
text
stringlengths 23
371k
| source
stringlengths 32
152
|
|---|---|
@gradio/uploadbutton
## 0.3.4
### Patch Changes
- Updated dependencies [[`828fb9e`](https://github.com/gradio-app/gradio/commit/828fb9e6ce15b6ea08318675a2361117596a1b5d), [`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144)]:
- @gradio/client@0.9.3
- @gradio/upload@0.5.6
- @gradio/button@0.2.13
## 0.3.3
### Patch Changes
- Updated dependencies [[`245d58e`](https://github.com/gradio-app/gradio/commit/245d58eff788e8d44a59d37a2d9b26d0f08a62b4)]:
- @gradio/client@0.9.2
- @gradio/button@0.2.12
- @gradio/upload@0.5.5
## 0.3.2
### Patch Changes
- Updated dependencies [[`5d51fbc`](https://github.com/gradio-app/gradio/commit/5d51fbce7826da840a2fd4940feb5d9ad6f1bc5a), [`34f9431`](https://github.com/gradio-app/gradio/commit/34f943101bf7dd6b8a8974a6131c1ed7c4a0dac0)]:
- @gradio/upload@0.5.4
- @gradio/client@0.9.1
- @gradio/button@0.2.11
## 0.3.1
### Patch Changes
- Updated dependencies [[`6a9151d`](https://github.com/gradio-app/gradio/commit/6a9151d5c9432c724098da7d88a539aaaf5ffe88), [`d76bcaa`](https://github.com/gradio-app/gradio/commit/d76bcaaaf0734aaf49a680f94ea9d4d22a602e70), [`67ddd40`](https://github.com/gradio-app/gradio/commit/67ddd40b4b70d3a37cb1637c33620f8d197dbee0)]:
- @gradio/upload@0.5.3
- @gradio/client@0.9.0
- @gradio/button@0.2.10
## 0.3.0
### Features
- [#6584](https://github.com/gradio-app/gradio/pull/6584) [`9bcb1da`](https://github.com/gradio-app/gradio/commit/9bcb1da189a9738d023ef6daad8c6c827e3f6371) - Feat: make UploadButton accept icon. Thanks [@Justin-Xiang](https://github.com/Justin-Xiang)!
## 0.2.2
### Patch Changes
- Updated dependencies [[`71f1a1f99`](https://github.com/gradio-app/gradio/commit/71f1a1f9931489d465c2c1302a5c8d768a3cd23a)]:
- @gradio/client@0.8.2
- @gradio/button@0.2.8
- @gradio/upload@0.5.1
## 0.2.1
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/upload@0.5.0
- @gradio/button@0.2.7
## 0.2.0
### Features
- [#6461](https://github.com/gradio-app/gradio/pull/6461) [`6b53330a5`](https://github.com/gradio-app/gradio/commit/6b53330a5be53579d9128aea4858713082ce302d) - UploadButton tests. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.1.5
### Patch Changes
- Updated dependencies [[`324867f63`](https://github.com/gradio-app/gradio/commit/324867f63c920113d89a565892aa596cf8b1e486)]:
- @gradio/client@0.8.1
- @gradio/button@0.2.5
- @gradio/upload@0.4.1
## 0.1.4
### Patch Changes
- Updated dependencies [[`854b482f5`](https://github.com/gradio-app/gradio/commit/854b482f598e0dc47673846631643c079576da9c), [`f1409f95e`](https://github.com/gradio-app/gradio/commit/f1409f95ed39c5565bed6a601e41f94e30196a57)]:
- @gradio/upload@0.4.0
- @gradio/client@0.8.0
- @gradio/button@0.2.4
## 0.1.3
### Patch Changes
- Updated dependencies [[`bca6c2c80`](https://github.com/gradio-app/gradio/commit/bca6c2c80f7e5062427019de45c282238388af95), [`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780)]:
- @gradio/client@0.7.2
- @gradio/upload@0.3.3
- @gradio/button@0.2.3
## 0.1.2
### Patch Changes
- Updated dependencies [[`aaa55ce85`](https://github.com/gradio-app/gradio/commit/aaa55ce85e12f95aba9299445e9c5e59824da18e)]:
- @gradio/upload@0.3.2
- @gradio/button@0.2.2
## 0.1.1
### Features
- [#6181](https://github.com/gradio-app/gradio/pull/6181) [`62ec2075c`](https://github.com/gradio-app/gradio/commit/62ec2075ccad8025a7721a08d0f29eb5a4f87fad) - modify preprocess to use pydantic models. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.1.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - fix circular dependency with client + upload. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Image v4. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
## 0.1.0-beta.7
### Features
- [#6143](https://github.com/gradio-app/gradio/pull/6143) [`e4f7b4b40`](https://github.com/gradio-app/gradio/commit/e4f7b4b409323b01aa01b39e15ce6139e29aa073) - fix circular dependency with client + upload. Thanks [@pngwn](https://github.com/pngwn)!
- [#6136](https://github.com/gradio-app/gradio/pull/6136) [`667802a6c`](https://github.com/gradio-app/gradio/commit/667802a6cdbfb2ce454a3be5a78e0990b194548a) - JS Component Documentation. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6094](https://github.com/gradio-app/gradio/pull/6094) [`c476bd5a5`](https://github.com/gradio-app/gradio/commit/c476bd5a5b70836163b9c69bf4bfe068b17fbe13) - Image v4. Thanks [@pngwn](https://github.com/pngwn)!
- [#6149](https://github.com/gradio-app/gradio/pull/6149) [`90318b1dd`](https://github.com/gradio-app/gradio/commit/90318b1dd118ae08a695a50e7c556226234ab6dc) - swap `mode` on the frontned to `interactive` to match the backend. Thanks [@pngwn](https://github.com/pngwn)!
## 0.1.0-beta.6
### Features
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6044](https://github.com/gradio-app/gradio/pull/6044) [`9053c95a1`](https://github.com/gradio-app/gradio/commit/9053c95a10de12aef572018ee37c71106d2da675) - Simplify File Component. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.1.0-beta.5
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.0.12
### Patch Changes
- Updated dependencies [[`4e62b8493`](https://github.com/gradio-app/gradio/commit/4e62b8493dfce50bafafe49f1a5deb929d822103)]:
- @gradio/client@0.5.2
- @gradio/upload@0.3.3
- @gradio/button@0.2.3
## 0.0.11
### Patch Changes
- Updated dependencies [[`796145e2c`](https://github.com/gradio-app/gradio/commit/796145e2c48c4087bec17f8ec0be4ceee47170cb)]:
- @gradio/client@0.5.1
## 0.0.10
### Patch Changes
- Updated dependencies [[`e4a307ed6`](https://github.com/gradio-app/gradio/commit/e4a307ed6cde3bbdf4ff2f17655739addeec941e), [`caeee8bf7`](https://github.com/gradio-app/gradio/commit/caeee8bf7821fd5fe2f936ed82483bed00f613ec), [`c0fef4454`](https://github.com/gradio-app/gradio/commit/c0fef44541bfa61568bdcfcdfc7d7d79869ab1df)]:
- @gradio/client@0.5.0
- @gradio/utils@0.1.2
- @gradio/button@0.2.2
- @gradio/upload@0.3.2
## 0.0.9
### Patch Changes
- Updated dependencies [[`6e56a0d9b`](https://github.com/gradio-app/gradio/commit/6e56a0d9b0c863e76c69e1183d9d40196922b4cd)]:
- @gradio/client@0.4.2
## 0.0.8
### Patch Changes
- Updated dependencies []:
- @gradio/upload@0.3.1
- @gradio/button@0.2.1
## 0.0.7
### Patch Changes
- Updated dependencies [[`78e7cf516`](https://github.com/gradio-app/gradio/commit/78e7cf5163e8d205e8999428fce4c02dbdece25f)]:
- @gradio/client@0.4.1
## 0.0.6
### Patch Changes
- Updated dependencies [[`c57f1b75e`](https://github.com/gradio-app/gradio/commit/c57f1b75e272c76b0af4d6bd0c7f44743ff34f26), [`40de3d217`](https://github.com/gradio-app/gradio/commit/40de3d2178b61ebe424b6f6228f94c0c6f679bea), [`ea0e00b20`](https://github.com/gradio-app/gradio/commit/ea0e00b207b4b90a10e9d054c4202d4e705a29ba), [`75ddeb390`](https://github.com/gradio-app/gradio/commit/75ddeb390d665d4484667390a97442081b49a423)]:
- @gradio/client@0.4.0
- @gradio/button@0.2.0
- @gradio/upload@0.3.0
## 0.0.5
### Patch Changes
- Updated dependencies [[`26fef8c7`](https://github.com/gradio-app/gradio/commit/26fef8c7f85a006c7e25cdbed1792df19c512d02)]:
- @gradio/client@0.3.1
- @gradio/utils@0.1.1
- @gradio/button@0.1.3
- @gradio/upload@0.2.1
## 0.0.4
### Patch Changes
- Updated dependencies [[`119c8343`](https://github.com/gradio-app/gradio/commit/119c834331bfae60d4742c8f20e9cdecdd67e8c2), [`abf1c57d`](https://github.com/gradio-app/gradio/commit/abf1c57d7d85de0df233ee3b38aeb38b638477db), [`79d8f9d8`](https://github.com/gradio-app/gradio/commit/79d8f9d891901683c5a1b7486efb44eab2478c96)]:
- @gradio/client@0.3.0
- @gradio/utils@0.1.0
- @gradio/upload@0.2.0
- @gradio/button@0.1.2
## 0.0.3
### Highlights
#### Improve startup performance and markdown support ([#5279](https://github.com/gradio-app/gradio/pull/5279) [`fe057300`](https://github.com/gradio-app/gradio/commit/fe057300f0672c62dab9d9b4501054ac5d45a4ec))
##### Improved markdown support
We now have better support for markdown in `gr.Markdown` and `gr.Dataframe`. Including syntax highlighting and Github Flavoured Markdown. We also have more consistent markdown behaviour and styling.
##### Various performance improvements
These improvements will be particularly beneficial to large applications.
- Rather than attaching events manually, they are now delegated, leading to a significant performance improvement and addressing a performance regression introduced in a recent version of Gradio. App startup for large applications is now around twice as fast.
- Optimised the mounting of individual components, leading to a modest performance improvement during startup (~30%).
- Corrected an issue that was causing markdown to re-render infinitely.
- Ensured that the `gr.3DModel` does re-render prematurely.
Thanks [@pngwn](https://github.com/pngwn)!
## 0.0.2
### Patch Changes
- Updated dependencies [[`61129052`](https://github.com/gradio-app/gradio/commit/61129052ed1391a75c825c891d57fa0ad6c09fc8), [`667875b2`](https://github.com/gradio-app/gradio/commit/667875b2441753e74d25bd9d3c8adedd8ede11cd), [`67265a58`](https://github.com/gradio-app/gradio/commit/67265a58027ef1f9e4c0eb849a532f72eaebde48), [`8b4eb8ca`](https://github.com/gradio-app/gradio/commit/8b4eb8cac9ea07bde31b44e2006ca2b7b5f4de36), [`37caa2e0`](https://github.com/gradio-app/gradio/commit/37caa2e0fe95d6cab8beb174580fb557904f137f)]:
- @gradio/client@0.2.0
- @gradio/upload@0.0.3
- @gradio/button@0.1.0
|
gradio-app/gradio/blob/main/js/uploadbutton/CHANGELOG.md
|
Metric Card for ROC AUC
## Metric Description
This metric computes the area under the curve (AUC) for the Receiver Operating Characteristic Curve (ROC). The return values represent how well the model used is predicting the correct classes, based on the input data. A score of `0.5` means that the model is predicting exactly at chance, i.e. the model's predictions are correct at the same rate as if the predictions were being decided by the flip of a fair coin or the roll of a fair die. A score above `0.5` indicates that the model is doing better than chance, while a score below `0.5` indicates that the model is doing worse than chance.
This metric has three separate use cases:
- **binary**: The case in which there are only two different label classes, and each example gets only one label. This is the default implementation.
- **multiclass**: The case in which there can be more than two different label classes, but each example still gets only one label.
- **multilabel**: The case in which there can be more than two different label classes, and each example can have more than one label.
## How to Use
At minimum, this metric requires references and prediction scores:
```python
>>> roc_auc_score = datasets.load_metric("roc_auc")
>>> refs = [1, 0, 1, 1, 0, 0]
>>> pred_scores = [0.5, 0.2, 0.99, 0.3, 0.1, 0.7]
>>> results = roc_auc_score.compute(references=refs, prediction_scores=pred_scores)
>>> print(round(results['roc_auc'], 2))
0.78
```
The default implementation of this metric is the **binary** implementation. If employing the **multiclass** or **multilabel** use cases, the keyword `"multiclass"` or `"multilabel"` must be specified when loading the metric:
- In the **multiclass** case, the metric is loaded with:
```python
>>> roc_auc_score = datasets.load_metric("roc_auc", "multiclass")
```
- In the **multilabel** case, the metric is loaded with:
```python
>>> roc_auc_score = datasets.load_metric("roc_auc", "multilabel")
```
See the [Examples Section Below](#examples_section) for more extensive examples.
### Inputs
- **`references`** (array-like of shape (n_samples,) or (n_samples, n_classes)): Ground truth labels. Expects different inputs based on use case:
- binary: expects an array-like of shape (n_samples,)
- multiclass: expects an array-like of shape (n_samples,)
- multilabel: expects an array-like of shape (n_samples, n_classes)
- **`prediction_scores`** (array-like of shape (n_samples,) or (n_samples, n_classes)): Model predictions. Expects different inputs based on use case:
- binary: expects an array-like of shape (n_samples,)
- multiclass: expects an array-like of shape (n_samples, n_classes). The probability estimates must sum to 1 across the possible classes.
- multilabel: expects an array-like of shape (n_samples, n_classes)
- **`average`** (`str`): Type of average, and is ignored in the binary use case. Defaults to `'macro'`. Options are:
- `'micro'`: Calculates metrics globally by considering each element of the label indicator matrix as a label. Only works with the multilabel use case.
- `'macro'`: Calculate metrics for each label, and find their unweighted mean. This does not take label imbalance into account.
- `'weighted'`: Calculate metrics for each label, and find their average, weighted by support (i.e. the number of true instances for each label).
- `'samples'`: Calculate metrics for each instance, and find their average. Only works with the multilabel use case.
- `None`: No average is calculated, and scores for each class are returned. Only works with the multilabels use case.
- **`sample_weight`** (array-like of shape (n_samples,)): Sample weights. Defaults to None.
- **`max_fpr`** (`float`): If not None, the standardized partial AUC over the range [0, `max_fpr`] is returned. Must be greater than `0` and less than or equal to `1`. Defaults to `None`. Note: For the multiclass use case, `max_fpr` should be either `None` or `1.0` as ROC AUC partial computation is not currently supported for `multiclass`.
- **`multi_class`** (`str`): Only used for multiclass targets, in which case it is required. Determines the type of configuration to use. Options are:
- `'ovr'`: Stands for One-vs-rest. Computes the AUC of each class against the rest. This treats the multiclass case in the same way as the multilabel case. Sensitive to class imbalance even when `average == 'macro'`, because class imbalance affects the composition of each of the 'rest' groupings.
- `'ovo'`: Stands for One-vs-one. Computes the average AUC of all possible pairwise combinations of classes. Insensitive to class imbalance when `average == 'macro'`.
- **`labels`** (array-like of shape (n_classes,)): Only used for multiclass targets. List of labels that index the classes in `prediction_scores`. If `None`, the numerical or lexicographical order of the labels in `prediction_scores` is used. Defaults to `None`.
### Output Values
This metric returns a dict containing the `roc_auc` score. The score is a `float`, unless it is the multilabel case with `average=None`, in which case the score is a numpy `array` with entries of type `float`.
The output therefore generally takes the following format:
```python
{'roc_auc': 0.778}
```
In contrast, though, the output takes the following format in the multilabel case when `average=None`:
```python
{'roc_auc': array([0.83333333, 0.375, 0.94444444])}
```
ROC AUC scores can take on any value between `0` and `1`, inclusive.
#### Values from Popular Papers
### <a name="examples_section"></a>Examples
Example 1, the **binary** use case:
```python
>>> roc_auc_score = datasets.load_metric("roc_auc")
>>> refs = [1, 0, 1, 1, 0, 0]
>>> pred_scores = [0.5, 0.2, 0.99, 0.3, 0.1, 0.7]
>>> results = roc_auc_score.compute(references=refs, prediction_scores=pred_scores)
>>> print(round(results['roc_auc'], 2))
0.78
```
Example 2, the **multiclass** use case:
```python
>>> roc_auc_score = datasets.load_metric("roc_auc", "multiclass")
>>> refs = [1, 0, 1, 2, 2, 0]
>>> pred_scores = [[0.3, 0.5, 0.2],
... [0.7, 0.2, 0.1],
... [0.005, 0.99, 0.005],
... [0.2, 0.3, 0.5],
... [0.1, 0.1, 0.8],
... [0.1, 0.7, 0.2]]
>>> results = roc_auc_score.compute(references=refs,
... prediction_scores=pred_scores,
... multi_class='ovr')
>>> print(round(results['roc_auc'], 2))
0.85
```
Example 3, the **multilabel** use case:
```python
>>> roc_auc_score = datasets.load_metric("roc_auc", "multilabel")
>>> refs = [[1, 1, 0],
... [1, 1, 0],
... [0, 1, 0],
... [0, 0, 1],
... [0, 1, 1],
... [1, 0, 1]]
>>> pred_scores = [[0.3, 0.5, 0.2],
... [0.7, 0.2, 0.1],
... [0.005, 0.99, 0.005],
... [0.2, 0.3, 0.5],
... [0.1, 0.1, 0.8],
... [0.1, 0.7, 0.2]]
>>> results = roc_auc_score.compute(references=refs,
... prediction_scores=pred_scores,
... average=None)
>>> print([round(res, 2) for res in results['roc_auc'])
[0.83, 0.38, 0.94]
```
## Limitations and Bias
## Citation
```bibtex
@article{doi:10.1177/0272989X8900900307,
author = {Donna Katzman McClish},
title ={Analyzing a Portion of the ROC Curve},
journal = {Medical Decision Making},
volume = {9},
number = {3},
pages = {190-195},
year = {1989},
doi = {10.1177/0272989X8900900307},
note ={PMID: 2668680},
URL = {https://doi.org/10.1177/0272989X8900900307},
eprint = {https://doi.org/10.1177/0272989X8900900307}
}
```
```bibtex
@article{10.1023/A:1010920819831,
author = {Hand, David J. and Till, Robert J.},
title = {A Simple Generalisation of the Area Under the ROC Curve for Multiple Class Classification Problems},
year = {2001},
issue_date = {November 2001},
publisher = {Kluwer Academic Publishers},
address = {USA},
volume = {45},
number = {2},
issn = {0885-6125},
url = {https://doi.org/10.1023/A:1010920819831},
doi = {10.1023/A:1010920819831},
journal = {Mach. Learn.},
month = {oct},
pages = {171–186},
numpages = {16},
keywords = {Gini index, AUC, error rate, ROC curve, receiver operating characteristic}
}
```
```bibtex
@article{scikit-learn,
title={Scikit-learn: Machine Learning in {P}ython},
author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V. and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P. and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.},
journal={Journal of Machine Learning Research},
volume={12},
pages={2825--2830},
year={2011}
}
```
## Further References
This implementation is a wrapper around the [Scikit-learn implementation](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.roc_auc_score.html). Much of the documentation here was adapted from their existing documentation, as well.
The [Guide to ROC and AUC](https://youtu.be/iCZJfO-7C5Q) video from the channel Data Science Bits is also very informative.
|
huggingface/datasets/blob/main/metrics/roc_auc/README.md
|
Contributor Covenant Code of Conduct
## Our Pledge
We as members, contributors, and leaders pledge to make participation in our
community a harassment-free experience for everyone, regardless of age, body
size, visible or invisible disability, ethnicity, sex characteristics, gender
identity and expression, level of experience, education, socio-economic status,
nationality, personal appearance, race, caste, color, religion, or sexual identity
and orientation.
We pledge to act and interact in ways that contribute to an open, welcoming,
diverse, inclusive, and healthy community.
## Our Standards
Examples of behavior that contributes to a positive environment for our
community include:
* Demonstrating empathy and kindness toward other people
* Being respectful of differing opinions, viewpoints, and experiences
* Giving and gracefully accepting constructive feedback
* Accepting responsibility and apologizing to those affected by our mistakes,
and learning from the experience
* Focusing on what is best not just for us as individuals, but for the
overall community
Examples of unacceptable behavior include:
* The use of sexualized language or imagery, and sexual attention or
advances of any kind
* Trolling, insulting or derogatory comments, and personal or political attacks
* Public or private harassment
* Publishing others' private information, such as a physical or email
address, without their explicit permission
* Other conduct which could reasonably be considered inappropriate in a
professional setting
## Enforcement Responsibilities
Community leaders are responsible for clarifying and enforcing our standards of
acceptable behavior and will take appropriate and fair corrective action in
response to any behavior that they deem inappropriate, threatening, offensive,
or harmful.
Community leaders have the right and responsibility to remove, edit, or reject
comments, commits, code, wiki edits, issues, and other contributions that are
not aligned to this Code of Conduct, and will communicate reasons for moderation
decisions when appropriate.
## Scope
This Code of Conduct applies within all community spaces, and also applies when
an individual is officially representing the community in public spaces.
Examples of representing our community include using an official e-mail address,
posting via an official social media account, or acting as an appointed
representative at an online or offline event.
## Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be
reported to the community leaders responsible for enforcement at
feedback@huggingface.co.
All complaints will be reviewed and investigated promptly and fairly.
All community leaders are obligated to respect the privacy and security of the
reporter of any incident.
## Enforcement Guidelines
Community leaders will follow these Community Impact Guidelines in determining
the consequences for any action they deem in violation of this Code of Conduct:
### 1. Correction
**Community Impact**: Use of inappropriate language or other behavior deemed
unprofessional or unwelcome in the community.
**Consequence**: A private, written warning from community leaders, providing
clarity around the nature of the violation and an explanation of why the
behavior was inappropriate. A public apology may be requested.
### 2. Warning
**Community Impact**: A violation through a single incident or series
of actions.
**Consequence**: A warning with consequences for continued behavior. No
interaction with the people involved, including unsolicited interaction with
those enforcing the Code of Conduct, for a specified period of time. This
includes avoiding interactions in community spaces as well as external channels
like social media. Violating these terms may lead to a temporary or
permanent ban.
### 3. Temporary Ban
**Community Impact**: A serious violation of community standards, including
sustained inappropriate behavior.
**Consequence**: A temporary ban from any sort of interaction or public
communication with the community for a specified period of time. No public or
private interaction with the people involved, including unsolicited interaction
with those enforcing the Code of Conduct, is allowed during this period.
Violating these terms may lead to a permanent ban.
### 4. Permanent Ban
**Community Impact**: Demonstrating a pattern of violation of community
standards, including sustained inappropriate behavior, harassment of an
individual, or aggression toward or disparagement of classes of individuals.
**Consequence**: A permanent ban from any sort of public interaction within
the community.
## Attribution
This Code of Conduct is adapted from the [Contributor Covenant][homepage],
version 2.0, available at
[https://www.contributor-covenant.org/version/2/0/code_of_conduct.html][v2.0].
Community Impact Guidelines were inspired by
[Mozilla's code of conduct enforcement ladder][Mozilla CoC].
For answers to common questions about this code of conduct, see the FAQ at
[https://www.contributor-covenant.org/faq][FAQ]. Translations are available
at [https://www.contributor-covenant.org/translations][translations].
[homepage]: https://www.contributor-covenant.org
[v2.0]: https://www.contributor-covenant.org/version/2/0/code_of_conduct.html
[Mozilla CoC]: https://github.com/mozilla/diversity
[FAQ]: https://www.contributor-covenant.org/faq
[translations]: https://www.contributor-covenant.org/translations
|
huggingface/datasets-server/blob/main/CODE_OF_CONDUCT.md
|
--
title: "Practical 3D Asset Generation: A Step-by-Step Guide"
thumbnail: /blog/assets/124_ml-for-games/thumbnail-3d.jpg
authors:
- user: dylanebert
---
# Practical 3D Asset Generation: A Step-by-Step Guide
## Introduction
Generative AI has become an instrumental part of artistic workflows for game development. However, as detailed in my [earlier post](https://huggingface.co/blog/ml-for-games-3), text-to-3D lags behind 2D in terms of practical applicability. This is beginning to change. Today, we'll be revisiting practical workflows for 3D Asset Generation and taking a step-by-step look at how to integrate Generative AI in a PS1-style 3D workflow.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/3d/result.png" alt="final result"/>
Why the PS1 style? Because it's much more forgiving to the low fidelity of current text-to-3D models, and allows us to go from text to usable 3D asset with as little effort as possible.
### Prerequisites
This tutorial assumes some basic knowledge of Blender and 3D concepts such as materials and UV mapping.
## Step 1: Generate a 3D Model
Start by visiting the Shap-E Hugging Face Space [here](https://huggingface.co/spaces/hysts/Shap-E) or down below. This space uses the open-source [Shap-E model](https://github.com/openai/shap-e), a recent diffusion model from OpenAI to generate 3D models from text.
<gradio-app theme_mode="light" space="hysts/Shap-E"></gradio-app>
Enter "Dilapidated Shack" as your prompt and click 'Generate'. When you're happy with the model, download it for the next step.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/3d/shape.png" alt="shap-e space"/>
## Step 2: Import and Decimate the Model
Next, open [Blender](https://www.blender.org/download/) (version 3.1 or higher). Go to File -> Import -> GLTF 2.0, and import your downloaded file. You may notice that the model has way more polygons than recommended for many practical applications, like games.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/3d/import.png" alt="importing the model in blender"/>
To reduce the polygon count, select your model, navigate to Modifiers, and choose the "Decimate" modifier. Adjust the ratio to a low number (i.e. 0.02). This is probably *not* going to look very good. However, in this tutorial, we're going to embrace the low fidelity.
## Step 3: Install Dream Textures
To add textures to our model, we'll be using [Dream Textures](https://github.com/carson-katri/dream-textures), a stable diffusion texture generator for Blender. Follow the instructions on the [official repository](https://github.com/carson-katri/dream-textures) to download and install the addon.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/3d/dreamtextures.png" alt="installing dream textures"/>
Once installed and enabled, open the addon preferences. Search for and download the [texture-diffusion](https://huggingface.co/dream-textures/texture-diffusion) model.
## Step 4: Generate a Texture
Let's generate a custom texture. Open the UV Editor in Blender and press 'N' to open the properties menu. Click the 'Dream' tab and select the texture-diffusion model. Set the prompt to 'texture' and seamless to 'both'. This will ensure the generated image is a seamless texture.
Under 'subject', type the texture you want, like 'Wood Wall', and click 'Generate'. When you're happy with the result, name it and save it.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/3d/generate.png" alt="generating a texture"/>
To apply the texture, select your model and navigate to 'Material'. Add a new material, and under 'base color', click the dot and choose 'Image Texture'. Finally, select your newly generated texture.
## Step 5: UV Mapping
Time for UV mapping, which wraps our 2D texture around the 3D model. Select your model and press 'Tab' to enter Edit Mode. Then, press 'U' to unwrap the model and choose 'Smart UV Project'.
To preview your textured model, switch to rendered view (hold 'Z' and select 'Rendered'). You can scale up the UV map to have it tile seamlessly over the model. Remember that we're aiming for a retro PS1 style, so don't make it too nice.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/3d/uv.png" alt="uv mapping"/>
## Step 6: Export the Model
When you're happy with your model, it's time to export it. Navigate to File -> Export -> FBX, and voila! You have a usable 3D Asset.
## Step 7: Import in Unity
Finally, let's see our model in action. Import it in [Unity](https://unity.com/download) or your game engine of choice. To recreate a nostalgic PS1 aesthetic, I've customized it with custom vertex-lit shading, no shadows, lots of fog, and glitchy post-processing. You can read more about recreating the PS1 aesthetic [here](https://www.david-colson.com/2021/11/30/ps1-style-renderer.html).
And there we have it - our low-fi, textured, 3D model in a virtual environment!
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/3d/result.png" alt="final result"/>
## Conclusion
That's a wrap on how to create practical 3D assets using a Generative AI workflow. While the results are low-fidelity, the potential is enormous: with sufficient effort, this method could be used to generate an infinite world in a low-fi style. And as these models improve, it may become feasible to transfer these techniques to high fidelity or realistic styles.
If you've followed along and created your own 3D assets, I'd love to see them. To share them, or if you have questions or want to get involved in our community, join the [Hugging Face Discord](https://hf.co/join/discord)!
|
huggingface/blog/blob/main/3d-assets.md
|
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Contribute to 🤗 Transformers
Everyone is welcome to contribute, and we value everybody's contribution. Code
contributions are not the only way to help the community. Answering questions, helping
others, and improving the documentation are also immensely valuable.
It also helps us if you spread the word! Reference the library in blog posts
about the awesome projects it made possible, shout out on Twitter every time it has
helped you, or simply ⭐️ the repository to say thank you.
However you choose to contribute, please be mindful and respect our
[code of conduct](https://github.com/huggingface/transformers/blob/main/CODE_OF_CONDUCT.md).
**This guide was heavily inspired by the awesome [scikit-learn guide to contributing](https://github.com/scikit-learn/scikit-learn/blob/main/CONTRIBUTING.md).**
## Ways to contribute
There are several ways you can contribute to 🤗 Transformers:
* Fix outstanding issues with the existing code.
* Submit issues related to bugs or desired new features.
* Implement new models.
* Contribute to the examples or to the documentation.
If you don't know where to start, there is a special [Good First
Issue](https://github.com/huggingface/transformers/contribute) listing. It will give you a list of
open issues that are beginner-friendly and help you start contributing to open-source. Just comment on the issue that you'd like to work
on.
For something slightly more challenging, you can also take a look at the [Good Second Issue](https://github.com/huggingface/transformers/labels/Good%20Second%20Issue) list. In general though, if you feel like you know what you're doing, go for it and we'll help you get there! 🚀
> All contributions are equally valuable to the community. 🥰
## Fixing outstanding issues
If you notice an issue with the existing code and have a fix in mind, feel free to [start contributing](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md/#create-a-pull-request) and open a Pull Request!
## Submitting a bug-related issue or feature request
Do your best to follow these guidelines when submitting a bug-related issue or a feature
request. It will make it easier for us to come back to you quickly and with good
feedback.
### Did you find a bug?
The 🤗 Transformers library is robust and reliable thanks to users who report the problems they encounter.
Before you report an issue, we would really appreciate it if you could **make sure the bug was not
already reported** (use the search bar on GitHub under Issues). Your issue should also be related to bugs in the library itself, and not your code. If you're unsure whether the bug is in your code or the library, please ask in the [forum](https://discuss.huggingface.co/) first. This helps us respond quicker to fixing issues related to the library versus general questions.
Once you've confirmed the bug hasn't already been reported, please include the following information in your issue so we can quickly resolve it:
* Your **OS type and version** and **Python**, **PyTorch** and
**TensorFlow** versions when applicable.
* A short, self-contained, code snippet that allows us to reproduce the bug in
less than 30s.
* The *full* traceback if an exception is raised.
* Attach any other additional information, like screenshots, you think may help.
To get the OS and software versions automatically, run the following command:
```bash
transformers-cli env
```
You can also run the same command from the root of the repository:
```bash
python src/transformers/commands/transformers_cli.py env
```
### Do you want a new feature?
If there is a new feature you'd like to see in 🤗 Transformers, please open an issue and describe:
1. What is the *motivation* behind this feature? Is it related to a problem or frustration with the library? Is it a feature related to something you need for a project? Is it something you worked on and think it could benefit the community?
Whatever it is, we'd love to hear about it!
2. Describe your requested feature in as much detail as possible. The more you can tell us about it, the better we'll be able to help you.
3. Provide a *code snippet* that demonstrates the features usage.
4. If the feature is related to a paper, please include a link.
If your issue is well written we're already 80% of the way there by the time you create it.
We have added [templates](https://github.com/huggingface/transformers/tree/main/templates) to help you get started with your issue.
## Do you want to implement a new model?
New models are constantly released and if you want to implement a new model, please provide the following information
* A short description of the model and a link to the paper.
* Link to the implementation if it is open-sourced.
* Link to the model weights if they are available.
If you are willing to contribute the model yourself, let us know so we can help you add it to 🤗 Transformers!
We have added a [detailed guide and templates](https://github.com/huggingface/transformers/tree/main/templates) to help you get started with adding a new model, and we also have a more technical guide for [how to add a model to 🤗 Transformers](https://huggingface.co/docs/transformers/add_new_model).
## Do you want to add documentation?
We're always looking for improvements to the documentation that make it more clear and accurate. Please let us know how the documentation can be improved such as typos and any content that is missing, unclear or inaccurate. We'll be happy to make the changes or help you make a contribution if you're interested!
For more details about how to generate, build, and write the documentation, take a look at the documentation [README](https://github.com/huggingface/transformers/tree/main/docs).
## Create a Pull Request
Before writing any code, we strongly advise you to search through the existing PRs or
issues to make sure nobody is already working on the same thing. If you are
unsure, it is always a good idea to open an issue to get some feedback.
You will need basic `git` proficiency to contribute to
🤗 Transformers. While `git` is not the easiest tool to use, it has the greatest
manual. Type `git --help` in a shell and enjoy! If you prefer books, [Pro
Git](https://git-scm.com/book/en/v2) is a very good reference.
You'll need **[Python 3.8]((https://github.com/huggingface/transformers/blob/main/setup.py#L426))** or above to contribute to 🤗 Transformers. Follow the steps below to start contributing:
1. Fork the [repository](https://github.com/huggingface/transformers) by
clicking on the **[Fork](https://github.com/huggingface/transformers/fork)** button on the repository's page. This creates a copy of the code
under your GitHub user account.
2. Clone your fork to your local disk, and add the base repository as a remote:
```bash
git clone git@github.com:<your Github handle>/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git
```
3. Create a new branch to hold your development changes:
```bash
git checkout -b a-descriptive-name-for-my-changes
```
🚨 **Do not** work on the `main` branch!
4. Set up a development environment by running the following command in a virtual environment:
```bash
pip install -e ".[dev]"
```
If 🤗 Transformers was already installed in the virtual environment, remove
it with `pip uninstall transformers` before reinstalling it in editable
mode with the `-e` flag.
Depending on your OS, and since the number of optional dependencies of Transformers is growing, you might get a
failure with this command. If that's the case make sure to install the Deep Learning framework you are working with
(PyTorch, TensorFlow and/or Flax) then do:
```bash
pip install -e ".[quality]"
```
which should be enough for most use cases.
5. Develop the features in your branch.
As you work on your code, you should make sure the test suite
passes. Run the tests impacted by your changes like this:
```bash
pytest tests/<TEST_TO_RUN>.py
```
For more information about tests, check out the
[Testing](https://huggingface.co/docs/transformers/testing) guide.
🤗 Transformers relies on `black` and `ruff` to format its source code
consistently. After you make changes, apply automatic style corrections and code verifications
that can't be automated in one go with:
```bash
make fixup
```
This target is also optimized to only work with files modified by the PR you're working on.
If you prefer to run the checks one after the other, the following command applies the
style corrections:
```bash
make style
```
🤗 Transformers also uses `ruff` and a few custom scripts to check for coding mistakes. Quality
controls are run by the CI, but you can run the same checks with:
```bash
make quality
```
Finally, we have a lot of scripts to make sure we don't forget to update
some files when adding a new model. You can run these scripts with:
```bash
make repo-consistency
```
To learn more about those checks and how to fix any issues with them, check out the
[Checks on a Pull Request](https://huggingface.co/docs/transformers/pr_checks) guide.
If you're modifying documents under the `docs/source` directory, make sure the documentation can still be built. This check will also run in the CI when you open a pull request. To run a local check
make sure you install the documentation builder:
```bash
pip install ".[docs]"
```
Run the following command from the root of the repository:
```bash
doc-builder build transformers docs/source/en --build_dir ~/tmp/test-build
```
This will build the documentation in the `~/tmp/test-build` folder where you can inspect the generated
Markdown files with your favorite editor. You can also preview the docs on GitHub when you open a pull request.
Once you're happy with your changes, add the changed files with `git add` and
record your changes locally with `git commit`:
```bash
git add modified_file.py
git commit
```
Please remember to write [good commit
messages](https://chris.beams.io/posts/git-commit/) to clearly communicate the changes you made!
To keep your copy of the code up to date with the original
repository, rebase your branch on `upstream/branch` *before* you open a pull request or if requested by a maintainer:
```bash
git fetch upstream
git rebase upstream/main
```
Push your changes to your branch:
```bash
git push -u origin a-descriptive-name-for-my-changes
```
If you've already opened a pull request, you'll need to force push with the `--force` flag. Otherwise, if the pull request hasn't been opened yet, you can just push your changes normally.
6. Now you can go to your fork of the repository on GitHub and click on **Pull Request** to open a pull request. Make sure you tick off all the boxes on our [checklist](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md/#pull-request-checklist) below. When you're ready, you can send your changes to the project maintainers for review.
7. It's ok if maintainers request changes, it happens to our core contributors
too! So everyone can see the changes in the pull request, work in your local
branch and push the changes to your fork. They will automatically appear in
the pull request.
### Pull request checklist
☐ The pull request title should summarize your contribution.<br>
☐ If your pull request addresses an issue, please mention the issue number in the pull
request description to make sure they are linked (and people viewing the issue know you
are working on it).<br>
☐ To indicate a work in progress please prefix the title with `[WIP]`. These are
useful to avoid duplicated work, and to differentiate it from PRs ready to be merged.<br>
☐ Make sure existing tests pass.<br>
☐ If adding a new feature, also add tests for it.<br>
- If you are adding a new model, make sure you use
`ModelTester.all_model_classes = (MyModel, MyModelWithLMHead,...)` to trigger the common tests.
- If you are adding new `@slow` tests, make sure they pass using
`RUN_SLOW=1 python -m pytest tests/models/my_new_model/test_my_new_model.py`.
- If you are adding a new tokenizer, write tests and make sure
`RUN_SLOW=1 python -m pytest tests/models/{your_model_name}/test_tokenization_{your_model_name}.py` passes.
- CircleCI does not run the slow tests, but GitHub Actions does every night!<br>
☐ All public methods must have informative docstrings (see
[`modeling_bert.py`](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bert/modeling_bert.py)
for an example).<br>
☐ Due to the rapidly growing repository, don't add any images, videos and other
non-text files that'll significantly weigh down the repository. Instead, use a Hub
repository such as [`hf-internal-testing`](https://huggingface.co/hf-internal-testing)
to host these files and reference them by URL. We recommend placing documentation
related images in the following repository:
[huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images).
You can open a PR on this dataset repostitory and ask a Hugging Face member to merge it.
For more information about the checks run on a pull request, take a look at our [Checks on a Pull Request](https://huggingface.co/docs/transformers/pr_checks) guide.
### Tests
An extensive test suite is included to test the library behavior and several examples. Library tests can be found in
the [tests](https://github.com/huggingface/transformers/tree/main/tests) folder and examples tests in the
[examples](https://github.com/huggingface/transformers/tree/main/examples) folder.
We like `pytest` and `pytest-xdist` because it's faster. From the root of the
repository, specify a *path to a subfolder or a test file* to run the test.
```bash
python -m pytest -n auto --dist=loadfile -s -v ./tests/models/my_new_model
```
Similarly, for the `examples` directory, specify a *path to a subfolder or test file* to run the test. For example, the following command tests the text classification subfolder in the PyTorch `examples` directory:
```bash
pip install -r examples/xxx/requirements.txt # only needed the first time
python -m pytest -n auto --dist=loadfile -s -v ./examples/pytorch/text-classification
```
In fact, this is actually how our `make test` and `make test-examples` commands are implemented (not including the `pip install`)!
You can also specify a smaller set of tests in order to test only the feature
you're working on.
By default, slow tests are skipped but you can set the `RUN_SLOW` environment variable to
`yes` to run them. This will download many gigabytes of models so make sure you
have enough disk space, a good internet connection or a lot of patience!
<Tip warning={true}>
Remember to specify a *path to a subfolder or a test file* to run the test. Otherwise, you'll run all the tests in the `tests` or `examples` folder, which will take a very long time!
</Tip>
```bash
RUN_SLOW=yes python -m pytest -n auto --dist=loadfile -s -v ./tests/models/my_new_model
RUN_SLOW=yes python -m pytest -n auto --dist=loadfile -s -v ./examples/pytorch/text-classification
```
Like the slow tests, there are other environment variables available which not enabled by default during testing:
- `RUN_CUSTOM_TOKENIZERS`: Enables tests for custom tokenizers.
- `RUN_PT_FLAX_CROSS_TESTS`: Enables tests for PyTorch + Flax integration.
- `RUN_PT_TF_CROSS_TESTS`: Enables tests for TensorFlow + PyTorch integration.
More environment variables and additional information can be found in the [testing_utils.py](src/transformers/testing_utils.py).
🤗 Transformers uses `pytest` as a test runner only. It doesn't use any
`pytest`-specific features in the test suite itself.
This means `unittest` is fully supported. Here's how to run tests with
`unittest`:
```bash
python -m unittest discover -s tests -t . -v
python -m unittest discover -s examples -t examples -v
```
### Style guide
For documentation strings, 🤗 Transformers follows the [Google Python Style Guide](https://google.github.io/styleguide/pyguide.html).
Check our [documentation writing guide](https://github.com/huggingface/transformers/tree/main/docs#writing-documentation---specification)
for more information.
### Develop on Windows
On Windows (unless you're working in [Windows Subsystem for Linux](https://learn.microsoft.com/en-us/windows/wsl/) or WSL), you need to configure git to transform Windows `CRLF` line endings to Linux `LF` line endings:
```bash
git config core.autocrlf input
```
One way to run the `make` command on Windows is with MSYS2:
1. [Download MSYS2](https://www.msys2.org/), and we assume it's installed in `C:\msys64`.
2. Open the command line `C:\msys64\msys2.exe` (it should be available from the **Start** menu).
3. Run in the shell: `pacman -Syu` and install `make` with `pacman -S make`.
4. Add `C:\msys64\usr\bin` to your PATH environment variable.
You can now use `make` from any terminal (Powershell, cmd.exe, etc.)! 🎉
### Sync a forked repository with upstream main (the Hugging Face repository)
When updating the main branch of a forked repository, please follow these steps to avoid pinging the upstream repository which adds reference notes to each upstream PR, and sends unnecessary notifications to the developers involved in these PRs.
1. When possible, avoid syncing with the upstream using a branch and PR on the forked repository. Instead, merge directly into the forked main.
2. If a PR is absolutely necessary, use the following steps after checking out your branch:
```bash
git checkout -b your-branch-for-syncing
git pull --squash --no-commit upstream main
git commit -m '<your message without GitHub references>'
git push --set-upstream origin your-branch-for-syncing
```
|
huggingface/transformers/blob/main/CONTRIBUTING.md
|
The Frontend 🌐⭐️
This guide will cover everything you need to know to implement your custom component's frontend.
Tip: Gradio components use Svelte. Writing Svelte is fun! If you're not familiar with it, we recommend checking out their interactive [guide](https://learn.svelte.dev/tutorial/welcome-to-svelte).
## The directory structure
The frontend code should have, at minimum, three files:
* `Index.svelte`: This is the main export and where your component's layout and logic should live.
* `Example.svelte`: This is where the example view of the component is defined.
Feel free to add additional files and subdirectories.
If you want to export any additional modules, remember to modify the `package.json` file
```json
"exports": {
".": "./Index.svelte",
"./example": "./Example.svelte",
"./package.json": "./package.json"
},
```
## The Index.svelte file
Your component should expose the following props that will be passed down from the parent Gradio application.
```typescript
import type { LoadingStatus } from "@gradio/statustracker";
import type { Gradio } from "@gradio/utils";
export let gradio: Gradio<{
event_1: never;
event_2: never;
}>;
export let elem_id = "";
export let elem_classes: string[] = [];
export let scale: number | null = null;
export let min_width: number | undefined = undefined;
export let loading_status: LoadingStatus | undefined = undefined;
export let mode: "static" | "interactive";
```
* `elem_id` and `elem_classes` allow Gradio app developers to target your component with custom CSS and JavaScript from the Python `Blocks` class.
* `scale` and `min_width` allow Gradio app developers to control how much space your component takes up in the UI.
* `loading_status` is used to display a loading status over the component when it is the output of an event.
* `mode` is how the parent Gradio app tells your component whether the `interactive` or `static` version should be displayed.
* `gradio`: The `gradio` object is created by the parent Gradio app. It stores some application-level configuration that will be useful in your component, like internationalization. You must use it to dispatch events from your component.
A minimal `Index.svelte` file would look like:
```typescript
<script lang="ts">
import type { LoadingStatus } from "@gradio/statustracker";
import { Block } from "@gradio/atoms";
import { StatusTracker } from "@gradio/statustracker";
import type { Gradio } from "@gradio/utils";
export let gradio: Gradio<{
event_1: never;
event_2: never;
}>;
export let value = "";
export let elem_id = "";
export let elem_classes: string[] = [];
export let scale: number | null = null;
export let min_width: number | undefined = undefined;
export let loading_status: LoadingStatus | undefined = undefined;
export let mode: "static" | "interactive";
</script>
<Block
visible={true}
{elem_id}
{elem_classes}
{scale}
{min_width}
allow_overflow={false}
padding={true}
>
{#if loading_status}
<StatusTracker
autoscroll={gradio.autoscroll}
i18n={gradio.i18n}
{...loading_status}
/>
{/if}
<p>{value}</p>
</Block>
```
## The Example.svelte file
The `Example.svelte` file should expose the following props:
```typescript
export let value: string;
export let type: "gallery" | "table";
export let selected = false;
export let samples_dir: string;
export let index: number;
```
* `value`: The example value that should be displayed.
* `type`: This is a variable that can be either `"gallery"` or `"table"` depending on how the examples are displayed. The `"gallery"` form is used when the examples correspond to a single input component, while the `"table"` form is used when a user has multiple input components, and the examples need to populate all of them.
* `selected`: You can also adjust how the examples are displayed if a user "selects" a particular example by using the selected variable.
* `samples_dir`: A URL to prepend to `value` if your example is fetching a file from the server
* `index`: The current index of the selected value.
* Any additional props your "non-example" component takes!
This is the `Example.svelte` file for the code `Radio` component:
```typescript
<script lang="ts">
export let value: string;
export let type: "gallery" | "table";
export let selected = false;
</script>
<div
class:table={type === "table"}
class:gallery={type === "gallery"}
class:selected
>
{value}
</div>
<style>
.gallery {
padding: var(--size-1) var(--size-2);
}
</style>
```
## Handling Files
If your component deals with files, these files **should** be uploaded to the backend server.
The `@gradio/client` npm package provides the `upload`, `prepare_files`, and `normalise_file` utility functions to help you do this.
The `prepare_files` function will convert the browser's `File` datatype to gradio's internal `FileData` type.
You should use the `FileData` data in your component to keep track of uploaded files.
The `upload` function will upload an array of `FileData` values to the server.
The `normalise_file` function will generate the correct URL for your component to fetch the file from and set it to the `data` property of the `FileData.`
Tip: Be sure you call `normalise_file` whenever your files are updated!
Here's an example of loading files from an `<input>` element when its value changes.
```typescript
<script lang="ts">
import { upload, prepare_files, normalise_file, type FileData } from "@gradio/client";
export let root;
export let value;
let uploaded_files;
$: value: normalise_file(uploaded_files, root)
async function handle_upload(file_data: FileData[]): Promise<void> {
await tick();
uploaded_files = await upload(file_data, root);
}
async function loadFiles(files: FileList): Promise<void> {
let _files: File[] = Array.from(files);
if (!files.length) {
return;
}
if (file_count === "single") {
_files = [files[0]];
}
let file_data = await prepare_files(_files);
await handle_upload(file_data);
}
async function loadFilesFromUpload(e: Event): Promise<void> {
const target = e.target;
if (!target.files) return;
await loadFiles(target.files);
}
</script>
<input
type="file"
on:change={loadFilesFromUpload}
multiple={true}
/>
```
The component exposes a prop named `root`.
This is passed down by the parent gradio app and it represents the base url that the files will be uploaded to and fetched from.
For WASM support, you should get the upload function from the `Context` and pass that as the third parameter of the `upload` function.
```typescript
<script lang="ts">
import { getContext } from "svelte";
const upload_fn = getContext<typeof upload_files>("upload_files");
async function handle_upload(file_data: FileData[]): Promise<void> {
await tick();
await upload(file_data, root, upload_fn);
}
</script>
```
## Leveraging Existing Gradio Components
Most of Gradio's frontend components are published on [npm](https://www.npmjs.com/), the javascript package repository.
This means that you can use them to save yourself time while incorporating common patterns in your component, like uploading files.
For example, the `@gradio/upload` package has `Upload` and `ModifyUpload` components for properly uploading files to the Gradio server.
Here is how you can use them to create a user interface to upload and display PDF files.
```typescript
<script>
import { type FileData, normalise_file, Upload, ModifyUpload } from "@gradio/upload";
import { Empty, UploadText, BlockLabel } from "@gradio/atoms";
</script>
<BlockLabel Icon={File} label={label || "PDF"} />
{#if value === null && interactive}
<Upload
filetype="application/pdf"
on:load={handle_load}
{root}
>
<UploadText type="file" i18n={gradio.i18n} />
</Upload>
{:else if value !== null}
{#if interactive}
<ModifyUpload i18n={gradio.i18n} on:clear={handle_clear}/>
{/if}
<iframe title={value.orig_name || "PDF"} src={value.data} height="{height}px" width="100%"></iframe>
{:else}
<Empty size="large"> <File/> </Empty>
{/if}
```
You can also combine existing Gradio components to create entirely unique experiences.
Like rendering a gallery of chatbot conversations.
The possibilities are endless, please read the documentation on our javascript packages [here](https://gradio.app/main/docs/js).
We'll be adding more packages and documentation over the coming weeks!
## Matching Gradio Core's Design System
You can explore our component library via Storybook. You'll be able to interact with our components and see them in their various states.
For those interested in design customization, we provide the CSS variables consisting of our color palette, radii, spacing, and the icons we use - so you can easily match up your custom component with the style of our core components. This Storybook will be regularly updated with any new additions or changes.
[Storybook Link](https://gradio.app/main/docs/js/storybook)
## Conclusion
You now how to create delightful frontends for your components!
|
gradio-app/gradio/blob/main/guides/05_custom-components/05_frontend.md
|
Hugging Face on Amazon SageMaker

## Deep Learning Containers
Deep Learning Containers (DLCs) are Docker images pre-installed with deep learning frameworks and libraries such as 🤗 Transformers, 🤗 Datasets, and 🤗 Tokenizers. The DLCs allow you to start training models immediately, skipping the complicated process of building and optimizing your training environments from scratch. Our DLCs are thoroughly tested and optimized for deep learning environments, requiring no configuration or maintenance on your part. In particular, the Hugging Face Inference DLC comes with a pre-written serving stack which drastically lowers the technical bar of deep learning serving.
Our DLCs are available everywhere [Amazon SageMaker](https://aws.amazon.com/sagemaker/) is [available](https://aws.amazon.com/about-aws/global-infrastructure/regional-product-services/). While it is possible to use the DLCs without the SageMaker Python SDK, there are many advantages to using SageMaker to train your model:
- Cost-effective: Training instances are only live for the duration of your job. Once your job is complete, the training cluster stops, and you won't be billed anymore. SageMaker also supports [Spot instances]((https://docs.aws.amazon.com/sagemaker/latest/dg/model-managed-spot-training.html)), which can reduce costs up to 90%.
- Built-in automation: SageMaker automatically stores training metadata and logs in a serverless managed metastore and fully manages I/O operations with S3 for your datasets, checkpoints, and model artifacts.
- Multiple security mechanisms: SageMaker offers [encryption at rest](https://docs.aws.amazon.com/sagemaker/latest/dg/encryption-at-rest-nbi.html), [in transit](https://docs.aws.amazon.com/sagemaker/latest/dg/encryption-in-transit.html), [Virtual Private Cloud](https://docs.aws.amazon.com/sagemaker/latest/dg/interface-vpc-endpoint.html) connectivity, and [Identity and Access Management](https://docs.aws.amazon.com/sagemaker/latest/dg/security_iam_service-with-iam.html) to secure your data and code.
Hugging Face DLCs are open source and licensed under Apache 2.0. Feel free to reach out on our [community forum](https://discuss.huggingface.co/c/sagemaker/17) if you have any questions. For premium support, our [Expert Acceleration Program](https://huggingface.co/support) gives you direct dedicated support from our team.
## Features & benefits 🔥
Hugging Face Deep DLCs make it easier than ever to train Transformer models in SageMaker. Here is why you should consider using Hugging Face DLCs to train and deploy your next machine learning models:
**One command is all you need**
With the new Hugging Face DLCs, train cutting-edge Transformers-based NLP models in a single line of code. Choose from multiple DLC variants, each one optimized for TensorFlow and PyTorch, single-GPU, single-node multi-GPU, and multi-node clusters.
**Accelerate machine learning from science to production**
In addition to Hugging Face DLCs, we created a first-class Hugging Face extension for the SageMaker Python SDK to accelerate data science teams, reducing the time required to set up and run experiments from days to minutes.
You can use the Hugging Face DLCs with SageMaker's automatic model tuning to optimize your training hyperparameters and increase the accuracy of your models.
Deploy your trained models for inference with just one more line of code or select any of the 10,000+ publicly available models from the [model Hub](https://huggingface.co/models) and deploy them with SageMaker.
Easily track and compare your experiments and training artifacts in SageMaker Studio's web-based integrated development environment (IDE).
**Built-in performance**
Hugging Face DLCs feature built-in performance optimizations for PyTorch and TensorFlow to train NLP models faster. The DLCs also give you the flexibility to choose a training infrastructure that best aligns with the price/performance ratio for your workload.
The Hugging Face Training DLCs are fully integrated with SageMaker distributed training libraries to train models faster than ever, using the latest generation of instances available on Amazon Elastic Compute Cloud.
Hugging Face Inference DLCs provide you with production-ready endpoints that scale quickly with your AWS environment, built-in monitoring, and a ton of enterprise features.
---
## Resources, Documentation & Samples 📄
Take a look at our published blog posts, videos, documentation, sample notebooks and scripts for additional help and more context about Hugging Face DLCs on SageMaker.
### Blogs and videos
- [AWS: Embracing natural language processing with Hugging Face](https://aws.amazon.com/de/blogs/opensource/embracing-natural-language-processing-with-hugging-face/)
- [Deploy Hugging Face models easily with Amazon SageMaker](https://huggingface.co/blog/deploy-hugging-face-models-easily-with-amazon-sagemaker)
- [AWS and Hugging Face collaborate to simplify and accelerate adoption of natural language processing models](https://aws.amazon.com/blogs/machine-learning/aws-and-hugging-face-collaborate-to-simplify-and-accelerate-adoption-of-natural-language-processing-models/)
- [Walkthrough: End-to-End Text Classification](https://youtu.be/ok3hetb42gU)
- [Working with Hugging Face models on Amazon SageMaker](https://youtu.be/leyrCgLAGjMn)
- [Distributed Training: Train BART/T5 for Summarization using 🤗 Transformers and Amazon SageMaker](https://huggingface.co/blog/sagemaker-distributed-training-seq2seq)
- [Deploy a Hugging Face Transformers Model from S3 to Amazon SageMaker](https://youtu.be/pfBGgSGnYLs)
- [Deploy a Hugging Face Transformers Model from the Model Hub to Amazon SageMaker](https://youtu.be/l9QZuazbzWM)
### Documentation
- [Run training on Amazon SageMaker](/docs/sagemaker/train)
- [Deploy models to Amazon SageMaker](/docs/sagemaker/inference)
- [Reference](/docs/sagemaker/reference)
- [Amazon SageMaker documentation for Hugging Face](https://docs.aws.amazon.com/sagemaker/latest/dg/hugging-face.html)
- [Python SDK SageMaker documentation for Hugging Face](https://sagemaker.readthedocs.io/en/stable/frameworks/huggingface/index.html)
- [Deep Learning Container](https://github.com/aws/deep-learning-containers/blob/master/available_images.md#huggingface-training-containers)
- [SageMaker's Distributed Data Parallel Library](https://docs.aws.amazon.com/sagemaker/latest/dg/data-parallel.html)
- [SageMaker's Distributed Model Parallel Library](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel.html)
### Sample notebooks
- [All notebooks](https://github.com/huggingface/notebooks/tree/master/sagemaker)
- [Getting Started with Pytorch](https://github.com/huggingface/notebooks/blob/main/sagemaker/01_getting_started_pytorch/sagemaker-notebook.ipynb)
- [Getting Started with Tensorflow](https://github.com/huggingface/notebooks/blob/main/sagemaker/02_getting_started_tensorflow/sagemaker-notebook.ipynb)
- [Distributed Training Data Parallelism](https://github.com/huggingface/notebooks/blob/main/sagemaker/03_distributed_training_data_parallelism/sagemaker-notebook.ipynb)
- [Distributed Training Model Parallelism](https://github.com/huggingface/notebooks/blob/main/sagemaker/04_distributed_training_model_parallelism/sagemaker-notebook.ipynb)
- [Spot Instances and continue training](https://github.com/huggingface/notebooks/blob/main/sagemaker/05_spot_instances/sagemaker-notebook.ipynb)
- [SageMaker Metrics](https://github.com/huggingface/notebooks/blob/main/sagemaker/06_sagemaker_metrics/sagemaker-notebook.ipynb)
- [Distributed Training Data Parallelism Tensorflow](https://github.com/huggingface/notebooks/blob/main/sagemaker/07_tensorflow_distributed_training_data_parallelism/sagemaker-notebook.ipynb)
- [Distributed Training Summarization](https://github.com/huggingface/notebooks/blob/main/sagemaker/08_distributed_summarization_bart_t5/sagemaker-notebook.ipynb)
- [Image Classification with Vision Transformer](https://github.com/huggingface/notebooks/blob/main/sagemaker/09_image_classification_vision_transformer/sagemaker-notebook.ipynb)
- [Deploy one of the 10 000+ Hugging Face Transformers to Amazon SageMaker for Inference](https://github.com/huggingface/notebooks/blob/main/sagemaker/11_deploy_model_from_hf_hub/deploy_transformer_model_from_hf_hub.ipynb)
- [Deploy a Hugging Face Transformer model from S3 to SageMaker for inference](https://github.com/huggingface/notebooks/blob/main/sagemaker/10_deploy_model_from_s3/deploy_transformer_model_from_s3.ipynb)
|
huggingface/hub-docs/blob/main/docs/sagemaker/index.md
|
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# XLS-R
## Overview
The XLS-R model was proposed in [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman
Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
The abstract from the paper is the following:
*This paper presents XLS-R, a large-scale model for cross-lingual speech representation learning based on wav2vec 2.0.
We train models with up to 2B parameters on nearly half a million hours of publicly available speech audio in 128
languages, an order of magnitude more public data than the largest known prior work. Our evaluation covers a wide range
of tasks, domains, data regimes and languages, both high and low-resource. On the CoVoST-2 speech translation
benchmark, we improve the previous state of the art by an average of 7.4 BLEU over 21 translation directions into
English. For speech recognition, XLS-R improves over the best known prior work on BABEL, MLS, CommonVoice as well as
VoxPopuli, lowering error rates by 14-34% relative on average. XLS-R also sets a new state of the art on VoxLingua107
language identification. Moreover, we show that with sufficient model size, cross-lingual pretraining can outperform
English-only pretraining when translating English speech into other languages, a setting which favors monolingual
pretraining. We hope XLS-R can help to improve speech processing tasks for many more languages of the world.*
Relevant checkpoints can be found under https://huggingface.co/models?other=xls_r.
The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
## Usage tips
- XLS-R is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
- XLS-R model was trained using connectionist temporal classification (CTC) so the model output has to be decoded using
[`Wav2Vec2CTCTokenizer`].
<Tip>
XLS-R's architecture is based on the Wav2Vec2 model, refer to [Wav2Vec2's documentation page](wav2vec2) for API reference.
</Tip>
|
huggingface/transformers/blob/main/docs/source/en/model_doc/xls_r.md
|
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# PhoBERT
## Overview
The PhoBERT model was proposed in [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92.pdf) by Dat Quoc Nguyen, Anh Tuan Nguyen.
The abstract from the paper is the following:
*We present PhoBERT with two versions, PhoBERT-base and PhoBERT-large, the first public large-scale monolingual
language models pre-trained for Vietnamese. Experimental results show that PhoBERT consistently outperforms the recent
best pre-trained multilingual model XLM-R (Conneau et al., 2020) and improves the state-of-the-art in multiple
Vietnamese-specific NLP tasks including Part-of-speech tagging, Dependency parsing, Named-entity recognition and
Natural language inference.*
This model was contributed by [dqnguyen](https://huggingface.co/dqnguyen). The original code can be found [here](https://github.com/VinAIResearch/PhoBERT).
## Usage example
```python
>>> import torch
>>> from transformers import AutoModel, AutoTokenizer
>>> phobert = AutoModel.from_pretrained("vinai/phobert-base")
>>> tokenizer = AutoTokenizer.from_pretrained("vinai/phobert-base")
>>> # INPUT TEXT MUST BE ALREADY WORD-SEGMENTED!
>>> line = "Tôi là sinh_viên trường đại_học Công_nghệ ."
>>> input_ids = torch.tensor([tokenizer.encode(line)])
>>> with torch.no_grad():
... features = phobert(input_ids) # Models outputs are now tuples
>>> # With TensorFlow 2.0+:
>>> # from transformers import TFAutoModel
>>> # phobert = TFAutoModel.from_pretrained("vinai/phobert-base")
```
<Tip>
PhoBERT implementation is the same as BERT, except for tokenization. Refer to [EART documentation](bert) for information on
configuration classes and their parameters. PhoBERT-specific tokenizer is documented below.
</Tip>
## PhobertTokenizer
[[autodoc]] PhobertTokenizer
|
huggingface/transformers/blob/main/docs/source/en/model_doc/phobert.md
|
Use with JAX
This document is a quick introduction to using `datasets` with JAX, with a particular focus on how to get
`jax.Array` objects out of our datasets, and how to use them to train JAX models.
<Tip>
`jax` and `jaxlib` are required to reproduce to code above, so please make sure you
install them as `pip install datasets[jax]`.
</Tip>
## Dataset format
By default, datasets return regular Python objects: integers, floats, strings, lists, etc., and
string and binary objects are unchanged, since JAX only supports numbers.
To get JAX arrays (numpy-like) instead, you can set the format of the dataset to `jax`:
```py
>>> from datasets import Dataset
>>> data = [[1, 2], [3, 4]]
>>> ds = Dataset.from_dict({"data": data})
>>> ds = ds.with_format("jax")
>>> ds[0]
{'data': DeviceArray([1, 2], dtype=int32)}
>>> ds[:2]
{'data': DeviceArray([
[1, 2],
[3, 4]], dtype=int32)}
```
<Tip>
A [`Dataset`] object is a wrapper of an Arrow table, which allows fast reads from arrays in the dataset to JAX arrays.
</Tip>
Note that the exact same procedure applies to `DatasetDict` objects, so that
when setting the format of a `DatasetDict` to `jax`, all the `Dataset`s there
will be formatted as `jax`:
```py
>>> from datasets import DatasetDict
>>> data = {"train": {"data": [[1, 2], [3, 4]]}, "test": {"data": [[5, 6], [7, 8]]}}
>>> dds = DatasetDict.from_dict(data)
>>> dds = dds.with_format("jax")
>>> dds["train"][:2]
{'data': DeviceArray([
[1, 2],
[3, 4]], dtype=int32)}
```
Another thing you'll need to take into consideration is that the formatting is not applied
until you actually access the data. So if you want to get a JAX array out of a dataset,
you'll need to access the data first, otherwise the format will remain the same.
Finally, to load the data in the device of your choice, you can specify the `device` argument,
but note that `jaxlib.xla_extension.Device` is not supported as it's not serializable with neither
`pickle` not `dill`, so you'll need to use its string identifier instead:
```py
>>> import jax
>>> from datasets import Dataset
>>> data = [[1, 2], [3, 4]]
>>> ds = Dataset.from_dict({"data": data})
>>> device = str(jax.devices()[0]) # Not casting to `str` before passing it to `with_format` will raise a `ValueError`
>>> ds = ds.with_format("jax", device=device)
>>> ds[0]
{'data': DeviceArray([1, 2], dtype=int32)}
>>> ds[0]["data"].device()
TFRT_CPU_0
>>> assert ds[0]["data"].device() == jax.devices()[0]
True
```
Note that if the `device` argument is not provided to `with_format` then it will use the default
device which is `jax.devices()[0]`.
## N-dimensional arrays
If your dataset consists of N-dimensional arrays, you will see that by default they are considered as nested lists.
In particular, a JAX formatted dataset outputs a `DeviceArray` object, which is a numpy-like array, so it does not
need the [`Array`] feature type to be specified as opposed to PyTorch or TensorFlow formatters.
```py
>>> from datasets import Dataset
>>> data = [[[1, 2],[3, 4]], [[5, 6],[7, 8]]]
>>> ds = Dataset.from_dict({"data": data})
>>> ds = ds.with_format("jax")
>>> ds[0]
{'data': DeviceArray([[1, 2],
[3, 4]], dtype=int32)}
```
## Other feature types
[`ClassLabel`] data is properly converted to arrays:
```py
>>> from datasets import Dataset, Features, ClassLabel
>>> labels = [0, 0, 1]
>>> features = Features({"label": ClassLabel(names=["negative", "positive"])})
>>> ds = Dataset.from_dict({"label": labels}, features=features)
>>> ds = ds.with_format("jax")
>>> ds[:3]
{'label': DeviceArray([0, 0, 1], dtype=int32)}
```
String and binary objects are unchanged, since JAX only supports numbers.
The [`Image`] and [`Audio`] feature types are also supported.
<Tip>
To use the [`Image`] feature type, you'll need to install the `vision` extra as
`pip install datasets[vision]`.
