np.clip(current / target - 1, -0.2, 0.2)
mult = 1 + proportional_error * n_steps / self.hparams.horizon
self.value *= mult
```
- For the `sentiment` and `descriptiveness` tasks examined in this work, we have `init_kl_coef=0.15, hparams.target=6, hparams.horizon=10000`.
## **PyTorch Adam optimizer numerical issues w.r.t RLHF**
- This implementation detail is so interesting that it deserves a full section.
- PyTorch Adam optimizer ([torch.optim.Adam.html](https://pytorch.org/docs/stable/generated/torch.optim.Adam.html)) has a different implementation compared to TensorFlow’s Adam optimizer (TF1 Adam at [tensorflow/v1.15.2/adam.py](https://github.com/tensorflow/tensorflow/blob/v1.15.2/tensorflow/python/training/adam.py), TF2 Adam at [keras/adam.py#L26-L220](https://github.com/keras-team/keras/blob/v2.13.1/keras/optimizers/adam.py#L26-L220)). In particular, **PyTorch follows Algorithm 1** of the Kingma and Ba’s Adam paper ([arxiv/1412.6980](https://arxiv.org/pdf/1412.6980.pdf)), but **TensorFlow uses the formulation just before Section 2.1** of the paper and its `epsilon` referred to here is `epsilon hat` in the paper. In a pseudocode comparison, we have the following
```python
### pytorch adam implementation:
bias_correction1 = 1 - beta1 ** step
bias_correction2 = 1 - beta2 ** step
step_size = lr / bias_correction1
bias_correction2_sqrt = _dispatch_sqrt(bias_correction2)
denom = (exp_avg_sq.sqrt() / bias_correction2_sqrt).add_(eps)
param.addcdiv_(exp_avg, denom, value=-step_size)
### tensorflow adam implementation:
lr_t = lr * _dispatch_sqrt((1 - beta2 ** step)) / (1 - beta1 ** step)
denom = exp_avg_sq.sqrt().add_(eps)
param.addcdiv_(exp_avg, denom, value=-lr_t)
```
- Let’s compare the update equations of pytorch-style and tensorflow-style adam. Following the notation of the adam paper [(Kingma and Ba, 2014)](https://arxiv.org/abs/1412.6980), we have the gradient update rules for pytorch adam (Algorithm 1 of Kingma and Ba’s paper) and tensorflow-style adam (the formulation just before Section 2.1 of Kingma and Ba’s paper) as below:
$$\begin{aligned}\text{pytorch adam :}\quad \theta_t & =\theta_{t-1}-\alpha \cdot \hat{m}_t /\left(\sqrt{\hat{v}_t}+\varepsilon\right) \\& =\theta_{t-1}- \alpha \underbrace{\left[m_t /\left(1-\beta_1^t\right)\right]}_{=\hat{m}_t} /\left[\sqrt{\underbrace{v_t /\left(1-\beta_2^t\right)}_{=\hat{v}_t} }+\varepsilon\right]\\& =\theta_{t-1}- \alpha\left[m_t /\left(1-\beta_1^t\right)\right]\frac{\sqrt{1-\beta_2^t}}{\sqrt{v_t}+\color{green}{\varepsilon \sqrt{1-\beta_2^t}}}\end{aligned}$$
$$\begin{aligned}\text{tensorflow adam:}\quad \theta_t & =\theta_{t-1}-\alpha_t m_t /\left(\sqrt{v_t}+\hat{\varepsilon}\right) \\& =\theta_{t-1}-\underbrace{\left[\alpha \sqrt{1-\beta_2^t} /\left(1-\beta_1^t\right)\right]}_{=\alpha_t} m_t /\left(\sqrt{v_t}+\hat{\varepsilon}\right) \\& =\theta_{t-1}- \alpha\left[m_t /\left(1-\beta_1^t\right)\right] \frac{\sqrt{1-\beta_2^t}}{\sqrt{v_t}+\color{green}{\hat{\varepsilon}}} \end{aligned}$$
- The equations above highlight that the distinction between pytorch and tensorflow implementation is their **normalization terms**, \\(\color{green}{\varepsilon \sqrt{1-\beta_2^t}}\\) and \\(\color{green}{\hat{\varepsilon}}\\). The two versions are equivalent if we set \\(\hat{\varepsilon} =\varepsilon \sqrt{1-\beta_2^t}\\) . However, in the pytorch and tensorflow APIs, we can only set \\(\varepsilon\\) (pytorch) and \\(\hat{\varepsilon}\\) (tensorflow) via the `eps` argument, causing differences in their update equations. What if we set \\(\varepsilon\\) and \\(\hat{\varepsilon}\\) to the same value, say, 1e-5? Then for tensorflow adam, the normalization term \\(\hat{\varepsilon} = \text{1e-5}\\) is just a constant. But for pytorch adam, the normalization term \\({\varepsilon \sqrt{1-\beta_2^t}}\\) changes over time. Importantly, initially much smaller than 1e-5 when the timestep \\(t\\) is small, the term \\({\varepsilon \sqrt{1-\beta_2^t}}\\) gradually approaches to 1e-5 as timesteps increase. The plot below compares these two normalization terms over timesteps:
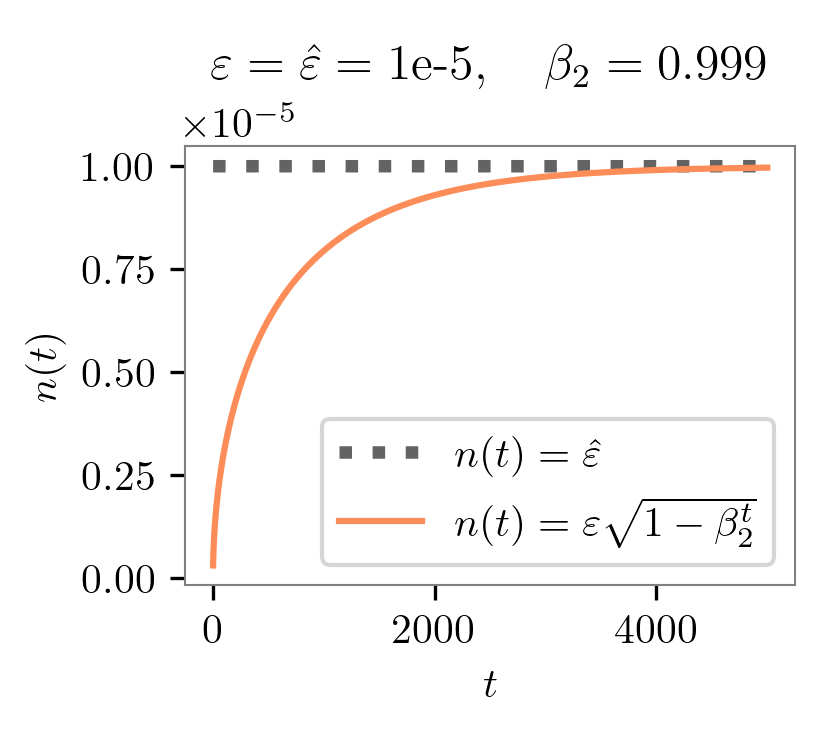
- The above figure shows that, if we set the same `eps` in pytorch adam and tensorflow adam, then pytorch-adam uses a much smaller normalization term than tensorflow-adam in the early phase of training. In other words, pytorch adam goes for **more aggressive gradient updates early in the training**. Our experiments support this finding, as we will demonstrate below.
- How does this impact reproducibility and performance? To align settings, we record the original query, response, and rewards from [https://github.com/openai/lm-human-preferences](https://github.com/openai/lm-human-preferences) and save them in [https://huggingface.co/datasets/vwxyzjn/lm-human-preferences-debug/tree/main](https://huggingface.co/datasets/vwxyzjn/lm-human-preferences-debug/tree/main). I also record the metrics of the first two epochs of training with TF1’s `AdamOptimizer` optimizer as the ground truth. Below are some key metrics:
| | OAI’s TF1 Adam | PyTorch’s Adam | Our custom Tensorflow-style Adam |
| --- | --- | --- | --- |
| policy/approxkl | 0.00037167023 | 0.0023672834504395723 | 0.000374998344341293 |
| policy/clipfrac | 0.0045572915 | 0.02018229104578495 | 0.0052083334885537624 |
| ratio_mean | 1.0051285 | 1.0105520486831665 | 1.0044583082199097 |
| ratio_var | 0.0007716546 | 0.005374275613576174 | 0.0007942612282931805 |
| ratio_max | 1.227216 | 1.8121057748794556 | 1.250215768814087 |
| ratio_min | 0.7400441 | 0.4011387825012207 | 0.7299948930740356 |
| logprob_diff_mean | 0.0047487603 | 0.008101251907646656 | 0.004073789343237877 |
| logprob_diff_var | 0.0007207897 | 0.004668936599045992 | 0.0007334011606872082 |
| logprob_diff_max | 0.20474821 | 0.594489574432373 | 0.22331619262695312 |
| logprob_diff_min | -0.30104542 | -0.9134478569030762 | -0.31471776962280273 |
- **PyTorch’s `Adam` produces a more aggressive update** for some reason. Here are some evidence:
- **PyTorch’s `Adam`'s `logprob_diff_var`** **is 6x higher**. Here `logprobs_diff = new_logprobs - logprobs` is the difference between the log probability of tokens between the initial and current policy after two epochs of training. Having a larger `logprob_diff_var` means the scale of the log probability changes is larger than that in OAI’s TF1 Adam.
- **PyTorch’s `Adam` presents a more extreme ratio max and min.** Here `ratio = torch.exp(logprobs_diff)`. Having a `ratio_max=1.8121057748794556` means that for some token, the probability of sampling that token is 1.8x more likely under the current policy, as opposed to only 1.2x with OAI’s TF1 Adam.
- **Larger `policy/approxkl` `policy/clipfrac`.** Because of the aggressive update, the ratio gets clipped **4.4x more often, and the approximate KL divergence is 6x larger.**
- The aggressive update is likely gonna cause further issues. E.g., `logprob_diff_mean` is 1.7x larger in PyTorch’s `Adam`, which would correspond to 1.7x larger KL penalty in the next reward calculation; this could get compounded. In fact, this might be related to the famous KL divergence issue — KL penalty is much larger than it should be and the model could pay more attention and optimizes for it more instead, therefore causing negative KL divergence.
- **Larger models get affected more.** We conducted experiments comparing PyTorch’s `Adam` (codename `pt_adam`) and our custom TensorFlow-style (codename `tf_adam`) with `gpt2` and `gpt2-xl`. We found that the performance are roughly similar under `gpt2`; however with `gpt2-xl`, we observed a more aggressive updates, meaning that larger models get affected by this issue more.
- When the initial policy updates are more aggressive in `gpt2-xl`, the training dynamics get affected. For example, we see a much larger `objective/kl` and `objective/scores` spikes with `pt_adam`, especially with `sentiment` — *the biggest KL was as large as 17.5* in one of the random seeds, suggesting an undesirable over-optimization.
- Furthermore, because of the larger KL, many other training metrics are affected as well. For example, we see a much larger `clipfrac` (the fraction of time the `ratio` gets clipped by PPO’s objective clip coefficient 0.2) and `approxkl`.
