
text
stringlengths 23
371k
| source
stringlengths 32
152
|
|---|---|
Developer guide
This document is intended for developers who want to install, test or contribute to the code.
## Install
To start working on the project:
```bash
git clone git@github.com:huggingface/datasets-server.git
cd datasets-server
```
Install docker (see https://docs.docker.com/engine/install/ubuntu/#install-using-the-repository and https://docs.docker.com/engine/install/linux-postinstall/)
Run the project locally:
```bash
make start
```
Run the project in development mode:
```bash
make dev-start
```
In development mode, you don't need to rebuild the docker images to apply a change in a worker.
You can just restart the worker's docker container and it will apply your changes.
To install a single job (in [jobs](./jobs)), library (in [libs](./libs)) or service (in [services](./services)), go to their respective directory, and install Python 3.9 (consider [pyenv](https://github.com/pyenv/pyenv)) and [poetry](https://python-poetry.org/docs/master/#installation) (don't forget to add `poetry` to the `PATH` environment variable).
If you use pyenv:
```bash
cd libs/libcommon/
pyenv install 3.9.18
pyenv local 3.9.18
poetry env use python3.9
```
then:
```bash
make install
```
It will create a virtual environment in a `./.venv/` subdirectory.
If you use VSCode, it might be useful to use the ["monorepo" workspace](./.vscode/monorepo.code-workspace) (see a [blogpost](https://medium.com/rewrite-tech/visual-studio-code-tips-for-monorepo-development-with-multi-root-workspaces-and-extension-6b69420ecd12) for more explanations). It is a multi-root workspace, with one folder for each library and service (note that we hide them from the ROOT to avoid editing there). Each folder has its own Python interpreter, with access to the dependencies installed by Poetry. You might have to manually select the interpreter in every folder though on first access, then VSCode stores the information in its local storage.
## Architecture
The repository is structured as a monorepo, with Python libraries and applications in [jobs](./jobs), [libs](./libs) and [services](./services):
- [jobs](./jobs) contains the one-time jobs run by Helm before deploying the pods. For now, the only job migrates the databases when needed.
- [libs](./libs) contains the Python libraries used by the services and workers. For now, the only library is [libcommon](./libs/libcommon), which contains the common code for the services and workers.
- [services](./services) contains the applications: the public API, the admin API (which is separated from the public API and might be published under its own domain at some point), the reverse proxy, and the worker that processes the queue asynchronously: it gets a "job" (caution: the jobs stored in the queue, not the Helm jobs), processes the expected response for the associated endpoint, and stores the response in the cache.
If you have access to the internal HF notion, see https://www.notion.so/huggingface2/Datasets-server-464848da2a984e999c540a4aa7f0ece5.
The application is distributed in several components.
[api](./services/api) is a web server that exposes the [API endpoints](https://huggingface.co/docs/datasets-server). Apart from some endpoints (`valid`, `is-valid`), all the responses are served from pre-computed responses. That's the main point of this project: generating these responses takes time, and the API server provides this service to the users.
The precomputed responses are stored in a Mongo database called "cache". They are computed by [workers](./services/worker) which take their jobs from a job queue stored in a Mongo database called "queue", and store the results (error or valid response) into the "cache" (see [libcommon](./libs/libcommon)).
The API service exposes the `/webhook` endpoint which is called by the Hub on every creation, update or deletion of a dataset on the Hub. On deletion, the cached responses are deleted. On creation or update, a new job is appended in the "queue" database.
Note that every worker has its own job queue:
- `/splits`: the job is to refresh a dataset, namely to get the list of [config](https://huggingface.co/docs/datasets/v2.1.0/en/load_hub#select-a-configuration) and [split](https://huggingface.co/docs/datasets/v2.1.0/en/load_hub#select-a-split) names, then to create a new job for every split for the workers that depend on it.
- `/first-rows`: the job is to get the columns and the first 100 rows of the split.
- `/parquet`: the job is to download the dataset, prepare a parquet version of every split (various sharded parquet files), and upload them to the `refs/convert/parquet` "branch" of the dataset repository on the Hub.
Note also that the workers create local files when the dataset contains images or audios. A shared directory (`ASSETS_STORAGE_DIRECTORY`) must therefore be provisioned with sufficient space for the generated files. The `/first-rows` endpoint responses contain URLs to these files, served by the API under the `/assets/` endpoint.
Hence, the working application has:
- one instance of the API service which exposes a port
- N1 instances of the `splits` worker, N2 instances of the `first-rows` worker (N2 should generally be higher than N1), N3 instances of the `parquet` worker
- a Mongo server with two databases: "cache" and "queue"
- a shared directory for the assets
The application also has:
- a reverse proxy in front of the API to serve static files and proxy the rest to the API server
- an admin server to serve technical endpoints
The following environments contain all the modules: reverse proxy, API server, admin API server, workers, and the Mongo database.
| Environment | URL | Type | How to deploy |
| ----------- | ---------------------------------------------------- | ----------------- | --------------------------------------- |
| Production | https://datasets-server.huggingface.co | Helm / Kubernetes | `make upgrade-prod` in [chart](./chart) |
| Development | https://datasets-server.us.dev.moon.huggingface.tech | Helm / Kubernetes | `make upgrade-dev` in [chart](./chart) |
| Local build | http://localhost:8100 | Docker compose | `make start` (builds docker images) |
## Quality
The CI checks the quality of the code through a [GitHub action](./.github/workflows/_quality-python.yml). To manually format the code of a job, library, service or worker:
```bash
make style
```
To check the quality (which includes checking the style, but also security vulnerabilities):
```bash
make quality
```
## Tests
The CI checks the tests a [GitHub action](./.github/workflows/unit-tests.yml). To manually test a job, library, service or worker:
```bash
make test
```
Note that it requires the resources to be ready, ie. mongo and the storage for assets.
To launch the end to end tests:
```bash
make e2e
```
## Poetry
### Versions
If service is updated, we don't update its version in the `pyproject.yaml` file. But we have to update the [helm chart](./chart/) with the new image tag, corresponding to the last build docker published on docker.io by the CI.
## Pull requests
All the contributions should go through a pull request. The pull requests must be "squashed" (ie: one commit per pull request).
## GitHub Actions
You can use [act](https://github.com/nektos/act) to test the GitHub Actions (see [.github/workflows/](.github/workflows/)) locally. It reduces the retroaction loop when working on the GitHub Actions, avoid polluting the branches with empty pushes only meant to trigger the CI, and allows to only run specific actions.
For example, to launch the build and push of the docker images to Docker Hub:
```
act -j build-and-push-image-to-docker-hub --secret-file my.secrets
```
with `my.secrets` a file with the secrets:
```
DOCKERHUB_USERNAME=xxx
DOCKERHUB_PASSWORD=xxx
GITHUB_TOKEN=xxx
```
## Set up development environment
### Linux
Install pyenv:
```bash
$ curl https://pyenv.run | bash
```
Install Python 3.9.18:
```bash
$ pyenv install 3.9.18
```
Check that the expected local version of Python is used:
```bash
$ cd services/worker
$ python --version
Python 3.9.18
```
Install Poetry:
```bash
curl -sSL https://install.python-poetry.org | POETRY_VERSION=1.4.2 python3 -
```
Set the Python version to use with Poetry:
```bash
poetry env use 3.9.18
```
Install the dependencies:
```bash
make install
```
### Mac OS
To install the [worker](./services/worker) on Mac OS, you can follow the next steps.
#### First: as an administrator
Install brew:
```bash
$ /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
```
Install ICU:
```bash
$ brew install icu4c
==> Caveats
icu4c is keg-only, which means it was not symlinked into /opt/homebrew,
because macOS provides libicucore.dylib (but nothing else).
If you need to have icu4c first in your PATH, run:
echo 'export PATH="/opt/homebrew/opt/icu4c/bin:$PATH"' >> ~/.zshrc
echo 'export PATH="/opt/homebrew/opt/icu4c/sbin:$PATH"' >> ~/.zshrc
For compilers to find icu4c you may need to set:
export LDFLAGS="-L/opt/homebrew/opt/icu4c/lib"
export CPPFLAGS="-I/opt/homebrew/opt/icu4c/include"
```
#### Then: as a normal user
Add ICU to the path:
```bash
$ echo 'export PATH="/opt/homebrew/opt/icu4c/bin:$PATH"' >> ~/.zshrc
$ echo 'export PATH="/opt/homebrew/opt/icu4c/sbin:$PATH"' >> ~/.zshrc
```
Install pyenv:
```bash
$ curl https://pyenv.run | bash
```
append the following lines to ~/.zshrc:
```bash
export PYENV_ROOT="$HOME/.pyenv"
command -v pyenv >/dev/null || export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init -)"
```
Logout and login again.
Install Python 3.9.18:
```bash
$ pyenv install 3.9.18
```
Check that the expected local version of Python is used:
```bash
$ cd services/worker
$ python --version
Python 3.9.18
```
Install poetry:
```bash
curl -sSL https://install.python-poetry.org | POETRY_VERSION=1.4.2 python3 -
```
append the following lines to ~/.zshrc:
```bash
export PATH="/Users/slesage2/.local/bin:$PATH"
```
Install rust:
```bash
$ curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
$ source $HOME/.cargo/env
```
Set the python version to use with poetry:
```bash
poetry env use 3.9.18
```
Avoid an issue with Apache beam (https://github.com/python-poetry/poetry/issues/4888#issuecomment-1208408509):
```bash
poetry config experimental.new-installer false
```
Install the dependencies:
```bash
make install
```
| huggingface/datasets-server/blob/main/DEVELOPER_GUIDE.md |
Handling Spaces Dependencies
## Default dependencies
The default Spaces environment comes with several pre-installed dependencies:
* The [`huggingface_hub`](https://huggingface.co/docs/huggingface_hub/index) client library allows you to manage your repository and files on the Hub with Python and programmatically access the Inference API from your Space. If you choose to instantiate the model in your app with the Inference API, you can benefit from the built-in acceleration optimizations. This option also consumes less computing resources, which is always nice for the environment! 🌎
Refer to this [page](https://huggingface.co/docs/huggingface_hub/how-to-inference) for more information on how to programmatically access the Inference API.
* [`requests`](https://docs.python-requests.org/en/master/) is useful for calling third-party APIs from your app.
* [`datasets`](https://github.com/huggingface/datasets) allows you to fetch or display any dataset from the Hub inside your app.
* The SDK you specified, which could be either `streamlit` or `gradio`. The version is specified in the `README.md` file.
* Common Debian packages, such as `ffmpeg`, `cmake`, `libsm6`, and few others.
## Adding your own dependencies
If you need other Python packages to run your app, add them to a **requirements.txt** file at the root of the repository. The Spaces runtime engine will create a custom environment on-the-fly. You can also add a **pre-requirements.txt** file describing dependencies that will be installed before your main dependencies. It can be useful if you need to update pip itself.
Debian dependencies are also supported. Add a **packages.txt** file at the root of your repository, and list all your dependencies in it. Each dependency should be on a separate line, and each line will be read and installed by `apt-get install`.
| huggingface/hub-docs/blob/main/docs/hub/spaces-dependencies.md |
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<!---
A useful guide for English-Traditional Japanese translation of Hugging Face documentation
- Use square quotes, e.g.,「引用」
Dictionary
API: API(翻訳しない)
add: 追加
checkpoint: チェックポイント
code: コード
community: コミュニティ
confidence: 信頼度
dataset: データセット
documentation: ドキュメント
example: 例
finetune: 微調整
Hugging Face: Hugging Face(翻訳しない)
implementation: 実装
inference: 推論
library: ライブラリ
module: モジュール
NLP/Natural Language Processing: NLPと表示される場合は翻訳されず、Natural Language Processingと表示される場合は翻訳される
online demos: オンラインデモ
pipeline: pipeline(翻訳しない)
pretrained/pretrain: 学習済み
Python data structures (e.g., list, set, dict): リスト、セット、ディクショナリと訳され、括弧内は原文英語
repository: repository(翻訳しない)
summary: 概要
token-: token-(翻訳しない)
Trainer: Trainer(翻訳しない)
transformer: transformer(翻訳しない)
tutorial: チュートリアル
user: ユーザ
-->
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers_logo_name.png" width="400"/>
<br>
</p>
<p align="center">
<a href="https://circleci.com/gh/huggingface/transformers">
<img alt="Build" src="https://img.shields.io/circleci/build/github/huggingface/transformers/main">
</a>
<a href="https://github.com/huggingface/transformers/blob/main/LICENSE">
<img alt="GitHub" src="https://img.shields.io/github/license/huggingface/transformers.svg?color=blue">
</a>
<a href="https://huggingface.co/docs/transformers/index">
<img alt="Documentation" src="https://img.shields.io/website/http/huggingface.co/docs/transformers/index.svg?down_color=red&down_message=offline&up_message=online">
</a>
<a href="https://github.com/huggingface/transformers/releases">
<img alt="GitHub release" src="https://img.shields.io/github/release/huggingface/transformers.svg">
</a>
<a href="https://github.com/huggingface/transformers/blob/main/CODE_OF_CONDUCT.md">
<img alt="Contributor Covenant" src="https://img.shields.io/badge/Contributor%20Covenant-v2.0%20adopted-ff69b4.svg">
</a>
<a href="https://zenodo.org/badge/latestdoi/155220641"><img src="https://zenodo.org/badge/155220641.svg" alt="DOI"></a>
</p>
<h4 align="center">
<p>
<a href="https://github.com/huggingface/transformers/">English</a> |
<a href="https://github.com/huggingface/transformers/blob/main/README_zh-hans.md">简体中文</a> |
<a href="https://github.com/huggingface/transformers/blob/main/README_zh-hant.md">繁體中文</a> |
<a href="https://github.com/huggingface/transformers/blob/main/README_ko.md">한국어</a> |
<a href="https://github.com/huggingface/transformers/blob/main/README_es.md">Español</a> |
<b>日本語</b> |
<a href="https://github.com/huggingface/transformers/blob/main/README_hd.md">हिन्दी</a>
<a href="https://github.com/huggingface/transformers//blob/main/README_te.md">తెలుగు</a> |
</p>
</h4>
<h3 align="center">
<p>JAX、PyTorch、TensorFlowのための最先端機械学習</p>
</h3>
<h3 align="center">
<a href="https://hf.co/course"><img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/course_banner.png"></a>
</h3>
🤗Transformersは、テキスト、視覚、音声などの異なるモダリティに対してタスクを実行するために、事前に学習させた数千のモデルを提供します。
これらのモデルは次のような場合に適用できます:
* 📝 テキストは、テキストの分類、情報抽出、質問応答、要約、翻訳、テキスト生成などのタスクのために、100以上の言語に対応しています。
* 🖼️ 画像分類、物体検出、セグメンテーションなどのタスクのための画像。
* 🗣️ 音声は、音声認識や音声分類などのタスクに使用します。
トランスフォーマーモデルは、テーブル質問応答、光学文字認識、スキャン文書からの情報抽出、ビデオ分類、視覚的質問応答など、**複数のモダリティを組み合わせた**タスクも実行可能です。
🤗Transformersは、与えられたテキストに対してそれらの事前学習されたモデルを素早くダウンロードして使用し、あなた自身のデータセットでそれらを微調整し、私たちの[model hub](https://huggingface.co/models)でコミュニティと共有するためのAPIを提供します。同時に、アーキテクチャを定義する各Pythonモジュールは完全にスタンドアロンであり、迅速な研究実験を可能にするために変更することができます。
🤗Transformersは[Jax](https://jax.readthedocs.io/en/latest/)、[PyTorch](https://pytorch.org/)、[TensorFlow](https://www.tensorflow.org/)という3大ディープラーニングライブラリーに支えられ、それぞれのライブラリをシームレスに統合しています。片方でモデルを学習してから、もう片方で推論用にロードするのは簡単なことです。
## オンラインデモ
[model hub](https://huggingface.co/models)から、ほとんどのモデルのページで直接テストすることができます。また、パブリックモデル、プライベートモデルに対して、[プライベートモデルのホスティング、バージョニング、推論API](https://huggingface.co/pricing)を提供しています。
以下はその一例です:
自然言語処理にて:
- [BERTによるマスクドワード補完](https://huggingface.co/bert-base-uncased?text=Paris+is+the+%5BMASK%5D+of+France)
- [Electraによる名前実体認識](https://huggingface.co/dbmdz/electra-large-discriminator-finetuned-conll03-english?text=My+name+is+Sarah+and+I+live+in+London+city)
- [GPT-2によるテキスト生成](https://huggingface.co/gpt2?text=A+long+time+ago%2C+)
- [RoBERTaによる自然言語推論](https://huggingface.co/roberta-large-mnli?text=The+dog+was+lost.+Nobody+lost+any+animal)
- [BARTによる要約](https://huggingface.co/facebook/bart-large-cnn?text=The+tower+is+324+metres+%281%2C063+ft%29+tall%2C+about+the+same+height+as+an+81-storey+building%2C+and+the+tallest+structure+in+Paris.+Its+base+is+square%2C+measuring+125+metres+%28410+ft%29+on+each+side.+During+its+construction%2C+the+Eiffel+Tower+surpassed+the+Washington+Monument+to+become+the+tallest+man-made+structure+in+the+world%2C+a+title+it+held+for+41+years+until+the+Chrysler+Building+in+New+York+City+was+finished+in+1930.+It+was+the+first+structure+to+reach+a+height+of+300+metres.+Due+to+the+addition+of+a+broadcasting+aerial+at+the+top+of+the+tower+in+1957%2C+it+is+now+taller+than+the+Chrysler+Building+by+5.2+metres+%2817+ft%29.+Excluding+transmitters%2C+the+Eiffel+Tower+is+the+second+tallest+free-standing+structure+in+France+after+the+Millau+Viaduct)
- [DistilBERTによる質問応答](https://huggingface.co/distilbert-base-uncased-distilled-squad?text=Which+name+is+also+used+to+describe+the+Amazon+rainforest+in+English%3F&context=The+Amazon+rainforest+%28Portuguese%3A+Floresta+Amaz%C3%B4nica+or+Amaz%C3%B4nia%3B+Spanish%3A+Selva+Amaz%C3%B3nica%2C+Amazon%C3%ADa+or+usually+Amazonia%3B+French%3A+For%C3%AAt+amazonienne%3B+Dutch%3A+Amazoneregenwoud%29%2C+also+known+in+English+as+Amazonia+or+the+Amazon+Jungle%2C+is+a+moist+broadleaf+forest+that+covers+most+of+the+Amazon+basin+of+South+America.+This+basin+encompasses+7%2C000%2C000+square+kilometres+%282%2C700%2C000+sq+mi%29%2C+of+which+5%2C500%2C000+square+kilometres+%282%2C100%2C000+sq+mi%29+are+covered+by+the+rainforest.+This+region+includes+territory+belonging+to+nine+nations.+The+majority+of+the+forest+is+contained+within+Brazil%2C+with+60%25+of+the+rainforest%2C+followed+by+Peru+with+13%25%2C+Colombia+with+10%25%2C+and+with+minor+amounts+in+Venezuela%2C+Ecuador%2C+Bolivia%2C+Guyana%2C+Suriname+and+French+Guiana.+States+or+departments+in+four+nations+contain+%22Amazonas%22+in+their+names.+The+Amazon+represents+over+half+of+the+planet%27s+remaining+rainforests%2C+and+comprises+the+largest+and+most+biodiverse+tract+of+tropical+rainforest+in+the+world%2C+with+an+estimated+390+billion+individual+trees+divided+into+16%2C000+species)
- [T5による翻訳](https://huggingface.co/t5-base?text=My+name+is+Wolfgang+and+I+live+in+Berlin)
コンピュータビジョンにて:
- [ViTによる画像分類](https://huggingface.co/google/vit-base-patch16-224)
- [DETRによる物体検出](https://huggingface.co/facebook/detr-resnet-50)
- [SegFormerによるセマンティックセグメンテーション](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
- [DETRによるパノプティックセグメンテーション](https://huggingface.co/facebook/detr-resnet-50-panoptic)
オーディオにて:
- [Wav2Vec2による自動音声認識](https://huggingface.co/facebook/wav2vec2-base-960h)
- [Wav2Vec2によるキーワード検索](https://huggingface.co/superb/wav2vec2-base-superb-ks)
マルチモーダルなタスクにて:
- [ViLTによる視覚的質問応答](https://huggingface.co/dandelin/vilt-b32-finetuned-vqa)
Hugging Faceチームによって作られた **[トランスフォーマーを使った書き込み](https://transformer.huggingface.co)** は、このリポジトリのテキスト生成機能の公式デモである。
## Hugging Faceチームによるカスタム・サポートをご希望の場合
<a target="_blank" href="https://huggingface.co/support">
<img alt="HuggingFace Expert Acceleration Program" src="https://cdn-media.huggingface.co/marketing/transformers/new-support-improved.png" style="max-width: 600px; border: 1px solid #eee; border-radius: 4px; box-shadow: 0 1px 2px 0 rgba(0, 0, 0, 0.05);">
</a><br>
## クイックツアー
与えられた入力(テキスト、画像、音声、...)に対してすぐにモデルを使うために、我々は`pipeline`というAPIを提供しております。pipelineは、学習済みのモデルと、そのモデルの学習時に使用された前処理をグループ化したものです。以下は、肯定的なテキストと否定的なテキストを分類するためにpipelineを使用する方法です:
```python
>>> from transformers import pipeline
# Allocate a pipeline for sentiment-analysis
>>> classifier = pipeline('sentiment-analysis')
>>> classifier('We are very happy to introduce pipeline to the transformers repository.')
[{'label': 'POSITIVE', 'score': 0.9996980428695679}]
```
2行目のコードでは、pipelineで使用される事前学習済みモデルをダウンロードしてキャッシュし、3行目では与えられたテキストに対してそのモデルを評価します。ここでは、答えは99.97%の信頼度で「ポジティブ」です。
自然言語処理だけでなく、コンピュータビジョンや音声処理においても、多くのタスクにはあらかじめ訓練された`pipeline`が用意されている。例えば、画像から検出された物体を簡単に抽出することができる:
``` python
>>> import requests
>>> from PIL import Image
>>> from transformers import pipeline
# Download an image with cute cats
>>> url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample.png"
>>> image_data = requests.get(url, stream=True).raw
>>> image = Image.open(image_data)
# Allocate a pipeline for object detection
>>> object_detector = pipeline('object-detection')
>>> object_detector(image)
[{'score': 0.9982201457023621,
'label': 'remote',
'box': {'xmin': 40, 'ymin': 70, 'xmax': 175, 'ymax': 117}},
{'score': 0.9960021376609802,
'label': 'remote',
'box': {'xmin': 333, 'ymin': 72, 'xmax': 368, 'ymax': 187}},
{'score': 0.9954745173454285,
'label': 'couch',
'box': {'xmin': 0, 'ymin': 1, 'xmax': 639, 'ymax': 473}},
{'score': 0.9988006353378296,
'label': 'cat',
'box': {'xmin': 13, 'ymin': 52, 'xmax': 314, 'ymax': 470}},
{'score': 0.9986783862113953,
'label': 'cat',
'box': {'xmin': 345, 'ymin': 23, 'xmax': 640, 'ymax': 368}}]
```
ここでは、画像から検出されたオブジェクトのリストが得られ、オブジェクトを囲むボックスと信頼度スコアが表示されます。左側が元画像、右側が予測結果を表示したものです:
<h3 align="center">
<a><img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample.png" width="400"></a>
<a><img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample_post_processed.png" width="400"></a>
</h3>
[このチュートリアル](https://huggingface.co/docs/transformers/task_summary)では、`pipeline`APIでサポートされているタスクについて詳しく説明しています。
`pipeline`に加えて、与えられたタスクに学習済みのモデルをダウンロードして使用するために必要なのは、3行のコードだけです。以下はPyTorchのバージョンです:
```python
>>> from transformers import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
>>> model = AutoModel.from_pretrained("bert-base-uncased")
>>> inputs = tokenizer("Hello world!", return_tensors="pt")
>>> outputs = model(**inputs)
```
そしてこちらはTensorFlowと同等のコードとなります:
```python
>>> from transformers import AutoTokenizer, TFAutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
>>> model = TFAutoModel.from_pretrained("bert-base-uncased")
>>> inputs = tokenizer("Hello world!", return_tensors="tf")
>>> outputs = model(**inputs)
```
トークナイザは学習済みモデルが期待するすべての前処理を担当し、単一の文字列 (上記の例のように) またはリストに対して直接呼び出すことができます。これは下流のコードで使用できる辞書を出力します。また、単純に ** 引数展開演算子を使用してモデルに直接渡すこともできます。
モデル自体は通常の[Pytorch `nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) または [TensorFlow `tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) (バックエンドによって異なる)で、通常通り使用することが可能です。[このチュートリアル](https://huggingface.co/docs/transformers/training)では、このようなモデルを従来のPyTorchやTensorFlowの学習ループに統合する方法や、私たちの`Trainer`APIを使って新しいデータセットで素早く微調整を行う方法について説明します。
## なぜtransformersを使う必要があるのでしょうか?
1. 使いやすい最新モデル:
- 自然言語理解・生成、コンピュータビジョン、オーディオの各タスクで高いパフォーマンスを発揮します。
- 教育者、実務者にとっての低い参入障壁。
- 学習するクラスは3つだけで、ユーザが直面する抽象化はほとんどありません。
- 学習済みモデルを利用するための統一されたAPI。
1. 低い計算コスト、少ないカーボンフットプリント:
- 研究者は、常に再トレーニングを行うのではなく、トレーニングされたモデルを共有することができます。
- 実務家は、計算時間や生産コストを削減することができます。
- すべてのモダリティにおいて、60,000以上の事前学習済みモデルを持つ数多くのアーキテクチャを提供します。
1. モデルのライフタイムのあらゆる部分で適切なフレームワークを選択可能:
- 3行のコードで最先端のモデルをトレーニング。
- TF2.0/PyTorch/JAXフレームワーク間で1つのモデルを自在に移動させる。
- 学習、評価、生産に適したフレームワークをシームレスに選択できます。
1. モデルやサンプルをニーズに合わせて簡単にカスタマイズ可能:
- 原著者が発表した結果を再現するために、各アーキテクチャの例を提供しています。
- モデル内部は可能な限り一貫して公開されています。
- モデルファイルはライブラリとは独立して利用することができ、迅速な実験が可能です。
## なぜtransformersを使ってはいけないのでしょうか?
- このライブラリは、ニューラルネットのためのビルディングブロックのモジュール式ツールボックスではありません。モデルファイルのコードは、研究者が追加の抽象化/ファイルに飛び込むことなく、各モデルを素早く反復できるように、意図的に追加の抽象化でリファクタリングされていません。
- 学習APIはどのようなモデルでも動作するわけではなく、ライブラリが提供するモデルで動作するように最適化されています。一般的な機械学習のループには、別のライブラリ(おそらく[Accelerate](https://huggingface.co/docs/accelerate))を使用する必要があります。
- 私たちはできるだけ多くの使用例を紹介するよう努力していますが、[examples フォルダ](https://github.com/huggingface/transformers/tree/main/examples) にあるスクリプトはあくまで例です。あなたの特定の問題に対してすぐに動作するわけではなく、あなたのニーズに合わせるために数行のコードを変更する必要があることが予想されます。
## インストール
### pipにて
このリポジトリは、Python 3.8+, Flax 0.4.1+, PyTorch 1.10+, TensorFlow 2.6+ でテストされています。
🤗Transformersは[仮想環境](https://docs.python.org/3/library/venv.html)にインストールする必要があります。Pythonの仮想環境に慣れていない場合は、[ユーザーガイド](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/)を確認してください。
まず、使用するバージョンのPythonで仮想環境を作成し、アクティベートします。
その後、Flax, PyTorch, TensorFlowのうち少なくとも1つをインストールする必要があります。
[TensorFlowインストールページ](https://www.tensorflow.org/install/)、[PyTorchインストールページ](https://pytorch.org/get-started/locally/#start-locally)、[Flax](https://github.com/google/flax#quick-install)、[Jax](https://github.com/google/jax#installation)インストールページで、お使いのプラットフォーム別のインストールコマンドを参照してください。
これらのバックエンドのいずれかがインストールされている場合、🤗Transformersは以下のようにpipを使用してインストールすることができます:
```bash
pip install transformers
```
もしサンプルを試したい、またはコードの最先端が必要で、新しいリリースを待てない場合は、[ライブラリをソースからインストール](https://huggingface.co/docs/transformers/installation#installing-from-source)する必要があります。
### condaにて
Transformersバージョン4.0.0から、condaチャンネルを搭載しました: `huggingface`。
🤗Transformersは以下のようにcondaを使って設置することができます:
```shell script
conda install -c huggingface transformers
```
Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それぞれのインストールページに従ってください。
> **_注意:_** Windowsでは、キャッシュの恩恵を受けるために、デベロッパーモードを有効にするよう促されることがあります。このような場合は、[このissue](https://github.com/huggingface/huggingface_hub/issues/1062)でお知らせください。
## モデルアーキテクチャ
🤗Transformersが提供する **[全モデルチェックポイント](https://huggingface.co/models)** は、[ユーザー](https://huggingface.co/users)や[組織](https://huggingface.co/organizations)によって直接アップロードされるhuggingface.co [model hub](https://huggingface.co)からシームレスに統合されています。
現在のチェックポイント数: 
🤗Transformersは現在、以下のアーキテクチャを提供しています(それぞれのハイレベルな要約は[こちら](https://huggingface.co/docs/transformers/model_summary)を参照してください):
1. **[ALBERT](https://huggingface.co/docs/transformers/model_doc/albert)** (Google Research and the Toyota Technological Institute at Chicago から) Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut から公開された研究論文: [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942)
1. **[ALIGN](https://huggingface.co/docs/transformers/model_doc/align)** (Google Research から) Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig. から公開された研究論文 [Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://arxiv.org/abs/2102.05918)
1. **[AltCLIP](https://huggingface.co/docs/transformers/model_doc/altclip)** (BAAI から) Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell から公開された研究論文: [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679)
1. **[Audio Spectrogram Transformer](https://huggingface.co/docs/transformers/model_doc/audio-spectrogram-transformer)** (MIT から) Yuan Gong, Yu-An Chung, James Glass から公開された研究論文: [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778)
1. **[Autoformer](https://huggingface.co/docs/transformers/model_doc/autoformer)** (from Tsinghua University) released with the paper [Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008) by Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long.
1. **[Bark](https://huggingface.co/docs/transformers/model_doc/bark)** (from Suno) released in the repository [suno-ai/bark](https://github.com/suno-ai/bark) by Suno AI team.
1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (Facebook から) Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer から公開された研究論文: [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461)
1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (École polytechnique から) Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis から公開された研究論文: [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321)
1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (VinAI Research から) Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen から公開された研究論文: [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701)
1. **[BEiT](https://huggingface.co/docs/transformers/model_doc/beit)** (Microsoft から) Hangbo Bao, Li Dong, Furu Wei から公開された研究論文: [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254)
1. **[BERT](https://huggingface.co/docs/transformers/model_doc/bert)** (Google から) Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova から公開された研究論文: [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805)
1. **[BERT For Sequence Generation](https://huggingface.co/docs/transformers/model_doc/bert-generation)** (Google から) Sascha Rothe, Shashi Narayan, Aliaksei Severyn から公開された研究論文: [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461)
1. **[BERTweet](https://huggingface.co/docs/transformers/model_doc/bertweet)** (VinAI Research から) Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen から公開された研究論文: [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/)
1. **[BigBird-Pegasus](https://huggingface.co/docs/transformers/model_doc/bigbird_pegasus)** (Google Research から) Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed から公開された研究論文: [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062)
1. **[BigBird-RoBERTa](https://huggingface.co/docs/transformers/model_doc/big_bird)** (Google Research から) Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed から公開された研究論文: [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062)
1. **[BioGpt](https://huggingface.co/docs/transformers/model_doc/biogpt)** (Microsoft Research AI4Science から) Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon and Tie-Yan Liu から公開された研究論文: [BioGPT: generative pre-trained transformer for biomedical text generation and mining](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9)
1. **[BiT](https://huggingface.co/docs/transformers/model_doc/bit)** (Google AI から) Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil から公開された研究論文: [Big Transfer (BiT)](https://arxiv.org/abs/1912.11370)Houlsby.
1. **[Blenderbot](https://huggingface.co/docs/transformers/model_doc/blenderbot)** (Facebook から) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston から公開された研究論文: [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637)
1. **[BlenderbotSmall](https://huggingface.co/docs/transformers/model_doc/blenderbot-small)** (Facebook から) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston から公開された研究論文: [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637)
1. **[BLIP](https://huggingface.co/docs/transformers/model_doc/blip)** (Salesforce から) Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi から公開された研究論文: [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086)
1. **[BLIP-2](https://huggingface.co/docs/transformers/model_doc/blip-2)** (Salesforce から) Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi. から公開された研究論文 [BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://arxiv.org/abs/2301.12597)
1. **[BLOOM](https://huggingface.co/docs/transformers/model_doc/bloom)** (BigScience workshop から) [BigScience Workshop](https://bigscience.huggingface.co/) から公開されました.
1. **[BORT](https://huggingface.co/docs/transformers/model_doc/bort)** (Alexa から) Adrian de Wynter and Daniel J. Perry から公開された研究論文: [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499)
1. **[BridgeTower](https://huggingface.co/docs/transformers/model_doc/bridgetower)** (Harbin Institute of Technology/Microsoft Research Asia/Intel Labs から) released with the paper [BridgeTower: Building Bridges Between Encoders in Vision-Language Representation Learning](https://arxiv.org/abs/2206.08657) by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan.
1. **[BROS](https://huggingface.co/docs/transformers/model_doc/bros)** (NAVER CLOVA から) Teakgyu Hong, Donghyun Kim, Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park. から公開された研究論文 [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://arxiv.org/abs/2108.04539)
1. **[ByT5](https://huggingface.co/docs/transformers/model_doc/byt5)** (Google Research から) Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel から公開された研究論文: [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626)
1. **[CamemBERT](https://huggingface.co/docs/transformers/model_doc/camembert)** (Inria/Facebook/Sorbonne から) Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot から公開された研究論文: [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894)
1. **[CANINE](https://huggingface.co/docs/transformers/model_doc/canine)** (Google Research から) Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting から公開された研究論文: [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874)
1. **[Chinese-CLIP](https://huggingface.co/docs/transformers/model_doc/chinese_clip)** (OFA-Sys から) An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou から公開された研究論文: [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335)
1. **[CLAP](https://huggingface.co/docs/transformers/model_doc/clap)** (LAION-AI から) Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov. から公開された研究論文 [Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation](https://arxiv.org/abs/2211.06687)
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (OpenAI から) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever から公開された研究論文: [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020)
1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (University of Göttingen から) Timo Lüddecke and Alexander Ecker から公開された研究論文: [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003)
1. **[CLVP](https://huggingface.co/docs/transformers/model_doc/clvp)** released with the paper [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (Salesforce から) Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong から公開された研究論文: [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474)
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (MetaAI から) Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve. から公開された研究論文 [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/)
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (Microsoft Research Asia から) Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang から公開された研究論文: [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152)
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (YituTech から) Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan から公開された研究論文: [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496)
1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (Facebook AI から) Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie から公開された研究論文: [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545)
1. **[ConvNeXTV2](https://huggingface.co/docs/transformers/model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
1. **[CPM](https://huggingface.co/docs/transformers/model_doc/cpm)** (Tsinghua University から) Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun から公開された研究論文: [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413)
1. **[CPM-Ant](https://huggingface.co/docs/transformers/model_doc/cpmant)** (OpenBMB から) [OpenBMB](https://www.openbmb.org/) から公開されました.
1. **[CTRL](https://huggingface.co/docs/transformers/model_doc/ctrl)** (Salesforce から) Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher から公開された研究論文: [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858)
1. **[CvT](https://huggingface.co/docs/transformers/model_doc/cvt)** (Microsoft から) Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang から公開された研究論文: [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808)
1. **[Data2Vec](https://huggingface.co/docs/transformers/model_doc/data2vec)** (Facebook から) Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli から公開された研究論文: [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555)
1. **[DeBERTa](https://huggingface.co/docs/transformers/model_doc/deberta)** (Microsoft から) Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen から公開された研究論文: [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654)
1. **[DeBERTa-v2](https://huggingface.co/docs/transformers/model_doc/deberta-v2)** (Microsoft から) Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen から公開された研究論文: [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654)
1. **[Decision Transformer](https://huggingface.co/docs/transformers/model_doc/decision_transformer)** (Berkeley/Facebook/Google から) Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch から公開された研究論文: [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345)
1. **[Deformable DETR](https://huggingface.co/docs/transformers/model_doc/deformable_detr)** (SenseTime Research から) Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai から公開された研究論文: [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159)
1. **[DeiT](https://huggingface.co/docs/transformers/model_doc/deit)** (Facebook から) Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou から公開された研究論文: [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877)
1. **[DePlot](https://huggingface.co/docs/transformers/model_doc/deplot)** (Google AI から) Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun. から公開された研究論文 [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505)
1. **[DETA](https://huggingface.co/docs/transformers/model_doc/deta)** (The University of Texas at Austin から) Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl. から公開された研究論文 [NMS Strikes Back](https://arxiv.org/abs/2212.06137)
1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (Facebook から) Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko から公開された研究論文: [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872)
1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (Microsoft Research から) Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan から公開された研究論文: [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536)
1. **[DiNAT](https://huggingface.co/docs/transformers/model_doc/dinat)** (SHI Labs から) Ali Hassani and Humphrey Shi から公開された研究論文: [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001)
1. **[DINOv2](https://huggingface.co/docs/transformers/model_doc/dinov2)** (Meta AI から) Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski. から公開された研究論文 [DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/abs/2304.07193)
1. **[DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)** (HuggingFace から), Victor Sanh, Lysandre Debut and Thomas Wolf. 同じ手法で GPT2, RoBERTa と Multilingual BERT の圧縮を行いました.圧縮されたモデルはそれぞれ [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation)、[DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation)、[DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) と名付けられました. 公開された研究論文: [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108)
1. **[DiT](https://huggingface.co/docs/transformers/model_doc/dit)** (Microsoft Research から) Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei から公開された研究論文: [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378)
1. **[Donut](https://huggingface.co/docs/transformers/model_doc/donut)** (NAVER から), Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park から公開された研究論文: [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664)
1. **[DPR](https://huggingface.co/docs/transformers/model_doc/dpr)** (Facebook から) Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih から公開された研究論文: [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906)
1. **[DPT](https://huggingface.co/docs/transformers/master/model_doc/dpt)** (Intel Labs から) René Ranftl, Alexey Bochkovskiy, Vladlen Koltun から公開された研究論文: [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413)
1. **[EfficientFormer](https://huggingface.co/docs/transformers/model_doc/efficientformer)** (Snap Research から) Yanyu Li, Geng Yuan, Yang Wen, Ju Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren. から公開された研究論文 [EfficientFormer: Vision Transformers at MobileNetSpeed](https://arxiv.org/abs/2206.01191)
1. **[EfficientNet](https://huggingface.co/docs/transformers/model_doc/efficientnet)** (from Google Brain) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan, Quoc V. Le.
1. **[ELECTRA](https://huggingface.co/docs/transformers/model_doc/electra)** (Google Research/Stanford University から) Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning から公開された研究論文: [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555)
1. **[EnCodec](https://huggingface.co/docs/transformers/model_doc/encodec)** (Meta AI から) Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi. から公開された研究論文 [High Fidelity Neural Audio Compression](https://arxiv.org/abs/2210.13438)
1. **[EncoderDecoder](https://huggingface.co/docs/transformers/model_doc/encoder-decoder)** (Google Research から) Sascha Rothe, Shashi Narayan, Aliaksei Severyn から公開された研究論文: [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461)
1. **[ERNIE](https://huggingface.co/docs/transformers/model_doc/ernie)** (Baidu から) Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu から公開された研究論文: [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223)
1. **[ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m)** (Baidu から) Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang. から公開された研究論文 [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674)
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (Meta AI から) はトランスフォーマープロテイン言語モデルです. **ESM-1b** は Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus から公開された研究論文: [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118). **ESM-1v** は Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives から公開された研究論文: [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648). **ESM-2** と **ESMFold** は Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives から公開された研究論文: [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902)
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (Google AI から) Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V から公開されたレポジトリー [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) Le, and Jason Wei
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (CNRS から) Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab から公開された研究論文: [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372)
1. **[FLAVA](https://huggingface.co/docs/transformers/model_doc/flava)** (Facebook AI から) Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela から公開された研究論文: [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482)
1. **[FNet](https://huggingface.co/docs/transformers/model_doc/fnet)** (Google Research から) James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon から公開された研究論文: [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824)
1. **[FocalNet](https://huggingface.co/docs/transformers/model_doc/focalnet)** (Microsoft Research から) Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao. から公開された研究論文 [Focal Modulation Networks](https://arxiv.org/abs/2203.11926)
1. **[Funnel Transformer](https://huggingface.co/docs/transformers/model_doc/funnel)** (CMU/Google Brain から) Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le から公開された研究論文: [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236)
1. **[Fuyu](https://huggingface.co/docs/transformers/model_doc/fuyu)** (ADEPT から) Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, Sağnak Taşırlar. から公開された研究論文 [blog post](https://www.adept.ai/blog/fuyu-8b)
1. **[GIT](https://huggingface.co/docs/transformers/model_doc/git)** (Microsoft Research から) Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang. から公開された研究論文 [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100)
1. **[GLPN](https://huggingface.co/docs/transformers/model_doc/glpn)** (KAIST から) Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim から公開された研究論文: [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436)
1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (OpenAI から) Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever から公開された研究論文: [Improving Language Understanding by Generative Pre-Training](https://blog.openai.com/language-unsupervised/)
1. **[GPT Neo](https://huggingface.co/docs/transformers/model_doc/gpt_neo)** (EleutherAI から) Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy から公開されたレポジトリー : [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo)
1. **[GPT NeoX](https://huggingface.co/docs/transformers/model_doc/gpt_neox)** (EleutherAI から) Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach から公開された研究論文: [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745)
1. **[GPT NeoX Japanese](https://huggingface.co/docs/transformers/model_doc/gpt_neox_japanese)** (ABEJA から) Shinya Otani, Takayoshi Makabe, Anuj Arora, and Kyo Hattori からリリース.
1. **[GPT-2](https://huggingface.co/docs/transformers/model_doc/gpt2)** (OpenAI から) Alec Radford*, Jeffrey Wu*, Rewon Child, David Luan, Dario Amodei** and Ilya Sutskever** から公開された研究論文: [Language Models are Unsupervised Multitask Learners](https://blog.openai.com/better-language-models/)
1. **[GPT-J](https://huggingface.co/docs/transformers/model_doc/gptj)** (EleutherAI から) Ben Wang and Aran Komatsuzaki から公開されたレポジトリー [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/)
1. **[GPT-Sw3](https://huggingface.co/docs/transformers/model_doc/gpt-sw3)** (AI-Sweden から) Ariel Ekgren, Amaru Cuba Gyllensten, Evangelia Gogoulou, Alice Heiman, Severine Verlinden, Joey Öhman, Fredrik Carlsson, Magnus Sahlgren から公開された研究論文: [Lessons Learned from GPT-SW3: Building the First Large-Scale Generative Language Model for Swedish](http://www.lrec-conf.org/proceedings/lrec2022/pdf/2022.lrec-1.376.pdf)
1. **[GPTBigCode](https://huggingface.co/docs/transformers/model_doc/gpt_bigcode)** (BigCode から) Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra. から公開された研究論文 [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988)
1. **[GPTSAN-japanese](https://huggingface.co/docs/transformers/model_doc/gptsan-japanese)** [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) 坂本俊之(tanreinama)からリリースされました.
1. **[Graphormer](https://huggingface.co/docs/transformers/model_doc/graphormer)** (Microsoft から) Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu から公開された研究論文: [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234).
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (UCSD, NVIDIA から) Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang から公開された研究論文: [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094)
1. **[HerBERT](https://huggingface.co/docs/transformers/model_doc/herbert)** (Allegro.pl, AGH University of Science and Technology から) Piotr Rybak, Robert Mroczkowski, Janusz Tracz, Ireneusz Gawlik. から公開された研究論文 [KLEJ: Comprehensive Benchmark for Polish Language Understanding](https://www.aclweb.org/anthology/2020.acl-main.111.pdf)
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (Facebook から) Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed から公開された研究論文: [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447)
1. **[I-BERT](https://huggingface.co/docs/transformers/model_doc/ibert)** (Berkeley から) Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer から公開された研究論文: [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321)
1. **[IDEFICS](https://huggingface.co/docs/transformers/model_doc/idefics)** (from HuggingFace) released with the paper [OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents](https://huggingface.co/papers/2306.16527) by Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander M. Rush, Douwe Kiela, Matthieu Cord, Victor Sanh.
1. **[ImageGPT](https://huggingface.co/docs/transformers/model_doc/imagegpt)** (OpenAI から) Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever から公開された研究論文: [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/)
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (Salesforce から) Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi. から公開された研究論文 [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500)
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (OpenAI から) Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever から公開された研究論文: [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf)
1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (from Microsoft Research Asia) released with the paper [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (Microsoft Research Asia から) Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou から公開された研究論文: [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318)
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (Microsoft Research Asia から) Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou から公開された研究論文: [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740)
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/model_doc/layoutlmv3)** (Microsoft Research Asia から) Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei から公開された研究論文: [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387)
1. **[LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutxlm)** (Microsoft Research Asia から) Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei から公開された研究論文: [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836)
1. **[LED](https://huggingface.co/docs/transformers/model_doc/led)** (AllenAI から) Iz Beltagy, Matthew E. Peters, Arman Cohan から公開された研究論文: [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150)
1. **[LeViT](https://huggingface.co/docs/transformers/model_doc/levit)** (Meta AI から) Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze から公開された研究論文: [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136)
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (South China University of Technology から) Jiapeng Wang, Lianwen Jin, Kai Ding から公開された研究論文: [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669)
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (The FAIR team of Meta AI から) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample. から公開された研究論文 [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971)
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (The FAIR team of Meta AI から) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom.. から公開された研究論文 [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX)
1. **[LLaVa](https://huggingface.co/docs/transformers/model_doc/llava)** (Microsoft Research & University of Wisconsin-Madison から) Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee. から公開された研究論文 [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485)
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (AllenAI から) Iz Beltagy, Matthew E. Peters, Arman Cohan から公開された研究論文: [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150)
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (Google AI から) Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang から公開された研究論文: [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916)
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (Studio Ousia から) Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto から公開された研究論文: [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057)
1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (UNC Chapel Hill から) Hao Tan and Mohit Bansal から公開された研究論文: [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490)
1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (Facebook から) Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert から公開された研究論文: [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161)
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (Facebook から) Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin から公開された研究論文: [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125)
1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (from Google) released with the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) by Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Jörg Tiedemann から. [OPUS](http://opus.nlpl.eu/) を使いながら学習された "Machine translation" (マシントランスレーション) モデル. [Marian Framework](https://marian-nmt.github.io/) はMicrosoft Translator Team が現在開発中です.
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (Microsoft Research Asia から) Junlong Li, Yiheng Xu, Lei Cui, Furu Wei から公開された研究論文: [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518)
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (FAIR and UIUC から) Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar. から公開された研究論文 [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527)
1. **[MaskFormer](https://huggingface.co/docs/transformers/model_doc/maskformer)** (Meta and UIUC から) Bowen Cheng, Alexander G. Schwing, Alexander Kirillov から公開された研究論文: [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278)
1. **[MatCha](https://huggingface.co/docs/transformers/model_doc/matcha)** (Google AI から) Fangyu Liu, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Yasemin Altun, Nigel Collier, Julian Martin Eisenschlos. から公開された研究論文 [MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering](https://arxiv.org/abs/2212.09662)
1. **[mBART](https://huggingface.co/docs/transformers/model_doc/mbart)** (Facebook から) Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer から公開された研究論文: [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210)
1. **[mBART-50](https://huggingface.co/docs/transformers/model_doc/mbart)** (Facebook から) Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan から公開された研究論文: [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401)
1. **[MEGA](https://huggingface.co/docs/transformers/model_doc/mega)** (Facebook から) Xuezhe Ma, Chunting Zhou, Xiang Kong, Junxian He, Liangke Gui, Graham Neubig, Jonathan May, and Luke Zettlemoyer. から公開された研究論文 [Mega: Moving Average Equipped Gated Attention](https://arxiv.org/abs/2209.10655)
1. **[Megatron-BERT](https://huggingface.co/docs/transformers/model_doc/megatron-bert)** (NVIDIA から) Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro から公開された研究論文: [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053)
1. **[Megatron-GPT2](https://huggingface.co/docs/transformers/model_doc/megatron_gpt2)** (NVIDIA から) Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro から公開された研究論文: [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053)
1. **[MGP-STR](https://huggingface.co/docs/transformers/model_doc/mgp-str)** (Alibaba Research から) Peng Wang, Cheng Da, and Cong Yao. から公開された研究論文 [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592)
1. **[Mistral](https://huggingface.co/docs/transformers/model_doc/mistral)** (from Mistral AI) by The Mistral AI team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed..
1. **[Mixtral](https://huggingface.co/docs/transformers/model_doc/mixtral)** (from Mistral AI) by The [Mistral AI](https://mistral.ai) team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
1. **[mLUKE](https://huggingface.co/docs/transformers/model_doc/mluke)** (Studio Ousia から) Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka から公開された研究論文: [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151)
1. **[MMS](https://huggingface.co/docs/transformers/model_doc/mms)** (Facebook から) Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, Michael Auli. から公開された研究論文 [Scaling Speech Technology to 1,000+ Languages](https://arxiv.org/abs/2305.13516)
1. **[MobileBERT](https://huggingface.co/docs/transformers/model_doc/mobilebert)** (CMU/Google Brain から) Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou から公開された研究論文: [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984)
1. **[MobileNetV1](https://huggingface.co/docs/transformers/model_doc/mobilenet_v1)** (Google Inc. から) Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam から公開された研究論文: [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861)
1. **[MobileNetV2](https://huggingface.co/docs/transformers/model_doc/mobilenet_v2)** (Google Inc. から) Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen から公開された研究論文: [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381)
1. **[MobileViT](https://huggingface.co/docs/transformers/model_doc/mobilevit)** (Apple から) Sachin Mehta and Mohammad Rastegari から公開された研究論文: [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178)
1. **[MobileViTV2](https://huggingface.co/docs/transformers/model_doc/mobilevitv2)** (Apple から) Sachin Mehta and Mohammad Rastegari. から公開された研究論文 [Separable Self-attention for Mobile Vision Transformers](https://arxiv.org/abs/2206.02680)
1. **[MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet)** (Microsoft Research から) Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu から公開された研究論文: [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297)
1. **[MPT](https://huggingface.co/docs/transformers/model_doc/mpt)** (MosaiML から) the MosaicML NLP Team. から公開された研究論文 [llm-foundry](https://github.com/mosaicml/llm-foundry/)
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (the University of Wisconsin - Madison から) Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh. から公開された研究論文 [Multi Resolution Analysis (MRA)](https://arxiv.org/abs/2207.10284)
1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (Google AI から) Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel から公開された研究論文: [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934)
1. **[MusicGen](https://huggingface.co/docs/transformers/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (RUC AI Box から) Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen から公開された研究論文: [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131)
1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (SHI Labs から) Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi から公開された研究論文: [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143)
1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (Huawei Noah’s Ark Lab から) Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu から公開された研究論文: [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204)
1. **[NLLB](https://huggingface.co/docs/transformers/model_doc/nllb)** (Meta から) the NLLB team から公開された研究論文: [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672)
1. **[NLLB-MOE](https://huggingface.co/docs/transformers/model_doc/nllb-moe)** (Meta から) the NLLB team. から公開された研究論文 [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672)
1. **[Nougat](https://huggingface.co/docs/transformers/model_doc/nougat)** (Meta AI から) Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic. から公開された研究論文 [Nougat: Neural Optical Understanding for Academic Documents](https://arxiv.org/abs/2308.13418)
1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (the University of Wisconsin - Madison から) Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh から公開された研究論文: [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902)
1. **[OneFormer](https://huggingface.co/docs/transformers/model_doc/oneformer)** (SHI Labs から) Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi から公開された研究論文: [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220)
1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released on GitHub (now removed).
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (Meta AI から) Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al から公開された研究論文: [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068)
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (Google AI から) Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby から公開された研究論文: [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230)
1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (Google AI から) Matthias Minderer, Alexey Gritsenko, Neil Houlsby. から公開された研究論文 [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683)
1. **[PatchTSMixer](https://huggingface.co/docs/transformers/model_doc/patchtsmixer)** ( IBM Research から) Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong, Jayant Kalagnanam. から公開された研究論文 [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf)
1. **[PatchTST](https://huggingface.co/docs/transformers/model_doc/patchtst)** (IBM から) Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam. から公開された研究論文 [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/pdf/2211.14730.pdf)
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (Google から) Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu から公開された研究論文: [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777)
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (Google から) Jason Phang, Yao Zhao, and Peter J. Liu から公開された研究論文: [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347)
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (Deepmind から) Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira から公開された研究論文: [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795)
1. **[Persimmon](https://huggingface.co/docs/transformers/model_doc/persimmon)** (ADEPT から) Erich Elsen, Augustus Odena, Maxwell Nye, Sağnak Taşırlar, Tri Dao, Curtis Hawthorne, Deepak Moparthi, Arushi Somani. から公開された研究論文 [blog post](https://www.adept.ai/blog/persimmon-8b)
1. **[Phi](https://huggingface.co/docs/transformers/model_doc/phi)** (from Microsoft) released with the papers - [Textbooks Are All You Need](https://arxiv.org/abs/2306.11644) by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li, [Textbooks Are All You Need II: phi-1.5 technical report](https://arxiv.org/abs/2309.05463) by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (VinAI Research から) Dat Quoc Nguyen and Anh Tuan Nguyen から公開された研究論文: [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/)
1. **[Pix2Struct](https://huggingface.co/docs/transformers/model_doc/pix2struct)** (Google から) Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova. から公開された研究論文 [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347)
1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (UCLA NLP から) Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang から公開された研究論文: [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333)
1. **[PoolFormer](https://huggingface.co/docs/transformers/model_doc/poolformer)** (Sea AI Labs から) Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng から公開された研究論文: [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418)
1. **[Pop2Piano](https://huggingface.co/docs/transformers/model_doc/pop2piano)** released with the paper [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi, Kyogu Lee.
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (Microsoft Research から) Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou から公開された研究論文: [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063)
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (Nanjing University, The University of Hong Kong etc. から) Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao. から公開された研究論文 [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf)
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (NVIDIA から) Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius から公開された研究論文: [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602)
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (Facebook から) Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela から公開された研究論文: [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401)
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (Google Research から) Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang から公開された研究論文: [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909)
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (Google Research から) Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya から公開された研究論文: [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451)
1. **[RegNet](https://huggingface.co/docs/transformers/model_doc/regnet)** (META Platforms から) Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár から公開された研究論文: [Designing Network Design Space](https://arxiv.org/abs/2003.13678)
1. **[RemBERT](https://huggingface.co/docs/transformers/model_doc/rembert)** (Google Research から) Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder から公開された研究論文: [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821)
1. **[ResNet](https://huggingface.co/docs/transformers/model_doc/resnet)** (Microsoft Research から) Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun から公開された研究論文: [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385)
1. **[RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta)** (Facebook から), Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov から公開された研究論文: [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692)
1. **[RoBERTa-PreLayerNorm](https://huggingface.co/docs/transformers/model_doc/roberta-prelayernorm)** (Facebook から) Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli から公開された研究論文: [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://arxiv.org/abs/1904.01038)
1. **[RoCBert](https://huggingface.co/docs/transformers/model_doc/roc_bert)** (WeChatAI から) HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou から公開された研究論文: [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf)
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (ZhuiyiTechnology から), Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu から公開された研究論文: [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864)
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (Bo Peng から) Bo Peng. から公開された研究論文 [this repo](https://github.com/BlinkDL/RWKV-LM)
1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
1. **[SeamlessM4Tv2](https://huggingface.co/docs/transformers/model_doc/seamless_m4t_v2)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (NVIDIA から) Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo から公開された研究論文: [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203)
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (Meta AI から) Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick. から公開された研究論文 [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf)
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (ASAPP から) Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi から公開された研究論文: [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870)
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (ASAPP から) Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi から公開された研究論文: [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870)
1. **[SpeechT5](https://huggingface.co/docs/transformers/model_doc/speecht5)** (Microsoft Research から) Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei. から公開された研究論文 [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205)
1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (Facebook から), Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino から公開された研究論文: [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171)
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (Facebook から), Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau から公開された研究論文: [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678)
1. **[Splinter](https://huggingface.co/docs/transformers/model_doc/splinter)** (Tel Aviv University から), Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy から公開された研究論文: [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438)
1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (Berkeley から) Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer から公開された研究論文: [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316)
1. **[SwiftFormer](https://huggingface.co/docs/transformers/model_doc/swiftformer)** (MBZUAI から) Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan. から公開された研究論文 [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://arxiv.org/abs/2303.15446)
1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (Microsoft から) Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo から公開された研究論文: [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030)
1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (Microsoft から) Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo から公開された研究論文: [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883)
1. **[Swin2SR](https://huggingface.co/docs/transformers/model_doc/swin2sr)** (University of Würzburg から) Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte から公開された研究論文: [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345)
1. **[SwitchTransformers](https://huggingface.co/docs/transformers/model_doc/switch_transformers)** (Google から) William Fedus, Barret Zoph, Noam Shazeer から公開された研究論文: [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961)
1. **[T5](https://huggingface.co/docs/transformers/model_doc/t5)** (Google AI から) Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu から公開された研究論文: [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683)
1. **[T5v1.1](https://huggingface.co/docs/transformers/model_doc/t5v1.1)** (Google AI から) Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu から公開されたレポジトリー [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511)
1. **[Table Transformer](https://huggingface.co/docs/transformers/model_doc/table-transformer)** (Microsoft Research から) Brandon Smock, Rohith Pesala, Robin Abraham から公開された研究論文: [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061)
1. **[TAPAS](https://huggingface.co/docs/transformers/model_doc/tapas)** (Google AI から) Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos から公開された研究論文: [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349)
1. **[TAPEX](https://huggingface.co/docs/transformers/model_doc/tapex)** (Microsoft Research から) Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou から公開された研究論文: [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653)
1. **[Time Series Transformer](https://huggingface.co/docs/transformers/model_doc/time_series_transformer)** (HuggingFace から).
1. **[TimeSformer](https://huggingface.co/docs/transformers/model_doc/timesformer)** (Facebook から) Gedas Bertasius, Heng Wang, Lorenzo Torresani から公開された研究論文: [Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095)
1. **[Trajectory Transformer](https://huggingface.co/docs/transformers/model_doc/trajectory_transformers)** (the University of California at Berkeley から) Michael Janner, Qiyang Li, Sergey Levine から公開された研究論文: [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039)
1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (Google/CMU から) Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov から公開された研究論文: [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860)
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (Microsoft から), Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei から公開された研究論文: [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282)
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill から), Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal から公開された研究論文: [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156)
1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (Intel から), Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding から公開された研究論文: [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995)
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (Google Research から) Yi Tay, Mostafa Dehghani, Vinh Q から公開された研究論文: [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (Google Research から) Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant. から公開された研究論文 [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi)
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (Microsoft Research から) Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang から公開された研究論文: [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597)
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (Microsoft Research から) Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu から公開された研究論文: [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752)
1. **[UnivNet](https://huggingface.co/docs/transformers/model_doc/univnet)** (from Kakao Corporation) released with the paper [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, and Juntae Kim.
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (Peking University から) Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun. から公開された研究論文 [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221)
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (Tsinghua University and Nankai University から) Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu から公開された研究論文: [Visual Attention Network](https://arxiv.org/abs/2202.09741)
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (Multimedia Computing Group, Nanjing University から) Zhan Tong, Yibing Song, Jue Wang, Limin Wang から公開された研究論文: [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602)
1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (NAVER AI Lab/Kakao Enterprise/Kakao Brain から) Wonjae Kim, Bokyung Son, Ildoo Kim から公開された研究論文: [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334)
1. **[VipLlava](https://huggingface.co/docs/transformers/model_doc/vipllava)** (University of Wisconsin–Madison から) Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee. から公開された研究論文 [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://arxiv.org/abs/2312.00784)
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (Google AI から) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby から公開された研究論文: [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929)
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (UCLA NLP から) Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang から公開された研究論文: [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557)
1. **[ViT Hybrid](https://huggingface.co/docs/transformers/model_doc/vit_hybrid)** (Google AI から) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby から公開された研究論文: [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929)
1. **[VitDet](https://huggingface.co/docs/transformers/model_doc/vitdet)** (Meta AI から) Yanghao Li, Hanzi Mao, Ross Girshick, Kaiming He. から公開された研究論文 [Exploring Plain Vision Transformer Backbones for Object Detection](https://arxiv.org/abs/2203.16527)
1. **[ViTMAE](https://huggingface.co/docs/transformers/model_doc/vit_mae)** (Meta AI から) Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick から公開された研究論文: [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377)
1. **[ViTMatte](https://huggingface.co/docs/transformers/model_doc/vitmatte)** (HUST-VL から) Jingfeng Yao, Xinggang Wang, Shusheng Yang, Baoyuan Wang. から公開された研究論文 [ViTMatte: Boosting Image Matting with Pretrained Plain Vision Transformers](https://arxiv.org/abs/2305.15272)
1. **[ViTMSN](https://huggingface.co/docs/transformers/model_doc/vit_msn)** (Meta AI から) Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas から公開された研究論文: [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141)
1. **[VITS](https://huggingface.co/docs/transformers/model_doc/vits)** (Kakao Enterprise から) Jaehyeon Kim, Jungil Kong, Juhee Son. から公開された研究論文 [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103)
1. **[ViViT](https://huggingface.co/docs/transformers/model_doc/vivit)** (from Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (Facebook AI から) Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli から公開された研究論文: [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477)
1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (Facebook AI から) Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino から公開された研究論文: [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171)
1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (Facebook AI から) Qiantong Xu, Alexei Baevski, Michael Auli から公開された研究論文: [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680)
1. **[WavLM](https://huggingface.co/docs/transformers/model_doc/wavlm)** (Microsoft Research から) Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei から公開された研究論文: [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900)
1. **[Whisper](https://huggingface.co/docs/transformers/model_doc/whisper)** (OpenAI から) Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever から公開された研究論文: [Robust Speech Recognition via Large-Scale Weak Supervision](https://cdn.openai.com/papers/whisper.pdf)
1. **[X-CLIP](https://huggingface.co/docs/transformers/model_doc/xclip)** (Microsoft Research から) Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling から公開された研究論文: [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816)
1. **[X-MOD](https://huggingface.co/docs/transformers/model_doc/xmod)** (Meta AI から) Jonas Pfeiffer, Naman Goyal, Xi Lin, Xian Li, James Cross, Sebastian Riedel, Mikel Artetxe. から公開された研究論文 [Lifting the Curse of Multilinguality by Pre-training Modular Transformers](http://dx.doi.org/10.18653/v1/2022.naacl-main.255)
1. **[XGLM](https://huggingface.co/docs/transformers/model_doc/xglm)** (From Facebook AI) Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li から公開された研究論文: [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668)
1. **[XLM](https://huggingface.co/docs/transformers/model_doc/xlm)** (Facebook から) Guillaume Lample and Alexis Conneau から公開された研究論文: [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291)
1. **[XLM-ProphetNet](https://huggingface.co/docs/transformers/model_doc/xlm-prophetnet)** (Microsoft Research から) Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou から公開された研究論文: [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063)
1. **[XLM-RoBERTa](https://huggingface.co/docs/transformers/model_doc/xlm-roberta)** (Facebook AI から), Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov から公開された研究論文: [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116)
1. **[XLM-RoBERTa-XL](https://huggingface.co/docs/transformers/model_doc/xlm-roberta-xl)** (Facebook AI から), Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau から公開された研究論文: [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572)
1. **[XLM-V](https://huggingface.co/docs/transformers/model_doc/xlm-v)** (Meta AI から) Davis Liang, Hila Gonen, Yuning Mao, Rui Hou, Naman Goyal, Marjan Ghazvininejad, Luke Zettlemoyer, Madian Khabsa から公開された研究論文: [XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models](https://arxiv.org/abs/2301.10472)
1. **[XLNet](https://huggingface.co/docs/transformers/model_doc/xlnet)** (Google/CMU から) Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le から公開された研究論文: [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237)
1. **[XLS-R](https://huggingface.co/docs/transformers/model_doc/xls_r)** (Facebook AI から) Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli から公開された研究論文: [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296)
1. **[XLSR-Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/xlsr_wav2vec2)** (Facebook AI から) Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli から公開された研究論文: [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979)
1. **[YOLOS](https://huggingface.co/docs/transformers/model_doc/yolos)** (Huazhong University of Science & Technology から) Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu から公開された研究論文: [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666)
1. **[YOSO](https://huggingface.co/docs/transformers/model_doc/yoso)** (the University of Wisconsin - Madison から) Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh から公開された研究論文: [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714)
1. 新しいモデルを投稿したいですか?新しいモデルを追加するためのガイドとして、**詳細なガイドとテンプレート**が追加されました。これらはリポジトリの[`templates`](./templates)フォルダにあります。PRを始める前に、必ず[コントリビューションガイド](./CONTRIBUTING.md)を確認し、メンテナに連絡するか、フィードバックを収集するためにissueを開いてください。
各モデルがFlax、PyTorch、TensorFlowで実装されているか、🤗Tokenizersライブラリに支えられた関連トークナイザを持っているかは、[この表](https://huggingface.co/docs/transformers/index#supported-frameworks)を参照してください。
これらの実装はいくつかのデータセットでテストされており(サンプルスクリプトを参照)、オリジナルの実装の性能と一致するはずである。性能の詳細は[documentation](https://github.com/huggingface/transformers/tree/main/examples)のExamplesセクションで見ることができます。
## さらに詳しく
| セクション | 概要 |
|-|-|
| [ドキュメント](https://huggingface.co/docs/transformers/) | 完全なAPIドキュメントとチュートリアル |
| [タスク概要](https://huggingface.co/docs/transformers/task_summary) | 🤗Transformersがサポートするタスク |
| [前処理チュートリアル](https://huggingface.co/docs/transformers/preprocessing) | モデル用のデータを準備するために`Tokenizer`クラスを使用 |
| [トレーニングと微調整](https://huggingface.co/docs/transformers/training) | PyTorch/TensorFlowの学習ループと`Trainer`APIで🤗Transformersが提供するモデルを使用 |
| [クイックツアー: 微調整/使用方法スクリプト](https://github.com/huggingface/transformers/tree/main/examples) | 様々なタスクでモデルの微調整を行うためのスクリプト例 |
| [モデルの共有とアップロード](https://huggingface.co/docs/transformers/model_sharing) | 微調整したモデルをアップロードしてコミュニティで共有する |
| [マイグレーション](https://huggingface.co/docs/transformers/migration) | `pytorch-transformers`または`pytorch-pretrained-bert`から🤗Transformers に移行する |
## 引用
🤗 トランスフォーマーライブラリに引用できる[論文](https://www.aclweb.org/anthology/2020.emnlp-demos.6/)が出来ました:
```bibtex
@inproceedings{wolf-etal-2020-transformers,
title = "Transformers: State-of-the-Art Natural Language Processing",
author = "Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = oct,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-demos.6",
pages = "38--45"
}
```
| huggingface/transformers/blob/main/README_ja.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Utilities for pipelines
This page lists all the utility functions the library provides for pipelines.
Most of those are only useful if you are studying the code of the models in the library.
## Argument handling
[[autodoc]] pipelines.ArgumentHandler
[[autodoc]] pipelines.ZeroShotClassificationArgumentHandler
[[autodoc]] pipelines.QuestionAnsweringArgumentHandler
## Data format
[[autodoc]] pipelines.PipelineDataFormat
[[autodoc]] pipelines.CsvPipelineDataFormat
[[autodoc]] pipelines.JsonPipelineDataFormat
[[autodoc]] pipelines.PipedPipelineDataFormat
## Utilities
[[autodoc]] pipelines.PipelineException
| huggingface/transformers/blob/main/docs/source/en/internal/pipelines_utils.md |
Inference API
Please refer to [Inference API Documentation](https://huggingface.co/docs/api-inference) for detailed information.
## What technology do you use to power the inference API?
For 🤗 Transformers models, [Pipelines](https://huggingface.co/docs/transformers/main_classes/pipelines) power the API.
On top of `Pipelines` and depending on the model type, there are several production optimizations like:
- compiling models to optimized intermediary representations (e.g. [ONNX](https://medium.com/microsoftazure/accelerate-your-nlp-pipelines-using-hugging-face-transformers-and-onnx-runtime-2443578f4333)),
- maintaining a Least Recently Used cache, ensuring that the most popular models are always loaded,
- scaling the underlying compute infrastructure on the fly depending on the load constraints.
For models from [other libraries](./models-libraries), the API uses [Starlette](https://www.starlette.io) and runs in [Docker containers](https://github.com/huggingface/api-inference-community/tree/main/docker_images). Each library defines the implementation of [different pipelines](https://github.com/huggingface/api-inference-community/tree/main/docker_images/sentence_transformers/app/pipelines).
## How can I turn off the inference API for my model?
Specify `inference: false` in your model card's metadata.
## Why don't I see an inference widget or why can't I use the inference API?
For some tasks, there might not be support in the inference API, and, hence, there is no widget.
For all libraries (except 🤗 Transformers), there is a [library-to-tasks.ts file](https://github.com/huggingface/huggingface.js/blob/main/packages/tasks/src/library-to-tasks.ts) of supported tasks in the API. When a model repository has a task that is not supported by the repository library, the repository has `inference: false` by default.
## Can I send large volumes of requests? Can I get accelerated APIs?
If you are interested in accelerated inference, higher volumes of requests, or an SLA, please contact us at `api-enterprise at huggingface.co`.
## How can I see my usage?
You can head to the [Inference API dashboard](https://api-inference.huggingface.co/dashboard/). Learn more about it in the [Inference API documentation](https://huggingface.co/docs/api-inference/usage).
## Is there programmatic access to the Inference API?
Yes, the `huggingface_hub` library has a client wrapper documented [here](https://huggingface.co/docs/huggingface_hub/how-to-inference).
| huggingface/hub-docs/blob/main/docs/hub/models-inference.md |
Enterprise Hub
Enterprise Hub adds advanced capabilities to organizations, enabling safe, compliant and managed collaboration for companies and teams on Hugging Face.
In this section we will document the following Enterprise Hub features:
- [SSO](./enterprise-sso)
- [Audit Logs](./audit-logs)
- [Storage Regions](./storage-regions)
| huggingface/hub-docs/blob/main/docs/hub/enterprise-hub.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Pipelines
Pipelines provide a simple way to run state-of-the-art diffusion models in inference by bundling all of the necessary components (multiple independently-trained models, schedulers, and processors) into a single end-to-end class. Pipelines are flexible and they can be adapted to use different schedulers or even model components.
All pipelines are built from the base [`DiffusionPipeline`] class which provides basic functionality for loading, downloading, and saving all the components. Specific pipeline types (for example [`StableDiffusionPipeline`]) loaded with [`~DiffusionPipeline.from_pretrained`] are automatically detected and the pipeline components are loaded and passed to the `__init__` function of the pipeline.
<Tip warning={true}>
You shouldn't use the [`DiffusionPipeline`] class for training. Individual components (for example, [`UNet2DModel`] and [`UNet2DConditionModel`]) of diffusion pipelines are usually trained individually, so we suggest directly working with them instead.
<br>
Pipelines do not offer any training functionality. You'll notice PyTorch's autograd is disabled by decorating the [`~DiffusionPipeline.__call__`] method with a [`torch.no_grad`](https://pytorch.org/docs/stable/generated/torch.no_grad.html) decorator because pipelines should not be used for training. If you're interested in training, please take a look at the [Training](../../training/overview) guides instead!
</Tip>
The table below lists all the pipelines currently available in 🤗 Diffusers and the tasks they support. Click on a pipeline to view its abstract and published paper.
| Pipeline | Tasks |
|---|---|
| [AltDiffusion](alt_diffusion) | image2image |
| [AnimateDiff](animatediff) | text2video |
| [Attend-and-Excite](attend_and_excite) | text2image |
| [Audio Diffusion](audio_diffusion) | image2audio |
| [AudioLDM](audioldm) | text2audio |
| [AudioLDM2](audioldm2) | text2audio |
| [BLIP Diffusion](blip_diffusion) | text2image |
| [Consistency Models](consistency_models) | unconditional image generation |
| [ControlNet](controlnet) | text2image, image2image, inpainting |
| [ControlNet with Stable Diffusion XL](controlnet_sdxl) | text2image |
| [ControlNet-XS](controlnetxs) | text2image |
| [ControlNet-XS with Stable Diffusion XL](controlnetxs_sdxl) | text2image |
| [Cycle Diffusion](cycle_diffusion) | image2image |
| [Dance Diffusion](dance_diffusion) | unconditional audio generation |
| [DDIM](ddim) | unconditional image generation |
| [DDPM](ddpm) | unconditional image generation |
| [DeepFloyd IF](deepfloyd_if) | text2image, image2image, inpainting, super-resolution |
| [DiffEdit](diffedit) | inpainting |
| [DiT](dit) | text2image |
| [GLIGEN](stable_diffusion/gligen) | text2image |
| [InstructPix2Pix](pix2pix) | image editing |
| [Kandinsky 2.1](kandinsky) | text2image, image2image, inpainting, interpolation |
| [Kandinsky 2.2](kandinsky_v22) | text2image, image2image, inpainting |
| [Kandinsky 3](kandinsky3) | text2image, image2image |
| [Latent Consistency Models](latent_consistency_models) | text2image |
| [Latent Diffusion](latent_diffusion) | text2image, super-resolution |
| [LDM3D](stable_diffusion/ldm3d_diffusion) | text2image, text-to-3D, text-to-pano, upscaling |
| [MultiDiffusion](panorama) | text2image |
| [MusicLDM](musicldm) | text2audio |
| [Paint by Example](paint_by_example) | inpainting |
| [ParaDiGMS](paradigms) | text2image |
| [Pix2Pix Zero](pix2pix_zero) | image editing |
| [PixArt-α](pixart) | text2image |
| [PNDM](pndm) | unconditional image generation |
| [RePaint](repaint) | inpainting |
| [Score SDE VE](score_sde_ve) | unconditional image generation |
| [Self-Attention Guidance](self_attention_guidance) | text2image |
| [Semantic Guidance](semantic_stable_diffusion) | text2image |
| [Shap-E](shap_e) | text-to-3D, image-to-3D |
| [Spectrogram Diffusion](spectrogram_diffusion) | |
| [Stable Diffusion](stable_diffusion/overview) | text2image, image2image, depth2image, inpainting, image variation, latent upscaler, super-resolution |
| [Stable Diffusion Model Editing](model_editing) | model editing |
| [Stable Diffusion XL](stable_diffusion/stable_diffusion_xl) | text2image, image2image, inpainting |
| [Stable Diffusion XL Turbo](stable_diffusion/sdxl_turbo) | text2image, image2image, inpainting |
| [Stable unCLIP](stable_unclip) | text2image, image variation |
| [Stochastic Karras VE](stochastic_karras_ve) | unconditional image generation |
| [T2I-Adapter](stable_diffusion/adapter) | text2image |
| [Text2Video](text_to_video) | text2video, video2video |
| [Text2Video-Zero](text_to_video_zero) | text2video |
| [unCLIP](unclip) | text2image, image variation |
| [Unconditional Latent Diffusion](latent_diffusion_uncond) | unconditional image generation |
| [UniDiffuser](unidiffuser) | text2image, image2text, image variation, text variation, unconditional image generation, unconditional audio generation |
| [Value-guided planning](value_guided_sampling) | value guided sampling |
| [Versatile Diffusion](versatile_diffusion) | text2image, image variation |
| [VQ Diffusion](vq_diffusion) | text2image |
| [Wuerstchen](wuerstchen) | text2image |
## DiffusionPipeline
[[autodoc]] DiffusionPipeline
- all
- __call__
- device
- to
- components
## FlaxDiffusionPipeline
[[autodoc]] pipelines.pipeline_flax_utils.FlaxDiffusionPipeline
## PushToHubMixin
[[autodoc]] utils.PushToHubMixin
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/overview.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Bark
## Overview
Bark is a transformer-based text-to-speech model proposed by Suno AI in [suno-ai/bark](https://github.com/suno-ai/bark).