</Tip>
```py
>>> from datasets import Dataset, Features, Image
>>> images = ["path/to/image.png"] * 10
>>> features = Features({"image": Image()})
>>> ds = Dataset.from_dict({"image": images}, features=features)
>>> ds = ds.with_format("jax")
>>> ds[0]["image"].shape
(512, 512, 3)
>>> ds[0]
{'image': DeviceArray([[[ 255, 255, 255],
[ 255, 255, 255],
...,
[ 255, 255, 255],
[ 255, 255, 255]]], dtype=uint8)}
>>> ds[:2]["image"].shape
(2, 512, 512, 3)
>>> ds[:2]
{'image': DeviceArray([[[[ 255, 255, 255],
[ 255, 255, 255],
...,
[ 255, 255, 255],
[ 255, 255, 255]]]], dtype=uint8)}
```
<Tip>
To use the [`Audio`] feature type, you'll need to install the `audio` extra as
`pip install datasets[audio]`.
</Tip>
```py
>>> from datasets import Dataset, Features, Audio
>>> audio = ["path/to/audio.wav"] * 10
>>> features = Features({"audio": Audio()})
>>> ds = Dataset.from_dict({"audio": audio}, features=features)
>>> ds = ds.with_format("jax")
>>> ds[0]["audio"]["array"]
DeviceArray([-0.059021 , -0.03894043, -0.00735474, ..., 0.0133667 ,
0.01809692, 0.00268555], dtype=float32)
>>> ds[0]["audio"]["sampling_rate"]
DeviceArray(44100, dtype=int32, weak_type=True)
```
## Data loading
JAX doesn't have any built-in data loading capabilities, so you'll need to use a library such
as [PyTorch](https://pytorch.org/) to load your data using a `DataLoader` or [TensorFlow](https://www.tensorflow.org/)
using a `tf.data.Dataset`. Citing the [JAX documentation](https://jax.readthedocs.io/en/latest/notebooks/Neural_Network_and_Data_Loading.html#data-loading-with-pytorch) on this topic:
"JAX is laser-focused on program transformations and accelerator-backed NumPy, so we don’t
include data loading or munging in the JAX library. There are already a lot of great data loaders
out there, so let’s just use them instead of reinventing anything. We’ll grab PyTorch’s data loader,
and make a tiny shim to make it work with NumPy arrays.".
So that's the reason why JAX-formatting in `datasets` is so useful, because it lets you use
any model from the HuggingFace Hub with JAX, without having to worry about the data loading
part.
### Using `with_format('jax')`
The easiest way to get JAX arrays out of a dataset is to use the `with_format('jax')` method. Lets assume
that we want to train a neural network on the [MNIST dataset](http://yann.lecun.com/exdb/mnist/) available
at the HuggingFace Hub at https://huggingface.co/datasets/mnist.
```py
>>> from datasets import load_dataset
>>> ds = load_dataset("mnist")
>>> ds = ds.with_format("jax")
>>> ds["train"][0]
{'image': DeviceArray([[ 0, 0, 0, ...],
[ 0, 0, 0, ...],
...,
[ 0, 0, 0, ...],
[ 0, 0, 0, ...]], dtype=uint8),
'label': DeviceArray(5, dtype=int32)}
```
Once the format is set we can feed the dataset to the JAX model in batches using the `Dataset.iter()`
method:
```py
>>> for epoch in range(epochs):
... for batch in ds["train"].iter(batch_size=32):
... x, y = batch["image"], batch["label"]
... ...
```
|
huggingface/datasets/blob/main/docs/source/use_with_jax.mdx
|
Build and load
Nearly every deep learning workflow begins with loading a dataset, which makes it one of the most important steps. With 🤗 Datasets, there are more than 900 datasets available to help you get started with your NLP task. All you have to do is call: [`load_dataset`] to take your first step. This function is a true workhorse in every sense because it builds and loads every dataset you use.
## ELI5: `load_dataset`
Let's begin with a basic Explain Like I'm Five.
A dataset is a directory that contains:
- Some data files in generic formats (JSON, CSV, Parquet, text, etc.)
- A dataset card named `README.md` that contains documentation about the dataset as well as a YAML header to define the datasets tags and configurations
- An optional dataset script if it requires some code to read the data files. This is sometimes used to load files of specific formats and structures.
The [`load_dataset`] function fetches the requested dataset locally or from the Hugging Face Hub.
The Hub is a central repository where all the Hugging Face datasets and models are stored.
If the dataset only contains data files, then [`load_dataset`] automatically infers how to load the data files from their extensions (json, csv, parquet, txt, etc.).
Under the hood, 🤗 Datasets will use an appropriate [`DatasetBuilder`] based on the data files format. There exist one builder per data file format in 🤗 Datasets:
* [`datasets.packaged_modules.text.Text`] for text
* [`datasets.packaged_modules.csv.Csv`] for CSV and TSV
* [`datasets.packaged_modules.json.Json`] for JSON and JSONL
* [`datasets.packaged_modules.parquet.Parquet`] for Parquet
* [`datasets.packaged_modules.arrow.Arrow`] for Arrow (streaming file format)
* [`datasets.packaged_modules.sql.Sql`] for SQL databases
* [`datasets.packaged_modules.imagefolder.ImageFolder`] for image folders
* [`datasets.packaged_modules.audiofolder.AudioFolder`] for audio folders
If the dataset has a dataset script, then it downloads and imports it from the Hugging Face Hub.
Code in the dataset script defines a custom [`DatasetBuilder`] the dataset information (description, features, URL to the original files, etc.), and tells 🤗 Datasets how to generate and display examples from it.
<Tip>
Read the [Share](./upload_dataset) section to learn more about how to share a dataset. This section also provides a step-by-step guide on how to write your own dataset loading script!
</Tip>
🤗 Datasets downloads the dataset files from the original URL, generates the dataset and caches it in an Arrow table on your drive.
If you've downloaded the dataset before, then 🤗 Datasets will reload it from the cache to save you the trouble of downloading it again.
Now that you have a high-level understanding about how datasets are built, let's take a closer look at the nuts and bolts of how all this works.
## Building a dataset
When you load a dataset for the first time, 🤗 Datasets takes the raw data file and builds it into a table of rows and typed columns. There are two main classes responsible for building a dataset: [`BuilderConfig`] and [`DatasetBuilder`].
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/builderconfig.png"/>
</div>
### BuilderConfig[[datasets-builderconfig]]
[`BuilderConfig`] is the configuration class of [`DatasetBuilder`]. The [`BuilderConfig`] contains the following basic attributes about a dataset:
| Attribute | Description |
|---------------|--------------------------------------------------------------|
| `name` | Short name of the dataset. |
| `version` | Dataset version identifier. |
| `data_dir` | Stores the path to a local folder containing the data files. |
| `data_files` | Stores paths to local data files. |
| `description` | Description of the dataset. |
If you want to add additional attributes to your dataset such as the class labels, you can subclass the base [`BuilderConfig`] class. There are two ways to populate the attributes of a [`BuilderConfig`] class or subclass:
- Provide a list of predefined [`BuilderConfig`] class (or subclass) instances in the datasets [`DatasetBuilder.BUILDER_CONFIGS`] attribute.
- When you call [`load_dataset`], any keyword arguments that are not specific to the method will be used to set the associated attributes of the [`BuilderConfig`] class. This will override the predefined attributes if a specific configuration was selected.
You can also set the [`DatasetBuilder.BUILDER_CONFIG_CLASS`] to any custom subclass of [`BuilderConfig`].
### DatasetBuilder[[datasets-datasetbuilder]]
[`DatasetBuilder`] accesses all the attributes inside [`BuilderConfig`] to build the actual dataset.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/datasetbuilder.png"/>
</div>
There are three main methods in [`DatasetBuilder`]:
1. [`DatasetBuilder._info`] is in charge of defining the dataset attributes. When you call `dataset.info`, 🤗 Datasets returns the information stored here. Likewise, the [`Features`] are also specified here. Remember, the [`Features`] are like the skeleton of the dataset. It provides the names and types of each column.
2. [`DatasetBuilder._split_generator`] downloads or retrieves the requested data files, organizes them into splits, and defines specific arguments for the generation process. This method has a [`DownloadManager`] that downloads files or fetches them from your local filesystem. Within the [`DownloadManager`], there is a [`DownloadManager.download_and_extract`] method that accepts a dictionary of URLs to the original data files, and downloads the requested files. Accepted inputs include: a single URL or path, or a list/dictionary of URLs or paths. Any compressed file types like TAR, GZIP and ZIP archives will be automatically extracted.
Once the files are downloaded, [`SplitGenerator`] organizes them into splits. The [`SplitGenerator`] contains the name of the split, and any keyword arguments that are provided to the [`DatasetBuilder._generate_examples`] method. The keyword arguments can be specific to each split, and typically comprise at least the local path to the data files for each split.
3. [`DatasetBuilder._generate_examples`] reads and parses the data files for a split. Then it yields dataset examples according to the format specified in the `features` from [`DatasetBuilder._info`]. The input of [`DatasetBuilder._generate_examples`] is actually the `filepath` provided in the keyword arguments of the last method.
The dataset is generated with a Python generator, which doesn't load all the data in memory. As a result, the generator can handle large datasets. However, before the generated samples are flushed to the dataset file on disk, they are stored in an `ArrowWriter` buffer. This means the generated samples are written by batch. If your dataset samples consumes a lot of memory (images or videos), then make sure to specify a low value for the `DEFAULT_WRITER_BATCH_SIZE` attribute in [`DatasetBuilder`]. We recommend not exceeding a size of 200 MB.
## Maintaining integrity
To ensure a dataset is complete, [`load_dataset`] will perform a series of tests on the downloaded files to make sure everything is there. This way, you don't encounter any surprises when your requested dataset doesn't get generated as expected. [`load_dataset`] verifies:
- The number of splits in the generated `DatasetDict`.
- The number of samples in each split of the generated `DatasetDict`.
- The list of downloaded files.
- The SHA256 checksums of the downloaded files (disabled by defaut).
If the dataset doesn't pass the verifications, it is likely that the original host of the dataset made some changes in the data files.
<Tip>
If it is your own dataset, you'll need to recompute the information above and update the `README.md` file in your dataset repository. Take a look at this [section](dataset_script#optional-generate-dataset-metadata) to learn how to generate and update this metadata.
</Tip>
In this case, an error is raised to alert that the dataset has changed.
To ignore the error, one needs to specify `verification_mode="no_checks"` in [`load_dataset`].
Anytime you see a verification error, feel free to open a discussion or pull request in the corresponding dataset "Community" tab, so that the integrity checks for that dataset are updated.
## Security
The dataset repositories on the Hub are scanned for malware, see more information [here](https://huggingface.co/docs/hub/security#malware-scanning).
Moreover the datasets without a namespace (originally contributed on our GitHub repository) have all been reviewed by our maintainers.
The code of these datasets is considered **safe**.
It concerns datasets that are not under a namespace, e.g. "squad" or "glue", unlike the other datasets that are named "username/dataset_name" or "org/dataset_name".
|
huggingface/datasets/blob/main/docs/source/about_dataset_load.mdx
|
The Problem of Variance in Reinforce [[the-problem-of-variance-in-reinforce]]
In Reinforce, we want to **increase the probability of actions in a trajectory proportionally to how high the return is**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit8/pg.jpg" alt="Reinforce"/>
- If the **return is high**, we will **push up** the probabilities of the (state, action) combinations.
- Otherwise, if the **return is low**, it will **push down** the probabilities of the (state, action) combinations.
This return \\(R(\tau)\\) is calculated using a *Monte-Carlo sampling*. We collect a trajectory and calculate the discounted return, **and use this score to increase or decrease the probability of every action taken in that trajectory**. If the return is good, all actions will be “reinforced” by increasing their likelihood of being taken.
\\(R(\tau) = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ...\\)
The advantage of this method is that **it’s unbiased. Since we’re not estimating the return**, we use only the true return we obtain.
Given the stochasticity of the environment (random events during an episode) and stochasticity of the policy, **trajectories can lead to different returns, which can lead to high variance**. Consequently, the same starting state can lead to very different returns.
Because of this, **the return starting at the same state can vary significantly across episodes**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit8/variance.jpg" alt="variance"/>
The solution is to mitigate the variance by **using a large number of trajectories, hoping that the variance introduced in any one trajectory will be reduced in aggregate and provide a "true" estimation of the return.**
However, increasing the batch size significantly **reduces sample efficiency**. So we need to find additional mechanisms to reduce the variance.
---
If you want to dive deeper into the question of variance and bias tradeoff in Deep Reinforcement Learning, you can check out these two articles:
- [Making Sense of the Bias / Variance Trade-off in (Deep) Reinforcement Learning](https://blog.mlreview.com/making-sense-of-the-bias-variance-trade-off-in-deep-reinforcement-learning-79cf1e83d565)
- [Bias-variance Tradeoff in Reinforcement Learning](https://www.endtoend.ai/blog/bias-variance-tradeoff-in-reinforcement-learning/)
---
|
huggingface/deep-rl-class/blob/main/units/en/unit6/variance-problem.mdx
|
--
title: "Making LLMs lighter with AutoGPTQ and transformers"
thumbnail: /blog/assets/159_autogptq_transformers/thumbnail.jpg
authors:
- user: marcsun13
- user: fxmarty
- user: PanEa
guest: true
- user: qwopqwop
guest: true
- user: ybelkada
- user: TheBloke
guest: true
---
# Making LLMs lighter with AutoGPTQ and transformers
Large language models have demonstrated remarkable capabilities in understanding and generating human-like text, revolutionizing applications across various domains. However, the demands they place on consumer hardware for training and deployment have become increasingly challenging to meet.
🤗 Hugging Face's core mission is to _democratize good machine learning_, and this includes making large models as accessible as possible for everyone. In the same spirit as our [bitsandbytes collaboration](https://huggingface.co/blog/4bit-transformers-bitsandbytes), we have just integrated the [AutoGPTQ](https://github.com/PanQiWei/AutoGPTQ) library in Transformers, making it possible for users to quantize and run models in 8, 4, 3, or even 2-bit precision using the GPTQ algorithm ([Frantar et al. 2023](https://arxiv.org/pdf/2210.17323.pdf)). There is negligible accuracy degradation with 4-bit quantization, with inference speed comparable to the `fp16` baseline for small batch sizes. Note that GPTQ method slightly differs from post-training quantization methods proposed by bitsandbytes as it requires to pass a calibration dataset.
This integration is available both for Nvidia GPUs, and RoCm-powered AMD GPUs.
## Table of contents
- [Resources](#resources)
- [**A gentle summary of the GPTQ paper**](#a-gentle-summary-of-the-gptq-paper)
- [AutoGPTQ library – the one-stop library for efficiently leveraging GPTQ for LLMs](#autogptq-library--the-one-stop-library-for-efficiently-leveraging-gptq-for-llms)
- [Native support of GPTQ models in 🤗 Transformers](#native-support-of-gptq-models-in-🤗-transformers)
- [Quantizing models **with the Optimum library**](#quantizing-models-with-the-optimum-library)
- [Running GPTQ models through ***Text-Generation-Inference***](#running-gptq-models-through-text-generation-inference)
- [**Fine-tune quantized models with PEFT**](#fine-tune-quantized-models-with-peft)
- [Room for improvement](#room-for-improvement)
* [Supported models](#supported-models)
- [Conclusion and final words](#conclusion-and-final-words)
- [Acknowledgements](#acknowledgements)
## Resources
This blogpost and release come with several resources to get started with GPTQ quantization:
- [Original Paper](https://arxiv.org/pdf/2210.17323.pdf)
- [Basic usage Google Colab notebook](https://colab.research.google.com/drive/1_TIrmuKOFhuRRiTWN94iLKUFu6ZX4ceb?usp=sharing) - This notebook shows how to quantize your transformers model with GPTQ method, how to do inference, and how to do fine-tuning with the quantized model.
- Transformers integration [documentation](https://huggingface.co/docs/transformers/main/en/main_classes/quantization)
- Optimum integration [documentation](https://huggingface.co/docs/optimum/llm_quantization/usage_guides/quantization)
- The Bloke [repositories](https://huggingface.co/TheBloke?sort_models=likes#models) with compatible GPTQ models.
## **A gentle summary of the GPTQ paper**
Quantization methods usually belong to one of two categories:
1. Post-Training Quantization (PTQ): We quantize a pre-trained model using moderate resources, such as a calibration dataset and a few hours of computation.
2. Quantization-Aware Training (QAT): Quantization is performed before training or further fine-tuning.
GPTQ falls into the PTQ category and this is particularly interesting for massive models, for which full model training or even fine-tuning can be very expensive.
Specifically, GPTQ adopts a mixed int4/fp16 quantization scheme where weights are quantized as int4 while activations remain in float16. During inference, weights are dequantized on the fly and the actual compute is performed in float16.
The benefits of this scheme are twofold:
- Memory savings close to x4 for int4 quantization, as the dequantization happens close to the compute unit in a fused kernel, and not in the GPU global memory.
- Potential speedups thanks to the time saved on data communication due to the lower bitwidth used for weights.
The GPTQ paper tackles the layer-wise compression problem:
Given a layer \\(l\\) with weight matrix \\(W_{l}\\) and layer input \\(X_{l}\\), we want to find a quantized version of the weight \\(\hat{W}_{l}\\) to minimize the mean squared error (MSE):
\\({\hat{W}_{l}}^{*} = argmin_{\hat{W_{l}}} \|W_{l}X-\hat{W}_{l}X\|^{2}_{2}\\)
Once this is solved per layer, a solution to the global problem can be obtained by combining the layer-wise solutions.
In order to solve this layer-wise compression problem, the author uses the Optimal Brain Quantization framework ([Frantar et al 2022](https://arxiv.org/abs/2208.11580)). The OBQ method starts from the observation that the above equation can be written as the sum of the squared errors, over each row of \\(W_{l}\\).
\\( \sum_{i=0}^{d_{row}} \|W_{l[i,:]}X-\hat{W}_{l[i,:]}X\|^{2}_{2} \\)
This means that we can quantize each row independently. This is called per-channel quantization. For each row \\(W_{l[i,:]}\\), OBQ quantizes one weight at a time while always updating all not-yet-quantized weights, in order to compensate for the error incurred by quantizing a single weight. The update on selected weights has a closed-form formula, utilizing Hessian matrices.
The GPTQ paper improves this framework by introducing a set of optimizations that reduces the complexity of the quantization algorithm while retaining the accuracy of the model.
Compared to OBQ, the quantization step itself is also faster with GPTQ: it takes 2 GPU-hours to quantize a BERT model (336M) with OBQ, whereas with GPTQ, a Bloom model (176B) can be quantized in less than 4 GPU-hours.
To learn more about the exact algorithm and the different benchmarks on perplexity and speedups, check out the original [paper](https://arxiv.org/pdf/2210.17323.pdf).
## AutoGPTQ library – the one-stop library for efficiently leveraging GPTQ for LLMs
The AutoGPTQ library enables users to quantize 🤗 Transformers models using the GPTQ method. While parallel community efforts such as [GPTQ-for-LLaMa](https://github.com/qwopqwop200/GPTQ-for-LLaMa), [Exllama](https://github.com/turboderp/exllama) and [llama.cpp](https://github.com/ggerganov/llama.cpp/) implement quantization methods strictly for the Llama architecture, AutoGPTQ gained popularity through its smooth coverage of a wide range of transformer architectures.
Since the AutoGPTQ library has a larger coverage of transformers models, we decided to provide an integrated 🤗 Transformers API to make LLM quantization more accessible to everyone. At this time we have integrated the most common optimization options, such as CUDA kernels. For more advanced options like Triton kernels or fused-attention compatibility, check out the [AutoGPTQ](https://github.com/PanQiWei/AutoGPTQ) library.
## Native support of GPTQ models in 🤗 Transformers
After [installing the AutoGPTQ library](https://github.com/PanQiWei/AutoGPTQ#quick-installation) and `optimum` (`pip install optimum`), running GPTQ models in Transformers is now as simple as:
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("TheBloke/Llama-2-7b-Chat-GPTQ", torch_dtype=torch.float16, device_map="auto")
```
Check out the Transformers [documentation](https://huggingface.co/docs/transformers/main/en/main_classes/quantization) to learn more about all the features.
Our AutoGPTQ integration has many advantages:
- Quantized models are serializable and can be shared on the Hub.
- GPTQ drastically reduces the memory requirements to run LLMs, while the inference latency is on par with FP16 inference.
- AutoGPTQ supports Exllama kernels for a wide range of architectures.
- The integration comes with native RoCm support for AMD GPUs.
- [Finetuning with PEFT](#--fine-tune-quantized-models-with-peft--) is available.
You can check on the Hub if your favorite model has already been quantized. TheBloke, one of Hugging Face top contributors, has quantized a lot of models with AutoGPTQ and shared them on the Hugging Face Hub. We worked together to make sure that these repositories will work out of the box with our integration.
This is a benchmark sample for the batch size = 1 case. The benchmark was run on a single NVIDIA A100-SXM4-80GB GPU. We used a prompt length of 512, and generated exactly 512 new tokens. The first row is the unquantized `fp16` baseline, while the other rows show memory consumption and performance using different AutoGPTQ kernels.
| gptq | act_order | bits | group_size | kernel | Load time (s) | Per-token latency (ms) | Throughput (tokens/s) | Peak memory (MB) |
|-------|-----------|------|------------|-------------------|---------------|------------------------|-----------------------|------------------|
| False | None | None | None | None | 26.0 | 36.958 | 27.058 | 29152.98 |
| True | False | 4 | 128 | exllama | 36.2 | 33.711 | 29.663 | 10484.34 |
| True | False | 4 | 128 | autogptq-cuda-old | 36.2 | 46.44 | 21.53 | 10344.62 |
A more comprehensive reproducible benchmark is available [here](https://github.com/huggingface/optimum/tree/main/tests/benchmark#gptq-benchmark).
## Quantizing models **with the Optimum library**
To seamlessly integrate AutoGPTQ into Transformers, we used a minimalist version of the AutoGPTQ API that is available in [Optimum](https://github.com/huggingface/optimum), Hugging Face's toolkit for training and inference optimization. By following this approach, we achieved easy integration with Transformers, while allowing people to use the Optimum API if they want to quantize their own models! Check out the Optimum [documentation](https://huggingface.co/docs/optimum/llm_quantization/usage_guides/quantization) if you want to quantize your own LLMs.
Quantizing 🤗 Transformers models with the GPTQ method can be done in a few lines:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfig
model_id = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(model_id)
quantization_config = GPTQConfig(bits=4, dataset = "c4", tokenizer=tokenizer)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", quantization_config=quantization_config)
```
Quantizing a model may take a long time. Note that for a 175B model, at least 4 GPU-hours are required if one uses a large dataset (e.g. `"c4"``). As mentioned above, many GPTQ models are already available on the Hugging Face Hub, which bypasses the need to quantize a model yourself in most use cases. Nevertheless, you can also quantize a model using your own dataset appropriate for the particular domain you are working on.
## Running GPTQ models through ***Text-Generation-Inference***
In parallel to the integration of GPTQ in Transformers, GPTQ support was added to the [Text-Generation-Inference library](https://github.com/huggingface/text-generation-inference) (TGI), aimed at serving large language models in production. GPTQ can now be used alongside features such as dynamic batching, paged attention and flash attention for a [wide range of architectures](https://huggingface.co/docs/text-generation-inference/main/en/supported_models).
As an example, this integration allows to serve a 70B model on a single A100-80GB GPU! This is not possible using a fp16 checkpoint as it exceeds the available GPU memory.
You can find out more about the usage of GPTQ in TGI in [the documentation](https://huggingface.co/docs/text-generation-inference/main/en/basic_tutorials/preparing_model#quantization).
Note that the kernel integrated in TGI does not scale very well with larger batch sizes. Although this approach saves memory, slowdowns are expected at larger batch sizes.
## **Fine-tune quantized models with PEFT**
You can not further train a quantized model using the regular methods. However, by leveraging the PEFT library, you can train adapters on top! To do that, we freeze all the layers of the quantized model and add the trainable adapters. Here are some examples on how to use PEFT with a GPTQ model: [colab notebook](https://colab.research.google.com/drive/1VoYNfYDKcKRQRor98Zbf2-9VQTtGJ24k?usp=sharing) and [finetuning](https://gist.github.com/SunMarc/dcdb499ac16d355a8f265aa497645996) script.
## Room for improvement
Our AutoGPTQ integration already brings impressive benefits at a small cost in the quality of prediction. There is still room for improvement, both in the quantization techniques and the kernel implementations.
First, while AutoGPTQ integrates (to the best of our knowledge) with the most performant W4A16 kernel (weights as int4, activations as fp16) from the [exllama implementation](https://github.com/turboderp/exllama), there is a good chance that the kernel can still be improved. There have been other promising implementations [from Kim et al.](https://arxiv.org/pdf/2211.10017.pdf) and from [MIT Han Lab](https://github.com/mit-han-lab/llm-awq) that appear to be promising. Moreover, from internal benchmarks, there appears to still be no open-source performant W4A16 kernel written in Triton, which could be a direction to explore.
On the quantization side, let’s emphasize again that this method only quantizes the weights. There have been other approaches proposed for LLM quantization that can quantize both weights and activations at a small cost in prediction quality, such as [LLM-QAT](https://arxiv.org/pdf/2305.17888.pdf) where a mixed int4/int8 scheme can be used, as well as quantization of the key-value cache. One of the strong advantages of this technique is the ability to use actual integer arithmetic for the compute, with e.g. [Nvidia Tensor Cores supporting int8 compute](https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/a100/pdf/nvidia-a100-datasheet-us-nvidia-1758950-r4-web.pdf). However, to the best of our knowledge, there are no open-source W4A8 quantization kernels available, but this may well be [an interesting direction to explore](https://www.qualcomm.com/news/onq/2023/04/floating-point-arithmetic-for-ai-inference-hit-or-miss).
On the kernel side as well, designing performant W4A16 kernels for larger batch sizes remains an open challenge.
### Supported models
In this initial implementation, only large language models with a decoder or encoder only architecture are supported. This may sound a bit restrictive, but it encompasses most state of the art LLMs such as Llama, OPT, GPT-Neo, GPT-NeoX.
Very large vision, audio, and multi-modal models are currently not supported.
## Conclusion and final words
In this blogpost we have presented the integration of the [AutoGPTQ library](https://github.com/PanQiWei/AutoGPTQ) in Transformers, making it possible to quantize LLMs with the GPTQ method to make them more accessible for anyone in the community and empower them to build exciting tools and applications with LLMs.
This integration is available both for Nvidia GPUs, and RoCm-powered AMD GPUs, which is a huge step towards democratizing quantized models for broader GPU architectures.
The collaboration with the AutoGPTQ team has been very fruitful, and we are very grateful for their support and their work on this library.
We hope that this integration will make it easier for everyone to use LLMs in their applications, and we are looking forward to seeing what you will build with it!
Do not miss the useful resources shared above for better understanding the integration and how to quickly get started with GPTQ quantization.
- [Original Paper](https://arxiv.org/pdf/2210.17323.pdf)
- [Basic usage Google Colab notebook](https://colab.research.google.com/drive/1_TIrmuKOFhuRRiTWN94iLKUFu6ZX4ceb?usp=sharing) - This notebook shows how to quantize your transformers model with GPTQ method, how to do inference, and how to do fine-tuning with the quantized model.
- Transformers integration [documentation](https://huggingface.co/docs/transformers/main/en/main_classes/quantization)
- Optimum integration [documentation](https://huggingface.co/docs/optimum/llm_quantization/usage_guides/quantization)
- The Bloke [repositories](https://huggingface.co/TheBloke?sort_models=likes#models) with compatible GPTQ models.
## Acknowledgements
We would like to thank [William](https://github.com/PanQiWei) for his support and his work on the amazing AutoGPTQ library and for his help in the integration.
We would also like to thank [TheBloke](https://huggingface.co/TheBloke) for his work on quantizing many models with AutoGPTQ and sharing them on the Hub and for his help with the integration.
We would also like to aknowledge [qwopqwop200](https://github.com/qwopqwop200) for his continuous contributions on AutoGPTQ library and his work on extending the library for CPU that is going to be released in the next versions of AutoGPTQ.
Finally, we would like to thank [Pedro Cuenca](https://github.com/pcuenca) for his help with the writing of this blogpost.
|
huggingface/blog/blob/main/gptq-integration.md
|
Metric Card for Accuracy
## Metric Description
Accuracy is the proportion of correct predictions among the total number of cases processed. It can be computed with:
Accuracy = (TP + TN) / (TP + TN + FP + FN)
Where:
TP: True positive
TN: True negative
FP: False positive
FN: False negative
## How to Use
At minimum, this metric requires predictions and references as inputs.
```python
>>> accuracy_metric = datasets.load_metric("accuracy")
>>> results = accuracy_metric.compute(references=[0, 1], predictions=[0, 1])
>>> print(results)
{'accuracy': 1.0}
```
### Inputs
- **predictions** (`list` of `int`): Predicted labels.
- **references** (`list` of `int`): Ground truth labels.
- **normalize** (`boolean`): If set to False, returns the number of correctly classified samples. Otherwise, returns the fraction of correctly classified samples. Defaults to True.
- **sample_weight** (`list` of `float`): Sample weights Defaults to None.
### Output Values
- **accuracy**(`float` or `int`): Accuracy score. Minimum possible value is 0. Maximum possible value is 1.0, or the number of examples input, if `normalize` is set to `True`.. A higher score means higher accuracy.
Output Example(s):
```python
{'accuracy': 1.0}
```
This metric outputs a dictionary, containing the accuracy score.
#### Values from Popular Papers
Top-1 or top-5 accuracy is often used to report performance on supervised classification tasks such as image classification (e.g. on [ImageNet](https://paperswithcode.com/sota/image-classification-on-imagenet)) or sentiment analysis (e.g. on [IMDB](https://paperswithcode.com/sota/text-classification-on-imdb)).
### Examples
Example 1-A simple example
```python
>>> accuracy_metric = datasets.load_metric("accuracy")
>>> results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0])
>>> print(results)
{'accuracy': 0.5}
```
Example 2-The same as Example 1, except with `normalize` set to `False`.
```python
>>> accuracy_metric = datasets.load_metric("accuracy")
>>> results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0], normalize=False)
>>> print(results)
{'accuracy': 3.0}
```
Example 3-The same as Example 1, except with `sample_weight` set.
```python
>>> accuracy_metric = datasets.load_metric("accuracy")
>>> results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0], sample_weight=[0.5, 2, 0.7, 0.5, 9, 0.4])
>>> print(results)
{'accuracy': 0.8778625954198473}
```
## Limitations and Bias
This metric can be easily misleading, especially in the case of unbalanced classes. For example, a high accuracy might be because a model is doing well, but if the data is unbalanced, it might also be because the model is only accurately labeling the high-frequency class. In such cases, a more detailed analysis of the model's behavior, or the use of a different metric entirely, is necessary to determine how well the model is actually performing.
## Citation(s)
```bibtex
@article{scikit-learn,
title={Scikit-learn: Machine Learning in {P}ython},
author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V.
and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P.
and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and
Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.},
journal={Journal of Machine Learning Research},
volume={12},
pages={2825--2830},
year={2011}
}
```
## Further References
|
huggingface/datasets/blob/main/metrics/accuracy/README.md
|
Hub API Endpoints
We have open endpoints that you can use to retrieve information from the Hub as well as perform certain actions such as creating model, dataset or Space repos. We offer a wrapper Python library, [`huggingface_hub`](https://github.com/huggingface/huggingface_hub), that allows easy access to these endpoints. We also provide [webhooks](./webhooks) to receive real-time incremental info about repos. Enjoy!
The base URL for those endpoints below is `https://huggingface.co`. For example, to construct the `/api/models` call below, one can call the URL [https://huggingface.co/api/models](https://huggingface.co/api/models)
## The Hub API Playground
Want to try out our API?
Try it out now on our [Playground](https://huggingface.co/spaces/enzostvs/hub-api-playground)!
<div class="flex justify-center">
<a href="https://huggingface.co/spaces/enzostvs/hub-api-playground" target="_blank">
<img class="w-full object-contain" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/hub-api-playground.png"/>
</a>
</div>
## Repo listing API
The following endpoints help get information about models, datasets, Spaces, and metrics stored on the Hub.
<Tip>
When making API calls to retrieve information about repositories, the <code>createdAt</code> attribute indicates the time when the respective repository was created. It's important to note that there is a unique value, <code>2022-03-02T23:29:04.000Z</code> assigned to all repositories that were created before we began storing creation dates.
</Tip>
### GET /api/models
Get information from all models in the Hub. The response is paginated, use the [`Link` header](https://docs.github.com/en/rest/guides/using-pagination-in-the-rest-api?apiVersion=2022-11-28#link-header) to get the next pages. You can specify additional parameters to have more specific results.
- `search`: Filter based on substrings for repos and their usernames, such as `resnet` or `microsoft`
- `author`: Filter models by an author or organization, such as `huggingface` or `microsoft`
- `filter`: Filter based on tags, such as `text-classification` or `spacy`.
- `sort`: Property to use when sorting, such as `downloads` or `author`.
- `direction`: Direction in which to sort, such as `-1` for descending, and anything else for ascending.
- `limit`: Limit the number of models fetched.
- `full`: Whether to fetch most model data, such as all tags, the files, etc.
- `config`: Whether to also fetch the repo config.
Payload:
```js
params = {
"search":"search",
"author":"author",
"filter":"filter",
"sort":"sort",
"direction":"direction",
"limit":"limit",
"full":"full",
"config":"config"
}
```
This is equivalent to `huggingface_hub.list_models()`.
### GET /api/models/{repo_id} or /api/models/{repo_id}/revision/{revision}
Get all information for a specific model.
This is equivalent to `huggingface_hub.model_info(repo_id, revision)`.
### GET /api/models-tags-by-type
Gets all the available model tags hosted in the Hub.
This is equivalent to `huggingface_hub.get_model_tags()`.
### GET /api/datasets
Get information from all datasets in the Hub. The response is paginated, use the [`Link` header](https://docs.github.com/en/rest/guides/using-pagination-in-the-rest-api?apiVersion=2022-11-28#link-header) to get the next pages. You can specify additional parameters to have more specific results.
- `search`: Filter based on substrings for repos and their usernames, such as `pets` or `microsoft`
- `author`: Filter datasets by an author or organization, such as `huggingface` or `microsoft`
- `filter`: Filter based on tags, such as `task_categories:text-classification` or `languages:en`.
- `sort`: Property to use when sorting, such as `downloads` or `author`.
- `direction`: Direction in which to sort, such as `-1` for descending, and anything else for ascending.
- `limit`: Limit the number of datasets fetched.
- `full`: Whether to fetch most dataset data, such as all tags, the files, etc.
Payload:
```js
params = {
"search":"search",
"author":"author",
"filter":"filter",
"sort":"sort",
"direction":"direction",
"limit":"limit",
"full":"full",
"config":"config"
}
```
This is equivalent to `huggingface_hub.list_datasets()`.
### GET /api/datasets/{repo_id} or /api/datasets/{repo_id}/revision/{revision}
Get all information for a specific dataset.
- `full`: Whether to fetch most dataset data, such as all tags, the files, etc.
Payload:
```js
params = {"full": "full"}
```
This is equivalent to `huggingface_hub.dataset_info(repo_id, revision)`.
### GET /api/datasets/{repo_id}/parquet
Get the list of auto-converted parquet files.
### GET /api/datasets/{repo_id}/parquet/{config}/{split}/{n}.parquet
Get the nth shard of the auto-converted parquet files.
### GET /api/datasets-tags-by-type
Gets all the available dataset tags hosted in the Hub.
This is equivalent to `huggingface_hub.get_dataset_tags()`.
### GET /api/spaces
Get information from all Spaces in the Hub. The response is paginated, use the [`Link` header](https://docs.github.com/en/rest/guides/using-pagination-in-the-rest-api?apiVersion=2022-11-28#link-header) to get the next pages. You can specify additional parameters to have more specific results.
- `search`: Filter based on substrings for repos and their usernames, such as `resnet` or `microsoft`
- `author`: Filter models by an author or organization, such as `huggingface` or `microsoft`
- `filter`: Filter based on tags, such as `text-classification` or `spacy`.
- `sort`: Property to use when sorting, such as `downloads` or `author`.
- `direction`: Direction in which to sort, such as `-1` for descending, and anything else for ascending.
- `limit`: Limit the number of models fetched.
- `full`: Whether to fetch most model data, such as all tags, the files, etc.
Payload:
```js
params = {
"search":"search",
"author":"author",
"filter":"filter",
"sort":"sort",
"direction":"direction",
"limit":"limit",
"full":"full",
"config":"config"
}
```
This is equivalent to `huggingface_hub.list_spaces()`.
### GET /api/spaces/{repo_id} or /api/spaces/{repo_id}/revision/{revision}
Get all information for a specific model.
This is equivalent to `huggingface_hub.space_info(repo_id, revision)`.
## Repo API
The following endpoints manage repository settings like creating and deleting a repository.
### POST /api/repos/create
Create a repository. It's a model repo by default.
Parameters:
- `type`: Type of repo (dataset or space; model by default).
- `name`: Name of repo.
- `organization`: Name of organization (optional).
- `private`: Whether the repo is private.
- `sdk`: When the type is `space` (streamlit, gradio, docker or static)
Payload:
```js
payload = {
"type":"model",
"name":"name",
"organization": "organization",
"private":"private",
"sdk": "sdk"
}
```
This is equivalent to `huggingface_hub.create_repo()`.
### DELETE /api/repos/delete
Delete a repository. It's a model repo by default.
Parameters:
- `type`: Type of repo (dataset or space; model by default).
- `name`: Name of repo.
- `organization`: Name of organization (optional).
Payload:
```js
payload = {
"type": "model",
"name": "name",
"organization": "organization",
}
```
This is equivalent to `huggingface_hub.delete_repo()`.
### PUT /api/repos/{repo_type}/{repo_id}/settings
Update repo visibility.
Payload:
```js
payload = {
"private": "private",
}
```
This is equivalent to `huggingface_hub.update_repo_visibility()`.
### POST /api/repos/move
Move a repository (rename within the same namespace or transfer from user to organization).
Parameters:
- `fromRepo`: repo to rename.
- `toRepo`: new name of the repo.
- `type`: Type of repo (dataset or space; model by default).
Payload:
```js
payload = {
"fromRepo" : "namespace/repo_name",
"toRepo" : "namespace2/repo_name2",
"type": "model",
}
```
This is equivalent to `huggingface_hub.move_repo()`.
## User API
The following endpoint gets information about a user.
### GET /api/whoami-v2
Get username and organizations the user belongs to.
Payload:
```js
headers = { "authorization" : "Bearer $token" }
```
This is equivalent to `huggingface_hub.whoami()`.
## Collections API
Use Collections to group repositories from the Hub (Models, Datasets, Spaces and Papers) on a dedicated page.
You can learn more about it in the Collections [guide](./collections.md). Collections can also be managed using the Python client (see [guide](https://huggingface.co/docs/huggingface_hub/main/en/guides/collections)).
### POST /api/collections
Create a new collection on the Hub with a title, a description (optional) and a first item (optional). An item is defined by a type (`model`, `dataset`, `space` or `paper`) and an id (repo_id or paper_id on the Hub).
Payload:
```js
payload = {
"title": "My cool models",
"namespace": "username_or_org",
"description": "Here is a shortlist of models I've trained.",
"item" : {
"type": "model",
"id": "username/cool-model",
}
"private": false,
}
```
This is equivalent to `huggingface_hub.create_collection()`.
### GET /api/collections/{namespace}/{slug}-{id}
Return information about a collection.
This is equivalent to `huggingface_hub.get_collection()`.
### GET /api/collections
List collections from the Hub, based on some criteria. The supported parameters are:
- `owner` (string): filter collections created by a specific user or organization.
- `item` (string): filter collections containing a specific item. Value must be the item_type and item_id concatenated. Example: `"models/teknium/OpenHermes-2.5-Mistral-7B"`, `"datasets/squad"` or `"papers/2311.12983"`.
- `sort` (string): sort the returned collections. Supported values are `"lastModified"`, `"trending"` (default) and `"upvotes"`.
- `limit` (int): maximum number (100) of collections per page.
- `q` (string): filter based on substrings for titles & descriptions.
If no parameter is set, all collections are returned.
The response is paginated. To get all collections, you must follow the [`Link` header](https://docs.github.com/en/rest/guides/using-pagination-in-the-rest-api?apiVersion=2022-11-28#link-header).
<Tip warning={true}>
When listing collections, the item list per collection is truncated to 4 items maximum. To retrieve all items from a collection, you need to make an additional call using its collection slug.
</Tip>
Payload:
```js
params = {
"owner": "TheBloke",
"item": "models/teknium/OpenHermes-2.5-Mistral-7B",
"sort": "lastModified",
"limit" : 1,
}
```
This is equivalent to `huggingface_hub.list_collections()`.
### PATCH /api/collections/{namespace}/{slug}-{id}
Update the metadata of a collection on the Hub. You can't add or modify the items of the collection with this method. All fields of the payload are optional.
Payload:
```js
payload = {
"title": "My cool models",
"description": "Here is a shortlist of models I've trained.",
"private": false,
"position": 0, // position of the collection on your profile
"theme": "green",
}
```
This is equivalent to `huggingface_hub.update_collection_metadata()`.
### DELETE /api/collections/{namespace}/{slug}-{id}
Return a collection. This is a non-revertible operation. A deleted collection cannot be restored.
This is equivalent to `huggingface_hub.delete_collection()`.
### POST /api/collections/{namespace}/{slug}-{id}/item
Add an item to a collection. An item is defined by a type (`model`, `dataset`, `space` or `paper`) and an id (repo_id or paper_id on the Hub). A note can also be attached to the item (optional).
Payload:
```js
payload = {
"item" : {
"type": "model",
"id": "username/cool-model",
}
"note": "Here is the model I trained on ...",
}
```
This is equivalent to `huggingface_hub.add_collection_item()`.
### PATCH /api/collections/{namespace}/{slug}-{id}/items/{item_id}
Update an item in a collection. You must know the item object id which is different from the repo_id/paper_id provided when adding the item to the collection. The `item_id` can be retrieved by fetching the collection.
You can update the note attached to the item or the position of the item in the collection. Both fields are optional.
```js
payload = {
"position": 0,
"note": "Here is the model I trained on ...",
}
```
This is equivalent to `huggingface_hub.update_collection_item()`.
### DELETE /api/collections/{namespace}/{slug}-{id}/items/{item_id}
Remove an item from a collection. You must know the item object id which is different from the repo_id/paper_id provided when adding the item to the collection. The `item_id` can be retrieved by fetching the collection.
This is equivalent to `huggingface_hub.delete_collection_item()`.
|
huggingface/hub-docs/blob/main/docs/hub/api.md
|
Displaying carbon emissions for your model
## Why is it beneficial to calculate the carbon emissions of my model?
Training ML models is often energy-intensive and can produce a substantial carbon footprint, as described by [Strubell et al.](https://arxiv.org/abs/1906.02243). It's therefore important to *track* and *report* the emissions of models to get a better idea of the environmental impacts of our field.
## What information should I include about the carbon footprint of my model?
If you can, you should include information about:
- where the model was trained (in terms of location)
- the hardware used -- e.g. GPU, TPU, or CPU, and how many
- training type: pre-training or fine-tuning
- the estimated carbon footprint of the model, calculated in real-time with the [Code Carbon](https://github.com/mlco2/codecarbon) package or after training using the [ML CO2 Calculator](https://mlco2.github.io/impact/).
## Carbon footprint metadata
You can add the carbon footprint data to the model card metadata (in the README.md file). The structure of the metadata should be:
```yaml
---
co2_eq_emissions:
emissions: number (in grams of CO2)
source: "source of the information, either directly from AutoTrain, code carbon or from a scientific article documenting the model"
training_type: "pre-training or fine-tuning"
geographical_location: "as granular as possible, for instance Quebec, Canada or Brooklyn, NY, USA. To check your compute's electricity grid, you can check out https://app.electricitymap.org."
hardware_used: "how much compute and what kind, e.g. 8 v100 GPUs"
---
```
## How is the carbon footprint of my model calculated? 🌎
Considering the computing hardware, location, usage, and training time, you can estimate how much CO<sub>2</sub> the model produced.
The math is pretty simple! ➕
First, you take the *carbon intensity* of the electric grid used for the training -- this is how much CO<sub>2</sub> is produced by KwH of electricity used. The carbon intensity depends on the location of the hardware and the [energy mix](https://electricitymap.org/) used at that location -- whether it's renewable energy like solar 🌞, wind 🌬️ and hydro 💧, or non-renewable energy like coal ⚫ and natural gas 💨. The more renewable energy gets used for training, the less carbon-intensive it is!
Then, you take the power consumption of the GPU during training using the `pynvml` library.
Finally, you multiply the power consumption and carbon intensity by the training time of the model, and you have an estimate of the CO<sub>2</sub> emission.
Keep in mind that this isn't an exact number because other factors come into play -- like the energy used for data center heating and cooling -- which will increase carbon emissions. But this will give you a good idea of the scale of CO<sub>2</sub> emissions that your model is producing!
To add **Carbon Emissions** metadata to your models:
1. If you are using **AutoTrain**, this is tracked for you 🔥
2. Otherwise, use a tracker like Code Carbon in your training code, then specify
```yaml
co2_eq_emissions:
emissions: 1.2345
```
in your model card metadata, where `1.2345` is the emissions value in **grams**.
To learn more about the carbon footprint of Transformers, check out the [video](https://www.youtube.com/watch?v=ftWlj4FBHTg), part of the Hugging Face Course!
|
huggingface/hub-docs/blob/main/docs/hub/model-cards-co2.md
|
hat is the ROUGE metric? For many NLP tasks we can use common metrics like accuracy or F1 score, but what do you do when you want to measure the quality of a summary from a model like T5? In this video, we'll take a look at a widely used metric for text summarization called ROUGE, which is short for Recall-Oriented Understudy for Gisting Evaluation. There are actually several variants of ROUGE, but the basic idea behind all of them is to assign a single numerical score to a summary that tells us how "good" it is compared to one or more reference summaries. In this example we have a book review that has been summarized by some model. If we compare the generated summary to some reference human summaries, we can see that the model is pretty good, and only differs by a word or two. So how can we measure the quality of a generated summary in an automatic way? The approach that ROUGE takes is to compare the n-grams of the generated summary to the n-grams of the references. An n-gram is just a fancy way of saying "a chunk of n words", so let's start with unigrams, which correspond to the individual words in a sentence. In this example you can see that six of the words in the generated summary are also found in one of the reference summaries. The ROUGE metric that compares unigrams is called ROUGE-1. Now that we've found our matches, one way to assign a score to the summary is to compute the recall of the unigrams. This means we just count the number of matching words in the generated and reference summaries and normalize the count by dividing by the number of word in the reference. In this example, we found 6 matching words and our reference has 6 words, so our unigram recall is perfect! This means that all of words in the reference summary have produced in the generated one. Perfect recall sounds great, but imagine if our generated summary had been “I really really really really loved reading the Hunger Games”. This would also have perfect recall, but is arguably a worse summary since it is verbose. To deal with these scenarios we can also compute precision, which in the ROUGE context measures how much of the generated summary was relevant. In this example, the precision is 6/7. In practice, both precision and recall are usually computed and then the F1-score is reported. We can change the granularity of the comparison by comparing bigrams instead of unigrams. With bigrams we chunk the sentence into pairs of consecutive words and then count how many pairs in the generated summary are present in the reference one. This gives us ROUGE-2 precision and recall, which we can see is lower than the ROUGE-1 scores we saw earlier. Note that if the summaries are long, the ROUGE-2 score will be small as there are typically fewer bigrams to match. This is also true for abstractive summarization, so both ROUGE-1 and ROUGE-2 scores are usually reported. The last ROUGE variant we'll discuss is ROUGE-L. ROUGE-L doesn't compare n-grams, but instead treats each summary as a sequence of words and then looks for the longest common subsequence or LCS. A subsequence is a sequence that appears in the same relative order, but not necessarily contiguous. So in this example, "I loved reading the Hunger Games" is the longest common subsequence. The main advantage of ROUGE-L over ROUGE-1 or ROUGE-2 is that is doesn't depend on consecutive n-gram matches, so it tends to capture sentence structure more accurately. To compute ROUGE scores in Hugging Face Datasets is very simple: just use the load_metric() function, provide your model's summaries along with the references and you're good to go! The output from the calculation contains a lot of information! The first thing we can see here is that the confidence intervals of each ROUGE score are provided in the low, mid, and high fields. This is really useful if you want to know the spread of your ROUGE scores when comparing two or more models. The second thing to notice is that we have four types of ROUGE score. We've already seen ROUGE-1, ROUGE-2 and ROUGE-L, so what is ROUGE-LSUM? Well, the “sum” in ROUGE-LSUM refers to the fact that this metric is computed over a whole summary, while ROUGE-L is computed as the average over individual sentences.
|
huggingface/course/blob/main/subtitles/en/raw/chapter7/05b_rouge.md
|
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Interact with Discussions and Pull Requests
The `huggingface_hub` library provides a Python interface to interact with Pull Requests and Discussions on the Hub.
Visit [the dedicated documentation page](https://huggingface.co/docs/hub/repositories-pull-requests-discussions)
for a deeper view of what Discussions and Pull Requests on the Hub are, and how they work under the hood.
## Retrieve Discussions and Pull Requests from the Hub
The `HfApi` class allows you to retrieve Discussions and Pull Requests on a given repo:
```python
>>> from huggingface_hub import get_repo_discussions
>>> for discussion in get_repo_discussions(repo_id="bigscience/bloom"):
... print(f"{discussion.num} - {discussion.title}, pr: {discussion.is_pull_request}")
# 11 - Add Flax weights, pr: True
# 10 - Update README.md, pr: True
# 9 - Training languages in the model card, pr: True
# 8 - Update tokenizer_config.json, pr: True
# 7 - Slurm training script, pr: False
[...]
```
`HfApi.get_repo_discussions` supports filtering by author, type (Pull Request or Discussion) and status (`open` or `closed`):
```python
>>> from huggingface_hub import get_repo_discussions
>>> for discussion in get_repo_discussions(
... repo_id="bigscience/bloom",
... author="ArthurZ",
... discussion_type="pull_request",
... discussion_status="open",
... ):
... print(f"{discussion.num} - {discussion.title} by {discussion.author}, pr: {discussion.is_pull_request}")
# 19 - Add Flax weights by ArthurZ, pr: True
```
`HfApi.get_repo_discussions` returns a [generator](https://docs.python.org/3.7/howto/functional.html#generators) that yields
[`Discussion`] objects. To get all the Discussions in a single list, run:
```python
>>> from huggingface_hub import get_repo_discussions
>>> discussions_list = list(get_repo_discussions(repo_id="bert-base-uncased"))
```
The [`Discussion`] object returned by [`HfApi.get_repo_discussions`] contains high-level overview of the
Discussion or Pull Request. You can also get more detailed information using [`HfApi.get_discussion_details`]:
```python
>>> from huggingface_hub import get_discussion_details
>>> get_discussion_details(
... repo_id="bigscience/bloom-1b3",
... discussion_num=2
... )
DiscussionWithDetails(
num=2,
author='cakiki',
title='Update VRAM memory for the V100s',
status='open',
is_pull_request=True,
events=[
DiscussionComment(type='comment', author='cakiki', ...),
DiscussionCommit(type='commit', author='cakiki', summary='Update VRAM memory for the V100s', oid='1256f9d9a33fa8887e1c1bf0e09b4713da96773a', ...),
],
conflicting_files=[],
target_branch='refs/heads/main',
merge_commit_oid=None,
diff='diff --git a/README.md b/README.md\nindex a6ae3b9294edf8d0eda0d67c7780a10241242a7e..3a1814f212bc3f0d3cc8f74bdbd316de4ae7b9e3 100644\n--- a/README.md\n+++ b/README.md\n@@ -132,7 +132,7 [...]',
)
```
[`HfApi.get_discussion_details`] returns a [`DiscussionWithDetails`] object, which is a subclass of [`Discussion`]
with more detailed information about the Discussion or Pull Request. Information includes all the comments, status changes,
and renames of the Discussion via [`DiscussionWithDetails.events`].
In case of a Pull Request, you can retrieve the raw git diff with [`DiscussionWithDetails.diff`]. All the commits of the
Pull Request are listed in [`DiscussionWithDetails.events`].
## Create and edit a Discussion or Pull Request programmatically
The [`HfApi`] class also offers ways to create and edit Discussions and Pull Requests.
You will need an [access token](https://huggingface.co/docs/hub/security-tokens) to create and edit Discussions
or Pull Requests.
The simplest way to propose changes on a repo on the Hub is via the [`create_commit`] API: just
set the `create_pr` parameter to `True`. This parameter is also available on other methods that wrap [`create_commit`]:
* [`upload_file`]
* [`upload_folder`]
* [`delete_file`]
* [`delete_folder`]
* [`metadata_update`]
```python
>>> from huggingface_hub import metadata_update
>>> metadata_update(
... repo_id="username/repo_name",
... metadata={"tags": ["computer-vision", "awesome-model"]},
... create_pr=True,
... )
```
You can also use [`HfApi.create_discussion`] (respectively [`HfApi.create_pull_request`]) to create a Discussion (respectively a Pull Request) on a repo.
Opening a Pull Request this way can be useful if you need to work on changes locally. Pull Requests opened this way will be in `"draft"` mode.
```python
>>> from huggingface_hub import create_discussion, create_pull_request
>>> create_discussion(
... repo_id="username/repo-name",
... title="Hi from the huggingface_hub library!",
... token="<insert your access token here>",
... )
DiscussionWithDetails(...)
>>> create_pull_request(
... repo_id="username/repo-name",
... title="Hi from the huggingface_hub library!",
... token="<insert your access token here>",
... )
DiscussionWithDetails(..., is_pull_request=True)
```
Managing Pull Requests and Discussions can be done entirely with the [`HfApi`] class. For example:
* [`comment_discussion`] to add comments
* [`edit_discussion_comment`] to edit comments
* [`rename_discussion`] to rename a Discussion or Pull Request
* [`change_discussion_status`] to open or close a Discussion / Pull Request
* [`merge_pull_request`] to merge a Pull Request
Visit the [`HfApi`] documentation page for an exhaustive reference of all available methods.
## Push changes to a Pull Request
*Coming soon !*
## See also
For a more detailed reference, visit the [Discussions and Pull Requests](../package_reference/community) and the [hf_api](../package_reference/hf_api) documentation page.
|
huggingface/huggingface_hub/blob/main/docs/source/en/guides/community.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# OFT
[Orthogonal Finetuning (OFT)](https://hf.co/papers/2306.07280) is a method developed for adapting text-to-image diffusion models. It works by reparameterizing the pretrained weight matrices with it's orthogonal matrix to preserve information in the pretrained model. To reduce the number of parameters, OFT introduces a block-diagonal structure in the orthogonal matrix.
The abstract from the paper is:
*Large text-to-image diffusion models have impressive capabilities in generating photorealistic images from text prompts. How to effectively guide or control these powerful models to perform different downstream tasks becomes an important open problem. To tackle this challenge, we introduce a principled finetuning method -- Orthogonal Finetuning (OFT), for adapting text-to-image diffusion models to downstream tasks. Unlike existing methods, OFT can provably preserve hyperspherical energy which characterizes the pairwise neuron relationship on the unit hypersphere. We find that this property is crucial for preserving the semantic generation ability of text-to-image diffusion models. To improve finetuning stability, we further propose Constrained Orthogonal Finetuning (COFT) which imposes an additional radius constraint to the hypersphere. Specifically, we consider two important finetuning text-to-image tasks: subject-driven generation where the goal is to generate subject-specific images given a few images of a subject and a text prompt, and controllable generation where the goal is to enable the model to take in additional control signals. We empirically show that our OFT framework outperforms existing methods in generation quality and convergence speed*.
## OFTConfig
[[autodoc]] tuners.oft.config.OFTConfig
## OFTModel
[[autodoc]] tuners.oft.model.OFTModel
|
huggingface/peft/blob/main/docs/source/package_reference/oft.md
|
Res2NeXt
**Res2NeXt** is an image model that employs a variation on [ResNeXt](https://paperswithcode.com/method/resnext) bottleneck residual blocks. The motivation is to be able to represent features at multiple scales. This is achieved through a novel building block for CNNs that constructs hierarchical residual-like connections within one single residual block. This represents multi-scale features at a granular level and increases the range of receptive fields for each network layer.
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('res2next50', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `res2next50`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('res2next50', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@article{Gao_2021,
title={Res2Net: A New Multi-Scale Backbone Architecture},
volume={43},
ISSN={1939-3539},
url={http://dx.doi.org/10.1109/TPAMI.2019.2938758},
DOI={10.1109/tpami.2019.2938758},
number={2},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
publisher={Institute of Electrical and Electronics Engineers (IEEE)},
author={Gao, Shang-Hua and Cheng, Ming-Ming and Zhao, Kai and Zhang, Xin-Yu and Yang, Ming-Hsuan and Torr, Philip},
year={2021},
month={Feb},
pages={652–662}
}
```
<!--
Type: model-index
Collections:
- Name: Res2NeXt
Paper:
Title: 'Res2Net: A New Multi-scale Backbone Architecture'
URL: https://paperswithcode.com/paper/res2net-a-new-multi-scale-backbone
Models:
- Name: res2next50
In Collection: Res2NeXt
Metadata:
FLOPs: 5396798208
Parameters: 24670000
File Size: 99019592
Architecture:
- Batch Normalization
- Convolution
- Global Average Pooling
- ReLU
- Res2NeXt Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x Titan Xp GPUs
ID: res2next50
LR: 0.1
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/res2net.py#L207
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-res2net/res2next50_4s-6ef7e7bf.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.24%
Top 5 Accuracy: 93.91%
-->
|
huggingface/pytorch-image-models/blob/main/hfdocs/source/models/res2next.mdx
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Prompt tuning for causal language modeling
[[open-in-colab]]
Prompting helps guide language model behavior by adding some input text specific to a task. Prompt tuning is an additive method for only training and updating the newly added prompt tokens to a pretrained model. This way, you can use one pretrained model whose weights are frozen, and train and update a smaller set of prompt parameters for each downstream task instead of fully finetuning a separate model. As models grow larger and larger, prompt tuning can be more efficient, and results are even better as model parameters scale.
<Tip>
💡 Read [The Power of Scale for Parameter-Efficient Prompt Tuning](https://arxiv.org/abs/2104.08691) to learn more about prompt tuning.
</Tip>
This guide will show you how to apply prompt tuning to train a [`bloomz-560m`](https://huggingface.co/bigscience/bloomz-560m) model on the `twitter_complaints` subset of the [RAFT](https://huggingface.co/datasets/ought/raft) dataset.
Before you begin, make sure you have all the necessary libraries installed:
```bash
!pip install -q peft transformers datasets
```
## Setup
Start by defining the model and tokenizer, the dataset and the dataset columns to train on, some training hyperparameters, and the [`PromptTuningConfig`]. The [`PromptTuningConfig`] contains information about the task type, the text to initialize the prompt embedding, the number of virtual tokens, and the tokenizer to use:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer, default_data_collator, get_linear_schedule_with_warmup
from peft import get_peft_config, get_peft_model, PromptTuningInit, PromptTuningConfig, TaskType, PeftType
import torch
from datasets import load_dataset
import os
from torch.utils.data import DataLoader
from tqdm import tqdm
device = "cuda"
model_name_or_path = "bigscience/bloomz-560m"
tokenizer_name_or_path = "bigscience/bloomz-560m"
peft_config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM,
prompt_tuning_init=PromptTuningInit.TEXT,
num_virtual_tokens=8,
prompt_tuning_init_text="Classify if the tweet is a complaint or not:",
tokenizer_name_or_path=model_name_or_path,
)
dataset_name = "twitter_complaints"
checkpoint_name = f"{dataset_name}_{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}_v1.pt".replace(
"/", "_"
)
text_column = "Tweet text"
label_column = "text_label"
max_length = 64
lr = 3e-2
num_epochs = 50
batch_size = 8
```
## Load dataset
For this guide, you'll load the `twitter_complaints` subset of the [RAFT](https://huggingface.co/datasets/ought/raft) dataset. This subset contains tweets that are labeled either `complaint` or `no complaint`:
```py
dataset = load_dataset("ought/raft", dataset_name)
dataset["train"][0]
{"Tweet text": "@HMRCcustomers No this is my first job", "ID": 0, "Label": 2}
```
To make the `Label` column more readable, replace the `Label` value with the corresponding label text and store them in a `text_label` column. You can use the [`~datasets.Dataset.map`] function to apply this change over the entire dataset in one step:
```py
classes = [k.replace("_", " ") for k in dataset["train"].features["Label"].names]
dataset = dataset.map(
lambda x: {"text_label": [classes[label] for label in x["Label"]]},
batched=True,
num_proc=1,
)
dataset["train"][0]
{"Tweet text": "@HMRCcustomers No this is my first job", "ID": 0, "Label": 2, "text_label": "no complaint"}
```
## Preprocess dataset
Next, you'll setup a tokenizer; configure the appropriate padding token to use for padding sequences, and determine the maximum length of the tokenized labels:
```py
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
target_max_length = max([len(tokenizer(class_label)["input_ids"]) for class_label in classes])
print(target_max_length)
3
```
Create a `preprocess_function` to:
1. Tokenize the input text and labels.
2. For each example in a batch, pad the labels with the tokenizers `pad_token_id`.
3. Concatenate the input text and labels into the `model_inputs`.
4. Create a separate attention mask for `labels` and `model_inputs`.
5. Loop through each example in the batch again to pad the input ids, labels, and attention mask to the `max_length` and convert them to PyTorch tensors.
```py
def preprocess_function(examples):
batch_size = len(examples[text_column])
inputs = [f"{text_column} : {x} Label : " for x in examples[text_column]]
targets = [str(x) for x in examples[label_column]]
model_inputs = tokenizer(inputs)
labels = tokenizer(targets)
for i in range(batch_size):
sample_input_ids = model_inputs["input_ids"][i]
label_input_ids = labels["input_ids"][i] + [tokenizer.pad_token_id]
# print(i, sample_input_ids, label_input_ids)
model_inputs["input_ids"][i] = sample_input_ids + label_input_ids
labels["input_ids"][i] = [-100] * len(sample_input_ids) + label_input_ids
model_inputs["attention_mask"][i] = [1] * len(model_inputs["input_ids"][i])
# print(model_inputs)
for i in range(batch_size):
sample_input_ids = model_inputs["input_ids"][i]
label_input_ids = labels["input_ids"][i]
model_inputs["input_ids"][i] = [tokenizer.pad_token_id] * (
max_length - len(sample_input_ids)
) + sample_input_ids
model_inputs["attention_mask"][i] = [0] * (max_length - len(sample_input_ids)) + model_inputs[
"attention_mask"
][i]
labels["input_ids"][i] = [-100] * (max_length - len(sample_input_ids)) + label_input_ids
model_inputs["input_ids"][i] = torch.tensor(model_inputs["input_ids"][i][:max_length])
model_inputs["attention_mask"][i] = torch.tensor(model_inputs["attention_mask"][i][:max_length])
labels["input_ids"][i] = torch.tensor(labels["input_ids"][i][:max_length])
model_inputs["labels"] = labels["input_ids"]
return model_inputs
```
Use the [`~datasets.Dataset.map`] function to apply the `preprocess_function` to the entire dataset. You can remove the unprocessed columns since the model won't need them:
```py
processed_datasets = dataset.map(
preprocess_function,
batched=True,
num_proc=1,
remove_columns=dataset["train"].column_names,
load_from_cache_file=False,
desc="Running tokenizer on dataset",
)
```
Create a [`DataLoader`](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader) from the `train` and `eval` datasets. Set `pin_memory=True` to speed up the data transfer to the GPU during training if the samples in your dataset are on a CPU.
```py
train_dataset = processed_datasets["train"]
eval_dataset = processed_datasets["test"]
train_dataloader = DataLoader(
train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True
)
eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
```
## Train
You're almost ready to setup your model and start training!
Initialize a base model from [`~transformers.AutoModelForCausalLM`], and pass it and `peft_config` to the [`get_peft_model`] function to create a [`PeftModel`]. You can print the new [`PeftModel`]'s trainable parameters to see how much more efficient it is than training the full parameters of the original model!
```py
model = AutoModelForCausalLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
print(model.print_trainable_parameters())
"trainable params: 8192 || all params: 559222784 || trainable%: 0.0014648902430985358"
```
Setup an optimizer and learning rate scheduler:
```py
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=(len(train_dataloader) * num_epochs),
)
```
Move the model to the GPU, then write a training loop to start training!