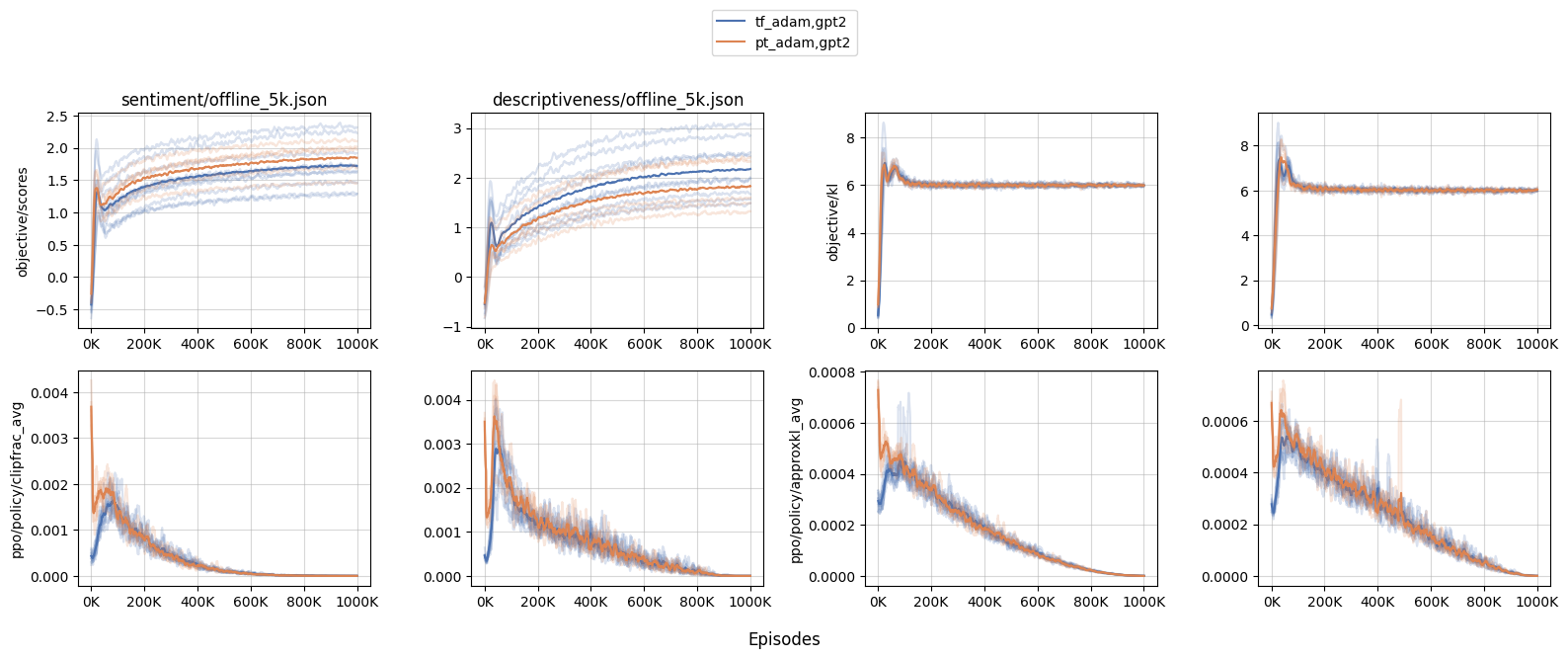
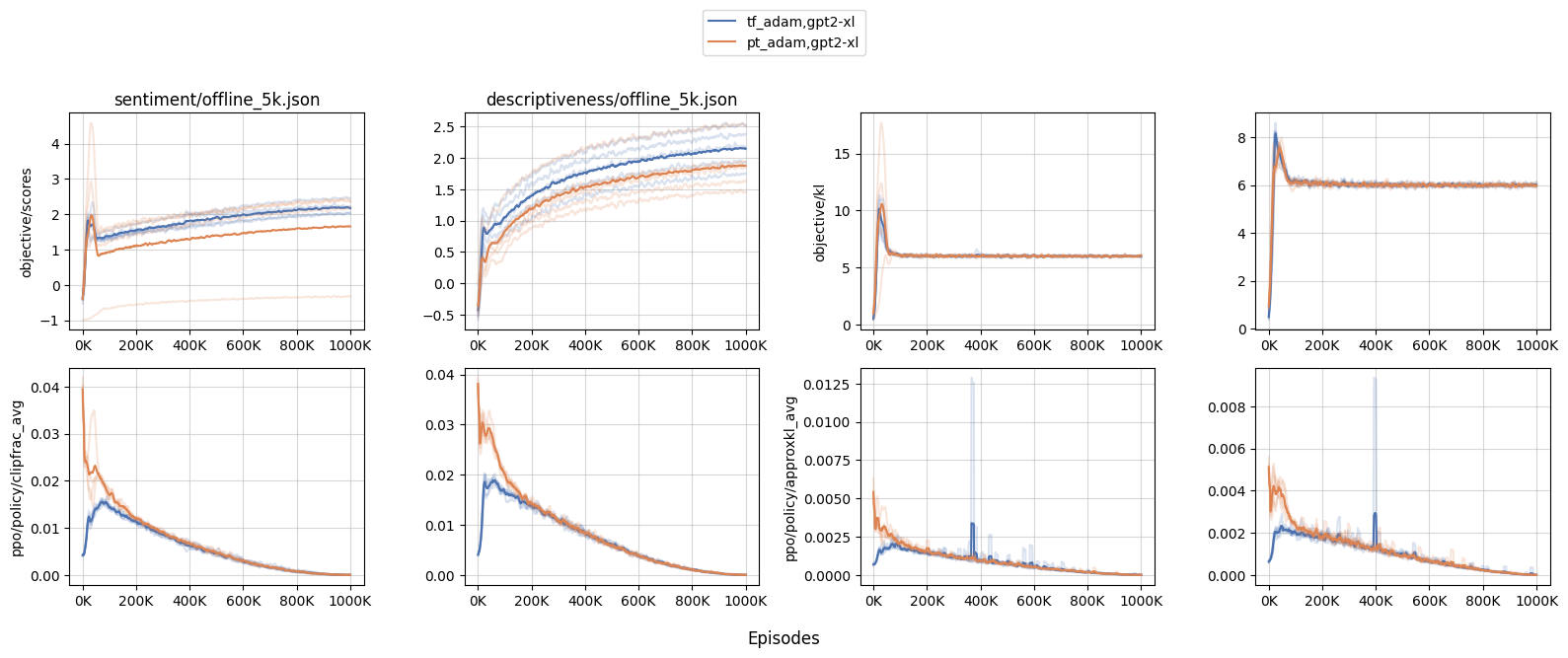
# Limitations
Noticed this work does not try to reproduce the summarization work in CNN DM or TL;DR. This was because we found the training to be time-consuming and brittle.
The particular training run we had showed poor GPU utilization (around 30%), so it takes almost 4 days to perform a training run, which is highly expensive (only AWS sells p3dn.24xlarge, and it costs $31.212 per hour)
Additionally, training was brittle. While the reward goes up, we find it difficult to reproduce the “smart copier” behavior reported by Ziegler et al. (2019). Below are some sample outputs — clearly, the agent overfits somehow. See [https://wandb.ai/openrlbenchmark/lm-human-preferences/runs/1ab47rqi/logs](https://wandb.ai/openrlbenchmark/lm-human-preferences/runs/1ab47rqi/logs?workspace=user-costa-huang) for more complete logs.
# Conclusion
In this work, we took a deep dive into OAI’s original RLHF codebase and compiled a list of its implementation details. We also created a minimal base which reproduces the same learning curves as OAI’s original RLHF codebase, when the dataset and hyperparameters are controlled. Furthermore, we identify surprising implementation details such as the adam optimizer’s setting which causes aggressive updates in early RLHF training.
# Acknowledgement
This work is supported by Hugging Face’s Big Science cluster 🤗. We also thank the helpful discussion with @lewtun and @natolambert.
# Bibtex
```bibtex
@article{Huang2023implementation,
author = {Huang, Shengyi and Liu, Tianlin and von Werra, Leandro},
title = {The N Implementation Details of RLHF with PPO},
journal = {Hugging Face Blog},
year = {2023},
note = {https://huggingface.co/blog/the_n_implementation_details_of_rlhf_with_ppo},
}
```
|
huggingface/blog/blob/main/the_n_implementation_details_of_rlhf_with_ppo.md
|
Datasets server maintenance job
> Job to run maintenance actions on the datasets-server
Available actions:
- `backfill`: backfill the cache (i.e. create jobs to add the missing entries or update the outdated entries)
- `collect-cache-metrics`: compute and store the cache metrics
- `collect-queue-metrics`: compute and store the queue metrics
- `clean-directory`: clean obsolete files/directories for a given path
- `post-messages`: post messages in Hub discussions
- `skip`: do nothing
## Configuration
The script can be configured using environment variables. They are grouped by scope.
- `DISCUSSIONS_BOT_ASSOCIATED_USER_NAME`: name of the Hub user associated with the Datasets Server bot app.
- `DISCUSSIONS_BOT_TOKEN`: token of the Datasets Server bot used to post messages in Hub discussions.
- `DISCUSSIONS_PARQUET_REVISION`: revision (branch) where the converted Parquet files are stored.
### Actions
Set environment variables to configure the job (`CACHE_MAINTENANCE_` prefix):
- `CACHE_MAINTENANCE_ACTION`: the action to launch, among `backfill`, `metrics`, `skip`. Defaults to `skip`.
Specific to the backfill action:
- `CACHE_MAINTENANCE_BACKFILL_ERROR_CODES_TO_RETRY`: the list of error codes to retry. Defaults to None.
### Common
See [../../libs/libcommon/README.md](../../libs/libcommon/README.md) for more information about the common configuration.
## Launch
```shell
make run
```
|
huggingface/datasets-server/blob/main/jobs/cache_maintenance/README.md
|
!---
Copyright 2023- The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Generating the documentation
To generate the documentation, you first have to build it. Several packages are necessary to build the doc,
you can install them with the following command, at the root of the code repository:
```bash
pip install -e ".[docs]"
```
Then you need to install our open source documentation builder tool:
```bash
pip install git+https://github.com/huggingface/doc-builder
```
---
**NOTE**
You only need to generate the documentation to inspect it locally (if you're planning changes and want to
check how they look before committing for instance). You don't have to commit the built documentation.
---
## Previewing the documentation
To preview the docs, first install the `watchdog` module with:
```bash
pip install watchdog
```
Then run the following command:
```bash
doc-builder preview {package_name} {path_to_docs}
```
For example:
```bash
doc-builder preview diffusers docs/source/en
```
The docs will be viewable at [http://localhost:3000](http://localhost:3000). You can also preview the docs once you have opened a PR. You will see a bot add a comment to a link where the documentation with your changes lives.
---
**NOTE**
The `preview` command only works with existing doc files. When you add a completely new file, you need to update `_toctree.yml` & restart `preview` command (`ctrl-c` to stop it & call `doc-builder preview ...` again).
---
## Adding a new element to the navigation bar
Accepted files are Markdown (.md).
Create a file with its extension and put it in the source directory. You can then link it to the toc-tree by putting
the filename without the extension in the [`_toctree.yml`](https://github.com/huggingface/diffusers/blob/main/docs/source/en/_toctree.yml) file.
## Renaming section headers and moving sections
It helps to keep the old links working when renaming the section header and/or moving sections from one document to another. This is because the old links are likely to be used in Issues, Forums, and Social media and it'd make for a much more superior user experience if users reading those months later could still easily navigate to the originally intended information.
Therefore, we simply keep a little map of moved sections at the end of the document where the original section was. The key is to preserve the original anchor.
So if you renamed a section from: "Section A" to "Section B", then you can add at the end of the file:
```md
Sections that were moved:
[ <a href="#section-b">Section A</a><a id="section-a"></a> ]
```
and of course, if you moved it to another file, then:
```md
Sections that were moved:
[ <a href="../new-file#section-b">Section A</a><a id="section-a"></a> ]
```
Use the relative style to link to the new file so that the versioned docs continue to work.