Bark is made of 4 main models:
- [`BarkSemanticModel`] (also referred to as the 'text' model): a causal auto-regressive transformer model that takes as input tokenized text, and predicts semantic text tokens that capture the meaning of the text.
- [`BarkCoarseModel`] (also referred to as the 'coarse acoustics' model): a causal autoregressive transformer, that takes as input the results of the [`BarkSemanticModel`] model. It aims at predicting the first two audio codebooks necessary for EnCodec.
- [`BarkFineModel`] (the 'fine acoustics' model), this time a non-causal autoencoder transformer, which iteratively predicts the last codebooks based on the sum of the previous codebooks embeddings.
- having predicted all the codebook channels from the [`EncodecModel`], Bark uses it to decode the output audio array.
It should be noted that each of the first three modules can support conditional speaker embeddings to condition the output sound according to specific predefined voice.
This model was contributed by [Yoach Lacombe (ylacombe)](https://huggingface.co/ylacombe) and [Sanchit Gandhi (sanchit-gandhi)](https://github.com/sanchit-gandhi).
The original code can be found [here](https://github.com/suno-ai/bark).
### Optimizing Bark
Bark can be optimized with just a few extra lines of code, which **significantly reduces its memory footprint** and **accelerates inference**.
#### Using half-precision
You can speed up inference and reduce memory footprint by 50% simply by loading the model in half-precision.
```python
from transformers import BarkModel
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16).to(device)
```
#### Using CPU offload
As mentioned above, Bark is made up of 4 sub-models, which are called up sequentially during audio generation. In other words, while one sub-model is in use, the other sub-models are idle.
If you're using a CUDA device, a simple solution to benefit from an 80% reduction in memory footprint is to offload the submodels from GPU to CPU when they're idle. This operation is called *CPU offloading*. You can use it with one line of code as follows:
```python
model.enable_cpu_offload()
```
Note that 🤗 Accelerate must be installed before using this feature. [Here's how to install it.](https://huggingface.co/docs/accelerate/basic_tutorials/install)
#### Using Better Transformer
Better Transformer is an 🤗 Optimum feature that performs kernel fusion under the hood. You can gain 20% to 30% in speed with zero performance degradation. It only requires one line of code to export the model to 🤗 Better Transformer:
```python
model = model.to_bettertransformer()
```
Note that 🤗 Optimum must be installed before using this feature. [Here's how to install it.](https://huggingface.co/docs/optimum/installation)
#### Using Flash Attention 2
Flash Attention 2 is an even faster, optimized version of the previous optimization.
##### Installation
First, check whether your hardware is compatible with Flash Attention 2. The latest list of compatible hardware can be found in the [official documentation](https://github.com/Dao-AILab/flash-attention#installation-and-features). If your hardware is not compatible with Flash Attention 2, you can still benefit from attention kernel optimisations through Better Transformer support covered [above](https://huggingface.co/docs/transformers/main/en/model_doc/bark#using-better-transformer).
Next, [install](https://github.com/Dao-AILab/flash-attention#installation-and-features) the latest version of Flash Attention 2:
```bash
pip install -U flash-attn --no-build-isolation
```
##### Usage
To load a model using Flash Attention 2, we can pass the `attn_implementation="flash_attention_2"` flag to [`.from_pretrained`](https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.PreTrainedModel.from_pretrained). We'll also load the model in half-precision (e.g. `torch.float16`), since it results in almost no degradation to audio quality but significantly lower memory usage and faster inference:
```python
model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to(device)
```
##### Performance comparison
The following diagram shows the latency for the native attention implementation (no optimisation) against Better Transformer and Flash Attention 2. In all cases, we generate 400 semantic tokens on a 40GB A100 GPU with PyTorch 2.1. Flash Attention 2 is also consistently faster than Better Transformer, and its performance improves even more as batch sizes increase:
<div style="text-align: center">
<img src="https://huggingface.co/datasets/ylacombe/benchmark-comparison/resolve/main/Bark%20Optimization%20Benchmark.png">
</div>
To put this into perspective, on an NVIDIA A100 and when generating 400 semantic tokens with a batch size of 16, you can get 17 times the [throughput](https://huggingface.co/blog/optimizing-bark#throughput) and still be 2 seconds faster than generating sentences one by one with the native model implementation. In other words, all the samples will be generated 17 times faster.
At batch size 8, on an NVIDIA A100, Flash Attention 2 is also 10% faster than Better Transformer, and at batch size 16, 25%.
#### Combining optimization techniques
You can combine optimization techniques, and use CPU offload, half-precision and Flash Attention 2 (or 🤗 Better Transformer) all at once.
```python
from transformers import BarkModel
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
# load in fp16 and use Flash Attention 2
model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to(device)
# enable CPU offload
model.enable_cpu_offload()
```
Find out more on inference optimization techniques [here](https://huggingface.co/docs/transformers/perf_infer_gpu_one).
### Usage tips
Suno offers a library of voice presets in a number of languages [here](https://suno-ai.notion.site/8b8e8749ed514b0cbf3f699013548683?v=bc67cff786b04b50b3ceb756fd05f68c).
These presets are also uploaded in the hub [here](https://huggingface.co/suno/bark-small/tree/main/speaker_embeddings) or [here](https://huggingface.co/suno/bark/tree/main/speaker_embeddings).
```python
>>> from transformers import AutoProcessor, BarkModel
>>> processor = AutoProcessor.from_pretrained("suno/bark")
>>> model = BarkModel.from_pretrained("suno/bark")
>>> voice_preset = "v2/en_speaker_6"
>>> inputs = processor("Hello, my dog is cute", voice_preset=voice_preset)
>>> audio_array = model.generate(**inputs)
>>> audio_array = audio_array.cpu().numpy().squeeze()
```
Bark can generate highly realistic, **multilingual** speech as well as other audio - including music, background noise and simple sound effects.
```python
>>> # Multilingual speech - simplified Chinese
>>> inputs = processor("惊人的!我会说中文")
>>> # Multilingual speech - French - let's use a voice_preset as well
>>> inputs = processor("Incroyable! Je peux générer du son.", voice_preset="fr_speaker_5")
>>> # Bark can also generate music. You can help it out by adding music notes around your lyrics.
>>> inputs = processor("♪ Hello, my dog is cute ♪")
>>> audio_array = model.generate(**inputs)
>>> audio_array = audio_array.cpu().numpy().squeeze()
```
The model can also produce **nonverbal communications** like laughing, sighing and crying.
```python
>>> # Adding non-speech cues to the input text
>>> inputs = processor("Hello uh ... [clears throat], my dog is cute [laughter]")
>>> audio_array = model.generate(**inputs)
>>> audio_array = audio_array.cpu().numpy().squeeze()
```
To save the audio, simply take the sample rate from the model config and some scipy utility:
```python
>>> from scipy.io.wavfile import write as write_wav
>>> # save audio to disk, but first take the sample rate from the model config
>>> sample_rate = model.generation_config.sample_rate
>>> write_wav("bark_generation.wav", sample_rate, audio_array)
```
## BarkConfig
[[autodoc]] BarkConfig
- all
## BarkProcessor
[[autodoc]] BarkProcessor
- all
- __call__
## BarkModel
[[autodoc]] BarkModel
- generate
- enable_cpu_offload
## BarkSemanticModel
[[autodoc]] BarkSemanticModel
- forward
## BarkCoarseModel
[[autodoc]] BarkCoarseModel
- forward
## BarkFineModel
[[autodoc]] BarkFineModel
- forward
## BarkCausalModel
[[autodoc]] BarkCausalModel
- forward
## BarkCoarseConfig
[[autodoc]] BarkCoarseConfig
- all
## BarkFineConfig
[[autodoc]] BarkFineConfig
- all
## BarkSemanticConfig
[[autodoc]] BarkSemanticConfig
- all
| huggingface/transformers/blob/main/docs/source/en/model_doc/bark.md |
Brief introduction to RL documentation
In this advanced topic, we address the question: **how should we monitor and keep track of powerful reinforcement learning agents that we are training in the real world and
interfacing with humans?**
As machine learning systems have increasingly impacted modern life, the **call for the documentation of these systems has grown**.
Such documentation can cover aspects such as the training data used — where it is stored, when it was collected, who was involved, etc.
— or the model optimization framework — the architecture, evaluation metrics, relevant papers, etc. — and more.
Today, model cards and datasheets are becoming increasingly available. For example, on the Hub
(see documentation [here](https://huggingface.co/docs/hub/model-cards)).
If you click on a [popular model on the Hub](https://huggingface.co/models), you can learn about its creation process.
These model and data specific logs are designed to be completed when the model or dataset are created, leaving them to go un-updated when these models are built into evolving systems in the future.
## Motivating Reward Reports
Reinforcement learning systems are fundamentally designed to optimize based on measurements of reward and time.
While the notion of a reward function can be mapped nicely to many well-understood fields of supervised learning (via a loss function),
understanding of how machine learning systems evolve over time is limited.
To that end, the authors introduce [*Reward Reports for Reinforcement Learning*](https://www.notion.so/Brief-introduction-to-RL-documentation-b8cbda5a6f5242338e0756e6bef72af4) (the pithy naming is designed to mirror the popular papers *Model Cards for Model Reporting* and *Datasheets for Datasets*).
The goal is to propose a type of documentation focused on the **human factors of reward** and **time-varying feedback systems**.
Building on the documentation frameworks for [model cards](https://arxiv.org/abs/1810.03993) and [datasheets](https://arxiv.org/abs/1803.09010) proposed by Mitchell et al. and Gebru et al., we argue the need for Reward Reports for AI systems.
**Reward Reports** are living documents for proposed RL deployments that demarcate design choices.
However, many questions remain about the applicability of this framework to different RL applications, roadblocks to system interpretability,
and the resonances between deployed supervised machine learning systems and the sequential decision-making utilized in RL.
At a minimum, Reward Reports are an opportunity for RL practitioners to deliberate on these questions and begin the work of deciding how to resolve them in practice.
## Capturing temporal behavior with documentation
The core piece specific to documentation designed for RL and feedback-driven ML systems is a *change-log*. The change-log updates information
from the designer (changed training parameters, data, etc.) along with noticed changes from the user (harmful behavior, unexpected responses, etc.).
The change log is accompanied by update triggers that encourage monitoring these effects.
## Contributing
Some of the most impactful RL-driven systems are multi-stakeholder in nature and behind the closed doors of private corporations.
These corporations are largely without regulation, so the burden of documentation falls on the public.
If you are interested in contributing, we are building Reward Reports for popular machine learning systems on a public
record on [GitHub](https://github.com/RewardReports/reward-reports).
For further reading, you can visit the Reward Reports [paper](https://arxiv.org/abs/2204.10817)
or look [an example report](https://github.com/RewardReports/reward-reports/tree/main/examples).
## Author
This section was written by <a href="https://twitter.com/natolambert"> Nathan Lambert </a>
| huggingface/deep-rl-class/blob/main/units/en/unitbonus3/rl-documentation.mdx |
Create a dataset loading script
<Tip>
The dataset loading script is likely not needed if your dataset is in one of the following formats: CSV, JSON, JSON lines, text, images, audio or Parquet.
With those formats, you should be able to load your dataset automatically with [`~datasets.load_dataset`],
as long as your dataset repository has a [required structure](./repository_structure).
</Tip>
<Tip warning=true>
In the next major release, the new safety features of 🤗 Datasets will disable running dataset loading scripts by default, and you will have to pass `trust_remote_code=True` to load datasets that require running a dataset script.
</Tip>
Write a dataset script to load and share datasets that consist of data files in unsupported formats or require more complex data preparation.
This is a more advanced way to define a dataset than using [YAML metadata in the dataset card](./repository_structure#define-your-splits-in-yaml).
A dataset script is a Python file that defines the different configurations and splits of your dataset, as well as how to download and process the data.
The script can download data files from any website, or from the same dataset repository.
A dataset loading script should have the same name as a dataset repository or directory. For example, a repository named `my_dataset` should contain `my_dataset.py` script. This way it can be loaded with:
```
my_dataset/
├── README.md
└── my_dataset.py
```
```py
>>> from datasets import load_dataset
>>> load_dataset("path/to/my_dataset")
```
The following guide includes instructions for dataset scripts for how to:
- Add dataset metadata.
- Download data files.
- Generate samples.
- Generate dataset metadata.
- Upload a dataset to the Hub.
Open the [SQuAD dataset loading script](https://huggingface.co/datasets/squad/blob/main/squad.py) template to follow along on how to share a dataset.
<Tip>
To help you get started, try beginning with the dataset loading script [template](https://github.com/huggingface/datasets/blob/main/templates/new_dataset_script.py)!
</Tip>
## Add dataset attributes
The first step is to add some information, or attributes, about your dataset in [`DatasetBuilder._info`]. The most important attributes you should specify are:
1. `DatasetInfo.description` provides a concise description of your dataset. The description informs the user what's in the dataset, how it was collected, and how it can be used for a NLP task.
2. `DatasetInfo.features` defines the name and type of each column in your dataset. This will also provide the structure for each example, so it is possible to create nested subfields in a column if you want. Take a look at [`Features`] for a full list of feature types you can use.
```py
datasets.Features(
{
"id": datasets.Value("string"),
"title": datasets.Value("string"),
"context": datasets.Value("string"),
"question": datasets.Value("string"),
"answers": datasets.Sequence(
{
"text": datasets.Value("string"),
"answer_start": datasets.Value("int32"),
}
),
}
)
```
3. `DatasetInfo.homepage` contains the URL to the dataset homepage so users can find more details about the dataset.
4. `DatasetInfo.citation` contains a BibTeX citation for the dataset.
After you've filled out all these fields in the template, it should look like the following example from the SQuAD loading script:
```py
def _info(self):
return datasets.DatasetInfo(
description=_DESCRIPTION,
features=datasets.Features(
{
"id": datasets.Value("string"),
"title": datasets.Value("string"),
"context": datasets.Value("string"),
"question": datasets.Value("string"),
"answers": datasets.features.Sequence(
{"text": datasets.Value("string"), "answer_start": datasets.Value("int32"),}
),
}
),
# No default supervised_keys (as we have to pass both question
# and context as input).
supervised_keys=None,
homepage="https://rajpurkar.github.io/SQuAD-explorer/",
citation=_CITATION,
)
```
### Multiple configurations
In some cases, your dataset may have multiple configurations. For example, the [SuperGLUE](https://huggingface.co/datasets/super_glue) dataset is a collection of 5 datasets designed to evaluate language understanding tasks. 🤗 Datasets provides [`BuilderConfig`] which allows you to create different configurations for the user to select from.
Let's study the [SuperGLUE loading script](https://huggingface.co/datasets/super_glue/blob/main/super_glue.py) to see how you can define several configurations.
1. Create a [`BuilderConfig`] subclass with attributes about your dataset. These attributes can be the features of your dataset, label classes, and a URL to the data files.
```py
class SuperGlueConfig(datasets.BuilderConfig):
"""BuilderConfig for SuperGLUE."""
def __init__(self, features, data_url, citation, url, label_classes=("False", "True"), **kwargs):
"""BuilderConfig for SuperGLUE.
Args:
features: *list[string]*, list of the features that will appear in the
feature dict. Should not include "label".
data_url: *string*, url to download the zip file from.
citation: *string*, citation for the data set.
url: *string*, url for information about the data set.
label_classes: *list[string]*, the list of classes for the label if the
label is present as a string. Non-string labels will be cast to either
'False' or 'True'.
**kwargs: keyword arguments forwarded to super.
"""
# Version history:
# 1.0.2: Fixed non-nondeterminism in ReCoRD.
# 1.0.1: Change from the pre-release trial version of SuperGLUE (v1.9) to
# the full release (v2.0).
# 1.0.0: S3 (new shuffling, sharding and slicing mechanism).
# 0.0.2: Initial version.
super().__init__(version=datasets.Version("1.0.2"), **kwargs)
self.features = features
self.label_classes = label_classes
self.data_url = data_url
self.citation = citation
self.url = url
```
2. Create instances of your config to specify the values of the attributes of each configuration. This gives you the flexibility to specify all the name and description of each configuration. These sub-class instances should be listed under `DatasetBuilder.BUILDER_CONFIGS`:
```py
class SuperGlue(datasets.GeneratorBasedBuilder):
"""The SuperGLUE benchmark."""
BUILDER_CONFIG_CLASS = SuperGlueConfig
BUILDER_CONFIGS = [
SuperGlueConfig(
name="boolq",
description=_BOOLQ_DESCRIPTION,
features=["question", "passage"],
data_url="https://dl.fbaipublicfiles.com/glue/superglue/data/v2/BoolQ.zip",
citation=_BOOLQ_CITATION,
url="https://github.com/google-research-datasets/boolean-questions",
),
...
...
SuperGlueConfig(
name="axg",
description=_AXG_DESCRIPTION,
features=["premise", "hypothesis"],
label_classes=["entailment", "not_entailment"],
data_url="https://dl.fbaipublicfiles.com/glue/superglue/data/v2/AX-g.zip",
citation=_AXG_CITATION,
url="https://github.com/rudinger/winogender-schemas",
),
```
3. Now, users can load a specific configuration of the dataset with the configuration `name`:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset('super_glue', 'boolq')
```
Additionally, users can instantiate a custom builder configuration by passing the builder configuration arguments to [`load_dataset`]:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset('super_glue', data_url="https://custom_url")
```
### Default configurations
Users must specify a configuration name when they load a dataset with multiple configurations. Otherwise, 🤗 Datasets will raise a `ValueError`, and prompt the user to select a configuration name. You can avoid this by setting a default dataset configuration with the `DEFAULT_CONFIG_NAME` attribute:
```py
class NewDataset(datasets.GeneratorBasedBuilder):
VERSION = datasets.Version("1.1.0")
BUILDER_CONFIGS = [
datasets.BuilderConfig(name="first_domain", version=VERSION, description="This part of my dataset covers a first domain"),
datasets.BuilderConfig(name="second_domain", version=VERSION, description="This part of my dataset covers a second domain"),
]
DEFAULT_CONFIG_NAME = "first_domain"
```
<Tip warning={true}>
Only use a default configuration when it makes sense. Don't set one because it may be more convenient for the user to not specify a configuration when they load your dataset. For example, multi-lingual datasets often have a separate configuration for each language. An appropriate default may be an aggregated configuration that loads all the languages of the dataset if the user doesn't request a particular one.
</Tip>
## Download data files and organize splits
After you've defined the attributes of your dataset, the next step is to download the data files and organize them according to their splits.
1. Create a dictionary of URLs in the loading script that point to the original SQuAD data files:
```py
_URL = "https://rajpurkar.github.io/SQuAD-explorer/dataset/"
_URLS = {
"train": _URL + "train-v1.1.json",
"dev": _URL + "dev-v1.1.json",
}
```
<Tip>
If the data files live in the same folder or repository of the dataset script, you can just pass the relative paths to the files instead of URLs.
</Tip>
2. [`DownloadManager.download_and_extract`] takes this dictionary and downloads the data files. Once the files are downloaded, use [`SplitGenerator`] to organize each split in the dataset. This is a simple class that contains:
- The `name` of each split. You should use the standard split names: `Split.TRAIN`, `Split.TEST`, and `Split.VALIDATION`.
- `gen_kwargs` provides the file paths to the data files to load for each split.
Your `DatasetBuilder._split_generator()` should look like this now:
```py
def _split_generators(self, dl_manager: datasets.DownloadManager) -> List[datasets.SplitGenerator]:
urls_to_download = self._URLS
downloaded_files = dl_manager.download_and_extract(urls_to_download)
return [
datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"filepath": downloaded_files["train"]}),
datasets.SplitGenerator(name=datasets.Split.VALIDATION, gen_kwargs={"filepath": downloaded_files["dev"]}),
]
```
## Generate samples
At this point, you have:
- Added the dataset attributes.
- Provided instructions for how to download the data files.
- Organized the splits.
The next step is to actually generate the samples in each split.
1. `DatasetBuilder._generate_examples` takes the file path provided by `gen_kwargs` to read and parse the data files. You need to write a function that loads the data files and extracts the columns.
2. Your function should yield a tuple of an `id_`, and an example from the dataset.
```py
def _generate_examples(self, filepath):
"""This function returns the examples in the raw (text) form."""
logger.info("generating examples from = %s", filepath)
with open(filepath) as f:
squad = json.load(f)
for article in squad["data"]:
title = article.get("title", "").strip()
for paragraph in article["paragraphs"]:
context = paragraph["context"].strip()
for qa in paragraph["qas"]:
question = qa["question"].strip()
id_ = qa["id"]
answer_starts = [answer["answer_start"] for answer in qa["answers"]]
answers = [answer["text"].strip() for answer in qa["answers"]]
# Features currently used are "context", "question", and "answers".
# Others are extracted here for the ease of future expansions.
yield id_, {
"title": title,
"context": context,
"question": question,
"id": id_,
"answers": {"answer_start": answer_starts, "text": answers,},
}
```
## (Optional) Generate dataset metadata
Adding dataset metadata is a great way to include information about your dataset. The metadata is stored in the dataset card `README.md` in YAML. It includes information like the number of examples required to confirm the dataset was correctly generated, and information about the dataset like its `features`.
Run the following command to generate your dataset metadata in `README.md` and make sure your new dataset loading script works correctly:
```
datasets-cli test path/to/<your-dataset-loading-script> --save_info --all_configs
```
If your dataset loading script passed the test, you should now have a `README.md` file in your dataset folder containing a `dataset_info` field with some metadata.
## Upload to the Hub
Once your script is ready, [create a dataset card](dataset_card) and [upload it to the Hub](share).
Congratulations, you can now load your dataset from the Hub! 🥳
```py
>>> from datasets import load_dataset
>>> load_dataset("<username>/my_dataset")
```
## Advanced features
### Sharding
If your dataset is made of many big files, 🤗 Datasets automatically runs your script in parallel to make it super fast!
It can help if you have hundreds or thousands of TAR archives, or JSONL files like [oscar](https://huggingface.co/datasets/oscar/blob/main/oscar.py) for example.
To make it work, we consider lists of files in `gen_kwargs` to be shards.
Therefore 🤗 Datasets can automatically spawn several workers to run `_generate_examples` in parallel, and each worker is given a subset of shards to process.
```python
class MyShardedDataset(datasets.GeneratorBasedBuilder):
def _split_generators(self, dl_manager: datasets.DownloadManager) -> List[datasets.SplitGenerator]:
downloaded_files = dl_manager.download([f"data/shard_{i}.jsonl" for i in range(1024)])
return [
datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"filepaths": downloaded_files}),
]
def _generate_examples(self, filepaths):
# Each worker can be given a slice of the original `filepaths` list defined in the `gen_kwargs`
# so that this code can run in parallel on several shards at the same time
for filepath in filepaths:
...
```
Users can also specify `num_proc=` in `load_dataset()` to specify the number of processes to use as workers.
### ArrowBasedBuilder
For some datasets it can be much faster to yield batches of data rather than examples one by one.
You can speed up the dataset generation by yielding Arrow tables directly, instead of examples.
This is especially useful if your data comes from Pandas DataFrames for example, since the conversion from Pandas to Arrow is as simple as:
```python
import pyarrow as pa
pa_table = pa.Table.from_pandas(df)
```
To yield Arrow tables instead of single examples, make your dataset builder inherit from [`ArrowBasedBuilder`] instead of [`GeneratorBasedBuilder`], and use `_generate_tables` instead of `_generate_examples`:
```python
class MySuperFastDataset(datasets.ArrowBasedBuilder):
def _generate_tables(self, filepaths):
idx = 0
for filepath in filepaths:
...
yield idx, pa_table
idx += 1
```
Don't forget to keep your script memory efficient, in case users run them on machines with a low amount of RAM.
| huggingface/datasets/blob/main/docs/source/dataset_script.mdx |
--
title: "Llama 2 is here - get it on Hugging Face"
thumbnail: /blog/assets/llama2/thumbnail.jpg
authors:
- user: philschmid
- user: osanseviero
- user: pcuenq
- user: lewtun
---
# Llama 2 is here - get it on Hugging Face
## Introduction
Llama 2 is a family of state-of-the-art open-access large language models released by Meta today, and we’re excited to fully support the launch with comprehensive integration in Hugging Face. Llama 2 is being released with a very permissive community license and is available for commercial use. The code, pretrained models, and fine-tuned models are all being released today 🔥
We’ve collaborated with Meta to ensure smooth integration into the Hugging Face ecosystem. You can find the 12 open-access models (3 base models & 3 fine-tuned ones with the original Meta checkpoints, plus their corresponding `transformers` models) on the Hub. Among the features and integrations being released, we have:
- [Models on the Hub](https://huggingface.co/meta-llama) with their model cards and license.
- [Transformers integration](https://github.com/huggingface/transformers/releases/tag/v4.31.0)
- Examples to fine-tune the small variants of the model with a single GPU
- Integration with [Text Generation Inference](https://github.com/huggingface/text-generation-inference) for fast and efficient production-ready inference
- Integration with Inference Endpoints
## Table of Contents
- [Why Llama 2?](#why-llama-2)
- [Demo](#demo)
- [Inference](#inference)
- [With Transformers](#using-transformers)
- [With Inference Endpoints](#using-text-generation-inference-and-inference-endpoints)
- [Fine-tuning with PEFT](#fine-tuning-with-peft)
- [How to Prompt Llama 2](#how-to-prompt-llama-2)
- [Additional Resources](#additional-resources)
- [Conclusion](#conclusion)
## Why Llama 2?
The Llama 2 release introduces a family of pretrained and fine-tuned LLMs, ranging in scale from 7B to 70B parameters (7B, 13B, 70B). The pretrained models come with significant improvements over the Llama 1 models, including being trained on 40% more tokens, having a much longer context length (4k tokens 🤯), and using grouped-query attention for fast inference of the 70B model🔥!
However, the most exciting part of this release is the fine-tuned models (Llama 2-Chat), which have been optimized for dialogue applications using [Reinforcement Learning from Human Feedback (RLHF)](https://huggingface.co/blog/rlhf). Across a wide range of helpfulness and safety benchmarks, the Llama 2-Chat models perform better than most open models and achieve comparable performance to ChatGPT according to human evaluations. You can read the paper [here](https://huggingface.co/papers/2307.09288).
_image from [Llama 2: Open Foundation and Fine-Tuned Chat Models](https://scontent-fra3-2.xx.fbcdn.net/v/t39.2365-6/10000000_6495670187160042_4742060979571156424_n.pdf?_nc_cat=104&ccb=1-7&_nc_sid=3c67a6&_nc_ohc=GK8Rh1tm_4IAX8b5yo4&_nc_ht=scontent-fra3-2.xx&oh=00_AfDtg_PRrV6tpy9UmiikeMRuQgk6Rej7bCPOkXZQVmUKAg&oe=64BBD830)_
If you’ve been waiting for an open alternative to closed-source chatbots, Llama 2-Chat is likely your best choice today!
| Model | License | Commercial use? | Pretraining length [tokens] | Leaderboard score |
| --- | --- | --- | --- | --- |
| [Falcon-7B](https://huggingface.co/tiiuae/falcon-7b) | Apache 2.0 | ✅ | 1,500B | 47.01 |
| [MPT-7B](https://huggingface.co/mosaicml/mpt-7b) | Apache 2.0 | ✅ | 1,000B | 48.7 |
| Llama-7B | Llama license | ❌ | 1,000B | 49.71 |
| [Llama-2-7B](https://huggingface.co/meta-llama/Llama-2-7b-hf) | Llama 2 license | ✅ | 2,000B | 54.32 |
| Llama-33B | Llama license | ❌ | 1,500B | * |
| [Llama-2-13B](https://huggingface.co/meta-llama/Llama-2-13b-hf) | Llama 2 license | ✅ | 2,000B | 58.67 |
| [mpt-30B](https://huggingface.co/mosaicml/mpt-30b) | Apache 2.0 | ✅ | 1,000B | 55.7 |
| [Falcon-40B](https://huggingface.co/tiiuae/falcon-40b) | Apache 2.0 | ✅ | 1,000B | 61.5 |
| Llama-65B | Llama license | ❌ | 1,500B | 62.1 |
| [Llama-2-70B](https://huggingface.co/meta-llama/Llama-2-70b-hf) | Llama 2 license | ✅ | 2,000B | * |
| [Llama-2-70B-chat](https://huggingface.co/meta-llama/Llama-2-70b-chat-hf)* | Llama 2 license | ✅ | 2,000B | 66.8 |
*we’re currently running evaluation of the Llama 2 70B (non chatty version). This table will be updated with the results.
## Demo
You can easily try the Big Llama 2 Model (70 billion parameters!) in [this Space](https://huggingface.co/spaces/ysharma/Explore_llamav2_with_TGI) or in the playground embedded below:
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.37.0/gradio.js"> </script>
<gradio-app theme_mode="light" space="ysharma/Explore_llamav2_with_TGI"></gradio-app>
Under the hood, this playground uses Hugging Face's [Text Generation Inference](https://github.com/huggingface/text-generation-inference), the same technology that powers [HuggingChat](https://huggingface.co/chat/), and which we'll share more in the following sections.
## Inference
In this section, we’ll go through different approaches to running inference of the Llama2 models. Before using these models, make sure you have requested access to one of the models in the official [Meta Llama 2](https://huggingface.co/meta-llama) repositories.
**Note: Make sure to also fill the official Meta form. Users are provided access to the repository once both forms are filled after few hours.**
### Using transformers
With transformers [release 4.31](https://github.com/huggingface/transformers/releases/tag/v4.31.0), one can already use Llama 2 and leverage all the tools within the HF ecosystem, such as:
- training and inference scripts and examples
- safe file format (`safetensors`)
- integrations with tools such as bitsandbytes (4-bit quantization) and PEFT (parameter efficient fine-tuning)
- utilities and helpers to run generation with the model
- mechanisms to export the models to deploy
Make sure to be using the latest `transformers` release and be logged into your Hugging Face account.
```
pip install transformers
huggingface-cli login
```
In the following code snippet, we show how to run inference with transformers. It runs on the free tier of Colab, as long as you select a GPU runtime.
```python
from transformers import AutoTokenizer
import transformers
import torch
model = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?\n',
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
```
```
Result: I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?
Answer:
Of course! If you enjoyed "Breaking Bad" and "Band of Brothers," here are some other TV shows you might enjoy:
1. "The Sopranos" - This HBO series is a crime drama that explores the life of a New Jersey mob boss, Tony Soprano, as he navigates the criminal underworld and deals with personal and family issues.
2. "The Wire" - This HBO series is a gritty and realistic portrayal of the drug trade in Baltimore, exploring the impact of drugs on individuals, communities, and the criminal justice system.
3. "Mad Men" - Set in the 1960s, this AMC series follows the lives of advertising executives on Madison Avenue, expl
```
And although the model has *only* 4k tokens of context, you can use techniques supported in `transformers` such as rotary position embedding scaling ([tweet](https://twitter.com/joao_gante/status/1679775399172251648)) to push it further!
### Using text-generation-inference and Inference Endpoints
**[Text Generation Inference](https://github.com/huggingface/text-generation-inference)** is a production-ready inference container developed by Hugging Face to enable easy deployment of large language models. It has features such as continuous batching, token streaming, tensor parallelism for fast inference on multiple GPUs, and production-ready logging and tracing.
You can try out Text Generation Inference on your own infrastructure, or you can use Hugging Face's **[Inference Endpoints](https://huggingface.co/inference-endpoints)**. To deploy a Llama 2 model, go to the **[model page](https://huggingface.co/meta-llama/Llama-2-7b-hf)** and click on the **[Deploy -> Inference Endpoints](https://ui.endpoints.huggingface.co/new?repository=meta-llama/Llama-2-7b-hf)** widget.
- For 7B models, we advise you to select "GPU [medium] - 1x Nvidia A10G".
- For 13B models, we advise you to select "GPU [xlarge] - 1x Nvidia A100".
- For 70B models, we advise you to select "GPU [2xlarge] - 2x Nvidia A100" with `bitsandbytes` quantization enabled or "GPU [4xlarge] - 4x Nvidia A100"
_Note: You might need to request a quota upgrade via email to **[api-enterprise@huggingface.co](mailto:api-enterprise@huggingface.co)** to access A100s_
You can learn more on how to [Deploy LLMs with Hugging Face Inference Endpoints in our blog](https://huggingface.co/blog/inference-endpoints-llm). The [blog](https://huggingface.co/blog/inference-endpoints-llm) includes information about supported hyperparameters and how to stream your response using Python and Javascript.
## Fine-tuning with PEFT
Training LLMs can be technically and computationally challenging. In this section, we look at the tools available in the Hugging Face ecosystem to efficiently train Llama 2 on simple hardware and show how to fine-tune the 7B version of Llama 2 on a single NVIDIA T4 (16GB - Google Colab). You can learn more about it in the [Making LLMs even more accessible blog](https://huggingface.co/blog/4bit-transformers-bitsandbytes).
We created a [script](https://github.com/lvwerra/trl/blob/main/examples/scripts/sft_trainer.py) to instruction-tune Llama 2 using QLoRA and the [`SFTTrainer`](https://huggingface.co/docs/trl/v0.4.7/en/sft_trainer) from [`trl`](https://github.com/lvwerra/trl).
An example command for fine-tuning Llama 2 7B on the `timdettmers/openassistant-guanaco` can be found below. The script can merge the LoRA weights into the model weights and save them as `safetensor` weights by providing the `merge_and_push` argument. This allows us to deploy our fine-tuned model after training using text-generation-inference and inference endpoints.
First pip install `trl` and clone the script:
```bash
pip install trl
git clone https://github.com/lvwerra/trl
```
Then you can run the script:
```bash
python trl/examples/scripts/sft_trainer.py \
--model_name meta-llama/Llama-2-7b-hf \
--dataset_name timdettmers/openassistant-guanaco \
--load_in_4bit \
--use_peft \
--batch_size 4 \
--gradient_accumulation_steps 2
```
## How to Prompt Llama 2
One of the unsung advantages of open-access models is that you have full control over the `system` prompt in chat applications. This is essential to specify the behavior of your chat assistant –and even imbue it with some personality–, but it's unreachable in models served behind APIs.
We're adding this section just a few days after the initial release of Llama 2, as we've had many questions from the community about how to prompt the models and how to change the system prompt. We hope this helps!
The prompt template for the first turn looks like this:
```
<s>[INST] <<SYS>>
{{ system_prompt }}
<</SYS>>
{{ user_message }} [/INST]
```
This template follows the model's training procedure, as described in [the Llama 2 paper](https://huggingface.co/papers/2307.09288). We can use any `system_prompt` we want, but it's crucial that the format matches the one used during training.
To spell it out in full clarity, this is what is actually sent to the language model when the user enters some text (`There's a llama in my garden 😱 What should I do?`) in [our 13B chat demo](https://huggingface.co/spaces/huggingface-projects/llama-2-13b-chat) to initiate a chat:
```b
<s>[INST] <<SYS>>
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
<</SYS>>
There's a llama in my garden 😱 What should I do? [/INST]
```
As you can see, the instructions between the special `<<SYS>>` tokens provide context for the model so it knows how we expect it to respond. This works because exactly the same format was used during training with a wide variety of system prompts intended for different tasks.
As the conversation progresses, _all_ the interactions between the human and the "bot" are appended to the previous prompt, enclosed between `[INST]` delimiters. The template used during multi-turn conversations follows this structure (🎩 h/t [Arthur Zucker](https://huggingface.co/ArthurZ) for some final clarifications):
```b
<s>[INST] <<SYS>>
{{ system_prompt }}
<</SYS>>
{{ user_msg_1 }} [/INST] {{ model_answer_1 }} </s><s>[INST] {{ user_msg_2 }} [/INST]
```
The model is stateless and does not "remember" previous fragments of the conversation, we must always supply it with all the context so the conversation can continue. This is the reason why **context length** is a very important parameter to maximize, as it allows for longer conversations and larger amounts of information to be used.
### Ignore previous instructions
In API-based models, people resort to tricks in an attempt to override the system prompt and change the default model behaviour. As imaginative as these solutions are, this is not necessary in open-access models: anyone can use a different prompt, as long as it follows the format described above. We believe that this will be an important tool for researchers to study the impact of prompts on both desired and unwanted characteristics. For example, when people [are surprised with absurdly cautious generations](https://twitter.com/lauraruis/status/1681612002718887936), you can explore whether maybe [a different prompt would work](https://twitter.com/overlordayn/status/1681631554672513025). (🎩 h/t [Clémentine Fourrier](https://huggingface.co/clefourrier) for the links to this example).
In our [`13B`](https://huggingface.co/spaces/huggingface-projects/llama-2-13b-chat) and [`7B`](https://huggingface.co/spaces/huggingface-projects/llama-2-7b-chat) demos, you can easily explore this feature by disclosing the "Advanced Options" UI and simply writing your desired instructions. You can also duplicate those demos and use them privately for fun or research!
## Additional Resources
- [Paper Page](https://huggingface.co/papers/2307.09288)
- [Models on the Hub](https://huggingface.co/meta-llama)
- [Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
- [Meta Examples and recipes for Llama model](https://github.com/facebookresearch/llama-recipes/tree/main)
- [Chat demo (7B)](https://huggingface.co/spaces/huggingface-projects/llama-2-7b-chat)
- [Chat demo (13B)](https://huggingface.co/spaces/huggingface-projects/llama-2-13b-chat)
- [Chat demo (70B) on TGI](https://huggingface.co/spaces/ysharma/Explore_llamav2_with_TGI)
## Conclusion
We're very excited about Llama 2 being out! In the incoming days, be ready to learn more about ways to run your own fine-tuning, execute the smallest models on-device, and many other exciting updates we're prepating for you!
| huggingface/blog/blob/main/llama2.md |
Security Policy
## Reporting a Vulnerability
If you discover a security vulnerability, we would be very grateful if you could email us at team@gradio.app. This is the preferred approach instead of opening a public issue. We take all vulnerability reports seriously, and will work to patch the vulnerability immediately. Whenever possible, we will credit the person or people who report the security vulnerabilities after it has been patched.
| gradio-app/gradio/blob/main/SECURITY.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
<p align="center">
<br>
<img src="https://raw.githubusercontent.com/huggingface/diffusers/77aadfee6a891ab9fcfb780f87c693f7a5beeb8e/docs/source/imgs/diffusers_library.jpg" width="400"/>
<br>
</p>
# Diffusers
🤗 Diffusers is the go-to library for state-of-the-art pretrained diffusion models for generating images, audio, and even 3D structures of molecules. Whether you're looking for a simple inference solution or want to train your own diffusion model, 🤗 Diffusers is a modular toolbox that supports both. Our library is designed with a focus on [usability over performance](conceptual/philosophy#usability-over-performance), [simple over easy](conceptual/philosophy#simple-over-easy), and [customizability over abstractions](conceptual/philosophy#tweakable-contributorfriendly-over-abstraction).
The library has three main components:
- State-of-the-art diffusion pipelines for inference with just a few lines of code. There are many pipelines in 🤗 Diffusers, check out the table in the pipeline [overview](api/pipelines/overview) for a complete list of available pipelines and the task they solve.
- Interchangeable [noise schedulers](api/schedulers/overview) for balancing trade-offs between generation speed and quality.
- Pretrained [models](api/models) that can be used as building blocks, and combined with schedulers, for creating your own end-to-end diffusion systems.
<div class="mt-10">
<div class="w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-2 md:gap-y-4 md:gap-x-5">
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./tutorials/tutorial_overview"
><div class="w-full text-center bg-gradient-to-br from-blue-400 to-blue-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">Tutorials</div>
<p class="text-gray-700">Learn the fundamental skills you need to start generating outputs, build your own diffusion system, and train a diffusion model. We recommend starting here if you're using 🤗 Diffusers for the first time!</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./using-diffusers/loading_overview"
><div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">How-to guides</div>
<p class="text-gray-700">Practical guides for helping you load pipelines, models, and schedulers. You'll also learn how to use pipelines for specific tasks, control how outputs are generated, optimize for inference speed, and different training techniques.</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./conceptual/philosophy"
><div class="w-full text-center bg-gradient-to-br from-pink-400 to-pink-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">Conceptual guides</div>
<p class="text-gray-700">Understand why the library was designed the way it was, and learn more about the ethical guidelines and safety implementations for using the library.</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./api/models/overview"
><div class="w-full text-center bg-gradient-to-br from-purple-400 to-purple-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">Reference</div>
<p class="text-gray-700">Technical descriptions of how 🤗 Diffusers classes and methods work.</p>
</a>
</div>
</div>
| huggingface/diffusers/blob/main/docs/source/en/index.md |
`tokenizers-android-arm-eabi`
This is the **armv7-linux-androideabi** binary for `tokenizers`
| huggingface/tokenizers/blob/main/bindings/node/npm/android-arm-eabi/README.md |
Configuring Your Custom Component
The custom components workflow focuses on [convention over configuration](https://en.wikipedia.org/wiki/Convention_over_configuration) to reduce the number of decisions you as a developer need to make when developing your custom component.
That being said, you can still configure some aspects of the custom component package and directory.
This guide will cover how.
## The Package Name
By default, all custom component packages are called `gradio_<component-name>` where `component-name` is the name of the component's python class in lowercase.
As an example, let's walkthrough changing the name of a component from `gradio_mytextbox` to `supertextbox`.
1. Modify the `name` in the `pyproject.toml` file.
```bash
[project]
name = "supertextbox"
```
2. Change all occurrences of `gradio_<component-name>` in `pyproject.toml` to `<component-name>`
```bash
[tool.hatch.build]
artifacts = ["/backend/supertextbox/templates", "*.pyi"]
[tool.hatch.build.targets.wheel]
packages = ["/backend/supertextbox"]
```
3. Rename the `gradio_<component-name>` directory in `backend/` to `<component-name>`
```bash
mv backend/gradio_mytextbox backend/supertextbox
```
Tip: Remember to change the import statement in `demo/app.py`!
## Top Level Python Exports
By default, only the custom component python class is a top level export.
This means that when users type `from gradio_<component-name> import ...`, the only class that will be available is the custom component class.
To add more classes as top level exports, modify the `__all__` property in `__init__.py`
```python
from .mytextbox import MyTextbox
from .mytextbox import AdditionalClass, additional_function
__all__ = ['MyTextbox', 'AdditionalClass', 'additional_function']
```
## Python Dependencies
You can add python dependencies by modifying the `dependencies` key in `pyproject.toml`
```bash
dependencies = ["gradio", "numpy", "PIL"]
```
Tip: Remember to run `gradio cc install` when you add dependencies!
## Javascript Dependencies
You can add JavaScript dependencies by modifying the `"dependencies"` key in `frontend/package.json`
```json
"dependencies": {
"@gradio/atoms": "0.2.0-beta.4",
"@gradio/statustracker": "0.3.0-beta.6",
"@gradio/utils": "0.2.0-beta.4",
"your-npm-package": "<version>"
}
```
## Directory Structure
By default, the CLI will place the Python code in `backend` and the JavaScript code in `frontend`.
It is not recommended to change this structure since it makes it easy for a potential contributor to look at your source code and know where everything is.
However, if you did want to this is what you would have to do:
1. Place the Python code in the subdirectory of your choosing. Remember to modify the `[tool.hatch.build]` `[tool.hatch.build.targets.wheel]` in the `pyproject.toml` to match!
2. Place the JavaScript code in the subdirectory of your choosing.
2. Add the `FRONTEND_DIR` property on the component python class. It must be the relative path from the file where the class is defined to the location of the JavaScript directory.
```python
class SuperTextbox(Component):
FRONTEND_DIR = "../../frontend/"
```
The JavaScript and Python directories must be under the same common directory!
## Conclusion
Sticking to the defaults will make it easy for others to understand and contribute to your custom component.
After all, the beauty of open source is that anyone can help improve your code!
But if you ever need to deviate from the defaults, you know how! | gradio-app/gradio/blob/main/guides/05_custom-components/03_configuration.md |
--
title: GLUE
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
GLUE, the General Language Understanding Evaluation benchmark
(https://gluebenchmark.com/) is a collection of resources for training,
evaluating, and analyzing natural language understanding systems.
---
# Metric Card for GLUE
## Metric description
This metric is used to compute the GLUE evaluation metric associated to each [GLUE dataset](https://huggingface.co/datasets/glue).
GLUE, the General Language Understanding Evaluation benchmark is a collection of resources for training, evaluating, and analyzing natural language understanding systems.
## How to use
There are two steps: (1) loading the GLUE metric relevant to the subset of the GLUE dataset being used for evaluation; and (2) calculating the metric.
1. **Loading the relevant GLUE metric** : the subsets of GLUE are the following: `sst2`, `mnli`, `mnli_mismatched`, `mnli_matched`, `qnli`, `rte`, `wnli`, `cola`,`stsb`, `mrpc`, `qqp`, and `hans`.
More information about the different subsets of the GLUE dataset can be found on the [GLUE dataset page](https://huggingface.co/datasets/glue).
2. **Calculating the metric**: the metric takes two inputs : one list with the predictions of the model to score and one lists of references for each translation.
```python
from evaluate import load
glue_metric = load('glue', 'sst2')
references = [0, 1]
predictions = [0, 1]
results = glue_metric.compute(predictions=predictions, references=references)
```
## Output values
The output of the metric depends on the GLUE subset chosen, consisting of a dictionary that contains one or several of the following metrics:
`accuracy`: the proportion of correct predictions among the total number of cases processed, with a range between 0 and 1 (see [accuracy](https://huggingface.co/metrics/accuracy) for more information).
`f1`: the harmonic mean of the precision and recall (see [F1 score](https://huggingface.co/metrics/f1) for more information). Its range is 0-1 -- its lowest possible value is 0, if either the precision or the recall is 0, and its highest possible value is 1.0, which means perfect precision and recall.
`pearson`: a measure of the linear relationship between two datasets (see [Pearson correlation](https://huggingface.co/metrics/pearsonr) for more information). Its range is between -1 and +1, with 0 implying no correlation, and -1/+1 implying an exact linear relationship. Positive correlations imply that as x increases, so does y, whereas negative correlations imply that as x increases, y decreases.
`spearmanr`: a nonparametric measure of the monotonicity of the relationship between two datasets(see [Spearman Correlation](https://huggingface.co/metrics/spearmanr) for more information). `spearmanr` has the same range as `pearson`.
`matthews_correlation`: a measure of the quality of binary and multiclass classifications (see [Matthews Correlation](https://huggingface.co/metrics/matthews_correlation) for more information). Its range of values is between -1 and +1, where a coefficient of +1 represents a perfect prediction, 0 an average random prediction and -1 an inverse prediction.
The `cola` subset returns `matthews_correlation`, the `stsb` subset returns `pearson` and `spearmanr`, the `mrpc` and `qqp` subsets return both `accuracy` and `f1`, and all other subsets of GLUE return only accuracy.
### Values from popular papers
The [original GLUE paper](https://huggingface.co/datasets/glue) reported average scores ranging from 58 to 64%, depending on the model used (with all evaluation values scaled by 100 to make computing the average possible).
For more recent model performance, see the [dataset leaderboard](https://paperswithcode.com/dataset/glue).
## Examples
Maximal values for the MRPC subset (which outputs `accuracy` and `f1`):
```python
from evaluate import load
glue_metric = load('glue', 'mrpc') # 'mrpc' or 'qqp'
references = [0, 1]
predictions = [0, 1]
results = glue_metric.compute(predictions=predictions, references=references)
print(results)
{'accuracy': 1.0, 'f1': 1.0}
```
Minimal values for the STSB subset (which outputs `pearson` and `spearmanr`):
```python
from evaluate import load
glue_metric = load('glue', 'stsb')
references = [0., 1., 2., 3., 4., 5.]
predictions = [-10., -11., -12., -13., -14., -15.]
results = glue_metric.compute(predictions=predictions, references=references)
print(results)
{'pearson': -1.0, 'spearmanr': -1.0}
```
Partial match for the COLA subset (which outputs `matthews_correlation`)
```python
from evaluate import load
glue_metric = load('glue', 'cola')
references = [0, 1]
predictions = [1, 1]
results = glue_metric.compute(predictions=predictions, references=references)
results
{'matthews_correlation': 0.0}
```
## Limitations and bias
This metric works only with datasets that have the same format as the [GLUE dataset](https://huggingface.co/datasets/glue).
While the GLUE dataset is meant to represent "General Language Understanding", the tasks represented in it are not necessarily representative of language understanding, and should not be interpreted as such.
Also, while the GLUE subtasks were considered challenging during its creation in 2019, they are no longer considered as such given the impressive progress made since then. A more complex (or "stickier") version of it, called [SuperGLUE](https://huggingface.co/datasets/super_glue), was subsequently created.
## Citation
```bibtex
@inproceedings{wang2019glue,
title={{GLUE}: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding},
author={Wang, Alex and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel R.},
note={In the Proceedings of ICLR.},
year={2019}
}
```
## Further References
- [GLUE benchmark homepage](https://gluebenchmark.com/)
- [Fine-tuning a model with the Trainer API](https://huggingface.co/course/chapter3/3?)
| huggingface/evaluate/blob/main/metrics/glue/README.md |
Gradio Demo: blocks_gpt
```
!pip install -q gradio
```
```
import gradio as gr
api = gr.load("huggingface/gpt2-xl")
def complete_with_gpt(text):
# Use the last 50 characters of the text as context
return text[:-50] + api(text[-50:])
with gr.Blocks() as demo:
textbox = gr.Textbox(placeholder="Type here and press enter...", lines=4)
btn = gr.Button("Generate")
btn.click(complete_with_gpt, textbox, textbox)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/blocks_gpt/run.ipynb |
--
title: "Introducing The World's Largest Open Multilingual Language Model: BLOOM"
thumbnail: /blog/assets/86_bloom/thumbnail.png
authors:
- user: bigscience
---
# 🌸 Introducing The World's Largest Open Multilingual Language Model: BLOOM 🌸
<a href="https://huggingface.co/bigscience/bloom"><img style="middle" width="950" src="/blog/assets/86_bloom/thumbnail-2.png"></a>
Large language models (LLMs) have made a significant impact on AI research. These powerful, general models can take on a wide variety of new language tasks from a user’s instructions. However, academia, nonprofits and smaller companies' research labs find it difficult to create, study, or even use LLMs as only a few industrial labs with the necessary resources and exclusive rights can fully access them. Today, we release [BLOOM](https://huggingface.co/bigscience/bloom), the first multilingual LLM trained in complete transparency, to change this status quo — the result of the largest collaboration of AI researchers ever involved in a single research project.
With its 176 billion parameters, BLOOM is able to generate text in 46 natural languages and 13 programming languages. For almost all of them, such as Spanish, French and Arabic, BLOOM will be the first language model with over 100B parameters ever created. This is the culmination of a year of work involving over 1000 researchers from 70+ countries and 250+ institutions, leading to a final run of 117 days (March 11 - July 6) training the BLOOM model on the [Jean Zay supercomputer](http://www.idris.fr/eng/info/missions-eng.html) in the south of Paris, France thanks to a compute grant worth an estimated €3M from French research agencies CNRS and GENCI.
Researchers can [now download, run and study BLOOM](https://huggingface.co/bigscience/bloom) to investigate the performance and behavior of recently developed large language models down to their deepest internal operations. More generally, any individual or institution who agrees to the terms of the model’s [Responsible AI License](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) (developed during the BigScience project itself) can use and build upon the model on a local machine or on a cloud provider. In this spirit of collaboration and continuous improvement, we’re also releasing, for the first time, the intermediary checkpoints and optimizer states of the training. Don’t have 8 A100s to play with? An inference API, currently backed by Google’s TPU cloud and a FLAX version of the model, also allows quick tests, prototyping, and lower-scale use. You can already play with it on the Hugging Face Hub.
<img class="mx-auto" style="center" width="950" src="/blog/assets/86_bloom/bloom-examples.jpg"></a>
This is only the beginning. BLOOM’s capabilities will continue to improve as the workshop continues to experiment and tinker with the model. We’ve started work to make it instructable as our earlier effort T0++ was and are slated to add more languages, compress the model into a more usable version with the same level of performance, and use it as a starting point for more complex architectures… All of the experiments researchers and practitioners have always wanted to run, starting with the power of a 100+ billion parameter model, are now possible. BLOOM is the seed of a living family of models that we intend to grow, not just a one-and-done model, and we’re ready to support community efforts to expand it.
| huggingface/blog/blob/main/bloom.md |
Latent Consistency Distillation Example:
[Latent Consistency Models (LCMs)](https://arxiv.org/abs/2310.04378) is a method to distill a latent diffusion model to enable swift inference with minimal steps. This example demonstrates how to use latent consistency distillation to distill stable-diffusion-v1.5 for inference with few timesteps.
## Full model distillation
### Running locally with PyTorch
#### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install -e .
```
Then cd in the example folder and run
```bash
pip install -r requirements.txt
```
And initialize an [🤗 Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
Or for a default accelerate configuration without answering questions about your environment
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell e.g. a notebook
```python
from accelerate.utils import write_basic_config
write_basic_config()
```
When running `accelerate config`, if we specify torch compile mode to True there can be dramatic speedups.
#### Example
The following uses the [Conceptual Captions 12M (CC12M) dataset](https://github.com/google-research-datasets/conceptual-12m) as an example, and for illustrative purposes only. For best results you may consider large and high-quality text-image datasets such as [LAION](https://laion.ai/blog/laion-400-open-dataset/). You may also need to search the hyperparameter space according to the dataset you use.
```bash
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="path/to/saved/model"
accelerate launch train_lcm_distill_sd_wds.py \
--pretrained_teacher_model=$MODEL_NAME \
--output_dir=$OUTPUT_DIR \
--mixed_precision=fp16 \
--resolution=512 \
--learning_rate=1e-6 --loss_type="huber" --ema_decay=0.95 --adam_weight_decay=0.0 \
--max_train_steps=1000 \
--max_train_samples=4000000 \
--dataloader_num_workers=8 \
--train_shards_path_or_url="pipe:curl -L -s https://huggingface.co/datasets/laion/conceptual-captions-12m-webdataset/resolve/main/data/{00000..01099}.tar?download=true" \
--validation_steps=200 \
--checkpointing_steps=200 --checkpoints_total_limit=10 \
--train_batch_size=12 \
--gradient_checkpointing --enable_xformers_memory_efficient_attention \
--gradient_accumulation_steps=1 \
--use_8bit_adam \
--resume_from_checkpoint=latest \
--report_to=wandb \
--seed=453645634 \
--push_to_hub
```
## LCM-LoRA
Instead of fine-tuning the full model, we can also just train a LoRA that can be injected into any SDXL model.
### Example
The following uses the [Conceptual Captions 12M (CC12M) dataset](https://github.com/google-research-datasets/conceptual-12m) as an example. For best results you may consider large and high-quality text-image datasets such as [LAION](https://laion.ai/blog/laion-400-open-dataset/).
```bash
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="path/to/saved/model"
accelerate launch train_lcm_distill_lora_sd_wds.py \
--pretrained_teacher_model=$MODEL_NAME \
--output_dir=$OUTPUT_DIR \
--mixed_precision=fp16 \
--resolution=512 \
--lora_rank=64 \
--learning_rate=1e-6 --loss_type="huber" --adam_weight_decay=0.0 \
--max_train_steps=1000 \
--max_train_samples=4000000 \
--dataloader_num_workers=8 \
--train_shards_path_or_url="pipe:curl -L -s https://huggingface.co/datasets/laion/conceptual-captions-12m-webdataset/resolve/main/data/{00000..01099}.tar?download=true" \
--validation_steps=200 \
--checkpointing_steps=200 --checkpoints_total_limit=10 \
--train_batch_size=12 \
--gradient_checkpointing --enable_xformers_memory_efficient_attention \
--gradient_accumulation_steps=1 \
--use_8bit_adam \
--resume_from_checkpoint=latest \
--report_to=wandb \
--seed=453645634 \
--push_to_hub \
``` | huggingface/diffusers/blob/main/examples/consistency_distillation/README.md |
imple image segmentation using gradio's AnnotatedImage component. | gradio-app/gradio/blob/main/demo/image_segmentation/DESCRIPTION.md |
Conclusion [[conclusion]]
Congrats on finishing this unit and the tutorial. You've just trained your first virtual robots 🥳.
**Take time to grasp the material before continuing**. You can also look at the additional reading materials we provided in the *additional reading* section.
Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then please 👉 [fill out this form](https://forms.gle/BzKXWzLAGZESGNaE9)
See you in next unit!
### Keep learning, stay awesome 🤗
| huggingface/deep-rl-class/blob/main/units/en/unit6/conclusion.mdx |
Scikit-Learn
To run the scikit-learn examples make sure you have installed the following library:
```bash
pip install -U scikit-learn
```
The metrics in `evaluate` can be easily integrated with an Scikit-Learn estimator or [pipeline](https://scikit-learn.org/stable/modules/generated/sklearn.pipeline.Pipeline.html#sklearn.pipeline.Pipeline).
However, these metrics require that we generate the predictions from the model. The predictions and labels from the estimators can be passed to `evaluate` mertics to compute the required values.
```python
import numpy as np
np.random.seed(0)
import evaluate
from sklearn.compose import ColumnTransformer
from sklearn.datasets import fetch_openml
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
```
Load data from https://www.openml.org/d/40945:
```python
X, y = fetch_openml("titanic", version=1, as_frame=True, return_X_y=True)
```
Alternatively X and y can be obtained directly from the frame attribute:
```python
X = titanic.frame.drop('survived', axis=1)
y = titanic.frame['survived']
```
We create the preprocessing pipelines for both numeric and categorical data. Note that pclass could either be treated as a categorical or numeric feature.
```python
numeric_features = ["age", "fare"]
numeric_transformer = Pipeline(
steps=[("imputer", SimpleImputer(strategy="median")), ("scaler", StandardScaler())]
)
categorical_features = ["embarked", "sex", "pclass"]
categorical_transformer = OneHotEncoder(handle_unknown="ignore")
preprocessor = ColumnTransformer(
transformers=[
("num", numeric_transformer, numeric_features),
("cat", categorical_transformer, categorical_features),
]
)
```
Append classifier to preprocessing pipeline. Now we have a full prediction pipeline.
```python
clf = Pipeline(
steps=[("preprocessor", preprocessor), ("classifier", LogisticRegression())]
)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
```
As `Evaluate` metrics use lists as inputs for references and predictions, we need to convert them to Python lists.
```python
# Evaluate metrics accept lists as inputs for values of references and predictions
y_test = y_test.tolist()
y_pred = y_pred.tolist()
# Accuracy
accuracy_metric = evaluate.load("accuracy")
accuracy = accuracy_metric.compute(references=y_test, predictions=y_pred)
print("Accuracy:", accuracy)
# Accuracy: 0.79
```
You can use any suitable `evaluate` metric with the estimators as long as they are compatible with the task and predictions.
| huggingface/evaluate/blob/main/docs/source/sklearn_integrations.mdx |
(Legacy) SE-ResNet
**SE ResNet** is a variant of a [ResNet](https://www.paperswithcode.com/method/resnet) that employs [squeeze-and-excitation blocks](https://paperswithcode.com/method/squeeze-and-excitation-block) to enable the network to perform dynamic channel-wise feature recalibration.
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('legacy_seresnet101', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `legacy_seresnet101`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('legacy_seresnet101', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{hu2019squeezeandexcitation,
title={Squeeze-and-Excitation Networks},
author={Jie Hu and Li Shen and Samuel Albanie and Gang Sun and Enhua Wu},
year={2019},
eprint={1709.01507},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: Legacy SE ResNet
Paper:
Title: Squeeze-and-Excitation Networks
URL: https://paperswithcode.com/paper/squeeze-and-excitation-networks
Models:
- Name: legacy_seresnet101
In Collection: Legacy SE ResNet
Metadata:
FLOPs: 9762614000
Parameters: 49330000
File Size: 197822624
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: legacy_seresnet101
LR: 0.6
Epochs: 100
Layers: 101
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/senet.py#L426
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-cadene/se_resnet101-7e38fcc6.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.38%
Top 5 Accuracy: 94.26%
- Name: legacy_seresnet152
In Collection: Legacy SE ResNet
Metadata:
FLOPs: 14553578160
Parameters: 66819999
File Size: 268033864
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: legacy_seresnet152
LR: 0.6
Epochs: 100
Layers: 152
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/senet.py#L433
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-cadene/se_resnet152-d17c99b7.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.67%
Top 5 Accuracy: 94.38%
- Name: legacy_seresnet18
In Collection: Legacy SE ResNet
Metadata:
FLOPs: 2328876024
Parameters: 11780000
File Size: 47175663
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: legacy_seresnet18
LR: 0.6
Epochs: 100
Layers: 18
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/senet.py#L405
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/seresnet18-4bb0ce65.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 71.74%
Top 5 Accuracy: 90.34%
- Name: legacy_seresnet34
In Collection: Legacy SE ResNet
Metadata:
FLOPs: 4706201004
Parameters: 21960000
File Size: 87958697
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: legacy_seresnet34
LR: 0.6
Epochs: 100
Layers: 34
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/senet.py#L412
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/seresnet34-a4004e63.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 74.79%
Top 5 Accuracy: 92.13%
- Name: legacy_seresnet50
In Collection: Legacy SE ResNet
Metadata:
FLOPs: 4974351024
Parameters: 28090000
File Size: 112611220
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: legacy_seresnet50
LR: 0.6
Epochs: 100
Layers: 50
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Image Size: '224'
Interpolation: bilinear
Minibatch Size: 1024
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/senet.py#L419
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-cadene/se_resnet50-ce0d4300.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.64%
Top 5 Accuracy: 93.74%
--> | huggingface/pytorch-image-models/blob/main/docs/models/legacy-se-resnet.md |
Monte Carlo vs Temporal Difference Learning [[mc-vs-td]]
The last thing we need to discuss before diving into Q-Learning is the two learning strategies.
Remember that an RL agent **learns by interacting with its environment.** The idea is that **given the experience and the received reward, the agent will update its value function or policy.**
Monte Carlo and Temporal Difference Learning are two different **strategies on how to train our value function or our policy function.** Both of them **use experience to solve the RL problem.**
On one hand, Monte Carlo uses **an entire episode of experience before learning.** On the other hand, Temporal Difference uses **only a step ( \\(S_t, A_t, R_{t+1}, S_{t+1}\\) ) to learn.**
We'll explain both of them **using a value-based method example.**
## Monte Carlo: learning at the end of the episode [[monte-carlo]]
Monte Carlo waits until the end of the episode, calculates \\(G_t\\) (return) and uses it as **a target for updating \\(V(S_t)\\).**
So it requires a **complete episode of interaction before updating our value function.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/monte-carlo-approach.jpg" alt="Monte Carlo"/>
If we take an example:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/MC-2.jpg" alt="Monte Carlo"/>
- We always start the episode **at the same starting point.**
- **The agent takes actions using the policy**. For instance, using an Epsilon Greedy Strategy, a policy that alternates between exploration (random actions) and exploitation.
- We get **the reward and the next state.**
- We terminate the episode if the cat eats the mouse or if the mouse moves > 10 steps.
- At the end of the episode, **we have a list of State, Actions, Rewards, and Next States tuples**
For instance [[State tile 3 bottom, Go Left, +1, State tile 2 bottom], [State tile 2 bottom, Go Left, +0, State tile 1 bottom]...]
- **The agent will sum the total rewards \\(G_t\\)** (to see how well it did).
- It will then **update \\(V(s_t)\\) based on the formula**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/MC-3.jpg" alt="Monte Carlo"/>
- Then **start a new game with this new knowledge**
By running more and more episodes, **the agent will learn to play better and better.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/MC-3p.jpg" alt="Monte Carlo"/>
For instance, if we train a state-value function using Monte Carlo:
- We initialize our value function **so that it returns 0 value for each state**
- Our learning rate (lr) is 0.1 and our discount rate is 1 (= no discount)
- Our mouse **explores the environment and takes random actions**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/MC-4.jpg" alt="Monte Carlo"/>
- The mouse made more than 10 steps, so the episode ends .
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/MC-4p.jpg" alt="Monte Carlo"/>
- We have a list of state, action, rewards, next_state, **we need to calculate the return \\(G{t=0}\\)**
\\(G_t = R_{t+1} + R_{t+2} + R_{t+3} ...\\) (for simplicity, we don't discount the rewards)
\\(G_0 = R_{1} + R_{2} + R_{3}…\\)
\\(G_0 = 1 + 0 + 0 + 0 + 0 + 0 + 1 + 1 + 0 + 0\\)
\\(G_0 = 3\\)
- We can now compute the **new** \\(V(S_0)\\):
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/MC-5.jpg" alt="Monte Carlo"/>
\\(V(S_0) = V(S_0) + lr * [G_0 — V(S_0)]\\)
\\(V(S_0) = 0 + 0.1 * [3 – 0]\\)
\\(V(S_0) = 0.3\\)
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/MC-5p.jpg" alt="Monte Carlo"/>
## Temporal Difference Learning: learning at each step [[td-learning]]
**Temporal Difference, on the other hand, waits for only one interaction (one step) \\(S_{t+1}\\)** to form a TD target and update \\(V(S_t)\\) using \\(R_{t+1}\\) and \\( \gamma * V(S_{t+1})\\).
The idea with **TD is to update the \\(V(S_t)\\) at each step.**
But because we didn't experience an entire episode, we don't have \\(G_t\\) (expected return). Instead, **we estimate \\(G_t\\) by adding \\(R_{t+1}\\) and the discounted value of the next state.**
This is called bootstrapping. It's called this **because TD bases its update in part on an existing estimate \\(V(S_{t+1})\\) and not a complete sample \\(G_t\\).**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/TD-1.jpg" alt="Temporal Difference"/>
This method is called TD(0) or **one-step TD (update the value function after any individual step).**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/TD-1p.jpg" alt="Temporal Difference"/>
If we take the same example,
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/TD-2.jpg" alt="Temporal Difference"/>
- We initialize our value function so that it returns 0 value for each state.
- Our learning rate (lr) is 0.1, and our discount rate is 1 (no discount).
- Our mouse begins to explore the environment and takes a random action: **going to the left**
- It gets a reward \\(R_{t+1} = 1\\) since **it eats a piece of cheese**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/TD-2p.jpg" alt="Temporal Difference"/>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/TD-3.jpg" alt="Temporal Difference"/>
We can now update \\(V(S_0)\\):
New \\(V(S_0) = V(S_0) + lr * [R_1 + \gamma * V(S_1) - V(S_0)]\\)
New \\(V(S_0) = 0 + 0.1 * [1 + 1 * 0–0]\\)
New \\(V(S_0) = 0.1\\)
So we just updated our value function for State 0.
Now we **continue to interact with this environment with our updated value function.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/TD-3p.jpg" alt="Temporal Difference"/>
To summarize:
- With *Monte Carlo*, we update the value function from a complete episode, and so we **use the actual accurate discounted return of this episode.**
- With *TD Learning*, we update the value function from a step, and we replace \\(G_t\\), which we don't know, with **an estimated return called the TD target.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Summary.jpg" alt="Summary"/>
| huggingface/deep-rl-class/blob/main/units/en/unit2/mc-vs-td.mdx |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# MPNet
## Overview
The MPNet model was proposed in [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
MPNet adopts a novel pre-training method, named masked and permuted language modeling, to inherit the advantages of
masked language modeling and permuted language modeling for natural language understanding.
The abstract from the paper is the following:
*BERT adopts masked language modeling (MLM) for pre-training and is one of the most successful pre-training models.
Since BERT neglects dependency among predicted tokens, XLNet introduces permuted language modeling (PLM) for
pre-training to address this problem. However, XLNet does not leverage the full position information of a sentence and
thus suffers from position discrepancy between pre-training and fine-tuning. In this paper, we propose MPNet, a novel
pre-training method that inherits the advantages of BERT and XLNet and avoids their limitations. MPNet leverages the
dependency among predicted tokens through permuted language modeling (vs. MLM in BERT), and takes auxiliary position
information as input to make the model see a full sentence and thus reducing the position discrepancy (vs. PLM in
XLNet). We pre-train MPNet on a large-scale dataset (over 160GB text corpora) and fine-tune on a variety of
down-streaming tasks (GLUE, SQuAD, etc). Experimental results show that MPNet outperforms MLM and PLM by a large
margin, and achieves better results on these tasks compared with previous state-of-the-art pre-trained methods (e.g.,
BERT, XLNet, RoBERTa) under the same model setting.*
The original code can be found [here](https://github.com/microsoft/MPNet).
## Usage tips
MPNet doesn't have `token_type_ids`, you don't need to indicate which token belongs to which segment. Just
separate your segments with the separation token `tokenizer.sep_token` (or `[sep]`).
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## MPNetConfig
[[autodoc]] MPNetConfig
## MPNetTokenizer
[[autodoc]] MPNetTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## MPNetTokenizerFast
[[autodoc]] MPNetTokenizerFast
<frameworkcontent>
<pt>
## MPNetModel
[[autodoc]] MPNetModel
- forward
## MPNetForMaskedLM
[[autodoc]] MPNetForMaskedLM
- forward
## MPNetForSequenceClassification
[[autodoc]] MPNetForSequenceClassification
- forward
## MPNetForMultipleChoice
[[autodoc]] MPNetForMultipleChoice
- forward
## MPNetForTokenClassification
[[autodoc]] MPNetForTokenClassification
- forward
## MPNetForQuestionAnswering
[[autodoc]] MPNetForQuestionAnswering
- forward
</pt>
<tf>
## TFMPNetModel
[[autodoc]] TFMPNetModel
- call
## TFMPNetForMaskedLM
[[autodoc]] TFMPNetForMaskedLM
- call
## TFMPNetForSequenceClassification
[[autodoc]] TFMPNetForSequenceClassification
- call
## TFMPNetForMultipleChoice
[[autodoc]] TFMPNetForMultipleChoice
- call
## TFMPNetForTokenClassification
[[autodoc]] TFMPNetForTokenClassification
- call
## TFMPNetForQuestionAnswering
[[autodoc]] TFMPNetForQuestionAnswering
- call
</tf>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/mpnet.md |
Gradio Demo: save_file_no_output
```
!pip install -q gradio
```
```
import random
import string
import gradio as gr
def save_image_random_name(image):
random_string = ''.join(random.choices(string.ascii_letters, k=20)) + '.png'
image.save(random_string)
print(f"Saved image to {random_string}!")
demo = gr.Interface(
fn=save_image_random_name,
inputs=gr.Image(type="pil"),
outputs=None,
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/save_file_no_output/run.ipynb |
@gradio/colorpicker
## 0.2.6
### Patch Changes
- Updated dependencies [[`828fb9e`](https://github.com/gradio-app/gradio/commit/828fb9e6ce15b6ea08318675a2361117596a1b5d), [`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144)]:
- @gradio/statustracker@0.4.3
- @gradio/atoms@0.4.1
## 0.2.5
### Patch Changes
- Updated dependencies [[`4d1cbbc`](https://github.com/gradio-app/gradio/commit/4d1cbbcf30833ef1de2d2d2710c7492a379a9a00)]:
- @gradio/atoms@0.4.0
- @gradio/statustracker@0.4.2
## 0.2.4
### Patch Changes
- Updated dependencies []:
- @gradio/atoms@0.3.1
- @gradio/statustracker@0.4.1
## 0.2.3
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/atoms@0.3.0
- @gradio/statustracker@0.4.0
## 0.2.2
### Patch Changes
- Updated dependencies [[`f816136a0`](https://github.com/gradio-app/gradio/commit/f816136a039fa6011be9c4fb14f573e4050a681a)]:
- @gradio/atoms@0.2.2
- @gradio/statustracker@0.3.2
## 0.2.1
### Patch Changes
- Updated dependencies [[`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780), [`fad92c29d`](https://github.com/gradio-app/gradio/commit/fad92c29dc1f5cd84341aae417c495b33e01245f)]:
- @gradio/atoms@0.2.1
- @gradio/statustracker@0.3.1
## 0.2.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
## 0.2.0-beta.8
### Features
- [#6136](https://github.com/gradio-app/gradio/pull/6136) [`667802a6c`](https://github.com/gradio-app/gradio/commit/667802a6cdbfb2ce454a3be5a78e0990b194548a) - JS Component Documentation. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6149](https://github.com/gradio-app/gradio/pull/6149) [`90318b1dd`](https://github.com/gradio-app/gradio/commit/90318b1dd118ae08a695a50e7c556226234ab6dc) - swap `mode` on the frontned to `interactive` to match the backend. Thanks [@pngwn](https://github.com/pngwn)!
## 0.2.0-beta.7
### Features
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.2.0-beta.6
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.1.5
### Patch Changes
- Updated dependencies [[`e70805d54`](https://github.com/gradio-app/gradio/commit/e70805d54cc792452545f5d8eccc1aa0212a4695)]:
- @gradio/atoms@0.2.0
- @gradio/statustracker@0.2.3
## 0.1.4
### Patch Changes
- Updated dependencies []:
- @gradio/utils@0.1.2
- @gradio/atoms@0.1.4
- @gradio/statustracker@0.2.2
## 0.1.3
### Patch Changes
- Updated dependencies []:
- @gradio/atoms@0.1.3
- @gradio/statustracker@0.2.1
## 0.1.2
### Patch Changes
- Updated dependencies [[`afac0006`](https://github.com/gradio-app/gradio/commit/afac0006337ce2840cf497cd65691f2f60ee5912)]:
- @gradio/statustracker@0.2.0
- @gradio/utils@0.1.1
- @gradio/atoms@0.1.2
## 0.1.1
### Patch Changes
- Updated dependencies [[`abf1c57d`](https://github.com/gradio-app/gradio/commit/abf1c57d7d85de0df233ee3b38aeb38b638477db)]:
- @gradio/utils@0.1.0
- @gradio/atoms@0.1.1
- @gradio/statustracker@0.1.1
## 0.1.0
### Highlights
#### Improve startup performance and markdown support ([#5279](https://github.com/gradio-app/gradio/pull/5279) [`fe057300`](https://github.com/gradio-app/gradio/commit/fe057300f0672c62dab9d9b4501054ac5d45a4ec))
##### Improved markdown support
We now have better support for markdown in `gr.Markdown` and `gr.Dataframe`. Including syntax highlighting and Github Flavoured Markdown. We also have more consistent markdown behaviour and styling.