```py
model = model.to(device)
for epoch in range(num_epochs):
model.train()
total_loss = 0
for step, batch in enumerate(tqdm(train_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
total_loss += loss.detach().float()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
eval_loss = 0
eval_preds = []
for step, batch in enumerate(tqdm(eval_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
eval_loss += loss.detach().float()
eval_preds.extend(
tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True)
)
eval_epoch_loss = eval_loss / len(eval_dataloader)
eval_ppl = torch.exp(eval_epoch_loss)
train_epoch_loss = total_loss / len(train_dataloader)
train_ppl = torch.exp(train_epoch_loss)
print(f"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")
```
## Share model
You can store and share your model on the Hub if you'd like. Log in to your Hugging Face account and enter your token when prompted:
```py
from huggingface_hub import notebook_login
notebook_login()
```
Use the [`~transformers.PreTrainedModel.push_to_hub`] function to upload your model to a model repository on the Hub:
```py
peft_model_id = "your-name/bloomz-560m_PROMPT_TUNING_CAUSAL_LM"
model.push_to_hub("your-name/bloomz-560m_PROMPT_TUNING_CAUSAL_LM", use_auth_token=True)
```
Once the model is uploaded, you'll see the model file size is only 33.5kB! 🤏
## Inference
Let's try the model on a sample input for inference. If you look at the repository you uploaded the model to, you'll see a `adapter_config.json` file. Load this file into [`PeftConfig`] to specify the `peft_type` and `task_type`. Then you can load the prompt tuned model weights, and the configuration into [`~PeftModel.from_pretrained`] to create the [`PeftModel`]:
```py
from peft import PeftModel, PeftConfig
peft_model_id = "stevhliu/bloomz-560m_PROMPT_TUNING_CAUSAL_LM"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path)
model = PeftModel.from_pretrained(model, peft_model_id)
```
Grab a tweet and tokenize it:
```py
inputs = tokenizer(
f'{text_column} : {"@nationalgridus I have no water and the bill is current and paid. Can you do something about this?"} Label : ',
return_tensors="pt",
)
```
Put the model on a GPU and *generate* the predicted label:
```py
model.to(device)
with torch.no_grad():
inputs = {k: v.to(device) for k, v in inputs.items()}
outputs = model.generate(
input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"], max_new_tokens=10, eos_token_id=3
)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
[
"Tweet text : @nationalgridus I have no water and the bill is current and paid. Can you do something about this? Label : complaint"
]
```
|
huggingface/peft/blob/main/docs/source/task_guides/clm-prompt-tuning.md
|
@gradio/simpledropdown
## 0.1.6
### Patch Changes
- Updated dependencies [[`828fb9e`](https://github.com/gradio-app/gradio/commit/828fb9e6ce15b6ea08318675a2361117596a1b5d), [`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144)]:
- @gradio/statustracker@0.4.3
- @gradio/atoms@0.4.1
## 0.1.5
### Patch Changes
- Updated dependencies [[`053bec9`](https://github.com/gradio-app/gradio/commit/053bec98be1127e083414024e02cf0bebb0b5142), [`4d1cbbc`](https://github.com/gradio-app/gradio/commit/4d1cbbcf30833ef1de2d2d2710c7492a379a9a00)]:
- @gradio/icons@0.3.2
- @gradio/atoms@0.4.0
- @gradio/statustracker@0.4.2
## 0.1.4
### Patch Changes
- Updated dependencies [[`206af31`](https://github.com/gradio-app/gradio/commit/206af31d7c1a31013364a44e9b40cf8df304ba50)]:
- @gradio/icons@0.3.1
- @gradio/atoms@0.3.1
- @gradio/statustracker@0.4.1
## 0.1.3
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/atoms@0.3.0
- @gradio/icons@0.3.0
- @gradio/statustracker@0.4.0
## 0.1.2
### Patch Changes
- Updated dependencies [[`f816136a0`](https://github.com/gradio-app/gradio/commit/f816136a039fa6011be9c4fb14f573e4050a681a)]:
- @gradio/atoms@0.2.2
- @gradio/icons@0.2.1
- @gradio/statustracker@0.3.2
## 0.1.1
### Patch Changes
- Updated dependencies [[`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780), [`fad92c29d`](https://github.com/gradio-app/gradio/commit/fad92c29dc1f5cd84341aae417c495b33e01245f)]:
- @gradio/atoms@0.2.1
- @gradio/statustracker@0.3.1
## 0.1.0
### Patch Changes
- Updated dependencies [[`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7), [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7), [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7)]:
- @gradio/icons@0.2.0
- @gradio/utils@0.2.0
- @gradio/atoms@0.2.0
- @gradio/statustracker@0.3.0
## 0.1.0-beta.3
### Features
- [#6149](https://github.com/gradio-app/gradio/pull/6149) [`90318b1dd`](https://github.com/gradio-app/gradio/commit/90318b1dd118ae08a695a50e7c556226234ab6dc) - swap `mode` on the frontned to `interactive` to match the backend. Thanks [@pngwn](https://github.com/pngwn)!
## 0.1.0-beta.2
### Features
- [#5996](https://github.com/gradio-app/gradio/pull/5996) [`9cf40f76f`](https://github.com/gradio-app/gradio/commit/9cf40f76fed1c0f84b5a5336a9b0100f8a9b4ee3) - V4: Simple dropdown. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
|
gradio-app/gradio/blob/main/js/simpledropdown/CHANGELOG.md
|
Test Coverage
Just a little reference docs to understand what is tested/ needs testing. Perhaps temporary until we are in a better place.
## Interface
## Flagging
## Blocks
## Block Layouts
## Themes
## Components
### Props/kwargs
| Component | `value` | `visible` | `elem_id` | `elem_classes` | `container` | `label` | `show_label` |
| --------------- | ------- | --------- | --------- | -------------- | ----------- | ------- | ------------ | --- |
| AnnotatedImage | `❌` | `✅` | `✅` | `✅` | `❌` | `✅` | `❌` |
| Audio | `❌` | `✅` | `✅` | `✅` | `❌` | `✅` | `❌` |
| BarPlot | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| Button | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| Chatbot | `❌` | `✅` | `✅` | `✅` | `❌` | `✅` | `❌` |
| Checkbox | `❌` | `✅` | `✅` | `✅` | `❌` | `✅` | `❌` |
| CheckboxGroup | `❌` | `✅` | `✅` | `✅` | `❌` | `✅` | `❌` |
| ClearButton | `❌` | `✅` | `✅` | `✅` | `❌` | `✅` | `❌` |
| Code | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| ColorPicker | `❌` | `✅` | `✅` | `✅` | `❌` | `✅` | `❌` |
| Dataframe | `❌` | `✅` | `✅` | `✅` | `❌` | `✅` | `❌` |
| Dropdown | `❌` | `✅` | `✅` | `✅` | `❌` | `✅` | `❌` |
| File | `❌` | `✅` | `✅` | `✅` | `❌` | `✅` | `❌` |
| Gallery | `❌` | `✅` | `✅` | `✅` | `❌` | `✅` | `❌` |
| HTML | `❌` | `✅` | `✅` | `✅` | `❌` | `✅` | `❌` |
| HighlightedText | `❌` | `✅` | `✅` | `✅` | `❌` | `✅` | `❌` |
| Image | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | |
| JSON | `❌` | `✅` | `✅` | `✅` | `❌` | `✅` | `❌` |
| Label | `❌` | `✅` | `✅` | `✅` | `❌` | `✅` | `❌` |
| Lineplot | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| Markdown | `❌` | `✅` | `✅` | `✅` | `❌` | `✅` | `❌` |
| Model3D | `❌` | `✅` | `✅` | `✅` | `❌` | `✅` | `❌` |
| Number | `❌` | `✅` | `✅` | `✅` | `❌` | `✅` | `❌` |
| Plot | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| Radio | `❌` | `✅` | `✅` | `✅` | `❌` | `✅` | `❌` |
| ScatterPlot | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| Slider | `❌` | `✅` | `✅` | `✅` | `❌` | `✅` | `❌` |
| Textbox | `❌` | `✅` | `✅` | `✅` | `❌` | `✅` | `❌` |
| Timeseries | `❌` | `✅` | `✅` | `✅` | `❌` | `✅` | `❌` |
| UploadButton | `❌` | `✅` | `✅` | `✅` | `❌` | `✅` | `❌` |
| Video | `❌` | `✅` | `✅` | `✅` | `❌` | `✅` | `❌` |
### Events
| Component | `value` | `visible` | `elem_id` | `elem_classes` | `container` | `label` | `show_label` |
| --------------- | ------- | --------- | --------- | -------------- | ----------- | ------- | ------------ | --- |
| AnnotatedImage | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| Audio | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| BarPlot | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| Button | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| Chatbot | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| Checkbox | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| CheckboxGroup | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| ClearButton | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| Code | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| ColorPicker | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| Dataframe | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| Dataset | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| Dropdown | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| File | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| Gallery | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| HTML | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| HighlightedText | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| Image | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | |
| Interpretation | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| JSON | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| Label | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| Lineplot | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| Markdown | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| Model3D | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| Number | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| Plot | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| Radio | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| ScatterPlot | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| Slider | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| State | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| Textbox | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| Timeseries | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| UploadButton | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
| Video | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` | `❌` |
### `AnnotatedImage`
### `Audio`
### `BarPlot`
### `Button`
### `Chatbot`
### `Checkbox`
### `CheckboxGroup`
### `ClearButton`
### `Code`
### `ColorPicker`
### `Dataframe`
### `Dataset`
### `Dropdown`
### `File`
### `Gallery`
### `HTML`
### `HighlightedText`
### `Image`
### `Interpretation`
### `JSON`
### `Label`
### `Lineplot`
### `Markdown`
### `Model3D`
### `Number`
### `Plot`
### `Radio`
### `ScatterPlot`
### `Slider`
### `State`
### `Textbox`
### `Timeseries`
### `UploadButton`
### `Video`
## Helpers
### Error
### load
### Examples
### Progress
### update
### make_waveform
### EventData
## Routes
### `Request`
### `mount_gradio_app`
## Clients
### Python (`gradio_client`)
### JavaScript (`@gradio/client`)
|
gradio-app/gradio/blob/main/js/app/test/tests.md
|
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the
License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an
"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
specific language governing permissions and limitations under the License. -->
# TrOCR
## Overview
The TrOCR model was proposed in [TrOCR: Transformer-based Optical Character Recognition with Pre-trained
Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang,
Zhoujun Li, Furu Wei. TrOCR consists of an image Transformer encoder and an autoregressive text Transformer decoder to
perform [optical character recognition (OCR)](https://en.wikipedia.org/wiki/Optical_character_recognition).
The abstract from the paper is the following:
*Text recognition is a long-standing research problem for document digitalization. Existing approaches for text recognition
are usually built based on CNN for image understanding and RNN for char-level text generation. In addition, another language
model is usually needed to improve the overall accuracy as a post-processing step. In this paper, we propose an end-to-end
text recognition approach with pre-trained image Transformer and text Transformer models, namely TrOCR, which leverages the
Transformer architecture for both image understanding and wordpiece-level text generation. The TrOCR model is simple but
effective, and can be pre-trained with large-scale synthetic data and fine-tuned with human-labeled datasets. Experiments
show that the TrOCR model outperforms the current state-of-the-art models on both printed and handwritten text recognition
tasks.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/trocr_architecture.jpg"
alt="drawing" width="600"/>
<small> TrOCR architecture. Taken from the <a href="https://arxiv.org/abs/2109.10282">original paper</a>. </small>
Please refer to the [`VisionEncoderDecoder`] class on how to use this model.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
[here](https://github.com/microsoft/unilm/tree/6f60612e7cc86a2a1ae85c47231507a587ab4e01/trocr).
## Usage tips
- The quickest way to get started with TrOCR is by checking the [tutorial
notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/TrOCR), which show how to use the model
at inference time as well as fine-tuning on custom data.
- TrOCR is pre-trained in 2 stages before being fine-tuned on downstream datasets. It achieves state-of-the-art results
on both printed (e.g. the [SROIE dataset](https://paperswithcode.com/dataset/sroie) and handwritten (e.g. the [IAM
Handwriting dataset](https://fki.tic.heia-fr.ch/databases/iam-handwriting-database>) text recognition tasks. For more
information, see the [official models](https://huggingface.co/models?other=trocr>).
- TrOCR is always used within the [VisionEncoderDecoder](vision-encoder-decoder) framework.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with TrOCR. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<PipelineTag pipeline="text-classification"/>
- A blog post on [Accelerating Document AI](https://huggingface.co/blog/document-ai) with TrOCR.
- A blog post on how to [Document AI](https://github.com/philschmid/document-ai-transformers) with TrOCR.
- A notebook on how to [finetune TrOCR on IAM Handwriting Database using Seq2SeqTrainer](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/TrOCR/Fine_tune_TrOCR_on_IAM_Handwriting_Database_using_Seq2SeqTrainer.ipynb).
- A notebook on [inference with TrOCR](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/TrOCR/Inference_with_TrOCR_%2B_Gradio_demo.ipynb) and Gradio demo.
- A notebook on [finetune TrOCR on the IAM Handwriting Database](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/TrOCR/Fine_tune_TrOCR_on_IAM_Handwriting_Database_using_native_PyTorch.ipynb) using native PyTorch.
- A notebook on [evaluating TrOCR on the IAM test set](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/TrOCR/Evaluating_TrOCR_base_handwritten_on_the_IAM_test_set.ipynb).
<PipelineTag pipeline="text-generation"/>
- [Casual language modeling](https://huggingface.co/docs/transformers/tasks/language_modeling) task guide.
⚡️ Inference
- An interactive-demo on [TrOCR handwritten character recognition](https://huggingface.co/spaces/nielsr/TrOCR-handwritten).
## Inference
TrOCR's [`VisionEncoderDecoder`] model accepts images as input and makes use of
[`~generation.GenerationMixin.generate`] to autoregressively generate text given the input image.
The [`ViTImageProcessor`/`DeiTImageProcessor`] class is responsible for preprocessing the input image and
[`RobertaTokenizer`/`XLMRobertaTokenizer`] decodes the generated target tokens to the target string. The
[`TrOCRProcessor`] wraps [`ViTImageProcessor`/`DeiTImageProcessor`] and [`RobertaTokenizer`/`XLMRobertaTokenizer`]
into a single instance to both extract the input features and decode the predicted token ids.
- Step-by-step Optical Character Recognition (OCR)
``` py
>>> from transformers import TrOCRProcessor, VisionEncoderDecoderModel
>>> import requests
>>> from PIL import Image
>>> processor = TrOCRProcessor.from_pretrained("microsoft/trocr-base-handwritten")
>>> model = VisionEncoderDecoderModel.from_pretrained("microsoft/trocr-base-handwritten")
>>> # load image from the IAM dataset
>>> url = "https://fki.tic.heia-fr.ch/static/img/a01-122-02.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
>>> pixel_values = processor(image, return_tensors="pt").pixel_values
>>> generated_ids = model.generate(pixel_values)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
See the [model hub](https://huggingface.co/models?filter=trocr) to look for TrOCR checkpoints.
## TrOCRConfig
[[autodoc]] TrOCRConfig
## TrOCRProcessor
[[autodoc]] TrOCRProcessor
- __call__
- from_pretrained
- save_pretrained
- batch_decode
- decode
## TrOCRForCausalLM
[[autodoc]] TrOCRForCausalLM
- forward
|
huggingface/transformers/blob/main/docs/source/en/model_doc/trocr.md
|
ECA-ResNet
An **ECA ResNet** is a variant on a [ResNet](https://paperswithcode.com/method/resnet) that utilises an [Efficient Channel Attention module](https://paperswithcode.com/method/efficient-channel-attention). Efficient Channel Attention is an architectural unit based on [squeeze-and-excitation blocks](https://paperswithcode.com/method/squeeze-and-excitation-block) that reduces model complexity without dimensionality reduction.
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('ecaresnet101d', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `ecaresnet101d`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('ecaresnet101d', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{wang2020ecanet,
title={ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks},
author={Qilong Wang and Banggu Wu and Pengfei Zhu and Peihua Li and Wangmeng Zuo and Qinghua Hu},
year={2020},
eprint={1910.03151},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: ECAResNet
Paper:
Title: 'ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks'
URL: https://paperswithcode.com/paper/eca-net-efficient-channel-attention-for-deep
Models:
- Name: ecaresnet101d
In Collection: ECAResNet
Metadata:
FLOPs: 10377193728
Parameters: 44570000
File Size: 178815067
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Efficient Channel Attention
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x RTX 2080Ti GPUs
ID: ecaresnet101d
LR: 0.1
Epochs: 100
Layers: 101
Crop Pct: '0.875'
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/resnet.py#L1087
Weights: https://imvl-automl-sh.oss-cn-shanghai.aliyuncs.com/darts/hyperml/hyperml/job_45402/outputs/ECAResNet101D_281c5844.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 82.18%
Top 5 Accuracy: 96.06%
- Name: ecaresnet101d_pruned
In Collection: ECAResNet
Metadata:
FLOPs: 4463972081
Parameters: 24880000
File Size: 99852736
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Efficient Channel Attention
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: ecaresnet101d_pruned
Layers: 101
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/resnet.py#L1097
Weights: https://imvl-automl-sh.oss-cn-shanghai.aliyuncs.com/darts/hyperml/hyperml/job_45610/outputs/ECAResNet101D_P_75a3370e.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.82%
Top 5 Accuracy: 95.64%
- Name: ecaresnet50d
In Collection: ECAResNet
Metadata:
FLOPs: 5591090432
Parameters: 25580000
File Size: 102579290
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Efficient Channel Attention
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x RTX 2080Ti GPUs
ID: ecaresnet50d
LR: 0.1
Epochs: 100
Layers: 50
Crop Pct: '0.875'
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/resnet.py#L1045
Weights: https://imvl-automl-sh.oss-cn-shanghai.aliyuncs.com/darts/hyperml/hyperml/job_45402/outputs/ECAResNet50D_833caf58.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.61%
Top 5 Accuracy: 95.31%
- Name: ecaresnet50d_pruned
In Collection: ECAResNet
Metadata:
FLOPs: 3250730657
Parameters: 19940000
File Size: 79990436
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Efficient Channel Attention
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: ecaresnet50d_pruned
Layers: 50
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/resnet.py#L1055
Weights: https://imvl-automl-sh.oss-cn-shanghai.aliyuncs.com/darts/hyperml/hyperml/job_45899/outputs/ECAResNet50D_P_9c67f710.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.71%
Top 5 Accuracy: 94.88%
- Name: ecaresnetlight
In Collection: ECAResNet
Metadata:
FLOPs: 5276118784
Parameters: 30160000
File Size: 120956612
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Efficient Channel Attention
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: ecaresnetlight
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/resnet.py#L1077
Weights: https://imvl-automl-sh.oss-cn-shanghai.aliyuncs.com/darts/hyperml/hyperml/job_45402/outputs/ECAResNetLight_4f34b35b.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.46%
Top 5 Accuracy: 95.25%
-->
|
huggingface/pytorch-image-models/blob/main/docs/models/ecaresnet.md
|
--
title: "Introducing the Data Measurements Tool: an Interactive Tool for Looking at Datasets"
thumbnail: /blog/assets/37_data-measurements-tool/datametrics.png
authors:
- user: sasha
- user: yjernite
- user: meg
---
# Introducing the 🤗 Data Measurements Tool: an Interactive Tool for Looking at Datasets
***tl;dr:*** We made a tool you can use online to build, measure, and compare datasets.
[Click to access the 🤗 Data Measurements Tool here.](https://huggingface.co/spaces/huggingface/data-measurements-tool)
-----
As developers of a fast-growing unified repository for Machine Learning datasets ([Lhoest et al. 2021](https://arxiv.org/abs/2109.02846)), the 🤗 Hugging Face [team](https://huggingface.co/huggingface) has been working on supporting good practices for dataset documentation ([McMillan-Major et al., 2021](https://arxiv.org/abs/2108.07374)). While static (if evolving) documentation represents a necessary first step in this direction, getting a good sense of what is actually in a dataset requires well-motivated measurements and the ability to interact with it, dynamically visualizing different aspects of interest.
To this end, we introduce an open-source Python library and no-code interface called the [🤗 Data Measurements Tool](https://huggingface.co/spaces/huggingface/data-measurements-tool), using our [Dataset](https://huggingface.co/datasets) and [Spaces](https://huggingface.co/spaces/launch) Hubs paired with the great [Streamlit tool](https://streamlit.io/). This can be used to help understand, build, curate, and compare datasets.
## What is the 🤗 Data Measurements Tool?
The [Data Measurements Tool (DMT)](https://huggingface.co/spaces/huggingface/data-measurements-tool) is an interactive interface and open-source library that lets dataset creators and users automatically calculate metrics that are meaningful and useful for responsible data development.
## Why have we created this tool?
Thoughtful curation and analysis of Machine Learning datasets is often overlooked in AI development. Current norms for “big data” in AI ([Luccioni et al., 2021](https://arxiv.org/abs/2105.02732), [Dodge et al., 2021](https://arxiv.org/abs/2104.08758)) include using data scraped from various websites, with little or no attention paid to concrete measurements of what the different data sources represent, nor the nitty-gritty details of how they may influence what a model learns. Although dataset annotation approaches can help to curate datasets that are more in line with a developer’s goals, the methods for “measuring” different aspects of these datasets are fairly limited ([Sambasivan et al., 2021](https://storage.googleapis.com/pub-tools-public-publication-data/pdf/0d556e45afc54afeb2eb6b51a9bc1827b9961ff4.pdf)).
A new wave of research in AI has called for a fundamental paradigm shift in how the field approaches ML datasets ([Paullada et al., 2020](https://arxiv.org/abs/2012.05345), [Denton et al., 2021](https://journals.sagepub.com/doi/full/10.1177/20539517211035955)). This includes defining fine-grained requirements for dataset creation from the start ([Hutchinson et al., 2021](https://dl.acm.org/doi/pdf/10.1145/3442188.3445918)), curating datasets in light of problematic content and bias concerns ([Yang et al., 2020](https://dl.acm.org/doi/abs/10.1145/3351095.3375709), [Prabhu and Birhane, 2020](https://arxiv.org/abs/2006.16923)), and making explicit the values inherent in dataset construction and maintenance ([Scheuerman et al., 2021](https://dl.acm.org/doi/pdf/10.1145/3476058), [Birhane et al., 2021](https://arxiv.org/abs/2110.01963)). Although there is general agreement that dataset development is a task that people from many different disciplines should be able to inform, in practice there is often a bottleneck in interfacing with the raw data itself, which tends to require complex coding skills in order to analyze and query the dataset.
Despite this, there are few tools openly available to the public to enable people from different disciplines to measure, interrogate, and compare datasets. We aim to help fill this gap. We learn and build from recent tools such as [Know Your Data](https://knowyourdata.withgoogle.com/) and [Data Quality for AI](https://www.ibm.com/products/dqaiapi), as well as research proposals for dataset documentation such as [Vision and Language Datasets (Ferraro et al., 2015)](https://aclanthology.org/D15-1021/), [Datasheets for Datasets (Gebru et al, 2018)](https://arxiv.org/abs/1803.09010), and [Data Statements (Bender & Friedman 2019)](https://aclanthology.org/Q18-1041/). The result is an open-source library for dataset measurements, and an accompanying no-code interface for detailed dataset analysis.
## When can I use the 🤗 Data Measurements Tool?
The 🤗 Data Measurements Tool can be used iteratively for exploring one or more existing NLP datasets, and will soon support iterative development of datasets from scratch. It provides actionable insights informed by research on datasets and responsible dataset development, allowing users to hone in on both high-level information and specific items.
## What can I learn using the 🤗 Data Measurements Tool?
### Dataset Basics
**For a high-level overview of the dataset**
*This begins to answer questions like “What is this dataset? Does it have missing items?”. You can use this as “sanity checks” that the dataset you’re working with is as you expect it to be.*
- A description of the dataset (from the Hugging Face Hub)
- Number of missing values or NaNs
### Descriptive Statistics
**To look at the surface characteristics of the dataset**
*This begins to answer questions like “What kind of language is in this dataset? How diverse is it?”*
- The dataset vocabulary size and word distribution, for both [open- and closed-class words](https://dictionary.apa.org/open-class-words).
- The dataset label distribution and information about class (im)balance.
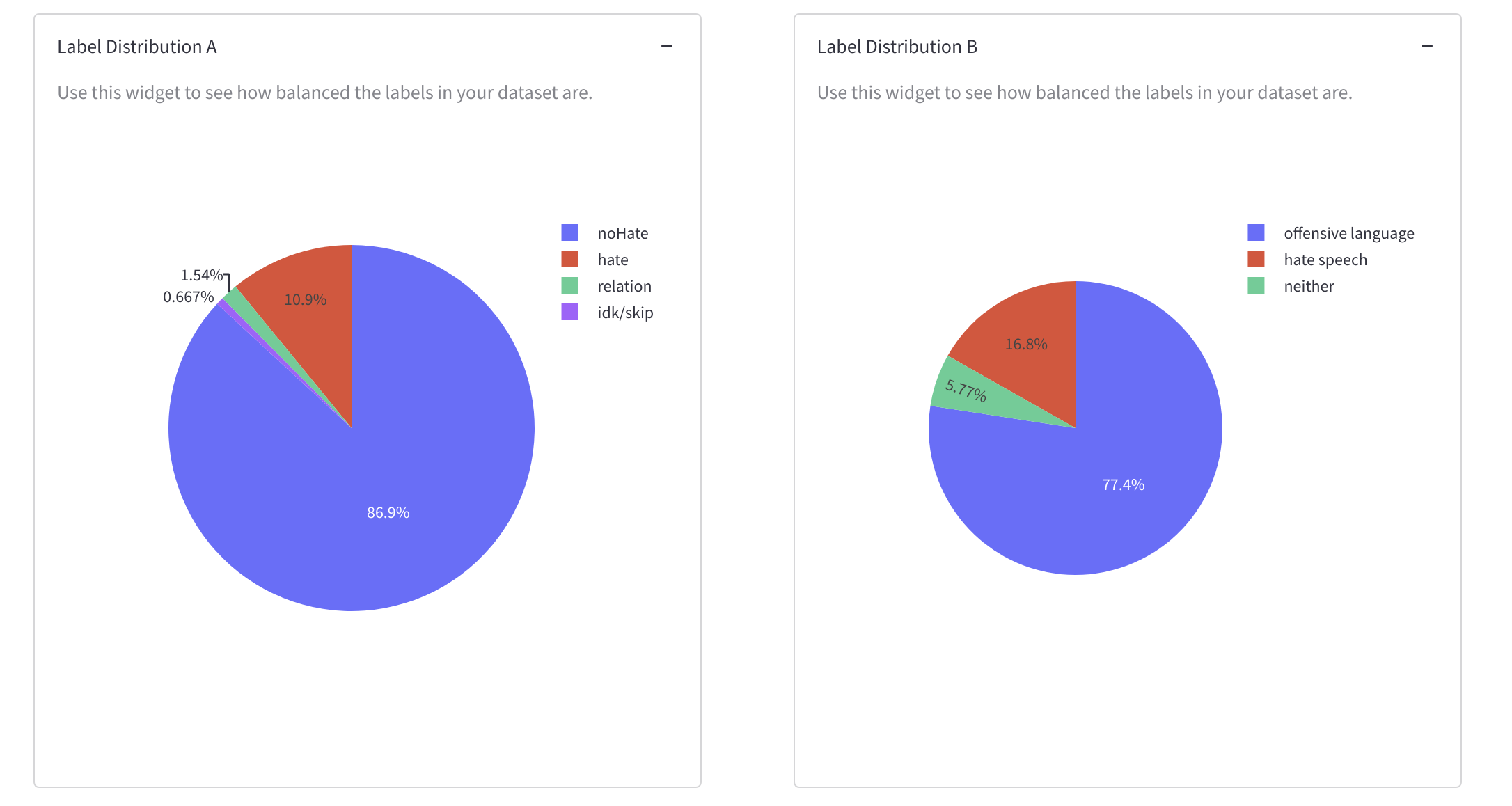
- The mean, median, range, and distribution of instance lengths.
- The number of duplicates in the dataset and how many times they are repeated.
You can use these widgets to check whether what is most and least represented in the dataset make sense for the goals of the dataset. These measurements are intended to inform whether the dataset can be useful in capturing a variety of contexts or if what it captures is more limited, and to measure how ''balanced'' the labels and instance lengths are. You can also use these widgets to identify outliers and duplicates you may want to remove.
### Distributional Statistics
**To measure the language patterns in the dataset**
*This begins to answer questions like “How does the language behave in this dataset?”*
- Adherence to [Zipf’s law](https://en.wikipedia.org/wiki/Zipf%27s_law), which provides measurements of how closely the distribution over words in the dataset fits to the expected distribution of words in natural language.
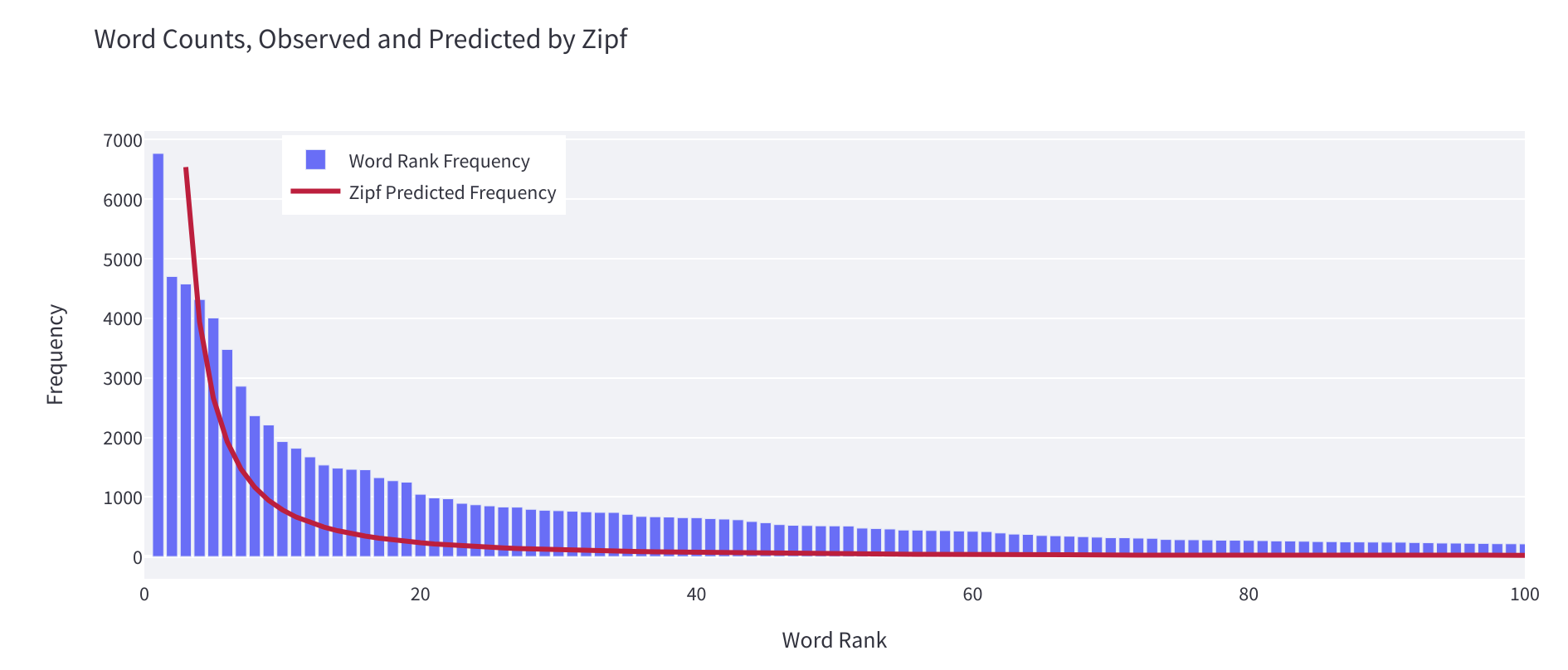
You can use this to figure out whether your dataset represents language as it tends to behave in the natural world or if there are things that are more unnatural about it. If you’re someone who enjoys optimization, then you can view the alpha value this widget calculates as a value to get as close as possible to 1 during dataset development. Further details on alpha values following Zipf’s law in different languages is available here.
In general, an alpha greater than 2 or a minimum rank greater than 10 (take with a grain of salt) means that your distribution is relatively unnatural for natural language. This can be a sign of mixed artefacts in the dataset, such as HTML markup. You can use this information to clean up your dataset or to guide you in determining how further language you add to the dataset should be distributed.
### Comparison statistics
*This begins to answer questions like “What kinds of topics, biases, and associations are in this dataset?”*
- Embedding clusters to pinpoint any clusters of similar language in the dataset.
Taking in the diversity of text represented in a dataset can be challenging when it is made up of hundreds to hundreds of thousands of sentences. Grouping these text items based on a measure of similarity can help users gain some insights into their distribution. We show a hierarchical clustering of the text fields in the dataset based on a [Sentence-Transformer](https://hf.co/sentence-transformers/all-mpnet-base-v2) model and a maximum dot product [single-linkage criterion](https://en.wikipedia.org/wiki/Single-linkage_clustering). To explore the clusters, you can:
- hover over a node to see the 5 most representative examples (deduplicated)
- enter an example in the text box to see which leaf clusters it is most similar to
- select a cluster by ID to show all of its examples
- The [normalized pointwise mutual information (nPMI)](https://en.wikipedia.org/wiki/Pointwise_mutual_information#Normalized_pointwise_mutual_information_(npmi)) between word pairs in the dataset, which may be used to identify problematic stereotypes.
You can use this as a tool in dealing with dataset “bias”, where here the term “bias” refers to stereotypes and prejudices for identity groups along the axes of gender and sexual orientation. We will add further terms in the near future.
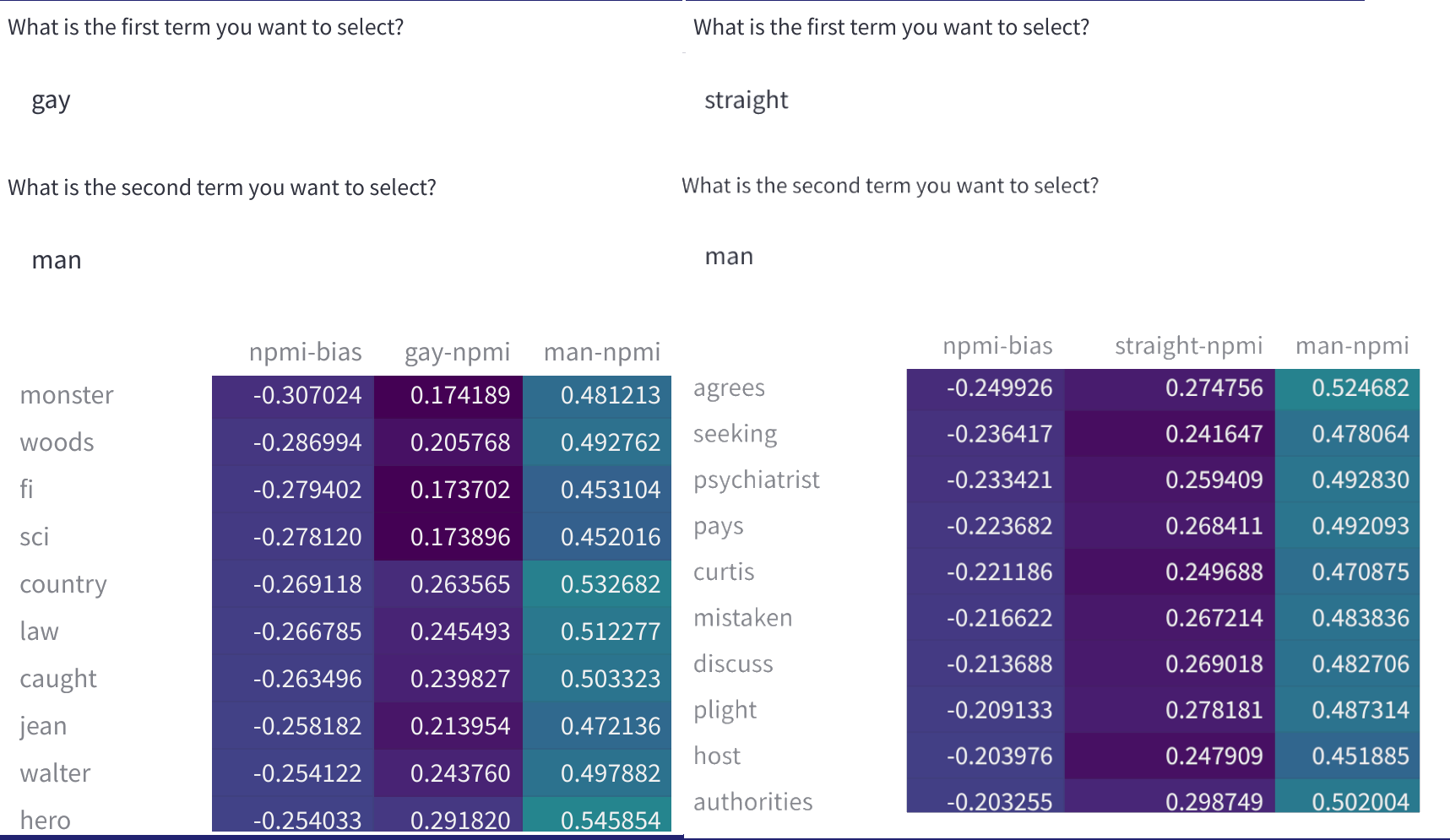
## What is the status of 🤗 Data Measurements Tool development?
We currently present the alpha version (v0) of the tool, demonstrating its usefulness on a handful of popular English-language datasets (e.g. SQuAD, imdb, C4, ...) available on the [Dataset Hub](https://huggingface.co/datasets), with the functionalities described above. The words that we selected for nPMI visualization are a subset of identity terms that came up frequently in the datasets that we were working with.
In coming weeks and months, we will be extending the tool to:
- Cover more languages and datasets present in the 🤗 Datasets library.
- Provide support for user-provided datasets and iterative dataset building.
- Add more features and functionalities to the tool itself. For example, we will make it possible to add your own terms for the nPMI visualization so you can pick the words that matter most to you.
### Acknowledgements
Thank you to Thomas Wolf for initiating this work, as well as other members of the 🤗 team (Quentin, Lewis, Sylvain, Nate, Julien C., Julien S., Clément, Omar, and many others!) for their help and support.
|
huggingface/blog/blob/main/data-measurements-tool.md
|
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Integrate any ML framework with the Hub
The Hugging Face Hub makes hosting and sharing models with the community easy. It supports
[dozens of libraries](https://huggingface.co/docs/hub/models-libraries) in the Open Source ecosystem. We are always
working on expanding this support to push collaborative Machine Learning forward. The `huggingface_hub` library plays a
key role in this process, allowing any Python script to easily push and load files.
There are four main ways to integrate a library with the Hub:
1. **Push to Hub:** implement a method to upload a model to the Hub. This includes the model weights, as well as
[the model card](https://huggingface.co/docs/huggingface_hub/how-to-model-cards) and any other relevant information
or data necessary to run the model (for example, training logs). This method is often called `push_to_hub()`.
2. **Download from Hub:** implement a method to load a model from the Hub. The method should download the model
configuration/weights and load the model. This method is often called `from_pretrained` or `load_from_hub()`.
3. **Inference API:** use our servers to run inference on models supported by your library for free.
4. **Widgets:** display a widget on the landing page of your models on the Hub. It allows users to quickly try a model
from the browser.
In this guide, we will focus on the first two topics. We will present the two main approaches you can use to integrate
a library, with their advantages and drawbacks. Everything is summarized at the end of the guide to help you choose
between the two. Please keep in mind that these are only guidelines that you are free to adapt to you requirements.
If you are interested in Inference and Widgets, you can follow [this guide](https://huggingface.co/docs/hub/models-adding-libraries#set-up-the-inference-api).
In both cases, you can reach out to us if you are integrating a library with the Hub and want to be listed
[in our docs](https://huggingface.co/docs/hub/models-libraries).
## A flexible approach: helpers
The first approach to integrate a library to the Hub is to actually implement the `push_to_hub` and `from_pretrained`
methods by yourself. This gives you full flexibility on which files you need to upload/download and how to handle inputs
specific to your framework. You can refer to the two [upload files](./upload) and [download files](./download) guides
to learn more about how to do that. This is, for example how the FastAI integration is implemented (see [`push_to_hub_fastai`]
and [`from_pretrained_fastai`]).
Implementation can differ between libraries, but the workflow is often similar.
### from_pretrained
This is how a `from_pretrained` method usually look like:
```python
def from_pretrained(model_id: str) -> MyModelClass:
# Download model from Hub
cached_model = hf_hub_download(
repo_id=repo_id,
filename="model.pkl",
library_name="fastai",
library_version=get_fastai_version(),
)
# Load model
return load_model(cached_model)
```
### push_to_hub
The `push_to_hub` method often requires a bit more complexity to handle repo creation, generate the model card and save weights.
A common approach is to save all of these files in a temporary folder, upload it and then delete it.
```python
def push_to_hub(model: MyModelClass, repo_name: str) -> None:
api = HfApi()
# Create repo if not existing yet and get the associated repo_id
repo_id = api.create_repo(repo_name, exist_ok=True)
# Save all files in a temporary directory and push them in a single commit
with TemporaryDirectory() as tmpdir:
tmpdir = Path(tmpdir)
# Save weights
save_model(model, tmpdir / "model.safetensors")
# Generate model card
card = generate_model_card(model)
(tmpdir / "README.md").write_text(card)
# Save logs
# Save figures
# Save evaluation metrics
# ...
# Push to hub
return api.upload_folder(repo_id=repo_id, folder_path=tmpdir)
```
This is of course only an example. If you are interested in more complex manipulations (delete remote files, upload
weights on the fly, persist weights locally, etc.) please refer to the [upload files](./upload) guide.
### Limitations
While being flexible, this approach has some drawbacks, especially in terms of maintenance. Hugging Face users are often
used to additional features when working with `huggingface_hub`. For example, when loading files from the Hub, it is
common to offer parameters like:
- `token`: to download from a private repo
- `revision`: to download from a specific branch
- `cache_dir`: to cache files in a specific directory
- `force_download`/`resume_download`/`local_files_only`: to reuse the cache or not
- `api_endpoint`/`proxies`: configure HTTP session
When pushing models, similar parameters are supported:
- `commit_message`: custom commit message
- `private`: create a private repo if missing
- `create_pr`: create a PR instead of pushing to `main`
- `branch`: push to a branch instead of the `main` branch
- `allow_patterns`/`ignore_patterns`: filter which files to upload
- `token`
- `api_endpoint`
- ...
All of these parameters can be added to the implementations we saw above and passed to the `huggingface_hub` methods.
However, if a parameter changes or a new feature is added, you will need to update your package. Supporting those
parameters also means more documentation to maintain on your side. To see how to mitigate these limitations, let's jump
to our next section **class inheritance**.
## A more complex approach: class inheritance
As we saw above, there are two main methods to include in your library to integrate it with the Hub: upload files
(`push_to_hub`) and download files (`from_pretrained`). You can implement those methods by yourself but it comes with
caveats. To tackle this, `huggingface_hub` provides a tool that uses class inheritance. Let's see how it works!
In a lot of cases, a library already implements its model using a Python class. The class contains the properties of
the model and methods to load, run, train, and evaluate it. Our approach is to extend this class to include upload and
download features using mixins. A [Mixin](https://stackoverflow.com/a/547714) is a class that is meant to extend an
existing class with a set of specific features using multiple inheritance. `huggingface_hub` provides its own mixin,
the [`ModelHubMixin`]. The key here is to understand its behavior and how to customize it.
The [`ModelHubMixin`] class implements 3 *public* methods (`push_to_hub`, `save_pretrained` and `from_pretrained`). Those
are the methods that your users will call to load/save models with your library. [`ModelHubMixin`] also defines 2
*private* methods (`_save_pretrained` and `_from_pretrained`). Those are the ones you must implement. So to integrate
your library, you should:
1. Make your Model class inherit from [`ModelHubMixin`].
2. Implement the private methods:
- [`~ModelHubMixin._save_pretrained`]: method taking as input a path to a directory and saving the model to it.
You must write all the logic to dump your model in this method: model card, model weights, configuration files,
training logs, and figures. Any relevant information for this model must be handled by this method.
[Model Cards](https://huggingface.co/docs/hub/model-cards) are particularly important to describe your model. Check
out [our implementation guide](./model-cards) for more details.
- [`~ModelHubMixin._from_pretrained`]: **class method** taking as input a `model_id` and returning an instantiated
model. The method must download the relevant files and load them.
3. You are done!
The advantage of using [`ModelHubMixin`] is that once you take care of the serialization/loading of the files, you
are ready to go. You don't need to worry about stuff like repo creation, commits, PRs, or revisions. All
of this is handled by the mixin and is available to your users. The Mixin also ensures that public methods are well
documented and type annotated.
### A concrete example: PyTorch
A good example of what we saw above is [`PyTorchModelHubMixin`], our integration for the PyTorch framework. This is a
ready-to-use integration.
#### How to use it?
Here is how any user can load/save a PyTorch model from/to the Hub:
```python
>>> import torch
>>> import torch.nn as nn
>>> from huggingface_hub import PyTorchModelHubMixin
# 1. Define your Pytorch model exactly the same way you are used to
>>> class MyModel(nn.Module, PyTorchModelHubMixin): # multiple inheritance
... def __init__(self):
... super().__init__()
... self.param = nn.Parameter(torch.rand(3, 4))
... self.linear = nn.Linear(4, 5)
... def forward(self, x):
... return self.linear(x + self.param)
>>> model = MyModel()
# 2. (optional) Save model to local directory
>>> model.save_pretrained("path/to/my-awesome-model")
# 3. Push model weights to the Hub
>>> model.push_to_hub("my-awesome-model")
# 4. Initialize model from the Hub
>>> model = MyModel.from_pretrained("username/my-awesome-model")
```
#### Implementation
The implementation is actually very straightforward, and the full implementation can be found [here](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/hub_mixin.py).
1. First, inherit your class from `ModelHubMixin`:
```python
from huggingface_hub import ModelHubMixin
class PyTorchModelHubMixin(ModelHubMixin):
(...)
```
2. Implement the `_save_pretrained` method:
```py
from huggingface_hub import ModelCard, ModelCardData
class PyTorchModelHubMixin(ModelHubMixin):
(...)
def _save_pretrained(self, save_directory: Path):
"""Generate Model Card and save weights from a Pytorch model to a local directory."""
model_card = ModelCard.from_template(
card_data=ModelCardData(
license='mit',
library_name="pytorch",
...
),
model_summary=...,
model_type=...,
...
)
(save_directory / "README.md").write_text(str(model))
torch.save(obj=self.module.state_dict(), f=save_directory / "pytorch_model.bin")
```
3. Implement the `_from_pretrained` method:
```python
class PyTorchModelHubMixin(ModelHubMixin):
(...)
@classmethod # Must be a classmethod!
def _from_pretrained(
cls,
*,
model_id: str,
revision: str,
cache_dir: str,
force_download: bool,
proxies: Optional[Dict],
resume_download: bool,
local_files_only: bool,
token: Union[str, bool, None],
map_location: str = "cpu", # additional argument
strict: bool = False, # additional argument
**model_kwargs,
):
"""Load Pytorch pretrained weights and return the loaded model."""
if os.path.isdir(model_id): # Can either be a local directory
print("Loading weights from local directory")
model_file = os.path.join(model_id, "pytorch_model.bin")
else: # Or a model on the Hub
model_file = hf_hub_download( # Download from the hub, passing same input args
repo_id=model_id,
filename="pytorch_model.bin",
revision=revision,
cache_dir=cache_dir,
force_download=force_download,
proxies=proxies,
resume_download=resume_download,
token=token,
local_files_only=local_files_only,
)
# Load model and return - custom logic depending on your framework
model = cls(**model_kwargs)
state_dict = torch.load(model_file, map_location=torch.device(map_location))
model.load_state_dict(state_dict, strict=strict)
model.eval()
return model
```
And that's it! Your library now enables users to upload and download files to and from the Hub.
## Quick comparison
Let's quickly sum up the two approaches we saw with their advantages and drawbacks. The table below is only indicative.
Your framework might have some specificities that you need to address. This guide is only here to give guidelines and
ideas on how to handle integration. In any case, feel free to contact us if you have any questions!
<!-- Generated using https://www.tablesgenerator.com/markdown_tables -->
| Integration | Using helpers | Using [`ModelHubMixin`] |
|:---:|:---:|:---:|
| User experience | `model = load_from_hub(...)`<br>`push_to_hub(model, ...)` | `model = MyModel.from_pretrained(...)`<br>`model.push_to_hub(...)` |
| Flexibility | Very flexible.<br>You fully control the implementation. | Less flexible.<br>Your framework must have a model class. |
| Maintenance | More maintenance to add support for configuration, and new features. Might also require fixing issues reported by users. | Less maintenance as most of the interactions with the Hub are implemented in `huggingface_hub`. |
| Documentation / Type annotation | To be written manually. | Partially handled by `huggingface_hub`. |
|
huggingface/huggingface_hub/blob/main/docs/source/en/guides/integrations.md
|
Train and deploy Hugging Face on Amazon SageMaker
The get started guide will show you how to quickly use Hugging Face on Amazon SageMaker. Learn how to fine-tune and deploy a pretrained 🤗 Transformers model on SageMaker for a binary text classification task.
💡 If you are new to Hugging Face, we recommend first reading the 🤗 Transformers [quick tour](https://huggingface.co/docs/transformers/quicktour).
<iframe width="560" height="315" src="https://www.youtube.com/embed/pYqjCzoyWyo" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
📓 Open the [agemaker-notebook.ipynb file](https://github.com/huggingface/notebooks/blob/main/sagemaker/01_getting_started_pytorch/sagemaker-notebook.ipynb) to follow along!
## Installation and setup
Get started by installing the necessary Hugging Face libraries and SageMaker. You will also need to install [PyTorch](https://pytorch.org/get-started/locally/) and [TensorFlow](https://www.tensorflow.org/install/pip#tensorflow-2-packages-are-available) if you don't already have it installed.
```python
pip install "sagemaker>=2.140.0" "transformers==4.26.1" "datasets[s3]==2.10.1" --upgrade
```
If you want to run this example in [SageMaker Studio](https://docs.aws.amazon.com/sagemaker/latest/dg/studio.html), upgrade [ipywidgets](https://ipywidgets.readthedocs.io/en/latest/) for the 🤗 Datasets library and restart the kernel:
```python
%%capture
import IPython
!conda install -c conda-forge ipywidgets -y
IPython.Application.instance().kernel.do_shutdown(True)
```
Next, you should set up your environment: a SageMaker session and an S3 bucket. The S3 bucket will store data, models, and logs. You will need access to an [IAM execution role](https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-roles.html) with the required permissions.
If you are planning on using SageMaker in a local environment, you need to provide the `role` yourself. Learn more about how to set this up [here](https://huggingface.co/docs/sagemaker/train#installation-and-setup).
⚠️ The execution role is only available when you run a notebook within SageMaker. If you try to run `get_execution_role` in a notebook not on SageMaker, you will get a region error.
```python
import sagemaker
sess = sagemaker.Session()
sagemaker_session_bucket = None
if sagemaker_session_bucket is None and sess is not None:
sagemaker_session_bucket = sess.default_bucket()
role = sagemaker.get_execution_role()
sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)
```
## Preprocess
The 🤗 Datasets library makes it easy to download and preprocess a dataset for training. Download and tokenize the [IMDb](https://huggingface.co/datasets/imdb) dataset:
```python
from datasets import load_dataset
from transformers import AutoTokenizer
# load dataset
train_dataset, test_dataset = load_dataset("imdb", split=["train", "test"])
# load tokenizer
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
# create tokenization function
def tokenize(batch):
return tokenizer(batch["text"], padding="max_length", truncation=True)
# tokenize train and test datasets
train_dataset = train_dataset.map(tokenize, batched=True)
test_dataset = test_dataset.map(tokenize, batched=True)
# set dataset format for PyTorch
train_dataset = train_dataset.rename_column("label", "labels")
train_dataset.set_format("torch", columns=["input_ids", "attention_mask", "labels"])
test_dataset = test_dataset.rename_column("label", "labels")
test_dataset.set_format("torch", columns=["input_ids", "attention_mask", "labels"])
```
## Upload dataset to S3 bucket
Next, upload the preprocessed dataset to your S3 session bucket with 🤗 Datasets S3 [filesystem](https://huggingface.co/docs/datasets/filesystems.html) implementation:
```python
# save train_dataset to s3
training_input_path = f's3://{sess.default_bucket()}/{s3_prefix}/train'
train_dataset.save_to_disk(training_input_path)
# save test_dataset to s3
test_input_path = f's3://{sess.default_bucket()}/{s3_prefix}/test'
test_dataset.save_to_disk(test_input_path)
```
## Start a training job
Create a Hugging Face Estimator to handle end-to-end SageMaker training and deployment. The most important parameters to pay attention to are:
* `entry_point` refers to the fine-tuning script which you can find in [train.py file](https://github.com/huggingface/notebooks/blob/main/sagemaker/01_getting_started_pytorch/scripts/train.py).
* `instance_type` refers to the SageMaker instance that will be launched. Take a look [here](https://aws.amazon.com/sagemaker/pricing/) for a complete list of instance types.
* `hyperparameters` refers to the training hyperparameters the model will be fine-tuned with.
```python
from sagemaker.huggingface import HuggingFace
hyperparameters={
"epochs": 1, # number of training epochs
"train_batch_size": 32, # training batch size
"model_name":"distilbert-base-uncased" # name of pretrained model
}
huggingface_estimator = HuggingFace(
entry_point="train.py", # fine-tuning script to use in training job
source_dir="./scripts", # directory where fine-tuning script is stored
instance_type="ml.p3.2xlarge", # instance type
instance_count=1, # number of instances
role=role, # IAM role used in training job to acccess AWS resources (S3)
transformers_version="4.26", # Transformers version
pytorch_version="1.13", # PyTorch version
py_version="py39", # Python version
hyperparameters=hyperparameters # hyperparameters to use in training job
)
```
Begin training with one line of code:
```python
huggingface_estimator.fit({"train": training_input_path, "test": test_input_path})
```
## Deploy model
Once the training job is complete, deploy your fine-tuned model by calling `deploy()` with the number of instances and instance type:
```python
predictor = huggingface_estimator.deploy(initial_instance_count=1,"ml.g4dn.xlarge")
```
Call `predict()` on your data:
```python
sentiment_input = {"inputs": "It feels like a curtain closing...there was an elegance in the way they moved toward conclusion. No fan is going to watch and feel short-changed."}
predictor.predict(sentiment_input)
```
After running your request, delete the endpoint:
```python
predictor.delete_endpoint()
```
## What's next?
Congratulations, you've just fine-tuned and deployed a pretrained 🤗 Transformers model on SageMaker! 🎉
For your next steps, keep reading our documentation for more details about training and deployment. There are many interesting features such as [distributed training](/docs/sagemaker/train#distributed-training) and [Spot instances](/docs/sagemaker/train#spot-instances).
|
huggingface/hub-docs/blob/main/docs/sagemaker/getting-started.md
|
ControlNet training example for Stable Diffusion XL (SDXL)
The `train_controlnet_sdxl.py` script shows how to implement the ControlNet training procedure and adapt it for [Stable Diffusion XL](https://huggingface.co/papers/2307.01952).
## Running locally with PyTorch
### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install -e .
```
Then cd in the `examples/controlnet` folder and run
```bash
pip install -r requirements_sdxl.txt
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
Or for a default accelerate configuration without answering questions about your environment
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell (e.g., a notebook)
```python
from accelerate.utils import write_basic_config
write_basic_config()
```
When running `accelerate config`, if we specify torch compile mode to True there can be dramatic speedups.
## Circle filling dataset
The original dataset is hosted in the [ControlNet repo](https://huggingface.co/lllyasviel/ControlNet/blob/main/training/fill50k.zip). We re-uploaded it to be compatible with `datasets` [here](https://huggingface.co/datasets/fusing/fill50k). Note that `datasets` handles dataloading within the training script.
## Training
Our training examples use two test conditioning images. They can be downloaded by running
```sh
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_1.png
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_2.png
```
Then run `huggingface-cli login` to log into your Hugging Face account. This is needed to be able to push the trained ControlNet parameters to Hugging Face Hub.
```bash
export MODEL_DIR="stabilityai/stable-diffusion-xl-base-1.0"
export OUTPUT_DIR="path to save model"
accelerate launch train_controlnet_sdxl.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--mixed_precision="fp16" \
--resolution=1024 \
--learning_rate=1e-5 \
--max_train_steps=15000 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--validation_steps=100 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--report_to="wandb" \
--seed=42 \
--push_to_hub
```
To better track our training experiments, we're using the following flags in the command above:
* `report_to="wandb` will ensure the training runs are tracked on Weights and Biases. To use it, be sure to install `wandb` with `pip install wandb`.
* `validation_image`, `validation_prompt`, and `validation_steps` to allow the script to do a few validation inference runs. This allows us to qualitatively check if the training is progressing as expected.
Our experiments were conducted on a single 40GB A100 GPU.
### Inference
Once training is done, we can perform inference like so:
```python
from diffusers import StableDiffusionXLControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
from diffusers.utils import load_image
import torch
base_model_path = "stabilityai/stable-diffusion-xl-base-1.0"
controlnet_path = "path to controlnet"
controlnet = ControlNetModel.from_pretrained(controlnet_path, torch_dtype=torch.float16)
pipe = StableDiffusionXLControlNetPipeline.from_pretrained(
base_model_path, controlnet=controlnet, torch_dtype=torch.float16
)
# speed up diffusion process with faster scheduler and memory optimization
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
# remove following line if xformers is not installed or when using Torch 2.0.
pipe.enable_xformers_memory_efficient_attention()
# memory optimization.
pipe.enable_model_cpu_offload()
control_image = load_image("./conditioning_image_1.png")
prompt = "pale golden rod circle with old lace background"
# generate image
generator = torch.manual_seed(0)
image = pipe(
prompt, num_inference_steps=20, generator=generator, image=control_image
).images[0]
image.save("./output.png")
```
## Notes
### Specifying a better VAE
SDXL's VAE is known to suffer from numerical instability issues. This is why we also expose a CLI argument namely `--pretrained_vae_model_name_or_path` that lets you specify the location of a better VAE (such as [this one](https://huggingface.co/madebyollin/sdxl-vae-fp16-fix)).
|
huggingface/diffusers/blob/main/examples/controlnet/README_sdxl.md
|
Instagram ResNeXt WSL
A **ResNeXt** repeats a [building block](https://paperswithcode.com/method/resnext-block) that aggregates a set of transformations with the same topology. Compared to a [ResNet](https://paperswithcode.com/method/resnet), it exposes a new dimension, *cardinality* (the size of the set of transformations) \\( C \\), as an essential factor in addition to the dimensions of depth and width.
This model was trained on billions of Instagram images using thousands of distinct hashtags as labels exhibit excellent transfer learning performance.
Please note the CC-BY-NC 4.0 license on theses weights, non-commercial use only.
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('ig_resnext101_32x16d', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `ig_resnext101_32x16d`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('ig_resnext101_32x16d', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{mahajan2018exploring,
title={Exploring the Limits of Weakly Supervised Pretraining},
author={Dhruv Mahajan and Ross Girshick and Vignesh Ramanathan and Kaiming He and Manohar Paluri and Yixuan Li and Ashwin Bharambe and Laurens van der Maaten},
year={2018},
eprint={1805.00932},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: IG ResNeXt
Paper:
Title: Exploring the Limits of Weakly Supervised Pretraining
URL: https://paperswithcode.com/paper/exploring-the-limits-of-weakly-supervised
Models:
- Name: ig_resnext101_32x16d
In Collection: IG ResNeXt
Metadata:
FLOPs: 46623691776
Parameters: 194030000
File Size: 777518664
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- IG-3.5B-17k
- ImageNet
Training Resources: 336x GPUs
ID: ig_resnext101_32x16d
Epochs: 100
Layers: 101
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 8064
Image Size: '224'
Weight Decay: 0.001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnet.py#L874
Weights: https://download.pytorch.org/models/ig_resnext101_32x16-c6f796b0.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 84.16%
Top 5 Accuracy: 97.19%
- Name: ig_resnext101_32x32d
In Collection: IG ResNeXt
Metadata:
FLOPs: 112225170432
Parameters: 468530000
File Size: 1876573776
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- IG-3.5B-17k
- ImageNet
Training Resources: 336x GPUs
ID: ig_resnext101_32x32d
Epochs: 100
Layers: 101
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 8064
Image Size: '224'
Weight Decay: 0.001
Interpolation: bilinear
Minibatch Size: 8064
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnet.py#L885
Weights: https://download.pytorch.org/models/ig_resnext101_32x32-e4b90b00.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 85.09%
Top 5 Accuracy: 97.44%
- Name: ig_resnext101_32x48d
In Collection: IG ResNeXt
Metadata:
FLOPs: 197446554624
Parameters: 828410000
File Size: 3317136976
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- IG-3.5B-17k
- ImageNet
Training Resources: 336x GPUs
ID: ig_resnext101_32x48d
Epochs: 100
Layers: 101
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 8064
Image Size: '224'
Weight Decay: 0.001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnet.py#L896
Weights: https://download.pytorch.org/models/ig_resnext101_32x48-3e41cc8a.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 85.42%
Top 5 Accuracy: 97.58%
- Name: ig_resnext101_32x8d
In Collection: IG ResNeXt
Metadata:
FLOPs: 21180417024
Parameters: 88790000
File Size: 356056638
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- IG-3.5B-17k
- ImageNet
Training Resources: 336x GPUs
ID: ig_resnext101_32x8d
Epochs: 100
Layers: 101
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 8064
Image Size: '224'
Weight Decay: 0.001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnet.py#L863
Weights: https://download.pytorch.org/models/ig_resnext101_32x8-c38310e5.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 82.7%
Top 5 Accuracy: 96.64%
-->
|
huggingface/pytorch-image-models/blob/main/hfdocs/source/models/ig-resnext.mdx
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Image-to-image
[[open-in-colab]]
Image-to-image is similar to [text-to-image](conditional_image_generation), but in addition to a prompt, you can also pass an initial image as a starting point for the diffusion process. The initial image is encoded to latent space and noise is added to it. Then the latent diffusion model takes a prompt and the noisy latent image, predicts the added noise, and removes the predicted noise from the initial latent image to get the new latent image. Lastly, a decoder decodes the new latent image back into an image.
With 🤗 Diffusers, this is as easy as 1-2-3:
1. Load a checkpoint into the [`AutoPipelineForImage2Image`] class; this pipeline automatically handles loading the correct pipeline class based on the checkpoint:
```py
import torch
from diffusers import AutoPipelineForImage2Image
from diffusers.utils import load_image, make_image_grid
pipeline = AutoPipelineForImage2Image.from_pretrained(
"kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16, use_safetensors=True
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
```
<Tip>
You'll notice throughout the guide, we use [`~DiffusionPipeline.enable_model_cpu_offload`] and [`~DiffusionPipeline.enable_xformers_memory_efficient_attention`], to save memory and increase inference speed. If you're using PyTorch 2.0, then you don't need to call [`~DiffusionPipeline.enable_xformers_memory_efficient_attention`] on your pipeline because it'll already be using PyTorch 2.0's native [scaled-dot product attention](../optimization/torch2.0#scaled-dot-product-attention).
</Tip>
2. Load an image to pass to the pipeline:
```py
init_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/cat.png")
```
3. Pass a prompt and image to the pipeline to generate an image:
```py
prompt = "cat wizard, gandalf, lord of the rings, detailed, fantasy, cute, adorable, Pixar, Disney, 8k"
image = pipeline(prompt, image=init_image).images[0]
make_image_grid([init_image, image], rows=1, cols=2)
```
<div class="flex gap-4">
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/cat.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">initial image</figcaption>
</div>
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">generated image</figcaption>
</div>
</div>
## Popular models
The most popular image-to-image models are [Stable Diffusion v1.5](https://huggingface.co/runwayml/stable-diffusion-v1-5), [Stable Diffusion XL (SDXL)](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0), and [Kandinsky 2.2](https://huggingface.co/kandinsky-community/kandinsky-2-2-decoder). The results from the Stable Diffusion and Kandinsky models vary due to their architecture differences and training process; you can generally expect SDXL to produce higher quality images than Stable Diffusion v1.5. Let's take a quick look at how to use each of these models and compare their results.
### Stable Diffusion v1.5
Stable Diffusion v1.5 is a latent diffusion model initialized from an earlier checkpoint, and further finetuned for 595K steps on 512x512 images. To use this pipeline for image-to-image, you'll need to prepare an initial image to pass to the pipeline. Then you can pass a prompt and the image to the pipeline to generate a new image:
```py
import torch
from diffusers import AutoPipelineForImage2Image
from diffusers.utils import make_image_grid, load_image
pipeline = AutoPipelineForImage2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
# prepare image
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-init.png"
init_image = load_image(url)
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
# pass prompt and image to pipeline
image = pipeline(prompt, image=init_image).images[0]
make_image_grid([init_image, image], rows=1, cols=2)
```
<div class="flex gap-4">
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-init.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">initial image</figcaption>
</div>
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-sdv1.5.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">generated image</figcaption>
</div>
</div>
### Stable Diffusion XL (SDXL)
SDXL is a more powerful version of the Stable Diffusion model. It uses a larger base model, and an additional refiner model to increase the quality of the base model's output. Read the [SDXL](sdxl) guide for a more detailed walkthrough of how to use this model, and other techniques it uses to produce high quality images.
```py
import torch
from diffusers import AutoPipelineForImage2Image
from diffusers.utils import make_image_grid, load_image
pipeline = AutoPipelineForImage2Image.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
# prepare image
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-sdxl-init.png"
init_image = load_image(url)
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
# pass prompt and image to pipeline
image = pipeline(prompt, image=init_image, strength=0.5).images[0]
make_image_grid([init_image, image], rows=1, cols=2)
```
<div class="flex gap-4">
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-sdxl-init.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">initial image</figcaption>
</div>
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-sdxl.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">generated image</figcaption>
</div>
</div>
### Kandinsky 2.2
The Kandinsky model is different from the Stable Diffusion models because it uses an image prior model to create image embeddings. The embeddings help create a better alignment between text and images, allowing the latent diffusion model to generate better images.
The simplest way to use Kandinsky 2.2 is:
```py
import torch
from diffusers import AutoPipelineForImage2Image
from diffusers.utils import make_image_grid, load_image
pipeline = AutoPipelineForImage2Image.from_pretrained(
"kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16, use_safetensors=True
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
# prepare image
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-init.png"
init_image = load_image(url)
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
# pass prompt and image to pipeline
image = pipeline(prompt, image=init_image).images[0]
make_image_grid([init_image, image], rows=1, cols=2)
```
<div class="flex gap-4">
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-init.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">initial image</figcaption>
</div>
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-kandinsky.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">generated image</figcaption>
</div>
</div>
## Configure pipeline parameters
There are several important parameters you can configure in the pipeline that'll affect the image generation process and image quality. Let's take a closer look at what these parameters do and how changing them affects the output.
### Strength
`strength` is one of the most important parameters to consider and it'll have a huge impact on your generated image. It determines how much the generated image resembles the initial image. In other words:
- 📈 a higher `strength` value gives the model more "creativity" to generate an image that's different from the initial image; a `strength` value of 1.0 means the initial image is more or less ignored
- 📉 a lower `strength` value means the generated image is more similar to the initial image
The `strength` and `num_inference_steps` parameters are related because `strength` determines the number of noise steps to add. For example, if the `num_inference_steps` is 50 and `strength` is 0.8, then this means adding 40 (50 * 0.8) steps of noise to the initial image and then denoising for 40 steps to get the newly generated image.