For an example of a rich moved section set please see the very end of [the transformers Trainer doc](https://github.com/huggingface/transformers/blob/main/docs/source/en/main_classes/trainer.md).
## Writing Documentation - Specification
The `huggingface/diffusers` documentation follows the
[Google documentation](https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html) style for docstrings,
although we can write them directly in Markdown.
### Adding a new tutorial
Adding a new tutorial or section is done in two steps:
- Add a new Markdown (.md) file under `docs/source/<languageCode>`.
- Link that file in `docs/source/<languageCode>/_toctree.yml` on the correct toc-tree.
Make sure to put your new file under the proper section. It's unlikely to go in the first section (*Get Started*), so
depending on the intended targets (beginners, more advanced users, or researchers) it should go in sections two, three, or four.
### Adding a new pipeline/scheduler
When adding a new pipeline:
- Create a file `xxx.md` under `docs/source/<languageCode>/api/pipelines` (don't hesitate to copy an existing file as template).
- Link that file in (*Diffusers Summary*) section in `docs/source/api/pipelines/overview.md`, along with the link to the paper, and a colab notebook (if available).
- Write a short overview of the diffusion model:
- Overview with paper & authors
- Paper abstract
- Tips and tricks and how to use it best
- Possible an end-to-end example of how to use it
- Add all the pipeline classes that should be linked in the diffusion model. These classes should be added using our Markdown syntax. By default as follows:
```
[[autodoc]] XXXPipeline
- all
- __call__
```
This will include every public method of the pipeline that is documented, as well as the `__call__` method that is not documented by default. If you just want to add additional methods that are not documented, you can put the list of all methods to add in a list that contains `all`.
```
[[autodoc]] XXXPipeline
- all
- __call__
- enable_attention_slicing
- disable_attention_slicing
- enable_xformers_memory_efficient_attention
- disable_xformers_memory_efficient_attention
```
You can follow the same process to create a new scheduler under the `docs/source/<languageCode>/api/schedulers` folder.
### Writing source documentation
Values that should be put in `code` should either be surrounded by backticks: \`like so\`. Note that argument names
and objects like True, None, or any strings should usually be put in `code`.
When mentioning a class, function, or method, it is recommended to use our syntax for internal links so that our tool
adds a link to its documentation with this syntax: \[\`XXXClass\`\] or \[\`function\`\]. This requires the class or
function to be in the main package.
If you want to create a link to some internal class or function, you need to
provide its path. For instance: \[\`pipelines.ImagePipelineOutput\`\]. This will be converted into a link with
`pipelines.ImagePipelineOutput` in the description. To get rid of the path and only keep the name of the object you are
linking to in the description, add a ~: \[\`~pipelines.ImagePipelineOutput\`\] will generate a link with `ImagePipelineOutput` in the description.
The same works for methods so you can either use \[\`XXXClass.method\`\] or \[\`~XXXClass.method\`\].
#### Defining arguments in a method
Arguments should be defined with the `Args:` (or `Arguments:` or `Parameters:`) prefix, followed by a line return and
an indentation. The argument should be followed by its type, with its shape if it is a tensor, a colon, and its
description:
```
Args:
n_layers (`int`): The number of layers of the model.
```
If the description is too long to fit in one line, another indentation is necessary before writing the description
after the argument.
Here's an example showcasing everything so far:
```
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`AlbertTokenizer`]. See [`~PreTrainedTokenizer.encode`] and
[`~PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
```
For optional arguments or arguments with defaults we follow the following syntax: imagine we have a function with the
following signature:
```py
def my_function(x: str=None, a: float=3.14):
```
then its documentation should look like this:
```
Args:
x (`str`, *optional*):
This argument controls ...
a (`float`, *optional*, defaults to `3.14`):
This argument is used to ...
```
Note that we always omit the "defaults to \`None\`" when None is the default for any argument. Also note that even
if the first line describing your argument type and its default gets long, you can't break it on several lines. You can
however write as many lines as you want in the indented description (see the example above with `input_ids`).
#### Writing a multi-line code block
Multi-line code blocks can be useful for displaying examples. They are done between two lines of three backticks as usual in Markdown:
````
```
# first line of code
# second line
# etc
```
````
#### Writing a return block
The return block should be introduced with the `Returns:` prefix, followed by a line return and an indentation.
The first line should be the type of the return, followed by a line return. No need to indent further for the elements
building the return.
Here's an example of a single value return:
```
Returns:
`List[int]`: A list of integers in the range [0, 1] --- 1 for a special token, 0 for a sequence token.
```
Here's an example of a tuple return, comprising several objects:
```
Returns:
`tuple(torch.FloatTensor)` comprising various elements depending on the configuration ([`BertConfig`]) and inputs:
- ** loss** (*optional*, returned when `masked_lm_labels` is provided) `torch.FloatTensor` of shape `(1,)` --
Total loss is the sum of the masked language modeling loss and the next sequence prediction (classification) loss.
- **prediction_scores** (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`) --
Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
```
#### Adding an image
Due to the rapidly growing repository, it is important to make sure that no files that would significantly weigh down the repository are added. This includes images, videos, and other non-text files. We prefer to leverage a hf.co hosted `dataset` like
the ones hosted on [`hf-internal-testing`](https://huggingface.co/hf-internal-testing) in which to place these files and reference
them by URL. We recommend putting them in the following dataset: [huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images).
If an external contribution, feel free to add the images to your PR and ask a Hugging Face member to migrate your images
to this dataset.
## Styling the docstring
We have an automatic script running with the `make style` command that will make sure that:
- the docstrings fully take advantage of the line width
- all code examples are formatted using black, like the code of the Transformers library
This script may have some weird failures if you made a syntax mistake or if you uncover a bug. Therefore, it's
recommended to commit your changes before running `make style`, so you can revert the changes done by that script
easily.
|
huggingface/diffusers/blob/main/docs/README.md
|
Gradio Demo: input_output
```
!pip install -q gradio
```
```
import gradio as gr
def image_mod(text):
return text[::-1]
demo = gr.Blocks()
with demo:
text = gr.Textbox(label="Input-Output")
btn = gr.Button("Run")
btn.click(image_mod, text, text)
if __name__ == "__main__":
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/input_output/run.ipynb
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# VAE Image Processor
The [`VaeImageProcessor`] provides a unified API for [`StableDiffusionPipeline`]s to prepare image inputs for VAE encoding and post-processing outputs once they're decoded. This includes transformations such as resizing, normalization, and conversion between PIL Image, PyTorch, and NumPy arrays.
All pipelines with [`VaeImageProcessor`] accept PIL Image, PyTorch tensor, or NumPy arrays as image inputs and return outputs based on the `output_type` argument by the user. You can pass encoded image latents directly to the pipeline and return latents from the pipeline as a specific output with the `output_type` argument (for example `output_type="latent"`). This allows you to take the generated latents from one pipeline and pass it to another pipeline as input without leaving the latent space. It also makes it much easier to use multiple pipelines together by passing PyTorch tensors directly between different pipelines.
## VaeImageProcessor
[[autodoc]] image_processor.VaeImageProcessor
## VaeImageProcessorLDM3D
The [`VaeImageProcessorLDM3D`] accepts RGB and depth inputs and returns RGB and depth outputs.
[[autodoc]] image_processor.VaeImageProcessorLDM3D
|
huggingface/diffusers/blob/main/docs/source/en/api/image_processor.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Fuyu
## Overview
The Fuyu model was created by [ADEPT](https://www.adept.ai/blog/fuyu-8b), and authored by Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, Sağnak Taşırlar.
The authors introduced Fuyu-8B, a decoder-only multimodal model based on the classic transformers architecture, with query and key normalization. A linear encoder is added to create multimodal embeddings from image inputs.
By treating image tokens like text tokens and using a special image-newline character, the model knows when an image line ends. Image positional embeddings are removed. This avoids the need for different training phases for various image resolutions. With 8 billion parameters and licensed under CC-BY-NC, Fuyu-8B is notable for its ability to handle both text and images, its impressive context size of 16K, and its overall performance.
<Tip warning={true}>
The `Fuyu` models were trained using `bfloat16`, but the original inference uses `float16` The checkpoints uploaded on the hub use `torch_dtype = 'float16'` which will be
used by the `AutoModel` API to cast the checkpoints from `torch.float32` to `torch.float16`.
The `dtype` of the online weights is mostly irrelevant, unless you are using `torch_dtype="auto"` when initializing a model using `model = AutoModelForCausalLM.from_pretrained("path", torch_dtype = "auto")`. The reason is that the model will first be downloaded ( using the `dtype` of the checkpoints online) then it will be cast to the default `dtype` of `torch` (becomes `torch.float32`). Users should specify the `torch_dtype` they want, and if they don't it will be `torch.float32`.
Finetuning the model in `float16` is not recommended and known to produce `nan`, as such the model should be fine-tuned in `bfloat16`.
</Tip>
Tips:
- To convert the model, you need to clone the original repository using `git clone https://github.com/persimmon-ai-labs/adept-inference`, then get the checkpoints:
```bash
git clone https://github.com/persimmon-ai-labs/adept-inference
wget path/to/fuyu-8b-model-weights.tar
tar -xvf fuyu-8b-model-weights.tar
python src/transformers/models/fuyu/convert_fuyu_weights_to_hf.py --input_dir /path/to/downloaded/fuyu/weights/ --output_dir /output/path \
--pt_model_path /path/to/fuyu_8b_release/iter_0001251/mp_rank_00/model_optim_rng.pt
--ada_lib_path /path/to/adept-inference
```
For the chat model:
```bash
wget https://axtkn4xl5cip.objectstorage.us-phoenix-1.oci.customer-oci.com/n/axtkn4xl5cip/b/adept-public-data/o/8b_chat_model_release.tar
tar -xvf 8b_base_model_release.tar
```
Then, model can be loaded via:
```py
from transformers import FuyuConfig, FuyuForCausalLM
model_config = FuyuConfig()
model = FuyuForCausalLM(model_config).from_pretrained('/output/path')
```
Inputs need to be passed through a specific Processor to have the correct formats.
A processor requires an image_processor and a tokenizer. Hence, inputs can be loaded via:
```py
from PIL import Image
from transformers import AutoTokenizer
from transformers.models.fuyu.processing_fuyu import FuyuProcessor
from transformers.models.fuyu.image_processing_fuyu import FuyuImageProcessor
tokenizer = AutoTokenizer.from_pretrained('adept-hf-collab/fuyu-8b')
image_processor = FuyuImageProcessor()
processor = FuyuProcessor(image_processor=image_processor, tokenizer=tokenizer)
text_prompt = "Generate a coco-style caption.\\n"
bus_image_url = "https://huggingface.co/datasets/hf-internal-testing/fixtures-captioning/resolve/main/bus.png"
bus_image_pil = Image.open(io.BytesIO(requests.get(bus_image_url).content))
inputs_to_model = processor(text=text_prompt, images=image_pil)
```
This model was contributed by [Molbap](https://huggingface.co/Molbap).
The original code can be found [here](https://github.com/persimmon-ai-labs/adept-inference).
- Fuyu uses a `sentencepiece` based tokenizer, with a `Unigram` model. It supports bytefallback, which is only available in `tokenizers==0.14.0` for the fast tokenizer.
The `LlamaTokenizer` is used as it is a standard wrapper around sentencepiece.