##### Various performance improvements
These improvements will be particularly beneficial to large applications.
- Rather than attaching events manually, they are now delegated, leading to a significant performance improvement and addressing a performance regression introduced in a recent version of Gradio. App startup for large applications is now around twice as fast.
- Optimised the mounting of individual components, leading to a modest performance improvement during startup (~30%).
- Corrected an issue that was causing markdown to re-render infinitely.
- Ensured that the `gr.3DModel` does re-render prematurely.
Thanks [@pngwn](https://github.com/pngwn)!
### Features
- [#5215](https://github.com/gradio-app/gradio/pull/5215) [`fbdad78a`](https://github.com/gradio-app/gradio/commit/fbdad78af4c47454cbb570f88cc14bf4479bbceb) - Lazy load interactive or static variants of a component individually, rather than loading both variants regardless. This change will improve performance for many applications. Thanks [@pngwn](https://github.com/pngwn)!
- [#5216](https://github.com/gradio-app/gradio/pull/5216) [`4b58ea6d`](https://github.com/gradio-app/gradio/commit/4b58ea6d98e7a43b3f30d8a4cb6f379bc2eca6a8) - Update i18n tokens and locale files. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.0.2
### Fixes
- [#5118](https://github.com/gradio-app/gradio/pull/5118) [`1b017e68`](https://github.com/gradio-app/gradio/commit/1b017e68f6a9623cc2ec085bd20e056229552028) - Add `interactive` args to `gr.ColorPicker`. Thanks [@hannahblair](https://github.com/hannahblair)!
| gradio-app/gradio/blob/main/js/colorpicker/CHANGELOG.md |
Hugging Face Hub Client library
## Download files from the Hub
The `hf_hub_download()` function is the main function to download files from the Hub. One
advantage of using it is that files are cached locally, so you won't have to
download the files multiple times. If there are changes in the repository, the
files will be automatically downloaded again.
### `hf_hub_download`
The function takes the following parameters, downloads the remote file,
stores it to disk (in a version-aware way) and returns its local file path.
Parameters:
- a `repo_id` (a user or organization name and a repo name, separated by `/`, like `julien-c/EsperBERTo-small`)
- a `filename` (like `pytorch_model.bin`)
- an optional Git revision id (can be a branch name, a tag, or a commit hash)
- a `cache_dir` which you can specify if you want to control where on disk the
files are cached.
```python
from huggingface_hub import hf_hub_download
hf_hub_download("lysandre/arxiv-nlp", filename="config.json")
```
### `snapshot_download`
Using `hf_hub_download()` works well when you know which files you want to download;
for example a model file alongside a configuration file, both with static names.
There are cases in which you will prefer to download all the files of the remote
repository at a specified revision. That's what `snapshot_download()` does. It
downloads and stores a remote repository to disk (in a versioning-aware way) and
returns its local file path.
Parameters:
- a `repo_id` in the format `namespace/repository`
- a `revision` on which the repository will be downloaded
- a `cache_dir` which you can specify if you want to control where on disk the
files are cached
### `hf_hub_url`
Internally, the library uses `hf_hub_url()` to return the URL to download the actual files:
`https://huggingface.co/julien-c/EsperBERTo-small/resolve/main/pytorch_model.bin`
Parameters:
- a `repo_id` (a user or organization name and a repo name seperated by a `/`, like `julien-c/EsperBERTo-small`)
- a `filename` (like `pytorch_model.bin`)
- an optional `subfolder`, corresponding to a folder inside the model repo
- an optional `repo_type`, such as `dataset` or `space`
- an optional Git revision id (can be a branch name, a tag, or a commit hash)
If you check out this URL's headers with a `HEAD` http request (which you can do
from the command line with `curl -I`) for a few different files, you'll see
that:
- small files are returned directly
- large files (i.e. the ones stored through
[git-lfs](https://git-lfs.github.com/)) are returned via a redirect to a
Cloudfront URL. Cloudfront is a Content Delivery Network, or CDN, that ensures
that downloads are as fast as possible from anywhere on the globe.
<br>
## Publish files to the Hub
If you've used Git before, this will be very easy since Git is used to manage
files in the Hub. You can find a step-by-step guide on how to upload your model
to the Hub: https://huggingface.co/docs/hub/adding-a-model.
### API utilities in `hf_api.py`
You don't need them for the standard publishing workflow (ie. using git command line), however, if you need a
programmatic way of creating a repo, deleting it (`⚠️ caution`), pushing a
single file to a repo or listing models from the Hub, you'll find helpers in
`hf_api.py`. Some example functionality available with the `HfApi` class:
* `whoami()`
* `create_repo()`
* `list_repo_files()`
* `list_repo_objects()`
* `delete_repo()`
* `update_repo_visibility()`
* `create_commit()`
* `upload_file()`
* `delete_file()`
* `delete_folder()`
Those API utilities are also exposed through the `huggingface-cli` CLI:
```bash
huggingface-cli login
huggingface-cli logout
huggingface-cli whoami
huggingface-cli repo create
```
With the `HfApi` class there are methods to query models, datasets, and metrics by specific tags (e.g. if you want to list models compatible with your library):
- **Models**:
- `list_models()`
- `model_info()`
- `get_model_tags()`
- **Datasets**:
- `list_datasets()`
- `dataset_info()`
- `get_dataset_tags()`
- **Spaces**:
- `list_spaces()`
- `space_info()`
These lightly wrap around the API Endpoints. Documentation for valid parameters and descriptions can be found [here](https://huggingface.co/docs/hub/endpoints).
### Advanced programmatic repository management
The `Repository` class helps manage both offline Git repositories and Hugging
Face Hub repositories. Using the `Repository` class requires `git` and `git-lfs`
to be installed.
Instantiate a `Repository` object by calling it with a path to a local Git
clone/repository:
```python
>>> from huggingface_hub import Repository
>>> repo = Repository("<path>/<to>/<folder>")
```
The `Repository` takes a `clone_from` string as parameter. This can stay as
`None` for offline management, but can also be set to any URL pointing to a Git
repo to clone that repository in the specified directory:
```python
>>> repo = Repository("huggingface-hub", clone_from="https://github.com/huggingface/huggingface_hub")
```
The `clone_from` method can also take any Hugging Face model ID as input, and
will clone that repository:
```python
>>> repo = Repository("w2v2", clone_from="facebook/wav2vec2-large-960h-lv60")
```
If the repository you're cloning is one of yours or one of your organisation's,
then having the ability to commit and push to that repository is important. In
order to do that, you should make sure to be logged-in using `huggingface-cli
login`, and to have the `token` parameter set to `True` (the default)
when instantiating the `Repository` object:
```python
>>> repo = Repository("my-model", clone_from="<user>/<model_id>", token=True)
```
This works for models, datasets and spaces repositories; but you will need to
explicitely specify the type for the last two options:
```python
>>> repo = Repository("my-dataset", clone_from="<user>/<dataset_id>", token=True, repo_type="dataset")
```
You can also change between branches:
```python
>>> repo = Repository("huggingface-hub", clone_from="<user>/<dataset_id>", revision='branch1')
>>> repo.git_checkout("branch2")
```
The `clone_from` method can also take any Hugging Face model ID as input, and
will clone that repository:
```python
>>> repo = Repository("w2v2", clone_from="facebook/wav2vec2-large-960h-lv60")
```
Finally, you can choose to specify the Git username and email attributed to that
clone directly by using the `git_user` and `git_email` parameters. When
committing to that repository, Git will therefore be aware of who you are and
who will be the author of the commits:
```python
>>> repo = Repository(
... "my-dataset",
... clone_from="<user>/<dataset_id>",
... token=True,
... repo_type="dataset",
... git_user="MyName",
... git_email="me@cool.mail"
... )
```
The repository can be managed through this object, through wrappers of
traditional Git methods:
- `git_add(pattern: str, auto_lfs_track: bool)`. The `auto_lfs_track` flag
triggers auto tracking of large files (>10MB) with `git-lfs`
- `git_commit(commit_message: str)`
- `git_pull(rebase: bool)`
- `git_push()`
- `git_checkout(branch)`
The `git_push` method has a parameter `blocking` which is `True` by default. When set to `False`, the push will
happen behind the scenes - which can be helpful if you would like your script to continue on while the push is
happening.
LFS-tracking methods:
- `lfs_track(pattern: Union[str, List[str]], filename: bool)`. Setting
`filename` to `True` will use the `--filename` parameter, which will consider
the pattern(s) as filenames, even if they contain special glob characters.
- `lfs_untrack()`.
- `auto_track_large_files()`: automatically tracks files that are larger than
10MB. Make sure to call this after adding files to the index.
On top of these unitary methods lie some useful additional methods:
- `push_to_hub(commit_message)`: consecutively does `git_add`, `git_commit` and
`git_push`.
- `commit(commit_message: str, track_large_files: bool)`: this is a context
manager utility that handles committing to a repository. This automatically
tracks large files (>10Mb) with `git-lfs`. The `track_large_files` argument can
be set to `False` if you wish to ignore that behavior.
These two methods also have support for the `blocking` parameter.
Examples using the `commit` context manager:
```python
>>> with Repository("text-files", clone_from="<user>/text-files", token=True).commit("My first file :)"):
... with open("file.txt", "w+") as f:
... f.write(json.dumps({"hey": 8}))
```
```python
>>> import torch
>>> model = torch.nn.Transformer()
>>> with Repository("torch-model", clone_from="<user>/torch-model", token=True).commit("My cool model :)"):
... torch.save(model.state_dict(), "model.pt")
```
### Non-blocking behavior
The pushing methods have access to a `blocking` boolean parameter to indicate whether the push should happen
asynchronously.
In order to see if the push has finished or its status code (to spot a failure), one should use the `command_queue`
property on the `Repository` object.
For example:
```python
from huggingface_hub import Repository
repo = Repository("<local_folder>", clone_from="<user>/<model_name>")
with repo.commit("Commit message", blocking=False):
# Save data
last_command = repo.command_queue[-1]
# Status of the push command
last_command.status
# Will return the status code
# -> -1 will indicate the push is still ongoing
# -> 0 will indicate the push has completed successfully
# -> non-zero code indicates the error code if there was an error
# if there was an error, the stderr may be inspected
last_command.stderr
# Whether the command finished or if it is still ongoing
last_command.is_done
# Whether the command errored-out.
last_command.failed
```
When using `blocking=False`, the commands will be tracked and your script will exit only when all pushes are done, even
if other errors happen in your script (a failed push counts as done).
### Need to upload very large (>5GB) files?
To upload large files (>5GB 🔥) from git command-line, you need to install the custom transfer agent
for git-lfs, bundled in this package.
To install, just run:
```bash
$ huggingface-cli lfs-enable-largefiles
```
This should be executed once for each model repo that contains a model file
>5GB. If you just try to push a file bigger than 5GB without running that
command, you will get an error with a message reminding you to run it.
Finally, there's a `huggingface-cli lfs-multipart-upload` command but that one
is internal (called by lfs directly) and is not meant to be called by the user.
<br>
## Using the Inference API wrapper
`huggingface_hub` comes with a wrapper client to make calls to the Inference
API! You can find some examples below, but we encourage you to visit the
Inference API
[documentation](https://api-inference.huggingface.co/docs/python/html/detailed_parameters.html)
to review the specific parameters for the different tasks.
When you instantiate the wrapper to the Inference API, you specify the model
repository id. The pipeline (`text-classification`, `text-to-speech`, etc) is
automatically extracted from the
[repository](https://huggingface.co/docs/hub/main#how-is-a-models-type-of-inference-api-and-widget-determined),
but you can also override it as shown below.
### Examples
Here is a basic example of calling the Inference API for a `fill-mask` task
using the `bert-base-uncased` model. The `fill-mask` task only expects a string
(or list of strings) as input.
```python
from huggingface_hub.inference_api import InferenceApi
inference = InferenceApi("bert-base-uncased", token=API_TOKEN)
inference(inputs="The goal of life is [MASK].")
>> [{'sequence': 'the goal of life is life.', 'score': 0.10933292657136917, 'token': 2166, 'token_str': 'life'}]
```
This is an example of a task (`question-answering`) which requires a dictionary
as input thas has the `question` and `context` keys.
```python
inference = InferenceApi("deepset/roberta-base-squad2", token=API_TOKEN)
inputs = {"question":"What's my name?", "context":"My name is Clara and I live in Berkeley."}
inference(inputs)
>> {'score': 0.9326569437980652, 'start': 11, 'end': 16, 'answer': 'Clara'}
```
Some tasks might also require additional params in the request. Here is an
example using a `zero-shot-classification` model.
```python
inference = InferenceApi("typeform/distilbert-base-uncased-mnli", token=API_TOKEN)
inputs = "Hi, I recently bought a device from your company but it is not working as advertised and I would like to get reimbursed!"
params = {"candidate_labels":["refund", "legal", "faq"]}
inference(inputs, params)
>> {'sequence': 'Hi, I recently bought a device from your company but it is not working as advertised and I would like to get reimbursed!', 'labels': ['refund', 'faq', 'legal'], 'scores': [0.9378499388694763, 0.04914155602455139, 0.013008488342165947]}
```
Finally, there are some models that might support multiple tasks. For example,
`sentence-transformers` models can do `sentence-similarity` and
`feature-extraction`. You can override the configured task when initializing the
API.
```python
inference = InferenceApi("bert-base-uncased", task="feature-extraction", token=API_TOKEN)
```
| huggingface/huggingface_hub/blob/main/src/huggingface_hub/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BLIP
## Overview
The BLIP model was proposed in [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) by Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
BLIP is a model that is able to perform various multi-modal tasks including:
- Visual Question Answering
- Image-Text retrieval (Image-text matching)
- Image Captioning
The abstract from the paper is the following:
*Vision-Language Pre-training (VLP) has advanced the performance for many vision-language tasks.
However, most existing pre-trained models only excel in either understanding-based tasks or generation-based tasks. Furthermore, performance improvement has been largely achieved by scaling up the dataset with noisy image-text pairs collected from the web, which is a suboptimal source of supervision. In this paper, we propose BLIP, a new VLP framework which transfers flexibly to both vision-language understanding and generation tasks. BLIP effectively utilizes the noisy web data by bootstrapping the captions, where a captioner generates synthetic captions and a filter removes the noisy ones. We achieve state-of-the-art results on a wide range of vision-language tasks, such as image-text retrieval (+2.7% in average recall@1), image captioning (+2.8% in CIDEr), and VQA (+1.6% in VQA score). BLIP also demonstrates strong generalization ability when directly transferred to videolanguage tasks in a zero-shot manner. Code, models, and datasets are released.*

This model was contributed by [ybelkada](https://huggingface.co/ybelkada).
The original code can be found [here](https://github.com/salesforce/BLIP).
## Resources
- [Jupyter notebook](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_blip.ipynb) on how to fine-tune BLIP for image captioning on a custom dataset
## BlipConfig
[[autodoc]] BlipConfig
- from_text_vision_configs
## BlipTextConfig
[[autodoc]] BlipTextConfig
## BlipVisionConfig
[[autodoc]] BlipVisionConfig
## BlipProcessor
[[autodoc]] BlipProcessor
## BlipImageProcessor
[[autodoc]] BlipImageProcessor
- preprocess
<frameworkcontent>
<pt>
## BlipModel
[[autodoc]] BlipModel
- forward
- get_text_features
- get_image_features
## BlipTextModel
[[autodoc]] BlipTextModel
- forward
## BlipVisionModel
[[autodoc]] BlipVisionModel
- forward
## BlipForConditionalGeneration
[[autodoc]] BlipForConditionalGeneration
- forward
## BlipForImageTextRetrieval
[[autodoc]] BlipForImageTextRetrieval
- forward
## BlipForQuestionAnswering
[[autodoc]] BlipForQuestionAnswering
- forward
</pt>
<tf>
## TFBlipModel
[[autodoc]] TFBlipModel
- call
- get_text_features
- get_image_features
## TFBlipTextModel
[[autodoc]] TFBlipTextModel
- call
## TFBlipVisionModel
[[autodoc]] TFBlipVisionModel
- call
## TFBlipForConditionalGeneration
[[autodoc]] TFBlipForConditionalGeneration
- call
## TFBlipForImageTextRetrieval
[[autodoc]] TFBlipForImageTextRetrieval
- call
## TFBlipForQuestionAnswering
[[autodoc]] TFBlipForQuestionAnswering
- call
</tf>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/blip.md |
Conclusion [[conclusion]]
Congrats on finishing this chapter! There was a lot of information. And congrats on finishing the tutorial. You’ve just trained your first Deep Q-Learning agent and shared it on the Hub 🥳.
Take time to really grasp the material before continuing.
Don't hesitate to train your agent in other environments (Pong, Seaquest, QBert, Ms Pac Man). The **best way to learn is to try things on your own!**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit4/atari-envs.gif" alt="Environments"/>
In the next unit, **we're going to learn about Optuna**. One of the most critical tasks in Deep Reinforcement Learning is to find a good set of training hyperparameters. Optuna is a library that helps you to automate the search.
Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then please 👉 [fill this form](https://forms.gle/BzKXWzLAGZESGNaE9)
### Keep Learning, stay awesome 🤗
| huggingface/deep-rl-class/blob/main/units/en/unit3/conclusion.mdx |
Gradio Demo: code_component
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
gr.Code(
value="""def hello_world():
return "Hello, world!"
print(hello_world())""",
language="python",
interactive=True,
show_label=False,
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/code_component/run.ipynb |
Gradio Demo: fake_diffusion
### This demo uses a fake model to showcase iterative output. The Image output will update every time a generator is returned until the final image.
```
!pip install -q gradio numpy
```
```
import gradio as gr
import numpy as np
import time
def fake_diffusion(steps):
for i in range(steps):
time.sleep(1)
image = np.random.random((600, 600, 3))
yield image
image = np.ones((1000,1000,3), np.uint8)
image[:] = [255, 124, 0]
yield image
demo = gr.Interface(fake_diffusion, inputs=gr.Slider(1, 10, 3), outputs="image")
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/fake_diffusion/run.ipynb |
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# mLUKE
## Overview
The mLUKE model was proposed in [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka. It's a multilingual extension
of the [LUKE model](https://arxiv.org/abs/2010.01057) trained on the basis of XLM-RoBERTa.
It is based on XLM-RoBERTa and adds entity embeddings, which helps improve performance on various downstream tasks
involving reasoning about entities such as named entity recognition, extractive question answering, relation
classification, cloze-style knowledge completion.
The abstract from the paper is the following:
*Recent studies have shown that multilingual pretrained language models can be effectively improved with cross-lingual
alignment information from Wikipedia entities. However, existing methods only exploit entity information in pretraining
and do not explicitly use entities in downstream tasks. In this study, we explore the effectiveness of leveraging
entity representations for downstream cross-lingual tasks. We train a multilingual language model with 24 languages
with entity representations and show the model consistently outperforms word-based pretrained models in various
cross-lingual transfer tasks. We also analyze the model and the key insight is that incorporating entity
representations into the input allows us to extract more language-agnostic features. We also evaluate the model with a
multilingual cloze prompt task with the mLAMA dataset. We show that entity-based prompt elicits correct factual
knowledge more likely than using only word representations.*
This model was contributed by [ryo0634](https://huggingface.co/ryo0634). The original code can be found [here](https://github.com/studio-ousia/luke).
## Usage tips
One can directly plug in the weights of mLUKE into a LUKE model, like so:
```python
from transformers import LukeModel
model = LukeModel.from_pretrained("studio-ousia/mluke-base")
```
Note that mLUKE has its own tokenizer, [`MLukeTokenizer`]. You can initialize it as follows:
```python
from transformers import MLukeTokenizer
tokenizer = MLukeTokenizer.from_pretrained("studio-ousia/mluke-base")
```
<Tip>
As mLUKE's architecture is equivalent to that of LUKE, one can refer to [LUKE's documentation page](luke) for all
tips, code examples and notebooks.
</Tip>
## MLukeTokenizer
[[autodoc]] MLukeTokenizer
- __call__
- save_vocabulary
| huggingface/transformers/blob/main/docs/source/en/model_doc/mluke.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Blenderbot
## Overview
The Blender chatbot model was proposed in [Recipes for building an open-domain chatbot](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu,
Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston on 30 Apr 2020.
The abstract of the paper is the following:
*Building open-domain chatbots is a challenging area for machine learning research. While prior work has shown that
scaling neural models in the number of parameters and the size of the data they are trained on gives improved results,
we show that other ingredients are important for a high-performing chatbot. Good conversation requires a number of
skills that an expert conversationalist blends in a seamless way: providing engaging talking points and listening to
their partners, and displaying knowledge, empathy and personality appropriately, while maintaining a consistent
persona. We show that large scale models can learn these skills when given appropriate training data and choice of
generation strategy. We build variants of these recipes with 90M, 2.7B and 9.4B parameter models, and make our models
and code publicly available. Human evaluations show our best models are superior to existing approaches in multi-turn
dialogue in terms of engagingness and humanness measurements. We then discuss the limitations of this work by analyzing
failure cases of our models.*
This model was contributed by [sshleifer](https://huggingface.co/sshleifer). The authors' code can be found [here](https://github.com/facebookresearch/ParlAI) .
## Usage tips and example
Blenderbot is a model with absolute position embeddings so it's usually advised to pad the inputs on the right
rather than the left.
An example:
```python
>>> from transformers import BlenderbotTokenizer, BlenderbotForConditionalGeneration
>>> mname = "facebook/blenderbot-400M-distill"
>>> model = BlenderbotForConditionalGeneration.from_pretrained(mname)
>>> tokenizer = BlenderbotTokenizer.from_pretrained(mname)
>>> UTTERANCE = "My friends are cool but they eat too many carbs."
>>> inputs = tokenizer([UTTERANCE], return_tensors="pt")
>>> reply_ids = model.generate(**inputs)
>>> print(tokenizer.batch_decode(reply_ids))
["<s> That's unfortunate. Are they trying to lose weight or are they just trying to be healthier?</s>"]
```
## Implementation Notes
- Blenderbot uses a standard [seq2seq model transformer](https://arxiv.org/pdf/1706.03762.pdf) based architecture.
- Available checkpoints can be found in the [model hub](https://huggingface.co/models?search=blenderbot).
- This is the *default* Blenderbot model class. However, some smaller checkpoints, such as
`facebook/blenderbot_small_90M`, have a different architecture and consequently should be used with
[BlenderbotSmall](blenderbot-small).
## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## BlenderbotConfig
[[autodoc]] BlenderbotConfig
## BlenderbotTokenizer
[[autodoc]] BlenderbotTokenizer
- build_inputs_with_special_tokens
## BlenderbotTokenizerFast
[[autodoc]] BlenderbotTokenizerFast
- build_inputs_with_special_tokens
<frameworkcontent>
<pt>
## BlenderbotModel
See [`~transformers.BartModel`] for arguments to *forward* and *generate*
[[autodoc]] BlenderbotModel
- forward
## BlenderbotForConditionalGeneration
See [`~transformers.BartForConditionalGeneration`] for arguments to *forward* and *generate*
[[autodoc]] BlenderbotForConditionalGeneration
- forward
## BlenderbotForCausalLM
[[autodoc]] BlenderbotForCausalLM
- forward
</pt>
<tf>
## TFBlenderbotModel
[[autodoc]] TFBlenderbotModel
- call
## TFBlenderbotForConditionalGeneration
[[autodoc]] TFBlenderbotForConditionalGeneration
- call
</tf>
<jax>
## FlaxBlenderbotModel
[[autodoc]] FlaxBlenderbotModel
- __call__
- encode
- decode
## FlaxBlenderbotForConditionalGeneration
[[autodoc]] FlaxBlenderbotForConditionalGeneration
- __call__
- encode
- decode
</jax>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/blenderbot.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# How to add a model to 🤗 Transformers?
The 🤗 Transformers library is often able to offer new models thanks to community contributors. But this can be a challenging project and requires an in-depth knowledge of the 🤗 Transformers library and the model to implement. At Hugging Face, we're trying to empower more of the community to actively add models and we've put together this guide to walk you through the process of adding a PyTorch model (make sure you have [PyTorch installed](https://pytorch.org/get-started/locally/)).
<Tip>
If you're interested in implementing a TensorFlow model, take a look at the [How to convert a 🤗 Transformers model to TensorFlow](add_tensorflow_model) guide!
</Tip>
Along the way, you'll:
- get insights into open-source best practices
- understand the design principles behind one of the most popular deep learning libraries
- learn how to efficiently test large models
- learn how to integrate Python utilities like `black`, `ruff`, and `make fix-copies` to ensure clean and readable code
A Hugging Face team member will be available to help you along the way so you'll never be alone. 🤗 ❤️
To get started, open a [New model addition](https://github.com/huggingface/transformers/issues/new?assignees=&labels=New+model&template=new-model-addition.yml) issue for the model you want to see in 🤗 Transformers. If you're not especially picky about contributing a specific model, you can filter by the [New model label](https://github.com/huggingface/transformers/labels/New%20model) to see if there are any unclaimed model requests and work on it.
Once you've opened a new model request, the first step is to get familiar with 🤗 Transformers if you aren't already!
## General overview of 🤗 Transformers
First, you should get a general overview of 🤗 Transformers. 🤗 Transformers is a very opinionated library, so there is a
chance that you don't agree with some of the library's philosophies or design choices. From our experience, however, we
found that the fundamental design choices and philosophies of the library are crucial to efficiently scale 🤗
Transformers while keeping maintenance costs at a reasonable level.
A good first starting point to better understand the library is to read the [documentation of our philosophy](philosophy). As a result of our way of working, there are some choices that we try to apply to all models:
- Composition is generally favored over-abstraction
- Duplicating code is not always bad if it strongly improves the readability or accessibility of a model
- Model files are as self-contained as possible so that when you read the code of a specific model, you ideally only
have to look into the respective `modeling_....py` file.
In our opinion, the library's code is not just a means to provide a product, *e.g.* the ability to use BERT for
inference, but also as the very product that we want to improve. Hence, when adding a model, the user is not only the
person who will use your model, but also everybody who will read, try to understand, and possibly tweak your code.
With this in mind, let's go a bit deeper into the general library design.
### Overview of models
To successfully add a model, it is important to understand the interaction between your model and its config,
[`PreTrainedModel`], and [`PretrainedConfig`]. For exemplary purposes, we will
call the model to be added to 🤗 Transformers `BrandNewBert`.
Let's take a look:
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers_overview.png"/>
As you can see, we do make use of inheritance in 🤗 Transformers, but we keep the level of abstraction to an absolute
minimum. There are never more than two levels of abstraction for any model in the library. `BrandNewBertModel`
inherits from `BrandNewBertPreTrainedModel` which in turn inherits from [`PreTrainedModel`] and
that's it. As a general rule, we want to make sure that a new model only depends on
[`PreTrainedModel`]. The important functionalities that are automatically provided to every new
model are [`~PreTrainedModel.from_pretrained`] and
[`~PreTrainedModel.save_pretrained`], which are used for serialization and deserialization. All of the
other important functionalities, such as `BrandNewBertModel.forward` should be completely defined in the new
`modeling_brand_new_bert.py` script. Next, we want to make sure that a model with a specific head layer, such as
`BrandNewBertForMaskedLM` does not inherit from `BrandNewBertModel`, but rather uses `BrandNewBertModel`
as a component that can be called in its forward pass to keep the level of abstraction low. Every new model requires a
configuration class, called `BrandNewBertConfig`. This configuration is always stored as an attribute in
[`PreTrainedModel`], and thus can be accessed via the `config` attribute for all classes
inheriting from `BrandNewBertPreTrainedModel`:
```python
model = BrandNewBertModel.from_pretrained("brandy/brand_new_bert")
model.config # model has access to its config
```
Similar to the model, the configuration inherits basic serialization and deserialization functionalities from
[`PretrainedConfig`]. Note that the configuration and the model are always serialized into two
different formats - the model to a *pytorch_model.bin* file and the configuration to a *config.json* file. Calling
[`~PreTrainedModel.save_pretrained`] will automatically call
[`~PretrainedConfig.save_pretrained`], so that both model and configuration are saved.
### Code style
When coding your new model, keep in mind that Transformers is an opinionated library and we have a few quirks of our
own regarding how code should be written :-)
1. The forward pass of your model should be fully written in the modeling file while being fully independent of other
models in the library. If you want to reuse a block from another model, copy the code and paste it with a
`# Copied from` comment on top (see [here](https://github.com/huggingface/transformers/blob/v4.17.0/src/transformers/models/roberta/modeling_roberta.py#L160)
for a good example and [there](pr_checks#check-copies) for more documentation on Copied from).
2. The code should be fully understandable, even by a non-native English speaker. This means you should pick
descriptive variable names and avoid abbreviations. As an example, `activation` is preferred to `act`.
One-letter variable names are strongly discouraged unless it's an index in a for loop.
3. More generally we prefer longer explicit code to short magical one.
4. Avoid subclassing `nn.Sequential` in PyTorch but subclass `nn.Module` and write the forward pass, so that anyone
using your code can quickly debug it by adding print statements or breaking points.
5. Your function signature should be type-annotated. For the rest, good variable names are way more readable and
understandable than type annotations.
### Overview of tokenizers
Not quite ready yet :-( This section will be added soon!
## Step-by-step recipe to add a model to 🤗 Transformers
Everyone has different preferences of how to port a model so it can be very helpful for you to take a look at summaries
of how other contributors ported models to Hugging Face. Here is a list of community blog posts on how to port a model:
1. [Porting GPT2 Model](https://medium.com/huggingface/from-tensorflow-to-pytorch-265f40ef2a28) by [Thomas](https://huggingface.co/thomwolf)
2. [Porting WMT19 MT Model](https://huggingface.co/blog/porting-fsmt) by [Stas](https://huggingface.co/stas)
From experience, we can tell you that the most important things to keep in mind when adding a model are:
- Don't reinvent the wheel! Most parts of the code you will add for the new 🤗 Transformers model already exist
somewhere in 🤗 Transformers. Take some time to find similar, already existing models and tokenizers you can copy
from. [grep](https://www.gnu.org/software/grep/) and [rg](https://github.com/BurntSushi/ripgrep) are your
friends. Note that it might very well happen that your model's tokenizer is based on one model implementation, and
your model's modeling code on another one. *E.g.* FSMT's modeling code is based on BART, while FSMT's tokenizer code
is based on XLM.
- It's more of an engineering challenge than a scientific challenge. You should spend more time creating an
efficient debugging environment rather than trying to understand all theoretical aspects of the model in the paper.
- Ask for help, when you're stuck! Models are the core component of 🤗 Transformers so we at Hugging Face are more
than happy to help you at every step to add your model. Don't hesitate to ask if you notice you are not making
progress.
In the following, we try to give you a general recipe that we found most useful when porting a model to 🤗 Transformers.
The following list is a summary of everything that has to be done to add a model and can be used by you as a To-Do
List:
☐ (Optional) Understood the model's theoretical aspects<br>
☐ Prepared 🤗 Transformers dev environment<br>
☐ Set up debugging environment of the original repository<br>
☐ Created script that successfully runs the `forward()` pass using the original repository and checkpoint<br>
☐ Successfully added the model skeleton to 🤗 Transformers<br>
☐ Successfully converted original checkpoint to 🤗 Transformers checkpoint<br>
☐ Successfully ran `forward()` pass in 🤗 Transformers that gives identical output to original checkpoint<br>
☐ Finished model tests in 🤗 Transformers<br>
☐ Successfully added tokenizer in 🤗 Transformers<br>
☐ Run end-to-end integration tests<br>
☐ Finished docs<br>
☐ Uploaded model weights to the Hub<br>
☐ Submitted the pull request<br>
☐ (Optional) Added a demo notebook
To begin with, we usually recommend starting by getting a good theoretical understanding of `BrandNewBert`. However,
if you prefer to understand the theoretical aspects of the model *on-the-job*, then it is totally fine to directly dive
into the `BrandNewBert`'s code-base. This option might suit you better if your engineering skills are better than
your theoretical skill, if you have trouble understanding `BrandNewBert`'s paper, or if you just enjoy programming
much more than reading scientific papers.
### 1. (Optional) Theoretical aspects of BrandNewBert
You should take some time to read *BrandNewBert's* paper, if such descriptive work exists. There might be large
sections of the paper that are difficult to understand. If this is the case, this is fine - don't worry! The goal is
not to get a deep theoretical understanding of the paper, but to extract the necessary information required to
effectively re-implement the model in 🤗 Transformers. That being said, you don't have to spend too much time on the
theoretical aspects, but rather focus on the practical ones, namely:
- What type of model is *brand_new_bert*? BERT-like encoder-only model? GPT2-like decoder-only model? BART-like
encoder-decoder model? Look at the [model_summary](model_summary) if you're not familiar with the differences between those.
- What are the applications of *brand_new_bert*? Text classification? Text generation? Seq2Seq tasks, *e.g.,*
summarization?
- What is the novel feature of the model that makes it different from BERT/GPT-2/BART?
- Which of the already existing [🤗 Transformers models](https://huggingface.co/transformers/#contents) is most
similar to *brand_new_bert*?
- What type of tokenizer is used? A sentencepiece tokenizer? Word piece tokenizer? Is it the same tokenizer as used
for BERT or BART?
After you feel like you have gotten a good overview of the architecture of the model, you might want to write to the
Hugging Face team with any questions you might have. This might include questions regarding the model's architecture,
its attention layer, etc. We will be more than happy to help you.
### 2. Next prepare your environment
1. Fork the [repository](https://github.com/huggingface/transformers) by clicking on the ‘Fork' button on the
repository's page. This creates a copy of the code under your GitHub user account.
2. Clone your `transformers` fork to your local disk, and add the base repository as a remote:
```bash
git clone https://github.com/[your Github handle]/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git
```
3. Set up a development environment, for instance by running the following command:
```bash
python -m venv .env
source .env/bin/activate
pip install -e ".[dev]"
```
Depending on your OS, and since the number of optional dependencies of Transformers is growing, you might get a
failure with this command. If that's the case make sure to install the Deep Learning framework you are working with
(PyTorch, TensorFlow and/or Flax) then do:
```bash
pip install -e ".[quality]"
```
which should be enough for most use cases. You can then return to the parent directory
```bash
cd ..
```
4. We recommend adding the PyTorch version of *brand_new_bert* to Transformers. To install PyTorch, please follow the
instructions on https://pytorch.org/get-started/locally/.
**Note:** You don't need to have CUDA installed. Making the new model work on CPU is sufficient.
5. To port *brand_new_bert*, you will also need access to its original repository:
```bash
git clone https://github.com/org_that_created_brand_new_bert_org/brand_new_bert.git
cd brand_new_bert
pip install -e .
```
Now you have set up a development environment to port *brand_new_bert* to 🤗 Transformers.
### 3.-4. Run a pretrained checkpoint using the original repository
At first, you will work on the original *brand_new_bert* repository. Often, the original implementation is very
“researchy”. Meaning that documentation might be lacking and the code can be difficult to understand. But this should
be exactly your motivation to reimplement *brand_new_bert*. At Hugging Face, one of our main goals is to *make people
stand on the shoulders of giants* which translates here very well into taking a working model and rewriting it to make
it as **accessible, user-friendly, and beautiful** as possible. This is the number-one motivation to re-implement
models into 🤗 Transformers - trying to make complex new NLP technology accessible to **everybody**.
You should start thereby by diving into the original repository.
Successfully running the official pretrained model in the original repository is often **the most difficult** step.
From our experience, it is very important to spend some time getting familiar with the original code-base. You need to
figure out the following:
- Where to find the pretrained weights?
- How to load the pretrained weights into the corresponding model?
- How to run the tokenizer independently from the model?
- Trace one forward pass so that you know which classes and functions are required for a simple forward pass. Usually,
you only have to reimplement those functions.
- Be able to locate the important components of the model: Where is the model's class? Are there model sub-classes,
*e.g.* EncoderModel, DecoderModel? Where is the self-attention layer? Are there multiple different attention layers,
*e.g.* *self-attention*, *cross-attention*...?
- How can you debug the model in the original environment of the repo? Do you have to add *print* statements, can you
work with an interactive debugger like *ipdb*, or should you use an efficient IDE to debug the model, like PyCharm?
It is very important that before you start the porting process, you can **efficiently** debug code in the original
repository! Also, remember that you are working with an open-source library, so do not hesitate to open an issue, or
even a pull request in the original repository. The maintainers of this repository are most likely very happy about
someone looking into their code!
At this point, it is really up to you which debugging environment and strategy you prefer to use to debug the original
model. We strongly advise against setting up a costly GPU environment, but simply work on a CPU both when starting to
dive into the original repository and also when starting to write the 🤗 Transformers implementation of the model. Only
at the very end, when the model has already been successfully ported to 🤗 Transformers, one should verify that the
model also works as expected on GPU.
In general, there are two possible debugging environments for running the original model
- [Jupyter notebooks](https://jupyter.org/) / [google colab](https://colab.research.google.com/notebooks/intro.ipynb)
- Local python scripts.
Jupyter notebooks have the advantage that they allow for cell-by-cell execution which can be helpful to better split
logical components from one another and to have faster debugging cycles as intermediate results can be stored. Also,
notebooks are often easier to share with other contributors, which might be very helpful if you want to ask the Hugging
Face team for help. If you are familiar with Jupyter notebooks, we strongly recommend you work with them.
The obvious disadvantage of Jupyter notebooks is that if you are not used to working with them you will have to spend
some time adjusting to the new programming environment and you might not be able to use your known debugging tools
anymore, like `ipdb`.
For each code-base, a good first step is always to load a **small** pretrained checkpoint and to be able to reproduce a
single forward pass using a dummy integer vector of input IDs as an input. Such a script could look like this (in
pseudocode):
```python
model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = [0, 4, 5, 2, 3, 7, 9] # vector of input ids
original_output = model.predict(input_ids)
```
Next, regarding the debugging strategy, there are generally a few from which to choose from:
- Decompose the original model into many small testable components and run a forward pass on each of those for
verification
- Decompose the original model only into the original *tokenizer* and the original *model*, run a forward pass on
those, and use intermediate print statements or breakpoints for verification
Again, it is up to you which strategy to choose. Often, one or the other is advantageous depending on the original code
base.
If the original code-base allows you to decompose the model into smaller sub-components, *e.g.* if the original
code-base can easily be run in eager mode, it is usually worth the effort to do so. There are some important advantages
to taking the more difficult road in the beginning:
- at a later stage when comparing the original model to the Hugging Face implementation, you can verify automatically
for each component individually that the corresponding component of the 🤗 Transformers implementation matches instead
of relying on visual comparison via print statements
- it can give you some rope to decompose the big problem of porting a model into smaller problems of just porting
individual components and thus structure your work better
- separating the model into logical meaningful components will help you to get a better overview of the model's design
and thus to better understand the model
- at a later stage those component-by-component tests help you to ensure that no regression occurs as you continue
changing your code
[Lysandre's](https://gist.github.com/LysandreJik/db4c948f6b4483960de5cbac598ad4ed) integration checks for ELECTRA
gives a nice example of how this can be done.
However, if the original code-base is very complex or only allows intermediate components to be run in a compiled mode,
it might be too time-consuming or even impossible to separate the model into smaller testable sub-components. A good
example is [T5's MeshTensorFlow](https://github.com/tensorflow/mesh/tree/master/mesh_tensorflow) library which is
very complex and does not offer a simple way to decompose the model into its sub-components. For such libraries, one
often relies on verifying print statements.
No matter which strategy you choose, the recommended procedure is often the same that you should start to debug the
starting layers first and the ending layers last.
It is recommended that you retrieve the output, either by print statements or sub-component functions, of the following
layers in the following order:
1. Retrieve the input IDs passed to the model
2. Retrieve the word embeddings
3. Retrieve the input of the first Transformer layer
4. Retrieve the output of the first Transformer layer
5. Retrieve the output of the following n - 1 Transformer layers
6. Retrieve the output of the whole BrandNewBert Model
Input IDs should thereby consists of an array of integers, *e.g.* `input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]`
The outputs of the following layers often consist of multi-dimensional float arrays and can look like this:
```
[[
[-0.1465, -0.6501, 0.1993, ..., 0.1451, 0.3430, 0.6024],
[-0.4417, -0.5920, 0.3450, ..., -0.3062, 0.6182, 0.7132],
[-0.5009, -0.7122, 0.4548, ..., -0.3662, 0.6091, 0.7648],
...,
[-0.5613, -0.6332, 0.4324, ..., -0.3792, 0.7372, 0.9288],
[-0.5416, -0.6345, 0.4180, ..., -0.3564, 0.6992, 0.9191],
[-0.5334, -0.6403, 0.4271, ..., -0.3339, 0.6533, 0.8694]]],
```
We expect that every model added to 🤗 Transformers passes a couple of integration tests, meaning that the original
model and the reimplemented version in 🤗 Transformers have to give the exact same output up to a precision of 0.001!
Since it is normal that the exact same model written in different libraries can give a slightly different output
depending on the library framework, we accept an error tolerance of 1e-3 (0.001). It is not enough if the model gives
nearly the same output, they have to be almost identical. Therefore, you will certainly compare the intermediate
outputs of the 🤗 Transformers version multiple times against the intermediate outputs of the original implementation of
*brand_new_bert* in which case an **efficient** debugging environment of the original repository is absolutely
important. Here is some advice to make your debugging environment as efficient as possible.
- Find the best way of debugging intermediate results. Is the original repository written in PyTorch? Then you should
probably take the time to write a longer script that decomposes the original model into smaller sub-components to
retrieve intermediate values. Is the original repository written in Tensorflow 1? Then you might have to rely on
TensorFlow print operations like [tf.print](https://www.tensorflow.org/api_docs/python/tf/print) to output
intermediate values. Is the original repository written in Jax? Then make sure that the model is **not jitted** when
running the forward pass, *e.g.* check-out [this link](https://github.com/google/jax/issues/196).
- Use the smallest pretrained checkpoint you can find. The smaller the checkpoint, the faster your debug cycle
becomes. It is not efficient if your pretrained model is so big that your forward pass takes more than 10 seconds.
In case only very large checkpoints are available, it might make more sense to create a dummy model in the new
environment with randomly initialized weights and save those weights for comparison with the 🤗 Transformers version
of your model
- Make sure you are using the easiest way of calling a forward pass in the original repository. Ideally, you want to
find the function in the original repository that **only** calls a single forward pass, *i.e.* that is often called
`predict`, `evaluate`, `forward` or `__call__`. You don't want to debug a function that calls `forward`
multiple times, *e.g.* to generate text, like `autoregressive_sample`, `generate`.
- Try to separate the tokenization from the model's *forward* pass. If the original repository shows examples where
you have to input a string, then try to find out where in the forward call the string input is changed to input ids
and start from this point. This might mean that you have to possibly write a small script yourself or change the
original code so that you can directly input the ids instead of an input string.
- Make sure that the model in your debugging setup is **not** in training mode, which often causes the model to yield
random outputs due to multiple dropout layers in the model. Make sure that the forward pass in your debugging
environment is **deterministic** so that the dropout layers are not used. Or use *transformers.utils.set_seed*
if the old and new implementations are in the same framework.
The following section gives you more specific details/tips on how you can do this for *brand_new_bert*.
### 5.-14. Port BrandNewBert to 🤗 Transformers
Next, you can finally start adding new code to 🤗 Transformers. Go into the clone of your 🤗 Transformers' fork:
```bash
cd transformers
```
In the special case that you are adding a model whose architecture exactly matches the model architecture of an
existing model you only have to add a conversion script as described in [this section](#write-a-conversion-script).
In this case, you can just re-use the whole model architecture of the already existing model.
Otherwise, let's start generating a new model. You have two choices here:
- `transformers-cli add-new-model-like` to add a new model like an existing one
- `transformers-cli add-new-model` to add a new model from our template (will look like BERT or Bart depending on the type of model you select)
In both cases, you will be prompted with a questionnaire to fill in the basic information of your model. The second command requires to install `cookiecutter`, you can find more information on it [here](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model).
**Open a Pull Request on the main huggingface/transformers repo**
Before starting to adapt the automatically generated code, now is the time to open a “Work in progress (WIP)” pull
request, *e.g.* “[WIP] Add *brand_new_bert*”, in 🤗 Transformers so that you and the Hugging Face team can work
side-by-side on integrating the model into 🤗 Transformers.
You should do the following:
1. Create a branch with a descriptive name from your main branch
```bash
git checkout -b add_brand_new_bert
```
2. Commit the automatically generated code:
```bash
git add .
git commit
```
3. Fetch and rebase to current main
```bash
git fetch upstream
git rebase upstream/main
```
4. Push the changes to your account using:
```bash
git push -u origin a-descriptive-name-for-my-changes
```
5. Once you are satisfied, go to the webpage of your fork on GitHub. Click on “Pull request”. Make sure to add the
GitHub handle of some members of the Hugging Face team as reviewers, so that the Hugging Face team gets notified for
future changes.
6. Change the PR into a draft by clicking on “Convert to draft” on the right of the GitHub pull request web page.
In the following, whenever you have made some progress, don't forget to commit your work and push it to your account so
that it shows in the pull request. Additionally, you should make sure to update your work with the current main from
time to time by doing:
```bash
git fetch upstream
git merge upstream/main
```
In general, all questions you might have regarding the model or your implementation should be asked in your PR and
discussed/solved in the PR. This way, the Hugging Face team will always be notified when you are committing new code or
if you have a question. It is often very helpful to point the Hugging Face team to your added code so that the Hugging
Face team can efficiently understand your problem or question.
To do so, you can go to the “Files changed” tab where you see all of your changes, go to a line regarding which you
want to ask a question, and click on the “+” symbol to add a comment. Whenever a question or problem has been solved,
you can click on the “Resolve” button of the created comment.
In the same way, the Hugging Face team will open comments when reviewing your code. We recommend asking most questions
on GitHub on your PR. For some very general questions that are not very useful for the public, feel free to ping the
Hugging Face team by Slack or email.
**5. Adapt the generated models code for brand_new_bert**
At first, we will focus only on the model itself and not care about the tokenizer. All the relevant code should be
found in the generated files `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` and
`src/transformers/models/brand_new_bert/configuration_brand_new_bert.py`.
Now you can finally start coding :). The generated code in
`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` will either have the same architecture as BERT if
it's an encoder-only model or BART if it's an encoder-decoder model. At this point, you should remind yourself what
you've learned in the beginning about the theoretical aspects of the model: *How is the model different from BERT or
BART?*". Implement those changes which often means changing the *self-attention* layer, the order of the normalization
layer, etc… Again, it is often useful to look at the similar architecture of already existing models in Transformers to
get a better feeling of how your model should be implemented.
**Note** that at this point, you don't have to be very sure that your code is fully correct or clean. Rather, it is
advised to add a first *unclean*, copy-pasted version of the original code to
`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` until you feel like all the necessary code is
added. From our experience, it is much more efficient to quickly add a first version of the required code and
improve/correct the code iteratively with the conversion script as described in the next section. The only thing that
has to work at this point is that you can instantiate the 🤗 Transformers implementation of *brand_new_bert*, *i.e.* the
following command should work:
```python
from transformers import BrandNewBertModel, BrandNewBertConfig
model = BrandNewBertModel(BrandNewBertConfig())
```
The above command will create a model according to the default parameters as defined in `BrandNewBertConfig()` with
random weights, thus making sure that the `init()` methods of all components works.
Note that all random initialization should happen in the `_init_weights` method of your `BrandnewBertPreTrainedModel`
class. It should initialize all leaf modules depending on the variables of the config. Here is an example with the
BERT `_init_weights` method:
```py
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
```
You can have some more custom schemes if you need a special initialization for some modules. For instance, in
`Wav2Vec2ForPreTraining`, the last two linear layers need to have the initialization of the regular PyTorch `nn.Linear`
but all the other ones should use an initialization as above. This is coded like this:
```py
def _init_weights(self, module):
"""Initialize the weights"""
if isinstnace(module, Wav2Vec2ForPreTraining):
module.project_hid.reset_parameters()
module.project_q.reset_parameters()
module.project_hid._is_hf_initialized = True
module.project_q._is_hf_initialized = True
elif isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
```
The `_is_hf_initialized` flag is internally used to make sure we only initialize a submodule once. By setting it to
`True` for `module.project_q` and `module.project_hid`, we make sure the custom initialization we did is not overridden later on,
the `_init_weights` function won't be applied to them.
**6. Write a conversion script**
Next, you should write a conversion script that lets you convert the checkpoint you used to debug *brand_new_bert* in
the original repository to a checkpoint compatible with your just created 🤗 Transformers implementation of
*brand_new_bert*. It is not advised to write the conversion script from scratch, but rather to look through already
existing conversion scripts in 🤗 Transformers for one that has been used to convert a similar model that was written in
the same framework as *brand_new_bert*. Usually, it is enough to copy an already existing conversion script and
slightly adapt it for your use case. Don't hesitate to ask the Hugging Face team to point you to a similar already
existing conversion script for your model.
- If you are porting a model from TensorFlow to PyTorch, a good starting point might be BERT's conversion script [here](https://github.com/huggingface/transformers/blob/7acfa95afb8194f8f9c1f4d2c6028224dbed35a2/src/transformers/models/bert/modeling_bert.py#L91)
- If you are porting a model from PyTorch to PyTorch, a good starting point might be BART's conversion script [here](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bart/convert_bart_original_pytorch_checkpoint_to_pytorch.py)
In the following, we'll quickly explain how PyTorch models store layer weights and define layer names. In PyTorch, the
name of a layer is defined by the name of the class attribute you give the layer. Let's define a dummy model in
PyTorch, called `SimpleModel` as follows:
```python
from torch import nn
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.dense = nn.Linear(10, 10)
self.intermediate = nn.Linear(10, 10)
self.layer_norm = nn.LayerNorm(10)
```
Now we can create an instance of this model definition which will fill all weights: `dense`, `intermediate`,
`layer_norm` with random weights. We can print the model to see its architecture
```python
model = SimpleModel()
print(model)
```
This will print out the following:
```
SimpleModel(
(dense): Linear(in_features=10, out_features=10, bias=True)
(intermediate): Linear(in_features=10, out_features=10, bias=True)
(layer_norm): LayerNorm((10,), eps=1e-05, elementwise_affine=True)
)
```
We can see that the layer names are defined by the name of the class attribute in PyTorch. You can print out the weight
values of a specific layer:
```python
print(model.dense.weight.data)
```
to see that the weights were randomly initialized
```
tensor([[-0.0818, 0.2207, -0.0749, -0.0030, 0.0045, -0.1569, -0.1598, 0.0212,
-0.2077, 0.2157],
[ 0.1044, 0.0201, 0.0990, 0.2482, 0.3116, 0.2509, 0.2866, -0.2190,
0.2166, -0.0212],
[-0.2000, 0.1107, -0.1999, -0.3119, 0.1559, 0.0993, 0.1776, -0.1950,
-0.1023, -0.0447],
[-0.0888, -0.1092, 0.2281, 0.0336, 0.1817, -0.0115, 0.2096, 0.1415,
-0.1876, -0.2467],
[ 0.2208, -0.2352, -0.1426, -0.2636, -0.2889, -0.2061, -0.2849, -0.0465,
0.2577, 0.0402],
[ 0.1502, 0.2465, 0.2566, 0.0693, 0.2352, -0.0530, 0.1859, -0.0604,
0.2132, 0.1680],
[ 0.1733, -0.2407, -0.1721, 0.1484, 0.0358, -0.0633, -0.0721, -0.0090,
0.2707, -0.2509],
[-0.1173, 0.1561, 0.2945, 0.0595, -0.1996, 0.2988, -0.0802, 0.0407,
0.1829, -0.1568],
[-0.1164, -0.2228, -0.0403, 0.0428, 0.1339, 0.0047, 0.1967, 0.2923,
0.0333, -0.0536],
[-0.1492, -0.1616, 0.1057, 0.1950, -0.2807, -0.2710, -0.1586, 0.0739,
0.2220, 0.2358]]).
```
In the conversion script, you should fill those randomly initialized weights with the exact weights of the
corresponding layer in the checkpoint. *E.g.*
```python
# retrieve matching layer weights, e.g. by
# recursive algorithm
layer_name = "dense"
pretrained_weight = array_of_dense_layer
model_pointer = getattr(model, "dense")
model_pointer.weight.data = torch.from_numpy(pretrained_weight)
```
While doing so, you must verify that each randomly initialized weight of your PyTorch model and its corresponding
pretrained checkpoint weight exactly match in both **shape and name**. To do so, it is **necessary** to add assert
statements for the shape and print out the names of the checkpoints weights. E.g. you should add statements like:
```python
assert (
model_pointer.weight.shape == pretrained_weight.shape
), f"Pointer shape of random weight {model_pointer.shape} and array shape of checkpoint weight {pretrained_weight.shape} mismatched"
```
Besides, you should also print out the names of both weights to make sure they match, *e.g.*
```python
logger.info(f"Initialize PyTorch weight {layer_name} from {pretrained_weight.name}")
```
If either the shape or the name doesn't match, you probably assigned the wrong checkpoint weight to a randomly
initialized layer of the 🤗 Transformers implementation.
An incorrect shape is most likely due to an incorrect setting of the config parameters in `BrandNewBertConfig()` that
do not exactly match those that were used for the checkpoint you want to convert. However, it could also be that
PyTorch's implementation of a layer requires the weight to be transposed beforehand.
Finally, you should also check that **all** required weights are initialized and print out all checkpoint weights that
were not used for initialization to make sure the model is correctly converted. It is completely normal, that the
conversion trials fail with either a wrong shape statement or a wrong name assignment. This is most likely because either
you used incorrect parameters in `BrandNewBertConfig()`, have a wrong architecture in the 🤗 Transformers
implementation, you have a bug in the `init()` functions of one of the components of the 🤗 Transformers
implementation or you need to transpose one of the checkpoint weights.
This step should be iterated with the previous step until all weights of the checkpoint are correctly loaded in the
Transformers model. Having correctly loaded the checkpoint into the 🤗 Transformers implementation, you can then save
the model under a folder of your choice `/path/to/converted/checkpoint/folder` that should then contain both a
`pytorch_model.bin` file and a `config.json` file:
```python
model.save_pretrained("/path/to/converted/checkpoint/folder")
```
**7. Implement the forward pass**
Having managed to correctly load the pretrained weights into the 🤗 Transformers implementation, you should now make
sure that the forward pass is correctly implemented. In [Get familiar with the original repository](#34-run-a-pretrained-checkpoint-using-the-original-repository), you have already created a script that runs a forward
pass of the model using the original repository. Now you should write an analogous script using the 🤗 Transformers
implementation instead of the original one. It should look as follows:
```python
model = BrandNewBertModel.from_pretrained("/path/to/converted/checkpoint/folder")
input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]
output = model(input_ids).last_hidden_states
```
It is very likely that the 🤗 Transformers implementation and the original model implementation don't give the exact
same output the very first time or that the forward pass throws an error. Don't be disappointed - it's expected! First,
you should make sure that the forward pass doesn't throw any errors. It often happens that the wrong dimensions are
used leading to a *Dimensionality mismatch* error or that the wrong data type object is used, *e.g.* `torch.long`
instead of `torch.float32`. Don't hesitate to ask the Hugging Face team for help, if you don't manage to solve
certain errors.
The final part to make sure the 🤗 Transformers implementation works correctly is to ensure that the outputs are
equivalent to a precision of `1e-3`. First, you should ensure that the output shapes are identical, *i.e.*
`outputs.shape` should yield the same value for the script of the 🤗 Transformers implementation and the original
implementation. Next, you should make sure that the output values are identical as well. This one of the most difficult
parts of adding a new model. Common mistakes why the outputs are not identical are:
- Some layers were not added, *i.e.* an *activation* layer was not added, or the residual connection was forgotten
- The word embedding matrix was not tied
- The wrong positional embeddings are used because the original implementation uses on offset
- Dropout is applied during the forward pass. To fix this make sure *model.training is False* and that no dropout
layer is falsely activated during the forward pass, *i.e.* pass *self.training* to [PyTorch's functional dropout](https://pytorch.org/docs/stable/nn.functional.html?highlight=dropout#torch.nn.functional.dropout)
The best way to fix the problem is usually to look at the forward pass of the original implementation and the 🤗
Transformers implementation side-by-side and check if there are any differences. Ideally, you should debug/print out
intermediate outputs of both implementations of the forward pass to find the exact position in the network where the 🤗
Transformers implementation shows a different output than the original implementation. First, make sure that the
hard-coded `input_ids` in both scripts are identical. Next, verify that the outputs of the first transformation of
the `input_ids` (usually the word embeddings) are identical. And then work your way up to the very last layer of the
network. At some point, you will notice a difference between the two implementations, which should point you to the bug
in the 🤗 Transformers implementation. From our experience, a simple and efficient way is to add many print statements
in both the original implementation and 🤗 Transformers implementation, at the same positions in the network
respectively, and to successively remove print statements showing the same values for intermediate presentations.
When you're confident that both implementations yield the same output, verify the outputs with
`torch.allclose(original_output, output, atol=1e-3)`, you're done with the most difficult part! Congratulations - the
work left to be done should be a cakewalk 😊.
**8. Adding all necessary model tests**
At this point, you have successfully added a new model. However, it is very much possible that the model does not yet
fully comply with the required design. To make sure, the implementation is fully compatible with 🤗 Transformers, all
common tests should pass. The Cookiecutter should have automatically added a test file for your model, probably under
the same `tests/models/brand_new_bert/test_modeling_brand_new_bert.py`. Run this test file to verify that all common
tests pass:
```bash
pytest tests/models/brand_new_bert/test_modeling_brand_new_bert.py
```
Having fixed all common tests, it is now crucial to ensure that all the nice work you have done is well tested, so that
- a) The community can easily understand your work by looking at specific tests of *brand_new_bert*
- b) Future changes to your model will not break any important feature of the model.
At first, integration tests should be added. Those integration tests essentially do the same as the debugging scripts
you used earlier to implement the model to 🤗 Transformers. A template of those model tests has already added by the
Cookiecutter, called `BrandNewBertModelIntegrationTests` and only has to be filled out by you. To ensure that those
tests are passing, run
```bash
RUN_SLOW=1 pytest -sv tests/models/brand_new_bert/test_modeling_brand_new_bert.py::BrandNewBertModelIntegrationTests
```
<Tip>
In case you are using Windows, you should replace `RUN_SLOW=1` with `SET RUN_SLOW=1`
</Tip>
Second, all features that are special to *brand_new_bert* should be tested additionally in a separate test under
`BrandNewBertModelTester`/``BrandNewBertModelTest`. This part is often forgotten but is extremely useful in two
ways:
- It helps to transfer the knowledge you have acquired during the model addition to the community by showing how the
special features of *brand_new_bert* should work.
- Future contributors can quickly test changes to the model by running those special tests.
**9. Implement the tokenizer**
Next, we should add the tokenizer of *brand_new_bert*. Usually, the tokenizer is equivalent to or very similar to an
already existing tokenizer of 🤗 Transformers.
It is very important to find/extract the original tokenizer file and to manage to load this file into the 🤗
Transformers' implementation of the tokenizer.
To ensure that the tokenizer works correctly, it is recommended to first create a script in the original repository
that inputs a string and returns the `input_ids``. It could look similar to this (in pseudo-code):
```python
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = model.tokenize(input_str)
```
You might have to take a deeper look again into the original repository to find the correct tokenizer function or you
might even have to do changes to your clone of the original repository to only output the `input_ids`. Having written
a functional tokenization script that uses the original repository, an analogous script for 🤗 Transformers should be
created. It should look similar to this:
```python
from transformers import BrandNewBertTokenizer
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
tokenizer = BrandNewBertTokenizer.from_pretrained("/path/to/tokenizer/folder/")
input_ids = tokenizer(input_str).input_ids
```
When both `input_ids` yield the same values, as a final step a tokenizer test file should also be added.
Analogous to the modeling test files of *brand_new_bert*, the tokenization test files of *brand_new_bert* should
contain a couple of hard-coded integration tests.
**10. Run End-to-end integration tests**
Having added the tokenizer, you should also add a couple of end-to-end integration tests using both the model and the
tokenizer to `tests/models/brand_new_bert/test_modeling_brand_new_bert.py` in 🤗 Transformers.
Such a test should show on a meaningful
text-to-text sample that the 🤗 Transformers implementation works as expected. A meaningful text-to-text sample can
include *e.g.* a source-to-target-translation pair, an article-to-summary pair, a question-to-answer pair, etc… If none
of the ported checkpoints has been fine-tuned on a downstream task it is enough to simply rely on the model tests. In a
final step to ensure that the model is fully functional, it is advised that you also run all tests on GPU. It can
happen that you forgot to add some `.to(self.device)` statements to internal tensors of the model, which in such a
test would show in an error. In case you have no access to a GPU, the Hugging Face team can take care of running those
tests for you.
**11. Add Docstring**
Now, all the necessary functionality for *brand_new_bert* is added - you're almost done! The only thing left to add is
a nice docstring and a doc page. The Cookiecutter should have added a template file called
`docs/source/model_doc/brand_new_bert.md` that you should fill out. Users of your model will usually first look at
this page before using your model. Hence, the documentation must be understandable and concise. It is very useful for
the community to add some *Tips* to show how the model should be used. Don't hesitate to ping the Hugging Face team
regarding the docstrings.
Next, make sure that the docstring added to `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` is
correct and included all necessary inputs and outputs. We have a detailed guide about writing documentation and our docstring format [here](writing-documentation). It is always to good to remind oneself that documentation should
be treated at least as carefully as the code in 🤗 Transformers since the documentation is usually the first contact
point of the community with the model.
**Code refactor**
Great, now you have added all the necessary code for *brand_new_bert*. At this point, you should correct some potential
incorrect code style by running:
```bash
make style
```
and verify that your coding style passes the quality check:
```bash
make quality
```
There are a couple of other very strict design tests in 🤗 Transformers that might still be failing, which shows up in
the tests of your pull request. This is often because of some missing information in the docstring or some incorrect
naming. The Hugging Face team will surely help you if you're stuck here.
Lastly, it is always a good idea to refactor one's code after having ensured that the code works correctly. With all
tests passing, now it's a good time to go over the added code again and do some refactoring.
You have now finished the coding part, congratulation! 🎉 You are Awesome! 😎
**12. Upload the models to the model hub**
In this final part, you should convert and upload all checkpoints to the model hub and add a model card for each
uploaded model checkpoint. You can get familiar with the hub functionalities by reading our [Model sharing and uploading Page](model_sharing). You should work alongside the Hugging Face team here to decide on a fitting name for each
checkpoint and to get the required access rights to be able to upload the model under the author's organization of
*brand_new_bert*. The `push_to_hub` method, present in all models in `transformers`, is a quick and efficient way to push your checkpoint to the hub. A little snippet is pasted below:
```python
brand_new_bert.push_to_hub("brand_new_bert")
# Uncomment the following line to push to an organization.
# brand_new_bert.push_to_hub("<organization>/brand_new_bert")
```
It is worth spending some time to create fitting model cards for each checkpoint. The model cards should highlight the
specific characteristics of this particular checkpoint, *e.g.* On which dataset was the checkpoint
pretrained/fine-tuned on? On what down-stream task should the model be used? And also include some code on how to
correctly use the model.
**13. (Optional) Add notebook**
It is very helpful to add a notebook that showcases in-detail how *brand_new_bert* can be used for inference and/or
fine-tuned on a downstream task. This is not mandatory to merge your PR, but very useful for the community.
**14. Submit your finished PR**
You're done programming now and can move to the last step, which is getting your PR merged into main. Usually, the
Hugging Face team should have helped you already at this point, but it is worth taking some time to give your finished
PR a nice description and eventually add comments to your code, if you want to point out certain design choices to your
reviewer.
### Share your work!!
Now, it's time to get some credit from the community for your work! Having completed a model addition is a major
contribution to Transformers and the whole NLP community. Your code and the ported pre-trained models will certainly be
used by hundreds and possibly even thousands of developers and researchers. You should be proud of your work and share
your achievements with the community.
**You have made another model that is super easy to access for everyone in the community! 🤯**
| huggingface/transformers/blob/main/docs/source/en/add_new_model.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# ControlNet
The ControlNet model was introduced in [Adding Conditional Control to Text-to-Image Diffusion Models](https://huggingface.co/papers/2302.05543) by Lvmin Zhang, Anyi Rao, Maneesh Agrawala. It provides a greater degree of control over text-to-image generation by conditioning the model on additional inputs such as edge maps, depth maps, segmentation maps, and keypoints for pose detection.
The abstract from the paper is:
*We present ControlNet, a neural network architecture to add spatial conditioning controls to large, pretrained text-to-image diffusion models. ControlNet locks the production-ready large diffusion models, and reuses their deep and robust encoding layers pretrained with billions of images as a strong backbone to learn a diverse set of conditional controls. The neural architecture is connected with "zero convolutions" (zero-initialized convolution layers) that progressively grow the parameters from zero and ensure that no harmful noise could affect the finetuning. We test various conditioning controls, eg, edges, depth, segmentation, human pose, etc, with Stable Diffusion, using single or multiple conditions, with or without prompts. We show that the training of ControlNets is robust with small (<50k) and large (>1m) datasets. Extensive results show that ControlNet may facilitate wider applications to control image diffusion models.*
## Loading from the original format
By default the [`ControlNetModel`] should be loaded with [`~ModelMixin.from_pretrained`], but it can also be loaded
from the original format using [`FromOriginalControlnetMixin.from_single_file`] as follows:
```py
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
url = "https://huggingface.co/lllyasviel/ControlNet-v1-1/blob/main/control_v11p_sd15_canny.pth" # can also be a local path
controlnet = ControlNetModel.from_single_file(url)
url = "https://huggingface.co/runwayml/stable-diffusion-v1-5/blob/main/v1-5-pruned.safetensors" # can also be a local path
pipe = StableDiffusionControlNetPipeline.from_single_file(url, controlnet=controlnet)
```
## ControlNetModel
[[autodoc]] ControlNetModel
## ControlNetOutput
[[autodoc]] models.controlnet.ControlNetOutput
## FlaxControlNetModel
[[autodoc]] FlaxControlNetModel
## FlaxControlNetOutput
[[autodoc]] models.controlnet_flax.FlaxControlNetOutput
| huggingface/diffusers/blob/main/docs/source/en/api/models/controlnet.md |
Gradio Demo: altair_plot
```
!pip install -q gradio altair vega_datasets
```
```
import altair as alt
import gradio as gr
import numpy as np
import pandas as pd
from vega_datasets import data
def make_plot(plot_type):
if plot_type == "scatter_plot":
cars = data.cars()
return alt.Chart(cars).mark_point().encode(
x='Horsepower',
y='Miles_per_Gallon',
color='Origin',
)
elif plot_type == "heatmap":
# Compute x^2 + y^2 across a 2D grid
x, y = np.meshgrid(range(-5, 5), range(-5, 5))
z = x ** 2 + y ** 2
# Convert this grid to columnar data expected by Altair
source = pd.DataFrame({'x': x.ravel(),
'y': y.ravel(),
'z': z.ravel()})
return alt.Chart(source).mark_rect().encode(
x='x:O',
y='y:O',
color='z:Q'
)
elif plot_type == "us_map":
states = alt.topo_feature(data.us_10m.url, 'states')
source = data.income.url
return alt.Chart(source).mark_geoshape().encode(
shape='geo:G',
color='pct:Q',
tooltip=['name:N', 'pct:Q'],
facet=alt.Facet('group:N', columns=2),
).transform_lookup(
lookup='id',
from_=alt.LookupData(data=states, key='id'),
as_='geo'
).properties(
width=300,
height=175,
).project(
type='albersUsa'
)
elif plot_type == "interactive_barplot":
source = data.movies.url
pts = alt.selection(type="single", encodings=['x'])
rect = alt.Chart(data.movies.url).mark_rect().encode(
alt.X('IMDB_Rating:Q', bin=True),
alt.Y('Rotten_Tomatoes_Rating:Q', bin=True),
alt.Color('count()',
scale=alt.Scale(scheme='greenblue'),
legend=alt.Legend(title='Total Records')
)
)
circ = rect.mark_point().encode(
alt.ColorValue('grey'),
alt.Size('count()',
legend=alt.Legend(title='Records in Selection')
)
).transform_filter(
pts
)
bar = alt.Chart(source).mark_bar().encode(
x='Major_Genre:N',
y='count()',
color=alt.condition(pts, alt.ColorValue("steelblue"), alt.ColorValue("grey"))
).properties(
width=550,
height=200
).add_selection(pts)
plot = alt.vconcat(
rect + circ,
bar
).resolve_legend(
color="independent",
size="independent"
)
return plot
elif plot_type == "radial":
source = pd.DataFrame({"values": [12, 23, 47, 6, 52, 19]})
base = alt.Chart(source).encode(
theta=alt.Theta("values:Q", stack=True),
radius=alt.Radius("values", scale=alt.Scale(type="sqrt", zero=True, rangeMin=20)),
color="values:N",
)
c1 = base.mark_arc(innerRadius=20, stroke="#fff")
c2 = base.mark_text(radiusOffset=10).encode(text="values:Q")
return c1 + c2
elif plot_type == "multiline":
source = data.stocks()
highlight = alt.selection(type='single', on='mouseover',
fields=['symbol'], nearest=True)
base = alt.Chart(source).encode(
x='date:T',
y='price:Q',
color='symbol:N'
)
points = base.mark_circle().encode(
opacity=alt.value(0)
).add_selection(
highlight
).properties(
width=600
)
lines = base.mark_line().encode(
size=alt.condition(~highlight, alt.value(1), alt.value(3))
)
return points + lines
with gr.Blocks() as demo:
button = gr.Radio(label="Plot type",
choices=['scatter_plot', 'heatmap', 'us_map',
'interactive_barplot', "radial", "multiline"], value='scatter_plot')
plot = gr.Plot(label="Plot")
button.change(make_plot, inputs=button, outputs=[plot])
demo.load(make_plot, inputs=[button], outputs=[plot])
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/altair_plot/run.ipynb |
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Keras callbacks
When training a Transformers model with Keras, there are some library-specific callbacks available to automate common
tasks:
## KerasMetricCallback
[[autodoc]] KerasMetricCallback
## PushToHubCallback
[[autodoc]] PushToHubCallback
| huggingface/transformers/blob/main/docs/source/en/main_classes/keras_callbacks.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Kandinsky
[[open-in-colab]]
The Kandinsky models are a series of multilingual text-to-image generation models. The Kandinsky 2.0 model uses two multilingual text encoders and concatenates those results for the UNet.
[Kandinsky 2.1](../api/pipelines/kandinsky) changes the architecture to include an image prior model ([`CLIP`](https://huggingface.co/docs/transformers/model_doc/clip)) to generate a mapping between text and image embeddings. The mapping provides better text-image alignment and it is used with the text embeddings during training, leading to higher quality results. Finally, Kandinsky 2.1 uses a [Modulating Quantized Vectors (MoVQ)](https://huggingface.co/papers/2209.09002) decoder - which adds a spatial conditional normalization layer to increase photorealism - to decode the latents into images.
[Kandinsky 2.2](../api/pipelines/kandinsky_v22) improves on the previous model by replacing the image encoder of the image prior model with a larger CLIP-ViT-G model to improve quality. The image prior model was also retrained on images with different resolutions and aspect ratios to generate higher-resolution images and different image sizes.
[Kandinsky 3](../api/pipelines/kandinsky3) simplifies the architecture and shifts away from the two-stage generation process involving the prior model and diffusion model. Instead, Kandinsky 3 uses [Flan-UL2](https://huggingface.co/google/flan-ul2) to encode text, a UNet with [BigGan-deep](https://hf.co/papers/1809.11096) blocks, and [Sber-MoVQGAN](https://github.com/ai-forever/MoVQGAN) to decode the latents into images. Text understanding and generated image quality are primarily achieved by using a larger text encoder and UNet.
This guide will show you how to use the Kandinsky models for text-to-image, image-to-image, inpainting, interpolation, and more.
Before you begin, make sure you have the following libraries installed:
```py
# uncomment to install the necessary libraries in Colab
#!pip install -q diffusers transformers accelerate
```
<Tip warning={true}>
Kandinsky 2.1 and 2.2 usage is very similar! The only difference is Kandinsky 2.2 doesn't accept `prompt` as an input when decoding the latents. Instead, Kandinsky 2.2 only accepts `image_embeds` during decoding.
<br>
Kandinsky 3 has a more concise architecture and it doesn't require a prior model. This means it's usage is identical to other diffusion models like [Stable Diffusion XL](sdxl).
</Tip>
## Text-to-image
To use the Kandinsky models for any task, you always start by setting up the prior pipeline to encode the prompt and generate the image embeddings. The prior pipeline also generates `negative_image_embeds` that correspond to the negative prompt `""`. For better results, you can pass an actual `negative_prompt` to the prior pipeline, but this'll increase the effective batch size of the prior pipeline by 2x.
<hfoptions id="text-to-image">
<hfoption id="Kandinsky 2.1">
```py
from diffusers import KandinskyPriorPipeline, KandinskyPipeline
import torch
prior_pipeline = KandinskyPriorPipeline.from_pretrained("kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16).to("cuda")
pipeline = KandinskyPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16).to("cuda")
prompt = "A alien cheeseburger creature eating itself, claymation, cinematic, moody lighting"
negative_prompt = "low quality, bad quality" # optional to include a negative prompt, but results are usually better
image_embeds, negative_image_embeds = prior_pipeline(prompt, negative_prompt, guidance_scale=1.0).to_tuple()
```
Now pass all the prompts and embeddings to the [`KandinskyPipeline`] to generate an image:
```py
image = pipeline(prompt, image_embeds=image_embeds, negative_prompt=negative_prompt, negative_image_embeds=negative_image_embeds, height=768, width=768).images[0]
image
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/kandinsky-docs/cheeseburger.png"/>
</div>
</hfoption>
<hfoption id="Kandinsky 2.2">
```py
from diffusers import KandinskyV22PriorPipeline, KandinskyV22Pipeline
import torch
prior_pipeline = KandinskyV22PriorPipeline.from_pretrained("kandinsky-community/kandinsky-2-2-prior", torch_dtype=torch.float16).to("cuda")
pipeline = KandinskyV22Pipeline.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16).to("cuda")
prompt = "A alien cheeseburger creature eating itself, claymation, cinematic, moody lighting"
negative_prompt = "low quality, bad quality" # optional to include a negative prompt, but results are usually better
image_embeds, negative_image_embeds = prior_pipeline(prompt, guidance_scale=1.0).to_tuple()
```
Pass the `image_embeds` and `negative_image_embeds` to the [`KandinskyV22Pipeline`] to generate an image:
```py
image = pipeline(image_embeds=image_embeds, negative_image_embeds=negative_image_embeds, height=768, width=768).images[0]
image
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/kandinsky-text-to-image.png"/>
</div>
</hfoption>
<hfoption id="Kandinsky 3">
Kandinsky 3 doesn't require a prior model so you can directly load the [`Kandinsky3Pipeline`] and pass a prompt to generate an image:
```py
from diffusers import Kandinsky3Pipeline
import torch
pipeline = Kandinsky3Pipeline.from_pretrained("kandinsky-community/kandinsky-3", variant="fp16", torch_dtype=torch.float16)
pipeline.enable_model_cpu_offload()
prompt = "A alien cheeseburger creature eating itself, claymation, cinematic, moody lighting"
image = pipeline(prompt).images[0]
image
```
</hfoption>
</hfoptions>
🤗 Diffusers also provides an end-to-end API with the [`KandinskyCombinedPipeline`] and [`KandinskyV22CombinedPipeline`], meaning you don't have to separately load the prior and text-to-image pipeline. The combined pipeline automatically loads both the prior model and the decoder. You can still set different values for the prior pipeline with the `prior_guidance_scale` and `prior_num_inference_steps` parameters if you want.