```py
import torch
from diffusers import AutoPipelineForImage2Image
from diffusers.utils import make_image_grid, load_image
pipeline = AutoPipelineForImage2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
# prepare image
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-init.png"
init_image = load_image(url)
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
# pass prompt and image to pipeline
image = pipeline(prompt, image=init_image, strength=0.8).images[0]
make_image_grid([init_image, image], rows=1, cols=2)
```
<div class="flex flex-row gap-4">
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-strength-0.4.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">strength = 0.4</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-strength-0.6.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">strength = 0.6</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-strength-1.0.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">strength = 1.0</figcaption>
</div>
</div>
### Guidance scale
The `guidance_scale` parameter is used to control how closely aligned the generated image and text prompt are. A higher `guidance_scale` value means your generated image is more aligned with the prompt, while a lower `guidance_scale` value means your generated image has more space to deviate from the prompt.
You can combine `guidance_scale` with `strength` for even more precise control over how expressive the model is. For example, combine a high `strength + guidance_scale` for maximum creativity or use a combination of low `strength` and low `guidance_scale` to generate an image that resembles the initial image but is not as strictly bound to the prompt.
```py
import torch
from diffusers import AutoPipelineForImage2Image
from diffusers.utils import make_image_grid, load_image
pipeline = AutoPipelineForImage2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
# prepare image
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-init.png"
init_image = load_image(url)
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
# pass prompt and image to pipeline
image = pipeline(prompt, image=init_image, guidance_scale=8.0).images[0]
make_image_grid([init_image, image], rows=1, cols=2)
```
<div class="flex flex-row gap-4">
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-guidance-0.1.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">guidance_scale = 0.1</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-guidance-3.0.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">guidance_scale = 5.0</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-guidance-7.5.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">guidance_scale = 10.0</figcaption>
</div>
</div>
### Negative prompt
A negative prompt conditions the model to *not* include things in an image, and it can be used to improve image quality or modify an image. For example, you can improve image quality by including negative prompts like "poor details" or "blurry" to encourage the model to generate a higher quality image. Or you can modify an image by specifying things to exclude from an image.
```py
import torch
from diffusers import AutoPipelineForImage2Image
from diffusers.utils import make_image_grid, load_image
pipeline = AutoPipelineForImage2Image.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
# prepare image
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-init.png"
init_image = load_image(url)
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
negative_prompt = "ugly, deformed, disfigured, poor details, bad anatomy"
# pass prompt and image to pipeline
image = pipeline(prompt, negative_prompt=negative_prompt, image=init_image).images[0]
make_image_grid([init_image, image], rows=1, cols=2)
```
<div class="flex flex-row gap-4">
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-negative-1.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">negative_prompt = "ugly, deformed, disfigured, poor details, bad anatomy"</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-negative-2.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">negative_prompt = "jungle"</figcaption>
</div>
</div>
## Chained image-to-image pipelines
There are some other interesting ways you can use an image-to-image pipeline aside from just generating an image (although that is pretty cool too). You can take it a step further and chain it with other pipelines.
### Text-to-image-to-image
Chaining a text-to-image and image-to-image pipeline allows you to generate an image from text and use the generated image as the initial image for the image-to-image pipeline. This is useful if you want to generate an image entirely from scratch. For example, let's chain a Stable Diffusion and a Kandinsky model.
Start by generating an image with the text-to-image pipeline:
```py
from diffusers import AutoPipelineForText2Image, AutoPipelineForImage2Image
import torch
from diffusers.utils import make_image_grid
pipeline = AutoPipelineForText2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
text2image = pipeline("Astronaut in a jungle, cold color palette, muted colors, detailed, 8k").images[0]
text2image
```
Now you can pass this generated image to the image-to-image pipeline:
```py
pipeline = AutoPipelineForImage2Image.from_pretrained(
"kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16, use_safetensors=True
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
image2image = pipeline("Astronaut in a jungle, cold color palette, muted colors, detailed, 8k", image=text2image).images[0]
make_image_grid([text2image, image2image], rows=1, cols=2)
```
### Image-to-image-to-image
You can also chain multiple image-to-image pipelines together to create more interesting images. This can be useful for iteratively performing style transfer on an image, generating short GIFs, restoring color to an image, or restoring missing areas of an image.
Start by generating an image:
```py
import torch
from diffusers import AutoPipelineForImage2Image
from diffusers.utils import make_image_grid, load_image
pipeline = AutoPipelineForImage2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
# prepare image
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-init.png"
init_image = load_image(url)
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
# pass prompt and image to pipeline
image = pipeline(prompt, image=init_image, output_type="latent").images[0]
```
<Tip>
It is important to specify `output_type="latent"` in the pipeline to keep all the outputs in latent space to avoid an unnecessary decode-encode step. This only works if the chained pipelines are using the same VAE.
</Tip>
Pass the latent output from this pipeline to the next pipeline to generate an image in a [comic book art style](https://huggingface.co/ogkalu/Comic-Diffusion):
```py
pipeline = AutoPipelineForImage2Image.from_pretrained(
"ogkalu/Comic-Diffusion", torch_dtype=torch.float16
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
# need to include the token "charliebo artstyle" in the prompt to use this checkpoint
image = pipeline("Astronaut in a jungle, charliebo artstyle", image=image, output_type="latent").images[0]
```
Repeat one more time to generate the final image in a [pixel art style](https://huggingface.co/kohbanye/pixel-art-style):
```py
pipeline = AutoPipelineForImage2Image.from_pretrained(
"kohbanye/pixel-art-style", torch_dtype=torch.float16
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
# need to include the token "pixelartstyle" in the prompt to use this checkpoint
image = pipeline("Astronaut in a jungle, pixelartstyle", image=image).images[0]
make_image_grid([init_image, image], rows=1, cols=2)
```
### Image-to-upscaler-to-super-resolution
Another way you can chain your image-to-image pipeline is with an upscaler and super-resolution pipeline to really increase the level of details in an image.
Start with an image-to-image pipeline:
```py
import torch
from diffusers import AutoPipelineForImage2Image
from diffusers.utils import make_image_grid, load_image
pipeline = AutoPipelineForImage2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
# prepare image
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-init.png"
init_image = load_image(url)
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
# pass prompt and image to pipeline
image_1 = pipeline(prompt, image=init_image, output_type="latent").images[0]
```
<Tip>
It is important to specify `output_type="latent"` in the pipeline to keep all the outputs in *latent* space to avoid an unnecessary decode-encode step. This only works if the chained pipelines are using the same VAE.
</Tip>
Chain it to an upscaler pipeline to increase the image resolution:
```py
from diffusers import StableDiffusionLatentUpscalePipeline
upscaler = StableDiffusionLatentUpscalePipeline.from_pretrained(
"stabilityai/sd-x2-latent-upscaler", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
)
upscaler.enable_model_cpu_offload()
upscaler.enable_xformers_memory_efficient_attention()
image_2 = upscaler(prompt, image=image_1, output_type="latent").images[0]
```
Finally, chain it to a super-resolution pipeline to further enhance the resolution:
```py
from diffusers import StableDiffusionUpscalePipeline
super_res = StableDiffusionUpscalePipeline.from_pretrained(
"stabilityai/stable-diffusion-x4-upscaler", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
)
super_res.enable_model_cpu_offload()
super_res.enable_xformers_memory_efficient_attention()
image_3 = super_res(prompt, image=image_2).images[0]
make_image_grid([init_image, image_3.resize((512, 512))], rows=1, cols=2)
```
## Control image generation
Trying to generate an image that looks exactly the way you want can be difficult, which is why controlled generation techniques and models are so useful. While you can use the `negative_prompt` to partially control image generation, there are more robust methods like prompt weighting and ControlNets.
### Prompt weighting
Prompt weighting allows you to scale the representation of each concept in a prompt. For example, in a prompt like "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k", you can choose to increase or decrease the embeddings of "astronaut" and "jungle". The [Compel](https://github.com/damian0815/compel) library provides a simple syntax for adjusting prompt weights and generating the embeddings. You can learn how to create the embeddings in the [Prompt weighting](weighted_prompts) guide.
[`AutoPipelineForImage2Image`] has a `prompt_embeds` (and `negative_prompt_embeds` if you're using a negative prompt) parameter where you can pass the embeddings which replaces the `prompt` parameter.
```py
from diffusers import AutoPipelineForImage2Image
import torch
pipeline = AutoPipelineForImage2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
image = pipeline(prompt_embeds=prompt_embeds, # generated from Compel
negative_prompt_embeds=negative_prompt_embeds, # generated from Compel
image=init_image,
).images[0]
```
### ControlNet
ControlNets provide a more flexible and accurate way to control image generation because you can use an additional conditioning image. The conditioning image can be a canny image, depth map, image segmentation, and even scribbles! Whatever type of conditioning image you choose, the ControlNet generates an image that preserves the information in it.
For example, let's condition an image with a depth map to keep the spatial information in the image.
```py
from diffusers.utils import load_image, make_image_grid
# prepare image
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-init.png"
init_image = load_image(url)
init_image = init_image.resize((958, 960)) # resize to depth image dimensions
depth_image = load_image("https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth/resolve/main/images/control.png")
make_image_grid([init_image, depth_image], rows=1, cols=2)
```
Load a ControlNet model conditioned on depth maps and the [`AutoPipelineForImage2Image`]:
```py
from diffusers import ControlNetModel, AutoPipelineForImage2Image
import torch
controlnet = ControlNetModel.from_pretrained("lllyasviel/control_v11f1p_sd15_depth", torch_dtype=torch.float16, variant="fp16", use_safetensors=True)
pipeline = AutoPipelineForImage2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16, variant="fp16", use_safetensors=True
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
```
Now generate a new image conditioned on the depth map, initial image, and prompt:
```py
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image_control_net = pipeline(prompt, image=init_image, control_image=depth_image).images[0]
make_image_grid([init_image, depth_image, image_control_net], rows=1, cols=3)
```
<div class="flex flex-row gap-4">
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-init.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">initial image</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth/resolve/main/images/control.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">depth image</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-controlnet.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">ControlNet image</figcaption>
</div>
</div>
Let's apply a new [style](https://huggingface.co/nitrosocke/elden-ring-diffusion) to the image generated from the ControlNet by chaining it with an image-to-image pipeline:
```py
pipeline = AutoPipelineForImage2Image.from_pretrained(
"nitrosocke/elden-ring-diffusion", torch_dtype=torch.float16,
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
prompt = "elden ring style astronaut in a jungle" # include the token "elden ring style" in the prompt
negative_prompt = "ugly, deformed, disfigured, poor details, bad anatomy"
image_elden_ring = pipeline(prompt, negative_prompt=negative_prompt, image=image_control_net, strength=0.45, guidance_scale=10.5).images[0]
make_image_grid([init_image, depth_image, image_control_net, image_elden_ring], rows=2, cols=2)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-elden-ring.png">
</div>
## Optimize
Running diffusion models is computationally expensive and intensive, but with a few optimization tricks, it is entirely possible to run them on consumer and free-tier GPUs. For example, you can use a more memory-efficient form of attention such as PyTorch 2.0's [scaled-dot product attention](../optimization/torch2.0#scaled-dot-product-attention) or [xFormers](../optimization/xformers) (you can use one or the other, but there's no need to use both). You can also offload the model to the GPU while the other pipeline components wait on the CPU.
```diff
+ pipeline.enable_model_cpu_offload()
+ pipeline.enable_xformers_memory_efficient_attention()
```
With [`torch.compile`](../optimization/torch2.0#torchcompile), you can boost your inference speed even more by wrapping your UNet with it:
```py
pipeline.unet = torch.compile(pipeline.unet, mode="reduce-overhead", fullgraph=True)
```
To learn more, take a look at the [Reduce memory usage](../optimization/memory) and [Torch 2.0](../optimization/torch2.0) guides.
|
huggingface/diffusers/blob/main/docs/source/en/using-diffusers/img2img.md
|
--
title: "New ViT and ALIGN Models From Kakao Brain"
thumbnail: /blog//assets/132_vit_align/thumbnail.png
authors:
- user: adirik
- user: Unso
- user: dylan-m
- user: jun-untitled
---
# Kakao Brain’s Open Source ViT, ALIGN, and the New COYO Text-Image Dataset
Kakao Brain and Hugging Face are excited to release a new open-source image-text dataset [COYO](https://github.com/kakaobrain/coyo-dataset) of 700 million pairs and two new visual language models trained on it, [ViT](https://github.com/kakaobrain/coyo-vit) and [ALIGN](https://github.com/kakaobrain/coyo-align). This is the first time ever the ALIGN model is made public for free and open-source use and the first release of ViT and ALIGN models that come with the train dataset.
Kakao Brain’s ViT and ALIGN models follow the same architecture and hyperparameters as provided in the original respective Google models but are trained on the open source [COYO](https://github.com/kakaobrain/coyo-dataset) dataset. Google’s [ViT](https://ai.googleblog.com/2020/12/transformers-for-image-recognition-at.html) and [ALIGN](https://ai.googleblog.com/2021/05/align-scaling-up-visual-and-vision.html) models, while trained on huge datasets (ViT trained on 300 million images and ALIGN trained on 1.8 billion image-text pairs respectively), cannot be replicated because the datasets are not public. This contribution is particularly valuable to researchers who want to reproduce visual language modeling with access to the data as well. More detailed information on the Kakao ViT and ALIGN models can be found [here](https://huggingface.co/kakaobrain).
This blog will introduce the new [COYO](https://github.com/kakaobrain/coyo-dataset) dataset, Kakao Brain's ViT and ALIGN models, and how to use them! Here are the main takeaways:
* First open-source ALIGN model ever!
* First open ViT and ALIGN models that have been trained on an open-source dataset [COYO](https://github.com/kakaobrain/coyo-dataset)
* Kakao Brain's ViT and ALIGN models perform on-par with the Google versions
* ViT and ALIGN demos are available on HF! You can play with the ViT and ALIGN demos online with image samples of your own choice!
## Performance Comparison
Kakao Brain's released ViT and ALIGN models perform on par and sometimes better than what Google has reported about their implementation. Kakao Brain's `ALIGN-B7-Base` model, while trained on a much fewer pairs (700 million pairs vs 1.8 billion), performs on par with Google's `ALIGN-B7-Base` on the Image KNN classification task and better on MS-COCO retrieval image-to-text, text-to-image tasks. Kakao Brain's `ViT-L/16` performs similarly to Google's `ViT-L/16` when evaluated on ImageNet and ImageNet-ReaL at model resolutions 384 and 512. This means the community can use Kakao Brain's ViT and ALIGN models to replicate Google's ViT and ALIGN releases especially when users require access to the training data. We are excited to see open-source and transparent releases of these model that perform on par with the state of the art!
<p>
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/132_vit_align/vit-align-performance.png" alt="ViT and ALIGN performance"/>
</center>
</p>
## COYO DATASET
<p>
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/132_vit_align/coyo-samples.png" alt="COYO samples"/>
</center>
</p>
What's special about these model releases is that the models are trained on the free and accessible COYO dataset. [COYO](https://github.com/kakaobrain/coyo-dataset#dataset-preview) is an image-text dataset of 700 million pairs similar to Google's `ALIGN 1.8B` image-text dataset which is a collection of "noisy" alt-text and image pairs from webpages, but open-source. `COYO-700M` and `ALIGN 1.8B` are "noisy" because minimal filtering was applied. `COYO` is similar to the other open-source image-text dataset, `LAION` but with the following differences. While `LAION` 2B is a much larger dataset of 2 billion English pairs, compared to `COYO`’s 700 million pairs, `COYO` pairs come with more metadata that give users more flexibility and finer-grained control over usage. The following table shows the differences: `COYO` comes equipped with aesthetic scores for all pairs, more robust watermark scores, and face count data.
| COYO | LAION 2B| ALIGN 1.8B |
| :----: | :----: | :----: |
| Image-text similarity score calculated with CLIP ViT-B/32 and ViT-L/14 models, they are provided as metadata but nothing is filtered out so as to avoid possible elimination bias | Image-text similarity score provided with CLIP (ViT-B/32) - only examples above threshold 0.28 | Minimal, Frequency based filtering |
| NSFW filtering on images and text | NSFW filtering on images | [Google Cloud API](https://cloud.google.com/vision) |
| Face recognition (face count) data provided as meta-data | No face recognition data | NA |
| 700 million pairs all English | 2 billion English| 1.8 billion |
| From CC 2020 Oct - 2021 Aug| From CC 2014-2020| NA |
|Aesthetic Score | Aesthetic Score Partial | NA|
|More robust Watermark score | Watermark Score | NA|
|Hugging Face Hub | Hugging Face Hub | Not made public |
| English | English | English? |
## How ViT and ALIGN work
So what do these models do? Let's breifly discuss how the ViT and ALIGN models work.
ViT -- Vision Transformer -- is a vision model [proposed by Google in 2020](https://ai.googleblog.com/2020/12/transformers-for-image-recognition-at.html) that resembles the text Transformer architecture.
It is a new approach to vision, distinct from convolutional neural nets (CNNs) that have dominated vision tasks since 2012's AlexNet. It is upto four times more computationally efficient than similarly performing CNNs and domain agnostic. ViT takes as input an image which is broken up into a sequence of image patches - just as the text Transformer takes as input a sequence of text - and given position embeddings to each patch to learn the image structure. ViT performance is notable in particular for having an excellent performance-compute trade-off. While some of Google's ViT models are open-source, the JFT-300 million image-label pair dataset they were trained on has not been released publicly. While Kakao Brain's trained on [COYO-Labeled-300M](https://github.com/kakaobrain/coyo-dataset/tree/main/subset/COYO-Labeled-300M), which has been released publicly, and released ViT model performs similarly on various tasks, its code, model, and training data(COYO-Labeled-300M) are made entirely public for reproducibility and open science.
<p>
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/132_vit_align/vit-architecture.gif" alt="ViT architecture" width="700"/>
</center>
</p>
<p>
<center>
<em>A Visualization of How ViT Works from <a href="https://ai.googleblog.com/2020/12/transformers-for-image-recognition-at.html">Google Blog</a></em>
</center>
</p>
[Google then introduced ALIGN](https://ai.googleblog.com/2021/05/align-scaling-up-visual-and-vision.html) -- a Large-scale Image and Noisy Text Embedding model in 2021 -- a visual-language model trained on "noisy" text-image data for various vision and cross-modal tasks such as text-image retrieval. ALIGN has a simple dual-encoder architecture trained on image and text pairs, learned via a contrastive loss function. ALIGN's "noisy" training corpus is notable for balancing scale and robustness. Previously, visual language representational learning had been trained on large-scale datasets with manual labels, which require extensive preprocessing. ALIGN's corpus uses the image alt-text data, text that appears when the image fails to load, as the caption to the image -- resulting in an inevitably noisy, but much larger (1.8 billion pair) dataset that allows ALIGN to perform at SoTA levels on various tasks. Kakao Brain's ALIGN is the first open-source version of this model, trained on the `COYO` dataset and performs better than Google's reported results.
<p>
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/132_vit_align/align-architecture.png" width="700" />
</center>
</p>
<p>
<center>
<em>ALIGN Model from <a href="https://ai.googleblog.com/2021/05/align-scaling-up-visual-and-vision.html">Google Blog</a>
</em>
</center>
<p>
## How to use the COYO dataset
We can conveniently download the `COYO` dataset with a single line of code using the 🤗 Datasets library. To preview the `COYO` dataset and learn more about the data curation process and the meta attributes included, head over to the dataset page on the [hub](https://huggingface.co/datasets/kakaobrain/coyo-700m) or the original Git [repository](https://github.com/kakaobrain/coyo-dataset). To get started, let's install the 🤗 Datasets library: `pip install datasets` and download it.
```shell
>>> from datasets import load_dataset
>>> dataset = load_dataset('kakaobrain/coyo-700m')
>>> dataset
```
While it is significantly smaller than the `LAION` dataset, the `COYO` dataset is still massive with 747M image-text pairs and it might be unfeasible to download the whole dataset to your local. In order to download only a subset of the dataset, we can simply pass in the `streaming=True` argument to the `load_dataset()` method to create an iterable dataset and download data instances as we go.
```shell
>>> from datasets import load_dataset
>>> dataset = load_dataset('kakaobrain/coyo-700m', streaming=True)
>>> print(next(iter(dataset['train'])))
{'id': 2680060225205, 'url': 'https://cdn.shopify.com/s/files/1/0286/3900/2698/products/TVN_Huile-olive-infuse-et-s-227x300_e9a90ffd-b6d2-4118-95a1-29a5c7a05a49_800x.jpg?v=1616684087', 'text': 'Olive oil infused with Tuscany herbs', 'width': 227, 'height': 300, 'image_phash': '9f91e133b1924e4e', 'text_length': 36, 'word_count': 6, 'num_tokens_bert': 6, 'num_tokens_gpt': 9, 'num_faces': 0, 'clip_similarity_vitb32': 0.19921875, 'clip_similarity_vitl14': 0.147216796875, 'nsfw_score_opennsfw2': 0.0058441162109375, 'nsfw_score_gantman': 0.018961310386657715, 'watermark_score': 0.11015450954437256, 'aesthetic_score_laion_v2': 4.871710777282715}
```
## How to use ViT and ALIGN from the Hub
Let’s go ahead and experiment with the new ViT and ALIGN models. As ALIGN is newly added to 🤗 Transformers, we will install the latest version of the library: `pip install -q git+https://github.com/huggingface/transformers.git` and get started with ViT for image classification by importing the modules and libraries we will use. Note that the newly added ALIGN model will be a part of the PyPI package in the next release of the library.
```py
import requests
from PIL import Image
import torch
from transformers import ViTImageProcessor, ViTForImageClassification
```
Next, we will download a random image of two cats and remote controls on a couch from the COCO dataset and preprocess the image to transform it to the input format expected by the model. To do this, we can conveniently use the corresponding preprocessor class (`ViTProcessor`). To initialize the model and the preprocessor, we will use one of the [Kakao Brain ViT repos](https://huggingface.co/models?search=kakaobrain/vit) on the hub. Note that initializing the preprocessor from a repository ensures that the preprocessed image is in the expected format required by that specific pretrained model.
```py
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = ViTImageProcessor.from_pretrained('kakaobrain/vit-large-patch16-384')
model = ViTForImageClassification.from_pretrained('kakaobrain/vit-large-patch16-384')
```
The rest is simple, we will forward preprocess the image and use it as input to the model to retrive the class logits. The Kakao Brain ViT image classification models are trained on ImageNet labels and output logits of shape (batch_size, 1000).
```py
# preprocess image or list of images
inputs = processor(images=image, return_tensors="pt")
# inference
with torch.no_grad():
outputs = model(**inputs)
# apply SoftMax to logits to compute the probability of each class
preds = torch.nn.functional.softmax(outputs.logits, dim=-1)
# print the top 5 class predictions and their probabilities
top_class_preds = torch.argsort(preds, descending=True)[0, :5]
for c in top_class_preds:
print(f"{model.config.id2label[c.item()]} with probability {round(preds[0, c.item()].item(), 4)}")
```
And we are done! To make things even easier and shorter, we can also use the convenient image classification [pipeline](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.ImageClassificationPipeline) and pass the Kakao Brain ViT repo name as our target model to initialize the pipeline. We can then pass in a URL or a local path to an image or a Pillow image and optionally use the `top_k` argument to return the top k predictions. Let's go ahead and get the top 5 predictions for our image of cats and remotes.
```shell
>>> from transformers import pipeline
>>> classifier = pipeline(task='image-classification', model='kakaobrain/vit-large-patch16-384')
>>> classifier('http://images.cocodataset.org/val2017/000000039769.jpg', top_k=5)
[{'score': 0.8223727941513062, 'label': 'remote control, remote'}, {'score': 0.06580372154712677, 'label': 'tabby, tabby cat'}, {'score': 0.0655883178114891, 'label': 'tiger cat'}, {'score': 0.0388941615819931, 'label': 'Egyptian cat'}, {'score': 0.0011215205304324627, 'label': 'lynx, catamount'}]
```
If you want to experiment more with the Kakao Brain ViT model, head over to its [Space](https://huggingface.co/spaces/adirik/kakao-brain-vit) on the 🤗 Hub.
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/132_vit_align/vit_demo.png" alt="vit performance" width="900"/>
</center>
Let's move on to experimenting with ALIGN, which can be used to retrieve multi-modal embeddings of texts or images or to perform zero-shot image classification. ALIGN's transformers implementation and usage is similar to [CLIP](https://huggingface.co/docs/transformers/main/en/model_doc/clip). To get started, we will first download the pretrained model and its processor, which can preprocess both the images and texts such that they are in the expected format to be fed into the vision and text encoders of ALIGN. Once again, let's import the modules we will use and initialize the preprocessor and the model.
```py
import requests
from PIL import Image
import torch
from transformers import AlignProcessor, AlignModel
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = AlignProcessor.from_pretrained('kakaobrain/align-base')
model = AlignModel.from_pretrained('kakaobrain/align-base')
```
We will start with zero-shot image classification first. To do this, we will suppy candidate labels (free-form text) and use AlignModel to find out which description better describes the image. We will first preprocess both the image and text inputs and feed the preprocessed input to the AlignModel.
```py
candidate_labels = ['an image of a cat', 'an image of a dog']
inputs = processor(images=image, text=candidate_labels, return_tensors='pt')
with torch.no_grad():
outputs = model(**inputs)
# this is the image-text similarity score
logits_per_image = outputs.logits_per_image
# we can take the softmax to get the label probabilities
probs = logits_per_image.softmax(dim=1)
print(probs)
```
Done, easy as that. To experiment more with the Kakao Brain ALIGN model for zero-shot image classification, simply head over to its [demo](https://huggingface.co/spaces/adirik/ALIGN-zero-shot-image-classification) on the 🤗 Hub. Note that, the output of `AlignModel` includes `text_embeds` and `image_embeds` (see the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/align) of ALIGN). If we don't need to compute the per-image and per-text logits for zero-shot classification, we can retrieve the vision and text embeddings using the convenient `get_image_features()` and `get_text_features()` methods of the `AlignModel` class.
```py
text_embeds = model.get_text_features(
input_ids=inputs['input_ids'],
attention_mask=inputs['attention_mask'],
token_type_ids=inputs['token_type_ids'],
)
image_embeds = model.get_image_features(
pixel_values=inputs['pixel_values'],
)
```
Alternatively, we can use the stand-along vision and text encoders of ALIGN to retrieve multi-modal embeddings. These embeddings can then be used to train models for various downstream tasks such as object detection, image segmentation and image captioning. Let's see how we can retrieve these embeddings using `AlignTextModel` and `AlignVisionModel`. Note that we can use the convenient AlignProcessor class to preprocess texts and images separately.
```py
from transformers import AlignTextModel
processor = AlignProcessor.from_pretrained('kakaobrain/align-base')
model = AlignTextModel.from_pretrained('kakaobrain/align-base')
# get embeddings of two text queries
inputs = processor(['an image of a cat', 'an image of a dog'], return_tensors='pt')
with torch.no_grad():
outputs = model(**inputs)
# get the last hidden state and the final pooled output
last_hidden_state = outputs.last_hidden_state
pooled_output = outputs.pooler_output
```
We can also opt to return all hidden states and attention values by setting the output_hidden_states and output_attentions arguments to True during inference.
```py
with torch.no_grad():
outputs = model(**inputs, output_hidden_states=True, output_attentions=True)
# print what information is returned
for key, value in outputs.items():
print(key)
```
Let's do the same with `AlignVisionModel` and retrieve the multi-modal embedding of an image.
```py
from transformers import AlignVisionModel
processor = AlignProcessor.from_pretrained('kakaobrain/align-base')
model = AlignVisionModel.from_pretrained('kakaobrain/align-base')
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors='pt')
with torch.no_grad():
outputs = model(**inputs)
# print the last hidden state and the final pooled output
last_hidden_state = outputs.last_hidden_state
pooled_output = outputs.pooler_output
```
Similar to ViT, we can use the zero-shot image classification [pipeline](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.ZeroShotImageClassificationPipeline) to make our work even easier. Let's see how we can use this pipeline to perform image classification in the wild using free-form text candidate labels.
```shell
>>> from transformers import pipeline
>>> classifier = pipeline(task='zero-shot-image-classification', model='kakaobrain/align-base')
>>> classifier(
... 'https://huggingface.co/datasets/Narsil/image_dummy/raw/main/parrots.png',
... candidate_labels=['animals', 'humans', 'landscape'],
... )
[{'score': 0.9263709783554077, 'label': 'animals'}, {'score': 0.07163811475038528, 'label': 'humans'}, {'score': 0.0019908479880541563, 'label': 'landscape'}]
>>> classifier(
... 'https://huggingface.co/datasets/Narsil/image_dummy/raw/main/parrots.png',
... candidate_labels=['black and white', 'photorealist', 'painting'],
... )
[{'score': 0.9735308885574341, 'label': 'black and white'}, {'score': 0.025493400171399117, 'label': 'photorealist'}, {'score': 0.0009757201769389212, 'label': 'painting'}]
```
## Conclusion
There have been incredible advances in multi-modal models in recent years, with models such as CLIP and ALIGN unlocking various downstream tasks such as image captioning, zero-shot image classification, and open vocabulary object detection. In this blog, we talked about the latest open source ViT and ALIGN models contributed to the Hub by Kakao Brain, as well as the new COYO text-image dataset. We also showed how you can use these models to perform various tasks with a few lines of code both on their own or as a part of 🤗 Transformers pipelines.
That was it! We are continuing to integrate the most impactful computer vision and multi-modal models and would love to hear back from you. To stay up to date with the latest news in computer vision and multi-modal research, you can follow us on Twitter: [@adirik](https://twitter.com/https://twitter.com/alaradirik), [@a_e_roberts](https://twitter.com/a_e_roberts), [@NielsRogge](https://twitter.com/NielsRogge), [@RisingSayak](https://twitter.com/RisingSayak), and [@huggingface](https://twitter.com/huggingface).
|
huggingface/blog/blob/main/vit-align.md
|
Res2Net
**Res2Net** is an image model that employs a variation on bottleneck residual blocks, [Res2Net Blocks](https://paperswithcode.com/method/res2net-block). The motivation is to be able to represent features at multiple scales. This is achieved through a novel building block for CNNs that constructs hierarchical residual-like connections within one single residual block. This represents multi-scale features at a granular level and increases the range of receptive fields for each network layer.
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('res2net101_26w_4s', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `res2net101_26w_4s`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('res2net101_26w_4s', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@article{Gao_2021,
title={Res2Net: A New Multi-Scale Backbone Architecture},
volume={43},
ISSN={1939-3539},
url={http://dx.doi.org/10.1109/TPAMI.2019.2938758},
DOI={10.1109/tpami.2019.2938758},
number={2},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
publisher={Institute of Electrical and Electronics Engineers (IEEE)},
author={Gao, Shang-Hua and Cheng, Ming-Ming and Zhao, Kai and Zhang, Xin-Yu and Yang, Ming-Hsuan and Torr, Philip},
year={2021},
month={Feb},
pages={652–662}
}
```
<!--
Type: model-index
Collections:
- Name: Res2Net
Paper:
Title: 'Res2Net: A New Multi-scale Backbone Architecture'
URL: https://paperswithcode.com/paper/res2net-a-new-multi-scale-backbone
Models:
- Name: res2net101_26w_4s
In Collection: Res2Net
Metadata:
FLOPs: 10415881200
Parameters: 45210000
File Size: 181456059
Architecture:
- Batch Normalization
- Convolution
- Global Average Pooling
- ReLU
- Res2Net Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x Titan Xp GPUs
ID: res2net101_26w_4s
LR: 0.1
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/res2net.py#L152
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-res2net/res2net101_26w_4s-02a759a1.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.19%
Top 5 Accuracy: 94.43%
- Name: res2net50_14w_8s
In Collection: Res2Net
Metadata:
FLOPs: 5403546768
Parameters: 25060000
File Size: 100638543
Architecture:
- Batch Normalization
- Convolution
- Global Average Pooling
- ReLU
- Res2Net Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x Titan Xp GPUs
ID: res2net50_14w_8s
LR: 0.1
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/res2net.py#L196
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-res2net/res2net50_14w_8s-6527dddc.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.14%
Top 5 Accuracy: 93.86%
- Name: res2net50_26w_4s
In Collection: Res2Net
Metadata:
FLOPs: 5499974064
Parameters: 25700000
File Size: 103110087
Architecture:
- Batch Normalization
- Convolution
- Global Average Pooling
- ReLU
- Res2Net Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x Titan Xp GPUs
ID: res2net50_26w_4s
LR: 0.1
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/res2net.py#L141
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-res2net/res2net50_26w_4s-06e79181.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.99%
Top 5 Accuracy: 93.85%
- Name: res2net50_26w_6s
In Collection: Res2Net
Metadata:
FLOPs: 8130156528
Parameters: 37050000
File Size: 148603239
Architecture:
- Batch Normalization
- Convolution
- Global Average Pooling
- ReLU
- Res2Net Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x Titan Xp GPUs
ID: res2net50_26w_6s
LR: 0.1
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/res2net.py#L163
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-res2net/res2net50_26w_6s-19041792.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.57%
Top 5 Accuracy: 94.12%
- Name: res2net50_26w_8s
In Collection: Res2Net
Metadata:
FLOPs: 10760338992
Parameters: 48400000
File Size: 194085165
Architecture:
- Batch Normalization
- Convolution
- Global Average Pooling
- ReLU
- Res2Net Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x Titan Xp GPUs
ID: res2net50_26w_8s
LR: 0.1
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/res2net.py#L174
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-res2net/res2net50_26w_8s-2c7c9f12.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.19%
Top 5 Accuracy: 94.37%
- Name: res2net50_48w_2s
In Collection: Res2Net
Metadata:
FLOPs: 5375291520
Parameters: 25290000
File Size: 101421406
Architecture:
- Batch Normalization
- Convolution
- Global Average Pooling
- ReLU
- Res2Net Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x Titan Xp GPUs
ID: res2net50_48w_2s
LR: 0.1
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/res2net.py#L185
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-res2net/res2net50_48w_2s-afed724a.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.53%
Top 5 Accuracy: 93.56%
-->
|
huggingface/pytorch-image-models/blob/main/docs/models/res2net.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Optimize inference using torch.compile()
This guide aims to provide a benchmark on the inference speed-ups introduced with [`torch.compile()`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) for [computer vision models in 🤗 Transformers](https://huggingface.co/models?pipeline_tag=image-classification&library=transformers&sort=trending).
## Benefits of torch.compile
Depending on the model and the GPU, `torch.compile()` yields up to 30% speed-up during inference. To use `torch.compile()`, simply install any version of `torch` above 2.0.
Compiling a model takes time, so it's useful if you are compiling the model only once instead of every time you infer.
To compile any computer vision model of your choice, call `torch.compile()` on the model as shown below:
```diff
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained(MODEL_ID).to("cuda")
+ model = torch.compile(model)
```
`compile()` comes with multiple modes for compiling, which essentially differ in compilation time and inference overhead. `max-autotune` takes longer than `reduce-overhead` but results in faster inference. Default mode is fastest for compilation but is not as efficient compared to `reduce-overhead` for inference time. In this guide, we used the default mode. You can learn more about it [here](https://pytorch.org/get-started/pytorch-2.0/#user-experience).
We benchmarked `torch.compile` with different computer vision models, tasks, types of hardware, and batch sizes on `torch` version 2.0.1.
## Benchmarking code
Below you can find the benchmarking code for each task. We warm up the GPU before inference and take the mean time of 300 inferences, using the same image each time.
### Image Classification with ViT
```python
import torch
from PIL import Image
import requests
import numpy as np
from transformers import AutoImageProcessor, AutoModelForImageClassification
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
model = AutoModelForImageClassification.from_pretrained("google/vit-base-patch16-224").to("cuda")
model = torch.compile(model)
processed_input = processor(image, return_tensors='pt').to(device="cuda")
with torch.no_grad():
_ = model(**processed_input)
```
#### Object Detection with DETR
```python
from transformers import AutoImageProcessor, AutoModelForObjectDetection
processor = AutoImageProcessor.from_pretrained("facebook/detr-resnet-50")
model = AutoModelForObjectDetection.from_pretrained("facebook/detr-resnet-50").to("cuda")
model = torch.compile(model)
texts = ["a photo of a cat", "a photo of a dog"]
inputs = processor(text=texts, images=image, return_tensors="pt").to("cuda")
with torch.no_grad():
_ = model(**inputs)
```
#### Image Segmentation with Segformer
```python
from transformers import SegformerImageProcessor, SegformerForSemanticSegmentation
processor = SegformerImageProcessor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512").to("cuda")
model = torch.compile(model)
seg_inputs = processor(images=image, return_tensors="pt").to("cuda")
with torch.no_grad():
_ = model(**seg_inputs)
```
Below you can find the list of the models we benchmarked.
**Image Classification**
- [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224)
- [microsoft/beit-base-patch16-224-pt22k-ft22k](https://huggingface.co/microsoft/beit-base-patch16-224-pt22k-ft22k)
- [facebook/convnext-large-224](https://huggingface.co/facebook/convnext-large-224)
- [microsoft/resnet-50](https://huggingface.co/)
**Image Segmentation**
- [nvidia/segformer-b0-finetuned-ade-512-512](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
- [facebook/mask2former-swin-tiny-coco-panoptic](https://huggingface.co/facebook/mask2former-swin-tiny-coco-panoptic)
- [facebook/maskformer-swin-base-ade](https://huggingface.co/facebook/maskformer-swin-base-ade)
- [google/deeplabv3_mobilenet_v2_1.0_513](https://huggingface.co/google/deeplabv3_mobilenet_v2_1.0_513)
**Object Detection**
- [google/owlvit-base-patch32](https://huggingface.co/google/owlvit-base-patch32)
- [facebook/detr-resnet-101](https://huggingface.co/facebook/detr-resnet-101)
- [microsoft/conditional-detr-resnet-50](https://huggingface.co/microsoft/conditional-detr-resnet-50)
Below you can find visualization of inference durations with and without `torch.compile()` and percentage improvements for each model in different hardware and batch sizes.
<div class="flex">
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/a100_batch_comp.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/v100_batch_comp.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/t4_batch_comp.png" />
</div>
</div>
<div class="flex">
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_duration.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_percentage.png" />
</div>
</div>
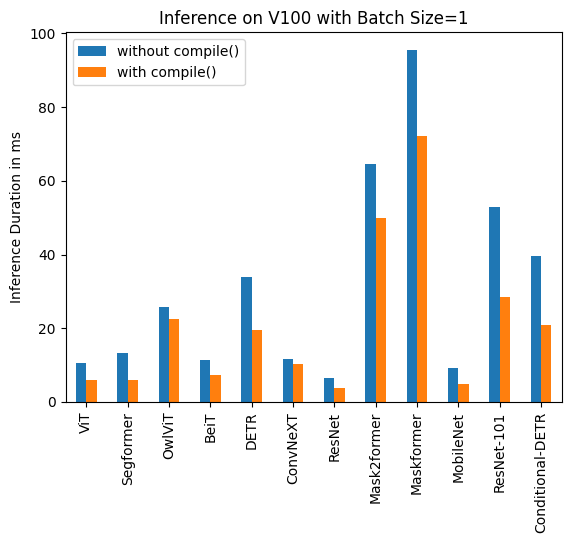
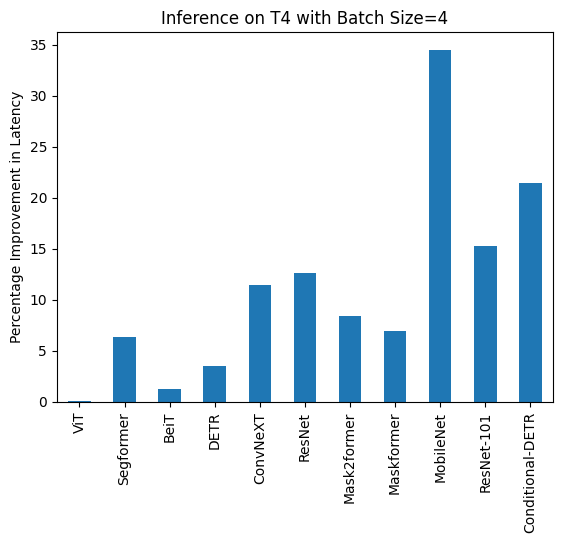
Below you can find inference durations in milliseconds for each model with and without `compile()`. Note that OwlViT results in OOM in larger batch sizes.
### A100 (batch size: 1)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 9.325 | 7.584 |
| Image Segmentation/Segformer | 11.759 | 10.500 |
| Object Detection/OwlViT | 24.978 | 18.420 |
| Image Classification/BeiT | 11.282 | 8.448 |
| Object Detection/DETR | 34.619 | 19.040 |
| Image Classification/ConvNeXT | 10.410 | 10.208 |
| Image Classification/ResNet | 6.531 | 4.124 |
| Image Segmentation/Mask2former | 60.188 | 49.117 |
| Image Segmentation/Maskformer | 75.764 | 59.487 |
| Image Segmentation/MobileNet | 8.583 | 3.974 |
| Object Detection/Resnet-101 | 36.276 | 18.197 |
| Object Detection/Conditional-DETR | 31.219 | 17.993 |
### A100 (batch size: 4)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 14.832 | 14.499 |
| Image Segmentation/Segformer | 18.838 | 16.476 |
| Image Classification/BeiT | 13.205 | 13.048 |
| Object Detection/DETR | 48.657 | 32.418|
| Image Classification/ConvNeXT | 22.940 | 21.631 |
| Image Classification/ResNet | 6.657 | 4.268 |
| Image Segmentation/Mask2former | 74.277 | 61.781 |
| Image Segmentation/Maskformer | 180.700 | 159.116 |
| Image Segmentation/MobileNet | 14.174 | 8.515 |
| Object Detection/Resnet-101 | 68.101 | 44.998 |
| Object Detection/Conditional-DETR | 56.470 | 35.552 |
### A100 (batch size: 16)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 40.944 | 40.010 |
| Image Segmentation/Segformer | 37.005 | 31.144 |
| Image Classification/BeiT | 41.854 | 41.048 |
| Object Detection/DETR | 164.382 | 161.902 |
| Image Classification/ConvNeXT | 82.258 | 75.561 |
| Image Classification/ResNet | 7.018 | 5.024 |
| Image Segmentation/Mask2former | 178.945 | 154.814 |
| Image Segmentation/Maskformer | 638.570 | 579.826 |
| Image Segmentation/MobileNet | 51.693 | 30.310 |
| Object Detection/Resnet-101 | 232.887 | 155.021 |
| Object Detection/Conditional-DETR | 180.491 | 124.032 |
### V100 (batch size: 1)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 10.495 | 6.00 |
| Image Segmentation/Segformer | 13.321 | 5.862 |
| Object Detection/OwlViT | 25.769 | 22.395 |
| Image Classification/BeiT | 11.347 | 7.234 |
| Object Detection/DETR | 33.951 | 19.388 |
| Image Classification/ConvNeXT | 11.623 | 10.412 |
| Image Classification/ResNet | 6.484 | 3.820 |
| Image Segmentation/Mask2former | 64.640 | 49.873 |
| Image Segmentation/Maskformer | 95.532 | 72.207 |
| Image Segmentation/MobileNet | 9.217 | 4.753 |
| Object Detection/Resnet-101 | 52.818 | 28.367 |
| Object Detection/Conditional-DETR | 39.512 | 20.816 |
### V100 (batch size: 4)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 15.181 | 14.501 |
| Image Segmentation/Segformer | 16.787 | 16.188 |
| Image Classification/BeiT | 15.171 | 14.753 |
| Object Detection/DETR | 88.529 | 64.195 |
| Image Classification/ConvNeXT | 29.574 | 27.085 |
| Image Classification/ResNet | 6.109 | 4.731 |
| Image Segmentation/Mask2former | 90.402 | 76.926 |
| Image Segmentation/Maskformer | 234.261 | 205.456 |
| Image Segmentation/MobileNet | 24.623 | 14.816 |
| Object Detection/Resnet-101 | 134.672 | 101.304 |
| Object Detection/Conditional-DETR | 97.464 | 69.739 |
### V100 (batch size: 16)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 52.209 | 51.633 |
| Image Segmentation/Segformer | 61.013 | 55.499 |
| Image Classification/BeiT | 53.938 | 53.581 |
| Object Detection/DETR | OOM | OOM |
| Image Classification/ConvNeXT | 109.682 | 100.771 |
| Image Classification/ResNet | 14.857 | 12.089 |
| Image Segmentation/Mask2former | 249.605 | 222.801 |
| Image Segmentation/Maskformer | 831.142 | 743.645 |
| Image Segmentation/MobileNet | 93.129 | 55.365 |
| Object Detection/Resnet-101 | 482.425 | 361.843 |
| Object Detection/Conditional-DETR | 344.661 | 255.298 |
### T4 (batch size: 1)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 16.520 | 15.786 |
| Image Segmentation/Segformer | 16.116 | 14.205 |
| Object Detection/OwlViT | 53.634 | 51.105 |
| Image Classification/BeiT | 16.464 | 15.710 |
| Object Detection/DETR | 73.100 | 53.99 |
| Image Classification/ConvNeXT | 32.932 | 30.845 |
| Image Classification/ResNet | 6.031 | 4.321 |
| Image Segmentation/Mask2former | 79.192 | 66.815 |
| Image Segmentation/Maskformer | 200.026 | 188.268 |
| Image Segmentation/MobileNet | 18.908 | 11.997 |
| Object Detection/Resnet-101 | 106.622 | 82.566 |
| Object Detection/Conditional-DETR | 77.594 | 56.984 |
### T4 (batch size: 4)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 43.653 | 43.626 |
| Image Segmentation/Segformer | 45.327 | 42.445 |
| Image Classification/BeiT | 52.007 | 51.354 |
| Object Detection/DETR | 277.850 | 268.003 |
| Image Classification/ConvNeXT | 119.259 | 105.580 |
| Image Classification/ResNet | 13.039 | 11.388 |
| Image Segmentation/Mask2former | 201.540 | 184.670 |
| Image Segmentation/Maskformer | 764.052 | 711.280 |
| Image Segmentation/MobileNet | 74.289 | 48.677 |
| Object Detection/Resnet-101 | 421.859 | 357.614 |
| Object Detection/Conditional-DETR | 289.002 | 226.945 |
### T4 (batch size: 16)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 163.914 | 160.907 |
| Image Segmentation/Segformer | 192.412 | 163.620 |
| Image Classification/BeiT | 188.978 | 187.976 |
| Object Detection/DETR | OOM | OOM |
| Image Classification/ConvNeXT | 422.886 | 388.078 |
| Image Classification/ResNet | 44.114 | 37.604 |
| Image Segmentation/Mask2former | 756.337 | 695.291 |
| Image Segmentation/Maskformer | 2842.940 | 2656.88 |
| Image Segmentation/MobileNet | 299.003 | 201.942 |
| Object Detection/Resnet-101 | 1619.505 | 1262.758 |
| Object Detection/Conditional-DETR | 1137.513 | 897.390|
## PyTorch Nightly
We also benchmarked on PyTorch nightly (2.1.0dev, find the wheel [here](https://download.pytorch.org/whl/nightly/cu118)) and observed improvement in latency both for uncompiled and compiled models.
### A100
| **Task/Model** | **Batch Size** | **torch 2.0 - no compile** | **torch 2.0 -<br> compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 12.462 | 6.954 |
| Image Classification/BeiT | 4 | 14.109 | 12.851 |
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
| Object Detection/DETR | Unbatched | 30.484 | 15.221 |
| Object Detection/DETR | 4 | 46.816 | 30.942 |
| Object Detection/DETR | 16 | 163.749 | 163.706 |
### T4
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 14.408 | 14.052 |
| Image Classification/BeiT | 4 | 47.381 | 46.604 |
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
| Object Detection/DETR | Unbatched | 68.382 | 53.481 |
| Object Detection/DETR | 4 | 269.615 | 204.785 |
| Object Detection/DETR | 16 | OOM | OOM |
### V100
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 13.477 | 7.926 |
| Image Classification/BeiT | 4 | 15.103 | 14.378 |
| Image Classification/BeiT | 16 | 52.517 | 51.691 |
| Object Detection/DETR | Unbatched | 28.706 | 19.077 |
| Object Detection/DETR | 4 | 88.402 | 62.949|
| Object Detection/DETR | 16 | OOM | OOM |
## Reduce Overhead
We benchmarked `reduce-overhead` compilation mode for A100 and T4 in Nightly.
### A100
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/ConvNeXT | Unbatched | 11.758 | 7.335 |
| Image Classification/ConvNeXT | 4 | 23.171 | 21.490 |
| Image Classification/ResNet | Unbatched | 7.435 | 3.801 |
| Image Classification/ResNet | 4 | 7.261 | 2.187 |
| Object Detection/Conditional-DETR | Unbatched | 32.823 | 11.627 |
| Object Detection/Conditional-DETR | 4 | 50.622 | 33.831 |
| Image Segmentation/MobileNet | Unbatched | 9.869 | 4.244 |
| Image Segmentation/MobileNet | 4 | 14.385 | 7.946 |
### T4
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/ConvNeXT | Unbatched | 32.137 | 31.84 |
| Image Classification/ConvNeXT | 4 | 120.944 | 110.209 |
| Image Classification/ResNet | Unbatched | 9.761 | 7.698 |
| Image Classification/ResNet | 4 | 15.215 | 13.871 |
| Object Detection/Conditional-DETR | Unbatched | 72.150 | 57.660 |
| Object Detection/Conditional-DETR | 4 | 301.494 | 247.543 |
| Image Segmentation/MobileNet | Unbatched | 22.266 | 19.339 |
| Image Segmentation/MobileNet | 4 | 78.311 | 50.983 |
|
huggingface/transformers/blob/main/docs/source/en/perf_torch_compile.md
|
Dataset Cards
## What are Dataset Cards?
Each dataset may be documented by the `README.md` file in the repository. This file is called a **dataset card**, and the Hugging Face Hub will render its contents on the dataset's main page. To inform users about how to responsibly use the data, it's a good idea to include information about any potential biases within the dataset. Generally, dataset cards help users understand the contents of the dataset and give context for how the dataset should be used.
You can also add dataset metadata to your card. The metadata describes important information about a dataset such as its license, language, and size. It also contains tags to help users discover a dataset on the Hub, and [data files configuration](./datasets-manual-configuration.md) options. Tags are defined in a YAML metadata section at the top of the `README.md` file.
## Dataset card metadata
A dataset repo will render its README.md as a dataset card. To control how the Hub displays the card, you should create a YAML section in the README file to define some metadata. Start by adding three --- at the top, then include all of the relevant metadata, and close the section with another group of --- like the example below:
```yaml
language:
- "List of ISO 639-1 code for your language"
- lang1
- lang2
pretty_name: "Pretty Name of the Dataset"
tags:
- tag1
- tag2
license: "any valid license identifier"
task_categories:
- task1
- task2
```
The metadata that you add to the dataset card enables certain interactions on the Hub. For example:
* Allow users to filter and discover datasets at https://huggingface.co/datasets.
* If you choose a license using the keywords listed in the right column of [this table](./repositories-licenses), the license will be displayed on the dataset page.
When creating a README.md file in a dataset repository on the Hub, use Metadata UI to fill the main metadata:
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-metadata-ui.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-metadata-ui-dark.png"/>
</div>
To see metadata fields, see the detailed [Dataset Card specifications](https://github.com/huggingface/hub-docs/blob/main/datasetcard.md?plain=1).
### Dataset card creation guide
For a step-by-step guide on creating a dataset card, check out the [Create a dataset card](https://huggingface.co/docs/datasets/dataset_card) guide.
Reading through existing dataset cards, such as the [ELI5 dataset card](https://huggingface.co/datasets/eli5/blob/main/README.md), is a great way to familiarize yourself with the common conventions.
### Linking a Paper
If the dataset card includes a link to a paper on arXiv, the Hub will extract the arXiv ID and include it in the dataset tags with the format `arxiv:<PAPER ID>`. Clicking on the tag will let you:
* Visit the Paper page
* Filter for other models on the Hub that cite the same paper.
<div class="flex justify-center">
<img class="block dark:hidden" width="300" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-arxiv.png"/>
<img class="hidden dark:block" width="300" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-arxiv-dark.png"/>
</div>
Read more about paper pages [here](./paper-pages).
|
huggingface/hub-docs/blob/main/docs/hub/datasets-cards.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# HeunDiscreteScheduler
The Heun scheduler (Algorithm 1) is from the [Elucidating the Design Space of Diffusion-Based Generative Models](https://huggingface.co/papers/2206.00364) paper by Karras et al. The scheduler is ported from the [k-diffusion](https://github.com/crowsonkb/k-diffusion) library and created by [Katherine Crowson](https://github.com/crowsonkb/).
## HeunDiscreteScheduler
[[autodoc]] HeunDiscreteScheduler
## SchedulerOutput
[[autodoc]] schedulers.scheduling_utils.SchedulerOutput
|
huggingface/diffusers/blob/main/docs/source/en/api/schedulers/heun.md
|
Using sample-factory at Hugging Face
[`sample-factory`](https://github.com/alex-petrenko/sample-factory) is a codebase for high throughput asynchronous reinforcement learning. It has integrations with the Hugging Face Hub to share models with evaluation results and training metrics.
## Exploring sample-factory in the Hub
You can find `sample-factory` models by filtering at the left of the [models page](https://huggingface.co/models?library=sample-factory).
All models on the Hub come up with useful features:
1. An automatically generated model card with a description, a training configuration, and more.
2. Metadata tags that help for discoverability.
3. Evaluation results to compare with other models.
4. A video widget where you can watch your agent performing.
## Install the library
To install the `sample-factory` library, you need to install the package:
`pip install sample-factory`
SF is known to work on Linux and MacOS. There is no Windows support at this time.
## Loading models from the Hub
### Using load_from_hub
To download a model from the Hugging Face Hub to use with Sample-Factory, use the `load_from_hub` script:
```
python -m sample_factory.huggingface.load_from_hub -r <HuggingFace_repo_id> -d <train_dir_path>
```
The command line arguments are:
- `-r`: The repo ID for the HF repository to download from. The repo ID should be in the format `<username>/<repo_name>`
- `-d`: An optional argument to specify the directory to save the experiment to. Defaults to `./train_dir` which will save the repo to `./train_dir/<repo_name>`
### Download Model Repository Directly
Hugging Face repositories can be downloaded directly using `git clone`:
```
git clone git@hf.co:<Name of HuggingFace Repo> # example: git clone git@hf.co:bigscience/bloom
```
## Using Downloaded Models with Sample-Factory
After downloading the model, you can run the models in the repo with the enjoy script corresponding to your environment. For example, if you are downloading a `mujoco-ant` model, it can be run with:
```
python -m sf_examples.mujoco.enjoy_mujoco --algo=APPO --env=mujoco_ant --experiment=<repo_name> --train_dir=./train_dir
```
Note, you may have to specify the `--train_dir` if your local train_dir has a different path than the one in the `cfg.json`
## Sharing your models
### Using push_to_hub
If you want to upload without generating evaluation metrics or a replay video, you can use the `push_to_hub` script:
```
python -m sample_factory.huggingface.push_to_hub -r <hf_username>/<hf_repo_name> -d <experiment_dir_path>
```
The command line arguments are:
- `-r`: The repo_id to save on HF Hub. This is the same as `hf_repository` in the enjoy script and must be in the form `<hf_username>/<hf_repo_name>`
- `-d`: The full path to your experiment directory to upload
### Using enjoy.py
You can upload your models to the Hub using your environment's `enjoy` script with the `--push_to_hub` flag. Uploading using `enjoy` can also generate evaluation metrics and a replay video.
The evaluation metrics are generated by running your model on the specified environment for a number of episodes and reporting the mean and std reward of those runs.
Other relevant command line arguments are:
- `--hf_repository`: The repository to push to. Must be of the form `<username>/<repo_name>`. The model will be saved to `https://huggingface.co/<username>/<repo_name>`
- `--max_num_episodes`: Number of episodes to evaluate on before uploading. Used to generate evaluation metrics. It is recommended to use multiple episodes to generate an accurate mean and std.
- `--max_num_frames`: Number of frames to evaluate on before uploading. An alternative to `max_num_episodes`
- `--no_render`: A flag that disables rendering and showing the environment steps. It is recommended to set this flag to speed up the evaluation process.
You can also save a video of the model during evaluation to upload to the hub with the `--save_video` flag
- `--video_frames`: The number of frames to be rendered in the video. Defaults to -1 which renders an entire episode
- `--video_name`: The name of the video to save as. If `None`, will save to `replay.mp4` in your experiment directory
For example:
```
python -m sf_examples.mujoco_examples.enjoy_mujoco --algo=APPO --env=mujoco_ant --experiment=<repo_name> --train_dir=./train_dir --max_num_episodes=10 --push_to_hub --hf_username=<username> --hf_repository=<hf_repo_name> --save_video --no_render
```
|
huggingface/hub-docs/blob/main/docs/hub/sample-factory.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# ONNX Runtime
🤗 [Optimum](https://github.com/huggingface/optimum) provides a Stable Diffusion pipeline compatible with ONNX Runtime. You'll need to install 🤗 Optimum with the following command for ONNX Runtime support:
```bash
pip install -q optimum["onnxruntime"]
```
This guide will show you how to use the Stable Diffusion and Stable Diffusion XL (SDXL) pipelines with ONNX Runtime.
## Stable Diffusion
To load and run inference, use the [`~optimum.onnxruntime.ORTStableDiffusionPipeline`]. If you want to load a PyTorch model and convert it to the ONNX format on-the-fly, set `export=True`:
```python
from optimum.onnxruntime import ORTStableDiffusionPipeline
model_id = "runwayml/stable-diffusion-v1-5"
pipeline = ORTStableDiffusionPipeline.from_pretrained(model_id, export=True)
prompt = "sailing ship in storm by Leonardo da Vinci"
image = pipeline(prompt).images[0]
pipeline.save_pretrained("./onnx-stable-diffusion-v1-5")
```
<Tip warning={true}>
Generating multiple prompts in a batch seems to take too much memory. While we look into it, you may need to iterate instead of batching.
</Tip>
To export the pipeline in the ONNX format offline and use it later for inference,
use the [`optimum-cli export`](https://huggingface.co/docs/optimum/main/en/exporters/onnx/usage_guides/export_a_model#exporting-a-model-to-onnx-using-the-cli) command:
```bash
optimum-cli export onnx --model runwayml/stable-diffusion-v1-5 sd_v15_onnx/
```
Then to perform inference (you don't have to specify `export=True` again):
```python
from optimum.onnxruntime import ORTStableDiffusionPipeline
model_id = "sd_v15_onnx"
pipeline = ORTStableDiffusionPipeline.from_pretrained(model_id)
prompt = "sailing ship in storm by Leonardo da Vinci"
image = pipeline(prompt).images[0]
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/optimum/documentation-images/resolve/main/onnxruntime/stable_diffusion_v1_5_ort_sail_boat.png">
</div>
You can find more examples in 🤗 Optimum [documentation](https://huggingface.co/docs/optimum/), and Stable Diffusion is supported for text-to-image, image-to-image, and inpainting.
## Stable Diffusion XL
To load and run inference with SDXL, use the [`~optimum.onnxruntime.ORTStableDiffusionXLPipeline`]:
```python
from optimum.onnxruntime import ORTStableDiffusionXLPipeline
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
pipeline = ORTStableDiffusionXLPipeline.from_pretrained(model_id)
prompt = "sailing ship in storm by Leonardo da Vinci"
image = pipeline(prompt).images[0]
```
To export the pipeline in the ONNX format and use it later for inference, use the [`optimum-cli export`](https://huggingface.co/docs/optimum/main/en/exporters/onnx/usage_guides/export_a_model#exporting-a-model-to-onnx-using-the-cli) command:
```bash
optimum-cli export onnx --model stabilityai/stable-diffusion-xl-base-1.0 --task stable-diffusion-xl sd_xl_onnx/
```
SDXL in the ONNX format is supported for text-to-image and image-to-image.
|
huggingface/diffusers/blob/main/docs/source/en/optimization/onnx.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Depth-to-image
The Stable Diffusion model can also infer depth based on an image using [MiDaS](https://github.com/isl-org/MiDaS). This allows you to pass a text prompt and an initial image to condition the generation of new images as well as a `depth_map` to preserve the image structure.
<Tip>
Make sure to check out the Stable Diffusion [Tips](overview#tips) section to learn how to explore the tradeoff between scheduler speed and quality, and how to reuse pipeline components efficiently!
If you're interested in using one of the official checkpoints for a task, explore the [CompVis](https://huggingface.co/CompVis), [Runway](https://huggingface.co/runwayml), and [Stability AI](https://huggingface.co/stabilityai) Hub organizations!
</Tip>
## StableDiffusionDepth2ImgPipeline
[[autodoc]] StableDiffusionDepth2ImgPipeline
- all
- __call__
- enable_attention_slicing
- disable_attention_slicing
- enable_xformers_memory_efficient_attention
- disable_xformers_memory_efficient_attention
- load_textual_inversion
- load_lora_weights
- save_lora_weights
## StableDiffusionPipelineOutput
[[autodoc]] pipelines.stable_diffusion.StableDiffusionPipelineOutput
|
huggingface/diffusers/blob/main/docs/source/en/api/pipelines/stable_diffusion/depth2img.md
|
Metric Card for CER
## Metric description
Character error rate (CER) is a common metric of the performance of an automatic speech recognition (ASR) system. CER is similar to Word Error Rate (WER), but operates on character instead of word.
Character error rate can be computed as:
`CER = (S + D + I) / N = (S + D + I) / (S + D + C)`
where
`S` is the number of substitutions,
`D` is the number of deletions,
`I` is the number of insertions,
`C` is the number of correct characters,
`N` is the number of characters in the reference (`N=S+D+C`).
## How to use
The metric takes two inputs: references (a list of references for each speech input) and predictions (a list of transcriptions to score).
```python
from datasets import load_metric
cer = load_metric("cer")
cer_score = cer.compute(predictions=predictions, references=references)
```
## Output values
This metric outputs a float representing the character error rate.
```
print(cer_score)
0.34146341463414637
```
The **lower** the CER value, the **better** the performance of the ASR system, with a CER of 0 being a perfect score.
However, CER's output is not always a number between 0 and 1, in particular when there is a high number of insertions (see [Examples](#Examples) below).
### Values from popular papers
This metric is highly dependent on the content and quality of the dataset, and therefore users can expect very different values for the same model but on different datasets.
Multilingual datasets such as [Common Voice](https://huggingface.co/datasets/common_voice) report different CERs depending on the language, ranging from 0.02-0.03 for languages such as French and Italian, to 0.05-0.07 for English (see [here](https://github.com/speechbrain/speechbrain/tree/develop/recipes/CommonVoice/ASR/CTC) for more values).
## Examples
Perfect match between prediction and reference:
```python
from datasets import load_metric
cer = load_metric("cer")
predictions = ["hello world", "good night moon"]
references = ["hello world", "good night moon"]
cer_score = cer.compute(predictions=predictions, references=references)
print(cer_score)
0.0
```
Partial match between prediction and reference:
```python
from datasets import load_metric
cer = load_metric("cer")
predictions = ["this is the prediction", "there is an other sample"]
references = ["this is the reference", "there is another one"]
cer_score = cer.compute(predictions=predictions, references=references)
print(cer_score)
0.34146341463414637
```
No match between prediction and reference:
```python
from datasets import load_metric
cer = load_metric("cer")
predictions = ["hello"]
references = ["gracias"]
cer_score = cer.compute(predictions=predictions, references=references)
print(cer_score)
1.0
```
CER above 1 due to insertion errors:
```python
from datasets import load_metric
cer = load_metric("cer")
predictions = ["hello world"]
references = ["hello"]
cer_score = cer.compute(predictions=predictions, references=references)
print(cer_score)
1.2
```
## Limitations and bias
CER is useful for comparing different models for tasks such as automatic speech recognition (ASR) and optic character recognition (OCR), especially for multilingual datasets where WER is not suitable given the diversity of languages. However, CER provides no details on the nature of translation errors and further work is therefore required to identify the main source(s) of error and to focus any research effort.
Also, in some cases, instead of reporting the raw CER, a normalized CER is reported where the number of mistakes is divided by the sum of the number of edit operations (`I` + `S` + `D`) and `C` (the number of correct characters), which results in CER values that fall within the range of 0–100%.
## Citation
```bibtex
@inproceedings{morris2004,
author = {Morris, Andrew and Maier, Viktoria and Green, Phil},
year = {2004},
month = {01},
pages = {},
title = {From WER and RIL to MER and WIL: improved evaluation measures for connected speech recognition.}
}
```
## Further References
- [Hugging Face Tasks -- Automatic Speech Recognition](https://huggingface.co/tasks/automatic-speech-recognition)
|
huggingface/datasets/blob/main/metrics/cer/README.md
|
@gradio/code
## 0.3.3
### Patch Changes
- Updated dependencies [[`828fb9e`](https://github.com/gradio-app/gradio/commit/828fb9e6ce15b6ea08318675a2361117596a1b5d), [`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144)]:
- @gradio/statustracker@0.4.3
- @gradio/atoms@0.4.1
- @gradio/upload@0.5.6
## 0.3.2
### Patch Changes
- Updated dependencies []:
- @gradio/upload@0.5.5
## 0.3.1
### Patch Changes
- Updated dependencies [[`5d51fbc`](https://github.com/gradio-app/gradio/commit/5d51fbce7826da840a2fd4940feb5d9ad6f1bc5a)]:
- @gradio/upload@0.5.4
## 0.3.0
### Features
- [#6398](https://github.com/gradio-app/gradio/pull/6398) [`67ddd40`](https://github.com/gradio-app/gradio/commit/67ddd40b4b70d3a37cb1637c33620f8d197dbee0) - Lite v4. Thanks [@whitphx](https://github.com/whitphx)!