- The authors suggest to use the following prompt for image captioning: `f"Generate a coco-style caption.\\n"`
## FuyuConfig
[[autodoc]] FuyuConfig
## FuyuForCausalLM
[[autodoc]] FuyuForCausalLM
- forward
## FuyuImageProcessor
[[autodoc]] FuyuImageProcessor
- __call__
## FuyuProcessor
[[autodoc]] FuyuProcessor
- __call__
|
huggingface/transformers/blob/main/docs/source/en/model_doc/fuyu.md
|
Datasets server - storage admin
> A Ubuntu machine to log into and manage the storage manually
|
huggingface/datasets-server/blob/main/services/storage-admin/README.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Trainer
The [`Trainer`] is a complete training and evaluation loop for PyTorch models implemented in the Transformers library. You only need to pass it the necessary pieces for training (model, tokenizer, dataset, evaluation function, training hyperparameters, etc.), and the [`Trainer`] class takes care of the rest. This makes it easier to start training faster without manually writing your own training loop. But at the same time, [`Trainer`] is very customizable and offers a ton of training options so you can tailor it to your exact training needs.
<Tip>
In addition to the [`Trainer`] class, Transformers also provides a [`Seq2SeqTrainer`] class for sequence-to-sequence tasks like translation or summarization. There is also the [`~trl.SFTTrainer`] class from the [TRL](https://hf.co/docs/trl) library which wraps the [`Trainer`] class and is optimized for training language models like Llama-2 and Mistral with autoregressive techniques. [`~trl.SFTTrainer`] also supports features like sequence packing, LoRA, quantization, and DeepSpeed for efficiently scaling to any model size.
<br>
Feel free to check out the [API reference](./main_classes/trainer) for these other [`Trainer`]-type classes to learn more about when to use which one. In general, [`Trainer`] is the most versatile option and is appropriate for a broad spectrum of tasks. [`Seq2SeqTrainer`] is designed for sequence-to-sequence tasks and [`~trl.SFTTrainer`] is designed for training language models.
</Tip>
Before you start, make sure [Accelerate](https://hf.co/docs/accelerate) - a library for enabling and running PyTorch training across distributed environments - is installed.
```bash
pip install accelerate
# upgrade
pip install accelerate --upgrade
```
This guide provides an overview of the [`Trainer`] class.
## Basic usage
[`Trainer`] includes all the code you'll find in a basic training loop:
1. perform a training step to calculate the loss
2. calculate the gradients with the [`~accelerate.Accelerator.backward`] method
3. update the weights based on the gradients
4. repeat this process until you've reached a predetermined number of epochs
The [`Trainer`] class abstracts all of this code away so you don't have to worry about manually writing a training loop every time or if you're just getting started with PyTorch and training. You only need to provide the essential components required for training, such as a model and a dataset, and the [`Trainer`] class handles everything else.
If you want to specify any training options or hyperparameters, you can find them in the [`TrainingArguments`] class. For example, let's define where to save the model in `output_dir` and push the model to the Hub after training with `push_to_hub=True`.
```py
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="your-model",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=2,
weight_decay=0.01,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
push_to_hub=True,
)
```
Pass `training_args` to the [`Trainer`] along with a model, dataset, something to preprocess the dataset with (depending on your data type it could be a tokenizer, feature extractor or image processor), a data collator, and a function to compute the metrics you want to track during training.
Finally, call [`~Trainer.train`] to start training!
```py
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
trainer.train()
```
### Checkpoints
The [`Trainer`] class saves your model checkpoints to the directory specified in the `output_dir` parameter of [`TrainingArguments`]. You'll find the checkpoints saved in a `checkpoint-000` subfolder where the numbers at the end correspond to the training step. Saving checkpoints are useful for resuming training later.
```py
# resume from latest checkpoint
trainer.train(resume_from_checkpoint=True)
# resume from specific checkpoint saved in output directory
trainer.train(resume_from_checkpoint="your-model/checkpoint-1000")
```
You can save your checkpoints (the optimizer state is not saved by default) to the Hub by setting `push_to_hub=True` in [`TrainingArguments`] to commit and push them. Other options for deciding how your checkpoints are saved are set up in the [`hub_strategy`](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments.hub_strategy) parameter:
* `hub_strategy="checkpoint"` pushes the latest checkpoint to a subfolder named "last-checkpoint" from which you can resume training
* `hug_strategy="all_checkpoints"` pushes all checkpoints to the directory defined in `output_dir` (you'll see one checkpoint per folder in your model repository)
When you resume training from a checkpoint, the [`Trainer`] tries to keep the Python, NumPy, and PyTorch RNG states the same as they were when the checkpoint was saved. But because PyTorch has various non-deterministic default settings, the RNG states aren't guaranteed to be the same. If you want to enable full determinism, take a look at the [Controlling sources of randomness](https://pytorch.org/docs/stable/notes/randomness#controlling-sources-of-randomness) guide to learn what you can enable to make your training fully deterministic. Keep in mind though that by making certain settings deterministic, training may be slower.
## Customize the Trainer
While the [`Trainer`] class is designed to be accessible and easy-to-use, it also offers a lot of customizability for more adventurous users. Many of the [`Trainer`]'s method can be subclassed and overridden to support the functionality you want, without having to rewrite the entire training loop from scratch to accommodate it. These methods include:
* [`~Trainer.get_train_dataloader`] creates a training DataLoader
* [`~Trainer.get_eval_dataloader`] creates an evaluation DataLoader
* [`~Trainer.get_test_dataloader`] creates a test DataLoader
* [`~Trainer.log`] logs information on the various objects that watch training
* [`~Trainer.create_optimizer_and_scheduler`] creates an optimizer and learning rate scheduler if they weren't passed in the `__init__`; these can also be separately customized with [`~Trainer.create_optimizer`] and [`~Trainer.create_scheduler`] respectively
* [`~Trainer.compute_loss`] computes the loss on a batch of training inputs
* [`~Trainer.training_step`] performs the training step
* [`~Trainer.prediction_step`] performs the prediction and test step
* [`~Trainer.evaluate`] evaluates the model and returns the evaluation metrics
* [`~Trainer.predict`] makes predictions (with metrics if labels are available) on the test set
For example, if you want to customize the [`~Trainer.compute_loss`] method to use a weighted loss instead.
```py
from torch import nn
from transformers import Trainer
class CustomTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs.pop("labels")
# forward pass
outputs = model(**inputs)
logits = outputs.get("logits")
# compute custom loss for 3 labels with different weights
loss_fct = nn.CrossEntropyLoss(weight=torch.tensor([1.0, 2.0, 3.0], device=model.device))
loss = loss_fct(logits.view(-1, self.model.config.num_labels), labels.view(-1))
return (loss, outputs) if return_outputs else loss
```
### Callbacks
Another option for customizing the [`Trainer`] is to use [callbacks](callbacks). Callbacks *don't change* anything in the training loop. They inspect the training loop state and then execute some action (early stopping, logging results, etc.) depending on the state. In other words, a callback can't be used to implement something like a custom loss function and you'll need to subclass and override the [`~Trainer.compute_loss`] method for that.
For example, if you want to add an early stopping callback to the training loop after 10 steps.
```py
from transformers import TrainerCallback
class EarlyStoppingCallback(TrainerCallback):
def __init__(self, num_steps=10):
self.num_steps = num_steps
def on_step_end(self, args, state, control, **kwargs):
if state.global_step >= self.num_steps:
return {"should_training_stop": True}
else:
return {}
```
Then pass it to the [`Trainer`]'s `callback` parameter.
```py
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
callback=[EarlyStoppingCallback()],
)
```
## Logging
<Tip>
Check out the [logging](./main_classes/logging) API reference for more information about the different logging levels.
</Tip>
The [`Trainer`] is set to `logging.INFO` by default which reports errors, warnings, and other basic information. A [`Trainer`] replica - in distributed environments - is set to `logging.WARNING` which only reports errors and warnings. You can change the logging level with the [`log_level`](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments.log_level) and [`log_level_replica`](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments.log_level_replica) parameters in [`TrainingArguments`].
To configure the log level setting for each node, use the [`log_on_each_node`](https://huggingface.co/docs/transformers/main/en/main_classes/trainer#transformers.TrainingArguments.log_on_each_node) parameter to determine whether to use the log level on each node or only on the main node.
<Tip>
[`Trainer`] sets the log level separately for each node in the [`Trainer.__init__`] method, so you may want to consider setting this sooner if you're using other Transformers functionalities before creating the [`Trainer`] object.
</Tip>
For example, to set your main code and modules to use the same log level according to each node:
```py
logger = logging.getLogger(__name__)
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
trainer = Trainer(...)
```
Use different combinations of `log_level` and `log_level_replica` to configure what gets logged on each of the nodes.
<hfoptions id="logging">
<hfoption id="single node">
```bash
my_app.py ... --log_level warning --log_level_replica error
```
</hfoption>
<hfoption id="multi-node">
Add the `log_on_each_node 0` parameter for multi-node environments.
```bash
my_app.py ... --log_level warning --log_level_replica error --log_on_each_node 0
# set to only report errors
my_app.py ... --log_level error --log_level_replica error --log_on_each_node 0
```
</hfoption>
</hfoptions>
## NEFTune
[NEFTune](https://hf.co/papers/2310.05914) is a technique that can improve performance by adding noise to the embedding vectors during training. To enable it in [`Trainer`], set the `neftune_noise_alpha` parameter in [`TrainingArguments`] to control how much noise is added.
```py
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(..., neftune_noise_alpha=0.1)
trainer = Trainer(..., args=training_args)
```
NEFTune is disabled after training to restore the original embedding layer to avoid any unexpected behavior.
## Accelerate and Trainer
The [`Trainer`] class is powered by [Accelerate](https://hf.co/docs/accelerate), a library for easily training PyTorch models in distributed environments with support for integrations such as [FullyShardedDataParallel (FSDP)](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/) and [DeepSpeed](https://www.deepspeed.ai/).
<Tip>
Learn more about FSDP sharding strategies, CPU offloading, and more with the [`Trainer`] in the [Fully Sharded Data Parallel](fsdp) guide.
</Tip>
To use Accelerate with [`Trainer`], run the [`accelerate.config`](https://huggingface.co/docs/accelerate/package_reference/cli#accelerate-config) command to set up training for your training environment. This command creates a `config_file.yaml` that'll be used when you launch your training script. For example, some example configurations you can setup are:
<hfoptions id="config">
<hfoption id="DistributedDataParallel">
```yml
compute_environment: LOCAL_MACHINE
distributed_type: MULTI_GPU
downcast_bf16: 'no'
gpu_ids: all
machine_rank: 0 #change rank as per the node
main_process_ip: 192.168.20.1
main_process_port: 9898
main_training_function: main
mixed_precision: fp16
num_machines: 2
num_processes: 8
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
</hfoption>
<hfoption id="FSDP">
```yml
compute_environment: LOCAL_MACHINE
distributed_type: FSDP
downcast_bf16: 'no'
fsdp_config:
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_backward_prefetch_policy: BACKWARD_PRE
fsdp_forward_prefetch: true
fsdp_offload_params: false
fsdp_sharding_strategy: 1
fsdp_state_dict_type: FULL_STATE_DICT
fsdp_sync_module_states: true
fsdp_transformer_layer_cls_to_wrap: BertLayer
fsdp_use_orig_params: true
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
</hfoption>
<hfoption id="DeepSpeed">
```yml
compute_environment: LOCAL_MACHINE
deepspeed_config:
deepspeed_config_file: /home/user/configs/ds_zero3_config.json
zero3_init_flag: true
distributed_type: DEEPSPEED
downcast_bf16: 'no'
machine_rank: 0
main_training_function: main
num_machines: 1
num_processes: 4
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
</hfoption>
<hfoption id="DeepSpeed with Accelerate plugin">
```yml
compute_environment: LOCAL_MACHINE
deepspeed_config:
gradient_accumulation_steps: 1
gradient_clipping: 0.7
offload_optimizer_device: cpu
offload_param_device: cpu
zero3_init_flag: true
zero_stage: 2
distributed_type: DEEPSPEED
downcast_bf16: 'no'
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 4
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
</hfoption>
</hfoptions>
The [`accelerate_launch`](https://huggingface.co/docs/accelerate/package_reference/cli#accelerate-launch) command is the recommended way to launch your training script on a distributed system with Accelerate and [`Trainer`] with the parameters specified in `config_file.yaml`. This file is saved to the Accelerate cache folder and automatically loaded when you run `accelerate_launch`.