Use the [`AutoPipelineForText2Image`] to automatically call the combined pipelines under the hood:
<hfoptions id="text-to-image">
<hfoption id="Kandinsky 2.1">
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
pipeline.enable_model_cpu_offload()
prompt = "A alien cheeseburger creature eating itself, claymation, cinematic, moody lighting"
negative_prompt = "low quality, bad quality"
image = pipeline(prompt=prompt, negative_prompt=negative_prompt, prior_guidance_scale=1.0, guidance_scale=4.0, height=768, width=768).images[0]
image
```
</hfoption>
<hfoption id="Kandinsky 2.2">
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16)
pipeline.enable_model_cpu_offload()
prompt = "A alien cheeseburger creature eating itself, claymation, cinematic, moody lighting"
negative_prompt = "low quality, bad quality"
image = pipeline(prompt=prompt, negative_prompt=negative_prompt, prior_guidance_scale=1.0, guidance_scale=4.0, height=768, width=768).images[0]
image
```
</hfoption>
</hfoptions>
## Image-to-image
For image-to-image, pass the initial image and text prompt to condition the image to the pipeline. Start by loading the prior pipeline:
<hfoptions id="image-to-image">
<hfoption id="Kandinsky 2.1">
```py
import torch
from diffusers import KandinskyImg2ImgPipeline, KandinskyPriorPipeline
prior_pipeline = KandinskyPriorPipeline.from_pretrained("kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
pipeline = KandinskyImg2ImgPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
```
</hfoption>
<hfoption id="Kandinsky 2.2">
```py
import torch
from diffusers import KandinskyV22Img2ImgPipeline, KandinskyPriorPipeline
prior_pipeline = KandinskyPriorPipeline.from_pretrained("kandinsky-community/kandinsky-2-2-prior", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
pipeline = KandinskyV22Img2ImgPipeline.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
```
</hfoption>
<hfoption id="Kandinsky 3">
Kandinsky 3 doesn't require a prior model so you can directly load the image-to-image pipeline:
```py
from diffusers import Kandinsky3Img2ImgPipeline
from diffusers.utils import load_image
import torch
pipeline = Kandinsky3Img2ImgPipeline.from_pretrained("kandinsky-community/kandinsky-3", variant="fp16", torch_dtype=torch.float16)
pipeline.enable_model_cpu_offload()
```
</hfoption>
</hfoptions>
Download an image to condition on:
```py
from diffusers.utils import load_image
# download image
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
original_image = load_image(url)
original_image = original_image.resize((768, 512))
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"/>
</div>
Generate the `image_embeds` and `negative_image_embeds` with the prior pipeline:
```py
prompt = "A fantasy landscape, Cinematic lighting"
negative_prompt = "low quality, bad quality"
image_embeds, negative_image_embeds = prior_pipeline(prompt, negative_prompt).to_tuple()
```
Now pass the original image, and all the prompts and embeddings to the pipeline to generate an image:
<hfoptions id="image-to-image">
<hfoption id="Kandinsky 2.1">
```py
from diffusers.utils import make_image_grid
image = pipeline(prompt, negative_prompt=negative_prompt, image=original_image, image_embeds=image_embeds, negative_image_embeds=negative_image_embeds, height=768, width=768, strength=0.3).images[0]
make_image_grid([original_image.resize((512, 512)), image.resize((512, 512))], rows=1, cols=2)
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/kandinsky-docs/img2img_fantasyland.png"/>
</div>
</hfoption>
<hfoption id="Kandinsky 2.2">
```py
from diffusers.utils import make_image_grid
image = pipeline(image=original_image, image_embeds=image_embeds, negative_image_embeds=negative_image_embeds, height=768, width=768, strength=0.3).images[0]
make_image_grid([original_image.resize((512, 512)), image.resize((512, 512))], rows=1, cols=2)
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/kandinsky-image-to-image.png"/>
</div>
</hfoption>
<hfoption id="Kandinsky 3">
```py
image = pipeline(prompt, negative_prompt=negative_prompt, image=image, strength=0.75, num_inference_steps=25).images[0]
image
```
</hfoption>
</hfoptions>
🤗 Diffusers also provides an end-to-end API with the [`KandinskyImg2ImgCombinedPipeline`] and [`KandinskyV22Img2ImgCombinedPipeline`], meaning you don't have to separately load the prior and image-to-image pipeline. The combined pipeline automatically loads both the prior model and the decoder. You can still set different values for the prior pipeline with the `prior_guidance_scale` and `prior_num_inference_steps` parameters if you want.
Use the [`AutoPipelineForImage2Image`] to automatically call the combined pipelines under the hood:
<hfoptions id="image-to-image">
<hfoption id="Kandinsky 2.1">
```py
from diffusers import AutoPipelineForImage2Image
from diffusers.utils import make_image_grid, load_image
import torch
pipeline = AutoPipelineForImage2Image.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16, use_safetensors=True)
pipeline.enable_model_cpu_offload()
prompt = "A fantasy landscape, Cinematic lighting"
negative_prompt = "low quality, bad quality"
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
original_image = load_image(url)
original_image.thumbnail((768, 768))
image = pipeline(prompt=prompt, negative_prompt=negative_prompt, image=original_image, strength=0.3).images[0]
make_image_grid([original_image.resize((512, 512)), image.resize((512, 512))], rows=1, cols=2)
```
</hfoption>
<hfoption id="Kandinsky 2.2">
```py
from diffusers import AutoPipelineForImage2Image
from diffusers.utils import make_image_grid, load_image
import torch
pipeline = AutoPipelineForImage2Image.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16)
pipeline.enable_model_cpu_offload()
prompt = "A fantasy landscape, Cinematic lighting"
negative_prompt = "low quality, bad quality"
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
original_image = load_image(url)
original_image.thumbnail((768, 768))
image = pipeline(prompt=prompt, negative_prompt=negative_prompt, image=original_image, strength=0.3).images[0]
make_image_grid([original_image.resize((512, 512)), image.resize((512, 512))], rows=1, cols=2)
```
</hfoption>
</hfoptions>
## Inpainting
<Tip warning={true}>
⚠️ The Kandinsky models use ⬜️ **white pixels** to represent the masked area now instead of black pixels. If you are using [`KandinskyInpaintPipeline`] in production, you need to change the mask to use white pixels:
```py
# For PIL input
import PIL.ImageOps
mask = PIL.ImageOps.invert(mask)
# For PyTorch and NumPy input
mask = 1 - mask
```
</Tip>
For inpainting, you'll need the original image, a mask of the area to replace in the original image, and a text prompt of what to inpaint. Load the prior pipeline:
<hfoptions id="inpaint">
<hfoption id="Kandinsky 2.1">
```py
from diffusers import KandinskyInpaintPipeline, KandinskyPriorPipeline
from diffusers.utils import load_image, make_image_grid
import torch
import numpy as np
from PIL import Image
prior_pipeline = KandinskyPriorPipeline.from_pretrained("kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
pipeline = KandinskyInpaintPipeline.from_pretrained("kandinsky-community/kandinsky-2-1-inpaint", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
```
</hfoption>
<hfoption id="Kandinsky 2.2">
```py
from diffusers import KandinskyV22InpaintPipeline, KandinskyV22PriorPipeline
from diffusers.utils import load_image, make_image_grid
import torch
import numpy as np
from PIL import Image
prior_pipeline = KandinskyV22PriorPipeline.from_pretrained("kandinsky-community/kandinsky-2-2-prior", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
pipeline = KandinskyV22InpaintPipeline.from_pretrained("kandinsky-community/kandinsky-2-2-decoder-inpaint", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
```
</hfoption>
</hfoptions>
Load an initial image and create a mask:
```py
init_image = load_image("https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinsky/cat.png")
mask = np.zeros((768, 768), dtype=np.float32)
# mask area above cat's head
mask[:250, 250:-250] = 1
```
Generate the embeddings with the prior pipeline:
```py
prompt = "a hat"
prior_output = prior_pipeline(prompt)
```
Now pass the initial image, mask, and prompt and embeddings to the pipeline to generate an image:
<hfoptions id="inpaint">
<hfoption id="Kandinsky 2.1">
```py
output_image = pipeline(prompt, image=init_image, mask_image=mask, **prior_output, height=768, width=768, num_inference_steps=150).images[0]
mask = Image.fromarray((mask*255).astype('uint8'), 'L')
make_image_grid([init_image, mask, output_image], rows=1, cols=3)
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/kandinsky-docs/inpaint_cat_hat.png"/>
</div>
</hfoption>
<hfoption id="Kandinsky 2.2">
```py
output_image = pipeline(image=init_image, mask_image=mask, **prior_output, height=768, width=768, num_inference_steps=150).images[0]
mask = Image.fromarray((mask*255).astype('uint8'), 'L')
make_image_grid([init_image, mask, output_image], rows=1, cols=3)
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/kandinskyv22-inpaint.png"/>
</div>
</hfoption>
</hfoptions>
You can also use the end-to-end [`KandinskyInpaintCombinedPipeline`] and [`KandinskyV22InpaintCombinedPipeline`] to call the prior and decoder pipelines together under the hood. Use the [`AutoPipelineForInpainting`] for this:
<hfoptions id="inpaint">
<hfoption id="Kandinsky 2.1">
```py
import torch
import numpy as np
from PIL import Image
from diffusers import AutoPipelineForInpainting
from diffusers.utils import load_image, make_image_grid
pipe = AutoPipelineForInpainting.from_pretrained("kandinsky-community/kandinsky-2-1-inpaint", torch_dtype=torch.float16)
pipe.enable_model_cpu_offload()
init_image = load_image("https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinsky/cat.png")
mask = np.zeros((768, 768), dtype=np.float32)
# mask area above cat's head
mask[:250, 250:-250] = 1
prompt = "a hat"
output_image = pipe(prompt=prompt, image=init_image, mask_image=mask).images[0]
mask = Image.fromarray((mask*255).astype('uint8'), 'L')
make_image_grid([init_image, mask, output_image], rows=1, cols=3)
```
</hfoption>
<hfoption id="Kandinsky 2.2">
```py
import torch
import numpy as np
from PIL import Image
from diffusers import AutoPipelineForInpainting
from diffusers.utils import load_image, make_image_grid
pipe = AutoPipelineForInpainting.from_pretrained("kandinsky-community/kandinsky-2-2-decoder-inpaint", torch_dtype=torch.float16)
pipe.enable_model_cpu_offload()
init_image = load_image("https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinsky/cat.png")
mask = np.zeros((768, 768), dtype=np.float32)
# mask area above cat's head
mask[:250, 250:-250] = 1
prompt = "a hat"
output_image = pipe(prompt=prompt, image=original_image, mask_image=mask).images[0]
mask = Image.fromarray((mask*255).astype('uint8'), 'L')
make_image_grid([init_image, mask, output_image], rows=1, cols=3)
```
</hfoption>
</hfoptions>
## Interpolation
Interpolation allows you to explore the latent space between the image and text embeddings which is a cool way to see some of the prior model's intermediate outputs. Load the prior pipeline and two images you'd like to interpolate:
<hfoptions id="interpolate">
<hfoption id="Kandinsky 2.1">
```py
from diffusers import KandinskyPriorPipeline, KandinskyPipeline
from diffusers.utils import load_image, make_image_grid
import torch
prior_pipeline = KandinskyPriorPipeline.from_pretrained("kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
img_1 = load_image("https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinsky/cat.png")
img_2 = load_image("https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinsky/starry_night.jpeg")
make_image_grid([img_1.resize((512,512)), img_2.resize((512,512))], rows=1, cols=2)
```
</hfoption>
<hfoption id="Kandinsky 2.2">
```py
from diffusers import KandinskyV22PriorPipeline, KandinskyV22Pipeline
from diffusers.utils import load_image, make_image_grid
import torch
prior_pipeline = KandinskyV22PriorPipeline.from_pretrained("kandinsky-community/kandinsky-2-2-prior", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
img_1 = load_image("https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinsky/cat.png")
img_2 = load_image("https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinsky/starry_night.jpeg")
make_image_grid([img_1.resize((512,512)), img_2.resize((512,512))], rows=1, cols=2)
```
</hfoption>
</hfoptions>
<div class="flex gap-4">
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinsky/cat.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">a cat</figcaption>
</div>
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinsky/starry_night.jpeg"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">Van Gogh's Starry Night painting</figcaption>
</div>
</div>
Specify the text or images to interpolate, and set the weights for each text or image. Experiment with the weights to see how they affect the interpolation!
```py
images_texts = ["a cat", img_1, img_2]
weights = [0.3, 0.3, 0.4]
```
Call the `interpolate` function to generate the embeddings, and then pass them to the pipeline to generate the image:
<hfoptions id="interpolate">
<hfoption id="Kandinsky 2.1">
```py
# prompt can be left empty
prompt = ""
prior_out = prior_pipeline.interpolate(images_texts, weights)
pipeline = KandinskyPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
image = pipeline(prompt, **prior_out, height=768, width=768).images[0]
image
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/kandinsky-docs/starry_cat.png"/>
</div>
</hfoption>
<hfoption id="Kandinsky 2.2">
```py
# prompt can be left empty
prompt = ""
prior_out = prior_pipeline.interpolate(images_texts, weights)
pipeline = KandinskyV22Pipeline.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
image = pipeline(prompt, **prior_out, height=768, width=768).images[0]
image
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/kandinskyv22-interpolate.png"/>
</div>
</hfoption>
</hfoptions>
## ControlNet
<Tip warning={true}>
⚠️ ControlNet is only supported for Kandinsky 2.2!
</Tip>
ControlNet enables conditioning large pretrained diffusion models with additional inputs such as a depth map or edge detection. For example, you can condition Kandinsky 2.2 with a depth map so the model understands and preserves the structure of the depth image.
Let's load an image and extract it's depth map:
```py
from diffusers.utils import load_image
img = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinskyv22/cat.png"
).resize((768, 768))
img
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinskyv22/cat.png"/>
</div>
Then you can use the `depth-estimation` [`~transformers.Pipeline`] from 🤗 Transformers to process the image and retrieve the depth map:
```py
import torch
import numpy as np
from transformers import pipeline
def make_hint(image, depth_estimator):
image = depth_estimator(image)["depth"]
image = np.array(image)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
detected_map = torch.from_numpy(image).float() / 255.0
hint = detected_map.permute(2, 0, 1)
return hint
depth_estimator = pipeline("depth-estimation")
hint = make_hint(img, depth_estimator).unsqueeze(0).half().to("cuda")
```
### Text-to-image [[controlnet-text-to-image]]
Load the prior pipeline and the [`KandinskyV22ControlnetPipeline`]:
```py
from diffusers import KandinskyV22PriorPipeline, KandinskyV22ControlnetPipeline
prior_pipeline = KandinskyV22PriorPipeline.from_pretrained(
"kandinsky-community/kandinsky-2-2-prior", torch_dtype=torch.float16, use_safetensors=True
).to("cuda")
pipeline = KandinskyV22ControlnetPipeline.from_pretrained(
"kandinsky-community/kandinsky-2-2-controlnet-depth", torch_dtype=torch.float16
).to("cuda")
```
Generate the image embeddings from a prompt and negative prompt:
```py
prompt = "A robot, 4k photo"
negative_prior_prompt = "lowres, text, error, cropped, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, out of frame, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck, username, watermark, signature"
generator = torch.Generator(device="cuda").manual_seed(43)
image_emb, zero_image_emb = prior_pipeline(
prompt=prompt, negative_prompt=negative_prior_prompt, generator=generator
).to_tuple()
```
Finally, pass the image embeddings and the depth image to the [`KandinskyV22ControlnetPipeline`] to generate an image:
```py
image = pipeline(image_embeds=image_emb, negative_image_embeds=zero_image_emb, hint=hint, num_inference_steps=50, generator=generator, height=768, width=768).images[0]
image
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinskyv22/robot_cat_text2img.png"/>
</div>
### Image-to-image [[controlnet-image-to-image]]
For image-to-image with ControlNet, you'll need to use the:
- [`KandinskyV22PriorEmb2EmbPipeline`] to generate the image embeddings from a text prompt and an image
- [`KandinskyV22ControlnetImg2ImgPipeline`] to generate an image from the initial image and the image embeddings
Process and extract a depth map of an initial image of a cat with the `depth-estimation` [`~transformers.Pipeline`] from 🤗 Transformers:
```py
import torch
import numpy as np
from diffusers import KandinskyV22PriorEmb2EmbPipeline, KandinskyV22ControlnetImg2ImgPipeline
from diffusers.utils import load_image
from transformers import pipeline
img = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinskyv22/cat.png"
).resize((768, 768))
def make_hint(image, depth_estimator):
image = depth_estimator(image)["depth"]
image = np.array(image)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
detected_map = torch.from_numpy(image).float() / 255.0
hint = detected_map.permute(2, 0, 1)
return hint
depth_estimator = pipeline("depth-estimation")
hint = make_hint(img, depth_estimator).unsqueeze(0).half().to("cuda")
```
Load the prior pipeline and the [`KandinskyV22ControlnetImg2ImgPipeline`]:
```py
prior_pipeline = KandinskyV22PriorEmb2EmbPipeline.from_pretrained(
"kandinsky-community/kandinsky-2-2-prior", torch_dtype=torch.float16, use_safetensors=True
).to("cuda")
pipeline = KandinskyV22ControlnetImg2ImgPipeline.from_pretrained(
"kandinsky-community/kandinsky-2-2-controlnet-depth", torch_dtype=torch.float16
).to("cuda")
```
Pass a text prompt and the initial image to the prior pipeline to generate the image embeddings:
```py
prompt = "A robot, 4k photo"
negative_prior_prompt = "lowres, text, error, cropped, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, out of frame, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck, username, watermark, signature"
generator = torch.Generator(device="cuda").manual_seed(43)
img_emb = prior_pipeline(prompt=prompt, image=img, strength=0.85, generator=generator)
negative_emb = prior_pipeline(prompt=negative_prior_prompt, image=img, strength=1, generator=generator)
```
Now you can run the [`KandinskyV22ControlnetImg2ImgPipeline`] to generate an image from the initial image and the image embeddings:
```py
image = pipeline(image=img, strength=0.5, image_embeds=img_emb.image_embeds, negative_image_embeds=negative_emb.image_embeds, hint=hint, num_inference_steps=50, generator=generator, height=768, width=768).images[0]
make_image_grid([img.resize((512, 512)), image.resize((512, 512))], rows=1, cols=2)
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinskyv22/robot_cat.png"/>
</div>
## Optimizations
Kandinsky is unique because it requires a prior pipeline to generate the mappings, and a second pipeline to decode the latents into an image. Optimization efforts should be focused on the second pipeline because that is where the bulk of the computation is done. Here are some tips to improve Kandinsky during inference.
1. Enable [xFormers](../optimization/xformers) if you're using PyTorch < 2.0:
```diff
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
+ pipe.enable_xformers_memory_efficient_attention()
```
2. Enable `torch.compile` if you're using PyTorch >= 2.0 to automatically use scaled dot-product attention (SDPA):
```diff
pipe.unet.to(memory_format=torch.channels_last)
+ pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
```
This is the same as explicitly setting the attention processor to use [`~models.attention_processor.AttnAddedKVProcessor2_0`]:
```py
from diffusers.models.attention_processor import AttnAddedKVProcessor2_0
pipe.unet.set_attn_processor(AttnAddedKVProcessor2_0())
```
3. Offload the model to the CPU with [`~KandinskyPriorPipeline.enable_model_cpu_offload`] to avoid out-of-memory errors:
```diff
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
+ pipe.enable_model_cpu_offload()
```
4. By default, the text-to-image pipeline uses the [`DDIMScheduler`] but you can replace it with another scheduler like [`DDPMScheduler`] to see how that affects the tradeoff between inference speed and image quality:
```py
from diffusers import DDPMScheduler
from diffusers import DiffusionPipeline
scheduler = DDPMScheduler.from_pretrained("kandinsky-community/kandinsky-2-1", subfolder="ddpm_scheduler")
pipe = DiffusionPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", scheduler=scheduler, torch_dtype=torch.float16, use_safetensors=True).to("cuda")
```
| huggingface/diffusers/blob/main/docs/source/en/using-diffusers/kandinsky.md |
Gradio Demo: native_plots
```
!pip install -q gradio vega_datasets
```
```
# Downloading files from the demo repo
import os
!wget -q https://github.com/gradio-app/gradio/raw/main/demo/native_plots/bar_plot_demo.py
!wget -q https://github.com/gradio-app/gradio/raw/main/demo/native_plots/line_plot_demo.py
!wget -q https://github.com/gradio-app/gradio/raw/main/demo/native_plots/scatter_plot_demo.py
```
```
import gradio as gr
from scatter_plot_demo import scatter_plot
from line_plot_demo import line_plot
from bar_plot_demo import bar_plot
with gr.Blocks() as demo:
with gr.Tabs():
with gr.TabItem("Scatter Plot"):
scatter_plot.render()
with gr.TabItem("Line Plot"):
line_plot.render()
with gr.TabItem("Bar Plot"):
bar_plot.render()
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/native_plots/run.ipynb |
Part 1 completed![[part-1-completed]]
<CourseFloatingBanner
chapter={4}
classNames="absolute z-10 right-0 top-0"
/>
This is the end of the first part of the course! Part 2 will be released on November 15th with a big community event, see more information [here](https://huggingface.co/blog/course-launch-event).
You should now be able to fine-tune a pretrained model on a text classification problem (single or pairs of sentences) and upload the result to the Model Hub. To make sure you mastered this first section, you should do exactly that on a problem that interests you (and not necessarily in English if you speak another language)! You can find help in the [Hugging Face forums](https://discuss.huggingface.co/) and share your project in [this topic](https://discuss.huggingface.co/t/share-your-projects/6803) once you're finished.
We can't wait to see what you will build with this!
| huggingface/course/blob/main/chapters/en/chapter4/5.mdx |
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Run training on Amazon SageMaker
The documentation has been moved to [hf.co/docs/sagemaker](https://huggingface.co/docs/sagemaker). This page will be removed in `transformers` 5.0.
### Table of Content
- [Train Hugging Face models on Amazon SageMaker with the SageMaker Python SDK](https://huggingface.co/docs/sagemaker/train)
- [Deploy Hugging Face models to Amazon SageMaker with the SageMaker Python SDK](https://huggingface.co/docs/sagemaker/inference)
| huggingface/transformers/blob/main/docs/source/en/sagemaker.md |
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# LoRA for semantic similarity tasks
Low-Rank Adaptation (LoRA) is a reparametrization method that aims to reduce the number of trainable parameters with low-rank representations. The weight matrix is broken down into low-rank matrices that are trained and updated. All the pretrained model parameters remain frozen. After training, the low-rank matrices are added back to the original weights. This makes it more efficient to store and train a LoRA model because there are significantly fewer parameters.
<Tip>
💡 Read [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) to learn more about LoRA.
</Tip>
In this guide, we'll be using a LoRA [script](https://github.com/huggingface/peft/tree/main/examples/lora_dreambooth) to fine-tune a [`intfloat/e5-large-v2`](https://huggingface.co/intfloat/e5-large-v2) model on the [`smangrul/amazon_esci`](https://huggingface.co/datasets/smangrul/amazon_esci) dataset for semantic similarity tasks. Feel free to explore the script to learn how things work in greater detail!
## Setup
Start by installing 🤗 PEFT from [source](https://github.com/huggingface/peft), and then navigate to the directory containing the training scripts for fine-tuning DreamBooth with LoRA:
```bash
cd peft/examples/feature_extraction
```
Install all the necessary required libraries with:
```bash
pip install -r requirements.txt
```
Next, import all the necessary libraries:
- 🤗 Transformers for loading the `intfloat/e5-large-v2` model and tokenizer
- 🤗 Accelerate for the training loop
- 🤗 Datasets for loading and preparing the `smangrul/amazon_esci` dataset for training and inference
- 🤗 Evaluate for evaluating the model's performance
- 🤗 PEFT for setting up the LoRA configuration and creating the PEFT model
- 🤗 huggingface_hub for uploading the trained model to HF hub
- hnswlib for creating the search index and doing fast approximate nearest neighbor search
<Tip>
It is assumed that PyTorch with CUDA support is already installed.
</Tip>
## Train
Launch the training script with `accelerate launch` and pass your hyperparameters along with the `--use_peft` argument to enable LoRA.
This guide uses the following [`LoraConfig`]:
```py
peft_config = LoraConfig(
r=8,
lora_alpha=16,
bias="none",
task_type=TaskType.FEATURE_EXTRACTION,
target_modules=["key", "query", "value"],
)
```
Here's what a full set of script arguments may look like when running in Colab on a V100 GPU with standard RAM:
```bash
accelerate launch \
--mixed_precision="fp16" \
peft_lora_embedding_semantic_search.py \
--dataset_name="smangrul/amazon_esci" \
--max_length=70 --model_name_or_path="intfloat/e5-large-v2" \
--per_device_train_batch_size=64 \
--per_device_eval_batch_size=128 \
--learning_rate=5e-4 \
--weight_decay=0.0 \
--num_train_epochs 3 \
--gradient_accumulation_steps=1 \
--output_dir="results/peft_lora_e5_ecommerce_semantic_search_colab" \
--seed=42 \
--push_to_hub \
--hub_model_id="smangrul/peft_lora_e5_ecommerce_semantic_search_colab" \
--with_tracking \
--report_to="wandb" \
--use_peft \
--checkpointing_steps "epoch"
```
## Dataset for semantic similarity
The dataset we'll be using is a small subset of the [esci-data](https://github.com/amazon-science/esci-data.git) dataset (it can be found on Hub at [smangrul/amazon_esci](https://huggingface.co/datasets/smangrul/amazon_esci)).
Each sample contains a tuple of `(query, product_title, relevance_label)` where `relevance_label` is `1` if the product matches the intent of the `query`, otherwise it is `0`.
Our task is to build an embedding model that can retrieve semantically similar products given a product query.
This is usually the first stage in building a product search engine to retrieve all the potentially relevant products of a given query.
Typically, this involves using Bi-Encoder models to cross-join the query and millions of products which could blow up quickly.
Instead, you can use a Transformer model to retrieve the top K nearest similar products for a given query by
embedding the query and products in the same latent embedding space.
The millions of products are embedded offline to create a search index.
At run time, only the query is embedded by the model, and products are retrieved from the search index with a
fast approximate nearest neighbor search library such as [FAISS](https://github.com/facebookresearch/faiss) or [HNSWlib](https://github.com/nmslib/hnswlib).
The next stage involves reranking the retrieved list of products to return the most relevant ones;
this stage can utilize cross-encoder based models as the cross-join between the query and a limited set of retrieved products.
The diagram below from [awesome-semantic-search](https://github.com/rom1504/awesome-semantic-search) outlines a rough semantic search pipeline:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/semantic_search_pipeline.png"
alt="Semantic Search Pipeline"/>
</div>
For this task guide, we will explore the first stage of training an embedding model to predict semantically similar products
given a product query.
## Training script deep dive
We finetune [e5-large-v2](https://huggingface.co/intfloat/e5-large-v2) which tops the [MTEB benchmark](https://huggingface.co/spaces/mteb/leaderboard) using PEFT-LoRA.
[`AutoModelForSentenceEmbedding`] returns the query and product embeddings, and the `mean_pooling` function pools them across the sequence dimension and normalizes them:
```py
class AutoModelForSentenceEmbedding(nn.Module):
def __init__(self, model_name, tokenizer, normalize=True):
super(AutoModelForSentenceEmbedding, self).__init__()
self.model = AutoModel.from_pretrained(model_name)
self.normalize = normalize
self.tokenizer = tokenizer
def forward(self, **kwargs):
model_output = self.model(**kwargs)
embeddings = self.mean_pooling(model_output, kwargs["attention_mask"])
if self.normalize:
embeddings = torch.nn.functional.normalize(embeddings, p=2, dim=1)
return embeddings
def mean_pooling(self, model_output, attention_mask):
token_embeddings = model_output[0] # First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
def __getattr__(self, name: str):
"""Forward missing attributes to the wrapped module."""
try:
return super().__getattr__(name) # defer to nn.Module's logic
except AttributeError:
return getattr(self.model, name)
def get_cosine_embeddings(query_embs, product_embs):
return torch.sum(query_embs * product_embs, axis=1)
def get_loss(cosine_score, labels):
return torch.mean(torch.square(labels * (1 - cosine_score) + torch.clamp((1 - labels) * cosine_score, min=0.0)))
```
The `get_cosine_embeddings` function computes the cosine similarity and the `get_loss` function computes the loss. The loss enables the model to learn that a cosine score of `1` for query and product pairs is relevant, and a cosine score of `0` or below is irrelevant.
Define the [`PeftConfig`] with your LoRA hyperparameters, and create a [`PeftModel`]. We use 🤗 Accelerate for handling all device management, mixed precision training, gradient accumulation, WandB tracking, and saving/loading utilities.
## Results
The table below compares the training time, the batch size that could be fit in Colab, and the best ROC-AUC scores between a PEFT model and a fully fine-tuned model:
| Training Type | Training time per epoch (Hrs) | Batch Size that fits | ROC-AUC score (higher is better) |
| ----------------- | ------------- | ---------- | -------- |
| Pre-Trained e5-large-v2 | - | - | 0.68 |
| PEFT | 1.73 | 64 | 0.787 |
| Full Fine-Tuning | 2.33 | 32 | 0.7969 |
The PEFT-LoRA model trains **1.35X** faster and can fit **2X** batch size compared to the fully fine-tuned model, and the performance of PEFT-LoRA is comparable to the fully fine-tuned model with a relative drop of **-1.24%** in ROC-AUC. This gap can probably be closed with bigger models as mentioned in [The Power of Scale for Parameter-Efficient Prompt Tuning
](https://huggingface.co/papers/2104.08691).
## Inference
Let's go! Now we have the model, we need to create a search index of all the products in our catalog.
Please refer to `peft_lora_embedding_semantic_similarity_inference.ipynb` for the complete inference code.
1. Get a list of ids to products which we can call `ids_to_products_dict`:
```bash
{0: 'RamPro 10" All Purpose Utility Air Tires/Wheels with a 5/8" Diameter Hole with Double Sealed Bearings (Pack of 2)',
1: 'MaxAuto 2-Pack 13x5.00-6 2PLY Turf Mower Tractor Tire with Yellow Rim, (3" Centered Hub, 3/4" Bushings )',
2: 'NEIKO 20601A 14.5 inch Steel Tire Spoon Lever Iron Tool Kit | Professional Tire Changing Tool for Motorcycle, Dirt Bike, Lawn Mower | 3 pcs Tire Spoons | 3 Rim Protector | Valve Tool | 6 Valve Cores',
3: '2PK 13x5.00-6 13x5.00x6 13x5x6 13x5-6 2PLY Turf Mower Tractor Tire with Gray Rim',
4: '(Set of 2) 15x6.00-6 Husqvarna/Poulan Tire Wheel Assy .75" Bearing',
5: 'MaxAuto 2 Pcs 16x6.50-8 Lawn Mower Tire for Garden Tractors Ridings, 4PR, Tubeless',
6: 'Dr.Roc Tire Spoon Lever Dirt Bike Lawn Mower Motorcycle Tire Changing Tools with Durable Bag 3 Tire Irons 2 Rim Protectors 1 Valve Stems Set TR412 TR413',
7: 'MARASTAR 21446-2PK 15x6.00-6" Front Tire Assembly Replacement-Craftsman Mower, Pack of 2',
8: '15x6.00-6" Front Tire Assembly Replacement for 100 and 300 Series John Deere Riding Mowers - 2 pack',
9: 'Honda HRR Wheel Kit (2 Front 44710-VL0-L02ZB, 2 Back 42710-VE2-M02ZE)',
10: 'Honda 42710-VE2-M02ZE (Replaces 42710-VE2-M01ZE) Lawn Mower Rear Wheel Set of 2' ...
```
2. Use the trained [smangrul/peft_lora_e5_ecommerce_semantic_search_colab](https://huggingface.co/smangrul/peft_lora_e5_ecommerce_semantic_search_colab) model to get the product embeddings:
```py
# base model
model = AutoModelForSentenceEmbedding(model_name_or_path, tokenizer)
# peft config and wrapping
model = PeftModel.from_pretrained(model, peft_model_id)
device = "cuda"
model.to(device)
model.eval()
model = model.merge_and_unload()
import numpy as np
num_products= len(dataset)
d = 1024
product_embeddings_array = np.zeros((num_products, d))
for step, batch in enumerate(tqdm(dataloader)):
with torch.no_grad():
with torch.amp.autocast(dtype=torch.bfloat16, device_type="cuda"):
product_embs = model(**{k:v.to(device) for k, v in batch.items()}).detach().float().cpu()
start_index = step*batch_size
end_index = start_index+batch_size if (start_index+batch_size) < num_products else num_products
product_embeddings_array[start_index:end_index] = product_embs
del product_embs, batch
```
3. Create a search index using HNSWlib:
```py
def construct_search_index(dim, num_elements, data):
# Declaring index
search_index = hnswlib.Index(space = 'ip', dim = dim) # possible options are l2, cosine or ip
# Initializing index - the maximum number of elements should be known beforehand
search_index.init_index(max_elements = num_elements, ef_construction = 200, M = 100)
# Element insertion (can be called several times):
ids = np.arange(num_elements)
search_index.add_items(data, ids)
return search_index
product_search_index = construct_search_index(d, num_products, product_embeddings_array)
```
4. Get the query embeddings and nearest neighbors:
```py
def get_query_embeddings(query, model, tokenizer, device):
inputs = tokenizer(query, padding="max_length", max_length=70, truncation=True, return_tensors="pt")
model.eval()
with torch.no_grad():
query_embs = model(**{k:v.to(device) for k, v in inputs.items()}).detach().cpu()
return query_embs[0]
def get_nearest_neighbours(k, search_index, query_embeddings, ids_to_products_dict, threshold=0.7):
# Controlling the recall by setting ef:
search_index.set_ef(100) # ef should always be > k
# Query dataset, k - number of the closest elements (returns 2 numpy arrays)
labels, distances = search_index.knn_query(query_embeddings, k = k)
return [(ids_to_products_dict[label], (1-distance)) for label, distance in zip(labels[0], distances[0]) if (1-distance)>=threshold]
```
5. Let's test it out with the query `deep learning books`:
```py
query = "deep learning books"
k = 10
query_embeddings = get_query_embeddings(query, model, tokenizer, device)
search_results = get_nearest_neighbours(k, product_search_index, query_embeddings, ids_to_products_dict, threshold=0.7)
print(f"{query=}")
for product, cosine_sim_score in search_results:
print(f"cosine_sim_score={round(cosine_sim_score,2)} {product=}")
```
Output:
```bash
query='deep learning books'
cosine_sim_score=0.95 product='Deep Learning (The MIT Press Essential Knowledge series)'
cosine_sim_score=0.93 product='Practical Deep Learning: A Python-Based Introduction'
cosine_sim_score=0.9 product='Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems'
cosine_sim_score=0.9 product='Machine Learning: A Hands-On, Project-Based Introduction to Machine Learning for Absolute Beginners: Mastering Engineering ML Systems using Scikit-Learn and TensorFlow'
cosine_sim_score=0.9 product='Mastering Machine Learning on AWS: Advanced machine learning in Python using SageMaker, Apache Spark, and TensorFlow'
cosine_sim_score=0.9 product='The Hundred-Page Machine Learning Book'
cosine_sim_score=0.89 product='Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems'
cosine_sim_score=0.89 product='Machine Learning: A Journey from Beginner to Advanced Including Deep Learning, Scikit-learn and Tensorflow'
cosine_sim_score=0.88 product='Mastering Machine Learning with scikit-learn'
cosine_sim_score=0.88 product='Mastering Machine Learning with scikit-learn - Second Edition: Apply effective learning algorithms to real-world problems using scikit-learn'
```
Books on deep learning and machine learning are retrieved even though `machine learning` wasn't included in the query. This means the model has learned that these books are semantically relevant to the query based on the purchase behavior of customers on Amazon.
The next steps would ideally involve using ONNX/TensorRT to optimize the model and using a Triton server to host it. Check out 🤗 [Optimum](https://huggingface.co/docs/optimum/index) for related optimizations for efficient serving!
| huggingface/peft/blob/main/docs/source/task_guides/semantic-similarity-lora.md |
How to configure SAML SSO with Okta
In this guide, we will use Okta as the SSO provider and with the Security Assertion Markup Language (SAML) protocol as our preferred identity protocol.
We currently support SP-initiated and IdP-initiated authentication. User provisioning is not yet supported at this time.
<Tip warning={true}>
This feature is part of the <a href="https://huggingface.co/enterprise" target="_blank">Enterprise Hub</a>.
</Tip>
### Step 1: Create a new application in your Identity Provider
Open a new tab/window in your browser and sign in to your Okta account.
Navigate to "Admin/Applications" and click the "Create App Integration" button.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-okta-guide-1.png"/>
</div>
Then choose an "SAML 2.0" application and click "Create".
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-okta-guide-saml-1.png"/>
</div>
### Step 2: Configure your application on Okta
Open a new tab/window in your browser and navigate to the SSO section of your organization's settings. Select the SAML protocol.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-navigation-settings.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-navigation-settings-dark.png"/>
</div>
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-settings-saml.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-settings-saml-dark.png"/>
</div>
Copy the "Assertion Consumer Service URL" from the organization's settings on Hugging Face, and paste it in the "Single sign-on URL" field on Okta.
The URL looks like this: `https://huggingface.co/organizations/[organizationIdentifier]/saml/consume`.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-okta-guide-saml-2.png"/>
</div>
On Okta, set the following settings:
* Set Audience URI (SP Entity Id) to match the "SP Entity ID" value on Hugging Face.
* Set Name ID format to EmailAddress.
* Under "Show Advanced Settings", verify that Response and Assertion Signature are set to: Signed.
Save your new application.
### Step 3: Finalize configuration on Hugging Face
In your Okta application, under "Sign On/Settings/More details", find the following fields:
- Sign-on URL
- Public certificate
- SP Entity ID
You will need them to finalize the SSO setup on Hugging Face.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-okta-guide-saml-4.png"/>
</div>
In the SSO section of your organization's settings, copy-paste these values from Okta:
- Sign-on URL
- SP Entity ID
- Public certificate
The public certificate must have the following format:
```
-----BEGIN CERTIFICATE-----
{certificate}
-----END CERTIFICATE-----
```
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-okta-guide-saml-5.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-okta-guide-saml-5-dark.png"/>
</div>
You can now click on "Update and Test SAML configuration" to save the settings.
You should be redirected to your SSO provider (IdP) login prompt. Once logged in, you'll be redirected to your organization's settings page.
A green check mark near the SAML selector will attest that the test was successful.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-okta-guide-saml-6.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-okta-guide-saml-6-dark.png"/>
</div>
### Step 4: Enable SSO in your organization
Now that Single Sign-On is configured and tested, you can enable it for members of your organization by clicking on the "Enable" button.
Once enabled, members of your organization must complete the SSO authentication flow described in the [How does it work?](./security-sso#how-does-it-work) section.
| huggingface/hub-docs/blob/main/docs/hub/security-sso-okta-saml.md |
create-svelte
Everything you need to build a Svelte project, powered by [`create-svelte`](https://github.com/sveltejs/kit/tree/master/packages/create-svelte).
## Creating a project
If you're seeing this, you've probably already done this step. Congrats!
```bash
# create a new project in the current directory
npm create svelte@latest
# create a new project in my-app
npm create svelte@latest my-app
```
## Developing
Once you've created a project and installed dependencies with `npm install` (or `pnpm install` or `yarn`), start a development server:
```bash
npm run dev
# or start the server and open the app in a new browser tab
npm run dev -- --open
```
## Building
To create a production version of your app:
```bash
npm run build
```
You can preview the production build with `npm run preview`.
> To deploy your app, you may need to install an [adapter](https://kit.svelte.dev/docs/adapters) for your target environment.
| gradio-app/gradio/blob/main/js/_website/README.md |
EfficientNet
**EfficientNet** is a convolutional neural network architecture and scaling method that uniformly scales all dimensions of depth/width/resolution using a *compound coefficient*. Unlike conventional practice that arbitrary scales these factors, the EfficientNet scaling method uniformly scales network width, depth, and resolution with a set of fixed scaling coefficients. For example, if we want to use $2^N$ times more computational resources, then we can simply increase the network depth by $\alpha ^ N$, width by $\beta ^ N$, and image size by $\gamma ^ N$, where $\alpha, \beta, \gamma$ are constant coefficients determined by a small grid search on the original small model. EfficientNet uses a compound coefficient $\phi$ to uniformly scales network width, depth, and resolution in a principled way.
The compound scaling method is justified by the intuition that if the input image is bigger, then the network needs more layers to increase the receptive field and more channels to capture more fine-grained patterns on the bigger image.
The base EfficientNet-B0 network is based on the inverted bottleneck residual blocks of [MobileNetV2](https://paperswithcode.com/method/mobilenetv2), in addition to [squeeze-and-excitation blocks](https://paperswithcode.com/method/squeeze-and-excitation-block).
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('efficientnet_b0', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `efficientnet_b0`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('efficientnet_b0', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{tan2020efficientnet,
title={EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks},
author={Mingxing Tan and Quoc V. Le},
year={2020},
eprint={1905.11946},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
<!--
Type: model-index
Collections:
- Name: EfficientNet
Paper:
Title: 'EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks'
URL: https://paperswithcode.com/paper/efficientnet-rethinking-model-scaling-for
Models:
- Name: efficientnet_b0
In Collection: EfficientNet
Metadata:
FLOPs: 511241564
Parameters: 5290000
File Size: 21376743
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: efficientnet_b0
Layers: 18
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/efficientnet.py#L1002
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/efficientnet_b0_ra-3dd342df.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.71%
Top 5 Accuracy: 93.52%
- Name: efficientnet_b1
In Collection: EfficientNet
Metadata:
FLOPs: 909691920
Parameters: 7790000
File Size: 31502706
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: efficientnet_b1
Crop Pct: '0.875'
Image Size: '240'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/efficientnet.py#L1011
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/efficientnet_b1-533bc792.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.71%
Top 5 Accuracy: 94.15%
- Name: efficientnet_b2
In Collection: EfficientNet
Metadata:
FLOPs: 1265324514
Parameters: 9110000
File Size: 36788104
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: efficientnet_b2
Crop Pct: '0.875'
Image Size: '260'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/efficientnet.py#L1020
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/efficientnet_b2_ra-bcdf34b7.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.38%
Top 5 Accuracy: 95.08%
- Name: efficientnet_b2a
In Collection: EfficientNet
Metadata:
FLOPs: 1452041554
Parameters: 9110000
File Size: 49369973
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: efficientnet_b2a
Crop Pct: '1.0'
Image Size: '288'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/efficientnet.py#L1029
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/efficientnet_b3_ra2-cf984f9c.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.61%
Top 5 Accuracy: 95.32%
- Name: efficientnet_b3
In Collection: EfficientNet
Metadata:
FLOPs: 2327905920
Parameters: 12230000
File Size: 49369973
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: efficientnet_b3
Crop Pct: '0.904'
Image Size: '300'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/efficientnet.py#L1038
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/efficientnet_b3_ra2-cf984f9c.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 82.08%
Top 5 Accuracy: 96.03%
- Name: efficientnet_b3a
In Collection: EfficientNet
Metadata:
FLOPs: 2600628304
Parameters: 12230000
File Size: 49369973
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: efficientnet_b3a
Crop Pct: '1.0'
Image Size: '320'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/efficientnet.py#L1047
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/efficientnet_b3_ra2-cf984f9c.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 82.25%
Top 5 Accuracy: 96.11%
- Name: efficientnet_em
In Collection: EfficientNet
Metadata:
FLOPs: 3935516480
Parameters: 6900000
File Size: 27927309
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: efficientnet_em
Crop Pct: '0.882'
Image Size: '240'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/efficientnet.py#L1118
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/efficientnet_em_ra2-66250f76.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.26%
Top 5 Accuracy: 94.79%
- Name: efficientnet_es
In Collection: EfficientNet
Metadata:
FLOPs: 2317181824
Parameters: 5440000
File Size: 22003339
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: efficientnet_es
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/efficientnet.py#L1110
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/efficientnet_es_ra-f111e99c.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.09%
Top 5 Accuracy: 93.93%
- Name: efficientnet_lite0
In Collection: EfficientNet
Metadata:
FLOPs: 510605024
Parameters: 4650000
File Size: 18820005
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: efficientnet_lite0
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/efficientnet.py#L1163
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/efficientnet_lite0_ra-37913777.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.5%
Top 5 Accuracy: 92.51%
--> | huggingface/pytorch-image-models/blob/main/docs/models/efficientnet.md |
``python
import argparse
import os
import torch
from torch.optim import AdamW
from torch.utils.data import DataLoader
from peft import (
get_peft_config,
get_peft_model,
get_peft_model_state_dict,
set_peft_model_state_dict,
PeftType,
PrefixTuningConfig,
PromptEncoderConfig,
)
import evaluate
from datasets import load_dataset
from transformers import AutoModelForSequenceClassification, AutoTokenizer, get_linear_schedule_with_warmup, set_seed
from tqdm import tqdm
```
```python
batch_size = 32
model_name_or_path = "roberta-large"
task = "mrpc"
peft_type = PeftType.P_TUNING
device = "cuda"
num_epochs = 20
```
```python
peft_config = PromptEncoderConfig(task_type="SEQ_CLS", num_virtual_tokens=20, encoder_hidden_size=128)
lr = 1e-3
```
```python
if any(k in model_name_or_path for k in ("gpt", "opt", "bloom")):
padding_side = "left"
else:
padding_side = "right"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, padding_side=padding_side)
if getattr(tokenizer, "pad_token_id") is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
datasets = load_dataset("glue", task)
metric = evaluate.load("glue", task)
def tokenize_function(examples):
# max_length=None => use the model max length (it's actually the default)
outputs = tokenizer(examples["sentence1"], examples["sentence2"], truncation=True, max_length=None)
return outputs
tokenized_datasets = datasets.map(
tokenize_function,
batched=True,
remove_columns=["idx", "sentence1", "sentence2"],
)
# We also rename the 'label' column to 'labels' which is the expected name for labels by the models of the
# transformers library
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
def collate_fn(examples):
return tokenizer.pad(examples, padding="longest", return_tensors="pt")
# Instantiate dataloaders.
train_dataloader = DataLoader(tokenized_datasets["train"], shuffle=True, collate_fn=collate_fn, batch_size=batch_size)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], shuffle=False, collate_fn=collate_fn, batch_size=batch_size
)
```
```python
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
model
```
```python
optimizer = AdamW(params=model.parameters(), lr=lr)
# Instantiate scheduler
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=0, # 0.06*(len(train_dataloader) * num_epochs),
num_training_steps=(len(train_dataloader) * num_epochs),
)
```
```python
model.to(device)
for epoch in range(num_epochs):
model.train()
for step, batch in enumerate(tqdm(train_dataloader)):
batch.to(device)
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
for step, batch in enumerate(tqdm(eval_dataloader)):
batch.to(device)
with torch.no_grad():
outputs = model(**batch)
predictions = outputs.logits.argmax(dim=-1)
predictions, references = predictions, batch["labels"]
metric.add_batch(
predictions=predictions,
references=references,
)
eval_metric = metric.compute()
print(f"epoch {epoch}:", eval_metric)
```
## Share adapters on the 🤗 Hub
```python
model.push_to_hub("smangrul/roberta-large-peft-p-tuning", use_auth_token=True)
```
## Load adapters from the Hub
You can also directly load adapters from the Hub using the commands below:
```python
import torch
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
peft_model_id = "smangrul/roberta-large-peft-p-tuning"
config = PeftConfig.from_pretrained(peft_model_id)
inference_model = AutoModelForSequenceClassification.from_pretrained(config.base_model_name_or_path)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
# Load the Lora model
inference_model = PeftModel.from_pretrained(inference_model, peft_model_id)
inference_model.to(device)
inference_model.eval()
for step, batch in enumerate(tqdm(eval_dataloader)):
batch.to(device)
with torch.no_grad():
outputs = inference_model(**batch)
predictions = outputs.logits.argmax(dim=-1)
predictions, references = predictions, batch["labels"]
metric.add_batch(
predictions=predictions,
references=references,
)
eval_metric = metric.compute()
print(eval_metric)
```
| huggingface/peft/blob/main/examples/sequence_classification/P_Tuning.ipynb |
# Diffusers examples with ONNXRuntime optimizations
**This research project is not actively maintained by the diffusers team. For any questions or comments, please contact Isamu Isozaki(isamu-isozaki) on github with any questions.**
The aim of this project is to provide retrieval augmented diffusion models to diffusers! | huggingface/diffusers/blob/main/examples/research_projects/rdm/README.md |
--
title: "Optimum-NVIDIA Unlocking blazingly fast LLM inference in just 1 line of code"
thumbnail: /blog/assets/optimum_nvidia/hf_nvidia_banner.png
authors:
- user: laikh-nvidia
guest: true
- user: mfuntowicz
---
# Optimum-NVIDIA on Hugging Face enables blazingly fast LLM inference in just 1 line of code
Large Language Models (LLMs) have revolutionized natural language processing and are increasingly deployed to solve complex problems at scale. Achieving optimal performance with these models is notoriously challenging due to their unique and intense computational demands. Optimized performance of LLMs is incredibly valuable for end users looking for a snappy and responsive experience, as well as for scaled deployments where improved throughput translates to dollars saved.
That's where the [Optimum-NVIDIA](https://github.com/huggingface/optimum-nvidia) inference library comes in. Available on Hugging Face, Optimum-NVIDIA dramatically accelerates LLM inference on the NVIDIA platform through an extremely simple API.
By changing **just a single line of code**, you can unlock up to **28x faster inference and 1,200 tokens/second** on the NVIDIA platform.
Optimum-NVIDIA is the first Hugging Face inference library to benefit from the new `float8` format supported on the NVIDIA Ada Lovelace and Hopper architectures.
FP8, in addition to the advanced compilation capabilities of [NVIDIA TensorRT-LLM software](https://developer.nvidia.com/blog/nvidia-tensorrt-llm-supercharges-large-language-model-inference-on-nvidia-h100-gpus/) software, dramatically accelerates LLM inference.
### How to Run
You can start running LLaMA with blazingly fast inference speeds in just 3 lines of code with a pipeline from Optimum-NVIDIA.
If you already set up a pipeline from Hugging Face’s transformers library to run LLaMA, you just need to modify a single line of code to unlock peak performance!
```diff
- from transformers.pipelines import pipeline
+ from optimum.nvidia.pipelines import pipeline
# everything else is the same as in transformers!
pipe = pipeline('text-generation', 'meta-llama/Llama-2-7b-chat-hf', use_fp8=True)
pipe("Describe a real-world application of AI in sustainable energy.")
```
You can also enable FP8 quantization with a single flag, which allows you to run a bigger model on a single GPU at faster speeds and without sacrificing accuracy.
The flag shown in this example uses a predefined calibration strategy by default, though you can provide your own calibration dataset and customized tokenization to tailor the quantization to your use case.
The pipeline interface is great for getting up and running quickly, but power users who want fine-grained control over setting sampling parameters can use the Model API.
```diff
- from transformers import AutoModelForCausalLM
+ from optimum.nvidia import AutoModelForCausalLM
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-13b-chat-hf", padding_side="left")
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-13b-chat-hf",
+ use_fp8=True,
)
model_inputs = tokenizer(
["How is autonomous vehicle technology transforming the future of transportation and urban planning?"],
return_tensors="pt"
).to("cuda")
generated_ids, generated_length = model.generate(
**model_inputs,
top_k=40,
top_p=0.7,
repetition_penalty=10,
)
tokenizer.batch_decode(generated_ids[0], skip_special_tokens=True)
```
For more details, check out our [documentation](https://github.com/huggingface/optimum-nvidia)
### Performance Evaluation
When evaluating the performance of an LLM, we consider two metrics: First Token Latency and Throughput.
First Token Latency (also known as Time to First Token or prefill latency) measures how long you wait from the time you enter your prompt to the time you begin receiving your output, so this metric can tell you how responsive the model will feel.
Optimum-NVIDIA delivers up to 3.3x faster First Token Latency compared to stock transformers:
<br>
<figure class="image">
<img alt="" src="assets/optimum_nvidia/first_token_latency.svg" />
<figcaption>Figure 1. Time it takes to generate the first token (ms)</figcaption>
</figure>
<br>
Throughput, on the other hand, measures how fast the model can generate tokens and is particularly relevant when you want to batch generations together.
While there are a few ways to calculate throughput, we adopted a standard method to divide the end-to-end latency by the total sequence length, including both input and output tokens summed over all batches.
Optimum-NVIDIA delivers up to 28x better throughput compared to stock transformers:
<br>
<figure class="image">
<img alt="" src="assets/optimum_nvidia/throughput.svg" />
<figcaption>Figure 2. Throughput (token / second)</figcaption>
</figure>
<br>
Initial evaluations of the [recently announced NVIDIA H200 Tensor Core GPU](https://www.nvidia.com/en-us/data-center/h200/) show up to an additional 2x boost in throughput for LLaMA models compared to an NVIDIA H100 Tensor Core GPU.
As H200 GPUs become more readily available, we will share performance data for Optimum-NVIDIA running on them.
### Next steps
Optimum-NVIDIA currently provides peak performance for the LLaMAForCausalLM architecture + task, so any [LLaMA-based model](https://huggingface.co/models?other=llama,llama2), including fine-tuned versions, should work with Optimum-NVIDIA out of the box today.
We are actively expanding support to include other text generation model architectures and tasks, all from within Hugging Face.
We continue to push the boundaries of performance and plan to incorporate cutting-edge optimization techniques like In-Flight Batching to improve throughput when streaming prompts and INT4 quantization to run even bigger models on a single GPU.
Give it a try: we are releasing the [Optimum-NVIDIA repository](https://github.com/huggingface/optimum-nvidia) with instructions on how to get started. Please share your feedback with us! 🤗
| huggingface/blog/blob/main/optimum-nvidia.md |
Glossary [[glossary]]
This is a community-created glossary. Contributions are welcomed!
### Agent
An agent learns to **make decisions by trial and error, with rewards and punishments from the surroundings**.
### Environment
An environment is a simulated world **where an agent can learn by interacting with it**.
### Markov Property
It implies that the action taken by our agent is **conditional solely on the present state and independent of the past states and actions**.
### Observations/State
- **State**: Complete description of the state of the world.
- **Observation**: Partial description of the state of the environment/world.
### Actions
- **Discrete Actions**: Finite number of actions, such as left, right, up, and down.
- **Continuous Actions**: Infinite possibility of actions; for example, in the case of self-driving cars, the driving scenario has an infinite possibility of actions occurring.
### Rewards and Discounting
- **Rewards**: Fundamental factor in RL. Tells the agent whether the action taken is good/bad.
- RL algorithms are focused on maximizing the **cumulative reward**.
- **Reward Hypothesis**: RL problems can be formulated as a maximisation of (cumulative) return.
- **Discounting** is performed because rewards obtained at the start are more likely to happen as they are more predictable than long-term rewards.
### Tasks
- **Episodic**: Has a starting point and an ending point.
- **Continuous**: Has a starting point but no ending point.
### Exploration v/s Exploitation Trade-Off
- **Exploration**: It's all about exploring the environment by trying random actions and receiving feedback/returns/rewards from the environment.
- **Exploitation**: It's about exploiting what we know about the environment to gain maximum rewards.
- **Exploration-Exploitation Trade-Off**: It balances how much we want to **explore** the environment and how much we want to **exploit** what we know about the environment.
### Policy
- **Policy**: It is called the agent's brain. It tells us what action to take, given the state.
- **Optimal Policy**: Policy that **maximizes** the **expected return** when an agent acts according to it. It is learned through *training*.
### Policy-based Methods:
- An approach to solving RL problems.
- In this method, the Policy is learned directly.
- Will map each state to the best corresponding action at that state. Or a probability distribution over the set of possible actions at that state.
### Value-based Methods:
- Another approach to solving RL problems.
- Here, instead of training a policy, we train a **value function** that maps each state to the expected value of being in that state.
Contributions are welcomed 🤗
If you want to improve the course, you can [open a Pull Request.](https://github.com/huggingface/deep-rl-class/pulls)
This glossary was made possible thanks to:
- [@lucifermorningstar1305](https://github.com/lucifermorningstar1305)
- [@daspartho](https://github.com/daspartho)
- [@misza222](https://github.com/misza222)
| huggingface/deep-rl-class/blob/main/units/en/unit1/glossary.mdx |
--
title: "Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA"
thumbnail: /blog/assets/96_hf_bitsandbytes_integration/Thumbnail_blue.png
authors:
- user: ybelkada
- user: timdettmers
guest: true
- user: artidoro
guest: true
- user: sgugger
- user: smangrul
---
# Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA
LLMs are known to be large, and running or training them in consumer hardware is a huge challenge for users and accessibility.
Our [LLM.int8 blogpost](https://huggingface.co/blog/hf-bitsandbytes-integration) showed how the techniques in the [LLM.int8 paper](https://arxiv.org/abs/2208.07339) were integrated in transformers using the `bitsandbytes` library.
As we strive to make models even more accessible to anyone, we decided to collaborate with bitsandbytes again to allow users to run models in 4-bit precision. This includes a large majority of HF models, in any modality (text, vision, multi-modal, etc.). Users can also train adapters on top of 4bit models leveraging tools from the Hugging Face ecosystem. This is a new method introduced today in the QLoRA paper by Dettmers et al. The abstract of the paper is as follows:
> We present QLoRA, an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance. QLoRA backpropagates gradients through a frozen, 4-bit quantized pretrained language model into Low Rank Adapters~(LoRA). Our best model family, which we name Guanaco, outperforms all previous openly released models on the Vicuna benchmark, reaching 99.3% of the performance level of ChatGPT while only requiring 24 hours of finetuning on a single GPU. QLoRA introduces a number of innovations to save memory without sacrificing performance: (a) 4-bit NormalFloat (NF4), a new data type that is information theoretically optimal for normally distributed weights (b) double quantization to reduce the average memory footprint by quantizing the quantization constants, and (c) paged optimizers to manage memory spikes. We use QLoRA to finetune more than 1,000 models, providing a detailed analysis of instruction following and chatbot performance across 8 instruction datasets, multiple model types (LLaMA, T5), and model scales that would be infeasible to run with regular finetuning (e.g. 33B and 65B parameter models). Our results show that QLoRA finetuning on a small high-quality dataset leads to state-of-the-art results, even when using smaller models than the previous SoTA. We provide a detailed analysis of chatbot performance based on both human and GPT-4 evaluations showing that GPT-4 evaluations are a cheap and reasonable alternative to human evaluation. Furthermore, we find that current chatbot benchmarks are not trustworthy to accurately evaluate the performance levels of chatbots. A lemon-picked analysis demonstrates where Guanaco fails compared to ChatGPT. We release all of our models and code, including CUDA kernels for 4-bit training.
## Resources
This blogpost and release come with several resources to get started with 4bit models and QLoRA:
- [Original paper](https://arxiv.org/abs/2305.14314)
- [Basic usage Google Colab notebook](https://colab.research.google.com/drive/1ge2F1QSK8Q7h0hn3YKuBCOAS0bK8E0wf?usp=sharing) - This notebook shows how to use 4bit models in inference with all their variants, and how to run GPT-neo-X (a 20B parameter model) on a free Google Colab instance 🤯
- [Fine tuning Google Colab notebook](https://colab.research.google.com/drive/1VoYNfYDKcKRQRor98Zbf2-9VQTtGJ24k?usp=sharing) - This notebook shows how to fine-tune a 4bit model on a downstream task using the Hugging Face ecosystem. We show that it is possible to fine tune GPT-neo-X 20B on a Google Colab instance!
- [Original repository for replicating the paper's results](https://github.com/artidoro/qlora)
- [Guanaco 33b playground](https://huggingface.co/spaces/uwnlp/guanaco-playground-tgi) - or check the playground section below
## Introduction
If you are not familiar with model precisions and the most common data types (float16, float32, bfloat16, int8), we advise you to carefully read the introduction in [our first blogpost](https://huggingface.co/blog/hf-bitsandbytes-integration) that goes over the details of these concepts in simple terms with visualizations.
For more information we recommend reading the fundamentals of floating point representation through [this wikibook document](https://en.wikibooks.org/wiki/A-level_Computing/AQA/Paper_2/Fundamentals_of_data_representation/Floating_point_numbers#:~:text=In%20decimal%2C%20very%20large%20numbers,be%20used%20for%20binary%20numbers.).
The recent QLoRA paper explores different data types, 4-bit Float and 4-bit NormalFloat. We will discuss here the 4-bit Float data type since it is easier to understand.
FP8 and FP4 stand for Floating Point 8-bit and 4-bit precision, respectively. They are part of the minifloats family of floating point values (among other precisions, the minifloats family also includes bfloat16 and float16).
Let’s first have a look at how to represent floating point values in FP8 format, then understand how the FP4 format looks like.
### FP8 format
As discussed in our previous blogpost, a floating point contains n-bits, with each bit falling into a specific category that is responsible for representing a component of the number (sign, mantissa and exponent). These represent the following.
The FP8 (floating point 8) format has been first introduced in the paper [“FP8 for Deep Learning”](https://arxiv.org/pdf/2209.05433.pdf) with two different FP8 encodings: E4M3 (4-bit exponent and 3-bit mantissa) and E5M2 (5-bit exponent and 2-bit mantissa).
|  |
|:--:|
| <b>Overview of Floating Point 8 (FP8) format. Source: Original content from [`sgugger`](https://huggingface.co/sgugger) </b>|
Although the precision is substantially reduced by reducing the number of bits from 32 to 8, both versions can be used in a variety of situations. Currently one could use [Transformer Engine library](https://github.com/NVIDIA/TransformerEngine) that is also integrated with HF ecosystem through accelerate.
The potential floating points that can be represented in the E4M3 format are in the range -448 to 448, whereas in the E5M2 format, as the number of bits of the exponent increases, the range increases to -57344 to 57344 - but with a loss of precision because the number of possible representations remains constant.
It has been empirically proven that the E4M3 is best suited for the forward pass, and the second version is best suited for the backward computation
### FP4 precision in a few words
The sign bit represents the sign (+/-), the exponent bits a base two to the power of the integer represented by the bits (e.g. `2^{010} = 2^{2} = 4`), and the fraction or mantissa is the sum of powers of negative two which are “active” for each bit that is “1”. If a bit is “0” the fraction remains unchanged for that power of `2^-i` where i is the position of the bit in the bit-sequence. For example, for mantissa bits 1010 we have `(0 + 2^-1 + 0 + 2^-3) = (0.5 + 0.125) = 0.625`. To get a value, we add *1* to the fraction and multiply all results together, for example, with 2 exponent bits and one mantissa bit the representations 1101 would be:
`-1 * 2^(2) * (1 + 2^-1) = -1 * 4 * 1.5 = -6`
For FP4 there is no fixed format and as such one can try combinations of different mantissa/exponent combinations. In general, 3 exponent bits do a bit better in most cases. But sometimes 2 exponent bits and a mantissa bit yield better performance.
## QLoRA paper, a new way of democratizing quantized large transformer models
In few words, QLoRA reduces the memory usage of LLM finetuning without performance tradeoffs compared to standard 16-bit model finetuning. This method enables 33B model finetuning on a single 24GB GPU and 65B model finetuning on a single 46GB GPU.
More specifically, QLoRA uses 4-bit quantization to compress a pretrained language model. The LM parameters are then frozen and a relatively small number of trainable parameters are added to the model in the form of Low-Rank Adapters. During finetuning, QLoRA backpropagates gradients through the frozen 4-bit quantized pretrained language model into the Low-Rank Adapters. The LoRA layers are the only parameters being updated during training. Read more about LoRA in the [original LoRA paper](https://arxiv.org/abs/2106.09685).
QLoRA has one storage data type (usually 4-bit NormalFloat) for the base model weights and a computation data type (16-bit BrainFloat) used to perform computations. QLoRA dequantizes weights from the storage data type to the computation data type to perform the forward and backward passes, but only computes weight gradients for the LoRA parameters which use 16-bit bfloat. The weights are decompressed only when they are needed, therefore the memory usage stays low during training and inference.
QLoRA tuning is shown to match 16-bit finetuning methods in a wide range of experiments. In addition, the Guanaco models, which use QLoRA finetuning for LLaMA models on the [OpenAssistant dataset (OASST1)](https://huggingface.co/datasets/OpenAssistant/oasst1), are state-of-the-art chatbot systems and are close to ChatGPT on the Vicuna benchmark. This is an additional demonstration of the power of QLoRA tuning.
For a more detailed reading, we recommend you read the [QLoRA paper](https://arxiv.org/abs/2305.14314).
## How to use it in transformers?
In this section let us introduce the transformers integration of this method, how to use it and which models can be effectively quantized.
### Getting started
As a quickstart, load a model in 4bit by (at the time of this writing) installing accelerate and transformers from source, and make sure you have installed the latest version of bitsandbytes library (0.39.0).
```bash
pip install -q -U bitsandbytes
pip install -q -U git+https://github.com/huggingface/transformers.git
pip install -q -U git+https://github.com/huggingface/peft.git
pip install -q -U git+https://github.com/huggingface/accelerate.git
```
### Quickstart
The basic way to load a model in 4bit is to pass the argument `load_in_4bit=True` when calling the `from_pretrained` method by providing a device map (pass `"auto"` to get a device map that will be automatically inferred).
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_4bit=True, device_map="auto")
...
```
That's all you need!
As a general rule, we recommend users to not manually set a device once the model has been loaded with `device_map`. So any device assignment call to the model, or to any model’s submodules should be avoided after that line - unless you know what you are doing.
Keep in mind that loading a quantized model will automatically cast other model's submodules into `float16` dtype. You can change this behavior, (if for example you want to have the layer norms in `float32`), by passing `torch_dtype=dtype` to the `from_pretrained` method.
### Advanced usage
You can play with different variants of 4bit quantization such as NF4 (normalized float 4 (default)) or pure FP4 quantization. Based on theoretical considerations and empirical results from the paper, we recommend using NF4 quantization for better performance.
Other options include `bnb_4bit_use_double_quant` which uses a second quantization after the first one to save an additional 0.4 bits per parameter. And finally, the compute type. While 4-bit bitsandbytes stores weights in 4-bits, the computation still happens in 16 or 32-bit and here any combination can be chosen (float16, bfloat16, float32 etc).
The matrix multiplication and training will be faster if one uses a 16-bit compute dtype (default torch.float32). One should leverage the recent `BitsAndBytesConfig` from transformers to change these parameters. An example to load a model in 4bit using NF4 quantization below with double quantization with the compute dtype bfloat16 for faster training:
```python
from transformers import BitsAndBytesConfig
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16
)
model_nf4 = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=nf4_config)
```
#### Changing the compute dtype
As mentioned above, you can also change the compute dtype of the quantized model by just changing the `bnb_4bit_compute_dtype` argument in `BitsAndBytesConfig`.
```python
import torch
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16
)
```
#### Nested quantization
For enabling nested quantization, you can use the `bnb_4bit_use_double_quant` argument in `BitsAndBytesConfig`. This will enable a second quantization after the first one to save an additional 0.4 bits per parameter. We also use this feature in the training Google colab notebook.
```python
from transformers import BitsAndBytesConfig
double_quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
)
model_double_quant = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=double_quant_config)
```
And of course, as mentioned in the beginning of the section, all of these components are composable. You can combine all these parameters together to find the optimial use case for you. A rule of thumb is: use double quant if you have problems with memory, use NF4 for higher precision, and use a 16-bit dtype for faster finetuning. For instance in the [inference demo](https://colab.research.google.com/drive/1ge2F1QSK8Q7h0hn3YKuBCOAS0bK8E0wf?usp=sharing), we use nested quantization, bfloat16 compute dtype and NF4 quantization to fit gpt-neo-x-20b (40GB) entirely in 4bit in a single 16GB GPU.
### Common questions
In this section, we will also address some common questions anyone could have regarding this integration.
#### Does FP4 quantization have any hardware requirements?
Note that this method is only compatible with GPUs, hence it is not possible to quantize models in 4bit on a CPU. Among GPUs, there should not be any hardware requirement about this method, therefore any GPU could be used to run the 4bit quantization as long as you have CUDA>=11.2 installed.
Keep also in mind that the computation is not done in 4bit, the weights and activations are compressed to that format and the computation is still kept in the desired or native dtype.
#### What are the supported models?
Similarly as the integration of LLM.int8 presented in [this blogpost](https://huggingface.co/blog/hf-bitsandbytes-integration) the integration heavily relies on the `accelerate` library. Therefore, any model that supports accelerate loading (i.e. the `device_map` argument when calling `from_pretrained`) should be quantizable in 4bit. Note also that this is totally agnostic to modalities, as long as the models can be loaded with the `device_map` argument, it is possible to quantize them.
For text models, at this time of writing, this would include most used architectures such as Llama, OPT, GPT-Neo, GPT-NeoX for text models, Blip2 for multimodal models, and so on.
At this time of writing, the models that support accelerate are:
```python
[
'bigbird_pegasus', 'blip_2', 'bloom', 'bridgetower', 'codegen', 'deit', 'esm',
'gpt2', 'gpt_bigcode', 'gpt_neo', 'gpt_neox', 'gpt_neox_japanese', 'gptj', 'gptsan_japanese',
'lilt', 'llama', 'longformer', 'longt5', 'luke', 'm2m_100', 'mbart', 'mega', 'mt5', 'nllb_moe',
'open_llama', 'opt', 'owlvit', 'plbart', 'roberta', 'roberta_prelayernorm', 'rwkv', 'switch_transformers',
't5', 'vilt', 'vit', 'vit_hybrid', 'whisper', 'xglm', 'xlm_roberta'
]
```
Note that if your favorite model is not there, you can open a Pull Request or raise an issue in transformers to add the support of accelerate loading for that architecture.
#### Can we train 4bit/8bit models?
It is not possible to perform pure 4bit training on these models. However, you can train these models by leveraging parameter efficient fine tuning methods (PEFT) and train for example adapters on top of them. That is what is done in the paper and is officially supported by the PEFT library from Hugging Face. We also provide a [training notebook](https://colab.research.google.com/drive/1VoYNfYDKcKRQRor98Zbf2-9VQTtGJ24k?usp=sharing) and recommend users to check the [QLoRA repository](https://github.com/artidoro/qlora) if they are interested in replicating the results from the paper.
|  |
|:--:|
| <b>The output activations original (frozen) pretrained weights (left) are augmented by a low rank adapter comprised of weight matrics A and B (right). </b>|
#### What other consequences are there?
This integration can open up several positive consequences to the community and AI research as it can affect multiple use cases and possible applications.
In RLHF (Reinforcement Learning with Human Feedback) it is possible to load a single base model, in 4bit and train multiple adapters on top of it, one for the reward modeling, and another for the value policy training. A more detailed blogpost and announcement will be made soon about this use case.
We have also made some benchmarks on the impact of this quantization method on training large models on consumer hardware. We have run several experiments on finetuning 2 different architectures, Llama 7B (15GB in fp16) and Llama 13B (27GB in fp16) on an NVIDIA T4 (16GB) and here are the results
| Model name | Half precision model size (in GB) | Hardware type / total VRAM | quantization method (CD=compute dtype / GC=gradient checkpointing / NQ=nested quantization) | batch_size | gradient accumulation steps | optimizer | seq_len | Result |
| ----------------------------------- | --------------------------------- | -------------------------- | ------------------------------------------------------------------------------------------- | ---------- | --------------------------- | ----------------- | ------- | ------ |
| | | | | | | | | |
| <10B scale models | | | | | | | | |
| decapoda-research/llama-7b-hf | 14GB | 1xNVIDIA-T4 / 16GB | LLM.int8 (8-bit) + GC | 1 | 4 | AdamW | 512 | **No OOM** |
| decapoda-research/llama-7b-hf | 14GB | 1xNVIDIA-T4 / 16GB | LLM.int8 (8-bit) + GC | 1 | 4 | AdamW | 1024 | OOM |
| decapoda-research/llama-7b-hf | 14GB | 1xNVIDIA-T4 / 16GB | 4bit + NF4 + bf16 CD + no GC | 1 | 4 | AdamW | 512 | **No OOM** |
| decapoda-research/llama-7b-hf | 14GB | 1xNVIDIA-T4 / 16GB | 4bit + FP4 + bf16 CD + no GC | 1 | 4 | AdamW | 512 | **No OOM** |
| decapoda-research/llama-7b-hf | 14GB | 1xNVIDIA-T4 / 16GB | 4bit + NF4 + bf16 CD + no GC | 1 | 4 | AdamW | 1024 | OOM |
| decapoda-research/llama-7b-hf | 14GB | 1xNVIDIA-T4 / 16GB | 4bit + FP4 + bf16 CD + no GC | 1 | 4 | AdamW | 1024 | OOM |
| decapoda-research/llama-7b-hf | 14GB | 1xNVIDIA-T4 / 16GB | 4bit + NF4 + bf16 CD + GC | 1 | 4 | AdamW | 1024 | **No OOM** |
| | | | | | | | | |
| 10B+ scale models | | | | | | | | |
| decapoda-research/llama-13b-hf | 27GB | 2xNVIDIA-T4 / 32GB | LLM.int8 (8-bit) + GC | 1 | 4 | AdamW | 512 | **No OOM** |
| decapoda-research/llama-13b-hf | 27GB | 1xNVIDIA-T4 / 16GB | LLM.int8 (8-bit) + GC | 1 | 4 | AdamW | 512 | OOM |
| decapoda-research/llama-13b-hf | 27GB | 1xNVIDIA-T4 / 16GB | 4bit + FP4 + bf16 CD + no GC | 1 | 4 | AdamW | 512 | OOM |
| decapoda-research/llama-13b-hf | 27GB | 1xNVIDIA-T4 / 16GB | 4bit + FP4 + fp16 CD + no GC | 1 | 4 | AdamW | 512 | OOM |
| decapoda-research/llama-13b-hf | 27GB | 1xNVIDIA-T4 / 16GB | 4bit + NF4 + fp16 CD + GC | 1 | 4 | AdamW | 512 | **No OOM** |
| decapoda-research/llama-13b-hf | 27GB | 1xNVIDIA-T4 / 16GB | 4bit + NF4 + fp16 CD + GC | 1 | 4 | AdamW | 1024 | OOM |
| decapoda-research/llama-13b-hf | 27GB | 1xNVIDIA-T4 / 16GB | 4bit + NF4 + fp16 CD + GC + NQ | 1 | 4 | AdamW | 1024 | **No OOM** |
We have used the recent `SFTTrainer` from TRL library, and the benchmarking script can be found [here](https://gist.github.com/younesbelkada/f48af54c74ba6a39a7ae4fd777e72fe8)
## Playground
Try out the Guananco model cited on the paper on [the playground](https://huggingface.co/spaces/uwnlp/guanaco-playground-tgi) or directly below
<!-- [SPACE WITH GREEDY DECODING PERFORMANCE NUMBERS] -->
<script
type="module"
src="https://gradio.s3-us-west-2.amazonaws.com/3.32.0/gradio.js"
></script>
<gradio-app theme_mode="light" space="uwnlp/guanaco-playground-tgi"></gradio-app>
## Acknowledgements
The HF team would like to acknowledge all the people involved in this project from University of Washington, and for making this available to the community.