## 0.2.9
### Patch Changes
- Updated dependencies [[`206af31`](https://github.com/gradio-app/gradio/commit/206af31d7c1a31013364a44e9b40cf8df304ba50)]:
- @gradio/icons@0.3.1
- @gradio/atoms@0.3.1
- @gradio/statustracker@0.4.1
- @gradio/upload@0.5.2
## 0.2.8
### Patch Changes
- Updated dependencies []:
- @gradio/upload@0.5.1
## 0.2.7
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/atoms@0.3.0
- @gradio/icons@0.3.0
- @gradio/statustracker@0.4.0
- @gradio/upload@0.5.0
## 0.2.6
### Patch Changes
- Updated dependencies [[`2f805a7dd`](https://github.com/gradio-app/gradio/commit/2f805a7dd3d2b64b098f659dadd5d01258290521), [`f816136a0`](https://github.com/gradio-app/gradio/commit/f816136a039fa6011be9c4fb14f573e4050a681a)]:
- @gradio/upload@0.4.2
- @gradio/atoms@0.2.2
- @gradio/icons@0.2.1
- @gradio/statustracker@0.3.2
## 0.2.5
### Patch Changes
- Updated dependencies []:
- @gradio/upload@0.4.1
## 0.2.4
### Fixes
- [#6323](https://github.com/gradio-app/gradio/pull/6323) [`55fda81fa`](https://github.com/gradio-app/gradio/commit/55fda81fa5918b48952729232d6e2fc55af9351d) - Textbox and Code Component Blur/Focus Fixes. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
## 0.2.3
### Patch Changes
- Updated dependencies [[`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780), [`fad92c29d`](https://github.com/gradio-app/gradio/commit/fad92c29dc1f5cd84341aae417c495b33e01245f)]:
- @gradio/atoms@0.2.1
- @gradio/upload@0.3.3
- @gradio/statustracker@0.3.1
## 0.2.2
### Patch Changes
- Updated dependencies [[`aaa55ce85`](https://github.com/gradio-app/gradio/commit/aaa55ce85e12f95aba9299445e9c5e59824da18e)]:
- @gradio/upload@0.3.2
## 0.2.1
### Patch Changes
- Updated dependencies []:
- @gradio/upload@0.3.1
## 0.2.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
## 0.2.0-beta.8
### Features
- [#6136](https://github.com/gradio-app/gradio/pull/6136) [`667802a6c`](https://github.com/gradio-app/gradio/commit/667802a6cdbfb2ce454a3be5a78e0990b194548a) - JS Component Documentation. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6149](https://github.com/gradio-app/gradio/pull/6149) [`90318b1dd`](https://github.com/gradio-app/gradio/commit/90318b1dd118ae08a695a50e7c556226234ab6dc) - swap `mode` on the frontned to `interactive` to match the backend. Thanks [@pngwn](https://github.com/pngwn)!
## 0.2.0-beta.7
### Features
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.2.0-beta.6
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.2.3
### Patch Changes
- Updated dependencies [[`e70805d54`](https://github.com/gradio-app/gradio/commit/e70805d54cc792452545f5d8eccc1aa0212a4695)]:
- @gradio/atoms@0.2.0
- @gradio/statustracker@0.2.3
- @gradio/upload@0.3.3
## 0.2.2
### Patch Changes
- Updated dependencies []:
- @gradio/utils@0.1.2
- @gradio/atoms@0.1.4
- @gradio/statustracker@0.2.2
- @gradio/upload@0.3.2
## 0.2.1
### Patch Changes
- Updated dependencies [[`8f0fed857`](https://github.com/gradio-app/gradio/commit/8f0fed857d156830626eb48b469d54d211a582d2)]:
- @gradio/icons@0.2.0
- @gradio/atoms@0.1.3
- @gradio/statustracker@0.2.1
- @gradio/upload@0.3.1
## 0.2.0
### Features
- [#5554](https://github.com/gradio-app/gradio/pull/5554) [`75ddeb390`](https://github.com/gradio-app/gradio/commit/75ddeb390d665d4484667390a97442081b49a423) - Accessibility Improvements. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.1.2
### Patch Changes
- Updated dependencies [[`afac0006`](https://github.com/gradio-app/gradio/commit/afac0006337ce2840cf497cd65691f2f60ee5912)]:
- @gradio/statustracker@0.2.0
- @gradio/utils@0.1.1
- @gradio/atoms@0.1.2
- @gradio/upload@0.2.1
## 0.1.1
### Patch Changes
- Updated dependencies [[`abf1c57d`](https://github.com/gradio-app/gradio/commit/abf1c57d7d85de0df233ee3b38aeb38b638477db), [`79d8f9d8`](https://github.com/gradio-app/gradio/commit/79d8f9d891901683c5a1b7486efb44eab2478c96)]:
- @gradio/icons@0.1.0
- @gradio/utils@0.1.0
- @gradio/upload@0.2.0
- @gradio/atoms@0.1.1
- @gradio/statustracker@0.1.1
## 0.1.0
### Highlights
#### Improve startup performance and markdown support ([#5279](https://github.com/gradio-app/gradio/pull/5279) [`fe057300`](https://github.com/gradio-app/gradio/commit/fe057300f0672c62dab9d9b4501054ac5d45a4ec))
##### Improved markdown support
We now have better support for markdown in `gr.Markdown` and `gr.Dataframe`. Including syntax highlighting and Github Flavoured Markdown. We also have more consistent markdown behaviour and styling.
##### Various performance improvements
These improvements will be particularly beneficial to large applications.
- Rather than attaching events manually, they are now delegated, leading to a significant performance improvement and addressing a performance regression introduced in a recent version of Gradio. App startup for large applications is now around twice as fast.
- Optimised the mounting of individual components, leading to a modest performance improvement during startup (~30%).
- Corrected an issue that was causing markdown to re-render infinitely.
- Ensured that the `gr.3DModel` does re-render prematurely.
Thanks [@pngwn](https://github.com/pngwn)!
### Features
- [#5215](https://github.com/gradio-app/gradio/pull/5215) [`fbdad78a`](https://github.com/gradio-app/gradio/commit/fbdad78af4c47454cbb570f88cc14bf4479bbceb) - Lazy load interactive or static variants of a component individually, rather than loading both variants regardless. This change will improve performance for many applications. Thanks [@pngwn](https://github.com/pngwn)!
- [#5216](https://github.com/gradio-app/gradio/pull/5216) [`4b58ea6d`](https://github.com/gradio-app/gradio/commit/4b58ea6d98e7a43b3f30d8a4cb6f379bc2eca6a8) - Update i18n tokens and locale files. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.0.3
### Patch Changes
- Updated dependencies [[`667875b2`](https://github.com/gradio-app/gradio/commit/667875b2441753e74d25bd9d3c8adedd8ede11cd)]:
- @gradio/upload@0.0.3
## 0.0.2
### Patch Changes
- Updated dependencies []:
- @gradio/atoms@0.0.2
- @gradio/upload@0.0.2
|
gradio-app/gradio/blob/main/js/code/CHANGELOG.md
|
--
title: "Smaller is better: Q8-Chat, an efficient generative AI experience on Xeon"
thumbnail: /blog/assets/143_q8chat/thumbnail.png
authors:
- user: juliensimon
---
# Smaller is better: Q8-Chat, an efficient generative AI experience on Xeon
Large language models (LLMs) are taking the machine learning world by storm. Thanks to their [Transformer](https://arxiv.org/abs/1706.03762) architecture, LLMs have an uncanny ability to learn from vast amounts of unstructured data, like text, images, video, or audio. They perform very well on many [task types](https://huggingface.co/tasks), either extractive like text classification or generative like text summarization and text-to-image generation.
As their name implies, LLMs are *large* models that often exceed the 10-billion parameter mark. Some have more than 100 billion parameters, like the [BLOOM](https://huggingface.co/bigscience/bloom) model. LLMs require lots of computing power, typically found in high-end GPUs, to predict fast enough for low-latency use cases like search or conversational applications. Unfortunately, for many organizations, the associated costs can be prohibitive and make it difficult to use state-of-the-art LLMs in their applications.
In this post, we will discuss optimization techniques that help reduce LLM size and inference latency, helping them run efficiently on Intel CPUs.
## A primer on quantization
LLMs usually train with 16-bit floating point parameters (a.k.a FP16/BF16). Thus, storing the value of a single weight or activation value requires 2 bytes of memory. In addition, floating point arithmetic is more complex and slower than integer arithmetic and requires additional computing power.
Quantization is a model compression technique that aims to solve both problems by reducing the range of unique values that model parameters can take. For instance, you can quantize models to lower precision like 8-bit integers (INT8) to shrink them and replace complex floating-point operations with simpler and faster integer operations.
In a nutshell, quantization rescales model parameters to smaller value ranges. When successful, it shrinks your model by at least 2x, without any impact on model accuracy.
You can apply quantization during training, a.k.a quantization-aware training ([QAT](https://arxiv.org/abs/1910.06188)), which generally yields the best results. If you’d prefer to quantize an existing model, you can apply post-training quantization ([PTQ](https://www.tensorflow.org/lite/performance/post_training_quantization#:~:text=Post%2Dtraining%20quantization%20is%20a,little%20degradation%20in%20model%20accuracy.)), a much faster technique that requires very little computing power.
Different quantization tools are available. For example, PyTorch has built-in support for [quantization](https://pytorch.org/docs/stable/quantization.html). You can also use the Hugging Face [Optimum Intel](https://huggingface.co/docs/optimum/intel/index) library, which includes developer-friendly APIs for QAT and PTQ.
## Quantizing LLMs
Recent studies [[1]](https://arxiv.org/abs/2206.01861)[[2]](https://arxiv.org/abs/2211.10438) show that current quantization techniques don’t work well with LLMs. In particular, LLMs exhibit large-magnitude outliers in specific activation channels across all layers and tokens. Here’s an example with the OPT-13B model. You can see that one of the activation channels has much larger values than all others across all tokens. This phenomenon is visible in all the Transformer layers of the model.
<kbd>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/143_q8chat/pic1.png">
</kbd>
<br>*Source: SmoothQuant*
The best quantization techniques to date quantize activations token-wise, causing either truncated outliers or underflowing low-magnitude activations. Both solutions hurt model quality significantly. Moreover, quantization-aware training requires additional model training, which is not practical in most cases due to lack of compute resources and data.
SmoothQuant [[3]](https://arxiv.org/abs/2211.10438)[[4]](https://github.com/mit-han-lab/smoothquant) is a new quantization technique that solves this problem. It applies a joint mathematical transformation to weights and activations, which reduces the ratio between outlier and non-outlier values for activations at the cost of increasing the ratio for weights. This transformation makes the layers of the Transformer "quantization-friendly" and enables 8-bit quantization without hurting model quality. As a consequence, SmoothQuant produces smaller, faster models that run well on Intel CPU platforms.
<kbd>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/143_q8chat/pic2.png">
</kbd>
<br>*Source: SmoothQuant*
Now, let’s see how SmoothQuant works when applied to popular LLMs.
## Quantizing LLMs with SmoothQuant
Our friends at Intel have quantized several LLMs with SmoothQuant-O3: OPT [2.7B](https://huggingface.co/facebook/opt-2.7b) and [6.7B](https://huggingface.co/facebook/opt-6.7b) [[5]](https://arxiv.org/pdf/2205.01068.pdf), LLaMA [7B](https://huggingface.co/decapoda-research/llama-7b-hf) [[6]](https://ai.facebook.com/blog/large-language-model-llama-meta-ai/), Alpaca [7B](https://huggingface.co/tatsu-lab/alpaca-7b-wdiff) [[7]](https://crfm.stanford.edu/2023/03/13/alpaca.html), Vicuna [7B](https://huggingface.co/lmsys/vicuna-7b-delta-v1.1) [[8]](https://vicuna.lmsys.org/), BloomZ [7.1B](https://huggingface.co/bigscience/bloomz-7b1) [[9]](https://huggingface.co/bigscience/bloomz) MPT-7B-chat [[10]](https://www.mosaicml.com/blog/mpt-7b). They also evaluated the accuracy of the quantized models, using [Language Model Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness).
The table below presents a summary of their findings. The second column shows the ratio of benchmarks that have improved post-quantization. The third column contains the mean average degradation (_* a negative value indicates that the benchmark has improved_). You can find the detailed results at the end of this post.
<kbd>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/143_q8chat/table0.png">
</kbd>
As you can see, OPT models are great candidates for SmoothQuant quantization. Models are ~2x smaller compared to pretrained 16-bit models. Most of the metrics improve, and those who don’t are only marginally penalized.
The picture is a little more contrasted for LLaMA 7B and BloomZ 7.1B. Models are compressed by a factor of ~2x, with about half the task seeing metric improvements. Again, the other half is only marginally impacted, with a single task seeing more than 3% relative degradation.
The obvious benefit of working with smaller models is a significant reduction in inference latency. Here’s a [video](https://drive.google.com/file/d/1Iv5_aV8mKrropr9HeOLIBT_7_oYPmgNl/view?usp=sharing) demonstrating real-time text generation with the MPT-7B-chat model on a single socket Intel Sapphire Rapids CPU with 32 cores and a batch size of 1.
In this example, we ask the model: “*What is the role of Hugging Face in democratizing NLP?*”. This sends the following prompt to the model:
"*A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: What is the role of Hugging Face in democratizing NLP? ASSISTANT:*"
<figure class="image table text-center m-0 w-full">
<video
alt="MPT-7B Demo"
style="max-width: 70%; margin: auto;"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/143_q8chat/mpt-7b-int8-hf-role.mov" type="video/mp4">
</video>
</figure>
The example shows the additional benefits you can get from 8bit quantization coupled with 4th Gen Xeon resulting in very low generation time for each token. This level of performance definitely makes it possible to run LLMs on CPU platforms, giving customers more IT flexibility and better cost-performance than ever before.
## Chat experience on Xeon
Recently, Clement, the CEO of HuggingFace, recently said: “*More companies would be better served focusing on smaller, specific models that are cheaper to train and run.*” The emergence of relatively smaller models like Alpaca, BloomZ and Vicuna, open a new opportunity for enterprises to lower the cost of fine-tuning and inference in production. As demonstrated above, high-quality quantization brings high-quality chat experiences to Intel CPU platforms, without the need of running mammoth LLMs and complex AI accelerators.
Together with Intel, we're hosting a new exciting demo in Spaces called [Q8-Chat](https://huggingface.co/spaces/Intel/Q8-Chat) (pronounced "Cute chat"). Q8-Chat offers you a ChatGPT-like chat experience, while only running on a single socket Intel Sapphire Rapids CPU with 32 cores and a batch size of 1.
<iframe src="https://intel-q8-chat.hf.space" frameborder="0" width="100%" height="1600"></iframe>
## Next steps
We’re currently working on integrating these new quantization techniques into the Hugging Face [Optimum Intel](https://huggingface.co/docs/optimum/intel/index) library through [Intel Neural Compressor](https://github.com/intel/neural-compressor).
Once we’re done, you’ll be able to replicate these demos with just a few lines of code.
Stay tuned. The future is 8-bit!
*This post is guaranteed 100% ChatGPT-free.*
## Acknowledgment
This blog was made in conjunction with Ofir Zafrir, Igor Margulis, Guy Boudoukh and Moshe Wasserblat from Intel Labs.
Special thanks to them for their great comments and collaboration.
## Appendix: detailed results
A negative value indicates that the benchmark has improved.
<kbd>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/143_q8chat/table1.png">
</kbd>
<kbd>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/143_q8chat/table2.png">
</kbd>
<kbd>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/143_q8chat/table3.png">
</kbd>
<kbd>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/143_q8chat/table4.png">
</kbd>
|
huggingface/blog/blob/main/generative-ai-models-on-intel-cpu.md
|
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# PyTorch training on Apple silicon
Previously, training models on a Mac was limited to the CPU only. With the release of PyTorch v1.12, you can take advantage of training models with Apple's silicon GPUs for significantly faster performance and training. This is powered in PyTorch by integrating Apple's Metal Performance Shaders (MPS) as a backend. The [MPS backend](https://pytorch.org/docs/stable/notes/mps.html) implements PyTorch operations as custom Metal shaders and places these modules on a `mps` device.
<Tip warning={true}>
Some PyTorch operations are not implemented in MPS yet and will throw an error. To avoid this, you should set the environment variable `PYTORCH_ENABLE_MPS_FALLBACK=1` to use the CPU kernels instead (you'll still see a `UserWarning`).
<br>
If you run into any other errors, please open an issue in the [PyTorch](https://github.com/pytorch/pytorch/issues) repository because the [`Trainer`] only integrates the MPS backend.
</Tip>
With the `mps` device set, you can:
* train larger networks or batch sizes locally
* reduce data retrieval latency because the GPU's unified memory architecture allows direct access to the full memory store
* reduce costs because you don't need to train on cloud-based GPUs or add additional local GPUs
Get started by making sure you have PyTorch installed. MPS acceleration is supported on macOS 12.3+.
```bash
pip install torch torchvision torchaudio
```
[`TrainingArguments`] uses the `mps` device by default if it's available which means you don't need to explicitly set the device. For example, you can run the [run_glue.py](https://github.com/huggingface/transformers/blob/main/examples/pytorch/text-classification/run_glue.py) script with the MPS backend automatically enabled without making any changes.
```diff
export TASK_NAME=mrpc
python examples/pytorch/text-classification/run_glue.py \
--model_name_or_path bert-base-cased \
--task_name $TASK_NAME \
- --use_mps_device \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/ \
--overwrite_output_dir
```
Backends for [distributed setups](https://pytorch.org/docs/stable/distributed.html#backends) like `gloo` and `nccl` are not supported by the `mps` device which means you can only train on a single GPU with the MPS backend.
You can learn more about the MPS backend in the [Introducing Accelerated PyTorch Training on Mac](https://pytorch.org/blog/introducing-accelerated-pytorch-training-on-mac/) blog post.
|
huggingface/transformers/blob/main/docs/source/en/perf_train_special.md
|
--
title: SARI
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
SARI is a metric used for evaluating automatic text simplification systems.
The metric compares the predicted simplified sentences against the reference
and the source sentences. It explicitly measures the goodness of words that are
added, deleted and kept by the system.
Sari = (F1_add + F1_keep + P_del) / 3
where
F1_add: n-gram F1 score for add operation
F1_keep: n-gram F1 score for keep operation
P_del: n-gram precision score for delete operation
n = 4, as in the original paper.
This implementation is adapted from Tensorflow's tensor2tensor implementation [3].
It has two differences with the original GitHub [1] implementation:
(1) Defines 0/0=1 instead of 0 to give higher scores for predictions that match
a target exactly.
(2) Fixes an alleged bug [2] in the keep score computation.
[1] https://github.com/cocoxu/simplification/blob/master/SARI.py
(commit 0210f15)
[2] https://github.com/cocoxu/simplification/issues/6
[3] https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/utils/sari_hook.py
---
# Metric Card for SARI
## Metric description
SARI (***s**ystem output **a**gainst **r**eferences and against the **i**nput sentence*) is a metric used for evaluating automatic text simplification systems.
The metric compares the predicted simplified sentences against the reference and the source sentences. It explicitly measures the goodness of words that are added, deleted and kept by the system.
SARI can be computed as:
`sari = ( F1_add + F1_keep + P_del) / 3`
where
`F1_add` is the n-gram F1 score for add operations
`F1_keep` is the n-gram F1 score for keep operations
`P_del` is the n-gram precision score for delete operations
The number of n grams, `n`, is equal to 4, as in the original paper.
This implementation is adapted from [Tensorflow's tensor2tensor implementation](https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/utils/sari_hook.py).
It has two differences with the [original GitHub implementation](https://github.com/cocoxu/simplification/blob/master/SARI.py):
1) It defines 0/0=1 instead of 0 to give higher scores for predictions that match a target exactly.
2) It fixes an [alleged bug](https://github.com/cocoxu/simplification/issues/6) in the keep score computation.
## How to use
The metric takes 3 inputs: sources (a list of source sentence strings), predictions (a list of predicted sentence strings) and references (a list of lists of reference sentence strings)
```python
from evaluate import load
sari = load("sari")
sources=["About 95 species are currently accepted."]
predictions=["About 95 you now get in."]
references=[["About 95 species are currently known.","About 95 species are now accepted.","95 species are now accepted."]]
sari_score = sari.compute(sources=sources, predictions=predictions, references=references)
```
## Output values
This metric outputs a dictionary with the SARI score:
```
print(sari_score)
{'sari': 26.953601953601954}
```
The range of values for the SARI score is between 0 and 100 -- the higher the value, the better the performance of the model being evaluated, with a SARI of 100 being a perfect score.
### Values from popular papers
The [original paper that proposes the SARI metric](https://aclanthology.org/Q16-1029.pdf) reports scores ranging from 26 to 43 for different simplification systems and different datasets. They also find that the metric ranks all of the simplification systems and human references in the same order as the human assessment used as a comparison, and that it correlates reasonably with human judgments.
More recent SARI scores for text simplification can be found on leaderboards for datasets such as [TurkCorpus](https://paperswithcode.com/sota/text-simplification-on-turkcorpus) and [Newsela](https://paperswithcode.com/sota/text-simplification-on-newsela).
## Examples
Perfect match between prediction and reference:
```python
from evaluate import load
sari = load("sari")
sources=["About 95 species are currently accepted ."]
predictions=["About 95 species are currently accepted ."]
references=[["About 95 species are currently accepted ."]]
sari_score = sari.compute(sources=sources, predictions=predictions, references=references)
print(sari_score)
{'sari': 100.0}
```
Partial match between prediction and reference:
```python
from evaluate import load
sari = load("sari")
sources=["About 95 species are currently accepted ."]
predictions=["About 95 you now get in ."]
references=[["About 95 species are currently known .","About 95 species are now accepted .","95 species are now accepted ."]]
sari_score = sari.compute(sources=sources, predictions=predictions, references=references)
print(sari_score)
{'sari': 26.953601953601954}
```
## Limitations and bias
SARI is a valuable measure for comparing different text simplification systems as well as one that can assist the iterative development of a system.
However, while the [original paper presenting SARI](https://aclanthology.org/Q16-1029.pdf) states that it captures "the notion of grammaticality and meaning preservation", this is a difficult claim to empirically validate.
## Citation
```bibtex
@inproceedings{xu-etal-2016-optimizing,
title = {Optimizing Statistical Machine Translation for Text Simplification},
authors={Xu, Wei and Napoles, Courtney and Pavlick, Ellie and Chen, Quanze and Callison-Burch, Chris},
journal = {Transactions of the Association for Computational Linguistics},
volume = {4},
year={2016},
url = {https://www.aclweb.org/anthology/Q16-1029},
pages = {401--415},
}
```
## Further References
- [NLP Progress -- Text Simplification](http://nlpprogress.com/english/simplification.html)
- [Hugging Face Hub -- Text Simplification Models](https://huggingface.co/datasets?filter=task_ids:text-simplification)
|
huggingface/evaluate/blob/main/metrics/sari/README.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the
License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an
"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
specific language governing permissions and limitations under the License. -->
# Nougat
## Overview
The Nougat model was proposed in [Nougat: Neural Optical Understanding for Academic Documents](https://arxiv.org/abs/2308.13418) by
Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic. Nougat uses the same architecture as [Donut](donut), meaning an image Transformer
encoder and an autoregressive text Transformer decoder to translate scientific PDFs to markdown, enabling easier access to them.
The abstract from the paper is the following:
*Scientific knowledge is predominantly stored in books and scientific journals, often in the form of PDFs. However, the PDF format leads to a loss of semantic information, particularly for mathematical expressions. We propose Nougat (Neural Optical Understanding for Academic Documents), a Visual Transformer model that performs an Optical Character Recognition (OCR) task for processing scientific documents into a markup language, and demonstrate the effectiveness of our model on a new dataset of scientific documents. The proposed approach offers a promising solution to enhance the accessibility of scientific knowledge in the digital age, by bridging the gap between human-readable documents and machine-readable text. We release the models and code to accelerate future work on scientific text recognition.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/nougat_architecture.jpg"
alt="drawing" width="600"/>
<small> Nougat high-level overview. Taken from the <a href="https://arxiv.org/abs/2308.13418">original paper</a>. </small>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
[here](https://github.com/facebookresearch/nougat).
## Usage tips
- The quickest way to get started with Nougat is by checking the [tutorial
notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Nougat), which show how to use the model
at inference time as well as fine-tuning on custom data.
- Nougat is always used within the [VisionEncoderDecoder](vision-encoder-decoder) framework. The model is identical to [Donut](donut) in terms of architecture.
## Inference
Nougat's [`VisionEncoderDecoder`] model accepts images as input and makes use of
[`~generation.GenerationMixin.generate`] to autoregressively generate text given the input image.
The [`NougatImageProcessor`] class is responsible for preprocessing the input image and
[`NougatTokenizerFast`] decodes the generated target tokens to the target string. The
[`NougatProcessor`] wraps [`NougatImageProcessor`] and [`NougatTokenizerFast`] classes
into a single instance to both extract the input features and decode the predicted token ids.
- Step-by-step PDF transcription
```py
>>> from huggingface_hub import hf_hub_download
>>> import re
>>> from PIL import Image
>>> from transformers import NougatProcessor, VisionEncoderDecoderModel
>>> from datasets import load_dataset
>>> import torch
>>> processor = NougatProcessor.from_pretrained("facebook/nougat-base")
>>> model = VisionEncoderDecoderModel.from_pretrained("facebook/nougat-base")
>>> device = "cuda" if torch.cuda.is_available() else "cpu"
>>> model.to(device) # doctest: +IGNORE_RESULT
>>> # prepare PDF image for the model
>>> filepath = hf_hub_download(repo_id="hf-internal-testing/fixtures_docvqa", filename="nougat_paper.png", repo_type="dataset")
>>> image = Image.open(filepath)
>>> pixel_values = processor(image, return_tensors="pt").pixel_values
>>> # generate transcription (here we only generate 30 tokens)
>>> outputs = model.generate(
... pixel_values.to(device),
... min_length=1,
... max_new_tokens=30,
... bad_words_ids=[[processor.tokenizer.unk_token_id]],
... )
>>> sequence = processor.batch_decode(outputs, skip_special_tokens=True)[0]
>>> sequence = processor.post_process_generation(sequence, fix_markdown=False)
>>> # note: we're using repr here such for the sake of printing the \n characters, feel free to just print the sequence
>>> print(repr(sequence))
'\n\n# Nougat: Neural Optical Understanding for Academic Documents\n\n Lukas Blecher\n\nCorrespondence to: lblecher@'
```
See the [model hub](https://huggingface.co/models?filter=nougat) to look for Nougat checkpoints.
<Tip>
The model is identical to [Donut](donut) in terms of architecture.
</Tip>
## NougatImageProcessor
[[autodoc]] NougatImageProcessor
- preprocess
## NougatTokenizerFast
[[autodoc]] NougatTokenizerFast
## NougatProcessor
[[autodoc]] NougatProcessor
- __call__
- from_pretrained
- save_pretrained
- batch_decode
- decode
- post_process_generation
|
huggingface/transformers/blob/main/docs/source/en/model_doc/nougat.md
|
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Hubert
## Overview
Hubert was proposed in [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan
Salakhutdinov, Abdelrahman Mohamed.
The abstract from the paper is the following:
*Self-supervised approaches for speech representation learning are challenged by three unique problems: (1) there are
multiple sound units in each input utterance, (2) there is no lexicon of input sound units during the pre-training
phase, and (3) sound units have variable lengths with no explicit segmentation. To deal with these three problems, we
propose the Hidden-Unit BERT (HuBERT) approach for self-supervised speech representation learning, which utilizes an
offline clustering step to provide aligned target labels for a BERT-like prediction loss. A key ingredient of our
approach is applying the prediction loss over the masked regions only, which forces the model to learn a combined
acoustic and language model over the continuous inputs. HuBERT relies primarily on the consistency of the unsupervised
clustering step rather than the intrinsic quality of the assigned cluster labels. Starting with a simple k-means
teacher of 100 clusters, and using two iterations of clustering, the HuBERT model either matches or improves upon the
state-of-the-art wav2vec 2.0 performance on the Librispeech (960h) and Libri-light (60,000h) benchmarks with 10min, 1h,
10h, 100h, and 960h fine-tuning subsets. Using a 1B parameter model, HuBERT shows up to 19% and 13% relative WER
reduction on the more challenging dev-other and test-other evaluation subsets.*
This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
# Usage tips
- Hubert is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
- Hubert model was fine-tuned using connectionist temporal classification (CTC) so the model output has to be decoded
using [`Wav2Vec2CTCTokenizer`].
## Resources
- [Audio classification task guide](../tasks/audio_classification)
- [Automatic speech recognition task guide](../tasks/asr)
## HubertConfig
[[autodoc]] HubertConfig
<frameworkcontent>
<pt>
## HubertModel
[[autodoc]] HubertModel
- forward
## HubertForCTC
[[autodoc]] HubertForCTC
- forward
## HubertForSequenceClassification
[[autodoc]] HubertForSequenceClassification
- forward
</pt>
<tf>
## TFHubertModel
[[autodoc]] TFHubertModel
- call
## TFHubertForCTC
[[autodoc]] TFHubertForCTC
- call
</tf>
</frameworkcontent>
|
huggingface/transformers/blob/main/docs/source/en/model_doc/hubert.md
|
--
title: "An overview of inference solutions on Hugging Face"
thumbnail: /blog/assets/116_inference_update/widget.png
authors:
- user: juliensimon
---
# An Overview of Inference Solutions on Hugging Face
Every day, developers and organizations are adopting models hosted on [Hugging Face](https://huggingface.co/models) to turn ideas into proof-of-concept demos, and demos into production-grade applications. For instance, Transformer models have become a popular architecture for a wide range of machine learning (ML) applications, including natural language processing, computer vision, speech, and more. Recently, diffusers have become a popular architecuture for text-to-image or image-to-image generation. Other architectures are popular for other tasks, and we host all of them on the HF Hub!
At Hugging Face, we are obsessed with simplifying ML development and operations without compromising on state-of-the-art quality. In this respect, the ability to test and deploy the latest models with minimal friction is critical, all along the lifecycle of an ML project. Optimizing the cost-performance ratio is equally important, and we'd like to thank our friends at [Intel](https://huggingface.co/intel) for sponsoring our free CPU-based inference solutions. This is another major step in our [partnership](https://huggingface.co/blog/intel). It's also great news for our user community, who can now enjoy the speedup delivered by the [Intel Xeon Ice Lake](https://www.intel.com/content/www/us/en/products/docs/processors/xeon/3rd-gen-xeon-scalable-processors-brief.html) architecture at zero cost.
Now, let's review your inference options with Hugging Face.
## Free Inference Widget
One of my favorite features on the Hugging Face hub is the Inference [Widget](https://huggingface.co/docs/hub/models-widgets). Located on the model page, the Inference Widget lets you upload sample data and predict it in a single click.
Here's a sentence similarity example with the `sentence-transformers/all-MiniLM-L6-v2` [model](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2):
<kbd>
<img src="assets/116_inference_update/widget.png">
</kbd>
It's the best way to quickly get a sense of what a model does, its output, and how it performs on a few samples from your dataset. The model is loaded on-demand on our servers and unloaded when it's not needed anymore. You don't have to write any code and the feature is free. What's not to love?
## Free Inference API
The [Inference API](https://huggingface.co/docs/api-inference/) is what powers the Inference widget under the hood. With a simple HTTP request, you can load any hub model and predict your data with it in seconds. The model URL and a valid hub token are all you need.
Here's how I can load and predict with the `xlm-roberta-base` [model](https://huggingface.co/xlm-roberta-base) in a single line:
```
curl https://api-inference.huggingface.co/models/xlm-roberta-base \
-X POST \
-d '{"inputs": "The answer to the universe is <mask>."}' \
-H "Authorization: Bearer HF_TOKEN"
```
The Inference API is the simplest way to build a prediction service that you can immediately call from your application during development and tests. No need for a bespoke API, or a model server. In addition, you can instantly switch from one model to the next and compare their performance in your application. And guess what? The Inference API is free to use.
As rate limiting is enforced, we don't recommend using the Inference API for production. Instead, you should consider Inference Endpoints.
## Production with Inference Endpoints
Once you're happy with the performance of your ML model, it's time to deploy it for production. Unfortunately, when leaving the sandbox, everything becomes a concern: security, scaling, monitoring, etc. This is where a lot of ML stumble and sometimes fall.
We built [Inference Endpoints](https://huggingface.co/inference-endpoints) to solve this problem.
In just a few clicks, Inference Endpoints let you deploy any hub model on secure and scalable infrastructure, hosted in your AWS or Azure region of choice. Additional settings include CPU and GPU hosting, built-in auto-scaling, and more. This makes finding the appropriate cost/performance ratio easy, with [pricing](https://huggingface.co/pricing#endpoints) starting as low as $0.06 per hour.
Inference Endpoints support three security levels:
* Public: the endpoint runs in a public Hugging Face subnet, and anyone on the Internet can access it without any authentication.
* Protected: the endpoint runs in a public Hugging Face subnet, and anyone on the Internet with the appropriate Hugging Face token can access it.
* Private: the endpoint runs in a private Hugging Face subnet and is not accessible on the Internet. It's only available through a private connection in your AWS or Azure account. This will satisfy the strictest compliance requirements.
<kbd>
<img src="assets/116_inference_update/endpoints.png">
</kbd>
To learn more about Inference Endpoints, please read this [tutorial](https://huggingface.co/blog/inference-endpoints) and the [documentation](https://huggingface.co/docs/inference-endpoints/).
## Spaces
Finally, Spaces is another production-ready option to deploy your model for inference on top of a simple UI framework (Gradio for instance), and we also support [hardware upgrades](/docs/hub/spaces-gpus) like advanced Intel CPUs and NVIDIA GPUs. There's no better way to demo your models!
<kbd>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/spaces-gpu-settings.png">
</kbd>
To learn more about Spaces, please take a look at the [documentation](https://huggingface.co/docs/hub/spaces) and don't hesitate to browse posts or ask questions in our [forum](https://discuss.huggingface.co/c/spaces/24).
## Getting started
It couldn't be simpler. Just log in to the Hugging Face [hub](https://huggingface.co/) and browse our [models](https://huggingface.co/models). Once you've found one that you like, you can try the Inference Widget directly on the page. Clicking on the "Deploy" button, you'll get auto-generated code to deploy the model on the free Inference API for evaluation, and a direct link to deploy it to production with Inference Endpoints or Spaces.
Please give it a try and let us know what you think. We'd love to read your feedback on the Hugging Face [forum](https://discuss.huggingface.co/).
Thank you for reading!
|
huggingface/blog/blob/main/inference-update.md
|
hub-docs
This repository regroups documentation and information that is hosted on the Hugging Face website.
You can access the Hugging Face Hub documentation in the `docs` folder at [hf.co/docs/hub](https://hf.co/docs/hub).
For some related components, check out the [Hugging Face Hub JS repository](https://github.com/huggingface/huggingface.js)
- Utilities to interact with the Hub: [huggingface/huggingface.js/packages/hub](https://github.com/huggingface/huggingface.js/tree/main/packages/hub)
- Hub Widgets: [huggingface/huggingface.js/packages/widgets](https://github.com/huggingface/huggingface.js/tree/main/packages/widgets)
- Hub Tasks (as visible on the page [hf.co/tasks](https://hf.co/tasks)): [huggingface/huggingface.js/packages/tasks](https://github.com/huggingface/huggingface.js/tree/main/packages/tasks)
### How to contribute to the docs
Just add/edit the Markdown files, commit them, and create a PR.
Then the CI bot will build the preview page and provide a url for you to look at the result!
For simple edits, you don't need a local build environment.
### Previewing locally
```bash
# install doc-builder (if not done already)
pip install hf-doc-builder
# you may also need to install some extra dependencies
pip install black watchdog
# run `doc-builder preview` cmd
doc-builder preview hub {YOUR_PATH}/hub-docs/docs/hub/ --not_python_module
```
|
huggingface/hub-docs/blob/main/README.md
|
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Dilated Neighborhood Attention Transformer
## Overview
DiNAT was proposed in [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001)
by Ali Hassani and Humphrey Shi.
It extends [NAT](nat) by adding a Dilated Neighborhood Attention pattern to capture global context,
and shows significant performance improvements over it.
The abstract from the paper is the following:
*Transformers are quickly becoming one of the most heavily applied deep learning architectures across modalities,
domains, and tasks. In vision, on top of ongoing efforts into plain transformers, hierarchical transformers have
also gained significant attention, thanks to their performance and easy integration into existing frameworks.
These models typically employ localized attention mechanisms, such as the sliding-window Neighborhood Attention (NA)
or Swin Transformer's Shifted Window Self Attention. While effective at reducing self attention's quadratic complexity,
local attention weakens two of the most desirable properties of self attention: long range inter-dependency modeling,
and global receptive field. In this paper, we introduce Dilated Neighborhood Attention (DiNA), a natural, flexible and
efficient extension to NA that can capture more global context and expand receptive fields exponentially at no
additional cost. NA's local attention and DiNA's sparse global attention complement each other, and therefore we
introduce Dilated Neighborhood Attention Transformer (DiNAT), a new hierarchical vision transformer built upon both.
DiNAT variants enjoy significant improvements over strong baselines such as NAT, Swin, and ConvNeXt.
Our large model is faster and ahead of its Swin counterpart by 1.5% box AP in COCO object detection,
1.3% mask AP in COCO instance segmentation, and 1.1% mIoU in ADE20K semantic segmentation.
Paired with new frameworks, our large variant is the new state of the art panoptic segmentation model on COCO (58.2 PQ)
and ADE20K (48.5 PQ), and instance segmentation model on Cityscapes (44.5 AP) and ADE20K (35.4 AP) (no extra data).
It also matches the state of the art specialized semantic segmentation models on ADE20K (58.2 mIoU),
and ranks second on Cityscapes (84.5 mIoU) (no extra data). *
<img
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/dilated-neighborhood-attention-pattern.jpg"
alt="drawing" width="600"/>
<small> Neighborhood Attention with different dilation values.
Taken from the <a href="https://arxiv.org/abs/2209.15001">original paper</a>.</small>
This model was contributed by [Ali Hassani](https://huggingface.co/alihassanijr).
The original code can be found [here](https://github.com/SHI-Labs/Neighborhood-Attention-Transformer).
## Usage tips
DiNAT can be used as a *backbone*. When `output_hidden_states = True`,
it will output both `hidden_states` and `reshaped_hidden_states`. The `reshaped_hidden_states` have a shape of `(batch, num_channels, height, width)` rather than `(batch_size, height, width, num_channels)`.
Notes:
- DiNAT depends on [NATTEN](https://github.com/SHI-Labs/NATTEN/)'s implementation of Neighborhood Attention and Dilated Neighborhood Attention.
You can install it with pre-built wheels for Linux by referring to [shi-labs.com/natten](https://shi-labs.com/natten), or build on your system by running `pip install natten`.
Note that the latter will likely take time to compile. NATTEN does not support Windows devices yet.
- Patch size of 4 is only supported at the moment.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DiNAT.
<PipelineTag pipeline="image-classification"/>
- [`DinatForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## DinatConfig
[[autodoc]] DinatConfig
## DinatModel
[[autodoc]] DinatModel
- forward
## DinatForImageClassification
[[autodoc]] DinatForImageClassification
- forward
|
huggingface/transformers/blob/main/docs/source/en/model_doc/dinat.md
|
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# The Tasks Manager
Exporting a model from one framework to some format (also called backend here) involves specifying inputs and outputs information that the export function needs. The way `optimum.exporters` is structured for each backend is as follows:
- Configuration classes containing the information for each model to perform the export.
- Exporting functions using the proper configuration for the model to export.
The role of the [`~optimum.exporters.tasks.TasksManager`] is to be the main entry-point to load a model given a name and a task, and to get the proper configuration for a given (architecture, backend) couple. That way, there is a centralized place to register the `task -> model class` and `(architecture, backend) -> configuration` mappings. This allows the export functions to use this, and to rely on the various checks it provides.
## Task names
The tasks supported might depend on the backend, but here are the mappings between a task name and the auto class for both PyTorch and TensorFlow.
<Tip>
It is possible to know which tasks are supported for a model for a given backend, by doing:
```python
>>> from optimum.exporters.tasks import TasksManager
>>> model_type = "distilbert"
>>> # For instance, for the ONNX export.
>>> backend = "onnx"
>>> distilbert_tasks = list(TasksManager.get_supported_tasks_for_model_type(model_type, backend).keys())
>>> print(distilbert_tasks)
['default', 'fill-mask', 'text-classification', 'multiple-choice', 'token-classification', 'question-answering']
```
</Tip>
### PyTorch
| Task | Auto Class |
|--------------------------------------|--------------------------------------|
| `text-generation`, `text-generation-with-past` | `AutoModelForCausalLM` |
| `feature-extraction`, `feature-extraction-with-past` | `AutoModel` |
| `fill-mask` | `AutoModelForMaskedLM` |
| `question-answering` | `AutoModelForQuestionAnswering` |
| `text2text-generation`, `text2text-generation-with-past` | `AutoModelForSeq2SeqLM` |
| `text-classification` | `AutoModelForSequenceClassification` |
| `token-classification` | `AutoModelForTokenClassification` |
| `multiple-choice` | `AutoModelForMultipleChoice` |
| `image-classification` | `AutoModelForImageClassification` |
| `object-detection` | `AutoModelForObjectDetection` |
| `image-segmentation` | `AutoModelForImageSegmentation` |
| `masked-im` | `AutoModelForMaskedImageModeling` |
| `semantic-segmentation` | `AutoModelForSemanticSegmentation` |
| `automatic-speech-recognition` | `AutoModelForSpeechSeq2Seq` |
### TensorFlow
| Task | Auto Class |
|--------------------------------------|----------------------------------------|
| `text-generation`, `text-generation-with-past` | `TFAutoModelForCausalLM` |
| `default`, `default-with-past` | `TFAutoModel` |
| `fill-mask` | `TFAutoModelForMaskedLM` |
| `question-answering` | `TFAutoModelForQuestionAnswering` |
| `text2text-generation`, `text2text-generation-with-past` | `TFAutoModelForSeq2SeqLM` |
| `text-classification` | `TFAutoModelForSequenceClassification` |
| `token-classification` | `TFAutoModelForTokenClassification` |
| `multiple-choice` | `TFAutoModelForMultipleChoice` |
| `semantic-segmentation` | `TFAutoModelForSemanticSegmentation` |
## Reference
[[autodoc]] exporters.tasks.TasksManager
|
huggingface/optimum/blob/main/docs/source/exporters/task_manager.mdx
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# SeamlessM4T
## Overview
The SeamlessM4T model was proposed in [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team from Meta AI.
This is the **version 1** release of the model. For the updated **version 2** release, refer to the [Seamless M4T v2 docs](https://huggingface.co/docs/transformers/main/model_doc/seamless_m4t_v2).
SeamlessM4T is a collection of models designed to provide high quality translation, allowing people from different linguistic communities to communicate effortlessly through speech and text.
SeamlessM4T enables multiple tasks without relying on separate models:
- Speech-to-speech translation (S2ST)
- Speech-to-text translation (S2TT)
- Text-to-speech translation (T2ST)
- Text-to-text translation (T2TT)
- Automatic speech recognition (ASR)
[`SeamlessM4TModel`] can perform all the above tasks, but each task also has its own dedicated sub-model.
The abstract from the paper is the following:
*What does it take to create the Babel Fish, a tool that can help individuals translate speech between any two languages? While recent breakthroughs in text-based models have pushed machine translation coverage beyond 200 languages, unified speech-to-speech translation models have yet to achieve similar strides. More specifically, conventional speech-to-speech translation systems rely on cascaded systems that perform translation progressively, putting high-performing unified systems out of reach. To address these gaps, we introduce SeamlessM4T, a single model that supports speech-to-speech translation, speech-to-text translation, text-to-speech translation, text-to-text translation, and automatic speech recognition for up to 100 languages. To build this, we used 1 million hours of open speech audio data to learn self-supervised speech representations with w2v-BERT 2.0. Subsequently, we created a multimodal corpus of automatically aligned speech translations. Filtered and combined with human-labeled and pseudo-labeled data, we developed the first multilingual system capable of translating from and into English for both speech and text. On FLEURS, SeamlessM4T sets a new standard for translations into multiple target languages, achieving an improvement of 20% BLEU over the previous SOTA in direct speech-to-text translation. Compared to strong cascaded models, SeamlessM4T improves the quality of into-English translation by 1.3 BLEU points in speech-to-text and by 2.6 ASR-BLEU points in speech-to-speech. Tested for robustness, our system performs better against background noises and speaker variations in speech-to-text tasks compared to the current SOTA model. Critically, we evaluated SeamlessM4T on gender bias and added toxicity to assess translation safety. Finally, all contributions in this work are open-sourced and accessible at https://github.com/facebookresearch/seamless_communication*
## Usage
First, load the processor and a checkpoint of the model:
```python
>>> from transformers import AutoProcessor, SeamlessM4TModel
>>> processor = AutoProcessor.from_pretrained("facebook/hf-seamless-m4t-medium")
>>> model = SeamlessM4TModel.from_pretrained("facebook/hf-seamless-m4t-medium")
```
You can seamlessly use this model on text or on audio, to generated either translated text or translated audio.
Here is how to use the processor to process text and audio:
```python
>>> # let's load an audio sample from an Arabic speech corpus
>>> from datasets import load_dataset
>>> dataset = load_dataset("arabic_speech_corpus", split="test", streaming=True)
>>> audio_sample = next(iter(dataset))["audio"]
>>> # now, process it
>>> audio_inputs = processor(audios=audio_sample["array"], return_tensors="pt")
>>> # now, process some English test as well
>>> text_inputs = processor(text = "Hello, my dog is cute", src_lang="eng", return_tensors="pt")
```
### Speech
[`SeamlessM4TModel`] can *seamlessly* generate text or speech with few or no changes. Let's target Russian voice translation:
```python
>>> audio_array_from_text = model.generate(**text_inputs, tgt_lang="rus")[0].cpu().numpy().squeeze()
>>> audio_array_from_audio = model.generate(**audio_inputs, tgt_lang="rus")[0].cpu().numpy().squeeze()
```
With basically the same code, I've translated English text and Arabic speech to Russian speech samples.
### Text
Similarly, you can generate translated text from audio files or from text with the same model. You only have to pass `generate_speech=False` to [`SeamlessM4TModel.generate`].
This time, let's translate to French.
```python
>>> # from audio
>>> output_tokens = model.generate(**audio_inputs, tgt_lang="fra", generate_speech=False)
>>> translated_text_from_audio = processor.decode(output_tokens[0].tolist()[0], skip_special_tokens=True)
>>> # from text
>>> output_tokens = model.generate(**text_inputs, tgt_lang="fra", generate_speech=False)
>>> translated_text_from_text = processor.decode(output_tokens[0].tolist()[0], skip_special_tokens=True)
```
### Tips
#### 1. Use dedicated models
[`SeamlessM4TModel`] is transformers top level model to generate speech and text, but you can also use dedicated models that perform the task without additional components, thus reducing the memory footprint.
For example, you can replace the audio-to-audio generation snippet with the model dedicated to the S2ST task, the rest is exactly the same code:
```python
>>> from transformers import SeamlessM4TForSpeechToSpeech
>>> model = SeamlessM4TForSpeechToSpeech.from_pretrained("facebook/hf-seamless-m4t-medium")
```
Or you can replace the text-to-text generation snippet with the model dedicated to the T2TT task, you only have to remove `generate_speech=False`.
```python
>>> from transformers import SeamlessM4TForTextToText
>>> model = SeamlessM4TForTextToText.from_pretrained("facebook/hf-seamless-m4t-medium")
```
Feel free to try out [`SeamlessM4TForSpeechToText`] and [`SeamlessM4TForTextToSpeech`] as well.
#### 2. Change the speaker identity
You have the possibility to change the speaker used for speech synthesis with the `spkr_id` argument. Some `spkr_id` works better than other for some languages!
#### 3. Change the generation strategy
You can use different [generation strategies](./generation_strategies) for speech and text generation, e.g `.generate(input_ids=input_ids, text_num_beams=4, speech_do_sample=True)` which will successively perform beam-search decoding on the text model, and multinomial sampling on the speech model.
#### 4. Generate speech and text at the same time
Use `return_intermediate_token_ids=True` with [`SeamlessM4TModel`] to return both speech and text !
## Model architecture
SeamlessM4T features a versatile architecture that smoothly handles the sequential generation of text and speech. This setup comprises two sequence-to-sequence (seq2seq) models. The first model translates the input modality into translated text, while the second model generates speech tokens, known as "unit tokens," from the translated text.
Each modality has its own dedicated encoder with a unique architecture. Additionally, for speech output, a vocoder inspired by the [HiFi-GAN](https://arxiv.org/abs/2010.05646) architecture is placed on top of the second seq2seq model.
Here's how the generation process works:
- Input text or speech is processed through its specific encoder.
- A decoder creates text tokens in the desired language.
- If speech generation is required, the second seq2seq model, following a standard encoder-decoder structure, generates unit tokens.
- These unit tokens are then passed through the final vocoder to produce the actual speech.
This model was contributed by [ylacombe](https://huggingface.co/ylacombe). The original code can be found [here](https://github.com/facebookresearch/seamless_communication).
## SeamlessM4TModel
[[autodoc]] SeamlessM4TModel
- generate
## SeamlessM4TForTextToSpeech
[[autodoc]] SeamlessM4TForTextToSpeech
- generate
## SeamlessM4TForSpeechToSpeech
[[autodoc]] SeamlessM4TForSpeechToSpeech
- generate
## SeamlessM4TForTextToText
[[autodoc]] transformers.SeamlessM4TForTextToText
- forward
- generate
## SeamlessM4TForSpeechToText
[[autodoc]] transformers.SeamlessM4TForSpeechToText
- forward
- generate
## SeamlessM4TConfig
[[autodoc]] SeamlessM4TConfig
## SeamlessM4TTokenizer
[[autodoc]] SeamlessM4TTokenizer
- __call__
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## SeamlessM4TTokenizerFast
[[autodoc]] SeamlessM4TTokenizerFast
- __call__
## SeamlessM4TFeatureExtractor
[[autodoc]] SeamlessM4TFeatureExtractor
- __call__
## SeamlessM4TProcessor
[[autodoc]] SeamlessM4TProcessor
- __call__
## SeamlessM4TCodeHifiGan
[[autodoc]] SeamlessM4TCodeHifiGan
## SeamlessM4THifiGan
[[autodoc]] SeamlessM4THifiGan
## SeamlessM4TTextToUnitModel
[[autodoc]] SeamlessM4TTextToUnitModel
## SeamlessM4TTextToUnitForConditionalGeneration
[[autodoc]] SeamlessM4TTextToUnitForConditionalGeneration
|
huggingface/transformers/blob/main/docs/source/en/model_doc/seamless_m4t.md
|
!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Troubleshoot
Sometimes errors occur, but we are here to help! This guide covers some of the most common issues we've seen and how you can resolve them. However, this guide isn't meant to be a comprehensive collection of every 🤗 Transformers issue. For more help with troubleshooting your issue, try:
<Youtube id="S2EEG3JIt2A"/>
1. Asking for help on the [forums](https://discuss.huggingface.co/). There are specific categories you can post your question to, like [Beginners](https://discuss.huggingface.co/c/beginners/5) or [🤗 Transformers](https://discuss.huggingface.co/c/transformers/9). Make sure you write a good descriptive forum post with some reproducible code to maximize the likelihood that your problem is solved!
<Youtube id="_PAli-V4wj0"/>
2. Create an [Issue](https://github.com/huggingface/transformers/issues/new/choose) on the 🤗 Transformers repository if it is a bug related to the library. Try to include as much information describing the bug as possible to help us better figure out what's wrong and how we can fix it.
3. Check the [Migration](migration) guide if you use an older version of 🤗 Transformers since some important changes have been introduced between versions.
For more details about troubleshooting and getting help, take a look at [Chapter 8](https://huggingface.co/course/chapter8/1?fw=pt) of the Hugging Face course.
## Firewalled environments
Some GPU instances on cloud and intranet setups are firewalled to external connections, resulting in a connection error. When your script attempts to download model weights or datasets, the download will hang and then timeout with the following message:
```
ValueError: Connection error, and we cannot find the requested files in the cached path.
Please try again or make sure your Internet connection is on.
```
In this case, you should try to run 🤗 Transformers on [offline mode](installation#offline-mode) to avoid the connection error.
## CUDA out of memory
Training large models with millions of parameters can be challenging without the appropriate hardware. A common error you may encounter when the GPU runs out of memory is:
```
CUDA out of memory. Tried to allocate 256.00 MiB (GPU 0; 11.17 GiB total capacity; 9.70 GiB already allocated; 179.81 MiB free; 9.85 GiB reserved in total by PyTorch)
```
Here are some potential solutions you can try to lessen memory use:
- Reduce the [`per_device_train_batch_size`](main_classes/trainer#transformers.TrainingArguments.per_device_train_batch_size) value in [`TrainingArguments`].
- Try using [`gradient_accumulation_steps`](main_classes/trainer#transformers.TrainingArguments.gradient_accumulation_steps) in [`TrainingArguments`] to effectively increase overall batch size.
<Tip>
Refer to the Performance [guide](performance) for more details about memory-saving techniques.
</Tip>
## Unable to load a saved TensorFlow model
TensorFlow's [model.save](https://www.tensorflow.org/tutorials/keras/save_and_load#save_the_entire_model) method will save the entire model - architecture, weights, training configuration - in a single file. However, when you load the model file again, you may run into an error because 🤗 Transformers may not load all the TensorFlow-related objects in the model file. To avoid issues with saving and loading TensorFlow models, we recommend you:
- Save the model weights as a `h5` file extension with [`model.save_weights`](https://www.tensorflow.org/tutorials/keras/save_and_load#save_the_entire_model) and then reload the model with [`~TFPreTrainedModel.from_pretrained`]:
```py
>>> from transformers import TFPreTrainedModel
>>> from tensorflow import keras
>>> model.save_weights("some_folder/tf_model.h5")
>>> model = TFPreTrainedModel.from_pretrained("some_folder")
```
- Save the model with [`~TFPretrainedModel.save_pretrained`] and load it again with [`~TFPreTrainedModel.from_pretrained`]:
```py
>>> from transformers import TFPreTrainedModel
>>> model.save_pretrained("path_to/model")
>>> model = TFPreTrainedModel.from_pretrained("path_to/model")
```
## ImportError
Another common error you may encounter, especially if it is a newly released model, is `ImportError`:
```
ImportError: cannot import name 'ImageGPTImageProcessor' from 'transformers' (unknown location)
```
For these error types, check to make sure you have the latest version of 🤗 Transformers installed to access the most recent models:
```bash
pip install transformers --upgrade
```
## CUDA error: device-side assert triggered
Sometimes you may run into a generic CUDA error about an error in the device code.
```
RuntimeError: CUDA error: device-side assert triggered
```
You should try to run the code on a CPU first to get a more descriptive error message. Add the following environment variable to the beginning of your code to switch to a CPU:
```py
>>> import os
>>> os.environ["CUDA_VISIBLE_DEVICES"] = ""
```
Another option is to get a better traceback from the GPU. Add the following environment variable to the beginning of your code to get the traceback to point to the source of the error:
```py
>>> import os
>>> os.environ["CUDA_LAUNCH_BLOCKING"] = "1"
```
## Incorrect output when padding tokens aren't masked
In some cases, the output `hidden_state` may be incorrect if the `input_ids` include padding tokens. To demonstrate, load a model and tokenizer. You can access a model's `pad_token_id` to see its value. The `pad_token_id` may be `None` for some models, but you can always manually set it.
```py
>>> from transformers import AutoModelForSequenceClassification
>>> import torch
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
>>> model.config.pad_token_id
0
```
The following example shows the output without masking the padding tokens:
```py
>>> input_ids = torch.tensor([[7592, 2057, 2097, 2393, 9611, 2115], [7592, 0, 0, 0, 0, 0]])
>>> output = model(input_ids)
>>> print(output.logits)
tensor([[ 0.0082, -0.2307],
[ 0.1317, -0.1683]], grad_fn=<AddmmBackward0>)
```
Here is the actual output of the second sequence:
```py
>>> input_ids = torch.tensor([[7592]])
>>> output = model(input_ids)
>>> print(output.logits)
tensor([[-0.1008, -0.4061]], grad_fn=<AddmmBackward0>)
```
Most of the time, you should provide an `attention_mask` to your model to ignore the padding tokens to avoid this silent error. Now the output of the second sequence matches its actual output:
<Tip>
By default, the tokenizer creates an `attention_mask` for you based on your specific tokenizer's defaults.
</Tip>
```py
>>> attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1], [1, 0, 0, 0, 0, 0]])
>>> output = model(input_ids, attention_mask=attention_mask)
>>> print(output.logits)
tensor([[ 0.0082, -0.2307],
[-0.1008, -0.4061]], grad_fn=<AddmmBackward0>)
```
🤗 Transformers doesn't automatically create an `attention_mask` to mask a padding token if it is provided because:
- Some models don't have a padding token.
- For some use-cases, users want a model to attend to a padding token.
## ValueError: Unrecognized configuration class XYZ for this kind of AutoModel
Generally, we recommend using the [`AutoModel`] class to load pretrained instances of models. This class
can automatically infer and load the correct architecture from a given checkpoint based on the configuration. If you see
this `ValueError` when loading a model from a checkpoint, this means the Auto class couldn't find a mapping from
the configuration in the given checkpoint to the kind of model you are trying to load. Most commonly, this happens when a
checkpoint doesn't support a given task.
For instance, you'll see this error in the following example because there is no GPT2 for question answering:
```py
>>> from transformers import AutoProcessor, AutoModelForQuestionAnswering
>>> processor = AutoProcessor.from_pretrained("gpt2-medium")
>>> model = AutoModelForQuestionAnswering.from_pretrained("gpt2-medium")
ValueError: Unrecognized configuration class <class 'transformers.models.gpt2.configuration_gpt2.GPT2Config'> for this kind of AutoModel: AutoModelForQuestionAnswering.
Model type should be one of AlbertConfig, BartConfig, BertConfig, BigBirdConfig, BigBirdPegasusConfig, BloomConfig, ...
```
|
huggingface/transformers/blob/main/docs/source/en/troubleshooting.md
|
Inference Endpoints
Inference Endpoints provides a secure production solution to easily deploy any `transformers`, `sentence-transformers`, and `diffusers` models on a dedicated and autoscaling infrastructure managed by Hugging Face. An Inference Endpoint is built from a model from the [Hub](https://huggingface.co/models).
In this guide, we will learn how to programmatically manage Inference Endpoints with `huggingface_hub`. For more information about the Inference Endpoints product itself, check out its [official documentation](https://huggingface.co/docs/inference-endpoints/index).
This guide assumes `huggingface_hub` is correctly installed and that your machine is logged in. Check out the [Quick Start guide](https://huggingface.co/docs/huggingface_hub/quick-start#quickstart) if that's not the case yet. The minimal version supporting Inference Endpoints API is `v0.19.0`.
## Create an Inference Endpoint
The first step is to create an Inference Endpoint using [`create_inference_endpoint`]:
```py
>>> from huggingface_hub import create_inference_endpoint
>>> endpoint = create_inference_endpoint(
... "my-endpoint-name",
... repository="gpt2",
... framework="pytorch",
... task="text-generation",
... accelerator="cpu",
... vendor="aws",
... region="us-east-1",
... type="protected",
... instance_size="medium",
... instance_type="c6i"
... )
```
In this example, we created a `protected` Inference Endpoint named `"my-endpoint-name"`, to serve [gpt2](https://huggingface.co/gpt2) for `text-generation`. A `protected` Inference Endpoint means your token is required to access the API. We also need to provide additional information to configure the hardware requirements, such as vendor, region, accelerator, instance type, and size. You can check out the list of available resources [here](https://api.endpoints.huggingface.cloud/#/v2%3A%3Aprovider/list_vendors). Alternatively, you can create an Inference Endpoint manually using the [Web interface](https://ui.endpoints.huggingface.co/new) for convenience. Refer to this [guide](https://huggingface.co/docs/inference-endpoints/guides/advanced) for details on advanced settings and their usage.
The value returned by [`create_inference_endpoint`] is an [`InferenceEndpoint`] object:
```py
>>> endpoint
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='pending', url=None)
```
It's a dataclass that holds information about the endpoint. You can access important attributes such as `name`, `repository`, `status`, `task`, `created_at`, `updated_at`, etc. If you need it, you can also access the raw response from the server with `endpoint.raw`.
Once your Inference Endpoint is created, you can find it on your [personal dashboard](https://ui.endpoints.huggingface.co/).
#### Using a custom image
By default the Inference Endpoint is built from a docker image provided by Hugging Face. However, it is possible to specify any docker image using the `custom_image` parameter. A common use case is to run LLMs using the [text-generation-inference](https://github.com/huggingface/text-generation-inference) framework. This can be done like this:
```python
# Start an Inference Endpoint running Zephyr-7b-beta on TGI
>>> from huggingface_hub import create_inference_endpoint
>>> endpoint = create_inference_endpoint(
... "aws-zephyr-7b-beta-0486",
... repository="HuggingFaceH4/zephyr-7b-beta",
... framework="pytorch",
... task="text-generation",
... accelerator="gpu",
... vendor="aws",
... region="us-east-1",
... type="protected",
... instance_size="medium",
... instance_type="g5.2xlarge",
... custom_image={
... "health_route": "/health",
... "env": {
... "MAX_BATCH_PREFILL_TOKENS": "2048",
... "MAX_INPUT_LENGTH": "1024",
... "MAX_TOTAL_TOKENS": "1512",
... "MODEL_ID": "/repository"
... },
... "url": "ghcr.io/huggingface/text-generation-inference:1.1.0",
... },
... )
```
The value to pass as `custom_image` is a dictionary containing a url to the docker container and configuration to run it. For more details about it, checkout the [Swagger documentation](https://api.endpoints.huggingface.cloud/#/v2%3A%3Aendpoint/create_endpoint).
### Get or list existing Inference Endpoints
In some cases, you might need to manage Inference Endpoints you created previously. If you know the name, you can fetch it using [`get_inference_endpoint`], which returns an [`InferenceEndpoint`] object. Alternatively, you can use [`list_inference_endpoints`] to retrieve a list of all Inference Endpoints. Both methods accept an optional `namespace` parameter. You can set the `namespace` to any organization you are a part of. Otherwise, it defaults to your username.
```py
>>> from huggingface_hub import get_inference_endpoint, list_inference_endpoints
# Get one
>>> get_inference_endpoint("my-endpoint-name")
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='pending', url=None)
# List all endpoints from an organization
>>> list_inference_endpoints(namespace="huggingface")
[InferenceEndpoint(name='aws-starchat-beta', namespace='huggingface', repository='HuggingFaceH4/starchat-beta', status='paused', url=None), ...]
# List all endpoints from all organizations the user belongs to
>>> list_inference_endpoints(namespace="*")
[InferenceEndpoint(name='aws-starchat-beta', namespace='huggingface', repository='HuggingFaceH4/starchat-beta', status='paused', url=None), ...]
```
## Check deployment status
In the rest of this guide, we will assume that we have a [`InferenceEndpoint`] object called `endpoint`. You might have noticed that the endpoint has a `status` attribute of type [`InferenceEndpointStatus`]. When the Inference Endpoint is deployed and accessible, the status should be `"running"` and the `url` attribute is set:
```py
>>> endpoint
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='running', url='https://jpj7k2q4j805b727.us-east-1.aws.endpoints.huggingface.cloud')
```
Before reaching a `"running"` state, the Inference Endpoint typically goes through an `"initializing"` or `"pending"` phase. You can fetch the new state of the endpoint by running [`~InferenceEndpoint.fetch`]. Like every other method from [`InferenceEndpoint`] that makes a request to the server, the internal attributes of `endpoint` are mutated in place:
```py
>>> endpoint.fetch()
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='pending', url=None)
```
Instead of fetching the Inference Endpoint status while waiting for it to run, you can directly call [`~InferenceEndpoint.wait`]. This helper takes as input a `timeout` and a `fetch_every` parameter (in seconds) and will block the thread until the Inference Endpoint is deployed. Default values are respectively `None` (no timeout) and `5` seconds.
```py
# Pending endpoint
>>> endpoint
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='pending', url=None)
# Wait 10s => raises a InferenceEndpointTimeoutError
>>> endpoint.wait(timeout=10)
raise InferenceEndpointTimeoutError("Timeout while waiting for Inference Endpoint to be deployed.")
huggingface_hub._inference_endpoints.InferenceEndpointTimeoutError: Timeout while waiting for Inference Endpoint to be deployed.
# Wait more
>>> endpoint.wait()
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='running', url='https://jpj7k2q4j805b727.us-east-1.aws.endpoints.huggingface.cloud')
```
If `timeout` is set and the Inference Endpoint takes too much time to load, a [`InferenceEndpointTimeoutError`] timeout error is raised.
## Run inference
Once your Inference Endpoint is up and running, you can finally run inference on it!
[`InferenceEndpoint`] has two properties `client` and `async_client` returning respectively an [`InferenceClient`] and an [`AsyncInferenceClient`] objects.
```py
# Run text_generation task:
>>> endpoint.client.text_generation("I am")
' not a fan of the idea of a "big-budget" movie. I think it\'s a'
# Or in an asyncio context:
>>> await endpoint.async_client.text_generation("I am")
```
If the Inference Endpoint is not running, an [`InferenceEndpointError`] exception is raised:
```py
>>> endpoint.client
huggingface_hub._inference_endpoints.InferenceEndpointError: Cannot create a client for this Inference Endpoint as it is not yet deployed. Please wait for the Inference Endpoint to be deployed using `endpoint.wait()` and try again.
```
For more details about how to use the [`InferenceClient`], check out the [Inference guide](../guides/inference).
## Manage lifecycle
Now that we saw how to create an Inference Endpoint and run inference on it, let's see how to manage its lifecycle.
<Tip>
In this section, we will see methods like [`~InferenceEndpoint.pause`], [`~InferenceEndpoint.resume`], [`~InferenceEndpoint.scale_to_zero`], [`~InferenceEndpoint.update`] and [`~InferenceEndpoint.delete`]. All of those methods are aliases added to [`InferenceEndpoint`] for convenience. If you prefer, you can also use the generic methods defined in `HfApi`: [`pause_inference_endpoint`], [`resume_inference_endpoint`], [`scale_to_zero_inference_endpoint`], [`update_inference_endpoint`], and [`delete_inference_endpoint`].