For example, to run the [run_glue.py](https://github.com/huggingface/transformers/blob/f4db565b695582891e43a5e042e5d318e28f20b8/examples/pytorch/text-classification/run_glue.py#L4) training script with the FSDP configuration:
```bash
accelerate launch \
./examples/pytorch/text-classification/run_glue.py \
--model_name_or_path bert-base-cased \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 16 \
--learning_rate 5e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/ \
--overwrite_output_dir
```
You could also specify the parameters from the `config_file.yaml` file directly in the command line:
```bash
accelerate launch --num_processes=2 \
--use_fsdp \
--mixed_precision=bf16 \
--fsdp_auto_wrap_policy=TRANSFORMER_BASED_WRAP \
--fsdp_transformer_layer_cls_to_wrap="BertLayer" \
--fsdp_sharding_strategy=1 \
--fsdp_state_dict_type=FULL_STATE_DICT \
./examples/pytorch/text-classification/run_glue.py
--model_name_or_path bert-base-cased \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 16 \
--learning_rate 5e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/ \
--overwrite_output_dir
```
Check out the [Launching your Accelerate scripts](https://huggingface.co/docs/accelerate/basic_tutorials/launch) tutorial to learn more about `accelerate_launch` and custom configurations.
|
huggingface/transformers/blob/main/docs/source/en/trainer.md
|
--
title: "Accelerate Large Model Training using PyTorch Fully Sharded Data Parallel"
thumbnail: /blog/assets/62_pytorch_fsdp/fsdp-thumbnail.png
authors:
- user: smangrul
- user: sgugger
---
# Accelerate Large Model Training using PyTorch Fully Sharded Data Parallel
In this post we will look at how we can leverage **[Accelerate](https://github.com/huggingface/accelerate)** Library for training large models which enables users to leverage the latest features of **[PyTorch FullyShardedDataParallel (FSDP)](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/)**.
# Motivation 🤗
**With the ever increasing scale, size and parameters of the Machine Learning (ML) models, ML practitioners are finding it difficult to train or even load such large models on their hardware.** On one hand, it has been found that large models learn quickly (data and compute efficient) and are significantly more performant when compared to smaller models [1]; on the other hand, it becomes prohibitive to train such models on most of the available hardware.
Distributed training is the key to enable training such large ML models. There have been major recent advances in the field of **Distributed Training at Scale**. Few the most notable advances are given below:
1. Data Parallelism using ZeRO - Zero Redundancy Optimizer [2]
1. Stage 1: Shards optimizer states across data parallel workers/GPUs
2. Stage 2: Shards optimizer states + gradients across data parallel workers/GPUs
3. Stage 3: Shards optimizer states + gradients + model parameters across data parallel workers/GPUs
4. CPU Offload: Offloads the gradients + optimizer states to CPU building on top of ZERO Stage 2 [3]
2. Tensor Parallelism [4]: Form of model parallelism wherein sharding parameters of individual layers with huge number of parameters across accelerators/GPUs is done in a clever manner to achieve parallel computation while avoiding expensive communication synchronization overheads.
3. Pipeline Parallelism [5]: Form of model parallelism wherein different layers of the model are put across different accelerators/GPUs and pipelining is employed to keep all the accelerators running simultaneously. Here, for instance, the second accelerator/GPU computes on the first micro-batch while the first accelerator/GPU computes on the second micro-batch.
4. 3D parallelism [3]: Employs Data Parallelism using ZERO + Tensor Parallelism + Pipeline Parallelism to train humongous models in the order of 100s of Billions of parameters. For instance, BigScience 176B parameters Language Model employ this [6].
In this post we will look at Data Parallelism using ZeRO and more specifically the latest PyTorch feature **[FullyShardedDataParallel (FSDP)](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/)**. **[DeepSpeed](https://github.com/microsoft/deepspeed)** and **[FairScale](https://github.com/facebookresearch/fairscale/)** have implemented the core ideas of the ZERO paper. These have already been integrated in `transformers` Trainer and accompanied by great blog [Fit More and Train Faster With ZeRO via DeepSpeed and FairScale](https://huggingface.co/blog/zero-deepspeed-fairscale) [10]. PyTorch recently upstreamed the Fairscale FSDP into PyTorch Distributed with additional optimizations.
# Accelerate 🚀: Leverage PyTorch FSDP without any code changes
We will look at the task of Causal Language Modelling using GPT-2 Large (762M) and XL (1.5B) model variants.
Below is the code for pre-training GPT-2 model. It is similar to the official causal language modeling example [here](https://github.com/huggingface/transformers/blob/main/examples/pytorch/language-modeling/run_clm_no_trainer.py) with the addition of 2 arguments `n_train` (2000) and `n_val` (500) to prevent preprocessing/training on entire data in order to perform quick proof of concept benchmarks.
<a href="./assets/62_pytorch_fsdp/run_clm_no_trainer.py" target="_parent">run_clm_no_trainer.py</a>
Sample FSDP config after running the command `accelerate config`:
```bash
compute_environment: LOCAL_MACHINE
deepspeed_config: {}
distributed_type: FSDP
fsdp_config:
min_num_params: 2000
offload_params: false
sharding_strategy: 1
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: 'no'
num_machines: 1
num_processes: 2
use_cpu: false
```
## Multi-GPU FSDP
Here, we experiment on the Single-Node Multi-GPU setting. We compare the performance of Distributed Data Parallel (DDP) and FSDP in various configurations. First, GPT-2 Large(762M) model is used wherein DDP works with certain batch sizes without throwing Out Of Memory (OOM) errors. Next, GPT-2 XL (1.5B) model is used wherein DDP fails with OOM error even on batch size of 1. We observe that FSDP enables larger batch sizes for GPT-2 Large model and it enables training the GPT-2 XL model with decent batch size unlike DDP.
**Hardware setup**: 2X24GB NVIDIA Titan RTX GPUs.
Command for training GPT-2 Large Model (762M parameters):
```bash
export BS=#`try with different batch sizes till you don't get OOM error,
#i.e., start with larger batch size and go on decreasing till it fits on GPU`
time accelerate launch run_clm_no_trainer.py \
--model_name_or_path gpt2-large \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--per_device_train_batch_size $BS
--per_device_eval_batch_size $BS
--num_train_epochs 1
--block_size 12
```
Sample FSDP Run:

| Method | Batch Size Max ($BS) | Approx Train Time (minutes) | Notes |
| --- | --- | --- | --- |
| DDP (Distributed Data Parallel) | 7 | 15 | |
| DDP + FP16 | 7 | 8 | |
| FSDP with SHARD_GRAD_OP | 11 | 11 | |
| FSDP with min_num_params = 1M + FULL_SHARD | 15 | 12 | |
| FSDP with min_num_params = 2K + FULL_SHARD | 15 | 13 | |
| FSDP with min_num_params = 1M + FULL_SHARD + Offload to CPU | 20 | 23 | |
| FSDP with min_num_params = 2K + FULL_SHARD + Offload to CPU | 22 | 24 | |
Table 1: Benchmarking FSDP on GPT-2 Large (762M) model
With respect to DDP, from Table 1 we can observe that FSDP **enables larger batch sizes**, up to **2X-3X** without and with CPU offload setting, respectively. In terms of train time, DDP with mixed precision is the fastest followed by FSDP using ZERO Stage 2 and Stage 3, respectively. As the task of causal language modelling always has fixed context sequence length (--block_size), the train time speedup with FSDP wasn’t that great. For applications with dynamic batching, FSDP which enables larger batch sizes will likely have considerable speed up in terms of train time. FSDP mixed precision support currently has few [issues](https://github.com/pytorch/pytorch/issues/75676) with transformer. Once this is supported, the training time speed up will further improve considerably.
### CPU Offloading to enable training humongous models that won’t fit the GPU memory
Command for training GPT-2 XL Model (1.5B parameters):
```bash
export BS=#`try with different batch sizes till you don't get OOM error,
#i.e., start with larger batch size and go on decreasing till it fits on GPU`
time accelerate launch run_clm_no_trainer.py \
--model_name_or_path gpt2-xl \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--per_device_train_batch_size $BS
--per_device_eval_batch_size $BS
--num_train_epochs 1
--block_size 12
```
| Method | Batch Size Max ($BS) | Num GPUs | Approx Train Time (Hours) | Notes |
| --- | --- | --- | --- | --- |
| DDP | 1 | 1 | NA | OOM Error RuntimeError: CUDA out of memory. Tried to allocate 40.00 MiB (GPU 0; 23.65 GiB total capacity; 22.27 GiB already allocated; 20.31 MiB free; 22.76 GiB reserved in total by PyTorch) |
| DDP | 1 | 2 | NA | OOM Error RuntimeError: CUDA out of memory. Tried to allocate 40.00 MiB (GPU 0; 23.65 GiB total capacity; 22.27 GiB already allocated; 20.31 MiB free; 22.76 GiB reserved in total by PyTorch) |
| DDP + FP16 | 1 | 1 | NA | OOM Error RuntimeError: CUDA out of memory. Tried to allocate 40.00 MiB (GPU 0; 23.65 GiB total capacity; 22.27 GiB already allocated; 20.31 MiB free; 22.76 GiB reserved in total by PyTorch) |
| FSDP with min_num_params = 2K | 5 | 2 | 0.6 | |
| FSDP with min_num_params = 2K + Offload to CPU | 10 | 1 | 3 | |
| FSDP with min_num_params = 2K + Offload to CPU | 14 | 2 | 1.16 | |
Table 2: Benchmarking FSDP on GPT-2 XL (1.5B) model
From Table 2, we can observe that DDP (w and w/o fp16) isn’t even able to run with batch size of 1 and results in CUDA OOM error. FSDP with Zero-Stage 3 is able to be run on 2 GPUs with batch size of 5 (effective batch size =10 (5 X 2)). FSDP with CPU offload can further increase the max batch size to 14 per GPU when using 2 GPUs. **FSDP with CPU offload enables training GPT-2 1.5B model on a single GPU with a batch size of 10**. This enables ML practitioners with minimal compute resources to train such large models, thereby democratizing large model training.
## Capabilities and limitations of the FSDP Integration
Let’s dive into the current support that Accelerate provides for FSDP integration and the known limitations.
**Required PyTorch version for FSDP support**: PyTorch Nightly (or 1.12.0 if you read this after it has been released) as the model saving with FSDP activated is only available with recent fixes.
**Configuration through CLI:**
1. **Sharding Strategy**: [1] FULL_SHARD, [2] SHARD_GRAD_OP
2. **Min Num Params**: FSDP's minimum number of parameters for Default Auto Wrapping.
3. **Offload Params**: Decides Whether to offload parameters and gradients to CPU.
For more control, users can leverage the `FullyShardedDataParallelPlugin` wherein they can specify `auto_wrap_policy`, `backward_prefetch` and `ignored_modules`.
After creating an instance of this class, users can pass it when creating the Accelerator object.