The authors would also like to thank [Pedro Cuenca](https://huggingface.co/pcuenq) for kindly reviewing the blogpost, [Olivier Dehaene](https://huggingface.co/olivierdehaene) and [Omar Sanseviero](https://huggingface.co/osanseviero) for their quick and strong support for the integration of the paper's artifacts on the HF Hub.
| huggingface/blog/blob/main/4bit-transformers-bitsandbytes.md |
Self-training
This is an implementation of the self-training algorithm (without task augmentation) in the [EMNLP 2021](https://2021.emnlp.org/) paper: [STraTA: Self-Training with Task Augmentation for Better Few-shot Learning](https://arxiv.org/abs/2109.06270). Please check out https://github.com/google-research/google-research/tree/master/STraTA for the original codebase.
**Note**: The code can be used as a tool for automatic data labeling.
## Table of Contents
* [Installation](#installation)
* [Self-training](#self-training)
* [Running self-training with a base model](#running-self-training-with-a-base-model)
* [Hyperparameters for self-training](#hyperparameters-for-self-training)
* [Distributed training](#distributed-training)
* [Demo](#demo)
* [How to cite](#how-to-cite)
## Installation
This repository is tested on Python 3.8+, PyTorch 1.10+, and the 🤗 Transformers 4.16+.
You should install all necessary Python packages in a [virtual environment](https://docs.python.org/3/library/venv.html). If you are unfamiliar with Python virtual environments, please check out the [user guide](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
Below, we create a virtual environment with the [Anaconda Python distribution](https://www.anaconda.com/products/distribution) and activate it.
```sh
conda create -n strata python=3.9
conda activate strata
```
Next, you need to install 🤗 Transformers. Please refer to [🤗 Transformers installation page](https://github.com/huggingface/transformers#installation) for a detailed guide.
```sh
pip install transformers
```
Finally, install all necessary Python packages for our self-training algorithm.
```sh
pip install -r STraTA/selftraining/requirements.txt
```
This will install PyTorch as a backend.
## Self-training
### Running self-training with a base model
The following example code shows how to run our self-training algorithm with a base model (e.g., `BERT`) on the `SciTail` science entailment dataset, which has two classes `['entails', 'neutral']`. We assume that you have a data directory that includes some training data (e.g., `train.csv`), evaluation data (e.g., `eval.csv`), and unlabeled data (e.g., `infer.csv`).
```python
import os
from selftraining import selftrain
data_dir = '/path/to/your/data/dir'
parameters_dict = {
'max_selftrain_iterations': 100,
'model_name_or_path': '/path/to/your/base/model', # could be the id of a model hosted by 🤗 Transformers
'output_dir': '/path/to/your/output/dir',
'train_file': os.path.join(data_dir, 'train.csv'),
'infer_file': os.path.join(data_dir, 'infer.csv'),
'eval_file': os.path.join(data_dir, 'eval.csv'),
'evaluation_strategy': 'steps',
'task_name': 'scitail',
'label_list': ['entails', 'neutral'],
'per_device_train_batch_size': 32,
'per_device_eval_batch_size': 8,
'max_length': 128,
'learning_rate': 2e-5,
'max_steps': 100000,
'eval_steps': 1,
'early_stopping_patience': 50,
'overwrite_output_dir': True,
'do_filter_by_confidence': False,
# 'confidence_threshold': 0.3,
'do_filter_by_val_performance': True,
'finetune_on_labeled_data': False,
'seed': 42,
}
selftrain(**parameters_dict)
```
**Note**: We checkpoint periodically during self-training. In case of preemptions, just re-run the above script and self-training will resume from the latest iteration.
### Hyperparameters for self-training
If you have development data, you might want to tune some hyperparameters for self-training.
Below are hyperparameters that could provide additional gains for your task.
- `finetune_on_labeled_data`: If set to `True`, the resulting model from each self-training iteration is further fine-tuned on the original labeled data before the next self-training iteration. Intuitively, this would give the model a chance to "correct" ifself after being trained on pseudo-labeled data.
- `do_filter_by_confidence`: If set to `True`, the pseudo-labeled data in each self-training iteration is filtered based on the model confidence. For instance, if `confidence_threshold` is set to `0.3`, pseudo-labeled examples with a confidence score less than or equal to `0.3` will be discarded. Note that `confidence_threshold` should be greater or equal to `1/num_labels`, where `num_labels` is the number of class labels. Filtering out the lowest-confidence pseudo-labeled examples could be helpful in some cases.
- `do_filter_by_val_performance`: If set to `True`, the pseudo-labeled data in each self-training iteration is filtered based on the current validation performance. For instance, if your validation performance is 80% accuracy, you might want to get rid of 20% of the pseudo-labeled data with the lowest the confidence scores.
### Distributed training
We strongly recommend distributed training with multiple accelerators. To activate distributed training, please try one of the following methods:
1. Run `accelerate config` and answer to the questions asked. This will save a `default_config.yaml` file in your cache folder for 🤗 Accelerate. Now, you can run your script with the following command:
```sh
accelerate launch your_script.py --args_to_your_script
```
2. Run your script with the following command:
```sh
python -m torch.distributed.launch --nnodes="{$NUM_NODES}" --nproc_per_node="{$NUM_TRAINERS}" --your_script.py --args_to_your_script
```
3. Run your script with the following command:
```sh
torchrun --nnodes="{$NUM_NODES}" --nproc_per_node="{$NUM_TRAINERS}" --your_script.py --args_to_your_script
```
## Demo
Please check out `run.sh` to see how to perform our self-training algorithm with a `BERT` Base model on the SciTail science entailment dataset using 8 labeled examples per class. You can configure your training environment by specifying `NUM_NODES` and `NUM_TRAINERS` (number of processes per node). To launch the script, simply run `source run.sh`.
## How to cite
If you extend or use this code, please cite the [paper](https://arxiv.org/abs/2109.06270) where it was introduced:
```bibtex
@inproceedings{vu-etal-2021-strata,
title = "{ST}ra{TA}: Self-Training with Task Augmentation for Better Few-shot Learning",
author = "Vu, Tu and
Luong, Minh-Thang and
Le, Quoc and
Simon, Grady and
Iyyer, Mohit",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.462",
doi = "10.18653/v1/2021.emnlp-main.462",
pages = "5715--5731",
}
```
| huggingface/transformers/blob/main/examples/research_projects/self-training-text-classification/README.md |
--
title: "Optimum+ONNX Runtime - Easier, Faster training for your Hugging Face models"
thumbnail: /blog/assets/optimum_onnxruntime-training/thumbnail.png
authors:
- user: Jingya
- user: kshama-msft
guest: true
- user: askhade
guest: true
- user: weicwang
guest: true
- user: zhijiang
guest: true
---
# Optimum + ONNX Runtime: Easier, Faster training for your Hugging Face models
## Introduction
Transformer based models in language, vision and speech are getting larger to support complex multi-modal use cases for the end customer. Increasing model sizes directly impact the resources needed to train these models and scale them as the size increases. Hugging Face and Microsoft’s ONNX Runtime teams are working together to build advancements in finetuning large Language, Speech and Vision models. Hugging Face’s [Optimum library](https://huggingface.co/docs/optimum/index), through its integration with ONNX Runtime for training, provides an open solution to __improve training times by 35% or more__ for many popular Hugging Face models. We present details of both Hugging Face Optimum and the ONNX Runtime Training ecosystem, with performance numbers highlighting the benefits of using the Optimum library.
## Performance results
The chart below shows impressive acceleration __from 39% to 130%__ for Hugging Face models with Optimum when __using ONNX Runtime and DeepSpeed ZeRO Stage 1__ for training. The performance measurements were done on selected Hugging Face models with PyTorch as the baseline run, only ONNX Runtime for training as the second run, and ONNX Runtime + DeepSpeed ZeRO Stage 1 as the final run, showing maximum gains. The Optimizer used for the baseline PyTorch runs is the AdamW optimizer and the ORT Training runs use the Fused Adam Optimizer. The runs were performed on a single Nvidia A100 node with 8 GPUs.
<figure class="image table text-center m-0 w-full">
<img src="assets/optimum_onnxruntime-training/onnxruntime-training-benchmark.png" alt="Optimum-onnxruntime Training Benchmark"/>
</figure>
Additional details on configuration settings to turn on Optimum for training acceleration can be found [here](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/trainer). The version information used for these runs is as follows:
```
PyTorch: 1.14.0.dev20221103+cu116; ORT: 1.14.0.dev20221103001+cu116; DeepSpeed: 0.6.6; HuggingFace: 4.24.0.dev0; Optimum: 1.4.1.dev0; Cuda: 11.6.2
```
## Optimum Library
Hugging Face is a fast-growing open community and platform aiming to democratize good machine learning. We extended modalities from NLP to audio and vision, and now covers use cases across Machine Learning to meet our community's needs following the success of the [Transformers library](https://huggingface.co/docs/transformers/index). Now on [Hugging Face Hub](https://huggingface.co/models), there are more than 120K free and accessible model checkpoints for various machine learning tasks, 18K datasets, and 20K ML demo apps. However, scaling transformer models into production is still a challenge for the industry. Despite high accuracy, training and inference of transformer-based models can be time-consuming and expensive.
To target these needs, Hugging Face built two open-sourced libraries: __Accelerate__ and __Optimum__. While [🤗 Accelerate](https://huggingface.co/docs/accelerate/index) focuses on out-of-the-box distributed training, [🤗 Optimum](https://huggingface.co/docs/optimum/index), as an extension of transformers, accelerates model training and inference by leveraging the maximum efficiency of users’ targeted hardware. Optimum integrated machine learning accelerators like ONNX Runtime and specialized hardware like [Intel's Habana Gaudi](https://huggingface.co/blog/habana-gaudi-2-benchmark), so users can benefit from considerable speedup in both training and inference. Besides, Optimum seamlessly integrates other Hugging Face’s tools while inheriting the same ease of use as Transformers. Developers can easily adapt their work to achieve lower latency with less computing power.
## ONNX Runtime Training
[ONNX Runtime](https://onnxruntime.ai/) accelerates [large model training](https://onnxruntime.ai/docs/get-started/training-pytorch.html) to speed up throughput by up to 40% standalone, and 130% when composed with [DeepSpeed](https://www.deepspeed.ai/tutorials/zero/) for popular HuggingFace transformer based models. ONNX Runtime is already integrated as part of Optimum and enables faster training through Hugging Face’s Optimum training framework.
ONNX Runtime Training achieves such throughput improvements via several memory and compute optimizations. The memory optimizations enable ONNX Runtime to maximize the batch size and utilize the available memory efficiently whereas the compute optimizations speed up the training time. These optimizations include, but are not limited to, efficient memory planning, kernel optimizations, multi tensor apply for Adam Optimizer (which batches the elementwise updates applied to all the model’s parameters into one or a few kernel launches), FP16 optimizer (which eliminates a lot of device to host memory copies), mixed precision training and graph optimizations like node fusions and node eliminations. ONNX Runtime Training supports both [NVIDIA](https://techcommunity.microsoft.com/t5/ai-machine-learning-blog/accelerate-pytorch-transformer-model-training-with-onnx-runtime/ba-p/2540471) and [AMD GPUs](https://cloudblogs.microsoft.com/opensource/2021/07/13/onnx-runtime-release-1-8-1-previews-support-for-accelerated-training-on-amd-gpus-with-the-amd-rocm-open-software-platform/), and offers extensibility with custom operators.
In short, it empowers AI developers to take full advantage of the ecosystem they are familiar with, like PyTorch and Hugging Face, and use acceleration from ONNX Runtime on the target device of their choice to save both time and resources.
## ONNX Runtime Training in Optimum
Optimum provides an `ORTTrainer` API that extends the `Trainer` in Transformers to use ONNX Runtime as the backend for acceleration. `ORTTrainer` is an easy-to-use API containing feature-complete training loop and evaluation loop. It supports features like hyperparameter search, mixed-precision training and distributed training with multiple GPUs. `ORTTrainer` enables AI developers to compose ONNX Runtime and other third-party acceleration techniques when training Transformers’ models, which helps accelerate the training further and gets the best out of the hardware. For example, developers can combine ONNX Runtime Training with distributed data parallel and mixed-precision training integrated in Transformers’ Trainer. Besides, `ORTTrainer` makes it easy to compose ONNX Runtime Training with DeepSpeed ZeRO-1, which saves memory by partitioning the optimizer states. After the pre-training or the fine-tuning is done, developers can either save the trained PyTorch model or convert it to the ONNX format with APIs that Optimum implemented for ONNX Runtime to ease the deployment for Inference. And just like `Trainer`, `ORTTrainer` has full integration with Hugging Face Hub: after the training, users can upload their model checkpoints to their Hugging Face Hub account.
So concretely, what should users do with Optimum to take advantage of the ONNX Runtime acceleration for training? If you are already using `Trainer`, you just need to adapt a few lines of code to benefit from all the improvements mentioned above. There are mainly two replacements that need to be applied. Firstly, replace `Trainer` with `ORTTrainer`, then replace `TrainingArguments` with `ORTTrainingArguments` which contains all the hyperparameters the trainer will use for training and evaluation. `ORTTrainingArguments` extends `TrainingArguments` to apply some extra arguments empowered by ONNX Runtime. For example, users can apply Fused Adam Optimizer for extra performance gain. Here is an example:
```diff
-from transformers import Trainer, TrainingArguments
+from optimum.onnxruntime import ORTTrainer, ORTTrainingArguments
# Step 1: Define training arguments
-training_args = TrainingArguments(
+training_args = ORTTrainingArguments(
output_dir="path/to/save/folder/",
- optim = "adamw_hf",
+ optim = "adamw_ort_fused",
...
)
# Step 2: Create your ONNX Runtime Trainer
-trainer = Trainer(
+trainer = ORTTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
+ feature="sequence-classification",
...
)
# Step 3: Use ONNX Runtime for training!🤗
trainer.train()
```
## Looking Forward
The Hugging Face team is working on open sourcing more large models and lowering the barrier for users to benefit from them with acceleration tools on both training and inference. We are collaborating with the ONNX Runtime training team to bring more training optimizations to newer and larger model architectures, including Whisper and Stable Diffusion. Microsoft has also packaged its state-of-the-art training acceleration technologies in the [Azure Container for PyTorch](https://techcommunity.microsoft.com/t5/ai-machine-learning-blog/enabling-deep-learning-with-azure-container-for-pytorch-in-azure/ba-p/3650489). This is a light-weight curated environment including DeepSpeed and ONNX Runtime to improve productivity for AI developers training with PyTorch. In addition to large model training, the ONNX Runtime training team is also building new solutions for learning on the edge – training on devices that are constrained on memory and power.
## Getting Started
We invite you to check out the links below to learn more about, and get started with, Optimum ONNX Runtime Training for your Hugging Face models.
* [Optimum ONNX Runtime Training Documentation](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/trainer)
* [Optimum ONNX Runtime Training Examples](https://github.com/huggingface/optimum/tree/main/examples/onnxruntime/training)
* [Optimum Github repo](https://github.com/huggingface/optimum/tree/main)
* [ONNX Runtime Training Examples](https://github.com/microsoft/onnxruntime-training-examples/)
* [ONNX Runtime Training Github repo](https://github.com/microsoft/onnxruntime/tree/main/orttraining)
* [ONNX Runtime](https://onnxruntime.ai/)
* [DeepSpeed](https://www.deepspeed.ai/) and [ZeRO](https://www.deepspeed.ai/tutorials/zero/) Tutorial
* [Azure Container for PyTorch](https://techcommunity.microsoft.com/t5/ai-machine-learning-blog/enabling-deep-learning-with-azure-container-for-pytorch-in-azure/ba-p/3650489)
---
🏎Thanks for reading! If you have any questions, feel free to reach us through [Github](https://github.com/huggingface/optimum/issues), or on the [forum](https://discuss.huggingface.co/c/optimum/). You can also connect with me on [Twitter](https://twitter.com/Jhuaplin) or [LinkedIn](https://www.linkedin.com/in/jingya-huang-96158b15b/). | huggingface/blog/blob/main/optimum-onnxruntime-training.md |
p align="center">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://huggingface.co/datasets/safetensors/assets/raw/main/banner-dark.svg">
<source media="(prefers-color-scheme: light)" srcset="https://huggingface.co/datasets/safetensors/assets/raw/main/banner-light.svg">
<img alt="Hugging Face Safetensors Library" src="https://huggingface.co/datasets/safetensors/assets/raw/main/banner-light.svg" style="max-width: 100%;">
</picture>
<br/>
<br/>
</p>
Python
[](https://pypi.org/pypi/safetensors/)
[](https://huggingface.co/docs/safetensors/index)
[](https://codecov.io/gh/huggingface/safetensors)
[](https://pepy.tech/project/safetensors)
Rust
[](https://crates.io/crates/safetensors)
[](https://docs.rs/safetensors/)
[](https://codecov.io/gh/huggingface/safetensors)
[](https://deps.rs/repo/github/huggingface/safetensors?path=safetensors)
# safetensors
## Safetensors
This repository implements a new simple format for storing tensors
safely (as opposed to pickle) and that is still fast (zero-copy).
### Installation
#### Pip
You can install safetensors via the pip manager:
```bash
pip install safetensors
```
#### From source
For the sources, you need Rust
```bash
# Install Rust
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
# Make sure it's up to date and using stable channel
rustup update
git clone https://github.com/huggingface/safetensors
cd safetensors/bindings/python
pip install setuptools_rust
pip install -e .
```
### Getting started
```python
import torch
from safetensors import safe_open
from safetensors.torch import save_file
tensors = {
"weight1": torch.zeros((1024, 1024)),
"weight2": torch.zeros((1024, 1024))
}
save_file(tensors, "model.safetensors")
tensors = {}
with safe_open("model.safetensors", framework="pt", device="cpu") as f:
for key in f.keys():
tensors[key] = f.get_tensor(key)
```
[Python documentation](https://huggingface.co/docs/safetensors/index)
### Format
- 8 bytes: `N`, an unsigned little-endian 64-bit integer, containing the size of the header
- N bytes: a JSON UTF-8 string representing the header.
- The header data MUST begin with a `{` character (0x7B).
- The header data MAY be trailing padded with whitespace (0x20).
- The header is a dict like `{"TENSOR_NAME": {"dtype": "F16", "shape": [1, 16, 256], "data_offsets": [BEGIN, END]}, "NEXT_TENSOR_NAME": {...}, ...}`,
- `data_offsets` point to the tensor data relative to the beginning of the byte buffer (i.e. not an absolute position in the file),
with `BEGIN` as the starting offset and `END` as the one-past offset (so total tensor byte size = `END - BEGIN`).
- A special key `__metadata__` is allowed to contain free form string-to-string map. Arbitrary JSON is not allowed, all values must be strings.
- Rest of the file: byte-buffer.
Notes:
- Duplicate keys are disallowed. Not all parsers may respect this.
- In general the subset of JSON is implicitly decided by `serde_json` for
this library. Anything obscure might be modified at a later time, that odd ways
to represent integer, newlines and escapes in utf-8 strings. This would only
be done for safety concerns
- Tensor values are not checked against, in particular NaN and +/-Inf could
be in the file
- Empty tensors (tensors with 1 dimension being 0) are allowed.
They are not storing any data in the databuffer, yet retaining size in the header.
They don't really bring a lot of values but are accepted since they are valid tensors
from traditional tensor libraries perspective (torch, tensorflow, numpy, ..).
- 0-rank Tensors (tensors with shape `[]`) are allowed, they are merely a scalar.
- The byte buffer needs to be entirely indexed, and cannot contain holes. This prevents
the creation of polyglot files.
- Endianness: Little-endian.
moment.
- Order: 'C' or row-major.
### Yet another format ?
The main rationale for this crate is to remove the need to use
`pickle` on `PyTorch` which is used by default.
There are other formats out there used by machine learning and more general
formats.
Let's take a look at alternatives and why this format is deemed interesting.
This is my very personal and probably biased view:
| Format | Safe | Zero-copy | Lazy loading | No file size limit | Layout control | Flexibility | Bfloat16/Fp8
| ----------------------- | --- | --- | --- | --- | --- | --- | --- |
| pickle (PyTorch) | ✗ | ✗ | ✗ | 🗸 | ✗ | 🗸 | 🗸 |
| H5 (Tensorflow) | 🗸 | ✗ | 🗸 | 🗸 | ~ | ~ | ✗ |
| SavedModel (Tensorflow) | 🗸 | ✗ | ✗ | 🗸 | 🗸 | ✗ | 🗸 |
| MsgPack (flax) | 🗸 | 🗸 | ✗ | 🗸 | ✗ | ✗ | 🗸 |
| Protobuf (ONNX) | 🗸 | ✗ | ✗ | ✗ | ✗ | ✗ | 🗸 |
| Cap'n'Proto | 🗸 | 🗸 | ~ | 🗸 | 🗸 | ~ | ✗ |
| Arrow | ? | ? | ? | ? | ? | ? | ✗ |
| Numpy (npy,npz) | 🗸 | ? | ? | ✗ | 🗸 | ✗ | ✗ |
| pdparams (Paddle) | ✗ | ✗ | ✗ | 🗸 | ✗ | 🗸 | 🗸 |
| SafeTensors | 🗸 | 🗸 | 🗸 | 🗸 | 🗸 | ✗ | 🗸 |
- Safe: Can I use a file randomly downloaded and expect not to run arbitrary code ?
- Zero-copy: Does reading the file require more memory than the original file ?
- Lazy loading: Can I inspect the file without loading everything ? And loading only
some tensors in it without scanning the whole file (distributed setting) ?
- Layout control: Lazy loading, is not necessarily enough since if the information about tensors is spread out in your file, then even if the information is lazily accessible you might have to access most of your file to read the available tensors (incurring many DISK -> RAM copies). Controlling the layout to keep fast access to single tensors is important.
- No file size limit: Is there a limit to the file size ?
- Flexibility: Can I save custom code in the format and be able to use it later with zero extra code ? (~ means we can store more than pure tensors, but no custom code)
- Bfloat16/Fp8: Does the format support native bfloat16/fp8 (meaning no weird workarounds are
necessary)? This is becoming increasingly important in the ML world.
### Main oppositions
- Pickle: Unsafe, runs arbitrary code
- H5: Apparently now discouraged for TF/Keras. Seems like a great fit otherwise actually. Some classic use after free issues: <https://www.cvedetails.com/vulnerability-list/vendor_id-15991/product_id-35054/Hdfgroup-Hdf5.html>. On a very different level than pickle security-wise. Also 210k lines of code vs ~400 lines for this lib currently.
- SavedModel: Tensorflow specific (it contains TF graph information).
- MsgPack: No layout control to enable lazy loading (important for loading specific parts in distributed setting)
- Protobuf: Hard 2Go max file size limit
- Cap'n'proto: Float16 support is not present [link](https://capnproto.org/language.html#built-in-types) so using a manual wrapper over a byte-buffer would be necessary. Layout control seems possible but not trivial as buffers have limitations [link](https://stackoverflow.com/questions/48458839/capnproto-maximum-filesize).
- Numpy (npz): No `bfloat16` support. Vulnerable to zip bombs (DOS). Not zero-copy.
- Arrow: No `bfloat16` support. Seem to require decoding [link](https://arrow.apache.org/docs/python/parquet.html#reading-parquet-and-memory-mapping)
### Notes
- Zero-copy: No format is really zero-copy in ML, it needs to go from disk to RAM/GPU RAM (that takes time). On CPU, if the file is already in cache, then it can
truly be zero-copy, whereas on GPU there is not such disk cache, so a copy is always required
but you can bypass allocating all the tensors on CPU at any given point.
SafeTensors is not zero-copy for the header. The choice of JSON is pretty arbitrary, but since deserialization is <<< of the time required to load the actual tensor data and is readable I went that way, (also space is <<< to the tensor data).
- Endianness: Little-endian. This can be modified later, but it feels really unnecessary at the
moment.
- Order: 'C' or row-major. This seems to have won. We can add that information later if needed.
- Stride: No striding, all tensors need to be packed before being serialized. I have yet to see a case where it seems useful to have a strided tensor stored in serialized format.
### Benefits
Since we can invent a new format we can propose additional benefits:
- Prevent DOS attacks: We can craft the format in such a way that it's almost
impossible to use malicious files to DOS attack a user. Currently, there's a limit
on the size of the header of 100MB to prevent parsing extremely large JSON.
Also when reading the file, there's a guarantee that addresses in the file
do not overlap in any way, meaning when you're loading a file you should never
exceed the size of the file in memory
- Faster load: PyTorch seems to be the fastest file to load out in the major
ML formats. However, it does seem to have an extra copy on CPU, which we
can bypass in this lib by using `torch.UntypedStorage.from_file`.
Currently, CPU loading times are extremely fast with this lib compared to pickle.
GPU loading times are as fast or faster than PyTorch equivalent.
Loading first on CPU with memmapping with torch, and then moving all tensors to GPU seems
to be faster too somehow (similar behavior in torch pickle)
- Lazy loading: in distributed (multi-node or multi-gpu) settings, it's nice to be able to
load only part of the tensors on the various models. For
[BLOOM](https://huggingface.co/bigscience/bloom) using this format enabled
to load the model on 8 GPUs from 10mn with regular PyTorch weights down to 45s.
This really speeds up feedbacks loops when developing on the model. For instance
you don't have to have separate copies of the weights when changing the distribution
strategy (for instance Pipeline Parallelism vs Tensor Parallelism).
License: Apache-2.0
| huggingface/safetensors/blob/main/safetensors/README.md |
--
title: "SafeCoder vs. Closed-source Code Assistants"
thumbnail: /blog/assets/safecoder-vs-closed-source-code-assistants/image.png
authors:
- user: juliensimon
---
# SafeCoder vs. Closed-source Code Assistants
For decades, software developers have designed methodologies, processes, and tools that help them improve code quality and increase productivity. For instance, agile, test-driven development, code reviews, and CI/CD are now staples in the software industry.
In "How Google Tests Software" (Addison-Wesley, 2012), Google reports that fixing a bug during system tests - the final testing stage - is 1000x more expensive than fixing it at the unit testing stage. This puts much pressure on developers - the first link in the chain - to write quality code from the get-go.
For all the hype surrounding generative AI, code generation seems a promising way to help developers deliver better code fast. Indeed, early studies show that managed services like [GitHub Copilot](https://github.blog/2023-06-27-the-economic-impact-of-the-ai-powered-developer-lifecycle-and-lessons-from-github-copilot) or [Amazon CodeWhisperer](https://aws.amazon.com/codewhisperer/) help developers be more productive.
However, these services rely on closed-source models that can't be customized to your technical culture and processes. Hugging Face released [SafeCoder](https://huggingface.co/blog/starcoder) a few weeks ago to fix this. SafeCoder is a code assistant solution built for the enterprise that gives you state-of-the-art models, transparency, customizability, IT flexibility, and privacy.
In this post, we'll compare SafeCoder to closed-source services and highlight the benefits you can expect from our solution.
## State-of-the-art models
SafeCoder is currently built on top of the [StarCoder](https://huggingface.co/blog/starcoder) models, a family of open-source models designed and trained within the [BigCode](https://huggingface.co/bigcode) collaborative project.
StarCoder is a 15.5 billion parameter model trained for code generation in over 80 programming languages. It uses innovative architectural concepts, like [Multi-Query Attention](https://arxiv.org/abs/1911.02150) (MQA), to improve throughput and reduce latency, a technique also present in the [Falcon](https://huggingface.co/blog/falcon) and adapted for [LLaMa 2](https://huggingface.co/blog/llama2) models.
StarCoder has an 8192-token context window, helping it take into account more of your code to generate new code. It can also do fill-in-the-middle, i.e., insert within your code, instead of just appending new code at the end.
Lastly, like [HuggingChat](https://huggingface.co/chat/), SafeCoder will introduce new state-of-the-art models over time, giving you a seamless upgrade path.
Unfortunately, closed-source code assistant services don't share information about the underlying models, their capabilities, and their training data.
## Transparency
In line with the [Chinchilla Scaling Law](https://arxiv.org/abs/2203.15556v1), SafeCoder is a compute-optimal model trained on 1 trillion (1,000 billion) code tokens. These tokens are extracted from [The Stack](https://huggingface.co/datasets/bigcode/the-stack), a 2.7 terabyte dataset built from permissively licensed open-source repositories.
All efforts are made to honor opt-out requests, and we built a [tool](https://huggingface.co/spaces/bigcode/in-the-stack) that lets repository owners check if their code is part of the dataset.
In the spirit of transparency, our [research paper](https://arxiv.org/abs/2305.06161) discloses the model architecture, the training process, and detailed metrics.
Unfortunately, closed-source services stick to vague information, such as "[the model was trained on] billions of lines of code." To the best of our knowledge, no metrics are available.
## Customization
The StarCoder models have been specifically designed to be customizable, and we have already built different versions:
* [StarCoderBase](https://huggingface.co/bigcode/starcoderbase): the original model trained on 80+ languages from The Stack.
* [StarCoder](https://huggingface.co/bigcode/starcoder): StarCoderBase further trained on Python.
* [StarCoder+](https://huggingface.co/bigcode/starcoderplus): StarCoderBase further trained on English web data for coding conversations.
We also shared the [fine-tuning code](https://github.com/bigcode-project/starcoder/) on GitHub.
Every company has its preferred languages and coding guidelines, i.e., how to write inline documentation or unit tests, or do's and don'ts on security and performance. With SafeCoder, we can help you train models that learn the peculiarities of your software engineering process. Our team will help you prepare high-quality datasets and fine-tune StarCoder on your infrastructure. Your data will never be exposed to anyone.
Unfortunately, closed-source services cannot be customized.
## IT flexibility
SafeCoder relies on Docker containers for fine-tuning and deployment. It's easy to run on-premise or in the cloud on any container management service.
In addition, SafeCoder includes our [Optimum](https://github.com/huggingface/optimum) hardware acceleration libraries. Whether you work with CPU, GPU, or AI accelerators, Optimum will kick in automatically to help you save time and money on training and inference. Since you control the underlying hardware, you can also tune the cost-performance ratio of your infrastructure to your needs.
Unfortunately, closed-source services are only available as managed services.
## Security and privacy
Security is always a top concern, all the more when source code is involved. Intellectual property and privacy must be protected at all costs.
Whether you run on-premise or in the cloud, SafeCoder is under your complete administrative control. You can apply and monitor your security checks and maintain strong and consistent compliance across your IT platform.
SafeCoder doesn't spy on any of your data. Your prompts and suggestions are yours and yours only. SafeCoder doesn't call home and send telemetry data to Hugging Face or anyone else. No one but you needs to know how and when you're using SafeCoder. SafeCoder doesn't even require an Internet connection. You can (and should) run it fully air-gapped.
Closed-source services rely on the security of the underlying cloud. Whether this works or not for your compliance posture is your call. For enterprise users, prompts and suggestions are not stored (they are for individual users). However, we regret to point out that GitHub collects ["user engagement data"](https://docs.github.com/en/copilot/overview-of-github-copilot/about-github-copilot-for-business) with no possibility to opt-out. AWS does the same by default but lets you [opt out](https://docs.aws.amazon.com/codewhisperer/latest/userguide/sharing-data.html).
## Conclusion
We're very excited about the future of SafeCoder, and so are our customers. No one should have to compromise on state-of-the-art code generation, transparency, customization, IT flexibility, security, and privacy. We believe SafeCoder delivers them all, and we'll keep working hard to make it even better.
If you’re interested in SafeCoder for your company, please [contact us](mailto:api-enterprise@huggingface.co). Our team will contact you shortly to learn more about your use case and discuss requirements.
Thanks for reading!
| huggingface/blog/blob/main/safecoder-vs-closed-source-code-assistants.md |
Offline vs. Online Reinforcement Learning
Deep Reinforcement Learning (RL) is a framework **to build decision-making agents**. These agents aim to learn optimal behavior (policy) by interacting with the environment through **trial and error and receiving rewards as unique feedback**.
The agent’s goal **is to maximize its cumulative reward**, called return. Because RL is based on the *reward hypothesis*: all goals can be described as the **maximization of the expected cumulative reward**.
Deep Reinforcement Learning agents **learn with batches of experience**. The question is, how do they collect it?:
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit12/offlinevsonlinerl.gif" alt="Unit bonus 3 thumbnail">
<figcaption>A comparison between Reinforcement Learning in an Online and Offline setting, figure taken from <a href="https://offline-rl.github.io/">this post</a></figcaption>
</figure>
- In *online reinforcement learning*, which is what we've learned during this course, the agent **gathers data directly**: it collects a batch of experience by **interacting with the environment**. Then, it uses this experience immediately (or via some replay buffer) to learn from it (update its policy).
But this implies that either you **train your agent directly in the real world or have a simulator**. If you don’t have one, you need to build it, which can be very complex (how to reflect the complex reality of the real world in an environment?), expensive, and insecure (if the simulator has flaws that may provide a competitive advantage, the agent will exploit them).
- On the other hand, in *offline reinforcement learning*, the agent only **uses data collected from other agents or human demonstrations**. It does **not interact with the environment**.
The process is as follows:
- **Create a dataset** using one or more policies and/or human interactions.
- Run **offline RL on this dataset** to learn a policy
This method has one drawback: the *counterfactual queries problem*. What do we do if our agent **decides to do something for which we don’t have the data?** For instance, turning right on an intersection but we don’t have this trajectory.
There exist some solutions on this topic, but if you want to know more about offline reinforcement learning, you can [watch this video](https://www.youtube.com/watch?v=k08N5a0gG0A)
## Further reading
For more information, we recommend you check out the following resources:
- [Offline Reinforcement Learning, Talk by Sergei Levine](https://www.youtube.com/watch?v=qgZPZREor5I)
- [Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems](https://arxiv.org/abs/2005.01643)
## Author
This section was written by <a href="https://twitter.com/ThomasSimonini"> Thomas Simonini</a>
| huggingface/deep-rl-class/blob/main/units/en/unitbonus3/offline-online.mdx |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Pipelines for inference
The [`pipeline`] makes it simple to use any model from the [Hub](https://huggingface.co/models) for inference on any language, computer vision, speech, and multimodal tasks. Even if you don't have experience with a specific modality or aren't familiar with the underlying code behind the models, you can still use them for inference with the [`pipeline`]! This tutorial will teach you to:
* Use a [`pipeline`] for inference.
* Use a specific tokenizer or model.
* Use a [`pipeline`] for audio, vision, and multimodal tasks.
<Tip>
Take a look at the [`pipeline`] documentation for a complete list of supported tasks and available parameters.
</Tip>
## Pipeline usage
While each task has an associated [`pipeline`], it is simpler to use the general [`pipeline`] abstraction which contains
all the task-specific pipelines. The [`pipeline`] automatically loads a default model and a preprocessing class capable
of inference for your task. Let's take the example of using the [`pipeline`] for automatic speech recognition (ASR), or
speech-to-text.
1. Start by creating a [`pipeline`] and specify the inference task:
```py
>>> from transformers import pipeline
>>> transcriber = pipeline(task="automatic-speech-recognition")
```
2. Pass your input to the [`pipeline`]. In the case of speech recognition, this is an audio input file:
```py
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': 'I HAVE A DREAM BUT ONE DAY THIS NATION WILL RISE UP LIVE UP THE TRUE MEANING OF ITS TREES'}
```
Not the result you had in mind? Check out some of the [most downloaded automatic speech recognition models](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition&sort=trending)
on the Hub to see if you can get a better transcription.
Let's try the [Whisper large-v2](https://huggingface.co/openai/whisper-large) model from OpenAI. Whisper was released
2 years later than Wav2Vec2, and was trained on close to 10x more data. As such, it beats Wav2Vec2 on most downstream
benchmarks. It also has the added benefit of predicting punctuation and casing, neither of which are possible with
Wav2Vec2.
Let's give it a try here to see how it performs:
```py
>>> transcriber = pipeline(model="openai/whisper-large-v2")
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}
```
Now this result looks more accurate! For a deep-dive comparison on Wav2Vec2 vs Whisper, refer to the [Audio Transformers Course](https://huggingface.co/learn/audio-course/chapter5/asr_models).
We really encourage you to check out the Hub for models in different languages, models specialized in your field, and more.
You can check out and compare model results directly from your browser on the Hub to see if it fits or
handles corner cases better than other ones.
And if you don't find a model for your use case, you can always start [training](training) your own!
If you have several inputs, you can pass your input as a list:
```py
transcriber(
[
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac",
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/1.flac",
]
)
```
Pipelines are great for experimentation as switching from one model to another is trivial; however, there are some ways to optimize them for larger workloads than experimentation. See the following guides that dive into iterating over whole datasets or using pipelines in a webserver:
of the docs:
* [Using pipelines on a dataset](#using-pipelines-on-a-dataset)
* [Using pipelines for a webserver](./pipeline_webserver)
## Parameters
[`pipeline`] supports many parameters; some are task specific, and some are general to all pipelines.
In general, you can specify parameters anywhere you want:
```py
transcriber = pipeline(model="openai/whisper-large-v2", my_parameter=1)
out = transcriber(...) # This will use `my_parameter=1`.
out = transcriber(..., my_parameter=2) # This will override and use `my_parameter=2`.
out = transcriber(...) # This will go back to using `my_parameter=1`.
```
Let's check out 3 important ones:
### Device
If you use `device=n`, the pipeline automatically puts the model on the specified device.
This will work regardless of whether you are using PyTorch or Tensorflow.
```py
transcriber = pipeline(model="openai/whisper-large-v2", device=0)
```
If the model is too large for a single GPU and you are using PyTorch, you can set `device_map="auto"` to automatically
determine how to load and store the model weights. Using the `device_map` argument requires the 🤗 [Accelerate](https://huggingface.co/docs/accelerate)
package:
```bash
pip install --upgrade accelerate
```
The following code automatically loads and stores model weights across devices:
```py
transcriber = pipeline(model="openai/whisper-large-v2", device_map="auto")
```
Note that if `device_map="auto"` is passed, there is no need to add the argument `device=device` when instantiating your `pipeline` as you may encounter some unexpected behavior!
### Batch size
By default, pipelines will not batch inference for reasons explained in detail [here](https://huggingface.co/docs/transformers/main_classes/pipelines#pipeline-batching). The reason is that batching is not necessarily faster, and can actually be quite slower in some cases.
But if it works in your use case, you can use:
```py
transcriber = pipeline(model="openai/whisper-large-v2", device=0, batch_size=2)
audio_filenames = [f"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/{i}.flac" for i in range(1, 5)]
texts = transcriber(audio_filenames)
```
This runs the pipeline on the 4 provided audio files, but it will pass them in batches of 2
to the model (which is on a GPU, where batching is more likely to help) without requiring any further code from you.
The output should always match what you would have received without batching. It is only meant as a way to help you get more speed out of a pipeline.
Pipelines can also alleviate some of the complexities of batching because, for some pipelines, a single item (like a long audio file) needs to be chunked into multiple parts to be processed by a model. The pipeline performs this [*chunk batching*](./main_classes/pipelines#pipeline-chunk-batching) for you.
### Task specific parameters
All tasks provide task specific parameters which allow for additional flexibility and options to help you get your job done.
For instance, the [`transformers.AutomaticSpeechRecognitionPipeline.__call__`] method has a `return_timestamps` parameter which sounds promising for subtitling videos:
```py
>>> transcriber = pipeline(model="openai/whisper-large-v2", return_timestamps=True)
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.', 'chunks': [{'timestamp': (0.0, 11.88), 'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its'}, {'timestamp': (11.88, 12.38), 'text': ' creed.'}]}
```
As you can see, the model inferred the text and also outputted **when** the various sentences were pronounced.
There are many parameters available for each task, so check out each task's API reference to see what you can tinker with!
For instance, the [`~transformers.AutomaticSpeechRecognitionPipeline`] has a `chunk_length_s` parameter which is helpful
for working on really long audio files (for example, subtitling entire movies or hour-long videos) that a model typically
cannot handle on its own:
```python
>>> transcriber = pipeline(model="openai/whisper-large-v2", chunk_length_s=30, return_timestamps=True)
>>> transcriber("https://huggingface.co/datasets/sanchit-gandhi/librispeech_long/resolve/main/audio.wav")
{'text': " Chapter 16. I might have told you of the beginning of this liaison in a few lines, but I wanted you to see every step by which we came. I, too, agree to whatever Marguerite wished, Marguerite to be unable to live apart from me. It was the day after the evening...
```
If you can't find a parameter that would really help you out, feel free to [request it](https://github.com/huggingface/transformers/issues/new?assignees=&labels=feature&template=feature-request.yml)!
## Using pipelines on a dataset
The pipeline can also run inference on a large dataset. The easiest way we recommend doing this is by using an iterator:
```py
def data():
for i in range(1000):
yield f"My example {i}"
pipe = pipeline(model="gpt2", device=0)
generated_characters = 0
for out in pipe(data()):
generated_characters += len(out[0]["generated_text"])
```
The iterator `data()` yields each result, and the pipeline automatically
recognizes the input is iterable and will start fetching the data while
it continues to process it on the GPU (this uses [DataLoader](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader) under the hood).
This is important because you don't have to allocate memory for the whole dataset
and you can feed the GPU as fast as possible.
Since batching could speed things up, it may be useful to try tuning the `batch_size` parameter here.
The simplest way to iterate over a dataset is to just load one from 🤗 [Datasets](https://github.com/huggingface/datasets/):
```py
# KeyDataset is a util that will just output the item we're interested in.
from transformers.pipelines.pt_utils import KeyDataset
from datasets import load_dataset
pipe = pipeline(model="hf-internal-testing/tiny-random-wav2vec2", device=0)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation[:10]")
for out in pipe(KeyDataset(dataset, "audio")):
print(out)
```
## Using pipelines for a webserver
<Tip>
Creating an inference engine is a complex topic which deserves it's own
page.
</Tip>
[Link](./pipeline_webserver)
## Vision pipeline
Using a [`pipeline`] for vision tasks is practically identical.
Specify your task and pass your image to the classifier. The image can be a link, a local path or a base64-encoded image. For example, what species of cat is shown below?

```py
>>> from transformers import pipeline
>>> vision_classifier = pipeline(model="google/vit-base-patch16-224")
>>> preds = vision_classifier(
... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.4335, 'label': 'lynx, catamount'}, {'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}, {'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}, {'score': 0.0239, 'label': 'Egyptian cat'}, {'score': 0.0229, 'label': 'tiger cat'}]
```
## Text pipeline
Using a [`pipeline`] for NLP tasks is practically identical.
```py
>>> from transformers import pipeline
>>> # This model is a `zero-shot-classification` model.
>>> # It will classify text, except you are free to choose any label you might imagine
>>> classifier = pipeline(model="facebook/bart-large-mnli")
>>> classifier(
... "I have a problem with my iphone that needs to be resolved asap!!",
... candidate_labels=["urgent", "not urgent", "phone", "tablet", "computer"],
... )
{'sequence': 'I have a problem with my iphone that needs to be resolved asap!!', 'labels': ['urgent', 'phone', 'computer', 'not urgent', 'tablet'], 'scores': [0.504, 0.479, 0.013, 0.003, 0.002]}
```
## Multimodal pipeline
The [`pipeline`] supports more than one modality. For example, a visual question answering (VQA) task combines text and image. Feel free to use any image link you like and a question you want to ask about the image. The image can be a URL or a local path to the image.
For example, if you use this [invoice image](https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png):
```py
>>> from transformers import pipeline
>>> vqa = pipeline(model="impira/layoutlm-document-qa")
>>> vqa(
... image="https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png",
... question="What is the invoice number?",
... )
[{'score': 0.42515, 'answer': 'us-001', 'start': 16, 'end': 16}]
```
<Tip>
To run the example above you need to have [`pytesseract`](https://pypi.org/project/pytesseract/) installed in addition to 🤗 Transformers:
```bash
sudo apt install -y tesseract-ocr
pip install pytesseract
```
</Tip>
## Using `pipeline` on large models with 🤗 `accelerate`:
You can easily run `pipeline` on large models using 🤗 `accelerate`! First make sure you have installed `accelerate` with `pip install accelerate`.
First load your model using `device_map="auto"`! We will use `facebook/opt-1.3b` for our example.
```py
# pip install accelerate
import torch
from transformers import pipeline
pipe = pipeline(model="facebook/opt-1.3b", torch_dtype=torch.bfloat16, device_map="auto")
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)
```
You can also pass 8-bit loaded models if you install `bitsandbytes` and add the argument `load_in_8bit=True`
```py
# pip install accelerate bitsandbytes
import torch
from transformers import pipeline
pipe = pipeline(model="facebook/opt-1.3b", device_map="auto", model_kwargs={"load_in_8bit": True})
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)
```
Note that you can replace the checkpoint with any of the Hugging Face model that supports large model loading such as BLOOM!
| huggingface/transformers/blob/main/docs/source/en/pipeline_tutorial.md |
Quiz
The best way to learn and [to avoid the illusion of competence](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
### Q1: What are the advantages of policy-gradient over value-based methods? (Check all that apply)
<Question
choices={[
{
text: "Policy-gradient methods can learn a stochastic policy",
explain: "",
correct: true,
},
{
text: "Policy-gradient methods are more effective in high-dimensional action spaces and continuous actions spaces",
explain: "",
correct: true,
},
{
text: "Policy-gradient converges most of the time on a global maximum.",
explain: "No, frequently, policy-gradient converges on a local maximum instead of a global optimum.",
},
]}
/>
### Q2: What is the Policy Gradient Theorem?
<details>
<summary>Solution</summary>
*The Policy Gradient Theorem* is a formula that will help us to reformulate the objective function into a differentiable function that does not involve the differentiation of the state distribution.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/policy_gradient_theorem.png" alt="Policy Gradient"/>
</details>
### Q3: What's the difference between policy-based methods and policy-gradient methods? (Check all that apply)
<Question
choices={[
{
text: "Policy-based methods are a subset of policy-gradient methods.",
explain: "",
},
{
text: "Policy-gradient methods are a subset of policy-based methods.",
explain: "",
correct: true,
},
{
text: "In Policy-based methods, we can optimize the parameter θ **indirectly** by maximizing the local approximation of the objective function with techniques like hill climbing, simulated annealing, or evolution strategies.",
explain: "",
correct: true,
},
{
text: "In Policy-gradient methods, we optimize the parameter θ **directly** by performing the gradient ascent on the performance of the objective function.",
explain: "",
correct: true,
},
]}
/>
### Q4: Why do we use gradient ascent instead of gradient descent to optimize J(θ)?
<Question
choices={[
{
text: "We want to minimize J(θ) and gradient ascent gives us the gives the direction of the steepest increase of J(θ)",
explain: "",
},
{
text: "We want to maximize J(θ) and gradient ascent gives us the gives the direction of the steepest increase of J(θ)",
explain: "",
correct: true
},
]}
/>
Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read the chapter again to reinforce (😏) your knowledge.
| huggingface/deep-rl-class/blob/main/units/en/unit4/quiz.mdx |
Gradio Demo: same-person-or-different
### This demo identifies if two speakers are the same person using Gradio's Audio and HTML components.
```
!pip install -q gradio git+https://github.com/huggingface/transformers torchaudio
```
```
# Downloading files from the demo repo
import os
!wget -q https://github.com/gradio-app/gradio/raw/main/demo/same-person-or-different/packages.txt
os.mkdir('samples')
!wget -q -O samples/cate_blanch.mp3 https://github.com/gradio-app/gradio/raw/main/demo/same-person-or-different/samples/cate_blanch.mp3
!wget -q -O samples/cate_blanch_2.mp3 https://github.com/gradio-app/gradio/raw/main/demo/same-person-or-different/samples/cate_blanch_2.mp3
!wget -q -O samples/heath_ledger.mp3 https://github.com/gradio-app/gradio/raw/main/demo/same-person-or-different/samples/heath_ledger.mp3
```
```
import gradio as gr
import torch
from torchaudio.sox_effects import apply_effects_file
from transformers import AutoFeatureExtractor, AutoModelForAudioXVector
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
OUTPUT_OK = (
"""
<div class="container">
<div class="row"><h1 style="text-align: center">The speakers are</h1></div>
<div class="row"><h1 class="display-1 text-success" style="text-align: center">{:.1f}%</h1></div>
<div class="row"><h1 style="text-align: center">similar</h1></div>
<div class="row"><h1 class="text-success" style="text-align: center">Welcome, human!</h1></div>
<div class="row"><small style="text-align: center">(You must get at least 85% to be considered the same person)</small><div class="row">
</div>
"""
)
OUTPUT_FAIL = (
"""
<div class="container">
<div class="row"><h1 style="text-align: center">The speakers are</h1></div>
<div class="row"><h1 class="display-1 text-danger" style="text-align: center">{:.1f}%</h1></div>
<div class="row"><h1 style="text-align: center">similar</h1></div>
<div class="row"><h1 class="text-danger" style="text-align: center">You shall not pass!</h1></div>
<div class="row"><small style="text-align: center">(You must get at least 85% to be considered the same person)</small><div class="row">
</div>
"""
)
EFFECTS = [
["remix", "-"],
["channels", "1"],
["rate", "16000"],
["gain", "-1.0"],
["silence", "1", "0.1", "0.1%", "-1", "0.1", "0.1%"],
["trim", "0", "10"],
]
THRESHOLD = 0.85
model_name = "microsoft/unispeech-sat-base-plus-sv"
feature_extractor = AutoFeatureExtractor.from_pretrained(model_name)
model = AutoModelForAudioXVector.from_pretrained(model_name).to(device)
cosine_sim = torch.nn.CosineSimilarity(dim=-1)
def similarity_fn(path1, path2):
if not (path1 and path2):
return '<b style="color:red">ERROR: Please record audio for *both* speakers!</b>'
wav1, _ = apply_effects_file(path1, EFFECTS)
wav2, _ = apply_effects_file(path2, EFFECTS)
print(wav1.shape, wav2.shape)
input1 = feature_extractor(wav1.squeeze(0), return_tensors="pt", sampling_rate=16000).input_values.to(device)
input2 = feature_extractor(wav2.squeeze(0), return_tensors="pt", sampling_rate=16000).input_values.to(device)
with torch.no_grad():
emb1 = model(input1).embeddings
emb2 = model(input2).embeddings
emb1 = torch.nn.functional.normalize(emb1, dim=-1).cpu()
emb2 = torch.nn.functional.normalize(emb2, dim=-1).cpu()
similarity = cosine_sim(emb1, emb2).numpy()[0]
if similarity >= THRESHOLD:
output = OUTPUT_OK.format(similarity * 100)
else:
output = OUTPUT_FAIL.format(similarity * 100)
return output
inputs = [
gr.Audio(sources=["microphone"], type="filepath", label="Speaker #1"),
gr.Audio(sources=["microphone"], type="filepath", label="Speaker #2"),
]
output = gr.HTML(label="")
description = (
"This demo from Microsoft will compare two speech samples and determine if they are from the same speaker. "
"Try it with your own voice!"
)
article = (
"<p style='text-align: center'>"
"<a href='https://huggingface.co/microsoft/unispeech-sat-large-sv' target='_blank'>🎙️ Learn more about UniSpeech-SAT</a> | "
"<a href='https://arxiv.org/abs/2110.05752' target='_blank'>📚 UniSpeech-SAT paper</a> | "
"<a href='https://www.danielpovey.com/files/2018_icassp_xvectors.pdf' target='_blank'>📚 X-Vector paper</a>"
"</p>"
)
examples = [
["samples/cate_blanch.mp3", "samples/cate_blanch_2.mp3"],
["samples/cate_blanch.mp3", "samples/heath_ledger.mp3"],
]
interface = gr.Interface(
fn=similarity_fn,
inputs=inputs,
outputs=output,
layout="horizontal",
allow_flagging=False,
live=False,
examples=examples,
cache_examples=False
)
interface.launch()
```
| gradio-app/gradio/blob/main/demo/same-person-or-different/run.ipynb |
Hands-on: advanced Deep Reinforcement Learning. Using Sample Factory to play Doom from pixels
<CourseFloatingBanner classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/deep-rl-class/blob/main/notebooks/unit8/unit8_part2.ipynb"}
]}
askForHelpUrl="http://hf.co/join/discord" />
The colab notebook:
[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit8/unit8_part2.ipynb)
# Unit 8 Part 2: Advanced Deep Reinforcement Learning. Using Sample Factory to play Doom from pixels
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/thumbnail2.png" alt="Thumbnail"/>
In this notebook, we will learn how to train a Deep Neural Network to collect objects in a 3D environment based on the game of Doom, a video of the resulting policy is shown below. We train this policy using [Sample Factory](https://www.samplefactory.dev/), an asynchronous implementation of the PPO algorithm.
Please note the following points:
* [Sample Factory](https://www.samplefactory.dev/) is an advanced RL framework and **only functions on Linux and Mac** (not Windows).
* The framework performs best on a **GPU machine with many CPU cores**, where it can achieve speeds of 100k interactions per second. The resources available on a standard Colab notebook **limit the performance of this library**. So the speed in this setting **does not reflect the real-world performance**.
* Benchmarks for Sample Factory are available in a number of settings, check out the [examples](https://github.com/alex-petrenko/sample-factory/tree/master/sf_examples) if you want to find out more.
```python
from IPython.display import HTML
HTML(
"""<video width="640" height="480" controls>
<source src="https://huggingface.co/edbeeching/doom_health_gathering_supreme_3333/resolve/main/replay.mp4"
type="video/mp4">Your browser does not support the video tag.</video>"""
)
```
To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push one model:
- `doom_health_gathering_supreme` get a result of >= 5.
To find your result, go to the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
If you don't find your model, **go to the bottom of the page and click on the refresh button**
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
## Set the GPU 💪
- To **accelerate the agent's training, we'll use a GPU**. To do that, go to `Runtime > Change Runtime type`
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/gpu-step1.jpg" alt="GPU Step 1">
- `Hardware Accelerator > GPU`
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/gpu-step2.jpg" alt="GPU Step 2">
Before starting to train our agent, let's **study the library and environments we're going to use**.
## Sample Factory
[Sample Factory](https://www.samplefactory.dev/) is one of the **fastest RL libraries focused on very efficient synchronous and asynchronous implementations of policy gradients (PPO)**.
Sample Factory is thoroughly **tested, used by many researchers and practitioners**, and is actively maintained. Our implementation is known to **reach SOTA performance in a variety of domains while minimizing RL experiment training time and hardware requirements**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/samplefactoryenvs.png" alt="Sample factory"/>
### Key features
- Highly optimized algorithm [architecture](https://www.samplefactory.dev/06-architecture/overview/) for maximum learning throughput
- [Synchronous and asynchronous](https://www.samplefactory.dev/07-advanced-topics/sync-async/) training regimes
- [Serial (single-process) mode](https://www.samplefactory.dev/07-advanced-topics/serial-mode/) for easy debugging
- Optimal performance in both CPU-based and [GPU-accelerated environments](https://www.samplefactory.dev/09-environment-integrations/isaacgym/)
- Single- & multi-agent training, self-play, supports [training multiple policies](https://www.samplefactory.dev/07-advanced-topics/multi-policy-training/) at once on one or many GPUs
- Population-Based Training ([PBT](https://www.samplefactory.dev/07-advanced-topics/pbt/))
- Discrete, continuous, hybrid action spaces
- Vector-based, image-based, dictionary observation spaces
- Automatically creates a model architecture by parsing action/observation space specification. Supports [custom model architectures](https://www.samplefactory.dev/03-customization/custom-models/)
- Designed to be imported into other projects, [custom environments](https://www.samplefactory.dev/03-customization/custom-environments/) are first-class citizens
- Detailed [WandB and Tensorboard summaries](https://www.samplefactory.dev/05-monitoring/metrics-reference/), [custom metrics](https://www.samplefactory.dev/05-monitoring/custom-metrics/)
- [HuggingFace 🤗 integration](https://www.samplefactory.dev/10-huggingface/huggingface/) (upload trained models and metrics to the Hub)
- [Multiple](https://www.samplefactory.dev/09-environment-integrations/mujoco/) [example](https://www.samplefactory.dev/09-environment-integrations/atari/) [environment](https://www.samplefactory.dev/09-environment-integrations/vizdoom/) [integrations](https://www.samplefactory.dev/09-environment-integrations/dmlab/) with tuned parameters and trained models
All of the above policies are available on the 🤗 hub. Search for the tag [sample-factory](https://huggingface.co/models?library=sample-factory&sort=downloads)
### How sample-factory works
Sample-factory is one of the **most highly optimized RL implementations available to the community**.
It works by **spawning multiple processes that run rollout workers, inference workers and a learner worker**.
The *workers* **communicate through shared memory, which lowers the communication cost between processes**.
The *rollout workers* interact with the environment and send observations to the *inference workers*.
The *inferences workers* query a fixed version of the policy and **send actions back to the rollout worker**.
After *k* steps the rollout works send a trajectory of experience to the learner worker, **which it uses to update the agent’s policy network**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/samplefactory.png" alt="Sample factory"/>
### Actor Critic models in Sample-factory
Actor Critic models in Sample Factory are composed of three components:
- **Encoder** - Process input observations (images, vectors) and map them to a vector. This is the part of the model you will most likely want to customize.
- **Core** - Intergrate vectors from one or more encoders, can optionally include a single- or multi-layer LSTM/GRU in a memory-based agent.
- **Decoder** - Apply additional layers to the output of the model core before computing the policy and value outputs.
The library has been designed to automatically support any observation and action spaces. Users can easily add their custom models. You can find out more in the [documentation](https://www.samplefactory.dev/03-customization/custom-models/#actor-critic-models-in-sample-factory).
## ViZDoom
[ViZDoom](https://vizdoom.cs.put.edu.pl/) is an **open-source python interface for the Doom Engine**.
The library was created in 2016 by Marek Wydmuch, Michal Kempka at the Institute of Computing Science, Poznan University of Technology, Poland.
The library enables the **training of agents directly from the screen pixels in a number of scenarios**, including team deathmatch, shown in the video below. Because the ViZDoom environment is based on a game the was created in the 90s, it can be run on modern hardware at accelerated speeds, **allowing us to learn complex AI behaviors fairly quickly**.
The library includes feature such as:
- Multi-platform (Linux, macOS, Windows),
- API for Python and C++,
- [OpenAI Gym](https://www.gymlibrary.dev/) environment wrappers
- Easy-to-create custom scenarios (visual editors, scripting language, and examples available),
- Async and sync single-player and multiplayer modes,
- Lightweight (few MBs) and fast (up to 7000 fps in sync mode, single-threaded),
- Customizable resolution and rendering parameters,
- Access to the depth buffer (3D vision),
- Automatic labeling of game objects visible in the frame,
- Access to the audio buffer
- Access to the list of actors/objects and map geometry,
- Off-screen rendering and episode recording,
- Time scaling in async mode.
## We first need to install some dependencies that are required for the ViZDoom environment
Now that our Colab runtime is set up, we can start by installing the dependencies required to run ViZDoom on linux.
If you are following on your machine on Mac, you will want to follow the installation instructions on the [github page](https://github.com/Farama-Foundation/ViZDoom/blob/master/doc/Quickstart.md#-quickstart-for-macos-and-anaconda3-python-36).
```python
# Install ViZDoom deps from
# https://github.com/mwydmuch/ViZDoom/blob/master/doc/Building.md#-linux
apt-get install build-essential zlib1g-dev libsdl2-dev libjpeg-dev \
nasm tar libbz2-dev libgtk2.0-dev cmake git libfluidsynth-dev libgme-dev \
libopenal-dev timidity libwildmidi-dev unzip ffmpeg
# Boost libraries
apt-get install libboost-all-dev
# Lua binding dependencies
apt-get install liblua5.1-dev
```
## Then we can install Sample Factory and ViZDoom
- This can take 7min
```bash
pip install sample-factory
pip install vizdoom
```
## Setting up the Doom Environment in sample-factory
```python
import functools
from sample_factory.algo.utils.context import global_model_factory
from sample_factory.cfg.arguments import parse_full_cfg, parse_sf_args
from sample_factory.envs.env_utils import register_env
from sample_factory.train import run_rl
from sf_examples.vizdoom.doom.doom_model import make_vizdoom_encoder
from sf_examples.vizdoom.doom.doom_params import add_doom_env_args, doom_override_defaults
from sf_examples.vizdoom.doom.doom_utils import DOOM_ENVS, make_doom_env_from_spec
# Registers all the ViZDoom environments
def register_vizdoom_envs():
for env_spec in DOOM_ENVS:
make_env_func = functools.partial(make_doom_env_from_spec, env_spec)
register_env(env_spec.name, make_env_func)
# Sample Factory allows the registration of a custom Neural Network architecture
# See https://github.com/alex-petrenko/sample-factory/blob/master/sf_examples/vizdoom/doom/doom_model.py for more details
def register_vizdoom_models():
global_model_factory().register_encoder_factory(make_vizdoom_encoder)
def register_vizdoom_components():
register_vizdoom_envs()
register_vizdoom_models()
# parse the command line args and create a config
def parse_vizdoom_cfg(argv=None, evaluation=False):
parser, _ = parse_sf_args(argv=argv, evaluation=evaluation)
# parameters specific to Doom envs
add_doom_env_args(parser)
# override Doom default values for algo parameters
doom_override_defaults(parser)
# second parsing pass yields the final configuration
final_cfg = parse_full_cfg(parser, argv)
return final_cfg
```
Now that the setup if complete, we can train the agent. We have chosen here to learn a ViZDoom task called `Health Gathering Supreme`.
### The scenario: Health Gathering Supreme
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/Health-Gathering-Supreme.png" alt="Health-Gathering-Supreme"/>
The objective of this scenario is to **teach the agent how to survive without knowing what makes it survive**. The Agent know only that **life is precious** and death is bad so **it must learn what prolongs its existence and that its health is connected with survival**.
The map is a rectangle containing walls and with a green, acidic floor which **hurts the player periodically**. Initially there are some medkits spread uniformly over the map. A new medkit falls from the skies every now and then. **Medkits heal some portions of player's health** - to survive, the agent needs to pick them up. The episode finishes after the player's death or on timeout.
Further configuration:
- Living_reward = 1
- 3 available buttons: turn left, turn right, move forward
- 1 available game variable: HEALTH
- death penalty = 100
You can find out more about the scenarios available in ViZDoom [here](https://github.com/Farama-Foundation/ViZDoom/tree/master/scenarios).
There are also a number of more complex scenarios that have been create for ViZDoom, such as the ones detailed on [this github page](https://github.com/edbeeching/3d_control_deep_rl).
## Training the agent
- We're going to train the agent for 4000000 steps. It will take approximately 20min
```python
## Start the training, this should take around 15 minutes
register_vizdoom_components()
# The scenario we train on today is health gathering
# other scenarios include "doom_basic", "doom_two_colors_easy", "doom_dm", "doom_dwango5", "doom_my_way_home", "doom_deadly_corridor", "doom_defend_the_center", "doom_defend_the_line"
env = "doom_health_gathering_supreme"
cfg = parse_vizdoom_cfg(
argv=[f"--env={env}", "--num_workers=8", "--num_envs_per_worker=4", "--train_for_env_steps=4000000"]
)
status = run_rl(cfg)
```
## Let's take a look at the performance of the trained policy and output a video of the agent.
```python
from sample_factory.enjoy import enjoy
cfg = parse_vizdoom_cfg(
argv=[f"--env={env}", "--num_workers=1", "--save_video", "--no_render", "--max_num_episodes=10"], evaluation=True
)
status = enjoy(cfg)
```
## Now lets visualize the performance of the agent
```python
from base64 import b64encode
from IPython.display import HTML
mp4 = open("/content/train_dir/default_experiment/replay.mp4", "rb").read()
data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
HTML(
"""
<video width=640 controls>
<source src="%s" type="video/mp4">
</video>
"""
% data_url
)
```
The agent has learned something, but its performance could be better. We would clearly need to train for longer. But let's upload this model to the Hub.
## Now lets upload your checkpoint and video to the Hugging Face Hub
To be able to share your model with the community there are three more steps to follow:
1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join
2️⃣ Sign in and get your authentication token from the Hugging Face website.
- Create a new token (https://huggingface.co/settings/tokens) **with write role**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/create-token.jpg" alt="Create HF Token">
- Copy the token
- Run the cell below and paste the token
If you don't want to use Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
```python
from huggingface_hub import notebook_login
notebook_login()
!git config --global credential.helper store
```
```python
from sample_factory.enjoy import enjoy
hf_username = "ThomasSimonini" # insert your HuggingFace username here
cfg = parse_vizdoom_cfg(
argv=[
f"--env={env}",
"--num_workers=1",
"--save_video",
"--no_render",
"--max_num_episodes=10",
"--max_num_frames=100000",
"--push_to_hub",
f"--hf_repository={hf_username}/rl_course_vizdoom_health_gathering_supreme",
],
evaluation=True,
)
status = enjoy(cfg)
```
## Let's load another model
This agent's performance was good, but we can do better! Let's download and visualize an agent trained for 10B timesteps from the hub.
```bash
#download the agent from the hub
python -m sample_factory.huggingface.load_from_hub -r edbeeching/doom_health_gathering_supreme_2222 -d ./train_dir
```
```bash
ls train_dir/doom_health_gathering_supreme_2222
```
```python
env = "doom_health_gathering_supreme"
cfg = parse_vizdoom_cfg(
argv=[
f"--env={env}",
"--num_workers=1",
"--save_video",
"--no_render",
"--max_num_episodes=10",
"--experiment=doom_health_gathering_supreme_2222",
"--train_dir=train_dir",
],
evaluation=True,
)
status = enjoy(cfg)
```
```python
mp4 = open("/content/train_dir/doom_health_gathering_supreme_2222/replay.mp4", "rb").read()
data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
HTML(
"""
<video width=640 controls>
<source src="%s" type="video/mp4">
</video>
"""
% data_url
)
```
## Some additional challenges 🏆: Doom Deathmatch
Training an agent to play a Doom deathmatch **takes many hours on a more beefy machine than is available in Colab**.
Fortunately, we have have **already trained an agent in this scenario and it is available in the 🤗 Hub!** Let’s download the model and visualize the agent’s performance.
```python
# Download the agent from the hub
python -m sample_factory.huggingface.load_from_hub -r edbeeching/doom_deathmatch_bots_2222 -d ./train_dir
```
Given the agent plays for a long time the video generation can take **10 minutes**.
```python
from sample_factory.enjoy import enjoy
register_vizdoom_components()
env = "doom_deathmatch_bots"
cfg = parse_vizdoom_cfg(
argv=[
f"--env={env}",
"--num_workers=1",
"--save_video",
"--no_render",
"--max_num_episodes=1",
"--experiment=doom_deathmatch_bots_2222",
"--train_dir=train_dir",
],
evaluation=True,
)
status = enjoy(cfg)
mp4 = open("/content/train_dir/doom_deathmatch_bots_2222/replay.mp4", "rb").read()
data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
HTML(
"""
<video width=640 controls>
<source src="%s" type="video/mp4">
</video>
"""
% data_url
)
```
You **can try to train your agent in this environment** using the code above, but not on colab.
**Good luck 🤞**
If you prefer an easier scenario, **why not try training in another ViZDoom scenario such as `doom_deadly_corridor` or `doom_defend_the_center`.**
---
This concludes the last unit. But we are not finished yet! 🤗 The following **bonus section include some of the most interesting, advanced, and cutting edge work in Deep Reinforcement Learning**.
## Keep learning, stay awesome 🤗
| huggingface/deep-rl-class/blob/main/units/en/unit8/hands-on-sf.mdx |
--
title: "Optimizing your LLM in production"
thumbnail: /blog/assets/163_optimize_llm/optimize_llm.png
authors:
- user: patrickvonplaten
---
# Optimizing your LLM in production
<a target="_blank" href="https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Getting_the_most_out_of_LLMs.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
***Note***: *This blog post is also available as a documentation page on [Transformers](https://huggingface.co/docs/transformers/llm_tutorial_optimization).*
Large Language Models (LLMs) such as GPT3/4, [Falcon](https://huggingface.co/tiiuae/falcon-40b), and [LLama](https://huggingface.co/meta-llama/Llama-2-70b-hf) are rapidly advancing in their ability to tackle human-centric tasks, establishing themselves as essential tools in modern knowledge-based industries.
Deploying these models in real-world tasks remains challenging, however:
- To exhibit near-human text understanding and generation capabilities, LLMs currently require to be composed of billions of parameters (see [Kaplan et al](https://arxiv.org/abs/2001.08361), [Wei et. al](https://arxiv.org/abs/2206.07682)). This consequently amplifies the memory demands for inference.
- In many real-world tasks, LLMs need to be given extensive contextual information. This necessitates the model's capability to manage very long input sequences during inference.
The crux of these challenges lies in augmenting the computational and memory capabilities of LLMs, especially when handling expansive input sequences.
In this blog post, we will go over the most effective techniques at the time of writing this blog post to tackle these challenges for efficient LLM deployment:
1. **Lower Precision**: Research has shown that operating at reduced numerical precision, namely 8-bit and 4-bit, can achieve computational advantages without a considerable decline in model performance.
2. **Flash Attention:** Flash Attention is a variation of the attention algorithm that not only provides a more memory-efficient approach but also realizes increased efficiency due to optimized GPU memory utilization.
3. **Architectural Innovations:** Considering that LLMs are always deployed in the same way during inference, namely autoregressive text generation with a long input context, specialized model architectures have been proposed that allow for more efficient inference. The most important advancement in model architectures hereby are [Alibi](https://arxiv.org/abs/2108.12409), [Rotary embeddings](https://arxiv.org/abs/2104.09864), [Multi-Query Attention (MQA)](https://arxiv.org/abs/1911.02150) and [Grouped-Query-Attention (GQA)]((https://arxiv.org/abs/2305.13245)).
Throughout this notebook, we will offer an analysis of auto-regressive generation from a tensor's perspective. We delve into the pros and cons of adopting lower precision, provide a comprehensive exploration of the latest attention algorithms, and discuss improved LLM architectures. While doing so, we run practical examples showcasing each of the feature improvements.
## 1. Harnessing the Power of Lower Precision
Memory requirements of LLMs can be best understood by seeing the LLM as a set of weight matrices and vectors and the text inputs as a sequence of vectors. In the following, the definition *weights* will be used to signify all model weight matrices and vectors.
At the time of writing this post, LLMs consist of at least a couple billion parameters. Each parameter thereby is made of a decimal number, e.g. `4.5689` which is usually stored in either [float32](https://en.wikipedia.org/wiki/Single-precision_floating-point_format), [bfloat16](https://en.wikipedia.org/wiki/Bfloat16_floating-point_format), or [float16](https://en.wikipedia.org/wiki/Half-precision_floating-point_format) format. This allows us to easily compute the memory requirement to load the LLM into memory:
> *Loading the weights of a model having X billion parameters requires roughly 4 * X GB of VRAM in float32 precision*
Nowadays, models are however rarely trained in full float32 precision, but usually in bfloat16 precision or less frequently in float16 precision. Therefore the rule of thumb becomes:
> *Loading the weights of a model having X billion parameters requires roughly 2 * X GB of VRAM in bfloat16/float16 precision*
For shorter text inputs (less than 1024 tokens), the memory requirement for inference is very much dominated by the memory requirement to load the weights. Therefore, for now, let's assume that the memory requirement for inference is equal to the memory requirement to load the model into the GPU VRAM.
To give some examples of how much VRAM it roughly takes to load a model in bfloat16:
- **GPT3** requires 2 \* 175 GB = **350 GB** VRAM
- [**Bloom**](https://huggingface.co/bigscience/bloom) requires 2 \* 176 GB = **352 GB** VRAM
- [**Llama-2-70b**](https://huggingface.co/meta-llama/Llama-2-70b-hf) requires 2 \* 70 GB = **140 GB** VRAM
- [**Falcon-40b**](https://huggingface.co/tiiuae/falcon-40b) requires 2 \* 40 GB = **80 GB** VRAM
- [**MPT-30b**](https://huggingface.co/mosaicml/mpt-30b) requires 2 \* 30 GB = **60 GB** VRAM
- [**bigcode/starcoder**](https://huggingface.co/bigcode/starcoder) requires 2 \* 15.5 = **31 GB** VRAM
As of writing this document, the largest GPU chip on the market is the A100 offering 80GB of VRAM. Most of the models listed before require more than 80GB just to be loaded and therefore necessarily require [tensor parallelism](https://huggingface.co/docs/transformers/perf_train_gpu_many#tensor-parallelism) and/or [pipeline parallelism](https://huggingface.co/docs/transformers/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism).
🤗 Transformers does not support tensor parallelism out of the box as it requires the model architecture to be written in a specific way. If you're interested in writing models in a tensor-parallelism-friendly way, feel free to have a look at [the text-generation-inference library](https://github.com/huggingface/text-generation-inference/tree/main/server/text_generation_server/models/custom_modeling).
Naive pipeline parallelism is supported out of the box. For this, simply load the model with `device="auto"` which will automatically place the different layers on the available GPUs as explained [here](https://huggingface.co/docs/accelerate/v0.22.0/en/concept_guides/big_model_inference).
Note, however that while very effective, this naive pipeline parallelism does not tackle the issues of GPU idling. For this more advanced pipeline parallelism is required as explained [here](https://huggingface.co/docs/transformers/v4.15.0/parallelism#naive-model-parallel-vertical-and-pipeline-parallel).
If you have access to an 8 x 80GB A100 node, you could load BLOOM as follows
```bash
!pip install transformers accelerate bitsandbytes optimum
```
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("bigscience/bloom", device_map="auto", pad_token_id=0)
```
By using `device_map="auto"` the attention layers would be equally distributed over all available GPUs.
In this notebook, we will use [bigcode/octocoder](https://huggingface.co/bigcode/octocoder) as it can be run on a single 40 GB A100 GPU device chip. Note that all memory and speed optimizations that we will apply going forward, are equally applicable to models that require model or tensor parallelism.
Since the model is loaded in bfloat16 precision, using our rule of thumb above, we would expect the memory requirement to run inference with `bigcode/octocoder` to be around 31 GB VRAM. Let's give it a try.
We first load the model and tokenizer and then pass both to Transformers' [pipeline](https://huggingface.co/docs/transformers/main_classes/pipelines) object.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
import torch
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto", pad_token_id=0)
tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
```
```python
prompt = "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer:"
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result
```
**Output**:
```
Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single
```
Nice, we can now directly use the result to convert bytes into Gigabytes.
```python
def bytes_to_giga_bytes(bytes):
return bytes / 1024 / 1024 / 1024
```
Let's call [`torch.cuda.max_memory_allocated`](https://pytorch.org/docs/stable/generated/torch.cuda.max_memory_allocated.html) to measure the peak GPU memory allocation.
