Datasets:


license: apache-2.0
CodeEditorBench
🌐 Homepage | 🤗 Dataset | 📖 arXiv | GitHub
Introduction
Large Language Models (LLMs) for code are rapidly evolving, with code editing emerging as a critical capability. We introduce CodeEditorBench, an evaluation framework designed to rigorously assess the performance of LLMs in code editing tasks, including debugging, translating, polishing, and requirement switching. Unlike existing benchmarks focusing solely on code generation, CodeEditorBench emphasizes real-world scenarios and practical aspects of software development. We curate diverse coding challenges and scenarios from five sources, covering various programming languages, complexity levels, and editing tasks. Evaluation of 19 LLMs reveals that closed-source models (particularly Gemini-Ultra and GPT-4), outperform open-source models in CodeEditorBench, highlighting differences in model performance based on problem types and prompt sensitivities. CodeEditorBench aims to catalyze advancements in LLMs by providing a robust platform for assessing code editing capabilities. We will release all prompts and datasets to enable the community to expand the dataset and benchmark emerging LLMs. By introducing CodeEditorBench, we contribute to the advancement of LLMs in code editing and provide a valuable resource for researchers and practitioners.

Results
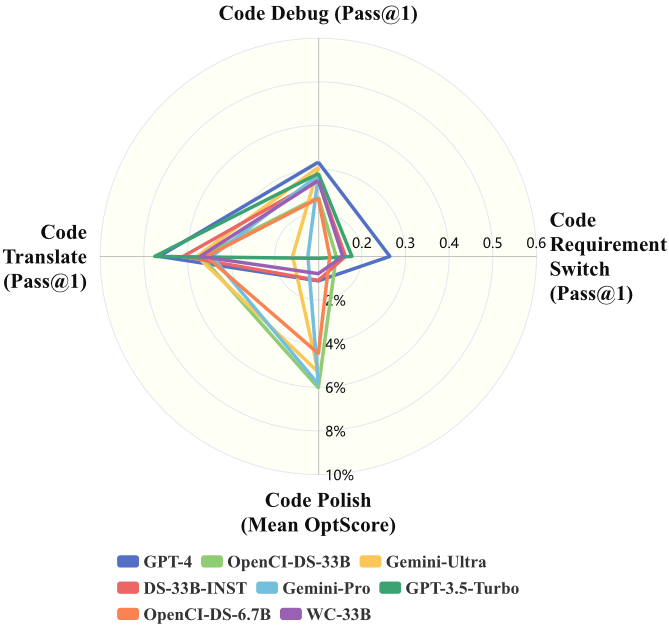
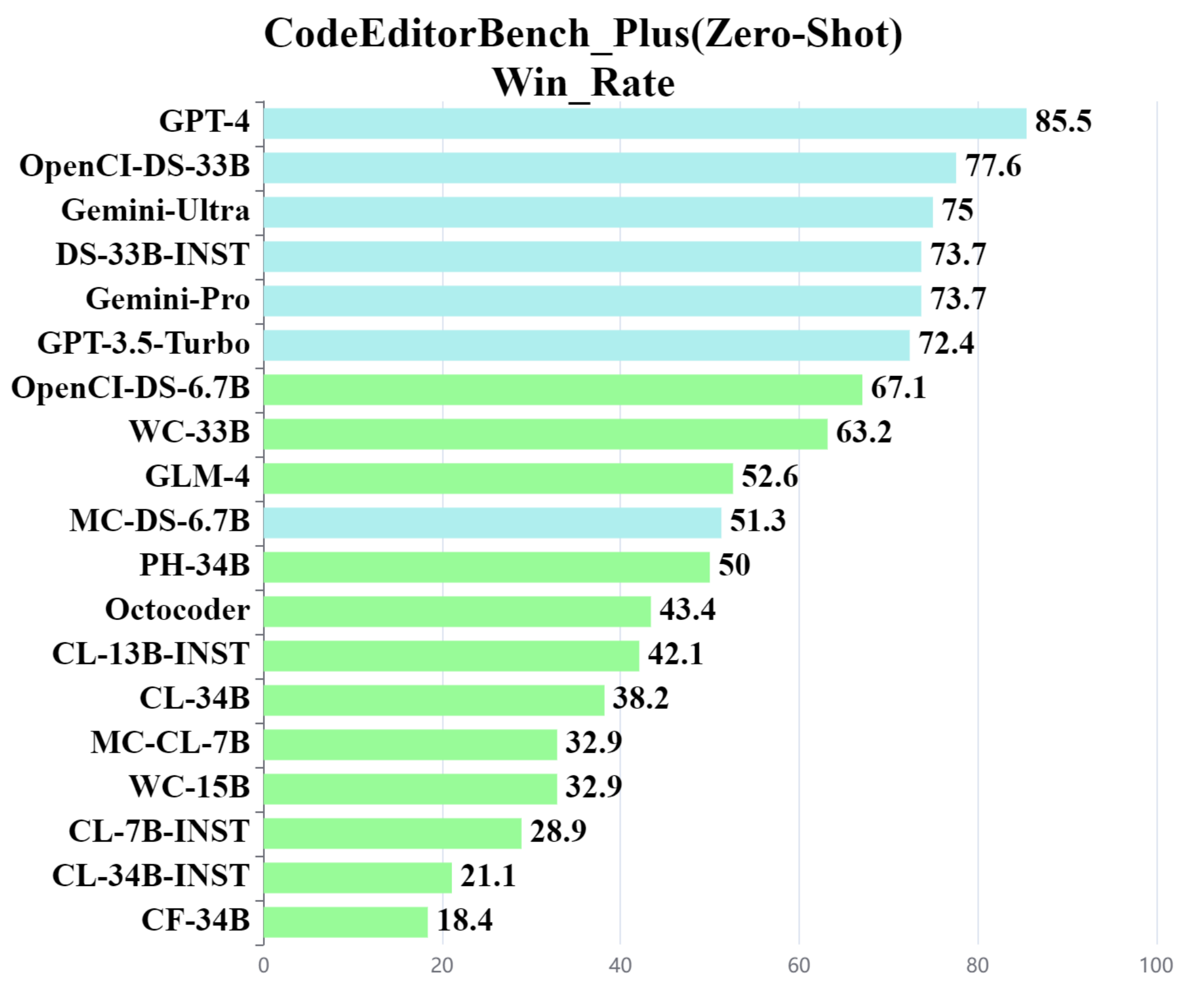