For more information on these options, please refer to the PyTorch [FullyShardedDataParallel](https://github.com/pytorch/pytorch/blob/0df2e863fbd5993a7b9e652910792bd21a516ff3/torch/distributed/fsdp/fully_sharded_data_parallel.py#L236) code.
Next, we will see the importance of the `min_num_params` config. Below is an excerpt from [8] detailing the importance of FSDP Auto Wrap Policy.

(Source: [link](https://pytorch.org/tutorials/intermediate/FSDP_tutorial.html))
When using the `default_auto_wrap_policy`, a layer is wrapped in FSDP module if the number of parameters in that layer is more than the min_num_params . The code for finetuning BERT-Large (330M) model on the GLUE MRPC task is the official complete NLP example outlining how to properly use FSDP feature with the addition of utilities for tracking peak memory usage.
[fsdp_with_peak_mem_tracking.py](https://github.com/huggingface/accelerate/tree/main/examples/by_feature/fsdp_with_peak_mem_tracking.py)
We leverage the tracking functionality support in Accelerate to log the train and evaluation peak memory usage along with evaluation metrics. Below is the snapshot of the plots from wandb [run](https://wandb.ai/smangrul/FSDP-Test?workspace=user-smangrul).

We can observe that the DDP takes twice as much memory as FSDP with auto wrap. FSDP without auto wrap takes more memory than FSDP with auto wrap but considerably less than that of DDP. FSDP with auto wrap with min_num_params=2k takes marginally less memory when compared to setting with min_num_params=1M. This highlights the importance of the FSDP Auto Wrap Policy and users should play around with the `min_num_params` to find the setting which considerably saves memory and isn’t resulting in lot of communication overhead. PyTorch team is working on auto tuning tool for this config as mentioned in [8].
### **Few caveats to be aware of**
- PyTorch FSDP auto wraps sub-modules, flattens the parameters and shards the parameters in place. Due to this, any optimizer created before model wrapping gets broken and occupies more memory. Hence, it is highly recommended and efficient to prepare model before creating optimizer. `Accelerate` will automatically wrap the model and create an optimizer for you in case of single model with a warning message.
> FSDP Warning: When using FSDP, it is efficient and recommended to call prepare for the model before creating the optimizer
>
However, below is the recommended way to prepare model and optimizer while using FSDP:
```diff
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", return_dict=True)
+ model = accelerator.prepare(model)
optimizer = torch.optim.AdamW(params=model.parameters(), lr=lr)
- model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(model,
- optimizer, train_dataloader, eval_dataloader, lr_scheduler
- )
+ optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
+ optimizer, train_dataloader, eval_dataloader, lr_scheduler
+ )
```
- In case of a single model, if you have created optimizer with multiple parameter groups and called prepare with them together, then the parameter groups will be lost and the following warning is displayed:
> FSDP Warning: When using FSDP, several parameter groups will be conflated into a single one due to nested module wrapping and parameter flattening.
>
This is because parameter groups created before wrapping will have no meaning post wrapping due parameter flattening of nested FSDP modules into 1D arrays (which can consume many layers). For instance, below are the named parameters of FSDP model on GPU 0 (When using 2 GPUs. Around 55M (110M/2) params in 1D arrays as this will have the 1st shard of the parameters). Here, if one has applied no weight decay for [bias, LayerNorm.weight] named parameters of unwrapped BERT-Base model, it can’t be applied to the below FSDP wrapped model as there are no named parameters with either of those strings and the parameters of those layers are concatenated with parameters of various other layers. More details mentioned in this [issue](https://github.com/pytorch/pytorch/issues/76501) (`The original model parameters' .grads are not set, meaning that they cannot be optimized separately (which is why we cannot support multiple parameter groups)`).
```
{
'_fsdp_wrapped_module.flat_param': torch.Size([494209]),
'_fsdp_wrapped_module._fpw_module.bert.embeddings.word_embeddings._fsdp_wrapped_module.flat_param': torch.Size([11720448]),
'_fsdp_wrapped_module._fpw_module.bert.encoder._fsdp_wrapped_module.flat_param': torch.Size([42527232])
}
```
- In case of multiple models, it is necessary to prepare the models before creating optimizers else it will throw an error.
- Mixed precision is currently not supported with FSDP as we wait for PyTorch to fix support for it.
# How it works 📝

(Source: [link](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/))
The above workflow gives an overview of what happens behind the scenes when FSDP is activated. Let's first understand how DDP works and how FSDP improves it. In DDP, each worker/accelerator/GPU has a replica of the entire model parameters, gradients and optimizer states. Each worker gets a different batch of data, it goes through the forwards pass, a loss is computed followed by the backward pass to generate gradients. Now, an all-reduce operation is performed wherein each worker gets the gradients from the remaining workers and averaging is done. In this way, each worker now has the same global gradients which are used by the optimizer to update the model parameters. We can see that having full replicas consume a lot of redundant memory on each GPU, which limits the batch size as well as the size of the models.
FSDP precisely addresses this by sharding the optimizer states, gradients and model parameters across the data parallel workers. It further facilitates CPU offloading of all those tensors, thereby enabling loading large models which won't fit the available GPU memory. Similar to DDP, each worker gets a different batch of data. During the forward pass, if the CPU offload is enabled, the parameters of the local shard are first copied to the GPU/accelerator. Then, each worker performs all-gather operation for a given FSDP wrapped module/layer(s) to all get the needed parameters, computation is performed followed by releasing/emptying the parameter shards of other workers. This continues for all the FSDP modules. The loss gets computed after the forward pass and during the backward pass, again an all-gather operation is performed to get all the needed parameters for a given FSDP module, computation is performed to get local gradients followed by releasing the shards of other workers. Now, the local gradients are averaged and sharded to each relevant workers using reduce-scatter operation. This allows each worker to update the parameters of its local shard. If CPU offload is activated, the gradients are passed to CPU for updating parameters directly on CPU.
Please refer [7, 8, 9] for all the in-depth details on the workings of the PyTorch FSDP and the extensive experimentation carried out using this feature.
# Issues
If you encounter any issues with the integration part of PyTorch FSDP, please open an Issue in [accelerate](https://github.com/huggingface/accelerate/issues).
But if you have problems with PyTorch FSDP configuration, and deployment - you need to ask the experts in their domains, therefore, please, open a [PyTorch Issue](https://github.com/pytorch/pytorch/issues) instead.
# References
[1] [Train Large, Then Compress: Rethinking Model Size for Efficient Training and Inference of Transformers](http://nlp.cs.berkeley.edu/pubs/Li-Wallace-Shen-Lin-Keutzer-Klein-Gonzalez_2020_Transformers_paper.pdf)
[2] [ZeRO: Memory Optimizations Toward Training Trillion Parameter Models](https://arxiv.org/pdf/1910.02054v3.pdf)
[3] [DeepSpeed: Extreme-scale model training for everyone - Microsoft Research](https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/)
[4] [Megatron-LM: Training Multi-Billion Parameter Language Models Using
Model Parallelism](https://arxiv.org/pdf/1909.08053.pdf)
[5] [Introducing GPipe, an Open Source Library for Efficiently Training Large-scale Neural Network Models](https://ai.googleblog.com/2019/03/introducing-gpipe-open-source-library.html)
[6] [Which hardware do you need to train a 176B parameters model?](https://bigscience.huggingface.co/blog/which-hardware-to-train-a-176b-parameters-model)
[7] [Introducing PyTorch Fully Sharded Data Parallel (FSDP) API | PyTorch](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/)
[8] [Getting Started with Fully Sharded Data Parallel(FSDP) — PyTorch Tutorials 1.11.0+cu102 documentation](https://pytorch.org/tutorials/intermediate/FSDP_tutorial.html)
[9] [Training a 1 Trillion Parameter Model With PyTorch Fully Sharded Data Parallel on AWS | by PyTorch | PyTorch | Mar, 2022 | Medium](https://medium.com/pytorch/training-a-1-trillion-parameter-model-with-pytorch-fully-sharded-data-parallel-on-aws-3ac13aa96cff)
[10] [Fit More and Train Faster With ZeRO via DeepSpeed and FairScale](https://huggingface.co/blog/zero-deepspeed-fairscale)
|
huggingface/blog/blob/main/pytorch-fsdp.md
|
Subtitles for the course videos
This folder contains all the subtitles for the course videos on YouTube.
## How to translate the subtitles
To translate the subtitles, we'll use two nifty libraries that can (a) grab all the YouTube videos associated with the course playlist and (b) translate them on the fly.
To get started, install the following:
```bash
python -m pip install youtube_transcript_api youtube-search-python pandas tqdm
```
Next, run the following script:
```bash
python utils/generate_subtitles.py --language LANG_CODE
```
where `LANG_CODE` is the same language ID used to denote the chosen language the `chapters` folder. If everything goes well, you should end up with a set of translated `.srt` files with timestamps in the `subtitles/LANG_CODE` folder along with some metadata in `metadata.csv`.
Some languages like Simplified Chinese have a different YouTube language code (`zh-Hans`) to the one used in the course (`zh-CN`). For these languages, you also need to specify the YouTube language code, e.g.:
```bash
python utils/generate_subtitles.py --language zh-CN --youtube_language_code zh-Hans
```
Once you have the `.srt` files you can manually fix any translation errors and then open a pull request with the new files.
# Convert bilingual subtitles to monolingual subtitles
In some SRT files, the English caption line is conventionally placed at the last line of each subtitle block to enable easier comparison when correcting the machine translation.
For example, in the `zh-CN` subtitles, each block has the following format:
```
1
00:00:05,850 --> 00:00:07,713
欢迎来到 Hugging Face 课程。
Welcome to the Hugging Face Course.
```
To upload the SRT file to YouTube, we need the subtitle in monolingual format, i.e. the above block should read:
```
1
00:00:05,850 --> 00:00:07,713
欢迎来到 Hugging Face 课程。
```
To handle this, we provide a script that converts the bilingual SRT files to monolingual ones. To perform the conversion, run:
```bash
python utils/convert_bilingual_monolingual.py --input_language_folder subtitles/LANG_ID --output_language_folder tmp-subtitles
```
|
huggingface/course/blob/main/subtitles/README.md
|
--
title: "Hosting your Models and Datasets on Hugging Face Spaces using Streamlit"
thumbnail: /blog/assets/29_streamlit-spaces/thumbnail.png
authors:
- user: merve
---
# Hosting your Models and Datasets on Hugging Face Spaces using Streamlit
## Showcase your Datasets and Models using Streamlit on Hugging Face Spaces
[Streamlit](https://streamlit.io/) allows you to visualize datasets and build demos of Machine Learning models in a neat way. In this blog post we will walk you through hosting models and datasets and serving your Streamlit applications in Hugging Face Spaces.
## Building demos for your models
You can load any Hugging Face model and build cool UIs using Streamlit. In this particular example we will recreate ["Write with Transformer"](https://transformer.huggingface.co/doc/gpt2-large) together. It's an application that lets you write anything using transformers like GPT-2 and XLNet.

We will not dive deep into how the inference works. You only need to know that you need to specify some hyperparameter values for this particular application. Streamlit provides many [components](https://docs.streamlit.io/en/stable/api.html) for you to easily implement custom applications. We will use some of them to receive necessary hyperparameters inside the inference code.
- The ```.text_area``` component creates a nice area to input sentences to be completed.
- The Streamlit ```.sidebar``` method enables you to accept variables in a sidebar.
- The ```slider``` is used to take continuous values. Don't forget to give ```slider``` a step, otherwise it will treat the values as integers.
- You can let the end-user input integer vaues with ```number_input``` .