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**Output**:
```bash
29.0260648727417
```
Close enough to our back-of-the-envelope computation! We can see the number is not exactly correct as going from bytes to kilobytes requires a multiplication of 1024 instead of 1000. Therefore the back-of-the-envelope formula can also be understood as an "at most X GB" computation.
Note that if we had tried to run the model in full float32 precision, a whopping 64 GB of VRAM would have been required.
> Almost all models are trained in bfloat16 nowadays, there is no reason to run the model in full float32 precision if [your GPU supports bfloat16](https://discuss.pytorch.org/t/bfloat16-native-support/117155/5). Float32 won't give better inference results than the precision that was used to train the model.
If you are unsure in which format the model weights are stored on the Hub, you can always look into the checkpoint's config under `"torch_dtype"`, *e.g.* [here](https://huggingface.co/meta-llama/Llama-2-7b-hf/blob/6fdf2e60f86ff2481f2241aaee459f85b5b0bbb9/config.json#L21). It is recommended to set the model to the same precision type as written in the config when loading with `from_pretrained(..., torch_dtype=...)` except when the original type is float32 in which case one can use both `float16` or `bfloat16` for inference.
Let's define a `flush(...)` function to free all allocated memory so that we can accurately measure the peak allocated GPU memory.
```python
del pipe
del model
import gc
import torch
def flush():
gc.collect()
torch.cuda.empty_cache()
torch.cuda.reset_peak_memory_stats()
```
Let's call it now for the next experiment.
```python
flush()
```
In the recent version of the accelerate library, you can also use an utility method called `release_memory()`
```python
from accelerate.utils import release_memory
# ...
release_memory(model)
```
Now what if your GPU does not have 32 GB of VRAM? It has been found that model weights can be quantized to 8-bit or 4-bits without a significant loss in performance (see [Dettmers et al.](https://arxiv.org/abs/2208.07339)).
Model can be quantized to even 3 or 2 bits with an acceptable loss in performance as shown in the recent [GPTQ paper](https://arxiv.org/abs/2210.17323) 🤯.
Without going into too many details, quantization schemes aim at reducing the precision of weights while trying to keep the model's inference results as accurate as possible (*a.k.a* as close as possible to bfloat16).
Note that quantization works especially well for text generation since all we care about is choosing the *set of most likely next tokens* and don't really care about the exact values of the next token *logit* distribution.
All that matters is that the next token *logit* distribution stays roughly the same so that an `argmax` or `topk` operation gives the same results.
There are various quantization techniques, which we won't discuss in detail here, but in general, all quantization techniques work as follows:
- 1. Quantize all weights to the target precision
- 2. Load the quantized weights, and pass the input sequence of vectors in bfloat16 precision
- 3. Dynamically dequantize weights to bfloat16 to perform the computation with their input vectors in bfloat16 precision
- 4. Quantize the weights again to the target precision after computation with their inputs.
In a nutshell, this means that *inputs-weight matrix* multiplications, with \\( X \\) being the *inputs*, \\( W \\) being a weight matrix and \\( Y \\) being the output:
$$ Y = X * W $$
are changed to
$$ Y = X * \text{dequantize}(W); \text{quantize}(W) $$
for every matrix multiplication. Dequantization and re-quantization is performed sequentially for all weight matrices as the inputs run through the network graph.
Therefore, inference time is often **not** reduced when using quantized weights, but rather increases.
Enough theory, let's give it a try! To quantize the weights with Transformers, you need to make sure that
the [`bitsandbytes`](https://github.com/TimDettmers/bitsandbytes) library is installed.
```bash
!pip install bitsandbytes
```
We can then load models in 8-bit quantization by simply adding a `load_in_8bit=True` flag to `from_pretrained`.
```python
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_8bit=True, pad_token_id=0)
```
Now, let's run our example again and measure the memory usage.
```python
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result
```
**Output**:
```
Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single
```
Nice, we're getting the same result as before, so no loss in accuracy! Let's look at how much memory was used this time.
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**Output**:
```
15.219234466552734
```
Significantly less! We're down to just a bit over 15 GBs and could therefore run this model on consumer GPUs like the 4090.
We're seeing a very nice gain in memory efficiency and more or less no degradation to the model's output. However, we can also notice a slight slow-down during inference.
We delete the models and flush the memory again.
```python
del model
del pipe
```
```python
flush()
```
Let's see what peak GPU memory consumption 4-bit quantization gives. Quantizing the model to 4-bit can be done with the same API as before - this time by passing `load_in_4bit=True` instead of `load_in_8bit=True`.
```python
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_4bit=True, low_cpu_mem_usage=True, pad_token_id=0)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result
```
**Output**:
```
Here is a Python function that transforms bytes to Giga bytes:\n\n```\ndef bytes_to_gigabytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single argument
```
We're almost seeing the same output text as before - just the `python` is missing just before the code snippet. Let's see how much memory was required.
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**Output**:
```
9.543574333190918
```
Just 9.5GB! That's really not a lot for a >15 billion parameter model.
While we see very little degradation in accuracy for our model here, 4-bit quantization can in practice often lead to different results compared to 8-bit quantization or full `bfloat16` inference. It is up to the user to try it out.
Also note that inference here was again a bit slower compared to 8-bit quantization which is due to the more aggressive quantization method used for 4-bit quantization leading to \\( \text{quantize} \\) and \\( \text{dequantize} \\) taking longer during inference.
```python
del model
del pipe
```
```python
flush()
```
Overall, we saw that running OctoCoder in 8-bit precision reduced the required GPU VRAM from 32G GPU VRAM to only 15GB and running the model in 4-bit precision further reduces the required GPU VRAM to just a bit over 9GB.
4-bit quantization allows the model to be run on GPUs such as RTX3090, V100, and T4 which are quite accessible for most people.
For more information on quantization and to see how one can quantize models to require even less GPU VRAM memory than 4-bit, we recommend looking into the [`AutoGPTQ`](https://huggingface.co/docs/transformers/main/en/main_classes/quantization#autogptq-integration%60) implementation.
> As a conclusion, it is important to remember that model quantization trades improved memory efficiency against accuracy and in some cases inference time.
If GPU memory is not a constraint for your use case, there is often no need to look into quantization. However many GPUs simply can't run LLMs without quantization methods and in this case, 4-bit and 8-bit quantization schemes are extremely useful tools.
For more in-detail usage information, we strongly recommend taking a look at the [Transformers Quantization Docs](https://huggingface.co/docs/transformers/main_classes/quantization#general-usage).
Next, let's look into how we can improve computational and memory efficiency by using better algorithms and an improved model architecture.
# 2. Flash Attention: A Leap Forward
Today's top-performing LLMs share more or less the same fundamental architecture that consists of feed-forward layers, activation layers, layer normalization layers, and most crucially, self-attention layers.
Self-attention layers are central to Large Language Models (LLMs) in that they enable the model to understand the contextual relationships between input tokens.
However, the peak GPU memory consumption for self-attention layers grows *quadratically* both in compute and memory complexity with number of input tokens (also called *sequence length*) that we denote in the following by \\( N \\) .
While this is not really noticeable for shorter input sequences (of up to 1000 input tokens), it becomes a serious problem for longer input sequences (at around 16000 input tokens).
Let's take a closer look. The formula to compute the output \\( \mathbf{O} \\) of a self-attention layer for an input \\( \mathbf{X} \\) of length \\( N \\) is:
$$ \textbf{O} = \text{Attn}(\mathbf{X}) = \mathbf{V} \times \text{Softmax}(\mathbf{QK}^T) \text{ with } \mathbf{Q} = \mathbf{W}_q \mathbf{X}, \mathbf{V} = \mathbf{W}_v \mathbf{X}, \mathbf{K} = \mathbf{W}_k \mathbf{X} $$
\\( \mathbf{X} = (\mathbf{x}_1, ... \mathbf{x}_{N}) \\) is thereby the input sequence to the attention layer. The projections \\( \mathbf{Q} \\) and \\( \mathbf{K} \\) will each consist of \\( N \\) vectors resulting in the \\( \mathbf{QK}^T \\) being of size \\( N^2 \\) .
LLMs usually have multiple attention heads, thus doing multiple self-attention computations in parallel.
Assuming, the LLM has 40 attention heads and runs in bfloat16 precision, we can calculate the memory requirement to store the \\( \mathbf{QK^T} \\) matrices to be \\( 40 * 2 * N^2 \\) bytes. For \\( N=1000 \\) only around 50 MB of VRAM are needed, however, for \\( N=16000 \\) we would need 19 GB of VRAM, and for \\( N=100,000 \\) we would need almost 1TB just to store the \\( \mathbf{QK}^T \\) matrices.
Long story short, the default self-attention algorithm quickly becomes prohibitively memory-expensive for large input contexts.
As LLMs improve in text comprehension and generation, they are applied to increasingly complex tasks. While models once handled the translation or summarization of a few sentences, they now manage entire pages, demanding the capability to process extensive input lengths.
How can we get rid of the exorbitant memory requirements for large input lengths? We need a new way to compute the self-attention mechanism that gets rid of the \\( QK^T \\) matrix. [Tri Dao et al.](https://arxiv.org/abs/2205.14135) developed exactly such a new algorithm and called it **Flash Attention**.
In a nutshell, Flash Attention breaks the \\(\mathbf{V} \times \text{Softmax}(\mathbf{QK}^T\\)) computation apart and instead computes smaller chunks of the output by iterating over multiple softmax computation steps:
$$ \textbf{O}_i \leftarrow s^a_{ij} * \textbf{O}_i + s^b_{ij} * \mathbf{V}_{j} \times \text{Softmax}(\mathbf{QK}^T_{i,j}) \text{ for multiple } i, j \text{ iterations} $$
with \\( s^a_{ij} \\) and \\( s^b_{ij} \\) being some softmax normalization statistics that need to be recomputed for every \\( i \\) and \\( j \\) .
Please note that the whole Flash Attention is a bit more complex and is greatly simplified here as going in too much depth is out of scope for this notebook. The reader is invited to take a look at the well-written [Flash Attention paper](https://arxiv.org/abs/2205.14135) for more details.
The main takeaway here is:
> By keeping track of softmax normalization statistics and by using some smart mathematics, Flash Attention gives **numerical identical** outputs compared to the default self-attention layer at a memory cost that only increases linearly with \\( N \\) .
Looking at the formula, one would intuitively say that Flash Attention must be much slower compared to the default self-attention formula as more computation needs to be done. Indeed Flash Attention requires more FLOPs compared to normal attention as the softmax normalization statistics have to constantly be recomputed (see [paper](https://arxiv.org/abs/2205.14135) for more details if interested)
> However, Flash Attention is much faster in inference compared to default attention which comes from its ability to significantly reduce the demands on the slower, high-bandwidth memory of the GPU (VRAM), focusing instead on the faster on-chip memory (SRAM).
Essentially, Flash Attention makes sure that all intermediate write and read operations can be done using the fast *on-chip* SRAM memory instead of having to access the slower VRAM memory to compute the output vector \\( \mathbf{O} \\) .
In practice, there is currently absolutely no reason to **not** use Flash Attention if available. The algorithm gives mathematically the same outputs, and is both faster and more memory-efficient.
Let's look at a practical example.
Our OctoCoder model now gets a significantly longer input prompt which includes a so-called *system prompt*. System prompts are used to steer the LLM into a better assistant that is tailored to the users' task.
In the following, we use a system prompt that will make OctoCoder a better coding assistant.
```python
system_prompt = """Below are a series of dialogues between various people and an AI technical assistant.
The assistant tries to be helpful, polite, honest, sophisticated, emotionally aware, and humble but knowledgeable.
The assistant is happy to help with code questions and will do their best to understand exactly what is needed.
It also tries to avoid giving false or misleading information, and it caveats when it isn't entirely sure about the right answer.
That said, the assistant is practical really does its best, and doesn't let caution get too much in the way of being useful.
The Starcoder models are a series of 15.5B parameter models trained on 80+ programming languages from The Stack (v1.2) (excluding opt-out requests).
The model uses Multi Query Attention, was trained using the Fill-in-the-Middle objective, and with 8,192 tokens context window for a trillion tokens of heavily deduplicated data.
-----
Question: Write a function that takes two lists and returns a list that has alternating elements from each input list.
Answer: Sure. Here is a function that does that.
def alternating(list1, list2):
results = []
for i in range(len(list1)):
results.append(list1[i])
results.append(list2[i])
return results
Question: Can you write some test cases for this function?
Answer: Sure, here are some tests.
assert alternating([10, 20, 30], [1, 2, 3]) == [10, 1, 20, 2, 30, 3]
assert alternating([True, False], [4, 5]) == [True, 4, False, 5]
assert alternating([], []) == []
Question: Modify the function so that it returns all input elements when the lists have uneven length. The elements from the longer list should be at the end.
Answer: Here is the modified function.
def alternating(list1, list2):
results = []
for i in range(min(len(list1), len(list2))):
results.append(list1[i])
results.append(list2[i])
if len(list1) > len(list2):
results.extend(list1[i+1:])
else:
results.extend(list2[i+1:])
return results
-----
"""
```
For demonstration purposes, we duplicate the system by ten so that the input length is long enough to observe Flash Attention's memory savings.
We append the original text prompt `"Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here"`
```python
long_prompt = 10 * system_prompt + prompt
```
We instantiate our model again in bfloat16 precision.
```python
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
```
Let's now run the model just like before *without Flash Attention* and measure the peak GPU memory requirement and inference time.
```python
import time
start_time = time.time()
result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
print(f"Generated in {time.time() - start_time} seconds.")
result
```
**Output**:
```
Generated in 10.96854019165039 seconds.
Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndef
````
We're getting the same output as before, however this time, the model repeats the answer multiple times until it's 60 tokens cut-off. This is not surprising as we've repeated the system prompt ten times for demonstration purposes and thus cued the model to repeat itself.
**Note** that the system prompt should not be repeated ten times in real-world applications - one time is enough!
Let's measure the peak GPU memory requirement.
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**Output**:
```bash
37.668193340301514
```
As we can see the peak GPU memory requirement is now significantly higher than in the beginning, which is largely due to the longer input sequence. Also the generation takes a little over a minute now.
We call `flush()` to free GPU memory for our next experiment.
```python
flush()
```
For comparison, let's run the same function, but enable Flash Attention instead.
To do so, we convert the model to [BetterTransformers](https://huggingface.co/docs/optimum/bettertransformer/overview) and by doing so enabling PyTorch's [SDPA self-attention](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention) which in turn is based on Flash Attention.
```python
model.to_bettertransformer()
```
Now we run the exact same code snippet as before and under the hood Transformers will make use of Flash Attention.
```py
start_time = time.time()
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
print(f"Generated in {time.time() - start_time} seconds.")
result
```
**Output**:
```
Generated in 3.0211617946624756 seconds.
Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndef
```
We're getting the exact same result as before, but can observe a very significant speed-up thanks to Flash Attention.
Let's measure the memory consumption one last time.
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**Output**:
```
32.617331981658936
```
And we're almost back to our original 29GB peak GPU memory from the beginning.
We can observe that we only use roughly 100MB more GPU memory when passing a very long input sequence with Flash Attention compared to passing a short input sequence as done in the beginning.
```py
flush()
```
## 3. The Science Behind LLM Architectures: Strategic Selection for Long Text Inputs and Chat
So far we have looked into improving computational and memory efficiency by:
- Casting the weights to a lower precision format
- Replacing the self-attention algorithm with a more memory- and compute efficient version
Let's now look into how we can change the architecture of an LLM so that it is most effective and efficient for task that require long text inputs, *e.g.*:
- Retrieval augmented Questions Answering,
- Summarization,
- Chat
Note that *chat* not only requires the LLM to handle long text inputs, but it also necessitates that the LLM is able to efficiently handle the back-and-forth dialogue between user and assistant (such as ChatGPT).
Once trained, the fundamental LLM architecture is difficult to change, so it is important to make considerations about the LLM's tasks beforehand and accordingly optimize the model's architecture.
There are two important components of the model architecture that quickly become memory and/or performance bottlenecks for large input sequences.
- The positional embeddings
- The key-value cache
Let's go over each component in more detail
### 3.1 Improving positional embeddings of LLMs
Self-attention puts each token in relation to each other's tokens.
As an example, the \\( \text{Softmax}(\mathbf{QK}^T) \\) matrix of the text input sequence *"Hello", "I", "love", "you"* could look as follows:
Each word token is given a probability mass at which it attends all other word tokens and, therefore is put into relation with all other word tokens. E.g. the word *"love"* attends to the word *"Hello"* with 5%, to *"I"* with 30%, and to itself with 65%.
A LLM based on self-attention, but without position embeddings would have great difficulties in understanding the positions of the text inputs to each other.
This is because the probability score computed by \\( \mathbf{QK}^T \\) relates each word token to each other word token in \\( O(1) \\) computations regardless of their relative positional distance to each other.
Therefore, for the LLM without position embeddings each token appears to have the same distance to all other tokens, *e.g.* differentiating between *"Hello I love you"* and *"You love I hello"* would be very challenging.
For the LLM to understand sentence order, an additional *cue* is needed and is usually applied in the form of *positional encodings* (or also called *positional embeddings*).
Positional encodings, encode the position of each token into a numerical presentation that the LLM can leverage to better understand sentence order.
The authors of the [*Attention Is All You Need*](https://arxiv.org/abs/1706.03762) paper introduced sinusoidal positional embeddings \\( \mathbf{P} = \mathbf{p}_1, \ldots, \mathbf{p}_N \\) .
where each vector \\( \mathbf{p}_i \\) is computed as a sinusoidal function of its position \\( i \\) .
The positional encodings are then simply added to the input sequence vectors \\( \mathbf{\hat{X}} = \mathbf{\hat{x}}_1, \ldots, \mathbf{\hat{x}}_N \\) = \\( \mathbf{x}_1 + \mathbf{p}_1, \ldots, \mathbf{x}_N + \mathbf{p}_N \\) thereby cueing the model to better learn sentence order.
Instead of using fixed position embeddings, others (such as [Devlin et al.](https://arxiv.org/abs/1810.04805)) used learned positional encodings for which the positional embeddings
\\( \mathbf{P} \\) are learned during training.
Sinusoidal and learned position embeddings used to be the predominant methods to encode sentence order into LLMs, but a couple of problems related to these positional encodings were found:
1. Sinusoidal and learned position embeddings are both absolute positional embeddings, *i.e.* encoding a unique embedding for each position id: \\( 0, \ldots, N \\) . As shown by [Huang et al.](https://arxiv.org/abs/2009.13658) and [Su et al.](https://arxiv.org/abs/2104.09864), absolute positional embeddings lead to poor LLM performance for long text inputs. For long text inputs, it is advantageous if the model learns the relative positional distance input tokens have to each other instead of their absolute position.
2. When using learned position embeddings, the LLM has to be trained on a fixed input length \\( N \\), which makes it difficult to extrapolate to an input length longer than what it was trained on.
Recently, relative positional embeddings that can tackle the above mentioned problems have become more popular, most notably:
- [Rotary Position Embedding (RoPE)](https://arxiv.org/abs/2104.09864)
- [ALiBi](https://arxiv.org/abs/2108.12409)
Both *RoPE* and *ALiBi* argue that it's best to cue the LLM about sentence order directly in the self-attention algorithm as it's there that word tokens are put into relation with each other. More specifically, sentence order should be cued by modifying the \\( \mathbf{QK}^T \\) computation.
Without going into too many details, *RoPE* notes that positional information can be encoded into query-key pairs, *e.g.* \\( \mathbf{q}_i \\) and \\( \mathbf{x}_j \\) by rotating each vector by an angle \\( \theta * i \\) and \\( \theta * j \\) respectively with \\( i, j \\) describing each vectors sentence position:
$$ \mathbf{\hat{q}}_i^T \mathbf{\hat{x}}_j = \mathbf{{q}}_i^T \mathbf{R}_{\theta, i -j} \mathbf{{x}}_j. $$
\\( \mathbf{R}_{\theta, i - j} \\) thereby represents a rotational matrix. \\( \theta \\) is *not* learned during training, but instead set to a pre-defined value that depends on the maximum input sequence length during training.
> By doing so, the propability score between \\( \mathbf{q}_i \\) and \\( \mathbf{q}_j \\) is only affected if \\( i \ne j \\) and solely depends on the relative distance \\( i - j \\) regardless of each vector's specific positions \\( i \\) and \\( j \\) .
*RoPE* is used in multiple of today's most important LLMs, such as:
- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
- [**Llama**](https://arxiv.org/abs/2302.13971)
- [**PaLM**](https://arxiv.org/abs/2204.02311)
As an alternative, *ALiBi* proposes a much simpler relative position encoding scheme. The relative distance that input tokens have to each other is added as a negative integer scaled by a pre-defined value `m` to each query-key entry of the \\( \mathbf{QK}^T \\) matrix right before the softmax computation.
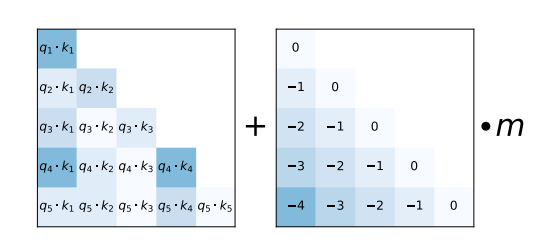
As shown in the [ALiBi](https://arxiv.org/abs/2108.12409) paper, this simple relative positional encoding allows the model to retain a high performance even at very long text input sequences.
*ALiBi* is used in multiple of today's most important LLMs, such as:
- [**MPT**](https://huggingface.co/mosaicml/mpt-30b)
- [**BLOOM**](https://huggingface.co/bigscience/bloom)
Both *RoPE* and *ALiBi* position encodings can extrapolate to input lengths not seen during training whereas it has been shown that extrapolation works much better out-of-the-box for *ALiBi* as compared to *RoPE*.
For ALiBi, one simply increases the values of the lower triangular position matrix to match the length of the input sequence.
For *RoPE*, keeping the same \\( \theta \\) that was used during training leads to poor results when passing text inputs much longer than those seen during training, *c.f* [Press et al.](https://arxiv.org/abs/2108.12409). However, the community has found a couple of effective tricks that adapt \\( \theta \\), thereby allowing *RoPE* position embeddings to work well for extrapolated text input sequences (see [here](https://github.com/huggingface/transformers/pull/24653)).
> Both RoPE and ALiBi are relative positional embeddings that are *not* learned during training, but instead are based on the following intuitions:
- Positional cues about the text inputs should be given directly to the \\( QK^T \\) matrix of the self-attention layer
- The LLM should be incentivized to learn a constant *relative* distance positional encodings have to each other
- The further text input tokens are from each other, the lower the probability of their query-value probability. Both RoPE and ALiBi lower the query-key probability of tokens far away from each other. RoPE by decreasing their vector product by increasing the angle between the query-key vectors. ALiBi by adding large negative numbers to the vector product
In conclusion, LLMs that are intended to be deployed in tasks that require handling large text inputs are better trained with relative positional embeddings, such as RoPE and ALiBi. Also note that even if an LLM with RoPE and ALiBi has been trained only on a fixed length of say \\( N_1 = 2048 \\) it can still be used in practice with text inputs much larger than \\( N_1 \\), like \\( N_2 = 8192 > N_1 \\) by extrapolating the positional embeddings.
### 3.2 The key-value cache
Auto-regressive text generation with LLMs works by iteratively putting in an input sequence, sampling the next token, appending the next token to the input sequence, and continuing to do so until the LLM produces a token that signifies that the generation has finished.
Please have a look at [Transformer's Generate Text Tutorial](https://huggingface.co/docs/transformers/llm_tutorial#generate-text) to get a more visual explanation of how auto-regressive generation works.
Let's run a quick code snippet to show how auto-regressive works in practice. We will simply take the most likely next token via `torch.argmax`.
```python
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
next_logits = model(input_ids)["logits"][:, -1:]
next_token_id = torch.argmax(next_logits,dim=-1)
input_ids = torch.cat([input_ids, next_token_id], dim=-1)
print("shape of input_ids", input_ids.shape)
generated_text = tokenizer.batch_decode(input_ids[:, -5:])
generated_text
```
**Output**:
```
shape of input_ids torch.Size([1, 21])
shape of input_ids torch.Size([1, 22])
shape of input_ids torch.Size([1, 23])
shape of input_ids torch.Size([1, 24])
shape of input_ids torch.Size([1, 25])
[' Here is a Python function']
```
As we can see every time we increase the text input tokens by the just sampled token.
With very few exceptions, LLMs are trained using the [causal language modeling objective](https://huggingface.co/docs/transformers/tasks/language_modeling#causal-language-modeling) and therefore mask the upper triangle matrix of the attention score - this is why in the two diagrams above the attention scores are left blank (*a.k.a* have 0 probability). For a quick recap on causal language modeling you can refer to the [*Illustrated Self Attention blog*](https://jalammar.github.io/illustrated-gpt2/#part-2-illustrated-self-attention).
As a consequence, tokens *never* depend on previous tokens, more specifically the \\( \mathbf{q}_i \\) vector is never put in relation with any key, values vectors \\( \mathbf{k}_j, \mathbf{v}_j \\) if \\( j > i \\) . Instead \\( \mathbf{q}_i \\) only attends to previous key-value vectors \\( \mathbf{k}_{m < i}, \mathbf{v}_{m < i} \text{ , for } m \in \{0, \ldots i - 1\} \\). In order to reduce unnecessary computation, one can therefore cache each layer's key-value vectors for all previous timesteps.
In the following, we will tell the LLM to make use of the key-value cache by retrieving and forwarding it for each forward pass.
In Transformers, we can retrieve the key-value cache by passing the `use_cache` flag to the `forward` call and can then pass it with the current token.
```python
past_key_values = None # past_key_values is the key-value cache
generated_tokens = []
next_token_id = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
next_logits, past_key_values = model(next_token_id, past_key_values=past_key_values, use_cache=True).to_tuple()
next_logits = next_logits[:, -1:]
next_token_id = torch.argmax(next_logits, dim=-1)
print("shape of input_ids", next_token_id.shape)
print("length of key-value cache", len(past_key_values[0][0])) # past_key_values are of shape [num_layers, 0 for k, 1 for v, batch_size, length, hidden_dim]
generated_tokens.append(next_token_id.item())
generated_text = tokenizer.batch_decode(generated_tokens)
generated_text
```
**Output**:
```
shape of input_ids torch.Size([1, 1])
length of key-value cache 20
shape of input_ids torch.Size([1, 1])
length of key-value cache 21
shape of input_ids torch.Size([1, 1])
length of key-value cache 22
shape of input_ids torch.Size([1, 1])
length of key-value cache 23
shape of input_ids torch.Size([1, 1])
length of key-value cache 24
[' Here', ' is', ' a', ' Python', ' function']
```
As one can see, when using the key-value cache the text input tokens are *not* increased in length, but remain a single input vector. The length of the key-value cache on the other hand is increased by one at every decoding step.
> Making use of the key-value cache means that the \\( \mathbf{QK}^T \\) is essentially reduced to \\( \mathbf{q}_c\mathbf{K}^T \\) with \\( \mathbf{q}_c \\) being the query projection of the currently passed input token which is *always* just a single vector.
Using the key-value cache has two advantages:
- Significant increase in computational efficiency as less computations are performed compared to computing the full \\( \mathbf{QK}^T \\) matrix. This leads to an increase in inference speed
- The maximum required memory is not increased quadratically with the number of generated tokens, but only increases linearly.
> One should *always* make use of the key-value cache as it leads to identical results and a significant speed-up for longer input sequences. Transformers has the key-value cache enabled by default when making use of the text pipeline or the [`generate` method](https://huggingface.co/docs/transformers/main_classes/text_generation).
Note that the key-value cache is especially useful for applications such as chat where multiple passes of auto-regressive decoding are required. Let's look at an example.
```
User: How many people live in France?
Assistant: Roughly 75 million people live in France
User: And how many are in Germany?
Assistant: Germany has ca. 81 million inhabitants
```
In this chat, the LLM runs auto-regressive decoding twice:
- 1. The first time, the key-value cache is empty and the input prompt is `"User: How many people live in France?"` and the model auto-regressively generates the text `"Roughly 75 million people live in France"` while increasing the key-value cache at every decoding step.
- 2. The second time the input prompt is `"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many in Germany?"`. Thanks to the cache, all key-value vectors for the first two sentences are already computed. Therefore the input prompt only consists of `"User: And how many in Germany?"`. While processing the shortened input prompt, it's computed key-value vectors are concatenated to the key-value cache of the first decoding. The second Assistant's answer `"Germany has ca. 81 million inhabitants"` is then auto-regressively generated with the key-value cache consisting of encoded key-value vectors of `"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many are in Germany?"`.
Two things should be noted here:
1. Keeping all the context is crucial for LLMs deployed in chat so that the LLM understands all the previous context of the conversation. E.g. for the example above the LLM needs to understand that the user refers to the population when asking `"And how many are in Germany"`.
2. The key-value cache is extremely useful for chat as it allows us to continuously grow the encoded chat history instead of having to re-encode the chat history again from scratch (as e.g. would be the case when using an encoder-decoder architecture).
There is however one catch. While the required peak memory for the \\( \mathbf{QK}^T \\) matrix is significantly reduced, holding the key-value cache in memory can become very memory expensive for long input sequences or multi-turn chat. Remember that the key-value cache needs to store the key-value vectors for all previous input vectors \\( \mathbf{x}_i \text{, for } i \in \{1, \ldots, c - 1\} \\) for all self-attention layers and for all attention heads.
Let's compute the number of float values that need to be stored in the key-value cache for the LLM `bigcode/octocoder` that we used before.
The number of float values amounts to two times the sequence length times the number of attention heads times the attention head dimension and times the number of layers.
Computing this for our LLM at a hypothetical input sequence length of 16000 gives:
```python
config = model.config
2 * 16_000 * config.n_layer * config.n_head * config.n_embd // config.n_head
```
**Output**:
```
7864320000
```
Roughly 8 billion float values! Storing 8 billion float values in `float16` precision requires around 15 GB of RAM which is circa half as much as the model weights themselves!
Researchers have proposed two methods that allow to significantly reduce the memory cost of storing the key-value cache:
1. [Multi-Query-Attention (MQA)](https://arxiv.org/abs/1911.02150)
Multi-Query-Attention was proposed in Noam Shazeer's *Fast Transformer Decoding: One Write-Head is All You Need* paper. As the title says, Noam found out that instead of using `n_head` key-value projections weights, one can use a single head-value projection weight pair that is shared across all attention heads without that the model's performance significantly degrades.
> By using a single head-value projection weight pair, the key value vectors \\( \mathbf{k}_i, \mathbf{v}_i \\) have to be identical across all attention heads which in turn means that we only need to store 1 key-value projection pair in the cache instead of `n_head` ones.
As most LLMs use between 20 and 100 attention heads, MQA significantly reduces the memory consumption of the key-value cache. For the LLM used in this notebook we could therefore reduce the required memory consumption from 15 GB to less than 400 MB at an input sequence length of 16000.
In addition to memory savings, MQA also leads to improved computational efficiency as explained in the following.
In auto-regressive decoding, large key-value vectors need to be reloaded, concatenated with the current key-value vector pair to be then fed into the \\( \mathbf{q}_c\mathbf{K}^T \\) computation at every step. For auto-regressive decoding, the required memory bandwidth for the constant reloading can become a serious time bottleneck. By reducing the size of the key-value vectors less memory needs to be accessed, thus reducing the memory bandwidth bottleneck. For more detail, please have a look at [Noam's paper](https://arxiv.org/abs/1911.02150).
The important part to understand here is that reducing the number of key-value attention heads to 1 only makes sense if a key-value cache is used. The peak memory consumption of the model for a single forward pass without key-value cache stays unchanged as every attention head still has a unique query vector so that each attention head still has a different \\( \mathbf{QK}^T \\) matrix.
MQA has seen wide adoption by the community and is now used by many of the most popular LLMs:
- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
- [**PaLM**](https://arxiv.org/abs/2204.02311)
- [**MPT**](https://huggingface.co/mosaicml/mpt-30b)
- [**BLOOM**](https://huggingface.co/bigscience/bloom)
Also, the checkpoint used in this notebook - `bigcode/octocoder` - makes use of MQA.
2. [Grouped-Query-Attention (GQA)](https://arxiv.org/abs/2305.13245)
Grouped-Query-Attention, as proposed by Ainslie et al. from Google, found that using MQA can often lead to quality degradation compared to using vanilla multi-key-value head projections. The paper argues that more model performance can be kept by less drastically reducing the number of query head projection weights. Instead of using just a single key-value projection weight, `n < n_head` key-value projection weights should be used. By choosing `n` to a significantly smaller value than `n_head`, such as 2,4 or 8 almost all of the memory and speed gains from MQA can be kept while sacrificing less model capacity and thus arguably less performance.
Moreover, the authors of GQA found out that existing model checkpoints can be *uptrained* to have a GQA architecture with as little as 5% of the original pre-training compute. While 5% of the original pre-training compute can still be a massive amount, GQA *uptraining* allows existing checkpoints to be useful for longer input sequences.
GQA was only recently proposed which is why there is less adoption at the time of writing this notebook.
The most notable application of GQA is [Llama-v2](https://huggingface.co/meta-llama/Llama-2-70b-hf).
> As a conclusion, it is strongly recommended to make use of either GQA or MQA if the LLM is deployed with auto-regressive decoding and is required to handle large input sequences as is the case for example for chat.
## Conclusion
The research community is constantly coming up with new, nifty ways to speed up inference time for ever-larger LLMs. As an example, one such promising research direction is [speculative decoding](https://arxiv.org/abs/2211.17192) where "easy tokens" are generated by smaller, faster language models and only "hard tokens" are generated by the LLM itself. Going into more detail is out of the scope of this notebook, but can be read upon in this [nice blog post](https://huggingface.co/blog/assisted-generation).
The reason massive LLMs such as GPT3/4, Llama-2-70b, Claude, PaLM can run so quickly in chat-interfaces such as [Hugging Face Chat](https://huggingface.co/chat/) or ChatGPT is to a big part thanks to the above-mentioned improvements in precision, algorithms, and architecture.
Going forward, accelerators such as GPUs, TPUs, etc... will only get faster and allow for more memory, but one should nevertheless always make sure to use the best available algorithms and architectures to get the most bang for your buck 🤗
| huggingface/blog/blob/main/optimize-llm.md |
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# P-tuning for sequence classification
It is challenging to finetune large language models for downstream tasks because they have so many parameters. To work around this, you can use *prompts* to steer the model toward a particular downstream task without fully finetuning a model. Typically, these prompts are handcrafted, which may be impractical because you need very large validation sets to find the best prompts. *P-tuning* is a method for automatically searching and optimizing for better prompts in a continuous space.
<Tip>
💡 Read [GPT Understands, Too](https://arxiv.org/abs/2103.10385) to learn more about p-tuning.
</Tip>
This guide will show you how to train a [`roberta-large`](https://huggingface.co/roberta-large) model (but you can also use any of the GPT, OPT, or BLOOM models) with p-tuning on the `mrpc` configuration of the [GLUE](https://huggingface.co/datasets/glue) benchmark.
Before you begin, make sure you have all the necessary libraries installed:
```bash
!pip install -q peft transformers datasets evaluate
```
## Setup
To get started, import 🤗 Transformers to create the base model, 🤗 Datasets to load a dataset, 🤗 Evaluate to load an evaluation metric, and 🤗 PEFT to create a [`PeftModel`] and setup the configuration for p-tuning.
Define the model, dataset, and some basic training hyperparameters:
```py
from transformers import (
AutoModelForSequenceClassification,
AutoTokenizer,
DataCollatorWithPadding,
TrainingArguments,
Trainer,
)
from peft import (
get_peft_config,
get_peft_model,
get_peft_model_state_dict,
set_peft_model_state_dict,
PeftType,
PromptEncoderConfig,
)
from datasets import load_dataset
import evaluate
import torch
model_name_or_path = "roberta-large"
task = "mrpc"
num_epochs = 20
lr = 1e-3
batch_size = 32
```
## Load dataset and metric
Next, load the `mrpc` configuration - a corpus of sentence pairs labeled according to whether they're semantically equivalent or not - from the [GLUE](https://huggingface.co/datasets/glue) benchmark:
```py
dataset = load_dataset("glue", task)
dataset["train"][0]
{
"sentence1": 'Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
"sentence2": 'Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .',
"label": 1,
"idx": 0,
}
```
From 🤗 Evaluate, load a metric for evaluating the model's performance. The evaluation module returns the accuracy and F1 scores associated with this specific task.
```py
metric = evaluate.load("glue", task)
```
Now you can use the `metric` to write a function that computes the accuracy and F1 scores. The `compute_metric` function calculates the scores from the model predictions and labels:
```py
import numpy as np
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
return metric.compute(predictions=predictions, references=labels)
```
## Preprocess dataset
Initialize the tokenizer and configure the padding token to use. If you're using a GPT, OPT, or BLOOM model, you should set the `padding_side` to the left; otherwise it'll be set to the right. Tokenize the sentence pairs and truncate them to the maximum length.
```py
if any(k in model_name_or_path for k in ("gpt", "opt", "bloom")):
padding_side = "left"
else:
padding_side = "right"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, padding_side=padding_side)
if getattr(tokenizer, "pad_token_id") is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
def tokenize_function(examples):
# max_length=None => use the model max length (it's actually the default)
outputs = tokenizer(examples["sentence1"], examples["sentence2"], truncation=True, max_length=None)
return outputs
```
Use [`~datasets.Dataset.map`] to apply the `tokenize_function` to the dataset, and remove the unprocessed columns because the model won't need those. You should also rename the `label` column to `labels` because that is the expected name for the labels by models in the 🤗 Transformers library.
```py
tokenized_datasets = dataset.map(
tokenize_function,
batched=True,
remove_columns=["idx", "sentence1", "sentence2"],
)
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
```
Create a collator function with [`~transformers.DataCollatorWithPadding`] to pad the examples in the batches to the `longest` sequence in the batch:
```py
data_collator = DataCollatorWithPadding(tokenizer=tokenizer, padding="longest")
```
## Train
P-tuning uses a prompt encoder to optimize the prompt parameters, so you'll need to initialize the [`PromptEncoderConfig`] with several arguments:
- `task_type`: the type of task you're training on, in this case it is sequence classification or `SEQ_CLS`
- `num_virtual_tokens`: the number of virtual tokens to use, or in other words, the prompt
- `encoder_hidden_size`: the hidden size of the encoder used to optimize the prompt parameters
```py
peft_config = PromptEncoderConfig(task_type="SEQ_CLS", num_virtual_tokens=20, encoder_hidden_size=128)
```
Create the base `roberta-large` model from [`~transformers.AutoModelForSequenceClassification`], and then wrap the base model and `peft_config` with [`get_peft_model`] to create a [`PeftModel`]. If you're curious to see how many parameters you're actually training compared to training on all the model parameters, you can print it out with [`~peft.PeftModel.print_trainable_parameters`]:
```py
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
"trainable params: 1351938 || all params: 355662082 || trainable%: 0.38011867680626127"
```
From the 🤗 Transformers library, set up the [`~transformers.TrainingArguments`] class with where you want to save the model to, the training hyperparameters, how to evaluate the model, and when to save the checkpoints:
```py
training_args = TrainingArguments(
output_dir="your-name/roberta-large-peft-p-tuning",
learning_rate=1e-3,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
num_train_epochs=2,
weight_decay=0.01,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
)
```
Then pass the model, `TrainingArguments`, datasets, tokenizer, data collator, and evaluation function to the [`~transformers.Trainer`] class, which'll handle the entire training loop for you. Once you're ready, call [`~transformers.Trainer.train`] to start training!
```py
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
trainer.train()
```
## Share model
You can store and share your model on the Hub if you'd like. Log in to your Hugging Face account and enter your token when prompted:
```py
from huggingface_hub import notebook_login
notebook_login()
```
Upload the model to a specifc model repository on the Hub with the [`~transformers.PreTrainedModel.push_to_hub`] function:
```py
model.push_to_hub("your-name/roberta-large-peft-p-tuning", use_auth_token=True)
```
## Inference
Once the model has been uploaded to the Hub, anyone can easily use it for inference. Load the configuration and model:
```py
import torch
from peft import PeftModel, PeftConfig
from transformers import AutoModelForSequenceClassification, AutoTokenizer
peft_model_id = "smangrul/roberta-large-peft-p-tuning"
config = PeftConfig.from_pretrained(peft_model_id)
inference_model = AutoModelForSequenceClassification.from_pretrained(config.base_model_name_or_path)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
model = PeftModel.from_pretrained(inference_model, peft_model_id)
```
Get some text and tokenize it:
```py
classes = ["not equivalent", "equivalent"]
sentence1 = "Coast redwood trees are the tallest trees on the planet and can grow over 300 feet tall."
sentence2 = "The coast redwood trees, which can attain a height of over 300 feet, are the tallest trees on earth."
inputs = tokenizer(sentence1, sentence2, truncation=True, padding="longest", return_tensors="pt")
```
Pass the inputs to the model to classify the sentences:
```py
with torch.no_grad():
outputs = model(**inputs).logits
print(outputs)
paraphrased_text = torch.softmax(outputs, dim=1).tolist()[0]
for i in range(len(classes)):
print(f"{classes[i]}: {int(round(paraphrased_text[i] * 100))}%")
"not equivalent: 4%"
"equivalent: 96%"
``` | huggingface/peft/blob/main/docs/source/task_guides/ptuning-seq-classification.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# XLM-V
## Overview
XLM-V is multilingual language model with a one million token vocabulary trained on 2.5TB of data from Common Crawl (same as XLM-R).
It was introduced in the [XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models](https://arxiv.org/abs/2301.10472)
paper by Davis Liang, Hila Gonen, Yuning Mao, Rui Hou, Naman Goyal, Marjan Ghazvininejad, Luke Zettlemoyer and Madian Khabsa.
From the abstract of the XLM-V paper:
*Large multilingual language models typically rely on a single vocabulary shared across 100+ languages.
As these models have increased in parameter count and depth, vocabulary size has remained largely unchanged.
This vocabulary bottleneck limits the representational capabilities of multilingual models like XLM-R.
In this paper, we introduce a new approach for scaling to very large multilingual vocabularies by
de-emphasizing token sharing between languages with little lexical overlap and assigning vocabulary capacity
to achieve sufficient coverage for each individual language. Tokenizations using our vocabulary are typically
more semantically meaningful and shorter compared to XLM-R. Leveraging this improved vocabulary, we train XLM-V,
a multilingual language model with a one million token vocabulary. XLM-V outperforms XLM-R on every task we
tested on ranging from natural language inference (XNLI), question answering (MLQA, XQuAD, TyDiQA), and
named entity recognition (WikiAnn) to low-resource tasks (Americas NLI, MasakhaNER).*
This model was contributed by [stefan-it](https://huggingface.co/stefan-it), including detailed experiments with XLM-V on downstream tasks.
The experiments repository can be found [here](https://github.com/stefan-it/xlm-v-experiments).
## Usage tips
- XLM-V is compatible with the XLM-RoBERTa model architecture, only model weights from [`fairseq`](https://github.com/facebookresearch/fairseq)
library had to be converted.
- The `XLMTokenizer` implementation is used to load the vocab and performs tokenization.
A XLM-V (base size) model is available under the [`facebook/xlm-v-base`](https://huggingface.co/facebook/xlm-v-base) identifier.
<Tip>
XLM-V architecture is the same as XLM-RoBERTa, refer to [XLM-RoBERTa documentation](xlm-roberta) for API reference, and examples.
</Tip> | huggingface/transformers/blob/main/docs/source/en/model_doc/xlm-v.md |
--
title: "Deploy GPT-J 6B for inference using Hugging Face Transformers and Amazon SageMaker"
thumbnail: /blog/assets/45_gptj_sagemaker/thumbnail.png
authors:
- user: philschmid
---
# Deploy GPT-J 6B for inference using Hugging Face Transformers and Amazon SageMaker
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
Almost 6 months ago to the day, [EleutherAI](https://www.eleuther.ai/) released [GPT-J 6B](https://huggingface.co/EleutherAI/gpt-j-6B), an open-source alternative to [OpenAIs GPT-3](https://openai.com/blog/gpt-3-apps/). [GPT-J 6B](https://huggingface.co/EleutherAI/gpt-j-6B) is the 6 billion parameter successor to [EleutherAIs](https://www.eleuther.ai/) GPT-NEO family, a family of transformer-based language models based on the GPT architecture for text generation.
[EleutherAI](https://www.eleuther.ai/)'s primary goal is to train a model that is equivalent in size to GPT-3 and make it available to the public under an open license.
Over the last 6 months, `GPT-J` gained a lot of interest from Researchers, Data Scientists, and even Software Developers, but it remained very challenging to deploy `GPT-J` into production for real-world use cases and products.
There are some hosted solutions to use `GPT-J` for production workloads, like the [Hugging Face Inference API](https://huggingface.co/inference-api), or for experimenting using [EleutherAIs 6b playground](https://6b.eleuther.ai/), but fewer examples on how to easily deploy it into your own environment.
In this blog post, you will learn how to easily deploy `GPT-J` using [Amazon SageMaker](https://aws.amazon.com/de/sagemaker/) and the [Hugging Face Inference Toolkit](https://github.com/aws/sagemaker-huggingface-inference-toolkit) with a few lines of code for scalable, reliable, and secure real-time inference using a regular size GPU instance with NVIDIA T4 (~500$/m).
But before we get into it, I want to explain why deploying `GPT-J` into production is challenging.
---
## Background
The weights of the 6 billion parameter model represent a ~24GB memory footprint. To load it in float32, one would need at least 2x model size CPU RAM: 1x for initial weights and another 1x to load the checkpoint. So for `GPT-J` it would require at least 48GB of CPU RAM to just load the model.
To make the model more accessible, [EleutherAI](https://www.eleuther.ai/) also provides float16 weights, and `transformers` has new options to reduce the memory footprint when loading large language models. Combining all this it should take roughly 12.1GB of CPU RAM to load the model.
```python
from transformers import GPTJForCausalLM
import torch
model = GPTJForCausalLM.from_pretrained(
"EleutherAI/gpt-j-6B",
revision="float16",
torch_dtype=torch.float16,
low_cpu_mem_usage=True
)
```
The caveat of this example is that it takes a very long time until the model is loaded into memory and ready for use. In my experiments, it took `3 minutes and 32 seconds` to load the model with the code snippet above on a `P3.2xlarge` AWS EC2 instance (the model was not stored on disk). This duration can be reduced by storing the model already on disk, which reduces the load time to `1 minute and 23 seconds`, which is still very long for production workloads where you need to consider scaling and reliability.
For example, Amazon SageMaker has a [60s limit for requests to respond](https://docs.aws.amazon.com/general/latest/gr/sagemaker.html#sagemaker_region), meaning the model needs to be loaded and the predictions to run within 60s, which in my opinion makes a lot of sense to keep the model/endpoint scalable and reliable for your workload. If you have longer predictions, you could use [batch-transform](https://docs.aws.amazon.com/sagemaker/latest/dg/batch-transform.html).
In [Transformers](https://github.com/huggingface/transformers) the models loaded with the `from_pretrained` method are following PyTorch's [recommended practice](https://pytorch.org/tutorials/beginner/saving_loading_models.html#save-load-state-dict-recommended), which takes around `1.97 seconds` for BERT [[REF]](https://colab.research.google.com/drive/1-Y5f8PWS8ksoaf1A2qI94jq0GxF2pqQ6?usp=sharing). PyTorch offers an [additional alternative way of saving and loading models](https://pytorch.org/tutorials/beginner/saving_loading_models.html#save-load-entire-model) using `torch.save(model, PATH)` and `torch.load(PATH)`.
*“Saving a model in this way will save the entire module using Python’s [pickle](https://docs.python.org/3/library/pickle.html) module. The disadvantage of this approach is that the serialized data is bound to the specific classes and the exact directory structure used when the model is saved.”*
This means that when we save a model with `transformers==4.13.2` it could be potentially incompatible when trying to load with `transformers==4.15.0`. However, loading models this way reduces the loading time by **~12x,** down to `0.166s` for BERT.
Applying this to `GPT-J` means that we can reduce the loading time from `1 minute and 23 seconds` down to `7.7 seconds`, which is ~10.5x faster.
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Model Load time of BERT and GPTJ" src="assets/45_gptj_sagemaker/model_load_time.png"></medium-zoom>
<figcaption>Figure 1. Model load time of BERT and GPTJ</figcaption>
</figure>
<br>
## Tutorial
With this method of saving and loading models, we achieved model loading performance for `GPT-J` compatible with production scenarios. But we need to keep in mind that we need to align:
> Align PyTorch and Transformers version when saving the model with `torch.save(model,PATH)` and loading the model with `torch.load(PATH)` to avoid incompatibility.
>
### Save `GPT-J` using `torch.save`
To create our `torch.load()` compatible model file we load `GPT-J` using Transformers and the `from_pretrained` method, and then save it with `torch.save()`.
```python
from transformers import AutoTokenizer,GPTJForCausalLM
import torch
# load fp 16 model
model = GPTJForCausalLM.from_pretrained("EleutherAI/gpt-j-6B", revision="float16", torch_dtype=torch.float16)
# save model with torch.save
torch.save(model, "gptj.pt")
```
Now we are able to load our `GPT-J` model with `torch.load()` to run predictions.
```python
from transformers import pipeline
import torch
# load model
model = torch.load("gptj.pt")
# load tokenizer
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-j-6B")
# create pipeline
gen = pipeline("text-generation",model=model,tokenizer=tokenizer,device=0)
# run prediction
gen("My Name is philipp")
#[{'generated_text': 'My Name is philipp k. and I live just outside of Detroit....
```
---
### Create `model.tar.gz` for the Amazon SageMaker real-time endpoint
Since we can load our model quickly and run inference on it let’s deploy it to Amazon SageMaker.
There are two ways you can deploy transformers to Amazon SageMaker. You can either [“Deploy a model from the Hugging Face Hub”](https://huggingface.co/docs/sagemaker/inference#deploy-a-model-from-the-%F0%9F%A4%97-hub) directly or [“Deploy a model with `model_data` stored on S3”](https://huggingface.co/docs/sagemaker/inference#deploy-with-model_data). Since we are not using the default Transformers method we need to go with the second option and deploy our endpoint with the model stored on S3.
For this, we need to create a `model.tar.gz` artifact containing our model weights and additional files we need for inference, e.g. `tokenizer.json`.
**We provide uploaded and publicly accessible `model.tar.gz` artifacts, which can be used with the `HuggingFaceModel` to deploy `GPT-J` to Amazon SageMaker.**
See [“Deploy `GPT-J` as Amazon SageMaker Endpoint”](https://www.notion.so/Deploy-GPT-J-6B-for-inference-using-Hugging-Face-Transformers-and-Amazon-SageMaker-ce65921edf2246e6a71bb3073e5b3bc7) on how to use them.
If you still want or need to create your own `model.tar.gz`, e.g. because of compliance guidelines, you can use the helper script [convert_gpt.py](https://github.com/philschmid/amazon-sagemaker-gpt-j-sample/blob/main/convert_gptj.py) for this purpose, which creates the `model.tar.gz` and uploads it to S3.
```bash
# clone directory
git clone https://github.com/philschmid/amazon-sagemaker-gpt-j-sample.git
# change directory to amazon-sagemaker-gpt-j-sample
cd amazon-sagemaker-gpt-j-sample
# create and upload model.tar.gz
pip3 install -r requirements.txt
python3 convert_gptj.py --bucket_name {model_storage}
```
The `convert_gpt.py` should print out an S3 URI similar to this. `s3://hf-sagemaker-inference/gpt-j/model.tar.gz`.
### Deploy `GPT-J` as Amazon SageMaker Endpoint
To deploy our Amazon SageMaker Endpoint we are going to use the [Amazon SageMaker Python SDK](https://sagemaker.readthedocs.io/en/stable/) and the `HuggingFaceModel` class.
The snippet below uses the `get_execution_role` which is only available inside Amazon SageMaker Notebook Instances or Studio. If you want to deploy a model outside of it check [the documentation](https://huggingface.co/docs/sagemaker/train#installation-and-setup#).
The `model_uri` defines the location of our `GPT-J` model artifact. We are going to use the publicly available one provided by us.
```python
from sagemaker.huggingface import HuggingFaceModel
import sagemaker
# IAM role with permissions to create endpoint
role = sagemaker.get_execution_role()
# public S3 URI to gpt-j artifact
model_uri="s3://huggingface-sagemaker-models/transformers/4.12.3/pytorch/1.9.1/gpt-j/model.tar.gz"
# create Hugging Face Model Class
huggingface_model = HuggingFaceModel(
model_data=model_uri,
transformers_version='4.12.3',
pytorch_version='1.9.1',
py_version='py38',
role=role,
)
# deploy model to SageMaker Inference
predictor = huggingface_model.deploy(
initial_instance_count=1, # number of instances
instance_type='ml.g4dn.xlarge' #'ml.p3.2xlarge' # ec2 instance type
)
```
If you want to use your own `model.tar.gz` just replace the `model_uri` with your S3 Uri.
The deployment should take around 3-5 minutes.
### Run predictions
We can run predictions using the `predictor` instances created by our `.deploy` method. To send a request to our endpoint we use the `predictor.predict` with our `inputs`.
```python
predictor.predict({
"inputs": "Can you please let us know more details about your "
})
```
If you want to customize your predictions using additional `kwargs` like `min_length`, check out “Usage best practices” below.
## Usage best practices
When using generative models, most of the time you want to configure or customize your prediction to fit your needs, for example by using beam search, configuring the max or min length of the generated sequence, or adjust the temperature to reduce repetition. The Transformers library provides different strategies and `kwargs` to do this, the Hugging Face Inference toolkit offers the same functionality using the `parameters` attribute of your request payload. Below you can find examples on how to generate text without parameters, with beam search, and using custom configurations. If you want to learn about different decoding strategies check out this [blog post](https://huggingface.co/blog/how-to-generate).
### Default request
This is an example of a default request using `greedy` search.
Inference-time after the first request: `3s`
```python
predictor.predict({
"inputs": "Can you please let us know more details about your "
})
```
### Beam search request
This is an example of a request using `beam` search with 5 beams.
Inference-time after the first request: `3.3s`
```python
predictor.predict({
"inputs": "Can you please let us know more details about your ",
"parameters" : {
"num_beams": 5,
}
})
```
### Parameterized request
This is an example of a request using a custom parameter, e.g. `min_length` for generating at least 512 tokens.
Inference-time after the first request: `38s`
```python
predictor.predict({
"inputs": "Can you please let us know more details about your ",
"parameters" : {
"max_length": 512,
"temperature": 0.9,
}
})
```
### Few-Shot example (advanced)
This is an example of how you could `eos_token_id` to stop the generation on a certain token, e.g. `\n` ,`.` or `###` for few-shot predictions. Below is a few-shot example for generating tweets for keywords.
Inference-time after the first request: `15-45s`
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-j-6B")
end_sequence="###"
temperature=4
max_generated_token_length=25
prompt= """key: markets
tweet: Take feedback from nature and markets, not from people.
###
key: children
tweet: Maybe we die so we can come back as children.
###
key: startups
tweet: Startups shouldn’t worry about how to put out fires, they should worry about how to start them.
###
key: hugging face
tweet:"""
predictor.predict({
'inputs': prompt,
"parameters" : {
"max_length": int(len(prompt) + max_generated_token_length),
"temperature": float(temperature),
"eos_token_id": int(tokenizer.convert_tokens_to_ids(end_sequence)),
"return_full_text":False
}
})
```
---
To delete your endpoint you can run.
```python
predictor.delete_endpoint()
```
## Conclusion
We successfully managed to deploy `GPT-J`, a 6 billion parameter language model created by [EleutherAI](https://www.eleuther.ai/), using Amazon SageMaker. We reduced the model load time from 3.5 minutes down to 8 seconds to be able to run scalable, reliable inference.
Remember that using `torch.save()` and `torch.load()` can create incompatibility issues. If you want to learn more about scaling out your Amazon SageMaker Endpoints check out my other blog post: [“MLOps: End-to-End Hugging Face Transformers with the Hub & SageMaker Pipelines”](https://www.philschmid.de/mlops-sagemaker-huggingface-transformers).
---
Thanks for reading! If you have any question, feel free to contact me, through [Github](https://github.com/huggingface/transformers), or on the [forum](https://discuss.huggingface.co/c/sagemaker/17). You can also connect with me on [Twitter](https://twitter.com/_philschmid) or [LinkedIn](https://www.linkedin.com/in/philipp-schmid-a6a2bb196/).
| huggingface/blog/blob/main/gptj-sagemaker.md |
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Installation
Before you start, you will need to setup your environment by installing the appropriate packages.
`huggingface_hub` is tested on **Python 3.8+**.
## Install with pip
It is highly recommended to install `huggingface_hub` in a [virtual environment](https://docs.python.org/3/library/venv.html).
If you are unfamiliar with Python virtual environments, take a look at this [guide](https://packaging.python.org/en/latest/guides/installing-using-pip-and-virtual-environments/).
A virtual environment makes it easier to manage different projects, and avoid compatibility issues between dependencies.
Start by creating a virtual environment in your project directory:
```bash
python -m venv .env
```
Activate the virtual environment. On Linux and macOS:
```bash
source .env/bin/activate
```
Activate virtual environment on Windows:
```bash
.env/Scripts/activate
```
Now you're ready to install `huggingface_hub` [from the PyPi registry](https://pypi.org/project/huggingface-hub/):
```bash
pip install --upgrade huggingface_hub
```
Once done, [check installation](#check-installation) is working correctly.
### Install optional dependencies
Some dependencies of `huggingface_hub` are [optional](https://setuptools.pypa.io/en/latest/userguide/dependency_management.html#optional-dependencies) because they are not required to run the core features of `huggingface_hub`. However, some features of the `huggingface_hub` may not be available if the optional dependencies aren't installed.
You can install optional dependencies via `pip`:
```bash
# Install dependencies for tensorflow-specific features
# /!\ Warning: this is not equivalent to `pip install tensorflow`
pip install 'huggingface_hub[tensorflow]'
# Install dependencies for both torch-specific and CLI-specific features.
pip install 'huggingface_hub[cli,torch]'
```
Here is the list of optional dependencies in `huggingface_hub`:
- `cli`: provide a more convenient CLI interface for `huggingface_hub`.
- `fastai`, `torch`, `tensorflow`: dependencies to run framework-specific features.
- `dev`: dependencies to contribute to the lib. Includes `testing` (to run tests), `typing` (to run type checker) and `quality` (to run linters).
### Install from source
In some cases, it is interesting to install `huggingface_hub` directly from source.
This allows you to use the bleeding edge `main` version rather than the latest stable version.
The `main` version is useful for staying up-to-date with the latest developments, for instance
if a bug has been fixed since the last official release but a new release hasn't been rolled out yet.
However, this means the `main` version may not always be stable. We strive to keep the
`main` version operational, and most issues are usually resolved
within a few hours or a day. If you run into a problem, please open an Issue so we can
fix it even sooner!
```bash
pip install git+https://github.com/huggingface/huggingface_hub
```
When installing from source, you can also specify a specific branch. This is useful if you
want to test a new feature or a new bug-fix that has not been merged yet:
```bash
pip install git+https://github.com/huggingface/huggingface_hub@my-feature-branch
```
Once done, [check installation](#check-installation) is working correctly.
### Editable install
Installing from source allows you to setup an [editable install](https://pip.pypa.io/en/stable/topics/local-project-installs/#editable-installs).
This is a more advanced installation if you plan to contribute to `huggingface_hub`
and need to test changes in the code. You need to clone a local copy of `huggingface_hub`
on your machine.
```bash
# First, clone repo locally
git clone https://github.com/huggingface/huggingface_hub.git
# Then, install with -e flag
cd huggingface_hub
pip install -e .
```
These commands will link the folder you cloned the repository to and your Python library paths.
Python will now look inside the folder you cloned to in addition to the normal library paths.
For example, if your Python packages are typically installed in `./.venv/lib/python3.11/site-packages/`,
Python will also search the folder you cloned `./huggingface_hub/`.
## Install with conda
If you are more familiar with it, you can install `huggingface_hub` using the [conda-forge channel](https://anaconda.org/conda-forge/huggingface_hub):
```bash
conda install -c conda-forge huggingface_hub
```
Once done, [check installation](#check-installation) is working correctly.
## Check installation
Once installed, check that `huggingface_hub` works properly by running the following command:
```bash
python -c "from huggingface_hub import model_info; print(model_info('gpt2'))"
```
This command will fetch information from the Hub about the [gpt2](https://huggingface.co/gpt2) model.
Output should look like this:
```text
Model Name: gpt2
Tags: ['pytorch', 'tf', 'jax', 'tflite', 'rust', 'safetensors', 'gpt2', 'text-generation', 'en', 'doi:10.57967/hf/0039', 'transformers', 'exbert', 'license:mit', 'has_space']
Task: text-generation
```
## Windows limitations
With our goal of democratizing good ML everywhere, we built `huggingface_hub` to be a
cross-platform library and in particular to work correctly on both Unix-based and Windows
systems. However, there are a few cases where `huggingface_hub` has some limitations when
run on Windows. Here is an exhaustive list of known issues. Please let us know if you
encounter any undocumented problem by opening [an issue on Github](https://github.com/huggingface/huggingface_hub/issues/new/choose).
- `huggingface_hub`'s cache system relies on symlinks to efficiently cache files downloaded
from the Hub. On Windows, you must activate developer mode or run your script as admin to
enable symlinks. If they are not activated, the cache-system still works but in an non-optimized
manner. Please read [the cache limitations](./guides/manage-cache#limitations) section for more details.
- Filepaths on the Hub can have special characters (e.g. `"path/to?/my/file"`). Windows is
more restrictive on [special characters](https://learn.microsoft.com/en-us/windows/win32/intl/character-sets-used-in-file-names)
which makes it impossible to download those files on Windows. Hopefully this is a rare case.
Please reach out to the repo owner if you think this is a mistake or to us to figure out
a solution.
## Next steps
Once `huggingface_hub` is properly installed on your machine, you might want
[configure environment variables](package_reference/environment_variables) or [check one of our guides](guides/overview) to get started. | huggingface/huggingface_hub/blob/main/docs/source/en/installation.md |
Multi Subject DreamBooth training
[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few(3~5) images of a subject.
This `train_multi_subject_dreambooth.py` script shows how to implement the training procedure for one or more subjects and adapt it for stable diffusion. Note that this code is based off of the `examples/dreambooth/train_dreambooth.py` script as of 01/06/2022.
This script was added by @kopsahlong, and is not actively maintained. However, if you come across anything that could use fixing, feel free to open an issue and tag @kopsahlong.
## Running locally with PyTorch
### Installing the dependencies
Before running the script, make sure to install the library's training dependencies:
To start, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install -e .
```
Then cd into the folder `diffusers/examples/research_projects/multi_subject_dreambooth` and run the following:
```bash
pip install -r requirements.txt
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
Or for a default accelerate configuration without answering questions about your environment
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell e.g. a notebook
```python
from accelerate.utils import write_basic_config
write_basic_config()
```
### Multi Subject Training Example
In order to have your model learn multiple concepts at once, we simply add in the additional data directories and prompts to our `instance_data_dir` and `instance_prompt` (as well as `class_data_dir` and `class_prompt` if `--with_prior_preservation` is specified) as one comma separated string.
See an example with 2 subjects below, which learns a model for one dog subject and one human subject:
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export OUTPUT_DIR="path-to-save-model"
# Subject 1
export INSTANCE_DIR_1="path-to-instance-images-concept-1"
export INSTANCE_PROMPT_1="a photo of a sks dog"
export CLASS_DIR_1="path-to-class-images-dog"
export CLASS_PROMPT_1="a photo of a dog"
# Subject 2
export INSTANCE_DIR_2="path-to-instance-images-concept-2"
export INSTANCE_PROMPT_2="a photo of a t@y person"
export CLASS_DIR_2="path-to-class-images-person"
export CLASS_PROMPT_2="a photo of a person"
accelerate launch train_multi_subject_dreambooth.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir="$INSTANCE_DIR_1,$INSTANCE_DIR_2" \
--output_dir=$OUTPUT_DIR \
--train_text_encoder \
--instance_prompt="$INSTANCE_PROMPT_1,$INSTANCE_PROMPT_2" \
--with_prior_preservation \
--prior_loss_weight=1.0 \
--class_data_dir="$CLASS_DIR_1,$CLASS_DIR_2" \
--class_prompt="$CLASS_PROMPT_1,$CLASS_PROMPT_2"\
--num_class_images=50 \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=1 \
--learning_rate=1e-6 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=1500
```
This example shows training for 2 subjects, but please note that the model can be trained on any number of new concepts. This can be done by continuing to add in the corresponding directories and prompts to the corresponding comma separated string.
Note also that in this script, `sks` and `t@y` were used as tokens to learn the new subjects ([this thread](https://github.com/XavierXiao/Dreambooth-Stable-Diffusion/issues/71) inspired the use of `t@y` as our second identifier). However, there may be better rare tokens to experiment with, and results also seemed to be good when more intuitive words are used.
**Important**: New parameters are added to the script, making possible to validate the progress of the training by
generating images at specified steps. Taking also into account that a comma separated list in a text field for a prompt
it's never a good idea (simply because it is very common in prompts to have them as part of a regular text) we
introduce the `concept_list` parameter: allowing to specify a json-like file where you can define the different
configuration for each subject that you want to train.
An example of how to generate the file:
```python
import json
# here we are using parameters for prior-preservation and validation as well.
concepts_list = [
{
"instance_prompt": "drawing of a t@y meme",
"class_prompt": "drawing of a meme",
"instance_data_dir": "/some_folder/meme_toy",
"class_data_dir": "/data/meme",
"validation_prompt": "drawing of a t@y meme about football in Uruguay",
"validation_negative_prompt": "black and white"
},
{
"instance_prompt": "drawing of a sks sir",
"class_prompt": "drawing of a sir",
"instance_data_dir": "/some_other_folder/sir_sks",
"class_data_dir": "/data/sir",
"validation_prompt": "drawing of a sks sir with the Uruguayan sun in his chest",
"validation_negative_prompt": "an old man",
"validation_guidance_scale": 20,
"validation_number_images": 3,
"validation_inference_steps": 10
}
]
with open("concepts_list.json", "w") as f:
json.dump(concepts_list, f, indent=4)
```
And then just point to the file when executing the script:
```bash
# exports...
accelerate launch train_multi_subject_dreambooth.py \
# more parameters...
--concepts_list="concepts_list.json"
```
You can use the helper from the script to get a better sense of each parameter.
### Inference
Once you have trained a model using above command, the inference can be done simply using the `StableDiffusionPipeline`. Make sure to include the `identifier`(e.g. sks in above example) in your prompt.
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "path-to-your-trained-model"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
prompt = "A photo of a t@y person petting an sks dog"
image = pipe(prompt, num_inference_steps=200, guidance_scale=7.5).images[0]
image.save("person-petting-dog.png")
```
### Inference from a training checkpoint
You can also perform inference from one of the checkpoints saved during the training process, if you used the `--checkpointing_steps` argument. Please, refer to [the documentation](https://huggingface.co/docs/diffusers/main/en/training/dreambooth#performing-inference-using-a-saved-checkpoint) to see how to do it.
## Additional Dreambooth documentation
Because the `train_multi_subject_dreambooth.py` script here was forked from an original version of `train_dreambooth.py` in the `examples/dreambooth` folder, I've included the original applicable training documentation for single subject examples below.
This should explain how to play with training variables such as prior preservation, fine tuning the text encoder, etc. which is still applicable to our multi subject training code. Note also that the examples below, which are single subject examples, also work with `train_multi_subject_dreambooth.py`, as this script supports 1 (or more) subjects.
### Single subject dog toy example
Let's get our dataset. Download images from [here](https://drive.google.com/drive/folders/1BO_dyz-p65qhBRRMRA4TbZ8qW4rB99JZ) and save them in a directory. This will be our training data.
And launch the training using
**___Note: Change the `resolution` to 768 if you are using the [stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) 768x768 model.___**
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export INSTANCE_DIR="path-to-instance-images"
export OUTPUT_DIR="path-to-save-model"
accelerate launch train_dreambooth.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--output_dir=$OUTPUT_DIR \
--instance_prompt="a photo of sks dog" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=1 \
--learning_rate=5e-6 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=400
```
### Training with prior-preservation loss
Prior-preservation is used to avoid overfitting and language-drift. Refer to the paper to learn more about it. For prior-preservation we first generate images using the model with a class prompt and then use those during training along with our data.
According to the paper, it's recommended to generate `num_epochs * num_samples` images for prior-preservation. 200-300 works well for most cases. The `num_class_images` flag sets the number of images to generate with the class prompt. You can place existing images in `class_data_dir`, and the training script will generate any additional images so that `num_class_images` are present in `class_data_dir` during training time.
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export INSTANCE_DIR="path-to-instance-images"
export CLASS_DIR="path-to-class-images"
export OUTPUT_DIR="path-to-save-model"
accelerate launch train_dreambooth.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--class_data_dir=$CLASS_DIR \
--output_dir=$OUTPUT_DIR \
--with_prior_preservation --prior_loss_weight=1.0 \
--instance_prompt="a photo of sks dog" \
--class_prompt="a photo of dog" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=1 \
--learning_rate=5e-6 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--num_class_images=200 \
--max_train_steps=800
```
### Training on a 16GB GPU:
With the help of gradient checkpointing and the 8-bit optimizer from bitsandbytes it's possible to run train dreambooth on a 16GB GPU.
To install `bitandbytes` please refer to this [readme](https://github.com/TimDettmers/bitsandbytes#requirements--installation).
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export INSTANCE_DIR="path-to-instance-images"
export CLASS_DIR="path-to-class-images"
export OUTPUT_DIR="path-to-save-model"
accelerate launch train_dreambooth.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--class_data_dir=$CLASS_DIR \
--output_dir=$OUTPUT_DIR \
--with_prior_preservation --prior_loss_weight=1.0 \
--instance_prompt="a photo of sks dog" \
--class_prompt="a photo of dog" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=2 --gradient_checkpointing \
--use_8bit_adam \
--learning_rate=5e-6 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--num_class_images=200 \
--max_train_steps=800
```
### Training on a 8 GB GPU:
By using [DeepSpeed](https://www.deepspeed.ai/) it's possible to offload some
tensors from VRAM to either CPU or NVME allowing to train with less VRAM.
DeepSpeed needs to be enabled with `accelerate config`. During configuration
answer yes to "Do you want to use DeepSpeed?". With DeepSpeed stage 2, fp16
mixed precision and offloading both parameters and optimizer state to cpu it's
possible to train on under 8 GB VRAM with a drawback of requiring significantly
more RAM (about 25 GB). See [documentation](https://huggingface.co/docs/accelerate/usage_guides/deepspeed) for more DeepSpeed configuration options.
Changing the default Adam optimizer to DeepSpeed's special version of Adam
`deepspeed.ops.adam.DeepSpeedCPUAdam` gives a substantial speedup but enabling
it requires CUDA toolchain with the same version as pytorch. 8-bit optimizer
does not seem to be compatible with DeepSpeed at the moment.
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export INSTANCE_DIR="path-to-instance-images"
export CLASS_DIR="path-to-class-images"
export OUTPUT_DIR="path-to-save-model"
accelerate launch --mixed_precision="fp16" train_dreambooth.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--class_data_dir=$CLASS_DIR \
--output_dir=$OUTPUT_DIR \
--with_prior_preservation --prior_loss_weight=1.0 \
--instance_prompt="a photo of sks dog" \
--class_prompt="a photo of dog" \
--resolution=512 \
--train_batch_size=1 \
--sample_batch_size=1 \
--gradient_accumulation_steps=1 --gradient_checkpointing \
--learning_rate=5e-6 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--num_class_images=200 \
--max_train_steps=800
```
### Fine-tune text encoder with the UNet.
The script also allows to fine-tune the `text_encoder` along with the `unet`. It's been observed experimentally that fine-tuning `text_encoder` gives much better results especially on faces.
Pass the `--train_text_encoder` argument to the script to enable training `text_encoder`.
___Note: Training text encoder requires more memory, with this option the training won't fit on 16GB GPU. It needs at least 24GB VRAM.___
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export INSTANCE_DIR="path-to-instance-images"
export CLASS_DIR="path-to-class-images"
export OUTPUT_DIR="path-to-save-model"
accelerate launch train_dreambooth.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_text_encoder \
--instance_data_dir=$INSTANCE_DIR \
--class_data_dir=$CLASS_DIR \
--output_dir=$OUTPUT_DIR \
--with_prior_preservation --prior_loss_weight=1.0 \
--instance_prompt="a photo of sks dog" \
--class_prompt="a photo of dog" \
--resolution=512 \
--train_batch_size=1 \
--use_8bit_adam \
--gradient_checkpointing \
--learning_rate=2e-6 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--num_class_images=200 \
--max_train_steps=800
```
### Using DreamBooth for other pipelines than Stable Diffusion
Altdiffusion also support dreambooth now, the runing comman is basically the same as above, all you need to do is replace the `MODEL_NAME` like this:
One can now simply change the `pretrained_model_name_or_path` to another architecture such as [`AltDiffusion`](https://huggingface.co/docs/diffusers/api/pipelines/alt_diffusion).
```
export MODEL_NAME="CompVis/stable-diffusion-v1-4" --> export MODEL_NAME="BAAI/AltDiffusion-m9"
or
export MODEL_NAME="CompVis/stable-diffusion-v1-4" --> export MODEL_NAME="BAAI/AltDiffusion"
```
### Training with xformers:
You can enable memory efficient attention by [installing xFormers](https://github.com/facebookresearch/xformers#installing-xformers) and padding the `--enable_xformers_memory_efficient_attention` argument to the script. This is not available with the Flax/JAX implementation.
You can also use Dreambooth to train the specialized in-painting model. See [the script in the research folder for details](https://github.com/huggingface/diffusers/tree/main/examples/research_projects/dreambooth_inpaint). | huggingface/diffusers/blob/main/examples/research_projects/multi_subject_dreambooth/README.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# OWL-ViT
## Overview
The OWL-ViT (short for Vision Transformer for Open-World Localization) was proposed in [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby. OWL-ViT is an open-vocabulary object detection network trained on a variety of (image, text) pairs. It can be used to query an image with one or multiple text queries to search for and detect target objects described in text.
The abstract from the paper is the following:
*Combining simple architectures with large-scale pre-training has led to massive improvements in image classification. For object detection, pre-training and scaling approaches are less well established, especially in the long-tailed and open-vocabulary setting, where training data is relatively scarce. In this paper, we propose a strong recipe for transferring image-text models to open-vocabulary object detection. We use a standard Vision Transformer architecture with minimal modifications, contrastive image-text pre-training, and end-to-end detection fine-tuning. Our analysis of the scaling properties of this setup shows that increasing image-level pre-training and model size yield consistent improvements on the downstream detection task. We provide the adaptation strategies and regularizations needed to attain very strong performance on zero-shot text-conditioned and one-shot image-conditioned object detection. Code and models are available on GitHub.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/owlvit_architecture.jpg"
alt="drawing" width="600"/>
<small> OWL-ViT architecture. Taken from the <a href="https://arxiv.org/abs/2205.06230">original paper</a>. </small>
This model was contributed by [adirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
## Usage tips
OWL-ViT is a zero-shot text-conditioned object detection model. OWL-ViT uses [CLIP](clip) as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
[`OwlViTImageProcessor`] can be used to resize (or rescale) and normalize images for the model and [`CLIPTokenizer`] is used to encode the text. [`OwlViTProcessor`] wraps [`OwlViTImageProcessor`] and [`CLIPTokenizer`] into a single instance to both encode the text and prepare the images. The following example shows how to perform object detection using [`OwlViTProcessor`] and [`OwlViTForObjectDetection`].