</Tip>
### Pause or scale to zero
To reduce costs when your Inference Endpoint is not in use, you can choose to either pause it using [`~InferenceEndpoint.pause`] or scale it to zero using [`~InferenceEndpoint.scale_to_zero`].
<Tip>
An Inference Endpoint that is *paused* or *scaled to zero* doesn't cost anything. The difference between those two is that a *paused* endpoint needs to be explicitly *resumed* using [`~InferenceEndpoint.resume`]. On the contrary, a *scaled to zero* endpoint will automatically start if an inference call is made to it, with an additional cold start delay. An Inference Endpoint can also be configured to scale to zero automatically after a certain period of inactivity.
</Tip>
```py
# Pause and resume endpoint
>>> endpoint.pause()
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='paused', url=None)
>>> endpoint.resume()
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='pending', url=None)
>>> endpoint.wait().client.text_generation(...)
...
# Scale to zero
>>> endpoint.scale_to_zero()
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='scaledToZero', url='https://jpj7k2q4j805b727.us-east-1.aws.endpoints.huggingface.cloud')
# Endpoint is not 'running' but still has a URL and will restart on first call.
```
### Update model or hardware requirements
In some cases, you might also want to update your Inference Endpoint without creating a new one. You can either update the hosted model or the hardware requirements to run the model. You can do this using [`~InferenceEndpoint.update`]:
```py
# Change target model
>>> endpoint.update(repository="gpt2-large")
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2-large', status='pending', url=None)
# Update number of replicas
>>> endpoint.update(min_replica=2, max_replica=6)
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2-large', status='pending', url=None)
# Update to larger instance
>>> endpoint.update(accelerator="cpu", instance_size="large", instance_type="c6i")
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2-large', status='pending', url=None)
```
### Delete the endpoint
Finally if you won't use the Inference Endpoint anymore, you can simply call [`~InferenceEndpoint.delete()`].
<Tip warning={true}>
This is a non-revertible action that will completely remove the endpoint, including its configuration, logs and usage metrics. You cannot restore a deleted Inference Endpoint.
</Tip>
## An end-to-end example
A typical use case of Inference Endpoints is to process a batch of jobs at once to limit the infrastructure costs. You can automate this process using what we saw in this guide:
```py
>>> import asyncio
>>> from huggingface_hub import create_inference_endpoint
# Start endpoint + wait until initialized
>>> endpoint = create_inference_endpoint(name="batch-endpoint",...).wait()
# Run inference
>>> client = endpoint.client
>>> results = [client.text_generation(...) for job in jobs]
# Or with asyncio
>>> async_client = endpoint.async_client
>>> results = asyncio.gather(*[async_client.text_generation(...) for job in jobs])
# Pause endpoint
>>> endpoint.pause()
```
Or if your Inference Endpoint already exists and is paused:
```py
>>> import asyncio
>>> from huggingface_hub import get_inference_endpoint
# Get endpoint + wait until initialized
>>> endpoint = get_inference_endpoint("batch-endpoint").resume().wait()
# Run inference
>>> async_client = endpoint.async_client
>>> results = asyncio.gather(*[async_client.text_generation(...) for job in jobs])
# Pause endpoint
>>> endpoint.pause()
```
|
huggingface/huggingface_hub/blob/main/docs/source/en/guides/inference_endpoints.md
|
WordPiece tokenization[[wordpiece-tokenization]]
<CourseFloatingBanner chapter={6}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter6/section6.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter6/section6.ipynb"},
]} />
WordPiece is the tokenization algorithm Google developed to pretrain BERT. It has since been reused in quite a few Transformer models based on BERT, such as DistilBERT, MobileBERT, Funnel Transformers, and MPNET. It's very similar to BPE in terms of the training, but the actual tokenization is done differently.
<Youtube id="qpv6ms_t_1A"/>
<Tip>
💡 This section covers WordPiece in depth, going as far as showing a full implementation. You can skip to the end if you just want a general overview of the tokenization algorithm.
</Tip>
## Training algorithm[[training-algorithm]]
<Tip warning={true}>
⚠️ Google never open-sourced its implementation of the training algorithm of WordPiece, so what follows is our best guess based on the published literature. It may not be 100% accurate.
</Tip>
Like BPE, WordPiece starts from a small vocabulary including the special tokens used by the model and the initial alphabet. Since it identifies subwords by adding a prefix (like `##` for BERT), each word is initially split by adding that prefix to all the characters inside the word. So, for instance, `"word"` gets split like this:
```
w ##o ##r ##d
```
Thus, the initial alphabet contains all the characters present at the beginning of a word and the characters present inside a word preceded by the WordPiece prefix.
Then, again like BPE, WordPiece learns merge rules. The main difference is the way the pair to be merged is selected. Instead of selecting the most frequent pair, WordPiece computes a score for each pair, using the following formula:
$$\mathrm{score} = (\mathrm{freq\_of\_pair}) / (\mathrm{freq\_of\_first\_element} \times \mathrm{freq\_of\_second\_element})$$
By dividing the frequency of the pair by the product of the frequencies of each of its parts, the algorithm prioritizes the merging of pairs where the individual parts are less frequent in the vocabulary. For instance, it won't necessarily merge `("un", "##able")` even if that pair occurs very frequently in the vocabulary, because the two pairs `"un"` and `"##able"` will likely each appear in a lot of other words and have a high frequency. In contrast, a pair like `("hu", "##gging")` will probably be merged faster (assuming the word "hugging" appears often in the vocabulary) since `"hu"` and `"##gging"` are likely to be less frequent individually.
Let's look at the same vocabulary we used in the BPE training example:
```
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
```
The splits here will be:
```
("h" "##u" "##g", 10), ("p" "##u" "##g", 5), ("p" "##u" "##n", 12), ("b" "##u" "##n", 4), ("h" "##u" "##g" "##s", 5)
```
so the initial vocabulary will be `["b", "h", "p", "##g", "##n", "##s", "##u"]` (if we forget about special tokens for now). The most frequent pair is `("##u", "##g")` (present 20 times), but the individual frequency of `"##u"` is very high, so its score is not the highest (it's 1 / 36). All pairs with a `"##u"` actually have that same score (1 / 36), so the best score goes to the pair `("##g", "##s")` -- the only one without a `"##u"` -- at 1 / 20, and the first merge learned is `("##g", "##s") -> ("##gs")`.
Note that when we merge, we remove the `##` between the two tokens, so we add `"##gs"` to the vocabulary and apply the merge in the words of the corpus:
```
Vocabulary: ["b", "h", "p", "##g", "##n", "##s", "##u", "##gs"]
Corpus: ("h" "##u" "##g", 10), ("p" "##u" "##g", 5), ("p" "##u" "##n", 12), ("b" "##u" "##n", 4), ("h" "##u" "##gs", 5)
```
At this point, `"##u"` is in all the possible pairs, so they all end up with the same score. Let's say that in this case, the first pair is merged, so `("h", "##u") -> "hu"`. This takes us to:
```
Vocabulary: ["b", "h", "p", "##g", "##n", "##s", "##u", "##gs", "hu"]
Corpus: ("hu" "##g", 10), ("p" "##u" "##g", 5), ("p" "##u" "##n", 12), ("b" "##u" "##n", 4), ("hu" "##gs", 5)
```
Then the next best score is shared by `("hu", "##g")` and `("hu", "##gs")` (with 1/15, compared to 1/21 for all the other pairs), so the first pair with the biggest score is merged:
```
Vocabulary: ["b", "h", "p", "##g", "##n", "##s", "##u", "##gs", "hu", "hug"]
Corpus: ("hug", 10), ("p" "##u" "##g", 5), ("p" "##u" "##n", 12), ("b" "##u" "##n", 4), ("hu" "##gs", 5)
```
and we continue like this until we reach the desired vocabulary size.
<Tip>
✏️ **Now your turn!** What will the next merge rule be?
</Tip>
## Tokenization algorithm[[tokenization-algorithm]]
Tokenization differs in WordPiece and BPE in that WordPiece only saves the final vocabulary, not the merge rules learned. Starting from the word to tokenize, WordPiece finds the longest subword that is in the vocabulary, then splits on it. For instance, if we use the vocabulary learned in the example above, for the word `"hugs"` the longest subword starting from the beginning that is inside the vocabulary is `"hug"`, so we split there and get `["hug", "##s"]`. We then continue with `"##s"`, which is in the vocabulary, so the tokenization of `"hugs"` is `["hug", "##s"]`.
With BPE, we would have applied the merges learned in order and tokenized this as `["hu", "##gs"]`, so the encoding is different.
As another example, let's see how the word `"bugs"` would be tokenized. `"b"` is the longest subword starting at the beginning of the word that is in the vocabulary, so we split there and get `["b", "##ugs"]`. Then `"##u"` is the longest subword starting at the beginning of `"##ugs"` that is in the vocabulary, so we split there and get `["b", "##u, "##gs"]`. Finally, `"##gs"` is in the vocabulary, so this last list is the tokenization of `"bugs"`.
When the tokenization gets to a stage where it's not possible to find a subword in the vocabulary, the whole word is tokenized as unknown -- so, for instance, `"mug"` would be tokenized as `["[UNK]"]`, as would `"bum"` (even if we can begin with `"b"` and `"##u"`, `"##m"` is not the vocabulary, and the resulting tokenization will just be `["[UNK]"]`, not `["b", "##u", "[UNK]"]`). This is another difference from BPE, which would only classify the individual characters not in the vocabulary as unknown.
<Tip>
✏️ **Now your turn!** How will the word `"pugs"` be tokenized?
</Tip>
## Implementing WordPiece[[implementing-wordpiece]]
Now let's take a look at an implementation of the WordPiece algorithm. Like with BPE, this is just pedagogical, and you won't able to use this on a big corpus.
We will use the same corpus as in the BPE example:
```python
corpus = [
"This is the Hugging Face Course.",
"This chapter is about tokenization.",
"This section shows several tokenizer algorithms.",
"Hopefully, you will be able to understand how they are trained and generate tokens.",
]
```
First, we need to pre-tokenize the corpus into words. Since we are replicating a WordPiece tokenizer (like BERT), we will use the `bert-base-cased` tokenizer for the pre-tokenization:
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
```
Then we compute the frequencies of each word in the corpus as we do the pre-tokenization:
```python
from collections import defaultdict
word_freqs = defaultdict(int)
for text in corpus:
words_with_offsets = tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str(text)
new_words = [word for word, offset in words_with_offsets]
for word in new_words:
word_freqs[word] += 1
word_freqs
```
```python out
defaultdict(
int, {'This': 3, 'is': 2, 'the': 1, 'Hugging': 1, 'Face': 1, 'Course': 1, '.': 4, 'chapter': 1, 'about': 1,
'tokenization': 1, 'section': 1, 'shows': 1, 'several': 1, 'tokenizer': 1, 'algorithms': 1, 'Hopefully': 1,
',': 1, 'you': 1, 'will': 1, 'be': 1, 'able': 1, 'to': 1, 'understand': 1, 'how': 1, 'they': 1, 'are': 1,
'trained': 1, 'and': 1, 'generate': 1, 'tokens': 1})
```
As we saw before, the alphabet is the unique set composed of all the first letters of words, and all the other letters that appear in words prefixed by `##`:
```python
alphabet = []
for word in word_freqs.keys():
if word[0] not in alphabet:
alphabet.append(word[0])
for letter in word[1:]:
if f"##{letter}" not in alphabet:
alphabet.append(f"##{letter}")
alphabet.sort()
alphabet
print(alphabet)
```
```python out
['##a', '##b', '##c', '##d', '##e', '##f', '##g', '##h', '##i', '##k', '##l', '##m', '##n', '##o', '##p', '##r', '##s',
'##t', '##u', '##v', '##w', '##y', '##z', ',', '.', 'C', 'F', 'H', 'T', 'a', 'b', 'c', 'g', 'h', 'i', 's', 't', 'u',
'w', 'y']
```
We also add the special tokens used by the model at the beginning of that vocabulary. In the case of BERT, it's the list `["[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]"]`:
```python
vocab = ["[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]"] + alphabet.copy()
```
Next we need to split each word, with all the letters that are not the first prefixed by `##`:
```python
splits = {
word: [c if i == 0 else f"##{c}" for i, c in enumerate(word)]
for word in word_freqs.keys()
}
```
Now that we are ready for training, let's write a function that computes the score of each pair. We'll need to use this at each step of the training:
```python
def compute_pair_scores(splits):
letter_freqs = defaultdict(int)
pair_freqs = defaultdict(int)
for word, freq in word_freqs.items():
split = splits[word]
if len(split) == 1:
letter_freqs[split[0]] += freq
continue
for i in range(len(split) - 1):
pair = (split[i], split[i + 1])
letter_freqs[split[i]] += freq
pair_freqs[pair] += freq
letter_freqs[split[-1]] += freq
scores = {
pair: freq / (letter_freqs[pair[0]] * letter_freqs[pair[1]])
for pair, freq in pair_freqs.items()
}
return scores
```
Let's have a look at a part of this dictionary after the initial splits:
```python
pair_scores = compute_pair_scores(splits)
for i, key in enumerate(pair_scores.keys()):
print(f"{key}: {pair_scores[key]}")
if i >= 5:
break
```
```python out
('T', '##h'): 0.125
('##h', '##i'): 0.03409090909090909
('##i', '##s'): 0.02727272727272727
('i', '##s'): 0.1
('t', '##h'): 0.03571428571428571
('##h', '##e'): 0.011904761904761904
```
Now, finding the pair with the best score only takes a quick loop:
```python
best_pair = ""
max_score = None
for pair, score in pair_scores.items():
if max_score is None or max_score < score:
best_pair = pair
max_score = score
print(best_pair, max_score)
```
```python out
('a', '##b') 0.2
```
So the first merge to learn is `('a', '##b') -> 'ab'`, and we add `'ab'` to the vocabulary:
```python
vocab.append("ab")
```
To continue, we need to apply that merge in our `splits` dictionary. Let's write another function for this:
```python
def merge_pair(a, b, splits):
for word in word_freqs:
split = splits[word]
if len(split) == 1:
continue
i = 0
while i < len(split) - 1:
if split[i] == a and split[i + 1] == b:
merge = a + b[2:] if b.startswith("##") else a + b
split = split[:i] + [merge] + split[i + 2 :]
else:
i += 1
splits[word] = split
return splits
```
And we can have a look at the result of the first merge:
```py
splits = merge_pair("a", "##b", splits)
splits["about"]
```
```python out
['ab', '##o', '##u', '##t']
```
Now we have everything we need to loop until we have learned all the merges we want. Let's aim for a vocab size of 70:
```python
vocab_size = 70
while len(vocab) < vocab_size:
scores = compute_pair_scores(splits)
best_pair, max_score = "", None
for pair, score in scores.items():
if max_score is None or max_score < score:
best_pair = pair
max_score = score
splits = merge_pair(*best_pair, splits)
new_token = (
best_pair[0] + best_pair[1][2:]
if best_pair[1].startswith("##")
else best_pair[0] + best_pair[1]
)
vocab.append(new_token)
```
We can then look at the generated vocabulary:
```py
print(vocab)
```
```python out
['[PAD]', '[UNK]', '[CLS]', '[SEP]', '[MASK]', '##a', '##b', '##c', '##d', '##e', '##f', '##g', '##h', '##i', '##k',
'##l', '##m', '##n', '##o', '##p', '##r', '##s', '##t', '##u', '##v', '##w', '##y', '##z', ',', '.', 'C', 'F', 'H',
'T', 'a', 'b', 'c', 'g', 'h', 'i', 's', 't', 'u', 'w', 'y', 'ab', '##fu', 'Fa', 'Fac', '##ct', '##ful', '##full', '##fully',
'Th', 'ch', '##hm', 'cha', 'chap', 'chapt', '##thm', 'Hu', 'Hug', 'Hugg', 'sh', 'th', 'is', '##thms', '##za', '##zat',
'##ut']
```
As we can see, compared to BPE, this tokenizer learns parts of words as tokens a bit faster.
<Tip>
💡 Using `train_new_from_iterator()` on the same corpus won't result in the exact same vocabulary. This is because the 🤗 Tokenizers library does not implement WordPiece for the training (since we are not completely sure of its internals), but uses BPE instead.
</Tip>
To tokenize a new text, we pre-tokenize it, split it, then apply the tokenization algorithm on each word. That is, we look for the biggest subword starting at the beginning of the first word and split it, then we repeat the process on the second part, and so on for the rest of that word and the following words in the text:
```python
def encode_word(word):
tokens = []
while len(word) > 0:
i = len(word)
while i > 0 and word[:i] not in vocab:
i -= 1
if i == 0:
return ["[UNK]"]
tokens.append(word[:i])
word = word[i:]
if len(word) > 0:
word = f"##{word}"
return tokens
```
Let's test it on one word that's in the vocabulary, and another that isn't:
```python
print(encode_word("Hugging"))
print(encode_word("HOgging"))
```
```python out
['Hugg', '##i', '##n', '##g']
['[UNK]']
```
Now, let's write a function that tokenizes a text:
```python
def tokenize(text):
pre_tokenize_result = tokenizer._tokenizer.pre_tokenizer.pre_tokenize_str(text)
pre_tokenized_text = [word for word, offset in pre_tokenize_result]
encoded_words = [encode_word(word) for word in pre_tokenized_text]
return sum(encoded_words, [])
```
We can try it on any text:
```python
tokenize("This is the Hugging Face course!")
```
```python out
['Th', '##i', '##s', 'is', 'th', '##e', 'Hugg', '##i', '##n', '##g', 'Fac', '##e', 'c', '##o', '##u', '##r', '##s',
'##e', '[UNK]']
```
That's it for the WordPiece algorithm! Now let's take a look at Unigram.
|
huggingface/course/blob/main/chapters/en/chapter6/6.mdx
|
emory mapping and streaming. In this video we'll take a look at two core features of the Datasets library that allow you to load and process huge datasets without blowing up your laptop's CPU.
Nowadays it is not uncommon to find yourself working with multi-GB sized datasets, especially if you’re planning to pretrain a transformer like BERT or GPT-2 from scratch. In these cases, even *loading* the data can be a challenge. For example, the C4 corpus used to
pretrain T5 consists of over 2 terabytes of data!
To handle these large datasets, the Datasets library is built on two core features: the Apache Arrow format and a streaming API. Arrow is designed for high-performance data processing and represents each table-like dataset with an in-memory columnar format. As you can see in this example, columnar formats group the elements of a table in consecutive blocks of RAM and this unlocks fast access and processing. Arrow is great at processing data at any scale, but some datasets are so large that you can't even fit them on your hard disk. For these cases, the Datasets library provides a streaming API that allows you to progressively download the raw data one element at a time. The result is a special object called an IterableDataset that we'll see in more detail soon. Let's start by looking at why Arrow is so powerful. The first feature is that it treat every dataset as a memory-mapped file. Memory mapping is a mechanism that maps a portion of a file or an entire file on disk to a chunk of virtual memory. This allows applications to access can access segments in an extremely large file without having to read the entire file into memory first. Another cool feature of Arrow's memory mapping capability is that it allows multiple processes to work with the same large dataset without moving it or copying it in any way. This "zero-copy" feature of Arrow makes it extremely fast for iterating over a dataset. In this example you can see that we iterate over 15 million rows in about a minute using a standard laptop - that's not too bad at all! Let's now take a look at how we can stream a large dataset. The only change you need to make is to set the streaming=True argument in the load_dataset() function. This will return a special IterableDataset object, which is a bit different to the Dataset objects we've seen in other videos. This object is an iterable, which means we can't index it to access elements, but instead iterate on it using the iter and next methods. This will download and access a single example from the dataset, which means you can progressively iterate through a huge dataset without having to download it first. Tokenizing text with the map() method also works in a similar way. We first stream the dataset and then apply the map() method with the tokenizer. To get the first tokenized example we apply iter and next. The main difference with an IterableDataset is that instead of using the select() method to return example, we use the take() and skip() methods because we can't index into the dataset. The take() method returns the first N examples in the dataset, while skip() skips the first N and returns the rest. You can see examples of both in action here, where we create a validation set from the first 1000 examples and then skip those to create the training set.
|
huggingface/course/blob/main/subtitles/en/raw/chapter5/04_memory-mapping.md
|
An introduction to Multi-Agents Reinforcement Learning (MARL)
## From single agent to multiple agents
In the first unit, we learned to train agents in a single-agent system. When our agent was alone in its environment: **it was not cooperating or collaborating with other agents**.
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit10/patchwork.jpg" alt="Patchwork"/>
<figcaption>
A patchwork of all the environments you've trained your agents on since the beginning of the course
</figcaption>
</figure>
When we do multi-agents reinforcement learning (MARL), we are in a situation where we have multiple agents **that share and interact in a common environment**.
For instance, you can think of a warehouse where **multiple robots need to navigate to load and unload packages**.
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit10/warehouse.jpg" alt="Warehouse"/>
<figcaption> [Image by upklyak](https://www.freepik.com/free-vector/robots-warehouse-interior-automated-machines_32117680.htm#query=warehouse robot&position=17&from_view=keyword) on Freepik </figcaption>
</figure>
Or a road with **several autonomous vehicles**.
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit10/selfdrivingcar.jpg" alt="Self driving cars"/>
<figcaption>
[Image by jcomp](https://www.freepik.com/free-vector/autonomous-smart-car-automatic-wireless-sensor-driving-road-around-car-autonomous-smart-car-goes-scans-roads-observe-distance-automatic-braking-system_26413332.htm#query=self driving cars highway&position=34&from_view=search&track=ais) on Freepik
</figcaption>
</figure>
In these examples, we have **multiple agents interacting in the environment and with the other agents**. This implies defining a multi-agents system. But first, let's understand the different types of multi-agent environments.
## Different types of multi-agent environments
Given that, in a multi-agent system, agents interact with other agents, we can have different types of environments:
- *Cooperative environments*: where your agents need **to maximize the common benefits**.
For instance, in a warehouse, **robots must collaborate to load and unload the packages efficiently (as fast as possible)**.
- *Competitive/Adversarial environments*: in this case, your agent **wants to maximize its benefits by minimizing the opponent's**.
For example, in a game of tennis, **each agent wants to beat the other agent**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit10/tennis.png" alt="Tennis"/>
- *Mixed of both adversarial and cooperative*: like in our SoccerTwos environment, two agents are part of a team (blue or purple): they need to cooperate with each other and beat the opponent team.
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit10/soccertwos.gif" alt="SoccerTwos"/>
<figcaption>This environment was made by the <a href="https://github.com/Unity-Technologies/ml-agents">Unity MLAgents Team</a></figcaption>
</figure>
So now we might wonder: how can we design these multi-agent systems? Said differently, **how can we train agents in a multi-agent setting** ?
|
huggingface/deep-rl-class/blob/main/units/en/unit7/introduction-to-marl.mdx
|
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Running Simulate on GCP
## Setting up the VM
We recommend using Google’s [Deep Learning VM](https://cloud.google.com/deep-learning-vm) to quickly suitable a compatible VM instance.
In addition, we recommend attaching a GPU in order to render camera observations and train more quickly. We also recommend setting the vCPU count to be as high as possible.
## Installing Dependencies for Headless Rendering
In order to perform offscreen rendering, there are a number of additional dependencies to install.
Please run the following:
```
sudo apt update
sudo apt upgrade
sudo apt install -y xorg-dev libglu1-mesa libglu1-mesa-dev libgl1-mesa-dev freeglut3-dev mesa-common-dev xvfb libxinerama1 libxcursor1 mesa-utils
sudo apt-get install xserver-xorg
Now we need to identify which busid your GPU is using:
```
Now we need to identify which build your GPU is using and add it to your xorg config file:
```
# run this command to find your GPU bus id (for example PCI:0:30:0)
nvidia-xconfig --query-gpu-info
# replace the busid flag with your value
# Note: with headless GPUs (e.g. Tesla T4), which don't have display outputs, remove the --use-display-device=none option
sudo nvidia-xconfig --busid=PCI:0:30:0 --use-display-device=none --virtual=1280x1024
```
We can now start an X server:
```
sudo Xorg :0
```
Run the following to confirm that offscreen rendering is working.
```
DISPLAY=:0 glxinfo | grep version
DISPLAY=:0 glxgears
nvidia-smi # xorg should show up in the running programs
```
**Important!** The `DISPLAY=:0` environment variable must be set before you launch Simulate.
```
export DISPLAY=:0
```
## Install Simulate
Your VM is now set up for headless training. Follow the installation instructions from the [README](https://github.com/huggingface/simulate#readme)
|
huggingface/simulate/blob/main/docs/source/howto/run_on_gcp.mdx
|
Datasets Download Stats
## How are download stats generated for datasets?
The Hub provides download stats for all datasets loadable via the `datasets` library. To determine the number of downloads, the Hub counts every time `load_dataset` is called in Python, excluding Hugging Face's CI tooling on GitHub. No information is sent from the user, and no additional calls are made for this. The count is done server-side as we serve files for downloads. This means that:
* The download count is the same regardless of whether the data is directly stored on the Hub repo or if the repository has a [script](https://huggingface.co/docs/datasets/dataset_script) to load the data from an external source.
* If a user manually downloads the data using tools like `wget` or the Hub's user interface (UI), those downloads will not be included in the download count.
|
huggingface/hub-docs/blob/main/docs/hub/datasets-download-stats.md
|
Gradio Demo: text_analysis
### This simple demo takes advantage of Gradio's HighlightedText, JSON and HTML outputs to create a clear NER segmentation.
```
!pip install -q gradio spacy
```
```
import gradio as gr
import os
os.system('python -m spacy download en_core_web_sm')
import spacy
from spacy import displacy
nlp = spacy.load("en_core_web_sm")
def text_analysis(text):
doc = nlp(text)
html = displacy.render(doc, style="dep", page=True)
html = (
"<div style='max-width:100%; max-height:360px; overflow:auto'>"
+ html
+ "</div>"
)
pos_count = {
"char_count": len(text),
"token_count": 0,
}
pos_tokens = []
for token in doc:
pos_tokens.extend([(token.text, token.pos_), (" ", None)])
return pos_tokens, pos_count, html
demo = gr.Interface(
text_analysis,
gr.Textbox(placeholder="Enter sentence here..."),
["highlight", "json", "html"],
examples=[
["What a beautiful morning for a walk!"],
["It was the best of times, it was the worst of times."],
],
)
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/text_analysis/run.ipynb
|
Gradio Demo: diff_texts
```
!pip install -q gradio
```
```
from difflib import Differ
import gradio as gr
def diff_texts(text1, text2):
d = Differ()
return [
(token[2:], token[0] if token[0] != " " else None)
for token in d.compare(text1, text2)
]
demo = gr.Interface(
diff_texts,
[
gr.Textbox(
label="Text 1",
info="Initial text",
lines=3,
value="The quick brown fox jumped over the lazy dogs.",
),
gr.Textbox(
label="Text 2",
info="Text to compare",
lines=3,
value="The fast brown fox jumps over lazy dogs.",
),
],
gr.HighlightedText(
label="Diff",
combine_adjacent=True,
show_legend=True,
color_map={"+": "red", "-": "green"}),
theme=gr.themes.Base()
)
if __name__ == "__main__":
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/diff_texts/run.ipynb
|
Scripts
A train, validation, inference, and checkpoint cleaning script included in the github root folder. Scripts are not currently packaged in the pip release.
The training and validation scripts evolved from early versions of the [PyTorch Imagenet Examples](https://github.com/pytorch/examples). I have added significant functionality over time, including CUDA specific performance enhancements based on
[NVIDIA's APEX Examples](https://github.com/NVIDIA/apex/tree/master/examples).
## Training Script
The variety of training args is large and not all combinations of options (or even options) have been fully tested. For the training dataset folder, specify the folder to the base that contains a `train` and `validation` folder.
To train an SE-ResNet34 on ImageNet, locally distributed, 4 GPUs, one process per GPU w/ cosine schedule, random-erasing prob of 50% and per-pixel random value:
```bash
./distributed_train.sh 4 /data/imagenet --model seresnet34 --sched cosine --epochs 150 --warmup-epochs 5 --lr 0.4 --reprob 0.5 --remode pixel --batch-size 256 --amp -j 4
```
<Tip>
It is recommended to use PyTorch 1.9+ w/ PyTorch native AMP and DDP instead of APEX AMP. --amp defaults to native AMP as of timm ver 0.4.3. --apex-amp will force use of APEX components if they are installed.
</Tip>
## Validation / Inference Scripts
Validation and inference scripts are similar in usage. One outputs metrics on a validation set and the other outputs topk class ids in a csv. Specify the folder containing validation images, not the base as in training script.
To validate with the model's pretrained weights (if they exist):
```bash
python validate.py /imagenet/validation/ --model seresnext26_32x4d --pretrained
```
To run inference from a checkpoint:
```bash
python inference.py /imagenet/validation/ --model mobilenetv3_large_100 --checkpoint ./output/train/model_best.pth.tar
```
## Training Examples
### EfficientNet-B2 with RandAugment - 80.4 top-1, 95.1 top-5
These params are for dual Titan RTX cards with NVIDIA Apex installed:
```bash
./distributed_train.sh 2 /imagenet/ --model efficientnet_b2 -b 128 --sched step --epochs 450 --decay-epochs 2.4 --decay-rate .97 --opt rmsproptf --opt-eps .001 -j 8 --warmup-lr 1e-6 --weight-decay 1e-5 --drop 0.3 --drop-path 0.2 --model-ema --model-ema-decay 0.9999 --aa rand-m9-mstd0.5 --remode pixel --reprob 0.2 --amp --lr .016
```
### MixNet-XL with RandAugment - 80.5 top-1, 94.9 top-5
This params are for dual Titan RTX cards with NVIDIA Apex installed:
```bash
./distributed_train.sh 2 /imagenet/ --model mixnet_xl -b 128 --sched step --epochs 450 --decay-epochs 2.4 --decay-rate .969 --opt rmsproptf --opt-eps .001 -j 8 --warmup-lr 1e-6 --weight-decay 1e-5 --drop 0.3 --drop-path 0.2 --model-ema --model-ema-decay 0.9999 --aa rand-m9-mstd0.5 --remode pixel --reprob 0.3 --amp --lr .016 --dist-bn reduce
```
### SE-ResNeXt-26-D and SE-ResNeXt-26-T
These hparams (or similar) work well for a wide range of ResNet architecture, generally a good idea to increase the epoch # as the model size increases... ie approx 180-200 for ResNe(X)t50, and 220+ for larger. Increase batch size and LR proportionally for better GPUs or with AMP enabled. These params were for 2 1080Ti cards:
```bash
./distributed_train.sh 2 /imagenet/ --model seresnext26t_32x4d --lr 0.1 --warmup-epochs 5 --epochs 160 --weight-decay 1e-4 --sched cosine --reprob 0.4 --remode pixel -b 112
```
### EfficientNet-B3 with RandAugment - 81.5 top-1, 95.7 top-5
The training of this model started with the same command line as EfficientNet-B2 w/ RA above. After almost three weeks of training the process crashed. The results weren't looking amazing so I resumed the training several times with tweaks to a few params (increase RE prob, decrease rand-aug, increase ema-decay). Nothing looked great. I ended up averaging the best checkpoints from all restarts. The result is mediocre at default res/crop but oddly performs much better with a full image test crop of 1.0.
### EfficientNet-B0 with RandAugment - 77.7 top-1, 95.3 top-5
[Michael Klachko](https://github.com/michaelklachko) achieved these results with the command line for B2 adapted for larger batch size, with the recommended B0 dropout rate of 0.2.
```bash
./distributed_train.sh 2 /imagenet/ --model efficientnet_b0 -b 384 --sched step --epochs 450 --decay-epochs 2.4 --decay-rate .97 --opt rmsproptf --opt-eps .001 -j 8 --warmup-lr 1e-6 --weight-decay 1e-5 --drop 0.2 --drop-path 0.2 --model-ema --model-ema-decay 0.9999 --aa rand-m9-mstd0.5 --remode pixel --reprob 0.2 --amp --lr .048
```
### ResNet50 with JSD loss and RandAugment (clean + 2x RA augs) - 79.04 top-1, 94.39 top-5
Trained on two older 1080Ti cards, this took a while. Only slightly, non statistically better ImageNet validation result than my first good AugMix training of 78.99. However, these weights are more robust on tests with ImageNetV2, ImageNet-Sketch, etc. Unlike my first AugMix runs, I've enabled SplitBatchNorm, disabled random erasing on the clean split, and cranked up random erasing prob on the 2 augmented paths.
```bash
./distributed_train.sh 2 /imagenet -b 64 --model resnet50 --sched cosine --epochs 200 --lr 0.05 --amp --remode pixel --reprob 0.6 --aug-splits 3 --aa rand-m9-mstd0.5-inc1 --resplit --split-bn --jsd --dist-bn reduce
```
### EfficientNet-ES (EdgeTPU-Small) with RandAugment - 78.066 top-1, 93.926 top-5
Trained by [Andrew Lavin](https://github.com/andravin) with 8 V100 cards. Model EMA was not used, final checkpoint is the average of 8 best checkpoints during training.
```bash
./distributed_train.sh 8 /imagenet --model efficientnet_es -b 128 --sched step --epochs 450 --decay-epochs 2.4 --decay-rate .97 --opt rmsproptf --opt-eps .001 -j 8 --warmup-lr 1e-6 --weight-decay 1e-5 --drop 0.2 --drop-path 0.2 --aa rand-m9-mstd0.5 --remode pixel --reprob 0.2 --amp --lr .064
```
### MobileNetV3-Large-100 - 75.766 top-1, 92,542 top-5
```bash
./distributed_train.sh 2 /imagenet/ --model mobilenetv3_large_100 -b 512 --sched step --epochs 600 --decay-epochs 2.4 --decay-rate .973 --opt rmsproptf --opt-eps .001 -j 7 --warmup-lr 1e-6 --weight-decay 1e-5 --drop 0.2 --drop-path 0.2 --model-ema --model-ema-decay 0.9999 --aa rand-m9-mstd0.5 --remode pixel --reprob 0.2 --amp --lr .064 --lr-noise 0.42 0.9
```
### ResNeXt-50 32x4d w/ RandAugment - 79.762 top-1, 94.60 top-5
These params will also work well for SE-ResNeXt-50 and SK-ResNeXt-50 and likely 101. I used them for the SK-ResNeXt-50 32x4d that I trained with 2 GPU using a slightly higher LR per effective batch size (lr=0.18, b=192 per GPU). The cmd line below are tuned for 8 GPU training.
```bash
./distributed_train.sh 8 /imagenet --model resnext50_32x4d --lr 0.6 --warmup-epochs 5 --epochs 240 --weight-decay 1e-4 --sched cosine --reprob 0.4 --recount 3 --remode pixel --aa rand-m7-mstd0.5-inc1 -b 192 -j 6 --amp --dist-bn reduce
```
|
huggingface/pytorch-image-models/blob/main/hfdocs/source/training_script.mdx
|
Student Works
Since the launch of the Deep Reinforcement Learning Course, **many students have created amazing projects that you should check out and consider participating in**.
If you've created an interesting project, don't hesitate to [add it to this list by opening a pull request on the GitHub repository](https://github.com/huggingface/deep-rl-class).
The projects are **arranged based on the date of publication in this page**.
## Space Scavanger AI
This project is a space game environment with trained neural network for AI.
AI is trained by Reinforcement learning algorithm based on UnityMLAgents and RLlib frameworks.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit12/spacescavangerai.png" alt="Space Scavanger AI"/>
Play the Game here 👉 https://swingshuffle.itch.io/spacescalvagerai
Check the Unity project here 👉 https://github.com/HighExecutor/SpaceScalvagerAI
## Neural Nitro 🏎️
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit12/neuralnitro.png" alt="Neural Nitro" />
In this project, Sookeyy created a low poly racing game and trained a car to drive.
Check out the demo here 👉 https://sookeyy.itch.io/neuralnitro
## Space War 🚀
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit12/spacewar.jpg" alt="SpaceWar" />
In this project, Eric Dong recreates Bill Seiler's 1985 version of Space War in Pygame and uses reinforcement learning (RL) to train AI agents.
Check out the project here 👉 https://github.com/e-dong/space-war-rl
Check out his blog here 👉 https://dev.to/edong/space-war-rl-0-series-introduction-25dh
|
huggingface/deep-rl-class/blob/main/units/en/unitbonus3/student-works.mdx
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Pix2Struct
## Overview
The Pix2Struct model was proposed in [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
The abstract from the paper is the following:
> Visually-situated language is ubiquitous -- sources range from textbooks with diagrams to web pages with images and tables, to mobile apps with buttons and forms. Perhaps due to this diversity, previous work has typically relied on domain-specific recipes with limited sharing of the underlying data, model architectures, and objectives. We present Pix2Struct, a pretrained image-to-text model for purely visual language understanding, which can be finetuned on tasks containing visually-situated language. Pix2Struct is pretrained by learning to parse masked screenshots of web pages into simplified HTML. The web, with its richness of visual elements cleanly reflected in the HTML structure, provides a large source of pretraining data well suited to the diversity of downstream tasks. Intuitively, this objective subsumes common pretraining signals such as OCR, language modeling, image captioning. In addition to the novel pretraining strategy, we introduce a variable-resolution input representation and a more flexible integration of language and vision inputs, where language prompts such as questions are rendered directly on top of the input image. For the first time, we show that a single pretrained model can achieve state-of-the-art results in six out of nine tasks across four domains: documents, illustrations, user interfaces, and natural images.
Tips:
Pix2Struct has been fine tuned on a variety of tasks and datasets, ranging from image captioning, visual question answering (VQA) over different inputs (books, charts, science diagrams), captioning UI components etc. The full list can be found in Table 1 of the paper.
We therefore advise you to use these models for the tasks they have been fine tuned on. For instance, if you want to use Pix2Struct for UI captioning, you should use the model fine tuned on the UI dataset. If you want to use Pix2Struct for image captioning, you should use the model fine tuned on the natural images captioning dataset and so on.
If you want to use the model to perform conditional text captioning, make sure to use the processor with `add_special_tokens=False`.
This model was contributed by [ybelkada](https://huggingface.co/ybelkada).
The original code can be found [here](https://github.com/google-research/pix2struct).
## Resources
- [Fine-tuning Notebook](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_pix2struct.ipynb)
- [All models](https://huggingface.co/models?search=pix2struct)
## Pix2StructConfig
[[autodoc]] Pix2StructConfig
- from_text_vision_configs
## Pix2StructTextConfig
[[autodoc]] Pix2StructTextConfig
## Pix2StructVisionConfig
[[autodoc]] Pix2StructVisionConfig
## Pix2StructProcessor
[[autodoc]] Pix2StructProcessor
## Pix2StructImageProcessor
[[autodoc]] Pix2StructImageProcessor
- preprocess
## Pix2StructTextModel
[[autodoc]] Pix2StructTextModel
- forward
## Pix2StructVisionModel
[[autodoc]] Pix2StructVisionModel
- forward
## Pix2StructForConditionalGeneration
[[autodoc]] Pix2StructForConditionalGeneration
- forward
|
huggingface/transformers/blob/main/docs/source/en/model_doc/pix2struct.md
|
Using TensorBoard
TensorBoard provides tooling for tracking and visualizing metrics as well as visualizing models. All repositories that contain TensorBoard traces have an automatic tab with a hosted TensorBoard instance for anyone to check it out without any additional effort!
## Exploring TensorBoard models on the Hub
Over 52k repositories have TensorBoard traces on the Hub. You can find them by filtering at the left of the [models page](https://huggingface.co/models?filter=tensorboard). As an example, if you go to the [aubmindlab/bert-base-arabertv02](https://huggingface.co/aubmindlab/bert-base-arabertv02) repository, there is a **Metrics** tab. If you select it, you'll view a TensorBoard instance.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-tensorflow.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-tensorflow-dark.png"/>
</div>
## Adding your TensorBoard traces
The Hub automatically detects TensorBoard traces (such as `tfevents`). Once you push your TensorBoard files to the Hub, they will automatically start an instance.
## Additional resources
* TensorBoard [documentation](https://www.tensorflow.org/tensorboard).
|
huggingface/hub-docs/blob/main/docs/hub/tensorboard.md
|
Stable Diffusion XL text-to-image fine-tuning
The `train_text_to_image_sdxl.py` script shows how to fine-tune Stable Diffusion XL (SDXL) on your own dataset.
🚨 This script is experimental. The script fine-tunes the whole model and often times the model overfits and runs into issues like catastrophic forgetting. It's recommended to try different hyperparamters to get the best result on your dataset. 🚨
## Running locally with PyTorch
### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install -e .
```
Then cd in the `examples/text_to_image` folder and run
```bash
pip install -r requirements_sdxl.txt
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
Or for a default accelerate configuration without answering questions about your environment
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell (e.g., a notebook)
```python
from accelerate.utils import write_basic_config
write_basic_config()
```
When running `accelerate config`, if we specify torch compile mode to True there can be dramatic speedups.
Note also that we use PEFT library as backend for LoRA training, make sure to have `peft>=0.6.0` installed in your environment.
### Training
```bash
export MODEL_NAME="stabilityai/stable-diffusion-xl-base-1.0"
export VAE_NAME="madebyollin/sdxl-vae-fp16-fix"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch train_text_to_image_sdxl.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--pretrained_vae_model_name_or_path=$VAE_NAME \
--dataset_name=$DATASET_NAME \
--enable_xformers_memory_efficient_attention \
--resolution=512 --center_crop --random_flip \
--proportion_empty_prompts=0.2 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 --gradient_checkpointing \
--max_train_steps=10000 \
--use_8bit_adam \
--learning_rate=1e-06 --lr_scheduler="constant" --lr_warmup_steps=0 \
--mixed_precision="fp16" \
--report_to="wandb" \
--validation_prompt="a cute Sundar Pichai creature" --validation_epochs 5 \
--checkpointing_steps=5000 \
--output_dir="sdxl-pokemon-model" \
--push_to_hub
```
**Notes**:
* The `train_text_to_image_sdxl.py` script pre-computes text embeddings and the VAE encodings and keeps them in memory. While for smaller datasets like [`lambdalabs/pokemon-blip-captions`](https://hf.co/datasets/lambdalabs/pokemon-blip-captions), it might not be a problem, it can definitely lead to memory problems when the script is used on a larger dataset. For those purposes, you would want to serialize these pre-computed representations to disk separately and load them during the fine-tuning process. Refer to [this PR](https://github.com/huggingface/diffusers/pull/4505) for a more in-depth discussion.
* The training script is compute-intensive and may not run on a consumer GPU like Tesla T4.
* The training command shown above performs intermediate quality validation in between the training epochs and logs the results to Weights and Biases. `--report_to`, `--validation_prompt`, and `--validation_epochs` are the relevant CLI arguments here.
* SDXL's VAE is known to suffer from numerical instability issues. This is why we also expose a CLI argument namely `--pretrained_vae_model_name_or_path` that lets you specify the location of a better VAE (such as [this one](https://huggingface.co/madebyollin/sdxl-vae-fp16-fix)).
### Inference
```python
from diffusers import DiffusionPipeline
import torch
model_path = "you-model-id-goes-here" # <-- change this
pipe = DiffusionPipeline.from_pretrained(model_path, torch_dtype=torch.float16)
pipe.to("cuda")
prompt = "A pokemon with green eyes and red legs."
image = pipe(prompt, num_inference_steps=30, guidance_scale=7.5).images[0]
image.save("pokemon.png")
```
### Inference in Pytorch XLA
```python
from diffusers import DiffusionPipeline
import torch
import torch_xla.core.xla_model as xm
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
pipe = DiffusionPipeline.from_pretrained(model_id)
device = xm.xla_device()
pipe.to(device)
prompt = "A pokemon with green eyes and red legs."
start = time()
image = pipe(prompt, num_inference_steps=inference_steps).images[0]
print(f'Compilation time is {time()-start} sec')
image.save("pokemon.png")
start = time()
image = pipe(prompt, num_inference_steps=inference_steps).images[0]
print(f'Inference time is {time()-start} sec after compilation')
```
Note: There is a warmup step in PyTorch XLA. This takes longer because of
compilation and optimization. To see the real benefits of Pytorch XLA and
speedup, we need to call the pipe again on the input with the same length
as the original prompt to reuse the optimized graph and get the performance
boost.
## LoRA training example for Stable Diffusion XL (SDXL)
Low-Rank Adaption of Large Language Models was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
In a nutshell, LoRA allows adapting pretrained models by adding pairs of rank-decomposition matrices to existing weights and **only** training those newly added weights. This has a couple of advantages:
- Previous pretrained weights are kept frozen so that model is not prone to [catastrophic forgetting](https://www.pnas.org/doi/10.1073/pnas.1611835114).
- Rank-decomposition matrices have significantly fewer parameters than original model, which means that trained LoRA weights are easily portable.
- LoRA attention layers allow to control to which extent the model is adapted toward new training images via a `scale` parameter.
[cloneofsimo](https://github.com/cloneofsimo) was the first to try out LoRA training for Stable Diffusion in the popular [lora](https://github.com/cloneofsimo/lora) GitHub repository.
With LoRA, it's possible to fine-tune Stable Diffusion on a custom image-caption pair dataset
on consumer GPUs like Tesla T4, Tesla V100.
### Training
First, you need to set up your development environment as is explained in the [installation section](#installing-the-dependencies). Make sure to set the `MODEL_NAME` and `DATASET_NAME` environment variables and, optionally, the `VAE_NAME` variable. Here, we will use [Stable Diffusion XL 1.0-base](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0) and the [Pokemons dataset](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions).
**___Note: It is quite useful to monitor the training progress by regularly generating sample images during training. [Weights and Biases](https://docs.wandb.ai/quickstart) is a nice solution to easily see generating images during training. All you need to do is to run `pip install wandb` before training to automatically log images.___**
```bash
export MODEL_NAME="stabilityai/stable-diffusion-xl-base-1.0"
export VAE_NAME="madebyollin/sdxl-vae-fp16-fix"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
```
For this example we want to directly store the trained LoRA embeddings on the Hub, so
we need to be logged in and add the `--push_to_hub` flag.
```bash
huggingface-cli login
```
Now we can start training!
```bash
accelerate launch train_text_to_image_lora_sdxl.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--pretrained_vae_model_name_or_path=$VAE_NAME \
--dataset_name=$DATASET_NAME --caption_column="text" \
--resolution=1024 --random_flip \
--train_batch_size=1 \
--num_train_epochs=2 --checkpointing_steps=500 \
--learning_rate=1e-04 --lr_scheduler="constant" --lr_warmup_steps=0 \
--mixed_precision="fp16" \
--seed=42 \
--output_dir="sd-pokemon-model-lora-sdxl" \
--validation_prompt="cute dragon creature" --report_to="wandb" \
--push_to_hub
```
The above command will also run inference as fine-tuning progresses and log the results to Weights and Biases.
**Notes**:
* SDXL's VAE is known to suffer from numerical instability issues. This is why we also expose a CLI argument namely `--pretrained_vae_model_name_or_path` that lets you specify the location of a better VAE (such as [this one](https://huggingface.co/madebyollin/sdxl-vae-fp16-fix)).
### Finetuning the text encoder and UNet
The script also allows you to finetune the `text_encoder` along with the `unet`.
🚨 Training the text encoder requires additional memory.
Pass the `--train_text_encoder` argument to the training script to enable finetuning the `text_encoder` and `unet`:
```bash
accelerate launch train_text_to_image_lora_sdxl.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME --caption_column="text" \
--resolution=1024 --random_flip \
--train_batch_size=1 \
--num_train_epochs=2 --checkpointing_steps=500 \
--learning_rate=1e-04 --lr_scheduler="constant" --lr_warmup_steps=0 \
--seed=42 \
--output_dir="sd-pokemon-model-lora-sdxl-txt" \
--train_text_encoder \
--validation_prompt="cute dragon creature" --report_to="wandb" \
--push_to_hub
```
### Inference
Once you have trained a model using above command, the inference can be done simply using the `DiffusionPipeline` after loading the trained LoRA weights. You
need to pass the `output_dir` for loading the LoRA weights which, in this case, is `sd-pokemon-model-lora-sdxl`.
```python
from diffusers import DiffusionPipeline
import torch
model_path = "takuoko/sd-pokemon-model-lora-sdxl"
pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16)
pipe.to("cuda")
pipe.load_lora_weights(model_path)
prompt = "A pokemon with green eyes and red legs."
image = pipe(prompt, num_inference_steps=30, guidance_scale=7.5).images[0]
image.save("pokemon.png")
```
|
huggingface/diffusers/blob/main/examples/text_to_image/README_sdxl.md
|
--
title: METEOR
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
METEOR, an automatic metric for machine translation evaluation
that is based on a generalized concept of unigram matching between the
machine-produced translation and human-produced reference translations.
Unigrams can be matched based on their surface forms, stemmed forms,
and meanings; furthermore, METEOR can be easily extended to include more
advanced matching strategies. Once all generalized unigram matches
between the two strings have been found, METEOR computes a score for
this matching using a combination of unigram-precision, unigram-recall, and
a measure of fragmentation that is designed to directly capture how
well-ordered the matched words in the machine translation are in relation
to the reference.
METEOR gets an R correlation value of 0.347 with human evaluation on the Arabic
data and 0.331 on the Chinese data. This is shown to be an improvement on
using simply unigram-precision, unigram-recall and their harmonic F1
combination.
---
# Metric Card for METEOR
## Metric description
METEOR (Metric for Evaluation of Translation with Explicit ORdering) is a machine translation evaluation metric, which is calculated based on the harmonic mean of precision and recall, with recall weighted more than precision.
METEOR is based on a generalized concept of unigram matching between the machine-produced translation and human-produced reference translations. Unigrams can be matched based on their surface forms, stemmed forms, and meanings. Once all generalized unigram matches between the two strings have been found, METEOR computes a score for this matching using a combination of unigram-precision, unigram-recall, and a measure of fragmentation that is designed to directly capture how well-ordered the matched words in the machine translation are in relation to the reference.
## How to use
METEOR has two mandatory arguments:
`predictions`: a `list` of predictions to score. Each prediction should be a string with tokens separated by spaces.
`references`: a `list` of references (in the case of one `reference` per `prediction`), or a `list` of `lists` of references (in the case of multiple `references` per `prediction`. Each reference should be a string with tokens separated by spaces.
It also has several optional parameters:
`alpha`: Parameter for controlling relative weights of precision and recall. The default value is `0.9`.
`beta`: Parameter for controlling shape of penalty as a function of fragmentation. The default value is `3`.
`gamma`: The relative weight assigned to fragmentation penalty. The default is `0.5`.
Refer to the [METEOR paper](https://aclanthology.org/W05-0909.pdf) for more information about parameter values and ranges.
```python
>>> meteor = evaluate.load('meteor')
>>> predictions = ["It is a guide to action which ensures that the military always obeys the commands of the party"]
>>> references = ["It is a guide to action that ensures that the military will forever heed Party commands"]
>>> results = meteor.compute(predictions=predictions, references=references)
```
## Output values
The metric outputs a dictionary containing the METEOR score. Its values range from 0 to 1, e.g.:
```
{'meteor': 0.9999142661179699}
```
### Values from popular papers
The [METEOR paper](https://aclanthology.org/W05-0909.pdf) does not report METEOR score values for different models, but it does report that METEOR gets an R correlation value of 0.347 with human evaluation on the Arabic data and 0.331 on the Chinese data.
## Examples
One `reference` per `prediction`:
```python
>>> meteor = evaluate.load('meteor')
>>> predictions = ["It is a guide to action which ensures that the military always obeys the commands of the party"]
>>> reference = ["It is a guide to action which ensures that the military always obeys the commands of the party"]
>>> results = meteor.compute(predictions=predictions, references=reference)
>>> print(round(results['meteor'], 2))
1.0
```
Multiple `references` per `prediction`:
```python
>>> meteor = evaluate.load('meteor')
>>> predictions = ["It is a guide to action which ensures that the military always obeys the commands of the party"]
>>> references = [['It is a guide to action that ensures that the military will forever heed Party commands', 'It is the guiding principle which guarantees the military forces always being under the command of the Party', 'It is the practical guide for the army always to heed the directions of the party']]
>>> results = meteor.compute(predictions=predictions, references=references)
>>> print(round(results['meteor'], 2))
1.0
```
Multiple `references` per `prediction`, partial match:
```python
>>> meteor = evaluate.load('meteor')
>>> predictions = ["It is a guide to action which ensures that the military always obeys the commands of the party"]
>>> references = [['It is a guide to action that ensures that the military will forever heed Party commands', 'It is the guiding principle which guarantees the military forces always being under the command of the Party', 'It is the practical guide for the army always to heed the directions of the party']]
>>> results = meteor.compute(predictions=predictions, references=references)
>>> print(round(results['meteor'], 2))
0.69
```
## Limitations and bias
While the correlation between METEOR and human judgments was measured for Chinese and Arabic and found to be significant, further experimentation is needed to check its correlation for other languages.
Furthermore, while the alignment and matching done in METEOR is based on unigrams, using multiple word entities (e.g. bigrams) could contribute to improving its accuracy -- this has been proposed in [more recent publications](https://www.cs.cmu.edu/~alavie/METEOR/pdf/meteor-naacl-2010.pdf) on the subject.
## Citation
```bibtex
@inproceedings{banarjee2005,
title = {{METEOR}: An Automatic Metric for {MT} Evaluation with Improved Correlation with Human Judgments},
author = {Banerjee, Satanjeev and Lavie, Alon},
booktitle = {Proceedings of the {ACL} Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization},
month = jun,
year = {2005},
address = {Ann Arbor, Michigan},
publisher = {Association for Computational Linguistics},
url = {https://www.aclweb.org/anthology/W05-0909},
pages = {65--72},
}
```
## Further References
- [METEOR -- Wikipedia](https://en.wikipedia.org/wiki/METEOR)
- [METEOR score -- NLTK](https://www.nltk.org/_modules/nltk/translate/meteor_score.html)
|
huggingface/evaluate/blob/main/metrics/meteor/README.md
|
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Configuration
The configuration classes are the way to specify how a task should be done. There are two tasks supported with the ONNX Runtime package:
1. Optimization: Performed by the [`~onnxruntime.ORTOptimizer`], this task can be tweaked using an [`~onnxruntime.configuration.OptimizationConfig`].
2. Quantization: Performed by the [`~onnxruntime.ORTQuantizer`], quantization can be set using a [`~onnxruntime.configuration.QuantizationConfig`]. A calibration step is required in some cases (post training static quantization), which can be specified using a [`~onnxruntime.configuration.CalibrationConfig`].
## OptimizationConfig
[[autodoc]] onnxruntime.configuration.OptimizationConfig
[[autodoc]] onnxruntime.configuration.AutoOptimizationConfig
## QuantizationConfig
[[autodoc]] onnxruntime.configuration.QuantizationConfig
## AutoQuantizationConfig
[[autodoc]] onnxruntime.configuration.AutoQuantizationConfig
- all
### CalibrationConfig
[[autodoc]] onnxruntime.configuration.CalibrationConfig
## ORTConfig
[[autodoc]] onnxruntime.configuration.ORTConfig
|
huggingface/optimum/blob/main/docs/source/onnxruntime/package_reference/configuration.mdx
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Metal Performance Shaders (MPS)
🤗 Diffusers is compatible with Apple silicon (M1/M2 chips) using the PyTorch [`mps`](https://pytorch.org/docs/stable/notes/mps.html) device, which uses the Metal framework to leverage the GPU on MacOS devices. You'll need to have:
- macOS computer with Apple silicon (M1/M2) hardware
- macOS 12.6 or later (13.0 or later recommended)
- arm64 version of Python
- [PyTorch 2.0](https://pytorch.org/get-started/locally/) (recommended) or 1.13 (minimum version supported for `mps`)
The `mps` backend uses PyTorch's `.to()` interface to move the Stable Diffusion pipeline on to your M1 or M2 device:
```python
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
pipe = pipe.to("mps")
# Recommended if your computer has < 64 GB of RAM
pipe.enable_attention_slicing()
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image
```
<Tip warning={true}>
Generating multiple prompts in a batch can [crash](https://github.com/huggingface/diffusers/issues/363) or fail to work reliably. We believe this is related to the [`mps`](https://github.com/pytorch/pytorch/issues/84039) backend in PyTorch. While this is being investigated, you should iterate instead of batching.
</Tip>
If you're using **PyTorch 1.13**, you need to "prime" the pipeline with an additional one-time pass through it. This is a temporary workaround for an issue where the first inference pass produces slightly different results than subsequent ones. You only need to do this pass once, and after just one inference step you can discard the result.
```diff
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5").to("mps")
pipe.enable_attention_slicing()
prompt = "a photo of an astronaut riding a horse on mars"
# First-time "warmup" pass if PyTorch version is 1.13
+ _ = pipe(prompt, num_inference_steps=1)
# Results match those from the CPU device after the warmup pass.
image = pipe(prompt).images[0]
```
## Troubleshoot
M1/M2 performance is very sensitive to memory pressure. When this occurs, the system automatically swaps if it needs to which significantly degrades performance.
To prevent this from happening, we recommend *attention slicing* to reduce memory pressure during inference and prevent swapping. This is especially relevant if your computer has less than 64GB of system RAM, or if you generate images at non-standard resolutions larger than 512×512 pixels. Call the [`~DiffusionPipeline.enable_attention_slicing`] function on your pipeline:
```py
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, variant="fp16", use_safetensors=True).to("mps")
pipeline.enable_attention_slicing()
```
Attention slicing performs the costly attention operation in multiple steps instead of all at once. It usually improves performance by ~20% in computers without universal memory, but we've observed *better performance* in most Apple silicon computers unless you have 64GB of RAM or more.
|
huggingface/diffusers/blob/main/docs/source/en/optimization/mps.md
|
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Managing local and online repositories
The `Repository` class is a helper class that wraps `git` and `git-lfs` commands. It provides tooling adapted
for managing repositories which can be very large.
It is the recommended tool as soon as any `git` operation is involved, or when collaboration will be a point
of focus with the repository itself.
## The Repository class
[[autodoc]] Repository
- __init__
- current_branch
- all
## Helper methods
[[autodoc]] huggingface_hub.repository.is_git_repo
[[autodoc]] huggingface_hub.repository.is_local_clone
[[autodoc]] huggingface_hub.repository.is_tracked_with_lfs
[[autodoc]] huggingface_hub.repository.is_git_ignored
[[autodoc]] huggingface_hub.repository.files_to_be_staged
[[autodoc]] huggingface_hub.repository.is_tracked_upstream
[[autodoc]] huggingface_hub.repository.commits_to_push
## Following asynchronous commands
The `Repository` utility offers several methods which can be launched asynchronously:
- `git_push`
- `git_pull`
- `push_to_hub`
- The `commit` context manager
See below for utilities to manage such asynchronous methods.
[[autodoc]] Repository
- commands_failed
- commands_in_progress
- wait_for_commands
[[autodoc]] huggingface_hub.repository.CommandInProgress
|
huggingface/huggingface_hub/blob/main/docs/source/en/package_reference/repository.md
|
Introduction[[introduction]]
<CourseFloatingBanner
chapter={2}
classNames="absolute z-10 right-0 top-0"
/>
As you saw in [Chapter 1](/course/chapter1), Transformer models are usually very large. With millions to tens of *billions* of parameters, training and deploying these models is a complicated undertaking. Furthermore, with new models being released on a near-daily basis and each having its own implementation, trying them all out is no easy task.
The 🤗 Transformers library was created to solve this problem. Its goal is to provide a single API through which any Transformer model can be loaded, trained, and saved. The library's main features are:
- **Ease of use**: Downloading, loading, and using a state-of-the-art NLP model for inference can be done in just two lines of code.
- **Flexibility**: At their core, all models are simple PyTorch `nn.Module` or TensorFlow `tf.keras.Model` classes and can be handled like any other models in their respective machine learning (ML) frameworks.
- **Simplicity**: Hardly any abstractions are made across the library. The "All in one file" is a core concept: a model's forward pass is entirely defined in a single file, so that the code itself is understandable and hackable.
This last feature makes 🤗 Transformers quite different from other ML libraries. The models are not built on modules
that are shared across files; instead, each model has its own layers. In addition to making the models more approachable and understandable, this allows you to easily experiment on one model without affecting others.
This chapter will begin with an end-to-end example where we use a model and a tokenizer together to replicate the `pipeline()` function introduced in [Chapter 1](/course/chapter1). Next, we'll discuss the model API: we'll dive into the model and configuration classes, and show you how to load a model and how it processes numerical inputs to output predictions.
Then we'll look at the tokenizer API, which is the other main component of the `pipeline()` function. Tokenizers take care of the first and last processing steps, handling the conversion from text to numerical inputs for the neural network, and the conversion back to text when it is needed. Finally, we'll show you how to handle sending multiple sentences through a model in a prepared batch, then wrap it all up with a closer look at the high-level `tokenizer()` function.
<Tip>
⚠️ In order to benefit from all features available with the Model Hub and 🤗 Transformers, we recommend <a href="https://huggingface.co/join">creating an account</a>.
</Tip>
|
huggingface/course/blob/main/chapters/en/chapter2/1.mdx
|
--
title: CharacTER
emoji: 🔤
colorFrom: orange
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
- machine-translation
description: >-
CharacTer is a character-level metric inspired by the commonly applied translation edit rate (TER).
---
# Metric Card for CharacTER
## Metric Description
CharacTer is a character-level metric inspired by the translation edit rate (TER) metric. It is
defined as the minimum number of character edits required to adjust a hypothesis, until it completely matches the
reference, normalized by the length of the hypothesis sentence. CharacTer calculates the character level edit
distance while performing the shift edit on word level. Unlike the strict matching criterion in TER, a hypothesis
word is considered to match a reference word and could be shifted, if the edit distance between them is below a
threshold value. The Levenshtein distance between the reference and the shifted hypothesis sequence is computed on the
character level. In addition, the lengths of hypothesis sequences instead of reference sequences are used for
normalizing the edit distance, which effectively counters the issue that shorter translations normally achieve lower
TER.
## Intended Uses
CharacTER was developed for machine translation evaluation.
## How to Use
```python
import evaluate
character = evaluate.load("character")
# Single hyp/ref
preds = ["this week the saudis denied information published in the new york times"]
refs = ["saudi arabia denied this week information published in the american new york times"]
results = character.compute(references=refs, predictions=preds)
# Corpus example
preds = ["this week the saudis denied information published in the new york times",
"this is in fact an estimate"]
refs = ["saudi arabia denied this week information published in the american new york times",
"this is actually an estimate"]
results = character.compute(references=refs, predictions=preds)
```
### Inputs
- **predictions**: a single prediction or a list of predictions to score. Each prediction should be a string with
tokens separated by spaces.
- **references**: a single reference or a list of reference for each prediction. Each reference should be a string with
tokens separated by spaces.
### Output Values
*=only when a list of references/hypotheses are given
- **count** (*): how many parallel sentences were processed
- **mean** (*): the mean CharacTER score
- **median** (*): the median score
- **std** (*): standard deviation of the score
- **min** (*): smallest score
- **max** (*): largest score
- **cer_scores**: all scores, one per ref/hyp pair
### Output Example
```python
{
'count': 2,
'mean': 0.3127282211789254,
'median': 0.3127282211789254,
'std': 0.07561653111280243,
'min': 0.25925925925925924,
'max': 0.36619718309859156,
'cer_scores': [0.36619718309859156, 0.25925925925925924]
}
```
## Citation
```bibtex
@inproceedings{wang-etal-2016-character,
title = "{C}harac{T}er: Translation Edit Rate on Character Level",
author = "Wang, Weiyue and
Peter, Jan-Thorsten and
Rosendahl, Hendrik and
Ney, Hermann",
booktitle = "Proceedings of the First Conference on Machine Translation: Volume 2, Shared Task Papers",
month = aug,
year = "2016",
address = "Berlin, Germany",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/W16-2342",
doi = "10.18653/v1/W16-2342",
pages = "505--510",
}
```
## Further References
- Repackaged version that is used in this HF implementation: [https://github.com/bramvanroy/CharacTER](https://github.com/bramvanroy/CharacTER)
- Original version: [https://github.com/rwth-i6/CharacTER](https://github.com/rwth-i6/CharacTER)
|
huggingface/evaluate/blob/main/metrics/character/README.md
|
# How to contribute to Optimum?
Optimum is an open source project, so all contributions and suggestions are welcome.
You can contribute in many different ways: giving ideas, answering questions, reporting bugs, proposing enhancements, improving the documentation, fixing bugs,...
Many thanks in advance to every contributor.
## How to work on an open Issue?
You have the list of open Issues at: https://github.com/huggingface/optimum/issues
Some of them may have the label `help wanted`: that means that any contributor is welcomed!
If you would like to work on any of the open Issues:
1. Make sure it is not already assigned to someone else. You have the assignee (if any) on the top of the right column of the Issue page.
2. You can self-assign it by commenting on the Issue page with one of the keywords: `#take` or `#self-assign`.
3. Work on your self-assigned issue and eventually create a Pull Request.
## How to create a Pull Request?
1. Fork the [repository](https://github.com/huggingface/optimum) by clicking on the 'Fork' button on the repository's page. This creates a copy of the code under your GitHub user account.
2. Clone your fork to your local disk, and add the base repository as a remote:
```bash
git clone git@github.com:<your Github handle>/optimum.git
cd optimum
git remote add upstream https://github.com/huggingface/optimum.git
```
3. Create a new branch to hold your development changes:
```bash
git checkout -b a-descriptive-name-for-my-changes
```
**do not** work on the `main` branch.
4. Set up a development environment by running the following command in a virtual environment:
```bash
pip install -e ".[dev]"
```
(If optimum was already installed in the virtual environment, remove
it with `pip uninstall optimum` before reinstalling it in editable
mode with the `-e` flag.)