``` python
import streamlit as st
# adding the text that will show in the text box as default
default_value = "See how a modern neural network auto-completes your text 🤗 This site, built by the Hugging Face team, lets you write a whole document directly from your browser, and you can trigger the Transformer anywhere using the Tab key. Its like having a smart machine that completes your thoughts 😀 Get started by typing a custom snippet, check out the repository, or try one of the examples. Have fun!"
sent = st.text_area("Text", default_value, height = 275)
max_length = st.sidebar.slider("Max Length", min_value = 10, max_value=30)
temperature = st.sidebar.slider("Temperature", value = 1.0, min_value = 0.0, max_value=1.0, step=0.05)
top_k = st.sidebar.slider("Top-k", min_value = 0, max_value=5, value = 0)
top_p = st.sidebar.slider("Top-p", min_value = 0.0, max_value=1.0, step = 0.05, value = 0.9)
num_return_sequences = st.sidebar.number_input('Number of Return Sequences', min_value=1, max_value=5, value=1, step=1)
```
The inference code returns the generated output, you can print the output using simple ```st.write```.
```st.write(generated_sequences[-1])```
Here's what our replicated version looks like.

You can checkout the full code [here](https://huggingface.co/spaces/merve/write-with-transformer).
## Showcase your Datasets and Data Visualizations
Streamlit provides many components to help you visualize datasets. It works seamlessly with 🤗 [Datasets](https://huggingface.co/docs/datasets/), [pandas](https://pandas.pydata.org/docs/index.html), and visualization libraries such as [matplotlib](https://matplotlib.org/stable/index.html), [seaborn](https://seaborn.pydata.org/) and [bokeh](https://bokeh.org/).
Let's start by loading a dataset. A new feature in `Datasets`, called [streaming](https://huggingface.co/docs/datasets/dataset_streaming.html), allows you to work immediately with very large datasets, eliminating the need to download all of the examples and load them into memory.
``` python
from datasets import load_dataset
import streamlit as st
dataset = load_dataset("merve/poetry", streaming=True)
df = pd.DataFrame.from_dict(dataset["train"])
```
If you have structured data like mine, you can simply use ```st.dataframe(df) ``` to show your dataset. There are many Streamlit components to plot data interactively. One such component is ```st.barchart() ```, which I used to visualize the most used words in the poem contents.
``` python
st.write("Most appearing words including stopwords")
st.bar_chart(words[0:50])
```
If you'd like to use libraries like matplotlib, seaborn or bokeh, all you have to do is to put ```st.pyplot() ``` at the end of your plotting script.
``` python
st.write("Number of poems for each author")
sns.catplot(x="author", data=df, kind="count", aspect = 4)
plt.xticks(rotation=90)
st.pyplot()
```
You can see the interactive bar chart, dataframe component and hosted matplotlib and seaborn visualizations below. You can check out the code [here](https://huggingface.co/spaces/merve/streamlit-dataset-demo).

## Hosting your Projects in Hugging Face Spaces
You can simply drag and drop your files as shown below. Note that you need to include your additional dependencies in the requirements.txt. Also note that the version of Streamlit you have on your local is the same. For seamless usage, refer to [Spaces API reference](https://huggingface.co/docs/hub/spaces-config-reference).

There are so many components and [packages](https://streamlit.io/components) you can use to demonstrate your models, datasets, and visualizations. You can get started [here](https://huggingface.co/spaces).
|
huggingface/blog/blob/main/streamlit-spaces.md
|
!---
Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Speech Recognition Pre-Training
## Wav2Vec2 Speech Pre-Training
The script [`run_speech_wav2vec2_pretraining_no_trainer.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py) can be used to pre-train a [Wav2Vec2](https://huggingface.co/transformers/model_doc/wav2vec2.html?highlight=wav2vec2) model from scratch.
In the script [`run_speech_wav2vec2_pretraining_no_trainer`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py), a Wav2Vec2 model is pre-trained on audio data alone using [Wav2Vec2's contrastive loss objective](https://arxiv.org/abs/2006.11477).
The following examples show how to fine-tune a `"base"`-sized Wav2Vec2 model as well as a `"large"`-sized Wav2Vec2 model using [`accelerate`](https://github.com/huggingface/accelerate).
---
**NOTE 1**
Wav2Vec2's pre-training is known to be quite unstable.
It is advised to do a couple of test runs with a smaller dataset,
*i.e.* `--dataset_config_names clean clean`, `--dataset_split_names validation test`
to find good hyper-parameters for `learning_rate`, `batch_size`, `num_warmup_steps`,
and the optimizer.
A good metric to observe during training is the gradient norm which should ideally be between 0.5 and 2.
---
---
**NOTE 2**
When training a model on large datasets it is recommended to run the data preprocessing
in a first run in a **non-distributed** mode via `--preprocessing_only` so that
when running the model in **distributed** mode in a second step the preprocessed data
can easily be loaded on each distributed device.
---
### Demo
In this demo run we pre-train a `"base-sized"` Wav2Vec2 model simply only on the validation
and test data of [librispeech_asr](https://huggingface.co/datasets/librispeech_asr).
The demo is run on two Titan RTX (24 GB RAM each). In case you have less RAM available
per device, consider reducing `--batch_size` and/or the `--max_duration_in_seconds`.
```bash
accelerate launch run_wav2vec2_pretraining_no_trainer.py \
--dataset_name="librispeech_asr" \
--dataset_config_names clean clean \
--dataset_split_names validation test \
--model_name_or_path="patrickvonplaten/wav2vec2-base-v2" \
--output_dir="./wav2vec2-pretrained-demo" \
--max_train_steps="20000" \
--num_warmup_steps="32000" \
--gradient_accumulation_steps="8" \
--learning_rate="0.005" \
--weight_decay="0.01" \
--max_duration_in_seconds="20.0" \
--min_duration_in_seconds="2.0" \
--logging_steps="1" \
--saving_steps="10000" \
--per_device_train_batch_size="8" \
--per_device_eval_batch_size="8" \
--adam_beta1="0.9" \
--adam_beta2="0.98" \
--adam_epsilon="1e-06" \
--gradient_checkpointing \
--mask_time_prob="0.65" \
--mask_time_length="10"
```
The results of this run can be seen [here](https://wandb.ai/patrickvonplaten/wav2vec2-pretrained-demo/reports/Wav2Vec2-PreTraining-Demo-Run--VmlldzoxMDk3MjAw?accessToken=oa05s1y57lizo2ocxy3k01g6db1u4pt8m6ur2n8nl4cb0ug02ms2cw313kb8ruch).
### Base
To pre-train `"base-sized"` Wav2Vec2 model, *e.g.* [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base)
on [librispeech_asr](https://huggingface.co/datasets/librispeech_asr), the following command can be run:
```bash
accelerate launch run_wav2vec2_pretraining_no_trainer.py \
--dataset_name=librispeech_asr \
--dataset_config_names clean clean other \
--dataset_split_names train.100 train.360 train.500 \
--model_name_or_path="patrickvonplaten/wav2vec2-base-v2" \
--output_dir="./wav2vec2-pretrained-demo" \
--max_train_steps="200000" \
--num_warmup_steps="32000" \
--gradient_accumulation_steps="4" \
--learning_rate="0.001" \
--weight_decay="0.01" \
--max_duration_in_seconds="20.0" \
--min_duration_in_seconds="2.0" \
--logging_steps="1" \
--saving_steps="10000" \
--per_device_train_batch_size="8" \
--per_device_eval_batch_size="8" \
--adam_beta1="0.9" \
--adam_beta2="0.98" \
--adam_epsilon="1e-06" \
--gradient_checkpointing \
--mask_time_prob="0.65" \
--mask_time_length="10"
```
The experiment was run on 8 GPU V100 (16 GB RAM each) for 4 days.
In case you have more than 8 GPUs available for a higher effective `batch_size`,
it is recommended to increase the `learning_rate` to `0.005` for faster convergence.
The results of this run can be seen [here](https://wandb.ai/patrickvonplaten/test/reports/Wav2Vec2-Base--VmlldzoxMTUyODQ0?accessToken=rg6e8u9yizx964k8q47zctq1m4afpvtn1i3qi9exgdmzip6xwkfzvagfajpzj55n) and the checkpoint pretrained for 85,000 steps can be accessed [here](https://huggingface.co/patrickvonplaten/wav2vec2-base-repro-960h-libri-85k-steps)
### Large
To pre-train `"large-sized"` Wav2Vec2 model, *e.g.* [facebook/wav2vec2-large-lv60](https://huggingface.co/facebook/wav2vec2-large-lv60),
on [librispeech_asr](https://huggingface.co/datasets/librispeech_asr), the following command can be run:
```bash
accelerate launch run_wav2vec2_pretraining_no_trainer.py \
--dataset_name=librispeech_asr \
--dataset_config_names clean clean other \
--dataset_split_names train.100 train.360 train.500 \
--output_dir=./test \
--max_train_steps=200000 \
--num_warmup_steps=32000 \
--gradient_accumulation_steps=8 \
--learning_rate=0.001 \
--weight_decay=0.01 \
--max_duration_in_seconds=20.0 \
--min_duration_in_seconds=2.0 \
--model_name_or_path=./
--logging_steps=1 \
--saving_steps=10000 \
--per_device_train_batch_size=2 \
--per_device_eval_batch_size=4 \
--adam_beta1=0.9 \
--adam_beta2=0.98 \
--adam_epsilon=1e-06 \
--gradient_checkpointing \
--mask_time_prob=0.65 \
--mask_time_length=10
```
The experiment was run on 8 GPU V100 (16 GB RAM each) for 7 days.
In case you have more than 8 GPUs available for a higher effective `batch_size`,
it is recommended to increase the `learning_rate` to `0.005` for faster convergence.
The results of this run can be seen [here](https://wandb.ai/patrickvonplaten/pretraining-wav2vec2/reports/Wav2Vec2-Large--VmlldzoxMTAwODM4?accessToken=wm3qzcnldrwsa31tkvf2pdmilw3f63d4twtffs86ou016xjbyilh55uoi3mo1qzc) and the checkpoint pretrained for 120,000 steps can be accessed [here](https://huggingface.co/patrickvonplaten/wav2vec2-large-repro-960h-libri-120k-steps)
|
huggingface/transformers/blob/main/examples/pytorch/speech-pretraining/README.md
|
Loading methods
Methods for listing and loading datasets and metrics:
## Datasets
[[autodoc]] datasets.list_datasets
[[autodoc]] datasets.load_dataset
[[autodoc]] datasets.load_from_disk
[[autodoc]] datasets.load_dataset_builder
[[autodoc]] datasets.get_dataset_config_names
[[autodoc]] datasets.get_dataset_infos
[[autodoc]] datasets.get_dataset_split_names
[[autodoc]] datasets.inspect_dataset
## Metrics
<Tip warning={true}>
Metrics is deprecated in 🤗 Datasets. To learn more about how to use metrics, take a look at the library 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index)! In addition to metrics, you can find more tools for evaluating models and datasets.
</Tip>
[[autodoc]] datasets.list_metrics
[[autodoc]] datasets.load_metric
[[autodoc]] datasets.inspect_metric
## From files
Configurations used to load data files.
They are used when loading local files or a dataset repository:
- local files: `load_dataset("parquet", data_dir="path/to/data/dir")`
- dataset repository: `load_dataset("allenai/c4")`
You can pass arguments to `load_dataset` to configure data loading.