```python
>>> import requests
>>> from PIL import Image
>>> import torch
>>> from transformers import OwlViTProcessor, OwlViTForObjectDetection
>>> processor = OwlViTProcessor.from_pretrained("google/owlvit-base-patch32")
>>> model = OwlViTForObjectDetection.from_pretrained("google/owlvit-base-patch32")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = [["a photo of a cat", "a photo of a dog"]]
>>> inputs = processor(text=texts, images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # Target image sizes (height, width) to rescale box predictions [batch_size, 2]
>>> target_sizes = torch.Tensor([image.size[::-1]])
>>> # Convert outputs (bounding boxes and class logits) to Pascal VOC format (xmin, ymin, xmax, ymax)
>>> results = processor.post_process_object_detection(outputs=outputs, target_sizes=target_sizes, threshold=0.1)
>>> i = 0 # Retrieve predictions for the first image for the corresponding text queries
>>> text = texts[i]
>>> boxes, scores, labels = results[i]["boxes"], results[i]["scores"], results[i]["labels"]
>>> for box, score, label in zip(boxes, scores, labels):
... box = [round(i, 2) for i in box.tolist()]
... print(f"Detected {text[label]} with confidence {round(score.item(), 3)} at location {box}")
Detected a photo of a cat with confidence 0.707 at location [324.97, 20.44, 640.58, 373.29]
Detected a photo of a cat with confidence 0.717 at location [1.46, 55.26, 315.55, 472.17]
```
## Resources
A demo notebook on using OWL-ViT for zero- and one-shot (image-guided) object detection can be found [here](https://github.com/huggingface/notebooks/blob/main/examples/zeroshot_object_detection_with_owlvit.ipynb).
## OwlViTConfig
[[autodoc]] OwlViTConfig
- from_text_vision_configs
## OwlViTTextConfig
[[autodoc]] OwlViTTextConfig
## OwlViTVisionConfig
[[autodoc]] OwlViTVisionConfig
## OwlViTImageProcessor
[[autodoc]] OwlViTImageProcessor
- preprocess
- post_process_object_detection
- post_process_image_guided_detection
## OwlViTFeatureExtractor
[[autodoc]] OwlViTFeatureExtractor
- __call__
- post_process
- post_process_image_guided_detection
## OwlViTProcessor
[[autodoc]] OwlViTProcessor
## OwlViTModel
[[autodoc]] OwlViTModel
- forward
- get_text_features
- get_image_features
## OwlViTTextModel
[[autodoc]] OwlViTTextModel
- forward
## OwlViTVisionModel
[[autodoc]] OwlViTVisionModel
- forward
## OwlViTForObjectDetection
[[autodoc]] OwlViTForObjectDetection
- forward
- image_guided_detection
| huggingface/transformers/blob/main/docs/source/en/model_doc/owlvit.md |
Security Policy
## Reporting a Vulnerability
🤗 We have our bug bounty program set up with HackerOne. Please feel free to submit vulnerability reports to our private program at https://hackerone.com/hugging_face.
Note that you'll need to be invited to our program, so send us a quick email at security@huggingface.co if you've found a vulnerability.
| huggingface/transformers/blob/main/SECURITY.md |
Dreambooth with OFT
This Notebook assumes that you already ran the train_dreambooth.py script to create your own adapter.
```python
from diffusers import DiffusionPipeline
from diffusers.utils import check_min_version, get_logger
from peft import PeftModel
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.10.0.dev0")
logger = get_logger(__name__)
BASE_MODEL_NAME = "stabilityai/stable-diffusion-2-1-base"
ADAPTER_MODEL_PATH = "INSERT MODEL PATH HERE"
```
```python
pipe = DiffusionPipeline.from_pretrained(
BASE_MODEL_NAME,
)
pipe.to("cuda")
pipe.unet = PeftModel.from_pretrained(pipe.unet, ADAPTER_MODEL_PATH + "/unet", adapter_name="default")
pipe.text_encoder = PeftModel.from_pretrained(
pipe.text_encoder, ADAPTER_MODEL_PATH + "/text_encoder", adapter_name="default"
)
```
```python
prompt = "A photo of a sks dog"
image = pipe(
prompt,
num_inference_steps=50,
height=512,
width=512,
).images[0]
image
```
| huggingface/peft/blob/main/examples/oft_dreambooth/oft_dreambooth_inference.ipynb |
Metric Card for Competition MATH
## Metric description
This metric is used to assess performance on the [Mathematics Aptitude Test of Heuristics (MATH) dataset](https://huggingface.co/datasets/competition_math).
It first canonicalizes the inputs (e.g., converting `1/2` to `\\frac{1}{2}`) and then computes accuracy.
## How to use
This metric takes two arguments:
`predictions`: a list of predictions to score. Each prediction is a string that contains natural language and LaTeX.
`references`: list of reference for each prediction. Each reference is a string that contains natural language and LaTeX.
```python
>>> from datasets import load_metric
>>> math = load_metric("competition_math")
>>> references = ["\\frac{1}{2}"]
>>> predictions = ["1/2"]
>>> results = math.compute(references=references, predictions=predictions)
```
N.B. To be able to use Competition MATH, you need to install the `math_equivalence` dependency using `pip install git+https://github.com/hendrycks/math.git`.
## Output values
This metric returns a dictionary that contains the [accuracy](https://huggingface.co/metrics/accuracy) after canonicalizing inputs, on a scale between 0.0 and 1.0.
### Values from popular papers
The [original MATH dataset paper](https://arxiv.org/abs/2103.03874) reported accuracies ranging from 3.0% to 6.9% by different large language models.
More recent progress on the dataset can be found on the [dataset leaderboard](https://paperswithcode.com/sota/math-word-problem-solving-on-math).
## Examples
Maximal values (full match):
```python
>>> from datasets import load_metric
>>> math = load_metric("competition_math")
>>> references = ["\\frac{1}{2}"]
>>> predictions = ["1/2"]
>>> results = math.compute(references=references, predictions=predictions)
>>> print(results)
{'accuracy': 1.0}
```
Minimal values (no match):
```python
>>> from datasets import load_metric
>>> math = load_metric("competition_math")
>>> references = ["\\frac{1}{2}"]
>>> predictions = ["3/4"]
>>> results = math.compute(references=references, predictions=predictions)
>>> print(results)
{'accuracy': 0.0}
```
Partial match:
```python
>>> from datasets import load_metric
>>> math = load_metric("competition_math")
>>> references = ["\\frac{1}{2}","\\frac{3}{4}"]
>>> predictions = ["1/5", "3/4"]
>>> results = math.compute(references=references, predictions=predictions)
>>> print(results)
{'accuracy': 0.5}
```
## Limitations and bias
This metric is limited to datasets with the same format as the [Mathematics Aptitude Test of Heuristics (MATH) dataset](https://huggingface.co/datasets/competition_math), and is meant to evaluate the performance of large language models at solving mathematical problems.
N.B. The MATH dataset also assigns levels of difficulty to different problems, so disagregating model performance by difficulty level (similarly to what was done in the [original paper](https://arxiv.org/abs/2103.03874) can give a better indication of how a given model does on a given difficulty of math problem, compared to overall accuracy.
## Citation
```bibtex
@article{hendrycksmath2021,
title={Measuring Mathematical Problem Solving With the MATH Dataset},
author={Dan Hendrycks
and Collin Burns
and Saurav Kadavath
and Akul Arora
and Steven Basart
and Eric Tang
and Dawn Song
and Jacob Steinhardt},
journal={arXiv preprint arXiv:2103.03874},
year={2021}
}
```
## Further References
- [MATH dataset](https://huggingface.co/datasets/competition_math)
- [MATH leaderboard](https://paperswithcode.com/sota/math-word-problem-solving-on-math)
- [MATH paper](https://arxiv.org/abs/2103.03874)
| huggingface/datasets/blob/main/metrics/competition_math/README.md |
--
title: "Visualize proteins on Hugging Face Spaces"
thumbnail: /blog/assets/98_spaces_3dmoljs/thumbnail.png
authors:
- user: simonduerr
guest: true
---
# Visualize proteins on Hugging Face Spaces
In this post we will look at how we can visualize proteins on Hugging Face Spaces.
## Motivation 🤗
Proteins have a huge impact on our life - from medicines to washing powder. Machine learning on proteins is a rapidly growing field to help us design new and interesting proteins. Proteins are complex 3D objects generally composed of a series of building blocks called amino acids that are arranged in 3D space to give the protein its function. For machine learning purposes a protein can for example be represented as coordinates, as graph or as 1D sequence of letters for use in a protein language model.
A famous ML model for proteins is AlphaFold2 which predicts the structure of a protein sequence using a multiple sequence alignment of similar proteins and a structure module.
Since AlphaFold2 made its debut many more such models have come out such as OmegaFold, OpenFold etc. (see this [list](https://github.com/yangkky/Machine-learning-for-proteins) or this [list](https://github.com/sacdallago/folding_tools) for more).
## Seeing is believing
The structure of a protein is an integral part to our understanding of what a protein does. Nowadays, there are a few tools available to visualize proteins directly in the browser such as [mol*](molstar.org) or [3dmol.js](https://3dmol.csb.pitt.edu/). In this post, you will learn how to integrate structure visualization into your Hugging Face Space using 3Dmol.js and the HTML block.
## Prerequisites
Make sure you have the `gradio` Python package already [installed](/getting_started) and basic knowledge of Javascript/JQuery.
## Taking a Look at the Code
Let's take a look at how to create the minimal working demo of our interface before we dive into how to setup 3Dmol.js.
We will build a simple demo app that can accept either a 4-digit PDB code or a PDB file. Our app will then retrieve the pdb file from the RCSB Protein Databank and display it or use the uploaded file for display.
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.1.7/gradio.js"></script>
<gradio-app theme_mode="light" space="simonduerr/3dmol.js"></gradio-app>
```python
import gradio as gr
def update(inp, file):
# in this simple example we just retrieve the pdb file using its identifier from the RCSB or display the uploaded file
pdb_path = get_pdb(inp, file)
return molecule(pdb_path) # this returns an iframe with our viewer
demo = gr.Blocks()
with demo:
gr.Markdown("# PDB viewer using 3Dmol.js")
with gr.Row():
with gr.Box():
inp = gr.Textbox(
placeholder="PDB Code or upload file below", label="Input structure"
)
file = gr.File(file_count="single")
btn = gr.Button("View structure")
mol = gr.HTML()
btn.click(fn=update, inputs=[inp, file], outputs=mol)
demo.launch()
```
`update`: This is the function that does the processing of our proteins and returns an `iframe` with the viewer
Our `get_pdb` function is also simple:
```python
import os
def get_pdb(pdb_code="", filepath=""):
if pdb_code is None or len(pdb_code) != 4:
try:
return filepath.name
except AttributeError as e:
return None
else:
os.system(f"wget -qnc https://files.rcsb.org/view/{pdb_code}.pdb")
return f"{pdb_code}.pdb"
```
Now, how to visualize the protein since Gradio does not have 3Dmol directly available as a block?
We use an `iframe` for this.
Our `molecule` function which returns the `iframe` conceptually looks like this:
```python
def molecule(input_pdb):
mol = read_mol(input_pdb)
# setup HTML document
x = ("""<!DOCTYPE html><html> [..] </html>""") # do not use ' in this input
return f"""<iframe [..] srcdoc='{x}'></iframe>
```
This is a bit clunky to setup but is necessary because of the security rules in modern browsers.
3Dmol.js setup is pretty easy and the documentation provides a [few examples](https://3dmol.csb.pitt.edu/).
The `head` of our returned document needs to load 3Dmol.js (which in turn also loads JQuery).
```html
<head>
<meta http-equiv="content-type" content="text/html; charset=UTF-8" />
<style>
.mol-container {
width: 100%;
height: 700px;
position: relative;
}
.mol-container select{
background-image:None;
}
</style>
<script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/3.6.3/jquery.min.js" integrity="sha512-STof4xm1wgkfm7heWqFJVn58Hm3EtS31XFaagaa8VMReCXAkQnJZ+jEy8PCC/iT18dFy95WcExNHFTqLyp72eQ==" crossorigin="anonymous" referrerpolicy="no-referrer"></script>
<script src="https://3Dmol.csb.pitt.edu/build/3Dmol-min.js"></script>
</head>
```
The styles for `.mol-container` can be used to modify the size of the molecule viewer.
The `body` looks as follows:
```html
<body>
<div id="container" class="mol-container"></div>
<script>
let pdb = mol // mol contains PDB file content, check the hf.space/simonduerr/3dmol.js for full python code
$(document).ready(function () {
let element = $("#container");
let config = { backgroundColor: "white" };
let viewer = $3Dmol.createViewer(element, config);
viewer.addModel(pdb, "pdb");
viewer.getModel(0).setStyle({}, { cartoon: { colorscheme:"whiteCarbon" } });
viewer.zoomTo();
viewer.render();
viewer.zoom(0.8, 2000);
})
</script>
</body>
```
We use a template literal (denoted by backticks) to store our pdb file in the html document directly and then output it using 3dmol.js.
And that's it, now you can couple your favorite protein ML model to a fun and easy to use gradio app and directly visualize predicted or redesigned structures. If you are predicting properities of a structure (e.g how likely each amino acid is to bind a ligand), 3Dmol.js also allows to use a custom `colorfunc` based on a property of each atom.
You can check the [source code](https://huggingface.co/spaces/simonduerr/3dmol.js/blob/main/app.py) of the 3Dmol.js space for the full code.
For a production example, you can check the [ProteinMPNN](https://hf.space/simonduerr/ProteinMPNN) space where a user can upload a backbone, the inverse folding model ProteinMPNN predicts new optimal sequences and then one can run AlphaFold2 on all predicted sequences to verify whether they adopt the initial input backbone. Successful redesigns that qualitiatively adopt the same structure as predicted by AlphaFold2 with high pLDDT score should be tested in the lab.
<gradio-app theme_mode="light" space="simonduerr/ProteinMPNN"></gradio-app>
# Issues
If you encounter any issues with the integration of 3Dmol.js in Gradio/HF spaces, please open a discussion in [hf.space/simonduerr/3dmol.js](https://hf.space/simonduerr/3dmol.js/discussions).
If you have problems with 3Dmol.js configuration - you need to ask the developers, please, open a [3Dmol.js Issue](https://github.com/3dmol/3Dmol.js/issues) instead and describe your problem.
| huggingface/blog/blob/main/spaces_3dmoljs.md |
Metric Card for SARI
## Metric description
SARI (***s**ystem output **a**gainst **r**eferences and against the **i**nput sentence*) is a metric used for evaluating automatic text simplification systems.
The metric compares the predicted simplified sentences against the reference and the source sentences. It explicitly measures the goodness of words that are added, deleted and kept by the system.
SARI can be computed as:
`sari = ( F1_add + F1_keep + P_del) / 3`
where
`F1_add` is the n-gram F1 score for add operations
`F1_keep` is the n-gram F1 score for keep operations
`P_del` is the n-gram precision score for delete operations
The number of n grams, `n`, is equal to 4, as in the original paper.
This implementation is adapted from [Tensorflow's tensor2tensor implementation](https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/utils/sari_hook.py).
It has two differences with the [original GitHub implementation](https://github.com/cocoxu/simplification/blob/master/SARI.py):
1) It defines 0/0=1 instead of 0 to give higher scores for predictions that match a target exactly.
2) It fixes an [alleged bug](https://github.com/cocoxu/simplification/issues/6) in the keep score computation.
## How to use
The metric takes 3 inputs: sources (a list of source sentence strings), predictions (a list of predicted sentence strings) and references (a list of lists of reference sentence strings)
```python
from datasets import load_metric
sari = load_metric("sari")
sources=["About 95 species are currently accepted."]
predictions=["About 95 you now get in."]
references=[["About 95 species are currently known.","About 95 species are now accepted.","95 species are now accepted."]]
sari_score = sari.compute(sources=sources, predictions=predictions, references=references)
```
## Output values
This metric outputs a dictionary with the SARI score:
```
print(sari_score)
{'sari': 26.953601953601954}
```
The range of values for the SARI score is between 0 and 100 -- the higher the value, the better the performance of the model being evaluated, with a SARI of 100 being a perfect score.
### Values from popular papers
The [original paper that proposes the SARI metric](https://aclanthology.org/Q16-1029.pdf) reports scores ranging from 26 to 43 for different simplification systems and different datasets. They also find that the metric ranks all of the simplification systems and human references in the same order as the human assessment used as a comparison, and that it correlates reasonably with human judgments.
More recent SARI scores for text simplification can be found on leaderboards for datasets such as [TurkCorpus](https://paperswithcode.com/sota/text-simplification-on-turkcorpus) and [Newsela](https://paperswithcode.com/sota/text-simplification-on-newsela).
## Examples
Perfect match between prediction and reference:
```python
from datasets import load_metric
sari = load_metric("sari")
sources=["About 95 species are currently accepted ."]
predictions=["About 95 species are currently accepted ."]
references=[["About 95 species are currently accepted ."]]
sari_score = sari.compute(sources=sources, predictions=predictions, references=references)
print(sari_score)
{'sari': 100.0}
```
Partial match between prediction and reference:
```python
from datasets import load_metric
sari = load_metric("sari")
sources=["About 95 species are currently accepted ."]
predictions=["About 95 you now get in ."]
references=[["About 95 species are currently known .","About 95 species are now accepted .","95 species are now accepted ."]]
sari_score = sari.compute(sources=sources, predictions=predictions, references=references)
print(sari_score)
{'sari': 26.953601953601954}
```
## Limitations and bias
SARI is a valuable measure for comparing different text simplification systems as well as one that can assist the iterative development of a system.
However, while the [original paper presenting SARI](https://aclanthology.org/Q16-1029.pdf) states that it captures "the notion of grammaticality and meaning preservation", this is a difficult claim to empirically validate.
## Citation
```bibtex
@inproceedings{xu-etal-2016-optimizing,
title = {Optimizing Statistical Machine Translation for Text Simplification},
authors={Xu, Wei and Napoles, Courtney and Pavlick, Ellie and Chen, Quanze and Callison-Burch, Chris},
journal = {Transactions of the Association for Computational Linguistics},
volume = {4},
year={2016},
url = {https://www.aclweb.org/anthology/Q16-1029},
pages = {401--415},
}
```
## Further References
- [NLP Progress -- Text Simplification](http://nlpprogress.com/english/simplification.html)
- [Hugging Face Hub -- Text Simplification Models](https://huggingface.co/datasets?filter=task_ids:text-simplification)
| huggingface/datasets/blob/main/metrics/sari/README.md |
Logging methods
🤗 Evaluate strives to be transparent and explicit about how it works, but this can be quite verbose at times. We have included a series of logging methods which allow you to easily adjust the level of verbosity of the entire library. Currently the default verbosity of the library is set to `WARNING`.
To change the level of verbosity, use one of the direct setters. For instance, here is how to change the verbosity to the `INFO` level:
```py
import evaluate
evaluate.logging.set_verbosity_info()
```
You can also use the environment variable `EVALUATE_VERBOSITY` to override the default verbosity, and set it to one of the following: `debug`, `info`, `warning`, `error`, `critical`:
```bash
EVALUATE_VERBOSITY=error ./myprogram.py
```
All the methods of this logging module are documented below. The main ones are:
- [`logging.get_verbosity`] to get the current level of verbosity in the logger
- [`logging.set_verbosity`] to set the verbosity to the level of your choice
In order from the least to the most verbose (with their corresponding `int` values):
1. `logging.CRITICAL` or `logging.FATAL` (int value, 50): only report the most critical errors.
2. `logging.ERROR` (int value, 40): only report errors.
3. `logging.WARNING` or `logging.WARN` (int value, 30): only reports error and warnings. This the default level used by the library.
4. `logging.INFO` (int value, 20): reports error, warnings and basic information.
5. `logging.DEBUG` (int value, 10): report all information.
By default, `tqdm` progress bars will be displayed during evaluate download and processing. [`logging.disable_progress_bar`] and [`logging.enable_progress_bar`] can be used to suppress or unsuppress this behavior.
## Functions
[[autodoc]] evaluate.logging.get_verbosity
[[autodoc]] evaluate.logging.set_verbosity
[[autodoc]] evaluate.logging.set_verbosity_info
[[autodoc]] evaluate.logging.set_verbosity_warning
[[autodoc]] evaluate.logging.set_verbosity_debug
[[autodoc]] evaluate.logging.set_verbosity_error
[[autodoc]] evaluate.logging.disable_propagation
[[autodoc]] evaluate.logging.enable_propagation
[[autodoc]] evaluate.logging.get_logger
[[autodoc]] evaluate.logging.enable_progress_bar
[[autodoc]] evaluate.logging.disable_progress_bar
## Levels
### evaluate.logging.CRITICAL
evaluate.logging.CRITICAL = 50
### evaluate.logging.DEBUG
evaluate.logging.DEBUG = 10
### evaluate.logging.ERROR
evaluate.logging.ERROR = 40
### evaluate.logging.FATAL
evaluate.logging.FATAL = 50
### evaluate.logging.INFO
evaluate.logging.INFO = 20
### evaluate.logging.NOTSET
evaluate.logging.NOTSET = 0
### evaluate.logging.WARN
evaluate.logging.WARN = 30
### evaluate.logging.WARNING
evaluate.logging.WARNING = 30
| huggingface/evaluate/blob/main/docs/source/package_reference/logging_methods.mdx |
How to Create a Custom Chatbot with Gradio Blocks
Tags: NLP, TEXT, CHAT
Related spaces: https://huggingface.co/spaces/gradio/chatbot_streaming, https://huggingface.co/spaces/project-baize/Baize-7B,
## Introduction
**Important Note**: if you are getting started, we recommend using the `gr.ChatInterface` to create chatbots -- its a high-level abstraction that makes it possible to create beautiful chatbot applications fast, often with a single line of code. [Read more about it here](/guides/creating-a-chatbot-fast).
This tutorial will show how to make chatbot UIs from scratch with Gradio's low-level Blocks API. This will give you full control over your Chatbot UI. You'll start by first creating a a simple chatbot to display text, a second one to stream text responses, and finally a chatbot that can handle media files as well. The chatbot interface that we create will look something like this:
$demo_chatbot_streaming
**Prerequisite**: We'll be using the `gradio.Blocks` class to build our Chatbot demo.
You can [read the Guide to Blocks first](https://gradio.app/quickstart/#blocks-more-flexibility-and-control) if you are not already familiar with it. Also please make sure you are using the **latest version** version of Gradio: `pip install --upgrade gradio`.
## A Simple Chatbot Demo
Let's start with recreating the simple demo above. As you may have noticed, our bot simply randomly responds "How are you?", "I love you", or "I'm very hungry" to any input. Here's the code to create this with Gradio:
$code_chatbot_simple
There are three Gradio components here:
- A `Chatbot`, whose value stores the entire history of the conversation, as a list of response pairs between the user and bot.
- A `Textbox` where the user can type their message, and then hit enter/submit to trigger the chatbot response
- A `ClearButton` button to clear the Textbox and entire Chatbot history
We have a single function, `respond()`, which takes in the entire history of the chatbot, appends a random message, waits 1 second, and then returns the updated chat history. The `respond()` function also clears the textbox when it returns.
Of course, in practice, you would replace `respond()` with your own more complex function, which might call a pretrained model or an API, to generate a response.
$demo_chatbot_simple
## Add Streaming to your Chatbot
There are several ways we can improve the user experience of the chatbot above. First, we can stream responses so the user doesn't have to wait as long for a message to be generated. Second, we can have the user message appear immediately in the chat history, while the chatbot's response is being generated. Here's the code to achieve that:
$code_chatbot_streaming
You'll notice that when a user submits their message, we now _chain_ three event events with `.then()`:
1. The first method `user()` updates the chatbot with the user message and clears the input field. This method also makes the input field non interactive so that the user can't send another message while the chatbot is responding. Because we want this to happen instantly, we set `queue=False`, which would skip any queue had it been enabled. The chatbot's history is appended with `(user_message, None)`, the `None` signifying that the bot has not responded.
2. The second method, `bot()` updates the chatbot history with the bot's response. Instead of creating a new message, we just replace the previously-created `None` message with the bot's response. Finally, we construct the message character by character and `yield` the intermediate outputs as they are being constructed. Gradio automatically turns any function with the `yield` keyword [into a streaming output interface](/guides/key-features/#iterative-outputs).
3. The third method makes the input field interactive again so that users can send another message to the bot.
Of course, in practice, you would replace `bot()` with your own more complex function, which might call a pretrained model or an API, to generate a response.
Finally, we enable queuing by running `demo.queue()`, which is required for streaming intermediate outputs. You can try the improved chatbot by scrolling to the demo at the top of this page.
## Liking / Disliking Chat Messages
Once you've created your `gr.Chatbot`, you can add the ability for users to like or dislike messages. This can be useful if you would like users to vote on a bot's responses or flag inappropriate results.
To add this functionality to your Chatbot, simply attach a `.like()` event to your Chatbot. A chatbot that has the `.like()` event will automatically feature a thumbs-up icon and a thumbs-down icon next to every bot message.
The `.like()` method requires you to pass in a function that is called when a user clicks on these icons. In your function, you should have an argument whose type is `gr.LikeData`. Gradio will automatically supply the parameter to this argument with an object that contains information about the liked or disliked message. Here's a simplistic example of how you can have users like or dislike chat messages:
```py
import gradio as gr
def greet(history, input):
return history + [(input, "Hello, " + input)]
def vote(data: gr.LikeData):
if data.liked:
print("You upvoted this response: " + data.value)
else:
print("You downvoted this response: " + data.value)
with gr.Blocks() as demo:
chatbot = gr.Chatbot()
textbox = gr.Textbox()
textbox.submit(greet, [chatbot, textbox], [chatbot])
chatbot.like(vote, None, None) # Adding this line causes the like/dislike icons to appear in your chatbot
demo.launch()
```
## Adding Markdown, Images, Audio, or Videos
The `gr.Chatbot` component supports a subset of markdown including bold, italics, and code. For example, we could write a function that responds to a user's message, with a bold **That's cool!**, like this:
```py
def bot(history):
response = "**That's cool!**"
history[-1][1] = response
return history
```
In addition, it can handle media files, such as images, audio, and video. To pass in a media file, we must pass in the file as a tuple of two strings, like this: `(filepath, alt_text)`. The `alt_text` is optional, so you can also just pass in a tuple with a single element `(filepath,)`, like this:
```python
def add_file(history, file):
history = history + [((file.name,), None)]
return history
```
Putting this together, we can create a _multimodal_ chatbot with a textbox for a user to submit text and an file upload button to submit images / audio / video files. The rest of the code looks pretty much the same as before:
$code_chatbot_multimodal
$demo_chatbot_multimodal
And you're done! That's all the code you need to build an interface for your chatbot model. Finally, we'll end our Guide with some links to Chatbots that are running on Spaces so that you can get an idea of what else is possible:
- [project-baize/Baize-7B](https://huggingface.co/spaces/project-baize/Baize-7B): A stylized chatbot that allows you to stop generation as well as regenerate responses.
- [MAGAer13/mPLUG-Owl](https://huggingface.co/spaces/MAGAer13/mPLUG-Owl): A multimodal chatbot that allows you to upvote and downvote responses.
| gradio-app/gradio/blob/main/guides/04_chatbots/02_creating-a-custom-chatbot-with-blocks.md |
Using 🧨 `diffusers` at Hugging Face
Diffusers is the go-to library for state-of-the-art pretrained diffusion models for generating images, audio, and even 3D structures of molecules. Whether you’re looking for a simple inference solution or want to train your own diffusion model, Diffusers is a modular toolbox that supports both. The library is designed with a focus on usability over performance, simple over easy, and customizability over abstractions.
## Exploring Diffusers in the Hub
There are over 10,000 `diffusers` compatible pipelines on the Hub which you can find by filtering at the left of [the models page](https://huggingface.co/models?library=diffusers&sort=downloads). Diffusion systems are typically composed of multiple components such as text encoder, UNet, VAE, and scheduler. Even though they are not standalone models, the pipeline abstraction makes it easy to use them for inference or training.
You can find diffusion pipelines for many different tasks:
* Generating images from natural language text prompts ([text-to-image](https://huggingface.co/models?library=diffusers&pipeline_tag=text-to-image&sort=downloads)).
* Transforming images using natural language text prompts ([image-to-image](https://huggingface.co/models?library=diffusers&pipeline_tag=image-to-image&sort=downloads)).
* Generating videos from natural language descriptions ([text-to-video](https://huggingface.co/models?library=diffusers&pipeline_tag=text-to-video&sort=downloads)).
You can try out the models directly in the browser if you want to test them out without downloading them, thanks to the in-browser widgets!
<div class="flex justify-center">
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/refs%2Fpr%2F35/hub/libraries-diffusers_widget.png"/>
</div>
## Using existing pipelines
All `diffusers` pipelines are a line away from being used! To run generation we recommended to always start from the `DiffusionPipeline`:
```py
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0")
```
If you want to load a specific pipeline component such as the UNet, you can do so by:
```py
from diffusers import UNet2DConditionModel
unet = UNet2DConditionModel.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", subfolder="unet")
```
## Sharing your pipelines and models
All the [pipeline classes](https://huggingface.co/docs/diffusers/main/api/pipelines/overview), [model classes](https://huggingface.co/docs/diffusers/main/api/models/overview), and [scheduler classes](https://huggingface.co/docs/diffusers/main/api/schedulers/overview) are fully compatible with the Hub. More specifically, they can be easily loaded from the Hub using the `from_pretrained()` method and can be shared with others using the `push_to_hub()` method.
For more details, please check out the [documentation](https://huggingface.co/docs/diffusers/main/en/using-diffusers/push_to_hub).
## Additional resources
* Diffusers [library](https://github.com/huggingface/diffusers).
* Diffusers [docs](https://huggingface.co/docs/diffusers/index).
| huggingface/hub-docs/blob/main/docs/hub/diffusers.md |
Gradio Demo: video_component_events
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
input_video = gr.Video(label="Input Video")
with gr.Column():
output_video = gr.Video(label="Output Video")
with gr.Column():
num_change = gr.Number(label="# Change Events", value=0)
num_load = gr.Number(label="# Upload Events", value=0)
num_play = gr.Number(label="# Play Events", value=0)
num_pause = gr.Number(label="# Pause Events", value=0)
input_video.upload(lambda s, n: (s, n + 1), [input_video, num_load], [output_video, num_load])
input_video.change(lambda n: n + 1, num_change, num_change)
input_video.play(lambda n: n + 1, num_play, num_play)
input_video.pause(lambda n: n + 1, num_pause, num_pause)
input_video.change(lambda n: n + 1, num_change, num_change)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/video_component_events/run.ipynb |
Inference Examples
**The inference examples folder is deprecated and will be removed in a future version**.
**Officially supported inference examples can be found in the [Pipelines folder](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines)**.
- For `Image-to-Image text-guided generation with Stable Diffusion`, please have a look at the official [Pipeline examples](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines#examples)
- For `In-painting using Stable Diffusion`, please have a look at the official [Pipeline examples](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines#examples)
- For `Tweak prompts reusing seeds and latents`, please have a look at the official [Pipeline examples](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines#examples)
| huggingface/diffusers/blob/main/examples/inference/README.md |
Bias and limitations[[bias-and-limitations]]
<CourseFloatingBanner chapter={1}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter1/section8.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter1/section8.ipynb"},
]} />
If your intent is to use a pretrained model or a fine-tuned version in production, please be aware that, while these models are powerful tools, they come with limitations. The biggest of these is that, to enable pretraining on large amounts of data, researchers often scrape all the content they can find, taking the best as well as the worst of what is available on the internet.
To give a quick illustration, let's go back the example of a `fill-mask` pipeline with the BERT model:
```python
from transformers import pipeline
unmasker = pipeline("fill-mask", model="bert-base-uncased")
result = unmasker("This man works as a [MASK].")
print([r["token_str"] for r in result])
result = unmasker("This woman works as a [MASK].")
print([r["token_str"] for r in result])
```
```python out
['lawyer', 'carpenter', 'doctor', 'waiter', 'mechanic']
['nurse', 'waitress', 'teacher', 'maid', 'prostitute']
```
When asked to fill in the missing word in these two sentences, the model gives only one gender-free answer (waiter/waitress). The others are work occupations usually associated with one specific gender -- and yes, prostitute ended up in the top 5 possibilities the model associates with "woman" and "work." This happens even though BERT is one of the rare Transformer models not built by scraping data from all over the internet, but rather using apparently neutral data (it's trained on the [English Wikipedia](https://huggingface.co/datasets/wikipedia) and [BookCorpus](https://huggingface.co/datasets/bookcorpus) datasets).
When you use these tools, you therefore need to keep in the back of your mind that the original model you are using could very easily generate sexist, racist, or homophobic content. Fine-tuning the model on your data won't make this intrinsic bias disappear.
| huggingface/course/blob/main/chapters/en/chapter1/8.mdx |
--
title: "Announcing our new Content Guidelines and Policy"
thumbnail: /blog/assets/content-guidelines-blogpost/thumbnail.png
authors:
- user: giadap
---
# Announcing our new Community Policy
As a community-driven platform that aims to advance Open, Collaborative, and Responsible Machine Learning, we are thrilled to support and maintain a welcoming space for our entire community! In support of this goal, we've updated our [Content Policy](https://huggingface.co/content-guidelines).
We encourage you to familiarize yourself with the complete document to fully understand what it entails. Meanwhile, this blog post serves to provide an overview, outline the rationale, and highlight the values driving the update of our Content Policy. By delving into both resources, you'll gain a comprehensive understanding of the expectations and goals for content on our platform.
## Moderating Machine Learning Content
Moderating Machine Learning artifacts introduces new challenges. Even more than static content, the risks associated with developing and deploying artificial intelligence systems and/or models require in-depth analysis and a wide-ranging approach to foresee possible harms. That is why the efforts to draft this new Content Policy come from different members and expertise in our cross-company teams, all of which are indispensable to have both a general and a detailed picture to provide clarity on how we enable responsible development and deployment on our platform.
Furthermore, as the field of AI and machine learning continues to expand, the variety of use cases and applications proliferates. This makes it essential for us to stay up-to-date with the latest research, ethical considerations, and best practices. For this reason, promoting user collaboration is also vital to the sustainability of our platform. Namely, through our community features, such as the Community Tab, we encourage and foster collaborative solutions between repository authors, users, organizations, and our team.
## Consent as a Core Value
As we prioritize respecting people's rights throughout the development and use of Machine Learning systems, we take a forward-looking view to account for developments in the technology and law affecting those rights. New ways of processing information enabled by Machine Learning are posing entirely new questions, both in the field of AI and in regulatory circles, about people's agency and rights with respect to their work, their image, and their privacy. Central to these discussions are how people's rights should be operationalized -- and we offer one avenue for addressing this here.
In this evolving legal landscape, it becomes increasingly important to emphasize the intrinsic value of "consent" to avoid enabling harm. By doing so, we focus on the individual's agency and subjective experiences. This approach not only supports forethought and a more empathetic understanding of consent but also encourages proactive measures to address cultural and contextual factors. In particular, our Content Policy aims to address consent related to what users see, and to how people's identities and expressions are represented.
This consideration for people's consent and experiences on the platform extends to Community Content and people's behaviors on the Hub. To maintain a safe and welcoming environment, we do not allow aggressive or harassing language directed at our users and/or the Hugging Face staff. We focus on fostering collaborative resolutions for any potential conflicts between users and repository authors, intervening only when necessary. To promote transparency, we encourage open discussions to occur within our Community tab.
Our approach is a reflection of our ongoing efforts to adapt and progress, which is made possible by the invaluable input of our users who actively collaborate and share their feedback. We are committed to being receptive to comments and constantly striving for improvement. We encourage you to reach out to [feedback@huggingface.co](mailto:feedback@huggingface.co) with any questions or concerns.
Let's join forces to build a friendly and supportive community that encourages open AI and ML collaboration! Together, we can make great strides forward in fostering a welcoming environment for everyone.
| huggingface/blog/blob/main/content-guidelines-update.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# MobileNet V2
## Overview
The MobileNet model was proposed in [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381) by Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen.
The abstract from the paper is the following:
*In this paper we describe a new mobile architecture, MobileNetV2, that improves the state of the art performance of mobile models on multiple tasks and benchmarks as well as across a spectrum of different model sizes. We also describe efficient ways of applying these mobile models to object detection in a novel framework we call SSDLite. Additionally, we demonstrate how to build mobile semantic segmentation models through a reduced form of DeepLabv3 which we call Mobile DeepLabv3.*
*The MobileNetV2 architecture is based on an inverted residual structure where the input and output of the residual block are thin bottleneck layers opposite to traditional residual models which use expanded representations in the input an MobileNetV2 uses lightweight depthwise convolutions to filter features in the intermediate expansion layer. Additionally, we find that it is important to remove non-linearities in the narrow layers in order to maintain representational power. We demonstrate that this improves performance and provide an intuition that led to this design. Finally, our approach allows decoupling of the input/output domains from the expressiveness of the transformation, which provides a convenient framework for further analysis. We measure our performance on Imagenet classification, COCO object detection, VOC image segmentation. We evaluate the trade-offs between accuracy, and number of operations measured by multiply-adds (MAdd), as well as the number of parameters.*
This model was contributed by [matthijs](https://huggingface.co/Matthijs). The original code and weights can be found [here for the main model](https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet) and [here for DeepLabV3+](https://github.com/tensorflow/models/tree/master/research/deeplab).
## Usage tips
- The checkpoints are named **mobilenet\_v2\_*depth*\_*size***, for example **mobilenet\_v2\_1.0\_224**, where **1.0** is the depth multiplier (sometimes also referred to as "alpha" or the width multiplier) and **224** is the resolution of the input images the model was trained on.
- Even though the checkpoint is trained on images of specific size, the model will work on images of any size. The smallest supported image size is 32x32.
- One can use [`MobileNetV2ImageProcessor`] to prepare images for the model.
- The available image classification checkpoints are pre-trained on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k) (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes). However, the model predicts 1001 classes: the 1000 classes from ImageNet plus an extra “background” class (index 0).
- The segmentation model uses a [DeepLabV3+](https://arxiv.org/abs/1802.02611) head. The available semantic segmentation checkpoints are pre-trained on [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/).
- The original TensorFlow checkpoints use different padding rules than PyTorch, requiring the model to determine the padding amount at inference time, since this depends on the input image size. To use native PyTorch padding behavior, create a [`MobileNetV2Config`] with `tf_padding = False`.
Unsupported features:
- The [`MobileNetV2Model`] outputs a globally pooled version of the last hidden state. In the original model it is possible to use an average pooling layer with a fixed 7x7 window and stride 1 instead of global pooling. For inputs that are larger than the recommended image size, this gives a pooled output that is larger than 1x1. The Hugging Face implementation does not support this.
- The original TensorFlow checkpoints include quantized models. We do not support these models as they include additional "FakeQuantization" operations to unquantize the weights.
- It's common to extract the output from the expansion layers at indices 10 and 13, as well as the output from the final 1x1 convolution layer, for downstream purposes. Using `output_hidden_states=True` returns the output from all intermediate layers. There is currently no way to limit this to specific layers.
- The DeepLabV3+ segmentation head does not use the final convolution layer from the backbone, but this layer gets computed anyway. There is currently no way to tell [`MobileNetV2Model`] up to which layer it should run.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with MobileNetV2.
<PipelineTag pipeline="image-classification"/>
- [`MobileNetV2ForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
**Semantic segmentation**
- [Semantic segmentation task guide](../tasks/semantic_segmentation)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## MobileNetV2Config
[[autodoc]] MobileNetV2Config
## MobileNetV2FeatureExtractor
[[autodoc]] MobileNetV2FeatureExtractor
- preprocess
- post_process_semantic_segmentation
## MobileNetV2ImageProcessor
[[autodoc]] MobileNetV2ImageProcessor
- preprocess
- post_process_semantic_segmentation
## MobileNetV2Model
[[autodoc]] MobileNetV2Model
- forward
## MobileNetV2ForImageClassification
[[autodoc]] MobileNetV2ForImageClassification
- forward
## MobileNetV2ForSemanticSegmentation
[[autodoc]] MobileNetV2ForSemanticSegmentation
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/mobilenet_v2.md |
n this video, we'll study the encoder-decoder architecture. An example of a popular encoder-decoder model is T5. In order to understand how the encoder-decoder works, we recommend you check out the videos on encoders and decoders as standalone models. Understanding how they behave individually will help understanding how an encoder-decoder behaves. Let's start from what we've seen about the encoder. The encoder takes words as inputs, casts them through the encoder, and retrieves a numerical representation for each word cast through it. We now know that the numerical representation holds information about the meaning of the sequence. Let's put this aside and add the decoder to the diagram. In this scenario, we're using the decoder in a manner that we haven't seen before. We're passing the outputs of the encoder directly to it! Additionally to the encoder outputs, we also give the decoder a sequence. When prompting the decoder for an output with no initial sequence, we can give it the value that indicates the start of a sequence. And that's where the encoder-decoder magic happens. The encoder accepts a sequence as input. It computes a prediction, and outputs a numerical representation. Then, it sends that over to the decoder. It has, in a sense, encoded the sequence. And the decoder, in turn, using this input alongside its usual sequence input, will take a stab at decoding the sequence. The decoder decodes the sequence, and outputs a word. As of now, we don't need to make sense of that word, but we can understand that the decoder is essentially decoding what the encoder has output. The "start of sequence word" indicates that it should start decoding the sequence. Now that we have both the feature vector and an initial generated word, we don't need the encoder anymore. As we have seen before with the decoder, it can act in an auto-regressive manner; the word it has just output can now be used as an input. This, in combination with the numerical representation output by the encoder, can now be used to generate a second word. Please note that the first word is still here; as the model still outputs it. However, it is greyed out as we have no need for it anymore. We can continue on and on; for example until the decoder outputs a value that we consider a "stopping value", like a dot, meaning the end of a sequence. Here, we've seen the full mechanism of the encoder-decoder transformer: let's go over it one more time. We have an initial sequence, that is sent to the encoder. That encoder output is then sent to the decoder, for it to be decoded. While we can now discard the encoder after a single use, the decoder will be used several times: until we have generated every word that we need. Let's see a concrete example; with Translation Language Modeling; also called transduction; the act of translating a sequence. Here, we would like to translate this English sequence "Welcome to NYC" in French. We're using a transformer model that is trained for that task explicitly. We use the encoder to create a representation of the English sentence. We cast this to the decoder and, with the use of the start of sequence word, we ask it to output the first word. It outputs Bienvenue, which means "Welcome". We then use "Bienvenue" as the input sequence for the decoder. This, alongside the feature vector, allows the decoder to predict the second word, "à", which is "to" in English. Finally, we ask the decoder to predict a third word; it predicts "NYC", which is, once again, correct. We've translated the sentence! Where the encoder-decoder really shines, is that we have an encoder and a decoder; which often do not share weights. We, therefore, have an entire block (the encoder) that can be trained to understand the sequence, and extract the relevant information. For the translation scenario we've seen earlier, for example, this would mean parsing and understanding what was said in the English language; extracting information from that language, and putting all of that in a vector dense in information. On the other hand, we have the decoder, whose sole purpose is to decode the feature output by the encoder. This decoder can be specialized in a completely different language, or even modality like images or speech. Encoders-decoders are special for several reasons. Firstly, they're able to manage sequence to sequence tasks, like translation that we have just seen. Secondly, the weights between the encoder and the decoder parts are not necessarily shared. Let's take another example of translation. Here we're translating "Transformers are powerful" in French. Firstly, this means that from a sequence of three words, we're able to generate a sequence of four words. One could argue that this could be handled with a decoder; that would generate the translation in an auto-regressive manner; and they would be right! Another example of where sequence to sequence transformers shine is in summarization. Here we have a very long sequence, generally a full text, and we want to summarize it. Since the encoder and decoders are separated, we can have different context lengths (for example a very long context for the encoder which handles the text, and a smaller context for the decoder which handles the summarized sequence). There are a lot of sequence to sequence models. This contains a few examples of popular encoder-decoder models available in the transformers library. Additionally, you can load an encoder and a decoder inside an encoder-decoder model! Therefore, according to the specific task you are targeting, you may choose to use specific encoders and decoders, which have proven their worth on these specific tasks. This wraps things up for the encoder-decoders. Thanks for watching! | huggingface/course/blob/main/subtitles/en/raw/chapter1/07_encoder-decoders.md |
Introducing the Clipped Surrogate Objective Function
## Recap: The Policy Objective Function
Let’s remember what the objective is to optimize in Reinforce:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/lpg.jpg" alt="Reinforce"/>
The idea was that by taking a gradient ascent step on this function (equivalent to taking gradient descent of the negative of this function), we would **push our agent to take actions that lead to higher rewards and avoid harmful actions.**
However, the problem comes from the step size:
- Too small, **the training process was too slow**
- Too high, **there was too much variability in the training**
With PPO, the idea is to constrain our policy update with a new objective function called the *Clipped surrogate objective function* that **will constrain the policy change in a small range using a clip.**
This new function **is designed to avoid destructively large weights updates** :
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/ppo-surrogate.jpg" alt="PPO surrogate function"/>
Let’s study each part to understand how it works.
## The Ratio Function
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/ratio1.jpg" alt="Ratio"/>
This ratio is calculated as follows:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/ratio2.jpg" alt="Ratio"/>
It’s the probability of taking action \\( a_t \\) at state \\( s_t \\) in the current policy, divided by the same for the previous policy.
As we can see, \\( r_t(\theta) \\) denotes the probability ratio between the current and old policy:
- If \\( r_t(\theta) > 1 \\), the **action \\( a_t \\) at state \\( s_t \\) is more likely in the current policy than the old policy.**
- If \\( r_t(\theta) \\) is between 0 and 1, the **action is less likely for the current policy than for the old one**.
So this probability ratio is an **easy way to estimate the divergence between old and current policy.**
## The unclipped part of the Clipped Surrogate Objective function
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/unclipped1.jpg" alt="PPO"/>
This ratio **can replace the log probability we use in the policy objective function**. This gives us the left part of the new objective function: multiplying the ratio by the advantage.
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/unclipped2.jpg" alt="PPO"/>
<figcaption><a href="https://arxiv.org/pdf/1707.06347.pdf">Proximal Policy Optimization Algorithms</a></figcaption>
</figure>
However, without a constraint, if the action taken is much more probable in our current policy than in our former, **this would lead to a significant policy gradient step** and, therefore, an **excessive policy update.**
## The clipped Part of the Clipped Surrogate Objective function
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/clipped.jpg" alt="PPO"/>
Consequently, we need to constrain this objective function by penalizing changes that lead to a ratio far away from 1 (in the paper, the ratio can only vary from 0.8 to 1.2).
**By clipping the ratio, we ensure that we do not have a too large policy update because the current policy can't be too different from the older one.**
To do that, we have two solutions:
- *TRPO (Trust Region Policy Optimization)* uses KL divergence constraints outside the objective function to constrain the policy update. But this method **is complicated to implement and takes more computation time.**
- *PPO* clip probability ratio directly in the objective function with its **Clipped surrogate objective function.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/clipped.jpg" alt="PPO"/>
This clipped part is a version where \\( r_t(\theta) \\) is clipped between \\( [1 - \epsilon, 1 + \epsilon] \\).
With the Clipped Surrogate Objective function, we have two probability ratios, one non-clipped and one clipped in a range between \\( [1 - \epsilon, 1 + \epsilon] \\), epsilon is a hyperparameter that helps us to define this clip range (in the paper \\( \epsilon = 0.2 \\).).
Then, we take the minimum of the clipped and non-clipped objective, **so the final objective is a lower bound (pessimistic bound) of the unclipped objective.**
Taking the minimum of the clipped and non-clipped objective means **we'll select either the clipped or the non-clipped objective based on the ratio and advantage situation**.
| huggingface/deep-rl-class/blob/main/units/en/unit8/clipped-surrogate-objective.mdx |
Gradio Demo: bar_plot
```
!pip install -q gradio pandas
```
```
import gradio as gr
import pandas as pd
import random
simple = pd.DataFrame(
{
"a": ["A", "B", "C", "D", "E", "F", "G", "H", "I"],
"b": [28, 55, 43, 91, 81, 53, 19, 87, 52],
}
)
fake_barley = pd.DataFrame(
{
"site": [
random.choice(
[
"University Farm",
"Waseca",
"Morris",
"Crookston",
"Grand Rapids",
"Duluth",
]
)
for _ in range(120)
],
"yield": [random.randint(25, 75) for _ in range(120)],
"variety": [
random.choice(
[
"Manchuria",
"Wisconsin No. 38",
"Glabron",
"No. 457",
"No. 462",
"No. 475",
]
)
for _ in range(120)
],
"year": [
random.choice(
[
"1931",
"1932",
]
)
for _ in range(120)
],
}
)
def bar_plot_fn(display):
if display == "simple":
return gr.BarPlot(
simple,
x="a",
y="b",
title="Simple Bar Plot with made up data",
tooltip=["a", "b"],
y_lim=[20, 100],
)
elif display == "stacked":
return gr.BarPlot(
fake_barley,
x="variety",
y="yield",
color="site",
title="Barley Yield Data",
tooltip=["variety", "site"],
)
elif display == "grouped":
return gr.BarPlot(
fake_barley.astype({"year": str}),
x="year",
y="yield",
color="year",
group="site",
title="Barley Yield by Year and Site",
group_title="",
tooltip=["yield", "site", "year"],
)
elif display == "simple-horizontal":
return gr.BarPlot(
simple,
x="a",
y="b",
x_title="Variable A",
y_title="Variable B",
title="Simple Bar Plot with made up data",
tooltip=["a", "b"],
vertical=False,
y_lim=[20, 100],
)
elif display == "stacked-horizontal":
return gr.BarPlot(
fake_barley,
x="variety",
y="yield",
color="site",
title="Barley Yield Data",
vertical=False,
tooltip=["variety", "site"],
)
elif display == "grouped-horizontal":
return gr.BarPlot(
fake_barley.astype({"year": str}),
x="year",
y="yield",
color="year",
group="site",
title="Barley Yield by Year and Site",
group_title="",
tooltip=["yield", "site", "year"],
vertical=False,
)
with gr.Blocks() as bar_plot:
with gr.Row():
with gr.Column():
display = gr.Dropdown(
choices=[
"simple",
"stacked",
"grouped",
"simple-horizontal",
"stacked-horizontal",
"grouped-horizontal",
],
value="simple",
label="Type of Bar Plot",
)
with gr.Column():
plot = gr.BarPlot()
display.change(bar_plot_fn, inputs=display, outputs=plot)
bar_plot.load(fn=bar_plot_fn, inputs=display, outputs=plot)
bar_plot.launch()
```
| gradio-app/gradio/blob/main/demo/bar_plot/run.ipynb |
--
title: "Fine-Tune MMS Adapter Models for low-resource ASR"
thumbnail: /blog/assets/151_mms/mms_map.png
authors:
- user: patrickvonplaten
---
# **Fine-tuning MMS Adapter Models for Multi-Lingual ASR**
<a target="_blank" href="https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_Tune_MMS_on_Common_Voice.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
***New (06/2023)***: *This blog post is strongly inspired by ["Fine-tuning XLS-R on Multi-Lingual ASR"](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2)* and can be seen as an improved version of it.
**Wav2Vec2** is a pretrained model for Automatic Speech Recognition (ASR) and was released in [September 2020](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) by *Alexei Baevski, Michael Auli, and Alex Conneau*. Soon after the strong performance of Wav2Vec2 was demonstrated on one of the most popular English datasets for ASR, called [LibriSpeech](https://huggingface.co/datasets/librispeech_asr), *Facebook AI* presented two multi-lingual versions of Wav2Vec2, called [XLSR](https://arxiv.org/abs/2006.13979) and [XLM-R](https://ai.facebook.com/blog/-xlm-r-state-of-the-art-cross-lingual-understanding-through-self-supervision/), capable of recognising speech in up to 128 languages. XLSR stands for *cross-lingual speech representations* and refers to the model's ability to learn speech representations that are useful across multiple languages.
Meta AI's most recent release, [**Massive Multilingual Speech (MMS)**](https://ai.facebook.com/blog/multilingual-model-speech-recognition/) by *Vineel Pratap, Andros Tjandra, Bowen Shi, et al.* takes multi-lingual speech representations to a new level. Over 1,100 spoken languages can be identified, transcribed and generated with the various [language identification, speech recognition, and text-to-speech checkpoints released](https://huggingface.co/models?other=mms).
In this blog post, we show how MMS's Adapter training achieves astonishingly low word error rates after just 10-20 minutes of fine-tuning.
For low-resource languages, we **strongly** recommend using MMS' Adapter training as opposed to fine-tuning the whole model as is done in ["Fine-tuning XLS-R on Multi-Lingual ASR"](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2).
In our experiments, MMS' Adapter training is both more memory efficient, more robust and yields better performance for low-resource languages. For medium to high resource languages it can still be advantegous to fine-tune the whole checkpoint instead of using Adapter layers though.

## **Preserving the world's language diversity**
According to https://www.ethnologue.com/ around 3000, or 40% of all "living" languages, are endangered due to fewer and fewer native speakers.
This trend will only continue in an increasingly globalized world.
**MMS** is capable of transcribing many languages which are endangered, such as *Ari* or *Kaivi*. In the future, MMS can play a vital role in keeping languages alive by helping the remaining speakers to create written records and communicating in their native tongue.
To adapt to 1000+ different vocabularies, **MMS** uses of Adapters - a training method where only a small fraction of model weights are trained.
Adapter layers act like linguistic bridges, enabling the model to leverage knowledge from one language when deciphering another.
## **Fine-tuning MMS**
**MMS** unsupervised checkpoints were pre-trained on more than **half a million** hours of audio in over **1,400** languages, ranging from 300 million to one billion parameters.
You can find the pretrained-only checkpoints on the 🤗 Hub for model sizes of 300 million parameters (300M) and one billion parameters (1B):
- [**`mms-300m`**](https://huggingface.co/facebook/mms-300m)
- [**`mms-1b`**](https://huggingface.co/facebook/mms-1b)
*Note*: If you want to fine-tune the base models, you can do so in the exact same way as shown in ["Fine-tuning XLS-R on Multi-Lingual ASR"](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2).
Similar to [BERT's masked language modeling objective](http://jalammar.github.io/illustrated-bert/), MMS learns contextualized speech representations by randomly masking feature vectors before passing them to a transformer network during self-supervised pre-training.
For ASR, the pretrained [`MMS-1B` checkpoint](https://huggingface.co/facebook/mms-1b) was further fine-tuned in a supervised fashion on 1000+ languages with a joint vocabulary output layer. As a final step, the joint vocabulary output layer was thrown away and language-specific adapter layers were kept instead. Each adapter layer contains **just** ~2.5M weights, consisting of small linear projection layers for each attention block as well as a language-specific vocabulary output layer.
Three **MMS** checkpoints fine-tuned for speech recognition (ASR) have been released. They include 102, 1107, and 1162 adapter weights respectively (one for each language):
- [**`mms-1b-fl102`**](https://huggingface.co/facebook/mms-1b-fl102)
- [**`mms-1b-l1107`**](https://huggingface.co/facebook/mms-1b-l1107)
- [**`mms-1b-all`**](https://huggingface.co/facebook/mms-1b-all)
You can see that the base models are saved (as usual) as a [`model.safetensors` file](https://huggingface.co/facebook/mms-1b-all/blob/main/model.safetensors), but in addition these repositories have many adapter weights stored in the repository, *e.g.* under the name [`adapter.fra.safetensors`](https://huggingface.co/facebook/mms-1b-all/blob/main/adapter.fra.safetensors) for French.
The Hugging Face docs [explain very well how such checkpoints can be used for inference](https://huggingface.co/docs/transformers/main/en/model_doc/mms#loading), so in this blog post we will instead focus on learning how we can efficiently train highly performant adapter models based on any of the released ASR checkpoints.
## Training adaptive weights
In machine learning, adapters are a method used to fine-tune pre-trained models while keeping the original model parameters unchanged. They do this by inserting small, trainable modules, called [adapter layers](https://arxiv.org/pdf/1902.00751.pdf), between the pre-existing layers of the model, which then adapt the model to a specific task without requiring extensive retraining.
Adapters have a long history in speech recognition and especially **speaker recognition**. In speaker recognition, adapters have been effectively used to tweak pre-existing models to recognize individual speaker idiosyncrasies, as highlighted in [Gales and Woodland's (1996)](https://www.isca-speech.org/archive_v0/archive_papers/icslp_1996/i96_1832.pdf) and [Miao et al.'s (2014)](https://www.cs.cmu.edu/~ymiao/pub/tasl_sat.pdf) work. This approach not only greatly reduces computational requirements compared to training the full model, but also allows for better and more flexible speaker-specific adjustments.
The work done in **MMS** leverages this idea of adapters for speech recognition across different languages. A small number of adapter weights are fine-tuned to grasp unique phonetic and grammatical traits of each target language. Thereby, MMS enables a single large base model (*e.g.*, the [**`mms-1b-all`**](https://huggingface.co/facebook/mms-1b-all) checkpoint) and 1000+ small adapter layers (2.5M weights each for **`mms-1b-all`**) to comprehend and transcribe multiple languages. This dramatically reduces the computational demand of developing distinct models for each language.
Great! Now that we understood the motivation and theory, let's look into fine-tuning adapter weights for **`mms-1b-all`** 🔥
## Notebook Setup
As done previously in the ["Fine-tuning XLS-R on Multi-Lingual ASR"](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) blog post, we fine-tune the model on the low resource ASR dataset of [Common Voice](https://huggingface.co/datasets/common_voice) that contains only *ca.* 4h of validated training data.
Just like Wav2Vec2 or XLS-R, MMS is fine-tuned using Connectionist Temporal Classification (CTC), which is an algorithm that is used to train neural networks for sequence-to-sequence problems, such as ASR and handwriting recognition.
For more details on the CTC algorithm, I highly recommend reading the well-written blog post [*Sequence Modeling with CTC (2017)*](https://distill.pub/2017/ctc/) by Awni Hannun.
Before we start, let's install `datasets` and `transformers`. Also, we need `torchaudio` to load audio files and `jiwer` to evaluate our fine-tuned model using the [word error rate (WER)](https://huggingface.co/metrics/wer) metric \\( {}^1 \\).
```bash
%%capture
!pip install --upgrade pip
!pip install datasets[audio]
!pip install evaluate
!pip install git+https://github.com/huggingface/transformers.git
!pip install jiwer
!pip install accelerate
```
We strongly suggest to upload your training checkpoints directly to the [🤗 Hub](https://huggingface.co/) while training. The Hub repositories have version control built in, so you can be sure that no model checkpoint is lost during training.
To do so you have to store your authentication token from the Hugging Face website (sign up [here](https://huggingface.co/join) if you haven't already!)
```python
from huggingface_hub import notebook_login
notebook_login()
```
## Prepare Data, Tokenizer, Feature Extractor
ASR models transcribe speech to text, which means that we both need a feature extractor that processes the speech signal to the model's input format, *e.g.* a feature vector, and a tokenizer that processes the model's output format to text.
In 🤗 Transformers, the MMS model is thus accompanied by both a feature extractor, called [Wav2Vec2FeatureExtractor](https://huggingface.co/transformers/master/model_doc/wav2vec2.html#wav2vec2featureextractor), and a tokenizer, called [Wav2Vec2CTCTokenizer](https://huggingface.co/transformers/master/model_doc/wav2vec2.html#wav2vec2ctctokenizer).
Let's start by creating the tokenizer to decode the predicted output classes to the output transcription.
### Create `Wav2Vec2CTCTokenizer`
Fine-tuned MMS models, such as [**`mms-1b-all`**](https://huggingface.co/facebook/mms-1b-all) already have a [tokenizer](https://huggingface.co/facebook/mms-1b-all/blob/main/tokenizer_config.json) accompanying the model checkpoint. However since we want to fine-tune the model on specific low-resource data of a certain language, it is recommended to fully remove the tokenizer and vocabulary output layer, and simply create new ones based on the training data itself.
Wav2Vec2-like models fine-tuned on CTC transcribe an audio file with a single forward pass by first processing the audio input into a sequence of processed context representations and then using the final vocabulary output layer to classify each context representation to a character that represents the transcription.
The output size of this layer corresponds to the number of tokens in the vocabulary, which we will extract from the labeled dataset used for fine-tuning. So in the first step, we will take a look at the chosen dataset of Common Voice and define a vocabulary based on the transcriptions.
For this notebook, we will use [Common Voice's 6.1 dataset](https://huggingface.co/datasets/mozilla-foundation/common_voice_6_1) for Turkish. Turkish corresponds to the language code `"tr"`.
Great, now we can use 🤗 Datasets' simple API to download the data. The dataset name is `"mozilla-foundation/common_voice_6_1"`, the configuration name corresponds to the language code, which is `"tr"` in our case.
**Note**: Before being able to download the dataset, you have to access it by logging into your Hugging Face account, going on the [dataset repo page](https://huggingface.co/datasets/mozilla-foundation/common_voice_6_1) and clicking on "Agree and Access repository"
Common Voice has many different splits including `invalidated`, which refers to data that was not rated as "clean enough" to be considered useful. In this notebook, we will only make use of the splits `"train"`, `"validation"` and `"test"`.
Because the Turkish dataset is so small, we will merge both the validation and training data into a training dataset and only use the test data for validation.
```python
from datasets import load_dataset, load_metric, Audio
common_voice_train = load_dataset("mozilla-foundation/common_voice_6_1", "tr", split="train+validation", use_auth_token=True)
common_voice_test = load_dataset("mozilla-foundation/common_voice_6_1", "tr", split="test", use_auth_token=True)
```
Many ASR datasets only provide the target text (`'sentence'`) for each audio array (`'audio'`) and file (`'path'`). Common Voice actually provides much more information about each audio file, such as the `'accent'`, etc. Keeping the notebook as general as possible, we only consider the transcribed text for fine-tuning.
```python
common_voice_train = common_voice_train.remove_columns(["accent", "age", "client_id", "down_votes", "gender", "locale", "segment", "up_votes"])
common_voice_test = common_voice_test.remove_columns(["accent", "age", "client_id", "down_votes", "gender", "locale", "segment", "up_votes"])
```
Let's write a short function to display some random samples of the dataset and run it a couple of times to get a feeling for the transcriptions.
```python
from datasets import ClassLabel
import random
import pandas as pd
from IPython.display import display, HTML
def show_random_elements(dataset, num_examples=10):
assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset."
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
display(HTML(df.to_html()))
```
```python
show_random_elements(common_voice_train.remove_columns(["path", "audio"]), num_examples=10)
```
```bash
Oylar teker teker elle sayılacak.
Son olaylar endişe seviyesini yükseltti.
Tek bir kart hepsinin kapılarını açıyor.
Blogcular da tam bundan bahsetmek istiyor.
Bu Aralık iki bin onda oldu.
Fiyatın altmış altı milyon avro olduğu bildirildi.
Ardından da silahlı çatışmalar çıktı.
"Romanya'da kurumlar gelir vergisi oranı yüzde on altı."
Bu konuda neden bu kadar az şey söylendiğini açıklayabilir misiniz?
```
Alright! The transcriptions look fairly clean. Having translated the transcribed sentences, it seems that the language corresponds more to written-out text than noisy dialogue. This makes sense considering that [Common Voice](https://huggingface.co/datasets/common_voice) is a crowd-sourced read speech corpus.
We can see that the transcriptions contain some special characters, such as `,.?!;:`. Without a language model, it is much harder to classify speech chunks to such special characters because they don't really correspond to a characteristic sound unit. *E.g.*, the letter `"s"` has a more or less clear sound, whereas the special character `"."` does not.
Also in order to understand the meaning of a speech signal, it is usually not necessary to include special characters in the transcription.
Let's simply remove all characters that don't contribute to the meaning of a word and cannot really be represented by an acoustic sound and normalize the text.
```python
import re
chars_to_remove_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\']'
def remove_special_characters(batch):
batch["sentence"] = re.sub(chars_to_remove_regex, '', batch["sentence"]).lower()
return batch
```
```python
common_voice_train = common_voice_train.map(remove_special_characters)
common_voice_test = common_voice_test.map(remove_special_characters)
```
Let's look at the processed text labels again.
```python
show_random_elements(common_voice_train.remove_columns(["path","audio"]))
```
```bash
i̇kinci tur müzakereler eylül ayında başlayacak
jani ve babası bu düşüncelerinde yalnız değil
onurun gözlerindeki büyü
bandiç oyların yüzde kırk sekiz virgül elli dördünü topladı
bu imkansız
bu konu açık değildir
cinayet kamuoyunu şiddetle sarstı
kentin sokakları iki metre su altında kaldı
muhalefet partileri hükümete karşı ciddi bir mücadele ortaya koyabiliyorlar mı
festivale tüm dünyadan elli film katılıyor
```
Good! This looks better. We have removed most special characters from transcriptions and normalized them to lower-case only.
Before finalizing the pre-processing, it is always advantageous to consult a native speaker of the target language to see whether the text can be further simplified.
For this blog post, [Merve](https://twitter.com/mervenoyann) was kind enough to take a quick look and noted that "hatted" characters - like `â` - aren't really used anymore in Turkish and can be replaced by their "un-hatted" equivalent, *e.g.* `a`.
This means that we should replace a sentence like `"yargı sistemi hâlâ sağlıksız"` to `"yargı sistemi hala sağlıksız"`.
Let's write another short mapping function to further simplify the text labels. Remember - the simpler the text labels, the easier it is for the model to learn to predict those labels.
```python
def replace_hatted_characters(batch):
batch["sentence"] = re.sub('[â]', 'a', batch["sentence"])
batch["sentence"] = re.sub('[î]', 'i', batch["sentence"])
batch["sentence"] = re.sub('[ô]', 'o', batch["sentence"])
batch["sentence"] = re.sub('[û]', 'u', batch["sentence"])
return batch
```
```python
common_voice_train = common_voice_train.map(replace_hatted_characters)
common_voice_test = common_voice_test.map(replace_hatted_characters)
```
In CTC, it is common to classify speech chunks into letters, so we will do the same here.
Let's extract all distinct letters of the training and test data and build our vocabulary from this set of letters.
We write a mapping function that concatenates all transcriptions into one long transcription and then transforms the string into a set of chars.
It is important to pass the argument `batched=True` to the `map(...)` function so that the mapping function has access to all transcriptions at once.
```python
def extract_all_chars(batch):
all_text = " ".join(batch["sentence"])
vocab = list(set(all_text))
return {"vocab": [vocab], "all_text": [all_text]}
```
```python
vocab_train = common_voice_train.map(extract_all_chars, batched=True, batch_size=-1, keep_in_memory=True, remove_columns=common_voice_train.column_names)
vocab_test = common_voice_test.map(extract_all_chars, batched=True, batch_size=-1, keep_in_memory=True, remove_columns=common_voice_test.column_names)
```
Now, we create the union of all distinct letters in the training dataset and test dataset and convert the resulting list into an enumerated dictionary.
```python
vocab_list = list(set(vocab_train["vocab"][0]) | set(vocab_test["vocab"][0]))
```
```python
vocab_dict = {v: k for k, v in enumerate(sorted(vocab_list))}
vocab_dict
```
```bash
{' ': 0,
'a': 1,
'b': 2,
'c': 3,
'd': 4,
'e': 5,
'f': 6,
'g': 7,
'h': 8,
'i': 9,
'j': 10,
'k': 11,
'l': 12,
'm': 13,
'n': 14,
'o': 15,
'p': 16,
'q': 17,
'r': 18,
's': 19,
't': 20,
'u': 21,
'v': 22,
'w': 23,
'x': 24,
'y': 25,
'z': 26,
'ç': 27,
'ë': 28,
'ö': 29,
'ü': 30,
'ğ': 31,
'ı': 32,
'ş': 33,
'̇': 34}
```
Cool, we see that all letters of the alphabet occur in the dataset (which is not really surprising) and we also extracted the special characters `""` and `'`. Note that we did not exclude those special characters because the model has to learn to predict when a word is finished, otherwise predictions would always be a sequence of letters that would make it impossible to separate words from each other.
One should always keep in mind that pre-processing is a very important step before training your model. E.g., we don't want our model to differentiate between `a` and `A` just because we forgot to normalize the data. The difference between `a` and `A` does not depend on the "sound" of the letter at all, but more on grammatical rules - *e.g.* use a capitalized letter at the beginning of the sentence. So it is sensible to remove the difference between capitalized and non-capitalized letters so that the model has an easier time learning to transcribe speech.
To make it clearer that `" "` has its own token class, we give it a more visible character `|`. In addition, we also add an "unknown" token so that the model can later deal with characters not encountered in Common Voice's training set.
```python
vocab_dict["|"] = vocab_dict[" "]
del vocab_dict[" "]
```
Finally, we also add a padding token that corresponds to CTC's "*blank token*". The "blank token" is a core component of the CTC algorithm. For more information, please take a look at the "Alignment" section [here](https://distill.pub/2017/ctc/).
```python
vocab_dict["[UNK]"] = len(vocab_dict)
vocab_dict["[PAD]"] = len(vocab_dict)
len(vocab_dict)
```
```bash
37
```
Cool, now our vocabulary is complete and consists of 37 tokens, which means that the linear layer that we will add on top of the pretrained MMS checkpoint as part of the adapter weights will have an output dimension of 37.
Since a single MMS checkpoint can provide customized weights for multiple languages, the tokenizer can also consist of multiple vocabularies. Therefore, we need to nest our `vocab_dict` to potentially add more languages to the vocabulary in the future. The dictionary should be nested with the name that is used for the adapter weights and that is saved in the tokenizer config under the name [`target_lang`](https://huggingface.co/docs/transformers/model_doc/wav2vec2#transformers.Wav2Vec2CTCTokenizer.target_lang).
Let's use the ISO-639-3 language codes like the original [**`mms-1b-all`**](https://huggingface.co/facebook/mms-1b-all) checkpoint.
```python
target_lang = "tur"
```
Let's define an empty dictionary to which we can append the just created vocabulary
```python
new_vocab_dict = {target_lang: vocab_dict}
```
**Note**: In case you want to use this notebook to add a new adapter layer to *an existing model repo* make sure to **not** create an empty, new vocab dict, but instead re-use one that already exists. To do so you should uncomment the following cells and replace `"patrickvonplaten/wav2vec2-large-mms-1b-turkish-colab"` with a model repo id to which you want to add your adapter weights.
```python
# from transformers import Wav2Vec2CTCTokenizer
# mms_adapter_repo = "patrickvonplaten/wav2vec2-large-mms-1b-turkish-colab" # make sure to replace this path with a repo to which you want to add your new adapter weights
# tokenizer = Wav2Vec2CTCTokenizer.from_pretrained(mms_adapter_repo)
# new_vocab = tokenizer.vocab
# new_vocab[target_lang] = vocab_dict
```
Let's now save the vocabulary as a json file.
```python
import json
with open('vocab.json', 'w') as vocab_file:
json.dump(new_vocab_dict, vocab_file)
```
In a final step, we use the json file to load the vocabulary into an instance of the `Wav2Vec2CTCTokenizer` class.
```python
from transformers import Wav2Vec2CTCTokenizer
tokenizer = Wav2Vec2CTCTokenizer.from_pretrained("./", unk_token="[UNK]", pad_token="[PAD]", word_delimiter_token="|", target_lang=target_lang)
```
If one wants to re-use the just created tokenizer with the fine-tuned model of this notebook, it is strongly advised to upload the `tokenizer` to the [🤗 Hub](https://huggingface.co/). Let's call the repo to which we will upload the files
`"wav2vec2-large-mms-1b-turkish-colab"`:
```python
repo_name = "wav2vec2-large-mms-1b-turkish-colab"
```
and upload the tokenizer to the [🤗 Hub](https://huggingface.co/).
```python
tokenizer.push_to_hub(repo_name)
```
```bash
CommitInfo(commit_url='https://huggingface.co/patrickvonplaten/wav2vec2-large-mms-1b-turkish-colab/commit/48cccbfd6059aa6ce655e9d94b8358ba39536cb7', commit_message='Upload tokenizer', commit_description='', oid='48cccbfd6059aa6ce655e9d94b8358ba39536cb7', pr_url=None, pr_revision=None, pr_num=None)
```
Great, you can see the just created repository under `https://huggingface.co/<your-username>/wav2vec2-large-mms-1b-tr-colab`
### Create `Wav2Vec2FeatureExtractor`
Speech is a continuous signal and to be treated by computers, it first has to be discretized, which is usually called **sampling**. The sampling rate hereby plays an important role in that it defines how many data points of the speech signal are measured per second. Therefore, sampling with a higher sampling rate results in a better approximation of the *real* speech signal but also necessitates more values per second.
A pretrained checkpoint expects its input data to have been sampled more or less from the same distribution as the data it was trained on. The same speech signals sampled at two different rates have a very different distribution, *e.g.*, doubling the sampling rate results in twice as many data points. Thus,
before fine-tuning a pretrained checkpoint of an ASR model, it is crucial to verify that the sampling rate of the data that was used to pretrain the model matches the sampling rate of the dataset used to fine-tune the model.
A `Wav2Vec2FeatureExtractor` object requires the following parameters to be instantiated:
- `feature_size`: Speech models take a sequence of feature vectors as an input. While the length of this sequence obviously varies, the feature size should not. In the case of Wav2Vec2, the feature size is 1 because the model was trained on the raw speech signal \\( {}^2 \\).
- `sampling_rate`: The sampling rate at which the model is trained on.
- `padding_value`: For batched inference, shorter inputs need to be padded with a specific value
- `do_normalize`: Whether the input should be *zero-mean-unit-variance* normalized or not. Usually, speech models perform better when normalizing the input
- `return_attention_mask`: Whether the model should make use of an `attention_mask` for batched inference. In general, XLS-R models checkpoints should **always** use the `attention_mask`.
```python
from transformers import Wav2Vec2FeatureExtractor
feature_extractor = Wav2Vec2FeatureExtractor(feature_size=1, sampling_rate=16000, padding_value=0.0, do_normalize=True, return_attention_mask=True)
```
Great, MMS's feature extraction pipeline is thereby fully defined!
For improved user-friendliness, the feature extractor and tokenizer are *wrapped* into a single `Wav2Vec2Processor` class so that one only needs a `model` and `processor` object.
```python
from transformers import Wav2Vec2Processor
processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
```
Next, we can prepare the dataset.
### Preprocess Data
So far, we have not looked at the actual values of the speech signal but just the transcription. In addition to `sentence`, our datasets include two more column names `path` and `audio`. `path` states the absolute path of the audio file and `audio` represent already loaded audio data. MMS expects the input in the format of a 1-dimensional array of 16 kHz. This means that the audio file has to be loaded and resampled.