5. Develop the features on your branch.
6. Format your code. Run black and ruff so that your newly added files look nice with the following command:
```bash
make style
```
7. Once you're happy with your changes, add the changed files using `git add` and make a commit with `git commit` to record your changes locally:
```bash
git add modified_file.py
git commit
```
It is a good idea to sync your copy of the code with the original
repository regularly. This way you can quickly account for changes:
```bash
git fetch upstream
git rebase upstream/main
```
Push the changes to your account using:
```bash
git push -u origin a-descriptive-name-for-my-changes
```
8. Once you are satisfied, go the webpage of your fork on GitHub. Click on "Pull request" to send your to the project maintainers for review.
## Code of conduct
This project adheres to the HuggingFace [code of conduct](CODE_OF_CONDUCT.md).
By participating, you are expected to uphold this code.
|
huggingface/optimum/blob/main/CONTRIBUTING.md
|
--
title: "Hugging Face's TensorFlow Philosophy"
thumbnail: /blog/assets/96_tensorflow_philosophy/thumbnail.png
authors:
- user: rocketknight1
---
# Hugging Face's TensorFlow Philosophy
### Introduction
Despite increasing competition from PyTorch and JAX, TensorFlow remains [the most-used deep learning framework](https://twitter.com/fchollet/status/1478404084881190912?lang=en). It also differs from those other two libraries in some very important ways. In particular, it’s quite tightly integrated with its high-level API `Keras`, and its data loading library `tf.data`.
There is a tendency among PyTorch engineers (picture me staring darkly across the open-plan office here) to see this as a problem to be overcome; their goal is to figure out how to make TensorFlow get out of their way so they can use the low-level training and data-loading code they’re used to. This is entirely the wrong way to approach TensorFlow! Keras is a great high-level API. If you push it out of the way in any project bigger than a couple of modules you’ll end up reproducing most of its functionality yourself when you realize you need it.
As refined, respected and highly attractive TensorFlow engineers, we want to use the incredible power and flexibility of cutting-edge models, but we want to handle them with the tools and API we’re familiar with. This blogpost will be about the choices we make at Hugging Face to enable that, and what to expect from the framework as a TensorFlow programmer.
### Interlude: 30 Seconds to 🤗
Experienced users can feel free to skim or skip this section, but if this is your first encounter with Hugging Face and `transformers`, I should start by giving you an overview of the core idea of the library: You just ask for a pretrained model by name, and you get it in one line of code. The easiest way is to just use the `TFAutoModel` class:
```py
from transformers import TFAutoModel
model = TFAutoModel.from_pretrained("bert-base-cased")
```
This one line will instantiate the model architecture and load the weights, giving you an exact replica of the original, famous [BERT](https://arxiv.org/abs/1810.04805) model. This model won’t do much on its own, though - it lacks an output head or a loss function. In effect, it is the “stem” of a neural net that stops right after the last hidden layer. So how do you put an output head on it? Simple, just use a different `AutoModel` class. Here we load the [Vision Transformer (ViT)](https://arxiv.org/abs/2010.11929) model and add an image classification head:
```py
from transformers import TFAutoModelForImageClassification
model_name = "google/vit-base-patch16-224"
model = TFAutoModelForImageClassification.from_pretrained(model_name)
```
Now our `model` has an output head and, optionally, a loss function appropriate for its new task. If the new output head differs from the original model, then its weights will be randomly initialized. All other weights will be loaded from the original model. But why do we do this? Why would we use the stem of an existing model, instead of just making the model we need from scratch?
It turns out that large models pretrained on lots of data are much, much better starting points for almost any ML problem than the standard method of simply randomly initializing your weights. This is called **transfer learning**, and if you think about it, it makes sense - solving a textual task well requires some knowledge of language, and solving a visual task well requires some knowledge of images and space. The reason ML is so data-hungry without transfer learning is simply that this basic domain knowledge has to be relearned from scratch for every problem, which necessitates a huge volume of training examples. By using transfer learning, however, a problem can be solved with a thousand training examples that might have required a million without it, and often with a higher final accuracy. For more on this topic, check out the relevant sections of the [Hugging Face Course](https://www.youtube.com/watch?v=BqqfQnyjmgg)!
When using transfer learning, however, it's very important that you process inputs to the model the same way that they were processed during training. This ensures that the model has to relearn as little as possible when we transfer its knowledge to a new problem. In `transformers`, this preprocessing is often handled with **tokenizers**. Tokenizers can be loaded in the same way as models, using the `AutoTokenizer` class. Be sure that you load the tokenizer that matches the model you want to use!
```py
from transformers import TFAutoModel, AutoTokenizer
# Make sure to always load a matching tokenizer and model!
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
model = TFAutoModel.from_pretrained("bert-base-cased")
# Let's load some data and tokenize it
test_strings = ["This is a sentence!", "This is another one!"]
tokenized_inputs = tokenizer(test_strings, return_tensors="np", padding=True)
# Now our data is tokenized, we can pass it to our model, or use it in fit()!
outputs = model(tokenized_inputs)
```
This is just a taste of the library, of course - if you want more, you can check out our [notebooks](https://huggingface.co/docs/transformers/notebooks), or our [code examples](https://github.com/huggingface/transformers/tree/main/examples/tensorflow). There are also several other [examples of the library in action at keras.io](https://keras.io/examples/#natural-language-processing)!
At this point, you now understand some of the basic concepts and classes in `transformers`. Everything I’ve written above is framework-agnostic (with the exception of the “TF” in `TFAutoModel`), but when you want to actually train and serve your model, that’s when things will start to diverge between the frameworks. And that brings us to the main focus of this article: As a TensorFlow engineer, what should you expect from `transformers`?
#### Philosophy #1: All TensorFlow models should be Keras Model objects, and all TensorFlow layers should be Keras Layer objects.
This almost goes without saying for a TensorFlow library, but it’s worth emphasizing regardless. From the user’s perspective, the most important effect of this choice is that you can call Keras methods like `fit()`, `compile()` and `predict()` directly on our models.
For example, assuming your data is already prepared and tokenized, then getting predictions from a sequence classification model with TensorFlow is as simple as:
```py
model = TFAutoModelForSequenceClassification.from_pretrained(my_model)
model.predict(my_data)
```
And if you want to train that model instead, it's just:
```py
model.fit(my_data, my_labels)
```
However, this convenience doesn’t mean you’re limited to tasks that we support out of the box. Keras models can be composed as layers in other models, so if you have a giant galactic brain idea that involves splicing together five different models then there’s nothing stopping you, except possibly your limited GPU memory. Maybe you want to merge a pretrained language model with a pretrained vision transformer to create a hybrid, like [Deepmind’s recent Flamingo](https://arxiv.org/abs/2204.14198), or you want to create the next viral text-to-image sensation like ~Dall-E Mini~ [Craiyon](https://www.craiyon.com/)? Here's an example of a hybrid model using Keras [subclassing](https://www.tensorflow.org/guide/keras/custom_layers_and_models):
```py
class HybridVisionLanguageModel(tf.keras.Model):
def __init__(self):
super().__init__()
self.language = TFAutoModel.from_pretrained("gpt2")
self.vision = TFAutoModel.from_pretrained("google/vit-base-patch16-224")
def call(self, inputs):
# I have a truly wonderful idea for this
# which this code box is too short to contain
```
#### Philosophy #2: Loss functions are provided by default, but can be easily changed.
In Keras, the standard way to train a model is to create it, then `compile()` it with an optimizer and loss function, and finally `fit()` it. It’s very easy to load a model with transformers, but setting the loss function can be tricky - even for standard language model training, your loss function can be surprisingly non-obvious, and some hybrid models have extremely complex losses.
Our solution to that is simple: If you `compile()` without a loss argument, we’ll give you the one you probably wanted. Specifically, we’ll give you one that matches both your base model and output type - if you `compile()` a BERT-based masked language model without a loss, we’ll give you a masked language modelling loss that handles padding and masking correctly, and will only compute losses on corrupted tokens, exactly matching the original BERT training process. If for some reason you really, really don’t want your model to be compiled with any loss at all, then simply specify `loss=None` when compiling.
```py
model = TFAutoModelForQuestionAnswering.from_pretrained("bert-base-cased")
model.compile(optimizer="adam") # No loss argument!
model.fit(my_data, my_labels)
```
But also, and very importantly, we want to get out of your way as soon as you want to do something more complex. If you specify a loss argument to `compile()`, then the model will use that instead of the default loss. And, of course, if you make your own subclassed model like the `HybridVisionLanguageModel` above, then you have complete control over every aspect of the model’s functionality via the `call()` and `train_step()` methods you write.
#### ~Philosophy~ Implementation Detail #3: Labels are flexible
One source of confusion in the past was where exactly labels should be passed to the model. The standard way to pass labels to a Keras model is as a separate argument, or as part of an (inputs, labels) tuple:
```py
model.fit(inputs, labels)
```
In the past, we instead asked users to pass labels in the input dict when using the default loss. The reason for this was that the code for computing the loss for that particular model was contained in the `call()` forward pass method. This worked, but it was definitely non-standard for Keras models, and caused several issues including incompatibilities with standard Keras metrics, not to mention some user confusion. Thankfully, this is no longer necessary. We now recommend that labels are passed in the normal Keras way, although the old method still works for backward compatibility reasons. In general, a lot of things that used to be fiddly should now “just work” for our TensorFlow models - give them a try!
#### Philosophy #4: You shouldn’t have to write your own data pipeline, especially for common tasks
In addition to `transformers`, a huge open repository of pre-trained models, there is also 🤗 `datasets`, a huge open repository of datasets - text, vision, audio and more. These datasets convert easily to TensorFlow Tensors and Numpy arrays, making it easy to use them as training data. Here’s a quick example showing us tokenizing a dataset and converting it to Numpy. As always, make sure your tokenizer matches the model you want to train with, or things will get very weird!
```py
from datasets import load_dataset
from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
from tensorflow.keras.optimizers import Adam
dataset = load_dataset("glue", "cola") # Simple text classification dataset
dataset = dataset["train"] # Just take the training split for now
# Load our tokenizer and tokenize our data
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
tokenized_data = tokenizer(dataset["text"], return_tensors="np", padding=True)
labels = np.array(dataset["label"]) # Label is already an array of 0 and 1
# Load and compile our model
model = TFAutoModelForSequenceClassification.from_pretrained("bert-base-cased")
# Lower learning rates are often better for fine-tuning transformers
model.compile(optimizer=Adam(3e-5))
model.fit(tokenized_data, labels)
```
This approach is great when it works, but for larger datasets you might find it starting to become a problem. Why? Because the tokenized array and labels would have to be fully loaded into memory, and because Numpy doesn’t handle “jagged” arrays, so every tokenized sample would have to be padded to the length of the longest sample in the whole dataset. That’s going to make your array even bigger, and all those padding tokens will slow down training too!
As a TensorFlow engineer, this is normally where you’d turn to `tf.data` to make a pipeline that will stream the data from storage rather than loading it all into memory. That’s a hassle, though, so we’ve got you. First, let’s use the `map()` method to add the tokenizer columns to the dataset. Remember that our datasets are disc-backed by default - they won’t load into memory until you convert them into arrays!
```py
def tokenize_dataset(data):
# Keys of the returned dictionary will be added to the dataset as columns
return tokenizer(data["text"])
dataset = dataset.map(tokenize_dataset)
```
Now our dataset has the columns we want, but how do we train on it? Simple - wrap it with a `tf.data.Dataset` and all our problems are solved - data is loaded on-the-fly, and padding is applied only to batches rather than the whole dataset, which means that we need way fewer padding tokens:
```py
tf_dataset = model.prepare_tf_dataset(
dataset,
batch_size=16,
shuffle=True
)
model.fit(tf_dataset)
```
Why is [prepare_tf_dataset()](https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.TFPreTrainedModel.prepare_tf_dataset) a method on your model? Simple: Because your model knows which columns are valid as inputs, and automatically filters out columns in the dataset that aren't valid input names! If you’d rather have more precise control over the `tf.data.Dataset` being created, you can use the lower level [Dataset.to_tf_dataset()](https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.Dataset.to_tf_dataset) instead.
#### Philosophy #5: XLA is great!
[XLA](https://www.tensorflow.org/xla) is the just-in-time compiler shared by TensorFlow and JAX. It converts linear algebra code into more optimized versions that run quicker and use less memory. It’s really cool and we try to make sure that we support it as much as possible. It’s extremely important for allowing models to be run on TPU, but it offers speed boosts for GPU and even CPU as well! To use it, simply `compile()` your model with the `jit_compile=True` argument (this works for all Keras models, not just Hugging Face ones):
```py
model.compile(optimizer="adam", jit_compile=True)
```
We’ve made a number of major improvements recently in this area. Most significantly, we’ve updated our `generate()` code to use XLA - this is a function that iteratively generates text output from language models. This has resulted in massive performance improvements - our legacy TF code was much slower than PyTorch, but the new code is much faster than it, and similar to JAX in speed! For more information, please see [our blogpost about XLA generation](https://huggingface.co/blog/tf-xla-generate).
XLA is useful for things besides generation too, though! We’ve also made a number of fixes to ensure that you can train your models with XLA, and as a result our TF models have reached JAX-like speeds for tasks like language model training.
It’s important to be clear about the major limitation of XLA, though: XLA expects input shapes to be static. This means that if your task involves variable sequence lengths, you will need to run a new XLA compilation for each different input shape you pass to your model, which can really negate the performance benefits! You can see some examples of how we deal with this in our [TensorFlow notebooks](https://huggingface.co/docs/transformers/notebooks) and in the XLA generation blogpost above.
#### Philosophy #6: Deployment is just as important as training
TensorFlow has a rich ecosystem, particularly around model deployment, that the other more research-focused frameworks lack. We’re actively working on letting you use those tools to deploy your whole model for inference. We're particularly interested in supporting `TF Serving` and `TFX`. If this is interesting to you, please check out [our blogpost on deploying models with TF Serving](https://huggingface.co/blog/tf-serving-vision)!
One major obstacle in deploying NLP models, however, is that inputs will still need to be tokenized, which means it isn't enough to just deploy your model. A dependency on `tokenizers` can be annoying in a lot of deployment scenarios, and so we're working to make it possible to embed tokenization into your model itself, allowing you to deploy just a single model artifact to handle the whole pipeline from input strings to output predictions. Right now, we only support the most common models like BERT, but this is an active area of work! If you want to try it, though, you can use a code snippet like this:
```py
# This is a new feature, so make sure to update to the latest version of transformers!
# You will also need to pip install tensorflow_text
import tensorflow as tf
from transformers import TFAutoModel, TFBertTokenizer
class EndToEndModel(tf.keras.Model):
def __init__(self, checkpoint):
super().__init__()
self.tokenizer = TFBertTokenizer.from_pretrained(checkpoint)
self.model = TFAutoModel.from_pretrained(checkpoint)
def call(self, inputs):
tokenized = self.tokenizer(inputs)
return self.model(**tokenized)
model = EndToEndModel(checkpoint="bert-base-cased")
test_inputs = [
"This is a test sentence!",
"This is another one!",
]
model.predict(test_inputs) # Pass strings straight to model!
```
#### Conclusion: We’re an open-source project, and that means community is everything
Made a cool model? Share it! Once you’ve [made an account and set your credentials](https://huggingface.co/docs/transformers/main/en/model_sharing) it’s as easy as:
```py
model_name = "google/vit-base-patch16-224"
model = TFAutoModelForImageClassification.from_pretrained(model_name)
model.fit(my_data, my_labels)
model.push_to_hub("my-new-model")
```
You can also use the [PushToHubCallback](https://huggingface.co/docs/transformers/main_classes/keras_callbacks#transformers.PushToHubCallback) to upload checkpoints regularly during a longer training run! Either way, you’ll get a model page and an autogenerated model card, and most importantly of all, anyone else can use your model to get predictions, or as a starting point for further training, using exactly the same API as they use to load any existing model:
```py
model_name = "your-username/my-new-model"
model = TFAutoModelForImageClassification.from_pretrained(model_name)
```
I think the fact that there’s no distinction between big famous foundation models and models fine-tuned by a single user exemplifies the core belief at Hugging Face - the power of users to build great things. Machine learning was never meant to be a trickle of results from closed models held at a rarefied few companies; it should be a collection of open tools, artifacts, practices and knowledge that’s constantly being expanded, tested, critiqued and built upon - a bazaar, not a cathedral. If you hit upon a new idea, a new method, or you train a new model with great results, let everyone know!
And, in a similar vein, are there things you’re missing? Bugs? Annoyances? Things that should be intuitive but aren’t? Let us know! If you’re willing to get a (metaphorical) shovel and start fixing it, that’s even better, but don’t be shy to speak up even if you don’t have the time or skillset to improve the codebase yourself. Often, the core maintainers can miss problems because users don’t bring them up, so don’t assume that we must be aware of something! If it’s bothering you, please [ask on the forums](https://discuss.huggingface.co/), or if you’re pretty sure it’s a bug or a missing important feature, then [file an issue](https://github.com/huggingface/transformers).
A lot of these things are small details, sure, but to coin a (rather clunky) phrase, great software is made from thousands of small commits. It’s through the constant collective effort of users and maintainers that open-source software improves. Machine learning is going to be a major societal issue in the 2020s, and the strength of open-source software and communities will determine whether it becomes an open and democratic force open to critique and re-evaluation, or whether it is dominated by giant black-box models whose owners will not allow outsiders, even those whom the models make decisions about, to see their precious proprietary weights. So don’t be shy - if something’s wrong, if you have an idea for how it could be done better, if you want to contribute but don’t know where, then tell us!
<small>(And if you can make a meme to troll the PyTorch team with after your cool new feature is merged, all the better.)</small>
|
huggingface/blog/blob/main/tensorflow-philosophy.md
|
Gradio Demo: code
```
!pip install -q gradio
```
```
# Downloading files from the demo repo
import os
!wget -q https://github.com/gradio-app/gradio/raw/main/demo/code/file.css
```
```
import gradio as gr
import os
from time import sleep
css_file = os.path.join(os.path.abspath(''), "file.css")
def set_lang(language):
print(language)
return gr.Code(language=language)
def set_lang_from_path():
sleep(1)
return gr.Code((css_file,), language="css")
def code(language, code):
return gr.Code(code, language=language)
io = gr.Interface(lambda x: x, "code", "code")
with gr.Blocks() as demo:
lang = gr.Dropdown(value="python", choices=gr.Code.languages)
with gr.Row():
code_in = gr.Code(
language="python",
label="Input",
value='def all_odd_elements(sequence):\n """Returns every odd element of the sequence."""',
)
code_out = gr.Code(label="Output")
btn = gr.Button("Run")
btn_two = gr.Button("Load File")
lang.change(set_lang, inputs=lang, outputs=code_in)
btn.click(code, inputs=[lang, code_in], outputs=code_out)
btn_two.click(set_lang_from_path, inputs=None, outputs=code_out)
io.render()
if __name__ == "__main__":
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/code/run.ipynb
|
Reactive Interfaces
Finally, we cover how to get Gradio demos to refresh automatically or continuously stream data.
## Live Interfaces
You can make interfaces automatically refresh by setting `live=True` in the interface. Now the interface will recalculate as soon as the user input changes.
$code_calculator_live
$demo_calculator_live
Note there is no submit button, because the interface resubmits automatically on change.
## Streaming Components
Some components have a "streaming" mode, such as `Audio` component in microphone mode, or the `Image` component in webcam mode. Streaming means data is sent continuously to the backend and the `Interface` function is continuously being rerun.
The difference between `gr.Audio(source='microphone')` and `gr.Audio(source='microphone', streaming=True)`, when both are used in `gr.Interface(live=True)`, is that the first `Component` will automatically submit data and run the `Interface` function when the user stops recording, whereas the second `Component` will continuously send data and run the `Interface` function _during_ recording.
Here is example code of streaming images from the webcam.
$code_stream_frames
Streaming can also be done in an output component. A `gr.Audio(streaming=True)` output component can take a stream of audio data yielded piece-wise by a generator function and combines them into a single audio file.
$code_stream_audio_out
For a more detailed example, see our guide on performing [automatic speech recognition](/guides/real-time-speech-recognition) with Gradio.
|
gradio-app/gradio/blob/main/guides/02_building-interfaces/04_reactive-interfaces.md
|
`tokenizers-linux-arm-gnueabihf`
This is the **armv7-unknown-linux-gnueabihf** binary for `tokenizers`
|
huggingface/tokenizers/blob/main/bindings/node/npm/linux-arm-gnueabihf/README.md
|
!---
Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Examples
This folder contains actively maintained examples of the use of 🤗 Transformers organized into different ML tasks. All examples in this folder are **TensorFlow** examples and are written using native Keras rather than classes like `TFTrainer`, which we now consider deprecated. If you've previously only used 🤗 Transformers via `TFTrainer`, we highly recommend taking a look at the new style - we think it's a big improvement!
In addition, all scripts here now support the [🤗 Datasets](https://github.com/huggingface/datasets) library - you can grab entire datasets just by changing one command-line argument!
## A note on code folding
Most of these examples have been formatted with #region blocks. In IDEs such as PyCharm and VSCode, these blocks mark
named regions of code that can be folded for easier viewing. If you find any of these scripts overwhelming or difficult
to follow, we highly recommend beginning with all regions folded and then examining regions one at a time!
## The Big Table of Tasks
Here is the list of all our examples:
| Task | Example datasets |
|---|---|
| [**`language-modeling`**](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling) | WikiText-2
| [**`multiple-choice`**](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/multiple-choice) | SWAG
| [**`question-answering`**](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/question-answering) | SQuAD
| [**`summarization`**](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization) | XSum
| [**`text-classification`**](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/text-classification) | GLUE
| [**`token-classification`**](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/token-classification) | CoNLL NER
| [**`translation`**](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/translation) | WMT
## Coming soon
- **Colab notebooks** to easily run through these scripts!
|
huggingface/transformers/blob/main/examples/tensorflow/README.md
|
Patience-based Early Exit
Patience-based Early Exit (PABEE) is a plug-and-play inference method for pretrained language models.
We have already implemented it on BERT and ALBERT. Basically, you can make your LM faster and more robust with PABEE. It can even improve the performance of ALBERT on GLUE. The only sacrifice is that the batch size can only be 1.
Learn more in the paper ["BERT Loses Patience: Fast and Robust Inference with Early Exit"](https://arxiv.org/abs/2006.04152) and the official [GitHub repo](https://github.com/JetRunner/PABEE).

## Training
You can fine-tune a pretrained language model (you can choose from BERT and ALBERT) and train the internal classifiers by:
```bash
export GLUE_DIR=/path/to/glue_data
export TASK_NAME=MRPC
python ./run_glue_with_pabee.py \
--model_type albert \
--model_name_or_path bert-base-uncased/albert-base-v2 \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--do_lower_case \
--data_dir "$GLUE_DIR/$TASK_NAME" \
--max_seq_length 128 \
--per_gpu_train_batch_size 32 \
--per_gpu_eval_batch_size 32 \
--learning_rate 2e-5 \
--save_steps 50 \
--logging_steps 50 \
--num_train_epochs 5 \
--output_dir /path/to/save/ \
--evaluate_during_training
```
## Inference
You can inference with different patience settings by:
```bash
export GLUE_DIR=/path/to/glue_data
export TASK_NAME=MRPC
python ./run_glue_with_pabee.py \
--model_type albert \
--model_name_or_path /path/to/save/ \
--task_name $TASK_NAME \
--do_eval \
--do_lower_case \
--data_dir "$GLUE_DIR/$TASK_NAME" \
--max_seq_length 128 \
--per_gpu_eval_batch_size 1 \
--learning_rate 2e-5 \
--logging_steps 50 \
--num_train_epochs 15 \
--output_dir /path/to/save/ \
--eval_all_checkpoints \
--patience 3,4,5,6,7,8
```
where `patience` can be a list of patience settings, separated by a comma. It will help determine which patience works best.
When evaluating on a regression task (STS-B), you may add `--regression_threshold 0.1` to define the regression threshold.
## Results
On the GLUE dev set:
| Model | \#Param | Speed | CoLA | MNLI | MRPC | QNLI | QQP | RTE | SST\-2 | STS\-B |
|--------------|---------|--------|-------|-------|-------|-------|-------|-------|--------|--------|
| ALBERT\-base | 12M | | 58\.9 | 84\.6 | 89\.5 | 91\.7 | 89\.6 | 78\.6 | 92\.8 | 89\.5 |
| \+PABEE | 12M | 1\.57x | 61\.2 | 85\.1 | 90\.0 | 91\.8 | 89\.6 | 80\.1 | 93\.0 | 90\.1 |
| Model | \#Param | Speed\-up | MNLI | SST\-2 | STS\-B |
|---------------|---------|-----------|-------|--------|--------|
| BERT\-base | 108M | | 84\.5 | 92\.1 | 88\.9 |
| \+PABEE | 108M | 1\.62x | 83\.6 | 92\.0 | 88\.7 |
| ALBERT\-large | 18M | | 86\.4 | 94\.9 | 90\.4 |
| \+PABEE | 18M | 2\.42x | 86\.8 | 95\.2 | 90\.6 |
## Citation
If you find this resource useful, please consider citing the following paper:
```bibtex
@misc{zhou2020bert,
title={BERT Loses Patience: Fast and Robust Inference with Early Exit},
author={Wangchunshu Zhou and Canwen Xu and Tao Ge and Julian McAuley and Ke Xu and Furu Wei},
year={2020},
eprint={2006.04152},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
huggingface/transformers/blob/main/examples/research_projects/bert-loses-patience/README.md
|
`@gradio/theme`
css for gradio
|
gradio-app/gradio/blob/main/js/theme/README.md
|
Gradio Demo: chatbot_simple
```
!pip install -q gradio
```
```
import gradio as gr
import random
import time
with gr.Blocks() as demo:
chatbot = gr.Chatbot()
msg = gr.Textbox()
clear = gr.ClearButton([msg, chatbot])
def respond(message, chat_history):
bot_message = random.choice(["How are you?", "I love you", "I'm very hungry"])
chat_history.append((message, bot_message))
time.sleep(2)
return "", chat_history
msg.submit(respond, [msg, chatbot], [msg, chatbot])
if __name__ == "__main__":
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/chatbot_simple/run.ipynb
|
his sentiment analaysis demo takes in input text and returns its classification for either positive, negative or neutral using Gradio's Label output.
|
gradio-app/gradio/blob/main/demo/sentiment_analysis/DESCRIPTION.md
|
Introduction [[introduction]]
In this bonus unit, we'll reinforce what we learned in the first unit by teaching Huggy the Dog to fetch the stick and then [play with him directly in your browser](https://huggingface.co/spaces/ThomasSimonini/Huggy) 🐶
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit2/thumbnail.png" alt="Unit bonus 1 thumbnail" width="100%">
So let's get started 🚀
|
huggingface/deep-rl-class/blob/main/units/en/unitbonus1/introduction.mdx
|
Long Form Question Answering
Author: @yjernite
This folder contains the code for the Long Form Question answering [demo](http://35.226.96.115:8080/) as well as methods to train and use a fully end-to-end Long Form Question Answering system using the [🤗transformers](https://github.com/huggingface/transformers) and [🤗datasets](https://github.com/huggingface/datasets) libraries.
You can use these methods to train your own system by following along the associate [notebook](https://github.com/huggingface/notebooks/blob/master/longform-qa/Long_Form_Question_Answering_with_ELI5_and_Wikipedia.ipynb) or [blog post](https://yjernite.github.io/lfqa.html).
|
huggingface/transformers/blob/main/examples/research_projects/longform-qa/README.md
|
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# DeiT
## Overview
The DeiT model was proposed in [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre
Sablayrolles, Hervé Jégou. The [Vision Transformer (ViT)](vit) introduced in [Dosovitskiy et al., 2020](https://arxiv.org/abs/2010.11929) has shown that one can match or even outperform existing convolutional neural
networks using a Transformer encoder (BERT-like). However, the ViT models introduced in that paper required training on
expensive infrastructure for multiple weeks, using external data. DeiT (data-efficient image transformers) are more
efficiently trained transformers for image classification, requiring far less data and far less computing resources
compared to the original ViT models.
The abstract from the paper is the following:
*Recently, neural networks purely based on attention were shown to address image understanding tasks such as image
classification. However, these visual transformers are pre-trained with hundreds of millions of images using an
expensive infrastructure, thereby limiting their adoption. In this work, we produce a competitive convolution-free
transformer by training on Imagenet only. We train them on a single computer in less than 3 days. Our reference vision
transformer (86M parameters) achieves top-1 accuracy of 83.1% (single-crop evaluation) on ImageNet with no external
data. More importantly, we introduce a teacher-student strategy specific to transformers. It relies on a distillation
token ensuring that the student learns from the teacher through attention. We show the interest of this token-based
distillation, especially when using a convnet as a teacher. This leads us to report results competitive with convnets
for both Imagenet (where we obtain up to 85.2% accuracy) and when transferring to other tasks. We share our code and
models.*
This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version of this model was added by [amyeroberts](https://huggingface.co/amyeroberts).
## Usage tips
- Compared to ViT, DeiT models use a so-called distillation token to effectively learn from a teacher (which, in the
DeiT paper, is a ResNet like-model). The distillation token is learned through backpropagation, by interacting with
the class ([CLS]) and patch tokens through the self-attention layers.
- There are 2 ways to fine-tune distilled models, either (1) in a classic way, by only placing a prediction head on top
of the final hidden state of the class token and not using the distillation signal, or (2) by placing both a
prediction head on top of the class token and on top of the distillation token. In that case, the [CLS] prediction
head is trained using regular cross-entropy between the prediction of the head and the ground-truth label, while the
distillation prediction head is trained using hard distillation (cross-entropy between the prediction of the
distillation head and the label predicted by the teacher). At inference time, one takes the average prediction
between both heads as final prediction. (2) is also called "fine-tuning with distillation", because one relies on a
teacher that has already been fine-tuned on the downstream dataset. In terms of models, (1) corresponds to
[`DeiTForImageClassification`] and (2) corresponds to
[`DeiTForImageClassificationWithTeacher`].
- Note that the authors also did try soft distillation for (2) (in which case the distillation prediction head is
trained using KL divergence to match the softmax output of the teacher), but hard distillation gave the best results.
- All released checkpoints were pre-trained and fine-tuned on ImageNet-1k only. No external data was used. This is in
contrast with the original ViT model, which used external data like the JFT-300M dataset/Imagenet-21k for
pre-training.
- The authors of DeiT also released more efficiently trained ViT models, which you can directly plug into
[`ViTModel`] or [`ViTForImageClassification`]. Techniques like data
augmentation, optimization, and regularization were used in order to simulate training on a much larger dataset
(while only using ImageNet-1k for pre-training). There are 4 variants available (in 3 different sizes):
*facebook/deit-tiny-patch16-224*, *facebook/deit-small-patch16-224*, *facebook/deit-base-patch16-224* and
*facebook/deit-base-patch16-384*. Note that one should use [`DeiTImageProcessor`] in order to
prepare images for the model.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DeiT.
<PipelineTag pipeline="image-classification"/>
- [`DeiTForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
Besides that:
- [`DeiTForMaskedImageModeling`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining).
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## DeiTConfig
[[autodoc]] DeiTConfig
## DeiTFeatureExtractor
[[autodoc]] DeiTFeatureExtractor
- __call__
## DeiTImageProcessor
[[autodoc]] DeiTImageProcessor
- preprocess
<frameworkcontent>
<pt>
## DeiTModel
[[autodoc]] DeiTModel
- forward
## DeiTForMaskedImageModeling
[[autodoc]] DeiTForMaskedImageModeling
- forward
## DeiTForImageClassification
[[autodoc]] DeiTForImageClassification
- forward
## DeiTForImageClassificationWithTeacher
[[autodoc]] DeiTForImageClassificationWithTeacher
- forward
</pt>
<tf>
## TFDeiTModel
[[autodoc]] TFDeiTModel
- call
## TFDeiTForMaskedImageModeling
[[autodoc]] TFDeiTForMaskedImageModeling
- call
## TFDeiTForImageClassification
[[autodoc]] TFDeiTForImageClassification
- call
## TFDeiTForImageClassificationWithTeacher
[[autodoc]] TFDeiTForImageClassificationWithTeacher
- call
</tf>
</frameworkcontent>
|
huggingface/transformers/blob/main/docs/source/en/model_doc/deit.md
|
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# MobileViT
## Overview
The MobileViT model was proposed in [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari. MobileViT introduces a new layer that replaces local processing in convolutions with global processing using transformers.
The abstract from the paper is the following:
*Light-weight convolutional neural networks (CNNs) are the de-facto for mobile vision tasks. Their spatial inductive biases allow them to learn representations with fewer parameters across different vision tasks. However, these networks are spatially local. To learn global representations, self-attention-based vision trans-formers (ViTs) have been adopted. Unlike CNNs, ViTs are heavy-weight. In this paper, we ask the following question: is it possible to combine the strengths of CNNs and ViTs to build a light-weight and low latency network for mobile vision tasks? Towards this end, we introduce MobileViT, a light-weight and general-purpose vision transformer for mobile devices. MobileViT presents a different perspective for the global processing of information with transformers, i.e., transformers as convolutions. Our results show that MobileViT significantly outperforms CNN- and ViT-based networks across different tasks and datasets. On the ImageNet-1k dataset, MobileViT achieves top-1 accuracy of 78.4% with about 6 million parameters, which is 3.2% and 6.2% more accurate than MobileNetv3 (CNN-based) and DeIT (ViT-based) for a similar number of parameters. On the MS-COCO object detection task, MobileViT is 5.7% more accurate than MobileNetv3 for a similar number of parameters.*
This model was contributed by [matthijs](https://huggingface.co/Matthijs). The TensorFlow version of the model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code and weights can be found [here](https://github.com/apple/ml-cvnets).
## Usage tips
- MobileViT is more like a CNN than a Transformer model. It does not work on sequence data but on batches of images. Unlike ViT, there are no embeddings. The backbone model outputs a feature map. You can follow [this tutorial](https://keras.io/examples/vision/mobilevit) for a lightweight introduction.
- One can use [`MobileViTImageProcessor`] to prepare images for the model. Note that if you do your own preprocessing, the pretrained checkpoints expect images to be in BGR pixel order (not RGB).
- The available image classification checkpoints are pre-trained on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k) (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes).
- The segmentation model uses a [DeepLabV3](https://arxiv.org/abs/1706.05587) head. The available semantic segmentation checkpoints are pre-trained on [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/).
- As the name suggests MobileViT was designed to be performant and efficient on mobile phones. The TensorFlow versions of the MobileViT models are fully compatible with [TensorFlow Lite](https://www.tensorflow.org/lite).
You can use the following code to convert a MobileViT checkpoint (be it image classification or semantic segmentation) to generate a
TensorFlow Lite model:
```py
from transformers import TFMobileViTForImageClassification
import tensorflow as tf
model_ckpt = "apple/mobilevit-xx-small"
model = TFMobileViTForImageClassification.from_pretrained(model_ckpt)
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS,
tf.lite.OpsSet.SELECT_TF_OPS,
]
tflite_model = converter.convert()
tflite_filename = model_ckpt.split("/")[-1] + ".tflite"
with open(tflite_filename, "wb") as f:
f.write(tflite_model)
```
The resulting model will be just **about an MB** making it a good fit for mobile applications where resources and network
bandwidth can be constrained.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with MobileViT.
<PipelineTag pipeline="image-classification"/>
- [`MobileViTForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
**Semantic segmentation**
- [Semantic segmentation task guide](../tasks/semantic_segmentation)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## MobileViTConfig
[[autodoc]] MobileViTConfig
## MobileViTFeatureExtractor
[[autodoc]] MobileViTFeatureExtractor
- __call__
- post_process_semantic_segmentation
## MobileViTImageProcessor
[[autodoc]] MobileViTImageProcessor
- preprocess
- post_process_semantic_segmentation
<frameworkcontent>
<pt>
## MobileViTModel
[[autodoc]] MobileViTModel
- forward
## MobileViTForImageClassification
[[autodoc]] MobileViTForImageClassification
- forward
## MobileViTForSemanticSegmentation
[[autodoc]] MobileViTForSemanticSegmentation
- forward
</pt>
<tf>
## TFMobileViTModel
[[autodoc]] TFMobileViTModel
- call
## TFMobileViTForImageClassification
[[autodoc]] TFMobileViTForImageClassification
- call
## TFMobileViTForSemanticSegmentation
[[autodoc]] TFMobileViTForSemanticSegmentation
- call
</tf>
</frameworkcontent>
|
huggingface/transformers/blob/main/docs/source/en/model_doc/mobilevit.md
|
`tokenizers-linux-arm64-gnu`
This is the **aarch64-unknown-linux-gnu** binary for `tokenizers`
|
huggingface/tokenizers/blob/main/bindings/node/npm/linux-arm64-gnu/README.md
|
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Question answering
[[open-in-colab]]
<Youtube id="ajPx5LwJD-I"/>
Question answering tasks return an answer given a question. If you've ever asked a virtual assistant like Alexa, Siri or Google what the weather is, then you've used a question answering model before. There are two common types of question answering tasks:
- Extractive: extract the answer from the given context.
- Abstractive: generate an answer from the context that correctly answers the question.
This guide will show you how to:
1. Finetune [DistilBERT](https://huggingface.co/distilbert-base-uncased) on the [SQuAD](https://huggingface.co/datasets/squad) dataset for extractive question answering.
2. Use your finetuned model for inference.
<Tip>
The task illustrated in this tutorial is supported by the following model architectures:
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
[ALBERT](../model_doc/albert), [BART](../model_doc/bart), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CANINE](../model_doc/canine), [ConvBERT](../model_doc/convbert), [Data2VecText](../model_doc/data2vec-text), [DeBERTa](../model_doc/deberta), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ErnieM](../model_doc/ernie_m), [Falcon](../model_doc/falcon), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [OpenAI GPT-2](../model_doc/gpt2), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT-J](../model_doc/gptj), [I-BERT](../model_doc/ibert), [LayoutLMv2](../model_doc/layoutlmv2), [LayoutLMv3](../model_doc/layoutlmv3), [LED](../model_doc/led), [LiLT](../model_doc/lilt), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [LXMERT](../model_doc/lxmert), [MarkupLM](../model_doc/markuplm), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [MPT](../model_doc/mpt), [MRA](../model_doc/mra), [MT5](../model_doc/mt5), [MVP](../model_doc/mvp), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [OPT](../model_doc/opt), [QDQBert](../model_doc/qdqbert), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [Splinter](../model_doc/splinter), [SqueezeBERT](../model_doc/squeezebert), [T5](../model_doc/t5), [UMT5](../model_doc/umt5), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
<!--End of the generated tip-->
</Tip>
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers datasets evaluate
```
We encourage you to login to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to login:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Load SQuAD dataset
Start by loading a smaller subset of the SQuAD dataset from the 🤗 Datasets library. This'll give you a chance to experiment and make sure everything works before spending more time training on the full dataset.
```py
>>> from datasets import load_dataset
>>> squad = load_dataset("squad", split="train[:5000]")
```
Split the dataset's `train` split into a train and test set with the [`~datasets.Dataset.train_test_split`] method:
```py
>>> squad = squad.train_test_split(test_size=0.2)
```
Then take a look at an example:
```py
>>> squad["train"][0]
{'answers': {'answer_start': [515], 'text': ['Saint Bernadette Soubirous']},
'context': 'Architecturally, the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend "Venite Ad Me Omnes". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.',
'id': '5733be284776f41900661182',
'question': 'To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?',
'title': 'University_of_Notre_Dame'
}
```
There are several important fields here:
- `answers`: the starting location of the answer token and the answer text.
- `context`: background information from which the model needs to extract the answer.
- `question`: the question a model should answer.
## Preprocess
<Youtube id="qgaM0weJHpA"/>
The next step is to load a DistilBERT tokenizer to process the `question` and `context` fields:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
```
There are a few preprocessing steps particular to question answering tasks you should be aware of:
1. Some examples in a dataset may have a very long `context` that exceeds the maximum input length of the model. To deal with longer sequences, truncate only the `context` by setting `truncation="only_second"`.
2. Next, map the start and end positions of the answer to the original `context` by setting
`return_offset_mapping=True`.
3. With the mapping in hand, now you can find the start and end tokens of the answer. Use the [`~tokenizers.Encoding.sequence_ids`] method to
find which part of the offset corresponds to the `question` and which corresponds to the `context`.
Here is how you can create a function to truncate and map the start and end tokens of the `answer` to the `context`:
```py
>>> def preprocess_function(examples):
... questions = [q.strip() for q in examples["question"]]
... inputs = tokenizer(
... questions,
... examples["context"],
... max_length=384,
... truncation="only_second",
... return_offsets_mapping=True,
... padding="max_length",
... )
... offset_mapping = inputs.pop("offset_mapping")
... answers = examples["answers"]
... start_positions = []
... end_positions = []
... for i, offset in enumerate(offset_mapping):
... answer = answers[i]
... start_char = answer["answer_start"][0]
... end_char = answer["answer_start"][0] + len(answer["text"][0])
... sequence_ids = inputs.sequence_ids(i)
... # Find the start and end of the context
... idx = 0
... while sequence_ids[idx] != 1:
... idx += 1
... context_start = idx
... while sequence_ids[idx] == 1:
... idx += 1
... context_end = idx - 1
... # If the answer is not fully inside the context, label it (0, 0)
... if offset[context_start][0] > end_char or offset[context_end][1] < start_char:
... start_positions.append(0)
... end_positions.append(0)
... else:
... # Otherwise it's the start and end token positions
... idx = context_start
... while idx <= context_end and offset[idx][0] <= start_char:
... idx += 1
... start_positions.append(idx - 1)
... idx = context_end
... while idx >= context_start and offset[idx][1] >= end_char:
... idx -= 1
... end_positions.append(idx + 1)
... inputs["start_positions"] = start_positions
... inputs["end_positions"] = end_positions
... return inputs
```
To apply the preprocessing function over the entire dataset, use 🤗 Datasets [`~datasets.Dataset.map`] function. You can speed up the `map` function by setting `batched=True` to process multiple elements of the dataset at once. Remove any columns you don't need:
```py
>>> tokenized_squad = squad.map(preprocess_function, batched=True, remove_columns=squad["train"].column_names)
```
Now create a batch of examples using [`DefaultDataCollator`]. Unlike other data collators in 🤗 Transformers, the [`DefaultDataCollator`] does not apply any additional preprocessing such as padding.
<frameworkcontent>
<pt>
```py
>>> from transformers import DefaultDataCollator
>>> data_collator = DefaultDataCollator()
```
</pt>
<tf>
```py
>>> from transformers import DefaultDataCollator
>>> data_collator = DefaultDataCollator(return_tensors="tf")
```
</tf>
</frameworkcontent>
## Train
<frameworkcontent>
<pt>
<Tip>
If you aren't familiar with finetuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#train-with-pytorch-trainer)!
</Tip>
You're ready to start training your model now! Load DistilBERT with [`AutoModelForQuestionAnswering`]:
```py
>>> from transformers import AutoModelForQuestionAnswering, TrainingArguments, Trainer
>>> model = AutoModelForQuestionAnswering.from_pretrained("distilbert-base-uncased")
```
At this point, only three steps remain:
1. Define your training hyperparameters in [`TrainingArguments`]. The only required parameter is `output_dir` which specifies where to save your model. You'll push this model to the Hub by setting `push_to_hub=True` (you need to be signed in to Hugging Face to upload your model).
2. Pass the training arguments to [`Trainer`] along with the model, dataset, tokenizer, and data collator.
3. Call [`~Trainer.train`] to finetune your model.
```py
>>> training_args = TrainingArguments(
... output_dir="my_awesome_qa_model",
... evaluation_strategy="epoch",
... learning_rate=2e-5,
... per_device_train_batch_size=16,
... per_device_eval_batch_size=16,
... num_train_epochs=3,
... weight_decay=0.01,
... push_to_hub=True,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=tokenized_squad["train"],
... eval_dataset=tokenized_squad["test"],
... tokenizer=tokenizer,
... data_collator=data_collator,
... )
>>> trainer.train()
```
Once training is completed, share your model to the Hub with the [`~transformers.Trainer.push_to_hub`] method so everyone can use your model:
```py
>>> trainer.push_to_hub()
```
</pt>
<tf>
<Tip>
If you aren't familiar with finetuning a model with Keras, take a look at the basic tutorial [here](../training#train-a-tensorflow-model-with-keras)!
</Tip>
To finetune a model in TensorFlow, start by setting up an optimizer function, learning rate schedule, and some training hyperparameters:
```py
>>> from transformers import create_optimizer
>>> batch_size = 16
>>> num_epochs = 2
>>> total_train_steps = (len(tokenized_squad["train"]) // batch_size) * num_epochs
>>> optimizer, schedule = create_optimizer(
... init_lr=2e-5,
... num_warmup_steps=0,
... num_train_steps=total_train_steps,
... )
```
Then you can load DistilBERT with [`TFAutoModelForQuestionAnswering`]:
```py
>>> from transformers import TFAutoModelForQuestionAnswering
>>> model = TFAutoModelForQuestionAnswering("distilbert-base-uncased")
```
Convert your datasets to the `tf.data.Dataset` format with [`~transformers.TFPreTrainedModel.prepare_tf_dataset`]:
```py
>>> tf_train_set = model.prepare_tf_dataset(
... tokenized_squad["train"],
... shuffle=True,
... batch_size=16,
... collate_fn=data_collator,
... )
>>> tf_validation_set = model.prepare_tf_dataset(
... tokenized_squad["test"],
... shuffle=False,
... batch_size=16,
... collate_fn=data_collator,
... )
```
Configure the model for training with [`compile`](https://keras.io/api/models/model_training_apis/#compile-method):
```py
>>> import tensorflow as tf
>>> model.compile(optimizer=optimizer)
```
The last thing to setup before you start training is to provide a way to push your model to the Hub. This can be done by specifying where to push your model and tokenizer in the [`~transformers.PushToHubCallback`]:
```py
>>> from transformers.keras_callbacks import PushToHubCallback
>>> callback = PushToHubCallback(
... output_dir="my_awesome_qa_model",
... tokenizer=tokenizer,
... )
```
Finally, you're ready to start training your model! Call [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) with your training and validation datasets, the number of epochs, and your callback to finetune the model:
```py
>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=3, callbacks=[callback])
```
Once training is completed, your model is automatically uploaded to the Hub so everyone can use it!
</tf>
</frameworkcontent>
<Tip>
For a more in-depth example of how to finetune a model for question answering, take a look at the corresponding
[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb)
or [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb).
</Tip>
## Evaluate
Evaluation for question answering requires a significant amount of postprocessing. To avoid taking up too much of your time, this guide skips the evaluation step. The [`Trainer`] still calculates the evaluation loss during training so you're not completely in the dark about your model's performance.
If have more time and you're interested in how to evaluate your model for question answering, take a look at the [Question answering](https://huggingface.co/course/chapter7/7?fw=pt#postprocessing) chapter from the 🤗 Hugging Face Course!
## Inference
Great, now that you've finetuned a model, you can use it for inference!
Come up with a question and some context you'd like the model to predict:
```py
>>> question = "How many programming languages does BLOOM support?"
>>> context = "BLOOM has 176 billion parameters and can generate text in 46 languages natural languages and 13 programming languages."
```
The simplest way to try out your finetuned model for inference is to use it in a [`pipeline`]. Instantiate a `pipeline` for question answering with your model, and pass your text to it:
```py
>>> from transformers import pipeline
>>> question_answerer = pipeline("question-answering", model="my_awesome_qa_model")
>>> question_answerer(question=question, context=context)
{'score': 0.2058267742395401,
'start': 10,
'end': 95,
'answer': '176 billion parameters and can generate text in 46 languages natural languages and 13'}
```
You can also manually replicate the results of the `pipeline` if you'd like:
<frameworkcontent>
<pt>
Tokenize the text and return PyTorch tensors:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_qa_model")
>>> inputs = tokenizer(question, context, return_tensors="pt")
```
Pass your inputs to the model and return the `logits`:
```py
>>> import torch
>>> from transformers import AutoModelForQuestionAnswering
>>> model = AutoModelForQuestionAnswering.from_pretrained("my_awesome_qa_model")
>>> with torch.no_grad():
... outputs = model(**inputs)
```
Get the highest probability from the model output for the start and end positions:
```py
>>> answer_start_index = outputs.start_logits.argmax()
>>> answer_end_index = outputs.end_logits.argmax()
```
Decode the predicted tokens to get the answer:
```py
>>> predict_answer_tokens = inputs.input_ids[0, answer_start_index : answer_end_index + 1]
>>> tokenizer.decode(predict_answer_tokens)
'176 billion parameters and can generate text in 46 languages natural languages and 13'
```
</pt>
<tf>
Tokenize the text and return TensorFlow tensors:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_qa_model")
>>> inputs = tokenizer(question, text, return_tensors="tf")
```
Pass your inputs to the model and return the `logits`:
```py
>>> from transformers import TFAutoModelForQuestionAnswering
>>> model = TFAutoModelForQuestionAnswering.from_pretrained("my_awesome_qa_model")
>>> outputs = model(**inputs)
```
Get the highest probability from the model output for the start and end positions:
```py
>>> answer_start_index = int(tf.math.argmax(outputs.start_logits, axis=-1)[0])
>>> answer_end_index = int(tf.math.argmax(outputs.end_logits, axis=-1)[0])
```
Decode the predicted tokens to get the answer:
```py
>>> predict_answer_tokens = inputs.input_ids[0, answer_start_index : answer_end_index + 1]
>>> tokenizer.decode(predict_answer_tokens)
'176 billion parameters and can generate text in 46 languages natural languages and 13'
```
</tf>
</frameworkcontent>
|
huggingface/transformers/blob/main/docs/source/en/tasks/question_answering.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Textual Inversion
[Textual Inversion](https://hf.co/papers/2208.01618) is a training technique for personalizing image generation models with just a few example images of what you want it to learn. This technique works by learning and updating the text embeddings (the new embeddings are tied to a special word you must use in the prompt) to match the example images you provide.
If you're training on a GPU with limited vRAM, you should try enabling the `gradient_checkpointing` and `mixed_precision` parameters in the training command. You can also reduce your memory footprint by using memory-efficient attention with [xFormers](../optimization/xformers). JAX/Flax training is also supported for efficient training on TPUs and GPUs, but it doesn't support gradient checkpointing or xFormers. With the same configuration and setup as PyTorch, the Flax training script should be at least ~70% faster!
This guide will explore the [textual_inversion.py](https://github.com/huggingface/diffusers/blob/main/examples/textual_inversion/textual_inversion.py) script to help you become more familiar with it, and how you can adapt it for your own use-case.
Before running the script, make sure you install the library from source:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Navigate to the example folder with the training script and install the required dependencies for the script you're using:
<hfoptions id="installation">
<hfoption id="PyTorch">
```bash
cd examples/textual_inversion
pip install -r requirements.txt
```
</hfoption>
<hfoption id="Flax">
```bash
cd examples/textual_inversion
pip install -r requirements_flax.txt
```
</hfoption>
</hfoptions>
<Tip>
🤗 Accelerate is a library for helping you train on multiple GPUs/TPUs or with mixed-precision. It'll automatically configure your training setup based on your hardware and environment. Take a look at the 🤗 Accelerate [Quick tour](https://huggingface.co/docs/accelerate/quicktour) to learn more.
</Tip>
Initialize an 🤗 Accelerate environment:
```bash
accelerate config
```
To setup a default 🤗 Accelerate environment without choosing any configurations:
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell, like a notebook, you can use:
```bash
from accelerate.utils import write_basic_config
write_basic_config()
```
Lastly, if you want to train a model on your own dataset, take a look at the [Create a dataset for training](create_dataset) guide to learn how to create a dataset that works with the training script.
<Tip>
The following sections highlight parts of the training script that are important for understanding how to modify it, but it doesn't cover every aspect of the script in detail. If you're interested in learning more, feel free to read through the [script](https://github.com/huggingface/diffusers/blob/main/examples/textual_inversion/textual_inversion.py) and let us know if you have any questions or concerns.
</Tip>
## Script parameters
The training script has many parameters to help you tailor the training run to your needs. All of the parameters and their descriptions are listed in the [`parse_args()`](https://github.com/huggingface/diffusers/blob/839c2a5ece0af4e75530cb520d77bc7ed8acf474/examples/textual_inversion/textual_inversion.py#L176) function. Where applicable, Diffusers provides default values for each parameter such as the training batch size and learning rate, but feel free to change these values in the training command if you'd like.
For example, to increase the number of gradient accumulation steps above the default value of 1:
```bash
accelerate launch textual_inversion.py \
--gradient_accumulation_steps=4
```
Some other basic and important parameters to specify include:
- `--pretrained_model_name_or_path`: the name of the model on the Hub or a local path to the pretrained model
- `--train_data_dir`: path to a folder containing the training dataset (example images)
- `--output_dir`: where to save the trained model
- `--push_to_hub`: whether to push the trained model to the Hub
- `--checkpointing_steps`: frequency of saving a checkpoint as the model trains; this is useful if for some reason training is interrupted, you can continue training from that checkpoint by adding `--resume_from_checkpoint` to your training command
- `--num_vectors`: the number of vectors to learn the embeddings with; increasing this parameter helps the model learn better but it comes with increased training costs
- `--placeholder_token`: the special word to tie the learned embeddings to (you must use the word in your prompt for inference)
- `--initializer_token`: a single-word that roughly describes the object or style you're trying to train on
- `--learnable_property`: whether you're training the model to learn a new "style" (for example, Van Gogh's painting style) or "object" (for example, your dog)
## Training script
Unlike some of the other training scripts, textual_inversion.py has a custom dataset class, [`TextualInversionDataset`](https://github.com/huggingface/diffusers/blob/b81c69e489aad3a0ba73798c459a33990dc4379c/examples/textual_inversion/textual_inversion.py#L487) for creating a dataset. You can customize the image size, placeholder token, interpolation method, whether to crop the image, and more. If you need to change how the dataset is created, you can modify `TextualInversionDataset`.
Next, you'll find the dataset preprocessing code and training loop in the [`main()`](https://github.com/huggingface/diffusers/blob/839c2a5ece0af4e75530cb520d77bc7ed8acf474/examples/textual_inversion/textual_inversion.py#L573) function.
The script starts by loading the [tokenizer](https://github.com/huggingface/diffusers/blob/b81c69e489aad3a0ba73798c459a33990dc4379c/examples/textual_inversion/textual_inversion.py#L616), [scheduler and model](https://github.com/huggingface/diffusers/blob/b81c69e489aad3a0ba73798c459a33990dc4379c/examples/textual_inversion/textual_inversion.py#L622):
```py
# Load tokenizer
if args.tokenizer_name:
tokenizer = CLIPTokenizer.from_pretrained(args.tokenizer_name)
elif args.pretrained_model_name_or_path:
tokenizer = CLIPTokenizer.from_pretrained(args.pretrained_model_name_or_path, subfolder="tokenizer")
# Load scheduler and models
noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
text_encoder = CLIPTextModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision
)
vae = AutoencoderKL.from_pretrained(args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision)
unet = UNet2DConditionModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision
)
```
The special [placeholder token](https://github.com/huggingface/diffusers/blob/b81c69e489aad3a0ba73798c459a33990dc4379c/examples/textual_inversion/textual_inversion.py#L632) is added next to the tokenizer, and the embedding is readjusted to account for the new token.
Then, the script [creates a dataset](https://github.com/huggingface/diffusers/blob/b81c69e489aad3a0ba73798c459a33990dc4379c/examples/textual_inversion/textual_inversion.py#L716) from the `TextualInversionDataset`:
```py
train_dataset = TextualInversionDataset(
data_root=args.train_data_dir,
tokenizer=tokenizer,
size=args.resolution,
placeholder_token=(" ".join(tokenizer.convert_ids_to_tokens(placeholder_token_ids))),
repeats=args.repeats,
learnable_property=args.learnable_property,
center_crop=args.center_crop,
set="train",
)
train_dataloader = torch.utils.data.DataLoader(
train_dataset, batch_size=args.train_batch_size, shuffle=True, num_workers=args.dataloader_num_workers
)
```
Finally, the [training loop](https://github.com/huggingface/diffusers/blob/b81c69e489aad3a0ba73798c459a33990dc4379c/examples/textual_inversion/textual_inversion.py#L784) handles everything else from predicting the noisy residual to updating the embedding weights of the special placeholder token.
If you want to learn more about how the training loop works, check out the [Understanding pipelines, models and schedulers](../using-diffusers/write_own_pipeline) tutorial which breaks down the basic pattern of the denoising process.
## Launch the script
Once you've made all your changes or you're okay with the default configuration, you're ready to launch the training script! 🚀
For this guide, you'll download some images of a [cat toy](https://huggingface.co/datasets/diffusers/cat_toy_example) and store them in a directory. But remember, you can create and use your own dataset if you want (see the [Create a dataset for training](create_dataset) guide).
```py
from huggingface_hub import snapshot_download
local_dir = "./cat"
snapshot_download(
"diffusers/cat_toy_example", local_dir=local_dir, repo_type="dataset", ignore_patterns=".gitattributes"
)
```
Set the environment variable `MODEL_NAME` to a model id on the Hub or a path to a local model, and `DATA_DIR` to the path where you just downloaded the cat images to. The script creates and saves the following files to your repository:
- `learned_embeds.bin`: the learned embedding vectors corresponding to your example images
- `token_identifier.txt`: the special placeholder token
- `type_of_concept.txt`: the type of concept you're training on (either "object" or "style")
<Tip warning={true}>
A full training run takes ~1 hour on a single V100 GPU.
</Tip>
One more thing before you launch the script. If you're interested in following along with the training process, you can periodically save generated images as training progresses. Add the following parameters to the training command:
```bash
--validation_prompt="A <cat-toy> train"
--num_validation_images=4
--validation_steps=100
```
<hfoptions id="training-inference">
<hfoption id="PyTorch">
```bash
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export DATA_DIR="./cat"
accelerate launch textual_inversion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$DATA_DIR \
--learnable_property="object" \
--placeholder_token="<cat-toy>" \
--initializer_token="toy" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=3000 \
--learning_rate=5.0e-04 \
--scale_lr \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--output_dir="textual_inversion_cat" \
--push_to_hub
```
</hfoption>
<hfoption id="Flax">
```bash
export MODEL_NAME="duongna/stable-diffusion-v1-4-flax"
export DATA_DIR="./cat"
python textual_inversion_flax.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$DATA_DIR \
--learnable_property="object" \
--placeholder_token="<cat-toy>" \
--initializer_token="toy" \
--resolution=512 \
--train_batch_size=1 \
--max_train_steps=3000 \
--learning_rate=5.0e-04 \
--scale_lr \
--output_dir="textual_inversion_cat" \
--push_to_hub
```
</hfoption>
</hfoptions>
After training is complete, you can use your newly trained model for inference like:
<hfoptions id="training-inference">
<hfoption id="PyTorch">
```py
from diffusers import StableDiffusionPipeline
import torch
pipeline = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16).to("cuda")
pipeline.load_textual_inversion("sd-concepts-library/cat-toy")
image = pipeline("A <cat-toy> train", num_inference_steps=50).images[0]
image.save("cat-train.png")
```
</hfoption>
<hfoption id="Flax">
Flax doesn't support the [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] method, but the textual_inversion_flax.py script [saves](https://github.com/huggingface/diffusers/blob/c0f058265161178f2a88849e92b37ffdc81f1dcc/examples/textual_inversion/textual_inversion_flax.py#L636C2-L636C2) the learned embeddings as a part of the model after training. This means you can use the model for inference like any other Flax model:
```py
import jax
import numpy as np
from flax.jax_utils import replicate
from flax.training.common_utils import shard
from diffusers import FlaxStableDiffusionPipeline
model_path = "path-to-your-trained-model"
pipeline, params = FlaxStableDiffusionPipeline.from_pretrained(model_path, dtype=jax.numpy.bfloat16)
prompt = "A <cat-toy> train"
prng_seed = jax.random.PRNGKey(0)
num_inference_steps = 50
num_samples = jax.device_count()
prompt = num_samples * [prompt]
prompt_ids = pipeline.prepare_inputs(prompt)
# shard inputs and rng
params = replicate(params)
prng_seed = jax.random.split(prng_seed, jax.device_count())
prompt_ids = shard(prompt_ids)
images = pipeline(prompt_ids, params, prng_seed, num_inference_steps, jit=True).images
images = pipeline.numpy_to_pil(np.asarray(images.reshape((num_samples,) + images.shape[-3:])))
image.save("cat-train.png")
```
</hfoption>
</hfoptions>
## Next steps
Congratulations on training your own Textual Inversion model! 🎉 To learn more about how to use your new model, the following guides may be helpful:
- Learn how to [load Textual Inversion embeddings](../using-diffusers/loading_adapters) and also use them as negative embeddings.
- Learn how to use [Textual Inversion](textual_inversion_inference) for inference with Stable Diffusion 1/2 and Stable Diffusion XL.
|
huggingface/diffusers/blob/main/docs/source/en/training/text_inversion.md
|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# MMS
## Overview
The MMS model was proposed in [Scaling Speech Technology to 1,000+ Languages](https://arxiv.org/abs/2305.13516)
by Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, Michael Auli
The abstract from the paper is the following:
*Expanding the language coverage of speech technology has the potential to improve access to information for many more people.
However, current speech technology is restricted to about one hundred languages which is a small fraction of the over 7,000
languages spoken around the world.
The Massively Multilingual Speech (MMS) project increases the number of supported languages by 10-40x, depending on the task.
The main ingredients are a new dataset based on readings of publicly available religious texts and effectively leveraging
self-supervised learning. We built pre-trained wav2vec 2.0 models covering 1,406 languages,
a single multilingual automatic speech recognition model for 1,107 languages, speech synthesis models
for the same number of languages, as well as a language identification model for 4,017 languages.
Experiments show that our multilingual speech recognition model more than halves the word error rate of
Whisper on 54 languages of the FLEURS benchmark while being trained on a small fraction of the labeled data.*
Here are the different models open sourced in the MMS project. The models and code are originally released [here](https://github.com/facebookresearch/fairseq/tree/main/examples/mms). We have add them to the `transformers` framework, making them easier to use.
### Automatic Speech Recognition (ASR)
The ASR model checkpoints can be found here : [mms-1b-fl102](https://huggingface.co/facebook/mms-1b-fl102), [mms-1b-l1107](https://huggingface.co/facebook/mms-1b-l1107), [mms-1b-all](https://huggingface.co/facebook/mms-1b-all). For best accuracy, use the `mms-1b-all` model.
Tips:
- All ASR models accept a float array corresponding to the raw waveform of the speech signal. The raw waveform should be pre-processed with [`Wav2Vec2FeatureExtractor`].
- The models were trained using connectionist temporal classification (CTC) so the model output has to be decoded using
[`Wav2Vec2CTCTokenizer`].
- You can load different language adapter weights for different languages via [`~Wav2Vec2PreTrainedModel.load_adapter`]. Language adapters only consists of roughly 2 million parameters
and can therefore be efficiently loaded on the fly when needed.
#### Loading
By default MMS loads adapter weights for English. If you want to load adapter weights of another language
make sure to specify `target_lang=<your-chosen-target-lang>` as well as `"ignore_mismatched_sizes=True`.
The `ignore_mismatched_sizes=True` keyword has to be passed to allow the language model head to be resized according
to the vocabulary of the specified language.
Similarly, the processor should be loaded with the same target language
```py
from transformers import Wav2Vec2ForCTC, AutoProcessor
model_id = "facebook/mms-1b-all"
target_lang = "fra"
processor = AutoProcessor.from_pretrained(model_id, target_lang=target_lang)
model = Wav2Vec2ForCTC.from_pretrained(model_id, target_lang=target_lang, ignore_mismatched_sizes=True)
```
<Tip>
You can safely ignore a warning such as:
```text
Some weights of Wav2Vec2ForCTC were not initialized from the model checkpoint at facebook/mms-1b-all and are newly initialized because the shapes did not match:
- lm_head.bias: found shape torch.Size([154]) in the checkpoint and torch.Size([314]) in the model instantiated
- lm_head.weight: found shape torch.Size([154, 1280]) in the checkpoint and torch.Size([314, 1280]) in the model instantiated
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
```
</Tip>
If you want to use the ASR pipeline, you can load your chosen target language as such:
```py
from transformers import pipeline
model_id = "facebook/mms-1b-all"
target_lang = "fra"
pipe = pipeline(model=model_id, model_kwargs={"target_lang": "fra", "ignore_mismatched_sizes": True})
```
#### Inference
Next, let's look at how we can run MMS in inference and change adapter layers after having called [`~PretrainedModel.from_pretrained`]
First, we load audio data in different languages using the [Datasets](https://github.com/huggingface/datasets).
```py
from datasets import load_dataset, Audio
# English
stream_data = load_dataset("mozilla-foundation/common_voice_13_0", "en", split="test", streaming=True)
stream_data = stream_data.cast_column("audio", Audio(sampling_rate=16000))
en_sample = next(iter(stream_data))["audio"]["array"]
# French
stream_data = load_dataset("mozilla-foundation/common_voice_13_0", "fr", split="test", streaming=True)
stream_data = stream_data.cast_column("audio", Audio(sampling_rate=16000))
fr_sample = next(iter(stream_data))["audio"]["array"]
```
Next, we load the model and processor
```py
from transformers import Wav2Vec2ForCTC, AutoProcessor
import torch
model_id = "facebook/mms-1b-all"
processor = AutoProcessor.from_pretrained(model_id)
model = Wav2Vec2ForCTC.from_pretrained(model_id)
```
Now we process the audio data, pass the processed audio data to the model and transcribe the model output,
just like we usually do for [`Wav2Vec2ForCTC`].
```py
inputs = processor(en_sample, sampling_rate=16_000, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs).logits
ids = torch.argmax(outputs, dim=-1)[0]
transcription = processor.decode(ids)
# 'joe keton disapproved of films and buster also had reservations about the media'
```
We can now keep the same model in memory and simply switch out the language adapters by
calling the convenient [`~Wav2Vec2ForCTC.load_adapter`] function for the model and [`~Wav2Vec2CTCTokenizer.set_target_lang`] for the tokenizer.
We pass the target language as an input - `"fra"` for French.
```py
processor.tokenizer.set_target_lang("fra")
model.load_adapter("fra")
inputs = processor(fr_sample, sampling_rate=16_000, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs).logits
ids = torch.argmax(outputs, dim=-1)[0]
transcription = processor.decode(ids)
# "ce dernier est volé tout au long de l'histoire romaine"
```
In the same way the language can be switched out for all other supported languages. Please have a look at:
```py
processor.tokenizer.vocab.keys()
```
to see all supported languages.