For example you can specify the `sep` parameter to define the [`~datasets.packaged_modules.csv.CsvConfig`] that is used to load the data:
```python
load_dataset("csv", data_dir="path/to/data/dir", sep="\t")
```
### Text
[[autodoc]] datasets.packaged_modules.text.TextConfig
[[autodoc]] datasets.packaged_modules.text.Text
### CSV
[[autodoc]] datasets.packaged_modules.csv.CsvConfig
[[autodoc]] datasets.packaged_modules.csv.Csv
### JSON
[[autodoc]] datasets.packaged_modules.json.JsonConfig
[[autodoc]] datasets.packaged_modules.json.Json
### Parquet
[[autodoc]] datasets.packaged_modules.parquet.ParquetConfig
[[autodoc]] datasets.packaged_modules.parquet.Parquet
### Arrow
[[autodoc]] datasets.packaged_modules.arrow.ArrowConfig
[[autodoc]] datasets.packaged_modules.arrow.Arrow
### SQL
[[autodoc]] datasets.packaged_modules.sql.SqlConfig
[[autodoc]] datasets.packaged_modules.sql.Sql
### Images
[[autodoc]] datasets.packaged_modules.imagefolder.ImageFolderConfig
[[autodoc]] datasets.packaged_modules.imagefolder.ImageFolder
### Audio
[[autodoc]] datasets.packaged_modules.audiofolder.AudioFolderConfig
[[autodoc]] datasets.packaged_modules.audiofolder.AudioFolder
### WebDataset
[[autodoc]] datasets.packaged_modules.webdataset.WebDataset
|
huggingface/datasets/blob/main/docs/source/package_reference/loading_methods.mdx
|
Spaces Configuration Reference
Spaces are configured through the `YAML` block at the top of the **README.md** file at the root of the repository. All the accepted parameters are listed below.
<!-- Trailing whitespaces are intended : they render as a newline in the hub documentation -->
**`title`** : _string_
Display title for the Space.
**`emoji`** : _string_
Space emoji (emoji-only character allowed).
**`colorFrom`** : _string_
Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray).
**`colorTo`** : _string_
Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray).
**`sdk`** : _string_
Can be either `gradio`, `streamlit`, `docker`, or `static`.
**`python_version`**: _string_
Any valid Python `3.x` or `3.x.x` version.
Defaults to `3.10`.
**`sdk_version`** : _string_
Specify the version of the selected SDK (Streamlit or Gradio).
All versions of Gradio are supported.
All versions of Streamlit from `0.79.0` are supported.
**`suggested_hardware`** : _string_
Specify the suggested [hardware](https://huggingface.co/docs/hub/spaces-gpus) on which this Space must be run.
Useful for Spaces that are meant to be duplicated by other users.
Setting this value will not automatically assign an hardware to this Space.
Value must be a valid hardware flavor (e.g. `"cpu-upgrade"`, `"t4-small"`, `"t4-medium"`, `"a10g-small"`, `"a10g-large"`, `"a10g-largex2"`, `"a10g-largex4"` or `"a100-large"`).
**`suggested_storage`** : _string_
Specify the suggested [permanent storage](https://huggingface.co/docs/hub/spaces-storage) on which this Space must be run.
Useful for Spaces that are meant to be duplicated by other users.
Setting this value will not automatically assign a permanent storage to this Space.
Value must be one of `"small"`, `"medium"` or `"large"`.
**`app_file`** : _string_
Path to your main application file (which contains either `gradio` or `streamlit` Python code, or `static` html code).
Path is relative to the root of the repository.
**`app_port`** : _int_
Port on which your application is running. Used only if `sdk` is `docker`. Default port is `7860`.
**`base_path`**: _string_
For non-static Spaces, initial url to render. Needs to start with `/`. For static Spaces, use `app_file` instead.
**`fullWidth`**: _boolean_
Whether your Space is rendered inside a full-width (when `true`) or fixed-width column (ie. "container" CSS) inside the iframe.
Defaults to false in `gradio`, and to true for other sdks.
**`models`** : _List[string]_
HF model IDs (like `gpt2` or `deepset/roberta-base-squad2`) used in the Space.
Will be parsed automatically from your code if not specified here.
**`datasets`** : _List[string]_
HF dataset IDs (like `common_voice` or `oscar-corpus/OSCAR-2109`) used in the Space.
Will be parsed automatically from your code if not specified here.
**`tags`** : _List[string]_
List of terms that describe your Space task or scope.
**`pinned`** : _boolean_
Whether the Space stays on top of your profile. Can be useful if you have a lot of Spaces so you and others can quickly see your best Space.
**`hf_oauth`** : _boolean_
Whether a connected OAuth app is associated to this Space. See [Adding a Sign-In with HF button to your Space](https://huggingface.co/docs/hub/spaces-oauth) for more details.
**`hf_oauth_scopes`** : _List[string]_
Authorized scopes of the connected OAuth app. `openid` and `profile` are authorized by default and do not need this parameter. See [Adding a Sign-In with HF button to your space](https://huggingface.co/docs/hub/spaces-oauth) for more details.
**`disable_embedding`** : _boolean_
Whether the Space iframe can be embedded in other websites.
Defaults to false, i.e. Spaces *can* be embedded.
**`startup_duration_timeout`**: _string_
Set a custom startup duration timeout for your Space. This is the maximum time your Space is allowed to start before it times out and is flagged as unhealthy.
Defaults to 30 minutes, but any valid duration (like `1h`, `30m`) is acceptable.
**`custom_headers`** : _Dict[string, string]_
Set custom HTTP headers that will be added to all HTTP responses when serving your Space.
For now, only the [cross-origin-embedder-policy](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Cross-Origin-Embedder-Policy) (COEP), [cross-origin-opener-policy](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Cross-Origin-Opener-Policy) (COOP), and [cross-origin-resource-policy](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Cross-Origin-Resource-Policy) (CORP) headers are allowed. These headers can be used to set up a cross-origin isolated environment and enable powerful features like `SharedArrayBuffer`, for example:
```yaml
custom_headers:
cross-origin-embedder-policy: require-corp
cross-origin-opener-policy: same-origin
cross-origin-resource-policy: cross-origin
```
*Note:* all headers and values must be lowercase.
**`preload_from_hub`**: _List[string]_
Specify a list of Hugging Face Hub models or other large files to be preloaded during the build time of your Space. This optimizes the startup time by having the files ready when your application starts. This is particularly useful for Spaces that rely on large models or datasets that would otherwise need to be downloaded at runtime.
The format for each item is `"repository_name"` to download all files from a repository, or `"repository_name file1,file2"` for downloading specific files within that repository. You can also specify a specific commit to download using the format `"repository_name file1,file2 commit_sha256"`.
Example usage:
```yaml
preload_from_hub:
- warp-ai/wuerstchen-prior text_encoder/model.safetensors,prior/diffusion_pytorch_model.safetensors
- coqui/XTTS-v1
- gpt2 config.json 11c5a3d5811f50298f278a704980280950aedb10
```
In this example, the Space will preload specific .safetensors files from `warp-ai/wuerstchen-prior`, the complete `coqui/XTTS-v1` repository, and a specific revision of the `config.json` file in the `gpt2` repository from the Hugging Face Hub during build time.
<Tip warning={true}>
Files are saved in the default `huggingface_hub` disk cache `~/.cache/huggingface/hub`. If you application expects them elsewhere or you changed your `HF_HOME` variable, this pre-loading does not follow that at this time.
</Tip>
|
huggingface/hub-docs/blob/main/docs/hub/spaces-config-reference.md
|
p align="center"> <img src="http://sayef.tech:8082/uploads/FSNER-LOGO-2.png" alt="FSNER LOGO"> </p>
<p align="center">
Implemented by <a href="https://huggingface.co/sayef"> sayef </a>.
</p>
## Overview
The FSNER model was proposed in [Example-Based Named Entity Recognition](https://arxiv.org/abs/2008.10570) by Morteza Ziyadi, Yuting Sun, Abhishek Goswami, Jade Huang, Weizhu Chen. To identify entity spans in a new domain, it uses a train-free few-shot learning approach inspired by question-answering.
## Abstract
----
> We present a novel approach to named entity recognition (NER) in the presence of scarce data that we call example-based NER. Our train-free few-shot learning approach takes inspiration from question-answering to identify entity spans in a new and unseen domain. In comparison with the current state-of-the-art, the proposed method performs significantly better, especially when using a low number of support examples.
## Model Training Details
-----
| identifier | epochs | datasets |
| ---------- |:----------:| :-----:|
| [sayef/fsner-bert-base-uncased](https://huggingface.co/sayef/fsner-bert-base-uncased) | 10 | ontonotes5, conll2003, wnut2017, and fin (Alvarado et al.). |
## Installation and Example Usage
------
You can use the FSNER model in 3 ways:
1. Install directly from PyPI: `pip install fsner` and import the model as shown in the code example below
or
2. Install from source: `python setup.py install` and import the model as shown in the code example below
or
3. Clone repo and change directory to `src` and import the model as shown in the code example below
```python
from fsner import FSNERModel, FSNERTokenizerUtils
model = FSNERModel("sayef/fsner-bert-base-uncased")
tokenizer = FSNERTokenizerUtils("sayef/fsner-bert-base-uncased")
# size of query and supports must be the same. If you want to find all the entitites in one particular query, just repeat the same query n times where n is equal to the number of supports (or entities).
query = [
'KWE 4000 can reach with a maximum speed from up to 450 P/min an accuracy from 50 mg',
'I would like to order a computer from eBay.',
]
# each list in supports are the examples of one entity type
# wrap entities around with [E] and [/E] in the examples
supports = [
[
'Horizontal flow wrapper [E] Pack 403 [/E] features the new retrofit-kit „paper-ON-form“',
'[E] Paloma Pick-and-Place-Roboter [/E] arranges the bakery products for the downstream tray-forming equipment',
'Finally, the new [E] Kliklok ACE [/E] carton former forms cartons and trays without the use of glue',
'We set up our pilot plant with the right [E] FibreForm® [/E] configuration to make prototypes for your marketing tests and package validation',
'The [E] CAR-T5 [/E] is a reliable, purely mechanically driven cartoning machine for versatile application fields'
],
[
"[E] Walmart [/E] is a leading e-commerce company",
"I recently ordered a book from [E] Amazon [/E]",
"I ordered this from [E] ShopClues [/E]",
"[E] Flipkart [/E] started it's journey from zero"
]
]
device = 'cpu'
W_query = tokenizer.tokenize(query).to(device)
W_supports = tokenizer.tokenize(supports).to(device)
start_prob, end_prob = model(W_query, W_supports)
output = tokenizer.extract_entity_from_scores(query, W_query, start_prob, end_prob, thresh=0.50)
print(output)
```
|
huggingface/transformers/blob/main/examples/research_projects/fsner/README.md
|
Generalization in Reinforcement Learning
Generalization plays a pivotal role in the realm of Reinforcement Learning. While **RL algorithms demonstrate good performance in controlled environments**, the real world presents a **unique challenge due to its non-stationary and open-ended nature**.
As a result, the development of RL algorithms that stay robust in the face of environmental variations, coupled with the capability to transfer and adapt to uncharted yet analogous tasks and settings, becomes fundamental for real world application of RL.
If you're interested to dive deeper into this research subject, we recommend exploring the following resource:
- [Generalization in Reinforcement Learning by Robert Kirk](https://robertkirk.github.io/2022/01/17/generalisation-in-reinforcement-learning-survey.html): this comprehensive survey provides an insightful **overview of the concept of generalization in RL**, making it an excellent starting point for your exploration.
- [Improving Generalization in Reinforcement Learning using Policy Similarity Embeddings](https://blog.research.google/2021/09/improving-generalization-in.html?m=1)
|
huggingface/deep-rl-class/blob/main/units/en/unitbonus3/generalisation.mdx
|
Subsets and Splits
Transformers Source Texts
This query retrieves specific examples from the dataset related to transformers, providing a limited view of the data with basic filtering.