We propose evaluating LLMs across four scenarios capturing various code editing capabilities, namely code debug, code translate, code polish, and code requirement switch.The figure in left depicts various model performances across the four scenarios available in CodeEditorBench_Plus in a radial plot – highlighting how relative differences across models change across the scenarios. We also give the Performance of open-source and closed-source models on CodeEditorBench_Plus in zero-shot evaluated through win_rate in the right figure.
🎯All results of models are generated by greedy decoding.
✨Code Debug, Code Translate and Code Requirement Switch are evaluated with pass@1, while Code Polish is evaluated with Mean OptScore.
Disclaimers
The guidelines for the annotators emphasized strict compliance with copyright and licensing rules from the initial data source, specifically avoiding materials from websites that forbid copying and redistribution. Should you encounter any data samples potentially breaching the copyright or licensing regulations of any site, we encourage you to contact us. Upon verification, such samples will be promptly removed.
Contact
- Ge Zhang: zhangge@01.ai
- Wenhu Chen: wenhuchen@uwaterloo.ca
- Jie Fu: jiefu@ust.hk
Citation
BibTeX:
@misc{guo2024codeeditorbench,
title={CodeEditorBench: Evaluating Code Editing Capability of Large Language Models},
author={Jiawei Guo and Ziming Li and Xueling Liu and Kaijing Ma and Tianyu Zheng and Zhouliang Yu and Ding Pan and Yizhi LI and Ruibo Liu and Yue Wang and Shuyue Guo and Xingwei Qu and Xiang Yue and Ge Zhang and Wenhu Chen and Jie Fu},
year={2024},
eprint={2404.03543},
archivePrefix={arXiv},
primaryClass={cs.SE}
}