To further improve performance from ASR models, language model decoding can be used. See the documentation [here](https://huggingface.co/facebook/mms-1b-all) for further details.
### Speech Synthesis (TTS)
MMS-TTS uses the same model architecture as VITS, which was added to 🤗 Transformers in v4.33. MMS trains a separate
model checkpoint for each of the 1100+ languages in the project. All available checkpoints can be found on the Hugging
Face Hub: [facebook/mms-tts](https://huggingface.co/models?sort=trending&search=facebook%2Fmms-tts), and the inference
documentation under [VITS](https://huggingface.co/docs/transformers/main/en/model_doc/vits).
#### Inference
To use the MMS model, first update to the latest version of the Transformers library:
```bash
pip install --upgrade transformers accelerate
```
Since the flow-based model in VITS is non-deterministic, it is good practice to set a seed to ensure reproducibility of
the outputs.
- For languages with a Roman alphabet, such as English or French, the tokenizer can be used directly to
pre-process the text inputs. The following code example runs a forward pass using the MMS-TTS English checkpoint:
```python
import torch
from transformers import VitsTokenizer, VitsModel, set_seed
tokenizer = VitsTokenizer.from_pretrained("facebook/mms-tts-eng")
model = VitsModel.from_pretrained("facebook/mms-tts-eng")
inputs = tokenizer(text="Hello - my dog is cute", return_tensors="pt")
set_seed(555) # make deterministic
with torch.no_grad():
outputs = model(**inputs)
waveform = outputs.waveform[0]
```
The resulting waveform can be saved as a `.wav` file:
```python
import scipy
scipy.io.wavfile.write("synthesized_speech.wav", rate=model.config.sampling_rate, data=waveform)
```
Or displayed in a Jupyter Notebook / Google Colab:
```python
from IPython.display import Audio
Audio(waveform, rate=model.config.sampling_rate)
```
For certain languages with non-Roman alphabets, such as Arabic, Mandarin or Hindi, the [`uroman`](https://github.com/isi-nlp/uroman)
perl package is required to pre-process the text inputs to the Roman alphabet.
You can check whether you require the `uroman` package for your language by inspecting the `is_uroman` attribute of
the pre-trained `tokenizer`:
```python
from transformers import VitsTokenizer
tokenizer = VitsTokenizer.from_pretrained("facebook/mms-tts-eng")
print(tokenizer.is_uroman)
```
If required, you should apply the uroman package to your text inputs **prior** to passing them to the `VitsTokenizer`,
since currently the tokenizer does not support performing the pre-processing itself.
To do this, first clone the uroman repository to your local machine and set the bash variable `UROMAN` to the local path:
```bash
git clone https://github.com/isi-nlp/uroman.git
cd uroman
export UROMAN=$(pwd)
```
You can then pre-process the text input using the following code snippet. You can either rely on using the bash variable
`UROMAN` to point to the uroman repository, or you can pass the uroman directory as an argument to the `uromaize` function:
```python
import torch
from transformers import VitsTokenizer, VitsModel, set_seed
import os
import subprocess
tokenizer = VitsTokenizer.from_pretrained("facebook/mms-tts-kor")
model = VitsModel.from_pretrained("facebook/mms-tts-kor")
def uromanize(input_string, uroman_path):
"""Convert non-Roman strings to Roman using the `uroman` perl package."""
script_path = os.path.join(uroman_path, "bin", "uroman.pl")
command = ["perl", script_path]
process = subprocess.Popen(command, stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
# Execute the perl command
stdout, stderr = process.communicate(input=input_string.encode())
if process.returncode != 0:
raise ValueError(f"Error {process.returncode}: {stderr.decode()}")
# Return the output as a string and skip the new-line character at the end
return stdout.decode()[:-1]
text = "이봐 무슨 일이야"
uromaized_text = uromanize(text, uroman_path=os.environ["UROMAN"])
inputs = tokenizer(text=uromaized_text, return_tensors="pt")
set_seed(555) # make deterministic
with torch.no_grad():
outputs = model(inputs["input_ids"])
waveform = outputs.waveform[0]
```
**Tips:**
* The MMS-TTS checkpoints are trained on lower-cased, un-punctuated text. By default, the `VitsTokenizer` *normalizes* the inputs by removing any casing and punctuation, to avoid passing out-of-vocabulary characters to the model. Hence, the model is agnostic to casing and punctuation, so these should be avoided in the text prompt. You can disable normalisation by setting `noramlize=False` in the call to the tokenizer, but this will lead to un-expected behaviour and is discouraged.
* The speaking rate can be varied by setting the attribute `model.speaking_rate` to a chosen value. Likewise, the randomness of the noise is controlled by `model.noise_scale`:
```python
import torch
from transformers import VitsTokenizer, VitsModel, set_seed
tokenizer = VitsTokenizer.from_pretrained("facebook/mms-tts-eng")
model = VitsModel.from_pretrained("facebook/mms-tts-eng")
inputs = tokenizer(text="Hello - my dog is cute", return_tensors="pt")
# make deterministic
set_seed(555)
# make speech faster and more noisy
model.speaking_rate = 1.5
model.noise_scale = 0.8
with torch.no_grad():
outputs = model(**inputs)
```
### Language Identification (LID)
Different LID models are available based on the number of languages they can recognize - [126](https://huggingface.co/facebook/mms-lid-126), [256](https://huggingface.co/facebook/mms-lid-256), [512](https://huggingface.co/facebook/mms-lid-512), [1024](https://huggingface.co/facebook/mms-lid-1024), [2048](https://huggingface.co/facebook/mms-lid-2048), [4017](https://huggingface.co/facebook/mms-lid-4017).
#### Inference
First, we install transformers and some other libraries
```bash
pip install torch accelerate datasets[audio]
pip install --upgrade transformers
````
Next, we load a couple of audio samples via `datasets`. Make sure that the audio data is sampled to 16000 kHz.
```py
from datasets import load_dataset, Audio
# English
stream_data = load_dataset("mozilla-foundation/common_voice_13_0", "en", split="test", streaming=True)
stream_data = stream_data.cast_column("audio", Audio(sampling_rate=16000))
en_sample = next(iter(stream_data))["audio"]["array"]
# Arabic
stream_data = load_dataset("mozilla-foundation/common_voice_13_0", "ar", split="test", streaming=True)
stream_data = stream_data.cast_column("audio", Audio(sampling_rate=16000))
ar_sample = next(iter(stream_data))["audio"]["array"]
```
Next, we load the model and processor
```py
from transformers import Wav2Vec2ForSequenceClassification, AutoFeatureExtractor
import torch
model_id = "facebook/mms-lid-126"
processor = AutoFeatureExtractor.from_pretrained(model_id)
model = Wav2Vec2ForSequenceClassification.from_pretrained(model_id)
```
Now we process the audio data, pass the processed audio data to the model to classify it into a language, just like we usually do for Wav2Vec2 audio classification models such as [ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition](https://huggingface.co/harshit345/xlsr-wav2vec-speech-emotion-recognition)
```py
# English
inputs = processor(en_sample, sampling_rate=16_000, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs).logits
lang_id = torch.argmax(outputs, dim=-1)[0].item()
detected_lang = model.config.id2label[lang_id]
# 'eng'
# Arabic
inputs = processor(ar_sample, sampling_rate=16_000, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs).logits
lang_id = torch.argmax(outputs, dim=-1)[0].item()
detected_lang = model.config.id2label[lang_id]
# 'ara'
```
To see all the supported languages of a checkpoint, you can print out the language ids as follows:
```py
processor.id2label.values()
```
### Audio Pretrained Models
Pretrained models are available for two different sizes - [300M](https://huggingface.co/facebook/mms-300m) ,
[1Bil](https://huggingface.co/facebook/mms-1b).
<Tip>
The MMS for ASR architecture is based on the Wav2Vec2 model, refer to [Wav2Vec2's documentation page](wav2vec2) for further
details on how to finetune with models for various downstream tasks.
MMS-TTS uses the same model architecture as VITS, refer to [VITS's documentation page](vits) for API reference.
</Tip>
|
huggingface/transformers/blob/main/docs/source/en/model_doc/mms.md
|
Gradio Demo: count_generator
```
!pip install -q gradio
```
```
import gradio as gr
import time
def count(n):
for i in range(int(n)):
time.sleep(0.5)
yield i
def show(n):
return str(list(range(int(n))))
with gr.Blocks() as demo:
with gr.Column():
num = gr.Number(value=10)
with gr.Row():
count_btn = gr.Button("Count")
list_btn = gr.Button("List")
with gr.Column():
out = gr.Textbox()
count_btn.click(count, num, out)
list_btn.click(show, num, out)
demo.queue()
if __name__ == "__main__":
demo.launch()
```
|
gradio-app/gradio/blob/main/demo/count_generator/run.ipynb
|
Overview
🤗 Optimum provides an integration with ONNX Runtime, a cross-platform, high performance engine for Open Neural Network Exchange (ONNX) models.
<div class="mt-10">
<div class="w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-3 md:gap-y-4 md:gap-x-5">
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./usage_guides/pipelines"
><div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">How-to guides</div>
<p class="text-gray-700">Practical guides to help you achieve a specific goal. Take a look at these guides to learn how to use 🤗 Optimum to solve real-world problems.</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./concept_guides/onnx"
><div class="w-full text-center bg-gradient-to-br from-pink-400 to-pink-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">Conceptual guides</div>
<p class="text-gray-700">High-level explanations for building a better understanding about important topics such as quantization and graph optimization.</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./package_reference/modeling_ort"
><div class="w-full text-center bg-gradient-to-br from-purple-400 to-purple-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">Reference</div>
<p class="text-gray-700">Technical descriptions of how the ONNX Runtime classes and methods of 🤗 Optimum work.</p>
</a>
</div>
</div>
|
huggingface/optimum/blob/main/docs/source/onnxruntime/overview.mdx
|
!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Text classification
By running the script [`run_classification.py`](https://github.com/huggingface/optimum/blob/main/examples/onnxruntime/training/text-classification/run_classification.py),
we will be able to leverage the [`ONNX Runtime`](https://github.com/microsoft/onnxruntime) accelerator to fine-tune the models from the
[HuggingFace hub](https://huggingface.co/models) for text classification task.
__The following example applies the acceleration features powered by ONNX Runtime.__
### ONNX Runtime Training
The following example fine-tunes [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) on the [Amazon Reviews Dataset](https://huggingface.co/datasets/amazon_reviews_multi).
```bash
torchrun --nproc_per_node=NUM_GPUS_YOU_HAVE run_classification.py \
--model_name_or_path meta-llama/Llama-2-7b-hf \
--dataset_name amazon_reviews_multi \
--dataset_config_name en \
--shuffle_train_dataset \
--metric_name accuracy \
--text_column_name 'review_title,review_body,product_category' \
--text_column_delimiter ' ' \
--label_column_name stars \
--do_train \
--do_eval \
--fp16 \
--max_seq_length 128 \
--per_device_train_batch_size 16 \
--learning_rate 2e-5 \
--num_train_epochs 1 \
--deepspeed zero_stage_2.json \
--use_peft \
--output_dir /tmp/ort-llama-2/
```
### Performance
We get the following results for [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) using mixed-precision-training/LoRA/ZeRO-Stage-2 under PyTorch and ONNX Runtime backends. 8 Nvidia V100 cards were used to run the
experiment for 10 epochs:
| Model | Backend | Runtime(s) | Train samples(/s) |
| --------------------------- |------------- | --------------- | ------------------- |
| meta-llama/Llama-2-7b-hf | PyTorch | 17035.9055 | 117.399 |
| meta-llama/Llama-2-7b-hf | ONNX Runtime | 15532.2403 | 128.764 |
We observe the gain of ONNX Runtime compared to PyTorch as follow:
| Model | Latency | Throughput |
| ------------------------- | ------- | ---------- |
| meta-llama/Llama-2-7b-hf | 8.83% | 9.68% |
#### DeepSpeed
[zero_stage_2.json](https://github.com/huggingface/optimum/blob/main/examples/onnxruntime/training/text-classification/zero_stage_2.json) is an example DeepSpeed config file to enable Stage-2 parameter sharing for training meta-llama/Llama-2-7b. More information can be found at [DeepSpeed's official repo](https://github.com/microsoft/DeepSpeed).
## GLUE Tasks
By running the script [`run_glue.py`](https://github.com/huggingface/optimum/blob/main/examples/onnxruntime/training/text-classification/run_glue.py),
we will be able to leverage the [`ONNX Runtime`](https://github.com/microsoft/onnxruntime) accelerator to fine-tune the models from the
[HuggingFace hub](https://huggingface.co/models) for sequence classification on the [GLUE benchmark](https://gluebenchmark.com/).
__The following example applies the acceleration features powered by ONNX Runtime.__
### ONNX Runtime Training
The following example fine-tunes a BERT on the sst-2 task.
```bash
torchrun --nproc_per_node=NUM_GPUS_YOU_HAVE run_glue.py \
--model_name_or_path bert-base-uncased \
--task_name sst2 \
--do_train \
--do_eval \
--output_dir /tmp/ort-bert-sst2/
```
### Performance
We get the following results for [roberta-base](https://huggingface.co/roberta-base) and [roberta-large](https://huggingface.co/roberta-large)
mixed precision training(fp16) on sst2 dataset under PyTorch and ONNX Runtime backends. A single Nvidia A100 card was used to run the
experiment for 3 epochs::
| Model | Backend | Runtime(s) | Train samples(/s) |
| --------------- |------------- | ---------- | ----------------- |
| roberta-base | PyTorch | 752.3 | 268.6 |
| roberta-base | ONNX Runtime | 729.7 | 276.9 |
| roberta-large | PyTorch | 3523.7 | 57.3 |
| roberta-large | ONNX Runtime | 2986.6 | 67.7 |
We observe the gain of ONNX Runtime compared to PyTorch as follow:
| Model | Latency | Throughput |
| ------------- | ------- | ---------- |
| roberta-base | 2.99% | 3.08% |
| roberta-large | 15.24% | 17.98% |
__Note__
> *To enable ONNX Runtime training, your devices need to be equipped with GPU. Install the dependencies either with our prepared*
*[Dockerfiles](https://github.com/huggingface/optimum/blob/main/examples/onnxruntime/training/docker/) or follow the instructions*
*in [`torch_ort`](https://github.com/pytorch/ort/blob/main/torch_ort/docker/README.md).*
> *The inference will use PyTorch by default, if you want to use ONNX Runtime backend instead, add the flag `--inference_with_ort`.*
---
|
huggingface/optimum/blob/main/examples/onnxruntime/training/text-classification/README.md
|
--
title: The Age of Machine Learning As Code Has Arrived
thumbnail: /blog/assets/31_age_of_ml_as_code/05_vision_transformer.png
authors:
- user: juliensimon
---
# The Age of Machine Learning As Code Has Arrived
The 2021 edition of the [State of AI Report](https://www.stateof.ai/2021-report-launch.html) came out last week. So did the Kaggle [State of Machine Learning and Data Science Survey](https://www.kaggle.com/c/kaggle-survey-2021). There's much to be learned and discussed in these reports, and a couple of takeaways caught my attention.
> "AI is increasingly being applied to mission critical infrastructure like national electric grids and automated supermarket warehousing calculations during pandemics. However, there are questions about whether the maturity of the industry has caught up with the enormity of its growing deployment."
There's no denying that Machine Learning-powered applications are reaching into every corner of IT. But what does that mean for companies and organizations? How do we build rock-solid Machine Learning workflows? Should we all hire 100 Data Scientists ? Or 100 DevOps engineers?
> "Transformers have emerged as a general purpose architecture for ML. Not just for Natural Language Processing, but also Speech, Computer Vision or even protein structure prediction."
Old timers have learned the hard way that there is [no silver bullet](https://en.wikipedia.org/wiki/No_Silver_Bullet) in IT. Yet, the [Transformer](https://arxiv.org/abs/1706.03762) architecture is indeed very efficient on a wide variety of Machine Learning tasks. But how can we all keep up with the frantic pace of innovation in Machine Learning? Do we really need expert skills to leverage these state of the art models? Or is there a shorter path to creating business value in less time?
Well, here's what I think.
### Machine Learning For The Masses!
Machine Learning is everywhere, or at least it's trying to be. A few years ago, Forbes wrote that "[Software ate the world, now AI is eating Software](https://www.forbes.com/sites/cognitiveworld/2019/08/29/software-ate-the-world-now-ai-is-eating-software/)", but what does this really mean? If it means that Machine Learning models should replace thousands of lines of fossilized legacy code, then I'm all for it. Die, evil business rules, die!
Now, does it mean that Machine Learning will actually replace Software Engineering? There's certainly a lot of fantasizing right now about [AI-generated code](https://www.wired.com/story/ai-latest-trick-writing-computer-code/), and some techniques are certainly interesting, such as [finding bugs and performance issues](https://aws.amazon.com/codeguru). However, not only shouldn't we even consider getting rid of developers, we should work on empowering as many as we can so that Machine Learning becomes just another boring IT workload (and [boring technology is great](http://boringtechnology.club/)). In other words, what we really need is for Software to eat Machine Learning!
### Things are not different this time
For years, I've argued and swashbuckled that decade-old best practices for Software Engineering also apply to Data Science and Machine Learning: versioning, reusability, testability, automation, deployment, monitoring, performance, optimization, etc. I felt alone for a while, and then the Google cavalry unexpectedly showed up:
> "Do machine learning like the great engineer you are, not like the great machine learning expert you aren't." - [Rules of Machine Learning](https://developers.google.com/machine-learning/guides/rules-of-ml), Google
There's no need to reinvent the wheel either. The DevOps movement solved these problems over 10 years ago. Now, the Data Science and Machine Learning community should adopt and adapt these proven tools and processes without delay. This is the only way we'll ever manage to build robust, scalable and repeatable Machine Learning systems in production. If calling it MLOps helps, fine: I won't argue about another buzzword.
It's really high time we stopped considering proof of concepts and sandbox A/B tests as notable achievements. They're merely a small stepping stone toward production, which is the only place where assumptions and business impact can be validated. Every Data Scientist and Machine Learning Engineer should obsess about getting their models in production, as quickly and as often as possible. **An okay production model beats a great sandbox model every time**.
### Infrastructure? So what?
It's 2021. IT infrastructure should no longer stand in the way. Software has devoured it a while ago, abstracting it away with cloud APIs, infrastructure as code, Kubeflow and so on. Yes, even on premises.
The same is quickly happening for Machine Learning infrastructure. According to the Kaggle survey, 75% of respondents use cloud services, and over 45% use an Enterprise ML platform, with Amazon SageMaker, Databricks and Azure ML Studio taking the top 3 spots.
<kbd>
<img src="assets/31_age_of_ml_as_code/01_entreprise_ml.png">
</kbd>
With MLOps, software-defined infrastructure and platforms, it's never been easier to drag all these great ideas out of the sandbox, and to move them to production. To answer my original question, I'm pretty sure you need to hire more ML-savvy Software and DevOps engineers, not more Data Scientists. But deep down inside, you kind of knew that, right?
Now, let's talk about Transformers.
---
### Transformers! Transformers! Transformers! ([Ballmer style](https://www.youtube.com/watch?v=Vhh_GeBPOhs))
Says the State of AI report: "The Transformer architecture has expanded far beyond NLP and is emerging as a general purpose architecture for ML". For example, recent models like Google's [Vision Transformer](https://paperswithcode.com/method/vision-transformer), a convolution-free transformer architecture, and [CoAtNet](https://paperswithcode.com/paper/coatnet-marrying-convolution-and-attention), which mixes transformers and convolution, have set new benchmarks for image classification on ImageNet, while requiring fewer compute resources for training.
<kbd>
<img src="assets/31_age_of_ml_as_code/02_vision_transformer.png">
</kbd>
Transformers also do very well on audio (say, speech recognition), as well as on point clouds, a technique used to model 3D environments like autonomous driving scenes.
The Kaggle survey echoes this rise of Transformers. Their usage keeps growing year over year, while RNNs, CNNs and Gradient Boosting algorithms are receding.
<kbd>
<img src="assets/31_age_of_ml_as_code/03_transformers.png">
</kbd>
On top of increased accuracy, Transformers also keep fulfilling the transfer learning promise, allowing teams to save on training time and compute costs, and to deliver business value quicker.
<kbd>
<img src="assets/31_age_of_ml_as_code/04_general_transformers.png">
</kbd>
With Transformers, the Machine Learning world is gradually moving from "*Yeehaa!! Let's build and train our own Deep Learning model from scratch*" to "*Let's pick a proven off the shelf model, fine-tune it on our own data, and be home early for dinner.*"
It's a Good Thing in so many ways. State of the art is constantly advancing, and hardly anyone can keep up with its relentless pace. Remember that Google Vision Transformer model I mentioned earlier? Would you like to test it here and now? With Hugging Face, it's [the simplest thing](https://huggingface.co/google/vit-base-patch16-224).
<kbd>
<img src="assets/31_age_of_ml_as_code/05_vision_transformer.png">
</kbd>
How about the latest [zero-shot text generation models](https://huggingface.co/bigscience) from the [Big Science project](https://bigscience.huggingface.co/)?
<kbd>
<img src="assets/31_age_of_ml_as_code/06_big_science.png">
</kbd>
You can do the same with another [16,000+ models](https://huggingface.co/models) and [1,600+ datasets](https://huggingface.co/datasets), with additional tools for [inference](https://huggingface.co/inference-api), [AutoNLP](https://huggingface.co/autonlp), [latency optimization](https://huggingface.co/infinity), and [hardware acceleration](https://huggingface.co/hardware). We can also help you get your project off the ground, [from modeling to production](https://huggingface.co/support).
Our mission at Hugging Face is to make Machine Learning as friendly and as productive as possible, for beginners and experts alike.
We believe in writing as little code as possible to train, optimize, and deploy models.
We believe in built-in best practices.
We believe in making infrastructure as transparent as possible.
We believe that nothing beats high quality models in production, fast.
### Machine Learning as Code, right here, right now!
A lot of you seem to agree. We have over 52,000 stars on [Github](https://github.com/huggingface). For the first year, Hugging Face is also featured in the Kaggle survey, with usage already over 10%.
<kbd>
<img src="assets/31_age_of_ml_as_code/07_kaggle.png">
</kbd>
**Thank you all**. And yeah, we're just getting started.
---
*Interested in how Hugging Face can help your organization build and deploy production-grade Machine Learning solutions? Get in touch at [julsimon@huggingface.co](mailto:julsimon@huggingface.co) (no recruiters, no sales pitches, please).*
|
huggingface/blog/blob/main/the-age-of-ml-as-code.md
|
Creating a Real-Time Dashboard from Google Sheets
Tags: TABULAR, DASHBOARD, PLOTS
[Google Sheets](https://www.google.com/sheets/about/) are an easy way to store tabular data in the form of spreadsheets. With Gradio and pandas, it's easy to read data from public or private Google Sheets and then display the data or plot it. In this blog post, we'll build a small _real-time_ dashboard, one that updates when the data in the Google Sheets updates.
Building the dashboard itself will just be 9 lines of Python code using Gradio, and our final dashboard will look like this:
<gradio-app space="gradio/line-plot"></gradio-app>
**Prerequisites**: This Guide uses [Gradio Blocks](/guides/quickstart/#blocks-more-flexibility-and-control), so make you are familiar with the Blocks class.
The process is a little different depending on if you are working with a publicly accessible or a private Google Sheet. We'll cover both, so let's get started!
## Public Google Sheets
Building a dashboard from a public Google Sheet is very easy, thanks to the [`pandas` library](https://pandas.pydata.org/):
1\. Get the URL of the Google Sheets that you want to use. To do this, simply go to the Google Sheets, click on the "Share" button in the top-right corner, and then click on the "Get shareable link" button. This will give you a URL that looks something like this:
```html
https://docs.google.com/spreadsheets/d/1UoKzzRzOCt-FXLLqDKLbryEKEgllGAQUEJ5qtmmQwpU/edit#gid=0
```
2\. Now, let's modify this URL and then use it to read the data from the Google Sheets into a Pandas DataFrame. (In the code below, replace the `URL` variable with the URL of your public Google Sheet):
```python
import pandas as pd
URL = "https://docs.google.com/spreadsheets/d/1UoKzzRzOCt-FXLLqDKLbryEKEgllGAQUEJ5qtmmQwpU/edit#gid=0"
csv_url = URL.replace('/edit#gid=', '/export?format=csv&gid=')
def get_data():
return pd.read_csv(csv_url)
```
3\. The data query is a function, which means that it's easy to display it real-time using the the `gr.DataFrame` component, or plot it real-time using the `gr.LinePlot` component (of course, depending on the data, a different plot may be appropriate). To do this, just pass the function into the respective components, and set the `every` parameter based on how frequently (in seconds) you would like the component to refresh. Here's the Gradio code:
```python
import gradio as gr
with gr.Blocks() as demo:
gr.Markdown("# 📈 Real-Time Line Plot")
with gr.Row():
with gr.Column():
gr.DataFrame(get_data, every=5)
with gr.Column():
gr.LinePlot(get_data, every=5, x="Date", y="Sales", y_title="Sales ($ millions)", overlay_point=True, width=500, height=500)
demo.queue().launch() # Run the demo with queuing enabled
```
And that's it! You have a dashboard that refreshes every 5 seconds, pulling the data from your Google Sheet.
## Private Google Sheets
For private Google Sheets, the process requires a little more work, but not that much! The key difference is that now, you must authenticate yourself to authorize access to the private Google Sheets.
### Authentication
To authenticate yourself, obtain credentials from Google Cloud. Here's [how to set up google cloud credentials](https://developers.google.com/workspace/guides/create-credentials):
1\. First, log in to your Google Cloud account and go to the Google Cloud Console (https://console.cloud.google.com/)
2\. In the Cloud Console, click on the hamburger menu in the top-left corner and select "APIs & Services" from the menu. If you do not have an existing project, you will need to create one.
3\. Then, click the "+ Enabled APIs & services" button, which allows you to enable specific services for your project. Search for "Google Sheets API", click on it, and click the "Enable" button. If you see the "Manage" button, then Google Sheets is already enabled, and you're all set.
4\. In the APIs & Services menu, click on the "Credentials" tab and then click on the "Create credentials" button.
5\. In the "Create credentials" dialog, select "Service account key" as the type of credentials to create, and give it a name. **Note down the email of the service account**
6\. After selecting the service account, select the "JSON" key type and then click on the "Create" button. This will download the JSON key file containing your credentials to your computer. It will look something like this:
```json
{
"type": "service_account",
"project_id": "your project",
"private_key_id": "your private key id",
"private_key": "private key",
"client_email": "email",
"client_id": "client id",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://accounts.google.com/o/oauth2/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/email_id"
}
```
### Querying
Once you have the credentials `.json` file, you can use the following steps to query your Google Sheet:
1\. Click on the "Share" button in the top-right corner of the Google Sheet. Share the Google Sheets with the email address of the service from Step 5 of authentication subsection (this step is important!). Then click on the "Get shareable link" button. This will give you a URL that looks something like this:
```html
https://docs.google.com/spreadsheets/d/1UoKzzRzOCt-FXLLqDKLbryEKEgllGAQUEJ5qtmmQwpU/edit#gid=0
```
2\. Install the [`gspread` library](https://docs.gspread.org/en/v5.7.0/), which makes it easy to work with the [Google Sheets API](https://developers.google.com/sheets/api/guides/concepts) in Python by running in the terminal: `pip install gspread`
3\. Write a function to load the data from the Google Sheet, like this (replace the `URL` variable with the URL of your private Google Sheet):
```python
import gspread
import pandas as pd
# Authenticate with Google and get the sheet
URL = 'https://docs.google.com/spreadsheets/d/1_91Vps76SKOdDQ8cFxZQdgjTJiz23375sAT7vPvaj4k/edit#gid=0'
gc = gspread.service_account("path/to/key.json")
sh = gc.open_by_url(URL)
worksheet = sh.sheet1
def get_data():
values = worksheet.get_all_values()
df = pd.DataFrame(values[1:], columns=values[0])
return df
```
4\. The data query is a function, which means that it's easy to display it real-time using the the `gr.DataFrame` component, or plot it real-time using the `gr.LinePlot` component (of course, depending on the data, a different plot may be appropriate). To do this, we just pass the function into the respective components, and set the `every` parameter based on how frequently (in seconds) we would like the component to refresh. Here's the Gradio code:
```python
import gradio as gr
with gr.Blocks() as demo:
gr.Markdown("# 📈 Real-Time Line Plot")
with gr.Row():
with gr.Column():
gr.DataFrame(get_data, every=5)
with gr.Column():
gr.LinePlot(get_data, every=5, x="Date", y="Sales", y_title="Sales ($ millions)", overlay_point=True, width=500, height=500)
demo.queue().launch() # Run the demo with queuing enabled
```
You now have a Dashboard that refreshes every 5 seconds, pulling the data from your Google Sheet.
## Conclusion
And that's all there is to it! With just a few lines of code, you can use `gradio` and other libraries to read data from a public or private Google Sheet and then display and plot the data in a real-time dashboard.
|
gradio-app/gradio/blob/main/guides/07_tabular-data-science-and-plots/creating-a-realtime-dashboard-from-google-sheets.md
|
@gradio/number
## 0.3.6
### Patch Changes
- Updated dependencies [[`828fb9e`](https://github.com/gradio-app/gradio/commit/828fb9e6ce15b6ea08318675a2361117596a1b5d), [`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144)]:
- @gradio/statustracker@0.4.3
- @gradio/atoms@0.4.1
## 0.3.5
### Patch Changes
- Updated dependencies [[`4d1cbbc`](https://github.com/gradio-app/gradio/commit/4d1cbbcf30833ef1de2d2d2710c7492a379a9a00)]:
- @gradio/atoms@0.4.0
- @gradio/statustracker@0.4.2
## 0.3.4
### Patch Changes
- Updated dependencies []:
- @gradio/atoms@0.3.1
- @gradio/statustracker@0.4.1
## 0.3.3
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/atoms@0.3.0
- @gradio/statustracker@0.4.0
## 0.3.2
### Patch Changes
- Updated dependencies [[`f816136a0`](https://github.com/gradio-app/gradio/commit/f816136a039fa6011be9c4fb14f573e4050a681a)]:
- @gradio/atoms@0.2.2
- @gradio/statustracker@0.3.2
## 0.3.1
### Patch Changes
- Updated dependencies [[`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780), [`fad92c29d`](https://github.com/gradio-app/gradio/commit/fad92c29dc1f5cd84341aae417c495b33e01245f)]:
- @gradio/atoms@0.2.1
- @gradio/statustracker@0.3.1
## 0.3.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
## 0.3.0-beta.8
### Features
- [#6149](https://github.com/gradio-app/gradio/pull/6149) [`90318b1dd`](https://github.com/gradio-app/gradio/commit/90318b1dd118ae08a695a50e7c556226234ab6dc) - swap `mode` on the frontned to `interactive` to match the backend. Thanks [@pngwn](https://github.com/pngwn)!
## 0.3.0-beta.7
### Features
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6026](https://github.com/gradio-app/gradio/pull/6026) [`338969af2`](https://github.com/gradio-app/gradio/commit/338969af290de032f9cdc204dab8a50be3bf3cc5) - V4: Single-file implementation of form components. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.3.0-beta.6
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.3.3
### Patch Changes
- Updated dependencies [[`e70805d54`](https://github.com/gradio-app/gradio/commit/e70805d54cc792452545f5d8eccc1aa0212a4695)]:
- @gradio/atoms@0.2.0
- @gradio/statustracker@0.2.3
## 0.3.2
### Patch Changes
- Updated dependencies []:
- @gradio/utils@0.1.2
- @gradio/atoms@0.1.4
- @gradio/statustracker@0.2.2
## 0.3.1
### Patch Changes
- Updated dependencies []:
- @gradio/atoms@0.1.3
- @gradio/statustracker@0.2.1
## 0.3.0
### Features
- [#5554](https://github.com/gradio-app/gradio/pull/5554) [`75ddeb390`](https://github.com/gradio-app/gradio/commit/75ddeb390d665d4484667390a97442081b49a423) - Accessibility Improvements. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.2.2
### Patch Changes
- Updated dependencies [[`afac0006`](https://github.com/gradio-app/gradio/commit/afac0006337ce2840cf497cd65691f2f60ee5912)]:
- @gradio/statustracker@0.2.0
- @gradio/utils@0.1.1
- @gradio/atoms@0.1.2
## 0.2.1
### Patch Changes
- Updated dependencies [[`abf1c57d`](https://github.com/gradio-app/gradio/commit/abf1c57d7d85de0df233ee3b38aeb38b638477db)]:
- @gradio/utils@0.1.0
- @gradio/atoms@0.1.1
- @gradio/statustracker@0.1.1
## 0.2.0
### Highlights
#### Improve startup performance and markdown support ([#5279](https://github.com/gradio-app/gradio/pull/5279) [`fe057300`](https://github.com/gradio-app/gradio/commit/fe057300f0672c62dab9d9b4501054ac5d45a4ec))
##### Improved markdown support
We now have better support for markdown in `gr.Markdown` and `gr.Dataframe`. Including syntax highlighting and Github Flavoured Markdown. We also have more consistent markdown behaviour and styling.
##### Various performance improvements
These improvements will be particularly beneficial to large applications.
- Rather than attaching events manually, they are now delegated, leading to a significant performance improvement and addressing a performance regression introduced in a recent version of Gradio. App startup for large applications is now around twice as fast.
- Optimised the mounting of individual components, leading to a modest performance improvement during startup (~30%).
- Corrected an issue that was causing markdown to re-render infinitely.
- Ensured that the `gr.3DModel` does re-render prematurely.
Thanks [@pngwn](https://github.com/pngwn)!
### Features
- [#5215](https://github.com/gradio-app/gradio/pull/5215) [`fbdad78a`](https://github.com/gradio-app/gradio/commit/fbdad78af4c47454cbb570f88cc14bf4479bbceb) - Lazy load interactive or static variants of a component individually, rather than loading both variants regardless. This change will improve performance for many applications. Thanks [@pngwn](https://github.com/pngwn)!
- [#5216](https://github.com/gradio-app/gradio/pull/5216) [`4b58ea6d`](https://github.com/gradio-app/gradio/commit/4b58ea6d98e7a43b3f30d8a4cb6f379bc2eca6a8) - Update i18n tokens and locale files. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.1.0
### Features
- [#5047](https://github.com/gradio-app/gradio/pull/5047) [`883ac364`](https://github.com/gradio-app/gradio/commit/883ac364f69d92128774ac446ce49bdf8415fd7b) - Add `step` param to `Number`. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#5005](https://github.com/gradio-app/gradio/pull/5005) [`f5539c76`](https://github.com/gradio-app/gradio/commit/f5539c7618e31451420bd3228754774da14dc65f) - Enhancement: Add focus event to textbox and number component. Thanks [@JodyZ0203](https://github.com/JodyZ0203)!
|
gradio-app/gradio/blob/main/js/number/CHANGELOG.md
|
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# How to contribute to Evaluate
Everyone is welcome to contribute, and we value everybody's contribution. Code
is not the only way to help the community. Answering questions, helping
others, reaching out and improving the documentations are immensely valuable to
the community.
It also helps us if you spread the word: reference the library from blog posts
on the awesome projects it made possible, shout out on Twitter every time it has
helped you, or simply star the repo to say "thank you".
Whichever way you choose to contribute, please be mindful to respect our
[code of conduct](https://github.com/huggingface/evaluate/blob/main/CODE_OF_CONDUCT.md).
## You can contribute in so many ways!
There are four ways you can contribute to `evaluate`:
* Fixing outstanding issues with the existing code;
* Implementing new evaluators and metrics;
* Contributing to the examples and documentation;
* Submitting issues related to bugs or desired new features.
Open issues are tracked directly on the repository [here](https://github.com/huggingface/evaluate/issues).
If you would like to work on any of the open issues:
* Make sure it is not already assigned to someone else. The assignee (if any) is on the top right column of the Issue page. If it's not taken, self-assign it.
* Work on your self-assigned issue and create a Pull Request!
## Submitting a new issue or feature request
Following these guidelines when submitting an issue or a feature
request will make it easier for us to come back to you quickly and with good
feedback.
### Do you want to implement a new metric?
All evaluation modules, be it metrics, comparisons, or measurements live on the 🤗 Hub in a [Space](https://huggingface.co/docs/hub/spaces) (see for example [Accuracy](https://huggingface.co/spaces/evaluate-metric/accuracy)). Evaluation modules can be either **community** or **canonical**.
* **Canonical** metrics are well-established metrics which already broadly adopted.
* **Community** metrics are new or custom metrics. It is simple to add a new community metric to use with `evaluate`. Please see our guide to adding a new evaluation metric [here](https://huggingface.co/docs/evaluate/creating_and_sharing)!
The only functional difference is that canonical metrics are integrated into the `evaluate` library directly and do not require a namespace when being loaded.
We encourage contributors to share new evaluation modules they contribute broadly! If they become widely adopted then they will be integrated into the core `evaluate` library as a canonical module.
### Do you want to request a new feature (that is not a metric)?
We would appreciate it if your feature request addresses the following points:
1. Motivation first:
* Is it related to a problem/frustration with the library? If so, please explain
why. Providing a code snippet that demonstrates the problem is best.
* Is it related to something you would need for a project? We'd love to hear
about it!
* Is it something you worked on and think could benefit the community?
Awesome! Tell us what problem it solved for you.
2. Write a *full paragraph* describing the feature;
3. Provide a **code snippet** that demonstrates its future use;
4. In case this is related to a paper, please attach a link;
5. Attach any additional information (drawings, screenshots, etc.) you think may help.
### Did you find a bug?
Thank you for reporting an issue. If the bug is related to a community metric, please open an issue or pull request directly on the repository of the metric on the Hugging Face Hub.
If the bug is related to the `evaluate` library and not a community metric, we would really appreciate it if you could **make sure the bug was not already reported** (use the search bar on Github under Issues). If it's not already logged, please open an issue with these details:
* Include your **OS type and version**, the versions of **Python**, **PyTorch** and
**Tensorflow** when applicable;
* A short, self-contained, code snippet that allows us to reproduce the bug in
less than 30s;
* Provide the *full* traceback if an exception is raised.
## Start contributing! (Pull Requests)
Before writing code, we strongly advise you to search through the existing PRs or
issues to make sure that nobody is already working on the same thing. If you are
unsure, it is always a good idea to open an issue to get some feedback.
1. Fork the [repository](https://github.com/huggingface/evaluate) by
clicking on the 'Fork' button on the repository's page. This creates a copy of the code
under your GitHub user account.
2. Clone your fork to your local disk, and add the base repository as a remote:
```bash
$ git clone git@github.com:<your Github handle>/evaluate.git
$ cd evaluate
$ git remote add upstream https://github.com/huggingface/evaluate.git
```
3. Create a new branch to hold your development changes:
```bash
$ git checkout -b a-descriptive-name-for-my-changes
```
**Do not** work on the `main` branch.
4. Set up a development environment by running the following command in a virtual environment:
```bash
$ pip install -e ".[dev]"
```
5. Develop the features on your branch.
As you work on the features, you should make sure that the test suite
passes. You should run the tests impacted by your changes like this:
```bash
$ pytest tests/<TEST_TO_RUN>.py
```
To run a specific test, for example the `test_model_init` test in test_evaluator.py,
```bash
python -m pytest ./tests/test_evaluator.py::TestQuestionAnsweringEvaluator::test_model_init
```
You can also run the full suite with the following command:
```bash
$ python -m pytest ./tests/
```
🤗 Evaluate relies on `black` and `isort` to format its source code
consistently. After you make changes, apply automatic style corrections and code verifications
that can't be automated in one go with:
```bash
$ make fixup
```
This target is also optimized to only work with files modified by the PR you're working on.
If you prefer to run the checks one after the other, the following command apply the
style corrections:
```bash
$ make style
```
🤗 Evaluate also uses `flake8` and a few custom scripts to check for coding mistakes. Quality
control runs in CI, however you can also run the same checks with:
```bash
$ make quality
```
If you're modifying documents under `docs/source`, make sure to validate that
they can still be built. This check also runs in CI. To run a local check
make sure you have installed the documentation builder requirements. First you will need to clone the
repository containing our tools to build the documentation:
```bash
$ pip install git+https://github.com/huggingface/doc-builder
```
Then, make sure you have all the dependencies to be able to build the doc with:
```bash
$ pip install ".[docs]"
```
Finally, run the following command from the root of the repository:
```bash
$ doc-builder build evaluate docs/source/ --build_dir ~/tmp/test-build
```
This will build the documentation in the `~/tmp/test-build` folder where you can inspect the generated
Markdown files with your favorite editor. You won't be able to see the final rendering on the website
before your PR is merged, we are actively working on adding a tool for this.
Once you're happy with your changes, add changed files using `git add` and
make a commit with `git commit` to record your changes locally:
```bash
$ git add modified_file.py
$ git commit
```
Please write [good commit
messages](https://chris.beams.io/posts/git-commit/).
It is a good idea to sync your copy of the code with the original
repository regularly. This way you can quickly account for changes:
```bash
$ git fetch upstream
$ git rebase upstream/main
```
Push the changes to your account using:
```bash
$ git push -u origin a-descriptive-name-for-my-changes
```
6. Once you are satisfied, go to the webpage of your fork on GitHub. Click on 'Pull request' to send your changes
to the project maintainers for review.
7. It's ok if maintainers ask you for changes. It happens to core contributors
too! So everyone can see the changes in the Pull request, work in your local
branch and push the changes to your fork. They will automatically appear in
the pull request.
### Checklist
1. The title of your pull request should be a summary of its contribution;
2. If your pull request addresses an issue, please mention the issue number in
the pull request description to make sure they are linked (and people
consulting the issue know you are working on it);
3. To indicate a work in progress please prefix the title with `[WIP]`. These
are useful to avoid duplicated work, and to differentiate it from PRs ready
to be merged;
4. Make sure existing tests pass;
5. Add high-coverage tests. No quality testing = no merge.
6. All public methods must have informative docstrings that work nicely with sphinx.
7. Due to the rapidly growing repository, it is important to make sure that no files that would significantly weigh down the repository are added. This includes images, videos and other non-text files. We prefer to leverage a hf.co hosted `dataset` like
the ones hosted on [`hf-internal-testing`](https://huggingface.co/hf-internal-testing) in which to place these files and reference
them by URL.
### Style guide
For documentation strings, 🤗 Evaluate follows the [google style](https://google.github.io/styleguide/pyguide.html).
Check our [documentation writing guide](https://github.com/huggingface/transformers/tree/main/docs#writing-documentation---specification)
for more information.
**This guide was heavily inspired by the awesome [scikit-learn guide to contributing](https://github.com/scikit-learn/scikit-learn/blob/main/CONTRIBUTING.md).**
### Develop on Windows
On Windows, you need to configure git to transform Windows `CRLF` line endings to Linux `LF` line endings:
`git config core.autocrlf input`
One way one can run the make command on Window is to pass by MSYS2:
1. [Download MSYS2](https://www.msys2.org/), we assume to have it installed in C:\msys64
2. Open the command line C:\msys64\msys2.exe (it should be available from the start menu)
3. Run in the shell: `pacman -Syu` and install make with `pacman -S make`
4. Add `C:\msys64\usr\bin` to your PATH environment variable.
You can now use `make` from any terminal (Powershell, cmd.exe, etc) 🎉
### Syncing forked main with upstream (HuggingFace) main
To avoid pinging the upstream repository which adds reference notes to each upstream PR and sends unnecessary notifications to the developers involved in these PRs,
when syncing the main branch of a forked repository, please, follow these steps:
1. When possible, avoid syncing with the upstream using a branch and PR on the forked repository. Instead, merge directly into the forked main.
2. If a PR is absolutely necessary, use the following steps after checking out your branch:
```
$ git checkout -b your-branch-for-syncing
$ git pull --squash --no-commit upstream main
$ git commit -m '<your message without GitHub references>'
$ git push --set-upstream origin your-branch-for-syncing
```
|
huggingface/evaluate/blob/main/CONTRIBUTING.md
|
ResNeSt
A **ResNeSt** is a variant on a [ResNet](https://paperswithcode.com/method/resnet), which instead stacks [Split-Attention blocks](https://paperswithcode.com/method/split-attention). The cardinal group representations are then concatenated along the channel dimension: \\( V = \text{Concat} \\){\\( V^{1},V^{2},\cdots{V}^{K} \\)}. As in standard residual blocks, the final output \\( Y \\) of otheur Split-Attention block is produced using a shortcut connection: \\( Y=V+X \\), if the input and output feature-map share the same shape. For blocks with a stride, an appropriate transformation \\( \mathcal{T} \\) is applied to the shortcut connection to align the output shapes: \\( Y=V+\mathcal{T}(X) \\). For example, \\( \mathcal{T} \\) can be strided convolution or combined convolution-with-pooling.
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('resnest101e', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `resnest101e`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('resnest101e', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{zhang2020resnest,
title={ResNeSt: Split-Attention Networks},
author={Hang Zhang and Chongruo Wu and Zhongyue Zhang and Yi Zhu and Haibin Lin and Zhi Zhang and Yue Sun and Tong He and Jonas Mueller and R. Manmatha and Mu Li and Alexander Smola},
year={2020},
eprint={2004.08955},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: ResNeSt
Paper:
Title: 'ResNeSt: Split-Attention Networks'
URL: https://paperswithcode.com/paper/resnest-split-attention-networks
Models:
- Name: resnest101e
In Collection: ResNeSt
Metadata:
FLOPs: 17423183648
Parameters: 48280000
File Size: 193782911
Architecture:
- 1x1 Convolution
- Convolution
- Dense Connections
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Connection
- Softmax
- Split Attention
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- DropBlock
- Label Smoothing
- Mixup
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 64x NVIDIA V100 GPUs
ID: resnest101e
LR: 0.1
Epochs: 270
Layers: 101
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 4096
Image Size: '256'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnest.py#L182
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-resnest/resnest101-22405ba7.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 82.88%
Top 5 Accuracy: 96.31%
- Name: resnest14d
In Collection: ResNeSt
Metadata:
FLOPs: 3548594464
Parameters: 10610000
File Size: 42562639
Architecture:
- 1x1 Convolution
- Convolution
- Dense Connections
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Connection
- Softmax
- Split Attention
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- DropBlock
- Label Smoothing
- Mixup
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 64x NVIDIA V100 GPUs
ID: resnest14d
LR: 0.1
Epochs: 270
Layers: 14
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 8192
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnest.py#L148
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/gluon_resnest14-9c8fe254.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.51%
Top 5 Accuracy: 92.52%
- Name: resnest200e
In Collection: ResNeSt
Metadata:
FLOPs: 45954387872
Parameters: 70200000
File Size: 193782911
Architecture:
- 1x1 Convolution
- Convolution
- Dense Connections
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Connection
- Softmax
- Split Attention
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- DropBlock
- Label Smoothing
- Mixup
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 64x NVIDIA V100 GPUs
ID: resnest200e
LR: 0.1
Epochs: 270
Layers: 200
Dropout: 0.2
Crop Pct: '0.909'
Momentum: 0.9
Batch Size: 2048
Image Size: '320'
Weight Decay: 0.0001
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnest.py#L194
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-resnest/resnest101-22405ba7.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 83.85%
Top 5 Accuracy: 96.89%
- Name: resnest269e
In Collection: ResNeSt
Metadata:
FLOPs: 100830307104
Parameters: 110930000
File Size: 445402691
Architecture:
- 1x1 Convolution
- Convolution
- Dense Connections
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Connection
- Softmax
- Split Attention
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- DropBlock
- Label Smoothing
- Mixup
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 64x NVIDIA V100 GPUs
ID: resnest269e
LR: 0.1
Epochs: 270
Layers: 269
Dropout: 0.2
Crop Pct: '0.928'
Momentum: 0.9
Batch Size: 2048
Image Size: '416'
Weight Decay: 0.0001
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnest.py#L206
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-resnest/resnest269-0cc87c48.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 84.53%
Top 5 Accuracy: 96.99%
- Name: resnest26d
In Collection: ResNeSt
Metadata:
FLOPs: 4678918720
Parameters: 17070000
File Size: 68470242
Architecture:
- 1x1 Convolution
- Convolution
- Dense Connections
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Connection
- Softmax
- Split Attention
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- DropBlock
- Label Smoothing
- Mixup
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 64x NVIDIA V100 GPUs
ID: resnest26d
LR: 0.1
Epochs: 270
Layers: 26
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 8192
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnest.py#L159
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/gluon_resnest26-50eb607c.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.48%
Top 5 Accuracy: 94.3%
- Name: resnest50d
In Collection: ResNeSt
Metadata:
FLOPs: 6937106336
Parameters: 27480000
File Size: 110273258
Architecture:
- 1x1 Convolution
- Convolution
- Dense Connections
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Connection
- Softmax
- Split Attention
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- DropBlock
- Label Smoothing
- Mixup
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 64x NVIDIA V100 GPUs
ID: resnest50d
LR: 0.1
Epochs: 270
Layers: 50
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 8192
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnest.py#L170
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-resnest/resnest50-528c19ca.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.96%
Top 5 Accuracy: 95.38%
- Name: resnest50d_1s4x24d
In Collection: ResNeSt
Metadata:
FLOPs: 5686764544
Parameters: 25680000
File Size: 103045531
Architecture:
- 1x1 Convolution
- Convolution
- Dense Connections
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Connection
- Softmax
- Split Attention
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- DropBlock
- Label Smoothing
- Mixup
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 64x NVIDIA V100 GPUs
ID: resnest50d_1s4x24d
LR: 0.1
Epochs: 270
Layers: 50
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 8192
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnest.py#L229
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-resnest/resnest50_fast_1s4x24d-d4a4f76f.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.0%
Top 5 Accuracy: 95.33%
- Name: resnest50d_4s2x40d
In Collection: ResNeSt
Metadata:
FLOPs: 5657064720
Parameters: 30420000
File Size: 122133282
Architecture:
- 1x1 Convolution
- Convolution
- Dense Connections
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Connection
- Softmax
- Split Attention
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- DropBlock
- Label Smoothing
- Mixup
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 64x NVIDIA V100 GPUs
ID: resnest50d_4s2x40d
LR: 0.1
Epochs: 270
Layers: 50
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 8192
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnest.py#L218
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-resnest/resnest50_fast_4s2x40d-41d14ed0.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.11%
Top 5 Accuracy: 95.55%
-->
|
huggingface/pytorch-image-models/blob/main/hfdocs/source/models/resnest.mdx
|
--
title: "Introducing Storage Regions on the HF Hub"
thumbnail: /blog/assets/172_regions/thumbnail.png
authors:
- user: coyotte508
- user: rtrm
- user: XciD
- user: michellehbn
- user: violette
- user: julien-c
---
# Introducing Storage Regions on the Hub
As part of our [Enterprise Hub](https://huggingface.co/enterprise) plan, we recently released support for **Storage Regions**.
Regions let you decide where your org's models and datasets will be stored. This has two main benefits, which we'll briefly go over in this blog post:
- **Regulatory and legal compliance**, and more generally, better digital sovereignty
- **Performance** (improved download and upload speeds and latency)
Currently we support the following regions:
- US 🇺🇸
- EU 🇪🇺
- coming soon: Asia-Pacific 🌏
But first, let's see how to setup this feature in your organization's settings 🔥
## Org settings
If your organization is not an Enterprise Hub org yet, you will see the following screen:
As soon as you subscribe, you will be able to see the Regions settings page:
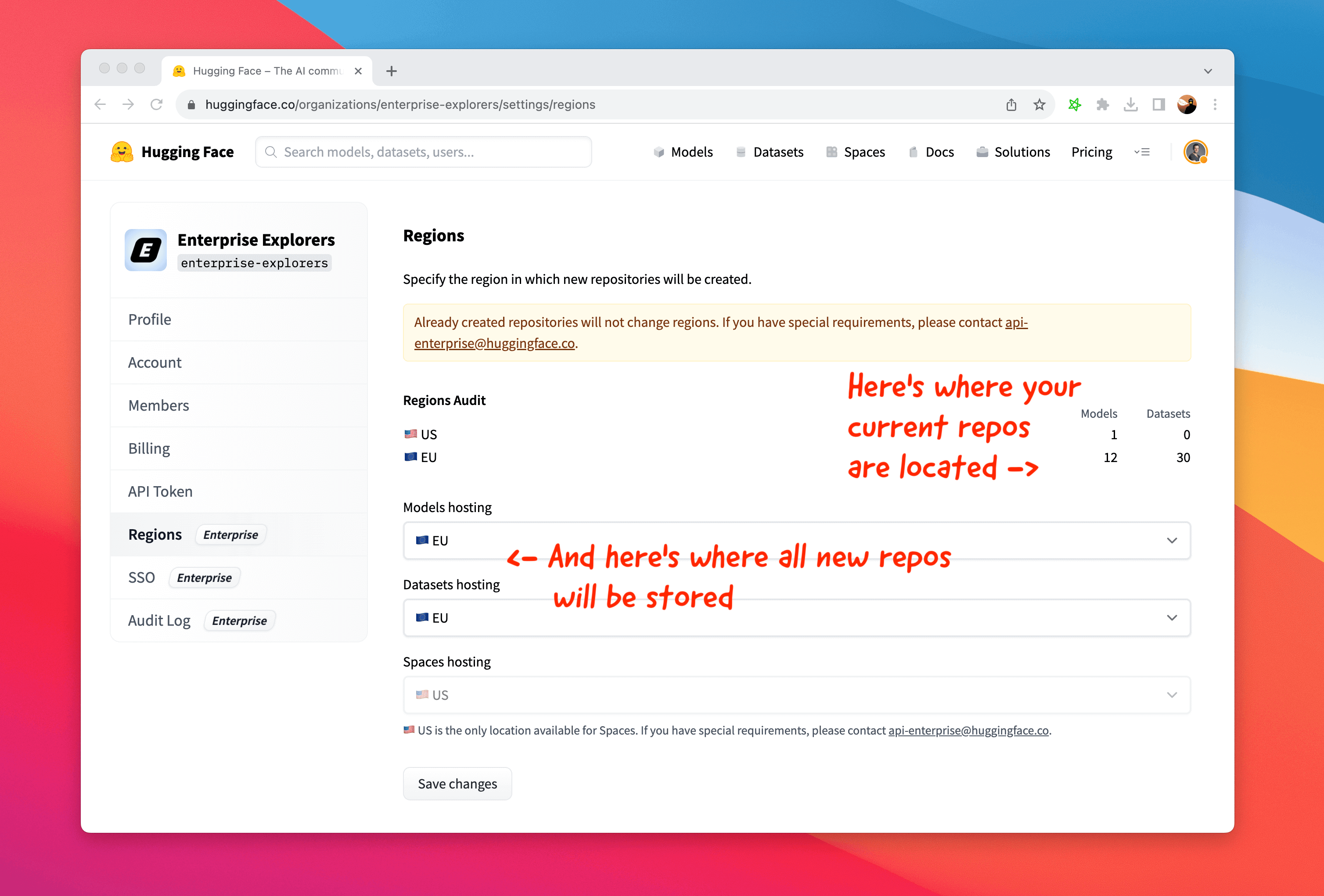
On that page you can see:
- an audit of where your orgs' repos are currently located
- dropdowns to select where your repos will be created
## Repository Tag
Any repo (model or dataset) stored in a non-default location will display its Region directly as a tag. That way your organization's members can see at a glance where repos are located.

## Regulatory and legal compliance
In many regulated industries, you may have a requirement to store your data in a specific area.
For companies in the EU, that means you can use the Hub to build ML in a GDPR compliant way: with datasets, models and inference endpoints all stored within EU data centers.
If you are an Enterprise Hub customer and have further questions about this, please get in touch!
## Performance
Storing your models or your datasets closer to your team and infrastructure also means significantly improved performance, for both uploads and downloads.
This makes a big difference considering model weights and dataset files are usually very large.

As an example, if you are located in Europe and store your repositories in the EU region, you can expect to see ~4-5x faster upload and download speeds vs. if they were stored in the US.
|
huggingface/blog/blob/main/regions.md
|
``python
from transformers import AutoModelForCausalLM
from peft import get_peft_config, get_peft_model, PromptTuningInit, PromptTuningConfig, TaskType, PeftType
import torch
from datasets import load_dataset
import os
from transformers import AutoTokenizer
from torch.utils.data import DataLoader
from transformers import default_data_collator, get_linear_schedule_with_warmup
from tqdm import tqdm
from datasets import load_dataset
device = "cuda"
model_name_or_path = "bigscience/bloomz-560m"
tokenizer_name_or_path = "bigscience/bloomz-560m"
peft_config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM,
prompt_tuning_init=PromptTuningInit.TEXT,
num_virtual_tokens=8,
prompt_tuning_init_text="Classify if the tweet is a complaint or not:",
tokenizer_name_or_path=model_name_or_path,
)
dataset_name = "twitter_complaints"
checkpoint_name = f"{dataset_name}_{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}_v1.pt".replace(
"/", "_"
)
text_column = "Tweet text"
label_column = "text_label"
max_length = 64
lr = 3e-2
num_epochs = 50
batch_size = 8
```
```python
from datasets import load_dataset
dataset = load_dataset("ought/raft", dataset_name)
classes = [k.replace("_", " ") for k in dataset["train"].features["Label"].names]
print(classes)
dataset = dataset.map(
lambda x: {"text_label": [classes[label] for label in x["Label"]]},
batched=True,
num_proc=1,
)
print(dataset)
dataset["train"][0]
```
```python
# data preprocessing
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
target_max_length = max([len(tokenizer(class_label)["input_ids"]) for class_label in classes])
print(target_max_length)
def preprocess_function(examples):
batch_size = len(examples[text_column])
inputs = [f"{text_column} : {x} Label : " for x in examples[text_column]]
targets = [str(x) for x in examples[label_column]]
model_inputs = tokenizer(inputs)
labels = tokenizer(targets, add_special_tokens=False) # don't add bos token because we concatenate with inputs
for i in range(batch_size):
sample_input_ids = model_inputs["input_ids"][i]
label_input_ids = labels["input_ids"][i] + [tokenizer.eos_token_id]
# print(i, sample_input_ids, label_input_ids)
model_inputs["input_ids"][i] = sample_input_ids + label_input_ids
labels["input_ids"][i] = [-100] * len(sample_input_ids) + label_input_ids
model_inputs["attention_mask"][i] = [1] * len(model_inputs["input_ids"][i])
# print(model_inputs)
for i in range(batch_size):
sample_input_ids = model_inputs["input_ids"][i]
label_input_ids = labels["input_ids"][i]
model_inputs["input_ids"][i] = [tokenizer.pad_token_id] * (
max_length - len(sample_input_ids)
) + sample_input_ids
model_inputs["attention_mask"][i] = [0] * (max_length - len(sample_input_ids)) + model_inputs[
"attention_mask"
][i]
labels["input_ids"][i] = [-100] * (max_length - len(sample_input_ids)) + label_input_ids
model_inputs["input_ids"][i] = torch.tensor(model_inputs["input_ids"][i][:max_length])
model_inputs["attention_mask"][i] = torch.tensor(model_inputs["attention_mask"][i][:max_length])
labels["input_ids"][i] = torch.tensor(labels["input_ids"][i][:max_length])
model_inputs["labels"] = labels["input_ids"]
return model_inputs
processed_datasets = dataset.map(
preprocess_function,
batched=True,
num_proc=1,
remove_columns=dataset["train"].column_names,
load_from_cache_file=False,
desc="Running tokenizer on dataset",
)
train_dataset = processed_datasets["train"]
eval_dataset = processed_datasets["train"]
train_dataloader = DataLoader(
train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True
)
eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
```
```python
def test_preprocess_function(examples):
batch_size = len(examples[text_column])
inputs = [f"{text_column} : {x} Label : " for x in examples[text_column]]
model_inputs = tokenizer(inputs)
# print(model_inputs)
for i in range(batch_size):
sample_input_ids = model_inputs["input_ids"][i]
model_inputs["input_ids"][i] = [tokenizer.pad_token_id] * (
max_length - len(sample_input_ids)
) + sample_input_ids
model_inputs["attention_mask"][i] = [0] * (max_length - len(sample_input_ids)) + model_inputs[
"attention_mask"
][i]
model_inputs["input_ids"][i] = torch.tensor(model_inputs["input_ids"][i][:max_length])
model_inputs["attention_mask"][i] = torch.tensor(model_inputs["attention_mask"][i][:max_length])
return model_inputs
test_dataset = dataset["test"].map(
test_preprocess_function,
batched=True,
num_proc=1,
remove_columns=dataset["train"].column_names,
load_from_cache_file=False,
desc="Running tokenizer on dataset",
)
test_dataloader = DataLoader(test_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
next(iter(test_dataloader))
```
```python
next(iter(train_dataloader))
```
```python
len(test_dataloader)
```
```python
next(iter(test_dataloader))
```
```python
# creating model
model = AutoModelForCausalLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
```
```python
# model
# optimizer and lr scheduler
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=(len(train_dataloader) * num_epochs),
)
```
```python
# training and evaluation
model = model.to(device)
for epoch in range(num_epochs):
model.train()
total_loss = 0
for step, batch in enumerate(tqdm(train_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
# print(batch)
# print(batch["input_ids"].shape)
outputs = model(**batch)
loss = outputs.loss
total_loss += loss.detach().float()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
eval_loss = 0
eval_preds = []
for step, batch in enumerate(tqdm(eval_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
eval_loss += loss.detach().float()
eval_preds.extend(
tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True)
)
eval_epoch_loss = eval_loss / len(eval_dataloader)
eval_ppl = torch.exp(eval_epoch_loss)
train_epoch_loss = total_loss / len(train_dataloader)
train_ppl = torch.exp(train_epoch_loss)
print(f"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")
```
```python
model.eval()
i = 33
inputs = tokenizer(f'{text_column} : {dataset["test"][i]["Tweet text"]} Label : ', return_tensors="pt")
print(dataset["test"][i]["Tweet text"])
print(inputs)
with torch.no_grad():
inputs = {k: v.to(device) for k, v in inputs.items()}
outputs = model.generate(
input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"], max_new_tokens=10, eos_token_id=3
)
print(outputs)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
```
You can push model to hub or save model locally.
- Option1: Pushing the model to Hugging Face Hub
```python
model.push_to_hub(
f"{dataset_name}_{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}".replace("/", "_"),
token = "hf_..."
)
```
token (`bool` or `str`, *optional*):
`token` is to be used for HTTP Bearer authorization when accessing remote files. If `True`, will use the token generated
when running `huggingface-cli login` (stored in `~/.huggingface`). Will default to `True` if `repo_url`
is not specified.
Or you can get your token from https://huggingface.co/settings/token
```
- Or save model locally
```python
peft_model_id = f"{dataset_name}_{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}".replace("/", "_")
model.save_pretrained(peft_model_id)
```
```python
# saving model
peft_model_id = f"{dataset_name}_{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}".replace(
"/", "_"
)
model.save_pretrained(peft_model_id)
```
```python
ckpt = f"{peft_model_id}/adapter_model.bin"
!du -h $ckpt
```
```python
from peft import PeftModel, PeftConfig
peft_model_id = f"{dataset_name}_{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}".replace(
"/", "_"
)
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path)
model = PeftModel.from_pretrained(model, peft_model_id)
```
```python
model.to(device)
model.eval()
i = 4
inputs = tokenizer(f'{text_column} : {dataset["test"][i]["Tweet text"]} Label : ', return_tensors="pt")
print(dataset["test"][i]["Tweet text"])
print(inputs)
with torch.no_grad():
inputs = {k: v.to(device) for k, v in inputs.items()}
outputs = model.generate(
input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"], max_new_tokens=10, eos_token_id=3
)
print(outputs)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
```
|
huggingface/peft/blob/main/examples/causal_language_modeling/peft_prompt_tuning_clm.ipynb
|
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Search the Hub
In this tutorial, you will learn how to search models, datasets and spaces on the Hub using `huggingface_hub`.
## How to list repositories ?
`huggingface_hub` library includes an HTTP client [`HfApi`] to interact with the Hub.
Among other things, it can list models, datasets and spaces stored on the Hub:
```py
>>> from huggingface_hub import HfApi
>>> api = HfApi()
>>> models = api.list_models()
```
The output of [`list_models`] is an iterator over the models stored on the Hub.
Similarly, you can use [`list_datasets`] to list datasets and [`list_spaces`] to list Spaces.
## How to filter repositories ?
Listing repositories is great but now you might want to filter your search.
The list helpers have several attributes like:
- `filter`
- `author`
- `search`
- ...
Two of these parameters are intuitive (`author` and `search`), but what about that `filter`?
`filter` takes as input a [`ModelFilter`] object (or [`DatasetFilter`]). You can instantiate
it by specifying which models you want to filter.
Let's see an example to get all models on the Hub that does image classification, have been
trained on the imagenet dataset and that runs with PyTorch. That can be done with a single
[`ModelFilter`]. Attributes are combined as "logical AND".
```py
models = hf_api.list_models(
filter=ModelFilter(
task="image-classification",
library="pytorch",
trained_dataset="imagenet"
)
)
```
While filtering, you can also sort the models and take only the top results. For example,
the following example fetches the top 5 most downloaded datasets on the Hub:
```py
>>> list(list_datasets(sort="downloads", direction=-1, limit=5))
[DatasetInfo(
id='argilla/databricks-dolly-15k-curated-en',
author='argilla',
sha='4dcd1dedbe148307a833c931b21ca456a1fc4281',
last_modified=datetime.datetime(2023, 10, 2, 12, 32, 53, tzinfo=datetime.timezone.utc),
private=False,
downloads=8889377,
(...)
```
To explore available filter on the Hub, visit [models](https://huggingface.co/models) and [datasets](https://huggingface.co/datasets) pages
in your browser, search for some parameters and look at the values in the URL.
|
huggingface/huggingface_hub/blob/main/docs/source/en/guides/search.md
|
Subsets and Splits
Transformers Source Texts
This query retrieves specific examples from the dataset related to transformers, providing a limited view of the data with basic filtering.