Thankfully, `datasets` does this automatically when the column name is `audio`. Let's try it out.
```python
common_voice_train[0]["audio"]
```
```bash
{'path': '/root/.cache/huggingface/datasets/downloads/extracted/71ba9bd154da9d8c769b736301417178729d2b87b9e00cda59f6450f742ed778/cv-corpus-6.1-2020-12-11/tr/clips/common_voice_tr_17346025.mp3',
'array': array([ 0.00000000e+00, -2.98378618e-13, -1.59835903e-13, ...,
-2.01663317e-12, -1.87991593e-12, -1.17969588e-12]),
'sampling_rate': 48000}
```
In the example above we can see that the audio data is loaded with a sampling rate of 48kHz whereas the model expects 16kHz, as we saw. We can set the audio feature to the correct sampling rate by making use of [`cast_column`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=cast_column#datasets.DatasetDict.cast_column):
```python
common_voice_train = common_voice_train.cast_column("audio", Audio(sampling_rate=16_000))
common_voice_test = common_voice_test.cast_column("audio", Audio(sampling_rate=16_000))
```
Let's take a look at `"audio"` again.
```python
common_voice_train[0]["audio"]
```
{'path': '/root/.cache/huggingface/datasets/downloads/extracted/71ba9bd154da9d8c769b736301417178729d2b87b9e00cda59f6450f742ed778/cv-corpus-6.1-2020-12-11/tr/clips/common_voice_tr_17346025.mp3',
'array': array([ 9.09494702e-13, -6.13908924e-12, -1.09139364e-11, ...,
1.81898940e-12, 4.54747351e-13, 3.63797881e-12]),
'sampling_rate': 16000}
This seemed to have worked! Let's do a final check that the data is correctly prepared, by printing the shape of the speech input, its transcription, and the corresponding sampling rate.
```python
rand_int = random.randint(0, len(common_voice_train)-1)
print("Target text:", common_voice_train[rand_int]["sentence"])
print("Input array shape:", common_voice_train[rand_int]["audio"]["array"].shape)
print("Sampling rate:", common_voice_train[rand_int]["audio"]["sampling_rate"])
```
```bash
Target text: bağış anlaşması bir ağustosta imzalandı
Input array shape: (70656,)
Sampling rate: 16000
```
Good! Everything looks fine - the data is a 1-dimensional array, the sampling rate always corresponds to 16kHz, and the target text is normalized.
Finally, we can leverage `Wav2Vec2Processor` to process the data to the format expected by `Wav2Vec2ForCTC` for training. To do so let's make use of Dataset's [`map(...)`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=map#datasets.DatasetDict.map) function.
First, we load and resample the audio data, simply by calling `batch["audio"]`.
Second, we extract the `input_values` from the loaded audio file. In our case, the `Wav2Vec2Processor` only normalizes the data. For other speech models, however, this step can include more complex feature extraction, such as [Log-Mel feature extraction](https://en.wikipedia.org/wiki/Mel-frequency_cepstrum).
Third, we encode the transcriptions to label ids.
**Note**: This mapping function is a good example of how the `Wav2Vec2Processor` class should be used. In "normal" context, calling `processor(...)` is redirected to `Wav2Vec2FeatureExtractor`'s call method. When wrapping the processor into the `as_target_processor` context, however, the same method is redirected to `Wav2Vec2CTCTokenizer`'s call method.
For more information please check the [docs](https://huggingface.co/transformers/master/model_doc/wav2vec2.html#transformers.Wav2Vec2Processor.__call__).
```python
def prepare_dataset(batch):
audio = batch["audio"]
# batched output is "un-batched"
batch["input_values"] = processor(audio["array"], sampling_rate=audio["sampling_rate"]).input_values[0]
batch["input_length"] = len(batch["input_values"])
batch["labels"] = processor(text=batch["sentence"]).input_ids
return batch
```
Let's apply the data preparation function to all examples.
```python
common_voice_train = common_voice_train.map(prepare_dataset, remove_columns=common_voice_train.column_names)
common_voice_test = common_voice_test.map(prepare_dataset, remove_columns=common_voice_test.column_names)
```
**Note**: `datasets` automatically takes care of audio loading and resampling. If you wish to implement your own costumized data loading/sampling, feel free to just make use of the `"path"` column instead and disregard the `"audio"` column.
Awesome, now we are ready to start training!
## Training
The data is processed so that we are ready to start setting up the training pipeline. We will make use of 🤗's [Trainer](https://huggingface.co/transformers/master/main_classes/trainer.html?highlight=trainer) for which we essentially need to do the following:
- Define a data collator. In contrast to most NLP models, MMS has a much larger input length than output length. *E.g.*, a sample of input length 50000 has an output length of no more than 100. Given the large input sizes, it is much more efficient to pad the training batches dynamically meaning that all training samples should only be padded to the longest sample in their batch and not the overall longest sample. Therefore, fine-tuning MMS requires a special padding data collator, which we will define below
- Evaluation metric. During training, the model should be evaluated on the word error rate. We should define a `compute_metrics` function accordingly
- Load a pretrained checkpoint. We need to load a pretrained checkpoint and configure it correctly for training.
- Define the training configuration.
After having fine-tuned the model, we will correctly evaluate it on the test data and verify that it has indeed learned to correctly transcribe speech.
### Set-up Trainer
Let's start by defining the data collator. The code for the data collator was copied from [this example](https://github.com/huggingface/transformers/blob/7e61d56a45c19284cfda0cee8995fb552f6b1f4e/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py#L219).
Without going into too many details, in contrast to the common data collators, this data collator treats the `input_values` and `labels` differently and thus applies two separate padding functions on them (again making use of MMS processor's context manager). This is necessary because, in speech recognition, input and output are of different modalities so they should not be treated by the same padding function.
Analogous to the common data collators, the padding tokens in the labels with `-100` so that those tokens are **not** taken into account when computing the loss.
```python
import torch
from dataclasses import dataclass, field
from typing import Any, Dict, List, Optional, Union
@dataclass
class DataCollatorCTCWithPadding:
"""
Data collator that will dynamically pad the inputs received.
Args:
processor (:class:`~transformers.Wav2Vec2Processor`)
The processor used for proccessing the data.
padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
among:
* :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
sequence if provided).
* :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
maximum acceptable input length for the model if that argument is not provided.
* :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
different lengths).
"""
processor: Wav2Vec2Processor
padding: Union[bool, str] = True
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lenghts and need
# different padding methods
input_features = [{"input_values": feature["input_values"]} for feature in features]
label_features = [{"input_ids": feature["labels"]} for feature in features]
batch = self.processor.pad(
input_features,
padding=self.padding,
return_tensors="pt",
)
labels_batch = self.processor.pad(
labels=label_features,
padding=self.padding,
return_tensors="pt",
)
# replace padding with -100 to ignore loss correctly
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
batch["labels"] = labels
return batch
```
```python
data_collator = DataCollatorCTCWithPadding(processor=processor, padding=True)
```
Next, the evaluation metric is defined. As mentioned earlier, the
predominant metric in ASR is the word error rate (WER), hence we will use it in this notebook as well.
```python
from evaluate import load
wer_metric = load("wer")
```
The model will return a sequence of logit vectors:
\\( \mathbf{y}_1, \ldots, \mathbf{y}_m \\) with \\( \mathbf{y}_1 = f_{\theta}(x_1, \ldots, x_n)[0] \\) and \\( n >> m \\).
A logit vector \\( \mathbf{y}_1 \\) contains the log-odds for each word in the vocabulary we defined earlier, thus \\( \text{len}(\mathbf{y}_i) = \\) `config.vocab_size`. We are interested in the most likely prediction of the model and thus take the `argmax(...)` of the logits. Also, we transform the encoded labels back to the original string by replacing `-100` with the `pad_token_id` and decoding the ids while making sure that consecutive tokens are **not** grouped to the same token in CTC style \\( {}^1 \\).
```python
def compute_metrics(pred):
pred_logits = pred.predictions
pred_ids = np.argmax(pred_logits, axis=-1)
pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
pred_str = processor.batch_decode(pred_ids)
# we do not want to group tokens when computing the metrics
label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
wer = wer_metric.compute(predictions=pred_str, references=label_str)
return {"wer": wer}
```
Now, we can load the pretrained checkpoint of [`mms-1b-all`](https://huggingface.co/facebook/mms-1b-all). The tokenizer's `pad_token_id` must be to define the model's `pad_token_id` or in the case of `Wav2Vec2ForCTC` also CTC's *blank token* \\( {}^2 \\).
Since, we're only training a small subset of weights, the model is not prone to overfitting. Therefore, we make sure to disable all dropout layers.
**Note**: When using this notebook to train MMS on another language of Common Voice those hyper-parameter settings might not work very well. Feel free to adapt those depending on your use case.
```python
from transformers import Wav2Vec2ForCTC
model = Wav2Vec2ForCTC.from_pretrained(
"facebook/mms-1b-all",
attention_dropout=0.0,
hidden_dropout=0.0,
feat_proj_dropout=0.0,
layerdrop=0.0,
ctc_loss_reduction="mean",
pad_token_id=processor.tokenizer.pad_token_id,
vocab_size=len(processor.tokenizer),
ignore_mismatched_sizes=True,
)
```
```bash
Some weights of Wav2Vec2ForCTC were not initialized from the model checkpoint at facebook/mms-1b-all and are newly initialized because the shapes did not match:
- lm_head.bias: found shape torch.Size([154]) in the checkpoint and torch.Size([39]) in the model instantiated
- lm_head.weight: found shape torch.Size([154, 1280]) in the checkpoint and torch.Size([39, 1280]) in the model instantiated
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
```
**Note**: It is expected that some weights are newly initialized. Those weights correspond to the newly initialized vocabulary output layer.
We now want to make sure that only the adapter weights will be trained and that the rest of the model stays frozen.
First, we re-initialize all the adapter weights which can be done with the handy `init_adapter_layers` method. It is also possible to not re-initilize the adapter weights and continue fine-tuning, but in this case one should make sure to load fitting adapter weights via the [`load_adapter(...)` method](https://huggingface.co/docs/transformers/main/en/model_doc/wav2vec2#transformers.Wav2Vec2ForCTC.load_adapter) before training. Often the vocabulary still will not match the custom training data very well though, so it's usually easier to just re-initialize all adapter layers so that they can be easily fine-tuned.
```python
model.init_adapter_layers()
```
Next, we freeze all weights, **but** the adapter layers.
```python
model.freeze_base_model()
adapter_weights = model._get_adapters()
for param in adapter_weights.values():
param.requires_grad = True
```
In a final step, we define all parameters related to training.
To give more explanation on some of the parameters:
- `group_by_length` makes training more efficient by grouping training samples of similar input length into one batch. This can significantly speed up training time by heavily reducing the overall number of useless padding tokens that are passed through the model
- `learning_rate` was chosen to be 1e-3 which is a common default value for training with Adam. Other learning rates might work equally well.
For more explanations on other parameters, one can take a look at the [docs](https://huggingface.co/transformers/master/main_classes/trainer.html?highlight=trainer#trainingarguments).
To save GPU memory, we enable PyTorch's [gradient checkpointing](https://pytorch.org/docs/stable/checkpoint.html) and also set the loss reduction to "*mean*".
MMS adapter fine-tuning converges extremely fast to very good performance, so even for a dataset as small as 4h we will only train for 4 epochs.
During training, a checkpoint will be uploaded asynchronously to the hub every 200 training steps. It allows you to also play around with the demo widget even while your model is still training.
**Note**: If one does not want to upload the model checkpoints to the hub, simply set `push_to_hub=False`.
```python
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir=repo_name,
group_by_length=True,
per_device_train_batch_size=32,
evaluation_strategy="steps",
num_train_epochs=4,
gradient_checkpointing=True,
fp16=True,
save_steps=200,
eval_steps=100,
logging_steps=100,
learning_rate=1e-3,
warmup_steps=100,
save_total_limit=2,
push_to_hub=True,
)
```
Now, all instances can be passed to Trainer and we are ready to start training!
```python
from transformers import Trainer
trainer = Trainer(
model=model,
data_collator=data_collator,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=common_voice_train,
eval_dataset=common_voice_test,
tokenizer=processor.feature_extractor,
)
```
------------------------------------------------------------------------
\\( {}^1 \\) To allow models to become independent of the speaker rate, in CTC, consecutive tokens that are identical are simply grouped as a single token. However, the encoded labels should not be grouped when decoding since they don't correspond to the predicted tokens of the model, which is why the `group_tokens=False` parameter has to be passed. If we wouldn't pass this parameter a word like `"hello"` would incorrectly be encoded, and decoded as `"helo"`.
\\( {}^2 \\) The blank token allows the model to predict a word, such as `"hello"` by forcing it to insert the blank token between the two l's. A CTC-conform prediction of `"hello"` of our model would be `[PAD] [PAD] "h" "e" "e" "l" "l" [PAD] "l" "o" "o" [PAD]`.
### Training
Training should take less than 30 minutes depending on the GPU used.
```python
trainer.train()
```
| Training Loss | Training Steps | Validation Loss | Wer |
|:-------------:|:----:|:---------------:|:------:|
| 4.905 | 100 | 0.215| 0.280 |
| 0.290 | 200 | 0.167 | 0.232 |
| 0.2659 | 300 | 0.161 | 0.229 |
| 0.2398 | 400 | 0.156 | 0.223 |
The training loss and validation WER go down nicely.
We see that fine-tuning adapter layers of `mms-1b-all` for just 100 steps outperforms fine-tuning the whole `xls-r-300m` checkpoint shown [here](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2#training-1) already by a large margin.
From the [official paper](https://scontent-cdg4-3.xx.fbcdn.net/v/t39.8562-6/348827959_6967534189927933_6819186233244071998_n.pdf?_nc_cat=104&ccb=1-7&_nc_sid=ad8a9d&_nc_ohc=fSo3qQ7uxr0AX8EWnWl&_nc_ht=scontent-cdg4-3.xx&oh=00_AfBL34K0MAAPb0CgnthjbHfiB6pSnnwbn5esj9DZVPvyoA&oe=6495E802) and this quick comparison it becomes clear that `mms-1b-all` has a much higher capability of transfering knowledge to a low-resource language and should be preferred over `xls-r-300m`. In addition, training is also more memory-efficient as only a small subset of layers are trained.
The adapter weights will be uploaded as part of the model checkpoint, but we also want to make sure to save them seperately so that they can easily be off- and onloaded.
Let's save all the adapter layers into the training output dir so that it can be correctly uploaded to the Hub.
```python
from safetensors.torch import save_file as safe_save_file
from transformers.models.wav2vec2.modeling_wav2vec2 import WAV2VEC2_ADAPTER_SAFE_FILE
import os
adapter_file = WAV2VEC2_ADAPTER_SAFE_FILE.format(target_lang)
adapter_file = os.path.join(training_args.output_dir, adapter_file)
safe_save_file(model._get_adapters(), adapter_file, metadata={"format": "pt"})
```
Finally, you can upload the result of the training to the 🤗 Hub.
```python
trainer.push_to_hub()
```
One of the main advantages of adapter weights training is that the "base" model which makes up roughly 99% of the model weights is kept unchanged and only a small [2.5M adapter checkpoint](https://huggingface.co/patrickvonplaten/wav2vec2-large-mms-1b-turkish-colab/blob/main/adapter.tur.safetensors) has to be shared in order to use the trained checkpoint.
This makes it extremely simple to train additional adapter layers and add them to your repository.
You can do so very easily by simply re-running this script and changing the language you would like to train on to a different one, *e.g.* `swe` for Swedish. In addition, you should make sure that the vocabulary does not get completely overwritten but that the new language vocabulary is **appended** to the existing one as stated above in the commented out cells.
To demonstrate how different adapter layers can be loaded, I have trained and uploaded also an adapter layer for Swedish under the iso language code `swe` as you can see [here](https://huggingface.co/patrickvonplaten/wav2vec2-large-mms-1b-turkish-colab/blob/main/adapter.swe.safetensors)
You can load the fine-tuned checkpoint as usual by using `from_pretrained(...)`, but you should make sure to also add a `target_lang="<your-lang-code>"` to the method so that the correct adapter is loaded. You should also set the target language correctly for your tokenizer.
Let's see how we can load the Turkish checkpoint first.
```python
model_id = "patrickvonplaten/wav2vec2-large-mms-1b-turkish-colab"
model = Wav2Vec2ForCTC.from_pretrained(model_id, target_lang="tur").to("cuda")
processor = Wav2Vec2Processor.from_pretrained(model_id)
processor.tokenizer.set_target_lang("tur")
```
Let's check that the model can correctly transcribe Turkish
```python
from datasets import Audio
common_voice_test_tr = load_dataset("mozilla-foundation/common_voice_6_1", "tr", data_dir="./cv-corpus-6.1-2020-12-11", split="test", use_auth_token=True)
common_voice_test_tr = common_voice_test_tr.cast_column("audio", Audio(sampling_rate=16_000))
```
Let's process the audio, run a forward pass and predict the ids
```python
input_dict = processor(common_voice_test_tr[0]["audio"]["array"], sampling_rate=16_000, return_tensors="pt", padding=True)
logits = model(input_dict.input_values.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)[0]
```
Finally, we can decode the example.
```python
print("Prediction:")
print(processor.decode(pred_ids))
print("\nReference:")
print(common_voice_test_tr[0]["sentence"].lower())
```
**Output**:
```bash
Prediction:
pekçoğuda roman toplumundan geliyor
Reference:
pek çoğu da roman toplumundan geliyor.
```
This looks like it's almost exactly right, just two empty spaces should have been added in the first word.
Now it is very simple to change the adapter to Swedish by calling [`model.load_adapter(...)`](mozilla-foundation/common_voice_6_1) and by changing the tokenizer to Swedish as well.
```python
model.load_adapter("swe")
processor.tokenizer.set_target_lang("swe")
```
We again load the Swedish test set from common voice
```python
common_voice_test_swe = load_dataset("mozilla-foundation/common_voice_6_1", "sv-SE", data_dir="./cv-corpus-6.1-2020-12-11", split="test", use_auth_token=True)
common_voice_test_swe = common_voice_test_swe.cast_column("audio", Audio(sampling_rate=16_000))
```
and transcribe a sample:
```python
input_dict = processor(common_voice_test_swe[0]["audio"]["array"], sampling_rate=16_000, return_tensors="pt", padding=True)
logits = model(input_dict.input_values.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)[0]
print("Prediction:")
print(processor.decode(pred_ids))
print("\nReference:")
print(common_voice_test_swe[0]["sentence"].lower())
```
**Output**:
```bash
Prediction:
jag lämnade grovjobbet åt honom
Reference:
jag lämnade grovjobbet åt honom.
```
Great, this looks like a perfect transcription!
We've shown in this blog post how MMS Adapter Weights fine-tuning not only gives state-of-the-art performance on low-resource languages, but also significantly speeds up training time and allows to easily build a collection of customized adapter weights.
*Related posts and additional links are listed here:*
- [**Official paper**](https://huggingface.co/papers/2305.13516)
- [**Original cobebase**](https://github.com/facebookresearch/fairseq/tree/main/examples/mms/asr)
- [**Official demo**](https://huggingface.co/spaces/facebook/MMS)
- [**Transformers Docs**](https://huggingface.co/docs/transformers/index)
- [**Related XLS-R blog post**](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2)
- [**Models on the Hub**](https://huggingface.co/models?other=mms)
| huggingface/blog/blob/main/mms_adapters.md |
Quiz
The best way to learn and [to avoid the illusion of competence](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
### Q1: Chose the option which fits better when comparing different types of multi-agent environments
- Your agents aim to maximize common benefits in ____ environments
- Your agents aim to maximize common benefits while minimizing opponent's in ____ environments
<Question
choices={[
{
text: "competitive, cooperative",
explain: "You maximize common benefit in cooperative, while in competitive you also aim to reduce opponent's score",
correct: false,
},
{
text: "cooperative, competitive",
explain: "",
correct: true,
},
]}
/>
### Q2: Which of the following statements are true about `decentralized` learning?
<Question
choices={[
{
text: "Each agent is trained independently from the others",
explain: "",
correct: true,
},
{
text: "Inputs from other agents are just considered environment data",
explain: "",
correct: true,
},
{
text: "Considering other agents part of the environment makes the environment stationary",
explain: "In decentralized learning, agents ignore the existence of other agents and consider them part of the environment. However, this means the environment is in constant change, becoming non-stationary.",
correct: false,
},
]}
/>
### Q3: Which of the following statements are true about `centralized` learning?
<Question
choices={[
{
text: "It learns one common policy based on the learnings from all agents' interactions",
explain: "",
correct: true,
},
{
text: "The reward is global",
explain: "",
correct: true,
},
{
text: "The environment with this approach is stationary",
explain: "",
correct: true,
},
]}
/>
### Q4: Explain in your own words what is the `Self-Play` approach
<details>
<summary>Solution</summary>
`Self-play` is an approach to instantiate copies of agents with the same policy as your as opponents, so that your agent learns from agents with same training level.
</details>
### Q5: When configuring `Self-play`, several parameters are important. Could you identify, by their definition, which parameter are we talking about?
- The probability of playing against the current self vs an opponent from a pool
- Variety (dispersion) of training levels of the opponents you can face
- The number of training steps before spawning a new opponent
- Opponent change rate
<Question
choices={[
{
text: "window, play_against_latest_model_ratio, save_steps, swap_steps+team_change",
explain: "",
correct: false,
},
{
text: "play_against_latest_model_ratio, save_steps, window, swap_steps+team_change",
explain: "",
correct: false,
},
{
text: "play_against_latest_model_ratio, window, save_steps, swap_steps+team_change",
explain: "",
correct: true,
},
{
text: "swap_steps+team_change, save_steps, play_against_latest_model_ratio, window",
explain: "",
correct: false,
},
]}
/>
### Q6: What are the main motivations to use a ELO rating Score?
<Question
choices={[
{
text: "The score takes into account the different of skills between you and your opponent",
explain: "",
correct: true,
},
{
text: "Although more points can be exchanged depending on the result of the match and given the levels of the agents, the sum is always the same",
explain: "",
correct: true,
},
{
text: "It's easy for an agent to keep a high score rate",
explain: "That is called the `Rating deflation`: keeping a high rate requires much skill over time",
correct: false,
},
{
text: "It works well calculating the individual contributions of each player in a team",
explain: "ELO uses the score achieved by the whole team, but individual contributions are not calculated",
correct: false,
},
]}
/>
Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read the chapter again to reinforce (😏) your knowledge.
| huggingface/deep-rl-class/blob/main/units/en/unit7/quiz.mdx |
Security
The Hugging Face Hub offers several security features to ensure that your code and data are secure. Beyond offering [private repositories](./repositories-settings#private-repositories) for models, datasets, and Spaces, the Hub supports access tokens, commit signatures, and malware scanning.
Hugging Face is GDPR compliant. If a contract or specific data storage is something you'll need, we recommend taking a look at our [Expert Acceleration Program](https://huggingface.co/support). Hugging Face can also offer Business Associate Addendums or GDPR data processing agreements through an [Enterprise Plan](https://huggingface.co/pricing).
Hugging Face is also [SOC2 Type 2 certified](https://us.aicpa.org/interestareas/frc/assuranceadvisoryservices/aicpasoc2report.html), meaning we provide security certification to our customers and actively monitor and patch any security weaknesses.
<img width="150" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/security-soc-1.jpg">
For any other security questions, please feel free to send us an email at security@huggingface.co.
## Contents
- [User Access Tokens](./security-tokens)
- [Git over SSH](./security-git-ssh)
- [Signing commits with GPG](./security-gpg)
- [Single Sign-On (SSO)](./security-sso)
- [Malware Scanning](./security-malware)
- [Pickle Scanning](./security-pickle)
- [Secrets Scanning](./security-secrets)
| huggingface/hub-docs/blob/main/docs/hub/security.md |
Installation
Before you start, you will need to setup your environment and install the appropriate packages. 🤗 Evaluate is tested on **Python 3.7+**.
## Virtual environment
You should install 🤗 Evaluate in a [virtual environment](https://docs.python.org/3/library/venv.html) to keep everything neat and tidy.
1. Create and navigate to your project directory:
```bash
mkdir ~/my-project
cd ~/my-project
```
2. Start a virtual environment inside the directory:
```bash
python -m venv .env
```
3. Activate and deactivate the virtual environment with the following commands:
```bash
# Activate the virtual environment
source .env/bin/activate
# Deactivate the virtual environment
source .env/bin/deactivate
```
Once you have created your virtual environment, you can install 🤗 Evaluate in it.
## pip
The most straightforward way to install 🤗 Evaluate is with pip:
```bash
pip install evaluate
```
Run the following command to check if 🤗 Evaluate has been properly installed:
```bash
python -c "import evaluate; print(evaluate.load('exact_match').compute(references=['hello'], predictions=['hello']))"
```
This should return:
```bash
{'exact_match': 1.0}
```
## source
Building 🤗 Evaluate from source lets you make changes to the code base. To install from source, clone the repository and install with the following commands:
```bash
git clone https://github.com/huggingface/evaluate.git
cd evaluate
pip install -e .
```
Again, you can check if 🤗 Evaluate has been properly installed with:
```bash
python -c "import evaluate; print(evaluate.load('exact_match').compute(references=['hello'], predictions=['hello']))"
``` | huggingface/evaluate/blob/main/docs/source/installation.mdx |
Metric Card for Mean IoU
## Metric Description
IoU (Intersection over Union) is the area of overlap between the predicted segmentation and the ground truth divided by the area of union between the predicted segmentation and the ground truth.
For binary (two classes) or multi-class segmentation, the *mean IoU* of the image is calculated by taking the IoU of each class and averaging them.
## How to Use
The Mean IoU metric takes two numeric arrays as input corresponding to the predicted and ground truth segmentations:
```python
>>> import numpy as np
>>> mean_iou = datasets.load_metric("mean_iou")
>>> predicted = np.array([[2, 2, 3], [8, 2, 4], [3, 255, 2]])
>>> ground_truth = np.array([[1, 2, 2], [8, 2, 1], [3, 255, 1]])
>>> results = mean_iou.compute(predictions=predicted, references=ground_truth, num_labels=10, ignore_index=255)
```
### Inputs
**Mandatory inputs**
- `predictions` (`List[ndarray]`): List of predicted segmentation maps, each of shape (height, width). Each segmentation map can be of a different size.
- `references` (`List[ndarray]`): List of ground truth segmentation maps, each of shape (height, width). Each segmentation map can be of a different size.
- `num_labels` (`int`): Number of classes (categories).
- `ignore_index` (`int`): Index that will be ignored during evaluation.
**Optional inputs**
- `nan_to_num` (`int`): If specified, NaN values will be replaced by the number defined by the user.
- `label_map` (`dict`): If specified, dictionary mapping old label indices to new label indices.
- `reduce_labels` (`bool`): Whether or not to reduce all label values of segmentation maps by 1. Usually used for datasets where 0 is used for background, and background itself is not included in all classes of a dataset (e.g. ADE20k). The background label will be replaced by 255. The default value is `False`.
### Output Values
The metric returns a dictionary with the following elements:
- `mean_iou` (`float`): Mean Intersection-over-Union (IoU averaged over all categories).
- `mean_accuracy` (`float`): Mean accuracy (averaged over all categories).
- `overall_accuracy` (`float`): Overall accuracy on all images.
- `per_category_accuracy` (`ndarray` of shape `(num_labels,)`): Per category accuracy.
- `per_category_iou` (`ndarray` of shape `(num_labels,)`): Per category IoU.
The values of all of the scores reported range from from `0.0` (minimum) and `1.0` (maximum).
Output Example:
```python
{'mean_iou': 0.47750000000000004, 'mean_accuracy': 0.5916666666666666, 'overall_accuracy': 0.5263157894736842, 'per_category_iou': array([0. , 0. , 0.375, 0.4 , 0.5 , 0. , 0.5 , 1. , 1. , 1. ]), 'per_category_accuracy': array([0. , 0. , 0.75 , 0.66666667, 1. , 0. , 0.5 , 1. , 1. , 1. ])}
```
#### Values from Popular Papers
The [leaderboard for the CityScapes dataset](https://paperswithcode.com/sota/semantic-segmentation-on-cityscapes) reports a Mean IOU ranging from 64 to 84; that of [ADE20k](https://paperswithcode.com/sota/semantic-segmentation-on-ade20k) ranges from 30 to a peak of 59.9, indicating that the dataset is more difficult for current approaches (as of 2022).
### Examples
```python
>>> from datasets import load_metric
>>> import numpy as np
>>> mean_iou = load_metric("mean_iou")
>>> # suppose one has 3 different segmentation maps predicted
>>> predicted_1 = np.array([[1, 2], [3, 4], [5, 255]])
>>> actual_1 = np.array([[0, 3], [5, 4], [6, 255]])
>>> predicted_2 = np.array([[2, 7], [9, 2], [3, 6]])
>>> actual_2 = np.array([[1, 7], [9, 2], [3, 6]])
>>> predicted_3 = np.array([[2, 2, 3], [8, 2, 4], [3, 255, 2]])
>>> actual_3 = np.array([[1, 2, 2], [8, 2, 1], [3, 255, 1]])
>>> predictions = [predicted_1, predicted_2, predicted_3]
>>> references = [actual_1, actual_2, actual_3]
>>> results = mean_iou.compute(predictions=predictions, references=references, num_labels=10, ignore_index=255, reduce_labels=False)
>>> print(results) # doctest: +NORMALIZE_WHITESPACE
{'mean_iou': 0.47750000000000004, 'mean_accuracy': 0.5916666666666666, 'overall_accuracy': 0.5263157894736842, 'per_category_iou': array([0. , 0. , 0.375, 0.4 , 0.5 , 0. , 0.5 , 1. , 1. , 1. ]), 'per_category_accuracy': array([0. , 0. , 0.75 , 0.66666667, 1. , 0. , 0.5 , 1. , 1. , 1. ])}
```
## Limitations and Bias
Mean IOU is an average metric, so it will not show you where model predictions differ from the ground truth (i.e. if there are particular regions or classes that the model does poorly on). Further error analysis is needed to gather actional insights that can be used to inform model improvements.
## Citation(s)
```bibtex
@software{MMSegmentation_Contributors_OpenMMLab_Semantic_Segmentation_2020,
author = {{MMSegmentation Contributors}},
license = {Apache-2.0},
month = {7},
title = {{OpenMMLab Semantic Segmentation Toolbox and Benchmark}},
url = {https://github.com/open-mmlab/mmsegmentation},
year = {2020}
}"
```
## Further References
- [Wikipedia article - Jaccard Index](https://en.wikipedia.org/wiki/Jaccard_index)
| huggingface/datasets/blob/main/metrics/mean_iou/README.md |
Using SpanMarker at Hugging Face
[SpanMarker](https://github.com/tomaarsen/SpanMarkerNER) is a framework for training powerful Named Entity Recognition models using familiar encoders such as BERT, RoBERTa and DeBERTa. Tightly implemented on top of the 🤗 Transformers library, SpanMarker can take good advantage of it. As a result, SpanMarker will be intuitive to use for anyone familiar with Transformers.
## Exploring SpanMarker in the Hub
You can find `span_marker` models by filtering at the left of the [models page](https://huggingface.co/models?library=span-marker).
All models on the Hub come with these useful features:
1. An automatically generated model card with a brief description.
2. An interactive widget you can use to play with the model directly in the browser.
3. An Inference API that allows you to make inference requests.
## Installation
To get started, you can follow the [SpanMarker installation guide](https://tomaarsen.github.io/SpanMarkerNER/install.html). You can also use the following one-line install through pip:
```
pip install -U span_marker
```
## Using existing models
All `span_marker` models can easily be loaded from the Hub.
```py
from span_marker import SpanMarkerModel
model = SpanMarkerModel.from_pretrained("tomaarsen/span-marker-bert-base-fewnerd-fine-super")
```
Once loaded, you can use [`SpanMarkerModel.predict`](https://tomaarsen.github.io/SpanMarkerNER/api/span_marker.modeling.html#span_marker.modeling.SpanMarkerModel.predict) to perform inference.
```py
model.predict("Amelia Earhart flew her single engine Lockheed Vega 5B across the Atlantic to Paris.")
```
```json
[
{"span": "Amelia Earhart", "label": "person-other", "score": 0.7629689574241638, "char_start_index": 0, "char_end_index": 14},
{"span": "Lockheed Vega 5B", "label": "product-airplane", "score": 0.9833564758300781, "char_start_index": 38, "char_end_index": 54},
{"span": "Atlantic", "label": "location-bodiesofwater", "score": 0.7621214389801025, "char_start_index": 66, "char_end_index": 74},
{"span": "Paris", "label": "location-GPE", "score": 0.9807717204093933, "char_start_index": 78, "char_end_index": 83}
]
```
If you want to load a specific SpanMarker model, you can click `Use in SpanMarker` and you will be given a working snippet!
<!--
TODO: Add this, but then with SpanMarker
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-speechbrain_snippet1.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-speechbrain_snippet1-dark.png"/>
</div>
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-speechbrain_snippet2.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-speechbrain_snippet2-dark.png"/>
</div>
-->
## Additional resources
* SpanMarker [repository](https://github.com/tomaarsen/SpanMarkerNER)
* SpanMarker [docs](https://tomaarsen.github.io/SpanMarkerNER)
| huggingface/hub-docs/blob/main/docs/hub/span_marker.md |
--
title: "Policy Gradient with PyTorch"
thumbnail: /blog/assets/85_policy_gradient/thumbnail.gif
authors:
- user: ThomasSimonini
---
# Policy Gradient with PyTorch
<h2>Unit 5, of the <a href="https://github.com/huggingface/deep-rl-class">Deep Reinforcement Learning Class with Hugging Face 🤗</a></h2>
⚠️ A **new updated version of this article is available here** 👉 [https://huggingface.co/deep-rl-course/unit1/introduction](https://huggingface.co/deep-rl-course/unit4/introduction)
*This article is part of the Deep Reinforcement Learning Class. A free course from beginner to expert. Check the syllabus [here.](https://huggingface.co/deep-rl-course/unit0/introduction)*
<img src="assets/85_policy_gradient/thumbnail.gif" alt="Thumbnail"/>
---
⚠️ A **new updated version of this article is available here** 👉 [https://huggingface.co/deep-rl-course/unit1/introduction](https://huggingface.co/deep-rl-course/unit4/introduction)
*This article is part of the Deep Reinforcement Learning Class. A free course from beginner to expert. Check the syllabus [here.](https://huggingface.co/deep-rl-course/unit0/introduction)*
[In the last unit](https://huggingface.co/blog/deep-rl-dqn), we learned about Deep Q-Learning. In this value-based Deep Reinforcement Learning algorithm, we **used a deep neural network to approximate the different Q-values for each possible action at a state.**
Indeed, since the beginning of the course, we only studied value-based methods, **where we estimate a value function as an intermediate step towards finding an optimal policy.**
<img src="https://huggingface.co/blog/assets/70_deep_rl_q_part1/link-value-policy.jpg" alt="Link value policy" />
Because, in value-based, **π exists only because of the action value estimates, since policy is just a function** (for instance, greedy-policy) that will select the action with the highest value given a state.
But, with policy-based methods, we want to optimize the policy directly **without having an intermediate step of learning a value function.**
So today, **we'll study our first Policy-Based method**: Reinforce. And we'll implement it from scratch using PyTorch. Before testing its robustness using CartPole-v1, PixelCopter, and Pong.
<figure class="image table text-center m-0 w-full">
<img src="assets/85_policy_gradient/envs.gif" alt="Environments"/>
</figure>
Let's get started,
- [What are Policy-Gradient Methods?](#what-are-policy-gradient-methods)
- [An Overview of Policy Gradients](#an-overview-of-policy-gradients)
- [The Advantages of Policy-Gradient Methods](#the-advantages-of-policy-gradient-methods)
- [The Disadvantages of Policy-Gradient Methods](#the-disadvantages-of-policy-gradient-methods)
- [Reinforce (Monte Carlo Policy Gradient)](#reinforce-monte-carlo-policy-gradient)
## What are Policy-Gradient Methods?
Policy-Gradient is a subclass of Policy-Based Methods, a category of algorithms that **aims to optimize the policy directly without using a value function using different techniques.** The difference with Policy-Based Methods is that Policy-Gradient methods are a series of algorithms that aim to optimize the policy directly **by estimating the weights of the optimal policy using Gradient Ascent.**
### An Overview of Policy Gradients
Why do we optimize the policy directly by estimating the weights of an optimal policy using Gradient Ascent in Policy Gradients Methods?
Remember that reinforcement learning aims **to find an optimal behavior strategy (policy) to maximize its expected cumulative reward.**
We also need to remember that a policy is a function that **given a state, outputs, a distribution over actions** (in our case using a stochastic policy).
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/blog/assets/63_deep_rl_intro/pbm_2.jpg" alt="Stochastic Policy"/>
</figure>
Our goal with Policy-Gradients is to control the probability distribution of actions by tuning the policy such that **good actions (that maximize the return) are sampled more frequently in the future.**
Let’s take a simple example:
- We collect an episode by letting our policy interact with its environment.
- We then look at the sum of rewards of the episode (expected return). If this sum is positive, we **consider that the actions taken during the episodes were good:** Therefore, we want to increase the P(a|s) (probability of taking that action at that state) for each state-action pair.
The Policy Gradient algorithm (simplified) looks like this:
<figure class="image table text-center m-0 w-full">
<img src="assets/85_policy_gradient/pg_bigpicture.jpg" alt="Policy Gradient Big Picture"/>
</figure>
But Deep Q-Learning is excellent! Why use policy gradient methods?
### The Advantages of Policy-Gradient Methods
There are multiple advantages over Deep Q-Learning methods. Let's see some of them:
1. The simplicity of the integration: **we can estimate the policy directly without storing additional data (action values).**
2. Policy gradient methods can **learn a stochastic policy while value functions can't**.
This has two consequences:
a. We **don't need to implement an exploration/exploitation trade-off by hand**. Since we output a probability distribution over actions, the agent explores **the state space without always taking the same trajectory.**
b. We also get rid of the problem of **perceptual aliasing**. Perceptual aliasing is when two states seem (or are) the same but need different actions.
Let's take an example: we have an intelligent vacuum cleaner whose goal is to suck the dust and avoid killing the hamsters.
<figure class="image table text-center m-0 w-full">
<img src="assets/85_policy_gradient/hamster1.jpg" alt="Hamster 1"/>
</figure>
Our vacuum cleaner can only perceive where the walls are.
The problem is that the two red cases are aliased states because the agent perceives an upper and lower wall for each.
<figure class="image table text-center m-0 w-full">
<img src="assets/85_policy_gradient/hamster2.jpg" alt="Hamster 1"/>
</figure>
Under a deterministic policy, the policy will either move right when in a red state or move left. **Either case will cause our agent to get stuck and never suck the dust**.
Under a value-based RL algorithm, we learn a quasi-deterministic policy ("greedy epsilon strategy"). Consequently, our agent can spend a lot of time before finding the dust.
On the other hand, an optimal stochastic policy will randomly move left or right in grey states. Consequently, **it will not be stuck and will reach the goal state with a high probability**.
<figure class="image table text-center m-0 w-full">
<img src="assets/85_policy_gradient/hamster3.jpg" alt="Hamster 1"/>
</figure>
3. Policy gradients are **more effective in high-dimensional action spaces and continuous actions spaces**
Indeed, the problem with Deep Q-learning is that their **predictions assign a score (maximum expected future reward) for each possible action**, at each time step, given the current state.
But what if we have an infinite possibility of actions?
For instance, with a self-driving car, at each state, you can have a (near) infinite choice of actions (turning the wheel at 15°, 17.2°, 19,4°, honking, etc.). We'll need to output a Q-value for each possible action! And taking the max action of a continuous output is an optimization problem itself!
Instead, with a policy gradient, we output a **probability distribution over actions.**
### The Disadvantages of Policy-Gradient Methods
Naturally, Policy Gradient methods have also some disadvantages:
- **Policy gradients converge a lot of time on a local maximum instead of a global optimum.**
- Policy gradient goes faster, **step by step: it can take longer to train (inefficient).**
- Policy gradient can have high variance (solution baseline).
👉 If you want to go deeper on the why the advantages and disadvantages of Policy Gradients methods, [you can check this video](https://youtu.be/y3oqOjHilio).
Now that we have seen the big picture of Policy-Gradient and its advantages and disadvantages, **let's study and implement one of them**: Reinforce.
## Reinforce (Monte Carlo Policy Gradient)
Reinforce, also called Monte-Carlo Policy Gradient, **uses an estimated return from an entire episode to update the policy parameter** \\(\theta\\).
We have our policy π which has a parameter θ. This π, given a state, **outputs a probability distribution of actions**.
<figure class="image table text-center m-0 w-full">
<img src="assets/85_policy_gradient/policy.jpg" alt="Policy"/>
</figure>
Where \\(\pi_\theta(a_t|s_t)\\) is the probability of the agent selecting action at from state st, given our policy.
**But how do we know if our policy is good?** We need to have a way to measure it. To know that we define a score/objective function called \\(J(\theta)\\).
The score function J is the expected return:
<figure class="image table text-center m-0 w-full">
<img src="assets/85_policy_gradient/objective.jpg" alt="Return"/>
</figure>
Remember that policy gradient can be seen as an optimization problem. So we must find the best parameters (θ) to maximize the score function, J(θ).
To do that we’re going to use the [Policy Gradient Theorem](https://www.youtube.com/watch?v=AKbX1Zvo7r8). I’m not going to dive on the mathematical details but if you’re interested check [this video](https://www.youtube.com/watch?v=AKbX1Zvo7r8)
The Reinforce algorithm works like this:
Loop:
- Use the policy \\(\pi_\theta\\) to collect an episode \\(\tau\\)
- Use the episode to estimate the gradient \\(\hat{g} = \nabla_\theta J(\theta)\\)
<figure class="image table text-center m-0 w-full">
<img src="assets/85_policy_gradient/pg.jpg" alt="Policy Gradient"/>
</figure>
- Update the weights of the policy: \\(\theta \leftarrow \theta + \alpha \hat{g}\\)
The interpretation we can make is this one:
- \\(\nabla_\theta log \pi_\theta(a_t|s_t)\\) is the direction of **steepest increase of the (log) probability** of selecting action at from state st.
=> This tells use **how we should change the weights of policy** if we want to increase/decrease the log probability of selecting action at at state st.
- \\(R(\tau)\\): is the scoring function:
- If the return is high, it will push up the probabilities of the (state, action) combinations.
- Else, if the return is low, it will push down the probabilities of the (state, action) combinations.
Now that we studied the theory behind Reinforce, **you’re ready to code your Reinforce agent with PyTorch**. And you'll test its robustness using CartPole-v1, PixelCopter, and Pong.
Start the tutorial here 👉 https://colab.research.google.com/github/huggingface/deep-rl-class/blob/main/unit5/unit5.ipynb
The leaderboard to compare your results with your classmates 🏆 👉 https://huggingface.co/spaces/chrisjay/Deep-Reinforcement-Learning-Leaderboard
<figure class="image table text-center m-0 w-full">
<img src="assets/85_policy_gradient/envs.gif" alt="Environments"/>
</figure>
---
Congrats on finishing this chapter! There was a lot of information. And congrats on finishing the tutorial. You’ve just coded your first Deep Reinforcement Learning agent from scratch using PyTorch and shared it on the Hub 🥳.
It's **normal if you still feel confused** with all these elements. **This was the same for me and for all people who studied RL.**
Take time to really grasp the material before continuing.
Don't hesitate to train your agent in other environments. The **best way to learn is to try things on your own!**
We published additional readings in the syllabus if you want to go deeper 👉 **[https://github.com/huggingface/deep-rl-class/blob/main/unit5/README.md](https://github.com/huggingface/deep-rl-class/blob/main/unit5/README.md)**
In the next unit, we’re going to learn about a combination of Policy-Based and Value-based methods called Actor Critic Methods.
And don't forget to share with your friends who want to learn 🤗!
Finally, we want **to improve and update the course iteratively with your feedback**. If you have some, please fill this form 👉 **[https://forms.gle/3HgA7bEHwAmmLfwh9](https://forms.gle/3HgA7bEHwAmmLfwh9)**
### **Keep learning, stay awesome 🤗,**
| huggingface/blog/blob/main/deep-rl-pg.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# PLBart
## Overview
The PLBART model was proposed in [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
This is a BART-like model which can be used to perform code-summarization, code-generation, and code-translation tasks. The pre-trained model `plbart-base` has been trained using multilingual denoising task
on Java, Python and English.
According to the abstract
*Code summarization and generation empower conversion between programming language (PL) and natural language (NL),
while code translation avails the migration of legacy code from one PL to another. This paper introduces PLBART,
a sequence-to-sequence model capable of performing a broad spectrum of program and language understanding and generation tasks.
PLBART is pre-trained on an extensive collection of Java and Python functions and associated NL text via denoising autoencoding.
Experiments on code summarization in the English language, code generation, and code translation in seven programming languages
show that PLBART outperforms or rivals state-of-the-art models. Moreover, experiments on discriminative tasks, e.g., program
repair, clone detection, and vulnerable code detection, demonstrate PLBART's effectiveness in program understanding.
Furthermore, analysis reveals that PLBART learns program syntax, style (e.g., identifier naming convention), logical flow
(e.g., if block inside an else block is equivalent to else if block) that are crucial to program semantics and thus excels
even with limited annotations.*
This model was contributed by [gchhablani](https://huggingface.co/gchhablani). The Authors' code can be found [here](https://github.com/wasiahmad/PLBART).
## Usage examples
PLBart is a multilingual encoder-decoder (sequence-to-sequence) model primarily intended for code-to-text, text-to-code, code-to-code tasks. As the
model is multilingual it expects the sequences in a different format. A special language id token is added in both the
source and target text. The source text format is `X [eos, src_lang_code]` where `X` is the source text. The
target text format is `[tgt_lang_code] X [eos]`. `bos` is never used.
However, for fine-tuning, in some cases no language token is provided in cases where a single language is used. Please refer to [the paper](https://arxiv.org/abs/2103.06333) to learn more about this.
In cases where the language code is needed, the regular [`~PLBartTokenizer.__call__`] will encode source text format
when you pass texts as the first argument or with the keyword argument `text`, and will encode target text format if
it's passed with the `text_target` keyword argument.
### Supervised training
```python
>>> from transformers import PLBartForConditionalGeneration, PLBartTokenizer
>>> tokenizer = PLBartTokenizer.from_pretrained("uclanlp/plbart-base", src_lang="en_XX", tgt_lang="python")
>>> example_python_phrase = "def maximum(a,b,c):NEW_LINE_INDENTreturn max([a,b,c])"
>>> expected_translation_english = "Returns the maximum value of a b c."
>>> inputs = tokenizer(example_python_phrase, text_target=expected_translation_english, return_tensors="pt")
>>> model(**inputs)
```
### Generation
While generating the target text set the `decoder_start_token_id` to the target language id. The following
example shows how to translate Python to English using the `uclanlp/plbart-python-en_XX` model.
```python
>>> from transformers import PLBartForConditionalGeneration, PLBartTokenizer
>>> tokenizer = PLBartTokenizer.from_pretrained("uclanlp/plbart-python-en_XX", src_lang="python", tgt_lang="en_XX")
>>> example_python_phrase = "def maximum(a,b,c):NEW_LINE_INDENTreturn max([a,b,c])"
>>> inputs = tokenizer(example_python_phrase, return_tensors="pt")
>>> model = PLBartForConditionalGeneration.from_pretrained("uclanlp/plbart-python-en_XX")
>>> translated_tokens = model.generate(**inputs, decoder_start_token_id=tokenizer.lang_code_to_id["en_XX"])
>>> tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
"Returns the maximum value of a b c."
```
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## PLBartConfig
[[autodoc]] PLBartConfig
## PLBartTokenizer
[[autodoc]] PLBartTokenizer
- build_inputs_with_special_tokens
## PLBartModel
[[autodoc]] PLBartModel
- forward
## PLBartForConditionalGeneration
[[autodoc]] PLBartForConditionalGeneration
- forward
## PLBartForSequenceClassification
[[autodoc]] PLBartForSequenceClassification
- forward
## PLBartForCausalLM
[[autodoc]] PLBartForCausalLM
- forward | huggingface/transformers/blob/main/docs/source/en/model_doc/plbart.md |
--
title: Word Count
emoji: 🤗
colorFrom: green
colorTo: purple
sdk: gradio
sdk_version: 3.0.2
app_file: app.py
pinned: false
tags:
- evaluate
- measurement
description: >-
Returns the total number of words, and the number of unique words in the input data.
---
# Measurement Card for Word Count
## Measurement Description
The `word_count` measurement returns the total number of word count of the input string, using the sklearn's [`CountVectorizer`](https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.CountVectorizer.html)
## How to Use
This measurement requires a list of strings as input:
```python
>>> data = ["hello world and hello moon"]
>>> wordcount= evaluate.load("word_count")
>>> results = wordcount.compute(data=data)
```
### Inputs
- **data** (list of `str`): The input list of strings for which the word length is calculated.
- **max_vocab** (`int`): (optional) the top number of words to consider (can be specified if dataset is too large)
### Output Values
- **total_word_count** (`int`): the total number of words in the input string(s).
- **unique_words** (`int`): the number of unique words in the input string(s).
Output Example(s):
```python
{'total_word_count': 5, 'unique_words': 4}
### Examples
Example for a single string
```python
>>> data = ["hello sun and goodbye moon"]
>>> wordcount = evaluate.load("word_count")
>>> results = wordcount.compute(data=data)
>>> print(results)
{'total_word_count': 5, 'unique_words': 5}
```
Example for a multiple strings
```python
>>> data = ["hello sun and goodbye moon", "foo bar foo bar"]
>>> wordcount = evaluate.load("word_count")
>>> results = wordcount.compute(data=data)
>>> print(results)
{'total_word_count': 9, 'unique_words': 7}
```
Example for a dataset from 🤗 Datasets:
```python
>>> imdb = datasets.load_dataset('imdb', split = 'train')
>>> wordcount = evaluate.load("word_count")
>>> results = wordcount.compute(data=imdb['text'])
>>> print(results)
{'total_word_count': 5678573, 'unique_words': 74849}
```
## Citation(s)
## Further References
- [Sklearn `CountVectorizer`](https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.CountVectorizer.html)
| huggingface/evaluate/blob/main/measurements/word_count/README.md |
Gradio Demo: progress_simple
```
!pip install -q gradio
```
```
import gradio as gr
import time
def slowly_reverse(word, progress=gr.Progress()):
progress(0, desc="Starting")
time.sleep(1)
progress(0.05)
new_string = ""
for letter in progress.tqdm(word, desc="Reversing"):
time.sleep(0.25)
new_string = letter + new_string
return new_string
demo = gr.Interface(slowly_reverse, gr.Text(), gr.Text())
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/progress_simple/run.ipynb |
--
title: "Hugging Face Platform on the AWS Marketplace: Pay with your AWS Account"
thumbnail: /blog/assets/158_aws_marketplace/thumbnail.jpg
authors:
- user: philschmid
- user: sbrandeis
- user: jeffboudier
---
# Hugging Face Platform on the AWS Marketplace: Pay with your AWS Account
The [Hugging Face Platform](https://aws.amazon.com/marketplace/pp/prodview-n6vsyhdjkfng2) has landed on the AWS Marketplace. Starting today, you can subscribe to the Hugging Face Platform through AWS Marketplace to pay for your Hugging Face usage directly with your AWS account. This new integrated billing method makes it easy to manage payment for usage of all our managed services by all members of your organization, including Inference Endpoints, Spaces Hardware Upgrades, and AutoTrain to easily train, test and deploy the most popular machine learning models like Llama 2, StarCoder, or BERT.
By making [Hugging Face available on AWS Marketplace](https://aws.amazon.com/marketplace/pp/prodview-n6vsyhdjkfng2), we are removing barriers to adopting AI and making it easier for companies to leverage large language models. Now with just a few clicks, AWS customers can subscribe and connect their Hugging Face Account with their AWS account.
By subscribing through AWS Marketplace, Hugging Face organization usage charges for services like Inference Endpoints will automatically appear on your AWS bill, instead of being charged by Hugging Face to the credit card on file for your organization.
We are excited about this launch as it will bring our technology to more developers who rely on AWS, and make it easier for businesses to consume Hugging Face services.
## Getting Started
Before you can connect your AWS Account with your Hugging Face account, you need to fulfill the following prerequisites:
- Have access to an active AWS account with access to subscribe to products on the AWS Marketplace.
- Create a [Hugging Face organization account](https://huggingface.co/organizations/new) with a registered and confirmed email. (You cannot connect user accounts)
- Be a member of the Hugging Face organization you want to connect with the [“admin” role](https://huggingface.co/docs/hub/organizations-security).
- Logged into the Hugging Face Platform.
Once you meet these requirements, you can proceed with connecting your AWS and Hugging Face accounts.
### 1. Subscribe to the Hugging Face Platform
The first step is to go to the [AWS Marketplace offering](https://aws.amazon.com/marketplace/pp/prodview-n6vsyhdjkfng2) and subscribe to the Hugging Face Platform. There you open the [offer](https://aws.amazon.com/marketplace/pp/prodview-n6vsyhdjkfng2) and then click on “View purchase options” at the top right screen.

You are now on the “subscribe” page, where you can see the summary of pricing and where you can subscribe. To subscribe to the offer, click “Subscribe”.

After you successfully subscribe, you should see a green banner at the top with a button “Set up your account”. You need to click on “Set up your account” to connect your Hugging Face Account with your AWS account.

After clicking the button, you will be redirected to the Hugging Face Platform, where you can select the Hugging Face organization account you want to link to your AWS account. After selecting your account, click “Submit”

After clicking "Submit", you will be redirected to the Billings settings of the Hugging Face organization, where you can see the current state of your subscription, which should be `subscribe-pending`.

After a few minutes you should receive 2 emails: 1 from AWS confirming your subscription, and 1 from Hugging Face, which should look like the image below:

If you have received this, your AWS Account and Hugging Face organization account are now successfully connected!
To confirm it, you can open the Billing settings for [your organization account](https://huggingface.co/settings/organizations), where you should now see a `subscribe-success` status.

Congratulations! 🥳 All members of your organization can now start using Hugging Face premium services with billing directly managed by your AWS account:
- [Inference Endpoints Deploy models in minutes](https://ui.endpoints.huggingface.co/)
- [AutoTrain creates ML models without code](https://huggingface.co/autotrain)
- [Enterprise Hub accelerates your AI roadmap](https://huggingface.co/enterprise)
- [Spaces Hardware upgrades](https://huggingface.co/docs/hub/spaces-gpus)
Pricing for Hugging Face Platform through the AWS marketplace offer is identical to the [public Hugging Face pricing](https://huggingface.co/pricing), but will be billed through your AWS Account. You can monitor the usage and billing of your organization at any time within the Billing section of your [organization settings](https://huggingface.co/settings/organizations).
---
Thanks for reading! If you have any questions, feel free to contact us at [api-enterprise@huggingface.co](mailto:api-enterprise@huggingface.co).
| huggingface/blog/blob/main/aws-marketplace.md |
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BEiT
## Overview
The BEiT model was proposed in [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by
Hangbo Bao, Li Dong and Furu Wei. Inspired by BERT, BEiT is the first paper that makes self-supervised pre-training of
Vision Transformers (ViTs) outperform supervised pre-training. Rather than pre-training the model to predict the class
of an image (as done in the [original ViT paper](https://arxiv.org/abs/2010.11929)), BEiT models are pre-trained to
predict visual tokens from the codebook of OpenAI's [DALL-E model](https://arxiv.org/abs/2102.12092) given masked
patches.
The abstract from the paper is the following:
*We introduce a self-supervised vision representation model BEiT, which stands for Bidirectional Encoder representation
from Image Transformers. Following BERT developed in the natural language processing area, we propose a masked image
modeling task to pretrain vision Transformers. Specifically, each image has two views in our pre-training, i.e, image
patches (such as 16x16 pixels), and visual tokens (i.e., discrete tokens). We first "tokenize" the original image into
visual tokens. Then we randomly mask some image patches and fed them into the backbone Transformer. The pre-training
objective is to recover the original visual tokens based on the corrupted image patches. After pre-training BEiT, we
directly fine-tune the model parameters on downstream tasks by appending task layers upon the pretrained encoder.
Experimental results on image classification and semantic segmentation show that our model achieves competitive results
with previous pre-training methods. For example, base-size BEiT achieves 83.2% top-1 accuracy on ImageNet-1K,
significantly outperforming from-scratch DeiT training (81.8%) with the same setup. Moreover, large-size BEiT obtains
86.3% only using ImageNet-1K, even outperforming ViT-L with supervised pre-training on ImageNet-22K (85.2%).*
This model was contributed by [nielsr](https://huggingface.co/nielsr). The JAX/FLAX version of this model was
contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/beit).
## Usage tips
- BEiT models are regular Vision Transformers, but pre-trained in a self-supervised way rather than supervised. They
outperform both the [original model (ViT)](vit) as well as [Data-efficient Image Transformers (DeiT)](deit) when fine-tuned on ImageNet-1K and CIFAR-100. You can check out demo notebooks regarding inference as well as
fine-tuning on custom data [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer) (you can just replace
[`ViTFeatureExtractor`] by [`BeitImageProcessor`] and
[`ViTForImageClassification`] by [`BeitForImageClassification`]).
- There's also a demo notebook available which showcases how to combine DALL-E's image tokenizer with BEiT for
performing masked image modeling. You can find it [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/BEiT).
- As the BEiT models expect each image to be of the same size (resolution), one can use
[`BeitImageProcessor`] to resize (or rescale) and normalize images for the model.
- Both the patch resolution and image resolution used during pre-training or fine-tuning are reflected in the name of
each checkpoint. For example, `microsoft/beit-base-patch16-224` refers to a base-sized architecture with patch
resolution of 16x16 and fine-tuning resolution of 224x224. All checkpoints can be found on the [hub](https://huggingface.co/models?search=microsoft/beit).
- The available checkpoints are either (1) pre-trained on [ImageNet-22k](http://www.image-net.org/) (a collection of
14 million images and 22k classes) only, (2) also fine-tuned on ImageNet-22k or (3) also fine-tuned on [ImageNet-1k](http://www.image-net.org/challenges/LSVRC/2012/) (also referred to as ILSVRC 2012, a collection of 1.3 million
images and 1,000 classes).
- BEiT uses relative position embeddings, inspired by the T5 model. During pre-training, the authors shared the
relative position bias among the several self-attention layers. During fine-tuning, each layer's relative position
bias is initialized with the shared relative position bias obtained after pre-training. Note that, if one wants to
pre-train a model from scratch, one needs to either set the `use_relative_position_bias` or the
`use_relative_position_bias` attribute of [`BeitConfig`] to `True` in order to add
position embeddings.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/beit_architecture.jpg"
alt="drawing" width="600"/>
<small> BEiT pre-training. Taken from the <a href="https://arxiv.org/abs/2106.08254">original paper.</a> </small>
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BEiT.
<PipelineTag pipeline="image-classification"/>
- [`BeitForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
**Semantic segmentation**
- [Semantic segmentation task guide](../tasks/semantic_segmentation)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## BEiT specific outputs
[[autodoc]] models.beit.modeling_beit.BeitModelOutputWithPooling
[[autodoc]] models.beit.modeling_flax_beit.FlaxBeitModelOutputWithPooling
## BeitConfig
[[autodoc]] BeitConfig
## BeitFeatureExtractor
[[autodoc]] BeitFeatureExtractor
- __call__
- post_process_semantic_segmentation
## BeitImageProcessor
[[autodoc]] BeitImageProcessor
- preprocess
- post_process_semantic_segmentation
<frameworkcontent>
<pt>
## BeitModel
[[autodoc]] BeitModel
- forward
## BeitForMaskedImageModeling
[[autodoc]] BeitForMaskedImageModeling
- forward
## BeitForImageClassification
[[autodoc]] BeitForImageClassification
- forward
## BeitForSemanticSegmentation
[[autodoc]] BeitForSemanticSegmentation
- forward
</pt>
<jax>
## FlaxBeitModel
[[autodoc]] FlaxBeitModel
- __call__
## FlaxBeitForMaskedImageModeling
[[autodoc]] FlaxBeitForMaskedImageModeling
- __call__
## FlaxBeitForImageClassification
[[autodoc]] FlaxBeitForImageClassification
- __call__
</jax>
</frameworkcontent> | huggingface/transformers/blob/main/docs/source/en/model_doc/beit.md |
--
title: seqeval
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
seqeval is a Python framework for sequence labeling evaluation.
seqeval can evaluate the performance of chunking tasks such as named-entity recognition, part-of-speech tagging, semantic role labeling and so on.
This is well-tested by using the Perl script conlleval, which can be used for
measuring the performance of a system that has processed the CoNLL-2000 shared task data.
seqeval supports following formats:
IOB1
IOB2
IOE1
IOE2
IOBES
See the [README.md] file at https://github.com/chakki-works/seqeval for more information.
---
# Metric Card for seqeval
## Metric description
seqeval is a Python framework for sequence labeling evaluation. seqeval can evaluate the performance of chunking tasks such as named-entity recognition, part-of-speech tagging, semantic role labeling and so on.
## How to use
Seqeval produces labelling scores along with its sufficient statistics from a source against one or more references.
It takes two mandatory arguments:
`predictions`: a list of lists of predicted labels, i.e. estimated targets as returned by a tagger.
`references`: a list of lists of reference labels, i.e. the ground truth/target values.
It can also take several optional arguments:
`suffix` (boolean): `True` if the IOB tag is a suffix (after type) instead of a prefix (before type), `False` otherwise. The default value is `False`, i.e. the IOB tag is a prefix (before type).
`scheme`: the target tagging scheme, which can be one of [`IOB1`, `IOB2`, `IOE1`, `IOE2`, `IOBES`, `BILOU`]. The default value is `None`.
`mode`: whether to count correct entity labels with incorrect I/B tags as true positives or not. If you want to only count exact matches, pass `mode="strict"` and a specific `scheme` value. The default is `None`.
`sample_weight`: An array-like of shape (n_samples,) that provides weights for individual samples. The default is `None`.
`zero_division`: Which value to substitute as a metric value when encountering zero division. Should be one of [`0`,`1`,`"warn"`]. `"warn"` acts as `0`, but the warning is raised.
```python
>>> seqeval = evaluate.load('seqeval')
>>> predictions = [['O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'I-MISC', 'O'], ['B-PER', 'I-PER', 'O']]
>>> references = [['O', 'O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'O'], ['B-PER', 'I-PER', 'O']]
>>> results = seqeval.compute(predictions=predictions, references=references)
```
## Output values
This metric returns a dictionary with a summary of scores for overall and per type:
Overall:
`accuracy`: the average [accuracy](https://huggingface.co/metrics/accuracy), on a scale between 0.0 and 1.0.
`precision`: the average [precision](https://huggingface.co/metrics/precision), on a scale between 0.0 and 1.0.
`recall`: the average [recall](https://huggingface.co/metrics/recall), on a scale between 0.0 and 1.0.
`f1`: the average [F1 score](https://huggingface.co/metrics/f1), which is the harmonic mean of the precision and recall. It also has a scale of 0.0 to 1.0.
Per type (e.g. `MISC`, `PER`, `LOC`,...):
`precision`: the average [precision](https://huggingface.co/metrics/precision), on a scale between 0.0 and 1.0.
`recall`: the average [recall](https://huggingface.co/metrics/recall), on a scale between 0.0 and 1.0.
`f1`: the average [F1 score](https://huggingface.co/metrics/f1), on a scale between 0.0 and 1.0.
### Values from popular papers
The 1995 "Text Chunking using Transformation-Based Learning" [paper](https://aclanthology.org/W95-0107) reported a baseline recall of 81.9% and a precision of 78.2% using non Deep Learning-based methods.
More recently, seqeval continues being used for reporting performance on tasks such as [named entity detection](https://www.mdpi.com/2306-5729/6/8/84/htm) and [information extraction](https://ieeexplore.ieee.org/abstract/document/9697942/).
## Examples
Maximal values (full match) :
```python
>>> seqeval = evaluate.load('seqeval')
>>> predictions = [['O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'I-MISC', 'O'], ['B-PER', 'I-PER', 'O']]
>>> references = [['O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'I-MISC', 'O'], ['B-PER', 'I-PER', 'O']]
>>> results = seqeval.compute(predictions=predictions, references=references)
>>> print(results)
{'MISC': {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 1}, 'PER': {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 1}, 'overall_precision': 1.0, 'overall_recall': 1.0, 'overall_f1': 1.0, 'overall_accuracy': 1.0}
```
Minimal values (no match):
```python
>>> seqeval = evaluate.load('seqeval')
>>> predictions = [['O', 'B-MISC', 'I-MISC'], ['B-PER', 'I-PER', 'O']]
>>> references = [['B-MISC', 'O', 'O'], ['I-PER', '0', 'I-PER']]
>>> results = seqeval.compute(predictions=predictions, references=references)
>>> print(results)
{'MISC': {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 1}, 'PER': {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 2}, '_': {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 1}, 'overall_precision': 0.0, 'overall_recall': 0.0, 'overall_f1': 0.0, 'overall_accuracy': 0.0}
```
Partial match:
```python
>>> seqeval = evaluate.load('seqeval')
>>> predictions = [['O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'I-MISC', 'O'], ['B-PER', 'I-PER', 'O']]
>>> references = [['O', 'O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'O'], ['B-PER', 'I-PER', 'O']]
>>> results = seqeval.compute(predictions=predictions, references=references)
>>> print(results)
{'MISC': {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 1}, 'PER': {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 1}, 'overall_precision': 0.5, 'overall_recall': 0.5, 'overall_f1': 0.5, 'overall_accuracy': 0.8}
```
## Limitations and bias
seqeval supports following IOB formats (short for inside, outside, beginning) : `IOB1`, `IOB2`, `IOE1`, `IOE2`, `IOBES`, `IOBES` (only in strict mode) and `BILOU` (only in strict mode).
For more information about IOB formats, refer to the [Wikipedia page](https://en.wikipedia.org/wiki/Inside%E2%80%93outside%E2%80%93beginning_(tagging)) and the description of the [CoNLL-2000 shared task](https://aclanthology.org/W02-2024).
## Citation
```bibtex
@inproceedings{ramshaw-marcus-1995-text,
title = "Text Chunking using Transformation-Based Learning",
author = "Ramshaw, Lance and
Marcus, Mitch",
booktitle = "Third Workshop on Very Large Corpora",
year = "1995",
url = "https://www.aclweb.org/anthology/W95-0107",
}
```
```bibtex
@misc{seqeval,
title={{seqeval}: A Python framework for sequence labeling evaluation},
url={https://github.com/chakki-works/seqeval},
note={Software available from https://github.com/chakki-works/seqeval},
author={Hiroki Nakayama},
year={2018},
}
```
## Further References
- [README for seqeval at GitHub](https://github.com/chakki-works/seqeval)
- [CoNLL-2000 shared task](https://www.clips.uantwerpen.be/conll2002/ner/bin/conlleval.txt)
| huggingface/evaluate/blob/main/metrics/seqeval/README.md |
Disk usage on Spaces
Every Space comes with a small amount of disk storage. This disk space is ephemeral, meaning its content will be lost if your Space restarts or is stopped.
If you need to persist data with a longer lifetime than the Space itself, you can:
- [Subscribe to a persistent storage upgrade](#persistent-storage)
- [Use a dataset as a data store](#dataset-storage)
## Persistent storage
You can upgrade your Space to have access to persistent disk space from the **Settings** tab.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/spaces-storage-settings.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/spaces-storage-settings-dark.png"/>
</div>
You can choose the storage tier of your choice to access disk space that persists across restarts of your Space.
Persistent storage acts like traditional disk storage mounted on `/data`.
That means you can `read` and `write to` this storage from your Space as you would with a traditional hard drive or SSD.
Persistent disk space can be upgraded to a larger tier at will, though it cannot be downgraded to a smaller tier. If you wish to use a smaller persistent storage tier, you must delete your current (larger) storage first.
If you are using Hugging Face open source libraries, you can make your Space restart faster by setting the environment variable `HF_HOME` to `/data/.huggingface`. Libraries like `transformers`, `diffusers`, `datasets` and others use that environment variable to cache any assets downloaded from the Hugging Face Hub. Setting this variable to the persistent storage path will make sure that cached resources do not need to be re-downloaded when the Space is restarted.
<Tip warning={true}>
WARNING: all data stored in the storage is lost when you delete it.
</Tip>
### Persistent storage specs
Here are the specifications for each of the different upgrade options:
| **Tier** | **Disk space** | **Persistent** | **Monthly Price** |
|------------------ |------------------ |------------------ |---------------------- |
| Free tier | 50GB | No (ephemeral) | Free! |
| Small | 20GB | Yes | $5 |
| Medium | 150 GB | Yes | $25 |
| Large | 1TB | Yes | $100 |
### Billing
Billing of Spaces is based on hardware usage and is computed by the minute: you get charged for every minute the Space runs on the requested hardware, regardless of whether the Space is used.
Persistent storage upgrades are billed until deleted, even when the Space is not running and regardless of Space status or running state.
Additional information about billing can be found in the [dedicated Hub-wide section](./billing).
## Dataset storage
If you need to persist data that lives longer than your Space, you could use a [dataset repo](./datasets).
You can find an example of persistence [here](https://huggingface.co/spaces/Wauplin/space_to_dataset_saver), which uses the [`huggingface_hub` library](https://huggingface.co/docs/huggingface_hub/index) for programmatically uploading files to a dataset repository. This Space example along with [this guide](https://huggingface.co/docs/huggingface_hub/main/en/guides/upload#scheduled-uploads) will help you define which solution fits best your data type.
Visit the [`datasets` library](https://huggingface.co/docs/datasets/index) documentation and the [`huggingface_hub` client library](https://huggingface.co/docs/huggingface_hub/index)
documentation for more information on how to programmatically interact with dataset repos.
| huggingface/hub-docs/blob/main/docs/hub/spaces-storage.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Decision Transformer
## Overview
The Decision Transformer model was proposed in [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345)
by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
The abstract from the paper is the following:
*We introduce a framework that abstracts Reinforcement Learning (RL) as a sequence modeling problem.
This allows us to draw upon the simplicity and scalability of the Transformer architecture, and associated advances
in language modeling such as GPT-x and BERT. In particular, we present Decision Transformer, an architecture that
casts the problem of RL as conditional sequence modeling. Unlike prior approaches to RL that fit value functions or
compute policy gradients, Decision Transformer simply outputs the optimal actions by leveraging a causally masked
Transformer. By conditioning an autoregressive model on the desired return (reward), past states, and actions, our
Decision Transformer model can generate future actions that achieve the desired return. Despite its simplicity,
Decision Transformer matches or exceeds the performance of state-of-the-art model-free offline RL baselines on
Atari, OpenAI Gym, and Key-to-Door tasks.*
This version of the model is for tasks where the state is a vector.
This model was contributed by [edbeeching](https://huggingface.co/edbeeching). The original code can be found [here](https://github.com/kzl/decision-transformer).
## DecisionTransformerConfig
[[autodoc]] DecisionTransformerConfig
## DecisionTransformerGPT2Model
[[autodoc]] DecisionTransformerGPT2Model
- forward
## DecisionTransformerModel
[[autodoc]] DecisionTransformerModel
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/decision_transformer.md |
et's have a look inside the token classification pipeline. In the pipeline video, we looked at the different applications the Transformers library supports out of the box, one of them being token classification, for instance predicting for each word in a sentence whether they correspond to a person, an organization or a location. We can even group together the tokens corresponding to the same entity, for instance all the tokens that formed the word Sylvain here, or Hugging and Face. The token classification pipeline works the same way as the text classification pipeline we studied in a previous video. There are three steps: the tokenization, the model, and the post processing. The first two steps are identical to the text classification pipeline, except we use an auto token classification model instead of a sequence classification one. We tokenize our text then feed it to the model. Instead of getting one number for each possible label for the whole sentence, we get one number for each of the possible 9 labels for every token in the sentence, here 19. Like all the other models of the Transformers library, our model outputs logits, which we turn into predictions by using a SoftMax. We also get the predicted label for each token by taking the maximum prediction (since the softmax function preserves the order, we could have done it on the logits if we had no need of the predictions). The model config contains the label mapping in its id2label field. Using it, we can map every token to its corresponding label. The label O correspond to "no entity", which is why we didn't see it in our results in the first slide. On top of the label and the probability, those results included the start and end character in the sentence. We will need to use the offset mapping of the tokenizer to get those (look at the video linked below if you don't know about them already). Then, looping through each token that has a label distinct from O, we can build the list of results we got with our first pipeline. The last step is to group together tokens that correspond to the same entity.This is why we had two labels for each type of entity: I-PER and B-PER for instance. It allows us to know if a token is in the same entity as the previous one.() Note that there are two ways of labelling used for token classification, one (in pink here) uses the B-PER label at the beginning of each new entity, but the other (in blue) only uses it to separate two adjacent entities of the same type. In both cases, we can flag a new entity each time we see a new label appearing (either with the I or B prefix) then take all the following tokens labelled the same, with an I-flag. This, coupled with the offset mapping to get the start and end characters allows us to get the span of texts for each entity. | huggingface/course/blob/main/subtitles/en/raw/chapter6/03c_tokenization-pipeline-pt.md |
p align="center">
<br>
<img src="https://huggingface.co/datasets/evaluate/media/resolve/main/evaluate-banner.png" width="400"/>
<br>
</p>
# 🤗 Evaluate
A library for easily evaluating machine learning models and datasets.
With a single line of code, you get access to dozens of evaluation methods for different domains (NLP, Computer Vision, Reinforcement Learning, and more!). Be it on your local machine or in a distributed training setup, you can evaluate your models in a consistent and reproducible way!
Visit the 🤗 Evaluate [organization](https://huggingface.co/evaluate-metric) for a full list of available metrics. Each metric has a dedicated Space with an interactive demo for how to use the metric, and a documentation card detailing the metrics limitations and usage.
<div class="mt-10">
<div class="w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-2 md:gap-y-4 md:gap-x-5">
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./installation"
><div class="w-full text-center bg-gradient-to-br from-blue-400 to-blue-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">Tutorials</div>
<p class="text-gray-700">Learn the basics and become familiar with loading, computing, and saving with 🤗 Evaluate. Start here if you are using 🤗 Evaluate for the first time!</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./choosing_a_metric"
><div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">How-to guides</div>
<p class="text-gray-700">Practical guides to help you achieve a specific goal. Take a look at these guides to learn how to use 🤗 Evaluate to solve real-world problems.</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./types_of_evaluations"
><div class="w-full text-center bg-gradient-to-br from-pink-400 to-pink-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">Conceptual guides</div>
<p class="text-gray-700">High-level explanations for building a better understanding of important topics such as considerations going into evaluating a model or dataset and the difference between metrics, measurements, and comparisons.</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./package_reference/main_classes"
><div class="w-full text-center bg-gradient-to-br from-purple-400 to-purple-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">Reference</div>
<p class="text-gray-700">Technical descriptions of how 🤗 Evaluate classes and methods work.</p>
</a>
</div>
</div>
| huggingface/evaluate/blob/main/docs/source/index.mdx |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.